Работа с файлом robots.txt на WordPress-сайте
Необязательный в использовании файл, предназначенный для ограничения доступа поисковым роботам к содержимому сайта – это robots.txt. Появившийся более 20 лет назад, успел получить поддержку от большинства поисковых систем. Задает необходимые параметры индексации при помощи набора инструкций.
Основная информация и предназначение
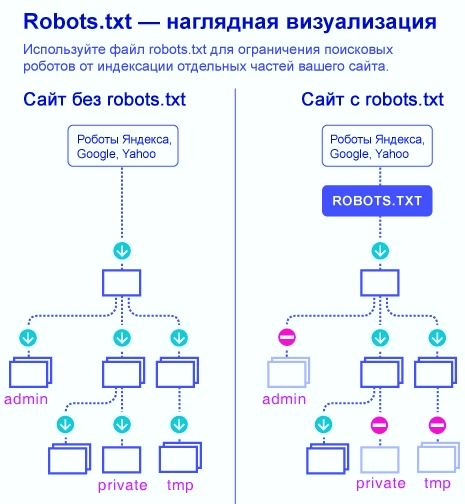
Предоставляет поисковым системам путь для индексации важных элементов ресурса. Под этим подразумевается установка ограничений для директорий, страниц, а также указывается путь к зеркалу и карте сайта. Первым делом поисковая машина находит robots.txt (размещен в корневой папке) и после этого следует указанным директивам. При отсутствии этого файла – робот проводит полное сканирование сайта.
Отметим, что содержимое документа является рекомендацией, а не обязательной командой. Нет гарантий того, что скрытая страница не попадет в индекс.
Внимание! Все записи осуществляются латинскими символами.
При использовании доменного имени на кириллице, стоит воспользоваться сервисом кодирования Punycode.

Работа с файлом robots.txt позволяет сократить время обработки ресурса. Будут индексироваться только необходимые страницы – это существенно снизит нагрузку на сервер.
Обязательному запрету подлежат:
Основные директивы и спецсимволы
Основные директивы устанавливают правила и определяют, какой конкретно робот должен их выполнять.
- User-agent – указывает кому адресованы инструкции;
- Disallow – устанавливает запрет на индексацию указанной части ресурса;
- Allow – разрешает доступ поисковика к директории;
- Sitemap – адрес расположения карты сайта.
User-agent
Является своеобразным приветствием для поисковиков, после директивы указывается имя бота. Список часто используемых значений:
- Googlebot – основной бот Google;
- Googlebot-Image – для изображений;
- Yandex – основной робот Яндекс;
- YandexDirect – обработка информации для контекстной рекламы;
- YandexImages – для изображений;
- YandexMetrika – система статистики;
Чтобы обратиться ко всем роботам, необходимо после директивы указать звездочку: «-agent: *».
Будет интересно – “Настройка файла robots.txt для WordPress”
Disallow и Allow
Использование Disallow необходимо для запрета сканирования определенного каталога или страницы. Чтобы робот не индексировал весь сайт, необходимо использовать слеш:
User-agent: * Disallow: /
Для закрытия доступа к определенной директории, указывается ее название (слеш перед и после названия папки):
User-agent: * Disallow: /category/
Таким же образом происходит запрет на индексацию отдельных файлов:
User-agent: * Disallow: /category/samplepage.html
Если каталог заблокирован, а сканирование страницы, находящейся внутри обязательно – вносят следующие правки:
User-agent: * Disallow: /category/ Allow: /category/samplepage.html
Данная комбинация осуществляет запрет на индексацию файлов одного типа:
User-agent: * Disallow: /*.jpg$
Sitemap и Host
При наличии одной или нескольких карт сайта, указывается адрес каждой:
User-agent: * Sitemap: https://yoursite.com/sitemap1.xml Sitemap: https://yoursite.com/sitemap2.xml
Директива Host предназначена только для Яндекса, указывает основное зеркало сайта.
User-agent: Yandex
Host: yoursite.com
Спецсимволы
Звездочка (*) используется для запрета всех url, в имени которых содержится указанное слово, к примеру, закрываем доступ к файлам, имеющих в названии «semki»:
User-agent: * Disallow: /*semki
Для отмены правила запрета, прописывается символ $ в конце строки. При этом, доступ закрыт только к указанной директории, ее содержимое будет доступно:
User-agent: * Disallow: /page$ #доступ к /page запрещен #доступ к /page.html открыт
Слеш указывается в каждой директиве, запрещает доступ к папке или вложенным страницам.
User-agent: * Disallow: /category/ #доступ к файлам директории /category/ запрещен Disallow: /category #запрещается доступ ко всем файлам, начинающимся с /category
Решетка служит для добавления комментариев, необходимых для личного удобства.
По теме –“Карта сайта для WordPress с помощью плагина Google XML Sitemaps”
Стандартный robots.txt
Работа с файлом robots.txt на WordPress-сайте может создавать некоторые путаницы для неопытных вебмастеров, поскольку рекомендуемый код, в некоторых строках, лишен логики. Для каждого ресурса требуются свои запреты и разрешения, все зависит от направления деятельности и предпочтений владельца ресурса. Рекомендуем к изучению стандартное содержимое robots.txt:
User-agent: * Disallow: /wp-admin Disallow: /wp-content Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: /xmlrpc.php Disallow: */feed Disallow: */author User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/ host: yoursite.com Sitemap: http://yoursite.com/sitemap.xml
В приведенном примере, директива указывает правила для всех поисковых машин, следующие строки закрывают доступ к административной части и служебным папкам.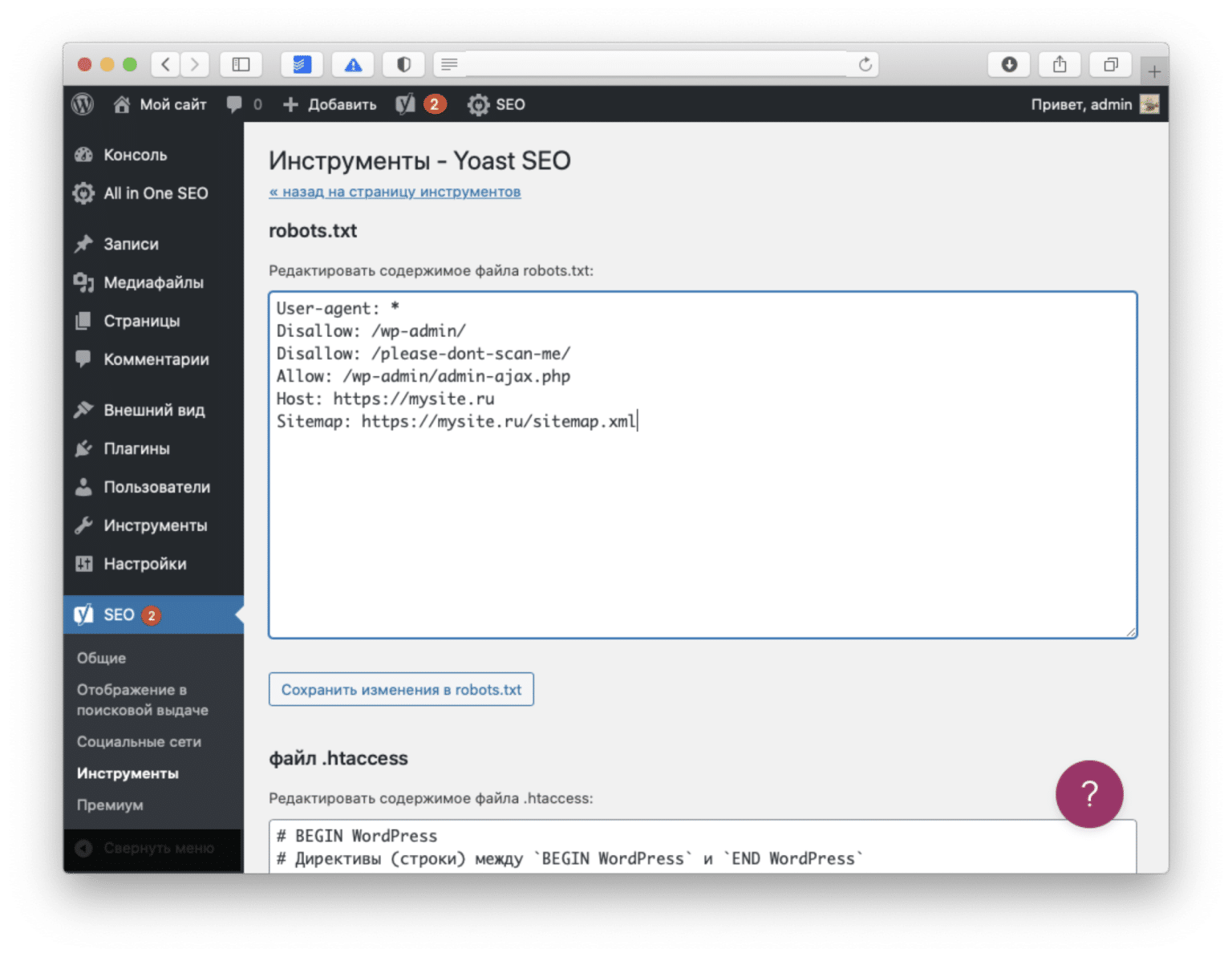 Запрещаются для индексации авторские страницы и лента RSS. Далее открывается доступ к индексации медиафайлов для ботов изображений популярных поисковиков. В конце прописывается хост и карта сайта. Также рекомендуется добавить запрет на сканирование архивов и меток, если не используются SEO-плагины (Yoast SEO, All in One SEO Pack).
Запрещаются для индексации авторские страницы и лента RSS. Далее открывается доступ к индексации медиафайлов для ботов изображений популярных поисковиков. В конце прописывается хост и карта сайта. Также рекомендуется добавить запрет на сканирование архивов и меток, если не используются SEO-плагины (Yoast SEO, All in One SEO Pack).
Специально для вас – “Clearfy Pro: чистый код сайта на WordPress”
Данный код является наиболее сбалансированным и логичным, закрывает уязвимые файлы и директории:
User-agent: * Disallow: /cgi-bin # закрывает каталог скриптов на сервере Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search # поиск Disallow: /author/ # архив автора Disallow: *?attachment_id= # страница вложения. Вообще-то на ней редирект... Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */page/ # все виды пагинации Allow: */uploads # открываем uploads Allow: /*/*.js # внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. #Disallow: /wp/ # когда WP установлен в подкаталог wp Sitemap: http://yoursite.com/sitemap.xml Sitemap: http://yoursite.com/sitemap2.xml # еще один файл #Sitemap: http://yoursite.com/sitemap.xml.gz # сжатая версия (.gz) Host: www.yoursite.com # для Яндекса
Первая строка указывает, что правила задействованы ко всем поисковым роботам.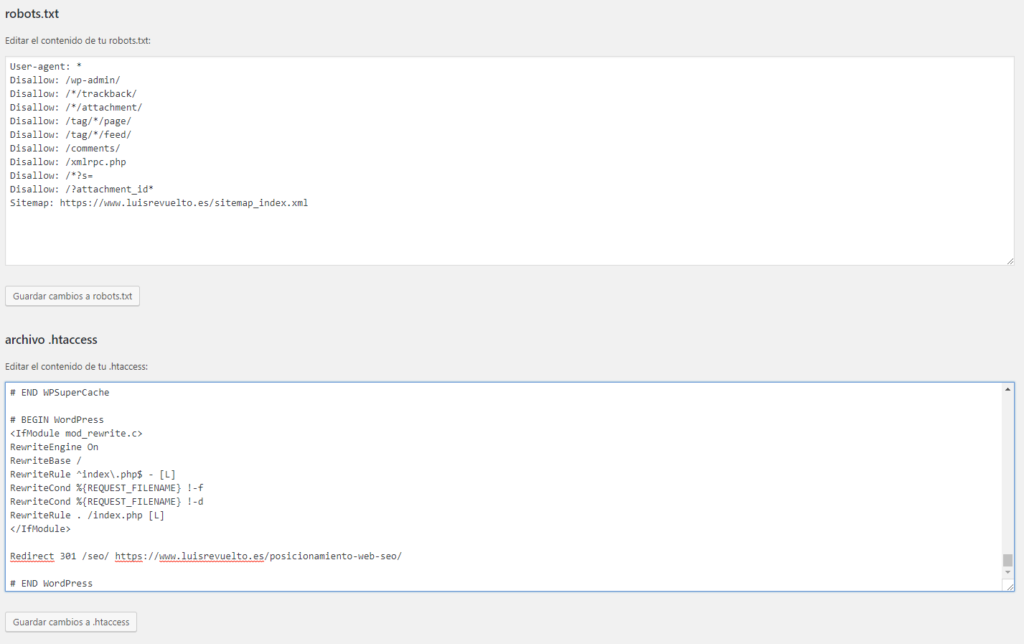
По последней информации, поисковики начали требовать открытие доступа к CSS и JS. Но, не стоит открывать весь каталог, ненужные скрипты и ресурсы страниц можно скрывать.
Создание и загрузка на сервер
Классический вариант – создать новый текстовый документ с именем robots, после чего внести данные при помощи редактора (рекомендуется Notepad+ или Alkepad). Добавляются рассмотренные вначале директивы, согласно требованиям администратора. Можно адаптировать готовые образцы, которые представлены на многих специализированных сайтах или блогах.
Еще один вариант – воспользоваться сервисами генерации robots.txt, к примеру: SeoLib, PR-CY, MediaSova, 4SEO. На этих ресурсах можно детально настроить правила индексирования, выбрать для каких роботов указываются инструкции, вписать конкретные страницы, папки и карту сайта. После этого, в окне результатов появится предпросмотр содержимого файла – если все устраивает, документ готов к сохранению.
Отобрано редакцией – “Установка и настройка CMS WordPress”
Инструмент Google:
- Позволяет проанализировать код на наличие ошибок.
- Все правки осуществляются прямо в панели проверки, после чего исправленный документ можно повторно загрузить на сервер.
- Указывает разрешения и запреты, как реагирует бот на внесенные правила.

Инструмент Яндекс:
- После авторизации можно проверять robots.txt без подтверждения прав на сайт.
- Возможность пакетной обработки страниц.
- Демонстрируются все ошибки директив, которые неправильно обрабатываются ботом.
P.S.
Работа с файлом robots.txt на WordPress-сайте заключается в тщательном анализе каталогов, которые подлежат запрету или разрешению к индексации. Стоит внимательно изучить основные директивы и важность определенных каталогов для поисковых машин. Процесс создания не затруднит малоопытных вебмастеров, поскольку в сети присутствует множество примеров и специальных сервисов для их генерации. Есть 2 основных правила при самостоятельном написании кода: строки, относящиеся к одному роботу – не должны содержать пропусков, разделение правил для разных ботов осуществляется при помощи пустой строки.
Интересно и по теме – “10 лучших SEO плагинов и инструментов WordPress в 2017 году”
Редактируем Robots.
 txt в WordPress с помощью плагина All in One SEO
txt в WordPress с помощью плагина All in One SEOФайл robots.txt – это мощный инструмент SEO, поскольку он работает как руководство по веб-сайту для роботов или роботов, выполняющих сканирование поисковых систем. Указание ботам не сканировать ненужные страницы может увеличить скорость загрузки вашего сайта и улучшить рейтинг в поисковых системах.
Несмотря на то, что однажды я уже создавал пост про этот важный файл для оптимизации работы сайтов, в этом мануале я более подробно расскажу вам, что такое файл robots.txt и почему он важен. А так же шаг за шагом покажу, как редактировать и как редактировать его в WordPress.
Что такое файл Robots.txt?
Файл robots.txt сообщает поисковым системам, как сканировать ваш сайт – где им можно это делать, а где нельзя.
Поисковые системы, такие как Google, используют этих поисковых роботов, иногда называемых веб-роботами, для архивирования и классификации веб-сайтов.
Большинство ботов настроены на поиск файла robots.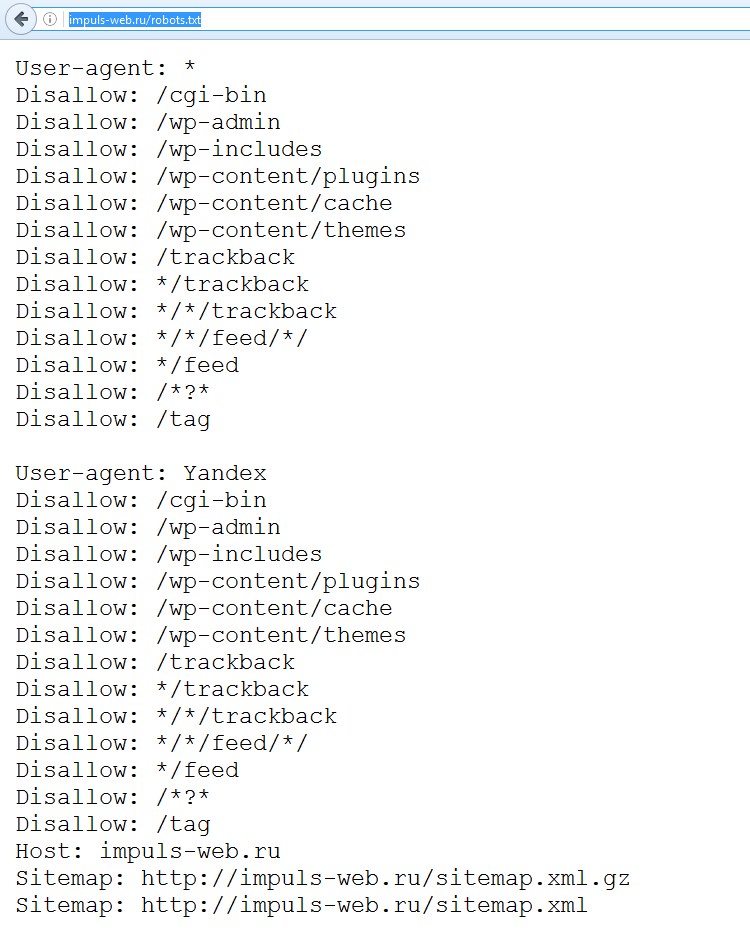 txt на сервере до того, как он прочитает любой другой файл с вашего сайта. Это делается для того, чтобы увидеть, добавили ли вы особые инструкции по сканированию и индексированию вашего сайта.
txt на сервере до того, как он прочитает любой другой файл с вашего сайта. Это делается для того, чтобы увидеть, добавили ли вы особые инструкции по сканированию и индексированию вашего сайта.
Файл robots.txt обычно хранится в корневом каталоге, также известном как основная папка веб-сайта. URL-адрес может выглядеть так: http://www.example.com/robots.txt
Чтобы проверить файл robots.txt на своем веб-сайте, просто замените http://www.example.com/ на свой домен и добавьте robots.txt в конце.
Сейчас же, давайте посмотрим, как выглядит основной формат файла robots.txt:
User-agent: [user-agent name]
Disallow: [URL string not to be crawled]
User-agent: [user-agent name]
Allow: [URL string to be crawled]
Sitemap: [URL of your XML Sitemap]Чтобы это имело смысл, сначала нужно объяснить, что означает User-agent.
По сути, это имя бота или робота поисковой системы, которому вы хотите заблокировать или разрешить сканировать ваш сайт (например, робот Googlebot).
Во-вторых, вы можете включить несколько инструкций, чтобы разрешить или запретить определенные URL-адреса, а также добавить несколько карт сайта. Как вы, наверное, догадались, опция запрета указывает роботам поисковых систем не сканировать эти URL-адреса.
Файл Robots.txt по умолчанию в WordPress
По умолчанию WordPress автоматически создает файл robots.txt для вашего сайта. Так что, даже если вы не пошевелите пальцем, на вашем сайте уже должен быть файл robots.txt WordPress по умолчанию.
Но когда вы позже настроите его своими собственными правилами, содержимое по умолчанию будет заменено.
Стандартные файлы robots.txt выглядит так:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpЗвездочка после User-agent: * означает, что файл robots.txt предназначен для всех веб-роботов, посещающих ваш сайт. И, как уже упоминалось, Disallow: / wp-admin / указывает роботам не посещать вашу страницу wp-admin.
Вы можете протестировать свой файл robots. txt, добавив /robots.txt в конце своего доменного имени. Например, если вы введете в адресную строку браузера запись https://aioseo.com/robots.txt , то в нем отобразится файл robots.txt для сайта плагина AIOSEO, который его разработчики настроили вот так:
txt, добавив /robots.txt в конце своего доменного имени. Например, если вы введете в адресную строку браузера запись https://aioseo.com/robots.txt , то в нем отобразится файл robots.txt для сайта плагина AIOSEO, который его разработчики настроили вот так:
Теперь, когда вы знаете, что такое файл robots.txt и основы его работы, давайте посмотрим, почему файл robots.txt имеет значение в первую очередь.
Почему важен файл Robots.txt?
Файл robots.txt важен, потому, что с помощью него вы:
1. Оптимизируйте скорость загрузки вашего сайта – указав ботам не тратить время на страницы, которые вы не хотите, чтобы они сканировали и индексировали, вы можете освободить ресурсы и увеличить скорость загрузки вашего сайта.
2. Оптимизируете использования сервера – блокировка ботов, которые тратят ресурсы впустую, очистит ваш сервер и уменьшит количество ошибок 404.
Когда использовать мета-тег Noindex вместо robots.txt
Однако, если ваша основная цель – предотвратить включение определенных страниц в результаты поисковых систем, правильным подходом является использование метатега noindex.
Это связано с тем, что файл robots.txt напрямую не говорит поисковым системам не индексировать контент – он просто говорит им не сканировать его.
Другими словами, вы можете использовать файл robots.txt для добавления определенных правил взаимодействия поисковых систем и других ботов с вашим сайтом, но он не будет явно контролировать, индексируется ли ваш контент или нет.
С учетом сказанного, давайте покажем вам, как легко шаг за шагом редактировать файл robots.txt в WordPress с помощью сео-плагина для WordPress – All in One SEO (AIOSEO)
Как редактировать файл Robots.txt в WordPress с помощью AIOSEO
Самый простой способ отредактировать файл robots.txt – использовать лучший плагин WordPress SEO All in One SEO (AIOSEO). Если вы его установили, то это позволит вам контролировать свой веб-сайт и настраивать файл robots.txt, который заменяет файл WordPress по умолчанию.
Если вы этого еще не знали, AIOSEO – это полноценный плагин WordPress для SEO,
который позволяет вам оптимизировать контент для поисковых систем и повысить рейтинг всего за несколько кликов.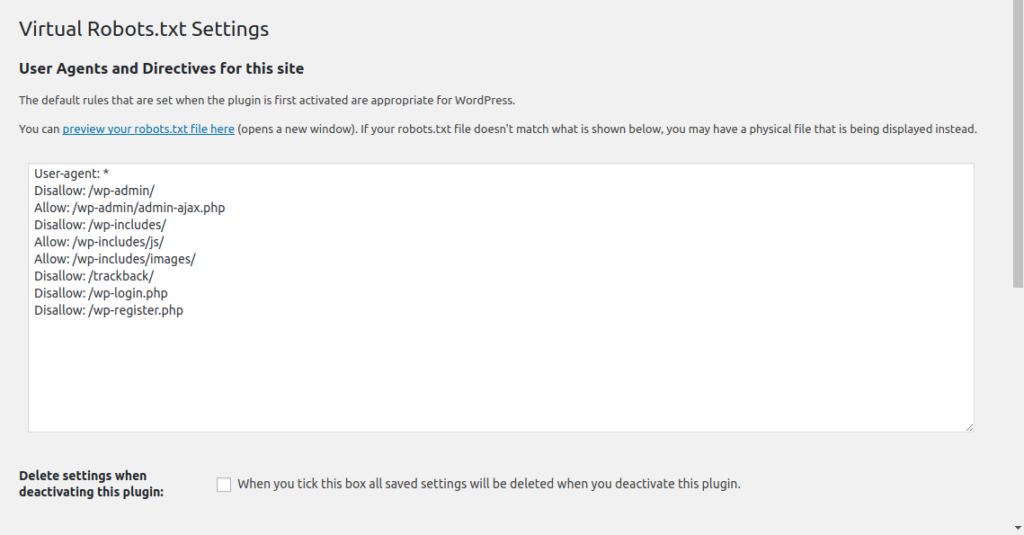 Ознакомьтесь с его мощными инструментами и функциями SEO здесь.
Ознакомьтесь с его мощными инструментами и функциями SEO здесь.
Включаем пользовательский файл Robots.txt
Чтобы приступить к редактированию файла robots.txt, с помощью уже установленного плагина AIOSEO, выберите в меню плагина строку «Инструменты». Таким образом вы откроете вкладку «Редактор Robots.txt». Далее приступаем к настройкам плагина.
Примечание* Если у вас уже был настроен файл и он вас вполне устраивает, вы можете просто импортировать его в AIOSEO.
Перевод страницы предупреждения и рекомендаций, если у вас уже был установлен файл: “AIOSEO обнаружила физический файл robots.txt в корневой папке вашей установки WordPress. Мы рекомендуем удалить этот файл, так как он может вызвать конфликт с динамически созданным файлом WordPress. AIOSEO может импортировать этот файл и удалить его, или вы можете просто удалить его”.Теперь на странице редактирования можно легко добавлять или удалять необходимые правила. Если вы пожелаете удалить ранее созданный файл-роботс – просто импортируйте и удалите его и пользуйтесь настройками по умолчанию. Но действовать нужно с осторожностью и не спешить удалять старый, несмотря на предупреждения плагина, а лучше используйте редактор.
Но действовать нужно с осторожностью и не спешить удалять старый, несмотря на предупреждения плагина, а лучше используйте редактор.
AIOSEO сгенерирует динамический файл robots.txt. Его содержимое хранится в вашей базе данных WordPress и может быть просмотрено в вашем веб-браузере.
После того, как вы вошли в редактор Robots.txt, вам необходимо включить Custom Robots.txt.
Кнопка включения окна редактирования файла robots.txtЗатем вы увидите раздел предварительного просмотра файла Robots.txt в нижней части экрана, в котором показаны правила WordPress по умолчанию, которые вы можете заменить своими собственными.
Правила по умолчанию предписывают роботам не сканировать ваши основные файлы WordPress (страницы администратора). Также не рекомендуется сканировать плагины и темы. Они не содержат релевантного содержания и не нужны поисковым системам для сканирования.
Теперь давайте перейдем к тому, как вы можете добавить (или редактировать уже созданные) свои собственные правила с помощью создателя правил.
Добавление правил с помощью создателя правил
Конструктор правил используется для добавления ваших собственных правил для того, какие страницы роботы должны сканировать или нет.
Например, если вы хотите добавить правило, которое блокирует всех роботов из временного каталога (имеется в виду временная папка, например, на жестком диске), вы можете использовать для этого создатель правил.
Чтобы добавить собственное правило, просто введите User Agent (например, поисковый робот Googlebot) в поле User Agent. Или вы можете использовать символ *, чтобы ваше правило применялось ко всем пользовательским агентам (роботам).
Затем выберите «Разрешить» или «Запретить», или удалить (справа в таблице значок корзины), чтобы разрешить или заблокировать User Agent.
Или добавить новое правило:
По окончании редактирования и внесения изменений, вернитесь на верх страницы и осуществите просмотр файла в адресной строке браузера “Open Robots.txt”:
Что бы операция установки редактирования файла robots. txt была завершена, не забудьте сохранить изменения, кликнув на соответствующую кнопку в самом верху или внизу страницы редактирования.
txt была завершена, не забудьте сохранить изменения, кликнув на соответствующую кнопку в самом верху или внизу страницы редактирования.
Надеюсь, что это руководство показало вам, как легко редактировать файл robots.txt в WordPress. Теперь продолжайте и добавляйте свои собственные правила, и вы в кратчайшие сроки убедитесь, что ваш веб-сайт оптимизирован для достижения оптимальной производительности.
(Visited 1 times, 2 visits today)
Настройка robots.txt для WordPress, где находится и какой плагин использовать
06.04.2021 АлександрТеперь, когда вы выполнили первоначальную настройку и готовы приступить к наполнению сайта или решили запустить проект в работу, то самое время настроить файл robots.txt для WordPress и/или WooCommerce.
Где в WordPress robots.txt
Если вы самостоятельно установили свежую версию Вордпресс, то данный файл, необходимо создать и сохранить его в корневой папке сайта на хостинге.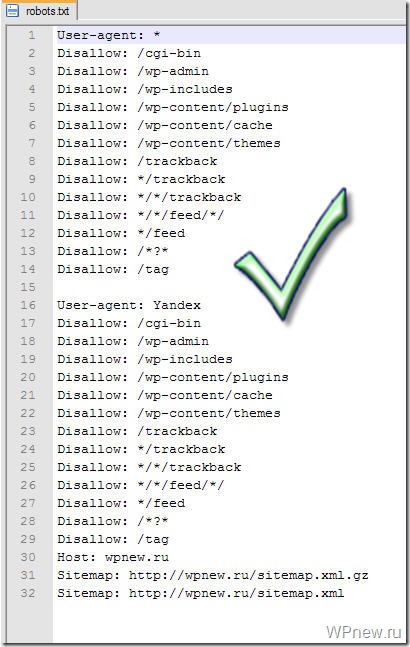 После этого, файл будет доступен по адресу https://домен вашего сайта/robots.txt или http://домен вашего сайта/robots.txt.
После этого, файл будет доступен по адресу https://домен вашего сайта/robots.txt или http://домен вашего сайта/robots.txt.
Если вам достался готовый и рабочий проект, то тут возможно два варианта:
- файл robots.txt уже настроен и находится в корневой папке сайта;
- его забыли создать.
Индексация сайта на момент разработки
Если проект находится в разработке, то желательно активировать функцию, которая в WordPress находится: «Настройки», «Чтение», «Видимость для поисковых систем», «Попросить поисковые системы не индексировать сайт» и нажмите кнопку «Сохранить изменения». А в файле robots.txt временно запретить доступ к корневой папке поисковым роботам.
Зачем это нужно? — спросите вы.
Дело в том, что при создании сайта/блога в виду множества причин, будут не раз меняться url страниц и файлов сайта (меняются расположение рубрик/страниц/записей/карточек товаров, подключается транслитерация кириллицы для страниц и загружаемых файлов, создаются тестовые страницы. ..).
..).
Чтобы «неправильные» адреса не попали в поисковую выдачу, необходимо сделать выше написанное. А когда все будет готово — то пункт «Видимость для поисковых систем» верните в исходное положение (убрать флажок в чекбоксе) и настройте правильный robots.txt для WordPress и/или WooCommerce.
Добавлять сайт в кабинет Яндекс Вебмастер и/или в Google Search Console – необходимо только тогда, когда будите готовы запустить проект в работу и на сайте будет настроен robots.txt и сформирована карта сайта в формате xml.
Настройка через хостинг и плагин
Если вы создаете файл самостоятельно, то для работы с ним рекомендуется использовать текстовый редактор, который не добавляет лишний код в разметку, например, Notepad++.
Основные директивы, которые понадобятся в настройке robots.txt через хостинг или плагин, например, Yoast SEO — выглядят следующим образом:
- User-agent: — указывает к каким поисковым роботам применяется правило, например, Yandex, * (роботы всех ПС), Googlebot;
- Disallow: — запрещает индексацию;
- Allow: — индексация разрешена;
- Sitemap: — указывает на расположение файла sitemap.
 xml. В данном файле содержатся все страницы, предназначенные для индексирования;
xml. В данном файле содержатся все страницы, предназначенные для индексирования; - Host: — указывает на главное зеркало сайта, например, https://домен.ru/. В данный момент, директива Host не используется и прописывать ее в файле robots.txt — не надо.
Как запретить индексирование сайта в robots.txt
Чтобы запретить индексирование сайта в robots.txt для всех поисковых роботов, используйте следующую конструкцию:
User-agent: * Disallow: /
robots для блога/сайта на WordPress
Файл robots.txt для WordPress выглядит следующим образом:
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /tag Disallow: /*?* Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://заменить на домен вашего сайта/sitemap.xml (если не используете плагин Yoast SEO) Sitemap: https://заменить на домен вашего сайта/sitemap_index.xml (если используете плагин Yoast SEO)
Для WooCommerce
Файл robots.txt для WooCommerce выглядит следующим образом:
User-agent: * Disallow: /cgi-bin Disallow: /wp- Disallow: /tag Disallow: /wp-admin Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: *?replytocom Disallow: *?* Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Disallow: /my-account/ Disallow: /wp-login.php Disallow: /wp-register.php Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /tag Disallow: *?replytocom Disallow: *?* Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Disallow: /my-account/ Disallow: /wp-login.php Disallow: /wp-register.php Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://заменить на домен вашего сайта/sitemap.xml (если не используете плагин Yoast SEO) Sitemap: https://заменить на домен вашего сайта/sitemap_index.xml (если используете плагин Yoast SEO)
Готовый файл robots.txt загрузите на хостинг, в корень сайта или создайте его там через стандартный менеджер файлов и сохраните изменения.
Повторюсь, если редактируете robots.txt на компьютере или работаете с любым другим файлом, который содержит в себе код, то используйте для этого Notepad++.
Для примера, этот текст написан в OpenOffice и если его скопировать и вставить, например, в онлайн HTML-редактор, то увидите это:
Некоторые редакторы автоматически добавляют теги разметки в текст, а чтобы этого не происходило — используйте предназначенные для этого инструменты.
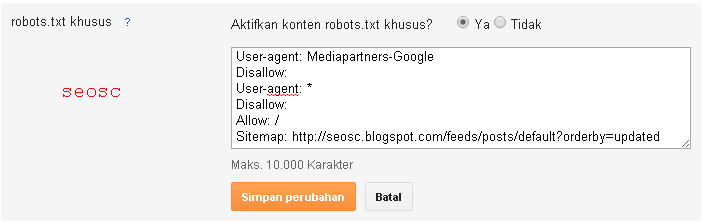
Настройка через плагин Yoast SEO
Если у вас установлен плагин Yoast SEO, то для создания и редактирования файла robots. txt в нем предусмотрена эта функция.
txt в нем предусмотрена эта функция.
Для того,чтобы создать или редактировать — перейдите в настройки «SEO» и выберите пункт «Инструменты».
Если файла нет, то плагин предложит создать его.
Для этого нажмите на соответствующую кнопку «Создать файл robots.txt». В поле ниже автоматически появятся следующие строки:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Если вы хотите запретить поисковым роботам индексировать сайт на момент разработки, то измените содержимое на:
User-agent: * Disallow: /
Если вы готовы запустить проект, то настройте содержимое файла через редактор плагина.
Не забудьте сохранить настройки.
Как создать sitemap.xml для WordPress
Файл sitemap.xml для WordPress создает тот же плагин Yoast SEO автоматически и доступен по адресу: https://домен вашего сайта/sitemap_index.xml.
Данный плагин имеет всего две настройки xml-карты:
Чтобы активировать или выключить эту функцию, необходимо перейти в «SEO», «Общие», дополнительная вкладка «Возможности», пункт «XML-карта сайта» и установить в желаемое положение.
Здесь вы найдете и ссылку, перейдя по которой можно просмотреть карту сайта WordPress в формате xml.
Закрыть от индексации отдельные страницы
Часто требуется закрыть технические страницы от индексации. И забегая вперед, отмечу, что не стоит закрывать от индексации страницы в robots.txt – в Google Search Console быстро появиться ошибка.
Как быть?
Для того, чтобы закрыть от индексации отдельно взятые страницы сайта собранного на WordPress, используйте плагин Yoast SEO, в котором предусмотренный эти настройки.
Для этого переходим в редактирование страницы, записи или карточки товара и спускаемся вниз, к SEO блоку Yoast.
Под вкладкой «Ключевое содержимое» находим вкладку «Дополнительно». В ней необходимо указать следующие настройки:
- Разрешить поисковым системам показывать тип записей «Страница» в результатах поиска? — Нет;
- Должны ли поисковые системы проходить по ссылкам в этой записи типа «Страница»? — No;
- Расширенная настройка тега Meta Robots – Не архивировать.
Затем нажмите в правом верхнем углу «Обновить».
Теперь данная страница не будет учитываться в результатах поиска, поскольку в исходном коде страницы будут прописаны атрибуты noindex и nofollow для Robots Tag.
Чтобы просмотреть исходный код страницы, нажмите сочетание клавиш ctrl + u.
На этом я завершаю и надеюсь, что настройка robots.txt для WordPress не вызовет у вас затруднений, после изучения данной статьи. Вы теперь знаете где он находится и какой плагин использовать для его редактирования через админку.
Александр
Пишу SEO-тексты, и наполняю ими страницы коммерческих сайтов и/или дорабатываю уже существующий контент.
Правильный файл Robots.txt для WordPress (Яндекс, Google)
Содержание статьи:
Здравствуйте! После того как мы разобрались с правильной структурой сайта настало время поговорить о robots.
 txt, что это такое и с чем его едят. Кроме того, из данной статьи вы узнаете, каков он, идеально правильный robots.txt для WordPress, как с его помощью запретить индексацию сайта или разрешить всё.
txt, что это такое и с чем его едят. Кроме того, из данной статьи вы узнаете, каков он, идеально правильный robots.txt для WordPress, как с его помощью запретить индексацию сайта или разрешить всё.Robots.txt – что это такое?
Файл robots.txt – это файл, с помощью которого можно выставить запрет на индексацию каких-либо частей сайта или блога поисковым роботом.
Создается единый стандартный robots txt для Яндекса и для Google, просто вначале прописываются запреты для одной поисковой сети, а затем для другой. В принципе в нём можно прописать параметры для всех поисковых систем, однако, зачастую не имеет смысла это делать, т.к. конкретно для России основными считают Яндекс и Гугл, с остальных поисковых систем трафик настолько мал, что ради них нет необходимости прописывать отдельные запреты и разрешения.
Зачем он нужен?
Если вы сомневаетесь нужен ли robots txt вообще, то ответ однозначный – ДА. Данный файл показывает поисковым системам куда им ходить нужно, а куда нет.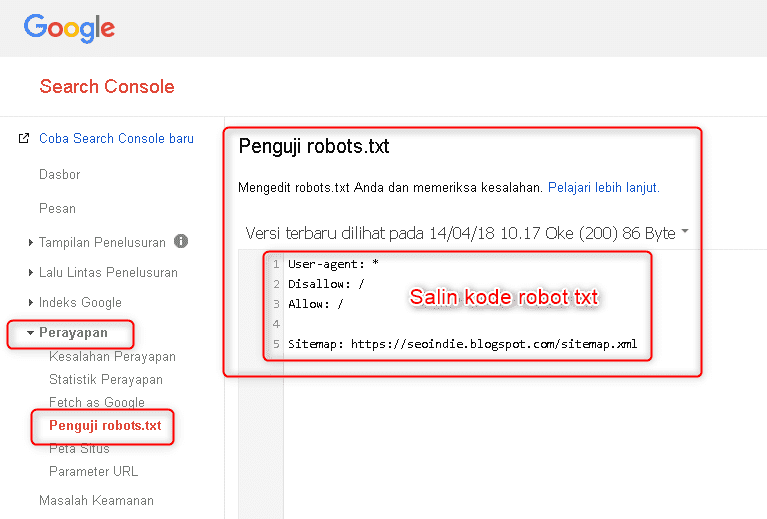 Таким образом, с помощью «Роботса» можно манипулировать поисковыми системами и не давать индексировать те документы, которые вы бы хотели оставить в тайне.
Таким образом, с помощью «Роботса» можно манипулировать поисковыми системами и не давать индексировать те документы, которые вы бы хотели оставить в тайне.
Важно! К файлу robots txt Яндекс относится, так сказать, с уважением, он всегда учитывает все нововведения и поступает так, как указано в файле. С Google ситуация сложнее, чаще всего поисковый гигант игнорирует запреты от «Роботса», но тем не менее лично я рекомендую всё равно прописывать все необходимые данные в этот файлик.
Зачем не пускать поисковики к каким-то файлам или директориям?
- Во-первых, некоторые директории (например теги в WordPress или страницы пагинации) оставляют много “мусора” в выдаче, что негативно сказывается на самом сайте.
- Во-вторых, быть может вы разместили неуникальный контент, но очень нужно, чтобы он был на сайте, с помощью robots.txt можно не дать поисковому роботу добраться до такого документа.
Где находится?
Файл robots.txt располагается в корне сайта, т. е. он всегда доступен по адресу site.ru/robots.txt. Так что если вы раньше не знали, как найти robots txt на сайте, то теперь вы с лёгкостью сможете посмотреть и возможно отредактировать его.
е. он всегда доступен по адресу site.ru/robots.txt. Так что если вы раньше не знали, как найти robots txt на сайте, то теперь вы с лёгкостью сможете посмотреть и возможно отредактировать его.
Зная, где находится данный файл, вы теперь без труда сможете заменить старый и добавить новый robots.txt на сайт, если в этом есть необходимость.
Robots txt для WordPress
Правильный robots.txt для WordPress вы можете скачать с моего блога, он располагается по адресу //vysokoff.ru/robots.txt . Это идеальный и правильно оформленный «Роботс», вы можете добавить его к себе на сайт.
После того как вы скачали мой robots.txt для WordPress, в нём необходимо будет исправить домен на свой, после этого смело заливайте файлик к себе на сервер и радуйтесь тому, как из поисковой выдачи выпадают ненужные «хвосты».
Кстати, не пугайтесь, если после 1-2 АПов Яндекса у вас вдруг резко сократится количество страниц в поисковой выдаче. Это нормально, даже наоборот – это отлично, значит ваш robots. txt начал работать и в скором времени вы избавитесь от не нужного хлама, который раньше висел в SERP’e.
txt начал работать и в скором времени вы избавитесь от не нужного хлама, который раньше висел в SERP’e.
Так что если вы не знаете, как создать robots txt для WordPress самостоятельно, то рекомендую просто скачать готовый вариант с моего блога, лучше вы вряд ли составите.
Теперь давайте поговорим о том, как полностью закрыть от индексации весь сайт с помощью данного чудо-файлика или наоборот, как разрешить всё, используя robots.txt.
Пример Robots.txt: disallow и allow, host и sitemap
Как было сказано выше, с помощью robots txt можно как запретить индексацию сайта, так и разрешить всё.
Disallow
Данной командой вы закроете весь сайт от индексации поисковых систем. Выглядеть это будет так:
User-agent: *
Disallow: /
Таким образом, вы полностью закроете сайт от индексации. Для чего это делать? Ну, например, как я рассказывал ранее, в статье про стратегию наполнения нового сайта. Изначально вы добавляете файл robots. txt в корень сайта и прописываете код, который указан выше.
txt в корень сайта и прописываете код, который указан выше.
Артём Высоков
Автор блога о SEO и заработке на сайтах — Vysokoff.ru. Продвигаю информационные и коммерческие сайты с 2013 года.
Задать вопрос Загрузка …Добавляете необходимое количество статей, а затем, скачав мой идеальный robots txt, открываете от индексации только необходимые разделы на сайте или блоге.
Чтобы в robots txt разрешить всё, вам необходимо написать в файле следующее:
User-agent: *
Disallow:
Т.е. убрав слэш, мы показываем поисковым системам, что можно индексировать абсолютно всё.
Кроме того, если вам необходимо закрыть какую-то конкретную директорию или статью от индексации, необходимо просто дописывать после слэша путь до них:
Disallow: /page.htm
Disallow: /dir/page2.htm
Allow
Данный параметр наоборот открывает для индексации какую-то конкретную страницу из закрытой Disallow директории.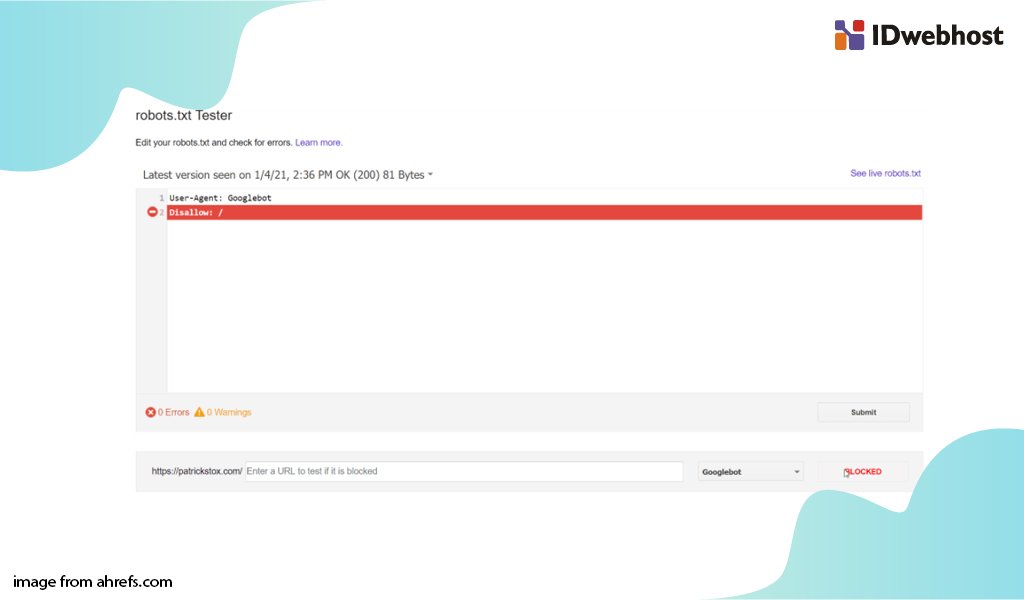 Пример:
Пример:
Disallow: /dir/
Allow: /dir/ page2.htm
Прописываем Host и карту сайта
В конце файла robots txt вам необходимо прописать два параметра host и sitemap, делается это так:
Host: www.site.ru
Sitemap: www.site.ru/sitemap.xml
Host указывается для определения правильного зеркала сайта, а второе помогает роботу узнать, где находится карта сайта.
Проверка Robots.txt Яндексом и Google
После того как вы сделали правильный robots.txt и разместили его на сайте, вам необходимо добавить и проверить его в вебмастере Яндекса и Гугла, кстати, о том, как добавить сайт в вебмастеры этих поисковых систем я уже писал.
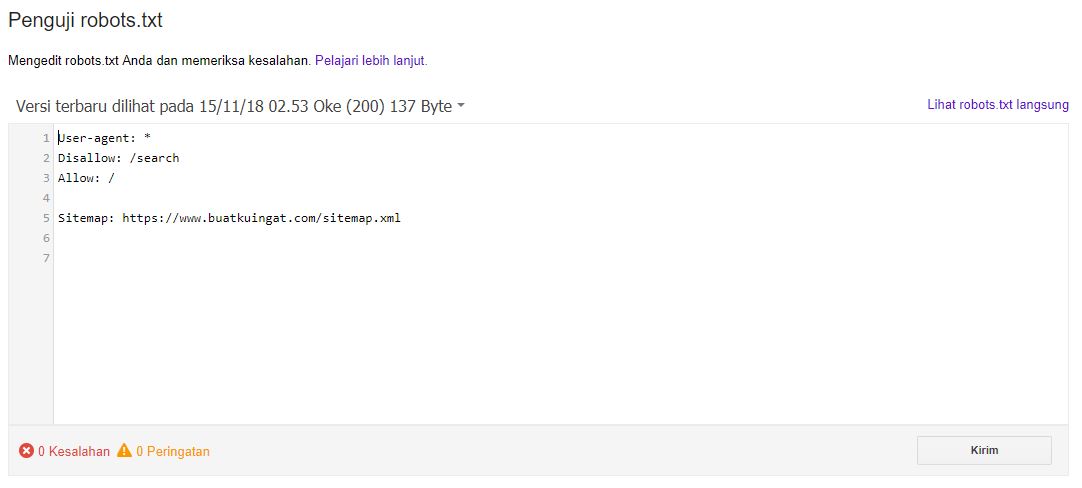
Чтобы проверить Robots.txt Яндексом необходимо зайти в https://webmaster.yandex.ru/ —> Настройка индексирования —> Анализ robots.txt.
В Google заходим http://google.ru/webmasters —> Сканирование —> Инструмент проверки файла robots.txt
Таким образом вы сможете проверить свой robots. txt на ошибки и внести необходимые коррективы, если они есть.
txt на ошибки и внести необходимые коррективы, если они есть.
Резюме
Ну вот, думаю, мне удалось объяснить вам, что такое robots.txt, для чего он нужен. Кроме того, напоминаю, скачать файл robots txt вы можете здесь.
В следующий раз я расскажу вам о супер-плагине WordPress SEO by Yoast, без которого, я считаю, нельзя начинать успешное продвижение сайта.
Готовый robots.txt под WordPress — IT портал
В этой статье пример оптимального, на наш взгляд, кода для файла robots.txt под WordPress, который вы можете использовать в своих сайтах.
Для начала, вспомним зачем нужен robots.txt — файл robots.txt нужен исключительно для поисковых роботов, чтобы «сказать» им какие разделы/страницы сайта посещать, а какие посещать не нужно. Страницы, которые закрыты от посещения не будут попадать в индекс поисковиков (Yandex, Google и т.д.).
Вариант 1: оптимальный код robots.
 txt для WordPress
txt для WordPressUser-agent: *
Disallow: /cgi-bin # классика...
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search # поиск
Disallow: /author/ # архив автора
Disallow: *?attachment_id= # страница вложения. Вообще-то на ней редирект...
Disallow: */trackback
Disallow: */feed # все фиды
Disallow: */embed # все встраивания
Disallow: */page/ # все виды пагинации
Allow: */uploads # открываем uploads
Allow: /*/*.js # внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.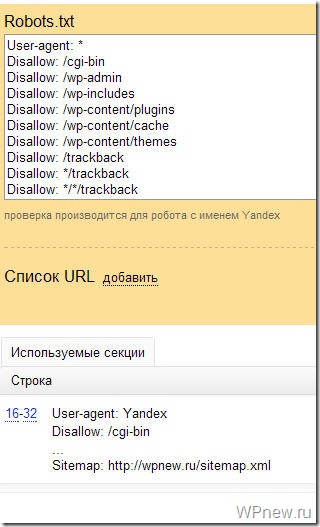 д.
д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
#Disallow: /wp/ # когда WP установлен в подкаталог wp
Host: www.site.ru
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap2.xml
# Версия кода: 1.0
# Не забудьте поменять <code>site.ru на ваш сайт.
Разбор кода:
В строке User-agent: * мы указываем, что все нижеприведенные правила будут работать для всех поисковых роботов *. Если нужно, чтобы эти правила работали только для одного, конкретного робота, то вместо * указываем имя робота (User-agent: Yandex, User-agent: Googlebot).
В строке Allow: */uploads мы намеренно разрешаем индексировать ссылки, в которых встречается /uploads. Это правило обязательно, т.к. выше мы запрещаем индексировать ссылки начинающихся с /wp-, а /wp- входит в /wp-content/uploads.
Disallow: /wp- нужна строчка Allow: */uploads, ведь по ссылкам типа /wp-content/uploads/... у нас могут лежать картинки, которые должны индексироваться, так же там могут лежать какие-то загруженные файлы, которые незачем скрывать. Allow: может быть «до» или «после» Disallow:.
Остальные строчки запрещают роботам «ходить» по ссылкам, которые начинаются с:
Disallow: /cgi-bin — закрывает каталог скриптов на сервереDisallow: /feed — закрывает RSS фид блогаDisallow: /trackback — закрывает уведомленияDisallow: ?s= или Disallow: *?s= — закрыавет страницы поискаDisallow: */page/ — закрывает все виды пагинации
Правило Sitemap: http://site.ru/sitemap.xml указывает роботу на файл с картой сайта в формате XML. Если у вас на сайте есть такой файл, то пропишите полный путь к нему. Таких файлов может быть несколько, тогда указываем путь к каждому отдельно.
В строке Host: site.ru мы указываем главное зеркало сайта. Если у сайта существуют зеркала (копии сайта на других доменах), то чтобы Яндекс индексировал всех их одинаково, нужно указывать главное зеркало. Директива Host: понимает только Яндекс, Google не понимает! Если сайт работает под https протоколом, то его обязательно нужно указать в Host: Host: https://site.ru
Из документации Яндекса: «Host — независимая директива и работает в любом месте файла (межсекционная)». Поэтому её ставим наверх или в самый конец файла, через пустую строку.
Это важно: сортировка правил перед обработкой
Yandex и Google обрабатывает директивы Allow и Disallow не по порядку в котором они указаны, а сначала сортирует их от короткого правила к длинному, а затем обрабатывает последнее подходящее правило:
User-agent: *
Allow: */uploads
Disallow: /wp-
будет прочитана как:
User-agent: *
Disallow: /wp-
Allow: */uploads
Таким образом, если проверяется ссылка вида: /wp-content/uploads/file., правило  jpg
jpgDisallow: /wp- ссылку запретит, а следующее правило Allow: */uploads её разрешит и ссылка будет доступна для сканирования.
Чтобы быстро понять и применять особенность сортировки, запомните такое правило: «чем длиннее правило в robots.txt, тем больший приоритет оно имеет. Если длина правил одинаковая, то приоритет отдается директиве Allow.»
Вариант 2: стандартный robots.txt для WordPress
Не знаю кто как, а я за первый вариант! Потому что он логичнее — не надо полностью дублировать секцию ради того, чтобы указать директиву Host для Яндекса, которая является межсекционной (понимается роботом в любом месте шаблона, без указания к какому роботу она относится). Что касается нестандартной директивы Allow, то она работает для Яндекса и Гугла и если она не откроет папку uploads для других роботов, которые её не понимают, то в 99% ничего опасного это за собой не повлечет. Я пока не заметил что первый robots работает не так как нужно.
Вышеприведенный код немного не корректный.
1. Некоторые роботы (не Яндекса и Гугла) — не понимают более 2 директив: User-agent: и Disallow:;
2. Директиву Яндекса Host: нужно использовать после Disallow:, потому что некоторые роботы (не Яндекса и Гугла), могут не понять её и вообще забраковать robots.txt. Cамому же Яндексу, судя по документации, абсолютно все равно где и как использовать Host:, хоть вообще создавай robots.txt с одной только строчкой Host: www.site.ru, для того, чтобы склеить все зеркала сайта;
3. Sitemap: межсекционная директива для Яндекса и Google и видимо для многих других роботов тоже, поэтому её пишем в конце через пустую строку и она будет работать для всех роботов сразу.
На основе этих поправок, корректный код должен выглядеть так:
User-agent: Yandex
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /wp-login. php
php
Disallow: /wp-register.php
Disallow: /comments
Disallow: */trackback
Disallow: */embed
Disallow: */feed
Disallow: /cgi-bin
Disallow: *?s=
Host: site.ru
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /comments
Disallow: */trackback
Disallow: */embed
Disallow: */feed
Disallow: /cgi-bin
Disallow: *?s=
Sitemap: http://site.ru/sitemap.xml
Дописываем под себя
Если вам нужно запретить еще какие-либо страницы или группы страниц, можете внизу добавить правило (директиву) Disallow:. Например, нам нужно закрыть от индексации все записи в категории news, тогда перед Sitemap: добавляем правило:
Disallow: /news
Оно запретить роботам ходить по подобным ссылками:http://site.ru**/news**
http://site.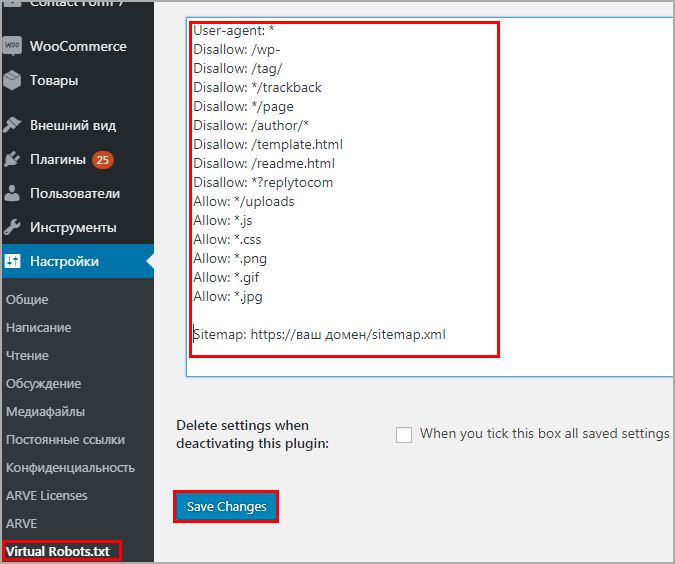 ru**/news**/drugoe-nazvanie/
ru**/news**/drugoe-nazvanie/
Если нужно закрыть любые вхождения /news, то пишем:
Disallow: */news
Закроет:http://site.ru**/news**
http://site.ru**/news**/drugoe-nazvanie/
http://site.ru/category**/news**letter-nazvanie.html
Проверка robots.txt
Проверить правильно ли работают прописанные правила можно по следующим ссылкам:
Яндекс: http://webmaster.yandex.ru/robots.xml.
В Google это делается в Search console. Нужна авторизация и наличия сайта в панели веб-мастера…
Сервис для создания файла robots.txt: http://pr-cy.ru/robots/
Сервис для создания и проверки robots.txt: https://seolib.ru/tools/generate/robots/
Источник
Вот и все, если Вы хотите «поблагодарить» наше IT сообщество — у вас есть такая возможность: справа есть варианты для пожертвований на развитие портала. Или поделитесь статьей в ваших соц.сетях через сервис ниже.
Похожие материалы:
Правильный файл robots.
 txt для сайта на WordPress в 2021
txt для сайта на WordPress в 2021Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
Пример правильного файла robots.txt для сайта на WordPress
- User-agent: *
- Disallow: /cgi-bin
- Disallow: /wp-admin/
- Disallow: /wp-includes/
- Disallow: /wp-content/plugins/
- Disallow: /wp-content/cache/
- Disallow: /wp-content/themes/
- Disallow: /wp-trackback
- Disallow: /wp-feed
- Disallow: /wp-comments
- Disallow: /author/
- Disallow: */embed*
- Disallow: */wp-json*
- Disallow: */page/*
- Disallow: /*?
- Disallow: */trackback
- Disallow: */comments
- Disallow: /*.php
- Host: https://seopulses.ru
- Sitemap: https://seopulses.ru/sitemap_index.xml
Где можно найти файл robots.txt и как его создать или редактировать
Чтобы проверить файл robots.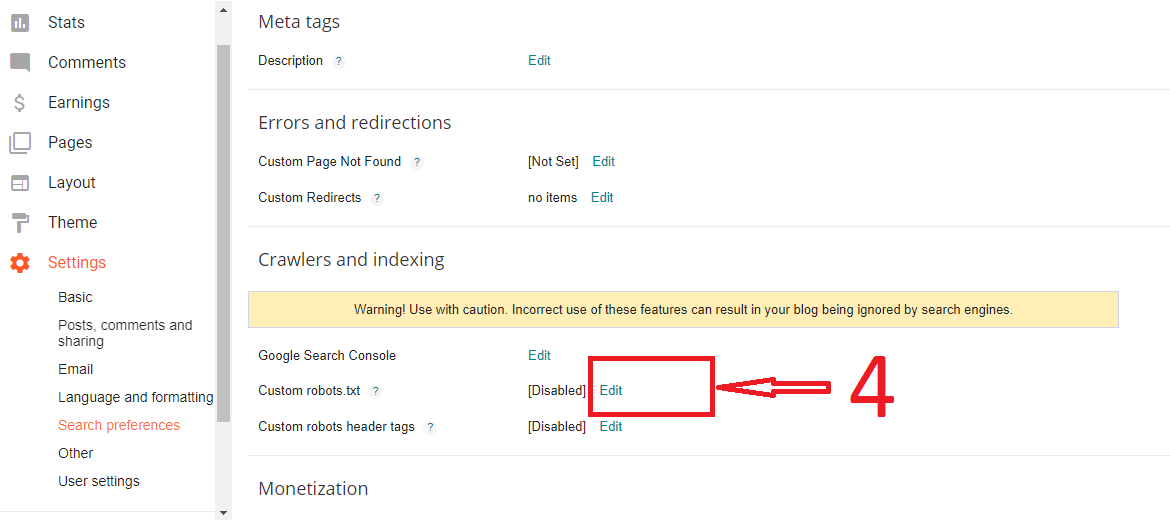 txt сайта, следует добавить к домену «/robots.txt», примеры:
txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
- Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
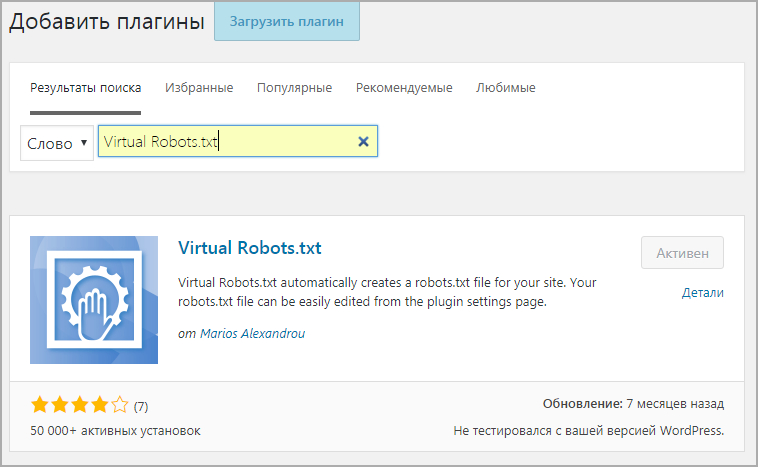
Virtual Robots.txt
https://opencartforum.com/files/file/5141-edit-robotstxt/
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Инструкция по работе с robots.
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site. ru/feed/.
ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.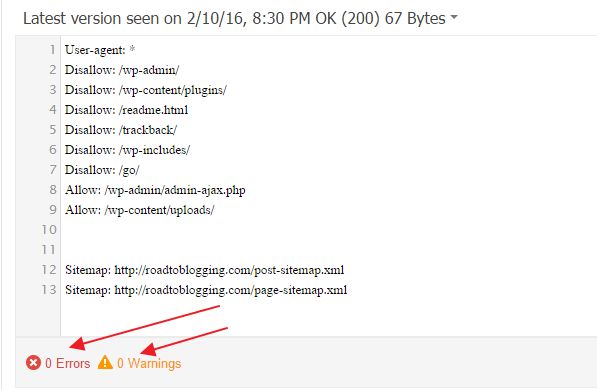
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс. Вебмастер и Google Search Console.
Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Файл robots.txt для WordPress
Что же такое файл robots.txt? Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта.
В нём записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации некоторые разделы, или страницы на сайте, такие как “админ”, конфиденциальная информация клиентов сайта, и тому подобные.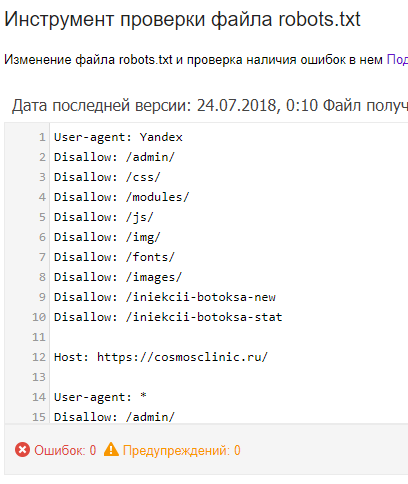
Этот файл рекомендует поисковому роботу соблюдать определенный временной интервал, между скачиванием документов с сервера, и указывает путь к карте сайта sitemap.xml.
Последнее время его роль в SEO, несколько ослабла, и появляются всё новые рекомендации по его применению, но актуальности robots не потерял.
Чтоб быть в курсе всех изменений и рекомендаций, советую вступить в «Сообщество Google для веб-мастеров».
Ну а пока посмотрим, как создаётся, и что из себя представляет файл robots.txt.
Создать его можно двумя способами: вручную, если Вы пишете сайт самостоятельно, и при помощи плагина, если Вы используете CMS, хотя заполнять плагин всё равно приходится вручную.
Итак, для WordPress плагин называется WP Robots Txt. Вносим это название в строку “искать плагины”, находящуюся в консоль-плагины-добавить плагин, и устанавливаем на наш сайт.
Затем, “Активировать” плагин, и заходим в “Настройки – приватность (или конфиденциальность, у кого как)”.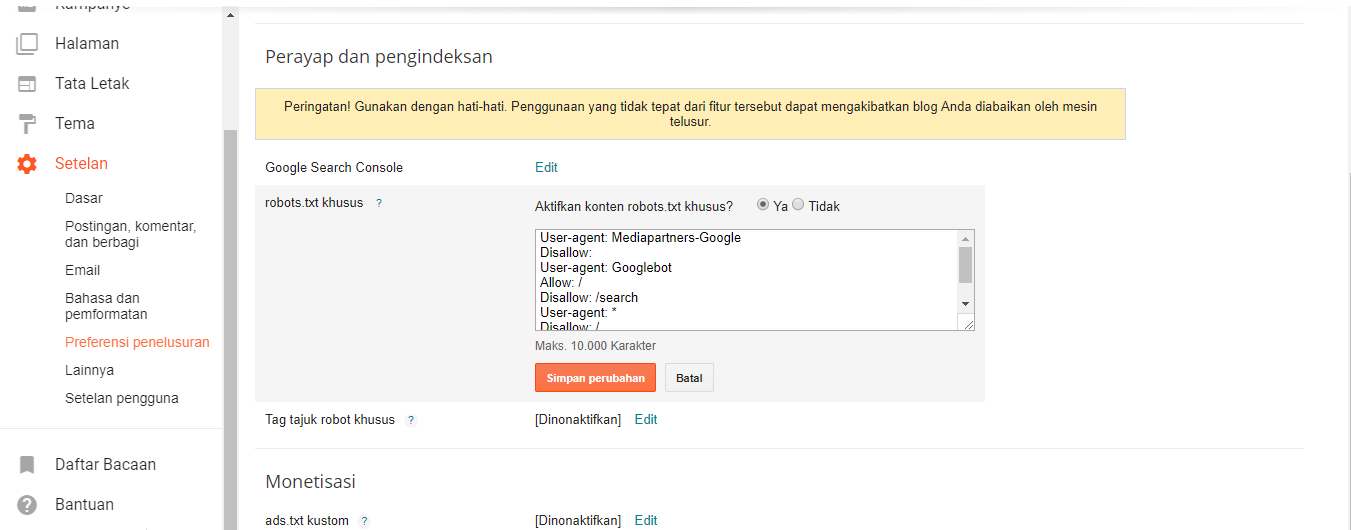 В ней нам откроется опция позволяющая редактировать плагин.
В ней нам откроется опция позволяющая редактировать плагин.
И вот тут, признаюсь, меня ждал очень интересный сюрприз.
И тем не менее, раз уж столько народа так настоятельно советуют создать файл robots.txt, думаю не стоит игнорировать общественное мнение. К тому же ничего сложного в этом нет, а дополнительные знания будут только на пользу.
Для того, чтобы настроить файл robots.txt, используются следующие директивы:
User-agent – указывает какому поисковому роботу адресована инструкция;
Disallow – запрещающая индексацию;
Allow – разрешающая индексацию;
Host – определяет какую страницу сайта считать главной;
Sitemap – указывает путь к карте сайта sitemar.txt;
В свете последних тенденций, поисковики рекомендуют делать файл robots.txt максимально открытым, поэтому
в общем и целом он выглядит так:
User-agent: *
Disallow: /wp-includes
Disallow: /wp-feed
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Host: starper55plys. ru
ru
Sitemap: https://starper55plys.ru/sitemap.xml
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Что же запрещается для индексирования. В первую очередь это ядро движка, кеш, файлы шаблона и плагинов, ленты rss в общем всю техническую часть сайта.
Если у Вас на сайте есть конфиденциальная информация посетителей, то её тоже нужно закрыть, но насколько это действенно, Вы уже убедились прочитав заметку при настройке плагина.
В общем, вносите все эти данные в окно редактирования плагина, и жмите “сохранить изменения”.
В дальнейшем, когда Вы перенесёте Ваш сайт с Денвера на реальный хостинг, нужно будет проверить, как работает файл robots.txt. Для этого просто пройдите по по ссылке проверка robots.txt.
Если же Вы не используете CMS, а пишете сайт на чистом HTML, то открываете HTML редактор (Notepad++), переписываете или копируете в него код файла, меняете адреса на свои, и сохраняете его с названием robots. txt, в директорию сайта.
txt, в директорию сайта.
Перемена
— Винтовка для солдата — лучший друг, не правда ли? — Не знаю, господин генерал! Вчера, когда я ее чистил, она выстрелила мне в ногу!
Приходит Сара к раввину.
— Ребе, я завтра замуж выхожу, посоветуйте, как лучше лечь в постель в первую ночь: в рубашке или без?
Тут подбегает Рабинович.
— Ребе, посоветуйте, куда лучше вложить деньги, в акции или ценные бумаги?
Ребе отвечает:
— Как ты, Сарочка, ни ляжешь, тебя все равно поимеют. К Вам, Рабинович, это тоже относится.
Администратор гостиницы говорит клиенту:
— Я могу поселить вас с этой женщиной, лишь тогда, когда вы докажите, — что она ваша жена.
Клиент отвечает:
— А если вы докажите обратное, я буду благодарен вам до самой смерти.
Во времена борьбы с пьянством — стоит около винного огромная очередь, к очереди подбегает мужик:
— Мужики! Пропустите меня, а?.. У меня машина стоит…
— Да пошел ты! «Машина стоит»… У нас заводы стоят!
Создание xml карты сайта на WordPress < < < В раздел > > > Оптимизация изображений
ботов и индексация в Pantheon
Боты являются частью жизненного цикла каждого общедоступного веб-сайта.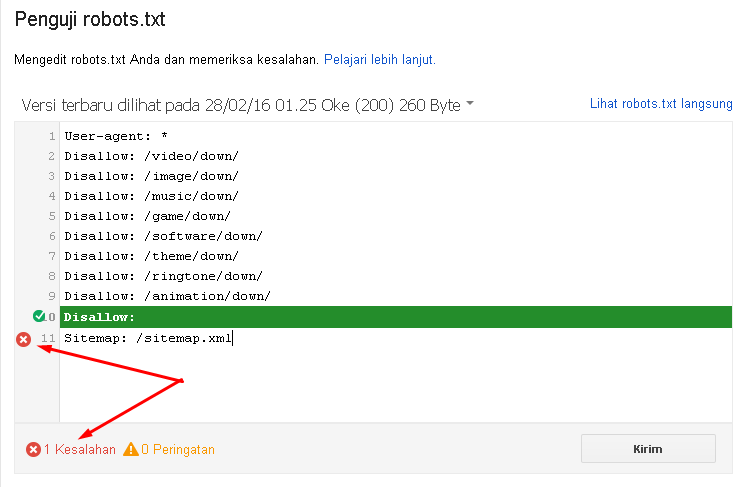 Без них мы не смогли бы найти ничего в Интернете! Боты выполняют тяжелую работу, которая считается само собой разумеющейся, при просмотре множества проиндексированных результатов поиска из любой данной поисковой системы. В чужих руках боты могут стать раздражающими, замедляя или даже останавливая ваш сайт.
Без них мы не смогли бы найти ничего в Интернете! Боты выполняют тяжелую работу, которая считается само собой разумеющейся, при просмотре множества проиндексированных результатов поиска из любой данной поисковой системы. В чужих руках боты могут стать раздражающими, замедляя или даже останавливая ваш сайт.
Боты не просматривают страницы, как люди. Анализ шаблонов доступа в журнале nginx — один из самых быстрых способов определить наличие ботов.
Rapid Fire Requests / Duplicates
В приведенном ниже фрагменте журнала есть несколько запросов, поступающих по одному и тому же пути в быстрой последовательности. Отметка времени отражает 5 идентичных запросов в одну и ту же миллисекунду. Вам следует изучить эти запросы.
127.0.0.1 - - [11 / ноя / 2013: 19: 05: 24 +0000] "POST /index.php?q=comment/reply/545 HTTP / 1.0" 500 588 "http: // www. mywebsite.com/node/545?page=399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "0. 848" 195.200.54.200, 10.200.200.21, :: ffff: 127.0.0.1, :: ffff: 127.0.0.1 "
unix: - - [11 / ноя / 2013: 19: 05: 24 +0000] "POST /index.php?q=comment/reply/545 HTTP / 1.0" 500 588 "http://www.mywebsite.com/ node / 545? page = 399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.059" 195.200.54.200, 10.200.200.21, :: ffff: 127.0.0.1, :: ffff: 127.0.0.1 "
127.0.0.1 - - [11 / ноя / 2013: 19: 05: 24 +0000] "POST /index.php?q=comment/reply/545 HTTP / 1.0" 500 588 "http: //www.mywebsite.com / node / 545? page = 399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.059" 195.200.54.200, 10.200.200.21, :: ffff: 127.0. 0.1, :: ffff: 127.0.0.1 "
unix: - - [11 / ноя / 2013: 19: 05: 24 +0000] "POST /index.php?q=comment/reply/545 HTTP / 1.0" 500 588 "http://www.mywebsite.com/ node / 545? page = 399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.271" 195.200.54.200, 10.200.200.21, :: ffff: 127.
848" 195.200.54.200, 10.200.200.21, :: ffff: 127.0.0.1, :: ffff: 127.0.0.1 "
unix: - - [11 / ноя / 2013: 19: 05: 24 +0000] "POST /index.php?q=comment/reply/545 HTTP / 1.0" 500 588 "http://www.mywebsite.com/ node / 545? page = 399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.059" 195.200.54.200, 10.200.200.21, :: ffff: 127.0.0.1, :: ffff: 127.0.0.1 "
127.0.0.1 - - [11 / ноя / 2013: 19: 05: 24 +0000] "POST /index.php?q=comment/reply/545 HTTP / 1.0" 500 588 "http: //www.mywebsite.com / node / 545? page = 399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.059" 195.200.54.200, 10.200.200.21, :: ffff: 127.0. 0.1, :: ffff: 127.0.0.1 "
unix: - - [11 / ноя / 2013: 19: 05: 24 +0000] "POST /index.php?q=comment/reply/545 HTTP / 1.0" 500 588 "http://www.mywebsite.com/ node / 545? page = 399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.271" 195.200.54.200, 10.200.200.21, :: ffff: 127. 0.0.1, :: ffff: 127.0.0.1 "
127.0.0.1 - - [11 / ноя / 2013: 19: 05: 24 +0000] «POST / index.php? q = comment / reply / 545 HTTP / 1.0 "500 588" http://www.mywebsite.com/node/545?page=399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.271" 195.200.54.200, 10.200.200.21, :: ffff: 127.0.0.1, :: ffff: 127.0.0.1 "
unix: \ xC8 \ xFB \ x7F - - [11 / ноя / 2013: 19: 05: 24 +0000] "POST /index.php?q=comment/reply/545 HTTP / 1.0" 500 588 "http: // www.mywebsite.com/node/545?page=399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.481" 195.200.54.200, 10.200.200.21, :: ffff: 127.0.0.1, :: ffff: 127.0.0.1 "
127.0.0.1 - - [11 / ноя / 2013: 19: 05: 24 +0000] "POST /index.php?q=comment/reply/545 HTTP / 1.0" 500 588 "http://www.mywebsite.com / node / 545? page = 399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.482" 195.200.54.200, 10.200.200.21, :: ffff: 127.0.0.1 , :: ffff: 127.
0.0.1, :: ffff: 127.0.0.1 "
127.0.0.1 - - [11 / ноя / 2013: 19: 05: 24 +0000] «POST / index.php? q = comment / reply / 545 HTTP / 1.0 "500 588" http://www.mywebsite.com/node/545?page=399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.271" 195.200.54.200, 10.200.200.21, :: ffff: 127.0.0.1, :: ffff: 127.0.0.1 "
unix: \ xC8 \ xFB \ x7F - - [11 / ноя / 2013: 19: 05: 24 +0000] "POST /index.php?q=comment/reply/545 HTTP / 1.0" 500 588 "http: // www.mywebsite.com/node/545?page=399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.481" 195.200.54.200, 10.200.200.21, :: ffff: 127.0.0.1, :: ffff: 127.0.0.1 "
127.0.0.1 - - [11 / ноя / 2013: 19: 05: 24 +0000] "POST /index.php?q=comment/reply/545 HTTP / 1.0" 500 588 "http://www.mywebsite.com / node / 545? page = 399 "" Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1; SV1; MRA 4.3 (сборка 51720)) "1.482" 195.200.54.200, 10.200.200.21, :: ffff: 127.0.0.1 , :: ffff: 127. 0.0.1 "
0.0.1 " Боты сходятся на страницах с ошибками
Некоторые легитимные боты / сканеры / прокси (например, BingBot или AdsBotGoogle) идентифицируют себя.Поскольку поисковая индексация желательна для большинства сайтов, действуйте осторожно, чтобы не нанести ущерб поисковой оптимизации сайта. Тем не менее, могут быть случаи, когда сканеры / пауки сходятся на странице с ошибкой (502 в примере ниже). Эти повторяющиеся запросы могут увеличить проблемы с загрузкой страниц, увеличивая нагрузку на сервер. Немедленно исследуйте эти ошибки. Когда ошибка будет исправлена, боты / краулеры больше не будут зависать на пути предоставления.
127.0.0.1 - - [26 / июл / 2013: 15: 27: 38 +0000] "GET /index.php?q=shop/kits/shebang-kit HTTP / 1.0" 502 166 "-" "Mozilla / 5.0 (совместимый; bingbot / 2.0; + http: //www.bing.com/bingbot.htm) "14.188" 157.56.93.49, 10.183.252.21, 127.0.0.1,127.0.0.1 "
unix: - - [26 / июл / 2013: 15: 27: 38 +0000] "GET /index.php?q=shop/kits/shebang-kit HTTP / 1.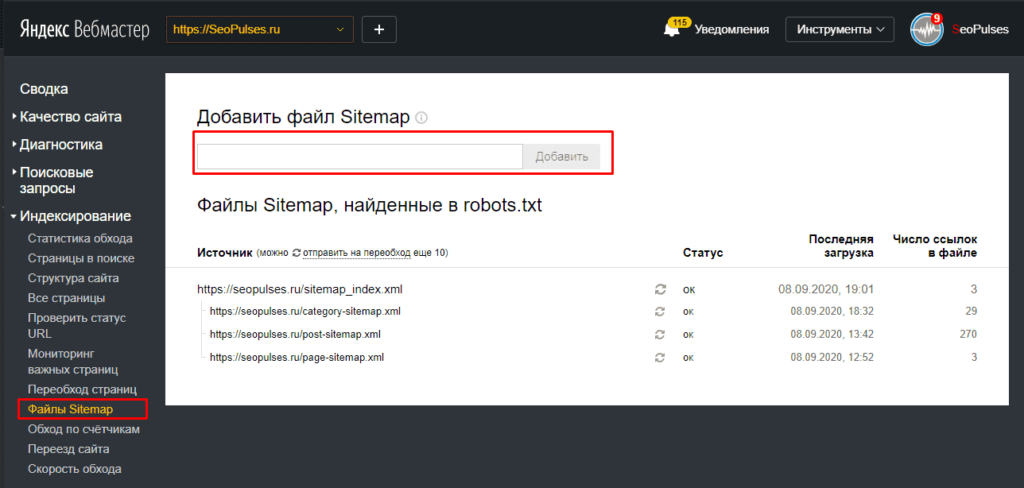 0" 502 166 "-" "Mozilla / 5.0 (совместимый ; bingbot / 2.0; + http: //www.bing.com/bingbot.htm) "14.476" 157.56.93.49, 10.183.252.21, 127.0.0.1,127.0.0.1 "
127.0.0.1 - - [26 / июл / 2013: 15: 27: 38 +0000] «GET / index.php? q = shop / kits / shebang-kit HTTP / 1.0 "502 166" - "" Mozilla / 5.0 (совместимый; bingbot / 2.0; + http: //www.bing.com/bingbot.htm) "14.477" 157.56 .93.49, 10.183.252.21, 127.0.0.1,127.0.0.1 "
127.0.0.1 - - [26 / июл / 2013: 15: 26: 37 +0000] "GET /index.php?q=gush/content/name-pimp-november-2008&page=17 HTTP / 1.0" 502 166 "- "" Mozilla / 5.0 (совместимый; bingbot / 2.0; + http: //www.bing.com/bingbot.htm) "14.722" 157.56.93.49, 10.183.252.21, 127.0.0.1,127.0.0.1 "
10.208.128.192 - - [26 / июл / 2013: 15: 26: 37 +0000] «GET / gush / content / name-pimp-november-2008? Page = 17 HTTP / 1.1 "502 166" - "" Mozilla / 5.0 (совместимый; bingbot / 2.0; + http: //www.bing.com/bingbot.htm) "14.999" 157.56.93.49, 10.183.252.21, 127.0.0.1,127.0. 0,1 "
unix: - - [26 / июл / 2013: 15: 26: 37 +0000] "GET /index.
0" 502 166 "-" "Mozilla / 5.0 (совместимый ; bingbot / 2.0; + http: //www.bing.com/bingbot.htm) "14.476" 157.56.93.49, 10.183.252.21, 127.0.0.1,127.0.0.1 "
127.0.0.1 - - [26 / июл / 2013: 15: 27: 38 +0000] «GET / index.php? q = shop / kits / shebang-kit HTTP / 1.0 "502 166" - "" Mozilla / 5.0 (совместимый; bingbot / 2.0; + http: //www.bing.com/bingbot.htm) "14.477" 157.56 .93.49, 10.183.252.21, 127.0.0.1,127.0.0.1 "
127.0.0.1 - - [26 / июл / 2013: 15: 26: 37 +0000] "GET /index.php?q=gush/content/name-pimp-november-2008&page=17 HTTP / 1.0" 502 166 "- "" Mozilla / 5.0 (совместимый; bingbot / 2.0; + http: //www.bing.com/bingbot.htm) "14.722" 157.56.93.49, 10.183.252.21, 127.0.0.1,127.0.0.1 "
10.208.128.192 - - [26 / июл / 2013: 15: 26: 37 +0000] «GET / gush / content / name-pimp-november-2008? Page = 17 HTTP / 1.1 "502 166" - "" Mozilla / 5.0 (совместимый; bingbot / 2.0; + http: //www.bing.com/bingbot.htm) "14.999" 157.56.93.49, 10.183.252.21, 127.0.0.1,127.0. 0,1 "
unix: - - [26 / июл / 2013: 15: 26: 37 +0000] "GET /index. php?q=gush/content/name-pimp-november-2008&page=17 HTTP / 1.0" 502 166 "-" "Mozilla / 5.0 (совместимый; bingbot / 2.0; + http: //www.bing.com/bingbot.htm)" 14.998 "157.56.93.49, 10.183.252.21, 127.0.0.1,127.0.0.1"
10.208.128.192 - - [26 / июл / 2013: 15: 31: 03 +0000] "GET / HTTP / 1.1" 500 109 "-" "check.panopta.com" 0.126 "5.63.145.72, 10.183.252.21, 127.0.0.1,127.0.0.1"
php?q=gush/content/name-pimp-november-2008&page=17 HTTP / 1.0" 502 166 "-" "Mozilla / 5.0 (совместимый; bingbot / 2.0; + http: //www.bing.com/bingbot.htm)" 14.998 "157.56.93.49, 10.183.252.21, 127.0.0.1,127.0.0.1"
10.208.128.192 - - [26 / июл / 2013: 15: 31: 03 +0000] "GET / HTTP / 1.1" 500 109 "-" "check.panopta.com" 0.126 "5.63.145.72, 10.183.252.21, 127.0.0.1,127.0.0.1" Важно отметить, что каждая среда вашего сайта имеет файл robots.txt , связанный с доменом платформы (например, dev- site-name.pantheonsite.io ) или пользовательский домен Vanity (например, dev-sites.myagency.com ), который содержит следующее:
# Документация Pantheon на robots.txt: https://pantheon.io / docs / bots-and-indexing /
Пользовательский агент: *
Запретить: /
Пользовательский агент: dotbot
Пользовательский агент: PetalBot
Пользовательский агент: PowerMapper
Пользовательский агент: RavenCrawler
Пользовательский агент: rogerbot
Пользовательский агент: SemrushBot
Пользовательский агент: SemrushBot-SA
Пользовательский агент: Swiftbot
Allow: / Кроме того, пограничный уровень Pantheon добавляет HTTP-заголовок X-Robots-Tag: noindex при обслуживании запросов от доменов платформы (например,грамм.
live-site-name.pantheonsite.io ). Это дает указание большинству ботов / поисковых роботов не индексировать страницу и предотвращает ее отображение в результатах поиска.
Индексирование перед запуском
Домены pantheonsite.io предназначены для использования в разработке и не могут использоваться в производственной среде. В то время как Drupal и WordPress по умолчанию генерируют свой собственный файл robots.txt , пользовательский или стандартный для CMS файл robots.txt будет работать только в Live-средах с пользовательским доменом.Добавление субдоменов (например, dev.example.com , test.example.com ) для DEV или TEST удалит только заголовок X-Robots-Tag: noindex , но по-прежнему будет обслуживать Pantheon robots.txt из домена платформы.
Для поддержки предварительного тестирования SEO и поиска по сайту мы разрешаем следующим ботам доступ к доменам платформы:
Некоторые инструменты (например, Siteimprove или ScreamingFrog) могут быть настроены так, чтобы игнорировать robots. при сканировании. Если вы тестируете ссылки или оптимизируете поисковую оптимизацию с помощью других инструментов, вы можете запросить добавление этого инструмента к нашим роботам 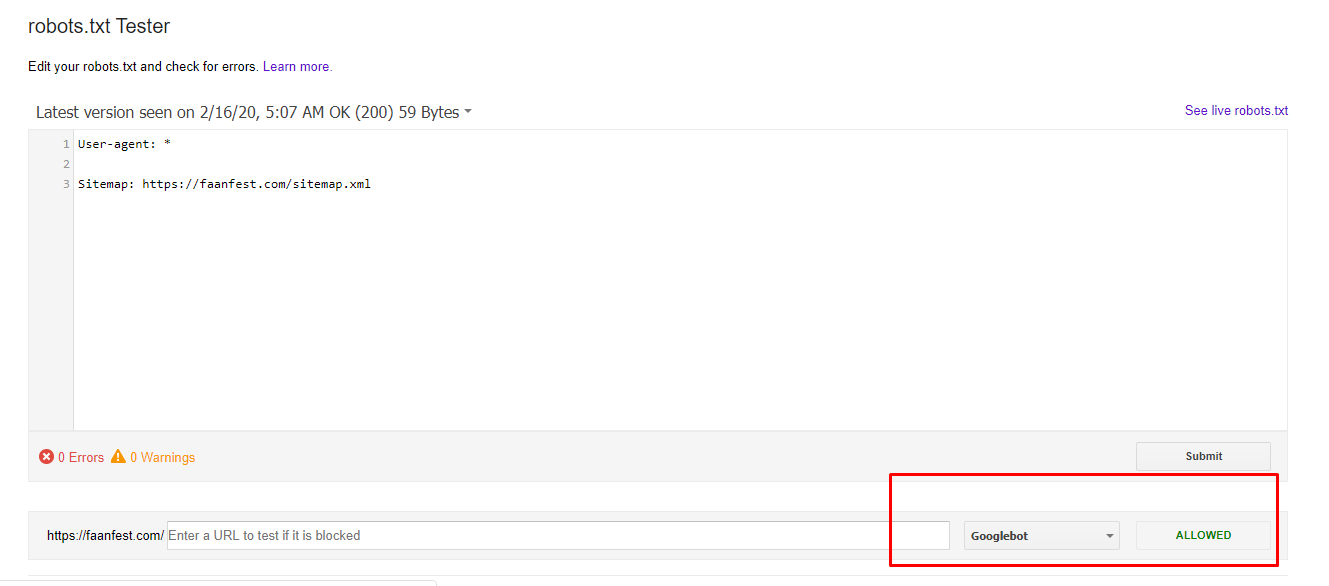 txt
txt .txt , обратившись в службу поддержки, чтобы создать запрос функции. В противном случае вы можете подключить собственный домен (например, seo.example.com ) к среде Live и протестировать свои ссылки, следующие за альтернативным доменом.
Если вы запускаете инструменты SEO локально, вы можете использовать запись файла / etc / hosts в вашем локальном окне разработки, чтобы подделать ваш производственный домен на Pantheon:
Обратите внимание, что для изменения файла hosts обычно требуются административные привилегии от ОПЕРАЦИОННЫЕ СИСТЕМЫ.
Расположение файла hosts и зависит от вашей операционной системы:
- MacOS / Linux:
/ etc / hosts - Windows:
C: \\ Windows \ System32 \ Drivers \ etc \ hosts
Добавьте строки в файл hosts вашей операционной системы в следующем формате:
203. 0.113.10 example.com
203.0.113.20 www.example.com
0.113.10 example.com
203.0.113.20 www.example.com В приведенном выше примере замените IP-адреса на те, которые предоставляет Pantheon, а домены на свои собственные.
Вы можете проиндексировать свой сайт в производственном домене после того, как он будет добавлен в среду Live. Существует множество вариантов модуля contrib для создания карт сайта для Drupal, включая XMLSiteMap и Site_Map. Пользователи WordPress могут установить Google XML Sitemaps или Yoast SEO плагины, которые будут поддерживать обновления карты сайта автоматически. Вы можете настроить расширения для работы по своему усмотрению. Pantheon не поддерживает модули Drupal или плагины WordPress.
Карты сайта создают белый экран смерти (WSOD)
Некоторые модули или плагины по умолчанию настроены на получение всех URL-адресов одновременно во время генерации карты сайта, что может привести к появлению пустой белой страницы (WSOD) из-за превышения лимита памяти PHP.Чтобы решить эту проблему, настройте плагин или конфигурацию модуля так, чтобы URL-адреса выбирались индивидуально, а не все сразу.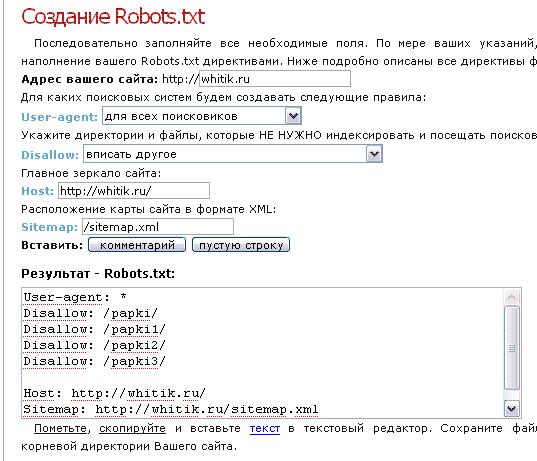
Например, если у вас есть сайт Drupal, использующий модуль XMLSiteMap, перейдите к admin / config / search / xmlsitemap / settings и снимите флажок Prefetch URL aliases во время создания карты сайта . Сохраните конфигурацию и очистите кеши для среды Live на панели управления Pantheon или через Terminus:
Props to Will Hall для выделения этого решения в соответствующем сообщении в блоге.
Отправка устаревших карт сайта Создание 404
Карты сайта можно (и нужно) отправлять непосредственно в Инструменты Google для веб-мастеров. Однако, если есть устаревшие заявки, генерирующие 404, вам необходимо перенаправить через PHP в пределах wp-config.php или settings.php . Например, сайты WordPress с плагином Yoast SEO могут использовать следующее:
if (($ _SERVER ['REQUEST_URI'] == '/sitemap.xml') &&
(php_sapi_name ()! = "cli")) {
заголовок ('HTTP / 1.0 301 Перемещено навсегда ');
заголовок ('Расположение: /sitemap_index. xml');
выход();
}
xml');
выход();
} Дополнительные примеры перенаправления через PHP см. В разделе «Настройка перенаправления».
Неверный вывод robots.txt в WordPress
В WordPress не включайте Запретите поисковым системам индексировать этот сайт в средах разработки или тестирования. Этот параметр установлен в Settings > Reading > Search Engine Visibility на панели администратора WordPress.
Этот параметр создает встроенный файл robots.txt , который запрещает или блокирует поисковые роботы. Хотя файл, применяемый платформой, обычно переопределяет его, этого не происходит, если в конце URL-адреса есть косая черта, указывающая на robots.txt .
В качестве обходного пути вы можете переопределить вывод, создав собственный фильтр для robots_txt . Вы можете добавить это как собственный плагин или запись в файле вашей темы functions.php :
add_filter ('robots_txt', 'custom_robots_txt', 10, 2);
function custom_robots_txt ($ output, $ public) {
$ robots_txt = "Пользовательский агент: * \ n";
$ robots_txt.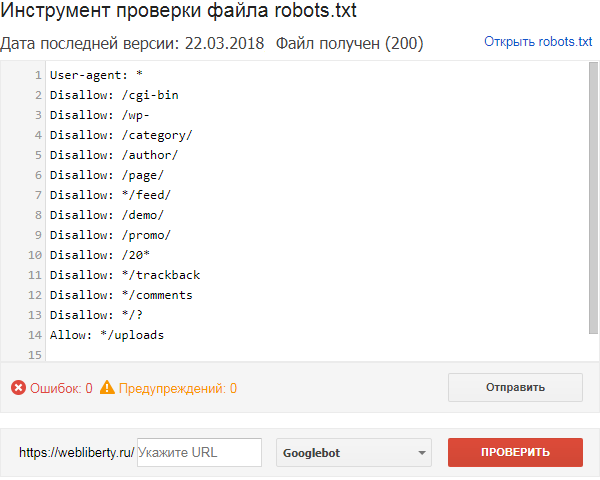 = "Карта сайта: https://www.example.com/sitemap_index.xml \ n";
$ robots_txt. = "Запретить: / secure /";
вернуть $ robots_txt;
}
= "Карта сайта: https://www.example.com/sitemap_index.xml \ n";
$ robots_txt. = "Запретить: / secure /";
вернуть $ robots_txt;
} Robot Txt File Учебное пособие для веб-сайта WordPress
Текстовый файл робота, более известный как robots.txt, представляет собой давно действующий веб-стандарт, который помогает предотвратить доступ Google и других поисковых систем к частям вашего сайта.
Почему вы хотите заблокировать Google для некоторых частей вашего сайта? Одна из важных причин - запретить Google индексировать страницы вашего сайта, которые являются дубликатами страниц других сайтов, например, страниц WordPress по умолчанию.Google наказывает сайты с дублированным контентом.
Еще одна важная причина - запретить Google ссылаться на незащищенный премиум-контент на вашем веб-сайте. Например, вы раздаете бесплатную электронную книгу людям, подписавшимся на ваш список рассылки. Вы не хотите, чтобы Google напрямую ссылался на эту электронную книгу, поэтому вы используете текстовый файл робота, чтобы Google не мог его проиндексировать.
Например, электронные книги могут храниться в папке в корневом домене под названием PDF. Это то, что вы сделали бы, чтобы заблокировать все поисковые системы.
User-Agent: *
Disallow: / PDF /
С другой стороны, если вы хотите, чтобы ваша бесплатная книга стала вирусной, не блокируйте доступ к книге поисковым системам.
Некоторым людям также нравится запрещать Google использовать их изображения в поиске Google или загружать большие файлы.
Кроме того, если у вас есть крупный сайт WordPress, Google может загружать одну и ту же страницу под несколькими разными именами, используя большую часть вашей пропускной способности и вычислительной мощности веб-сервера.Специальные шаблоны текстовых файлов роботов могут указывать Google на доступ к страницам только один раз.
Наконец, вы можете сообщить Google о своей XML-карте или текстовой карте сайта с помощью файла robots.txt, чтобы он индексировал новые страницы вашего сайта намного быстрее, чем просто ждал, пока он повторно просканирует ваш сайт.
Текстовый файл робота - это необязательный файл в корневом каталоге веб-сайта. Поскольку вы читаете это, я предполагаю, что у вас есть веб-сайт. Найдите минутку, чтобы проверить, есть ли у вас текстовый файл робота, перейдя по следующему URL-адресу: http: // example.com / robots.txt
(Замените example.com на свое доменное имя.)
Вот мое: Обратите внимание, это работа в стадии разработки. Недавно я изменил свою тему WordPress, что также потребовало, чтобы я сам редактировал текстовые файлы своего робота.
Robot Txt File Учебник для веб-сайта WordPress
Вы должны быть осторожны при редактировании этого файла, так как вы легко можете сделать ошибку и заблокировать доступ поисковых систем к вашему сайту.
Если вы получаете ошибку 404 File Not Found, у вас нет текстового файла робота.В противном случае вы увидите простой текстовый файл со строками User-Agent, Allow, Disallow и Sitemap, плюс пустые строки и строки комментариев («#»).
Что означает текстовый файл робота
• User-Agent означает пользовательский агент веб-браузера, посещающий ваш сайт. Текстовый файл робота предназначен только для роботов, также называемых пауками, которые сканируют ваш веб-сайт в поисках и других автоматизированных онлайн-инструментах. Робот-сканер Google называется Googlebot, хотя у Google также есть несколько других роботов для других инструментов поиска.
• Разрешить сообщает роботам, что им разрешено посещать URL-адреса, содержащие определенный путь. Большинство текстовых файлов роботов сообщают роботам, что корневой путь («/») можно сканировать.
• Disallow сообщает роботам, куда они не могут попасть. Большую часть времени редактирование файла robots.txt будет потрачено на создание запрещающих строк.
• Карта сайта указывает на карту вашего сайта (или на несколько карт сайта, если у вас большой сайт). Для этого вам понадобится карта сайта, для чего требуется что-то вроде плагина WordPress XML Sitemap Generator.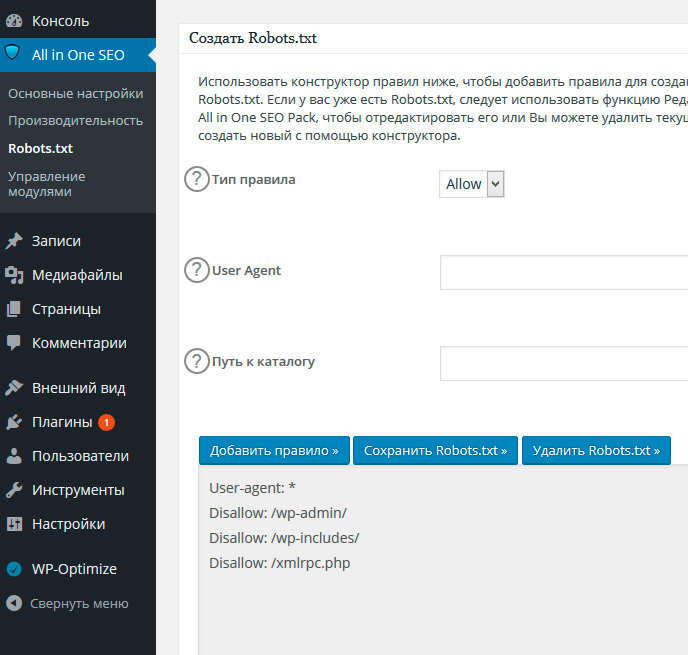
Следующие инструкции будут работать только в том случае, если вы используете WordPress для управления корневым каталогом своего веб-сайта. Это означает, что на главной странице вашего блога нет слов после имени домена.
Например, если ваша главная страница WordPress - http://example.com/, то WordPress, вероятно, управляет вашим файлом robots.txt. Но если ваша главная страница WordPress - http://example.com/blog, вероятно, WordPress не управляет вашими роботами.txt, и вам придется работать с ним напрямую, используя загрузку по FTP.
По умолчанию WordPress создает ограничительный файл robots.txt, если вы используете настройки WordPress, чтобы пометить свой блог как частный. У большинства людей есть общедоступные сайты, поэтому текстовый файл робота WordPress по умолчанию пуст.
Некоторые хостинговые компании предоставляют текстовый файл робота по умолчанию для WordPress, особенно если вы использовали установку WordPress в один клик. В этом случае вам может потребоваться отредактировать файл robots.txt с помощью загрузки по FTP.
В этом случае вам может потребоваться отредактировать файл robots.txt с помощью загрузки по FTP.
Но если ничего из вышеперечисленного не соответствует действительности, вы, вероятно, можете попросить WordPress сгенерировать для вас файл robots.txt.
Robots.txt Плагины WordPressНесколько плагинов SEO могут создавать файл robots.txt. Я был бы осторожен с их использованием, если вы занимаетесь чем-либо помимо ведения блога на своем сайте, потому что они могут помешать Google индексировать допустимые страницы. Это может быть одна из тех глупых ошибок, из-за которых рейтинг вашего сайта быстро падает.
Другой плагин, который автоматически создает текстовый файл робота, - XML Sitemap Generator.Он ничего не блокирует и не разрешает - он просто включает строку Sitemap, чтобы сообщить Google и другим поисковым системам, где найти вашу карту сайта.
Примером может быть:
Карта сайта: http://tips4pc.com/sitemap.xml
Есть также очень старый плагин WordPress, который позволяет редактировать текстовый файл вашего робота из WordPress. Я не использовал этот плагин, поэтому не знаю, работает ли он до сих пор.
Я не использовал этот плагин, поэтому не знаю, работает ли он до сих пор.
Если вам нужен собственный текстовый файл робота, вы можете создать его по старинке.Откройте Блокнот Windows, Mac OSX TextEdit или vi или emacs для Linux. Введите следующий текст:
User-Agent: *
Allow: /
В приведенном выше примере файла роботы будут действовать точно так же, как если бы у вас не было текстового файла робота, поэтому он ничего не сломает. твой сайт. Сохраните файл как robots.txt и загрузите его в корневой каталог своего веб-сервера с помощью инструмента FTP или онлайн-менеджера файлов вашей компании, предоставляющей услуги хостинга веб-сайтов.
(Корневой каталог - это тот же каталог, в который вы добавляете файл кода подтверждения веб-сайта Google, если вы это делали раньше.)
После загрузки файла откройте страницу http://example.com/robots.txt в своем веб-браузере (но вместо этого используйте свой домен). Вы должны увидеть только что загруженный файл. Если вы этого не сделаете, вам нужно будет обратиться за помощью к своей хостинговой компании.
Вы должны увидеть только что загруженный файл. Если вы этого не сделаете, вам нужно будет обратиться за помощью к своей хостинговой компании.
Текстовый файл робота может быть таким же простым, как приведенный выше пример, или намного сложнее. В общем, вы хотите заблокировать следующее:
• Каталоги входа и справки WordPress, которые начинаются с wp.Поместите этот код в раздел «allow: /»
Disallow: / wp- *
• В приведенном выше примере Google не индексирует каталог загрузок WordPress, в котором вы храните изображения. Если вы хотите, чтобы ваши изображения появлялись в поиске изображений Google и Bing, добавьте следующий код:
Разрешить: / wp-content / uploads
• Если Google попытается проиндексировать трекбек, он просто получит страницу с ошибкой, поэтому добавьте это также код:
Disallow: * / trackback
• Если вы используете Google AdSense, рекомендуется использовать эту строку, чтобы разрешить Google сканировать весь контент, чтобы они могли показывать целевую рекламу.
User-agent: Mediapartners-Google *
Allow: /
Эти простые команды текстового файла робота должны охватывать наиболее важные части вашего сайта, но если вы хотите больше идей, перейдите на свой любимый веб-сайт на базе WordPress и посмотрите их файл robots.txt.
Дополнительные технические статьи от Business 2 Community:
Как использовать файл WordPress Robots.txt для улучшения SEO
Если вы управляете сайтом WordPress, скорее всего, вы слышали о файле robots.txt.Тем не менее, вы, вероятно, задаетесь вопросом, что это такое. Кроме того, вы могли спросить себя: «Это важная часть моего сайта?» Что ж, мы вас прикрыли. В этом посте вы получите четкое представление о том, что такое WordPress robot.txt, и как он управляет и помогает повысить безопасность вашего веб-сайта .
Если вы являетесь владельцем бизнеса и используете веб-сайт WordPress для взаимодействия со своими клиентами, его продвижение в поисковых системах имеет решающее значение для вас. Оптимизация поисковой системы включает в себя множество важных шагов.Один из них создает хороший файл для WordPress Robots.txt .
Оптимизация поисковой системы включает в себя множество важных шагов.Один из них создает хороший файл для WordPress Robots.txt .
Прежде чем углубляться в подробности о WordPress Robots.txt , давайте сначала определим, что означает «робот» в данном контексте. Однако мы сделаем это на примере поисковых роботов. Они «ползают» по Интернету и помогают поисковым системам, таким как Google, индексировать и ранжировать страницы. Ознакомьтесь с советами, как заставить Google индексировать ваш сайт.Кроме того, эти сканеры являются «ботами» или «роботами», посещающими веб-сайты в Интернете.
Чтобы было понятно, боты - необходимая вещь для Интернета. Тем не менее, это не означает, что вы должны позволять им бесконтрольно бегать по вашему сайту. Файл WordPress Robots.txt называется «Протокол исключения роботов».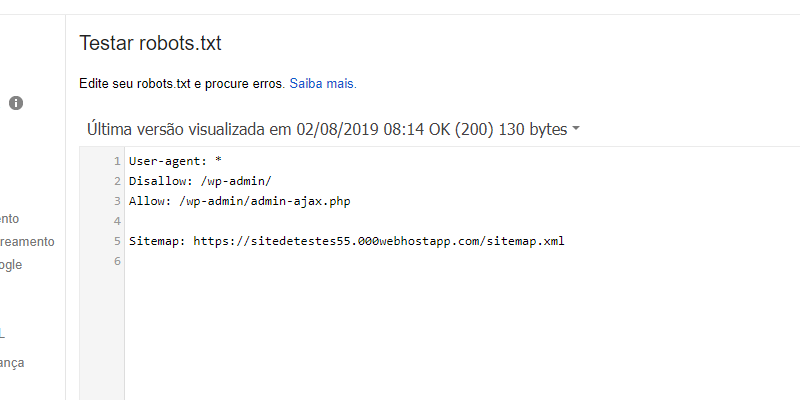 Они были разработаны, потому что владельцев сайтов хотели контролировать свое взаимодействие с сайтами. Файл robots.txt можно использовать для ограничения доступа ботов к определенным областям сайта или даже для их полной блокировки.
Они были разработаны, потому что владельцев сайтов хотели контролировать свое взаимодействие с сайтами. Файл robots.txt можно использовать для ограничения доступа ботов к определенным областям сайта или даже для их полной блокировки.
Тем не менее, это правило имеет определенные ограничения. Например, бота нельзя заставить выполнять команды файла robots.txt. Также вредоносные боты могут игнорировать файл. Google и другие известные организации игнорируют некоторые элементы управления, которые вы добавляете в robots.txt. Если у вас много проблем с ботами, вам пригодится защитное решение. Например, Cloudflare или Sucuri могут быть весьма полезны.
Как файл WordPress Robots.txt помогает вашему сайту? У хорошо интегрированных роботов WordPress есть два основных преимущества.txt файл. Во-первых, блокировка ботов, которые тратят ресурсы вашего сервера. Следовательно, это увеличивает эффективность вашего сайта . Во-вторых, он оптимизирует ресурсы сканирования поисковых систем. Он делает это, сообщая им, какие URL-адреса на нашем сайте им разрешено индексировать. Что происходит перед тем, как поисковая система просканирует любую страницу в домене, с которой она раньше не сталкивалась? Открывается файл domain robots.txt и анализируются его команды. В отличие от предполагаемого, robots.txt не предназначен для регулирования индексации страниц в поисковых системах.
Следовательно, это увеличивает эффективность вашего сайта . Во-вторых, он оптимизирует ресурсы сканирования поисковых систем. Он делает это, сообщая им, какие URL-адреса на нашем сайте им разрешено индексировать. Что происходит перед тем, как поисковая система просканирует любую страницу в домене, с которой она раньше не сталкивалась? Открывается файл domain robots.txt и анализируются его команды. В отличие от предполагаемого, robots.txt не предназначен для регулирования индексации страниц в поисковых системах.
Является ли ваша главная цель - предотвратить включение определенных страниц в результаты поиска? Если это так, лучший способ сделать это - использовать метатег без индекса или другой не менее прямой подход. Причина в том, что robots.txt не дает указателям поисковым системам полностью индексировать контент. Вместо этого он только приказывает им не сканировать его. В результате это означает, что даже если Google не будет сканировать указанные области на вашем сайте. Даже в этом случае эти страницы будут индексироваться всякий раз, когда на них ссылается внешний сайт.
Даже в этом случае эти страницы будут индексироваться всякий раз, когда на них ссылается внешний сайт.
На вашем сайте уже будет файл robots.txt, созданный для него WordPress. Файл WordPress Robots.txt всегда находится в корне вашего домена. Итак, если ваш домен - www.nameofwebsite.com, его следует найти по адресу http://nameofwebsite.com/robots.txt. Это виртуальный файл. Таким образом, его нельзя редактировать. Чтобы иметь возможность редактировать файл robots.txt, вам нужно создать физический файл на своем сервере.Затем его можно настроить в соответствии с вашими требованиями.
Создание и редактирование Robots.Txt с помощью Yoast SEO
Это очень популярный плагин. Кроме того, его интерфейс позволяет создавать / редактировать файл robots.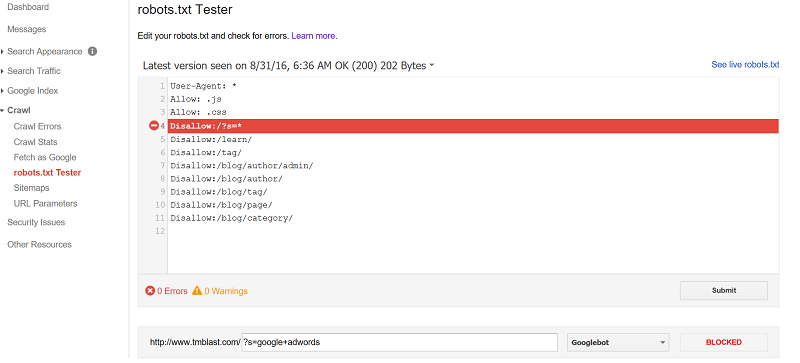 txt. Вот шаги, которые необходимо выполнить:
txt. Вот шаги, которые необходимо выполнить:
1
Во-первых, вам нужно включить расширенные функции Yoast SEO. Это можно сделать, зайдя в SEO, нажав на «Панель управления» и выбрав «Функции» в появившемся меню. Затем включите страницы дополнительных настроек и включите их.2
После активации перейдите в SEO и выберите «Инструменты», затем нажмите «Редактор файлов». затем получите возможность создать файл robots.txt .3
Нажмите кнопку «Создать файл robots.txt». Следовательно, вам будет разрешено использовать тот же интерфейс для редактирования содержимого вашего файла.
Далее в этой статье мы поговорим о том, какие типы команд нужно поместить в файл WordPress Robots.txt .
Создание и редактирование роботов.txt с All in One SEO
По популярности плагин All in One SEO Pack почти не уступает Yoast SEO.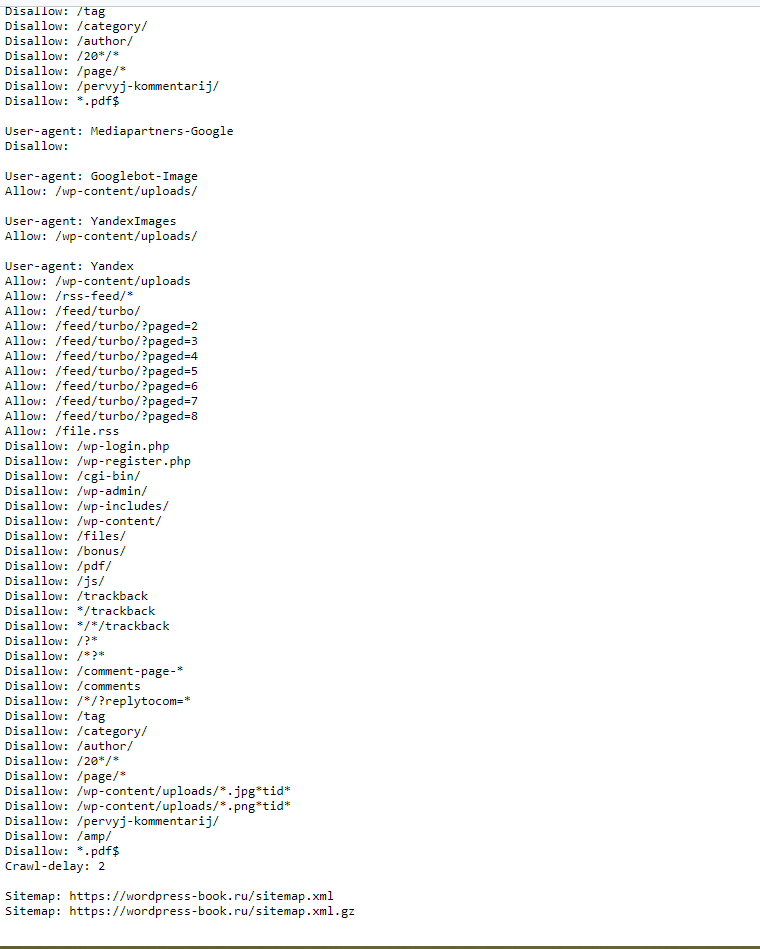 Интерфейс этого плагина можно использовать для создания и редактирования файла WordPress Robots.txt . Просто выполните следующие простые шаги:
Интерфейс этого плагина можно использовать для создания и редактирования файла WordPress Robots.txt . Просто выполните следующие простые шаги:
- Перейдите на панель управления плагином, выберите «Диспетчер функций» и активируйте функцию Robots.txt.
- Теперь выберите Robots.txt, и вы сможете управлять своим файлом robots.txt здесь.
Создание и редактирование роботов.txt через FTP
Используете ли вы плагин SEO для ранжирования, который предлагает robots.txt? Следовательно, не о чем беспокоиться. Файл WordPress Robots.txt все еще можно создавать и редактировать с помощью SFTP. Выполните следующие действия:
- Создайте пустой файл с именем «robots.txt» с помощью любого текстового редактора и сохраните его.
- Загрузите этот файл в корневую папку вашего сайта, когда вы подключены к своему сайту через SFTP.
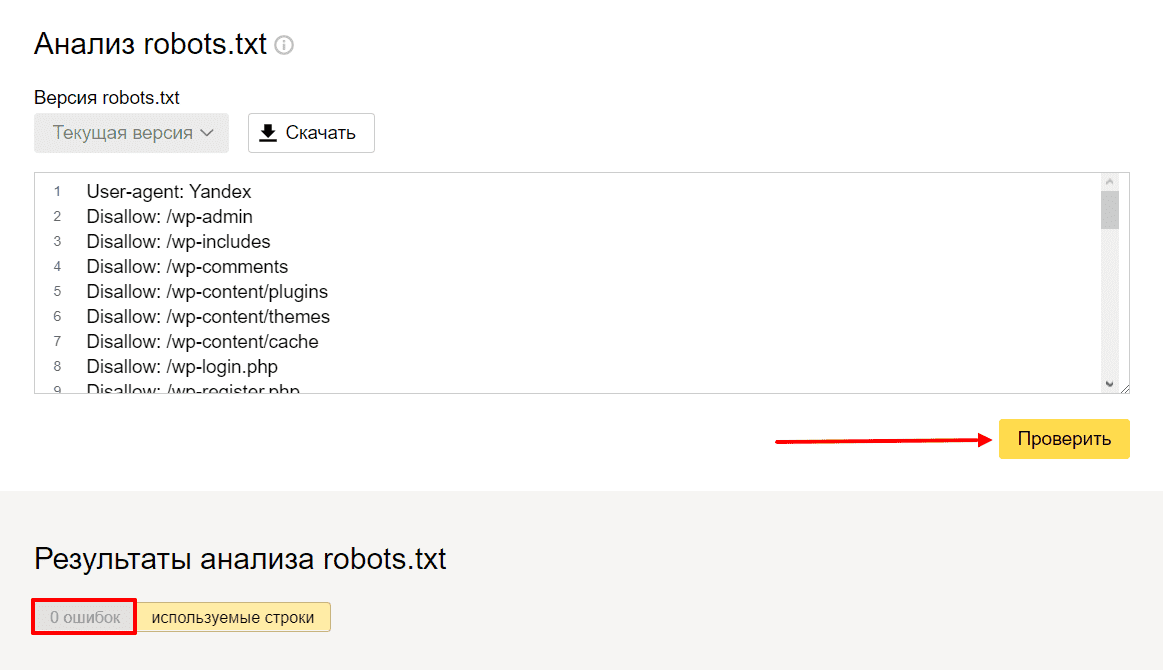
- Теперь вы можете использовать STFP, чтобы вносить изменения и редактировать файлы robots.txt файл. Вы также можете загрузить новые версии файла, если хотите.
Теперь, когда у вас есть физический файл robots.txt, вы можете настроить и отредактировать его в соответствии с вашими требованиями. Давайте посмотрим, что вы можете сделать с помощью этого файла. Мы уже говорили о важности WordPress Robots.txt для управления ботами и вашим сайтом. Теперь мы обсудим две основные команды, которые необходимы для этого.
- Целью управления User-agent является нацеливание на определенных ботов. Эта команда поможет вам создать правило, которое будет применяться к одной поисковой системе, но не к другой. Боты используют пользовательские агенты для идентификации себя.
- Команда Disallow позволяет запретить роботам доступ к определенным областям вашего сайта.
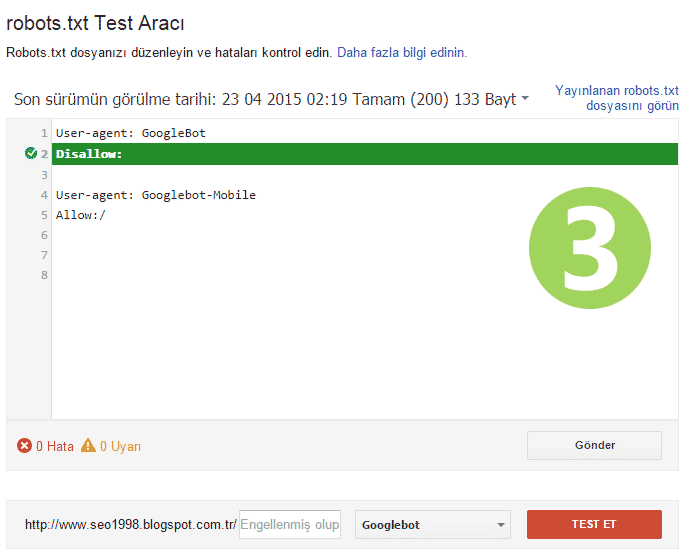
Кроме того, есть еще одна команда под названием «Разрешить». Команда используется, когда вы запрещаете доступ к папке и ее подпапкам.Тем не менее, вы хотите разрешить доступ к определенной папке из них. Имейте в виду, что весь контент на вашем сайте по умолчанию помечается как «Разрешить». Таким образом, при добавлении правил первое, что вы должны сделать, это указать пользовательский агент, к которому будет применяться правило. Затем укажите правила, которые будут вводить его в действие, используя функции разрешения и запрета.
Конкретные варианты использования для WordPress robots.txtИспользование robots.txt для блокировки доступа ко всему сайту
Если ваш сайт все еще находится на стадии разработки, вы можете заблокировать доступ к нему для сканера.Для этого вам нужно будет добавить следующий код в файл WordPress Robots. txt :
txt :
Как работает этот код?
* (звездочка) после пользовательского агента означает «все пользовательские агенты», а / (косая черта) после Disallow означает, что доступ ко всем страницам, содержащим « www.nameofwebsite.com /» (каждая страница на вашем сайте) следует запретить.
- Использование robots.txt для блокировки доступа определенного бота к вашему сайту
Теперь предположим, что вы хотите запретить определенной поисковой системе сканировать ваш контент.Например, вы можете разрешить Google сканировать ваш сайт, но запретить Bing. Вы можете сделать это, просто заменив * (звездочку) в предыдущем примере на Bingbot.
User-agent: Bingbot
Disallow: /
- Использование robots.
 txt для блокировки доступа к определенной папке / файлу
txt для блокировки доступа к определенной папке / файлу
Если вы хотите заблокировать доступ только к определенной папке или файлу (и, следовательно, к ее вложенным файлам). папки), это команда, которой вы должны следовать.
User-agent: *
Disallow: / wp-admin
Disallow: / wp-login.php /
Здесь мы используем пример файла wp-admin . Это может быть любой файл в соответствии с вашими требованиями, и все, что вам нужно сделать, это заменить «wp-admin» в приведенном выше коде на имя папки или файла, которые вы хотите предотвратить от сканирования поисковыми системами.
- Использование robots.txt для разрешения доступа к определенному файлу в папке, которая в противном случае полностью запрещена
Допустим, вы хотите заблокировать всю папку, но все же разрешить доступ к определенному файлу в ней. В предыдущем примере мы полностью заблокировали доступ к папке администратора WordPress. Что, если мы хотим заблокировать доступ ко всему содержимому папки / wp-admin /, ЗА ИСКЛЮЧЕНИЕМ файла /wp-admin/admin-ajax.php? Все, что вам нужно сделать, это добавить к коду в предыдущем примере команду «Разрешить».
В предыдущем примере мы полностью заблокировали доступ к папке администратора WordPress. Что, если мы хотим заблокировать доступ ко всему содержимому папки / wp-admin /, ЗА ИСКЛЮЧЕНИЕМ файла /wp-admin/admin-ajax.php? Все, что вам нужно сделать, это добавить к коду в предыдущем примере команду «Разрешить».
User-agent: *
Disallow: / wp-admin /
Allow: /wp-admin/admin-ajax.php
- Использование robots.txt для предотвращения сканирования роботами результатов поиска WordPress
Если вы Если вы хотите, чтобы поисковые роботы не сканировали ваши страницы результатов поиска, есть очень простая команда, которая спасет положение.WordPress по умолчанию использует параметр запроса «? S =». Просто добавьте эту команду, чтобы заблокировать доступ. Например:
User-agent: *
Disallow: /? S =
Disallow: / search /
- Использование robots.
 txt для создания разных правил для разных ботов
txt для создания разных правил для разных ботов
Во всех вышеупомянутых случаях мы работали с одним правилом, достигшим единственной цели. Однако что произойдет, если вы захотите создать разные наборы команд для разных ботов? Это сделать проще. Все, что вам нужно сделать, это создать отдельный набор правил под командой user-agent для каждого бота.Например, вам нужен один заказ для всех ботов, но отдельный заказ только для Bingbot, вот что вы сделаете:
В этом случае вы блокируете доступ всех ботов к файлу wp-admin. Тем не менее, вы блокируете Bingbot от доступа ко всему вашему сайту.
Как проверить свой WordPress Robots.txt Вы можете проверить свой файл WordPress Robots.txt , чтобы узнать, доступен ли для сканирования весь ваш сайт, если вы заблокировали определенные URL-адреса или уже заблокировали или запретил определенные сканеры. Вы можете сделать это в поисковой консоли Google. Вам просто нужно зайти на свой сайт и перейти в режим «Сканирование». Под ним выберите «robots.txt Tester» и введите любой URL-адрес, чтобы проверить его доступность.
Ваш файл WordPress Robots.txt может выглядеть нормально, но действительно имеет серьезную проблему. Например, вы можете обнаружить, что данные директивы не соблюдаются, и страницы, сканирование которых не предполагается, на самом деле сканируются.Причина этого почти всегда сводится к невидимому символу, называемому спецификацией UTF-8.
Здесь BOM обозначает отметку порядка байтов, и иногда ее добавляют в файлы старые текстовые редакторы. Если этот символ присутствует в вашем файле robots.txt, Google, возможно, не сможет его прочитать и пожаловаться на «Синтаксис непонятен». Это существенно влияет на SEO и может сделать ваш файл robots. txt бесполезным. Пока вы тестируете свой файл robots.txt , обязательно проверьте спецификацию UTF-8, проверив, не понимает ли Google какой-либо из ваших синтаксисов.
txt бесполезным. Пока вы тестируете свой файл robots.txt , обязательно проверьте спецификацию UTF-8, проверив, не понимает ли Google какой-либо из ваших синтаксисов.
Давайте закончим это руководство быстрым напоминанием. Хотя блоки robots.txt сканируются, это не обязательно останавливает индексацию. Тем не менее, robots.txt поможет вам добавить рекомендации. Они контролируют и определяют взаимодействие вашего сайта с поисковыми системами и ботами. Тем не менее, он не контролирует явно, будет ли ваш контент проиндексирован. Настройка файла robots.txt вашего сайта может быть очень полезной, если вы намереваетесь:
- Исправить ваш сайт, у которого проблемы с конкретным ботом.
- Чтобы лучше контролировать поисковые системы и некоторый контент / плагины на вашем сайте. Тем не менее, если вы не соответствуете вышеуказанным требованиям, вам необходимо изменить виртуальный файл robots.
 txt по умолчанию на вашем сайте.
txt по умолчанию на вашем сайте.
Как оптимизировать Wo
rdPress Robots.txtWordPress Robots.txt обычно находится в корневой папке вашего сайта. Вам нужно будет установить ссылку на свой сайт с помощью FTP-клиента или просмотреть его с помощью файлового менеджера вашей cPanel. Если у вас нет robots.txt в корневом каталоге вашего сайта, затем вы можете его создать. Все, что вам нужно сделать, это создать новый текстовый файл и сохранить его на свой компьютер как robots.txt. Затем просто загрузите его в корневую папку на своем сайте.
заключение В этой статье мы рассказали о файле WordPress Robots.txt , который является очень популярным компонентом, позволяющим сделать роботов поисковых систем более заметными для сайта. Есть много причин для оптимизации вашего робота WordPress. txt, в котором основная цель оптимизации файла robots.txt - запретить поисковым системам сканировать закрытые для общего доступа страницы. Мы предлагаем вам следовать приведенному выше формату, чтобы создать файл WordPress Robots.txt для вашего сайта. Мы надеемся, что это полное руководство поможет вам на улучшить SEO .
txt, в котором основная цель оптимизации файла robots.txt - запретить поисковым системам сканировать закрытые для общего доступа страницы. Мы предлагаем вам следовать приведенному выше формату, чтобы создать файл WordPress Robots.txt для вашего сайта. Мы надеемся, что это полное руководство поможет вам на улучшить SEO .
Полное руководство по оптимизации WordPress Robots.txt для SEO
Для того, чтобы ваш веб-сайт мог быстро индексироваться, оптимизироваться для SEO и повышать рейтинг на странице результатов поиска SERP, прежде всего, вам необходимо создать технический файл robots.txt для WordPress. Файл Robots.txt показывает, как сканировать и настраивать ваш индексный сайт, в частности, делая его чрезвычайно мощным инструментом SEO. Следовательно, в этой статье мы предложим полное руководство по улучшению файла robots.txt WordPress для SEO.
Что такое WordPress Robots.txt? Это текстовый файл в корневой папке веб-сайта, содержащий инструкции для поисковой системы, для которых страницы могут быть проиндексированы.
Если вы ранее знакомы с рабочим процессом поисковых систем, вы знаете, что на этапе сканирования и индексации веб-браузеры пытаются найти общедоступные страницы в Интернете, которые они могут включить в свой индекс.
Первое, что выполняет веб-браузер при посещении веб-сайта, - это находит и проверяет содержимое файла robots.txt. В зависимости от правил, указанных в файле, они создают список URL-адресов, которые можно сканировать, а затем специально индексировать для сайта.
Зачем нужно создавать файл robots.txt WordPress?Во многих случаях роботам поисковых систем запрещается или ограничивается «сканирование» вашего веб-сайта:
Содержимое недействительно и дублируетсяФактически, на вашем веб-сайте он отображает много другой информации, такой как файлы настройки системы, плагины WordPress и т. Д.
Эта информация не представляет ценности для пользователя. Более того, есть несколько ситуаций, когда контент веб-сайта дублируется.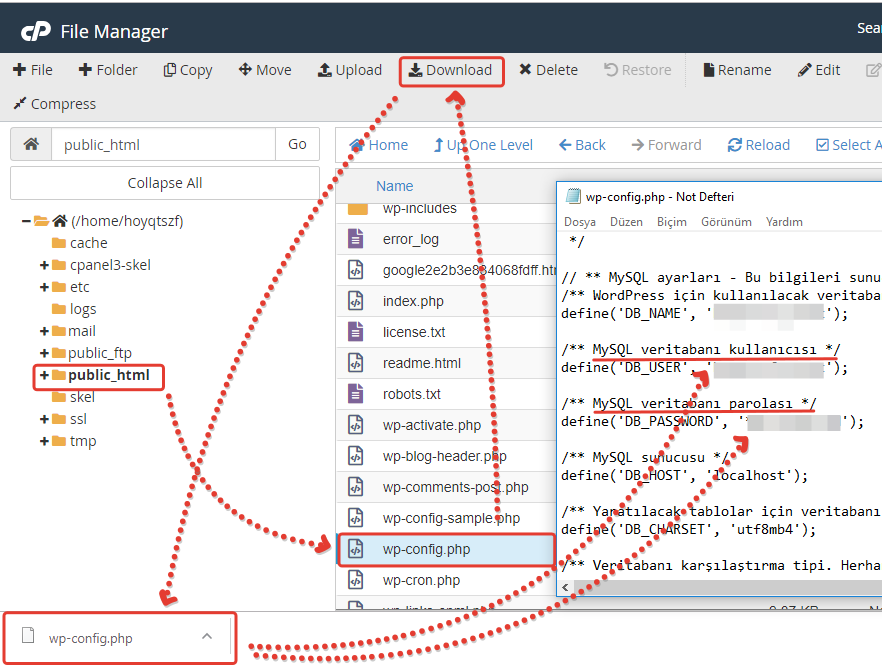 Если контент по-прежнему проиндексирован, он разбавит веб-сайт, снизив фактическое качество содержимого веб-сайта.
Если контент по-прежнему проиндексирован, он разбавит веб-сайт, снизив фактическое качество содержимого веб-сайта.
В этом случае, возможно, при создании нового веб-сайта WordPress вы не завершили процесс проектирования и настройки веб-сайта, как правило, не готовы для пользователя, вам необходимо принять меры для предотвращения «сканирования» и проверки роботами поисковых систем. их веб-сайт.
Не только это, но на некоторых веб-сайтах также есть множество подстраниц, которые используются только для тестирования функций и дизайна веб-сайта, и предоставление пользователям доступа к таким сайтам повлияет на качество веб-сайта и профессионализм вашей компании.
Веб-сайт большой емкости долго загружается У каждого робота поисковой системы есть только ограниченная возможность «сканирования» при посещении веб-сайта. Когда на вашем веб-сайте много контента, ботам потребуется больше времени для анализа, потому что, если он проработал достаточно для одного посещения, оставшийся контент на веб-сайте должен дождаться следующего запуска ботов. можно сканировать и снова индексировать.
можно сканировать и снова индексировать.
Если на вашем веб-сайте все еще есть ненужные файлы и контент, но он сначала проиндексирован, это не только снизит качество веб-сайта, но и потратит больше времени на индексацию ботов.
Снижает скорость веб-страницы при постоянном индексированииКогда файл robots.txt отсутствует, боты все равно будут сканировать все содержимое вашего веб-сайта. Помимо показа контента, который ваши клиенты не хотят видеть, постоянное сканирование и индексирование также могут снизить скорость загрузки страницы.
Скорость Интернета является важным аспектом веб-сайта, влияющим на качество и удобство работы пользователей при посещении вашего веб-сайта. страница тоже выше.
По этим причинам вам следует создать такой технический файл для WordPress, чтобы инструктировать ботов: «Боты сканируют одну сторону, не сканируйте другую!». Использование стандартного файла robots.txt WordPress помогает повысить эффективность сканирования и индексации веб-сайтов ботами.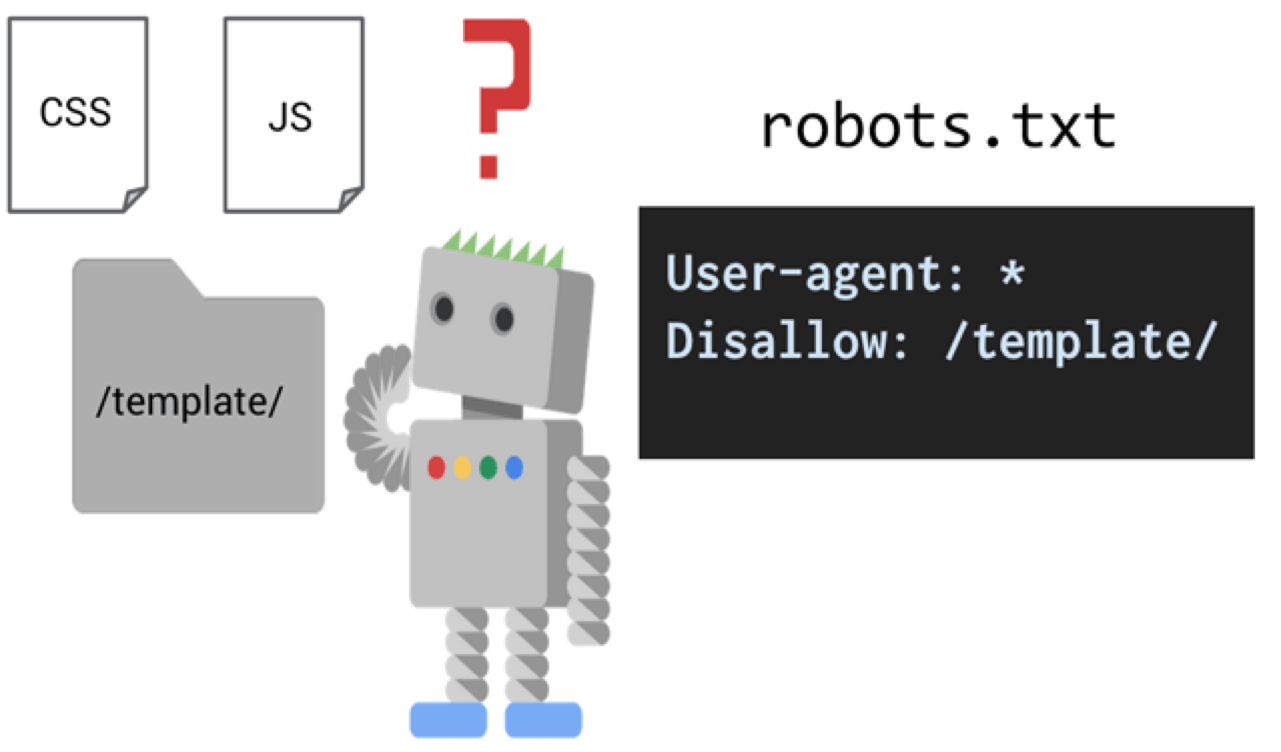 Оттуда улучшите результаты SEO для вашего сайта.
Оттуда улучшите результаты SEO для вашего сайта.
Если вы не используете карту сайта, вы все равно будете тащиться и оценивать свой сайт.Однако поисковые системы не могут сказать, какие страницы или папки не следует запускать.
Когда вы начинаете вести блог, это не имеет большого значения. Однако вам может потребоваться больше контроля над тем, как ваш сайт будет изменяться и индексироваться по мере роста вашего сайта и наличия большого количества контента.
У поискового бота есть квота сканирования для каждого веб-сайта. Это означает, что они сканируют определенные страницы во время сеанса сканирования. Если они не завершили все страницы вашего веб-сайта, они будут сканировать снова в следующем сеансе.Они все еще существуют и никуда не денутся.
Это может снизить скорость индексации вашего веб-сайта. Но вы можете исправить это, запретив поисковым роботам сканировать ненужные страницы, такие как страница администратора wp-admin, каталог плагинов и каталог тем.
Отклонив ненужные страницы, вы можете сохранить квоту сканирования. Это позволяет поисковым системам быстрее индексировать страницы вашего сайта.
Еще одна веская причина использовать файлы robots.txt - запретить поисковым системам индексировать сообщения или страницы.Это не самый безопасный способ скрыть содержимое поисковой системы, но он помогает предотвратить выдачу результатов поиска.
Идеальное руководство по оптимизации Robots.txt для содержания SEOМногие сайты блогов предпочитают запускать очень скромный файл robots.txt в своей сети WordPress. Их содержание может варьироваться в зависимости от потребностей конкретного веб-сайта:
Пользовательский агент: *
Запрещено:
Карта сайта: http://www.example.com/post-sitemap.xml
Карта сайта: http://www.example.com/page-sitemap.xml
Этот файл robots.txt передает всем ботам соединение с XML-картой сайта для обозначения всего содержимого.
Мы рекомендуем следующие рекомендации некоторых полезных файлов для веб-сайтов WordPress:
Пользовательский агент: *
Разрешить: / wp-content / uploads /
Запретить: / wp-content / plugins /
Запретить: / wp-admin /
Disallow: / readme.html
Запрещено: / ссылка /
Карта сайта: http://www.example.com/post-sitemap.xml
Карта сайта: http://www.example.com/page-sitemap.xml
Все картинки и файлы WordPress проиндексированы. Поисковые роботы могут даже индексировать файлы плагинов, админку, файлы readme и партнерские ссылки.
Вы также можете легко разрешить роботам Google находить все страницы вашего веб-сайта, добавив карту в файл robots.txt.
Создание роботов WordPress.txt для вашего сайта Создайте файл robots.txt с помощью БлокнотаNotepad - это минималистичный текстовый редактор от Microsoft. Он предназначен для написания кода, обслуживающего Паскаль, C +, язык программирования HTML,…
Текстовый файл ASCII или UTF-8, правильно сохраненный в исходном файле веб-сайта под именем robots.txt, необходим для файла robots.txt WordPress. Каждый файл содержит множество правил, и каждое правило находится в одной строке.
Вы можете создать новый файл блокнота и сохранить его как robots.txt и добавьте правила, как описано выше.
После этого загрузка файла для WordPress в каталог public_html завершена.
Создайте файл robots.txt с помощью плагина Yoast SEO ПлагинYoast SEO - один из лучших плагинов, который поможет вам оптимизировать SEO вашего сайта с точки зрения содержания. Однако Yoast SEO также можно рассматривать как плагин WordPress robots.txt, который помогает вам создавать инновационные файлы для оптимизации ваших сайтов.
Сначала вы переходите на панель инструментов .
На панели инструментов => Выбрать SEO => Выбрать Инструменты или Панель инструментов => Выбрать Инструменты => Выбрать Yoast SEO (для других версий / тем WordPress) .
На странице администрирования Yoast SEO => Выберите File Editor.
Выберите Create New , чтобы запустить файл для WordPress или отредактировать существующий файл.
Выберите Сохранить изменения в robots.txt, чтобы убедиться, что пользовательский файл robots.txt завершен.
Посетите веб-сайт еще раз, и вы увидите новые правила, которые вы только что установили.
Проверьте файл robots.txt в консоли поиска GoogleВы можете войти в Google Search Console и зарегистрировать свой веб-сайт, чтобы начать работу.
Выберите Перейти к старой версии , чтобы вернуться к старому интерфейсу и разрешить использование.
Под Сканирование => Выберите robots.txt Tester => Введите Установленные правила => Нажмите Отправить.
Проверьте результат количества ошибок и предупреждений => Выполните исправление, если таковое имеется.
Выберите Загрузить обновленный код , чтобы загрузить новый файл robots.txt и повторно загрузить новый файл в исходный каталог, или выберите Попросить Google обновить для автоматического обновления.
Final МыслиИз этой статьи вы узнали о важности, а также о способе создания файла robots.txt для WordPress. Наличие стандартного файла robots.txt поможет вашему веб-сайту и роботам поисковых систем лучше взаимодействовать, поэтому информация на сайте будет точно обновляться и расширять возможности охвата большего числа пользователей.
Давайте начнем с создания вашего собственного технического файла для WordPress и сразу же улучшим SEO сайта!
Подробнее: 10 лучших бесплатных плагинов WP Backup для защиты WordPress
Что такое роботы.txt и почему он важен?
Когда мы говорим robots.txt, возможно, вы имеете в виду что-то вроде фильма Disney-Pixar Wall-E или другого известного робота в поп-культуре.
Файлы Robots.txt на самом деле играют чрезвычайно важную роль для владельцев веб-сайтов и маркетологов. Мы уже писали о сканировании сайтов раньше, поскольку файл robots.txt является одним из наиболее важных инструментов, если вы хотите оптимизировать свой сайт и повысить свой рейтинг.
Этот пост начинает становиться немного более техническим, когда дело доходит до поисковой оптимизации. Если вы новичок в SEO, ознакомьтесь с нашим полным введением в SEO здесь!
В этом сообщении в блоге будут рассмотрены основы роботов.txt, его важность и то, как вы настраиваете его на разных платформах управления контентом.
Продолжайте читать или переходите к следующему шагу, щелкнув платформу для получения инструкций по настройке файла robots.txt:
Как отредактировать файл robots.txt в WordPress
Как отредактировать файл robots.txt в SquareSpace
Как редактировать файл robots.txt в Wix
Как редактировать файл robots.txt в HubSpot
Как редактировать файл robots.txt в Webflow
Как редактировать файл robots.txt в Shopify
Что такое файл Robots.txt?
Хотя файл robots.txt может показаться устрашающим, это довольно простая концепция.
Файл robots.txt - это набор файлов для веб-сайта, который сообщает сканерам поисковых систем, какие страницы сканер может или не может анализировать и индексировать.
Другими словами, он сообщает Google, какие страницы запрещены для анализа и отображения в результатах поиска. При поиске в Интернете информации об этих файлах вы также можете встретить термин «протокол исключения роботов», относящийся к той же концепции.
Вам может быть интересно, зачем мне нужно, чтобы из страниц были скрыты от Google. В конце концов, чем больше у Google контента с веб-сайта, тем лучше, не так ли?
Закрыть - не весь контент представляет ценность, и вы будете удивлены, увидев, сколько страниц для веб-сайта автоматически создается, которые либо не стоит показывать в результатах поиска, либо потенциально содержат личную информацию, которая вообще не должна индексироваться.
Например, наш веб-сайт построен с помощью WordPress, и в результате многие страницы автоматически создаются для различных тегов и категорий, которые у нас есть для нашего блога.Эти страницы категорий не имеют особой ценности, поскольку они просто перечисляют страницы нашего блога.
Другим примером может быть интернет-магазин, у которого есть страницы оформления заказа или биллинга, которые не следует сканировать и индексировать. Эти страницы содержат личную информацию или могут находиться за логином, поэтому единственное содержание, которое Google мог бы получить, было бы сообщением об ошибке. В любом случае, индексировать эти страницы не стоит.
Хотя высокий рейтинг в SEO является важной целью, вы должны думать о качестве и количестве страниц на вашем веб-сайте.
Когда вы отправляете веб-сайт для сканирования, поисковый робот будет анализировать каждую страницу на вашем веб-сайте. Задача Google - оценить качество веб-сайта, просмотрев все страницы, к которым у него есть доступ. Предоставление Google доступа к страницам, которые не представляют ценности, может нанести ущерб вашему рейтингу и повредить вашей способности появляться в результатах поиска.
Также важно управлять количеством страниц, к которым у Google есть доступ, и ограничивать количество страниц, сканируемых их сканерами. Google устанавливает «краулинговый бюджет» при сканировании сайта, который ограничен двумя факторами.
Первый - это ограничение скорости сканирования. Ограничение скорости сканирования ограничивает максимальную загрузку для данного сайта. Это число представляет количество параллельных подключений, которые сканер использует для обхода сайта, а также время между выборками.
Второй фактор известен как потребность сканирования. Если предел сканирования не достигнут, но потребность в индексировании низкая, активность сканера будет низкой. Популярность веб-сайта - это один из способов определить, будет ли страница сканироваться чаще других.
Из-за этого бюджета сканирования вы хотите сообщить Google, какие страницы наиболее важны для вашего веб-сайта. Вы не хотите, чтобы краулер тратил время на анализ страниц, которые не генерируют наибольший объем трафика. Вот где в игру вступает сила файлов robots.txt.
Как выглядит файл Robots.txt?
После прочтения всего этого фактический файл robots.txt может показаться немного разочаровывающим. Файл robots.txt представляет собой простой список URL-адресов, которые Google не может сканировать. Обычно это выглядит примерно так:
User-agent: *
Disallow: / wp-admin /
Disallow: / wp-логин.php
Disallow: / author /
Disallow: / category /
Disallow: / tag /
Здесь следует отметить два момента: пользовательский агент и путь запрета.
Пользовательский агент назначает поисковому роботу конкретную блокировку. Звездочка (*) означает, что каждому сканеру / поисковой системе запрещено анализировать следующие URL-адреса. Некоторые файлы robots.txt будут более сложными и будут содержать имена конкретных поисковых роботов для настройки правил для каждой поисковой системы, но для большинства веб-сайтов это не обязательно.
После пользовательского агента следует ряд строк, начинающихся со слова Disallow . Каждый из них представляет собой URL-адрес, который поисковые роботы не могут анализировать. Это не полные URL-адреса, вместо этого они представляют собой фрагмент URL-адреса, который вы не хотите, чтобы поисковая система анализировала. В результате любой URL-адрес, содержащий этот путь, не будет сканироваться.
Где я могу найти robots.txt на моем веб-сайте?
Сканеры всегда ищут файл robots.txt в одном конкретном месте : в главном каталоге вашего веб-сайта.
Это означает, что они ищут его по URL-адресу yourdomain / robots.txt , например, наш можно найти по адресу www.centori.io/robots.txt. Если бы файл robots.txt существовал, но с другим URL-адресом, скажем, yourdomain.com/index/robotst.xt , он не был бы найден сканерами (они умны, но не настолько умны).
Не беспокойтесь - любая система управления контентом настроит это автоматически, вам не нужно беспокоиться о том, что ваш файл robots.txt не будет найден. Если вы когда-нибудь захотите увидеть свой файл robots.txt, просто добавьте «/robots.txt» после URL-адреса вашей домашней страницы, и вы сможете просмотреть его.
Как редактировать файлы Robots.txt в WordPress
Чтобы получить доступ к файлам robots.txt для WordPress, вам необходимо загрузить плагин. Самый простой вариант - от Yoast.
Вы можете скачать бесплатный плагин Yoast по этой ссылке или в каталоге плагинов. Мы используем WordPress для нашего собственного сайта, и, хотя он нам нравится, нужно помнить об одном - ваш сайт не будет иметь всех возможностей SEO, если вы не добавите его.
После загрузки плагина теперь вы можете редактировать файлы robots.txt в удобном интерфейсе. Сначала перейдите к Yoast в меню боковой панели и выберите Инструменты .
Оттуда вы попадете в список инструментов Yoast, оттуда выберите File Editor .
И вуаля! У вас есть настроенный файл robots.txt, который вы можете легко редактировать.
Итак, что мы добавляем к этому файлу?
Предположим на мгновение, что вы хотите, чтобы сайт сканировал все, кроме страниц администратора в WordPress.Вот что вы должны ввести:
User-agent: *
Disallow: / wp-admin /
Disallow: /wp-login.php
Этот пример сообщает GoogleBot (и другим поисковым роботам, которые слушают robots.txt) чтобы избежать часто конфиденциального контента за вашим сайтом, позволяя поисковому роботу сосредоточиться в первую очередь на том, что видит ваша аудитория.
Как редактировать файлы Robots.txt на SquareSpace
Если WordPress полностью «подключи и работай», SquareSpace занимает противоположную позицию - они настраивают роботов.txt для вас.
Итак, короткий ответ - «вы не можете», но давайте разберемся с этим немного.
SquareSpace не разрешает доступ для управления файлом robots.txt вашего собственного веб-сайта, поскольку они устанавливают стандартный для всех веб-сайтов, созданных на их платформе. Они автоматически просят Google не сканировать определенные страницы, потому что они предназначены только для внутреннего использования или отображают дублирующийся контент.
В этом образце файла robots.txt вы можете увидеть полный список разрешенных и запрещенных для сканирования сайтов. Если настройка - это ваша проблема, SquareSpace может не быть CMS для вас, для нетехнических людей, хотя это обеспечивает отличное решение сложной проблемы.
Как редактировать файлы Robots.txt на Wix
Wix похож на SquareSpace в том, что они также не позволяют редактировать файл robots.txt для вашего веб-сайта.
Wix не позволяет автоматически сканировать страницы администраторов, поскольку их чтение поисковыми системами бесполезно. Как и SquareSpace, они вас там прикрывают.
Вы можете обойти это и скрыть страницу от поисковой системы, добавив к отдельной странице тег «без индекса», который скроет страницу из результатов поиска.
Как редактировать файлы Robots.txt на HubSpot
HubSpot предоставляет полный доступ к файлу robots.txt, предоставляя вам полную настройку в довольно удобном интерфейсе.
Просто перейдите в настройки, щелкнув значок шестеренки в главном меню, затем выберите Website и Pages из меню боковой панели. Выберите домен, который вы хотите изменить (если у вас их несколько), а затем перейдите на SEO & Crawlers , где откроется редактор robots.txt.
Нажмите Сохранить , и все готово!
Как редактировать файлы Robots.txt в Webflow
Как и HubSpot, Webflow предоставляет полный доступ к вашему файлу robots.txt в простом интерфейсе.
Перейдите к Project Settings , затем SEO и Indexing , что приведет вас к редактору robots.txt. Добавьте свои правила и сохраните изменения, и все готово! Довольно просто, правда?
Как редактировать файлы Robots.txt на Shopify
Как и другие платформы, которые стремятся к простоте, Shopify не позволяет редактировать ваших роботов.txt напрямую.
Однако, как и в случае с Wix, лучший обходной путь - это добавить тег «без индекса» к страницам, которые не должны индексироваться Google.
Shopfiy советует пользователям добавить этот фрагмент кода в раздел
страницы, если они хотят, чтобы он был скрыт: {% if handle contains 'page-handle-you-want-to-exclude'%}
{% endif%}
Или, если вы хотите исключить шаблон результатов поиска, вы можете добавить это:
{%, если шаблон содержит 'search'%}
{% endif%}
Идем вперед
Надеюсь, это поможет вам стать мастером поисковой оптимизации и сканирования!
Мастер сейчас может показаться сильным словом, но получите ваших роботов.txt, настроенный и оптимизированный, дает вам гигантский скачок к тому, чтобы ваш сайт занял наилучшее положение в рейтинге.
Ваш Ultimate Robots.txt Руководство для начинающих «SEOPressor - WordPress SEO плагин
Знаете ли вы, что теперь у вас больше власти над поисковыми системами, чем когда-либо ?! Да, это правда, теперь вы можете контролировать, кто сканирует или индексирует ваш веб-сайт, используя robots.txt.
Но что такое robots.текст?
Это обычный текстовый файл в корневом каталоге вашего сайта, который сообщает поисковым роботам, открывать или игнорировать определенные страницы, папки, а также другие данные на вашем сайте. Он использует стандартный протокол исключения роботов, разработанный в 1994 году для взаимодействия сайтов с роботами-поисковиками.
Теперь это жизненно важный инструмент, который вы можете использовать для отображения вашего сайта в поисковых системах так, как вы хотите, чтобы они его видели.
На фундаментальном уровне поисковые системы, особенно Google, обычно очень суровы и строгие судьи о характере, поэтому вы должны произвести хорошее впечатление, если хотите выделиться.
И при правильном использовании robots.txt может помочь вам в этом за счет увеличения частоты сканирования , что, в свою очередь, положительно повлияет на ваши усилия по поисковой оптимизации.
Nitty Gritty; Robots.txt
Несколько десятилетий назад, когда Всемирная паутина еще была в подгузниках, разработчики сайтов разработали способ, с помощью которого боты могут сканировать и индексировать новые страницы в Интернете.
Ботов называли «пауками».
Паук от Google называется GooglebotВремя от времени пауки переходили на сайты, которые были не предназначены для индексации или сканирования , например, веб-сайты, находящиеся на техническом обслуживании.
Именно из-за таких проблем разработчики придумали решение, по которому в 1994 году была создана дорожная карта для всех ботов. В протоколе излагаются правила, которых должен придерживаться каждый настоящий робот, в том числе ботов Google .
Незаконные боты, такие как шпионское ПО, вредоносное ПО и другие, работают вне этого протокола.
Чтобы проверить robots.txt любого сайта, введите URL-адрес и добавьте в конце «/robots.txt».
Вам нужно настроить файл Robots.txt?
Роботы.txt не обязательно должен быть на каждом веб-сайте, особенно маленьком или новом. Однако нет никаких веских причин не иметь файл, поскольку он дает вам больше полномочий в отношении того, где различные поисковые системы могут и не могут заходить на ваш сайт, и это может помочь;
- Предотвратить сканирование реплицированных страниц
- Сохранять конфиденциальность определенных частей сайта
- Предотвратить сканирование результатов внутреннего поиска
- Предотвратить перегрузку сервера
- Предотвратить появление файлов ресурсов, видео и изображений в результатах поиска
Инструкции, используемые в роботы.txt
Файл должен быть сохранен как ASCII или UTF-8 в корневом каталоге вашей веб-страницы. Имя файла должно быть уникальным и содержать одно или несколько правил, созданных в удобочитаемом формате. Правила структурированы сверху вниз, при этом прописные и строчные буквы различаются.
Используемые термины
- User-agent; обозначает имя поискового робота
- Disallow; предотвращает доступ сканеров к отдельным веб-страницам, каталогам и конкретным файлам
- Разрешить; перезаписывает другие инструкции, включая запрет на сканирование каталогов, веб-страниц и файлов
- *; Обозначает цифры символа
- $; Обозначает конец строки.
Теперь инструкции в файле обычно состоят из двух частей.В первом разделе вы указываете, к каким роботам применяется инструкция. Второй раздел включает инструкцию разрешения или запрета.
Например. «Пользователь-агент; BingBot »плюс инструкция« allow: / clients / »означает, что BingBot разрешен поиск в каталоге / clients /.
Например, файл robots.txt для сайта https://www.bot.com/ может выглядеть так:
Пользовательский агент: *
Разрешить: / логин /
Disallow: / card /
Разрешить: / fotos /
Disallow: / temp /
Запретить: / search /
Asallow: / *.pdf $
Карта сайта: https://www.bot.com/sitemap.xml
Сложно настроить?
Настроить файл не так сложно, как вы думаете. Просто откройте любой пустой документ и начните вводить инструкции. Например, если вы хотите разрешить поисковым системам сканировать ваш административный каталог, это будет выглядеть так:
Пользовательский агент: *
Запрет: / admin /
Вы можете продолжать делать это до тех пор, пока вас не устроит то, что вы видите, а затем сохраните директивы как «robots.текст." Есть также инструменты, которые вы можете использовать для этого. Одним из основных преимуществ использования надежных инструментов является то, что вы минимизируете синтаксические ошибки .
И это очень важно, потому что простая ошибка может привести к краху SEO для вашего сайта. Обратной стороной является то, что они каким-то образом ограничены, когда дело доходит до настраиваемости .
Почему важен Robots.txt? Что происходит, если он не настроен должным образом?
Как упоминалось ранее, robots txt контролирует, как различные поисковые системы получают доступ к вашему сайту.В нем есть инструкции, которые указывают поисковым системам, к каким страницам обращаться, а к каким не открывать .
Хотя это полезный инструмент при правильном использовании, он также может отрицательно повлиять на ваш сайт при неправильном использовании.
Вот случаи, когда НЕ использовать файл robot.txt для;
Поисковые системы должны иметь доступ ко всем ресурсам на ваших веб-сайтах, чтобы правильно отображать страницы, что жизненно важно для поддержания хорошего рейтинга. Запрет поисковым роботам доступа к файлам JavaScript, которые изменяют взаимодействие с пользователем , может привести к алгоритмическим или ручным штрафам .
Например, если вы перенаправляете посетителей своего сайта с помощью файла JavaScript, к которому поисковые системы не могут получить доступ, это может быть расценено как маскировка , и рейтинг вашего сайта может быть скорректирован в сторону понижения.
Блокирование URL-адресов в файле мешает ссылкам переходить на сайт. По сути, это означает, что если Google не может перейти по ссылке с другого сайта, ваш веб-сайт не получит авторитет , который предлагают ссылки, и, как таковой, ваш рейтинг в целом может быть невысоким
- Предоставление указаний, игнорирующих поисковые роботы социальных сетей
Если вы хотите получить хороший рейтинг, вы должны разрешить социальным сетям доступ к некоторым страницам вашего сайта для разработки фрагмента .Например, если вы разместите URL своего сайта в Facebook, он попытается посетить каждую страницу, чтобы получить полезный фрагмент. Поэтому не давайте указания, запрещающие социальным сетям доступ к вашему сайту.
- Разрешить или запретить доступ ко всему
Это неприемлемо
Пользовательский агент: *
Разрешить: /
Или так:
Пользовательский агент: *
Disallow:
Полное запрещение доступа к вашему сайту вредно для вашего сайта; ваш сайт не будет проиндексирован поисковыми системами, что повлияет на ваш рейтинг.Точно так же оставлять свой сайт незащищенным, разрешая доступ ко всему, - нехорошо.
Кроме того, нет необходимости в такой директиве, если вы не работаете на статическом 4-страничном сайте, на котором нечего скрывать.
- Robots.txt, несовместимый с XML-картой сайта
Неверное направление поисковых систем - ужасная идея.
Если в файле sitemap.xml вашего веб-сайта есть URL-адреса, которые явно заблокированы файлом robots.txt, вы, , сами вводите в заблуждение.Чаще всего это происходит, если файл и файлы карты сайта разрабатываются разными инструментами и не проверяются впоследствии .
Чтобы проверить, есть ли на вашем сайте эта проблема, зайдите на Google Search Console . Добавьте свой сайт, подтвердите его и отправьте для него карту сайта в формате XML. Вы увидите на карте сайта на вкладке "Индекс".
Мы рекомендуем использовать правила robots.txt только для проблем с эффективностью сканирования . Проблемы с сервером или , например, боты, тратящие время на сканирование неиндексируемых разделов вашего сайта.Некоторые страницы, сканирование которых может быть запрещено ботами, включают:
- Внутренние поисковые страницы;
- Страницы, содержащие конфиденциальные данные
- Пользовательские данные, которые нельзя модерировать
- Страницы без стандартной сортировки
Что такое robots.txt в SEO?
Robots.txt оказывает существенное влияние на SEO, поскольку позволяет управлять поисковыми роботами .
Однако, если пользовательские агенты сильно ограничены директивами dis-allow, они могут отрицательно повлиять на рейтинг вашего сайта.Кроме того, не будет ранжироваться среди страниц, сканирование и индексирование которых запрещено вами .
С другой стороны, если директив запрета очень мало, могут быть проиндексированы дублирующих страниц, , что может отрицательно сказаться на рейтинге страниц.
Кроме того, перед сохранением файла в каталоге вашего сайта, подтвердите синтаксис .
Даже минимальные ошибки могут привести к тому, что боты проигнорируют ваши инструкции разрешения или запрета.
Такие ошибки могут привести к сканированию сайтов, которые не следует индексировать, а также к недоступности страниц для ботов из-за запрета.Google Search Console может помочь вам подтвердить правильность вашего файла.
Тем не менее, правильное использование robots.txt обеспечит сканирование всех основных разделов вашего сайта поисковыми роботами, что приведет к индексации вашего контента Google и другими соответствующими поисковыми системами.
Robots.txt для WordPress
WordPress по умолчанию создает виртуальных роботов.
Итак, если вы ничего не делаете на вашем сайте, у него должен быть файл. Вы можете подтвердить это, добавив «/ robots.txt »в конец доменного имени вашего сайта.
Например, «https://google.com/robots.txt» вызывает файл robots.txt, который использует платформа. Теперь, поскольку это виртуальный файл, вы не можете его редактировать. Если вы должны его отредактировать, вам нужно будет создать физический файл на своем сервере.
Вот простой способ управлять своим robots.txt с помощью SEOPressor:
Вы можете вручную выбрать, что запрещать для каждого нового сообщения, которое вы создаете, на мета-вкладке SEOpressor.
Это действительно просто и удобно для новичков. Все, что вам нужно сделать, это отметить несколько полей, и готово!
Завершение!
В безупречном обществе robots.txt бесполезен. Если бы все части сайта были разработаны для публики, то технически Google и другим поисковым системам был бы разрешен доступ ко всем из них.
К сожалению, мир не идеален. На многих веб-сайтах есть закрытые страницы, проблемы с каноническими URL и ловушки для пауков, которые не должны попадать в Google.Вот здесь-то и пригодятся файлы robots.txt, которые сделают ваш сайт еще более привлекательным.
Кроме того, robots.txt отлично подходит для поисковой оптимизации. Это позволяет легко указать Google, что индексировать, а что нет. Как бы то ни было, с этим нужно обращаться осторожно, потому что одна неверная конфигурация может легко привести к DE-индексации вашего сайта.
Обновлено: 26 мая 2021 г.
Полиглот погрузился в темно-синий мир SEO и входящего маркетинга, вооруженный пылкой страстью к письмам и восхищением тем, как эта вещь вращается во всемирной паутине.
WordPress robots.txt | Бесплатные и премиальные плагины WordPress от WpDevArt
WordPress robots.txt очень важен для SEO. Чтобы обеспечить высокий рейтинг вашего сайта в результатах поисковых систем, вам необходимо сделать его наиболее важные страницы удобными для поиска и индексации «роботов» («ботов») поисковых систем. Хорошо структурированный файл robots.txt поможет направить этих ботов на страницы, которые вы хотите проиндексировать.
В этой статье мы собираемся выявить такие вопросы:
- Что такое файл robots.txt и почему он важен
- Расположение txt для роботов в WordPress
- Лучший текст для роботов для WordPress
- Как создать файл robots.txt
- Как проверить файл robots.txt и отправить его в консоль поиска Google.
Что такое файл robots.txt для WordPress и почему он важен?
Когда вы создаете новый веб-сайт, поисковые системы будут отправлять своих роботов для сканирования и создания карты всех его страниц.Таким образом, они будут знать, какие страницы показывать в результате поиска по релевантным ключевым словам. На базовом уровне это довольно просто (также проверьте этот полезный пост - файл .htaccess по умолчанию WordPress).
Проблема в том, что современные веб-сайты содержат много других элементов помимо страниц. WordPress позволяет устанавливать, например, плагины, у которых часто есть собственные каталоги. Нет необходимости показывать это в результатах поиска, поскольку они не соответствуют содержанию.
Что за robots.txt представляет собой набор рекомендаций для поисковых роботов. Он говорит им: «Посмотрите сюда и проиндексируйте эти страницы, но не заходите в другие области!». Этот файл может быть сколь угодно подробным, и его очень легко создать, даже если вы новичок.
На практике поисковые системы все равно будут сканировать ваш сайт, даже если вы не создадите файл robots.txt. Однако не создавать его - очень иррациональный шаг. Без этого файла вы оставляете роботов индексировать весь контент вашего сайта, и они решают, что вам нужно показать все части вашего сайта, даже те, которые вы хотели бы скрыть от общего доступа (также проверьте - Лучшие плагины для электронной коммерции WordPress ).
Более важный момент, без файла robots.txt на ваш сайт будет много обращений от роботов вашего сайта. Это отрицательно скажется на его работоспособности. Даже если посещаемость вашего сайта по-прежнему невелика, скорость загрузки страницы всегда должна быть в приоритете и на самом высоком уровне. В конце концов, есть только несколько вещей, которые людям не нравятся больше, чем медленная загрузка веб-сайтов.
WordPress robots txt расположение
При создании веб-сайта WordPress файл robots.txt создается автоматически и располагается в вашем основном каталоге на сервере. Например, если ваш сайт находится здесь - wpdevart.com, вы можете найти его по адресу wpdevart.com/robots.txt и увидеть что-то вроде этого:
Это пример простейшего файла robots.txt. При переводе на понятный человеку язык, правая часть после User-agent: объявляет
, для каких роботов действуют правила. Звездочка означает, что правило универсальное и применяется ко всем роботам. В этом случае файл сообщает роботам, что они не могут сканировать каталоги wp-admin и wp-includes.Смысл этих правил в том, что эти каталоги содержат множество файлов, требующих защиты от публичного доступа (также проверьте наш плагин WordPress Countdown).
Конечно, вы можете добавить в файл дополнительные правила. Перед тем как это сделать, необходимо понять, что это виртуальный файл. Обычно файл robots.txt WordPress находится в корневом каталоге, который часто называется public_html или www (или по имени вашего веб-сайта):
Следует отметить, что файл robots.txt для WordPress, созданный по умолчанию, недоступен для вас из любого каталога.Это работает, но если вы хотите внести изменения, вам нужно создать свой собственный файл и загрузить его в корневой каталог.
Мы рассмотрим несколько способов создания файла robots.txt для WordPress. Теперь давайте обсудим, как определить, какие правила включать в файл.
Best robots txt для WordPress
Создать лучший текстовый файл robots txt для вашего сайта WordPress не так уж и сложно. Итак, какие правила нужно включить в файл robots.txt. В предыдущем разделе мы видели пример файла robots.txt, созданный WordPress. В нем всего два коротких правила, но для большинства сайтов их достаточно. Давайте взглянем на два разных файла robots.txt и посмотрим, что делает каждый из них.
Вот наш первый пример файла robots.txt WordPress:
Пользовательский агент: *
Позволять: /
# Запрещенные подкаталоги
Disallow: / payout /
Запретить: / фотографии /
Disallow: / форумы / Этот файл robots.txt создан для форума.Поисковые системы обычно индексируют каждую ветку форума. В зависимости от темы вашего форума вы можете запретить индексацию. Например, Google не будет индексировать сотни коротких обсуждений пользователей. Вы также можете установить правила, указывающие на конкретную ветку форума, чтобы исключить ее и разрешить поисковым системам индексировать остальные.
Вы также заметили строку, которая начинается с Разрешить: / в верхней части файла. Эта строка сообщает роботам, что они могут сканировать все страницы вашего сайта, за исключением ограничений, установленных ниже.Вы также заметили, что мы установили эти правила как универсальные (со звездочкой), как это было в виртуальном файле robots.txt WordPress (также вы можете проверить наш плагин WordPress Pricing table).
Давайте посмотрим на другой образец файла robots.txt WordPress:
Пользовательский агент: *
Запретить: / wp-admin /
Запретить: / wp-includes /
Пользовательский агент: Bingbot
Disallow: / В этом файле мы устанавливаем те же правила, что и в WordPress по умолчанию.Хотя мы также добавляем новый набор правил, которые запрещают поисковым роботам Bing сканировать наш сайт. Как видите, Bingbot - это имя робота.
Вы можете ввести имена других поисковых систем, чтобы также ограничить / разрешить им доступ. На практике, конечно, Bingbot очень хорош (даже если не так хорош, как Googlebot). Однако есть много вредоносных роботов.
Плохая новость в том, что они не всегда следуют инструкциям в файле robots.txt (они по-прежнему работают как террористы).Следует иметь в виду, что, хотя большинство роботов будут использовать инструкции, представленные в этом файле, вы не можете заставить их сделать это.
Если вы углубитесь в тему, вы найдете много предложений о том, что разрешить и что заблокировать на вашем сайте WordPress. Хотя, по нашему опыту, чем меньше правил, тем лучше. Вот пример
best robots txt для веб-сайта WordPress, но для разных веб-сайтов он может быть другим:
Пользовательский агент: *
Disallow: / cgi-bin
Запретить: /?
Запретить: / wp-
Запретить: / wp /
Запретить: *? S =
Запретить: * & s =
Запретить: / поиск /
Запретить: / author /
Запретить: / users /
Disallow: * / trackback
Disallow: * / feed
Запрещение: * / rss
Disallow: * / embed
Запретить: * / wlwmanifest.xml
Запретить: /xmlrpc.php
Запретить: * utm * =
Запретить: * openstat =
Разрешить: * / uploads
Карта сайта: https://wpdevart.com/sitemap.xml Традиционно WordPress любит закрывать каталоги wp-admin и wp-includes. Однако это уже не лучшее решение. Кроме того, если вы добавляете метатеги для своих изображений с целью продвижения (SEO), нет смысла запрещать роботам индексировать содержимое этих каталогов.
Что должно содержать ваш robots.txt будет зависеть от потребностей вашего сайта. Так что не стесняйтесь проводить дополнительные исследования!
Как создать robots.txt
Что может быть проще, чем создать текстовый файл (txt). Все, что вам нужно сделать, это открыть свой любимый редактор (например, Блокнот или TextEdit) и ввести несколько строк. Затем вы сохраняете файл, используя robots и расширение txt (robots.txt). Это займет несколько секунд, поэтому вы можете создать robots.txt для WordPress без использования плагина.
Мы сохранили этот файл локально на компьютере.После того, как вы создали свой собственный файл, вам необходимо подключиться к своему сайту через FTP (возможно, с помощью FileZilla).
После подключения к вашему сайту перейдите в каталог public_html. Теперь все, что вам нужно сделать, это загрузить файл robots.txt со своего компьютера на сервер. Вы можете сделать это, щелкнув правой кнопкой мыши файл в локальном FTP-навигаторе или просто перетащив его с помощью мыши.
Это займет всего несколько секунд. Как видите, этот метод проще, чем использование плагина.
Как проверить файл robots.txt WordPress и отправить его в консоль поиска Google
После создания и загрузки файла robots.txt WordPress вы можете проверить наличие ошибок в консоли поиска Google. Search Console - это набор инструментов Google, предназначенных для того, чтобы помочь вам отслеживать, как ваш контент отображается в результатах поиска. Один из этих инструментов проверяет robots.txt, вы легко найдете его на странице администратора инструментов Google для веб-мастеров (также проверьте The 50 Best WordPress Plugins 2020).
Там вы найдете поле редактора, в которое вы можете добавить код для вашего файла robots.