Шаблон файла Robots.txt для WordPress
Расширенная версия Robots.txt. для WP
Для вас наверняка не будет откровением то, что все сайты на WP имеют единую структуру. Этот факт, позволяет специалистам разрабатывать наиболее оптимальные варианты robots.
Я, не стал исключением. За долго подбирал для себя тот вид роботса, который мог бы полностью меня удовлетворить. И сейчас я хочу с вами им поделиться.
User-agent: * # Для всех поисковых систем, кроме Яндекса и Гугла
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.
php Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/ # Закрываем метки
Disallow: /readme.html # Закрываем бесполезный мануал по установке WordPress (лежит в корне)
Disallow: *?replytocom
Allow: */uploads
User-agent: GoogleBot # Для Гугла
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/ # Закрываем метки Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.
php
User-agent: Yandex # Для Яндекса
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: /tag/ # Закрываем метки
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign
Clean-Param: openstat
Sitemap: https://site.com/sitemap_index.xml # Карта сайта, меняем site.com на нужный адрес.
Ранее, в Robots.txt. использовалась директива Host, которая указывала на главное зеркало сайта.
Sitemap с протоколом https указывается по причине того, что большая часть сайтов использует защищенное соединение. Если у вас нет SSL, просто измените протокол на http.
Хочу заострить ваше внимание на том, что я закрываю теги, ведь они создают огромное количество дублей, что плохо сказывается на SEO. В том случае, если вы хотите их открыть, тогда вам необходимо удалить строку disallow: /tag/ из файла.
что это такое и как его использовать в WordPress
Всем привет!
Сегодня я выношу на ваш суд полное руководство по файлу robots.txt для WordPress. Удачно оно или нет — решать вам. Но думаю многие почерпнут из него много интересных и нужных знаний.
Когда-нибудь слышали термин robots.txt и задавались вопросом, как он применяется к вашему сайту? Большинство веб-сайтов имеют файл robots.txt, но это не означает, что большинство веб-мастеров понимают его. В этом посте я надеюсь изменить это, предложив глубокое погружение в файл WordPress robots. txt, а также узнав, как он может контролировать и ограничивать доступ к вашему сайту. К концу вы сможете ответить на такие вопросы, как:
txt, а также узнав, как он может контролировать и ограничивать доступ к вашему сайту. К концу вы сможете ответить на такие вопросы, как:
Есть еще много чего, так что давайте начнем!
Что такое WordPress robots.txt?
Прежде чем мы сможем поговорить о файле robots.txt в WordPress, важно определить, что такое «robot» в этом случае. Роботы — это любой тип «бота», который посещает веб-сайты в интернете. Наиболее распространенный пример — поисковые роботы. Эти боты «ползают» по сети, чтобы помочь таким поисковым системам, как Яндекс и Google, и ранжировать миллиарды страниц в интернете.
Итак, боты, в общем, полезны для интернета … или, по крайней мере, необходимы. Но это не обязательно означает, что вы или другие веб-мастера хотите, чтобы боты бегали без ограничений. Желание контролировать взаимодействие веб-роботов с веб-сайтами привело к созданию стандарта исключения роботов в середине 1990-х годов. Robots.txt является практической реализацией этого стандарта — он позволяет вам контролировать, как участвующие боты взаимодействуют с вашим сайтом. Вы можете полностью блокировать ботов, ограничить их доступ к определенным областям вашего сайта и многое другое.
Вы можете полностью блокировать ботов, ограничить их доступ к определенным областям вашего сайта и многое другое.
Эта «участвующая» часть важна. Robots.txt не может заставить бота следовать его директивам. А вредоносные боты могут и будут игнорировать файл robots.txt. Кроме того, даже авторитетные организации игнорируют некоторые команды, которые вы можете поместить в robots.txt. Например, Google будет игнорировать любые правила, которые вы добавляете в свой robots.txt, относительно того, как часто его сканеры посещают. Если у вас много проблем с ботами, вам может пригодиться решение для безопасности, такое как Cloudflare или Sucuri.
Почему вы должны заботиться о своем файле robots.txt?
Для большинства веб-мастеров преимущества хорошо структурированного файла robots.txt сводятся к двум категориям:
- Оптимизация ресурсов сканирования поисковых систем, сказав им не тратить время на страницы, которые вы не хотите индексировать. Это помогает поисковым системам сосредоточиться на сканировании страниц, которые вас интересуют больше всего.

- Оптимизация использования ваших исследований путем блокировки ботов, которые тратят ресурсы вашего сервера.
Robots.txt не касается конкретно того, какие страницы индексируются в поисковых системах
Robots.txt не является надежным способом контроля того, какие страницы индексируют поисковые системы. Если ваша основная цель состоит в том, чтобы не допустить включения определенных страниц в результаты поиска, правильный подход — использовать метатег «noindex» или другой аналогичный прямой метод.
Это потому, что ваш robots.txt прямо не говорит поисковым системам не индексировать контент — он просто говорит им не сканировать его. Хотя Google не будет сканировать отмеченные области внутри вашего сайта, Google сам заявляет, что если внешний сайт ссылается на страницу, которую вы исключаете в файле robots.txt, Google все равно может проиндексировать эту страницу.
Джон Мюллер, аналитик Google для веб-мастеров, также подтвердил, что, если на страницу есть ссылки, указывающие на нее, даже если она заблокирована файлом robots. txt, она все равно может быть проиндексирована. Вот что он хотел сказать в видеовстрече для веб-мастеров:
txt, она все равно может быть проиндексирована. Вот что он хотел сказать в видеовстрече для веб-мастеров:
Здесь следует иметь в виду одну вещь: если эти страницы заблокированы файлом robots.txt, теоретически может случиться так, что кто-то случайным образом сделает ссылку на одну из этих страниц. И если они это сделают, то может случиться так, что мы проиндексируем этот URL без какого-либо контента, потому что он заблокирован robots.txt. Таким образом, мы бы не знали, что вы не хотите, чтобы эти страницы были действительно проиндексированы.
Принимая во внимание, что если они не заблокированы robots.txt, вы можете поместить метатег «noindex» на эти страницы. И если кто-то ссылается на них, и мы случайно просматриваем эту ссылку и думаем, что здесь может быть что-то полезное, мы бы знали, что эти страницы не нужно индексировать, и мы можем просто пропустить их индексацию полностью.
Таким образом, в этом отношении, если на этих страницах есть что-то, что вы не хотите индексировать, не запрещайте их, используйте вместо этого тег «noindex».
Как создать и отредактировать файл robots.txt
По умолчанию WordPress автоматически создает виртуальный файл robots.txt для вашего сайта. Таким образом, даже если вы не поднимите палец для этого, на вашем сайте уже должен быть файл robots.txt по умолчанию. Вы можете проверить, так ли это, добавив «/robots.txt» в конец вашего доменного имени. Например, «https://zacompom.ru/robots.txt» вызывает файл robots.txt, который я используем здесь:
Пример файла robots.txt
Поскольку этот файл является виртуальным, вы не можете его редактировать. Если вы хотите отредактировать свой файл robots.txt, вам необходимо создать физический файл на вашем сервере, которым вы сможете манипулировать по мере необходимости. Вот три простых способа сделать это …
Как создать и отредактировать файл robots.txt с помощью Yoast SEO
Если вы используете популярный плагин Yoast SEO, вы можете создать (и отредактировать) свой файл robots.txt прямо из интерфейса Yoast. Однако прежде чем вы сможете получить к нему доступ, вам нужно включить расширенные функции Yoast SEO, перейдя в раздел «SEO — Панель инструментов — Функции» и переключиться на «Страницах» — «Дополнительные настройки»:
Как включить расширенные функции Yoast
После того, как это активировано, вы можете перейти к «SEO — Инструменты» и нажать на «Редактор файлов»:
Как получить доступ к редактору файлов Yoast
Предполагая, что у вас еще нет физического файла robots. txt, Yoast предложит вам «создать файл robots.txt»:
txt, Yoast предложит вам «создать файл robots.txt»:
Как создать robots.txt в Yoast
И после того, как вы нажмете эту кнопку, вы сможете редактировать содержимое файла robots.txt непосредственно из того же интерфейса:
Как редактировать robots.txt в Yoast
По мере того, как вы читаете дальше, мы более подробно рассмотрим, какие типы директив следует поместить в ваш файл robots.txt.
Как создать и отредактировать файл robots.txt в «All In One SEO»
Если вы используете плагин СЕО-пакета «All In One SEO» в формате Yoast, вы также можете создавать и редактировать файл robots.txt прямо из интерфейса плагина. Все, что вам нужно сделать, это зайти в «All In One SEO — Диспетчер по функциям» и активировать robots.txt функции:
Как создать robots.txt в All in One SEO Pack
Затем вы сможете управлять своим файлом robots.txt, перейдя в раздел «All in One SEO Pack — Robots.txt»:
Как редактировать robots.txt в All in One SEO Pack
Как создать и редактировать файл robots.
 txt через FTP
txt через FTPЕсли вы не используете плагин SEO, который предлагает функциональность robots.txt, вы все равно можете создавать и управлять своим файлом robots.txt через SFTP. Сначала используйте любой текстовый редактор, чтобы создать пустой файл с именем «robots.txt»:
Как создать свой собственный файл robots.txt
Затем подключитесь к своему сайту через SFTP и загрузите этот файл в корневую папку вашего сайта. Вы можете внести дополнительные изменения в свой файл robots.txt, отредактировав его через SFTP или загрузив новую версию файла.
Что надо прописывать в ваш файл robots.txt
Хорошо, теперь у вас есть физический файл robots.txt на вашем сервере, который вы можете редактировать по мере необходимости. Но что вы на самом деле можете делать с этим файлом? Ну, как вы узнали из первого раздела, robots.txt позволяет вам контролировать взаимодействие роботов с вашим сайтом. Вы делаете это с помощью двух основных команд:
- User-agent — позволяет вам ориентироваться на конкретных ботов.
 User-agent — это то, что боты используют для идентификации себя. С их помощью вы можете, например, создать правило, которое применяется к Яндекс, но не к Google.
User-agent — это то, что боты используют для идентификации себя. С их помощью вы можете, например, создать правило, которое применяется к Яндекс, но не к Google. - Disallow — эта директива позволяет вам запретить роботам доступ к определенным областям вашего сайта.
Также есть команда Allow, которую вы будете использовать в нишевых ситуациях. По умолчанию все на вашем сайте помечено как Allow, поэтому нет необходимости использовать команду Allow в 99% случаев. Но это очень удобно, когда вы хотите запретить (Disallow) доступ к папке и ее дочерним папкам, но разрешить (Allow) доступ к одной определенной дочерней папке.
Вы добавляете правила, сначала указывая, к какому User-agent должно применяться правило, а затем перечисляя, какие правила применять, используя Disallow и Allow. Есть также некоторые другие команды, такие как Crawl-delay и Sitemap, но они либо:
- Игнорируется большинством основных сканеров или интерпретируется совершенно по-разному (в случае задержки сканирования)
- Сделано избыточным с помощью таких инструментов, как Google Search Console (для файлов сайтов)
Давайте рассмотрим некоторые конкретные случаи использования, чтобы показать вам, как все это происходит вместе.
Как использовать robots.txt, чтобы заблокировать доступ ко всему сайту
Допустим, вы хотите заблокировать доступ всем сканерам к вашему сайту. Это вряд ли произойдет на живом сайте, но это пригодится для разработки сайта. Для этого вы должны добавить этот код в ваш файл WordPress robots.txt:
User-agent: *
Disallow: /
Что происходит в этом коде?
Звездочка (*) рядом с User-agent означает «все User-agent». Звездочка — это подстановочный знак, означающий, что он применяется к каждому агенту пользователя. Слэш (/) рядом с Disallow говорит, что вы хотите, чтобы запретить доступ ко всем страницам, которые содержат «yourdomain.com/» (каждую страницу на вашем сайте).
Как использовать robots.txt, чтобы заблокировать доступ одного сайта к вашему сайту
Давайте изменим это. В этом примере мы представим, что вам не нравится тот факт, что Bing сканирует ваши страницы. Вы — команда Google, и даже не хотите, чтобы Bing просматривал ваш сайт. Чтобы заблокировать только Bing от сканирования вашего сайта, вы должны заменить звездочку (*) с Bingbot:
User-agent: Bingbot
Disallow: /
По существу, приведенный выше код говорит только применить правило Disallow для бота с именем «Bingbot».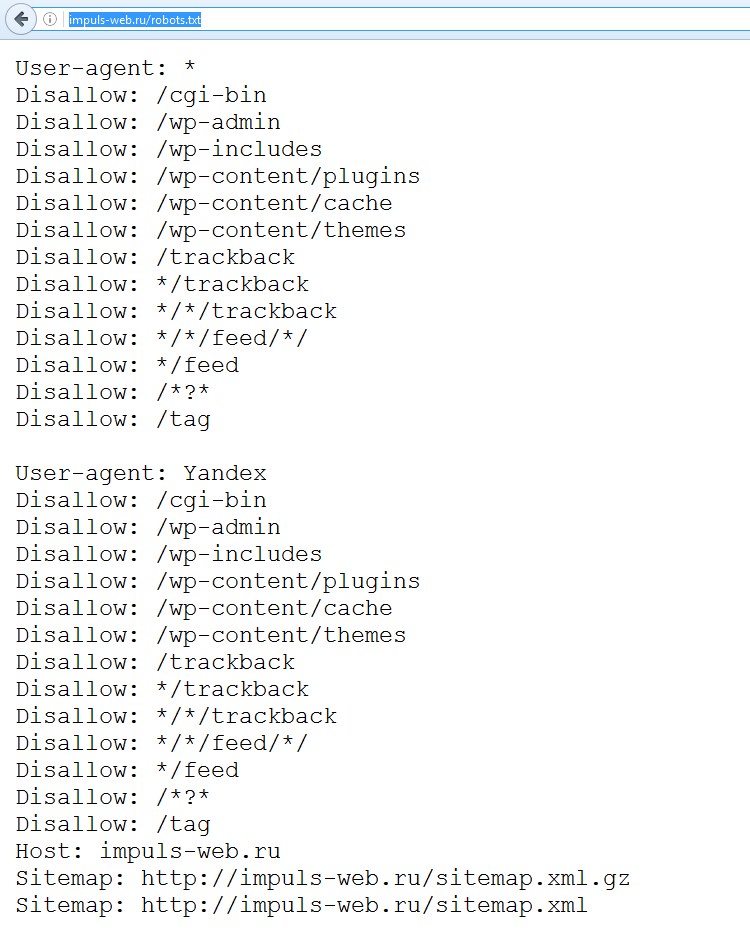 Теперь вы вряд ли захотите заблокировать доступ к Bing, но этот сценарий пригодится, если есть конкретный бот, которому вы не хотите разрешать заходить на свой сайт.
Теперь вы вряд ли захотите заблокировать доступ к Bing, но этот сценарий пригодится, если есть конкретный бот, которому вы не хотите разрешать заходить на свой сайт.
Как использовать robots.txt, чтобы заблокировать доступ к определенной папке или файлу
В этом примере предположим, что вы хотите заблокировать доступ только к определенному файлу или папке (и всем подпапкам этой папки). Чтобы применить это к WordPress, допустим, вы хотите заблокировать:
- Вся папка wp-admin
- wp-login.php
Вы можете использовать следующие команды:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.php
Как использовать robots.txt, чтобы разрешить доступ к определенному файлу в запрещенной папке
Хорошо, теперь давайте скажем, что вы хотите заблокировать всю папку, но вы по-прежнему хотите разрешить доступ к определенному файлу внутри этой папки. Вот где команда Allow пригодится. И это на самом деле очень применимо к WordPress. Фактически, виртуальный файл WordPress robots. txt прекрасно иллюстрирует этот пример:
txt прекрасно иллюстрирует этот пример:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Этот фрагмент кода блокирует доступ ко всей папки wp-admin, за исключением файла /wp-admin/admin-ajax.php.
Как использовать robots.txt, чтобы остановить роботов от сканирования результатов поиска WordPress
Один из специфических трюков WordPress, который вы можете захотеть сделать — запретить поисковым роботам сканировать страницу результатов поиска. По умолчанию WordPress использует параметр запроса «?S=». Таким образом, чтобы заблокировать доступ, все, что вам нужно сделать, это добавить следующее правило:
User-agent: *
Disallow: /?s=
Disallow: /search/
Это может быть эффективным способом остановки программных ошибок 404, если вы их получаете.
Как создать разные правила для разных ботов в robots.txt
 Например, если вы хотите создать одно правило, которое применяется ко всем ботам, и другое правило, которое относится только к Bingbot, вы можете сделать это следующим образом:
Например, если вы хотите создать одно правило, которое применяется ко всем ботам, и другое правило, которое относится только к Bingbot, вы можете сделать это следующим образом:
User-agent: *
Disallow: /wp-admin/
User-agent: Bingbot
Disallow: /
В этом примере всем ботам будет заблокирован доступ к /wp-admin/, но Bingbot будет запрещен доступ ко всему сайту.
Тестирование вашего файла robots.txt
Вы можете проверить файл robots.txt в консоли поиска Google, чтобы убедиться, что он правильно настроен. Просто нажмите на свой сайт, и в разделе «Сканирование» нажмите «Тестировать robots.txt». Затем вы можете отправить любой URL, включая свою домашнюю страницу. Вы должны увидеть зеленый Allowed, если все можно сканировать. Вы также можете проверить заблокированные URL-адреса, чтобы убедиться, что они действительно заблокированы и/или Disallowed.
Тест файла robots.txt
Остерегайтесь спецификации UTF-8
Спецификация обозначает метку порядка байтов и в основном является невидимым символом, который иногда добавляется в файлы старыми текстовыми редакторами и т. п. Если это происходит с вашим файлом robots.txt, Google может не прочитать его правильно. Вот почему важно проверить ваш файл на наличие ошибок. Например, как показано ниже, наш файл имел невидимый символ, и Google жалуется, что синтаксис не понятен. Это фактически делает недействительной первую строку нашего файла robots.txt, что не очень хорошо! У Гленна Гейба есть отличная статья о том, как UTF-8 BOM может убить ваше СЕО.
п. Если это происходит с вашим файлом robots.txt, Google может не прочитать его правильно. Вот почему важно проверить ваш файл на наличие ошибок. Например, как показано ниже, наш файл имел невидимый символ, и Google жалуется, что синтаксис не понятен. Это фактически делает недействительной первую строку нашего файла robots.txt, что не очень хорошо! У Гленна Гейба есть отличная статья о том, как UTF-8 BOM может убить ваше СЕО.
UTF-8 BOM в вашем файле robots.txt
Googlebot в основном в США
Также важно не блокировать робота Google из США, даже если вы ориентируетесь на местный регион за пределами США. Иногда они выполняют локальное сканирование, ну а робот Google в основном базируется в США.
Что помещают в свои файлы robots.txt популярные сайты на WordPress
Чтобы фактически обеспечить некоторый контекст для пунктов, перечисленных выше, вот как некоторые из самых популярных сайтов на WordPress используют свои файлы robots.txt.
TechCrunch
В дополнение к ограничению доступа к ряду уникальных страниц TechCrunch особенно запрещает сканерам:
Они также устанавливают специальные ограничения для двух ботов:
В случае, если вам интересно, IRLbot является краулером исследовательского проекта Texas A&M University. Это странно!
The Obama Foundation
The Obama Foundation не сделал никаких специальных дополнений, решив исключительно ограничить доступ к папке /wp-admin/.
Angry Birds
Angry Birds имеет ту же настройку по умолчанию, что и The Obama Foundation. Ничего особенного не добавляется.
Drift
Наконец, Drift решает определить свои sitemap сайта в файле robots.txt, но в противном случае оставляет те же ограничения по умолчанию, что и The Obama Foundation и Angry Birds.
Используйте файл robots.txt правильно
Завершая свое руководство по robots.txt, я хотел бы еще раз напомнить вам, что использование команды Disallow в вашем файле robots.txt отличается от использования тега noindex. Robots.txt блокирует сканирование, но не индексирование. Вы можете использовать его для добавления определенных правил, чтобы определить, как поисковые системы и другие боты взаимодействуют с вашим сайтом, но он не будет явно контролировать, проиндексирован ли ваш контент или нет.
Для большинства случайных пользователей WordPress нет необходимости срочно изменять виртуальный файл robots.txt по умолчанию. Но если у вас проблемы с конкретным ботом или вы хотите изменить взаимодействие поисковых систем с определенным плагином или темой, которую вы используете, вы можете добавить свои собственные правила.
Я надеюсь, что вам понравилось это руководство, и обязательно оставьте комментарий, если у вас возникнут дополнительные вопросы об использовании файла robots.txt в WordPress.
До скорых встреч!
Навигация по записям
Юрич:
Занимаюсь созданием сайтов на WordPress более 6 лет. Ранее работал в нескольких веб-студиях и решил делиться своим опытом на данном сайте. Пишите комментарии, буду рад общению.
Не забудьте подписаться на обновления:
Похожие записи
Оставить свой комментарий
Как создать файл Robots.txt для WordPress
10 августа | Автор З. Владимир | 5 комментариевВсем привет! Начитался и поэкспериментировал я с Robots. txt для WordPress, что информация уже сама просится с кем-нибудь поделиться. Ладно, если было бы что-то страшное и архисложное, а так простенький, текстовый файл, который всего лишь нужно создать на рабочем столе с помощью правой кнопки мыши, переименовать его в robots.txt, записать в нем несколько директив и (закинуть) перенести, с помощью Ftp-клиента ( Total Commander или FileZilla) на сервер, в корневой каталог вашего сайта. Все господа! Дело сделано! Можно теперь и «Трубку Мира» закурить. Но без нескольких уточнений, все же, нам не обойтись.
txt для WordPress, что информация уже сама просится с кем-нибудь поделиться. Ладно, если было бы что-то страшное и архисложное, а так простенький, текстовый файл, который всего лишь нужно создать на рабочем столе с помощью правой кнопки мыши, переименовать его в robots.txt, записать в нем несколько директив и (закинуть) перенести, с помощью Ftp-клиента ( Total Commander или FileZilla) на сервер, в корневой каталог вашего сайта. Все господа! Дело сделано! Можно теперь и «Трубку Мира» закурить. Но без нескольких уточнений, все же, нам не обойтись.
• Для чего нужен Robots.txt?
Все очень просто. Чтобы поисковые роботы-пауки не «шастали» по вашему сайту где им не следует и не индексировали все, что попало им в «лапы», мы, с помощью разрешающих (Allow) или запрещающих (Disallow) директив (команд), даем им указание (а скорее рекомендуем), что нужно индексировать, а на что не стоит тратить время и трафик.
Кстати, потраченное поисковиком время на сканирование сайта/блога, может отразиться на том, как часто робот будет заходить на вашу интернет-страницу в будущем и, к тому же, будет влиять на дальнейшее seo – продвижение вашего проекта. И если у вас Seo-файла robots.txt нет вообще, или он создан не правильно или с ошибками, то не стоит надеяться на ежедневное сканирование страниц вашего сайта, а это, в свою очередь, чревато редкой индексацией контента. Потому, советую отнестись к составлению Robots.txt со всей ответственностью и, лучше всего, если сделаете это на самом начальном этапе настройки блога/сайта.
♦ Как создать Robots.txt
Даже у новичков, надеюсь, это действие не должно вызвать больших проблем. Но, на всякий случай, предлагаю посмотреть скриншот:
Повторюсь. На рабочем столе нажимаем правую кнопку мыши и выбираем «Создать» — «Текстовый документ»:
Созданному файлу нужно присвоить имя. Наводим курсор мыши на файл, нажимаем правую кнопку и выбираем «Переименовать».
Теперь в этот файл нужно записать некоторые директивы.
Основываясь на своей практике, перед тем как создать «robots.txt», было бы не плохо хорошенько изучить дизайн своего блога ( если не вы его делали а, например, поставили шаблонный дизайн), и особенно, обратить внимание на формирование шаблоном ссылок комментариев, rss, feed, меток и т.д., а так же внимательно ознакомьтесь с внутренними файлами и папками, находящимися в корневом каталоге. От этого будет зависеть правильность составления «robots.txt».
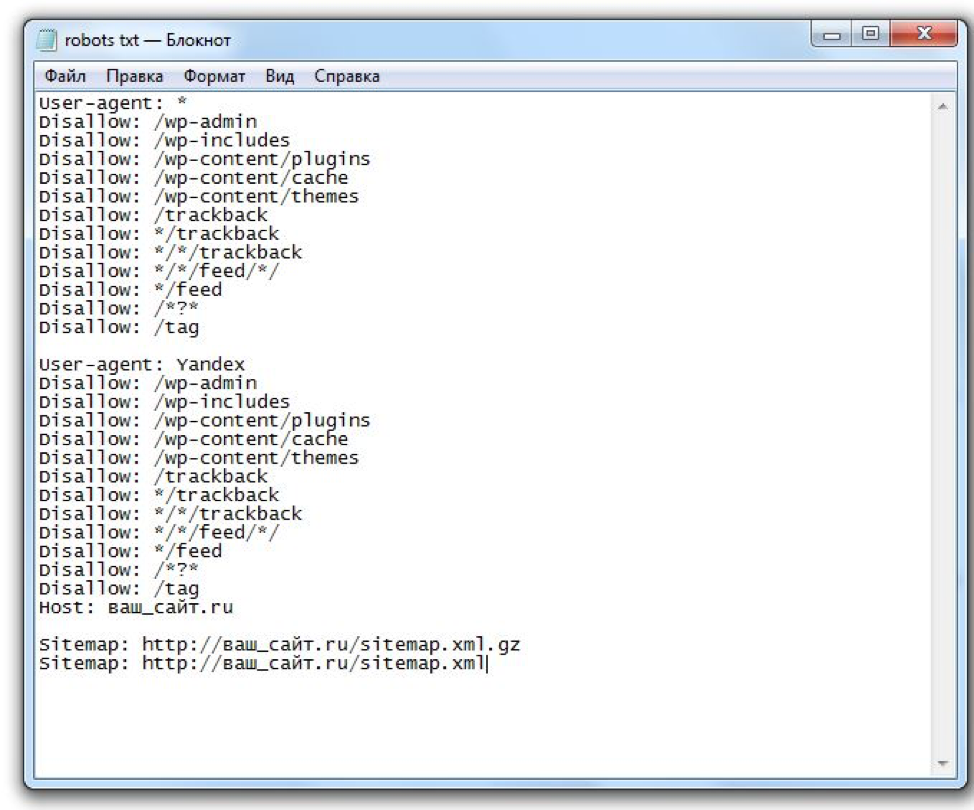
Давайте как пример, рассмотрим директивы в моем файле, который можете посмотреть по этой ссылке https://webodyssey.info/robots.txt
User-agent: *
Allow: /wp-content/uploads/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/languages
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /wp-comments
Disallow: */comments
Disallow: /xmlrpc.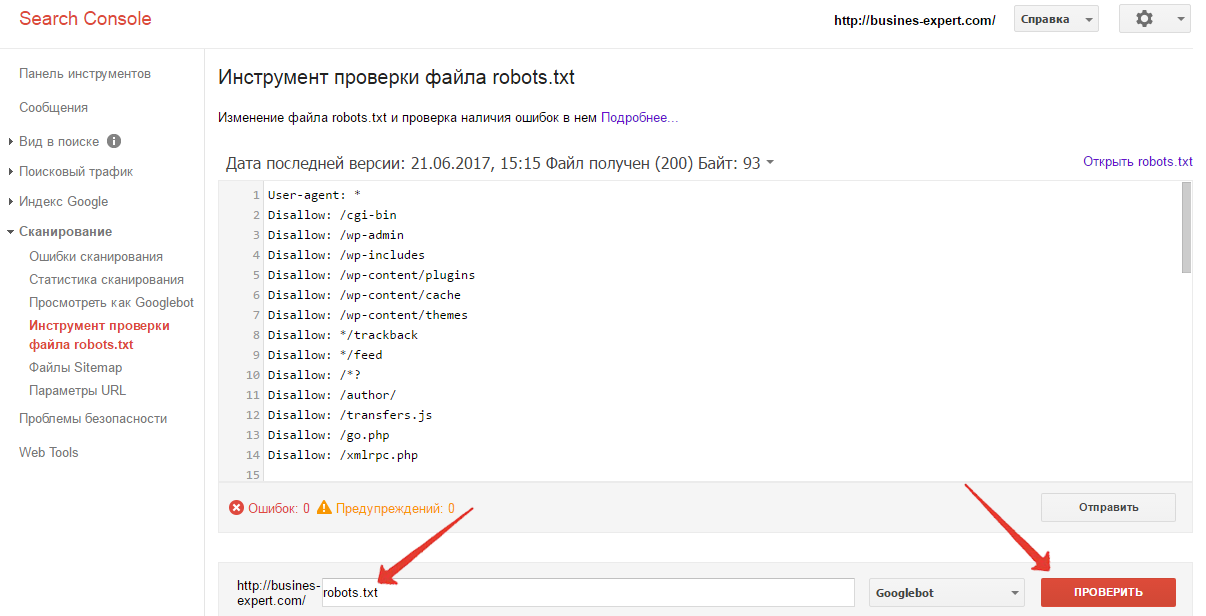 php
php
Disallow: /trackback
Disallow: /trackback
Disallow: */trackback
Disallow: /feed/
Disallow: */feed
Disallow: /*?*
Disallow: /*?
Вторая часть файла
User-agent: Yandex
Allow: /wp-content/uploads/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/languages
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /wp-comments
Disallow: */comments
Disallow: /xmlrpc.php
Disallow: /trackback
Disallow: /trackback
Disallow: */trackback
Disallow: /feed/
Disallow: */feed
Disallow: /*?*
Disallow: /*?
Host: webodyssey.info
.
Sitemap: https://webodyssey.info/sitemap.xml
User-agent: — этой записью вы обращаетесь к какому-нибудь поисковому роботу. Как пример, можем записать так: User-agent: Yahoo
В моем случае, в «User-agent: *» — использован знак подстановки «*», то есть обращение направлено для всех роботов без исключений, тогда как в другой части, те же правила, но предназначены уже для поисковика Yandex.
Allow: /wp-content/uploads/ — Этой командой я разрешил индексировать папку
Uploads, (в которой находятся все картинки используемые в статьях), которая, в свою очередь, находится в каталоге wp-content. Эту директорию я прописал в качестве эксперимента, так как мне не очень нравилось, как Гугл индексирует мои картинки.
Вам это делать не обязательно и вполне хватит запрещающих команд Disallow:
Ведь то, что не запрещено – значит разрешено. Кстати, спустя три месяца, индексация картинок так и не улучшилась (видно причина в другом), потому мне эту строчку, скорее всего, придется убрать.
Disallow: /wp-login.php – такой директивой закроем файл с помощью которого мы, вводя логин и пароль, заходим на блог. К таким служебным, системным файлам и папкам можно отнести:
/wp-register.php
/wp-admin
/wp-includes
/wp-content/languages
/wp-content/plugins
/wp-content/cache
/wp-content/themes
/wp-comments
Чтобы запретить роботам индексировать трекбеки, фид и комментарии нужно внести такие записи:
*/comments
/xmlrpc. php
php
/trackback
/trackback
*/trackback
/feed/
*/feed
Этими записями мы запретим дубли страниц в поисковой выдаче.
Disallow: /*?*
Disallow: /*?
Дальше прописан Host: для Яндекса, что бы он видел главное зеркало ( с www или без) вашего блога. Я, например, для пущей уверенности, указал этот же адрес еще и в Вебмастер Яндекс
Ну и в завершении, мы записываем адрес карты сайта в формате .xml. Это делается для облегчения поиска Яндексом этого файла на вашем блоге.
На этом буду заканчивать. Удачи Вам! и до следующих статей.
С огромным Уважением, Vladimir Zadorozhnyuk
Понравилась статья? Подпишитесь на новости блога или поделитесь в социальных сетях, а я отвечу вам ВЗАИМНОСТЬЮ
Обратите внимание на другие интересные статьи:
Как создать и установить файл robots.txt для WordPress
Файл robots.txt служит для улучшения индексации сайта. В директивах файла задаются установки для роботов поисковых систем,
что и как индексировать, а что нет.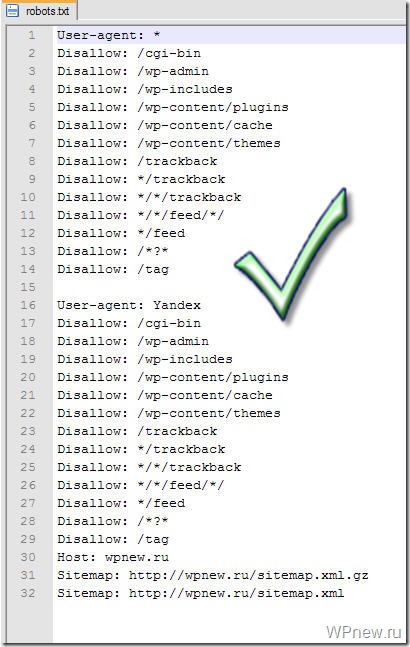 Указывается основной домен, Sitemap и другое.
Указывается основной домен, Sitemap и другое.
Сайт, конечно, будет индексироваться и без созданного файла, но гораздо хуже. Во первых, на сайте имеется множество разделов и файлов не нужных для индексации: admin, login, register и так далее, не говоря уж о дублях страниц, которые очень отрицательно сказываются на ранжировании ресурса.
Файл robots.txt располагается в корневой папке домена под этим же именем, писать имя с большой буквы — нельзя.
Рекомендуемый robots.txt для WordPress
User-Agent: *
Allow: /wp-content/uploads/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /template.html
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content
Disallow: /tag
Disallow: /category
Disallow: /archive
Disallow: */trackback/
Disallow: */feed/
Disallow: */comments/
Disallow: /?feed=
Disallow: /?s=
Host: сайт
Sitemap: http://сайт/sitemap.xml
#(Примечание: вместо «сайт» — ваш домен)
Как создать и установить файл robots.
 txt в корневую папку сайта — инструкция
txt в корневую папку сайта — инструкцияКак правило, хостинг предоставляет возможность создавать файлы, приведу пример.
В панели управления сайтом на сервере хостинга нужно создать файл с именем «robots.txt»
Установить robots.txt
- Откройте созданный robots.txt
- Скопируйте рекомендованный файл для WordPress
- Вставьте в поле содержимое
- Вместо «сайт» впишите свой domen.ru
- Сохраните изменения
Вы можете увидеть свой файл, набрав в адресной строке браузера: http://сайт.ru/robots.txt, или в сервисе Яндекс.Вебмастер если им пользуетесь.
В дальнейшем, вы можете изменять файл, указывая адреса страниц, которые не нужно индексировать, задавать другие команды ботам. Но нужно знать, что поисковики не гарантируют полного исполнения директив, заданных в robots.txt, но как правило, выполняют их.
- < Назад
- Вперёд >
Robots.txt для WordPress: рабочий пример
Если кто-то думает, что без robots.txt можно обойтись — сильно ошибается. Чтобы там не говорили о «виртуальном роботсе» или не актуальности его создания для ПС Google, файл Robots был и остается важнейшим системным файлом, с помощью которого можно контролировать индексацию веб-страниц поисковыми ботами. В этой заметке я расскажу как создать правильный Robots для CMS WordPress.
Что такое Robots.txt и зачем он нужен?
Robots.txt — это стандарт исключений для поисковых ботов, принят консорциумом W3C 30 января 1994 года. Создается в виде txt-файла и помещается в корневую директорию домена. Содержит специальные директивы — правила для поисковых ботов. Каждая директива указывается с новой строки. Правила нужны для того, чтобы исключить из поиска определенные файлы и папки сайта.
При отствуствующем robots.txt — поисковик будет парсить и вытягивать на поверхность все, что проиндексирует. Это иогут быть и конфеденциальные данные. Поэтому, Robots.txt помогает улучшить безопасность сайта и сохранить чистоту индекса, не дав попасть в поиск чему-то лишнему.
WordPress и виртуальный Robots.txt
После создания сайта, CMS WordPress автоматически создает виртуальный robots.txt с базовыми директивами. Выглядит он так:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpSitemap: https://mywebsite.com/sitemap.xml
Как видно, он не закрывает от поиска системные, конфиденциальные и служебные разделы. Пока сайт маленький — вы не сильно замечаете проблемы, связанные с этим. Но когда набирается достаточное количество трафика, вы сразу же увидите статистику, сколько посетителей попадают на не желательные страницы вашего сайта и поймете, что «виртуальный роботс» не спасает и нужно создавать нормальный robots. txt.
txt.
Пример работающего Robots.txt для WordPress
Файл создается c расширением .txt в стандартной кодировке UTF-8 (без BOM!) и помещается в корневую директорию сайта:
User-agent: * # правила для всех роботов Disallow: /cgi-bin # скрипты на сервере Disallow: /? # все параметры URL со знаком ? Disallow: /wp- # все сис. папки и файлы WP Disallow: *?s= # параметры URL со спецсимволом Disallow: *&s= # см. выше Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: */trackback # уведомления в комментариях Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с картинками Allow: /*/*.js # открываем js-скрипты Allow: /*/*.css # открываем css-файлы Allow: /wp-*.png # изображения в плагинах Allow: /wp-*.jpg # картинки в плагинах Allow: /wp-*.jpeg # изображения в плагинах Allow: /wp-*.gif # картинки в плагинах Allow: /wp-*.svg # изображения в плагинах Allow: /wp-*.pdf # файлы в плагинах Allow: /wp-admin/admin-ajax.php # используется плагинами Sitemap: http://example.com/sitemap.xml # путь к карте сайта
Как проверить Robots.
 txt на ошибки
txt на ошибкиВ Панелях Вебмастера Яндекс и Google есть специальные инструменты для тестирования файла robots:
Создавая robots.txt будьте внимательными и придерживайтесь официальных рекомендаций.
Настройка файла robots.txt для WordPress
Исторически сложилось так, что главным способом указать параметры для индексации сайта с помощью поисковых систем стал обычный текстовый файл robots.txt, размещаемый в корне веб-проекта. Именно на него ориентируются все поисковые боты, формирующие выдачу в Google, Yandex и в других системах. Поскольку этот файл заполняется по определённым правилам, очень важно знать все их «подводные камни». Небрежное отношение к его содержимому может стать причиной отсутствия в поиске или наоборот стать источником утечки конфиденциальной информации.
Зачем нужен robots.txt?
Структура любого сайта напоминает дерево папок на локальном компьютере, в которых хранятся отдельные файлы. Записи в файле robots.txt являются ничем иным, как директивами для поисковых ботов. С помощью специального синтаксиса им можно разрешать или запрещать доступ к отдельным частям вашего веб-проекта.
Записи в файле robots.txt являются ничем иным, как директивами для поисковых ботов. С помощью специального синтаксиса им можно разрешать или запрещать доступ к отдельным частям вашего веб-проекта.
Поведение поискового бота на сайте
Типичный поисковый бот нацелен на обнаружение нового и уникального контента, который он индексирует, чтобы передать своей системе. Главное правило поискового робота — слушаться команд из robots.txt. Оказываясь на вашем сайте, он первым делом считывает информацию оттуда, а затем заглядывает только в те разделы, доступ к которым не был ограничен.
Рассмотрим ситуацию, когда этот файл отсутствует или является пустым. В этом случае бот начинает исследовать все уголки сайта, включая корневую директорию. Поскольку чаще всего именно там хранятся настройки вашего проекта, то они очень скоро могут стать достоянием всех пользователей интернета. Чтобы этого избежать, нужно проследить за тем, чтобы в файле с директивами содержались правильные записи.
Как создать и куда поместить robots.txt?
Поскольку файл с директивами является самым простым текстовым файлом, то для его создания подойдёт любой редактор. Важно лишь при сохранении дать ему правильное название, то есть «robots.txt». Каждая команда внутри представляет собой отдельную строку.
Готовый файл следует разместить в корневой директории сайта. Только в этом случае есть гарантия того, что он будет замечен и прочитан ботом. Если случайно перенести файл в другую папку, то поисковый механизм его просто не увидит, то есть останется бесконтрольным.
После чтения инструкций послушный бот заглянет только в те разделы, в которые ему разрешили доступ и проигнорирует все остальные.
Структура robots.txt
Файл с директивами состоит из отдельных блоков, о предназначении каждого из которых мы расскажем ниже.
Поскольку у каждого поисковика по сети путешествуют свои боты, иногда хорошей идеей является задать для каждого из них отдельные инструкции.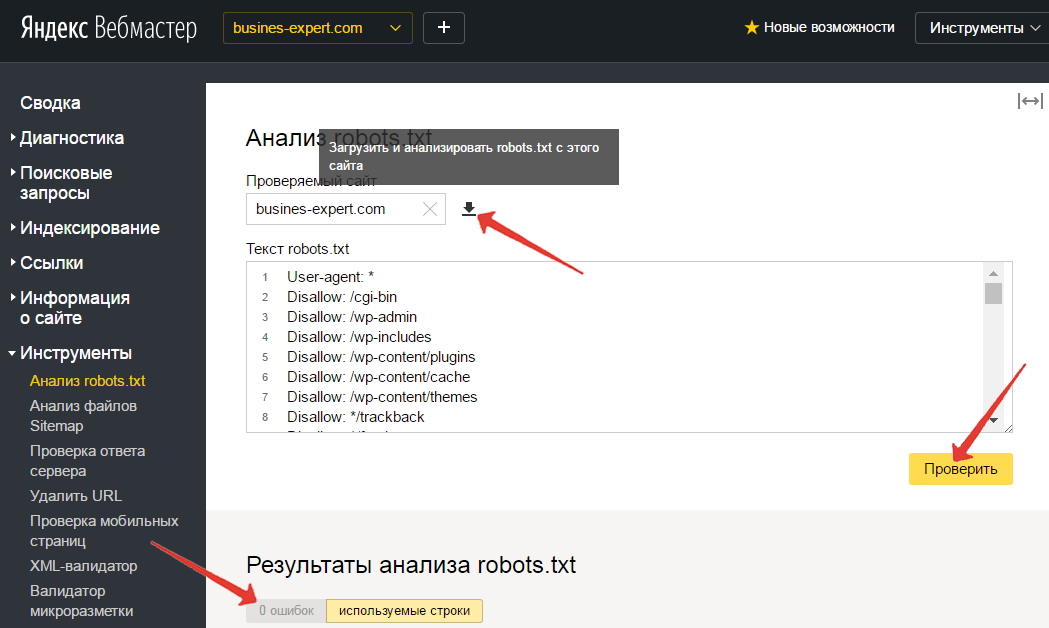 Делается это с помощью директивы User-agent.
Делается это с помощью директивы User-agent.
Чтобы инструкциям из файла следовали абсолютно все поисковики, достаточно указать строку «User-agent: *». Из-за большого количества ботов сложно создать файл, учитывающий их все. На практике чаще всего раздельные правила индексирования требуется в явном виде разместить лишь для Google и Yandex.
Запрет на посещение определённых разделов сайта устанавливается с помощью команды Disallow. Обратной ей является директива Allow, которая наоборот открытым текстом даёт понять, что соответствующий раздел доступен для индексирования.
Для того, чтобы задать название главного хоста проекта, используйте команду Host.
Размещение карты сайта в формате xlm очень важно для полного и качественного индексирования сайта в поисковых системах. Указать его место положение можно с помощью ключевого слова Sitemap.
Полезно: лучший плагин для защиты от спама
Настраиваем robots.txt правильно
Прежде, чем мы расскажем о правильных настройках robots, необходимо ясно понимать, что главным для поисковых механизмов является полезная информация, которая будет востребована потенциальными посетителями вашего сайта. Если бот будет индексировать служебный контент, то пользы от его работы для вас нет. Даже наоборот — в открытый доступ могут попасть данные для доступа к сайту и его базе данных, чему очень порадуются злоумышленники.
Если бот будет индексировать служебный контент, то пользы от его работы для вас нет. Даже наоборот — в открытый доступ могут попасть данные для доступа к сайту и его базе данных, чему очень порадуются злоумышленники.
В корне любого сайта на WP располагается внушительное количество папок, содержимое которых лучше всего никому не показывать. Для этого явно запретим к ним доступ. Пример ниже.
Disallow: /wp- # Блокируем доступ к папкам, которые начинаются на wp- и содержат основные файлы для администрирования
Disallow: */trackback
Disallow: /*?* # Эта команда устанавливает запрет на индексирование всех ссылок, то есть защищает от дублирования
Disallow: /?s=*
Disallow: */author # Запрет на доступ к авторской папке
Disallow: /2021
Disallow: /xmlrpc.php
Allow: /wp-content/uploads/
Allow: *.js # Разрешаем индексировать скрипты
Allow: *.css # Разрешаем индексировать стили
Host: project.ru # Здесь указываем главное зеркало сайта
Sitemap: http://project.ru/sitemap.xml # Указываем местоположение карты сайтаЕсли структура вашего сайта отличается от стандартной, то вышеприведённая последовательность команд может выглядеть иначе.
Как ещё можно улучшить robots?
Даже использование примера выше не гарантирует полного контроля за действиями поисковых машин. В отдельных случаях ссылки на чувствительные разделы всё равно могут появиться в выдаче, но уже без содержимого. В этом нет угрозы безопасности сайту, однако не помешало бы убрать и эти следы.
Здесь мы подошли к моменту, когда не получится дать универсальной рекомендации, которая подойдёт для всех поисковиков.
В случае с Google достаточно воспользоваться набором фирменных инструментов для администраторов сайтов — Google Webmaster Tools. Чтобы запретить индексацию всех ссылок, оканчивающихся на feed, добавьте необходимые параметры в панели и сохраните настройки. Кстати, в случае с Yandex повторять аналогичные настройки не рекомендуется.
Дополнительным методом оптимизации является запрет на индексацию пагинации. Легче всего этого добиться с помощью популярного плагина All in One SEO. Достаточно в его настройках активировать канонические ссылки, после чего включить запрет на их панагацию.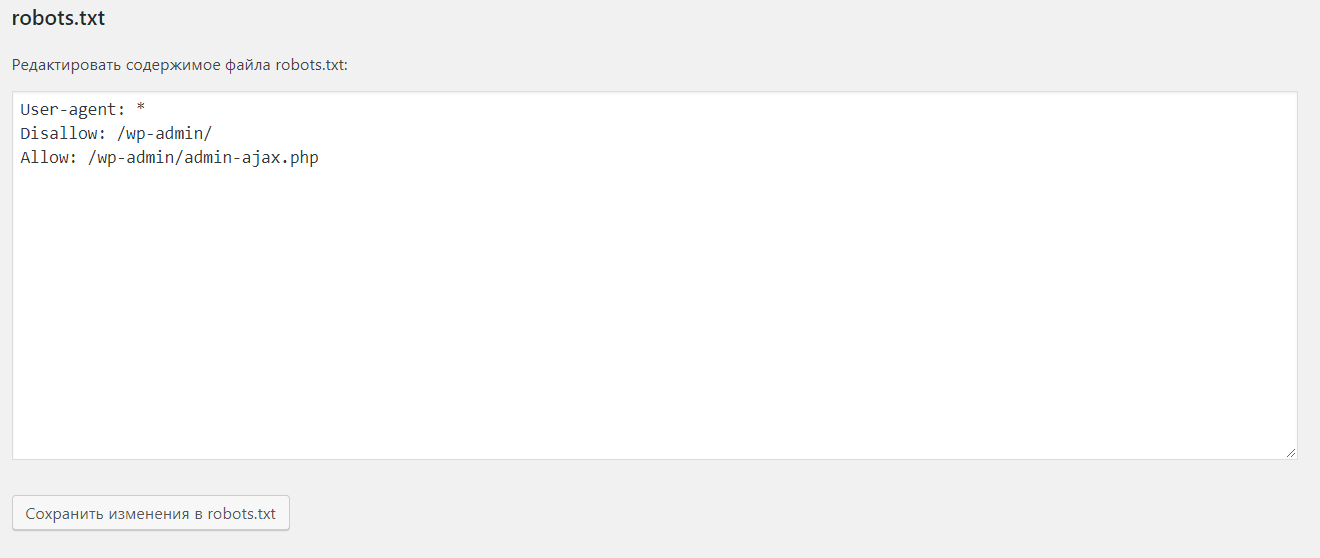 Это позволит поисковым ботам без ошибок определять основное содержимое сайта, не отвлекаясь на дубликаты. Дополнительно здесь рекомендуется включить noindex для всех архивов, страницы поиска, 404-ой страницы, а также для страниц и записей с панагацией. Чтобы завершить настройку, также отметьте флажком использование nofollow для страниц с панагацией.
Это позволит поисковым ботам без ошибок определять основное содержимое сайта, не отвлекаясь на дубликаты. Дополнительно здесь рекомендуется включить noindex для всех архивов, страницы поиска, 404-ой страницы, а также для страниц и записей с панагацией. Чтобы завершить настройку, также отметьте флажком использование nofollow для страниц с панагацией.
Если для оформления сайта вы используете тему, то откройте поисковикам доступ к её картинкам. Если этого не сделать, вы рискуете столкнуться с исчезновением нужной информации из поисковой выдачи.
Другими методами улучшения качества индексации является оптимизация меток и рубрик. Дело в том, что рубрикация приводит к двоению контента, что дезориентирует поисковики. Следует обратить внимание, что простой запрет на индексацию в данном случае является лишь одной из стратегий. Альтернативным вариантом будет внесение небольших изменений в код, что позволит рубрикам обрести уникальность. Если всё сделать правильно, то вы получите больше посетителей.
Завершая настройку robots, не забудьте про команду Host. Если явно не указать основное зеркало, то внимание бота будет отвлечено на дублирующие страницы, а вы потеряете часть своих пользователей.
Настройка robots для 2 поисковиков
В случаях, когда требуется указать раздельные инструкции для различных поисковиков, очень важно соблюсти их порядок. Лучшим решением будет сначала прописать инструкции Allow и Disallow для всех поисковиков, а затем отдельный блок посвятить конкретному. Пример структуры роботс для этого случая приведён ниже.
User-agent: *
Disallow: /feed
…
User-agent: Yahoo
Disallow: /feed
…
Host: myproject.ru
Sitemap: http://myproject.ru/sitemap.xmlЗаключение
Очевидно, что редактирование файла с инструкциями для ботов поисковых систем не следует откладывать на потом. Сделайте это сразу после того, как будет определена структура сайта. Прежде всего стоит обеспокоиться тем, чтобы скрыть от посторонних глаз важную информацию, влияющую на безопасность ресурса. Далее важно указать ботам на наиболее привлекательные с точки зрения контента части вашего проекта. Это даст ему возможность присутствовать в поисковой выдаче на высоких позициях и получать органический трафик. В случае крупных изменений в структуре сайта, каждый раз заново просматривайте файл. При необходимости вносите в него правки.
Далее важно указать ботам на наиболее привлекательные с точки зрения контента части вашего проекта. Это даст ему возможность присутствовать в поисковой выдаче на высоких позициях и получать органический трафик. В случае крупных изменений в структуре сайта, каждый раз заново просматривайте файл. При необходимости вносите в него правки.
robots.txt для wordpress или как запретить индексацию
Robots.txt для wordpressRobots.txt для wordpress один из главных инструментов настройки индексации. Ранее мы говорили об ускорении и улучшении процесса индексации статей. Причем рассматривали этот вопрос так, как будто поисковый робот ничего не знает и не умеет. А мы ему должны подсказать. Для этого мы использовали карту сайта файл sitemap.xml.
Возможно вы еще не догадывается, как поисковый робот индексирует ваш сайт? По умолчанию индексировать ему разрешено всё. Но делает он это не сразу. Робот, получив сигнал о том, что нужно посетить сайт, ставит его в очередь. Поэтому индексация происходит не мгновенно по нашему требованию, а через какое-то время. Как только очередь доходит до вашего сайта, этот робот-паук тут как тут. Первым делом он ищет файл robots.txt.
Поэтому индексация происходит не мгновенно по нашему требованию, а через какое-то время. Как только очередь доходит до вашего сайта, этот робот-паук тут как тут. Первым делом он ищет файл robots.txt.
Содержание статьи:
Что такое файл robots.txt
Если robots.txt найден, то прочитывает все директивы, а в конце видит адрес файла sitemap.xml. Дальше робот, в соответствии с картой сайта, обходит все материалы предоставленные для индексации. Делает он это в пределах какого-то ограниченного промежутка времени. Именно поэтому, если вы создали сайт на несколько тысяч страниц и выложили его целиком, то робот просто не успеет обойти все страницы за один заход. И в индекс попадут только те, которые он успел просмотреть. А ходит робот по всему сайту и тратит на это свое время. И не факт что в первую очередь он будет просматривать именно те странички, которые вы так ждёте в результатах поиска.
А ходит робот по всему сайту и тратит на это свое время. И не факт что в первую очередь он будет просматривать именно те странички, которые вы так ждёте в результатах поиска.
Если робот файл robots.txt не находит, то считает, что индексировать разрешено всё. И начинает шарить по всем закаулкам. Сделав полную копию всего, что ему удалось найти, он покидает ваш сайт, до следующего раза. Как вы понимаете, после такого обшаривания в базу индекса поисковика попадает всё, что надо и всё, что не надо. То что надо вы знаете — это ваши статьи, страницы, картинки, ролики и т.д. А вот чего индексировать не надо?
Для WordPress это оказывается очень важный вопрос. Ответ на него затрагивает и ускорение индексации содержимого вашего сайта, и его безопасность. Дело в том, что всю служебную информацию индексировать не надо. А файлы WordPress вообще желательно спрятать от чужих глаз. Это уменьшит вероятность взлома вашего сайта.
WordPress создаёт очень много копий ваших статей с разными адресами, но одним и тем же содержанием. Выглядит это так:
Выглядит это так:
//название_сайта/название_статьи,
//название_сайта/название_рубрики/название_статьи,
//название_сайта/название_рубрики/название_подрубрики/название_статьи,
//название_сайта/название_тега/название_статьи,
//название_сайта/дата_создания_архива/название_статьи
С тегами и архивами вообще караул. К скольким тегам привязана статья, столько копий и создаётся. При редактировании статьи, сколько архивов в разные даты будет создано, столько и новых адресов с практически похожим содержанием появится. А есть ещё копии статей с адресами для каждого комментария. Это вообще просто ужас.
Огромное количество дублей поисковые системы оценивают как плохой сайт. Если все эти копии проиндексировать и предоставить в поиске то вес главной статьи размажется на все копии, что очень плохо. И не факт, что будет показана в результате поиска именно статья с главным адресом. Следовательно надо запретить индексирование всех копий.
WordPress оформляет картинки как отдельные статьи без текста.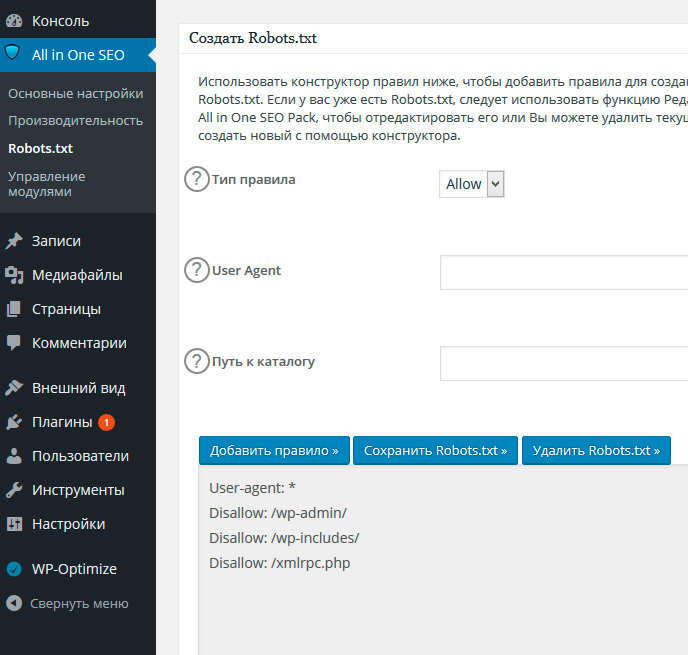 В таком виде без текста и описания они как статьи выглядят абсолютно некорректно. Следовательно нужно принять меры чтобы эти адреса не попали в индекс поисковиков.
В таком виде без текста и описания они как статьи выглядят абсолютно некорректно. Следовательно нужно принять меры чтобы эти адреса не попали в индекс поисковиков.
Почему же не надо всё это индексировать?
Пять причин для запрета индексации!
- Полное индексирование создаёт лишнюю нагрузку на ваш сервер.
- Отнимает драгоценное время самого робота.
- Пожалуй это самое главное, некорректная информация может быть неправильно интерпретирована поисковыми системами. Это приведет к неправильному ранжированию статей и страниц, а в последствии и к некорректной выдаче в результатах поиска.
- Папки с шаблонами и плагинами содержат огромное количество ссылок на сайты создателей и рекламодателей. Это очень плохо для молодого сайта, когда на ваш сайт ссылок из вне еще нет или очень мало.
- Индексируя все копии ваших статей в архивах и комментариях, у поисковика складывается плохое мнение о вашем сайте. Много дублей. Много исходящих ссылок Поисковая машина будет понижать ваш сайт в результатах поиска в плоть до фильтра.
 А картинки, оформленные в виде отдельной статьи с названием и без текста, приводят робота просто в ужас. Если их очень много, то сайт может загреметь под фильтр АГС Яндекса. Мой сайт там был. Проверено!
А картинки, оформленные в виде отдельной статьи с названием и без текста, приводят робота просто в ужас. Если их очень много, то сайт может загреметь под фильтр АГС Яндекса. Мой сайт там был. Проверено!
Теперь после всего сказанного возникает резонный вопрос: «А можно ли как то запретить индексировать то что не надо?». Оказывается можно. Хотя бы не в приказном порядке, а в рекомендательном. Ситуация не полного запрета индексации некоторых объектов возникает из-за файла sitemap.xml, который обрабатывается после robots.txt. Получается так: robots.txt запрещает, а sitemap.xml разрешает. И всё же решить эту задачу мы можем. Как это сделать правильно сейчас и рассмотрим.
robots.txt для wordpressФайл robots.txt для wordpress по умолчанию динамический и реально в wordpress не существует. А генерируется только в тот момент, когда его кто-то запрашивает, будь это робот или просто посетитель. То есть если через FTP соединение вы зайдете на сайт, то в корневой папке файла robots. txt для wordpress вы там просто не найдете. А если в браузере укажите его конкретный адрес http://название_вашего_сайта/robots.txt, то на экране получите его содержимое, как будто файл существует. Содержимое этого сгенерированного файла robots.txt для wordpress будет такое:
txt для wordpress вы там просто не найдете. А если в браузере укажите его конкретный адрес http://название_вашего_сайта/robots.txt, то на экране получите его содержимое, как будто файл существует. Содержимое этого сгенерированного файла robots.txt для wordpress будет такое:
User-agent: *
В правилах составления файла robots.txt по умолчанию разрешено индексировать всё. Директива User-agent: * указывает на то, что все последующие команды относятся ко всем поисковым агентам ( * ). Но далее ничего не ограничивается. И как вы понимаете этого не достаточно. Мы с вами уже обсудили папок и записей, имеющих ограниченный доступ, достаточно много.
Чтобы можно было внести изменения в файл robots.txt и они там сохранились, его нужно создать в статичном постоянном виде.
Как создать robots.txt для wordpress
В любом текстовом редакторе (только ни в коем случае не используйте MS Word и ему подобные с элементами автоматического форматирования текста) создайте текстовый файл с примерным содержимым приведенным ниже и отправьте его в корневую папку вашего сайта.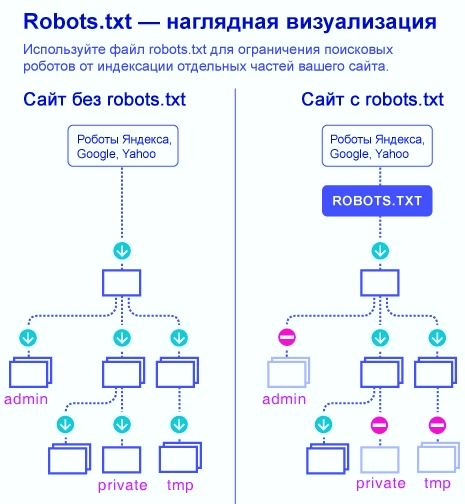 Изменения можно делать в зависимости от необходимости.
Изменения можно делать в зависимости от необходимости.
Только надо учитывать особенности составления файла:
В начале строк цифр, как здесь в статье, быть не должно. Цифры здесь указаны для удобства рассмотрения содержимого файла. В конце каждой строки не должно быть ни каких лишних знаков включая пробелы или табуляторы. Между блоками должна быть пустая строка без каких либо знаков включая пробелы. Всего один пробел может принести вам огромный вред — БУДЬТЕ ВНИМАТЕЛЬНЫ.
Как проверить robots.txt для wordpress
Проверить robots.txt на наличие лишних пробелов можно следующим образом. В текстовом редакторе выделить весь текст, нажав кнопки Ctrl+A. Если пробелов в конце строк и в пустых строках нет, вы это заметите. А если есть выделенная пустота, то вам надо убрать пробелы и всё будет ОК.
Проверить правильно ли работают прописанные правила можно по следующим ссылкам:
- Анализ robots.txt в Яндекс Вебмастере
- Сервис для создания файла robots.
 txt: http://pr-cy.ru/robots/
txt: http://pr-cy.ru/robots/ - Сервис для создания и проверки robots.txt: https://seolib.ru/tools/generate/robots/
- Документация от Яндекса
- Документация от google (англ.)
Есть ещё один способ проверить файл robots.txt для сайта wordpress, это загрузить его содержимое в вебмастер яндекса или указать адрес его расположения. Если есть какие-либо ошибки вы тут же узнаете.
Правильный robots.txt для wordpress
Теперь давайте перейдем непосредственно к содержимому файла robots.txt для сайта wordpress. Какие директивы в нем должны присутствовать обязательно. Примерное содержание файла robots.txt для wordpress, учитывая его особенности приведено ниже:
User-agent: * Disallow: /wp-login.php Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: */*comments Disallow: */*category Disallow: */*tag Disallow: */trackback Disallow: */*feed Disallow: /*?* Disallow: /?s= Allow: /wp-admin/admin-ajax.php Allow: /wp-content/uploads/ Allow: /*?replytocom User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: */comments Disallow: */*category Disallow: */*tag Disallow: */trackback Disallow: */*feed Disallow: /*?* Disallow: /*?s= Allow: /wp-admin/admin-ajax.php Allow: /wp-content/uploads/ Allow: /*?replytocom Crawl-delay: 2,0 Host: site.ru Sitemap: http://site.ru/sitemap.xml
Директивы файла robots.txt для wordpress
Теперь давайте рассмотрим поподробнее:
1 – 16 строки блок настроек для всех роботов
User-agent: — Это обязательная директива, определяющая поискового агента. Звездочка говорит, что директива для роботов всех поисковых систем. Если блок предназначен для конкретного робота, то необходимо указать его имя, например Yandex, как в 18 строке.
По умолчанию для индексирования разрешено всё. Это равнозначно директиве Allow: /.
Поэтому для запрета индексирования конкретных папок или файлов используется специальная директива Disallow: .
В нашем примере с помощью названий папок и масок названий файлов, сделан запрет на все служебные папки вордпресса, такие как admin, themes, plugins, comments, category, tag… Если указать директиву в таком виде Disallow: /, то будет дан запрет индексирования всего сайта.
Allow: — как я уже говорил директива разрешающая индексирование папок или файлов. Её нужно использовать когда в глубине запрещённых папок есть файлы которые всё же надо проиндексировать.
В моём примере строка 3 Disallow: /wp-admin — запрещает индексирование папки /wp-admin, а 14 строка Allow: /wp-admin/admin-ajax.php — разрешает индексирование файла /admin-ajax.php расположенного в запрещенной к индексированию папке /wp-admin/.
17 — Пустая строка (просто нажатие кнопки Enter без пробелов)
18 — 33 блок настроек конкретно для агента Яндекса (User-agent: Yandex).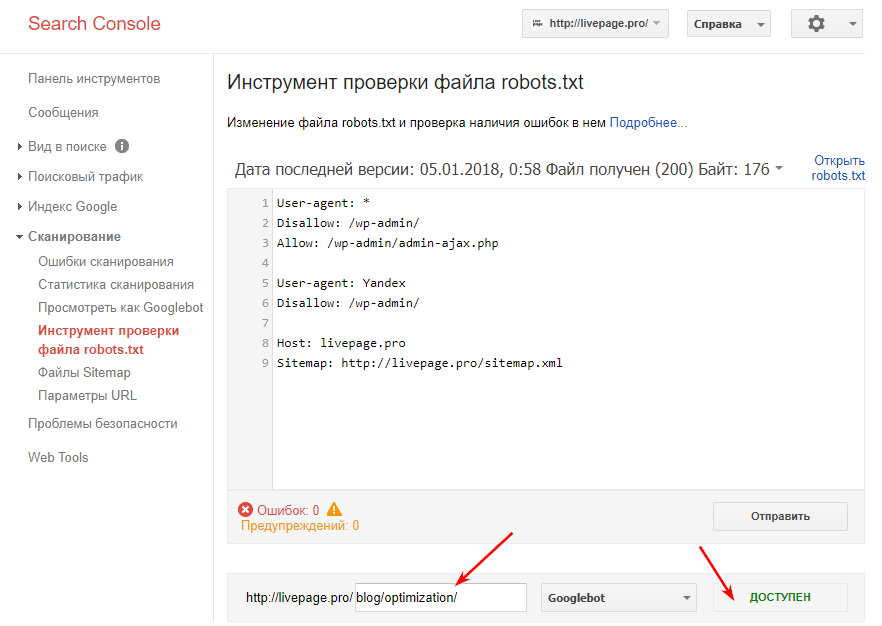 Как вы заметили этот блок полностью повторяет все команды предыдущего блока. И возникает вопрос: «А на фига такая заморочка?». Так вот это всё сделано всего лишь из-за нескольких директив которые рассмотрим дальше.
Как вы заметили этот блок полностью повторяет все команды предыдущего блока. И возникает вопрос: «А на фига такая заморочка?». Так вот это всё сделано всего лишь из-за нескольких директив которые рассмотрим дальше.
34 — Crawl-delay — Необязательная директива только для Яндекса. Используется когда сервер сильно нагружен и не успевает отрабатывать запросы робота. Она позволяет задать поисковому роботу минимальную задержку (в секундах и десятых долях секунды) между окончанием загрузки одной страницы и началом загрузки следующей. Максимальное допустимое значение 2,0 секунды. Добавляется непосредственно после директив Disallow и Allow.
35 — Пустая строка
36 — Host: site.ru — доменное имя вашего сайта (ОБЯЗАТЕЛЬНАЯ директива для блока Яндекса). Если наш сайт использует протокол HTTPS, то адрес надо указывать полностью как показано ниже:
Host: https://site.ru
37 — Пустая строка (просто нажатие кнопки Enter без пробелов) обязательно должна присутствовать.
38 — Sitemap: http://site. ru/sitemap.xml — адрес расположения файла (файлов) карты сайта sitemap.xml (ОБЯЗАТЕЛЬНАЯ директива), располагается в конце файла после пустой строки и относится ко всем блокам.
ru/sitemap.xml — адрес расположения файла (файлов) карты сайта sitemap.xml (ОБЯЗАТЕЛЬНАЯ директива), располагается в конце файла после пустой строки и относится ко всем блокам.
Маски к директивам файла robots.txt для wordpress
Теперь немного как создавать маски:
- Disallow: /wp-register.php — Запрещает индексировать файл wp-register.php, расположенный в корневой папке.
- Disallow: /wp-admin — запрещает индексировать содержимое папки wp-admin, расположенной в корневой папке.
- Disallow: /trackback — запрещает индексировать уведомления.
- Disallow: /wp-content/plugins — запрещает индексировать содержимое папки plugins, расположенной в подпапке (папке второго уровня) wp-content.
- Disallow: /feed — запрещает индексировать канал feed т.е. закрывает RSS канал сайта.
- * — означает любая последовательность символов, поэтому может заменять как один символ, так и часть названия или полностью название файла или папки. Отсутствие конкретного названия в конце равносильно написанию *.

- Disallow: */*comments — запрещает индексировать содержимое папок и файлов в названии которых присутствует comments и расположенных в любых папках. В данном случае запрещает индексировать комментарии.
- Disallow: *?s= — запрещает индексировать страницы поиска
Приведенные выше строки вполне можно использовать в качестве рабочего файла robots.txt для wordpress. Только в 36, 38 строках необходимо вписать адрес вашего сайта и ОБЯЗАТЕЛЬНО УБРАТЬ номера строк. И у вас получится рабочий файл robots.txt для wordpress, адаптированный под любую поисковую систему.
Единственная особенность — размер рабочего файла robots.txt для сайта wordpress не должен превышать 32 кБ дискового пространства.
Ещё одна маленькая рекомендация.
Если вас абсолютно не интересует Яндекс, то строки 18-35 вам не понадобятся вообще. На этом пожалуй всё. Надеюсь что статья оказалась полезной. Если есть вопросы пишите в комментариях.
Robots.txt и WordPress | WP Engine®
Поддержание поисковой оптимизации (SEO) вашего сайта имеет решающее значение для привлечения органического трафика. Однако есть некоторые страницы, такие как дублированный контент или промежуточные области, которые вы не можете захотеть, чтобы пользователи находили через поисковые системы. К счастью, есть способ запретить таким системам, как Google, получать доступ к определенным страницам и отображать их для поисковиков. Редактируя файл
Однако есть некоторые страницы, такие как дублированный контент или промежуточные области, которые вы не можете захотеть, чтобы пользователи находили через поисковые системы. К счастью, есть способ запретить таким системам, как Google, получать доступ к определенным страницам и отображать их для поисковиков. Редактируя файл robots.txt своего сайта, вы можете контролировать, какой контент будет отображаться на страницах результатов поиска (SERP).
ПРИМЕЧАНИЕ. По умолчанию WP Engine ограничивает трафик поисковых систем на любой сайт, использующий среду , домен .wpengine.com . Это означает, что поисковые системы не смогут посещать сайты , а не , которые в настоящее время находятся в разработке, с использованием личного домена.
О
Robots.txt Файл robots.txt содержит инструкции для поисковых систем о том, как находить и извлекать информацию с вашего веб-сайта.Этот процесс называется «сканированием». После того, как страница просканирована, она будет проиндексирована, чтобы поисковая система могла быстро найти и отобразить ее позже.
После того, как страница просканирована, она будет проиндексирована, чтобы поисковая система могла быстро найти и отобразить ее позже.
Первое, что делает сканер поисковой системы, когда попадает на сайт, — это ищет файл robots.txt . Если его нет, он продолжит сканирование остальной части сайта в обычном режиме. Если он найдет этот файл, сканер будет искать в нем какие-либо команды, прежде чем продолжить.
В роботе есть четыре общие команды.txt файл:
-
Disallowзапрещает сканерам поисковых систем проверять и индексировать указанные файлы сайта. Это может помочь вам предотвратить появление в поисковой выдаче дублированного контента, промежуточных областей или других личных файлов. -
Разрешитьразрешает доступ к подпапкам, в то время как родительские папки запрещены. -
Crawl-delayпредписывает поисковым роботам подождать определенное время перед загрузкой файла. -
Sitemapуказывает расположение любых файлов Sitemap, связанных с вашим сайтом.
Файлы Robots.txt всегда форматируются одинаково, чтобы их директивы были понятны:
Каждая директива начинается с идентификации агента пользователя , который обычно является сканером поисковой системы. Если вы хотите, чтобы команда применялась ко всем потенциальным пользовательским агентам, вы можете использовать звездочку * . Чтобы вместо этого настроить таргетинг на определенный пользовательский агент, вы можете добавить его имя. Например, мы могли бы заменить звездочку выше на Googlebot , чтобы только запретить Google сканирование страницы администратора.
Понимание того, как использовать и редактировать файл robots.txt , имеет жизненно важное значение. Включенные в него директивы будут определять, как поисковые системы взаимодействуют с вашим сайтом. Они могут помочь вам, скрывая контент, от которого вы хотите отвлечь пользователей, что улучшит общее SEO вашего сайта.
Протестируйте файл
Robots. txt Файл
txt Файл Вы можете проверить, есть ли у вас файл robots.txt , добавив /robots.txt в конец URL-адреса вашего сайта в браузере (Пример: https: // wpengine.com / robots.txt ). Это вызовет файл, если он существует. Однако наличие вашего файла не обязательно означает, что он работает правильно.
К счастью, проверить файл robots.txt просто. Вы можете просто скопировать и вставить свой файл в тестер robots.txt. Инструмент выделит все ошибки в файле. Важно отметить, что изменения, внесенные в редактор robots.txt тестера, не будут применяться к фактическому файлу — вам все равно придется отредактировать файл на своем сервере.
Некоторые распространенные ошибки включают запрет на использование файлов CSS или JavaScript, неправильное использование подстановочных знаков, таких как * и долларов США, а также случайное запрещение важных страниц. Также важно помнить, что сканеры поисковых систем чувствительны к регистру, поэтому все URL-адреса в файле robots. должны отображаться так же, как и в вашем браузере. txt
txt
Создание файла
Robots.txt с подключаемым модулем Если на вашем сайте отсутствует robots.txt , вы можете легко добавить его в WordPress с помощью плагина Yoast SEO. Это избавит вас от необходимости создавать простой текстовый файл и вручную загружать его на сервер. Если вы предпочитаете создать его вручную, перейдите к разделу «Создание файла Robots.txt вручную» ниже.
Перейдите к инструментам Yoast SEO
Для начала вам необходимо установить и активировать плагин Yoast SEO. Затем вы можете перейти на панель администратора WordPress и выбрать SEO > Tools на боковой панели :
.Это приведет вас к списку полезных инструментов, к которым пользователи Yoast могут получить доступ для эффективного улучшения своего SEO.
Использование редактора файлов для создания файла
Robots.txt Одним из инструментов, доступных в списке, является редактор файлов. Это позволяет вам редактировать файлы, связанные с SEO вашего сайта, в том числе файл
Это позволяет вам редактировать файлы, связанные с SEO вашего сайта, в том числе файл robots.txt :
Поскольку на вашем сайте его еще нет, выберите Создать файл robots.txt :
Откроется редактор файлов, в котором вы сможете редактировать и сохранять новый файл.
Измените роботов
по умолчанию.txt и сохраните его По умолчанию новый файл robots.txt , созданный с помощью Yoast, включает директиву, скрывающую вашу папку wp-admin и разрешающую доступ к вашему файлу admin-ajax.php для всех пользовательских агентов. Рекомендуется оставить эту директиву в файле:
Перед сохранением файла вы также можете добавить любые другие директивы, которые хотите включить. В этом примере мы запретили поисковым роботам Bing доступ ко всем нашим файлам, добавили задержку сканирования в десять миллисекунд для поискового робота Yahoo Slurp и направили поисковые роботы в расположение нашей карты сайта. Когда вы закончите вносить свои изменения, не забудьте их сохранить!
Когда вы закончите вносить свои изменения, не забудьте их сохранить!
Руководство
Robots.txt Создание файла Если вам нужно создать файл robots.txt вручную, процесс так же прост, как создание и загрузка файла на ваш сервер.
- Создайте файл с именем
robots.txt- Убедитесь, что имя написано в нижнем регистре.
- Убедитесь, что расширение —
.txt, а не.html
- Добавьте в файл любые необходимые директивы и сохранить
- Загрузите файл с помощью SFTP или SSH-шлюза в корневой каталог вашего сайта
ПРИМЕЧАНИЕ : Если в корне вашего сайта есть физический файл с именем robots.txt , он перезапишет любой динамически сгенерированный файл robots.txt , созданный плагином или темой.
Использование файла robots.txt
Файл robots.txt разбивается на блоки пользовательским агентом. Внутри блока каждая директива указывается в новой строке. Например:
Внутри блока каждая директива указывается в новой строке. Например:
Агент пользователя: * Запретить: / Пользовательский агент: Googlebot Запретить: Пользовательский агент: bingbot Запретить: / no-bing-crawl / Запрещено: wp-admin
Пользовательские агенты обычно сокращаются до более общего имени, но это не требуется .
Значения директивы чувствительны к регистру.
- URL-адреса
no-bing-crawlиNo-Bing-Crawl— это разных .
Глобализация и регулярные выражения не поддерживаются полностью .
-
*в поле User-agent — это специальное значение, означающее «любой робот».
Ограничить доступ всех ботов к вашему сайту
(Все сайты в среде .wpengine.com , автоматически применяется следующий файл robots.txt .)
Агент пользователя: * Disallow: /
Ограничить доступ одного робота ко всей площадке
Агент пользователя: BadBotName Disallow: /
Ограничить доступ ботов к определенным каталогам и файлам
Пример запрещает ботов на всех страницах wp-admin и wp-login.. Это хороший стандартный или начальный  php
php роботов.txt файл.
Агент пользователя: * Запретить: / wp-admin / Запрещено: /wp-login.php
Ограничить доступ бота ко всем файлам определенного типа
В примере используется тип файла .pdf
Агент пользователя: * Disallow: /*.pdf$
Ограничить конкретную поисковую систему
Пример использования Googlebot-Image в / wp-content / загружает каталог
User-Agent: Googlebot-Image Запретить: / wp-content / uploads /
Ограничить всех ботов, кроме одного
Пример разрешает только Google
Пользовательский агент: Google Запретить: Пользовательский агент: * Disallow: /
Добавление правильных комбинаций директив может быть сложным.К счастью, есть плагины, которые также создают (и тестируют) файл robots. за вас. Примеры плагинов: txt
txt
Если вам нужна дополнительная помощь в настройке правил в файле robots.txt, мы рекомендуем посетить Google Developers или The Web Robots Pages для получения дополнительных инструкций.
Задержка сканирования
Если вы видите слишком высокий трафик ботов и это влияет на производительность сервера, задержка сканирования может быть хорошим вариантом. Задержка сканирования позволяет ограничить время, которое должен пройти бот перед сканированием следующей страницы.
Для настройки задержки сканирования используйте следующую директиву, значение настраивается и указывается в секундах:
задержка сканирования: 10
Например, чтобы запретить сканирование всем ботам wp-admin , wp-login.php и установить задержку сканирования для всех ботов на 600 секунд (10 минут):
Агент пользователя: * Запретить: /wp-login.php Запретить: / wp-admin / Задержка сканирования: 600
ПРИМЕЧАНИЕ : Службы обхода контента могут иметь свои собственные требования для установки задержки обхода.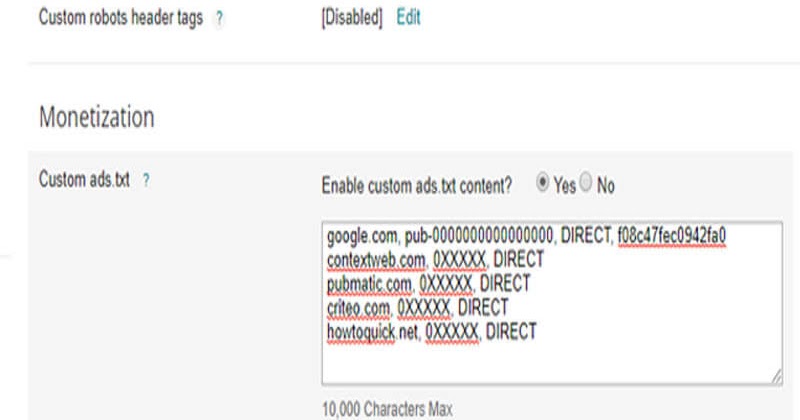 Как правило, лучше всего напрямую связаться со службой для получения требуемого метода.
Как правило, лучше всего напрямую связаться со службой для получения требуемого метода.
Отрегулируйте задержку сканирования для SEMrush
- SEMrush — отличный сервис, но сканирование может оказаться очень тяжелым, что в конечном итоге ухудшит производительность вашего сайта. По умолчанию боты SEMrush игнорируют директивы задержки сканирования в вашем файле robots.txt, поэтому обязательно войдите в их панель управления и включите Уважение задержки сканирования robots.txt .
- Дополнительную информацию о SEMrush можно найти здесь.
Настроить задержку сканирования Bingbot
- Bingbot должен соблюдать директивы
crawl-delay, однако они также позволяют вам установить шаблон управления сканированием.
Настройте задержку сканирования для Google
Подробнее см. В документации поддержки Google)
Откройте страницу настроек скорости сканирования вашего ресурса.
- Если ваша скорость сканирования описана как , рассчитанная как оптимальная , единственный способ уменьшить скорость сканирования — это подать специальный запрос.Вы не можете увеличить скорость сканирования .
- В противном случае , выберите нужный вариант и затем ограничьте скорость сканирования по желанию. Новая скорость сканирования будет действовать в течение 90 дней.
ПРИМЕЧАНИЕ . Хотя эта конфигурация запрещена на нашей платформе, стоит отметить, что задержка сканирования Googlebot не может быть изменена для сайтов, размещенных в подкаталогах, таких как domain.com/blog .
Лучшие Лрактики
Прежде всего следует помнить о следующем: непроизводственные сайты должны запрещать использование всех пользовательских агентов.WP Engine автоматически делает это для любых сайтов, использующих домен environmentname .wpengine.. Только когда вы будете готовы «запустить» свой сайт, вы можете добавить файл  com
com robots.txt .
Во-вторых, если вы хотите заблокировать определенного User-Agent, помните, что роботы не обязаны следовать правилам, установленным в вашем файле robots.txt . Лучше всего использовать брандмауэр, такой как Sucuri WAF или Cloudflare, который позволяет блокировать злоумышленников до того, как они попадут на ваш сайт.Или вы можете обратиться в службу поддержки за дополнительной помощью по блокировке трафика.
Наконец, если у вас очень большая библиотека сообщений и страниц на вашем сайте, Google и другие поисковые системы, индексирующие ваш сайт, могут вызвать проблемы с производительностью. Увеличение срока действия кеша или ограничение скорости сканирования поможет компенсировать это влияние.
СЛЕДУЮЩИЙ ШАГ: устранение ошибок 504
Virtual Robots.txt — плагин для WordPress
Virtual Robots. txt — это простое (то есть автоматизированное) решение для создания файла robots.txt для вашего сайта. Вместо того, чтобы возиться с FTP, файлами, разрешениями и т. Д., Просто загрузите и активируйте плагин, и все готово.
txt — это простое (то есть автоматизированное) решение для создания файла robots.txt для вашего сайта. Вместо того, чтобы возиться с FTP, файлами, разрешениями и т. Д., Просто загрузите и активируйте плагин, и все готово.
По умолчанию плагин Virtual Robots.txt разрешает доступ к тем частям WordPress, которые нужны хорошим ботам, таким как Google. Остальные части заблокированы.
Если плагин обнаруживает существующий файл карты сайта XML, ссылка на него будет автоматически добавлена в ваш файл robots.txt.
- Загрузите папку pc-robotstxt в каталог
/ wp-content / plugins / - Активируйте плагин через меню «Плагины» в WordPress.
- После установки и активации плагина вы увидите новый файл Robots.txt в меню настроек. Щелкните эту ссылку меню, чтобы увидеть страницу настроек плагина. Оттуда вы можете редактировать содержимое вашего файла robots.txt.
Будет ли он конфликтовать с существующим файлом robots.
 txt?
txt?Если на вашем сайте существует физический файл robots.txt, WordPress не будет обрабатывать для него какие-либо запросы, поэтому конфликта не будет.
Будет ли это работать для установки WordPress в подпапках?
Из коробки, нет.Поскольку WordPress находится в подпапке, он не «узнает», когда кто-то запрашивает файл robots.txt, который должен находиться в корне сайта.
Изменяет ли этот плагин отдельные сообщения, страницы или категории?
Нет, это не так.
Почему плагин по умолчанию блокирует определенные файлы и папки?
По умолчанию виртуальный robots.txt настроен на блокировку файлов и папок WordPress, к которым не требуется доступ поисковых систем.Конечно, если вы не согласны со значениями по умолчанию, вы можете легко их изменить.
Отлично работает, прост в использовании и настройке. Он уже установил по умолчанию каталоги, которые необходимо исключить из сканирования / индексации поисковых систем . ..
Очень им доволен!
..
Очень им доволен!
То, что я увидел, было не тем, что я получил. XML-карта сайта не была включена в файл robots.txt, хотя это было описано как функция, которая должна работать из коробки.Кроме того, при установке этого плагина он без запроса блокировал определенные каталоги. Наконец, он вставляет строку вверху файла, продвигая плагин. Это должна быть дополнительная функция, которую пользователи могут отключить. В целом, он предлагает функциональные возможности, но не хватает и разочаровывает в других областях.
Я думал, это будет просто. Конечно, звучит просто. Но после того, как я сохранил предложенный вами текст в моем новом файле «virtual robots.txt «, я щелкнул ссылку, где написано:» Вы можете предварительно просмотреть свой файл robots.txt здесь (открывается в новом окне). Если ваш файл robots.txt не соответствует тому, что показано ниже, возможно, вместо него отображается физический файл «. В этом новом окне отображается текст, который действительно отличается от текста плагина. Я понимаю, что это означает, что на моем сервере есть физический файл robots.txt. Итак, какой из них на самом деле будет использоваться? Ваш FAQ предлагает следующее:
В: Будет ли он конфликтовать с существующим файлом robots.txt?
О: Если в файле robots.txt существует на вашем сайте, WordPress не будет обрабатывать запросы на него, поэтому конфликта не будет. Если физический файл существует, WP не будет обрабатывать НИКАКИХ запросов на него? Эти ЗВУКИ, такие как WP, будут игнорировать как физический файл, так и ваш виртуальный. В таком случае какой смысл? Мне кажется, может и не быть. Когда я вручную перехожу на mydomain.com/robots.txt, я вижу, что находится в физическом файле, а не то, что сохранил плагин. Итак … это работает? Я не знаю! Следует ли мне удалить физический файл и предположить, что виртуальный будет работать? Я не знаю! Следует ли мне удалить этот плагин и отредактировать физический файл вручную? Вероятно.2 звезды вместо 1, потому что я ценю возможность включения предложенных строк в мой файл.
Я понимаю, что это означает, что на моем сервере есть физический файл robots.txt. Итак, какой из них на самом деле будет использоваться? Ваш FAQ предлагает следующее:
В: Будет ли он конфликтовать с существующим файлом robots.txt?
О: Если в файле robots.txt существует на вашем сайте, WordPress не будет обрабатывать запросы на него, поэтому конфликта не будет. Если физический файл существует, WP не будет обрабатывать НИКАКИХ запросов на него? Эти ЗВУКИ, такие как WP, будут игнорировать как физический файл, так и ваш виртуальный. В таком случае какой смысл? Мне кажется, может и не быть. Когда я вручную перехожу на mydomain.com/robots.txt, я вижу, что находится в физическом файле, а не то, что сохранил плагин. Итак … это работает? Я не знаю! Следует ли мне удалить физический файл и предположить, что виртуальный будет работать? Я не знаю! Следует ли мне удалить этот плагин и отредактировать физический файл вручную? Вероятно.2 звезды вместо 1, потому что я ценю возможность включения предложенных строк в мой файл.
Мне нравится, что он такой чистый. Спасибо за создание!
Awesome, простое решение распространенной проблемы (менеджеры контента сайтов, которые хотят скрыть определенные страницы из результатов поиска Google). Небольшое примечание: в моем случае существующий файл Sitemap, созданный плагином «Google (XML) Sitemaps Generator» Арне Браххолда, не был обнаружен.
Посмотреть все 7 отзывов«Virtual Robots.txt» — это программное обеспечение с открытым исходным кодом. Следующие люди внесли свой вклад в этот плагин.
авторов1,10
- Исправление, предотвращающее сохранение тегов HTML в поле формы robots.txt. Спасибо TrustWave за выявление этой проблемы.
1,9
- Исправление для PHP 7. Спасибо SharmPRO.
1,8
- Отмена последних исправлений, так как они имели непредвиденные побочные эффекты.
1,7
- Дальнейшие исправления проблемы с удалением новой строки.
 Спасибо FAMC за отчет и исправление кода.
Спасибо FAMC за отчет и исправление кода. - После обновления посетите и повторно сохраните свои настройки и убедитесь, что они выглядят правильно.
1,6
- Исправлена ошибка, при которой удалялись символы новой строки. Спасибо FAMC за репортаж.
1,5
- Исправлена ошибка, из-за которой плагин предполагал, что robots.txt будет находиться по адресу http, тогда как он может находиться по адресу https.Спасибо jeffmcneill за сообщение.
1,4
- Исправлена ошибка ссылки на robots.txt, которая не настраивалась для установки подпапок WordPress.
- Обновлены директивы robots.txt по умолчанию в соответствии с последними практиками для WordPress.
- Разработка и поддержка плагина переданы Мариосу Александру.
1,3
- Теперь использует хук do_robots и проверяет is_robots () в действии плагина.
1,2
- Добавлена поддержка существующей карты сайта.
 xml.gz файл.
xml.gz файл.
1,1
- Добавлена ссылка на страницу настроек, возможность удаления настроек.
1,0
Мгновенно создавайте собственный файл robots.txt!
Обзор нашего онлайн-генератора Robots.txt
Наш инструмент Robots.txt Generator разработан, чтобы помочь веб-мастерам, специалистам по поисковой оптимизации и маркетологам создавать файлы robots.txt без особых технических знаний. Однако будьте осторожны, поскольку создание файла robots.txt может существенно повлиять на возможность доступа Google к вашему веб-сайту, независимо от того, создан ли он на WordPress или другой CMS.
Хотя наш инструмент прост в использовании, мы рекомендуем вам ознакомиться с инструкциями Google перед его использованием. Это связано с тем, что неправильная реализация может привести к тому, что поисковые системы, такие как Google, не смогут сканировать важные страницы вашего сайта или даже всего вашего домена, что может очень негативно повлиять на ваше SEO.
Давайте углубимся в некоторые функции, которые предоставляет наш онлайн-генератор Robots.txt.
Как создать файл Robots.txt
Как создать своего первого робота.txt файл?
Первый вариант, который вам будет предложен, — разрешить или запретить всем поисковым роботам доступ к вашему сайту. Это меню позволяет вам решить, нужно ли сканировать ваш сайт; однако могут быть причины, по которым вы можете отказаться от индексации своего веб-сайта в Google.
Второй вариант, который вы увидите, — добавлять ли файл карты сайта xml. Просто введите его местоположение в это поле. (Если вам нужно создать карту сайта в формате XML, вы можете использовать наш бесплатный инструмент.)
Наконец, вам предоставляется возможность заблокировать определенные страницы или каталоги от индексации поисковыми системами.Обычно это делается для страниц, которые не предоставляют никакой полезной информации для Google и пользователей, например страниц входа, корзины и параметров.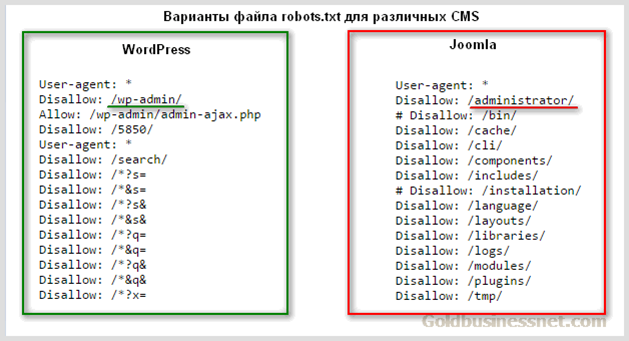
Когда это будет сделано, вы можете скачать текстовый файл.
После создания файла robots.txt обязательно загрузите его в корневой каталог своего домена. Например, ваш файл robots.txt должен появиться по адресу: www.yourdomain.com/robots.txt
.Звук полезный? Мы надеемся на это!
Создайте свой первый файл robots.txt с помощью нашего инструмента и сообщите нам, как он работает для вас.
Что такое файл Robots.txt?
Файл robots.txt — это действительно простой файл в текстовом формате. Его основная функция — предотвращать сканирование и индексацию контента на веб-сайте определенными сканерами поисковых систем, такими как Google, в целях SEO.
Если вы не уверены, есть ли на вашем веб-сайте или на веб-сайте вашего клиента файл robots.txt, это легко проверить:
Просто введите yourdomain.com/robots.txt. Вы найдете либо страницу с ошибкой, либо страницу простого формата. Если вы используете WordPress и у вас установлен Yoast, то Yoast также может создать для вас текстовый файл.
Подробнее о файлах Robots.txt
Некоторые сложные фразы, которые вы можете найти в файле robots.txt, включают:
Агент пользователя:
Поскольку каждая поисковая система имеет своего собственного сканера (наиболее распространенным является робот Googlebot), «пользовательский агент» позволяет вам уведомлять определенные поисковые системы о том, что для них предназначен следующий набор инструкций.
Обычно вы встретите «user-agent», за которым следует *, иначе известный как подстановочный знак. Это означает, что все поисковые системы должны принять к сведению следующий набор инструкций.Обычно после подстановочного знака есть фраза по умолчанию, которая говорит всем поисковым системам не индексировать какие-либо веб-страницы на вашем сайте.
Фраза по умолчанию — запретить индексирование символа «/», что, по сути, запрещает роботам все внутренние страницы, кроме вашего основного URL. Очень важно проверить эту фразу и немедленно удалить ее со страницы robots.txt.
Это будет примерно так:
User-agent: *
Disallow: /
Запрещено:
Термин «Disallow», за которым следует любой URL-адрес, дает строгие инструкции для вышеупомянутого пользовательского агента, которые должны появиться в строке выше.
Например, вы можете заблокировать определенные страницы от поисковых систем, которые, по вашему мнению, бесполезны для пользователей. Обычно к ним относятся страницы входа в систему WordPress или страницы корзины, поэтому в файлах robots.txt на сайтах WordPress вы обычно видите следующие строки текста:
User-agent: *
Disallow: / wp-admin /
XML Sitemap:
Другая фраза, которую вы можете увидеть, — это ссылка на расположение вашего XML-файла карты сайта. Обычно это последняя строка вашего файла robots.txt, и он указывает поисковым системам, где находится ваша карта сайта. Включение этого упрощает сканирование и индексацию.
Вы можете оптимизировать свой собственный веб-сайт, введя следующую простую функцию:
Sitemap: yourdomain.com/sitemap.xml (или точный URL-адрес вашего xml-файла карты сайта).
Как получить доступ и изменить файл robots.txt в WordPress (руководство)
Последнее обновление 7 мая 2021 г.
В этом кратком руководстве я покажу вам, как создавать, открывать и изменять robots.txt в WordPress 4 простыми способами.
Если вы серьезно относитесь к своему веб-сайту (и особенно если у вас есть сайт большего размера), вам обязательно нужно контролировать его файл robots.txt. К счастью, с веб-сайтами WordPress это сделать довольно просто.
Позвольте мне показать вам 4 простых способа доступа к файлу robots.txt в WordPress.
Основная информация о файле robots.txt
Robots.txt — это файл, который информирует роботов поисковых систем о страницах или файлах, которые следует или не следует сканировать.
- Файл robots.txt должен защищать веб-сайт от перегрузки его запросами от сканеров (см. Мое полное руководство по оптимизации бюджета сканирования ).
- Файл robots.txt не позволяет заблокировать индексирование веб-страниц или файлов и их отображение в результатах поиска.
- Сканеры поисковых систем всегда начинают сканирование вашего веб-сайта с проверки директив в файле robots.txt .
- Поисковые системы должны, но не всегда соблюдать директивы, содержащиеся в robots.txt (Google делает).
Если вам нужно небольшое напоминание, вот основная техническая информация о robots.txt :
- Единственное правильное расположение robots.txt — это корень (основной каталог) веб-сайта. Это применимо к любому веб-сайту, независимо от того, является ли он веб-сайтом WordPress.
- На одном веб-сайте может быть только один файл robots.txt .
- Единственное допустимое имя для файла — robots.txt .
- Robots.txt должен быть текстовым файлом в кодировке UTF-8.
Имея это в виду, расположение файла robots.txt в WordPress такое же, как и для любого другого веб-сайта. Это корень веб-сайта. В случае моего веб-сайта это https://seosly.com/robots.txt.
Так выглядит стандартный файл robots.txt WordPress.Хорошая особенность WordPress заключается в том, что он позволяет вам получить доступ к вашему robots.txt несколькими способами, даже если у вас нет доступа к FTP.
☝️ Если вы хотите узнать больше о файле robots.txt, о том, как он работает, что это такое, обязательно ознакомьтесь с введением в robots.txt в Центре поиска Google.
4 способа получить доступ к robots.txt в WordPress
А вот четыре способа получить доступ к файлу robots.txt на вашем сайте WordPress и изменить его.
# 1: Используйте плагин SEO
Существует много плагинов для SEO для WordPress, но реально учитываются только два:
Существует также All in One SEO , но я не большой поклонник этого плагина.Все эти плагины SEO позволяют легко открывать и изменять robots.txt.
Доступ к robots.txt с помощью Rank Math
Если вы используете Rank Math, вам нужно сделать следующее:
- Войдите в свою панель управления WordPress как администратор. Обратите внимание, что только администраторы могут изменять плагины.
- Перейти к Rank Math SEO .
- На левой боковой панели под Rank Math вы увидите различные настройки Rank Math.Щелкните Общие настройки s.
- Теперь вы увидите список общих настроек SEO. Щелкните Изменить robots.txt .
- Если вы ничего не сделаете, Rank Math автоматически обработает файл robots.txt, как вы можете видеть на скриншоте ниже.
- Если вы хотите изменить robots.txt, просто начните вводить текст в текстовое поле и нажмите Сохранить изменения .
- Если вы не уверены, что добавить в robots.txt или вы делаете что-то не так, просто нажмите Параметры сброса .
Вот и все для Rank Math и robots.txt.
Доступ к robots.txt с помощью Yoast SEO
Вот что делать, если вы используете Yoast SEO:
- Войдите в свою панель управления WordPress как администратор. Помните, что только администраторы могут изменять настройки плагина.
- Перейдите к SEO .
- На левой боковой панели вы увидите несколько настроек в разделе SEO .Щелкните Tools .
- Теперь вы можете изменить файл robots.txt.
- Когда вы закончите, просто нажмите Сохранить изменения в robots.txt.
На большинстве веб-сайтов WordPress подойдут эти два метода с использованием этих двух плагинов SEO. Но есть и другие способы.
# 2: Используйте специальный плагин robots.txt
Существует также множество различных плагинов WordPress, специально разработанных для редактирования robots.текст.
Вот самые популярные плагины robots.txt для WordPress, которые вы, возможно, захотите проверить:
Каждый из них позволяет легко открывать и изменять файл robots.txt. Ниже приведены быстрые шаги, которые нужно предпринять для доступа к файлу robots.txt с помощью этих 3 плагинов WordPress.
❗ Обратите внимание, что некоторые плагины создают файл robots.txt, который помещается в корень вашего веб-сайта, в то время как другие создают его динамически. Если файл robots.txt создается динамически, вы не найдете его в корневом каталоге своего веб-сайта (например,грамм. через FTP).
❗ Не используйте одновременно несколько плагинов robots.txt!
Virtual Robots.txt
Вот как использовать плагин Virtual Robots.txt:
- На панели инструментов WordPress перейдите к Settings , а затем к Virtual Robots.txt .
- Теперь вы можете просмотреть свой файл robots.txt и изменить его. Когда вы закончите, нажмите Сохранить изменения .
Вот оно!
Лучшие роботы.txt
Этот плагин robots.txt немного отличается от плагинов, которые я показал вам выше. С Better Robots.txt вы не изменяете текстовый файл, а просто настраиваете параметры на удобной панели внутри WordPress.
Вот что:
- Установите и активируйте Better Robots.txt. Плагин также называется оптимизацией WordPress Robots.txt.
- Предоставьте подключаемому модулю необходимые разрешения.
- Перейдите к Better Robots.txt . Плагин будет доступен на левой боковой панели.
- Теперь вы увидите множество полезных и удобных настроек.
- Плагин также позволяет вручную разрешать или запрещать использование определенных поисковых роботов.
- Вы также можете изменить некоторые настройки для защиты данных или оптимизации загрузки.
- Плагин предлагает и другие интересные настройки. Я рекомендую проверить их.
Лучшие роботы.txt по сути позволяет вам создать полностью настраиваемый файл robots.txt, не касаясь ни строчки кода.
Редактор Robots.txt
А вот как использовать редактор Robots.txt:
- Перейдите к Плагины > Установленные плагины на панели инструментов WordPress. Вы также можете получить доступ к robots.txt, выбрав «Настройки»> « Чтение ».
- Щелкните Настройки в разделе Роботы.txt Редактор.
- Теперь вы можете получить доступ к файлу robots.txt и отредактировать его. Когда вы закончите, нажмите Сохранить изменения .
❗ Будьте осторожны и избегайте одновременного использования нескольких редакторов robots.txt. Это действительно может все испортить. Если вы используете плагин SEO, вам следует придерживаться только его редактора robots.txt.
# 3: Доступ к robots.txt через cPanel на вашем хостинге
Здесь я покажу вам, как загружать robots.txt в WordPress без доступа по FTP.
Вы также можете использовать cPanel на своем хостинге для создания или изменения robots.txt.
Обратите внимание, что некоторые из показанных выше подключаемых модулей динамически создают файл robots.txt. Это означает, что вы не сможете найти файл в корневом каталоге своего сайта.
❗ Если вы используете плагин для создания файла robots.txt и управления им, вам не следует пытаться вручную добавить новый файл robots.txt с помощью cPanel или FTP (см. Ниже).
Однако, если вы не полагаетесь на эти плагины, вы можете вручную создать и обновить файл robots.txt на свой сайт WordPress.
Вот как это сделать с помощью Bluehost:
- Войдите в cPanel на вашем хостинге.
- Развернуть раздел Расширенный .
- Перейдите в корневой каталог вашего веб-сайта.
- Если вы не используете плагин, который динамически генерирует robots.txt, вы должны увидеть файл robots.txt в корне.
- Щелкните файл robots.txt и выберите Изменить .
- Теперь вы можете редактировать содержимое robots.txt. Когда закончите, нажмите Сохранить изменение s.
Если на вашем веб-сайте нет файла robots.txt, вам необходимо создать и загрузить его.
Вот что нужно делать:
- Откройте редактор текстовых файлов, например «Блокнот» или «Блокнот ++».
- Создайте файл robots.txt.
- Загрузите файл в основную директорию вашего сайта. В случае с Bluehost вы просто нажимаете Загрузить в диспетчере файлов.Просто убедитесь, что вы находитесь в корне.
Этот метод будет работать как для сайтов WordPress, так и не на WordPress.
# 4: Используйте FTP для доступа к robots.txt
Здесь я покажу вам, как получить доступ к robots.txt через FTP.
Самый быстрый и «профессиональный» способ получить доступ к robots.txt — использовать FTP. Этот метод также работает для любого типа веб-сайтов, включая сайты WordPress.
❗ Я не рекомендую этот метод, если вы используете плагин для автоматической генерации роботов.txt для вас.
Этот метод аналогичен тому, что вы делаете с помощью cPanel на своем хостинге, за исключением того, что на этот раз вы используете FTP-клиент для доступа к своему веб-сайту.
Для использования этого метода вам потребуются имя пользователя и пароль FTP, а также клиент FTP, например Filezilla .
Вот что вам нужно сделать:
- Подключитесь к своему сайту через FTP-клиент.
- Перейдите в корневой каталог вашего веб-сайта, если вы еще не там.
- Загрузите файл robots.txt, если он есть.
- Откройте файл robots.txt в текстовом редакторе, например Notepad ++.
- Измените файл, если необходимо. Сохранить изменения.
- Загрузите файл в корневой каталог. Это перезапишет существующий файл robots.txt.
Если на вашем веб-сайте нет файла robots.txt, вы также можете создать и загрузить его.
Как протестировать файл robots.txt на своем веб-сайте
Если вы внесли некоторые изменения в robots.txt, я настоятельно рекомендую вам протестировать свой robots.txt, чтобы убедиться, что файл правильный и действительно выполняет то, что должен делать.
Вот что нужно делать:
Вот другие руководства, которые могут вас заинтересовать:
Удалось ли вам получить доступ к файлу robots.txt на вашем веб-сайте? Какой метод вы использовали? Было ли это руководство полезным?
Сообщите мне, что вы думаете. Если вам нравится это руководство, поделитесь им с другими оптимизаторами поисковых систем.Спасибо! ❤️
Ольга Зарзечна — старший SEO-специалист с опытом работы более 8 лет. Она занималась поисковой оптимизацией как для крупнейших мировых брендов, так и для малых предприятий. На данный момент она провела более 100 SEO-аудитов. Ольга закончила курсы SEO и получила ученую степень в университетах, таких как Калифорнийский университет в Дэвисе, Мичиганский университет и Университет Джона Хопкинса. Она также закончила Академию Moz! И, конечно же, имеет сертификаты Google. Она продолжает изучать SEO, и ей это нравится. Ольга также является экспертом по продуктам Google, специализируясь в таких областях, как поиск Google и веб-мастера Google.
Как оптимизировать ваш WordPress Robots.txt для SEO
В этом блоге мы узнаем несколько советов о том, как можно улучшить SEO своего сайта за счет оптимизации файла robts.txt.
На самом деле, файл Robots.txt играет важную роль с точки зрения SEO, потому что он сообщает поисковым системам, как можно сканировать ваш сайт. По этой причине файлы Robot.txt считаются одним из самых мощных инструментов SEO.
Позже вы также узнаете, как создавать и оптимизировать роботов WordPress.txt для SEO.
Что вы подразумеваете под файлом robots.txt?
Текстовый файл, созданный владельцами веб-сайтов, чтобы сообщить роботам поисковых систем о том, как они могут сканировать свой веб-сайт и индексировать страницы, известен как Robots.txt
Собственно, в корневом каталоге и хранится этот файл. Этот каталог также называется основной папкой вашего веб-сайта. Ниже указан формат файла robots.txt
.Пользовательский агент: [имя пользовательского агента] Disallow: [строка URL, которую нельзя сканировать] Пользовательский агент: [имя пользовательского агента] Разрешить: [строка URL для сканирования] Карта сайта: [URL-адрес вашего XML-файла Sitemap]
Чтобы разрешить или запретить определенные URL-адреса, вы можете иметь разные строки инструкций.Кроме того, вы также можете добавлять разные карты сайта. Боты поисковых систем будут считать, что им разрешено сканировать страницы, если это разрешает URL.
Пример robots.txt приведен ниже
Пользовательский агент: * Разрешить: / wp-content / uploads / Запретить: / wp-content / plugins / Запретить: / wp-admin / Карта сайта: https://example.com/sitemap_index.xml
В приведенном выше примере мы разрешили сканировать страницы поисковыми системами и получать их индексные файлы в папке загрузок WordPress.
После этого мы не разрешили поисковым роботам сканировать и индексировать административные папки и плагины WordPress.
Наконец, мы упомянули URL-адрес карты сайта XML.
Требуется ли для вашего сайта WordPress файл Robots.txt?
Поисковая система начнет сканирование и индексирование ваших страниц, даже если у вас нет текстового файла, например Robots.txt. Но, к сожалению, вы не можете сообщить своей поисковой системе, какую конкретную папку или страницу нужно сканировать.
Это не принесет прибыли или не окажет никакого влияния, если вы только что создали веб-сайт или блог с меньшим количеством контента.
Однако, как только вы настроите свой веб-сайт с большим количеством контента и когда он начнет расти, вам потребуется контроль над просканированными и проиндексированными страницами вашего веб-сайта.
Первая причина приведена ниже
Для каждого веб-сайта у поисковых роботов есть квота сканирования.
Это явно означает, что во время сеанса сканирования он просканирует определенное количество страниц. Предположим, сканирование на вашем веб-сайте остается незавершенным, тогда оно вернется еще раз и возобновит сканирование в другом сеансе.
Из-за этого индекс индексации вашего сайта будет падать.
Вы можете решить эту проблему, запретив поисковым роботам сканировать ненужные страницы. Некоторые неважные страницы могут включать файлы плагинов, страницы администратора WordPress и папки тем.
Квоту сканирования можно сохранить, запретив сканирование нежелательных страниц. Этот шаг будет более полезным, потому что теперь поисковые системы будут сканировать страницы веб-сайта и смогут их проиндексировать в кратчайшие сроки.
Еще одна причина, по которой вам следует использовать и оптимизировать файл WordPress Robots.txt, приведена ниже
Если вам нужно запретить поисковым системам индексировать страницы или сообщения на вашем сайте, вы можете использовать этот файл.
На самом деле, это один из самых неподходящих способов скрыть контент вашего веб-сайта от широкой публики, но он окажется лучшим средством защиты их от появления в результатах поиска.
Как выглядит файл Robots.txt?
Очень простой робот.txt используется наиболее популярными блогами. Контент может отличаться в зависимости от требований конкретного веб-сайта.
Пользовательский агент: * Запретить: Карта сайта: http://www.example.com/post-sitemap.xml Карта сайта: http://www.example.com/page-sitemap.xml Файл robots.txt разрешит всем ботам индексировать каждый контент и предлагать ссылки на веб-сайт XML-карты сайта. В файлах robots.txt упоминаются следующие правила, которые необходимо соблюдать. Пользовательский агент: * Разрешить: / wp-content / uploads / Запретить: / wp-content / plugins / Запретить: / wp-admin / Запретить: / readme.html Запретить: / ссылаться / Карта сайта: http://www.example.com/post-sitemap.xml Карта сайта: http://www.example.com/page-sitemap.xml
Это укажет боту на индексацию всех файлов и изображений WordPress. Это не позволит поисковым роботам индексировать админку WordPress, файлы плагинов WordPress, партнерские ссылки и файл readme WordPress.
В файлы robots.txt вы можете добавить карты сайта, которые помогут роботам Google распознавать все страницы вашего сайта.
Теперь вы знаете, как файл robots.txt, теперь мы узнаем, как можно создать файл robots.txt в WordPress.
Как создать файл robots.txt в WordPress?
Есть много способов создать файл robots.txt в WordPress. Некоторые из лучших методов перечислены ниже, вы можете выбрать любой из них, который лучше всего подходит для вас.
Метод 1. Использование All in One SEO, изменение файла Robots.txt
All in One SEO — самый известный плагин WordPress для SEO на рынке, который используется более чем 1 миллионом веб-сайтов.
ПлагинAll in One SEO очень прост в использовании, поэтому он предлагает генератор файлов robotx.txt. Также полезно оптимизировать WordPress Robots.txt
.Если вы еще не интегрировали этот плагин SEO, сначала установите и активируйте его с панели инструментов WordPress. Бесплатная версия также доступна для начинающих пользователей, так что они могут использовать ее функции, не вкладывая деньги.
После активации плагина вы можете начать использовать его для создания или изменения файла robots.txt напрямую из админки WordPress.
Для использования
- Перейти к универсальному SEO
- Теперь, чтобы отредактировать файл robots.txt, нажмите на инструменты
- Теперь, нажав «включить пользовательский файл robots.txt», вы включите параметр редактирования.
- В WordPress вы также можете создать собственный файл robots.txt с помощью этого переключателя.
- Теперь ваш существующий файл robots.txt будет отображаться с помощью плагина All in One SEO в разделе robots.txt preview. Его можно просмотреть в нижней части веб-экрана.
Для WordPress правило по умолчанию, которое было добавлено, будет отображаться в этой версии.
Правила по умолчанию, которые появляются, чтобы предложить вашей поисковой системе, что им не нужно сканировать основные файлы WordPress, предлагают ссылку на веб-сайт карты сайта XML , и разрешить ботам индексировать все его содержимое.
Чтобы улучшить ваш robots.txt для SEO, можно добавить новые собственные правила.
Добавьте пользовательский агент в поле «Пользовательский агент», чтобы добавить правило. Правило будет применяться ко всем пользовательским агентам с использованием файла *.
Теперь выберите, хотите ли вы разрешить или не разрешить поисковой системе сканировать страницы.
Теперь добавьте путь к каталогу, имя файла в поле «Путь к каталогу».
К вашему robots.txt правило будет применено автоматически. Нажмите кнопку «Добавить правило», чтобы добавить новое правило.
Если вы не создадите идеальный формат robotx.txt, мы предлагаем вам добавить новые правила.
Добавленные вами пользовательские правила будут иметь вид
Чтобы сохранить изменения, не упустите возможность нажать «Сохранить изменения»
Метод 2. Измените роботов.txt вручную с помощью FTP
Другой метод оптимизации WordPress Robots.txt — использование функций FTP-клиентов для начала изменения файла robots.txt.
Вам просто нужно подключиться к своей учетной записи хостинга WordPress с помощью FTP-клиента
После входа в систему в корневой папке веб-сайта вы сможете просмотреть файл robots.txt.
Если вы не можете его найти, значит, у вас нет файла robots.txt
В такой ситуации нужно создать робота.txt файл.
Как упоминалось ранее, файл robots.txt обычно представляет собой простой текстовый файл, который можно загрузить на ваш компьютер. Однако вы даже можете изменить его с помощью обычного текстового редактора, такого как TextEdit, Notepad или WordPad.
После того, как вы выполнили все изменения, пришло время их сохранить. Вы можете загрузить этот файл в корневую папку вашего сайта.
Как можно выполнить тестирование файла Robots.txt?
Тестирование можно проводить с помощью роботов.txt тестер.
В Интернете вы найдете множество инструментов для тестирования robots.txt. Одна из лучших — это Google Search Console.
Для работы с этим инструментом сначала необходимо иметь веб-сайт, связанный с поисковой консолью Google. После этого вы можете начать использовать его функции.
Из выпадающего списка вам просто нужно выбрать вашу собственность.
Однако он автоматически выберет файл robots.txt вашего веб-сайта и выделит все предупреждения и ошибки.Это один из лучших инструментов, который поможет вам легко оптимизировать файл WordPress Robots.txt.
Заключение:
Главный девиз оптимизации этого файла robots.txt — защитить страницы от сканирования. Например, страницы в папке администратора WordPress или страницы в папке wp-plugin.
Самый распространенный миф заключается в том, что вы можете улучшить скорость сканирования, ускорить индексирование и получить более высокий рейтинг, заблокировав категорию WordPress, достигнув страниц и тегов.
Но это не сработает, поскольку согласно рекомендациям Google для веб-мастеров, произойдет сбой.
Мы настоятельно рекомендуем вам прочитать и принять во внимание все пункты, упомянутые выше.
Мы надеемся, что этот блог поможет вам создать файл robots.txt в правильном формате для вашего веб-сайта. И это поможет вам оптимизировать WordPress Robots.txt.
О сообщениях Shri
Shri делится интересными темами WordPress, плагинами и другими новостями, связанными с WordPress, для наших зрителей.Он также время от времени публикует интервью с избранными разработчиками WordPress.Посмотреть все сообщения Shri Posts
Как улучшить WordPress Robots.txt для улучшения SEO — Theme4Press
CMS WordPress предлагает множество важных преимуществ для SEO. На протяжении многих лет бесконечная оптимизация, проводимая известными разработчиками, гарантировала, что у пользователей WordPress не будет недостатка в преимуществах SEO.
Тем не менее, пользователям также необходимо внести некоторые изменения, чтобы обеспечить лучший сайт, оптимизированный для поисковых систем.
Имея это в виду, сегодня мы сосредоточимся на том, как импровизировать файл robots.txt WordPress для улучшения SEO.
Что такое файл Robots.txt?
Каждый пользователь WordPress слышит о файле robots.txt, и часто он используется по умолчанию без каких-либо изменений. Хотя версия по умолчанию работает хорошо, но ее изменение даст большее преимущество — преимущество SEO 😉.
Файл Robots.txt похож на шлюз. Всякий раз, когда боты поисковых систем посещают сайт, они обращаются к robots.txt сначала. Этот файл запугивает роботов поисковых систем относительно того, какие страницы следует посещать и индексировать, а какие не индексировать.
Robots.txt — это веб-стандарт, разработанный протоколом исключения роботов (REP) для регулирования поведения роботов и индексации поисковыми системами.
Короче говоря, если на сайте есть определенные страницы, которые не должны открываться и индексироваться поисковыми системами, используется файл robots.txt, чтобы гарантировать, что это не так.
Также помните, что поисковые системы не обязаны выполнять команды, данные в файле robots.txt файл. Поисковые системы могут решить их обойти, но обычно они этого не делают.
Можете ли вы скрыть файл Robots.txt?
Нет, нельзя.
Robots.txt — это общедоступный файл. Кто угодно может проверить, какие части веб-сайта скрыты веб-мастером.
Легко получить доступ к файлу robots.txt; нет скрытых URL. Просто введите имя домена и добавьте «robots.txt» в конец URL-адреса (без кавычек).
Например: http: // yourdomain.ru / robots.txt
Некоторые эксперты по SEO считают, что robots.txt не рекомендуется для сокрытия конфиденциальной информации, доступной на сайте, потому что боты поисковых систем могут получить к ним доступ, даже если в файле robots.txt указано иное. Следует использовать более эффективные и безопасные способы, такие как защита паролем.
Структура файла Robots.txt и модификации SEO
Обычно немодифицированный файл robots.txt WordPress выглядит так:
User-agent: *
Disallow: / wp-admin /
Значок * (звездочка) с ‘User-agent’ означает, что разрешены все поисковые системы. проиндексировать сайт.Условие «Disallow» не позволяет поисковым системам индексировать некоторые части сайта, такие как wp-admin, плагины и темы, потому что они являются конфиденциальной информацией, и если их индексирование разрешено, это подвергнет сайт серьезному риску.
Итак, какие все модификации на основе SEO можно внести в файл robots.txt по умолчанию?
Посмотрим.
Использование «Disallow»
В каждой строке допускается только один URL с тегом Disallow. Не повторяйте URL-адреса. Помните, что блокировка страницы, категории или публикации с помощью robots.txt означает, что поисковая система не будет его сканировать.
Однако это не означает, что поисковые системы не будут индексировать страницы и не отображать их в результатах — это будет. Вы можете исключить эту возможность на следующем шаге, приведенном ниже.
Мета Ноиндекс
Это самый безопасный и рекомендуемый метод, чтобы запретить поисковым системам индексировать и отображать определенные страницы в результатах поиска.
Как добавить тег Meta Noindex?
Есть много способов. Плагин WordPress SEO от Yoast используется в качестве справочника.Если вы действительно хотите создать сайт с сильной SEO-приверженностью, используйте этот плагин.
Плагин Yoast позволяет добавлять тег Meta Noindex двумя способами:
- Страница / Уровень записи
Когда вы добавляете сообщение или страницу, проверьте настройки Yoast SEO в разделе «Дополнительно», и вы найдете список параметров, спрашивающих, что делать со страницей или публикацией.
Просто выберите «Noindex» и опубликуйте сообщение или страницу — страница не будет проиндексирована поисковой системой.Простой?
- Уровень сайта
Проверьте настройку Yoast SEO ‘Title & Metas’ на панели инструментов WordPress, и вы найдете список таксономий, спрашивающих, как они должны быть представлены.
Например, вы можете захотеть Noindex категорий, тегов, медиафайлов, партнерских ссылок, ссылок на авторов и так далее. Это полностью ваш выбор.
Вы можете полностью контролировать применимость тега Meta Noindex, используя эти два метода.
Ссылки NoFollow
Вы можете использовать «nofollow» ссылки, чтобы поисковые системы не индексировали и отображали ссылки; но это опять же не надежная стратегия. Поисковые системы по-прежнему могут обнаруживать ссылки, по которым нет перехода.
Чтобы добавить параметр nofollow, выполните следующее:
Сохраните страницу или сообщение, и к ссылке (-ам) будет добавлен параметр «nofollow».
Следует добавить файл Sitemap в Robots.txt файл?
Хорошая практика SEO — добавить ссылку на карту сайта в файл robots.txt. В предыдущем примере карта сайта не была включена, но если вы проверите карту сайта в блоге Blogger, она будет выглядеть следующим образом.
Рекомендуется добавить карту сайта в robots.txt.
Для этого в WordPress вам необходимо отредактировать файл robots.txt. Вы можете добавить одну карту сайта или несколько (по одной карте сайта на строку). После этого сохраните файл robots.txt, и все готово.
Как редактировать файл Robots.txt?
Вы можете получить доступ к файлу robots.txt двумя следующими способами:
Инструменты Google для веб-мастеров
Войдите в Инструменты Google для веб-мастеров, выберите сайт и нажмите «Сканировать». В раскрывающемся меню вы увидите «robots.txt tester». Добавьте URL-адреса карты сайта и нажмите «Отправить».
Плагин Yoast SEO
На панели инструментов Yoast SEO перейдите в раздел «Инструменты», и вы увидите параметр «Редактор файлов» для редактирования файлов robots.txt файл.
Нажмите «создать файл robots.txt», добавьте текст и сохраните его.
Пример файла Ideal Robots.txt
Позвольте мне показать вам один пример идеального файла robots.txt:
User-agent: *
Disallow: / cgi-bin /
Disallow: / wp-admin /
Disallow: / wp-content / plugins /
Disallow: / wp-content / cache /
Disallow: / wp-content / themes /
User-agent: Mediapartners-Google *
Разрешить: /
Агент пользователя: Googlebot-Image
Разрешить: / wp-content / uploads /
Карта сайта: http: // www.yoursite.com/sitemap.xml
Это базовая и безопасная версия файла robots.txt, которая работает на большинстве сайтов WordPress.
Заключение
Оптимизация файла robots.txt становится неизбежной по мере роста веб-сайта. Вы не хотите, чтобы все было видимым и доступным, поэтому необходимо использовать определенные методы. Одно из них — изменение файла robots.txt.
Мы надеемся, что это руководство было для вас информативным. Если у вас есть сомнения или вопросы, задавайте их в комментариях — мы с радостью ответим.
WordPress и файл Robots.txt: примеры и передовые методы [версия 2020]
Вопрос : Я использую WordPress, и мне интересно, следует ли мне создать файл robots.txt. В разных местах я читал, что должен, и в других местах, что WordPress создает свой собственный файл robots.txt. Какая реальная история? – Тим, Мэдисон, Висконсин
WordPress и файл Robots.txt: что лучше для вас
Тим, еще один отличный вопрос. Что делать с файлом robots.txt при использовании WordPress?
Есть два ответа на этот вопрос. Первый — это краткий и быстрый ответ, а второй — длинный и сложный… вы услышите, как эксперты обсуждают файл WordPress robots.txt и до тошноты .
Итак, давайте сначала перейдем к быстрому ответу, а затем мы рассмотрим «длинный ответ» и засыпаем вас ссылками, в которых эксперты обсуждают этот вопрос до посинения.
WordPress и Роботы.Файл TXT: виртуальный файл Robots.Txt по умолчанию
Тим, быстрый ответ:
Вам не нужно создавать файл robots.txt, потому что WordPress автоматически создает для вас виртуальный robots.txt.
Чтобы просмотреть этот файл, посетите http://yoursite.com/robots.txt .
Файл должен выглядеть примерно так:
Агент пользователя: * Запретить: / wp-admin / Запретить: / wp-includes / Карта сайта: http://yoursite.com/sitemap.xml.gz
Первая строка этого файла, строка «user-agent», — это объявление бота . Звездочкой * отмечены все поисковые боты (например, Google, Yahoo и т. Д.). И по умолчанию все будет проиндексировано, кроме тех строк, которые мы упоминаем ниже.
Вторая и третья строки этого файла говорят пользовательским агентам ( в данном случае все ) не выполнять поиск в этих конкретных каталогах WordPress, потому что они не предоставляют добавленного контента.
Наконец, строка карты «Карта сайта» сообщает ботам о местонахождении вашего файла карты сайта.Это строка , предположительно полезная , и ее следует включить в ваш файл robots.txt. Если вы используете плагин Google XML sitemaps (что вам следует), эта строка будет включена … и разрыв строки после последней строки disallow также должен быть там.
Что делать, если вы не видите файл Robots.Txt?
Тим, у некоторых есть эта проблема, поэтому я подумал, что дам ответ и на нее.
Если вы не видите виртуальный файл robots.txt, который должен был создать WordPress, возможно, вы используете устаревшую версию WordPress ИЛИ виртуальный файл robots.txt мог быть вытеснен плагином.
В этом случае вы можете легко создать свой собственный файл robots.txt. Используя приведенный выше пример WordPress, просто скопируйте и вставьте информацию в текстовый файл, назовите его robots.txt и затем загрузите его в свой корневой каталог. Очевидно, вы хотите изменить yoursite на фактический URL-адрес вашего веб-сайта.
Создайте свой собственный Robots.Txt: Примеры
Могут быть случаи, когда вы хотите, чтобы другие каталоги (каталоги, которые, возможно, существуют за пределами вашей среды WordPress) также были запрещены, потому что вы не хотите, чтобы они отображались в результатах поиска.
Это также легко сделать, создав собственный файл robots.txt . Если у вас есть подкаталог вашего веб-сайта, который вы не хотите, чтобы боты включали, вы просто добавляете такую строку:
Запретить: / thisdirectory /
Не забудьте добавить завершающий «/» ! Если вы этого не сделаете, он не будет индексировать что-либо, начинающееся со слов «thisdirectory».
Будет ли ваш файл robots.txt перезаписан виртуальным файлом robots.Txt WordPress?
Да.Если вы загрузите свой собственный файл robots.txt, вы увидите, что теперь это активный файл , посетив http://yoursite.com/robots.txt .
Пример файла robots.Txt для загрузки
Тим, если вам не нужно запрещать использование других файлов, можно использовать виртуальный файл robots.txt WordPress.
Однако, если вы не видите виртуальный файл robots.txt или вам нужно создать его вручную, чтобы исключить другие подкаталоги на вашем веб-сайте, используйте следующие строки в качестве шаблона:
Пользовательский агент: * Запретить: / wp-admin / Запретить: / wp-includes / Запретить: / subdirdontindex1 / Запретить: / subdirdontindex2 / Карта сайта: http: // ваш сайт.ru / sitemap.xml
Приложение: файл WordPress Robots.Txt — подробное обсуждение
Для большинства из вас я считаю, что упомянутых выше стратегий достаточно. Это связано с тем, что «окончательный ответ» не был объявлен со 100% уверенностью, и, если не считать серьезной ошибки, например, непреднамеренного запрета доступа ко всему сайту ( уже сделано! ), с файлом robots.txt все должно быть в порядке.
Тем не менее, продолжается исчерпывающее обсуждение WordPress и Robots.txt.
Вот несколько ссылок, по которым обсуждается этот вопрос, с кратким описанием каждой ссылки:
Поисковая оптимизация для WordPress: это обсуждение на сайте WordPress.org SEO для WordPress, и здесь они представляют рекомендуемый файл robots.txt. Вы, конечно, можете использовать их рекомендуемый файл robots.txt, но он был опровергнут в нескольких статьях из-за запрета слишком многого.
WordPress Robots.txt Guide — Что это такое и как его использовать. Узнайте больше о robots.txt с этим подробным сообщением Kinsta.com.
Как оптимизировать ваш WordPress Robots.txt для SEO Этот сайт посвящен WordPress, и в этой статье они уделяют внимание файлу robots.txt с множеством убедительных примеров того, что вы должны и не должны делать.
WordPress robots.txt Пример. Один автор, которого я очень уважаю, потому что он является создателем лучшего плагина WordPress для SEO, говорит, что рекомендации WordPress слишком строгие. Он говорит, что единственная строчка, которая должна быть в вашем robots.txt: «User-agent: *».
WordPress требуется файл robots.txt по умолчанию и многое другое…: Знаете ли вы, что WordPress.org имеет раздел идей и ? Что ж, они это делают, и одна из идей — предоставить файл robots.txt по умолчанию. Мне нравится эта идея (хотя она действительно существует с виртуальным файлом robots.txt), и она позволит всем нам удовлетвориться одним ответом.
Инструменты создания Robots.txt: Если вам неудобно создавать собственный файл robots.txt, по этой ссылке есть инструменты, которые помогут вам.
Ричард Каммингс
Директор по SEO, социальным сетям и разработке веб-контента в The SEO SystemРичард Каммингс много лет занимается онлайн-маркетингом, настроил и оптимизировал сотни сайтов WordPress.