Правильный robots.txt для WordPress сайта
|
Просмотров: 1 509
Привет всем! Сегодня тема очень важная это — robots.txt для WordPress сайта / блога. Поисковые роботы заходя на сайт или блог первым делом ищут файл robots.txt. Файл robots.txt сообщает поисковой системе, куда разрешено заходить на вашем сайте. Что такое robots.txt?
Robots.txt — служебный файл, который находится в корневом каталоге сайта и содержит набор директив, позволяющих управлять индексацией сайта. Он позволяет указывать поисковым системам, какие страницы сайта или файлы должны присутствовать в поиске, а какие — нет. Когда краулер приходит на хостинг, файл robots.txt является одним из первых документов, к которому он обращается.
Создание robots. txt для сайта WordPress
txt для сайта WordPressКак создать файл robots.txt для WordPress
Robots.txt в большинстве случаев используется для исключения дубликатов, служебных страниц, удаленных страниц и других ненужных страниц из индекса поисковых систем. Кроме того, именно через robots.txt можно указать ПС адрес карты сайта.
Воспользуйтесь любым текстовым редактором (например, блокнотом), создайте файл с именем robots.txt и заполните его как показано ниже. Файл должен называться robots.txt, а не так — Robots.txt или ROBOTS.TXT.
После этого необходимо загрузить файл в корневой каталог вашего сайта.
Файл robots.txt должен располагаться строго в корне сайта и он должен быть единственным.
Оптимальный, правильный robots.txt для сайта WordPress. Общий для Google и Яндекс . Такой robots.txt у меня стоял на всех сайтах:
User-agent: * Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /core/ Disallow: */feed Disallow: *?s= Disallow: *&s= Disallow: /search Disallow: */embed Disallow: *?attachment_id= Disallow: /id_date Disallow: */page/ Disallow: *?stats_author Disallow: *?all_comments Disallow: *?post_type=func Disallow: /filecode Disallow: /profile Disallow: /qtag/ Disallow: /articles/ Disallow: /artictag/ Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /*ajax Sitemap: http://example.com/sitemap.xml

Стандартный robots.txt WordPress
Раздельный для Google и Yandex:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-json/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */embed Disallow: */page/ Disallow: /cgi-bin Disallow: *?s= Allow: /wp-admin/admin-ajax.php Host: site.ru User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-json/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */embed Disallow: */page/ Disallow: /cgi-bin Disallow: *?s= Allow: /wp-admin/admin-ajax.php Sitemap: http://сайт.ру/sitemap.xml
Замените сайт.ру на ваш URL адрес блога. Смело можете скормить данным файлом поисковые системы Яндекс и Google.
А теперь, прочитав статью от Yoast SEO я стал использовать вот такой robots.
User-agent: * Sitemap: https://wordpressmania.ru/sitemap_index.xml
Для большинства сайтов WordPress рекомендуется robots.txt:
User-agent: *
Все поисковые роботы могут свободно сканировать этот сайт без ограничений.
Стандарт robots.txt поддерживает добавление в файл ссылки на ваши XML-карты сайта. Это помогает поисковым системам обнаруживать местонахождение и содержание вашего сайта.
Yoast SEO всегда считали это излишним. Вы уже должны это сделать, добавив карту сайта в Google Search Console, Яндекс Вебмастер и Bing для веб-мастеров, чтобы получить доступ к аналитике и данным о производительности. Если вы это сделали, вам не нужна ссылка в файле robots.txt.
Читайте подробный пост о том — как создать robots.txt для сайта WordPress.
Как настроить индивидуально важный файл robots.txt можно прочитав эти справки:
На странице помощи Яндекса. Проверить правильность составления файла можно в webmaster.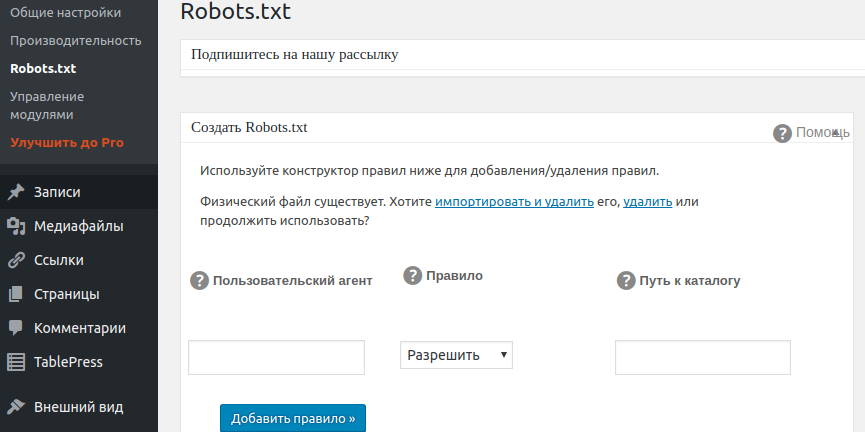 yandex — Настройка индексирования — Анализ robots.txt. Далее, в Google robots.txt можно проверить по этой ссылке. Не забудьте что проверяемый блог должен быть добавлен в Инструменты для веб-мастеров Google и Яндекс.
yandex — Настройка индексирования — Анализ robots.txt. Далее, в Google robots.txt можно проверить по этой ссылке. Не забудьте что проверяемый блог должен быть добавлен в Инструменты для веб-мастеров Google и Яндекс.
Обратите внимание, что для Яндекса и Google правила составления robots.txt немного различаются. Вот ещё полезный ресурс для изучения robotstxt.org.ru. Вот и всё.
Теперь остаётся загрузить созданный файл в корневой каталог вашего блога. Корень блога это — папка public_html, где находятся файл config.php, index.php и так далее.
В заключение
Создание и тщательная подготовка robots.txt крайне важны. При его отсутствии поисковые роботы собирают всю информацию, относящуюся к сайту. В поиске могут появиться незаполненные страницы, служебная информация или тестовая версия сайта.
Вот на этом позвольте с вами не надолго попрощаться. Удачи. До новых встреч на страницах блога.
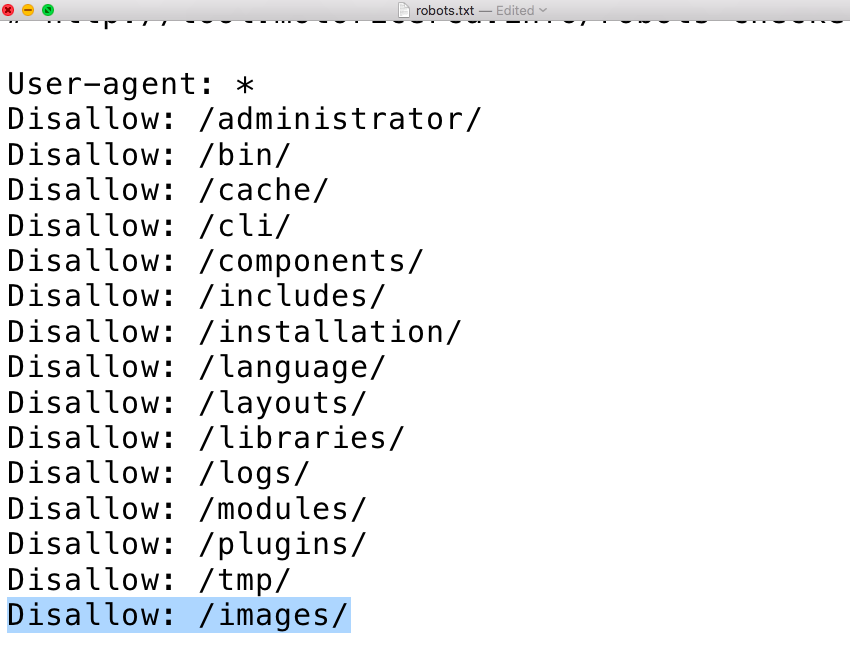
Правильный robots.txt для сайта wordpress, как закрыть ссылки от индексации
Индексация сайта представляет собой процесс, благодаря которому страницы вашего сайта попадают в поисковые системы.
Для того чтобы сайт индексировался хорошо, вам нужно создать правильный файл robots txt и вписать туда необходимые директивы.
Файл можно создать в стандартной программе «Блокнот», которая доступна абсолютно каждому пользователю ПК.
Добавляется файл robots txt в корневую папку сайта. Для того чтобы осуществить это действие, вам потребуется программа FileZilla или же обычный Total Commander при условии наличия FTP соединения. На некоторых хостингах есть возможность непосредственного добавления каких-либо файлов.
Содержание
Что будет, если файл robots txt неправильно настроен
Чтобы ответить на данный вопрос, давайте представим, что сайт wordpress это офис, в который приходят клиенты. В вашем офисе есть как гостевые комнаты, так и служебные, вход в которые доступен только сотрудникам. На дверях служебных помещений обычно вешается табличка с надписью «вход воспрещен» или «вход только для сотрудников». Таким образом, ваши клиенты будут понимать, что туда им лучше не соваться.
Таким образом, ваши клиенты будут понимать, что туда им лучше не соваться.
Теперь поговорим о сайте wordpress. Если придерживаться аналогии, то его гостевыми комнатами будут открытые к индексации страницы, а служебными — закрытые к индексации страницы. Клиенты же являются поисковыми роботами, которые посещают сайт и вносят в поисковый индекс определенные страницы.
После небольшого экскурса перейдем непосредственно к последствиям, которые могут возникнуть при неправильной настройке файла роботс. Если вы не впишите запрещающие директивы, то поисковый робот будет индексировать абсолютно все подряд, включая данные панели администратора сайта, тем, скриптов и так далее. Также в выдаче могут появиться страницы-дубли. Поисковый робот может запутаться и случайно проиндексировать одну и ту же страницу несколько раз. Бывают случаи, когда роботы вовсе не индексируют сайт из-за того, что директивы файла индексации неправильно настроены, но чаще всего такое последствие является санкцией, которая возлагается на сайт при продаже ссылок. Чтобы выяснить причину, вам нужно зайти в панель управления, которую предоставляют поисковые системы, которая отказывается индексировать сайт и обратить внимание на какие-либо оповещения.
Чтобы выяснить причину, вам нужно зайти в панель управления, которую предоставляют поисковые системы, которая отказывается индексировать сайт и обратить внимание на какие-либо оповещения.
Настройка robots txt
Запомните, что правильный файл robots txt состоит из 3 компонентов: выбор робота, которому вы задаете директивы; запрет на индексацию; разрешение индексации.
Для того чтобы указать конкретного робота, которому будут адресоваться правила, можно использовать директиву User-agent. Ниже представлены возможные примеры.
- User-agent: * (правила будут распространятся на всех поисковых роботов).
- User-agent: название поискового робота (правила будут распространятся только на тех роботов, которых вы впишете). В большинстве случаев сюда вписывают yandex и googlebot.
Чтобы запретить индексацию определенных разделов на wordpress, вам стоит использовать правильный комплекс директив Disallow. Помимо разделов вы можете также запретить индексировать какую-либо папку или файл. Итак, перейдем к примерам.
Помимо разделов вы можете также запретить индексировать какую-либо папку или файл. Итак, перейдем к примерам.
- Disallow: (на индексацию нет никаких запретов).
- Disallow: /file.pdf (закрыть файл file.pdf). Таким же образом можете попросить закрыть конкретные папки.
- Disallow: /nazvanie-razdela (закрыть страницы, которые находятся в разделе «nazvanie-razdela»).
- Disallow: */*slovo (закрыть страницы, ссылки на которые включают в себя «slovo»). Звездочки означают любой текст ссылки, который стоит перед или после указанного вами слова. При использовании такой комбинации символов поисковый робот будет считать, что звездочка находится и в конце. Поэтому, если хотите закрыть страницы, ссылки на которые заканчиваются определенным текстом, то вам стоит добавить еще «$» после директивы.
- Disallow: / (закрыть весь сайт).
Если же хотите разрешить индексирование конкретных файлов сайта, которые находятся в запрещенных для индексации разделах, то вам поможет директива Allow.
адресуется поисковым роботам Google
User-agent: googlebot
закрыть страницы, которые находятся в разделе «nazvanie-razdela»
Disallow: /nazvanie-razdela
разрешено добавлять в индекс абсолютно все файлы с расширением txt, независимо от раздела сайта
Allow: *.txt$
В случае наличия XML карты сайта вы можете указать текст ее ссылки в директиву Sitemap. Она является неофициальной и поддерживается не всеми поисковыми роботами. Основными же (Yandex, Google, Bing и Yahoo) эта директива поддерживается. Если у сайта есть несколько XML карт, то вы можете указать все, используя ссылки на них. Никаких проблем не должно возникнуть. Основная ваша задача это правильно указать адрес ссылки каждой из них.
Sitemap: сайт.ru/название-карты-сайта.xml
Sitemap: сайт.ru/название-карты-сайта1.xml
У многих сайтов вордпресс есть зеркала. Чтобы указать основное, вам потребуется вписать адрес его ссылки в директиву Host.
Host: основное-зеркало.ru
Теперь, зная директивы, вы можете самостоятельно создать правильный файл роботс под любые поисковые системы. Для этого вам нужно в первую очередь проанализировать структуру сайта вордпресс и решить, что же закрыть от поисковиков, а что открыть. Если же вам лень этим заниматься, то можете использовать пример, который представлен ниже.
Для удобства вам рекомендуется использовать плагин wordpress All in One Seo Pack. Он содержит опцию, благодаря которой можно закрыть индексацию архивов, тегов и страниц поиска. Если у вас нет такого плагина, то вам стоит дописать в robots txt представленные ниже атрибуты после директивы Disallow.
- */20 — отвечает за архивы
- */tag — отвечает за теги
- *?s= — отвечает за страницы поиска
Если вам лень прописывать полное название служебных разделов, то можете прописать директиву Disallow: /wp- при условии, что на вашем сайте wordpress нет страниц с таким названием, которые вы бы хотели добавить в индекс. Поэтому будьте внимательны при выборе названия для неслужебных разделов.
При изменении директив файла robots txt вам стоит помнить, что его индексация это не быстрый процесс. Иногда на это требуется не одна неделя. Чтобы проверить статус индексирования этого файла Яндексом, вам нужно перейти в панель вебмастера сервиса Яндекс, выбрать сайт и перейти в раздел «Настройка индексирования». Потом вам нужно будет выбрать «Анализ robots txt».
Чтобы проверить статус индексирования файла в Google, вам нужно перейти в раздел «Сканирование» и выбрать «Инструмент проверки robots txt».
После того как настроите директивы, поисковики должны начать добавлять ваш сайт wordpress в индекс. Стоит отметить, что этот процесс может пойти не так гладко, как вы думаете. Многие вебмастера жалуются на Google из-за того, что он вопреки каким-либо запретам производит индексацию сайта так, как пожелает. Работники Google говорят, что файл роботс является не более, чем рекомендацией.
Даже если прописать запрещающие директивы отдельно для Google, то желаемый результат вы не факт, что получите. К тому же, из-за произвольной индексации роботов Google могут появиться страницы-дубли. Их количество со временем может увеличиться и сайт может попасть под фильтр. Чаще всего это Panda.
Чтобы справиться с этой проблемой, вы можете поставить пароль в панели управления wordpress на конкретный файл или же добавить атрибут noindex в метатеги страниц, на которые желаете наложить запрет индексации. Выглядеть это будет так.
<meta name="robots" content="noindex">
Альтернативой для атрибута noindex является атрибут nofollow. Разница между ними лишь в том, что они по-разному оцениваются поисковыми системами. В случае же с Google вам лучше использовать noindex. Если прислушаться к рекомендации, то вы добьетесь желаемого результата.
В справке сервиса Google можно более детально изучить особенности использования атрибута noindex.
Если вы не хотите вручную создавать роботс для своего wordpress, то можете воспользоваться плагином DL Robots.txt. Его можно установить прямо в панели администратора. Для этого вам нужно будет кликнуть по разделу «Плагины» и выбрать «Добавить новый». Теперь вам останется лишь вписать название и кликнуть «Установить», а затем «Активировать». После этого в панели администратора должна появиться вкладка с названием плагина. Кликнув на нее, вы перейдете в настройки и сможете посмотреть обучающее видео. После проведения настройки вы получите адрес ссылки вашего роботс.
Альтернативами данного плагина wordpress являются PC Robots.txt и iRobots.txt. Они имеют свои особенности, но в целом похожи и являются легкими в настройке. Так что, если первый по каким-либо причинам не будет работать, вы всегда можете воспользоваться последними.
Несколько советов и примечаний
- Помните, что правильный файл роботс wordpress не должен занимать более 32 Кбайта дискового пространства. В противном случае могут возникнуть проблемы и индексацией. Чем меньше вес, тем быстрее обработка.
- Не желательно указывать несколько директив в одной строке.
- Не нужно добавлять в кавычки каждый атрибут директивы, который находится в роботс.
- При отсутствии файла роботс поисковики будут считать, что запрет на индексацию не установлен. Произвольная индексация может привести к фильтрации.
- Стоит отметить, что правильный роботс не должен содержать пробелы в начале каждой строки директивы.
Как импровизировать WordPress Robots.
 txt для преимуществ SEO
txt для преимуществ SEOWordPress CMS предлагает множество важных преимуществ SEO. На протяжении многих лет бесконечная оптимизация известными разработчиками гарантировала, что пользователи WordPress не испытывают недостатка в преимуществах SEO.
Тем не менее, пользователям также необходимо внести некоторые изменения, чтобы убедиться, что их сайт лучше оптимизирован для поисковых систем.
Имея это в виду, сегодня мы сосредоточимся на том, как импровизировать файл WordPress robots.txt для улучшения SEO.
Что такое файл robots.txt?
Каждый пользователь WordPress слышал о файле robots.txt, и часто он используется в своих функциях по умолчанию без каких-либо изменений. Хотя версия по умолчанию работает хорошо, ее модификация даст большее преимущество — SEO-преимущество ;).
Файл robots.txt похож на шлюз. Всякий раз, когда боты поисковых систем посещают сайт, они сначала обращаются к файлу robots.txt. Этот файл запугивает роботов поисковых систем относительно того, какие страницы следует посещать и индексировать, а какие не индексировать.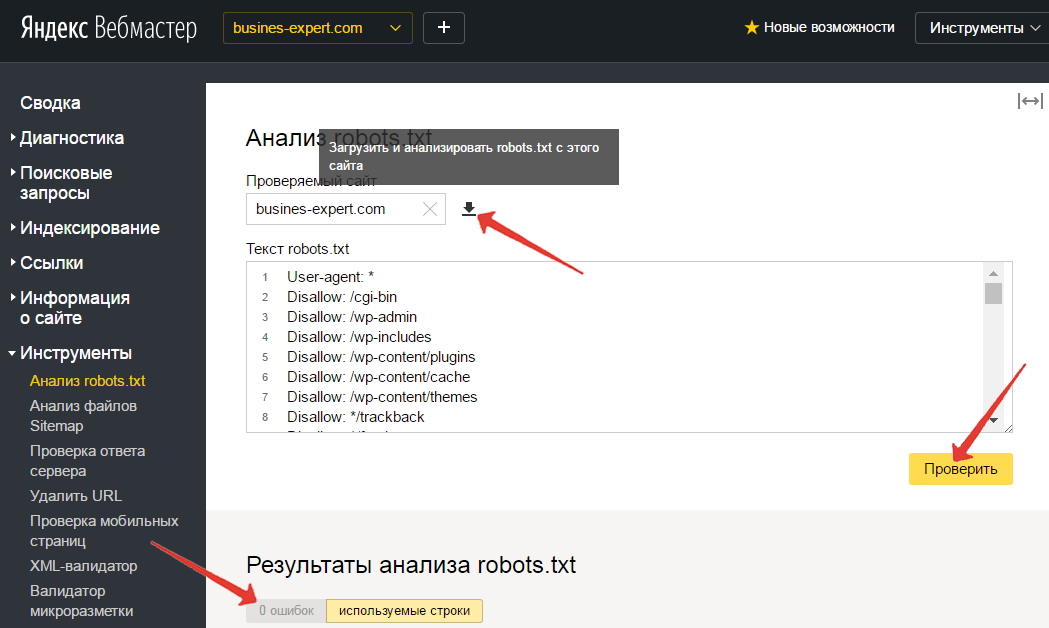
Robots.txt — это веб-стандарт, разработанный протоколом исключения роботов (REP) для регулирования поведения роботов и индексации поисковыми системами.
Короче говоря, если на сайте есть определенные страницы, которые не должны открываться и индексироваться поисковыми системами, файл robots.txt используется для того, чтобы этого не произошло.
Также помните, что поисковые системы не обязаны выполнять команды, данные в файле robots.txt. Поисковые системы могут обойти их, но обычно они этого не делают.
Можно ли скрыть файл robots.txt?
Нет, нельзя.
Robots.txt — полностью общедоступный файл. Любой может проверить, какие части веб-сайта скрыты веб-мастером.
Легко получить доступ к файлу robots.txt; нет скрытых URL. Просто введите доменное имя и добавьте «robots.txt» в конце URL-адреса (без кавычек).
Например, http://yourdomain.com/robots.txt
Некоторые специалисты по поисковой оптимизации считают, что файл robots. txt не рекомендуется для сокрытия конфиденциальной информации, доступной на сайте, поскольку роботы поисковых систем могут получить к ним доступ, даже если иначе упоминается в файле robots.txt. Следует использовать лучшие и безопасные способы, такие как защита паролем.
txt не рекомендуется для сокрытия конфиденциальной информации, доступной на сайте, поскольку роботы поисковых систем могут получить к ним доступ, даже если иначе упоминается в файле robots.txt. Следует использовать лучшие и безопасные способы, такие как защита паролем.
Структура файла robots.txt и SEO-модификации
Обычно немодифицированный файл robots.txt WordPress выглядит следующим образом:
User-agent: *
Disallow: /wp-admin/
Знак * (звездочка) с «User-agent» означает, что всем поисковым системам разрешено индексировать сайт. Условие «Запретить» не позволяет поисковым системам индексировать некоторые части сайта, такие как wp-admin, плагины и темы, потому что они являются конфиденциальной информацией, и если их индексирование разрешено, это подвергнет сайт серьезному риску.
Итак, какие все SEO-модификации можно внести в файл robots.txt по умолчанию?
Посмотрим.
Использование «Запретить»
В каждой строке разрешен только один URL-адрес с тегом «Запретить».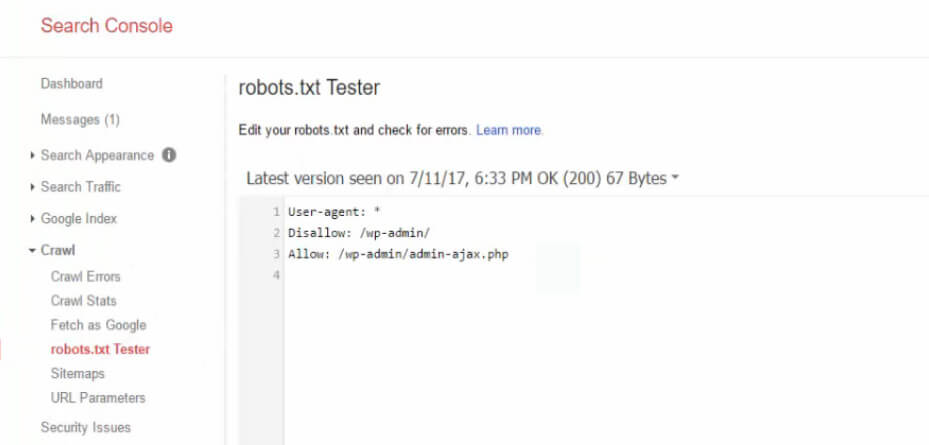 Не повторяйте URL-адреса. Помните, что блокировка страницы, категории или публикации с помощью файла robots.txt означает только то, что поисковая система не будет их сканировать.
Не повторяйте URL-адреса. Помните, что блокировка страницы, категории или публикации с помощью файла robots.txt означает только то, что поисковая система не будет их сканировать.
Это, однако, не означает, что поисковые системы не будут индексировать страницы и не показывать их в результатах — они будут. Вы можете отменить эту возможность на следующем шаге, указанном ниже.
Meta Noindex
Это самый безопасный и рекомендуемый метод запретить поисковым системам индексировать и отображать определенные страницы в результатах поиска.
Как добавить тег Meta Noindex?
Способов много. Плагин WordPress SEO от Yoast используется в качестве эталона. Если вы действительно хотите создать сильный SEO-ориентированный сайт, используйте этот плагин.
Плагин Yoast позволяет добавить метатег Noindex двумя способами:
- Уровень страницы/сообщения
Когда вы добавляете сообщение или страницу, проверьте настройки Yoast SEO в разделе «Дополнительно», и вы найдете список параметров, спрашивающих, что делать со страницей или сообщением.
Просто выберите «Без индекса» и опубликуйте пост или страницу — страница не будет проиндексирована поисковой системой. Простой?
- Уровень сайта
Проверьте настройку Yoast SEO «Заголовок и метаданные» на панели инструментов WordPress, и вы найдете список таксономий с вопросом, как они должны быть представлены.
Например, вы можете не индексировать категории, теги, медиафайлы, партнерские ссылки, авторские ссылки и так далее. Это ваш выбор полностью.
Вы можете полностью контролировать применимость тега Meta Noindex, используя эти два метода.
Ссылки NoFollow
Вы можете использовать ссылки nofollow, чтобы запретить поисковым системам индексировать и отображать ссылки, но это опять же не надежная стратегия. Поисковые системы по-прежнему могут обнаруживать ссылки «nofollow».
Чтобы добавить параметр nofollow, выполните следующее:
Сохраните страницу или сообщение, и ссылки будут иметь ‘ добавлен параметр nofollow.
Следует ли добавлять карту сайта в файл robots.txt?
Хорошей практикой SEO будет добавление ссылки на карту сайта в файл robots.txt. В предыдущем примере карта сайта не была включена, но если вы проверите карту сайта блога Blogger, она будет выглядеть так.
Рекомендуется добавлять карту сайта в robots.txt.
Чтобы сделать это в WordPress, вам нужно отредактировать файл robots.txt. Вы можете добавить одну карту сайта или несколько (по одной карте сайта на строку). После этого сохраните файл robots.txt, и все готово.
Как редактировать файл robots.txt?
Вы можете получить доступ к файлу robots.txt двумя следующими способами:
Инструменты Google для веб-мастеров
Войдите в Инструменты Google для веб-мастеров, выберите сайт и нажмите «Сканирование». В выпадающем меню вы увидите «тестер robots.txt». Добавьте URL-адреса карты сайта и нажмите «Отправить».
Плагин Yoast SEO
В панели инструментов Yoast SEO перейдите в раздел «Инструменты», и вы увидите опцию «Редактор файлов» для редактирования файла robots. txt.
txt.
Нажмите «Создать файл robots.txt», добавьте свой текст и сохраните его. Пример идеального файла robots.txt /
Запретить: /wp-content/plugins/
Запретить: /wp-content/cache/
Запретить: /wp-content/themes/
Агент пользователя: Mediapartners-Google*
Разрешить: /
Агент пользователя: Googlebot-Image
Разрешить: /wp-content /uploads/
Карта сайта: http://www.yoursite.com/sitemap.xml
Выше приведена базовая и безопасная версия файла robots.txt, которая работает на большинстве сайтов WordPress.
Заключение
Оптимизация файла robots.txt становится неизбежной по мере роста веб-сайта. Вы не хотите, чтобы все было видно и доступно, и поэтому необходимо использовать определенные методы. Одним из них является изменение файла robots.txt.
Мы надеемся, что урок был для вас информативным. Если у вас есть какие-либо сомнения или вопросы, не стесняйтесь спрашивать нас в разделе комментариев — мы будем рады ответить.
Как оптимизировать WordPress Robots.txt для SEO на примере
SEO является главным приоритетом для владельцев веб-сайтов. Поскольку первые пять результатов получают 75% кликов, гонка за более высокий рейтинг была сложной задачей. Существуют различные внестраничные и внутренние методы SEO, которые вступают в игру. Оптимизация файла Robot.txt — один из тех приемов, которые могут усилить SEO вашего сайта.
Однако большинство новичков не знают, как оптимизировать WordPress Robots.txt для SEO. Некоторые могут даже не знать, что такое файл robots.txt.
К счастью, эта статья вам в помощь.
Здесь мы объясним, что такое файл robots.txt, как создать файл robots.txt и как оптимизировать файл robots.txt для SEO. Мы также добавили несколько часто задаваемых вопросов в конце. Так что убедитесь, что вы с нами до конца.
Теперь приступим!
Содержание
- Что такое файл robots.txt?
- Как выглядит файл robots.txt?
- Зачем вам нужен файл robots.
 txt в WordPress?
txt в WordPress? - Как создать файл robots.txt для вашего веб-сайта?
- Способ 1. Создание файла Robots.txt с помощью подключаемого модуля Rank Math
- Способ 2. Создание файла Robots.txt с помощью FTP
- Куда поместить файл Robots.txt?
- Как проверить файл robots.txt?
- Плюсы файла robots.txt
- Минусы файла robots.txt
- Часто задаваемые вопросы (FAQ)
- Что такое веб-сканирование?
- Что такое индексация?
- Что такое краулинговый бюджет?
- Заключение
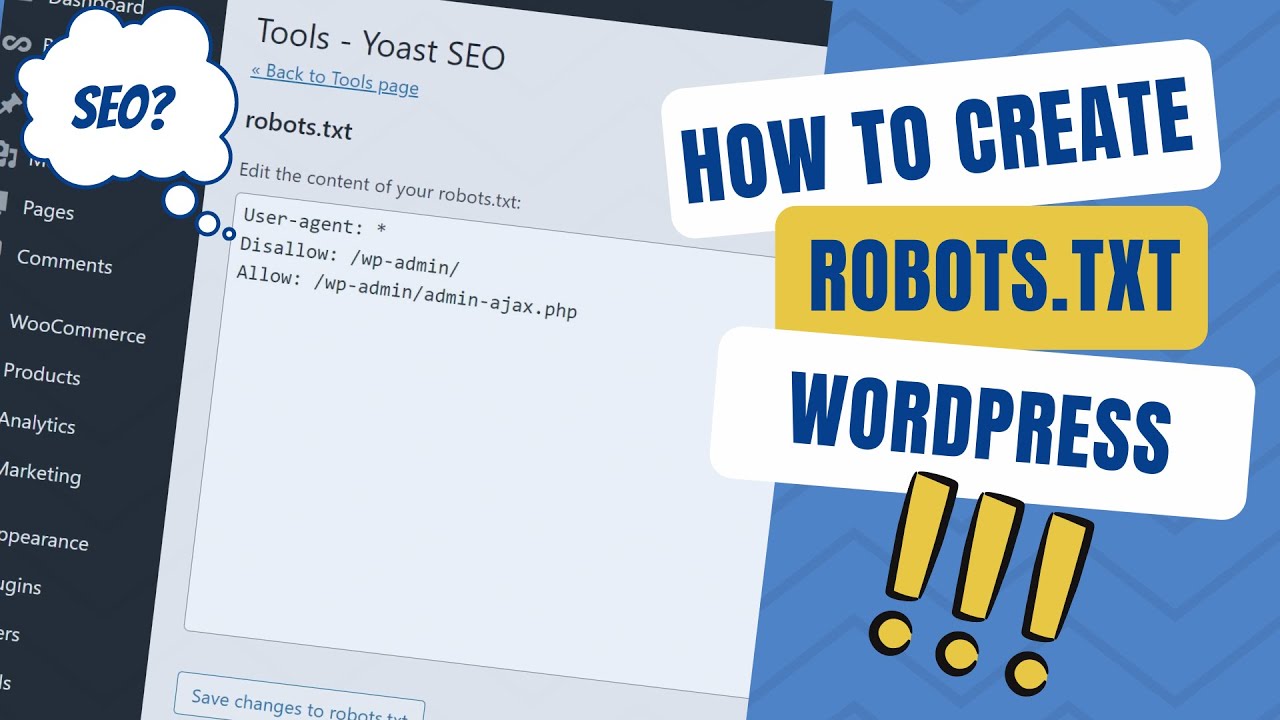
Что такое файл Robots.txt?
Robots.txt в WordPress — это обычный текстовый файл, который информирует роботов поисковых систем, какие страницы вашего сайта следует сканировать и индексировать. Вы также можете отформатировать файл, чтобы исключить страницы из индексации.
Файл robots.txt хранится в корневом каталоге WordPress. Этот файл имеет базовый формат, который выглядит следующим образом:
Агент пользователя: [имя пользователя] Disallow: [URL строки, которую нельзя сканировать] Разрешить: [URL строки для сканирования] Карта сайта: [URL вашей карты сайта WordPress XML]
Как выглядит файл robots.
 txt?
txt?Файл robots.txt — это всего лишь несколько строк текста, которые указывают поисковым системам, как и что сканировать на вашем сайте. У вас есть несколько строк в этом файле, чтобы разрешить или ограничить определенные URL-адреса страниц. Вы также можете добавить несколько файлов Sitemap. Если вы запретите URL-адрес, боты поисковых систем не будут сканировать эту страницу.
Вот пример файла robots.txt:
User-Agent: * Разрешить: /wp-content/uploads/ Запретить: /wp-content/plugins/ Карта сайта: https://URL/sitemap_index.xml
Теперь давайте узнаем об этих четырех основных терминах, которые вы можете найти в файле robots:
- User-agent : User-agent — это конкретный поисковый робот, к которому вы даете инструкцию обхода. Обычно это поисковая система.
- Разрешить : Разрешить — это команда, которая сообщает роботу Googlebot, что он может получить доступ к странице или вложенной папке, даже если ее вложенная папка или родительская страница могут быть запрещены.

- Disallow : Команда disallow указывает агенту пользователя не сканировать определенный URL-адрес. Вы можете включить только одну строку «Disallow:» для каждого URL-адреса.
- Карта сайта : Карта сайта используется для определения местоположения любых карт сайта в формате XML, связанных с этим URL-адресом. Эта команда поддерживается только Google, Bing, Ask и Yahoo.
В приведенном выше примере мы разрешили поисковым роботам сканировать и индексировать папку загрузок, но ограничили папку плагинов. В конце концов, мы разрешили индексацию XML-карты сайта.
Знак звездочки после User-Agent означает, что текст применим ко всем ботам поисковых систем. У каждой поисковой системы есть свой пользовательский агент для индексации сайтов. Вот некоторые пользовательские агенты некоторых популярных поисковых систем:
- Google: Googlebot
- Googlebot Images: Googlebot-Image
- Googlebot News: Googlebot-News
- Googlebot Video: Googlebot-Video
- Yahoo: Slurp Bot 900 69
- Bing: Bingbot
- Amazon Alexa: ia_archiver
- DuckDuckGo: DuckDuckBot
- Яндекс: YandexBot
- Baidu: Baiduspider
- Exalead: ExaBot
В настоящее время существует так много пользовательских агентов. Если вы хотите сосредоточиться на конкретной поисковой системе, вы даже можете указать ее в файле robots.txt. То есть, чтобы настроить инструкции для робота Googlebot, вы можете написать первую строку файла robots.txt следующим образом:
Если вы хотите сосредоточиться на конкретной поисковой системе, вы даже можете указать ее в файле robots.txt. То есть, чтобы настроить инструкции для робота Googlebot, вы можете написать первую строку файла robots.txt следующим образом:
User-agent: Googlebot
Зачем вам нужен файл robots.txt в WordPress?
Поисковые роботы будут сканировать и индексировать ваш сайт, даже если у вас нет файла robots.txt. Итак, зачем вам это действительно нужно? Что ж, с помощью файла robots.txt вы можете указать поисковым системам расставлять приоритеты при индексации определенных страниц. Кроме того, вы можете исключить страницы или папки, которые не хотите индексировать.
Это не оказывает большого влияния, когда вы впервые начинаете вести блог и у вас мало контента. Однако после того, как ваш сайт разрастется и на нем будет много контента, вам может потребоваться установить приоритет индексации определенной страницы/записи/папки и отменить некоторые из них.
Видите ли, для каждого поискового бота есть квота на каждый сайт. Это означает, что боты сканируют определенное количество страниц за определенный сеанс сканирования. Если боты не завершают сканирование в этом конкретном сеансе, бот возвращается и возобновляет сканирование в следующем сеансе. Это замедляет индексацию вашего сайта.
Таким образом, с помощью файла robots.txt вы можете указать поисковым роботам, какие страницы, файлы и папки вы хотите проиндексировать, а какие включить. Тем самым вы сохраняете квоту сканирования. Возможно, это не самый безопасный способ скрыть ваш контент от общественности, но он предотвращает появление исключенного контента в поисковой выдаче.
Как создать robots.txt для вашего сайта?
Вы можете создать файл robots.txt двумя разными способами. Мы объясним эти методы ниже. Затем вы можете следовать методу, который, по вашему мнению, будет работать лучше всего для вас.
Способ 1. Создание файла robots.txt с помощью плагина Rank Math
Здесь мы покажем вам, как создать файл robots. txt с помощью популярного плагина Rank Math.
txt с помощью популярного плагина Rank Math.
Rank Math — это SEO-плагин для WordPress, который упрощает оптимизацию контента вашего веб-сайта с помощью встроенных предложений, основанных на общепринятых передовых методах. С помощью этого удобного инструмента вы можете легко настроить важные параметры SEO и контролировать индексируемые страницы.
Чтобы создать файл robots.txt с помощью плагина Rank Math, сначала загрузите плагин, выбрав Плагины -> Добавить новый из панели администратора WordPress.
Теперь найдите Rank Math в строке поиска и нажмите кнопку Установить сейчас и Активировать после того, как найдете плагин.
После активации плагина перейдите на страницу Rank Math -> General Settings -> Edit robots.txt из панели управления WordPress.
Теперь введите следующий код или скопируйте код из предыдущего примера в пустое место и нажмите кнопку Сохранить изменения .
Ну вот! Вы успешно создали файл robots.txt с помощью подключаемого модуля Rank Math.
Способ 2. Создание файла robots.txt с использованием FTP
Второй метод заключается в создании файла robots.txt вручную на локальном компьютере, а затем его загрузке в корневую папку сайта WordPress.
Вам потребуется доступ к вашему хостингу WordPress с помощью FTP-клиента. После входа в FTP-клиент вы увидите файл robots.txt в корневой папке веб-сайта. Щелкните правой кнопкой мыши и выберите параметр Редактировать .
Теперь добавьте собственное правило в файл и сохраните изменения. Например:
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
Если вы не видите файл в корневой папке, вы можете создать его на локальном компьютере с помощью блокнота. Добавьте к нему свои правила, а затем загрузите его в корневую папку с помощью FTP.
Куда поместить файл robots.txt?
Файл robots. txt всегда следует размещать в корневом каталоге вашего веб-сайта. Например, если ваш сайт domainname.com , то домен вашего файла robots.txt будет https://domainname.com/robots.txt.
txt всегда следует размещать в корневом каталоге вашего веб-сайта. Например, если ваш сайт domainname.com , то домен вашего файла robots.txt будет https://domainname.com/robots.txt.
В дополнение к добавлению файла robots.txt в корневую директорию, вот несколько дополнительных советов:
- Файл должен называться robots.txt.
- Имя файла чувствительно к регистру. Таким образом, вам нужно сделать это правильно, иначе это не сработает.
- Для каждого нового правила необходимо добавлять новую строку.
- Добавьте знак «$» для обозначения конца URL-адреса.
- Используйте каждый пользовательский агент только один раз.
Как проверить файл robots.txt?
После создания файла robots.txt его можно протестировать с помощью Google Search Console. Здесь вы найдете инструмент для тестирования Open robot.txt.
- Выберите свою недвижимость из выпадающего списка.
Инструмент извлекает файл robots. txt вашего сайта и выделяет ошибки и предупреждения, если они обнаружены.
txt вашего сайта и выделяет ошибки и предупреждения, если они обнаружены.
Примечание : раскрывающийся список свойств отображается только в том случае, если вы связали свой сайт WordPress с Google Search Console.
Если вы этого не сделали, вы можете быстро связать свой сайт следующим образом:
- Войдите в Google Search Console и создайте учетную запись. Вы можете настроить свою учетную запись, используя префикс домена или URL. Рекомендуется использовать префикс URL, так как это сравнительно проще.
- Введите URL вашего веб-сайта.
- Теперь нажмите кнопку «Продолжить».
- Теперь вы должны подтвердить право собственности на сайт. Вы можете сделать это, используя любой из предложенных вариантов. Однако мы рекомендуем использовать опцию тега HTML.
- Скопируйте указанный код и перейдите на панель инструментов WordPress.
Теперь вы можете проверить код с помощью плагина Insert Headers and Footers. Чтобы проверить:
Чтобы проверить:
- Перейдите к Плагины -> Добавить новый из панели администратора WordPress.
- Теперь найдите плагин «Вставить верхние и нижние колонтитулы» в строке поиска, а затем «Установите и активируйте плагин».
- После этого перенаправьте на Настройки -> Верхний и нижний колонтитулы с панели инструментов WordPress, а затем вставьте скопированный код на вкладку Верхний и нижний колонтитулы. Когда вы закончите, нажмите кнопку Сохранить.
- Вернитесь на вкладку Google Search Console в браузере. Затем нажмите кнопку подтверждения.
- Google проверяет право собственности и отображает готовое сообщение, как только это будет сделано.
- Нажмите «Перейти к ресурсу», чтобы получить доступ к панели инструментов Google Search Console.
Теперь вернитесь к инструменту Open robot.txt tester и проверьте файл robots.txt, как указано выше.
Плюсы файла Robots.
 txt
txtВот преимущества использования файла Robots.txt в контексте SEO:
- Он помогает оптимизировать краулинговый бюджет поисковой системы, пропуская индексирование страниц, которые вам не нужны. боты ползают. Это создает для поисковой системы приоритет для сканирования только тех страниц, которые важны для вас.
- Это помогает оптимизировать веб-сервер, ограничивая ботов, которые без необходимости потребляют ресурсы.
- Помогает скрыть страницы входа, целевые страницы, страницы благодарности от индексации поисковыми системами. Таким образом, он оптимизирует работу сайта.
Минусы файла robots.txt
- Создать файл robots.txt довольно просто, как мы объяснили выше. Однако файл robots.txt также содержит URL-адреса ваших внутренних страниц, которые вы не хотите индексировать сканирующими ботами, например страницу входа. Это делает ваш сайт уязвимым для нарушений безопасности.
- Хотя создать файл robots.txt несложно, даже простая ошибка может свести на нет все ваши усилия.
 Например, если вы добавите или поместите не туда один символ в файле, это сведет на нет все ваши усилия по SEO.
Например, если вы добавите или поместите не туда один символ в файле, это сведет на нет все ваши усилия по SEO.
Часто задаваемые вопросы (FAQ)
Что такое веб-сканирование?
Поисковые системы рассылают по сети свои поисковые роботы (также известные как боты или пауки). Эти боты представляют собой интеллектуальное программное обеспечение, которое перемещается по всей сети в поисках новых страниц, ссылок и веб-сайтов. Этот процесс обнаружения известен как веб-сканирование.
Что такое индексация?
Когда поисковые роботы обнаруживают ваш веб-сайт, они упорядочивают ваши страницы в пригодную для использования структуру данных. Этот организационный процесс называется индексацией.
Что такое краулинговый бюджет?
Бюджет обхода — это ограничение на количество URL-адресов, которое поисковый робот может просканировать за данный сеанс. Каждый сайт имеет определенное распределение краулингового бюджета. Поэтому вам нужно убедиться, что вы тратите их наиболее полезным для вашего сайта способом.