Правильный robots txt для WordPress сайта – инструкция на 2019-2020 год без плагинов
Для чего нужен robots.txt
Robots.txt создан для регулирования поведения поисковых роботов на сайтах, а именно куда им заходить можно и брать в поиск, а куда нельзя. Лет 10 назад сила данного файла была велика, по его правилам работали все поисковые системы, но сейчас он скорее как рекомендация, чем правило.
Но пока не отменили, вебмастера должны делать его и настраивать правильно исходя из структуры и иерархии сайтов. Отдельная тема это WordPress, потому что CMS содержит множество элементов, которые не нужно сканировать и отдавать в индекс. Разберемся как правильно составить robots.txt
Где лежит файл robots в WordPress
На любом из ресурсов robots.txt должен лежать в корневой папке. В случае с вордпресс, там где находится папка wp-admin и ей подобные.
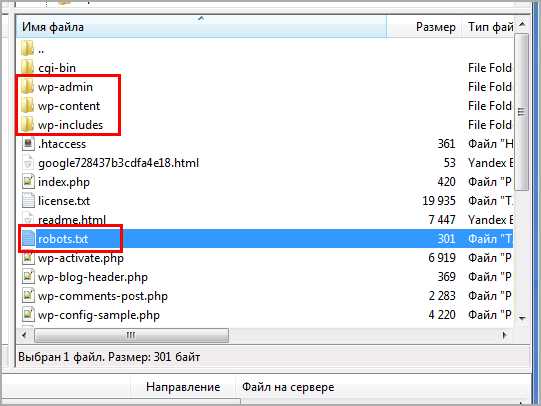 Расположение на сервере
Расположение на сервереЕсли не создавался и не загружался администратором сайта, то по умолчанию на сервере не найти. Стандартная сборка WordPress не предусматривает наличие такого объекта.
Как создать правильный robots txt
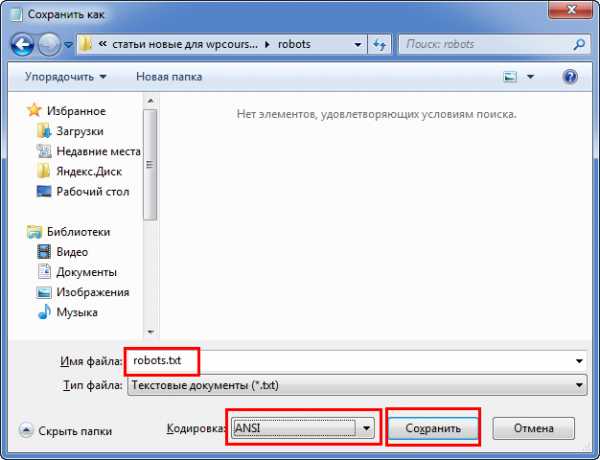
Создать правильный robots txt задача не трудная, сложнее прописать в нем правильные директивы. Сначала создадим документ, открываем программу блокнот и нажимаем сохранить как.
 Сохраняем документ
Сохраняем документВ следующем окне задаем название robots, оставляем расширение txt, кодировку ANSI и нажимаем сохранить. Объект появится в папке куда произошло сохранение. Пока документ пустой и ничего не содержит в себе, давайте разберемся какие именно директивы он может поддерживать.
При желании можете сразу скачать его на сервер в корень через программу FileZilla.
 Сохранение роботса
Сохранение роботсаНастройка команд
Выделю четыре основные команды:
- User-agent: показывает правила для разных поисковых роботов, либо для всех, либо для отдельных
- Disalow: запрещает доступ
- Allow: разрешаем доступ
- Sitemap: адрес до XML карты
Устаревшие и ненужные конфигурации:
- Host: указывает главное зеркало, стало не нужным, потому что поиск сам определит правильный вариант
- Crawl-delay: ограничивает время на пребывание робота на странице, сейчас сервера мощные и беспокоится о производительности не нужно
- Clean-param: ограничивает загрузку дублирующегося контента, прописать можно, но толку не будет, поисковик проиндексирует все, что есть на сайте и возьмет по–максимому страниц
Рабочий пример инструкций для WordPress
Дело в том что поисковой робот не любит запрещающие директивы, и все равно возьмет в оборот, что ему нужно. Запрет на индексацию должен быть объектов, которые 100% не должны быть в поиске и в базе Яндекса и Гугла. Данный рабочий пример кода помещаем в robots txt.
User-agent: *
Disallow: /wp-
Disallow: /tag/
Disallow: */trackback
Disallow: */page
Disallow: /author/*
Disallow: /template.html
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: *.js
Allow: *.css
Allow: *.png
Allow: *.gif
Allow: *.jpg
Sitemap: https://ваш домен/sitemap.xmlРазберемся с текстом и посмотрим что именно мы разрешили, а что запретили:
- User-agent, поставили знак *, тем самым сообщив что все поисковые машины должны подчиняться правилам
- Блок с Disallow запрещает к индексу все технические страницы и дубли. обратите внимание что я заблокировал папки начинающиеся на wp-
- Блок Allow разрешает сканировать скрипты, картинки и css файлы, это необходимо для правильного представления проекта в поиске иначе вы получите портянку без оформления
- Sitemap: показывает путь до XML карты сайта, обязательно нужно ее сделать, а так же заменить надпись»ваш домен»
Остальные директивы рекомендую не вносить, после сохранения и внесения правок, загружаем стандартный robots txt в корень WordPress. Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так.
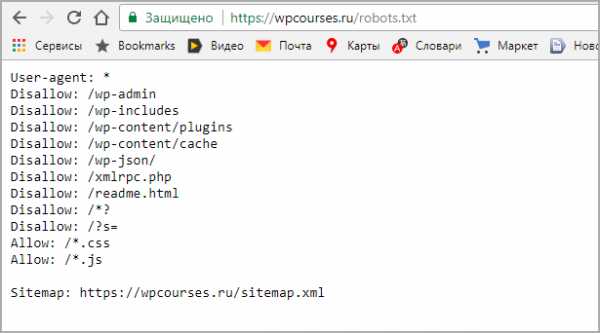 Адрес в строке запроса
Адрес в строке запросаКак проверить работу robots.txt
Стандартный способ проверить через сервис yandex webmaster. Для лучшего анализа нужно зарегистрировать и установить на сайт сервис. Вверху видим загрузившийся robots, нажимаем проверить.
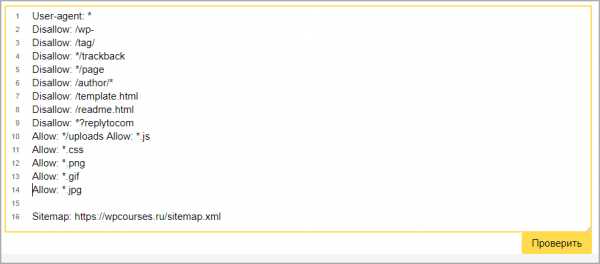 Проверка документа в yandex
Проверка документа в yandexНиже появится блок с ошибками, если их нет то переходим к следующему шагу, если неверно отображается команда, то исправляем и снова проверяем.
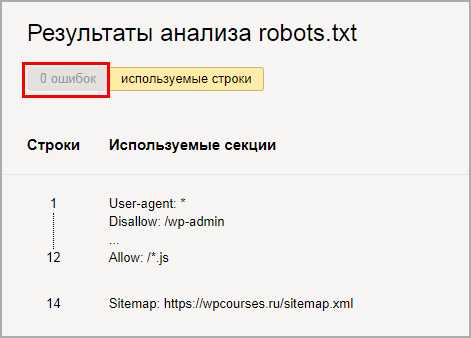 Отсутствие ошибок в валидаторе
Отсутствие ошибок в валидатореПроверим правильно ли Яндекс обрабатывает команды, спускаемся чуть ниже, введем два запрещенных и разрешенных адреса, не забываем нажать проверить. На снимке видим что инструкция сработала, красным помечено что вход запрещен, а зеленой галочкой, что индексирование записей разрешена.
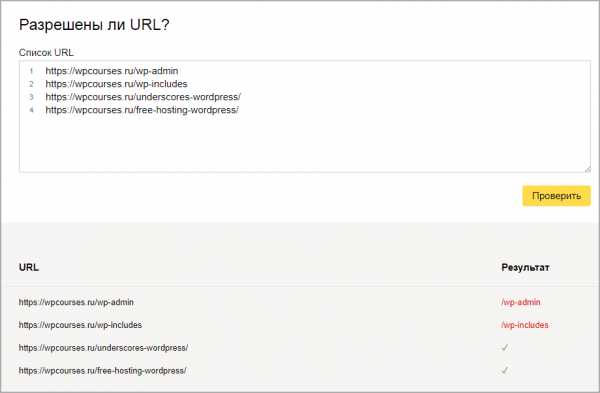 Проверка папок и страниц в яндексе
Проверка папок и страниц в яндексеПроверили, все срабатывает, перейдем к следующему способу это настройка robots с помощью плагинов. Если процесс не понятен, то смотрите наше видео.
Плагин–генератор Virtual Robots.txt
Если не хочется связываться с FTP подключением, то приходит на помощь один отличный WordPress плагин–генератор называется Virtual Robots.txt. Устанавливаем стандартно из админки вордпресс поиском или загрузкой архива, выглядит так.
 Как выглядит Virtual Robots.txt
Как выглядит Virtual Robots.txtПереходим в админку Настройки > Virtual Robots.txt, видим знакомую конфигурацию, но нам нужно ее заменить, на нашу из статьи. Копируем и вставляем, не забываем сохранять.
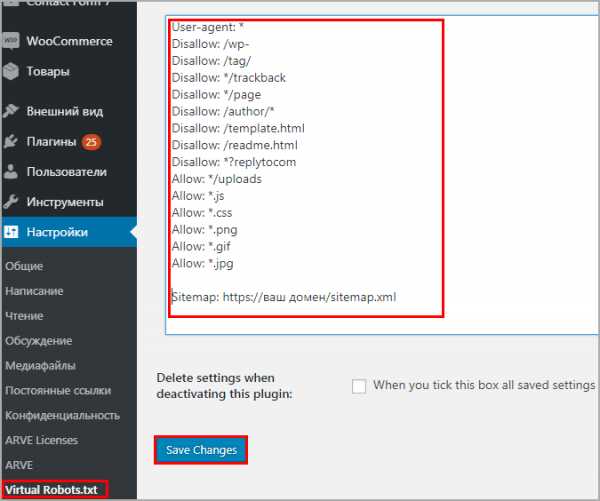 Настройка Virtual Robots.txt
Настройка Virtual Robots.txtРоботс автоматически создастся и станет доступен по тому же адресу. При желании проверить есть он в файлах WordPress – ничего не увидим, потому что документ виртуальный и редактировать можно только из плагина, но Yandex и Google он будет виден.
Добавить с помощью Yoast SEO
Знаменитый плагин Yoast SEO предоставляет возможность добавить и изменить robots.txt из панели WordPress. Причем созданный файл появляется на сервере (а не виртуально) и находится в корне сайта, то есть после удаления или деактивации роботс остается. Переходим в Инструменты > Редактор.
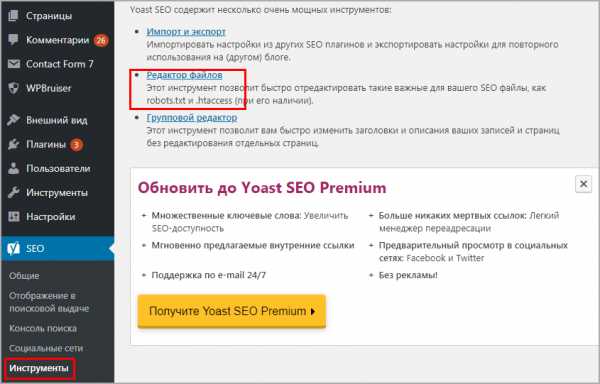 Yoast SEO редактор файлов
Yoast SEO редактор файловЕсли robots есть, то отобразится на странице, если нет есть кнопка «создать», нажимаем на нее.
Кнопка создания robotsВыйдет текстовая область, записываем, имеющийся текст из универсальной конфигурации и сохраняем. Можно проверить по FTP соединению документ появится.
Изменить модулем в All in One SEO
Старый плагин All in One SEO умеет изменять robots txt, чтобы активировать возможность переходим в раздел модули и находим одноименный пункт, нажимаем Activate.
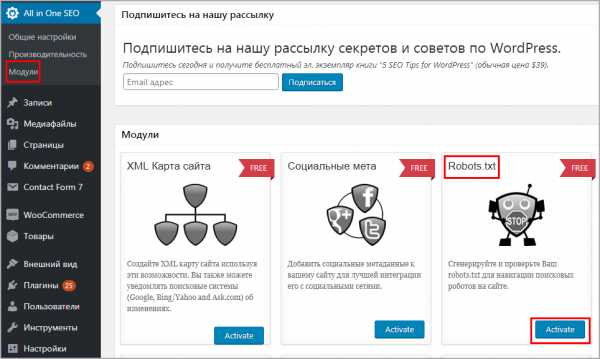 Модули в All In one Seo
Модули в All In one SeoВ меню All in One SEO появится новый раздел, заходим, видим функционал конструктора.
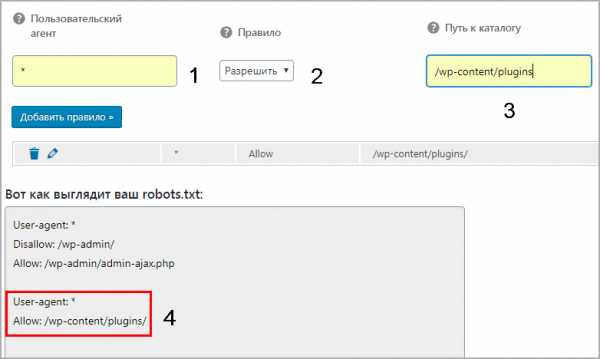 Работа в модуле AIOS
Работа в модуле AIOS- Записываем имя агента, в нашем случае * или оставляем пустым
- Разрешаем или запрещаем индексацию
- Директория или страница куда не нужно идти
- Результат
Модуль не удобный, создать по такому принципу валидный и корректный robots.txt трудно. Лучше используйте другие инструменты.
Правильная настройка для плагина WooCommerce
Чтобы сделать правильную настройку для плагина интернет магазина на WordPress WooCommerce, добавьте эти строки к остальным:
Disallow: /cart/
Disallow: /checkout/
Disallow: /*add-to-cart=*
Делаем аналогичные действия и загружаем на сервер через FTP или плагином.
Итог
Подведем итог что нужно сделать чтобы на сайте WordPress был корректный файл для поисковиков:
- Создаем вручную или с помощью плагина файл
- Записываем в него инструкции из статьи
- Загружаем на сервер
- Проверяем в валидаторе Yandex
- Не пользуйтесь генераторами robots txt в интернете, пошевелите немного руками
Совершенствуйте свои блоги на WordPress, продвигайтесь и правильно настраивайте все параметры, а мы в этом поможем, успехов!
wpcourses.ru
Правильный Robots.txt для WordPress (2019) — как сделать?
В интернете можно найти много публикаций на тему, как составить лучший (или даже самый лучший) файл robots.txt для WordPress. При этом в ряде таких популярных статей многие правила не объясняются и, как мне кажется, вряд ли понимаются самими авторами. Единственный обзор, который я нашел и который действительно заслуживает внимания, — это статья в блоге wp-kama. Однако и там я нашел не совсем корректные рекомендации. Понятно, что на каждом сайте будут свои нюансы при составлении файла robots.txt. Но существует ряд общих моментов для совершенно разных сайтов, которые можно взять за основу. Robots.txt, опубликованный в этой статье, можно будет просто копировать и вставлять на новый сайт и далее дорабатывать в соответствии со своими нюансами.
Более подробно о составлении robots.txt и значении всех его директив я писал здесь. Ниже я не буду подробно останавливаться на значении каждого правила. Ограничусь тем, что кратко прокомментирую что для чего необходимо.
Правильный Robots.txt для WordPress
Действительно самый лучший robots.txt, который я видел на данный момент, это роботс, предложенный в блоге wp-kama. Ряд директив и комментариев я возьму из его образца + внесу свои корректировки. Корректировки коснутся нескольких правил, почему так напишу ниже. Кроме того, напишем индивидуальные правила для всех роботов, для Яндекса и для Google.
Ниже привожу короткий и расширенный вариант. Короткий не включает отдельные блоки для Google и Яндекса. Расширенный уже менее актуален, т.к. теперь нет принципиальных особенностей между двумя крупными поисковиками: обеим системам нужно индексировать файлы скриптов и изображений, обе не поддерживают директиву Host. Тем не менее, если в этом мире снова что-то изменится, либо вам потребуется все-таки как-то по-отдельному управлять индексацией файлов на сайте Яндексом и Гугл, сохраню в этой статье и второй вариант.
Еще раз обращаю внимание, что это базовый файл robots.txt. В каждом конкретном случае нужно смотреть реальный сайт и по-необходимости вносить корректировки. Поручайте это дело опытным специалистам!
Короткий вариант (оптимальный)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ruРасширенный вариант (отдельные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ruВ примере я не добавляю правило Crawl-Delay, т.к. в большинстве случаев эта директива не нужна. Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает). Подробнее про это читайте в статье Robots.txt.
Ошибочные рекомендации других блогеров для Robots.txt на WordPress
- Использовать правила только для User-agent: *
Для многих поисковых систем не требуется индексация JS и CSS для улучшения ранжирования, кроме того, для менее значимых роботов вы можете настроить большее значение Crawl-Delay и снизить за их счет нагрузку на ваш сайт. - Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt - Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Однако подобные советы я находил даже в статье с пафосным названием «Самые правильный robots для WordPress 2018»! Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше. - Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика - Закрывать от индексации страницы пагинации /page/
Это делать не нужно. Для таких страниц настраивается тег rel=»canonical», таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса. - Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей. - Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например:Disallow: /20— по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше 🙂
Спорные рекомендации других блогеров для Robots.txt на WordPress
- Комментарии
Некоторые ребята советуют закрывать от индексирования комментарииDisallow: /commentsиDisallow: */comment-*. - Открыть папку uploads только для Googlebot-Image и YandexImages
User-agent: Googlebot-ImageСовет достаточно сомнительный, т.к. для ранжирования страницы необходима информация о том, какие изображения и файлы размещены на ней.
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Спасибо за ваше внимание! Если у вас возникнут вопросы или предложения, пишите в комментариях!
Оцените статью
Загрузка…Друзья, буду благодарен за ваши вопросы, дополнения и рекомендации по теме статьи. Пишите ниже в комментариях.
Буду благодарен, если поставите оценку статье.
seogio.ru
Правильный robots.txt для WordPress
О том, как сделать правильный robots.txt для WordPress написано уже достаточно. Однако, чтобы угодить своим читателям, я решил опубликовать свой пост на эту тему. Тем более, что моими коллегами эта тема раскрыта не полностью и тут можно многое добавить.

Что такое robots.txt и зачем он нужен?
robots.txt это текстовый документ, составленный в обыкновенном блокноте, расположенный в корневой директории блога и содержащий в себе инструкции по индексации для поисковых роботов. Проще говоря, что индексировать, а что нет. Наличие этого файла является обязательным условием для качественной внутренней поисковой оптимизации блога.
Как известно, блоги на платформе WordPress содержат в себе множество дублей (копий основного содержимого блога), а также целый набор служебных файлов. Дубли контента снижают его уникальность на домене и поисковые роботы могут наложить на блог серьезные штрафные санкции.
Чтобы повысить уникальность контента, облегчить поисковым ботам работу и тем самым улучшить качество индексации блога, нам и нужен robots.txt.

Правильный robots.txt для WordPress
Рассмотрим на примере моего robots.txt, как его правильно оформить и что в него должно входить.
Скачайте его себе на жесткий диск по этой ссылке и откройте для редактирования. В качестве редактора текстовых файлов настоятельно рекомендую использовать Notepad++.

Строки 6,7: Принято считать, что необходимо закрывать поисковым роботам доступ к служебным файлам в папках «wp-content» и «wp-includes». Но, Гугл по этому поводу нам говорит следующее:
Чтобы обеспечить правильное индексирование и отображение страниц, нужно предоставить роботу Googlebot доступ к JavaScript, CSS и графическим файлам на сайте. Робот Googlebot должен видеть ваш сайт как обычный пользователь. Если в файле robots.txt закрыт доступ к этим ресурсам, то Google не удастся правильно проанализировать и проиндексировать содержание. Это может ухудшить позиции вашего сайта в Поиске.
Таким образом, для Googlebot не рекомендуется запрещать доступ к файлам в этих папках.
Строка 40: С весны 2018 года директива «Host», указывающая главное зеркало сайта Яндексу, больше не действует. Главное зеркало для нашей поисковой системы теперь определяется только через 301 редирект.
Строки 42,43: Если у Вас еще не создана карта сайта, обязательно сделайте ее. В пути к файлам карты вместо моего адреса wordpress-book.ru пропишите свой. Этот ход сделает индексацию блога поисковиками полной и увеличит ее скорость.
Уже сейчас, можно сказать, что ваш правильный robots.txt для WordPress готов. В таком виде он подойдет для абсолютного большинства блогов и сайтов. Останется только закачать его в корень блога (обычно в папку public_html).

Сделать robots.txt для блога можно и с помощью плагина, например, PC Robots.txt. С его помощью вы сможете создать и редактировать свой robots.txt прямо в админке блога. Но я не советую использовать плагины для создания robots.txt, чтобы исключить лишнюю нагрузку на блог.
Содержание robots.txt любого блога или сайта, если он конечно есть, вы всегда можете посмотреть. Для этого достаточно в адресной строке браузера ввести к нему путь – https://wordpress-book.ru/robots.txt.
Ниже приведена информация по содержанию этого документа и некоторые рекомендации по его оформлению и анализу.
Звездочка «*», прописанная в тексте robots.txt, означает, что на ее месте допускается последовательность любых символов.
Директива «User-agent» определяет, для каких поисковых роботов даны указания по индексации, прописанные под ней. Таким образом, «User-agent: *» (строка 1) указывает, что инструкции, прописанные под ней, предназначены для всех поисковых систем.
Строка 21: Персонально для Яндекса под «User-agent: Yandex» дублируем список этих команд. Дублирование инструкций для Яндекса дает нам гарантию их выполнения поисковой системой.
Директива «Disallow» запрещает индексацию прописанного для нее каталога или страниц. Директива «Allow» разрешает. Командой «Disallow: /wp-content/» (строка 7) я запретил индексацию служебного каталога «wp-content» на сервере и соответственно всех папок в ней с их содержимым, но командой «Allow: /wp-content/uploads» (строка 8) разрешил индексировать все картинки в папке «upload» каталога «wp-content». Так как «Allow» является приоритетной директивой для поисковых роботов, то в индекс попадут только изображения папки «upload» каталога «wp-content».
Для директивы «Disallow» имеет смысл в некоторых случаях дополнительно прописывать следующие запреты:
- — /amp/ — дубли ускоренных мобильных страниц. На всякий случай для Яндекса.
- — /comments — закрыть от индексации комментарии. Зачем закрывать содержащийся в комментариях уникальный контент? Для большей релевантности ключевых слов и неиндексации исходящих ссылок в комментариях. Вряд ли это поможет.
- — /comment-page-* — другое дело древовидные комментарии. Когда комментарии не помещаются на одну страницу (их количество вы проставили в настройках админки), создается дубль страницы типа wordpress-book.ru/…/comment-page-1. Эти дубли конечно же надо закрывать.
- — /xmlrpc.php — служебный файл для удаленных вызовов. У меня его нет и соответственно нет индексации и без запрета.
- — /webstat/ — папка со статистикой сайта. Эта папка есть тоже далеко не у всех.
Нельзя не упомянуть про редко используемую, но очень полезную директиву для Яндекса — «Crawl-delay». Она задает роботу паузу во времени в секундах между скачиванием страниц, прописывается после групп директив «Disallow» и «Allow» и используется в случае повышенной нагрузки на сервер. Прописью «Crawl-delay: 2» я задал эту паузу в 2 секунды. При нормальной работе сервера качество индексации не пострадает, а при пиковых нагрузках не ухудшится.
Некоторым веб-мастерам может понадобится запретить индексацию файлов определенного типа, например, с расширением pdf. Для этого пропишите — «Disallow: *.pdf$». Или поместите все файлы, индексацию которых требуется запретить, в предварительно созданную новую папку, например, pdf, и пропишите «Disallow: /pdf/».
При необходимости запрета индексации всей рубрики, такое бывает ,например, при публикации в нее чужих интересных записей, пропишите — «Disallow: /nazvanie-rubriki/*», где «nazvanie-rubriki», как вы уже догадались — название рубрики, записи которой поисковикам индексировать не следует.
Тем, кто зарабатывает на своем блоге размещением контекстной рекламы в партнерстве с Google AdSense, будет нелишним прописать следующие две директивы:
User-agent: Mediapartners-Google
Disallow:
Это поможет роботу AdSense избежать ошибок сканирования страниц сайта и подбирать для них более релевантные объявления.
wp-content/uploads/2014/02/YouTube_Downloader_dlya_Ope.jpg»,tid: «OIP.M3a4a31010ee6a500049754479585407do0
Обнаружил у себя только что вот такой вот новый вид дублей в Яндекс Вебмастере. 96 штук уже накопилось и это не предел. А ведь совсем недавно у wordpress-book.ru с дублями был полный порядок. Есть подозрение, что шлак с идентификатором tid:»OIP появляется в индексе поисковика после скачивания картинок роботом Яндекса. Если не лень, посмотрите сколько таких несуществующих страниц разных сайтов уже участвуют в поиске.
Понятно, что с этим чудом надо что-то делать. Достаточно добавить запрещающую директиву — «Disallow: /wp-content/uploads/*.jpg*tid*» в robots.txt. Если на сайте есть картинки png, gif и т.д., добавьте директивы с соответствующими расширениями изображений.
При редактировании robots.txt, учтите, что:
— перед каждой новой директивой «User-agent» должна быть пустая строка, которая обозначает конец инструкций для предыдущего поисковика. И соответственно после «User-agent» и между «Disallow» и «Allow» пустых строк быть не должно;
— запретом индексации страниц в результатах поиска «Disallow: /*?*» вы заодно можете случайно запретить индексацию всего контента, если адреса страниц вашего блога заданы по умолчанию со знаком вопроса в виде — /?p=123. Советую сделать для адресов ЧПУ (человеко понятные урлы :-)). Для этого в настройках постоянных ссылок выберите произвольный шаблон и поставьте плагин Rus-to-Lat.
Анализ robots.txt
Теперь, когда ваш robots.txt отредактирован и залит на сервер, остается только проверить, правильно ли он работает.
Зайдите в свой аккаунт Яндекс Вебмастер и перейдите «Настройки индексирования» → «Анализ robots.txt». Нажмите на кнопку «Загрузить robots.txt с сайта» и далее на кнопку «Проверить».
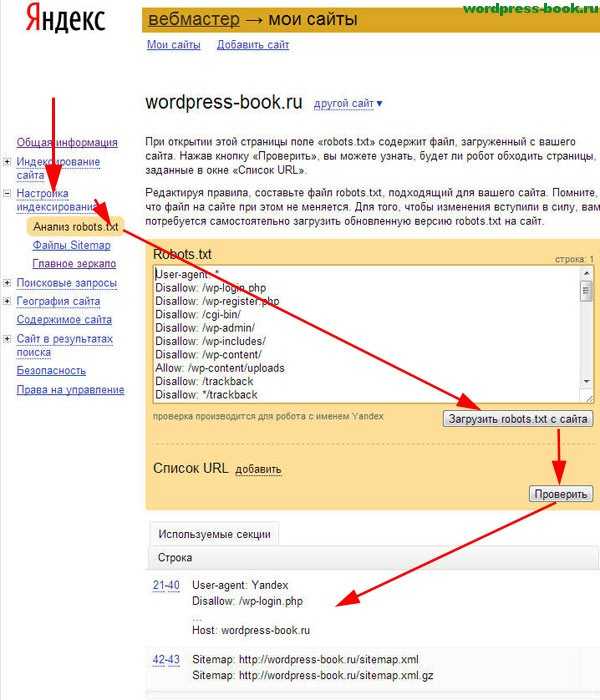
Если Яндексу понравится ваш файл, под кнопкой «Проверить» появится сообщение, примерно как на картинке выше.
Недавно в инструментах для веб-мастеров Гугла появилось очень полезная функция — «Инструмент проверки файла robots.txt«. Можно проверить свой файл на наличие ошибок и предупреждений.
Просто в своем аккаунте перейдите «Сканирование» → «Инструмент проверки файла robots.txt«.
Через некоторое время, когда бот Яндекса скачает ваш robots.txt, проанализируйте в Яндекс Вебмастере адреса страниц вошедших в индекс и исключенных из него в robots.txt. Вошедшие в индекс дубли срочно запрещайте к индексации.
Теперь ваш robots.txt для WordPress правильный и можно поставить еще одну галочку под пунктом выполнения задач по внутренней поисковой оптимизации блога.
robots.txt запретить индексацию всем
При создании тестового блога или при самом его рождении, если вы хотите полностью запретить индексацию сайта всеми поисковыми системами, в robots.txt должно быть прописано всего лишь следующее:
User-agent: *
Disallow: /
wordpress-book.ru
Правильный robots txt для WordPress (и не только)
Правильный robots txt для WordPress.
Содержание статьи
Приветствую, дорогие вебмастера! С помощью этой статьи, я хочу показать вам как правильно настроить файл robots.txt для конкретного сайта. Но, чтобы научиться его составлять, вам необходимо вдумчиво прочитать эту статью (возможно, не один раз). Только поняв, что вы будете делать, вы сможете настраивать этот файл для любого сайта. Будь то интернет-магазин, корпоративный сайт или блог, не важно.
Для тех, кто ищет готовый вариант (универсальный) для всех сайтов, я вас разочарую… Такого не существует! На каждом сайте есть свои собственные разделы, папки и файлы, о которых невозможно предугадать заранее. Так что, лучше научиться один раз и не мучить каждый раз поисковик.
Составлять правильный файл robots txt мы будем сразу и для Яндекс’а и для Google одновременно. Иначе, смысла особого вообще не вижу. Я считаю, продвигаться нужно сразу в обоих и глупо делать упор только на один. Алгоритмы меняются постоянно и то, что работало сегодня во благо, завтра может сработать против.
Псевдо – правильный файл robots
Итак, для начала давайте разберемся что нужно закрывать в этом самом файле, а что уже давно кануло в лету. Все примеры правильного роботса, которые вы сможете найти в интернете (или уже нашли), написаны зачастую для конкретного сайта и к вашему не имеет вообще никакого отношения.
Обычно, в файле роботс советуют закрывать страницу входа в админку wp-login.php, саму страницу админки wp-admin, да и вообще всю директорию wp. Так же закрывают стили и скрипты js и css, и конечно же не нужные для индексирования страницы и всё в этом духе…
Но возникает вопрос, а нужно ли? Ведь большинство директорий, которые нужно было закрывать в роботс.тхт раньше, теперь закрываются более разумным методом – тегом robots. Почему более разумный спросите вы? На этот вопрос поможет ответить представитель Google Джон Мюллер в этом видео (включите русские титры, видео начинается с нужного места):
Немного поясню. Джон предупредил, что если в robots txt закрыть какую-то страницу или директорию, но при этом на неё вдруг будет проставлена ссылка в интернете, то эта страница или директория будет проиндексирована не зависимо от правила файла роботс.
С каждым годом, файл robots txt становиться всё бесполезнее и бессмысленнее. И этот ответ, тому подтверждение. Закрытие в этом файле вас уже можно сказать не спасёт, ссылка может появиться тысячами способов как автоматических, так и ручных. Поэтому Мюллер рекомендует закрывать не нужные страницы не файлом роботс, а тегом robots. Что собственно и я советую вам научиться делать.
Бессмысленность файла роботс.
Проанализируйте сами, большинство директив в файле уже упразднили к 2019 году:
- Crawl-delay (таймаут для роботов) перестали учитывать.
- Host (главное зеркало) тоже упразднили.
- Закрывать js и css Гугл не рекомендует, вебмастер ругается.
- Директива wp- и другие технические страницы закрываются тегом.
- Собственно, всё. Закрывать больше нечего.
А судя по тому, что как минимум, поисковик Google может проиндексировать закрытые страницы в файле роботс (не удивлюсь что и Яндекс тоже), то смысла закрывать не нужные страницы таким образом уже нет.
Единственное, что осталось для файла robots, так это пользовательские папки и директории, на которые точно никто не будет ссылаться и нет возможности проставить тег robots. К ним относятся собственные папки и пользовательские файлы у которых нет собственных страниц (например файлы для скачивания).
Что касается get параметров, в Яндекс’е есть специальная директива Clean-param, но используют её единицы. В Google же вообще не упоминается об этой директиве, похоже поэтому она и не обрела популярности в глазах вебмастеров. Поэтому, если вы всё же решили закрыть страницы с get параметрами, то закрывайте обычным синтаксисом.
Синтаксис файла для поисковиков.
Ниже представлена официальная документация для наших двух поисковиков. В принципе, этого будет достаточно, потому что остальным поисковикам приходиться ровняться на этих двух гигантов.
- Синтаксис файла robots.txt Яндекс.
- Синтаксис файла robots.txt Google.
Но я считаю, это бессмысленная затея, закрывать генерируемые страницы с get параметрами. Я никогда не закрываю такие страницы и проблем не возникало. Так что, решайте сами, этот пункт абсолютно не критичен.
Правильная настройка robots txt.
Простое удаление портянки из файла проблему не решит конечно же. Перед этим, нужно настроить закрытие не нужных страниц тегом robots, а уже потом удалять всё ненужное из файла. В идеале, у вас должен получиться вот такой роботс /robots.txt. То есть, закрыты только пользовательские директории и файлы, которые не должны быть в индексе и на которые никто не будет ссылаться в принципе. Директиву Host можете оставить, а можете и удалить. Поисковики её уже не учитывают, поэтому не парьтесь. Я оставил, мне она не мешает.
Закрывать ли wp-admin, wp-login и т.д.?
Закрывать эти директории уже нет необходимости и вот почему. Все технические страницы WordPress перенаправляет для не авторизованных пользователей на страницу входа wp-login.php. А если открыть код этой страницы CTRL+U и проверить его, вы увидите тег проставленный ВП автоматически:
<meta name='robots' content='noindex,noarchive' />
То есть, движок уже закрыл эту страницу от индексации. И все остальные страницы тоже, так как не авторизованный пользователь на них не сможет попасть, в том числе и краулер поисковиков. Так что, директории wp-… можно смело удалять из файла robots txt. Идем дальше.
Закрывать ли от индексации js и css?
Как вы уже наверное знаете, поисковики очень много внимания уделяют мобильным (адаптивным) версиям сайта. И чтобы определить на сколько мобильна страница, краулеру необходимо проиндексировать файлы стилей и скриптов, чтобы понять это. Так вот, если вы будете закрывать стили css и скрипты js от индексации, большая вероятность что краулер посчитает ваш сайт убогим не адаптивным. Отсюда понижение выдачи, потеря посещаемости и все вытекающие.
Вот так должны воспринимать ваш сайт поисковики:
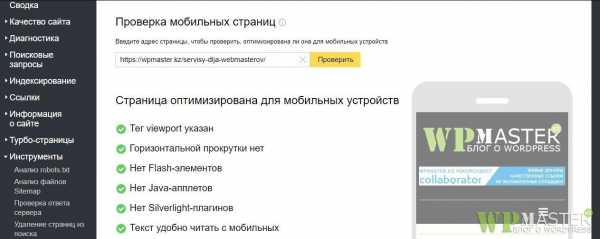 Адаптивность под мобильные Яндекс
Адаптивность под мобильные Яндекс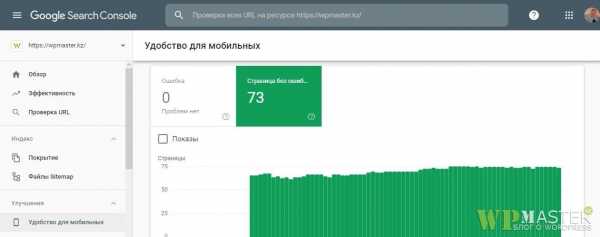 Адаптивность под мобильные Google
Адаптивность под мобильные GoogleКонечно же, не стоит забывать о самой мобильности. Если сайт не адаптирован, открытие или закрытие тут явно не поможет избавиться от ошибок в вебмастерах. Исходя из выше описанного, закрытие стилей и скриптов в файле robots txt не желательное занятие. Удаляйте эти директивы и забудьте о них. Едем дальше.
Закрывать ли wp-json, author, embed, page и т.д.?
Все эти технические страницы закрываются с помощью тега роботс. Отлично с этим справляется плагин Yoast SEO, рекомендую ознакомиться с обзором. В нем можно будет закрыть все не нужные архивы и метки в автоматическом режиме.
Что касается embed, pingback и подобных приблуд, с этим отлично справляются плагины Clearfy Webcraftic или Wpshop. Там вы сможете отключить не нужные директории сайта программно и закрывать их дополнительно ещё где либо не потребуется.
И наконец, что касается страниц пагинации page. Закрывать от индексации их даже тегом роботс не рекомендуется. Для таких страниц отлично подходит тег rel=»canonical», подробнее про него я писал ранее.
Разбор примера популярного роботса для ВП.
Вижу что многим читателям трудно воспринять теорию без практики, поэтому дополняю статью конкретным примером. Возьмём популярный вариант robots и разберём его по полочкам. Итак, вот он сам файл:
User-agent: * Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: */comments Disallow: /category/*/* Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /feed/ Disallow: /*?* Disallow: /?s= User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /feed/ Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */comments Disallow: /category/*/* Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /?s= Host: https://kakoytosite.ru Sitemap: https://kakoytosite.ru/sitemap.xml
Что мы видим? Первое что бросается в глаза, это дублирование условий для всех роботов user-agent: * и отдельно зачем-то для Яндекса user-agent: Yandex. Хочется сразу же спросить у автора – Вы действительно думаете что робот Яндекса тупой и не поймёт общие правила со звёздочкой?
(это конечно же риторический вопрос).
Ну что ж, а теперь по порядку:
Disallow: /wp-login.php Disallow: /wp-register.php
Если вы читаете эту статью не из прошлого, то на борту у вас минимум должна быть версия WordPress 5.x.x не меньше. Так вот, страницы входа wp-login.php и wp-register.php по умолчанию наделены специальным тегом robots – nofollow. То есть, ВордПресс уже сам закрыл эти страницы от индексации и вам не нужно их больше нигде закрывать.
Disallow: /cgi-bin
Директория сервера это классика, только не понятно откуда она взялась. Эта директория изначально отдает 403 ошибку сервиса при переходе, поэтому она никак не может быть проиндексирована поисковиками. Стало быть, этот пункт из файла можно так же смело удалить.
Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes
Первые две директории wp-admin и wp-includes являются техническими. То есть, к ним нет доступа не авторизованным пользователям. В том числе и пауку (краулеру) не удастся попасть на эти страницы. Он будет автоматически перенаправлен на страницу входа wp-login.php которая уже закрыта тегом роботс от индексации.
Директории /wp-content/… отвечают за файлы ваших тем и плагинов, в том числе и за файлы js и css. Если закрывать эти файлы от индексации, то Google не сможет прочитать их и в вебмастере вы увидите ошибки, что сайт не адаптирован. Хотя он может быть полностью мобильным.
Disallow: */comments Disallow: /category/*/*
Скорее всего, это пользовательские директивы, которые были прописаны под конкретный сайт (как я и говорил в начале) и никаким боком к вашему не относятся. Но все просто копируют готовый и даже не думают, что они делают.
Disallow: /trackback Disallow: */trackback Disallow: */*/trackback
Это одна из приблуд движка WordPress. С помощью неё движок посылает уведомления на сайты, ссылки на которые у вас будут в статьях. Отключается это штатными средствами. В админке перейдите по пути Настройки > Обсуждение и уберите галочки на первых двух (верхних) пунктах.
Disallow: */*/feed/*/ Disallow: */feed Disallow: /feed/
Вообще не понимаю, зачем закрывать фиды от индексации? Поисковик фиды не индексирует и не выводит в выдаче. Вы хоть раз видели в поиске страницу фидов?
Это один из бесполезных сео-маразмов. Удаляйте эти бессмысленные правила.Disallow: /*?* Disallow: /?s=
Эти директории отвечают за страницы с get параметрами и за страницу поиска по сайту. Здесь уже решать вам, нужны ли они в индексе или нет. Я никогда их не закрываю и бед не знаю.
Что же закрывать в robots txt.
Исходя из выше написанного, остается закрывать только пользовательские папки и файлы, которые не относятся на прямую к самому сайту WordPress. То есть, ни папки темы, ни плагинов, а собственные, со сторонними файлами (например для скачивания и т.д.).
Закрывать картинки от индексирования – считаю маразмом. Это относиться к тому случаю, когда вы начитавшись, что не уникальные картинки портят репутацию, решаете их закрыть. Это бред собачий, но это личное ИМХО.
А вот различные рекламные баннеры и файлы для скачивания, можно поместить в отдельную пользовательскую папку (или в несколько) и закрыть эту папку от индексации в файле роботс. Собственно так я и поступил с папкой files в моём роботсе.
Заключение.
Как видите, файл robots txt потерял свою актуальность к 2019 году (по крайней мере в мире WordPress). Закрывать практически нечего, поэтому данный файл обречен пустовать и мозолить всем вебмастерам глаз. Надеюсь я был убедителен, если есть что сказать, прошу в комментарии. На этом блоге свобода слова, так что высказывайтесь на здоровье. На этом у меня всё, увидимся на страницах wpmaster.kz!
wpmaster.kz
Самый правильный файл robots.txt для wordpress!
Автор: Александр Борисов
/ Дата: 2010-11-22 в 18:13

Здравствуйте друзья! WordPress robots.txt — файл ограничения доступа к содержимому на вашем блоге, сайте и т.д. Более подробно об этом вы можете прочитать здесь — ссылка
Этот файл необходимо создать в корне вашего сайта и прописать в нем некоторые строки. Так как я работаю на движке wordpress я буду писать именно о файле robots.txt для wordpress.
Итак. Если у вас еще нет этого файла на вашем блоге, то создайте его и поместите его в корень вашего блога на сервере.
Когда поисковый робот заходит на ваш блог, он сразу же ищет этот файл, потому что именно он указывает что индексировать на блоге можно, а что нельзя.
Так же он указывает на наличие sitemap.xml на сервере, если у вас нет и sitemap.xml, то это говорит о том, что вы еще новичок в блоговедении и вам следует почитать вот этот пост.
На блоге wordpress имеется куча папок которые не нужно индексировать поисковикам, поэтому можно сделать так, чтобы поисковик не тратил на них время а индексировал, только самое необходимое. Вы можете подумать, — «Ну и что, не мое же время».
А это очень важный момент, так как робот может устать индексировать всякую хрень и пропустить некоторые важные страницы вашего блога, так что советую придать файлу robots.txt особое внимание.
Как сделать файл robots.txt? Очень просто. Создайте у себя на рабочем столе текстовый файл robots.txt откройте его и пропишите следующее:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/Вместо site.ru — укажите адрес вашего блога. Готово!
Не бойтесь, здесь все составлено четко, ваши посты в безопасности =))) Сами разработчики wordpress рекомендуют такой файл wordpress robots.txt. Ну вот и вы теперь знаете как составить правильный wordpress robots.txt! Успехов!!!
P.S. Как вам статья? Советую получать свежие статьи на e-mail, чтобы не пропустить информацию о новых бесплатных видеокурсах и конкурсах блога!
C уважением, Александр Борисов

isif-life.ru
Правильный robots.txt для WordPress сайта
(Последнее обновление: 31.05.2019)Привет всем! Сегодня тема очень важная это — robots.txt для сайта WordPress. Поисковые роботы заходя на сайт или блог первым делом ищут файл robots.txt. Что такое robots.txt? Robots.txt — служебный файл, который находится в корневом каталоге сайта и содержит набор директив, позволяющих управлять индексацией сайта. Он позволяет указывать поисковым системам, какие страницы сайта или файлы должны присутствовать в поиске, а какие — нет. Когда краулер приходит на хостинг, файл robots.txt является одним из первых документов, к которому он обращается.

Создание robots.txt для сайта WordPress
Как создать файл robots.txt для WordPress
Robots.txt в большинстве случаев используется для исключения дубликатов, служебных страниц, удаленных страниц и других ненужных страниц из индекса поисковых систем. Кроме того, именно через robots.txt можно указать ПС адрес карты сайта.
Воспользуйтесь любым текстовым редактором (например, блокнотом), создайте файл с именем robots.txt и заполните его как показано ниже. Файл должен называться robots.txt, а не так — Robots.txt или ROBOTS.TXT.
После этого необходимо загрузить файл в корневой каталог вашего сайта.
Файл robots.txt должен располагаться строго в корне сайта и он должен быть единственным.
Оптимальный, правильный robots.txt для сайта WordPress. Общий для Google и Яндекс . Такой robots.txt у меня стоит на всех сайтах:
User-agent: * Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /core/ Disallow: */feed Disallow: *?s= Disallow: *&s= Disallow: /search Disallow: */embed Disallow: *?attachment_id= Disallow: /id_date Disallow: */page/ Disallow: *?stats_author Disallow: *?all_comments Disallow: *?post_type=func Disallow: /filecode Disallow: /profile Disallow: /qtag/ Disallow: /articles/ Disallow: /artictag/ Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /*ajax Sitemap: http://example.com/sitemap.xml
Стандартный robots.txt WordPress
Раздельный для Google и Yandex :
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-json/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */embed Disallow: */page/ Disallow: /cgi-bin Disallow: *?s= Allow: /wp-admin/admin-ajax.php Host: site.ru User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-json/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */embed Disallow: */page/ Disallow: /cgi-bin Disallow: *?s= Allow: /wp-admin/admin-ajax.php Sitemap: http://сайт.ру/sitemap.xml
Замените сайт.ру на ваш URL адрес блога. Смело можете скормить данным файлом поисковые системы Яндекс и Google.
Как настроить индивидуально важный файл robots.txt можно прочитав эти справки:
На странице помощи Яндекса. Проверить правильность составления файла можно в webmaster.yandex — Настройка индексирования — Анализ robots.txt. Далее, в Google robots.txt можно проверить по этой ссылке. Не забудьте что проверяемый блог должен быть добавлен в Инструменты для веб-мастеров Google и Яндекс.
Обратите внимание, что для Яндекса и Google правила составления robots.txt немного различаются. Вот ещё полезный ресурс для изучения robotstxt.org.ru. Вот и всё.
Теперь остаётся загрузить созданный файл в корневой каталог вашего блога. Корень блога это — папка public_html, где находятся файл config.php, index.php и так далее.
В заключение
Создание и тщательная подготовка robots.txt крайне важны. При его отсутствии поисковые роботы собирают всю информацию, относящуюся к сайту. В поиске могут появиться незаполненные страницы, служебная информация или тестовая версия сайта.
Вот на этом позвольте с вами не надолго попрощаться. Удачи. До новых встреч на страницах блога.
Поделиться в социальных сетях
wordpressmania.ru
Правильный robots.txt для WordPress в 2019 году
Несмотря на громкий заголовок, мой robots.txt не «Священный Грааль», но при этом все его директивы отражают суть движка WordPress и принцип работы основных поисковиков. Пример моего roborts.txt, который я приведу в этой статье, взят не из головы, а выстрадан в прямом смысле. Мне пришлось пройти через многие проблемы, которые всегда приводило к падению трафика из-за недоступности полезных ресурсов или наоборот, доступности некачественных страниц, в результате чего я пришел к этой версии robots.txt.
Что такое robots.txt и какая от него польза
Все мы знаем что roborts.txt нужен для SEO, но в чем именно заключается его работа и благодаря чему он улучшает качество сайта, знают немногие. Именно непонимание природы roborts.txt и его логики ведет к серьезным ошибкам результат которых неправильное индексирование сайта поисковиками.
Какие задачи решает roborts.txt? Да по большому счету задач немного, их по сути две:
- Сокрытие от поисковиков малоинформативных страниц.
- Экономия краулингового бюджета.
Задачи две, но решаются они одним действием. Закрывая от поисковиков некачественные страницы, мы автоматически экономим краулинговый бюджет. Для чего необходима экономить краулинговый бюджет? Ответ довольно прост, для оперативного индексирования новых страниц на вашем сайте. Давайте рассмотрим это на простом примере:
Как-то мне в руки попался интернет-магазин, у которого было около 800 товаров и несколько десятков статей в блоге плюс кучка технических страниц. В общей сложности полезных страниц на сайте было чуть больше 1000. Предположим вы решили внести изменения на некоторые страницы, несколько товаров удалили, а несколько добавили. Допустим у вас получилось 1043 страницы. Давайте посчитаем сколько времени понадобится роботу того же Яндекса чтобы обойти весь сайт и найти измененные страницы, узнать об удаленных и добавить в индекс новые. При максимальной скорости обхода (30 запросов в секунду) Яндексу потребуется всего 34,8 сек для обхода сайта, а при минимальной (0,6 запроса в секунду) уже 29 минут. Но проблема этого интернет-магазина была в том, что у него был неправильно заполненный robots.txt и в индексе было свыше 7000 страниц при свыше 4 млн загруженных. То есть чтобы выискать нормальные страницы на сайте, ботам поисковиков нужно было обойти свыше 4 миллионов страниц. По времени это займет:
- 37 часов на максимальной скорости обхода
- 77,1 суток, то есть больше двух месяцев
Само собой максимальную скорость обхода сможет выдержать далеко не каждый сайт и само собой поисковики стараются использовать низкую скорость обхода. В итоге любое изменение на сайте замечалось поисковиками через продолжительное время, а обилие страниц низкого качества в поиске, ухудшало и качество сайта. Только одной директивой «Disallow: *?*» я закрыл доступ к нескольким миллионам страниц. Спросите откуда миллионы страниц? Из-за фильтров интернет-магазина, движок самописный и не очень грамотный в техническом плане.
Таким образом robots.txt – это инструмент управления индексацией сайта. Настроили грамотно – новые странички будут оперативно залетать в индекс, а отредактированные быстро переиндексироваться. Если напихали директив от балды – прощай позиции, трафик и оперативное обновление индекса.
Почему стандартный robots.txt бесполезен
У WordPress нет стандартного robots.txt, но его создает в частности плагин YoastSEO (за другие не знаю). В этом, автоматически созданном, robots.txt имеется всего две директивы для всех роботов:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Удивительно что создатели плагина для SEO-оптимизации не смогли подготовить универсальный robots.txt. Я не понимаю зачем закрывать от индексации эти две директории, если там нечего индексировать. И многие владельцы сайтов почему-то втыкают «Disallow: /wp-admin» без малейшей попытки пораскинуть мозгами и понять что админка редиректит на страницу авторизации если ты не авторизован и индексировать там нечего. Также и «wp-includes» бессмысленно закрывать, поисковики там ничего не найдут полезного для себя поскольку нечего там индексировать.
Наша с вами задача не описать в robots.txt куда можно, а куда нельзя поисковику используя директивы «disallow» и «allow» налево и направо, а исключить из индекса страницы, которых там быть не должно. Для этого вам самим кроме копипаста придется ещё и информацию из кабинетов для веб-мастеров поизучать на предмет ненужных страниц в индексе поисковиков.
Я вам дам совет исходя из своего опыта на базе моего сайта, по-этому скопировав мой пример, дополните его своими директивами, наверняка у вас есть на сайте не совсем стандартные для WrdPress страницы, которые поисковикам нет смысла индексировать.
Кто стучится в дверь ко мне
Прежде чем нафаршировать свой robots.txt директивами, давайте сначала разберемся с тем, кто вообще ползает по нашему сайту. На самом деле роботов, кои топчутся по нашим с вами сайтам, превеликое множество. Среди них есть несколько известных, а ещё больше неизвестных, которым плевать на robots.txt. Давайте разберемся что это за роботы и как с ними быть.
Роботы Яндекса
Обратите внимание на то, что многие вебмастеры добавляют в robots.txt для Яндекса user-agent: Yandex, но мало кто понимает разницу между Yandex и YandexBot, а разница весьма существенна.
User-agent: YandexBot # будет использоваться только основным индексирующим роботом
User-agent: Yandex # будет использована всеми роботами Яндекса
Какие вообще бывают боты у Яндекса? Их множество, вот некоторые из них:
- YandexBot — основной индексирующий робот.
- YandexImages — индексатор Яндекс.Картинок.
- YandexMedia — робот, индексирующий мультимедийные данные.
- YandexPagechecker — валидатор микроразметки.
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы, особым образом интерпретирует robots.txt.
Полный список роботов Яндекса смотрите на этой странице.
Роботы Google
- Googlebot – основной индексирующий робот
- Googlebot-Image – робот индексирующий изображения.
- Mediapartners-Google – робот отвечающий за размещение рекламы на сайте. Важен для тех, у кого крутится реклама от AdSense. Благодаря этому user-agent вы можете управлять размещение рекламы запрещая или разрешая её на тех или иных страницах.
Полный список роботов Google смотрите на этой странице.
Робот Twitter
Полезный робот, который ходит на наш сайт за расширенной информацией когда кто-либо в твиттере делится ссылкой на наш сайт. Чтобы вместо ссылки появлялся красивый пост, то надо явно в robots.txt разрешить доступ к сайту роботу твиттера.
Директивы robots.txt, параметры и логика работы
Несмотря на свою простоту и элементарность, даже у опытных сеошников порой возникают трудности с составлением параметров для директив. Что там говорить, я сам не исключение и иногда допускаю ошибки при закрытии URL от индексации и потом приходится разгребать последствия.
В нашем распоряжении по сути несколько директив
User-Agent
С этой директивы начинается блок правил, а её значение указывает на то, для какого поисковика предназначается данный набор правил. Например, значение «YandexBot» обозначает что этот блок предназначен исключительно для основного Яндекс бота, а значение директивы «*» говорит что этот блок для всех роботов.
Причем необходимо понимать логику интерпретации директивы «User-agent» ботами Яндекса, если в файле robots.txt присутствует две директивы «User-agent: *» и «User-agent: Yandex», то блок директив после «User-agent: *» будет проигнорирован ботами Яндекса. По этой причине для основного бота Яндекса я выделяю отдельный блок, второй для всех остальных. Почему именно так, вы поймете ниже, когда я объясню назначение директив.
Disallow и Allow
Собственно основные директивы файла robots.txt. Данные директивы запрещают или разрешают поисковикам индексировать страницу или раздел указанный в значении данной директивы. В качестве параметра этим директивам мы передаем часть URL страниц, которые необходимо запретить индексировать или разрешить к индексации.
Иногда меня спрашивают зачем нужна Allow? Логика вопрошающего очевидна, если с помощью Disallow мы запретили некоторые вещи, то получается все остальное доступно, а значит не запрещено. Но давайте рассмотрим простой пример:
- Disallow: *?* – запретит к индексации все страницы ссылки на которые содержат «?».
Каковы последствия работы такой директивы? Последствия такой директивы вот такие:

Спросите в чем связь? Ответ не очевиден, но он прост. Вышеуказанной директивой мы запрещаем роботам загружать файлы стилей, ссылка на которые содержит «?ver=5.1.1». А стили темы оформления отвечают за адаптивность дизайна, которая как раз и определяет оптимизацию сайта под мобильные устройства. Тут нас как раз спасает директива Allow:
Таким образом мы вернем доступ роботам к файлам стилей и наш сайт станет снова оптимизированным под мобильные устройства.
Знак «*» заменяет нам один или несколько символов, но его использование не всегда очевидно. Давайте поиграемся с примерами.
Данная директива запретит к индексации все страницы, ссылки которых начинаются с /news. Например:
- /news/hello-world
- /news/finance
- /news/auto
А вот ссылки такого плана:
Такая директива уже не закроет. А что будет, если мы добавим вот такую директиву:
Тогда мы запретим доступ роботам ко всем ссылкам, коиторые имеют в себе вхождение «news». Например:
- /news/hwllo-world
- /its-fake-news
Как видите с директивами нужно быть крайне осторожным в их формулировке.
Также стоит особо отметить один немаловажный нюанс – это порядок обработки директив. Да, да, вне зависимости от того, как вы их расположите в файле robots.txt, они будут отсортированы и применены в порядке возрастания. То есть первыми будут применены короткие,, а самые длинные последними.
Является ли это важным? Весьма. Чем длиньше параметр директивы, тем больше её приоритет. Допустим у нас с вами в robots.txt есть несколько директив, выстроим их в порядок возрастания и посмотрим на логику робота:
- Disallow: /
- Allow: /news
- Allow: /catalog
Таким образом получается так, первым делом робот видит что первая директива запрещает ему индексировать весь сайт, но вторая и третья открывают ему раздели новостей и каталог. Таким образом мы можем сначала запретить весь сайт, а потом открывать только те части, которые необходимо индексировать. Обычно при составлении директив robots.txt мы руководствуемся другой логикой, поскольку обычно запрещаем те вещи, на которые ругается Яндекс или Google.
Одинм из важных моментов является наличие кириллицы в URL, который мы хотим запретить или открыть. Поскольку я категорически не приемлю кириллицу в URL, я не сталкивался с проблемами связанными с кириллицей, но некоторые сайты в принципе не парятся по этому поводу. Допустим на сайте надо скрыть страницу, доступную по ссылке «/каталог»:
- Disallow: /каталог – не правильно.
- Disallow: /%D0%BA%D0%B0%D1%82%D0%B0%D0%BB%D0%BE%D0%B3 – правильно.
Host
Устаревшая директива, которая указывала ботам Яндекса, какое зеркало делать основным. Вот что Яндекс говорит по поводу этой директивы:
Как мы писали ранее, мы отказываемся от директивы Host. Теперь эту директиву можно удалять из robots.txt, но важно, чтобы на всех не главных зеркалах вашего сайта теперь стоял 301-й постраничный редирект. Вебмастерам, которые, по нашим данным, ещё не установили перенаправление, мы отправили соответствующее уведомление.
Источник
Sitemap
Соответственно эта директива указывает путь к файлу sitemap. Эта директива является межсекционной, то есть её достаточно указать всего лишь один раз. Обычено она указывается в самом конце файла robots.txt. Добавление директивы Sitemap в каждую секцию «User-agent» является ошибкой.
Где взять sitemap? За генерацию этой штуки отвечает SEO-плагин, в моем случае это Yoast SEO. Содержимое этого файла зависит от настроек отображения в поисковой выдаче, которые располагаются в одноименном разделе плагина.
Crawl-delay
Указывает поисковому роботу промежуток времени в секундах, который должен пройти с момента окончания загрузки одной страницы и началом загрузки другой. Значением директивы может быть любое число как целое, так и дробное.
На текущий момент по сути бесполезная директива, поскольку роботы Google и Яндекс не отказались от учета директивы Crawl-delay. Таймаут роботам можно указать в панели вебмастера.
Clean-param
Если на Вашем сайте используются параметры, которые не влияют на отображение страницы, то в значении этой директивы Вы можете указать эти параметры. Допустим у Вас на сайте есть каталог, в котором пользователю доступны некоторые возможности, такие как сортировка, допустим ссылка выглядит так:
- http://site.ru/catalog.php?sort_by=price&sort=desc
Что бы указать роботу на параметры, которые необходимо исключить, то нам потребуется указать директиву с соответствующими параметрами:
- Clean-param: sort_by /catalog.php # если необходимо исключить только sort_by
- Clean-param: sort_by&sort /catalog.php # если необходимо исключить sort_by и sort
Лично я не пользуюсь подобной директивой, поскольку её логика работы не очевидна. На мой взгляд проще всего страницы с параметрами проще закрыть директивой «Disallow», тем самым явно сэкономив краулинговый бюджет.
Что нужно закрыть от индексации в WordPress
Предлагаю не просто скопировать готовый robots.txt, а попытаемся понять, почему мы закрыли от индексации именно эти страницы.
- Disallow: /cgi-bin – по сути такая же бесполезная директива как и «Disallow: /wp-admin», но до тех пор, пока не начнете работать с Cloudflare, например ради халявного SSL, тогда на сайте появляется куча ссылок, которые начинаются с «/cgi-bin».
- Disallow: /xmlrpc.php – закрываем из-за пустой страницы при обращении к этому файлу.
- Disallow: /author – с точки зрения поиска, это бесполезная страница.
- Disallow: /wp-json – закрываем ибо возвращает пустую страницу.
- Disallow: /wp-login.php – закрываем ибо эта страница является малоинформативной и не несет в себе смысловой нагрузки выполняя чисто техническую роль.
- Disallow: */feed* – RSS-лента, очевидно не несет в себе пользы для поисковиков.
- Disallow: /wp-content/uploads – закрываем именно эту папку, поскольку она может содержать разного рода документы, например, PDF, DOC и т.д., которые не стоит пускать в индекс. Закрывать «wp-content» полностью чревато проблемами.
- Disallow: /category – страница категорий, естественно при определенных настройках постоянных ссылок. Категории также являются малоинформативными страницами, если конечно вы не уделили этому внимания и не наполнили каждую категорию полезной информацией, в ином случае лучше прикрыть, поисковикам там делать нечего.
- Disallow: /attachment – закрываем страницы вложений. Не всегда они бывают доступны по ссылке, но лучше перебдеть. Один раз мне эти странички, высыпавшись в индекс, не хило так посещалку обвалили.
- Disallow: */page/ – закрываем пагинацию. В сети существует много споров закрывать или не закрывать страницы пагинации, но я закрываю. Некоторые SEOшники говорят что таким образом мы лишаемся некоторых внутренних факторов в виде анкоров во внутренних ссылках. Но я считаю эти страницы малоинформативными, а внутренние факторы не такими важными. В моем случае пользы от прикрытия пагинации больше чем от открытия, при 100+ страницах в индексе мой сайт посещает почти 2 000 человек в сутки и этот показатель растет.
Ну вот по сути это основные моменты, которые стоит прикрыть от поисковых роботов на сайте с CMS WordPress.
Мой вариант robots.txt
#Разрешаем роботу Яндекса, который индексирует изображения, доступ к папке с вложениями.
User-Agent: YandexImages
Allow: /wp-content/uploads
#Делаем тоже самое для гугловского бота, которые индексирует изображения
User-Agent: Googlebot-Image
Allow: /wp-content/uploads
#Говорим рекламе что сайт весь в её распоряжении
User-agent: Mediapartners-Google
Allow: /
#Открываем доступ твиттеру
User-agent: Twitterbot
Allow: /
#Поскольку Яндекс проигнорирует секцию с User-agent: *, то придется перечислить все для него
User-Agent: YandexBot
Disallow: /cgi-bin
Disallow: /xmlrpc.php
Disallow: /author
Disallow: /blog
Disallow: /wp-json
Disallow: /wp-login.php
Disallow: */feed*
Allow: /feed/turbo/ #открываем доступ к RSS для турбостраниц ибо чуть выше мы запретили к ним доступ.
Disallow: /wp-content/uploads
Disallow: /category
Disallow: /attachment
Disallow: */page/
Disallow: *?*
Disallow: */amp #закрываем доступ к AMP-страницам
Allow: *.css?ver=*
User-Agent: *
Disallow: /cgi-bin
Disallow: /xmlrpc.php
Disallow: /author
Disallow: *readme.txt
Disallow: /blog
Disallow: /wp-json
Disallow: /wp-login.php
Disallow: */feed*
Disallow: /wp-content/uploads
Disallow: /category
Disallow: /attachment
Disallow: */page/
Disallow: *?*
Allow: *?ver=*
Sitemap: https://dampi.ru/sitemap_index.xml
Некоторые директивы я прокомментировал, которые не описал в главе выше.
Добавление robots.txt в WordPress
По сути в случае с сайтом на WordPress существует три способа редактирования и соответственно загрузки robots.txt на наш сайт, но рассмотрю я только два, характерных именно для WordPress, поскольку третий – это загрузка файла по FTP и этот способ универсален. Давайте рассмотрим эти два способа.
Способ первый: с помощью специального плагина
Не надо качать FTP-киент, лезть на сервер, создавать текстовый файл, а потом каждый раз из-за каждой мелочи снова и снова соваться туда. Есть вполне себе изящное решение в виде простого плагина, который создает «виртуальный» robots.txt.
С установкой разберетесь сами, там ничего сложного. После установки и активации плагина необходимо пройти на страницу с настройками этого плагина
Страница настроек предельно проста, там всего лишь текстовое поле, куда надо поместить наши директивы и один чекбокс, отметив который мы указываем плагину что необходимо подтереть свои настроки при деактивации.
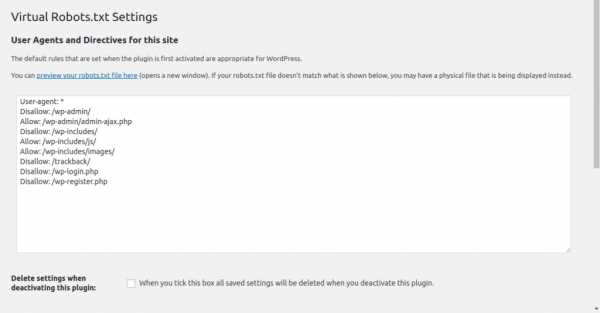
Как видите ничего сверх естественного. Подтираем дефолтный текст и вбиваем наши директивы.
Способ второй: с помощью SEO-плагинов
Поскольку я пользуюсь плагином Yoast SEO, то расскажу на его примере. Для создания и редактирования файла robots.txt необходимо пройти в раздел «Инструменты» плагина:

Нас интересует «Редактор файлов», переходим туда и уже там видим следующее:
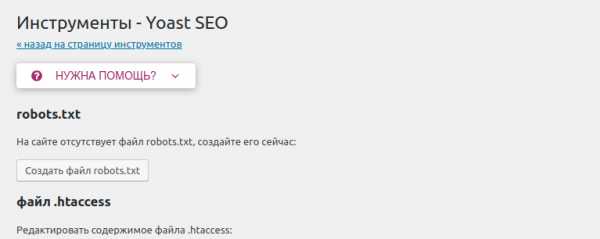
У меня файл robots.txt физически отсутствует ибо он создается плагином «на лету», иначе тут было бы видно его содержимое. Вам остается выбрать подходящий способ редактирования, скопировать директивы нашего robots.txt и сохранить. Дальше вам потребуется отслеживать поведение вашего сайта в поиске.
Проверка robots.txt в панели вебмастера
Для проверки правильности robots.txt у Яндекс и Google предусмотрены специальные инструменты. Использование данных инструментов довольно элементарный процесс. Давайте рассмотрим оба варианта.
Search Console от Google
В соответствующем разделе мы видим содержимое нашего robots.txt
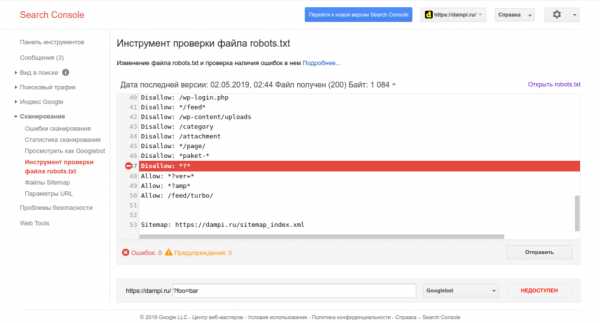
Кроме содержимого robots.txt мы видим сообщения с ошибками и предупреждениями. В моем случае их счетчики по нолям. В поле ниже мы можем указать URL, который хотим проверить. Если введенный нами URL запрещен в файле robots.txt, то вы увидите сообщение справа и выделенную директиву, которая запрещает индексирование данного URL. Вполне удобно.
Яндекс Вебмастер
Проходим в «Инструменты»->«Анализ robots.txt» и видим вот такую картину.
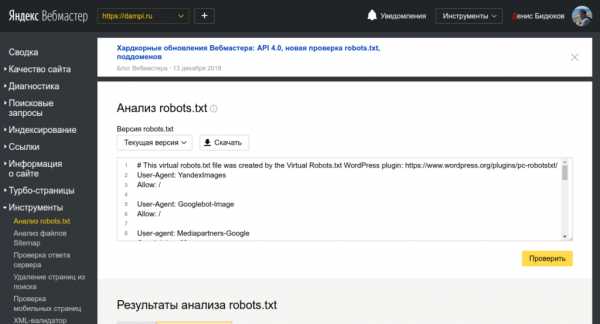
Эта страница устроена чуть сложнее. Страница разделена на три части, в первой все содержимое robots.txt, вторая часть показывает какие директивы использует основной робот, а третья часть отвечает за проверку URL. Обратите внимание на то, что тут поле позволяет проверять URL пачками, что гораздо удобнее чем в инструменте проверки от Google.
Как добавить robots.txt в Яндекс и Google
В отличии от sitemap, адрес которого необходимо указывать в robots.txt или в панели вебмастера, robots.txt не нужно никуда загружать. Его наличие поисковые роботы проверяют каждый раз обращаясь к сайту. По этой причине для «загрузки robots.txt» в Яндекс и Google достаточно просто создать его на своем сайте.
Имя этого файла и его расположение является жестким требованием и соответственно все знают что robots.txt лежит в корне сайта. По этому кроме его создания и заполнения никаких действий больше не требуется, разве что проверить его на ошибки, с помощью описанных выше инструментов.
dampi.ru