Правильный файл robots.txt для WordPress (2020) — Robots.Txt по-русски
Файл robots.txt для WordPress (WP)
Приводим два варианта файла robots.txt для WordPress: стандартный и расширенный. Стандартный не содержит отдельные блоки для поисковых ботов Google и Яндекса. Расширенный уже менее актуален, т.к. теперь нет принципиальных различий между поисковыми системами Яндекс и Google: обеим системам нужно индексировать файлы скриптов и изображений, обе не поддерживают директиву Host.
Стандартный вариант
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
Host: www.site.ru

Расширенный вариант
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploadsUser-agent: GoogleBot
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.phpUser-agent: Yandex
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign
Clean-Param: openstatSitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gzHost: www.site.ru
Важная информация:
Директива Host — игнорируется Яндексом. Теперь это делается при помощи редиректа.
Директива Crawl-delay — игнорируется Яндексом. Теперь что бы ограничить скорость необходимо в Яндекс.Вебмастер воспользоваться инструментом «Скорость обхода» в раздел «Индексирование».
Правильный robots.txt для WordPress
Относительно того, что должно быть внутри файла robots.txt до сих пор возникает куча споров. Вообще, на мой взгляд, этот файл должен содержать две обязательные вещи:
Скрывать в нём все функциональные PHP-файлы (как делают некоторые вебмастера) я не вижу смысла. А уж страницы сайта тем более. Я проводил эксперимент со скрытием страниц через
Для скрытия от индексации страниц сайта используйте метатег:
<meta name="robots" content="noindex, follow" />
Функция do_robots()
Выводит несколько директив для файла robots.txt, рекомендуемые для WordPress.
Параметров не имеет, зато имеет 1 хук и 1 фильтр.
Рассмотрим по порядку, как работает функция:
- В первую очередь функция устанавливает
Content-Typeдокумента на - Затем запускается экшен
do_robotstxt(без параметров). - Третьим шагом идёт проверка, отмечена ли галочка «Попросить поисковые системы не индексировать сайт» в настройках чтения:
- Если отмечена, содержимое
robots.txtбудет:User-agent: * Disallow: /
Если не отмечена:
User-agent: * Disallow: /wp-admin/
- Непосредственно перед выводом срабатывает фильтр
robots_txt(WordPress 3.0+) с двумя параметрами —$output(то, что подготовлено для вывода вrobots.txt) и$public(отмечена ли галочка в пункте 3).
Готовый robots.txt
К результату функции  txt для WordPress:
txt для WordPress:
User-agent: * Disallow: /wp-admin/ User-agent: Yandex Disallow: /wp-admin/ Host: truemisha.ru Sitemap: https://misha.agency/sitemap.xml
Создать его вы можете при помощи любого текстового редактора. Сохраните его там же, где находятся директории wp-admin и wp-content.
Миша
Недавно я осознал, что моя миссия – способствовать распространению WordPress. Ведь WordPress – это лучший движок для разработки сайтов – как для тех, кто готов использовать заложенную структуру этой CMS, так и для тех, кто предпочитает headless решения.
Сам же я впервые познакомился с WordPress в 2009 году. Организатор WordCamp. Преподаватель в школах Epic Skills и LoftSchool.
Если вам нужна помощь с вашим сайтом или может даже разработка с нуля на WordPress / WooCommerce — пишите. Я и моя команда сделаем вам всё на лучшем уровне.
Как сделать robots.txt для WordPress.Создаем правильный robots.
 txt для сайта на WordPress
txt для сайта на WordPressПриветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет.
Создание файла robots.txt
1. Создайте обычный текстовый файл с названием robots в формате .txt.
2. Добавьте в него следующую информацию :
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= Host: site.com Sitemap: http://site.com/sitemap.xml
3. Замените в в текстовом файле строчку site.com на адрес Вашего сайта.
4. Сохраните изменения и загрузите файл robots.txt (с помощью FTP) в корневую папку Вашего сайта.
5. Готово.
Для просмотра и скачки примера, нажмите кнопку ниже и сохраните файл (Ctrl + S на клавиатуре).
Скачать пример файла robots.txtРазбираемся в файле robots.txt (директивы)
Давайте теперь более детально разберем, что именно и зачем мы добавили в файл robots.txt.
User-agent — директива, которая используется для указания названия поискового робота. С помощью этой директивы можно запретить или разрешить поисковым роботам посещать Ваш сайт. Примеры:
Запрещаем роботу Яндекса просматривать папку с кэшем:
User-agent: Yandex Disallow: /wp-content/cache
Разрешаем роботу Bing просматривать папку themes (с темами сайта):
User-agent: bingbot Allow: /wp-content/themes
Allow и Disallow — разрешающая и запрещающая директива. Примеры:
Примеры:
Разрешим боту Яндекса просматривать папку wp-admin:
User-agent: Yandex Allow: /wp-admin
Запретим всем ботам просматривать папку wp-content:
User-agent: * Disallow: /wp-content
В нашем robots.txt мы не используем директиву Allow, так как всё, что не запрещено боту с помощью Disallow — по умолчанию будет разрешено.
Host
Sitemap — используя эту директиву, нужно указать путь к карте сайта. Напомню, что карта сайта является очень важным инструментом при продвижении сайта! Обязательно указывайте её в этой директиве!
Если остались какие-то вопросы — задавайте их в комментарий. Если же информации в этом уроке для Вас оказалось недостаточно, рекомендую почитать подробнее о всех директивах и способах их использования перейдя по этой ссылке.
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет. Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет. Создание файла robots.txt 1. Создайте обычный текстовый файл с названием robots в формате .txt. 2. Добавьте в него следующую информацию : User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes…
Создание и настройка robots.txt
Рейтинг: 4. 51 ( 33 голосов ) 100
51 ( 33 голосов ) 100Robots.txt Editor — Плагин для WordPress
Плагин позволяет создать и редактировать файл robots.txt на вашем сайте.
Возможности
- Работает в сети сайтов Multisite на поддоменах;
- Пример правильного файла robots.txt для WordPress;
- Не требует дополнительных настроек;
- Абсолютно бесплатный.
- Настройки Robots.txt
- Распакуйте скачанный zip-файл.
- Загрузите папку плагина в директорию
wp-content/plugins/вашего сайта. - Активируйте
Robots.txt Editorна странице установки плагинов
Great plugin out from the box as they say. Not packed with spam or upsells, in fact, nothing at all. Simply good!
Such a useful plugin for viewing and editing contents of Robots.txt easily. I don’t use two of the SEO plugins which enable Robots. txt editing, and I find using FTP and Notepad too cumbersome/time consuming. Using this plugin instead saves me valuable time. So thanks for creating this plugin!
txt editing, and I find using FTP and Notepad too cumbersome/time consuming. Using this plugin instead saves me valuable time. So thanks for creating this plugin!
Works flawlessly, out-of-the-box, easy as there is no configuration to be made. Just «set and forget».
Lightweight and perfect for multisite installations. But in documentation need to say where the option/editor is installed (Settings > Read options).
Thank you for the plugin. It is so nice to find one that is so easy to use for multi-sites. I hope you will keep the plugin updated.
A very simple and effective plugin
Посмотреть все 7 отзывов«Robots.txt Editor» — проект с открытым исходным кодом. В развитие плагина внесли свой вклад следующие участники:
Участники1.1.4
Release Date: Jan 16, 2021
- Compatibility with WordPress 5.
 6
6
1.1.3
Release Date: Apr 19, 2020
- Compatibility with WordPress 5.4
1.1.2
Release Date: Jul 27, 2019
- Add — WordPress 5.2.2 compatibility
1.1.1
Release Date: May 06, 2019
- Improved — site map detection
1.1
Release Date: May 06, 2019
- Add — View robots.txt link
1.0
Release Date: May 02, 2019
- Релиз первой версии плагина.
Что должно быть в файле Robots.txt на WordPress?
Виктор Саркисов
Middle SEO IM
Добрый день, спасибо за ваш вопрос!
В сети достаточно много статей написано про то какой должен быть Robots.txt для WordPress либо другой CMS. Проблема стандартных файлов Robots.txt для WP заключается в том что они содержат абсолютно всё что только может быть на этом движке. Даже мусорные страницы, которые создают популярные плагины, хоть они и не установлены сайте. В общем — указано всё подряд.
В общем — указано всё подряд.
Содержимое файла Robots.txt для WordPress нужно создавать исходя из конкретного сайта. В вашем примере указана директива:
Disallow: */page/
Может статься так, что пагинация (а значит, и пагинация категорий) реализована через этот фрагмент. В таком случае вы закроете от сканирования странички пагинации, содержащие карточки товаров, которые роботу полезно видеть. Мы не рекомендуем закрывать страницы пагинации от сканирования.
В обязательном порядке стоит закрыть от сканирования страницы административной панели, при помощи директивы:
Disallow: /wp-admin/
Всё остальные ошибки следует исправлять либо при помощи редиректов, либо же закрывать от индексации через мета тег robots. Проблема заключается в том что файл Robots.txt для Google содержит рекомендации по сканированию, а не индексированию. Даже если документ будет закрыт от сканирования в файле Robots.txt, то он может быть проиндексирован. Более подробно проблема описана и даны варианты решения тут.
Мы рекомендуем действовать следующим образом
- Установить плагин для WordPress Clearfy Pro. Он исправляет 90% всех ошибок на сайте WP, автоматически ставит редиректы со страниц архивов, feed, авторов и прочее.
- Просканировать сайт через Netpeak Spider. Закрыть от индексации при помощи мета тега robots все мусорные страницы.
- Прописать в файле Robots.txt следующее:
User-agent: *
Disallow: /wp-admin/
Sitemap: https://site.ua/sitemap.xml
Таким образом файл Robots.txt не будет содержать множество бесполезных директив, а все мусорные страницы, которые создает WordPress либо его плагины не будут индексироваться поисковыми системами.
Дата сообщения: 21.05.2019, 13:25
Virtual Robots.txt — Плагин для WordPress
Virtual Robots.txt is an easy (i.e. automated) solution to creating and managing a robots.txt file for your site. Instead of mucking about with FTP, files, permissions ..etc, just upload and activate the plugin and you’re done.
Instead of mucking about with FTP, files, permissions ..etc, just upload and activate the plugin and you’re done.
By default, the Virtual Robots.txt plugin allows access to the parts of WordPress that good bots like Google need to access. Other parts are blocked.
If the plugin detects an existing XML sitemap file, a reference to it will be automatically added to your robots.txt file.
- Upload pc-robotstxt folder to the
/wp-content/plugins/directory - Активируйте плагин используя меню ‘Плагины’ в WordPress.
- Once you have the plugin installed and activated, you’ll see a new Robots.txt menu link under the Settings menu. Click that menu link to see the plugin settings page. From there you can edit the contents of your robots.txt file.
Will it conflict with an existing robots.txt file?
If a physical robots.txt file exists on your site, WordPress won’t process any request for one, so there will be no conflict.

Will this work for sub-folder installations of WordPress?
Out of the box, no. Because WordPress is in a sub-folder, it won’t «know» when someone is requesting the robots.txt file which must be at the root of the site.
Does this plugin modify individual posts, pages, or categories?
No it doesn’t.
Why does the default plugin block certain files and folders?
By default, the virtual robots.txt is set to block WordPress files and folders that don’t need to be accessed by search engines. Of course, if you disagree with the defaults, you can easily change them.
Works great and easy to use and customise. It already set by default the directories that need to be left out of Search Engines scanning/indexing… Very happy with it!
What I saw wasn’t what I got. The XML sitemap wasn’t included in the robots. txt file, even thought this was described as a feature that should work out of the box. In addition to that, upon installing this plugin, it blocked certain directories without asking. Lastly, it inserts a line at the top of the file, promoting the plugin. That should be an optional feature that users are empowered to turn off. All in all, it offers the functionality, but falls short and disappoints in other areas.
txt file, even thought this was described as a feature that should work out of the box. In addition to that, upon installing this plugin, it blocked certain directories without asking. Lastly, it inserts a line at the top of the file, promoting the plugin. That should be an optional feature that users are empowered to turn off. All in all, it offers the functionality, but falls short and disappoints in other areas.
I thought this would be simple. Sure sounds simple. But after I saved your suggested text to my brand new «virtual robots.txt», I clicked the link where it says «You can preview your robots.txt file here (opens a new window). If your robots.txt file doesn’t match what is shown below, you may have a physical file that is being displayed instead.» That new window shows text that is indeed different from the plugin’s. So I understand that to mean there’s a physical robots.txt file on my server. So which one is actually going to be used? Your FAQ offers this:
Q: Will it conflict with any existing robots. txt file?
A: If a physical robots.txt file exists on your site, WordPress won’t process any request for one, so there will be no conflict. If a physical file exists, WP won’t process ANY request for one? This SOUNDS like WP will ignore BOTH the physical file AND your virtual one. In which case, what’s the point? Might as well not have one, it seems to me. When I manually go to mydomain.com/robots.txt, I see what’s in the physical file, not what the plugin saved. So… is it working? I don’t know! Should I delete the physical file and assume the virtual one will work? I don’t know! Should I delete this plugin and edit the physical file manually? Most likely. 2 stars instead of 1 because I appreciate getting the suggested lines to include in my file.
txt file?
A: If a physical robots.txt file exists on your site, WordPress won’t process any request for one, so there will be no conflict. If a physical file exists, WP won’t process ANY request for one? This SOUNDS like WP will ignore BOTH the physical file AND your virtual one. In which case, what’s the point? Might as well not have one, it seems to me. When I manually go to mydomain.com/robots.txt, I see what’s in the physical file, not what the plugin saved. So… is it working? I don’t know! Should I delete the physical file and assume the virtual one will work? I don’t know! Should I delete this plugin and edit the physical file manually? Most likely. 2 stars instead of 1 because I appreciate getting the suggested lines to include in my file.
I like the fact that it’s so clean. Thanks for building it!
Awesome, a simple solution to a common issue (site content managers who want to hide certain pages from Google search results). Just a little note: in my case, the existing Sitemap created by the plugin «Google (XML) Sitemaps Generator» by Arne Brachhold wasn’t detected.
Just a little note: in my case, the existing Sitemap created by the plugin «Google (XML) Sitemaps Generator» by Arne Brachhold wasn’t detected.
«Virtual Robots.txt» — проект с открытым исходным кодом. В развитие плагина внесли свой вклад следующие участники:
Участники1.9
- Fix for PHP 7. Thanks to SharmPRO.
1.8
- Undoing last fixes as they had unintended side-effects.
1.7
- Further fixes to issue with newlines being removed. Thanks to FAMC for reporting and for providing the code fix.
- After upgrading, visit and re-save your settings and confirm they look correct.
1.6
- Fixed bug where newlines were being removed. Thanks to FAMC for reporting.
1.5
- Fixed bug where plugin assumed robots.txt would be at http when it may reside at https. Thanks to jeffmcneill for reporting.
1.4
- Fixed bug for link to robots.
 txt that didn’t adjust for sub-folder installations of WordPress.
txt that didn’t adjust for sub-folder installations of WordPress. - Updated default robots.txt directives to match latest practices for WordPress.
- Plugin development and support transferred to Marios Alexandrou.
1.3
- Now uses do_robots hook and checks for is_robots() in plugin action.
1.2
- Added support for existing sitemap.xml.gz file.
1.1
- Added link to settings page, option to delete settings.
1.0
- Первая версия.
Правильный robots.txt для WordPress
Правильно созданный файл robots.txt способствует быстрой индексации страниц сайта. Этот файл является служебным и призван улучшать поисковую оптимизацию сайта. Внутренняя оптимизация страниц сайта на WordPress также немаловажна для проекта и ею нужно заниматься.
Файл robots.txt позволяет ограничить индексацию тех страниц, которые индексировать не нужно. Поисковые роботы обращают внимание на этот служебный файл с целью запрета показа страниц в поисковых системах, которые закрыты от индексации. Кстати, в файле также указываются карта сайта и его зеркало.
Кстати, в файле также указываются карта сайта и его зеркало.
Как создать robots.txt для WordPress
Чтобы приступить к созданию правильного файла, для начала давайте поймем, где находится robots.txt WordPress. Он располагается в корне сайта. Чтобы просмотреть корневые папки и файлы вашего проекта, необходимо воспользоваться любым FTP-клиентом, для этого просто нужно нажать на настроенное «Соединение».
Чтобы посмотреть содержимое нашего служебного файла, достаточно просто набрать в адресной строке после имени сайта robots.txt. Пример: https://mysite.com/robots.txt
WordPress robots.txt где лежит вы знаете, осталось взглянуть, как должен выглядеть идеальный служебный файл для указанного выше движка.
- В первую очередь в файле необходимо указать пусть к карте сайта:
Sitemap: http://web-profy.com/sitemap.xml
- А теперь непосредственно правильная структура файла robots.
 txt для WordPress:
txt для WordPress:
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: mysite.com
Sitemap: http://mysite.com/sitemap.xml.gz
Sitemap: http://mysite.com/sitemap.xml
Достаточно просто скопировать эти данные в свой файл. Так выглядит правильный robots.txt для WordPress.
Теперь рассмотрим, что означает каждая из строк в структуре служебного файла:
User-agent: * — строка, которая показывает, что все введенные ниже данные будут применимы относительно всех поисковых систем.
Однако для Яндекса правило будет выглядеть следующим образом: User-agent: Yandex.
Allow: — страницы, которые поисковые роботы могут индексировать.
Disallow: — страницы, которые поисковым роботам индексировать запрещено.
Host: mysite.com — зеркало сайта, которое нужно указывать в данном служебном файле.
Sitemap: — путь к карте сайта.
robots.txt для сайта WordPress, на котором не настроены ЧПУ
robots.txt для сайта WordPress, где находится список правил будет выглядеть несколько иначе в случае, если на сайте не настроены ЧПУ.
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Host: mysite. com
com
Sitemap: http://mysite.com /sitemap.xml.gz
Sitemap: http://mysite.com /sitemap.xml
Какие могут возникнуть проблемы на WordPress сайте, если нет настроены ЧПУ. Строка в служебном файле robots.txt Disallow: /*?* не позволяет индексировать страницы сайта, а именно так выглядят адреса страниц проекта при отсутствии настроек ЧПУ. Это может негативно отражаться на рейтинге интернет-проекта в поисковиках, поскольку нужный пользователям контент просто не будет им показываться в результатах выдачи.
Конечно, эту строку можно в файле можно легко удалить. Тогда сайт будет работать в нормальном режиме.
Как убедиться в том, что robots.txt составлен правильно
Сделать это можно при помощи специального инструмента от Яндекс — Яндекс.Вебмастер.
Необходимо зайти в Настройки индексирования — Анализ robots.txt
Внутри все интуитивно понятно. Необходимо нажать на «Загрузить robots.txt с сайта». Также вы можете каждую страницу отдельно просмотреть на наличие возможности ее индексации. В «Список URL» можно просто ввести адрес интересующих вас страниц, система покажет все сама.
Необходимо нажать на «Загрузить robots.txt с сайта». Также вы можете каждую страницу отдельно просмотреть на наличие возможности ее индексации. В «Список URL» можно просто ввести адрес интересующих вас страниц, система покажет все сама.
Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь несколько месяцев.
Как правильно сохранять файл robots.txt
Чтобы наш служебный файл был доступен в такой поисковой системе, как Google, его необходимо сохранить следующим образом:
- Файл в обязательном порядке должен иметь текстовый формат;
- Разместить его необходимо корне вашего сайта;
- Файл должен иметь имя robots.txt и никакое другое больше.
Адрес, по которому поисковые роботы находят robots.txt должен иметь следующий вид — https://mysite.com/robots.txt
WordPress Руководство Robots.txt — что это такое и как его использовать
Вы когда-нибудь слышали термин robots. txt и задавались вопросом, как он применим к вашему веб-сайту? На большинстве веб-сайтов есть файл robots.txt, но это не значит, что большинство веб-мастеров его понимают. В этом посте мы надеемся изменить это, предложив более подробное описание файла robots.txt WordPress, а также того, как он может контролировать и ограничивать доступ к вашему сайту. К концу вы сможете ответить на такие вопросы, как:
txt и задавались вопросом, как он применим к вашему веб-сайту? На большинстве веб-сайтов есть файл robots.txt, но это не значит, что большинство веб-мастеров его понимают. В этом посте мы надеемся изменить это, предложив более подробное описание файла robots.txt WordPress, а также того, как он может контролировать и ограничивать доступ к вашему сайту. К концу вы сможете ответить на такие вопросы, как:
Есть много чего рассказать, так что приступим!
Что такое роботы WordPress.текст?
Прежде чем мы сможем говорить о файле robots.txt WordPress, важно определить, что в данном случае представляет собой «робот». Роботы — это любой тип «ботов», посещающих веб-сайты в Интернете. Самый распространенный пример — сканеры поисковых систем. Эти боты «ползают» по сети, чтобы помочь поисковым системам, таким как Google, индексировать и ранжировать миллиарды страниц в Интернете.
Итак, боты есть, вообще , вещь для интернета хорошая… или хотя бы необходимая вещь. Но это не обязательно означает, что вы или другие веб-мастера хотите, чтобы боты работали без ограничений.Желание контролировать взаимодействие веб-роботов с веб-сайтами привело к созданию в середине 1990-х годов стандарта исключения роботов . Robots.txt — это практическая реализация этого стандарта — , он позволяет вам контролировать, как участвующие боты взаимодействуют с вашим сайтом. . Вы можете полностью заблокировать ботов, ограничить их доступ к определенным областям вашего сайта и многое другое.
Но это не обязательно означает, что вы или другие веб-мастера хотите, чтобы боты работали без ограничений.Желание контролировать взаимодействие веб-роботов с веб-сайтами привело к созданию в середине 1990-х годов стандарта исключения роботов . Robots.txt — это практическая реализация этого стандарта — , он позволяет вам контролировать, как участвующие боты взаимодействуют с вашим сайтом. . Вы можете полностью заблокировать ботов, ограничить их доступ к определенным областям вашего сайта и многое другое.
Тем не менее, эта «участвующая» часть важна. Файл robots.txt не может заставить бота следовать его директивам.А вредоносные боты могут и будут игнорировать файл robots.txt. Кроме того, даже авторитетные организации игнорируют некоторые команды , которые вы можете поместить в Robots.txt. Например, Google проигнорирует любые правила, которые вы добавляете в свой robots.txt, о том, как часто его сканеры посещают. Если у вас много проблем с ботами, вам может пригодиться такое решение безопасности, как Cloudflare или Sucuri.
Почему вам следует заботиться о своем файле Robots.txt?
Для большинства веб-мастеров преимущества хорошо структурированного файла robots.txt можно разделить на две категории:
- Оптимизация ресурсов сканирования поисковых систем путем указания им не тратить время на страницы, которые вы не хотите индексировать. Это помогает гарантировать, что поисковые системы сосредоточатся на сканировании наиболее важных для вас страниц.
- Оптимизация использования вашего сервера за счет блокировки ботов, тратящих ресурсы впустую.
Robots.txt конкретно не о контроле того, какие страницы индексируются в поисковых системах
Robots.txt — не надежный способ контролировать, какие страницы индексируются поисковыми системами.Если ваша основная цель — предотвратить включение определенных страниц в результаты поисковой системы, правильный подход — использовать метатег noindex или другой аналогичный прямой метод.
Это связано с тем, что ваш Robots. txt напрямую не сообщает поисковым системам не индексировать контент — он просто говорит им не сканировать его. Хотя Google не будет сканировать отмеченные области внутри вашего сайта, сам Google заявляет, что если внешний сайт ссылается на страницу, которую вы исключили с помощью файла Robots.txt, Google все равно может проиндексировать эту страницу.
txt напрямую не сообщает поисковым системам не индексировать контент — он просто говорит им не сканировать его. Хотя Google не будет сканировать отмеченные области внутри вашего сайта, сам Google заявляет, что если внешний сайт ссылается на страницу, которую вы исключили с помощью файла Robots.txt, Google все равно может проиндексировать эту страницу.
Джон Мюллер, аналитик Google для веб-мастеров, также подтвердил, что, если на странице есть ссылки, указывающие на нее, даже если она заблокирована файлом robots.txt, все равно может проиндексироваться. Вот что он сказал на видеовстрече в Центре веб-мастеров:
Здесь следует иметь в виду одну вещь: если эти страницы заблокированы файлом robots.txt, то теоретически может случиться так, что кто-то случайным образом ссылается на одну из этих страниц. И если они это сделают, то может случиться так, что мы проиндексируем этот URL без какого-либо контента, потому что он заблокирован роботами.текст.
Таким образом, мы не узнаем, что вы не хотите, чтобы эти страницы действительно индексировались.
Если они не заблокированы файлом robots.txt, вы можете поместить на эти страницы метатег noindex. И если кто-нибудь будет ссылаться на них, и мы просканируем эту ссылку и подумаем, что, может быть, здесь есть что-то полезное, тогда мы будем знать, что эти страницы не нужно индексировать, и мы можем просто полностью пропустить их из индексации.
Итак, в связи с этим, если на этих страницах есть что-то, что вы не хотите индексировать, не запрещайте их, используйте вместо этого noindex .
Как создать и отредактировать файл WordPress Robots.txt
По умолчанию WordPress автоматически создает виртуальный файл robots.txt для вашего сайта. Поэтому, даже если вы и пальцем не пошевелите, на вашем сайте уже должен быть файл robots.txt по умолчанию. Вы можете проверить, так ли это, добавив «/robots.txt» в конец своего доменного имени. Например, «https://kinsta.com/robots.txt» вызывает файл robots.txt, который мы используем здесь, в Kinsta:
Например, «https://kinsta.com/robots.txt» вызывает файл robots.txt, который мы используем здесь, в Kinsta:
Пример файла Robots.txt
Поскольку этот файл виртуальный, вы не можете его редактировать.Если вы хотите отредактировать файл robots.txt, вам нужно будет фактически создать на своем сервере физический файл, которым вы можете манипулировать по мере необходимости. Вот три простых способа сделать это…
Как создать и отредактировать файл Robots.txt с помощью Yoast SEO
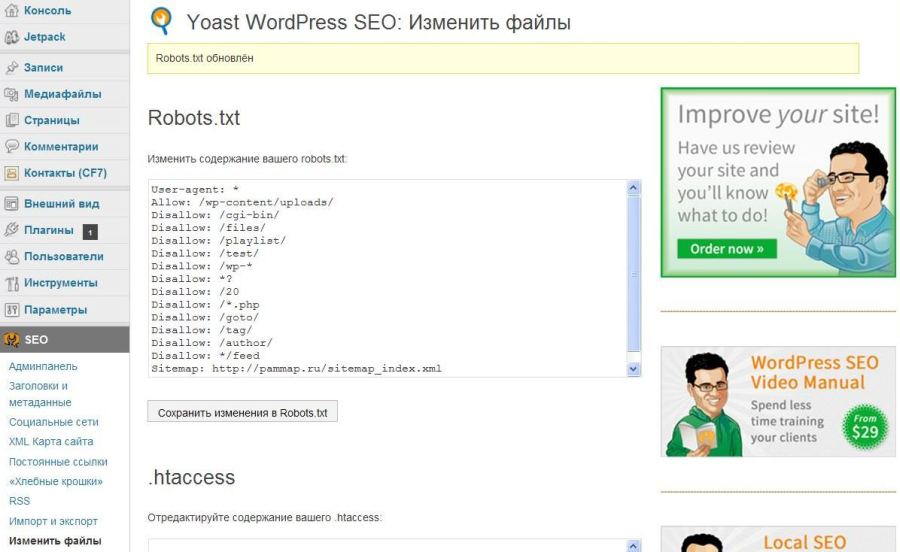
Если вы используете популярный плагин Yoast SEO, вы можете создать (а позже отредактировать) файл robots.txt прямо из интерфейса Yoast. Однако, прежде чем вы сможете получить к нему доступ, вам необходимо включить расширенные функции Yoast SEO, перейдя в SEO → Dashboard → Features и переключившись на страницы дополнительных настроек :
Как включить расширенные функции Yoast
После активации перейдите в SEO → Инструменты и нажмите Редактор файлов :
Как получить доступ к редактору файлов Yoast
Если у вас еще нет физического робота. txt, Yoast предоставит вам возможность Создать файл robots.txt :
txt, Yoast предоставит вам возможность Создать файл robots.txt :
Как создать Robots.txt в Yoast
И как только вы нажмете эту кнопку, вы сможете редактировать содержимое файла Robots.txt прямо из того же интерфейса:
Как редактировать Robots.txt в Yoast
По мере чтения мы подробнее рассмотрим, какие типы директив следует добавлять в файл robots.txt WordPress.
Как создать и отредактировать файл Robots.txt с помощью All In One SEO
Если вы используете почти такой же популярный, как Yoast All in One SEO Pack плагин, вы также можете создавать и редактировать свои роботы WordPress.txt прямо из интерфейса плагина. Все, что вам нужно сделать, это перейти к All in One SEO → Feature Manager и Активировать файл Robots.txt feature:
Как создать Robots.txt в All In One SEO
Затем вы сможете управлять своим файлом Robots.txt, перейдя в All in One SEO → Robots. txt:
Как редактировать Robots.txt в All In One SEO
Как создать и отредактировать файл Robots.txt через FTP
Если вы не используете плагин SEO, который предлагает robots.txt, вы по-прежнему можете создавать файл robots.txt и управлять им через SFTP. Сначала с помощью любого текстового редактора создайте пустой файл с именем «robots.txt»:
.Как создать свой собственный файл Robots.txt
Затем подключитесь к своему сайту через SFTP и загрузите этот файл в корневую папку вашего сайта. Вы можете внести дополнительные изменения в свой файл robots.txt, отредактировав его через SFTP или загрузив новые версии файла.
Что помещать в файл robots.txt
Хорошо, теперь у вас есть физический робот.txt на вашем сервере, который вы можете редактировать по мере необходимости. Но что вы на самом деле делаете с этим файлом? Как вы узнали из первого раздела, robots.txt позволяет вам контролировать взаимодействие роботов с вашим сайтом. Вы делаете это с помощью двух основных команд:
Вы делаете это с помощью двух основных команд:
- User-agent — позволяет настраивать таргетинг на определенных ботов. Пользовательские агенты — это то, что боты используют для идентификации себя. С их помощью вы можете, например, создать правило, которое применяется к Bing, но не к Google.
- Запретить — это позволяет запретить роботам доступ к определенным областям вашего сайта.
Существует также команда Allow , которую вы будете использовать в нишевых ситуациях. По умолчанию все на вашем сайте помечено как Allow , поэтому нет необходимости использовать команду Allow в 99% случаев. Но он пригодится там, где вы хотите Запретить доступ к папке и ее дочерним папкам, но Разрешить доступ к одной конкретной дочерней папке.
Вы добавляете правила, сначала указывая, к какому User-agent должно применяться правило, а затем перечисляя, какие правила применять, используя Disallow и Allow . Есть также некоторые другие команды, такие как Crawl-delay и Sitemap , но это либо:
Есть также некоторые другие команды, такие как Crawl-delay и Sitemap , но это либо:
- Игнорируется большинством основных поисковых роботов или интерпретируется совершенно по-разному (в случае задержки сканирования)
- Изменилось с помощью таких инструментов, как Google Search Console (для карт сайта)
Давайте рассмотрим некоторые конкретные варианты использования, чтобы показать вам, как все это сочетается.
Как использовать Robots.txt для блокировки доступа ко всему сайту
Допустим, вы хотите заблокировать всем поисковым роботам доступ к вашему сайту.Это маловероятно на действующем сайте, но может пригодиться для сайта разработки. Для этого вы должны добавить этот код в свой файл robots.txt WordPress:
Агент пользователя: *
Disallow: / Что происходит в этом коде?
Звездочка * рядом с User-agent означает «все пользовательские агенты». Звездочка — это подстановочный знак, означающий, что он применяется к каждому пользовательскому агенту. / косая черта рядом с Disallow означает, что вы хотите запретить доступ к всем страницам , которые содержат «yourdomain.com / »(т.е. каждая страница вашего сайта).
Звездочка — это подстановочный знак, означающий, что он применяется к каждому пользовательскому агенту. / косая черта рядом с Disallow означает, что вы хотите запретить доступ к всем страницам , которые содержат «yourdomain.com / »(т.е. каждая страница вашего сайта).
Как использовать Robots.txt, чтобы заблокировать доступ одного бота к вашему сайту
Давайте изменим ситуацию. В этом примере мы сделаем вид, что вам не нравится, что Bing сканирует ваши страницы. Вы все время работаете в команде Google и даже не хотите, чтобы Bing просматривал ваш сайт. Чтобы заблокировать сканирование вашего сайта только Bing, замените подстановочный знак * звездочку на Bingbot:
Подпишитесь на информационный бюллетень
Мы увеличили наш трафик на 1187% с помощью WordPress.
Присоединяйтесь к 20 000+ другим, кто получает нашу еженедельную рассылку с инсайдерскими советами по WordPress!
Подпишись сейчас Агент пользователя: Bingbot
Disallow: / По сути, приведенный выше код говорит только применить правило Disallow к ботам с пользовательским агентом «Bingbot» . Вы вряд ли захотите блокировать доступ к Bing, но этот сценарий действительно пригодится, если есть конкретный бот, которому вы не хотите получать доступ к своему сайту.На этом сайте есть хороший список известных имен User-agent большинства сервисов.
Вы вряд ли захотите блокировать доступ к Bing, но этот сценарий действительно пригодится, если есть конкретный бот, которому вы не хотите получать доступ к своему сайту.На этом сайте есть хороший список известных имен User-agent большинства сервисов.
Как использовать Robots.txt для блокировки доступа к определенной папке или файлу
В этом примере предположим, что вы хотите заблокировать доступ только к определенному файлу или папке (и всем подпапкам этой папки). Чтобы применить это к WordPress, допустим, вы хотите заблокировать:
- Вся папка wp-admin
- wp-login.php
Вы можете использовать следующие команды:
Агент пользователя: *
Запретить: / wp-admin /
Запретить: / wp-login.php Как использовать Robots.txt для разрешения доступа к определенному файлу в запрещенной папке
Хорошо, теперь допустим, что вы хотите заблокировать всю папку, но все же хотите разрешить доступ к определенному файлу внутри этой папки. Здесь вам пригодится команда Allow . И это действительно очень применимо к WordPress. Фактически, виртуальный файл robots.txt WordPress прекрасно иллюстрирует этот пример:
Здесь вам пригодится команда Allow . И это действительно очень применимо к WordPress. Фактически, виртуальный файл robots.txt WordPress прекрасно иллюстрирует этот пример:
Агент пользователя: *
Запретить: / wp-admin /
Разрешить: / wp-admin / admin-ajax.php Этот фрагмент блокирует доступ ко всей папке / wp-admin / , за исключением файла /wp-admin/admin-ajax.php .
Как использовать Robots.txt, чтобы запретить ботам сканировать результаты поиска WordPress
Одна специальная настройка WordPress, которую вы, возможно, захотите сделать, — это запретить поисковым роботам сканировать ваши страницы результатов поиска. По умолчанию WordPress использует параметр запроса «? S =». Итак, чтобы заблокировать доступ, все, что вам нужно сделать, это добавить следующее правило:
Агент пользователя: *
Запретить: /? S =
Disallow: / search / Это также может быть эффективным способом остановить мягкие ошибки 404, если вы их получаете. Обязательно прочтите наше подробное руководство о том, как ускорить поиск в WordPress.
Обязательно прочтите наше подробное руководство о том, как ускорить поиск в WordPress.
Как создать разные правила для разных ботов в robots.txt
До сих пор все примеры касались одного правила за раз. Но что, если вы хотите применить разные правила к разным ботам? Вам просто нужно добавить каждый набор правил в объявление User-agent для каждого бота. Например, если вы хотите создать одно правило, которое применяется к , все боты , а другое правило, которое применяется к , только Bingbot , вы можете сделать это так:
Агент пользователя: *
Запретить: / wp-admin /
Пользовательский агент: Bingbot
Disallow: / В этом примере для всем ботам будет заблокирован доступ к / wp-admin /, но для Bingbot будет заблокирован доступ ко всему вашему сайту.
Тестирование файла Robots.txt
Вы можете протестировать свой файл robots.txt WordPress в Google Search Console, чтобы убедиться, что он правильно настроен. Просто нажмите на свой сайт и в разделе «Сканирование» нажмите «Тестер robots.txt». Затем вы можете отправить любой URL, включая вашу домашнюю страницу. Вы должны увидеть зеленый Разрешено , если все доступно для сканирования. Вы также можете проверить URL-адреса, которые вы заблокировали, чтобы убедиться, что они действительно заблокированы, или Disallowed .
Просто нажмите на свой сайт и в разделе «Сканирование» нажмите «Тестер robots.txt». Затем вы можете отправить любой URL, включая вашу домашнюю страницу. Вы должны увидеть зеленый Разрешено , если все доступно для сканирования. Вы также можете проверить URL-адреса, которые вы заблокировали, чтобы убедиться, что они действительно заблокированы, или Disallowed .
Тестовый файл robots.txt
Остерегайтесь спецификации UTF-8
BOM обозначает знак порядка байтов и в основном является невидимым символом, который иногда добавляется к файлам старыми текстовыми редакторами и т.п.Если это произойдет с вашим файлом robots.txt, Google может неправильно его прочитать. Вот почему так важно проверять файл на наличие ошибок. Например, как показано ниже, в нашем файле был невидимый символ, и Google жалуется на непонятный синтаксис. Это по существу делает недействительной первую строку нашего файла robots.txt, что не очень хорошо! У Гленна Гейба есть отличная статья о том, как бомба UTF-8 может убить вашего SEO.
Спецификация UTF-8 в вашем файле robots.txt
Робот Googlebot в основном базируется в США
Также важно не блокировать робота Googlebot из США, даже если вы нацеливаетесь на регион за пределами США.Иногда они выполняют локальное сканирование, но Googlebot в основном находится в США .
Робот Googlebot в основном находится в США, но иногда мы также выполняем локальное сканирование. https://t.co/9KnmN4yXpe
— Центр поиска Google (@googlesearchc) 13 ноября 2017 г.
Что популярные сайты WordPress помещают в свой файл Robots.txt
Чтобы на самом деле предоставить некоторый контекст для пунктов, перечисленных выше, вот как некоторые из самых популярных сайтов WordPress используют своих роботов.txt файлы.
TechCrunch
TechCrunch Файл Robots.txt
Помимо ограничения доступа к ряду уникальных страниц, TechCrunch, в частности, запрещает поисковым роботам:
Еще они установили особые ограничения для двух ботов:
Если вам интересно, IRLbot — это сканер из исследовательского проекта Техасского университета A&M. Это странно!
Это странно!
Фонд Обамы
Файл Robots.txt Фонда Обамы
Фонд Обамы не делал никаких специальных дополнений, предпочитая ограничивать доступ исключительно к / wp-admin /.
Злые птицы
Angry Birds Файл Robots.txt
Angry Birds имеет те же настройки по умолчанию, что и The Obama Foundation. Ничего особенного не добавлено.
Дрифт
Drift Robots.txt Файл
Наконец, Drift решает определить свои карты сайта в файле Robots.txt, но в остальном оставляет те же ограничения по умолчанию, что и The Obama Foundation и Angry Birds.
Правильно используйте Robots.txt
Завершая наше руководство по robots.txt, мы хотим еще раз напомнить вам, что использование команды Disallow в вашем файле robots.txt — это не то же самое, что использовать тег noindex . Robots.txt блокирует сканирование, но не обязательно индексацию. Вы можете использовать его для добавления определенных правил, определяющих, как поисковые системы и другие боты взаимодействуют с вашим сайтом, но он не будет явно контролировать, индексируется ваш контент или нет.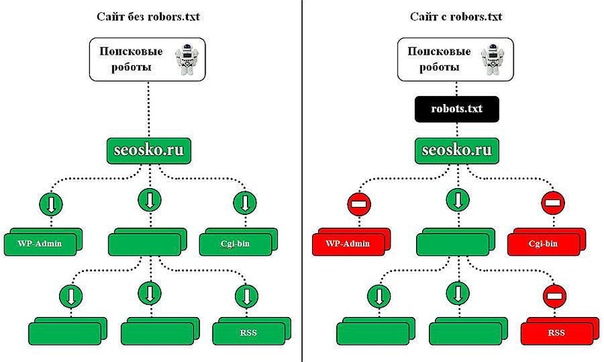
Для большинства обычных пользователей WordPress нет необходимости срочно изменять виртуальный файл robots.txt по умолчанию. Но если у вас возникли проблемы с конкретным ботом или вы хотите изменить способ взаимодействия поисковых систем с определенным плагином или темой, которую вы используете, вы можете добавить свои собственные правила.
Мы надеемся, что вам понравилось это руководство, и обязательно оставьте комментарий, если у вас возникнут дополнительные вопросы об использовании файла robots.txt в WordPress.
Если вам понравилась эта статья, то вам понравится хостинговая платформа Kinsta WordPress. Ускорьте свой сайт и получите круглосуточную поддержку от нашей опытной команды WordPress. Наша инфраструктура на базе Google Cloud ориентирована на автоматическое масштабирование, производительность и безопасность. Позвольте нам показать вам разницу в Kinsta! Ознакомьтесь с нашими тарифами
Передовой пример для SEO • Yoast
Джоно Алдерсон Джоно — цифровой стратег, технолог по маркетингу и разработчик полного цикла. Он занимается техническим SEO, новыми технологиями и стратегией бренда.
Он занимается техническим SEO, новыми технологиями и стратегией бренда.
Файл robots.txt — мощный инструмент, когда вы работаете над поисковой оптимизацией веб-сайта, но с ним следует обращаться осторожно. Он позволяет запрещать поисковым системам доступ к различным файлам и папкам, но часто не лучший способ оптимизировать ваш сайт. Здесь мы объясним, как, по нашему мнению, веб-мастера должны использовать свой файл robots.txt, и предложим «передовой» подход, подходящий для большинства веб-сайтов.
Ниже на этой странице вы найдете пример robots.txt, который работает для подавляющего большинства веб-сайтов WordPress. Если вы хотите узнать больше о том, как работает ваш файл robots.txt, вы можете прочитать наше полное руководство по robots.txt.
Как выглядит «передовой опыт»?
Поисковые системы постоянно улучшают способы сканирования Интернета и индексации контента. Это означает, что то, что считалось оптимальным несколько лет назад, больше не работает или даже может нанести вред вашему сайту.
Сегодня лучшая практика означает как можно меньше полагаться на файл robots.txt. Фактически, действительно необходимо блокировать URL-адреса в файле robots.txt только тогда, когда у вас есть сложные технические проблемы (например, большой веб-сайт электронной коммерции с фасетной навигацией) или когда нет другого выхода.
Блокировка URL-адресов через robots.txt — это метод «грубой силы», который может вызвать больше проблем, чем решить.
Для большинства сайтов WordPress рекомендуется следующий пример:
# Это поле намеренно оставлено пустым
# Если вы хотите узнать, почему наш robots.txt выглядит так, прочтите этот пост: https://yoa.st/robots-txt
Пользовательский агент: * Мы даже используем этот подход в нашем собственном файле robots.txt.
Что делает этот код?
- Инструкция
User-agent: *гласит, что все следующие инструкции применимы ко всем поисковым роботам.
- Поскольку мы не предоставляем никаких дополнительных инструкций, мы говорим, что «все сканеры могут свободно сканировать этот сайт без ограничений».
- Мы также предоставляем некоторую информацию людям, просматривающим файл (ссылаясь на эту самую страницу), чтобы они понимали, почему файл «пуст».
Если вам нужно запретить URL-адреса
Если вы хотите запретить поисковым системам сканировать или индексировать определенные части вашего сайта WordPress, почти всегда лучше сделать это, добавив метатеги для роботов или для HTTP-заголовков роботов .
В нашем полном руководстве по метатегам роботов объясняется, как «правильно» управлять сканированием и индексированием, а наш плагин Yoast SEO предоставляет инструменты, которые помогут вам реализовать эти теги на своих страницах.
Если на вашем сайте есть проблемы со сканированием или индексированием, которые нельзя устранить с помощью метатегов или HTTP-заголовков , или если вам необходимо предотвратить доступ для роботов по другим причинам, вам следует прочитать наше полное руководство по роботам. текст.
текст.
Обратите внимание, что WordPress и Yoast SEO уже автоматически предотвращают индексацию некоторых конфиденциальных файлов и URL-адресов, например, вашей административной области WordPress (через HTTP-заголовок x-robots).
Почему этот «минимализм» лучше всего подходит?
Robots.txt создает тупики
Прежде чем вы сможете соревноваться за видимость в результатах поиска, поисковым системам необходимо обнаружить, просканировать и проиндексировать ваши страницы. Если вы заблокировали определенные URL-адреса с помощью robots.txt, поисковые системы больше не смогут сканировать эти страницы с по для обнаружения других.Это может означать, что ключевые страницы не будут обнаружены.
Robots.txt запрещает ссылкам их значение
Одно из основных правил SEO заключается в том, что ссылки с других страниц могут влиять на вашу эффективность. Если URL-адрес заблокирован, поисковые системы не только не будут его сканировать, но и не будут распространять «значение ссылки», указывающее на этот URL-адрес или с по на другие страницы сайта.
Google полностью отображает ваш сайт
Люди раньше блокировали доступ к файлам CSS и JavaScript, чтобы поисковые системы фокусировались на этих важнейших страницах с контентом.
В настоящее время Google извлекает все ваши стили и JavaScript и полностью отображает ваши страницы. Понимание макета и презентации вашей страницы является ключевой частью оценки качества. Таким образом, Google совсем не нравится , когда вы запрещаете ему доступ к вашим файлам CSS или JavaScript.
Предыдущая передовая практика блокировки доступа к вашему каталогу wp-includes и каталогу ваших плагинов через файл robots.txt больше не действует, поэтому мы работали с WordPress, чтобы удалить правило disallow по умолчанию для wp-includes в версии 4.0.
Многие темы WordPress также используют асинхронные запросы JavaScript — так называемый AJAX — для добавления содержимого на веб-страницы. WordPress по умолчанию блокировал это для Google, но мы исправили это в WordPress 4. 4.
4.
Вам (обычно) не нужно ссылаться на карту сайта
Стандарт robots.txt поддерживает добавление в файл ссылки на ваши XML-карты сайта. Это помогает поисковым системам определять местонахождение и содержание вашего сайта.
Нам всегда казалось, что это лишнее; вы уже должны это сделать, добавив карту сайта в свои учетные записи Google Search Console и Bing Webmaster Tools, чтобы получить доступ к аналитике и данным о производительности.Если вы это сделали, то ссылка в файле robots.txt вам не понадобится.
Подробнее: Предотвращение индексации вашего сайта: правильный путь »
Robots.txt и WordPress | WP Engine®
Поддержание поисковой оптимизации (SEO) вашего сайта имеет решающее значение для привлечения органического трафика. Однако есть некоторые страницы, такие как дублированный контент или промежуточные области, которые вы не можете захотеть, чтобы пользователи находили через поисковые системы. К счастью, есть способ запретить таким системам, как Google, получать доступ к определенным страницам и отображать их для поисковиков. Редактируя файл robots.txt своего сайта, вы можете контролировать, какой контент будет отображаться на страницах результатов поиска (SERP).
Редактируя файл robots.txt своего сайта, вы можете контролировать, какой контент будет отображаться на страницах результатов поиска (SERP).
ПРИМЕЧАНИЕ. По умолчанию WP Engine ограничивает трафик поисковых систем на любой сайт, использующий домен install.wpengine.com . Это означает, что поисковые системы не смогут посещать сайты , а не , которые в настоящее время находятся в разработке, с использованием личного домена.
О
Robots.txtА роботов.txt содержит инструкции для поисковых систем о том, как находить и извлекать информацию с вашего веб-сайта. Этот процесс называется «сканированием». После того, как страница просканирована, она будет проиндексирована, чтобы поисковая система могла быстро найти и отобразить ее позже.
Первое, что делает сканер поисковой системы, когда попадает на сайт, — это ищет файл robots.txt . Если его нет, он продолжит сканирование остальной части сайта в обычном режиме. Если он найдет этот файл, сканер будет искать в нем какие-либо команды, прежде чем продолжить.
Если он найдет этот файл, сканер будет искать в нем какие-либо команды, прежде чем продолжить.
В файле robots.txt можно найти четыре общие команды:
- Disallow запрещает сканерам поисковых систем проверять и индексировать указанные файлы сайта. Это может помочь вам предотвратить появление в поисковой выдаче дублированного контента, промежуточных областей или других личных файлов.
- Разрешить разрешает доступ к подпапкам, в то время как родительские папки запрещены.
- Задержка сканирования предписывает поисковым роботам подождать определенное время перед загрузкой файла.
- Sitemap указывает расположение любых файлов Sitemap, связанных с вашим сайтом.
Файлы Robots.txt всегда форматируются одинаково, чтобы их директивы были понятны:
Каждая директива начинается с определения «агента пользователя», которым обычно является сканер поисковой системы. Если вы хотите, чтобы команда применялась ко всем потенциальным пользовательским агентам, вы можете использовать звездочку (*). Чтобы вместо этого настроить таргетинг на определенный пользовательский агент, вы можете добавить его имя. Например, мы могли бы заменить звездочку выше на «Googlebot», чтобы запретить Google сканирование страницы администратора.
Чтобы вместо этого настроить таргетинг на определенный пользовательский агент, вы можете добавить его имя. Например, мы могли бы заменить звездочку выше на «Googlebot», чтобы запретить Google сканирование страницы администратора.
Понимание того, как использовать и редактировать файл robots.txt , имеет жизненно важное значение. Включенные в него директивы будут определять, как поисковые системы взаимодействуют с вашим сайтом. Они могут помочь вам, скрывая контент, от которого вы хотите отвлечь пользователей, что улучшит общее SEO вашего сайта.
Протестируйте файл
Robots.txtВы можете проверить, есть ли у вас файл robots.txt и , добавив «/robots.txt» в конец URL-адреса вашего сайта в браузере. Это вызовет файл, если он существует.Однако наличие вашего файла не обязательно означает, что он работает правильно.
К счастью, проверить файл robots.txt просто. Вы можете просто скопировать и вставить свой файл в тестер robots. txt . Инструмент выделит все ошибки в файле. Важно отметить, что изменения, внесенные вами в редактор тестера robots.txt , не будут применяться к фактическому файлу — вам все равно придется отредактировать файл на своем сервере.
txt . Инструмент выделит все ошибки в файле. Важно отметить, что изменения, внесенные вами в редактор тестера robots.txt , не будут применяться к фактическому файлу — вам все равно придется отредактировать файл на своем сервере.
Некоторые распространенные ошибки включают запрет на использование файлов CSS или JavaScript, неправильное использование подстановочных знаков, таких как * и $, и случайное запрещение важных страниц.Также важно помнить, что сканеры поисковых систем чувствительны к регистру, поэтому все URL-адреса в файле robots.txt должны отображаться так же, как и в вашем браузере.
Создание файла
Robots.txt с подключаемым модулем Если на вашем сайте отсутствует файл robots.txt , вы можете легко добавить его в WordPress с помощью плагина Yoast SEO. Это избавит вас от необходимости создавать простой текстовый файл и вручную загружать его на сервер. Если вы предпочитаете создать его вручную, перейдите к разделу «Роботы вручную».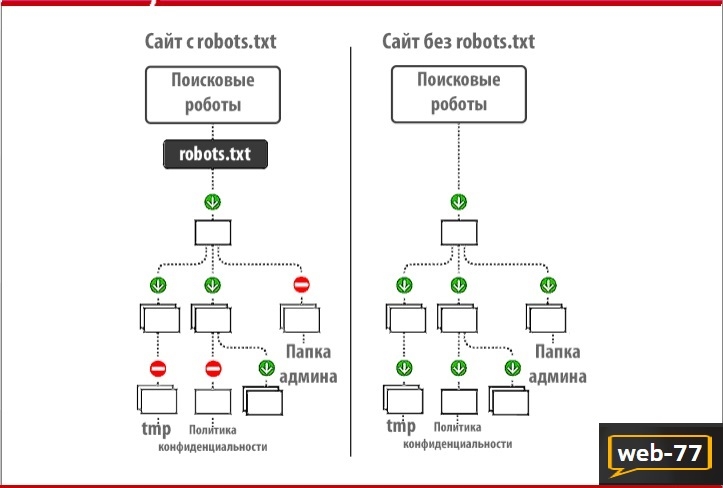 txt ниже в разделе «Создание файла».
txt ниже в разделе «Создание файла».
Перейдите к инструментам Yoast SEO
Для начала вам необходимо установить и активировать плагин Yoast SEO. Затем вы можете перейти на панель администратора WordPress и выбрать SEO > Tools на боковой панели :
.Это приведет вас к списку полезных инструментов, к которым пользователи Yoast могут получить доступ для эффективного улучшения своего SEO.
Используйте редактор файлов для создания файла
Robots.txtОдним из инструментов, доступных в списке, является редактор файлов.Это позволяет вам редактировать файлы, связанные с SEO вашего сайта, включая файл robots.txt :
Поскольку на вашем сайте его еще нет, выберите Создать файл robots.txt :
Откроется редактор файлов, в котором вы сможете редактировать и сохранять новый файл.
Отредактируйте файл по умолчанию
Robots.txt и сохраните его По умолчанию новый файл robots.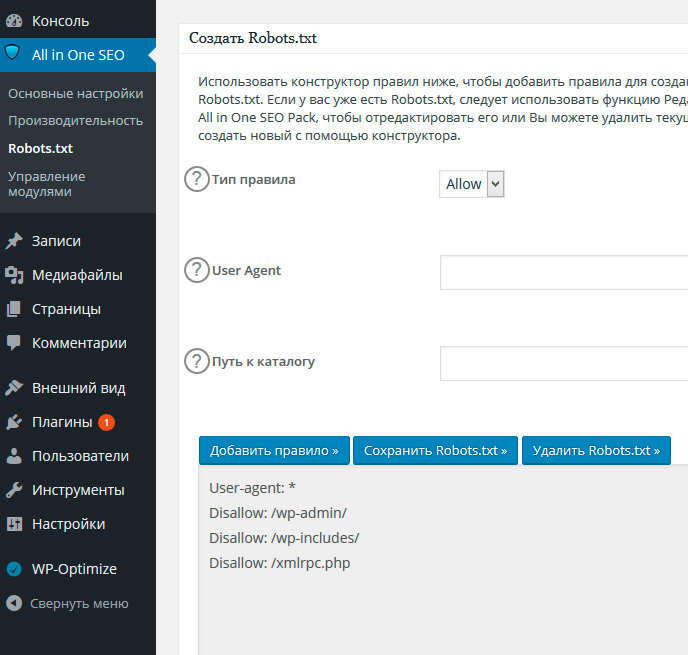 txt , созданный с помощью Yoast, включает директиву, скрывающую вашу папку wp-admin и разрешающую доступ к вашему admin-ajax.php для всех пользовательских агентов. Рекомендуется оставить эту директиву в файле:
txt , созданный с помощью Yoast, включает директиву, скрывающую вашу папку wp-admin и разрешающую доступ к вашему admin-ajax.php для всех пользовательских агентов. Рекомендуется оставить эту директиву в файле:
Перед сохранением файла вы также можете добавить любые другие директивы, которые хотите включить. В этом примере мы запретили поисковым роботам Bing доступ ко всем нашим файлам, добавили задержку сканирования в десять миллисекунд для поискового робота Yahoo (Slurp) и направили поисковые роботы в расположение нашей карты сайта. Когда вы закончите вносить свои изменения, не забудьте их сохранить!
Руководство
Роботы.txt Создание файлаЕсли вам нужно создать файл robots.txt вручную, процесс так же прост, как создание и загрузка файла на ваш сервер.
- Создайте файл с именем
robots.txt- Убедитесь, что имя написано в нижнем регистре
- Убедитесь, что расширение —
., а неtxt
.html
- Добавьте в файл любые необходимые директивы и сохранить
- Загрузите файл с помощью шлюза SFTP или SSH в корневой каталог вашего сайта
ПРИМЕЧАНИЕ : Если в корне вашего сайта есть физический файл, который называется robots.txt , он перезапишет любой динамически сгенерированный файл robots.txt , созданный плагином или темой.
Использование файла robots.txt
Файл robots.txt разбит на блоки пользовательским агентом. Внутри блока каждая директива указывается в новой строке. Например:
Агент пользователя: * Запретить: / Пользовательский агент: Googlebot Запретить: Пользовательский агент: bingbot Запретить: / no-bing-crawl / Запрещено: wp-admin
Пользовательские агенты обычно сокращаются до более общего имени, но это не требуется .
Значения директивы чувствительны к регистру.
- URL-адреса
no-bing-crawlиNo-Bing-Crawl— это разных .
Глобализация и регулярные выражения не поддерживаются полностью .
-
*в поле User-agent — это специальное значение, означающее «любой робот».
Ограничить доступ всех ботов к вашему сайту
(Все сайты в среде .Для URL wpengine.com автоматически применяется следующий файл robots.txt .)
Агент пользователя: * Disallow: /
Ограничить доступ одного робота ко всей площадке
Агент пользователя: BadBotName Disallow: /
Ограничить доступ бота к определенным каталогам и файлам
Пример запрещает ботов на всех страницах wp-admin и странице wp-login.php . Это хороший стандартный или стартовый робот .txt файл.
Агент пользователя: * Запретить: / wp-admin / Disallow: /wp-login.php
Ограничить доступ бота ко всем файлам определенного типа
В примере используется тип файла .pdf
Агент пользователя: * Disallow: /*.pdf$
Ограничить конкретную поисковую систему
Пример использования Googlebot-Image в / wp-content / загружает каталог
User-Agent: Googlebot-Image Запретить: / wp-content / uploads /
Ограничить всех ботов, кроме одного
Пример разрешает только Google
Агент пользователя: Google Запретить: Пользовательский агент: * Disallow: /
Добавление правильных комбинаций директив может быть сложным.К счастью, есть плагины, которые также создают (и тестируют) файл robots.txt за вас. Примеры плагинов:
Если вам нужна дополнительная помощь в настройке правил в файле robots.txt, мы рекомендуем посетить Google Developers или The Web Robots Pages для получения дополнительных инструкций.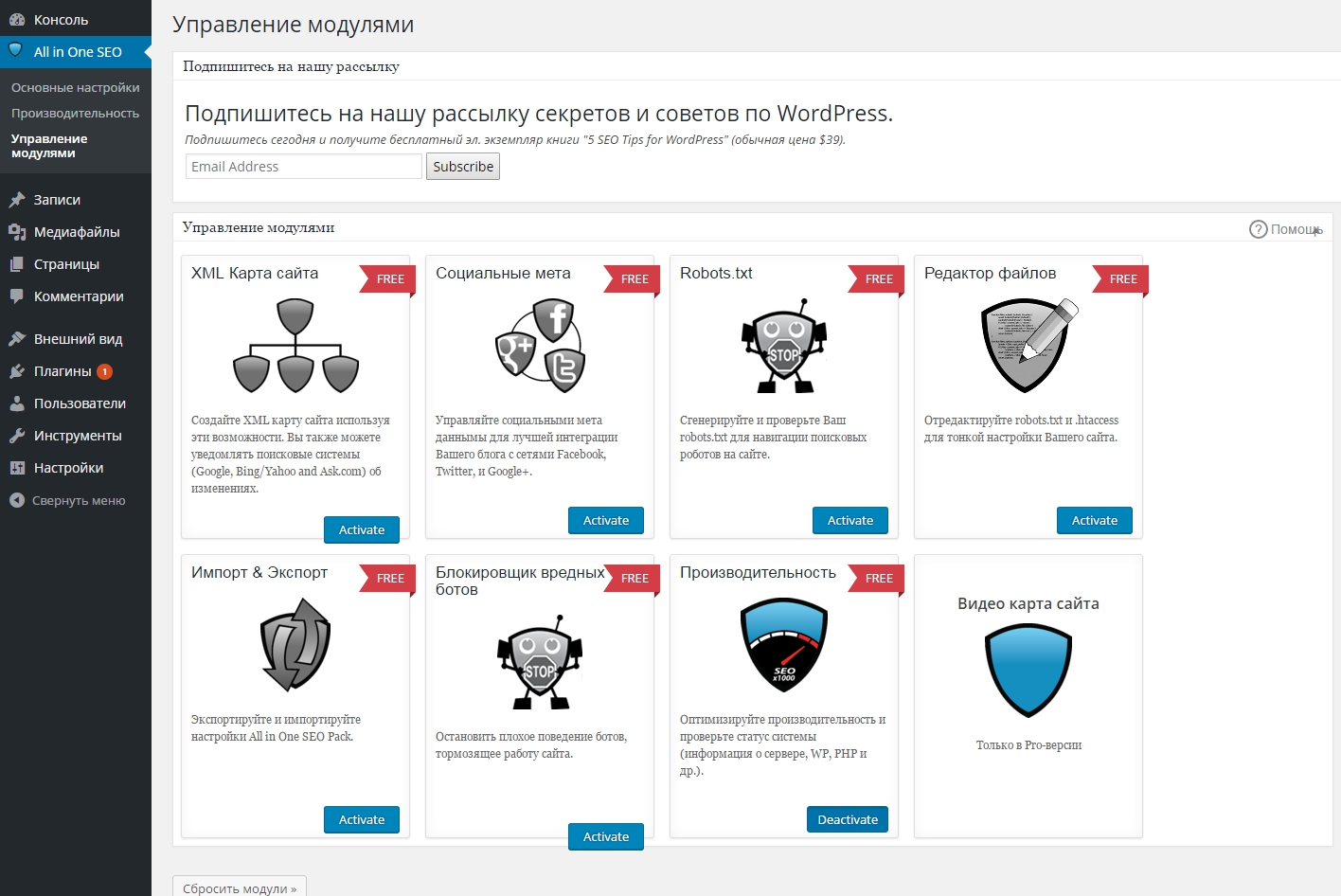
Задержка сканирования
Если вы видите слишком высокий трафик ботов и это влияет на производительность сервера, задержка сканирования может быть хорошим вариантом. Задержка сканирования позволяет ограничить время, которое должен пройти бот перед сканированием следующей страницы.
Для настройки задержки сканирования используйте следующую директиву, значение настраивается и указывается в секундах:
задержка сканирования: 10
Например, чтобы запретить сканирование всем ботам wp-admin , wp-login.php и установить задержку сканирования для всех ботов на 600 секунд (10 минут):
Агент пользователя: * Запретить: /wp-login.php Запретить: / wp-admin / Задержка сканирования: 600
ПРИМЕЧАНИЕ : службы обхода контента могут иметь свои собственные требования для установки задержки обхода.Как правило, лучше всего напрямую связаться со службой для получения требуемого метода.
Отрегулируйте задержку сканирования для SEMrush
- SEMrush — отличный сервис, но сканирование может оказаться очень тяжелым, что в конечном итоге ухудшит производительность вашего сайта.
 По умолчанию боты SEMrush игнорируют директивы задержки сканирования в файле robots.txt, поэтому обязательно войдите в их панель управления и включите Уважение задержки сканирования robots.txt .
По умолчанию боты SEMrush игнорируют директивы задержки сканирования в файле robots.txt, поэтому обязательно войдите в их панель управления и включите Уважение задержки сканирования robots.txt . - Дополнительную информацию о SEMrush можно найти здесь.
Настроить задержку сканирования Bingbot
- Bingbot должен соблюдать директивы
crawl-delay, однако они также позволяют вам установить шаблон управления сканированием.
Настройте задержку сканирования для Google
Подробнее см. В документации поддержки Google)
Откройте страницу настроек скорости сканирования вашего ресурса.
- Если ваша скорость сканирования описывается как , рассчитанная как оптимальная , единственный способ уменьшить скорость сканирования — это подать специальный запрос.Вы не можете увеличить скорость сканирования .
- В противном случае выберите нужный вариант и затем ограничьте скорость сканирования по желанию.
Новая скорость сканирования будет действовать в течение 90 дней.
ПРИМЕЧАНИЕ : Хотя эта конфигурация запрещена на нашей платформе, стоит отметить, что задержка сканирования Googlebot не может быть изменена для сайтов, размещенных в подкаталогах, таких как domain.com/blog
Лучшие Лрактики
Прежде всего следует помнить о следующем: непроизводственные сайты должны запрещать использование всех пользовательских агентов.WP Engine автоматически делает это для любых сайтов, использующих домен environmentname .wpengine.com. Только когда вы будете готовы «запустить» свой сайт, вы можете добавить файл robots.txt.
Во-вторых, если вы хотите заблокировать определенного User-Agent, помните, что роботы не обязаны следовать правилам, установленным в вашем файле robots.txt. Лучшей практикой было бы использовать брандмауэр, такой как Sucuri WAF или Cloudflare, который позволяет вам блокировать злоумышленников до того, как они попадут на ваш сайт. Или вы можете обратиться в службу поддержки за дополнительной помощью по блокировке трафика.
Или вы можете обратиться в службу поддержки за дополнительной помощью по блокировке трафика.
Наконец, если у вас очень большая библиотека сообщений и страниц на вашем сайте, Google и другие поисковые системы, индексирующие ваш сайт, могут вызвать проблемы с производительностью. Увеличение срока действия кеша или ограничение скорости сканирования поможет компенсировать это влияние.
СЛЕДУЮЩИЙ ШАГ: устранение ошибок 504
Robots.txt и WordPress | WP Engine®
Поддержание поисковой оптимизации (SEO) вашего сайта имеет решающее значение для привлечения органического трафика.Однако есть некоторые страницы, такие как дублированный контент или промежуточные области, которые вы не можете захотеть, чтобы пользователи находили через поисковые системы. К счастью, есть способ запретить таким системам, как Google, получать доступ к определенным страницам и отображать их для поисковиков. Редактируя файл robots.txt своего сайта, вы можете контролировать, какой контент будет отображаться на страницах результатов поиска (SERP).
ПРИМЕЧАНИЕ. По умолчанию WP Engine ограничивает трафик поисковых систем на любой сайт с помощью установки .wpengine.com домен. Это означает, что поисковые системы не смогут посещать сайты , а не , которые в настоящее время находятся в разработке, с использованием личного домена.
О
Robots.txtФайл robots.txt содержит инструкции для поисковых систем о том, как находить и извлекать информацию с вашего веб-сайта. Этот процесс называется «сканированием». После того, как страница просканирована, она будет проиндексирована, чтобы поисковая система могла быстро найти и отобразить ее позже.
Первое, что делает сканер поисковой системы, когда попадает на сайт, — это ищет файл robots.txt . Если его нет, он продолжит сканирование остальной части сайта в обычном режиме. Если он найдет этот файл, сканер будет искать в нем какие-либо команды, прежде чем продолжить.
В файле robots. txt можно найти четыре общие команды:
txt можно найти четыре общие команды:
- Disallow запрещает сканерам поисковых систем проверять и индексировать указанные файлы сайта.Это может помочь вам предотвратить появление в поисковой выдаче дублированного контента, промежуточных областей или других личных файлов.
- Разрешить разрешает доступ к подпапкам, в то время как родительские папки запрещены.
- Задержка сканирования предписывает поисковым роботам подождать определенное время перед загрузкой файла.
- Sitemap указывает расположение любых файлов Sitemap, связанных с вашим сайтом.
Файлы Robots.txt всегда форматируются одинаково, чтобы их директивы были понятны:
Каждая директива начинается с определения «агента пользователя», которым обычно является сканер поисковой системы.Если вы хотите, чтобы команда применялась ко всем потенциальным пользовательским агентам, вы можете использовать звездочку (*). Чтобы вместо этого настроить таргетинг на определенный пользовательский агент, вы можете добавить его имя. Например, мы могли бы заменить звездочку выше на «Googlebot», чтобы запретить Google сканирование страницы администратора.
Например, мы могли бы заменить звездочку выше на «Googlebot», чтобы запретить Google сканирование страницы администратора.
Понимание того, как использовать и редактировать файл robots.txt , имеет жизненно важное значение. Включенные в него директивы будут определять, как поисковые системы взаимодействуют с вашим сайтом. Они могут помочь вам, скрывая контент, от которого вы хотите отвлечь пользователей, что улучшит общее SEO вашего сайта.
Протестируйте файл
Robots.txtВы можете проверить, есть ли у вас файл robots.txt и , добавив «/robots.txt» в конец URL-адреса вашего сайта в браузере. Это вызовет файл, если он существует. Однако наличие вашего файла не обязательно означает, что он работает правильно.
К счастью, проверить файл robots.txt просто. Вы можете просто скопировать и вставить свой файл в тестер robots.txt .Инструмент выделит все ошибки в файле. Важно отметить, что изменения, внесенные вами в редактор тестера robots. txt , не будут применяться к фактическому файлу — вам все равно придется отредактировать файл на своем сервере.
txt , не будут применяться к фактическому файлу — вам все равно придется отредактировать файл на своем сервере.
Некоторые распространенные ошибки включают запрет на использование файлов CSS или JavaScript, неправильное использование подстановочных знаков, таких как * и $, и случайное запрещение важных страниц. Также важно помнить, что сканеры поисковых систем чувствительны к регистру, поэтому все URL-адреса в вашем файле robots.txt должен появиться так же, как и в вашем браузере.
Создание файла
Robots.txt с подключаемым модулемЕсли на вашем сайте отсутствует файл robots.txt , вы можете легко добавить его в WordPress с помощью плагина Yoast SEO. Это избавит вас от необходимости создавать простой текстовый файл и вручную загружать его на сервер. Если вы предпочитаете создать его вручную, перейдите к разделу «Создание файла Robots.txt вручную» ниже.
Перейдите к инструментам Yoast SEO
Для начала вам необходимо установить и активировать плагин Yoast SEO. Затем вы можете перейти на панель администратора WordPress и выбрать SEO > Tools на боковой панели :
Затем вы можете перейти на панель администратора WordPress и выбрать SEO > Tools на боковой панели :
Это приведет вас к списку полезных инструментов, к которым пользователи Yoast могут получить доступ для эффективного улучшения своего SEO.
Используйте редактор файлов для создания файла
Robots.txtОдним из инструментов, доступных в списке, является редактор файлов. Это позволяет вам редактировать файлы, связанные с SEO вашего сайта, включая файл robots.txt :
Поскольку на вашем сайте его еще нет, выберите «Создать роботов».txt файл:
Откроется редактор файлов, в котором вы сможете редактировать и сохранять новый файл.
Отредактируйте файл по умолчанию
Robots.txt и сохраните его По умолчанию новый файл robots.txt , созданный с помощью Yoast, включает директиву, скрывающую вашу папку wp-admin и разрешающую доступ к вашему файлу admin-ajax. php для всех пользовательских агентов. Рекомендуется оставить эту директиву в файле:
php для всех пользовательских агентов. Рекомендуется оставить эту директиву в файле:
Перед сохранением файла вы также можете добавить любые другие директивы, которые хотите включить.В этом примере мы запретили поисковым роботам Bing доступ ко всем нашим файлам, добавили задержку сканирования в десять миллисекунд для поискового робота Yahoo (Slurp) и направили поисковые роботы в расположение нашей карты сайта. Когда вы закончите вносить свои изменения, не забудьте их сохранить!
Руководство
Robots.txt Создание файлаЕсли вам нужно создать файл robots.txt вручную, процесс так же прост, как создание и загрузка файла на ваш сервер.
- Создайте файл с именем
robots.txt- Убедитесь, что имя написано в нижнем регистре
- Убедитесь, что расширение —
.txt, а не.html
- Добавьте в файл любые необходимые директивы и сохраните
- Загрузите файл с помощью SFTP или SSH-шлюз в корневой каталог вашего сайта
ПРИМЕЧАНИЕ : Если в корне вашего сайта есть физический файл с именем robots., он перезапишет любой динамически сгенерированный файл  txt
txt robots.txt , созданный плагин или тема.
Использование файла robots.txt
Файл robots.txt разбит на блоки пользовательским агентом. Внутри блока каждая директива указывается в новой строке. Например:
Агент пользователя: * Запретить: / Пользовательский агент: Googlebot Запретить: Пользовательский агент: bingbot Запретить: / no-bing-crawl / Запрещено: wp-admin
Пользовательские агенты обычно сокращаются до более общего имени, но это не требуется .
Значения директивы чувствительны к регистру.
- URL-адреса
no-bing-crawlиNo-Bing-Crawl— это разных .
Глобализация и регулярные выражения не поддерживаются полностью .
-
*в поле User-agent — это специальное значение, означающее «любой робот».
Ограничить доступ всех ботов к вашему сайту
(Все сайты в среде URL . wpengine.com имеют следующие
wpengine.com имеют следующие robots.txt применяется автоматически.)
Агент пользователя: * Disallow: /
Ограничить доступ одного робота ко всей площадке
Агент пользователя: BadBotName Disallow: /
Ограничить доступ бота к определенным каталогам и файлам
Пример запрещает ботов на всех страницах wp-admin и странице wp-login.php . Это хороший файл по умолчанию или начальный файл robots.txt .
Агент пользователя: * Запретить: / wp-admin / Запретить: / wp-login.php
Ограничить доступ бота ко всем файлам определенного типа
В примере используется тип файла .pdf
Агент пользователя: * Disallow: /*.pdf$
Ограничить конкретную поисковую систему
Пример использования Googlebot-Image в / wp-content / загружает каталог
User-Agent: Googlebot-Image Запретить: / wp-content / uploads /
Ограничить всех ботов, кроме одного
Пример разрешает только Google
Агент пользователя: Google Запретить: Пользовательский агент: * Disallow: /
Добавление правильных комбинаций директив может быть сложным. К счастью, есть плагины, которые также создают (и тестируют) файл robots.txt за вас. Примеры плагинов:
К счастью, есть плагины, которые также создают (и тестируют) файл robots.txt за вас. Примеры плагинов:
Если вам нужна дополнительная помощь в настройке правил в файле robots.txt, мы рекомендуем посетить Google Developers или The Web Robots Pages для получения дополнительных инструкций.
Задержка сканирования
Если вы видите слишком высокий трафик ботов и это влияет на производительность сервера, задержка сканирования может быть хорошим вариантом. Задержка сканирования позволяет ограничить время, которое должен пройти бот перед сканированием следующей страницы.
Для настройки задержки сканирования используйте следующую директиву, значение настраивается и указывается в секундах:
задержка сканирования: 10
Например, чтобы запретить сканирование всем ботам wp-admin , wp-login.php и установить задержку сканирования для всех ботов на 600 секунд (10 минут):
Агент пользователя: * Запретить: /wp-login.php Запретить: / wp-admin / Задержка сканирования: 600
ПРИМЕЧАНИЕ : службы обхода контента могут иметь свои собственные требования для установки задержки обхода.Как правило, лучше всего напрямую связаться со службой для получения требуемого метода.
Отрегулируйте задержку сканирования для SEMrush
- SEMrush — отличный сервис, но сканирование может оказаться очень тяжелым, что в конечном итоге ухудшит производительность вашего сайта. По умолчанию боты SEMrush игнорируют директивы задержки сканирования в файле robots.txt, поэтому обязательно войдите в их панель управления и включите Уважение задержки сканирования robots.txt .
- Дополнительную информацию о SEMrush можно найти здесь.
Настроить задержку сканирования Bingbot
- Bingbot должен соблюдать директивы
crawl-delay, однако они также позволяют вам установить шаблон управления сканированием.
Настройте задержку сканирования для Google
Подробнее см. В документации поддержки Google)
Откройте страницу настроек скорости сканирования вашего ресурса.
- Если ваша скорость сканирования описывается как , рассчитанная как оптимальная , единственный способ уменьшить скорость сканирования — это подать специальный запрос.Вы не можете увеличить скорость сканирования .
- В противном случае выберите нужный вариант и затем ограничьте скорость сканирования по желанию. Новая скорость сканирования будет действовать в течение 90 дней.
ПРИМЕЧАНИЕ : Хотя эта конфигурация запрещена на нашей платформе, стоит отметить, что задержка сканирования Googlebot не может быть изменена для сайтов, размещенных в подкаталогах, таких как domain.com/blog
Лучшие Лрактики
Прежде всего следует помнить о следующем: непроизводственные сайты должны запрещать использование всех пользовательских агентов. WP Engine автоматически делает это для любых сайтов, использующих домен environmentname .wpengine.com. Только когда вы будете готовы «запустить» свой сайт, вы можете добавить файл robots.txt.
WP Engine автоматически делает это для любых сайтов, использующих домен environmentname .wpengine.com. Только когда вы будете готовы «запустить» свой сайт, вы можете добавить файл robots.txt.
Во-вторых, если вы хотите заблокировать определенного User-Agent, помните, что роботы не обязаны следовать правилам, установленным в вашем файле robots.txt. Лучшей практикой было бы использовать брандмауэр, такой как Sucuri WAF или Cloudflare, который позволяет вам блокировать злоумышленников до того, как они попадут на ваш сайт. Или вы можете обратиться в службу поддержки за дополнительной помощью по блокировке трафика.
Наконец, если у вас очень большая библиотека сообщений и страниц на вашем сайте, Google и другие поисковые системы, индексирующие ваш сайт, могут вызвать проблемы с производительностью. Увеличение срока действия кеша или ограничение скорости сканирования поможет компенсировать это влияние.
СЛЕДУЮЩИЙ ШАГ: устранение ошибок 504
Robots.
 txt и WordPress | WP Engine®
txt и WordPress | WP Engine®Поддержание поисковой оптимизации (SEO) вашего сайта имеет решающее значение для привлечения органического трафика.Однако есть некоторые страницы, такие как дублированный контент или промежуточные области, которые вы не можете захотеть, чтобы пользователи находили через поисковые системы. К счастью, есть способ запретить таким системам, как Google, получать доступ к определенным страницам и отображать их для поисковиков. Редактируя файл robots.txt своего сайта, вы можете контролировать, какой контент будет отображаться на страницах результатов поиска (SERP).
ПРИМЕЧАНИЕ. По умолчанию WP Engine ограничивает трафик поисковых систем на любой сайт с помощью установки .wpengine.com домен. Это означает, что поисковые системы не смогут посещать сайты , а не , которые в настоящее время находятся в разработке, с использованием личного домена.
О
Robots.txt Файл robots. txt содержит инструкции для поисковых систем о том, как находить и извлекать информацию с вашего веб-сайта. Этот процесс называется «сканированием». После того, как страница просканирована, она будет проиндексирована, чтобы поисковая система могла быстро найти и отобразить ее позже.
txt содержит инструкции для поисковых систем о том, как находить и извлекать информацию с вашего веб-сайта. Этот процесс называется «сканированием». После того, как страница просканирована, она будет проиндексирована, чтобы поисковая система могла быстро найти и отобразить ее позже.
Первое, что делает сканер поисковой системы, когда попадает на сайт, — это ищет файл robots.txt . Если его нет, он продолжит сканирование остальной части сайта в обычном режиме. Если он найдет этот файл, сканер будет искать в нем какие-либо команды, прежде чем продолжить.
В файле robots.txt можно найти четыре общие команды:
- Disallow запрещает сканерам поисковых систем проверять и индексировать указанные файлы сайта.Это может помочь вам предотвратить появление в поисковой выдаче дублированного контента, промежуточных областей или других личных файлов.
- Разрешить разрешает доступ к подпапкам, в то время как родительские папки запрещены.

- Задержка сканирования предписывает поисковым роботам подождать определенное время перед загрузкой файла.
- Sitemap указывает расположение любых файлов Sitemap, связанных с вашим сайтом.
Файлы Robots.txt всегда форматируются одинаково, чтобы их директивы были понятны:
Каждая директива начинается с определения «агента пользователя», которым обычно является сканер поисковой системы.Если вы хотите, чтобы команда применялась ко всем потенциальным пользовательским агентам, вы можете использовать звездочку (*). Чтобы вместо этого настроить таргетинг на определенный пользовательский агент, вы можете добавить его имя. Например, мы могли бы заменить звездочку выше на «Googlebot», чтобы запретить Google сканирование страницы администратора.
Понимание того, как использовать и редактировать файл robots.txt , имеет жизненно важное значение. Включенные в него директивы будут определять, как поисковые системы взаимодействуют с вашим сайтом. Они могут помочь вам, скрывая контент, от которого вы хотите отвлечь пользователей, что улучшит общее SEO вашего сайта.
Они могут помочь вам, скрывая контент, от которого вы хотите отвлечь пользователей, что улучшит общее SEO вашего сайта.
Протестируйте файл
Robots.txtВы можете проверить, есть ли у вас файл robots.txt и , добавив «/robots.txt» в конец URL-адреса вашего сайта в браузере. Это вызовет файл, если он существует. Однако наличие вашего файла не обязательно означает, что он работает правильно.
К счастью, проверить файл robots.txt просто. Вы можете просто скопировать и вставить свой файл в тестер robots.txt .Инструмент выделит все ошибки в файле. Важно отметить, что изменения, внесенные вами в редактор тестера robots.txt , не будут применяться к фактическому файлу — вам все равно придется отредактировать файл на своем сервере.
Некоторые распространенные ошибки включают запрет на использование файлов CSS или JavaScript, неправильное использование подстановочных знаков, таких как * и $, и случайное запрещение важных страниц.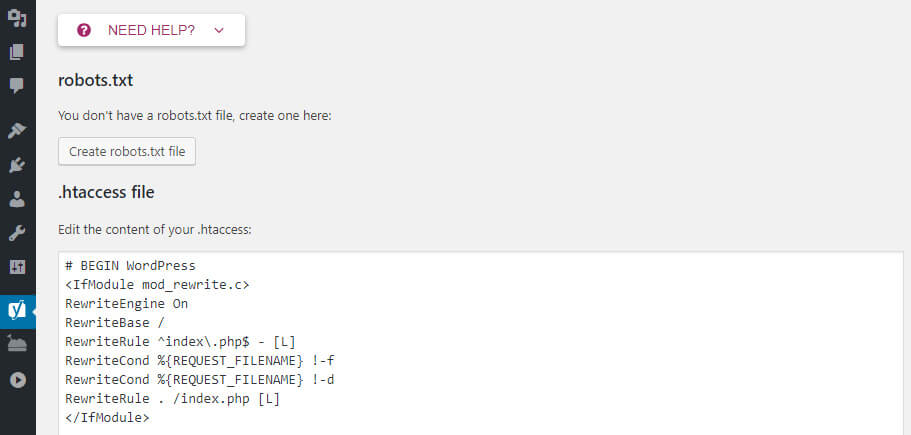 Также важно помнить, что сканеры поисковых систем чувствительны к регистру, поэтому все URL-адреса в вашем файле robots.txt должен появиться так же, как и в вашем браузере.
Также важно помнить, что сканеры поисковых систем чувствительны к регистру, поэтому все URL-адреса в вашем файле robots.txt должен появиться так же, как и в вашем браузере.
Создание файла
Robots.txt с подключаемым модулемЕсли на вашем сайте отсутствует файл robots.txt , вы можете легко добавить его в WordPress с помощью плагина Yoast SEO. Это избавит вас от необходимости создавать простой текстовый файл и вручную загружать его на сервер. Если вы предпочитаете создать его вручную, перейдите к разделу «Создание файла Robots.txt вручную» ниже.
Перейдите к инструментам Yoast SEO
Для начала вам необходимо установить и активировать плагин Yoast SEO.Затем вы можете перейти на панель администратора WordPress и выбрать SEO > Tools на боковой панели :
.Это приведет вас к списку полезных инструментов, к которым пользователи Yoast могут получить доступ для эффективного улучшения своего SEO.
Используйте редактор файлов для создания файла
Robots. txt
txt Одним из инструментов, доступных в списке, является редактор файлов. Это позволяет вам редактировать файлы, связанные с SEO вашего сайта, включая файл robots.txt :
Поскольку на вашем сайте его еще нет, выберите «Создать роботов».txt файл:
Откроется редактор файлов, в котором вы сможете редактировать и сохранять новый файл.
Отредактируйте файл по умолчанию
Robots.txt и сохраните егоПо умолчанию новый файл robots.txt , созданный с помощью Yoast, включает директиву, скрывающую вашу папку wp-admin и разрешающую доступ к вашему файлу admin-ajax.php для всех пользовательских агентов. Рекомендуется оставить эту директиву в файле:
Перед сохранением файла вы также можете добавить любые другие директивы, которые хотите включить.В этом примере мы запретили поисковым роботам Bing доступ ко всем нашим файлам, добавили задержку сканирования в десять миллисекунд для поискового робота Yahoo (Slurp) и направили поисковые роботы в расположение нашей карты сайта. Когда вы закончите вносить свои изменения, не забудьте их сохранить!
Когда вы закончите вносить свои изменения, не забудьте их сохранить!
Руководство
Robots.txt Создание файлаЕсли вам нужно создать файл robots.txt вручную, процесс так же прост, как создание и загрузка файла на ваш сервер.
- Создайте файл с именем
robots.txt- Убедитесь, что имя написано в нижнем регистре
- Убедитесь, что расширение —
.txt, а не.html
- Добавьте в файл любые необходимые директивы и сохраните
- Загрузите файл с помощью SFTP или SSH-шлюз в корневой каталог вашего сайта
ПРИМЕЧАНИЕ : Если в корне вашего сайта есть физический файл с именем robots.txt , он перезапишет любой динамически сгенерированный файл robots.txt , созданный плагин или тема.
Использование файла robots.txt
Файл robots.txt разбит на блоки пользовательским агентом. Внутри блока каждая директива указывается в новой строке. Например:
Внутри блока каждая директива указывается в новой строке. Например:
Агент пользователя: * Запретить: / Пользовательский агент: Googlebot Запретить: Пользовательский агент: bingbot Запретить: / no-bing-crawl / Запрещено: wp-admin
Пользовательские агенты обычно сокращаются до более общего имени, но это не требуется .
Значения директивы чувствительны к регистру.
- URL-адреса
no-bing-crawlиNo-Bing-Crawl— это разных .
Глобализация и регулярные выражения не поддерживаются полностью .
-
*в поле User-agent — это специальное значение, означающее «любой робот».
Ограничить доступ всех ботов к вашему сайту
(Все сайты в среде URL .wpengine.com имеют следующие robots.txt применяется автоматически.)
Агент пользователя: * Disallow: /
Ограничить доступ одного робота ко всей площадке
Агент пользователя: BadBotName Disallow: /
Ограничить доступ бота к определенным каталогам и файлам
Пример запрещает ботов на всех страницах wp-admin и странице wp-login.. Это хороший файл по умолчанию или начальный файл  php
php robots.txt .
Агент пользователя: * Запретить: / wp-admin / Запретить: / wp-login.php
Ограничить доступ бота ко всем файлам определенного типа
В примере используется тип файла .pdf
Агент пользователя: * Disallow: /*.pdf$
Ограничить конкретную поисковую систему
Пример использования Googlebot-Image в / wp-content / загружает каталог
User-Agent: Googlebot-Image Запретить: / wp-content / uploads /
Ограничить всех ботов, кроме одного
Пример разрешает только Google
Агент пользователя: Google Запретить: Пользовательский агент: * Disallow: /
Добавление правильных комбинаций директив может быть сложным.К счастью, есть плагины, которые также создают (и тестируют) файл robots. txt за вас. Примеры плагинов:
txt за вас. Примеры плагинов:
Если вам нужна дополнительная помощь в настройке правил в файле robots.txt, мы рекомендуем посетить Google Developers или The Web Robots Pages для получения дополнительных инструкций.
Задержка сканирования
Если вы видите слишком высокий трафик ботов и это влияет на производительность сервера, задержка сканирования может быть хорошим вариантом. Задержка сканирования позволяет ограничить время, которое должен пройти бот перед сканированием следующей страницы.
Для настройки задержки сканирования используйте следующую директиву, значение настраивается и указывается в секундах:
задержка сканирования: 10
Например, чтобы запретить сканирование всем ботам wp-admin , wp-login.php и установить задержку сканирования для всех ботов на 600 секунд (10 минут):
Агент пользователя: * Запретить: /wp-login.php Запретить: / wp-admin / Задержка сканирования: 600
ПРИМЕЧАНИЕ : службы обхода контента могут иметь свои собственные требования для установки задержки обхода. Как правило, лучше всего напрямую связаться со службой для получения требуемого метода.
Как правило, лучше всего напрямую связаться со службой для получения требуемого метода.
Отрегулируйте задержку сканирования для SEMrush
- SEMrush — отличный сервис, но сканирование может оказаться очень тяжелым, что в конечном итоге ухудшит производительность вашего сайта. По умолчанию боты SEMrush игнорируют директивы задержки сканирования в файле robots.txt, поэтому обязательно войдите в их панель управления и включите Уважение задержки сканирования robots.txt .
- Дополнительную информацию о SEMrush можно найти здесь.
Настроить задержку сканирования Bingbot
- Bingbot должен соблюдать директивы
crawl-delay, однако они также позволяют вам установить шаблон управления сканированием.
Настройте задержку сканирования для Google
Подробнее см. В документации поддержки Google)
Откройте страницу настроек скорости сканирования вашего ресурса.
- Если ваша скорость сканирования описывается как , рассчитанная как оптимальная , единственный способ уменьшить скорость сканирования — это подать специальный запрос.Вы не можете увеличить скорость сканирования .
- В противном случае выберите нужный вариант и затем ограничьте скорость сканирования по желанию. Новая скорость сканирования будет действовать в течение 90 дней.
ПРИМЕЧАНИЕ : Хотя эта конфигурация запрещена на нашей платформе, стоит отметить, что задержка сканирования Googlebot не может быть изменена для сайтов, размещенных в подкаталогах, таких как domain.com/blog
Лучшие Лрактики
Прежде всего следует помнить о следующем: непроизводственные сайты должны запрещать использование всех пользовательских агентов.WP Engine автоматически делает это для любых сайтов, использующих домен environmentname .wpengine.com. Только когда вы будете готовы «запустить» свой сайт, вы можете добавить файл robots. txt.
txt.
Во-вторых, если вы хотите заблокировать определенного User-Agent, помните, что роботы не обязаны следовать правилам, установленным в вашем файле robots.txt. Лучшей практикой было бы использовать брандмауэр, такой как Sucuri WAF или Cloudflare, который позволяет вам блокировать злоумышленников до того, как они попадут на ваш сайт. Или вы можете обратиться в службу поддержки за дополнительной помощью по блокировке трафика.
Наконец, если у вас очень большая библиотека сообщений и страниц на вашем сайте, Google и другие поисковые системы, индексирующие ваш сайт, могут вызвать проблемы с производительностью. Увеличение срока действия кеша или ограничение скорости сканирования поможет компенсировать это влияние.
СЛЕДУЮЩИЙ ШАГ: устранение ошибок 504
Полное руководство по WordPress robots.txt (и как его использовать для SEO)
WordPress
access_time21 февраля 2021 г.
hourglass_empty7min Read
Чтобы обеспечить высокий рейтинг вашего сайта в результатах поиска Pages (SERPs), вам нужно будет упростить поисковым роботам поиск наиболее важных страниц.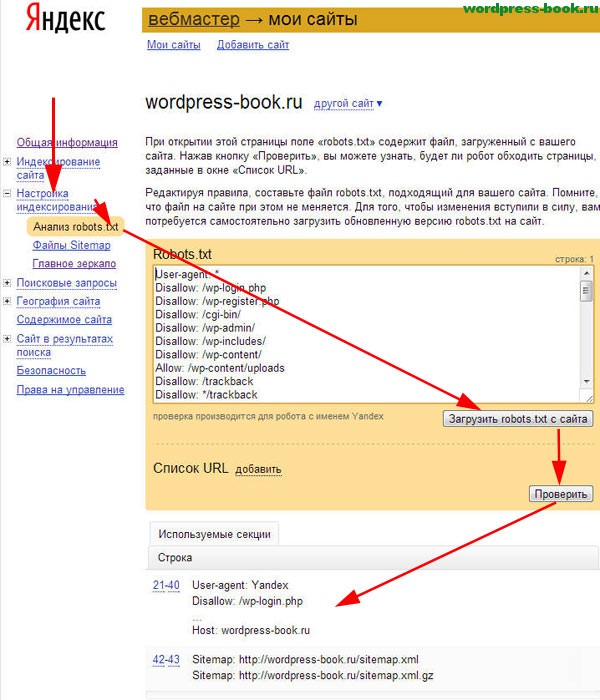 Наличие хорошо структурированного файла robots.txt поможет направить этих ботов на страницы, которые вы хотите проиндексировать (и избежать остальных).
Наличие хорошо структурированного файла robots.txt поможет направить этих ботов на страницы, которые вы хотите проиндексировать (и избежать остальных).
В этой статье мы расскажем:
- Что такое файл robots.txt и почему он важен
- Где находится файл robots.txt WordPress .
- Как создать файл robots.txt .
- Какие правила включить в файл robots.txt WordPress .
- Как протестировать файл robots.txt и отправить его в Google Search Console.
К концу нашего обсуждения у вас будет все необходимое для настройки идеального файла robots.txt для вашего веб-сайта WordPress. Давайте нырнем!
Что такое файл robots.txt
WordPress (и зачем он вам нужен) Файл robots.txt по умолчанию для WordPress является довольно простым, но вы можете легко заменить его. Когда вы создаете новый веб-сайт, поисковые системы будут отправлять своих миньонов (или ботов), чтобы они «пролезли» по нему и составили карту всех содержащихся на нем страниц. Таким образом, они будут знать, какие страницы отображать в качестве результатов, когда кто-то ищет похожие ключевые слова. На базовом уровне это достаточно просто.
Таким образом, они будут знать, какие страницы отображать в качестве результатов, когда кто-то ищет похожие ключевые слова. На базовом уровне это достаточно просто.
Проблема в том, что современные веб-сайты содержат на много, на элементов больше, чем просто страницы. WordPress позволяет вам, например, устанавливать плагины, которые часто имеют свои собственные каталоги. Однако вы не хотите, чтобы они отображались в результатах вашей поисковой системы, поскольку это не релевантный контент.
Файл robots.txt предоставляет набор инструкций для роботов поисковых систем.Он говорит им: «Эй, вы можете посмотреть сюда, но не заходите в те комнаты там!» Этот файл может быть сколь угодно подробным, и его довольно легко создать, даже если вы не технический мастер.
На практике поисковые системы все равно будут сканировать ваш веб-сайт, даже если у вас не настроен файл robots.txt . Однако не создавать его неэффективно. Без этого файла вы предоставляете ботам индексировать весь ваш контент, и они настолько тщательны, что могут в конечном итоге показать те части вашего веб-сайта, к которым вы не хотите, чтобы другие люди имели доступ.
Что еще более важно, без файла robots.txt у вас будет много ботов, которые будут сканировать весь ваш сайт. Это может отрицательно сказаться на его производительности. Даже если попадание незначительно, скорость страницы всегда должна быть в верхней части вашего списка приоритетов. В конце концов, есть несколько вещей, которые люди ненавидят так же сильно, как медленные веб-сайты (в том числе и мы!).
Где находится файл robots.txt WordPress
Когда вы создаете веб-сайт WordPress, он автоматически устанавливает виртуальный robots.txt , расположенный в основной папке вашего сервера. Например, если ваш сайт расположен по адресу yourfakewebsite.com , вы сможете посетить адрес yourfakewebsite.com/robots.txt, и увидеть такой файл:
User-agent: * Запретить: / wp-admin / Disallow: / wp-includes /
Это пример очень простого файла robots.txt . Проще говоря, часть сразу после User-agent: объявляет, к каким ботам применяются приведенные ниже правила.Звездочка означает, что правила универсальны и применимы ко всем ботам. В этом случае файл сообщает этим ботам, что они не могут войти в ваши каталоги wp-admin и wp-includes . В этом есть определенный смысл, поскольку эти две папки содержат много конфиденциальных файлов.
Проще говоря, часть сразу после User-agent: объявляет, к каким ботам применяются приведенные ниже правила.Звездочка означает, что правила универсальны и применимы ко всем ботам. В этом случае файл сообщает этим ботам, что они не могут войти в ваши каталоги wp-admin и wp-includes . В этом есть определенный смысл, поскольку эти две папки содержат много конфиденциальных файлов.
Однако вы можете добавить дополнительные правила в свой собственный файл. Прежде чем вы сможете это сделать, вам нужно понять, что это виртуальный файл . Обычно расположение robots.txt WordPress находится в корневом каталоге , который часто называется public_html или www (или назван в честь вашего веб-сайта):
Однако файл robots.txt , созданный WordPress по умолчанию, вообще недоступен из любого каталога. Он работает, но если вы хотите внести в него изменения, вам нужно будет создать свой собственный файл и загрузить его в корневую папку в качестве замены.
Мы рассмотрим несколько способов создания нового файла robots.txt для WordPress за минуту. А пока давайте поговорим о том, как определить, какие правила следует включать в ваши.
Какие правила включить в ваш WordPress
robots.txt ФайлВ последнем разделе вы видели пример сгенерированного WordPress файла robots.txt . Он включал только два коротких правила, но большинство веб-сайтов устанавливали больше. Давайте взглянем на два разных файла robots.txt и и поговорим о том, что каждый из них делает по-своему.
Вот наш первый WordPress robots.txt , пример:
User-agent: * Позволять: / # Запрещенные подкаталоги Disallow: / checkout / Запретить: / images / Disallow: / forum /
Это общий robots.txt для сайта с форумом. Поисковые системы часто индексируют каждую ветку форума. Однако в зависимости от того, для чего предназначен ваш форум, вы можете запретить его. Таким образом, Google не будет индексировать сотни сообщений о пользователях, которые ведут светскую беседу. Вы также можете установить правила, указывающие на определенные подфорумы, которых следует избегать, и позволить поисковым системам сканировать остальные из них.
Таким образом, Google не будет индексировать сотни сообщений о пользователях, которые ведут светскую беседу. Вы также можете установить правила, указывающие на определенные подфорумы, которых следует избегать, и позволить поисковым системам сканировать остальные из них.
Вы также заметите строку с надписью Allow: / в верхней части файла. Эта строка сообщает ботам, что они могут сканировать все страницы вашего веб-сайта, за исключением исключений, которые вы установили ниже.Точно так же вы заметите, что мы установили эти правила как универсальные (со звездочкой), как это делает виртуальный файл robots.txt WordPress.
Теперь давайте посмотрим на другой пример файла robots.txt в WordPress:
User-agent: * Запретить: / wp-admin / Запретить: / wp-includes / Пользовательский агент: Bingbot Disallow: /
В этом файле мы устанавливаем те же правила, что и WordPress по умолчанию. Однако мы также добавили новый набор правил, которые не позволяют поисковому роботу Bing сканировать наш веб-сайт. Bingbot, как вы могли догадаться, — это имя этого бота.
Bingbot, как вы могли догадаться, — это имя этого бота.
Вы можете довольно точно определить, какие боты поисковых систем получают доступ к вашему сайту, а какие нет. На практике, конечно, Bingbot довольно безобиден (даже если он не такой крутой, как Googlebot). Однако есть — это вредоносных ботов.
Плохая новость в том, что они не всегда следуют инструкциям вашего файла robots.txt (в конце концов, они бунтовщики). Следует иметь в виду, что, хотя большинство ботов будут следовать инструкциям, которые вы предоставили в этом файле, вы не заставляете их делать это.Вы просто вежливо просите.
Если вы прочтете эту тему, вы найдете множество предложений о том, что разрешить и что заблокировать на своем веб-сайте WordPress. Однако, по нашему опыту, чем меньше правил, тем лучше. Вот пример того, как мы рекомендуем, чтобы ваш первый файл robots.txt выглядел так:
User-Agent: * Разрешить: / wp-content / uploads / Disallow: / wp-content / plugins /
Традиционно WordPress любит блокировать доступ к каталогам wp-admin и wp-includes . Однако это больше не считается оптимальной практикой. Кроме того, если вы добавляете метаданные к изображениям в целях поисковой оптимизации (SEO), не имеет смысла запрещать ботам сканировать эту информацию. Вместо этого два приведенных выше правила охватывают то, что требуется для большинства основных сайтов.
Однако это больше не считается оптимальной практикой. Кроме того, если вы добавляете метаданные к изображениям в целях поисковой оптимизации (SEO), не имеет смысла запрещать ботам сканировать эту информацию. Вместо этого два приведенных выше правила охватывают то, что требуется для большинства основных сайтов.
Однако то, что вы включите в файл robots.txt , будет зависеть от вашего конкретного сайта и потребностей. Так что не стесняйтесь проводить дополнительные исследования самостоятельно!
Как создать WordPress
robots.txt Файл (3 метода)После того, как вы определились, что будет помещено в ваш файл robots.txt , остается только создать его. Вы можете редактировать robots.txt и в WordPress с помощью плагина или вручную. В этом разделе мы научим вас использовать два популярных плагина для выполнения работы и обсудим, как создать и загрузить файл самостоятельно. Поехали!
1. Используйте Yoast SEO
Yoast SEO вряд ли нуждается в представлении.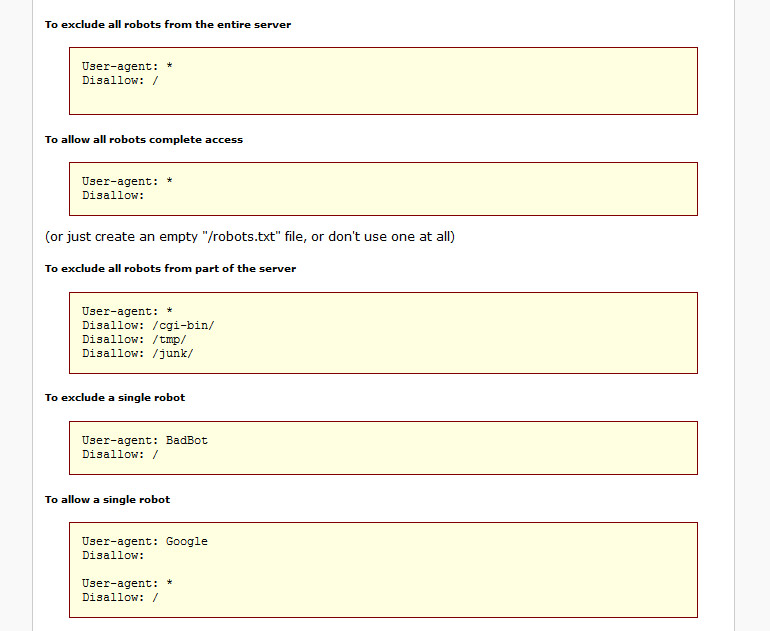 Это самый популярный плагин SEO для WordPress, который позволяет вам оптимизировать ваши сообщения и страницы, чтобы лучше использовать ваши ключевые слова.Кроме того, он также оказывает вам помощь, когда дело доходит до повышения читабельности вашего контента, а это значит, что он сможет понравиться большему количеству людей.
Это самый популярный плагин SEO для WordPress, который позволяет вам оптимизировать ваши сообщения и страницы, чтобы лучше использовать ваши ключевые слова.Кроме того, он также оказывает вам помощь, когда дело доходит до повышения читабельности вашего контента, а это значит, что он сможет понравиться большему количеству людей.
Лично мы поклонники Yoast SEO из-за простоты его использования. То же самое относится и к созданию файла robots.txt . После установки и активации плагина перейдите на вкладку SEO ›Инструменты на панели инструментов и найдите параметр с надписью Редактор файлов:
. При нажатии на эту ссылку вы перейдете на новую страницу, где сможете отредактируйте свой .htaccess , не покидая панели управления. Также есть удобная кнопка с надписью Create robots.txt file , которая делает именно то, что вы ожидаете:
После того, как вы нажмете эту кнопку, на вкладке появится новый редактор, в котором вы можете изменить свой robots. txt файл напрямую. Имейте в виду, что Yoast SEO устанавливает свои собственные правила по умолчанию, которые отменяют существующий виртуальный файл robots.txt .
txt файл напрямую. Имейте в виду, что Yoast SEO устанавливает свои собственные правила по умолчанию, которые отменяют существующий виртуальный файл robots.txt .
Каждый раз, когда вы добавляете или удаляете правила, не забудьте нажать Сохранить изменения в robots.txt , чтобы они остались:
Это достаточно просто! Теперь посмотрим, как другой популярный плагин делает то же самое.
2. Плагин All in One SEO Pack
All in One SEO Pack — еще одно громкое имя, когда речь идет о WordPress SEO. Он включает в себя большинство функций Yoast SEO, но некоторые люди предпочитают его, потому что это более легкий плагин. Что касается robots.txt и , создание файла с помощью этого плагина также просто.
После настройки плагина перейдите на страницу All in One SEO> Feature Manager на панели инструментов.Внутри вы найдете опцию Robots.txt с заметной кнопкой Activate прямо под ней. Идите вперед и нажмите на это:
Идите вперед и нажмите на это:
Теперь новая вкладка Robots.txt появится под вашим меню All in One SEO . Если вы нажмете на нее, вы увидите варианты добавления новых правил в файл, сохранения внесенных вами изменений или полного удаления:
Обратите внимание, что вы не можете вносить изменения в файл robots.txt и напрямую. используя этот плагин.Сам файл выделен серым цветом, в отличие от Yoast SEO, который позволяет вам вводить все, что вы хотите:
В любом случае добавить новые правила просто, поэтому не позволяйте этому небольшому недостатку обескураживать вас. Что еще более важно, All in One SEO Pack также включает функцию, которая может помочь вам блокировать «плохих» ботов, доступ к которым вы можете получить на вкладке All in One SEO :
Это все, что вам нужно сделать, если вы решите использовать это метод. Однако давайте поговорим о том, как создать файл robots.txt вручную, если вы не хотите устанавливать дополнительный плагин только для выполнения этой задачи.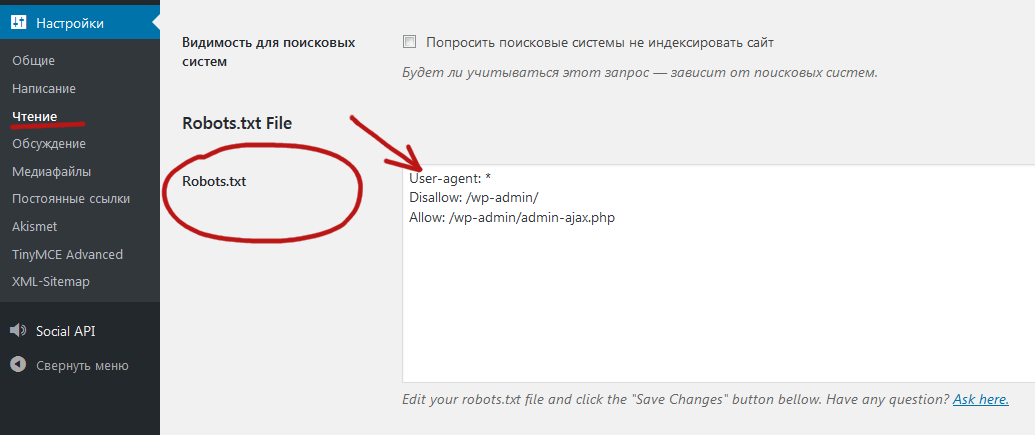
3. Создайте и загрузите свой файл WordPress
robots.txt через FTPСоздание файла txt не может быть проще. Все, что вам нужно сделать, это открыть свой любимый текстовый редактор (например, Блокнот или TextEdit) и ввести несколько строк. Затем вы можете сохранить файл, используя любое имя и тип файла txt . На это уходит буквально секунда, поэтому имеет смысл отредактировать robots.txt в WordPress без использования плагина.
Вот быстрый пример одного из таких файлов:
Для целей этого руководства мы сохранили этот файл непосредственно на нашем компьютере. После того, как вы создали и сохранили свой собственный файл, вам нужно будет подключиться к своему веб-сайту через FTP. Если вы не знаете, как это сделать, у нас есть руководство, как это сделать с помощью удобного для новичков клиента FileZilla.
После подключения к своему сайту перейдите в папку public_html . Затем все, что вам нужно сделать, это загрузить robots.txt с вашего компьютера на ваш сервер. Вы можете сделать это, щелкнув файл правой кнопкой мыши с помощью локального навигатора FTP-клиента или просто перетащив его на место:
Затем все, что вам нужно сделать, это загрузить robots.txt с вашего компьютера на ваш сервер. Вы можете сделать это, щелкнув файл правой кнопкой мыши с помощью локального навигатора FTP-клиента или просто перетащив его на место:
Загрузка файла должна занять всего несколько секунд. Как видите, этот метод почти так же прост, как использование плагина.
Как протестировать файл robots.txt WordPress и отправить его в консоль поиска Google
После создания и загрузки файла robots.txt WordPress можно использовать консоль поиска Google, чтобы проверить его на наличие ошибок.Search Console — это набор инструментов, которые Google предлагает, чтобы помочь вам отслеживать, как ваш контент отображается в результатах поиска. Одним из этих инструментов является программа проверки robots.txt , которую вы можете использовать, войдя в консоль и перейдя на вкладку robots.txt Tester :
Внутри вы найдете поле редактора, в которое вы можете добавить свой WordPress robots.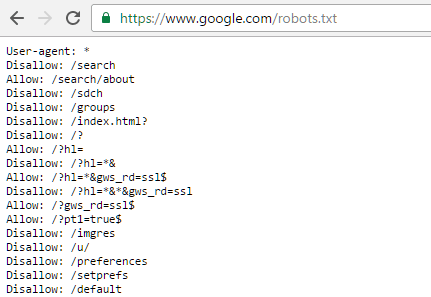 txt код файла и нажмите кнопку Отправить справа внизу. Консоль поиска Google спросит, хотите ли вы использовать этот новый код или вытащите файл со своего веб-сайта.Нажмите на вариант с надписью Попросите Google обновить , чтобы отправить его вручную:
txt код файла и нажмите кнопку Отправить справа внизу. Консоль поиска Google спросит, хотите ли вы использовать этот новый код или вытащите файл со своего веб-сайта.Нажмите на вариант с надписью Попросите Google обновить , чтобы отправить его вручную:
Теперь платформа проверит ваш файл на наличие ошибок. Если есть, он укажет вам на них. Однако к настоящему времени вы видели более одного примера файла robots.txt для WordPress , так что велики шансы, что ваш пример идеален!
Заключение
Чтобы повысить популярность вашего сайта, вам необходимо убедиться, что роботы поисковых систем сканируют наиболее релевантную информацию.Как мы видели, хорошо настроенный файл robots.txt WordPress позволит вам точно определять, как эти боты взаимодействуют с вашим сайтом. Таким образом, они смогут предоставить пользователям более релевантный и полезный контент.
У вас есть вопросы о том, как отредактировать robots. txt в WordPress? Дайте нам знать в комментариях ниже!
txt в WordPress? Дайте нам знать в комментариях ниже!
Как оптимизировать файл WordPress Robots.txt для улучшения SEO
Если вам интересно, как оптимизировать роботов WordPress.txt для улучшения SEO, вы попали в нужное место.
В этом кратком руководстве я объясню, что такое файл robots.txt, почему так важно улучшить ваш поисковый рейтинг, а также как внести в него изменения и отправить в Google.
Давайте нырнем!
Что такое файл robots.txt WordPress и нужно ли мне о нем беспокоиться?
Файл robots.txt — это файл на вашем сайте, который позволяет запрещать поисковым системам доступ к определенным файлам и папкам. Вы можете использовать его, чтобы запретить роботам Google (и других поисковых систем) сканировать определенные страницы вашего сайта.Вот пример файла:
Итак, как отказ в доступе к поисковым системам на самом деле улучшает ваше SEO? Кажется нелогичным…
Это работает так: чем больше страниц на вашем сайте, тем больше страниц Google должен сканировать.
Например, если в вашем блоге много страниц с категориями и тегами, эти страницы имеют низкое качество и не нуждаются в сканировании поисковыми системами; они просто расходуют бюджет сканирования вашего сайта (выделенное количество страниц, которые Google будет сканировать на вашем сайте в любой момент времени).
Бюджет сканирования важен, потому что он определяет, насколько быстро Google улавливает изменения на вашем сайте и, следовательно, насколько быстро вы занимаетесь рейтингом. Это может особенно помочь в SEO электронной коммерции!
Просто будьте осторожны, делая это правильно, так как это может навредить вашему SEO, если будет сделано плохо. Для получения дополнительной информации о том, как правильно не индексировать нужные страницы, ознакомьтесь с этим руководством DeepCrawl.
Итак, вам нужно возиться с вашим файлом robots.txt в WordPress?
Если вы находитесь в высококонкурентной нише с большим сайтом, возможно.Однако, если вы только начинаете свой первый блог, создание ссылок на ваш контент и создание множества высококачественных статей являются более важными приоритетами.
Как оптимизировать файл robots.txt WordPress для улучшения SEO
Теперь давайте обсудим, как на самом деле получить (или создать) и оптимизировать файл robots.txt WordPress.
Robots.txt обычно находится в корневой папке вашего сайта. Вам нужно будет подключиться к своему сайту с помощью FTP-клиента или с помощью файлового менеджера cPanel, чтобы просмотреть его.Это обычный текстовый файл, который затем можно открыть в Блокноте.
Если у вас нет файла robots.txt в корневом каталоге вашего сайта, вы можете его создать. Все, что вам нужно сделать, это создать новый текстовый файл на вашем компьютере и сохранить его как robots.txt. Затем просто загрузите его в корневую папку своего сайта.
Как выглядит идеальный файл robots.txt?
Формат файла robots.txt действительно прост. В первой строке обычно указывается пользовательский агент. Пользовательский агент — это имя поискового бота, с которым вы пытаетесь связаться.Например, Googlebot или Bingbot . Вы можете использовать звездочку
Вы можете использовать звездочку * , чтобы проинструктировать всех ботов.
Следующая строка следует с инструкциями Allow или Disallow для поисковых систем, чтобы они знали, какие части вы хотите, чтобы они индексировали, а какие — нет.
Вот пример:
Пользовательский агент: *
Разрешить: /? Display = wide
Разрешить: / wp-content / uploads /
Запретить: /readme.html
Запретить: / ссылаться /
Карта сайта: http: // www.codeinwp.com/post-sitemap.xml
Карта сайта: http://www.codeinwp.com/page-sitemap.xml
Карта сайта: http://www.codeinwp.com/deals-sitemap.xml
Карта сайта: http://www.codeinwp.com/hosting-sitemap.xml Обратите внимание: если вы используете такой плагин, как Yoast или All in One SEO, вам может не понадобиться добавлять раздел карты сайта, поскольку они пытаются сделать это автоматически. Если это не удается, вы можете добавить его вручную, как в примере выше.
Что мне запретить или noindex?
В руководстве Google для веб-мастеров они советуют веб-мастерам не использовать своих роботов. txt, чтобы скрыть некачественный контент. Таким образом, использование файла robots.txt для предотвращения индексации Google вашей категории, даты и других страниц архива может быть неразумным выбором.
txt, чтобы скрыть некачественный контент. Таким образом, использование файла robots.txt для предотвращения индексации Google вашей категории, даты и других страниц архива может быть неразумным выбором.
Помните, что цель файла robots.txt — указать ботам, что делать с содержимым, которое они сканируют на вашем сайте. Это не мешает им сканировать ваш сайт.
Кроме того, вам не нужно добавлять страницу входа в WordPress, каталог администратора или страницу регистрации в robots.txt, потому что страницы входа и регистрации содержат тег noindex, автоматически добавляемый WordPress.
Однако я рекомендую вам запретить использование файла readme.html в вашем файле robots.txt. Этот файл readme может использовать кто-то, пытающийся выяснить, какую версию WordPress вы используете. Если это человек, он может легко получить доступ к файлу, просто перейдя к нему. Кроме того, установка тега запрета может блокировать злонамеренные атаки.
Как мне отправить мой файл robots.
 txt WordPress в Google?
txt WordPress в Google?После обновления или создания файла robots.txt вы можете отправить его в Google с помощью консоли поиска Google.
Однако я рекомендую сначала протестировать его с помощью инструмента тестирования Google robots.txt.
Если вы не видите здесь созданную версию, вам придется повторно загрузить созданный вами файл robots.txt на свой сайт WordPress. Вы можете сделать это с помощью Yoast SEO.
Заключение
Теперь вы знаете, как оптимизировать файл robots.txt WordPress для улучшения SEO.
Не забывайте проявлять осторожность при внесении каких-либо серьезных изменений в ваш сайт через robots.txt. Хотя эти изменения могут улучшить ваш поисковый трафик, они также могут принести больше вреда, чем пользы, если вы не будете осторожны.
И если вы очень хотите узнать больше, ознакомьтесь с нашим полным обзором руководств по WordPress!
Дайте нам знать в комментариях; у вас есть вопросы по оптимизации файла robots.