Robots.txt для WordPress, идеальный вариант robots.txt для WP
Файл robots.txt это первоначальный, и один из главнейших инструментов для корректной индексации ваших сайтов и их контента. Отсутствие данного файла приведет к печальным последствиям которые тяжело будет исправить. От того как вы настроите robots.txt зависит что попадет в выдачу по запросам в поисковых системах. Сейчас рассмотрим правильный файл robots.txt для WordPress сайта.
- Для чего использовать robots.txt?
Перед тем как приступать к созданию и наполнению давайте разберем саму суть данного файла.
Ваш сайт это набор файлов и папок, некоторые из которых нужно защитить от чтения от сторонних глаз, которыми являются так же и поисковые роботы, пришедшие прочитать и запомнить наш контент, для дальнейшей выдачи в поиске.
Чем занимается поисковой робот на сайте?
Итак, к примеру ваш сайт посетил поисковой робот, что он делает в первую очередь? Во-первых пытается найти уникальную информацию, которую сможет занести в свою базу данных. Если роботс отсутствует, а именно к нему в первую очередь обращается робот, тогда он начинает «читать» файлы находящиеся в корне сайта, что конечно же нам не очень понравиться, ведь он не только не найдет там нужную ему информацию, а и прочитает наши данные настроек, которые созданы для нашей личной цели. Именно для этого и существует robots.txt. Он дает указания роботу куда ходить нужно, а куда заглядывать не стоит.
Если роботс отсутствует, а именно к нему в первую очередь обращается робот, тогда он начинает «читать» файлы находящиеся в корне сайта, что конечно же нам не очень понравиться, ведь он не только не найдет там нужную ему информацию, а и прочитает наши данные настроек, которые созданы для нашей личной цели. Именно для этого и существует robots.txt. Он дает указания роботу куда ходить нужно, а куда заглядывать не стоит.
Создание и размещение файла на сайте WordPress.
Для того что бы создать путеводитель для роботов, вам потребуется обычный блокнот windows, в котором вы будете прописывать нужные команды для поисковых роботов. После этого нужно сохранить файл в формате «txt», под названием «robots». На этом создание завершено, далее в статье мы рассмотрим какие же команды должны находиться в robots.txt для WordPress.
Где размещать?
Robots.txt размещается на вашем хостинге, непосредственно в корневой папке сайта, куда мы перенесли наш сайт. Теперь поисковой робот перед тем как лазить по нашему сайту, сначала спросит разрешение куда ему можно, а куда запрещено заходить.
Теперь поисковой робот перед тем как лазить по нашему сайту, сначала спросит разрешение куда ему можно, а куда запрещено заходить.
Важно: при размещении документа в подкаталогах, роботы не смогут найти этот файл.
Зайдя к вам на сайт робот заходит смотрит предназначеную для него «инструкцию» и начинает его изучать. Изучив до конца он пойдет по выбранному вами пути индексации, и будет игнорировать те директории, папки и URL к которым вы запретили обращаться.
Что включает в себя роботс?
Robots.txt несет в себе информативные данные для поисковых роботов и включает в себя такие основные «команды»:
User-agent
Указывает на имя потенциального робота посетителя. Синтаксис «User-agent: *» будет означать что данным командам должны следовать все роботы. Варианты для отдельных роботов рассматривать не будем, их очень много. По этому для примера будет только два варианта (для всех роботов и отдельно для Яндекс).
Disallow
Команда для роботов, рассказывающая о том куда ходить не стоит, запрещает чтение указанных адресов и файлов.
Allow
Команда которая рекомендует «направление» на индексирования данного адреса или файла.
Host
Данная команда указывает роботу, какой из вариантов сайта будет нашим главным зеркалом сайта.
Sitemap
Место нахождения xml карты сайта по которой должен пробежаться посетивший нас робот, в той части за которой он пришел (контент сайта).
Правильный robots.txt для сайта на CMS WordPress.
Для того что бы правильно настроить файл robots.txt специально под «движок» WordPress нужно для начала понимать что ищут роботы и что им будет интересно.
А наши паучки ищут контент нашего ресурса, и им совершенно не нужно знать о всех остальных конфигурационных данных наших сайтов. Во первых они им приходятся не по вкусу, и от переедания таковых они могут покинуть наш сайт так и не найдя то что нам бы хотелось да еще и вынесут наши запрещенные для общего глаза данные на общее обозрение.
Во первых они им приходятся не по вкусу, и от переедания таковых они могут покинуть наш сайт так и не найдя то что нам бы хотелось да еще и вынесут наши запрещенные для общего глаза данные на общее обозрение.
Говоря о требуемых размещения директорий в robots.txt для WordPress, нам нужно разобраться с главной (корневой) папкой нашего сайта, в которой мы обнаружим огромное количество стандартных файлов и папок. Роботам незачем их читать, они не найдут там то что ищут, по этому нужно запрещать индексировать по возможности весь «лишний мусор».
Подумайте сами чем может сулить нам например индексация нашего wp-config.php. Робот просто возьмет и «расскажет» всем о наших вводных данных к нашим базам данных, а это крайне плохо для нас.
Сейчас я покажу готовый вариант. Затем разберем каждую строчку в расширенном описании. Итак, правильный robots.txt для WordPress должен выглядеть так:
Disallow: /wp-
Disallow: */trackback
Disallow: /*?*
Disallow: /?s=*
Disallow: */author
Disallow: /2016
Disallow: /xmlrpc. php
php
Allow: /wp-content/uploads/
Allow: *.js
Allow: *.css
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Теперь посмотрим как мы смогли добиться такого короткого содержания файла robots.txt для WordPress, рассмотрим расширенную версию файла и постепенно уберем повторы:
Disallow: /wp-admin # Блокируем индексацию папки admin
Disallow: /wp-includes # папки includes
Disallow: /wp-content/languages # папки content/languages
Disallow: /wp-content/plugins # папки content/plugins
Disallow: /wp-content/cache # папки content/cache
Disallow: /wp-content/themes # папки content/themes
Disallow: /trackback # блокируем индекс всех возможных трекбеков
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed # блокируем индексацию фидов, новостных лент всех вариантов
Disallow: /feed/
Disallow: /?feed=
Disallow: */*/feed
Disallow: */*/feed/*/
Disallow: /*?* # запрет индекса всех ссылок (защита от дублей)
Disallow: /tag # каталоги находящихся в разных директориях ( метки, категории )
Disallow: /tag/*
Disallow: /?s=*
Disallow: /page/* # запрещаем лишние страницы в WP, создающие дубли
Disallow: /author # блокировка индексации автора
Disallow: /2015 # дублирование ссылок с архива # далее блокировка всех административных файлов
Disallow: /xmlrpc. php
php
Disallow: /wp-activate.php
Disallow: /wp-blog-header.php
Disallow: /wp-comments-post.php
Disallow: /wp-config.php
Disallow: /wp-cron.php
Disallow: /wp-links-opml.php
Disallow: /wp-load.php
Disallow: /wp-login.php
Disallow: /wp-mail.php
Disallow: /wp-register.php
Disallow: /wp-settings.php
Disallow: /wp-signup.php
Disallow: /wp-trackback.php
Disallow: /wp-config-sample.php
Allow: /wp-content/uploads/ # Разрешаем индексировать наши загруженные картинки
Host: site.ru # Указываем основное зеркало
Sitemap: http://site.ru/sitemap.xml # Направляем робота на наши страницы контента
Указанный выше пример заблокирует от индексации все ненужные для поисковой оптимизации файлы и ссылки и укажет на тот материал который должен быть проиндексирован.
Ну уж очень длинный у нас вышел пример, сейчас мы его будем упрощать. Для начала возьмемся за файлы и папки с префиксом «wp-« их все можно объединить воедино.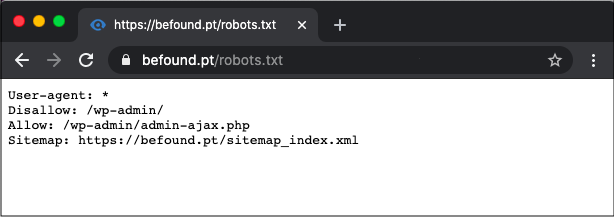
Disallow: /wp-
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed
Disallow: /feed/
Disallow: /?feed=
Disallow: */*/feed
Disallow: */*/feed/*/
Disallow: /*?*
Disallow: /tag
Disallow: /tag/*
Disallow: /?s=*
Disallow: /page/*
Disallow: /author
Disallow: /2015
Disallow: /xmlrpc.php
Allow: /wp-content/uploads/
Allow: *.js
Allow: *.css
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Значительно уменьшили, но это не предел, пойдем немножко дальше и постараемся еще сократить, да еще и проделать необходимые внутренние настройки.
Все дело в том что при таком варианте файла, Google все равно внесет запрещенные вами страницы в индекс, но выглядеть они будут иначе:
Это не столь опасно как открытые дубли, но все же лучше от этого избавляться. Для того что бы исправить данную ситуацию можно воспользоваться сразу несколькими методами. Я расскажу о самом быстром и простом — запрет индексирования страниц с помощью Google Webmasters Tools «Параметры URL». Кстати в рекомендациях для Яндекса лучше оставить параметр «feed» в указанном варианте.
Кстати в рекомендациях для Яндекса лучше оставить параметр «feed» в указанном варианте.
Избавились от feed с помощью Google, теперь для альтернативы запретим индексирование пагинации с помощью плагина, который скорее всего используется вами, если же это не так, тогда альтернативный так же подойдет. Речь идет о All in One SEO и его настройках тегов «robots» и «canonical».
Для того что бы запретить индексировать поисковикам не нужные нам страницы, такие как страницы пагинации всех видов (главной, рубрик и меток) нужно всего навсего поставить галочки в нужных местах.
Сперва включим канонические ссылки на главные страницы, для избежания их дублирования.
Что мы сделали? В общем все что было нужно, мы указали на страницах которые дублируют наш контент ссылку на основную страницу, что укажет роботу что именно нужно сканировать и считать за основной контент. Теперь добавим еще мета тег robots.
После проведенных настроек, снова обращаемся к нашему варианту файла и смотрим что получилось:
Disallow: /wp-
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: /*?*
Disallow: /?s=*
Disallow: /author
Disallow: /2015
Disallow: /xmlrpc. php
php
Allow: /wp-content/uploads/
Allow: *.js
Allow: *.css
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
По поводу меток и рубрик вопрос спорный, вы можете оптимизировать рубрики, и добиться результата с которым ваши страницы категорий будут не вредны, а наоборот принесут дополнительный трафик. Метки можно подогнать под поисковики аналогично рубрикам.
Если тема, которую вы установили использует картинки, тогда лучше открыть их для индекса:
Allow: /wp-content/themes/название вашей темы/images
Если вы проигнорируете это, у вас могут возникнуть проблемы с поисковиками, они не любят когда от них скрывают важную информацию.
Пример можно расширять, например добавлением запрета для индексации определенных ссылок на страницы, обычно это страницы повторы которые вредят нашей оптимизации.
В документе обычно не указывают конкретно для всех поисковых роботов по отдельности, а делаю два набора команд один для всех второй для Яндекса.
User-agent: *
Disallow: /wp-
…
User-agent: Yandex
Disallow: /wp-
…
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Host — нужно обязательно указывать, пренебрежение приведет к дублирования индексации ваших страниц между www.site.ru и site.ru, что рассеет ваш трафик и пагубно скажется на вашем сайте.
Как правильно создать карту сайта можно почитать в отдельных уроках по WordPress.
На этом урок по созданию файла robots.txt заканчивается, и помните что от этого по большей степени зависит судьба индексации ваших страниц.
Правильный robots.txt для wordpress, зачем нужен robots.txt, тэг more
Здравствуйте, дорогие читатели моего блога!
Сегодня я Вам расскажу о том, как составить правильный robots.txt для WordPress.
Многие новички в блоггинге совершают одну очень важную ошибку: они забывают составлять, или составляют неправильно очень важный файл, который называется robots.txt.
Зачем нужен robots.
 txt?
txt?Платформа WordPress является очень удобной платформой, однако у нее имеется ряд недостатков. Самым главным из которых является дублирование контента.
Вот смотрите, если вы опубликовали статью, то она появляется сразу на нескольких страницах и может иметь разные адреса (урлы).
Статья появляется на главной странице, в архиве, в рубрике, в ленте RSS, в поиске и т.д.
Так вот, если на блоге появляется несколько статей с одинаковым содержанием и различными адресами, то это называется дублирование контента.
Это все равно, что скопировать контент с чужого блога и вставить на свой. Эти статьи будут неуникальными.
За такие действия поисковые системы однозначно наложат на блог санкции в виде всеми любимого фильтра АГС.
Чтобы избежать дублирования контента на платформе wordpress, необходимо использовать некоторые обязательные мероприятия. Одним из которых является запрет индексации поисковыми системами тех разделов блога, на которых дубли создаются ввиду особенностей самой платформы.
Как раз robots.txt позволяет нам исключить из индекса поисковиков подобные страницы.
Кроме этого в корне блога содержатся различные служебные каталоги (например, для хранения файлов), которые тоже желательно исключать из индекса.
Как составить правильный robots.txt для WordPress?
Перед тем как приступить к составлению этого файла, нам необходимо знать основные правила его написания – директивы.
1. Директива User-agent
Эта директива определяет, какому именно поисковому роботу следует выполнять команды, которые будут указаны далее.
Например, если Вы хотите запретить индексацию чего-либо поисковому роботу Яндекса, то следует для этой директивы задать следующий параметр:
User-agent: Yandex
Если Вы хотите дать указание всем без исключения поисковым системам, то директива будет выглядеть следующим образом:
User-agent: *
В случае с рунетом, особые указания необходимо задать для Яндекса, а для роботов остальных поисковых систем подойдут общие, которые мы зададим так:
User-agent: *
2.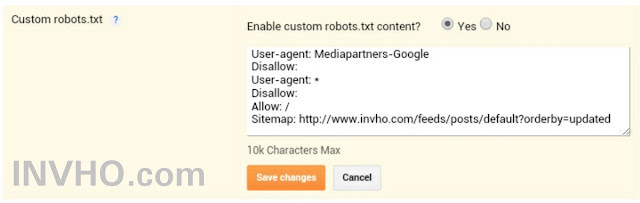 Следующими директивами являются «Allow» и «Disallow».
Следующими директивами являются «Allow» и «Disallow».
Allow – разрешает индексацию указанных в ней элементов.
Disallow – соответственно запрещает индексацию.
Правильный robots.txt должен обязательно содержать директиву «Disallow».
Если написать так:
User-agent: Yandex
Disallow:
То мы разрешим индексацию поисковому роботу Яндекса всего блога полностью.
Если написать так:
User-agent: Yandex
Disallow: /
То запретим Яндексу индексировать весь ресурс.
Таким образом, мы можем разрешать или запрещать индексацию своего блога отдельным или всем роботам.
Например:
User-agent: *
Disallow:
User-agent: Yandex
Disallow: /
Здесь мы разрешили индексирование всем поисковикам, а Яндексу запретили. Надеюсь, это понятно.
Теперь нам необходимо знать, что именно следует запретить для индексации в WordPress, то есть какие разделы могут содержать дубли страниц и другой мусор.
1. все системные и служебные файлы:
— wp-login.php
— wp-register.php
— wp-content/
— wp-admin/
— wp-includes/
Отдельно хочу сказать про каталог wp-content. В принципе, все содержимое в нем необходимо закрыть, за исключением папки «uploads» в которой располагаются изображения. Потому что, в случае запрета индексирования «uploads», ваши картинки на блоге индексироваться не будут.
Поэтому будем закрывать каталоги, размещенные внутри папки «wp-content» отдельно:
Disallow: /wp-content/themes
Disallow: /wp-content/plugins
Disallow: /wp-content/languages
Disallow: /wp-content/cache
Если в каталоге «wp-content» Вашего блога есть еще какие-либо папки, то можно (и даже нужно) их закрыть (за исключением «uploads»).
2. Дубли страниц в категориях:
— category/*/*
3. RSS ленту:
— feed
4. Дубли страниц в результатах поиска:
Дубли страниц в результатах поиска:
— *?*
— *?
5. Комментарии:
— comments
6. Трэкбэки:
— trackback
Я не буду описывать структуру WordPress, а выкладываю Вам свой файл robots.txt, который установлен на моем блоге. Я считаю, что он наиболее правильный. Если Вы найдете в нем какие-либо недочеты, то просьба написать об этом в комментариях.
User-agent: *
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /webstat/
Disallow: /feed/
Disallow: /trackback
Disallow: */trackback
Disallow: */feed
Disallow: */comments
Disallow: /*?*
Disallow: /*?
Disallow: /category/*/*
Disallow: /wp-content/themes
Disallow: /wp-content/plugins
Disallow: /wp-content/languages
Disallow: /wp-content/cache
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /comments
Здесь же нужно задать отдельные указания Яндексу:
User-agent: Yandex
Disallow: /wp-login. php
php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /webstat/
Disallow: /feed/
Disallow: /trackback
Disallow: */trackback
Disallow: */feed
Disallow: */comments
Disallow: /*?*
Disallow: /*?
Disallow: /category/*/*
Disallow: /wp-content/themes
Disallow: /wp-content/plugins
Disallow: /wp-content/languages
Disallow: /wp-content/cache
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /comments
Host: mysite.ru
Sitemap: http://mysite.ru/sitemap.xml
Sitemap: http:// mysite.ru/sitemap.xml.gz
Если Вы не составляли файл robots.txt или сомневаетесь в правильности его составления, советую Вам использовать этот.
Для этого необходимо создать обычный текстовый документ, скопировать весь текст, представленный выше, вставить его в свой файл. Затем сохранить его под именем: robots.txt (первая буква не должна быть заглавной).
Не забудьте поменять mysite.ru на свой.
После создания файл robots. txt необходимо разместить в корне блога, затем добавить его в панель вебмастера Яндекса.
txt необходимо разместить в корне блога, затем добавить его в панель вебмастера Яндекса.
Рекомендую Вам посмотреть видео, посвященное дублированию контента:
Еще пару слов о дублировании контента. Тэг «More»
Дело в том, что у нас на главной странице блога (mysite.ru) тоже выводятся статьи.
При нажатии на заголовок поста, мы переходим на его страницу (mysite.ru/…./….html). Таким образом, часть поста (та, что на главной) является дублем такой же части текста основной статьи.
Закрыть от индексации здесь ничего нельзя. Поэтому рекомендую Вам выводить на главную страницу как можно меньше текста основной статьи.
А именно приветствие и небольшой анонс.
Пример Вы можете посмотреть у меня на главной странице (анонс к этой статье).
Для этого используется тэг more.
Проще говоря: набрали небольшой фрагмент (приветствие и анонс), который будет выведен на главную, перешли в редактор HTML и вставили следующий код:
<!- -more- ->
И продолжаете дальше писать статью.
Вся часть текста, расположенная перед тэгом more, будет выведена на главную страницу.
Рекомендую посмотреть видео: «Что такое Robots.txt?»:
На этом у меня все. Обязательно создайте правильный robots.txt для WordPress!
С уважением, Александр Бобрин
Поделись с друзьями:
Метки: Блог на WordPress
Обратите внимание:
Примеры robots.txt WordPress для Яндекса и Google. Как правильно составить robots.txt
В сегодняшнем видео уроке по WordPress SEO я расскажу и покажу на примерах особенности создания и использования файла robots. txt для WordPress, этот урок не планировался как исчерпывающее руководство по robots.txt, но он должен дать вам хорошее представление о том что это за файл и что туда добавлять для минимизации попадания ненужных файлов в индекс поисковых систем и как его использовать для управления тем как поисковые роботы Google и Яндекс индексируют ваш сайт. Если у вас возникнут вопросы — пишите в комметариях, ниже привожу текстовый транскрипт видео, на тот случай если у вас возникнут вопросы или будет нужен фрагмент кода в текстовом виде.
txt для WordPress, этот урок не планировался как исчерпывающее руководство по robots.txt, но он должен дать вам хорошее представление о том что это за файл и что туда добавлять для минимизации попадания ненужных файлов в индекс поисковых систем и как его использовать для управления тем как поисковые роботы Google и Яндекс индексируют ваш сайт. Если у вас возникнут вопросы — пишите в комметариях, ниже привожу текстовый транскрипт видео, на тот случай если у вас возникнут вопросы или будет нужен фрагмент кода в текстовом виде.
Текстовый транскрипт видео:
Оглавление
- 1 Для чего нужен файл robots.txt
- 2 Пример robots.txt для WordPress
- 3 Проверка robots.txt в Google Webmaster Tools
- 4 Проверка robots.txt в Яндекс Вебмастер
- 5 Заключение
Здравствуйте,
Меня зовут Дмитрий, и в этом видео вы узнаете о том, как контролировать индексирование вашего сайта поисковыми системами с помощью файла robots.txt. Плюс в качестве примера мы разберем robots. txt для WordPress, который минимизирует индексирование ненужных файлов поисковыми системами. Итак, приступим.
txt для WordPress, который минимизирует индексирование ненужных файлов поисковыми системами. Итак, приступим.
Для чего нужен файл robots.txt
Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции, запрещающие посещение и индексирование отдельных разделов сайта. robots.txt предназначен для использования ботами, в качестве примера ботов можно назвать поисковых роботов Яндекса и Google или ботов архиваторов, как например робот Web Archive.
Для создания robots.txt воспользуйтесь любым текстовым редактором, заполните его в соответствии с вашими пожеланиями и примерами в этом видео и сохраните как просто тест без форматирования, расширение файла должно быть .txt. После этого необходимо загрузить файл в корневой каталог вашего сайта.
Используйте файл robots.txt для ограничения поисковых роботов от индексации отдельных разделов вашего сайта. Вы можете указать параметры индексирования своего сайта как для всех роботов сразу, так и для каждой поисковой системы в отдельности, используя директиву User-Agent. Для списка роботов популярных поисковых систем перейдите по ссылке в описании этого видео.
Вы можете указать параметры индексирования своего сайта как для всех роботов сразу, так и для каждой поисковой системы в отдельности, используя директиву User-Agent. Для списка роботов популярных поисковых систем перейдите по ссылке в описании этого видео.
Пример robots.txt для WordPress
В качестве примера robots.txt для WordPress, который минимизирует индексирование ненужных файлов поисковыми системами, вы можете использовать следующий шаблон:
User-Agent: * Disallow: /wp-content/plugins/ Disallow: /wp-content/themes/ Disallow: /wp-admin/ Disallow: /*.swf Disallow: /*.flv Disallow: /*.pdf Disallow: /*.doc Disallow: /*.exe Disallow: /*.htm Disallow: /*.html Disallow: /*.zip Allow: /
Давайте разберем по порядку, что здесь написано. Строчка User-Agent: * говорит, что это относится к любым агентам, к любым поисковым системам, к любым ботам, которые посещают сайт. Строчки, начинающиеся с Disallow: — это директивы, запрещающие индексирование какой-либо части сайта.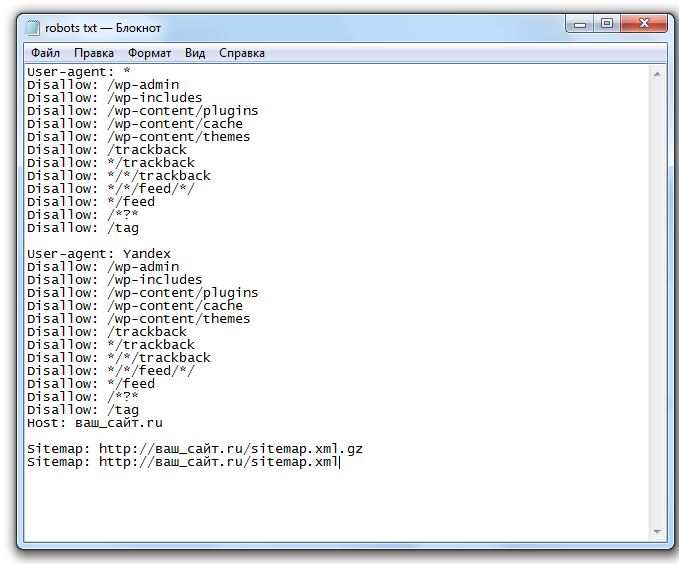 Например, строчка Disallow: /wp-admin/ запрещает индексирование папки /wp-admin/, любых файлов, которые находятся в папке /wp-admin/. Сейчас у нас запрещены к индексированию папки – плагины, темы и wp-admin (/plugins/ /themes/ /wp-admin/). Директива Disallow: /*. и расширение файла запрещает к индексированию определенный тип файлов. В данный момент запрещены к индексированию .swf, *.flv, *.pdf, *.doc, *.exe, *.js, *.htm, *.html, *.zip. Последняя строчка Allow: / разрешает индексирование любых других частей сайта и любых других файлов.
Например, строчка Disallow: /wp-admin/ запрещает индексирование папки /wp-admin/, любых файлов, которые находятся в папке /wp-admin/. Сейчас у нас запрещены к индексированию папки – плагины, темы и wp-admin (/plugins/ /themes/ /wp-admin/). Директива Disallow: /*. и расширение файла запрещает к индексированию определенный тип файлов. В данный момент запрещены к индексированию .swf, *.flv, *.pdf, *.doc, *.exe, *.js, *.htm, *.html, *.zip. Последняя строчка Allow: / разрешает индексирование любых других частей сайта и любых других файлов.
Если вы используете плагин кеширования, который генерирует статичные версии ваших страниц или структуру постоянных ссылок, оканчивающуюся .htm/.html, уберите строчки
Disallow: /*.htm Disallow: /*.html
В общем, если в адресной строке браузера адреса ваших страниц заканчиваются на .htm или .html, то уберите эти две строчки из robots.txt, иначе вы запретите к индексированию большую часть вашего сайта. Если вы хотите открыть все разделы сайта для индексирования всем роботам, то можете использовать следующий фрагмент:
User-agent: * Disallow:
Так как помимо полезных ботов (например, роботы поисковых систем, которые соблюдают директивы указанные в robots. txt) ваш сайт посещается вредными ботами (спам боты, скрейперы контента, боты которые ищут возможности для инъекции вредоносного кода), которые не только не соблюдают правила, указанные в robots.txt, а, наоборот, посещают запрещенные папки и файлы с целью выявления уязвимостей и кражи пользовательских данных. В таком случае если вы не хотите явно указывать адрес папки или файла, запрещенного к индексированию, вы можете воспользоваться директивой частичного совпадения. Например, у вас есть папка /shop-zakaz/, которую вы хотите запретить к индексированию. Для того, чтобы явно не указывать адрес этой папки для скрейперов и ботов шпионов вы можете указать часть адреса:
txt) ваш сайт посещается вредными ботами (спам боты, скрейперы контента, боты которые ищут возможности для инъекции вредоносного кода), которые не только не соблюдают правила, указанные в robots.txt, а, наоборот, посещают запрещенные папки и файлы с целью выявления уязвимостей и кражи пользовательских данных. В таком случае если вы не хотите явно указывать адрес папки или файла, запрещенного к индексированию, вы можете воспользоваться директивой частичного совпадения. Например, у вас есть папка /shop-zakaz/, которую вы хотите запретить к индексированию. Для того, чтобы явно не указывать адрес этой папки для скрейперов и ботов шпионов вы можете указать часть адреса:
Disallow: *op-za*
или
Disallow:*zakaz*
Символ * заменяет произвольное количество символов, тогда любые папки и файлы, содержащие в своем названии эту комбинацию, будут запрещены к индексированию. Старайтесь выбирать часть адреса, который уникален для этой папки, потому что если эта комбинация встретится в других файлах и папках, вы запретите их к индексированию.
Для того, чтобы случайно не запретить к индексированию нужную часть сайта всегда имеет смысл проверить, как поисковые системы воспринимают правила, указанные в вашем robots.txt. Если вы — подтвержденный владелец сайта в инструментах вебмастера Google или Яндекс — вы можете воспользоваться встроенными инструментами для проверки правил robots.txt.
Для того, чтобы проверить robots.txt в Google Webmaster Tools перейдите в секцию «Crawl>Blocked URLs», здесь вы можете воспользоваться текущей версией robots.txt или же отредактировать ее, чтобы протестировать изменения, затем добавьте список URL, которые вы хотите протестировать и нажмите на кнопку «Проверить». Результаты теста покажут, какие из указанных URL разрешены к индексированию, а какие запрещены.
Проверка robots.txt в Яндекс ВебмастерДля того, чтобы проверить robots.txt в Яндекс Вебмастер перейдите в секцию «Настройка индексирования>Анализ robots. txt», при необходимости внесите изменения в robots.txt, добавьте список URL и нажмите кнопку «Проверить». Результаты теста покажут, какие из указанных URL разрешены к индексированию, а какие запрещены.
txt», при необходимости внесите изменения в robots.txt, добавьте список URL и нажмите кнопку «Проверить». Результаты теста покажут, какие из указанных URL разрешены к индексированию, а какие запрещены.
Редактируя правила составьте файл robots.txt, подходящий для вашего сайта. Помните, что файл на сайте при этом не меняется. Для того, чтобы изменения вступили в силу, вам потребуется самостоятельно загрузить обновленную версию robots.txt на сайт.
ЗаключениеНу, вот мы и осветили основные моменты работы с robots.txt. Если вам нужны фрагменты и примеры файлов robots.txt, которые я использовал в этом видео, перейдите по ссылке, которая указана в описании этого видео. Спасибо за то, что посмотрели это видео, мне было приятно его для вас делать, буду вам благодарен, если вы поделитесь им в социальных сетях)) Ставьте «палец вверх» и подписывайтесь на новые видео.
Если у вас возникли проблемы с просмотром – вы можете посмотреть видео «Уроки WordPress — правильный файл robots. txt WordPress для Яндекса и Google» на YouTube.
txt WordPress для Яндекса и Google» на YouTube.
Оптимизация файла WordPress Robots.txt — Visualmodo
Хорошо оптимизированный файл Robots.txt может повысить рейтинг вашего сайта в поисковых системах. В этой статье вы узнаете, как его настроить и оптимизировать.
Вы слышали о файле Robots.txt? Если вы знакомы с WordPress, возможно, вы знаете файл robots. Это имеет очень важное влияние на эффективность SEO вашего сайта. Хорошо оптимизированный файл Robots может улучшить рейтинг вашего сайта в поисковых системах. С другой стороны, неправильно настроенный файл Robots.txt может сильно повлиять на SEO вашего сайта.
WordPress автоматически создает файл Robots.txt для вашего веб-сайта. Но все же, вам нужно предпринять некоторые действия, чтобы правильно его оптимизировать. Есть так много других факторов для SEO, но этот файл неизбежен. Поскольку его редактирование предполагает использование некоторой строки кода, большинство владельцев веб-сайтов не решаются вносить в него изменения.
Что такое файл robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем) о том, как сканировать страницы на их веб-сайте. Кроме того, файл robots.txt является частью протокола исключения роботов (REP). Группа веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает такие директивы, как метароботы. А также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «follow» или «nofollow»).
Robots.txt в использовании WordPress
Я уже говорил, что каждый сайт WordPress имеет файл robots.txt по умолчанию в корневом каталоге. Вы можете проверить файл robots.txt, перейдя по адресу http://yourdomain.com/robots.txt. Например, вы можете проверить наш файл robots.txt здесь: https://visualmodo.com/robots.txt
Если у вас нет файла robots, вам придется его создать. Это очень легко сделать. Просто создайте текстовый файл на своем компьютере и сохраните его как .txt. Наконец, загрузите его в корневой каталог. Вы можете загрузить его через FTP-менеджер или файловый менеджер cPanel.
Теперь давайте посмотрим, как отредактировать файл .txt. Вы можете редактировать файл robots с помощью FTP-менеджера или файлового менеджера cPanel. Однако это долго и немного сложно.
Плагин WordPress Robots
Лучший способ редактировать файл Robots — использовать плагин. Существует несколько плагинов WordPress .txt. Я предпочитаю Yoast SEO. Это лучший SEO-плагин для WordPress. Я уже рассказывал, как настроить Yoast SEO. В результате этот плагин позволяет вам изменять файл robots из вашей административной области WordPress. Однако, если вы не хотите использовать плагин Yoast. Вы можете использовать другие плагины, такие как WP Robots Txt. После того, как вы установили и активировали плагин Yoast SEO, перейдите в Панель администратора WordPress > SEO > Инструменты.
Существует несколько плагинов WordPress .txt. Я предпочитаю Yoast SEO. Это лучший SEO-плагин для WordPress. Я уже рассказывал, как настроить Yoast SEO. В результате этот плагин позволяет вам изменять файл robots из вашей административной области WordPress. Однако, если вы не хотите использовать плагин Yoast. Вы можете использовать другие плагины, такие как WP Robots Txt. После того, как вы установили и активировали плагин Yoast SEO, перейдите в Панель администратора WordPress > SEO > Инструменты.
Затем нажмите «Редактор файлов». после этого нужно нажать на «Создать файл robots.txt». Затем вы получите редактор файла Robots.txt. Здесь вы можете настроить файл robots. Прежде чем редактировать файл, вам нужно понять команды файла. В основном это три команды.
User-agent — определяет имя ботов поисковых систем, таких как Googlebot или Bingbot. Вы можете использовать звездочку (*) для обозначения всех ботов поисковых систем. Итак, Disallow — указывает поисковым системам не сканировать и не индексировать некоторые части вашего сайта. Разрешить — указывает поисковым системам сканировать и индексировать, какие части вы хотите индексировать.
Разрешить — указывает поисковым системам сканировать и индексировать, какие части вы хотите индексировать.
Вот пример файла Robots.txt.
User-agent: *
Disallow: /wp-admin/
Alow: /
Этот файл robots указывает всем ботам поисковых систем сканировать сайт. Во второй строке он сообщает поисковым роботам не сканировать часть /wp-admin/. В 3-й строке. Таким образом, он указывает ботам поисковых систем сканировать и индексировать весь веб-сайт.
Настройки для лучшего SEO
Простая неправильная настройка в файле Robots может полностью деиндексировать ваш сайт из поисковых систем. Например, если вы используете команду «Запретить: /» в файле Robots, ваш сайт будет деиндексирован поисковыми системами. Так что нужно быть осторожным при настройке.
Еще одним важным моментом является оптимизация файла Robots.txt для SEO. Прежде чем перейти к лучшим практикам роботов SEO, я хотел бы предупредить вас о некоторых плохих практиках.
- Файл WordPress Robots для скрытия некачественного содержимого. Лучше всего использовать метатеги noindex и nofollow. Вы можете сделать это с помощью плагина Yoast SEO.
- Файл Robots.txt, чтобы запретить поисковым системам индексировать ваши категории, теги, архивы, страницы авторов и т. д. Вы можете добавить на эти страницы метатеги nofollow и noindex с помощью плагина Yoast SEO.
- Используйте файл Robots.txt для обработки повторяющегося содержимого. Есть и другие способы.
Сделать файл роботов оптимизированным для SEO.
Во-первых, вам нужно определить, какие части вашего сайта не должны сканироваться роботами поисковых систем. Я предпочитаю запрещать /wp-admin/, /wp-content/plugins/, /readme.html, /trackback/. Во-вторых, производные «Разрешить: /» в файле Robots не так важны, так как боты все равно будут сканировать ваш сайт. Но вы можете использовать его для конкретного бота. Добавление карты сайта в файл Robots также является хорошей практикой.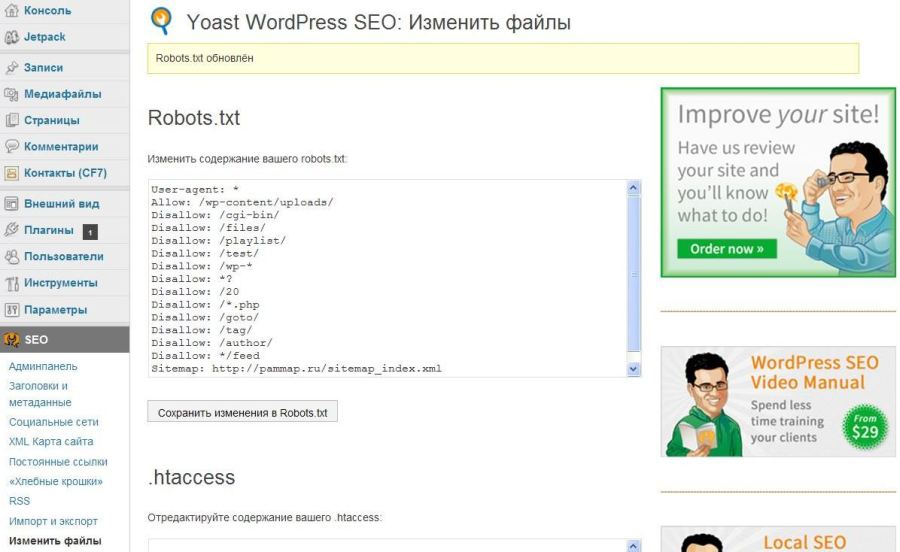 Кроме того, прочитайте эту статью о картах сайта WordPress.
Кроме того, прочитайте эту статью о картах сайта WordPress.
Вот пример идеального файла .txt для WordPress.
Агент пользователя: *
Запретить: /wp-admin/
Запретить: /readme.html
Разрешить: /wp-admin/admin-ajax.phpЗапретить: /wp-content/plugins/
Разрешить: /wp-content/uploads/Запретить: /trackback/
Карта сайта: https://visualmodo.com/post-sitemap.xml
Запретить: /go/
Карта сайта: https://visualmodo.com/page -sitemap.xml
Инструменты Google для веб-мастеров WordPress Robots Test
После обновления файла Robots.txt необходимо протестировать файл Robots.txt, чтобы проверить, не повлияло ли обновление на какой-либо контент.
Вы можете использовать Google Search Console, чтобы проверить, есть ли какие-либо «Ошибки» или «Предупреждения» для вашего файла Robots. Просто войдите в Google Search Console и выберите сайт. Затем перейдите в Crawl > robots Test the er и нажмите кнопку «Отправить». Появится окно. Просто нажмите на кнопку «Отправить».
Появится окно. Просто нажмите на кнопку «Отправить».
Наконец, перезагрузите страницу и проверьте, обновлен ли файл. Обновление файла robots может занять некоторое время. Если он еще не обновлен, вы можете ввести код файла Robots в поле, чтобы проверить наличие ошибок или предупреждений. Он покажет ошибки и предупреждения там. Сохранить
Если вы заметили какие-либо ошибки или предупреждения в файле, вы должны исправить их, отредактировав файл robots.
Как использовать файл robots.txt с WordPress
Не знаете, как использовать файл robots.txt? Хотите верьте, хотите нет, но это один из самых важных файлов с точки зрения SEO. Вам нужно использовать файл, чтобы указать, какие разделы вашего сайта должны и какие не должны быть доступны для поисковых систем. Например, вам не нужно, чтобы каталог wp-admin сканировался и индексировался поисковыми системами, потому что он предназначен только для внутреннего использования. Robots.txt — это обычный текстовый (. txt) файл, который следует поместить в корневой каталог на вашем сервере, что означает, что вам нужно поместить его в ту же папку, где находятся файлы и папки вашего веб-сайта на сервере. Вам нужно специально назвать его robots.txt . В противном случае это не сработает.
txt) файл, который следует поместить в корневой каталог на вашем сервере, что означает, что вам нужно поместить его в ту же папку, где находятся файлы и папки вашего веб-сайта на сервере. Вам нужно специально назвать его robots.txt . В противном случае это не сработает.
Виртуальный файл robots.txt в WordPress
WordPress использует виртуальный файл robots.txt. Это означает, что вы не найдете его на своем ftp-сервере, если попытаетесь получить к нему доступ для редактирования, потому что он создается динамически каждый раз, когда пользователь посещает ваш сайт. Хотя он виден, если вы добавите /robots.txt к URL-адресу своего сайта, он будет недоступен на вашем сервере, если вы попытаетесь найти его с помощью ftp-менеджера, такого как CuteFTP, FileZilla или CyberDuck.
Как редактировать robots.txt с помощью WordPress
Если вы хотите иметь возможность редактировать файл robots.txt вручную, вам следует установить плагин WP Robots.txt. Это позволит вам редактировать файл robots. txt прямо в панели управления WordPress. Итак, давайте установим плагин и посмотрим, как он работает.
txt прямо в панели управления WordPress. Итак, давайте установим плагин и посмотрим, как он работает.
Как установить плагин WP Robots.txt
- Находясь в панели управления WordPress, перейдите в раздел «Плагины» и выберите «Добавить новый».
- Введите WP Robots.txt в текстовое поле «Поиск» и нажмите кнопку «Поиск плагинов».
- Найдя подключаемый модуль, просто нажмите ссылку «Установить сейчас». Теперь у вас должно появиться всплывающее окно, которое дважды проверяет, действительно ли вы хотите установить плагин. Просто нажмите ОК.
- Теперь нажмите «Активировать плагин».
- На этом этапе вы можете просто развернуть раскрывающееся меню «Настройки» и выбрать «Чтение».
- Теперь просто найдите текстовое поле Robots.txt Content. Поле содержит содержимое вашего фактического файла Robots.txt.
Содержимое вашего файла WordPress Robots.txt
У вас должен быть аналогичный контент по умолчанию:
User-agent: *
Запретить: /wp-admin/
Запретить: /wp-includes/
Таким образом, приведенный выше код просто запрещает всем поисковым роботам просматривать каталоги /wp-admin/ и /wp-includes/ на вашем сервере.
Улучшенный контент для вашего файла robots.txt
Хотя настройки по умолчанию также работают, лучше всего с точки зрения оптимизации WordPress немного изменить их, чтобы ваш файл robots.txt выглядел следующим образом:
Агент пользователя: *
Запретить: /кормить/
Запретить: /трекбэк/
Запретить: /wp-admin/
Запретить: /wp-контент/
Запретить: /wp-includes/
Запретить: /xmlrpc.php
Запретить: /wp-
Разрешить: /wp-content/uploads/
Карта сайта: http://example.com/sitemap.xml
Первая строка показывает, какой именно ползающий робот или роботы вы хотите нацелить. * означает, что вы нацелены на всех роботов. Другими словами, вы говорите: «Эй, все вы, поисковые роботы, действуйте следующим образом».
В качестве альтернативы вы можете указать определенные поисковые роботы, такие как Googlebot, Rogerbot и т. д. Вы хотите сделать это, если использование звездочки * по той или иной причине не нацелено на конкретный поисковый робот.
У меня лично была такая проблема с Роберботом. Вам также может потребоваться указать его явно. Итак, вместо:
User-agent: *
Вы можете конкретно нацелиться на Moz Rogerbot:
User-agent: Rogerbot
Большая часть приведенного выше кода просто запрещает доступ к указанным каталогам (/trackback/, /wp-admin/ и т. д.), поскольку содержимое этих каталогов не представляет интереса ни для посетителей вашего сайта, ни для поисковых систем.
Запретить: /канал/
Запретить: /трекбэк/
Запретить: /wp-admin/
Запретить: /wp-контент/
Запретить: /wp-includes/
Запретить: /xmlrpc.php
Запретить: /wp-
Поскольку вы хотите иметь возможность ранжироваться в поисковых системах с контентом, который находится в каталоге загрузки (например, изображения и тому подобное), предпоследняя строка разрешает доступ к каталогу /wp-content/uploads/ .
Разрешить: /wp-content/uploads/
И последняя строка просто указывает на расположение вашего файла sitemap.
Карта сайта: http://example.com/sitemap.xml
Опасный файл
Неправильная настройка файла robots.txt может привести к тому, что он будет полностью невидим для поисковых систем. Наихудшей конфигурацией будет следующая:
Disallow: /
Приведенный выше код запрещает доступ ко всему вашему сайту. Таким образом, поисковые системы не будут индексировать НИЧЕГО. Просто имейте в виду, что вы не хотите, чтобы это правило было в вашем файле robots.txt.
Шутка для SEO-ботаников
Взгляните на эту SEO-ботанику шутку. Понятно? Это действительно здорово! 🙂
Эта телка запрещает парню все. Эта шутка может помочь вам лучше понять, как работает disallow: /. Хорошо, давайте двигаться дальше.
Как выполнить точную настройку синтаксиса robots.txt
Если вы хотите точно настроить параметры файла robots. txt, вам может понадобиться знать следующее.
txt, вам может понадобиться знать следующее.
Чтобы указать конкретный каталог, просто заключите его имя в косую черту. например /wp-контент/.
Запретить: /wp-content/
Чтобы указать конкретный файл, вам просто нужно указать путь к этому файлу вместе с его именем:
Запретить: /wp-content/your-file.php
Вы можете указать таким образом все типы файлов:
Запретить: /wp-content/your-file.html
Запретить: /wp-content/your-file.png
Запретить: /wp-content/your-file.jpeg
Запретить: /wp-content/your-file.css
Отключить динамическое индексирование URL
Скорее всего, вы столкнетесь с этой очень распространенной проблемой. Возможно, вам потребуется отключить динамическую индексацию URL-адресов. Динамический URL — это тот, который содержит ? вопросительный знак. Такие URL-адреса могут вызывать всевозможные проблемы SEO (дублированный контент, повторяющийся заголовок страницы и т. д.), и вы хотите запретить поисковым системам индексировать страницы с такими URL-адресами. Это легко сделать с помощью файла robots.txt. Просто добавьте следующую строку:
д.), и вы хотите запретить поисковым системам индексировать страницы с такими URL-адресами. Это легко сделать с помощью файла robots.txt. Просто добавьте следующую строку:
Запретить: /*?
Скринкаст о Robots.txt для пользователей WordPress
Этот скринкаст — образец курса SEO, над которым я сейчас работаю. Курс называется SEO Crash Course для пользователей WordPress. Если вы хотите быть в курсе, когда он будет запущен, обязательно подпишитесь на мою рассылку в конце поста.
Полезные ссылки
Robots.txt: Полное руководство
Заключение
Вы просто не можете называть себя оптимизатором или интернет-маркетологом, если вам не нравится файл robots.txt, потому что он определяет, как поисковые системы видят ваш сайт. Обязательно редактируйте файл robots.txt, только если вы знаете, что делаете. В противном случае ваш сайт может просто исчезнуть из Интернета, и вы даже не узнаете почему.
В противном случае ваш сайт может просто исчезнуть из Интернета, и вы даже не узнаете почему.
Существует множество плагинов WordPress, которые позволяют обрабатывать ваш файл robots.txt. Знаете ли вы что-нибудь, что работает лучше, чем плагин WP Robots.txt, о котором я рассказал в этом посте?
Основное руководство по роботам WordPress txt
Если вы являетесь владельцем бизнеса и используете веб-сайт WordPress для общения со своими клиентами, для вас жизненно важно продвигать его в поисковых системах. Поисковая оптимизация включает в себя множество важных шагов. Одним из них является создание хорошего файла robots.txt.
Для чего вам нужен этот файл? Какова его роль? Где он находится на вашем сайте WordPress? Какие есть способы его создания?
Что такое текстовый файл robots?
Где находится файл robots.txt для WordPress?
Некоторые основные требования к текстовому файлу роботов WordPress
Виды инструкций robots.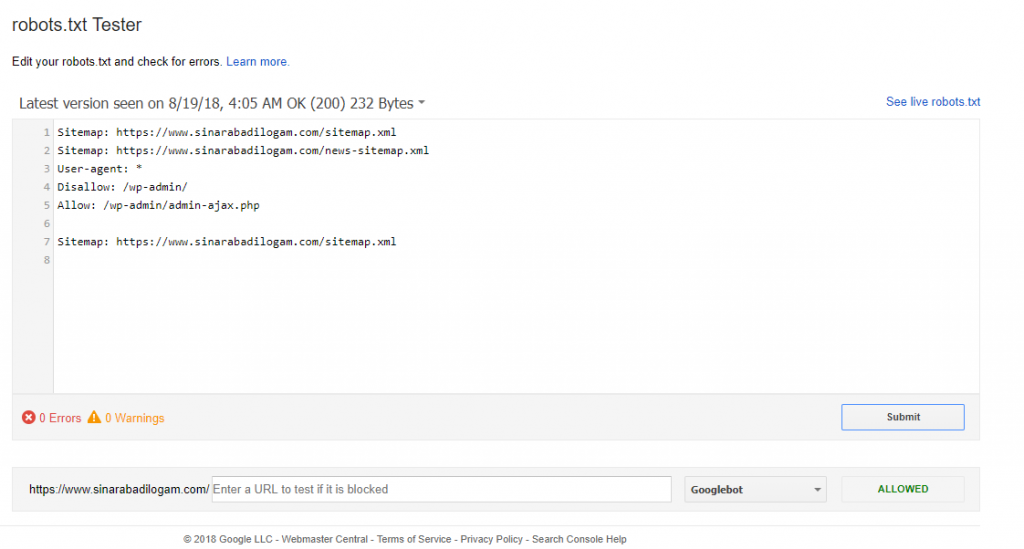 txt для поисковых роботов:
txt для поисковых роботов:
Когда следует использовать robots.txt?
Структура файла robots.txt
Типичные ошибки в файле robots.txt
Как создать файл robots.txt для вашего сайта WordPress
Использование плагина Yoast SEO
Использование плагина All in One SEO Pack
Создание и загрузка файла robots.txt для WordPress через FTP
Как протестировать файл robots.txt для вашего сайта WordPress
Вывод
Давайте рассмотрим подробнее.
Что такое текстовый файл robots?
Когда вы создаете новый веб-сайт, поисковые системы, такие как Google, Bing и т. д., используют специальных ботов для его сканирования. После этого он создает подробную карту всех своих страниц. Это помогает им определить, какие страницы показывать, когда кто-то вводит поисковый запрос, используя соответствующие ключевые слова.
Проблема в том, что современные веб-сайты помимо страниц содержат множество других элементов. Например, WordPress позволяет устанавливать плагины, которые часто имеют собственные каталоги. Не рекомендуется показывать их на странице результатов поиска, поскольку эти папки содержат конфиденциальный контент, который может представлять большую угрозу безопасности для сайта.
Например, WordPress позволяет устанавливать плагины, которые часто имеют собственные каталоги. Не рекомендуется показывать их на странице результатов поиска, поскольку эти папки содержат конфиденциальный контент, который может представлять большую угрозу безопасности для сайта.
Чтобы указать, какие папки сканировать, большинство владельцев веб-сайтов используют файл WordPress robots.txt, который содержит набор рекомендаций для ботов поисковых систем. Вы можете настроить, какие папки можно сканировать, а какие должны оставаться скрытыми от поисковых ботов. Этот файл может быть настолько подробным, насколько вы хотите, и его очень легко создать.
На практике поисковые системы все равно будут сканировать ваш сайт, даже если вы не создадите файл robots.txt. Однако не создавать его — очень нерациональный шаг. Без этого файла вы разрешаете поисковым роботам индексировать все содержимое вашего сайта и они решают, что вы можете показывать все части вашего сайта, даже те, которые вы хотели бы скрыть от общего доступа.
Более важный момент: без txt-файла для роботов WordPress поисковые роботы будут слишком часто заходить на ваш сайт. Это негативно скажется на его работе. Даже если посещаемость вашего сайта пока невелика, скорость загрузки страниц — это то, что всегда должно быть в приоритете и на самом высоком уровне. В конце концов, есть всего несколько вещей, которые людям не нравятся больше, чем медленная загрузка сайта.
Где находится файл robots.txt для WordPress?
Когда вы создаете веб-сайт WordPress, сервер автоматически создает файл robots.txt и размещает его в вашем корневом каталоге на сервере. Например, если адрес вашего веб-сайта — example.com, вы можете найти его по адресу example.com/robots.txt. Вы можете открыть и отредактировать его в любом текстовом редакторе. Он будет содержать следующие строки:
.- Агент пользователя: *
- Запретить: /wp-admin/
- Запретить: /wp-includes/
Это пример самого простого базового файла robots. txt. Переводя на человеческий язык, правая часть после User-agent: объявляет, для каких роботов предназначены правила. Звездочка означает, что правило универсально и распространяется на всех ботов. В этом случае файл сообщает ботам, что они не могут сканировать каталоги wp-admin и wp-includes. Смысл этих правил в том, что в этих каталогах содержится множество файлов, требующих защиты от публичного доступа.
txt. Переводя на человеческий язык, правая часть после User-agent: объявляет, для каких роботов предназначены правила. Звездочка означает, что правило универсально и распространяется на всех ботов. В этом случае файл сообщает ботам, что они не могут сканировать каталоги wp-admin и wp-includes. Смысл этих правил в том, что в этих каталогах содержится множество файлов, требующих защиты от публичного доступа.
Конечно, вы можете добавить в свой файл дополнительные правила. Прежде чем это сделать, нужно понимать, что это виртуальный файл. Обычно файл WordPress robots.txt находится в корневом каталоге, который часто называется public_html, www или по названию вашего сайта:
Вы можете использовать любой FTP-менеджер, например FileZilla, для доступа к этому файлу и загрузки новой версии на сервер. Все, что вам нужно, это знать логин и пароль для FTP-подключения. Вы можете связаться со службой технической поддержки, чтобы узнать больше.
Некоторые основные требования к текстовому файлу роботов WordPress
- Должен быть доступен в корне сайта.
 Его адрес будет иметь вид example.com/robots.txt.
Его адрес будет иметь вид example.com/robots.txt. - Размер файла не должен превышать 32 килобайта.
- Текст должен содержать только латинские символы. Если в вашем доменном имени используются другие символы, воспользуйтесь специальным программным обеспечением, чтобы правильно преобразовать его в латинские символы.
Не забывайте, что:
Инструкции- txt носят рекомендательный характер. Настройки
- txt не влияют на другие сайты (в robots.txt можно закрыть только страницы или файлы на текущем сайте). Команды
- txt чувствительны к регистру.
Типы robots.txt инструкция к поисковым роботам:
- Частичный доступ к определенным частям сайта.
- Запрет полной проверки.
Когда следует использовать robots.txt?
С помощью txt файла WordPress robots мы можем закрыть страницы от поисковых роботов, которые вы не хотите индексировать, например:
- страниц с личной информацией пользователя;
- страниц с документацией и служебной информацией, не влияющей на отображение интерфейса на экране;
- определенные типы файлов, например файлы PDF;
- панель инструментов WordPress и т.
 д.
д.
Структура файла robots.txt
Веб-мастер может создать текстовый файл роботов WordPress с помощью любого текстового редактора. Его синтаксис включает три основных элемента:
.1 User-agent: [имя поискового робота]
2 Запретить: [путь, к которому вы хотите закрыть доступ]
3 Разрешить: [путь, к которому вы хотите открыть доступ]
Кроме того, файл может содержать еще два дополнительных элемента:
1 Карта сайта: [адрес карты сайта]
Затем поместите созданный файл robots.txt в корневой каталог сайта. Если ваш сайт использует основной домен, файл будет находиться в папке /public_html/ или /www/. Это зависит от хостинг-провайдера. В некоторых случаях это может быть немного иначе, но большинство компаний используют указанную структуру. Если домен дополнительный, имя папки будет включать имя веб-сайта и выглядеть как /example.com/.
Для размещения файла в соответствующей папке вам потребуется FTP-клиент (например, FileZilla) и доступ к FTP, который вам дает провайдер при покупке хостинг-плана.
Агент пользователя
Все инструкции воспринимаются роботами как единое целое и относятся только к тем поисковым роботам, которые были указаны в первой строке. Всего насчитывается около 300 различных поисковых роботов. Если вы хотите применить ко всем поисковым роботам одинаковые правила, то в поле «User-agent» достаточно поставить звездочку (*). Этот символ означает любую последовательность символов. В итоге это будет выглядеть так:
1 Агент пользователя: *
Запретить
Эта команда дает рекомендации поисковым роботам, какие части сайта не следует сканировать. Если в robots.txt поставить Disallow:/, то он закроет весь контент сайта от сканирования. Если вам нужно закрыть определенную папку от сканирования, используйте Disallow: /folder.
Точно так же вы можете скрыть определенный URL-адрес, файл или определенный формат файла. Например, если вам нужно закрыть все PDF-файлы на сайте от индексации, вам нужно написать в WordPress robots txt следующую инструкцию:
1 Запретить: /*. pdf$
pdf$
Звездочка перед расширением файла означает любую последовательность символов (любое имя), а знак доллара в конце означает, что вы закрываете от индексации только файлы с расширением .pdf.
В следующих справочных материалах от Google вы найдете список команд для блокировки URL-адресов в файле robots.txt.
Разрешить
Эта команда позволяет сканировать любой файл, папку или страницу. Допустим, нужно открыть для сканирования роботами только те страницы, которые содержат слово /other, и закрыть весь остальной контент. В этом случае используйте следующую комбинацию:
1 Агент пользователя: *
2 Разрешить: /другое
3 Запретить: /
Правила «Разрешить» и «Запретить» сортируются по префиксу URL-адреса (от самого короткого до самого длинного) и применяются последовательно. В примере будет следующий порядок инструкций: сначала робот просканирует Disallow:/, а затем Allow:/other, то есть будет проиндексирована папка /other.
Типичные ошибки в файле robots.txt
Неправильный порядок команд. Должна быть четкая логическая последовательность инструкций. Сначала агент пользователя, затем разрешить и запретить. Если вы разрешаете весь сайт, но запрещаете какие-то отдельные разделы или файлы, то сначала ставьте Разрешить, а после него Запретить. Если вы запрещаете весь раздел, но хотите открыть некоторые его части, то Disallow будет располагаться выше, чем Allow.
Несколько папок или каталогов в одной инструкции Разрешить или Запретить. Если вы хотите прописать в файле robots.txt несколько разных инструкций Allow и Disallow, то вводите каждую из них с новой строки:
Запретить: /папка
Запретить: /admin
Неверное имя файла. Имя должно быть исключительно «robots.txt», состоящим только из строчных латинских букв.
Пустое правило агента пользователя. Если вы хотите установить общие инструкции для всех роботов, то поставьте звездочку.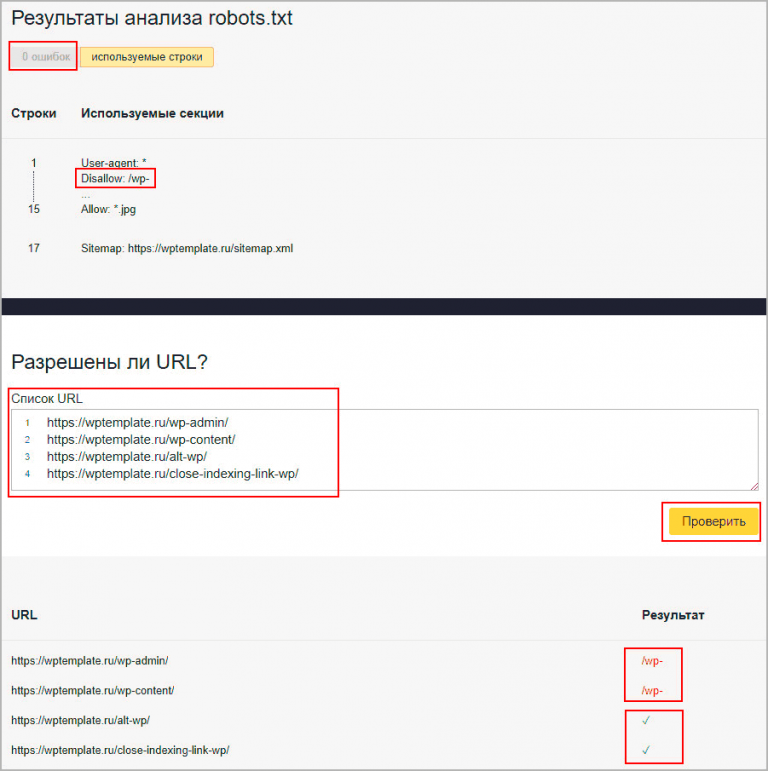
Синтаксические ошибки. Если вы ошибочно указали один из дополнительных синтаксических элементов в одной из инструкций, робот может их неправильно интерпретировать.
Как создать файл robots.txt для вашего веб-сайта WordPress
Как только вы решите создать файл robots.txt, все, что вам нужно, это найти способ его создать. Вы можете отредактировать robots.txt в WordPress с помощью плагина или сделать это вручную. В этом разделе мы научим вас использовать два самых популярных плагина для этой задачи и обсудим, как создать и скачать файл вручную. Пойдем!
Использование плагина Yoast SEO
Плагин Yoast SEO очень популярен для внедрения. Это самый известный SEO-плагин для WordPress, он позволяет улучшать посты и страницы, чтобы лучше использовать ключевые слова. Кроме того, он также оценит читабельность вашего контента, а это увеличит потенциальную аудиторию. Многие разработчики восхищаются плагином Yoast SEO из-за его простоты и удобства.
Одной из его основных функций является создание файла robots.txt для вашего веб-сайта. После установки и активации плагина перейдите на вкладку SEO — Tools в консоли плагина и найдите параметр File Editor:
Нажав на эту ссылку, вы сможете редактировать файл .htaccess, не выходя из консоли администратора. Также есть кнопка Создать файл robots.txt:
После нажатия кнопки на вкладке плагин отобразит новый редактор, где вы сможете напрямую редактировать файл robots.txt. Обратите внимание, что Yoast SEO устанавливает свои правила по умолчанию, которые переопределяют правила существующего виртуального файла robots.txt.
После удаления или добавления правил нажмите кнопку «Сохранить изменения» в файле robots.txt, чтобы применить их:
Вот и все! Давайте теперь посмотрим на другой популярный плагин, который позволит выполнить ту же задачу.
Использование плагина All in One SEO Pack
Плагин All in One SEO Pack — еще один отличный плагин WordPress для поисковой оптимизации. Он включает в себя большинство функций плагина Yoast SEO, но некоторые владельцы веб-сайтов предпочитают его, потому что он более легкий. Что касается создания файла robots.txt, то создать его в этом плагине тоже несложно.
Он включает в себя большинство функций плагина Yoast SEO, но некоторые владельцы веб-сайтов предпочитают его, потому что он более легкий. Что касается создания файла robots.txt, то создать его в этом плагине тоже несложно.
После установки плагина перейдите в All in One SEO — Manage Modules в консоли. Внутри вы найдете опцию Robots.txt с большой синей кнопкой «Активировать» в правом нижнем углу. Нажмите на него:
Теперь вы сможете найти новую вкладку Robots.txt в меню All in One SEO. Нажмите на нее, чтобы увидеть настройки добавления новых правил в ваш файл. Далее сохраняем изменения или удаляем все:
Обратите внимание, что в отличие от Yoast SEO, который позволяет вам вводить все, что вы хотите, вы не можете напрямую изменять файл robots.txt с помощью этого плагина. Содержимое файла будет неактивным. Вы просто увидите серый фон.
Но так как добавлять новые правила очень просто, этот факт не должен вас расстраивать. Что еще более важно, All in One SEO Pack также включает в себя функцию, которая поможет вам блокировать «плохих» ботов. Вы можете найти его во вкладке All in One SEO:
Вы можете найти его во вкладке All in One SEO:
Это все, что вам нужно сделать, если вы выберете этот метод. Теперь поговорим о том, как создать txt файл WordPress robots вручную, если вы не хотите устанавливать дополнительный плагин только для этой задачи.
Создание и загрузка файла robots.txt для WordPress через FTP
Чтобы создать файл robots.txt вручную, откройте свой любимый редактор (например, Блокнот или TextEdit), добавьте все необходимые команды и сохраните файл с расширением txt на локальный диск. Это буквально займет несколько секунд, поэтому вы можете создать robots.txt для WordPress без использования плагина.
Вот краткий пример такого файла:
После того, как вы создали свой собственный файл, вам необходимо подключиться к вашему сайту через FTP и поместить файл в корневую папку. В большинстве случаев это каталог public_html или www. Вы можете загрузить файл, щелкнув правой кнопкой мыши файл в локальном FTP-менеджере или просто перетащив файл:
Это также занимает несколько секунд.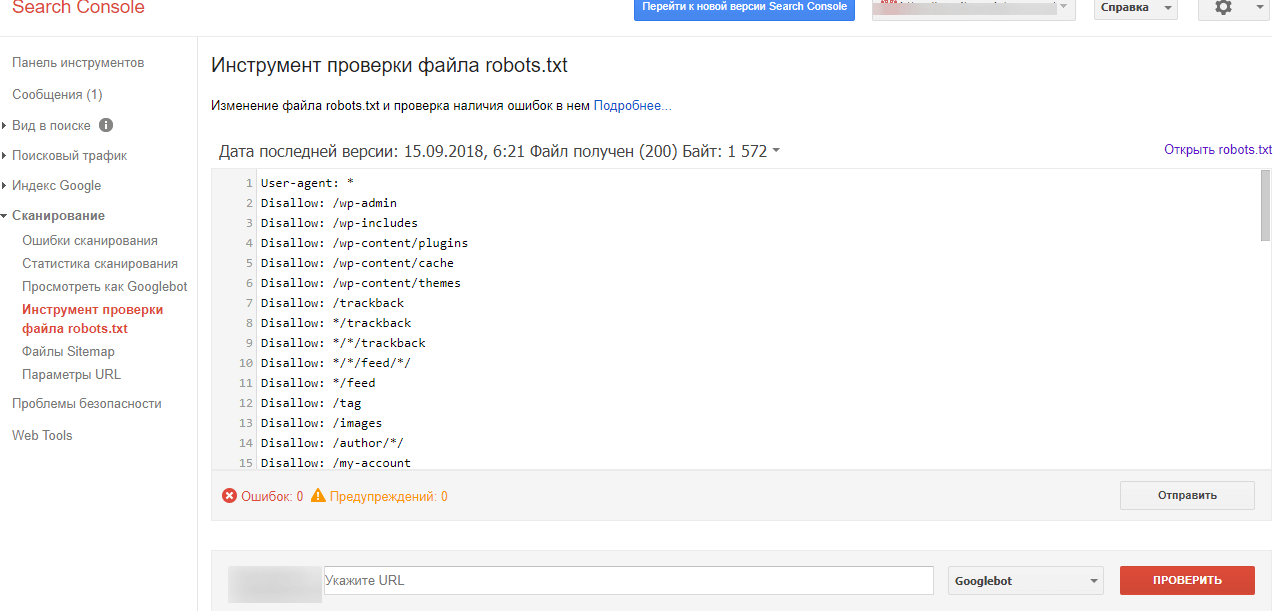 Как видите, этот способ не сложнее, чем использование плагина.
Как видите, этот способ не сложнее, чем использование плагина.
Как протестировать файл robots.txt для вашего веб-сайта WordPress
Теперь пришло время проверить файл robots.txt на наличие ошибок в Google Search Console. Search Console — это один из инструментов Google, предназначенный для отслеживания того, как ваш контент отображается на странице результатов поиска. Один из этих инструментов проверяет robots.txt, вы можете использовать его, перейдя к файлу Robots.txt в разделе Check Tool вашей консоли:
Здесь вы найдете поле редактора, в которое вы можете добавить код для вашего файла WordPress robots.txt, и нажмите «Отправить». Консоль поиска Google спросит, хотите ли вы использовать новый код или загрузить файл с вашего сайта. Выберите параметр «Попросить Google обновить», чтобы опубликовать код вручную:
.Теперь платформа проверит ваш файл на наличие ошибок. Если он найдет ошибку, он немедленно уведомит вас.
Заключение
Текстовый файл WordPress robots — очень мощный инструмент для повышения видимости веб-сайта для ботов поисковых систем.