Информационно-поисковые системы Internet | Открытые системы. СУБД
Пользователям Internet хорошо известны названия таких сервисов и информационных служб, как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и др. — без услуг этих систем сегодня практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Что собой представляют эти сервисы изнутри, как они устроены, почему результат поиска в терабайтных массивах информации осуществляется достаточно быстро и как устроено ранжирование документов при выдаче — все это обычно остается за кадром. Тем не менее без правильного планирования стратегии поиска, знакомства с основными положениями теории ИПС (Информационно-Поисковых Систем), насчитывающей уже двадцатилетнюю историю, трудно эффективно использовать даже такие скорострельные сервисы, как AltaVista или Lycos. Архитектура современных ИПС для WWW Информационные ресурсы и их представление в ИПС Индекс поиска Информационно-поисковый язык системы Интерфейс системы Заключение Литература Пользователям Internet уже хорошо известны названия таких сервисов
Пользователям Internet хорошо известны названия таких сервисов и информационных служб, как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и др. — без услуг этих систем сегодня практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Что собой представляют эти сервисы изнутри, как они устроены, почему результат поиска в терабайтных массивах информации осуществляется достаточно быстро и как устроено ранжирование документов при выдаче — все это обычно остается за кадром. Тем не менее без правильного планирования стратегии поиска, знакомства с основными положениями теории ИПС (Информационно-Поисковых Систем), насчитывающей уже двадцатилетнюю историю, трудно эффективно использовать даже такие скорострельные сервисы, как AltaVista или Lycos.
— без услуг этих систем сегодня практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Что собой представляют эти сервисы изнутри, как они устроены, почему результат поиска в терабайтных массивах информации осуществляется достаточно быстро и как устроено ранжирование документов при выдаче — все это обычно остается за кадром. Тем не менее без правильного планирования стратегии поиска, знакомства с основными положениями теории ИПС (Информационно-Поисковых Систем), насчитывающей уже двадцатилетнюю историю, трудно эффективно использовать даже такие скорострельные сервисы, как AltaVista или Lycos.
Информационно-поисковые системы появились на свет достаточно давно. Теории и практике построения таких систем посвящено множество статей, основная масса которых приходится на конец 70-х — начало 80-х годов. Среди отечественных источников следует выделить научно-технический сборник «Научно-техническая информация. Серия 2», который выходит до сих пор. На русском языке издана так же и «библия» по разработке ИПС — «Динамические библиотечно-информационные системы» Ж.
При использовании иерархической модели Gopher приходится довольно долго бродить по дереву каталогов, пока не встретишь нужную информацию. Эти каталоги должны кем-то поддерживаться, и при этом их тематическое разбиение должно совпадать с информационными потребностями пользователя. Учитывая анархичность Internet и огромное количество всевозможных интересов у пользователей Сети, понятно, что кому-то может и не повезти и в сети не будет каталога, отражающего конкретную предметную область. Именно по этой причине для множества серверов Gopher, называемого GopherSpace была разработана информационно-поисковая программа Veronica (Very Easy Rodent-Oriented Net-wide Index of Computerized Archives).
Именно по этой причине для множества серверов Gopher, называемого GopherSpace была разработана информационно-поисковая программа Veronica (Very Easy Rodent-Oriented Net-wide Index of Computerized Archives).
Аналогичное развитие событий наблюдается и в World Wide Web. Собственно еще в 1988 году в специальном выпуске журнала «Communication of the ACM» [2] среди прочих проблем разработки гипертекстовых систем и их использования Франк Халаз назвал в качестве первоочередной задачи для следующего поколения систем этого типа назвал проблему организации поиска информации в больших гипертекстовых сетях. До сих пор многие идеи, высказанные в той статье, не нашли еще своей реализации. Естественно, что система, предложенная Бернерсом-Ли [3] и получившая такое широкое распространение в Internet, должна была столкнуться с теми же проблемами, что и ее локальные предшественники. Реальное подтверждение этому было продемонстрировано на второй конференции по World Wide Web осенью 1994 года, на которой были представлены доклады о разработке информационно-поисковых систем для Web, а система World Wide Web Worm, разработанная Оливером МакБрайном из Университета Колорадо, получила приз как лучшее навигационное средство.
Разработка новых информационных систем для Web не завершена. Причем как на стадии написания коммерческих систем, так и на стадии исследований. За прошедшие два года снят только верхний слой возможных решений. Однако многие проблемы, которые ставит перед разработчиками ИПС Internet, не решены до сих пор. Именно этим обстоятельством и вызвано появление проектов типа AltaVista компании Digital [4], главной целью которого является разработка программных средств информационного поиска для Web и подбор архитектуры для информационного сервера Web.
Архитектура современных ИПС для WWW
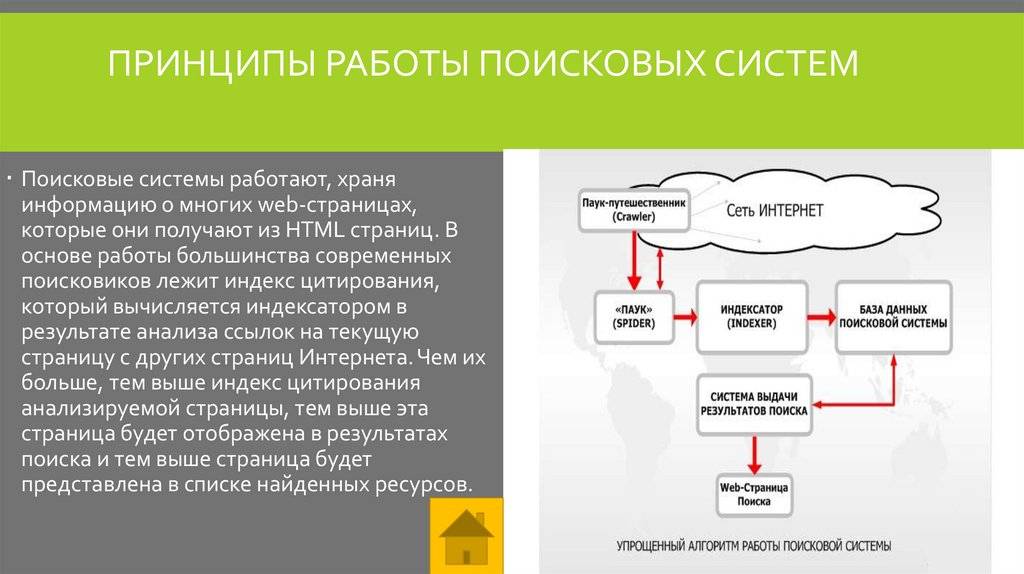
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения рассмотрим типовую схему такой системы. В различных публикациях, посвященных конкретным системам, например [5,6], приводятся схемы, которые отличаются друг от друга только способом применения конкретных программных решений, а не принципом организации различных компонентов системы. Поэтому рассмотрим эту схему на примере, взятом из работы [6] (рис.).
Рис. Типовая схема информационно-поисковой системы.
Client (клиент) на этой схеме — это программа просмотра конкретного информационного ресурса. Наиболее популярны сегодня мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов WWW, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
User interface (пользовательский интерфейс) — это не просто программа просмотра, в случае информационно-поисковой системы под этим словосочетанием понимают также способ общения пользователя с поисковым аппаратом: системой формирования запросов и просмотров результатов поиска.
Search engine (поисковая машина) — служит для трансляции запроса на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
Index database (индекс базы данных) — индекс, который является основным массивом данных ИПС и служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.
Queries (запросы пользователя) — сохраняются в его (пользователя) личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно запоминать запросы, на которые система дает хорошие ответы.
Index robot (робот-индексировщик) — служит для сканирования Internet и поддержания базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
Рассмотрим теперь назначение и принципу построения каждого из этих компонентов более подробно и определим, в чем отличие данной системы от традиционной ИПС локального типа.
Информационные ресурсы и их представление в ИПС
Как видно из рисунка, документальным массивом ИПС Internet является все множество документов шести основных типов: WWW-страницы, Gopher-файлы, документы Wais, записи архивов FTP, новости Usenet и статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак несогласованных друг с другом форматов данных: тексты, графическая и аудиоинформация и вообще все, что имеется в указанных хранилищах.
В традиционных системах используется понятие поискового образа документа — ПОД. Обычно, этим термином обозначают нечто, заменяющее собой документ и использующееся при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель [7], в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Если быть более точным, то документу приписывается вектор размерности, равный числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия или отсутствия термина в ПОД. В более сложных моделях термины взвешиваются — элемент вектора равен не 1 или 0, а некоторому числу (весу), отражающему соответствие данного термина документу. Именно последняя модель стала наиболее популярной в ИПС Internet [4,6,7].
Вообще говоря, существуют и другие модели описания документов: вероятностная модель информационных потоков и поиска и модель поиска в нечетких множествах [7]. Не вдаваясь в подробности, имеет смысл обратить внимание на то, что пока только линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText и AliWeb. Однако ведутся исследования по применению и других моделей, результаты которых отражены в работах [4,6]. Таким образом, первая задача, которую должна решить ИПС, — это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием. Часто, однако, индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов в которых он встречается. Такая процедура является только частным случаем, а точнее, техническим аспектом создания поискового аппарата ИПС. Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы, и все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы, и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы, и все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы, и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
Теперь представим себе возможность такой процедуры в анархичном Internet, где ресурсы появляются и исчезают ежедневно. При создании программы Veronica для GopherSpace предполагалось, что все серверы должны быть зарегистрированы, и таким образом велся учет наличия или отсутствия ресурса. Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД для документов Gopher. В WWW ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики [8]. Разработка роботов — это довольно нетривиальная задача; существует опасность зацикливания робота или его попадания на виртуальные страницы. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, что за термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. Сегодня роботы обычно используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки, заглавия (h2,h3), аннотации, списки ключевых слов, полные тексты документов, а также сообщения администраторов о своих Web-страницах [9]. Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков поля Subject и Keywords.
Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД для документов Gopher. В WWW ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики [8]. Разработка роботов — это довольно нетривиальная задача; существует опасность зацикливания робота или его попадания на виртуальные страницы. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, что за термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. Сегодня роботы обычно используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки, заглавия (h2,h3), аннотации, списки ключевых слов, полные тексты документов, а также сообщения администраторов о своих Web-страницах [9]. Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков поля Subject и Keywords. Наибольший простор для построения ПОД дают HTML документы. Однако не следует думать, что все термины из перечисленных элементов документов попадают в их поисковые образы. Очень активно применяются списки запрещенных слов (stop-words), которые не могут быть употреблены для индексирования, общих слов (предлоги, союзы и т.п.). Таким образом даже то, что в OpenText, например, называется полнотекстовым индексированием реально является выбором слов из текста документа и сравнением с набором различных словарей, после которого термин попадает в ПОД, а потом и в индекс системы. Для того чтобы не раздувать словарей и индексов (индекс системы Lycos уже сегодня равен 4 Тбайт), применяется такое понятие, как вес термина [10]. Документ обычно индексируется через 40 — 100 наиболее «тяжелых» терминов.
Наибольший простор для построения ПОД дают HTML документы. Однако не следует думать, что все термины из перечисленных элементов документов попадают в их поисковые образы. Очень активно применяются списки запрещенных слов (stop-words), которые не могут быть употреблены для индексирования, общих слов (предлоги, союзы и т.п.). Таким образом даже то, что в OpenText, например, называется полнотекстовым индексированием реально является выбором слов из текста документа и сравнением с набором различных словарей, после которого термин попадает в ПОД, а потом и в индекс системы. Для того чтобы не раздувать словарей и индексов (индекс системы Lycos уже сегодня равен 4 Тбайт), применяется такое понятие, как вес термина [10]. Документ обычно индексируется через 40 — 100 наиболее «тяжелых» терминов.
Индекс поиска
После того как ресурсы заиндексированы и система составила массив ПОД, начинается построение поискового аппарата. Совершенно очевидно, что лобовой просмотр файла или файлов ПОД займет много времени, что абсолютно не приемлемо для интерактивной системы WWW. Для ускорения поиска строится индекс, которым в большинстве систем является набор связанных между собой файлов, ориентированных на быстрый поиск данных по запросу. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов: размер массива поисковых образов, информационно-поисковый язык, размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы [6], для которой можно реализовывать не только примитивный булевый, но и контекстный и взвешенный поиск, а также ряд других возможностей, отсутствующие во многих поисковых системах Internet, например Yahoo. Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного (IL) и прямого списка (FL).
Для ускорения поиска строится индекс, которым в большинстве систем является набор связанных между собой файлов, ориентированных на быстрый поиск данных по запросу. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов: размер массива поисковых образов, информационно-поисковый язык, размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы [6], для которой можно реализовывать не только примитивный булевый, но и контекстный и взвешенный поиск, а также ряд других возможностей, отсутствующие во многих поисковых системах Internet, например Yahoo. Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного (IL) и прямого списка (FL).
Page-ID отображает идентификаторы страниц в их URL, Keyword-ID — каждое ключевое слов в уникальный идентификатор этого слова, таблица заголовков — идентификатор страницы в заголовок страницы, таблица гипертекстовых ссылок — идентификатор страниц в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову документа список пар — идентификатор страницы, позиция слова в странице. Прямой список — это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них является файл инвертированного списка. Результат поиска в данном файле — это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками возвращается пользователю в его программу просмотра Web. Для того чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, начинающихся с этих пар. Кроме этого, применяется механизм прямого доступа к данным — хеширование. Для обновления индекса используется комбинация двух подходов. Первый можно назвать коррекцией индекса «на ходу» с помощью таблицы модификации страниц.
Инвертированный список ставит в соответствие каждому ключевому слову документа список пар — идентификатор страницы, позиция слова в странице. Прямой список — это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них является файл инвертированного списка. Результат поиска в данном файле — это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками возвращается пользователю в его программу просмотра Web. Для того чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, начинающихся с этих пар. Кроме этого, применяется механизм прямого доступа к данным — хеширование. Для обновления индекса используется комбинация двух подходов. Первый можно назвать коррекцией индекса «на ходу» с помощью таблицы модификации страниц. Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса — его перезагрузка. Эффективность поиска в каждой конкретной ИПС определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является «секретом фирмы» и ее гордостью. Для того чтобы убедиться в этом, достаточно почитать материалы OpenText [11].
Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса — его перезагрузка. Эффективность поиска в каждой конкретной ИПС определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является «секретом фирмы» и ее гордостью. Для того чтобы убедиться в этом, достаточно почитать материалы OpenText [11].
Информационно-поисковый язык системы
Индекс — это только часть поискового аппарата, скрытая от пользователя. Второй частью этого аппарата является информационно-поисковый язык (ИПЯ), позволяющий сформулировать запрос к системе в простой и наглядной форме. Уже давно осталась позади романтика создания ИПЯ, как естественного языка, — именно этот подход использовался в системе Wais на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это еще не значит, что система будет осуществлять семантический разбор запроса пользователя. Проза жизни заключается в том, что обычно фраза разбивается на слова, из которых удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом, запрос типа:
Проза жизни заключается в том, что обычно фраза разбивается на слова, из которых удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом, запрос типа:
>Software that is used on Unix Platform
будет преобразован в:
>Unix AND Platform AND Software
что будет означать примерно следующее: «Найди все документы, в которых слова Unix, Platform и Software встречаются одновременно«.
Возможны и варианты. Так, в большинстве систем фраза «Unix Platform» будет опознана как ключевая фраза и не будет разделяться на отдельные слова. Другой подход заключается в вычислении степени близости между запросом и документом. Именно этот подход используется в Lycos. В этом случае в соответствии с векторной моделью представления документов и запросов вычисляется их мера близости. Сегодня известно около дюжины различных мер близости. Наиболее часто применяется косинус угла между поисковым образом документа и запросом пользователя. Обычно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Обычно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Наиболее развитым языком запросов из современных ИПС Internet обладает Alta Vista. Кроме обычного набора AND, OR, NOT эта система позволяет использовать еще и NEAR, позволяющий организовать контекстный поиск. Все документ в системе разбиты на поля, поэтому в запросе можно указать, в какой части документа пользователь надеется увидеть ключевое слово: ссылка, заглавие, аннотация и т.п. Можно также задавать поле ранжирования выдачи и критерий близости документов запросу.
Интерфейс системы
Важным фактором является вид представления информации в программе-интерфейсе. Различают два типа интерфейсных страниц: страницы запросов и страницы результатов поиска.
При составлении запроса к системе используют либо меню — ориентированный подход, либо командную строку. Первый позволяет ввести список терминов, обычно разделяемых пробелом, и выбрать тип логической связи между ними. Логическая связь распространяется на все термины. На схеме из рисунка указаны сохраненные запросы пользователя — в большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один способ использования сохраненных запросов, называемый расширением или уточнением запроса. Для выполнения этой операции традиционная ИПС хранит не запрос как таковой, а результат поиска — список идентификаторов документов, который объединяется/пересекается со списком, полученным при поиске документов по новым терминам. К сожалению, сохранение списка идентификаторов найденных документов в WWW не практикуется, что было вызвано особенностью протоколов взаимодействия программы-клиента и сервера, не поддерживающих сеансовый режим работы.
Логическая связь распространяется на все термины. На схеме из рисунка указаны сохраненные запросы пользователя — в большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один способ использования сохраненных запросов, называемый расширением или уточнением запроса. Для выполнения этой операции традиционная ИПС хранит не запрос как таковой, а результат поиска — список идентификаторов документов, который объединяется/пересекается со списком, полученным при поиске документов по новым терминам. К сожалению, сохранение списка идентификаторов найденных документов в WWW не практикуется, что было вызвано особенностью протоколов взаимодействия программы-клиента и сервера, не поддерживающих сеансовый режим работы.
Итак, результат поиска в базе данных ИПС — это список указателей на удовлетворяющие запросу документы. Различные системы представляют этот список по-разному. В некоторых выдается только список ссылок, а в таких, как Lycos, Alta Vista и Yahoo, дается еще и краткое описание, которое заимствуется либо из заголовков, либо из тела самого документа. Кроме этого, система сообщает, на сколько найденный документ соответствует запросу. В Yahoo, например, это количество терминов запроса, содержащихся в ПОД, в соответствии с которым ранжируется результат поиска. Система Lycos выдает меру соответствия документа запросу, по которой производится ранжирование.
Кроме этого, система сообщает, на сколько найденный документ соответствует запросу. В Yahoo, например, это количество терминов запроса, содержащихся в ПОД, в соответствии с которым ранжируется результат поиска. Система Lycos выдает меру соответствия документа запросу, по которой производится ранжирование.
При обзоре интерфейсов и средств поиска нельзя пройти мимо процедуры коррекции запросов по релевантности [7]. Релевантность — это мера соответствия найденного системой документа потребности пользователя. Различают формальную релевантность и реальную. Первую вычисляет система, и на основании чего ранжируется выборка найденных документов. Вторая — это оценка самим пользователем найденных документов. Некоторые системы имеют для этого специальное поле [6], где пользователь может отметить документ как релевантный. При следующей поисковой итерации запрос расширяется терминами этого документа, а результат снова ранжируется. Так происходит до тех пор, пока не наступит стабилизация, означающая, что ничего лучше, чем полученная выборка, от данной системы не добьешься.
Кроме ссылок на документы в списке, полученном пользователем, могут оказаться ссылки на части документов или на их поля. Это происходит при наличии ссылок типа http://host/path#mark или ссылок по схеме WAIS. Возможны ссылки и на скрипты, но обычно такие ссылки роботы пропускают, и система их не индексирует. Если с http-ссылками все более или менее понятно, то ссылки WAIS — это гораздо более сложные объекты. Дело в том, что WAIS реализует архитектуру распределенной информационно-поисковой системы, при которой одна ИПС, например Lycos, строит поисковый аппарат над поисковым аппаратом другой системы — WAIS. При этом серверы WAIS имеют свои собственные локальные базы данных. При загрузке документов в WAIS администратор может описать структуру документов, разбив их на поля, и хранить документы в виде одного файла. Индекс WAIS будет ссылаться на отдельные документы и их поля как на самостоятельные единицы хранения, программа просмотра ресурсов Internet в этом случае должна уметь работать с протоколом WAIS, чтобы получить доступ к этим документам.
Заключение
В обзорной статье были рассмотрены основные элементы информационно-поисковых систем и принципы их построения. Сегодня ИПС являются наиболее мощным механизмом поиска сетевых информационных ресурсов Internet. К сожалению, в российском секторе Internet пока не наблюдается активного изучения этой проблемы за исключением, может быть, проекта LIBWEB, финансируемого РФФИ и системы «Паук», которая работает недостаточно надежно. Наибольшим опытом разработки такого сорта систем безусловно обладает ВИНИТИ, но здесь работа сосредоточена пока на размещении своих собственных ресурсов в Сети, что принципиально отличается от информационно-поисковых систем Internet типа Lycos, OpenText, Alta Vista, Yahoo, InfoSeek и т.п. Казалось бы, что такая работа могла быть сосредоточена в рамках таких проектов, как Россия On-line компании SovamTeleport, но здесь мы пока наблюдаются ссылки на чужие поисковые машины. Развитие ИПС для Internet в США началось два года назад, учитывая отечественные реалии и темпы развития технологий Сети в России, можно надеяться, что у нас еще все впереди.
Литература
1. Дж. Солтон. Динамические библиотечно-информационные системы. Мир, Москва, 1979.
2. Frank G. Halasz. Reflection notecards: seven issues for the next generation of hypermedia systems. Communication of the acm, V31, N7, 1988, p.836-852.
3. Tim Berners-Lee. World Wide Web: Proposal for HyperText Project. 1990.
4. Alta Vista. Digital Equipment Corporation, 1996.
5. Brain Pinkerton. Finding What People Want: Experiences with the WebCrawler.
6. Bodi Yuwono, Savio L.Lam, Jerry H.Ying, Dik L.Lee. A World Wide Web Resource Discovery System.
7. Martin Bartschi. An Overview of Information Retrieval Subjects. IEEE Computer, N5, 1985,p.67-84.
8. Michel L. Mauldin, John R.R. Leavitt. Web Agent Related Research at the Center for Machine Translation.
9. Ian R.Winship. World Wide Web searching tools -an evaluation. VINE (99).
10. G.Salton, C.Buckley. Term-Weighting Approachs in Automatic Text Retrieval. Information Processing & Management, 24(5), pp. 513-523, 1988.
513-523, 1988.
11. Open Text Corporation Releases Industry»s Highest Performance Text Retrieval System.
Павел Храмцов ([email protected]) — независимый эксперт, (Москва).
Поиск информации в Интернете
УТВЕРЖДАЮ Заведующий кафедрой КИПР
______________В.Н. ТАТАРИНОВ
“___” ___________2012 г.
Методические указания к лабораторной работе по дисциплинам «Информатика» и «Информатика и информационные технологии» для студентов специальностей 211000.62 (бакалавриат) и 162107.65 (специалитет)
Разработчик: Доцент кафедры КИПР
____________Ю.П. Кобрин
Томск 2012
|
| 2 |
|
| СОДЕРЖАНИЕ |
1 | ЦЕЛЬ РАБОТЫ………………………………………………………………………………………………………………….. | 3 |
2 | ПОРЯДОК ВЫПОЛНЕНИЯ РАБОТЫ. | 3 |
3 | КОНТРОЛЬНЫЕ ВОПРОСЫ ……………………………………………………………………………………………………. | 3 |
4 | ПРАКТИЧЕСКИЕ ЗАДАНИЯ ……………………………………………………………………………………………………. | 4 |
5 | СПИСОК ЛИТЕРАТУРЫ ………………………………………………………………………………………………………… | 5 |
 …………………………………………………………………………………………..
…………………………………………………………………………………………..3
1Цель работы
1.Освоить технологию информационного поиска в Интернет.
2.Получить практические навыки и компетенции по работе с разнообразными интернет-браузерами и поисковыми системами.
2Порядок выполнения работы
1)Ознакомьтесь с назначением, основными возможностями и приемами поиска информации в Интернете с помощью Web-браузеров, используя [1] [2] [3].
2)Изучите возможности программы для создания быстрых заметок и организации личной информации Microsoft OneNote, являющейся частью пакета Microsoft Office. Используйте справочную систему Microsoft OneNote, а также [2] [4] .
3)Познакомьтесь с технологией поиска информации в Интернете с помощью по-
пулярных поисковых машин Yandex, Google, Bing, Rambler [1] [2] [3] [5] [6] [7] [3] [8] [9] [10]
[11][12].
4)Если какие-то определения или описания покажутся актуальными, кратко законспектируйте их в отчете.
5)Ответить на контрольные вопросы (устно). Ответы на сложные вопросы также можно включить в отчет.
6)Выполнить все предусмотренные программой лабораторной работы практические задания.
7)Результаты продемонстрировать преподавателю в виде отчета о выполненной работе и защитить их у преподавателя.
3Контрольные вопросы
1)Что такое World Wide Web (WWW)? В чем заключаются основные компоненты технологии WWW?
2)Каково назначение Web-браузеров?
3)Что Вы знаете о наиболее популярных Web-браузерах, их возможностях (настройках, закладках, истории и т. п.). Какими Web-браузерами Вы пользуетесь и почему?
п.). Какими Web-браузерами Вы пользуетесь и почему?
4)Какой пункт меню используют для настройки внешнего вида браузера?
5)Как выяснить адреса недавно посещенных страниц?
6)Как и для чего применяются закладки при просмотре Web-страниц?
7)Какие ключевые слова применяют в поисковых серверах и что они означают?
8)Назвать два основных вида ресурсов Интернет для информационного поиска.
9)Какие поисковые системы Вам известны?
10)Как зависит количество найденных документов в Интернет от числа ключевых слов, используемых в запросе?
11)Как можно распорядиться с найденными документами? Какие типы файлов можно применять для сохранения Web-страницы?
12)Каково назначение Microsoft OneNote?
4
4Практические задания
1.Запустите Microsoft Internet Explorer и ознакомьтесь с назначением всех элементов рабочего окна, используя справочную систему, а также [1] [2] [3]. Изучите разде-
лы Приступая к работе с Internet Explorer и Советы по поиску в Интернете.
Установите в качестве начальной (домашней) страницы, которая автоматически загружается при запуске программы Internet Explorer, адрес www.yandex.ru — web-сайта поисковой системы Yandex. Для этого выберите в меню Сервис команду Свойства обозревателя и в диалоговом окне Свойства обозревателя выберите вкладку Общие и в поле Домашняя страница задайте адрес начальной web-страницы. Для применения заданных изменений свойств web-обозревателя щелкните кнопку «Применить».
При помощи поискового сайта www.yandex.ru найдите данные о погоде у своих родителей на ближайшие дни. Сохраните найденную Web-страницу в файле с именем Погода в доме в своей рабочей папке.
Для сохранения найденной web-страницы выберите в меню Файл команду Сохранить как, затем в диалоговом окне Сохранение web-страницы в поле Имя файла задайте имя файла, в списке Тип файла выберите вариант сохранения web-страницы. Тип сохраняемого файла Веб-страница полностью означает, что сохраняется HTML страница, а к ней прилагается папка в которой будут сохранены все составные части страницы с рисунками, элементами оформления и т. п. Если Вы выбрали Веб-архив, один файл (*.mht), то данные сохраняются в виде единого файла в закодированном виде — ни текстовые программы, ни система поиска в нем не разберутся. При выборе типа сохраняемого файла Веб-страница, только HTML — web-страница быстро сохраняется в виде одного файла, и форматирование страницы сохраняется. Однако графических элементов и рисунков не будет. Попробуйте разные варианты, потренируйтесь. Сравните.
п. Если Вы выбрали Веб-архив, один файл (*.mht), то данные сохраняются в виде единого файла в закодированном виде — ни текстовые программы, ни система поиска в нем не разберутся. При выборе типа сохраняемого файла Веб-страница, только HTML — web-страница быстро сохраняется в виде одного файла, и форматирование страницы сохраняется. Однако графических элементов и рисунков не будет. Попробуйте разные варианты, потренируйтесь. Сравните.
2.Выполните поиск информации с помощью поискового сервера www.rambler.ru набрав его адрес в поле Адрес браузера Mozilla Firefox.
Вокне поискового сервера Rambler щелкните ссылку Расширенный поиск и для получения подсказки наберите в строке поиска «правила поиска в рамблере». После поиска в окне Rambler будет выведен список найденных web-страниц. Щелкнув самую верхнюю ссылку, перейдите к документу, расположенному в Интернете. После этого в окне web-обозревателя откроется web-страница с указанным документом. Если этот документ не удовлетворяет Вашим запросам, то щелкните следующую из найденных ссылок.
3.Найдите с помощью поисковой системы www.bing.ru в Интернете информацию о наиболее важных событиях, произошедших за последние сутки в нашей стране или в мире. При помощи буфера обмена скопируйте найденные новости в документе Microsoft Word`, сохраните его с именем Новости в своей рабочей папке.
Если вы хотите сохранить информацию в документе Microsoft Word, то в окне браузера с помощью курсора мыши выделите необходимый Вам фрагмент web-страницы (можно с рисунками) и затем скопируйте его в буфер обмена (Ctrl+C). Перейдите в окно редактора Microsoft Word (нажав клавиши Alt+Tab или щелкнув ярлык Word в панели за-
5
дач Windows). В окне Microsoft Word укажите место в документе и вставьте из буфера обмена скопированный фрагмент текста (Ctrl+V).
Сохраните один из рисунков из найденной web-страницы отдельно, для чего следует выделить его мышью и, щелкнув правую кнопку мыши, вызвать контекстное меню. Затем, выбрав в контекстном меню команду Сохранить Рисунок как, откройте окно сохранения рисунка. Выбрав диск и рабочую папку, задайте имя файла рисунка и щелкните на кнопке «Сохранить».
Выбрав диск и рабочую папку, задайте имя файла рисунка и щелкните на кнопке «Сохранить».
4.При помощи поисковой системы www.google.ru или www.yandex.ru в браузере Internet Explorer произвести поиск информации о своей семье, родственниках, знаменитых однофамильцах и т.п. Сохраните ее в Microsoft OneNote в виде заметок, а затем сформируйте из них документ Microsoft Word. При необходимости (по согласованию с преподавателем) можно произвести поиск по другой, произвольно взятой фамилии.
5.Найдите с помощью поисковой системы www.google.ru официальный сайт любой телевизионной передачи («Вести», «Здоровье», «КВН», «Пусть говорят» и т.д.). Ссылку на найденный сайт поместите в папку Избранное.
Если Вы желаете сохранить ссылку на найденную web-страницу в документе Microsoft Word, то в поле Адрес окна Internet Explorer с помощью мыши выделите адрес найденного сайта или страницы. Затем скопируйте выделенный адрес в буфер обмена (Ctrl+C) и перейдите в окно редактора Microsoft Word (нажав клавиши Alt+Tab или щелкнув ярлык Word в панели задач Windows). Укажите место в документе Microsoft Word и вставьте из буфера обмена скопированный адрес (Ctrl+V). Выделите этот адрес, нажмите правую кнопку мыши и вызовите контекстное меню, в котором щелкните кнопку «Гиперссылка». Введите аннотацию к вставленной ссылке (можно набрать текст аннотации с клавиатуры или выделить и скопировать через буфер обмена подходящую для аннотации как текстовую, так и графическую информацию из найденной web-страницы).
Укажите место в документе Microsoft Word и вставьте из буфера обмена скопированный адрес (Ctrl+V). Выделите этот адрес, нажмите правую кнопку мыши и вызовите контекстное меню, в котором щелкните кнопку «Гиперссылка». Введите аннотацию к вставленной ссылке (можно набрать текст аннотации с клавиатуры или выделить и скопировать через буфер обмена подходящую для аннотации как текстовую, так и графическую информацию из найденной web-страницы).
6.По заданию преподавателя с помощью любой поисковой системы найдите информацию о некотором радиоэлементе или приборе (размеры, технические характеристики, цена и изготовитель). Для хранения информационных фрагментов используйте заметки Microsoft OneNote. Окончательно информацию в отформатированном виде сохраните в своей рабочей папке в документе Microsoft Word.
7.С помощью разных поисковых систем провести поиск используя ключевые слова «информационные&технологии?проектирования&РЭС» или по свободной теме, например, «характеристика алгоритмического языка паскаль» (по согласованию с преподавателем). Дайте анализ полученных результатов (по первой странице поиска) с точки зрения количества найденных документов и их релевантности (содержательном соответствии поисковому запросу и ссылке, которая на нее ведет – в процентах).
Дайте анализ полученных результатов (по первой странице поиска) с точки зрения количества найденных документов и их релевантности (содержательном соответствии поисковому запросу и ссылке, которая на нее ведет – в процентах).
5Список литературы
1.Кобрин, Ю.П. Приложение к лабораторной работе «Поиск информации в Интернете». — Томск : ТУСУР, кафедра КИПР, 2012. — 29 с.
2.Леонтьев, В. П. Новейшая энциклопедия компьютера 2011. – М. : ОЛМА Медиа Групп, 2010. – 960 с.
6
3.Симонович С.В. и др. Информатика. Базовый курс. — СПб. : Питер, 2010. — 640 с.
4.Руководство по продукту Microsoft OneNote 2010. б.м. : Корпорация Майкрософт, 2010. —
51 с.
5.Крупник, А.Б. Поиск в Интернете: Самоучитель. 3-е изд. — СПб. : Питер, 2006. — 268 с.
6.Халявин Василий (Хохряков Евгений). Все секреты Интернета. Практическое руководство пользователя. — М. : Мартин, 2012. — 128 с.
7.Волков В.Б., Макарова Н.В. Информатика: Учебник для вузов. Стандарт третьего поколения.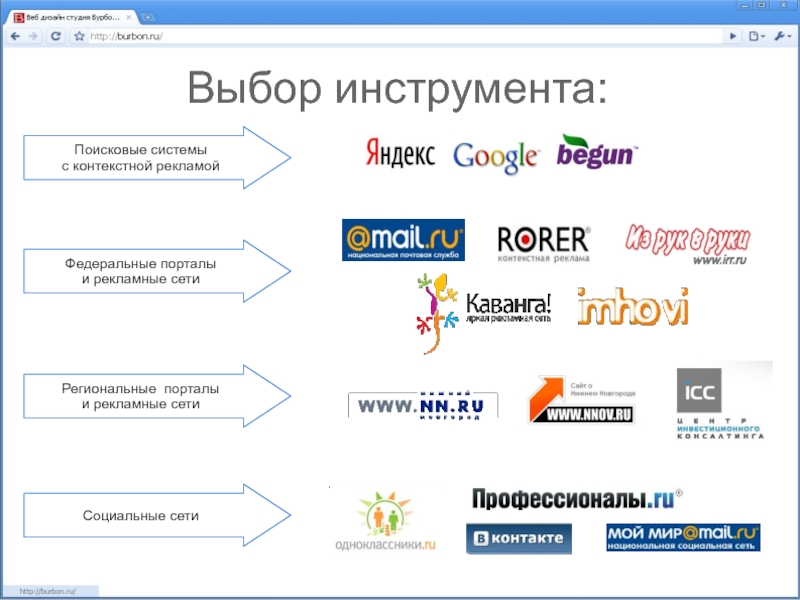 — СПб : Питер, 2011. — 576 с.
— СПб : Питер, 2011. — 576 с.
8.Степанов , А.Н. Информатика. . 4-е изд. — СПб. : Питер, 2006. — 684 с.
9.Леонтьев, В.П. Знакомства и общение в интернете. — М. : ОЛМА Медиа Групп, 2008. —
154 с.
10.Акулов О. А., Медведев Н. В. Информатика: базовый курс: учеб. пособие для студентов вузов, обучающихся по направлениям 552800,654600 «Информатика и вычислительная техника»/О.А. Акулов, Н.В. Медведев. 2-е изд., испр. и доп. — М. : Омега-Л, 2005. — 552 с.
11.Гладкий, Алексей. Интернет на 100%. Подробный самоучитель: от «чайника» – до профессионала. — М. : Литрес, 2012 — 295 с.
12.Кузьмин А.В., Золотарева Н.Н. Поиск в Интернете. Как искать, чтобы найти. Все, от поиска информации, файлов, видео и фотографий до поиска товаров и работы через Интернет
/Под ред. М. В. Финкова. Серия «Просто о сложном». . — СПб. : Наука и Техника, 2006. — 160 с.
Каковы 10 самых популярных поисковых систем?
Вы знаете, кроме самый очевидный поисковик.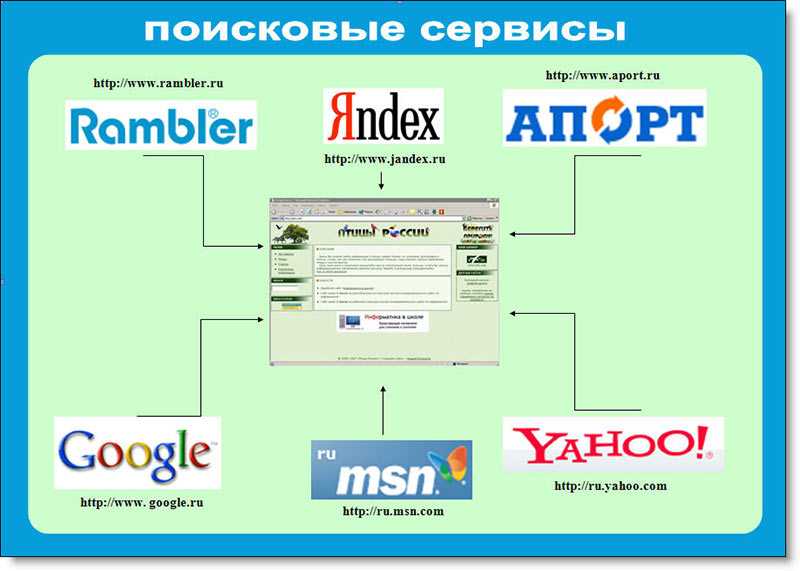 И, возможно, второй самый очевидный тоже. Начну опять, какие восемь самых популярных поисковых систем после Google и Bing?
И, возможно, второй самый очевидный тоже. Начну опять, какие восемь самых популярных поисковых систем после Google и Bing?
Первый список ниже содержит самые популярные поисковые системы, доступные в настоящее время, отсортированные по популярности в США. Рейтинг составлен по версии eBiz в порядке расчетного числа уникальных посетителей в месяц и актуален по состоянию на август 2016 г.
Второй список представляет собой глобальный обзор самых популярных поисковых систем согласно Net Market Share, который ранжируется в порядке доли рынка и снова является точным по состоянию на август 2016 года.
В отличие от нашего предыдущего списка альтернативных поисковых систем для Google, этот список будет сосредоточен исключительно на информационном поиске, а не на… Gif или изображениях без авторских прав.
США
1) Google
Оценка уникальных посетителей в месяц: 1,6 миллиарда
Alexa Rank: 1
Почему вы должны его использовать?
Имея 72,48% доли мирового рынка поиска, у вас как у маркетолога нет выбора не использовать его как для платного, так и для органического охвата.
Как обычный пользователь, несмотря на весь наш цинизм и иногда легкомысленные ссылки на The Circle, вы должны признать, что Google совершенно незаменим в вашей повседневной жизни. На каждое вмешательство (постоянное урезание результатов органической выдачи) приходится 10 триумфов… Google Maps, Gmail, ужасающая релевантность Knowledge Graph, убийство рекламы займов до зарплаты, AMP…
Где бы мы все были без… да, я скажу это… поискового гиганта.
2) Bing
Ресурсы
Расчетное количество уникальных посетителей в месяц: 400 миллионов
Alexa Rank: 22
90 003 Почему вы должны его использовать?
Как я уже говорил ранее в этом году в вышеупомянутом посте «альтернативы Google», есть несколько веских причин для выбора Bing:
- Поиск видео в Bing значительно лучше, чем в Google.
- Bing часто дает в два раза больше предложений автозаполнения, чем Google.
- В Bing есть отличная функция linkfromdomain:[имя сайта] , которая выделяет исходящие ссылки с этого сайта с лучшим рейтингом, помогая вам выяснить, на какие другие сайты больше всего ссылается выбранный вами сайт.

3) Yahoo
Расчетное количество уникальных посетителей в месяц: 300 миллионов
Alexa Rank: н/д
Почему вы должны его использовать?
На данный момент все это находится в подвешенном состоянии, поскольку Verizon только что приобрела Yahoo за 4,8 миллиарда долларов и планирует объединить ее с AoL.
Yahoo будет продолжать работать независимо до одобрения сделки регулирующими органами, которая, как ожидается, будет завершена к началу 2017 года. После этого все новостные, финансовые и спортивные платформы Yahoo будут добавлены к медиаактивам AOL, включая The Huffington Post. и TechCrunch.
4) Спросите
Расчетное количество уникальных посетителей в месяц: 245 миллионов
Alexa Rank: 31
Почему вы должны его использовать?
Несмотря на решимость Google быть основным источником всех знаний в своей собственной поисковой выдаче, Ask по-прежнему хорош для поиска, связанного с конкретными вопросами, с результатами, основанными на совпадениях, связанных с вопросами и ответами.
И эй, иногда приятно получить помощь от дворецкого.
5) Aol Search
Расчетное количество уникальных посетителей в месяц: 125 миллионов
Alexa Rank: н/д
Почему вы должны его использовать?
Как упоминалось выше, AOL, которую вы знаете и, возможно, любите, может стать другим зверем после того, как Verizon Communications объединит ее с Yahoo.
Давайте вспомним более простые времена…
6) Wow
Расчетное количество уникальных посетителей в месяц: 100 миллионов
Alexa Rank: 767
Почему вы должны его использовать?
Потому что он больше похож на новостной сайт, чем на поисковую систему, что удобно, если вам нужно все в одном месте. Существует сильный уклон к новостям и статьям о знаменитостях, а не к чистой информации в стиле Википедии, но удобные ссылки на соответствующие социальные каналы и вики-страницы полезны.
Существует сильный уклон к новостям и статьям о знаменитостях, а не к чистой информации в стиле Википедии, но удобные ссылки на соответствующие социальные каналы и вики-страницы полезны.
7) WebCrawler
Расчетное количество уникальных посетителей в месяц: 65 миллионов
Alexa Rank: 674
Почему вы должны его использовать?
WebCrawler имеет гораздо более четкое разграничение между платной поисковой рекламой и обычными результатами. Кроме того, кажется, что у него гораздо больше естественных «синих ссылок», чем у Google.
8) MyWebSearch
Расчетное количество уникальных посетителей в месяц: 60 миллионов
Alexa Rank: 405
Почему вы должны его использовать?
Э… не надо.
Согласно Malware Wikia, MyWebSearch — это программа-шпион и панель инструментов поиска, которая позволяет пользователю запрашивать различные популярные поисковые системы и поставляется в комплекте с утомительным набором «плюшек», таких как Smiley Central, Webfetti, Cursor Mania, My Mail Stationary, My Mail Signature, My Mail Stamps, FunBuddyIcons… веселье продолжается и продолжается.
Самое ужасное, что Malware Wikia сообщает, что, несмотря на отсутствие каких-либо атрибутов вредоносного ПО, независимая ремонтная лаборатория классифицировала панель инструментов как неприятную из-за «замедления работы в обмен на функции, которые уже встроены во многие современные веб-браузеры».
9) Информационное пространство
Расчетное количество уникальных посетителей в месяц: 24 миллиона
Alexa Rank: 2,110
Почему вы должны его использовать?
Возможно, вы уже используете его… InfoSpace является «поставщиком решений для поиска и монетизации с использованием белой этикетки», а также управляет собственными фирменными поисковыми сайтами, включая метапоисковик Dogpile, а также Zoo.com и WebCrawler (как упоминалось выше.)
10) Info.com
Расчетное количество уникальных посетителей в месяц: 13,5 миллионов
Alexa Rank: 1 938
Почему вы должны его использовать ?
Info. com собирает результаты из проиндексированных веб-каналов И социальных сетей. Он отслеживает социальные разговоры в режиме реального времени и, по их словам, предоставляет «заслуживающие внимания, актуальные и популярные результаты до того, как они попадут в проиндексированную сеть». Эти потоки классифицируются по структурированным темам, что обеспечивает дополнительный контекст и понимание.
com собирает результаты из проиндексированных веб-каналов И социальных сетей. Он отслеживает социальные разговоры в режиме реального времени и, по их словам, предоставляет «заслуживающие внимания, актуальные и популярные результаты до того, как они попадут в проиндексированную сеть». Эти потоки классифицируются по структурированным темам, что обеспечивает дополнительный контекст и понимание.
Бонус: 11) DuckDuckGo
Почетное упоминание DuckDuckGo, новой компании, которая не хранит вашу личную информацию, которая привлекла 13 миллионов уникальных посетителей в месяц и в настоящее время является 11-й по популярности поисковой системой в мире. НАС.
Мировой
Вот доля рынка поисковых систем в мире… 3 3) Yahoo – 7,78%
4) Baidu – 7,14%
5) Ask – 0,22%
6) AOL – 0,15%
7) Excite – 0,01% 900 07
Подробнее:
15 лучших поисковых систем в the World (Google, Bing и др.
 )
)Давайте поговорим о поисковых системах.
Знаете ли вы, что помимо Google существуют поисковые системы? И что использование другой поисковой системы может вам больше подойти?
Возможно, вы предпочитаете проверенный и надежный поисковый инструмент. Или тяготеть к более социально сознательным и экологичным вариантам. Или, может быть, конфиденциальность — ваша самая большая проблема.
Какими бы ни были ваши причины, у вас есть выбор.
Хотя Google является самой популярной поисковой системой, занимающей более 80% мирового рынка, существует множество альтернатив Google.
В этом посте будут представлены 15 лучших поисковых систем, некоторые из которых могут вас удивить.
Но прежде всего, задумывались ли вы когда-нибудь о том, что такое поисковая система? Согласно Techopedia, «поисковая система — это служба, которая позволяет пользователям Интернета искать контент во всемирной паутине (WWW)».
Просто, правда?
Итак, имея в виду это определение… давайте проверим их!
15 лучших поисковых систем
1.
 Google
GoogleКомпания Google сосредоточилась на том, чтобы дать людям то, что они хотят, и быстро стала поисковой системой №1 в мире с долей рынка 87%.
Алгоритм Google изучает привычки и желания пользователей, чтобы быстро доставлять целевую информацию. Блоггеры оптимизируют эти алгоритмы Google, чтобы зарабатывать деньги на своих блогах.
Часть того, что делает Google таким эффективным, — это сбор данных о просмотрах пользователей (которыми он делится с маркетологами). Очевидно, что конфиденциальность не является их приоритетом.
Примечательные функции
- Фильтры (книги, изображения, Google Scholar) помогают точно настроить результаты поиска.
- «Местный поиск» и «Карты Google» позволяют пользователям на ходу находить местные предприятия.
- «Мне повезет» приводит пользователя прямо к статье, занимающей первое место.
2. Майкрософт Бинг
Microsoft Bing — поисковая система по умолчанию для ПК с Windows.
С меньшим количеством наворотов, чем у Google, Bing обеспечивает отличные результаты поиска, обеспечивая при этом большую конфиденциальность и безопасность.
Лаконичный внешний вид Bing обеспечивает приятное взаимодействие с пользователем, особенно для старшей аудитории.
Примечательные функции
- Их программа поощрения позволяет пользователям накапливать баллы за такие продукты, как приложения и фильмы, во время поиска информации в Интернете.
- Искатели могут использовать свой голос, изображение или текст для поиска на панели инструментов.
- «Мои сохранения» действуют как инструмент закладок.
3. Baidu
С функциями, аналогичными Google, Baidu является самой популярной поисковой системой Китая, обслуживающей 72% китайского рынка.
Первоначально финансируемая инвесторами Силиконовой долины, Baidu является китайской компанией, соблюдающей законы и цензуру Китая.
Эта поисковая система ориентирована на потребности местного (не глобального) рынка, и хотя она доступна во всем мире, результаты поиска Baidu отображаются только на китайском языке.
Их результаты на первой странице в основном представляют собой рекламу, основанную на широко распространенном китайском убеждении, что возможность платить за рекламу указывает на надежную компанию.
Примечательные особенности
- «Карты Baidu» охватывают регион Большого Китая.
- «Baidu Knows» предоставляет зарегистрированным участникам сайт, на котором они могут размещать сообщения и отвечать на вопросы, чтобы поделиться своими знаниями и опытом.
- «Baidu Translate» поддерживает 200 языков.
4. Yahoo
Yahoo! (Yet Another Hierarchical Officious Oracle) — это веб-портал, который предоставляет множество услуг, включая поисковую систему, электронную почту, онлайн-форумы, новости, развлечения и многое другое.
Одна из старейших поисковых систем Yahoo! является фаворитом среди 65+ толпы.
Это поисковая система по умолчанию для браузера Firefox.
Примечательные особенности
- Инструмент «Отель» позволяет пользователям сравнивать наличие мест в отелях и цены.
- «Отслеживание цен» автоматически сравнивает цены, чтобы помочь пользователям получить лучшее предложение.
- «Безопасный поиск» блокирует материалы для взрослых и откровенно сексуального характера.
5. Яндекс
Яндекс (еще один индексер) — российская поисковая система, используемая в основном в России, Беларуси, Казахстане, Турции и Украине.
43% россиян используют Яндекс.
На его простой домашней странице отображаются значки избранного, которые делают каналы поиска очевидными.
Результаты поиска доступны на 10 языках. А если вас не устраивают результаты Яндекса, вы можете нажать на опцию Google или Bing внизу каждой страницы результатов поиска.
Примечательные функции
- «Быстрые ответы» отвечают на запросы пользователей с подробными сведениями, относящимися к каждому поисковому запросу.
- Режимы фильтрации (без фильтрации, умеренный, семейный поиск) помогают избежать нежелательного контента.

- «Временная метка видео» запускает видео в точном месте «поискового запроса», пропуская нерелевантный контент.
6. Ask
Первоначально известный как Ask Jeeves, этот веб-сайт был переименован в Ask в 2006 году с упором на информацию о культуре, путешествиях и развлечениях.
Их миссия — «дать любознательным людям возможность найти нужную им информацию».
Ask.com владеет Ask.fm, сайтом вопросов и ответов, где люди могут анонимно задавать спорные вопросы и отвечать на них.
Примечательные особенности
- Домашняя страница Ask заполнена актуальными и популярными статьями.
- Результаты основаны на популярности конкретной темы, которая добавляет редакционный оттенок.
- Минимум рекламы создает приятный пользовательский опыт.
7. DuckDuckGo
Если вы любите уединение, попробуйте DuckDuckGo.
Эта поисковая система с открытым исходным кодом не собирает, не хранит и не передает информацию о пользователях. И поскольку они не профилируют своих пользователей, все видят одинаковые результаты.
И поскольку они не профилируют своих пользователей, все видят одинаковые результаты.
Обратной стороной этой конфиденциальности является то, что отображаемые объявления не так релевантны для искателя, а результаты поиска могут быть более низкого качества.
Примечательные функции
- Функция «Мгновенные ответы» дает вам быстрый ответ в верхней части страницы,
- ярлыков «!bangs» позволяют выполнять поиск на 13 564 веб-сайтах непосредственно из DuckDuckGo, .
- Результаты поиска прокручиваются бесконечно, поэтому не нужно нажимать «следующая страница».
Naver (образовано от «навигация») — веб-портал и поисковая система №1 в Корее.
У него загруженная домашняя страница типа Yahoo! с последними новостями, прогнозами погоды и большим количеством рекламы.
Его результаты поиска похожи на Google и отображаются на корейском и английском языках.
Как и Google, Naver уделяет особое внимание пользовательскому опыту.
Примечательные особенности
- Пользователи видят 10–15 рекламных объявлений на странице.
- «Комплексный поиск» разбивает результаты на разделы для удобства просмотра.
- «Naver Knowledge» находит фрагменты полезной информации на основе запроса пользователя и отображает ее в виде текста, списка или таблицы.
9. AOL
Как и Yahoo!, AOL является американским веб-порталом и поставщиком онлайн-услуг.
Наиболее известен с первых дней, когда вы «подключались» к интернет-соединению.
Функция поисковой системы метко называется AOL Search.
Важные особенности
- Домашняя страница отображает последние новости по различным темам.
- Результаты поиска AOL выглядят как старомодная страница Google: много органических ссылок с небольшим количеством платной рекламы.
- «Безопасный поиск» AOL предотвращает появление сайтов с откровенно сексуальным содержанием в результатах поиска.

И AOL, и Yahoo будут проданы Apollo Group в 2021 году, поэтому вскоре в этой поисковой системе могут произойти большие изменения.
10. Ecosia
Ecosia известна как «поисковик, сажающий деревья».
Эта немецкая компания получает доход от рекламы, которая затем оплачивает посадку деревьев, восстановление леса и социальные проекты.
Эта альтернативная поисковая система, работающая на платформе Bing, имеет простую и удобную структуру.
Как и DuckDuckGo, Ecosia не отслеживает и не продает данные.
Если для вас важна неприкосновенность частной жизни и вас беспокоит изменение климата, попробуйте Ecosia.
Примечательные особенности
- Они обещают быть прозрачными в отношении прибыли, углеродно-нейтральными и безопасными для конфиденциальности.
- Приблизительно 45 поисковых запросов приносят достаточный доход для одного дерева; Ecosia финансирует дерево в секунду.
- Значок «Зеленый поиск» указывает, является ли веб-сайт безопасным для планеты (зеленый лист) или способствует изменению климата (завод по производству ископаемого топлива).

11. YouTube
YouTube — это платформа для социальных сетей, занимающая второе место по популярности после материнской компании Google.
2,3 миллиарда пользователей YouTube просматривают более 1 миллиарда часов видео каждый день.
Каждую минуту на YouTube загружается более 500 часов видео, искателей могут найти видео практически на что угодно.
Примечательные функции
- Хэштеги упрощают поиск видео по определенной теме.
- «YouTube Music» — ведущая платформа для потоковой передачи музыки.
- «YouTube Go» позволяет загружать видео и просматривать их в автономном режиме.
- «YouTube Originals» представляет оригинальный контент (сериалы, фильмы, события), часто предоставляя эксклюзивный доступ к бонусному контенту (например, режиссерским версиям и дополнительным сценам).
- «Content ID» идентифицирует защищенный авторским правом контент на YouTube и управляет им.
12.
 Amazon
AmazonAmazon начинался как небольшой книжный онлайн-магазин и превратился в мощную поисковую систему электронной коммерции.
Фактически, 63% покупателей начинают поиск покупок в Интернете на Amazon.
Если вы хотите купить или исследовать продукт, вам будет трудно превзойти Amazon.
Примечательные особенности
- Подробные описания, изображения, видео, вопросы и ответы, отзывы покупателей и цены облегчают поиск, изучение и сравнение продуктов.
- Amazon сопоставляет потребителям релевантные продукты на основе их поискового запроса.
- Более 1,9 миллиона малых и средних предприятий продают товары на Amazon, что составляет почти 60% розничных продаж Amazon.
13. Facebook
Facebook — это и социальная сеть, и мощная поисковая система.
Facebook является третьим по посещаемости веб-сайтом в мире и заявляет о более чем 2 миллиардах поисковых запросов в день.
Запросы по ключевым словам находят результаты от друзей, людей, с которыми взаимодействовали ваши друзья, или страниц, которые вам нравятся.
Примечательные функции
- Фильтры нацелены на релевантную информацию (сообщения, группы, видео, события и т. д.).
- «Места» — это мощный локальный бизнес-справочник.
- 600 миллионов человек посещают бизнес-страницы Facebook каждый день.
14. Twitter
Twitter, простая в использовании платформа для социальных сетей, также функционирует как мощная поисковая система.
С 326 миллионами пользователей в месяц и 500 миллионами ежедневных твитов вы найдете информацию практически по любой теме в режиме реального времени.
Примечательные функции
- «Список» обеспечивает легкий доступ к темам и людям, на которых вы подписаны.
- «Закладка» сохраняет слишком хорошие твиты, чтобы их потерять.
- Во время кризиса или чрезвычайной ситуации твиттеры, находящиеся рядом с событиями, часто сообщают самые свежие новости.
15. Интернет-архив
Интернет-архив, законный и безопасный в использовании сайт, представляет собой американскую поисковую систему, миссией которой является «всеобщий доступ ко всем знаниям».