Поисковый движок — Search engine
Для использования в других целях, см. Поисковая система (значения) .
Учебное пособие по использованию поисковых систем для исследования статей Википедии см. В разделе « Википедия: тест поисковой системы» .
Результаты поиска для термина «лунное затмение» в веб- поиска изображений двигателя
Поисковая система представляет собой программный комплекс, который предназначен для проведения веб — поиска . Они осуществляют систематический поиск во всемирной паутине конкретной информации, указанной в текстовом поисковом запросе . Результаты поиска обычно представлены в виде строки результатов, часто называемой страницами результатов поисковой системы (SERP). Информация может представлять собой смесь ссылок на веб-страницы, изображения, видео, инфографику, статьи, исследовательские работы и другие типы файлы. Некоторые поисковые системы также добывают данные, доступные в базах данных или открытых каталогах.
СОДЕРЖАНИЕ
- 1 История
- 1.1 До 1990-х годов
- 1.2 1990-е годы: рождение поисковых систем
- 1.3 2000-е годы – настоящее время: пузырь после доткомов
- 2 подход
- 2.1 Локальный поиск
- 3 Доля рынка
- 3.1 Россия и Восточная Азия
- 3,2 Европа
- 4 Предвзятость поисковой системы
- 5 настраиваемых результатов и пузырей фильтров
- 6 религиозные поисковики
- 7 Представление поисковой системы
- 8 См. Также
- 9 ссылки
- 10 Дальнейшее чтение
- 11 Внешние ссылки
История
Дополнительная информация: Хронология поисковых систем.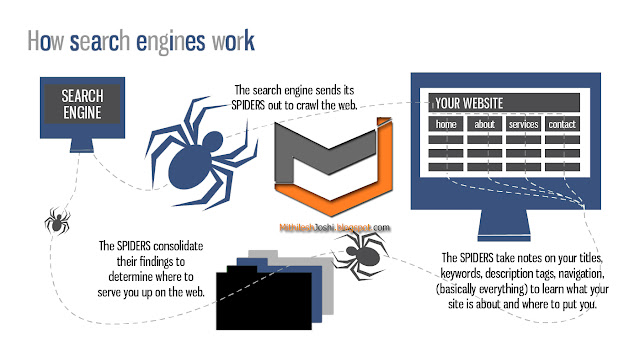
| Год | Двигатель | Текущий статус |
|---|---|---|
| 1993 г. | W3Каталог | Активный |
| Aliweb | Активный | |
| JumpStation | Неактивный | |
| WWW Червь | Неактивный | |
| 1994 г. | WebCrawler | Активный |
| Go.com | Неактивен, перенаправляет на Дисней | |
| Lycos | Активный | |
| Infoseek | Неактивен, перенаправляет на Дисней | |
| 1995 г. | Yahoo! Поиск | Активная, изначально функция поиска для Yahoo! Каталог |
| Даум | Активный | |
| Магеллан | Неактивный | |
| Возбудить | Активный | |
| SAPO | Активный | |
| MetaCrawler | Активный | |
| AltaVista | Неактивно, приобретено Yahoo! в 2003 году с 2013 года перенаправляет на Yahoo! | |
1996 г. | RankDex | Неактивен, включен в Baidu в 2000 г. |
| Собачья куча | Активный, агрегатор | |
| Инктоми | Неактивно, приобретено Yahoo! | |
| HotBot | Активный | |
| Спросите Дживса | Активный (переименован в ask.com) | |
| 1997 г. | AOL NetFind | Активный (ребрендинг AOL Search с 1999 г.) |
| Северное сияние | Неактивный | |
| Яндекс | Активный | |
| 1998 г. | Активный | |
| Ixquick | Активен как Startpage.com | |
| Поиск MSN | Активен как Bing | |
| эмпас | Неактивно (объединено с NATE) | |
| 1999 г. | AlltheWeb | Неактивен (URL-адрес перенаправлен на Yahoo!) |
| GenieKnows | Активный, ребрендированный Yellowee (перенаправление на justlocalbusiness. com) com) | |
| Naver | Активный | |
| Теома | Актив (© АПН, ООО) | |
| 2000 г. | Baidu | Активный |
| Exalead | Неактивный | |
| Гигабласт | Активный | |
| 2001 г. | Kartoo | Неактивный |
| 2003 г. | Info.com | Активный |
| 2004 г. | A9.com | Неактивный |
| Clusty | Активный (как Yippy) | |
| Mojeek | Активный | |
| Согоу | Активный | |
| 2005 г. | Найди меня | Неактивный |
| KidzSearch | Активный, поиск в | |
| 2006 г. | Так-так | Неактивен, слился с Sogou |
| Quaero | Неактивный | |
| Search.com | Активный | |
| ЧаЧа | Неактивный | |
Ask. com com | Активный | |
| Живой поиск | Активен как Bing, имеет ребрендинг MSN Search | |
| 2007 г. | викисик | Неактивный |
| Sproose | Неактивный | |
| Wikia Search | Неактивный | |
| Blackle.com | Активный, поиск в | |
| 2008 г. | Powerset | Неактивен (перенаправляет на Bing) |
| Пиколятор | Неактивный | |
| Viewzi | Неактивный | |
| Бугами | Неактивный | |
| LeapFish | Неактивный | |
| Forestle | Неактивен (перенаправляет на Ecosia) | |
| УткаУтка | Активный | |
| 2009 г. | Bing | Активный интерактивный поиск с ребрендингом |
| Yebol | Неактивный | |
| Мугурды | Неактивен из-за отсутствия финансирования | |
| Разведчик (бычок) | Активный | |
| NATE | Активный | |
| Экозия | Активный | |
Startpage. com com | Активный, родственный двигатель Ixquick | |
| 2010 г. | Блэкко | Неактивен, продан IBM |
| Cuil | Неактивный | |
| Яндекс (английский) | Активный | |
| Парсиджу | Активный | |
| 2011 г. | YaCy | Активный, P2P |
| 2012 г. | Volunia | Неактивный |
| 2013 | Qwant | Активный |
| 2014 г. | Эгерин | Активный, Курдский / Сорани |
| Swisscows | Активный | |
| Searx | Активный | |
| 2015 г. | Йуз | Активный |
| Cliqz | Неактивный | |
| 2016 г. | Kiddle | Активный, поиск в |
До 1990-х годов
Система поиска опубликованной информации, предназначенная для преодоления все возрастающей сложности поиска информации в постоянно растущих централизованных указателях научной работы, была описана в 1945 году Ванневаром Бушем, который написал в The Atlantic Monthly статью под названием « Как мы можем думать », в которой он представлял себе исследовательские библиотеки со связанными аннотациями, мало чем отличающиеся от современных гиперссылок .
1990-е годы: рождение поисковых систем
Первые поисковые машины в Интернете появились еще до появления Интернета в декабре 1990 года: поиск пользователей WHOIS восходит к 1982 году, а многосетевой поиск пользователей службы Knowbot Information Service впервые был реализован в 1989 году. а именно файлы FTP, был Archie, который дебютировал 10 сентября 1990 года.
До сентября 1993 года всемирная паутина полностью индексировалась вручную. Был список веб-серверов, отредактированный Тимом Бернерсом-Ли и размещенный на веб-сервере ЦЕРН . Один моментальный снимок списка 1992 года сохранился, но по мере того, как все больше и больше веб-серверов выходили в онлайн, центральный список больше не мог поддерживать. На сайте NCSA были анонсированы новые серверы под заголовком «Что нового!»
Первым инструментом, используемым для поиска контента (в отличие от пользователей) в Интернете, был Archie . Название расшифровывается как «архив» без буквы «v». Он был создан Аланом Эмтаджем, студентом факультета информатики Университета Макгилла в Монреале, Квебек, Канада. Программа загрузила списки каталогов всех файлов, расположенных на общедоступных анонимных сайтах FTP ( протокол передачи файлов ), создав базу данных имен файлов с возможностью поиска ; однако поисковая система Archie не индексировала содержимое этих сайтов, поскольку объем данных был настолько ограничен, что их можно было легко найти вручную.
Название расшифровывается как «архив» без буквы «v». Он был создан Аланом Эмтаджем, студентом факультета информатики Университета Макгилла в Монреале, Квебек, Канада. Программа загрузила списки каталогов всех файлов, расположенных на общедоступных анонимных сайтах FTP ( протокол передачи файлов ), создав базу данных имен файлов с возможностью поиска ; однако поисковая система Archie не индексировала содержимое этих сайтов, поскольку объем данных был настолько ограничен, что их можно было легко найти вручную.
Подъем Gopher (создан в 1991 году Марком McCahill в Университете штата Миннесота ) привели к двум новым поисковых программ, Veronica и Jughead . Как и Арчи, они искали имена и заголовки файлов, хранящиеся в индексных системах Gopher. Вероника ( V ERy Е ASY R odent- O riented Н и др шириной Я NDEX к C omputerized A rchives) при условии, поиск по ключевым словам большинства названий меню Gopher в целых списков Gopher. Jughead ( J onzy — х U niversal G Офер Н ierarchy Е xcavation й Д жаемый) является инструментом для получения информации меню от конкретного Gopher серверов. В то время как название поисковой системы « Archie Search Engine » не было отсылкой к серии комиксов Арчи, « Вероника » и « Джагхед » являются персонажами этого сериала, отсылая, таким образом, к своему предшественнику.
В то время как название поисковой системы « Archie Search Engine » не было отсылкой к серии комиксов Арчи, « Вероника » и « Джагхед » являются персонажами этого сериала, отсылая, таким образом, к своему предшественнику.
Летом 1993 года поисковой машины в Интернете не существовало, хотя многочисленные специализированные каталоги поддерживались вручную. Оскар Ньерстрассы в Женевском университете написали ряд Perl скриптов, которые периодически зеркальные эти страницы и переписали их в стандартный формат. Это легло в основу W3Catalog, первой примитивной поисковой системы в Интернете, выпущенной 2 сентября 1993 года.
В июне 1993 года Мэтью Грей, работавший тогда в Массачусетском технологическом институте, создал, вероятно, первого веб-робота, основанного на Perl World Wide Web Wanderer, и использовал его для создания индекса под названием «Wandex». Цель Wanderer состояла в том, чтобы измерить размер всемирной паутины, что он и делал до конца 1995 года. Вторая поисковая машина в сети, Aliweb, появилась в ноябре 1993 года. Aliweb не использовала веб-робота, а зависела от уведомления веб-сайта. наличие у администраторов на каждом сайте индексного файла в определенном формате.
Aliweb не использовала веб-робота, а зависела от уведомления веб-сайта. наличие у администраторов на каждом сайте индексного файла в определенном формате.
JumpStation (созданная в декабре 1993 года Джонатоном Флетчером ) использовала веб-робота для поиска веб-страниц и создания своего индекса, а также использовала веб-форму в качестве интерфейса для своей программы запросов. Таким образом, это был первый инструмент для обнаружения ресурсов WWW, который сочетал в себе три основные функции поисковой машины в Интернете (сканирование, индексирование и поиск), как описано ниже. Из-за ограниченных ресурсов, доступных на платформе, на которой он работал, его индексирование и, следовательно, поиск были ограничены заголовками и заголовками, найденными на веб-страницах, с которыми столкнулся поисковый робот.
Одной из первых поисковых систем, основанных на «полнотекстовом» роботе, была WebCrawler, которая появилась в 1994 году. В отличие от своих предшественников, она позволяла пользователям искать любое слово на любой веб-странице, которая с тех пор стала стандартом для всех основных поисковых систем. Это была также поисковая машина, которая была широко известна публике. Также в 1994 году была запущена Lycos (которая началась в Университете Карнеги-Меллона ), ставшая крупным коммерческим предприятием.
Это была также поисковая машина, которая была широко известна публике. Также в 1994 году была запущена Lycos (которая началась в Университете Карнеги-Меллона ), ставшая крупным коммерческим предприятием.
Первой популярной поисковой системой в Интернете была Yahoo! Искать . Первый продукт Yahoo! , Основанная Джерри Янг и Дэвид Фило в январе 1994 года был каталог Web называется Yahoo! Справочник . В 1995 году была добавлена функция поиска, позволяющая пользователям выполнять поиск в Yahoo! Справочник! Он стал одним из самых популярных способов найти интересующие веб-страницы, но его функция поиска работала в его веб-каталоге, а не в полнотекстовых копиях веб-страниц.
Вскоре после этого появился ряд поисковых систем, которые боролись за популярность. К ним относятся Magellan, Excite, Infoseek, Inktomi, Northern Light и AltaVista . Лица, ищущие информацию, могут также просматривать каталог вместо поиска по ключевым словам.
В 1996 году Робин Ли разработал алгоритм ранжирования сайта RankDex для ранжирования страниц результатов поисковых систем и получил патент США на эту технологию. Это была первая поисковая система, которая использовала гиперссылки для измерения качества индексируемых веб-сайтов, предшествовавшая патенту на очень похожий алгоритм, поданному двумя годами позже в 1998 году. Ларри Пейдж ссылался на работу Ли в некоторых своих патентах США на PageRank. Позже Ли использовал свою технологию Rankdex для поисковой системы Baidu, основанной Робином Ли в Китае и запущенной в 2000 году.
Это была первая поисковая система, которая использовала гиперссылки для измерения качества индексируемых веб-сайтов, предшествовавшая патенту на очень похожий алгоритм, поданному двумя годами позже в 1998 году. Ларри Пейдж ссылался на работу Ли в некоторых своих патентах США на PageRank. Позже Ли использовал свою технологию Rankdex для поисковой системы Baidu, основанной Робином Ли в Китае и запущенной в 2000 году.
В 1996 году Netscape хотела предоставить единственной поисковой системе эксклюзивную сделку в качестве основной поисковой системы в веб-браузере Netscape. Интерес был настолько велик, что вместо этого Netscape заключила сделки с пятью основными поисковыми машинами: за 5 миллионов долларов в год каждая поисковая машина будет поочередно размещаться на странице поисковой системы Netscape. Пятью движками были Yahoo !, Magellan, Lycos, Infoseek и Excite.
перенял идею продажи поисковых запросов в 1998 году от небольшой поисковой компании goto.com . Этот шаг оказал значительное влияние на бизнес SE, который превратился из тяжелого бизнеса в один из самых прибыльных в Интернете.
Поисковые системы также были известны как одни из самых ярких звезд в безумном инвестировании в Интернет, которое произошло в конце 1990-х годов. Несколько компаний впечатляюще вышли на рынок, получив рекордную прибыль во время своих первичных публичных размещений . Некоторые закрыли свои общедоступные поисковые системы и продают корпоративные версии, такие как Northern Light. Многие компании, занимающиеся поисковыми системами, оказались вовлечены в пузырь доткомов — рыночный бум, вызванный спекуляциями, пик которого пришелся на 1990 год и закончился в 2000 году.
2000-е – настоящее время: пузырь доткомов
Примерно в 2000 году поисковая система приобрела известность. Компания достигла лучших результатов по многим поисковым запросам с помощью алгоритма под названием PageRank, как было объяснено в статье « Анатомия поисковой системы», написанной Сергеем Брином и Ларри Пейджем, более поздними основателями . Этот итеративный алгоритм ранжирует веб-страницы на основе количества и PageRank других веб-сайтов и страниц, которые на них ссылаются, при условии, что хорошие или желательные страницы связаны больше, чем другие.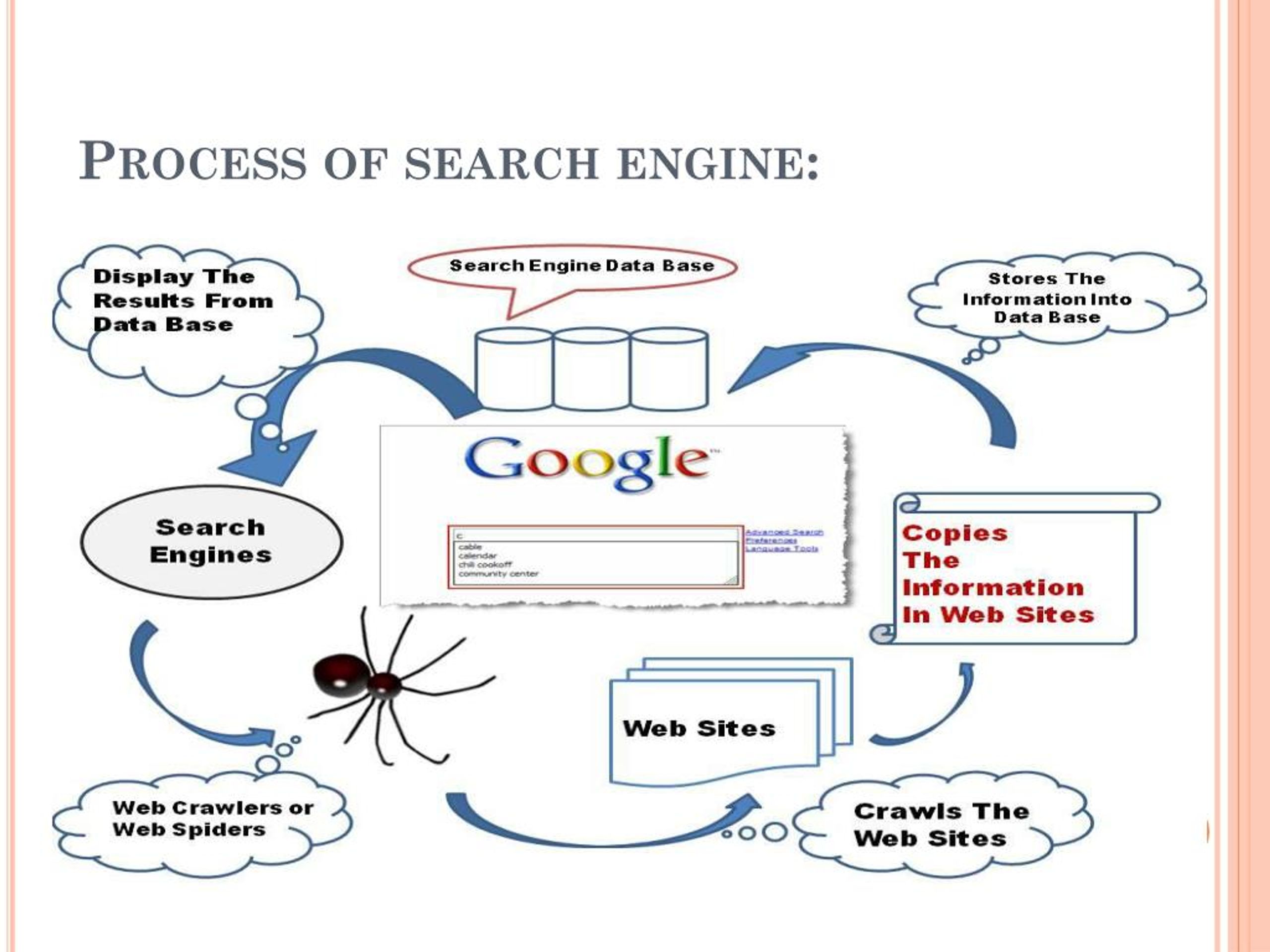 Патент Ларри Пейджа на PageRank ссылается на более ранний патент Робина Ли RankDex как на влияние. также сохранил минималистичный интерфейс своей поисковой системы. Напротив, многие из его конкурентов встроили поисковую систему в веб-портал . Фактически, поисковая система стала настолько популярной, что появились спуфинговые машины, такие как Mystery Seeker .
Патент Ларри Пейджа на PageRank ссылается на более ранний патент Робина Ли RankDex как на влияние. также сохранил минималистичный интерфейс своей поисковой системы. Напротив, многие из его конкурентов встроили поисковую систему в веб-портал . Фактически, поисковая система стала настолько популярной, что появились спуфинговые машины, такие как Mystery Seeker .
К 2000 году Yahoo! предоставлял поисковые услуги на основе поисковой системы Inktomi. Yahoo! приобрела Inktomi в 2002 году и Overture (которой принадлежали AlltheWeb и AltaVista) в 2003 году. Yahoo! перешла на поисковую систему до 2004 года, когда она запустила собственную поисковую систему, основанную на комбинированных технологиях своих приобретений.
Microsoft впервые запустила MSN Search осенью 1998 года, используя результаты поиска Inktomi. В начале 1999 года сайт начал отображать списки Looksmart, смешанные с результатами Inktomi. На короткое время в 1999 году поисковая система MSN вместо этого использовала результаты AltaVista. В 2004 году Microsoft начала переход на собственную технологию поиска, основанную на собственном поисковом роботе (называемом msnbot ).
В 2004 году Microsoft начала переход на собственную технологию поиска, основанную на собственном поисковом роботе (называемом msnbot ).
Обновленная поисковая система Microsoft, Bing, была запущена 1 июня 2009 года. 29 июля 2009 года Yahoo! и Microsoft завершили сделку, по которой Yahoo! Поиск будет основан на технологии Microsoft Bing.
По состоянию на 2019 год активные сканеры поисковых систем включают , Petal, Sogou, Baidu, Bing, Gigablast, Mojeek, DuckDuckGo и Яндекс .
Подход
Основная статья: Технология поисковых систем
Поисковая система поддерживает следующие процессы почти в реальном времени:
- Веб-сканирование
- Индексирование
- Searching
Поисковые системы получают информацию путем обхода веб-страниц с сайта на сайт. «Паук» проверяет адресованное ему стандартное имя файла robots.txt . Файл robots.txt содержит директивы для поисковых роботов, сообщающие ему, какие страницы сканировать, а какие не сканировать. Проверив файл robots.txt и найдя его или нет, паук отправляет определенную информацию обратно для индексации в зависимости от многих факторов, таких как заголовки, содержимое страницы, JavaScript, каскадные таблицы стилей (CSS), заголовки или свои метаданные в Мета-теги HTML . После определенного количества просканированных страниц, количества проиндексированных данных или времени, проведенного на веб-сайте, паук прекращает сканирование и продолжает движение. «[Нет] веб-сканер может фактически сканировать всю доступную сеть. Из-за бесконечного количества веб-сайтов, ловушек-пауков, спама и других требований реальной сети поисковые роботы вместо этого применяют политику сканирования, чтобы определить, когда сканирование сайта должно считаться достаточно. Некоторые веб-сайты сканируются полностью, а другие — только частично «.
Проверив файл robots.txt и найдя его или нет, паук отправляет определенную информацию обратно для индексации в зависимости от многих факторов, таких как заголовки, содержимое страницы, JavaScript, каскадные таблицы стилей (CSS), заголовки или свои метаданные в Мета-теги HTML . После определенного количества просканированных страниц, количества проиндексированных данных или времени, проведенного на веб-сайте, паук прекращает сканирование и продолжает движение. «[Нет] веб-сканер может фактически сканировать всю доступную сеть. Из-за бесконечного количества веб-сайтов, ловушек-пауков, спама и других требований реальной сети поисковые роботы вместо этого применяют политику сканирования, чтобы определить, когда сканирование сайта должно считаться достаточно. Некоторые веб-сайты сканируются полностью, а другие — только частично «.
Индексирование означает связывание слов и других определяемых токенов, найденных на веб-страницах, с их доменными именами и полями на основе HTML . Связи размещаются в общедоступной базе данных, доступной для поисковых запросов в Интернете. Запрос от пользователя может состоять из одного слова, нескольких слов или предложения. Индекс помогает как можно быстрее найти информацию, относящуюся к запросу. Некоторые методы индексирования и кэширования являются коммерческой тайной, тогда как сканирование в Интернете — это простой процесс посещения всех сайтов на систематической основе.
Запрос от пользователя может состоять из одного слова, нескольких слов или предложения. Индекс помогает как можно быстрее найти информацию, относящуюся к запросу. Некоторые методы индексирования и кэширования являются коммерческой тайной, тогда как сканирование в Интернете — это простой процесс посещения всех сайтов на систематической основе.
Между посещениями паука кэшированная версия страницы (часть или весь контент, необходимый для ее отображения), хранящаяся в рабочей памяти поисковой системы, быстро отправляется запрашивающему. Если посещение просрочено, поисковая система может вместо этого действовать как веб-прокси . В этом случае страница может отличаться от проиндексированных поисковых запросов. Кэшированная страница сохраняет внешний вид версии, слова которой были ранее проиндексированы, поэтому кешированная версия страницы может быть полезна для веб-сайта, когда фактическая страница была потеряна, но эта проблема также считается легкой формой ссылки .
Архитектура высокого уровня стандартного поискового робота
Обычно, когда пользователь вводит запрос в поисковую систему, это несколько ключевых слов . В индексе уже есть названия сайтов, содержащих ключевые слова, и они мгновенно получаются из индекса. Реальная нагрузка обработки связана с созданием веб-страниц, которые являются списком результатов поиска: каждая страница во всем списке должна быть взвешена в соответствии с информацией в индексах. Затем для самого верхнего элемента результатов поиска требуется выполнить поиск, реконструкцию и разметку фрагментов, показывающих контекст совпадающих ключевых слов. Это только часть обработки, необходимой для каждой веб-страницы результатов поиска, а для последующих страниц (рядом с верхними) требуется дополнительная обработка этой публикации.
В индексе уже есть названия сайтов, содержащих ключевые слова, и они мгновенно получаются из индекса. Реальная нагрузка обработки связана с созданием веб-страниц, которые являются списком результатов поиска: каждая страница во всем списке должна быть взвешена в соответствии с информацией в индексах. Затем для самого верхнего элемента результатов поиска требуется выполнить поиск, реконструкцию и разметку фрагментов, показывающих контекст совпадающих ключевых слов. Это только часть обработки, необходимой для каждой веб-страницы результатов поиска, а для последующих страниц (рядом с верхними) требуется дополнительная обработка этой публикации.
Помимо простого поиска по ключевым словам, поисковые системы предлагают собственные операторы с графическим интерфейсом или команды и параметры поиска для уточнения результатов поиска. Они обеспечивают необходимые элементы управления для пользователя, вовлеченного в цикл обратной связи, создаваемый пользователями путем фильтрации и взвешивания при уточнении результатов поиска с учетом начальных страниц первых результатов поиска. Например, с 2007 года поисковая система .com позволяла фильтровать по дате, щелкая «Показать инструменты поиска» в крайнем левом столбце начальной страницы результатов поиска, а затем выбирая желаемый диапазон дат. Также возможно взвешивание по дате, потому что у каждой страницы есть время модификации. Большинство поисковых систем поддерживают использование логических операторов AND, OR и NOT, чтобы помочь конечным пользователям уточнить поисковый запрос . Логические операторы предназначены для буквального поиска, которые позволяют пользователю уточнить и расширить условия поиска. Двигатель ищет слова или фразы в точности так, как они были введены. Некоторые поисковые системы предоставляют расширенную функцию, называемую поиском по близости, которая позволяет пользователям определять расстояние между ключевыми словами. Существует также поиск на основе концепций, при котором исследование включает использование статистического анализа страниц, содержащих искомые слова или фразы.
Например, с 2007 года поисковая система .com позволяла фильтровать по дате, щелкая «Показать инструменты поиска» в крайнем левом столбце начальной страницы результатов поиска, а затем выбирая желаемый диапазон дат. Также возможно взвешивание по дате, потому что у каждой страницы есть время модификации. Большинство поисковых систем поддерживают использование логических операторов AND, OR и NOT, чтобы помочь конечным пользователям уточнить поисковый запрос . Логические операторы предназначены для буквального поиска, которые позволяют пользователю уточнить и расширить условия поиска. Двигатель ищет слова или фразы в точности так, как они были введены. Некоторые поисковые системы предоставляют расширенную функцию, называемую поиском по близости, которая позволяет пользователям определять расстояние между ключевыми словами. Существует также поиск на основе концепций, при котором исследование включает использование статистического анализа страниц, содержащих искомые слова или фразы.
Полезность поисковой системы зависит от значимости этого набора результатов он возвращает. Хотя могут быть миллионы веб-страниц, содержащих определенное слово или фразу, некоторые страницы могут быть более релевантными, популярными или авторитетными, чем другие. Большинство поисковых систем используют методы ранжирования результатов, чтобы в первую очередь предоставлять «лучшие» результаты. То, как поисковая система определяет, какие страницы лучше всего подходят и в каком порядке должны отображаться результаты, сильно различается от одной системы к другой. Методы также меняются со временем по мере того, как меняется использование Интернета и появляются новые методы. Развиваются два основных типа поисковых систем: первый — это система заранее определенных и иерархически упорядоченных ключевых слов, которые люди широко запрограммировали. Другой — система, которая генерирует « перевернутый индекс », анализируя тексты, которые она находит. Эта первая форма в большей степени полагается на сам компьютер, который выполняет основную часть работы.
Большинство поисковых систем — это коммерческие предприятия, поддерживаемые доходами от рекламы, и поэтому некоторые из них позволяют рекламодателям за определенную плату повышать рейтинг своих объявлений в результатах поиска. Поисковые системы, которые не принимают деньги за результаты поиска, зарабатывают деньги, размещая объявления, связанные с поиском, рядом с результатами обычных поисковых систем. Поисковые системы зарабатывают деньги каждый раз, когда кто-то нажимает на одно из этих объявлений.
Локальный поиск
Локальный поиск — это процесс, оптимизирующий усилия местных предприятий. Они сосредоточены на изменениях, чтобы обеспечить согласованность всех поисковых запросов. Это важно, потому что многие люди определяют, куда они планируют пойти и что купить, на основе своих запросов.
Рыночная доля
По состоянию на август 2021 года является самой используемой поисковой системой в мире с долей рынка 92,03%, а другими наиболее часто используемыми поисковыми системами в мире были Bing, Yahoo! , Baidu, Яндекс и DuckDuckGo .
Россия и Восточная Азия
В России доля Яндекса составляет 61,9% по сравнению с 28,3% у . В Китае Baidu — самая популярная поисковая система. Собственный поисковый портал Южной Кореи Naver используется для 70% поисковых запросов в стране. Yahoo! Япония и Yahoo! Тайвань является наиболее популярным местом для поиска в Интернете в Японии и на Тайване соответственно. Китай — одна из немногих стран, где не входит в тройку ведущих поисковых систем по доле рынка. Ранее был ведущей поисковой системой в Китае, но отказался от нее после разногласий с правительством по поводу цензуры и кибератаки.
Европа
На рынках большинства стран Европейского Союза доминирует , за исключением Чехии, где Seznam является сильным конкурентом.
Поисковая система Qwant базируется в Париже, Франция, откуда она привлекает большую часть своих 50 миллионов зарегистрированных пользователей в месяц.
Предвзятость поисковой системы
Хотя поисковые системы запрограммированы на ранжирование веб-сайтов на основе некоторого сочетания их популярности и релевантности, эмпирические исследования указывают на различные политические, экономические и социальные предубеждения в предоставляемой ими информации и лежащих в основе предположениях о технологии.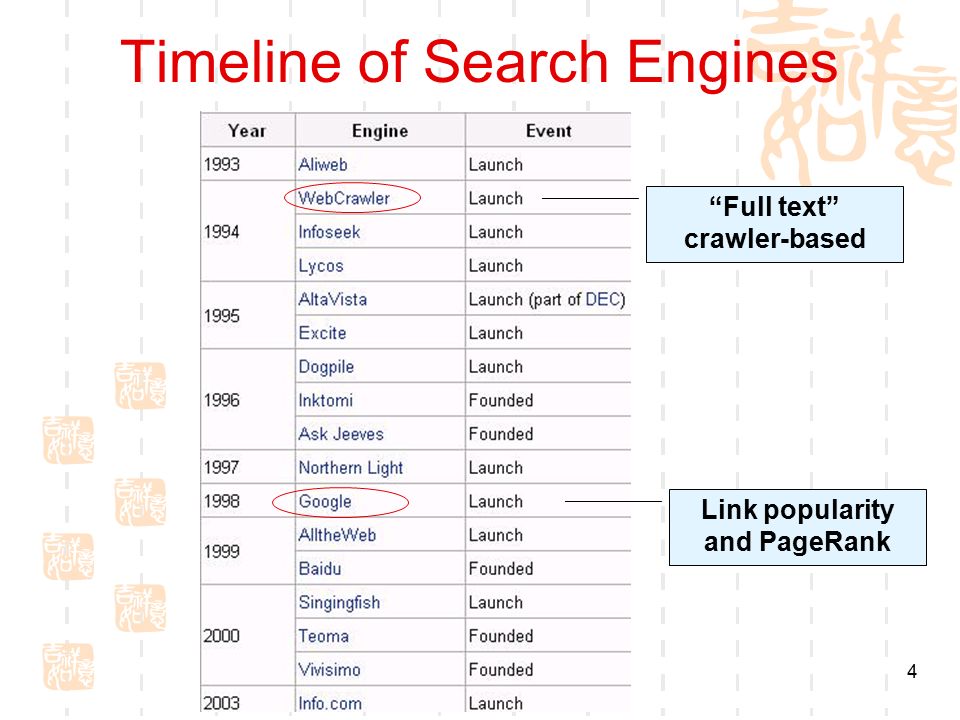 Эти предубеждения могут быть прямым результатом экономических и коммерческих процессов (например, компании, которые размещают рекламу с помощью поисковой системы, также могут стать более популярными в своих органических результатах поиска ), и политических процессов (например, удаление результатов поиска в соответствии с местным законодательством ). Например, не будет отображать некоторые неонацистские веб — сайты во Франции и Германии, где отрицание Холокоста является незаконным.
Эти предубеждения могут быть прямым результатом экономических и коммерческих процессов (например, компании, которые размещают рекламу с помощью поисковой системы, также могут стать более популярными в своих органических результатах поиска ), и политических процессов (например, удаление результатов поиска в соответствии с местным законодательством ). Например, не будет отображать некоторые неонацистские веб — сайты во Франции и Германии, где отрицание Холокоста является незаконным.
Предубеждения также могут быть результатом социальных процессов, поскольку алгоритмы поисковых систем часто предназначены для исключения ненормативных точек зрения в пользу более «популярных» результатов. Алгоритмы индексирования основных поисковых систем смещены в сторону охвата сайтов из США, а не из стран за пределами США.
Использование Bombing является одним из примеров попытки манипулировать результатами поиска по политическим, социальным или коммерческим причинам.
Несколько ученых изучали культурные изменения, вызванные поисковыми системами, и отражение некоторых спорных тем в их результатах, таких как терроризм в Ирландии, отрицание изменения климата и теории заговора .
Настраиваемые результаты и пузыри фильтров
Многие поисковые системы, такие как и Bing, предоставляют индивидуальные результаты на основе истории активности пользователя. Это приводит к эффекту, который получил название пузыря фильтра . Этот термин описывает явление, при котором веб-сайты используют алгоритмы, чтобы выборочно угадывать, какую информацию пользователь хотел бы видеть, на основе информации о пользователе (такой как местоположение, прошлые клики и история поиска). В результате веб-сайты, как правило, показывают только ту информацию, которая соответствует прошлой точке зрения пользователя. Это ставит пользователя в состояние интеллектуальной изоляции без информации об обратном. Яркими примерами являются персонализированные результаты поиска и персонализированный поток новостей Facebook . По словам Эли Паризера, придумавшего этот термин, пользователи меньше сталкиваются с противоречивыми точками зрения и интеллектуально изолированы в собственном информационном пузыре. Паризер привел пример, в котором один пользователь искал в по запросу «BP» и получил инвестиционные новости о British Petroleum, в то время как другой искатель получил информацию о разливе нефти Deepwater Horizon и о том, что две страницы результатов поиска «разительно разные». По мнению Паризера, эффект пузыря может иметь негативные последствия для гражданского дискурса. С тех пор, как эта проблема была выявлена, появились конкурирующие поисковые системы, которые стремятся избежать этой проблемы, не отслеживая и не «вспучивая» пользователей, такие как DuckDuckGo . Другие ученые не разделяют точку зрения Паризера, считая доказательства в поддержку его тезиса неубедительными.
Паризер привел пример, в котором один пользователь искал в по запросу «BP» и получил инвестиционные новости о British Petroleum, в то время как другой искатель получил информацию о разливе нефти Deepwater Horizon и о том, что две страницы результатов поиска «разительно разные». По мнению Паризера, эффект пузыря может иметь негативные последствия для гражданского дискурса. С тех пор, как эта проблема была выявлена, появились конкурирующие поисковые системы, которые стремятся избежать этой проблемы, не отслеживая и не «вспучивая» пользователей, такие как DuckDuckGo . Другие ученые не разделяют точку зрения Паризера, считая доказательства в поддержку его тезиса неубедительными.
Религиозные поисковые системы
Глобальный рост Интернета и электронных СМИ в арабском и мусульманском мире за последнее десятилетие побудил приверженцев ислама на Ближнем Востоке и на азиатском субконтиненте попробовать свои собственные поисковые системы, свои собственные поисковые порталы с фильтрами, которые позволили бы пользователям выполнять безопасный поиск .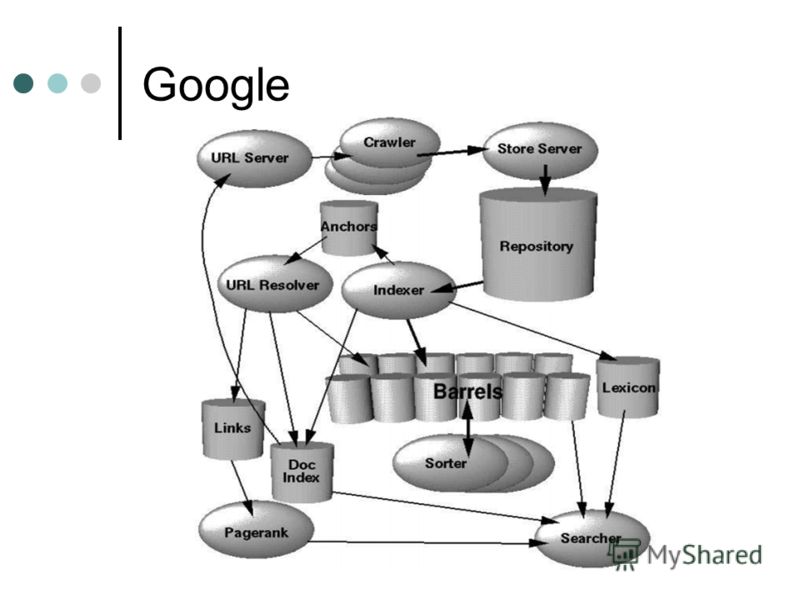 Эти исламские веб-порталы, более чем обычные фильтры безопасного поиска, классифицируют веб-сайты как « халяльные » или « харам » на основании толкования «Закона ислама» . ImHalal пришел онлайн в сентябре 2011 года Halalgoogling пришел онлайн в июле 2013 г. Эти используют Хары фильтров на коллекции от и Bing (и других).
Эти исламские веб-порталы, более чем обычные фильтры безопасного поиска, классифицируют веб-сайты как « халяльные » или « харам » на основании толкования «Закона ислама» . ImHalal пришел онлайн в сентябре 2011 года Halalgoogling пришел онлайн в июле 2013 г. Эти используют Хары фильтров на коллекции от и Bing (и других).
В то время как отсутствие инвестиций и медленные темпы развития технологий в мусульманском мире препятствовали прогрессу и препятствовали успеху исламской поисковой системы, ориентированной на основных потребителей, приверженцев ислама, такие проекты, как Muxlim, сайт о мусульманском образе жизни, действительно получили миллионы долларов от таких инвесторов, как Rite Internet Ventures, и это тоже пошатнулось. Другие поисковые системы, ориентированные на религию, — это Jewogle, еврейская версия , и SeekFind.org, которая является христианской. SeekFind фильтрует сайты, которые атакуют или унижают их веру.
Представление поисковой системы
Отправка веб-сайта в поисковую систему — это процесс, в котором веб-мастер отправляет веб-сайт непосредственно в поисковую систему. Хотя отправка в поисковую систему иногда представляется как способ продвижения веб-сайта, обычно в этом нет необходимости, поскольку основные поисковые системы используют веб-сканеры, которые в конечном итоге находят большинство веб-сайтов в Интернете без посторонней помощи. Они могут либо отправлять по одной веб-странице за раз, либо они могут отправлять весь сайт с помощью карты сайта, но обычно требуется только отправить домашнюю страницу веб-сайта, поскольку поисковые системы могут сканировать хорошо спроектированный веб-сайт. Есть две оставшиеся причины для отправки веб-сайта или веб-страницы в поисковую систему: добавить совершенно новый веб-сайт, не дожидаясь, пока поисковая машина обнаружит его, и обновить запись веб-сайта после существенного изменения дизайна.
Хотя отправка в поисковую систему иногда представляется как способ продвижения веб-сайта, обычно в этом нет необходимости, поскольку основные поисковые системы используют веб-сканеры, которые в конечном итоге находят большинство веб-сайтов в Интернете без посторонней помощи. Они могут либо отправлять по одной веб-странице за раз, либо они могут отправлять весь сайт с помощью карты сайта, но обычно требуется только отправить домашнюю страницу веб-сайта, поскольку поисковые системы могут сканировать хорошо спроектированный веб-сайт. Есть две оставшиеся причины для отправки веб-сайта или веб-страницы в поисковую систему: добавить совершенно новый веб-сайт, не дожидаясь, пока поисковая машина обнаружит его, и обновить запись веб-сайта после существенного изменения дизайна.
Некоторое программное обеспечение для отправки в поисковые системы не только отправляет веб-сайты в несколько поисковых систем, но также добавляет ссылки на веб-сайты с их собственных страниц. Это может оказаться полезным для повышения рейтинга веб-сайта, поскольку внешние ссылки являются одним из наиболее важных факторов, определяющих рейтинг веб-сайта. Однако Джон Мюллер из заявил, что это «может привести к появлению огромного количества неестественных ссылок для вашего сайта», что отрицательно скажется на рейтинге сайта.
Однако Джон Мюллер из заявил, что это «может привести к появлению огромного количества неестественных ссылок для вашего сайта», что отрицательно скажется на рейтинге сайта.
Смотрите также
- Сравнение поисковых систем
- Пузырь с фильтром
- Эффект
- Поиск информации
- Использование поисковых систем в библиотеках
- Список поисковых систем
- Ответ на вопрос
- Эффект манипуляции поисковой системой
- Конфиденциальность поисковой системы
- Семантическая сеть
- Программа проверки орфографии
- Инструменты веб-разработки
использованная литература
дальнейшее чтение
- Стив Лоуренс; К. Ли Джайлз (1999). «Доступность информации в сети» . Природа . 400 (6740): 107–9. Bibcode : 1999Natur.400..107L . DOI : 10.1038 / 21987 . PMID 10428673 . S2CID 4347646 .CS1 maint: несколько имен: список авторов ( ссылка )
- Бинг Лю (2007 г.), Интеллектуальный анализ веб-данных: изучение гиперссылок, содержимого и данных об использовании .
 Springer, ISBN 3-540-37881-2
Springer, ISBN 3-540-37881-2 - Бар-Илан, Дж. (2004). Использование поисковых машин в Интернете в исследованиях в области информатики. АРИСТ, 38, 231–288.
- Левен, Марк (2005). Введение в поисковые системы и веб-навигацию . Пирсон.
- Хок, Рэндольф (2007). Справочник искателя крайностей .ISBN 978-0-910965-76-7
- Джавед Мостафа (февраль 2005 г.). «В поисках лучших результатов поиска в Интернете». Scientific American . 292 (2): 66–73. Bibcode : 2005SciAm.292b..66M . DOI : 10.1038 / Scientificamerican0205-66 .
- Росс, Нэнси; Вольфрам, Дитмар (2000). «Поиск конечных пользователей в Интернете: анализ тематических пар терминов, представленных поисковой системе Excite». Журнал Американского общества информационных наук . 51 (10): 949–958. DOI : 10.1002 / 1097-4571 (2000) 51:10 <949 :: AID-ASI70> 3.0.CO; 2-5 .
- Се, М .; и другие. (1998).
 «Параметры качества поисковых систем Интернета». Журнал информатики . 24 (5): 365–372. DOI : 10.1177 / 016555159802400509 . S2CID 34686531 .
«Параметры качества поисковых систем Интернета». Журнал информатики . 24 (5): 365–372. DOI : 10.1177 / 016555159802400509 . S2CID 34686531 . - Поиск информации: внедрение и оценка поисковых систем . MIT Press. 2010 г.
внешние ссылки
- Поисковые системы в Curlie
<img src=»//en.wikipedia.org/wiki/Special:CentralAutoLogin/start?type=1×1″ alt=»»>
Поисковый движок
Для использования в других целях см. Поисковая система (значения).
За туториал по использованию нансов досталась лысинаВикипедия: Тест поисковой системы.
Эта статья нуждается в более полном цитаты за проверка. Пожалуйста помоги улучшить эту статью к добавление недостающей информации о цитировании так что источники можно четко идентифицировать. Цитирование должно включать название, публикацию, автора, дату и (для материалов с разбивкой на страницы) номер (а) страницы. |
 Несколько шаблонов доступны для помощи в форматировании. Материал, полученный из ненадлежащего источника, может быть оспорен и удален. (Сентябрь 2018 г.) (Узнайте, как и когда удалить этот шаблон сообщения)
Несколько шаблонов доступны для помощи в форматировании. Материал, полученный из ненадлежащего источника, может быть оспорен и удален. (Сентябрь 2018 г.) (Узнайте, как и когда удалить этот шаблон сообщения)Результаты поиска по запросу «лунное затмение» в веб- поиск изображений двигатель
А поисковый движок это программная система, предназначенная для выполнения поиск в Интернете (Поиск в Интернете), что означает поиск Всемирная паутина систематическим образом для конкретной информации, указанной в текстовом поисковый запрос в Интернете. Результаты поиска обычно представлены в виде строки результатов, часто называемой страницы результатов поисковой системы (Поисковая выдача). Информация может представлять собой сочетание ссылок на веб-страница, изображения, видео, инфографика, статьи, исследовательские работы и другие типы файлов. Некоторые поисковые системы также мои данные доступно в базы данных или же открытые каталоги. В отличие от веб-каталоги, которые обслуживаются только редакторами, поисковые системы также поддерживают в реальном времени информацию, запустив алгоритм на поисковый робот. Интернет-контент, который не может быть найден поисковой системой в Интернете, обычно описывается как глубокая паутина.
В отличие от веб-каталоги, которые обслуживаются только редакторами, поисковые системы также поддерживают в реальном времени информацию, запустив алгоритм на поисковый робот. Интернет-контент, который не может быть найден поисковой системой в Интернете, обычно описывается как глубокая паутина.
Содержание
- 1 История
- 2 Подход
- 2.1 Локальный поиск
- 3 Рыночная доля
- 3.1 Восточная Азия и Россия
- 3.2 Европа
- 4 Предвзятость поисковой системы
- 5 Индивидуальные результаты и пузыри фильтров
- 6 Религиозные поисковые системы
- 7 Представление поисковой системы
- 8 Смотрите также
- 9 Рекомендации
- 10 дальнейшее чтение
- 11 внешняя ссылка
История
Дальнейшая информация: Хронология поисковых систем
| Год | Двигатель | Текущее состояние |
|---|---|---|
| 1993 | W3Каталог | Активный |
| Aliweb | Активный | |
| JumpStation | Неактивный | |
| WWW Червь | Неактивный | |
| 1994 | WebCrawler | Активный |
Go. com com | Неактивен, перенаправляет на Disney | |
| Lycos | Активный | |
| Infoseek | Неактивен, перенаправляет на Disney | |
| 1995 | Yahoo! Поиск | Активный, изначально функция поиска для Yahoo! Каталог |
| Даум | Активный | |
| Магеллан | Неактивный | |
| Возбудить | Активный | |
| SAPO | Активный | |
| MetaCrawler | Активный | |
| AltaVista | Неактивно, приобретено Yahoo! в 2003 году с 2013 года перенаправляет на Yahoo! | |
| 1996 | RankDex | Неактивен, включен в Baidu в 2000 г. |
| Собачья куча | Активный, Агрегатор | |
| Инктоми | Неактивно, приобретено Yahoo! | |
| HotBot | Активный | |
| Спросите Дживса | Активный (переименован в ask.com) | |
| 1997 | AOL NetFind | Активный (переименован Поиск AOL с 1999 г. ) ) |
| Северное сияние | Неактивный | |
| Яндекс | Активный | |
| 1998 | Активный | |
| Ixquick | Активен как Startpage.com | |
| Поиск MSN | Активен как Bing | |
| эмпас | Неактивно (объединено с NATE) | |
| 1999 | AlltheWeb | Неактивен (URL-адрес перенаправлен на Yahoo!) |
| GenieKnows | Активный, ребрендированный Yellowee (перенаправление на justlocalbusiness.com) | |
| Naver | Активный | |
| Теома | Актив (© АПН, ООО) | |
| 2000 | Baidu | Активный |
| Exalead | Неактивный | |
| Гигабласт | Активный | |
| 2001 | Kartoo | Неактивный |
| 2003 | Info.com | Активный |
| Scroogle | Неактивный | |
| 2004 | A9. com com | Неактивный |
| Clusty | Активный (как Yippy) | |
| Mojeek | Активный | |
| Согоу | Активный | |
| 2005 | Найди меня | Неактивный |
| KidzSearch | Активный, поиск в Google | |
| 2006 | Так-так | Неактивен, объединен с Согоу |
| Quaero | Неактивный | |
| Search.com | Активный | |
| ЧаЧа | Неактивный | |
| Ask.com | Активный | |
| Живой поиск | Активен как Bing, имеет ребрендинг MSN Search | |
| 2007 | викисик | Неактивный |
| Sproose | Неактивный | |
| Wikia Search | Неактивный | |
| Blackle.com | Активный, поиск в Google | |
| 2008 | Powerset | Неактивен (перенаправляет на Bing) |
| Пиколлатор | Неактивный | |
| Viewzi | Неактивный | |
| Бугами | Неактивный | |
| LeapFish | Неактивный | |
| Forestle | Неактивен (перенаправляет на Ecosia) | |
| УткаУтка | Активный | |
| 2009 | Bing | Активный интерактивный поиск с ребрендингом |
| Yebol | Неактивный | |
| Мугурды | Неактивен из-за отсутствия финансирования | |
| Разведчик (бычок) | Активный | |
| NATE | Активный | |
| Ecosia | Активный | |
Startpage. com com | Активный, родственный двигатель Ixquick | |
| 2010 | Блекко | Неактивен, продан IBM |
| Cuil | Неактивный | |
| Яндекс (Английский) | Активный | |
| Парсиджу | Активный | |
| 2011 | YaCy | Активный, P2P |
| 2012 | Volunia | Неактивный |
| 2013 | Qwant | Активный |
| 2014 | Эгерин | Активный, Курдский / Сорани |
| Swisscows | Активный | |
| 2015 | Йуз | Активный |
| Cliqz | Неактивный | |
| 2016 | Kiddle | Активный, поиск в Google |
Идея индексирования информации возникла еще в 1945 году в Ванневар Буш The Atlantic Monthly статья «Как мы можем думать «.[1] Ванневар подчеркнул важность информации в будущем и необходимость для ученых разработать способ включения информации, найденной в журналах. [2] Он предложил устройство памяти под названием Memex, используется для сжатия и хранения информации, которая затем может быть извлечена быстро и гибко.[3] Сами поисковые системы в Интернете появились еще до появления Интернета в декабре 1990 года. Кто поиск пользователей датируется 1982 годом[4] и Информационная служба Knowbot Многосетевой поиск пользователей впервые был реализован в 1989 году.[5] Первая хорошо документированная поисковая система, выполнявшая поиск файлов с контентом, а именно FTP файлы, было Арчи, который дебютировал 10 сентября 1990 года.[6]
[2] Он предложил устройство памяти под названием Memex, используется для сжатия и хранения информации, которая затем может быть извлечена быстро и гибко.[3] Сами поисковые системы в Интернете появились еще до появления Интернета в декабре 1990 года. Кто поиск пользователей датируется 1982 годом[4] и Информационная служба Knowbot Многосетевой поиск пользователей впервые был реализован в 1989 году.[5] Первая хорошо документированная поисковая система, выполнявшая поиск файлов с контентом, а именно FTP файлы, было Арчи, который дебютировал 10 сентября 1990 года.[6]
До сентября 1993 г. Всемирная паутина был полностью проиндексирован вручную. Был список веб-серверы Отредактировано Тим Бернерс-Ли и размещен на ЦЕРН веб сервер. Один снимок списка 1992 года остается,[7] но по мере того, как в сеть выходило все больше и больше веб-серверов, центральный список уже не успевал. На NCSA сайта были анонсированы новые серверы под заголовком «Что нового!»[8]
Первый инструмент, используемый для поиска контента (в отличие от пользователей) на Интернет был Арчи. [9] Название расшифровывается как «архив» без «v».,[10] Он был создан Алан Эмтадж[10][11][12][13] студент информатики в Университет Макгилла в Монреаль, Квебек, Канада. Программа загрузила списки каталогов всех файлов, находящихся на общедоступном анонимном FTP (протокол передачи файлов ) сайты, создающие базу данных имен файлов с возможностью поиска; тем не мение, Поисковая система Archie не индексировали содержимое этих сайтов, поскольку объем данных был настолько ограничен, что их можно было легко найти вручную.
[9] Название расшифровывается как «архив» без «v».,[10] Он был создан Алан Эмтадж[10][11][12][13] студент информатики в Университет Макгилла в Монреаль, Квебек, Канада. Программа загрузила списки каталогов всех файлов, находящихся на общедоступном анонимном FTP (протокол передачи файлов ) сайты, создающие базу данных имен файлов с возможностью поиска; тем не мение, Поисковая система Archie не индексировали содержимое этих сайтов, поскольку объем данных был настолько ограничен, что их можно было легко найти вручную.
Подъем Суслик (создан в 1991 г. Марк МакКахилл на Университет Миннесоты ) привело к появлению двух новых поисковых программ, Вероника и Джагхед. Как и Арчи, они искали имена и заголовки файлов, хранящиеся в индексных системах Gopher. Вероника (Vэри Eаси родент-Овозбужденный Nпо всему миру яndex к Cкомпьютеризованный Аrchives) обеспечил поиск по ключевым словам большинства заголовков меню Gopher во всех списках Gopher. Джагхед (Jонзи Uуниверсальный граммофер ЧАСиерархия Eкавитация Аnd Display) был инструментом для получения информации о меню с определенных серверов Gopher. Пока название поисковика «Поисковая система Archie «не было ссылкой на Комикс Арчи серии, «Вероника » и «Джагхед «- персонажи сериала, отсылающие к своему предшественнику.
Джагхед (Jонзи Uуниверсальный граммофер ЧАСиерархия Eкавитация Аnd Display) был инструментом для получения информации о меню с определенных серверов Gopher. Пока название поисковика «Поисковая система Archie «не было ссылкой на Комикс Арчи серии, «Вероника » и «Джагхед «- персонажи сериала, отсылающие к своему предшественнику.
Летом 1993 года поисковой машины для Интернета не существовало, хотя многочисленные специализированные каталоги поддерживались вручную. Оскар Нирстраз на Женевский университет написал серию Perl скрипты, которые периодически отображали эти страницы и переписывали их в стандартный формат. Это легло в основу W3Каталог, первая примитивная поисковая система в Интернете, выпущенная 2 сентября 1993 года.[14]
В июне 1993 года Мэтью Грей, затем в Массачусетский технологический институт, произвел, вероятно, первый веб-робот, то Perl -основан Странник по всемирной паутине, и использовал его для создания индекса под названием «Вандекс». Целью Wanderer было измерить размер Всемирной паутины, что он и делал до конца 1995 года. Вторая поисковая машина в сети. Aliweb появился в ноябре 1993 года. Aliweb не использовал веб-робот, но вместо этого зависели от уведомлений администраторов веб-сайтов о существовании на каждом сайте индексного файла в определенном формате.
Целью Wanderer было измерить размер Всемирной паутины, что он и делал до конца 1995 года. Вторая поисковая машина в сети. Aliweb появился в ноябре 1993 года. Aliweb не использовал веб-робот, но вместо этого зависели от уведомлений администраторов веб-сайтов о существовании на каждом сайте индексного файла в определенном формате.
JumpStation (создан в декабре 1993 г.[15] к Джонатон Флетчер ) использовал веб-робот для поиска веб-страниц и создания их индекса и использовал веб-форма как интерфейс к его программе запросов. Таким образом, это был первый WWW инструмент обнаружения ресурсов для объединения трех основных функций поисковой системы в Интернете (сканирование, индексирование и поиск), как описано ниже. Из-за ограниченных ресурсов, доступных на платформе, на которой он работал, его индексация и, следовательно, поиск были ограничены заголовками и заголовками, найденными на веб-страницах, с которыми столкнулся поисковый робот.
Одной из первых поисковых систем, основанных на полностью текстовых роботах, была WebCrawler, который вышел в 1994 году. В отличие от своих предшественников, он позволял пользователям искать любое слово на любой веб-странице, что с тех пор стало стандартом для всех основных поисковых систем. Это была также поисковая машина, которая была широко известна публике. Также в 1994 г. Lycos (который начался в Университет Карнеги Меллон ) был запущен и стал крупным коммерческим предприятием.
В отличие от своих предшественников, он позволял пользователям искать любое слово на любой веб-странице, что с тех пор стало стандартом для всех основных поисковых систем. Это была также поисковая машина, которая была широко известна публике. Также в 1994 г. Lycos (который начался в Университет Карнеги Меллон ) был запущен и стал крупным коммерческим предприятием.
Первой популярной поисковой системой в Интернете была Yahoo! Поиск.[16] Первый продукт от Yahoo!, основан Джерри Янг и Дэвид Фило в январе 1994 г. Интернет-каталог называется Yahoo! Каталог. В 1995 году была добавлена функция поиска, позволяющая пользователям выполнять поиск в Yahoo! Справочник![17][18] Он стал одним из самых популярных способов найти интересующие веб-страницы, но его функция поиска работала в его веб-каталоге, а не в полнотекстовых копиях веб-страниц.
Вскоре после этого появился ряд поисковых систем, которые боролись за популярность. К ним относятся Магеллан, Возбудить, Infoseek, Инктоми, Северное сияние, и AltaVista. Ищущие информацию могут также просматривать каталог вместо поиска по ключевым словам.
Ищущие информацию могут также просматривать каталог вместо поиска по ключевым словам.
В 1996 г. Робин Ли разработал RankDex алгоритм оценки сайта для ранжирования страниц результатов поисковых систем[19][20][21] и получил патент США на технологию.[22] Это была первая поисковая система, которая использовала гиперссылки для измерения качества индексируемых веб-сайтов,[23] предшествующий очень похожему патенту на алгоритм, поданному Google два года спустя, в 1998 году.[24]Ларри Пейдж сослался на работу Ли в некоторых своих патентах США на PageRank.[25] Позже Ли использовал свою технологию Rankdex для Baidu поисковая система, основанная Робином Ли в Китае и запущенная в 2000 году.
В 1996 г. Netscape стремился предоставить единственной поисковой системе эксклюзивную сделку в качестве популярной поисковой системы в веб-браузере Netscape. Интерес был настолько велик, что вместо этого Netscape заключила сделки с пятью основными поисковыми машинами: за 5 миллионов долларов в год каждая поисковая машина будет попеременно отображаться на странице поисковой системы Netscape. Пятью движками были Yahoo !, Magellan, Lycos, Infoseek и Excite.[26][27]
Пятью движками были Yahoo !, Magellan, Lycos, Infoseek и Excite.[26][27]
Google переняла идею продажи поисковых запросов в 1998 году от небольшой поисковой компании под названием goto.com. Этот шаг оказал значительное влияние на бизнес SE, который превратился из тяжелого бизнеса в один из самых прибыльных предприятий в Интернете.[28]
Поисковые системы также были известны как одни из самых ярких звезд в безумном инвестировании в Интернет, которое произошло в конце 1990-х годов.[29] Несколько компаний впечатляюще вышли на рынок, получив рекордные прибыли за время своего существования. первичные публичные предложения. Некоторые закрыли свои общедоступные поисковые системы и продают корпоративные версии, такие как Northern Light. Многие поисковые компании оказались в ловушке пузырь доткомов, рыночный бум, вызванный спекуляциями, пик которого пришелся на 1990 год и закончился в 2000 году.
Около 2000 г. Поисковая система Google стал известен. [30] Компания добилась лучших результатов по многим поисковым запросам с помощью алгоритма под названием PageRank, как было объяснено в статье Анатомия поисковой системы написано Сергей Брин и Ларри Пейдж, более поздние основатели Google.[31] Этот итерационный алгоритм ранжирует веб-страницы на основе количества и PageRank других веб-сайтов и страниц, которые на них ссылаются, исходя из того, что хорошие или желательные страницы связаны больше, чем другие. Патент Ларри Пейджа на PageRank цитирует Робин Ли раньше RankDex патент как влияние.[25][32] Google также сохранил минималистичный интерфейс своей поисковой системы. Напротив, многие из его конкурентов встроили поисковую систему в Веб-портал. Фактически, поисковая система Google стала настолько популярной, что появились спуфинговые системы, такие как Искатель тайн.
[30] Компания добилась лучших результатов по многим поисковым запросам с помощью алгоритма под названием PageRank, как было объяснено в статье Анатомия поисковой системы написано Сергей Брин и Ларри Пейдж, более поздние основатели Google.[31] Этот итерационный алгоритм ранжирует веб-страницы на основе количества и PageRank других веб-сайтов и страниц, которые на них ссылаются, исходя из того, что хорошие или желательные страницы связаны больше, чем другие. Патент Ларри Пейджа на PageRank цитирует Робин Ли раньше RankDex патент как влияние.[25][32] Google также сохранил минималистичный интерфейс своей поисковой системы. Напротив, многие из его конкурентов встроили поисковую систему в Веб-портал. Фактически, поисковая система Google стала настолько популярной, что появились спуфинговые системы, такие как Искатель тайн.
К 2000 г. Yahoo! предоставлял поисковые услуги на основе поисковой системы Inktomi. Yahoo! приобрела Inktomi в 2002 году и Увертюра (который владел AlltheWeb и AltaVista) в 2003 году. Yahoo! перешла на поисковую систему Google до 2004 года, когда она запустила свою собственную поисковую систему, основанную на комбинированных технологиях своих приобретений.
Yahoo! перешла на поисковую систему Google до 2004 года, когда она запустила свою собственную поисковую систему, основанную на комбинированных технологиях своих приобретений.
Microsoft впервые запустил поиск MSN осенью 1998 года, используя результаты поиска Inktomi. В начале 1999 г. на сайте стали появляться объявления из Выглядит умным, в сочетании с результатами от Inktomi. На короткое время в 1999 году поисковая система MSN вместо этого использовала результаты AltaVista. В 2004 г. Microsoft начал переход на собственную технологию поиска, основанную на собственном поисковый робот (называется msnbot ).
Ребрендинг поисковой системы Microsoft, Bing, был запущен 1 июня 2009 года. 29 июля 2009 года Yahoo! и Microsoft заключили сделку, по которой Yahoo! Поиск будет работать на технологии Microsoft Bing.
По состоянию на 2019 год активные сканеры поисковых систем включают Google, Согоу, Baidu, Bing, Гигабласт, Mojeek, УткаУтка и Яндекс.
Подход
Основная статья: Технология поисковых систем
Поисковая система поддерживает следующие процессы почти в реальном времени:
- Веб-сканирование
- Индексирование
- Поиск[33]
Поисковые системы получают информацию сканирование сети с сайта на сайт. «Паук» проверяет стандартное имя файла robots.txt, обратился к нему. Файл robots.txt содержит директивы для поисковых роботов, указывающие, какие страницы сканировать. Проверив файл robots.txt и найдя его или нет, паук отправляет определенную информацию обратно в индексированный в зависимости от многих факторов, таких как заголовки, содержание страницы, JavaScript, Каскадные таблицы стилей (CSS), заголовки или их метаданные в HTML Мета-теги. После определенного количества просканированных страниц, проиндексированных данных или времени, проведенного на сайте, паук прекращает сканирование и продолжает свое движение. «[Нет] веб-сканер может фактически сканировать всю доступную сеть. Из-за бесконечного количества веб-сайтов, ловушек пауков, спама и других требований реальной сети поисковые роботы вместо этого применяют политику сканирования, чтобы определить, когда сканирование сайта должно считаться достаточно. Некоторые веб-сайты сканируются полностью, а другие — только частично «.
«Паук» проверяет стандартное имя файла robots.txt, обратился к нему. Файл robots.txt содержит директивы для поисковых роботов, указывающие, какие страницы сканировать. Проверив файл robots.txt и найдя его или нет, паук отправляет определенную информацию обратно в индексированный в зависимости от многих факторов, таких как заголовки, содержание страницы, JavaScript, Каскадные таблицы стилей (CSS), заголовки или их метаданные в HTML Мета-теги. После определенного количества просканированных страниц, проиндексированных данных или времени, проведенного на сайте, паук прекращает сканирование и продолжает свое движение. «[Нет] веб-сканер может фактически сканировать всю доступную сеть. Из-за бесконечного количества веб-сайтов, ловушек пауков, спама и других требований реальной сети поисковые роботы вместо этого применяют политику сканирования, чтобы определить, когда сканирование сайта должно считаться достаточно. Некоторые веб-сайты сканируются полностью, а другие — только частично «. [34]
[34]
Индексирование означает связывание слов и других определяемых токенов, найденных на веб-страницах, с их доменными именами и HTML -основные поля. Связи размещаются в общедоступной базе данных, доступной для поисковых запросов в Интернете. Запрос от пользователя может состоять из одного слова, нескольких слов или предложения. Индекс помогает как можно быстрее найти информацию, относящуюся к запросу.[33] Некоторые методы индексации и кеширование являются коммерческой тайной, тогда как сканирование Интернета — это простой процесс посещения всех сайтов на систематической основе.
Между визитами паук, кешированная версия страницы (часть или весь контент, необходимый для ее отображения), хранящаяся в рабочей памяти поисковой системы, быстро отправляется запрашивающему. Если визит просрочен, поисковая система может просто действовать как веб-прокси вместо. В этом случае страница может отличаться от проиндексированных поисковых запросов.[33] Кэшированная страница сохраняет внешний вид версии, слова которой были ранее проиндексированы, поэтому кешированная версия страницы может быть полезна для веб-сайта, когда фактическая страница была потеряна, но эта проблема также считается легкой формой Linkrot.
Архитектура высокого уровня стандартного поискового робота
Обычно, когда пользователь входит в запрос в поисковике это несколько ключевые слова.[35] В индекс уже есть названия сайтов, содержащих ключевые слова, и они мгновенно получаются из индекса. Реальная нагрузка обработки связана с созданием веб-страниц, которые являются списком результатов поиска: каждая страница во всем списке должна быть взвешенный согласно информации в указателях.[33] Тогда для элемента результатов поиска с наибольшей популярностью требуется поиск, реконструкция и разметка фрагменты показывающий контекст совпадающих ключевых слов. Это только часть обработки, необходимой для каждой веб-страницы результатов поиска, а для последующих страниц (рядом с верхними) требуется дополнительная обработка этой публикации.
Помимо простого поиска по ключевым словам, поисковые системы предлагают собственные операторы с графическим интерфейсом или командами и параметры поиска для уточнения результатов поиска. Они обеспечивают необходимые элементы управления для пользователя, вовлеченного в цикл обратной связи, который пользователи создают фильтрация и взвешивание при уточнении результатов поиска с учетом начальных страниц первых результатов поиска. Например, с 2007 года поисковая система Google.com позволяла фильтр по дате, щелкнув «Показать инструменты поиска» в крайнем левом столбце начальной страницы результатов поиска, а затем выбрав нужный диапазон дат.[36] Также возможно масса по дате, потому что у каждой страницы есть время модификации. Большинство поисковых систем поддерживают использование логические операторы И, ИЛИ, и НЕ, чтобы помочь конечным пользователям уточнить поисковый запрос. Логические операторы предназначены для буквального поиска, которые позволяют пользователю уточнить и расширить условия поиска. Двигатель ищет слова или фразы в точности так, как они были введены. Некоторые поисковые системы предоставляют расширенную функцию, называемую поиск близости, который позволяет пользователям определять расстояние между ключевыми словами.
Они обеспечивают необходимые элементы управления для пользователя, вовлеченного в цикл обратной связи, который пользователи создают фильтрация и взвешивание при уточнении результатов поиска с учетом начальных страниц первых результатов поиска. Например, с 2007 года поисковая система Google.com позволяла фильтр по дате, щелкнув «Показать инструменты поиска» в крайнем левом столбце начальной страницы результатов поиска, а затем выбрав нужный диапазон дат.[36] Также возможно масса по дате, потому что у каждой страницы есть время модификации. Большинство поисковых систем поддерживают использование логические операторы И, ИЛИ, и НЕ, чтобы помочь конечным пользователям уточнить поисковый запрос. Логические операторы предназначены для буквального поиска, которые позволяют пользователю уточнить и расширить условия поиска. Двигатель ищет слова или фразы в точности так, как они были введены. Некоторые поисковые системы предоставляют расширенную функцию, называемую поиск близости, который позволяет пользователям определять расстояние между ключевыми словами. [33] Существует также концептуальный поиск где исследование предполагает использование статистического анализа страниц, содержащих искомые слова или фразы. Кроме того, запросы на естественном языке позволяют пользователю вводить вопрос в той же форме, в которой он задается человеку.[37] Такой сайт будет называться ask.com.[38]
[33] Существует также концептуальный поиск где исследование предполагает использование статистического анализа страниц, содержащих искомые слова или фразы. Кроме того, запросы на естественном языке позволяют пользователю вводить вопрос в той же форме, в которой он задается человеку.[37] Такой сайт будет называться ask.com.[38]
Полезность поисковой системы зависит от актуальность из набор результатов он отдает. Хотя могут быть миллионы веб-страниц, содержащих определенное слово или фразу, некоторые страницы могут быть более релевантными, популярными или авторитетными, чем другие. Большинство поисковых систем используют методы классифицировать результаты, чтобы сначала обеспечить «лучшие» результаты. То, как поисковая система определяет, какие страницы лучше всего подходят и в каком порядке должны отображаться результаты, сильно различается от одной системы к другой.[33] Методы также меняются с течением времени по мере изменения использования Интернета и появления новых технологий. Развиваются два основных типа поисковых систем: первый — это система заранее определенных и иерархически упорядоченных ключевых слов, которые люди широко запрограммировали. Другой — система, которая генерирует «инвертированный индекс «путем анализа найденных текстов. Эта первая форма в гораздо большей степени полагается на сам компьютер, который выполняет основную часть работы.
Развиваются два основных типа поисковых систем: первый — это система заранее определенных и иерархически упорядоченных ключевых слов, которые люди широко запрограммировали. Другой — система, которая генерирует «инвертированный индекс «путем анализа найденных текстов. Эта первая форма в гораздо большей степени полагается на сам компьютер, который выполняет основную часть работы.
Большинство поисковых систем — это коммерческие предприятия, поддерживаемые Реклама доход, и поэтому некоторые из них позволяют рекламодателям повысить рейтинг своих объявлений в результатах поиска за определенную плату. Поисковые системы, которые не принимают деньги за результаты поиска, зарабатывают деньги, запустив поиск похожих объявлений наряду с обычными результатами поиска. Поисковые системы зарабатывают деньги каждый раз, когда кто-то нажимает на одно из этих объявлений.[39]
С развитием технологий были разработаны новые способы поиска, такие как поиск 3D-моделей. Некоторые 3D-порталы используют поисковые системы по термину, форме, цвету, функциональности, эскизу / рисунку и т. Д.
Д.
Локальный поиск
Локальный поиск это процесс, оптимизирующий усилия местных предприятий. Они сосредоточены на изменениях, чтобы обеспечить согласованность всех поисковых запросов. Это важно, потому что многие люди определяют, куда они планируют пойти и что купить, на основе своих запросов.[40]
Рыночная доля
По состоянию на сентябрь 2020 г.,[41]Google это самая используемая поисковая система в мире с долей рынка 92,96%, а самые популярные поисковые системы в мире:
Восточная Азия и Россия
В России, Яндекс занимает 61,9% рынка по сравнению с 28,3% у Google.[42] В Китае Baidu — самая популярная поисковая система.[43] Собственный поисковый портал Южной Кореи, Naver, используется для 70 процентов онлайн-поисков в стране.[44]Yahoo! Япония и Yahoo! Тайвань являются наиболее популярными способами поиска в Интернете в Японии и на Тайване соответственно.[45] Китай — одна из немногих стран, где Google не входит в первую тройку поисковых систем по доле рынка. Ранее Google был ведущей поисковой системой в Китае, но был вынужден отказаться от нее из-за несоблюдения законов Китая.[46]
Ранее Google был ведущей поисковой системой в Китае, но был вынужден отказаться от нее из-за несоблюдения законов Китая.[46]
Европа
На рынках большинства стран Западной Европы доминирует Google, за исключением Чехия, куда Сезнам сильный конкурент.[47]
Предвзятость поисковой системы
Хотя поисковые системы запрограммированы на ранжирование веб-сайтов на основе некоторой комбинации их популярности и релевантности, эмпирические исследования указывают на различные политические, экономические и социальные предубеждения в предоставляемой ими информации.[48][49] и основные предположения о технологии.[50] Эти предубеждения могут быть прямым результатом экономических и коммерческих процессов (например, компании, которые размещают рекламу в поисковой системе, также могут стать более популярными в своих обычный поиск результаты) и политические процессы (например, удаление результатов поиска в соответствии с местным законодательством). [51] Например, Google не покажет определенные неонацистский сайты во Франции и Германии, где Отрицание холокоста незаконно.
[51] Например, Google не покажет определенные неонацистский сайты во Франции и Германии, где Отрицание холокоста незаконно.
Предубеждения также могут быть результатом социальных процессов, поскольку алгоритмы поисковых систем часто предназначены для исключения ненормативных точек зрения в пользу более «популярных» результатов.[52] Алгоритмы индексирования основных поисковых систем смещены в сторону охвата сайтов из США, а не из стран, не входящих в США.[49]
Google Bombing является одним из примеров попытки манипулировать результатами поиска по политическим, социальным или коммерческим причинам.
Несколько ученых изучали культурные изменения, вызванные поисковыми системами,[53] и представление некоторых спорных тем в их результатах, таких как терроризм в Ирландии,[54]отрицание изменения климата,[55] и теории заговора.[56]
Индивидуальные результаты и пузыри фильтров
Многие поисковые системы, такие как Google и Bing, предоставляют индивидуальные результаты на основе истории активности пользователя. Это приводит к эффекту, который получил название пузырьковый фильтр. Этот термин описывает явление, при котором веб-сайты используют алгоритмы выборочно угадывать, какую информацию пользователь хотел бы видеть, основываясь на информации о пользователе (например, о местонахождении, прошлых кликах и истории поиска). В результате веб-сайты, как правило, показывают только ту информацию, которая соответствует предыдущей точке зрения пользователя. Это ставит пользователя в состояние интеллектуальной изоляции без информации об обратном. Яркие примеры — Google персонализированный поиск результаты и Facebook персонализированный поток новостей. В соответствии с Эли Паризер, кто придумал этот термин, пользователи меньше сталкиваются с противоречивыми точками зрения и интеллектуально изолированы в собственном информационном пузыре. Паризер привел пример, в котором один пользователь поискал в Google по запросу «ВР» и получил инвестиционные новости о British Petroleum в то время как другой поисковик получил информацию о Разлив нефти Deepwater Horizon и что две страницы результатов поиска были «разительно разными».
Это приводит к эффекту, который получил название пузырьковый фильтр. Этот термин описывает явление, при котором веб-сайты используют алгоритмы выборочно угадывать, какую информацию пользователь хотел бы видеть, основываясь на информации о пользователе (например, о местонахождении, прошлых кликах и истории поиска). В результате веб-сайты, как правило, показывают только ту информацию, которая соответствует предыдущей точке зрения пользователя. Это ставит пользователя в состояние интеллектуальной изоляции без информации об обратном. Яркие примеры — Google персонализированный поиск результаты и Facebook персонализированный поток новостей. В соответствии с Эли Паризер, кто придумал этот термин, пользователи меньше сталкиваются с противоречивыми точками зрения и интеллектуально изолированы в собственном информационном пузыре. Паризер привел пример, в котором один пользователь поискал в Google по запросу «ВР» и получил инвестиционные новости о British Petroleum в то время как другой поисковик получил информацию о Разлив нефти Deepwater Horizon и что две страницы результатов поиска были «разительно разными». [57][58][59] По словам Паризера, эффект пузыря может иметь негативные последствия для гражданского дискурса.[60] С тех пор, как эта проблема была выявлена, появились конкурирующие поисковые системы, которые стремятся избежать этой проблемы, не отслеживая или не «всплывая» пользователей, например УткаУтка. Другие ученые не разделяют точку зрения Паризера, считая доказательства в поддержку его тезиса неубедительными.[61]
[57][58][59] По словам Паризера, эффект пузыря может иметь негативные последствия для гражданского дискурса.[60] С тех пор, как эта проблема была выявлена, появились конкурирующие поисковые системы, которые стремятся избежать этой проблемы, не отслеживая или не «всплывая» пользователей, например УткаУтка. Другие ученые не разделяют точку зрения Паризера, считая доказательства в поддержку его тезиса неубедительными.[61]
Религиозные поисковые системы
Глобальный рост Интернета и электронных СМИ в Араб и Мусульманин В течение последнего десятилетия мир поощрял приверженцев ислама в Ближний Восток и Азиатский субконтинент, чтобы попробовать свои собственные поисковые системы, свои собственные отфильтрованные поисковые порталы, которые позволили бы пользователям выполнять безопасный поиск. Больше, чем обычно безопасный поиск фильтры, эти исламские веб-порталы классифицируют веб-сайты как «халяль » или же «харам «, основанный на толковании «Закон ислама». ИмХалал появился в сети в сентябре 2011 года. Халяльный поиск появился в сети в июле 2013 года. Они используют харам фильтры по коллекциям из Google и Bing (и другие).[62]
ИмХалал появился в сети в сентябре 2011 года. Халяльный поиск появился в сети в июле 2013 года. Они используют харам фильтры по коллекциям из Google и Bing (и другие).[62]
В то время как недостаток инвестиций и медленные темпы развития технологий в мусульманском мире препятствовали прогрессу и препятствовали успеху исламской поисковой системы, ориентированной на основных потребителей, приверженцев ислама, такие проекты, как Muxlim сайт, посвященный мусульманскому образу жизни, действительно получил миллионы долларов от таких инвесторов, как Rite Internet Ventures, и он также не работал. Другие поисковые системы, ориентированные на религию, — это Jewogle, еврейская версия Google,[63] и SeekFind.org, что является христианским. SeekFind фильтрует сайты, которые атакуют или унижают их веру.[64]
Представление поисковой системы
Представление поисковой системы это процесс, в котором веб-мастер отправляет веб-сайт непосредственно в поисковую систему. Хотя отправка в поисковую систему иногда представляется как способ продвижения веб-сайта, обычно в этом нет необходимости, потому что основные поисковые системы используют поисковые роботы, которые в конечном итоге находят большинство веб-сайтов в Интернете без посторонней помощи. Они могут либо отправлять по одной веб-странице за раз, либо они могут отправлять весь сайт, используя карта сайта, но обычно требуется только отправить домашняя страница веб-сайта, поскольку поисковые системы могут сканировать хорошо спроектированный веб-сайт. Есть две оставшиеся причины для отправки веб-сайта или веб-страницы в поисковую систему: добавить совершенно новый веб-сайт, не дожидаясь, пока поисковая машина обнаружит его, и обновить запись веб-сайта после существенного изменения дизайна.
Хотя отправка в поисковую систему иногда представляется как способ продвижения веб-сайта, обычно в этом нет необходимости, потому что основные поисковые системы используют поисковые роботы, которые в конечном итоге находят большинство веб-сайтов в Интернете без посторонней помощи. Они могут либо отправлять по одной веб-странице за раз, либо они могут отправлять весь сайт, используя карта сайта, но обычно требуется только отправить домашняя страница веб-сайта, поскольку поисковые системы могут сканировать хорошо спроектированный веб-сайт. Есть две оставшиеся причины для отправки веб-сайта или веб-страницы в поисковую систему: добавить совершенно новый веб-сайт, не дожидаясь, пока поисковая машина обнаружит его, и обновить запись веб-сайта после существенного изменения дизайна.
Некоторые программы для отправки в поисковые системы не только отправляют веб-сайты в несколько поисковых систем, но также добавляют ссылки на веб-сайты со своих собственных страниц. Это может оказаться полезным для повышения рейтинга веб-сайта, поскольку внешние ссылки являются одним из наиболее важных факторов, определяющих рейтинг веб-сайта. Шварц, Барри (2012-10-29). «Google: услуги отправки в поисковые системы могут быть вредными». Круглый стол поисковой системы. Получено 2016-04-04.
Шварц, Барри (2012-10-29). «Google: услуги отправки в поисковые системы могут быть вредными». Круглый стол поисковой системы. Получено 2016-04-04.
дальнейшее чтение
- Стив Лоуренс; К. Ли Джайлз (1999). «Доступность информации в сети». Природа. 400 (6740): 107–9. Bibcode:1999Натура 400..107л. Дои:10.1038/21987. PMID 10428673.CS1 maint: несколько имен: список авторов (связь)
- Бин Лю (2007), Веб-интеллектуальный анализ данных: изучение гиперссылок, содержимого и данных об использовании. Спрингер,ISBN 3-540-37881-2
- Бар-Илан, Дж. (2004). Использование поисковых систем в исследованиях в области информатики. АРИСТ, 38, 231–288.
- Левен, Марк (2005). Введение в поисковые системы и веб-навигацию. Пирсон.
- Хок, Рэндольф (2007). Справочник искателя крайностей.ISBN 978-0-910965-76-7
- Джавед Мостафа (февраль 2005 г.). «В поисках лучших результатов поиска в Интернете».
 Scientific American. 292 (2): 66–73. Bibcode:2005SciAm.292b..66M. Дои:10.1038 / scientificamerican0205-66.
Scientific American. 292 (2): 66–73. Bibcode:2005SciAm.292b..66M. Дои:10.1038 / scientificamerican0205-66. - Росс, Нэнси; Вольфрам, Дитмар (2000). «Поиск конечного пользователя в Интернете: анализ тематических пар терминов, представленных поисковой системе Excite». Журнал Американского общества информационных наук. 51 (10): 949–958. Дои:10.1002 / 1097-4571 (2000) 51:10 3.0.CO; 2-5.
- Се, М .; и другие. (1998). «Параметры качества поисковых систем Интернета». Журнал информатики. 24 (5): 365–372. Дои:10.1177/016555159802400509.
- Поиск информации: внедрение и оценка поисковых систем. MIT Press. 2010 г.
внешняя ссылка
- Поисковые системы в Керли
поисковый движок — Русские Блоги
Теги: Сайт Daquan поисковый движок
Этот блог sumizes некоторые общие поисковые системы
1.Google
поиск Google является самым высоким в мире, конечно же, не может быть использован в Китае.
2.Baidu
Самый большой в мире китайский поисковик и крупнейший китайский сайт
3.Поиск
Поиск является поиск сайт Tencent, который является одним из основных бизнес-подразделения Tencent в. Сайт был официально выпущен и запущен в марте 2006 года. Сосо стал одним из трех основных поисковых систем, предпочитаемых Китай жителей сети, главным образом, обеспечивая пользователь Интернета с практичной и удобной поисковой службой, и принимает на себя весь Поиск бизнес Tencent, которая является одним из важных компонентов общей стратегии онлайн жизни Tencent.
4.360 интегрированный поиск
360 Интегрированный поиск, принадлежит к Юань Search Engine, один из поисковых систем, чтобы помочь пользователям выбрать и использовать соответствующие (даже одновременно используя несколько) поисковых систем с помощью единого пользовательского интерфейса для осуществления поисковых операций в нескольких поисковых системах Это глобальный механизм контроля, который распространяется в различных поисковых инструментов, распределенных в сети.
5.поиск Sogou
Sogou является дочерней компанией Sohu компании, запущенной на 3 августа 2004 года, цель заключается в повышении sohu.com навыков поиска, в основном работает поиск бизнес Sohu в. При поиске бизнеса, метод ввода Sogou также запускается, Sogou высокоскоростной браузер.
6.должен
Бинг новый поисковый движок запущен Microsoft 28 мая 2009 года. Должен иметь ряд уникальных особенностей, в том числе ежедневной домашней странице, супер функции поиска, которые слиты с ОС Windows 8.1 глубины, а также новый режим навигации результатов поиска и т.д. Пользователи могут войти в систему Microsoft обязательно должна первой странице, откройте встроенный в Windows8 операционной системы, или непосредственно нажмите кнопку поиска для Windows Phone, можно получить быстрый доступ к необходимым веб-страницы, картинки, видео, словарь, перевод, информация, карты и т.д. информация службы поиска. В глобальной поисковой системы близко к китайским пользователям, Microsoft должна была стремится предоставить китайским пользователям с эстетикой, высокое качество, международных китайских и английских поисковых служб.
7.кварк
Творог является обновлением Quark браузера. Творог является интеллектуальный поиск приложения на Али, оснащен двигателем скорости Ai.
8.Алибаба
Алибаба все вокруг поисковой системы не только умный китайский поисковик, но и первоклассный интегрированный сайт, который любит китайский народ. «Алибаба» может автоматически собирать английский, китайский международный код и большой веб-страницу пять-кода, пользователи могут искать и читать все веб-страницы с помощью браузеров, которые поддерживают китайский код.
9.поиск Yahoo
10.Baidu Google
11.Baidu Google должен начать 360 тусовки
12.поиск МАГИ
МАГИ являются информационной машиной на основе извлечена и поисковая системы , разработанная компанией Peak Labs, которая может извлекать знание текстов на естественном языке в любой области , в структурированные данные, а также непрерывная агрегация и исправление ошибок через всю жизнь обучение, и в своей очереди , человек пользователей и другие искусственным интеллект обеспечивает решения, поиск, прослеживаемые систем знаний.
Интеллектуальная рекомендация
[Ytu] _2475 (C ++ Упражняет множественное наследство)
Описание Укажите класс учителей и класс Cadre (Cadres) и используйте множественные методы наследования, чтобы получить новый класс Class Teacher_cadre (учитель и кадра). Требовать: (1) Участники данны…
Сеть обнаружения Android — это нормальный код!
В разработке Android, если приложение необходимо подключиться к сетевому запросу, то лучше всего выяснить, следует ли определить, является ли сеть в Интернете. Сеть продолжит выполнять запрос, если в …
Понять структуру данных
Программа = структура данных + алгоритм основная концепция Данные: опишите символ объективных вещей, является объектом, который можно управлять на компьютере, может быть идентифицирован компьютером и …
Глава 8 «Как работает Tomcat»: загрузчик классов
Основное содержание этой главы разделено на три части: первая часть рассказывает о «модели делегирования» jvm, вторая и третья части — это класс WebappLoader и класс WebappClassLoader.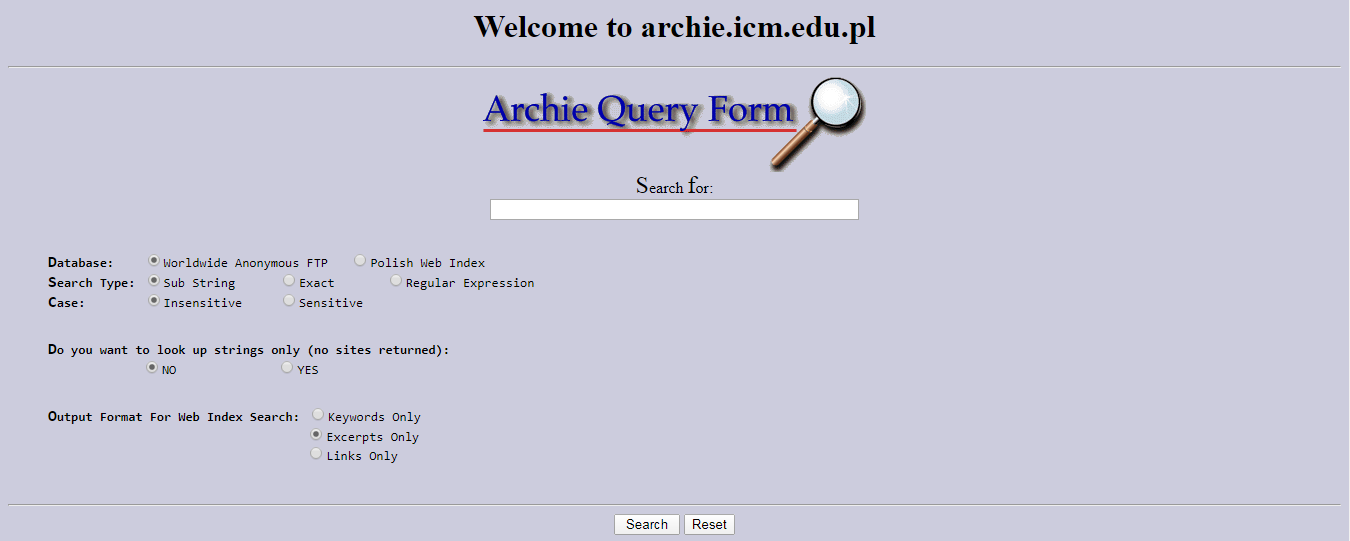 Мод…
Мод…
Ява фонд
Во-первых, основной тип 1. Основные типы и виды упаковки 2. Основное введение Java не использует ключевое слово new для основных типов данных, но напрямую хранит переменные в стеке, что более эффектив…
Вам также может понравиться
Сопоставление метода настройки суперпараметров
В машинном обучении вы всегда будете сталкиваться с такими скучными и трудоемкими вещами, как настройка параметров. К счастью, существует множество библиотек и соответствующих методов, которые …
Springboot + Springsecurity + Keycloak Integration
Недавние проекты команды Доступ к KeyCloak Unified управляемые пользователи, а также аутентификацию входа в систему, и аутентификация независимо реализована каждым проектом. 1. Настройте клиент в KeyC…
ListView
<1> Введение ListView — часто используемый компонент в разработке для Android. Он отображает определенный контент в виде списка и может отображаться адаптивно в зависимости от длины данных. Для …
Для …
Безопасность Android [Базовые знания]
Android lifecycle: Android system file introduce: Activity lifecycle: App system file introduce: 1. Архитектура Android Уровень приложений Android: apk Уровень платформы Android: DEX Уровень ви…
Структура таблицы виртуальной функции C ++
Оригинальный анализ таблиц виртуальной функции C ++ Различные объекты одного класса имеют одну и ту же виртуальную функциональную таблицу. Любая функция указателя выводит непосредственно от Cout до 1,…
Как создать собственную поисковую систему
Custom Search Engine (CSE) — мощный инструмент профессионального сорсера. С его помощью можно создать поисковый движок, который будет находить нужных вам кандидатов именно в тех источниках, которые вы укажете.
Основатель кадрового агентства Tech-recruiter и Академии IT-рекрутинга Язиля Насибуллина объяснила, как создать и настроить CSE. А для тех, кто не хочет возиться с настройками, Язиля рассказала про готовые движки для поиска на GitHub, LinkedIn, Behance, Хабр Карьере и в других источниках.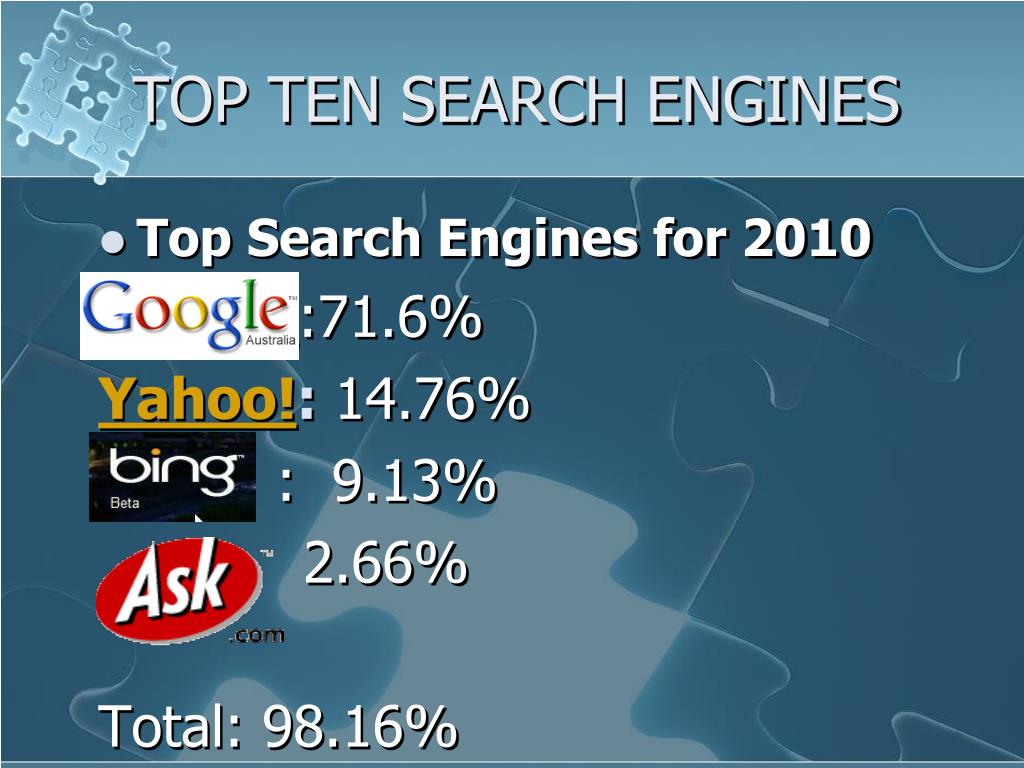
⭐ Что такое CSE и зачем он нужен
⭐ Как создать поисковый движок в стандартном интерфейсе
⭐ Как создать поисковый движок в новом интерфейсе
⭐ Настройка: как добавить запрос
⭐ Настройка: как добавить уточнения
⭐ Настройка: как добавить синонимы
⭐ Как искать с помощью CSE
⭐ Где взять готовые поисковые движки
Язиля Насибуллина, основатель агентства Tech-recruiter, автор канала IT-рекрутинг
Зачем сорсеру CSE
CSE — это инструмент от компании Гугл, который позволяет настроить поиск под свои задачи:
- выбрать ресурсы или даже разделы сайтов, которые нужно сканировать;
- искать в определенных регионах;
- задать синонимы, которые будут автоматически подставляться в запрос;
- нацелить поиск на конкретные типы файлов;
- и многое другое, о чем я еще расскажу.
Владельцы сайтов пользуются CSE, чтобы организовать внутренний поиск по своим ресурсам. А сорсеры применяют этот инструмент, чтобы экономить время и получать максимально качественные выдачи.
А сорсеры применяют этот инструмент, чтобы экономить время и получать максимально качественные выдачи.
Когда полезен Custom Search Engine:
- Не хватает возможностей X-ray и внутреннего поиска по сайту. Например, можно создать поисковый движок для GitHub и LinkedIn, используя операторы, которые работают только внутри CSE. Кроме того, поисковый запрос в Гугле ограничен 32 словами — Custom Search Engine позволяет обойти этот лимит.
- Нужно ограничить поиск на определенных сайтах, добавить или исключить конкретные регионы. В стандартном поиске Гугла это сделать сложнее — часто в выдачу попадают нерелевантные результаты, несмотря на оператор «-».
- Надо настроить поиск для начинающих ресечеров и рекрутеров. Например, опытный сорсер создает набор движков, которыми будут пользоваться его коллеги — просто вбивать название должности и получать резюме. Но нужно учитывать, что один и тот же запрос может давать разные результаты в зависимости от настроек и страны нахождения пользователя.
- Необходимо найти редкого эксперта с уникальным стеком — можно создать под него отдельный движок. И наоборот: чем стандартнее запрос и больше кандидатов на рынке, тем меньше нужны все эти «сорсинговые штучки».
Как создать поисковый движок
Зайдите в сервис «Программируемая поисковая система» и выберите, в каком интерфейсе будете работать — в стандартном или новом.
Создание движка в стандартном интерфейсе
Здесь нужно указать:
- сайты для поиска;
- язык;
- название системы — желательно осмысленное, чтобы быстро находить нужный вариант, когда у вас будет набор движков на все случаи жизни.
Например, создаю систему для поиска по профилям пользователей на LinkedIn:
Здесь я указываю адрес linkedin.com/in, где хранятся личные страницы пользователей, и использую символ *, чтобы искать по всем доменам соцсети. В поле «Язык» можно выбрать язык выдаваемого профиля, но я не советую этого делать. Даже если вы ищете русскоязычных разработчиков, то стоит помнить — это международный сайт, поэтому многие пользователи заполняют профиль на английском.
Даже если вы ищете русскоязычных разработчиков, то стоит помнить — это международный сайт, поэтому многие пользователи заполняют профиль на английском.
Как только докажу, что я не робот, и нажму на кнопку «Создать», меня перебросит на следующую страницу со ссылкой на поисковую систему — движок уже будет работать.
Создание движка в новом интерфейсе
Сначала нужно выбрать название системы и указать сайты, по которым надо искать. Потом этот список сайтов можно будет изменить в настройках. Например, создам движок для Хабр Карьеры:
Кстати, можно не ограничиваться конкретными сайтами, а задать целые доменные зоны, например так: *.ru или *.com. Когда я нажму кнопку «Создать», мне предложат настроить систему:
- Выбрать регион поиска — разрешается указать только один. По моему опыту, лучше оставить «Все регионы», а зоны поиска корректировать с помощью доменов и ключевых слов.
- Добавить в поиск новые сайты.
- Исключить из поиска какие-то адреса.
 Можно убрать из области поиска не только сайт целиком, но и отдельные веб-страницы или разделы (www.example.com/jobs/*), а также весь домен (*.example.com).
Можно убрать из области поиска не только сайт целиком, но и отдельные веб-страницы или разделы (www.example.com/jobs/*), а также весь домен (*.example.com).
Я настраиваю поиск кандидатов по Хабр Карьере, так что исключу разделы с вакансиями, курсами и информацией о компаниях:
Продвинутая настройка CSE
Предупрежу сразу: все настройки я буду проводить в стандартном интерфейсе — так привычнее. Кроме того, на момент выхода этой статьи новая версия панели управления считается предварительной — многое еще может поменяться. В целом, различия между версиями косметические. Если научиться работать в старом интерфейсе, то будет легко найти аналогичные разделы в новой панели.
Самые полезные настройки находятся в подразделе «Функции в результатах поиска» раздела «Изменение поисковой системы»:
Добавление запроса
Можно прописать дополнительные запросы, которые будут включаться в поиск автоматически. Для этого:
Для этого:
- В разделе «Функции в результатах поиска» нужно перейти во вкладку «Дополнительно».
- Открыть там раздел «Настройки веб-поиска».
- В поле «Добавление запроса» вписать фразу, которая будет подставляться автоматически — писать ее при каждом запросе не придется.
Например, сделаю движок для поиска файлов в формате pdf и docx — предполагается, что это будут резюме. Использую оператор «filetype»:
Уточнения
Усовершенствую движок для LinkedIn — настрою поиск так, чтобы отдельно показывались профили кандидатов с контактными данными. Это можно сделать с помощью уточнений.
В разделе «Функции в результатах поиска» нужно перейти во вкладку «Уточнения», нажать на кнопку «Добавить» и создать дополнительные условия поиска. Результаты по каждому условию будут выводиться на отдельную вкладку.
Например, добавлю поиск по всем профилям, в которых есть почта на gmail.com и ссылка на телеграм:
Синонимы
Вручную прописывать десятки синонимов через OR при каждом запросе утомительно. В CSE для каждого ключевого слова можно задать набор синонимов, которые будут добавляться автоматически.
В CSE для каждого ключевого слова можно задать набор синонимов, которые будут добавляться автоматически.
Для этого надо:
- Перейти в раздел «Функции в результатах поиска», а оттуда — во вкладку «Синонимы».
- Нажать на кнопку «Добавить».
- На верхней строчке написать ключевое слово, а на нижней — набор синонимов к нему.
Как искать с помощью CSE
Если перейдете по ссылке вашего поискового движка, то вы увидите обычную поисковую строку и больше ничего. Не нужно писать «site:» и название сайта для поиска — этот запрос скрыт «под капотом» системы, как и остальные настройки. А в остальном здесь работают все стандартные операторы, в том числе: OR, — , “ ”.
Например, так будет выглядеть запрос в движке для LinkedIn на поиск PHP-разработчиков из Москвы:
Сейчас движок сканирует всю страницу пользователя целиком. Но существуют операторы, которые позволяют ориентировать его поиск по конкретным блокам и элементам профиля. Например, в LinkedIn, Xing, ResearchGate, Google Scholar и Speakerhub работают такие операторы:
Например, в LinkedIn, Xing, ResearchGate, Google Scholar и Speakerhub работают такие операторы:
- «more:p:person-jobtitle:» — поиск по позиции;
- «more:p:person-org:» — поиск по компании или учебному заведению;
- «more:p:person-role:» — поиск в заголовке страницы.
А у GitHub есть свой оператор, который обращается к строке «о себе» — «more:p:metatags-og_description:».
Готовые поисковые движки
Вам не обязательно создавать движок самостоятельно — можно воспользоваться готовыми вариантами, если они подходят под ваши задачи. Например, поисковики от Ирины Шамаевой и Балажа Парочай:
- XING,
- HackerRank,
- MeetUp,
- ResearchGate.
Мои поисковые системы:
- GitHub.
- Behance — поиск резюме. Настройки самые простые: в сайтах для поиска я указала «behance.net/*/resume» — раздел, где хранятся резюме пользователей.
- Хабр Карьера. Здесь к каждому допросу автоматически добавляется фраза «последний визит», чтобы искать только по личным страницам пользователей.
- Европейский LinkedIn. Я занимаюсь международным рекрутингом и ищу кандидатов по всей Европе. Для этого сделала движок поиска по доменным областям LinkedIn тех стран, которые мне интересны.
Главное про CSE
- Custom Search Engine — инструмент для создания собственных поисковых систем. С его помощью сорсер экономит время и получает более релевантные результаты.
- Принцип простой: вы один раз проводите настройку, убирая повторяющиеся части запросов и синонимы «под капот», а потом используете систему, чтобы находить подходящих кандидатов.
- Чтобы часть запроса подставлялась автоматически:
- перейдите во вкладку «Дополнительно» в разделе «Функции в результатах поиска»;
- откройте раздел «Настройки веб-поиска»;
- в поле «Добавление запроса» впишите нужную фразу.
- Можно добавлять или исключать из поиска целые доменные зоны, сайты целиком, отдельные страницы и разделы.
- Настройка «синонимы» позволяет задать набор синонимов, которые будут автоматически добавляться к запросу для каждого ключевого слова.
- С помощью уточнений вы можете создать вкладки с результатами ответов на дополнительные запросы. Например, это удобно, когда нужно посмотреть, у кого из найденных кандидатов есть контактные данные в профиле.
Одним кликом добавляйте найденные резюме в Хантфлоу
типы и для чего они нужны
Хотите узнать о поисковых системах? То поисковая система Это механизм, который организует информацию, генерируемую в сети. Вся информация доставляется пользователям, которые выражают свои запросы с помощью Ключевые слова этого двигателя.
Рассмотрим Интернет как хозяин этой эпохи, информации, самого быстрого и эффективного инструмента познания. Сегодня он охватывает большую часть общения.
Но помимо личной выгоды, интернета и поисковые системы они также предлагают преимущества для бизнеса. Этот сегмент относится к вашему бренду, бизнесу или организации, которая выживает благодаря интернет-движению.
Этот сегмент относится к вашему бренду, бизнесу или организации, которая выживает благодаря интернет-движению.
Конечно, когда вы думаете о поисковых системах, Google первое и почти единственное, что приходит на ум.
Но оказывается другие поисковые системы у них есть потенциал для широкой мобилизации наших брендов и бизнес-сайтов. Возможно, мы теряем время, если не понимаем этого потенциала.
Именно поэтому мы познакомим вас с огромным миром поисковые системы и как вы можете использовать их, чтобы улучшить свое цифровое присутствие. Мы надеемся, что вы будете с нами до конца.
Что такое поисковая машина?
Un поисковая система — это система, которая собирает информацию с веб-серверов и предоставляет ее пользователям посредством процесса, называемого сканированием. В котором пауки поисковых систем отображают данные, хранящиеся в Интернете.
Чтобы найти эти файлы, веб-браузер полагается на идентификация ключевого слова используется лицом, проводившим поиск. Таким образом, клиент получает список ссылок на веб-сайты, содержащие темы, связанные с ключевыми словами.
Таким образом, клиент получает список ссылок на веб-сайты, содержащие темы, связанные с ключевыми словами.
Типы поисковых систем
главный виды поисковых систем в интернете его
- Иерархические поисковые системы
Этот тип поисковый движок это текстовый интерфейс запросов. Паук обращается к базе данных веб-страниц и собирает данные о содержимом, соответствующем запросу клиента.
После создания запроса он ранжирует результаты на основе их релевантности конкретному запросу и история просмотров клиентов.
- Справочники
поисковые системы каталогов Это ссылки на страницы, сгруппированные по категориям. Они очень просты в использовании, но не работают без помощи человека и постоянного обслуживания.
эти веб-поисковой системы они не ищут страницы и не хранят контент, они просто группируют ссылки по категориям или упорядочивают их по дате публикации, и не учитывают релевантность или состоятельность запроса, сделанного клиентом.
Пример такого типа интернет-поисковик — это проект Open Directory, широко известный как Dmoz.
- Метапоисковые системы
Эти интерфейсы работают, отправляя результаты поиска в несколько поисковых систем одновременно.
То есть вы передаете свой поисковый запрос другим сайтам для изучения результатов, которые они показывают. Объем одних и тех же результатов расширяется, результаты публикуются, а ссылки классифицируются в порядке, определяемом структурной системой метапоисковика.
Сколько существует поисковых систем?
Честно говоря, довольно сложно сначала не посмотреть Google. Однако помимо Google существует множество других поисковые системы в Интернете. Правда в том, что они малоизвестны, а тех, что известны, можно пересчитать по пальцам одной руки. Это не так?
Но это нормально. Вот почему мы сделали эту статью, чтобы рассказать вам, что существуют сотни поисковых систем в мире. Несколько из лучшие поисковые системы в интернете доступны на сегодняшний день:
Несколько из лучшие поисковые системы в интернете доступны на сегодняшний день:
- Yahoo!
- Bing
- Просить
- Go
- утка утка иди
- AOL
- Перейти Ямс
- Boing
- хватка
- Концерты
- АУРА!
- Yippi
- MSN Поиск
- тупой штраф
- Гугл конечно.
лучшие поисковые системы
Да их сотни. Однако сегодня мы увидим самые релевантные поисковые системы, и начнем мы со знаменитого Google.
Он самый старший и лучшая поисковая система. Его критерии основаны на использовании PageRank, который предполагает, что страницы, которые чаще всего ищут, чаще всего связаны другими страницами.
Этот процесс поиска основан на найти совпадение между ценностью контента, найденного в Интернете, и терминами, используемыми клиентом. Для создания этого фильтра Google использует ряд алгоритмы для определения порядка отображения веб-сайтов.
В последние годы Google попытался выйти за рамки традиционной модели поиска, используя Discover. Ресурс, интерпретирующий поведение мобильных клиентов рекомендовать контент.
Bing
Является ли второй интернет-поисковик мира. Это собственная поисковая система, используемая новыми устройствами Microsoft начиная с Windows 8.
Yahoo
Yahoo Search был запущен в 2004 году и представляет собой скорее веб-сайт, чем поисковый движок. Он предлагает веб-поиск, электронную почту, новости, покупки, туристические агентства, игры и развлечения.
MSN поиск
Поиск MSN был запущен, чтобы конкурировать с Google и Yahoo. Эта служба добавляет другие поисковые системы в Интернете, такие как Hotmail и поддержка новостей, для простого и мгновенного поиска.
Просить
Это поисковая система, в которой пользователи задают свои вопросы и своевременно получают своевременные ответы на свои вопросы или сомнения.
Для чего нужна поисковая система?
Есть разные типы поисковые системы, и само собой разумеется, что каждый из них имеет определенную функцию. Если вы хотите получить хорошие результаты, желательно знать, что они собой представляют.
Хотя это правда, что 80% поисковых запросов выполняются через Google, есть конкретные, труднодоступные результаты, которые можно найти только с помощью других поисковых систем в Интернете. Вот почему полезно знать, как они работают.
Поисковые системы, решающие простые запросы
к Общие запросы, вы можете выбрать одну из следующих поисковых систем.
С вашей базой данных Google — поисковая система номер один. Мгновенный поиск, расширенный поиск, поиск изображений и многое другое предлагают наилучшие возможности поиска.
- ¡Yahoo!
Это одна из самые популярные поисковые системы в интернете и у него есть поисковая система изображений. Здесь вы можете искать изображения по размеру, основному цвету, GIF, портрету, крупному плану и другим типам изображений.
Здесь вы можете искать изображения по размеру, основному цвету, GIF, портрету, крупному плану и другим типам изображений.
Поисковики с быстрым откликом
- Wolfram Alpha
Это место, предназначенное для получения ответов на вопросы математика, астрономия, биология, финансы, физика и химия.
- факты
Это английская поисковая система который работает как словарь для поиска информации об университетах и базах данных. Ответы носят академический характер.
- Yahoo Ответы
Популярное и удобное место для получения ответов на ваши вопросы и простых задач.
Есть еще такие сайты Квора и Реддит.
Поисковые системы для документов, отчетов, запросов и т. д.
Если вы ищете данные и статистику, вы можете использовать поисковые системы, такие как следующие:
- Zanran
Программа для поиска статистических данных.
- NationMaster
Этот поисковик идеально подходит для поиска статистических данных по территориям. Вы можете сравнить различные показатели на основе информации, предоставленной Всемирным банком.
Поисковые системы, которые уважают вашу конфиденциальность
- Duck Duck Go
Очень похоже на Google, но способ отображения результатов дает лучший ответ на заданный вопрос. Он фокусируется не на позиционировании страницы, а на содержимом, которое она предоставляет по запросу пользователя.
- Поиск шифрования
Эта альтернативная поисковая система разработана с учетом конфиденциальности пользователей. Search Encrypt позволяет выполнять поиск конфиденциально и безопасно, избегая перехвата.
Поисковая система для поиска данных об организациях и учреждениях
Если вам нужна информация об организации, такая как юридический адрес или счет-фактура, мы рекомендуем использовать следующие поисковые системы:
- Kompass
Для поиска организаций B2B по всему миру.
- Дунс и Брэдстрит
Найдите организации со всего мира с их финансовыми данными. Используйте этот поиск, чтобы определить идеи контента, которые имеют отношение к различным сегментам рынка, и изучить их конкурентоспособность.
Поисковик в социальных сетях
- Расширенный поиск на Facebook
Facebook стал огромным банком информации, а использование расширенного поиска находится в зачаточном состоянии.
При выполнении поиска вы увидите опцию «Показать все результаты из…». Если щелкнуть здесь, отобразятся все параметры, и вы сможете уточнить результаты поиска.
Это замечательная альтернатива искать людей и любой тип информации, опубликованной или переданной в Facebook.
Зачем мне знать о поисковых системах?
Если вы заинтересованы в маркетинг, вы должны иметь хорошее представление о многих аспектах знания. Поскольку вы интересуетесь цифровым маркетингом, вы также должны знать все возможности, которые предлагает Интернет, такие как поисковые системыs.
Как мы уже говорили в начале, когда вы работаете в Интернете, вы должны найти способ позиционировать себя как можно лучше в поисковых системах, и когда вы делаете это, вы часто работаете только для того, чтобы Google. Важно, чтобы вы учитывали, что:
- Есть другие поисковые системы, которыми пользуется наша аудитория, а мы растрачиваем свой потенциал.
- Наш розничный бизнес может быть привязан к определенному режиму поиска, а мы этого не имели в виду.
Единственное, что вам нужно сделать, это исследовать и ознакомиться со сценариями, которые каждый из них предлагает, чтобы вы занимали первые места в результатах поиска.
Эта статья дает лишь довольно универсальный и неглубокий мира поисковых систем Интернета. Здесь мы хотим подчеркнуть, что вы должны постоянно думать о своем нужен как бренд, как бизнес и даже как клиент, и знать, какую тактику поиска применять и почему вам нужно повысить эффективность SEO.
Поисковые системы | Научная библиотека РГУ имени С.А. Есенина
- Bing – поисковая система, разработанная международной корпорацией Microsoft. За свою историю этот поисковик несколько раз менял название. Начиная с 1998 и до 2006 гг., он назывался MSN Search, потом Windows Live Search, затем просто Live Search и, наконец, – Bing.
Использует свой собственный движок для осуществления поисковых задач не только в рунете, но и в глобальной сети Интернет. - DuckDuckGo – поисковая система с открытым исходным кодом, которая использует информацию из многих источников с целью предоставления более точных, актуальных и более разнообразных результатов поиска, чем обычные поисковики. Был основан Гэбриелом Вайнбергом в 2008 г.
Политика DuckDuckGo особо подчеркивает конфиденциальность пользовательских данных, отказ от записи и хранения какой-либо пользовательской информации и слежения за пользователями.
Данный поисковик не использует «пузырь фильтров», как это делают большинство поисковых систем, например, Google, Bing, Яндекс и т. д. Такая особенность позволяет пользователю вырваться из информационной ловушки и получать всю информацию, имеющуюся у поисковой системы.
д. Такая особенность позволяет пользователю вырваться из информационной ловушки и получать всю информацию, имеющуюся у поисковой системы. - Google – крупнейшая поисковая система Интернета. Принадлежит корпорации Google Inc. Первая по популярности система в мире обрабатывает свыше 41 млрд 300 млн запросов в месяц, индексирует более 25 миллиардов веб-страниц. Была создана в 1998 г. в качестве учебного проекта студентов Стэнфордского университета Ларри Пейджа и Сергея Брина.
В России русскоязычная версия данной поисковой системы (Google.ru) появилась лишь в 2004 г.
Отличительной особенностью Google является технология определения степени релевантности документа путем анализа ссылок других источников на данный ресурс. Чем больше ссылок на какую-либо страницу имеется на других страницах, тем выше ее рейтинг в поисковой системе Google.< - Yahoo! – американская компания, владеющая второй по популярности в мире поисковой системой и предоставляющая ряд сервисов, объединенных Интернет-порталом Yahoo! Directory.
 Данный портал включает в себя популярный сервис электронной почты Yahoo! Mail, один из старейших и наиболее популярных в Интернете. Появился в январе 1994 г. благодаря усилиям аспирантов Стэнфордского университета Дэвида Фило и Джерри Янга. Созданный ими веб-сайт назывался «Путеводитель Джерри по Всемирной Паутине», который представлял собой каталог других сайтов. В апреле 1994 г. сайт был переименован в Yahoo!.
Данный портал включает в себя популярный сервис электронной почты Yahoo! Mail, один из старейших и наиболее популярных в Интернете. Появился в январе 1994 г. благодаря усилиям аспирантов Стэнфордского университета Дэвида Фило и Джерри Янга. Созданный ими веб-сайт назывался «Путеводитель Джерри по Всемирной Паутине», который представлял собой каталог других сайтов. В апреле 1994 г. сайт был переименован в Yahoo!.
Доля этого поисковика в России и в русскоязычном Интернете в целом очень мала. В настоящее время сложно говорить о Yahoo! как о поисковой системе: представители Yahoo! заключили с Microsoft договор, по которому на всех площадках принадлежащих Yahoo!будет использоваться поисковый движок Bing. - Поиск@Mail.Ru – поисковая система от компании Mail.Ru. Первые поисковые технологии в компании Mail.Ru начали разрабатываться в 2004 г. под руководством Михаила Костина. Результатом работы стал открытый в 2007 г. сайт GoGo.Ru. Поисковик имел первый на тот момент в рунете поиск по видео, а также поиск по картинкам.
 К отличительным особенностям поисковика можно отнести русскоязычный поиск по видеороликам, а также по базе данных проекта Ответы@mail.ru. Также разработчики предусмотрели возможность тематической фильтрации результатов текстового поиска.
К отличительным особенностям поисковика можно отнести русскоязычный поиск по видеороликам, а также по базе данных проекта Ответы@mail.ru. Также разработчики предусмотрели возможность тематической фильтрации результатов текстового поиска.
GoGo так и не стал основным поисковиком на главной странице Mail.Ru. С 2004 по 2006 гг. его роль выполнял Google, в 2007-2009 гг. – Яндекс.
С 1 июля 2013 г. сервис использует собственные поисковые технологии, которые разрабатывались командой инженеров Mail.Ru.
Поисковая доля Mail.Ru не велика, но уже приближается к 10 %. В то же время такая цифра обусловливается огромным электоратом различных сервисов этой мегакорпарации (Одноклассники, Мой мир, почты Mail.ru и т.п.). - Рамблер – одна из первых российских поисковых систем. Считается старейшим поисковиком в Интернете. Стоял у истоков российского Интернета. Rambler появился в 1996 г. и быстро завоевал огромную популярность, что позволяло ему оставаться ведущей поисковой системой в России вплоть до 2001 г.
 Как поисковая система Rambler просуществовал до 2011 г.
Как поисковая система Rambler просуществовал до 2011 г.
В настоящее время не является поисковиком в общеизвестном смысле слова, а представляет собой набор сервисов с достаточно высокой посещаемостью, на которых в качестве поиска используется движок Яндекса. Сегодня Rambler позиционирует себя как популярный медийно-сервисный Интернет-портал. - Яндекс (Яndex) – самая популярная в настоящее время отечественная поисковая система. Наиболее заметное положение занимает на рынках России, Турции, Украины, Белоруссии и Казахстана. Занимает четвертое место среди поисковых систем мира по количеству обработанных поисковых запросов. Впервые была официально анонсирована 23 сентября 1997 г.
Первоначально приоритетным направлением в развитии данной поисковой системы выступала разработка поискового механизма, но за годы работы «Яндекс» превратился в мультипортал. В 2016 г. «Яндекс» предоставляет более 50 служб: Яндекс.Поиск, Яндекс.Карты, Яндекс.Маркет, Поиск по блогам, Яндекс. Пробки и др.
Пробки и др.
<
Информационно-поисковые системы:
- Академия Google – новая поисковая система, разработанная специально для студентов, ученых и исследователей, предназначена для поиска информации в онлайновых академических журналах и материалах, прошедших экспертную оценку.
- GreenFILE – полнотекстовая база данных по охране окружающей среды компании EBSCO Publishing.
Тематический охват: ресайклинг, переработка отходов, гибридные автомобили, электромобили, солнечные батареи и др. - Mendeley – это бесплатный менеджер ссылок и академическая социальная сеть, которая может помочь вам организовать свое исследование, сотрудничать с другими в интернете, и узнать о последних научных исследованиях. Данный ресурс позволяет автоматически формироватью библиографию, легко сотрудничать с другими исследователями в режиме онлайн, легко импортировать документы из других научно-исследовательских программ, найти соответствующие документы, основанные на том, что вы читаете, открыть ваши документы из любой точки мира в режиме онлайн, читать документы на ходу с мобильных операционных систем iOS и Android.

- ScienceResearch.com – поисковая система предоставляет возможность одновременного поиска в научных журналах крупнейших издательств, таких как Elsevier, Highwire, IEEE, Nature, Taylor and Francis и др. А также в открытых базах данных: Directory of Open Access Journals, Library of Congress Online Catalog, Science.gov и Scientific News.
Поиск в журналах возможен по 12 отдельным предметным рубрикам. Полные тексты статей из журналов доступны только для подписчиков. - Semantic Scholar – поисковая система, запущенная в ноябре 2015 г. специалистами Института искусственного интеллекта Аллена (США). Ресурс выполняет роль архива научных данных и при этом может выдавать в ответ на запросы список публикаций по заданным ключевым фразам. Обладает свойствами искусственного интеллекта.
<
<
10 лучших систем поиска видео
Видеоконтент сегодня суперпопулярен .
Фактически, пользователи Интернета тратят в среднем 6 часов 48 минут на просмотр видео в неделю.
Это на 59% больше, чем в 2016 году!
Более того, пользователи проводят в среднем в 2,6 раза больше времени на страницах с видео, чем без него.
Так почему бы не оживить свой блог интересными актуальными видео?
Хорошая новость заключается в том, что существует множество поисковых систем, которые вы можете использовать, чтобы найти идеальное видео для своего блога или вдохновить вас на создание собственного.
Вот список из 10 лучших.
10 систем поиска видео, которые следует использовать для поиска отличного видеоконтента
Мы все знаем о Google и YouTube, но слышали ли вы когда-нибудь о системах поиска видео, таких как Dailymotion и Metacafe?
Эти видео поисковые системы станут золотыми , когда вы научитесь ими пользоваться.
Читайте ниже, чтобы найти сочетание знакомых и новых систем поиска видео.
1. Google
Мы не можем не упомянуть Google, хотя в сети о нем знают все. Он слишком большой и популярный, чтобы вычеркнуть его из нашего списка.
Итак, что особенного в видео Google?
Вы можете искать практически любое видео в Google, используя панель поиска Videos .
Сначала введите ключевое слово в Google.
Затем нажмите Видео.
Вуаля! Вы получаете тонны видео на основе ключевого слова, которое вы использовали. Это так просто.
2. YouTube
YouTube является вторым по посещаемости сайтом в мире (после Google).
И это неудивительно, ведь каждую минуту на YouTube загружается более 500 часов видео!
Вот пример поиска на YouTube по запросу «белая клубника».
Если у вас нет вдохновения для следующего видео, зайдите на YouTube и введите редкое ключевое слово.
Скорее всего, вы найдете на нем уникальное видео.
3. Bing
Если вы похожи на массу других людей, вы думаете о Bing как о поисковой системе, «живущей в тени Google».
Но Bing не уступает Google, он просто другой.
Например, его видеоплатформа.
Вот три удивительные вещи, которые вы не знали о видео Bing:
- Они оптимизированы для использования на мобильных устройствах.
- Играют прямо с сайта.
- Вы можете легко найти платный видеоконтент.
Найти вдохновляющие видео в Bing очень просто.
Просто введите ключевое слово в поисковую систему и выберите Видео .
4. Dailymotion
Dailymotion — это платформа с миллионами видео.
Прямо на его главной странице вы можете смотреть популярные видеоролики о последних новостях, развлечениях, музыке и спорте.
Ищете что-то конкретное?
Перейдите к строке поиска в правом углу и введите ключевое слово.
Вы даже можете создать личную библиотеку со всеми вашими любимыми видео на платформе.
5. DuckDuckGo
Если для вас важна конфиденциальность и вам не нравится, что все, что вы делаете в Интернете, записывается, вам следует использовать DuckDuckGo.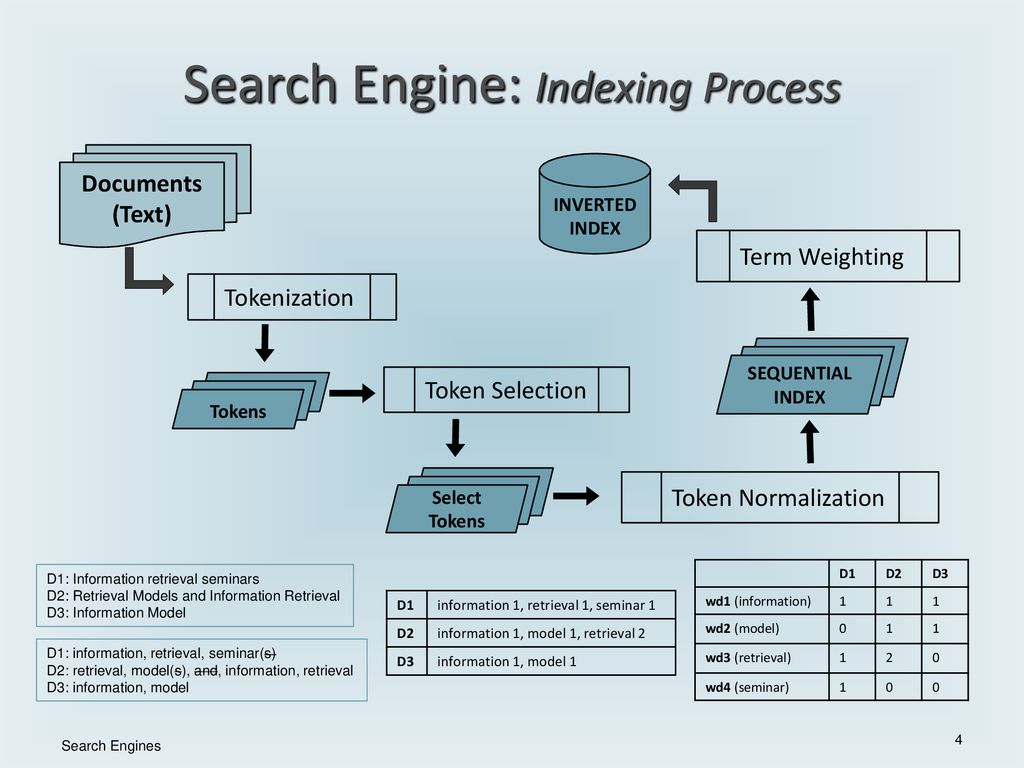
DuckDuckGo делает для вас три вещи:
- Блокирует трекеры.
- Позволяет вести частный поиск.
- Обеспечивает безопасное соединение.
Пользоваться поисковой системой очень просто благодаря ее простому интерфейсу.
Если вы ищете видео, просто введите ключевое слово в поле поиска и нажмите Видео .
Еще одна забавная вещь, которую вы можете сделать, это выполнить поиск по разным странам.
Вы будете в восторге, узнав, что выбор другой страны приводит к другим результатам видео!
Например, вот лучшие видео по ключевому слову «контент-маркетинг» в США
Теперь выберите другую страну. Скажем, Аргентина. Это то, что ты получаешь.
6. Yahoo
Помните Yahoo?
Что ж, учитывая, что доля рынка поисковых систем Yahoo составляет менее 2% мирового рынка, вы не одиноки, если вы этого не сделаете.
Однако, как и другие поисковые системы, Yahoo упрощает просмотр множества видео.
Что интересно, хотя Bing поддерживает результаты поиска Yahoo, вы не получите одинаковые результаты видео, если введете одно и то же ключевое слово на обеих платформах.
Давайте посмотрим.
Вот «советы по маркетингу» на Yahoo.
А вот и «маркетинговые советы» по Bing.
Поскольку поиск в Yahoo и Bing даст разные результаты, стоит попробовать каждый из них, если вы хотите найти скрытые жемчужины.
7. Metacafe
Metacafe — это место, где можно найти забавные и необычные видео.
Он предлагает множество категорий на выбор, включая художественную анимацию, комедию, развлечения, инструкции, моду и многое другое.
Вы также можете искать популярные видео с помощью панели поиска в верхней части страницы.
Если вы страдаете от творческого кризиса и вам нужно вдохновение, Metacafe — отличная поисковая система для поиска видео.
8. Спросить
Когда-то Ask был популярным конкурентом таких поисковых систем, как Google и Yahoo.
Сегодня он известен как сайт вопросов и ответов.
Но вы по-прежнему можете искать видео в Ask.
Просто введите ключевое слово в поле поиска и нажмите Видео.
При поиске видео на Ask вы получите результаты прямо с YouTube.
Но опять же, вы не получите тех же результатов, что и при использовании того же ключевого слова на YouTube.
9. Яндекс
Яндекс — Google России.
Это огромная поисковая система, предлагающая почту, карты, браузер, перевод, изображения и многое другое.
Конечно, в Яндексе тоже есть панель поиска видео.
10. Swisscows
Swisscows — это поисковая система, которая позиционирует себя как «удобную для всей семьи».
Он также предлагает пользователям уникальное обещание: он не собирает и не хранит никаких пользовательских данных.
Помимо музыки, изображений и веб-контента, Swisscows предлагает широкий выбор видео.
Как найти потрясающие видео для вашего контента
Да, видео сегодня очень популярно.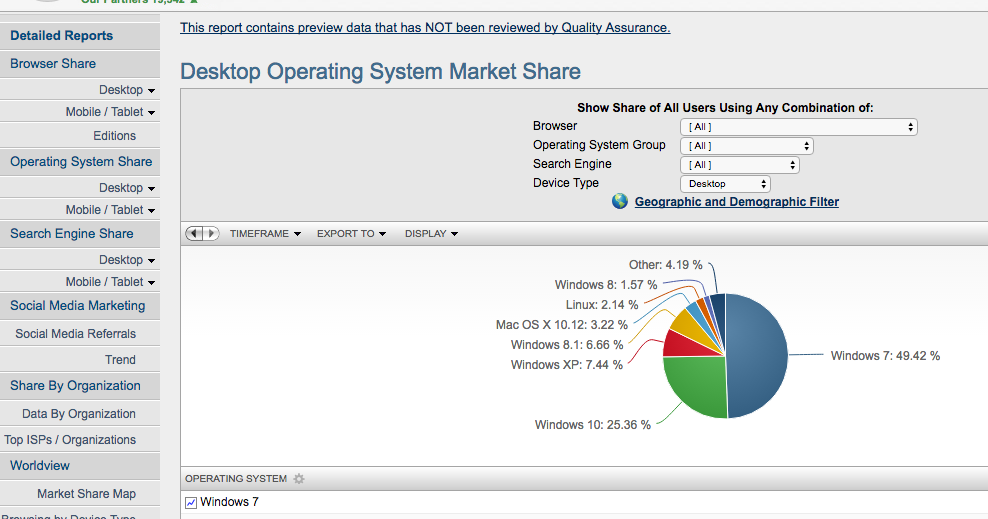
Интернет-пользователи предпочитают смотреть видео, а не читать длинные блоки текста.
На самом деле, 85% интернет-пользователей в США ежемесячно просматривают онлайн-видеоконтент.
Но создавать видео непросто.
Бывают дни, когда вам просто не хватает вдохновения и вам нужен глоток свежего воздуха, чтобы дать волю своим творческим сокам.
Когда это произойдет, обязательно посетите лучшие поисковые системы видео в Интернете.
Дополнительные ресурсы:
- 4 причины, почему ваши видео не так успешны, как сообщения в блоге
- Как сделать убедительные видео с вопросами и ответами, чтобы укрепить доверие к вашему бренду
- Как максимально эффективно использовать временные метки видео в поиске Google
Авторы изображений
Все скриншоты сделаны автором, апрель 2020 г.
Категория Содержание Инструменты
Search Engine Land — Новости, Поисковая оптимизация (SEO), Pay-Per-Click (PPC)
SEO
Понимание типов источников, которые Google отображает в поисковой выдаче, помогает SEO-специалистам понять, насколько эффективно ранжирование по определенным запросам.
Дэн Тейлор | 22 сентября 2022 г., 8:00 по восточному времени
КПП
Структурируете обучение цифровому маркетингу? Вот как убедиться, что вы и ваш ученик получаете максимальную отдачу от совместной работы.
Нава Хопкинс | 22 сентября 2022 г., 6:00 по восточному времени
КПП
Горячие сбои в работе Google Ad в вашем районе
Николь Фарли | 21 сентября 2022 г., 15:38 по восточному времени
Маркетинг в социальных сетях
Подтвержденная учетная запись, отмеченная синей галочкой, означает, что платформа подтвердила право собственности на учетную запись.
Николь Фарли | 21 сентября 2022 г., 15:10 по восточному времени
Маркетинг в социальных сетях
Новые рекомендации в Твиттере могут стать отличным инструментом для поиска новых аккаунтов и связи с ними. Но иногда они просто ошибаются.
Николь Фарли | 21 сентября 2022 г., 12:27 по восточному времени
КПП
Бренды могут использовать совместную рекламу для охвата активных покупателей, одновременно увеличивая трафик и продажи на сайте, в приложении или магазине своих розничных партнеров.
Николь Фарли | 21 сентября 2022 г., 12:25 по восточному времени
КПП
Партнерство гиганта розничной торговли с социальными платформами и платформами CTV открывает глаза рекламодателям и брендам.
Николь Фарли | 21 сентября 2022 г., 10:13 по восточному времени
SEO
Данные получены от инструментов отслеживания, и вот что эти инструменты показывают с последним обновлением алгоритма Google.
Барри Шварц | 21 сентября 2022 г., 9:15 по восточному времени
SEO
Сеть продаж уже не так ценна, как раньше. Пришло время сосредоточиться на вашем самом важном продавце — веб-сайте вашей компании.
Брюс Клей | 21 сентября 2022 г., 8:00 по восточному времени
КПП
Это основные должности, роли, задачи и обязанности для должностей в поисковом маркетинге, когда вы переходите от младших к старшим ролям.
Джозеф Кершбаум | 21 сентября 2022 г., 6:00 по восточному времени
SEO
Собственные стратегии управления данными, обеспечивающие безопасность данных ваших клиентов и процветание вашего бизнеса.
Синтия Рамсаран | 20 сентября 2022 г., 17:58 по восточному времени
КПП
Переход с версии 1 на версию 2 требует обновления URL-адресов конечных точек для вызова версии 2 и обновления приложения для учета критических изменений.
Николь Фарли | 20 сентября 2022 г., 17:56 по восточному времени
SEO
Согласно индексу участия в мероприятиях MarTech, большинство маркетологов настроены оптимистично, что они вернутся на очные мероприятия.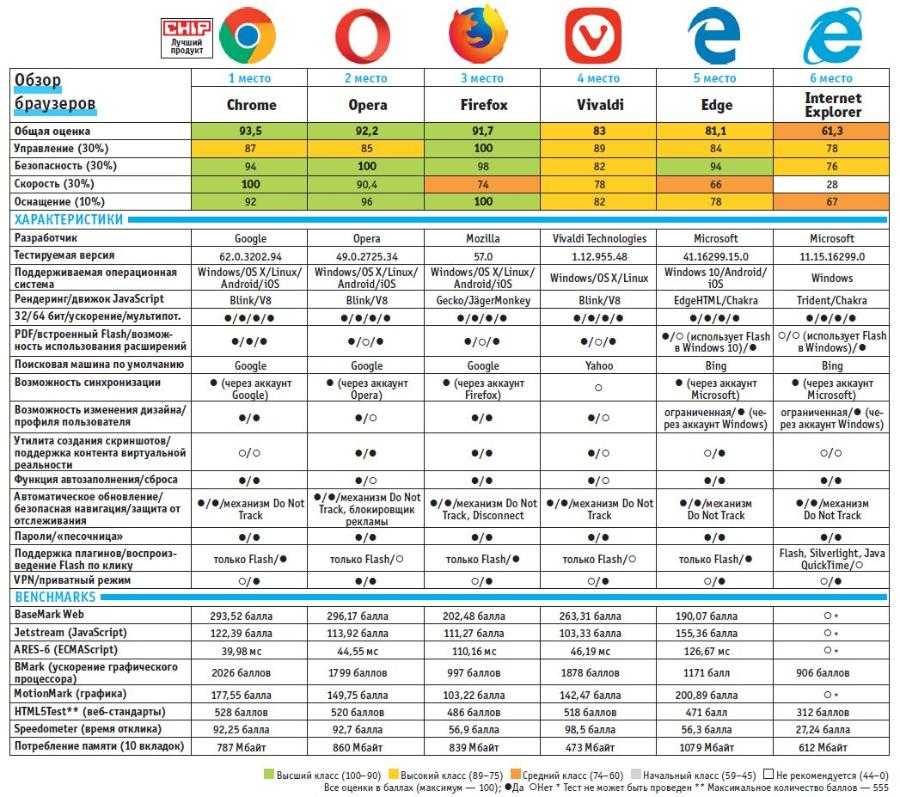
Ким Дэвис | 20 сентября 2022 г., 14:01 по восточному времени
КПП
Рекламодатели могут получить доступ к своему статусу режима согласия на странице сводки конверсий в своем рекламном аккаунте. Вы сможете сразу сказать, правильно ли реализован режим согласия.
Николь Фарли | 20 сентября 2022 г., 13:07 по восточному времени
SEO
Неоптимизированные веб-страницы могут повредить SEO. Вот как убедиться, что целевые страницы PPC не влияют на эффективность вашего обычного поиска.
Сара Тахер | 20 сентября 2022 г., 8:00 по восточному времени
SEO
Базовые показатели SEO не являются эффективными индикаторами успеха. Вот как повысить показатели трафика, рейтинга, конверсии и ссылок.
Адам Тангвай | 20 сентября 2022 г., 6:00 по восточному времени
SEO
Это пятое обновление обзоров продуктов Google, которое выходит примерно через месяц после последнего обновления.
Барри Шварц | 20 сентября 2022 г., 5:18 по восточному времени
SEO
Не ждите, пока Google предложит вам помочь. Вот как создать авторитетный контент для социальных сетей, ориентированный на людей, для вашего бренда.
Эрин Джонс | 19 сентября 2022 г., 8:00 по восточному времени
Контент-маркетинг
Вознаграждение более качественного контента за счет поискового рейтинга также поднимет планку для более эффективного использования генеративного ИИ.
Джаспер | 19 сентября 2022 г., 7:00 по восточному времени
Должна ли Apple создать собственную поисковую систему и исключить Google из списка?
Нет недостатка в слухах, когда речь идет о Apple (AAPL -0,58%) и новом техническом оборудовании. Помните Apple TV (Apple, конечно, предлагает множество услуг для телевидения)? Слухи (или, может быть, надежды) все еще ходят о возможном Apple Car, и ходят упорные слухи о том, что гарнитура Apple AR / VR, как сообщается, находится в разработке.
Но дело не только в оборудовании. Также ходят слухи, что Apple также создает собственную службу поиска в Интернете. Это было бы плохой новостью для Alphabet (GOOGL 0,87%) (GOOG 0,69%) и его главного кормильца, Google. Но действительно ли Apple пошла бы на такой шаг и исключила бы Google из своей прибыльной аппаратной империи?
Невероятный аппаратный бизнес с беспрецедентной мощностью
Во-первых, краткое введение. По сей день империя Apple в основном основана на продажах оборудования — и она проделала большую работу по привлечению потребителей в свою экосистему (которая включает в себя Mac, iPhone, iPad, часы и т. д.) и удержанию их там. Это классическая стратегия «земли и расширения»: после регистрации продажи (например, iPhone) Apple может продвигать другие типы устройств, рекламируя, насколько тесно они все интегрированы.
Но с годами бизнес-модель, ориентированная на устройства, постепенно менялась. Программное обеспечение и другие доходы, не связанные с продажей вычислительных устройств — сегмент услуг — принесли доход в размере 19,6 млрд долларов в третьем квартале 2022 финансового года Apple (который закончился 25 июня).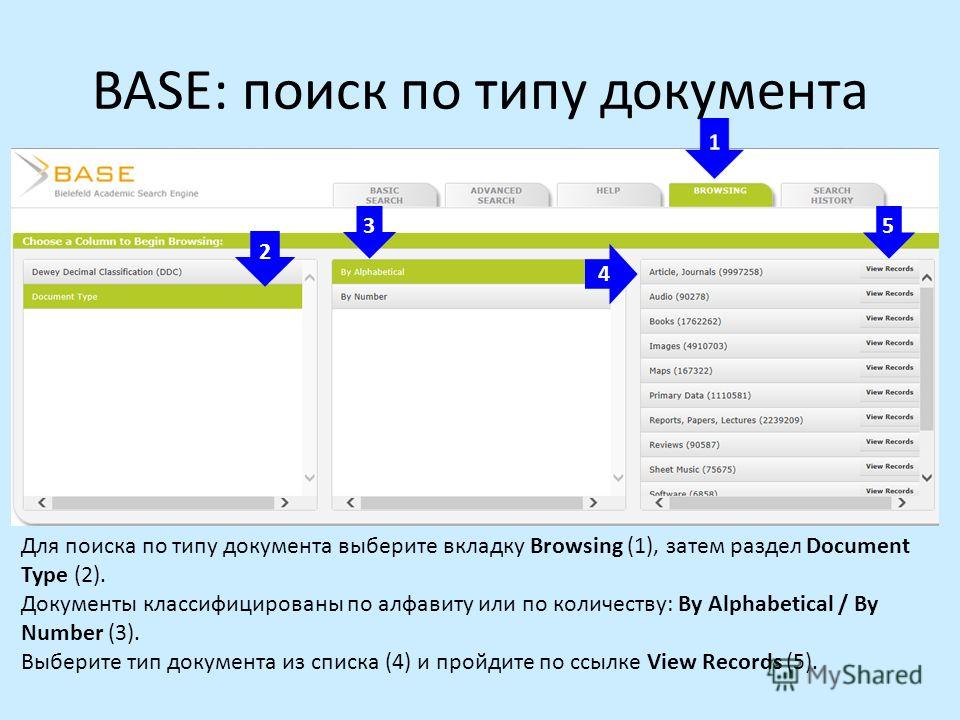 Это на 12% больше, чем годом ранее, и составляет почти 24% от общего дохода, что делает сервисы самым быстрорастущим сегментом Apple.
Это на 12% больше, чем годом ранее, и составляет почти 24% от общего дохода, что делает сервисы самым быстрорастущим сегментом Apple.
Алфавит происходит с другой стороны уравнения. Это софтверный бизнес, и он монетизируется в основном за счет рекламы. Компания медленно приближается к игре с аппаратным обеспечением, но реклама остается ключевым фактором ее интернет-бизнеса. Доступ к глобальной установленной базе устройств Apple, используемых в настоящее время (охватывающей 2 миллиарда активных устройств, большинство из которых — iPhone), имеет большое значение для Google. Сообщается, что он выкладывает миллиарды долларов за то, чтобы стать поисковой системой по умолчанию на устройствах Apple.
Ни Apple, ни Google фактически не раскрывают, сколько Google платит Apple за привилегии поиска в Интернете. Но оценки указывают на то, что в 2021 году он составит 15 миллиардов долларов, а в 2022 году вырастет до 18–20 миллиардов долларов. Другими словами, значительный рост услуг Apple (и значительная часть этого сегмента доходов в целом) обусловлен полученные из поисковой рекламы в Интернете.
Поскольку Apple жестко контролирует свою экосистему устройств, почему бы просто не использовать эти огромные платежи от Google для создания собственной поисковой системы и в конечном итоге полностью отказаться от Google? Однажды это может иметь смысл. В конце концов, рекламный бизнес Google приносит довольно приличную прибыль, даже после значительных затрат на привлечение трафика (TAC), выплаченных Apple. Только во втором квартале 2022 года сегмент собственных услуг Google (в основном состоящий из рекламы) принес операционную прибыль в размере 22,8 миллиарда долларов, а рентабельность составила 36%.
Кстати, платежи Alphabet TAC — это то, откуда в первую очередь берутся оценки роялти Apple. Alphabet заявляет, что TAC Google превысила 24 миллиарда долларов за первую половину 2022 года. Если мобильная операционная система Apple составляет немногим более половины доли рынка США и приближается к 30% в мире (баланс Alphabet составляет Android), по оценкам, примерно 40% что TAC (или от 18 до 20 миллиардов долларов) ежегодно переходит в Apple.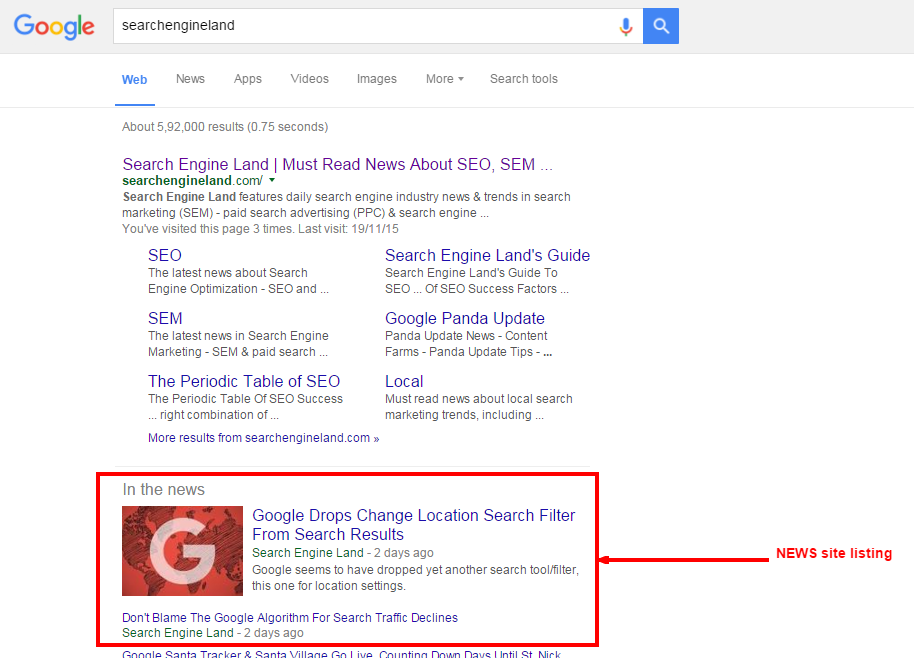
Apple уже закладывает основу для поисковой системы?
Apple, возможно, уже пробует почву для конкурирующей поисковой системы в Интернете. В конце концов, антимонопольное регулирование уже проводит проверку Apple, принимающей платежи от Google. Но помимо этого, Apple уже много лет монетизирует поиск с помощью рекламы в своем App Store. Разработчики программного обеспечения могут платить Apple за продвижение своего приложения, чтобы оно привлекало внимание большего числа пользователей Apple.
Но есть и новая функция прозрачности отслеживания активности (ATT) от Apple (это подсказка, которую Apple отправляет вам с вопросом, хотите ли вы подписаться на приложение, отслеживающее активность использования вашего устройства). Apple рекламирует эту функцию как доказательство того, насколько она заботится о вашей конфиденциальности. Но многие разработчики и маркетологи утверждают, что Apple использует ATT, чтобы ограничить доступ сторонних компаний к данным пользователей и продвигать свои собственные рекламные каналы (которые имеют доступ к пользовательским данным) в своей огромной базе устройств. Учитывая, что с годами продажи устройств в целом замедлились, а Apple уделяет все больше внимания услугам, создание собственной рекламной империи имеет смысл с финансовой точки зрения.
На самом деле, отчеты предполагают, что Apple агрессивно наращивает набор сотрудников для собственного рекламного сегмента. Сегмент рекламы Apple, возможно, уже перенаправляет миллиарды долларов в год на внутреннюю таргетированную рекламу с помощью ATT, а также мешает Google, Meta Platforms (то есть Facebook) и другим продавать высокодоходные таргетированная реклама. Если утверждения верны, Apple ослабляет способность других маркетологов продавать рекламу на iPhone и тому подобное, одновременно продвигая вместо этого свои собственные целевые рекламные каналы.
Как это связано с разработкой интернет-поисковика Apple? Создание рекламного бизнеса — основного средства монетизации интернет-поиска, по крайней мере, сегодня — может стать возможным предшественником того, что Apple столкнется лицом к лицу с Google. Однако каталогизация самого Интернета — это масштабная задача, требующая умения собирать и обрабатывать ошеломляющие объемы данных. Google владеет парой десятков дата-центров по всему миру и арендует гораздо больше места для своих серверов в сторонних дата-центрах. Даже для Apple создание правильной инфраструктуры для надлежащей службы поиска в Интернете было бы сложной задачей. 20 миллиардов долларов в год от Google пойдут только на создание новой интернет-инфраструктуры, не говоря уже о большом объеме разработки программного обеспечения, необходимого поверх нее.
Учитывая это, я думаю, что Google в обозримом будущем безопасно останется поисковой системой Apple по умолчанию (если сначала не вступят в силу регулирующие факторы). Apple, вероятно, более чем счастлива получать эти ежегодные платежи в размере десятков миллиардов долларов от Google. Я вижу, что статус-кво в интернет-поиске еще какое-то время остается неизменным, поскольку это просто имеет финансовый смысл как для Apple, так и для Google.
Сюзанна Фрей, исполнительный директор Alphabet, является членом совета директоров The Motley Fool. Рэнди Цукерберг, бывший директор по развитию рынка и пресс-секретарь Facebook и сестра генерального директора Meta Platforms Марка Цукерберга, является членом совета директоров The Motley Fool. Николас Россолильо и его клиенты занимают позиции в Alphabet (акции C), Apple и Meta Platforms, Inc. The Motley Fool имеет позиции и рекомендует Alphabet (акции A), Alphabet (акции C), Apple и Meta Platforms, Inc. The Motley Fool рекомендует следующие варианты: длинные мартовские коллы 2023 года по $120 на Apple и короткие коллы на $130 на Apple в марте 2023 года. У Motley Fool есть политика раскрытия информации.
SEO Для издателей новостей: Ваше следующее обязательное мероприятие
Этот пост был спонсирован Новостным и редакционным SEO Summit (NESS). Мнения, выраженные в этой статье, принадлежат спонсору.
Поисковая оптимизация имеет разные тактики в разных отраслях, особенно для издателей новостей.
Наши усилия по поисковой оптимизации отличаются от, скажем, электронной коммерции или локальных продаж.
Мы знаем, что это не универсальный подход.
Вот почему Новостной и редакционный SEO-саммит (NESS) идеально подходит для вас!
4 и 5 октября вы можете получить доступ к лучшим специалистам в области SEO и издательского дела, которые поделятся своими знаниями и опытом.
Вы узнаете:
- Наиболее эффективные стратегии для новостного контента и вечнозеленого SEO.
- Что движет алгоритмами Google, основанными на качестве, в новостях и рекомендациях.
- Последние новости об AMP и техническом SEO для издателей.
- Как использовать данные аналитики для ускорения цифрового роста.
Это мероприятие, организованное NewsSEO.io, одним из самых активных новостных SEO-сообществ в Интернете, предоставит вам важную информацию о стратегиях органического поиска, которые помогут увеличить ваш трафик.
Откройте для себя множество новостей Опыт SEO
На NESS 2022 выступят докладчики из авторитетных изданий, а также одни из ведущих экспертов в области поиска сегодня.
Спикеры NESS 2022
Получите новую актуальную информацию о SEO, контент, советы и рекомендации от величайших умов SEO в новостной индустрии:
- Клаудио Э. Кабрера , The Athletic: журналистика в прямом эфире, SEO-стратегии и тактика.
- Леони Родерик и Бен Дилкс , The Times: Что означает платный доступ для SEO?
- Марк Бурка , Angi: Коммерческое и партнерское SEO для издателей.
- Кэролайн Шелби , Dawn Patrol LLC: успешное использование автоматизированных статей.
- Алли Берри , TheStreet: Процессы работы с контентом для доминирования в поисковой выдаче.
- Koray Tuğberk GÜBÜR , Целостное SEO и цифровые технологии: как поисковые системы используют статьи, основанные на мнениях, для ранжирования.
- Джон Шехата , Condé Nast, NESS и NewzDash Основатель: Top Stories State of the Union.
- Барри Адамс , Polemic Digital & NESS Основатель: Новейшее техническое SEO для новостных сайтов.

Изображение Создано NESS, сентябрь 2022 г.
Панели NESS 2022
В дополнение к нашим 10 отдельным мероприятиям на высшем уровне у вас будет возможность задать более конкретные вопросы по новостям SEO на наших двух панельных дискуссиях, ориентированных на рост:
- Спросите SEO-специалистов : где вы можете задать этой группе экспертов, Клаудио Э. Кабрере, Кэролин Шелби, Кораю ГУБУРу, Барри Адамсу и Джону Шехате любые вопросы о поисковой оптимизации их веб-сайта.
- Карьерный рост : Послушайте, как Лили Рэй, Крис Моран, Пол Шапиро, Луиза Фрам, Барри Адамс и Джон Шехата рассказывают о своем карьерном пути в области поисковой оптимизации и публикации новостей.
Посетив это мероприятие, вы сможете применить полученные знания на своих веб-сайтах, чтобы увеличить органический трафик.
Используйте «SEJ22», чтобы сэкономить 25% на вашем билете →
Убедитесь, что ваши знания о внутренней и технической SEO актуальны. Со всеми увольнениями и внезапными обновлениями алгоритмов повышение квалификации и налаживание связей сейчас важнее, чем когда-либо.
Задайте свои новости SEO вопросы: полностью онлайн и в прямом эфире
Все сессии будут проходить в прямом эфире, а записи будут доступны только обладателям билетов после мероприятия.
Мы будем имитировать настоящее живое мероприятие, где у вас будет отличная возможность пообщаться с экспертами, поговорить с ними один на один и расширить свои связи и знания, общаясь в кабинках!
С единым билетом вы получите полный доступ ко всем выступлениям за оба дня и возможность задать свои вопросы непосредственно нашим спикерам на закрытии мероприятия.
Что такое новостной и редакционный SEO Summit?
Несмотря на то, что существует множество SEO-сообществ и саммитов, не было ни одного мероприятия, посвященного новостным издателям или SEO-специалистам, работающим с новостными сайтами.
Видимость в экосистеме Google — важнейший источник читателей для всех онлайн-издателей, и найти информацию о том, как максимально увеличить ее, бывает непросто.
Саммит по SEO для новостей и редакционных материалов (NESS) проводится для решения уникальных проблем, с которыми сталкивается новостная индустрия в отношении SEO.
Это второе ежегодное онлайн-мероприятие в прямом эфире предоставит экспертную информацию, рекомендации и бесценные возможности для общения с лучшими умами в области издательского дела и SEO.
От Google News до Discover, от Top Stories до новостных приложений — вы узнаете, что нужно, чтобы расширить свое присутствие во всех органических местах, где показываются новости.
Саммит для издателей новостей
NESS отлично подходит для:
- Журналистов и редакторов, ежедневно занимающихся написанием и публикацией новостного контента, которые хотят, чтобы их статьи получали наилучшие шансы на ранжирование в Top Stories и Google News.
- Веб-разработчики, которые хотят, чтобы их веб-сайты соответствовали последним техническим требованиям Google и следовали передовым методам SEO для сканирования и индексирования.
- SEO-специалистов, работающих с издателями, которые хотят расширить свои знания и поучиться у экспертов в этой области.
- Стратеги по увеличению аудитории ищут способы максимизировать трафик и находят новые возможности для посещений из органического поиска.
Заявите о себе и купите билет на второй ежегодный саммит NESS уже сегодня!
КУПИТЬ БИЛЕТ
Категория Карьера SEO Рекламные посты
GSC vs. Ahrefs vs. Semrush vs. Moz
Search Engine Land » Канал » SEO » Вскрытие размера ключевого слова без каких-либо ограничений: GSC vs. Ahrefs vs. Semrush vs. Moz
Когда дело доходит до инструменты, у всех нас есть свои фавориты как у профессионалов SEO. Ahrefs, Moz и Semrush стремятся выполнять одни и те же задачи на высоком уровне, но вам будет трудно найти специалиста по SEO, у которого нет твердого мнения о способности каждого инструмента делать это.
Любой опытный специалист по поисковой оптимизации знает, что одни только мнения могут привести вас примерно к тому, чтобы спросить Джона Мюллера из Google об авторитетности домена (подсказка: недалеко).
Наша команда SEO недавно проверила наше мнение и отклонила его в сторону, чтобы сравнить размер ключевых слов в Google Search Console (GSC), Ahrefs, Semrush и Moz для клиентов, которыми мы управляем.
Хотя вы можете прочитать больше в разделах «Методология» и «Предостережения и соображения» ниже, указание на то, что эти данные не являются окончательными, в заголовке заключается в том, что это не так. Данные были получены только для 51 домена, все из которых связаны с фармацевтической отраслью. Так что это небольшая, нерепрезентативная выборка. Вы предупреждены.
У GSC было более чем на 36% больше ключевых слов, чем у других источников
вместе взятых Сравнение Google Search Console, Ahrefs, Semrush и Moz по среднему количеству ранжирующих ключевых слов или ключевых слов, регистрирующих хотя бы один показ среди 51 домена в мае 2022 года.Патрик Стокс из Ahrefs опубликовал фантастическое исследование ключевых слов, скрытых в Google Search Console. Я рекомендую вам прочитать его, но суть в том, что, хотя количество кликов сильно различается в зависимости от сайта, почти половина всех кликов приходится на скрытые термины.
Учитывая, что Google Search Console скрывает ключевые слова с меньшим объемом запросов, которые составляют большинство поисковых запросов, это, вероятно, означает, что значительно больше половины ключевых слов недоступны для конечного пользователя.
Но такова реальность. GSC по-прежнему может быть лучшим, что у нас есть , когда речь идет о размере видимости ключевых слов.
Среди трех тройки у Ahrefs было наибольшее количество ключевых слов для 98% веб-сайтов
Размер относительного рейтинга ключевых слов по доменам
| Source | 1st | 2nd | 3rd |
| Ahrefs | 50 domains | 0 domains | 1 domain |
| Semrush | 0 domains | 50 доменов | 1 Домен |
| MOZ | 1 Домен | 1 Домен | 49 Домен |
39. 0002 Во многих отношениях некорректно сравнивать Ahrefs, Semrush и Moz с Google Search Console. Метрики GSC и предполагаемое использование немного отличаются от трех других инструментов.
Итак, при удалении GSC мы ранжировали размер ключевого слова для каждого из 51 сайта в нашем хранилище данных. Я буду честен; Я был потрясен стабильностью результатов.
Ahrefs почти безоговорочно занял первое место, а Семруш и Моз постоянно занимали второе и третье места.
В среднем у Ahrefs было в два раза больше ключевых слов, чем у Semrush, у которого их было в два раза больше, чем у Moz. У Ahrefs почти в пять раз больше рейтинговых ключевых слов для наших клиентов, чем у Moz. Это невероятное несоответствие!
Вам может быть интересно, если Ahrefs имеет такое доминирующее преимущество над Semrush и Moz, почему бы просто не использовать Ahrefs?
Каким бы сильным ни был Ahrefs, он пропустил 87% ключевых слов
Первая диаграмма: общее количество ключевых слов в рейтинге в Ahrefs по сравнению с общим количеством ключевых слов в рейтинге или ключевых слов, регистрирующих хотя бы один показ, найденный в Moz, Semrush и/или Google Search Console и нет в Ahrefs для 51 домена в мае 2022 года.
Вторая диаграмма: общее количество ключевых слов с рейтингом в Ahrefs по сравнению с общим количеством ключевых слов с рейтингом, найденных в Moz и/или Semrush, а не в Ahrefs для 51 домена в мае 2022 года.
Во-первых, тот факт, что Ahrefs можно даже сравнивать с другими источниками, сложенными вместе, является мощным. Это далеко не удар по нему. Однако, если бы все наши яйца были в корзине Ahrefs, мы бы упустили значительный объем данных о ключевых словах.
Даже если вы удалите Google Search Console, Ahrefs все равно не будет содержать 32% ключевых слов.
В то же время отсутствие использования Moz (наш самый маленький источник) оставляет некоторые белые пятна.
По сравнению с Ahrefs и Semrush 13% ключевых слов были эксклюзивными для Moz
Первая диаграмма: ключевые слова с общим рейтингом или ключевые слова, зарегистрировавшие хотя бы один показ исключительно для одного источника, сравнивающие Ahrefs, Moz, Semrush и Google Search Console для 51 домена в мае 2022 года.
Вторая диаграмма: ключевые слова с общим рейтингом, исключающие один источник, сравнивающие Ahrefs, Moz и Semrush для 51 домена в мае 2022 года.
Глядя на диаграмму справа, трудно игнорировать отсутствие 13% от общего числа ключевых слов.
Эксклюзивные номера Moz резко упали, когда к ним добавили GSC с менее чем 2% ключевых слов. Но, как я уже упоминал ранее, эти инструменты не совсем эквивалентны в том, что они охватывают.
Процент эксклюзивности Semrush подскочил до 24% по сравнению с Ahrefs и Moz, но он также оставался ниже 2%, когда был включен GSC.
Давайте посмотрим на противоположный конец спектра. Где вместо эксклюзивности был полный охват? Если мы вытащим случайное ключевое слово из шляпы, насколько вероятно, что оно будет найдено в каждом из четырех проанализированных нами источников?
Менее 1% ключевых слов было найдено во всех четырех источниках.
Количество ключевых слов ранжирования или ключевых слов, по которым был зарегистрирован хотя бы один показ по количеству представленных источников среди Ahrefs, Google Search Console, Moz и Ahrefs для 51 домена в мае 2022 г.Невероятное количество ключевых слов в нашем наборе данных было найдено только в одном источнике. И наоборот, лишь немногие избранные были представлены во всех четырех источниках.
Количество ключевых слов незначительно увеличилось с 0,4% до 2,6% при переходе от четырех источников к трем. Даже два источника не охватывают 10% от общего числа ключевых слов.
Получайте ежедневный информационный бюллетень, на который полагаются поисковые маркетологи.
Методология
Сбор данных
- Google Search Console : Нефильтрованные поисковые данные на уровне запроса сохранялись в нашем хранилище данных через API Google Search Console каждый день с 1 по 31 мая для 51 клиентского домена. Ключевые слова были дедуплицированы по доменам и объединены в месячные итоги.
- Semrush : В мае в нашем хранилище данных для 51 клиентского домена был сохранен один вызов API в реальном времени с помощью отчета Semrush Domain Organic Search Keywords. США были обозначенным регионом.
- Moz: Ранжирование ключевых слов в обычном поиске было вручную экспортировано из внешнего интерфейса Moz’s Keyword Explorer с использованием настроек по умолчанию в мае для 51 клиентского домена.
- Ahrefs : Рейтинги ключевых слов в обычном поиске были вручную экспортированы из внешнего интерфейса обозревателя ключевых слов Ahrefs с использованием настроек по умолчанию в мае для 51 клиентского домена.
Обработка и анализ
Матрица запроса-источника была создана для того, чтобы определить, где было совпадение и эксклюзивность между Ahrefs, Google Search Console, Moz и Semrush по клиентскому домену и в совокупности.
Предостережения и соображения
Образец данных
Я упоминал об этом во введении, но стоит повторить. Наш анализ включал как небольшую, так и отраслевую выборку ранжирования доменов. Вы не должны делать какие-либо выводы относительно общего относительного размера ключевых слов, сравниваемых этими инструментами .
Так зачем публиковать результаты? Как также упоминалось в разделе ключевых выводов ниже, помимо того, что данные представляют интерес и могут стать поводом для полезного диалога, я хотел подчеркнуть ценность анализа этих инструментов с точки зрения вашей отрасли.
Доступность источника
Ahrefs, Google Search Console, Moz и Semrush — не единственные продукты с уникальными наборами данных видимости ключевых слов. Serpstat, seoClarity, Brightedge Data Cube и другие инструменты могли бы стать частью этого исследования, чтобы сделать его более всесторонним. Если кто-либо из представителей этих инструментов читает это, нам было бы интересно сравнить ваш инструмент с остальными в следующий раз. Ударь меня!
Сопоставимость источников
Для Ahrefs, Moz и Semrush это были разовые выборки данных в течение мая. Однако с Google Search Console был сделан 31 отдельный вызов API. Возможно, это немного завысило показатели GSC.
Если бы в мае мы каждый день производили рейтинги для других инструментов, было бы добавлено больше уникальных ключевых слов либо из-за изменения рейтинга доменов, либо из-за обновлений базы данных ключевых слов. Как бы то ни было, я не верю, что это повлияло бы на какие-либо всеобъемлющие тенденции или выводы.
Кроме того, данные Google Search Console включали ключевые слова для мобильных и настольных компьютеров из всех стран, в то время как из других источников мы учитывали только рейтинги для настольных компьютеров в США. Это снова увеличило бы показатели GSC, но вряд ли до такой степени, чтобы существенно изменить какие-либо тенденции.
Исключение объема ключевого слова
Объем ключевого слова не был включен в это упражнение, что ограничивает его потенциальную ценность. При прочих равных условиях я бы больше беспокоился, если бы Моз пропустил ключевое слово с 25 000 MSV, чем ключевое слово с 25 MSV.
При следующем запуске этого анализа мы планируем включить объем. Однако нам нужно будет создать логику для того, чтобы наилучшим образом включить показы GSC в качестве прокси-сервера MSV, а также как рассчитать объем ключевых слов, найденных в нескольких инструментах.
Актуальность данных
Актуальность данных в этом анализе не учитывалась. Из-за того, как работают его метрики, Google Search Console по своей сути является свежим. Другими словами, если бы мы извлекли данные GSC за май, эти ключевые слова определенно были бы видны в мае (пусть даже на мгновение).
Однако возможно, что другие источники содержали ключевые слова без обновленного ранжирования с мая. Если бы какой-либо из этих инструментов имел непропорционально устаревшие данные, это могло бы изменить результаты.
Основные выводы
1. Проверьте свои предположения
Перед тем, как представить результаты моей команде, я попросил их ранжировать четыре источника в порядке охвата ключевых слов, исходя из их собственного чутья. Около 10 человек угадали, включая меня, но ни один из нас не угадал !
Semrush регулярно получал более низкие оценки, чем мы предполагали, а GSC не получал должного внимания. Однако с GSC это более вероятно из-за того, что они используются для извлечения данных из внешнего пользовательского интерфейса.
Мы все можем быть виноваты в том, что слишком доверяем своей интуиции и предчувствиям, и это выходит далеко за рамки инструментов SEO. Как маркетологи, мы должны постоянно проверять наши позиции и быть готовыми изменить свое мнение.
2. Используйте GSC API
При извлечении данных непосредственно из пользовательского интерфейса Google Search Console вы ограничены 1000 строками данных. Если бы мы просто загрузили данные из GSC с диапазоном дат с 1 по 31 мая, этот инструмент уже не был бы лидером (это далеко не так).
Запрос GSC из API по-прежнему имеет свои ограничения, но значительно увеличивает объем доступных данных.
3. Используйте все инструменты
По общему признанию, этот вывод немного противоречит моему мнению. Как указано в разделе выше, мы даже не используем все инструменты и не планируем это делать. Тем не менее, я постоянно выступаю за то, чтобы не использовать только один инструмент SEO.
Мой реальный совет таков: инвестируйте в месячную подписку и/или бесплатные пробные версии, чтобы оценить относительную производительность в вашей конкретной категории. Оттуда вы можете выбрать лучший инструмент (ы) для вас, исходя из ваших конкретных вертикалей, бюджета и целей. В рекламе наших клиентов-фармацевтов часто говорится: «Результаты могут отличаться», и то же самое относится и к этому. Потратьте дополнительное время, чтобы увидеть, что лучше для вас.
Кроме того, при тестировании инструментов для вашей конкретной отрасли и потребностей не ограничивайтесь только размерами ключевых слов. Также можно учитывать размер, точность, удобство работы с пользователем, поддержку клиентов, интеграцию технологий и многое другое.
4. Повторите и улучшите свои тесты
Наш первый официальный тест завершен, но мы не планируем его прекращать. Semrush недавно стал публичным. Moz был приобретен чуть более года назад. Ahrefs запустил поисковую систему.
Это гонка вооружений, и если мы не будем периодически обновлять эти результаты, мы можем принимать решения на основе устаревших и неточных данных.
Мнения, высказанные в этой статье, принадлежат приглашенному автору и не обязательно принадлежат Search Engine Land. Штатные авторы перечислены здесь.
Новое в системе поиска
Об авторе
Как обрабатывать целевые страницы PPC для SEO
Каждый компетентный оптимизатор знает, что «SEO — это не остров». Нам необходимо работать с различными заинтересованными сторонами, чтобы согласовать наши маркетинговые усилия.
Но одним из наиболее недоиспользуемых отношений в маркетинговых командах являются отношения между специалистами по поисковой оптимизации и контекстной рекламе.
Исходя из моего опыта работы с агентствами и внутри компании, сотрудничество со специалистами PPC может принести огромную пользу стратегии SEO и наоборот.
В конце концов, онлайн-бизнес нередко использует стратегии PPC и SEO для роста. Оба канала необходимы для любой стратегии онлайн-маркетинга.
Хотя тактика PPC отличается от методов SEO, есть несколько случаев, когда оба канала должны сотрудничать для повышения общей эффективности бизнеса.
Взгляд на целевые страницы PPC
Одной из точек соприкосновения между PPC и SEO являются целевые страницы, созданные специально для кампаний PPC. Создание альтернативных целевых страниц PPC — отличный способ оптимизировать страницы для конверсий — и не обязательно для поиска.
Взгляните на этот пример целевой страницы, используемой для рекламы PPC.
Скриншот из SpyFuНа странице очень мало текста и нет схемы (что неудивительно, поскольку это не SEO-страница).
Скриншот с сайта pspdfkit.com/tryИ если вы посмотрите на органические ключевые слова, которые эта страница привлекает в Semrush, вы увидите, что она ранжируется только по двум ключевым словам, и одно из них брендировано.
Скриншот из Semrush(Фактическое количество органических ключевых слов может быть выше, но ожидается, что оно будет брендовым, и низкий рейтинг по небрендированным ключевым словам, если их больше.)
Это пример целевой страницы, не оптимизированной для поиска, но используемой для целей контекстной рекламы. Для кампаний PPC могут потребоваться страницы с большим акцентом на брендинг или креативные заголовки, меньше текста, больше графики и четкие призывы к действию.
И поскольку SEO-специалисты могут быть очень щепетильны в отношении своих заголовков, ключевых слов, длины контента и многого другого, PPC-страницы предлагают PPC-менеджеру выход.
Могут ли PPC-страницы мешать усилиям SEO?
Если коротко, то да. Любая страница, которая индексируется в поиске, должна быть оптимизирована для поиска.
Создание PPC-страниц без учета того влияния, которое они могут оказать на SEO, может повлиять на органическую производительность двумя способами:
- Каннибализация. Когда существует PPC-версия существующей SEO-страницы, целевая PPC-страница может поставить под угрозу производительность аналогичной SEO-страницы.
- Создание целевых страниц с оплатой за клик означает наличие на вашем веб-сайте страниц с небольшим количеством слов и минимальным содержанием, которые во время полезного обновления контента Google могут фактически повлиять на общую производительность веб-сайта, включая страницы, которые хорошо оптимизированы и приносят пользу пользователи.
Зачем нужны целевые страницы PPC?
Целевую страницу можно использовать как для целей SEO, так и для целей контекстной рекламы, так зачем нам создавать целевую страницу платной рекламы?
С точки зрения маркетинга, PPC-страницы привлекают клиентов с помощью рекламы. Таким образом, содержимое страницы должно соответствовать рекламному сообщению. Это означает, что самый заметный текст на странице может быть таким же, как сообщения, используемые в рекламе PPC.
Так, например, если ваше рекламное объявление говорит что-то вроде «Мы лучшие на канадском рынке», ваш h2 может быть точно таким же текстом. Некоторые PPC-менеджеры даже используют заголовок объявления как h2, а описание объявления как h3, чтобы улучшить CRO своих объявлений.
Еще одна проблема с целевыми страницами PPC заключается в том, что они созданы для устранения отвлекающих факторов. Они сосредоточены на том, чтобы пользователь, который нажал на объявление, совершил конверсию. В SEO контент служит как пользователям, так и алгоритму поиска, который решает, приносит ли эта страница наибольшую ценность пользователю.
Как работать с платными страницами с точки зрения SEO
Вы можете использовать любую из следующих тактик, чтобы работать с целевыми страницами платной рекламы на своем веб-сайте до их создания.
1. Отметьте свои целевые страницы PPC как noindex
Это самое простое решение, и тег noindex не повлияет на эффективность кампании PPC.
2. Создайте свои целевые страницы PPC на субдомене
Создание целевых страниц PPC на субдомене:
- Не требует междоменного отслеживания.
- Поддерживает порядок на вашем сайте.
- Не повлияет на органическую производительность вашего основного домена, поскольку Google рассматривает поддомены как отдельный домен.
Это решение не может быть на 100 % надежным. Дэнни Салливан из Google ответил на вопрос о том, считает ли полезное обновление контента субдомены частью основных доменов, сказав: «Мы склонны видеть субдомены отдельно от корневых доменов, но это также может зависеть от многих факторов».
Обычно мы видим субдомены помимо корневых доменов, но это также может зависеть от многих факторов.
— Дэнни Салливан (@dannysullivan) 18 августа 2022 г.
3. Сделайте и то, и другое
Учитывая всю эту информацию, вы можете захотеть сделать и то, и другое, если вы обрабатываете страницы PPC до их создания. Короче говоря, создайте PPC-страницы на поддомене и , пометьте их как noindex.
Получайте ежедневный информационный бюллетень, на который полагаются поисковые маркетологи.
Что делать, если целевые страницы PPC уже существуют?
Решение может быть немного сложнее, если вы только начали работать над веб-сайтом и обнаружили, что целевые страницы PPC уже существуют.
Во-первых, вам нужно просмотреть данные о производительности этих страниц в Google Search Console и оценить количество показов и кликов, которые эти страницы получают из поиска.
Если целевая страница PPC
, а не работает хорошоЕсли страница плохо работает в поиске и для нее есть альтернативная SEO-страница, вы можете просто пометить ее как noindex и переместить в поддомен.
Вы можете попробовать канонизировать страницу PPC вместо использования тега noindex на ее альтернативной странице SEO. Однако это может не помочь решить проблемы с дублированием или каннибализацией, поскольку Google может игнорировать канонический тег и выбрать индексирование обеих страниц.
Тем не менее, поскольку это решение требует наименьших усилий, вы можете сначала протестировать его и попробовать реализовать правильные канонические символы на нескольких целевых страницах PPC и посмотреть, выполняет ли Google ваши канонические символы.
Если целевая страница PPC работает хорошо и нет альтернативной SEO-страницы
Если страница PPC хорошо работает в поиске или имеет потенциал для хороших результатов в поиске при оптимизации (на что можно указать, увидев, что страница получает много показов в GSC) и нет соответствующей SEO-страницы, вы можете скопируйте содержимое страницы PPC на новую SEO-страницу с оптимизированным URL-адресом.
Затем вы можете перенаправить существующую страницу PPC на вновь созданную страницу SEO. Наконец, вы можете воссоздать страницу PPC по другому URL-адресу и пометить ее как noindex, чтобы кампания PPC не прерывалась.
Используйте этот подход, если вы хотите иметь две отдельные страницы для PPC и SEO и хотите, чтобы URL-адрес был оптимизирован, а на странице PPC было меньше оптимизаций контента.
Примечание. Если URL-адрес страницы PPC подходит, и вам разрешено оптимизировать страницу PPC для SEO, то определенно используйте этот гораздо более простой подход.
Если целевая страница PPC работает хорошо и есть альтернативная страница SEO
Если страница PPC работает хорошо и привлекает несколько кликов из поиска и для нее есть альтернатива SEO, вы можете просто перенаправить страницу PPC на страницу SEO страницу, создайте новую страницу PPC по другому URL-адресу и пометьте ее как noindex.
Вот инфографика, обобщающая процесс SEO для обработки целевых страниц PPC.
На что следует обратить внимание перед внесением изменений
Есть грань между идеальными SEO-рекомендациями и тем, что вы действительно можете выполнить в реальной жизни.
Не всегда возможно запретить индексацию каждой PPC-страницы и переместить ее в субдомен. Нам необходимо учитывать следующее:
- Количество страниц: Возникает ли проблема на 2-3 страницах или на сотнях страниц? Если вы имеете дело только с несколькими страницами, вы легко сможете реализовать подход «не индексировать, а затем перейти на поддомен».
- Серверная часть: Есть ли у клиента ресурсы для создания и перемещения страниц в поддомен? Если это не так, вы можете пропустить эту часть и придерживаться noindex.
- Воздействие/усилия: Требуются ресурсы для создания новых страниц и перенаправления существующих страниц PPC. Стоит ли это усилий? Оправдывает ли ожидаемый результат воздействие обработки существующих страниц PPC по сравнению с минимальными настройками SEO для страницы PPC?
Практический подход
Для одного клиента, небольшого предприятия электронной коммерции, я решил внести минимальные SEO-настройки в их существующие PPC-страницы и оставить их в покое.