Алгоритмы поисковых систем. Изменение алгоритмов и их влияние на поисковую выдачу
Алгоритм ранжирования поисковой системы определяет, какой документ из базы данных (в данном случае какая интернет страница) будет находиться на первом и последующих местах поисковой выдачи, по заданному ключевому запросу пользователя. Для каждой популярной поисковой машины разрабатывается свой собственный алгоритм ранжирования, а точная формула и вес всех факторов влияющих на выдачу держится в секрете и является главной коммерческой тайной поисковика.Не смотря на желание программистов и разработчиков поисковой машины скрыть точную формулу ранжирования, так или иначе, оказывается возможным определить факторы влияющие на положение сайта в выдаче. Воздействуя на эти факторы можно улучшить позиции по нескольким ключевым запросам, в результатах поиска по базе данных поисковика.
Одна из задач оптимизации, как раз, и состоит в том, чтобы максимально эффективно влиять на алгоритм с целью улучшений позиций (многие считают это даже основной целью поискового продвижения сайта).
Зачем держать алгоритм ранжирования в секрете?
Основную идею, почему программисты ведущих поисковых систем, таких как Яндекс, Гугл и Рамблер не раскрывают формулы ранжирования можно понять как забота о качестве поисковой выдачи. Если большое число вебмастеров смогут высокоточно воздействовать на алгоритм, ты выдача по многим неоднозначным запросам будет сильно подвержена SEO-прессингу. Под SEO-прессингом понимается подавляющее число однообразных сайтов в выдаче в ответ на неоднозначный информационный пользовательский запрос.Примером такого информационного запроса может служить запрос «дизайн», «дерево», «автомашина» и другие. Лучшей выдачей на такие запросы, было бы присутствие в первой десятке сайтов из различных отраслей и категорий знаний. Так, в ответ на «автомобиль» поисковик «должен» выдать сайты об
Взамен на такое разнообразие категорий, часто выдаётся десятка однообразных сайтов о продаже и покупке новых и б/у автомобилей. Это связано с коммерческой окупаемостью вложений в продвижение, именно в этой области (проекты об истории и науках не являются коммерческими и их продвижение в поисковиках крайне ограничено).
Конечно, помимо заботы о пользователях поисковых систем, алгоритм также не раскрывается и по причине заботы об уникальности поисковика и не желанию раскрывать все аспекты поиска конкурентам. На российском рынке поиска, поисковики-гиганты которыми являются Яндекс и Гугл постепенно вытесняют с рынка меньшие. Так, Рамблер потерял за год более половины своей поисковой аудитории (Рис.1) по данным счётчика Liveinternet.ru.
Улучшение алгоритмов ранжирования. Яндекс и региональная формула ранжирования
Время от времени поисковые системы изменяют алгоритм ранжирования. Это может быть как небольшое изменение действующих весов факторов, так и внесение кардинальных изменений в формулу.
Этот принцип лежит в основе работы алгоритма Арзамас поисковой системы Яндекс, отличительная черта его работы это локальные результаты поиска. Сейчас региональная формула используется для ранжирования результатов по гео-зависимым запросам в Санкт-Петербурге, Екатеринбурге, Новосибирске, Красноярске, Омске, Ростове-на-Дону, Краснодаре, Нижнем Новгороде, Уфе, Перми, Казани, Самаре, Челябинске, Владивостоке, Кемерово, Иркутске, Барнауле и Воронеже. Таким образом, Яндекс расширяет список регионом где действует региональная формула.
← Назад в раздел
Алгоритмы поисковых систем: внешние ссылки и ранжирование
Алгоритмы поисковых систем: внешние ссылки и ранжированиеВнешние ссылки — один из существенных факторов в ранжировании сайтов поисковыми системами. Однако, поисковыми алгоритмами учитываются далеко не любые ссылки и не все ссылки полезны.
Однако, поисковыми алгоритмами учитываются далеко не любые ссылки и не все ссылки полезны.
Общий принцип прост — отрицательно на позиции сайта могут повлиять неестественные ссылки. Или такие ссылки просто не будут учтены. В норме, если сайт хороший, то на него ставят ссылки с таких же хороших сайтов, количество внешних ссылок, как правило, растёт, а не уменьшается, а рост ссылочной массы обычно постепенный.
Ссылочные факторы, которые могут отрицательно повлиять на позиции сайта в поисковой выдаче или могут быть проигнорированы:- «Спаммерские ссылки» — например, ссылки из комментариев в блогах, постов на форумах, с досок бесплатных объявлений и с немодерируемых каталогов.
- «Ссылки с плохих сайтов» — ссылки с сайтов, которые только и созданы, чтобы ссылки с них продавать — как правило, такие сайты имеют отвратительное оформление, сгенерированный автоматически или ворованный контент, а также не имеют никакой аудитории (а Яндекс и Google про это всё прекрасно знают).
 В сообществе оптимизаторов такие сайты называют ГС (аббревиатура от термина «говносайт»).
В сообществе оптимизаторов такие сайты называют ГС (аббревиатура от термина «говносайт»). - «Явно покупные ссылки» — как правило, такие ссылки расположены в «подвале» сайта или в ином труднодоступном месте, сгруппированы с десятком подобных, текст страницы, на которой установлена ссылка, никак не связан по тематике с сайтом, на который эта ссылка ведёт, общее количество ссылок с «продажного сайта» измеряется тысячами, а реальные пользователи по таким ссылкам никогда не переходят.
- Резкий рост ссылочной массы с выходом на плато. Стандартный кейс закупки арендных ссылок — на выделенный бюджет арендуется некое количество ссылок, а затем (так как бюджет не меняется) это количество остаётся либо стабильным, либо плавно сокращается (инфляция, за фиксированный бюджет с каждым месяцем можно купить всё меньше и меньше ссылок).
- «Мигание» ссылок — ссылки то появляются, то исчезают. Как правило, такое происходит, если арендные ссылки не совсем вовремя продляются, то есть это говорит поисковым системам о предпринимаемой накрутке ссылочных факторов.

- «Падение» ссылочной массы — обычно происходит в результате отключения арендных ссылок, свидетельствует о накрутке ссылочных факторов.
- «Молодые» ссылки — даже проиндексированные поисковой системой ссылки, которые были проставлены на сайт недавно, скорее всего не будут учтены алгоритмами ранжирования, так как они еще «не заслужили доверия».
- «Обменные ссылки» — детектируются и не учитываются даже те ссылки, которые получены путём сложных схем обмена (треугольники, квадраты и прочие геометрические фигуры), а сайты, которые участвуют в подобном могут быть пессимизированы, то есть на на них могут быть наложены санкции.
Статья опубликована в 2014 году
Тематические статьи
Google Sandbox или «песочница» Гугла
Эффект песочницы — это фильтр, понижающий позиции в выдаче, который накладывается на новые сайты или сайты, которые резко изменились.
SEO
интернет-маркетинг
Статья опубликована в 2014 году
Поисковое продвижение сайта (SEO) — цели, задачи и методы достижения результатов
Каждый коммерческий сайт должен выполнять вполне конкретные задачи: привлекать новых клиентов и способствовать росту продаж. На сегодняшний день основной источник новых клиентов из интернета — это поисковые системы.
На сегодняшний день основной источник новых клиентов из интернета — это поисковые системы.
Большинство пользователей интернета начинают поиск информации об интересующих их товарах или услугах с поискового запроса в Яндексе или Google. Но получение посетителей из поисковых систем — задача непростая. Для того чтобы сайт отвечал требованиям поисковой системы, необходимо провести целый комплекс мероприятий по оптимизации внутренней структуры и содержания сайта, работать над usability, а также обеспечить высокую цитируемость ресурса внешними источниками.
SEO
интернет-маркетинг
Статья опубликована в 2019 году
Алгоритмы поисковых систем: история развития
Поисковые системы на сегодняшний день для ранжирования результатов поиска учитывают многочисленные факторы. Но за этой сложностью стоит уже почти 2 десятилетия развития поисковых алгоритмов.
SEO
интернет-маркетинг
Статья опубликована в 2014 году
Алгоритмы поисковых систем: поведенческие факторы
Откуда поисковые системы знают о происходящем на вашем сайте? И зачем им это вообще знать?
SEO
интернет-маркетинг
Статья опубликована в 2014 году
Алгоритмы поисковых систем: Матрикснет Яндекса
Яндекс с 2009 года использует при ранжировании сайтов систему машинного обучения, которая называется Матрикснет. Это позволяет поисковой системе учитывать очень много факторов при ранжировании сайтов.
Это позволяет поисковой системе учитывать очень много факторов при ранжировании сайтов.
SEO
машинное обучение
интернет-маркетинг
Статья опубликована в 2014 году
Алгоритмы поисковых систем: семантическая микроразметка
Семантическая микроразметка — это использование в HTML‑верстке дополнительных тегов, классов и иных атрибутов, которые либо дают поисковым системам дополнительную информацию о содержании страницы, либо упрощают классификацию содержания и формируют мета‑данные для содержания. Наиболее популярными на сегодняшний день являются форматы Schema.org, Open Graph и микроформаты.
интернет-маркетинг
SEO
HTML
фронтенд
веб-разработка
Статья опубликована в 2014 году
О гарантиях в сфере услуг, связанных с разработкой и продвижением сайтов
Гарантии в IT‑услугах встречаются не так уж и редко: это и SLA в поддержке, и гарантии трафика или позиций в продвижении, и гарантии качества в разработке. Но тем не менее, понимаются эти гарантии не всегда правильно.
управление проектами
SEO
интернет-маркетинг
Статья опубликована в 2014 году
Иллюзорные гарантии в разработке и продвижении сайтов
Давайте рассмотрим «иллюзорные» гарантии, которые вроде как присутствуют в том или ином виде, но на самом деле их нет.
управление проектами
SEO
интернет-маркетинг
Статья опубликована в 2014 году
Как создать собственный алгоритм ранжирования в поиске с помощью машинного обучения
«Любая достаточно продвинутая технология неотличима от магии». – Артур Кларк (1961)
Эта цитата как нельзя лучше применима к общим поисковым системам и алгоритмам веб-ранжирования.
Подумай об этом.
Вы можете спросить Bing почти о чем угодно, и вы получите 10 лучших результатов из миллиардов веб-страниц в течение нескольких секунд. Если это не магия, то я не знаю что!
Иногда запрос касается малоизвестного хобби. Иногда речь идет о новостном событии, которое вчера никто не мог предсказать.
Иногда даже непонятно о чем запрос! Все это не имеет значения. Когда пользователи вводят поисковый запрос, они ожидают свои 10 синих ссылок на другой стороне.
Чтобы решить эту сложную проблему масштабируемым и систематическим способом, мы приняли решение в самом начале истории Bing рассматривать веб-ранжирование как проблему машинного обучения.
Еще в 2005 году мы использовали нейронные сети для обеспечения работы нашей поисковой системы, и вы до сих пор можете найти редкие фотографии Сатьи Наделлы, в то время вице-президента по поиску и рекламе, демонстрирующие наши успехи в веб-рейтинге.
В этой статье будет рассмотрена проблема машинного обучения, известная как «Обучение рейтингу». И если вы хотите повеселиться, вы можете выполнить те же шаги, чтобы создать свой собственный алгоритм веб-рейтинга.
Почему машинное обучение?
Стандартное определение машинного обучения выглядит следующим образом:
«Машинное обучение — это наука о том, как заставить компьютеры действовать без явного программирования».
На высоком уровне машинное обучение хорошо выявляет закономерности в данных и делает обобщения на основе (относительно) небольшого набора примеров.
Для веб-рейтинга это означает построение модели, которая будет рассматривать некоторые идеальные результаты поисковой выдачи и определять, какие функции наиболее предсказуемы в отношении релевантности.
Это делает машинное обучение масштабируемым способом создания алгоритма веб-рейтинга. Вам не нужно нанимать экспертов по каждой возможной теме, чтобы тщательно разработать свой алгоритм.
Вместо этого, основываясь на шаблонах, общих для отличного футбольного сайта и отличного бейсбольного сайта, модель научится определять отличные сайты для баскетбола или даже отличные сайты для спорта, которого еще даже не существует!
Еще одним преимуществом рассмотрения веб-рейтинга как проблемы машинного обучения является то, что вы можете использовать десятилетия исследований для систематического решения этой проблемы.
Существует несколько ключевых шагов, практически одинаковых для каждого проекта машинного обучения. На приведенной ниже диаграмме показаны эти шаги в контексте поиска, а в остальной части этой статьи они будут рассмотрены более подробно.
Веб-рейтинг как задача машинного обучения1. Определите цель своего алгоритма
Правильная постановка измеримой цели является ключом к успеху любого проекта. В мире машинного обучения есть поговорка, которая очень хорошо подчеркивает критическую важность определения правильных показателей.
«Вы улучшаете только то, что измеряете».
Иногда цель проста: хот-дог или нет?
Даже без каких-либо указаний большинство людей согласятся, увидев различные изображения, независимо от того, изображают они хот-дог или нет.
И ответ на этот вопрос двоичный. Либо это, либо это не хот-дог.
В других случаях все гораздо более субъективно: является ли это идеальной поисковой выдачей для данного запроса?
У каждого будет свое мнение о том, что делает результат релевантным, авторитетным или контекстуальным. Каждый будет расставлять приоритеты и взвешивать эти аспекты по-разному.
Каждый будет расставлять приоритеты и взвешивать эти аспекты по-разному.
Вот где в игру вступают рекомендации по оценке качества поиска.
В Bing наша идеальная поисковая выдача — это та, которая максимально удовлетворяет пользователей. Команда много думала о том, что это значит и какие результаты нам нужно показать, чтобы сделать наших пользователей счастливыми.
Результат эквивалентен спецификации продукта для нашего алгоритма ранжирования. В этом документе описывается, что является хорошим (или плохим) результатом запроса, и делается попытка устранить субъективность из уравнения.
Дополнительный уровень сложности заключается в том, что качество поиска не является бинарным. Иногда вы получаете идеальные результаты, иногда вы получаете ужасные результаты, но чаще всего вы получаете что-то среднее.
Чтобы уловить эти тонкости, мы просим судей оценить каждый результат по 5-балльной шкале.
Наконец, для запроса и упорядоченного списка рейтинговых результатов вы можете оценить свою поисковую выдачу, используя некоторые классические формулы поиска информации.
Совокупная прибыль со скидкой (DCG) — это каноническая метрика, которая отражает интуицию, согласно которой чем выше результат в поисковой выдаче, тем важнее получить его правильно.
2. Соберите некоторые данные
Теперь у нас есть объективное определение качества, шкала для оценки любого данного результата и, соответственно, метрика для оценки любой заданной поисковой выдачи. Следующим шагом будет сбор данных для обучения нашего алгоритма.
Другими словами, мы собираемся собрать набор поисковой выдачи и попросить судей-людей оценить результаты, используя рекомендации.
Мы хотим, чтобы этот набор поисковой выдачи отражал то, что ищет наша широкая пользовательская база. Простой способ сделать это — попробовать некоторые из запросов, которые мы видели в прошлом в Bing.
При этом мы должны убедиться, что в наборе нет нежелательного смещения.
Например, может случиться так, что пользователей Bing на Восточном побережье непропорционально больше, чем в других частях США
Если бы поисковые привычки пользователей на Восточном побережье отличались от поисковых привычек на Среднем Западе или Западном побережье, это предубеждение было бы зафиксировано в алгоритме ранжирования.
Когда у нас есть хороший список SERP (как запросов, так и URL-адресов), мы отправляем этот список судьям-людям, которые оценивают их в соответствии с рекомендациями.
После этого у нас есть список пар запрос/URL вместе с их оценкой качества. Этот набор делится на «тренировочный набор» и «тестовый набор», которые соответственно используются для:
- Обучить алгоритм машинного обучения.
- Оцените, насколько хорошо он работает с запросами, с которыми он раньше не сталкивался (но для которых у нас есть оценка качества, позволяющая измерить производительность алгоритма).
3. Определите функции модели
Рейтинги качества поиска основаны на том, что люди видят на странице.
Компьютеры имеют совершенно другое представление этих веб-документов, которое основано на сканировании и индексировании, а также на значительной предварительной обработке.
Это потому, что машины рассуждают с числами, а не непосредственно с текстом, содержащимся на странице (хотя это, конечно, важный ввод).
Следующим шагом построения вашего алгоритма является преобразование документов в «функции».
В этом контексте функция — это определяющая характеристика документа, которую можно использовать для прогнозирования того, насколько он будет релевантным для данного запроса.
Вот несколько примеров.
- Простым признаком может быть количество слов в документе.
- Чуть более продвинутой функцией может быть обнаруженный язык документа (каждый язык представлен другим номером).
- Еще более сложной функцией может быть оценка документа на основе графа ссылок. Очевидно, что это потребует большого объема предварительной обработки!
- У вас могут быть даже синтетические функции, такие как квадрат длины документа, умноженный на логарифм количества исходящих ссылок. Небо это предел!
Было бы заманчиво смешать все сразу, но слишком большое количество функций может значительно увеличить время, необходимое для обучения модели, и повлиять на ее окончательную производительность.
В зависимости от сложности данной функции надежное предварительное вычисление может быть дорогостоящим.
Некоторые функции неизбежно будут иметь незначительный вес в окончательной модели в том смысле, что они так или иначе не помогают прогнозировать качество.
Некоторые функции могут даже иметь отрицательный вес, что означает, что они в какой-то мере предсказывают нерелевантность!
Кстати, запросы также будут иметь свои особенности. Поскольку мы пытаемся оценить качество результатов поиска по заданному запросу, важно, чтобы наш алгоритм учится на обоих.
4. Тренируйте свой алгоритм ранжирования
Здесь все сходится. Каждый документ в указателе представлен сотнями функций. У нас есть набор запросов и URL-адресов, а также их оценки качества.
Целью алгоритма ранжирования является максимизация рейтинга этих поисковой выдачи с использованием только функций документа (и запроса).
Интуитивно мы можем захотеть построить модель, которая предсказывает рейтинг каждой пары запрос/URL, также известную как «точечный» подход. Оказывается, это трудная проблема, и это не совсем то, что мы хотим.
Оказывается, это трудная проблема, и это не совсем то, что мы хотим.
Нам не особо важен точный рейтинг каждого отдельного результата. Что нас действительно волнует, так это то, что результаты правильно упорядочены в порядке убывания рейтинга.
Достойным показателем, который фиксирует это понятие правильного порядка, является количество инверсий в вашем рейтинге, количество раз, когда результат с более низким рейтингом появляется над результатом с более высоким рейтингом. Подход известен как «парный», и мы также называем эти инверсии «парными ошибками».
Пример парной ошибкиНе все парные ошибки одинаковы. Поскольку мы используем DCG в качестве оценочной функции, очень важно, чтобы алгоритм выдавал правильные результаты.
Таким образом, парная ошибка в позициях 1 и 2 намного серьезнее, чем ошибка в позициях 9 и 10, при прочих равных условиях. Наш алгоритм должен учитывать этот потенциальный выигрыш (или убыток) в DCG для каждой из пар результатов.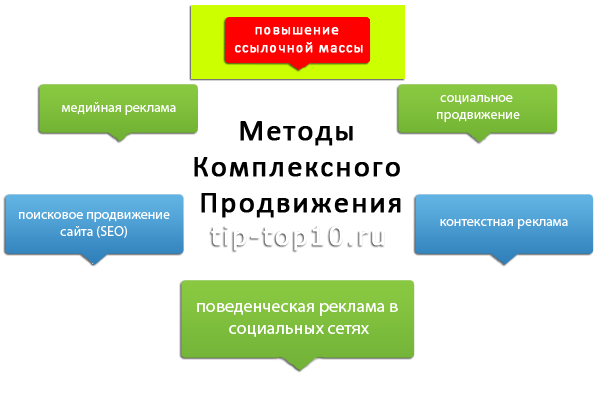
Процесс «обучения» модели машинного обучения, как правило, итеративный (и полностью автоматизированный). На каждом шаге модель настраивает вес каждого признака в том направлении, в котором ожидается максимальное уменьшение ошибки.
После каждого шага алгоритм повторно измеряет рейтинг всех результатов поисковой выдачи (на основе известных рейтингов пары URL/запрос), чтобы оценить, как он работает. Промыть и повторить.
В зависимости от того, сколько данных вы используете для обучения модели, для достижения удовлетворительного результата могут потребоваться часы, а может и дни. Но в конечном итоге модели потребуется меньше секунды, чтобы вернуть 10 синих ссылок, которые, по ее прогнозам, являются лучшими.
Конкретный алгоритм, который мы используем в Bing, называется LambdaMART, это усиленный ансамбль деревьев решений. Это преемник RankNet, первой нейронной сети, используемой общей поисковой системой для ранжирования результатов.
5. Оцените, насколько хорошо вы справились
Теперь у нас есть алгоритм ранжирования, готовый к испытаниям. Помните, что мы сохранили некоторые помеченные данные, которые не использовались для обучения модели машинного обучения.
Помните, что мы сохранили некоторые помеченные данные, которые не использовались для обучения модели машинного обучения.
Первое, что мы собираемся сделать, это измерить производительность нашего алгоритма на этом «тестовом наборе».
Если мы хорошо поработали, производительность нашего алгоритма на тестовом наборе должна быть сравнима с его производительностью на обучающем наборе. Иногда это не так. Основной риск заключается в том, что мы называем «переоснащением», что означает, что мы чрезмерно оптимизировали нашу модель для поисковой выдачи в обучающем наборе.
Давайте представим карикатурный сценарий, в котором алгоритм жестко запрограммирует лучшие результаты для каждого запроса. Тогда он будет отлично работать на тренировочном наборе, для которого он знает, каковы наилучшие результаты.
С другой стороны, на тестовом наборе, для которого у него нет такой информации, он бы провалился.
А вот и поворот…
Даже если наш алгоритм работает очень хорошо при измерении DCG, этого недостаточно.
Помните, наша цель — максимальное удовлетворение пользователей. Все началось с руководств, которые фиксируют то, что мы думает, что удовлетворяет пользователей.
Это смелое предположение, которое нам нужно проверить, чтобы замкнуть цикл.
Для этого мы проводим так называемую онлайн-оценку. Когда алгоритм ранжирования работает в реальном времени с реальными пользователями, наблюдаем ли мы поведение при поиске, которое подразумевает удовлетворенность пользователей?
Даже это неоднозначный вопрос.
Если вы вводите запрос и уходите через 5 секунд, не нажимая на результат, это потому, что вы получили ответ из подписей или потому, что не нашли ничего хорошего?
Если вы нажмете на результат и вернетесь к поисковой выдаче через 10 секунд, это потому, что целевая страница была ужасной или потому, что она была настолько хороша, что вы сразу получили нужную информацию?
В конечном счете, каждое изменение алгоритма ранжирования — это эксперимент, который позволяет нам больше узнать о наших пользователях, что дает нам возможность вернуться назад и улучшить наше видение идеальной поисковой системы.
Дополнительные ресурсы:
- Как работают алгоритмы поисковых систем: все, что вам нужно знать
- Bing делится 5 аналитическими данными об алгоритмах
- Полное руководство по SEO: что вам нужно знать в 2019 году
Кредиты изображений
Изображения в сообщении: Создано автором, март 2019 г.
Категория SEO
Как работает алгоритм поиска Google
Билл Видмер
Более 8 лет в качестве цифрового кочевника. Билл путешествует по миру и финансирует его с помощью SEO и контент-маркетинга.
Статистика статей
Ежемесячный трафик 1,414
Ссылки на сайты 221
Твиты 902 50 43
Показывает, сколько различных веб-сайтов ссылаются на этот фрагмент контента. Как правило, чем больше веб-сайтов ссылаются на вас, тем выше ваш рейтинг в Google.
Как правило, чем больше веб-сайтов ссылаются на вас, тем выше ваш рейтинг в Google.
Показывает приблизительный месячный поисковый трафик к этой статье по данным Ahrefs. Фактический поисковый трафик (по данным Google Analytics) обычно в 3-5 раз больше.
Сколько раз этой статьей поделились в Твиттере.
Поделитесь этой статьей
Получите лучший маркетинговый контент недели
Подписка по электронной почтеПодписка
Содержание
Алгоритм поиска Google, безусловно, является одной из самых влиятельных технологий, когда-либо созданных. Приблизительно 5,6 миллиарда поисковых запросов Google в день позволяют с уверенностью сказать, что Google оказывает сильное влияние на мир и на ваш бизнес.
Но что такое алгоритм поиска Google? Как это работает? И, самое главное, как вы можете получить более высокий рейтинг в Google и получить больше трафика?
Это руководство пытается демистифицировать загадочный алгоритм поиска Google:
- Что такое алгоритм поиска Google?
- Как работает алгоритм поиска Google?
- Каковы факторы ранжирования алгоритма поиска Google?
- Примечание об обновлениях алгоритма Google
- Где найти официальные обновления Google
Что такое алгоритм поиска Google?
Алгоритм поиска Google относится к процессу, который Google использует для ранжирования контента. Он учитывает сотни факторов, включая упоминания ключевых слов, удобство использования и обратные ссылки.
Он учитывает сотни факторов, включая упоминания ключевых слов, удобство использования и обратные ссылки.
Примечание.
У Google есть несколько поисковых алгоритмов, которые работают вместе для получения наилучших результатов. В этой статье мы сосредоточимся в основном на алгоритме (алгоритмах) ранжирования Google, поскольку мы считаем, что большинство людей имеют в виду именно его, когда говорят об алгоритме поиска Google.Как работает алгоритм поиска Google?
Алгоритм Google чрезвычайно сложен, и то, как он работает, не является общедоступной информацией. Считается, что существует более 200 факторов ранжирования, и никто не знает их всех.
Даже если и так, это не имеет значения, потому что алгоритм постоянно меняется. Google выпускает обновления своего алгоритма в среднем шесть раз в день. Это до 2000 раз в год.
Тем не менее, Google дает подсказки о том, как вы можете занять высокое место в его результатах.
Каковы факторы ранжирования алгоритма поиска Google?
Когда вы думаете об «алгоритме поиска» — в том, что касается поисковой оптимизации (SEO), — первое, что приходит на ум, вероятно, это факторы ранжирования Google. Другими словами, на что обращает внимание Google, решая, какие страницы ранжировать и в каком порядке?
Другими словами, на что обращает внимание Google, решая, какие страницы ранжировать и в каком порядке?
Если мы посмотрим на страницу Google «Как работает поиск», то увидим, что она напрямую раскрывает некоторые из наиболее важных факторов ранжирования Google:
- Обратные ссылки
- Свежесть
- Упоминания ключевых слов
- Пользовательский опыт
- Тематический авторитет 9 0098
Давайте разберем их.
1. Обратные ссылки
Google хочет отображать страницы, на которых «известные веб-сайты по теме ссылаются на страницу». С точки зрения непрофессионала, он хочет видеть обратные ссылки с авторитетных веб-сайтов (которые также актуальны), указывающие на ваши страницы.
Получение этих ссылок называется линкбилдингом, и, возможно, это одна из самых важных задач, которую вы должны выполнить, чтобы заставить Google доверять вашему веб-сайту и отображать его. С момента его создания в 1996 году это был самый важный решающий фактор Google при определении надежности сайта.
Вы можете определить, могут ли ссылки препятствовать ранжированию вашего контента, сравнив профиль обратных ссылок вашей страницы с профилями ваших конкурентов.
Сначала введите URL-адрес страницы, которую вы пытаетесь ранжировать, в Site Explorer от Ahrefs, и вы увидите, сколько обратных ссылок и ссылающихся доменов (ссылающихся веб-сайтов) в настоящее время имеет ваша страница.
Затем перейдите в Проводник ключевых слов Ahrefs и введите основное ключевое слово, на которое вы ориентируетесь для этой страницы. Прокрутить вниз. Вы найдете раздел обзора SERP, где вы можете увидеть, сколько обратных ссылок и ссылающихся доменов есть у ваших конкурентов.
Если вы заметили, что на страницы ваших конкурентов больше обратных ссылок, чем на вашу (как на нашу в приведенном выше примере), это означает, что вам, вероятно, нужно расставить приоритеты в создании ссылок, чтобы занять более высокое положение.
Вот несколько стратегий для начала работы по созданию ссылок:
- Гостевой блог
- Создание ссылок
- Создание битых ссылок
2.
 Свежесть
СвежестьСвежесть контента означает, насколько «свежим» является контент на вашей веб-странице. Когда в последний раз он обновлялся?
Этот фактор имеет большее значение для одних запросов, чем для других. Например, если вы ищете что-то связанное с новостями, Google обычно ранжирует результаты, опубликованные за последние 24 часа.
Однако, если вы ищете тему, которую не нужно обновлять так часто, свежесть не весьма как сильное влияние. Например, лучшие результаты для «идей для хранения жилых домов» были получены более двух лет назад:
. Это связано с тем, что хорошие идеи для хранения жилых домов сегодня в основном такие же, как и два года назад. Так что то, как недавно оно было опубликовано, не имеет большого значения. Такие руководства мы называем «вечнозеленым контентом». То есть контент, который будет полезен долгие годы без необходимости частых обновлений.
В целом, при определении важности актуальности ключевых слов, на которые вы ориентируетесь, вы всегда должны анализировать SERP для этого ключевого слова. Похоже, что Google ранжирует свежий контент? Если это так, вам нужно будет часто обновлять статью, чтобы иметь шанс остаться на вершине.
Похоже, что Google ранжирует свежий контент? Если это так, вам нужно будет часто обновлять статью, чтобы иметь шанс остаться на вершине.
3. Упоминания ключевых слов
Одной из вещей, о которых заботится Google, является «количество раз, когда ваши условия поиска появляются [на странице, которую вы пытаетесь ранжировать]».
В общем, рекомендуется попытаться включить точное ключевое слово на страницу несколько раз в нескольких местах, в том числе:
- Заголовок.
- Хотя бы один подзаголовок.
- URL страницы.
- Вводный абзац.
Тем не менее, мы не считаем, что вам нужно беспокоиться об упоминаниях ключевых слов помимо этого. Это происходит потому, что вы, естественно, упоминаете ключевое слово, на которое ориентируетесь, во всем контенте, когда пишете об этом.
Например, в нашей публикации о вечнозеленом контенте слова «вечнозеленый контент» упоминаются 18 раз, и мы не приложили для этого никаких усилий.
Вместо этого уделите больше внимания , чтобы убедиться, что ваша страница соответствует цели поиска и отвечает тому, что ищет ищущий. Другими словами, убедитесь, что вы рассказали все, что могут захотеть узнать пользователи, выполняющие поиск.
Другими словами, убедитесь, что вы рассказали все, что могут захотеть узнать пользователи, выполняющие поиск.
Google подчеркивает важность этого на своей странице «Как работает поиск»:
Только подумайте: когда вы ищете «собаки», вам, вероятно, не нужна страница, на которой сотни раз встречается слово «собаки». Имея это в виду, алгоритмы оценивают, содержит ли страница другой релевантный контент помимо ключевого слова «собаки», например изображения собак, видео или даже список пород .
Один из способов сделать это — использовать инструмент Ahrefs Content Gap для поиска подтем по заданному ключевому слову, которое вы должны упомянуть на своей странице. Подключите свой сайт к Site Explorer, затем нажмите «Пробел в содержании» слева.
Затем перейдите в Google, найдите ключевое слово, на которое вы ориентируетесь на своей странице, и извлеките первые три-пять URL-адресов ранжирования, которые соответствуют цели вашей страницы (например, если ваша страница является записью в блоге, выберите другие записи в блоге).
Когда у вас есть URL-адреса ваших конкурентов, подключите их к инструменту, как я сделал на скриншоте ниже, затем нажмите «Показать ключевые слова».
Я сделал это для нашего «Что такое ключевые слова?» гид. На снимке экрана ниже результат показывает, что мы потенциально можем улучшить статью, добавив раздел о том, актуальны ли ключевые слова для SEO.
Кроме того, выполняя этот тип исследования пробелов в контенте, вы также можете найти возможности для дополнительных статей, связанных с той, которую вы сейчас оптимизируете. Я нашел такие ключевые слова, как «лучшие методы поисковой оптимизации ключевых слов» и «что такое исследование ключевых слов», для которых мы потенциально можем писать контент.
Если вы хотите узнать больше о том, как оптимизировать страницу для ключевого слова и где разместить ключевое слово, ознакомьтесь с нашим руководством по поисковой оптимизации на странице.
4. Пользовательский опыт
Google заявляет, что его заботит «удобство страницы для пользователей». Но что считается «хорошим пользовательским опытом»?
Но что считается «хорошим пользовательским опытом»?
Пользовательский опыт (UX) включает в себя множество различных вещей, в том числе следующие:
- Скорость загрузки страницы (Google рекомендует менее двух секунд)
- Отсутствие навязчивых межстраничных объявлений, таких как реклама или всплывающие окна
- Интуитивно понятная навигация и внутренние ссылки
- Удобство для мобильных устройств
- Дизайн веб-сайта
- Метатеги (имеющие метазаголовок и описание, соответствующие поисковому запросу)
- И многое другое 90 101
- Лучшее время суток для приема протеина
- Можно ли беременным женщинам протеиновый порошок?
- Откуда берется протеиновый порошок?
- Обновление навязчивых межстраничных объявлений
- Переход на индексирование для мобильных устройств (называемое «Mobilegeddon»)
- RankBrain
- Panda
- Pen guin
- Hummingbird
- Pigeon
- Объяснение Google о том, как он ранжирует результаты
- Официальная страница Google в Twitter
- Канал Google Search Central на YouTube Передний край того, что Google делает со своим алгоритмом, он также предлагает регулярные часы работы под названием Google Search Central. Там такие люди, как Джон Мюллер, старший аналитик тенденций Google для веб-мастеров, ответят на ваши вопросы в прямом эфире.
Заключительные мысли
Алгоритм поиска Google — сложный зверь с множеством движущихся частей, и он постоянно меняется. Но его цель — получить наилучшие результаты для заданного поискового запроса — остается прежней.

Скорость, в частности, стала более важной для Google в последние несколько лет. Летом 2021 года Google выпустил крупное обновление. Из-за этого сейчас важнее пройти тест Google Core Web Vitals (CWV), который по сути является тестом скорости.
Вы можете проверить свой CWV и узнать, как повысить производительность вашего сайта, подключив свой сайт к аудиту сайта Ahrefs и нажав на вкладку «Отчет об эффективности». Вам нужно включить сканирование CWV в настройках. (Вы увидите уведомление об этом в верхней части отчета, как показано ниже.)
Вам нужно включить сканирование CWV в настройках. (Вы увидите уведомление об этом в верхней части отчета, как показано ниже.)
После того, как вы разрешили CWV с помощью Google API, запустите новое сканирование своего сайта. Когда это будет сделано, вы получите отчет, показывающий страницы, которые нуждаются в улучшении, и страницы с ошибками.
Чтобы просмотреть эти страницы, щелкните число рядом с «Требуется улучшение» или «Плохо». Он покажет вам, какие страницы не проходят оценку Lighthouse Score или производительность CrUX. (Это показатели скорости страницы, которые являются частью отчета CWV.)
Если вы хотите узнать больше о том, как оптимизировать свой сайт для удобства пользователей, следуйте нашему руководству по аудиту веб-сайта.
5. Тематический авторитет
Google хочет отображать «сайты, которые, по-видимому, ценятся многими пользователями по схожим запросам». Это означает сайты, которые имеют дополнительные, value контент о запросах, релевантных искомому.
Хотя Google не уточняет, что подразумевается под фразой «пользователи, кажется, ценят», мы можем с уверенностью предположить, что тематические обратные ссылки являются ее частью. Таким образом, помимо создания большого количества связанного контента, вам также необходимо получать ссылки с тематических сайтов.
Например, если вы хотите занять место в рейтинге «лучший протеиновый порошок», Google может с большей вероятностью ранжировать вас, если люди также будут заходить на ваш сайт за контентом по следующим темам:
Помимо контента по этим темам, вы также должны стремиться получить тематически релевантные обратные ссылки на них.
Наличие большого количества связанного контента и контекстно релевантных ссылок может показать Google (и его пользователям), что вы являетесь авторитетом в этой теме, и может помочь вам занять более высокое место в результатах поиска. Конечно, мы предполагаем, что вы также оптимизируете другие факторы ранжирования.
Конечно, мы предполагаем, что вы также оптимизируете другие факторы ранжирования.
Готовы исключить этот фактор ранжирования из своего списка? Начните создавать центры контента для SEO.
Заметка об обновлениях алгоритма Google
Google обновляет свой алгоритм почти каждый день и выпускает крупные обновления два-три раза в год, которые могут оказать значительное влияние на рейтинг.
Другими словами, все меняется. Важно быть в курсе факторов ранжирования Google, чтобы не отставать в поисковой выдаче из-за штрафа Google или изменения цели поиска.
Вот некоторые из основных обновлений Google:
Конечно, это неполный список. Более полный список обновлений алгоритма Google и других распространенных терминов SEO см. в нашем глоссарии SEO.
в нашем глоссарии SEO.
Где найти официальные обновления Google
У Google есть несколько каналов, которые публикуют общедоступные обновления об изменениях в своем алгоритме, и у него есть масса официальной общедоступной документации о том, как работает его алгоритм.
Вот несколько отличных источников, чтобы быть в курсе того, что Google делает: