Проверка количества проиндексированных на сайте страниц в поисковых системах Яндекс и Google
Проверка количества проиндексированных страниц сайта и получение их списка может показаться на первый взгляд достаточно простой задачей, но есть некоторые нюансы, о которых расскажем ниже.
Самые простые способы посмотреть индексацию любого сайта – операторы в поисковых системах Яндекс и Google. В Google это оператор site:site.ru (где вместо site.ru нужно указать анализируемый сайт). В Яндексе последнее время оператор site:site.ru перестал корректно работать, поэтому на данный момент количество страниц можно проверить с помощью оператора url:http://www.site.ru/* (с указанием www если сайт индексируется с www и наоборот).
Примеры:
Как узнать число новых страниц на сайте или число страниц, проиндексированных за определенный период
В Яндексе можно нажать на иконку расширенного поиска и выбрать диапазон дат:
В Google аналогичные настройки можно сделать через “инструменты->за период”:
Но не все так просто как кажется на первый взгляд.
Рассмотрим более точные методы проверки способы как получить больше информации для каждой поисковой системы.
 Рассмотрим более точные методы проверки способы как получить больше информации для каждой поисковой системы.
Рассмотрим более точные методы проверки способы как получить больше информации для каждой поисковой системы.Google Search Console
Часто в Google число страниц, выдаваемое через оператор site: сильно отличается от реального числа проиндексированных страниц. Сотрудники Google отвечают по этому поводу что конструкция site:site.ru всего лишь результат пустого поиска по сайту и не обязана выдавать все страницы сайта.
Также в поиске отображаются неиндексируемые страницы, запрещенные в robots.txt, на которые есть внешние ссылки. Это тоже искажает результат.
Более точно узнать число проиндексированных страниц в Google можно имея доступ к Google Search Console в разделе “статус индексирования”.
К сожалению, в данном отчете данные также могут не совпадать с реальными из-за применения фильтров. Разница может доходить до десятков-ста процентов.
Еще один способ, который считается одним из наиболее точных – отчет “Файлы Sitemap”.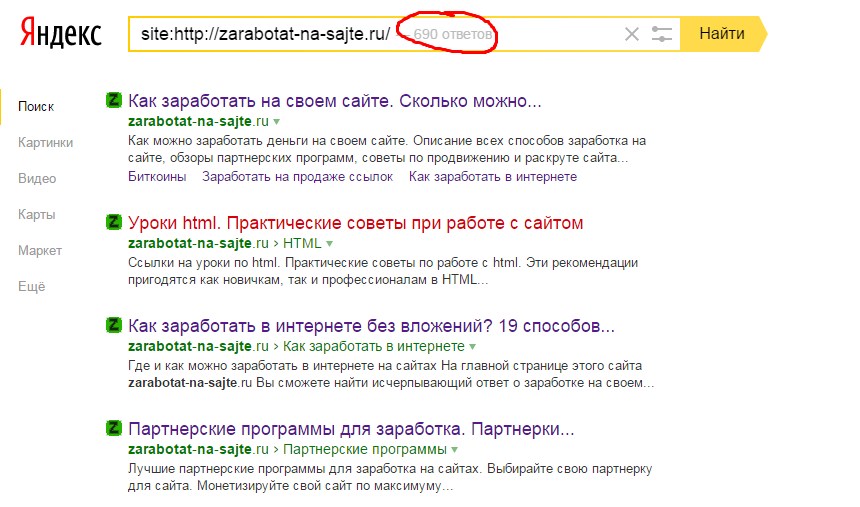 Здесь указано точное число индексируемых страниц, но с учетом что все полезные страницы были добавлены в файлы sitemap.xml.
Здесь указано точное число индексируемых страниц, но с учетом что все полезные страницы были добавлены в файлы sitemap.xml.
Яндекс Вебмастер
В Яндекс.Вебмастере содержатся достаточно точные данные по индексации сайта. Количество страниц, с динамикой можно посмотреть в разделе “страницы в поиске”.
Также в Яндекс.Вебмастере можно получить выгрузку страниц со статусами, включая индексацию, которая, правда ограничена 50.000 страницами. Пример выгрузки:
Выгрузку можно скачать в уже описанном выше отчете “страницы в поиске”.
Альтернативные способы проверки индексации сайта
Иногда перечисленные методы не подходят, тогда можно использовать альтернативные.
- Парсинг сайта (например, через программу Screaming Frog) и постраничная проверка индексации в Google/Yandex.
 Например, через сервис https://www.rush-analytics.ru/ -> “проверка индексации”. Минусы: не все страницы в индексе могут иметь ссылки из меню или страниц сайта, можно как дополнение использовать способы описанные в пунктах 2,3 ниже.
Например, через сервис https://www.rush-analytics.ru/ -> “проверка индексации”. Минусы: не все страницы в индексе могут иметь ссылки из меню или страниц сайта, можно как дополнение использовать способы описанные в пунктах 2,3 ниже. - Страницы, на которые есть органический трафик из перечисленных операционных систем (можно посмотреть через системы статистики Яндекс.Метрика и Google.Analytics).
- Страницы на которые есть внешние ссылки. Внешние ссылки можно получить через такие сервисы как Ahrefs.com.
Как удалить сайт и отдельные страницы из поиска Яндекс и Google
Неактуальное содержимое, закрытие ресурса, приостановка деятельности, обновление контента после покупки другого сайта. Да что угодно может послужить причиной для удаления сайта или его страниц из поиска. Этот мертвый груз в поиске не нужен, к тому же он может вводить людей в заблуждение. Также несуществующие страницы ухудшают продвижение в поисковой выдаче. Поэтому их лучше удалить из поиска вовсе.
Еще один важный аспект непопадания страниц в выдачу – это личные данные. Если вдруг на одной из страниц сайта есть чьи-то персональные данные, да даже просто ФИО с годом рождения, это может оказаться поводом для проблем, ведь не каждый хочет, чтобы в поиске красовались личные данные. Вконтакте, кстати, решили эту проблему: теперь человек сам выбирает, можно его найти в поиске Яндекс или Google или нет.
Решается это довольно просто: необходимо встроить на сайт авторизацию, через неё уж точно поисковые роботы пройти не смогут.
Зачастую несуществующие ссылки появляются в поиске из-за того, что пользователь не даёт наводку роботу о том, что страницы не существует. Страницу с сайта удалили, но не принудили сделать переобход роботом.
Так вот, ниже мы разберемся, как удалить свой сайт или отдельную его страницу из поиска Яндекс или Google.
Удаление сайта из поиска Google
Для этого потребуется аккаунт в Search Console с подтвержденными правами владельца сайта.
Google предоставляет 3 варианта удаления:
- временный;
- удаление сайта навсегда;
- удаление сайта из-за нежелательного контента.
Рассмотрим каждый по отдельности.
Временное удаление сайта
Изначально Google предполагает удаление сайта из поиска Google на 6 месяцев, а также его описание и кэшированную версию. Нельзя по клику удалить сайт навсегда.
Для этого в Search Console переходим в раздел «Индекс» =>»Удаления» и нажимаем на кнопку «Создать запрос», далее вводим URL сайта или страницы, который нужно удалить из поиска.
После клика по этой кнопке необходимо указать адрес страницы, который хотим удалить. Но если требуется ликвидировать весь сайт, то вводим его доменное имя.
Google даст на выбор два варианта удаления:
- Скрыть страницу из выдачи и кэша поисковика (на 6 месяцев)
- Скрыть весь каталог и страницы, которые с ним связаны
Дополнительно проверяем, доступна ли удаляемая страница (если удаляем страницу отдельно) по другим адресам, если да, то проделываем вышенаписанные манипуляции и с ними.
Важно понимать, что во время этого удаления Google продолжит сканировать страницы в штатном режиме, если пользователь не установит на неё пароль. По истечении срока страница появится в выдаче. Временное удаление можно включить повторно в этом же разделе.
Удаление страниц или сайта навсегда
Для удаления сайта навсегда из поиска Google нет волшебной кнопки, как для временного удаления, но Google рекомендует дополнительные меры:
- Удалить или изменить контент ресурса и удостовериться в том, что веб-сервер отдает код статуса HTTP 404 (не найдено) или 410 (удалено)
- Установить пароль, чтобы заблокировать доступ к контенту
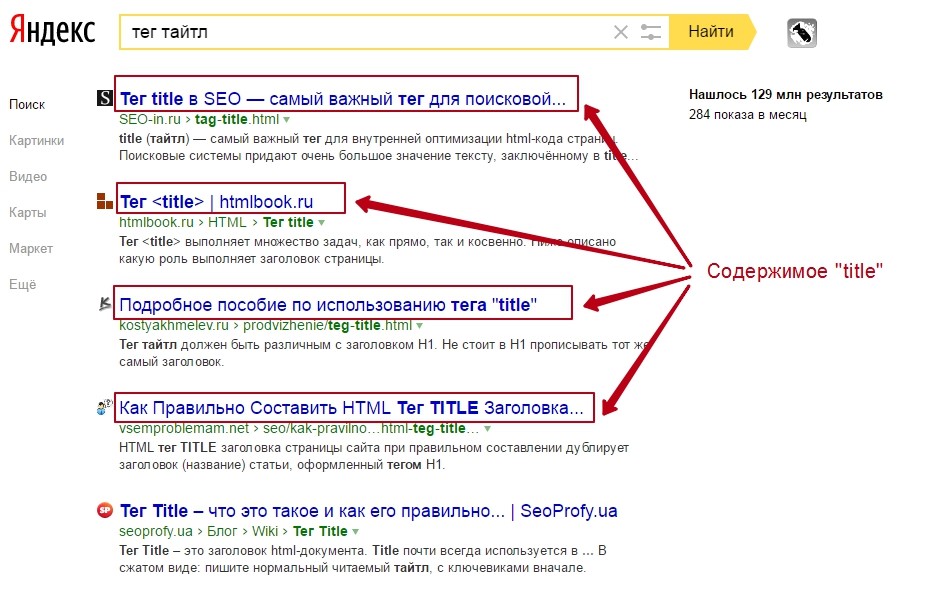
- С помощью метатега noindex запретить сканирование страницы: <meta name=»googlebot» content=»noindex«>
- Документы в формате PDF рекомендуется удалять с сервера полностью
Удаление сайта из-за нежелательного контента
Если кого-то лично задел контент сайта (неприемлемое содержание, например), то можно наябедничать.
Проходим по ссылке, выбираем продукт Google, где находится нежелательный контент.
Далее выбираем причину блокировки и нажимаем на кнопку «Следуйте инструкциям на этой странице». И следом заполняем форму от Google.
Далее Google поблагодарит вас за содействие. В этом варианте нет какой-то формы отслеживания заявки. Придется вручную проверять доступность ресурса.
Мы привели способы удалить сайт из поиска Google штатными средствами самих Google, теперь пора разобраться с Яндексом.
Удаление сайта из поиска Яндекс
В случае с Яндексом удаление страницы из поиска начинаем с robots.txt.
Если страница уже удалена с сайта, то прописываем директиву Disallow в robots.txt для User Agent Яндекса.
User-agent: Yandex
Disallow: /page
Далее настраиваем сервер так, чтобы при обращении робота к адресу страницы он отправлял статус с кодом 404 (Not Found), 403 (Frobidden) или 410 (Gone), для этого в файле .htaccess прописываем строку: ErrorDocument 404 http://example.
<meta name=»robots» content=»noindex» />
Далее для ускорения удаления страницы переходим в Вебмастер с аккаунта с подтвержденными правами на доступ к управлению сайтом. Затем в раздел «Инструменты» и в «Удаление страниц из поиска» и вводим URL либо отдельной страницы, либо всего сайта. Этим мы сообщаем роботу, что данные страницы должны быть в приоритете при обходе роботом.
После этого можно отслеживать состояние статуса в данном разделе:
- в очереди на добавление
- в процессе
- удалена
- отклонено
После очередного обхода страниц роботу станет известно о запрете на индексирование, и страница пропадет из результатов поиска в течение нескольких дней. После этого адрес страницы отобразится в разделе Индексирование => Страницы в поиске Вебмастера в списке исключенных.
Другие способы удаления страниц сайта из поиска
Редиректы
Убираем страницу из поиска с помощью 301 и 302 редиректа (переадресации).
Если на сайте есть страница с неактуальным контентом, и этот контент актуальным явно не станет в будущем (товар больше не появится в продаже, например), то и индексировать этот URL больше не нужно, и, следовательно, нужно убрать его из поля взора поисковых роботов. Взамен этой показать пользователям другую, актуальную страницу. Здесь и спасет 301 и 302 редирект.
- 301 редирект для навсегда удаленных или перемещенных страниц
- 302 редирект для временно неактуальных страниц, которые останутся в поиске
Для настройки редиректа можно воспользоваться специальным сервисом, указав там нужные ссылки. В первом поле вводим URL старой страницы, с которой будет осуществляться переадресация, а во втором поле вводим URL новой страницы, на которую будет переадресация. Далее в файле .htaccess вставляем сгенерированный код и сохраняем.
Метатег noindex
Noindex – сокрытие от поисковых ботов контента (целиком страницы или куска кода). Можно настроить для определенного бота, таким образом закрыть страницу от индексации отдельно для Яндекса или Google.
Устанавливается в HTML-коде страницы в <head>. Метатег блокирует работу ботов Яндекса и Google во время очередного обхода для вывода страницы в выдачу.
Прописывается noindex так:
-
Ищем страницу, которую нужно скрыть. Открываем HTML-файл этой страницы и прописываем meta-тег:
<meta name=»robots» content=»noindex»/>
…или…
<meta name=»yandex» content=»noindex»/>
<meta name=»googlebot» content=»noindex»/>
-
Для определенного бота, если вдруг хотим запретить индексацию конкретно для робота Яндекса или Google.
-
Далее сохраняем.
После этих манипуляций страница больше не будет выводиться в поиске, а роботы не будут обращать на неё внимание.
Также метатег noindex можно использовать совместно с тегом nofollow. Например, <meta name=»robots» content=»noindex, nofollow» /> дает запрет на индексацию контента на странице и запрещает роботам переходить по ссылкам.
Важно понимать, что для удаления контента может потребоваться не один день.
Disallow в robots.txt
Благодаря этой директиве в robots.txt пользователь дает указания роботу не посещать список внесенных страниц или всего ресурса. Обычно директиву используют для системных разделов, но если пользователю важно закрыть страницу с неактуальным контентом, то она подойдет.
Чтобы запретить индексацию всего сайта, достаточно в robots.txt прописать Disallow: /, если нужен запрет на определенную страницу, то пишем Disallow: /page
Если на эту страницу ссылаются другие страницы на сайте, то она может все равно быть проиндексирована, так что стоит обратить на это внимание заранее.
Также стоит помнить о том, что данные действия для поисковиков несут лишь рекомендательный характер для GoogleBot. Например, если на сайт есть внешние ссылки, то страница может быть проиндексирована.
Например, если на сайт есть внешние ссылки, то страница может быть проиндексирована.
Пароль на странице или разделе
Если раздел или сайт защитить паролем, то поисковики не смогут получить доступ к страницам, и из-за этого страницы не смогут попасть в индекс.
Вывод
На самом деле удалить страницу или даже сайт из поиска не так уж и трудно, главное – соблюдать некоторые правила, описанные выше. Также можно комбинировать эти способы.
Если у вас возникнут трудности при удалении страниц или сайта из поиска или любые другие технические проблемы, то всегда можно обратиться к нам – мы обязательно поможем.
#301-й редирект #google #поисковые запросы #404 ошибка #robots.txt #оптимизация сайта #алгоритмы google
Как исключить страницы из поиска?
Üzgünüz, bu belge Türkçe diline henüz çevrilmedi.
Sayfada belgenin varsayılan dili gösterilmektedir: İngilizce .
Иногда требуется исключить страницу сайта из результатов поиска, например, если она содержит конфиденциальную информацию, является дубликатом другой страницы или была удалена с сайта.
- Шаг 1. Запретить индексацию страницы или каталога
- Шаг 2. Ускорить удаление страницы
- Как вернуть страницу в результаты поиска?
- FAQ
Сделать это можно несколькими способами:
- Если страница удалена с сайта
Добавить директиву Disallow в файл robots.txt.
Настройте сервер таким образом, чтобы при доступе робота к URL-адресу страницы он отправлял статус HTTP с кодом 404 Not Found, 403 Forbidden или 410 Gone. Для удобства пользователей рекомендуем настроить редирект с кодом HTTP 301.
- Если страница не должна отображаться в поиске
Добавьте директиву Disallow в файл robots.txt.
Укажите метатег robots с директивой noindex.
Чтобы проверить правильность инструкций в файле robots.txt, используйте инструмент анализа Robots.txt.
Примечание. При сканировании сайта робот сначала обращается к файлу robots. txt, если он есть, а затем сканирует страницы сайта. Постраничное сканирование может занять некоторое время. Если вы хотите удалить много страниц из поиска, добавьте директиву Disallow для нужных страниц.
txt, если он есть, а затем сканирует страницы сайта. Постраничное сканирование может занять некоторое время. Если вы хотите удалить много страниц из поиска, добавьте директиву Disallow для нужных страниц.
| Способ исключения | Поведение робота |
|---|---|
| Запрет в файле robots.txt | Робот прекращает доступ к странице в течение 24 часа. |
| Статус HTTP с кодом 404, 403 или 410 | Робот продолжает посещать страницу некоторое время, чтобы убедиться, что ее статус не меняется. Если страница остается недоступной, робот перестает ее сканировать. |
| Метатег robots с директивой noindex |
Когда робот заходит на сайт и обнаруживает, что ему запрещено индексирование, страница пропадает из результатов поиска в течение недели. URL удаленной страницы отображается в списке исключенных страниц на странице Индексирование → Страницы в поиске в Яндекс.Вебмастере.
URL удаленной страницы отображается в списке исключенных страниц на странице Индексирование → Страницы в поиске в Яндекс.Вебмастере.
Исключение из поиска страниц, нарушающих авторские права, не является приоритетной задачей робота. Чтобы исключить страницу из поиска, воспользуйтесь способами, описанными в этом разделе.
Страницы, исключенные из результатов поиска, могут отображаться в Яндекс.Вебмастере до следующего сканирования сайта.
Чтобы ускорить удаление страницы из поиска, скажите Яндексу удалить ее, не дожидаясь запланированного обхода роботом.
Если ваш сайт не добавлен или не проверен в Яндекс.Вебмастере:
Перейдите на страницу Удалить страницы из результатов поиска в Яндекс.Вебмастере.
Введите URL-адрес исключаемой страницы в поле, например http://example.com/page.html.
Нажмите кнопку «Удалить».
Чтобы исключить из поиска несколько страниц, удаляйте их по одной.
Если ваш сайт добавлен в Яндекс.Вебмастер и вы подтвердили права на управление сайтом:
Перейдите в Инструменты → Удалить страницы из результатов поиска.
Установите переключатель в положение По URL.
Введите URL страницы в поле, например http://example.com/page.html.
Нажмите кнопку «Удалить».
Вы можете указать до 500 URL-адресов на сайт в день.
Вы можете удалить все страницы сайта, отдельные каталоги или страницы с указанными параметрами в URL, если ваш сайт добавлен в Яндекс.Вебмастер и вы подтвердили права на управление сайтом.
В Яндекс.Вебмастере перейдите в Инструменты → Удалить страницы из результатов поиска.
Установите переключатель в положение По префиксу.
- Укажите префикс:
Что удалить Пример Каталог сайта http://example.  com/catalogue /
com/catalogue / Все страницы сайта http://example.com / URL с параметрами http://example.com/page ? Вы можете отправлять до 20 префиксов на сайт в день.
Нажмите кнопку «Удалить».
Примечание. Робот удалит указанные в Яндекс.Вебмастере страницы только в том случае, если эти страницы указаны в директиве Disallow в файле robots.txt.
После отправки URL в Яндекс.Вебмастер вы можете отслеживать изменение статуса в Инструменты → Удаление страниц из результатов поиска:
| Статус | Описание | 90 070
|---|---|
| «В очереди на удаление» | Робот проверяет ответ сервера и запрещена ли страница к индексации. Проверка может занять несколько минут. Проверка может занять несколько минут. |
| «Выполняется» | Робот проверил страницу. Страница будет удалена из результатов поиска в течение 24 часов. |
| «Удалено» | Страница удалена из результатов поиска. |
| «Отклонено» | Страница разрешена для индексации или при обращении робота к URL страницы ответ сервера отличается от 404 Not Found, 403 Forbidden или 410 Gone. |
Снять запрет на индексацию: директива Disallow в файле robots.txt или метатег noindex. Страницы возвращаются в результаты поиска, когда робот просматривает сайт и узнает об изменениях. Это может занять до трех недель.
- Я настроил редирект на новые страницы, но старые все равно отображаются в результатах поиска
Если использовать редирект, то робот будет постепенно отслеживать редиректы и старые страницы будут исчезать из результатов поиска по мере обхода сайт. Чтобы робот быстрее узнал об изменениях, отправьте страницы на переиндексацию.
Если URL-адреса страниц изменились из-за того, что вы изменили доменное имя сайта, обновление данных поиска может занять больше месяца. Проверьте, правильно ли настроены зеркала.
Как парсить поисковые страницы Яндекса
Используйте самый эффективный API для краулинга и парсинга страниц Яндекса прямо сейчас!
• Высокомасштабируемые API с неограниченной пропускной способностью, использующие наши всемирные прокси.
• Улучшен искусственным интеллектом для обхода обнаружения ботов и CAPTCHA.
• Высококачественные вращающиеся прокси с практически нулевым временем простоя.
• Получите 1000 бесплатных запросов при регистрации. Подписка не требуется!
Подписка не требуется!
Создайте бесплатную учетную запись, а затем подайте заявку с панели управления.
Yandex N.V. в настоящее время является крупнейшей технологической компанией в России, предлагающей различные виды продуктов и услуг. Они наиболее известны своей поисковой системой Яндекс и другими сервисами, такими как электронная почта, карты и браузер. В настоящее время они занимают первое место по доле рынка в России, опережая Google на несколько процентов. Так что неудивительно, если вы захотите заполучить эти ценные данные. Однако, если вашему бизнесу требуется постоянный доступ к страницам Яндекса, вам может быть все труднее выполнять парсинг из-за таких препятствий, как CAPTCHA и блокировка IP-адресов.
При этом Crawlbase понимает, что именно необходимо для значительного улучшения вашего рабочего процесса. Мы предоставляем лучшие инструменты, чтобы избежать запросов на блокировку, сбоев прокси и капч при попытке сканирования страниц Яндекса. Чтобы гарантировать успешное выполнение каждого запроса, наш API построен на основе тысяч вращающихся прокси-серверов по всему миру. Вместе с нашим самым передовым искусственным интеллектом наша платформа станет вашим универсальным решением для всех ваших потребностей в парсинге.
Вместе с нашим самым передовым искусственным интеллектом наша платформа станет вашим универсальным решением для всех ваших потребностей в парсинге.
Безопасный доступ к общедоступным данным из поисковой системы Яндекса Результаты
Наш API создан на основе тысяч домашних прокси-серверов и прокси-серверов центров обработки данных, расположенных по всему миру, чтобы гарантировать, что ваш поисковый робот останется анонимным, и при этом эффективно обходит блокировки или CAPTCHA, которые Яндекс постоянно вам бросает.
Легко интегрируйте наш API в существующую систему, чтобы вы и ваша команда могли быстро начать извлекать ценные данные из результатов поиска Яндекса.
Начните сканирование за считанные минуты
Комплексное решение для сбора данных
Crawlbase идеально подходит для начинающих и экспертов, малых и больших проектов, случайных пользователей и разработчиков.
Используйте наш API сканирования, чтобы получить полный исходный код HTML и извлечь весь контент, необходимый для вашего бизнеса.
Делайте скриншоты любых страниц Яндекса в высоком разрешении, если хотите отслеживать любые визуальные изменения с помощью нашего API Скриншотов.
Заканчивается место для хранения? Отправляйте просканированные страницы прямо в облако с помощью облачного хранилища Crawlbase.
Для крупных проектов можно перейти на Crawler с асинхронными обратными вызовами, чтобы сократить затраты, повторные попытки и пропускную способность.
Эффективно очищайте страницы Яндекса без компромиссов
API можно использовать не только для поисковой выдачи Яндекса, но и с такими продуктами Яндекса, как карта и браузер. Мы создали наш API для максимально точной обработки каждого запроса. При скорости по умолчанию 20 запросов в секунду и среднем времени отклика от 4 до 10 секунд наш API считается одним из самых быстрых на рынке.
Сканирование и парсинг Яндекса
Отправляйте любые API-запросы с минимальными усилиями
Наши продукты обладают высокой масштабируемостью. Используйте API отдельно и сканируйте отдельные результаты поисковой выдачи Яндекса или интегрируйте базовую часть API в свою текущую систему и начните парсить тысячи или даже миллионы страниц за короткий промежуток времени.
Используйте API отдельно и сканируйте отдельные результаты поисковой выдачи Яндекса или интегрируйте базовую часть API в свою текущую систему и начните парсить тысячи или даже миллионы страниц за короткий промежуток времени.
Получите ключ аутентификации API, зарегистрировавшись, и попробуйте свой первый вызов с помощью простого запроса cURL:
Часто задаваемые вопросы
Можно ли вместо извлечения исходного кода HTML получить очищенный контент с помощью API?
Да, наш Crawling API поставляется с необязательным универсальным парсером данных для Яндекса. Если вы хотите увидеть фактические результаты, мы рекомендуем протестировать его, используя ваши бесплатные запросы после регистрации.
Возможно ли, чтобы мой запрос API был привязан к определенной стране?
Да, вы можете передавать параметр страны нашего API в каждом из ваших запросов. По умолчанию у вас будет доступ к 27 странам.
Ограничение скорости по умолчанию в 20 запросов в секунду может быть недостаточным.
