Проверка уникальности контента
Почему важно знать детали создания и защиты уникального контента? Потому что это позволит защитить ваш сайт от санкций поисковых систем по причине наличия неуникального контента. Если поисковая система определит текстовое содержание вашего сайта как неуникальное и применит свои санкции, то о конкурентной борьбе за потенциальных клиентов в Интернете можно будет забыть до тех пор, пока вы не добьетесь снятия санкций. Разбирательство может занять много времени и сил, а за это время вы упустите немало возможностей, которые предоставляет интернет маркетинг. Поэтому лучше приложить максимум усилий для предотвращения подобных проблем.
Текстовый контент (содержание) сайта — важнейший инструмент его seo-оптимизации и раскрутки. Если вы хотите на равных конкурировать в виртуальной сети, то будет недостаточно просто предоставить основную информацию о своей компании, и не заниматься написанием информативных статей.
Современные поисковые системы, к сожалению, далеки от совершенства, поэтому не могут анализировать юзабилити сайта или его дизайн для определения его качества.
Обращаясь к исследованиям поисковой системы Яндекс мы можем сразу определить, что качество контента — один из важнейших показателей ранжирования, иначе подробные исследования в этой области попросту не проводились бы. Итак, по исследованиям специалистов Яндекса можно выделить следующие интересные факты, касающиеся непосредственно текстового контента:
В текстовом формате (без учета дублей) в Рунете размещено более 140 тысяч Гб данных, а с учетом дублей — более 200 тысяч Гб. Следовательно, около 60 тысяч Гб (или приблизительно 33.3%) контента — не уникален.
Информация в сети распределена неравномерно. 88% всего текста находится менее чем на одном проценте сайтов. Впрочем, мы знаем, что в мире многое распределно неравномерно, ведь даже 90% всех денег в мире принадлежит всего лишь 1% людей.
Если все слова Рунета записать на бумаге, получится куб высотой с девятиэтажный дом.
89% всех сайтов содержат совсем немного текста — в среднем по 1630 слов, как полторы журнальных страницы. На один большой сайт (таких менее 1%) приходится в среднем 18 миллионов слов — объем текста небольшой домашней библиотеки из 250-300 книг.
Орфографических ошибок и опечаток в текстах, размещенных в интернете, не так много. Даже для тех слов, в которых часто делают ошибки (например, педиатр, агентство, геморрой), средняя доля ошибок не превышает 5-6%. Впрочем, бывает и так, что количество ошибок в одном лишь слове поражает своим количеством. Например, по исследованиям опять же Яндекса, зафиксировано около 1 200 ошибок и опечаток в запросе «одноклассники».
Это лишь часть данных исследования Яндекса, но и из них нас интересует, в основном, лишь первый пункт — отношение доли уникального контента к неуникальному. Напомню, что оно составляет приблизительно 67 к 33 процентам в пользу уникального содержания сайтов. Казалось бы, все не так плохо — ведь все еще уникальный контент преобладает. Тем не менее, 60 тысяч Гб информации представляют собой дубликаты уже размещенной информации.
Казалось бы, все не так плохо — ведь все еще уникальный контент преобладает. Тем не менее, 60 тысяч Гб информации представляют собой дубликаты уже размещенной информации.
Способы получения уникального контента
Самый очевидный способ получения уникального контента — написание его журналистами (копирайтерами).
Сканирование книг, журналов, газет. Существенные минусы — возможны претензии авторов, либо контент уже есть в сети.
Рерайт контента. Переписывание статьи своими слова, делая их уникальными для ПС и для пользователей.
Рассмотрим понятие рерайта подробнее.
Обычно под термином «рерайтинг» подразумевают работу с текстом, точнее — его литературную обработку с сохранением исходного смысла повествования. «Рерайт» же конечный результат этой работы, т.е. полностью переписанный и уникальный текст.
Несмотря на то, что рерайтинг считается более дешевой и менее творческой работой, чем его собрат — копирайтинг (то есть написание уникальных, авторских текстов), здесь тоже есть правила, которые нужно неукоснительно выполнять.
Следует сделать небольшое отступление и сказать о причинах, по которым рерайт выбирается как метод создания уникального контента. Все дело в разнообразии тематик и невозможности написания одним человеком статей на любую тему.
Если ваш интернет ресурс предназначен для рекламы и продажи специфического оборудования (например, техники для лесозаготовки), то статьи в информационном разделе не обязательно будут написаны профессионалом в деле лесозаготовки.
Профессиональный копирайтер при написании подобного текста скорее всего воспользуется рерайтом специализированных статей на данную тематику. Но это не означает, что в тексте лишь некоторые слова будут заменены синонимами или переставлены местами.
Как уже упоминалось, процедура рерайтинга имеет немало законов и правил, отступление от которых чревата нарушением логики в подаче материала или полную утраты смысла.
Главное правило рерайта: сначала определяются имеющиеся в тексте факты, фиксируется стиль и тип повествования, и уже на их основе создается статья.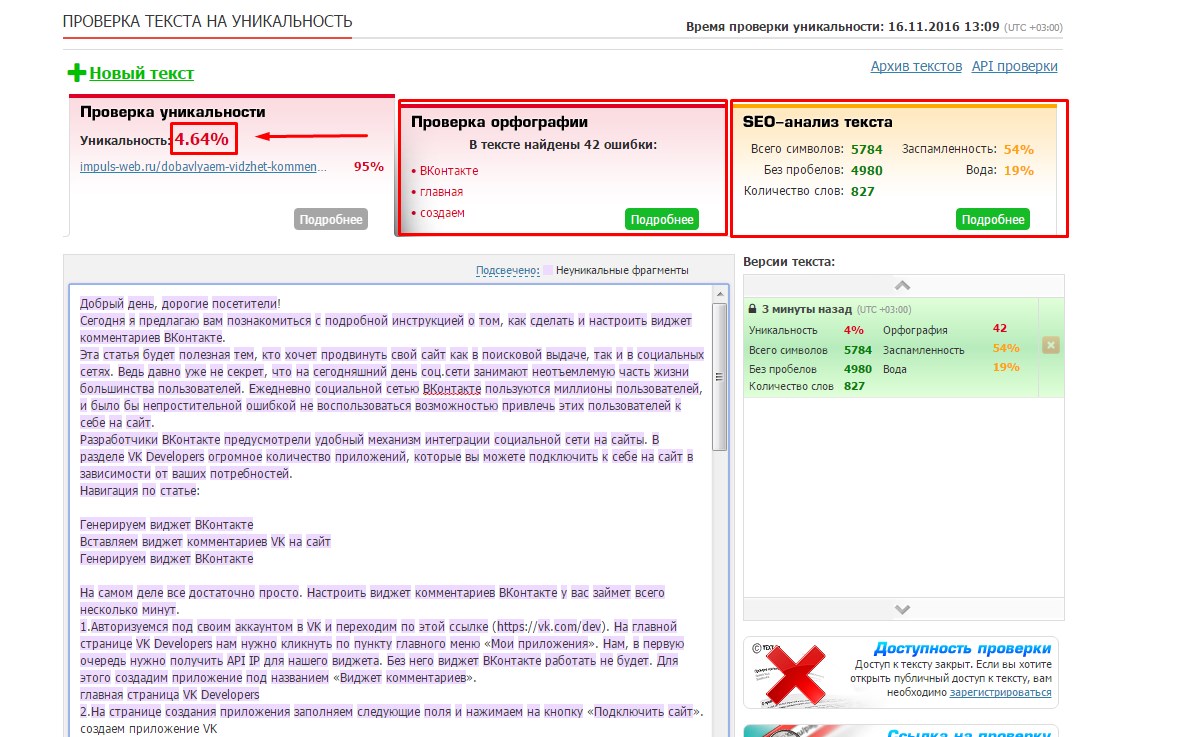
Рассмотрим пример.
Пример рерайта
Здесь мы будем использовать прием трансформации прямой речи в косвенную — один из наиболее распространенных приемов в рерайте:
Оригинальный текст: «Я не могу, когда в доме нет мужчины, — говорила Эдит Пиаф. — Это хуже, чем день без солнечного света. Без него, в конце концов, можно обойтись — есть электричество. Но дом, в котором не висит где-нибудь мужская рубашка или галстук… просто убивает!»
Правильный рерайт: «Великая певица Эдит Пиаф утверждала, что отсутствие мужчины в доме переносить тяжелее, чем день без единого лучика солнца. Ведь солнце можно заменить электричеством. А в доме, где нет ни галстука, ни рубашки любимого мужчины — не хочется жить»
Неправильный рерайт: «Если в жилище нет мужчины, то это наводит грусть и сравнимо лишь с отсутствием дневного света. Так говорила актриса Эдит Пиаф о своем муже. Ведь свет можно заменить! Невозможно жить в доме, где нет мужских вещей»
Проанализируем ошибки во втором, не совсем верном, варианте рерайта.

Отсутствие в доме мужчины сравнивается с отсутствием света, хотя в оригинальном сообщении было сказано: отсутствие мужчины хуже дня без света.
В неправильном тексте говорится про то, что можно заменить свет. Эдит Пиаф уточняла: солнце заменимо электричеством.
Эдит Пиаф не была актрисой, и это — фактическая ошибка.
И кто сказал, что она так говорила о своем муже?
Здесь мы видим две фактически и две более тонкие ошибки, которые часто допускаются при написании рерайта неопытными копирайтерами.
Делаем качественный рерайт. Советы и хитрости
Далее, постараемся рассмотреть процесс написания рерайт более системно и выделим основные этапы работы с ним.
Первая задача — выбрать исходный текст
Тут важны следующие вещи.
Объем. Размер исходного текста должен примерно соответствовать размеру того текста, который должен получиться.
Соответствие заявленной теме. Очень часто рерайтеры пытаются впарить заказчику статьи, которые притянуты к заказанным темам «за уши».
 Это происходит не из-за того, что рерайт плохой, а из-за того, что неправильно выбран исходный материал. Не жалейте времени — не так много его уйдет на то, чтобы вникнуть в тему, на которую Вы собрались писать. Обратите внимание, самые успешные рерайтеры, в основном, специализируются на весьма ограниченном круге «любимых» тем. Поверьте, это не потому, что они не могут писать на другие. Это потому, что они борются за качество рерайта. Согласитесь, не хочется получать плохие отзывы за неплохие, в общем-то, материалы.
Это происходит не из-за того, что рерайт плохой, а из-за того, что неправильно выбран исходный материал. Не жалейте времени — не так много его уйдет на то, чтобы вникнуть в тему, на которую Вы собрались писать. Обратите внимание, самые успешные рерайтеры, в основном, специализируются на весьма ограниченном круге «любимых» тем. Поверьте, это не потому, что они не могут писать на другие. Это потому, что они борются за качество рерайта. Согласитесь, не хочется получать плохие отзывы за неплохие, в общем-то, материалы.Разберитесь в терминологии. Этот пункт прямо вытекает из предыдущего. Прежде, чем писать на новую тему — въезжайте в неё, разбирайтесь в терминах. Уясните, что холодильная ванна — это «боннета», а не «боннет» или «бонетт», что мощность двигателя измеряют в лошадиных силах, а электрическую мощность — в джоулях. Это поможет избежать совсем уж глупых ошибок, которые могут сгубить всю вашу работу.
Сформулируйте основные вопросы, на которые должна ответить ваша статья.
 Исходная должна отвечать на все эти вопросы. Логично?
Исходная должна отвечать на все эти вопросы. Логично?
Вторая задача — перетасовать исходный текст
Суть рерайта в том, что результирующий текст не похож на оригинал! Соответственно, давайте для начала хотя бы перекрутим то, из чего мы будем делать свой шедевр.
Самое простое, что можно сделать. Безжалостно отрубаем вступление и развязку! Теперь делим исходный текст на смысловые абзацы и меняем их местами. Также как карты тасуют. До хаотичности. Да, кстати. Рекомендуется исходник сохранить отдельно, на случай, если вы всё-таки запутаетесь в собственном тексте или из него куда-нибудь смоются смысл и логика.
Теперь, приступаем к рерайту. Рерайтить будем те самые смысловые абзацы. Да-да, каждый из них сейчас для вас должен стать отдельным текстом. Со своей логикой, не противоречащей общей. Думаю, несколько строк текста каждый сможет пересказать своими словами.
Используйте синонимы
Меняйте конструкции предложений
Разбейте длинные предложения на несколько
Укрупните или объедините короткие
Можно и порядок предложений поменять
Комбинируйте методы. Не забывайте о том, что превращение фразы «Хлеб — всему голова» во фразу «Булка — всему башня!» — это, как бы помягче сказать-то… НЕ СОВСЕМ РЕРАЙТ. Точно также, как не совсем рерайт переработка фразы «Ночь. Улица. Фонарь. Аптека» во фразу «Ночь, улица и фонарь с аптекой». Они, как говорится в законе о защите прав потребителя «похожи до степени смешения».
Не забывайте о том, что превращение фразы «Хлеб — всему голова» во фразу «Булка — всему башня!» — это, как бы помягче сказать-то… НЕ СОВСЕМ РЕРАЙТ. Точно также, как не совсем рерайт переработка фразы «Ночь. Улица. Фонарь. Аптека» во фразу «Ночь, улица и фонарь с аптекой». Они, как говорится в законе о защите прав потребителя «похожи до степени смешения».
Заменяя слова синонимами, не потеряйте смысл. «Варочная поверхность» и «электроплита» — не всегда тождественны, а то, что все кильки являются рыбами — совсем не значит, что все рыбы — кильки. Кроме того, будет обидно вовсе потерять все умные слова. Да, и «пластиковые окна» на «пластиковые окошки» менять, как минимум, не оригинально.
Третья задача. Введение и развязка
Помните, в предыдущем пункте мы с вами безжалостно отрубили несчастному исходнику начало и конец? Чем же он будет думать? Для лучшего рерайта эти две вещи — введение и послесловие пишем заново. Сами. Когда все будет готово, на всякий случай, проверяем — не получилось ли между вашими мыслями и мыслями авторов исходника опасной близости. Если одно мучительно похоже на другое — переписываем! Теперь у нашего рерайта появилось хоть что-то уникальное.
Если одно мучительно похоже на другое — переписываем! Теперь у нашего рерайта появилось хоть что-то уникальное.
Что же такое «дубликат» и откуда он появляется в сети?
Несмотря на то, что существует такой прекрасный метод создания уникального контента, как рерайтинг (не говоря уже о создании уникального контента с нуля), в сети интернет все еще присутствует огромное количество дубликатов, нарушающих законные права их создателей на размещение исключительно на своих ресурсах.
Дубликаты разделяют на полные и нечеткие.
Полные дубликаты — это документы (часть контента сайта или весь контент целиком), которые поисковые системы считают уникальными, но каждый пользователь может легко заметить их совпадение.
Нечеткие дубликаты имеют незначительные отличия даже для визуального восприятия пользователя в виде перестановки блоков навигации, новостей или других элементов сайта.
Существует немало подходов к дублированию информации, а следовательно можно дифференцировать несколько источников дубликатов контента.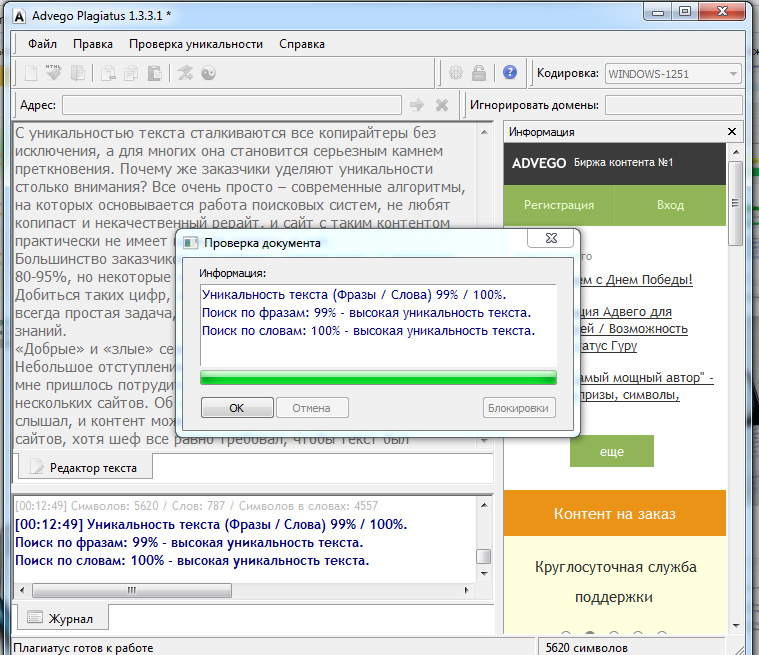
Как видим, методов создания дублей весьма немало.
Для того, чтобы бороться с дубликатами, нужно сначала научиться определять их, отличать от уникального контента в сети.
Существует немало синтаксических и лексических методов определения дубликатов в сети, на которых основаны современные программы по вычислению копий исходного документа или страницы в Интернете.
Рассмотрим наиболее популярные из них.
Программы для проверки уникальности контента
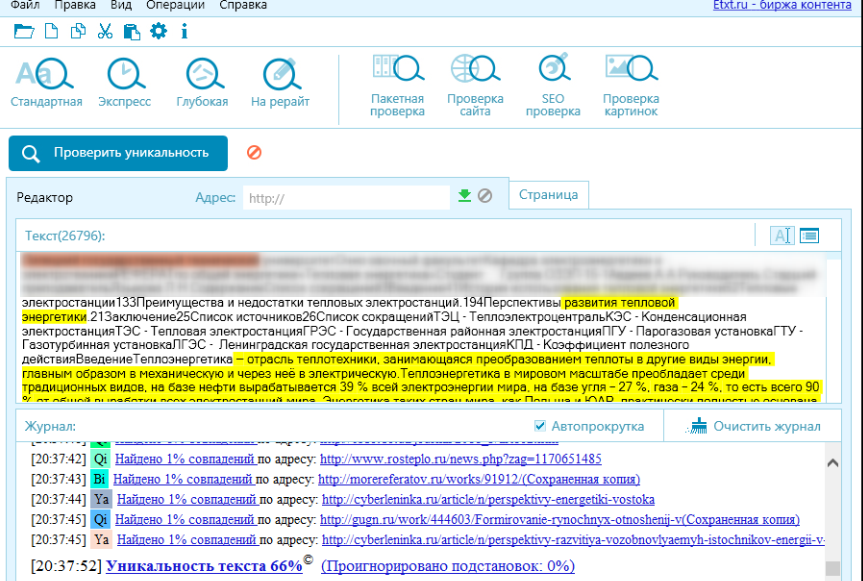
1. Advego PlagiatusAdvego Plagiatus — программа поиска в интернете частичных или полных копий текстового документа с интуитивным интерфейсом. Плагиатус показывает степень уникальности текста, источники текста, процент совпадения текста.
Этим сервисом пользуются, наверное, все копирайтеры которые пишут тексты на заказ. Это не сервис, а программа, чем еще даже удобнее. Эта программа пока бесплатная, чем и привлекает огромное количество пользователей.
Есть некоторые нюансы, например если текст хорошо оптимизирован под определенные ключевые слова, то понятное дело что они будут повторяться и добиться уникальности в 100% практически нельзя. Нормальный уникальный текст это от 85-95%.
Нормальный уникальный текст это от 85-95%.
Проверить контент на уникальность достаточно просто — нужно вставить текст в окошко сервиса и нажать «Проверить». В сервисе имеется история проверок. Без регистрации разрешается проверять тексты не более 5000 символов. Есть мнения в Интернете, что база сайтов для проверки у Антиплагиата маловата, и не всегда он может вычислить скопированный текст, поиск неточный. Бывает, что текст, который Антиплагиат определяет, как уникальный, при проверке другими сервисами находится на каком-нибудь сайте.
3. CopyscapeПростенький онлайн сервис (проверяет только тексты в сети), показывающий копии ваших документов во всемирной паутине WWW. Разрабатывался для европейских пользователей, но вполне успешно пользуется популярностью и в рунете. Предварительная публикация статьи на сайте для проверки — это неудобство, поэтому заказчикам статей у копирайтеров этот сервис может быть не интересен. В адресную строку вводите адрес для проверки страницы на уникальность, а сервис выведет список похожих документов в сети.
Ключевую фразу текста в кавычках вводим в поисковик для точного поиска. Точная цитата (кавычки) поддерживаются почти всеми поисковиками. Далее смотрим, нет ли совпадений на других сайтах. Проделать эту процедуру нужно несколько раз, выбрав разные цитаты текста из статьи, при этом свои запросы следует ограничивать 3-6 словами и 90 символами. Также из текста стоит убрать все разделители (кроме запятой и точки), поисковиками они не учитываются.
Самое простое — вставить небольшие отрывки из проверяемой статьи последовательно в поисковики. Это самый простой тест на уникальность текста, но самый долгий и нудный. Недостаток у него один — максимальный фрагмент текста для поиска небольшой, 160-255 знаков с пробелами.
5. AllsubmitterУдобная программа, использующая алгоритм проверки с помощью фрагментов текста по точным вхождениям в строке поисковых систем (предыдущий метод).
Кроме того, может использовать базу приложения Copyscape для проверки дубликатов.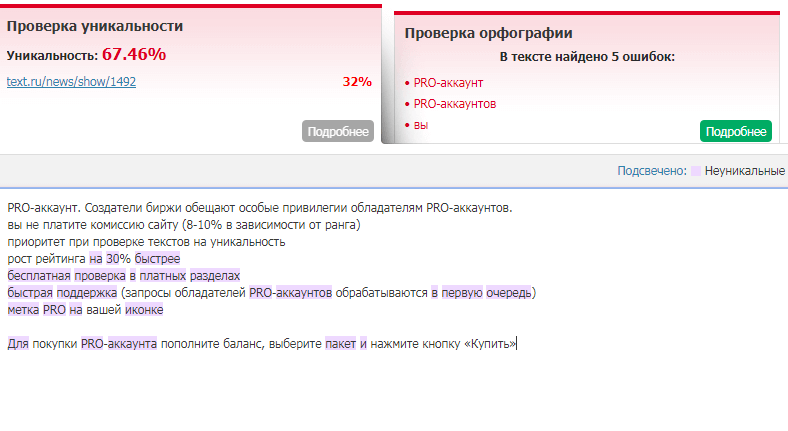
Чрезвычайно удобна автономностью своей работы (достаточно лишь ввести ссылку на сайт, уникальность контента, на котором необходимо проверить), а также гибкими настройками.
Контент можно проверять как в форме текста, так и уже выложенный на веб-страницах.
Как защитить свой контент?
Защита контента — непростая задача, которая требует разумного подхода веб-мастера к развитию своего сайта. Несмотря на то, что поисковые системы призваны помогать каждому сайту в его развитии, в ситуации с тотально распространенным копированием информации они могут сыграть злую шутку с авторами уникального контента.
В первую очередь, здесь следует упомянуть трастовость сайтов для поисковых систем. Например, крупные новостные порталы постоянно размещают контент, который в последствии копируется на множество сайтов по всей сети Интернет. Почему же эти крупные новостные сайты не теряют трастовость в поисковых системах?
Все дело в ссылках. Если любой веб-мастер менее трастового ресурса поставит ссылку на крупный новостной ресурс после размещения его контента, то это послужит лучшей защитой от копирования в восприятии поисковой системы..png?1549983414888)
Безусловно, не каждый веб-мастер окажется порядочным человеком, который ценит авторские права новостного ресурса, с которого он взял контент.
Как быть в этом случае? Решение лежит на поверхности — необходимо размещать тот же контент на менее трастовых сайтах со ссылкой на оригинал, источник. Чем больше таких ссылок получит источник, тем меньше поисковая система будет сомневаться в его авторском праве на этот контент.
Платное размещение статей на различных ресурсах сегодня не проблема для любого веб-мастера, поэтому такое решение оптимально для многих крупных новостных ресурсов, пример которых мы рассмотрели.
Кроме того, что при такой системе владельцы крупных новостных порталов могут быть уверены, что их репутация не пострадает за счет более мелких и менее добросоветсных ресурсов, владельцы менее трастовых ресурсов имеют возможность заработать на платном размещении статей со ссылкой на первоисточник контента.
Существуют и другие методы предотвращения воровства контента вашего сайта, которые можно отнести к программным. Программные методы подразумевают защиту контента от копирования на уровне скрипта сайта, в котором прописываются специальные команды или в котороый добавляются некоторые плагины. Например, для блогов системы WordPress существует плагин WP-CopyProtect, который попросту запрещает выделение текста на странице, а так же не дает использовать клики правой кнопкой мыши.
Программные методы подразумевают защиту контента от копирования на уровне скрипта сайта, в котором прописываются специальные команды или в котороый добавляются некоторые плагины. Например, для блогов системы WordPress существует плагин WP-CopyProtect, который попросту запрещает выделение текста на странице, а так же не дает использовать клики правой кнопкой мыши.
Но минус такого подхода состоит в том, что многие пользователи захотят скопировать ваш контент без всякого злого умысла, например, для прочтения в печатном варианте — и в этом случае их ждет разочарование.
Кроме того, современная судебная система Украины предполагает защиту авторских прав пользователей веб-ресурсов. Но и здесь есть существенные минусы:
Во-первых, законодательство Украины не будет рассматривать дело в том случае, если владелец сайта, который продублировал ваш контент, будет зарегистрирован на сервере другой страны.
Во-вторых, судебный процесс может сильно затянуться и отобрать огромное количество средств, в частности направленных на сбор доказательств и наем адвокатов.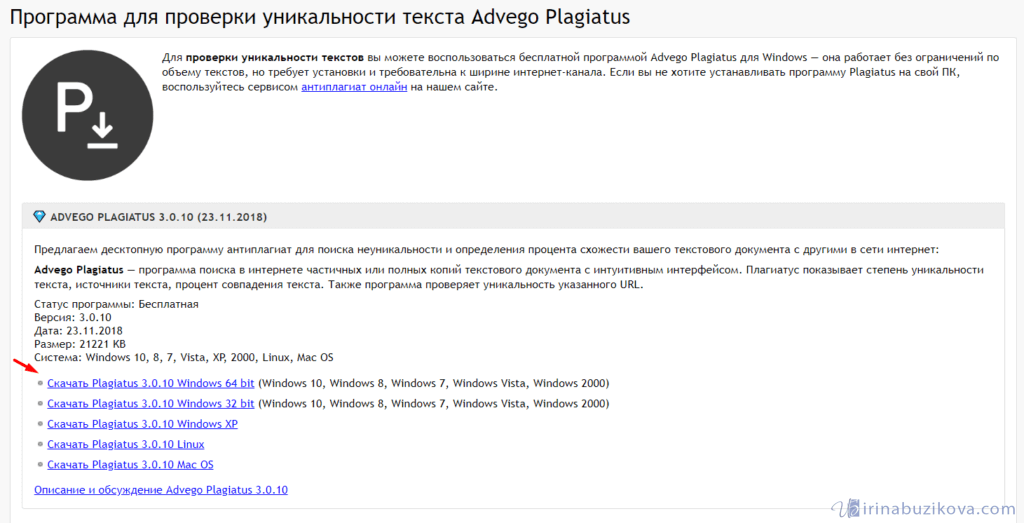
В случае, если вы видите обращение к «букве закона» единственно правильным решением, советую обратиться напрямую к владельцу сайта, продублировавшего ваш контент с претензией, в случае невыполнения которой обращаться к его хостеру.
Но так или иначе, размещение контент на менее трастовых сайтах со ссылкой на себя дает самый адекватный результат и лучшие гарантии избежания санкций от поисковых систем. При этом вам не нужно производить эксперименты на своих посетителях, запрещая им копировать контент.
Суммируя все вышесказанное, хотелось бы напомнить, что работа с контентом вашего сайта — это не только его написание самостоятельно, заказ у профессиональных копирайтеров или качественный рерайт, но и постоянный контроль и защита его от дублирования другими сайтами.
Другими словами, если вы создали новый сайт, который будет представлять вашу компанию в Интернете, то для его конкурентоспособности необходимо постоянно следить за уникальностью контента, обновлять его, а также предпринимать активные меры по продвижению — иначе ваш сайт рискует остаться незамеченным вашими потенциальными клиентами, попав под санкции поисковых систем..png?1549983278910)
Если все вышеперечисленное кажется вам слишком сложным или даже недостижимым, то вы всегда можете довериться профессионалам компании Netpeak, которые проведут весь комплекс работ с контеном со всей ответственностью и профессионализмом.
5 онлайн сервисов для проверки текста на уникальность
Из этой статьи вы узнаете о наиболее удобных, с нашей точки зрения, онлайн сервисах проверки контента на уникальность, грамотность и читабельность. Мы опробовали много сервисов и самые удобные из них — описаны в статье.
Ежедневно мы получаем огромное количество информации из интернета. Это бескрайнее море самого разного контента и самого же разного качества: статьи, ролики на YouTube, фотографии, рисунки и прочее.
Каждый раз, открывая статью или запуская видеоролик, мы хотим увидеть что-то интересное, то, чего не видели раньше, полезную информацию, которая развлечет или обучит. Поэтому, контент на сайте должен быть уникальным. Но что значит «уникальный» относительно содержимого сайта? Это означает, что контент не должен содержать плагиата и должен быть полезным, интересным и ценным для пользователя.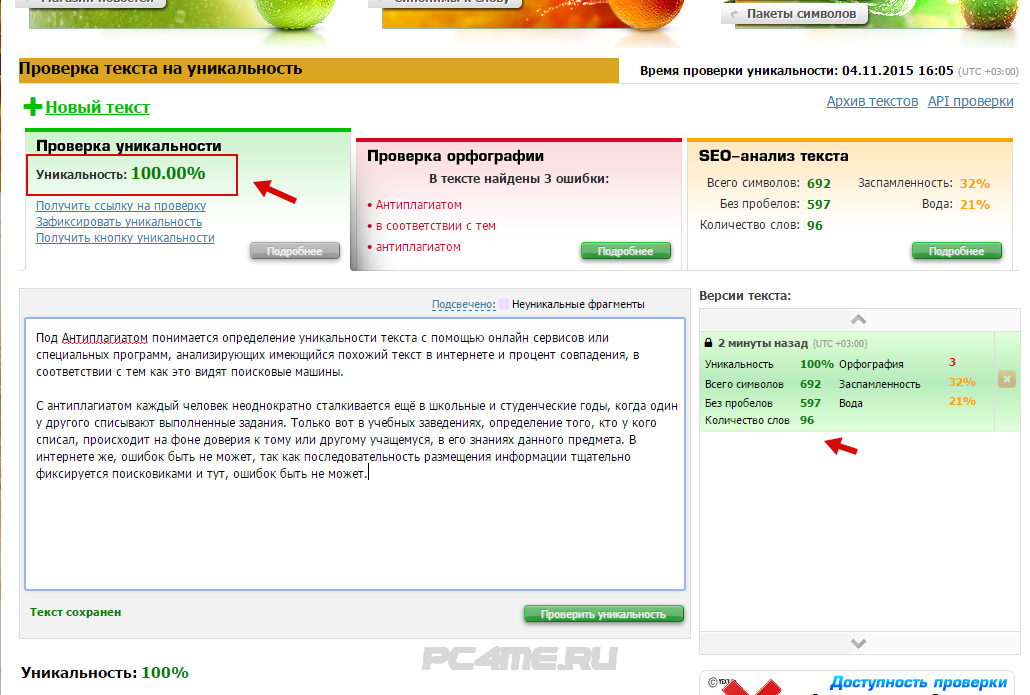
Если рассматривать вопрос не со стороны пользователя, а со стороны поисковых систем, то сайт за неуникальный контент может быть или не проиндексирован — тогда его не найдут пользователи, или, что еще хуже, заблокирован.
Уникальность контента принято измерять в процентах. Конечно, если текст имеет уникальность 100%, это отличный результат. Но и 90% считается приемлемым результатом, тем более, что различные сервисы могут показывать результат по одному и тому же тексту с разбросом в несколько процентов.
В сети достаточно сервисов, которые измеряют уникальность текста, проверяют орфографию, уровень заспамленности и т.д. Далее — коротко о каждом сервисе.
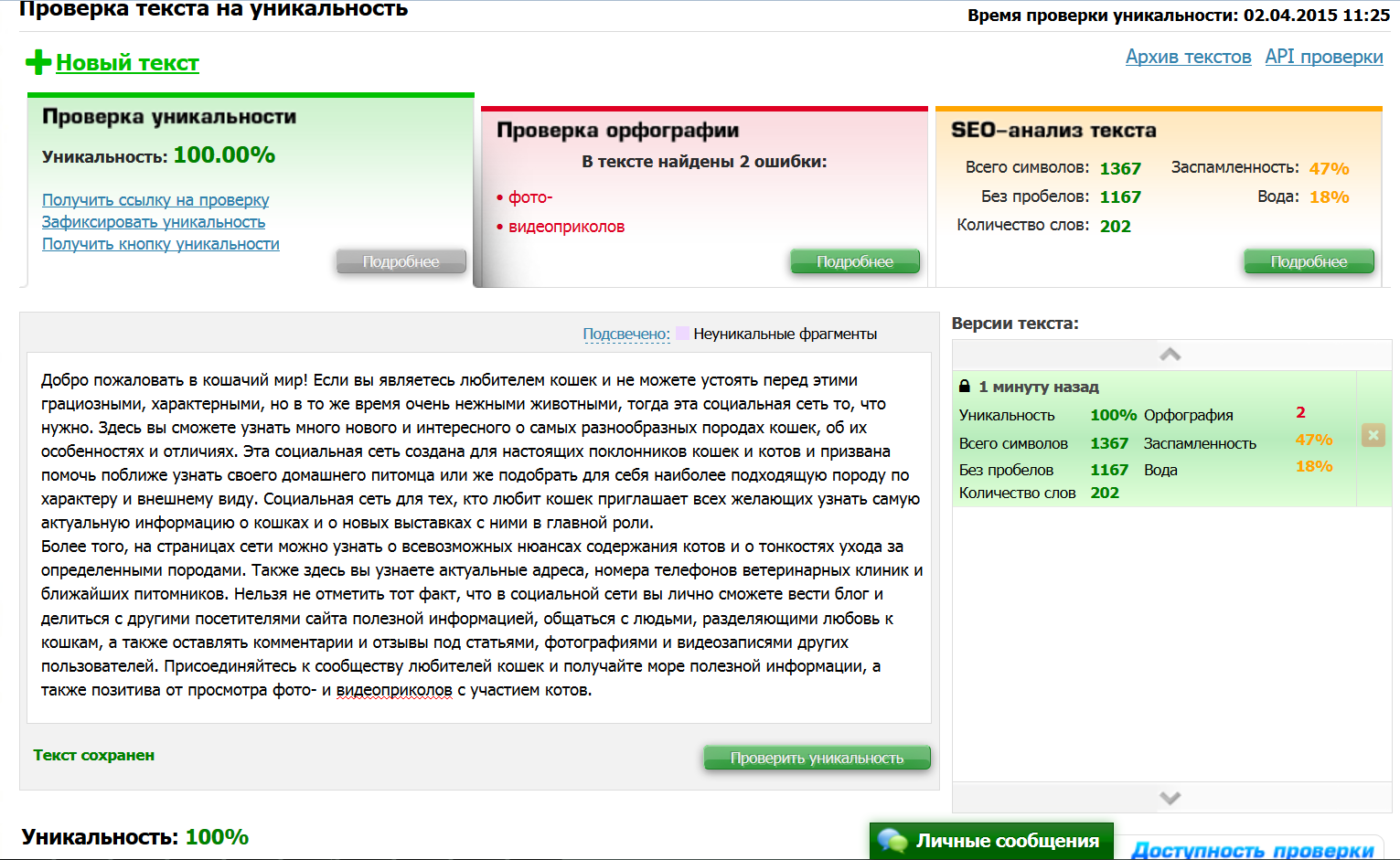
1. text.ru — бесплатный, удобный сервис для проверки текста на уникальность. Кроме того, одновременно идет проверка орфографии, уровень «воды» и заспамленности текста.
Для ускорения процесса проверки лучше всего зарегистрироваться на сайте, об этом предупреждает сам сервис: если вы зарегистрируетесь, проверка пройдет быстрее. До авторизации на сайте перед этим текстом в очереди было 24 текста, а после авторизации — 10. Кроме сервиса проверки на сайте есть биржи рерайтинга, копирайтинга, магазин статей и прочее.
До авторизации на сайте перед этим текстом в очереди было 24 текста, а после авторизации — 10. Кроме сервиса проверки на сайте есть биржи рерайтинга, копирайтинга, магазин статей и прочее.
Результат проверки этого текста на уникальность — 100%.
2. content-watch.ru — достаточно удобный сервис, с помощью которого можно не только узнать, насколько ваш текст уникален, но и защитить уже опубликованные тексты. Для того, чтобы в полной мере воспользоваться всеми возможностями сервиса, необходимо пройти регистрацию на сайте.
По результатам этой проверки — текст статьи уникален на 100%.
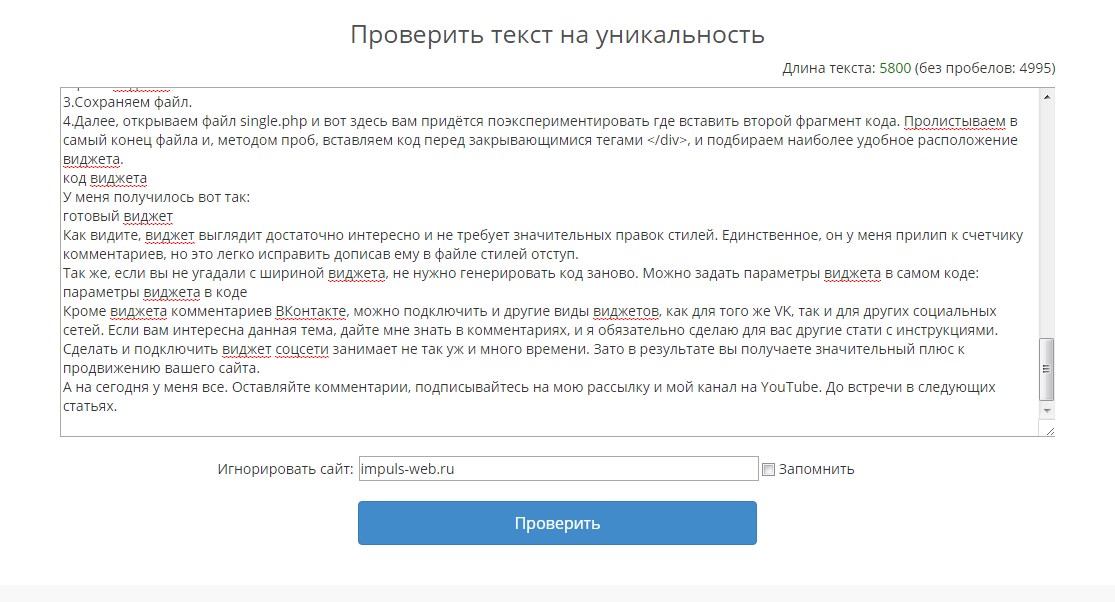
3. advego.ru — неудобство этого сервиса в том, что он требует установки программы, да к тому же может появиться капча.
После регистрации на сайте появляется возможность пройти онлайн проверку орфографии и сделать подробный семантический анализ текста. Проверить этот текст на уникальность онлайн, к сожалению, не удалось.
4. pr-cy.ru — еще один бесплатный сервис, который, однако, не позволяет незарегистрированному пользователю проверить менее 10 и более 1000 символов.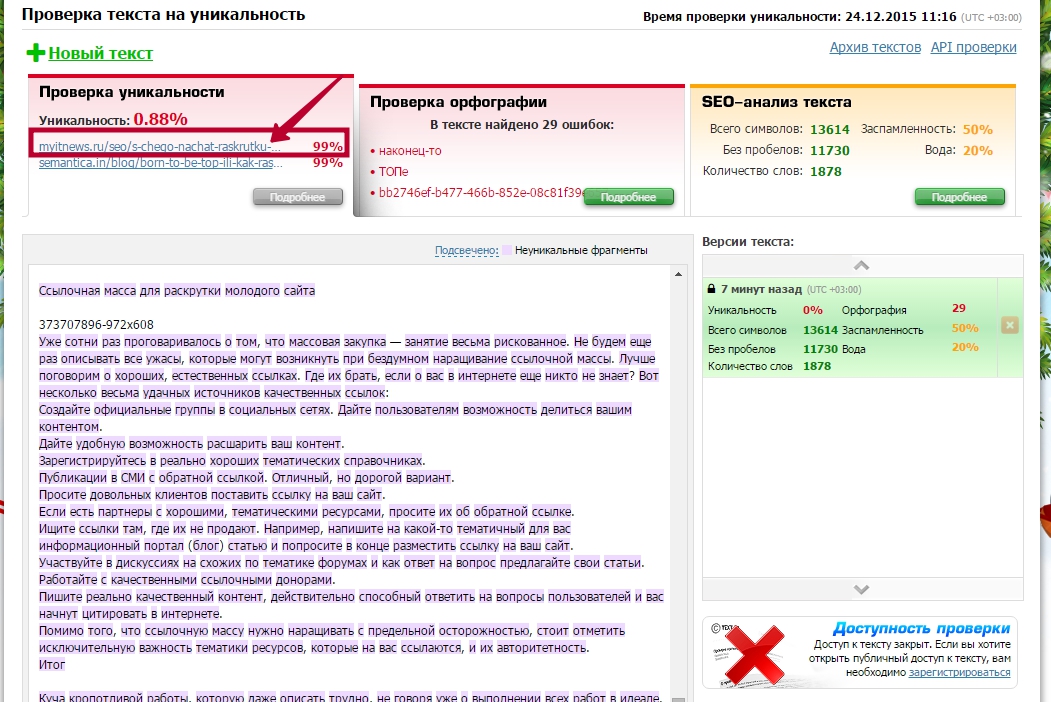 Кроме того при каждой проверке нужно заново вводить капчу. Уникальность этого текста — 100%.
Кроме того при каждой проверке нужно заново вводить капчу. Уникальность этого текста — 100%.
5. plagiarisma.ru — сервис предлагает проверку на 190 языках. При проверке текст разбивается на фразы, напротив каждой из которых пишется, уникальна данная фраза или нет. Если фраза неуникальна, то указывается источник с похожей фразой. Но это не обязательно означает, что эта фраза именно плагиат. Это может быть просто похожее по смыслу предложение. Например, как в нашем случае.
Проверка текста показала непривычно низкий процент уникальности — 84%. Но оказалось, что речь идет всего лишь об одной отдаленно похожей фразе из текста на сайте про … брендовый виски. Таким образом, нельзя считать эту проверку абсолютно верной.
Все тексты, которые публикуются в нашем блоге, проверены с помощью text.ru и content-watch.ru. С нашей точки зрения — это два наиболее удобных сервиса проверки уникальности текстов. Вы же можете с помощью этой статьи подобрать для своей работы сервис, который будет устраивать вас.
Успехов вам и уникальных текстов!
При подготовке материала использованы изображения с сайта Freepik.com
Хитрые жуки и копипаст: как проверить текст на плагиат? Где можно проверить текст на ошибки и уникальность?
Отдайте свои заботы о хорошем контенте на сайте в наши руки
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Почему вам стоит проверить сайт на уникальность текста?
Дело вот в чем: когда поисковики находят откровенный грязный копипаст (скопированную статью, повтор контента), они выбрасывают его из выдачи вместе с сайтом, на котором он размещен. Действительно, зачем показывать пользователю одно и то же? Соответственно позиции сайта тут же падают, а сеошники рыдают в углу.
Именно поэтому копирайтеры и сочувствующие трудятся над рерайтами, изучают словарь синонимов или стараются посмотреть на “велосипед” под совершенно другим углом.
Допустимая уникальность текста
Для каждого текста она может быть разной. К примеру, уникальность большой статьи-простыни в 10 тысяч знаков должна быть не меньше 95%.
Маленькие тексты с большим количеством общих фраз (“Рады видеть вас на нашем сайте”, “У нас вы можете заказать…”, “Удобные способы оплаты”) могут быть уникальны не менее чем на 87-85%..jpg)
Где проверить на плагиат большой текст: плюсы и минусы популярных онлайн-ресурсов
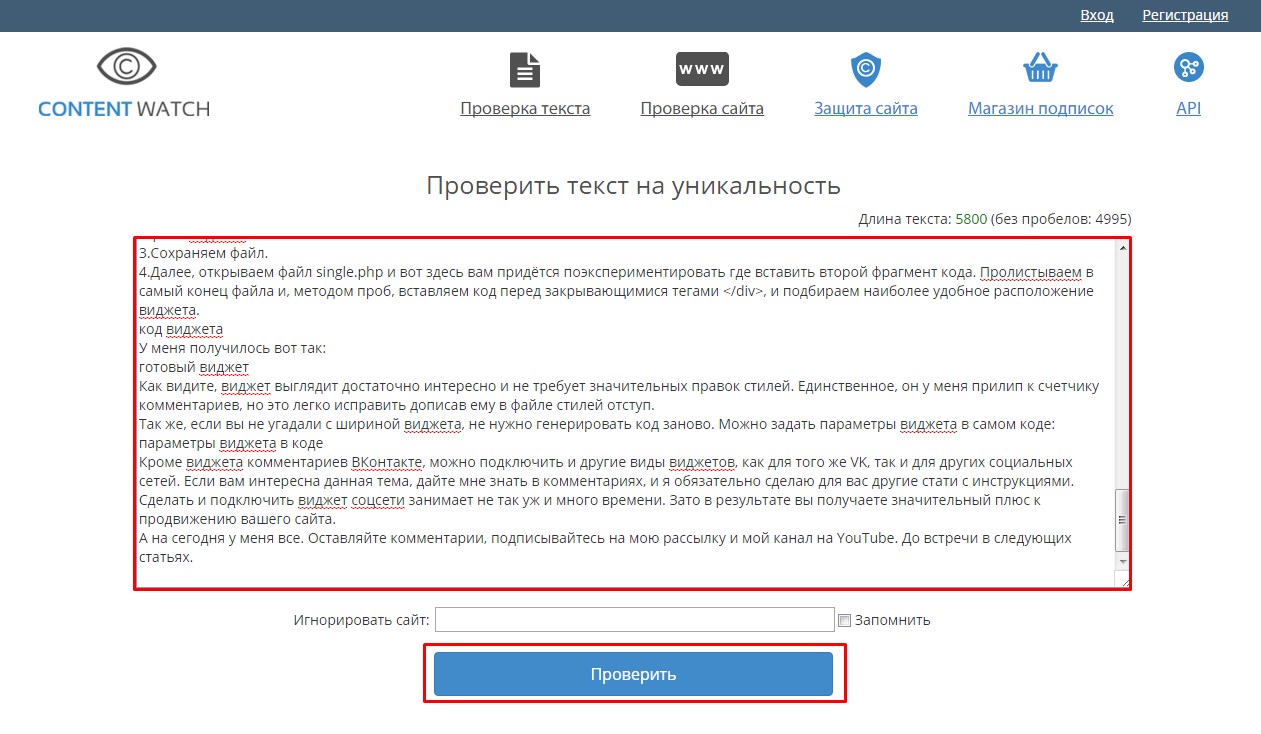
Content Watch
На главной странице проверить текст на плагиат по урлу у меня не получилось. Экран показывал, что проверка завершена, но никакого результата. Пробую проверить статью, вставив текст вручную. И тут опять незадача “слишком много букв”.
Плюсы:
- Можно поставить отметку “игнорировать сайт”.
- Есть возможность настройки приложения для автоматической проверки текстов на уникальность через сайт (услуга платная).
- Приятный и понятный интерфейс.
Минусы:
- Большинство примочек работает только за деньги, так что всех преимуществ этого сайта (если они есть) я оценить не смогу.
FindCopy
Очень долго. Просто невероятно долго. После 2 нетерпеливых минут ожидания я попыталась отменить проверку текста на ошибки и уникальность, но сайт завис.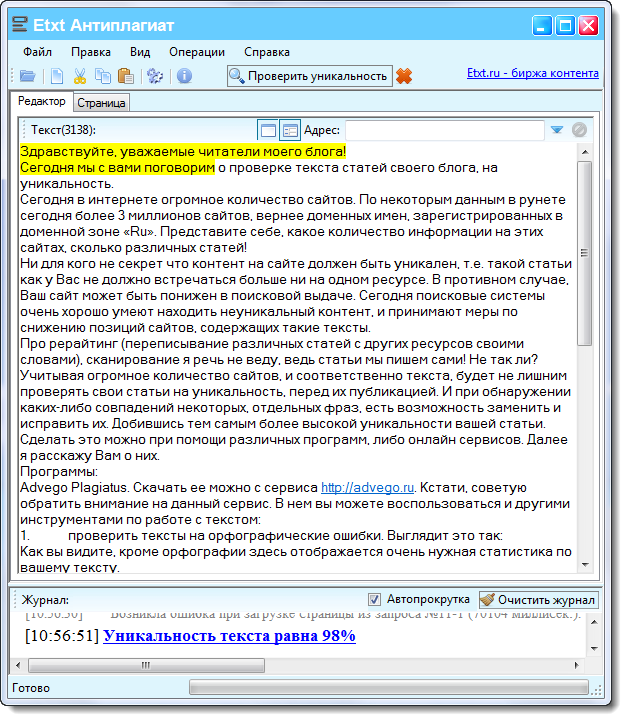 Потом мне выдало следующее:
Потом мне выдало следующее:
Затем я снова попыталась зайти на сайт с выдачи, картина та же. Вопрос: какого #$@ вы висите в ТОПе?
text.ru
Надписью “Из-за работ на сайте, проверить сайт на уникальность текста незарегистрированным пользователям временно невозможно” они вынудили меня отдать им свою почту. Уверена, что это умышленно.
Этот сайт проверки текста на плагиат действует по несколько иному алгоритму: он ищет совпадения не по шинглам, а отлавливает рерайт, даже если автор изменил окончания в словах и поменял местами слова и части текста.
Плюсы:
- Сначала я расстроилась, что мне не дали исключить домен, но потом выяснилось, что его можно исключить после, и процент автоматически преобразуется. Это даже удобней.
- Мне сразу посчитали орфографические ошибки, воду, заспамленость и количество символов.
- Дает возможность сравнить с источником.
Минусы:
- Не совсем удобная навигация.

- Дизайн оставляет желать лучшего.
Антиплагиат
Плюсы:
- Можно загрузить документ word или вставить текст вручную.
- Есть возможность выгрузки отчета.
Минусы:
- Заявил, что текст, который УЖЕ размещен на нашем сайте, уникален на 100%. И это притом что не было возможности поставить домен в игнор. Как вообще здесь можно проверить большой текст на уникальность, не понимаю.
pr-cy.ru
Плюсы:
- Подробно проверяет текст.
- Можно игнорировать домен.
Минусы:
- Можно добавлять текст лишь до 5 000 знаков
Где еще проверить уникальность текста: программы
Etxt
Плюсы:
Минусы:
- Непонятный интерфейс: 10 минут тыкала, чтобы понять, где можно проигнорировать домен. Не нашла:( Надо полагать, что если я захочу этой программой проверить уникальность текста, который уже есть на сайте, то у меня ничего не получится.

Программа Advego Plagiatus
Плюсы:
- Бесплатно.
- Есть возможность детальных настроек.
Минусы:
- Вас могут атаковать капчи.
Для эксперимента я взяла небольшой кусочек текста из уже опубликованной статьи в нашем блоге. Вот, что у меня получилось в итоге:
| Адвего | 89% |
| content-watch | 73.0% |
| Текст ру | 100% |
| Антиплагиат | 100% |
| pr-cy.ru | 100% |
| Etxt | 0% |
Что касается моего личного опыта, то мне хватает Адвего, который всегда очень строг. Текст ру иногда тоже использую, но, правда, при проверке чужих текстов.
Еще раз повторюсь: не смотрите на столь большую разницу результатов Адвего и Текст ру, у них разные алгоритмы.
Выводы
- Прежде чем неистово ругать себя или копирайтера за низкий процент уникальности, внимательно изучите все совпадения.
 Быть может, вы употребили слишком много цитат или вы просто пишите заурядно.
Быть может, вы употребили слишком много цитат или вы просто пишите заурядно. - Результаты проверки отличаются при разной скорости соединения.
- Почти невозможно написать текст объемом меньше 1000 символов на 100%.
- Это не имеет смысла (см. пункт выше)
На заметку:
Если открыв текст, который вам прислал копирайтер, вы видите совершенно обычные слова, подчеркнутые красным, не надо думать, что это просто какой-то сбой. Вам нужно проверить уникальность текста в программе Адвего. Если программа выделит отдельные буквы так, как показано на скриншоте, то велика вероятность, что ваш наемный писака — хитрый жук.
Почему? Да потому что своровал где-то текст (или его кусочек) и уникальности ради заменил все гласные в словах английскими буквами.
У руководителя SEO-отдела нашей студии я узнала, что публиковать такой текст не стоит, так как страница с большой вероятностью упадет в выдаче после переиндексации.
А какие уловки для повышения уникальности текста знаете вы?
Как проверить текст на уникальность: ТОП-5 сервисов
Один из наиболее часто задаваемых вопросов среди наших клиентов: «Как проверить текст на уникальность и какой сервис для этого лучше использовать?». Отвечаем кратким обзором самых популярных сервисов, которые испробовал наш редактор.
Сразу хотим отметить, что один и тот же текст в различных сервисах может иметь разный процент уникальности. Это связано с тем, что каждый сервис использует свой уникальный алгоритм поиска совпадений текста в интернете.
Наш ТОП-5 сервисов для проверки уникальности текста.
1. Text.ru. Сервис, который мы в WHAT agency ценим и юзаем чаще всего. Удобный и простой в пользовании, быстро осуществляет проверку. Неуникальные фрагменты подсвечивает цветом.
Счетчик очереди показывает сколько текстов проверяется перед вашим, а если пройти быструю бесплатную регистрацию, ваши тексты получают приоритетность в общей очереди.
Достоинства:
- Неограниченное количество проверок в день (нужна регистрация).
- Услуги проверки на уникальность бесплатные.
- Встроена функция проверки текста на орфографию.
- Встроены функции SEO-анализа текста (заспамленность, вода).
- Также доступны бесплатные услуги подбора синонимов слов, проверки уникальности документа прямо из файла.
Недостатки:
- Если проверять текст без регистрации, процесс проверки довольно медленный.
- Услуга проверки сайта на уникальность платная.
- Максимальная длина 1 текста: 15 тыс. символов.
2. Content-watch.ru. Данный сервис проверяет тексты в более быстром режиме без регистрации, чем Текст.ру, но имеет ограничения по количеству символов и проверок в день. Зарегистрированный пользователь может проверить на уникальность сайт или определенные страницы, но опять же ограниченное количество раз.
Этот сервис хорош для небольшого количества проверок в день, или если вы готовы купить платный пакет услуг (есть еще один способ, который позволяет «обойти» ограничения по количеству проверок, но мы не можем поделиться им здесь из соображений безопасности. Интересующихся просим в личные сообщения или чат в правом углу экрана:).
Достоинства:
- Проверка быстрая даже без регистрации (очередь отсутствует).
- Есть возможность проверить уникальность уже опубликованных текстов, для этого нужно ввести в строку «Игнорировать сайт» ссылку на страницу текста. Эта функция удобна, если вы, например, решили усовершенствовать существующий текст сайта и хотите проверить, насколько уникальной получилась новая версия.
- Бесплатная проверка сайта или отдельных страниц.
- В платной версии есть возможность установки плагинов на самые популярные CSM, которые позволяют автоматически проверять тексты прямо на сайте.
Недостатки
- В день можно проверить не более 7 текстов объемом до 10 тыс. символов (бесплатная версия)
- Ограничения для проверки сайта на уникальность: до 3 в день.
3. Advego Antiplagiatus. Когда-то была программой №1 для проверки текстов на плагиат. №1 потому что имеет массу достоинств и функций. Была — потому что с момента блокировки в Украине российских сервисов, в том числе Яндекса, украинские пользователи не могут получить релевантный результат проверки с программы Advego. Программа не может подключиться к поиску в Яндексе и не учитывает выдачу с этой поисковой системы. В результате выдает высокий процент уникальности даже для тех текстов, которые таковыми не являются.
Помимо этого, прекрасное ПО для проверки. Для пользователей остальных стран работает отлично.
Кстати, у сервиса есть еще онлайн-версия с теми же функциями, но она имеет ограничения по объему проверок (до 10 тыс. символов в день только для зарегистрированных пользователей).
Достоинства
- Установка программы бесплатна.
- Не имеет ограничений по количеству и объему проверок (программа).
- Можно проверять большие тексты — до 100 тыс. символов.
- Можно проверять тексты в различных режимах: быстрой и глубокой проверки.
- Изменять параметр длины шингла, то есть совпадения по фразам — сколько слов подряд во фразе считать как совпадение (плагиат).
- Текст проверяется и на SEO- параметры: заспамленность, водность, семантическое ядро с процентным соотношением.
- Присутствует функция «Игнорировать сайт» для проверки опубликованных текстов.
Недостатки
- Не проверяет совпадения в Яндексе, поэтому для пользователей Украины результаты проверки будут неточными.
- Программа устанавливается только на Windows.
- Для проверки через онлайн-сервис обязательна регистрация, ограничения по объему: до 10 тыс.
 символов в день.
символов в день.
Для англоязычного контента
Хоть и три вышеперечисленных сервиса подходят и для проверки текста на английском языке, иногда есть смысл дополнительно проверять англоязычный контент через зарубежные сервисы.
4. Copyscape. Этот сервис больше подходит для проверки отдельных страниц сайта, так вы сможете отслеживать уникальность опубликованного контента. Если ваш контент дублируется на каких-либо страницах в интернете, сервис покажет список этих ресурсов с ссылками.
Проверка на уникальность страниц сайта здесь бесплатна, а вот за каждую проверку текста нужно заплатить 0,05$.
Преимущества
- Бесплатная проверка страниц сайта
Недостатки
- Ограниченное количество проверок страниц сайта в день.
- Платная проверка отдельного текста (0,05$ за каждую проверку).
- Для проверки текста регистрация обязательна.

5. Duplichecker. Многофункциональный сервис, который кроме проверки текста на уникальность предлагает массу полезных инструментов: проверку грамматики и орфографии (англ. язык), плотность ключевых слов и др.
Текст на уникальность можно проверять путем вставки или загрузки вордовского файла.
Преимущества
- Неограниченное количество проверок для зарегистрированных пользователей (бесплатно).
- Широкий функционал проверки текста (SEO-параметры, орфография и грамматика — что особенно актуально для англоязычного контента).
Недостатки
- Для незарегистрированных пользователей действует ограничение по количеству проверок — до 3 в день.
- Ограничения по объему — текст должен быть не более 1000 слов.
Попробуйте воспользоваться несколькими сервисами из нашего списка и выберите для себя наиболее удобный. Надеемся, теперь проверка контента на уникальность не будет вызывать у вас вопросов. А заказать уникальный текст лучше всего у нас — в агентстве копирайтинга WHAT agency.
А заказать уникальный текст лучше всего у нас — в агентстве копирайтинга WHAT agency.
15 сервисов для проверки текста
В идеальной вселенной тексты пишутся быстро, просто и без ошибок, а читаются на одном дыхании. А ещё моментально попадают на первые позиции поисковиков.
В реальности всë не так: дедлайны постоянно поджимают, времени на тщательную вычитку и редактуру часто не хватает. Но даже если по всем правилам дать работе отлежаться и перечитать несколько раз, замыленный взгляд запросто пропустит несколько ошибок, тавтологию или ещë что похуже.
Специальные сервисы для проверки текста облегчают жизнь копирайтеру, редактору, маркетологу, SEO-специалисту.
В подборке — 15 разных решений. Сначала идут сервисы, где в основном проверяют читаемость и грамотность текстов. Потом — инструменты, которые больше специализируются на проверке уникальности и SEO.
Орфограммка
Веб-сервис, который проверяет текст по трём критериям:
- Грамотность.
Находит орфографические, грамматические, пунктуационные, стилистические, типографические, речевые и смысловые ошибки, опечатки. Замечает даже отсутствие буквы «ё» в словах (спокойно, противники «ё», этот тип проверки можно отключить).
- Красота. Видит тавтологии и неблагозвучия, помогает подбирать синонимы и эпитеты.
- Качество. Указывает на водность, частотные и неестественные ключевые фразы.
Это три разные вкладки. Можно «прогнать» текст по всем или выбрать одну-две.
Пример анализа текста в Орфограммке.
На примере выше: слева — загруженный пользователем текст, справа — объяснения ошибок. Можно выбрать только те типы примечаний, которые актуальны.
Много интересного прячется в разделе «Статистика» (открывается в правом верхнем углу во время проверки текста).
Пример отчёта по статистике.
Дополнительные возможности:
- Позволяет форматировать текст прямо в сервисе.
- Даёт ссылки на источники, которые использует при проверке.

- Не только указывает на ошибки, но и подсказывает, как их исправить.
Стоимость: можно платить за объём (от 100 ₽ за 100 000 знаков) или за время (от 300 ₽ за 1 месяц).
Яндекс.Спеллер
Находит орфографические ошибки. Понимает даже сильно искажённые слова («кипуратер» обязательно предложит исправить на «копирайтер») и учитывает контекст при поиске опечаток («поглядит кошку» — «погладит кошку»). Знает сотни миллионов слов и словосочетаний.
Простейший интерфейс, ничего лишнего.
Дополнительные возможности:
- Доступны русский, украинский, казахский, английский языки.
- Рекомендации для замены слов.
Стоимость: бесплатно.
LanguageTool
Корректор орфографии, грамматики и стилистики. Не так внимателен к ошибкам, как «Орфограммка» и «Яндекс.Спеллер»: уровень проверки зависит от тарифа (в бесплатном режиме — базовый, с ним сервис «видит» очень мало). Зато есть дополнения для Google Docs, Microsoft Word, OpenOffice, LibreOffice, а также расширение для браузера. С этим арсеналом можно постоянно отслеживать грамотность своих текстов.
Базовый режим замечает только самые очевидные ошибки.
Дополнительные возможности:
- Поддерживает более 30 языков.
- Если дважды кликнуть на слово, покажет его синонимы.
- Позволяет форматировать текст прямо в сервисе.
Стоимость: базовый уровень — бесплатно, продвинутый — от 124,92 ₽ в месяц.
Читайте также: Текст для сайта: каким он должен быть
Grammarly
Сервис для проверки текстов на английском языке. Grammarly улавливает контекст предложений и находит даже очень сложные ошибки.
Одна из главных особенностей сервиса — возможность настроить его по важным для текста параметрам:
- Выбрать целевую аудиторию (новички, разбирающиеся и эксперты).
- Стиль изложения (неформальный, нейтральный или формальный).
- Сферу (бизнес, e-mail, креатив и др.).
- Тон (нейтральный, дружеский, аналитический и т.
д.).
- Цель (информировать, описать, убедить, рассказать историю).
Настройка целей в Grammarly.
Во время проверки текста сервис будет опираться на установленные параметры и давать подходящие рекомендации. Например, если целевая аудитория — эксперты, Grammarly будет уделять особое внимание профессиональной терминологии.
Бесплатная версия показывает только орфографические, грамматические и пунктуационные ошибки. Платная подсказывает, как улучшить качество текста, выделяет часто повторяющиеся слова, жаргон, пассивный залог, предлагает синонимы.
Интерфейс сервиса.
Дополнительные возможности:
- Есть бесплатное расширение для браузера, надстройка для Microsoft Office, клавиатура для смартфона и приложение для iPad.
- Можно форматировать текст.
- Платная версия выявляет плагиат, оценивает читабельность, несоответствие общему тону письма, заботится о расширении словарного запаса пользователя.
Стоимость: есть базовая бесплатная версия и Premium (от $11,66 в месяц).
Главред
Сервис Максима Ильяхова — соавтора книги «Пиши, сокращай». Помогает очистить текст от так называемых стоп-слов, проверяет его на соответствие информационному стилю.
- Вкладка «Чистота» находит словесный мусор и вежливо просит его вынести — добавить больше фактуры, избавиться от штампов и оценочных суждений.
- «Читаемость» показывает, что тормозит текст — например, страдательный залог, слабые глаголы, сложный синтаксис и т.п.
Пример работы сервиса.
«Главред» даёт оценку чистоты и читаемости текста по 10-балльной шкале. Она показывает отношение стоп-слов к общему числу слов в тексте. Достойной считается оценка 7 и выше.
Многие не любят «Главред» за его стремление упростить, порезать, выбросить из текста всё, кроме скелета. Тут важно помнить: чтобы написать качественный текст, нельзя просто взять и довериться машинному анализу. Прежде чем удалять все качественные прилагательные и местоимения по советам сервиса, стоит разобраться, как работает инфостиль, кому он нужен, как писать и лаконично, и увлекательно.
Дополнительные возможности:
- Находит штампы, канцелярит, неточные формулировки, необъективные оценки, обобщения, плеоназмы, паразиты времени, неправильно используемые заимствования, некоторые синтаксические ошибки, страдательный залог, вводные конструкции, модальность, некоторые эвфемизмы.
- Не просто делает замечания, а объясняет, как улучшить текст (иногда с примерами), подсказывает, какие статьи почитать.
Стоимость: бесплатно.
Readability
Проверяет текст на читабельность, простоту восприятия. Для этого использует 5 разных формул, отображает результаты по каждой из них, а также выводит общую оценку.
Пример оценки.
С помощью Readability можно понять, стоит ли упростить текст или, наоборот, сделать его глубже (в зависимости от его целевой аудитории).
Дополнительные возможности: проверяет страницы сайтов.
Стоимость: бесплатно.
Читайте также: Я — успешный копирайтер.
Куда расти дальше?
Тургенев
Сервис оценивает риск попадания под «Баден-Баден» — фильтр Яндекса, который обнаруживает неестественные, переоптимизированные тексты и понижает такие страницы в поисковой выдаче.
- Выявляет переспам и воду.
- Находит стилистические ошибки (штампы, канцеляризмы, смешение стилей, перегруженные обороты).
- Выставляет оценку риска «Баден-Бадена».
«Тургенев» проверяет текст по 5 параметрам: общие проблемы, повторы, стилистика, запросы, стоп-слова (водность). Чем больше он увидит ключей в точной форме, тем хуже. Чем больше слов-пустышек, тем хуже. Чем больше текст похож на роботизированный (ориентирован не на читателя, а на алгоритмы поисковиков), тем хуже. Риск попасть под фильтр от 5 баллов считается средним, от 8 — высоким, от 13 — критическим.
Дополнительные возможности:
- Может форматировать текст.
- Проверяет страницы сайтов.
- В личном кабинете сохраняет историю проверок.

- Не только выделяет слабые места, но и даёт рекомендации, как их усилить.
Стоимость: вкладка «Стилистика» бесплатная. Стоимость проверок без подписки — 5 ₽ за текст или страницу до 20 тыс. символов. Стоимость подписки — от 150 ₽ в месяц.
Text.ru
Позиционирует себя как онлайн-сервис проверки текста на уникальность. Но умеет кое-что ещё:
- Находить орфографические, пунктуационные, грамматические, логические, типографические ошибки.
- Проводить SEO-анализ текста (определять процент заспамленности и водности).
Но в первую очередь здесь удобно проверять текст на плагиат. С его помощью можно обнаружить некачественный рерайт: изменение каждого пятого или четвёртого слова, падежей, времён, перестановку фраз и предложений местами и другие техники.
Сервис подсвечивает неуникальные фрагменты, выдаёт ссылку на страницу, где обнаружены совпадения, и расписывает всё в процентном соотношении.
Пример проверки.
Минус — долгая загрузка..png?1549983342654) Прежде чем проверить текст, нужно дождаться своей очереди. В рабочее время ожидание может длиться больше 10 минут. Эту проблему частично решает регистрация.
Прежде чем проверить текст, нужно дождаться своей очереди. В рабочее время ожидание может длиться больше 10 минут. Эту проблему частично решает регистрация.
Дополнительные возможности:
- Проверяет на наличие ошибок, но это не самая сильная сторона сервиса.
- Может проверить уникальность текста внутри платформы Яндекс.Дзен.
- Проверяет на уникальность документы и страницы сайтов.
- Поддерживает русский и английский языки.
- Можно добавить URL страниц, которые нужно игнорировать при проверке.
Стоимость: есть бесплатная версия (50000 символов в день, низкая скорость проверки) и PRO-аккаунт — 79 ₽ (за сутки) или 5 990 ₽ (за год).
Advego
Ещё один антиплагиат. Анализирует текст по нескольким алгоритмам:
- Алгоритм шинглов проверяет совпадения фраз, находит источники копипаста и другие страницы, на которых размещены такие же тексты.
- Алгоритм лексических совпадений находит схожесть терминов и значимых слов, источники рерайтинга и страницы, которые совпадают по тематике.

- Алгоритм псевдоуникализации видит наличие сторонних символов и признаков обработки текста специальными сервисами (например, синонимайзерами).
Отчёт об уникальности.
Также с помощью Advego можно провести SEO-анализ — посчитать количество стоп-слов, водность, тошноту, вычленить семантическое ядро текста и т.д.
Установлен лимит на бесплатные проверки, но если скачать программу, проверять можно без ограничений.
Анализ не мгновенный — временами здесь тоже придётся ждать своей очереди.
Дополнительные возможности:
- Поддерживает русский, английский, китайский, немецкий, испанский, французский, украинский языки.
- Есть защита от сервисов обхода антиплагиата.
- Сохраняет историю проверок.
- Проверяет орфографию (довольно поверхностно).
- Можно добавить URL страниц, которые нужно игнорировать при проверке.
Стоимость: есть бесплатная версия с ограниченным количеством символов (зависит от уровня аккаунта) и PRO-аккаунт (от 950 ₽). Также можно купить дополнительные символы на любую сумму (от 1 ₽).
Также можно купить дополнительные символы на любую сумму (от 1 ₽).
Content-Watch
Простой, быстрый сервис-антиплагиат.
Не такой точный, как упомянутые выше, но предлагает довольно полезный инструмент — регулярную проверку текстов на уникальность. Content-Watch может автоматически отслеживать контент на страницах сайта и раз в неделю присылать отчёт.
Быстрая оценка уникальности.
Дополнительные возможности:
- Хранит историю проверок.
- Поддерживает русский и английский языки.
- Проверяет как загруженные тексты, так и страницы сайта.
- Позволяет указывать страницы, которые не будут участвовать в проверке.
Стоимость: есть бесплатная версия (ограниченное количество символов и проверок в день) и подписка (от 140 ₽ в месяц). Функция регулярного мониторинга — от 270 ₽ в месяц.
Читайте также: 35+ ресурсов для обучения SEO и развития в профессии
eTXT
Если скачать этот антиплагиат-сервис и установить на компьютер, откроется гораздо больше возможностей, чем у онлайн-инструмента.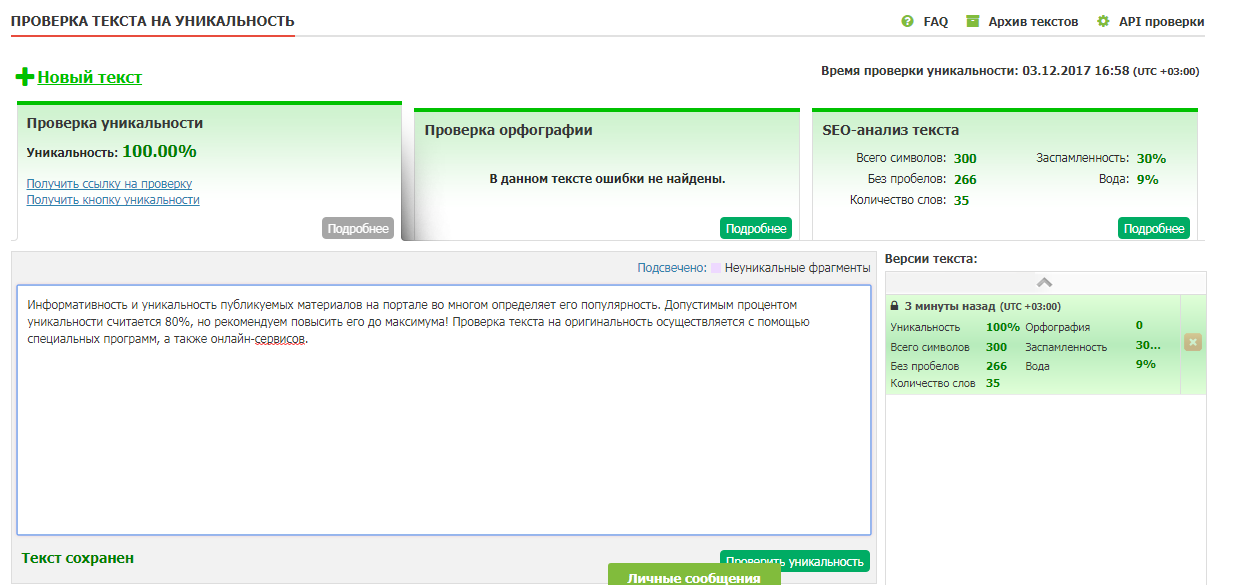
Минусы программы — долгий анализ (может занять несколько минут) и необходимость периодически вводить капчу, пока сервис ищет совпадения. Но это компенсирует польза. Программа проводит стандартную, глубокую или экспресс-проверку текстов, проверяет уникальность изображений, анализирует SEO-параметры, определяет рерайт, анализирует страницы сайтов.
Интерфейс ПО.
Для проверки текста в веб-сервисе нужно «отстоять» очередь, но платная версия должна ускорить процесс.
Так выглядит онлайн-сервис.
Дополнительные возможности:
- Сравнение текстов — исходного и отредактированного (в приложении).
- Определение копий (дословных совпадений) и рерайтинга (слегка отредактированных текстов).
Стоимость: есть бесплатная онлайн-версия (ограничены скорость и объём текста) и платная (1,5 ₽ за 1000 символов). Программу можно скачать бесплатно.
Пиксель Тулс
Здесь много полезных сервисов для SEO-специалистов. Для работы с текстами есть два инструмента:
Для работы с текстами есть два инструмента:
1. Проверка на уникальность.
Бывает, срабатывает точнее Text.ru и Advego. Результат быстрой проверки — процент уникальности, перечень источников и заимствованных фрагментов. Можно скачать их в виде CSV-файла.
Результат анализа.
Дополнительные возможности:
- Анализирует и отдельные тексты, и страницы сайтов.
- Можно задать список доменов-исключений.
Стоимость: условно-бесплатно. (На бесплатном тарифе выдается ограниченное количество лимитов. Если проверок много, придется докупать их отдельно или оплачивать подписку — от 950 ₽ в месяц.)
2. Оценка текста.
Проверяет частоту употребления слов в тексте, долю разных частей речи, стоп-слов, среднюю длину слов и предложений и другие параметры, которые важны для SEO.
Ещё одна важная функция — сервис может проверить текст на соответствие техзаданию. Для этого нужно загрузить файл с ТЗ, а инструмент сам найдёт нужные параметры по объёму текста, ключевым фразам, дополнительным словам, произведёт анализ и даст рекомендации.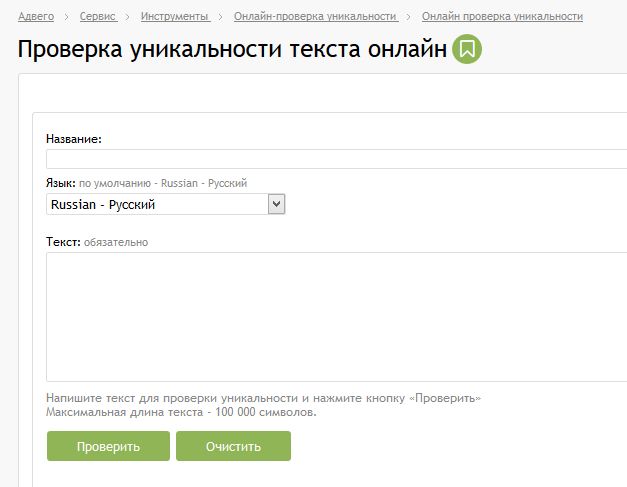
Возможности сервиса.
Дополнительные возможности: позволяет загрузить текст или URL страницы.
Стоимость: условно-бесплатно. (На бесплатном тарифе выдается ограниченное количество лимитов. Если проверок много, придется докупать их отдельно или оплачивать подписку — от 950 ₽ в месяц.)
Istio
Сервис для SEO-анализа текста. Показывает:
- насыщенность ключевыми словами;
- процент воды;
- заспамленность.
Общий анализ.
Несмотря на кажущуюся простоту, Istio детально анализирует семантические параметры текста и выдаёт подробную статистику. «Карта текста» наглядно демонстрирует, какие слова повторяются чаще всего.
«Карта» с часто используемыми словами.
Дополнительные возможности:
- Может определить язык и тематику текста.
- Проверяет орфографию.
- Может автоматически копировать текст с указанного сайта.
Стоимость: бесплатно.
Читайте также: 15 полезных инструментов для SEO-анализа сайта
Copywritely
Набор инструментов для оптимизации текста. Здесь можно:
- Быстро проверить уникальность текста, читабельность, воду, переспам.
- Выявить орфографические и грамматические ошибки.
- Рассчитать время чтения.
- Автоматически составить ТЗ для копирайтеров.
Сервис даёт рекомендации, как исправить текст, чтобы сделать его привлекательнее для поисковиков.
Проверка на читабельность.
Дополнительные возможности:
- Можно загружать текст документом или ссылкой.
- Есть расширение для Google Chrome, которое достаёт текст из активной вкладки и отправляет его на проверку.
- Доступно базовое форматирование текста (заголовки, жирный, курсив, списки).
- Поддерживает 11 языков.
Стоимость: есть бесплатная версия (5 проверок) и платные тарифы — от $18 в месяц.
Miratext.ru
Сервис проводит семантический анализ текста. Высчитывает тошноту, водность, количество повторений, составляет облако частотности слов.
Еще оценивает качество контента по закону Ципфа. (Если упорядочить слова в тексте по уменьшению частоты их использования, то частота каждого слова будет обратно пропорциональной его порядковому номеру. То есть второе должно повторяться в два раза реже, чем первое, третье — в три раза и т.д.) Если повторы не соответствуют этой схеме, текст считается неестественным — авторы сервиса предполагают, что тогда поисковик может понизить страницу в выдаче.
Результаты анализа.
Также есть инструмент для проверки текста на вхождение ключевых слов: точное, чистое, прямое, разбавленное, морфологическое, обратное или сложное. Инструкция, которая рассказывает о каждом из этих типов вхождения, прилагается.
Дополнительные возможности:
- Разрешает загрузить несколько текстов, провести общий анализ и сгенерировать ТЗ для копирайтера на их основе.

- Проверяет отдельный текст или контент на странице сайта.
- Позволяет форматировать текст с помощью инструмента «Контроль ключевых слов».
Стоимость: бесплатно.
На робота надейся, а сам не плошай — эти сервисы могут лишь подсказать, на что обратить внимание и где, скорее всего, стоит «подровнять» текст. Основная работа в любом случае ложится на плечи автора, редактора, маркетолога, SEO-специалиста или предпринимателя.
К тому же текст — только небольшая часть поисковой оптимизации и продвижения. Еще есть ссылки, поведенческие факторы, юзабилити и многое другое. Бесплатные вебинары, курсы и статьи по SEO от Cybermarketing помогут разобраться, как подходить комплексно и делать максимум, чтобы понравиться поисковикам.
Как проверить уникальность текста: обзор программ и сервисов
Обзор программ и сервисов
Интернет-технологии уже прочно вошли в нашу жизнь и стали ее неотъемлемой частью. Однако использование веб-пространства для бизнеса и профессиональной деятельности диктует свои особенные правила. Не стало исключением и SEO-продвижение — обширная область с большим количеством подводных течений. Ведь место в поисковом выдаче по ключевым словам играет важную роль в посещаемости Интернет-магазина, что, в свою очередь, непосредственно влияет на прибыльность.
Однако использование веб-пространства для бизнеса и профессиональной деятельности диктует свои особенные правила. Не стало исключением и SEO-продвижение — обширная область с большим количеством подводных течений. Ведь место в поисковом выдаче по ключевым словам играет важную роль в посещаемости Интернет-магазина, что, в свою очередь, непосредственно влияет на прибыльность.
При всем этом для поисковых систем важна уникальность контента. Проверить данный критерий достаточно легко. Просто воспользуйтесь соответствующим онлайн-сервисом или программой. Далее мы расскажем о самых популярных.
Программы для проверки текста на уникальность
Advego Plagiatus
Одна из наиболее популярных программ. Распространяется бесплатно. Проста в установке и использовании. Основное преимущество — проверка текста до 100 000 символов. Имеет минимальный набор настроек. Вы можете использовать прокси-сервер при проверке, чтобы избежать капчи и ускорить процесс. Также доступны изменения настроек соединения, размера шингла и поисковой фразы. Что касается поисковых систем, то Вы можете выбрать их из предоставленного программой списка, проставив галочки напротив необходимых Вам. Имеются такие варианты:
Также доступны изменения настроек соединения, размера шингла и поисковой фразы. Что касается поисковых систем, то Вы можете выбрать их из предоставленного программой списка, проставив галочки напротив необходимых Вам. Имеются такие варианты:
- Google;
- Yandex;
- Yahoo;
- Rambler;
- Nigma;
- Bing;
- QIP поиск.
Для того, чтобы приступить к проверке, Вы можете скопировать текст и внести его в основное поле или же скопировать ссылку и ввести в строку «Адрес». Затем выберите быструю или глубокую проверку. В первом случае нужно нажать кнопку с изображением флажка, во втором — с изображением символа “инь-ян”. Глубокая проверка будет более тщательной, но и более длительной.
2. Praide Unique Content Analyser
Данная утилита более сложная, чем Plagiatus и многие другие программы для проверки уникальности. Однако неоспоримое преимущество Praide Unique Content Analyser в том, что ее можно тщательнее настраивать. Но у этого имеется и побочный эффект — проверка длится достаточно долго (час и более).
Но у этого имеется и побочный эффект — проверка длится достаточно долго (час и более).
Вы можете на свое усмотрение выбирать для проверки поисковые системы. Просто отметьте их в настройках в уже имеющемся списке или добавьте самостоятельно.
Кроме того, в программе можно активировать защиту от капчи. И стандартная опция применения прокси-сервера. Также Вы можете оставить программу в фоновом режиме. Это очень удобно при длительных проверках.
Примечательно то, что в программу можно загружать не только текст из буфера обмена или ссылки на страницы, но и файлы. Правда только в форматах TXT и HTML.
Распространяется Praide Unique Content Analyser бесплатно.
3. Etxt Антиплагиат
Также достаточно популярная программа. Распространяется бесплатно. Простая в обращении. Самостоятельно автоматически обновляется. Основным преимуществом утилиты является то, что на плагиат Вы можете проверить не только текстовый контент, но и изображения.
Кроме того, программу можно устанавливать на различные операционные системы: Windows, Linux и Mac..jpg)
Онлайн-сервисы для проверки текста на уникальность
Text.ru
Данный сервис является одним из наиболее популярных среди аналогичных сайтов для проверки уникальности текста. Преимущество ресурса — набор полезных функций для SEO-копирайтинга. Недостаток — бесплатная проверка текста до 15 000 символов. Большее количество является платным.
На Text.ru Вы можете:
- проверить уникальность текста;
- проверить текст на переспам;
- проверить текст на воду;
- проверить орфографию.
Кроме того, на сайте имеется биржа копирайтинга, услугами которой при необходимости можно воспользоваться.
2. Content-watch
Этот сервис чрезвычайно прост в обращении. Запутаться в его использовании просто невозможно. Для проверки на уникальность есть окно для текста и строка для ссылки, если необходимо проверить уже залитый на сайт контент. Ресурсом можно воспользоваться бесплатно. Однако в таком случае Вы сможете проверить текст размером лишь до 10 000 символов.
Одно из неоспоримых преимуществ Content-watch (правда, это платное удовольствие) является то, что сервис может найти тех, кто украл Ваш текст.
Таким образом, на Content-watch можно:
- проверить уникальность текста;
- проверить уникальность сайта;
- защитить свой сайт.
3. Copyscape
Сервис Copyscape считается по праву одним из лучших ресурсов, при помощи которого можно найти тех, кто украл контент. Принцип работы базируется на алгоритмах поисковой системы. Недостаток сервиса в том, что проверка проходит только по ссылкам. Возможность проверить неопубликованный текст не предусмотрена.
Кроме того, бесплатная работа Copyscape имеет ограничения. Вы сможете проверить только лимитированное количество страниц сайтов. Для большего придется брать платный доступ.
Возможности ресурса:
- проверка русскоязычного контента;
- проверка англоязычного контента.
За отдельную плату сервис будет проводить постоянный мониторинг появившегося плагиата.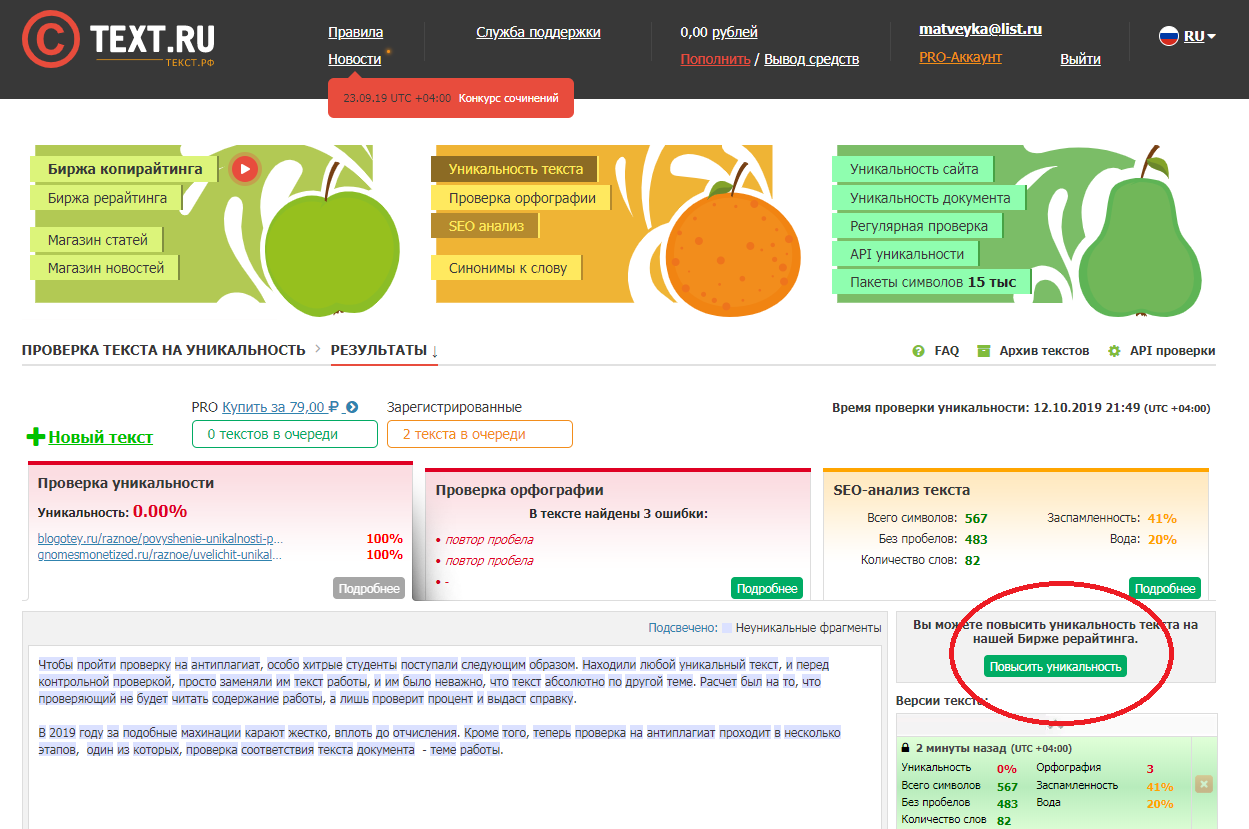 Можно проверку сделать ежедневной или еженедельной.
Можно проверку сделать ежедневной или еженедельной.
4. Miratools
На данном сервисе чрезвычайно удобна возможность проследить, с какого сайта был позаимствован тот или иной фрагмент. Достаточно поднести курсор к подсвеченному элементу, и сразу же появится всплывающее окно со ссылками.
Однако сервис имеет ряд недостатков. Один из основных — неоправданно длительное время проверки. Кроме того, бесплатная версия сайта имеет большие ограничения по количеству символов. Зато платный вариант Miratools может похвастаться такими дополнительными опциями:
- проверка нескольких текстов;
- наличие планировщика заданий;
- автоматический запуск проверки;
- настройка размера шингла;
- пропускаемый участок текста.
Выводы
Нельзя с точностью утверждать, какая из программ или какой из перечисленных выше ресурсов являются самыми лучшими и эффективными. В каждой из разработок используются собственные эксклюзивные алгоритмы. По этой причине остается лишь выбирать, что подходит именно Вам и положительно отразится непосредственно на Вашей деятельности. А в идеале просто используйте сразу несколько сервисов и программ. И у Вас обязательно все получится! Веб-студия NeoSeo желает Вашим веб-ресурсам только уникального контента и успешного продвижения!
По этой причине остается лишь выбирать, что подходит именно Вам и положительно отразится непосредственно на Вашей деятельности. А в идеале просто используйте сразу несколько сервисов и программ. И у Вас обязательно все получится! Веб-студия NeoSeo желает Вашим веб-ресурсам только уникального контента и успешного продвижения!
Как влияет уникальность текста на позиции сайта
Привет, Друзья! В этой статье Вы узнаете, как влияет уникальность текста на позиции сайта и как поисковые роботы проверяют качество и уникальность контента. Итак поехали!
Уникальность текста
Под термином уникальность текста подразумевают значимое свойство информационного материала, которое обозначает размещение контента в интернете только один раз. Обычно такой контент создается специально под тематику сайта, на котором он будет опубликован.
Уникальный текст или статья создаются при помощи копирайтинга – написание оригинальных текстов определенной тематики. Для качественного SEO-продвижения ресурса стоит публиковать на нем только уникальные статьи и фотографии к ним. Все тексты проходят индексацию поисковыми роботами, которые определяют, был ли этот контент ранее опубликован на каком-либо сайте. Сайты с уникальными текстами обычно находятся на вершине рейтинга при поисковом запросе.
Для качественного SEO-продвижения ресурса стоит публиковать на нем только уникальные статьи и фотографии к ним. Все тексты проходят индексацию поисковыми роботами, которые определяют, был ли этот контент ранее опубликован на каком-либо сайте. Сайты с уникальными текстами обычно находятся на вершине рейтинга при поисковом запросе.
Как проверить уникальность текста для сайта
Как правило, уникальность текста измеряется в процентах. Если процент уникальности низкий, то текст был просто переделан из другой статьи, причем весьма плохо. В таком случае это уже рерайтинг, а не копирайтинг. На сегодняшний момент в интернете существует большое количество специализированных сайтов, сервисов и программ по определению уровня уникальности текстов, вот несколько из них, которыми лично я пользуюсь:
https://text.ru
https://content-watch.ru/text/
https://advego.
com/plagiatus/
Проверить текст на уникальность на этих сайтах можно в режиме онлайн, что очень удобно. Также с сайта Адвего можно бесплатно скачать программу и установить на свой компьютер (только Windows) и делать это гораздо быстрее, чем в онлайн-режиме ожидая очередь.
Как проверяют уникальность текста поисковые роботы
Поисковые роботы в процессе индексации сайтов проверяют контент абсолютно всех сайтов на уникальность. Этой процедуры никак не избежать. Если в ходе данной проверки выясняется, что большая часть материалов или абсолютно все содержание сайта является плагиатом с других ресурсов, то поисковая система осуществляет пессимизацию сайта, то есть понижение его позиций при выдаче в поисковом запросе.
Из вышесказанного следует то, что для эффективного продвижения сайта необходимо использовать только оригинальные тексты. Стоит оговориться, что уникальность текста является первостепенным критерием при ранжировании сайтов в рейтинге всех поисковых систем.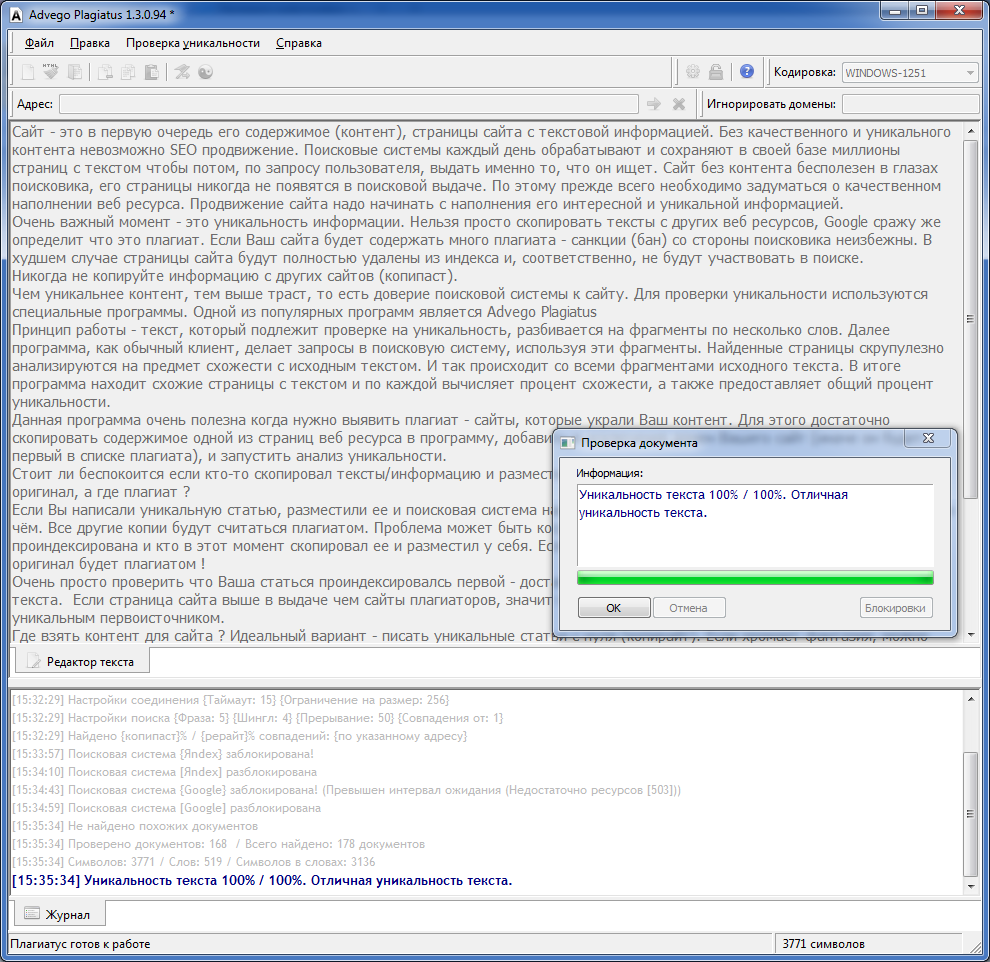 Думаю теперь всем понятно, как влияет уникальность текста на позиции сайта, но есть и исключения из правил.
Думаю теперь всем понятно, как влияет уникальность текста на позиции сайта, но есть и исключения из правил.
Почему не уникальные тексты занимают первые места
На сегодняшний момент Яндекс и Рамблер при поисковом запросе часто выдают в числе первых сайты с неоригинальным контентом, который был просто украден с других ресурсов. В процессе проверки уникальности текста программами используются определенные алгоритмы работы. Они подчиняются законам Зипфа, которые носят имя ученого. Джордж Зипф нашел последовательность частоты повторения слов в обычном тексте. Из этого анализа он сделал два вывода:
- Первый закон Зипфа говорит о том, что возможность применения какого-либо слова в тексте, помноженная на частоту его употребления, является неизменной величиной.
- Второй закон Зипфа говорит о том, что отношение частоты и числа слов, которые включены в текст с данной частотой, всегда одно и то же. Исходя из данных законов, поисковые системы распределяют содержание сайтов по группам.
В первую группу включают те элементы построения текстов, которые никак не влияют на их общий смысл. Это различные союзы и предлоги, не учитываемые при определении уникальности. Вторая группа включает ключевые слова, которые являются очень значимыми для посетителей. К третьей группе относятся случайные словосочетания.
Этот процесс распределения элементов текста получил название канонизация. После того как произошло деление на группы, поисковая система переходит к применению другого алгоритма. Он называется проверка по шинглам. При этом выполняется разделение ключевых фраз на связки по несколько слов, количество которых регламентируется величиной шингла. Причем крайнее слово в текущей связке используется в качестве первого слова в следующей связке. Благодаря этому происходит полная проверка уникальности текста.
При проверке этим алгоритмом для каждого шингла вычисляется определенная сумма, которая не может совпадать у разных текстов. Поэтому сравнение методом шинглов – это весьма достоверный способ проверить оригинальность текста. От суммы шинглов зависит процент уникальности. Если совпадений много, то текст будет менее уникальным. Такой метод определения помогает распознать как полностью ворованные тексты, так и частично заимствованные.
Поэтому сравнение методом шинглов – это весьма достоверный способ проверить оригинальность текста. От суммы шинглов зависит процент уникальности. Если совпадений много, то текст будет менее уникальным. Такой метод определения помогает распознать как полностью ворованные тексты, так и частично заимствованные.
Не стоит забывать и о недостатках проверки текстов алгоритмом шинглов. При использовании устойчивых выражений и цитировании процент уникальности может оказаться неоправданно низким.
Уникальный контент можно получить в результате работы копирайтеров и рерайтеров. Копирайтеры пишут авторские статьи по заданной тематике. Рерайтеры перерабатывают чужой текст в целях его изменения и написания уникального текста, по сути, это пересказ содержания текста другими словами.
Обучение продвижению сайтов
Более подробно о том, как выводить сайты в ТОП 10 поисковых систем Яндекс и Google, я рассказываю на своих онлайн-уроках по SEO-оптимизации (смотри видео ниже).
Все свои интернет-проекты я вывел на посещаемость более 1000 человек в сутки и могу научить этому Вас. Кому интересно обращайтесь!
На этом сегодня всё, всем удачи и до новых встреч!
Что такое уникальный контент и почему он важен для вашего сайта?
Уникальный контент необходим любому владельцу веб-сайта, который хочет, чтобы его сайт занимал первые позиции в результатах поиска. Если вы хотите купить уникальный контент для веб-сайта, вы попали в нужное место; мы предоставляем высококачественный контент, который на 100% уникален — всегда. Чтобы гарантировать это, наш внутренний процесс в Topcontent включает использование нашей ведущей команды писателей в сочетании с программным обеспечением для тщательной внешней проверки на плагиат. Он используется на каждом этапе процесса от написания до корректуры для подтверждения 100% уникальности вывода.
Зарегистрироваться и заказать контент
Уникальный контент, означающий
Уникальный контент — это общий термин, используемый в контексте SEO. Это текст, который нельзя найти в Интернете. Это один из ключевых факторов достижения верхних позиций в результатах поиска, поскольку поисковые системы не будут показывать вашу страницу в результатах поиска, если ее содержание скопировано с другого веб-сайта.
Это текст, который нельзя найти в Интернете. Это один из ключевых факторов достижения верхних позиций в результатах поиска, поскольку поисковые системы не будут показывать вашу страницу в результатах поиска, если ее содержание скопировано с другого веб-сайта.
Если вы не хотите выбросить все свои усилия и вложения в SEO, вам нужно отображать на своем веб-сайте только уникальный текст.
Использование скопированного контента с другого веб-сайта может нанести вред вашему сайту, снизив его рейтинг и резко уменьшив трафик. Если поисковые системы находят один и тот же контент более чем в одном месте, они не могут понять, какую страницу показывать по конкретному запросу. Они предпочтут отображать страницу, которая была проиндексирована ранее и имеет больше полномочий, а именно сайт, который вы использовали для копирования контента. Это приведет к тому, что ваша страница вообще не будет оцениваться.
Предоставляем только 100% уникальный текст Когда вы заказываете контент у нас, мы гарантируем, что он всегда на 100% уникален. Мы предоставляем нашим авторам инструменты и руководства для проведения исследований и преобразования существующей информации в уникальный текст и статьи. Каждая написанная статья затем проходит проверку на плагиат, чтобы убедиться, что она абсолютно уникальна.
Мы интегрировали внешний инструмент, уникальную программу проверки контента под названием Copyscape, в наш процесс создания контента. На каждом этапе процесса он сравнивает текст с двумя разными базами данных:
- Все материалы, опубликованные в Интернете
- Все статьи в нашей базе — более 2000000 из них
Таким образом, мы можем сравнивать неопубликованные работы наших авторов, а также все, что уже найдено в Интернете.Мы собираем любые проблемы или сходства, чтобы мы могли их исправить. Неуникальный контент буквально невозможно пройти через наш процесс, так как системе требуется исправить скопированный контент, прежде чем его можно будет отправить.
После того, как ваш запрос будет обработан и пройден через нашу процедуру проверки качества, вы получите полную ответственность за работу. Это означает, что вы владеете правами на любой контент, который вы приобрели у нас.
Почему стоит покупать уникальный контент для сайта- Гарантированный 100% уникальный результат — вам не нужно тратить время на проверку на плагиат.
- Сэкономьте деньги своей компании, когда вам не нужно покупать другой инструмент для проверки скопированного контента — мы сделаем это за вас в рамках пакета.
- Получение уникального контента гарантирует, что у вашего сайта есть шанс занять верхние позиции в результатах поиска.
Как проверить дублированный или скопированный контент
Duplicate Content Checker: краткое описание Копирование от кого-то другого — плохая идея.Независимо от того, являетесь ли вы учеником в классе или политиком, выступающим с речью, с социальной точки зрения неприемлемо украшать себя «заимствованными перьями» плагиата. Подобное поведение также не приветствуется в Интернете, хотя копировать контент особенно легко. Однако жертвам часто бывает очень сложно проверить, не воспроизвел ли кто-то их контент на другом веб-сайте. К счастью, для этой цели есть средства проверки дублированного контента, которые могут помочь отследить плагиат в Интернете.
Подобное поведение также не приветствуется в Интернете, хотя копировать контент особенно легко. Однако жертвам часто бывает очень сложно проверить, не воспроизвел ли кто-то их контент на другом веб-сайте. К счастью, для этой цели есть средства проверки дублированного контента, которые могут помочь отследить плагиат в Интернете.
Плагиат может стать серьезной проблемой для оператора веб-сайта — независимо от того, копируют ли другие их контент или они невольно используют тексты, которые не являются оригинальными и, следовательно, не публикуют уникальный контент. Google и другие поисковые системы очень настаивают на том, что веб-сайты должны использовать только уникальный контент. Когда Google обнаруживает, что на странице используется скопированный контент, он получает штраф в рейтинге и опускается в выдачу, что ставит сайт в невыгодное положение с точки зрения конкуренции.Средство проверки дублированного контента настоятельно рекомендуется для целей SEO и интернет-маркетинга. Этот тип программного обеспечения может помочь, когда возникает спор о происхождении любого фрагмента контента.
Этот тип программного обеспечения может помочь, когда возникает спор о происхождении любого фрагмента контента.
Например, если компания вложила большие средства в оптимизацию своего веб-сайта, чтобы улучшить его рейтинг по содержанию, было бы более чем неприятно, если бы этот успех не произошел из-за дублирования контента. Хотя это может быть результатом ошибок в SEO веб-сайта, это также может произойти из-за того, что другие скопировали и неправильно использовали контент в другом месте.Затем компания должна решить, принять ли это нарушение, которое также имеет юридические последствия, или попытаться защитить себя. В последнем случае у компании возникает другая проблема: она должна доказать, что ее собственный контент является оригинальным.
Эта проблема может быть решена довольно легко с помощью средства проверки дублированного контента, поскольку некоторые варианты этого программного обеспечения ведут постоянный учет каждой проверки на плагиат. Если вы проверяете свой собственный контент, как только вы его загружаете, есть два преимущества: во-первых, вы можете быть уверены, что случайно не используете скопированные тексты, и, во-вторых, легко доказать, когда именно ваш контент был размещен в сети — и таким образом покажите, что ваш контент является оригинальным, а не версией, используемой вашими конкурентами..png)
По сути, программа для борьбы с плагиатом работает аналогично поисковым системам, таким как Google. Он отбирает определенные отрывки текста или весь текст и сравнивает его с другим контентом, доступным в Интернете. Как правило, для этого программа проверки дублированного контента обращается к индексу Google. Если совпадение найдено, программа отображает URL-адрес страницы, на которой находится контент. Он также показывает, какие отрывки на самом деле дублируются.
Точная доступная функциональность всегда будет зависеть от используемого программного обеспечения. Например, многие средства проверки дублированного содержимого позволяют указать фактическую длину фрагментов, которые программа должна исследовать. Часто бывает полезно немного поэкспериментировать, потому что средство проверки не должно находить каждое маленькое случайное повторение, но оно также не должно быть слишком «щедрым», потому что в противном случае очевидные плагиаты остались бы незамеченными. Модели, доступные на рынке, также различаются с точки зрения интервалов аудита и типа предоставляемой документации для проверки.Например, некоторые средства проверки дублированного содержимого будут регулярно и автоматически проверять содержимое, в то время как другие выполняют задачу только один раз и требуют ручного запуска. Перед тем как принять решение о покупке, вам обязательно стоит ознакомиться с доступными функциями, а также подтвердить стоимость.
Модели, доступные на рынке, также различаются с точки зрения интервалов аудита и типа предоставляемой документации для проверки.Например, некоторые средства проверки дублированного содержимого будут регулярно и автоматически проверять содержимое, в то время как другие выполняют задачу только один раз и требуют ручного запуска. Перед тем как принять решение о покупке, вам обязательно стоит ознакомиться с доступными функциями, а также подтвердить стоимость.
Программа проверки на плагиат предназначена для того, чтобы дать пользователю уверенность в том, что он или она не использует какой-либо сторонний контент и что никто не использует его или ее собственный контент.Если вы посмотрите на то, как работает средство проверки дублированного контента, вы можете подумать, что такое программное обеспечение представляет собой надежную защиту от плагиата — впечатление, которое усиливается многими поставщиками программного обеспечения.
К сожалению, это обманчивое впечатление. Это не в последнюю очередь из-за эвристики, используемой для отслеживания плагиата. Здесь пользователь или провайдер должны выбрать тонкий баланс. Если программное обеспечение поражает слишком сильно, его становится очень трудно использовать, потому что ни у кого нет времени проверять десятки или даже сотни возможных плагиатов каждый день.Однако если параметры программного обеспечения слишком расплывчаты, плагиат может остаться незамеченным. Это, в свою очередь, приведет к ухудшению рейтинга, а дорогостоящие меры по поисковой оптимизации и маркетингу могут оказаться неэффективными.
Кроме того, у большинства средств проверки дублированного контента есть одна фундаментальная проблема: они обращаются к индексу Google, чтобы найти скопированный текст. Хотя это охватывает большое количество страниц, Google не включает все доступные веб-сайты в свой индекс. Это означает, что если страница не проиндексирована, она также будет пропущена любой проверкой на плагиат.
Таким образом, проверка дублированного содержимого является полезной мерой для предотвращения копирования вашего собственного содержимого. Однако программное обеспечение не может обеспечить полную защиту, и вы всегда должны знать об этом.
Какие доступны средства проверки дублированного контента?
Как и в большинстве других программных сред, диапазон средств проверки дублированного контента огромен и, на первый взгляд, их очень трудно понять. Следующие инструменты являются одними из самых популярных и известных примеров, доступных на рынке:
- Copyscape: Это программное обеспечение, вероятно, наиболее часто используется в Интернете, и не без причины.Он очень прост в эксплуатации, а алгоритмы обнаружения плагиата очень надежны. Если большие объемы страниц необходимо проверить на наличие уникального или повторяющегося контента, доступна платная премиум-версия. Кроме того, инструмент может отправлять уведомления, когда скопированный контент был обнаружен во время автоматического сканирования.
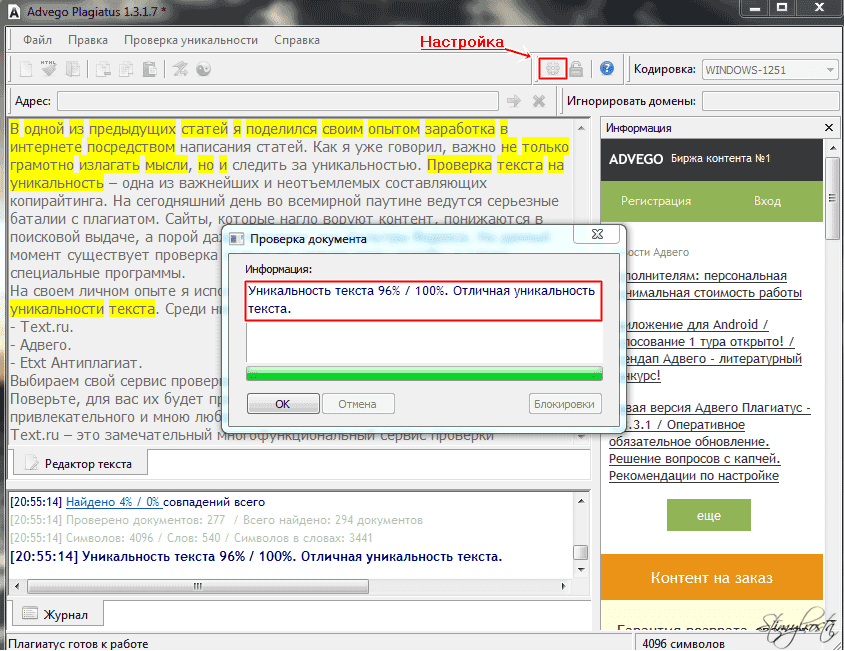
- Проверка статей: этот инструмент может не только проверять веб-сайты на дублированный контент, но и на отдельные тексты, которые просто копируются и вставляются в соответствующее окно. Многочисленные настройки, предлагаемые программой, дают этому продукту преимущество перед Copyscape.Однако его недостатком является то, что алгоритм, используемый для проверки на плагиат, не работает так надежно, как Copyscape.
- Plagium: это платный инструмент, который предлагает второй метод поиска, который является более дорогим, но при этом гораздо более тщательным. Кроме того, пользователь может решить, проводить ли поиск по всему Интернету или ограничивать поиск медиа-порталами или страницами социальных сетей. С помощью этого инструмента можно бесплатно проверить короткие тексты до 5000 символов.
- Copygator: Это программное обеспечение в основном нацелено на операторов блогов, поскольку оно ищет скопированный контент в RSS-каналах, а не в Интернете.Если во время проверки обнаруживается плагиат, инструмент автоматически отправляет сообщение, информирующее пользователя.
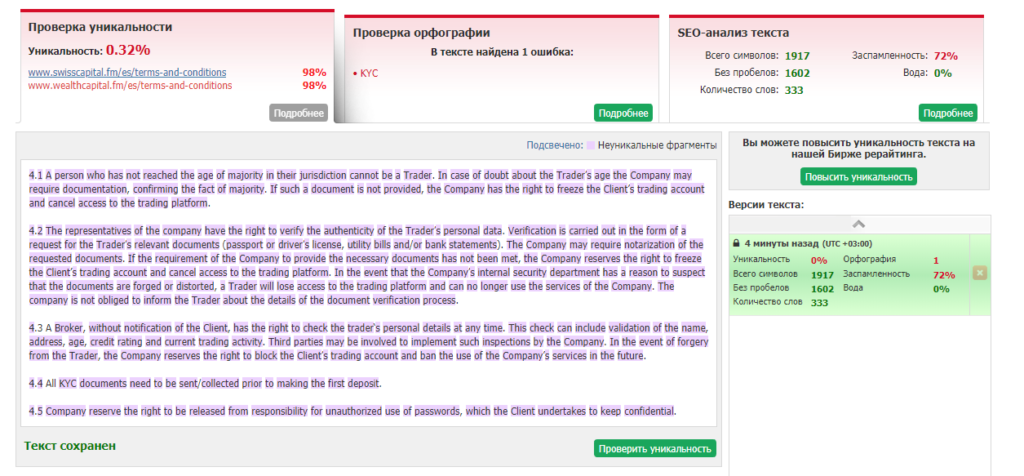
Средство проверки дублированного контента не может обеспечить абсолютную защиту от плагиата, но такое программное обеспечение, тем не менее, рекомендуется. Скопированный контент обычно обнаруживается очень надежно. Кроме того, соответствующий инструмент может предоставить подтверждение того, когда ваш собственный контент был загружен, таким образом показывая, какой контент является оригинальным, а какой был скопирован.Кроме того, средство проверки дублированного контента может предотвратить компрометацию мер SEO из-за эффекта скопированного контента.
«Предыдущая статья Дублирование содержимого Следующая статья» Динамическое содержимое
Как проверить содержимое веб-сайта перед публикацией: 11 удобных инструментов
Контент-маркетинг оказался неотъемлемой частью любой оптимизации веб-сайтов. Сегодня отделы маркетинга и продаж работают как никогда теснее.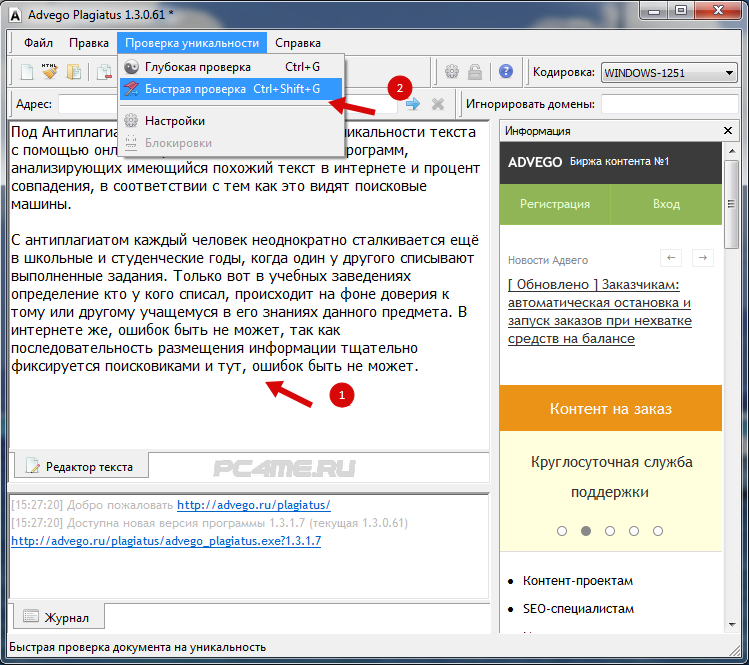 Трудно спорить с тем, что сегодняшний рынок ориентирован на пользователей и, вероятно, останется таковым в следующие десятилетия. Исследование показало, что 76% клиентов ожидают, что поставщики знают их потребности. Чтобы удовлетворить интересы читателей, все больше и больше маркетинговых команд откладывают рекламу продуктов и скидки, уделяя при этом внимание качественному содержанию веб-сайтов, а также взаимодействию между пользователями и бизнесом.
Трудно спорить с тем, что сегодняшний рынок ориентирован на пользователей и, вероятно, останется таковым в следующие десятилетия. Исследование показало, что 76% клиентов ожидают, что поставщики знают их потребности. Чтобы удовлетворить интересы читателей, все больше и больше маркетинговых команд откладывают рекламу продуктов и скидки, уделяя при этом внимание качественному содержанию веб-сайтов, а также взаимодействию между пользователями и бизнесом.
Чтобы быть на вершине конкурентов, необходимо предоставлять безупречный и первоклассный контент.Поднимаясь по карьерной лестнице в SEO, есть на что обратить внимание. Как говорится, дьявол кроется в деталях, поэтому найдите время, чтобы довести до совершенства свой контент. Чтобы ваш веб-сайт сиял как бриллиант, перед публикацией необходимо проверить следующее.
Найдите время для предварительной записи
Определенный набор инструментов может помочь задать тон для создания высококачественного контента. Эти инструменты используются для определения самых популярных тем, фраз, трендовых хэштегов. Их также можно использовать для генерации идей.Все больше людей будут просматривать контент, который построен вокруг органических ключевых слов. Один из таких инструментов — Feedly. Эта услуга может помочь:
Их также можно использовать для генерации идей.Все больше людей будут просматривать контент, который построен вокруг органических ключевых слов. Один из таких инструментов — Feedly. Эта услуга может помочь:
- поиск ключевых слов по отраслям и тенденциям
- установить оповещения по ключевым словам, привязанные к определенному бренду или компании
- открыть для себя связанные темы.
Найдите подходящие ключевые слова
Закончились ключевые слова? Тогда Moz Keyword Explorer поможет вам. Получите всю информацию и статистику по интересующему вас ключевому слову с помощью этого простого инструмента.Moz Keyword Explorer позволяет:
- исследуйте ключевые слова, корневые домены, поддомены или точные страницы
- отсортировать данные по странам.
Планируйте заранее с помощью Планировщика ключевых слов
Это бесплатный инструмент GoogleAds, используемый для анализа эффективности определенных комбинаций ключевых слов. Он использует статистику и историю использования определенных ключевых слов, чтобы показать, чего ожидать в будущем, подобно прогнозу погоды. Планировщик ключевых слов будет полезен как новым, так и опытным промоутерам контента.Планировщик ключевых слов позволит вам:
Он использует статистику и историю использования определенных ключевых слов, чтобы показать, чего ожидать в будущем, подобно прогнозу погоды. Планировщик ключевых слов будет полезен как новым, так и опытным промоутерам контента.Планировщик ключевых слов позволит вам:
найти точные ключевые слова и совпадения длиннохвостых ключевых слов
увидеть глобальную и локальную конкуренцию, т.е. сколько раз в месяц люди ищут определенную комбинацию слов
Источник
Отслеживайте контент и ключевые слова ваших конкурентов
Если вам интересно, как обстоят дела у ваших конкурентов, Ahrefs — один из лучших инструментов для использования. Ahrefs — это инструмент для отслеживания активности любого веб-сайта. Он показывает всевозможные статистические данные и количество просмотров, генерируемых каждым элементом контента.За несколько кликов можно получить список ключевых слов и обратных ссылок, которые ведут на сайт вашего конкурента. Ahrefs имеет несколько полезных функций:
- Обозреватель ключевых слов
- мониторинг профиля обратных ссылок конкурентов и органических ключевых слов
- контентный пробел
- ссылка пересекается
- Пакетный анализ (сравнение нескольких конкурентов)
Знай своего клиента
Используйте Google Search Console! Поскольку рынок ориентирован на потребителя, важно знать своего потребителя. Консоль поиска Google — один из лучших инструментов, позволяющих узнать, что ищут люди. Эта информация жизненно важна для оптимизации вашего сайта под естественные запросы. Консоль поиска Google покажет вам:
Консоль поиска Google — один из лучших инструментов, позволяющих узнать, что ищут люди. Эта информация жизненно важна для оптимизации вашего сайта под естественные запросы. Консоль поиска Google покажет вам:
- самые популярные поисковые запросы = какие ключевые слова люди вводят при показе вашей страницы
- сколько раз отображаются ваши веб-страницы
- сколько кликов получает каждая страница
- , оптимизирована ли ваша страница для мобильных устройств
- как сканировать = отправить свою страницу в индекс
Источник
Редактируйте контент с помощью приложения Hemingway
Этот инструмент помог бесчисленному количеству писателей и создателей контента по всему миру.Приложение Hemingway, пожалуй, лучший инструмент, который вы можете использовать для редактирования контента. Приложение выявляет любые стилистические ошибки и оценивает читабельность текста. Это еще и очень удобно, потому что не нужно ничего скачивать.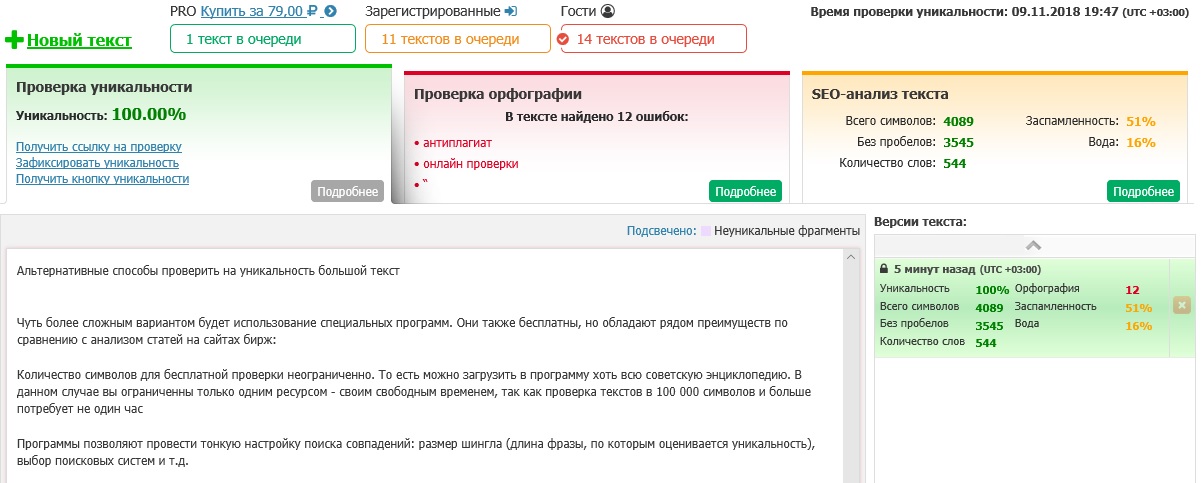 Преимущества приложения позволяют пользователям:
Преимущества приложения позволяют пользователям:
- улучшить читаемость текста
- сокращение длинных предложений
- перефразировать расплывчатые предложения
Найдите время, чтобы вычитать
Grammarly — самый популярный и известный плагин, который поможет вашему тексту выглядеть четким.Иногда мелкие пунктуационные и орфографические ошибки могут ускользнуть от человеческого глаза, особенно в спешке. Вам больше не придется беспокоиться о таких ошибках, когда Grammarly вас поддержит! Вот некоторые из основных функций Grammarly:
- выделение грамматических ошибок Встроенный словарь синонимов
- : если определенная фраза неоднократно встречается в тексте, Grammarly предложит использовать синонимы вместо нее
- Британское правописание
- Проверка на плагиат
Источник
Подготовьте качественный контент
Иногда лучше позволить профессионалам создавать контент для вашего сайта. Существует множество онлайн-платформ, авторы которых знакомы с методами SEO-написания. Автор творческого контента может создавать контент верхнего уровня для вашей маркетинговой кампании. В таких сервисах обычно есть опция творческого письма / написания веб-контента, которая позволяет вам:
Существует множество онлайн-платформ, авторы которых знакомы с методами SEO-написания. Автор творческого контента может создавать контент верхнего уровня для вашей маркетинговой кампании. В таких сервисах обычно есть опция творческого письма / написания веб-контента, которая позволяет вам:
- получить SEO-оптимизированные тексты нужной длины
- иметь контент без плагиата
- экономьте ваше время и деньги в долгосрочной перспективе
Проверить на плагиат
Проведите проверку на плагиат, на всякий случай.Copyscape — отличный инструмент для проверки на плагиат, который выходит далеко за рамки. Copyscape не только проверяет содержимое вашего сайта на оригинальность, но и предлагает некоторую защиту от плагиата после того, как вы разместите страницу в Интернете. Другие аналогичные инструменты включают:
- ProWritingAd
- Гадюка
- WhiteSmoke Проверка плагиата
- Duplichecker
- Проверка грамматического плагиата
Источник
Улучшите дизайн своего сайта
Попробуйте Canva, удобный инструмент перетаскивания, который используют как люди без опыта в дизайне, так и профессионалы.Сделайте свой сайт особенным! С Canva вы получаете доступ к миллионам фотографий и шрифтов для настройки внешнего вида вашей страницы. Canva позволит вам:
- Управляйте своей командой дизайнеров и делитесь макетами
- создавать любой дизайнерский контент: от небольших открыток и календарей до презентаций формата А4 и инфографики.
- установить нестандартные размеры
- скачать в форматах png / jpg
Источник
Изменить фрагмент
ПлагинYoast — это мультитул для SEO, который поможет вам оптимизировать контент, если вы используете платформу на базе WordPress.Используйте этот инструмент для:
- введите ключевые слова, которые будут проиндексированы Google
- отредактируйте фрагмент: введите мета-заголовок и мета-описание
- улучшите читаемость и длину ваших метаданных
Источник
Создание высококачественного контента для привлечения как поисковых систем, так и посетителей требует много времени и энергии. Не торопитесь, чтобы выбрать подходящие ключевые слова с наилучшим соотношением объема и конкуренции. Написав свой текст, запустите проверку на плагиат и тщательно отредактируйте свой контент.После этого не забудьте о SEO-оптимизации: добавьте ключевые слова, мета-заголовок и мета-описание.
Не торопитесь, чтобы выбрать подходящие ключевые слова с наилучшим соотношением объема и конкуренции. Написав свой текст, запустите проверку на плагиат и тщательно отредактируйте свой контент.После этого не забудьте о SEO-оптимизации: добавьте ключевые слова, мета-заголовок и мета-описание.
Вышеупомянутые инструменты — не единственный жизнеспособный вариант для владельцев веб-сайтов. Эти одиннадцать инструментов представляют собой универсально важные этапы создания контента и могут быть заменены. Будьте осторожны со своим контентом, поскольку это виртуальное лицо вашего продукта или услуги. Когда дело доходит до привлечения новых посетителей на ваш сайт, первое впечатление может повлиять на сделку или нарушить ее.
Об авторе: это гостевой пост Элизабет Прайс, творческого писателя-фрилансера, интересующегося образованием, маркетингом и темами, связанными с бизнесом.Бывшая студентка факультета психологии, в настоящее время она расширяет свой кругозор, изучая курс журналистики в Нью-Йорке, одновременно работая в EssayPro в качестве автора блога и помощника редактора.
Заглавное изображение Павла Козлова для иллюстрационного проекта Icons8
Просмотрите коллекции бесплатного программного обеспечения для рисования и бесплатных векторных инструментов и ознакомьтесь с некоторыми удобными инструментами для тестирования удобства использования
Хотите поделиться интересной статьей с нашими читателями? Давай опубликуем.
10 Лучшая бесплатная проверка на плагиат 2020 (ОБНОВЛЕНО)
Плагиат подразумевает использование чужой работы как своей для какой-то выгоды или выгоды. Плагиат — это неэтично и неправильно. Когда дело доходит до содержания веб-страницы, это также наносит ущерб SEO (поисковой оптимизации) и тому, как Google будет оценивать и ранжировать ваш контент.
Примером плагиата может быть выбор вами доступа к веб-сайту, посвященному теме, которую вы хотите охватить, а затем использование функции «копировать и вставить», чтобы украсть этот контент и выдать его за свой.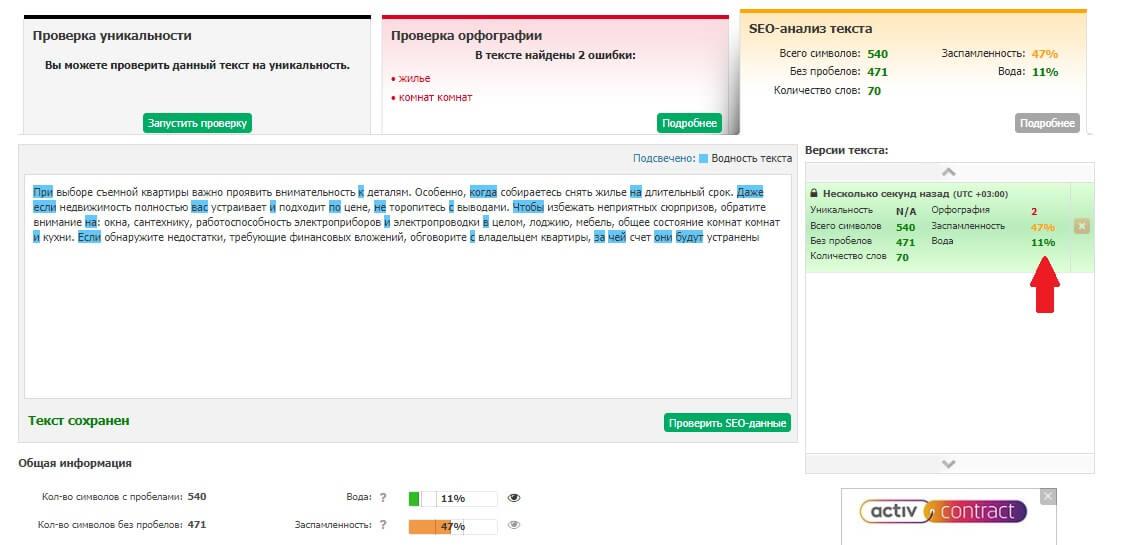
При написании любого онлайн-контента, будь то для веб-сайта или блога, всегда хорошо проверять, что ваше письмо уникально и еще не появилось нигде в Интернете, написано кем-то другим … Точно так же, если вы уверены, что контент, который вы пишете, является уникальным для вас, не помешает проверить, что ваш контент не был плагиатом.
Почему вам следует использовать бесплатную проверку на плагиат? Если вы действительно хотите писать качественный контент и приносить пользу своим читателям, то проверка на плагиат в любой форме стоит того, и это небольшая цена.
Мы снова и снова слышим, что «контент — король» в Интернете, и это все еще движущая сила SEO сегодня.
Чтобы лучше защитить ваш уникальный контент и помочь вам отсеять любой непреднамеренный плагиат, вот список 10 лучших бесплатных онлайн-средств проверки на плагиат: которые могут помочь вам удалить любой некачественный контент.
Duplichecker
PaperRater
Copyleaks
PlagScan
Плагиат
Проверка на плагиат
Quetext
Маленькие инструменты SEO — проверка на плагиат
Плагиум
Отчеты поисковых систем
Один хорошо известный бесплатный инструмент — Duplichecker. Этот инструмент великолепен, поскольку он включает в себя другие средства автоматизации, связанные с контентом, такие как проверка орфографии и грамматики.Легко использовать. Просто загрузите свой контент или скопируйте и вставьте его в текстовое поле, которое они предоставляют.
Этот инструмент великолепен, поскольку он включает в себя другие средства автоматизации, связанные с контентом, такие как проверка орфографии и грамматики.Легко использовать. Просто загрузите свой контент или скопируйте и вставьте его в текстовое поле, которое они предоставляют.
Оттуда осталось немного времени, чтобы получить результаты проверки — вам не нужно вводить адрес электронной почты или создавать учетную запись. Ограничение на один поиск — 1000 слов, но это не проблема.
Легкая, плавная и бесплатная программа проверки плагиата, которая работает.
Этот инструмент обнаружения плагиата работает как надстройка к средству проверки содержимого, поэтому убедитесь, что вы установили флажок, чтобы включить средство проверки на плагиат при проверке веб-страницы.
Есть еще несколько кнопок, на которые можно нажать, поэтому это может занять немного больше времени, чем Duplichecker, но обнаружение плагиата очень точное, так что подождать стоит..png?1549983310226)
Кроме того, в поиске вы найдете результаты с орфографическими ошибками, грамматикой, оценкой вашего содержания, предложениями по выбору слов и парой других вкладок.
Copyleaks — еще одна высокоточная программа проверки контента, которая может предоставить вам подробную информацию о плагиате.Хотя это бесплатно, вам необходимо создать учетную запись, и даже в этом случае вам разрешено сканировать только 10 страниц бесплатно каждый месяц. Так что, если вы создаете много контента, это может не подойти вам.
Вы можете загрузить контент для проверки либо из URL-адреса, либо из локального файла, либо добавить его с помощью обычного текста.
Используя учетную запись, вы получаете дополнительное преимущество в виде сохранения ваших предыдущих сканированных изображений для повторного открытия, когда захотите, а также дополнительный инструмент проверки грамматики.
PlagScan больше подходит для студентов, но также хорошо работает и для онлайн-контента. Интерфейс немного загроможден и, как и последний сканер на плагиат, вам действительно нужно создать учетную запись, вы делаете это с помощью «бесплатной пробной версии», но инструмент дает вам 20 бесплатных кредитов для выполнения 20 сканирований.
Интерфейс немного загроможден и, как и последний сканер на плагиат, вам действительно нужно создать учетную запись, вы делаете это с помощью «бесплатной пробной версии», но инструмент дает вам 20 бесплатных кредитов для выполнения 20 сканирований.
Поскольку стандартными каналами импорта являются URL, локальные файлы или добавление простого текста, PlagScan делает эту часть простой в использовании. Отсканированные изображения сохраняются в вашей учетной записи для доступа в любое время с дополнительной информацией, такой как количество слов и даты.
Анализируя веб-контент в Google и Bing, этот инструмент удобен для сообщений в блогах и другого онлайн-контента. Просматривая Интернет-индекс, вы можете увидеть, было ли скопировано содержание и на каких веб-сайтах существует подобное содержание.
Plagiarisma позволяет легко идентифицировать и отловить скопированный контент.
Сайт, содержащий эту программу проверки, устарел — вроде серьезно.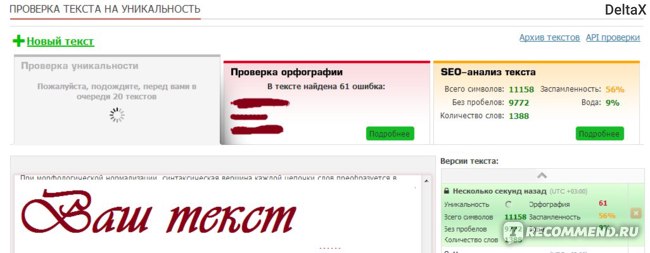 Однако им легко пользоваться прямо с главной страницы. Вы можете вставить свой контент и нажать поиск. Сам поиск выполняет переадресацию в Google и использует поисковые операторы для поиска дублированного содержания только в индексе Google, поэтому он не является невероятно точным. Вы можете настроить его на поиск в Yahoo, если это ваша предпочтительная поисковая система.
Однако им легко пользоваться прямо с главной страницы. Вы можете вставить свой контент и нажать поиск. Сам поиск выполняет переадресацию в Google и использует поисковые операторы для поиска дублированного содержания только в индексе Google, поэтому он не является невероятно точным. Вы можете настроить его на поиск в Yahoo, если это ваша предпочтительная поисковая система.
Этот инструмент идеально подходит для SEO и онлайн-контента.
Безусловно, самый красивый и простой в использовании инструмент проверки. Quetext позволяет вам копировать и вставлять ваш контент в текстовое поле и проверять наличие плагиата.
Однако вы не можете загрузить файл или связать веб-страницу для сканирования, поэтому вы очень ограничены в способах импорта контента.
Ваши результаты быстро и легко читаются, а содержание выделено с любыми проблемами.
Как и Duplichecker, это простой в использовании инструмент для борьбы с плагиатом, который быстро дает результаты.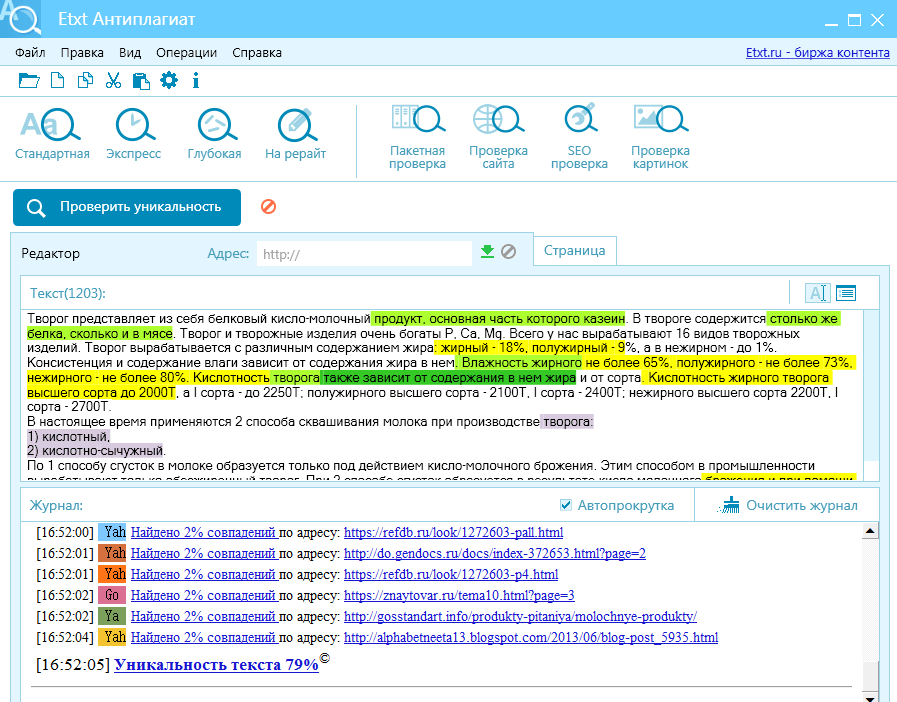 Вы можете загружать и вставлять свой контент через URL, локальные файлы или копировать и вставлять текст.Это 100% бесплатно без необходимости регистрироваться или вводить какие-либо личные данные.
Вы можете загружать и вставлять свой контент через URL, локальные файлы или копировать и вставлять текст.Это 100% бесплатно без необходимости регистрироваться или вводить какие-либо личные данные.
Вы можете легко увидеть плагиат по сравнению с уникальным контентом в процентном соотношении с совпадающими источниками, если контент был плагиатом.
В качестве бесплатного инструмента Plagium отлично работает. Текст легко ввести, а результаты поиска текста с плагиатом быстро отображаются под поиском. Они ищут плагиат в Интернете только для того, чтобы его нельзя было использовать для научных статей.
Опять же, это всего лишь проверка типа копирования и вставки, которая не предлагает никаких форматов файлов, поэтому ограниченная функциональность, но вы получаете полностью точные результаты для индекса Google. Вы можете использовать их инструмент «глубокого поиска», но это не бесплатно.
Глядя на этот интерфейс, он почти идентичен инструменту защиты от плагиата Small SEO Tools. Кнопки немного выключены, а реклама находится так близко к этим кнопкам, что это не самый доступный инструмент для использования в подобных ситуациях.Однако с загрузкой файлов, обычным текстом и даже возможностью импорта с диска Google вы можете использовать это в качестве альтернативы, если по какой-то причине программа проверки Small SEO Tools не работает.
Кнопки немного выключены, а реклама находится так близко к этим кнопкам, что это не самый доступный инструмент для использования в подобных ситуациях.Однако с загрузкой файлов, обычным текстом и даже возможностью импорта с диска Google вы можете использовать это в качестве альтернативы, если по какой-то причине программа проверки Small SEO Tools не работает.
Детектор бонусного плагиата:
Чумной
Если 10 было недостаточно, Plagly — это довольно новый инструмент, который предлагает проверку грамматики, проверку на плагиат и премиум-сервис. Бесплатный инструмент имеет ограничение в 1000 слов, и чтобы получить отчет, вам необходимо зарегистрироваться с адресом электронной почты.Они также предлагают его как расширение Google Chrome, чтобы вы могли быстро получить доступ к инструменту при написании нескольких фрагментов контента.
Итак, какая программа для проверки плагиата лучше? Small Seo Tools предоставляет одну из лучших бесплатных онлайн-проверок на плагиат. Благодаря простоте использования и точности он выходит на первое место. Идеальная программа для проверки плагиата как для студентов, так и для блогеров.
Благодаря простоте использования и точности он выходит на первое место. Идеальная программа для проверки плагиата как для студентов, так и для блогеров.
Но попробуйте сами. Вам не нужно загружать какое-либо программное обеспечение для этих чекеров. Все они онлайн (и все совершенно бесплатно).
Существует большая неуверенность в том, насколько точны средства проверки на плагиат, особенно если вы используете бесплатную версию. По большей части эти бесплатные инструменты работают отлично и могут использоваться как отдельная проверка. Однако помните, что они не везде проверяют скопированный контент. Будучи бесплатными, большинство этих программ проверки будут очищать только дублированный контент в Google, Bing и других поисковых системах. Но такая степень проверки часто не требуется. Пока контент не существует в Интернете, вы можете его использовать.
Независимо от того, являетесь ли вы писателем-фрилансером или студентом, проверяющим академические работы, эти инструменты помогут вам проверить наличие плагиата (непреднамеренного или иного) и написать оригинальный контент.
Следите за этим пространством, так как Creative Asset скоро выпустит нашу собственную бесплатную программу проверки на плагиат, чтобы управлять ими всеми.
Часто задаваемые вопросы о плагиатеПлагиат незаконен?
Не в себе. Это зависит от формы плагиата и наличия авторских прав на материалы.Плагиат — это моральный и этический вопрос, который в академических кругах регулируется кодексом чести. В коммерческом контексте плагиат регулируется законом об авторском праве. Таким образом, вы можете столкнуться с судебным иском, если вы используете плагиат материалов, защищенных авторским правом, для написания своего контента или не отправите оригинальную работу.
Использовал ли я плагиат моего письменного контента?
Чтобы точно знать, есть ли ваш контент где-то в сети, пропустите его через ряд лучших бесплатных программ проверки на плагиат и избегайте плагиата
Как работает бесплатная проверка на плагиат?
Лучшие бесплатные средства проверки на плагиат работают, просматривая индекс веб-сайтов в Интернете и сравнивая ваш письменный контент с тем, что уже есть в Интернете.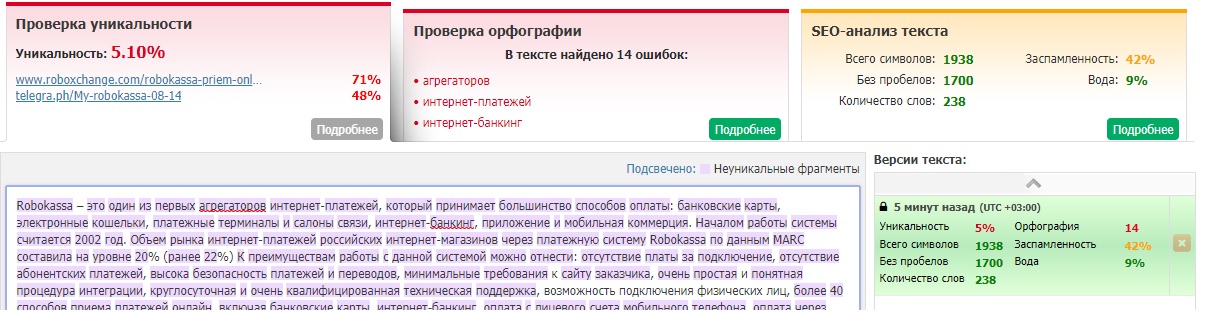 Кроме того, некоторые платные программы проверки премиум-класса также имеют доступ к частным академическим базам данных.
Кроме того, некоторые платные программы проверки премиум-класса также имеют доступ к частным академическим базам данных.
Плагиат — это то же самое, что и нарушение авторских прав?
Плагиат — это использование чужой работы и выдача ее за свою. Нарушение авторских прав может произойти, если эта работа была использована без предварительного разрешения автора. Вы заметите, что на большинстве веб-сайтов в нижнем колонтитуле имеется знак авторского права. Это означает, что вам потенциально может быть предъявлен иск, если вы нарушите любое их содержание.
Как мне сообщить о плагиате в Интернете?
Один из самых простых способов сообщить об этом в Интернете — это воспользоваться инструментом Google для удаления авторских прав. Вам нужно будет сообщить о странице и предоставить подтверждающие доказательства. Затем инструмент удалит веб-страницу (и, возможно, веб-сайт) из Google. Вы также можете использовать этот метод для подачи иска.
Почему я должен проверять контент на плагиат?
Вам следует проверить на плагиат по ряду причин.1.) Если контент будет написан где-то еще, вы можете испортить свои академические баллы. 2.) Это занимает 2 минуты, так почему бы и нет? 3.) Если вы пишете контент в Интернете и используете SEO для продвижения своего контента, плагиат будет реальной проблемой и будет удерживать ваш сайт в результатах поиска.
Контент, созданный плагиатом, — это то же самое, что дублированный контент ?
Нет, дублирующийся контент — это всего лишь 2 копии одного и того же основного текста. Таким образом, у вас может быть дублированный контент из-за наличия одного и того же контента на нескольких страницах вашего веб-сайта, но это не будет плагиатом.
20 лучших средств проверки дублированного контента
Опубликовано 2 октября 2019 г. в Content. Tagged: дублирование контента, плагиат.Плагиат по сей день остается большой проблемой в Интернете. Некоторые копируют из Википедии, а другие могут украсть вашу собственную работу. Кроме того, нанимаемые вами авторы контента могут случайно или намеренно использовать плагиат для своих статей. Вот почему так важна проверка на дублирующийся текст, и вот двадцать лучших средств проверки дублированного контента.
1.Инструменты обзора SEO
Инструменты обзора SEO Средство проверки дублированного содержимого считается одним из лучших средств проверки дублированного содержимого, доступных в настоящее время в Интернете. Он может обрабатывать как обычный текст, так и ввод URL. Инструменты проверки SEO также находят как внутренний, так и внешний дублированный контент для одной конкретной веб-страницы. Внутренний дублированный контент — это контент, который находится на нескольких страницах по одному и тому же URL-адресу, в то время как внешний относится к одному и тому же тексту, найденному в разных доменах.
2. Copyscape
Copyscape часто называют самой популярной программой проверки дублированного контента.Copyscape предлагает несколько инструментов, таких как Copyscape (онлайн-средство проверки плагиата), Copyscape Premium (платное, более мощное средство проверки плагиата), Copysentry (инструмент, который отправляет вам по электронной почте ежедневные или еженедельные отчеты о том, были ли ваши страницы скопированы в Интернете), и другие особенности.
3. Dupli Checker
Dupli Checker на самом деле предлагает не только проверку на плагиат, но и некоторые другие ценные инструменты, доступные на своем веб-сайте. К ним относятся такие вещи, как инструмент перефразирования, проверка обратных ссылок, счетчик слов, проверка авторитетности домена, обратный поиск изображений и положение ключевых слов.
4. Siteliner
Siteliner — это бесплатная программа для проверки дублированного контента, которая фокусируется на плагиате контента на внутренних страницах вашего веб-сайта. Он специализируется на сканировании и анализе трех основных факторов, которые влияют на рейтинг вашего веб-сайта: дублированный контент, неработающие ссылки, мощность страницы и отчеты.
5. Hive Digital
Hive Digital на данный момент считается наиболее полной онлайн-проверкой на плагиат.Он анализирует семь наиболее распространенных факторов, влияющих на текущие и потенциальные проблемы с контентом. Hive Digital на самом деле является агентством цифрового маркетинга, которое предоставляет различные услуги SEO и маркетинга, но их инструмент для создания дублированного контента бесплатный и очень эффективный.
6. Copyleaks
Copyleaks использует передовую технологию искусственного интеллекта для сканирования вашего текста и обнаружения плагиата и сообщений о содержании. Он также находит перефразированный контент и подтверждает оригинальность на каждом языке.Copyleaks идеально подходит для академического использования, то есть для студентов, университетов и школ.
7. Малые инструменты SEO
Маленькие инструменты SEO Программа проверки дублированного контента является бесплатной и была разработана с учетом глубоких исследований. Кроме того, он предлагает множество инструментов для написания и редактирования, включая проверку на плагиат, переписывание статей, проверку орфографии, счетчик слов и средство смены регистра текста.
8. Paper Rater
Paper Rater — это онлайн-инструмент для проверки на плагиат, который использует специальные алгоритмы для обнаружения скопированного текста.Он также обнаруживает грамматические ошибки в вашем тексте и предлагает инструмент для корректуры, чтобы отредактировать ваш текст и улучшить его.
9. Scanmyessay
Scanmyessay также известен как Viper Plagiarism Checker. Он обнаруживает плагиат и дублированный контент и используется тысячами людей по всему миру. Одним из самых больших преимуществ Scanmyessay является то, что он поддерживает более пятидесяти языков, включая английский, китайский, испанский, арабский и многие другие.
10. Grammarly
Grammarly в основном известен своей проверкой грамматики, но на самом деле также имеет средство проверки на плагиат, которое дает вам отчет после сканирования вашего текста. Он обнаруживает плагиат с миллиардов веб-страниц в дополнение к академическим базам данных ProQuest.
11. Prepostseo
Онлайн-программа проверки плагиата и дублирования контента Prepostseo идеально подходит для проверки оригинальности вашего контента.Вы можете скопировать и вставить свой текст или загрузить файл. На их веб-сайте также есть множество других инструментов, таких как счетчик слов, обратный поиск изображений, создание обратных ссылок, обрезка изображений, проверка авторитетности домена, проверка грамматики, инструмент перефразирования, индексатор Google, изображение в текст и многое другое.
12. Text Mechanic
Text Mechanic предоставляет вам все виды различных текстовых инструментов, включая средство проверки дублированного контента. Существуют также другие, такие как генератор комбинации строк, экстрактор столбцов с разделителями, замена текста, добавление разрыва строки, добавление префикса / суффикса, счетчик слов и многое другое.
13. Quetext
Quetext обслуживает более 2 миллионов пользователей, обнаруживая плагиат с помощью своей технологии DeepSearch. Между прочим, у него один из самых приятных интерфейсов среди всех средств проверки плагиата и дублирования текста в этом списке.
14. Plagiarisma
Plagiarisma — еще одна отличная бесплатная программа для проверки дублированного контента. Он имеет упрощенный дизайн, но это не должно вас пугать, поскольку, тем не менее, он все еще довольно эффективен.Кроме того, существуют мобильные версии для Android, Moodle и BlackBerry, а также настольная версия для Windows. Он также работает как веб-инструмент.
15. Webconfs
Webconfs определяет процент содержимого и сходство между двумя страницами. Если эти цифры слишком велики, значит, у вашего сайта проблемы с поисковым рейтингом. Webconfs также имеет инструменты для проверки скорости страницы, подсчета слов, кодирования и декодирования URL, проверки подозрительных доменов, поиска битых ссылок и так далее.
16. Bibme
Bibme улучшает структуру предложений, пунктуацию, стили письма и грамматику. Он также проверяет отсутствие цитат и непреднамеренного плагиата, а также добавляет цитаты и библиографию для нескольких стилей и типов источников.
17. PlagiarismChecker.com
Проверка на плагиат также имеет упрощенный дизайн, как и Plagiarisma. Это позволяет вам искать несколько фраз в вашем контенте, не вводя кавычек или специальных операторов.К тому же это абсолютно бесплатно.
18. Plagramme
Plagramme поддерживает восемнадцать языков, включая английский, немецкий, итальянский, французский, испанский, голландский, португальский, русский и другие. Он бесплатный и работает по логике процентной оценки. Этот инструмент идеально подходит как для студентов, так и для учителей.
19. Детектор плагиата
Детектор плагиата анализирует ваш контент в соответствии с лексической частотой, совпадающими фразами и выбором слов для обнаружения плагиата или скопированного текста.Студентам особенно полезно сохранять оригинальность текста на высоком уровне.
20. Plagium
И последнее, но не менее важное: Plagium анализирует текст, URL-адреса или файлы. Наряду с обнаружением повторяющегося текста он также применяет правила синтаксиса и использования слов для улучшения вашей грамматики. Рекомендуется для маркетологов, но может быть полезен и другим профессионалам.
Заключительные мысли
В общем, существует множество программ проверки дублированного контента на выбор, но они наиболее популярны среди пользователей всемирной паутины.Обязательно попробуйте их и посмотрите, какой из них лучше всего соответствует вашим потребностям.
Об авторе
Кристин Сэвидж питает, зажигает и придает силы, используя магию слова. Наряду с получением степени в области творческого письма, Кристин приобретала опыт работы в издательской индустрии, обладая знаниями в области маркетинговой стратегии для издателей и авторов. Сейчас она работает внештатным писателем в Studicus и GrabMyEssay. Вы можете найти ее на Facebook.
Комментарии закрыты.
Средство проверки дублированного содержимого / средство обнаружения плагиата
Средство проверки дублированного содержимого / обнаружение плагиата.
Обновления: 1. Средство проверки дублированного содержимого теперь также может обрабатывать ввод простого текста, помимо ввода URL. 2. Щелкнув поле расширенных параметров, вы можете выбрать вариант поиска повторяющегося содержимого на основе нескольких точек данных (выделение текста). 3. И я изменил способ представления возвращаемых результатов.
Используйте средство проверки дублированного содержимого, чтобы найти внутренний и внешний дублированный контент для определенной веб-страницы.Дублированный контент — важная проблема SEO, потому что поисковые системы стараются отфильтровать как можно больше дубликатов, чтобы обеспечить лучший поиск. Этот инструмент может обнаруживать два типа (текстового) дублированного контента. Типы дублированного контента:
- Внутренний дублированный контент. Это означает, что один и тот же текст находится на нескольких страницах по одному и тому же URL-адресу.
- Внешний дублированный контент. В этом случае один и тот же текст находится в нескольких доменах.
Почему важно предотвращать дублирование контента?
Как упоминалось выше, поисковые системы не любят дублированный контент / плагиат, потому что пользователи не заинтересованы в просмотре страницы результатов поиска, содержащей несколько URL-адресов, каждая из которых содержит более или менее одинаковый контент.Чтобы этого не произошло, поисковые системы пытаются определить исходный источник, чтобы они могли показать этот URL-адрес для соответствующего поискового запроса и отфильтровать все дубликаты. Как мы знаем, поисковые системы довольно хорошо справляются с фильтрацией дубликатов, но все же довольно сложно определить исходную веб-страницу. Это может случиться, когда один и тот же блок текста появляется на нескольких веб-сайтах, алгоритм решит, что страница с наивысшим авторитетом / наивысшим доверием будет отображаться в результатах поиска, даже если это не исходный источник.В случае, если Google обнаруживает дублированный контент с целью манипулирования рейтингом или обмана пользователей, Google внесет корректировки в рейтинг (, фильтр Panda, ) или сайт будет полностью удален из индекса Google и результатов поиска.
Как работает проверка дублированного контента?
- Найдите проиндексированный дублированный контент, используя ввод URL или ТЕКСТА.
- Используйте ввод URL для извлечения основного содержания статьи / текста, находящегося в теле веб-страницы. Элементы навигации удалены, чтобы уменьшить шум (в противном случае многие страницы были бы ошибочно идентифицированы как внутренние дубликаты.)
- Используйте ввод текста, чтобы получить больше контроля над вводом.
- Выберите дополнительные параметры, чтобы выбрать одну или несколько точек данных, используемых для обнаружения повторяющихся страниц. Выбор нескольких точек данных даст вам более точные и даже лучшие результаты сопоставления. (Эти точки данных автоматически извлекаются из содержимого страницы или ввода текста).
- Подобный контент извлекается, возвращается и помечается как: входной URL, внутренний дубликат, внешний дубликат.
- Экспорт результатов в.CSV. и используйте электронную таблицу Excel / Open Office, чтобы просматривать, редактировать или сообщать о своих результатах.
Как использовать эти результаты?
Внутренние дубликаты В большинстве случаев вы начнете решать внутренние проблемы дублирования. Потому что эти проблемы существуют в вашей собственной контролируемой среде (на вашем веб-сайте). Для удаления внутренних дубликатов можно использовать разные методы, в зависимости от характера проблемы. Некоторые примеры:
- Минимизировать повторение шаблонов
- Использовать постоянное перенаправление 301
- Использовать канонический тег
- Использовать обработку параметров в Инструментах Google для веб-мастеров
- Запретить индексирование URL.
Внешние дубликаты Внешние дубликаты — это отдельная история, потому что вы не можете просто внести изменения в свой собственный сайт и решить проблему. Некоторые примеры удаления внешних дубликатов:
- Обратитесь к веб-мастерам и попросите их удалить копии вашего контента.
- Если другой сайт дублирует ваш контент / в нарушение закона об авторских правах и обращение к нему не решает проблему, вы можете использовать эту форму, чтобы уведомить Google: https: // support.google.com/legal/troubleshooter/1114905.
Ограничения инструмента
- Этот инструмент автоматически извлекает текст из веб-страницы для использования в качестве входных данных для обнаружения дублированного контента. Это не всегда именно тот блок текста, который нужно проверять на наличие дубликатов. В этом случае лучше использовать поле ввода текста.
- Новое содержимое необходимо проиндексировать, прежде чем его можно будет вернуть с помощью этого инструмента. Если странице / контенту меньше 2 дней, шансы получить какие-либо результаты невелики.
- Не все дубликаты, найденные в Интернете, возвращаются этим инструментом. Но по сравнению с другими инструментами возвращает довольно большую сумму.
Внешние ресурсы:
Пожалуйста, поделитесь ❤ Инструменты для содержания SEO, Инструменты для SEOДублирующее содержание SEO
Рекомендации по дублированию контентаЦИТАТА: « Важно : Самый низкий рейтинг подходит, если все или почти все MC (основной контент) на странице — это , скопированный с минимальными затратами или без времени, усилий, опыта, ручного курирования или дополнительных преимуществ для пользователей. Такие страницы должны иметь самый низкий рейтинг , даже если страница присваивает кредит за содержание другому источнику ». – Рекомендации для оценщиков качества поиска Google, 2017 г.
У Google НЕТ штрафа за дублирование контента . Google награждает уникальный контент и сигналы, связанные с добавленной стоимостью . Google фильтрует дублированного контента в поисковой выдаче. Google DEMOTES скопировал контента в SERPS.Google ДЕМОНТИРУЕТ манипулятивный дублированный контент в SERPS. Google ПЕНАЛИЗИРУЕТ низкокачественное подробное содержимое, скопированное с других веб-страниц. НЕ ожидайте высокого рейтинга в Google с контентом, найденным на других, более надежных сайтах.
- Добавляйте на свои веб-страницы только уникальное рукописное содержимое
- Не добавляйте на свои страницы содержимое, которое дословно встречается на других страницах в Интернете
- Не используйте команду « вращать » на страницах вашего сайта
- Не создавайте тонкие страницы, которые не принесут пользы пользователям.
- Внедрите элемент ссылки rel = ”canonical” на всех страницах своего сайта, чтобы минимизировать дублированный контент.
- При необходимости примените 301 постоянное перенаправление.
- Используйте обработку параметров URL. инструмент в Google Search Console, где это необходимо.
- Уменьшите ожидания сканирования роботом Googlebot.
- Консолидация рейтинга и потенциала высококачественных канонических страниц
- Сведите к минимуму повторение шаблонов на вашем сайте
- Не блокируйте Google от вашего дублированного контента, просто лучше управляйте им
- Сайты с отдельными мобильными URL-адресами должны просто перейти на адаптивные design
- Канонические элементы ссылок могут игнорироваться Google
- Избегайте публикации заглушек для текста «скоро»
- Минимизируйте похожее содержимое на своих страницах
- НЕ канонизируйте страницы компонентов в серии до первой страницы.
- Google вообще не использует link-rel-next / prev. Вы можете использовать его, если хотите, но не полагайтесь только на него.
- Переведенный контент не является дублированным контентом.
- Запретить Google сканировать тонкие страницы результатов внутреннего поиска.
- Проверьте содержание на вашем сайте, которое дублирует содержание, найденное в другом месте.
- Самый простой способ найти дублирующийся контент — использовать поиск Google с использованием «кавычек».
- Используйте Google Search Console, чтобы исправить проблемы с дублированным контентом на вашем сайте.
Скопированный контент
TL; DR: «Дублирующееся содержимое » НЕ упоминается ** один раз ** в недавно опубликованном Руководстве по оценке качества поиска . «Скопированный контент», — .
Помимо семантики, дублированный контент , очевидно, обрабатывается Google иначе, чем скопированный контент, с той разницей, что НАМЕРЕНИЕ и природа дублированного текста.
Дублированный контент часто не является манипулятивным, является обычным явлением в Интернете и часто не имеет злонамеренного характера.Это не наказывается, но не оптимально. Скопированный контент часто может быть наказан алгоритмически или вручную. Не «крутите» «копируемый» текст, чтобы сделать его уникальным!
Google четко говорит, что практика создания более «уникального» текста с использованием низкокачественных методов, таких как добавление синонимов и родственных слов, выглядит следующим образом:
ЦИТАТА : «вероятно, более контрпродуктивно, чем на самом деле помогает вашему веб-сайту» Джон Мюллер, Google
Андрей Липатцев из Google непреклонен: у Google НЕТ штрафа за дублирование контента.
Он явно хочет, чтобы люди поняли, что это НЕ наказание, если Google обнаруживает, что ваш контент не является уникальным и не ставит вашу страницу выше страницы конкурента.
ЦИТАТА : « Вы правильно поняли, что нет штрафа за дублированный контент. … Я бы не стал говорить о штрафах за дублированный контент в целях спама, потому что тогда речь идет не о дублировании контента, а о создании очень часто в автоматическом режиме. таким образом контент, который не столько дублируется, сколько быстро и извлекается из нескольких мест, а затем потенциально, вероятно, монетизируется тем или иным образом, и он просто не служит никакой цели, кроме как получить трафик с перенаправлением трафика, возможно, заработать немного денег для человека кто его создал, речь идет не о контенте, который действительно создается по какой-либо причине, кроме просто для того, чтобы быть там, поэтому я, человек, я не думаю об этом как о дублированном контенте, просто это несоответствие, это то же самое, что сказать, что может быть, мы создали тарабарщину — это своего рода дублированное содержание слов, но в остальном тоже существует, как будто я действительно разделил бы эти две проблемы, потому что то, что Аамон вел в w с URL-адресами, сгенерированными на WordPress, и тем, что они собирались обсудить сегодня позже, возможно, о сайтах электронной коммерции и т. д. Я не хотел бы, чтобы люди путали эти два. »Андрей Липатцев, Google, 2016
Кроме того, как указывает Джон Мюллер, Google выбирает лучший вариант для отображения пользователей в зависимости от того, кто они и где находятся. Поэтому иногда ваш дублированный контент будет отображаться пользователям там, где это необходимо.
Этот последний совет от Google полезен тем, что он разъясняет позицию Google, которую я быстро перефразирую ниже:
- Нет штрафа за дублирование контента
- Google награждает УНИКАЛЬНОСТЬ и сигналы, связанные с ДОБАВЛЕННЫМ ЗНАЧЕНИЕМ
- Google ФИЛЬТРЫ дублированный контент
- Дублированный контент может замедлить поиск нового контента Google.
- XML-карты сайта — это едва ли не ЛУЧШИЙ технический метод, помогающий Google обнаружить ваш новый контент.
- Дублированный контент, вероятно, не вызовет пожар в вашем маркетинге.Скопированный и воспроизводимый контент, конечно же, тоже не является.
- Google хочет, чтобы вы сконцентрировали сигналы в канонических документах, и он хочет, чтобы вы сосредоточились на том, чтобы сделать эти канонические страницы ЛУЧШЕ для ПОЛЬЗОВАТЕЛЕЙ.
- Для SEO не обязательно изобилие дублированного контента на веб-сайте является реальной проблемой. Отсутствие положительных сигналов о том, что НИКАКОЙ уникальный контент или дополнительная ценность не может помочь вам быстрее и лучше ранжироваться в Google.
Разумная стратегия для SEO по-прежнему будет заключаться в снижении ожиданий робота Googlebot от сканирования и консолидации рейтинга и потенциала высококачественных канонических страниц, и вы делаете это, сводя к минимуму повторяющийся или почти повторяющийся контент.
Самоубийственная стратегия заключается в «оптимизации» низкокачественных или неуникальных страниц или представлении низкокачественных страниц пользователям.
Веб-мастера сбиты с толку насчет «штрафов» за дублированный контент, который является естественной частью веб-ландшафта, потому что Google утверждает, что нет штрафа за дублированный контент, но на рейтинг может негативно повлиять, по-видимому, то, что выглядит как проблемы с «дублированным контентом».
Реальность такова, что если Google классифицирует ваш дублированный контент как ТОНКИЙ контент, МАНИПУЛЯЦИОННЫЙ КОТЕЛЬНЫЙ ПЛИТ или БЛИЖАЙШИЙ ДУБЛИКАЦИОННЫЙ ‘SPUN’ контент, то у вас, вероятно, есть серьезная проблема, которая нарушает рекомендации Google по производительности веб-сайта, и это «нарушение» потребует «очищены» — если — конечно — вы намерены занять высокие позиции в Google.
Google хочет, чтобы мы понимали, что МАНИПУЛЯЦИОННАЯ ПЛИТА КОТЛА или БЛИЖАЙШИЙ ДУБЛИКАЦИОННЫЙ «ВРАЩЕНИЕ» НЕ является «дублирующим содержанием».
Повторяющееся содержание не обязательно является «спамом» для Google.
Остальное, например:
ЦИТАТА : « Контент, который копируется, но немного отличается от исходного . Этот тип копирования затрудняет поиск точного соответствия оригинальному источнику. Иногда меняются всего несколько слов или целые предложения, или выполняется модификация «найти и заменить», когда одно слово заменяется другим по всему тексту.Эти типы изменений сделаны намеренно, чтобы затруднить поиск исходного источника контента. Мы называем такой контент «скопированным с минимальными изменениями». Рекомендации для оценщиков качества поиска Google, 2017 г.
На десятиминутной отметке в недавнем видео Джон Мюллер из Google также пояснил с примерами, что есть:
ЦИТАТА : « Отсутствие штрафа за дублирование контента », Но« У нас есть кое-что, связанное с дублированием контента… которые заслуживают наказания. »Джон Мюллер, Google, 2015
Что такое дублированный контент?
Вот определение от Google:
ЦИТАТА : « Дублированный контент обычно относится к основным блокам контента внутри или между доменами, которые либо полностью соответствуют другому контенту, либо существенно похожи.По большей части, это не является обманчивым по происхождению. … .. »Рекомендации Google для веб-мастеров, 2020 г.
Важно понимать, что если, как веб-мастер, вы повторно публикуете сообщения, пресс-релизы, новости или описания продуктов, найденные на *** другом сайте *** сайты, то ваши страницы определенно будут бороться с , чтобы получить поддержку в поисковой выдаче Google (страницы результатов поисковых систем).
Google не любит использовать слово «штраф», но если весь ваш сайт полностью состоит из переизданного контента — Google не хочет ставить его выше других, которые предоставляют больше «добавленной стоимости» — и это может быть многие области.
Если у вас есть стратегия продажи одних и тех же продуктов на нескольких сайтах — вы, вероятно, собираетесь съесть свой трафик в долгосрочной перспективе, а не доминировать в нише, как раньше.
Это все сводится к тому, как поисковая система фильтрует дублированный контент, обнаруженный на других сайтах, и к опыту, который Google стремится предоставить своим пользователям и своим конкурентам.
Запутайтесь с дублированным контентом на веб-сайте, и это может выглядеть как штраф, поскольку конечный результат тот же — важные страницы, которые однажды были ранжированы, могут не ранжироваться снова, и в результате новый контент может сканироваться не так быстро.
Ваш веб-сайт может быть даже подвергнут «ручным мерам» в отношении тонкого содержания.
Хорошее эмпирическое правило: НЕ ожидайте высокого рейтинга в Google с контентом, найденным на других, более надежных сайтах, и не ожидайте вообще ранжирования, если все, что вы используете, — это автоматически генерируемые страницы без дополнительной ценности.
Хотя из этого правила есть исключения (и Google, безусловно, по-разному относится к вашему СОБСТВЕННОМУ дублированному контенту на вашем СОБСТВЕННОМ сайте), ваш лучший выбор для ранжирования — это иметь на вашем сайте одну единственную (каноническую) версию контента с богатым, уникальным текстовое содержимое, написанное специально для этой страницы.
Google хочет вознаграждать БОЛЬШОЙ, УНИКАЛЬНЫЙ, АКТУАЛЬНЫЙ, ИНФОРМАЦИОННЫЙ и ЗАМЕЧАТЕЛЬНЫЙ контент в своих органических списках — и за последние несколько лет он поднял планку качества.
Если вы хотите занять высокие позиции в Google по ценным ключевым фразам и в течение длительного времени — вам лучше для начала иметь хороший, оригинальный контент — и много его.
Очень интересным заявлением на недавней встрече для веб-мастеров было « насколько качественный у вас контент по сравнению с некачественным ».Это означает, что Google смотрит на это соотношение. Джон говорит, что нужно определить «, какие страницы являются высококачественными, а какие — более низкого качества, чтобы страницы, которые все же индексируются, действительно были высококачественными. “
Gary IILyes недавно подключился —
QUOTE :“ DYK Google не имеет штрафа за дублирование контента , но , имеющий много URL-адресов, обслуживающих один и тот же контент, сжигает бюджет сканирования и может ослаблять сигналы ” Гэри IIЛайс, Google, 2017 г.
В наши дни Google предоставляет нам гораздо более конкретную информацию в определенных областях.
ЦИТАТА : « что означает« дублированный контент »? Контент, скопированный с других веб-сайтов, или исходный контент, скопированный на веб-сайте? Какого из них следует избегать больше всего? Можно ли понизить рейтинг веб-сайта, если исходное содержание дублируется на страницах веб-сайта? »
На видеовстрече для веб-мастеров был задан вопрос, и Джон ответил:
ЦИТАТА :« , так что на самом деле это сложный вопрос. Таким образом, у нас есть разные типы дублированного контента, на которые мы смотрим, с нашей точки зрения, существует множество технических причин, по которым на веб-сайте у вас может быть один и тот же контент на нескольких страницах, и с нашей точки зрения мы пытаемся помочь исправить это для вы как можно больше »Джон Мюллер, Google 2018
И
ЦИТАТА :« , поэтому, если мы сможем распознать, что на этих страницах одинаковое содержание или одинаковое основное содержание, тогда мы попробуйте сложить это в одну и убедиться, что все сигналы, которые мы имеем, сосредоточены на этой странице. «Джон Мюллер, Google 2018
И вот где все усложняется:
ЦИТАТА :« на с другой стороны, если это контент, скопированный из нескольких мест, тогда это становится для нас немного сложнее, потому что тогда у нас есть ситуация, когда этот веб-сайт имеет то, что его контент на другом веб-сайте имеет тот же контент, который на самом деле является единственным t то, что нам нужно показывать и искать, становится намного сложнее, потому что тогда вопрос не в том, какую из ваших страниц мы хотим показать, а в том, какую из этих страниц, созданных разными людьми или на разных серверах, мы хотим показать. »Джон Мюллер, Google 2018
И когда появляется спам:
ЦИТАТА :« самый хитрый или, может быть, не самый хитрый, тот, на который действительно нужно остерегаться в отношении дублирования. контент — это если в вашем контенте большая часть контента скопирована из других источников или большая часть контента переписана и перепрофилирована из других источников, тогда, когда наши алгоритмы смотрят на ваш сайт, они выглядят хорошо, я видел все из этого веб-сайт раньше, здесь нет ничего ценного, что мы могли бы упустить, если бы не индексировали этот веб-сайт, потому что весь этот контент основан на том, что доступно в разных частях Интернета. »Джон Мюллер, Google 2018
И, наконец:
ЦИТАТА :« и в таком случае может случиться так, что наши алгоритмы скажут, что нам нужно как бы полностью игнорировать этот веб-сайт, нам не нужно сфокусируйтесь на нем в поиске, команда по ручному поиску может даже прийти и сказать, что на самом деле это пустая трата наших ресурсов даже смотреть на этот веб-сайт, потому что это просто чистые копии всех этих других веб-сайтов, возможно, слегка переписанных, но в этом нет ничего уникального здесь и в этих случаях мы можем полностью удалить веб-сайт из поиска, так что это тот вид, на который вам действительно нужно обратить внимание, если это действительно просто вопрос вашего контента на вашем веб-сайте в нескольких URL-адресах, тогда с технической точки зрения вы можете немного улучшить это, уменьшив количество копий на веб-сайте, но это не то, чего вам действительно нужно остерегаться. ”Джон Мюллер, Google 2018
Есть ли штраф за дублирование контента на веб-сайте?
Google дал нам несколько четких рекомендаций, когда дело доходит до управления дублированием контента.
Джон Мюллер четко заявляет в видео, где я взял это изображение:
ЦИТАТА : « У нас нет штрафа за дублирование контента . Это не значит, что мы бы понизили рейтинг сайта из-за большого количества повторяющегося контента. »Джон Мюллер, Google, 2014 г.
и
ЦИТАТА :« Вы не будете наказаны за дублированный контент такого типа. »- Джон Мюллер, Google, 2014 г.
… в котором он говорил об очень похожих страницах. Джон говорит: « предоставляет … настоящее уникальное значение » на ваших страницах.
Я думаю, что можно понять, что Google не обязан ранжировать ваш повторяющийся контент.
Если он игнорирует это, это отличается от штрафа.Например, ваш исходный контент все еще может оцениваться.
Если «, по сути, это то же самое, и просто варианты ключевых слов », это должно быть нормально, но если у вас их « миллионов » — робот Google может подумать, что вы создаете дорвеи, и это рискованно. .
Вообще говоря, Google определит лучшие страницы на вашем сайте, если у вас хорошая архитектура сайта и уникальный контент.
Совет: по возможности избегайте проблем с дублированием контента, и это должно быть здравым смыслом.
Google хочет (и вознаграждает) оригинальный контент — это отличный способ повысить стоимость SEO и в то же время улучшить взаимодействие с пользователем.
Google не любит, когда ЛЮБАЯ ТАКТИКА используется для манипулирования результатами, а повторная публикация контента, найденного на других веб-сайтах, является обычной практикой для многих сайтов, рассылающих спам.
ЦИТАТА : « Дублированный контент на сайте не является основанием для действий на этом сайте, если только не выяснится, что цель дублированного контента состоит в том, чтобы вводить в заблуждение и манипулировать результатами поиска . ”Google, 2020
Вы не хотите выглядеть как спам-сайт; это точно — и Google БУДЕТ классифицировать ваш сайт… как нечто.
Чем больше вы можете сделать так, чтобы каждая страница на странице за страницей выглядела искусственно, с содержанием, которое не отображается точно в других областях сайта, тем больше Google «понравится».
Google не любит автоматизацию, когда дело доходит до создания основного содержания страницы с большим количеством текста; это ясно.
Я не возражаю против нескольких копий статей на одном сайте — как вы обнаружите с категориями или тегами WordPress, но у меня не было бы, например, тегов категорий и , и я ожидал бы, что они будут хорошо ранжироваться на небольшом сайте с большой конкуренцией за более высокое качество, и особенно без нацеливания на одни и те же ключевые фразы таким образом, чтобы это могло каннибализировать ваш рейтинг.
Я предпочитаю избегать повторения ненужного контента на моем сайте, и когда у меня есть 100% автоматически сгенерированный или синдицированный контент на сайте, я говорю Google НЕ индексировать его с помощью noindex в метатегах, XRobots или Robots.txt это полностью.
Я, наверное, делаю самые безопасные вещи, так как это могло бы показаться манипулятивным, если бы я намеревался проиндексировать его.
Google также не поблагодарит вас за создание папки календаря с 10 000 пустых страниц или блога с большим количеством категорий, чем исходное содержание — потенциально много тонких страниц — зачем им?
Можете ли вы продублировать свой собственный контент на своем собственном сайте?
Да, в пределах разумного , но когда вы дублируете текст более чем на одной странице своего сайта, вы даете Google возможность ранжировать несколько страниц по одному и тому же запросу, и некоторые страницы ранжируются лучше, чем другие, что отрицательно влияет на уровень вашего органического трафика. более длительный срок.
Некоторые гораздо более крупные сайты повторно используют уникальный контент, например, на страницах продуктов и нескольких категорий.
Google не будет наказывать за эту практику, но:
ЦИТАТА : «Что обычно происходит в таком случае, так это то, что мы находим один и тот же фрагмент текста на нескольких страницах вашего веб-сайта, а — это совершенно нормально … Что, однако, произойдет — это , когда кто-то что-то ищет только в этом фрагменте текста, тогда все эти разные страницы как бы конкурируют друг с другом в результатах поиска, и мы попытаемся выбрать одну из этих страниц для отображения и попытаться выяснить, какая из них наиболее релевантный … Так что, возможно, страницы ваших категорий увидят больше трафика, но это будет происходить за счет меньшего трафика на страницах с подробными сведениями о продукте.”Джон Мюллер, Google 2018
Как Google определяет основную версию повторяющегося содержания?
Следующее утверждение коллеги из SEO очевидно на некоторых уровнях звучит правдоподобно:
ЦИТАТА : «Если в сети имеется несколько экземпляров одного и того же документа, URL с наивысшим авторитетом становится канонической версией. Остальные считаются дубликатами ». Дэн Петрович, Деян, 2018
На этой странице тоже есть интересный комментарий:
ЦИТАТА : «У меня есть клиент, у которого на сайте есть PDF-файл.Они не являются оригинальным бизнесом, чтобы представить это, многие люди являются дистрибьюторами этой линейки продуктов. Я заметил в GSC, что им приписываются входящие ссылки, т.к. PDF существует на других сайтах ». Непроверенный автор, 2018
Возможно, это не совсем точное утверждение и не полная картина, но это очень интересно .
Некоторые патенты Google, по крайней мере, указывают на то, что при определении основной версии дублированного контента на многих сайтах были предприняты определенные усилия, и, похоже, это не ограничивается авторитетом ссылки.
ЦИТАТА: « Это малоизвестный фактор ранжирования? Патент Google на определение первичной версии повторяющихся страниц, кажется, действительно находит некоторую важность в определении того, что он считает самой важной версией среди множества повторяющихся документов. . ”Билл Славски, 2018
Я долгое время считал разумным публиковать на вашем собственном сайте, сделав свой сайт каноническим или основным источником публикуемого вами контента. Публикуйте дублированный контент на других сайтах, чтобы его наверняка заметили, но там, где это разрешено, сделайте ссылку на исходную статью и, что еще лучше, используйте элемент канонической ссылки, чтобы указать на исходную статью на вашем собственном сайте и помочь Google направить законные положительные сигналы. вам (если Google хочет, то есть).
Что такое шаблонное содержимое?
Википедия говорит о «шаблонном» содержании:
ЦИТАТА : «Шаблон — это любой текст , который используется или может быть повторно использован в новых контекстах или приложениях без существенных изменений по сравнению с оригиналом». WIKI, 2020
… и Google сообщает:
ЦИТАТА : «Минимизируйте повторение шаблонов». Рекомендации Google для веб-мастеров, 2020
их собственный », — как любит говорить Джон Мюллер.
Как бы они это сделали алгоритмически? Что ж, они могли бы посмотреть, были ли текстовые блоки на ваших страницах уникальными для данной страницы или очень похожими блоками контента на другие страницы вашего сайта.
Если этот «шаблонный» контент составляет содержание P RIMARY на нескольких страницах, Google может легко отфильтровать, чтобы игнорировать или наказывать эту практику.
Разумным ходом было бы прислушаться к Google — и минимизировать — или, по крайней мере, рассеять — экземпляры шаблонного текста на страницах вашего веб-сайта.
Обратите внимание, что THIN CONTENT усугубляет проблемы SPUN BOILERPLATE TEXT на сайте — поскольку THIN CONTENT просто создает больше страниц, которые могут быть созданы только с помощью шаблонного текста, что само по себе является проблемой.
E.G. — если у продукта 10 URL-адресов — например, по одному URL-адресу для каждого цвета продукта — тогда НАЗВАНИЕ, МЕТА-ОПИСАНИЕ И ОПИСАНИЕ ПРОДУКТА (и другие элементы на странице) для этих дополнительных страниц, вероятно, будут полагаться на методы BOILERPLATE для их создания , и при этом вы создаете на сайте 10 URL-адресов, которые «не являются самостоятельными» и по сути дублируют текст на страницах.
Стоит прислушаться к недавнему совету Джона Мюллера по этому поводу. Он четко говорит, что практика создания более «уникального» текста с использованием низкокачественных методов такова:
ЦИТАТА : «вероятно, более контрпродуктивно, чем на самом деле помогает вашему веб-сайту» — Джон Мюллер, Google 2015
Если у вас есть много страниц с похожим содержанием на вашем сайте, у Google могут возникнуть проблемы с выбором страницы, которую вы хотите ранжировать, и это может ослабить ваши возможности ранжирования по тому, что вы делаете, для того, чтобы ранжироваться.
Как Google справляется с дублированием описаний продуктов на нескольких сайтах розничных продавцов?
ВОПРОС : «Часто с дизайнерской мебелью описание этой мебели дизайнером используется на десятках сайтов с очень незначительными изменениями…» Аамон Джонс, 2017
Джон Мюллер ответил:
ЦИТАТА : « Я думаю, это две разные вещи, две разные вещи, на которые нам нужно смотреть, с одной стороны, когда вся страница дублируется, это своего рода простая ситуация, когда мы можем хорошо сказать, что это, вероятно, именно то, что мы можем отчасти пропустите это, а второй — это то, о чем вы говорите, когда часть страницы дублируется, например, эта реклама мебели, что на многих сайтах, может быть, нижний колонтитул, или, может быть, у них есть какой-то отказ от ответственности внизу такие вещи где мы видим, что этот кусок текста дублируется на большом количестве разных страниц, и что происходит в этих случаях, мы индексируем все эти страницы, потому что остальная часть страницы является своего рода уникальной и своего рода ценной, поэтому мы индексируем эти страницы se, а затем, когда дело доходит до создания результатов поиска, если мы можем сказать, что на самом деле часть, которую люди ищут, дублируется на всех этих страницах, тогда мы выберем одну из этих страниц и покажем ее, потому что они по сути эквивалентны так что если у вас есть рекламное объявление по умолчанию для предмета мебели, и кто-то ищет фрагмент текста в этом рекламном объявлении по умолчанию, мы хорошо знаем, что это один и тот же текст на всех этих сайтах, фрагмент будет то же самое, поэтому на самом деле не имеет смысла показывать все эти разные страницы этому пользователю в то время , конечно, как только мы узнаем больше о запросе, если это не только из этого дублированного фрагмента текста, тогда он Нам намного проще сказать, что это тот, который действительно соответствует тому, что ищет этот пользователь, поэтому для мебели может быть местоположение, возможно, если у них есть дополнительные сведения в запросе о том типе мебели, которую они ищут, поэтому все эти вещи могут помочь нам f Подумайте, какую из этих страниц с дублированной рекламной аннотацией мы хотим показать людям. ”Джон Мюллер, Google, 2017
Стоит ли переписывать описания продуктов, чтобы текст был уникальным?
Наверное.
Что бы вы ни делали, остерегайтесь «крутить текст» — Google может иметь алгоритм или два, ориентированные на такого рода вещи:
Джон также пояснил:
ЦИТАТА : « Можем ли мы получить выгоду Если на страницах наших продуктов больше виртуальных описаний, чем на других страницах в Интернете с такими же продуктами? Можно ли считать хорошо написанные описания продуктов лучше? » Больше не обязательно лучше.Так что действительно ли у вас есть что-то полезное для пользователя? Это актуально для людей, которые ищут? Тогда, может быть, мы попробуем это показать. И всего лишь искусственно переписываемых материалов часто идут на вращение контента, когда вы просто делаете его уникальным, но на самом деле вы не пишете что-то уникальное. Затем это часто приводит к просто более низкому качеству контента на этих страницах. Так что искусственное переписывание таких вещей, как замена синонимов и попытка сделать его уникальным, вероятно, более контрпродуктивно, чем на самом деле помогает вашему сайту.Поэтому вместо этого я бы действительно сосредоточился на уникальной ценности, которую вы могли бы предоставить через свой веб-сайт, которая может быть чем-то большим, чем просто слегка переписанное описание, а скорее вашим экспертным мнением по этому продукту, например, или опытом, который вы со временем создали этот конкретный продукт, который вы можете показать пользователям, который действительно представляет большую ценность для людей в Интернете. ”Джон Мюллер, 2015
Есть ли штраф Google за Spun Content?
Джон Мюллер подтвердил в сентябре 2019 года, что Google действительно будет наказывать спин-контент за создание « текстовых страниц ».Я думаю, это означает MC (Основное содержание страницы).
ЦИТАТА : « Наказывает ли Google за использование спин-контента? Да, , поэтому каждый раз, когда вы используете автоматически сгенерированный контент для создания страниц, подобные текстовые страницы будут рассматриваться как противоречащие нашим рекомендациям для веб-мастеров, поэтому я бы определенно постарался избежать этого. «. Джон Мюллер, Google, 2019
Может ли наличие разных URL-адресов для атрибута продукта (например, размера, количества, веса, цвета, объема) вызывать проблемы с дублированием контента?
ЦИТАТА : « Вы не сможете создавать отдельные страницы для каждого размера и цвета. Можно сказать, что эта обувь также доступна в этих пяти цветах или в этих семи размерах. Это то, что вы бы как бы смешали со страницей конкретного продукта, но не создавали бы для этого отдельные страницы. ”Джон Мюллер, Google, 2014
В недавнем прошлом у продукта с 10 цветами на сайте было 10 страниц, по одной для каждого атрибута цветового варианта. Глядя на страницы, все будет дублироваться от страницы к странице, за исключением цвета, размера или другого варианта атрибута продукта.
Веб-мастера пошли еще дальше, пытаясь сделать каждую страницу «уникальной»…. вручную или автоматически по ключевым словам изменяются варианты продукта и целые описания для ранжирования в Google, но не добавляют реальной ценности странице.
Для многих сайтов Google предпочитает не ранжировать страницы таким образом, вместо этого он предпочитает одну каноническую подробную страницу продукта со всеми атрибутами вариантов, упомянутыми на этой странице, ЕСЛИ у вас нет уникального контента для страницы вариантов, который не просто некачественный. закрученный текст.
ЦИТАТА : «варианты цветов продукта… для страницы продукта, но вы не можете создавать для этого отдельные страницы». С этим типом страниц вы «всегда балансируете между действительно, действительно сильными страницами для этих продуктов по сравнению со страницами среднего уровня для множества различных продуктов». Джон Мюллер, Google, 2014
Джон говорит :
QUOTE : «одна действительно, действительно сильная общая страница» превосходит «сотни» посредственных. Джон Мюллер, Google, 2014
Дело не столько в наказании за дублирование контента, сколько в том, что несколько вариантов страниц одного и того же продукта ослабляют сигналы ранжирования так, как одна каноническая страница продукта не может, и что страницы вариантов продукта часто не оптимальная настройка для ранжирования в Google.
Хорошее практическое правило состоит в том, что если у вас есть много страниц, которые кажутся вам дубликатами, за исключением одного или двух элементов на странице, то эти страницы, вероятно, следует «сложить вместе» в одну прочную страницу.
ЦИТАТА : « Итак, если у вас есть страница продукта, и у вас есть различные варианты, перечисленные на ней, то мы сможем выбрать их напрямую со страницы продукта. Я обычно рекомендую делать отдельные страницы, если вы действительно предлагаете что-то уникальное, что люди явно ищут. Так что, если люди явно ищут — я не знаю — розовый iPhone с определенным номером модели, и это что-то, что сильно отличается от всех других моделей iPhone, которые существуют, то это то, что может иметь смысл иметь отдельный страница для.Но тогда у вас также будет уникальный контент для него. Вам нужно объяснить, почему он розовый и светится в темноте или что-то особенное в этой конкретной модели. Так что это то, где, если у вас есть что-то, что вы хотите выделить как что-то отдельное, и вы хотите ранжироваться по этому отдельному пункту, я бы создал для этого отдельные страницы. »Джон Мюллер, Google, 2016
Джон продолжает:
ЦИТАТА :« С другой стороны, , если это просто атрибут существующего типа продукта — если это похоже, эта обувь доступна в этих пять размеров и эти три цвета — тогда это то, что я бы просто упомянул на самой нормальной странице продукта. Итак, то, что происходит всегда, — это то, что вы балансируете между наличием сильной страницы продукта, где у вас есть одна страница для этих различных вариантов, и своего рода разбавлением этого контента и его разделением на несколько страниц вариантов, где каждая из этих страниц вариантов будет иметь намного больше проблем с ранжированием , потому что мы должны ранжировать его отдельно. Так что если у вас есть что-то уникальное и привлекательное в одном конкретном варианте, тогда хорошо. Это может быть ранжировано само по себе.Но в противном случае я бы рекомендовал больше, чтобы сосредоточить все на одной действительно сильной странице продукта . »Джон Мюллер, Google, 2016
и
ЦИТАТА :« Если вы не можете сделать что-то уникальное для этого конкретного варианта, я бы просто свернул его на обычную страницу продукта . И люди, которые ищут этот вариант, все равно смогут найти эту страницу продукта. Так что это то, где, если вы не можете сделать что-то уникальное и особенное для этого конкретного варианта, вместо этого действительно создайте сильную страницу продукта.Потому что это еще можно ранжировать. У вас все еще есть перечисленные атрибуты. Так что, если кто-то ищет iPhone в розовом цвете, то у вас все равно есть такое совпадение этих двух фраз. »Джон Мюллер, Google, 2016
и
ЦИТАТА :« Итак, у вас может быть — я не знаю — 64 мегабайта или 64 гигабайта, 128 гигабайт или любые другие версии устройства. . И для всех этих вариантов вы не станете делать отдельные страницы, потому что это, по сути, просто атрибут этого продукта. »Джон Мюллер, Google, 2016
Совет по SEO для электронной торговли:
Создавайте и публикуйте подробные подробные страницы продуктов и не разбивайте содержание продукта на несколько альтернативных индексируемых URL-адресов вариантов продукта, чтобы упростить ранжирование для каждого человека. Вариант атрибута товара, будь то цвет, размер, вес или объем. Одна страница должна, так сказать, править всеми.
Как Google оценивает «
скопировано »?ЦИТАТА : « Здесь вы плывете вверх по течению.Скопированный основной контент, вероятно, получит низкий рейтинг. Скопированный контент не будет долгосрочной стратегией при создании уникальной страницы лучше, чем страницы ваших конкурентов. ”Шон Андерсон, Хобо 2020
Как управлять распределением контента между несколькими доменами
Это хорошее видео (обратите внимание, что в нем есть несколько устаревшая информация о междоменном реляционном каноническом взаимодействии)
Мэтт Каттс спойте междоменный rel canonical в следующем видео:
Если у вас есть контент, распределенный между несколькими доменами, не ожидайте, что все версии будут отображаться в результатах поиска Google одновременно.
Подобный дублированный контент также не улучшит показатели качества.
ЦИТАТА : « когда большие части веб-сайта копируются на оба этих сайта, тогда мы предполагаем, что на самом деле весь веб-сайт является своего рода копией другого , и мы пытаемся помочь вам, просто выбирая один и демонстрируя это, поэтому, если вы не хотите, чтобы это произошло, тогда убедитесь, что эти страницы действительно уникальны, что весь веб-сайт сам по себе может стоять сам по себе, не рассматривается как в основном копия другого . ”Джон Мюллер, Google 2018
Если вы соблюдаете правила при дублировании контента в нескольких доменах, я бы выбрал один канонический URL-адрес на одном веб-сайте (основном веб-сайте) и использовал бы элементы междоменной канонической ссылки, чтобы сообщить Google, какой из них является основной URL. Таким образом, вы соблюдаете рекомендации Google, не должны отрицательно влиять на показатели качества сайта, и вы объединяете все сигналы ранжирования в один из этих URL-адресов, чтобы он мог занять наилучшее место среди конкурирующих страниц.
Как бороться с распространением контента между несколькими TLD?ЦИТАТА : « Убедитесь, что он локализован.Так что пишите вещи так, как их произнесет кто-нибудь в Соединенном Королевстве. Или убедитесь, что ваши денежные единицы указаны правильно. Проверьте такие подробности. Но в целом я бы не стал беспокоиться о том, что это будет классифицировано как спам. ”Мэтт Каттс, Google (Ex) 2011
Считает ли Google переведенный контент дублированным?
ЦИТАТА : « Итак, если у вас есть контент на немецком и английском языках, даже если это тот же контент, но переведен, это не дублирует контент .Это разные слова. На странице разные слова. Это переводы, поэтому, естественно, это не дубликат. ”Джон Мюллер, Google, 2015
Нет. Однако не забывайте указывать языковые альтернативы с помощью атрибута hreflang.
ЦИТАТА : « Да, если контент такой же, то он рассматривается как дублированный контент, что вроде как определение дублированного контента, когда дело доходит до таких международных сайтов, как это обычно происходит, когда мы выбираем один URL как канонический, и мы будем использовать аннотации Href Lang для замены соответствующего URL-адреса в результатах поиска, поэтому при разумном индексировании мы стараемся сосредоточиться на одной версии, потому что она все одинакова, а в результатах поиска мы просто меняем URL-адрес. »Джон Мюллер, Google
Как управлять дублированным контентом при репортажах о новостях
ЦИТАТА :« Итак, если все, что вы делаете, это берете телеграмму или какой-либо другой созданный синдикат вещи, и вы это делаете, и это точно такой же текст, тогда, вероятно, пользователи не хотят видеть 17 разных копий этого, когда они выполняют поиск. Скорее всего, мы хотели бы видеть сайт, который считается более авторитетным, сайт, который делает оригинальные отчеты, сайт, который, по крайней мере, пишет свою собственную версию истории, а не просто повторно использует этот синдицированный конкретный документ.Дело не в том, что вам нужно беспокоиться о придумывании новостей. Если вы относитесь к тому типу сайтов, у которых есть опыт по определенной теме, я бы сказал, просто убедитесь, что вы пишете статью самостоятельно, а не просто используете ту же статью, которую используют все остальные. В то же время вам, вероятно, будет полезно спросить себя, есть ли у меня какая-то добавленная стоимость? Есть ли у меня опыт? Потому что, если все, что вы делаете, это берете историю и просто перефразируете ее, и не добавляете какой-либо уникальной идеи или чего-то другого, под другим углом, без уникального сообщения, вы не связались ни с кем в этой истории, тогда это Немного труднее быть замеченным, потому что иногда ты теряешься в шуме. ”Мэтт Каттс, Google 2012
Что такое» почти повторяющийся «контент для Google?
На вопрос в Твиттере гуглер Гэри Иллис ответил:
ЦИТАТА : «Думайте об этом как о фрагменте контента, который был слегка изменен, или если он был скопирован 1: 1, но шаблон другой». Гэри Иллис, Google, 2017
Судя по исследовательским работам, может случиться так, что, как только Google обнаружит, что страница является почти копией чего-то другого, ему будет трудно сопоставить эту страницу с источником.
Может ли дублироваться рейтинг контента в Google?Да. Есть стратегии, в которых это все еще будет работать в краткосрочной перспективе.
Возможности (по моему опыту) зарезервированы для локальных и длинных страниц результатов поиска, где страница с первой десяткой результатов уже забита низкокачественными результатами, а результаты поиска неубедительны — определенно не стратегия для конкурентных условий.
В результатах с длинным хвостом не так много трафика, если только вы не сделаете это массово и это может вызвать дополнительные проблемы с качеством сайта, но иногда стоит изучить, используется ли очень похожий контент с географическими модификаторами (например) на сайте с некоторыми «, орган власти домена » (точнее сказать) имеет такую возможность.
Очень похожий контент может быть полезен и для разных TLD. Немного спам, но если первые десять результатов уже немного спамят…
Если низкокачественные страницы хорошо работают в первой десятке существующей длинной поисковой выдачи — тогда стоит изучить — я использовал это в прошлом .
Я всегда думал, что если это улучшает пользовательский опыт и лучше, чем то, что есть в этих длинных поисковых запросах в настоящее время, кто жалуется?
Это не совсем лучшая практика SEO, и в наши дни я бы нервничал из-за создания на вашем сайте некачественных страниц.
Слишком большое количество некачественных страниц может вызвать в будущем проблемы на уровне всего сайта, а не только на уровне страниц.
Оригинальный контент — король, говорят они
Придерживайтесь оригинального контента, который находится только на одной странице вашего сайта, для достижения наилучших результатов — особенно если у вас новый / молодой сайт и вы создаете его постранично с течением времени … и вы получите более высокий рейтинг и больше трафика на ваш сайт (в том числе и для партнеров!).
Да, вы можете проявлять творческий подход и повторно использовать и переупаковывать контент, но я всегда удостоверяюсь, что если меня просят оценить страницу, мне потребуется исходный контент на странице.
Должен ли я заблокировать Google от индексации моего повторяющегося содержания?
Нет. НЕ ТРЕБУЕТСЯ блокировать ваш собственный Дублированный контент
Некоторое время назад на форумах Google был полезный пост с советом от Google, как обрабатывать очень похожий или идентичный контент:
«Теперь мы рекомендуем . не , блокирующий доступ к дублированному контенту на вашем веб-сайте, будь то файл robots.txt или другие методы »Джон Мюллер, Google, 2015
Джон также дает несколько полезных советов о том, как обрабатывать дублированный контент на вашем собственном сайте :
- Распознавайте дублированный контент на своем веб-сайте.
- Определите предпочтительные URL-адреса.
- Будьте последовательны на своем сайте.
- Применяйте 301 постоянное перенаправление там, где это необходимо и возможно.
- Реализуйте элемент ссылки rel = ”canonical” на своих страницах там, где это возможно.
- По возможности используйте инструмент обработки параметров URL в Google Search Console.
В руководстве для веб-мастеров по дублированию контента говорилось:
ЦИТАТА: « Рассмотрите возможность блокировки страниц из индексации : вместо того, чтобы позволять алгоритмам Google определять« лучшую »версию документа, вы можете помочь руководству нам на вашу предпочтительную версию.Например, если вы не хотите, чтобы мы индексировали печатные версии статей вашего сайта, запретите использование этих каталогов или используйте регулярные выражения в файле robots.txt ». Google, 2020
, но теперь Google ясно дает понять, что НЕ хочет, чтобы мы блокировали дублирующийся контент, и это отражено в рекомендациях.
Google не рекомендует блокировать доступ сканера к дублированному содержанию (dc) на вашем веб-сайте , будь то файл robots.txt или другие методы.
Если поисковые системы не могут сканировать страницы с помощью dc, они не могут автоматически определить, что эти URL-адреса указывают на одно и то же содержание, и поэтому им придется рассматривать их как отдельные уникальные страницы.
Лучшее решение — разрешить поисковым системам сканировать эти URL, но помечать их как дубликаты с помощью элемента ссылки
rel = "canonical", инструмента обработки параметров URL или переадресации 301.В тех случаях, когда DC заставляет нас сканировать слишком большую часть вашего веб-сайта, вы также можете настроить скорость сканирования в Инструментах для веб-мастеров.
DC на сайте не является основанием для действий на этом сайте, если только не выяснится, что намерение DC состоит в том, чтобы вводить в заблуждение и манипулировать результатами поиска. .
Если на вашем сайте возникают проблемы с постоянным током, и вы не следуете приведенным выше советам, мы хорошо постараемся выбрать версию содержания для отображения в наших результатах поиска.
Если вы хотите минимизировать дублирующий контент, а не блокировать его, я считаю, что лучшее решение проблемы — это индивидуальный подход.
Иногда я, , блокирует Google при использовании контента ДРУГИХ людей на страницах. Я никогда не запрещал Google разрабатывать мой собственный контент.
Google говорит, что ему необходимо обнаружить НАМЕРЕНИЕ, чтобы манипулировать Google, чтобы понести штраф, и вы должны быть в порядке, если ваше намерение невиновно, НО легко облажаться и СМОТРЕТЬ, как будто вы замышляете что-то подозрительное.
Также легко не воспользоваться преимуществами надлежащей канонизации и консолидации релевантного основного контента, если вы не выполняете базовые действия из-за отсутствия лучшего выражения.
Считается ли мобильный сайт повторяющимся содержимым?
ЦИТАТА : « сайтов с отдельными мобильными URL-адресами в любом случае следует просто перейти на адаптивный дизайн…. (Отдельные мобильные URL-адреса делают все намного сложнее, чем должно быть) ”Джон Мюллер, Google, 2019
Как Google выбирает канонический URL-адрес для вашей страницы?
В сентябре 2019 года на видео выше, Джон Мюллер из Google совсем недавно снова попытался прояснить, как Google выбирает канонический URL из всех доступных ему повторяющихся вариантов URL при сканировании вашего веб-сайта.и предлагает несколько советов о том, как помочь Google выбрать канонический URL-адрес для вашей страницы:
ЦИТАТА : «Для веб-сайта довольно часто используется несколько уникальных URL-адресов, ведущих к одному и тому же контенту… в идеале мы даже не запускали в любой из этих альтернативных версий, поэтому мы рекомендуем выбрать один формат URL и последовательно использовать его на вашем веб-сайте… »Джон Мюллер, Google, 2019
Как правильно использовать элементы канонических ссылок
Элемент канонической ссылки чрезвычайно мощный и очень важный для включения на вашу страницу.На каждой странице вашего сайта должен быть элемент канонической ссылки, даже если он ссылается на себя. Это простой способ объединить ранжирующие сигналы из нескольких версий одной и той же информации. Примечание. Google будет игнорировать неправильно используемые канонические символы в определенное время.
Google рекомендует использовать элемент канонической ссылки , чтобы минимизировать проблемы дублирования контента, и это один из самых мощных инструментов в нашем распоряжении.
ЦИТАТА : « Если ваш сайт содержит несколько страниц с в основном идентичным содержанием, вы можете указать Google предпочтительный URL-адрес несколькими способами.(Это называется «канонизацией».) »Google, 2020
Google SEO — Мэтт Каттс из Google поделился советами по тегу rel =» canonical «(точнее — элементу канонической ссылки ), который входит в тройку самых популярных поисковых запросов двигатели теперь поддерживают.
Google, Yahoo !, и Microsoft договорились работать вместе над:
ЦИТАТА : « совместными усилиями по сокращению дублирования контента на более крупных и сложных сайтах, и в результате появился новый Canonical Tag ».
Пример канонического тега из блога Google Webmaster Central:
Процесс прост. Вы можете поместить этот тег ссылки в заголовок URL-адресов дублированного контента, если считаете, что вам это нужно.
Должны ли страницы иметь самодостаточные канонические элементы ссылок?
ЦИТАТА : « Я рекомендую сделать это самореференциальный канонический, потому что он действительно дает нам понять, какую страницу вы хотите проиндексировать или каким должен быть URL при индексировании.Даже если у вас одна страница, иногда есть разные варианты URL, которые могут подтянуть эту страницу. Например, с параметрами в конце, возможно, с верхним нижним регистром или с www и без www. Все это можно исправить с помощью тега rel canonical. ”Джон Мюллер, Google, 2017
В наши дни я добавляю элемент канонической ссылки со ссылкой на себя в качестве стандарта — на ЛЮБУЮ веб-страницу — чтобы помочь Google определить, какой именно канонический URL я пытаюсь ранжировать.
Google, 2020 дал нам несколько советов по правильному использованию канонических символов:
Является ли rel = «canonical» подсказкой или директивой?
ЦИТАТА : « Это намек, который мы строго соблюдаем.Мы учтем ваши предпочтения вместе с другими сигналами при расчете наиболее релевантной страницы для отображения в результатах поиска. ”Google
Могу ли я использовать относительный путь для указания канонического, например,?
QUOTE : « Да, относительные пути распознаются, как ожидалось, с помощью тега . Кроме того, если вы включите в документ ссылку
, относительные пути будут разрешены в соответствии с базовым URL. ”Google, 2009 г.
Ничего страшного, если каноническое не является точной копией содержания?
ЦИТАТА : « Мы допускаем незначительные различия, например, в порядке сортировки таблицы продуктов. Мы также понимаем, что можем сканировать канонические и повторяющиеся страницы в разное время, поэтому время от времени мы можем видеть разные версии вашего контента. Все это нас устраивает. ”Google, 2009 г.
Что, если rel =» canonical «вернет 404?
ЦИТАТА : « Мы продолжим индексировать ваш контент и использовать эвристику для поиска канонических URL, но мы рекомендуем указывать существующие URL как канонические. «Google, 2009
Что делать, если rel =» canonical «еще не проиндексирован?
ЦИТАТА : « Как и весь общедоступный контент в Интернете, мы стремимся быстро обнаруживать и сканировать назначенный канонический URL. Как только мы его проиндексируем, мы сразу же пересмотрим подсказку rel = «canonical». ”Google, 2009
Что делать, если у меня есть противоречивые обозначения rel =» canonical «?
ЦИТАТА : « Наш алгоритм снисходителен: мы можем следовать каноническим цепочкам, но мы настоятельно рекомендуем вам обновить ссылки, чтобы они указывали на одну каноническую страницу, чтобы обеспечить оптимальные результаты канонизации. ”Google, 2009 г.
Можно ли использовать этот тег ссылки, чтобы предложить канонический URL-адрес в совершенно другом домене?
ЦИТАТА : Ответ — да! Теперь мы поддерживаем междоменный элемент ссылки rel = «canonical» «. Google, 2009
Канонические элементы ссылок могут игнорироваться Google:
ЦИТАТА : « Возможно, мы подобрали это и говорим, что это достаточно хорошо, но если страницы не эквивалентны, то они на самом деле не совпадают, тогда также возможно, что наши алгоритмы посмотрят на это и скажут, что этот rel canonical, вероятно, случайно установлен таким образом, и мы должны его игнорировать ”Джон Мюллер, Google 2018
Can rel =” canonical »Быть перенаправлением?
ЦИТАТА : « Да, вы можете указать URL-адрес, который выполняет перенаправление, как канонический URL-адрес.Затем Google обработает перенаправление как обычно и попытается проиндексировать его ». Google, 2009 г.
Канонические элементы ссылок можно рассматривать как перенаправления
ЦИТАТА : « в целом, когда у вас есть каноническая ссылка с одной страницы на другую, и мы замечаем, что это подтвержденная вещь и тот же контент находится на обеих этих страницах, и у вас есть внутренние ссылки, которые также указывают на ваш новый канонический, тогда обычно мы рассматриваем это как перенаправление »Джон Мюллер, Google 2018
Совет. Перенаправляйте старый, устаревший контент на новые, недавно обновленные статьи по этой теме, сводящие к минимуму некачественные страницы и дублированный контент, в то же время улучшая глубину и качество страницы, которую вы хотите ранжировать.
ЦИТАТА : « 301 Редирект — невероятно важная и часто упускаемая из виду область поисковой оптимизации» Шон Андерсон, Hobo 2020
Советы от Google
собственные критики по поводу использования дублированного контента на собственном сайте в своих целях:
Есть несколько шагов, которые вы можете предпринять, чтобы проактивно решать проблемы с дублированным контентом и гарантировать, что посетители видят контент, который вы хотите:
ЦИТАТА: « Используйте 301s : Если вы реструктурировали свой сайт, используйте 301 редирект (« RedirectPermanent ») в вашем.htaccess для перенаправления пользователей, робота Google и других пауков. (В Apache вы можете сделать это с помощью файла .htaccess; в IIS вы можете сделать это через административную консоль. ) »Google, 2020
ЦИТАТА:« Будьте последовательны : «Постарайтесь сохранить свои внутренние ссылки согласованы. Например, не используйте ссылки на
http://www.example.com/page/иhttp://www.example.com/pageиhttp://www.example.com/page/. index.htm. ”Google, 2020
Я также хотел бы убедиться, что все ваши ссылки написаны в одном и том же регистре и не использовать заглавные и строчные буквы в одном и том же URL.
Этот тип дублирования можно быстро отсортировать, поддерживая согласованность внутренних ссылок и правильное использование канонических элементов ссылок.
ЦИТАТА: « Используйте домены верхнего уровня : Чтобы помочь нам обслуживать наиболее подходящую версию документа, по возможности используйте домены верхнего уровня для обработки контента для конкретной страны. Мы с большей вероятностью узнаем, что
http://www.example.deсодержит контент, ориентированный, например, на Германию, чемhttp: // www.example.com/deилиhttp://de.example.com. »Google, 2020
Google также предлагает веб-мастерам выбрать предпочтительный домен для ранжирования в Google:
ЦИТАТА:« Используйте Инструменты для веб-мастеров, чтобы сообщить нам, как вы предпочитаете индексировать свой сайт. : Вы можете сообщите Google предпочитаемый домен (например,
http://www.example.comилиhttp://example.com). ”Google
… хотя вам следует убедиться, что вы обрабатываете такие перенаправления на стороне сервера, с перенаправлением 301, перенаправляющим все версии URL-адреса на один канонический URL-адрес (с элементом саморегулирующейся канонической ссылки).
ЦИТАТА: « Минимизируйте повторение шаблонов : Например, вместо того, чтобы включать длинный текст об авторских правах внизу каждой страницы, включите очень краткое резюме, а затем укажите ссылку на страницу с более подробной информацией. Кроме того, вы можете использовать инструмент обработки параметров, чтобы указать, как вы хотите, чтобы Google обрабатывал параметры URL. Изучите свою систему управления контентом : Убедитесь, что вы знакомы с тем, как контент отображается на вашем веб-сайте.Блоги, форумы и связанные с ними системы часто показывают один и тот же контент в разных форматах. Например, запись в блоге может отображаться на домашней странице блога, на странице архива и на странице других записей с таким же ярлыком. »Google, 2020
Поймите, производит ли ваша CMS« тонкий »контент или повторяющиеся страницы
Google говорит:
ЦИТАТА:« Разберитесь в своей системе управления контентом : Убедитесь, что вы знакомы с тем, как контент отображается на вашем сайте.Блоги, форумы и связанные с ними системы часто показывают один и тот же контент в разных форматах. Например, запись в блоге может отображаться на домашней странице блога, на странице архива и на странице других записей с таким же ярлыком. ”Google, 2020
WordPress, Magento, Joomla, Drupal — все они имеют несколько разные проблемы с поисковой оптимизацией, дублированием контента (и эффективностью сканирования).
Например, если у вас есть версии веб-страниц «ТОЛЬКО ДЛЯ ПЕЧАТИ» (раньше у Joomla были серьезные проблемы с этим), они могут отображаться в Google вместо вашей веб-страницы, если вы не обработали ее должным образом с помощью канонических. .
Это, вероятно, повлияет на конверсии. и создание ссылок — для начала. Плохо реализованные мобильные сайты также могут вызывать проблемы с дублированным контентом.
Я бы не стал создавать то, что может выглядеть как «дверные проемы» для Google, создавая слишком много ключевых слов, тегов или страниц категорий .
Будет ли Google наказывать вас за синдицированный контент?
Нет. Когда дело доходит до публикации вашего контента на других сайтах:
ЦИТАТА: « Тщательно распространяйте информацию : если вы распространяете свой контент на других сайтах, Google всегда будет показывать версию, которая, по нашему мнению, наиболее подходит для пользователей в каждом заданном поиске, который может быть или не соответствовать той версии, которую вы предпочитаете.Тем не менее, полезно убедиться, что на каждом сайте, на котором размещается ваш контент, есть ссылка на исходную статью. Вы также можете попросить тех, кто использует ваш синдицированный материал, использовать метатег noindex, чтобы поисковые системы не индексировали их версию контента. ”Google, 2020
Проблема с распространением вашего контента в том, что вы никогда не можете сказать, будет ли это в конечном итоге стоить вам органического трафика.
Если это есть на других веб-сайтах — они могут получать ВСЕ положительные сигналы от этого контента — не вы.
Также стоит отметить, что Google по-прежнему четко заявляет, что вы МОЖЕТЕ помещать ссылки на свою исходную статью в сообщения, которые публикуются в другом месте.
Но с этим тоже нужно быть осторожным — эти ссылки могут быть классифицированы как неестественные.
Самый безопасный способ справиться с этим — попросить другой сайт, который повторно опубликовал ваш контент на , добавить rel = canonical, указывающий на вашу исходную статью на вашем сайте . Тогда ваш сайт получит все преимущества SEO от повторной публикации вашего контента вместо другого сайта.
Ссылки в повторяющихся статьях учитываются, но это рискованно.
Несколько лет назад я заметил, что ссылок, которые присутствуют на дублированных постах, которые были украдены — дублированы и переизданы — ВСЕ ЕЩЕ передают значение текста привязки (даже если это небольшое увеличение).
В этом примере из моего сообщения «Что такое SEO» были удалены все мои ссылки, и статья была опубликована как его собственная.
Ну, он удалил все ссылки, кроме одной ссылки, которую он пропустил:
Да, ссылка на http: // www.duny * .com.pk / на самом деле все еще указывал на мою домашнюю страницу.
Это дало мне возможность кое-что посмотреть… ..
Сама статья не была на 100% дублирована — там был небольшой вступительный текст, насколько я могу судить. Глядя на Copyscape, стало ясно, какая часть статьи уникальна, а какая — дублирована.
Итак, это было 3 года. старая статья была повторно опубликована на некачественном сайте со ссылкой на мой сайт в части страницы, содержащей явно повторяющийся текст.
Я бы подумал, что Google просто проигнорировал эту ссылку.
Но нет, Google вернул мою страницу по следующему запросу (в то время):
Уведомление Google Cache (ниже) больше не доступно, но это был хороший маленький инструмент, чтобы копнуть немного глубже в том, как работает Google:
… что означает, что Google будет подсчитывать ссылки (НА НЕКОТОРЫМ УРОВНЕ) даже на повторяющиеся статьи, повторно опубликованные на других сайтах — вероятно, в зависимости от поискового запроса и качества выдачи на тот момент ( возможно, даже с учетом показателя качества сайта, которому доверяют?).
Я понятия не имею, так ли это даже сегодня.
Исторически сложилось так, что синдицирование вашего контента через RSS и поощрение людей к повторной публикации вашего контента на определенном уровне приносило ваши ссылки, которые учитывались (что может быть полезно для длинных поисков).
Google неплохо идентифицирует исходную статью, особенно , если сайт, на котором она опубликована, пользуется определенным доверием — у меня никогда не было проблем с распространением моего контента через RSS и возможностью перекрестной публикации других….но мне нравится хотя бы обратная ссылка, nofollow или нет.
Более серьезная проблема с распространением контента — это неестественных ссылок и , независимо от того, классифицирует ли Google ваши намерения как манипулятивные .
Если Google действительно классифицирует ваше намерение занять высокий рейтинг неестественными ссылками, то перед вами гораздо более серьезная проблема.
Наказывает ли Google «тонкий» контент на веб-сайте?
Да. Google также говорит о «тонком» содержании.
ЦИТАТА: « Избегайте публикации заглушек. : Пользователи не любят видеть« пустые »страницы, поэтому по возможности избегайте заполнителей. Например, не публикуйте страницы, для которых у вас еще нет реального содержания. Если вы действительно создаете страницы-заполнители, используйте метатег noindex, чтобы заблокировать индексирование этих страниц. »Google, 2020
и
ЦИТАТА:« Минимизируйте похожее содержимое : Если у вас много похожих страниц, рассмотрите возможность расширения каждой страницы или объединения страниц в одну.Например, если у вас есть туристический сайт с отдельными страницами для двух городов, но с одинаковой информацией на обеих страницах, вы можете либо объединить страницы в одну страницу об обоих городах, либо вы можете расширить каждую страницу, чтобы она содержала уникальный контент о каждом городе. ” Google, 2020
Ключевые вещи, которые следует понимать в отношении дублированного контента на ваших веб-страницах:
- «Дублированный контент» на вашем собственном веб-сайте не обязательно является «скопированным контентом»
- паутина.Google будет оценивать его — на время. Создано человеком или машиной, его очень много — и у Google есть большой опыт работы с этим, и есть много обстоятельств, когда Google находит дублированный контент на веб-сайтах. Не весь дублированный контент — это плохо.
- Если страница хорошо ранжируется и Google считает, что это манипулятивное использование дублированного содержания, Google может понизить рейтинг страницы, если захочет. Если будет сочтено, что намерение является манипулятивным и низкокачественным без добавления ценности, Google может предпринять соответствующие действия — используя ручные или алгоритмические действия.
- Существует очень тонкая грань между разумным дублированием контента и тонким контентом. Вот где возникает путаница.
- Google прямо заявляет, что у них нет штрафа за дублирование контента — , но у них есть ручное действие … что выглядит и ощущается как штраф .
У них также есть Google Panda , алгоритм специально , предназначенный для отсеивания некачественного контента на веб-сайтах.
Минимизируйте любую серию страниц с разбивкой на страницы на вашем сайте
ЦИТАТА : « Используйте категории или теги для перекрестных ссылок, чтобы у вас было несколько страниц с разбивкой на страницы для каждого типа, откуда вы будете ссылаться на сообщения блога.Сохраняйте хорошую и сбалансированную иерархию, не слишком плоскую и не слишком глубокую. ”Джон Мюллер, Google 2020
Использует ли Google разметку для разбивки на страницы?
В начале 2019 года возникла некоторая путаница по поводу того, стоит ли веб-мастерам использовать разметку для разбивки на страницы. Это произошло из-за того, что Google удалил документацию своего собственного справочного центра, в которой изложены передовые методы разметки страниц, и поясняющий комментарий Джона Мюллера в Twitter:
QUOTE : « Мы не используем link-rel-next / prev вообще.Мы заметили, что уже несколько лет не используем rel-next / prev для индексирования, поэтому подумали, что с таким же успехом можем удалить документы. Поскольку он давно не использовался, похоже, что на большинстве сайтов разбивка на страницы выполняется разумными способами, которые работают независимо от этих ссылок. Люди делают хорошие сайты, по большей части ». Джон Мюллер, Google, 2019
Другие сотрудники Google поспешили прояснить комментарий:
ЦИТАТА : « Нет, использовать нумерацию страниц .позвольте мне переосмыслить его … Робот Googlebot достаточно умен, чтобы найти вашу следующую страницу по ссылкам на странице, нам не нужен явный сигнал «предыдущая, следующая». и да, есть и другие веские причины (например, a11y), по которым вы можете захотеть или должны еще добавить их. Я думаю, здесь возникло недоразумение. Google Поиск не использует rel = prev, next в качестве сигнала не означает, что вы не можете или не должны использовать его на своих страницах; Поиск — всего лишь один из потребителей наценки помощи ». Илья Григорик — веб-инженер по производительности Google; Сопредседатель W3C Webperf WG, 2019
и Bing также пояснили, что они используют его, но опять же, не в «модели ранжирования», несколько добавив к тому, что Джон Мюллер из Google указал в своем твите.
ЦИТАТА : « Мы используем rel prev / next (как и большинство разметки) в качестве подсказок для поиска страниц и понимания структуры сайта. На данный момент мы не объединяем страницы вместе в индексе на основе этих и , мы не используем предыдущую / следующую в модели ранжирования . ”Фредерик Дубю, менеджер по веб-рейтингу и качеству в Bing (Microsoft), 2019
Я думаю, что простой ответ здесь…. продолжайте использовать разметку rel = next и rel = previous.
В любом случае я этим занимаюсь.
ЦИТАТА : « Что сейчас рекомендует Google? Теперь Google рекомендует стараться размещать свой контент на одной странице, а не разбивать его на несколько страниц для одного и того же фрагмента контента. Google сказал в Twitter: «Исследования показывают, что пользователи любят одностраничный контент, стремитесь к этому, когда это возможно, но и многостраничный контент также подходит для поиска Google. Знайте и делайте то, что лучше всего для * ваших * пользователей! ”Барри Шварц, Search Engine Land, 2019
Как решить проблемы с разбивкой на страницы на вашем веб-сайте
Страницы, разбитые на страницы, не дублируют контент, но часто для пользователя было бы более выгодно попасть на сайт первая страница последовательности.
Складывание страниц по порядку и представление канонического URL-адреса для группы страниц дает множество преимуществ.
Если вы думаете, что у вас есть проблемы с разбивкой на страницы контента на вашем веб-сайте, попытка исправить это может быть пугающей перспективой.
На самом деле это не так уж и сложно.
Google знает, что « сайтов разбивают контент на страницы по-разному, .», И он используется для решения этого типа проблем на разных типах сайтов, например:
Новостные и / или издательские сайты часто разделяют длинная статья на несколько более коротких страниц.
Сайты розничной торговли могут разделить список товаров в большой товарной категории на несколько страниц.
Дискуссионные форумы часто разбивают цепочки на последовательные URL-адреса.
Хотя Google утверждает, что вы можете « ничего не делать, » с разбитым на страницы контентом, это может быть рискованным в ряде областей, и часть SEO заключается в том, чтобы сосредоточиться на ранжировании канонической версии a URL постоянно .
То, что вы сделаете для обработки содержимого, разбитого на страницы, будет зависеть от ваших обстоятельств.
Лучшая рекомендация по предложению:
ЦИТАТА : «Укажите страницу« Просмотреть все ». Поисковики обычно предпочитают просматривать всю статью или категорию на одной странице. Поэтому, если мы думаем, что это именно то, что ищет поисковик, мы пытаемся показать страницу «Просмотреть все» в результатах поиска. Вы также можете добавить ссылку rel = «canonical» на страницы компонентов, чтобы сообщить Google, что версия «Просмотреть все» — это версия, которую вы хотите отображать в результатах поиска.»Google
и
ЦИТАТА :» Используйте
rel = "next"иrel = "prev"ссылок , чтобы указать взаимосвязь между URL-адресами компонентов. Эта разметка дает Google четкий намек на то, что вы хотели бы, чтобы мы рассматривали эти страницы как логическую последовательность, таким образом объединяя их свойства связывания и обычно отправляя поисковиков на первую страницу ». Google
Вы также можете использовать мета-роботы ‘ noindex, следовать указаниям ‘ для определенных типов содержимого с разбивкой на страницы (я делаю), однако я бы рекомендовал вам дважды подумать, прежде чем удалять такой контент из индекса Google, ЕСЛИ эти URL-адреса ( или часть этих URL-адресов) генерируют хороший объем трафика от Google, и у Google нет явной необходимости переходить по ссылкам для поиска контента.
Если страница получает трафик от Google, но должна выйти из индекса, то я обычно полагаюсь на реализацию, которая включает элемент канонической ссылки (или перенаправление).
В конечном итоге это зависит от ситуации и типа сайта, с которым вы имеете дело.
Как правильно использовать разметку Rel = Next & Rel = Previous
Вам не нужно внедрять разметку Rel = Next / Prevous, но это стандарт W3C, поэтому не стесняйтесь использовать его, если хотите.
Разбивка на страницы может быть сложной задачей, и ее легко испортить.
Вот несколько примечаний, которые также могут вам помочь:
- Разметка rel = «next» и rel = «previous» является стандартом для обозначения страниц с разбивкой на страницы (и это может включать любые параметры страницы).
- Rel Canonical is для дублированного контента. например для идентификаторов сеанса ИЛИ для контента, который является «надмножеством», например расширенный ПРОСМОТР ВСЕ СТРАНИЦЫ. Если алгоритмы Google ПРЕДОСТАВЛЯЮТ страницу со «неправильно используемым» каноническим символом, они выберут страницу, которую предпочитают (или их пользователи).Canonical — это НАМЕК, а не ДИРЕКТИВА, которую Google должен соблюдать. Страница, удаленная из индекса Google из-за неправильного использования canonical, со временем появится снова, если Google предпочтет ее, и она проигнорирует rel = canonical на этой странице и проиндексирует ее в обычном режиме.
Google НЕ полностью игнорирует канонические инструкции всего сайта при неправильном использовании — скорее, кажется, что он делает этот URL-адрес за URL-адресом — но это может повлиять на уровни трафика в основных обновлениях, PAGE TO PAGE, поскольку Google лучше понимает ваш сайт, особенно когда страницы его Предпочтение ПОЛЬЗОВАТЕЛЯ отличается (при сопоставлении с запросом) с URL-адресом, который ВЫ указываете в Rel = canonical.Это то, что Google подразумевает под «подсказкой», а не директивой. - Целевые URL-адреса разметки rel = «next» и rel = «previous» должны возвращать заголовок ответа 200 OK.
- Первая страница в серии должна иметь разметку rel = next, но не иметь кода rel = prev, а для последней страницы в серии верно обратное.
- Страницы в серии должны иметь канонический тег, ссылающийся на себя, если они не указывают «просмотреть всю страницу». rel = «canonical» указывает Google индексировать ТОЛЬКО контент на странице, указанной в rel = «canonical».
- rel = «canonical» — НЕ канонизировать страницы компонентов в серии до первой страницы.
Используйте rel = «canonical» ТОЛЬКО для указания на ПРОСМОТР ВСЕХ страниц, если таковая имеется. В СЛУЧАЕ ИНАЧЕ, все страницы ДОЛЖНЫ иметь САМОСсылающийся канонический тег.
ЦИТАТА : « В случаях разбивки на страницы контента мы рекомендуем использовать rel = canonical от компонентных страниц до одностраничной версии статьи, либо использовать rel =» prev «и rel =» next «для разбивки на страницы. разметка .”- Google
Распространенная ошибка веб-разработчиков — добавить rel = canonical на первую страницу в серии или добавить NOINDEX на страницы в серии из набора компонентов.
ЦИТАТА : «Хотя можно установить rel =» canonical «из URL-адреса компонента на единую страницу для просмотра всех страниц, установка канонического значения для первой страницы последовательности без параметров считается неправильным использованием». — Google, 2012
и
ЦИТАТА : «Когда вы реализуете rel =» next «и rel =» prev «на страницах компонентов серии, мы затем объединим свойства индексирования со страниц компонентов и попытаться направить пользователей на наиболее релевантную страницу / URL.Обычно это первая страница. Нет необходимости отмечать страницы со 2 по n серии с помощью noindex. » GOOGLE
Представитель Google объясняет, почему это здесь не оптимально: https://youtu.be/njn8uXTWiGg?t=11m52s
RE: Как обрабатывать последовательные во времени серии страниц (например, в блоге) Google предлагает это совет:
ВОПРОС:
ЦИТАТА : «Следует ли мне использовать rel next / prev в [sic] разделе блога, даже если два содержания не строго коррелированы (но они просто временны) ? »
ОТВЕТ:
ЦИТАТА :: «Относительно использования rel =» next »и rel =« prev »для записей в вашем блоге, которые« не коррелируют строго (но это просто время -последовательный) », разметка нумерации страниц, вероятно, не лучший вариант использования вашего времени — последовательные по времени страницы не так полезны для нашего процесса индексирования, как семантически связанный контент, такой как разбиение на страницы на страницах компонентов в статье или категории.
Это нормально, если вы добавите разметку на страницы с временной последовательностью, но учтите, что это не самый полезный вариант использования ». Джон Мюллер, Google, 2012
Итак, для внутренних страниц, упорядоченных по дате публикации, вероятно, лучше просто позволить Google сканировать их.
Каким образом Googe оценивает контент «
, намеренно дублируемый в доменах »?Он может рассматривать это как манипулятивное:
«… в некоторых случаях контент намеренно дублируется по доменам в в попытке манипулировать рейтингом в поисковых системах или привлечь больше трафика .
Обманные действия, подобные этому , могут привести к ухудшению взаимодействия с пользователем, когда посетитель видит практически одно и то же содержимое, повторяющееся в наборе результатов поиска.
Google изо всех сил пытается индексировать и отображать страницы с четкой информацией.
Эта фильтрация означает, например, что если на вашем сайте есть «обычная» и «печатная» версии каждой статьи, и ни одна из них не заблокирована метатегом noindex, мы выберем одну из них в список .
В тех редких случаях, когда Google считает, что дублированный контент может быть показан с намерением манипулировать нашим рейтингом и обмануть наших пользователей, мы также внесем соответствующие корректировки в индексирование и ранжирование задействованных сайтов .
В результате может пострадать рейтинг сайта или сайт может быть полностью удален из индекса Google, и в этом случае он больше не будет отображаться в результатах поиска. GOOGLE, 2020
Если вы пытаетесь конкурировать в конкурентных нишах, вам нужен оригинальный контент, которого нет на других страницах в той же форме на вашем сайте, и ЭТО, ЕЩЕ БОЛЬШЕ, ВАЖНО, КОГДА ЭТО СОДЕРЖАНИЕ НАХОДИТСЯ НА ДРУГИХ СТРАНИЦЫ НА ДРУГИХ ВЕБ-САЙТАХ.
Google не обязан оценивать вашу версию содержания — в конце концов, это зависит от того, у какого сайта наибольший авторитет домена или наибольшее количество ссылок, ведущих на страницу.
Ну, по крайней мере, исторически — это часто страница, которая удовлетворяет пользователей больше всего .
Если вы хотите избежать фильтрации с помощью алгоритмов дублирования контента, создаст уникальный контент .
Следует ли блокировать сканирование страниц результатов внутреннего поиска Google?
Да.По данным Google.
Google хочет, чтобы вы использовали текст роботов для блокировки результатов внутреннего поиска. Google рекомендует «не разрешать индексирование страниц внутреннего поиска».
Хотя есть способы обойти это руководство, которые не создают «бесконечного пространства поиска», разрешение Google индексировать и ранжировать ваши внутренние поисковые страницы является ОЧЕНЬ рискованным маневром (с течением времени), если вы работаете в конкурентной отрасли.
Эти рекомендации содержатся в руководстве для веб-мастеров.
ЦИТАТА : «Используйте файл robots.txt на своем веб-сервере для управления бюджетом сканирования, предотвращая сканирование бесконечных пространств, таких как страницы результатов поиска. Регулярно обновляйте файл robots.txt ». Google 2017
Разрешить Google сканировать и индексировать ваши внутренние страницы результатов поиска «неэффективно» со стороны сканирования и индексации.
Такие страницы вызывают «проблемы при поиске» у Google, и у Google есть история «откликов» на компании, которые нарушают такие правила ради своей прибыли.
СОВЕТ: «noindex, follow» «
по сути то же самое, что» «noindex, nofollow» Джон МюллерМногие используют NOINDEX, FOLLOW на таких страницах (подстраницы блога, архивы на основе даты и т. удаление их из индекса в недавнем выступлении Джона Мюллера означало бы изменение в том, как Google обрабатывает неиндексированные ссылки и атрибут «follow» в инструкции мета-роботов.
ЦИТАТА : « Так что с noindex довольно сложно.Я думаю, что это в некоторой степени заблуждение в сообществе SEO. В этом случае с noindex и последующим мы все еще видим noindex. И на первом этапе мы говорим: «Хорошо, вы не хотите, чтобы эта страница отображалась в результатах поиска». Мы по-прежнему сохраним его в нашем индексе, просто не будем показывать его, и тогда мы сможем перейти по этим ссылкам. Но если мы видим noindex там дольше, чем мы думаем, эта страница действительно не хочет использоваться в поиске, поэтому мы полностью удалим ее. И тогда мы все равно не будем переходить по ссылкам.Таким образом, noindex и follow — это то же самое, что noindex, nofollow. В конечном итоге большой разницы здесь нет. ”John Muller, 2017
Не делайте частые ссылки с ваших собственных сайтов на внутренние ссылки на страницы, которые не индексируются.
Дополнительная литература: https://webmasters.googleblog.com/2012/03/video-about-pagination-with-relnext-and.html
Считаются ли URL-адреса в верхнем и нижнем регистре ДВУМЯ разными страницами для Google?
Да.Заглавные и строчные версии URL-адреса классифицируются как ДВЕ разные страницы для Google.
В течение долгого времени передовой практикой было принудительное использование строчных URL-адресов на вашем сервере, соблюдение согласованности при ссылках на внутренние страницы вашего веб-сайта и использование только строчных URL-адресов при создании внутренних ссылок.
Видео ниже предлагает недавнее (2017 г.) подтверждение этой проблемы — с советом использовать канонические ссылки или перенаправления для решения этой проблемы, и это было бы более эффективным с точки зрения сканирования и индексации (что, по-моему, 301 перенаправляет в этом случае, где это необходимо, и капитальный ремонт внутренней структуры ссылок):
… и когда его недавно спросили (2017) в Twitter, бывший сотрудник Google Мэтт Каттс ответил:
ЦИТАТА : « Есть ли КАКАЯ-либо релевантная для SEO причина принудительно использовать строчные URL-адреса ? » 2017
Мэтт ответил:
ЦИТАТА : « Объединение ссылок на один URL » Мэтт Каттс, бывший Google, 2017 г.
Может ли скользящая косая черта вызывать дублирование контента на веб-сайте?
Иногда .Это зависит от того, находятся ли завершающие косые черты на внутренних страницах сайта или в корне, и какой протокол используется.
Google пояснил, вызывает ли проблема на вашем сайте забывание добавления косой черты в URL-адрес веб-сайта:
ЦИТАТА : «Я заметил некоторую путаницу вокруг конечных косых черт в URL-адресах, поэтому надеюсь, что это поможет. tl; dr: косая черта для root / hostname = не имеет значения; косая черта в другом месте = имеет значение (это разные URL-адреса) » Джон Мюллер, Google, 2017
Он предложил руководство, которое поможет исправить общие проблемы:
Примечание. Я стремлюсь использовать косую черту в конце почти во всех случаях. – помогают обеспечить согласованность канонических URL-адресов на сайте , когда речь идет о внутренних или внешних ссылках.
Перенаправить не WWW в WWW (или наоборот)
ЦИТАТА : « Предпочитаемый домен — это тот, который вы хотели бы использовать для индексации страниц вашего сайта (иногда его называют каноническим доменом. ). Ссылки могут указывать на ваш сайт с использованием версий URL как с www, так и без www (например, http://www.example.com и http://example.com). Предпочтительный домен — это версия, которую вы хотите использовать для своего сайта в результатах поиска. ”Google, 2018
У вашего сайта, вероятно, есть проблемы с канонизацией (особенно если у вас есть веб-сайт электронной коммерции), и он может начинаться на уровне домена, что может усугубить проблемы с дублированием контента на вашем веб-сайте.
Проще говоря, https://www.hobo-web.co.uk/ может рассматриваться Google как другой URL-адрес, чем http://hobo-web.co.uk/, даже если это одна и та же страница, и она может стать еще сложнее.
Его мысль, что НАСТОЯЩИЙ PageRank может быть ослаблен, если Google запутается с вашими URL-адресами и, говоря просто, вы не хотите разбавлять этот PR (теоретически). hobo-web.(. *) $ https://www.hobo-web.co.uk/$1 [L, R = 301]
По сути, вы перенаправляете все ресурсы Google на одну каноническую версию URL.
Это ДОЛЖНА ИМЕТЬ передовая практика.
Это упрощает оптимизацию для Google. Это должно быть записано; невероятно важно не смешивать два типа www / non-www на сайте при связывании ваших внутренних страниц !
Примечание. Google спросит, какой домен вы предпочитаете установить в качестве канонического домена в Инструментах Google для веб-мастеров.
ЦИТАТА : « Примечание: После того, как вы установили предпочтительный домен, вы можете использовать 301 редирект для перенаправления трафика с нежелательного домена, чтобы другие поисковые системы и посетители знали, какую версию вы используете. предпочитать.» Google
Применяет ли алгоритм Google Panda наказание за дублирование контента?
ЦИТАТА: « Обновление Google Panda — это поисковый фильтр, введенный в феврале 2011 года и предназначенный для предотвращения попадания сайтов с некачественным содержанием в лучших результатов поиска Google . Panda — это , обновляемые время от времени . Когда это происходит, ранее посещенные сайты могут ускользнуть, если они внесли правильные изменения. ”SearchEngineLand, 2020
Google Panda (несколько устаревший термин для SEO) — это название серии серьезных изменений результатов поиска Google, начавшихся еще в 2011 году. Простой ответ на вопрос -….
Нет — но если у вас есть «скопированный контент» на вашем сайте, то вы, вероятно, испытаете на себе различное негативное влияние.
Часть алгоритма Google Panda ориентирована на тонкие страницы и (многие думают) соотношение качественного и некачественного контента на сайте и отзывы пользователей в Google как показатель степени удовлетворенности.
В исходном объявлении о Google Panda нам было специально сказано, что следующее «плохо»:
ЦИТАТА : «Есть ли на сайте повторяющиеся, перекрывающиеся или повторяющиеся статьи?» Google, 2020
Если Google оценивает ваши страницы по качеству содержания или его отсутствию, как нам говорят, и удовлетворенность пользователей — на некотором уровне — и большая часть вашего сайта представляет собой дублированный контент, который не дает положительных результатов. отзыв об удовлетворенности пользователей в Google — тогда это тоже может быть проблемой.
Google дает несколько советов по тонким страницам (выделено мной):
ЦИТАТА : « Вот несколько распространенных примеров страниц, которые часто имеют тонкое содержание с небольшой добавленной стоимостью или без нее: 1. Автоматически генерируемый контент, 2. Тонкие партнерские страницы 3. Контент из других источников . Например: Обработанный контент или постов в гостевом блоге низкого качества . 4. Страницы дорвеев “
Все, что я выделил жирным шрифтом в последних двух цитатах, по сути, означает около , что многие SEO традиционно называют (ошибочно)« дублированным контентом ».
Это может быть «семантика», но Google называет такой тип повторяющегося содержания «спамом».
Google еще более откровенен, когда сообщает, как устранить это «нарушение»:
ЦИТАТА : « Затем выполните следующие действия, чтобы выявить и исправить нарушение (я) на вашем сайте: Проверьте, нет ли на вашем сайте контента, который дублирует контент из других источников. . ”Google
Так что будьте осторожны.
Google заявляет, что НЕТ штрафа за дублирование контента, но если Google классифицирует ваш «дублированный контент» как «скопированный контент», «тонкий контент» или «шаблонный», или поспешно переписанный или, что еще хуже, «синонимизированный» или «вращающийся текст», тогда У вас МОЖЕТ быть проблема!
серьезная проблема, , если весь ваш сайт построен таким образом.
И то, как Google оценивает тонкие страницы, меняется с течением времени, с планкой качества, которая всегда будет расти, и ваши страницы должны не отставать от нее.
Особенно, если вы занимаетесь перефразированием контента.
Google Panda не наказывает сайт за дублированный контент, но измеряет «качество» сайта и контента. Google Panda фактически Демонстрирует сайт, на котором он определяет намерение манипулировать алгоритмами.
Google Panda:
ЦИТАТА : «измеряет качество сайта в значительной степени, просматривая, по крайней мере, подавляющее большинство страниц.Но по сути позволяет нам принимать во внимание качество всего сайта при ранжировании страниц с этого конкретного сайта и соответствующим образом корректировать ранжирование страниц. [Google Panda] — это корректировка. По сути, мы полагали, что этот сайт пытается обмануть наши системы, и, к сожалению, успешно. Так что мы скорректируем ранг. Мы вернем сайт обратно, чтобы убедиться, что он больше не работает ». Гэри Иллис, официальный представитель Google, 2016 г.
СОВЕТ. Обратите внимание на программные ошибки 404 в инструментах Google для веб-мастеров (теперь они называются Google Search Console ) в качестве примеров страниц, которые Google классифицирует как некачественные, неудобные для пользователей тонкие страницы.
Использование Google Search Console для выявления дубликатов
Используйте Google Search Console для устранения проблем с дублирующимся контентом на вашем сайте.
Обратите внимание, что Google говорит:
ЦИТАТА : « Вы не должны ожидать, что все URL на вашем сайте будут проиндексированы. Ваша цель — получить каноническую версию каждой проиндексированной страницы. Любые повторяющиеся или альтернативные страницы будут помечены как «Исключенные» в этом отчете (отчет о состоянии индексации). Дубликаты или альтернативные страницы имеют практически то же содержание, что и каноническая страница. Помечать страницу как повторяющуюся или альтернативную — это хорошо; это означает, что мы нашли каноническую страницу и проиндексировали ее. Вы можете найти канонический для любого URL-адреса, запустив инструмент проверки URL-адресов. »Официальные рекомендации Google, 2019 г.
В отчете« Исключено »по существу перечислены:
ЦИТАТА :« Страница не проиндексирована, но мы думаем, что это было вашим намерением. (Например, вы могли намеренно исключить ее с помощью директивы noindex или это может быть дубликат канонической страницы, которую мы уже проиндексировали на вашем сайте.)…. Эти страницы обычно не индексируются, и мы думаем, что это уместно. Эти страницы либо дублируют проиндексированные страницы, либо заблокированы от индексации каким-либо механизмом на вашем сайте, либо не проиндексированы иным образом по причине, которая, по нашему мнению, не является ошибкой. »Официальные рекомендации Google, 2019
Советы, которые Google предоставляет в Search Console, включают« Все в порядке »:
ЦИТАТА:« Альтернативная страница с правильным каноническим тегом: Эта страница является дубликатом страницы. которые Google признает каноническими.Эта страница правильно указывает на каноническую страницу, поэтому вам нечего делать ». Google 2020
и два сообщения об ошибках, одно из которых« Дубликат без канонической версии, выбранной пользователем: »:
ЦИТАТА: « Дубликат без выбранной пользователем канонической версии: На этой странице есть дубликаты, ни один из которых не отмечен как канонический. Мы считаем эту страницу неканонической. Вы должны явно отметить каноничность для этой страницы. Проверка этого URL-адреса должна показать канонический URL-адрес, выбранный Google.«Search Console, 2019
и еще один,« Дубликат, Google выбрал канонический, отличный от пользовательского »:
ЦИТАТА:« Дубликат, Google выбрал канонический, отличный от пользовательского: эта страница отмечена как каноническая для набор страниц, но Google считает, что другой URL лучше каноничен. Google проиндексировал страницу, которую мы считаем канонической, а не эту. Мы рекомендуем вам явно пометить эту страницу как копию канонического URL.Эта страница была обнаружена без явного запроса на сканирование. Проверка этого URL должна показать канонический URL, выбранный Google ». Search Console, 2019
Как проверить наличие дублированного контента на сайте?
Самый простой способ найти повторяющийся контент — использовать поиск Google.
Просто возьмите фрагмент текстового содержания со своего сайта и поместите его «в кавычки» при поиске в Google.
Google сообщит вам, сколько страниц с этим содержанием он нашел на страницах в своем индексе Интернета.Страница, которая ранжируется по этому содержанию, часто также является оригинальной.
Самым известным онлайн-средством проверки дублированного содержимого является Copyscape, и мне особенно нравится этот небольшой инструмент, который проверяет соотношение дублированного содержимого между двумя выделениями текста.
Если вы обнаружите доказательства плагиата, вы можете подать DMCA или связаться с Google, но я никогда не беспокоился об этом, и многие люди переиздали мои статьи за эти годы.
Однажды я однажды нашел свою статью (слово в слово) в платной рекламе в печатном журнале раньше, для кого-то другого!
Комментарии:
Несколько маркетологов и представители Google прокомментировали эту статью в социальных кругах (представленных в виде изображений в этой статье)
Подробнее
.