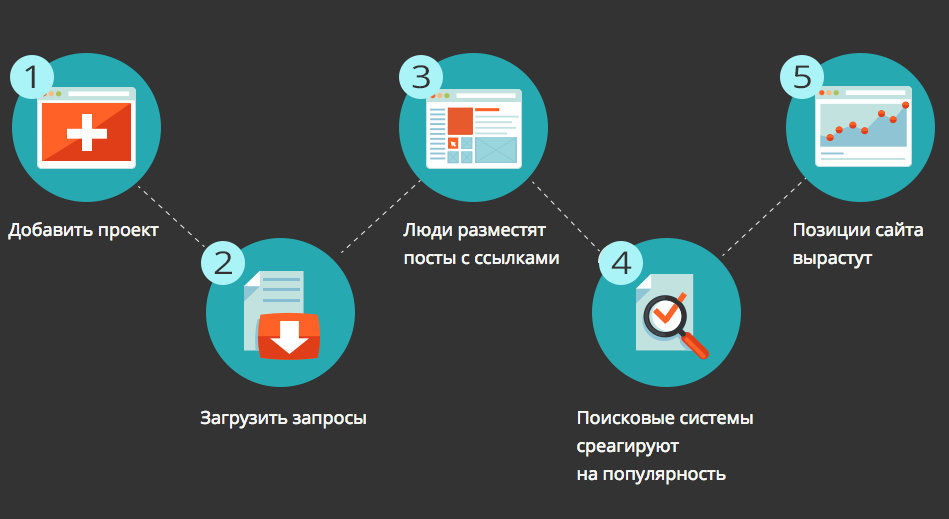
что это, как настроить и ускорить индексирование в поисковых системах
Как только вы создадите сайт для своего бизнеса, однозначно столкнетесь с понятием «индексация в поисковых системах». В статье постараемся как можно проще рассказать, что это такое, зачем нужно и как сделать, чтобы индексация проходила быстро и успешно.
Что такое индексация в поисковых системах
Под индексацией понимают добавление информации о сайте или странице в базу данных поисковой системы. Фактически поисковую базу можно сравнить с библиотечным каталогом, куда внесены данные о книгах. Только вместо книг здесь веб-страницы.
Если совсем просто, индексация — процесс сбора данных о сайте. Пока информация о новой странице не окажется в базе, ее не будут показывать по запросам пользователей. Это означает, что ваш сайт никто не увидит.
Индексация сайта — базовая часть работы по продвижению ресурса. Только потом уже добавляются все остальные элементы по оптимизации сайта. Если у веб-страницы будут проблемы с индексированием, ваш бизнес не получит клиентов с сайта и понесет убытки.
Если у веб-страницы будут проблемы с индексированием, ваш бизнес не получит клиентов с сайта и понесет убытки.
Как проходит процесс индексации
Давайте посмотрим, как происходит индексирование страниц сайта.
- Поисковый робот (краулер) обходит ресурсы и находит новую страницу.
- Данные анализируются: происходит очистка контента от ненужной информации, заодно формируется список лексем. Лексема — совокупность всех значений и грамматических форм слова в русском языке.
- Вся собранная информация упорядочивается, лексемы расставляются по алфавиту. Заодно происходит обработка данных, поисковая машина относит информацию к определенным тематикам.
- Формируется индексная запись.
Это стандартный процесс индексации документов для поисковых систем. При этом у «Яндекса» и Google существуют небольшие отличия в технических моментах, про это мы расскажем дальше.
Читайте также:
Отличия SEO под Яндекс и Google
Технологии и алгоритмы индексации
Сразу стоит оговориться, что точные алгоритмы индексирования — закрытая коммерческая информация. Поисковые системы тщательно охраняют эти данные. Поэтому в этом разделе расскажем про алгоритмы только в общих чертах
Вначале нужно отметить: «Яндекс» при индексации ориентируется в основном на файл robots.txt, а Google на файл sitemap.xml.
Основным отличием является использование технологии Mobile-first. Она подразумевает первоочередное сканирование и индексацию мобильной версии сайта. В индексе сохраняется именно мобильная версия. Получается, что если ваша страница при показе на мобильных устройствах будет содержать недостаточно нужной информации или в целом проигрывать основной версии сайта по качеству.
Также Google подтверждает наличие «краулингового бюджета» — регулярности и объема посещения сайта роботом. Чем больше краулинговый бюджет, тем быстрее новые страницы будут попадать в индекс. К сожалению, точных данных о способах расчета этого показателя представители компании не раскрывают. По наблюдениям специалистов, тут оказывают сильное влияние возраст сайта и частота обновлений.
«Яндекс»
В «Яндексе» основной версией считается десктопная версия сайта, поэтому в первую очередь сканируется именно она. Официально краулингового бюджета здесь нет, поэтому индексирование происходит вне зависимости от траста и других показателей вашего ресурса. Еще может влиять количество выложенных в сеть на данный момент страниц. Речь про страницы, которые конкуренты и другие пользователи выкладывают одновременно с вами.
Приоритет при индексации имеют сайты с большой посещаемостью. Чем выше посещаемость, тем быстрее новая страница окажется в поисковой выдаче.
Также Яндекс не индексирует документы с весом более 10 Мб. Учитывайте это при создании страниц сайта. Советуем также почитать кейс: Продвижение сайта REG.RU за процент от продаж.
Заказать продвижение сейчас
Сайт
Телефон
Как настроить индексацию сайта
В целом сайт должен индексироваться самостоятельно, даже если вы не будете ничего предпринимать для этого. Но если вы разберетесь с настройкой, то получите быструю и надежную индексацию и в случае возникновения проблем с сайтом будете понимать, в чем причина.
Первое, что стоит сделать, — создать файл robots.txt. У большей части систем управления сайтом (CMS) есть автоматизированные решения для его генерации. Но нужно как минимум понимать, какие директивы используются в этом файле. На скриншоте показан стандартный документ для сайта на WordPress:
 txt сайта на WordPress
txt сайта на WordPressОбратите внимание, что здесь нет директивы host: она не используется «Яндексом» с 2018 года, а Google никогда ее и не замечал. Но при этом до сих пор встречаются рекомендации по использованию этой директивы, и многие по инерции вставляют ее в файл.
В таблице ниже указаны основные параметры, используемые в robots.txt:
| Директива | Зачем используется |
|
User-agent:
|
Показывает поискового робота, для которого установлены правила |
| Disallow: | Запрещает индексацию страниц |
| sitemap: | Показывает путь к файлу sitemap.xml |
| Clean-param: | Указывает на страницы, где часть ссылок не нужно учитывать, например UTM-метки |
| Allow: | Разрешает индексацию документа |
| Crawl-delay: | Указывает поисковому роботу минимальное время ожидания между посещением предыдущей и следующей страницы сайта |
Рассмотрим более подробно код на следующем скриншоте. User-agent показывает, что директивы предназначены для «Яндекса». А директива Disallow показывает, какие страницы не должны попасть в индекс. Это технические документы, в частности админ-панель сайта и плагины.
User-agent показывает, что директивы предназначены для «Яндекса». А директива Disallow показывает, какие страницы не должны попасть в индекс. Это технические документы, в частности админ-панель сайта и плагины.
Фрагмент кода robots.txt
Более подробно о том, каким должен быть robots.txt для сайта, можно прочитать в справке сервиса «Яндекс.Вебмастер».
Далее делаем файл sitemap.xml: фактически это карта сайта, созданная в формате xml. Сделано это для упрощения считывания данных поисковыми роботами. В файл вносятся все страницы, которые должны быть проиндексированы.
Для правильной индексации файл не должен превышать 50 Мб или 50000 записей. Если нужно проиндексировать больше адресов, делают несколько файлов, которые в свою очередь перечисляются в файле с индексом sitemap.
На практике сайты, работающие с бизнесом, редко имеют потребность в подобном решении — просто имейте в виду такую особенность.
На скриншоте показан фрагмент кода sitemap.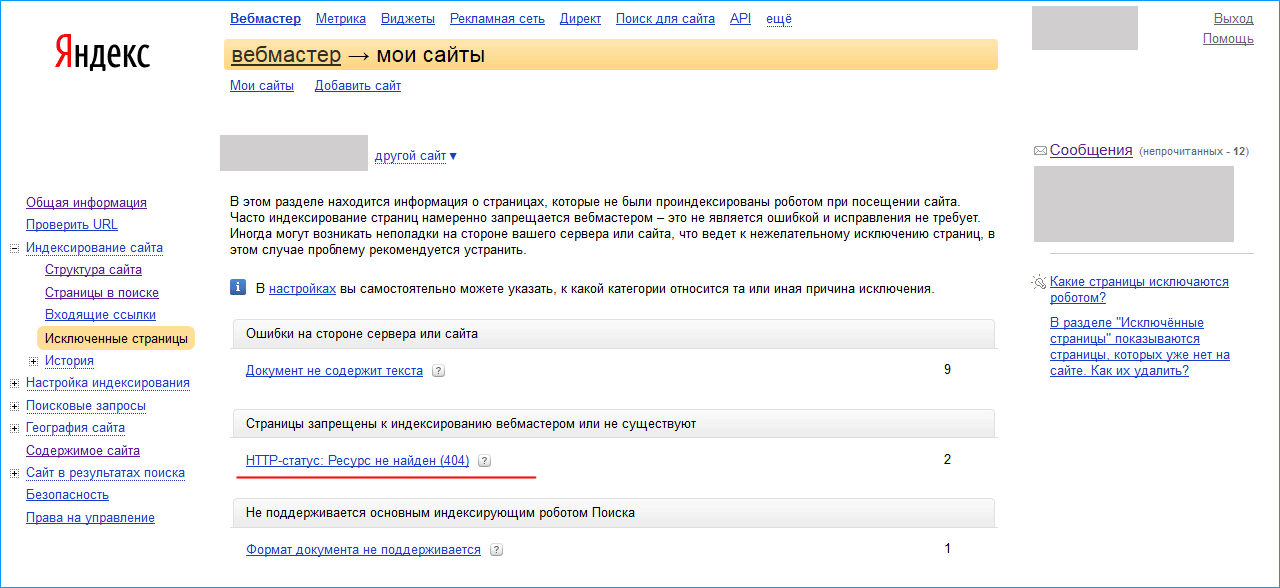 xml, сгенерированный одним из плагинов WordPress:
xml, сгенерированный одним из плагинов WordPress:
Так выглядит файл sitemap.xml «изнутри»
Остается разобраться, как создать файл sitemap.xml. Решение зависит от CMS вашего сайта. Если он сделан не на популярном «движке», придется делать все руками. Можно воспользоваться онлайн-генератором: например, mySitemapgenerator. Вводим адрес сайта и через короткое время получаем готовый файл.
Для сайтов на CMS WordPress сделать такую карту сайта еще проще. У вас все равно уже установлен один из плагинов для SEO-оптимизации ресурса. Заходим в настройки плагина и включаем генерацию sitemap.xml. На скриншоте показан пример включения карты сайта через плагин AIOSEO:
Плагин для настройки sitemap.xml в WP
Чтобы сайт максимально быстро индексировался, следует обеспечить перелинковку. Тогда поисковый робот без проблем будет переходить по страницам и своевременно найдет новый документ.
Далее необходимо выполнить настройку индексирования в «Яндекс.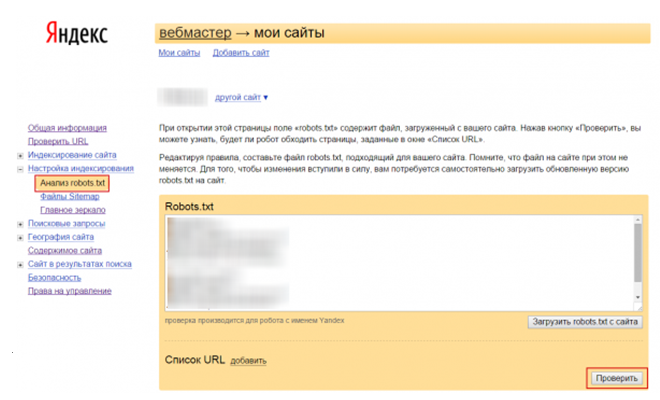 Вебмастер» и Google Search Console.
Вебмастер» и Google Search Console.
Читайте также:
Подробный гайд по оптимизации сайта на WordPress
Как ускорить индексацию сайта
В начале статьи мы рассказывали, как настроить индексирование. Теперь поговорим о том, как ускорить это процесс. В целом современные поисковые роботы довольно быстро собирают информацию о ресурсе: по моим наблюдениям, новые страницы появляются в индексе уже через 20–40 минут. Но так бывает не всегда, потому что может произойти сбой или еще какая-то нештатная ситуация, и страница будет индексироваться очень долго.
Появление адреса в списке проиндексированных страниц «Яндекс.Вебмастера» не совпадает с моментом индексации. На практике URL оказывается в индексе намного раньше, а в кабинете только при очередном апдейте.
При этом есть ситуации, когда индексирование нужно ускорить:
-
Сайт выходит из-под фильтров.
- Молодой ресурс обладает небольшим краулинговым бюджетом.
В обоих случаях рекомендуется подтолкнуть поисковых роботов. Отметим, что для «Яндекса» и Google подход будет разным.
Начнем с отечественной поисковой системы. Заходим в «Яндекс.Вебмастер» и в меню слева, во вкладке «Индексирование», находим ссылку «Переобход страниц». Переходим по ней:
Яндекс.Вебмастер — подраздел «Переобход страниц» в меню «Индексирование»
На следующей вкладке вводим URL новой страницы, после чего жмем кнопку «Отправить». Отследить статус заявки можно в расположенном ниже списке:
Процесс отправки страниц сайта на переобход
Так можно поступать не только с новыми страницами, но и в случае изменения уже имеющихся на сайте. Только помните, что количество отправок в сутки ограничено, причем все зависит от возраста и траста сайта.
В самом «Вебмастере» предлагается для ускорения индексирования подключать переобход по счетчику «Яндекс. Метрики». Это не самое лучшее решение. Дело в том, что поисковый робот может ходить по всем страницам — даже тем, которые не нужно индексировать, причем в приоритете будут наиболее посещаемые документы. Может получиться ситуация, когда старые страницы робот обошел, а новые не заметил. Или вообще в поиск попадут технические страницы: например, страница авторизации или корзина интернет-магазина.
Метрики». Это не самое лучшее решение. Дело в том, что поисковый робот может ходить по всем страницам — даже тем, которые не нужно индексировать, причем в приоритете будут наиболее посещаемые документы. Может получиться ситуация, когда старые страницы робот обошел, а новые не заметил. Или вообще в поиск попадут технические страницы: например, страница авторизации или корзина интернет-магазина.
У Google ускорение индексации состоит из двух этапов. Сначала идем в Search Console, где на главной странице вверху находится поле «Проверка всех URL». В него вставляем адрес страницы, которую нужно проиндексировать. Далее нажимаем на клавиатуре «Enter».
Поле для ввода URL страницы, которую мы хотим добавить для индексирования
Ждем около минуты. Сервис нам будет показывать вот такое окно:
Всплывающее окно в Search Console о получении данных из индекса
Следующая страница выглядит вот так:
Как видите написано, что URL отсутствует в индексе, поэтому нажимаем на кнопку «Запросить индексирование»
Некоторое время поисковая машина будет проверять, есть ли возможность проиндексировать адрес:
Техническое окно с сообщением о проверке
Если все прошло успешно, Google сообщает, что страница отправлена на индексирование. Остается только дождаться результатов.
Остается только дождаться результатов.
Сообщение об отправке запроса. Обратите внимание, что не стоит повторно отправлять на индексацию один и тот же URL
При отправке на индексирование страниц сайта, следует помнить, что Google до сих пор очень ценит ссылки. Поэтому, существует альтернативный способ ускорения индексации — Twitter.
Сразу после публикации страницы идем в Twitter и делаем твит с нужным адресом. Буквально через полчаса URL будет уже в индексе Google.
Лучше всего использовать эти обе способа совместно. Так будет надежнее.
Читайте также:
Внешняя оптимизация сайта: как продвигать сайт с помощью сторонних ресурсов
Как запретить индексацию страниц
В некоторых случаях может потребоваться не проиндексировать, а наоборот запретить индексацию. К примеру, вы только создаете страницу и на ней нет нужной информации, или вообще сайт в разработке и все страницы — тестовые и недоработанные.
К примеру, вы только создаете страницу и на ней нет нужной информации, или вообще сайт в разработке и все страницы — тестовые и недоработанные.
Существует несколько способов, чтобы «спрятать» страницу от поисковых роботов. Рассмотрим наиболее удобные варианты.
Способ первый
Если вам нужно скрыть всего один документ, можно добавить в код страницы метатег Noindex. Эта команда дает поисковому роботу команду не индексировать документ. Размещают его между тегами <head>. Вот код, который нужно разместить:
<meta name=»robots» content=»noindex» />
Большая часть CMS позволяют использовать этот метод в один клик, предлагая готовые решения. У WordPress, например, для этого имеется отдельная строчка в настройках редактора, а в «1С-Битрикс» путем настроек раздела и конкретной страницы.
Способ второй
Заключается в редактировании файла robots.txt. Разберем несколько примеров закрытия страниц от индексирования.
Начнем с полного закрытия сайта от индексирования. На скриншоте код, который выполняет эту задачу: звездочка говорит, что правило работает для всех поисковых роботов. Косая черта (слеш) показывает, что директива Disallow относится ко всему сайту.
Полное закрытие сайта от индексирования
Если нам нужно закрыть ресурс от индексирования в конкретной поисковой системе, указываем название ее краулера. На скриншоте показано закрытие от робота «Яндекса».
Закрываем сайт от индексации «Яндексом»
Когда нужно избежать индексирования конкретной страницы, после слеша указываем параметры пути к документу. Пример показан на скриншоте:
Закрытие одной страницы в Robots.txt
Для Google все перечисленные способы работают аналогично. С разницей лишь в том, что если страницу или целый сайт нужно скрыть конкретно от этой поисковой системы, в User-agent указывают атрибут Googlebot.
Закрытие страниц от индексации используется довольно часто. В процессе развития своего веб-ресурса вам часто придется делать новые страницы, или переделывать имеющиеся. Чтобы избежать попадания в поисковую выдачу не готовых к показу страниц, имеет смысл закрывать их от индексации.
В процессе развития своего веб-ресурса вам часто придется делать новые страницы, или переделывать имеющиеся. Чтобы избежать попадания в поисковую выдачу не готовых к показу страниц, имеет смысл закрывать их от индексации.
Присоединяйтесь к нашему Telegram-каналу!
- Теперь Вы можете читать последние новости из мира интернет-маркетинга в мессенджере Telegram на своём мобильном телефоне.
- Для этого вам необходимо подписаться на наш канал.
Распространенные ошибки индексации
Чаще всего проблемы возникают из-за случайного закрытия сайта от индексирования. У меня был случай, когда клиент при самостоятельном обновлении плагинов как-то внес изменения в файл robots.txt, и сайт исчез из поисковой выдачи. Поэтому при всех действиях, которые связаны с этим файлом, обязательно проверяйте, нет ли изменений в директивах.
Для проверки можно использовать инструмент Яндекс.Вебмастер «Анализ robots.txt».
Анализатор robots.txt — бесплатный и полезный инструмент проверки файла на корректность записанных директив
В некоторых случаях могут индексироваться технические страницы. К примеру, на WordPress при размещении изображений в виде медиафайла поисковый робот может индексировать каждую картинку в качестве отдельной страницы. В таком случае делаем редирект с этой страницы на тот документ, где изображение будет выводиться.
Читайте также:
Как сделать редирект — подробное руководство по настройке и использованию
Иногда встречаются проблемы с индексированием из-за неполадок на сервере или хостинге, но это уже нужно решать с администратором сервера, что выходит за рамки этой статьи.
Медленное индексирование может быть следствием наложения фильтров со стороны поисковых систем.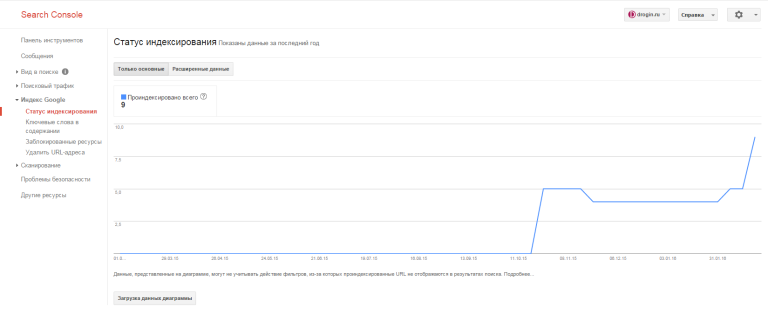 Посмотрите, нет ли предупреждений в сервисах для вебмастеров: если они есть, устраните проблемы.
Посмотрите, нет ли предупреждений в сервисах для вебмастеров: если они есть, устраните проблемы.
Как проверить индексацию сайта
Проверить индексацию сайта можно несколькими способами. Самым простой — в поисковой строке браузера набрать адрес сайта с оператором «site» или «url». Выглядит это вот так: «site: kokoc.com». На скриншоте показан запрос с проиндексированной страницей.
Проверка индексирования в поисковой системе
Если страница еще не вошла в индекс, вы увидите вот такую картину. Проверка в Google производится аналогично.
Страница не проиндексирована
Также можно посмотреть статус документа в «Яндекс.Вебмастер». Для этого находим в меню «Индексирование» и переходим на «Страницы в поиске».
Меню «Яндекс.Вебмастер»
Внизу страницы будут три вкладки. Нас интересуют «Все страницы», там можно увидеть статус документа, последнее посещение и заголовок.
Проиндексированные страницы
Обязательно посмотрите вкладку «Исключенные страницы». Тут вы увидите, какие документы оказались вне поискового индекса. Также указана причина исключения.
Тут вы увидите, какие документы оказались вне поискового индекса. Также указана причина исключения.
Исключенные страницы
При любых сложностях с индексированием в первую очередь следует смотреть конфигурационные файлы robots.txt и sitemap.xml. Если там все в порядке, проверяем, нет ли фильтров, и в последнюю очередь обращаемся к администратору хостинга.
Выводы
Индексация страниц сайта сейчас происходит в самые короткие сроки. При правильной настройке документы могут попадать в индекс поиска уже через полчаса после размещения.
Настройка сводится к созданию правильных конфигурационных файлов и созданию удобных условий для поискового робота для перехода по страницам сайта. Вот какие шаги нужно сделать для правильной индексации:
- Создаем и настраиваем файл robots.txt.
- Генерируем файл sitemap.xml.
-
Регистрируем сайт в сервисах Google Search Console и «Яндекс.
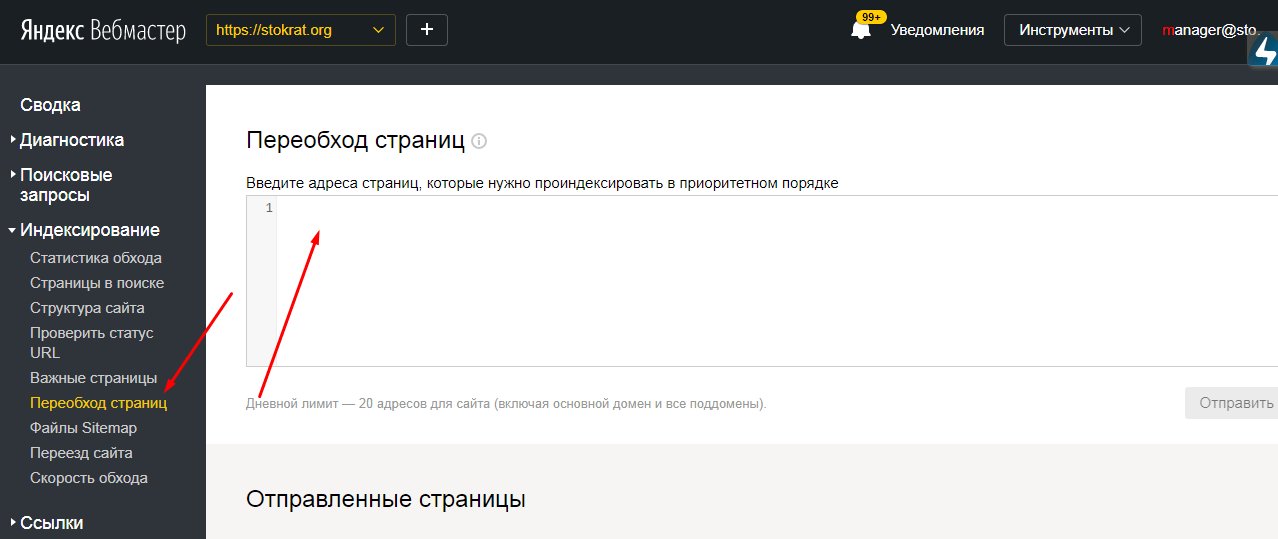 Вебмастер».
Вебмастер».
- Каждый раз после размещения статьи или новой страницы отправляем URL на проверку.
- Используем дополнительные инструменты: размещение ссылок в Twitter и на других трастовых ресурсах.
После этого вероятность возникновения каких-либо проблем с индексированием будет стремиться к нулю. Теперь нужно наращивать позиции в топе — но это уже совсем другая история…
Продвижение сайта в ТОП-10
- Оплата по дням нахождения в ТОП
- Подбираем запросы, которые приводят реальных покупателей!
Что такое индексация сайта и как её проверить — SEO на vc.ru
Чем бы вы ни занимались, интернет-магазином, корпоративным порталом или лендингом, сделать сайт — лишь полдела. Дальше начинается самое интересное — продвижение. Индексация в этом деле — первый шаг на пути к топу поисковой выдачи. Рассказываем о том, как она происходит, как её проверить и ускорить.
Дальше начинается самое интересное — продвижение. Индексация в этом деле — первый шаг на пути к топу поисковой выдачи. Рассказываем о том, как она происходит, как её проверить и ускорить.
25 863 просмотров
Как работает индексация
Продвижение начинается с попадания страниц сайта в индекс поисковых систем (ПС). В эти базы данных Яндекс, Google и другие сервисы заносят информацию о содержимом страниц: использованных на них ключевых словах, размещённом на них контенте и другую информацию. Затем, когда пользователь обращается к ПС с запросом, сервис анализирует собранные данные и подбирает наиболее подходящие варианты ответа из списка проиндексированных страниц.
Как попасть в индекс поисковых систем
Чтобы ваш сайт проиндексировали, о нём нужно сообщить поисковикам. Это можно сделать несколькими способами.
1. С помощью инструментов поисковых систем. Почти у всех поисковиков есть собственные сервисы для веб-мастеров.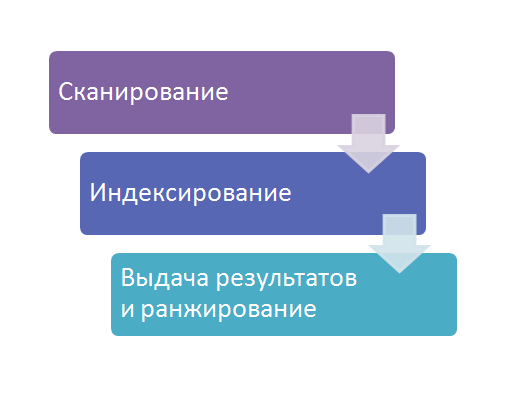 У самых популярных из них на территории СНГ — Google и Яндекс — это Search Console и Яндекс.Вебмастер. В последнем даже есть специальный инструмент, позволяющий отправлять от 20 ссылок в день на страницы, которые нужно проиндексировать в приоритетном порядке.
У самых популярных из них на территории СНГ — Google и Яндекс — это Search Console и Яндекс.Вебмастер. В последнем даже есть специальный инструмент, позволяющий отправлять от 20 ссылок в день на страницы, которые нужно проиндексировать в приоритетном порядке.
Однако когда речь заходит не о нескольких десятках страниц, а об индексации сайта в целом, более эффективным решением будет добавить его в Яндекс и Google, а затем указать ссылку на карту сайта (файл Sitemap) в Search Console и Яндекс.Вебмастер. Тогда поисковики начнут самостоятельно и регулярно посещать ваш сайт и его новые страницы, чтобы затем добавить их в индекс. О том, как составить карту сайта вы можете узнать в руководстве Google. Что касается скорости попадания в выдачу, она зависит от многих факторов, но в среднем занимает одну—две недели.
2. С помощью ссылок с других сайтов. Быстро обратить внимание поисковых систем на вашу новую страницу можно, разместив ссылки на неё на других порталах. Если один из них будет новостным, скорее всего, страница быстро попадёт в выдачу, так как поисковики часто проверяют такие сайты и ссылки на них считают полезными.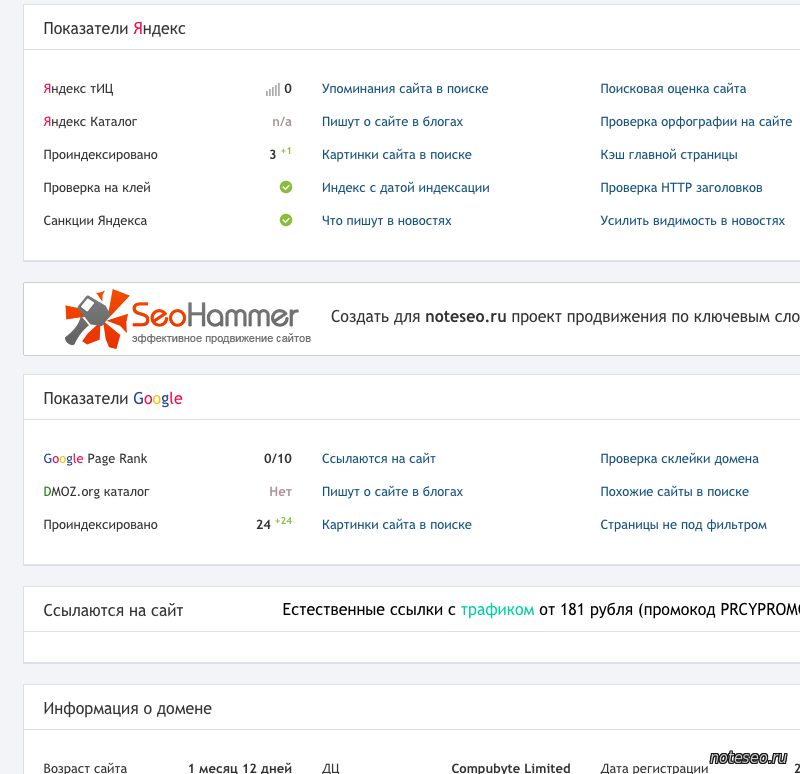 В некоторых случаях индексирование может занять меньше суток.
В некоторых случаях индексирование может занять меньше суток.
Попадёт ли страница в поисковую выдачу, зависит от её содержимого. Если с ней всё в порядке, робот проиндексирует её и в скором времени она появится в поисковой выдаче.
Как проверить индексацию сайта
Есть несколько способов узнать были ли проиндексированы нужные вам страницы.
1. С помощью Яндекс.Вебмастера и Search Console. В первом для этого есть специальный инструмент — «Проверить статус URL». Достаточно добавить в него ссылку на нужную страницу, и в течение двух минут (иногда — нескольких часов) вы узнаете о статусе страницы в ПС.
Чтобы проверить статус страницы в Search Console, нужно ввести ссылку на неё в поисковой строке, которая отображается в верхней части экрана. На открывшейся форме вы узнаете, была ли страница проиндексирована поисковиком.
2. С помощью команды «site». Если вы не хотите добавлять сайт в сервисы для веб-мастеров, вы можете проверить сразу все попавшие в индекс поисковиков страницы с помощью специальной команды. Для этого введите в поиск Яндекс или Google запрос вида «site:mysite.ru» (без кавычек), и вы увидите все страницы, попавшие в выдачу.
Для этого введите в поиск Яндекс или Google запрос вида «site:mysite.ru» (без кавычек), и вы увидите все страницы, попавшие в выдачу.
3. С помощью сервисов. Самый простой способ проверить индексацию определённых страниц — воспользоваться для этого сторонними сервисами. Например, Серпхант позволяет проверить индексацию сразу 50 страниц в Яндекс и Google. Введите ссылки на них в специальную форму (не забудьте про http:// или https://) и нажмите «Начать проверку». Иногда инструмент долго выдаёт результаты проверки по одной—двум позициям, но существенно на функциональность это не влияет.
Ещё один сервис — плагин RDS Bar для Chrome, Firefox и Opera — позволяет получить подробную информацию о любой открытой в браузере странице, в том числе и о том, проиндексирована ли она.
Как ускорить индексацию
Чем быстрее поисковые системы внесут страницу в индекс, тем быстрее на неё попадут посетители. Чтобы сократить время ожидания, следуйте следующим рекомендациям:
- Обязательно добавьте сайт в ПС через сервисы для веб-мастеров.

- В Search Console и Яндекс.Вебмастере укажите ссылки на файлы Sitemap и robots.txt.
- Регулярно добавляйте на сайт новый уникальный контент.
- Не забывайте перелинковывать страницы между собой.
- Добавляйте ссылки на новые страницы в социальные сети и на другие сайты.
Как закрыть сайт от индексации
Не все страницы нравятся поисковым системам. Некоторым из них — например, служебным страницам и тем, которые пока что находятся в разработке, — не только нечего делать в выдаче, но и лучше вообще не попадаться на глаза поисковым роботам. Чтобы предотвратить попадание таких страниц в выдачу, лучше сразу запретить их индексацию. Сделать это также можно несколькими способами:
1. Использовать команду Disallow в файле robots.txt. В этом файле указываются правила для поисковых роботов: какие-то страницы в нём можно разрешить индексировать определённым ПС, а какие-то — запретить. Чтобы страница не попала в выдачу, используйте команду Disallow. Подробнее о работе с файлом robots.txt читайте в руководстве Яндекса.
Чтобы страница не попала в выдачу, используйте команду Disallow. Подробнее о работе с файлом robots.txt читайте в руководстве Яндекса.
2. Добавить тег noindex в HTML-код страницы. Наверное, самый простой способ, когда нужно запретить роботу индексацию конкретной страницы или страниц определённого типа. Чтобы воспользоваться им, достаточно добавить в раздел HTML-кода страницы директиву .
3. Использовать авторизацию. Некоторые страницы — например, личный кабинет и «черновики», находящиеся в разработке, — можно закрыть от роботов формой авторизации. Это самый надёжный способ, так как даже те страницы, индексация которых запрещена в robots.txt или директивой noindex, могут попасть в поисковую выдачу, если на них ведут ссылки с других страниц.
Что такое индексация сайта (Как улучшить индексацию в Google)
Индексация сайта — это процесс сбора информации поисковой системой о содержимом вашего сайта. Во время индексации поисковые роботы (пауки) сканирую и обрабатывают web страницы, изображения, видео и другие доступные для сканирования файлы.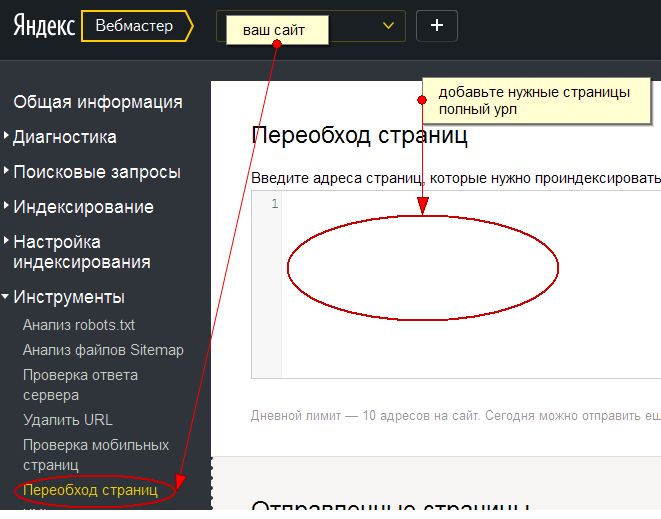 Чтобы поисковая система быстро проиндексировала сайт: создайте карту сайта и добавьте ее в Google Search Console.
Чтобы поисковая система быстро проиндексировала сайт: создайте карту сайта и добавьте ее в Google Search Console.
Сайт должен быть проиндексирован чтобы отображаться в поиске
Страницы, которые прошли сканирование и обработку, сохраняются в базу данных. Такая база называется “поисковой индекс”. Именно в этой базе данных поисковая система ищет результаты, отвечающие на запросы пользователей.
Важно понимать:
- Если страницы нет в поисковом индексе — ее невозможно найти в поисковой системе.
- Индексация нужна чтобы участвовать в поиске.
- У каждой поисковой системы свой поисковой индекс, свои поисковые боты.
- Поисковой бот от Google называется Googlebot.
- Настройка индексации сайта, это базовый уровень работ по SEO.
Содержание статьи
- Как проверить индексацию страницы
- Как проверить индексацию всего сайта
- Как добавить новый сайт в индекс поисковиков?
- Что делать, если сайт плохо индексируется
- Как происходит индексация сайта
- Этап 1: Сканирование
- Этап 2: Обработка данных
- От чего зависит индексация
Как проверить индексацию страницы?
Самый быстрый способ — написать в строку поиска команду site:[адрес страницы]. Такой поиск найдет все проиндексированные страницы сайта. Для того, чтобы просмотреть дату последнего сканирования страницы, напишите в строку поиска cache:[адрес проверяемой страницы]. Если вам нужно проверить индексацию конкретной страницы просто скопируйте ее адрес и введи в поиск запрос site:[адрес страницы]. Этот метод будет работать как в Google так и в Yandex или Bing.
Такой поиск найдет все проиндексированные страницы сайта. Для того, чтобы просмотреть дату последнего сканирования страницы, напишите в строку поиска cache:[адрес проверяемой страницы]. Если вам нужно проверить индексацию конкретной страницы просто скопируйте ее адрес и введи в поиск запрос site:[адрес страницы]. Этот метод будет работать как в Google так и в Yandex или Bing.
Совет: Сравните количество проиндексированных страниц с реальным количеством страниц на сайте. Это поможет быстро оценить есть ли у вашего сайта проблемы с индексацией. К примеру: если на сайте 100 товаров, 10 разделов и 10 информационных страниц (в сумме 120), а в индексе только 50 страниц, это означает, что поисковая система не знает о большей части вашего сайта.
Как проверить индексацию всего сайта
Для проверки индексации сайта нужно выполнить 2 простых шага:
- Узнать сколько страниц на сайте.
 Для этого просканируйте свой сайт специальными инструментами. Если ваш сайт до 500 страниц вам подойдет бесплатная версия Screaming Frog , если этого недостаточно используйте, бесплатный Site Analyzer. В разделе “HTML” вы увидите общее количество страниц вашего сайта.
Для этого просканируйте свой сайт специальными инструментами. Если ваш сайт до 500 страниц вам подойдет бесплатная версия Screaming Frog , если этого недостаточно используйте, бесплатный Site Analyzer. В разделе “HTML” вы увидите общее количество страниц вашего сайта. - Зайдите в инструменты для вебмастеров или Google Search Console (Что такое Google Search Consol ) откройте отчет “Покрытие” и просмотрите количество страниц в статусе “Без ошибок”. Количество страниц в сканере Site Analyzer и страниц в Google Search Console должно приблизительно совпадать. Это, будет означать, что основные страницы сайта сканируются. Если часть страниц попала в группу “Исключено” вы можете изучить причины исключения страниц. В этом же отчете вы можете познакомиться с историей индексации вашего сайта за последние 3, 6 или 12 месяцев.
- Довольно часто в отчете “Покрытие” вы можете увидеть большое количество страниц в статусе “Страница просканирована, но пока не проиндексирована” — это означает, что поисковая система уже получила данные о ваших страницах но пока не обработала их до конца.
 Так же, страницы могут находиться в этом статусе по причине низкого качества: пустые страницы или страницы с повторяющимся содержанием. Если количество “пока не проиндексированных” страниц не сокращается попробуйте уникализировать, добавить содержание или увеличить количество качественных внешних ссылок на свой сайт.
Так же, страницы могут находиться в этом статусе по причине низкого качества: пустые страницы или страницы с повторяющимся содержанием. Если количество “пока не проиндексированных” страниц не сокращается попробуйте уникализировать, добавить содержание или увеличить количество качественных внешних ссылок на свой сайт. - Если вам нужно массово проверить индексацию страниц вашего сайта, воспользуйтесь онлайн инструментом https://indexchecking.com
- Хорошая идея проверить свой сайт с помощью инструментов https://en.ryte.com — это поможет вам понять какие страницы закрыты от индексации. А так же, обнаружить страницы на которых есть технические проблемы.
Проверяем не закрыта ли отдельная страница от индексации
Если перед вами появилась задача, проверить запрет индексации конкретной страницы проще всего использовать инструменты для вебмастеров. Скопируйте адрес страницы которую вы хотите проверить и вставьте в инструмент “Проверка URL на ресурсе”.
В результате проверки вы получите информацию о запретах индексации. Обратите внимание на информацию о запретах, статусе страницы и канонический адрес.
Как добавить новый сайт в индекс поисковиков?
Сообщите поисковой системе о своем сайте в специальном инструменте Google или Yandex. Поделитесь своим сайтом в социальной сети или создайте на него ссылку с другого, уже проиндексированного сайта.
Узнайте больше о работе поисковой системы
Что делать, если сайт плохо индексируется?
Прежде всего нужно проверить не закрыт ли сайт от индексации. Это можно сделать по инструкции в этой статье чуть выше. Основные способы улучшить индексацию:
- Создайте карту сайта и загрузите в инструменты для вебмастеров.
- Обновите старые страницы.
- Удалите пустые страницы.
- Поставьте дополнительные ссылки на сайт с сторонних сайтов и соц.
 сетей.
сетей.
Как происходит индексация сайта
Для решения проблем нужно разобраться в процессе индексации подробнее. С технической точки зрения “индексацию сайта” правильнее рассматривать как два отдельных процесса:
- Сканирование страниц.
- Обработка страниц.
Этап 1: Сканирование
Сканирование или “обход” страниц — это основная задача, которую выполняет поисковой бот. Попадая на новую страницу, бот получает со страницы два набора данных:
- Содержание самой страницы, информацию о сервере и служебные данные. А именно: ответ сервера, html код страницы, файлы css стилей, скриптов, изображений.
- Перечень ссылок, которые находятся на странице.
Полученное содержание передается для дальнейшей обработки и сохранения в базу. Просканированные ссылки так же сохраняются в специальный список — “очередь сканирования”, для дальнейшей обработки.
Когда бот добавляет в очередь индексации страницу, которая уже есть в очереди, эта страница занимает более высокое место в списке и индексируется быстрее. А это значит, что первый способ ускорить сканирование сайта — увеличить количество ссылок на нужные страницы.
А это значит, что первый способ ускорить сканирование сайта — увеличить количество ссылок на нужные страницы.
Создавая очередь сканирования, google bot, как и другие поисковые боты, изучает карту сайта sitemap и добавляет в очередь ссылки из этой карты. Второй способ улучшить индексацию — создать карту сайта sitemap.xml и сообщить о ней поисковой системе. Карта сайта – самый простой способ отправить на индексацию все страницы в рамках нашего домена.
Есть несколько способов создать карту сайта:
- Бесплатный онлайн инструмент для сайтов до 500 страниц www.xml-sitemaps.com.
- Программа для сканирования сайта, с возможностью создания sitemap — xenu links.
- Библиотека приложений для создания sitemap.
- Самый популярный плагин для создания карты сайта для WordPress.
Чтобы Google узнал о вашем sitemap, нужно добавить ссылку на карту сайта в инструментах search console или файле robots.txt
Добавление карты сайта в Search Console:
- Зайдите в https://search.
 google.com/search-console/
google.com/search-console/ - Добавьте свой сайт или выберите из списка.
- Перейдите в раздел Сканирование – Файлы Sitemap.
- Выберите “добавить файл sitemap”, вставьте ссылку и добавьте карту сайта.
Добавление sitemap в robots.txt:
- Зайдите в корневой каталог сайта через ftp.
- Откройте файл robots.txt
- Добавьте в конец файла строку “Sitemap: [адрес сайта]/sitemap.xml” и сохраните файл.
Третий способ ускорить индексацию — сообщить поисковому боту о дате последнего изменения страницы. Для получения даты и времени изменения страницы боты используют данные из заголовка ответа сервера lastmod. Сообщить наличие изменений на странице можно с помощью кода ответа not modify.
Инструмент проверки заголовка lastmod и ответа сервера not modify.
Наличие настроек lastmod и not modify позволяют поисковой системе быстро получить информацию о том, изменилась ли страница с даты последнего сканирования. Благодаря этому поисковой бот ставит в приоритет новые и измененные страницы, а новые страницы быстрее индексируются.
Благодаря этому поисковой бот ставит в приоритет новые и измененные страницы, а новые страницы быстрее индексируются.
Для настройки lastmod и not modify вам нужно будет обратиться к веб разработчику.
Этап 2: Обработка данных
Перед тем как сохранить информацию в базу данных, она проходит обработку и структуризацию, которая необходима для ускорения дальнейшего поиска.
В первом шаге обработки программа-индексатор формирует страницу с учетом всех стилей, скриптов и эффектов. В этот момент программа-индексатор понимает расположение элементов на странице, определяет видимые и невидимые пользователю части, разделяет страницу на навигацию и содержание.
Важно чтобы google bot имел полный доступ к css и js файлам, ведь без них индексатор не сможет понять структуру страницы. Для проверки доступности всех служебных файлов зайдите в Google Search Console, отчет “Посмотреть как Googlebot” в разделе “Сканирование”. Проверьте с помощью этого инструмента основные страницы сайта, обратите внимание на различия между тем, как вашу страницу видит поисковой бот и как ее видит пользователи.
Изучите таблицу из отчета. Все ресурсы, которые размещены на вашем домене, должны быть открыты для сканирования.
Сейчас Google использует алгоритм индексации, который называется Caffeine. Он был запущен в 2009 году. Основные задачи этого алгоритма:
- Обработка современных страниц, использующих сложные js и css элементы.
- Максимально быстрое сканирование всех страниц в Интернете.
Анализ текста при индексации
После разделения страницы на зоны и определения их важности, алгоритм выделяет из содержания основные элементы для дальнейших расчетов. Так одним из самых популярных показателей, которые поисковая система извлекает из страницы, является частота упоминания ключевого слова.
Стоит отметить, что перед расчетом частоты упоминания слова, индексатор проводит упрощение слов к элементарной форме. Этот процесс называется стеминг. Такое упрощение позволяет учитывать слово в разных словоформах как одно слово.
Частота упоминания (Term frecency, ТА) слова рассчитывается как отношение упоминания слова к общему количеству слов страницы. Пример: если на странице 100 слов и слово “машина” встречалось на ней 2 раза — частота упоминания слова “машина” будет равна TF=0,02
Самый простой поисковой индекс легко представить в виде огромной таблицы, в столбцах которой перечислены все слова языка, а в строках — адреса всех страниц. При этом в ячейках указаны частоты слов на соответствующих страницах.
Именно такая таблица позволяет поисковой системе быстро находить страницы, которые содержат нужные слова. Конечно современные поисковые системы учитывают не только частоту упоминания слов, но и более сложные факторы. Поисковой индекс Google значительно сложнее чем приведенный пример.
Анализируя содержание поисковая система проверяет уникальность страницы. Тексты и прочее содержание, которое уже было проиндексировано на других страницах, не несет ценности для системы, так как не добавляет в базу новой информации.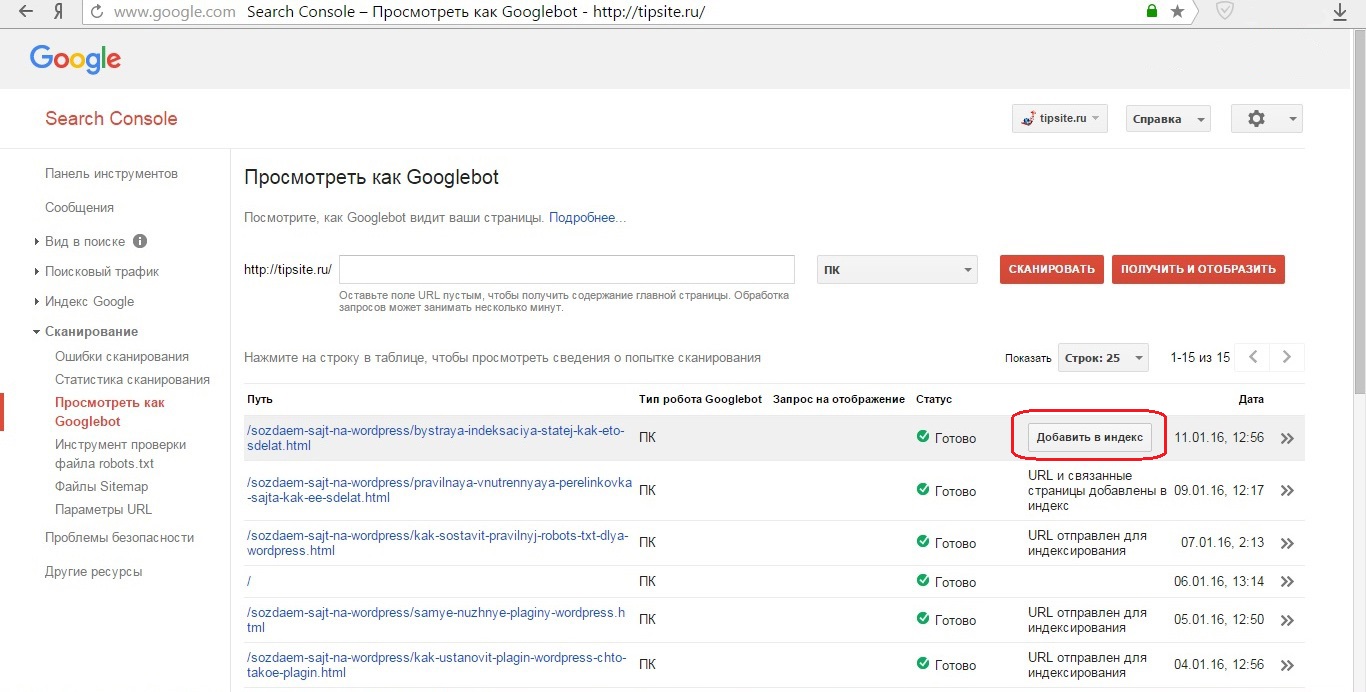 А это значит, что страницы с низкой уникальностью могут быть не проиндексированы. Проверить уникальность достаточно просто с помощью бесплатных инструментов.
А это значит, что страницы с низкой уникальностью могут быть не проиндексированы. Проверить уникальность достаточно просто с помощью бесплатных инструментов.
Старайтесь создавать максимально уникальный и полезный контент и он точно будет проиндексирован.
От чего зависит индексация сайта?
- Доступность сайта для индексации — если сканирование сайта запрещено поисковая система не сможет получить его страницы. Подробнее о инструментах управления индексацией: youtube.com Внутренняя оптимизация: robots.txt, sitemap
- Количество ссылок на ваш сайт — ссылки, это пути которые приводят поисковых роботов к вам на сайт. Чем больше ссылок с популярных ресурсов вы получаете, тем чаще будут сканироваться страницы вашего сайта.
- Частота обновления сайта. Поисковые системы всегда ищут новый интересный контент, чем чаще вы публикуете новое уникальное содержание, тем быстрее поисковая система будет его сканировать.
- Наличие сайта в инструментах поисковых систем.
 Видео в тему: Как зарегистрировать сайт в Google Search Console.
Видео в тему: Как зарегистрировать сайт в Google Search Console.
Подведем итоги
- Индексация — это процесс сканирования и обработки содержания для хранения в базе данных поисковой системы.
- Ускорить индексацию можно с помощью ссылок, карты сайта и настроек сервера.
Чтобы поисковая система понимала ваши страницы, все ресурсы вашего сайта должны быть доступны поисковому боту.
Мы можем проверить и настроить индексацию вашего сайта за вас.
SEO аудит с рекомендациями за 10 дней.
Надеюсь у вас больше не возникнет вопрос: “Что такое индексация сайта”.
Артем Пилипець
Керівник відділу пошукової оптимізації SEO7. Ведучий Youtube каналу Школа SEO
Индекс и индексация сайта: что это такое?
Оглавление
- Что такое индексация
 org/ListItem»>
Зачем индекс поисковым системам
org/ListItem»>
Зачем индекс поисковым системам- Скорость индексации страниц
- Как проверить индексацию в «Яндексе» и Google
- Как ускорить индексацию
Индекс поисковых систем – специальная база данных, в которую заносится информация, собираемая поисковыми роботами со страниц сайтов. При этом учитывается текстовое наполнение, внутренние и внешние ссылки, графические и некоторые другие объекты. Когда пользователь задает запрос поисковой системе, происходит обращение к базе данных.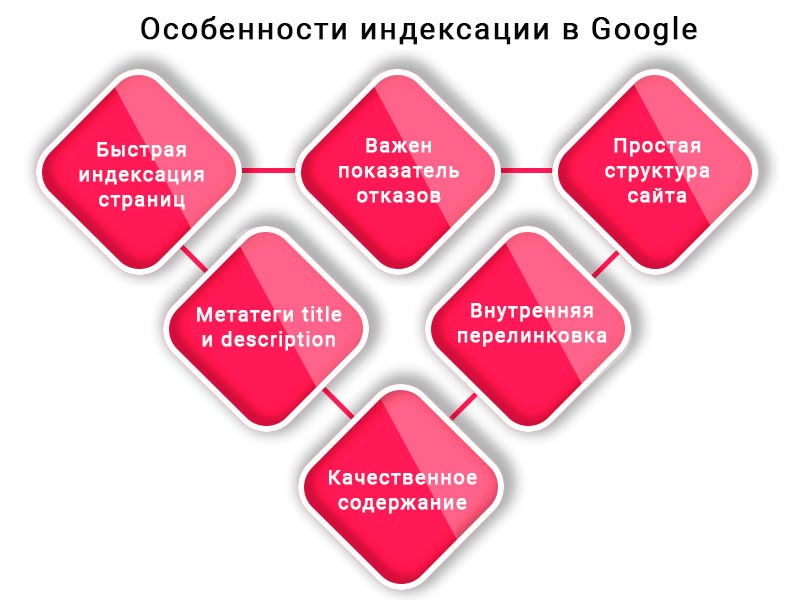 После этого выполняется ранжирование по релевантности – формирование списка сайтов по мере убывания их значимости.
После этого выполняется ранжирование по релевантности – формирование списка сайтов по мере убывания их значимости.
Что такое индексация
Процесс добавления роботами собранной информации в базу называется индексацией. Затем данные определенным образом обрабатываются и создается индекс – выжимка из документов. Процесс заполнения индекса осуществляется одним из двух способов: вручную или автоматически. В первом случае владелец ресурса должен самостоятельно добавить URL веб-ресурса в специальную форму, которая есть у «Яндекса», Google и других поисковых систем. Во втором робот сам находит сайт, планомерно переходя по внешним ссылкам с других площадок или сканируя файл-карту sitemap.xml.
Первые попытки индексировать веб-ресурсы были сделаны еще в середине 90-х годов прошлого столетия. Тогда база данных была похожа на обычный предметный указатель, в котором содержались ключевые слова, найденные роботами на посещенных ими сайтах. Почти за 30 лет этот алгоритм был значительно усовершенствован и усложнен.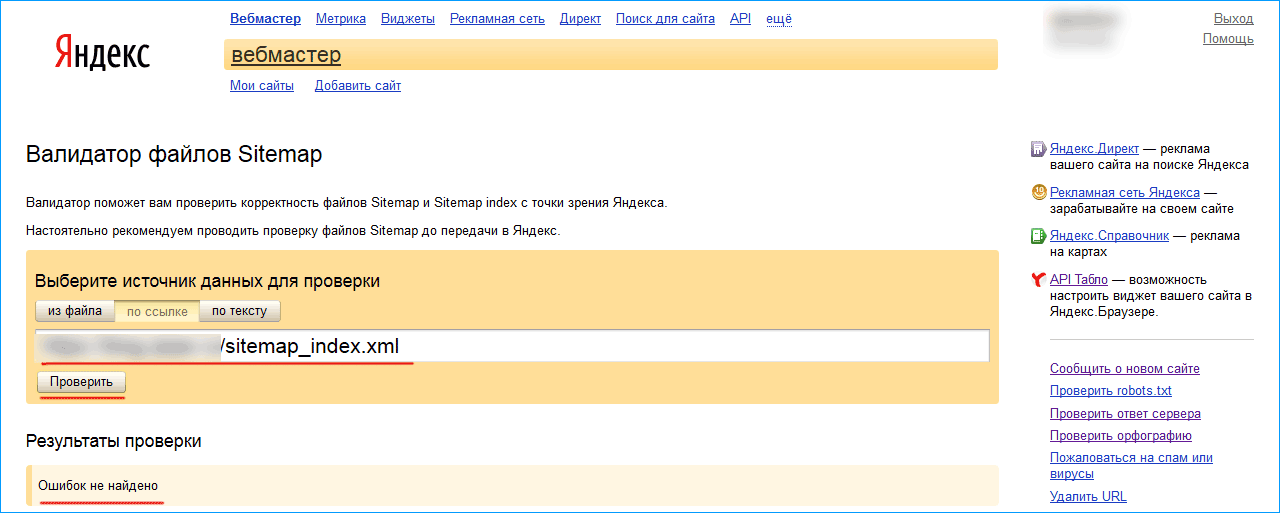 Например, сегодня информация перед попаданием в индекс обрабатывается по сложнейшим вычислительным алгоритмам с привлечением искусственного интеллекта.
Например, сегодня информация перед попаданием в индекс обрабатывается по сложнейшим вычислительным алгоритмам с привлечением искусственного интеллекта.
Зачем индекс поисковым системам
Индексация страниц сайта – неотъемлемая часть работы поисковых систем (не только Google и «Яндекса», но и всех остальных). База, полученная в процессе сканирования веб-ресурсов, используется для формирования релевантной выдачи. Основные роботы поисковых систем:
- основной – сканирует весь контент на сайте и его отдельных страницах;
- быстрый – индексирует только новую информацию, которая была добавлена после очередного обновления.
Также существуют роботы для индексации rss-ленты, картинок и др.
При первом посещении в базу попадают все новые сайты, если они подходят под требования поисковой системы. Во время повторного визита информация лишь дополняется деталями.
Скорость индексации страниц
Чем быстрее происходит добавление страницы в индекс, тем лучше для веб-ресурса. Однако поисковые роботы не могут выполнять такой большой объем работы так же часто, как обновляется наполнение сайтов. Индексация в «Яндекс» в среднем занимает одну-две недели, а в Google – несколько дней. С целью ускорения индексации ресурсов, для которых очень важно быстрое попадание информации в базу (новостные порталы и т. д.), применяется специальный робот, посещающий такие сайты от одного до нескольких раз в день.
Однако поисковые роботы не могут выполнять такой большой объем работы так же часто, как обновляется наполнение сайтов. Индексация в «Яндекс» в среднем занимает одну-две недели, а в Google – несколько дней. С целью ускорения индексации ресурсов, для которых очень важно быстрое попадание информации в базу (новостные порталы и т. д.), применяется специальный робот, посещающий такие сайты от одного до нескольких раз в день.
Как проверить индексацию в «Яндексе» и Google
Воспользоваться информацией из панели веб-мастеров. В списке сервисов Google откройте Search Console, а затем перейдите в раздел «Индекс Google». Нужная информация будет находиться в блоке «Статус индексирования». В «Яндекс.Вебмастер» необходимо перейти по следующей цепочке: «Индексирование сайта» — «Страницы в поиске». Еще один вариант: «Индексирование сайта» — «История» — «Страницы в поиске».
Задать поиск по сайту с использованием специальных операторов. Для этого используйте запрос с конструкцией «site:», указав далее адрес вашего ресурса в полном формате. Так вы узнаете количество проиндексированных страниц. Серьезные расхождения в значениях (до 80 %), полученных в разных поисковых системах, говорят о наличии проблем (например, веб-ресурс может находиться под фильтром).
Так вы узнаете количество проиндексированных страниц. Серьезные расхождения в значениях (до 80 %), полученных в разных поисковых системах, говорят о наличии проблем (например, веб-ресурс может находиться под фильтром).
Установить специальные плагины и букмарклеты. Это небольшие дополнения для браузера, которые позволяют выполнить проверку индексации страниц сайта. Одним из самых популярных среди них является RDS Bar.
Как ускорить индексацию
На скорость индексации сайта прямо влияют несколько факторов:
- отсутствие ошибок, замедляющих процесс сбора информации поисковым роботом;
- авторитетность ресурса;
- частота обновления контента на сайте;
- частота добавления нового контента на сайт;
- уровень вложенности страниц;
- корректно заполненный файл sitemap.xml;
- ограничения в robots.txt.
Чтобы ускорить индексацию сайта, выполните ряд правил:
- выберите быстрый и надежный хостинг;
- настройте robots.
 txt, установив правила индексации и сняв ненужные запреты;
txt, установив правила индексации и сняв ненужные запреты; - избавьтесь от дублей и ошибок в коде страниц;
- создайте карту сайта sitemap.xml и сохраните файл в корневой папке;
- по возможности организуйте навигацию таким образом, чтобы все страницы были в 3 кликах от главной;
- добавьте ресурс в панели веб-мастеров «Яндекса» и Google;
- сделайте внутреннюю перелинковку страниц;
- зарегистрируйте сайт в авторитетных рейтингах;
- регулярно обновляйте контент.
Дополнительно рекомендуем оценить объем flash-элементов с точки зрения их влияния на продвижение. Наличие визуальных объектов этого типа значительно снижает долю поискового трафика, так как не дает роботам выполнить индексацию в полной мере. Также не желательно размещения ключевой информации в PDF-файлах, сохраненных определенным образом (сканироваться может только текстовое содержимое документа).
Индексация сайта и ее основные принципы
12 мин — время чтения
Фев 18, 2020
Поделиться
Когда-нибудь задумывались, как сайты попадают в выдачу поисковых систем? И как поисковикам удается выдавать нам тонны информации за считанные секунды?
Секрет такой молниеносной работы — в поисковом индексе. Его можно сравнить с огромным и идеально упорядоченным каталогом-архивом всех веб-страниц. Попадание в индекс означает, что поисковик вашу страницу увидел, оценил и запомнил. А, значит, он может показывать ее в результатах поиска.
Его можно сравнить с огромным и идеально упорядоченным каталогом-архивом всех веб-страниц. Попадание в индекс означает, что поисковик вашу страницу увидел, оценил и запомнил. А, значит, он может показывать ее в результатах поиска.
Предлагаю разобраться в процессе индексации с нуля, чтобы понимать, как сайты попадают в выдачу, можно ли управлять этим процессом и что нужно знать про индексирование ресурсов с различными технологиями.
Что такое сканирование и индексация?
Сканирование страниц сайта — это процесс, когда поисковая система отправляет свои специальные программы (мы знаем их как поисковых роботов, краулеров, спайдеров, пауков) для сбора данных с новых и измененных страниц сайтов.
Индексация страниц сайта — это сканирование, считывание данных и добавление их в индекс (каталог) поисковыми роботами. Поисковик использует полученную информацию, чтобы узнать, о чем же ваш сайт и что находится на его страницах. После этого он может определить ключевые слова для каждой просканированной страницы и сохранить их копии в поисковом индексе. Для каждой страницы он хранит URL и информацию о контенте.
Для каждой страницы он хранит URL и информацию о контенте.
В результате, когда пользователи вводят поисковый запрос в интернете, поисковик быстро просматривает свой список просканированных сайтов и показывает только релевантные страницы в выдаче. Как библиотекарь, который ищет нужные вам книги в каталоге — по алфавиту, тематике и точному названию.
Индексация сайтов в разных поисковых системах отличается парой важных нюансов. Давайте разбираться, в чем же разница.
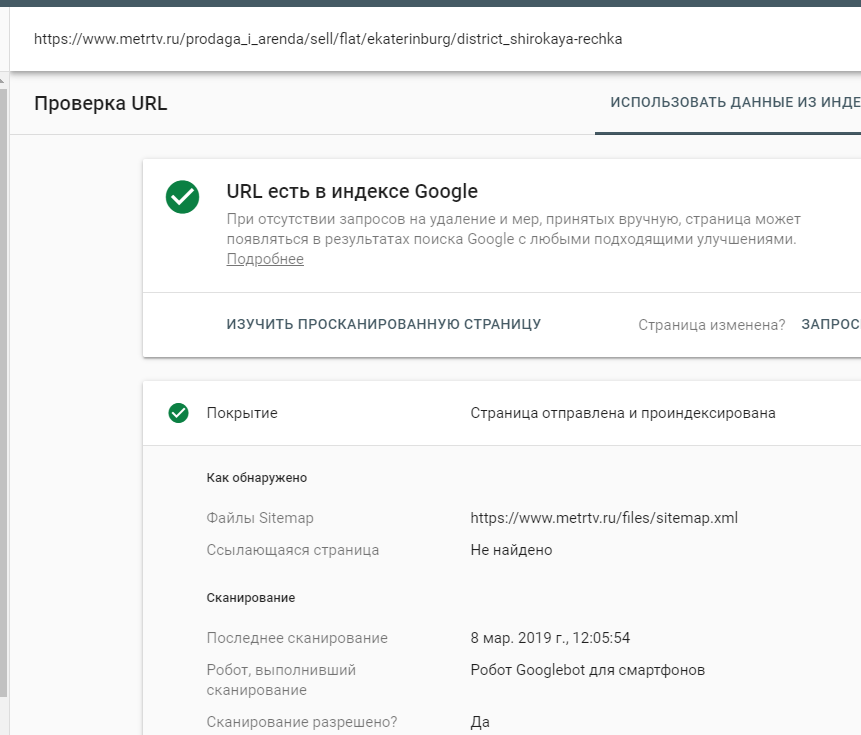
Индексация сайта в GoogleКогда мы гуглим что-то, поиск данных ведется не по сайтам в режиме реального времени, а по индексу Google, в котором хранятся сотни миллиардов страниц. Во время поиска учитываются разные факторы ― ваше местоположение, язык, тип устройства и т. д.
В 2019 году Google изменил свой основной принцип индексирования сайта — вы наверняка слышали о запуске Mobile-first. Основное отличие нового способа в том, что теперь поисковик хранит в индексе мобильную версию страниц. Раньше в первую очередь учитывалась десктопная версия, а теперь первым на ваш сайт приходит робот Googlebot для смартфонов — особенно, если сайт новый. Все остальные сайты постепенно переходят на новый способ индексирования, о чем владельцы узнают в Google Search Console.
Раньше в первую очередь учитывалась десктопная версия, а теперь первым на ваш сайт приходит робот Googlebot для смартфонов — особенно, если сайт новый. Все остальные сайты постепенно переходят на новый способ индексирования, о чем владельцы узнают в Google Search Console.
Еще несколько основных отличий индексации в Google:
- индекс обновляется постоянно;
- процесс индексирования сайта занимает от нескольких минут до недели;
- некачественные страницы обычно понижаются в рейтинге, но не удаляются из индекса.
В индекс попадают все просканированные страницы, а вот в выдачу по запросу — только самые качественные. Прежде чем показать пользователю какую-то веб-страницу по запросу, поисковик проверяет ее релевантность по более чем 200 критериям (факторам ранжирования) и отбирает самые подходящие.
Что поисковые роботы делают на вашем сайте, мы разобрались, а вот как они попадают туда? Существует несколько вариантов.
Как поисковые роботы узнают о вашем сайте
Если это новый ресурс, который до этого не индексировался, нужно «представить» его поисковикам. Получив приглашение от вашего ресурса, поисковые системы отправят на сайт своих краулеров для сбора данных.
Получив приглашение от вашего ресурса, поисковые системы отправят на сайт своих краулеров для сбора данных.
Вы можете пригласить поисковых ботов на сайт, если разместите на него ссылку на стороннем интернет-ресурсе. Но учтите: чтобы поисковики обнаружили ваш сайт, они должны просканировать страницу, на которой размещена эта ссылка. Этот способ работает для обоих поисковиков.
Также можно воспользоваться одним из перечисленных ниже вариантов:
- Создайте файл Sitemap, добавьте на него ссылку в robots.txt и отправьте файл Sitemap в Google.
- Отправьте запрос на индексацию страницы с изменениями в Search Console.
Каждый сеошник мечтает, чтобы его сайт быстрее проиндексировали, охватив как можно больше страниц. Но повлиять на это не в силах никто, даже лучший друг, который работает в Google.
Скорость сканирования и индексации зависит от многих факторов, включая количество страниц на сайте, скорость работы самого сайта, настройки в веб-мастере и краулинговый бюджет.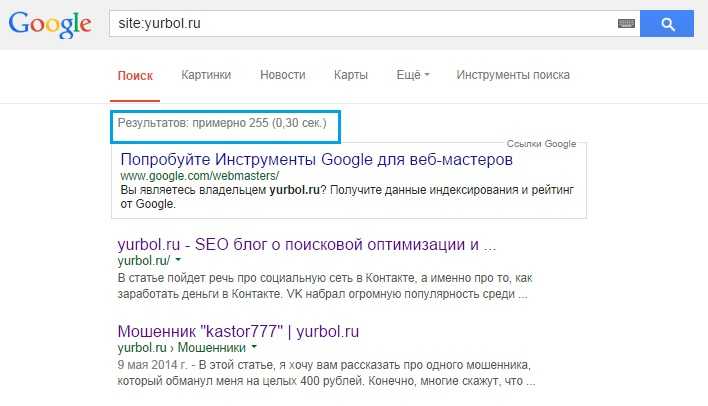 Если кратко, краулинговый бюджет — это количество URL вашего сайта, которые поисковый робот хочет и может просканировать.
Если кратко, краулинговый бюджет — это количество URL вашего сайта, которые поисковый робот хочет и может просканировать.
На что же мы все-таки можем повлиять в процессе индексации? На план обхода поисковыми роботами нашего сайта.
Как управлять поисковым роботом
Поисковая система скачивает информацию с сайта, учитывая robots.txt и sitemap. И именно там вы можете порекомендовать поисковику, что и как скачивать или не скачивать на вашем сайте.
Файл robots.txtЭто обычный текстовый файл, в котором указаны основные сведения — например, к каким поисковым роботам мы обращаемся (User-agent) и что запрещаем сканировать (Disallow).
Указания в robots.txt помогают поисковым роботам сориентироваться и не тратить свои ресурсы на сканирование маловажных страниц (например, системных файлов, страниц авторизации, содержимого корзины и т. д.). Например, строка Disallow:/admin запретит поисковым роботам просматривать страницы, URL которых начинается со слова admin, а Disallow:/*. pdf$ закроет им доступ к PDF-файлам на сайте.
pdf$ закроет им доступ к PDF-файлам на сайте.
Также в robots.txt стоит обязательно указать адрес карты сайта, чтобы указать поисковым роботам ее местоположение.
Чтобы проверить корректность robots.txt, воспользуйтесь отдельным инструментом в Google Search Console.
Файл SitemapЕще один файл, который поможет вам оптимизировать процесс сканирования сайта поисковыми роботами ― это карта сайта (Sitemap). В ней указывают, как организован контент на сайте, какие страницы подлежат индексации и как часто информация на них обновляется.
Если на вашем сайте несколько страниц, поисковик наверняка обнаружит их сам. Но когда у сайта миллионы страниц, ему приходится выбирать, какие из них сканировать и как часто. И тогда карта сайта помогает в их приоритезации среди прочих других факторов.
Также сайты, для которых очень важен мультимедийный или новостной контент, могут улучшить процесс индексации благодаря созданию отдельных карт сайта для каждого типа контента. Отдельные карты для видео также могут сообщить поисковикам о продолжительности видеоряда, типе файла и условиях лицензирования. Карты для изображений ― что изображено, какой тип файла и т. д. Для новостей ― дату публикации. название статьи и издания.
Отдельные карты для видео также могут сообщить поисковикам о продолжительности видеоряда, типе файла и условиях лицензирования. Карты для изображений ― что изображено, какой тип файла и т. д. Для новостей ― дату публикации. название статьи и издания.
Чтобы ни одна важная страница вашего сайта не осталась без внимания поискового робота, в игру вступают навигация в меню, «хлебные крошки», внутренняя перелинковка. Но если у вас есть страница, на которую не ведут ни внешние, ни внутренние ссылки, то обнаружить ее поможет именно карта сайта.
А еще в Sitemap можно указать:
- частоту обновления конкретной страницы — тегом <changefreq>;
- каноническую версию страницы ― атрибутом rel=canonical;
- версии страниц на других языках ― атрибутом hreflang.
Карта сайта также здорово помогает разобраться, почему возникают сложности при индексации вашего сайта. Например, если сайт очень большой, то там создается много карт сайта с разбивкой по категориям или типам страниц. И тогда в консоли легче понять, какие именно страницы не индексируются и дальше разбираться уже с ними.
И тогда в консоли легче понять, какие именно страницы не индексируются и дальше разбираться уже с ними.
Проверить правильность файла Sitemap можно в Google Search Console вашего сайта в разделе «Файлы Sitemap».
Итак, ваш сайт отправлен на индексацию, robots.txt и sitemap проверены, пора узнать, как прошло индексирование сайта и что поисковая система нашла на ресурсе.
Как проверить индексацию сайта
Проверка индексации сайта осуществляется несколькими способами:
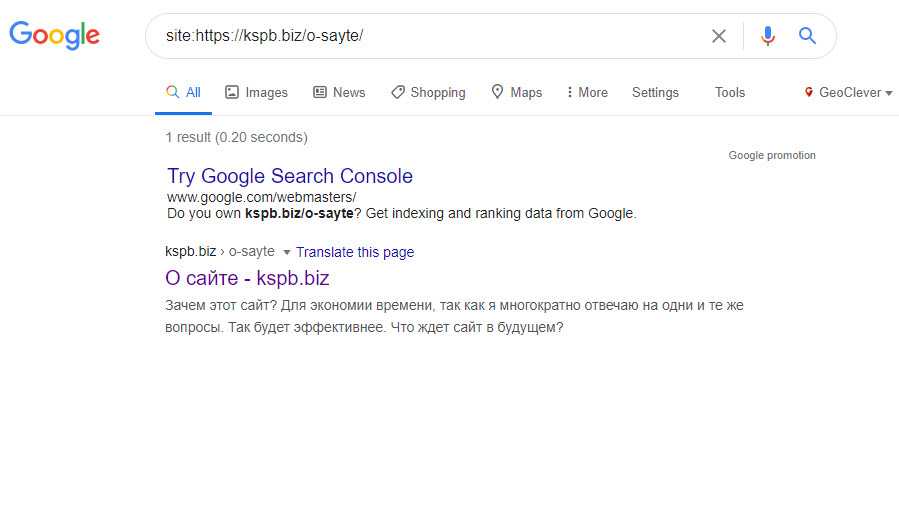
1. Через оператор site: в Google. Этот оператор не дает исчерпывающий список страниц, но даст общее понимание о том, какие страницы в индексе. Выдает результаты по основному домену и поддоменам.
2. Через Google Search Console. В консоли вашего сайта есть детальная информация по всем страницам ― какие из них проиндексированы, какие нет и почему.
3. Воспользоваться плагинами для браузера типа RDS Bar или специальными инструментами для проверки индексации. Например, узнать, какие страницы вашего сайта попали в индекс поисковика можно в инструменте «Проверка индексации» SE Ranking.
Например, узнать, какие страницы вашего сайта попали в индекс поисковика можно в инструменте «Проверка индексации» SE Ranking.
Для этого достаточно ввести нужную вам поисковую систему (Google, Yahoo, Bing), добавить список урлов сайта и начать проверку. Чтобы протестировать работу инструмента «Проверка индексации», зарегистрируйтесь на платформе SE Ranking и откройте тул в разделе «Инструменты».
В этом месте вы можете поднять руку и спросить «А что, если у меня сайт на AJAX? Он попадет в индекс?». Отвечаем 🙂
Особенности индексирования сайтов с разными технологиями
AjaxСегодня все чаще встречаются JS-сайты с динамическим контентом ― они быстро загружаются и удобны для пользователей. Одно из основных отличий таких сайтов на AJAX — все содержимое подгружается одним сплошным скриптом, без разделения на страницы с URL. Вместо этого ― страницы с хештегом #, которые не индексируются поисковиками. Как следствие — вместо URL типа https://mywebsite. ru/#example поисковый робот обращается к https://mywebsite.ru/. И так для каждого найденного URL с #.
ru/#example поисковый робот обращается к https://mywebsite.ru/. И так для каждого найденного URL с #.
В этом и кроется сложность для поисковых роботов, потому что они просто не могут «считать» весь контент сайта. Для поисковиков хороший сайт ― это текст, который они могут просканировать, а не интерактивное веб-приложение, которое игнорирует природу привычных нам веб-страниц с URL.
Буквально пять лет назад сеошники могли только мечтать о том, чтобы продвинуть такой сайт в поиске. Но все меняется. Уже сейчас в справочной информации Google есть данные о том, что нужно для индексации AJAX-сайтов и как избежать ошибок в этом процессе.
Сайты на AJAX с 2019 года рендерятся Google напрямую — это значит, что поисковые роботы сканируют и обрабатывают #! URL как есть, имитируя поведение человека. Поэтому вебмастерам больше не нужно прописывать HTML-версию страницы.
Но здесь важно проверить, не закрыты ли скрипты со стилями в вашем robots. txt. Если они закрыты, обязательно откройте их для индексирования поисковыми роботам. Для этого в robots.txt нужно добавить такие команды:
txt. Если они закрыты, обязательно откройте их для индексирования поисковыми роботам. Для этого в robots.txt нужно добавить такие команды:
User-agent: Googlebot Allow: /*.js Allow: /*.css Allow: /*.jpg Allow: /*.gif Allow: /*.pngФлеш-контент
С помощью технологии Flash, которая принадлежит компании Adobe, на страницах сайта можно создавать интерактивный контент с анимацией и звуком. За 20 лет своего развития у технологии было выявлено массу недостатков, включая большую нагрузку на процессор, ошибки в работе флеш-плеера и ошибки в индексировании контента поисковиками.
В 2019 году Google перестал индексировать флеш-контент, ознаменовав тем самым конец целой эпохи.
Поэтому не удивительно, что поисковик предлагает не использовать Flash на ваших сайтах. Если же дизайн сайта выполнен с применением этой технологии, сделайте и текстовую версию сайта. Она будет полезна как пользователям, у которых не установлена совсем или установлена устаревшая программа отображения Flash и пользователям мобильных устройств (они не отображают flash-контент).
Фрейм это HTML-документ, который не содержит собственного контента, а состоит из разных областей ― каждая с отдельной веб-страницей. Также у него отсутствует элемент BODY.
Как результат, поисковым роботам просто негде искать полезный контент для сканирования. Страницы с фреймами индексируются очень медленно и с ошибками.
Вот что известно от самого поисковика: Google может индексировать контент внутри встроенного фрейма iframe. Именно iframe поддерживается современными технологиями, так как он позволяет встраивать фреймы на страницы без применения тега <iframe>.
А вот теги <frame>, <noframes>, <frameset> устарели и уже не поддерживаются в HTML5, поэтому и не рекомендуется использовать их на сайтах. Ведь даже если страницы с фреймами будут проиндексированы, то трудностей в их продвижении вам все равно не избежать.
Что в итоге
Поисковые системы готовы проиндексировать столько страниц вашего сайта, сколько нужно. Только подумайте, объем индекса Google значительно превышает 100 млн гигабайт ― это сотни миллиардов проиндексированных страниц, количество которых растет с каждым днем.
Только подумайте, объем индекса Google значительно превышает 100 млн гигабайт ― это сотни миллиардов проиндексированных страниц, количество которых растет с каждым днем.
Но зачастую именно от вас зависит успех этого мероприятия. Понимая принципы индексации поисковых систем, вы не навредите своему сайту неправильными настройками. Если вы все правильно указали в robots.txt и карте сайта, учли технические требования поисковиков и позаботились о наличии качественного и полезного контента, поисковики не оставят ваш сайт без внимания.
Помните, что индексирование ― это не о том, попадет ваш сайт в выдачу или нет. Намного важнее ― сколько и каких страниц окажутся в индексе, какой контент на них будет просканирован и как он будет ранжироваться в поиске. И здесь ход за вами!
423 views
как краулер сканирует сайт и методы улучшения индексирования – Блог iSEO
В этой статье вы узнаете, что такое индексация сайтов, как индексируют сайты Google и Яндекс, как можно ускорить индексацию вашего сайта и какие проблемы встречаются чаще всего.![]()
Кому полезна статья?
Начинающим SEO-специалистам и маркетологам, веб-разработчикам и владельцам сайтов, желающим разобраться в принципах индексирования и методиках его улучшения.
Оглавление
- Индексирование сайта — что это и для чего необходимо?
- Сканирование и индексация сайта — как протекает процесс?
- Наиболее популярные ошибки
- Сайт или страницы закрыты в robots.txt
- Бот не получает код ответа 200
- Бот не может получить код страницы
- Страницы закрыты метатегом robots или заголовком X-Robots-Tag
- Как управлять сканированием и индексацией?
- Файл robots.txt
- Метатег robots
- HTTP-заголовок X-Robots-Tag
- Тег и HTTP-заголовок canonical
- HTTP-код ответа сервера, отличный от 200
- Удаление страниц в Яндекс.Вебмастере и Google Search Console
- Как отправлять страницы на индексацию/переиндексацию?
- Как улучшить сканирование и индексацию?
- Используйте XML-карту сайта
- Оптимизируйте перелинковку
- Внедрите поддержку IndexNow и Google Indexing API
- Анонсируйте новый контент в социальных сетях
- Выводы
Индексирование сайта — что это и для чего необходимо?
Прежде чем касаться вопроса индексации, необходимо вспомнить о целях любой поисковой системы. Главная задача поиска — ответ на запрос пользователя. Чем точнее и качественнее он будет, тем чаще пользователи будут пользоваться поисковиком.
Главная задача поиска — ответ на запрос пользователя. Чем точнее и качественнее он будет, тем чаще пользователи будут пользоваться поисковиком.
Поисковая система ищет подходящую информацию в своей базе данных, куда сайты попадают после их индексирования, а значит, только корректное индексирование может обеспечить попадание в выдачу.
Процесс можно разделить на 3 этапа:
Из схемы можно увидеть, что процесс сканирования и индексирования — это база для ранжирования любого сайта. Если возникают существенные проблемы на любом из указанных этапов, то можно забыть о высоких позициях, росте трафика и лидов. Рассмотрим эти этапы детальнее.
Сканирование и индексация сайта — как протекает процесс?
Сканирование сайта (или crawling) — процесс, при котором поисковые роботы обходят сайт и загружают страницы с целью определения внутренних ссылок и контента.
Источники, из которых поисковые системы могут узнавать о новых страницах на сайте:
- Из XML-карт сайта — ссылки на них, как правило, есть в robots.
 txt.
txt. - Из данных счетчиков — Яндекс.Метрика, Google Analytics.
- Из данных браузеров — Яндекс.Браузер, Google Chrome.
- Из сервисов для веб-мастеров — отправка на переобход в Яндекс.Вебмастере, запрос на индексацию URL в Google Search Console.
- Из RSS-фида — XML-файл в специальном формате.
- По протоколу IndexNow.
Уже просканированные страницы сайтов боты поисковых систем периодически переобходят для выявления изменений, способных повлиять на их ранжирование.
Алгоритм сканирования сайтов следующий:
После сканирования поисковые роботы добавляют страницы в поисковый индекс. Сама по себе индексация представляет собой процесс, при котором поисковые системы упорядочивают информацию перед поиском, чтобы обеспечить максимально быстрый ответ пользователю на запрос.
Каждый из этапов сканирования важно контролировать, так как любые ошибки могут критически влиять на индексацию страниц.
Наиболее популярные ошибки
При работе с сайтом каждый оптимизатор или маркетолог сталкивались с проблемами индексирования сайтов. Далее разберем примеры самых частых проблем.
Далее разберем примеры самых частых проблем.
Сайт или страницы закрыты в robots.txt
Наиболее популярная проблема, встречающаяся у всех типов сайтов.
Файл robots.txt — это текстовый документ, содержащий разрешающие и запрещающие директивы для ботов поисковых систем.
Если ваш robots.txt содержит строку «Disallow: /», это повод проверить, видит ли ваш сайт поисковый бот. Сделать это можно с помощью инструмента https://webmaster.yandex.ru/tools/robotstxt/.
Бот не получает код ответа 200
Вторая наиболее часто встречающаяся проблема индексирования — наличие кодов ответа 4XX или 5XX.
Примеры ошибок:
| Код ответа | Ошибка | Описание |
|---|---|---|
| 400 | Неверный запрос / Bad Request | Запрос не может быть понят сервером из-за некорректного синтаксиса. |
| 401 | Неавторизованный запрос / Unauthorized | Для доступа к документу необходимо вводить пароль или быть зарегистрированным пользователем.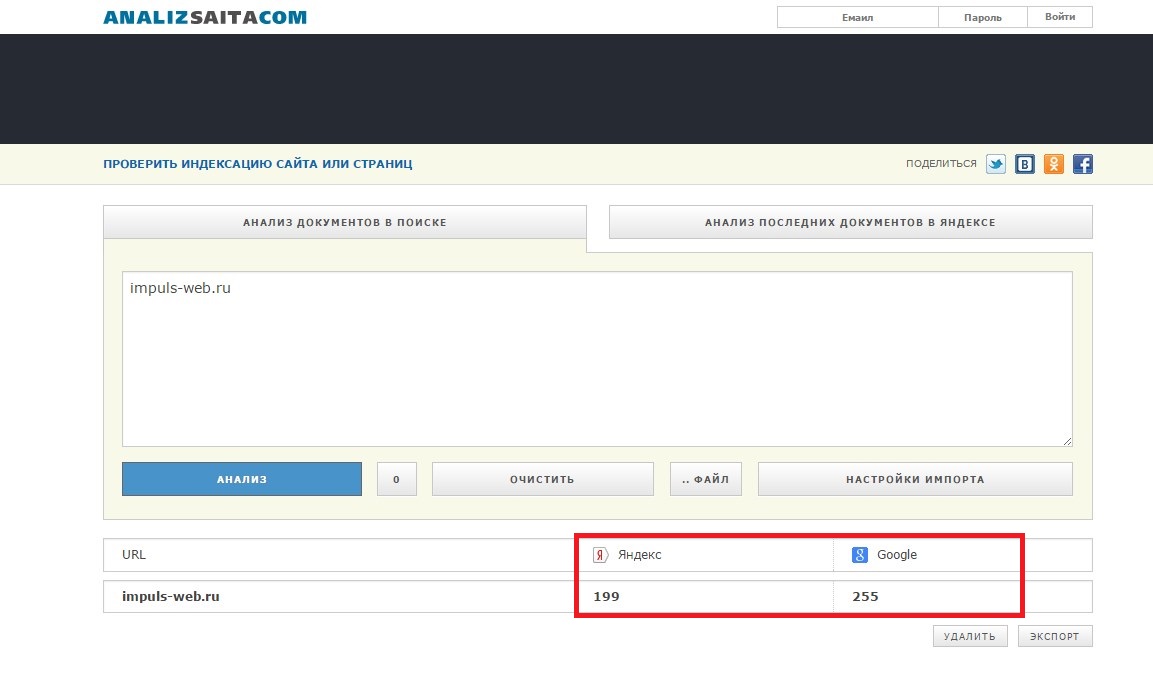 |
| 402 | Необходима оплата за запрос / Payment Required | Внутренняя ошибка или ошибка конфигурации сервера. |
| 403 | Доступ к ресурсу запрещен / Forbidden | Доступ к документу запрещен. Если вы хотите, чтобы страница индексировалась, необходимо разрешить доступ к ней. |
| 404 | Ресурс не найден / Not Found | Документ не существует. |
| 405 | Недопустимый метод / Method Not Allowed | Метод, определенный в строке запроса (Request-Line), не дозволено применять для указанного ресурса, поэтому робот не смог его проиндексировать. |
| 406 | Неприемлемый запрос / Not Acceptable | Нужный документ существует, но не в том формате (язык или кодировка не поддерживаются роботом). |
| 407 | Требуется идентификация прокси, файервола / Proxy Authentication Required | Необходима регистрация на прокси-сервере. |
| 408 | Время запроса истекло / Request Timeout | Робот не передал полный запрос в течение установленного времени, и сервер разорвал соединение.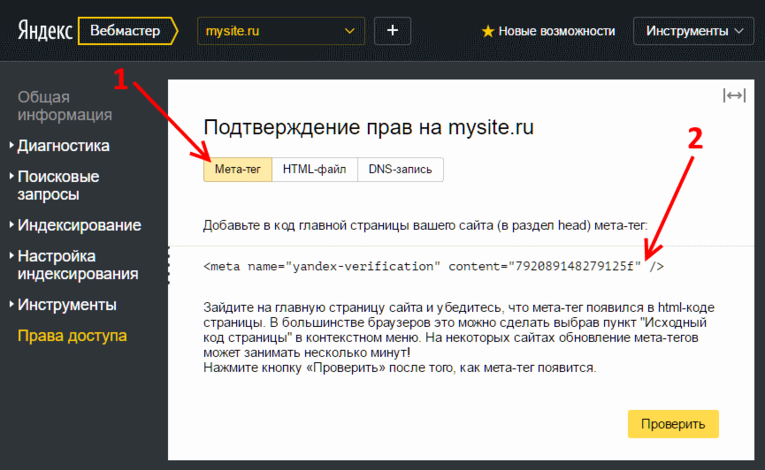 |
| 410 | Ресурс недоступен / Gone | Затребованный ресурс был окончательно удален с сайта. |
| 500 | Внутренняя ошибка сервера / Internal Server Error | Сервер столкнулся с непредвиденным условием, которое не позволяет ему выполнить запрос. |
| 501 | Метод не поддерживается / Not Implemented | Сервер не поддерживает функциональные возможности, требуемые для выполнения запроса. |
| 502 | Ошибка шлюза / Bad Gateway | Сервер, действуя в качестве шлюза или прокси-сервера, получил недопустимый ответ от следующего сервера в цепочке запросов, к которому обратился при попытке выполнить запрос. |
| 503 | Служба недоступна / Service Unavailable | Возникла ошибка из-за временной перегрузки или отключения сервера. |
| 504 | Время прохождения через межсетевой шлюз истекло / Gateway Timeout | Сервер при работе в качестве внешнего шлюза или прокси-сервера своевременно не получил отклик от вышестоящего сервера. |
Наличие HTTP-кодов ответа сервера, отличных от 200, может стать серьезной проблемой на пути сканирования и индексации сайта.
Проверить ответ сервера вы можете с помощью внутренних инструментов поисковых систем: https://webmaster.yandex.ru/tools/server-response/ и https://search.google.com/search-console/. Или с помощью внешних сервисов, например https://bertal.ru/.
Бот не может получить код страницы
Главное для поисковика — наличие исходного HTML-кода, который он сможет прочесть. С развитием JavaScript технологий сайты стали функциональнее и быстрее, однако из-за фреймворков может происходить их некорректная индексация и снижение трафика.
Основная проблема JS-фреймворков в том, что они развиваются быстрее поисковых систем. Особенно это было заметно в Яндексе, где у сайтов на JavaScript часто возникали проблемы с индексированием контента (но есть надежда, что в ближайшем будущем ситуация изменится).
Да и у Google процесс сканирования и индексирования JS-сайтов несколько отличается от обработки классического HTML. В процесс индексирования включается этап «отрисовки» (rendering), увеличивающий время индексирования:
В процесс индексирования включается этап «отрисовки» (rendering), увеличивающий время индексирования:
Поскольку рендеринг требует гораздо больше вычислительных ресурсов, чем разбор HTML, то возникают следующие проблемы:
- Этап рендеринга может длиться значительно дольше, чем индексация HTML-страницы. Он может занять несколько недель.
- Не все страницы сайта в принципе могут дойти до этапа рендеринга.
При работе с JS-сайтами учитываете требования поисковиков: https://yandex.ru/support/webmaster/yandex-indexing/rendering.html и https://developers.google.com/search/docs/advanced/javascript/javascript-seo-basics?hl=ru.
Проверить, как индексируется ваш сайт и настроен ли корректно рендринг, вы можете:
Используя сервис https://bertal.ru/ или аналогичный, выставив настройки «отображать HTML-код» и подходящий тип поискового робота:
Анализируя текстовую сохраненную копию страницы в выдаче Яндекса и Google. В случае, если вы наблюдаете проблемы с видимостью страниц на JS-фреймворках, проверьте сохраненную текстовую копию страницы прямо из выдачи:
В случае, если вы наблюдаете проблемы с видимостью страниц на JS-фреймворках, проверьте сохраненную текстовую копию страницы прямо из выдачи:
Анализируя страницы непосредственно в сервисах Яндекса и Google для веб мастеров — Яндекс.Вебмастере и Google Search Console. Рекомендуем обращать внимание не только на те страницы, что попали в индекс, но и на те, что не попали. Важно понять, должны ли эти страницы индексироваться и если должны, то по какой причине этого не происходит.
Страницы закрыты метатегом robots или заголовком X-Robots-Tag
Кроме файла robots.txt, поисковик может не получить доступ к конкретной странице, если на ней указан метатег robots, запрещающий её индексацию:
<meta name="robots" content="noindex, nofollow" />
Данный тег размещается внутрь тега…и дает поисковику команду не индексировать страницу (noindex) и не переходить по ее внутренним ссылкам (nofollow).
Аналогом метатега может быть блокировка сканирования страниц с помощью HTTP-заголовка X-Robots-Tag.
Проверить доступность страниц вы можете в инструментах для веб мастеров, например https://webmaster.yandex.ru/tools/server-response/, либо с помощью парсинга сайта программами Screaming Frog SEO Spider, Netpeak Spider и т. д.
Отметим, что отсутствие вышеперечисленных ошибок не может гарантировать корректного сканирования и индексирования сайта. Негативно могут влиять:
- мусорные страницы — например, страницы результатов сортировок или работы фильтров;
- дубли страниц — один и тот же контент, доступный по разным URL;
- технические/служебные страницы без полезного для пользователей контента;
- дубли страниц в формате PDF и т. д.
Как управлять сканированием и индексацией?
Для того чтобы сайт индексировался корректно, необходимо контролировать, как поиск видит сайт и расходует краулинговый бюджет.
Краулинговый бюджет — это квота страниц сайта, подлежащих индексированию в рамках одного обращения робота к сайту. Например, если краулер вместо целевых и полезных страниц ходит по мусорным документам, то индексация ухудшается, новые страницы не попадают в поиск, а потенциал трафика уменьшается.
Например, если краулер вместо целевых и полезных страниц ходит по мусорным документам, то индексация ухудшается, новые страницы не попадают в поиск, а потенциал трафика уменьшается.
Чтобы направлять краулер туда, куда необходимо, важно использовать следующие методы управления индексацией.
Файл robots.txt
Самый простой метод управления индексацией — текстовый файл robots.txt в корневой папке сайта. Как мы уже отметили ранее, поисковые роботы всегда обращаются к содержимому файла для понимания, какие страницы доступны к добавлению в поисковый индекс, а какие нет. Вы можете использовать файл для блокировки тех страниц, которые вы считаете неважными и ненужными к индексированию.
Пример:
Disallow: /folder-you-want-to-block/
Плюсы
- Как правило, легко внедрять корректировки.
- Быстро принимается и учитывается поиском.
- Есть возможность проверки файла с помощью Яндекс.Вебмастера и Google Search Console.
Минусы
- Google может проигнорировать директивы в robots.
 txt и добавить страницы в индекс. Google считает, что файл robots.txt управляет только сканированием сайта, а не его индексацией.
txt и добавить страницы в индекс. Google считает, что файл robots.txt управляет только сканированием сайта, а не его индексацией. - Ссылки на страницы, закрытые в robots.txt, расходуют т. н. «статический вес» страниц (PageRank, ВИЦ и подобные алгоритмы).
- С заблокированных страниц не передается вес на другие страницы сайта.
Важный факт. Для Яндекса существует полезная директива «Clean-param», где вы можете указать параметры URL, которые поиск должен игнорировать. Например, результаты сортировки или работы фильтра товаров. Плюс такого решения — передача сигналов ранжирования (например поведенческих метрик) на страницы без параметров, что очень важно для Яндекса.
Метатег robots
Метатег robots позволяет эффективнее блокировать страницы к индексированию. В частности, для Google это более важный сигнал, чем инструкции в файле robots.txt.
<meta name="robots" content="noindex, nofollow" />
Внедрив тег на страницу, вы сможете без участия файла robots. txt заблокировать её индексацию.
txt заблокировать её индексацию.
Плюсы
- Может эффективнее работать для блокировки страниц в Google, чем robots.txt.
- Хорошо воспринимается поисковыми ботами.
Минусы
- Более трудоемко, чем блокировка в robots.txt, если нужно заблокировать много страниц.
- Применим только для HTML-страниц.
- Ссылочный вес не передается на другие страницы.
При использовании метатега robots обращайте внимание на содержимое robots.txt. Чтобы Google увидел метатег robots на странице, она не должна быть заблокирована в файле robots.txt.
HTTP-заголовок X-Robots-Tag
Аналог метатега robots. Вы можете использовать тот или иной метод.
Плюсы
- Может эффективнее работать для блокировки страниц в Google, чем robots.txt.
- Хорошо воспринимается поисковыми ботами.
Минусы
- Более трудоемкая реализация, чем использование файла robots.
 txt или метатега robots.
txt или метатега robots.
На практике X-Robots-Tag применяется реже, чем предыдущие два метода. При этом данный метод отлично работает для документов, отличных от HTML. К примеру, с помощью X-Robots-Tag можно легко блокировать PDF и другие документы, изображения и скрипты, что метатег сделать не может.
Тег и HTTP-заголовок canonical
Метатег, применяемый для указания среди двух или более одинаковых страниц одной канонической, которую поисковик должен проиндексировать и добавить в поиск, при этом другие страницы будут признаны неканоническими и добавляться в индекс не будут. Пример тега:
<link rel="canonical" href="https://www.iseo.ru/blog/" />
По сравнению с другими методами, тег canonical не является блокирующим. Вы можете поменять каноническую страницу или полностью удалить тег.
Плюсы
- Передает сигналы ранжирования (например ссылочные факторы) с неканонических на каноническую страницу.
 Аналогично 301-му редиректу.
Аналогично 301-му редиректу. - Позволяет бороться с дублями страниц внутри сайта.
- Может быть использован для указания скопированного контента, если вы размещаете один и тот же контент на нескольких доменах. Но некоторые поисковые системы могут не поддерживать межхостовый canonical.
- Легко обратим, если править теги canonical позволяет ваша CMS.
Минусы
- Тег носит рекомендательный характер. Если страницы заметно различаются, то поисковый бот может сменить каноническую страницу и добавить в индексе не ту копию, что вам нужна.
- Не экономит краулинговый бюджет. Бот реже обходит неканонические URL, но не прекращает это делать.
Чтобы тег canonical работал, страницы-дубли не должны быть закрыты в robots.txt или метатегом robots, в противном случае он будет проигнорирован. Также не следует помещать на одну страницу два или более тегов canonical.
В качестве альтернативы тегу canonical можно использовать HTTP-заголовок. В частности, для указания канонических документов (не HTML-страниц). Пример:
В частности, для указания канонических документов (не HTML-страниц). Пример:
Link: <http://www.iseo.ru/downloads/some-file.pdf>; rel="canonical"
HTTP-код ответа сервера, отличный от 200
Альтернативным решением по исключению страниц из индекса является настройка HTTP-кодов ответа сервера отличных от 200.
К примеру, у вас большое количество мусорных страниц или страниц дублей, созданных по ошибке. Они не имеют ни трафика, ни ссылок. Для таких страниц можно настроить код ответа сервера 404 или 410.
Или же на сайте были созданы две похожих по интенту страницы, мешающих друг другу ранжироваться. В таком случае для сохранения ссылочного веса и передачи прочих сигналов ранжирования (например поведенческих факторов) вы можете использовать 301-ый редирект. Таким образом, одна из страниц со временем будет удалена из выдачи.
Частный случай этого метода — закрытие доступа к сайту, папке или странице/файлу с помощью пароля. При этом боты будут получать код ответа 403. Например, таким образом можно закрыть от индексации новую версию сайта на тестовом домене.
Например, таким образом можно закрыть от индексации новую версию сайта на тестовом домене.
Плюсы
- Высокая эффективность. В отличии от метатегов и директив в robots.txt, код ответа сервера воспринимается ботом всегда, а значит, вы наверняка сможете предотвратить появление лишних страниц в индексе.
- Возможность сохранить внешние ссылки при использовании 301-х редиректов.
- Высокая скорость индексирования изменений. В отличии от индексации тегов, поисковые роботы, как правило, очень быстро принимают и учитывают новый код ответа сервера.
Минусы
- Потеря веса внешних ссылок в случае настройки 5ХХ или 4ХХ ответов сервера.
- Долгая обратимость. В случае, если вы ошибетесь при настройке, возврат 200-го кода ответа сервера может не гарантировать возврат страницы на старые позиции, а значит, может быть потерян трафик.
Удаление страниц в Яндекс.Вебмастере и Google Search Console
Для ускорения удаления страниц из поиска вы можете воспользоваться инструментами Яндекса и Google для веб мастеров:
- Для Яндекса — https://webmaster.
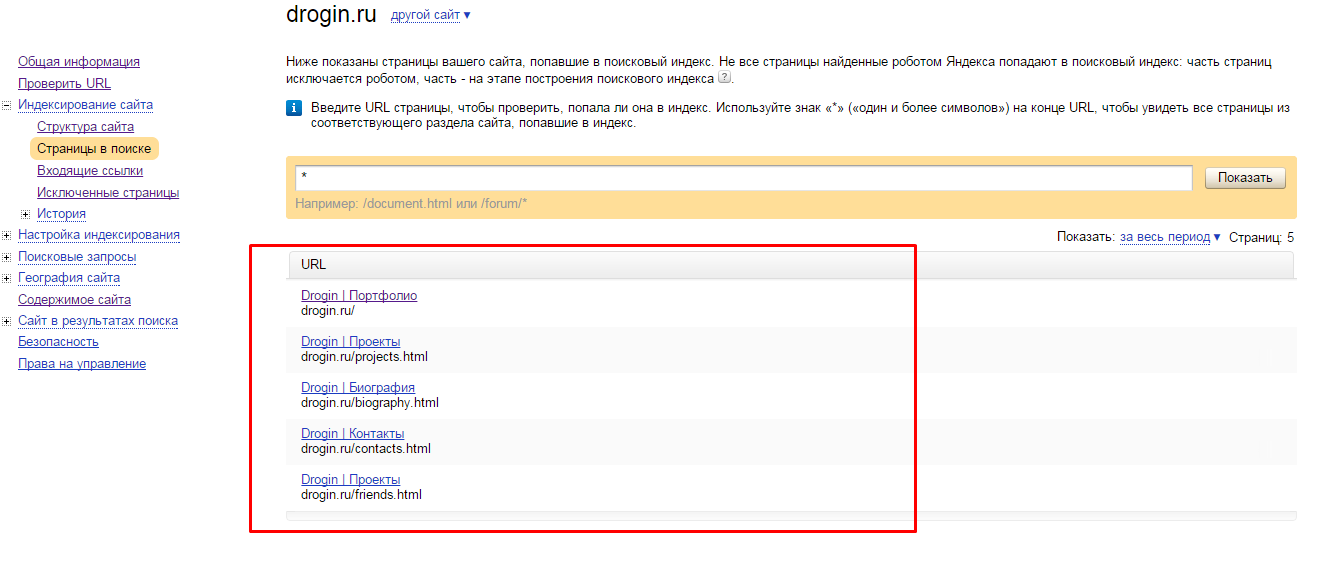 yandex.ru/site/tools/del-url/
yandex.ru/site/tools/del-url/ - Для Google — https://search.google.com/search-console/removals
Плюсы
- Высокая оперативность. К примеру, из Google страницы удаляются в течение двух дней.
Минусы
- Страницы блокируются от индексации не навсегда. Блокировка возникает на 6 месяцев для Google или на время присутствия запрещающих директив или кодов 403/404/410 для Яндекса.
- Есть разница в работе функционала. Для Google страница должна быть доступна для сканирования. При коде ответа 404, 502 или 503 блокировка отключается, а это значит, что если страница позже появится с кодом 200, то она может быть снова добавлена в поиск. Для Яндекса же наоборот, удаление может коснуться только тех страниц, что заблокированы в robots.txt или имеют код ответа 403, 404 или 410. Если страница отдает код 200 и открыта в robots.txt, запрос будет отклонен.
- Возможен расход краулингового бюджета на переобход заблокированных страниц.

Как отправлять страницы на индексацию/переиндексацию?
Можно не только удалять мусорные страницы, но и ускорять индексацию приоритетных. Воспользуйтесь Яндекс.Вебмастером и Google Search Console, чтобы сообщить поиску о новых страницах на вашем сайте или о появлении новых.
Для Яндекса — https://webmaster.yandex.ru/site/indexing/reindex/.
Добавьте URL в список страниц и отправьте его на переобход. Обратите внимание: для каждого сайта предусмотрен свой дневной лимит.
Для Google — https://search.google.com/u/3/search-console/inspect.
Добавьте адрес страницы в строку и запросите индексирование:
Используя данные инструменты, вы сможете:
- Оперативно уведомлять поисковые системы о появлении новых страниц, не дожидаясь обхода краулера.
- Сообщать ботам об изменениях на странице с целью ускоренной переиндексации контента.
Как улучшить сканирование и индексацию?
Добавление вручную страниц в консолях веб мастеров — хорошее решение для небольших сайтов.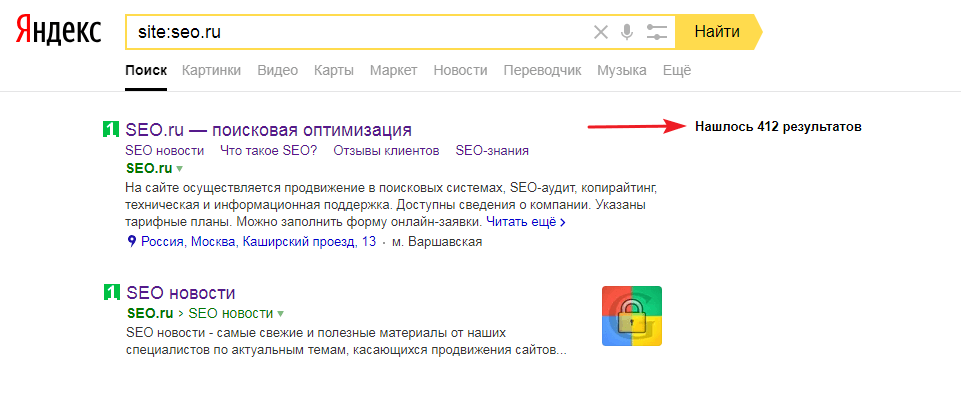 Но если у вас крупный сайт, лучше довериться поисковым роботам и упростить им работу за счет следующих решений.
Но если у вас крупный сайт, лучше довериться поисковым роботам и упростить им работу за счет следующих решений.
Используйте XML-карту сайта
XML-карта сайта — это файл со ссылками на все страницы, которые необходимо индексировать поисковым системам.
Поисковые системы разрабатывают алгоритмы, по которым краулеры узнают о сайтах и новых страницах, к примеру, переходя по внутренним и внешним ссылкам. Но иногда боты могут пропустить какие-то страницы, или же на целевые страницы мало или нет ссылок. XML-карта решает такие проблемы, отдавая полный список URL, доступных к индексации.
Рекомендации по использованию файлов XML-карт сайта:
- Не размещайте ссылки на закрытые от индексирования страницы.
- Не размещайте ссылки на страницы с кодом ответа сервера, отличным от 200.
- Используйте кодировку UTF-8.
- Не размещайте более 50 000 ссылок в одном файле. Если страниц больше, используйте индексный файл.
- Файл с XML-картой должен отдавать код 200 и быть доступным к обходу в robots.
 txt.
txt. - Укажите ссылку на XML-карту сайта в robots.txt. Либо добавьте ссылку на XML-карту в инструменты для вебмастеров Яндекса и Google.
После создания файла sitemap.xml следует отправить его на индексацию в Яндекс.Вебмастер и Google Search Console.
Оптимизируйте перелинковку
Внутренние ссылки — это главная артерия любого сайта. Именно по гиперссылкам переходят краулеры поисковых систем, оценивая ссылочный вес и релевантность страниц, а пользователи совершают внутренние переходы, улучшая поведенческие показатели. Далее приведем несколько примеров перелинковки.
HTML-карта сайта
Это аналог sitemap.xml, но с некоторыми отличиями:
- В HTML-карте не всегда выводят ссылки на все страницы. Иногда только на самые важные. Например, если у вас большой интернет-магазин, то имеет смысл вывести ссылки на основные листинги товаров (категории, подборки и т. п.), но не на страницы товаров.
- В отличие от XML-карты сайта, HTML-карта передает по ссылкам сигналы ранжирования (PagRank и т.
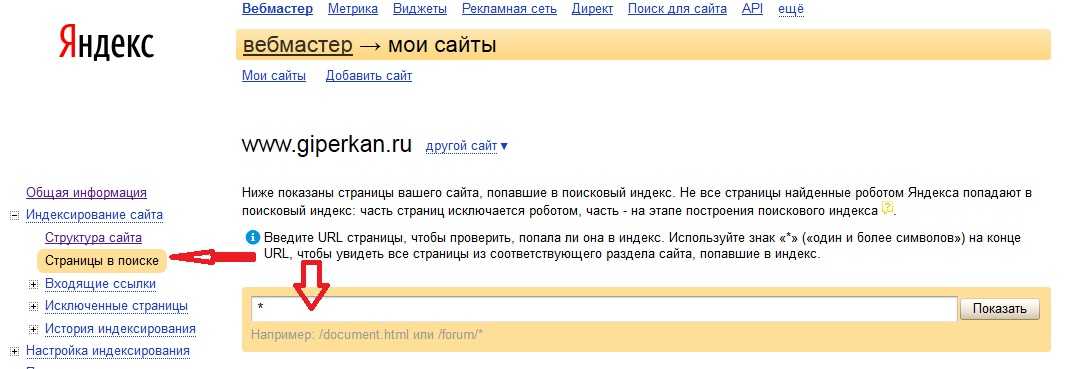 п.). Также учитываются анкоры ссылок.
п.). Также учитываются анкоры ссылок. - Сокращается вложенность страниц. Все страницы, на которые ссылается карта сайта, становятся доступны в два клика от главной страницы.
Пример небольшой карты сайта: https://www.iseo.ru/sitemap/.
Хлебные крошки
Навигационная цепочка, показывающая путь в структуре сайта от главной страницы к текущей. Пример со страницы https://shop.mts.ru/product/smartfon-apple-iphone-12-pro-max-256gb-tikhookeanskij-sinij:
Хлебные крошки решают следующие задачи:
- Передают статический вес страницам более высокого уровня.
- Улучшают юзабилити за счет понятного расположения страницы в иерархической структуре сайта.
- Могут быть размечены с помощью Schema.org и улучшить сниппет.
Ссылки на похожие товары или статьи
Блок перелинковки похожего контента — один из вариантов ускорения индексирования новых карточек товаров, статей и новостей.
Пример блока: https://www. iseo.ru/clients/internet-magazin-mts/
iseo.ru/clients/internet-magazin-mts/
Чаще всего данный блок работает автоматически. В контенте уже добавленных в индекс страниц выводятся ссылки на новые страницы. На это обращает внимание краулер и совершает их обход.
Ссылки с главной страницы
Как правило, главная страница обладает самым большим статическим весом по мнению поиска, так как чаще всего на нее ведет самое большое количество ссылок. Поэтому внедрение элементов перелинковки на главной странице имеет следующие плюсы:
- Высокая ценность таких ссылок. Страницы со ссылками с главной часто ранжируются лучше аналогичных без них.
- Ускорение индексации новых страниц.
Рекомендуем вам пользоваться главной страницей по максимуму при построении схем перелинковки.
Внедрите поддержку IndexNow и Google Indexing API
Кроме классических решений по ускорению индексации, вы можете подключить дополнительные протоколы типа IndexNow для Яндекса или Google Indexing API.
С их помощью вы можете не дожидаться, пока бот обнаружит все ваши страницы с помощью sitemap.xml или внутренней перелинковки. Вы сами можете уведомлять поисковики об обновлении, создании новых или удалении старых страниц. Причем делать это тысячами, не расходуя лимиты и время. Однако внедрение поддержки этих протоколов, скорее всего, потребует дополнительной разработки на стороне вашего сайта.
Подробнее о технологиях:
- Справка Яндекса по IndexNow — https://yandex.ru/support/webmaster/indexing-options/index-now.html
- Протокол IndexNow — https://www.indexnow.org/locale/ru_ru/index
- Справка по Google Indexing API — https://developers.google.com/search/apis/indexing-api/v3/using-api?hl=ru
Анонсируйте новый контент в социальных сетях
Еще одним решением по ускорению индексации являются соцсети.
Делитесь свежим контентом с пользователями в социальных сетях. Такие ссылки поисковики замечают быстрее, а значит, и контент будет проиндексирован раньше.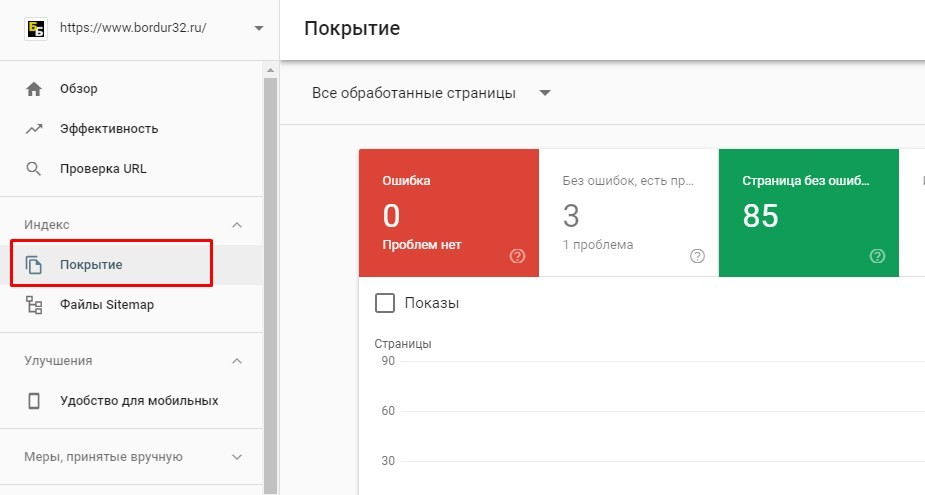 Бонусом здесь выступает трафик, который вы можете получить из социальных сетей.
Бонусом здесь выступает трафик, который вы можете получить из социальных сетей.
Выводы
Индексация — это отправная точка для органического трафика и продаж любого сайта. Если вы знаете, что у вас есть проблемы с индексированием, то исправляйте ошибки очень аккуратно и перепроверьте трижды результаты ваших решений.
А если вам нужна помощь экспертов, обращайтесь в нашу компанию за SEO-аудитом или поисковым продвижением вашего сайта.
Денис Яковенко
Руководитель группы SEO-специалистов
Что такое индексирование в поисковых системах и как оно работает?
Что происходит, когда поисковая система заканчивает сканирование страницы? Давайте рассмотрим процесс индексации, который поисковые системы используют для хранения информации о веб-страницах, что позволяет им быстро возвращать релевантные высококачественные результаты.
Какая потребность в индексации поисковыми системами?
Помните дни до Интернета, когда вам приходилось обращаться к энциклопедии, чтобы узнать о мире и копаться в Желтых страницах, чтобы найти сантехника? Даже на заре Интернета, до появления поисковых систем, нам приходилось искать информацию в каталогах. Какой трудоемкий процесс. Откуда у нас хватило терпения?
Какой трудоемкий процесс. Откуда у нас хватило терпения?
Поисковые системы произвели революцию в поиске информации, поскольку пользователи ожидают почти мгновенных ответов на свои поисковые запросы.
Что такое индексирование поисковыми системами?
Индексирование — это процесс, с помощью которого поисковые системы упорядочивают информацию перед поиском, чтобы обеспечить сверхбыстрые ответы на запросы.
Поиск на отдельных страницах по ключевым словам и темам будет очень медленным процессом для поисковых систем, чтобы определить релевантную информацию. Вместо этого поисковые системы (включая Google) используют инвертированный индекс, также известный как обратный индекс.
Что такое инвертированный индекс?
Инвертированный индекс — это система, в которой база данных текстовых элементов компилируется вместе с указателями на документы, содержащие эти элементы. Затем поисковые системы используют процесс, называемый токенизацией, чтобы сократить слова до их основного значения, тем самым уменьшая количество ресурсов, необходимых для хранения и извлечения данных. Это гораздо более быстрый подход, чем перечисление всех известных документов по всем релевантным ключевым словам и символам.
Это гораздо более быстрый подход, чем перечисление всех известных документов по всем релевантным ключевым словам и символам.
Пример инвертированной индексации
Ниже приведен очень простой пример, иллюстрирующий концепцию инвертированного индексирования. В примере видно, что каждое ключевое слово (или токен) связано со строкой документов, в которых этот элемент был идентифицирован.
| Ключевое слово | Путь к документу 1 | Путь документа 2 | Путь документа 3 |
| SEO | example.com/seo-tips | moz.com | … |
| HTTPS | deepcrawl.co.uk/https-скорость | example.com/https-будущее | … |
В этом примере используются URL-адреса, но это могут быть идентификаторы документов, в зависимости от структуры поисковой системы.
Кэшированная версия страницы
Помимо индексации страниц, поисковые системы могут также хранить сильно сжатую текстовую версию документа, включая все HTML и метаданные.
Кэшированный документ — это последний снимок страницы, просмотренный поисковой системой.
Доступ к кэшированной версии страницы можно получить (в Google), щелкнув маленькую зеленую стрелку рядом с URL-адресом каждого результата поиска и выбрав вариант кэширования. Кроме того, вы можете использовать оператор поиска Google «cache:» для просмотра кешированной версии страницы.
Bing предлагает те же возможности для просмотра кешированной версии страницы с помощью зеленой стрелки вниз рядом с каждым результатом поиска, но в настоящее время не поддерживает оператор поиска «кэш:».
Что такое PageRank?
«PageRank» — это алгоритм Google, названный в честь соучредителя Google Ларри Пейджа (да, действительно!) Это значение для каждой страницы, рассчитанное путем подсчета количества ссылок, указывающих на страницу, чтобы определить ценность страницы. относительно любой другой страницы в Интернете. Значение, передаваемое каждой отдельной ссылкой, основано на количестве и значении ссылок, которые указывают на страницу со ссылкой.
PageRank — это лишь один из многих сигналов, используемых в большом алгоритме ранжирования Google.
Приблизительные значения PageRank изначально были предоставлены Google, но они больше не являются общедоступными.
Хотя PageRank является термином Google, все коммерческие поисковые системы рассчитывают и используют эквивалентную метрику ссылочного капитала. Некоторые SEO-инструменты пытаются дать оценку PageRank, используя собственную логику и расчеты. Например, Page Authority в инструментах Moz, TrustFlow в Majestic или рейтинг URL в Ahrefs. DeepCrawl имеет метрику под названием DeepRank для измерения ценности страниц на основе внутренних ссылок на веб-сайте.
Как PageRank проходит через страницы
Страницы передают PageRank или ссылочный вес другим страницам через ссылки. Когда страница ссылается на контент в другом месте, это рассматривается как вотум уверенности и доверия, поскольку контент, на который ссылаются, рекомендуется как актуальный и полезный для пользователей. Количество этих ссылок и степень авторитетности ссылающегося веб-сайта определяют относительный PageRank страницы, на которую ссылаются.
PageRank поровну распределяется между всеми обнаруженными ссылками на странице. Например, если на вашей странице пять ссылок, каждая ссылка будет передавать 20% PageRank страницы через каждую ссылку на целевые страницы. Ссылки с атрибутом rel=»nofollow» не проходят PageRank.
Важность обратных ссылок
Обратные ссылки являются краеугольным камнем того, как поисковые системы понимают важность страницы. Было проведено множество исследований и тестов, чтобы определить корреляцию между обратными ссылками и рейтингом.
Исследование обратных ссылок, проведенное Moz, показывает, что в результатах 50 самых популярных поисковых запросов Google (около 15 000 результатов поиска) 99,2% из них содержали как минимум 1 внешнюю обратную ссылку. Кроме того, SEO-специалисты постоянно оценивают обратные ссылки как один из наиболее важных факторов ранжирования в опросах.
Далее: Отличия поисковых систем
Автор
Сэм Марсден
Сэм Марсден — бывший SEO-менеджер и контент-менеджер Deepcrawl. Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых изданий, таких как Search Engine Journal и State of Digital.
Индексирование Интернета | Американское общество индексирования
Навигация
Индексирование в стиле Back-of-the-Book
Индексируемые сайты
Метаданные и веб-индексирование
Индексирование тематического дерева
Технологии поисковых систем
Индексирование Интернета — непростая задача, и для удовлетворения информационных потребностей веб-пользователей развиваются три различных вида индексирования: традиционный стиль жестко запрограммированных индексных ссылок на веб-сайте, предметный деревья просмотренных сайтов и поисковые системы. Члены ASI, интересующиеся этой специализированной областью индексирования, могут присоединиться к SIG по индексированию цифровых публикаций ASI.
Некоторые организации понимают, что включение указателей на их веб-сайты так же важно, как и включение указателей в книги и онлайн-руководства. Мы видели некоторые хорошие и некоторые плохие, некоторые сгенерированные компьютером, некоторые явно не созданные профессиональными индексаторами, а некоторые профессионально подготовленные. В любом случае следует похвалить всех владельцев сайтов за осознание необходимости индекса. Мы хотели бы поделиться с вами некоторыми интересными индексами и информацией о том, как работает индексирование в поисковых системах. Посмотрите и посмотрите, какую ценность добавляют эти индексы! Этот список будет время от времени меняться, поэтому не забудьте добавить в закладки, распечатать, загрузить или сохранить другими способами те, к которым, как вы думаете, вы вернетесь позже.
Веб-индексирование в стиле Back-of-the-Book
Многие веб-сайты предоставляют функцию поиска по сайту. Хотя это, безусловно, лучше, чем ничего, пользователи сталкиваются с теми же проблемами в этом сценарии, что и при поиске в других полнотекстовых базах данных. Основная проблема, конечно же, в релевантности найденных в поиске предметов. Например, на сайте издателя программного обеспечения поиск продукта под названием Home Office приводит к получению всех документов со словом «офис», потому что в конце каждой страницы есть слово «дом». Если есть индекс сайта, вы можете перейти прямо в раздел «H» и найти одну релевантную страницу, тем самым сэкономив время для других проектов. Индекс не только отсеет такие нерелевантные элементы, но и многие важные подзаголовки дадут пользователям подсказку о том, какие из них с большей вероятностью ответят на их вопросы.
Эти избранные сайты представляют собой просто набор сайтов с интересными индексами, с которыми нам довелось столкнуться. Описания написаны теми, кто представляет предложение сайта. Перечисленные здесь сайты предназначены только для образовательных целей. Американское общество индексирования не поддерживает информационное содержание этих сайтов.
ПРИМЕЧАНИЕ ПО ПРЕДСТАВЛЕНИЯМ: мы приветствуем любые предложения от пользователей о сайтах для добавления. Предлагаемые URL-адреса должны сопровождаться (1) инструкциями о том, как перейти к индексу с главной страницы сайта, и (2) описанием полезного или необычного в индексе. Пожалуйста, помните, что мы хотим показать фактические индексы, а не просто набор ссылок, относящихся к определенной теме.
проиндексированных сайтов
- BC Гидро
- Чтобы перейти к указателю сайта, прокрутите до нижней части домашней страницы и щелкните ссылку «Указатель сайта». Этот алфавитный указатель с гиперссылками отображает удобную для пользователя типографику и макет.
- История Рочестера Индекс
- Это периодический указатель с гиперссылками на статьи, включая несколько гиперссылок по некоторым темам.
- UNIXhelp для пользователей
- Это интерактивное руководство содержит как индекс для просмотра, так и индекс для поиска по ключевым словам. Выберите «Ручной указатель» в меню на главной странице.
- Бюро переписи населения США
- Чтобы перейти к указателю, щелкните «Указатель от А до Я» на главной странице.

Метаданные и веб-индексирование
Тег META в HTML использовался с целью дать поисковым системам подсказки о содержании веб-страницы. Злоупотребление META-тегами со стороны веб-мастеров, которые пытаются искусственно повысить релевантность страницы, наполняя META-теги терминами, не связанными с фактическим содержанием страницы, приобрело угрожающие масштабы. Большинство коммерческих поисковых систем в настоящее время придают очень мало значения тексту, найденному в тегах META.
В ответ появились движения по стандартизации содержимого тегов META. Корпорации и правительственные органы, имеющие множество веб-сайтов, часто создают общедоступные порталы для своего веб-контента. Они могут улучшить результаты поиска для пользователей за счет осторожного использования структурированных мета-тегов, чтобы направлять свои поисковые системы на сайте. Индексаторы могут применить свои навыки анализа для создания этих структурированных тегов. Вот ссылки о метаданных, метатегах и индексации веб-страниц.
- Цифровая система идентификации объектов
- Цифровой идентификатор объекта (DOI) — это система для идентификации и обмена интеллектуальной собственностью в цифровой среде. Он обеспечивает основу для управления интеллектуальным контентом, для связи клиентов с поставщиками контента, для облегчения электронной коммерции и обеспечения автоматического управления авторскими правами для всех типов носителей. Использование DOI делает управление интеллектуальной собственностью в сетевой среде намного проще и удобнее, а также позволяет создавать автоматизированные услуги и транзакции для электронной коммерции.
- Инициатива по метаданным Dublin Core
- Инициатива по метаданным Dublin Core — это открытый форум, занимающийся разработкой интероперабельных стандартов онлайн-метаданных, которые поддерживают широкий спектр целей и бизнес-моделей. Деятельность DCMI включает в себя рабочие группы, основанные на консенсусе, глобальные семинары, конференции, взаимодействие по стандартам и образовательные мероприятия, направленные на широкое распространение стандартов и практик метаданных.
- Как использовать метатеги
- В этой статье SearchEngine Watch 2007 года объясняются метатеги, включая их ограничения.
- Служба поиска правительственной информации США (GILS)
- Цель Глобальной службы поиска информации — облегчить людям поиск всей необходимой им информации. GILS — это открытый стандарт для поиска основных информационных описаний. Такие описания могут быть вставлены в веб-документы с помощью таких инструментов, как TagGen, сгенерированы из баз данных с помощью таких инструментов, как MetaStar и Microsoft Access; или отредактированные каталогизаторами и просто сохраненные как документы. Основанный на стандарте поиска ISO 23950, GILS включает в себя наиболее часто понимаемые понятия, с помощью которых люди во всем мире находят источники информации в библиотеках, — такие понятия, как название, автор, издатель, дата и место.
Тематическое дерево и индексы проверенных сайтов
Некоторые инструменты веб-поиска просматривают каждый сайт человеческими глазами и мозгом, чтобы решить, какие категории и ключевые слова подходят сайту, а затем индексируют его соответствующим образом. Примером может служить Yahoo, где толпы людей создают индекс для Интернета, который также доступен для поиска с помощью поисковой системы.
Технологии поисковых систем
Подавляющее большинство индексаций в Интернете выполняется автоматически, с высоким уровнем поиска и низкой степенью релевантности. Большинство индексаторов считают, что уровень точности, предоставляемый большинством поисковых систем, просто не так хорош, как настоящая индексация. Но по мере того, как технологии поисковых систем становятся все более изощренными, мы должны увидеть некоторые изменения в уровне разочарования людей, использующих эти инструменты. Большинство поисковых систем на самом деле выполняют поиск по индексу — списку терминов, которые роботы возвращают из своих путешествий. Индексы можно манипулировать или создавать для использования этими механизмами, особенно во внутренней сети, путем осторожного использования тега META. Это область, которую индексаторы должны исследовать и понимать, чтобы мы могли индексировать для этих движков.
Search Engine Watch
Советы по поиску в Интернете, список всех основных поисковых систем и мета-поисковых систем, безопасный для детей поиск, тесты и рейтинги поисковых систем, технологии поисковых систем и новости. Также содержит текущий выпуск электронного журнала о новостях и технологиях поисковых систем; подписчики могут искать в архиве прошлых выпусков.
Что такое проиндексированные страницы? — Wiredelta
Индексированные страницы относятся к веб-страницам, которые данная поисковая система содержит в своей базе данных, другими словами, в своем «индексе». Индексация страниц — это процесс, посредством которого боты определенной поисковой системы сканируют Интернет в поисках новых страниц или обновлений на уже проиндексированных страницах.
Роботы, также известные как сканеры, обычно изучают каждую страницу веб-сайта, подробно анализируют все ее аспекты, а затем включают эти данные в свой индекс. Кроме того, поисковые роботы периодически возвращаются на веб-сайты, чтобы проверить наличие обновлений, хороших или плохих, которые они добавляют в свои реестры. Они также используют эти периодические обходы для оценки рейтинга веб-сайта. Таким образом, чем чаще веб-сайт обновляется — добавляется новый контент для поддержания актуальности сайта, исправляются проблемы с отзывчивостью, внедряются новые SEO-изменения и т. д. — тем выше рейтинг веб-сайта.
Напротив, сайт, который долгое время оставался без надлежащего обслуживания, будет становиться все менее и менее актуальным. И чем более она устаревает, тем менее интересна и достоверна информация, а значит, и ниже ранг.
Почему проиндексированные страницы важны?
Взаимосвязь между индексацией страниц и поисковой оптимизацией сложнее, чем кажется на первый взгляд. Начнем с того, что индексация URL-адреса необходима, если вы мечтаете о достижении целей позиционирования в результатах поиска. Как бы вы ни оптимизировали страницу, если она не проиндексирована, вы не получите никакого рейтинга в поисковой системе или посещений пользователей.
Таким образом, только проиндексированные страницы получают определенную позицию в поисковой выдаче. Но точная позиция будет зависеть от остальных внутренних и внешних факторов SEO, над которыми вы работали до и после этого момента. Правильно, ваша индексация изменится, если вы оставите свой сайт без присмотра.
К этим факторам присоединяются другие, которые мы можем контролировать в большей или меньшей степени, в зависимости от каждого из факторов. Факторы, о которых мы говорим:
- Скорость публикации контента;
- Качество контента;
- Обновления сайта;
- Существующие конкуренты
При этом индексация на количественном уровне также влияет на SEO-позиционирование страницы. Больше URL-адресов, проиндексированных в одном и том же домене, имеют больший вес в поисковой системе, чем конкуренты. Конечно, это только до тех пор, пока эти URL-адреса также являются качественными, поскольку количество не является единственным релевантным фактором.
Как сделать индексацию страниц в Google?
Google — самая используемая поисковая система в мире. Даже в странах с сильной внутренней ориентацией, таких как Россия, где нарицательным для долгой связи был Yandex.com, использование Google уже превысило 50%. Поэтому понятно, что веб-мастера заинтересованы в том, чтобы их страницы, статьи и индексация Google были как можно скорее.
Представьте, что вы предлагаете срочный контент или сезонные продукты, например. в начале учебного года, на Рождество или на летние каникулы — и вы только что запустили новый интернет-магазин или провели его ребрендинг и перенесли на новый домен. Насколько приветствуется раннее индексирование Google, когда от этого зависит будущее вашего бизнеса?
Есть несколько способов быстро проиндексировать ваши страницы или новый контент, которые помогут вам в этой ситуации. однако самыми быстрыми и, вероятно, наиболее эффективными из всех являются следующие две стратегии. Так что либо выберите один из шагов ниже, либо объедините их. Что бы вы ни делали, эти шаги позволят вам создать предпосылки для быстрой индексации контента — основного условия для получения раннего трафика.
Индексирование с помощью Инструментов для веб-мастеров и Google Search Console
Google может получать уведомления о создании новых страниц не только с помощью инструментов, которые обычно называют инструментами для веб-мастеров. Но поисковые системы Bing и Yahoo, например, используют свои собственные инструменты для веб-мастеров.
Однако наиболее интересующий нас набор инструментов Google когда-то назывался Google Webmaster Tools (GWM) и теперь разделен на отдельные блоки в зависимости от вашей направленности. В частности, для управления сайтами Google предоставляет Search Console, бесплатный сервис для администраторов, которые хотят отслеживать сайты, которыми они управляют, и их позиции в результатах поиска.
Веб-мастера могут предоставить Google точный URL-адрес страницы, в которую они внесли изменения, и гарантировать, что он проиндексирует ее как можно быстрее. Это особенно помогает в классических ситуациях, возникающих после переименования URL-адреса идентификатора, когда Google начинает индексировать ошибку 404 — страница не найдена по предыдущей ссылке. В худшем случае сканерам потребуется несколько месяцев, чтобы понять, что вы изменили идентификатор уже проиндексированных страниц. Но добавляя ссылку в Google Search Console, вы ускоряете процесс, избегая этих проблем.
То же самое касается как уже проиндексированных страниц, которые были просто обновлены, так и новых страниц. Веб-мастера просто уведомляют Google об изменениях, а затем Google отправляет своих поисковых роботов для анализа и индексации нового контента. Опять же, это не обязательный процесс, так как боты Google в конечном итоге доберутся до вашего контента — нового или обновленного — и проиндексируют его. Это просто система ускорения, позволяющая быстрее проиндексировать страницы.
Индексация по ссылкам
Еще один эффективный способ быстро проиндексировать веб-сайт — использовать внутренние ссылки, когда вы связываете новый контент с уже проиндексированными страницами. Чаще всего роботы посещают проиндексированные блоги или форумы с возможностью RSS-каналов, потому что их содержание часто меняется. Если вы управляете такой страницей и ее направленность позволяет это сделать, убедитесь, что вы всегда используете ссылки с сайта на новые страницы, и роботы поисковых систем легко найдут и проиндексируют ваш контент.
В качестве альтернативы поработайте над обратными ссылками и попросите ссылку у других, которые управляют интересными и связанными сайтами с уже проиндексированными страницами, похожими на ваши. Это поможет еще не проиндексированным страницам привлечь внимание ботов Google, но вы также привлечете больше трафика, и ваше общее SEO выиграет, поскольку Google рассматривает обратные ссылки как показатель авторитета.
Как проверить индексацию сайта в Google
7414 3
| How-to | – 8 мин чтения |
Дальнейшее продвижение сайта зависит от аспекта индексации
. Если вы создадите больше тысячи полноценных уникальных страниц, но пропустите этап индексации, вы не получите должного результата. Анализ индексации сайта необходим в целях SEO и продвижения.
Что такое индексация сайта
Индексация сайта — это процесс, при котором бот поисковой системы добавляет информацию о конкретном ресурсе в базу данных поисковой системы. Проверка индексации страниц нужна, чтобы показать вебмастеру, как роботы сканируют сайт, есть ли ошибки.
Мониторинг количества страниц осуществляется поисковой системой постоянно. Факт увеличения количества страниц в поисковых системах помогает сайту ранжироваться по большему количеству запросов и улучшает его позиции в результатах поиска.
Google Console
Индексация сайта в поисковых системах осуществляется отдельно для каждого поискового сервиса. Поэтому необходимо анализировать его отдельно.
Основным инструментом для работы с индексацией Google является сервис Search Console. Таким образом, вы будете управлять сканированием страниц. Например, можно отправить страницу на повторное сканирование после процесса устранения ошибки. Интерфейс Search Console выглядит так:
Как самостоятельно проверить индексацию сайта
Добавьте сайт в панель и подтвердите доступ.
Следить за индексацией по следующему алгоритму: Google Index > Статус индексации (статус индексации).
В расширенных данных вы получите информацию о страницах, заблокированных файлом robots.txt (индексация этих страниц невозможна). В то же время новая опция Search Console дает возможность увидеть все страницы, которые были проиндексированы, несмотря на запрет robots.txt.
Внимание: Большинство пользователей сталкиваются с распространенной ошибкой, которая выражается в блокировке индексации в терминах директив robots.txt. Если вы заметили, что сайт не индексируется, начните поиск решения проблемы прямо здесь.
Google Search Console официально заявляет, что информация может «частично соответствовать» результатам поисковой системы (эта информация представлена в разделе Техническая поддержка ресурса). Подробное объяснение доступно здесь. Пройдёмся по основным причинам:
Внимание: Вы получаете всю информацию об ошибке индексации на той же платформе. Они дублируются и с точки зрения электронного письма, поэтому регулярно проверяйте свой почтовый ящик. Все обнаруженные ошибки необходимо устранить, а страницы отправить на переиндексацию.
Как проверить полученную информацию Google Search Console
Полученную информацию легко проверить с помощью операторов:
Пример:
сайт:www.lego.com.us
Описание:
Команда предоставляет поисковой системе список проиндексированных страниц. Стоит заметить, что список содержит только те страницы, которые нашла поисковая система. Процедура оптимальна для пользователей, стремящихся узнать страницы конкурентов. Затем можно было провести анализ полученной информации.
Попробовав вариант «сайт», можно было увидеть следующее:
Плагины и букмарклеты
Некоторые онлайн-сервисы также предлагают массовую регистрацию индексации в нескольких поисковых системах сразу. Эти инструменты доступны бесплатно или на платной основе.
Работа со встроенными плагинами сэкономит время веб-мастерам. Например, панель RDS подойдет для самых разных целей. Услуга бесплатно устанавливается через магазин. Встроенный плагин работает прямо в панели Google Chrome.
Нажмите на иконку заметки браузера, и все необходимые данные об интересующем сайте будут доступны (также будет предоставлена информация о количестве страниц в индексе).
Дополнительные услуги для процедуры проверки индексации
Используйте эффективные инструменты с комплексным набором услуг для проведения анализа сайта. Например, комплексный аудит сайта (опция обзора сайта) от a.pr-cy поможет получить информацию о количестве проиндексированных страниц. Взгляните на онлайн-сервис и диапазон его опций, который необходимо учитывать:
Каждый SEO-анализатор в 80% случаев предоставляет информацию об индексации сайта. Такие анализаторы генерируют готовые отчеты, поэтому ручное управление не требуется. Есть ряд инструментов, которые успешно справляются со всеми SEO-задачами и позволяют добавлять в мониторинг разные сайты или компании. Это означает, что вся полученная информация будет сохранена в одном месте. Еще одно преимущество, на которое стоит обратить внимание пользователям.
Чтобы получить информацию по каждой странице, используйте Netpeak Checker. Загрузите все URL, и Netpeak Checker проверит индексацию страниц вашего сайта. Это займет некоторое время, но результат будет точным.
Персональная демонстрация
Наши специалисты свяжутся с вами и обсудят варианты дальнейшей работы. Это может быть личная демонстрация, пробный период, подробные обучающие статьи, записи вебинаров и индивидуальные советы от специалиста Serpstat. Наша цель — сделать так, чтобы вы чувствовали себя комфортно при использовании Serpstat.
Заключение
Все возможные способы проверки индексации сайта:
- с помощью Google Search Console;
- с помощью операторов;
- с помощью плагинов и букмарклетов;
- с помощью дополнительных услуг.
Регулярно отслеживайте индексацию веб-сайта и сообщайте о полученной информации. Составляйте такие таблицы данных вручную или используйте автоматические отчеты в рекомендуемых дополнительных сервисах. Все примеры показаны и описаны выше. Объедините несколько инструментов, чтобы повысить уровень точности информации.
Зачем это нужно? Чтобы всегда быть в курсе событий. Если все страницы уникальны и полноценны, но давно не индексируются, пора искать проблему и как можно быстрее ее выявить. Регулярно собирайте информацию. Важно исследовать соотношение проиндексированных страниц и динамику их индексации, следить за всеми тенденциями.
Такой подход даст вам возможность своевременно внести изменения в SEO-стратегию и сформировать успешную концепцию продвижения.
P.S. Попробуйте на странице SEO-проверку онлайн, чтобы пройти полный курс SEO-специалиста 🙂
Эта статья является частью инструмента Serpstat Checklist
Инструмент содержит шаблоны с обширным списком параметров разработки проекта, куда вы также можете добавить свои элементы и планы.| Попробуйте контрольный список сейчас |
Узнайте, как получить максимальную отдачу от Serpstat
Хотите получить личную демонстрацию, пробный период или множество успешных вариантов использования?
Отправьте запрос и наш специалист свяжется с вами 😉
Оцените статью по пятибалльной шкале
Статью уже оценили 0 человек в среднем из 5
Нашли ошибку? Выберите его и нажмите Ctrl + Enter, чтобы сообщить нам
Рекомендуемые сообщения
How-to
Denys Kondak
Как анализировать поведенческие факторы сайта
How-to
Денис Кондак
Как проводить A/B тестирование с Google Analytics
How-to
Денис Кондак
Как установить систему аналитики и мониторить интернет-магазин
Кейсы, лайфхаки , исследования и полезные статьи
Нет времени следить за новостями? Без проблем! Наш редактор подберет статьи, которые обязательно помогут вам в работе. Присоединяйтесь к нашему уютному сообществу 🙂
Нажимая на кнопку, вы соглашаетесь с нашей политикой конфиденциальности.
Поделитесь этой статьей с друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылки.
Сообщить об ошибке
Отмена
Подробное руководство по работе поиска Google | Центр поиска Google | Документация
Поиск Google – это полностью автоматизированная поисковая система, использующая программное обеспечение, известное как поисковые роботы.
регулярно исследуйте Интернет, чтобы найти страницы для добавления в наш индекс. На самом деле, подавляющее большинство
страницы, перечисленные в наших результатах, не отправляются вручную для включения, а обнаруживаются и добавляются
автоматически, когда наши поисковые роботы исследуют Интернет. Этот документ объясняет этапы того, как
Поиск работает в контексте вашего сайта. Наличие этих базовых знаний может помочь вам исправить
проблем со сканированием, проиндексируйте свои страницы и узнайте, как оптимизировать внешний вид вашего сайта в
Поиск Гугл.
Несколько замечаний, прежде чем мы начнем
Прежде чем мы углубимся в детали работы Поиска, важно отметить, что Google не принимать оплату, чтобы чаще сканировать сайт или повышать его рейтинг. Если кто-нибудь скажет вам в противном случае они ошибаются.
Google не гарантирует, что он будет сканировать, индексировать или обслуживать вашу страницу, даже если она следует Правила и политика Google для владельцев сайтов.
Знакомство с тремя этапами поиска Google
Поиск Google работает в три этапа, и не все страницы проходят через каждый этап:
- Сканирование: Google загружает текст, изображения и видео
со страниц, найденных в Интернете с помощью автоматических программ, называемых поисковыми роботами.
- Индексация: Google анализирует текст, изображения и видеофайлы на странице и сохраняет информацию в индексе Google, который является большим база данных.
- Обслуживание результатов поиска: Когда пользователь выполняет поиск на Google, Google возвращает информацию, относящуюся к запросу пользователя.
Ползание
Первый этап — выяснить, какие страницы существуют в Интернете. Нет центрального реестра
все веб-страницы, поэтому Google должен постоянно искать новые и обновленные страницы и добавлять их в свои
список известных страниц. Этот процесс называется «обнаружение URL». Некоторые страницы известны, потому что
Гугл их уже посещал. Другие страницы обнаруживаются, когда Google переходит по ссылке из
известной страницы на новую страницу: например, центральная страница, такая как страница категории, ссылается на новую
Сообщение блога. Другие страницы обнаруживаются, когда вы отправляете список страниц (
карта сайта) для сканирования Google.
Как только Google обнаружит URL-адрес страницы, он может посетить (или «просканировать») страницу, чтобы узнать, что находится на ней. Это. Мы используем огромное количество компьютеров для сканирования миллиардов страниц в Интернете. Программа, которая выборка называется Googlebot (также известный как робот, бот или паук). Googlebot использует алгоритмический процесс для определения какие сайты сканировать, как часто и сколько страниц получать с каждого сайта. Поисковые роботы Google также запрограммированы таким образом, что стараются не сканировать сайт слишком быстро, чтобы не перегружать его. Этот механизм основан на ответах сайта (например, Ошибки HTTP 500 означают «медленнее») а также настройки в Search Console.
Однако робот Googlebot не сканирует все обнаруженные страницы. Некоторые страницы могут быть
запрещен для сканирования
владельца сайта, другие страницы могут быть недоступны без авторизации на сайте, и другие
страницы могут быть дубликатами ранее просканированных страниц.
Например, многие сайты доступны через www ( www.example.com ) и
версия доменного имени без www ( example.com ), даже если содержимое
идентичен для обеих версий.
Во время сканирования Google отображает страницу и запускает любой найденный JavaScript используя последнюю версию Chrome, аналогично тому, как ваш браузер отображает страницы, которые вы посещаете. Рендеринг важен, потому что веб-сайты часто полагаются на JavaScript для отображения контента на странице. и без рендеринга Google может не увидеть этот контент.
Сканирование зависит от того, могут ли поисковые роботы Google получить доступ к сайту. Некоторые распространенные проблемы с Доступ к сайтам робота Googlebot включает:
- Проблемы с сервером, обрабатывающим сайт
- Проблемы с сетью
- директивы robots. txt, запрещающие роботу Googlebot доступ к странице
Индексация
После сканирования страницы Google пытается понять, о чем эта страница. Этот этап
называется индексированием и включает в себя обработку и анализ текстового контента и ключевого контента
теги и атрибуты, такие как <название> элементов
и атрибуты alt,
картинки,
видео и
более.
В процессе индексации Google определяет, является ли страница
дубликат другой страницы в Интернете или канонической.
Каноническая — это страница, которая может отображаться в результатах поиска. Для выбора канонического мы
сначала сгруппируем найденные в Интернете страницы с похожим содержанием, а затем
выберите тот, который наиболее репрезентативен для группы. Остальные страницы в группе
альтернативные версии, которые могут подаваться в разных контекстах, например, если пользователь ищет
с мобильного устройства или они ищут очень конкретную страницу из этого кластера.
Google также собирает сигналы о канонической странице и ее содержании, которые могут использоваться в следующий этап, где мы обслуживаем страницу в результатах поиска. Некоторые сигналы включают язык страницы, страны, в которой находится контент, удобство использования страницы и т. д.
Собранная информация о канонической странице и ее кластере может храниться в Google index, большая база данных, размещенная на тысячах компьютеров. Индексация не гарантируется; не каждый страница, которую обрабатывает Google, будет проиндексирована.
Индексация также зависит от содержания страницы и ее метаданных. Некоторые распространенные проблемы с индексацией может включать:
- Качество контента на странице низкое
- Метадирективы robots запрещают индексацию
- Дизайн сайта может затруднить индексацию
Обслуживание результатов поиска
Google не принимает плату за повышение ранжирования страниц, а ранжирование выполняется программно.Когда пользователь вводит запрос, наши машины ищут в индексе соответствующие страницы и возвращают результаты, которые мы считаем, являются самыми качественными и наиболее релевантными для пользователя. Релевантность определяется сотнями факторов, которые могут включать в себя такую информацию, как местоположение, язык и устройство (рабочий стол или телефон). Например, при поиске «ремонт велосипедов магазины» покажет пользователю в Париже разные результаты, чем пользователю в Гонконге.
Search Console может сказать вам, что страница проиндексирована, но вы не видите ее в результатах поиска. Это может быть потому, что:
- Содержание контента на странице не имеет отношения к пользователям
- Качество контента низкое
- Мета-директивы robots предотвращают обслуживание
Хотя в этом руководстве объясняется, как работает Поиск, мы постоянно работаем над улучшением наших алгоритмов. Вы можете отслеживать эти изменения, следуя
Блог Google Search Central.
10 способов заставить Google проиндексировать ваш сайт (которые действительно работают)
Джошуа Хардвик
Руководитель отдела контента @ Ahrefs (или, говоря простым языком, я отвечаю за то, чтобы каждый пост в блоге, который мы публикуем, был EPIC ).
Article stats
Monthly traffic 6,086
Linking websites 377
Tweets 118
Data from Content Explorer
Показывает, сколько разных веб-сайтов ссылаются на этот фрагмент контента. Как правило, чем больше веб-сайтов ссылаются на вас, тем выше ваш рейтинг в Google.
Показывает расчетный месячный поисковый трафик к этой статье по данным Ahrefs. Фактический поисковый трафик (по данным Google Analytics) обычно в 3-5 раз больше.
Сколько раз этой статьей поделились в Твиттере.
Поделиться этой статьей
Подпишитесь на еженедельные обновления
Подписка по электронной почте
Подписка
Содержание
Если Google не индексирует ваш сайт, вы практически невидимы. Вы не будете появляться ни по каким поисковым запросам, и вы не получите никакого органического трафика. пшик. Нада. Нуль.
Учитывая, что вы здесь, полагаю, для вас это не новость. Итак, давайте сразу к делу.
В этой статье рассказывается, как решить любую из этих трех проблем:
- Весь ваш веб-сайт не проиндексирован.
- Некоторые из ваших страниц проиндексированы, а другие нет.
- Недавно опубликованные веб-страницы недостаточно быстро индексируются.
Но сначала давайте удостоверимся, что мы находимся на одной странице и полностью понимаем эту ошибку индексации.
Что такое сканирование и индексирование?
Google обнаруживает новые веб-страницы путем сканирования веб-страниц, а затем добавляет эти страницы в свой индекс . Они делают это с помощью веб-паука под названием 9.0341 Гуглбот .
Запутались? Давайте определим несколько ключевых терминов.
- Сканирование : Процесс перехода по гиперссылкам в Интернете для обнаружения нового контента.
- Индексирование : Процесс хранения каждой веб-страницы в обширной базе данных.
- Веб-паук : Программное обеспечение, предназначенное для выполнения сканирования в масштабе.
- Googlebot : веб-паук Google .
Вот видео от Google, в котором более подробно объясняется процесс:
https://www. youtube.com/watch?v=BNHR6IQJGZs
Когда вы что-то ищете в Google, вы просите Google вернуть все соответствующие страницы. из их индекса. Поскольку часто есть миллионы страниц, которые соответствуют всем требованиям, алгоритм ранжирования Google делает все возможное, чтобы отсортировать страницы, чтобы вы сначала увидели лучшие и наиболее релевантные результаты.
Важным моментом, на который я здесь обращаю внимание, является то, что индексация и ранжирование это две разные вещи .
Индексация выставлена на гонку; Рейтинг выигрывает.
Вы не сможете победить, не придя на первое место в гонке.
Как проверить, проиндексированы ли вы в Google
Зайдите в Google, затем выполните поиск site:yourwebsite.com
Это число примерно показывает, сколько ваших страниц проиндексировано Google.
Если вы хотите проверить статус индекса определенного URL-адреса, используйте тот же site:yourwebsite. оператор. com/web-page-slug
Если страница не проиндексирована, результатов не будет.
Теперь стоит отметить, что если вы являетесь пользователем Google Search Console, вы можете использовать отчет Coverage , чтобы получить более точное представление о статусе индекса вашего веб-сайта. Просто перейдите по ссылке:
Google Search Console > Индекс > Покрытие
Посмотрите на количество действительных страниц (с предупреждениями и без них).
Если сумма этих двух чисел не равна нулю, то Google проиндексировал по крайней мере некоторые страницы вашего веб-сайта. Если нет, то у вас серьезная проблема, потому что ни одна из ваших веб-страниц не проиндексирована.
Примечание.
Не являетесь пользователем Google Search Console? Подписаться. Это бесплатно. Каждый, кто управляет веб-сайтом и заботится о получении трафика от Google, должен использовать Google Search Console. Это , что важно.
Вы также можете использовать Search Console, чтобы проверить, проиндексирована ли конкретная страница. Для этого вставьте URL-адрес в инструмент проверки URL-адресов.
Если эта страница проиндексирована, на ней будет написано «URL находится в Google».
Если страница не проиндексирована, вы увидите слова «URL не находится в Google».
Как проиндексироваться Google
Обнаружили, что ваш веб-сайт или веб-страница не проиндексированы в Google? Попробуйте это:
- Перейдите в Google Search Console
- Перейдите к инструменту проверки URL
- Вставьте URL, который вы хотите, чтобы Google проиндексировал, в строку поиска.
- Подождите, пока Google проверит URL
- Нажмите кнопку «Запросить индексацию»
Этот процесс является хорошей практикой, когда вы публикуете новую запись или страницу. Вы фактически сообщаете Google, что добавили что-то новое на свой сайт и что они должны на это взглянуть.
Однако запрос на индексацию вряд ли решит основные проблемы, мешающие Google индексировать старые страницы. В этом случае следуйте приведенному ниже контрольному списку, чтобы диагностировать и устранить проблему.
Вот несколько быстрых ссылок на каждую тактику — на случай, если вы уже пробовали некоторые из них:
- Удалить блоки сканирования в файле robots.txt
- Удалить мошеннические теги noindex
- Включить страницу в карту сайта
- Удалить мошеннические канонические теги
- Проверить, что страница не потеряна внутренние ссылки noflow Добавьте «мощные» внутренние ссылки
- Убедитесь, что страница ценна и уникальна
- Удалите некачественные страницы (для оптимизации «краулингового бюджета»)
- Создайте высококачественные обратные ссылки
1) Удалите блоки сканирования в файле robots. текстовый файл
Google не индексирует весь ваш сайт? Это может быть связано с блокировкой сканирования в файле robots. txt.
Чтобы проверить наличие этой проблемы, перейдите по адресу yourdomain.com/robots.txt .
Найдите любой из этих двух фрагментов кода:
User-agent: Googlebot Запретить: /
Агент пользователя: * Disallow: /
Оба они сообщают роботу Googlebot, что им не разрешено сканировать какие-либо страницы на вашем сайте. Чтобы устранить проблему, удалите их. Это , что простой.
Блокировка сканирования в файле robots.txt также может быть причиной, если Google не индексирует ни одну веб-страницу. Чтобы проверить, так ли это, вставьте URL-адрес в инструмент проверки URL-адресов в Google Search Console. Нажмите на блок «Покрытие», чтобы открыть более подробную информацию, затем найдите «Сканирование разрешено? Нет: заблокировано ошибкой robots.txt».
Это указывает на то, что страница заблокирована в robots.txt.
В этом случае перепроверьте файл robots.txt на наличие каких-либо правил «запрета», относящихся к странице или соответствующему подразделу.
Удалить при необходимости.
2) Удалите мошеннические теги noindex
Google не будет индексировать страницы, если вы запретите им это делать. Это полезно для сохранения конфиденциальности некоторых веб-страниц. Есть два способа сделать это:
Способ 1: метатег
Страницы с одним из этих метатегов в разделе не будут проиндексированы Google:
Это метатег роботов, который сообщает поисковым системам, могут ли они индексировать страницу.
Примечание.
Ключевой частью является значение «noindex». Если вы это видите, значит для страницы установлено значение noindex.
Чтобы найти все страницы с метатегом noindex на вашем сайте, запустите сканирование с помощью аудита сайта Ahrefs. Перейдите к отчету Indexability . Ищите предупреждения «Noindex page».
Нажмите, чтобы просмотреть все затронутые страницы. Удалите метатег noindex со всех страниц, которым он не принадлежит.
Метод 2: X-Robots-Tag
Искатели также учитывают заголовок HTTP-ответа X-Robots-Tag. Вы можете реализовать это с помощью языка сценариев на стороне сервера, такого как PHP, или в вашем файле .htaccess, или изменив конфигурацию вашего сервера.
Инструмент проверки URL-адресов в Search Console сообщает, заблокирован ли Google от сканирования страницы из-за этого заголовка. Просто введите свой URL-адрес, а затем найдите «Индексирование разрешено? Нет: «noindex» обнаружен в заголовке http «X-Robots-Tag»
Если вы хотите проверить наличие этой проблемы на своем сайте, запустите сканирование в инструменте аудита сайта Ahrefs, затем используйте фильтр «Информация о роботах в заголовке HTTP» в проводнике страниц:
Попросите вашего разработчика исключить страницы, которые вы хотите проиндексировать, возвращая этот заголовок.
Рекомендуем прочитать: Спецификации метатега Robots и X-Robots-Tag HTTP-заголовка
3) Включить страницу в карту сайта
Карта сайта сообщает Google, какие страницы на вашем сайте важны, а какие нет . Это также может дать некоторые рекомендации о том, как часто их следует повторно сканировать.
Google должен иметь возможность находить страницы на вашем веб-сайте независимо от того, находятся ли они в вашей карте сайта, но рекомендуется включать их. В конце концов, нет смысла усложнять жизнь Google.
Чтобы проверить, есть ли страница в вашей карте сайта, используйте инструмент проверки URL в Search Console. Если вы видите ошибку «URL не находится в Google» и «Карта сайта: Н/Д», значит, его нет в вашей карте сайта или он не проиндексирован.
Не используете Search Console? Перейдите по URL-адресу вашей карты сайта — обычно это 9.0341 yourdomain.com/sitemap.xml — и выполните поиск страницы.
Или, если вы хотите найти все сканируемые и индексируемые страницы, которых нет в вашей карте сайта, запустите сканирование в Аудит сайта Ahrefs. Перейдите к Page Explorer и примените следующие фильтры:
Эти страницы должны быть в вашей карте сайта, поэтому добавьте их. После этого сообщите Google, что вы обновили карту сайта, проверив этот URL:
http://www.google.com/ping?sitemap=http://yourwebsite.com/sitemap_url.xml 9.0520
Замените последнюю часть URL-адресом вашей карты сайта. Вы должны увидеть что-то вроде этого:
Это должно ускорить индексацию страницы Google.
4) Удаление мошеннических канонических тегов
Канонический тег сообщает Google, какая версия страницы является предпочтительной. Это выглядит примерно так:
Большинство страниц либо не имеют канонического тега, либо имеют так называемый самоссылающийся канонический тег. Это говорит Google сама страница является предпочтительной и, возможно, единственной версией, другими словами, вы хотите, чтобы эта страница была проиндексирована. 0004
Но если на вашей странице есть мошеннический канонический тег, то он может сообщать Google о предпочтительной версии этой страницы, которой не существует. В этом случае ваша страница не будет проиндексирована.
Чтобы проверить каноничность, используйте инструмент Google для проверки URL. Вы увидите предупреждение «Альтернативная страница с каноническим тегом», если канонический указывает на другую страницу.
Если этого не должно быть, и вы хотите проиндексировать страницу, удалите тег canonical.
Если вам нужен быстрый способ найти мошеннические канонические теги на всем сайте, запустите сканирование в инструменте аудита сайта Ahrefs. Перейдите в Проводник страниц. Используйте эти настройки:
Ищет страницы в вашей карте сайта с каноническими тегами, не ссылающимися на самих себя. Поскольку вы почти наверняка захотите проиндексировать страницы в своей карте сайта, вам следует дополнительно изучить, возвращает ли этот фильтр какие-либо результаты.
Весьма вероятно, что эти страницы либо имеют мошеннический канонический код, либо вообще не должны быть в вашей карте сайта.
5) Убедитесь, что страница не потеряна.
Страницы-сироты — это страницы, на которые не указывают внутренние ссылки .
Поскольку Google обнаруживает новый контент путем сканирования Интернета, он не может обнаружить бесхозные страницы с помощью этого процесса. Посетители сайта также не смогут их найти.
Чтобы проверить наличие потерянных страниц, просканируйте свой сайт с помощью аудита сайта Ahrefs. Затем проверьте отчет Links на наличие ошибок «Бесхозная страница (нет входящих внутренних ссылок)»:
Здесь показаны все страницы, которые одновременно индексируются и присутствуют в карте сайта, но не имеют внутренних ссылок, указывающих на них.
Не уверены, что все страницы, которые вы хотите проиндексировать, есть в вашей карте сайта? Попробуйте это:
- Загрузите полный список страниц вашего сайта (через вашу CMS)
- Просканируйте ваш сайт (с помощью инструмента, такого как Site Audit от Ahrefs)
- Сопоставьте два списка URL-адресов
Любые URL-адреса не найденные при сканировании страницы-сироты.
Исправить страницы-сироты можно двумя способами:
- Если страница не важна , удалите ее и удалите из карты сайта.
- Если страница важна , включите ее во внутреннюю структуру ссылок вашего веб-сайта.
6) Исправление внутренних ссылок nofollow
Ссылки nofollow — это ссылки с тегом rel=“nofollow”. Они предотвращают передачу PageRank на целевой URL. Google также не сканирует nofollow-ссылки.
Вот что Google говорит по этому поводу:
По сути, с использованием nofollow заставляет нас удалять целевые ссылки из нашего общего графа сети. Однако целевые страницы могут по-прежнему отображаться в нашем индексе, если другие сайты ссылаются на них без использования nofollow или если URL-адреса отправляются в Google в файле Sitemap.
Короче говоря, вы должны убедиться, что все внутренние ссылки на индексируемые страницы переходят.
Для этого используйте инструмент аудита сайта Ahrefs для сканирования вашего сайта. Проверьте отчет Links для индексируемых страниц с ошибками «Страница имеет nofollow только входящие внутренние ссылки»:
Удалите тег nofollow из этих внутренних ссылок, предполагая, что вы хотите, чтобы Google проиндексировал страницу. Если нет, либо удалите страницу, либо не индексируйте ее.
Рекомендуем прочитать: Что такое ссылка Nofollow? Все, что вам нужно знать (без жаргона!)
7) Добавьте «мощные» внутренние ссылки
Google обнаруживает новый контент, сканируя ваш веб-сайт. Если вы пренебрегаете внутренней ссылкой на рассматриваемую страницу, они могут не найти ее.
Простое решение этой проблемы — добавить на страницу несколько внутренних ссылок. Вы можете сделать это с любой другой веб-страницы, которую Google может сканировать и индексировать. Однако, если вы хотите, чтобы Google проиндексировал страницу как можно быстрее, имеет смысл сделать это с одной из ваших наиболее «мощных» страниц.
Почему? Потому что Google, скорее всего, будет повторно сканировать такие страницы быстрее, чем менее важные страницы.
Для этого перейдите в Site Explorer от Ahrefs, введите свой домен, а затем посетите отчет Best by links .
Здесь показаны все страницы вашего веб-сайта, отсортированные по URL-рейтингу (UR). Другими словами, в первую очередь отображаются наиболее авторитетные страницы.
Просмотрите этот список и найдите релевантные страницы, с которых можно добавить внутренние ссылки на рассматриваемую страницу.
Например, если бы мы хотели добавить внутреннюю ссылку в наше руководство по размещению гостевых постов, наше руководство по созданию ссылок, скорее всего, предложило бы подходящее место для этого. И так получилось, что эта страница является 11-й по авторитетности страницей в нашем блоге:
Google увидит эту ссылку и перейдет по ней при следующем повторном сканировании страницы.
8) Убедитесь, что страница ценна и уникальна.
Google вряд ли будет индексировать некачественные страницы, потому что они не представляют никакой ценности для пользователей. Вот что Джон Мюллер из Google сказал об индексации в 2018 году:
Мы никогда не индексируем все известные URL-адреса, это вполне нормально. Я бы сосредоточился на том, чтобы сделать сайт потрясающим и вдохновляющим, тогда все обычно работает лучше.
— 🍌 Джон 🍌 (@JohnMu) 3 января 2018 г.
Он подразумевает, что если вы хотите, чтобы Google проиндексировал ваш веб-сайт или веб-страницу, он должен быть «потрясающим и вдохновляющим».
Если вы исключили технические проблемы из-за отсутствия индексации, то причиной может быть отсутствие ценности. По этой причине стоит взглянуть на страницу свежим взглядом и спросить себя: действительно ли эта страница ценна? Найдет ли пользователь ценность на этой странице, если он нажмет на нее из результатов поиска?
Если ответ отрицательный ни на один из этих вопросов, вам нужно улучшить свой контент.
Вы можете найти больше потенциально некачественных страниц, которые не проиндексированы, с помощью инструмента аудита сайта Ahrefs и профилировщика URL. Для этого перейдите в Page Explorer в Ahrefs Site Audit и используйте следующие настройки:
Это вернет «тонкие» страницы, которые индексируются и в настоящее время не получают органического трафика. Другими словами, есть неплохая вероятность, что они не проиндексированы.
Экспортируйте отчет, затем вставьте все URL-адреса в URL Profiler и запустите проверку индексации Google.
Проверьте все неиндексированные страницы на наличие проблем с качеством. При необходимости улучшите, а затем запросите переиндексацию в Google Search Console.
Вы также должны стремиться устранить проблемы с дублирующимся содержимым. Google вряд ли проиндексирует повторяющиеся или почти повторяющиеся страницы. Используйте отчет Duplicate content в аудите сайта, чтобы проверить эти проблемы.
9) Удалите некачественные страницы (для оптимизации «краулингового бюджета»)
Наличие слишком большого количества некачественных страниц на вашем веб-сайте приводит только к трате краулингового бюджета.
Вот что говорит Google по этому поводу:
Трата ресурсов сервера на [страницы с низкой добавленной стоимостью] приведет к уменьшению активности сканирования со страниц, которые действительно имеют ценность, что может привести к значительной задержке в обнаружении отличного контента на сайте. .
Думайте об этом как об учителе, оценивающем эссе, одно из которых ваше. Если им нужно оценить десять сочинений, они довольно быстро доберутся до вашего. Если у них есть сотня, это займет у них немного больше времени. Если их тысячи, их рабочая нагрузка слишком высока, и они могут никогда не оценить ваше эссе.
Google утверждает, что «краулинговый бюджет […] — это не то, о чем стоит беспокоиться большинству издателей», и что «если на сайте меньше нескольких тысяч URL-адресов, в большинстве случаев он будет сканироваться эффективно».
Тем не менее, удаление некачественных страниц с вашего сайта никогда не помешает. Это может только положительно сказаться на краулинговом бюджете.
Вы можете использовать наш шаблон аудита контента , чтобы найти потенциально некачественные и нерелевантные страницы, которые можно удалить.
10) Создавайте высококачественные обратные ссылки
Обратные ссылки сообщают Google, что веб-страница важна. В конце концов, если кто-то ссылается на него, то он должен иметь какую-то ценность. Это страницы, которые Google хочет проиндексировать.
Для обеспечения полной прозрачности Google индексирует не только веб-страницы с обратными ссылками. Существует множество (миллиарды) проиндексированных страниц без обратных ссылок. Однако, поскольку Google считает страницы с качественными ссылками более важными, они, скорее всего, будут сканировать и повторно сканировать такие страницы быстрее, чем без них. Это приводит к более быстрой индексации.
У нас есть много ресурсов для создания высококачественных обратных ссылок в блоге.
Взгляните на несколько руководств ниже.
Дальнейшее чтение
Индексирование ≠ рейтинг
Индексация вашего веб-сайта или веб-страницы в Google не означает рейтинга или трафика.
Это две разные вещи.
Индексирование означает, что Google знает о вашем веб-сайте. Это не значит, что они будут ранжировать его по любым релевантным и стоящим запросам.
Вот где на помощь приходит SEO — искусство оптимизации ваших веб-страниц для ранжирования по определенным запросам.
Короче говоря, SEO включает в себя:
- Поиск того, что ищут ваши клиенты;
- Создание контента на эти темы;
- Оптимизация этих страниц под ваши целевые ключевые слова;
- Создание обратных ссылок;
- Регулярная перепубликация контента, чтобы он оставался «вечнозеленым».
Вот видео, которое поможет вам начать работу с SEO:
https://www.