как пользоваться и найти удаленный сайт
20.03.2019
Как найти информацию в Интернете, которую не отображают такие продвинутые поисковые системы как Google или Яндекс? Можно ли найти сайты, которые когда-то существовали в сети, но уже не работают, удалены или же заменены новыми? На эти вопросы мы постараемся дать ответ в этой статье.
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.
Главная страница сайта Archive.org
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».
Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).
Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).
Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.
Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Как скачать сайт из веб архива
Если вы желаете восстановить сайт из веб-архива, то вам в этом поможет программа Web Archive Downloader 6.0
история проекта, и том как использовать архив веб-страниц
Веб-архив сайтов (The Wayback Machine): история проекта, и том как использовать архив веб-страницПодробная информация о сервисе
История интернет архива, описание проекта, награды и блокировка
The Wayback Machine — это архив интернета (Internet Archive). По сути это некоммерческая организация, которая была основана в 1996 году.
Задачей данной организации является сбор и хранение всевозможной публичной информации собранной из интернета: веб-страницы, электронные книги, фото- и,
видео материалы. Основные сервера расположены в Сан-Франциско. Размер архива на февраль 2017 года составляет 13 петабайт и включает
в себя 525 миллиардов копий веб-страниц.
По сути это некоммерческая организация, которая была основана в 1996 году.
Задачей данной организации является сбор и хранение всевозможной публичной информации собранной из интернета: веб-страницы, электронные книги, фото- и,
видео материалы. Основные сервера расположены в Сан-Франциско. Размер архива на февраль 2017 года составляет 13 петабайт и включает
в себя 525 миллиардов копий веб-страниц.
Краткая история Archive.org
Основателем является Брюстер Кейл, который основал организацию в 1996 году. В том же оду начал процесс по архивации веб страниц. Проект назывался Wayback Machine. По сей день сохраненные копии доступны любому пользователю посетившему сайт.
Расширение организации в 1999 году, ознаменовалось хранением не только веб-страниц, но и видео,
аудио, изображения и даже программное обеспечение.
Основные направления работы
Archive.org имеется два основных проекта
В интернете не существует аналогов данному проекту. База архива собиралась в общей сложности около 20 лет. При этом, можно смело заявить что проект является волантерским.
The Wayback Machine
Работает с 1996 года
Веб-сервис по сбору и хранению веб-страниц сайтов со всем их содержимым. Фиксирует копии специальный робот. Результатом работы является возможность просмотра сайтов которых уже не существует, или не поддерживаются.
Open Library
Работает с 2005 года
Это общественный проект по сканированию всех книг в по всему миру.
Проект имеет 13 центров оцифровки оцифровки книг в крупных библиотеках. Архив книг насчитывает более 1, миллионов книг, и коллекция постоянно растет.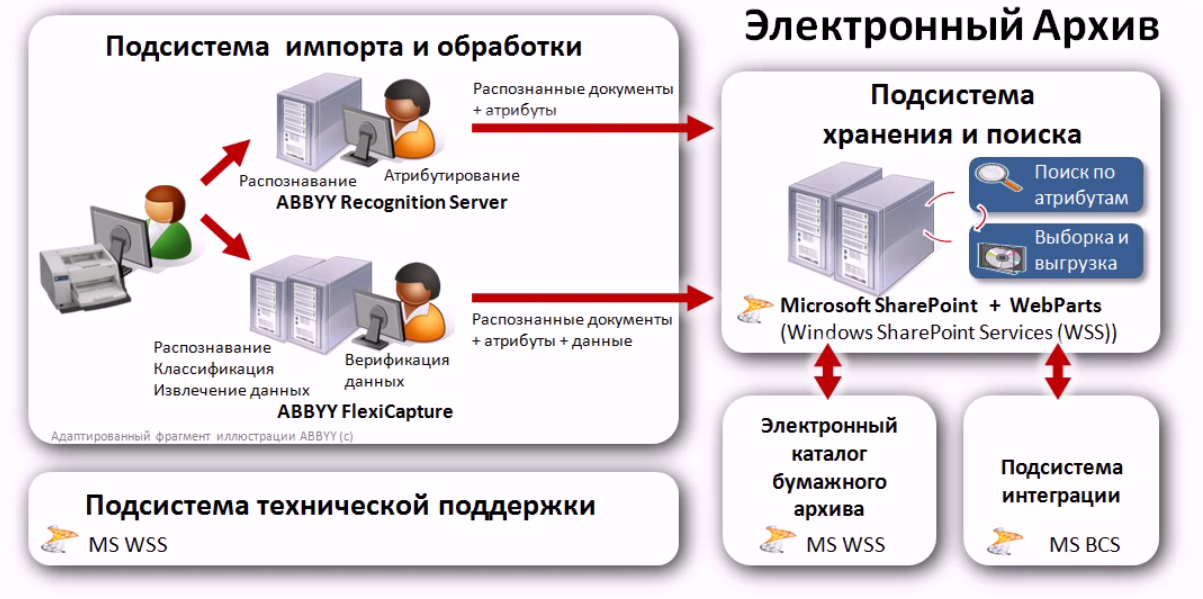
Проблемы на законодательном уровне
На сервис не единожды подавались иски в суд за нарушение авторских прав. Поэтому по требованию правообладателей архив удаляет из публичного доступа соответствующие материалы.
Мануал: как пользоваться сайтом archive.org?
Открываем сайт по адресу — https://archive.org. В поле сверху вводим доменное имя. Если сайт найден, то вы увидите в первом блоке выбор года и ниже месяцы и годы. Кликнув на определенную дату, Вам откроется сохраненная копия которую вы можете просмотреть перейдя по внутренним ссылкам.
Как найти нужный сайт и восстановить копию из веб-архива?
Чтобы скачать страницы сайта, Вам необходимо использовать специализированные сервисы или соответствующее программное обеспечение.
В открытом доступе такого программного обеспечения нет. Мы предлагаем Вам воспользоваться услугами сервиса — WEBARCHIVEORG.RU.
Мы предлагаем Вам воспользоваться услугами сервиса — WEBARCHIVEORG.RU.
Почему именно мы?
Восстановленный сайт будет работать на простом движке. По качеству нет аналогов. Неограниченное количество страниц за фиксированную цену. Адекватная служба поддержки.
Инструкция по настройке https, и редиректа www на нашей платформе
Как настроить редиректы http и www на восстановленном из веб-архива сайте? Подробнее об этом читайте…
Как установить счетчики, почистить и сделать замену участков кода?
Рассматриваем на примерах как самостоятельно отредактировать максимальное количество страниц с миним…
Руководство по установке сайта на ISPManager
Если на вашем хостинге установлена панель ISPManager, то данная инструкция поможет вам установить во…
API-интерфейсов Wayback Machine | Internet Archive
Internet Archive Wayback Machine поддерживает ряд различных API, чтобы сделать его
разработчикам проще получить информацию о данных захвата Wayback.
Ниже приведен список поддерживаемых в настоящее время API. Эта страница может часто меняться, пожалуйста, проверьте последнюю информацию.
Обновлено 24 сентября 2013 г.
Доступность Wayback JSON API
Этот простой API для Wayback позволяет проверить, заархивирован ли заданный URL-адрес. и в настоящее время доступны в Wayback Machine. Этот API полезен для предоставления обработчика ошибок 404 или другого, который проверяет Wayback. чтобы увидеть, есть ли у него архивная копия, готовая к отображению. API можно использовать следующим образом:
http://archive.org/wayback/available?url=example.com
, который может вернуть:
{
"archived_snapshots": {
"ближайший": {
«доступно»: правда,
"url": "http://web.archive.org/web/20130919044612/http://example.com/",
"отметка времени": "20130919044612",
"статус": "200"
}
}
}
, если URL-адрес доступен.
Если URL-адрес недоступен (не заархивирован или в настоящее время недоступен), ответ будет таким:
{"archived_snapshots":{}}
Другие опции
Дополнительные параметры, которые могут быть указаны: метка времени и обратный вызов
-
метка времени— метка времени для поиска в Wayback. Если не указано, возвращается самый последний доступный захват в Wayback. Формат временной метки — от 1 до 14 цифр (ГГГГММДДччммсс), например:
http://archive.org/wayback/available?url=example.com×tamp=20060101
может привести к следующему ответу (обратите внимание, что временная метка моментального снимка теперь близка к 20060101):
{
"archived_snapshots": {
"ближайший": {
«доступно»: правда,
"url": "http://web. archive.org/web/20060101064348/http://www.example.com:80/",
"отметка времени": "20060101064348",
"статус": "200"
}
}
}
archive.org/web/20060101064348/http://www.example.com:80/",
"отметка времени": "20060101064348",
"статус": "200"
}
}
}
обратный вызов — необязательный обратный вызов, который можно указать для получения ответа JSONP.
Память API
Internet Archive Wayback Machine также полностью совместима с Протокол памяти API Memento предоставляет дополнительные интерфейсы для запроса моментальных снимков (например, «Mementos») в Wayback Machine. API доступности частично основан на API Memento.
Вот некоторые конкретные примеры поддержки Memento в Wayback Machine
API-интерфейс Wayback CDX-сервера
Сервер CDX — это еще один API, который позволяет выполнять сложные запросы, фильтрация и анализ данных захвата Wayback. Если вы ищете более подробную информацию о машинных данных Wayback, пожалуйста, взгляните на API сервера CDX.
Последнюю документацию по серверу CDX можно найти по адресу: Сервер Wayback CDX на GitHub
Сохранение страниц в Wayback Machine — Справочный центр Internet Archive
Многие люди проявляют интерес к тому, чтобы в Wayback Machine были копии наиболее важных для них веб-страниц. Эти сохраненные страницы можно цитировать, делиться ими, на них можно ссылаться, и они будут продолжать существовать даже после изменения исходной страницы или ее удаления из Интернета.
Эти сохраненные страницы можно цитировать, делиться ими, на них можно ссылаться, и они будут продолжать существовать даже после изменения исходной страницы или ее удаления из Интернета.
Есть несколько способов сохранить страницы и целые сайты, чтобы они отображались в Wayback Machine. Вот 5 из них.
1. Сохранить страницу сейчас
Вводим URL в форму, нажимаем кнопку и сохраняем страницу. Вы мгновенно получите постоянный URL для своей страницы. Обратите внимание, этот метод сохраняет только одну страницу , а не весь сайт.
На данный момент есть несколько исключений для этого метода — некоторые сайты запрещают сканирование, некоторые имеют настройки SSL (безопасности), которые делают его неработоспособным — но этот метод будет работать для большинства страниц. Эта функция сохраняет страницу, которую вы вводите, включая изображения и CSS. Он не сохраняет исходящие ссылки и не может использоваться для запуска обхода всего веб-сайта.
2. Расширения и надстройки браузера
Установите расширение Wayback Machine Chrome в браузере. Перейдите на страницу, которую хотите заархивировать, щелкните значок на панели инструментов и выберите «Сохранить страницу сейчас». Мы сохраним страницу и предоставим вам постоянный URL.
Применяются те же оговорки, что и в «Сохранить страницу сейчас»: есть некоторые страницы, где это не работает, и за раз сохраняется только одна страница. Однако один плюс установки расширения заключается в том, что теперь, когда вы просматриваете страницу, когда вы сталкиваетесь с отсутствующей страницей, мы предупредим вас, если у нас есть сохраненная копия.
Другие расширения, приложения и надстройки:
- Дополнение для Firefox
- Расширение для Safari
- Приложение для iOS
- Приложение для Android
редактор Википедии. С этой целью они предлагают букмарклет Wayback Machine JavaScript, который позволяет быстро сохранять веб-страницу из любого браузера.
4. Волонтер в команде архивов
Команда архивов — это полностью добровольная группа, заинтересованная в сохранении истории Интернета. Многие сайты и страницы, которые они сохраняют, попадают в Wayback Machine. Посетите сайт Архивной команды , чтобы узнать больше о том, как стать волонтером.
5. Зарегистрируйте учетную запись Archive-It
Archive-это услуга подписки, предоставляемая Internet Archive, которая позволяет вам запускать собственные проекты сканирования без каких-либо технических знаний. Сообщите нам, что сканировать и как часто это сканировать, и мы выполним сканирование и поместим результаты в Wayback Machine.
Архив — это платная услуга по подписке с технической и веб-поддержкой архивариуса. Этот вариант наиболее подходит для организаций, которым поручено регулярно сохранять определенные типы или категории веб-контента. Если ваше учреждение является текущим партнером Archive-It, свяжитесь с ним, чтобы узнать, как вы можете внести свой вклад.