Веб Архив — О сервисе
О сервисе
Вебархив.ру | WEB ARCHIVE представляет собой электронную интернет библиотеку, осуществляющую сбор и хранение архивных копий сайтов.
Доступ к Архиву Интернет предоставляется бесплатно всем желающим.
Программный комплекс предназначен для доступа к архивным копиям страниц (сайтов) в сети Интернет, хранящимся в архиве Интернет, в том числе текста, фотоизображений, графических изображений, размещенных на страницах сайтов.
С помощью Вебархив можно получить доступ к копиям интернет-страниц или даже целым сайтам по состоянию на определенную дату в прошлом.
Веб архив функционирует как готовое программное решение. Программный комплекс по доступу к архивным копиям сайтов в сети Интернет «Веб-архив.ру» обеспечивает выполнение следующих функций:
- Направление электронных запросов к Архиву Интернет (Internet Archive 300 Funston AvenueSan Francisco, CA 94118) в отношении архивных копий страницы, адрес которой задается пользователем в интерфейсе Программного комплекса на сайте https://web-arhive.
 ru
ru - Получение ответа от Архива Интернет о количестве, дате и времени создания архивных копий страницы, адрес которой задан пользователем.
- Отображение архивной копии страницы в сети Интернет в интерфейсе браузера с указанием даты и времени создания архивной копии.
- Обеспечение технического взаимодействия с сервисом автоматической фиксации доказательств в Интернет WEBJUSTICE (screenshot.legal) для фиксации информации отображаемой на архивной копии заданной интернет-страницы в виде графического образа (скриншота) и формирования архивной справки.
 ru
ruПрограммный комплекс Веб-архив.ру зарегистрирован Роспатентом в реестре программ для ЭВМ, что подтверждается Свидетельством №2016616556 от 15 июня 2016 г. о государственной регистрации Программы для ЭВМ «Программный комплекс по доступу к архивным копиям сайтов в сети Интернет «Веб-архив.ру» версия 1.0»
Данные из Интернет-архива могут быть использованы для личных, научных, образовательных и иных целей, а также для доказывания определенных обстоятельств по различным судебным спорам, например связанным с защитой прав на объекты интеллектуальной собственности.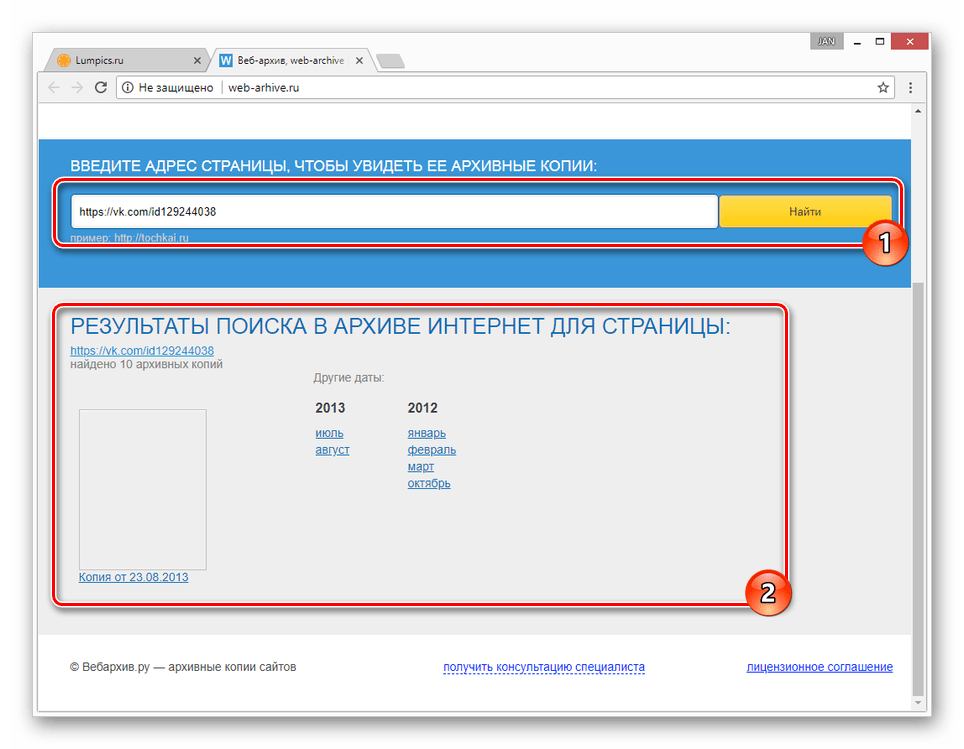
Чаще всего сведения из Архива Интернет используются в качестве доказательств по делам о защите прав на объекты интеллектуальных прав, по делам о защите чести, достоинства и деловой репутации, а также по другим категориям дел.
Как правило, Вебархив используется для подтверждения следующих фактов:
- Наличие или отсутствие правонарушения
- Длительность правонарушения
- Характер и обстоятельства правонарушения
- Иные факты, имеющие правовое значение
Подробнее об использовании данных из Архива Интернет юристами для защиты в суде читайте в блоге Вебджастис.
При необходимости информация об архивных страницах может быть выдана в виде Архивной справки. Формирование и выдача Архивных справок осуществляется за плату сервисом автоматической фиксации доказательств в сети Интернет «WEBJUSTICE» (screenshot.legal) при техническом взаимодействии с Вебархив.ру.
Веб Архив — Часто задаваемые вопросы
Часто задаваемые вопросы
Архивная справка — это электронный документ, формируемый на основании сведений, содержащихся в архиве Интернет в отношении одной или нескольких интернет-страниц, подтверждающий наличие архивных копий страниц и их внешний вид на определенную дату в прошлом.
Архивная справка (справка из Вебархива) включает в себя следующую информацию:
- дату и время и номер формирования справки, синхронизированные с сервером точного времени
- информацию о программном комплексе Веб-архив.ру и Архиве Интернет
- первичный адрес (URL) заархивированной интернет-страницы
- адрес (URL) размещения архивной копии интернет-страницы
- IP адрес лица, инициировавшего формирование протокола
- описание порядка фиксации, используемых технических и программных средств
- цветные скриншоты заданных интернет-страниц
- свидетельство о регистрации программного комплекса «Веб-архив.ру» в Роспатенте
- уникальный номер для проверки подлинности сформированного документа и снимков интернет-страниц в любой момент времени заинтер есованной стороной или судом
- QR-код для быстрого доступа к оригинальной электронной версии справки для ее скачивания и проверки
К сожалению не все интернет-страницы попадают в Архив Интернета, и не все страницы, попавшие в него, хранятся там постоянно.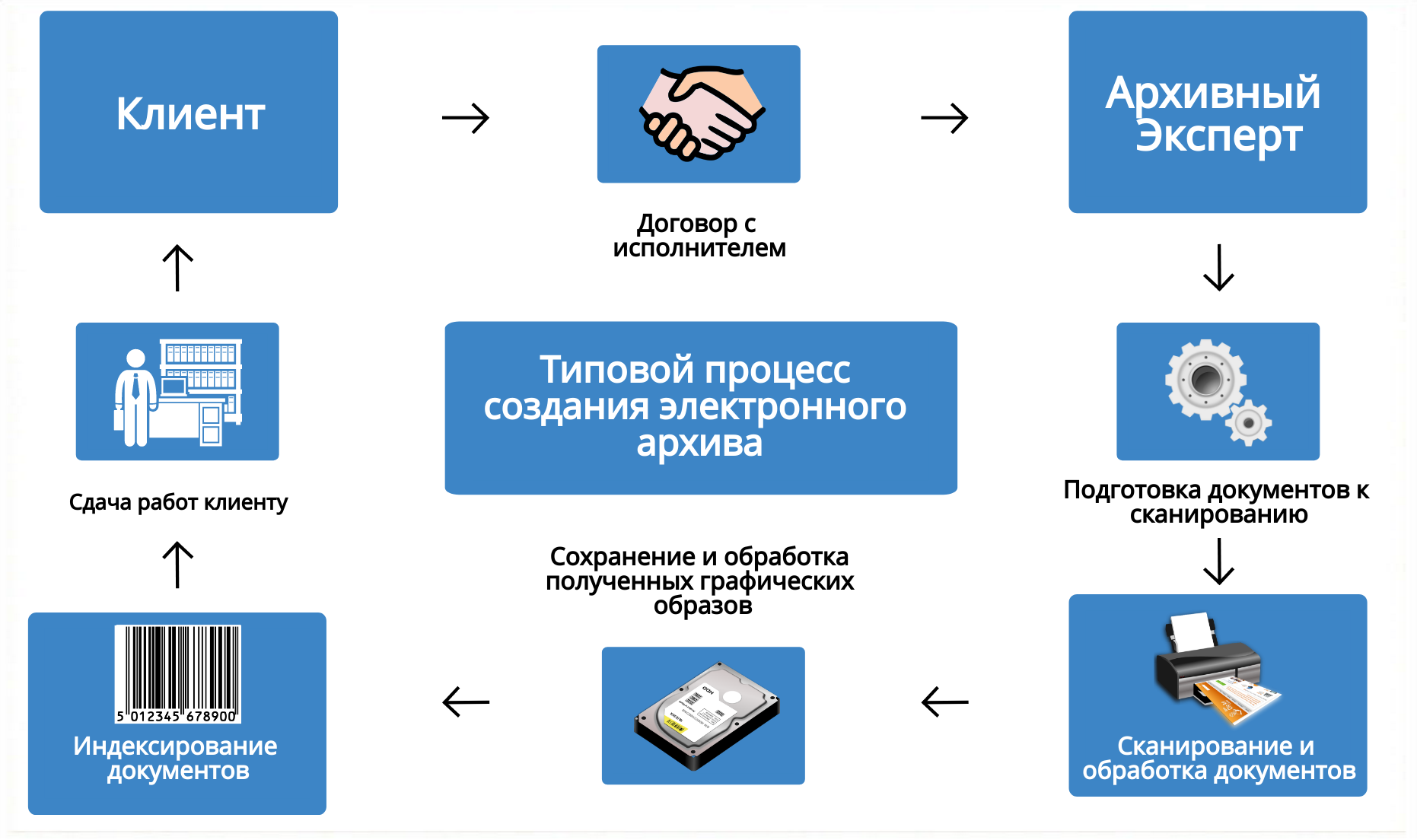
Часто бывает так, что доступные ранее архивные копии интернет-страниц исчезают или удаляются по требованию владельца сайта или по техническим причинам (например, запрет на индексацию)
Кроме этого, попытки распечатать архивные страницы через браузер чаще всего не позволяют получить бумажную версию в состоянии соответствующем оригинальному внешнему виду архивной страницы. Такие же проблемы возникают и при распечатке страниц обычных сайтов.
Архивная справка позволяет зафиксировать внешний вид архивной страницы в статичном состоянии и сохранить эту информацию на случай ее удаления из Вебархива.
Справка позволяет в удобной и доступной форме получить объективное подтверждение содержания и внешнего вида архивной страницы сайта для использования такой информации в качестве доказательства в суде или при переговорах.
В отличие от простой распечатки справка содержит элементы сведения, позволяющие утверждать и проверять достоверность указанной в ней информации
Для того чтобы сформировать архивную справку, найдите и откройте архивную копию необходимой страницы и нажмите зеленую кнопку «+» в нижней правой части экрана.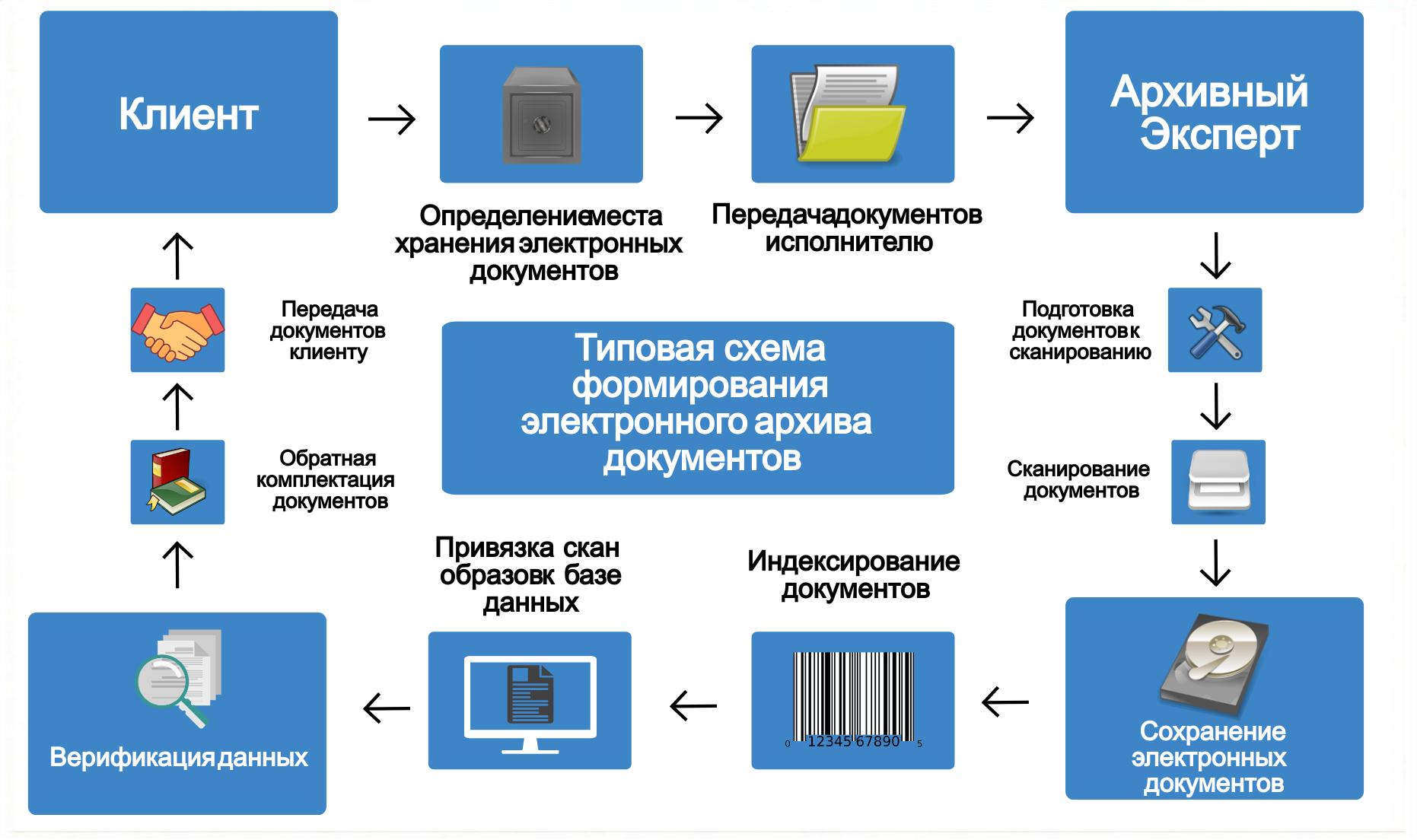 Далее следуйте инструкциям во всплывающем окне.
Далее следуйте инструкциям во всплывающем окне.
Если вам необходимо получить одну справку в отношении нескольких интернет-страниц, вы можете последовательно находить и открывать архивные копии нужных страниц и добавлять их в список для формирования архивной справки.
Формирование и хранение архивных справок осуществляется за плату. Стоимость архивной справки зависит от количества архивных страниц, включенных в справку.
Процессуальным законодательством Российской Федерации установлен специальный статус доказательств, удостоверенных нотариусом.
Согласно ст. 61 Гражданского процессуального кодекса РФ и 69 Арбитражного процессуального кодекса РФ, обстоятельства, установленные нотариусом, не требуют дальнейшего доказывания и поэтому такие доказательства имеют “особую юридическую силу”
Противопоставить что-либо против таких доказательств практически невозможно.
Все остальные письменные доказательства из интернет могут иметь различную степень доверия со стороны судей в зависимости от возможности их проверки на достоверность, но в силу действующего законодательства не обладают свойством неоспоримости.
Осмотр нотариусом Вебархива оформляется нотариальным протоколом. Такие протоколы принимаются всеми судебными инстанциями на территории Российской Федерации, а также за ее пределами. Согласно положениям Минской Конвенции 1993 года протоколы, заверенные нотариусами на территории РФ, используются в качестве доказательства в судах стран СНГ, в т.ч. Украины, Белоруссии, Казахстана. Для использования протокола в ряде стран дальнего зарубежья требуется его апостилировать.
Доступ к публичным (открытым) данным вебархива предоставляется бесплатно всем желающим.
Доступ к непубличным (закрытым) данным вебархива может быть предоставлен за плату, в размере, необходимом для поддержания деятельности вебархива, в том числе для покрытия расходов на архивацию и хранение данных, оплату услуг технических специалистов и т.п.
Отнесения данных к непубличным (закрытым) осуществляется лицом, инициировавшим архивацию таких данных.
Как архивировать веб-сайт?
Существует множество причин, по которым организация может захотеть заархивировать веб-сайт.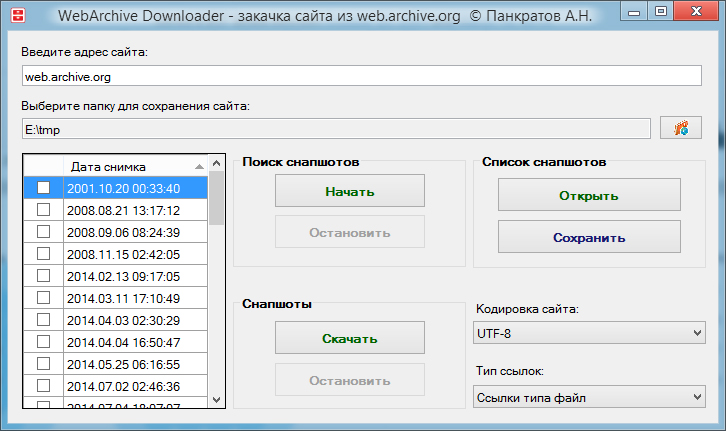 Например, это может быть государственный сектор или организация, предоставляющая финансовые услуги, которая по закону обязана вести точный учет всех данных веб-сайта. Или организация может стремиться лучше защитить себя от ложных заявлений и кражи интеллектуальной собственности контента веб-сайта. Или, возможно, запускается совершенно новый веб-сайт, а старый должен быть заархивирован, чтобы обеспечить долгосрочную сохранность того, что является важным историческим документом для организации.
Например, это может быть государственный сектор или организация, предоставляющая финансовые услуги, которая по закону обязана вести точный учет всех данных веб-сайта. Или организация может стремиться лучше защитить себя от ложных заявлений и кражи интеллектуальной собственности контента веб-сайта. Или, возможно, запускается совершенно новый веб-сайт, а старый должен быть заархивирован, чтобы обеспечить долгосрочную сохранность того, что является важным историческим документом для организации.
Независимо от причины, по-прежнему остается вопрос: как на самом деле захватить и сохранить веб-сайт — не просто конкретную веб-страницу, а целый веб-сайт с множеством страниц?
Как архивировать веб-сайт?
Существует несколько способов заархивировать веб-сайт. Одну веб-страницу можно просто сохранить на жесткий диск, можно использовать бесплатные онлайн-инструменты архивирования, такие как HTTrack и Wayback Machine, или вы можете положиться на резервную копию CMS. Но лучший способ зафиксировать сайт — это использовать автоматизированное решение для архивирования, которое фиксирует каждое изменение.
Но лучший способ зафиксировать сайт — это использовать автоматизированное решение для архивирования, которое фиксирует каждое изменение.
Wayback Machine великолепен, потому что он не только позволяет вам ввести практически любой веб-сайт и посмотреть, как он выглядел несколько лет назад (повторное посещение веб-сайта такой компании, как Apple, существовавшей до 2000-х годов, может быть очень интересным), но также позволяет архивировать веб-сайты.
К сожалению, это не автоматическое архивирование. Хотя он позволяет бесплатно архивировать веб-сайт в Интернете, вам придется вручную сохранять отдельные страницы, поэтому это может быть медленным и трудоемким процессом. Кроме того, если вы ищете полную запись вам нужно будет снова архивировать веб-страницу каждый раз, когда в нее вносятся изменения , чтобы точно фиксировать и сохранять изменения и удаления.
Wayback Machine позволяет легко архивировать веб-страницы.
HTTrack, напротив, стремится упростить архивирование всего веб-сайта. С помощью этого программного обеспечения можно загрузить веб-сайт на свой компьютер одним нажатием кнопки. HTTrack может даже обновить существующий зеркальный сайт и возобновить прерванные загрузки, поэтому обеспечить наличие архивной версии последней версии веб-сайта относительно просто.
С помощью этого программного обеспечения можно загрузить веб-сайт на свой компьютер одним нажатием кнопки. HTTrack может даже обновить существующий зеркальный сайт и возобновить прерванные загрузки, поэтому обеспечить наличие архивной версии последней версии веб-сайта относительно просто.
С другой стороны, HTTrack вряд ли предоставит вам полный архив веб-сайта с веб-страницами, которые выглядят точно так же, как онлайн-версия. Почему? Ну, современные веб-сайты невероятно сложны, и точно архивировать все эти данные непросто. Когда речь идет о таких вещах, как изображения, встроенные видео, фреймворки Javascript/Ajax, потоки веб-форм и страницы, защищенные паролем, бесплатное программное обеспечение, такое как HTTrack, вряд ли идеально захватит весь этот сложный контент. Крайне вероятны некоторые пробелы в содержании и отсутствующие изображения.
Кроме того, несмотря на то, что теоретически это позволяет вам загрузить весь сайт, это не полностью автоматизированный процесс; вам все равно придется вручную загружать сайт каждый раз, когда вы хотите создать новый архив.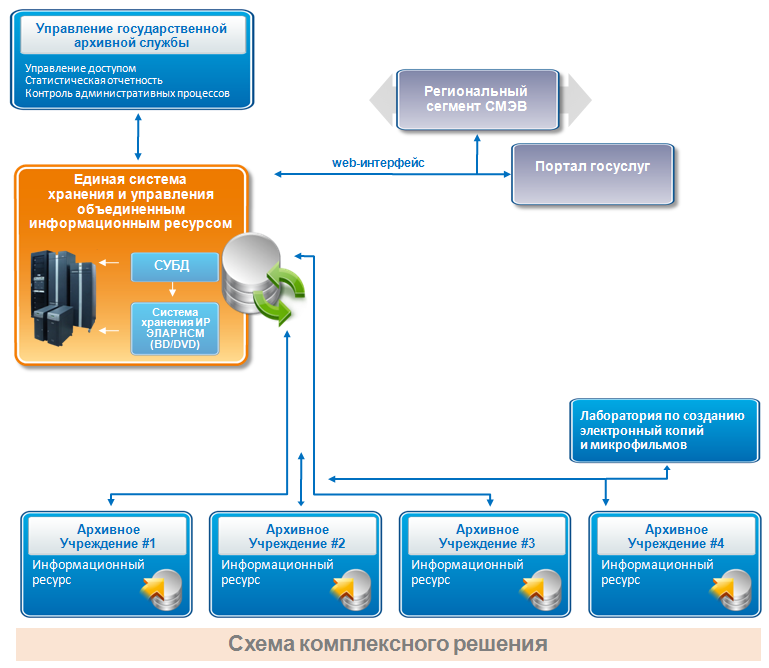
HTTrack позволяет загружать полные веб-сайты на ваш компьютер.
Почему резервная копия CMS не является архивом
Многие современные системы управления контентом, связанные с веб-сайтами, предлагают ту или иную форму резервного копирования, чтобы гарантировать, что важные данные не будут потеряны. И, как упоминалось ранее, некоторые организации предполагают, что они могут полагаться на эту резервную копию как на архив веб-сайта. Хотя это в определенной степени верно, средняя резервная копия CMS имеет много ограничений.
В традиционной резервной копии CMS отсутствует следующее:
- Полнотекстовый поиск: Большая часть ценности настоящего архива веб-сайта заключается в возможности найти определенную страницу, сообщение или даже фразу среди тысяч заархивированных страниц. Например, если контент с определенной страницы, опубликованной много лет назад, необходим для судебного разбирательства, полнотекстовый поиск становится чрезвычайно полезным для поиска этих конкретных данных.

- Цифровые подписи: Говоря о судебных разбирательствах, чтобы цифровые доказательства можно было защитить в суде, требуется цифровая подпись для их аутентификации и доказательства того, что они не были подделаны. Данные, взятые из резервной копии CMS, не будут иметь этой цифровой подписи.
- Легкий доступ к архивам: Чтобы архив веб-сайта действительно был полезен, такие отделы, как отдел кадров, юридический и маркетинговый отделы, должны иметь достаточно легкий доступ к этим данным. Если это требует слишком много времени и усилий, команды вряд ли будут использовать их в своей повседневной работе. Получить доступ к данным, скрытым в резервной копии CMS, часто бывает непросто.
- Прямая трансляция: Чем ближе любой архив напоминает внешний вид оригинальной платформы, тем легче ориентироваться и находить то, что вам нужно. Команда юристов, сталкивающаяся с резервной копией CMS, часто тратит часы на поиск нужной записи просто потому, что резервная копия не настроена для облегчения поиска.

- Метаданные: Как и в случае с цифровыми подписями, доступ к метаданным, связанным с любой записью веб-сайта, имеет решающее значение, когда речь идет о судебных разбирательствах или нормативных правках. А резервные копии CMS не позволяют юридическим группам легко экспортировать запись со всеми ее метаданными.
- Совместимое хранилище данных: Для регулируемых отраслей с особыми правилами ведения учета, таких как государственный сектор и финансовые услуги, резервная копия CMS не соответствует требованиям. Другими словами, если записи веб-сайта организации подлежат аудиту, простого предоставления данных из резервной копии CMS будет недостаточно.
- Доступность: Чтобы архив веб-сайта был действительно полезным, команды должны иметь возможность быстрого и легкого доступа к нему. Это редко случается с резервной копией CMS; получение доступа может занять несколько часов и потребовать участия ИТ-специалистов.

Автоматический захват веб-сайтов
Автоматизированная служба архивирования веб-сайтов, такая как Pagefreezer, позволяет организациям вести полный учет содержимого веб-сайтов. Мы используем технологию, аналогичную используемой поисковыми системами, такими как Google, для регулярного сканирования сайта и регистрации всех изменений и удалений. Через нашу удобную информационную панель клиенты могут просматривать хронологические версии любой данной страницы и мгновенно видеть, что изменилось — удаления выделены красным, а добавления — зеленым.
С помощью программного обеспечения для автоматического захвата веб-сайтов найти то, что вы ищете, и экспортировать эти данные также намного проще, чем с резервной копией CMS. Pagefreezer предлагает расширенный поиск, который позволяет быстро найти определенное ключевое слово или фразу в архиве, а затем экспортировать эту информацию (вместе с метаданными) в PDF или WARC.
Хотите узнать больше? Узнайте, как Pagefreezer архивирует 150 000 веб-страниц, чтобы удовлетворить потребности юридического и маркетингового отделов ведущей глобальной технологической компании.
Определение веб-страниц, веб-сайтов и веб-захватов
Опубликовано Автор Vinay Goel
Интернет-архив архивирует Интернет в течение 20 лет и сохраняет миллиарды веб-страниц с миллионов веб-сайтов. Эти веб-страницы часто состоят из множества изображений, видео, таблиц стилей, сценариев и других веб-объектов и ссылаются на них. За годы работы в Архиве сохранено более
Мы определяем веб-страницу как действительный веб-захват, который является документом HTML, текстовым документом или PDF.
Домен в Интернете — это принадлежащий владельцу раздел пространства имен в Интернете, например google.com, archive.org или bbc.co.uk. Хост
Мы определяем веб-сайт как хост, который обслуживает веб-страницы и имеет по крайней мере одну входящую ссылку с веб-страницы, принадлежащей другому домену.
На сегодняшний день Интернет-архив официально содержит 273 миллиарда веб-страниц с более чем 361 миллиона веб-сайтов, занимает 15 петабайт хранилища.
Рубрика: Объявления, Новости, Wayback Machine — веб-архив | 4 ответаПоиск:
Последние сообщения
- Музыкальная библиотека государственного университета Боулинг-Грин и Звуковой архив Билла Шурка сотрудничают с Интернет-архивом
- Book Talk: претворение теории в жизнь
- Сохраняя прошлое, расширяя возможности будущего: раскрывая жизненно важную роль Wayback Machine в следственной работе
- Создавайте, получайте доступ, анализируйте: представляем ARCH (вычислительный центр архивных исследований)
- Канадский музыкант использует Wayback Machine для иммиграционной документации
Категории
- 78 об/мин
- Объявления
- Архив версии 2
- Архив-Это
- Аудиоархив
- Архив книг
- Классные предметы
- Архив образования
- Эмуляция
- Событие
- Архив изображений
- Вакансии
- Прокат книг
- Архив живой музыки
- Архив фильмов
- Музыка
- Новости
- Информационный бюллетень
- Открытая библиотека
- Прошлое событие
- Архив программного обеспечения
- Технический
- Телевизионный архив
- Без категории
- Предстоящее событие
- Видеоархив
- Wayback Machine – веб-архив
- Веб-службы и службы данных
Архивы
Архивы Выбрать месяц Июль 2023 Июнь 2023 Май 2023 Апрель 2023 Март 2023 Февраль 2023 Январь 2023 Декабрь 2022 Ноябрь 2022 Октябрь 2022 Сентябрь 2022 Август 2022 Июль 2022 Июнь 2022 Май 2022 Апрель 2022 Март 2022 Февраль 2022 Январь 2022 Декабрь 2021 Ноябрь 2021 Октябрь 2021 Сентябрь 2021 Август 2021 Июль 2021 Июнь 2021 Май 2021 Апрель 2021 Март 2021 Февраль 2021 Январь 2021 Декабрь 2020 Ноябрь 2020 Октябрь 2020 Сентябрь 2020 Август 2020 Июль 2020 Июнь 2020 Май 2020 Апрель 2020 2 Марта 020 Февраль 2020 Январь 2020 Декабрь 2019Ноябрь 2019 Октябрь 2019 Сентябрь 2019 Август 2019 Июль 2019 Июнь 2019 Май 2019 Апрель 2019 Март 2019 Февраль 2019 Январь 2019 Декабрь 2018 Ноябрь 2018 Октябрь 2018 Сентябрь 2018 Август 2018 Июль 2018 Июнь 2018 Май 2018 Апрель 2018 Март 2018 Февраль 2018 Январь 2018 Декабрь 2017 Ноябрь 2017 Октябрь 2017 Сентябрь 2017 Август 2017 Июль 2017 Июнь 2017 Май 2017 Апрель 2017 Март 2017 Февраль 2017 Январь 2017 Декабрь 2016 Ноябрь 2016 Октябрь 2016 Сентябрь 2016 Август 2016 Июль 201 6 июня 2016 г. май 2016 г. апрель 2016 г. март 2016 г. февраль 2016 г. январь 2016 г. декабрь 2015 г. ноябрь 2015 г. октябрь 2015 г. сентябрь 2015 г. июль 2015 г. июнь 2015 г. май 2015 г. апрель 2015 г. 2014 Август 2014 Июль 2014 Июнь 2014 Май 2014 Апрель 2014 Март 2014 Февраль 2014 Январь 2014 Декабрь 2013 Ноябрь 2013 Октябрь 2013 Сентябрь 2013 Август 2013 Июль 2013 Июнь 2013 Май 2013 Апрель 2013 Март 2013 Февраль 2013 Январь 201 3 декабря 2012 г. ноябрь 2012 г. октябрь 2012 г. сентябрь 2012 г. август 2012 г. июль 2012 г. июнь 2012 г. май 2012 г. апрель 2012 г. март 2012 г. февраль 2012 г. январь 2012 г. декабрь 2011 г. ноябрь 2011 г. 2011 Март 2011 Февраль 2011 Январь 2011 Декабрь 2010 Ноябрь 2010 Октябрь 2010 Сентябрь 2010 Август 2010 Июль 2010 Июнь 2010 Май 2010 Апрель 2010 Март 2010 Февраль 2010 Январь 2010 Декабрь 2009Октябрь 2009 г. Сентябрь 2009 г. Август 2009 г. Июль 2009 г. Июнь 2009 г. Май 2009 г. Апрель 2009 г. Март 2009 г. Февраль 2009 г. Январь 2009 г. Декабрь 2008 г. Ноябрь 2008 г. Сентябрь 2008 г.
май 2016 г. апрель 2016 г. март 2016 г. февраль 2016 г. январь 2016 г. декабрь 2015 г. ноябрь 2015 г. октябрь 2015 г. сентябрь 2015 г. июль 2015 г. июнь 2015 г. май 2015 г. апрель 2015 г. 2014 Август 2014 Июль 2014 Июнь 2014 Май 2014 Апрель 2014 Март 2014 Февраль 2014 Январь 2014 Декабрь 2013 Ноябрь 2013 Октябрь 2013 Сентябрь 2013 Август 2013 Июль 2013 Июнь 2013 Май 2013 Апрель 2013 Март 2013 Февраль 2013 Январь 201 3 декабря 2012 г. ноябрь 2012 г. октябрь 2012 г. сентябрь 2012 г. август 2012 г. июль 2012 г. июнь 2012 г. май 2012 г. апрель 2012 г. март 2012 г. февраль 2012 г. январь 2012 г. декабрь 2011 г. ноябрь 2011 г. 2011 Март 2011 Февраль 2011 Январь 2011 Декабрь 2010 Ноябрь 2010 Октябрь 2010 Сентябрь 2010 Август 2010 Июль 2010 Июнь 2010 Май 2010 Апрель 2010 Март 2010 Февраль 2010 Январь 2010 Декабрь 2009Октябрь 2009 г. Сентябрь 2009 г. Август 2009 г. Июль 2009 г. Июнь 2009 г. Май 2009 г. Апрель 2009 г. Март 2009 г. Февраль 2009 г. Январь 2009 г. Декабрь 2008 г. Ноябрь 2008 г. Сентябрь 2008 г.