Что значит частотность запросов, как ее определить: виды и типы, инструкция
Частотность поискового запроса – это количественная величина обращений пользователей по конкретной фразе за расчетный период времени. Простыми словами частота показывает, сколько раз пользователи вбивали в поисковую строку тот или иной запрос в течение месяца.
Частность во многом зависит от направления бизнеса, а также сезонности спроса, региона и алгоритмов расчета поисковых систем. Бесплатные сервисы для работы с поисковыми запросами всем хорошо известны: Wordstat Yandex и Google AdWords. Существуют платные системы и программы определения частотности, например Serpstat, Букварикс, Key Collector и другие. Однако все они, так или иначе, работают с поисковой выдачей Яндекса и Google.
Ключевые запросы различаются по степени популярности среди пользователей, которые ищут ту или иную информацию в интернете. Какие-то фразы вводятся в поисковую строку 1-2 раза в месяц, другие 2-3 тысяч раз, а есть и популярные ключевики с сотнями тысяч показов.
Зачем нужны эти данные? Практическое применение частности – это анализ и прогноз трафика. Например, специалист по SEO посмотрит выкладку Вордстата по продвигаемому запросу и определит, какой трафик он получит на сайт в ТОПе выдачи. Также ни один специалист не возьмется составлять семантическое ядро сайта без данных по частотности ключевиков. Информация поможет ему отфильтровать нецелевые запросы, «пустышки» на ранних стадиях раскрутки проекта и быстрее вывести ресурс в ТОП выдачи.
Виды запросов по частотности
В SEO запросы распределяются по частотности на три категории. Первая и самая низкая частота – низкочастотные (НЧ). Эти запросы вводят в поисковую строку реже 150 раз в месяц. Вторая позиция – это среднечастотные запросы (СЧ). Ключевые фразы, которые показываются до 1500 раз в месяц. Третья позиция – высокочастотные запросы (ВЧ). В эту категорию попадают все запросы с частотностью от 1500 показов в месяц.
В эту категорию попадают все запросы с частотностью от 1500 показов в месяц.
Важно: соотношение частотностей условно. Конкретные значения зависят от выбранной ниши для продвижения. Например, в конкурентных тематиках и 3000 показов в месяц будет низкочастотным запросом.
Низкочастотные запросы
Запросы с низкой частотой показов обычно имеют узкую направленность и конкретизируют потребность целевой аудитории. Низкочастотники состоят из трех и более слов. Как правило, такие фразы вбивают в поиск люди, которые точно знают, что им нужно.
Например, «где купить куртку из натуральной кожи». Видим, что частотность 102 показа и ниже. Однако в этой нише можно найти многословные запросы с большей частотой.
В любом случае работать с низкочастотными ключами нужно на всех этапах продвижения сайта. SEO специалисты утверждают, что трафик по таким «предметным» ключам пойдет сразу.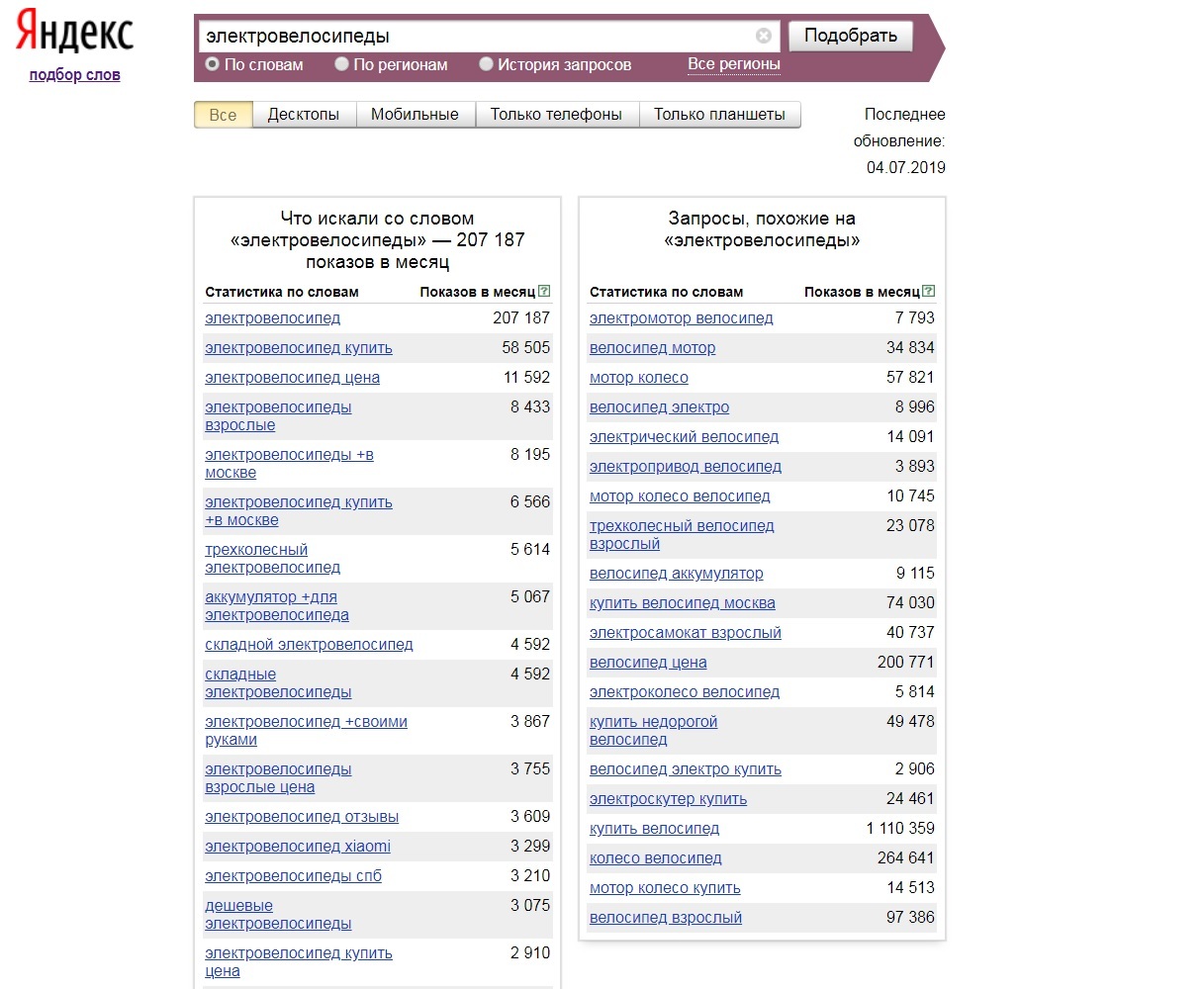 Чем больше НЧ вы используете в текстах на сайте, тем больше целевого трафика привлечете.
Чем больше НЧ вы используете в текстах на сайте, тем больше целевого трафика привлечете.
Среднечастотные запросы
Среднечастотники – это уже менее конкретные запросы, которые состоят из нескольких слов. Чаще всего в среднечастотной фразе 3-4 слова, не более. Показываться они могут до нескольких десятков тысяч раз в месяц. Конкретная популярность зависит от конкурентности ниши.
Например, запрос «купить пластиковый подоконник» с 7 654 показами и «купить подоконник для пластиковых окон» с 1 295 показами в месяц относятся к категории среднечастотников.
Эти виды частотностей хорошо подходят для неспешного продвижения сайтов и онлайн-магазинов в конкурентных нишах. Среднечастотные запросы охватывают более широкую аудиторию, чем низкочастотные. Однако это не массовый спрос, как в случае с высокочастотными ключами.
Высокочастотные запросы
Высокочастотники – это запросы широкой направленности, которые содержат одно или два ключевых слова.
Например, запрос «Самсунг» показывается почти 10 миллионов раз. Этот высокочастотный запрос, некая сборная солянка, которая включает в себя все возможные варианты фраз со словом «Самсунг».
Основное применение высокочастотников – имиджевая реклама, формирование положительного мнения о бренде, продуктах и услугах. Такие запросы подходят для кропотливой и дорогой работы на несколько лет. Важно учитывать, что в огромном потоке трафика большая доля нецелевой аудитории. К чему это может привести? К росту отказов, снижению ранга сайта, жесткой конкуренции, значительным тратам бюджета и прочим радостям SEO продвижения по высокочастотным ключам.
Виды частотностей в Яндексе
Что такое частотность в общем понимании мы разобрались. Рассмотрим теперь, как разделяет запросы по категориям Яндекс Вордстат. Сервис выделяет три частоты:
Сервис выделяет три частоты:
-
Базовая частота – это количество показов по всем возможным вариантам использования ключевого слова. Именно поэтому она является самой неточной, общей. Например, в запрос «купить смартфон» попадут все фразы, которые содержат эти два слова – «купить смартфон Samsung», «купить смартфон дешево», «купить смартфон в Туле недорого» и многие другие. С базовой частотой работают, когда нужно узнать общую заинтересованность тематикой у ЦА. Чтобы проверить базовую частотность в сервисе Яндекс Вордстат нужно ввести запрос как есть, то есть без спецсимволов (операторов).
2. Фразовая частота и оператор «» – показывает количество ввода конкретного запроса в разных склонениях. Например, тот же запрос «купить смартфон» возьмём в кавычки, чтобы определить фразовую частоту. Видим, что именно так фразу набирали 18 670 раз в месяц при базовой частоте 519 980. Количество показов резко уменьшилось, потому что в точной частотности не учитываются добавочные слова, вроде «купить», «заказать», «обзор» и другие.
3. Точная частотность и оператор (!) – показывает, сколько раз пользователи вводили запрос в конкретном виде с учетом склонения, числа, спряжения. Чтобы максимально узнать частоту нужно запрос взять в кавычки и перед каждым словом поставить восклицательный знак. Например, возьмем запрос «смартфон samsung galaxy» и рассчитаем уточненную частотность по нему. Мы видим, что именно так запрос набирали 480 раз в месяц при базовой частоте 88 056. Получается, что из высокочастотного ключевика запрос превратился в средне- или даже низкочастотный.
Какие запросы лучше для SEO продвижения?
Частотность – это показатель популярности поискового запроса у целевой аудитории. Если вы продвигаете коммерческий проект, то лучше использовать низко- и среднечастотные фразы, как наиболее предметные. По ним вы получите максимально целевой трафик.
Алгоритм примерно следующий:
-
Сайт не оптимизировался (стартап проект) – используйте сначала низкочастотные запросы.

-
Сайт уже оптимизирован под НЧ и СЧ – можно брать в работу высокочастотники.
В любом случае, если нужно больше целевых пользователей, используйте НЧ и ВЧ запросы. Если вы развиваете спрос, поднимаете имидж компании – это ВЧ запросы. Хотите максимальной конверсии страницы, делайте упор только на НЧ.
Сервисы для определения частотностей запросов
Самым популярным сервисом для определения статистики по запросам считается Яндекс Wordstat. Этот инструмент бесплатен и довольно прост в использовании. Чтобы посмотреть статистику по ключевикам войдите в сервис и в поисковой строке наберите нужный запрос, после чего нажмите кнопку «подобрать».
Можно отфильтровать сбор по городам, странам и областям, выбрав в выпадающем списке нужный регион.
Также вы можете узнать статистику по устройствам: десктопы, мобильные, только телефоны и только планшеты.
В Google AdWords также есть опция определения частотности запросов. Она находится в рекламном кабинете Google Ads в разделе «Инструменты» — планировщик ключевых слов.
В открывшемся окне планировщика нужно выбрать «получение статистики запросов и трендов», а в полях ввести искомые фразы вручную или загрузить списком. Также можно выставить таргетинг и отминусовать нецелевые фразы (минус-слова).
Выставив настройки, жмите «узнать количество запросов». Откроется окно с данными по частотности, уровню конкуренции и рекомендованной ставке в рекламе.
Также есть несколько интересных онлайн-платформ для анализа ключевых слов. Например, Serpstat – сервис помогает анализировать поисковые фразы в нише, а также собирать ключевики конкурентов. Зачастую удобнее и быстрее собрать семантику на сайтах из ТОП-10, чем перебирать десятки тысяч ключевиков в Вордстате.
Зачастую удобнее и быстрее собрать семантику на сайтах из ТОП-10, чем перебирать десятки тысяч ключевиков в Вордстате.
Лидер программного сбора и анализа ключевиков – это Key Collector. Программа должна быть у каждого SEO-оптимизатора по умолчанию. Софт парсит (собирает) данные с левой колонки выдачи Яндекс Вордстата, а также с сервиса Яндекс.Директ. Кроме того, собирает данные с Google Ads, поисковых подсказок и некоторых платных сервисов. Key Collector – сложный инструмент, но он позволяет максимально автоматизировать сбор и обработку огромного количества ключевиков.
Резюме
Мы узнали, что такое частотность запросов. Научились различать ключевики по видам – низкочастотные, среднечастотные и высокочастотные. Познакомились с операторами частотности в Яндекс.Вордстат, а также рассмотрели популярные сервисы и программы для работы с ключевыми запросами.Что такое частотность запроса и как ее определить?
Частотность запросов – это количество обращений пользователя с конкретным словом или фразой к поисковику за месяц.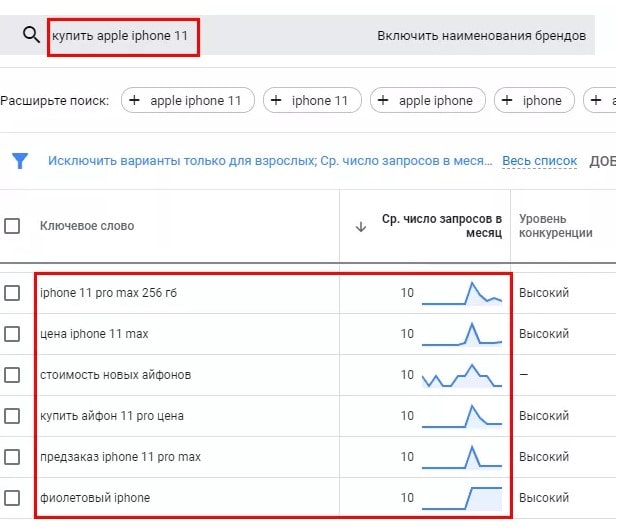 Выделяют три основных вида: высокочастотные (ВЧ), низкочастотные (НЧ) и среднечастотные (СЧ). Однако самих видов больше:
Выделяют три основных вида: высокочастотные (ВЧ), низкочастотные (НЧ) и среднечастотные (СЧ). Однако самих видов больше:
- Сверхчастотные – самые популярные слова или фразы, т.е. их запрашивают в конкретной тематике чаще всего. Обычно сВЧ-запросы — однословные, например, «смартфон» или «одежда». Они являются самыми конкурентными, т.к. по ним продвигаются многие компании в конкретных областях. Частота показов – от 100000 в месяц и выше. Продвижение по ним подходит далеко не каждому бизнесу, так как из-за отсутствия уточняющих фраз в запросе релевантность страниц, подобранных поисковиком, может размываться. Обычно при таких запросах поисковик старается показать как можно больше информации с искомым словом, к примеру при поиске слова «замок» Яндекс покажет как строения, так и механические устройства для запирания дверей.
- Высокочастотные. Отличаются от сверхчастотных тем, что в них может указываться дополнительное слово, но это не делает запрос менее частотным.
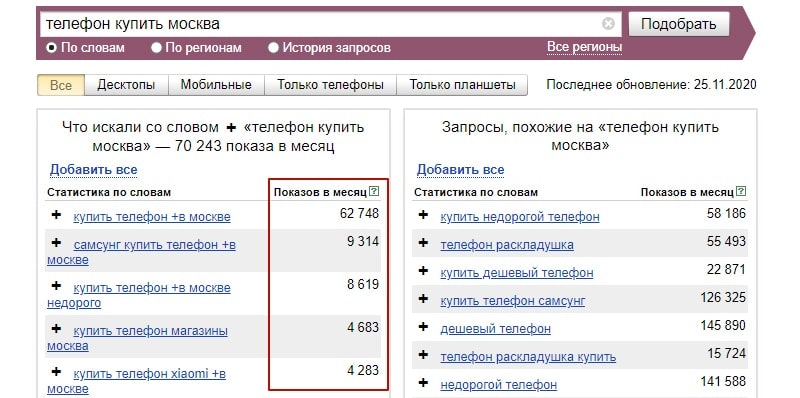 К примеру, запрос «квартира москва» (620 000 показов по МСК) остается высокочастотным, несмотря на то, что содержит уточняющее слово. Он не такой общий по сравнению с запросом «квартира» (5 250 000 показов по МСК). Частотность подобных запросов – от 10000. На профессиональном жаргоне ВЧ-запросы называют «жирными». Их грамотное продвижение помогает приводить на сайт максимальное число пользователей. Но по ВЧ-запросам продвигаются многие сайты, что рождает большую конкуренцию. Именно поэтому продвижение по ВЧ-запросам довольно затратно в финансовом и временном планах.
К примеру, запрос «квартира москва» (620 000 показов по МСК) остается высокочастотным, несмотря на то, что содержит уточняющее слово. Он не такой общий по сравнению с запросом «квартира» (5 250 000 показов по МСК). Частотность подобных запросов – от 10000. На профессиональном жаргоне ВЧ-запросы называют «жирными». Их грамотное продвижение помогает приводить на сайт максимальное число пользователей. Но по ВЧ-запросам продвигаются многие сайты, что рождает большую конкуренцию. Именно поэтому продвижение по ВЧ-запросам довольно затратно в финансовом и временном планах. - Среднечастотные – как правило, состоят из нескольких слов со средней частотой показов от 500 до 5000-10000. СЧ-запросы задают пользователи, знакомые с интересующей их областью, либо знающие, как им нужно уточнить исходный общий высокочастотный запрос.
- Низкочастотные – самый конкретный вид запросов, имеют узкую направленность.
 Пример: «купить телевизор Samsung в Санкт-Петербурге». Частота показов – от 50-100 до 500 в месяц.
Пример: «купить телевизор Samsung в Санкт-Петербурге». Частота показов – от 50-100 до 500 в месяц. - Микрочастотные – могут иметь частотность от 1 до 50. Запросы мНЧ считаются самыми неконкурентными, так как содержат длинный уточняющий «хвост» в запросе. Пример: «как положить деньги на расчётный счёт ооо».
Важно заметить, что частота одного и того же запроса сильно варьируется в различных поисковиках.
Яндекс намеренно замедляет продвижение веб-ресурсов по высококонкурентным позициям, комментируя это тем, что сначала сайт должен стать известным, заработать репутацию и отличаться стабильностью развития. И только после того, как он зарекомендует себя, поисковик даст ему возможность тягаться с топовыми конкурентами.
СЧ- и НЧ-запросы хоть и не требуют больших финансовых вложений, но также способны предоставить стабильное увеличение трафика на сайт и охватить большое число пользователей.
На основе анализа о запрашиваемых фразах SEO-оптимизатор составляет выборку самых популярных запросов и продвигает по ним проект.
Если вам необходимо проверить частотность запросов, можно воспользоваться специальными сервисами:
- Яндекс.Вордстат – инструмент, помогающий определять частотность нужных запросов в поисковой системе Яндекс. Недостаток сервиса – в том, что поверять запросы приходится вручную и по одному.
- Google Adwords – сервис поисковой статистики от Google. Дает всю необходимую информацию по запросам, есть возможность задать язык и регион, предоставляются синонимы. Внимание, если в аккаунте Adwords нет активных рекламных кампаний, то показания в сервисе могут быть очень приблизительными и не точными.
Частотность запросов и техника ее определения
Одним из главных инструментов при создании контента на сайте, являются правильно подобранные запросы. Частотность запросов позволяет создавать интересный для клиентов материал. О том, как получить информацию о частотности ключевых фраз, поговорим дальше.
Частотность запросов позволяет создавать интересный для клиентов материал. О том, как получить информацию о частотности ключевых фраз, поговорим дальше.
Что такое частотность запросов
Главное с чем нужно разобраться, что такое частотность запросов? Это число запросов на интересующие ключевые фразы, взятое за заданный период. Одни запросы могут задаваться единожды, тогда как другие, задаются по миллиону раз в неделю. Владельцам сайтов, которые хотят расширить аудиторию пользователей, выгоднее применять популярные запросы. В разных поисковых системах используется свой метод определения частотности.
Виды
Существуют следующие виды запросов по частотности:
- высокочастотные;
- среднечастотные;
- низкочастотные.
Определение частотности запросов продемонстрирует, к какой категории относятся используемые ключевые фразы.
Как распределить запросы по частотности
Распределение запросов по частотности проводится по следующим правилам:
- Высокочастотные ключевые фразы желательно размещать на главной странице.
- Использовать разные ключи для каждой страницы сайта. Это позволит избежать путаницы, когда поисковой системой будет выполняться проверка запросов на частотность.
- Использовать для страниц целевые запросы с максимальной частотой. Посмотреть частотность запросов можно в специальных программах, разработанных для каждой поисковой системы.
Эти правила имеют рекомендательный характер, но их использование поможет поднять рейтинг страницы.
Проверка частоты запросов в разных поисковых системах
Существует несколько топовых поисковых систем:
- Google;
- Яндекс;
- YouTube.
Поговорим подробнее, как в этих системах проходит проверка частотности запросов.
Как узнать частотность запроса в Google
Чтобы проверить частотность запросов в Google используется Google Ads, точнее, инструмент «Планировщик ключевых слов».
Чтобы его использовать, нужно:
- зарегистрироваться в Google Ads и найти пункт «Планировщик ключевых слов»;
- выбрать окно: «Найдите новые ключевые слова»;
- ввести целевой запрос;
- получить частотность запросов Гугл.

Сначала представлены фразы, что вводились перед тем, как узнать частотность запроса в Google. Дальше идут дополнительные фразы. Справа указана минимальная и максимальная стоимость одного клика. В верхней левой части страницы показаны основные инструменты для работы с ключами. Справа, в верхней части экрана, есть фильтры настройки временного диапазона.
Как проверить частотность запросов в «Яндексе»
Проверить частотность запросов в «Яндексе» можно через wordstat.yandex.ru:
- вписать интересующую фразу в поисковую строку программы;
- нажать клавишу «Подобрать».
Результат будет таким:
Программа покажет, сколько раз люди делали запросы с заданным словом, и какие именно фразы их интересовали. Верхняя цифра показывает общую частотность запросов «Яндекс».
Как проверить частотность запросов YouTube
То, что люди ищут на видео-хостинге, они будут искать в поисковых системах. Потому можно проверить частотность запросов YouTube, воспользовавшись вышеописанными способами для Яндекса и Гугл.
Неплохо провести оценку самых релевантных запросов в строке YouTube, введя «Топ самых…» и посмотрев на результат.
Массовая проверка частотности запросов
Искать частотность нескольких ключей затратно по времени, потому пользователей все больше интересует массовая проверка частотности запросов. Сделать ее можно с помощью таких инструментов, как программа Key Collector.
Чтобы начать с ней работать нужно:
- открыть «Вордстат», внести в поле ключи, нажать «Начать сбор»;
- проверить частотность, используя «Директ»;
- убрать ключи у которых «Частотность !» равна «0», указав > «1» и нажав «Применить».
С помощью этой программы можно узнать частотность запросов списком онлайн из таких популярных поисковых систем, как «Яндекс» и «Гугл».
А теперь предлагаем подписаться на рассылку блога:
{«0»:{«lid»:»1573230077755″,»ls»:»10″,»loff»:»»,»li_type»:»em»,»li_name»:»email»,»li_ph»:»Email»,»li_req»:»y»,»li_nm»:»email»},»1″:{«lid»:»1596820612019″,»ls»:»20″,»loff»:»»,»li_type»:»hd»,»li_name»:»country_code»,»li_nm»:»country_code»}}
Истории бизнеса и полезные фишки
Запомнить
- Частотность запросов — это число запросов на конкретные ключевые фразы, взятое за определенный период.

- Определение частотности запросов — задача первоочередной важности для составления адекватного семантического ядра, наполнения качественным контентом и контекстной рекламой.
- Каждая поисковая система имеет свои способы поиска высокочастотных запросов. Для Google — это Google AdWords. На «Яндекс» можно использовать wordstat.yandex.ru. А на «Ютубе» сработают все вышеперечисленные методы.
- Есть автоматизированный и ручной метод ввода ключевых фраз и слов. Существует возможность массового поиска запросов — с помощью программы Key Collector.
Виды частотностей поисковых запросов или почему позиция по однословнику не гарантирует получение трафика
У нас иногда спрашивают:
«Почему мой сайт в ТОПе по такому на первый взгляд «жирному» запросу как «металлоконструкции», но трафика на сайт с этого ключевика совсем мало. Какие-то 50-100 человек в месяц! Но ведь частотность у этого запроса огромная, аж 250 тысяч в месяц! Почему такое происходит?»
И правда, если вбить в wordstat. yandex.ru такой запрос, то частотность он нам покажет довольно внушительную:
yandex.ru такой запрос, то частотность он нам покажет довольно внушительную:
При такой частотности позиция даже на 10 месте в выдаче должна приносить много трафика, но на деле все происходит совершенно иначе. В чем же причина? Давайте разбираться по порядку. Здесь есть несколько моментов, которые нужно учитывать. Начнем с самых простых и далее – по нарастающей.
Регион
Первое, про что все часто забывают, – это выбор региона при съеме частотности. Ни один коммерческий сайт не может продвигаться сразу по всем регионам, если он, конечно, не имеет офисы в каждом из них. Поэтому частотность снимается именно по тому региону, где находится офис компании. Если регионов несколько – отмечаем их все.
Например, компания, которая специализируется на поставках металлоконструкций и металлопроката, имеет офис в Москве, который добавлен в Яндекс.Справочник. Таким образом, ни по каким другим регионам данный сайт ранжироваться не будет, поэтому и ориентироваться надо в первую очередь на посетителей из Москвы.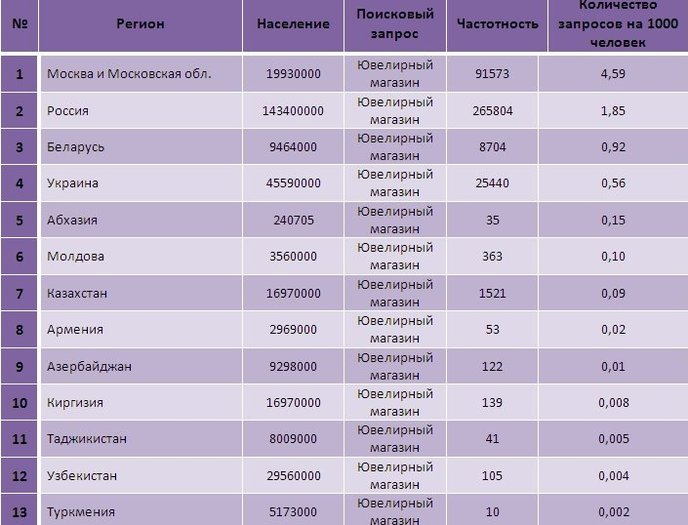 Значит, в wordstat нужно выставить соответствующий регион: Москва.Ключевой момент – наличие организации в Яндекс.Справочнике, так как именно по нему происходит привязка региона сайту.
Значит, в wordstat нужно выставить соответствующий регион: Москва.Ключевой момент – наличие организации в Яндекс.Справочнике, так как именно по нему происходит привязка региона сайту.
Иногда клиенты нам говорят:
«Я хочу продвигаться по всей России, мой интернет-магазин доставляет товар в любой регион».
И здесь мы вынуждены их разочаровать: к сожалению, даже внутри России интернет-магазин не может ранжироваться, если у него нет филиалов в соответствующих регионах. Под филиалами подразумевается привязанная в Яндекс.Справочнике карточка организации с подтвержденным офисом в регионе.Таким образом, при оценке спроса всегда нужно строго определять региональность.
Виды частотности
После выбора региона сразу видно, что частотность значительно уменьшилась.
Однако все равно это не реальные цифры конкретных фраз и, чтобы точно определить частотность каждого ключевика, нужно использовать специальный синтаксис.
Базовая частотность
Пока что мы собрали так называемую «Базовую частотность». Такой частотностью называют ту, которую мы получаем при вводе запроса в wordstat без какого-либо синтаксиса, выбрав регион или нет. Такая частотность представляет собой сумму частотностей всех фраз, где встречаются слова из запроса в любых словоформах и в любом порядке. Например, в нашем случае запрос «Металлоконструкции» без указания региона имел частотность около 250 тыс. в месяц по всему миру и 33 тыс по Москве. В эту частотность вошли все фразы, которые содержат слово «металлоконструкции». Причем слово может иметь разные окончания, то есть сюда войдут фразы: «завод металлоконструкций», «сварные металлоконструкции», «купить металлоконструкции недорого» и т.п.
Частотность в кавычках
Если мы хотим узнать частотность поискового запроса более точно, например, отсечь из нее те запросы, где присутствуют другие слова, то нужно брать запрос в кавычки. Иными словами, если вбить в wordstat запрос в таком виде – “металлоконструкции” – то получим следующую цифру:
Теперь мы видим, что отдельно слово «металлоконструкции» по Москве запрашивают в Яндексе только 948 человек. Однако сюда все равно еще подмешиваются словоформы, например, «металлоконструкций» «металлоконструкция». Чтобы их убрать, воспользуемся следующим видом частотности.
Однако сюда все равно еще подмешиваются словоформы, например, «металлоконструкций» «металлоконструкция». Чтобы их убрать, воспользуемся следующим видом частотности.
Частотность в кавычках и с восклицательным знаком (точная частотность)
Если задать запрос в wordstat в таком виде – “!металлоконструкции” – мы получим самую точную частотность. То есть будет отображаться частотность данного слова именно в таком виде, как мы написали:
В многословных запросах восклицательный знак нужно ставить перед каждым словом, так как данный оператор фиксирует словоформу каждого слова запроса по отдельности.
Таким образом, видна существенная разница в финальной частотности однословного запроса «металлоконструкции» по сравнению с изначальной базовой.
Точная частотность с учетом порядка слов
Однако, если мы подобным образом будем оценивать запрос, состоящий из двух слов, например, «купить металлоконструкции», то нужно еще учитывать порядок слов.
Так, например, если мы проверим точную частотность запросов: “!купить !металлоконструкции” и “!металлоконструкции !купить”, то обнаружим, что странным образом частотность у них будет одинаковая:
Это происходит по той причине, что операторы «кавычки» и «восклицательный знак» не учитывают порядок слов.Чтобы собрать точную частотность фразы «купить металлоконструкции» с учетом порядка слов, нужно использовать оператор «скобки» и вводить фразу следующим образом: “[!купить !металлоконструкции]”:
Таким образом, мы видим, что «купить металлоконструкции» ищут чаще, чем «металлоконструкции купить».
В результате мы разобрались, что основным фактором в оценке спроса по ключевым запросам, который обязательно нужно учитывать, является правильный съем частотности для семантического ядра. В качестве примера мы сравнили базовую и точную частотность для первых трех десятков фраз, которые выдает wordstat по запросу «металлоконструкции». В приведенной таблице в колонке «Показов в месяц» указана базовая частотность, которую выдал Яндекс без учета региона.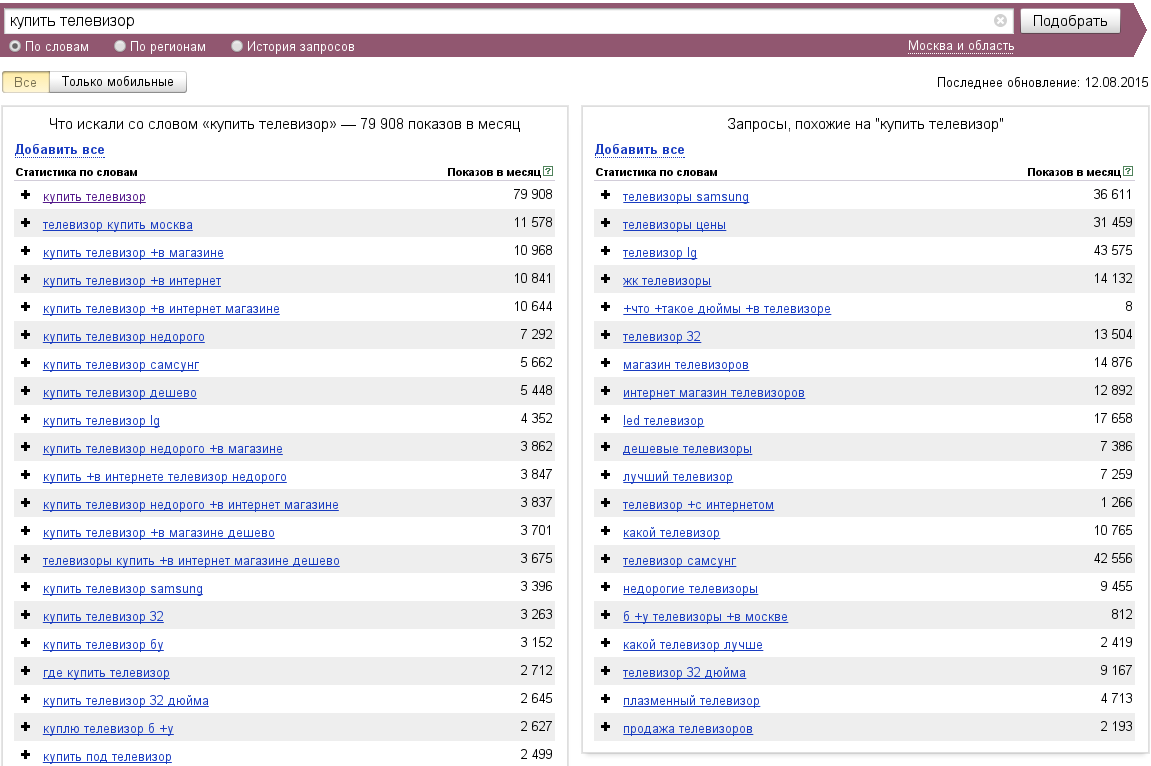 В колонке «Реальная частотность» указана уже точная частотность по региону Москва и снятая с использованием операторов «кавычки», «восклицательный знак» и «квадратные скобки».
В колонке «Реальная частотность» указана уже точная частотность по региону Москва и снятая с использованием операторов «кавычки», «восклицательный знак» и «квадратные скобки».
Как видно, точная частотность значительно меньше базовой. Если исходить из такой методики оценки спроса, то картина, при которой позиция в ТОП-10 Яндекса по ключевой фразе «металлоконструкции», имеющей частотность 839, приносит 50-100 посетителей, уже выглядит более реальной.
Распределение кликабельности на первой странице выдачи
Но можно справедливо возразить:
Неужели при позиции в ТОП-10 с ключевика частотностью 839 будет всего лишь 50-100 посещений?
В общем-то да!
По разным оценкам распределение CTR в органической выдаче в ТОП-10 примерно такое:
- ТОП-1: 15-35%
- ТОП-2: 10-25%
- ТОП-3: 7-20%
- ТОП-4: 5-15%
- ТОП-5 – ТОП-10: 3-12%
Подсчеты, конечно, очень обобщенные, но примерно отражают актуальную картину: 3 или даже 4 блока контекстной рекламы забирают больше половины всего CTR.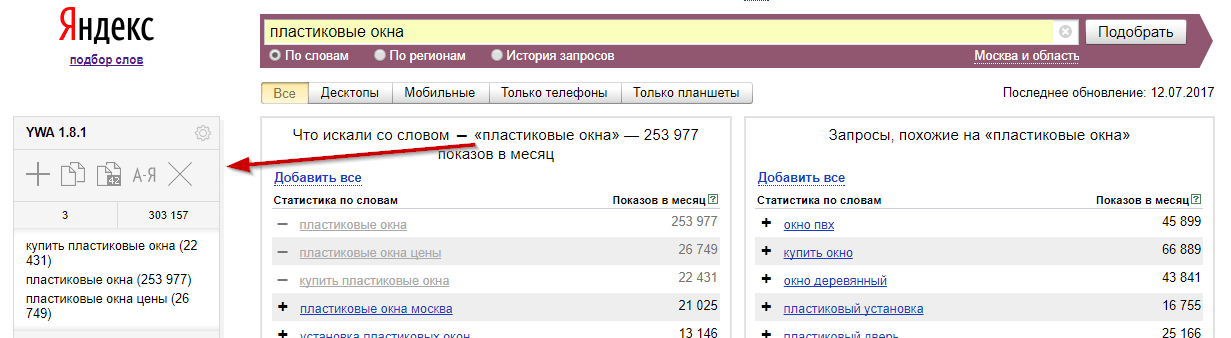 Далее могут идти сервисы Яндекса: маркет, картинки, карты, что делает кликабельность на обычные сайты еще меньше. Учитывая еще то, что позиция в Яндексе редко у какого сайта бывает стабильной в ТОП-10 вследствие работы так называемого алгоритма «бандита», можно смело заключить, что вышеприведенные цифры по количеству трафика являются нормальными.
Далее могут идти сервисы Яндекса: маркет, картинки, карты, что делает кликабельность на обычные сайты еще меньше. Учитывая еще то, что позиция в Яндексе редко у какого сайта бывает стабильной в ТОП-10 вследствие работы так называемого алгоритма «бандита», можно смело заключить, что вышеприведенные цифры по количеству трафика являются нормальными.
Оценка CTR через Яндекс.Директ
Наши слова легко проверить – достаточно зайти в Яндекс.Директ в прогноз бюджета и посмотреть там прогнозируемый CTR в зависимости от позиции в блоках контекстной рекламы на поиске.
Яндекс обычно слишком занижает показатели кликабельности в своих прогнозах, но это еще раз показывает, что даже высокая позиция по какому-либо запросу не гарантирует большого количества посетителей.
Заключение
В заключении подытожим, что для правильной оценки спроса и составления на ее основе стратегии поискового продвижения сайта важно собирать максимально полное семантическое ядро и правильно снимать частотность у всех фраз, а также задавать регион. Абсолютно неправильно «зацикливаться» на отдельных и предположительно самых «жирных» поисковых фразах и полагать, что, продвинувшись по ним в ТОП-10, сайт станет лидером тематики. Лидерство сайта в поисковом продвижении определяется исключительно совокупной видимостью сайта по определенному семантическому ядру, то есть многочисленному списку поисковых запросов различной частотности и длины.
Абсолютно неправильно «зацикливаться» на отдельных и предположительно самых «жирных» поисковых фразах и полагать, что, продвинувшись по ним в ТОП-10, сайт станет лидером тематики. Лидерство сайта в поисковом продвижении определяется исключительно совокупной видимостью сайта по определенному семантическому ядру, то есть многочисленному списку поисковых запросов различной частотности и длины.
какая бывает и в чем отличия?
Частотность запроса — показатель популярности поиского запроса или фразы в той или иной поисковой системе.
Запросы, в зависимости от их частотности бывают:
- ВЧ (высокочастотный) — обычно это общий информационный запрос, состоящий из одного–двух слов.
Используется обычно как имиджевая реклама (для роста узнаваемости бренда) или как источник трафика.
По ВЧ-запросам невозможно продвижение молодых сайтов, а в случае сайтов с возрастом от 1 года продвижение по высокочастотным запросам рекомендуется только после продвижения по СЧ- и НЧ-запросам.
Обычно, минимальная частотность ВЧ-запроса – от 1 000 запросов в месяц для региональных сайтов, и от 10 000 запросов в месяц для федеральных проектов Масштабные или крупные проекты, например, информационные порталы или интернет-магазины федерального уровня. .ВЧ-запросы обычно задают посетители, находящиеся на начальной стадии изучения предметной области, или только формирующие свою потребность в каком-либо товаре или услуге.
Высокочастотные запросы — самые конкурентные, а значит и самые дорогие в продвижении, при этом, как это ни парадоксально, они обладают самой низкой конверсией.
- СЧ (среднечастотный) — уточненный ВЧ-запрос, обычно 2–3 слова.
Используется такая частотность запросов при сео продвижении интернет-магазинов и других сайтов. Подходит для оптимизации сайтов любого возраста. Как и НЧ-запрос является фундаментом для продвижения по ВЧ-запросам.
Обычно, минимальная частотность СЧ-запроса – от 100 запросов в месяц.
СЧ-запросы обычно задают посетители, уже знакомые с предметной областью, или понявшие как им необходимо уточнить свой исходный общий ВЧ-запрос. - НЧ (низкочастотный) — самый точный запрос от посетителя поисковой системы, обычно состоящий из 3–6 слов. Его задают посетители, точно знающие какой товар и в какой комплектации они хотят приобрести.
Обычно минимальная частотность низкочастотного запроса – от 1 запроса в месяц.
Цель НЧ-запроса поисковику — узнать где есть конкретная модель товара или поиск данного товара/услуги по минимальной цене.НЧ-запросы — самые конверсионные и потому интересные для продаж любых сайтов. При этом, небольшой спрос по данным запросам делает их менее конкурентными (а значит более дешевыми) при seo-продвижении. Опытные оптимизаторы легко могут заменить ВЧ-запрос на множество уточняющих НЧ-запросов, сохранив суммарную частотность и получив при этом низкую стоимость продвижения и гораздо более высокую конверсию.
Примеры запросов разной частотности
Пример ВЧ-запроса для популярной тематики:
Пример СЧ-запроса для популярной тематики:
Пример НЧ-запроса:
В каждой тематике, в зависимости от ее популярности и суммарного спроса ВЧ-, СЧ- и НЧ-запросы могут иметь различное количество показов.
Общая и точная частотность запроса
Частотность поисковых запросов подразделяют на Общую, Точную и Уточненную. Для работы с запросами можно использовать специальный язык запросов.
- Базовая или общая частотность — количество запросов поискового слова по данным сервисов определение частотности запросов в общем случае. Рассчитать её очень легко, достаточно ввести в Вордстат запрос без использования каких-либо символов. Полученные данные не будут точными по причине, что будут включать в себя все остальные запросы, в которых есть те же слова.

например:
- Точная частотность — количество запросов в точном соответствии с регистром, последовательностью и составом фразы. Для расчёта необходимо взять запрос в специальные кавычки – » «. Полученная информация покажет количество ввода конкретного запроса, а также всех его склонений.
например:
- Уточненная частотность — для расчёта необходимо использовать запрос в кавычках » » и с восклицательным знаком перед каждым словом в запросе – !. Отражает данные исключительно по введённому запросу, игнорируя иные его формы (падежи, числа и т. д.). При составлении семантического ядра рекомендуется использовать именно этот вид частотности, потому что именно она отражает его популярность у аудитории.
например:
Кроме этого у любого запроса есть показатель эффективности данного запроса, называемый «полнота запроса», на основе которого имеет смысл принимать решение о применении или нет конкретного запроса при продвижении сайта.
Услуги, связанные с термином:
Частотность ключевых запросов в Яндекс и Google: методы определения
Эта статья рассчитана на новичков в SEO, а также на владельцев сайтов, которые выбрали себе запросы для продвижения, но не знают, частотные ли это запросы.
Итак, начнём.
Частотность запроса — это количество запросов или фраз, набранных пользователем в поисковой системе в определённый промежуток времени. Способы определения частотности запроса в поисковых системах отличаются. В этой статье мы рассмотрим частотность запросов в самых популярных поисковых системах — в Google и Яндексе.
Из этой статьи мы узнаем следующее:
- Как определять частотность запросов в Яндексе
- Как определять частотность запросов в Google
- Программный сбор частоты запросов
- Онлайн-сбор частоты
1. Как определять частотность запросов в Яндексе
1. 1. Сервис подбора слов в Яндексе
1. Сервис подбора слов в Яндексе
Для определения частоты запросов в Яндексе есть простой и удобный «Сервис подбора слов в Яндексе» или, как его ещё называют, Яндекс Wordstat.
Вбивая запрос в строку подбора, мы получаем следующую картину:
Мы видим, что по запросу [пластиковые окна] было 1 006 660 показов в месяц — это и есть его частота. То, что находится ниже, — это «Статистика по запросу» + «Словосочетания с этим запросом, которые также искали люди». Эти данные необходимы при сборе семантического ядра. Об этом есть статья в нашем блоге «Семантическое ядро: как правильно подобрать ключевые фразы для продвижения сайта».
Примечательно, что сейчас мы видим общую картину по показам в месяц, но можно посмотреть частоту запроса отдельно по виду устройств (планшеты, мобильные телефоны, компьютеры), с которых пользователи искали запрос.
Так, мы видим, что 269 733 показа от общего количества пришлись на телефоны.
1.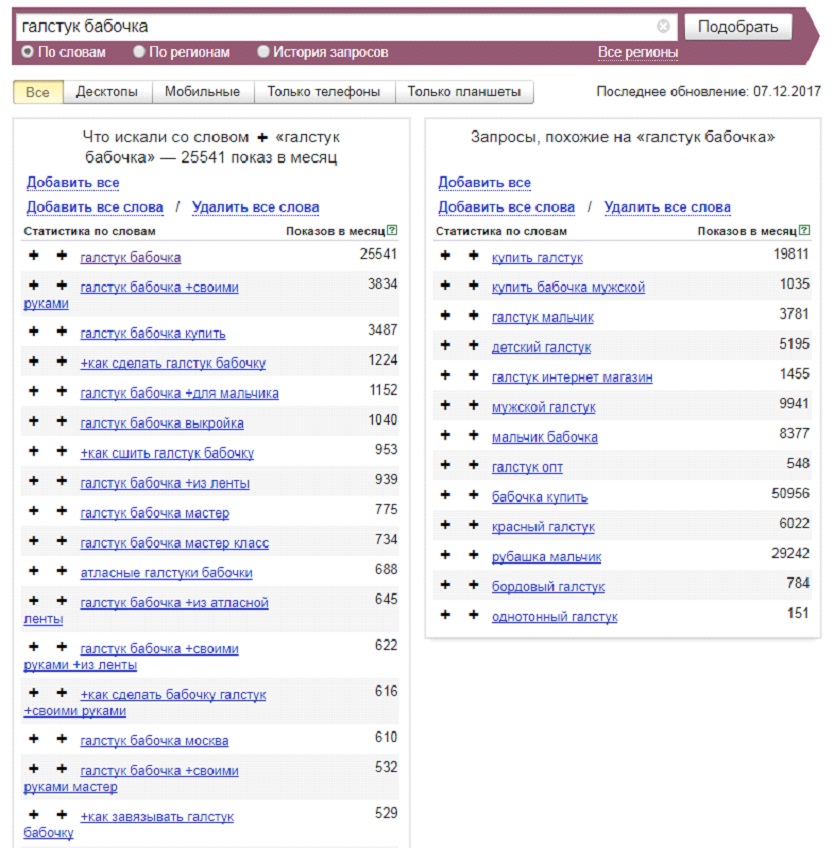 2. Виды частотности в Яндексе
2. Виды частотности в Яндексе
Итак, мы узнали, что у запроса [пластиковые окна] было 1 006 660 показов в месяц — это будет базовая частота запроса.
Всего в Яндекс Wordstat выделяют три вида частоты:
- Базовая частота — обозначает число показов по всем запросам с нужным ключевым запросом. В нашем случае это запрос [пластиковые окна]. При сборе базовой частоты по этому запросу были учтены все возможные словоформы, а также варианты запросов [купить пластиковые окна], [цены на пластиковые окна] и т. д.
- Фразовая частота — для её определения нужно взять запрос в кавычки. Это позволит нам узнать частоту запроса по интересующей нас фразе.
Как видно по скриншоту, фразовая частота значительно ниже базовой, так как во фразовой частоте могут учитываться словоформы, падежи, разные окончания, но игнорируются добавочные слова (например, запрос [купить пластиковые окна] при сборе фразовой частоты не учитывается).
- Точная частота — для её определения нужно взять запрос в кавычки и перед каждым словом в запросе поставить восклицательный знак.
В таком виде мы узнаем количество показов в месяц конкретно по этому запросу.
1.3. Геозависимость
Помимо различной частоты запроса, мы можем узнать частоту по запросам в разных регионах. Для этого нужно вместо пункта «По словам» отметить пункт «По регионам».
На скриншоте видно общее число запросов, а также их количество конкретно по регионам. К примеру, в регионе «Москва» 13 847 показов, региональная популярность составляет 206%.
Что такое региональная популярность? Ответ Яндекса:
«Региональная популярность» — это доля, которую занимает регион в показах по данному слову, делённая на долю всех показов результатов поиска, пришедшихся на этот регион. Популярность слова/словосочетания, равная 100%, означает, что данное слово в данном регионе ничем не выделено. Если популярность более 100%, это означает, что в данном регионе существует повышенный интерес к этому слову, если меньше 100% — пониженный. Для любителей статистики можем заметить, что региональная популярность – это affinity index.
Если популярность более 100%, это означает, что в данном регионе существует повышенный интерес к этому слову, если меньше 100% — пониженный. Для любителей статистики можем заметить, что региональная популярность – это affinity index.
Также можно задать регион при сборе частоты. По умолчанию установлен сбор по всем регионам.
Выбираем регион.
Таким образом, при поиске точной частоты запроса по конкретному региону можно узнать, какое количество людей ищут интересующий вас запрос в указанном регионе.
1.4. Как определить сезонность запроса
В Яндекс Wordstat есть ещё одна интересующая нас функция. Для её использования нужно отметить пункт «История запросов».
Таким образом, мы видим, какой была частота запроса по месяцам в разные периоды. С помощью этой информации можно примерно спрогнозировать падения/подъёмы трафика на сайте.
1.5. Плагины для удобства пользования сервисом
Сервис Wordstat полезный, но не очень удобный, поэтому для того чтобы облегчить себе жизнь, при работе с ним я использую плагин Yandex Wordstat Assistant.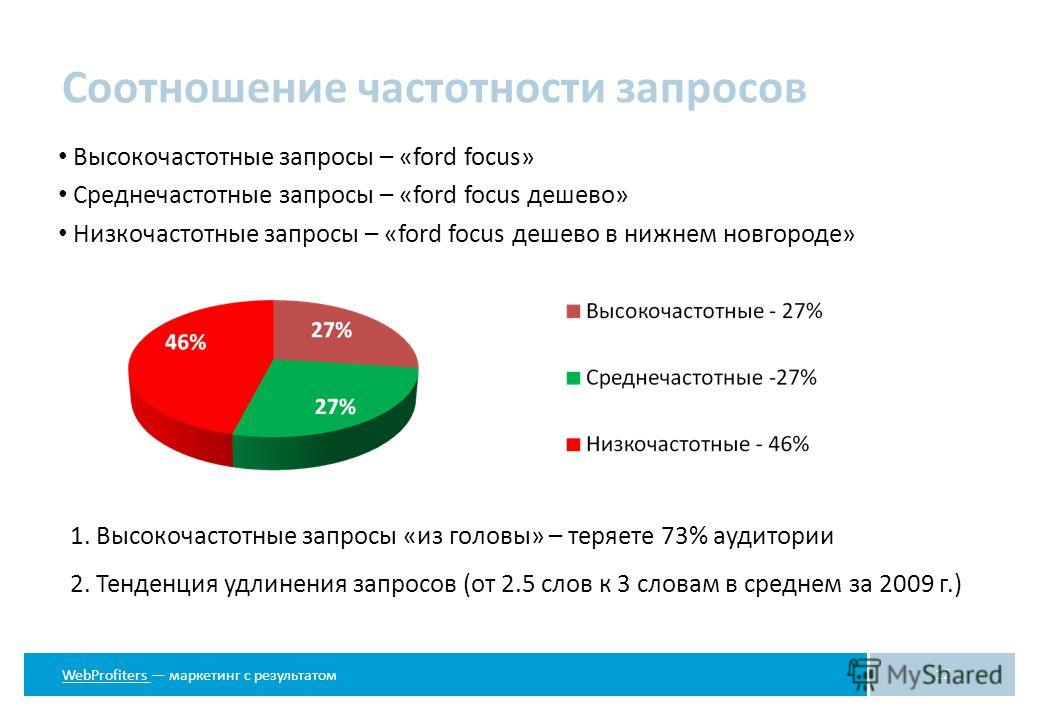
Вот так он выглядит в окне Вордстата:
Первое, что бросается в глаза, — это плюсы около запросов. Нажимая на них, мы добавляем запросы в колонку слева:
Это очень удобно, так как обычно нужно выделять каждый запрос и его частоту, чтобы его скопировать. Более того, можно спокойно переключаться на другие запросы, и список запросов, добавленных в колонку, сохранится.
Также этот плагин позволяет сортировать запросы прямо в колонке по частоте или алфавиту, а после — копировать эти запросы с частотой в нужный вам документ. Рекомендую использовать плагин для браузера Chrome, так как там более свежая версия, которая постоянно обновляется. Для FireFox тоже есть плагин, но он не обновлялся с апреля 2015 года, так что не все функции работают корректно.
2. Как определять частотность запросов в Google?
Если с Яндексом всё относительно просто, то узнать частоту запроса в Google будет сложнее. У Google нет сервиса вроде Яндекс Wordstat, поэтому приходится использовать сервис контекстной рекламы Google AdWords. Вам нужно будет зарегистрироваться в нём. После регистрации перед вами появится панель.
Вам нужно будет зарегистрироваться в нём. После регистрации перед вами появится панель.
Откройте вкладку меню «Инструменты» и в выпавшем меню найдите «Планировщик ключевых слов».
После этого откроется страница планировщика. На этой странице нужно выбрать «Получение статистики запросов и трендов». Там вбейте интересующий вас запрос и укажите регион.
Нажмите на кнопку «Узнать количество запросов». Вы получите такой результат:
Из-за ограничений AdWords у запроса среднее число запросов в месяц колеблется от 1000 до 10 000. Чтобы получить более подробную информацию, нужно создать и запустить кампанию.
При запущенной платной кампании частота запроса будет выглядеть следующим образом:
3. Программный сбор частоты запросов
Выше были описаны способы ручного сбора частоты запросов. При большом количестве запросов собирать их частоту вручную очень неудобно, поэтому я использую специальные программы.
3.1. Программа «Словоёб»
В статье в нашем блоге «Два подхода к подбору семантического ядра» подробно описано, как с помощью «Словоёба» парсить ключевые слова (скачать его можно бесплатно с сайта). Но программа будет полезна и в том случае, если у вас уже есть запросы и вам нужно только собрать частоту.
Обратите внимание: программа парсит данные из Яндекс Wordstat, следовательно, частоту запросов можно узнать только по Яндексу.
Чтобы собрать частоту по определённому списку запросов, нужно сделать следующее:
- Добавить запросы в программу, вызвать контекстное меню в окне программы и выбрать функцию «Добавить фразы»;
- В появившемся окне вставить списком запросы и нажать «Добавить в таблицу»;
- Указать «Регион» и в верхнем меню выбрать вид частоты.
Результат таков:
Как я уже говорил выше, программа парсит Яндекс Wordstat, так что в настройках меню Yandex.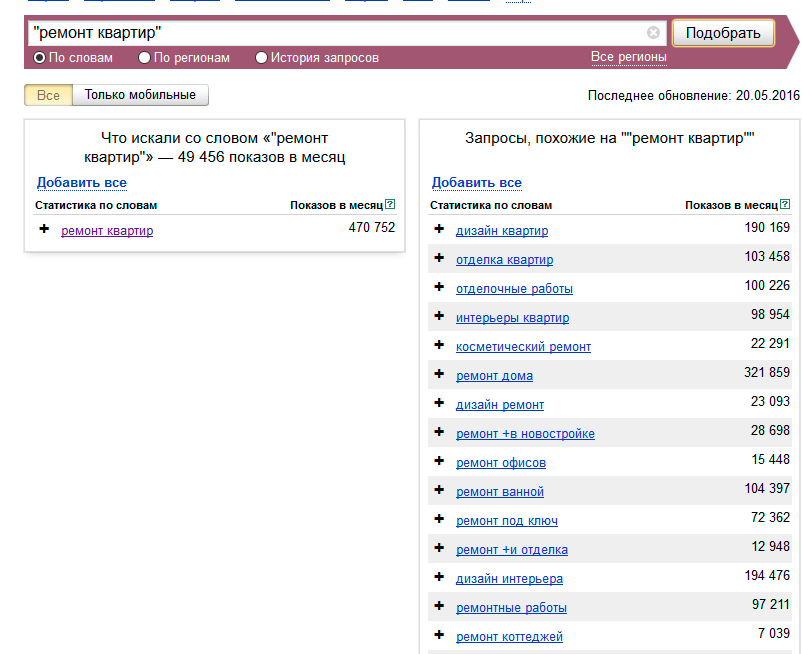 Direct нужно будет добавить любой аккаунт Яндекса. Также в настройках можно указать ключ для Антикапчи. Настроек немного, так что разобраться несложно. Программа бесплатная, потому воспользоваться ею может любой желающий.
Direct нужно будет добавить любой аккаунт Яндекса. Также в настройках можно указать ключ для Антикапчи. Настроек немного, так что разобраться несложно. Программа бесплатная, потому воспользоваться ею может любой желающий.
3.2. Программа Key Collector
Ещё одна программа, которую я хочу упомянуть, — это знаменитый Key Collector. Этой программой я пользуюсь регулярно и рекомендую всем, кто связан с SEO и постоянно работает с запросами.
Чтобы собрать частоту, нужно для начала настроить программу. О настройке программы Key Collector написано в статье «Как составить ТЗ копирайтеру, чтобы статья попала в ТОП без ссылок?».
После настройки программы нужно запустить её и так же, как и в случае со «Словоёбом», добавить запросы, указать «Регион» и нажать на «Сбор статистики Yandex. Direct».
Key Collector, в отличие от «Словоёба», парсит данные, используя Яндекс. Директ, что значительно ускоряет процесс парсинга. Жмём «Получить данные» и получаем результат:
Программа позволяет собирать частоту и для Google, используя Google AdWords. Для этого нужно её настроить. Настройки можно посмотреть на официальном сайте Key Collector. Затем нужно будет нажать на кнопку «Сбор статистики Google. Adwords», которая находится рядом с кнопкой «Сбор статистики Yandex.Direct».
Для этого нужно её настроить. Настройки можно посмотреть на официальном сайте Key Collector. Затем нужно будет нажать на кнопку «Сбор статистики Google. Adwords», которая находится рядом с кнопкой «Сбор статистики Yandex.Direct».
4. Онлайн-сбор частоты запросов
Иногда бывают ситуации, когда любимого инструмента нет под рукой, а частоту собрать нужно. В этом случае можно воспользоваться онлайн-сервисами для сбора частоты. Я рассмотрю 2 сервиса, которые использую сам. Один будет под Яндекс, другой — под Google.
4.1. Онлайн-инструмент для сбора частоты от SeoLib для Яндекса
У сервиса SeoLib есть множество удобных инструментов. Один из таких инструментов — «Подбор ключевых слов».
Всё, что нужно сделать, — это открыть вкладку «Анализ ключевых фраз» и скопировать в форму для запросов или прикрепить отдельным файлом список интересующих запросов. После этого нужно выбрать необходимую частоту и регион, при необходимости указать дополнительные параметры. После нажать на «Начать анализ».
После нажать на «Начать анализ».
Результат:
Инструмент платный, но цены демократичные. К примеру, список из этих 7 запросов по всем видам частотности обошёлся мне в 5,3 рубля.
4.2. Онлайн-инструмент для сбора частоты от Ahrefs для Google
Сервис Ahrefs популярен тем, что через него удобно анализировать ссылочную массу сайта. В нашем блоге сервису посвящена отдельная статья «Как проанализировать ссылочную массу сайта с помощью Ahrefs».
В сервисе есть инструмент «Анализ ключевых слов».
В форму нужно через запятую добавить ключевые слова и указать регион около кнопки «Пояса».
Результат:
Переходим во вкладку «Метрики»:
Отчёты содержат большое количество полезной информации для анализа. Сервис платный, но есть 2 недели пробного доступа для знакомства с функционалом.
Итоги
Работа с Яндексом:
- Если запросов несколько, можно смотреть их вручную через Яндекс Wordstat.
В таком случае я настоятельно рекомендую поставить плагин Yandex Wordstat Assistant — он заметно облегчает процесс;
- Если у вас есть список запросов и вам необходима быстрая разовая проверка, используйте онлайн-инструмент «Подбора ключевых слов» от SeoLib;
- Если вы постоянно работаете с запросами, рекомендую купить Key Collector. «Словоёб» хоть и бесплатный, но парсит слишком медленно, а время, которое вы сэкономите на парсинге запросов в Key Collector, с лихвой отобьёт затраты. «Словоёб» можно использовать, если вы работаете с небольшим списком запросов и пользуетесь им нечасто. Я сам им пользовался, когда начинал работу в SEO, но когда приобрёл Key Collector, пожалел, что не купил его раньше.
Работа с Google:
- Если запросов несколько, используйте Google AdWords;
- Если у вас есть список запросов, то удобнее будет воспользоваться онлайн-сервисом Ahrefs или настроить Key Collector.
Я перечислил сервисы, которые сам использую для сбора частоты запросов. Возможно, вы пользуетесь другими сервисами? Тогда укажите их в комментариях, буду рад ознакомиться с ними!
Возможно, вы пользуетесь другими сервисами? Тогда укажите их в комментариях, буду рад ознакомиться с ними!
На этом пока всё, желаю вам хороших позиций по частотным запросам!
Подписаться на рассылкуЕще по теме:
Андрей Д.
SEO-аналитик
Всегда знал, что моя работа будет связана с интернетом и компьютером. Начал самостоятельно учить HTML и пробовать себя в верстке. HTML давался легко, но верстать сайты было скучно. Тогда я и узнал о SEO.
С отличием завершил мастер-класс по обучению и управлению персоналом. Сдал письменный тест по английскому языку в Лондонской школе на 98%. Написал более десятка развивающих статей по SEО.
Работаю SEO-специалистом в компании SiteClinic, пишу статьи для блога. В свободное время хожу в походы.
Девиз: Just Do It
Оцените мою статью:
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.
Частота поисковых запросов отражает их популярность у пользователей
Общее определение
Частотность поисковых запросов – параметр, характеризующий популярность запросов у пользователей. Выражается цифрой, показывающей, сколько раз в месяц конкретный запрос был задан в поисковой системе. Эта цифра и является частотой данного запроса.
Количественное определение частотности запросов
В поисковой оптимизации сайтов (SEO) в целом принято выделять три основных категории запросов по частоте:
- высокочастотные (ВЧ),
- среднечастотные (СЧ),
- низкочастотные (НЧ).
Очень условно считается, что ВЧ-запросы имеют частоту выше 10000, СЧ-запросы – 1000–10000, НЧ-запросы – менее 1000. Но эта градация именно очень условная, поскольку критическое значение имеет тематика запросов. Если тематика популярна, значения частот поисковых запросов в ней будут большими. Если тематика не очень популярная или вообще редкая, значения частот запросов в ней будут небольшими.
Таким образом, при определении частот запросов в SEO, в частности для формирования семантического ядра сайта и определения бюджета продвижения, следует отталкиваться именно от конкретной тематики. В какой-то тематике запрос с частотой 2000 будет являться СЧ или даже НЧ (популярная тематика), а в какой-то – ВЧ (не очень популярная тематика).
Кроме этого на частоту запросов влияют и другие факторы: регион, сезонность и событийность. Например, частота запроса в целом по России будет выше, чем по Москве, а по Москве – выше, чем по небольшому городу. Также для многих тематик частота одних и тех же запросов изменяется в зависимости от времени года (сезонность запросов) или определённого события (событийность запросов), причём изменяться она может в десятки раз (см. ниже «Изменения частот поисковых запросов»). Всё это делает деление поисковых запросов на ВЧ, СЧ и НЧ ещё более условным, т.к. частота привязывается уже не только к отдельной теме, но и к региону, а также ко времени или событию.
Однако в контекстной рекламе частотность всех запросов (ключей – ключевых слов или фраз) в целом привязывается к некой общей базе, на основе которой определяется стоимость запроса – CPC (cost per click – цена за клик; подробнее – см.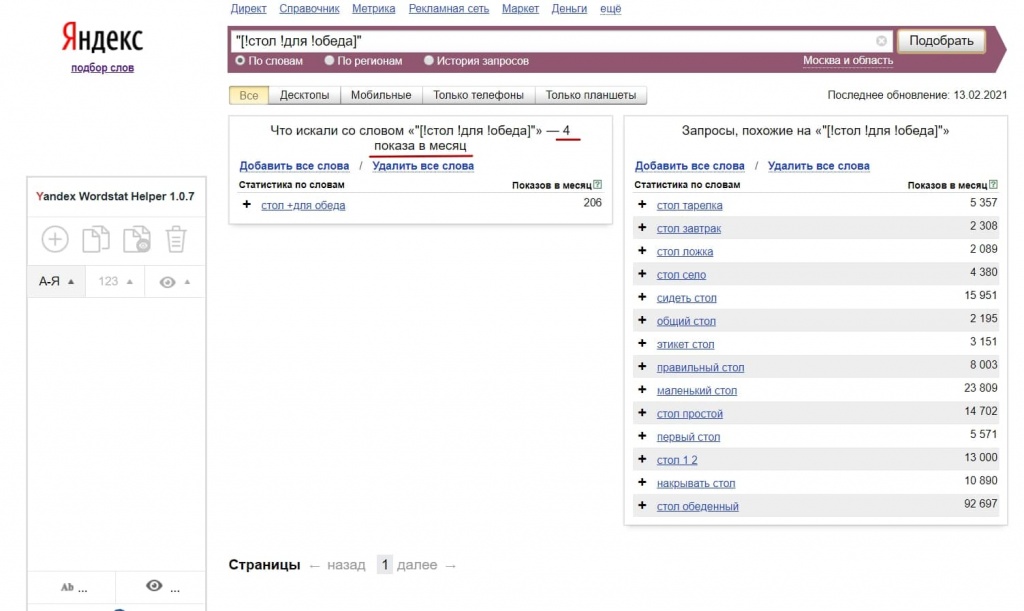 статью Контекстная реклама). То есть в контекстной рекламе работает общее правило: чем более популярен запрос в целом (выше его частота), тем выше его стоимость (CPС).
статью Контекстная реклама). То есть в контекстной рекламе работает общее правило: чем более популярен запрос в целом (выше его частота), тем выше его стоимость (CPС).
Помимо трёх основных категорий поисковых запросов – ВЧ, СЧ и НЧ – выделяют и дополнительные категории – в сторону уменьшения частоты. Однако значение этих категорий запросов возрастает – как для SEO, так и для контекстной рекламы. Это микро-, или сверхнизкочастотные запросы (сНЧ; здесь мы будем использовать данное понятие), а также мерцающие (мигающие), случайные и «нулевые» запросы. В целом эти понятия можно рассматривать как универсальные для любой тематики, поскольку значения частот данных запросов являются предельно низкими.
сНЧ-запросы имеют частоту 1–2. Мерцающие запросы имеют частоту 0–2. Это значит, что в какой-то месяц запрос может быть задан единожды или пару раз, а в какой-то – ни разу. Случайные запросы – те, которые возникли один раз и затем вообще никогда больше могут не повториться. Они, в принципе, близки к понятию «нулевые запросы» для которых Яндекс.Вордстат или планировщик ключевых слов Google вообще показывают стабильное значение частоты – ноль.
Они, в принципе, близки к понятию «нулевые запросы» для которых Яндекс.Вордстат или планировщик ключевых слов Google вообще показывают стабильное значение частоты – ноль.
Практическое значение частотности запросов мы рассмотрим чуть ниже.
Сервисы определения частоты запросов
Значение частот поисковых запросов определяются с помощью специализированных сервисов, которые называются Яндекс.Вордстат и планировщик ключевых слов Google (соответственно, для Яндекс и Google). Оба являются бесплатными. Но Яндекс.Вордстат находится в свободном широком доступе, т.е. с ним можно начать работать немедленно, а планировщик Google доступен только в рамках планирования контекстной рекламы Google Ads или имитации этого планирования. Для работы с данным сервисом необходимо иметь аккаунт в Google, сайт, для которого планируется реклама, и пройти ряд предварительных шагов в системе.
Таким образом, наиболее удобным для непосредственного («ручного») определения частот поисковых запросов на сегодняшний день является сервис Яндекс. Вордстат – тем более, что он имеет дополнительные очень полезные опции, например определение истории запросов (см. ниже).
Вордстат – тем более, что он имеет дополнительные очень полезные опции, например определение истории запросов (см. ниже).
Но, поскольку при формировании семантического ядра для SEO сайта или контекстной рекламы работа всегда ведётся с большим количеством запросов (нередко сотнями и даже тысячами), для их подбора и определения частот используют методы автоматизации. Наиболее популярным сервисом в этом отношении является инсталлируемая программа Key Collector, с помощью которой делается автоматический сбор (парсинг) запросов с Яндекс.Вордстата и Google-планировщика.
Практическое значение частотности запросов
Это значение имеет два аспекта – для SEO и для контекстной рекламы.
Значение частотности для SEO
На первый взгляд логично предположить, что, чем выше частота запроса, тем больше по нему трафик на сайт и тем, соответственно, запрос более эффективен: даёт больше потенциальных покупателей, если у нас, например, коммерческий ресурс.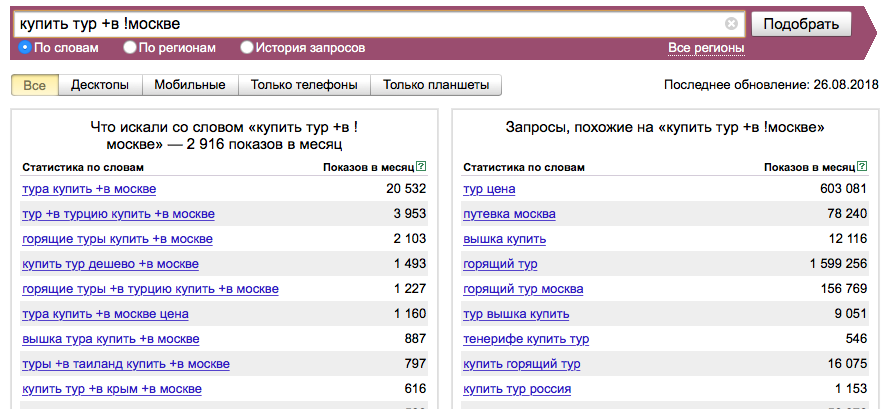 Но это именно на первый взгляд. На самом деле имеется три сильных аргумента против опоры на ВЧ-запросы в поисковом продвижении сайтов.
Но это именно на первый взгляд. На самом деле имеется три сильных аргумента против опоры на ВЧ-запросы в поисковом продвижении сайтов.
- Во-первых, ВЧ-запросы, как правило, являются и высококонкурентными (ВК). Конкурентность и частотность запросов – это не одно и то же, но во многих случаях они коррелируют (подробнее – см. ниже, а также статью Конкурентность поисковых запросов). Высокая конкуренция по запросу означает, что в ТОПе поисковой выдачи по нему присутствует очень много веб-страниц/сайтов. И это, в свою очередь, означает что продвинуть по данному запросу в ТОП новый сайт чрезвычайно трудно – долго и дорого.
- Во-вторых, в целом работает следующее правило: чем выше частота запроса, тем он менее специфичен (подробнее – см. статью Определённые и неопределённые поисковые запросы). А это означает, что по данному запросу на сайт будет приходить много нецелевых посетителей. Последнее плохо как для SEO, так и в целом для маркетинга. С точки зрения SEO нецелевые посетители будут давать сайту плохие поведенческие факторы (ПФ), т.е. быстро выходить с сайта. Поисковая система может расценивать это как реакцию на плохое качество сайта (он не нравится пользователям) и, соответственно, понижать сайт в своей поисковой выдаче. Для общего же маркетинга слишком нецелевая – «грязная» – аудитория также является нежелательной, поскольку отнимает много ресурсов на её обработку.
- Наконец, в-третьих, на самом деле, несмотря на высокую частоту, доля трафика на сайт по ВЧ-запросам является довольно невысокой. Подавляющий трафик (до 70%) складывается как раз из НЧ и особенно сНЧ, мерцающих и даже случайных и нулевых запросов. Это так называемый хвост, или шлейф запросов. Да, каждый такой запрос является редким или сверхредким, т.е. в одиночку даёт ничтожный трафик на сайт.
Но, здесь также работают три важных принципа:
- НЧ, сНЧ, мерцающие и даже случайные и нулевые запросы являются предельно целевыми, т.е. высококонверсионным, т.к. по ним на сайт приходят самые целевые клиенты («тёплые» и «горячие»).
- Подобные запросы, как правило, являются и низкоконкурентными (НК, сНК), а это значит, что по ним сайт с лёгкостью попадает в ТОП поисковой выдачи. То есть на продвижение по этим запросам тратится минимальное количество средств и времени, если не считать создание контента под такие запросы (копирайтинг). Последнее в данном случае, вообще-то, и есть самая основная и самая дорогая работа.
- В силу богатства языка НЧ/сНЧ-запросов по теме возникает очень много, а потому по совокупности трафик по таким запросам и составляет наибольшую долю в общем поисковом трафике на сайт (как сказано, до 70%).
Таким образом, выгодной SEO-стратегией является продвижение новых сайтов именно по НЧ/сНЧ-шлейфу запросов. Причём, при формировании семантического ядра сайта и отдельных веб-страниц, имеет смысл закладывать не просто мерцающие, но даже нулевые запросы – те, для которых Яндекс.Вордстат или планировщик Google показывают значение частоты ноль. Во-первых, обработка запросов данными системами на самом деле является статистической, так что формальный ноль – это не всегда ноль реальный. А во-вторых, если вы двигаете новую тему и считаете, что по ней должны появиться новые запросы, в т.ч. случайные, – их безусловно необходимо закладывать в семантическое ядро сайта.
Закладывать в семантическое ядро означает формировать структуру из ключевых слов и фраз, которая должна соответствовать структуре сайта (иерархии разделов и страниц). На самом сайте это воплощается в том, что определённые ключи (вхождения запросов) закладываются в текстовый контент определённых веб-страниц. Таким образом, чем богаче отдельная страница и сайт в целом насыщены точными по смыслу (релевантными), но при этом разнообразными НЧ-ключами, тем легче обеспечить максимальный по объёму и по релевантности трафик на сайт из поиска. В этом и состоит простой принцип SEO-продвижения по «хвосту» («шлейфу»). И основная задача в данном случае заключается именно в создании соответствующего контента на сайте – текстов, предельно насыщенных разнообразными релевантными НЧ/сНЧ-ключами и обладающих общей высокой релевантностью теме отдельной веб-страницы, сайта в целом, а также интересу (интенту) пользователей.
Значение частотности для контекстной рекламыПринципиально оно то же, что и для SEO. Только в случае контекстной рекламы работа с запросами (ключами) разной частоты имеет быстрое и гораздо более конкретное выражение в цифрах, в т.ч. денежное выражение.
Как сказано выше, в контекстной рекламе работает общее правило: чем выше частота запроса, тем выше его стоимость (CPC). На стоимость объявления по данному запросу также влияет и положение объявления (выше, ниже прочих объявлений, первая или вторая страница выдачи и т.д.), – но в целом именно стоимость запросов, зависящая от их частоты, является базовым фактором, определяющим стоимость запроса и рекламного объявления по нему.
Соответственно, если заложить в рекламу ВЧ-запрос, он даст большой трафик на сайт. Но, во-первых, бюджет такой рекламы будет очень высоким из-за высокой стоимости запроса. А во-вторых, трафик по этому запросу будет очень низкоспецифичным, т.к. ВЧ-запросы, как правило, имеют широкий смысл (см. выше). Это значит, что очень дорогая контекстная реклама даст очень низкоспецифичный трафик, а значит – низкий уровень продаж и, соответственно, низкий или даже отрицательный возврат инвестиций (ROI – return of investment). На языке специалистов по контекстной рекламе (таргетологов) это и называется «слить деньги на рекламу».
Поэтому выигрышной является стратегия построение контекстной рекламы на основе НЧ и даже сНЧ, мерцающих и случайных запросов. Да, таких запросов в рекламную кампанию может быть заложено очень много – сотни и даже тысячи, чтобы суммарно обеспечить по ним хороший трафик на сайт. Но, во-первых, из-за очень низкой стоимости таких запросов бюджет рекламной кампании в целом будет невысоким. А во-вторых, в силу высокой специфичности трафик по таким запросам будет давать высокий уровень продаж, т.е. обеспечивать высокий ROI рекламы. О такой рекламе говорят, что она высококонверсионная.
В целом же, оперируя конкретными запросами и связанными с ними конкретными показателями, в т.ч. финансовыми (CPC, средний чек, конверсия переходов в продажи и др.), можно довольно точно и выгодно оптимизировать рекламную кампанию – так, чтобы она давала необходимый профит (хороший ROI). И в отличие от SEO этот процесс занимает гораздо меньше времени (за несколько дней можно провести надлежащую оптимизацию рекламы) и опирается на конкретные показатели (KPI – key performance indicators).
Таким образом, параметр частотности поисковых запросов в контекстной рекламе является весьма конкретным (формализуемым) и ключевым для бизнеса (определяющим эффективность рекламы).
Изменения частоты поисковых запросов во времени
Это явление характерно для сезонных и событийных запросов. Подробнее они разбираются в соответствующих статьях Глоссария (см. ссылки ниже).
Здесь же кратко отметим, что для сезонных запросов их частота периодически колеблется от года к году в зависимости от времени года, а точнее – от месяца. Связано это с периодическим изменением популярности темы в годовых периодах. Например, в летнее время возрастает спрос на продукцию и услуги, связанные, с летним отдыхом. Соответственно, частоты запросов по этой теме имеют максимум в летние или поздние весенние месяцы и минимум в зимние месяцы. Для «зимних» тем/товаров наблюдается обратная зависимость.
Амплитуда частоты запросов в определённых темах в течение года может достигать десятков раз. Это можно отчётливо видеть, если выбрать в сервисе Яндекс.Вордастат опцию «история запроса», которая показывает изменения частоты поискового запроса за последние 12 месяцев, в т.ч. наглядно на графике. Так что этот инструмент является очень полезным для маркетологов, поскольку фактически позволяет прогнозировать изменение спроса в течение года в определённой рыночной нише – вплоть до спроса на конкретные товары и услуги в конкретных регионах в конкретные месяцы.
Изменение частоты характерно и для так называемых событийных запросов, когда их количество в поиске может буквально взлетать с нуля и до очень больших значений с наступлением какого-то события: олимпиады, чемпионата мира по футболу, президентских выборов, крупных политических форумов, сильно распиаренной рекламной кампании и т.д. Для некоторых событий взлёт частоты запросов также можно прогнозировать и, соответственно, планировать под них коммерческую деятельность – зарабатывать на событиях.
Частотность и конкурентность запросов
Наряду с частотность для поисковых запросов также выделяют понятие (параметр) конкурентность, или конкуренция по запросу. С одной стороны, оно вроде бы имеет больший практический смысл для бизнеса, т.к. подразумевает конкурентный фон, на котором предполагается продвигать сайт в определённой теме и по определённому запросу. С другой же стороны, этот параметр гораздо менее формализуем, т.е. менее понятен, чем частотность.
Аналогично частотности также выделяют
- высоко-,
- средне- и
- низкоконкурентные запросы.
Под самой же конкуренцией для запроса понимают количество по нему веб-страниц в ТОПе поисковой выдачи. Если страниц много – конкуренция по запросу высокая (ВК), если мало – низкая (НК), если что-то между «много» и «мало» – средняя (СК). Как понятно, эти слова (много, мало, средне) по сути ни о чём – и сами по себе, и потому что понятие «ТОП» поисковой выдачи является неясным (ТОП3, ТОП5, ТОП10, ТОП20 и т.д.), и потому что конкуренция по запросам сильно зависит от темы, да и вообще – потому что для параметра конкурентность в принципе отсутствуют цифры (для частотности они хотя бы есть).
Всё это делает работу с этим понятием – ориентацию на него – очень сложной. И, как уже сказано, конкурентность запросов во многом зависит от темы, по которой сайт продвигается в поиске.
Однако параметр конкурентности запроса применим не только к SEO, но и к контекстной рекламе. Общий принцип тот же: количество конкурентных ссылок по данному запросу – в данном случае конкурентных рекламных, а не поисковых ссылок. Поскольку работа с контекстной рекламой в целом формализуется гораздо лучше, чем SEO, использовать параметр конкурентности по запросу в контекстной рекламе также проще. Подробнее соответствующие вопросы рассматриваются в соответствующей статье Глоссария (см. ссылки ниже).
Дополнительно по теме – см. статьи Ключевые слова / фразы, Вхождения, Семантическое ядро, Определённые и неопределённые поисковые запросы, Конкурентность поисковых запросов, Контекстная реклама.
Полная классификация запросов представлена в статье Поисковые запросы.
По всем соответствующим практическим вопросам мы рекомендуем Вам обращаться в нашу компанию. Наши профессиональные специалисты не только дадут Вам подробные консультации, но и возьмут на себя полное продвижение Вашего веб-ресурса, включая SEO и контекстную рекламу.
Заказать интернет-продвижение
python — Hackerrank Frequency Queries
Вам задают вопросы. Каждый запрос имеет форму двух целых чисел, описанных ниже:
Вставьте x в структуру данных.
Удалите одно вхождение y из вашей структуры данных, если оно есть.
Проверить, присутствует ли какое-либо целое число с точной частотой. Если да, выведите 1 else 0.
Пример ввода:
запросов = [(1,1), (2,2), (3,2), (1,1), (1,1), (2,1), (3,2)]
Проблема довольно очевидна, и я думаю, что у меня есть достойное решение:
перебирает запросы и соответственно увеличивает и уменьшает частоту каждого числа в dict … одновременно в отдельном дикте отслеживать, сколько раз появляется каждая клавиша другого дикта
при проверке, присутствует ли какое-либо целое число, частота которого точно равна y для QUERY 3, вы должны проверить, существует ли количество y во втором dict …
Я прохожу большинство тестов, но проваливаю некоторые … Кто-нибудь может объяснить недостатки моего мышления.
def freqQuery (запросы):
частота = {}
результаты = []
frequencyValues = {}
для запроса в запросах:
q = запрос [0]
val = запрос [1]
если q == 1:
частота [val] = частота.получить (val, 0) + 1
freq = частота [значение]
frequencyValues [freq] = frequencyValues.get (freq, 0) + 1
frequencyValues [freq-1] = frequencyValues.get (freq-1, 1) - 1
elif q == 2:
если val в frequency.keys ():
частота [val] + = - 1
если частота [val] <0:
частота [val] = 0
freq = частота [значение]
frequencyValues [freq + 1] = frequencyValues.get (freq + 1, 1) - 1
frequencyValues [freq] = frequencyValues.получить (частота, 1) + 1
elif q == 3:
если значение равно в frequencyValues.keys ():
если frequencyValues [val]> 0:
results.append (1)
еще:
results.append (0)
еще:
results.append (0)
вернуть результаты
Какая частота запросов и как ее определить?
Частота запросов — SEO WIKI
Частота запросов — это количество раз, когда пользователь нажимает определенное слово или фразу для поисковой системы за месяц.Различают три основных типа: высокочастотный (HF), низкочастотный (LF) и среднечастотный (MF). Однако самих видов больше:
Superfrequency — самые популярные слова или фразы, т.е. они наиболее часто запрашиваются в определенной теме. Обычно микроволновые запросы состоят из одного слова, например «смартфон» или «одежда». Они наиболее конкурентоспособны, потому что их продвигают многие компании в определенных сферах. Частота показов — от 100 000 в месяц и выше.Продвижение на них подходит далеко не каждому бизнесу, поскольку из-за отсутствия в запросе уточняющих фраз релевантность страниц, выбранных поисковой системой, может быть размыта. Обычно при таких запросах поисковая система пытается показать как можно больше информации с искомым словом, например, при поиске слова «замок» Яндекс покажет и здания, и механические устройства для запирания дверей.
Высокая частота. Они отличаются от сверхчастотных тем, что могут указывать дополнительное слово, но это не делает запрос менее частым.Например, запрос «Московская квартира» (620 000 показов по московскому времени) остается частым, несмотря на то, что в нем есть уточняющее слово. Это не так уж и часто по сравнению с запросом «квартира» (5 250 000 показов MSC). Частота таких запросов от 10 000. На профессиональном жаргоне высокочастотные запросы называются «жирным». Их грамотное продвижение помогает привлечь на сайт максимальное количество пользователей. Но многие сайты продвигаются по высокочастотным запросам, что создает большую конкуренцию.Поэтому продвижение высокочастотных запросов обходится довольно дорого в финансовых и временных планах.
Midrange — как правило, состоят из нескольких слов со средней частотой показов от 500 до 5000-10000. Запросы среднего уровня задают пользователи, которые знакомы с их областью интересов или знают, как им нужно уточнить исходный общий высокочастотный запрос.
Низкочастотные — наиболее специфичный тип запросов, они имеют узкую направленность. Пример: «купите телевизор Samsung в Питере.Петербург ». Частота показов — от 50-100 до 500 в месяц.
Микрочастота — может иметь частоту от 1 до 50. Запросы на MF считаются самыми неконкурентными, так как содержат длинный квалифицирующий «хвост» в запросе. Пример: «как внести деньги на банковский счет ООО».
Важно отметить, что частота одного и того же запроса сильно различается в разных поисковых системах.
Яндекс сознательно тормозит продвижение веб-ресурсов на высококонкурентные позиции, комментируя то, что сайт должен сначала прославиться, заработать репутацию и быть стабильным в развитии.И только после того, как он зарекомендовал себя, поисковая система даст ему возможность составить конкуренцию ведущим конкурентам.
запросов MF и LF, хотя и не требуют больших финансовых вложений, также способны обеспечить постоянный рост трафика на сайт и охватить большое количество пользователей.
На основе анализа запрошенных фраз SEO-оптимизатор составляет подборку наиболее популярных запросов и продвигает проект по ним.
Если вам нужно проверить частоту запросов, вы можете воспользоваться специальными услугами:
Яндекс.Wordstat — это инструмент, который помогает определить частоту необходимых запросов в поисковой системе Яндекс. Недостатком сервиса является то, что вам нужно проверять запросы вручную и по одному.
Google Adwords — это служба статистики поиска Google. Предоставляет всю необходимую информацию по запросу, есть возможность установить язык и регион, предоставляются синонимы. Внимание, если в вашем аккаунте Adwords нет активных рекламных кампаний, то показания в сервисе могут быть очень приблизительными и неточными.
Выбор представления на основе частоты запросов: Business & Management Journal Статья
Предварительный просмотр статьи
НаверхВведение
Глобализация предприятий привела к тому, что с течением времени непрерывно генерируются огромные объемы данных. В наш век постоянно меняющихся данных и экономики, основанной на потребностях, легкодоступная и обновленная информация играет жизненно важную роль в формулировании оптимальных бизнес-стратегий для получения конкурентных преимуществ. Чтобы быть и оставаться конкурентоспособным на сегодняшнем нестабильном рынке, требуются значительные усилия, такие как проведение маркетинговых исследований для выявления требований клиентов в сравнении с их потребностями.В последние несколько десятилетий наблюдается экспоненциальный рост в областях информационных технологий и обработки информации. Надлежащая и своевременная доступность этой обработанной информации является ключом к выживанию бизнеса. Чтобы удовлетворить этот спрос на информацию, сбор и эффективное хранение турбулентных данных, которые должны обрабатываться с целью анализа, должны быть в центре внимания. Такие обработанные данные обычно оказываются полезными для работников умственного труда и / или лиц, принимающих решения, в процессе принятия решений.Доступность таких данных дает коммерческим компаниям существенное преимущество перед их конкурентами.
С наступлением эры технологических усовершенствований в области программного обеспечения, аналитики, аппаратных возможностей и передачи данных большинство организаций собирают огромные объемы необработанных данных. В результате, хотя большинство таких организаций имеют большое количество данных, им не хватает убедительной информации (Gray & Watson, 1998; Han & Kamber, 2000), что приводит к потере ценной информации внутри огромных данных, что приводит к тому, что организации борются за нужную информацию.Следовательно, доступность соответствующей информации для соответствующего лица задерживается. Это усиливает потребность в преобразовании данных, имеющихся в операционных / других источниках данных, в полезную информацию, чтобы позволить работникам умственного труда и / или лицам, принимающим решения, получать доступ и извлекать скрытые основные закономерности для принятия оптимальных решений в нужное время. Чтобы анализировать такие гигантские данные, необходима надежная система поддержки принятия решений для предложения решений бизнес-проблем / запросов, которые являются сложными и неструктурированными.В эту эпоху растущей конкуренции между организациями актуальная потребность состоит в том, чтобы иметь системы, способные извлекать, хранить и анализировать скрытую информацию, скрытую в огромных доступных данных. Есть два способа доступа к данным в источниках данных, а именно: ленивый подход или подход по запросу и подход нетерпеливый или заблаговременный (Widom, 1995). В первом случае доступ к оперативным источникам осуществляется в ответ на запросы, что сокращает накладные расходы на хранение, тогда как во втором данные предварительно вычисляются и сохраняются заранее, что приводит к снижению затрат на связь.Время ответа на запрос для подхода по требованию сравнительно велико, поскольку он исследует операционные источники в ответ на поставленный запрос. С другой стороны, данные предварительно вычисляются и сохраняются в хранилище, что приводит к сокращению времени ответа на запрос в случае активного или заблаговременного подхода. Хранилище данных основано на подходе «нетерпеливо» или «заблаговременно» (Widom, 1995).
Статистический анализ SQL, часть 1: Расчет частот и гистограмм
Разработчики баз данных и бизнес-аналитики (BI) ежедневно создают огромное количество отчетов, и анализ данных является их неотъемлемой частью.Если вам интересно, можете ли вы выполнять статистический анализ в SQL, ответ — «да». Прочтите мою статью, чтобы узнать, как это сделать!
Статистика очень полезна в качестве начального этапа более глубокого анализа, то есть для обзора данных и оценки качества данных. Однако возможности статистического анализа SQL несколько ограничены, поскольку в SQL Server не так много статистических функций. . К тому же хорошее понимание статистики не очень распространено среди практиков T-SQL.В SQL Server 2016 вы можете использовать R для вычисления всех видов статистических показателей, но многие разработчики SQL Server и администраторы баз данных не программируют на R. И не все сайты обновлены до SQL Server 2016.
В этой серии статей объясняются основы статистического анализа SQL. Используемый код основан на моем реальном опыте. Я занимаюсь проектами бизнес-аналитики, особенно интеллектуальным анализом данных, и мне часто приходится создавать множество статистических запросов на начальных этапах проекта. Во время этих проектов часто единственное программное обеспечение, на которое я могу положиться, — это СУБД.
Оптимизация статистических запросов SQL
Оптимизация статистических запросов отличается от оптимизации транзакционных запросов. Чтобы вычислить статистику, запрос обычно сканирует все данные. Если запрос выполняется слишком медленно, вы можете подготовить случайную выборку данных и отсканировать ее. Однако, если запросы слепо следуют формулам, они часто выполняют многократное сканирование данных. Оптимизация таких запросов означает минимизацию количества сканирований. Для этого необходимо разработать алгоритм, использующий дополнительную математику для преобразования формул в эквиваленты, которые можно лучше оптимизировать в SQL Server или любой другой СУБД.Вам также необходимо глубоко разбираться в SQL. Например, вам нужно действительно хорошо разбираться в оконных функциях и вычислениях SQL.
Помимо объяснения статистики и статистических запросов, эта серия также даст вам некоторые идеи по оптимизации статистических и нестатистических запросов.
Подготовка данных для статистического анализа SQL
Перед тем, как начать анализ, вам нужно понять, что вы анализируете. В статистике вы анализируете случаи, используя их переменные.В терминологии СУБД вы можете рассматривать случай как строку таблицы, а переменную — как столбец в одной и той же таблице. Для большинства статистических анализов вы готовите одну таблицу или представление. Иногда бывает не так просто точно определить ваш случай. Например, если вы проводите анализ кредитного риска, вы можете определить семью как случай, а не как одного клиента.
При подготовке данных для статистического анализа SQL необходимо соответствующим образом преобразовать исходные данные. Для каждого случая вам необходимо инкапсулировать всю доступную информацию в столбцы таблицы, которую вы собираетесь анализировать.
Непрерывные и дискретные переменные
Перед тем, как начать серьезный обзор данных, вы должны понять, как значения данных измеряются в вашем наборе данных. Возможно, вам придется уточнить это у специалиста в данной области и проанализировать бизнес-систему, являющуюся источником ваших данных. Есть несколько способов измерения значений данных и различных типов столбцов:
- Дискретные переменные могут принимать значение только из ограниченной области возможных значений.Дискретные значения включают категориальные или номинальные переменные, которые не имеют естественного порядка. Примеры включают состояния, коды состояния и цвета.
- Ранги также могут принимать значение только из дискретного набора значений. У них есть порядок, но не разрешены никакие арифметические операции. Примеры включают в себя рейтинги мнений и разделенные (сгруппированные, дискретизированные) истинные числовые значения.
- Есть также некоторые особые типы категориальных переменных . Однозначные переменные или константы не очень интересны для анализа, потому что они не несут никакой информации.Двузначные или дихотомические переменные имеют два значения, которые минимально необходимы для любого анализа. Бинарные переменные — это особые дихотомические переменные, которые принимают только значения 0 и 1.
- Непрерывные переменные могут принимать любое из неограниченного числа возможных значений; однако сам домен может иметь нижнюю и / или верхнюю границу.
- Интервалы имеют одну или две границы, имеют порядок и допускают некоторое арифметическое вычитание (но не всегда могут допускать суммирование).Примеры включают дату, время и температуру.
- Истинные числовые переменные поддерживают всю арифметику. Примеры включают суммы и значения.
- Монотонные переменные — это особый тип непрерывных переменных, которые монотонно неограниченно увеличиваются. Если это просто идентификаторы, они могут не быть интересными. Тем не менее, они могут быть преобразованы (разделены на категории), если постоянно растущий идентификатор содержит информацию о временном порядке (более низкие идентификаторы старше, чем более высокие идентификаторы).
Данные, используемые для статистического анализа SQL
Для этой и всех последующих статей я использую демонстрационную базу данных AdventureWorksDW2014 . Вы можете загрузить полную резервную копию этой базы данных с сайта примеров Microsoft SQL Server. Я запускаю весь код на SQL Server 2016 Developer Edition .
Я предпочитаю использовать образец базы данных AdventureWorks для SQL Server 2014 вместо образца базы данных WideWorldImportersDW в SQL Server 2016.База данных WideWorldImporters очень полезна для демонстрации новых функций SQL Server 2016, но в ее данных отсутствуют корреляции и ассоциации, необходимые для статистического анализа.
Использование распределения частот в SQL для понимания дискретных переменных
В SQL частотное распределение (обычно представленное в виде таблицы) используется для быстрого обзора дискретных переменных. Он может отображать как фактические значения, так и их:
- Абсолютная частота
- Абсолютный процент
- Суммарная частота
- Совокупный процент
Plus, частотное распределение SQL отображает гистограмму абсолютного процента значений.
Ниже я покажу вам несколько способов вычисления частотного распределения в SQL, начиная с одного, который является довольно неэффективным.
Распределение частот в SQL без использования оконных функций
Расчет абсолютной частоты и абсолютного процента значений представляет собой простое агрегирование. Однако вычисление совокупной частоты и совокупного процента означает вычисление промежуточных итогов. До того, как в SQL Server 2012 была добавлена поддержка агрегатных функций окна, для этой задачи приходилось использовать либо коррелированные подзапросы, либо неэквивалентные самосоединения.Ни один из методов не очень эффективен.
Выполните следующий код, который использует коррелированные подзапросы, чтобы проанализировать в SQL частотное распределение переменной NumberCarsOwned из представления dbo.vTargetMai l в демонстрационной базе данных AdventureWorksDW2014 .
ИСПОЛЬЗУЙТЕ AdventureWorksDW2014;
ИДТИ
С FreqCTE AS
(
ВЫБРАТЬ v.NumberCarsOwned,
COUNT (v.NumberCarsOwned) AS AbsFreq,
CAST (ROUND (100. * (COUNT (v.NumberCarsOwned)) /
(ВЫБРАТЬ СЧЕТЧИК (*) ИЗ vTargetMail), 0) КАК INT) КАК AbsPerc
ОТ dbo.vTargetMail AS v
ГРУППА ПО v.NumberCarsOwned
)
ВЫБЕРИТЕ c1.NumberCarsOwned AS NCars,
c1.AbsFreq,
(ВЫБРАТЬ СУММУ (c2.AbsFreq)
ОТ частоты AS c2
ГДЕ c2.NumberCarsOwned & amp; lt; = c1.NumberCarsOwned) AS CumFreq,
c1.AbsPerc,
(ВЫБРАТЬ СУММУ (c2.AbsPerc)
ОТ частоты AS c2
ГДЕ c2.NumberCarsOwned & amp; lt; = c1.NumberCarsOwned) AS CumPerc,
CAST (REPLICATE ('*', c1.AbsPerc) AS varchar (100)) AS Гистограмма
ОТ частоты AS c1
ЗАКАЗАТЬ ПО c1.NumberCarsOwned;
Это дает следующий результат:
NCars AbsFreq CumFreq AbsPerc Гистограмма CumPerc ----- ------- ------- ------- ------- ----------------- ------------------ 0 4238 4238 23 23 *********************** 1 4883 9121 26 49 ************************** 2 6457 15578 35 84 *********************************** 3 1645 17223 9 93 ********* 4 1261 18484 7 100 *******
Распределение частот в SQL с использованием оконных функций — Решение 1
При выполнении статистического анализа SQL могут оказаться полезными оконные агрегатные функции.Они предлагают гораздо лучшее решение. Как уже отмечалось, эти функции доступны в SQL Server версии 2012 и новее.
Если вы посмотрите на первую часть запроса, вы заметите, что запрос Common Table Expression, который вычисляет абсолютные числа, такой же, как и в предыдущем запросе. Однако кумулятивные значения — промежуточные итоги — рассчитываются с помощью оконных агрегатных функций.
С FreqCTE AS
(
ВЫБРАТЬ v.NumberCarsOwned,
COUNT (v.NumberCarsOwned) AS AbsFreq,
CAST (КРУГЛЫЙ (100.* (COUNT (v.NumberCarsOwned)) /
(ВЫБРАТЬ СЧЕТЧИК (*) ИЗ vTargetMail), 0) КАК INT) КАК AbsPerc
ОТ dbo.vTargetMail AS v
ГРУППА ПО v.NumberCarsOwned
)
ВЫБЕРИТЕ NumberCarsOwned,
AbsFreq,
СУММ (AbsFreq)
БОЛЕЕ (ЗАКАЗАТЬ ПО КОЛИЧЕСТВУ
РЯДЫ МЕЖДУ НЕОГРАНИЧЕННЫМИ ПРЕДЫДУЩИМИ
И ТЕКУЩАЯ СТРОКА) КАК CumFreq,
AbsPerc,
СУММ (AbsPerc)
БОЛЕЕ (ЗАКАЗАТЬ ПО КОЛИЧЕСТВУ
РЯДЫ МЕЖДУ НЕОГРАНИЧЕННЫМИ ПРЕДЫДУЩИМИ
И ТЕКУЩАЯ СТРОКА) КАК CumPerc,
CAST (REPLICATE ('*', AbsPerc) AS VARCHAR (50)) AS гистограмма
С ЧАСТОТЫ
ЗАКАЗАТЬ ПО NumberCarsOwned;
Результат этого запроса такой же, как результат предыдущего запроса.
Распределение частот в SQL с использованием оконных функций — Решение 2
Я нашел еще одно интересное решение, используя функции оконного анализа SQL. Функция CUME_DIST вычисляет совокупное распределение или относительное положение значения в группе значений. Для строки r , предполагая порядок возрастания, CUME_DIST для r — это количество строк со значениями, меньшими или равными значению r , деленное на количество строк, оцененных в разделе или наборе результатов запроса. .Функция PERCENT_RANK вычисляет относительный ранг строки в группе строк. Мы можем использовать PERCENT_RANK, чтобы оценить относительное положение значения в наборе результатов запроса или разделе.
Следующий запрос статистического анализа SQL вычисляет номер строки после разделения по столбцу NumberCarsOwned и номер строки по всему входному набору. Он также вычисляет процентный ранг и кумулятивное распределение по полному входному набору.
ВЫБЕРИТЕ NumberCarsOwned AS NCars, ROW_NUMBER () БОЛЕЕ (РАЗДЕЛЕНИЕ ПО NumberCarsOwned ЗАКАЗАТЬ ПО NumberCarsOwned, CustomerKey) AS Rn_AbsFreq, ROW_NUMBER () ВЫШЕ ( ЗАКАЗАТЬ ПО NumberCarsOwned, CustomerKey) AS Rn_CumFreq, PERCENT_RANK () ВЫШЕ (ЗАКАЗАТЬ ПО NumberCarsOwned) как Pr_AbsPerc, CUME_DIST () ВЫШЕ (ЗАКАЗАТЬ ПО NumberCarsOwned, CustomerKey) КАК Cd_CumPerc ОТ dbo.vTargetMail;
Частичный вывод, показывающий только те строки, которые имеют отношение к объяснению алгоритма вычисления частот:
NCars Rn_AbsFreq Rn_CumFre Pr_AbsPerc Cd_CumPerc ----- ---------- --------- ----------------- --------- ----------- 0 1 1 0 5.4100843973166E-05 0 2 2 0 0,000108201687946332 …………… 0 4238 4238 0 0.229279376758277 1 1 4239 0,22929178163718 0,229333477602251 …………… 1 4883 9121 0,22929178163718 0,493453797879247 2 1 9122 0,4934804955
Как видите, — номер последней строки, разделенный на на NumberCarsOwned в категории, на самом деле представляет собой абсолютную частоту значений в этой категории.Номер последней несекционированной строки в категории представляет совокупную частоту до текущей категории включительно. Например, абсолютная частота для NumberCarsOwned = «0» равна 4 238, а совокупная частота — 4 238; для NumberCarsOwned = «1» абсолютная частота равна 4883, а совокупная частота равна 9 121.
Затем рассмотрим функцию CUME_DIST (столбец Cd_CumPerc в выходных данных). CUME_DIST в последней строке категории возвращает совокупный процент до категории включительно. Если вы вычтите PERCENT_RANK (столбец Pr_AbsPerc в выходных данных) для последней строки в категории из CUME_DIST последней строки в той же категории, вы получите абсолютный процент для категории. Например, абсолютный процент для категории, где NumberCarsOwned = «1» больше 26 процентов (0,493453797879247 — 0,22929178163718 = 0,264162016242067).
Следующий запрос вычисляет распределение частот с использованием наблюдений по результатам предыдущего запроса.
С FreqCTE AS
(
ВЫБЕРИТЕ NumberCarsOwned,
ROW_NUMBER () БОЛЕЕ (РАЗДЕЛЕНИЕ ПО NumberCarsOwned
ЗАКАЗАТЬ ПО NumberCarsOwned, CustomerKey) AS Rn_AbsFreq,
ROW_NUMBER () ВЫШЕ (
ЗАКАЗАТЬ ПО NumberCarsOwned, CustomerKey) AS Rn_CumFreq,
ОКРУГЛ (100 * PERCENT_RANK ()
ВЫШЕ (ЗАКАЗАТЬ ПО NumberCarsOwned), 0) AS Pr_AbsPerc,
ОКРУГЛ (100 * CUME_DIST ()
ВЫШЕ (ЗАКАЗАТЬ ПО NumberCarsOwned, CustomerKey), 0) AS Cd_CumPerc
ОТ dbo.vTargetMail
)
ВЫБЕРИТЕ NumberCarsOwned AS NCars,
МАКС (Rn_AbsFreq) AS AbsFreq,
МАКС (Rn_CumFreq) как CumFreq,
MAX (Cd_CumPerc) - MAX (Pr_Absperc) AS AbsPerc,
МАКС (Cd_CumPerc) как CumPerc,
CAST (REPLICATE ('*', MAX (Cd_CumPerc) - MAX (Pr_Absperc)) AS varchar (100)) AS Гистограмма
С ЧАСТОТЫ
ГРУППА ПО КОЛИЧЕСТВУ
ЗАКАЗАТЬ ПО NumberCarsOwned;
Хотя идея этого последнего запроса очень интересна, этот запрос не так эффективен, как второй (с использованием функции агрегирования окна).Поэтому рекомендуется второе решение.
Заключение
Из этой статьи вы узнали, как вычислить частотное распределение SQL для дискретных переменных. Вы также видели решение, в котором требуется немного творчества. В следующих статьях вы познакомитесь с другими методами статистического анализа SQL. Следующий будет посвящен вычислению основных статистических показателей для непрерывных переменных. Вы также узнаете, как писать эффективные запросы, требующие математических знаний, а не творчества.
SQL-запрос, чтобы узнать частоту каждого элемента в столбце
Допустим, у нас есть таблица «Человек», как показано ниже, и нам нужно узнать частоту каждого возраста.
Id | Фамилия | Имя | Возраст | Городской |
1 | Смит | Иоанна | 33 | Нью-Йорк |
2 | Смит | Майк | 34 | Бостон |
3 | Пол | Райан | 39 | Чикаго |
4 | Уильям | Брайан | 45 | Балтимор |
5 | Rao | Сунита | 41 | Дейтон |
6 | Zing | Сью | 33 | Владеет Мельницы |
7 | Смит | Роберт | 45 | Нью-Йорк |
8 | Пол | Зеан | 33 | Чикаго |
9 | Шривастава | Подол | 33 | Балтимор |
10 | Rao | Венкат | 45 | Дейтон |
Распределение частот можно было узнать, выполнив SQL-запрос:
ВЫБРАТЬ Возраст, COUNT (Возраст) AS Частота
ОТ Человек
ГРУППА ПО Возрасту
ЗАКАЗАТЬ ПО
COUNT (Возраст) DESC
Линейно-пространственных структур данных для запросов диапазона частот на массивах и деревьях
Belazzougui, D., Botelho, F.C., Dietzfelbinger, M .: Hash, displace, and compress. В: Труды ESA, LNCS, т. 5757. С. 682–693. Springer (2009)
Belazzougui, D., Gagie, T., Navarro, G .: Улучшение пространственных границ для параметризованного большинства и меньшинства диапазона. В: Труды WADS, LNCS, т. 8037. Springer (2013)
Belazzougui, D., Navarro, G .: Новые нижние и верхние границы для представления последовательностей. В: Труды ESA, LNCS, т.7501, стр. 181–192. Springer (2012)
Belazzougui, D., Navarro, G., Valenzuela, D .: Улучшенные сжатые индексы для полнотекстового поиска документов. J. Дискретные алгоритмы 18 , 3–13 (2013)
MATH MathSciNet Статья Google Scholar
Бендер, М.А., Фарач-Колтон, М .: Возвращение к проблеме LCA. В: Труды LATIN, LNCS, vol. 1776. С. 88–94. Спрингер (2000)
Бендер, М.А., Фарач-Колтон, М., Пеммасани, Г., Скиена, С., Сумазин, П .: Наименьшие общие предки в деревьях и ориентированных ациклических графах. J. Алгоритмы 57 (2), 75–94 (2005)
MATH MathSciNet Статья Google Scholar
Бродал, Г.С., Гфеллер, Б., Йоргенсен, А.Г., Сандерс, П .: На пути к оптимальным медианам диапазона. Теор. Comput. Sci. 412 (24), 2588–2601 (2011)
MATH Статья Google Scholar
Чан, Т.М., Дюрохер, С., Ларсен, К.Г., Моррисон, Дж., Уилкинсон, Б.Т .: Структуры данных в линейном пространстве для запроса в режиме диапазона в массивах. В кн .: Труды СТАКС, т. 14, стр. 291–301 (2012)
Чан, Т.М., Дюрохер, С., Ларсен, К.Г., Моррисон, Дж., Уилкинсон, Б.Т .: Структуры данных в линейном пространстве для запросов в режиме диапазона в массивах. Теор. Comput. Syst. 55 (4), 719–741 (2014)
Чан, Т.М., Дюрохер, С., Скала, М., Уилкинсон, Б.Т .: Линейно-пространственные структуры данных для запроса меньшинства диапазона в массивах.В: Proceedings of SWAT, LNCS, vol. 7357, стр. 295–306. Springer (2012)
Chazelle, B .: Фильтрация поиска: новый подход к ответам на запросы. SIAM J. Comput. 15 (3), 703–724 (1986)
MATH MathSciNet Статья Google Scholar
Давуди П., Раман Р., Рао С.С. Лаконичные представления двоичных деревьев для запросов с минимальным диапазоном. В: Proceedings of COCOON, LNCS, vol. 7434, стр.396–407. Springer (2012)
Demaine, E.D., Landau, G.M., Weimann, O .: О декартовых деревьях и минимальных запросах диапазона. В: Proceedings of ICALP, LNCS, vol. 5555. С. 341–353. Springer (2009)
Durocher, S .: Простая структура данных в линейном пространстве для запроса минимального диапазона постоянного времени. В: Труды конференции по пространственно-эффективным структурам данных, потокам и алгоритмам (Munro Festschrift), т. 8066, стр. 48–60 (2013)
Durocher, S., Хе, М., Манро, Дж. И., Николсон, П.К., Скала, М .: Большинство диапазонов в постоянном времени и линейном пространстве. В: Proceedings of ICALP, LNCS, vol. 6755. С. 244–255. Springer (2011)
Дюрохер, С., Хе, М., Манро, Дж. И., Николсон, П.К., Скала, М .: Большинство диапазонов в постоянном времени и линейном пространстве. Инф. Comput. 222 , 169–179 (2013)
MATH MathSciNet Статья Google Scholar
Дюроше, С., Манро, Дж. И., Эль-Зейн, Х., Саккачан, С. В .: Структуры данных с низким объемом для запроса в режиме геометрического диапазона. В: Proceedings of CCCG (2014)
Durocher, S., Shah, R., Skala, M., Thankachan, S .: Линейно-пространственные структуры данных для запросов частотного диапазона к массивам и деревьям. В: Труды MFCS, LNCS, т. 8087. С. 325–336. Springer (2013)
Дюрохер, С., Шах, Р., Скала, М., Сакалачан, С .: Top — \ (k \) цветные запросы на путях к деревьям. В: Труды SPIRE, LNCS, т.8214. С. 109–115. Springer (2013)
Эмде Боас, П.В .: Сохранение порядка в лесу за меньшее, чем логарифмическое время и линейное пространство. Инф. Proc. Lett. 6 (3), 80–82 (1977)
MATH Статья Google Scholar
Фишер Дж .: Оптимальная лаконичность для запросов с минимальным диапазоном. В: Труды LATIN, LNCS, vol. 6034. С. 158–169. Springer (2010)
Фредман М.Л., Уиллард Д.Э .: Транс-дихотомические алгоритмы для минимальных остовных деревьев и кратчайших путей. J. Comput. Syst. Sci. 48 (3), 533–551 (1994)
MATH MathSciNet Статья Google Scholar
Гэги, Т., Хе, М., Манро, Дж. И., Николсон, П .: Поиск часто встречающихся элементов в сжатых 2D-массивах и строках. В: Труды SPIRE, LNCS, т. 7024. С. 295–300. Спрингер (2011)
Гэги, Т., Kärkkäinen, J., Navarro, G., Puglisi, S.J .: Запросы цветного диапазона и поиск документов. Теор. Comput. Sci. 483 , 36–50 (2013)
MATH Статья Google Scholar
Гэги Т., Пуглиси С.Дж., Терпин А. Запросы квантилей диапазона: еще одно достоинство вейвлет-деревьев. В: Труды SPIRE, LNCS, т. 5721, стр. 1–6. Springer (2009)
Гфеллер Б., Сандерс П .: На пути к оптимальным медианам диапазона.В: Proceedings of ICALP, LNCS, vol. 5555. С. 475–486. Springer (2009)
Hagerup, T., Tholey, T .: Эффективное минимальное идеальное хеширование в почти минимальном пространстве. В: Труды STACS, LNCS, т. 2010. С. 317–326. Springer (2001)
He, M., Munro, J.I., Zhou, G .: запросы пути во взвешенных деревьях. В: Proceedings of ISAAC, pp. 140–149 (2011)
He, M., Munro, J.I., Zhou, G .: Краткие структуры данных для запросов пути. В: Труды ЕКА, стр.575–586 (2012)
Hon, W.K., Shah, R., Vitter, J.S .: Компактная структура для задач поиска строк top-k. В: Proceedings of FOCS, pp. 713–722 (2009)
Jørgensen, A.G., Larsen, K.D .: Выбор диапазона и медиана: нижние границы жесткого зонда клеток и адаптивные структуры данных. В: Proceedings of SODA, pp. 805–813 (2011)
Карпинский, М., Некрич, Я .: Цветовые запросы Top-k для поиска документов. В: Труды SODA, стр.401–411 (2011)
Крижанц, Д., Морин, П., Смид, М .: Режим диапазона и медианные запросы диапазона для списков и деревьев. В: Proceedings of ISAAC, LNCS, vol. 2906, стр. 517–526. Springer (2003)
Крижанк, Д., Морин, П., Смид, М .: Режим диапазона и медианные запросы диапазона для списков и деревьев. Nordic J. Comput. 12 , 1–17 (2005)
MATH MathSciNet Google Scholar
Мутукришнан, С.: Эффективные алгоритмы поиска документов. В: Proceedings of SODA, pp. 657–666 (2002)
Navarro, G., Nekrich, Y .: Top — \ (k \) поиск документов в оптимальное время и в линейном пространстве. В: Proceedings of SODA, pp. 1066–1077 (2012)
Патил, М., Шах, Р., Танкачан, С.В .: Краткое представление взвешенных деревьев, поддерживающих запросы путей. J. Дискретные алгоритмы 17 , 103–108 (2012)
MATH MathSciNet Статья Google Scholar
Садакане К., Наварро Г .: Полнофункциональные лаконичные деревья. В: Proceedings of SODA, pp. 134–149 (2010)
Schmidt, J.P., Siegel, A .: Пространственная сложность не обращающих внимания на хэш-функции k-зонда. SIAM J. Comput. 19 (5), 775–786 (1990)
MATH MathSciNet Статья Google Scholar
Скала, М .: запросы диапазона массивов. В: Труды конференции по пространственно-эффективным структурам данных, потокам и алгоритмам (Munro Festschrift), т.8066, стр. 333–350 (2013)
Слеатор Д.Д., Тарьян Р.Э .: Структура данных для динамических деревьев. J. Comput. Syst. Sci. 26 (3), 362–391 (1983)
MATH MathSciNet Статья Google Scholar
Запрос общих терминов | Руководство по Elasticsearch [7.13]
Не рекомендуется в версии 7.3.0.
Вместо этого используйте Match, который эффективно пропускает блоки документов без какой-либо конфигурации, при условии, что общее количество совпадений не отслеживается.
Запрос общих терминов — это современная альтернатива стоп-словам, которые
повышает точность и запоминаемость результатов поиска (за счет использования игнорируемых слов
во внимание), не жертвуя производительностью.
Проблема
У каждого термина в запросе есть стоимость. Поиск "Коричневая лисица" требуется три запроса, по одному для каждого из "«, "коричневый" и «лиса» , все из которых выполняются для всех документов в индексе.Запрос "«, вероятно, будет соответствовать многим документам и, следовательно, имеет
гораздо меньшее влияние на релевантность, чем два других термина.
Ранее решение этой проблемы заключалось в игнорировании терминов с высоким
частота. Рассматривая "the" как стоп-слово , мы уменьшаем размер индекса.
и уменьшить количество термических запросов, которые необходимо выполнить.
Проблема с этим подходом в том, что в то время как стоп-слова имеют небольшой
влияют на актуальность, они по-прежнему важны.Если мы удалим стоп-слова,
мы теряем точность (например, мы не можем различить "счастливый" и «неудовлетворительно» ), и мы теряем отзыв (например, текст типа «The» или «Быть или не быть» просто не существовало бы в индексе).
Решение редактировать
Запрос common terms разделяет термины запроса на две группы: подробнее
важные (например, низкочастотные, терминов) и менее важные (например, высокочастотные
частота терминов, которые раньше были бы игнорируемыми словами).
Сначала он ищет документы, которые соответствуют наиболее важным условиям. Это термины, которые встречаются в меньшем количестве документов и имеют большую влияние на актуальность.
Затем он выполняет второй запрос для менее важных терминов — терминов.
которые появляются часто и мало влияют на релевантность. Но вместо
расчета оценки релевантности для всех совпадающих документов, это только
вычисляет _score для документов, уже сопоставленных первым
запрос.Таким образом, часто встречающиеся термины могут повысить релевантность
расчет без оплаты плохой работы.
Если запрос состоит только из часто встречающихся терминов, то один запрос
выполняется как запрос И (соединение), другими словами, все термины
обязательный. Несмотря на то, что каждый отдельный термин будет соответствовать многим документам,
комбинация терминов сужает набор результатов только до самых
уместным. Одиночный запрос также может быть выполнен как OR с
конкретный minimum_should_match ,
в этом случае, вероятно, следует использовать достаточно высокое значение.
Термины распределяются по высокочастотным или низкочастотным группам на основе cutoff_frequency , который можно указать как абсолютную частоту
(> = 1 ) или как относительная частота ( 0,0 .. 1,0 ). (Помните этот документ
частоты вычисляются на уровне сегментов, как описано в сообщении блога.
Актуальность нарушена.)
Возможно, наиболее интересным свойством этого запроса является то, что он адаптируется к
автоматические игнорируемые слова для конкретного домена. Например, на видеохостинге
сайт, общие термины, такие как "клип" или "видео" , будут вести себя автоматически
как стоп-слова без необходимости вести список вручную.
Примерыправить
В этом примере слова, частота которых в документе превышает 0,1%
(например, "это" и "равно" ) будет рассматриваться как общих терминов .
GET / _search
{
"запрос": {
"общий": {
"тело": {
"query": "это классный бонсай",
"cutoff_frequency": 0,001
}
}
}
} Количество терминов, которые должны совпадать, можно контролировать с помощью minimum_should_match ( high_freq , low_freq ), low_freq_operator (по умолчанию или ) и high_freq_operator (по умолчанию "или" ) параметры.
Для низкочастотных терминов установите low_freq_operator на "и" , чтобы
все необходимые условия:
GET / _search
{
"запрос": {
"общий": {
"тело": {
"query": "Нелли слоник в мультяшном стиле",
"cutoff_frequency": 0,001,
"low_freq_operator": "и"
}
}
}
} , что примерно эквивалентно:
GET / _search
{
"запрос": {
"bool": {
"должен": [
{"term": {"body": "nelly"}},
{"term": {"body": "elephant"}},
{"term": {"body": "cartoon"}}
],
"должен": [
{"term": {"body": "the"}},
{"term": {"body": "as"}},
{"термин": {"тело": "а"}}
]
}
}
} В качестве альтернативы используйте minimum_should_match чтобы указать минимальное количество или процент низкочастотных терминов, которые
должен присутствовать, например:
GET / _search
{
"запрос": {
"общий": {
"тело": {
"query": "Слоник в мультяшном стиле",
"cutoff_frequency": 0.001,
"minimum_should_match": 2
}
}
}
} , что примерно эквивалентно:
GET / _search
{
"запрос": {
"bool": {
"должен": {
"bool": {
"должен": [
{"term": {"body": "nelly"}},
{"term": {"body": "elephant"}},
{"term": {"body": "cartoon"}}
],
"minimum_should_match": 2
}
},
"должен": [
{"term": {"body": "the"}},
{"term": {"body": "as"}},
{"термин": {"тело": "а"}}
]
}
}
} Другой minimum_should_match может применяться для низкочастотных и высокочастотных терминов с дополнительным
Параметры low_freq и high_freq .Вот пример предоставления
дополнительные параметры (обратите внимание на изменение структуры):
GET / _search
{
"запрос": {
"общий": {
"тело": {
"query": "а слона не как мультик",
"cutoff_frequency": 0,001,
"minimum_should_match": {
"low_freq": 2,
"high_freq": 3
}
}
}
}
} , что примерно эквивалентно:
GET / _search
{
"запрос": {
"bool": {
"должен": {
"bool": {
"должен": [
{"term": {"body": "nelly"}},
{"term": {"body": "elephant"}},
{"term": {"body": "cartoon"}}
],
"minimum_should_match": 2
}
},
"должен": {
"bool": {
"должен": [
{"term": {"body": "the"}},
{"term": {"body": "not"}},
{"term": {"body": "as"}},
{"термин": {"тело": "а"}}
],
«minimum_should_match»: 3
}
}
}
}
} В данном случае это означает, что высокочастотные термины влияют только на
актуальность, когда их как минимум три.Но самый
интересное использование minimum_should_match для высокочастотных терминов — это когда есть только высокочастотные термины:
GET / _search
{
"запрос": {
"общий": {
"тело": {
"query": "как не быть",
"cutoff_frequency": 0,001,
"minimum_should_match": {
"low_freq": 2,
"high_freq": 3
}
}
}
}
} , что примерно эквивалентно:
GET / _search
{
"запрос": {
"bool": {
"должен": [
{"term": {"body": "как"}},
{"term": {"body": "not"}},
{"term": {"body": "to"}},
{"срок": {"тело": "быть"}}
],
"minimum_should_match": "3 <50%"
}
}
} Тогда часто генерируемый запрос немного менее строг.
чем с И .
Запрос общих терминов также поддерживает boost и анализатор как
параметры.