SQL: что это такое, как работает язык баз данных и СУБД
SQL — это структурированный язык запросов, созданный для того, чтобы получать из базы данных необходимую информацию. Если описать схему работы SQL простыми словами, то специалист формирует запрос и направляет его в базу. Та в свою очередь обрабатывает эту информацию, «понимает», что именно нужно специалисту, и отправляет ответ.
Данные хранятся в виде таблиц, они структурированы и разложены по строкам и столбцам, чтобы ими легче было оперировать. Такой способ хранения информации называют реляционными базами данных (от англ. relation — «отношения»). Название указывает на то, что объекты в такой базе связаны определенными отношениями.
Например, у маркетолога есть база, в которой собрана информация обо всех пиццериях в городе: названия, ассортимент, цены, график работы и прочее. Во время анализа конкурентов он решил выяснить, сколько пиццерий готовят пиццу с ананасами и оформляют доставку после 23:00. Для того чтобы получить такой список из базы, достаточно написать грамотный SQL-запрос.
Для чего нужен SQL
SQL — это не язык программирования, поэтому написать приложение или сайт с его помощью не получится, но при этом внутренняя работа сайта (backend) невозможна без запросов. Поиск информации в Google — это тоже модель использования SQL. Пользователь задает параметры, которые его интересуют, и отправляет запрос на сервер; затем происходит магия и в поисковой выдаче появляются результаты, соответствующие именно этому запросу.
SQL используют разные виды специалистов:
- Аналитики и продуктовые маркетологи. Знание SQL помогает этим специалистам не зависеть от программистов, а самостоятельно получать и обрабатывать данные.
- Разработчики и тестировщики. С помощью SQL они могут самостоятельно проектировать базы для быстрой и надежной работы с данными, улучшать с их помощью сайты и приложения.
- Руководители и менеджеры.

Как работают запросы
Чтобы разобраться, как именно работает магия запроса, давайте представим его путь от пользователя до нужных ему данных:
Пользователь → Клиент → Запрос → Система управления → База данных → Таблица с базами данных
Данные для работы с SQL хранятся в таблицах. Как именно они устроены — разберемся ниже; пока же просто представим их. На пути от пользователя к таблице находится несколько посредников:
- Клиент — способ введения запроса. В случае с Google, например, клиентом будет поисковая строка браузера, в которую пользователь вводит сформулированный запрос.
- Система управления базами данных (СУБД) — комплекс программ, которые позволяют управлять данными. Эта система помогает таблицам понять, чего хочет пользователь, а пользователю — что ему отвечают таблицы.
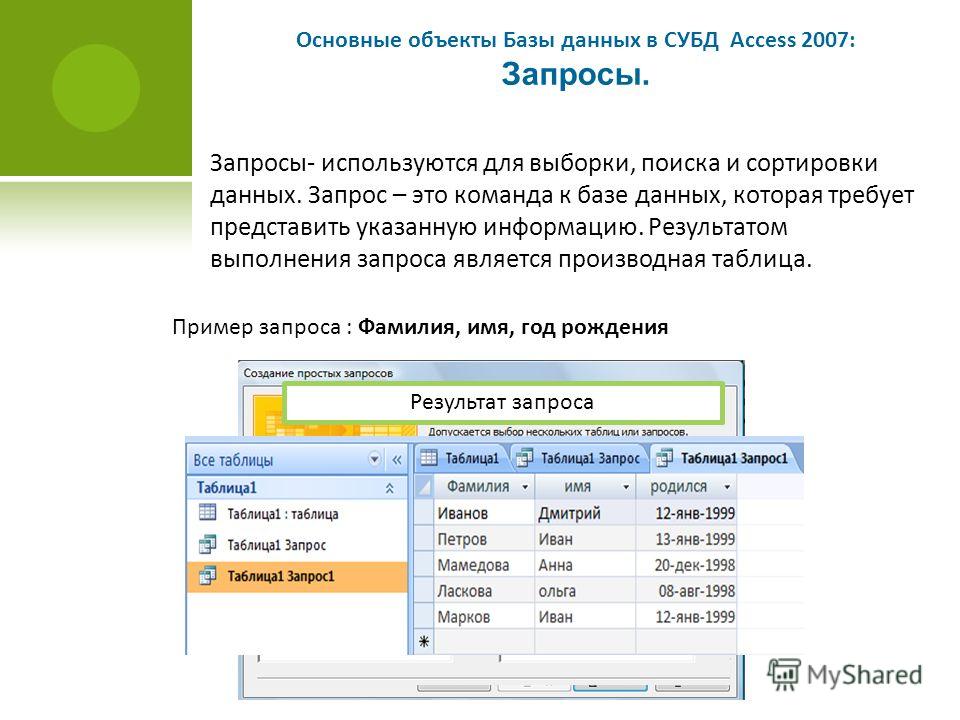
- База данных — система хранения таблиц, в которой они связаны между собой. База данных сама по себе не умеет манипулировать информацией — это просто хранилище, где у каждого объекта есть свое место.
Что такое база данных в SQL
SQL-запросы обращаются к данным в виде таблиц, то есть к реляционным базам данных. Упрощенный вариант такой базы — это таблицы Excel, в которых информация также упорядочена в столбцы и строки.
Основные понятия реляционной модели:
1. Отношение — это сама таблица, она двумерная и состоит из столбцов и строк.
2. Атрибут — столбец в таблице, который содержит один конкретный параметр: название, тип, дату, стоимость или другую характеристику.
3. Домен — это допустимые значения для каждого атрибута. Например, в столбце «Имя» или «Название» значения должны представлять собой набор буквенных символов, но они не могут начинаться с «ь» или «ъ» и не могут быть записаны числами.
4. Кортеж (строка или запись) — это табличная строка с порядковым номером, в которой содержится информация об одном конкретном объекте.
5. Значение — элемент таблицы, который находится на пересечении столбцов и строк.
6. Ключ — это самый важный столбец в таблице, за счет этих значений и происходит взаимодействие в реляционной базе данных, он связывает таблицы между собой.
Ключи бывают нескольких видов:
- Первичный ключ — идентификатор, такой как индекс или артикул.
- Потенциальный ключ — другое уникальное значение, которое может служить идентификатором.
- Внешний ключ — столбец-ссылка, используется для объединения двух таблиц, каждое значение внешнего ключа обязательно соответствует первичному ключу в другой таблице.
Например, для решения задачи — выбрать все пиццерии, которые смогут доставить пиццу с ананасами после 23:00, — кроме основной таблицы с графиками работы понадобятся также таблицы с ассортиментом каждого заведения, а также таблицы с составом каждой пиццы (чтобы понять, есть ли в ней ананасы).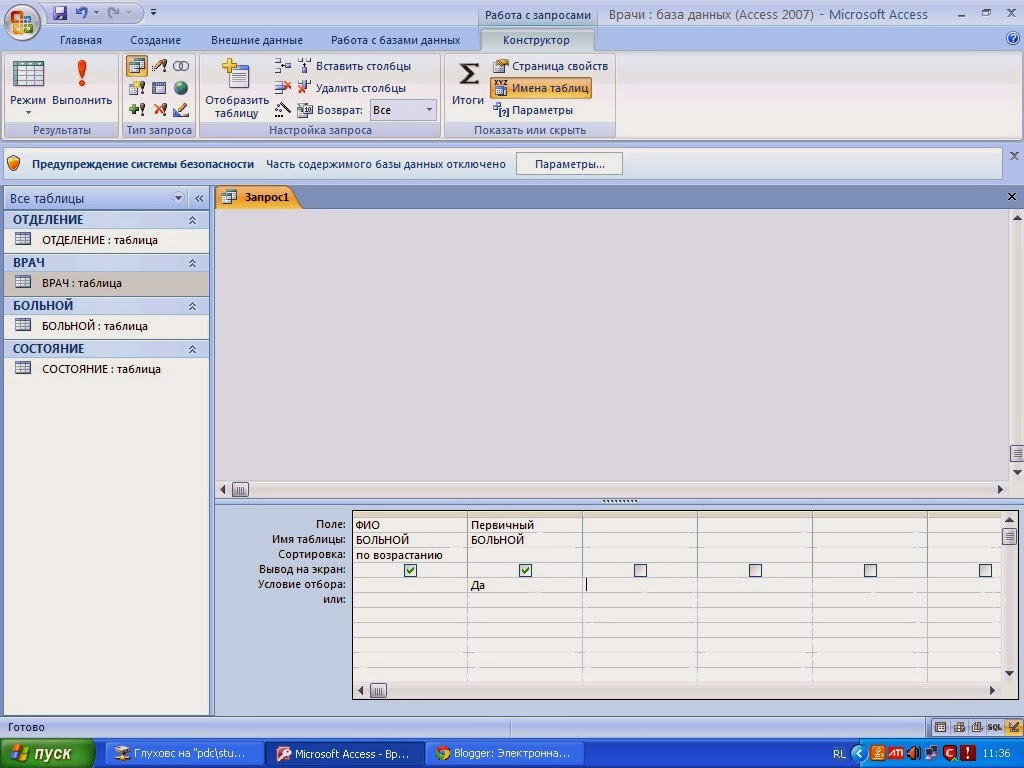
SQL-операторы
Работать с данными помогают операторы — определенные слова или символы, которые используются для выполнения конкретной операции — например, для выбора из множества по конкретному параметру. Если нам нужно из всех видов пиццы отсортировать те, в которых есть пармезан, — нужно использовать оператор SELECT (выбор в соответствии с условием).
Операторы в SQL делятся на несколько групп в соответствии с задачами, которые они решают.
DDL (Data Definition Language) — операторы определения данных. Они работают с объектами, то есть с целыми таблицами. Если базу нужно дополнить таблицей с новыми данными или, наоборот, убрать одну из таблиц с ошибочными данными — используется этот набор операторов.
- CREATE — создание объекта в базе данных
- ALTER — изменение объекта
- DROP — удаление объекта
DML (Data Manipulation Language) — операторы манипуляции данными. Эти операторы уже работают с содержимым таблиц — строками, атрибутами и значениями. С их помощью можно вносить изменения в конкретное значение. Например, заменить поле в колонке «Фамилия» в строке с данными сотрудницы компании посте того, как она вышла замуж. Или удалить строку с данными уволенного сотрудника.
Эти операторы уже работают с содержимым таблиц — строками, атрибутами и значениями. С их помощью можно вносить изменения в конкретное значение. Например, заменить поле в колонке «Фамилия» в строке с данными сотрудницы компании посте того, как она вышла замуж. Или удалить строку с данными уволенного сотрудника.
- SELECT — выбор данных в соответствии с условием
- INSERT — добавление новых данных
- UPDATE — изменение существующих данных
- DELETE — удаление данных
DCL (Data Control Language) — оператор определения доступа к данным. Он определяет, кто из пользователей может отправлять запросы к базе, менять объекты и значения. Например, можно отозвать доступ у сотрудника, перешедшего в другой отдел, а также открыть доступ к базе новому маркетологу или разработчику.
- GRANT — предоставление доступа к объекту
- REVOKE — отзыв ранее выданного разрешения
- DENY — запрет, который является приоритетным над разрешением
TCL (Transaction Control Language) — язык управления транзакциями. Транзакции — это набор команд, которые выполняются поочередно. Если все команды выполнены, транзакция считается успешной, а если где-то произошла ошибка — транзакция откатывается назад, отменяя все выполненные команды. Наглядный пример такой транзакции — оплата онлайн, когда банк просит сначала ввести сумму и получателя, затем проверить и подтвердить операцию, а после ввести одноразовый код. На каждом из этих этапов оплату можно отменить и транзакция откатится назад.
Транзакции — это набор команд, которые выполняются поочередно. Если все команды выполнены, транзакция считается успешной, а если где-то произошла ошибка — транзакция откатывается назад, отменяя все выполненные команды. Наглядный пример такой транзакции — оплата онлайн, когда банк просит сначала ввести сумму и получателя, затем проверить и подтвердить операцию, а после ввести одноразовый код. На каждом из этих этапов оплату можно отменить и транзакция откатится назад.
- BEGIN TRANSACTION — обозначение начала транзакции
- COMMIT TRANSACTION — изменение команд внутри транзакции
- ROLLBACK TRANSACTION — откат транзакции
- SAVE TRANSACTION — указание промежуточной точки сохранения внутри транзакции
Виды СУБД
Сами по себе таблицы или база данных не способны выполнять операции, а в СУБД можно создавать новые таблицы, удалять ненужные данные, настраивать ключи и обрабатывать запросы. Основные задачи СУБД:
- поддержка языков баз данных;
- непосредственное управление данными;
- управление транзакциями;
- резервное копирование и восстановление после сбоев.

Существуют разные виды таких систем, которые разрабатывает и техногиганты, вроде Google, Microsoft и Amazon, и более нишевые студии. Разработчики стремятся сделать свой продукт лучше, чтобы их система быстрее и качественнее других обрабатывала данные. Из-за этого появились разные виды языка SQL — так называемые SQL-диалекты. У каждой СУБД диалект имеет что-то общее со всеми, а также свои особенности, которые не будут работать в другой системе.
СУБД могут быть коммерческими или иметь открытый код. Системы управления с открытым кодом можно бесплатно использовать в проектах, а также дополнять их документацию и совершенствовать процесс работы с системой. Коммерческие СУБД имеют платный доступ к полным версиям — как правило, такие используют крупные корпорации.
- PostgreSQL — это объектно-ориентированная система, то есть она обрабатывает данные как абстрактные объекты. Каждый объект, в отличие от простых табличных значений, может иметь собственные характеристики и уникальные методы взаимодействия с другими объектами.
- MySQL — простая в изучении и функциональная система, которая работает с сайтами и веб-приложениями. Чаще всего используется в системах управления контентом сайтов (CMS), на сайтах с возможностью регистрации пользователей, в корпоративных системах CRM, в планировщиках, чатах и форумах. MySQL считается одним из самых безопасных и высокоскоростных решений, которое существует на рынке.
- SQLite — это облегченная встраиваемая версия СУБД. В ней нет возможности поделиться правами доступа, как во многих других системах, но благодаря своему устройству эта система быстрая и мощная. SQLite подходит для обработки запросов на сайтах с низким и средним трафиком, а также в однопользовательских мобильных приложениях и играх.
 Преимущество такой системы — файловая структура, то есть база в SQLite состоит из одного файла, поэтому ее очень легко переносить.
Преимущество такой системы — файловая структура, то есть база в SQLite состоит из одного файла, поэтому ее очень легко переносить. - Oracle — одна из первых СУБД, которая появилась еще в 1977 году и развивается до сих пор. Это кроссплатформенная система, которая может работать на Windows, Linux, MacOS, мобильных и других ОС. Система используется в крупных коммерческих проектах. Например, в России с Oracle сотрудничают операторы МТС и Теле2, банк «Открытие» и ВТБ.
- Google Cloud Spanner — это облачная система управления данными, которую Google разработал для управления собственными сервисами, например AdWords и Google Play. В 2017 году систему сделали общедоступной. Cloud Spanner относят к категории NewSQL — это системы, которые совмещают в себе преимущества реляционных и нереляционных СУБД.
Как начать работу с SQL
Для начала работы с SQL достаточно разбираться в основах Excel, чтобы понимать принцип работы запросов, а также иметь базовый уровень английского на уровне A1-A2.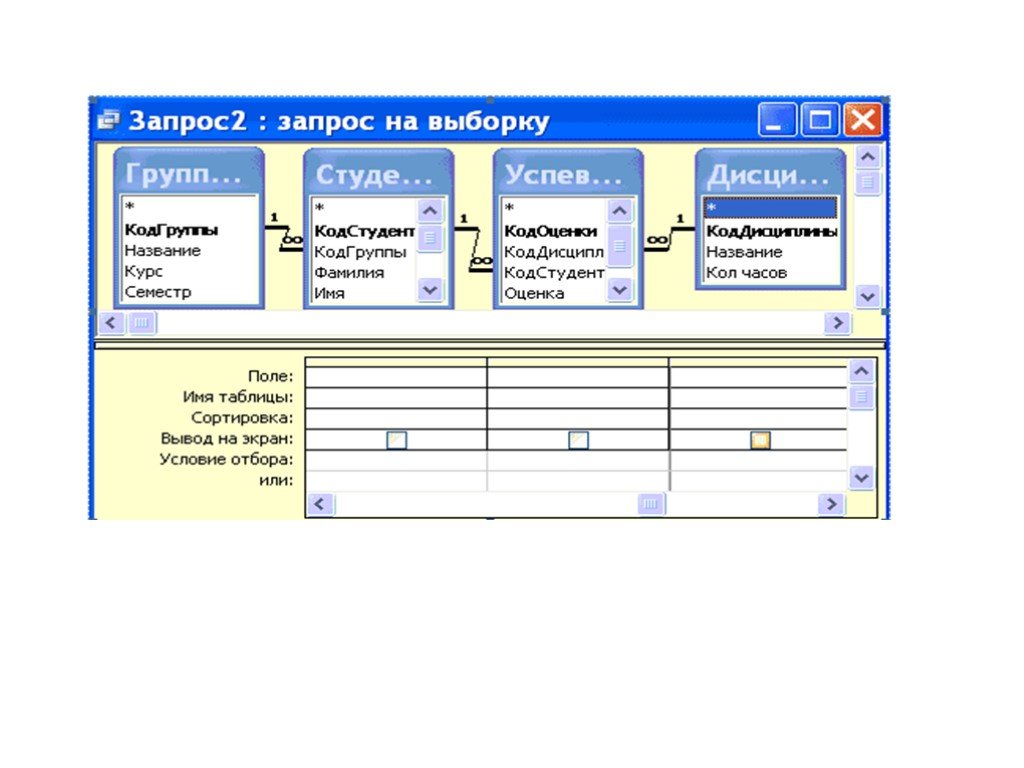 Эти навыки необходимы, чтобы понимать синтаксис SQL:
Эти навыки необходимы, чтобы понимать синтаксис SQL:
- SELECT — выбери данные
- FROM — вот отсюда
- JOIN — добавь еще эти таблицы
- WHERE — при таком условии
- GROUP BY — сгруппируй данные по этому признаку
- ORDER BY — отсортируй данные по этому признаку
- LIMIT — нужно такое количество результатов
- ; — конец предложения
Системы для работы с SQL имеют схожую структуру: есть редактор запросов, результат запросов и список таблиц, которые используются для обработки.
Самостоятельно начать изучение SQL можно с просмотра уроков на YouTube и чтения тематических статей в профильных медиа. Для более системного усвоения информации и экономии времени, потраченного на обучение, лучше записаться на курсы к опытным преподавателям, где вы сразу попадете в профессиональное сообщество и будете получать поддержку менторов.
Запрос к базе данных
Активити Запрос к базе данных позволяет подключаться к внешней базе данных и извлекать информацию из таблиц базы данных, записывать или заменять данные.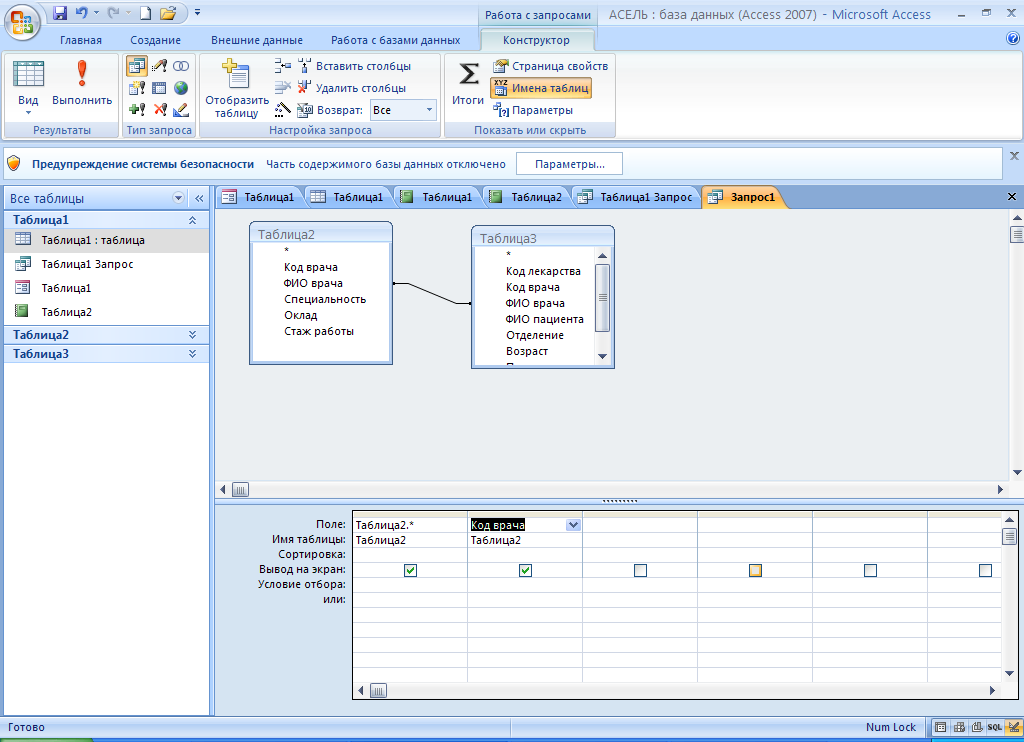 Это активити можно использовать для подключения к базам данных Oracle Database, SQL Server, MySQL, PostgreSQL и FoxPro.
Это активити можно использовать для подключения к базам данных Oracle Database, SQL Server, MySQL, PostgreSQL и FoxPro.
Чтобы открыть окно настроек, нажмите на активити на графической модели процесса.
Вкладка «Параметры»
На вкладке Параметры отображаются основные параметры активити.
Наименование — название активити на графической модели процесса. При добавлении активити его название задаётся по умолчанию. В этом поле название можно изменить.
Тип базы данных — из списка выберите тип базы данных, к которой делаете запрос.
В полях Строка подключения и Строка запроса вы можете ввести значение вручную или использовать контекстные переменные процесса, в которых хранятся значения. Чтобы добавить переменную, нажмите и выберите нужную или создайте новую, нажав . Значение добавляется в формате {$наименование переменной}.
Строка подключения — информация, которая необходима для подключения к базе данных. Строка подключения записывается в виде набора параметров Ключ=<Значение>. Параметры могут отличаться в зависимости от типа базы данных.
Строка подключения записывается в виде набора параметров Ключ=<Значение>. Параметры могут отличаться в зависимости от типа базы данных.
Oracle Database |
Data Source=<host>:<port>/XEPDB1; User Id=<login>; Password=<password>; |
SQL Server |
Server=<host>; Database=<login>; Trusted_Connection=True; |
MySQL |
Server=<host>; Database=<dbName>; Uid=<login>; Pwd=<password>; |
PostgreSQL |
Host=<host>; Database=<dbName>; Username=<login>; Password=<password>; |
FoxPro |
Provider=sqloledb; Server=<myServerName>,<myPortNumber>; Database=<myDataBase>; User Id=<myUsername>; Password=<myPassword>; |
Строку подключения также можно записать контекстной переменной типа Строка или Целое число.
Строка запроса — в этом поле содержится информация, которая передается при запросе к базе данных. Параметры строки запроса могут отличаться в зависимости от типа базы данных.
В таблице представлены примеры строки запроса выбора к базе данных.
Oracle Database |
SELECT table FROM tabs OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY |
PostgreSQL, MySQL, SQL Server, FoxPro |
SELECT * FROM table |
Строку запроса также можно записать контекстной переменной типа Строка, Дробное число или Целое число.
Таймаут — время ожидания, после которого прекратится попытка запроса к базе данных. Указывается в миллисекундах, по умолчанию — 1000.
Ожидание результатов — выберите Да, если после запроса на получение данных необходимо ожидать ответ из базы данных. Если не нужно ожидать получения ответа из базы данных (например, при запросе на обновление или внесение данных), выберите Нет.
Переменная — контекстная переменная, в которую сохранятся данные, полученные из базы данных в качестве ответа. Вы можете выбрать переменную из списка или создать новую, нажав . Для выбора доступны переменные типа Строка, Дата/Время, Да/Нет, Дробное число, Целое число и Таблица.
Вкладка «Обработчики»
О вкладке Обработчики можно прочитать в статье «Общие принципы настройки активити».
log-message.html extract-excel-file.html
Была ли статья полезной?ДаНетВыберите вариантРекомендации не помоглиТекст трудно понятьНет ответа на мой вопросСодержание статьи не соответствует заголовкуДругая причинаЗапросы к базе данных — Базы данных
Базы данных поддерживают либо необработанный SQL, либо построение запросов с использованием ядра SQLAlchemy.
Объявления таблиц
Если вы хотите выполнять запросы с использованием ядра SQLAlchemy, вам необходимо объявить ваши таблицы в коде. Как правило, это хорошая практика в любом случае, поскольку гораздо проще синхронизировать схему базы данных с кодом, к которому осуществляется доступ это. Это также позволяет вам использовать инструменты миграции базы данных для управления изменениями схемы.
импорт sqlalchemy
метаданные = sqlalchemy.MetaData()
примечания = sqlalchemy.Table(
"примечания",
метаданные,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column("текст", sqlalchemy.String(длина=100)),
sqlalchemy.Column("завершено", sqlalchemy.Boolean),
)
Вы можете использовать любой из типов столбцов SQLAlchemy, например sqlalchemy.JSON или
настраиваемые типы столбцов.
Создание таблиц
Базы данных не используют механизм SQLAlchemy для внутреннего доступа к базе данных. Обычный основной способ SQLAlchemy для создания таблиц с create_all поэтому недоступен. Чтобы обойти это, вы можете использовать SQLAlchemy для компиляции запроса в SQL, а затем выполнить его с базами данных:
Чтобы обойти это, вы можете использовать SQLAlchemy для компиляции запроса в SQL, а затем выполнить его с базами данных:
из базы данных импортировать базу данных
импортировать sqlalchemy
база данных = База данных ("postgresql+asyncpg://localhost/пример")
# Установить пул соединений
ожидание базы данных.connect()
метаданные = sqlalchemy.MetaData()
диалект = sqlalchemy.dialects.postgresql.dialect()
# Определите свою таблицу (таблицы)
примечания = sqlalchemy.Table(
"примечания",
метаданные,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column("текст", sqlalchemy.String(длина=100)),
sqlalchemy.Column("завершено", sqlalchemy.Boolean),
)
# Создаем таблицы
для таблицы в metadata.tables.values():
# Установите `if_not_exists=False`, если вы хотите, чтобы запрос выдавал
# исключение, когда таблица уже существует
схема = sqlalchemy.schema.CreateTable (таблица, if_not_exists = True)
запрос = ул(схема.компиляция(диалект=диалект))
ожидание базы данных. execute(запрос=запрос)
# Закрываем все соединения в пуле соединений
ожидание базы данных.отключить()
execute(запрос=запрос)
# Закрываем все соединения в пуле соединений
ожидание базы данных.отключить()
Обратите внимание, что этот способ создания таблиц полезен только для локальных экспериментов. Для серьезных проектов мы рекомендуем использовать подходящее решение для миграции схемы базы данных, такое как Alembic.
Запросы
Теперь вы можете использовать любые основные запросы SQLAlchemy (официальное руководство).
из базы данных импортировать базу данных
база данных = База данных('postgresql+asyncpg://localhost/пример')
# Установить пул соединений
ожидание базы данных.connect()
# Выполнять
запрос = примечания.вставка()
значения = {"текст": "example1", "completed": True}
await database.execute (запрос = запрос, значения = значения)
# Выполнить много
запрос = примечания.вставка()
значения = [
{"текст": "пример2", "завершено": ложь},
{"текст": "пример3", "завершено": правда},
]
ожидайте database.execute_many (запрос = запрос, значения = значения)
# Получить несколько строк
запрос = заметки.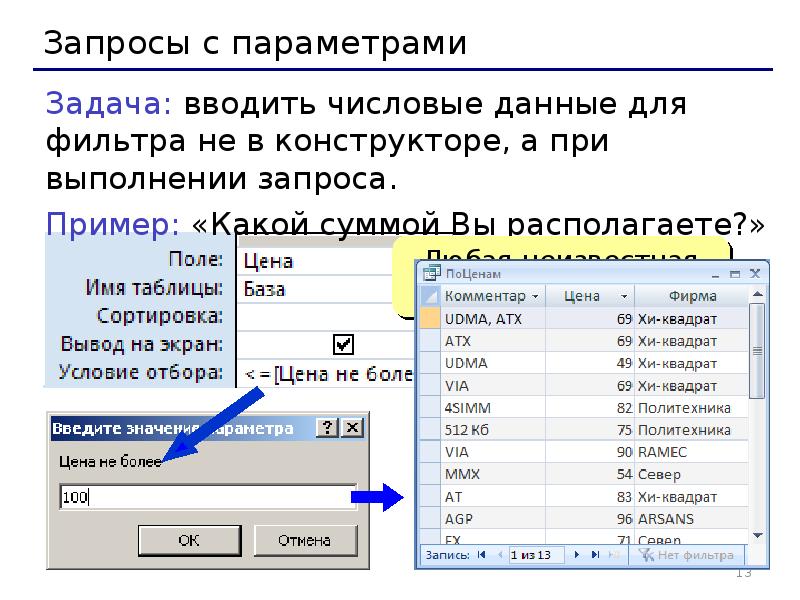 выбрать()
строки = ожидание database.fetch_all (запрос = запрос)
# Получить одну строку
запрос = заметки.выбрать()
строка = ожидание database.fetch_one (запрос = запрос)
# Получить одно значение, по умолчанию `column=0`.
запрос = заметки.выбрать()
значение = ожидание database.fetch_val (запрос = запрос)
# Извлечь несколько строк, не загружая их все в память одновременно
запрос = заметки.выбрать()
async для строки в database.iterate(query=query):
...
# Закрываем все соединения в пуле соединений
ожидание базы данных.отключить()
выбрать()
строки = ожидание database.fetch_all (запрос = запрос)
# Получить одну строку
запрос = заметки.выбрать()
строка = ожидание database.fetch_one (запрос = запрос)
# Получить одно значение, по умолчанию `column=0`.
запрос = заметки.выбрать()
значение = ожидание database.fetch_val (запрос = запрос)
# Извлечь несколько строк, не загружая их все в память одновременно
запрос = заметки.выбрать()
async для строки в database.iterate(query=query):
...
# Закрываем все соединения в пуле соединений
ожидание базы данных.отключить()
Соединения управляются как локальное состояние задачи с реализациями драйверов. прозрачно, используя пул соединений за кулисами.
Необработанные запросы
В дополнение к основным запросам SQLAlchemy вы также можете выполнять необработанные запросы SQL:
# Выполнить
query = "ВСТАВИТЬ В заметки (текст, завершено) ЗНАЧЕНИЯ (:текст, :завершено)"
значения = {"текст": "example1", "completed": True}
await database.execute (запрос = запрос, значения = значения)
# Выполнить много
query = "ВСТАВИТЬ В заметки (текст, завершено) ЗНАЧЕНИЯ (:текст, :завершено)"
значения = [
{"текст": "пример2", "завершено": ложь},
{"текст": "пример3", "завершено": правда},
]
ожидайте database. execute_many (запрос = запрос, значения = значения)
# Получить несколько строк
query = "ВЫБЕРИТЕ * ИЗ заметок, ГДЕ завершено = :completed"
строки = ожидание database.fetch_all (запрос = запрос, значения = {"завершено": True})
# Получить одну строку
query = "ВЫБЕРИТЕ * ИЗ заметок, ГДЕ id = :id"
результат = ожидание database.fetch_one (запрос = запрос, значения = {"id": 1})
execute_many (запрос = запрос, значения = значения)
# Получить несколько строк
query = "ВЫБЕРИТЕ * ИЗ заметок, ГДЕ завершено = :completed"
строки = ожидание database.fetch_all (запрос = запрос, значения = {"завершено": True})
# Получить одну строку
query = "ВЫБЕРИТЕ * ИЗ заметок, ГДЕ id = :id"
результат = ожидание database.fetch_one (запрос = запрос, значения = {"id": 1})
Обратите внимание, что аргументы запроса должны соответствовать стилю :query_arg .
Результат запроса
Чтобы соответствовать изменениям SQLAlchemy 1.4
объект результата запроса больше не реализует интерфейс сопоставления.
Чтобы получить доступ к результату запроса в виде сопоставления, вы должны использовать свойство _mapping .
Таким образом, вы можете обрабатывать как строки SQLAlchemy, так и записи баз данных из необработанных запросов.
с той же функцией без каких-либо проверок экземпляров.
запрос = "ВЫБЕРИТЕ * ИЗ заметок, ГДЕ id = :id" результат = ожидание database.fetch_one (запрос = запрос, значения = {"id": 1}) result.id # Доступ к полю через атрибут result._mapping['id'] # Доступ к полю через сопоставление
Трассировки транзакций: страница запросов к базе данных
В APM трассировки транзакций могут содержать данные запросов к базе данных. Используйте страницу запросов к базе данных , чтобы проанализировать медленную транзакцию или изменить параметры сбора запросов к базе данных.
Поиск запросов к базе данных
Если данные запроса к базе данных связаны с выбранной трассировкой транзакции, страница Запросы к базе данных будет видна на странице сведений Трассировка транзакции .
Если вы ожидаете увидеть данные базы данных для трассировки транзакции, но не видите их, вам может потребоваться изменить параметры запроса к базе данных.
Перейдите по адресу one.newrelic.com > APM и службы > (выберите приложение) > Монитор > Транзакции > (выберите трассировку транзакции) > Запросы к базе данных .
Используйте запросы к базе данных
Используйте страницу запросов к базе данных для анализа и устранения неполадок медленной транзакции. Например:
- Вы заметили на APM Обзор страница о том, что транзакция выполняется ненормально медленно.
- Вы выбираете трассировку транзакции, чтобы получить дополнительные сведения об этой транзакции.
- Если трассировка связана с данными базы данных, выберите страницу Запросы к базе данных , чтобы изучить медленные запросы в трассировке и использовать их в качестве основы для устранения неполадок и повышения производительности приложения.
Другие функции включают в себя:
Если вы хотите… | Сделайте это… |
|---|---|
Скрыть быстрые вызовы | По умолчанию New Relic показывает все запросы, включая быстрые вызовы ( |
Просмотр трассировки стека | Чтобы просмотреть трассировку стека, связанную с запросом к базе данных, щелкните базу данных значок (в таблице Общая продолжительность 9столбец 0054). |
 Чтобы скрыть эти быстрые вызовы, выберите переключатель Скрыть быстрые вызовы .
Чтобы скрыть эти быстрые вызовы, выберите переключатель Скрыть быстрые вызовы .Настройка параметров запроса к базе данных
Параметры запроса к базе данных можно изменить так же, как и другие параметры трассировки транзакций; например, через настройку агента New Relic или, для некоторых агентов, через пользовательский интерфейс.
Общие изменения параметров запросов к базе данных включают:
- Сбор необработанных данных запроса вместо обфускации или отключение сбора запросов
- Изменение порога трассировки стека
- Включение сбора объяснений запросов
Использование запросов к базе данных для повышения производительности
Вот несколько советов по повышению производительности базы данных вашего приложения:
Использование запросов к базе данных 900 96 | Комментарии |
|---|---|
Время | Ищите запросы, в которых |
Повторяющиеся запросы | Ищите запросы, которые повторно запрашивают информацию одного и того же типа; например, несколько запросов для поиска идентификаторов отдельных учетных записей. Попробуйте переписать запрос на |
Накладные расходы базы данных | Посмотрите на структуру ваших запросов, чтобы увидеть, есть ли возможности объединить различные типы информации в один вызов; например, запрос идентификатора учетной записи, имени и т. д. Это полезно, например, если ваш центр базы данных находится в другом географическом местоположении, поскольку это уменьшит накладные расходы. Время, необходимое для запроса и ответа базы данных, может быть очень быстрым. |
 Это указывает на хорошее место, чтобы попытаться улучшить запрос к базе данных с помощью индекса или какой-либо другой оптимизации.
Это указывает на хорошее место, чтобы попытаться улучшить запрос к базе данных с помощью индекса или какой-либо другой оптимизации.