5 стратегий работы с высокими нагрузками в MySQL
Этот текст написан несколько лет назад и может содержать неточностиMySQL — проверенная и очень мощная технология. В том числе и для построения систем с большой нагрузкой. Даже Facebook использует MySQL для управления огромными объемами данных. Рассмотрим основные стратегии для построения нагруженных систем на основе MySQL.
Оптимизация и индексы
Прежде всего убедитесь, что вы используете все стандартные возможности базы данных. Правильная работа с индексами даст огромные приросты в производительности. Сотни и даже тысячи раз. Освобождая при этом ресурсы для других задач. Сегодня стоимость жестких дисков постоянно снижается, а требования к скорости постоянно растут.
Индексы – это эффективный механизм перенести нагрузку с процессора на жесткий диск в правильных пропорциях.
Не спешите оптимизировать все запросы заранее. Используйте лог медленных запросов, чтобы понять, где существуют реальные проблемы.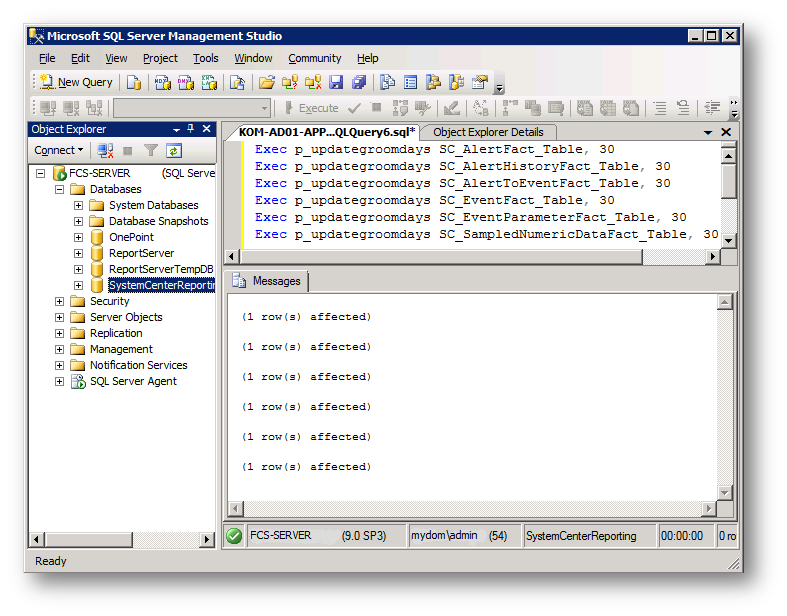
Сразу после установки MySQL не забудьте оптимизировать основные параметры. Стандартная настройка очень базовая и ориентирована на скромное железо и жесткие требования к сохранности.
Подстройка стандартных параметров даст существенный прирост в ускорении не только операций чтения, а и записи.
Кэширование
Очень популярным методом оптимизации производительности является кэширование.
Внутренний кэш MySQL
Перед тем как использовать внешнее решение, подумайте, стоит ли использовать внутренний кэш MySQL. Его имеет смысл включать в тех случаях, когда MySQL работает с очень большим количеством чтений (INSERT, DELETE и UPDATE).
Лучше не включать внутренний кэш Mysql в средах с большим количеством записей/обновлений.
Настройка кэша выполняется с помощью параметра mysql_query_cache_size.
Внешние решения
Более гибкое решение — использование внешних инструментов кэширования, вроде Memcache либо Redis. Есть целый ряд техник кэширования данных в приложениях.
Однако будьте осторожны. Кэширование — это часто не решение проблемы, а ее откладывание. Медленный запрос становится еще медленнее, а его влияние (при сбросе кэша) — менее прогнозируемым.
Кэширование лучше использовать только как промежуточные решения. В конце концов следует избавляться от медленных запросов.
Репликация
Несмотря на то, что репликация может помочь справиться с нагрузкой, ее лучше для этого не применять. Нужно помнить, что наряду с масштабированием у вас всегда будет стоять вопрос доступности. Если реплика, которая помогает обслуживать запросы, выйдет из строя, что случится с системой?
С другой стороны, реплика как раз позволяет обеспечить высокую доступность. Один из подходов выглядит так:
Один из подходов выглядит так:
- Использовать master-slave-репликацию для каждого сервера БД.
- Приложение всегда работает только с мастером.
- Если мастер выходит из строя, приложение переключается на слейв.
- Мы в это время поднимаем сломанный сервер и превращаем его в слейв (как это правильно сделать).
Таким образом, в новой схеме мастер и слейв поменялись местами, а приложение (то есть его пользователи) не заметило никаких проблем.
Репликацию стоит использовать только как механизм резервирования. Не для масштабирования под нагрузки.
Шардинг
Шардинг — это принцип масштабирования базы данных, когда данные разделяются по разным серверам. В нашем распоряжении есть два подхода:
Вертикальный шардинг
Его стоит использовать в первую очередь. Это простое распределение таблиц по серверам. Например, вы помещаете таблицу users на одном сервере, а таблицу orders на другом. В этом случае группы таблиц, по которым выполняются
В этом случае группы таблиц, по которым выполняются JOIN
Горизонтальный шардинг
Этот тип шардинга следует использовать следующим этапом. На этом этапе очень большие таблицы, которые перестают помещаться на одном сервере, разделяют на части и помещают разные их части на разных серверах. Это усложняет логику приложения, однако мир еще не придумал лучших механизмов масштабирования.
Шардинг — единственный подход для масштабирования действительно больших данных.
Другие задачи
Следует отметить, что есть задачи, с которым MySQL справляется крайне плохо. Один из примеров — выборки уникальных значений в разных диапазонах. Либо полнотекстовый поиск.
Обратите внимание на Handlersocket, который может стать заменой любого NoSQL-решения, в случае если оно используется для простых Key-Value операций.
MySQL — мощное, но не универсальное решение.
Redis, Elastic и другие технологии помогут решить дополнительные задачи.
Самое важное
MySQL вместе с современными подходами к оптимизации и масштабированию — это мощная платформа для построения огромных систем. Не забывайте использовать другие технологии для смежных задач, c которыми MySQL справляется не так эффективно.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Как управлять базой данных MySQL
 3. Выберите домен, базой данных которого нужно управлять. Нажмите «Базы данных»:
3. Выберите домен, базой данных которого нужно управлять. Нажмите «Базы данных»:
 Для управления базой данных используйте панель управления хостингом Plesk. Если у Вас есть статический ip-адрес (данный ip-адрес Вы можете заказать у Вашего интернет-провайдера),
который привязан к Вашему модему, то Вы можете обратиться в службу технической поддержки по адресу [email protected],
сообщить свой номер заказа, статический ip-адрес модема и попросить добавить данный ip-адрес в список разрешенных адресов
для подключения к серверу баз данных. После того, как для Вашего ip-адреса будет открыт доступ для подключения к серверу,
Вы сможете использовать программу Devart dbForge Studio for MySQL для управления базой данных, согласно инструкциям,
представленным ниже:
Для управления базой данных используйте панель управления хостингом Plesk. Если у Вас есть статический ip-адрес (данный ip-адрес Вы можете заказать у Вашего интернет-провайдера),
который привязан к Вашему модему, то Вы можете обратиться в службу технической поддержки по адресу [email protected],
сообщить свой номер заказа, статический ip-адрес модема и попросить добавить данный ip-адрес в список разрешенных адресов
для подключения к серверу баз данных. После того, как для Вашего ip-адреса будет открыт доступ для подключения к серверу,
Вы сможете использовать программу Devart dbForge Studio for MySQL для управления базой данных, согласно инструкциям,
представленным ниже: 
Порт: 3306
Имя: имя пользователя, созданного на шаге 7 инструкции Как создать базу данных в Plesk
Пароль: пароль пользователя, созданного на шаге 7 инструкции Как создать базу данных в Plesk
База данных: выберите базу данных, для которой устанавливается соединение
 6. Для выполнения SQL запроса откройте редактор SQL запросов, введите запрос и нажмите кнопку «Выполнить»:
6. Для выполнения SQL запроса откройте редактор SQL запросов, введите запрос и нажмите кнопку «Выполнить»:
15 ODBC мониторинг [Zabbix Documentation 3.0]
15 ODBC мониторинг
1 Обзор
ODBC мониторинг соответствует типу элемента данных Монитор баз данных в веб-интерфейсе Zabbix.
ODBC — язык программирования на C, промежуточная прослойка API для доступа к системам управления баз данных (DBMS). Концепт ODBC был разработан Microsoft и в дальнейшем портирован на другие платформы.
Zabbix может выполнять запросы к любой базе данных, которая поддерживается ODBC. Чтобы это сделать, Zabbix не подключается напрямую к базам данных, он использует интерфейс ODBC и драйвера установленные в ODBC. Эта функция позволяет мониторить различные базы данных с различными целями с большей эффективностью — например, проверка специфичных запросов к базе данных, статистика использования и прочее. Zabbix поддерживает unixODBC, которая наиболее часто используются в реализациях ODBC API с открытым исходным кодом.
Zabbix поддерживает unixODBC, которая наиболее часто используются в реализациях ODBC API с открытым исходным кодом.
2 Установка unixODBC
Предлагаемый вариант установки unixODBC состоит из использования репозитариев пакетов по умолчанию в Linux операционной системы. В наиболее популярные дистрибутивы Linux unixODBC включен в репозитарии пакетов по умолчанию. Если он недоступен, вы можете обратиться к домашней странице UnixODBC: http://www.unixodbc.org/download.html.
Установка unixODBC на системы на базе RedHat/Fedora с использованием менеджера пакетов yum:
shell> yum -y install unixODBC unixODBC-devel
Установка unixODBC на системы на базе SUSE с использованием менеджера пакетов zypper:
# zypper in unixODBC-devel
Пакет unixODBC-devel требуется для компиляции Zabbix с поддержкой unixODBC.
3 Установка драйверов unixODBC
Драйвер unixODBC базы данных должен быть установлен для базы данных, которая будет наблюдаться. unixODBC имеет список поддерживаемых баз данных и драйверов: http://www.unixodbc.org/drivers.html. В некоторых дистрибутивах Linux драйвера баз данных включены в репозитарии пакетов. Драйвера MySQL базы данных на системы на базе RedHat/Fedora можно установить с помощью менеджера пакетов yum:
unixODBC имеет список поддерживаемых баз данных и драйверов: http://www.unixodbc.org/drivers.html. В некоторых дистрибутивах Linux драйвера баз данных включены в репозитарии пакетов. Драйвера MySQL базы данных на системы на базе RedHat/Fedora можно установить с помощью менеджера пакетов yum:
shell> yum install mysql-connector-odbc
Установка MySQL драйвера на системы на базе SUSE с использованием менеджера пакетов zypper:
# zypper in MyODBC-unicODBC
4 Настройка unixODBC
Настройка ODBC выполняется редактированием файлов odbcinst.ini и odbc.ini. Для проверки размещения этих файлов введите:
shell> odbcinst -j
odbcinst.ini используется для перечисления установленных драйверов баз данных ODBC:
[mysql] Description = ODBC for MySQL Driver = /usr/lib/libmyodbc5.so
Подробная информация:
| Атрибут | Описание |
|---|---|
| mysql | Имя драйвера базы данных. |
| Description | Описание драйвера базы данных. |
| Driver | Размещение библиотеки драйвера базы данных. |
odbc.ini используется для определения источников данных:
[test] Description = MySQL test database Driver = mysql Server = 127.0.0.1 User = root Password = Port = 3306 Database = zabbix
Подробная информация:
| Атрибут | Описание |
|---|---|
| test | Имя источника данных (DSN). |
| Description | Описание источника данных. |
| Driver | Имя драйвера базы данных — как указано в odbcinst.ini |
| Server | IP/DNS сервера базы данных. |
| User | Пользователь базы данных для подключения. |
| Password | Пароль к базе данных. |
| Port | Порт подключения к базе данных. |
| Database | Имя базы данных. |
Для проверки работает ли соединение ODBC корректно, подключение к базе данных необходимо протестировать. Для этого можно воспользоваться утилитой isql (включена в пакет unixODBC):
shell> isql test +---------------------------------------+ | Connected! | | | | sql-statement | | help [tablename] | | quit | | | +---------------------------------------+ SQL>
5 Компиляция Zabbix с поддержкой ODBC
Для включения поддержки ODBC, Zabbix должен быть скомпилирован со следующим флагом:
--with-unixodbc[=ARG] use odbc driver against unixODBC package
6 Настройка элемента данных в веб-интерфейсе Zabbix
Настройка элемента данных для мониторинга базы данных:
Специально для элементов данных мониторинга баз данных вы должны указать:
| Тип | Выберите здесь Монитор баз данных. |
| Ключ | Введите db.odbc.select[уникальное_описание,имя_источника_данных] Уникальное описание будет служить идентификатором элемента данных в триггерах и тому подобном. Имя источника данных (DSN) должно быть указано как в настройках odbc.ini. |
| Имя пользователя | Введите имя пользователя для доступа к базе данных (опционально, если пользователь указан в odbc.ini) |
| Пароль | Введите пароль пользователя для доступа к базе данных (опционально, если пароль указан в odbc.ini) |
| SQL запрос | Введите необходимый SQL запрос |
| Тип информации | Очень важно знать какой тип информации будет возвращаться указанным запросом, то есть выберите корректный тип информации здесь. С некорректным типом информации элемент данных станет неподдерживаемым. |
7 Важные замечания
Zabbix не ограничивает время выполнения запроса.
 Пользователь вправе выбирать запросы, которые могут быть выполнены в разумное время.
Пользователь вправе выбирать запросы, которые могут быть выполнены в разумное время.- Значение параметра Timeout с Zabbix сервера используется как время ожидания подключения ODBC (обратите внимание, в зависимости от драйвера ODBC время ожидания подключения может быть проигнорировано).
Запрос должен возвращать только одно значение.
Если запрос возвращает более чем одну колонку, будет прочитана только первая колонка.
Если запрос возвращает более чем одну строку, будет прочитана только первая строка.
Команда SQL должна возвращать результирующий набор данных, как любой запрос с
select …. Синтаксис запроса будет зависеть от RDBMS, которая обрабатывает эти запросы. Синтаксис запроса к хранимым процедурам должен начинаться с ключевого словаcall.
8 Сообщения об ошибках
Начиная с версии Zabbix 2.0.8 сообщения об ошибках ODBC скомпонованы в поля для предоствления подробной информации.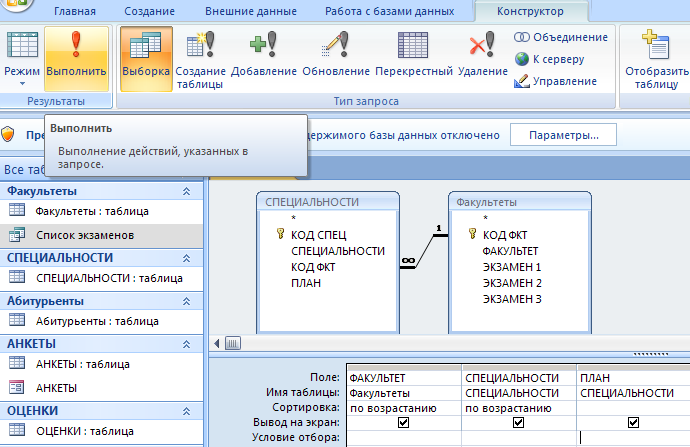 Например:
Например:
Cannot execute ODBC query:[SQL_ERROR]:[42601][7][ERROR: syntax error at or near ";"; Error while executing the query]|
------------------------- --------- ----- | ------------------------------------------------------------------- |
| | | `- Родной код ошибки `- сообщение об ошибке `- Разделитель записей
| | `-SQLState
`- Zabbix сообщение `- ODBC возвращаемый кодОбратите внимание что длина сообщения об ошибке ограничена 2048 байтами, поэтому сообщение может быть укорочено. Если есть более одной ODBC диагностической записи, Zabbix пытается их скомпоновать на сколько позволяет максимальная длина сообщения.Анализ производительности запросов в Базе данных Azure для MySQL
- Чтение занимает 2 мин
В этой статье
Применимо к: База данных Azure для MySQL 5.7, 8.0.Applies to: Azure Database for MySQL 5.7, 8.0
Этот компонент помогает быстро определить наиболее медленно выполняющиеся запросы, их изменение со временем и ожидания каких действий влияют на них.Query Performance Insight helps you to quickly identify what your longest running queries are, how they change over time, and what waits are affecting them.
Распространенные сценарииCommon scenarios
Длительные запросыLong running queries
- Определение самых медленно выполняющихся запросов за прошедшие X часов.Identifying longest running queries in the past X hours
- Определение основных N запросов, ожидающих ресурсы.Identifying top N queries that are waiting on resources
Статистика ожиданияWait statistics
- Понимание характера ожидания запроса.Understanding wait nature for a query
- Понимание тенденций ожидания ресурсов и причин состязания за ресурсы.Understanding trends for resource waits and where resource contention exists
РазрешенияPermissions
Чтобы просматривать текст запросов в анализе производительности запросов, требуются разрешения Владельца или Участника.Owner or Contributor permissions required to view the text of the queries in Query Performance Insight. Модуль чтения может просматривать графики и таблицы, но не текст запросов.Reader can view charts and tables but not query text.
Предварительные требованияPrerequisites
Чтобы компонент «Анализ производительности запросов» работал, данные должны находиться в хранилище запросов.For Query Performance Insight to function, data must exist in the Query Store.
Просмотр анализа производительностиViewing performance insights
Представление анализа производительности запросов на портале Azure содержит визуализации ключевых данных из хранилища запросов.The Query Performance Insight view in the Azure portal will surface visualizations on key information from Query Store.
На странице портала сервера Базы данных Azure для MySQL выберите Анализ производительности запросов в разделе Интеллектуальная производительность в строке меню.In the portal page of your Azure Database for MySQL server, select Query Performance Insight under the Intelligent Performance section of the menu bar.
Длительные запросыLong running queries
На вкладке Длительные запросы отображаются 5 наиболее частых запросов, упорядоченных по средней продолжительности выполнения и объединенных в 15-минутные интервалы.The Long running queries tab shows the top 5 queries by average duration per execution, aggregated in 15-minute intervals. Дополнительные запросы можно выбрать в раскрывающемся списке Количество запросов.You can view more queries by selecting from the Number of Queries drop down. При этом цвета, соответствующие тому или иному идентификатору запроса на графике, могут изменяться.The chart colors may change for a specific Query ID when you do this.
Чтобы уменьшить временной интервал графика, перетащите его границу.You can click and drag in the chart to narrow down to a specific time window. Кроме того, для просмотра более коротких или более длинных периодов используйте соответственно значки увеличения и уменьшения масштаба.Alternatively, use the zoom in and out icons to view a smaller or larger time period respectively.
Статистика ожиданияWait statistics
Примечание
Статистика ожидания предназначена для устранения проблем с производительностью запросов.Wait statistics are meant for troubleshooting query performance issues. Рекомендуется включать эту функцию только в целях устранения неполадок.It is recommended to be turned on only for troubleshooting purposes.
Если вы увидите на портале Azure сообщение об ошибке Возникла проблема с «Microsoft.DBforMySQL». Не удалось выполнить запрос. Если проблема сохраняется или является непредвиденной ошибкой, обратитесь в службу поддержки с этими сведениямиIf you receive the error message in the Azure portal «The issue encountered for ‘Microsoft.DBforMySQL’; cannot fulfill the request. If this issue continues or is unexpected, please contact support with this information.» при просмотре статистики ожидания, укажите меньший период времени.while viewing wait statistics, use a smaller time period.
Статистика ожидания обеспечивает представление событий ожидания, происходящих во время выполнения определенного запроса.Wait statistics provides a view of the wait events that occur during the execution of a specific query. Узнайте больше о типах событий ожидания в документации по ядру MySQL.Learn more about the wait event types in the MySQL engine documentation.
Откройте вкладку Статистика ожидания, чтобы посмотреть визуализации ожидания на сервере.Select the Wait Statistics tab to view the corresponding visualizations on waits in the server.
Сведения, отображаемые в представлении статистики ожидания, группируются по запросам с максимальным временем ожидания на заданном интервале времени.Queries displayed in the wait statistics view are grouped by the queries that exhibit the largest waits during the specified time interval.
Дальнейшие действияNext steps
Производительность MySQL. Часть 1. Анализ и оптимизация запросов. Хостинг в деталях
Страницы сайта генерируются медленно? Возникают ошибки 502 bad gateway и 504 gateway timeout? Хостер говорит, что сайт создает слишком большую нагрузку на процессор? Скорее всего, проблемы связаны с базой данных. В этой статье рассмотрим вопросы оптимизации производительности MySQL.
Как понять, что дело именно в MySQL
Если сайт работает на популярной CMS, то можно воспользоваться отчетом по SQL-запросам, выполняемым при генерации страницы. Например, в Drupal такой отчет доступен в модуле Devel, в Joomla – в режиме отладки, в WordPress – в расширении Debug bar. Если специальных инструментов нет, то можно до и после выполнения каждого SQL-запроса вызвать PHP-функцию microtime() и посчитать разность.
Drupal Devel
Если сайт размещается на VPS или выделенном сервере, аналогичные данные можно получить и непосредственно из MySQL. Например, из журнала медленных запросов.
Заняться оптимизацией однозначно стоит в случаях, когда при генерации страницы суммарное время выполнения запросов к базе данных превышает 1 секунду.
С чего начать оптимизацию
Итак, вы определили, какие запросы выполняются при генерации страницы. Дальше возможны варианты:
- Есть тяжелые запросы, занимающие сотни миллисекунд.
- Запросов много, но все они выполняются достаточно быстро.
В первом случае можно попробовать оптимизировать отдельные запросы. Здесь поможет SQL-оператор EXPLAIN и знания об индексах. Это решение применимо ко всем сайтам, в том числе размещенным на виртуальном хостинге.
Во втором случае имеет смысл заняться углубленным анализом логов и тонкой настройкой MySQL. На виртуальном хостинге сделать это не получится, только на VPS и выделенных серверах.
Но прежде, чем углубляться в детали, стоит сказать о кеше запросов – быстром и простом способе снять многие проблемы. Возможность включить кеш запросов есть у владельцев VPS и выделенных серверов.
Кеш запросов
В кеше запросов (query cache) сохраняются пары запрос-ответ. Когда запрос уже есть в кеше, ответ отдается практически мгновенно. Если данные в таблицах меняются не слишком часто, происходит ощутимый прирост производительности (в противном случае кеш быстро сбрасывается).
По умолчанию кеширование выключено. Включить его можно, добавив в конфигурационный файл my.cnf строчку вида query_cache_size = 64M . Через переменную query_cache_size задается размер оперативной памяти, выделяемой под кеш, в данном случае — 64 мегабайта.
Теперь нужно перезапустить MySQL. Сделать это можно из некоторых панелей управления (в ISPmanager: Management tools — Services), либо по SSH из командной строки примерно так:/usr/local/etc/rc.d/mysql-server stop
/usr/local/etc/rc.d/mysql-server start
Всё, кеш включен. Можно попробовать открыть страницу сайта и потом обновить. Во второй раз должна загрузиться быстрее.
Есть еще несколько переменных для настройки кеша:
- query_cache_type задает режим работы кеша, когда query_cache_size установлен больше нуля. Допустимые значения query_cache_type: 0 или OFF — кеширование выключено; 1 или ON — кеширование включено для всех выражений, кроме начинающихся с SELECT SQL_NO_CACHE; 2 или DEMAND — кеширование включено только для запросов, начинающихся с SELECT SQL_CACHE.
- query_cache_limit – максимально допустимый размер, при котором результат выполнения запроса будет сохранен в кеше.
- query_cache_min_res_unit – минимальный размер блоков памяти, выделяемых под кеш. По умолчанию 4 Кб. Если у вас много результатов значительно меньшего объема, query_cache_min_res_unit можно понизить, чтобы память использовалась эффективнее. Подходящее значение можно рассчитать по формуле (query_cache_size — Qcache_free_memory) / Qcache_queries_in_cache.
Пример my.cnf для небольшого VPS:query_cache_size = 64M
query_cache_limit = 2M
query_cache_type = 1
query_cache_min_res_unit = 2K
Посмотреть текущее состояние кеша можно в phpMyAdmin на вкладке Status, либо из командной строки:
# mysql -u root -p Password: ******** mysql> SHOW GLOBAL STATUS LIKE ‘Qcache%’; +----------------------------+------------+ | Variable_name | Value | +----------------------------+------------+ | Qcache_free_blocks | 130 | | Qcache_free_memory | 56705448 | | Qcache_hits | 57092 | | Qcache_inserts | 10412 | | Qcache_lowmem_prunes | 0 | | Qcache_not_cached | 5036 | | Qcache_queries_in_cache | 1023 | | Qcache_total_blocks | 2409 | +----------------------------+------------+ 8 rows in set (0.01 sec)
- Qcache_free_blocks – количество свободных блоков в кеше.
- Qcache_free_memory – объем свободной ОЗУ, отведенной под кеш.
- Qcache_hits – количество запросов, результаты которых были взяты из кеша.
- Qcache_inserts – количество запросов, которые были добавлены в кеш.
- Qcache_lowmem_prunes – количество запросов, которые были удалены из кеша из-за нехватки памяти.
- Qcache_not_cached – количество запросов, которые не были записаны в кеш (с SQL_NO_CACHE или некешируемые по другим причинам).
- Qcache_queries_in_cache – количество запросов, которые находятся в кеше.
- Qcache_total_blocks – общее количество блоков.
Долю закешированных запросов от их общего числа можно посчитать по формуле Qcache_hits / (Com_select + Qcache_hits). Степень использования кеша — Qcache_hits / Qcache_inserts.
О нюансах работы кеша MySQL можно почитать на mysqlperformanceblog.com (англ.)
Оптимизация отдельных запросов
Чтобы оптимизировать тяжелый запрос, сначала его нужно исследовать. Для этого допишите перед SELECT слово EXPLAIN, и MySQL покажет план выполнения запроса. В первую очередь интерес представляет информация об использовании индексов.
Результат работы оператора EXPLAIN
Индексы – это структуры данных, создаваемые с целью повышения производительности поиска записей в таблицах. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному критерию путем последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. [источник]
Индексы — ключ к высокой производительности MySQL, их важность увеличивается по мере роста объема данных в базе. Индексы нужно создавать для столбцов, по которым
- производится поиск в части WHERE
- соединяются таблицы при JOIN
- сортируются и группируются записи при ORDER BY и GROUP BY
- производится поиск MIN() и MAX()
Индексы могут быть составными, в этом случае важен порядок столбцов.
Разбирая вывод EXPLAIN, обратите особое внимание на столбцы
- type (значение ALL — плохо)
- key (NULL — плохо)
- ref (NULL — плохо)
- extra (Using filesort, Using temporary, Using where — плохо)
Описание всех значений и пример оптимизации запроса можно посмотреть в документации.
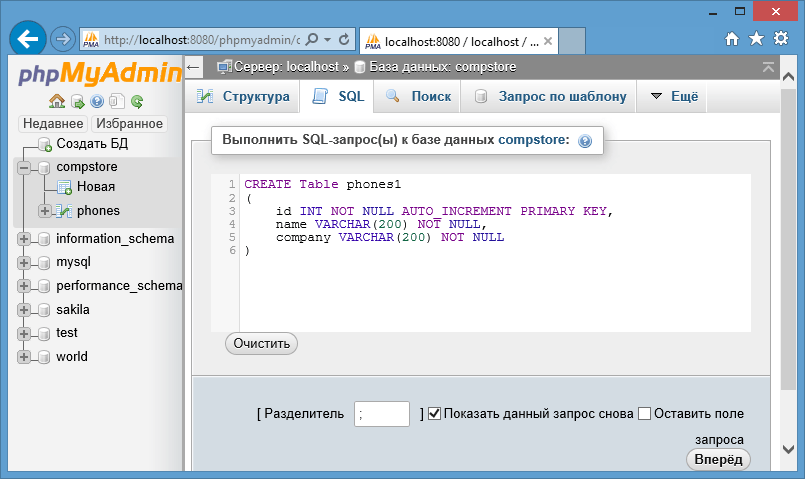
Добавить индексы можно из phpMyAdmin или с помощью запросов вида ALTER TABLE table_name ADD INDEX index_name (column_name)
Журнал медленных запросов
Если определить тяжелые запросы «на глаз» не получается, нужно собрать более обширную статистику. В этом поможет журнал медленных запросов (slow query log).
Для включения журнала в MySQL, начиная с версии 5.1.29, задайте переменной slow_query_log значение 1 или ON; для отключения журнала — 0 или OFF. В более старых версиях используется log-slow-queries = /var/db/mysql/slow_queries.log (путь можно задать другой).
Вторая важная настройка — long_query_time — порог времени выполнения, при превышении которого запрос считается медленным и записывается в журнал. Начиная с MySQL 5.1.21 может задаваться в микросекундах и может быть равен нулю.
Пара полезных дополнительных настроек:
- log-queries-not-using-indexes – запись в журнал запросов, не использующих индексы.
- slow_query_log_file – имя файла журнала. По умолчанию host_name-slow.log
Пример для записи в журнал всех запросов, выполняющихся дольше 50 миллисекунд:slow_query_log = 1
slow_query_log_file = /var/db/mysql/slow_queries.log
long_query_time = 0.05
log-queries-not-using-indexes = 1
Пример для старых версий MySQL, все запросы дольше 1 секунды:log-slow-queries = /var/db/mysql/slow_queries.log
long_query_time = 1
Для анализа журнала используются утилиты mysqldumpslow, mysqlsla и mysql_slow_log_filter. Они парсят журнал и выводят агрегированную информацию о медленных запросах.
mysqldumpslow – утилита из состава MySQL. Вызывается таким образом: mysqldumpslow [параметры] [файл_журнала ...] . Пример:
mysqldumpslow
Reading mysql slow query log from /usr/local/mysql/data/mysqld51-apple-slow.log
Count: 1 Time=4.32s (4s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
insert into t2 select * from t1
Count: 3 Time=2.53s (7s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
insert into t2 select * from t1 limit N
Count: 3 Time=2.13s (6s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
insert into t1 select * from t1
Count – сколько раз был выполнен запрос данного типа. Time – среднее время выполнения запроса, дальше в скобках – суммарное время выполнения всех запросов данного типа.
Некоторые параметры mysqldumpslow:
- -t N – отображать только первые N запросов.
- -g pattern — анализировать только запросы, которые соответствуют шаблону (как grep).
- -s sort_type — как сортировать вывод. Значения sort_type: t или at — сортировать по суммарному или среднему времени выполнения запросов, c — по количеству выполненных запросов данного типа.
mysqlsla – еще одна утилита для анализа логов MySQL с аналогичной функциональностью. Пример использования:
mysqlsla -lt slow /tmp/slow_queries.log
Подробности в документации.
mysql_slow_log_filter — perl-скрипт с похожей функциональностью. Пример использования:
tail –f mysql-slow.log | mysql_slow_log_filter –T 0.5 –R 1000
Эта команда в реальном времени покажет запросы, выполняющиеся дольше 0,5 секунды или сканирующие больше 1000 строк.
Выявленные медленные запросы дальше можно оптимизировать, используя EXPLAIN и индексы.
Вторая часть статьи будет посвящена тонкой настройке MySQL. Материал находится в разработке.
—
Евгений Демин, http://unixzen.ru
Дмитрий Сергеев, http://hosting101.ru
Как в 14 раз снизить нагрузку на базу данных MySQL / Русскоязычное сообщество MODX
TicketsЕсли кратко, то таблица modx_tickets_views — критически увеличивает нагрузку на базу данных MySQL. Уменьшить нагрузку можно отключив (если включен) счетчик просмотра неавторизованными пользователями tickets.count_guests или обнулить (очистить)/удалить таблицу modx_tickets_views из базы данных MySQL.
Ниже отрывки из переписки с ТП Бегет (может кому пригодится)
Прошу снять ограничения с сайтаНа вашем сайте sql запрос
SELECT COUNT(DISTINCT `TicketView`.`parent`, `TicketView`.`uid`, `TicketView`.`guest_key`) FROM `modx_tickets_views` AS `TicketView` WHERE `TicketView`.`parent` = 59;COUNT(DISTINCT ...)[email protected][modx3]> EXPLAIN SELECT COUNT(DISTINCT `TicketView`.`parent`, `TicketView`.`uid`, `TicketView`.`guest_key`) FROM `modx_tickets_views` AS `TicketView` WHERE `TicketView`.`parent`
= 59;
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------------------------------+
| 1 | SIMPLE | TicketView | NULL | range | PRIMARY | PRIMARY | 104 | NULL | 176437 | 100.00 | Using where; Using index for group-by (scanning) |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------------------------------+Если есть возможность, прошу помочь с перечисленной ниже оптимизацией:Здравствуйте, базу сайта перевел в innodb, создав отдельную базу — ххх, старую не стал трогать modx3, она также доступна в разделе MySQL. К сожалению запрос
Уменьшить конструкцию COUNT(DISTINCT …)
Сконвертировать всю базу данных в InnoDB
COUNT(DISTINCT ...)[modx3]> select count(*) from modx_tickets_views;
+----------+
| count(*) |
+----------+
| 2385727 |
+----------+
1 row in set (0,51 sec)И последний момент: Redis, за счет его высокой скорости работы, удобно использовать для хранения различных счетчиков, например, количества просмотров страниц сайта, или же каких-либо временных данных.Нет, изменения в работе сайтов автоматически не произойдут.
Означает ли это, что при включенном Redis данные таблицы modx_tickets_views начнут автоматически сохраняться в памяти Redis, а не в БД
Включение Redis, в данном случае означает, что у Вас появляется доступ к контейнеру с данной БД. Использовать его Вы можете как угодно.
Для реализации описанного Вами функционала потребует либо дополнительных настроек или установки плагина, либо вмешательство в код CMS.
Глава 5: DjangoBook по-русски | Django на русском
Глава 5. Модели
Перевод © Попов Руслан <ruslan.popov • gmail>
В главе «Представления и привязки URL» мы описали основы создания динамических сайтов с помощью Django: настройка представлений и схемы URL для них. Как было рассказано, представление отвечает за некоторую произвольную логику и возвращает отклик. В одном из примеров логикой являлось вычисление текущей даты и времени.
В современных веб-приложениях произвольная логика часто вовлечена в работу с базой данных. Обычно, сайт такого типа подключается к серверу базы данных, получает от него некоторые данные и, выполнив форматирование, отображает эти данные на странице. Так же сайт может предоставлять посетителям сайта возможность заполнять базу данных своими данными.
Множество сложных сайтов предоставляют некую комбинацию этих двух вариантов. Например, http://www.amazon.com/ является отличным примером такого сайта. Каждая страница продукта, по существу, является запросом в базу данных продуктов Amazon, отформатированном в виде HTML. А когда вы отсылаете свой комментарий, он помещается в базу данных отзывов.
Django отлично подходит для создания сайтов, ориентированных на использование совместно с базой данных, т.к., она поставляется с простыми, но мощными механизмами выполнения запросов к базе данных с помощью Python. Эта глава описывает этот механизм: слой Django для работы с базой данных.
Следует отметить, что необязательно знать основы теории баз данных и SQL для использования этого слоя Django, но это крайне рекомендуется. Введение в эти понятия находится вне сферы этой книги. Вероятно, вы сможете понять концепции, учитывая контекст изложения.
«Тупой» способ выполнения запросов в представлениях
Подобно определённому в главе «Представления и привязки URL» «тупому» способу генерации вывода с помощью представлений (вбивание руками текста прямо в код представления), существует «тупой» способ получения в представлениях информации из базы данных. Это просто: используйте любую существующую библиотеку языка Python для выполнения SQL запроса и обрабатывайте его результаты.
В этом примере представления мы используем библиотеку MySQLdb (доступную по адресу http://www.djangoproject.com/r/python-mysql/) для подключения к базе данных MySQL, получения нескольких записей и помещения их в шаблон для отображения на странице сайта:
from django.shortcuts import render_to_response
import MySQLdb
def book_list(request):
db = MySQLdb.connect(user='me', db='mydb', passwd='secret', host='localhost')
cursor = db.cursor()
cursor.execute('SELECT name FROM books ORDER BY name')
names = [row[0] for row in cursor.fetchall()]
db.close()
return render_to_response('book_list.html', {'names': names})
Такой подход работает, но вы должны немедленно столкнуться с некоторыми проблемами:
Мы жёстко определяем параметры соединения с базой данных. В идеале эти параметры должны храниться в конфигурации проекта Django.
Мы должны писать нудный код: создать соединение, создать курсор, выполнить оператор и закрыть соединение. В идеале всё, что мы должны сделать — указать необходимый нам результат.
Это привязывает нас к MySQL. Если, с течением времени, мы решим перейти с MySQL на PostgreSQL, нам потребуется использовать другой драйвер для базы данных (т.е., psycopg вместо MySQLdb), изменить параметры соединения и, в зависимости от природы SQL операторов, возможно, переписать SQL запросы. В идеале, мы должны рассматривать сервер базы данных абстрактно, т.е., для смены сервера мы должны внести изменения в одно только место проекта. (Эта проблема имеет особое значение в случае, если вы работаете над приложением Django с открытым кодом, которое вы желаете распространить среди максимально возможного количества пользователей.)
Как вы можете ожидать, слой Django для работы с базами данных помогает решать такие проблемы. Далее представлен пример как надо изменить предыдущее представление для использования Django API для работы с базами данных:
from django.shortcuts import render_to_response
from mysite.books.models import Book
def book_list(request):
books = Book.objects.order_by('name')
return render_to_response('book_list.html', {'books': books})
Мы разберём этот код немного позже в этой главе.
Введение в SQL
SQL — это стандартный язык для доступа к базам данных и управления ими.
Что такое SQL?
- SQL — это аббревиатура от языка структурированных запросов .
- SQL позволяет получать доступ к базам данных и управлять ими
- SQL стал стандартом Американского национального института стандартов (ANSI) в 1986 г. и Международной организации по стандартизации (ISO) в 1987
Что умеет SQL?
- SQL может выполнять запросы к базе данных
- SQL может извлекать данные из базы данных
- SQL может вставлять записи в базу данных
- SQL может обновлять записи в базе данных
- SQL может удалять записи из базы данных
- SQL может создавать новые базы данных
- SQL может создавать новые таблицы в базе данных
- SQL может создавать хранимые процедуры в базе данных
- SQL может создавать представления в базе данных
- SQL может устанавливать разрешения для таблиц, процедур и представлений
SQL — это Стандарт — НО….
Хотя SQL является стандартом ANSI / ISO, существуют разные версии языка SQL.
Однако, чтобы соответствовать стандарту ANSI, все они поддерживают, по крайней мере, основные команды (например, ВЫБЕРИТЕ , ОБНОВЛЕНИЕ , УДАЛИТЬ , ВСТАВИТЬ , WHERE ) аналогичным образом.
Примечание: Большинство программ баз данных SQL также имеют собственные проприетарные расширения в дополнение к стандарту SQL!
Использование SQL на вашем веб-сайте
Для создания веб-сайта, отображающего данные из базы данных, вам потребуется:
- Программа базы данных СУБД (т.е. MS Access, SQL Server, MySQL)
- Чтобы использовать язык сценариев на стороне сервера, например PHP или ASP
- Использование SQL для получения нужных данных
- Использование HTML / CSS для стилизации страницы
РСУБД
RDBMS — это система управления реляционными базами данных.
СУБДявляется основой для SQL и для всех современных систем баз данных, таких как MS SQL Server, IBM DB2, Oracle, MySQL и Microsoft Access.
Данные в СУБД хранятся в объектах базы данных, называемых таблицами.Таблица — это набор связанных записей данных, состоящий из столбцов и строк.
Посмотрите в таблице «Клиенты»:
Каждая таблица разбита на более мелкие объекты, называемые полями. Поля в таблица клиентов состоит из идентификатора клиента, имени клиента, имени контакта, адреса, Город, почтовый индекс и страна. Поле — это столбец в таблице, предназначенный для поддержки конкретная информация о каждой записи в таблице.
Запись, также называемая строкой, — это каждая отдельная запись, существующая в таблице.Например, в приведенной выше таблице «Клиенты» 91 запись. Рекорд — это горизонтальный объект в таблице.
Столбец — это вертикальный объект в таблице, который содержит всю информацию. связанный с определенным полем в таблице.
Синтаксис SQL
Таблицы базы данных
База данных чаще всего содержит одну или несколько таблиц. Каждая таблица идентифицирована по имени (например, «Клиенты» или «Заказы»). Таблицы содержат записи (строки) с данные.
В этом руководстве мы будем использовать хорошо известную базу данных Northwind. (входит в MS Access и MS SQL Server).
Ниже представлен выбор из таблицы «Клиенты»:
| Идентификатор клиента | CustomerName | ContactName | Адрес | Город | Почтовый индекс | Страна |
|---|---|---|---|---|---|---|
| 1 | Альфредс Футтеркисте | Мария Андерс | Obere Str.57 | Берлин | 12209 | Германия |
| 2 | Ana Trujillo Emparedados y helados | Ана Трухильо | Avda. de la Constitución 2222 | México D.F. | 05021 | Мексика |
| 3 | Антонио Морено Такерия | Антонио Морено | Матадерос 2312 | Мексика Д.F. | 05023 | Мексика |
| 4 | Вокруг Рога | Томас Харди | 120 Hanover Sq. | Лондон | WA1 1DP | UK |
| 5 | Berglunds snabbköp | Кристина Берглунд | Berguvsvägen 8 | Лулео | С-958 22 | Швеция |
Таблица выше содержит пять записей (по одной для каждого клиента) и семь столбцов. (CustomerID, CustomerName, ContactName, Address, City, PostalCode и Country).
Операторы SQL
Большинство действий, которые необходимо выполнить с базой данных, выполняются с помощью SQL. заявления.
Следующий оператор SQL выбирает все записи в таблице «Клиенты»:
В этом руководстве мы расскажем вам о различных операторах SQL.
Помните, что …
- Ключевые слова SQL НЕ чувствительны к регистру:
selectсовпадает сВЫБЕРИТЕ
В этом руководстве мы будем писать все ключевые слова SQL в верхнем регистре.
Точка с запятой после операторов SQL?
В некоторых системах баз данных в конце каждого оператора SQL требуется точка с запятой.
Точка с запятой — это стандартный способ разделения каждого оператора SQL в базе данных. системы, которые позволяют выполнять более одного оператора SQL в одном вызове к серверу.
В этом руководстве мы будем использовать точку с запятой в конце каждого оператора SQL.
Некоторые из наиболее важных команд SQL
-
SELECT— извлекает данные из базы данных -
UPDATE— обновляет данные в базе данных -
DELETE— удаляет данные из базы данных -
INSERT INTO— вставляет новые данные в базу данных -
CREATE DATABASE— создает новую базу данных -
ALTER DATABASE— изменяет базу данных -
CREATE TABLE— создает новую таблицу -
ALTER TABLE— изменяет таблицу -
DROP TABLE— удаляет таблицу -
CREATE INDEX— создает индекс (ключ поиска) -
DROP INDEX— удаляет индекс
SQL присоединяется к
SQL ПРИСОЕДИНЯТЬСЯ
Предложение JOIN используется для объединения строк из двух или более таблиц на основе
связанный столбец между ними.
Давайте посмотрим на выборку из таблицы «Заказы»:
| Код заказа | Идентификатор клиента | Дата заказа |
|---|---|---|
| 10308 | 2 | 1996-09-18 |
| 10309 | 37 | 1996-09-19 |
| 10310 | 77 | 1996-09-20 |
Затем посмотрите на выбор из таблицы «Клиенты»:
| Идентификатор клиента | CustomerName | ContactName | Страна |
|---|---|---|---|
| 1 | Альфредс Футтеркисте | Мария Андерс | Германия |
| 2 | Ana Trujillo Emparedados y helados | Ана Трухильо | Мексика |
| 3 | Антонио Морено Такерия | Антонио Морено | Мексика |
Обратите внимание, что столбец «CustomerID» в таблице «Заказы» относится к «CustomerID» в таблице «Клиенты».Связь между двумя таблицами выше столбец «CustomerID».
Затем мы можем создать следующий оператор SQL (который содержит ВНУТРЕННЕЕ СОЕДИНЕНИЕ ),
который выбирает записи, которые имеют совпадающие значения в обеих таблицах:
Пример
ВЫБЕРИТЕ Orders.OrderID, Customers.CustomerName, Orders.OrderDate
ИЗ Orders
ВНУТРЕННИЕ СОЕДИНЯЙТЕСЬ с клиентами НА Orders.CustomerID = Customers.CustomerID;
, и он выдаст что-то вроде этого:
| Код заказа | CustomerName | Дата заказа |
|---|---|---|
| 10308 | Ana Trujillo Emparedados y helados | 18.09.1996 |
| 10365 | Антонио Морено Такерия | 27.11.1996 |
| 10383 | Вокруг Рога | 16.12.1996 |
| 10355 | Вокруг Рога | 15.11.1996 |
| 10278 | Berglunds snabbköp | 12.08.1996 |
Различные типы SQL-соединений
Вот различные типы JOIN в SQL:
-
(INNER) JOIN: возвращает записи, которые имеют совпадающие значения в обеих таблицах -
LEFT (OUTER) JOIN: возвращает все записи из левой таблицы и соответствующие записи из правой таблицы -
RIGHT (OUTER) JOIN: возвращает все записи из правой таблицы и соответствующие записи из левой таблицы -
ПОЛНОЕ (ВНЕШНЕЕ) СОЕДИНЕНИЕ: Возвращает все записи, если есть совпадение в любом из левых или правый стол
Базовое руководство по MySQL
В этом базовом руководстве по MySQL объясняются некоторые основные операторы SQL.Если вы впервые используете систему управления реляционными базами данных, в этом руководстве вы найдете все, что вам нужно знать для работы с MySQL, например, запросы данных, обновление данных, управление базами данных и создание таблиц.
Если вы уже знакомы с другими системами управления реляционными базами данных, такими как PostgreSQL, Oracle и Microsoft SQL Server, вы можете использовать это руководство, чтобы освежить свои знания и понять, чем диалект SQL в MySQL отличается от других систем.
Раздел 1. Начало работы с MySQL
Этот раздел поможет вам начать работу с MySQL. Мы начнем установку MySQL, загрузку образца базы данных и загрузку данных на сервер MySQL для практики.
Раздел 2. Запрос данных
Этот раздел поможет вам узнать, как запрашивать данные с сервера базы данных MySQL. Мы начнем с простого оператора SELECT , который позволяет запрашивать данные из одной таблицы.
- SELECT — покажет, как использовать простой оператор
SELECTдля запроса данных из одной таблицы.
Раздел 3. Сортировка данных
- ORDER BY — покажет вам, как отсортировать набор результатов с помощью предложения
ORDER BY. Также будет рассмотрен пользовательский порядок сортировки с функциейFIELD.
Раздел 4. Фильтрация данных
- WHERE — узнайте, как использовать предложение
WHEREдля фильтрации строк на основе заданных условий. - SELECT DISTINCT — покажет, как использовать оператор
DISTINCTв оператореSELECTдля удаления повторяющихся строк в наборе результатов. - AND — познакомит вас с оператором
ANDдля комбинирования логических выражений для формирования сложного условия фильтрации данных. - OR– познакомит вас с оператором
ORи покажет, как комбинировать операторORс операторомANDдля фильтрации данных. - IN — покажет вам, как использовать оператор
INв предложенииWHERE, чтобы определить, соответствует ли значение какому-либо значению в списке или подзапросе. - BETWEEN — покажет, как запрашивать данные на основе диапазона с помощью оператора
BETWEEN. - LIKE — предоставить вам методику запроса данных на основе определенного шаблона.
- LIMIT — используйте
LIMIT, чтобы ограничить количество строк, возвращаемых операторомSELECT - IS NULL — проверьте, является ли значение
NULLили нет, используя операторIS NULL.
Раздел 5. Объединение таблиц
- Псевдонимы таблиц и столбцов — знакомство с псевдонимами таблиц и столбцов.
- Соединения — обзор соединений, поддерживаемых в MySQL, включая внутреннее соединение, левое соединение и правое соединение.
- INNER JOIN — запросить строки из таблицы, которая имеет совпадающие строки в другой таблице.
- LEFT JOIN — вернуть все строки из левой таблицы и совпадающие строки из правой таблицы или null, если в правой таблице не найдено совпадающих строк.
- RIGHT JOIN — вернуть все строки из правой таблицы и совпадающие строки из левой таблицы или null, если в левой таблице не найдено совпадающих строк.
- CROSS JOIN — создать декартово произведение строк из нескольких таблиц.
- Самосоединение — присоединить таблицу к самой себе, используя псевдоним таблицы, и соединить строки в одной таблице, используя внутреннее соединение и левое соединение.
Раздел 6. Группирование данных
- GROUP BY — покажет вам, как группировать строки в группы на основе столбцов или выражений.
- HAVING — фильтровать группы по определенному условию.
- ROLLUP — создание нескольких наборов группировок с учетом иерархии между столбцами, указанной в предложении
GROUP BY.
Раздел 7. Подзапросы
- Подзапрос — показывает, как вложить запрос (внутренний запрос) в другой запрос (внешний запрос) и использовать результат внутреннего запроса для внешнего запроса.
- Производная таблица — познакомит вас с концепцией производной таблицы и покажет, как ее использовать для упрощения сложных запросов.
- EXISTS — проверка на наличие строк.
Раздел 8. Общие табличные выражения
- Общее табличное выражение или CTE — объяснит вам концепцию общего табличного выражения и покажет, как использовать CTE для запроса данных из таблиц.
- Рекурсивный CTE — используйте рекурсивный CTE для просмотра иерархических данных.
Раздел 9.Операторы множества
- UNION и UNION ALL — объединяют два или более наборов результатов нескольких запросов в один набор результатов.
- INTERSECT — покажет вам несколько способов имитации оператора
INTERSECT. - MINUS — объясните вам оператор SQL MINUS и покажите, как его моделировать.
Раздел 10. Изменение данных в MySQL
В этом разделе вы узнаете, как вставлять, обновлять и удалять данные из таблиц с помощью различных операторов MySQL.
- INSERT — используйте различные формы оператора
INSERTдля вставки данных в таблицу. - INSERT Multiple Rows — вставить несколько строк в таблицу.
- INSERT INTO SELECT — вставить данные в таблицу из набора результатов запроса.
- INSERT IGNORE — объясните вам оператор
INSERT IGNORE, который вставляет строки в таблицу и игнорирует строки, вызывающие ошибки. - UPDATE — узнайте, как использовать оператор
UPDATEи его параметры для обновления данных в таблицах базы данных. - UPDATE JOIN — покажет вам, как выполнить обновление кросс-таблицы с помощью оператора
UPDATE JOINсINNER JOINиLEFT JOIN. - DELETE — покажет, как использовать оператор
DELETEдля удаления строк из одной или нескольких таблиц. - ON DELETE CASCADE — узнайте, как использовать
ON DELETE CASCADEссылочное действие для внешнего ключа для автоматического удаления данных из дочерней таблицы при удалении данных из родительской таблицы. - DELETE JOIN — покажет, как удалить данные из нескольких таблиц.
- REPLACE — узнать, как вставлять или обновлять данные, зависит от того, существуют ли данные в таблице или нет.
- Подготовленный оператор — покажет, как использовать подготовленный оператор для выполнения запроса.
Раздел 11. Транзакция MySQL
- Транзакция — узнайте о транзакциях MySQL и о том, как использовать
COMMITиROLLBACKдля управления транзакциями в MySQL. - Блокировка таблицы — узнайте, как использовать блокировку MySQL для совместного доступа к таблице между сеансами.
Раздел 12. Управление базами данных и таблицами MySQL
В этом разделе показано, как управлять наиболее важными объектами базы данных в MySQL, включая базы данных и таблицы.
- Выбор базы данных MySQL — покажет, как использовать оператор
USEдля выбора базы данных MySQL с помощью программыmysqlи MySQL Workbench. - Управление базами данных — изучите различные инструкции для управления базами данных MySQL, включая создание новой базы данных, удаление существующей базы данных, выбор базы данных и перечисление всех баз данных.
- CREATE DATABASE — покажет, как создать новую базу данных на сервере MySQL.
- DROP DATABASE — узнайте, как удалить существующую базу данных.
- Механизмы хранения MySQL — важно понимать особенности каждого механизма хранения, чтобы вы могли эффективно использовать их для максимальной производительности ваших баз данных.
- CREATE TABLE — покажет, как создавать новые таблицы в базе данных с помощью оператора
CREATE TABLE. - Последовательность MySQL — покажет, как использовать последовательность для автоматического создания уникальных чисел для столбца первичного ключа таблицы.
- ALTER TABLE — узнайте, как использовать оператор
ALTER TABLEдля изменения структуры таблицы. - Переименование таблицы — покажет, как переименовать таблицу с помощью оператора
RENAME TABLE. - Удаление столбца из таблицы — покажет, как использовать оператор
ALTER TABLE DROP COLUMNдля удаления одного или нескольких столбцов из таблицы. - Добавление нового столбца в таблицу — покажет, как добавить один или несколько столбцов в существующую таблицу с помощью оператора
ALTER TABLE ADD COLUMN. - DROP TABLE — показать вам, как удалить существующие таблицы с помощью оператора
DROP TABLE. - Временные таблицы — обсудите временную таблицу MySQL и покажите, как управлять временными таблицами.
- TRUNCATE TABLE — покажет вам, как использовать оператор
TRUNCATE TABLEдля быстрого удаления всех данных в таблице. - Сгенерированные столбцы — узнайте, как использовать сгенерированные MySQL столбцы для хранения данных, вычисленных из выражения или других столбцов.
Раздел 13.Типы данных MySQL
- Типы данных MySQL — покажут вам различные типы данных в MySQL, чтобы вы могли эффективно применять их при разработке таблиц базы данных.
- INT — покажет, как использовать целочисленный тип данных.
- DECIMAL — покажет, как использовать тип данных
DECIMALдля хранения точных значений в десятичном формате. - BIT — познакомим вас с типом данных
BIT ии как хранить битовые значения в MySQL. - BOOLEAN — объясните вам, как MySQL обрабатывает логические значения с помощью внутреннего использования
TINYINT (1). - CHAR — справочник по типу данных
CHARдля хранения строки фиксированной длины. - VARCHAR — даст вам необходимое руководство по типу данных
VARCHAR. - TEXT — покажет, как хранить текстовые данные с использованием типа данных
TEXT. - DATE — познакомит вас с типом данных
DATEи покажет вам некоторые функции даты для эффективной обработки данных даты. - TIME — познакомит вас с функциями типа данных
TIMEи покажет, как использовать некоторые полезные временные функции для обработки данных времени. - DATETIME — познакомит вас с типом данных
DATETIMEи некоторыми полезными функциями для управления значениямиDATETIME. - TIMESTAMP — познакомит вас с
TIMESTAMPи его функциями, называемыми автоматической инициализацией и автоматическим обновлением, которые позволяют вам определять автоматически инициализированные и автоматически обновляемые столбцы для таблицы. - JSON — покажите, как использовать тип данных JSON для хранения документов JSON.
- ENUM — узнайте, как правильно использовать тип данных
ENUMдля хранения значений перечисления.
Раздел 14. Ограничения MySQL
- Ограничение NOT NULL — познакомим вас с ограничением
NOT NULLи покажем, как объявить столбецNOT NULLили добавить ограничениеNOT NULLк существующему столбцу. - Ограничение первичного ключа — руководство по использованию ограничения первичного ключа для создания первичного ключа для таблицы.
- Ограничение внешнего ключа — познакомит вас с внешним ключом и покажет шаг за шагом, как создавать и удалять внешние ключи.
- Отключить проверку внешнего ключа — узнайте, как отключить проверку внешнего ключа.
- Ограничение UNIQUE — покажет, как использовать ограничение
UNIQUEдля обеспечения уникальности значений в столбце или группе столбцов в таблице. - Ограничение CHECK — узнайте, как создать ограничения
CHECKдля обеспечения целостности данных. - Эмуляция ограничения CHECK — если вы используете MySQL 8.0.15 или более раннюю версию, вы можете эмулировать ограничения
CHECKс помощью представлений или триггеров.
Раздел 15. Глобализация MySQL
- Набор символов — обсудите набор символов и покажите шаг за шагом, как выполнять различные операции с наборами символов.
- Сопоставление — обсудите сопоставление и покажите, как установить наборы символов и сопоставления для сервера MySQL, базы данных, таблиц и столбцов.
Раздел 16. Импорт и экспорт MySQL CSV
Раздел 17. Расширенные методы
- Естественная сортировка — познакомит вас с различными методами естественной сортировки в MySQL с использованием предложения
ORDER BY.
Список всех баз данных в MySQL
Резюме : в этом руководстве вы узнаете, как использовать команду MySQL SHOW DATABASES для вывода списка всех баз данных на сервере баз данных MySQL.
Использование MySQL SHOW DATABASES
Чтобы вывести список всех баз данных на хосте сервера MySQL, вы используете команду SHOW DATABASES следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
SHOW DATABASES;
Например, чтобы вывести список всех баз данных на локальном сервере базы данных MySQL, сначала войдите на сервер базы данных следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
> mysql -u root -п Введите пароль: ********** mysql>
А затем используйте команду SHOW DATABASES :
Язык кода: SQL (язык структурированных запросов) (sql)
mysql> SHOW DATABASES; + | База данных | + | классические модели | | information_schema | | mysql | | performance_schema | | sys | | тест | + 6 рядов в наборе (0.00 сек)
Команда SHOW SCHEMAS является синонимом SHOW DATABASES , поэтому следующая команда возвращает тот же результат, что и предыдущая:
Язык кода: SQL (язык структурированных запросов) (sql)
ПОКАЗАТЬ СХЕМЫ;
Если вы хотите запросить базу данных, которая соответствует определенному шаблону, вы используете предложение LIKE следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
SHOW DATABASES LIKE pattern;
Например, следующий оператор возвращает базу данных, которая заканчивается строкой 'schema' ;
Язык кода: SQL (язык структурированных запросов) (sql)
ПОКАЗАТЬ БАЗЫ ДАННЫХ КАК '% schema'; + | База данных (% схема) | + | information_schema | | performance_schema | + 2 ряда в наборе (0.00 сек)
Важно отметить, что если сервер базы данных MySQL запущен с --skip-show-database , вы не можете использовать оператор SHOW DATABASES если у вас нет привилегии SHOW DATABASES .
Запрос данных базы данных из information_schema
Если условия в предложении LIKE недостаточно, вы можете запросить информацию базы данных непосредственно из таблицы schemata в базе данных information_schema .
Например, следующий запрос возвращает тот же результат, что и команда SHOW DATABASES .
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ имя_схемы ИЗ information_schema.schemata;
Следующий оператор SELECT возвращает базы данных, имена которых заканчиваются на 'schema' или 's' .
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ имя_схемы ИЗ information_schema.schemata ГДЕ schema_name КАК '% schema' ИЛИ schema_name LIKE '% s';
Он возвращает следующий набор результатов:
Язык кода: SQL (язык структурированных запросов) (sql)
+ | SCHEMA_NAME | + | information_schema | | performance_schema | | sys | | классические модели | + 4 ряда в наборе (0.00 сек)
В этом руководстве вы узнали, как отобразить все базы данных на сервере MySQL с помощью команды SHOW DATABASES или запроса из таблицы схемы в База данных information_schema .
Было ли это руководство полезным?
Запрос данных с сервера MySQL с помощью оператора SELECT
В этой серии статей мы узнаем об основах работы с сервером баз данных MySQL.В этой статье я собираюсь объяснить, как мы можем запрашивать данные с сервера MySQFL с помощью оператора SELECT.
Для демонстрации я установил MySQL 8.0 и MySQL Workbench на свою рабочую станцию, а также восстановил демонстрационную базу данных с именем sakila. Эта статья поможет вам установить сервер MySQL в Windows 10. Вы можете скачать базу данных sakila отсюда, а шаги по установке описаны в этой статье.
Теперь, чтобы понять архитектуру схемы таблиц сакила, мы сгенерируем схему схемы путем обратного проектирования базы данных.
Создать схему схемы
Чтобы сгенерировать диаграмму схемы, откройте рабочую среду MySQL -> Подключиться к ядру базы данных MySQL -> В строке меню щелкните базу данных -> выберите Reverse Engineer . См. Следующее изображение:
На экране Reverse Engineer Database выберите имя соединения из раскрывающегося списка Stored Connection , выберите соответствующий метод подключения ( TCP / IP ИЛИ именованная труба ) из раскрывающегося списка Connection Method .Введите имя хоста или IP-адрес в текстовое поле Имя хоста. Введите соответствующий номер порта в текстовое поле Номер порта. И, наконец, введите соответствующее имя пользователя в текстовое поле Имя пользователя и нажмите Далее . См. Следующее изображение:
Теперь сервер базы данных MySQL пытается установить соединение между мастером обратного проектирования и сервером и получить информацию о базе данных, размещенной на сервере. Если это не удается, то ошибка будет отображаться на Подключитесь к СУБД и вызовите информационный экран.Соединение установлено успешно. См. Следующее изображение. Щелкните Далее.
На экране Select Schemas to Reverse Engineer вы можете выбрать базу данных. Мастер сгенерирует схему выбранной базы данных. Мы хотим сгенерировать схему базы данных сакила; следовательно, щелкните sakila и щелкните Далее. См. Следующее изображение:
На экране извлечения и обратного проектирования объекта схемы мастер заполняет объект схемы в базе данных sakila.Если что-то происходит, при извлечении объекта, он отображается на экране. Схема получена успешно. Щелкните Далее. См. Следующее изображение:
На экране Select objects to Reverse Engineer вы можете выбрать объекты, которые вы хотите реконструировать. Мы хотим сгенерировать диаграмму таблиц, поэтому выберите Import MySQL table object и нажмите Execute . См. Следующее изображение:
Начнется процесс обратного проектирования базы данных.Если возникает какая-либо ошибка, она отображается на экране процесса обратного проектирования. Процесс завершился успешно. Щелкните Далее. См. Следующее изображение:
На экране Reverse Engineering Result вы можете увидеть детали реконструированных объектов. Нажмите Готово, чтобы закрыть диалоговое окно. См. Следующее изображение:
После завершения процесса вы можете увидеть схематическую диаграмму созданной базы данных sakila.Диаграмма находится на вкладке EER рабочей среды MySQL. Если вы хотите использовать его позже, вы можете сохранить эту диаграмму. См. Следующее изображение:
Теперь, когда диаграмма подготовлена, мы можем использовать ее, чтобы понять структуру схемы базы данных и использовать таблицы, чтобы понять концепцию программирования базы данных MySQL. Во-первых, позвольте мне объяснить оператор SELECT.
Введение в оператор SELECT
Оператор SELECT используется для заполнения данных из любой таблицы сервера базы данных MySQL.Это ни DML (язык модификации данных), ни DDL (язык определения данных). Это ограниченная форма оператора DML, которая используется только для заполнения данных из базы данных. Базовый синтаксис оператора SELECT следующий
Выбрать <столбец_1>, <столбец_2>, .. из таблицы; |
В синтаксисе ключевое слово SELECT Ключевое слово указывает базе данных на получение данных.Второй сегмент — это список столбцов или выражений, которые вы хотите получить в результирующем наборе. Здесь вы можете указать список столбцов или выражений или указать звездочку (*). Теперь, когда мы указываем звездочку (*), запрос заполняет все столбцы.
Наконец, в ключевом слове FROM вы можете указать имя таблицы или представления. Если вы хотите отфильтровать данные или отсортировать данные, ключевые слова будут помещены после имени таблицы или представления.
В синтаксисе точка с запятой используется в качестве разделителя операторов. Точка с запятой считается концом запроса. Если вы хотите получить результат нескольких запросов, вы должны указать точку с запятой в конце отдельного запроса. Когда мы указываем его в конце нескольких запросов, MySQL выполняет их индивидуально и генерирует для них отдельные наборы результатов.
Примечание: Многие пользователи спрашивают, как можно запустить несколько операторов SELECT в MySQL Workbench.Если мы хотим использовать в запросе несколько операторов SELECT, вы должны указать точку с запятой в конце запроса. Набор результатов запросов будет отображаться на нескольких вкладках окна вывода.
Использование оператора SELECT для получения данных определенных столбцов таблицы
Например, я хочу заполнить только столбцы first_name, last_name и email таблицы клиентов базы данных sakila. Запрос следует записать следующим образом:
использовать сакила; выберите first_name, last_name, email от клиента; |
Результат ниже
Использование оператора SELECT для получения всех столбцов таблицы
Например, я хочу заполнить все столбцы таблицы клиентов базы данных sakila.Запрос следует записать следующим образом:
использовать сакила; выбрать * от заказчика; |
Результат показан ниже:
Несколько замечаний об использовании начала (*) в операторе Select
- Всегда помните, никогда не используйте таблицу SELECT * FROM без необходимости. SELECT * FROM всегда создает ненужный ввод-вывод в базе данных.Например, у вас есть таблица со столбцом, в котором хранятся данные BLOB, и когда вы используете SELECT * FROM для этой таблицы, запрос также заполняет столбец BLOB, что генерирует огромное количество операций ввода-вывода.
- Предположим, вы разработали приложение, и внутри приложения вы сохраняете вывод запроса в наборе данных и используете индекс столбцов. Теперь из-за бизнес-требований вам нужно добавить в таблицу больше столбцов. В таких случаях индекс столбцов будет изменен, поэтому в наборе данных вы получите неожиданный набор результатов
- Иногда он показывает пользователям конфиденциальную информацию.Например, индекс столбца user_id равен 0, индекс столбца first_name равен 2. Теперь кто-то добавляет столбец password в позицию индекса 1. Теперь на основе индекса столбцов, определенных в наборе данных. , приложение отображает данные в текстовых полях. Теперь, когда веб-страницы загружаются, в текстовом поле, в котором отображается имя пользователя, отображается пароль пользователя. Это одна из редких ошибок, но она может случиться с людьми, которые впервые разрабатывают приложение.
- Другой пример — это специальный запрос.Если вы используете в запросе SELECT * FROM , он также покажет столбец пароля. Это распространенная ошибка, но в настоящее время сервер базы данных MySQL достаточно умен, чтобы скрыть конфиденциальную информацию с помощью функции маскирования данных. Вы можете узнать больше об этом из этой статьи, Маскирование корпоративных данных в MySQL.
Сводка
В этой статье я объяснил, как мы можем сгенерировать схему существующей базы данных MySQL с помощью MySQL Workbench. Более того, я также объяснил оператор SELECT на сервере базы данных MySQL.В следующей статье я расскажу, как мы можем фильтровать и сортировать данные из таблицы. Следите за обновлениями..!!
Содержание
Нисарг Упадхай — администратор баз данных SQL Server и сертифицированный специалист Microsoft, имеющий более 8 лет опыта в администрировании SQL Server и 2 года в администрировании баз данных Oracle 10g.Он имеет опыт проектирования баз данных, настройки производительности, резервного копирования и восстановления, настройки высокой доступности и аварийного восстановления, миграции и обновления баз данных.Он получил степень бакалавра технических наук Ганпатского университета. С ним можно связаться по [email protected]
Последние сообщения Nisarg Upadhyay (посмотреть все)Понимание запросов MySQL с помощью Explain
Вы находитесь на новой работе в качестве администратора базы данных или инженера по данным и просто заблудились, пытаясь понять, что эти безумно выглядящие запросы должны означать и делать. Почему существует 5 объединений и почему ORDER BY используется в подзапросе еще до того, как произойдет одно из соединений? Помните, что вас наняли по какой-то причине — скорее всего, эта причина также связана со многими запутанными запросами, которые были созданы и отредактированы за последнее десятилетие.
Ключевое слово EXPLAIN используется в различных базах данных SQL и предоставляет информацию о том, как ваша база данных SQL выполняет запрос. В MySQL EXPLAIN может использоваться перед запросом, начинающимся с SELECT , INSERT , DELETE , REPLACE и UPDATE . Для простого запроса это будет выглядеть так:
EXPLAIN SELECT * FROM foo WHERE foo.bar = 'инфраструктура как услуга' ИЛИ foo.бар = 'iaas';
Вместо обычного вывода результатов MySQL затем покажет свой план выполнения оператора, объяснив, какие процессы и в каком порядке происходят при выполнении оператора.
Примечание: Если EXPLAIN не работает для вас, возможно, у пользователя вашей базы данных нет привилегии SELECT для таблиц или представлений, которые вы используете в своем операторе.
EXPLAIN — отличный инструмент для быстрого исправления медленных запросов. Хотя это, безусловно, может вам помочь, это не избавит вас от необходимости структурного мышления и хорошего обзора имеющихся моделей данных.Часто самым простым решением и самым быстрым советом является добавление индекса к конкретным столбцам таблицы, о которых идет речь, если они используются во многих запросах с проблемами производительности. Однако будьте осторожны, не используйте слишком много индексов, так как это может быть контрпродуктивным. Чтение индексов и таблицы имеет смысл только в том случае, если таблица имеет значительное количество строк и вам нужно всего несколько точек данных. Если вы получаете огромный набор результатов из таблицы и часто запрашиваете разные столбцы, индекс для каждого столбца не имеет смысла и больше снижает производительность, чем помогает.Чтобы узнать больше о фактических расчетах индекса по сравнению с отсутствием индекса, прочтите «Оценка производительности» в официальной документации MySQL.
Вещи, которые вы хотите избежать везде, где это возможно и применимо, — это сортировка и вычислений в запросах. Если вы думаете, что не можете избежать вычислений в своих запросах: да, вы можете. Запишите набор результатов где-нибудь в другом месте и вычислите точку данных вне запроса, это снизит нагрузку на базу данных и, следовательно, в целом будет лучше для вашего приложения.Просто убедитесь, что вы задокументировали, почему вы выполняете вычисления в своем приложении, а не сразу получаете результат в SQL. В противном случае следующий администратор или разработчик базы данных придет и у него возникнет великолепная идея использовать вычисление в запросе типа «о, смотрите, мой предшественник даже не знал, что вы можете сделать это в SQL!» Некоторые команды разработчиков, у которых еще не было неизбежной проблемы с умирающими базами данных, могут использовать вычисления в запросе для определения разницы чисел между датами или аналогичными точками данных.
Общее практическое правило для запросов SQL выглядит следующим образом:
Будьте точны и получайте только те результаты, которые вам нужны.
Давайте проверим более сложный запрос…
ВЫБЕРИТЕ site_options.domain, sites_users.user, site_taxes.monthly_statement_fee, site.name, AVG (цена) AS average_product_price FROM sites_orders_products, site_taxes, site, sites_users, site_options WHERE site_options.user_id И site_taxes.site_id = site.id И sites_orders_products.site_id = site.id ГРУППА ПО site.id ORDER BY site.date_modified desc LIMIT 5;
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| домен | пользователь | month_statement_fee | имя | average_product_price |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| www.xxxxxxxxxxxxxxxxxxx.com | [email protected] | 0,50 | xxxxxxxxxxxxxxxxxxxxx | 3.254781 |
| www.xxxxxxxxxxx.com | [email protected] | 0,50 | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx | 9.471022 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxxxx | 8.646297 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxx | 9.042460 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxxxxx | 6.679182 |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
5 рядов в наборе (0,00 сек)
… и его выход EXPLAIN .
+ ------ + ------------- + -------------------------- ------- + -------- + ----------------- + --------------- + --------- + --------------------------------- + ----- - + ----------- +
| id | select_type | стол | тип | possible_keys | ключ | key_len | ref | строки | Экстра |
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
| 1 | ПРОСТО | сайты | индекс | ПЕРВИЧНЫЙ, user_id | ПЕРВИЧНЫЙ | 4 | NULL | 858 | Использование временных; Использование файловой сортировки |
| 1 | ПРОСТО | sites_options | ref | site_id | site_id | 4 | услуга.sites.id | 1 | |
| 1 | ПРОСТО | sites_taxes | ref | site_id | site_id | 4 | service.sites.id | 1 | |
| 1 | ПРОСТО | sites_users | eq_ref | ПЕРВИЧНЫЙ | ПЕРВИЧНЫЙ | 4 | service.sites.user_id | 1 | |
| 1 | ПРОСТО | sites_orders_products | ref | site_id | site_id | 4 | service.sites.id | 4153 | | //
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
5 рядов в наборе (0.00 сек)
Столбцы в выходных данных EXPLAIN с теми, которые требуют особого внимания для выявления проблем, выделены жирным шрифтом:
- id (идентификатор запроса)
- select_type (тип выписки)
- таблица (ссылка на таблицу) Тип
- (соединительный тип)
- possible_keys (какие ключи могли быть использованы)
- ключ (ключ, который был использован)
- key_len (длина используемого ключа)
- ref (столбцы по сравнению с индексом)
- строк (количество найденных строк)
- Extra (доп. Информация)
Чем выше количество строк, в которых выполняется поиск, тем лучше должен быть уровень оптимизации индексов и точности запроса, чтобы максимизировать производительность.В столбце Extra показаны возможные действия, на которых вы могли бы сосредоточиться, чтобы улучшить свой запрос, если это применимо.
Показать предупреждения;
Если запрос, который вы использовали с EXPLAIN , не разбирается правильно, вы можете ввести SHOW WARNINGS; в ваш редактор запросов MySQL, чтобы показать информацию о последнем операторе, который был запущен и не был диагностическим, т.е. он не будет отображать информацию для таких операторов, как SHOW FULL PROCESSLIST; . Хотя он не может дать правильный план выполнения запроса, как EXPLAIN , он может дать вам подсказки о тех фрагментах запроса, которые он может обработать.Допустим, мы используем запрос EXPLAIN SELECT * FROM foo, ГДЕ foo.bar = 'инфраструктура как услуга' ИЛИ foo.bar = 'iaas'; в любой базе данных, в которой фактически нет таблицы foo . Результат MySQL будет:
ОШИБКА 1146 (42S02): таблица db.foo не существует
Если набрать ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ; вывод выглядит следующим образом:
+ ------- + ------ + -------------------------------- ----- +
| Уровень | Код | Сообщение |
+ ------- + ------ + ---------------------------------- --- +
| Ошибка | 1146 | Таблица 'db.foo 'не существует |
+ ------- + ------ + ---------------------------------- --- +
1 ряд в комплекте (0,00 сек)
Давайте попробуем это с намеренной синтаксической ошибкой.
EXPLAIN SELECT * FROM foo WHERE name = ///;
Это генерирует следующие предупреждения:
> ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ;
+ ------- + ------ + ---------------------------------- ----------------------------------- +
| Уровень | Код | Сообщение |
+ ------- + ------ + ---------------------------------- ----------------------------------- +
| Ошибка | 1064 | У вас есть ошибка в синтаксисе SQL; (...) рядом с '///' в строке 1 |
+ ------- + ------ + ---------------------------------- ----------------------------------- +
Этот вывод предупреждений довольно прост и сразу же отображается MySQL как вывод результата, но для более сложных запросов, которые не анализируются, все еще можно посмотреть, что происходит в тех фрагментах запроса, которые могут быть проанализированы. ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ; включает специальные маркеры, которые могут предоставлять полезную информацию, например:
-
(фрагмент запроса) -
(условие, выражение1, выражение2) -
(фрагмент запроса) -
<временная таблица>: здесь будет создана внутренняя таблица для сохранения временных результатов, например, в подзапросах перед объединениями.
Чтобы узнать больше об этих специальных маркерах, прочтите Extended Explain Output Format в официальной документации MySQL.
Есть несколько способов устранить основную причину плохой работы базы данных. Первое, на что следует обратить внимание, — это модель данных, то есть как структурированы данные и правильно ли вы используете базу данных? Для многих продуктов вполне подойдет база данных SQL. Следует помнить одну важную вещь — всегда отделять журналы доступа от обычной производственной базы данных, что, к сожалению, не происходит во многих компаниях. Чаще всего в этих случаях компания начинала с малого, росла и по сути все еще использовала одну и ту же базу данных, что означает, что они обращаются к одной и той же базе данных как для функций ведения журнала, так и для других транзакций.Это значительно снижает общую производительность, особенно по мере роста компании. Следовательно, очень важно создать подходящую и устойчивую модель данных.
Модель данных
Выбор модели данных, скорее всего, также покажет правильную форму базы данных (ов). Если ваш продукт не является очень простым, у вас, вероятно, будет несколько баз данных для нескольких вариантов использования — если вам нужно отображать числа, близкие к реальному времени, для журналов доступа, вам, скорее всего, понадобится высокопроизводительное хранилище данных, тогда как обычные транзакции могут происходить через SQL база данных, и у вас может быть база данных графов, в которой также накапливаются соответствующие точки данных обеих баз данных в механизм рекомендаций.
Программная архитектура всего продукта так же важна, как и сама база данных, поскольку плохой дизайн здесь приведет к возникновению узких мест, которые будут идти к базе данных и замедлить все как со стороны программного обеспечения, так и то, что база данных может выводить. Вам нужно будет выбрать, подходят ли контейнеры для вашего продукта, является ли монолит лучшим способом справиться с вещами, может ли вы иметь основной монолит с несколькими микросервисами, нацеленными на другие функции, распространенные в другом месте, и как вы получаете доступ, собираете, обрабатываете , и хранить данные.
Оборудование
Так же важно, как и ваша общая структура, ваше оборудование является ключевым компонентом производительности вашей базы данных. Exoscale предлагает вам различные варианты инстансов, которые вы можете использовать в зависимости от вашей транзакции и объема хранилища, а также желаемого времени отклика.
Крайне важно определить пиковые периоды вашего приложения и, следовательно, знать, когда по возможности пропускать более медленные административные запросы. Дисковый ввод-вывод и сетевая статистика также должны быть приняты во внимание при проектировании сроков транзакций и аналитики базы данных.
Сводка
В заключение, вот основные моменты для долгосрочной работы:
- создать устойчивую модель данных, которая соответствует потребностям вашей компании
- выберите нужную форму базы данных
- используйте программную архитектуру, соответствующую вашему продукту.
- выполняет регулярные итерации просмотра структуры ваших запросов и использует
EXPLAINдля более сложных запросов, оптимизирует использование для выбранных вами баз данных, а также в отношении обновлений баз данных и того, как они могут повлиять на вас - выберите экземпляры, которые наилучшим образом соответствуют потребностям вашего приложения и базы данных в соответствии с производительностью и пропускной способностью.