Базовый синтаксис SQL запроса
Одна из основных функций SQL — это получение выборок данных из СУБД. Для этого в SQL используется оператор SELECT. Давайте рассмотрим несколько простых запросов с его участием.
Для начала важно понимать, что через оператор SELECT можно выводить данные не только из таблиц базы данных, но и произвольные строки, числа, даты и т.д. Например, так можно вывести произвольную строку:
SELECT "Hello world"
Для вывода всех полей из определенной таблицы используется символ *. Давайте взглянем на схему базы данных и выведем данные одной из таблиц.
SELECT * FROM FamilyMembers
| member_id | status | member_name | birthday |
|---|---|---|---|
| 1 | father | Headley Quincey | 1960-05-13T00:00:00.000Z |
| 2 | mother | Flavia Quincey | 1963-02-16T00:00:00.000Z |
| 3 | son | Andie Quincey | 1983-06-05T00:00:00. |
| 4 | daughter | Lela Quincey | 1985-06-07T00:00:00.000Z |
| 5 | daughter | Annie Quincey | 1988-04-10T00:00:00.000Z |
| 6 | father | Ernest Forrest | 1961-09-11T00:00:00.000Z |
| 7 | mother | Constance Forrest | 1968-09-06T00:00:00.000Z |
Если необходимо вывести информацию только по определенным столбцам таблицы, а не всю сразу, то это можно сделать перечисляя названия столбцов через запятую:
SELECT member_id, member_name FROM FamilyMembers
| member_id | member_name |
|---|---|
| 1 | Headley Quincey |
| 2 | Flavia Quincey |
| 3 | Andie Quincey |
| 4 | Lela Quincey |
| 5 | Annie Quincey |
| 6 | Ernest Forrest |
| 7 | Constance Forrest |
В случае, если мы хотим вывести какие-то столбцы таблицы, но чтобы в итоговой выборке они были названы иначе,
мы можем использовать псевдонимы (их также называют алиасами).
Их синтаксис достаточно простой, мы должны использовать оператор AS. Как в примере ниже:
SELECT member_id, member_name AS Name FROM FamilyMembers
| member_id | Name |
|---|---|
| 1 | Headley Quincey |
| 2 | Flavia Quincey |
| 3 | Andie Quincey |
| 4 | Lela Quincey |
| 5 | Annie Quincey |
| 6 | Ernest Forrest |
| 7 | Constance Forrest |
Или же можно обойтись и без него, просто написав желаемое наименование поля через пробел.
SELECT member_id, member_name Name FROM FamilyMembers
Псевдонимы могут содержать до 255 знаков (включая пробелы, цифры и специальные символы)
Это наш первый урок практического модуля. До этого были лишь теоритеческие, направленные на восполнение потенциальных пробелов в теории реляционных баз данных. После каждого практического урока мы предлагаем группу заданий для самостоятельной работы, чтобы сразу же закрепить полученную информацию.
После каждого практического урока мы предлагаем группу заданий для самостоятельной работы, чтобы сразу же закрепить полученную информацию.
Если вы пропустили модуль «Введение», а именно статью «Структура курса» , где описывался принцип работы и интерфейс блока «Самостоятельные упражнения», то рекомендуем вернуться к нему .
SQL запрос | Community Creatio
Есть потребность выводить в реестр Контрагентов юридическое наименование и ИНН. Я в запросе для контрагента делаю следующее:
SELECT
[tbl_Account].[ID] AS [ID],
[tbl_Account].[Name] AS [Name],
[tbl_Account].[OfficialAccountName] AS [OfficialAccountName],
[tbl_Account].[AnnualRevenue] AS [AnnualRevenue],
[tbl_Account].[EmployeesNumber] AS [EmployeesNumber],
[tbl_Account].[Address] AS [Address],
[tbl_Account].[AddressTypeID] AS [AddressTypeID],
[tbl_Account].[Communication1] AS [Communication1],
[tbl_Account].[Communication1TypeID] AS [Communication1TypeID],
[tbl_Account].[Communication2] AS [Communication2],
[tbl_Account].
[tbl_Account].[Communication3] AS [Communication3],
[tbl_Account].[Communication3TypeID] AS [Communication3TypeID],
[tbl_Account].[Communication4] AS [Communication4],
[tbl_Account].[Communication4TypeID] AS [Communication4TypeID],
[tbl_Account].[Communication5] AS [Communication5],
[tbl_Account].[Communication5TypeID] AS [Communication5TypeID],
[tbl_City].[Name] AS [CityName],
[tbl_Account].[CityID] AS [CityID],
[tbl_Account].[ZIP] AS [ZIP],
[tbl_Campaign].[Name] AS [CampaignName],
[tbl_Account].[CampaignID] AS [CampaignID],
[tbl_Contact].[Name] AS [PrimaryContactName],
[tbl_Account].[PrimaryContactID] AS [PrimaryContactID],
[tbl_Account].[CountryID] AS [CountryID],
[tbl_State].[Name] AS [StateName],
[tbl_Account].[StateID] AS [StateID],
[tbl_Territory].[Name] AS [TerritoryName],
[tbl_Account].[TerritoryID] AS [TerritoryID],
[Owner].
 [Name] AS [OwnerName],
[Name] AS [OwnerName],[tbl_Account].[OwnerID] AS [OwnerID],
[tbl_Account].[ActivityID] AS [ActivityID],
[tbl_Activity].[Name] AS [ActivityName],
[tbl_Account].[FieldID] AS [FieldID],
[tbl_Field].[Name] AS [FieldName],
[tbl_Account].[AccountTypeID] AS [AccountTypeID],
[tbl_AddressType].[Name] AS [AddressTypeName],
[CommunicationType1].[Name] AS [Communication1TypeName],
[CommunicationType2].[Name] AS [Communication2TypeName],
[CommunicationType3].[Name] AS [Communication3TypeName],
[CommunicationType4].[Name] AS [Communication4TypeName],
[CommunicationType5].[Name] AS [Communication5TypeName],
[tbl_Account].[Code] AS [Code],
[tbl_Account].[TaxRegistrationCode] AS [TaxRegistrationCode],
[tbl_Account].[CreatedOn] AS [CreatedOn],
[tbl_Account].[CreatedByID] AS [CreatedByID],
[CreatedBy].[Name] AS [CreatedByName],
[tbl_Account].[ModifiedOn] AS [ModifiedOn],
 [ModifiedByID] AS [ModifiedByID],
[ModifiedByID] AS [ModifiedByID],[ModifiedBy].[Name] AS [ModifiedByName],
[tbl_Job].[NameOf] AS [JobNameOf],
[tbl_Account].[SettledCredit] AS [SettledCredit],
[tbl_Account].[PostponementPayment] AS [PostponementPayment],
NULL AS [UID1C],
NULL AS [Object1C],
[tbl_Account].[SiteID] AS [SiteID],
[tbl_Account].[IsActive] AS [IsActive],
[tbl_Account].[DoNotCall] AS [DoNotCall],
[vw_AppealInfo].[AppealDate] AS [AppealDate],
[vw_AppealInfo].[AppealStatusID] AS [AppealStatusID],
[AITaskStatus].[Status] AS [AppealStatus],
[AITaskType].[Name] AS [AppealTypeName],
[vw_LoyaltyInfo].[LoyContDate] AS [LoyContDate],
[vw_LoyaltyInfo].[LoyContTypeID] AS [LoyContTypeID],
[LITaskType].[Name] AS [LoyContTypeName],
[vw_LoyaltyInfo].[LoyOrderNum] AS [LoyOrderNum],
[vw_LoyaltyInfo].[LoyResultID] AS [LoyResultID],
[LITaskResult].[Result] AS [LoyResultName],
[vw_LoyaltyInfo].[LoyComment] AS [LoyComment],
[vw_LoyaltyRepInfo].
 [LoyRepCallDate] AS [LoyRepCallDate],
[LoyRepCallDate] AS [LoyRepCallDate],[vw_ReminderInfo].[RemContDate] AS [RemContDate],
[vw_ReminderInfo].[RemContTypeID] AS [RemContTypeID],
[vw_ReminderInfo].[RemOrderNum] AS [RemOrderNum],
[vw_ReminderInfo].[RemResultID] AS [RemResultID],
[RITaskResult].[Result] AS [RemResultName],
[vw_ReminderInfo].[RemComment] AS [RemComment],
[vw_ReminderRepInfo].[RemRepCallDate] AS [RemRepCallDate],
[tbl_Account].[SitePaymentRecID] AS [SitePaymentRecID],
[tbl_AccountBillingInfo].[INN] AS [INN],
[tbl_AccountBillingInfo].[Name] AS [NameUr]
FROM
[dbo].[tbl_Account] AS [tbl_Account]
LEFT OUTER JOIN
[dbo].[tbl_Contact] AS [tbl_Contact] ON [tbl_Contact].[ID] = [tbl_Account].[PrimaryContactID]
LEFT OUTER JOIN
[dbo].[tbl_Territory] AS [tbl_Territory] ON [tbl_Territory].[ID] = [tbl_Account].[TerritoryID]
[dbo].[tbl_Contact] AS [Owner] ON [Owner].[ID] = [tbl_Account].
 [OwnerID]
[OwnerID]LEFT OUTER JOIN
[dbo].[tbl_Campaign] AS [tbl_Campaign] ON [tbl_Campaign].[ID] = [tbl_Account].[CampaignID]
LEFT OUTER JOIN
[dbo].[tbl_City] AS [tbl_City] ON [tbl_City].[ID] = [tbl_Account].[CityID]
LEFT OUTER JOIN
[dbo].[tbl_State] AS [tbl_State] ON [tbl_State].[ID] = [tbl_Account].[StateID]
LEFT OUTER JOIN
[dbo].[tbl_Country] AS [tbl_Country] ON [tbl_Country].[ID] = [tbl_Account].[CountryID]
LEFT OUTER JOIN
LEFT OUTER JOIN
[dbo].[tbl_Field] AS [tbl_Field] ON [tbl_Field].[ID] = [tbl_Account].[FieldID]
LEFT OUTER JOIN
[dbo].[tbl_AccountType] AS [tbl_AccountType] ON [tbl_AccountType].[ID] = [tbl_Account].[AccountTypeID]
LEFT OUTER JOIN
[dbo].[tbl_Contact] AS [CreatedBy] ON [CreatedBy].[ID] = [tbl_Account].[CreatedByID]
LEFT OUTER JOIN
[dbo].[tbl_Contact] AS [ModifiedBy] ON [ModifiedBy].[ID] = [tbl_Account].[ModifiedByID]
LEFT OUTER JOIN
[dbo].
 [tbl_AddressType] AS [tbl_AddressType] ON [tbl_AddressType].[ID] = [tbl_Account].[AddressTypeID]
[tbl_AddressType] AS [tbl_AddressType] ON [tbl_AddressType].[ID] = [tbl_Account].[AddressTypeID]LEFT OUTER JOIN
[dbo].[tbl_CommunicationType] AS [CommunicationType1] ON [CommunicationType1].[ID] = [tbl_Account].[Communication1TypeID]
LEFT OUTER JOIN
[dbo].[tbl_CommunicationType] AS [CommunicationType2] ON [CommunicationType2].[ID] = [tbl_Account].[Communication2TypeID]
LEFT OUTER JOIN
[dbo].[tbl_CommunicationType] AS [CommunicationType3] ON [CommunicationType3].[ID] = [tbl_Account].[Communication3TypeID]
LEFT OUTER JOIN
[dbo].[tbl_CommunicationType] AS [CommunicationType4] ON [CommunicationType4].[ID] = [tbl_Account].[Communication4TypeID]
LEFT OUTER JOIN
[dbo].[tbl_CommunicationType] AS [CommunicationType5] ON [CommunicationType5].[ID] = [tbl_Account].[Communication5TypeID]
LEFT OUTER JOIN
[dbo].[tbl_Job] AS [tbl_Job] ON [tbl_Job].[ID] = [tbl_Contact].[JobID]
LEFT OUTER JOIN
[dbo].[vw_AppealInfo] AS [vw_AppealInfo] ON [vw_AppealInfo].
 [AccountID] = [tbl_Account].[ID]
[AccountID] = [tbl_Account].[ID]LEFT OUTER JOIN
[dbo].[vw_LoyaltyInfo] AS [vw_LoyaltyInfo] ON [vw_LoyaltyInfo].[AccountID] = [tbl_Account].[ID]
LEFT OUTER JOIN
[dbo].[vw_LoyaltyRepInfo] AS [vw_LoyaltyRepInfo] ON [vw_LoyaltyRepInfo].[AccountID] = [tbl_Account].[ID]
LEFT OUTER JOIN
[dbo].[vw_ReminderInfo] AS [vw_ReminderInfo] ON [vw_ReminderInfo].[AccountID] = [tbl_Account].[ID]
LEFT OUTER JOIN
[dbo].[vw_ReminderRepInfo] AS [vw_ReminderRepInfo] ON [vw_ReminderRepInfo].[AccountID] = [tbl_Account].[ID]
LEFT OUTER JOIN
[dbo].[tbl_TaskStatus] AS [AITaskStatus] ON [AITaskStatus].[ID] = [vw_AppealInfo].[AppealStatusID]
LEFT OUTER JOIN
[dbo].[tbl_TaskType] AS [AITaskType] ON [AITaskType].[ID] = [vw_AppealInfo].[AppealTypeID]
LEFT OUTER JOIN
[dbo].[tbl_TaskType] AS [LITaskType] ON [LITaskType].[ID] = [vw_LoyaltyInfo].[LoyContTypeID]
LEFT OUTER JOIN
[dbo].[tbl_TaskResult] AS [LITaskResult] ON [LITaskResult].[ID] = [vw_LoyaltyInfo].[LoyResultID]
LEFT OUTER JOIN
[dbo].
 [tbl_TaskType] AS [RITaskType] ON [RITaskType].[ID] = [vw_ReminderInfo].[RemContTypeID]
[tbl_TaskType] AS [RITaskType] ON [RITaskType].[ID] = [vw_ReminderInfo].[RemContTypeID]LEFT OUTER JOIN
[dbo].[tbl_TaskResult] AS [RITaskResult] ON [RITaskResult].[ID] = [vw_ReminderInfo].[RemResultID]
LEFT OUTER JOIN
[dbo].[tbl_AccountBillingInfo] AS [tbl_AccountBillingInfo] ON [tbl_AccountBillingInfo].[AccountID] = [tbl_Account].[ID]
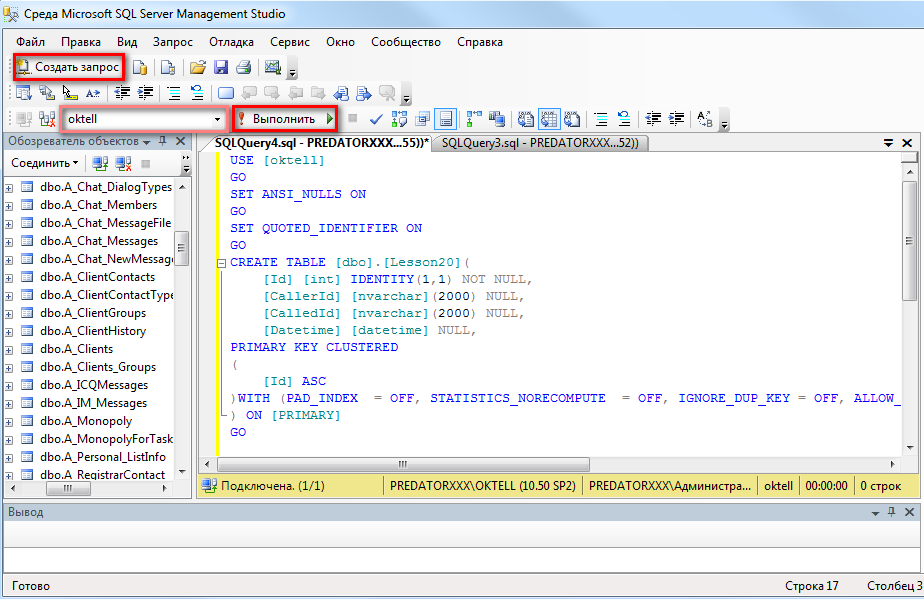
Использую левое соедиение с таблицей tbl_AccountBillingInfo.
Когда я вывожу колонки NameUr,INN в реестр контрагентов строка контрагентов начинает повторяться столько раз сколько у контрагента в детали строк, это логично, но мне нужно что бы в реестре строка контрагента выводилась только один раз без дублирований, помогите пожалуйста как это сделать.
Нравится 0
Нравится
Избранное
запросов — SQL Server | Microsoft Узнайте
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
- 2 минуты на чтение
Применяется к: SQL Server Azure SQL База данных Azure SQL Управляемый экземпляр Azure Synapse Analytics Analytics Platform System (PDW)
Язык манипулирования данными (DML) — это словарь, используемый для извлечения и работы с данными в SQL Server и базе данных SQL. Большинство из них также работают в Azure Synapse Analytics и Analytics Platform System (PDW) (подробности см. в каждом отдельном заявлении). Используйте эти операторы для добавления, изменения, запроса или удаления данных из базы данных SQL Server.
В следующей таблице перечислены операторы DML, используемые SQL Server.
МАССОВАЯ ВСТАВКА (Transact-SQL)
ВЫБОР (Transact-SQL)
УДАЛИТЬ (Transact-SQL)
ОБНОВЛЕНИЕ(Transact-SQL)
ВСТАВКА (Transact-SQL)
ОБНОВЛЕНИЕТЕКСТ (Transact-SQL)
СЛИЯНИЕ (Transact-SQL)
ЗАПИСАТЬТЕКСТ (Transact-SQL)
READTEXT (транзакт-SQL)
В следующей таблице перечислены предложения, которые используются в нескольких операторах или предложениях DML.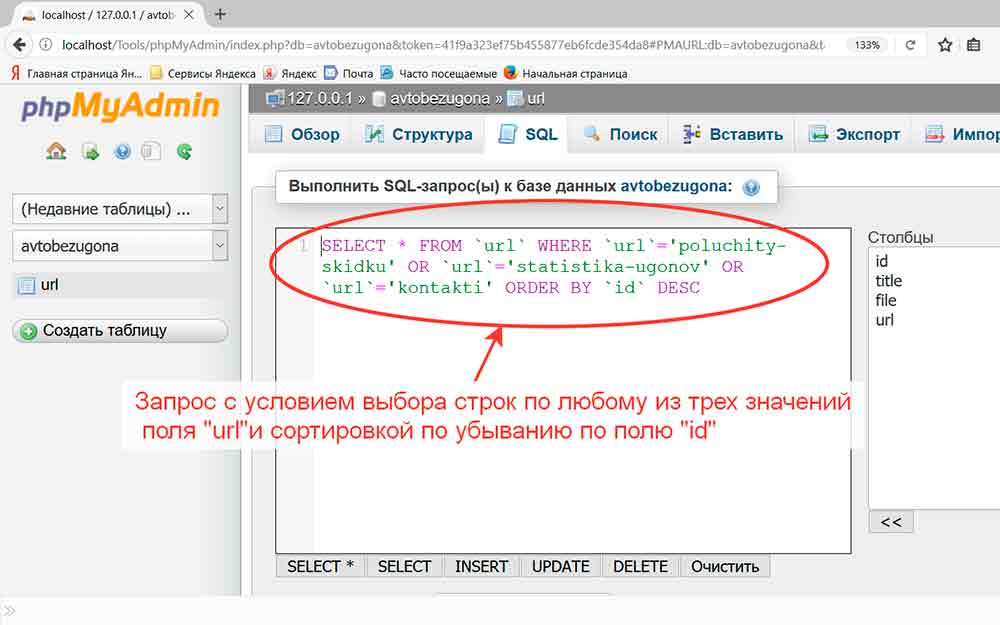
| Пункт | Может использоваться в этих заявлениях |
|---|---|
| ОТ (Transact-SQL) | УДАЛИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
| Подсказки (Transact-SQL) | УДАЛИТЬ, ВСТАВИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
| Предложение OPTION (Transact-SQL) | УДАЛИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
| Пункт OUTPUT (Transact-SQL) | УДАЛИТЬ, ВСТАВИТЬ, ОБЪЕДИНИТЬ, ОБНОВИТЬ |
| Условие поиска (Transact-SQL) | УДАЛИТЬ, ОБЪЕДИНИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
| Конструктор табличных значений (Transact-SQL) | ИЗ, ВСТАВИТЬ, ОБЪЕДИНИТЬ |
| ВЕРХ (Transact-SQL) | УДАЛИТЬ, ВСТАВИТЬ, ОБЪЕДИНИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
| ГДЕ (Transact-SQL) | УДАЛИТЬ, ВЫБРАТЬ, ОБНОВИТЬ, СОВПАДАТЬ |
| С выражением common_table_expression (Transact-SQL) | УДАЛИТЬ, ВСТАВИТЬ, ОБЪЕДИНИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
лучших практик написания SQL-запросов
- Правильность, удобочитаемость, затем оптимизация: в таком порядке
- Сделайте свои стога как можно меньше, прежде чем искать иголки
- Сначала узнайте свои данные
- Разработка вашего запроса
- Общий порядок выполнения запроса
- Некоторые рекомендации по запросам (не правила)
- Прокомментируйте свой код, особенно почему
- лучших практик SQL для FROM
- Соединение таблиц с помощью ключевого слова ON
- Псевдоним нескольких таблиц
- лучших практик SQL для WHERE
- Фильтр с WHERE до HAVING
- Избегайте функций для столбцов в предложениях WHERE
- Предпочтение
= отдоНРАВИТСЯ - Избегайте подстановочных знаков в операторах WHERE
- Предпочитает СУЩЕСТВУЕТ вместо IN
- лучших практик SQL для GROUP BY
- Упорядочить несколько групп по убыванию мощности
- лучших практик SQL для HAVING
- Используйте только HAVING для агрегатов фильтрации
- лучших практик SQL для SELECT
- ВЫБЕРИТЕ столбцы, а не звезды
- лучших практик SQL для UNION
- Предпочесть UNION All вместо UNION
- лучших практик SQL для ORDER BY
- По возможности избегайте сортировки, особенно в подзапросах
- лучших практик SQL для INDEX
- Добавление индексов
- Использовать частичные индексы
- Использовать составные индексы
- ОБЪЯСНИТЬ
- Поиск узких мест
- С
- Организуйте свои запросы с помощью Common Table Expressions (CTE)
- С метабазой вам даже не нужно использовать SQL
- Вопиющие ошибки или упущения?
В этой статье рассматриваются некоторые рекомендации по написанию SQL-запросов для аналитиков и специалистов по данным. Большая часть нашего обсуждения будет касаться SQL в целом, но мы включим некоторые заметки о функциях, специфичных для Metabase, которые упрощают написание SQL.
Большая часть нашего обсуждения будет касаться SQL в целом, но мы включим некоторые заметки о функциях, специфичных для Metabase, которые упрощают написание SQL.
Правильность, удобочитаемость, затем оптимизация: в таком порядке
Здесь применяется стандартное предупреждение о преждевременной оптимизации. Избегайте настройки SQL-запроса, пока не будете уверены, что ваш запрос возвращает нужные вам данные. И даже в этом случае оптимизируйте запрос в первую очередь только в том случае, если он выполняется часто (например, при включении популярной информационной панели) или если запрос проходит большое количество строк. В общем, прежде чем беспокоиться о производительности, отдайте предпочтение точности (выдает ли запрос ожидаемые результаты) и удобочитаемости (могут ли другие легко понять и изменить код).
Сделайте свои стога как можно меньше, прежде чем искать иголки
Возможно, здесь мы уже приступаем к оптимизации, но цель должна заключаться в том, чтобы указать базе данных сканировать минимальное количество значений, необходимых для получения ваших результатов.
Частью красоты SQL является его декларативный характер. Вместо того, чтобы сообщать базе данных, как извлекать записи, вам нужно только сообщить базе данных, какие записи вам нужны, и база данных должна определить наиболее эффективный способ получения этой информации. Следовательно, большая часть советов по повышению эффективности запросов сводится просто к тому, чтобы показать людям, как использовать инструменты SQL для более точного формулирования своих потребностей.
Мы пересмотрим общий порядок выполнения запросов и добавим советы по сокращению пространства поиска. Затем мы поговорим о трех основных инструментах, которые можно добавить в пояс: INDEX, EXPLAIN и WITH.
Сначала узнайте свои данные
Прежде чем писать хоть одну строку кода, ознакомьтесь со своими данными, изучив метаданные, чтобы убедиться, что столбец действительно содержит ожидаемые данные. Редактор SQL в Metabase имеет удобную справочную вкладку данных (доступную через значок книги ), где вы можете просматривать таблицы в своей базе данных и просматривать их столбцы и соединения (рис. 1):
1):
Вы также можете просмотреть примеры значений для определенных столбцов (рис. 2).
Рис. 2 . Используйте боковую панель Data Reference , чтобы просмотреть образцы данных. Метабазапредоставляет вам множество различных способов изучения ваших данных: вы можете просматривать таблицы, составлять вопросы с помощью построителя запросов и редактора блокнота, преобразовывать сохраненный вопрос в код SQL или создавать из существующего собственного запроса. Мы расскажем об этом в других статьях; а пока давайте рассмотрим общий рабочий процесс запроса.
Разработка запроса
Методы у всех разные, но вот пример рабочего процесса, которому нужно следовать при разработке запроса.
- Как и выше, изучите метаданные столбца и таблицы. Если вы используете собственный редактор запросов Metabase, вы также можете искать фрагменты SQL, содержащие код SQL для таблицы и столбцов, с которыми вы работаете.
 Фрагменты позволяют увидеть, как другие аналитики запрашивали данные. Или вы можете начать запрос из существующего вопроса SQL.
Фрагменты позволяют увидеть, как другие аналитики запрашивали данные. Или вы можете начать запрос из существующего вопроса SQL. - Чтобы получить представление о значениях таблицы, ВЫБЕРИТЕ * из таблиц, с которыми вы работаете, и ОГРАНИЧЬТЕ результаты. Применяйте LIMIT по мере уточнения столбцов (или добавляйте дополнительные столбцы с помощью объединений).
- Сократите столбцы до минимального набора, необходимого для ответа на ваш вопрос.
- Примените любые фильтры к этим столбцам.
- Если вам нужно агрегировать данные, агрегируйте небольшое количество строк и убедитесь, что агрегация соответствует вашим ожиданиям.
- Когда у вас есть запрос, возвращающий нужные вам результаты, найдите разделы запроса, чтобы сохранить их как Common Table Expression (CTE) для инкапсуляции этой логики.
- С помощью Metabase вы также можете сохранять код в виде фрагмента SQL для совместного использования и повторного использования в других запросах.

Общий порядок выполнения запроса
Прежде чем мы перейдем к отдельным советам по написанию кода SQL, важно иметь представление о том, как базы данных будут выполнять ваш запрос. Это отличается от порядка чтения (слева направо, сверху вниз), который вы используете для составления запроса. Оптимизаторы запросов могут изменить порядок следующего списка, но этот общий жизненный цикл SQL-запроса следует помнить при написании SQL. Мы будем использовать порядок выполнения, чтобы сгруппировать следующие советы по написанию хорошего SQL.
Эмпирическое правило здесь таково: чем раньше в этом списке вы сможете удалить данные, тем лучше.
- FROM (и JOIN) получает(ют) таблицы, на которые есть ссылки в запросе. Эти таблицы представляют максимальное пространство поиска, указанное вашим запросом. По возможности ограничьте это пространство поиска, прежде чем двигаться дальше.
- ГДЕ фильтрует данные.
- GROUP BY объединяет данные.
- HAVING отфильтровывает агрегированные данные, которые не соответствуют критериям.

- SELECT захватывает столбцы (затем дедуплицирует строки, если вызывается DISTINCT).
- UNION объединяет выбранные данные в набор результатов.
- ORDER BY сортирует результаты.
И, конечно же, всегда будут случаи, когда оптимизатор запросов для вашей конкретной базы данных разработает другой план запроса, так что не зацикливайтесь на этом порядке.
Некоторые рекомендации по запросам (не правила)
Следующие советы являются рекомендациями, а не правилами, призванными уберечь вас от неприятностей. Каждая база данных обрабатывает SQL по-своему, имеет немного отличающийся набор функций и использует разные подходы к оптимизации запросов. И это еще до того, как мы приступим к сравнению традиционных транзакционных баз данных с аналитическими базами данных, которые используют форматы хранения столбцов, которые имеют совершенно разные характеристики производительности.
Помогите людям (включая себя через три месяца), добавив комментарии, поясняющие различные части кода. Самое важное, что здесь нужно уловить, — это «почему». Например, очевидно, что приведенный ниже код отфильтровывает заказы с
Самое важное, что здесь нужно уловить, — это «почему». Например, очевидно, что приведенный ниже код отфильтровывает заказы с ID больше 10, но это происходит потому, что первые 10 заказов используются для тестирования.
ВЫБЕРИТЕ идентификатор, продукт ОТ заказы -- отфильтровать тестовые заказы ГДЕ идентификатор заказа> 10
Загвоздка здесь в том, что вы вносите небольшие накладные расходы на обслуживание: если вы меняете код, вам нужно убедиться, что комментарий по-прежнему актуален и актуален. Но это небольшая цена за читаемый код.
Лучшие практики SQLдля FROM
Соединение таблиц с использованием ключевого слова ON
Хотя можно «объединить» две таблицы с помощью предложения WHERE (то есть выполнить неявное соединение, например, SELECT * FROM a,b WHERE a.foo = b.bar ), вместо этого следует предпочесть явное ПРИСОЕДИНЕНИЕ:
ВЫБЕРИТЕ о.ид, о.общий, стр. поставщик ОТ заказы КАК О ПРИСОЕДИНЯЙТЕСЬ к продуктам КАК p ON o.product_id = p.id
В основном для удобства чтения, так как JOIN + 9Синтаксис 0152 ON отличает объединения от предложений WHERE , предназначенных для фильтрации результатов.
Псевдоним нескольких таблиц
При запросе нескольких таблиц используйте псевдонимы и применяйте эти псевдонимы в своем операторе выбора, чтобы базе данных (и вашему читателю) не нужно было анализировать, какой столбец принадлежит какой таблице. Обратите внимание, что если у вас есть столбцы с одинаковыми именами в нескольких таблицах, вам нужно будет явно ссылаться на них либо по имени таблицы, либо по псевдониму.
Избегать
ВЫБЕРИТЕ заголовок, фамилия, имя ИЗ художественных_книг ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ ПО fiction_books.author_id = fiction_authors.id
Предпочтительный
ВЫБЕРИТЕ книги.название, авторы.фамилия, авторы.first_name ИЗ художественных_книг КАК книги ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ к авторам фикции КАК авторам ПО books.author_id = author.id
Это тривиальный пример, но когда количество таблиц и столбцов в вашем запросе увеличивается, вашим читателям не нужно будет отслеживать, какой столбец находится в какой таблице. Это и ваши запросы могут сломаться, если вы присоединитесь к таблице с неоднозначным именем столбца (например, обе таблицы включают поле с именем Создан_В .
Обратите внимание, что фильтры полей несовместимы с псевдонимами таблиц, поэтому вам потребуется удалить псевдонимы при подключении виджетов фильтров к фильтрам полей.
Лучшие практики SQL для WHERE
Фильтр с WHERE перед HAVING
Используйте предложение WHERE для фильтрации лишних строк, чтобы вам не приходилось вычислять эти значения в первую очередь. Только после удаления ненужных строк, а также после объединения этих строк и их группировки следует включать Предложение HAVING для фильтрации агрегатов.
Избегайте функций для столбцов в предложениях WHERE
Использование функции для столбца в предложении WHERE может существенно замедлить ваш запрос, поскольку эта функция делает запрос недоступным для анализа (т. е. не позволяет базе данных использовать индекс для ускорения запроса). Вместо того, чтобы использовать индекс для перехода к соответствующим строкам, функция для столбца заставляет базу данных запускать функцию для каждой строки таблицы.
е. не позволяет базе данных использовать индекс для ускорения запроса). Вместо того, чтобы использовать индекс для перехода к соответствующим строкам, функция для столбца заставляет базу данных запускать функцию для каждой строки таблицы.
И помните, оператор конкатенации || — это тоже функция, так что не пытайтесь объединить строки для фильтрации нескольких столбцов. Вместо этого предпочесть несколько условий:
Избегать
ВЫБЕРИТЕ героя, помощника ОТ супергероев ГДЕ герой || помощник = 'БэтменРобин'
Предпочтительный
ВЫБЕРИТЕ героя, помощника ОТ супергероев ГДЕ герой = «Бэтмен» И помощник = 'Робин'
Предпочтение
= до НРАВИТСЯ Это не всегда так. Приятно знать, что LIKE сравнивает символы и может сочетаться с операторами подстановки, такими как % , тогда как оператор = сравнивает строки и числа для точного совпадения.
= могут использовать индексированные столбцы. Это относится не ко всем базам данных, поскольку LIKE может использовать индексы (если они существуют для поля), если вы избегаете префикса поискового запроса с оператором подстановки, % . Что подводит нас к следующему пункту:
Избегайте использования подстановочных знаков в операторах WHERE
Использование подстановочных знаков для поиска может быть дорогостоящим. Предпочитаю добавлять подстановочные знаки в конец строк. Префикс строки с подстановочным знаком может привести к полному сканированию таблицы.
Избегать
SELECT column FROM table WHERE col LIKE "%wizar%"
Предпочтительный
SELECT столбец FROM table WHERE col LIKE "wizar%"
Предпочитает СУЩЕСТВУЕТ, а не В
Если вам просто нужно проверить существование значения в таблице, выберите EXISTS 9От 0153 до IN , поскольку процесс EXISTS завершается, как только он находит искомое значение, тогда как IN просматривает всю таблицу.
IN следует использовать для поиска значений в списках.
Аналогичным образом предпочтите NOT EXISTS вместо NOT IN .
Рекомендации по SQL для GROUP BY
Упорядочить несколько групп по убыванию кардинальности
По возможности, СГРУППИРОВАТЬ НА столбца в порядке убывания кардинальности. То есть сначала группируйте по столбцам с более уникальными значениями (например, идентификаторы или номера телефонов), а затем группируйте по столбцам с меньшим количеством различных значений (например, штат или пол).
Лучшие практики SQL для HAVING
Используйте только HAVING для агрегатов фильтрации
А перед HAVING отфильтруйте значения с помощью предложения WHERE перед агрегированием и группировкой этих значений.
Рекомендации по SQL для SELECT
SELECT столбцы, а не звезды
Укажите столбцы, которые вы хотите включить в результаты (хотя можно использовать * при первом просмотре таблиц — только не забудьте LIMIT ваши результаты).
Рекомендации по SQL для UNION
Предпочесть UNION All вместо UNION
Если дубликаты не являются проблемой, ОБЪЕДИНЕНИЕ ВСЕХ не отбрасывает их, а поскольку ОБЪЕДИНЕНИЕ ВСЕХ не занимается удалением дубликатов, запрос будет более эффективным.
Рекомендации по SQL для ORDER BY
По возможности избегайте сортировки, особенно в подзапросах
Сортировка стоит дорого. Если вам необходимо выполнить сортировку, убедитесь, что ваши подзапросы не сортируют данные без необходимости.
Рекомендации по SQL для INDEX
Этот раздел предназначен для администраторов базы данных в толпе (и тема слишком велика, чтобы поместиться в этой статье). Одна из наиболее распространенных проблем, с которыми сталкиваются люди при возникновении проблем с производительностью в запросах к базе данных, — это отсутствие адекватной индексации.
Какие столбцы вы должны индексировать, обычно зависит от столбцов, по которым вы фильтруете (т. е. какие столбцы обычно попадают в ваши предложения
е. какие столбцы обычно попадают в ваши предложения WHERE ). Если вы обнаружите, что всегда фильтруете по общему набору столбцов, вам следует подумать об индексации этих столбцов.
Добавление индексов
Индексирование столбцов внешнего ключа и часто запрашиваемых столбцов может значительно сократить время запроса. Вот пример оператора для создания индекса:
CREATE INDEX product_title_index В продуктах (название)
Доступны различные типы индексов, наиболее распространенный тип индекса использует B-дерево для ускорения поиска. Ознакомьтесь с нашей статьей о том, как сделать информационные панели быстрее, и ознакомьтесь с документацией по вашей базе данных, чтобы узнать, как создать индекс.
Использовать частичные индексы
Для особенно больших наборов данных или неравномерных наборов данных, где определенные диапазоны значений появляются чаще, рассмотрите возможность создания индекса с предложением WHERE , чтобы ограничить количество индексируемых строк. Частичные индексы также могут быть полезны для диапазонов дат, например, если вы хотите индексировать данные только за последнюю неделю.
Частичные индексы также могут быть полезны для диапазонов дат, например, если вы хотите индексировать данные только за последнюю неделю.
Использовать составные индексы
Для столбцов, которые обычно используются вместе в запросах (например, last_name, first_name), рассмотрите возможность создания составного индекса. Синтаксис аналогичен созданию одного индекса. Например:
CREATE INDEX full_name_index ON клиентов (last_name, first_name)
ОБЪЯСНИТЬ
Поиск узких мест
Некоторые базы данных, такие как PostgreSQL, предлагают информацию о плане запроса на основе вашего кода SQL. Просто добавьте к своему коду префикс ключевых слов EXPLAIN ANALYZE . Эти команды можно использовать для проверки планов запросов и поиска узких мест или для сравнения планов одной версии запроса с другой, чтобы определить, какая версия более эффективна.
Вот пример запроса с использованием образца базы данных dvdrental , доступного для PostgreSQL.
EXPLAIN ANALYZE SELECT название, выпуск_год ИЗ фильма ГДЕ выпуск_год > 2000;
И вывод:
Seq Scan на пленке (стоимость=0,00..66,50 рядов=1000 ширина=19) (фактическое время=0,008..0,311 рядов=1000 петель=1) Фильтр: ((release_year)::integer > 2000) Время планирования: 0,062 мс Время выполнения: 0,416 мс
Вы увидите миллисекунды, необходимые для планирования времени, времени выполнения, а также стоимости, строк, ширины, времени, циклов, использования памяти и т. д. Чтение этих анализов — своего рода искусство, но вы можете использовать их для выявления проблемных областей в ваших запросах (таких как вложенные циклы или столбцы, индексация которых может быть полезна) по мере их уточнения.
Вот документация PostreSQL по использованию EXPLAIN.
С
Организуйте свои запросы с помощью общих табличных выражений (CTE)
Используйте предложение WITH для инкапсуляции логики в общем табличном выражении (CTE). Вот пример запроса, который ищет продукты с самым высоким средним доходом на единицу, проданную в 2019 году, а также максимальные и минимальные значения.
Вот пример запроса, который ищет продукты с самым высоким средним доходом на единицу, проданную в 2019 году, а также максимальные и минимальные значения.
С product_orders КАК (
ВЫБЕРИТЕ o.created_at AS order_date,
p.title КАК product_title,
(o.subtotal / o.quantity) КАК доход_на_единицу
ОТ заказов КАК o
LEFT JOIN products AS p ON o.product_id = p.id
-- Отфильтровывать заказы, размещенные службой поддержки клиентов, для взимания платы с клиентов.
ГДЕ о.количество > 0
)
ВЫБЕРИТЕ product_title КАК продукт,
AVG(доход_на_единицу) AS avg_revenue_per_unit,
MAX(доход_на_единицу) AS max_revenue_per_unit,
MIN(доход_на_единицу) AS min_revenue_per_unit
ОТ product_orders
ГДЕ order_date МЕЖДУ 2019 г.-01-01" И "31-12-2019"
СГРУППИРОВАТЬ ПО продукту
ЗАКАЗАТЬ ПО avg_revenue_per_unit DESC
Предложение WITH делает код читабельным, поскольку основной запрос (то, что вы на самом деле ищете) не прерывается длинным подзапросом.
Вы также можете использовать CTE, чтобы сделать ваш SQL более читабельным, если, например, в вашей базе данных есть поля с неудобными именами или для получения полезных данных требуется небольшая обработка данных. Например, CTE могут быть полезны при работе с полями JSON. Вот пример извлечения и преобразования полей из большого двоичного объекта JSON пользовательских событий.
С исходными_данными КАК (
ВЫБЕРИТЕ события->'данные'->>'имя' КАК событие_имя,
CAST(события->'данные'->>'ts' AS timestamp) AS event_timestamp
CAST(события->'данные'->>'cust_id' AS int) AS customer_id
ОТ пользовательской_активности
)
ВЫБЕРИТЕ имя_события,
event_timestamp,
Пользовательский ИД
ИЗ source_data
Кроме того, вы можете сохранить подзапрос как фрагмент SQL (рис. 3 — обратите внимание на круглые скобки вокруг фрагмента), чтобы легко повторно использовать этот код в других запросах.
Рис. 3 . Сохранение подзапроса во фрагменте и его использование в предложении FROM.
И да, как и следовало ожидать, аэродинамический кожаный тукан приносит самый высокий средний доход на проданную единицу.
С метабазой вам даже не нужно использовать SQL
SQL потрясающий. Но то же самое можно сказать и о построителе запросов Metabase и редакторе блокнотов. Вы можете составлять запросы с помощью графического интерфейса Metabase для объединения таблиц, фильтрации и суммирования данных, создания настраиваемых столбцов и многого другого. А с помощью пользовательских выражений вы можете справиться с подавляющим большинством аналитических вариантов использования, даже не прибегая к SQL. Вопросы, составленные с использованием Notebook Editor также имеет преимущества автоматической детализации, которая позволяет зрителям ваших диаграмм щелкать и исследовать данные, функция, недоступная для вопросов, написанных на SQL.
Вопиющие ошибки или упущения?
Существуют библиотеки книг по SQL, так что мы коснемся здесь только поверхности.