Директивы Disallow и Allow — Вебмастер. Справка
- Disallow
- Allow
- Совместное использование директив
- Директивы Allow и Disallow без параметров
- Использование спецсимволов * и $
- Примеры интерпретации директив
страницы с конфиденциальными данными;
страницы с результатами поиска по сайту;
статистика посещаемости сайта;
дубликаты страниц;
разнообразные логи;
сервисные страницы баз данных.
Примеры:
User-agent: Yandex Disallow: / # запрещает обход всего сайта User-agent: Yandex Disallow: /catalogue # запрещает обход страниц, адрес которых начинается с /catalogue User-agent: Yandex Disallow: /page? # запрещает обход страниц, URL которых содержит параметры
Директива разрешает индексирование разделов или отдельных страниц сайта.
Примеры:
User-agent: Yandex
Allow: /cgi-bin
Disallow: /
# запрещает скачивать все, кроме страниц
# начинающихся с '/cgi-bin' User-agent: Yandex
Allow: /file.xml
# разрешает скачивание файла file.xmlПримечание. Недопустимо наличие пустых переводов строки между директивами User-agent, Disallow и Allow.
Директивы Allow и Disallow из соответствующего User-agent
Примечание. При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow.
# Исходный robots.txt: User-agent: Yandex Allow: / Allow: /catalog/auto Disallow: /catalog # Сортированный robots.txt: User-agent: Yandex Allow: / Disallow: /catalog Allow: /catalog/auto # запрещает скачивать страницы, начинающиеся с '/catalog', # но разрешает скачивать страницы, начинающиеся с '/catalog/auto'.
Общий пример:
User-agent: Yandex Allow: /archive Disallow: / # разрешает все, что содержит '/archive', остальное запрещено User-agent: Yandex Allow: /obsolete/private/*.html$ # разрешает html файлы # по пути '/obsolete/private/...' Disallow: /*.php$ # запрещает все '*.php' на данном сайте Disallow: /*/private/ # запрещает все подпути содержащие # '/private/', но Allow выше отменяет # часть запрета Disallow: /*/old/*.zip$ # запрещает все '*.zip' файлы, содержащие # в пути '/old/' User-agent: Yandex Disallow: /add.php?*user= # запрещает все скрипты 'add.php?' с параметром 'user'
Если директивы не содержат параметры, робот учитывает данные следующим образом:
User-agent: Yandex
Disallow: # то же, что и Allow: /
User-agent: Yandex
Allow: # не учитывается роботомПри указании путей директив Allow и Disallow можно использовать спецсимволы * и $, чтобы задавать определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов. Примеры:
User-agent: Yandex
Disallow: /cgi-bin/*.aspx # запрещает '/cgi-bin/example.aspx'
# и '/cgi-bin/private/test.aspx'
Disallow: /*private # запрещает не только '/private',
# но и '/cgi-bin/private'По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *. Пример:
User-agent: Yandex
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с '/cgi-bin'
Disallow: /cgi-bin # то же самоеЧтобы отменить * на конце правила, можно использовать спецсимвол $, например:
User-agent: Yandex
Disallow: /example$ # запрещает '/example',
# но не запрещает '/example.html'User-agent: Yandex
Disallow: /example # запрещает и '/example',
# и '/example.html'User-agent: Yandex
Disallow: /example$ # запрещает только '/example'
Disallow: /example*$ # так же, как 'Disallow: /example'
# запрещает и /example.html и /exampleUser-agent: Yandex
Allow: /
Disallow: /
# все разрешается
User-agent: Yandex
Allow: /$
Disallow: /
# запрещено все, кроме главной страницы
User-agent: Yandex
Disallow: /private*html
# запрещается и '/private*html',
# и '/private/test.html', и '/private/html/test.
aspx' и т. п.
User-agent: Yandex
Disallow: /private$
# запрещается только '/private'
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
# так как робот Яндекса
# выделяет записи по наличию в строке 'User-agent:',
# результат — все разрешается| Mozilla/5.0 (compatible; YandexAccessibilityBot/3.0; +http://yandex.com/bots) | Скачивает страницы для проверки их доступности пользователям. Его максимальная частота обращений к сайту составляет 3 обращения в секунду. Робот игнорирует настройку в интерфейсе Яндекс.Вебмастера. | Нет |
| Mozilla/5.0 (compatible; YandexAdNet/1.0; +http://yandex.com/bots) | Робот Рекламной сети Яндекса. | Да |
| Mozilla/5.0 (compatible; YandexBlogs/0.99; robot; +http://yandex.com/bots) | Робот поиска по блогам, индексирующий комментарии постов. | Да |
| Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) | Основной индексирующий робот. | Да |
| Mozilla/5.0 (compatible; YandexBot/3.0; MirrorDetector; +http://yandex.com/bots) | Определяющий зеркала сайтов. | Да |
| Mozilla/5.0 (compatible; YandexCalendar/1.0; +http://yandex.com/bots) | Робот Яндекс.Календаря. Скачивает файлы календарей по инициативе пользователей, которые часто располагаются в запрещенных для индексации каталогах. | Нет |
| Mozilla/5.0 (compatible; YandexDialogs/1.0; +http://yandex.com/bots) | Отправляет запросы в навыки Алисы. | Нет |
| Mozilla/5.0 (compatible; YandexDirect/3.0; +http://yandex.com/bots) | Скачивает информацию о контенте сайтов-партнеров Рекламной сети Яндекса, чтобы уточнить их тематику для подбора релевантной рекламы. | Нет |
| Mozilla/5.0 (compatible; YandexDirectDyn/1.0; +http://yandex.com/bots | Генерирует динамические баннеры. | Нет |
| Mozilla/5.0 (compatible; YandexFavicons/1.0; +http://yandex.com/bots) | Скачивает файл фавиконки сайта для отображения в результатах поиска. | Нет |
| Mozilla/5.0 (compatible; YaDirectFetcher/1.0; Dyatel; +http://yandex.com/bots) | Скачивает целевые страницы рекламных объявлений для проверки их доступности и уточнения тематики. Это необходимо для размещения объявлений в поисковой выдаче и на сайтах-партнерах. | Нет. Робот не использует файл robots.txt, поэтому игнорирует директивы, установленные для него. |
| Mozilla/5.0 (compatible; YandexForDomain/1.0; +http://yandex.com/bots) | Робот почты для домена, используется при проверке прав на владение доменом. | Да |
Mozilla/5.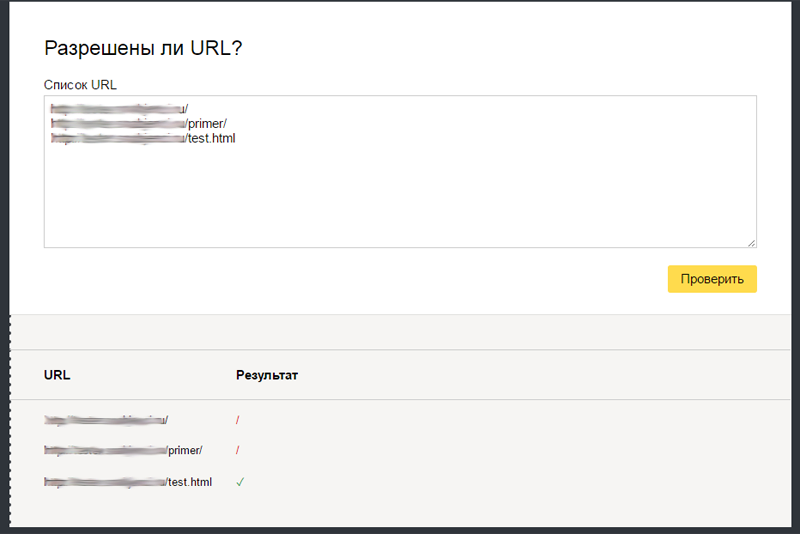 0 (compatible; YandexImages/3.0; +http://yandex.com/bots) 0 (compatible; YandexImages/3.0; +http://yandex.com/bots) | Индексирует изображения для показа на Яндекс.Картинках. | Да |
| Mozilla/5.0 (compatible; YandexImageResizer/2.0; +http://yandex.com/bots) | Робот мобильных сервисов. | Да |
| Mozilla/5.0 (iPhone; CPU iPhone OS 8_1 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B411 Safari/600.1.4 (compatible; YandexBot/3.0; +http://yandex.com/bots) | Индексирующий робот. | Да |
| Mozilla/5.0 (iPhone; CPU iPhone OS 8_1 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B411 Safari/600.1.4 (compatible; YandexMobileBot/3.0; +http://yandex.com/bots) | Определяет страницы с версткой, подходящей под мобильные устройства. | Нет |
| Mozilla/5.0 (compatible; YandexMarket/1.0; +http://yandex.com/bots) | Робот Яндекс.Маркета. | Да |
| Mozilla/5.0 (compatible; YandexMarket/2.0; +http://yandex.com/bots) | Нет | |
| Mozilla/5.0 (compatible; YandexMedia/3.0; +http://yandex.com/bots) | Индексирует мультимедийные данные. | Да |
| Mozilla/5.0 (compatible; YandexMetrika/2.0; +http://yandex.com/bots yabs01) | Скачивает страницы сайта для проверки их доступности, в том числе проверяет целевые страницы объявлений Яндекс.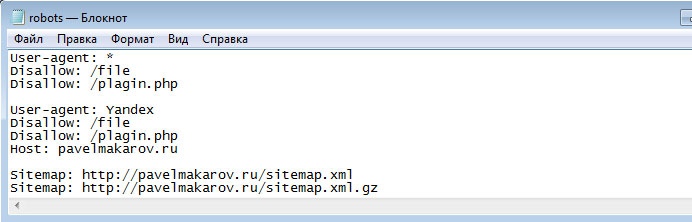 Директа. Директа. | Нет. Робот не использует файл robots.txt, поэтому игнорирует директивы, установленные для него. |
| Mozilla/5.0 (compatible; YandexMetrika/2.0; +http://yandex.com/bots) | Робот Яндекс.Метрики. | Нет |
| Mozilla/5.0 (compatible; YandexMetrika/3.0; +http://yandex.com/bots) | Нет | |
| Mozilla/5.0 (compatible; YandexMetrika/4.0; +http://yandex.com/bots) | Робот Яндекс.Метрики. Скачивает и кэширует CSS-стили для воспроизведения страниц сайта в Вебвизоре. | Нет. Робот не использует файл robots.txt, поэтому игнорирует директивы, установленные для него. |
| Mozilla/5.0 (compatible; YandexMobileScreenShotBot/1.0; +http://yandex.com/bots) | Делает снимок мобильной страницы. | Нет |
| Mozilla/5.0 (compatible; YandexNews/4.0; +http://yandex.com/bots) | Робот Яндекс.Новостей. | Да |
| Mozilla/5.0 (compatible; YandexOntoDB/1.0; +http://yandex.com/bots) | Робот объектного ответа. | Да |
| Mozilla/5.0 (compatible; YandexOntoDBAPI/1.0; +http://yandex.com/bots) | Робот объектного ответа, скачивающий динамические данные. | Нет |
Mozilla/5. 0 (compatible; YandexPagechecker/1.0; +http://yandex.com/bots) 0 (compatible; YandexPagechecker/1.0; +http://yandex.com/bots) | Обращается к странице при валидации микроразметки через форму Валидатор микроразметки. | Да |
| Mozilla/5.0 (compatible; YandexPartner/3.0; +http://yandex.com/bots) | Скачивает информацию о контенте сайтов-партнеров Яндекса | Нет |
| Mozilla/5.0 (compatible; YandexRCA/1.0; +http://yandex.com/bots) | Собирает данные для формирования превью. Например, колдунщика. | Нет |
| Mozilla/5.0 (compatible; YandexSearchShop/1.0; +http://yandex.com/bots) | Скачивает YML-файлы каталогов товаров (по инициативе пользователей), которые часто располагаются в запрещенных для индексации каталогах. | Нет |
| Mozilla/5.0 (compatible; YandexSitelinks; Dyatel; +http://yandex.com/bots) | Проверяет доступность страниц, которые используются в качестве быстрых ссылок. | Да |
| Mozilla/5.0 (compatible; YandexSpravBot/1.0; +http://yandex.com/bots) | Робот Яндекс.Справочника. | Да |
| Mozilla/5.0 (compatible; YandexTracker/1.0; +http://yandex.com/bots) | Робот Яндекс.Трекера. | Нет |
Mozilla/5.0 (compatible; YandexTurbo/1.0; +http://yandex.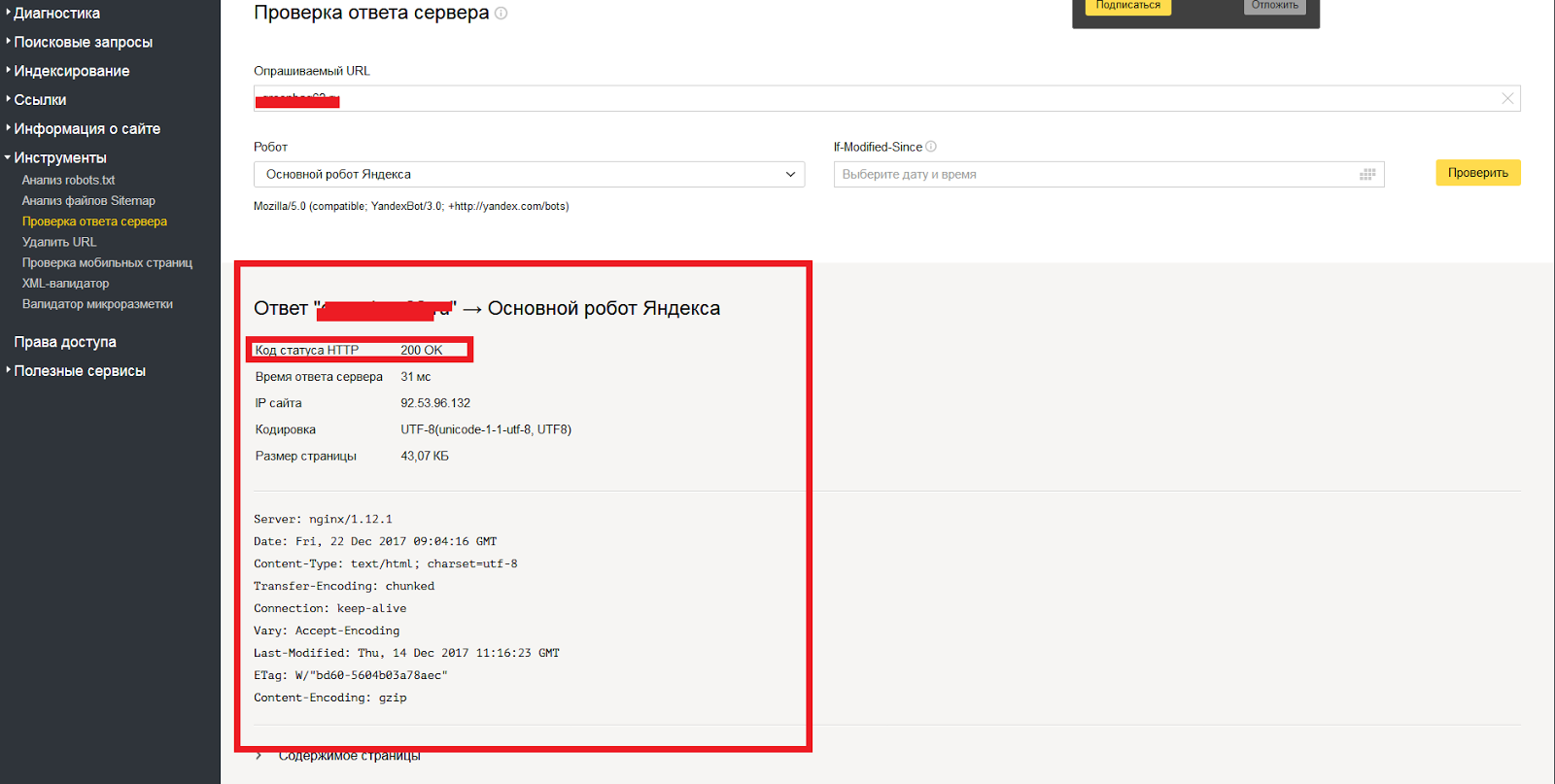 com/bots) com/bots) | Обходит RSS-канал, созданный для формирования Турбо-страниц. Его максимальная частота обращений к сайту составляет 3 обращения в секунду. Робот игнорирует настройку в интерфейсе Яндекс.Вебмастера и директиву Crawl-delay. | Да |
| Mozilla/5.0 (compatible; YandexVertis/3.0; +http://yandex.com/bots) | Робот поисковых вертикалей. | Да |
| Mozilla/5.0 (compatible; YandexVerticals/1.0; +http://yandex.com/bots) | Робот Яндекс.Вертикалей: Авто.ру, Янекс.Недвижимость, Яндекс.Работа, Яндекс.Отзывы. | Да |
| Mozilla/5.0 (compatible; YandexVideo/3.0; +http://yandex.com/bots) | Индексирует видео для показа на Яндекс.Видео. | Да |
| Mozilla/5.0 (compatible; YandexVideoParser/1.0; +http://yandex.com/bots) | Индексирует видео для показа на Яндекс.Видео. | Нет |
| Mozilla/5.0 (compatible; YandexWebmaster/2.0; +http://yandex.com/bots) | Робот Яндекс.Вебмастера. | Да |
| Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z* Safari/537.36 (compatible; YandexScreenshotBot/3.0; +http://yandex.com/bots) | Делает снимок страницы. | Нет |
Правильная настройка robots.txt для Google и Яндекс
Основные правила настройки robots.
 txt
txtПеред тем, как приступить к настройке роботса для вашего сайта, неплохо ознакомиться с официальными рекомендациями Яндекс и Google.
Теперь о том, что должно быть в файле robots.txt. В нем необходимо создавать 3 отдельных набора директив — для Яндекс, для Google, и для остальных роботов-краулеров. Почему отдельно? Да потому что есть директивы, предназначенные только для определенных ПС, а также можете считать это неким проявлением уважения к основным поисковикам рунета
Следовательно, роботс должен состоять из таких секций:
User-agent: * User-agent: Yandex User-agent: Googlebot
Между наборами директив для разных роботов необходимо оставлять пустую строку.
В robots.txt необходимо указать путь к XML карте сайта. Директива является межсекционной, поэтому она может быть размещена в любом месте файла, однако перед ней рекомендуется вставить пустой перевод строки. Запись должна выглядеть так:
Sitemap: http://site.com/sitemap.xml
Адрес сайта и сам путь к карте необходимо заменить на те, которые являются актуальными для вашего сайта. Также следует помнить, что для сайтов с большим количеством страниц (более 50 000) необходимо создать несколько карт и все их прописать в роботсе.
Настройка robots.txt для Яндекс
Для того, чтобы наглядно показать правильную настройку директив для Яши, я возьму в качестве примера стандартный robots.txt для WordPress.
User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: */trackback Disallow: */feed Host: site.com
Обратите внимание на директиву Host. Она указывает пауку-роботу Яндекса, какое из зеркал сайта является главным. Наиболее распространенная группа зеркал — site.com и www.site.com. Тут есть еще один тонкий нюанс, о котором редко упоминают. Дело в том, что директива Host не является прямой командой роботам считать зеркало главным.
Проверить корректность настройки robots.txt для Яндекса можно при помощи данного сервиса.
Настройка robots.txt для Google
Для Google настройка роботса мало чем отличается от уже написанного выше. Однако, есть пара моментов, на которые следует обратить внимание.
User-agent: Googlebot Allow: *.css Allow: *.js Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: */trackback Disallow: */feed
Как видно из примера, отсутствует директива Host — она распознается исключительно ботами Яндекса. Кроме этого, появились две директивы, разрешающие индексировать JS скрипты и CSS таблицы. Это связано с рекомендацией Google, в которой говорится, что следует разрешать роботу индексировать
файлы шаблона (темы) сайта. Естественно, скрипты и таблицы в поиск не попадут, однако это позволит роботам корректнее индексировать сайт и отображать его в результатах выдачи.
Ну а корректность настройки директив для Google вы можете проверить инструментом проверки файла robots.txt, который находится в Google Webmaster Tools.
Что еще стоит закрывать в роботсе?
Страницы поиска
Тут кое-кто может поспорить, так как бывают случаи, когда на сайте используют внутренний поиск именно для создания релевантных страниц. Однако, так поступают далеко не всегда и в большинстве случаев открытые результаты поиска могут наплодить невероятное количество дублей. Поэтому вердикт — закрыть.
Корзина и страница оформления/подтверждения заказа
Данная рекомендация актуальна для интернет-магазинов и других коммерческих сайтов, где есть форма заказа. Данные страницы ни в коем случае не должны попадать в индекс ПС.
Страницы пагинации. Обычно для таких страниц автоматически прописываются одинаковые мета-теги плюс на них размещен динамический контент, что приводит к дублям в выдаче. Поэтому пагинацию необходимо закрывать от индексации.
Фильтры и сравнение товаров. Рекомендация относится к интернет-магазинам и сайтам-каталогам.
Страницы регистрации и авторизации. Информация, которая вводится при регистрации или входе на сайт, является конфиденциальной. Поэтому следует избегать индексации подобных страниц, Google это оценит.
Системные каталоги и файлы. Каждый сайт состоит из множества данных — скриптов, таблиц CSS, административной части. Такие файлы следует также ограничить для просмотра роботам.
Замечу, что для выполнения некоторых из вышеописанных пунктов можно использовать и другие инструменты, например, rel=canonical, про который я позже напишу в отдельной статье.
Robots.txt для WordPress и Joomla
robots.txt для WordPress
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: */trackback Disallow: */feed Disallow: /*? Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: */trackback Disallow: */feed Disallow: /*? Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php Host: site.com User-agent: Googlebot Allow: *.css Allow: *.js Allow: /wp-includes/*.js Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/cache Disallow: */trackback Disallow: */feed Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php Disallow: /*? Sitemap: http://site.com/sitemap.xml
Обратите внимание, что директивы Sitemap и Host в вашем роботсе нужно заменить на необходимые вам.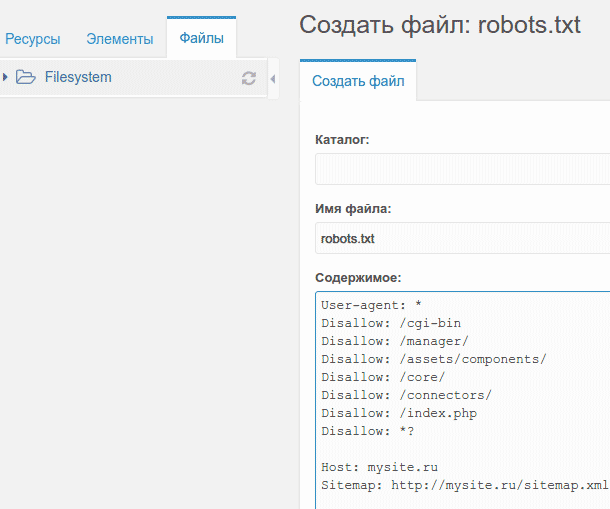
robots.txt для Joomla
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /language/ Disallow: /libraries/ Disallow: /logs/ Disallow: /media/ Disallow: /system/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /component/ Disallow: /*start Disallow: /*searchword User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /language/ Disallow: /libraries/ Disallow: /logs/ Disallow: /system/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /component/ Disallow: /*start Disallow: /*searchword Host: site.com User-agent: Googlebot Allow: *.css Allow: *.js Disallow: /administrator/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /language/ Disallow: /libraries/ Disallow: /logs/ Disallow: /system/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/ Disallow: /component/ Disallow: /*start Disallow: /*searchword Sitemap: http://site.com/sitemap.xml
Замечу, что в наборе поисковых правил для Joomla я закрыл пагинацию страниц в разделах, а также страницу поиска по сайту. Если вам необходимы данные страницы в поиске — можете убрать из robots.txt эти две строчки:
Disallow: /*start Disallow: /*searchword
Немного о нестандартном использовании robots.txt
С учетом написанного выше, тему правильной настройки robots.txt можно считать раскрытой, однако есть еще кое-что, о чем я бы хотел рассказать. Роботс можно с пользой применять помимо назначения и без вреда для сайта. Дело в том, что в файле можно использовать такой знак, как «#» — он обозначает комментарии, не учитываемые роботами. Данный знак действителен в пределах одной строки, там, где он используется. Его можно использовать для пометок, чтобы не забыть, что и зачем было закрыто от поисковых систем.
Но есть и другое применение. Например, после знака комментария, вы можете разместить полезную информацию: контакты сайта, вакансию для оптимизатора, ссылку на важную информацию, и даже рекламу. Не буду заниматься плагиатом, так как идея не моя, поэтому предлагаю ознакомиться с различными вариантами на блоге Devaka. Уверен, вы будете удивлены, узнав, насколько разнообразным может быть использование роботса не по назначению.
На этом все, правильная настройка robots.txt описана в полной мере, надеюсь, вы узнали что-то новое. Если же после прочтения статьи у вас остались вопросы — задавайте их в комментариях, и я постараюсь на них ответить.
Robots.txt – важные этапы при создании и проверке
Почему это важноRobots.txt – это текстовый файл с набором инструкций для поисковых роботов, который управляет правилами индексации сайтов. С его помощью можно обозначить для поисковых систем, какие страницы стоит проиндексировать в первую очередь (например, раздел «Новости компании», так как он часто обновляется) и какие страницы закрыты для индексирования (например, результаты внутреннего поиска, так как это может привести к дублированию данных в поисковой системе и ухудшению показателей ранжирования сайта). Подробней о дубликатах данных читайте в Рыбе «Дублируемый контент – как вовремя найти и обезвредить дубли».
Файл Robots.txt должен находиться в корне сайта и быть доступен по адресу:
http://site.ru/robots.txt
Если у вашего сайта несколько поддоменов (это сайты 3-го уровня, например: http://ru.site.com), то для каждого поддомена следует писать свой robots.txt.
Как создать robots.txt?Robots.txt – простой текстовый файл. Внимание: имя файла должно содержать только маленькие буквы (то есть имена «Robots.txt» и «ROBOTS.TXT» — неправильные). Ещё одно ограничение robots.txt – размер файла. У Google это до 500 кб, у Яндекса до 32 кб. Если ваш robots.txt превышает эти размеры, то он может работать некорректно.
Если ваш robots.txt превышает эти размеры, то он может работать некорректно.
Более подробные требования к оформлению файла прописаны в справках поисковых систем: для Google и для «Яндекс».
Какие директивы существуют?Директива «User-agent»Директива, указывающая, для какого поискового робота написаны правила.
Примеры использования:
User-agent: * – для всех поисковых роботов
User-agent: Yandex – для поискового робота Yandex
User-agent: Googlebot – для поискового робота Google
User-agent: Yahoo – для поискового робота Yahoo
Рекомендуется использовать:
User-agent: *
Ниже мы рассмотрим примеры директив, как и для чего стоит их использовать.
Директива «Disallow»Директива, запрещающая индексацию определённых файлов, страниц или категорий.
Эта директива применяется при необходимости закрыть дублирующие страницы (например, если это интернет-магазин, то страницы сортировки товаров, или же, если это новостной портал, то страницы печати новостей).
Также данная директива применима к «мусорным для поисковых роботов страницам». Такие страницы, как: «регистрация», «забыли пароль», «поиск» и тому подобные, – не несут полезности для поискового робота.
Примеры использования:
Disallow: /*sort – при помощи спец символа «*», мы даём понять поисковому роботу, что любой url, содержащий «SORT», будет исключён из индекса поисковой системы. Таким образом, в интернет-магазине мы сразу избавимся от всех страниц сортировки (учтите, что в некоторых CMS системах построение url сортировок может отличаться).
Disallow: /*print.php – аналогично сортировке мы исключаем все страницы «версия для печати».
Disallow: */telefon/ – в данном случае мы исключаем категорию «телефон», то есть url, содержащие «/telefon/».
Пример исключённых в данном случае url:
Пример не исключённых url в данном случае:
Disallow: /search – в данном случае мы исключим все страницы поиска, url которых начинаются с «/search». Давайте рассмотрим на примере исключенных страниц поиска:
Примеры не исключённых url в данном случае:
Disallow: / – закрыть весь сайт от индексации.
Рекомендуется использовать Disallow со специальным символом «*» для исключения большого количества страниц дублей.
Директива «Allow»Директива, разрешающая индексировать страницы (по умолчанию поисковой системе открыт весь сайт для индексации). Данная директива используется с директивой «Disallow».
Важно: директива «allow» всегда должна быть выше директивы «disallow».
Пример №1 использования директив:
Allow: /user/search
Disallow: *search
В данном случае мы запрещаем поисковому роботу индексировать страницы «поиска по сайту», за исключением страниц «поиска пользователей».
Пример №2 использование директив:
Allow: /nokia
Disallow: *telefon
В данном случае, если url-структура страниц такого типа:
Мы закрываем все телефоны от индексации, за исключением телефонов «nokia».
Такая методика, как правило, редко используется.
Директива «sitemap»Данная директива указывает поисковому роботу путь к карте сайта в формате «XML».
Директива должна содержать в себе полный путь к файлу.
Sitemap: http://site.ru/sitemap.xml
Рекомендации по использованию данной директивы: проверьте правильность указанного адреса.
Директива «Host»
Данная директива позволяет указать главное зеркало сайта. Ведь для поисковой системы это два разных сайта.
В данной директиве необходимо указывать главное зеркало сайта в виде:
Host: www. site.ru
site.ru
Либо:
Host: site.ru
Пример полноценного robots.txt
User-Agent: *
Disallow: /cgi-bin
Disallow: /*sort=*
Sitemap: http://www.site.ru/sitemap.xml
Host: www.site.ru
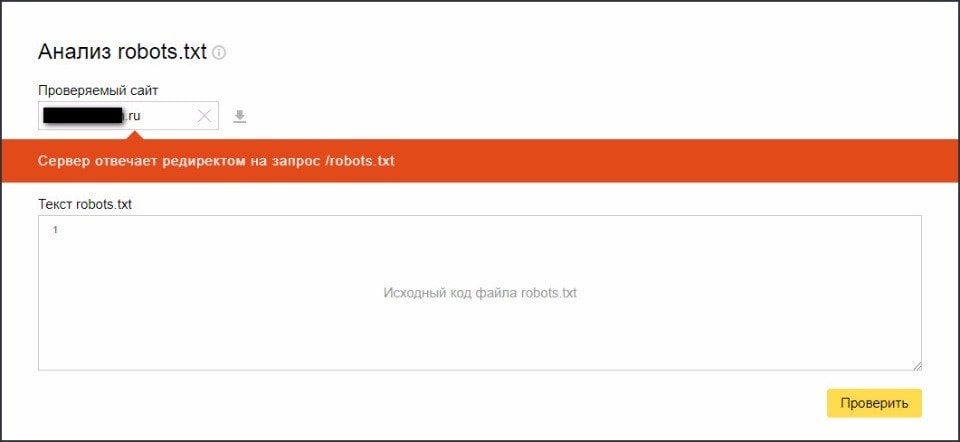
Корректность работы файла проверяется согласно правилам поисковых систем, в которых указаны правильные и актуальные директивы (ПС могут обновлять требования, поэтому важно следить за тем, чтобы ваш robots.txt оставался актуальным). Конечную проверку файла можно провести с помощью верификатора. В Google – это robots.txt Tester в панели инструментов для веб-мастеров, в ПС «Яндекс» — Анализ robots.txt.
ВыводыИнструкция robots.txt – важный момент в процессе оптимизации сайта. Файл позволяет указать поисковому роботу, какие страницы не следует индексировать. Это, в свою очередь, позволяет ускорить индексации нужных страниц, отчего повышается общая скорость индексации сайта.
Необходимо помнить, что robots.txt – это не указания, а только рекомендации поисковым системам.
Роботы Яндекса — «robots.txt» для Яндекса, директива «Host», HTML-тег «noindex», IP-адреса роботов Яндекса — Robots.Txt по-русски
Методы управления поведением робота Яндекса
Читайте в отдельной статье: методы управления поведением робота.
Виды роботов Яндекса
- Yandex/1.01.001 (compatible; Win16; I) — основной индексирующий робот
- Yandex/1.01.001 (compatible; Win16; P) — индексатор картинок
- Yandex/1.01.001 (compatible; Win16; H) — робот, определяющий зеркала сайтов
- Yandex/1.02.000 (compatible; Win16; F) — робот, индексирующий пиктограммы сайтов (favicons)
- Yandex/1.03.003 (compatible; Win16; D) — робот, обращающийся к странице при добавлении ее через форму «Добавить URL»
- Yandex/1.
 03.000 (compatible; Win16; M) — робот, обращающийся при открытии страницы по ссылке «Найденные слова»
03.000 (compatible; Win16; M) — робот, обращающийся при открытии страницы по ссылке «Найденные слова» - YaDirectBot/1.0 (compatible; Win16; I) — робот, индексирующий страницы сайтов, участвующих в Рекламной сети Яндекса
- YandexBlog/0.99.101 (compatible; DOS3.30,B) – робот, индексирующий xml-файлы для поиска по блогам.
- YandexSomething/1.0 – робот, индексирующий новостные потоки партнеров Яндекс-Новостей.
- Bond, James Bond (version 0.07) — робот, заходящий на сайты из подсети Яндекса. Официально никогда не упоминался. Ходит выборочно по страницам. Referer не передает. Картинки не загружает. Судя по повадкам, робот занимается проверкой сайтов на нарушения – клоакинг и пр.
IP-адреса роботов Яндекса
IP-адресов, с которых «ходит» робот Яндекса, много, и они могут меняться. Список адресов не разглашается.
Кроме роботов у Яндекса есть несколько агентов-«простукивалок», которые определяют, доступен ли в данный момент сайт или документ, на который стоит ссылка в соответствующем сервисе.
- Yandex/2.01.000 (compatible; Win16; Dyatel; C) — «простукивалка» Яндекс.Каталога. Если сайт недоступен в течение нескольких дней, он снимается с публикации. Как только сайт начинает отвечать, он автоматически появляется в Каталоге.
- Yandex/2.01.000 (compatible; Win16; Dyatel; Z) — «простукивалка» Яндекс.Закладок. Ссылки на недоступные сайты помечаются серым цветом.
- Yandex/2.01.000 (compatible; Win16; Dyatel; D) — «простукивалка» Яндекс.Директа. Она проверяет корректность ссылок из объявлений перед модерацией. Никаких автоматических действий не предпринимается.
- Yandex/2.01.000 (compatible; Win16; Dyatel; N) — «простукивалка» Яндекс.Новостей. Она формирует отчет для контент-менеджера, который оценивает масштаб проблем и, при необходимости, связывается с партнером.
Директива Host
Во избежания возникновения проблем с зеркалами сайта рекомендуется использовать директиву «Host». Директива «Host» указывает роботу Яндекса на главное зеркало данного сайта. С директивой «Disallow» никак не связана.
С директивой «Disallow» никак не связана.
User-agent: Yandex
Disallow: /cgi-bin
Host: www.site.ru
либо
User-agent: Yandex
Disallow: /cgi-bin
Host: site.ru
в зависимости от того что для вас оптимальнее.
Вот цитата из ЧаВо Яндекса:
Мой сайт показывается в результатах поиска не под тем именем. Как это исправить?
Скорее всего, ваш сайт имеет несколько зеркал, и робот выбрал как основное не то зеркало, которое хочется вам. Есть несколько решений:
- удалите зеркала вашего сайта;
- на всех зеркалах, кроме того, которое вы хотите выбрать основным, разместите файл robots.txt, полностью запрещающий индексацию сайта, либо выложите на зеркалах robots.txt с директивой Host;
- разместите на главных страницах неосновных зеркал тег <meta name=»robots» content=»noindex, nofollow»>, запрещающий их индексацию и обход по ссылкам;
- измените код главных страниц на неосновных зеркалах так, чтобы все (или почти все) ссылки с них вглубь сайта были абсолютными и вели на основное зеркало.
В случае реализации одного из вышеперечисленных советов ваше основное зеркало будет автоматически изменено по мере обхода робота.
Интересная информация об обработке директивы Host из ответов А. Садовского на вопросы оптимизаторов:
Вопрос: Когда планируется своевременное соблюдение директивы Host: в robots.txt? Если сайт индексируется как www.site.ru, когда указано Host: site.ru уже после того, как robots.txt был размещен 1–2 недели, то при этом сайт с www и без www не склеивается более 1–2 месяца и в Яндексе существуют одновременно 2 копии частично пересекающихся сайтов (один 550 страниц, другой 150 страниц, при этом 50 страниц одинаковых). Прокомментируйте, пожалуйста, проблемы с работой «зеркальщика».
Ответ: Расширение стандарта robots.txt, введенное Яндексом, директива Host — это не команда считать зеркалами два любых сайта, это указание, какой сайт из группы, определенных автоматически как зеркала, считать главным. Следовательно, когда сайты будут идентифицированы как зеркала, директива Host сработает.
HTML-тег <noindex>
Робот Яндекса поддерживает тег noindex, который запрещает роботу Яндекса индексировать заданные (служебные) участки текста. В начале служебного фрагмента ставится <noindex>, а в конце — </noindex>, и Яндекс не будет индексировать данный участок текста.
Тег работает аналогично мета-тегу noindex, но распространяется только на контент, заключенный внутри тега в формате:
<noindex>текст, индексирование которого нужно запретить</noindex>
Тег noindex не чувствителен к вложенности (может находиться в любом месте html-кода страницы). При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
<!––noindex––>текст, индексирование которого нужно запретить<!––/noindex––>
Ссылки по теме
Описание робота Яндекса на сайте Яндекса
Очень интересная запись о роботах на (не)?Путевых заметках
Яндекс и robots.txt – ньюансы
Яндекс накосячил с соблюдением стандарта файла robots.txt
Форма для добавления URL сайта в индекс
Форма для удаления URL сайта из индекса
Robots.txt глазами Яндекса (Анализ robots.txt)
Правильный robots.txt для Яндекса
Опубликовано: 01.05.2012г.
В предыдущей публикации был рассмотрен синтаксис и общие правила настройки robots.txt, однако, как показывает практика, далеко не все владельцы сайта знают, как создать «правильный» robots.txt на свой сайт для Яндекса. Ведь именно Яндекс является поисковой системой №1 в России уже более 10 лет. Его доля в последние годы не менее 60% от общего доли поискового трафика создаваемого русскоязычными пользователями России и стран ближнего зарубежья.
Для корректного создания robots.txt необходимо знать не только всю структуру собственного сайта, но и особенности CMS, на которой работает сайт.
Есть несколько общих правил. В поисковом индексе НЕ должно быть таких страниц, как:
Случайно генерируемые CMS страницы сайта без контента или с дублями, как полными, так и частичными
Классическим примером таких страниц, являются версии страниц сайта для печати, pdf версии, страницы пагинации (разбивки контента на отдельные страницы), аннотации.
В случае нахождения таких страниц в индексе, необходимо их запретить в robots.txt.
Пример: Сайт, созданный на Joomla с помощью сторонних компонентов (дополнительных расширений для увеличения функциональности), очень часто генерирует полные копии страниц при прямых запросах к компоненту в разделе сайта /component/ и версии страниц для печати с добавлением параметра ?tmpl=component&print=1 к оригинальному адресу страницы сайта.
В таком случае, правильный robots.txt для Joomla будет выглядеть так:
User-Agent: *
Disallow: /component/
Disallow: *?tmpl=component&print=1
User-Agent: Yandex
Disallow: /component/
Disallow: *?tmpl=component&print=1
Host: site.ru
Примечание: настоятельно не рекомендуется оставлять оригинальные robots.txt от CMS, поскольку по типовому содержанию файлов robots.txt осуществляется поиск сайтов на конкретных CMS с известными уязвимостями вирусами и хакерами для взлома.
Страницы, содержащие конфиденциальную информацию
К таким страницам относятся все страницы (файлы), которые содержат личную информацию о пользователях, данные о товарах и ценах не для общего пользования. Особенно такая проблема может быть актуальной, если сайт используется для автоматической генерации pdf счетов на оплату, систем оплаты, извещений или обмена сообщениями между пользователями.
Пример: Многие интернет-магазины имеют функцию генерации pdf счета для клиента при заказе с последующей отправкой этого счета по email.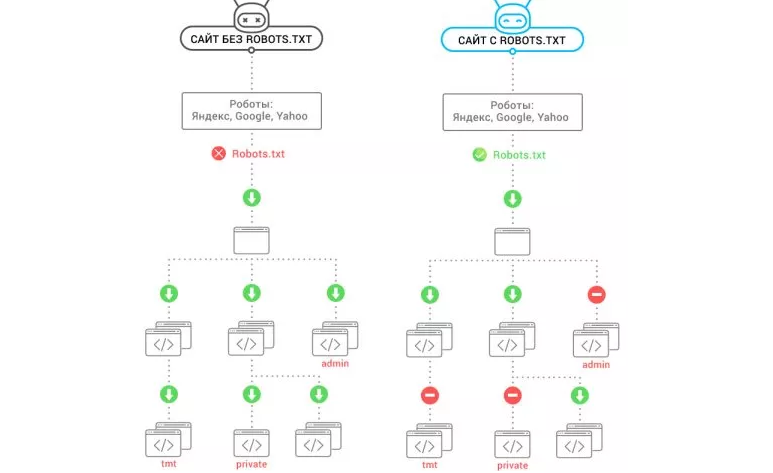 В случае отсутствия запрета на индексацию pdf файлов в разделе /files/ на сайте велика вероятность попадания данных счетов в публичный доступ.
В случае отсутствия запрета на индексацию pdf файлов в разделе /files/ на сайте велика вероятность попадания данных счетов в публичный доступ.
Если в конкретном случае известна директория (раздел) сайта, где хранятся pdf файлы, то можно запретить весь раздел:
User-Agent: *
Disallow: /files/
User-Agent: Yandex
Disallow: /files/
Host: site.ru
или запретить индексацию pdf файлов из данного раздела:
User-Agent: *
Disallow: /files/*.pdf$
User-Agent: Yandex
Disallow: /files/*.pdf$
Host: site.ru
Страницы, ошибочно генерируемые CMS
Данная проблема особенно актуальна при использовании бесплатных CMS и дополнительных SEF компонентов для создания ЧПУ урлов (человекопонятным адресом страниц). В этом случае, как правило при обходе поисковым роботом сайта данная страница генерируется под стандартным (не ЧПУ) адресом и ЧПУ урлом, созданным компонентом.
Пример: Для запрета индексации страниц под оригинальными не ЧПУ урлами на сайте, созданном на CMS Joomla, robots.txt будет таким:
User-Agent: *
Disallow: /index.php
User-Agent: Yandex
Disallow: /index.php
Host: site.ru
Страницы с не релевантным тематике сайта контентом
К таким страницам могут относится:
- страницы с дополнительной информацией, не касающейся собственно товаров и услуг компании;
- страницы с информацией справочного вида, как FAQ, типовые договора, лицензии, фотогалереи;
- страницы с рекламой и ссылками на другие, в т.ч. партнерские сайты;
- страницы форума, если таковой на сайте есть.
Запрет страниц с не тематическим контентом — это сложная работа, требующего глубокого анализа статистических данных из счетчика Яндекс Метрика и статистики поисковых запросов Яндекс Вордстат.
Решение о запрете таких страниц должно приниматься исключительно только профессиональным специалистом на основе вырабатаной стратегии продвижения сайта по семантическому ядру ключевых слов и словосочетаний.
Пример: на сайте есть раздел FAQ, в котором пользователи имеют возможность задавать вопросы, касаемо приобретения товаров, их цены и наличия. В силу того, что этот раздел постоянно обновляется и растет в объеме, он становится более релевантен с точки зрения поисковой системы ключевым словам и запросам, чем раздел с каталогом продукции, но в силу того, что информация, которую пользователь читает, уже может быть неактуальна, необходимо, чтобы в поисковой выдаче присутствовали только страницы с товарами и услугами, т.е. необходимо справочный раздел /faq/ закрыть от индексации:
User-Agent: *
Disallow: /faq/
User-Agent: Yandex
Disallow: /faq/
Host: site.ru
Примечание: Несмотря на то, что поисковые системы используют схожие алгоритмы для ранжирования сайтов, рекомендуется для основных поисковых систем в Рунете Яндекса и Google использовать отдельные директивы с учетом особенности работы каждой поисковой системы при закрытии от индексации страниц с не релевантным тематике сайта контентом.
Использование robots.txt | FORNEX
Robots.txt — текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
Как создать robots.txt
В текстовом редакторе создайте файл с именем robots.txt и заполните его в соответствии с представленными ниже правилами.
Проверьте файл в сервисе Яндекс. Вебмастер (пункт меню Анализ robots.txt).
Загрузите файл в корневую директорию вашего сайта.
Директива User-agent
Робот Яндекса поддерживает стандарт исключений для роботов с расширенными возможностями, которые описаны ниже.
В роботе используется сессионный принцип работы, на каждую сессию формируется определенный пул страниц, которые планирует загрузить робот.
Сессия начинается с загрузки файла robots.txt. Если файл отсутствует, не является текстовым или на запрос робота возвращается HTTP-статус отличный от 200 OK, робот считает, что доступ к документам не ограничен.
В файле robots.txt робот проверяет наличие записей, начинающихся с User-agent:, в них учитываются подстроки Yandex (регистр значения не имеет) или * . Если обнаружена строка User-agent: Yandex, директивы для User-agent: * не учитываются. Если строки User-agent: Yandex и User-agent: * отсутствуют, считается, что доступ роботу не ограничен.
Следующим роботам Яндекса можно указать отдельные директивы:
- ‘YandexBot’ — основной индексирующий робот;
- ‘YandexDirect’ — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы, интерпретирует robots.txt особым образом;
- ‘YandexDirectDyn’ — робот генерации динамических баннеров, интерпретирует robots.txt особым образом;
- ‘YandexMedia’ — робот, индексирующий мультимедийные данные;
- ‘YandexImages’ — индексатор Яндекс.Картинок;
- ‘YaDirectFetcher’ — робот Яндекс.Директа, интерпретирует robots.txt особым образом;
- ‘YandexBlogs’поиска по блогам — робот , индексирующий посты и комментарии;
- ‘YandexNews’ — робот Яндекс.Новостей;
- ‘YandexPagechecker’ — валидатор микроразметки;
- ‘YandexMetrika’ — робот Яндекс.Метрики;
- ‘YandexMarket’— робот Яндекс.Маркета;
- ‘YandexCalendar’ — робот Яндекс.Календаря.
User-agent: YandexBot # будет использоваться только основным индексирующим роботом
Disallow: /*id=
User-agent: Yandex # будет использована всеми роботами Яндекса
Disallow: /*sid= # кроме основного индексирующего
User-agent: * # не будет использована роботами Яндекса
Disallow: /cgi-bin
Директивы Disallow и Allow
Чтобы запретить доступ робота к сайту или некоторым его разделам, используйте директиву Disallow.
User-agent: Yandex
Disallow: / # блокирует доступ ко всему сайту
User-agent: Yandex
Disallow: /cgi-bin # блокирует доступ к страницам,
# начинающимся с '/cgi-bin'
В соответствии со стандартом перед каждой директивой User-agent рекомендуется вставлять пустой перевод строки.
Символ # предназначен для описания комментариев. Все, что находится после этого символа и до первого перевода строки не учитывается.
Чтобы разрешить доступ робота к сайту или некоторым его разделам, используйте директиву Allow
User-agent: Yandex
Allow: /cgi-bin
Disallow: /
# запрещает скачивать все, кроме страниц
# начинающихся с '/cgi-bin'
Совместное использование директив
Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом.
# Исходный robots.txt:
User-agent: Yandex
Allow: /catalog
Disallow: /
# Сортированный robots.txt:
User-agent: Yandex
Disallow: /
Allow: /catalog
# разрешает скачивать только страницы,
# начинающиеся с '/catalog'
# Исходный robots.txt:
User-agent: Yandex
Allow: /
Allow: /catalog/auto
Disallow: /catalog
# Сортированный robots.txt:
User-agent: Yandex
Allow: /
Disallow: /catalog
Allow: /catalog/auto
# запрещает скачивать страницы, начинающиеся с '/catalog',
# но разрешает скачивать страницы, начинающиеся с '/catalog/auto'.
Директива Sitemap
Если вы используете описание структуры сайта с помощью файла Sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все).
User-agent: Yandex
Allow: /
sitemap: https://example.com/site_structure/my_sitemaps1.xml
sitemap: https://example.com/site_structure/my_sitemaps2.xml
Директива является межсекционной, поэтому будет использоваться роботом вне зависимости от места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки.
Директива Host
Если у вашего сайта есть зеркала, специальный робот зеркальщик (Mozilla/5.0 (compatible; YandexBot/3.0; MirrorDetector; +http://yandex.com/bots)) определит их и сформирует группу зеркал вашего сайта. В поиске будет участвовать только главное зеркало. Вы можете указать его для всех зеркал в файле robots.txt: имя главного зеркала должно быть значением директивы Host.
Директива Host не гарантирует выбор указанного главного зеркала, тем не менее, алгоритм при принятии решения учитывает ее с высоким приоритетом.
#Если https://www.glavnoye-zerkalo.ru главное зеркало сайта, то #robots.txt для всех сайтов из группы зеркал выглядит так
User-Agent: *
Disallow: /forum
Disallow: /cgi-bin
Host: https://www.glavnoye-zerkalo.ru
Директива Crawl-delay
Если сервер сильно нагружен и не успевает отрабатывать запросы на загрузку, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
В целях совместимости с роботами, которые не полностью следуют стандарту при обработке robots.txt, директиву Crawl-delay необходимо добавить в группу, которая начинается с записи User-Agent (непосредственно после директив Disallow и Allow).
Поисковый робот Яндекса поддерживает дробные значения Crawl-Delay, например, 0.1. Это не гарантирует, что поисковый робот будет заходить на ваш сайт 10 раз в секунду, но позволяет ускорить обход сайта.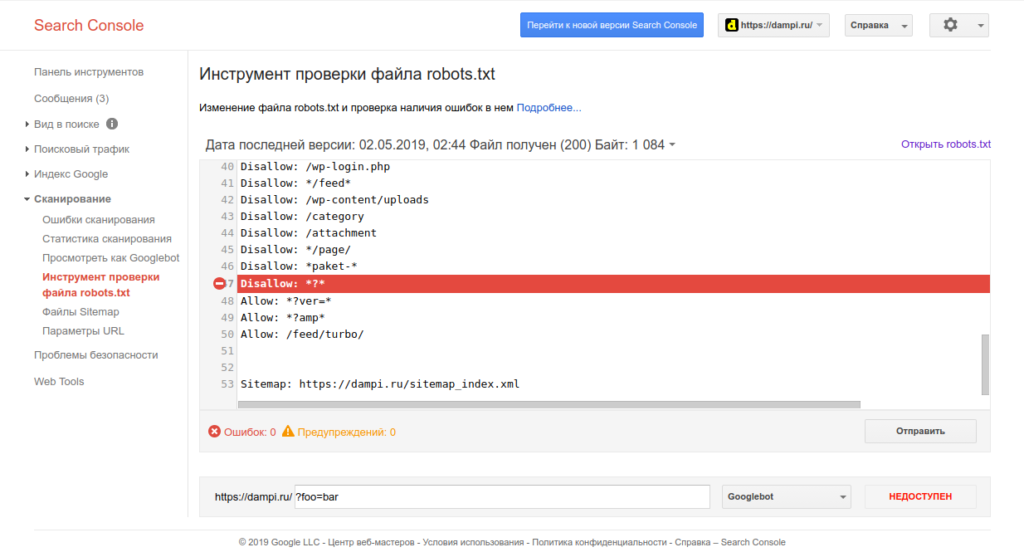
User-agent: Yandex
Crawl-delay: 2 # задает таймаут в 2 секунды
User-agent: *
Disallow: /search
Crawl-delay: 4.5 # задает таймаут в 4.5 секунды
Директива Clean-param
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (например: идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту информацию, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
С более подробной информацией можно ознакомиться на официальном сайте
Использование robots.txt — Webmaster. Справка
Яндекс поддерживает следующие директивы:
| Директива | Что он делает |
|---|---|
| User-agent * | Указывает на робота, к которому применяются правила, указанные в robots.txt. |
| Запретить | Запрещает индексирование разделов сайта или отдельных страниц. |
| Sitemap | Указывает путь к файлу Sitemap, который размещается на сайте. |
| Clean-param | Указывает роботу, что URL-адрес страницы содержит параметры (например, теги UTM), которые следует игнорировать при ее индексировании. |
| Разрешить | Разрешить индексирование разделов сайта или отдельных страниц. |
| Задержка сканирования | Определяет минимальный интервал (в секундах) ожидания поисковым роботом после загрузки одной страницы перед началом загрузки другой. Рекомендуем использовать настройку скорости сканирования в Яндекс.Вебмастер вместо директивы. |

* Обязательная директива.
Чаще всего вам понадобятся директивы Disallow, Sitemap и Clean-param. Примеры:
User-agent: * # указывает роботов, для которых установлены директивы.
Disallow: / bin / # запрещает ссылки из корзины покупок.
Disallow: / search / # запрещает ссылки на страницы поиска, встроенные на сайт
Disallow: / admin / # запрещает ссылки из админки.
Карта сайта: http: // example.com / sitemap # указывает путь к файлу Sitemap сайта для робота.
Clean-param: ref /some_dir/get_book.pl Роботы из других поисковых систем и служб могут интерпретировать директивы по-другому.
Примечание. Робот учитывает регистр подстрок (имя файла или путь, имя робота) и игнорирует регистр в именах директив.
| Mozilla / 5.0 (совместимо; YandexAccessibilityBot / 3.0; + http: //yandex.com/bots) | YandexAccessibilityBot загружает страницы, чтобы проверить их доступность для пользователей. Отправляет до 3-х запросов на сайт в секунду. Робот игнорирует настройку в интерфейсе Яндекс.Вебмастера. | № |
| Mozilla / 5.0 (совместимый; YandexAdNet / 1.0; + http: //yandex.com/bots) | Робот рекламной сети Яндекса. | Да |
| Mozilla / 5.0 (совместимо; ЯндексБлоги / 0.99; робот; + http: //yandex.com/bots) | Робот для поиска по блогам, который индексирует комментарии к публикациям. | Да |
Mozilla / 5. 0 (совместимый; YandexBot / 3.0; + http: //yandex.com/bots) 0 (совместимый; YandexBot / 3.0; + http: //yandex.com/bots) | Основной робот-индексатор. | Да |
| Mozilla / 5.0 (совместимый; YandexBot / 3.0; MirrorDetector; + http: //yandex.com/bots) | Обнаружение зеркал сайта. | Да |
| Mozilla / 5.0 (совместимый; ЯндексКалендарь / 1.0; + http: //yandex.com/bots) | Робот Яндекс.Календарь. Скачивает файлы календаря по запросу пользователей. Эти файлы часто находятся в каталогах, запрещенных для индексации. | Нет |
| Mozilla / 5.0 (совместимый; ЯндексДирект / 3.0; + http: //yandex.com/bots) | Загружает информацию о содержании сайтов партнеров рекламной сети Яндекса для определения тематических категорий для соответствия релевантной рекламе . | Нет |
| Mozilla / 5.0 (совместимый; YandexDirectDyn / 1.0; + http: //yandex.com/bots | Создает динамические баннеры. | Нет |
| Mozilla / 5.0 (совместимо; YandexFavicons / 1.0; + http: //yandex.com/ bots) | Загружает файл значка сайта для отображения в результатах поиска. | Нет |
| Mozilla / 5.0 (совместимый; YaDirectFetcher / 1.0; Dyatel; + http: //yandex.com/bots) | Загрузки целевых страниц объявлений, чтобы проверить их наличие и тематику, что необходимо для размещения рекламы в результатах поиска и на сайтах-партнерах. | Нет. Робот не использует файл robots.txt и игнорирует установленные для него директивы. |
| Mozilla / 5.0 (совместимый; YandexForDomain / 1.0; + http: //yandex.com/bots) | Робот Яндекс.Почты для домена, используемый для проверки прав владения доменом. | Да |
| Mozilla / 5.0 (совместимый; YandexImages / 3.0; + http: //yandex.com/bots) | Индексирует изображения для отображения в Яндекс.Изображениях. | Да |
| Mozilla / 5.0 (совместимый; YandexImageResizer / 2.0; + http: //yandex.com/bots) | Мобильные устройства robot. | Да |
| Mozilla / 5.0 (iPhone; CPU iPhone OS 8_1, как Mac OS X) AppleWebKit / 600.1.4 (KHTML, как Gecko) Версия / 8.0 Mobile / 12B411 Safari / 600.1.4 (совместимо; YandexBot / 3.0 ; + http: //yandex.com/bots) | Робот-индексатор. | Да |
| Mozilla / 5.0 (iPhone; CPU iPhone OS 8_1, как Mac OS X) AppleWebKit / 600.1.4 (KHTML, как Gecko) Версия / 8.0 Mobile / 12B411 Safari / 600.1.4 (совместимый; YandexMobileBot / 3.0; + http: //yandex.com/bots) | Определяет страницы с макетом, подходящим для мобильных устройств. | Нет |
| Mozilla / 5.0 (совместимый; ЯндексМаркет / 1.0; + http: //yandex.com/bots) | Робот Яндекс.Маркета. | Да |
| Mozilla / 5.0 (совместимый; ЯндексМаркет / 2.0; + http: //yandex.com/bots) | Нет | |
| Mozilla / 5.0 (совместимый; ЯндексМедиа / 3.0; + http: //yandex.com/bots) | Индексирует мультимедийные данные. | Да |
| Mozilla / 5.0 (совместимый; ЯндексМетрика / 2.0; + http: //yandex.com/bots yabs01) | Скачивает страницы сайта для проверки их доступности, в том числе целевые страницы объявлений Яндекс.Директа. | Нет. Робот не использует файл robots.txt и игнорирует установленные для него директивы. |
| Mozilla / 5.0 (совместимый; ЯндексМетрика / 2.0; + http: //yandex.com/bots) | Яндекс.Метрика робот. | № |
| Mozilla / 5.0 (совместимый; ЯндексМетрика / 3.0; + http: //yandex.com/bots) | № | |
| Mozilla / 5.0 (совместимый; ЯндексМетрика / 4.0; + http: // yandex.com/bots) | Робот Яндекс.Метрики. Загружает и кэширует стили CSS для отображения страниц сайта в Webvisor. | Нет. Робот не использует файл robots.txt и игнорирует установленные для него директивы. |
| Mozilla / 5.0 (совместимый; YandexMobileScreenShotBot / 1.0; + http: //yandex.com/bots) | Делает снимок экрана мобильной страницы. | Нет |
| Mozilla / 5.0 (совместимый; ЯндексНовости / 4.0; + http: //yandex.com/bots) | Робот Яндекс.Новости. | Да |
| Mozilla / 5.0 (совместимый; YandexOntoDB / 1.0; + http: //yandex.com/bots) | Робот ответа на объект. | Да |
| Mozilla / 5.0 (совместимый; YandexOntoDBAPI / 1.0; + http: //yandex.com/bots) | Робот ответа на объект, который загружает динамические данные. | Нет |
| Mozilla / 5.0 (совместимый; YandexPagechecker / 1.0; + http: //yandex.com/bots) | Открывает страницу для проверки микроразметки с помощью валидатора структурированных данных. | Да |
| Mozilla / 5.0 (совместимый; ЯндексПартнер / 3.0; + http: //yandex.com/bots) | Скачивает информацию о содержании партнерских сайтов Яндекса. | Нет |
| Mozilla / 5.0 (совместимый; YandexRCA / 1.0; + http: // yandex.com / bots) | Собирает данные для создания превью. Например, предварительный просмотр мастера. | Нет |
| Mozilla / 5.0 (совместимый; YandexSearchShop / 1.0; + http: //yandex.com/bots) | Скачивает каталоги товаров в файлах YML по запросам пользователей. Эти файлы часто помещаются в каталоги, запрещенные для индексации. | Нет |
| Mozilla / 5.0 (совместимый; ЯндексСсылки сайта; Дятел; + http: //yandex.com/bots) | Проверяет доступность страниц, используемых в качестве дополнительных ссылок. | Да |
| Mozilla / 5.0 (совместимый; ЯндексСправБот / 1.0; + http: //yandex.com/bots) | Робот Яндекс.Директории. | Да |
| Mozilla / 5.0 (совместимый; ЯндексТрекер / 1.0; + http: //yandex.com/bots) | Робот Яндекс.Трекер. | Нет |
| Mozilla / 5.0 (совместимый; YandexTurbo / 1.0; + http: //yandex.com/bots) | Сканирует RSS-канал, созданный для создания Турбо-страниц. Он отправляет до 3-х запросов на сайт в секунду.Робот игнорирует настройки в интерфейсе Яндекс.Вебмастера и директиву Crawl-delay. | Да |
| Mozilla / 5.0 (совместимый; YandexVertis / 3.0; + http: //yandex.com/bots) | Робот по поисковым вертикалям. | Да |
| Mozilla / 5.0 (совместимо; YandexVerticals / 1.0; + http: //yandex.com/bots) | Робот Яндекс.Verticals: Auto.ru, Yanex.Realty, Яндекс.Работа, Яндекс. Обзоры. | Да |
| Mozilla / 5.0 (совместимый; ЯндексВидео / 3.0; + http: //yandex.com/bots) | Индексирует видеоклипы для отображения в Яндекс.Видео. | Да |
| Mozilla / 5.0 (совместимый; YandexVideoParser / 1.0; + http: //yandex.com/bots) | Индексирует видеоклипы для отображения в Яндекс.Видео. | Нет |
| Mozilla / 5.0 (совместимый; ЯндексВебмастер / 2.0; + http: //yandex.com/bots) | Робот Яндекс.Вебмастер. | Да |
| Mozilla / 5.0 (X11; Linux x86_64) AppleWebKit / 537.36 (KHTML, как Gecko) Chrome / W.X.Y.Z * Safari / 537.36 (совместимый; YandexScreenshotBot / 3.0; + http: //yandex.com/bots) | Делает снимок экрана страницы. | Нет |
Директивы Disallow и Allow — Webmaster. Help
- Disallow
- Allow
- Объединение директив
- Разрешить и запретить директивы без параметров
- Использование специальных символов * и $
- Примеры интерпретации директив
Примеры:
User-agent: Яндекс
Disallow: / # запрещает сканирование всего сайта.
User-agent: Яндекс
Disallow: / catalog # запрещает сканирование страниц, начинающихся с / catalog.
User-agent: Яндекс
Disallow: / page? # Запрещает сканирование страниц с URL-адресом, который содержит параметры. Эта директива позволяет индексировать разделы сайта или отдельные страницы.
Примеры:
User-agent: Яндекс
Разрешить: / cgi-bin
Запретить: /
# запрещает скачивать что-либо кроме страниц
# начинающиеся с '/ cgi-bin' User-agent: Яндекс
Разрешить: /file.xml
# позволяет скачать file.xml Примечание. Между директивами User-agent , Disallow и Allow запрещены пустые разрывы строк.
Директивы Allow и Disallow из соответствующего блока User-agent сортируются по длине префикса URL (от самого короткого к самому длинному) и применяются по порядку.Если несколько директив соответствуют определенной странице сайта, робот выбирает последнюю в отсортированном списке. Таким образом, порядок директив в файле robots.txt не влияет на то, как они используются роботом.
Примечание. В случае конфликта между двумя директивами с префиксами одинаковой длины приоритет имеет директива Allow .
# Исходный файл robots.txt:
User-agent: Яндекс
Позволять: /
Разрешить: / catalog / auto
Disallow: / catalog
# Сортированный robots.txt:
User-agent: Яндекс
Позволять: /
Disallow: / catalog
Разрешить: / catalog / auto
# запрещает загрузку страниц, которые начинаются с '/ catalog',
# но позволяет загружать страницы, которые начинаются с '/ catalog / auto'. Типичный пример:
Пользовательский агент: Яндекс
Разрешить: / архив
Запретить: /
# разрешает все, что содержит '/ archive', остальное запрещено
User-agent: Яндекс
Разрешить: /obsolete/private/*.html$ # разрешает файлы HTML
# в пути '/ absolute / private / ...'
Disallow: /*.php$ # запрещает все '* .php' на сайте
Disallow: / * / private / # запрещает все подпути, содержащие
# '/ private /', но разрешение выше отрицает
# часть этого запрета
Запрещено: / * / старый / *.zip $ # запрещает все файлы '* .zip', содержащие
# '/ old /' в пути
User-agent: Яндекс
Запретить: /add.php?*user=
# запрещает все 'add.php?' скрипты с опцией user Если в директивах нет параметров, робот обрабатывает данные следующим образом:
User-agent: Яндекс
Disallow: # то же, что и Allow: /
User-agent: Яндекс
Allow: # не учитывается роботом Вы можете использовать специальные символы при указании путей директив Allow и Disallow * и $ для установки определенных регулярных выражений.
Символ * обозначает любую последовательность символов (или ее отсутствие). Примеры:
User-agent: Яндекс.
Disallow: /cgi-bin/*.aspx # запрещает /cgi-bin/example.aspx
# и '/cgi-bin/private/test.aspx'
Disallow: / * private # запрещает и '/ private', и
# и '/ cgi-bin / private' По умолчанию символ * добавляется в конец каждого правила, описанного в файле robots.txt. Пример:
User-agent: Яндекс.
Disallow: / cgi-bin * # блокирует доступ к страницам
# которые начинаются с '/ cgi-bin'
Disallow: / cgi-bin # то же Для отмены * в конце правила используйте символ $, например:
User-agent: Яндекс
Disallow: / example $ # запрещает '/ example',
# но не запрещает '/ example.html ' Пользовательский агент: Яндекс
Disallow: / example # запрещает и '/ example'
# и '/example.html' Символ $ не запрещает * в конце, то есть:
User-agent: Яндекс.
Disallow: / example $ # запрещает только '/ example'
Disallow: / example * $ # то же, что и Disallow: / example.
# prohibits /example.html и / example User-agent: Яндекс
Позволять: /
Запретить: /
# все позволено
User-agent: Яндекс
Разрешить: / $
Запретить: /
# запрещено все, кроме главной страницы
User-agent: Яндекс
Запретить: / private * html
# запрещает '/ private * html',
# '/ private / test.html ',' /private/html/test.aspx 'и т. д.
User-agent: Яндекс
Disallow: / private $
# запрещает только '/ private'
Пользовательский агент: *
Запретить: /
User-agent: Яндекс
Позволять: /
# так как робот Яндекс
# выбирает записи, в строке которых есть 'User-agent:',
# все разрешено Веб-робот YandexImages • VNTweb
Краткое описание интернет-робота YandexImages . Включая сведения о владельце, описание, пользовательский агент HTTP и соответствие этого робота стандарту исключения роботов.
Кому принадлежит робот YandexImages ? Робот хороший или плохой? И почему он посещает ваш сайт?
Ниже показан образец записи файла журнала для веб-робота ЯндексИзображения. Он получен из файла журнала веб-сервера Apache. Из записи журнала дается информация о том, как робот идентифицирует себя, HTTP-агент пользователя и где он размещается.
Файл журнала сервера
vntweb.co.uk 5.45.207.28 - - [24 / мар / 2019: 17: 25: 37 +0000] "GET / wp-content / uploads / 2018/01 / suite-crm-change-initial-quote-number -admin-screen-768x637.jpg HTTP / 1.1 "304 -" - "" Mozilla / 5.0 (совместимый; YandexImages / 3.0; + http: //yandex.com/bots) "
Пользовательский агент HTTP
ЯндексИзображений / 3,0
IP-адреса
Наблюдаемый IP-адрес: 5.45.207.28 .
Команда WHOIS DNS дает следующую информацию об IP-адресе:
| inetnum: | 5.45.207.0 — 5.45.207.255 |
| сетевое имя: | YANDEX-5-45-207 |
| адрес : | ООО «Яндекс» |
| адрес: | ул. Льва Толстого, 16 |
| адрес: | 119021 |
| адрес: | Москва |
| адрес: | Российская Федерация |
| последнее изменение: | 2018-08-03T07: 15: 46Z |
Как видно из вышеизложенного, наблюдаемый IP-адрес является частью блока, присвоенного ООО «Яндекс».
Владелец
ООО «Яндекс»
Страна
Российская Федерация
Исключение
Строка user-agent содержит ссылку на сайт http: // yandex.com / bots. В меню слева есть ссылка на использование robots.txt, где дается информация о настройке ботов Яндекса и конкретная информация для каждого из них.
Указанный веб-сайт подтверждает, что бот поддерживает текст исключения роботов, а также подчиняется задержке сканирования.
На веб-сайте Яндекса представлена подробная информация о том, как их робот соответствует стандарту исключения robots.txt, который был описан на http://www.robotstxt.org/wc/exclusion.html#robotstxt, но в настоящее время недоступен.Информация доступна на том же веб-сайте https://www.robotstxt.org/robotstxt.html, а также на веб-сайте w3c по адресу https://www.w3.org/TR/html4/appendix/notes.html#hB.4.1. .1.
Приведены подробные сведения о предотвращении индексирования веб-сайта роботом и о том, как настроить скорость его сканирования.
Они посоветовали включить следующую запись в файл robots.txt, чтобы предотвратить посещение вашего сайта YandexImages
User-agent: Яндекс Disallow: /
Также, чтобы контролировать частоту посещения вашего сайта Яндекс-изображениями, можно установить минимально допустимую задержку между последовательными запросами, добавив в файл robots.txt файл:
User-agent: Яндекс Задержка сканирования: 10
В этом примере задержка установлена на 10 секунд.
Помимо основного индексирующего робота, User-agent, который будет использоваться в ссылке robots.txt, — это Яндекс, как показано выше.
Как это обычно бывает со сканерами веб-сайтов, существует задержка между внесением изменений в файл robots.txt и внесением изменений.
Позаботьтесь о внесении изменений в файл robots.txt. Неправильное понимание конфигурации или ошибка конфигурации может привести к тому, что важные поисковые системы исключат ваш веб-сайт.
Дополнительная информация
Яндекс — один из роботов Интернета. Он ассоциируется с одноименной российской поисковой системой.
Яндекс — самая популярная поисковая система в России и одна из крупнейших интернет-компаний в Европе.
У Яндекса есть несколько страниц с информацией о своем боте. Эта страница — хорошее место для начала http://help.yandex.com/search/
YandexMobileBot Web Robot • VNTweb
Краткое описание Интернет-робота YandexMobileBot .Включая сведения о владельце, описание, пользовательский агент HTTP и соответствие этого робота стандарту исключения роботов.
Кому принадлежит робот YandexMobileBot ? Робот хороший или плохой? И почему он посещает ваш сайт?
Ниже приведен образец записи файла журнала для веб-робота ЯндексМобайлБот. Он получен из файла журнала веб-сервера Apache. Из записи журнала дается информация о том, как робот идентифицирует себя, HTTP-агент пользователя и где он размещается.
Файл журнала сервера
vntweb.co.uk 5.45.207.54 - - [13 / May / 2019: 19: 00: 19 +0100] "ПОЛУЧИТЬ /wp-content/themes/vntweb-17/fonts/fontawesome-webfont.woff2?v=4.6 .3 HTTP / 1.1 "200 71896" https://www.vntweb.co.uk/wp-content/themes/vntweb-17/css/font-awesome.min.css?ver=1.1 "" Mozilla / 5.0 ( iPhone; CPU iPhone OS 8_1, как Mac OS X) AppleWebKit / 600.1.4 (KHTML, как Gecko) Версия / 8.0 Mobile / 12B411 Safari / 600.1.4 (совместимый; YandexMobileBot / 3.0; + http: //yandex.com/bots ) "
HTTP User Agent
YandexMobileBot / 3.0
IP-адреса
Наблюдаемый IP-адрес: 5.45.207.54 .
Команда WHOIS DNS дает следующую информацию об IP-адресе:
| inetnum: | 5.45.207.0 — 5.45.207.255 |
| сетевое имя: | YANDEX-5-45-207 |
| адрес : | ООО «Яндекс» |
| адрес: | ул. Льва Толстого, 16 |
| адрес: | 119021 |
| адрес: | Москва |
| адрес: | Российская Федерация |
| последнее изменение: | 2012-05-25T12: 40: 45Z |
Как видно из вышеизложенного, наблюдаемый IP-адрес является частью блока, присвоенного ООО «Яндекс».
Владелец
ООО «Яндекс»
Страна
Российская Федерация
Исключение
Строка user-agent содержит ссылку на сайт http://yandex.com/bots. В меню слева есть ссылка на использование robots.txt, где дается информация о настройке ботов Яндекса и конкретная информация для каждого из них.
Указанный веб-сайт подтверждает, что бот поддерживает текст исключения роботов, а также подчиняется задержке сканирования.
На веб-сайте Яндекса представлена подробная информация о том, как их робот соответствует стандарту исключения robots.txt, который был описан на http://www.robotstxt.org/wc/exclusion.html#robotstxt, но в настоящее время недоступен. Информация доступна на том же веб-сайте https://www.robotstxt.org/robotstxt.html, а также на веб-сайте w3c по адресу https://www.w3.org/TR/html4/appendix/notes.html#hB.4.1. .1.
Приведены подробные сведения о предотвращении индексирования веб-сайта роботом и о том, как настроить скорость его сканирования.
Они посоветовали включить следующую запись в файл robots.txt, чтобы ЯндексMobileBot не заходил на ваш сайт
User-agent: Яндекс Disallow: /
Также, чтобы контролировать частоту посещения вашего сайта ЯндексМобилем, можно установить минимально допустимую задержку между последовательными запросами, добавив в файл robots.txt следующее:
User-agent: Яндекс Задержка сканирования: 10
В этом примере задержка установлена на 10 секунд.
Помимо основного индексирующего робота, User-agent, который будет использоваться в ссылке robots.txt, — это Яндекс, как показано выше.
Как это обычно бывает со сканерами веб-сайтов, существует задержка между внесением изменений в файл robots.txt и внесением изменений.
Позаботьтесь о внесении изменений в файл robots.txt. Неправильное понимание конфигурации или ошибка конфигурации может привести к тому, что важные поисковые системы исключат ваш веб-сайт.
Дополнительная информация
Яндекс — один из роботов Интернета.Он ассоциируется с одноименной российской поисковой системой.
Яндекс — самая популярная поисковая система в России и одна из крупнейших интернет-компаний в Европе.
У Яндекса есть несколько страниц с информацией о своем боте. Эта страница — хорошее место для начала http://help.yandex.com/search/
Полное руководство по robots.txt • Yoast
Йост де ВалкЙост де Валк — основатель и директор по продуктам Yoast.Он интернет-предприниматель, который незадолго до основания Yoast инвестировал и консультировал несколько стартапов. Его основная специализация — разработка программного обеспечения с открытым исходным кодом и цифровой маркетинг.
Файл robots.txt — это один из основных способов сообщить поисковой системе, где можно, а где нельзя переходить на ваш веб-сайт. Все основные поисковые системы поддерживают базовую функциональность, которую они предлагают, но некоторые из них реагируют на некоторые дополнительные правила, которые также могут быть полезны. В этом руководстве описаны все способы использования роботов.txt на вашем сайте.
Предупреждение!
Любые ошибки, которые вы делаете в своем robots.txt, могут серьезно повредить вашему сайту, поэтому убедитесь, что вы прочитали и поняли всю эту статью, прежде чем углубляться в нее.
Что такое файл robots.txt?
Директивы сканированияФайл robots.txt является одной из нескольких директив сканирования. У нас есть руководства по всем из них, и вы найдете их здесь.
Файл robots.txt — это текстовый файл, который читается поисковой системой (и другими системами).Файл robots.txt, также называемый «протоколом исключения роботов», является результатом консенсуса между разработчиками первых поисковых систем. Это не официальный стандарт, установленный какой-либо организацией по стандартизации; хотя его придерживаются все основные поисковые системы.
Для чего нужен файл robots.txt?
КэшированиеПоисковые системы обычно кэшируют содержимое файла robots.txt, чтобы не загружать его постоянно, но обычно обновляют его несколько раз в день. Это означает, что изменения в инструкциях обычно отражаются довольно быстро.
Поисковые системы обнаруживают и индексируют Интернет путем сканирования страниц. По мере того как они ползут, они находят ссылки и переходят по ним. Это переведет их с сайта A на сайт B на сайт C и так далее. Но прежде чем поисковая система посетит любую страницу в домене, с которым она раньше не сталкивалась, она откроет файл robots.txt этого домена. Это позволяет им узнать, какие URL-адреса на этом сайте им разрешено посещать (а какие — нет).
Куда мне поставить роботов.txt файл?
Файл robots.txt всегда должен находиться в корне вашего домена. Итак, если ваш домен — www.example.com , его нужно найти по адресу https://www.example.com/robots.txt .
Также очень важно, чтобы ваш файл robots.txt на самом деле назывался robots.txt. Имя чувствительно к регистру, так что сделайте это правильно, иначе оно просто не сработает.
Плюсы и минусы использования robots.txt
Pro: управление бюджетом сканирования
Обычно считается, что поисковый паук попадает на веб-сайт с заранее определенным «допуском» в отношении того, сколько страниц он будет сканировать (или сколько ресурсов / времени он потратит, в зависимости от авторитета / размера / репутации сайта, и насколько эффективно сервер отвечает).Оптимизаторы называют это краулинговым бюджетом .
Если вы считаете, что у вашего веб-сайта проблемы с бюджетом сканирования, то блокировка поисковых систем от «траты энергии» на несущественные части вашего сайта может означать, что они вместо этого сосредотачиваются на разделах, которые имеют значение .
Иногда может быть полезно заблокировать поисковые системы от сканирования проблемных разделов вашего сайта, особенно на сайтах, где требуется большая очистка SEO. После того, как вы наведете порядок, вы можете позволить им вернуться.
Примечание о блокировке параметров запроса
Одна из ситуаций, когда бюджет сканирования особенно важен, — это когда ваш сайт использует множество параметров строки запроса для , фильтр или сортировка списки . Допустим, у вас есть 10 разных параметров запроса, каждый с разными значениями, которые можно использовать в любой комбинации (например, футболки с несколькими цветами s и размером s). Это приводит к множеству возможных действительных URL-адресов, и все они могут быть просканированы.Блокирование параметров запроса от сканирования поможет убедиться, что поисковая система будет сканировать только основные URL-адреса вашего сайта и не попадет в огромную ловушку, которую вы в противном случае создали бы.
Con: не удалять страницу из результатов поиска
Даже если вы можете использовать файл robots.txt, чтобы сообщить пауку, где он не может перейти на ваш сайт, вы, , не можете использовать его, чтобы сообщить поисковой системе, какие URL-адреса не показывать в результатах поиска — другими словами , блокировка не помешает его индексации.Если поисковая система найдет достаточно ссылок на этот URL, она включит его, но просто не будет знать, что на этой странице. Итак, ваш результат будет выглядеть так:
Если вы хотите надежно заблокировать отображение страницы в результатах поиска, вам необходимо использовать мета-тег robots noindex . Это означает, что для того, чтобы найти тег noindex , поисковая система должна иметь доступ к этой странице, поэтому не блокирует с помощью robots.txt.
Раньше можно было добавлять директивы noindex в файл robots.txt, чтобы удалить URL-адреса из результатов поиска Google и избежать появления этих «фрагментов». Это больше не поддерживается (и технически никогда не поддерживалось).
Con: не распространяется значение ссылки
Если поисковая система не может сканировать страницу, она не может распределять значение ссылки по ссылкам на этой странице. Когда страница заблокирована с помощью robots.txt, это тупиковый путь. Любое значение ссылки, которая могла перейти на эту страницу (и через нее), теряется.
Синтаксис Robots.txt
WordPress robots.txtУ нас есть целая статья о том, как лучше всего настроить robots.txt для WordPress. Не забывайте, что вы можете редактировать файл robots.txt своего сайта в разделе Инструменты SEO Yoast → Редактор файлов.
Файл robots.txt состоит из одного или нескольких блоков директив, каждый из которых начинается со строки пользовательского агента. «Пользовательский агент» — это имя конкретного паука, к которому он обращается. У вас может быть один блок для всех поисковых систем, используя подстановочный знак для пользовательского агента, или определенные блоки для определенных поисковых систем.Паук поисковой системы всегда выбирает блок, который лучше всего соответствует его названию.
Эти блоки выглядят так (не пугайтесь, объясним ниже):
User-agent: *
Disallow: /User-agent: Googlebot
Disallow:User-agent: bingbot
Disallow: / not-for-bing /
Директивы, такие как Allow и Disallow не должны быть чувствительны к регистру, поэтому вам решать, писать ли вы их в нижнем регистре или использовать их с большой буквы.Значения чувствительны к регистру , однако / photo / — это не то же самое, что / Photo / . Нам нравится использовать директивы с заглавной буквы, потому что это облегчает чтение файла (для людей).
Директива агента пользователя
Первый бит каждого блока директив — это пользовательский агент, который идентифицирует конкретного паука. Поле user-agent сопоставляется с user-agent этого конкретного паука (обычно более длинного), поэтому, например, самый распространенный паук от Google имеет следующий пользовательский агент:
Mozilla / 5.0 (совместимый; Googlebot / 2.1; + http: //www.google.com/bot.html)
Итак, если вы хотите сказать этому пауку, что делать, сравнительно простая строка User-agent: Googlebot сделает свое дело.
У большинства поисковых систем есть несколько пауков. Они будут использовать специальный паук для своего обычного индекса, для своих рекламных программ, для изображений, для видео и т. Д.
Поисковые системы всегда выбирают наиболее конкретный блок директив, который они могут найти. Допустим, у вас есть 3 набора директив: один для * , один для Googlebot и один для Googlebot-News .Если используется бот, пользовательский агент которого Googlebot-Video , он будет следовать ограничениям Googlebot . Бот с пользовательским агентом Googlebot-News будет использовать более конкретные директивы Googlebot-News .
Наиболее распространенные пользовательские агенты для пауков поисковых систем
Вот список пользовательских агентов, которые можно использовать в файле robots.txt для поиска наиболее часто используемых поисковых систем:
| Поисковая система | Поле | User-agent | ||
|---|---|---|---|---|
| Baidu | General | baiduspider | ||
| Baidu | Изображения | baiduspider | ||
| Мобильный | baiduspider-mobile | |||
| Baidu | Новости | baiduspider-news | ||
| Baidu | Видео | baiduspider-video | Общие сведения bingbot | |
| Bing | Общие | msnbot | ||
| Bing | Изображения и видео | msnbot-media | ||
| Bing | Google Ads | 9049 | Общие | Googlebot |
| Изображения | Googlebot-Image | |||
| Мобильный | Googlebot-Mobile | |||
| Новости | 9049 Новости Google | 9049 | ||
| Видео | Googlebot-Video | |||
| AdSense | Mediapartners-Google | |||
| AdWords | AdsBot 9005! | General | slurp | |
| Yandex | General | yandex |
Директива disallow
Вторая строка в любом блоке директив - это строка Disallow .У вас может быть одна или несколько таких строк, указывающих, к каким частям сайта указанный паук не может получить доступ. Пустая строка Disallow означает, что вы ничего не запрещаете, поэтому в основном это означает, что паук может получить доступ ко всем разделам вашего сайта.
В приведенном ниже примере все поисковые системы, которые «слушают» robots.txt, не смогут сканировать ваш сайт.
Агент пользователя: *
Disallow: /
Если всего на один символ меньше, то в приведенном ниже примере позволит всем поисковым системам сканировать весь ваш сайт.
Агент пользователя: *
Disallow:
В приведенном ниже примере Google не сможет сканировать каталог Photo на вашем сайте - и все, что в нем.
User-agent: googlebot
Disallow: / Photo
Это означает, что все подкаталоги каталога / Photo также не будут проверяться. , а не , не заблокирует Google сканирование каталога / photo , поскольку эти строки чувствительны к регистру.
Это приведет к тому, что также заблокирует Google доступ к URL-адресам, содержащим / Photo , например / Photography / .
Как использовать подстановочные знаки / регулярные выражения
«Официально» стандарт robots.txt не поддерживает регулярные выражения или подстановочные знаки, однако все основные поисковые системы его понимают. Это означает, что вы можете использовать такие строки для блокировки групп файлов:
Запрещено: /*.php
Запрещено: /copyrighted-images/*.jpg
В приведенном выше примере * заменяется на любое имя файла, которому оно соответствует. Обратите внимание, что остальная часть строки по-прежнему чувствительна к регистру, поэтому вторая строка выше не будет блокировать файл с именем / copyrighted-images / example.JPG от сканирования.
Некоторые поисковые системы, такие как Google, позволяют использовать более сложные регулярные выражения, но имейте в виду, что некоторые поисковые системы могут не понимать эту логику. Самая полезная функция, которую он добавляет, - это долларов США, указывающее конец URL-адреса. В следующем примере вы можете увидеть, что это делает:
Запретить: /*.php$
Это означает, что /index.php нельзя проиндексировать, но /index.php?p=1 может быть .Конечно, это полезно только в очень определенных обстоятельствах, а также довольно опасно: легко разблокировать то, что вы на самом деле не хотели разблокировать.
Нестандартные директивы сканирования robots.txt
Помимо директив Disallow и User-agent , вы можете использовать еще несколько директив сканирования. Эти директивы поддерживаются не всеми сканерами поисковых систем, поэтому убедитесь, что вы знаете об их ограничениях.
Разрешающая директива
Хотя это и не входило в исходную «спецификацию», очень рано говорилось о директиве allow .Кажется, что большинство поисковых систем понимают это, и он допускает простые и очень удобочитаемые директивы, например:
Запретить: / wp-admin /
Разрешить: /wp-admin/admin-ajax.php
Единственным другим способом достижения того же результата без директивы allow было бы специально запретить каждый отдельный файл в папке wp-admin .
Директива хоста
Поддерживается Яндексом (а не Google, несмотря на то, что говорится в некоторых сообщениях), эта директива позволяет вам решить, хотите ли вы, чтобы поисковая система показывала пример .com или www.example.com . Просто укажите это так:
хост: example.com
Но поскольку только Яндекс поддерживает директиву host , мы не советуем вам полагаться на нее, тем более что она не позволяет вам определять схему (http или https). Лучшее решение, которое работает для всех поисковых систем, - это 301 перенаправление имен хостов, которые вам не нужны, в индексе, на версию, которую вы хотите .В нашем случае мы перенаправляем www.yoast.com на yoast.com.
Директива задержки сканирования
Bing и Яндекс иногда могут быть довольно голодными, но, к счастью, все они реагируют на директиву crawl-delay , которая их замедляет. И хотя эти поисковые системы имеют несколько разные способы чтения директивы, конечный результат в основном тот же.
Строка, подобная приведенной ниже, заставит эти поисковые системы изменить частоту запроса страниц на вашем сайте.
задержка сканирования: 10Различные интерпретации
Обратите внимание, что Bing интерпретирует это как инструкцию подождать 10 секунд после сканирования, в то время как Яндекс интерпретирует ее как указание на доступ к вашему сайту только один раз в каждые 10 секунд. Это небольшая разница, но все же интересно узнать.
Будьте осторожны при использовании директивы crawl-delay . Установив задержку сканирования в 10 секунд, вы разрешите этим поисковым системам доступ только к 8 640 страницам в день.Для небольшого сайта этого может показаться много, но для крупных сайтов не так уж много. С другой стороны, если вы почти не получаете трафика от этих поисковых систем, это хороший способ сэкономить часть полосы пропускания.
Директива карты сайта для XML-файлов Sitemap
С помощью директивы sitemap вы можете указать поисковым системам, в частности Bing, Yandex и Google, где найти вашу карту сайта XML. Вы, конечно, также можете отправить свои XML-карты сайта в каждую поисковую систему, используя соответствующие решения инструментов для веб-мастеров, и мы настоятельно рекомендуем вам это сделать, потому что программы инструментов для веб-мастеров поисковых систем предоставят вам много ценной информации о вашем сайте.Если вы не хотите этого делать, добавление строки sitemap в файл robots.txt - хорошая быстрая альтернатива.
Карта сайта: https://www.example.com/my-sitemap.xml
Проверьте свой robots.txt
Существуют различные инструменты, которые могут помочь вам проверить файл robots.txt, но когда дело доходит до проверки директив сканирования, мы всегда предпочитаем обращаться к источнику. У Google есть инструмент тестирования robots.txt в своей консоли поиска Google (в меню «Старая версия»), и мы настоятельно рекомендуем его использовать:
Обязательно тщательно протестируйте свои изменения, прежде чем вводить их в действие! Вы не станете первым, кто случайно воспользуется роботами.txt, чтобы заблокировать весь ваш сайт и уйти в небытие поисковой системы!
Увидеть Код
В июле 2019 года Google объявил, что делает свой парсер robots.txt открытым исходным кодом. Это означает, что, если вы действительно хотите разобраться в деталях, вы можете пойти и посмотреть, как работает их код (и даже использовать его самостоятельно или предложить модификации).
Все, что вам нужно знать
У вас больше контроля над поисковыми системами, чем вы думаете.
Это правда; вы можете управлять тем, кто сканирует и индексирует ваш сайт, вплоть до отдельных страниц. Чтобы контролировать это, вам нужно будет использовать файл robots.txt. Robots.txt - это простой текстовый файл, который находится в корневом каталоге вашего веб-сайта. Он сообщает роботам, которых отправляют поисковые системы, какие страницы сканировать, а какие игнорировать.
Хотя это не совсем универсальный инструмент, вы, вероятно, догадались, что это довольно мощный инструмент, который позволит вам представить свой веб-сайт в Google так, как вы хотите, чтобы они его увидели.Поисковые системы сурово разбираются в людях, поэтому очень важно произвести хорошее впечатление. При правильном использовании robots.txt может повысить частоту сканирования, что может повлиять на ваши усилия по поисковой оптимизации.
Итак, как его создать? Как Вы этим пользуетесь? Чего следует избегать? Прочтите этот пост, чтобы найти ответы на все эти вопросы.
Что такое файл Robots.txt?
В те времена, когда Интернет был всего лишь ребенком с детским лицом, способным творить великие дела, разработчики изобрели способ сканирования и индексации новых страниц в сети.Они назвали их «роботами» или «пауками».
Иногда эти маленькие ребята забредали на веб-сайты, которые не были предназначены для сканирования и индексации, например, на сайты, находящиеся на техническом обслуживании. Создатель первой в мире поисковой системы Aliweb порекомендовал решение - своего рода дорожную карту, которой должен следовать каждый робот.
Эта дорожная карта была завершена в июне 1994 года группой технически подкованных в Интернете специалистов под названием «Протокол исключения роботов».
Файл robots.txt является исполнением этого протокола.В протоколе изложены правила, которым должен следовать каждый настоящий робот, включая ботов Google. Некоторые незаконные роботы, такие как вредоносное ПО, шпионское ПО и т. Д., По определению, действуют вне этих правил.
Вы можете заглянуть за кулисы любого веб-сайта, введя любой URL-адрес и добавив в конце: /robots.txt.
Например, вот версия POD Digital:
Как видите, не обязательно иметь файл, состоящий только из песен и танцев, поскольку наш веб-сайт относительно небольшой.
Где найти файл Robots.txt
Ваш файл robots.txt будет храниться в корневом каталоге вашего сайта. Чтобы найти его, откройте свою FTP cPanel, и вы сможете найти файл в каталоге своего веб-сайта public_html.
В этих файлах нет ничего, чтобы они не были здоровенными - возможно, всего несколько сотен байт, если это так.
Как только вы откроете файл в текстовом редакторе, вас встретит что-то вроде этого:
Если вы не можете найти файл во внутренней работе вашего сайта, вам придется создать свой собственный.
Как собрать файл Robots.txt
Robots.txt - это очень простой текстовый файл, поэтому его просто создать. Все, что вам понадобится, это простой текстовый редактор, например Блокнот. Откройте лист и сохраните пустую страницу как robots.txt.
Теперь войдите в свою cPanel и найдите папку public_html, чтобы получить доступ к корневому каталогу сайта. Как только он откроется, перетащите в него свой файл.
Наконец, вы должны убедиться, что вы установили правильные разрешения для файла.Как правило, вам, как владельцу, нужно будет писать, читать и редактировать файл, но никакие другие стороны не должны иметь права делать это.
Файл должен отображать код разрешения «0644».
Если нет, вам нужно будет изменить это, поэтому щелкните файл и выберите «Разрешение файла».
Вуаля! У вас есть файл Robots.txt.
Robots.txt Синтаксис
Файл robots.txt состоит из нескольких разделов «директив», каждый из которых начинается с указанного пользовательского агента.Пользовательский агент - это имя конкретного робота-обходчика, с которым обращается код.
Доступны два варианта:
- Вы можете использовать подстановочный знак для одновременного обращения ко всем поисковым системам.
- Вы можете обращаться к конкретным поисковым системам индивидуально.
Когда бот развернут для сканирования веб-сайта, он будет привлечен к блокам, которые обращаются к нему.
Вот пример:
Директива пользователя-агента
Первые несколько строк в каждом блоке - это «пользовательский агент», который определяет конкретного бота.Пользовательский агент будет соответствовать определенному имени бота, например:
Итак, если вы хотите сказать роботу Google, что делать, например, начните с:
Пользовательский агент: Googlebot
Поисковые системы всегда пытаются чтобы определить конкретные директивы, которые наиболее к ним относятся.
Так, например, если у вас есть две директивы, одна для Googlebot-Video и одна для Bingbot. Бот, который поставляется вместе с пользовательским агентом Bingbot, будет следовать инструкциям. В то время как бот Googlebot-Video пропускает это и ищет более конкретную директиву.
В большинстве поисковых систем есть несколько разных ботов, вот список наиболее распространенных.
Директива хоста
Директива хоста в настоящее время поддерживается только Яндексом, хотя некоторые предположения говорят, что Google ее поддерживает. Эта директива позволяет пользователю решить, отображать ли www. перед URL, использующим этот блок:
Хост: poddigital.co.uk
Поскольку Яндекс является единственным подтвержденным сторонником директивы, полагаться на нее не рекомендуется.Вместо этого 301 перенаправляет имена хостов, которые вам не нужны, на те, которые вам нужны.
Disallow Directive
Мы рассмотрим это более конкретно чуть позже.
Вторая строка в блоке директив - Disallow. Вы можете использовать это, чтобы указать, какие разделы сайта не должны быть доступны ботам. Пустое запрещение означает, что это является бесплатным для всех, и боты могут угождать себе, где они делают, а где не ходят.
Директива карты сайта (XML-карты сайта)
Использование директивы карты сайта сообщает поисковым системам, где найти карту сайта в формате XML.
Однако, вероятно, наиболее полезным было бы отправить каждый из них в специальные инструменты для веб-мастеров поисковых систем. Это потому, что вы можете узнать много ценной информации от каждого о своем веб-сайте.
Однако, если у вас мало времени, директива карты сайта является жизнеспособной альтернативой.
Директива о задержке сканирования
Yahoo, Bing и Яндекс могут быть немного счастливы, когда дело доходит до сканирования, но они действительно реагируют на директиву задержки сканирования, которая удерживает их на некоторое время.
Применение этой строки к вашему блоку:
Crawl-delay: 10
означает, что вы можете заставить поисковые системы ждать десять секунд перед сканированием сайта или десять секунд, прежде чем они повторно получат доступ к сайту после сканирования - в основном это то же самое, но немного отличается в зависимости от поисковой системы.
Зачем использовать Robots.txt
Теперь, когда вы знаете об основах и о том, как использовать несколько директив, вы можете собрать свой файл. Однако этот следующий шаг будет зависеть от типа контента на вашем сайте.
Robots.txt не является важным элементом успешного веб-сайта; Фактически, ваш сайт может нормально функционировать и хорошо ранжироваться без него.
Однако есть несколько ключевых преимуществ, о которых вы должны знать, прежде чем отклонить его:
Направьте ботов в сторону от личных папок : Если запретить ботам проверять ваши личные папки, их будет намного сложнее найти и проиндексировать.
Держите ресурсы под контролем : Каждый раз, когда бот просматривает ваш сайт, он поглощает пропускную способность и другие ресурсы сервера.Для сайтов с тоннами контента и большим количеством страниц, например, на сайтах электронной коммерции могут быть тысячи страниц, и эти ресурсы могут быть истощены очень быстро. Вы можете использовать robots.txt, чтобы затруднить доступ ботам к отдельным скриптам и изображениям; это позволит сохранить ценные ресурсы для реальных посетителей.
Укажите местоположение вашей карты сайта : Это довольно важный момент, вы хотите, чтобы сканеры знали, где находится ваша карта сайта, чтобы они могли ее просканировать.
Держите дублированный контент подальше от результатов поиска : Добавив правило к своим роботам, вы можете запретить поисковым роботам индексировать страницы, содержащие дублированный контент.
Вы, естественно, захотите, чтобы поисковые системы находили путь к наиболее важным страницам вашего веб-сайта. Вежливо ограничивая определенные страницы, вы можете контролировать, какие страницы будут отображаться для поисковиков (однако убедитесь, что никогда не блокирует полностью поисковые системы от просмотра определенных страниц).
Например, если мы посмотрим на файл роботов POD Digital, мы увидим, что этот URL:
poddigital.co.uk/wp-admin был запрещен.
Поскольку эта страница предназначена только для того, чтобы мы могли войти в панель управления, нет смысла позволять ботам тратить свое время и энергию на ее сканирование.
Noindex
В июле 2019 года Google объявил о прекращении поддержки директивы noindex, а также многих ранее неподдерживаемых и неопубликованных правил, на которые многие из нас ранее полагались.
Многие из нас решили поискать альтернативные способы применения директивы noindex, и ниже вы можете увидеть несколько вариантов, которые вы могли бы выбрать вместо этого:
Тег Noindex / Заголовок ответа HTTP Noindex: Этот тег может быть реализован двумя способами: сначала будет заголовок ответа HTTP с тегом X-Robots-Tag или создать тег, который необходимо будет реализовать в
раздел.
Ваш тег должен выглядеть следующим образом:
СОВЕТ : помните, что если эта страница была заблокирована роботами.txt, поисковый робот никогда не увидит ваш тег noindex, и есть вероятность, что эта страница будет представлена в результатах поиска.
Защита паролем: Google заявляет, что в большинстве случаев, если вы скрываете страницу за логином, ее следует удалить из индекса Google. Единственное исключение представлено, если вы используете разметку схемы, которая указывает, что страница связана с подпиской или платным контентом.
Код состояния 404 и 410 HTTP: Коды состояния 404 и 410 представляют страницы, которые больше не существуют.После сканирования и полной обработки страницы со статусом 404/410 она должна автоматически удаляться из индекса Google.
Вам следует систематически сканировать свой веб-сайт, чтобы снизить риск появления страниц с ошибками 404 и 410, и при необходимости использовать переадресацию 301 для перенаправления трафика на существующую страницу.
Правило запрета в robots.txt: Добавив правило запрета для конкретной страницы в файл robots.txt, вы предотвратите сканирование страницы поисковыми системами.В большинстве случаев ваша страница и ее содержание не индексируются. Однако следует иметь в виду, что поисковые системы по-прежнему могут индексировать страницу на основе информации и ссылок с других страниц.
Инструмент удаления URL-адреса Search Console: Этот альтернативный корень не решает проблему индексации в полной мере, поскольку инструмент удаления URL-адреса Search Console удаляет страницу из результатов поиска на ограниченное время.
Однако это может дать вам достаточно времени, чтобы подготовить дальнейшие правила и теги роботов для полного удаления страниц из результатов поиска.
Инструмент удаления URL-адреса находится в левой части основной навигации в Google Search Console.
Noindex vs. Disallow
Многие из вас, вероятно, задаются вопросом, что лучше использовать тег noindex или правило запрета в вашем файле robots.txt. В предыдущей части мы уже рассмотрели, почему правило noindex больше не поддерживается в robots.txt и других альтернативах.
Если вы хотите убедиться, что одна из ваших страниц не проиндексируется поисковыми системами, вам обязательно стоит взглянуть на метатег noindex.Он позволяет ботам получить доступ к странице, но тег позволит роботам узнать, что эта страница не должна индексироваться и не должна отображаться в результатах поиска.
Правило запрета может быть не так эффективно, как тег noindex в целом. Конечно, добавляя его в robots.txt, вы блокируете сканирование вашей страницы ботами, но если упомянутая страница связана с другими страницами внутренними и внешними ссылками, боты все равно могут индексировать эту страницу на основе информации, предоставленной другими страницами. / сайты.
Вы должны помнить, что если вы запретите страницу и добавите тег noindex, то роботы никогда не увидят ваш тег noindex, что по-прежнему может вызывать появление страницы в поисковой выдаче.
Использование регулярных выражений и подстановочных знаков
Итак, теперь мы знаем, что такое файл robots.txt и как его использовать, но вы можете подумать: «У меня большой веб-сайт электронной коммерции, и я хотел бы запретить все страницы, которые содержат вопросительные знаки (?) в своих URL ".
Здесь мы хотели бы представить ваши подстановочные знаки, которые могут быть реализованы в файле robots.txt. В настоящее время у вас есть два типа подстановочных знаков на выбор.
* Подстановочные знаки - где * подстановочные знаки будут соответствовать любой последовательности символов по вашему желанию.Этот тип подстановочного знака будет отличным решением для ваших URL-адресов, которые следуют тому же шаблону. Например, вы можете запретить сканирование всех страниц с фильтрами, в URL-адресах которых стоит вопросительный знак (?).
$ Подстановочные знаки - где $ соответствует концу вашего URL. Например, если вы хотите убедиться, что ваш файл robots запрещает ботам доступ ко всем файлам PDF, вы можете добавить правило, подобное приведенному ниже:
Давайте быстро разберем приведенный выше пример.Ваш файл robots.txt позволяет любым ботам User-agent сканировать ваш веб-сайт, но запрещает доступ ко всем страницам, которые содержат конец .pdf.
Ошибок, которых следует избегать
Мы немного поговорили о том, что вы можете сделать, и о различных способах работы с файлом robots.txt. Мы собираемся немного углубиться в каждый пункт этого раздела и объяснить, как каждый из них может обернуться катастрофой для SEO, если его не использовать должным образом.
Не блокировать хороший контент
Важно не блокировать любой хороший контент, который вы хотите представить роботам для всеобщего сведения.txt или тега noindex. В прошлом мы видели много подобных ошибок, которые отрицательно сказывались на результатах SEO. Вам следует тщательно проверять свои страницы на наличие тегов noindex и запрещающих правил.
Чрезмерное использование Crawl-Delay
Мы уже объяснили, что делает директива crawl-delay, но вам не следует использовать ее слишком часто, поскольку вы ограничиваете страницы, просматриваемые ботами. Это может быть идеальным для некоторых веб-сайтов, но если у вас большой веб-сайт, вы можете выстрелить себе в ногу и помешать хорошему ранжированию и устойчивому трафику.
Чувствительность к регистру
Файл Robots.txt чувствителен к регистру, поэтому вы должны не забыть создать файл robots правильно. Вы должны называть файл роботов «robots.txt», все в нижнем регистре. Иначе ничего не получится!
Использование Robots.txt для предотвращения индексации содержимого
Мы уже немного рассмотрели это. Запрет доступа к странице - лучший способ предотвратить ее прямое сканирование ботами.
Но не сработает в следующих случаях:
Если на страницу есть ссылка из внешнего источника, боты по-прежнему будут проходить и индексировать страницу.
Незаконные боты по-прежнему будут сканировать и индексировать контент.
Использование Robots.txt для защиты частного содержимого
Некоторое личное содержимое, такое как PDF-файлы или страницы с благодарностью, можно индексировать, даже если вы направите роботов от него. Один из лучших способов дополнить директиву disallow - разместить весь ваш личный контент за логином.
Конечно, это означает, что он добавляет дополнительный шаг для ваших посетителей, но ваш контент останется в безопасности.
Использование Robots.txt для скрытия вредоносного дублированного содержимого
Дублированное содержимое иногда является неизбежным злом - например, страницы, удобные для печати.
Однако Google и другие поисковые системы достаточно умны, чтобы знать, когда вы пытаетесь что-то скрыть. Фактически, это может привлечь к нему больше внимания, и это потому, что Google распознает разницу между страницей, удобной для печати, и тем, кто пытается заткнуть себе глаза:
Есть еще шанс, что ее можно найти в любом случае.
Вот три способа работы с таким содержанием:
Перепишите контент - Создание захватывающего и полезного контента побудит поисковые системы рассматривать ваш сайт как надежный источник. Это предложение особенно актуально, если контент представляет собой задание копирования и вставки.
301 Redirect - 301 редирект информирует поисковые системы о том, что страница переместилась в другое место. Добавьте 301 на страницу с дублированным контентом и перенаправьте посетителей на исходное содержание на сайте.
Rel = «canonical » - это тег, который информирует Google об исходном местонахождении дублированного контента; это особенно важно для веб-сайта электронной коммерции, где CMS часто генерирует повторяющиеся версии одного и того же URL-адреса.
Момент истины: проверка вашего файла robots.txt
Теперь пора протестировать ваш файл, чтобы убедиться, что все работает так, как вы хотите.
Инструменты Google для веб-мастеров содержат файл robots.txt, но в настоящее время он доступен только в старой версии Google Search Console. Вы больше не сможете получить доступ к тестеру robot.txt с помощью обновленной версии GSC (Google усердно работает над добавлением новых функций в GSC, поэтому, возможно, в будущем мы сможем увидеть тестер Robots.txt в основная навигация).
Итак, сначала вам нужно посетить страницу поддержки Google, на которой представлен обзор возможностей тестера Robots.txt.
Там вы также найдете роботов.txt Tester tool:
Выберите свойство, над которым вы собираетесь работать, например, веб-сайт вашей компании из раскрывающегося списка.
Удалите все, что находится в коробке, замените его новым файлом robots.txt и нажмите, протестируйте:
. Если «Тест» изменится на «Разрешено», значит, вы получили полностью работающий robots.txt.
Правильное создание файла robots.