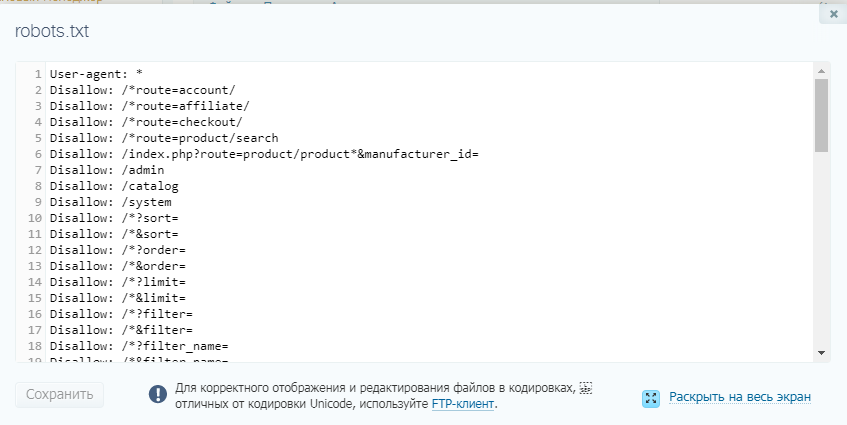
Файл robots.txt для сайта в 2023: пошаговая инструкция
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет. В данной статье рассмотрим, где можно найти robots.txt, как его редактировать и какие правила по его использовать в SEO-продвижении.
- Где найти;
- Как создать;
- Инструкция по работе;
- Синтаксис;
- Директивы;
- Как проверить.
Где можно найти файл robots.txt и как его создать или редактировать
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
- Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
- WordPress;
Virtual Robots.txt
- Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
- Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.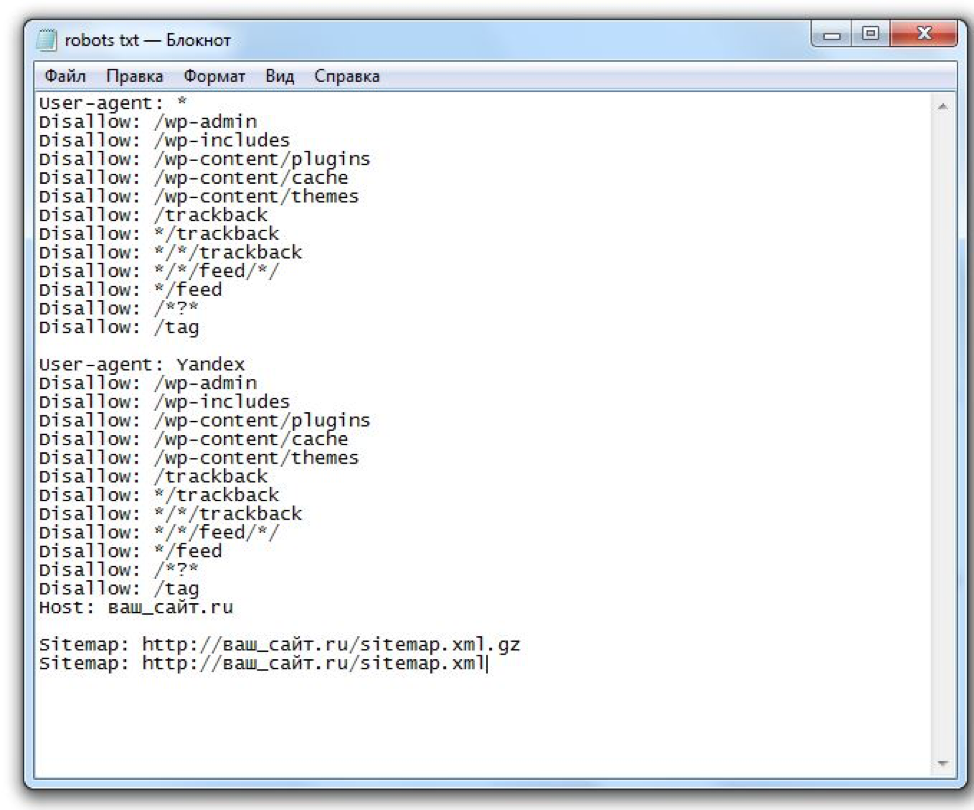
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.

Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.![]() com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
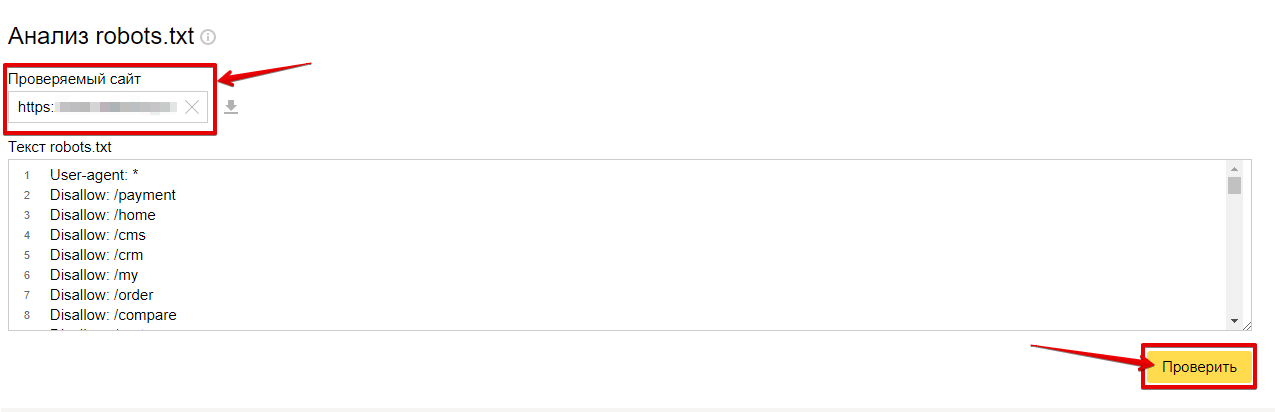
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.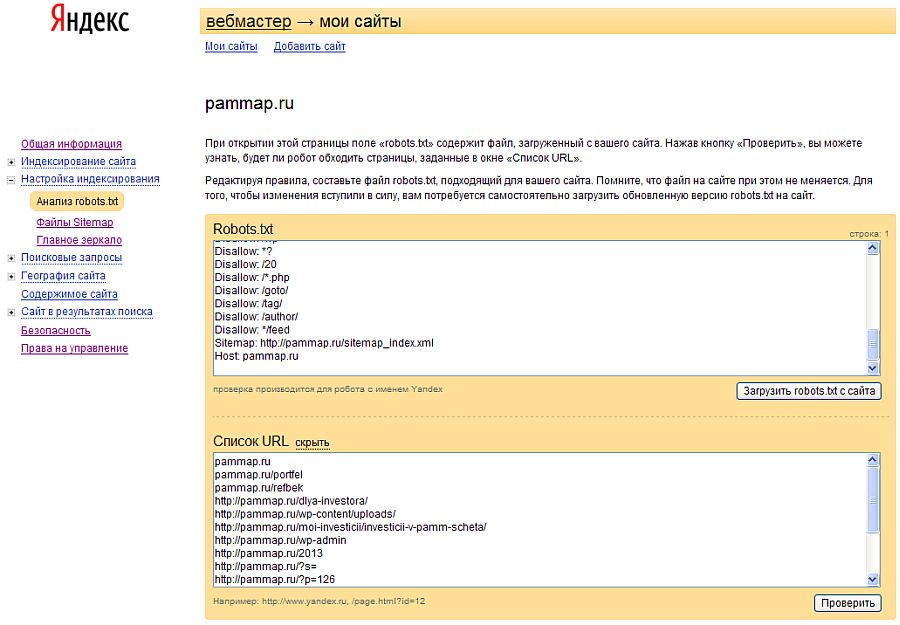
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Как управлять поисковым роботом Яндекса? — Учебный центр Unibrains
Как можно повлиять на робота, чтобы он индексировал то, что нам нужно или наоборот не индексировал? Это одна из самых популярных тем, которую кто только не разбирал, и в тоже время мы постоянно видим ошибки в файле robots. txt. Что же не так? Давайте разберемся.
txt. Что же не так? Давайте разберемся.
Твитнуть
Сам файл robots.txt – это строгий набор инструкций для индексирующего робота, показывающий, что можно индексировать, а что нет. Этот файл находится в корне вашего сайта, обязательно имеет название robots.txt и начинается со строки User-agent. Эта директива показывает какие правила, перечисленные ниже, будут использоваться для того или иного робота.
Распространенные директивы disallow/allow запрещают или разрешают индексирование страниц. Здесь можно запрещать и дублирующие страницы, и служебные, и скрипты, и все что угодно. Особенно важна эта директива, если у вас на сайте хранятся какие-то пользовательские данные: договор, адреса доставки, мобильный телефон и др. Эту информацию нужно закрыть от индексирующего робота, чтобы она не попала в результаты поиска.
Директива Clean-param позволяет удалять ненужные параметры из URL-адресов страниц, если вы их используете для отслеживания того, откуда пришел на ваш сайт индексирующий робот.
Директива Crawl-delay задает интервал между окончанием запроса одной страницы роботом и началом запроса другой. Очень эффективная директива, если вы открыли новый раздел на вашем сайте; робот пришел и начал скачивать кучу страниц, создавать дополнительную нагрузку сайту, ресурс перестает отвечать, недоступен для посетителей, и вы теряете своих клиентов.
Директива Sitemap указывает на наличие и адрес, т.е. местоположение соответствующего файла карты на вашем сайте. Директива Host указывает адрес главного зеркала.
Вот пример типичного файла robots.txt
Начинается файл с директивы User-agent: *. Где * — показывает, что используется для всех индексирующих роботов, если не указано иначе. Во втором блоке указано User-agent: Yandex. Это означает, что он предназначен только для индексирующих роботов Яндекса.
Директива Disallow:/admin указывает на то, что нужно запретить обход всех страниц, которые начинаются с admin.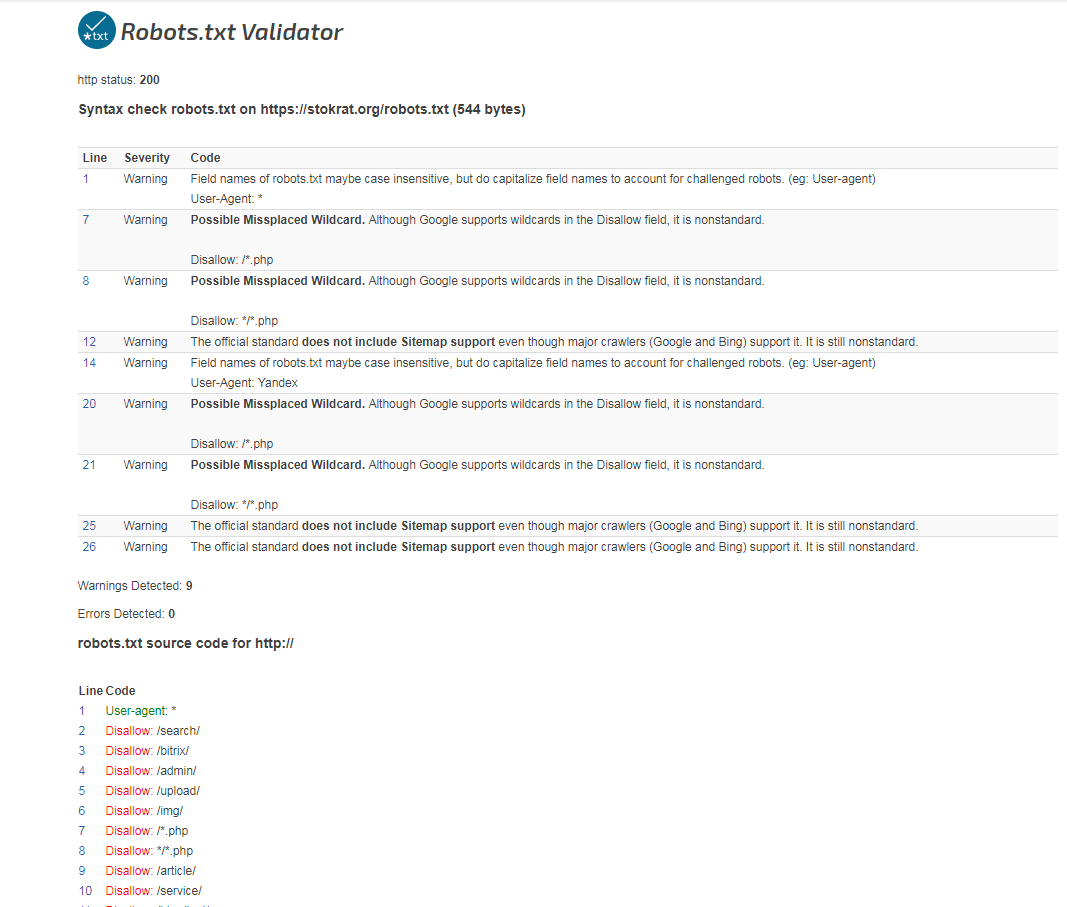 Disallow:*=? cart* запрещает любые действия, любые GET-параметры, содержащие этот адрес.
Disallow:*=? cart* запрещает любые действия, любые GET-параметры, содержащие этот адрес.
GET-параметры – это параметры, которые передаются серверу, когда совершается запрос. Со стороны пользователя это выглядит, как часть интернет адреса. Например, такой запрос http://www.examle.com/test?param1=value1¶m2=value2¶m3=value3.
Все, что идет после ? это GET-параметры. Они представляют собой список пар – ключ-значение, разделенные &. В данном случае это три пары: (param1, value1) (param2, value2) (param3, value3).
Дополнительные директивы: Clean-param: sid/ – очищает идентификатор сессии.
Crawl-delay: 0.5 – в данном случае робот будет запрашивать две страницы в 1 секунду.
Какие самые распространенные ошибки допускаются при работе с файлом robots.txt?
- Ошибки в содержимом файла. Даже самые опытные вебмастера допускают такие ошибки, допускают вылета сайта из результата поиска, так как сайт становится полностью недоступен для индексирующего робота.

- Код ответа НТТР отличный от кода 200. Самый распространенный случай, когда у вас есть служебный домен, и он вылез в результаты поиска. Что вы делаете? Вы закрываете Disallow all на служебном домене. И настраиваете индексирующему роботу НТТР-код ответа 403. Робот приходит, запрашивает ваш файл robots.txt и видит код ответа отличный от кода 200. Он игнорирует эту инструкцию и считает, что тут находится полностью разрешающий файл, что все адреса, которые ему известны, можно индексировать и включать в результаты поиска.
- Наличие кириллических символов в файле robots.txt. Такие символы использовать нельзя, робот их проигнорирует.
Самый распространенный случай ошибки, например, если ваш сайт лютикицветочки.рф, и в директиве Host – вы его указали не в закодированном виде. Хотя нужно указывать в закодированном понекоде (Punycode).
Punycode — алгоритм, который определяет однозначное преобразование символов Юникода (символы национального алфавита, например, россия.
рф) в строки ASCII-символов.
А как мы знаем, URL отправляются в интернет в ASCII-кодировке. Данная кодировка используется для передачи информации между компьютерами в интернете. ASCII расшифровывается как Американский Стандартный Код для Обмена информацией.
- Файл robots.txt превышает размер 32 Кб. Робот, получая такой файл, считает, что это не файл текстового типа, а обычная страничка, и что эту страничку не нужно учитывать при обходе сайта.
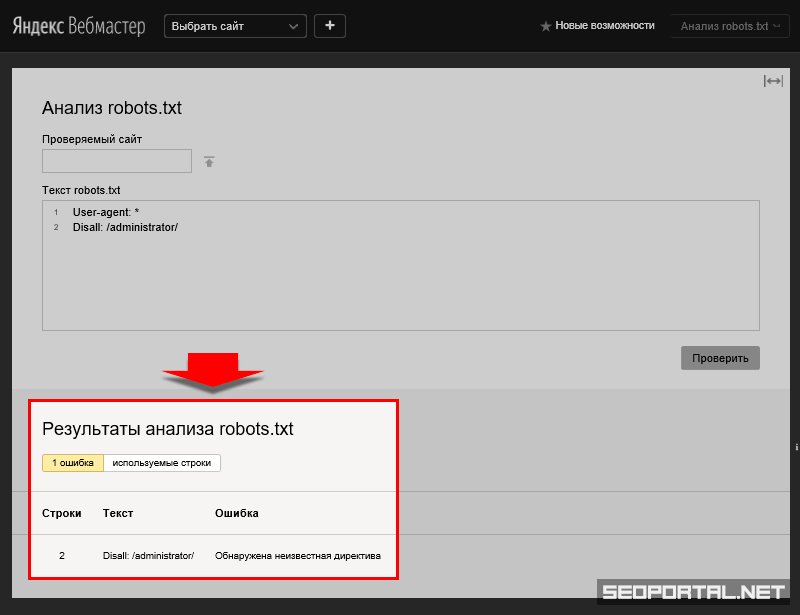
Все эти ошибки можно предотвратить, если пользоваться простейшим инструментом в «Яндекс.Вебмастер» — Анализатор robots.txt.
Анализ robots.txt в панеле Яндекс.ВебмастерВставляете адрес вашего сайта, нажимаете загрузить robots.txt, теперь можете увидеть, то, что сейчас там находится, добавляете список URL-адресов страниц, нажимаете кнопку проверить. Можно редактировать, посмотреть, как робот воспримет то или иное изменение. Если вы вносите какие-то серьезные изменения в файл robots.txt, даже если знаете и делали это много раз, то перестрахуйтесь, воспользовавшись этим инструментом.
Что такое карта сайта и как её рисовать?
Итак, мы с вами запретили роботу посещать те или иные страницы на сайте, но теперь нужно показать, какие страницы нужно индексировать и включать в поисковую выдачу.
Для этого существует специальный файл Sitemap – карта вашего сайта. Это текстовый или XML-файл, содержащий адреса страниц, которые необходимо индексировать. Ниже приведен пример файла sitemap.
Так выглядит типичная карта сайта. SitemapФайл должен начинаться со служебной строки, указывающей на кодировку. Обязательно стандарт, с которым он составлен, и обязательно тэг Url и Loc (location – показывает адрес страницы). Это самый простой файл, здесь всего одна страница – это «морда» (главная страница сайта). Плюс есть необязательные тэги, которые тоже можно передавать роботу, и которые робот может учитывать (lastmode – дата последнего изменения страницы , changefreq – периодичность ее изменения, priority – приоритет при обходе вашего сайта в целом).
Ошибки при работе с Sitemap
- Самая распространенная ошибка, с которой сталкиваются вебмастера – это, когда индексирующему роботу указывают файл sitemap, находящийся на другом сайте.
 Например, если вы используете бесплатный генератор файлов sitemap, то он автоматически размещает этот файл у себя на сайте. Робот не будет обрабатывать такой файл, потому что в соответствии со стандартом, файл должен обязательно находиться на том хосте, ссылки которого указаны внутри самого сайта. То есть, если у вас есть сайт лютикицветочки.рф в нем должны находиться только эти ссылки и сам файл должен находиться только на этом сайте.
Например, если вы используете бесплатный генератор файлов sitemap, то он автоматически размещает этот файл у себя на сайте. Робот не будет обрабатывать такой файл, потому что в соответствии со стандартом, файл должен обязательно находиться на том хосте, ссылки которого указаны внутри самого сайта. То есть, если у вас есть сайт лютикицветочки.рф в нем должны находиться только эти ссылки и сам файл должен находиться только на этом сайте. - Установленное перенаправление файла sitemap – это вторая проблема. К примеру, у вас файл находится по стандартному адресу (sitemap.xml), и там находится редирект, ведущий на какую-то внутреннюю страницу, на внутренний адрес. Робот не обрабатывает такие файлы sitemap. Файл sitemap обязательно должен возвращать код ответа 200.
- Критические ошибки внутри самого файла, которые тоже влияют на его обработку. Например, если отсутствует служебная строка с указанием кодировки (<?xml version=”1,0” encoding=”UTF-8”?>). Робот просто проигнорирует такой файл, и не будет использовать его при обходе.

В работе с файлом sitemap вам так же пригодится Валидатор в «Яндекс.Вебмастер», в котором можно проверить все эти ошибки, проверить ваш готовый файл, размещенный на сервере либо на компьютере. Поможет Стандарт файлов sitemap, переведенный на русский язык. И, конечно, раздел «Помощь вебмастеру».
Зеркала сайтов
Следующий вопрос, о котором хочется поговорить – это зеркала сайтов. Попробуем с ними разобраться. Как правило, любой сайт в интернете доступен по двум адресам: http://www.site.ru и http://site.ru. Для индексирующего робота это два изначально независимых ресурса, они индексируются независимо, и участвуют в поиске независимо друг от друга. Что это значит? Что у одного сайта может быть проиндексировано определенное количество страниц, они будут находиться по таким-то запросам. У второго сайта может быть совсем другая ситуация. И для того, чтобы избежать такого дублирования и перемешки, непонимания, мы используем зеркала сайтов.
Зеркала сайтов – это несколько сайтов, которые обладают одинаковым контентом.
В данном случае, это сайты с www или без www, сайты по протоколу https, и адрес сайта на кириллице. Это все распространенные случаи.
Зачем все это нужно? Основная причина, по которой сейчас используются зеркала сайтов – это перенос сайта на новый адрес с сохранением характеристик старого адреса. Например, вы решили сменить доменное имя по каким-либо причинам. Потому что выбрали его 10 лет назад, и сейчас он кажется вам не современным, так как сложно писать пользователям, которые вбивают его в адресную строку, постоянно делают ошибки. Во-вторых, для того, чтобы предотвратить ошибочные переходы по другим адресам.
В первом случае, если мы совершаем переезд с использованием зеркал, мы сохраняем все характеристики старого сайта для нового. Соответственно, мы минимизируем какие-либо возможные проблемы.
Каким образом сайты можно сделать зеркалами?
 txt. Указали адрес, это будет прямое направление роботу, что нужно включать адрес по определенному адресу в поиск.
txt. Указали адрес, это будет прямое направление роботу, что нужно включать адрес по определенному адресу в поиск.- Сообщить роботу об изменениях, если у вас уже есть сайт с www и без www, можно с помощью соответствующего инструмента «Главное зеркало» в «Яндекс.Вебмастер». Но сам по себе инструмент не позволяет изменить адрес главного зеркала. Это делает именно директива Host.
- Последний пункт, который я бы рекомендовал использовать, в крайнем случае — это северное перенаправление на главное зеркало. Например, с неглавного зеркала на новый адрес сайта. Почему? Одна из распространённых ошибок при использовании зеркал, это как раз серверное перенаправление.
Допустим ситуацию, что у нас есть два сайта: Сайт А (главное зеркало) и сайт В (не главное зеркало). Сайт А индексируется, участвует в результатах поиска, участвует по запросам. Есть сайт В, сейчас это не главное зеркало, и в выдаче мы его не видим. Мы принимаем решение, что нам нужно включать в результаты поиска именно сайт В.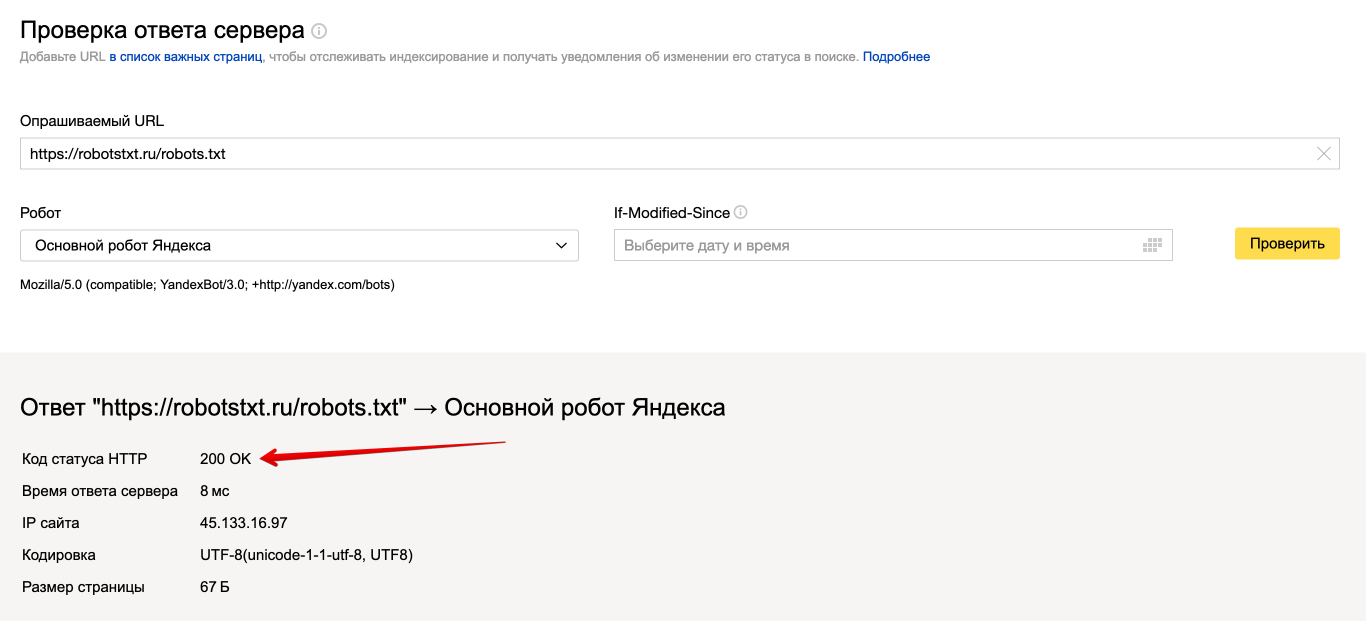 И устанавливаем перенаправление с сайта А на сайт В. Что происходит дальше? Главное наше зеркало (сайт А) перестает участвовать в результатах поиска, потому что сейчас на нем установлено перенаправление и его страницы не доступны для робота. Они начинают исключаться из поисковой выдачи. Сайт В при этом (поскольку является не главным зеркалом) в поиске не участвует, не индексируется и не показывается по каким-либо запросам.
И устанавливаем перенаправление с сайта А на сайт В. Что происходит дальше? Главное наше зеркало (сайт А) перестает участвовать в результатах поиска, потому что сейчас на нем установлено перенаправление и его страницы не доступны для робота. Они начинают исключаться из поисковой выдачи. Сайт В при этом (поскольку является не главным зеркалом) в поиске не участвует, не индексируется и не показывается по каким-либо запросам.
А теперь немного данных из «Яндекс.Метрики». После установки редиректа буквально в течение двух недель страницы сайта начали исключаться из поисковой выдачи, и переходы на сайт снизились. Все это продолжалось до того момента, когда изменился адрес главного зеркала.
Исключение страниц сайта из поисковой выдачи при неправильной работе с зеркалами сайтов.Типичные ошибки при работе с зеркалами.
- Разное содержимое на ваших сайтах при попытке склеить их или объединить в группу зеркал.
 К примеру, вы хотите одновременно изменить дизайн на вашем сайте и изменить адрес главного зеркала. Чтобы сайты были зеркалами, на них для робота должен находиться один и тот же контент. В данном случае, я советую делать это поэтапно: сначала делать редизайн, потом менять главное зеркало. Либо наоборот: размещать по старому адресу старый контент, ждать склейки, потом делать редизайн сайта. Чтобы не было проблем. Если контент будет разным, вы не склеите, то потеряете время и посетителей.
К примеру, вы хотите одновременно изменить дизайн на вашем сайте и изменить адрес главного зеркала. Чтобы сайты были зеркалами, на них для робота должен находиться один и тот же контент. В данном случае, я советую делать это поэтапно: сначала делать редизайн, потом менять главное зеркало. Либо наоборот: размещать по старому адресу старый контент, ждать склейки, потом делать редизайн сайта. Чтобы не было проблем. Если контент будет разным, вы не склеите, то потеряете время и посетителей. - Вторая распространённая проблема — это переезд вашего сайта в раздел другого ресурса. Например, у вас есть 2 сайта. Один сайт занимается роботами-пылесосами, а второй — бытовой техникой. Вы решаете, что роботы-пылесосы – это тоже бытовая техника, и что можно объединить их в один большой ресурс. Устанавливаете директиву Host, и ждете, но ничего не происходит, потому что у вас на одном адресе находится один сайт, а на другом — другой. Директива Host здесь не поможет, и объединить такие сайты в группу зеркал не получится.

В подобных ситуациях можно открывать раздел на вашем большом ресурсе, после того как эти страницы начнут индексироваться можно установить 301 редирект с вашего маленького сайта на этот раздел. К сожалению, склеить сайты в такой ситуации не получится.
- Еще одна распространенная проблема — это запрет или недоступность вашего старого зеркала. Бывает так, что вебмастера забывают продлить доменное имя. Спустя какое-то время они покупают доменное имя, хотят объединить данные сайты в группы зеркал. Поскольку доступ к вашему старому сайту уже утерян, склеить такие сайты не получится. Их нельзя склеить как-то вручную, применить какие-то настройки.
Чтобы сайты могли быть склеены, они должны быть доступны для индексирования и находиться в вашем управлении.
- Последнее по популярности — это противоречивые указания для индексирующего робота о том, по какому адресу сайт должен индексироваться и находиться в поисковой выдаче.
 Например, в директиве Host вы указали один адрес, редирект поставили по другому адресу. Робот автоматически выберет по своему усмотрению, в соответствии со своими алгоритмами, адрес главного зеркала. Иногда бывает, что это не тот адрес, который вы хотели. Поэтому тут нужно быть внимательным. Если вы решаете переехать на новый домен, все указания должны вести именно на него.
Например, в директиве Host вы указали один адрес, редирект поставили по другому адресу. Робот автоматически выберет по своему усмотрению, в соответствии со своими алгоритмами, адрес главного зеркала. Иногда бывает, что это не тот адрес, который вы хотели. Поэтому тут нужно быть внимательным. Если вы решаете переехать на новый домен, все указания должны вести именно на него.
Как заблокировать самые популярные поисковые роботы через robots.txt?
Задавать вопрос
спросил
Изменено 7 лет, 6 месяцев назад
Просмотрено 891 раз
Я хочу запретить индексацию моего веб-сайта через robots.txt роботами-пауками MSN/Bing, Yahoo, Ask Jeeves, Baidu и Yandex.
Я хочу запретить поисковым роботам контента и мультимедиа (изображений, видео).
Причина этого в том, что мой сайт предназначен только для рынка Google и США и расположен на хостинге с ограниченными ресурсами.
Я нашел разные правила, когда гуглил и объединял все вместе:
# Block Bing Агент пользователя: bingbot Запретить: / Агент пользователя: msnbot Запретить: / # Заблокировать Yahoo Агент пользователя: slurp Агент пользователя: yahoo Запретить: / # Заблокировать запрос Агент пользователя: jeeves Агент пользователя: teoma Запретить: / # Заблокировать Байду Агент пользователя: baidu Запретить: / # Заблокировать Яндекс Агент пользователя: yandex Запретить: /
Верны ли эти правила?
Или я что-то пропустил?
А может я что-то лишнее добавил?
Существуют ли официальные правила robots.txt для каждого поискового робота?
- поисковые роботы
- robots.txt
Если вы протестируете файл robots.txt в одном из многочисленных валидаторов robot.txt, вы увидите, что он делает то, что вам нужно.
Например, использование txt-валидатора seobook robot показывает, что при проверке URL / эти боты не должны сканировать ваш сайт.
Если вы действительно хотите, это другой вопрос. Если бот, сканирующий веб-сайт, слишком сильно нагружает ресурсы, то, возможно, вам следует также обратить внимание на производительность веб-сайта и/или сервера.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
поисковых роботов — Robots.txt не препятствует сканированию моего сайта
спросил
Изменено 3 года, 2 месяца назад
Просмотрено 2к раз
У меня проблема с robots.txt.
Я положил файл robots.txt в основную директорию сайта (а также в /var/www/html — чтобы работало на всех серверах) но роботы продолжают сканировать мои сайты.
это мой robots.txt:
User-agent: YandexBot Запретить: / Агент пользователя: SemrushBot Запретить: / Агент пользователя: AhrefsBot Запретить: / Агент пользователя: SemrushBot/1.2~bl Запретить: /
У вас есть предложения?
- поисковые роботы
- robots.txt
- яндекс
Обратите внимание, что ваш robots. txt недействителен (но это не обязательно означает, что это является причиной вашей проблемы; боты могут игнорировать такие ошибки).
txt недействителен (но это не обязательно означает, что это является причиной вашей проблемы; боты могут игнорировать такие ошибки).
Если бот будет разбирать ваш файл robots.txt строго в соответствии со спецификацией robots.txt, то этот бот увидит только одну запись, и эта запись будет относиться только к ботам с именем «ЯндексБот». Всем другим ботам будет позволено сканировать все.
Причина в том, что записи должны быть разделены пустыми строками. Так и должно быть:
Агент пользователя: YandexBot Запретить: / Агент пользователя: SemrushBot Запретить: / Агент пользователя: AhrefsBot Запретить: / Агент пользователя: SemrushBot/1.2~bl Запретить: /
Если у вас всегда будет один и тот же Disallow для всех этих ботов, вы можете использовать одну запись с несколькими строками User-agent , если хотите:
User-agent: YandexBot Агент пользователя: SemrushBot Агент пользователя: AhrefsBot Агент пользователя: SemrushBot/1.2~bl Запретить: /
(Возможно, вам придется использовать разные имена для некоторых ботов, которых вы собираетесь заблокировать, как предлагает @StephenOstermiller в своем ответе.)
После того как вы создадите файл robots.txt, поисковым роботам потребуется день или больше, чтобы получить его.
Яндекс имеет ряд ботов и документацию о том, как запретить их всех с помощью robots.txt здесь: https://yandex.com/support/webmaster/controlling-robot/robots-txt.xml Возможно, вы захотите рассмотреть изменить robots.txt на это для Яндекса:
User-agent: Яндекс Запретить: /
SEM У Раша есть два бота. Их документация по этому поводу находится здесь: https://www.semrush.com/bot/ Вы правильно запретили одно из них, но ваше второе правило с номером версии бота не будет действовать. Вы должны использовать эти правила, чтобы запретить сканирование SEM Rush:
Агент пользователя: SemrushBot Запретить: / Агент пользователя: SemrushBot-SA Запретить: /
Вы уже запрещаете AhrefsBot в соответствии с их документацией: https://ahrefs. com/robot
com/robot
Агент пользователя: AhrefsBot Запретить: /
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.