обновление алгоритма в декабре 2019 года
В декабре 2019 года Яндекс представил обновленный поиск под названием “Вега”. Как утверждают в самом Яндексе, в обновление вошли более 1 500 улучшений по 4 направлениям, которые скопились за прошедший год.
Давайте разберемся, что именно изменилось с нововведениями и насколько удобен новый алгоритм Яндекса “Вега”.
Улучшаем поиск с нейросетямиПервое, чем похвастался Яндекс в своем обновлении — повышение качества поиска. Еще с введения “Палеха” поиск Яндекса ориентируется не только на указанные слова, но и на их смысл. Благодаря нейросетям, смысл запроса сопоставляется с найденными веб-страницами.
Поисковый алгоритм “Вега” также учитывает контекст поиска. Но на этот раз веб-страницы объединяются в смысловые кластеры — новую систему хранения веб-документов. Таким образом Яндекс выбирает релевантные запросу кластеры страниц и документов, в которых находятся подходящие вашему поиску ответы.
Хорошая новость для редко посещаемых сайтов: попадая в тематический кластер, шанс выдачи по определенным тематикам возрастает. По крайней мере, так обещает нам сам Яндекс.
Плюсы: помимо того, что выдача результатов поиска стала более контекстной, точной и тематической, алгоритм “Вега” от Яндекса ускоряет поиск, сокращая место для хранения документов. Ответы теперь находятся быстрее и конкретнее.
Минусы: объединение страниц в тематические кластеры по желанию нейросетей — интересная, но настораживающая идея. Такое сужение вариантов ответов на ваш поисковый запрос наводит мысли на монополизацию, но на таком большом рынке это вполне естественный процесс.
Рисунок 1. Ваш поиск проанализирован нейросетями 😉
Второй улучшайзинг поиска заключается в моментальной скорости выдачи результатов. Новый алгоритм Яндекса ввел удобную функцию — пререндеринг. Эта технология будет угадывать ваш запрос с первых слов, которые вы набираете в строке поиска. Таким образом, результат сформирован заранее и показывается вам сразу же после нажатия заветного “Найти”.
Таким образом, результат сформирован заранее и показывается вам сразу же после нажатия заветного “Найти”.
Не забыл Яндекс и про функцию “Турбо-страниц” — теперь они открываются в 15 раз быстрее при переходе с поиска (не только в мобильной, но и в десктопной версии). Хотя нужно отметить, что скорость открытия “Турбо-страниц” повышается, если пользователь открывает их в “Яндекс.Браузере”. Так что заходите в Вебмастер и подключайте облегченные версии своих страниц — никто не любит долгих загрузок.
Плюсы: для пользователей все складывается максимально удобно — пререндеринг заранее угадает, что вы хотите найти, быстрый поиск не заставит вас ждать ответов больше 1-1,5 секунд, а переходить по каждой ссылке в поисках нужной статьи не обязательно.
Минусы: а вот здесь — внимание SEO-шникам и владельцам сайтов. Сам Яндекс утверждает:
“За год число запросов, на которые поиск ответил сразу в выдаче, выросло более чем на 20%”
Это значит, что 20% пользователей не перешли по ссылкам в поиске, а нашли ответы сразу. Разве не обидно быть на первой странице выдачи по определенному запросу и не получать с этого переходов?
Разве не обидно быть на первой странице выдачи по определенному запросу и не получать с этого переходов?
Также проглядывается тенденция “навязывания” сервисов Яндекса (об этом мы поговорим чуть ниже), одним из которых являются “Турбо-страницы”: хотите быстрее — подключайте в Вебмастере облегченные страницы.
Мнение экспертовМногие хорошо знакомы с перспективным и интересным проектом “The Question” — эксперты своего дела (а иногда и просто зарегистрированные пользователи, это важно!) отвечают на популярные вопросы, начиная от “Сколько варить курицу?” и заканчивая “Какой закон аэродинамики противоречит законам физики?”. Яндекс выкупил вопросник, и из него получился новый сервис “Яндекс.Кью”. Поисковик обещает, что на вопросы здоровья отвечает медик, а на вопросы про курицу — опытный повар, что должно повысить уровень доверия почемучек.
Экспертные ответы на вопросы теперь будут показываться в поиске в зависимости от тематики. Опять-таки, переходить по ссылке не обязательно: “Яндекс. Кью” покажет вам ответ самого высоко оцениваемого эксперта уже на странице результатов.
Кью” покажет вам ответ самого высоко оцениваемого эксперта уже на странице результатов.
Рисунок 2. Теперь экспертам доверять проще.
На этом работа экспертов в Яндексе не закончилась. “Вега” ввел новый алгоритм ранжирования, для которого важным сигналом является оценка ассесора-эксперта. Как утверждает сам Яндекс, эксперты, профессионалы своего дела, отбирались очень тщательно и внимательно, проходя задания, тесты и оценку профессионализма. Именно эти люди смогут объективно (будем надеяться) оценить соответствие отображаемой страницы поисковому запросу. Для этого алгоритма у ассесоров есть специальная система “Янг”, в которой и происходит экспертная оценка.
Плюсы: экспертное мнение всегда лучше ответа “просветленного” на “Ответах.Mail.ru”. Другой вопрос — насколько можно доверять Яндексу в отборе ассесоров и в объективности их оценки. Учитывая всю серьезность движения Яндекса к совершенствованию, пока что нет причин сомневаться в экспертах. Более того, ответ профессионального педиатра на тему детского здоровья вызывает куда больше доверия, чем ссылка на статью “мамского” форума.
Минусы: стремление создавать продуманный, интересный и правильный контент нельзя назвать минусом, а вот затраты на его совершенствование — еще как можно. Теперь нужно ориентироваться не только на обобщенную полезность — в наших общих интересах заполучить заветную положительную оценку ассесора в программе “Янг”. А еще обратите внимание на “Яндекс.Кью” — здесь экспертом может выступить компания, отвечая на вопросы пользователей. Очень хорошим решением будет подключить сотрудников к ответам, но, опять-таки, достаточно затратным.
Нам нужно больше Яндекса!Еще одним важным обновлением “Яндекса Веги” является ввод новых сервисов от самого Яндекса. Например, вышел из тестирования сервис “Яндекс Район”, в котором локально обсуждаются проблемы, новости и “скидываемся на ремонт лифта” жильцами определенных районов и даже конкретных домов. Почему домов? Потому что теперь в сервисе есть домовые чаты, которые сужают географию вплоть до подъезда. Аудитория сервиса — около 13 миллионов человек ежемесячно. Гиперлокальность, о которой говорит Яндекс, также является приоритетом еще одного нового сервиса — “Яндекс.Услуг”, который пришел на смену “Яндекс.Мастеру”, связывая клиентов и исполнителей. Сервис учитывает ваше положение и ориентируется не только на оценку услуги другими пользователями, но и на то, в течение какого времени вам ее смогут оказать. Репетитор для ребенка в соседнем подъезде, мастер по ремонту телефона, который приедет за 20 минут — все это говорит о том, что Яндекс учитывает ваше местоположение и ценит ваше время.
Аудитория сервиса — около 13 миллионов человек ежемесячно. Гиперлокальность, о которой говорит Яндекс, также является приоритетом еще одного нового сервиса — “Яндекс.Услуг”, который пришел на смену “Яндекс.Мастеру”, связывая клиентов и исполнителей. Сервис учитывает ваше положение и ориентируется не только на оценку услуги другими пользователями, но и на то, в течение какого времени вам ее смогут оказать. Репетитор для ребенка в соседнем подъезде, мастер по ремонту телефона, который приедет за 20 минут — все это говорит о том, что Яндекс учитывает ваше местоположение и ценит ваше время.
Рисунок 3. Придется регистрироваться в “Яндекс.Район”
Плюсы: время действительно является очень ценным ресурсом. А походы в ЖЭК или расклеивание объявлений о пропаже кота давно стали неудобными для большинства жителей. Новые сервисы учитывают потребности пользователей, их время и интересы. Решать важные вопросы через Яндекс стало удобнее — и это правда большой плюс.
Минусы: удобство для пользователей не всегда гарантирует удобство для рекламистов и владельцев сайтов. Теперь вашего клиента может забрать отличный мастер, зарегистрированный и зарекомендовавший себя на “Яндекс.Услугах”, а пользователю для этого даже не нужно будет переходить по ссылкам в поиске. Единственный правильный выход (вспоминаем о “навязывании”) — максимально приобщаться к сервисам Яндекса. И быть тем самым хорошим мастером 😉
Теперь вашего клиента может забрать отличный мастер, зарегистрированный и зарекомендовавший себя на “Яндекс.Услугах”, а пользователю для этого даже не нужно будет переходить по ссылкам в поиске. Единственный правильный выход (вспоминаем о “навязывании”) — максимально приобщаться к сервисам Яндекса. И быть тем самым хорошим мастером 😉
Первое впечатление? Хорошо. Новое обновление Яндекса выглядит максимальной заботой о пользователях: удобные сервисы, быстрая выдача, пререндеринг, экспертные оценки и релевантная выдача ответов.
Что же касается всех, кто беспокоится о своей выдаче в поиске — все не так радужно, но от обновления никуда не уйти, поэтому лучше с ним подружиться. И вот как это сделать:
- Следите за своим контентом. Полезные и интересные статьи просто приятнее читать, даже без давления Яндекса. Подключайте экспертов (или сами будьте экспертами своего дела), ориентируйтесь на боли и вопросы пользователей, давайте точную информацию и, главное, не скромничайте!
- Дружите с сервисами Яндекса.
 Тенденция обновлений Яндекса понятна уже давно — сервисы поисковика ставятся в приоритет. Ваша задача максимально с ними подружиться: пользуйтесь “Яндекс.Дзеном”, Картами, подключите свое мнение в “Яндекс.Кью”, регистрируйтесь в “Яндекс.Услугах” и предлагайте свои услуги в сервисе. Не забудьте про облегченные “Турбо-страницы” — пользователи любят, когда все работает без задержек. Можно делать это постепенно, ведь никто не отрицает затраты на подключение новых сервисов и время, которое необходимо, чтоб в них разобраться.
Тенденция обновлений Яндекса понятна уже давно — сервисы поисковика ставятся в приоритет. Ваша задача максимально с ними подружиться: пользуйтесь “Яндекс.Дзеном”, Картами, подключите свое мнение в “Яндекс.Кью”, регистрируйтесь в “Яндекс.Услугах” и предлагайте свои услуги в сервисе. Не забудьте про облегченные “Турбо-страницы” — пользователи любят, когда все работает без задержек. Можно делать это постепенно, ведь никто не отрицает затраты на подключение новых сервисов и время, которое необходимо, чтоб в них разобраться. - Слушайте вашу аудиторию. Именно это делает Яндекс, и у него получается сделать удобно и красиво. На самом деле, это достаточно общий совет, но все более актуальный. Чем лучше вы будете слышать свою аудиторию, тем больше вероятность, что полезность вашего сайта будет высоко оценена экспертами-ассесорами.
Уверенно сказать, насколько полезное и хорошее обновление Яндекс выпустил на этот раз, пока сложно. Время и реакция пользователей покажет, что нам ждать от “Веги” и новых сервисов.
И делитесь мнением в комментариях!
Заказать SEO аудит
Подпишись и следи за выходом новых статей в нашем монстрограмме
Остались вопросы?
Не нашли ответ на интересующий Вас вопрос? Или не нашли интересующую Вас статью? Задавайте вопросы и темы статей которые Вас интересуют в комментариях.
Как проходят алгоритмические секции на собеседованиях в Яндекс / Хабр
Алгоритмическая секция с написанием кода на доске или бумаге — один из важнейших этапов собеседования разработчиков для получения работы в Яндексе. Мы решили подробнее рассказать о том, как устроены эти секции, чтобы помочь будущим кандидатам в подготовке. Кроме того, надеюсь, многие из тех, кто не решается прийти в Яндекс на собеседование, опасаясь слишком сложных испытаний, после этого рассказа поймут, что в действительности всё не так уж и страшно!
Так что мы подготовили для вас следующие материалы:
- Специальный контест, содержащий задачи, похожие на те, что мы даём на интервью.

- Этот пост. В нём рассказывается, почему нужно проводить такие секции, а также разбираются все задачи контеста.
- Два видео, в которых разбираются задачи из контеста: в первом — задача попроще, во втором — две задачи посложнее. Из этих видео вы узнаете о типичных ошибках, допускаемых и при прохождении алгоритмических секций, и при написании продакшен-кода.
Как мы собеседуем разработчиков
Собеседование любого разработчика состоит из нескольких этапов:
- предварительная секция с рекрутером;
- техническое скайп-интервью;
- несколько очных секций;
- финальные интервью с нанимающими менеджерами.
На предварительной секции рекрутер знакомится с кандидатом, узнаёт его интересы и мотивы для того, чтобы понять, на какие позиции имеет смысл его рассматривать. Техническое скайп-интервью предназначено для предварительной оценки навыков кандидата и отсеивает тех, кто со всей определённостью не справится с очными секциями.
Очные секции — основной этап. Именно очные секции дают ответ на вопрос о том, что умеет кандидат. Алгоритмическая секция — одна из очных технических секций. Помимо алгоритмических, бывают и другие очные испытания: скажем, кандидаты в старшие разработчики обязательно проходят секцию по архитектуре, а будущие руководители ещё и отвечают на вопросы по управлению командами и проектами. Вообще, если у кандидата есть какая-то сильная сторона в специфической области (машинном обучении, низкоуровневой оптимизации, разработке высоконагруженных систем, мобильной разработке или любой другой) — мы обязательно организуем секцию с профильным специалистом.
Алгоритмическая секция проверяет, способен ли кандидат придумывать алгоритмы для решения несложных задач, оценивать сложность этих алгоритмов и реализации их без ошибок, в процессе соблюдая баланс между качеством тестирования и скоростью решения.
Зачем писать код на доске или бумаге
Естественное состояние для программиста — программирование в интегрированной среде разработки с подсветкой синтаксиса и возможностью трассировки. Поэтому идея на собеседовании писать код на доске или бумаге первоначально кажется не слишком естественной. Однако, этот способ позволяет проверить два очень важных для каждого разработчика свойства.
Поэтому идея на собеседовании писать код на доске или бумаге первоначально кажется не слишком естественной. Однако, этот способ позволяет проверить два очень важных для каждого разработчика свойства.
Первое из них — умение быстро разбираться с работоспособностью кода «на глаз». Представьте себе, что при написании каждого цикла, возникающего в программе, разработчику требуется потратить время на то, чтобы проверить его работоспособность трассировкой; или что при падении сервиса в продакшене ему всегда обязательно нужно запустить код под дебаггером. Ясно, что написание и отладка даже несложных программ будут занимать у него непозволительно много времени. Конечно, полезно уметь читать код и при код-ревью.
Второе важное свойство — способность заранее продумывать план решения и затем следовать ему. Если плана нет, это будет приводить к большому количеству исправлений, зачёркиваний (на бумаге) и переписыванию больших кусков кода. В реальной жизни всё это сильно замедляет разработку, но отчасти маскируется скоростью работы в редакторе кода. Доска и бумага в этом смысле являются беспощадными поверхностями.
Доска и бумага в этом смысле являются беспощадными поверхностями.
Естественно, мы учитываем, что писать код от руки — не слишком быстрое дело. Поэтому наши задачи обычно предполагают решение не намного длиннее десятка строк, а количество задач, которые необходимо решить в течение одной секции, обычно равняется двум или трём.
Алгоритмические секции и спортивное программирование
Спортивное программирование развивает в будущем разработчике, помимо прочего, и способность быстро и без ошибок реализовывать простые алгоритмы согласно заранее назначенному плану. Поэтому кандидаты с опытом спортивного программирования, действительно, неплохо справляются с алгоритмическими секциями на собеседованиях. Часто можно наблюдать ситуацию, когда будущие стажёры легко справляются с алгоритмической секцией, решая все задачи за 15-20 минут, тогда как более опытные программисты на те же задачи тратят целый час.
В то же время, алгоритмическая секция с написанием кода — лишь одна из секций, проверяющая минимально необходимые для любого разработчика навыки. С этой секцией справятся не только олимпиадные программисты, но и опытные промышленные разработчики. Будущего старшего разработчика или руководителя группы обязательно ждёт архитектурная секция, на которой он сможет раскрыть свои самые сильные стороны; конечно, эта секция никогда не ставится стажёрам и младшим разработчикам.
С этой секцией справятся не только олимпиадные программисты, но и опытные промышленные разработчики. Будущего старшего разработчика или руководителя группы обязательно ждёт архитектурная секция, на которой он сможет раскрыть свои самые сильные стороны; конечно, эта секция никогда не ставится стажёрам и младшим разработчикам.
Контест для подготовки к собеседованию
Специально для того, чтобы вы могли примерно представить себе содержание задач, которые мы даём на алгоритмических секциях, мы собрали контест, который можно использовать при подготовке к собеседованиям. Попробуйте решить все задачи, ни разу не запустив дебаггер; написать решение в Notepad’е без подсветки синтаксиса; придумать как можно более короткое решение, которые пройдёт все тесты; продумать все возможные проблемы заранее и сдать решение с первого раза.
Контест содержит пять задач. Вы можете попробовать решить их самостоятельно, а можете заранее прочитать разбор: это всё равно будет полезно, т. к. вы сможете потренировать свой навык безошибочного кодирования заранее известного алгоритма.
к. вы сможете потренировать свой навык безошибочного кодирования заранее известного алгоритма.
Разбор задач контеста
Задача A. Камни и украшения
Даны две строки строчных латинских символов: строка J и строка S. Символы, входящие в строку J, — «драгоценности», входящие в строку S — «камни». Нужно определить, какое количество символов из S одновременно являются «драгоценностями». Проще говоря, нужно проверить, какое количество символов из S входит в J.
Это очень простая разминочная задача, к которой прилагаются решения на нескольких языках программирования, чтобы участники могли освоиться с проверяющей системой.
Алгоритм достаточно простой: из строки с «драгоценностями» необходимо построить множество, затем пройтись по строке с «камнями» и каждый символ проверить на вхождение в это множество. Используйте такую реализацию множества, чтобы гарантировать линейную сложность полученного решения, несмотря на то, что входные строки очень короткие и поэтому возможно сдать даже квадратичный по сложности алгоритм.
Задача B. Последовательно идущие единицы
Требуется найти в бинарном векторе самую длинную последовательность единиц и вывести её длину.
Алгоритм решения следующий: пройтись по всем элементам массива; встретив единицу, нужно увеличить счётчик длины текущей последовательности, а, встретив ноль, нужно обнулить этот счётчик. В конце нужно вывести максимальное из значений, которые принимал счётчик.
Проверьте, что правильно обрабатываете ситуацию, когда массив заканчивается на искомую последовательность единиц. При аккуратной реализации такая ситуация не потребует специальной обработки.
Постарайтесь использовать лишь константный объём дополнительной памяти.
Задача C. Удаление дубликатов
Дан упорядоченный по неубыванию массив целых 32-разрядных чисел. Требуется удалить из него все повторения.
Правильный алгоритм последовательно обрабатывает элементы массива, сравнивая их с последним выведенным. Нужно не забыть обновлять переменную, содержащую последний выведенный элемент и, кроме того, не ошибиться при обработке последнего элемента.
Нужно не забыть обновлять переменную, содержащую последний выведенный элемент и, кроме того, не ошибиться при обработке последнего элемента.
При решении этой задачи также не нужно использовать дополнительную память.
Задача D. Генерация скобочных последовательностей
Дано целое число . Требуется вывести все правильные скобочные последовательности длины , упорядоченные лексикографически (см. https://ru.wikipedia.org/wiki/Лексикографический_порядок). В задаче используются только круглые скобки.
Это пример относительно сложной алгоритмической задачи. Будем генерировать последовательность по одному символу; в каждый момент мы можем к текущей последовательности приписать либо открывающую скобку, либо закрывающую. Открывающую скобку можно дописать, если до этого было добавлено менее n открывающих скобок, а закрывающую — если в текущей последовательности количество открывающих скобок превосходит количество закрывающих. Такой алгоритм при аккуратной реализации автоматически гарантирует лексикографический порядок в ответе; работает за время, пропорциональное произведению количества элементов в ответе на n; при этом требует линейное количество дополнительной памяти.
Примером неэффективного алгоритма был бы следующий: сгенерируем все возможные скобочные последовательности, а затем выведем лишь те из них, что окажутся правильными. При этом объём ответа не позволит решить задачу быстрее, чем тот алгоритм, что приведёт выше.
Задача E. Анаграммы
Эта достаточно простая задача — типичный пример задачи, для решения которой необходимо использовать ассоциативные массивы. При решении нужно учитывать, что символы могут повторяться, поэтому необходимо использовать не множества, а словари. Поэтому решение будет следующим: составим из каждой строки по словарю, который для каждого символа будет хранить количество его повторений; затем сравним получившиеся словари. Если они совпадают, необходимо вывести единицу, в противном случае — ноль.
Альтернативное решение: отсортируем входные строки, а затем сравним их. Это решение хуже в том, что оно работает медленнее, а также меняет входные данные. Зато такое решение не использует дополнительной памяти.
Если в процессе собеседования у вас возникло несколько вариантов решения, отличающихся своими по своим характеристикам, расскажите об этом. Всегда здорово, когда разработчик знает несколько вариантов решения задачи и может рассказать об их сильных и слабых сторонах.
Задача F. Слияние сортированных списков
Даны отсортированных в порядке неубывания массивов неотрицательных целых чисел, каждое из которых не превосходит 100. Требуется построить результат их слияния: отсортированный в порядке неубывания массив, содержащий все элементы исходных массивов. Длина каждого массива не превосходит .
Для каждого массива создадим по указателю; изначально каждый указатель расположен в начале соответствующего массива. Элементы, соответствующие позициям указателей, поместим в любую структуру данных, которая поддерживает извлечение минимума — это может быть мультимножество или, например, куча. Далее будем извлекать из этой структуры минимальный элемент, помещать его в ответ, сдвигать позицию указателя в соответствующем массиве и помещать в структуру данных очередной элемент из этого массива.
В этой задаче многие испытывают сложности с форматом ввода. Обратите внимание на то, что первые элементы строк не описывают элементы массивов, они описывают длины массивов!
FAQ по контесту
A: Я точно написал правильный код, но тесты не проходят; наверное, в них ошибка?
Q: Нет, все тесты правильные. Подумайте: вероятно, вы не предусмотрели какую-нибудь необычную ситуацию.
A: Я пишу на языке X, ему точно требуется больше памяти в задаче Y. Поднимите лимиты!
Q: Все лимиты выставлены таким образом, что решение возможно с использованием любого из доступных языков. Попробуйте проверить, не зачитываете ли вы случайно входной файл целиком в задачах со строгими лимитами по используемой памяти.
A: Некоторые задачи можно решить намного проще из-за указанных ограничений. Зачем вы так?
Q: Мы специально упростили ввод в некоторых задачах, чтобы участникам было проще сосредоточиться на реализации алгоритма и не думать, например, о скорости загрузки данных или каких-то других вещах, важных в спортивном программировании.
A: Не хочу проходить контест. Можно я не буду?
Q: Конечно! Контест не является обязательным к решению всеми кандидатами. Впрочем, я всё равно рекомендую его порешать: это в любом случае будет полезно.
A: Что ещё посоветуете для подготовки?
Q: Прочитайте наши советы на официальной странице про собеседования в Яндекс: https://yandex.ru/jobs/ya-interview. От себя добавлю, что решение задачек на leetcode.com является крайне полезным для любого практикующего разработчика, независимо от того, планирует ли он в ближайшее время проходить интервью или участвовать в соревнованиях по программированию. Даже небольшое количество практики позволяет почувствовать себя увереннее при решении рабочих задач.
Заключение
Я часто бываю на конференциях для разработчиков и руководителей разработки, состою во многих чатах, посвящённых разработке, провёл несколько сотен собеседований и нанял в Яндекс огромное количество разработчиков. Опыт подсказывает, что алгоритмические секции с написанием кода на доске или бумаге часто вызывают вопросы. В заключение статьи я отвечу на самые популярные из них.
Опыт подсказывает, что алгоритмические секции с написанием кода на доске или бумаге часто вызывают вопросы. В заключение статьи я отвечу на самые популярные из них.
Зачем проводить собеседование в условиях, столь сильно отличающихся от реальных условий работы разработчика?
Это позволяет понять, способен ли кандидат находить проблемы в программах, не запуская дебаггер; может ли он заранее придумать план алгоритма и затем безошибочно следовать ему; может ли он придумать небольшой, но достаточный, набор тестов и затем проверить свою реализацию на соответствие этому набору тестов.
Такие секции отдают несправедливое преимущество спортивным программистам?
Спортивное программирование развивает в разработчиках некоторые очень полезные навыки, поэтому участники олимпиад по программированию, действительно, хорошо справляются с алгоритмическими секциями. Так что преимущество имеется, но оно является справедливым. Алгоритмическая секция является лишь одной из многих, поэтому у каждого кандидата будет достаточно возможностей для того, чтобы показать свои самые сильные стороны!
Зачем проводить алгоритмические секции, если все алгоритмы уже давно реализованы, и нужно лишь уметь искать их реализации в готовых библиотеках?
На алгоритмических секциях, общих для всех разработчиков, мы проверяем лишь минимально необходимые навыки: умение придумать и без ошибок реализовать простой алгоритм, содержащий циклы, проверки условий и, возможно, требующий использования ассоциативных массивов.
Какой смысл в секции, которая не проверяет огромное количество навыков разработчика?
Алгоритмическая секция, действительно, проверяет лишь минимально необходимый для любого разработчика набор навыков. Другие навыки мы проверяем при помощи других секций.
Вы проводите алгоритмические секции для разработчиков всех специальностей?
Да. Алгоритмические секции проводятся для бекенд-разработчиков, аналитиков, мобильных и фронтенд-разработчиков, разработчиков инфраструктуры и методов машинного обучения, и так далее.
Сводка обновлений алгоритма Яндекса за 2019 год
Сводку обновлений алгоритма Яндекса за 2020 год можно найти здесь. Эта статья охватывает только 2019 год.
Основываясь на стороннем мониторинге наборов данных ключевых слов по ряду категорий и регионов в Яндексе, мы можем установить показатель волатильности — аналогичный трекерам волатильности SERP, которые используются для Google.
В разбивке основные категории отслеживаемых ключевых слов и поисковой выдачи:
- Автомобилестроение
- Юридические услуги
- Электронные и бытовые приборы
- Недвижимость
- Промышленное и торговое оборудование
- Мебель для дома
- Страхование
- Товары для дома, строительные материалы и инструменты
- Человеческая логистика (аренда автомобилей и т. д.)
- Онлайн-игры
- Путешествия и туризм
- Красота и здоровье
- Финансовый
- Одежда и аксессуары
Основываясь на отслеживании этих категорий, наборов ключевых слов и изменений в поисковой выдаче, дни с самым высоким уровнем волатильности в 2019 году, когда наиболее вероятно обновление алгоритма, были:
В январе было четыре всплеска «выше среднего» в середине месяца, в то время как в остальном период был относительно спокойным.
Февраль
- 1-й (потенциально)
- 7-й
Помимо двух высоких всплесков в начале месяца, также наблюдалось увеличение активности с 23 по 28 число, что привело к всплеску активности 1 марта.
Март
- 1-й
- 2-й
- 26
Стоит отметить, что после 26 марта активность была выше средней, но снижалась после всплеска.
апрель
- 9
Апрель был относительно активным месяцем для обновлений алгоритма Яндекса, причем 9-е число стало выдающимся всплеском среди изменений.
Май
- 22-е
- 28
Всплески 22 и 28 мая были яркими событиями месяца, но меньшими с точки зрения всплесков волатильности поисковой выдачи, наблюдавшихся в предыдущие месяцы. В целом май был относительно спокойным месяцем для изменений алгоритмов по сравнению с предыдущим кварталом.
июнь
- 4-й
4 июня произошел один из самых больших скачков волатильности за год, затронувший все вертикали.
После обновления от 4 июня некоторая активность была зарегистрирована в период с 18 по 21 июня, но месяц был более спокойным и менее изменчивым, чем май.
Июль
Июль был спокойным месяцем, ничего не регистрировалось, кроме ежедневной алгоритмической рутины.
Август
Август, как и июль, был тихим. 30 и 31 августа было два небольших всплеска.
30 августа более изменчивыми категориями были недвижимость и товары для дома, а 31 августа более изменчивыми категориями были финансовые и кадровая логистика (аренда автомобилей и т. д.).
Сентябрь
- 17
- 23
- 26
Первая половина сентября была относительно спокойной, как и август, однако во второй половине месяца наблюдалась повышенная волатильность с более сильными всплесками 17, 23 и 26 числа, при этом все категории показали различный уровень повышенной активности.
Октябрь
- 1-й
- 3-й
- 4-й
- 5-й
- 6-й
В начале октября наблюдался высокий уровень волатильности во всех категориях, при этом недвижимость, здоровье и красота, а также одежда и аксессуары демонстрировали наиболее устойчивый уровень повышенной активности.
ноябрь
- 2-й
Во втором ноябре наблюдался единственный всплеск активности за месяц, при этом основными категориями, демонстрирующими повышенную волатильность, были Здоровье и Красота (в Московской области и Алматинской области), Веб-услуги (в Санкт-Петербурге) и Логистика персонала (в Киеве). область).
Декабрь
Декабрь был относительно спокойным месяцем, без серьезных всплесков, несмотря на объявление об обновлении Vega, поэтому можно предположить, что любые серьезные год – или потенциально мог прийти во время октябрьской волатильности.
Яндекс объявляет о крупном обновлении алгоритма
Яндекс объявил об обновлении своей поисковой системы. Обновление называется Vega. Обновление предлагает много подробностей о том, как работают современные поисковые системы.
Обновление называется Vega. Обновление предлагает много подробностей о том, как работают современные поисковые системы.
Основные улучшения Яндекса
Яндекс называет свое обновление Vega. Это обновление содержит 1500 улучшений. Из этих улучшений Яндекс выделил два, которые, по их словам, существенно влияют на результаты поиска.
Одно из изменений добавляет экспертную человеческую обратную связь в обучение алгоритма. Вторым изменением стала возможность удвоить размер поискового индекса, не влияя на скорость результатов поиска.
Связанный: Полное руководство по Яндекс SEO
Crowd Sourcing Оценщики результатов поиска
Google нанимает подрядчиков, прошедших обучение в соответствии с рекомендациями Google по оценке качества для оценки их результатов поиска. Яндекс полагается на свою краудсорсинговую платформу Яндекс.Толока.
Хотя этот метод может показаться немного менее контролируемым, чем метод Google, Яндекс предоставляет рекомендации для оценщиков, чтобы повысить точность оценок.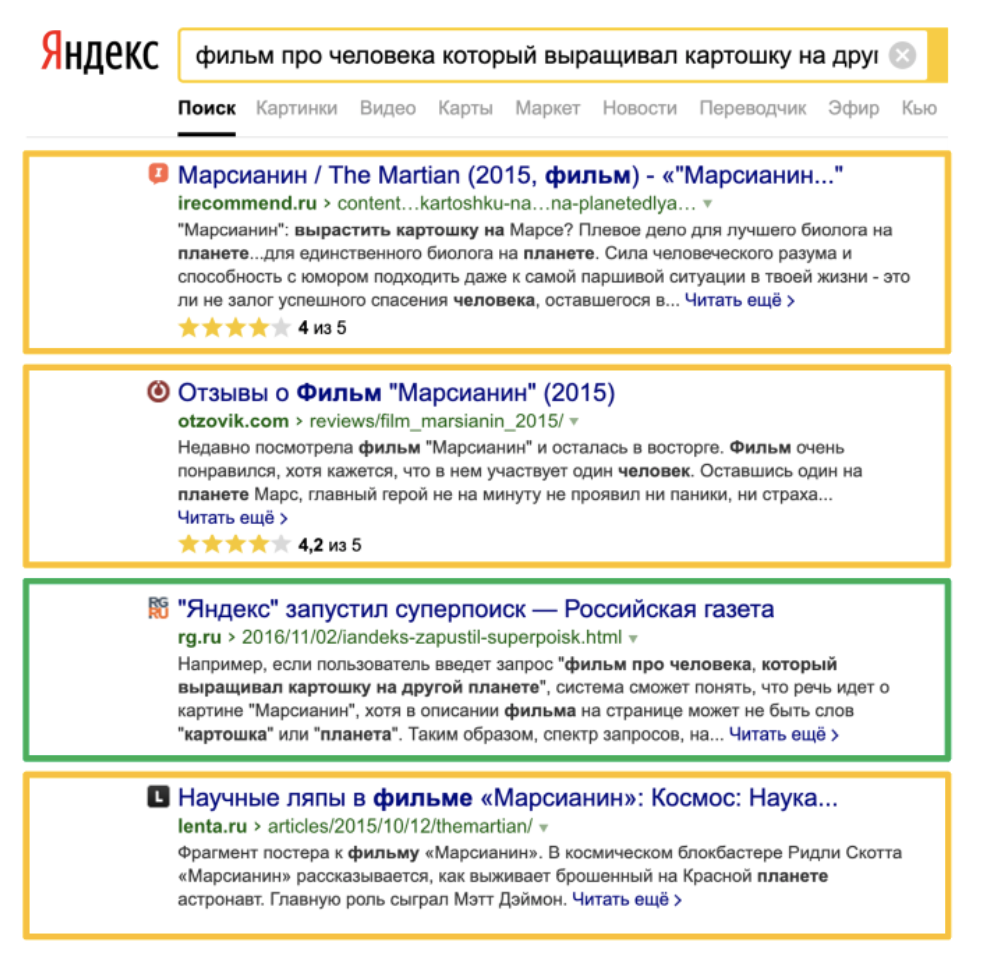
«Люди, или «оценщики», уже давно помогают обучать наши платформы машинного обучения через нашу краудсорсинговую платформу Яндекс.Толока.
Используя наши рекомендации по оценке результатов поиска, асессоры в Яндекс.Толоке выполняют задачи, которые помогают нам находить наиболее релевантные результаты для конкретных запросов».
Человеческий вклад в обучение алгоритмам
Мы знаем, что Google использует оценщиков качества для тестирования новых изменений алгоритмов. То же самое делает и Яндекс. Они называют своих оценщиков оценщиками, потому что они оценивают веб-результаты.
Изменение, внесенное Яндексом, заключалось в привлечении экспертов по заданной теме для проверки работы Асессоров с целью повышения точности их работы. Это означает, что обучающие данные, предоставленные алгоритму, будут лучше, поскольку они были проверены и подтверждены экспертом.
Поскольку обучающие данные Яндекса просматриваются экспертами по теме, алгоритм (предположительно) будет более точным, поскольку обучающие данные будут улучшены.
Вот как это объяснил Яндекс:
«Мы обновили алгоритм ранжирования с помощью нейронных сетей, обученных на данных, предоставленных реальными экспертами в нескольких областях, предоставляя пользователям еще более качественные решения их запросов.
Профессионалы, оценивающие оценщиков, варьируются от ИТ-администраторов для запросов данных до гидрологов для поиска, связанного с реками.
Эксперты-оценщики используют более сотни критериев для оценки работы оценщиков…
Обучая наши алгоритмы машинного обучения с экспертными оценками, наша поисковая система учится ранжировать релевантную информацию выше в результатах благодаря работе высококвалифицированной группы людей».
По теме: Интервью с поисковой командой Яндекса
Расширение поискового индекса с помощью кластеризации
Яндекс представил очень интересный способ обработки тематически похожих веб-страниц. Вместо того, чтобы искать ответ по всему индексу, Яндекс сгруппировал веб-страницы в тематические кластеры. Говорят, что это улучшает и ускоряет результаты поиска, позволяя поисковой системе выбирать ответ со страниц, которые имеют отношение к теме.
Говорят, что это улучшает и ускоряет результаты поиска, позволяя поисковой системе выбирать ответ со страниц, которые имеют отношение к теме.
«Наши алгоритмы используют нейронные сети для группировки страниц в кластеры на основе их сходства. Когда пользователь вводит запрос, он ищется среди наиболее релевантного кластера страниц, а не всего нашего индекса».
Технология кластеризации Яндекса позволила Яндексу удвоить свой поисковый индекс, не влияя на скорость выбора веб-страницы.
Это очень интересно, потому что похоже на алгоритмы ранжирования ссылок, которые начинаются с исходных сайтов как представителей тем. Веб-страницы, на которые больше ссылок, расцениваются как менее релевантные теме. Страницы, расположенные ближе к исходной теме, считаются более релевантными.
Прогнозирование поисковых запросов и результатов
Интересным обновлением Яндекса является использование алгоритмов для прогнозирования того, что спросит пользователь, и «предварительной визуализации» результатов для этого поискового запроса.