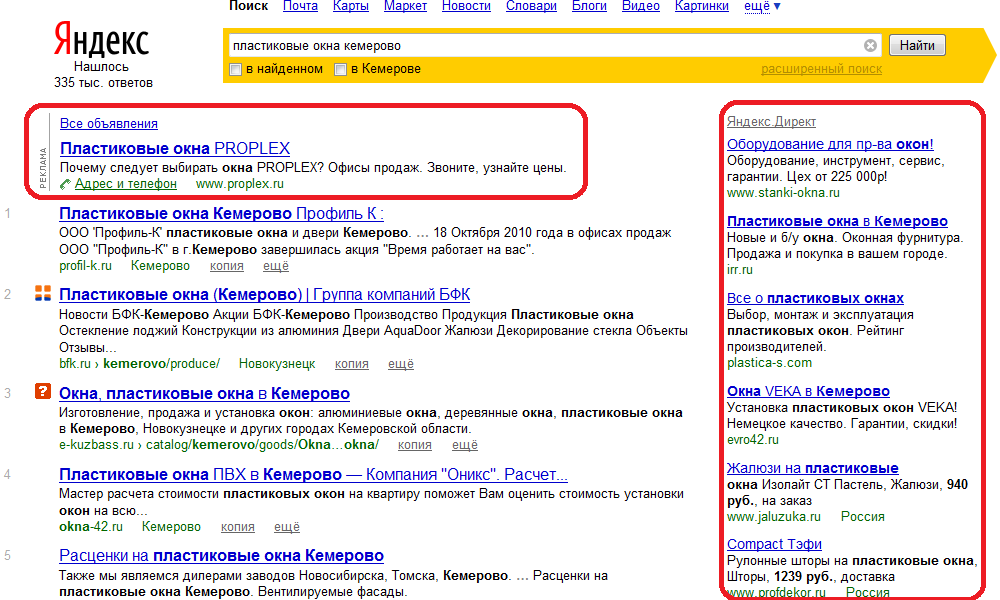
Как пользоваться поиском в Google: 30 хитростей
3 февраля 2021Технологии
Рассказываем, как искать нужную информацию быстро и легко.
Поделиться
01. Поиск точной фразы
Иногда бывает необходимо найти фразу именно в том виде, в котором мы её вводим. Допустим, когда мы ищем текст песни, но знаем только одно предложение. В таком случае вам нужно заключить его в кавычки. Например так: "Feel as though nobody cares".
2. Поиск по конкретному сайту
Google — отличный поисковик. Как правило, он содержит гораздо больше настроек, чем встроенный поиск на сайтах. Именно поэтому рациональнее использовать Google для поиска информации на каком-нибудь ресурсе. Для этого нужно ввести site:, указать доменное имя сайта и прописать нужный запрос. Вот как, к примеру, будет выглядеть поиск по «Википедии»: site:wikipedia.org масонская ложа.
3. Поиск слов в тексте
Если нужно, чтобы в тексте найденных результатов были все слова запроса, введите перед ним allintext:. Вот так, к примеру:
Вот так, к примеру: allintext: как быстро протрезветь.
Если одно слово запроса должно быть в тексте, а остальные — в любом другом месте страницы, включая заголовок или URL, поставьте перед словом intext:, а остальное напишите до этого. Например: intext:коронавирус у животных.
4. Поиск слов в заголовке
Если вы хотите, чтобы все слова запроса были в заголовке, используйте фразу allintitle:. Скажем, вот так: allintitle:тренировка дня.
Если только часть запроса должна быть в заголовке, а остальное — в другом месте документа или страницы, ставьте просто intitle:.
5. Поиск слов в URL
Чтобы найти страницы, у которых ваш запрос прописан в URL, введите allinurl: и нужный текст.
6. Поиск новостей для конкретной локации
Если нужны новости по определённой тематике из конкретной локации, используйте операторlocation: в запросе. Например, вот так: распродажи location:москва.
7. Поиск с несколькими пропущенными словами
Вам нужно найти предложение в документе или статье, но вы помните только слова в начале и в конце. Введите свой запрос и укажите с помощью оператора AROUND(число), сколько приблизительно слов было между теми словами, которые вы помните. Выглядит это так: У лукоморья AROUND(5) дубе том.
8. Поиск с неизвестным словом или цифрой
Забыли какое-то слово из поговорки, песни, цитаты? Не беда. Google всё равно поможет его найти — просто поставьте символ * (звёздочку) на месте забытого слова.
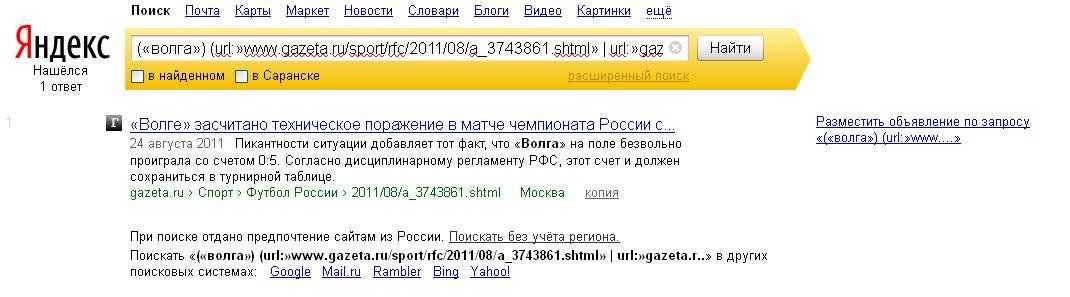
9. Поиск сайтов, которые ссылаются на интересующий вас ресурс
Этот пункт полезен владельцам блогов или сайтов. Если вам интересно, кто же ссылается на ваш ресурс или даже на определённую страницу, то достаточно ввести в поисковой строке адрес и поставить перед ним оператор link:. Например, вот так: link:lifehacker.ru.
10. Исключение результатов с ненужным словом
Представим ситуацию. Вы решили поехать отдыхать на острова. И вы совсем не хотите на Мальдивы. Чтобы Google не показывал их в результатах поиска, нужно просто ввести
Вы решили поехать отдыхать на острова. И вы совсем не хотите на Мальдивы. Чтобы Google не показывал их в результатах поиска, нужно просто ввести Отдых на островах -Мальдивы. То есть перед названием поставить символ - (дефис).
11. Поиск похожих сайтов
Вы желаете найти всех своих конкурентов. Или вам очень нравится сайт, но не хватает материала на нём, а вам хочется ещё и ещё. Вводим оператор related: и любуемся результатом. Выглядит это следующим образом: related:wikipedia.org.
12. Поиск «или-или»
Если хотите сэкономить время, можно получить выдачу сразу по двум запросам. В результатах будет информация, связанная с одним из указанных слов или с обоими. Это делается с помощью оператора OR, который можно заменить символом |. Например, безос OR маск или безос|маск.
13. Поиск разных слов в одном предложении
Для нахождения связей между объектами или просто для поиска упоминания двух личностей вместе можно использовать символ &.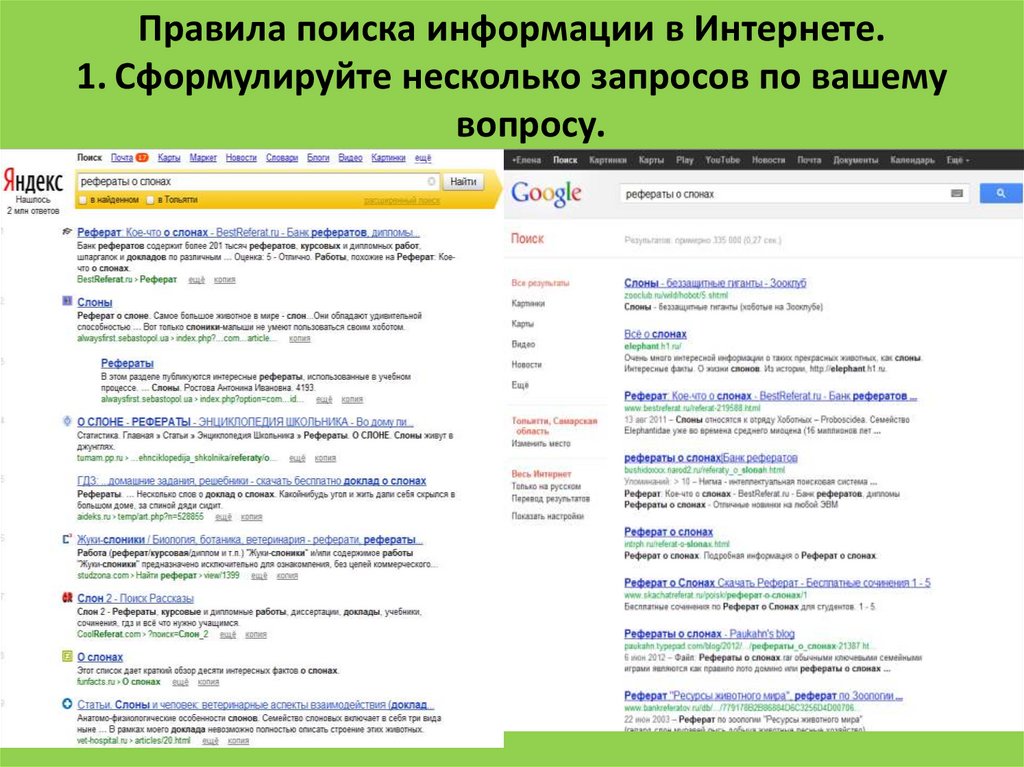 Пример:
Пример: Фрейд & Юнг.
14. Поиск по синонимам
Для охвата большего количества результатов можно добавить к запросу символ ~ и получить выдачу не только по заданному слову, но и по его синонимам. Например, если написать ~дешёвые умные часы, то поисковик также отобразит информацию, которая содержит слова «дешёвые», «недорогие», «доступные» и так далее.
15. Поиск в заданном диапазоне чисел
Очень полезный секрет поисковика. Он пригодится, если вам нужно найти, например, события, произошедшие в определённые года, или цены в определённом диапазоне. Просто поставьте две точки между числами. Google будет искать именно в этом диапазоне.
16. Поиск файлов определённого формата
Если вам нужно найти какой-нибудь документ или просто файл определённого формата, то и здесь может помочь Google. Достаточно добавить в конце вашего запроса filetype:doc. Вместо doc можно подставить нужный формат.
17.
 Поиск кешированных страниц
Поиск кешированных страницПолезная функция, которая здорово выручает в ситуациях, когда нужно прочитать удалённую новость или открыть страницу временно не работающего сайта. Чтобы воспользоваться ей, необходимо добавить оператор cache: перед названием ресурса или адресом страницы в поисковой строке.
18. Поиск по картинке
Google умеет искать не только картинки, но и по картинкам. То есть использовать в качестве запроса не текст, а изображение. Это пригодится в случаях, когда нужно найти товар по фото или более качественную версию картинки в высоком разрешении. Переключитесь на вкладку «Картинки», нажмите на иконку камеры в строке поиска и перетащите в специальную область файл изображения. Можно также просто вставить прямую ссылку на картинку.
19. Поиск в социальных сетях
Чтобы сузить область поиска, когда нужно найти информацию из социальных медиа, используйте оператор @ и название соцсети. Например, для поиска в Twitter поставьте после запроса @twitter.
20. Поиск по хештегам
Если нужно найти какие-нибудь посты в соцсетях, объединённые одним хештегом, то пригодится такой трюк. Просто поставьте перед запросом символ #. Выглядит это следующим образом — #ps5, #новыйгод.
Бонус: ещё 10 полезных функций Google
1. Google может поработать неплохим калькулятором. Для этого просто введите нужную операцию в поисковую строку. Поддерживаются арифметические операции, функции, площади фигур, а также формулы расчётов, теоремы и построение графиков.
2. Google может заменить толковый словарь. Если хотите узнать значение слова, а не просто посмотреть страницы по теме, добавляйте к слову define или значение.
3. Можно использовать поисковик в качестве конвертера величин и валют. Чтобы вызвать конвертер, наберите запрос с переводом, например 60 миль в км.
4. С помощью Google вы можете узнать погоду и время без необходимости заходить на сайты. Наберите запросы
Наберите запросы погода город, время город. Если не указывать город — поисковик покажет местную погоду и время.
5. Чтобы посмотреть результаты и расписание матчей спортивной команды, просто наберите в поисковике её название.
6. Чтобы перевести слово на любой язык, напишите в поисковой строке перевод слово и выберите нужный язык .
7. По запросу восход город Google показывает время восхода и заката (для последнего — соответствующий запрос).
8. Google содержит самую разнообразную справочную информацию — от физических величин до астрономических данных. У поисковика можно напрямую спросить плотность свинца, температуру Солнца, расстояние до Луны и многое другое.
9. Если вы вводите в поисковую строку номер авиарейса, Google выдаёт полную информацию о нём.
10. Чтобы увидеть таблицу с котировками конкретной компании, просто введите запрос акции компания, например акции apple.
Если у вас есть свои способы эффективнее использовать Google и быстрее находить нужную информацию, делитесь советами в комментариях к этой статье.
Текст обновлён 2 февраля 2021 года.
Читайте также 🧐
- 10 полезных сервисов Google, о которых вы могли не знать
- 8 поисковиков, которые лучше, чем Google
- 10 инструментов, которые помогут найти удалённую страницу или сайт
Что такое Linkbuilding и как он помогает продвигать сайты в поисковике?
Предлагаем вам гостевую статью от Jooble.
Linkbuilding (от англ “link” – ссылка, “building” – строительство) это элемент внешней оптимизации сайта. Этот метод предполагает улучшение позиций выдачи определенной страницы или сайта в поисковике путем большого количества ссылок на них из других источников. Ни для кого не секрет, что пользователи исследуют только первые страницы выдачи по определенному запросу. Чем ближе сайт (или страница) к верхним позициям в списке, тем больше шансов, что именно этот источник и используют.
Для обыденного юзера концепция линкбилдинга, другими словами наращивание массы ссылок на определенный ресурс, может смотреться достаточно отвлеченно. Для владельца же веб-сайта – это приоритетная работа. Над улучшением профиля ссылок на определенный сайт работают и SEO-специалисты, представители одной из самых перспективных ИТ вакансий на ресурсе по поиску работы Jooble Линкбилдерам (то есть специалистам, занимающимся наращиванием такой массы ссылок) предлагают достойную зарплату. Подробнее разберемся, что означает этот термин и как получение ценных ссылок влияет на позиционирование веб-сайтов?
Что такое Linkbuilding?
Линкбилдинг – это получение большого количества ссылок на определенный ресурс. Эффективной стратегия считается тогда, когда на заданный сайт ссылаются с авторитетных сайтов, которые высоко позиционирует сам поисковик. Нередко получение большого количества ссылок из ресурсов сомнительной репутации может принести больше проблем, чем пользы. Поисковые системы придирчиво относятся к неорганическому наращиванию профиля ссылок.
Эффективной стратегия считается тогда, когда на заданный сайт ссылаются с авторитетных сайтов, которые высоко позиционирует сам поисковик. Нередко получение большого количества ссылок из ресурсов сомнительной репутации может принести больше проблем, чем пользы. Поисковые системы придирчиво относятся к неорганическому наращиванию профиля ссылок.
Почему важно наращивать ссылочный профиль?
Ссылка на страницу рассматривается как гарантия ее ценности. Количество и качество ссылок на сайт – это своего рода рекомендация/сигнал для алгоритмов Google, Bing и т.д. Чем больше таких сигналов, особенно со стороны крупных порталов, тем лучше видимость страницы в поисковике. Похожая ситуация и с цитированием научной работы — чем больше статей на нее ссылаются, тем лучше. Продвижение сайта в поисковой системе позволяет привлечь больше реферального трафика, повысить узнаваемость бренда/предложения/продукта среди потенциальных клиентов. Благодаря правильно выстроенной концепции линкбилдинга ресурс можно позиционировать как информационный, а следовательно, способный отвечать на большее количество запросов, чем просто предоставление определенных услуг.
Какие основные методы наращивания массы ссылок?
Описанные методы лучше действуют в синергии. За основу всегда важно брать хороший контент самого ресурса и усовершенствовать его техническими SEO-инструментами.
Качественный контент
Самый главный инструмент линкбилдинга – это хороший контент, исчерпывающе отвечающий на вопросы пользователей. Он должен иметь четкую структуру, чтобы поисковой системе было легче понять, о чем идет речь на той или иной странице. Релевантный контент, связанный с другими темами, которые могут заинтересовать пользователей, повышает показатели сайта в глазах поисковой системы. Четкая структура, исчерпывающие ответы на вопросы, а также удобное оформление (абзацы, иллюстрации, схемы, интерактивные элементы) способствуют тому, что материал распространит все большее количество людей. В результате сайт действительно будет пользоваться популярностью среди пользователей и других ресурсов. Самое главное, чтобы ваш сайт приносил пользу. В таком случае ссылки не заставят долго себя ждать.
Приоритетность страниц
Хороший контент должна иметь любая страница. Но за высокие позиции по многим ключевым словам идет очень интенсивная борьба, поэтому оптимизировать все и сразу не получится. Просмотрите статистику вашего сайта и определите, у каких страниц самые высокие показатели. Пусть они станут приоритетной задачей по продвижению. Если они уже генерируют хороший трафик, вывести их в топ-10, по определенным словам, будет несколько проще. Если ваш ресурс хотя бы по одному из важных для вас ключевых слов выйдет на лидирующие позиции, другие тоже постепенно станут интересны пользователям.
Профиль ссылок конкурентов
Профиль ссылок ваших конкурентов в нише может очень многое рассказать о том, в какую сторону движется отрасль. Таким образом, можно быстрее сориентироваться, ресурсы какого типа охотнее размещают ссылки на сайты, подобные вашему. Не стоит следовать своим конкурентам буквально. Однако для понимания типов сайтов, с которыми можно взаимодействовать, такая тактика очень продуктивна. Она также позволяет понять, какие страницы (и, следовательно, какой тип контента) выводит ваших конкурентов на высокие места в выдаче. Таким образом, легче сориентироваться, с чего начинать оптимизацию собственного сайта.
Она также позволяет понять, какие страницы (и, следовательно, какой тип контента) выводит ваших конкурентов на высокие места в выдаче. Таким образом, легче сориентироваться, с чего начинать оптимизацию собственного сайта.
Получать ссылки можно и путем крауд-маркетинга (когда вы размещаете информацию о своих товарах или услугах на различных площадках, форумах, сайтах с рекомендациями). Здесь очень важно соблюдать баланс между рекламой продукта и ответом на запрос пользователей. Релевантные советы не спамового характера на сайтах или форумах могут существенно усилить профиль ссылки на ваш ресурс.
Не забывайте и о силе социальных сетей. Вирусность вашего контента и то, насколько он нравится пользователям, играет немаловажную роль для разнообразия самого профиля ссылок. Несмотря на то, что поисковики не могут учесть непосредственно ссылки в Facebook или Instagram, все же их наличие показывает Google или Bing, что пользователи знают о вашем ресурсе и охотно делятся им. Кроме того, через социальные сети можно усилить узнаваемость бренда. Как следствие, сайт будут искать гораздо чаще, ведь он уже «на слуху».
Как следствие, сайт будут искать гораздо чаще, ведь он уже «на слуху».
Откуда брать ссылки? Органически – путем взаимодействия с сайтами, которые видят ценность в том контенте, который вы предоставляете. Лучший способ – создавать качественный и релевантный контент и предлагать его размещение на платформах из вашей ниши. Будьте осторожны с обменом ссылок. Такая практика не приветствуется поисковиками. Однако если вы можете посоветовать свои услуги или знания там, где они нуждаются, такое сотрудничество способствует продвижению ресурса по необходимым ключевым словам.
Существует множество коммерческих способов наращивания массы ссылок. Они ограничены временем и бюджетом. Кроме того, они нуждаются и в определенных базовых знаниях SEO-оптимизации. Тогда ссылки действительно будут приносить пользу. Если у вас нет опыта, лучше обратиться за помощью к специалисту по SEO, который поможет вам избежать многих неудач и, в конце концов, штрафов со стороны Google.
Не имея опыта увеличивается вероятность:
- “сжигание SEO-бюджета на неэффективные ссылки;
- снижение стоимости сайта путём прикрепления некачественных ссылок;
- попадание под санкции ПС.

Остерегайтесь неестественных ссылок
Поисковые системы стали гораздо сложнее. Именно поэтому им гораздо проще фиксировать неестественные шаблоны ссылок. При этом процесс создания ссылок на страницы должен быть только одним из видов деятельности по поисковой оптимизации. Если не позаботимся об этом, сайт будет наказан алгоритмами Google и Яндекс.
Совет! Прежде чем начать активно закупать ссылки, сначала проверьте свой ресурс на предмет проблем с качеством и по возможности улучшите его содержание. Это более простое и дешевое вложение.
Есть ли ссылки на решение всех SEO проблем?
Точно нет. Вдобавок, умело применяя SEO на своем сайте, можно получить больше трафика по некоторым запросам даже без ссылок.
Занимаясь SEO-продвижением собственного ресурса, не забывайте, что в Интернете доминирует принцип рекомендаций. Создавая контент, задавайте себе вопрос, порекомендовали ли бы вы кому то, что пишете или делаете? Сочетайте качество с технической поддержкой и смело выходите на первые страницы поисковиков.
Поделиться Tweet
Раскрываем секреты правильного поиска необходимой информации в интернете
Набираешь запрос в гугле, а поисковик выдает сотню неподходящих ссылок вперемешку с рекламой. Знакомо? Давайте разберемся с Google: в поисковике есть несколько скрытых лайфхаков, которые сэкономят время.
Спрашивайте по-человечески
Конечно, поисковик — робот, но его уже давно научили понимать запросы на естественных языках. Поэтому формулируйте вопрос так, как задаете его человеку.
Неправильно: еда в Москве (получите массу ссылок: от ресторанов до супермаркетов и журналов).
Правильно: заказать еду с доставкой в Москве.
Используйте дополнительные инструменты поиска
Нажмите кнопку Tools (Инструменты) под поисковой строкой Google — появятся два раскрывающихся списка:
- Один из них, Time (Время), поможет выбрать временной интервал, который вам нужен.
Например, вас интересуют любая информация о Московском зоопарке, которая появилась в сети не раньше последнего месяца — выберите в списке Past month (последний месяц). Можно также выбрать произвольный интервал времени, например с 5 января по 23 апреля. Для этого нажмите Custom range и введите нужные даты вручную или с помощью календаря.
- Второй список, Verbatim (Дословно), позволяет выбрать из ответов только те, которые в точности соответствуют вашему запросу.
Эта функция полезна, когда гугл исправляет в вашем запросе ошибки, выдает похожие слова и синонимы, считает, что некоторые слова в вашем запросе не обязательны, и пропускает их. Ставьте галочку на Verbatim, чтобы поисковик не решал за вас.
Ставьте галочку на Verbatim, чтобы поисковик не решал за вас.
Используйте возможности расширенного поиска. Перейдите в меню Google [Settings – Advanced search]
Здесь можно указать:
- Должен ли результат содержать в точности все слова запроса.
- Должны ли в нём присутствовать (или отсутствовать) определённые слова.
- На каком языке должны быть данные.
- В каком регионе опубликованы.
- Когда обновлялись последний раз.
- В какой части страницы находятся (в заголовке, в тексте, в ссылке).
- Формат нужного документа.
- Нужно ли включить фильтр, который исключает из выдачи страницы, содержащие сексуальный контент.
Используйте операторы поиска
Существует ряд операторов поиска — символов, слов или их сочетаний, — которые позволяют настроить поиск очень точно. Все операторы, кроме «or» («или»), должны вводиться без пробела перед поисковым словом.
Все операторы, кроме «or» («или»), должны вводиться без пробела перед поисковым словом.
Поиск в социальных сетях
Введите перед словом символ @. Пример: Макдональдс@facebook.
Поиск цен
Введите перед суммой символ $. Пример: смартфон $500.
Поиск по хештегам
Введите перед словом символ #. Пример: #10yearchallenge.
Исключение результатов с определенными словами
Поставьте дефис (—) перед словом, которое нужно исключить. Пример: ласточка скорость — поезд.
Поиск точного слова или фразы
Поместите слово или фразу в кавычки. Пример: «выходные в Париже».
Поиск внутри числового диапазона
Введите .. между двумя числами. Пример: смартфон 3000..5000.
Объединение запросов
Введите OR между запросами. Пример: Москва OR столица РФ.
Поиск по определенному сайту
Введите site: перед адресом сайта или доменом. Пример: Кин-Дза-Дза site:youtube.com или закон о защите прав потребителей site:gov.ru.
Поиск сайтов с похожим содержанием
Введите related: перед нужным веб-адресом. Пример: related:forbes.ru.
Поиск кешированной версии сайта
Введите cache: перед адресом сайта.
Используйте специализированный поиск
У каждого поисковика есть собственная система вспомогательных сервисов, которая расширяет его возможности. Есть поиск по картинкам, по видео, по новостям — это знают все. Но предпринимателям гораздо больше пригодится, например, поиск по базе патентов.
Помните про полезные инструменты
С мобильных устройств Google предлагает возможности голосового и рукописного ввода. Активируйте их в настройках смартфона.
Страница не найдена
Страница не найдена
|
|
Пекин потребовал от Microsoft отключить «подсказки» в поисковике Bing
www.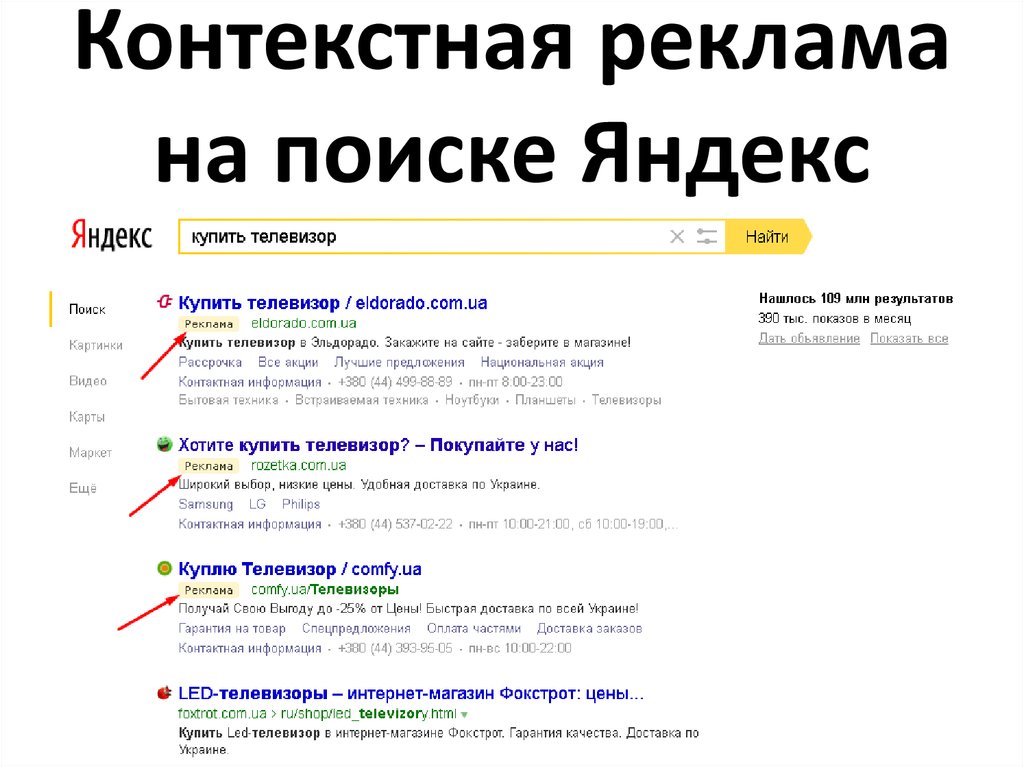 adv.rbc.ru
adv.rbc.ru
www.adv.rbc.ru
Инвестиции
Телеканал
Газета
Pro
Инвестиции
РБК+
Новая экономика
Тренды
Недвижимость
Спорт
Стиль
Национальные проекты
Город
Крипто
Дискуссионный клуб
Исследования
Кредитные рейтинги
Франшизы
Конференции
Спецпроекты СПб
Конференции СПб
Спецпроекты
Проверка контрагентов
РБК Библиотека
Подкасты
ESG-индекс
Политика
Экономика
Бизнес
Технологии и медиа
Финансы
РБК КомпанииРБК Life
www. adv.rbc.ru
adv.rbc.ru
Прямой эфир
Ошибка воспроизведения видео. Пожалуйста, обновите ваш браузер.
www.adv.rbc.ru
Фото: Shutterstock
Представители разработанной Microsoft Bing, единственной доступной в Китае крупной иностранной поисковой системы, заявили, что «соответствующее правительственное учреждение» потребовало от компании приостановить функцию автоподсказок на территории Китая на семь дней. Об этом сообщает Reuters.
В декабре Bing также была вынуждена временно отключить «подсказки» для пользователей из КНР. Причины приостановки работы компания не называет.
За последний год технологический сектор в Китае значительно пострадал от регулятивных мер Пекина, который ввел ряд новых ограничений в различных областях, начиная с создания контента и заканчивая политикой конфиденциальности.
Следите за новостями компаний в телеграм-канале «Каталог РБК Инвестиций»
Автор
Марина Стрельникова
Смотри на нашем YouTube-канале
Лидеры роста
Лидеры падения
Валюты
Товары
Индексы
Курсы валют ЦБ РФ
+14,61% ₽0,4 Купить «Энел Россия» ENRU
+11,11% $0,3 Купить VEON VEON
+9,4% $11,06 Купить Allogene ALLO
+8,76% ₽84,9 Купить НЛМК NLMK
+8,55% $11,94 Купить BioXcel BTAI
-22,33% $7,13 Купить Carnival CCL
-13,44% $38,12 Купить Royal Caribbean Cruises RCL
-8,77% ₽6 305 Купить «ФосАгро» PHOR
-8,65% ₽0,0028 Купить ТГК-2 TGKB
-8,26% $18,43 Купить Spirit Airlines SAVE
+2,72% ₽8,341 Купить CNY/RUB
+2,22% ₽56,700 Купить EUR/RUB
+2,17% ₽58,450 Купить USD/RUB
-0,29% $0,967 Купить EUR/USD
-20% ₽48,000 Купить GBP/RUB
— — Купить CHF/RUB
+2,25% $19,57 Silver +1,08% $1 681 GOLD +1,06% $908,8 Platinum -0,9% $88,7 BRENT
+0,18% 1 957,31 IMOEX +0,09% 790,17 IFX-Cbonds -1,34% 639,03 Индекс SPB100 -1,75% 1 055,72 RTSI
+2,13% ₽8,155 CNY
-3,68% ₽55,299 USD
-4,82% ₽52,738 EUR
Каталог
Начните инвестировать с профессионалами Подробнее
www.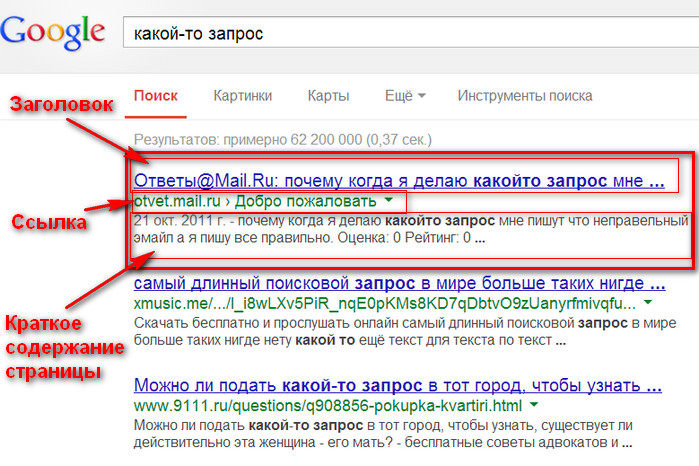 adv.rbc.ru
adv.rbc.ru
Чем DuckDuckGo лучше Google — Ведомости
Гэбриел Вайнберг: основатель поисковика DuckDuckGo / Getty Images
Слежка за пользователями в интернете и как ее избежать – модная тема. Apple, например, использует ее в маркетинге своих гаджетов – позиционирует их как безопасные. Но есть стартапы, которые давным-давно разыграли карту конфиденциальности. Казалось бы, как стать успешным на рынке поиска в интернете, если на нем доминирует Google? Эту задачу Microsoft с его Bing решил во многом благодаря деньгам плюс по умолчанию встраивает поисковик в другие свои продукты. А американец Гэбриел Вайнберг сделал конфиденциальность фишкой своего поисковика DuckDuckGo. Без шпионских штучек и с минимумом рекламы он занял прочное место на рынке, и он востребован. Да, с маленькой долей – 0,4% (здесь и далее данные по доле рынка – Statcounter). Но кто не мал в сравнении с Google (92,3%). А, например, с долей Yahoo! (1,6%) – сопоставимо. И стартап Вайнберга приносит ему прибыль.
Но кто не мал в сравнении с Google (92,3%). А, например, с долей Yahoo! (1,6%) – сопоставимо. И стартап Вайнберга приносит ему прибыль.
Ужастики Вайнберга
«Это миф, что поисковикам обязательно отслеживать вашу личную историю поиска, чтобы зарабатывать деньги или давать качественные результаты поиска, – рассказывает Вайнберг на сайте Quora. – Тот, кто заказывает рекламу в самом поисковике, покупает показы, основанные на словах запроса, а не профиле пользователя. Если вы ищете «машина», вы с большей вероятностью кликнете на объявление о машине, чем на рекламу того, что вы искали неделю назад, не так ли? Так почему же за вами следят? В Google ваши поиски отслеживают, извлекают и упаковывают в профиль – чтобы рекламодатели могли достать вас через огромные рекламные сети Google, встроенные в миллионы сайтов и приложений. Вот почему, стоит вам поискать что-то в Google, вы рискуете увидеть эту рекламу у себя везде: навязчивые, раздражающие, неистребимые баннерные объявления К сожалению, сейчас Google развертывает скрытые трекеры на 76% веб-сайтов, чтобы получать информацию о вашем поведении в интернете, а у Facebook есть скрытые трекеры примерно на 25% веб-сайтов – согласно отчету [в проекте Принстонского университета] Princeton Web Transparency & Accountability Project. Вполне вероятно, что Google и/или Facebook следят за вами на большинстве посещаемых вами сайтов». Дальше Вайнберг рассказывает страшилки, как могут быть использованы эти данные. От передачи «компаниям, о которых вы даже не слышали» до влияния на выборах.
Вполне вероятно, что Google и/или Facebook следят за вами на большинстве посещаемых вами сайтов». Дальше Вайнберг рассказывает страшилки, как могут быть использованы эти данные. От передачи «компаниям, о которых вы даже не слышали» до влияния на выборах.
Вайнберг умалчивает, что все эти данные поисковики передают в обезличенном виде. С другой стороны, в 2005 г. провайдер AOL случайно опубликовал детали поиска, выполненного 650 000 его пользователей через Google. А журналисты The New York Times наглядно показали, как на основе этой информации можно легко вычислить пользователя (в их случае это была 62-летняя женщина из штата Джорджия).
У Вайнберга много таких зловещих историй про интернет. Например, когда DuckDuckGo только появился, на странице с информацией о поисковике говорилось: слежка за пользователем может привести к тому, что онлайн-магазин станет предлагать вам один и тот же товар дешевле или дороже в зависимости от того, интересовались ли вы прежде люксовыми товарами или у вас потребительская корзина бедняка. Стоит вам однажды спросить, чем лечить лишай, как реклама средств против него полезет изо всех щелей, и любой человек, нечаянно взглянувший на экран компьютера или смартфона, догадается, чем вы болеете.
Стоит вам однажды спросить, чем лечить лишай, как реклама средств против него полезет изо всех щелей, и любой человек, нечаянно взглянувший на экран компьютера или смартфона, догадается, чем вы болеете.
Вайнберг предлагает эксперимент. Поставить рядом два компьютера – ваш и друга – и набирать в разных поисковиках один и тот же запрос. Как правило, результаты получатся разные. А вот в DuckDuckGo должны оказаться одинаковыми. Дело в так называемом пузыре фильтров – алгоритмах, запоминающих предыдущие поиски пользователя и ресурсы, которые он посещал. Эти алгоритмы пытаются угадать, какой сайт будет вам интереснее. С одной стороны, это может облегчить поиск. С другой – важная или противоречащая (по мнению компьютера) вашим взглядам информация может оказаться где-то в конце списка. «Если вы демократ, то будете видеть только статьи с сайта MSNBC, но никак не Fox», – подшучивает Вайнберг над американцами. DuckDuckGo не использует пузырь фильтров. Он не хранит данные пользователей: «Каждый раз, когда вы ищете на DuckDuckGo, вы здесь как будто впервые».
Как потерять друзей и деньги
Вайнберг родился 1 января 1979 г. Его отец – врач, специалист по инфекционным заболеваниям. Мать шила одежду и мастерила разные поделки. Первой работой Вайнберга как программиста была программа для мамы, обрабатывающая заказы онлайн. Он не был ботаником, в средней и старшей школе вовсю гонял в футбол, увлекался теннисом. Но, как и большинство ребят своего поколения, много времени проводил за компьютером, играя и программируя. А еще ему нравились естественные науки, особенно физика. Которую он изучил в Массачусетском технологическом институте (MIT). В аспирантуру, правда, не пошел.
Детская считалочка
Название DuckDuckGo появилось еще до того, как у Вайнберга возникла идея поисковика. Вайнберг гулял с женой, и ему пришло в голову: неплохо было бы назвать фразой из детской считалочки. В придумывании названий он явно не мастак и сильно удивился, когда жена впервые его похвалила.
Duck, Duck, Goose – разновидность салочек. Все садятся в круг. Ведущий ходит вдоль него, дотрагиваясь до головы каждого игрока. Пока он говорит «Утка» (Duck), все в порядке. Как только он произносит «Гусь» (Goose), тот, кого он в этот момент коснулся, должен встать и гоняться за ведущим, задача которого успеть занять освободившееся место утки до того, как его настигнут. Иначе ему снова ходить по кругу с этой считалочкой.
Ведущий ходит вдоль него, дотрагиваясь до головы каждого игрока. Пока он говорит «Утка» (Duck), все в порядке. Как только он произносит «Гусь» (Goose), тот, кого он в этот момент коснулся, должен встать и гоняться за ведущим, задача которого успеть занять освободившееся место утки до того, как его настигнут. Иначе ему снова ходить по кругу с этой считалочкой.
Первый стартап Вайнберг основал сразу после окончания MIT в 2000 г. «Мне повезло, бабушка оставила мне деньги на четыре года учебы. А я закончил за три года», – рассказывал он. Вдобавок он собрал деньги у друзей и родственников.
Назывался стартап ужасно, признает Вайнберг: Learnection («мне никогда не давались названия»). Впрочем, названия явно не самая сильная его сторона. Это была социальная сеть, направленная на вовлечение родителей в школьные дела. Преподаватели делились планами уроков, родители обсуждали учебные проблемы. На эту затею Вайнберг потратил 2,5 года, но ничего не вышло. Сделан сайт был криво. Идея явно опережала время – с ней стоило подождать, пока компьютеры не проникнут в общество сильнее. «К тому же я нанял друзей, потому что они мне нравились, хотя не подходили для проекта, – рассказывал Вайнберг. – Они ушли через год». Он потерял $30 000–45 000 только своих денег. Попытался продать стартап одной некоммерческой организации. Не смог, зато устроился туда наемным работником, чтобы было на что жить.
«К тому же я нанял друзей, потому что они мне нравились, хотя не подходили для проекта, – рассказывал Вайнберг. – Они ушли через год». Он потерял $30 000–45 000 только своих денег. Попытался продать стартап одной некоммерческой организации. Не смог, зато устроился туда наемным работником, чтобы было на что жить.
Одноклассники по-американски
Работая в штате, Вайнберг продолжал грезить о стартапе. Новой идеей стал прообраз социальной сети под названием NamesDatabase (опять совсем не зажигательным). Был замысел сделать в интернете адресную книгу с именами, телефонами, адресами и электронной почтой всех жителей США. Люди, которые ищут одноклассников, друзей, с которыми потерялась связь, должны были зарегистрироваться и ввести свои данные – так наращивалась база. А чтобы отправить кому-то личное сообщение, требовалось заплатить.
Чтобы проверить, как сработает идея, Вайнберг выдумал список людей, якобы уже зарегистрировавшихся, – из комбинаций самых популярных имен и фамилий. В те годы Google потребовалось шесть месяцев, чтобы проиндексировать новый сайт и начать показывать его в выдаче результатов поиска. Через полгода NamesDatabase вдруг стал получать 10 000 запросов в день – люди искали друг друга через Google, а этот сайт появлялся в результатах поиска одним из первых. Настоящего продукта еще не было, а первые пользователи уже зарегистрировались на NamesDatabase. Когда там стали появляться реальные данные, этот поток вырос.
В те годы Google потребовалось шесть месяцев, чтобы проиндексировать новый сайт и начать показывать его в выдаче результатов поиска. Через полгода NamesDatabase вдруг стал получать 10 000 запросов в день – люди искали друг друга через Google, а этот сайт появлялся в результатах поиска одним из первых. Настоящего продукта еще не было, а первые пользователи уже зарегистрировались на NamesDatabase. Когда там стали появляться реальные данные, этот поток вырос.
«Сейчас это совершенно архаичная концепция, учитывая Facebook, – признает Вайнберг. – Но все случилось между 2003 и 2006-м». (Facebook основан в 2004 г.) У его проекта были шансы – однако он стал безнадежно проигрывать в популярности детищу Марка Цукерберга. К 2006 г. у NamesDatabase было около 50 000 платных пользователей, а в Facebook зарегистрировалось около 7 млн бесплатных.
Как-то Вайнберг задумался, почему NamesDatabase так медленно развивается. Он уверяет, что вывод оказался для него парадоксальным – неинтересно. «Я не создан для соцсети.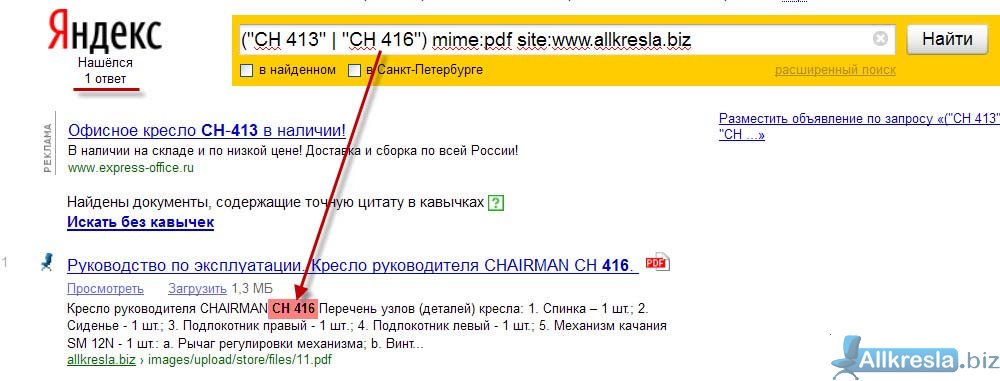 Хотелось работать над чем-то, чем восхищаюсь и чему могу посвятить десять или больше лет». Он продал NamesDatabase в 2006 г. за $10 млн соцсети Classmates.com («Одноклассники» – англ.). Той был всего год от роду, и она отчаянно нуждалась в резком росте пользовательской базы.
Хотелось работать над чем-то, чем восхищаюсь и чему могу посвятить десять или больше лет». Он продал NamesDatabase в 2006 г. за $10 млн соцсети Classmates.com («Одноклассники» – англ.). Той был всего год от роду, и она отчаянно нуждалась в резком росте пользовательской базы.
Сколько калорий в банане
Вайнберг стал миллионером в 27 лет. Незадолго до этого он женился. Первой большой тратой стал переезд. Молодожены не хотели жить в большом городе и уехали в городок Паоли – это примерно 30 миль от Филадельфии и несколько минут ходьбы от национального парка Вэлли-Фордж. Когда родились дети, Вайнберг обустроил рядом с компьютерным столом зону с игрушками, чтобы они играли рядом, пока он работает. The Washington Post писала, что его визиты в Кремниевую долину можно пересчитать по пальцам и его почти не встретить на больших технологических конференциях. «Там не очень-то все ориентировано на семью, – объяснял Вайнберг. – А моей целью никогда не было стать Марком Цукербергом. Я всегда хотел сделать что-то интересное и уникальное».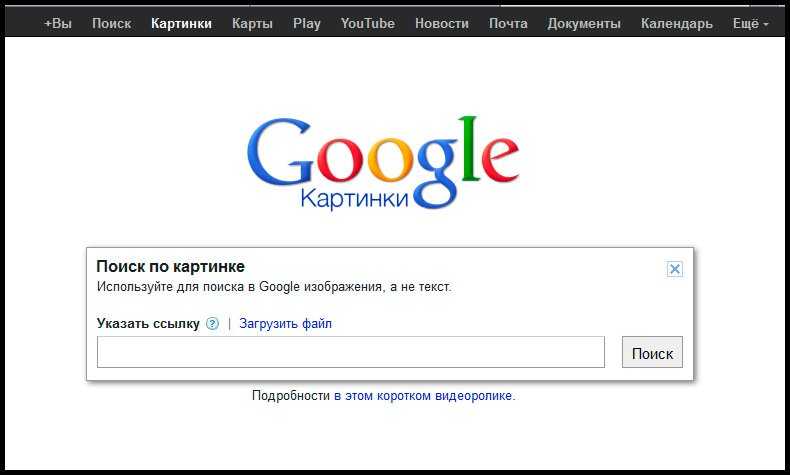
Вот только больших идей у него не было. Он кое-что пробовал. Сделал Groupomatic – аналог сервиса Meetup.com, который предлагает находить себе друзей по интересам. Kangadoo – фотосервис для бабушек и дедушек. Nth Club – cоцсеть для гольфистов, от которой была одна головная боль: Вайнберг ничего не понимал в гольфе и сам толком не мог объяснить, зачем с ним связался. Пробовал даже идею генеалогического древа онлайн.
Замысел поисковика пришел случайно, вспоминал Вайнберг. Сходил на мастер-класс по изготовлению витражей, а в конце получил от преподавателя листок с самыми полезными ссылками по предмету. Дома он поискал про витражи в Google и не обнаружил в топе выдачи ни одной из этих ссылок.
Первой его мыслью было создать поисковик, в котором легко искать, – ответ должен находиться в первых же двух-трех ссылках: «Я пытался улучшить свои результаты в Google. Удалить спам – в то время в выдаче было много результатов не по делу. Добавил мгновенные ответы».
У него не было достаточно сил для создания поисковой системы с нуля.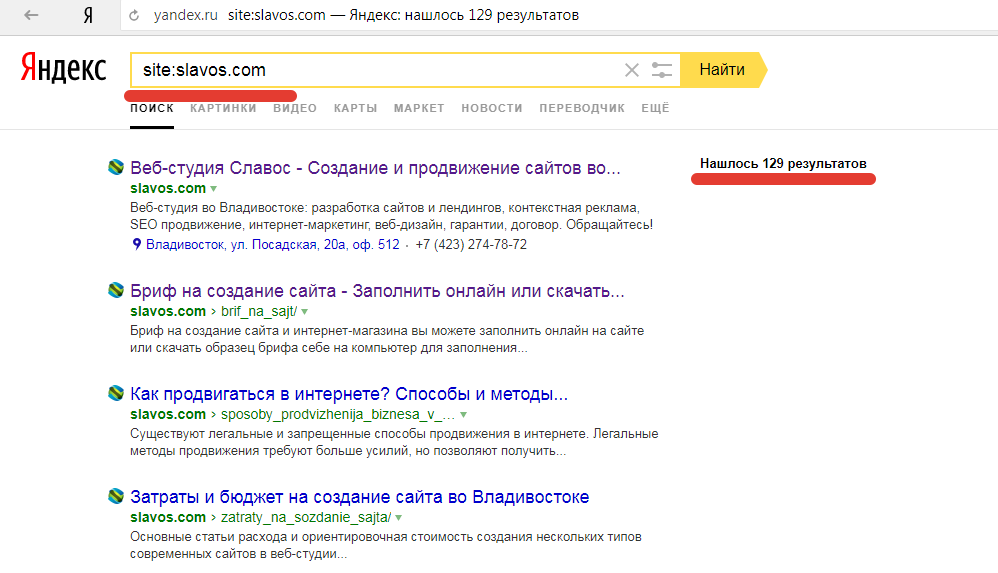 Вайнберг решил агрегировать данные из других источников и сделать фильтр, который выдавал бы наверх самое полезное. В 2008 г. DuckDuckGo был запущен. Когда кто-то вбивал запрос, поисковик запрашивал результаты по этим словам у «Википедии», поисковика Yahoo!, сервиса Yelp, который ищет расположенные по соседству с вами заведения вроде парикмахерских и ресторанов, и у других ресурсов. Результат выдавался по релевантности запроса, пристрастиями пользователей поисковик не интересовался.
Вайнберг решил агрегировать данные из других источников и сделать фильтр, который выдавал бы наверх самое полезное. В 2008 г. DuckDuckGo был запущен. Когда кто-то вбивал запрос, поисковик запрашивал результаты по этим словам у «Википедии», поисковика Yahoo!, сервиса Yelp, который ищет расположенные по соседству с вами заведения вроде парикмахерских и ресторанов, и у других ресурсов. Результат выдавался по релевантности запроса, пристрастиями пользователей поисковик не интересовался.
Как замечает The Washington Post, кое в чем DuckDuckGo опередил другие поисковики. Восемь лет назад в Google вы на запрос «калории в банане» получили бы страницу со ссылками на банан, а в DuckDuckGo – мгновенный ответ: «105 калорий», взятый из базы данных WolframAlpha. Сейчас крупные поисковики исправились и тоже выдают первым же результатом количество калорий.
Как продвигался DuckDuckGo
О приватности Вайнберг поначалу не думал. Ему просто не пришло в голову, что можно встроить в поисковик функцию по отслеживанию пользователей. Реклама Google и Bing шла даже по телевидению. У Вайнберга таких денег не было. Он начал с поисковой оптимизации, чтобы на слово «поисковик» или «новый поисковик» в результатах поиска Google одной из первых показывалась ссылка на DuckDuckGo. Это привлекло не очень многих. Затем был опробован контент-маркетинг: сначала блоги с рассказами об ужасах слежки и преимуществах DuckDuckGo, потом несколько небольших сайтов на эту тему, оптимизированные так, что поднимались довольно высоко в поиске у конкурентов.
Реклама Google и Bing шла даже по телевидению. У Вайнберга таких денег не было. Он начал с поисковой оптимизации, чтобы на слово «поисковик» или «новый поисковик» в результатах поиска Google одной из первых показывалась ссылка на DuckDuckGo. Это привлекло не очень многих. Затем был опробован контент-маркетинг: сначала блоги с рассказами об ужасах слежки и преимуществах DuckDuckGo, потом несколько небольших сайтов на эту тему, оптимизированные так, что поднимались довольно высоко в поиске у конкурентов.
В 2009 г., через год после запуска DuckDuckGo, у Вайнберга родился первый из двух детей. Он решил работать из дома и ухаживать за малышом. Первые годы Вайнберг, не торопясь, возился с поисковиком в одиночку. В 2011 г. ему удалось найти инвестора – $3 млн дала Union Square Ventures. Ее руководитель как-то признался, что инвестировал не потому, что верил в победу DuckDuckGo над Google, а потому, что «всем нужен поисковик, заботящийся о конфиденциальности»: «Мы сделали это ради всех интернет-анархистов».
На полученные деньги Вайнберг нанял первых программистов и открыл офис. А $7000 пустил на месячную аренду огромного билборда в Сан-Франциско. На нем был логотип DuckDuckGo и провокационная надпись: «Google следит за вами, мы – нет». В обществе тема входила в моду. О компании буквально в первый день написали Wired, USA Today и другие издания. Популярность DuckDuckGo стала расти, и уже в августе 2011 г. журнал Time включил DuckDuckGo.com в список 50 лучших сайтов года.
В конце января 2012 г. DuckDuckGo обрабатывал около 600 000 поисковых запросов в день. К середине февраля эта цифра впервые пробила 1 млн. Оказалось, спасибо за это надо говорить Google. 25 января поисковик изменил политику конфиденциальности. Разные его сервисы – поиск, почта, соцсети и т. д. – могли отныне обмениваться данными о пользователях. Это вызвало огромный шум в интернете, который подхватили СМИ. Популярность DuckDuckGo, который наотрез отказывался сохранять данные пользователей, подскочила. На него обратили внимание СМИ уровня The Washington Post.
Следующий подарок преподнес Эдвард Сноуден. В июне 2013 г. DuckDuckGo получал около 1,7 млн запросов в день. А к концу года, после разоблачений Сноудена, – почти 4 млн. Тревог по поводу слежки с тех пор меньше не стало. Сейчас DuckDuckGo обрабатывает в среднем около 53 млн запросов в сутки – 1,6 млрд в месяц.
Как зарабатывает DuckDuckGo
«DuckDuckGo приносит прибыль с 2014 г. – без хранения или передачи какой-либо личной информации о пользователях, – уверяет Вайнберг. – То, что вы ищете на DuckDuckGo, тайна даже для нас!»
Его поисковик зарабатывает двумя способами. Это реклама, которая показывается на основе ключевых слов из поиска. Если ввести «стиральная машина» – покажут баннер магазина стиральных машин. Это партнерские доходы. Если с DuckDuckGo перейти на сайт Amazon или eBay и чего-нибудь купить, стартап получит от этих компаний небольшую комиссию, а эти два онлайн-магазина не увидят никаких данных клиента, клянется Вайнберг.
DuckDuckGo – непубличная компания и не раскрывает показатели. Сайт FourWeekMBA оценивал ее выручку в 2015 г. более чем в $1 млн. В 2018 г. Forbes писал уже о $25 млн. Сейчас у проекта 83 сотрудника.
Сайт FourWeekMBA оценивал ее выручку в 2015 г. более чем в $1 млн. В 2018 г. Forbes писал уже о $25 млн. Сейчас у проекта 83 сотрудника.
DuckDuckGo поддерживают ресурсы вроде Tor – браузера, который устанавливает анонимное сетевое соединение и позволяет, например, китайцам посещать заблокированные в этой стране сайты. В Tor поисковиком по умолчанию установлен DuckDuckGo. С 2014 г. можно установить его поисковиком по умолчанию и на гаджетах Apple, и в браузерах – тех же Firefox, Chrome.
Сам DuckDuckGo поддерживает проекты по свободному интернету деньгами. В 2019 г., например, он пожертвовал $600 000 организациям, которые борются за права пользователей интернета. Часть из них досталась браузеру Tor.
«Меня никогда не интересовало, как максимизировать доход, – как-то сказал Вайнберг. – Мне нравится модель Craigslist. Работай с минимальными затратами. Сосредоточься на том, что ты делаешь хорошо». С другой стороны, он говорит, что постоянно ищет новые способы заработать, не связываясь с рекламой и слежением. Например, обдумывал такую идею: раз конфиденциальность так важна, почему не поэкспериментировать с анонимным поиском по подписке. В конце концов, кто сказал, что поиск вообще должен быть бесплатным?
Например, обдумывал такую идею: раз конфиденциальность так важна, почему не поэкспериментировать с анонимным поиском по подписке. В конце концов, кто сказал, что поиск вообще должен быть бесплатным?
Поиск с помощью поисковой системы // Purdue Writing Lab
Резюме:
Этот раздел посвящен поиску информации в Интернете. Он включает информацию о поисковых системах, логических операторах, веб-каталогах и невидимой сети. Он также включает обширный аннотированный раздел ссылок.
Поисковая система — это устройство, которое отправляет запросы на сайты в Интернете и каталогизирует любой веб-сайт, который он встречает, без его оценки. Методы запроса различаются от поисковой системы к поисковой системе, поэтому результаты, сообщаемые каждой из них, также будут различаться. Поисковые системы хранят невероятно большое количество сайтов в своих архивах, поэтому вы должны ограничить условия поиска, чтобы не оказаться перегруженным неуправляемым количеством ответов.
Поисковые системы хороши для поиска источников по четко определенным темам. Ввод общего термина, такого как «образование» или «Шекспир», приведет к слишком большому количеству результатов, но, сузив тему, вы сможете получить необходимую вам информацию (и объем).
Пример:
- Перейти на Google (поисковая система)
- Введите общий термин («образование»)
- Добавьте модификаторы, чтобы уточнить и сузить тему («Образование в сельских районах Индианы»)
- Будьте как можно конкретнее («сельское образование, начальная школа Индианы»)
- Отправьте запрос.
Скорректируйте поиск в зависимости от количества полученных вами ответов (если вы получили слишком мало ответов, выполните более общий поиск; если вы получили слишком много, добавьте больше модификаторов).
Узнайте, как работает поисковая система
Прочтите инструкции и часто задаваемые вопросы, расположенные в поисковой системе, чтобы узнать, как работает конкретный сайт. Каждая поисковая система немного отличается, и несколько минут обучения правильному использованию сайта сэкономят вам много времени и предотвратят бесполезный поиск.
Каждая поисковая система немного отличается, и несколько минут обучения правильному использованию сайта сэкономят вам много времени и предотвратят бесполезный поиск.
Каждая поисковая система имеет свои преимущества. Google — одна из крупнейших поисковых систем, за ней следуют MSN и Yahoo . Это означает, что эти три поисковые системы будут выполнять поиск в большей части Интернета, чем другие поисковые системы. Lycos позволяет выполнять поиск по региону, языку и дате. Ask позволяет сформулировать условия поиска в форме вопроса. Целесообразно использовать несколько поисковых систем, чтобы найти наиболее доступную информацию.
Тщательно выбирайте термины
Использование неточных или слишком общих терминов вызовет у вас проблемы. Если ваши термины слишком широкие или общие, поисковая система может их не обработать. Поисковые системы запрограммированы различными списками слов, которые дизайнеры определили настолько общими, что поиск выдаст сотни тысяч ссылок.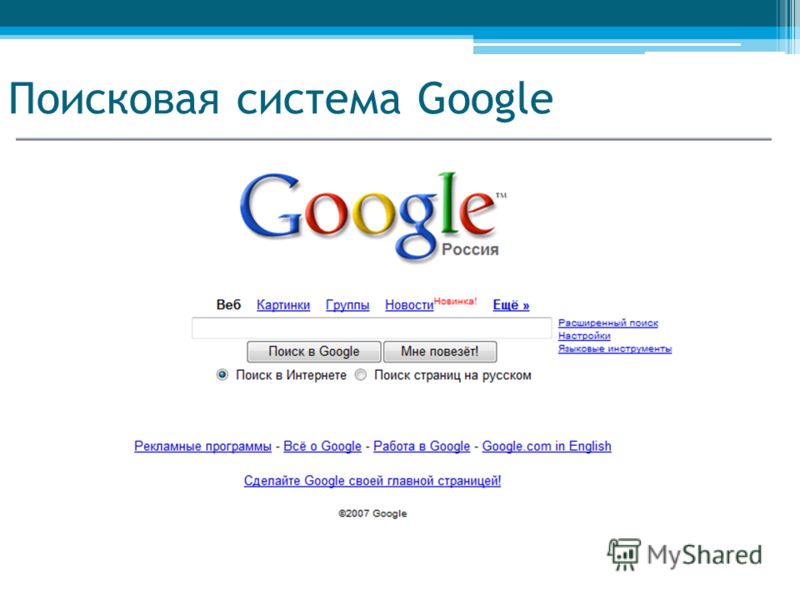 Проверьте поисковую систему, чтобы увидеть, есть ли у нее список таких стоп-слов . Одним из стоп-слов, например, является «компьютеры». Некоторые поисковые системы позволяют вам искать стоп-слова с определенным кодом (для Google ввод «+» перед словом позволяет вам искать его).
Проверьте поисковую систему, чтобы увидеть, есть ли у нее список таких стоп-слов . Одним из стоп-слов, например, является «компьютеры». Некоторые поисковые системы позволяют вам искать стоп-слова с определенным кодом (для Google ввод «+» перед словом позволяет вам искать его).
Если ваши ранние поиски выдают слишком много ссылок, попробуйте поискать некоторые релевантные, чтобы найти более конкретные или точные термины. Вы можете начать комбинировать эти конкретные термины с НЕ (см. раздел о логических операторах ниже), когда увидите, какие термины встречаются в ссылках, не относящихся к вашей теме. Другими словами, продолжайте уточнять свой поиск по мере того, как вы узнаете больше об условиях.
Вы также можете попытаться уточнить свои термины, заглянув в онлайн-каталог библиотеки. Например, отметьте THOR+ , онлайн-каталог библиотеки Университета Пердью, и попробуйте выполнить поиск по их тематическому слову. Или попробуйте поискать термин в онлайн-базах данных в библиотеке.
Большинство поисковых систем теперь имеют функцию «Расширенный поиск». Эти функции позволяют использовать логические операторы (ниже), а также указывать другие данные, такие как дата, язык или тип файла.
Знать логические операторы
Большинство поисковых систем позволяют комбинировать термины со словами (называемые логическими операторами), такими как «и», «или» или «не». Знание того, как использовать эти термины, очень важно для успешного поиска. Большинство поисковых систем позволяют применять логические операторы в опции «расширенного поиска».
И
И — самый полезный и самый важный термин. Он говорит поисковой системе найти ваше первое слово И ваше второе слово или термин. И, однако, может вызвать проблемы, особенно когда вы используете его с фразами или двумя терминами, каждый из которых является широким сам по себе или может использоваться вместе в других контекстах.
Например, если вы хотите получить информацию о баскетбольной команде «Чикаго Буллз» и ввести «Чикаго И Быки», вы получите ссылки на Чикаго и «Буллз». Поскольку Чикаго является центром крупной мясоперерабатывающей промышленности, многие ссылки будут об этом, поскольку вполне вероятно, что «Чикаго» и «бык» будут появляться во многих ссылках, относящихся к мясоперерабатывающей промышленности.
Поскольку Чикаго является центром крупной мясоперерабатывающей промышленности, многие ссылки будут об этом, поскольку вполне вероятно, что «Чикаго» и «бык» будут появляться во многих ссылках, относящихся к мясоперерабатывающей промышленности.
OR
Используйте OR, когда ключевой термин может использоваться двумя разными способами.
Например, если вам нужна информация о синдроме внезапной детской смерти, попробуйте «синдром внезапной детской смерти ИЛИ СВДС».
ИЛИ не всегда является полезным термином, потому что вы можете найти слишком много комбинаций с ИЛИ. Например, если вам нужна информация об американской экономике и вы наберете «американская экономика ИЛИ», вы получите тысячи ссылок на документы, содержащие слово «американская», и тысячи не связанных со словом «экономика».
NEAR
NEAR — это термин, который можно использовать только в некоторых поисковых системах, и он может быть очень полезным. Он указывает поисковой системе находить документы с обоими словами, но только тогда, когда они появляются рядом друг с другом, обычно в пределах нескольких слов.
Например, предположим, что вы ищете информацию о домах на колесах, почти на каждом сайте есть уведомление «щелкните здесь, чтобы вернуться на домашнюю страницу». Поскольку «дом» появляется на многих сайтах, поисковая система будет сообщать о ссылках на сайты со словом «мобильный» и «нажмите здесь, чтобы вернуться на домашнюю страницу», поскольку оба термина появляются на странице. Использование NEAR устранило бы эту проблему.
NOT
NOT указывает поисковой системе найти ссылку, содержащую один термин, но не содержащую другой. Это полезно, когда термин относится к нескольким понятиям.
Например, если вы работаете над информационной статьей об орлах, вы можете столкнуться с множеством веб-сайтов, на которых вместо этого обсуждается футбольная команда Philadelphia Eagles. Чтобы исключить футбольную команду из результатов поиска, вы можете ввести фразу «Иглз НЕ Филадельфия».
10 шагов к тому, чтобы вас нашли в поисковых системах
Давайте проведем эксперимент. Перейдите в Google и введите наиболее часто используемую версию названия вашей организации. Появляетесь ли вы первым в полученном списке сайтов? Что, если вы наберете короткую фразу, описывающую тип работы, которой вы хотели бы быть известны? Появляетесь ли вы на верхней странице этих результатов поиска?
Перейдите в Google и введите наиболее часто используемую версию названия вашей организации. Появляетесь ли вы первым в полученном списке сайтов? Что, если вы наберете короткую фразу, описывающую тип работы, которой вы хотели бы быть известны? Появляетесь ли вы на верхней странице этих результатов поиска?
Ваша позиция в поисковых системах, таких как Google или Yahoo Search, важна. Как минимум, вашим нынешним избирателям должно быть легко найти ваш сайт по названию вашей организации. Появление на первой странице результатов поиска по ключевым словам — например, что-то вроде «приют для женщин в Цинциннати», если это относится к вашей организации — также может иметь огромное значение в посещаемости вашего сайта, не говоря уже о потенциальных донорах, волонтерах, и способность клиентов найти вас и связаться с вами.
У вас нет полного контроля над тем, где и как ваш веб-сайт отображается в поисковых системах, но у вас больше власти, чем вы думаете. Процесс настройки сайта и охвата, который используется для повышения вашего положения в поисковых системах, называется поисковой оптимизацией (или сокращенно SEO ). Хотя SEO часто описывают таким образом, что это кажется мистической формой искусства, на самом деле ни один из ключевых шагов не является особенно трудным для понимания. Однако они часто занимают много времени, и для большинства из них требуется, по крайней мере, возможность обновлять текст вашего сайта, если не базовые навыки HTML .
Хотя SEO часто описывают таким образом, что это кажется мистической формой искусства, на самом деле ни один из ключевых шагов не является особенно трудным для понимания. Однако они часто занимают много времени, и для большинства из них требуется, по крайней мере, возможность обновлять текст вашего сайта, если не базовые навыки HTML .
Потратив время на сравнительно простые задачи, такие как включение ключевых фраз в заголовки и заголовки, можно получить существенные преимущества. Ниже мы предлагаем 10 шагов, которые могут помочь поисковым системам найти контент вашего сайта и определить его приоритетность. Хотя некоторые шаги являются более техническими, чем другие, эти концепции могут помочь любому понять и расставить приоритеты поисковой оптимизации для своей организации.
Краеугольным камнем любой стратегии оптимизации — или просто хорошей стратегии веб-сайта, если уж на то пошло, — является большое количество актуальной информации, предназначенной для тех, кого вы хотите привлечь на свой сайт. Большой объем высококачественного контента помогает выполнить ряд перечисленных ниже шагов — например, у вас больше шансов получить информацию, полезную для любого конкретного человека, у вас больше шансов включить ключевые фразы, которые интересуют людей. поиск, и другие сайты с большей вероятностью будут ссылаться на ваш.
Большой объем высококачественного контента помогает выполнить ряд перечисленных ниже шагов — например, у вас больше шансов получить информацию, полезную для любого конкретного человека, у вас больше шансов включить ключевые фразы, которые интересуют людей. поиск, и другие сайты с большей вероятностью будут ссылаться на ваш.
Не говоря уже о том, что потрясающий сайт с большей вероятностью привлечет людей, которые найдут вас через поисковые системы, и побудит их стать не только постоянными посетителями, но и друзьями вашей организации.
2. Помогите поисковым системам найти ваш сайт
Поисковые системы считывают огромные объемы информации в Интернете с помощью программ, называемых «роботами» или «пауками» (поскольку они перемещаются или «ползают» по сети). Эти пауки создают индекс, который содержит, по сути, все найденные ими страницы и содержащиеся на них слова.
Вам необходимо убедиться, что ваш веб-сайт включен в эти индексы. Вы можете легко проверить, проиндексирован ли ваш сайт индексом Google, выполнив поиск «site:www. yourdomain.org», т. е. site:www.idealware.org. Этот поиск покажет список всех страниц вашего сайта, включенных в индекс Google (в идеале, каждую страницу вашего сайта).
yourdomain.org», т. е. site:www.idealware.org. Этот поиск покажет список всех страниц вашего сайта, включенных в индекс Google (в идеале, каждую страницу вашего сайта).
Если вы не включены в индексы — например, если у вас есть новый веб-сайт или сайт с малой посещаемостью — ни один из приведенных ниже шагов не принесет пользы, пока вы не попадете. Как вы попадаете в список? Вы можете отправить свой сайт в поисковые системы — например, в Google или Yahoo, — но эксперты расходятся во мнениях относительно того, насколько это полезно. Конечно, это не быстрый способ быть включенным.
Лучше сделать так, чтобы другие проиндексированные сайты ссылались на ваш. Вы можете начать это с огромных каталогов общего интереса, таких как каталог DMOZ, но вы, вероятно, добьетесь большего или большего успеха с каталогами или списками, связанными с вашей областью. Есть ли онлайн-справочник детских сервисных организаций? Есть ли в вашем United Way список местных организаций? Есть ли у ваших спонсоров список грантополучателей онлайн? Любой из них (или, в идеале, все из них, как описано в следующем разделе) может предоставить ссылку, которую необходимо проиндексировать.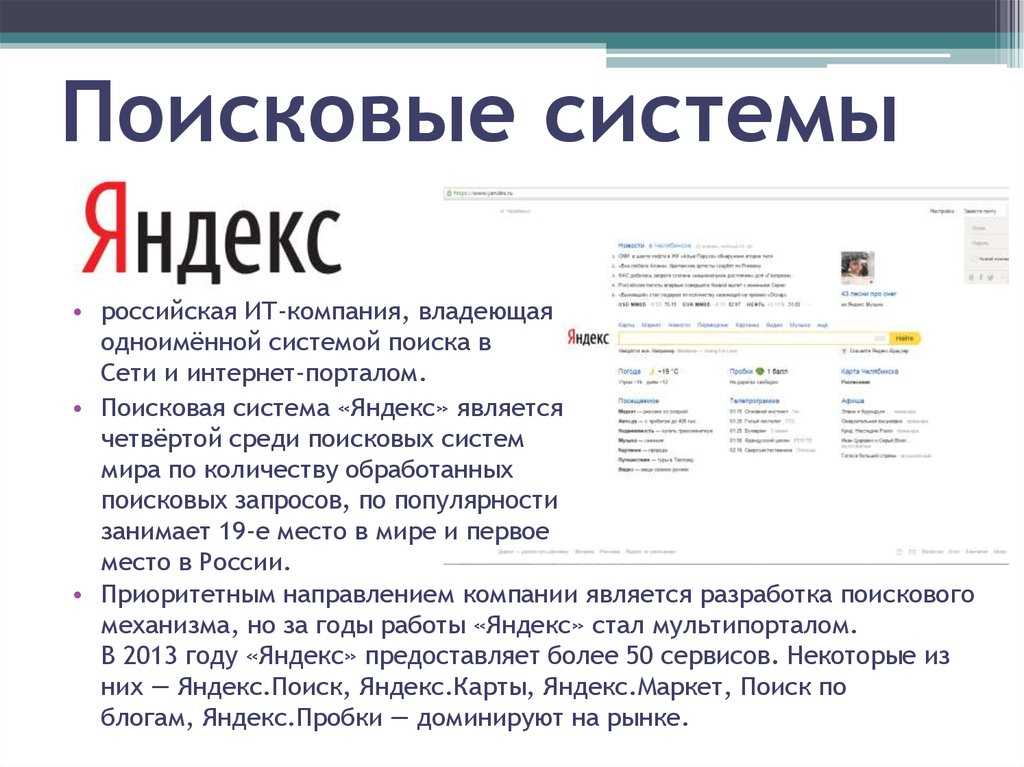
Некоторые онлайн-сервисы заявляют, что они автоматически отправят вас во множество каталогов и поисковых систем. Как правило, они не стоят денег, поскольку неизбирательные списки не так полезны, как те, которые ориентированы на ваш сектор.
Ссылки с других сайтов на ваш являются важным аспектом поисковой оптимизации. Пара ссылок поможет поисковым системам найти ваши сайты, но большое количество ссылок покажет им, что ваш сайт является центральным и важным ресурсом по определенным темам.
Чем больше у вас входящих ссылок от заслуживающих доверия организаций (то есть организаций, которые сами занимают высокие позиции в поисковых системах), тем выше вы будете в результатах поиска. Чтобы проверить ссылки, проиндексированные Google для вашего сайта, введите «link:www.yourdomain.org» в строку поиска Google. Результирующий список не включает все ссылки со всех сайтов, но является ориентиром для приблизительного количества качественных ссылок.
Как заставить людей ссылаться на вас? Как мы упоминали выше, вероятно, есть ряд организаций, у которых есть список организаций, подобных вашей. Убедитесь, что вы включены во все соответствующие каталоги, это хорошее начало. Посмотрите, будут ли партнерские организации ссылаться на вас. Выполните поиск по фразам, по которым вы хотите, чтобы вас нашли, и поищите способы заставить организации, находящиеся в верхней части результатов поиска, ссылаться на вас. Подумайте о контенте, который вы могли бы предоставить — возможно, отчеты, статьи, наборы инструментов, каталоги — это было бы настолько полезно, что организации были бы заинтересованы в том, чтобы ссылаться на него.
Убедитесь, что вы включены во все соответствующие каталоги, это хорошее начало. Посмотрите, будут ли партнерские организации ссылаться на вас. Выполните поиск по фразам, по которым вы хотите, чтобы вас нашли, и поищите способы заставить организации, находящиеся в верхней части результатов поиска, ссылаться на вас. Подумайте о контенте, который вы могли бы предоставить — возможно, отчеты, статьи, наборы инструментов, каталоги — это было бы настолько полезно, что организации были бы заинтересованы в том, чтобы ссылаться на него.
4. Определите ключевые слова, по которым вы хотели бы быть найдены
До сих пор мы говорили о том, как люди могут найти ваш сайт в целом, но маловероятно, что люди будут искать конкретно ваш сайт. Они с гораздо большей вероятностью будут искать полезную информацию или ресурс по определенной теме, которую они идентифицируют, вводя первые слова, которые приходят им на ум, когда они думают об этой теме, известной как ключевых слов в поисковой оптимизации.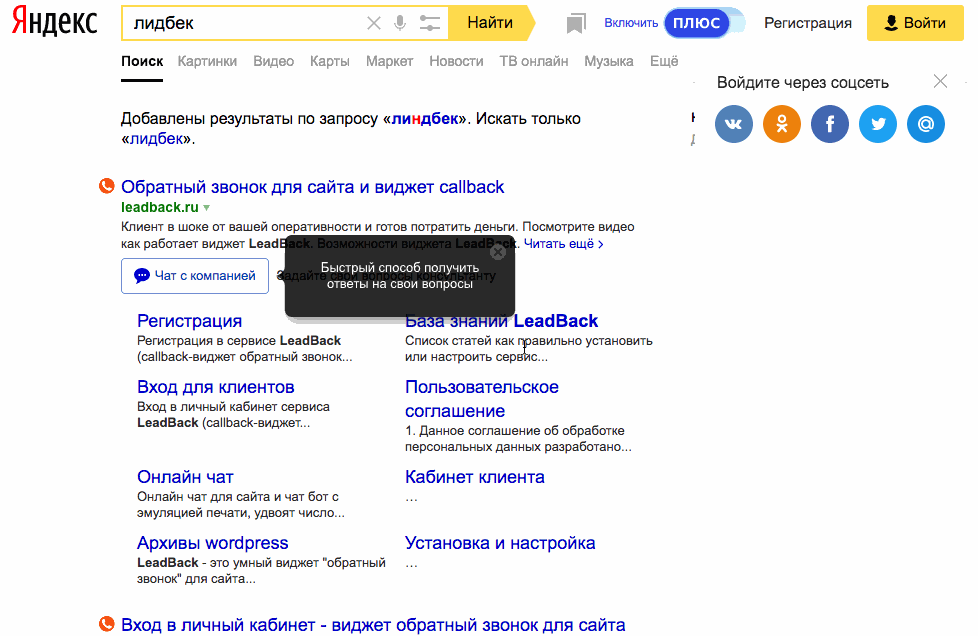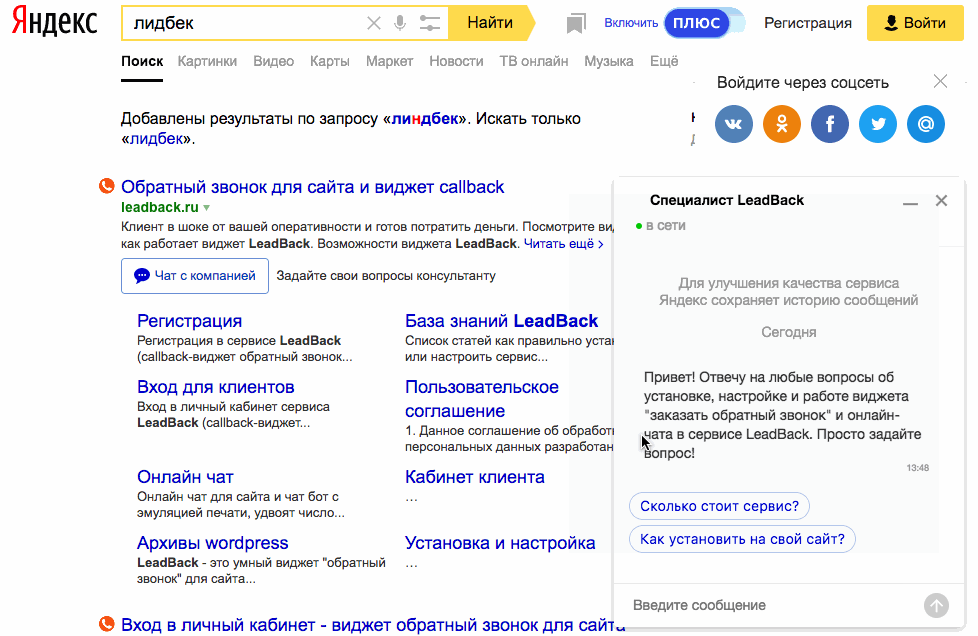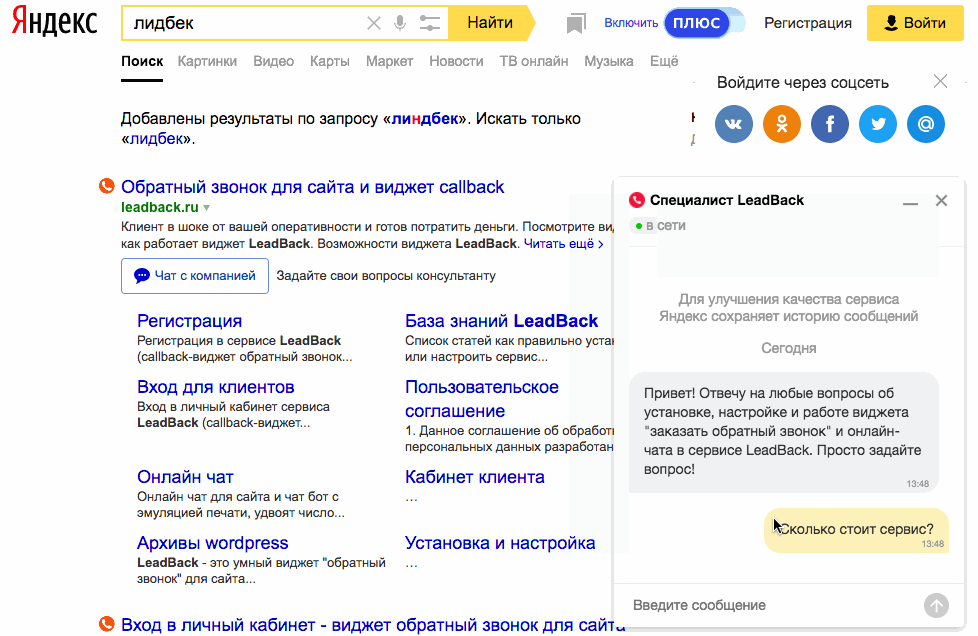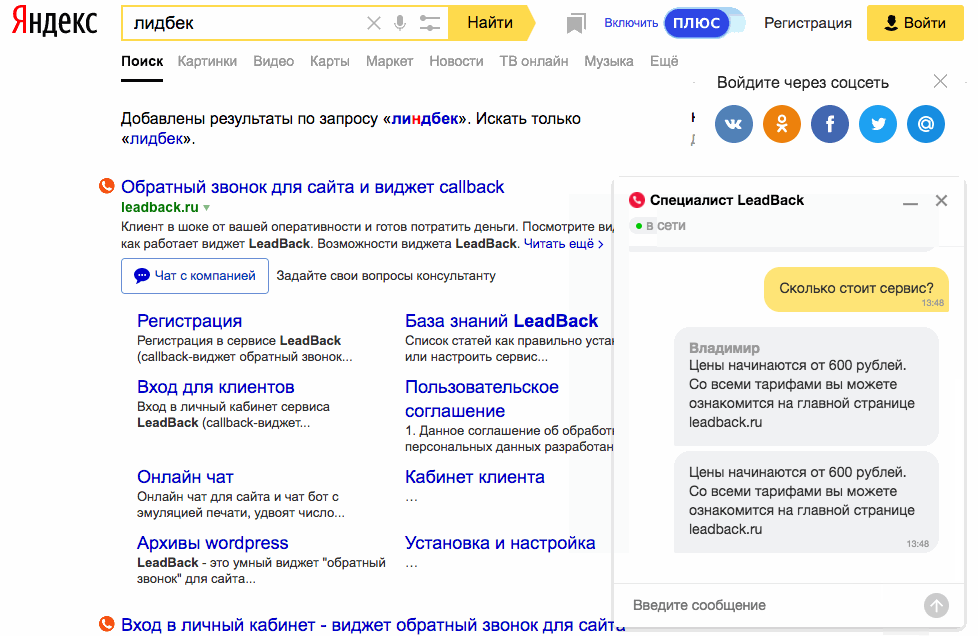 жаргон.
жаргон.
Определение ключевых слов, которые люди могут использовать и по которым вы хотели бы быть найдены, является важным шагом в поисковой оптимизации. В идеале вы должны продумать ключевые слова не только для вашей организации в целом, но и для каждой страницы контента, которая может содержать полезную информацию для вашей целевой аудитории. Например, «приют для женщин в Цинциннати» может привести людей к вашей организации, но если вы предлагаете содержательный контент на своем сайте, поиск по «признакам домашнего насилия» также может привести к вам.
Как определить основные ключевые слова? Это не наука. Во-первых, постарайтесь определить фразы, которые достаточно специфичны для вашей организации. Т
, пытающийся оказаться в верхней части результатов поиска по запросу «окружающая среда», скорее всего, будет проигрышной битвой, но «измерение качества речной воды» — более достижимая цель. Продумывая ключевые слова, учтите:
- Какие фразы связаны с вашей организацией? Начните процесс определения ключевых слов, перечислив слова и фразы, которые вы уже используете в своих маркетинговых материалах.
 Название вашей организации очевидно, как и имена любых известных людей, связанных с вами. У вас есть слоган или краткое заявление о миссии, которое кратко и полезно резюмирует то, что вы делаете? Какие фразы вы используете при этом?
Название вашей организации очевидно, как и имена любых известных людей, связанных с вами. У вас есть слоган или краткое заявление о миссии, которое кратко и полезно резюмирует то, что вы делаете? Какие фразы вы используете при этом? - Как люди в настоящее время находят вас? Если у вас есть доступ к инструменту аналитики веб-сайта, вы, вероятно, можете увидеть фразы поисковой системы, которые люди используют в настоящее время, чтобы найти вас. Это может быть полезной отправной точкой для понимания того, как люди ищут вашу информацию. Подумайте, как вы можете увеличить легкость, с которой вас можно будет найти по этим фразам, и используйте их, чтобы вдохновить на более важные фразы.
- Какие поисковые фразы люди используют в вашем домене? Такие инструменты, как Хорошие ключевые слова или WordTracker , могут помочь вам провести мозговой штурм ключевых слов, связанных с теми, которые вы уже идентифицировали, и найти фразу, которую пользователи, скорее всего, будут использовать при поиске.
Сколько ключевых слов у вас должно быть? Это зависит от вас. В идеале у вас должно быть хотя бы несколько ключевых фраз для каждой страницы вашего сайта. Некоторые организации оптимизируют тысячи ключевых слов. Однако начать с нескольких фраз и нескольких страниц гораздо лучше, чем ничего.
5. Разместите ключевые слова в лучших местах
После того, как вы определили свои приоритетные ключевые слова, следующим шагом будет их интеграция на ваши веб-страницы. Когда кто-то выполняет поиск по ключевой фразе, поисковая система ищет страницы, которые содержат заметные упоминания этой фразы: те, которые содержат ее несколько раз, показывают ее в верхней части страницы и включают в ключевые места.
К сожалению, ничто не заменит трудоемкую задачу включения ваших ключевых слов на каждую страницу контента. Для каждой страницы подумайте, как вы можете включить свои ключевые слова в:
- Заголовки и заголовки разделов. Текст, который заметно отформатирован (крупнее, жирнее, выше на странице), с большей вероятностью повлияет на размещение в поисковых системах, чем другой текст, поэтому ключевые слова будет иметь больший вес в заголовках.
- Текст ссылки. Слова, используемые в качестве ссылки на вашу страницу, имеют высокий приоритет, когда поисковые системы рассматривают эту страницу. Оптимизируйте ссылки на вашем собственном сайте и особенно любые внешние ссылки, которые вы контролируете, например, в своем блоге, подписях электронной почты, профилях социальных сетей и т. д. Поощряйте других ссылаться на вас, используя ваши ключевые слова — например, предоставляя ключевые слова и описания для ресурсов на вашем сайте.
- Метаданные заголовка страницы. На каждой странице есть так называемое «поле метаданных заголовка», которое управляет текстом, который отображается в строке заголовка в верхней части окна браузера, а также часто отображается в качестве заголовка страницы в результатах поиска. Это одно из самых важных мест для включения ваших ключевых слов. Это поле заголовка можно редактировать с помощью HTML-кода страницы или с помощью большинства методов, которые вы можете использовать для обновления своего сайта, например, с помощью Dreamweaver, Contribute и большинства систем управления контентом.
- Метаданные описания страницы. Каждая страница имеет поле «описание», более подробное описание содержимого страницы, доступ к которому можно получить аналогично метаданным «название». Описание — еще одно важное место для включения ваших ключевых слов, и оно также иногда отображается поисковыми системами как описание вашей страницы в результатах поиска.
- Текст страницы. Многократное повторение ваших ключевых слов (но не столько раз, чтобы раздражать ваших читателей, конечно) в тексте страницы, скорее всего, повысит вашу позицию.
- URL-адрес страницы. Если вы можете контролировать фактическое имя файла страницы (например, «search_engines.html»), ключевые слова, встроенные в URL-адрес, также считаются высокорелевантными.
Если вы ищете относительно быстрый способ оптимизации каждой страницы, добавление ключевых слов только в метаданные заголовка и описания может дать существенные результаты без полной переделки вашего сайта.
Обратите внимание, что ключевые слова должны отображаться в виде текста. Пауки не могут читать изображения, поэтому любая страница, заголовок или функция, отображаемые в виде графики, независимо от того, насколько они заметны на странице, невидимы для поисковых систем.
Пауки не могут читать изображения, поэтому любая страница, заголовок или функция, отображаемые в виде графики, независимо от того, насколько они заметны на странице, невидимы для поисковых систем.
6. Обеспечьте удобную для поиска архитектуру веб-сайта
Хорошо, нам нужно на минутку углубиться в некоторые технические детали. К сожалению, детальная структура веб-сайта может существенно повлиять на его позицию в поисковой системе. Если вы в целом не знакомы с концепциями построения веб-сайтов и HTML (языком веб-сайтов), вам может потребоваться пометить этот раздел как доверенный веб-разработчик.
Пауки читают не так, как люди, поэтому важно следовать некоторым основным правилам структуры сайта, чтобы они могли найти и прочитать вашу информацию:
- Убедитесь, что на каждую страницу вашего сайта есть простая ссылка. Схемы навигации JavaScript, особенно те, которые используют ролловеры, могут затруднить распознавание ссылок и переход по ним. Динамические URL-адреса, особенно те, которые обозначают параметр знаком вопроса, также могут быть проблематичными.
 Если ваш сайт динамический, рассмотрите возможность создания индекса сайта, который будет содержать ссылку на каждую страницу. В идеале преобразуйте свои динамические URL-адреса, чтобы они выглядели как статические страницы, с помощью такой команды, как mod_rewrite.
Если ваш сайт динамический, рассмотрите возможность создания индекса сайта, который будет содержать ссылку на каждую страницу. В идеале преобразуйте свои динамические URL-адреса, чтобы они выглядели как статические страницы, с помощью такой команды, как mod_rewrite. - Включайте контент в начале каждой HTML-страницы. При поиске ключевых слов контента поисковые системы отдают приоритет ключевым словам, которые появляются в начале текста страницы, а этот текст включает весь HTML-код. Постарайтесь структурировать страницу s
так, чтобы код HTML включал содержимое как можно раньше — в отличие, например, от включения кода для сложных заголовков, панелей навигации и боковых панелей, прежде чем переходить к фактическому тексту страницы. - Используйте стандартные теги заголовков. Некоторые поисковые системы отдают приоритет тексту, который отображается в стандартных тегах форматирования, таких как h2 или h3, поэтому стоит использовать их, а не создавать собственные имена для стилей заголовков.

- Остерегайтесь дубликатов страниц. Поисковые системы плохо реагируют на дублированный контент, так как это обычная уловка тех, кто пытается заспамить поисковую систему в лучшую сторону. Будьте осторожны со структурами, которые показывают одно и то же содержимое страницы по нескольким URL-адресам (например, в версии для печати). Если важны несколько версий, используйте метатег robots, чтобы указать, что дополнительные версии не должны индексироваться. Кроме того, обратите особое внимание на то, чтобы сайт не отображался полностью в нескольких доменах (например, как на http://www.idealware.org, так и на http://idealware.org) — вместо этого перенаправляйте из одного домена в другой.
Последнее предостережение: избегайте трюков. Читая эту и другие статьи, вы можете подумать, что нашли лазейки, чтобы получить более высокое место без работы. Это очень маловероятно. Поисковые системы тратят огромное количество времени на то, чтобы исключить короткие пути, и им не нравится, когда их обманывают. Если вы настроите свой сайт таким образом, что поисковая система будет выглядеть так, как будто вы пытаетесь их обмануть, они могут полностью удалить ваш сайт из своих списков.
Если вы настроите свой сайт таким образом, что поисковая система будет выглядеть так, как будто вы пытаетесь их обмануть, они могут полностью удалить ваш сайт из своих списков.
7. Поддерживайте актуальность вашего сайта
Поисковые системы любят новые страницы. Старайтесь добавлять новые истории, отчеты, выпуски новостей и тому подобное, чтобы поисковые системы чувствовали, что ваш сайт часто обновляется и, следовательно, должен часто индексироваться. Если ваш сайт редко обновляется, поисковым системам могут потребоваться месяцы, чтобы найти редкие новые добавления.
Блоги могут быть особенно полезным способом легкого добавления новых страниц на ваш сайт, а также могут предоставить полезную информацию, которая поощряет ссылки от других (не говоря уже обо всех других способах, которыми блоги могут помочь в маркетинге и пропаганде!).
8. Рассмотрим Google Grants
До сих пор мы сосредоточились на способах настройки и оптимизации вашего сайта, чтобы он бесплатно отображался в любой поисковой системе. Однако есть и другой способ попасть в список Google: Google раздает бесплатную рекламу в поисковых системах (ссылки, указанные как «рекламные ссылки» в правой части страницы результатов поиска) через свою программу Google Grants.
Однако есть и другой способ попасть в список Google: Google раздает бесплатную рекламу в поисковых системах (ссылки, указанные как «рекламные ссылки» в правой части страницы результатов поиска) через свою программу Google Grants.
Если вы одобрены для участия в программе (на данный момент Google, похоже, использует неконкурентный процесс проверки, хотя получение ответа может занять до шести месяцев или около того), вы можете размещать текстовые объявления, которые отображаются каждый раз, когда кто-то вводит ключевые фразы в окно поиска Google. Гранты часто предлагают достаточно бесплатной рекламы, чтобы вы могли размещать объявления по сотням ключевых слов.
Google Grants не заменяет описанные выше действия. Это влияет только на Google, а не на другие поисковые системы, и многие организации считают, что реклама на странице не приносит столько трафика, сколько ссылка на эту страницу из традиционных результатов поиска. Тем не менее, это простой процесс, который должна учитывать каждая некоммерческая организация.
9. Будьте терпеливы, но продолжайте проверять
Поисковые системы не реагируют на изменения в одночасье. Фактически, может пройти месяц или больше, прежде чем результаты ваших усилий отразятся в результатах поиска. Не теряйте надежды — продолжайте включать ключевые слова в новый контент и просите другие организации ссылаться на ваши ресурсы.
Как только вы увидите какие-то результаты, не останавливайтесь на достигнутом. Интернет — динамичное место, и новые веб-сайты, новые статьи и изменение приоритетов поисковых систем могут повлиять на ваше размещение. Проверяйте результаты поиска по вашим ключевым словам хотя бы раз в месяц или около того, чтобы поддерживать свою позицию и продолжать улучшать свою стратегию.
10. Наслаждайтесь плодами своего труда
К сожалению, поисковая оптимизация — не самый короткий и легкий путь. Но важно предпринять хотя бы некоторые из основных шагов — например, убедиться, что на ваш сайт есть ссылки с нескольких известных сайтов, и включить некоторые из ваших наиболее важных ключевых слов в заголовки и заголовки страниц.
Когда ваши новые доноры, волонтеры и клиенты упоминают, что нашли вас через поиск Google или Yahoo, вы будете рады, что нашли время.
Большое спасибо Хизер Гарднер-Мадрас из gardner-Madras | стратегического креативщика, Кевина Готтесмана из Gott Advertising и Майкла Штейна, специалиста по интернет-стратегии, которые также участвовали в написании этой статьи.
Эта статья любезно предоставлена компанией Idealware, которая предоставляет достоверную информацию, помогающую некоммерческим организациям выбирать эффективное программное обеспечение. Другие статьи и обзоры можно найти на www.idealware.org.
Copyright © 2008 CompuMentor. Эта работа опубликована под лицензией Creative Commons Attribution-NonCommercial-NoDerivs 3.0.
Поисковые системы
Содержание Что такое Интернет? Информация Поисковые системы Связь Безопасность Заключение Веб-ресурсы | Поисковые системы — это программы, позволяющие осуществлять поиск в Интернете с помощью
категории, ключевые слова или вопросы. Чтобы начать поиск, откройте веб-браузер. Теперь вы можете решить: Вы знаете, какую поисковую систему вы хотите использовать? Если вы этого не сделаете, нажмите на кнопку «Поиск» кнопка, которую можно найти в большинстве браузеров. Вы перейдете на страницу, где один из многих поисковые системы будут выбраны для выполнения поиска. Не все поисковые системы работают с поиском одинаково, но в основном они
выполнять ту же функцию. Тема поиска Два наиболее распространенных способа поиска — по теме или ключевому слову. Предмет
поиск полезен, если вам нужна информация по общей теме. Yahoo
(http://www.yahoo.com) — популярное место для проведения такого типа поиска. В
вверху главной страницы Yahoo находится поле, содержащее список общих категорий
(например, образование, развлечения, наука, путешествия и т. Поиск по ключевому слову Поиск по ключевым словам немного отличается тем, что он ищет веб-страницы для
слова, которые вы указываете, и возвращает список сайтов, содержащих это слово.
Большинство поисковых систем имеют текстовое поле в верхней части главной страницы, которое позволяет вам
чтобы ввести слова, которые вы ищете. Слова, которые вы вводите, относятся к
как «строка поиска» или «строка запроса». Поиск на естественном языке Некоторые поисковые системы позволяют вам попробовать запрос на «естественном языке», что означает, что вы
задать вопрос на обычном разговорном английском (который вы вводите в текстовое поле) и
поисковая система интерпретирует запрос и отправляет список ближайших
совпадающие ответы. AskJeeves (http://www.aj.com) и версия для детей
(http://www.ajkids.com) являются примерами такой поисковой системы. За
Например, вы вводите такой вопрос, как «Который час на Филиппинах?»
и Дживс представит вам список связанных вопросов, которые должны содержать
ответ на ваш вопрос. Вы выбираете вопрос, который кажется
наиболее актуальными. Дживс не всегда найдет для вас ответ, но направит
вам в другую поисковую систему, чтобы продолжить поиск. Некоторые поисковые системы экспериментируют с наличием различных поисковых сервисов. объединены в один. Многие из них предоставляют как тематический каталог, так и ключевое слово. поиск и другие услуги, такие как обновления новостей, электронные карты, онлайн покупки и бесплатная электронная почта. Некоторые также добавляют натуральный тип «Спросите Дживса». языковой запрос. Методы поиска Имея все эти варианты и разновидности доступных методов поиска,
поиск точной части информации, которую вы ищете, может быть сложным
задача. Одна из стратегий, которую используют многие люди, состоит в том, чтобы найти две или три поисковые системы, которые
как правило, дают адекватные результаты, а затем учатся очень хорошо их использовать. Помощь
доступны страницы с советами по поиску и методами поиска продвинутого уровня
с главных страниц большинства поисковых систем. Требуется короткое время для обучения
то, как работает конкретная поисковая система, может помочь вам получить более релевантные результаты и
сэкономить много времени на просмотр длинных списков результатов. Образец поиска по ключевому слову Допустим, вы хотели найти информацию о летучих мышах, обитающих в пещерах. Ты бы
подключитесь к Интернету, откройте веб-браузер и выберите поисковую систему (в этом
случай Альтависта). В верхней части страницы находится текстовое поле, в котором вы вводите
ключевое слово (летучие мыши), а затем нажмите кнопку поиска. Альтависта вернет страницу
со списком сайтов, связанных с «летучей мышью». Вы можете увидеть раздел страницы, который
говорит: «Альтависта знает ответы на следующие вопросы», а затем
вопрос типа «Где я могу найти краткую энциклопедическую статью
о летучих мышах?» Если есть ссылка на страницу с ответом на ваш вопрос,
вы закончили. Но предположим, вы не нашли то, что искали? Там
также будет список страниц, содержащих ваше ключевое слово «летучие мыши». Предполагать
52 250 документов соответствуют вашему запросу. Есть несколько способов сократить количество попаданий, которые вы получаете, в зависимости от того,
Тип информации, которую вы ищете. Если ввести строку поиска: +bats
+животные, на этот раз вы можете получить около 5000 просмотров. Пять тысяч все еще
много, но вы сократили количество просмотров до одной десятой того, что было раньше.
Знаки добавления в строке сообщают поисковой системе, что нужно возвращать только страницы
содержащие слово после знака сложения. Знак дополнения перед
первое слово важно. Без него поисковик будет требовать только
второе слово, которое появляется на любой возвращаемой странице; первое слово может или не может
появляться. Попробуйте ввести строку поиска: +летучие мыши -бейсбол. Знак минус говорит о поисковую систему, чтобы исключить любые страницы, содержащие слово, стоящее после знак минус. По этому запросу примерно 37 000 обращений. Четко, поиск «летучих мышей, которые являются животными» отличается от поиска «летучих мышей». которые не связаны с бейсболом.» Помните, что есть и другие виды спорта которые используют летучих мышей: крикет является одним из примеров. Использование сложения и вычитания операторов требует некоторого предусмотрительности, чтобы выяснить, что, скорее всего, даст вам нужные результаты. Если вы посмотрите на список ссылок, созданных при поиске +bat -baseball,
один из перечисленных может сказать что-то вроде «Луисвилльские летучие мыши-слаггеры». Почему? Ты
сказал поисковой системе исключить страницы о бейсболе, верно? Нет
в яблочко. Вы приказали исключить страницы, на которых используется слово «бейсбол», которое
немного отличается. Хотя обычно можно с уверенностью предположить, что страницы о
субъект будет использовать определенные слова, относящиеся к этому субъекту, это не всегда
кейс. Еще один способ сузить область поиска — использовать кавычки. если ты
были искать в строке: медицинская школа (без плюсов и минусов) вы бы получили
что-то вроде 6,4 миллиона просмотров. Вы можете подумать, что, набрав эту строку или
строка +medical +school может дать вам информацию о медицинских школах. Это
будет, но это также даст вам много информации, которая вам не нужна.
Поисковая система ищет слова, используемые в строке поиска, которые встречаются
в любом месте страницы, они не обязательно должны быть рядом друг с другом. Так
ваш поиск выдаст страницы о других типах школ, но где-то упоминается
слово «медицинский» или страницы, использующие термин «медицинский» и где-то использующие это слово
школа. Чтобы найти слова, которые появляются рядом друг с другом, но не обязательно рядом друг с другом другой, используйте круглые скобки вокруг слов. Если вы ищете (медицинская школа), вы найдут ссылки на страницы, содержащие такие фразы, как «медицинская и стоматологическая школа». а так же просто «медицинская школа». Помните, что есть четыре распространенных способа сузить область поиска:
Средства связи | Безопасность | Заключение | Ресурсы для родителей Последнее обновление: Пожалуйста, направляйте вопросы и комментарии об этой странице по адресу [email protected] © Copyright 1998 Образовательный фонд Шодор, Инк. |
 Поисковая система хранит записи о
миллионы веб-страниц и других интернет-ресурсов, таких как сообщения групп новостей.
Некоторые используют «роботов», то есть программы, которые тратят свое время на поиск веб-страниц и
отмечая, какие слова на каких страницах. Другие поисковые системы (называемые темой
каталоги) создаются людьми, которые просматривают новые сайты и индексируют их
по разным категориям. Существует несколько популярных поисковых систем и
тематические каталоги в Интернете: Yahoo, AltaVista, Lycos, Excite, Magellan,
и Webcrawler — лишь некоторые из них.
Поисковая система хранит записи о
миллионы веб-страниц и других интернет-ресурсов, таких как сообщения групп новостей.
Некоторые используют «роботов», то есть программы, которые тратят свое время на поиск веб-страниц и
отмечая, какие слова на каких страницах. Другие поисковые системы (называемые темой
каталоги) создаются людьми, которые просматривают новые сайты и индексируют их
по разным категориям. Существует несколько популярных поисковых систем и
тематические каталоги в Интернете: Yahoo, AltaVista, Lycos, Excite, Magellan,
и Webcrawler — лишь некоторые из них. Вы можете попробовать поискать одну и ту же тему в нескольких
различные двигатели, чтобы определить, как они работают и как они могут соответствовать
требования для вашего конкретного поиска. Один из недостатков программы
сети заключается в том, что в ней так много миллионов страниц, что ни одна поисковая система не может
найти все. Еще один фактор заключается в том, что поисковые системы не знают,
информация, которую они получают, действительно достоверна или именно то, что вы искали.
Они просто выполняют команду отправить вам список сайтов, содержащих
ключевые слова или тему, которую вы запросили.
Вы можете попробовать поискать одну и ту же тему в нескольких
различные двигатели, чтобы определить, как они работают и как они могут соответствовать
требования для вашего конкретного поиска. Один из недостатков программы
сети заключается в том, что в ней так много миллионов страниц, что ни одна поисковая система не может
найти все. Еще один фактор заключается в том, что поисковые системы не знают,
информация, которую они получают, действительно достоверна или именно то, что вы искали.
Они просто выполняют команду отправить вам список сайтов, содержащих
ключевые слова или тему, которую вы запросили. д.). Если вы нажмете на один из
эти категории, вы попадете в список подкатегорий, связанных с этим
тема. Каждая из этих ссылок ведет на страницу с большим количеством связанных категорий.
Сначала самые общие темы, и они становятся более конкретными по мере того, как вы углубляетесь.
В конце концов, вы должны найти страницу со списком ссылок, связанных с вашей темой.
Чтобы найти снимки, сделанные космическим телескопом Хаббл, вам
могут перейти по следующим ссылкам: Наука, Астрономия, Астрофотография, Изображения и
наконец, космический телескоп Хаббл.
д.). Если вы нажмете на один из
эти категории, вы попадете в список подкатегорий, связанных с этим
тема. Каждая из этих ссылок ведет на страницу с большим количеством связанных категорий.
Сначала самые общие темы, и они становятся более конкретными по мере того, как вы углубляетесь.
В конце концов, вы должны найти страницу со списком ссылок, связанных с вашей темой.
Чтобы найти снимки, сделанные космическим телескопом Хаббл, вам
могут перейти по следующим ссылкам: Наука, Астрономия, Астрофотография, Изображения и
наконец, космический телескоп Хаббл. Иногда поиск может дать очень
большое количество веб-страниц. Затем вы просматриваете эти страницы, чтобы найти, какие из них
действительно содержат информацию, которую вы искали. Существует множество стратегий для
сузив область поиска, чтобы получить более релевантные результаты.
Иногда поиск может дать очень
большое количество веб-страниц. Затем вы просматриваете эти страницы, чтобы найти, какие из них
действительно содержат информацию, которую вы искали. Существует множество стратегий для
сузив область поиска, чтобы получить более релевантные результаты.
 Следующее
параграфы дают подробное описание общих стратегий поиска, используемых
популярные поисковые системы.
Следующее
параграфы дают подробное описание общих стратегий поиска, используемых
популярные поисковые системы. Это не означает, что все 52 000 документов
о летучих мышах, это означает, что слово летучая мышь появляется на странице. Может быть, что
слово летучая мышь упоминается только один раз в контексте чего-то другого. 50 000
веб-страниц много, чтобы просмотреть. Как вы можете сузить этот фокус, чтобы найти то, что
вы конкретно ищете?
Это не означает, что все 52 000 документов
о летучих мышах, это означает, что слово летучая мышь появляется на странице. Может быть, что
слово летучая мышь упоминается только один раз в контексте чего-то другого. 50 000
веб-страниц много, чтобы просмотреть. Как вы можете сузить этот фокус, чтобы найти то, что
вы конкретно ищете?
 В данном случае слово «бейсбол» нигде не встречается.
текст страницы «Louisville Slugger Bats». Поисковые системы не идеальны.
Они могут уменьшить объем работы, которую вы должны приложить для поиска чего-либо, но
вам все равно придется тщательно просеивать информацию, которую они возвращают.
В данном случае слово «бейсбол» нигде не встречается.
текст страницы «Louisville Slugger Bats». Поисковые системы не идеальны.
Они могут уменьшить объем работы, которую вы должны приложить для поиска чего-либо, но
вам все равно придется тщательно просеивать информацию, которую они возвращают. Чтобы поисковая система нашла точную фразу медицинская школа, введите
слова в кавычках, «медицинская школа». Некоторые поисковые системы будут только
верните эту точную фразу, даже включая заглавные буквы (вы не увидите
«Медицинская школа» или «МЕДИЦИНСКАЯ ШКОЛА»), но другие не чувствительны к регистру.
Обратитесь к страницам справки поисковой системы, которую вы используете, чтобы узнать, как она работает.
цитаты.
Чтобы поисковая система нашла точную фразу медицинская школа, введите
слова в кавычках, «медицинская школа». Некоторые поисковые системы будут только
верните эту точную фразу, даже включая заглавные буквы (вы не увидите
«Медицинская школа» или «МЕДИЦИНСКАЯ ШКОЛА»), но другие не чувствительны к регистру.
Обратитесь к страницам справки поисковой системы, которую вы используете, чтобы узнать, как она работает.
цитаты.
Что такое поисковая система и какая разница, какой из них вы пользуетесь?
Попытка дать простое определение: поисковая система — это программная система, которая позволяет пользователям находить контент в Интернете на основе их ввода.
Появление основных поисковых систем привело к огромным изменениям в том, как мы пользуемся Интернетом.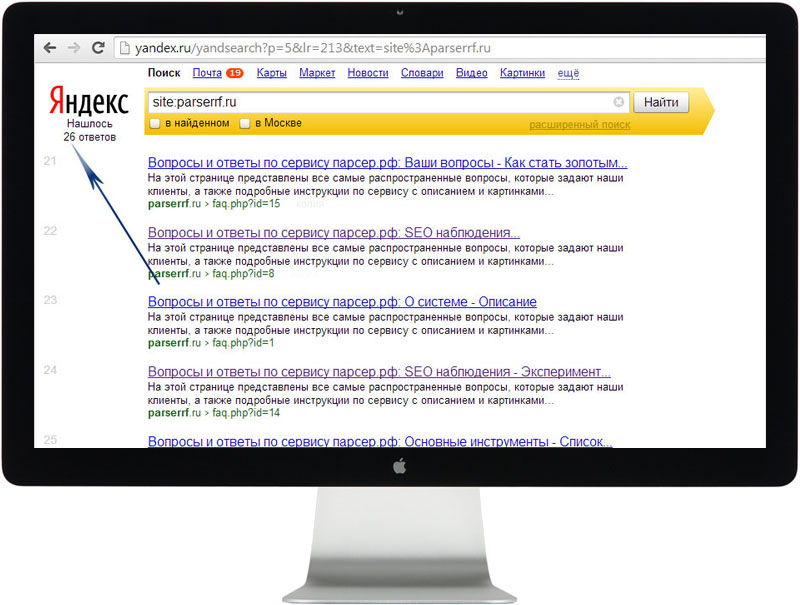 Для тех, кто знает, где искать, существует огромное количество знаний. Одна поисковая система стала настолько важным фактором нашей онлайн-жизни, что «гуглить» стало общепринятым глаголом. Американское диалектное общество даже назвало его «самым полезным словом 2002 года». На момент написания более 90% рынка поисковых систем было приобретено Google.
Для тех, кто знает, где искать, существует огромное количество знаний. Одна поисковая система стала настолько важным фактором нашей онлайн-жизни, что «гуглить» стало общепринятым глаголом. Американское диалектное общество даже назвало его «самым полезным словом 2002 года». На момент написания более 90% рынка поисковых систем было приобретено Google.
Поисковые запросы
Времена, когда ввод для поисковой системы ограничивался текстовыми запросами, давно прошли. Большинство основных поисковых систем также предлагают возможность обратного поиска изображений. Используя обратный поиск изображений, вы можете найти изображения, похожие на то, что вы запрашиваете.
Самые популярные поисковые запросы года могут подсказать историкам из будущего, что нас больше всего заботило в то время. В топ-3 на 2020 год вошли:
- Результаты выборов
- Коронавирус
- Коби Брайант
Поисковая оптимизация
Тот факт, что компании хотят быть найденными поисковыми системами, привел к набору маркетинговых методов, направленных на повышение популярности веб-сайта. Цель состоит в том, чтобы ваш сайт занимал первые места в результатах поиска, когда пользователь выполняет поиск по определенным ключевым словам, имеющим отношение к вашему бизнесу. Название этих методов — поисковая оптимизация (SEO). Рейтинг сайта в результатах поиска Google в первую очередь зависит от того, насколько хорошо оптимизирована страница, но он также основан на «репутации». Репутация страницы рассчитывается, среди прочего, с использованием количества внешних ссылок, указывающих на эту страницу. Очень помогает, если входящие ссылки приходят со страниц, посвященных одной и той же или смежной тематике, но также помогает большое количество ссылок, поступающих со всех видов сайтов.
Цель состоит в том, чтобы ваш сайт занимал первые места в результатах поиска, когда пользователь выполняет поиск по определенным ключевым словам, имеющим отношение к вашему бизнесу. Название этих методов — поисковая оптимизация (SEO). Рейтинг сайта в результатах поиска Google в первую очередь зависит от того, насколько хорошо оптимизирована страница, но он также основан на «репутации». Репутация страницы рассчитывается, среди прочего, с использованием количества внешних ссылок, указывающих на эту страницу. Очень помогает, если входящие ссылки приходят со страниц, посвященных одной и той же или смежной тематике, но также помогает большое количество ссылок, поступающих со всех видов сайтов.
Поисковая система по умолчанию
Иногда вы будете видеть сообщения о том, что поисковая система вашего браузера по умолчанию была изменена, или вас попросят изменить поисковую систему по умолчанию.
В приведенном выше примере Chrome предупреждает пользователя о взломщике поисковых систем, который получил контроль над поисковой системой пользователя по умолчанию. Вы также можете увидеть браузер, предлагающий вам вернуться к поисковой системе по умолчанию, с которой он поставляется, или даже веб-сайты, предлагающие вам изменить поисковую систему по умолчанию.
Вы также можете увидеть браузер, предлагающий вам вернуться к поисковой системе по умолчанию, с которой он поставляется, или даже веб-сайты, предлагающие вам изменить поисковую систему по умолчанию.
Как поисковые системы зарабатывают деньги?
Несмотря на то, что поисковые системы зарабатывают деньги разными способами, большинство из них связано с получением денег от компаний, которые хотят быть заметными в результатах поиска.
- Организации могут покупать рекламу, которая отображается над фактическими результатами поиска.
- Организации могут заплатить, чтобы их логотип и основная информация отображались в результатах поиска, ведущих на их веб-сайты.
- Организации могут платить за маркетинговые данные на основе привычек потребителей.
- Поисковые системы могут продавать свои результаты поиска другим, чтобы они могли создавать каталоги, вертикали или каталоги.
- Поисковые системы могут продавать клики по ссылкам в результатах поиска.

Доходы от этой деятельности настолько прибыльны, что некоторые потенциально нежелательные программы и рекламные программы приносят деньги своим создателям в виде поисковых угонщиков.
Как работают поисковые системы?
Где поисковые системы находят результаты, соответствующие запросу, и как они делают это так быстро? Большинство поисковых систем являются сканерами. Поисковый робот генерирует свои результаты путем автоматической компиляции веб-страниц и сайтов. Веб-сайты, которые нельзя просканировать, являются частью Deep Web. Глубокая паутина — это то, что мы называем неиндексированной частью Интернета, то есть любым сайтом, который не может найти поисковая система. Часть Deep Web, о которой вы, возможно, слышали, называется Dark Web. Даркнет намеренно скрыт, анонимен и широко известен своими незаконными действиями.
Или, как этот мем объясняет это, подмигивая тем, кто борется за хорошие результаты SEO:
Поисковые роботы — это каталоги и вертикали, которые представляют собой различные виды созданных пользователями коллекций результатов поиска и сайтов. Если эти выбранные результаты оплачиваются, то мы называем их спонсируемыми поисковыми системами.
Если эти выбранные результаты оплачиваются, то мы называем их спонсируемыми поисковыми системами.
Скорость, с которой основные поисковые системы могут выдавать результаты поиска, обусловлена наличием центров обработки данных по всему миру. Пока вы вводите свой поисковый запрос, поисковая система предугадывает остальную часть вашего запроса, просматривает миллиарды веб-страниц, ранжирует найденные сайты, изображения, видео и продукты и представляет вам самые лучшие результаты. И все это обычно происходит менее чем за десятую долю секунды. Для нас, простых людей, это практически мгновенно. В какой бы точке мира вы ни выполняли поиск Google, результаты, скорее всего, поступают к вам с ближайших компьютеров.
Какая самая закрытая поисковая система?
Существует несколько поисковых систем, которые помогут вам сохранить анонимность в Интернете при поиске ответов на ваши вопросы. Из них наиболее известны DuckDuckGo и Brave. Оба являются поисковыми роботами и могут быстро выдавать результаты, не отслеживая поисковые запросы пользователей, не создавая профили пользователей и не требуя использования внешнего, уже существующего поискового индекса для получения результатов.
А для тех, кто ищет поисковую систему, обеспечивающую конфиденциальность и защиту окружающей среды, обратите внимание на Ecosia.
Выбор поисковой системы
Вы можете найти и изменить поисковую систему по умолчанию в настройках вашего браузера. Где именно, зависит от вашего браузера, но в браузерах, которые я проверил, это один из основных пунктов в меню «Настройки».
Какой из них вы должны использовать? пока мы пытаемся предоставить им информацию, на которой они будут основывать свое решение.
Всем удачных поисков и берегите себя!
Как поисковые системы распространяют информацию о COVID-19 и почему они должны работать лучше
Как поисковые системы распространяют информацию о COVID-19 и почему они должны работать лучше | Обзор дезинформации HKS Перейти к основному содержаниюСпециальный выпуск: COVID-19
Это эссе было опубликовано в рамках специального выпуска о дезинформации и COVID-19 под гостевой редакцией доктора Меган МакГинти (директор по управлению в чрезвычайных ситуациях, NYC Health + Hospitals) и Нэт Гинес (директор , Meedan Digital Health Lab).
Подробнее из этого выпуска
Поделиться
Скачать PDF
Экспертная оценка
Доступ к точной и актуальной информации необходим для индивидуального и коллективного принятия решений, особенно в чрезвычайных ситуациях. 26 февраля 2020 года, за две недели до того, как Всемирная организация здравоохранения (ВОЗ) официально объявила чрезвычайную ситуацию, связанную с COVID-19, «пандемией», мы систематически собирали и анализировали результаты поиска по термину «коронавирус» на трех языках из шести поисковых систем. Мы обнаружили, что разные поисковые системы отдают приоритет определенным категориям источников информации, таким как веб-сайты, связанные с правительством, или альтернативные СМИ. Мы также заметили, что ранжирование источников в одной и той же поисковой системе подвергается рандомизации, что может привести к неравному доступу к информации среди пользователей.
By
Николай Махортых
Институт коммуникаций и медиа исследований, Бернский университет, Швейцария
Александра Урман
Институт коммуникаций и медиа исследований Бернского университета, Швейцария
Роберто Уллоа
Департамент вычислительных социальных наук, Институт социальных наук GESIS-Leibniz, Германия
Резюме эссе
- Используя несколько (N=200) виртуальных агентов (т. е. программ), мы изучили, как информация о коронавирусе распространяется в шести поисковых системах: Baidu, Bing, DuckDuckGo, Google, Yandex и Yahoo.
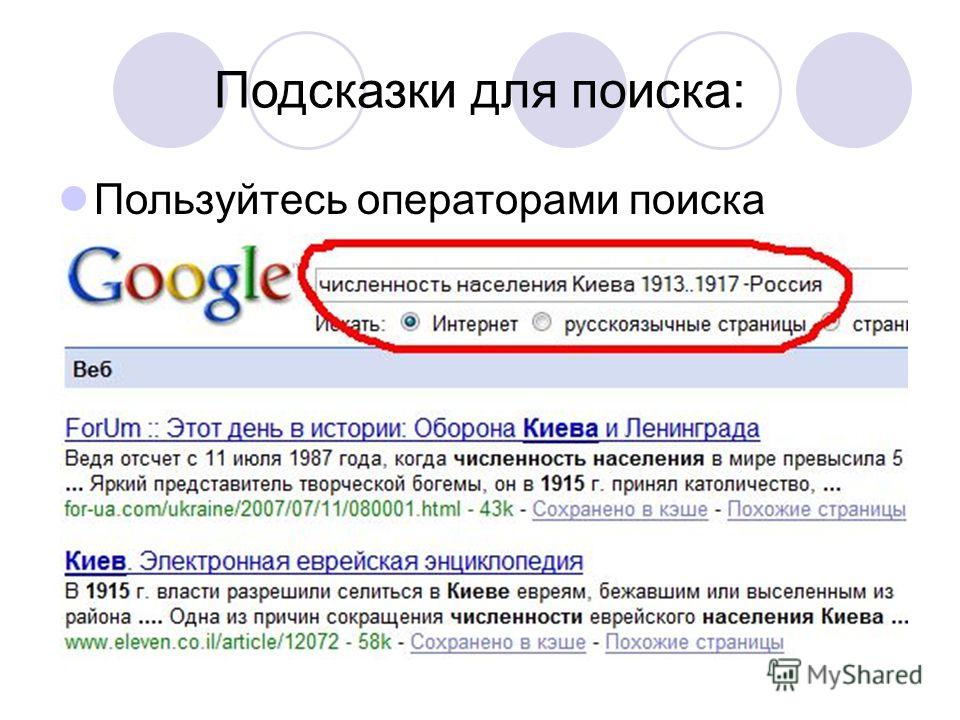 . Мы составили сценарий последовательности действий при просмотре для каждого агента, а затем отследили эти действия в контролируемых условиях, включая время, местоположение агента и историю браузера.
. Мы составили сценарий последовательности действий при просмотре для каждого агента, а затем отследили эти действия в контролируемых условиях, включая время, местоположение агента и историю браузера. - 26 февраля 2020 года агенты одновременно ввели поисковые запросы на основе наиболее распространенного термина, используемого для обозначения пандемии COVID-19 (т. е. «коронавирус» на английском, русском и китайском языках) в шесть поисковых систем.
- Анализ результатов поиска, полученных агентами, выявил тревожные различия в типах источников информации, приоритет которых определяется разными поисковыми системами. Мы также выявили значительное влияние рандомизации на ранжирование источников в одной и той же поисковой системе.
- Подобные расхождения в результатах поиска могут дезинформировать общественность и ограничивать права граждан принимать решения на основе достоверной и непротиворечивой информации, что вызывает особую озабоченность во время чрезвычайной ситуации, такой как пандемия COVID-19.

Последствия
Мы выявили большие расхождения в том, как разные поисковые системы распространяют информацию о пандемии COVID-19. Некоторые различия в результатах ожидаемы, учитывая, что поисковые системы персонализируют свои услуги (Hannak et al., 2013), но наше исследование подчеркивает, что даже неперсонализированные результаты поиска существенно различаются. Например, мы обнаружили, что некоторые алгоритмы поиска потенциально отдают предпочтение вводящим в заблуждение источникам информации, таким как альтернативные СМИ и контент социальных сетей в случае Яндекса, в то время как другие отдают приоритет авторитетным источникам (например, страницам, связанным с правительством), например, в случае Google.
Особую озабоченность вызывает рандомизация результатов поиска среди пользователей одной и той же поисковой системы. Мы обнаружили, что степень рандомизации различается между поисковыми системами: для некоторых, таких как Google и Bing, она в основном влияет на состав «длинного хвоста» результатов поиска, например, тех, которые находятся ниже 10 лучших результатов, в то время как для других, таких как DuckDuckGo и Яндекс также рандомизируют 10 лучших результатов. Рандомизация гарантирует, что то, что видит пользователь, не обязательно совпадает с тем, что он хочет видеть, и что разные пользователи получают разную информацию. С помощью рандомизации пользователь видит то, что поисковая система случайным образом решила, что этому конкретному пользователю разрешено видеть. Тогда в этом сценарии доступ к надежной информации — это просто вопрос удачи.
Рандомизация гарантирует, что то, что видит пользователь, не обязательно совпадает с тем, что он хочет видеть, и что разные пользователи получают разную информацию. С помощью рандомизации пользователь видит то, что поисковая система случайным образом решила, что этому конкретному пользователю разрешено видеть. Тогда в этом сценарии доступ к надежной информации — это просто вопрос удачи.
Хотя рандомизация может способствовать открытию знаний за счет диверсификации информации, получаемой отдельными лицами (Helberger, 2011), она может нанести ущерб, когда обществу срочно требуется доступ к последовательной и точной информации, например, во время кризиса в области общественного здравоохранения. Если предположить, что основной движущей силой рандомизации является максимальное вовлечение пользователей путем тестирования различных способов ранжирования результатов поиска и выбора оптимальной иерархии информационных ресурсов по конкретной теме (например, так называемого «Google Dance» (Battelle, 2005). )) то мы оказались бы в ситуации, когда частные интересы компаний прямо нарушают права людей на доступ к достоверной и проверяемой информации.
)) то мы оказались бы в ситуации, когда частные интересы компаний прямо нарушают права людей на доступ к достоверной и проверяемой информации.
Точное функционирование и обоснование рандомизации и различных приоритетов источников в настоящее время неизвестны. Критика алгоритмической непрозрачности в распространении информации не нова (Pasquale, 2015; Kemper & Kolkman, 2019; Noble, 2018). Однако отсутствие прозрачности особенно неприятно во время чрезвычайных ситуаций, когда предвзятость механизмов фильтрации и ранжирования становится вопросом общественного здравоохранения и национальной безопасности. Наши наблюдения показывают, что поисковые системы получают противоречивые и иногда вводящие в заблуждение результаты в отношении COVID-19., но остается неясным, какие факторы способствуют этим расхождениям в информации и какие принципы использует каждая машина для построения иерархии знаний. Эти проблемы вызывают множество вопросов, в том числе, что такое «хорошая» информация, кто должен принимать решения о ее качестве и могут ли эти решения применяться однозначно. Самое главное: должны ли поисковые системы приостанавливать рандомизацию во время чрезвычайных ситуаций?
Самое главное: должны ли поисковые системы приостанавливать рандомизацию во время чрезвычайных ситуаций?
Ответы на эти вопросы найти непросто, это потребует времени и соответствующих усилий. Одной из отправных точек для повышения прозрачности поиска может быть предоставление ресурсов для проведения «алгоритмического аудита» (то есть анализа эффективности алгоритмов, аналогичного тому, который реализован в данном исследовании) более доступными для академического сообщества и широкой общественности (Миттельштадт, 2016). В настоящее время не существует общедоступной и масштабируемой инфраструктуры, которую можно было бы использовать для сравнения производительности различных алгоритмов поисковых систем, а также их особенностей (например, рандомизации). Предоставляя такую инфраструктуру и делая данные о влиянии алгоритмов на распространение информации более доступными, компании, занимающиеся поисковыми системами, могут решить проблему отсутствия прозрачности в своих алгоритмических системах и повысить доверие к тому, что информационные технологии играют в нашем обществе (Foroohar, 2019). ).
).
Еще один момент, который следует учитывать, — это возможность реализации «механизмов контроля пользователей», которые могут гарантировать, что пользователи поисковых систем смогут решать алгоритмические функции (например, рандомизацию), мешающие их способности получать информацию (He, Parra, & Verbert, 2016; Harambam и др., 2019). Подходы, ориентированные на пользователя, могут варьироваться от четкой политики в отношении приоритизации источников (например, решение Google отдавать приоритет правительственным источникам информации о COVID-19, но последовательно применяться к другим темам поиска) до возможности отказаться не только от персонализации поиска, но и его рандомизация.
Выводы
Вывод 1: Ваша поисковая система определяет, что вы видите .
Мы обнаружили большие расхождения в результатах поиска (N=~50) между идентичными агентами, использующими разные поисковые системы (рис. 1). Несмотря на использование одних и тех же поисковых запросов, все метрики показали сходство результатов поиска между поисковыми системами менее чем на 25%, за исключением DuckDuckGo и Yahoo, у которых почти 50% результатов совпадают. Во многих случаях мы почти не наблюдали совпадений в результатах поиска (например, между Google и DuckDuckGo), что указывает на то, что пользователи получают совершенно разные наборы источников информации. Хотя различия в выборе источника не обязательно являются негативным аспектом, полное отсутствие общих ресурсов между поисковыми системами может привести к существенным расхождениям в информации среди их пользователей, что вызывает беспокойство во время чрезвычайной ситуации. Кроме того, как показывает вывод 3, поисковые системы отдают предпочтение не только разным источникам одного типа (например, различные устаревшие СМИ), но и разным типам источников, что напрямую влияет на качество информации, которую предоставляют поисковые системы.
Во многих случаях мы почти не наблюдали совпадений в результатах поиска (например, между Google и DuckDuckGo), что указывает на то, что пользователи получают совершенно разные наборы источников информации. Хотя различия в выборе источника не обязательно являются негативным аспектом, полное отсутствие общих ресурсов между поисковыми системами может привести к существенным расхождениям в информации среди их пользователей, что вызывает беспокойство во время чрезвычайной ситуации. Кроме того, как показывает вывод 3, поисковые системы отдают предпочтение не только разным источникам одного типа (например, различные устаревшие СМИ), но и разным типам источников, что напрямую влияет на качество информации, которую предоставляют поисковые системы.

Индекс Жаккара (JI), метрика, которая измеряет долю общих результатов между различными агентами, показал, что для большинства механизмов перекрытие источников происходило в длинном хвосте результатов, то есть за пределами первых 10 результатов. В топ-10 результатов перекрытие было выше только для пары Yahoo-Baidu; остальные результаты получены в основном из разных источников. Эти наблюдения были подтверждены ранжированным предвзятым перекрытием (RBO), метрикой, которая учитывает ранжирование результатов поиска. Параметр p определяет, насколько важны лучшие результаты: p 0,8 придает больший вес нескольким лучшим результатам, тогда как p = 0,9.5 более равномерно распределяет вес между 30 лучшими результатами. Наши значения RBO показали, что ранжирование результатов с длинным хвостом обычно было более согласованным между поисковыми системами, чем ранжирование лучших результатов поиска.
Вывод 2. Результаты поиска, которые вы получаете, рандомизированы .
Мы наблюдали существенные различия в результатах поиска, полученных одинаковыми агентами с использованием одной и той же поисковой системы и браузера (рис. 2). Для некоторых поисковых систем, таких как Yahoo и Baidu, мы обнаружили существенную согласованность в составе общих и первых 10 результатов (на что указывают значения JI). Однако, как показывают их значения RBO, ранжирование этих результатов было непоследовательным. Напротив, в Google и, в некоторой степени, в Bing первые 10 результатов были последовательными, тогда как остальные результаты были менее совпадающими. Наконец, в случае агентов, использующих DuckDuckGo в Chrome, общий выбор результатов был последовательным, но их рейтинги существенно различались.
2). Для некоторых поисковых систем, таких как Yahoo и Baidu, мы обнаружили существенную согласованность в составе общих и первых 10 результатов (на что указывают значения JI). Однако, как показывают их значения RBO, ранжирование этих результатов было непоследовательным. Напротив, в Google и, в некоторой степени, в Bing первые 10 результатов были последовательными, тогда как остальные результаты были менее совпадающими. Наконец, в случае агентов, использующих DuckDuckGo в Chrome, общий выбор результатов был последовательным, но их рейтинги существенно различались.
Одно из возможных объяснений такой рандомизации состоит в том, что алгоритмы поиска привносят определенную степень «прозорливости» в способ выбора результатов, чтобы дать возможность увидеть различные источники (Cornett, 2017). Более прагматичной причиной рандомизации может быть то, что поисковые системы постоянно экспериментируют с результатами, чтобы определить, какие из них максимизируют удовлетворенность пользователей и потенциально увеличивают прибыль от поисковой рекламы. Такие эксперименты кажутся особенно интенсивными в случае разворачивающихся и быстро меняющихся тем, для которых не существует ранее существовавших иерархий знаний.
Такие эксперименты кажутся особенно интенсивными в случае разворачивающихся и быстро меняющихся тем, для которых не существует ранее существовавших иерархий знаний.
Чтобы проверить последнее предположение, мы выполнили серию запросов, которые не были связаны с пандемией COVID-19, а были связаны с более устоявшимися новостными темами. Когда мы сравнили результаты поиска «коронавирус» с другими поисковыми запросами, выполненными ботами (например, «выборы в США»; см. Приложение), мы обнаружили более высокую волатильность результатов поиска коронавируса, что может быть связано с его новизной и отсутствием исторической информации о пользователе. предпочтения.
предпочтения.
Наконец, мы рассмотрели, влияет ли тип браузера на степень рандомизации. Для большинства поисковых систем (кроме DuckDuckGo, где ранжирование результатов в Chrome сильно рандомизировано) мы не наблюдали существенных различий между браузерами. Эти наблюдения могут указывать на то, что выбор браузера не оказывает существенного влияния на выбор результатов. В то же время отсутствие такого влияния также может быть связано с недавним случаем коронавируса, что приводит к отсутствию исторических данных, на основе которых алгоритмы предлагают более специфичный для браузера выбор результатов.
Вывод 3. Поисковые системы отдают приоритет разным типам источников .
Мы обнаружили, что поисковые системы присваивают разные приоритеты определенным категориям источников информации в отношении коронавируса. Наше изучение 20 наиболее часто встречающихся результатов поиска на английском языке (рис. 3) показало, что большинство поисковых систем отдавали приоритет источникам, связанным с традиционными СМИ (например, CNN) и организациями здравоохранения (включая организации общественного здравоохранения, такие как ВОЗ). Однако соотношение этих источников существенно различается: например, для Bing источники, связанные со здравоохранением, составили почти половину первых 20 результатов, тогда как для Google, Yandex и Yahoo они составили менее четверти лучших результатов. Напротив, Yahoo отдавала приоритет последним обновлениям информации о коронавирусе из устаревших СМИ, в то время как Google отдавал предпочтение веб-сайтам, связанным с правительством, таким как сайты городских советов.
Однако соотношение этих источников существенно различается: например, для Bing источники, связанные со здравоохранением, составили почти половину первых 20 результатов, тогда как для Google, Yandex и Yahoo они составили менее четверти лучших результатов. Напротив, Yahoo отдавала приоритет последним обновлениям информации о коронавирусе из устаревших СМИ, в то время как Google отдавал предпочтение веб-сайтам, связанным с правительством, таким как сайты городских советов.
Учитывая их способность распространять непроверенную информацию, эти различия в иерархии знаний, построенной поисковыми системами, вызывают беспокойство. Для некоторых поисковых систем самые популярные результаты поиска о пандемии включали социальные сети (например, Reddit) или информационно-развлекательные программы (например, HowStuffWorks). Такие источники, как правило, менее надежны, чем официальные информационные агентства или качественные СМИ. Более того, в случае с Яндексом в топ поисковой выдачи попали альтернативные СМИ (например, https://coronavirusleaks. com/), достоверность информации в которых вызывает сомнения.
com/), достоверность информации в которых вызывает сомнения.
Вывод 4. Выбор языка влияет на различия между двигателями .
Наконец, мы обнаружили, что степень расхождений между результатами поиска варьировалась в зависимости от языка, на котором выполнялись запросы. Различия между агентами, использующими одну и ту же поисковую систему, были относительно низкими, что позволяет предположить, что выбор языка не оказал существенного влияния на рандомизацию (за исключением Google, где результаты на китайском/русском языках были более рандомизированы, чем на английском).
РИСУНОК 4. СРЕДНЕЕ СХОДСТВО (%) ДЛЯ ПАРНЫХ АГЕНТОВ СОГЛАСНО ПОИСКОВЫМ СИСТЕМАМ НА РАЗНЫХ ЯЗЫКАХ. JI ОБОЗНАЧАЕТ ИНДЕКС ЖАККАРДА, а RBO ОБОЗНАЧАЕТ РЕЙТИНГОВОЕ СМЕЩЕННОЕ ПЕРЕКРЫТИЕ. НА ОСИ X ПОКАЗАН СРЕДНИЙ ПРОЦЕНТ ПО КАЖДОМУ ПОКАЗАТЕЛЮ СХОДСТВА, А НА ОСИ Y ПОКАЗАНЫ СРАВНЕННЫЕ ПАРЫ ПОИСКОВЫХ СИСТЕМ.
НА ОСИ X ПОКАЗАН СРЕДНИЙ ПРОЦЕНТ ПО КАЖДОМУ ПОКАЗАТЕЛЮ СХОДСТВА, А НА ОСИ Y ПОКАЗАНЫ СРАВНЕННЫЕ ПАРЫ ПОИСКОВЫХ СИСТЕМ. Мы заметили, что выбор языка приводит к более существенным различиям между парами поисковых систем (рис. 4). Для нескольких пар, таких как Bing и DuckDuckGo, мы обнаружили, что результаты поиска были более похожими для русского и китайского языков, чем для английского. Однако эта закономерность не была универсальной, о чем свидетельствуют результаты запроса «выборы в США» (рис. A1 в приложении). Эти наблюдения можно объяснить разным объемом информации на соответствующих языках, обрабатываемой поисковыми системами. Меньший объем данных на русском и китайском языках может увеличить вероятность дублирования источников. Тем не менее, эти языковые расхождения подтверждают наше общее утверждение об отсутствии единообразия среди поисковых систем.
МетодыСбор данных
Мы разработали распределенную облачную исследовательскую инфраструктуру для эмуляции и отслеживания поведения нескольких виртуальных агентов в Интернете. Используя Amazon Elastic Compute Cloud (Amazon EC2), мы создали 100 виртуальных машин CentosOS с двумя установленными браузерами (Firefox и Chrome) на каждой машине. В каждый браузер («агент») мы установили два браузерных расширения: бота и трекер. Бот эмулирует поведение при просмотре, ища термины из предварительно определенного списка, а затем перемещается по результатам поиска. Трекер собирает HTML-код с каждой страницы, которую посещает бот, и отправляет его на центральный сервер — другую машину, на которой хранятся все данные.
Используя Amazon Elastic Compute Cloud (Amazon EC2), мы создали 100 виртуальных машин CentosOS с двумя установленными браузерами (Firefox и Chrome) на каждой машине. В каждый браузер («агент») мы установили два браузерных расширения: бота и трекер. Бот эмулирует поведение при просмотре, ища термины из предварительно определенного списка, а затем перемещается по результатам поиска. Трекер собирает HTML-код с каждой страницы, которую посещает бот, и отправляет его на центральный сервер — другую машину, на которой хранятся все данные.
Мы рассмотрели шесть поисковых систем — Baidu, Bing, Google, Yahoo, Yandex и DuckDuckGo — и запросили у них термин «коронавирус» на английском, русском и китайском языках. Выбор первых пяти поисковых систем объясняется тем, что они наиболее часто используются во всем мире (см. Statista 2020), тогда как DuckDuckGo был выбран из-за его акцента на конфиденциальность (Schofield 2019), что означает, что он не использует личные данные пользователей для персонализации.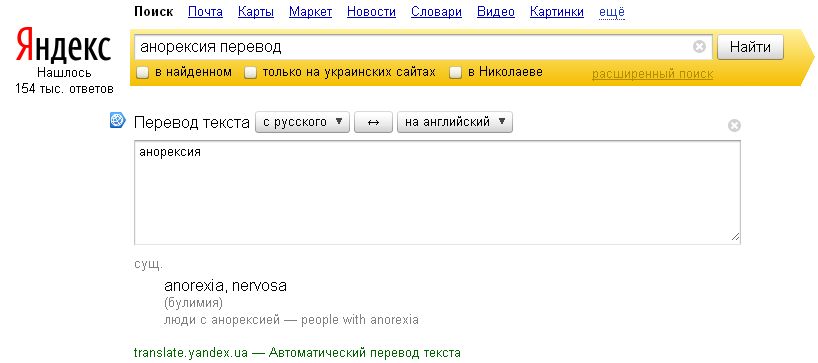 результаты поиска (Вайнберг, 2012). Мы выбрали слово «коронавирус» как наиболее распространенный термин, используемый в отношении продолжающейся пандемии на момент сбора данных (см. Google Trends (2020)) и термин, обозначающий широкое семейство вирусов, включающее COVID-19.. Во всех случаях мы использовали фиксированное написание термина (то есть «коронавирус», а не «коронавирус»), чтобы расхождения в запросах не влияли на результаты поиска.
результаты поиска (Вайнберг, 2012). Мы выбрали слово «коронавирус» как наиболее распространенный термин, используемый в отношении продолжающейся пандемии на момент сбора данных (см. Google Trends (2020)) и термин, обозначающий широкое семейство вирусов, включающее COVID-19.. Во всех случаях мы использовали фиксированное написание термина (то есть «коронавирус», а не «коронавирус»), чтобы расхождения в запросах не влияли на результаты поиска.
Мы разделили всех агентов на шесть групп (n=32/33; поровну распределены между Chrome и Firefox), каждая из которых была закреплена за определенной поисковой системой. 26 февраля 2020 г., за две недели до того, как ВОЗ объявила коронавирус пандемией, каждый агент выполнял аналогичную процедуру просмотра, состоящую из действий, типичных для навигации в веб-поиске, таких как набор текста, нажатие и прокрутка. Продолжительность подпрограммы не превышала трех минут, чтобы можно было собрать сопоставимый объем данных (~50 лучших результатов поиска). Все агенты были синхронизированы, чтобы запускать каждый запрос точно в одно и то же время (т. е. каждые семь минут). В случае сбоя сети инициировалось обновление страницы, чтобы включить повторную синхронизацию агента для следующего раунда запросов.
Все агенты были синхронизированы, чтобы запускать каждый запрос точно в одно и то же время (т. е. каждые семь минут). В случае сбоя сети инициировалось обновление страницы, чтобы включить повторную синхронизацию агента для следующего раунда запросов.
Мы также очищали данные браузера в начале каждого раунда запросов, чтобы уменьшить влияние предыдущих поисков на последующие. Во-первых, мы удалили данные, к которым может получить доступ поисковая система JavaScript, включая локальное хранилище, хранилище сеансов и файлы cookie. Во-вторых, мы удалили данные, доступ к которым может получить только браузер или расширения с расширенными привилегиями (полный список см. в таблице A1 в приложении), в том числе историю браузера и кеш.
Анализ данных
После сбора данных мы использовали BeautifulSoup (Python) и rvest (R) для извлечения URL-адресов результатов поиска из HTML для заданного запроса и для фильтрации нерелевантных URL-адресов (например, цифровых объявлений). Хотя мы признаем, что нерелевантные URL-адреса также могут влиять на то, как пользователи воспринимают информацию о коронавирусе, мы решили удалить их из-за нашего интереса к механизмам фильтрации и ранжирования поиска по умолчанию.
Хотя мы признаем, что нерелевантные URL-адреса также могут влиять на то, как пользователи воспринимают информацию о коронавирусе, мы решили удалить их из-за нашего интереса к механизмам фильтрации и ранжирования поиска по умолчанию.
Затем мы провели поиск между каждой парой двух агентов (200*199/2 = 19900 пар) с использованием двух показателей подобия: JI и RBO. JI измеряет перекрытие между двумя наборами результатов и может быть определен как доля идентичных результатов в обоих наборах среди всех уникальных результатов. Он часто используется для проверки алгоритмов поиска (Hannak et al., 2013; Kliman-Silver et al., 2015; Pushmann, 2019). Значение JI варьируется от 0 до 1, где 1 указывает, что сравниваемые наборы на 100% идентичны, а 0 — что они совершенно разные. Мы рассчитали два JI для каждой пары агентов: один измеряет перекрытие между полными наборами результатов поиска от каждого агента, а другой измеряет перекрытие для первых 10 результатов.
JI полезно оценить, сколько URL-адресов повторяется в результатах поиска, полученных агентами, но не учитывает порядок этих URL-адресов. Однако ранжирование источников имеет решающее значение для проверки алгоритмов поиска: состав двух наборов результатов может быть идентичным (следовательно, JI = 1), но порядок этих результатов может быть разным, что приводит к несовместимому пользовательскому опыту. Расхождения в ранжировании особенно важны, поскольку пользователи редко прокручивают страницу ниже нескольких первых результатов (Cutrell & Guan, 2007; González-Caro & Marcos, 2011).
Однако ранжирование источников имеет решающее значение для проверки алгоритмов поиска: состав двух наборов результатов может быть идентичным (следовательно, JI = 1), но порядок этих результатов может быть разным, что приводит к несовместимому пользовательскому опыту. Расхождения в ранжировании особенно важны, поскольку пользователи редко прокручивают страницу ниже нескольких первых результатов (Cutrell & Guan, 2007; González-Caro & Marcos, 2011).
Чтобы учесть различия в ранжировании результатов поиска, мы использовали показатель RBO, специально разработанный для изучения сходства результатов поисковых систем (Webber et al., 2010; Cardoso & Magalhães, 2011; Robertson et al., 2018). В отличие от JI, RBO взвешивает верхние результаты поиска больше, чем нижние, чтобы учесть, что ранжирование источника влияет на вероятность того, что пользователь увидит его (Cutrell & Guan, 2007). Подобно JI, значение RBO, равное 1, указывает на то, что состав результатов и их ранжирование на 100 % идентичны, тогда как значение RBO, равное 0, указывает на то, что и результаты, и их ранжирование совершенно разные.
Для RBO точный вес позиционирования результатов определяется параметром p. Значение параметра определяется исследователем и может быть любым числом в диапазоне 0 < p < 1. Чем ниже значение p, тем больший вес придается лучшим результатам. Мы провели наш анализ с двумя разными значениями p: 0,95 и 0,8. Первое значение позволяет более систематически анализировать различия в ранжировании между двумя агентами, тогда как второе фокусируется на различиях между лучшими результатами (Webber et al., 2010, стр. 24).
После расчета показателей сходства мы изучили типы источников информации, которым поисковые системы отдают предпочтение. Используя метод индуктивного кодирования, мы изучили 20 наиболее распространенных URL-адресов среди результатов поиска на английском языке для каждой из шести систем и закодировали каждый URL-адрес в соответствии с категорией источника информации, к которой он принадлежал. Мы определили 10 типов источников информации: 1) альтернативных СМИ : неосновные и нишевые источники, такие как анонимные блоги; 2) торговля : коммерческие источники и интернет-магазины; 3) правительство : источники, связанные с местными и национальными государственными органами; 4) здравоохранение : источники, связанные с организациями здравоохранения, такими как медицинские клиники и учреждения общественного здравоохранения; 5) информационно-развлекательная информация : источники новостей и развлечений, такие как HowStuffWorks; 6) унаследованные СМИ : источники, связанные с основными медиа-организациями, такими как CNN; 7) неправительственная организация (НПО) : источники, относящиеся к основным неправительственным организациям; 8) справочная работа : справочные онлайн-источники, такие как Википедия; 9) социальные сети : платформы социальных сетей, такие как Reddit; 10) аналитический центр : источники, связанные с исследовательскими институтами. Кодирование проводилось двумя авторами, которые кодировали разногласия между собой на основе консенсуса.
Кодирование проводилось двумя авторами, которые кодировали разногласия между собой на основе консенсуса.
Методическое приложение доступно в PDF-версии этой статьи.
Поделиться
Скачать PDF
Процитировать это эссе
Махортых М., Урман А. и Уллоа Р. (2020). Как поисковые системы распространяют информацию о COVID-19 и почему они должны работать лучше. Обзор дезинформации Гарвардской школы Кеннеди (HKS) . https://doi.org/10.37016/mr-2020-017
Библиография
Battelle, J. (2005). Поиск: как Google и его конкуренты переписали правила ведения бизнеса и изменили нашу культуру. Портфолио.
Кардосо, Б., и Магальяйнс, Дж. (2011). Google, Bing и новый взгляд на схожесть ранжирования. В материалах 20-й международной конференции ACM по управлению информацией и знаниями (стр. 1933–1936). АКМ Пресс.
Корнетт, Л. (2007, 17 августа). Поиск и интуиция: находите больше, когда знаете меньше. Страна поисковых систем. https://searchengineland.com/search-serendipity-finding-more-when-you-know-less-11971
Поиск и интуиция: находите больше, когда знаете меньше. Страна поисковых систем. https://searchengineland.com/search-serendipity-finding-more-when-you-know-less-11971
Катрелл, Э., и Гуан, З. (2007). Что Вы ищете? Исследование использования информации в веб-поиске с помощью отслеживания взгляда. В материалах конференции SIGCHI по человеческому фактору в вычислительных системах — CHI ’07 (стр. 407–416). АКМ Пресс.
Форухар, Р. (2019). Не будь злым: Дело против больших технологий. Пингвин Великобритания.
Гонсалес-Каро, К., и Маркос, М.К. (2011). Разные пользователи и намерения: анализ веб-поиска с помощью отслеживания взгляда. В материалах WSDM 11 (стр. 9–12). АКМ Пресс.
Google Тренды. (2020, 21 апреля). ковид-19, коронавирус. Google. https://trends.google.com/trends/explore?q=covid-19,coronavirus
Ханнак А., Сапезинский П., Молави Кахки А., Кришнамурти Б., Лазер Д., Мислов , А., и Уилсон, К. (2013). Измерение персонализации веб-поиска. В материалах 22-й международной конференции по всемирной паутине (стр. 527–538). АКМ Пресс.
527–538). АКМ Пресс.
Харамбам Дж., Бунтуридис Д., Махортых М. и Ван Хобокен Дж. (2019). Проектирование к лучшему с учетом пользователей: качественная оценка механизмов пользовательского контроля в (новостных) рекомендательных системах. В материалах 13-й конференции ACM по рекомендательным системам (стр. 69–77). АКМ Пресс.
Хе, К., Парра, Д., и Верберт, К. (2016). Интерактивные рекомендательные системы: обзор современного состояния и будущих исследовательских задач и возможностей. Экспертные системы с приложениями , 56 , 9-27.
Хелбергер, Н. (2011). Разнообразие по дизайну. Журнал информационной политики, 1, 441–469.
Джи, К. (2020, 20 апреля). WhatsApp ограничивает пересылку сообщений для борьбы с дезинформацией о коронавирусе. Обзор технологий Массачусетского технологического института. https://www.technologyreview.com/2020/04/07/998517/whatsapp-limits-message-forwarding-combat-coronavirus-misinformation/
Кемпер, Дж., и Колкман, Д. (2019). Прозрачный для кого? Никакой алгоритмической подотчетности без критической аудитории. Информация, коммуникации и общество, 22 (14), 2081–209.6.
(2019). Прозрачный для кого? Никакой алгоритмической подотчетности без критической аудитории. Информация, коммуникации и общество, 22 (14), 2081–209.6.
Климан-Сильвер, К., Ханнак, А., Лазер, Д., Уилсон, К., и Мислов, А. (2015). Местоположение, местоположение, местоположение: влияние геолокации на персонализацию веб-поиска. В материалах конференции по интернет-измерениям 2015 г. (стр. 121–127). АКМ Пресс.
Миттельштадт, Б. (2016). Автоматизация, алгоритмы и политика: аудит прозрачности систем персонализации контента. Международный журнал связи, 10: 4991–5002. Паскуале, Ф. (2015). Общество черного ящика. Издательство Гарвардского университета.
Ноубл, США (2018). Алгоритмы угнетения: как поисковые системы усиливают расизм. Нью-Йорк Пресс.
Пушманн, К. (2019). За пределами пузыря: оценка разнообразия результатов политического поиска. Цифровая журналистика, 7(6), 824–843.
Робертсон, Р. Э., Цзян, С., Джозеф, К., Фридланд, Л., Лазер, Д., и Уилсон, К.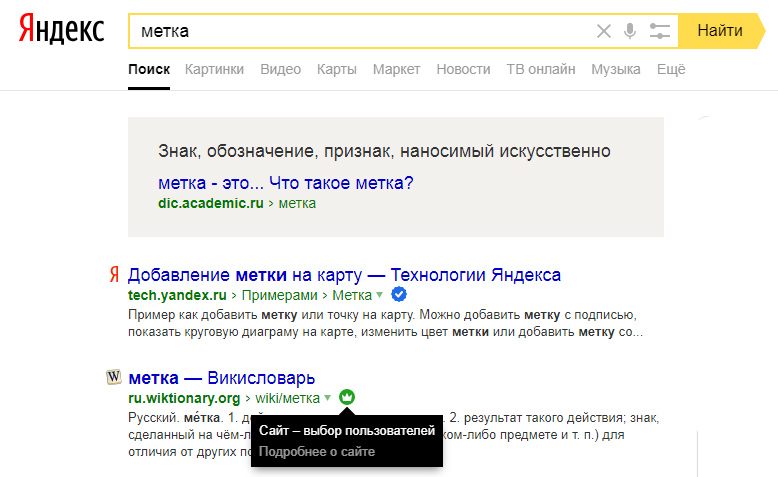 (2018). Аудит необъективной аудитории в поиске Google. Труды ACM по взаимодействию человека с компьютером, 2 (CSCW): 1–22.
(2018). Аудит необъективной аудитории в поиске Google. Труды ACM по взаимодействию человека с компьютером, 2 (CSCW): 1–22.
Шофилд, Дж. (2019 г., 12 декабря). Может ли DuckDuckGo заменить поиск Google, предлагая лучшую конфиденциальность? Хранитель. Получено с https://www.theguardian.com/technology/askjack/2019/dec/12/duckduckgo-google-search-engine-privacy
Statista. (2020). Доля ведущих поисковых систем на мировом рынке настольных ПК с января 2010 г. по январь 2020 г. А. и Зобель Дж. (2010). Мера сходства для неопределенного ранжирования. Транзакции ACM в информационных системах, 28 (4), 1–38.
Вайнберг, Г. (2012). Конфиденциальность. DuckDuckGo https://duckduckgo.com/privacy
Финансирование
Исследование проведено в рамках исследовательского проекта «Взаимные отношения между популистскими радикально-правыми установками и политическим информационным поведением: лонгитюдное исследование развития установок в информационном пространстве с высоким выбором среды», финансируемой Deutsche Forschungsgemeinschaft (номер проекта 4131
- ) и Швейцарским национальным научным фондом (номер проекта 182630).
- Регистрация в поисковых системах позволяет поисковым системам заметить ваш веб-сайт
- Регистрация в поисковых системах уведомляет поисковые системы о новых страницах веб-сайта
- Регистрация в поисковых системах оптимизирует ваше SEO

Конкурирующие интересы
Авторы заявили об отсутствии потенциального конфликта интересов в отношении исследования, авторства и/или публикации этой статьи.
Этика
Данные для проекта были получены из общедоступных источников и поэтому не подлежат проверке IRB.
Авторские права
Эта статья находится в открытом доступе и распространяется в соответствии с условиями лицензии Creative Commons Attribution, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии, что первоначальный автор и источник должным образом указаны.
Благодарность
Мы хотели бы поблагодарить двух анонимных рецензентов и редакторов журналов за очень полезные отзывы о нашей рукописи, а также ассистента Института коммуникаций и медиа исследований (Бернский университет) Мадлейну Ганзебум за ценную помощь во время Сбор данных.
Доступность данных
Все материалы, необходимые для воспроизведения этого исследования, доступны через Harvard Dataverse https://doi. org/10.7910/DVN/IJKIN3.
org/10.7910/DVN/IJKIN3.
Почему регистрация в поисковых системах ⋆ Медиа-площадка ⋆ (502) 855-4783
Опубликовано в 18:30 в Новости by cs_mv_4dmin
Представьте, что вы начинаете новый бизнес и только что опубликовали свой веб-сайт. После того, как вы запустите и просмотрите свой новый сайт, вы обращаетесь к поисковым системам, чтобы узнать, как он ранжируется. Вы используете несколько поисковых систем — Google, Yahoo и Bing — но ваш сайт так и не появляется. Ваш сайт не работает?
Проблема не в самом сайте: поисковые системы понятия не имеют о его существовании. Создание SEO занимает больше нескольких минут, и вероятность того, что поисковая система автоматически просканирует и проиндексирует ваш новый сайт за такой небольшой промежуток времени, практически равна нулю. Ну так что ты делаешь? Как сделать так, чтобы ваш сайт появился в поисковых системах?
Это простой шаг, но многие новые владельцы веб-сайтов забывают его выполнить: регистрация в поисковой системе.
Регистрация в поисковых системах — это этап, на котором ваш сайт должен быть представлен поисковым системам, чтобы они знали о его существовании. Регистрация вашего веб-сайта дает поисковым системам возможность «сканировать» и индексировать ваш веб-сайт. Это то, что позволяет вашему веб-сайту появляться в поисковых системах, чтобы потенциальные клиенты могли его обнаружить.
РЕГИСТРАЦИЯ В ПОИСКОВОЙ ДВИГАТЕЛЕ АВТОМАТИЧЕСКАЯ ИЛИ ВРУЧНУЮ?Регистрация в поисковых системах осуществляется как автоматически, так и вручную. Однако существуют важные различия в процессах каждого из них и преимущества выбора ручной регистрации по сравнению с автоматической регистрацией.
Автоматическая регистрация в поисковых системах По сути, автоматическая регистрация опирается на алгоритмы поисковых систем, которые сами находят ваш сайт. Это может произойти разными способами, включая обратную ссылку на ваш сайт.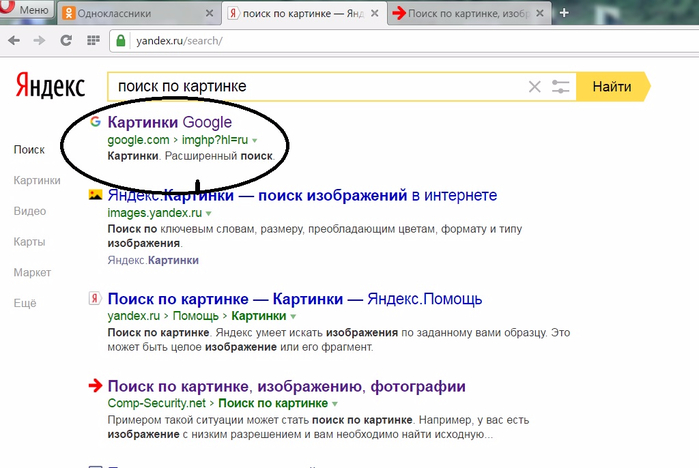 Однако вы никогда не знаете, сколько времени потребуется поисковым системам, чтобы найти эту обратную ссылку (или ваш сайт в целом), просканировать ваш сайт, а затем проиндексировать ваш сайт в поисковой системе; это делает автоматический SER неразумным выбором для вашего бизнеса.
Однако вы никогда не знаете, сколько времени потребуется поисковым системам, чтобы найти эту обратную ссылку (или ваш сайт в целом), просканировать ваш сайт, а затем проиндексировать ваш сайт в поисковой системе; это делает автоматический SER неразумным выбором для вашего бизнеса.
Ручная SER, с другой стороны, гораздо более эффективна и имеет более высокую вероятность более быстрых результатов. Как только ваш веб-сайт заработает, вы можете вручную зарегистрировать веб-сайт в поисковых системах, чтобы они знали, что он существует (вместо того, чтобы полагаться на алгоритмы, которым могут потребоваться недели, чтобы найти ваш сайт). Кроме того, ручная регистрация в поисковых системах позволяет вам обновлять поисковые системы, как только вы вносите изменения на свой веб-сайт.
Понимание различий Чтобы лучше понять разницу между автоматической и ручной регистрацией в поисковых системах, давайте рассмотрим пример.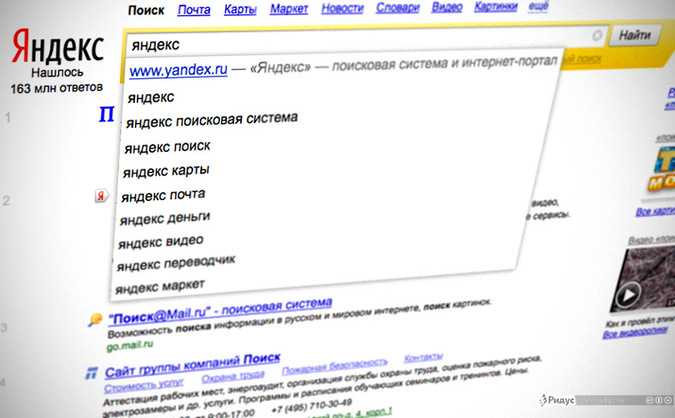 Допустим, вы владеете пекарней и зарегистрировали свой веб-сайт в поисковых системах, когда только начинали свой бизнес. Сейчас бизнес расширяется. Вместо того, чтобы сосредотачиваться исключительно на выпечке, вы решаете включить и торты. Теперь вы пытаетесь найти клиентов, которые купят ваши торты. Вы добавляете новую страницу на свой веб-сайт, чтобы отразить добавленную услугу. Хотя вы использовали ручную регистрацию, когда впервые запустили свой бизнес и веб-сайт, может пройти некоторое время, прежде чем поисковые системы снова просканируют ваш веб-сайт, чтобы увидеть, что вы добавили услугу торта на свой веб-сайт. Вы можете подождать, пока поисковые системы снова автоматически просканируют ваш сайт, но это может привести к тому, что вы упустите возможности для бизнеса.
Допустим, вы владеете пекарней и зарегистрировали свой веб-сайт в поисковых системах, когда только начинали свой бизнес. Сейчас бизнес расширяется. Вместо того, чтобы сосредотачиваться исключительно на выпечке, вы решаете включить и торты. Теперь вы пытаетесь найти клиентов, которые купят ваши торты. Вы добавляете новую страницу на свой веб-сайт, чтобы отразить добавленную услугу. Хотя вы использовали ручную регистрацию, когда впервые запустили свой бизнес и веб-сайт, может пройти некоторое время, прежде чем поисковые системы снова просканируют ваш веб-сайт, чтобы увидеть, что вы добавили услугу торта на свой веб-сайт. Вы можете подождать, пока поисковые системы снова автоматически просканируют ваш сайт, но это может привести к тому, что вы упустите возможности для бизнеса.
Как только вы добавите эту страницу на свой сайт, вы сможете зарегистрировать изменение в поисковых системах. Это даст вам более быстрые результаты о том, как ваш сайт и бизнес-предложения отображаются в поисковых системах.
Регистрация в поисковых системах важна по ряду причин:
Без регистрации вашего веб-сайта может пройти много времени, иногда даже недель, прежде чем ваш сайт будет замечен поисковыми системами. Не упустите потенциальных клиентов и доход, потому что вы не зарегистрировали свой сайт!
Каждый раз, когда вы добавляете новую страницу на свой веб-сайт, вам нужно зарегистрировать ее в поисковых системах. Это важный шаг для включения этих новых страниц в список поисковых систем, особенно если они включают новые продукты, услуги или ключевые слова, по которым вы хотите ранжироваться!
Поисковые системы помогают привлечь органический трафик для вашего сайта и показывать лучшие результаты на основе множества факторов, включая ключевые слова. Регистрация вашего сайта в поисковых системах помогает поисковым системам «читать» ваши страницы, определять ключевые слова и показывать результаты на основе целевого поискового запроса.
Регистрация вашего сайта в поисковых системах помогает поисковым системам «читать» ваши страницы, определять ключевые слова и показывать результаты на основе целевого поискового запроса.
Веб-сканирование (или просто «сканирование») — это интернет-версия наблюдения за тем, как связаны страницы, будь то на одном веб-сайте или на разных веб-сайтах.
Чтобы лучше понять сканирование веб-страниц, давайте вернемся к примеру с пекарней из предыдущего примера. На городском веб-сайте пекарня может быть указана в списке мест, где можно поесть. Если поисковая система сканирует страницу города в поисках местных мест, где можно поесть, и видит, что она связана с вашим сайтом (через обратную ссылку), теперь они видят их как связанные и будут «читать» оба сайта.
Кроме того, поисковая система может сканировать веб-сайт, чтобы увидеть, как разные страницы связаны друг с другом. Для веб-сайта пекарни поисковая система может увидеть, что домашняя страница ссылается на страницы с продуктами и услугами, контактной информацией и т. д. Затем поисковые системы будут «сканировать» каждую из этих страниц, на которые есть ссылки с главной страницы, любые дополнительные внутренние ссылки на эти страницы и любые внешние ссылки, ведущие на внешние сайты, чтобы увидеть, как они связаны друг с другом.
Для веб-сайта пекарни поисковая система может увидеть, что домашняя страница ссылается на страницы с продуктами и услугами, контактной информацией и т. д. Затем поисковые системы будут «сканировать» каждую из этих страниц, на которые есть ссылки с главной страницы, любые дополнительные внутренние ссылки на эти страницы и любые внешние ссылки, ведущие на внешние сайты, чтобы увидеть, как они связаны друг с другом.
Поисковые системы используют веб-сканирование для предоставления релевантной информации о веб-сайте в поисковых системах. Вот почему важно учитывать SEO при регистрации в поисковых системах!
Является ли регистрация в поисковой системе такой же, как отправка карты сайта?Нет. Карта сайта, по сути, сообщает поисковым системам, как взаимосвязаны страницы вашего веб-сайта (и помогает при сканировании), но отправка карты сайта не означает, что вы зарегистрировали свой сайт в поисковых системах.
КАК НАЧАТЬ РАБОТУ С SER Как видите, регистрация в поисковых системах чрезвычайно важна, если вы хотите, чтобы ваш сайт заметили.