Robots.txt для сайта — правильная настройка — Staurus.net
Всем нужны инструкции для работы, поисковые системы не исключения из правил, поэтому и придумали специальный файл под названием robots.txt. Этот файл должен лежать в корневой папке вашего сайта, или он может быть виртуальным, но обязательно открываться по запросу: www.вашсайт.ru/robots.txtПоисковые системы уже давно научились отличать нужные файлы html, от внутренних наборов скриптов вашей CMS системы, точнее они научились распознавать ссылки на контентные статьи и всяких хлам. Поэтому многие вебмастера уже забывают делать роботс для своих сайтов и думают, что все и так хорошо будет. Да они правы на 99%, ведь если у вашего сайта нет этого файла, то поисковые системы безграничны в своих поисках контента, но случаются нюансы, над ошибками которых, можно позаботиться заранее.
Если у вас возникли проблемы с этим файлом на сайте, пишите комментарии к этой статье и я быстро помогу вам в этом, абсолютно бесплатно.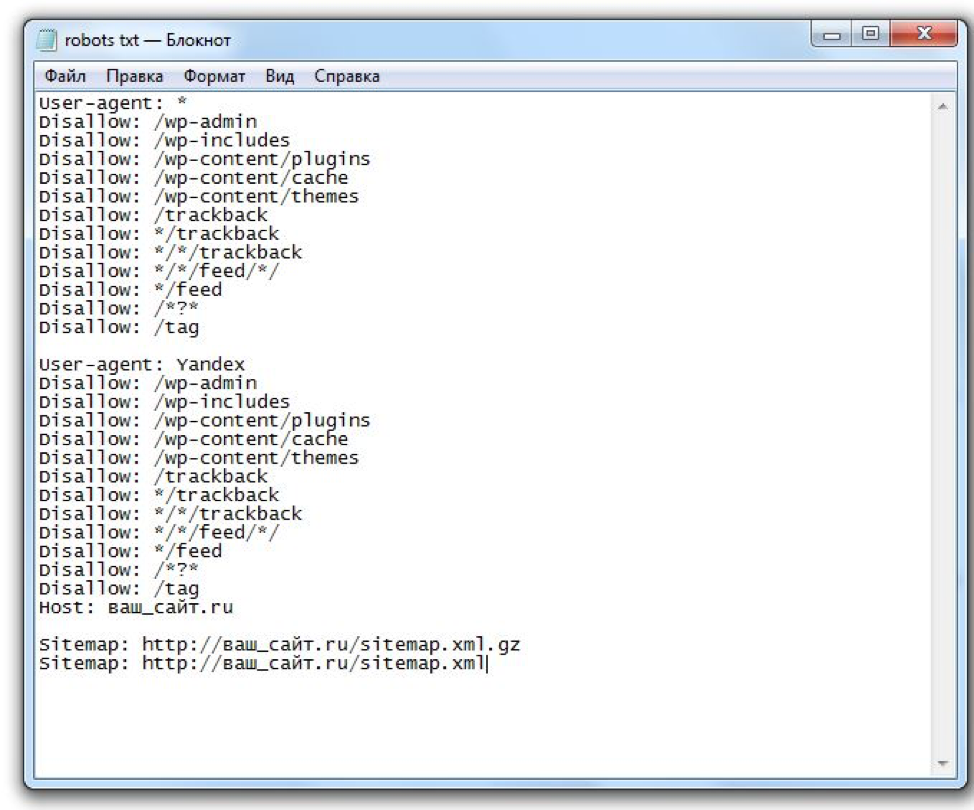 Очень часто вебмастера делают мелкие ошибки в нем, что приносит сайту плохую индексацию, или вообще исключение из индекса.
Очень часто вебмастера делают мелкие ошибки в нем, что приносит сайту плохую индексацию, или вообще исключение из индекса.
Для чего нужен robots.txt
Файл robots.txt создается для настройки правильной индексации сайта поисковым системам. То есть в нем содержатся правила разрешений и запретов на определенные пути вашего сайта или тип контента. Но это не панацея. Все правила в файле robots не являются указаниями точно им следовать, а просто рекомендация для поисковых систем. Google например пишет:
Нельзя использовать файл robots.txt, чтобы скрыть страницу из результатов Google Поиска. На нее могут ссылаться другие страницы, и она все равно будет проиндексирована.
Поисковые роботы сами решают что индексировать, а что нет, и как себя вести на сайте. У каждого поисковика свои задачи и свои функции. Как бы мы не хотели, этим способ их не укротить.
Но есть один трюк, который не касается напрямую тематики этой статьи. Чтобы полностью запретить роботам индексировать и показывать страницу в поисковой выдаче, нужно написать:
<meta name="robots" content="noindex" />
Вернемся к robots. Правилами в этой файле можно закрыть или разрешить доступ к следующим типам файлов:
- Неграфические файлы. В основном это html файлы, на которых содержится какая-либо информация. Вы можете закрыть дубликаты страниц, или страницы, которые не несут никакой полезной информации (страницы пагинации, страницы календаря, страницы с архивами, страницы с профилями и т.д.).
- Графические файлы. Если вы хотите, чтобы картинки сайта не отображались в поиске, вы можете это прописать в файле robots.
- Файлы ресурсов. Также с помощью robots вы можете заблокировать индексацию различных скриптов, файлы стилей CSS и другие маловажные ресурсы. Но не стоит блокировать ресурсы, которые отвечают за визуальную часть сайта для посетителей (например, если вы закроете css и js сайта, которые выводят красивые блоки или таблицы, этого не увидит поисковой робот, и будет ругаться на это).
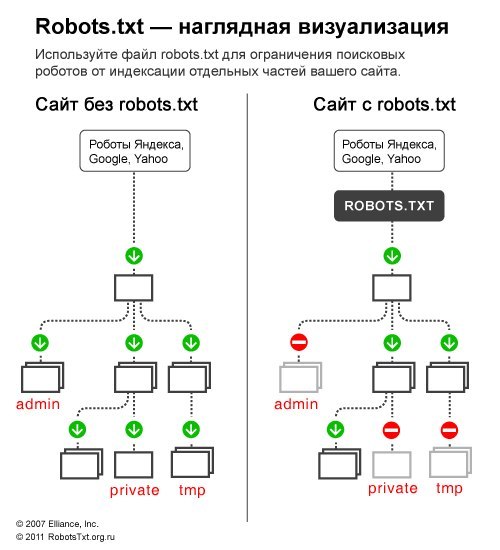
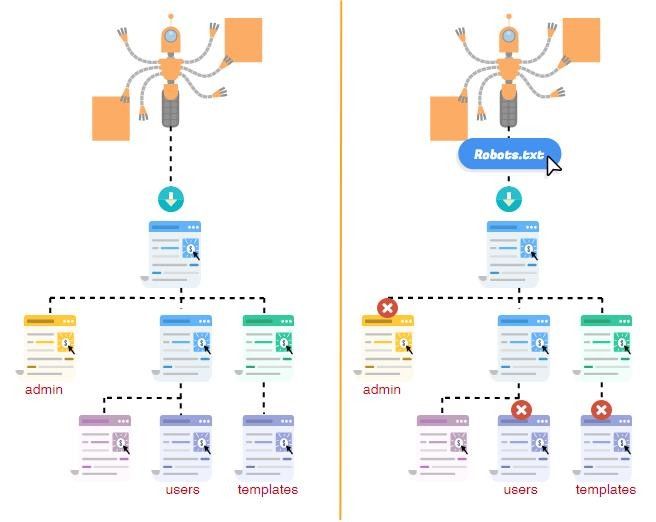
Чтобы наглядно показать, как работает robots, посмотрите на картинку ниже:
Поисковой робот, следуя на сайт, смотрит на правила индексации, затем начинает индексацию по рекомендациям файла. В зависимости от настроек правил, поисковик знает, что можно индексировать, а что нет.
В зависимости от настроек правил, поисковик знает, что можно индексировать, а что нет.Синтаксис файла robots.txt
Для написания правил поисковым системам в файле роботса используются директивы с различными параметрами, с помощью которых следуют роботы. Начнем с самой первой и наверное самой главной директивы:
Директива User-agent
User-agent — Этой директивой вы задает название роботу, которому следует использовать рекомендации в файле. Этих роботов официально в мире интернета — 302 штуки. Вы конечно можете прописать правила для всех по отдельности, но если у вас нет времени на это, просто пропишите:
User-agent: *
*-в данном примере означает «Все». Т.е. ваш файл robots.txt, должен начинаться с того, «для кого именно» предназначен файл. Чтобы не заморачиваться над всеми названиями роботов, просто пропишите «звездочку» в директиве user-agent.
Приведу вам подробные списки роботов популярных поисковых систем:
Google — Googlebot — основной робот
Остальные роботы Google Googlebot-News — робот поиска новостей
Googlebot-Image — робот картинок
Googlebot-Video — робот видео
Googlebot-Mobile — робот мобильной версии
AdsBot-Google — робот проверки качества целевой страницы
Mediapartners-Google — робот сервиса AdSense
Яндекс — YandexBot — основной индексирующий робот;
Остальные роботы Яндекса YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы, интерпретирует robots. txt особым образом;
txt особым образом;
YandexDirectDyn — робот генерации динамических баннеров, интерпретирует robots.txt особым образом;
YandexMedia — робот, индексирующий мультимедийные данные;
YandexImages — индексатор Яндекс.Картинок;
YaDirectFetcher — робот Яндекс.Директа, интерпретирует robots.txt особым образом;
YandexBlogs — робот поиск по блогам, индексирующий посты и комментарии;
YandexNews — робот Яндекс.Новостей;
YandexPagechecker — валидатор микроразметки;
YandexMetrika — робот Яндекс.Метрики;
YandexMarket— робот Яндекс.Маркета;
YandexCalendar — робот Яндекс.Календаря.
Директивы Disallow и Allow
Disallow — самое основное правило в robots, именно с помощью этой директивы вы запрещаете индексировать определенные места вашего сайта. Пишется директива так:
Disallow:
Очень часто можно наблюдать директиву Disallow: пустую, т. е. якобы говоря роботу, что ничего не запрещено на сайте, индексируй что хочешь. Будьте внимательны! Если вы поставите / в disallow, то вы полностью закроете сайт для индексации.
е. якобы говоря роботу, что ничего не запрещено на сайте, индексируй что хочешь. Будьте внимательны! Если вы поставите / в disallow, то вы полностью закроете сайт для индексации.
Поэтому самый стандартный вариант robots.txt, который «разрешает индексацию всего сайта для всех поисковых систем» выглядит так:
User-Agent: * Disallow:
Если вы не знаете что писать в robots.txt, но где-то слышали о нем, просто скопируйте код выше, сохраните в файл под названием robots.txt и загрузите его в корень вашего сайта. Или ничего не создавайте, так как и без него роботы будут индексировать все на вашем сайте. Или прочитайте статью до конца, и вы поймете, что закрывать на сайте, а что нет.
По правилам robots, директива disallow должна быть обязательна.
Этой директивой можно запретить как папку, так и отдельный файл.
Если вы хотите запретить папку вам следует написать:
Disallow: /papka/
Если вы хотите запретить определенный файл:
Disallow: /images/img.jpg
Если вы хотите запретить определенные типы файлов:
Disallow: /*.png$
!Регулярные выражения не поддерживаются многими поисковыми системами. Google поддерживает.
Allow: /content Disallow: /
эти директивы запрещают индексировать весь контент сайта, кроме папки content. Или вот еще популярные директивы в последнее время:
Allow: /themplate/*.js Allow: /themplate/*.css Disallow: /themplate
эти значения разрешают индексировать все файлы CSS и JS на сайте, но запрещают индексировать все в папке с вашим шаблоном. За последний год Google очень много отправил писем вебмастерам такого содержания:
Googlebot не может получить доступ к файлам CSS и JS на сайте
И соответствующий комментарий: Мы обнаружили на Вашем сайте проблему, которая может помешать его сканированию. Робот Googlebot не может обработать код JavaScript и/или файлы CSS из-за ограничений в файле robots.txt. Эти данные нужны, чтобы оценить работу сайта. Поэтому если доступ к ресурсам будет заблокирован, то это может ухудшить позиции Вашего сайта в Поиске.
Робот Googlebot не может обработать код JavaScript и/или файлы CSS из-за ограничений в файле robots.txt. Эти данные нужны, чтобы оценить работу сайта. Поэтому если доступ к ресурсам будет заблокирован, то это может ухудшить позиции Вашего сайта в Поиске.
Если вы добавите две директивы allow, которые написаны в последнем коде в ваш Robots.txt, то вы не увидите подобных сообщений от Google.
Использование спецсимволов в robots.txt
Теперь про знаки в директивах. Основные знаки (спецсимволы) в запрещающих или разрешающих это /,*,$
Про слеши (forward slash) «/»
Слеш очень обманчив в robots.txt. Я несколько десятков раз наблюдал интересную ситуацию, когда по незнанию в robots.txt добавляли:
User-Agent: * Disallow: /
Потому, что они где-то прочитали о структуре сайта и скопировали ее себе на сайте. Но, в данном случае вы запрещаете индексацию всего сайта. Чтобы запрещать индексацию именно каталога, со всеми внутренностями вам обязательно нужно ставить / в конце.
Внимательно смотрите на все / в вашем robots.txt
Всегда в конце директорий ставьте /. Если вы поставите / в Disallow, вы запретите индексацию всего сайта, но если вы не поставите / в Allow, вы также запретите индексацию всего сайта. / — в некотором понимании означает «Все что следует после директивы /».
Про звездочки * в robots.txt
Спецсимвол * означает любую (в том числе пустую) последовательность символов. Вы можете ее использовать в любом месте robots по примеру:
User-agent: * Disallow: /papka/*.aspx Disallow: /*old
Запрещает все файлы с расширением aspx в директории papka, также запрещает не только папку /old, но и директиву /papka/old. Замудрено? Вот и я вам не рекомендую баловаться символом * в вашем robots.
Замудрено? Вот и я вам не рекомендую баловаться символом * в вашем robots.
По умолчанию в файле правил индексации и запрета robots.txt стоит * на всех директивах!
Про спецсимвол $
Спецсимвол $ в robots заканчивает действие спецсимвола *. Например:
Disallow: /menu$
Это правило запрещает ‘/menu’, но не запрещает ‘/menu.html’, т.е. файл запрещает поисковым системам только директиву /menu, и не может запретить все файлы со словом menu в URL`е.
Директива host
Правило host работает только в Яндекс, поэтому является не обязательным, оно определяет основной домен из ваших зеркал сайта, если таковы есть. Например у вас есть домен dom.com, но и так же прикуплены и настроены следующие домены: dom2.com, dom3,com, dom4.com и с них идет редирект на основной домен dom.com
Чтобы Яндексу быстрее определить, где из них главных сайт (хост), пропишите директорию host в ваш robots. txt:
txt:
Host: staurus.net
Если у вашего сайта нет зеркал, то можете не прописывать это правило. Но сначала проверьте ваш сайт по IP адрессу, возможно и по нему открывается ваша главная страница, и вам следует прописать главное зеркало. Или возможно кто-то скопировал всю информацию с вашего сайта и сделал точную копию, запись в robots.txt, если она также была украдена, поможет вам в этом.
Запись host должны быть одна, и если нужно, с прописанным портом. (Host: staurus.net:8080)
Директива Crawl-delay
Эта директива была создана для того, чтобы убрать возможность нагрузки на ваш сервер. Поисковые роботы могут одновременно делать сотни запросов на ваш сайт и если ваш сервер слабый, это может вызвать незначительные сбои. Чтобы такого не произошло, придумали правило для роботов Crawl-delay — это минимальный период между загрузками страницы вашего сайта. Стандартное значение для этой директивы рекомендуют ставить 2 секунды. В Robots это выглядит так:
Crawl-delay: 2
Эта директива работает для Яндекса.
Директива Clean-param
Этот параметр тоже только для Яндекса. Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (например: идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту информацию, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.site.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.site.com/some_dir/get_book.pl?ref=site_3&book_id=123
Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
Тогда, если указать директиву следующим образом:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот Яндекса сведет все адреса страницы к одному:
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123,
Если на сайте доступна страница без параметров:
www.site.com/some_dir/get_book.pl?book_id=123
то все сведется именно к ней, когда она будет проиндексирована роботом. Другие страницы вашего сайта будут обходиться чаще, так как нет необходимости обновлять страницы:
www.site.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.site.com/some_dir/get_book.pl?ref=site_3&book_id=123
#для адресов вида: www.site1.com/forum/showthread.php?s=681498b9648949605&t=8243 www.site1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243 #robots.txt будет содержать: User-agent: Yandex Disallow: Clean-param: s /forum/showthread.php
Директива Sitemap
Этой директивой вы просто указываете месторасположение вашего sitemap. xml. Робот запоминает это, «говорит вам спасибо», и постоянно анализирует его по заданному пути. Выглядит это так:
xml. Робот запоминает это, «говорит вам спасибо», и постоянно анализирует его по заданному пути. Выглядит это так:
Sitemap: http://staurus.net/sitemap.xml
Общие вопросы и рекомендации по robots
А сейчас давайте рассмотрим общие вопросы, которые возникают при составлении роботса. В интернете много таких тем, поэтому разберем самые актуальные и самые частые.
Правильный robots.txt
Очень много но в этом слове «правильный», ведь для одного сайта на одной CMS он будет правильный, а на другой CMS — будет выдавать ошибки. «Правильно настроенный» для каждого сайта индивидуальный. В Robots.txt нужно закрывать от индексации те разделы и те файлы, которые не нужны пользователям и не несут никакой ценности для поисковиков. Самый простой и самый правильный вариант robots.txt
User-Agent: * Disallow: Sitemap: http://staurus.net/sitemap.xml User-agent: Yandex Disallow: Host: site.com
В этом файле стоят такие правила: настройки правил запрета для всех поисковых систем (User-Agent: *), полностью разрешена индексация всего сайта («Disallow:» или можете указать «Allow: /»), указан хост основного зеркала для Яндекса (Host: site.
Robots.txt для WordPress
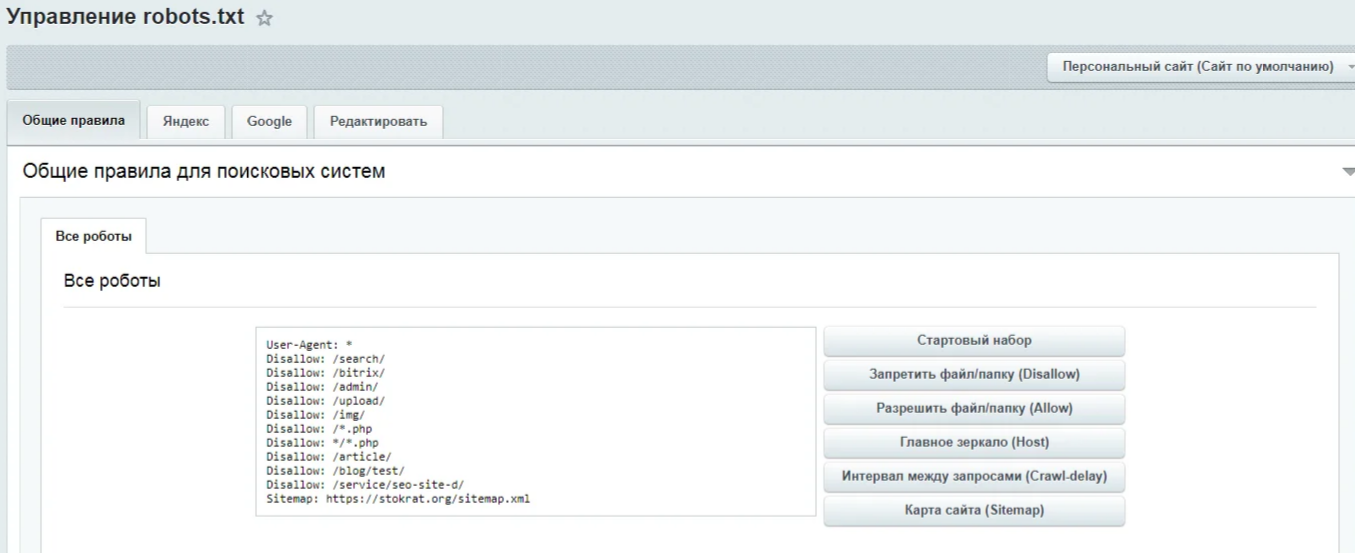
Опять же много вопросов, один сайт может быть интернет-магазинов, другой блог, третий — лендинг, четвертый — сайт-визитка фирмы, и это все может быть на CMS WordPress и правила для роботов будут совершенно разные. Вот мой robots.txt для этого блога:
User-Agent: * Allow: /wp-content/uploads/ Allow: /wp-content/*.js$ Allow: /wp-content/*.css$ Allow: /wp-includes/*.js$ Allow: /wp-includes/*.css$ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Disallow: /category Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: /?feed= Disallow: /job Disallow: /?s= Host: staurus.net Sitemap: http://staurus.net/sitemap.xml
Тут очень много настроек, давайте их разберем вместе.
Allow в WordPress. Первые разрешающие правила для контента, который нужен пользователям (это картинки в папке uploads), и роботам (это CSS и JS для отображения страниц). Именно по css и js часто ругается Google, поэтому мы оставили их открытыми. Можно было использовать метод всех файлов просто вставив «/*.css$», но запрещающая строка именно этих папок, где лежат файлы — не разрешала использовать их для индексации, поэтому пришлось прописать путь к запрещающей папке полностью.
Именно по css и js часто ругается Google, поэтому мы оставили их открытыми. Можно было использовать метод всех файлов просто вставив «/*.css$», но запрещающая строка именно этих папок, где лежат файлы — не разрешала использовать их для индексации, поэтому пришлось прописать путь к запрещающей папке полностью.
Allow всегда указывает на путь запрещенного в Disallow контента. Если у вас что-то не запрещено, не стоит ему прописывать allow, якобы думая, что вы даете толчок поисковикам, типа «Ну на же, вот тебе URL, индексируй быстрее». Так не получится.
Disallow в WordPress. Запрещать в CMS WP нужно очень многое. Множество различных плагинов, множество различных настроек и тем, куча скриптов и различных страниц, которые не несут в себе никакой полезной информации. Но я пошел дальше и совсем запретил индексировать все на своем блоге, кроме самих статей (записи) и страниц (об Авторе, Услуги). Я закрыл даже категории в блоге, открою, когда они будут оптимизированы под запросы и когда там появится текстовое описание для каждой из них, но сейчас это просто дубли превьюшек записей, которые не нужны поисковикам.
Ну Host и Sitemap стандартные директивы. Только нужно было вынести host отдельно для Яндекса, но я не стал заморачиваться по этому поводу. Вот пожалуй и закончим с Robots.txt для WP.
Как создать robots.txt
Это не так сложно как кажется на первый взгляд. Вам достаточно взять обычный блокнот (Notepad) и скопировать туда данные для вашего сайта по настройкам из этой статьи. Но если и это для вас сложно, в интернете есть ресурсы, которые позволяют генерировать роботс для ваших сайтов:
Генератор Robots от pr-cy — Один из самых простых генераторов Robots в Рунете. Просто укажите в инструменте ссылки, которым не стоит попадать в индекс и все.
Создание Robots от htmlweb — хороший генератор robots с возможность добавления host и Sitemap.
Где проверить свой robots.txt
Это один из самых важный и обязательных пунктов перед отправкой файла роботс на свой сервер — проверка. Если вы, что-то сделали не правильно, вы можете «похоронить» свой сайт в просторах поисковиков. Обычным ляпом, как это случается, запретить индексацию всего сайта.
Обычным ляпом, как это случается, запретить индексацию всего сайта.
Чтобы этого не произошло, вам стоит проверить свой файл запретов в одном из удобных проверочных сервисов:
Google Webmaster tool
Яндекс. Вебмастер
Никто не расскажет больше про ваш Robots.txt, как эти товарищи. Ведь именно для них вы и создаете свой «запретный файлик».
Теперь поговорим о некоторых мелких ошибках, которые могут быть в robots.
- «Пустая строка» — недопустимо делать пустую строку в директиве user-agent.
- При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow.
- Для каждого файла robots.txt обрабатывается только одна директива Host. Если в файле указано несколько директив, робот использует первую.
- Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
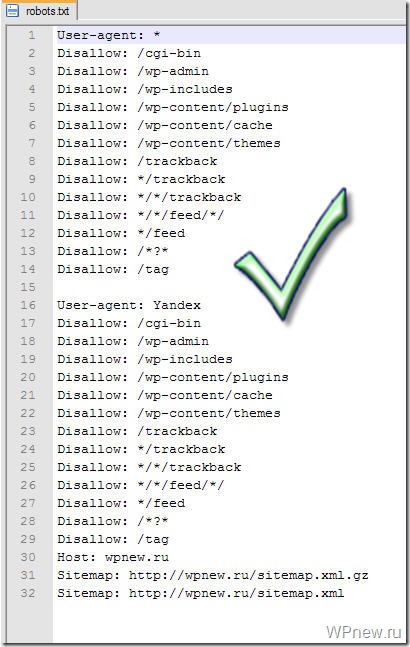
- Шесть роботов Яндекса не следуют правилам Robots.txt (YaDirectFetcher, YandexCalendar, YandexDirect, YandexDirectDyn, YandexMobileBot, YandexAccessibilityBot). Чтобы запретить им индексацию на сайте, следует сделать отдельные параметры user-agent для каждого из них.
- Директива User-agent, всегда должна писаться выше запрещающей директивы.
- Одна строка, для одной директории. Нельзя писать множество директорий на одной строке.
- Имя файл должно быть только таким: robots.txt. Никаких Robots.txt, ROBOTS.txt, и так далее. Только маленькие буквы в названии.
- В директиве host следует писать путь к домену без http и без слешей. Неправильно: Host: http://www.site.ru/, Правильно: Host: www.site.ru
- При использовании сайтом защищенного протокола https в директиве host (для робота Яндекса) нужно обязательно указывать именно с протоколом, так Host: https://www.
 site.ru
site.ru
Эта статья будет обновляться по мере поступления интересных вопросов и нюансов.
С вами был, ленивый Staurus.
FAQ robots.txt: часто задаваемые вопросы
Robots.txt — что это?
Файл robots.txt — это индексный файл в текстовом формате, который рекомендует поисковым роботам (например, Google, Yandex) какие страницы сканировать, а какие нет.
Нужен или нет robots.txt?
Однозначно да. Он помогает поисковым роботам быстрее разобраться какие страницы нужно индексировать, а какие нет.
Где находится файл robots.txt?
Файл располагается в корневой папке сайта и доступный для просмотра по адресу: https://site.ua/robots.txt
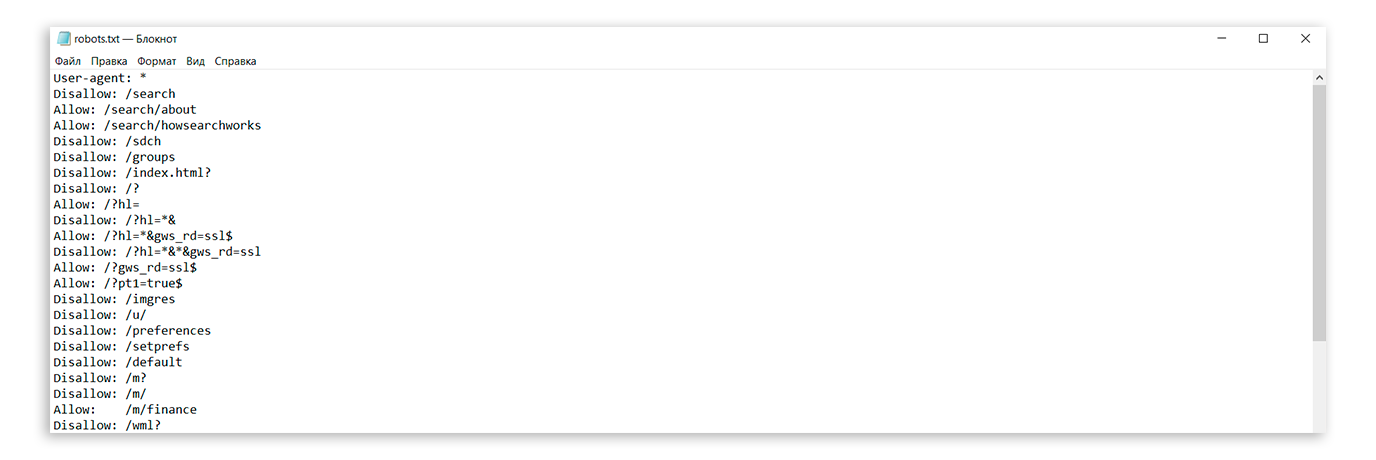
Как выглядит стандартный robots.txt?
Robots.txt пример:
Что должно быть в robots.txt?
Атрибуты robots.txt:
- User-agent — описывает каким именно роботам нужно смотреть инструкцию. Существует около 300 поисковых роботов (Googlebot, Yandexbot и т.
 д.). Чтобы указать инструкции сразу для всех роботов следует прописать:
д.). Чтобы указать инструкции сразу для всех роботов следует прописать:
Другие роботы:- Ahrefsbot;
- Exabot;
- SemrushBot;
- Baiduspider;
- Mail.RU_Bot.
- Disallow — указывает роботу, что не нужно сканировать.
Открыть для сканирования весь сайт (robots.txt разрешить все):
Запретить сканирование всего сайта (robots.txt запретить все):
Robots.txt запретить индексацию папки:
Запретить индексацию страницы в robots.txt:
Запретить индексацию конкретного файла:
Запрет индексации всех файлов на сайте с расширением .pdf:
Запретить индексацию поддомена в robots.txt:
Каждый поддомен имеет свой файл robots.txt. Если его нет — создайте и добавьте в корневую папку поддомена.
Закрыть все кроме главной в robots.txt: - Allow — разрешает роботу сканировать сайт/папку/конкретную страницу.

Например, чтобы разрешить роботу сканировать страницы каталога, а все остальное закрыть:
Как выглядит Robots.txt для Гугла и Яндекса?
Как указать главное зеркало в robots.txt?
Для обозначения главного зеркала (копии сайта, доступной по разным адресам) используют атрибут Host.
Host в robots.txt:
Как прописать карту сайта в robots.txt?
Карта сайта (sitemap.xml) сообщает поисковым роботам приоритетные страницы для индексации. Она находится по адресу: https://site.com/sitemap.xml.
Sitemap в robots.txt:
Что обозначают символы в robots.txt?
Наиболее часто используются следующие символы:
- “/” — закрытие от робота весь сайт/папку/страницу;
- “*” — любая последовательность символов;
- “$” — ограничение действия знака “*”;
- “#” — комментарии, которые не учитываются роботами.
Как настроить robots.txt?
В файле обязательно нужно отдельно для каждого робота прописать, что открыто для сканирования и что закрыто, прописать хост и карту сайта.
Файлы robots.txt различаются между собой в зависимости от используемой CMS.
Рекомендуем закрывать от индексации страницы: авторизации, фильтрации, поиска, страницу 404, вход в админку.
Пример идеального robots.txt:
Как проверить robots.txt?
Чтобы проверить валидность robots.txt (правильно ли заполнен файл) — используйте инструмент для вебмастеров Google Search Console. Для этого достаточно ввести код файла в форму, указать сайт и Вы получите отчет о корректности файла:
Ошибки в robots.txt
- Перепутали местами инструкции.
Неправильно:
Правильно: - Записали пару директорий сразу в одной инструкции:
- Не правильное название файла — не Robot.txt и не ROBOTS.TXT, а robots.txt!
- Правило User-agent не должно быть пустым, обязательно нужно указывать для каких роботов оно действует.
- Следите, чтобы не указать лишних символов в файле (“/”, “*”, “$” и т.
 д.).
д.). - Не открывайте для сканирования страницы, которые не нужны в индексе.
Подойдите со всей ответственностью к формированию файла robots.txt — и будет Вам счастье 😉
Как добавить robots.txt на свой сайт Django | Статьи о Джанго
robots.txt — это стандартный файл для связи со сканерами-роботами, такими как Googlebot, которые не должны сканировать страницы. Вы размещаете его на своем сайте по корневому URL /robots.txt, например https://example.com/robots.txt.
Чтобы добавить такой файл в приложение Django, у вас есть несколько вариантов.
Вы можете обслуживать его с помощью веб-сервера без использования вашего приложения, такого как nginx. Недостатком этого подхода является то, что если вы перенесете свое приложение на другой веб-сервер, вам придется переделать эту конфигурацию. Также вы можете отслеживать код своего приложения в Git, но не конфигурацию вашего веб-сервера, и лучше всего отслеживать изменения в правилах ваших роботов.
Также вы можете отслеживать код своего приложения в Git, но не конфигурацию вашего веб-сервера, и лучше всего отслеживать изменения в правилах ваших роботов.
Подход, который я одобряю, заключается в том, чтобы использовать его как обычный URL из Django. Это становится другим видом, который вы можете тестировать и обновлять с течением времени. Вот несколько подходов для этого.
С шаблоном
Это самый простой подход. Он сохраняет файл robots.txt в шаблоне и просто отображает его по URL-адресу.
Сначала добавьте новый шаблон robots.txt в корневой каталог шаблонов или в каталог шаблонов «основного» приложения:
User-Agent: *
Disallow: /private/
Disallow: /junk/Во-вторых, добавьте запись urlconf:
from django.urls import path
from django.views.generic.base import TemplateView
urlpatterns = [
# ...
path(
"robots. txt",
TemplateView.as_view(template_name="robots.txt", content_type="text/plain"),
),
]
txt",
TemplateView.as_view(template_name="robots.txt", content_type="text/plain"),
),
]Это создает новый вид непосредственно внутри URLconf, а не импортирует его из views.py. Это не лучшая идея, поскольку она смешивает слои в одном файле, но часто это делается прагматично, чтобы избежать лишних строк кода для простых представлений.
Нам нужно установить для content_type значение text/plain, чтобы он служил в качестве текстового документа, а не по умолчанию text/html.
После этого вы сможете запустить python manage.py runserver и увидеть файл, размещенный по адресу http://localhost: 8000/robots.txt (или аналогичный для вашего URL-адреса сервера запуска).
С пользовательским видом
Это немного более гибкий подход. Используя представление, вы можете добавить собственную логику, такую как проверка заголовка хоста и обслуживание различного контента для каждого домена. Это также означает, что вам не нужно беспокоиться о том, что в шаблоне экранированы HTML-переменные, которые могут оказаться неверными для текстового формата.
Это также означает, что вам не нужно беспокоиться о том, что в шаблоне экранированы HTML-переменные, которые могут оказаться неверными для текстового формата.
Сначала добавьте новый вид в ваше «основное» приложение:
from django.http import HttpResponse
from django.views.decorators.http import require_GET
@require_GET
def robots_txt(request):
lines = [
"User-Agent: *",
"Disallow: /private/",
"Disallow: /junk/",
]
return HttpResponse("\n".join(lines), content_type="text/plain")We’re using Django’s require_GET decorator to restrict to only GET requests. Class-based views already do this, but we need to think about it ourselves for function-based views.
Мы используем декоратор require_GET в Django, чтобы ограничивать только запросы GET. Представления на основе классов уже делают это, но нам нужно подумать об этом самим для представлений на основе функций.
Мы генерируем содержимое robots.txt внутри Python, комбинируя список строк с помощью str.join().
Во-вторых, добавьте запись urlconf:
from django.urls import path
from core.views import robots_txt
urlpatterns = [
# ...
path("robots.txt", robots_txt),
]Опять же, вы должны быть в состоянии проверить это на runserver.
Тестирование
Как я писал выше, одним из преимуществ обслуживания этого из Django является то, что мы можем проверить это. Автоматические тесты защитят от случайного взлома кода или удаления URL.
Вы можете добавить некоторые базовые тесты в файл, например, core/tests/test_views.py:
from http import HTTPStatus
from django.test import TestCase
class RobotsTxtTests(TestCase):
def test_get(self):
response = self.client. get("/robots.txt")
self.assertEqual(response.status_code, HTTPStatus.OK)
self.assertEqual(response["content-type"], "text/plain")
lines = response.content.decode().splitlines()
self.assertEqual(lines[0], "User-Agent: *")
def test_post_disallowed(self):
response = self.client.post("/robots.txt")
self.assertEqual(HTTPStatus.METHOD_NOT_ALLOWED, response.status_code)
get("/robots.txt")
self.assertEqual(response.status_code, HTTPStatus.OK)
self.assertEqual(response["content-type"], "text/plain")
lines = response.content.decode().splitlines()
self.assertEqual(lines[0], "User-Agent: *")
def test_post_disallowed(self):
response = self.client.post("/robots.txt")
self.assertEqual(HTTPStatus.METHOD_NOT_ALLOWED, response.status_code)Запустите тесты с помощью python manage.py test core.tests.test_views. Это также хорошая идея проверить, что они запускаются, заставляя их терпеть неудачу, например, закомментировав запись в URL conf.
Django-Robots
If you want to control your robots.txt rules in your database, there’s a Jazzband package called django-robots. I haven’t used it, but it seems well maintained. It also adds some less standard rules, like directing to the sitemap.
Если вы хотите контролировать свои правила robots. txt в своей базе данных, есть пакет от Jazzband под названием django-robots. Я не использовал его, но, кажется, в хорошем состоянии. Он также добавляет некоторые менее стандартные правила, такие как перенаправление на карту сайта.
txt в своей базе данных, есть пакет от Jazzband под названием django-robots. Я не использовал его, но, кажется, в хорошем состоянии. Он также добавляет некоторые менее стандартные правила, такие как перенаправление на карту сайта.
Итог
Не забывайте проверять файл robots.txt через соответствующие инструменты в интернет.
https://adamj.eu/tech/2020/02/10/robots-txt/
Поделитесь с другими:
Разный robots.txt на разных поддоменах
Для разделения robots.txt между поддоменами есть два варианта:
- первый — если просто нужно избежать склейки поддоменов (простой)
- второй — если нужны разные правила для разных регионов (сложный)
Robots.
 txt с одинаковыми правилами на разных поддоменах
txt с одинаковыми правилами на разных поддоменахИдём в Сервисы -> Регионы продаж, на вкладку «Robots.txt (простой путь)», где видим такую форму:
Теперь посмотрите, как адрес сайта в robots.txt выглядит у вас. Для этого с помощью браузера откройте на сайте путь «/robots.txt». Допустим, изначально файл выглядит вот так (это, кстати, стандартный набор правил для Битрикса):
User-Agent: * Disallow: */index.php Disallow: /bitrix/ Disallow: /*show_include_exec_time= Disallow: /*show_page_exec_time= Disallow: /*show_sql_stat= Disallow: /*bitrix_include_areas= Disallow: /*clear_cache= Disallow: /*clear_cache_session= Disallow: /*ADD_TO_COMPARE_LIST Disallow: /*ORDER_BY Disallow: /*PAGEN Disallow: /*?print= Disallow: /*&print= Disallow: /*print_course= Disallow: /*?action= Disallow: /*&action= Disallow: /*register= Disallow: /*forgot_password= Disallow: /*change_password= Disallow: /*login= Disallow: /*logout= Disallow: /*auth= Disallow: /*backurl= Disallow: /*back_url= Disallow: /*BACKURL= Disallow: /*BACK_URL= Disallow: /*back_url_admin= Disallow: /*?utm_source= Allow: /bitrix/components/ Allow: /bitrix/cache/ Allow: /bitrix/js/ Allow: /bitrix/templates/ Allow: /bitrix/panel/ Host: av-promo.ru
В примере мы видим, что использован адрес сайта — «av-promo.ru», значит в форму нужно подставить «av-promo.ru». После заполнения поля, нажимаем кнопку «Сделать динамическим», прописываем в .htaccess правило, которое показано ниже на странице, и проверяем результат на поддоменах. Всё, кроме адреса сайта напротив «Host», будет одинаковым для всех регионов. Но мы этим различием уберегаем себя от «склейки» поддоменов.
Robots.txt с разными правилами на разных поддоменах
Смысл этого способа в том, что можно прописывать абсолютно разные robots.txt с разными правилами для разных поддоменов. Например, запретить на определённом регионе индексацию страницы доставки.
Для этого в инфоблоке регионов создаём свойство элементов «robots.txt» типа «HTML/текст» (код, «ROBOTS_TXT») и заполняем его у разных регионов тем содержимым, которое нужно вам на соответствующем поддомене.
Затем идём на вкладку — «Robots. robots\.txt$ /robots.php [L]
robots\.txt$ /robots.php [L]
Если подмена не работает, скорее всего .txt-файлы у вас обрабатывает nginx. В таком случае напишите
хостерам, чтобы вынесли .txt-файлы из под обработки nginx, чтобы на них срабатывали правила из .htaccess.
Если они отказываются это сделать, а такое бывает на простых хостингах и недорогих тарифах, то зачастую для
срабатывания
правила помогает переименование/удаление robots.txt.
Что-то осталось непонятным или вы нашли неточность? Напишите, пожалуйста об этом в комментариях.
Идеальный robots.txt для OpenCart 2.3\3.x (ocStore)
Для самых нетерпеливых готовый robots.txt для вашего магазина на Opencart лежит в конце статьи. Не забудьте поменять site.ru на ваш домен!
Зачем нужен robots.txt?
Robots.txt это текстовый файл который содержит инструкции роботам для индексации сайта. Другими словами, мы говорим Google и Яндексу какие страницы мы хотим видеть в поисковой выдаче, а какие нет. Вот так выглядит сайт типографии с «кривым» файлом robots, в выдачу попадают макеты, технические страницы и прочий мусор. Эти некачественные страницы конкурируют с целевыми, сделанными под коммерческие запросы:
Вот так выглядит сайт типографии с «кривым» файлом robots, в выдачу попадают макеты, технические страницы и прочий мусор. Эти некачественные страницы конкурируют с целевыми, сделанными под коммерческие запросы:
Неправильный robots.txt
В случае с Opencart, нам нужно закрыть все страницы относящиеся к личному кабинету, оформлению заказа, регистрации и т.д.
Зачем еще его можно использовать
Для закрытия всего сайта при его разработке и наполнении товарами.
На этом этапе обычно url часто меняются и пересоздаються. Чтобы ваш сайт НЕ индексировался поисковиками, создаем файл следующего содержания:
User-agent: * Disallow: /
Распространённая ошибка — купить красивый домен и поставить на него голый движок с тестовыми товарами(посмотреть как все выглядит). Сайт в таком виде индексируют поисковики и сразу же пессимизируют за не уникальный контент. Обязательно нужно закрывать от индексации!
Для закрытия сайта от ненужных краулеров и spy-сервисов.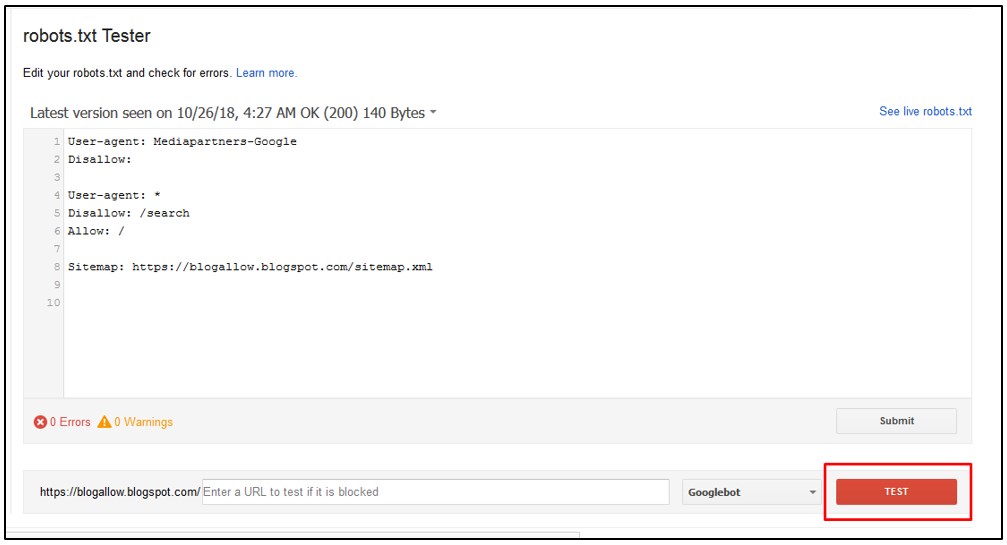
Если вы не хотите, чтобы ваш сайт проверяли конкуренты, например, через Ahrefs, Majestic и подобные сервисы, закрывайте им доступ. Еще робот Yahoo любит приходить на сайт по 5 раз в день и грузить сервер, но толку от Yahoo для РФ-магазина никакого.
Как создать файл robots.txt
- В Блокноте или Sublime Text создайте файл с именем robots.txt и скопируйте туда код, который лежит в конце статьи.
- Проверьте файл в Яндекс.Вебмастер и Google Search Console.
- Загрузите файл на хостинг в корневую директорию .
Как проверить, что индексируют поисковики?
Проверить, что проиндексировано Яндексом и Google можно с помощью параметра «site:» — в поисковой строке наберите «site:ваш.cайт» (для обоих поисковиков команда одинаковая). Вручную просмотрите списки страниц и добавьте ненужные в robots.txt. Если количество страниц слишком большое — воспользуйтесь Netpeak Spider или Seo Frog.
Правила написания
Директивы Disallow и Allow
Между директивами не должно быть пустых строк, пустые строки только между блоками User-agent. Порядок любой — можно сначала разрешать, а потом запрещать или наоборот, или вообще вперемешку.
Порядок любой — можно сначала разрешать, а потом запрещать или наоборот, или вообще вперемешку.
Sitemap и Host
Две директивы Яндекса. Для Host указываем главное зеркало сайта, обратите внимание, что оно указывается без http://, но, если у вас протокол https, то пишем — https://. Для Sitemap — путь к карте сайта, по умолчанию он выглядит вот так:
Sitemap: https://site.ru/index.php?route=feed/google_sitemap
Clean-Param и Crawl-delay
Еще две директивы, придуманные Яндексом, Google их не воспринимает и будет выводить ошибку в Search Console, не обращайте на это внимания.
Clean-Param обязательно используем, если на сайт ведется реклама через Яндекс.Директ, Google Adwords, таргет через соц.сети или реферальные ссылки. Иначе в индексацию будут залетать страницы с «хвостом» из параметров utm-меток и создавать дубли, а это повлечет песcимизацию в Яндексе.
Пример синтаксиса:
Clean-Param: utm_source&utm_medium&utm_campaign
Crawl-delay используют для уменьшения нагрузки на сервер.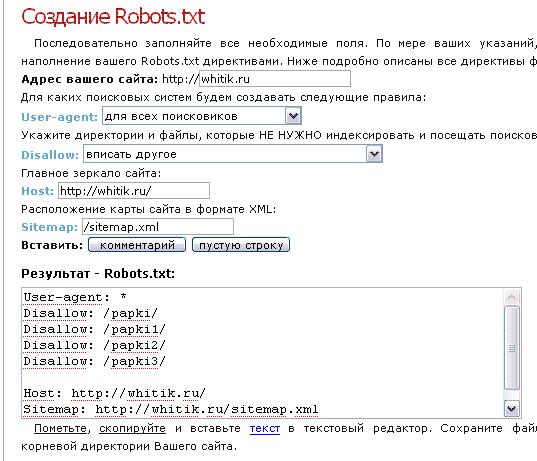 Для новых магазинов не прописываем.
Для новых магазинов не прописываем.
Что делать если у вас кириллический домен?
Использование кириллицу в robots.txt запрещено. Для того чтобы замаскировать кириллицу под понятные поисковым роботам символы используйте Punycode. Адреса страниц пишите в той же кодировке, что и весь сайт. Я пользуюсь вот этим конвертором (он же пригодится и для составления правильного файла sitemap.xml)
Например:
#Неправильно: User-agent: Yandex Disallow: /регистрация #Правильно: User-agent: Yandex Disallow: /xn--80affnb7bdhj6b9f
Правильный robots.txt для магазина на Opencart
Вместо site.ru подставьте ваш домен. Обратите внимание, что после установки некоторых модулей, могут меняться url страниц. Периодически проверяйте сайт на предмет попадания ненужных страниц в индекс. Сразу исключены из индекса страницы генерируемые модулем Simple.
User-agent: * Disallow: /*route=account/ Disallow: /*route=affiliate/ Disallow: /*route=checkout/ Disallow: /*route=product/search Disallow: /index.php?route=product/product*&manufacturer_id= Disallow: /admin Disallow: /catalog Disallow: /system Disallow: /*?sort= Disallow: /*&sort= Disallow: /*?order= Disallow: /*&order= Disallow: /*?limit= Disallow: /*&limit= Disallow: /*?filter_name= Disallow: /*&filter_name= Disallow: /*?filter_sub_category= Disallow: /*&filter_sub_category= Disallow: /*?filter_description= Disallow: /*&filter_description= Disallow: /*?tracking= Disallow: /*&tracking= Disallow: /*compare-products Disallow: /*search Disallow: /*cart Disallow: /*checkout Disallow: /*login Disallow: /*logout Disallow: /*vouchers Disallow: /*wishlist Disallow: /*my-account Disallow: /*order-history Disallow: /*newsletter Disallow: /*return-add Disallow: /*forgot-password Disallow: /*downloads Disallow: /*returns Disallow: /*transactions Disallow: /*create-account Disallow: /*recurring Disallow: /*address-book Disallow: /*reward-points Disallow: /*affiliate-forgot-password Disallow: /*create-affiliate-account Disallow: /*affiliate-login Disallow: /*affiliates Disallow: /*?filter_tag= Disallow: /*brands Disallow: /*specials Disallow: /*simpleregister Disallow: /*simplecheckout Disallow: *utm= Allow: /catalog/view/javascript/ Allow: /catalog/view/theme/*/ User-agent: Yandex Disallow: /*route=account/ Disallow: /*route=affiliate/ Disallow: /*route=checkout/ Disallow: /*route=product/search Disallow: /index.
php?route=product/product*&manufacturer_id= Disallow: /admin Disallow: /catalog Disallow: /system Disallow: /*?sort= Disallow: /*&sort= Disallow: /*?order= Disallow: /*&order= Disallow: /*?limit= Disallow: /*&limit= Disallow: /*?filter_name= Disallow: /*&filter_name= Disallow: /*?filter_sub_category= Disallow: /*&filter_sub_category= Disallow: /*?filter_description= Disallow: /*&filter_description= Disallow: /*compare-products Disallow: /*search Disallow: /*cart Disallow: /*checkout Disallow: /*login Disallow: /*logout Disallow: /*vouchers Disallow: /*wishlist Disallow: /*my-account Disallow: /*order-history Disallow: /*newsletter Disallow: /*return-add Disallow: /*forgot-password Disallow: /*downloads Disallow: /*returns Disallow: /*transactions Disallow: /*create-account Disallow: /*recurring Disallow: /*address-book Disallow: /*reward-points Disallow: /*affiliate-forgot-password Disallow: /*create-affiliate-account Disallow: /*affiliate-login Disallow: /*affiliates Disallow: /*?filter_tag= Disallow: /*brands Disallow: /*specials Disallow: /*simpleregister Disallow: /*simplecheckout Disallow: *utm= Allow: /catalog/view/javascript/ Allow: /catalog/view/theme/*/ Clean-Param: utm_source&utm_medium&utm_campaign site.
ru Host: https://site.ru Sitemap: https://site.ru/index.php?route=feed/google_sitemap
для чего нужен, из чего состоит, как создать и заполнить файл
Robots.txt — специальный текстовый файл, который предназначен для роботов поисковых систем. Главная его задача — «дать понять» роботам, какие страницы сайта необходимо проигнорировать и исключить из поисковой выдачи, а какие должны там присутствовать.
При помощи этого файла можно в несколько раз снизить число запросов, поступающих на сервер, что в свою очередь снизит его нагрузку. Robots.txt не используется для запрета показа конкретных страниц в выдаче поисковика.
SEO продвижение в ИТ
Пример Robots.txt
Стандартный формат файла Robots.txt выглядит примерно следующим образом:
User-agent: [идентификатор поискового бота]
[директива 1]
[директива 2]
[директива …]
User-agent: [второй идентификатор поискового бота]
[директива 1]
[директива 2]
[директива …]
Sitemap: [ссылка на карту сайта]
Существующие ограничения в использовании Robots.
 txt
txtПеред тем, как начать создание и редактирование файла Robots.txt для своего сайта, нужно знать обо всех наиболее важных нюансах:
- Директивы Robots.txt могут поддерживаться не каждой поисковой системой. То есть у этих директив нет никакого «абсолютного контроля» над поведением роботов поисковиков. Да, роботы Google и Яндекс обычно следуют директивам Robots.txt, но иногда могут их игнорировать. Поэтому, если вам нужно обеспечить максимально надежную защиту определенной страницы своего сайта, куда лучше поставить на нее пароль или использовать альтернативные методы.
- У каждого робота поисковой системы свои алгоритмы обработки данных из Robots.txt. Обычно поисковые системы «принимают во внимание» данные из Robots.txt, но как именно они будут интерпретировать прописанные в этом файле директивы, зависит конкретно от их алгоритмов. Поэтому перед тем, как переходить к настройкам Robots.txt, всегда важно изучать синтаксис для разных поисковых систем, после чего начинать работы по редактированию файла.

- Если в Robots.txt есть страница, закрытая для отображения в поисковой выдаче, она все же может там показаться. Особенно в том случае, если на нее ссылаются какие-либо сторонние ресурсы. Робот Google не напрямую индексирует ссылки и контент, прописанные в Robots.txt, и может найти ссылки на «закрытые» страницы на сторонних ресурсах. То есть сама ссылка или какая-либо часть общедоступных данных, касающихся конкретной страницы, в поисковой выдаче все же могут отобразиться. Чтобы избежать такой проблемы, лучше всего защитить данные паролем на уровне сервера, применить noindex-директиву в мета-теге или Http-заголовке страницы. Но надежнее всего полностью удалить ненужную страницу.
Помимо всего вышеописанного нужно понимать: если вы будете использовать одновременно несколько методов закрытия ссылок от поисковых роботов, то это может привести к конфликтам.
Правильный Robots.txt для Opencart — New-WebStudio
В этой статье речь пойдет о самом необходимом инструменте, без которого не может обойтись ни один специалист по продвижению сайтов. Разговор пойдет про файл robots.txt для Opencart. Если этого файла нет в списке файлов и каталогов на вашем хостинге, то необходимо его добавить. Для чего же он нужен? Данный файл предназначен для сокрытия содержимого избранных страниц вашего сайта от роботов поисковых систем.
Разговор пойдет про файл robots.txt для Opencart. Если этого файла нет в списке файлов и каталогов на вашем хостинге, то необходимо его добавить. Для чего же он нужен? Данный файл предназначен для сокрытия содержимого избранных страниц вашего сайта от роботов поисковых систем.
Для чего же это нужно? В некоторых случаях есть страницы, которые не предназначены для широкой публики и случайных посетителей. Но роботы поисковых систем, заходя на ваш сайт, все равно видят их, и это может существенным образом повлиять на позиции сайта в поисковых запросах. Это могут быть страницы административной части сайта, либо архивы, страницы с конфиденциальной информацией пользователей, личные кабинеты и тому подобное.
Для каждой CMS файл robots.txt будет иметь разное наполнение, но схожую структуру записей. Сегодня поговорим о такой известной CMS, предназначенной преимущественно для интернет-магазинов, как Opencart. В стандартном шаблоне, который можно скачать с официального сайта разработчика, к сожалению, не представлен файл robots. txt, поэтому его придется создавать и заполнять самостоятельно.
txt, поэтому его придется создавать и заполнять самостоятельно.
Стандартный файл robots.txt для Opencart будет иметь вид:
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/categoryUser-agent: Yandex
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*route=product/search
Disallow: /*?page=
Disallow: /*&page=
Clean-param: tracking
Clean-param: filter_name
Clean-param: filter_sub_category
Clean-param: filter_description
Disallow: /wishlist
Disallow: /login
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/categoryHost: Vash_domen
Sitemap: http://Vash_domen/sitemap.xml
Команда «Disallow:» позволяет скрыть необходимые ссылки от их просмотра роботами поисковых систем. Так же в этом файле изначально скрыта административная часть, личный кабинет с персональными данными пользователя, результаты фильтрации, сортировки, поиска по сайту и т.п. Вообщем, вся необходимая для сокрытия информация. Символ — « /* » обозначает, что скрывать мы будем только те разделы, адреса которых будут содержать параметры находящиеся в url после данного символа. После «Disallow:» так же можно размещать полную ссылку на необходимую нам страницу. Файл robots.txt для Opencart является важнейшим инструментом при продвижении сайта. Поэтому его правильному заполнению необходимо уделить должно внимание и тогда ваш сайт будет на высоте!
Google хочет установить официальный стандарт для использования Robots.txt
Google предложил официальный интернет-стандарт для правил, включенных в файлы robots. txt.
txt.
Эти правила, изложенные в Протоколе исключения роботов (REP), были неофициальным стандартом в течение последних 25 лет.
Хотя REP был принят поисковыми системами, он все еще не является официальным, что означает, что он открыт для интерпретации разработчиками. Кроме того, он никогда не обновлялся, чтобы охватить сегодняшние варианты использования.
Прошло 25 лет, а Протокол исключения роботов так и не стал официальным стандартом. Хотя он был принят всеми основными поисковыми системами, он не охватывал все: означает ли код статуса HTTP 500, что сканер может сканировать что угодно или ничего? 😕 pic.twitter.com/imqoVQW92V
— Google Webmasters (@googlewmc) 1 июля 2019 г.
Реклама
Продолжить чтение Ниже
Как заявляет Google, это создает проблему для владельцев веб-сайтов, поскольку двусмысленно написано, de- Факто стандарт затрудняет правильное написание правил.
Чтобы устранить эту проблему, Google задокументировал, как REP используется в современной сети, и отправил его на рассмотрение Инженерной группе Интернета (IETF).
Google объясняет, что включено в черновик:
«Предлагаемый проект REP отражает более чем 20-летний реальный опыт использования правил robots.txt, используемых как роботом Googlebot, так и другими основными сканерами, а также примерно половиной миллиард веб-сайтов, которые полагаются на REP. Эти мелкозернистые элементы управления дают издателю возможность решать, что они хотят сканировать на своем сайте и потенциально показывать заинтересованным пользователям.”
Реклама
Продолжить чтение ниже
Черновик не меняет никаких правил, установленных в 1994 году, он просто обновлен для современной сети.
Некоторые из обновленных правил включают:
- Любой протокол передачи на основе URI может использовать robots.txt. Это больше не ограничивается HTTP.
 Также может использоваться для FTP или CoAP.
Также может использоваться для FTP или CoAP. - Разработчики должны проанализировать как минимум первые 500 кибибайт файла robots.txt.
- Новое максимальное время кеширования в 24 часа или значение директивы кеширования, если доступно, что дает владельцам веб-сайтов гибкость при обновлении своих роботов.txt, когда захотят.
- Когда файл robots.txt становится недоступным из-за сбоев сервера, известные запрещенные страницы не сканируются в течение достаточно длительного периода времени.
Google полностью открыт для комментариев по предлагаемому проекту и заявляет, что стремится сделать его правильно.
Инструмент тестирования Robots.txt | Кричащая лягушка
Как проверить файл robots.txt с помощью SEO Spider
Файл robots.txt используется для указания роботам, какие URL-адреса можно сканировать на веб-сайте.Все основные боты поисковых систем соответствуют стандарту исключения роботов и будут читать и подчиняться инструкциям файла robots. txt, прежде чем получать любые другие URL-адреса с веб-сайта.
txt, прежде чем получать любые другие URL-адреса с веб-сайта.
могут быть настроены для применения к конкретным роботам в соответствии с их пользовательским агентом (например, «Googlebot»), а наиболее распространенная директива, используемая в robots.txt, — это «запретить», которая запрещает роботу обращаться к URL-путь.
Вы можете просматривать файлы robots.txt в браузере, просто добавляя / robots.txt в конец поддомена (например, www.screamingfrog.co.uk/robots.txt).
Хотя файлы robots.txt обычно довольно просто интерпретировать, при большом количестве строк, пользовательских агентов, директив и тысяч страниц бывает сложно определить, какие URL-адреса заблокированы, а какие разрешено сканировать. Очевидно, что последствия ошибочной блокировки URL-адресов могут иметь огромное влияние на видимость в результатах поиска.
Здесь находится тестер robots.txt, например программа Screaming Frog SEO Spider, и пользовательские роботы. txt может помочь проверить и подтвердить сайт robots.txt тщательно и в нужном масштабе.
txt может помочь проверить и подтвердить сайт robots.txt тщательно и в нужном масштабе.
Прежде всего, вам необходимо загрузить SEO Spider, который в облегченной форме предоставляется бесплатно для сканирования до 500 URL-адресов. Для более продвинутых пользовательских функций robots.txt требуется лицензия.
Вы можете выполнить следующие действия, чтобы протестировать файл robots.txt на сайте, который уже работает. Если вы хотите протестировать директивы robots.txt, которые еще не созданы, или синтаксис отдельных команд для роботов, прочитайте больше о пользовательских файлах robots.txt в разделе 3 нашего руководства.
1) Сканируйте URL или веб-сайт
Откройте SEO Spider, введите или скопируйте сайт, который вы хотите сканировать, в поле «введите URL-адрес для паука» и нажмите «Начать».
Если вы предпочитаете протестировать несколько URL-адресов или карту сайта в формате XML, вы можете просто загрузить их в режиме списка (в разделе «режим> список» на верхнем уровне навигации).
2) Просмотрите вкладку «Коды ответов» и фильтр «Заблокировано Robots.txt»
Запрещенные URL-адреса будут отображаться со статусом «Заблокировано роботами.txt »под фильтром« Заблокировано Robots.txt ».
Фильтр «Заблокировано Robots.txt» также отображает столбец «Соответствующая строка Robots.txt», в котором указывается номер строки и запрещающий путь записи robots.txt, исключающей каждый URL из сканирования.
Исходные страницы, которые ссылаются на URL-адреса, запрещенные в robots.txt, можно просмотреть, щелкнув вкладку «inlinks», которая заполняет нижнюю панель окна.
Вот более подробный вид нижней части окна, на которой подробно представлены данные «inlinks» —
Их также можно экспортировать массово с помощью «Групповой экспорт»> «Коды ответов»> «Заблокировано роботами».txt Inlinks ».
3) Тест с использованием настраиваемого файла Robots.txt
Имея лицензию, вы также можете загружать, редактировать и тестировать файл robots. txt сайта, используя настраиваемую функцию robots.txt в разделе «Конфигурация> robots.txt> Пользовательский».
Эта функция позволяет добавлять несколько robots.txt на уровне поддоменов, тестировать директивы в SEO Spider и просматривать URL-адреса, которые заблокированы или разрешены немедленно.
Вы также можете выполнять сканирование и фильтровать заблокированные URL-адреса на основе обновленных пользовательских файлов robots.txt («Коды ответа> Заблокировано robots.txt») и просмотрите соответствующую строку директивы robots.txt.
Пользовательский файл robots.txt использует выбранный пользовательский агент в конфигурации, который можно настроить для тестирования и проверки любых поисковых роботов.
Обратите внимание: изменения, которые вы вносите в robots.txt в SEO Spider, не влияют на ваш действующий robots.txt, загруженный на ваш сервер. Однако, когда вы довольны тестированием, вы можете скопировать содержимое в живую среду.
Как паук SEO подчиняется роботам.
 txt
txtThe Screaming Frog SEO Spider подчиняется robots.txt так же, как и Google. Он проверит robots.txt субдомена (ов) и будет следовать (разрешить / запретить) директивам специально для пользовательского агента «Screaming Frog SEO Spider», если не Googlebot, а затем ВСЕХ роботов.
URL-адресов, запрещенных в robots.txt, по-прежнему будут отображаться и «проиндексироваться» в пользовательском интерфейсе со статусом «Заблокировано Robots.txt», они просто не будут сканироваться, поэтому контент и исходящие ссылки страница не будет видна.Отображение внутренних или внешних ссылок, заблокированных robots.txt в пользовательском интерфейсе, можно отключить в настройках robots.txt.
Важно помнить, что URL-адреса, заблокированные в robots.txt, все равно могут индексироваться в поисковых системах, если на них есть внутренние или внешние ссылки. Файл robots.txt просто мешает поисковым системам видеть содержание страницы. Метатег «noindex» (или X-Robots-Tag) — лучший вариант для удаления контента из индекса.
Инструмент поддерживает сопоставление URL-адресов значений файлов (подстановочные знаки * / $), как и Googlebot.
Общие примеры Robots.txt
Звездочка рядом с командой «User-agent» (User-agent: *) указывает, что директивы применяются ко ВСЕМ роботам, в то время как определенные боты User-agent также могут использоваться для определенных команд (например, User-agent: Googlebot).
Если команды используются как для всех, так и для определенных пользовательских агентов, то «все» команды будут игнорироваться конкретным ботом пользовательского агента, и будут выполняться только его собственные директивы. Если вы хотите, чтобы выполнялись глобальные директивы, вам также необходимо включить эти строки в конкретный раздел User-agent.
Ниже приведены некоторые распространенные примеры директив, используемых в файле robots.txt.
Блокировать всех роботов со всех URL-адресов
User-agent: *
Disallow: /
Блокировать всех роботов из папки
User-agent: *
Disallow: / folder /
Блокировать всех роботов по URL-адресу
User-agent: *
Disallow: /a-specific-url.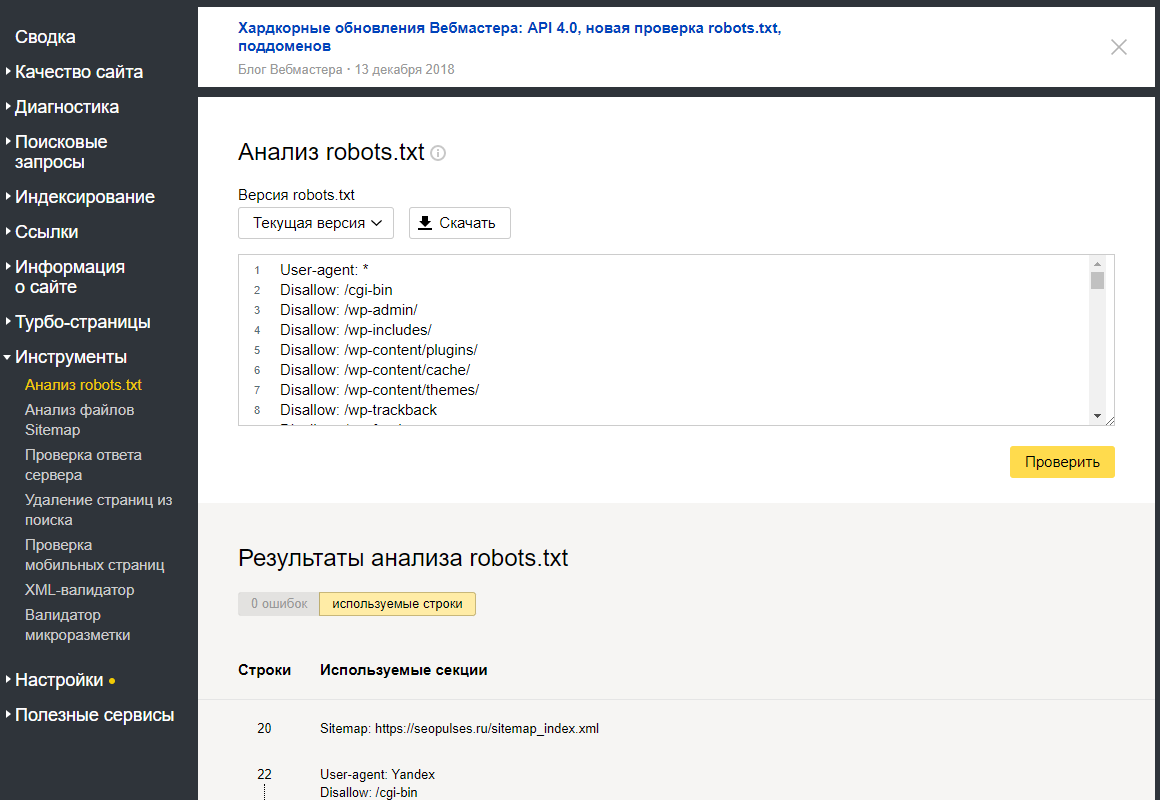 html
html
Запретить роботу Googlebot со всех URL-адресов
User-agent: Googlebot
Disallow: /
Блокировать и разрешать команды вместе
User-agent: Googlebot
Disallow: /
Allow: / crawl-this /
Если у вас есть конфликтующие директивы (т.e разрешить и запретить один и тот же путь к файлу), тогда соответствующая директива allow превосходит сопоставление disallow, если она содержит в команде равное или большее количество символов.
Robots.txt Соответствие подстановочных знаков URL
Google и Bing разрешают использование подстановочных знаков в robots.txt. Например, чтобы заблокировать доступ всех поисковых роботов ко всем URL-адресам, содержащим вопросительный знак (?).
User-agent: *
Disallow: / *?
Для соответствия концу URL-адреса можно использовать символ доллара ($). Например, чтобы заблокировать доступ всех поисковых роботов к.html расширение файла.
User-agent: *
Disallow: /*. html$
html$
Дополнительную информацию о значениях путей на основе сопоставления URL можно найти в руководстве по спецификациям файла robots.txt от Google.
Если у вас есть вопросы о том, как использовать тестер robots.txt в Screaming Frog SEO Spider, просто свяжитесь с нашей службой поддержки.
urllib.robotparser — Парсер для robots.txt — Python 3.9.5 документация
Исходный код: Lib / urllib / robotparser.py
Этот модуль предоставляет единственный класс RobotFileParser , который отвечает
вопросы о том, может ли конкретный пользовательский агент получить URL-адрес на
Веб-сайт, на котором опубликован файл robots.txt . Подробнее о
структура файлов robots.txt см. http://www.robotstxt.org/orig.html.
- класс
urllib.robotparser.RobotFileParser( url = » ) Этот класс предоставляет методы для чтения, анализа и ответа на вопросы о
robots.файл по адресу url . txt
txt -
set_url( url ) Устанавливает URL-адрес, относящийся к файлу
robots.txt.
-
читать() Считывает URL-адрес
robots.txtи передает его синтаксическому анализатору.
-
синтаксический анализ( строки ) Анализирует аргумент строк.
-
can_fetch( useragent , url ) Возвращает
Истина, если агенту пользователя разрешено получать URL-адрес по правилам содержащимся в разобранном файле robots.txt
-
mtime() Возвращает время
robots.txtпоследний раз был загружен. Это полезно для давно работающих веб-пауков, которым нужно проверять наличие новыхrobots.файла периодически. txt
txt
-
модифицированный() Устанавливает время последней загрузки файла
robots.txtв текущую время.
-
crawl_delay( агент пользователя ) Возвращает значение параметра
Crawl-delayотrobots.txtдля рассматриваемого агента . Если такого параметра нет или он не применяется к указанному агенту пользователя или записиrobots.txtесли этот параметр имеет недопустимый синтаксис, вернитеНет.
-
скорость_запроса( агент пользователя ) Возвращает содержимое параметра
Request-rateизrobots.txtкак именованный кортежRequestRate (запросы, секунды).Если такого параметра нет или он не применяется к агенту пользователя указан или записьrobots.для этого параметра недействительна синтаксис, возврат txt
txt Нет.
-
site_maps() Возвращает содержимое параметра
Sitemapизrobots.txtв виде списка(). Если нет такого параметр или записьrobots.txtдля этого параметра имеет неверный синтаксис, возвратНет.
-
Следующий пример демонстрирует базовое использование RobotFileParser класс:
>>> import urllib.robotparser
>>> rp = urllib.robotparser.RobotFileParser ()
>>> rp.set_url ("http://www.musi-cal.com/robots.txt")
>>> rp.read ()
>>> rrate = rp.request_rate ("*")
>>> rrate.requests
3
>>> rrate.seconds
20
>>> rp.crawl_delay ("*")
6
>>> rp.can_fetch ("*", "http: // www.musi-cal.com/cgi-bin/search?city=San+Francisco ")
Ложь
>>> rp.can_fetch ("*", "http://www.musi-cal.com/")
Правда
Избегайте исключений robots.
 txt — Справочный центр Archive-It
txt — Справочный центр Archive-ItНа этой странице:
Стандарт исключения роботов — это инструмент, используемый веб-мастером, чтобы заставить поисковый робот не сканировать все или определенные части своего веб-сайта. Веб-мастер размещает свой запрос в виде файла robots.txt , который легко найти на его веб-сайте (например,example.com/robots.txt). Archive-It (как и Google и большинство других поисковых систем) использует робота для сканирования и архивирования веб-страниц. По умолчанию наш сканер учитывает все запросы на исключение robots.txt. Однако в каждом конкретном случае вы можете настроить правила, чтобы игнорировать блокировку robots.txt для определенных сайтов.
Как найти и прочитать запрос на исключение роботов
Файл robots.txt всегда находится на самом верхнем уровне веб-сайта, а сам файл всегда называется robots.текст. Чтобы просмотреть файл robots любого веб-сайта, перейдите на сайт и просто добавьте /robots. txt к адресу сайта. Например, вы можете увидеть файл robots.txt Интернет-архива по адресу: www.archive.org/robots.txt
txt к адресу сайта. Например, вы можете увидеть файл robots.txt Интернет-архива по адресу: www.archive.org/robots.txt
Если вы видите этот текст на странице исключения роботов, значит все роботы исключены из сканирования сайта :
User-agent: *
Disallow: /
Если вы видите этот текст на странице исключения роботов, значит всем роботам разрешено сканирование сайта :
User-agent: *
Disallow:
Веб-мастера также могут запретить выбор, а не все роботов.В приведенном ниже примере Archive — это поисковый робот разрешен на сайт, но все остальные поисковые роботы не :
User-agent: archive.org_bot
Disallow:
User-agent: *
Disallow: /
Веб-мастера также могут блокировать определенные каталоги на своем сайте от робота-обходчика. В приведенном ниже примере вы можете видеть, что все сканеры заблокированы для сканирования изображений на сайте:
User-agent: *
Disallow: / images
Веб-мастера также могут установить задержку сканирования на своем сайте (в секундах). Ниже вы можете видеть, что все сканеры должны ждать 10 секунд между запросами страниц на сайте:
Ниже вы можете видеть, что все сканеры должны ждать 10 секунд между запросами страниц на сайте:
Агент пользователя: *
Задержка сканирования: 10
Вы можете определить, будет ли ваше сканирование заблокировано файлом robots.txt перед его запуском, обратившись к файлу целевого сайта описанным выше способом. Если робот-обходчик Archive-It’s специально указан в этом файле как «запрещенный» для всех или определенных разделов, то вы можете ожидать, что сканирование будет заблокировано для этих разделов.Вы можете узнать нашего краулера в этих файлах по его «user-agent» (имя): archive.org_bot .
Вы также можете определить, было ли ваше сканирование заблокировано файлом robots.txt после его запуска, просмотрев отчет по исходным файлам. В столбце «Статус исходного кода» этого отчета будет указано, был ли весь сайт заблокирован файлом robots.txt. Столбец «Заблокировано» в отчете «Хосты» вашего сканирования также покажет вам все определенные части хост-домена, которые были заблокированы роботом. txt файл.
txt файл.
Если веб-страница, которую вы хотите сканировать, не включает нашего робота-обходчика (archive.org_bot), вам следует сначала попытаться связаться с веб-мастером сайта, сообщить ему, почему вы хотите заархивировать его сайт, и попросить сделать исключение в своем файл robots.txt.
В этих случаях всегда полезно предоставить веб-мастеру следующую информацию:
- Имя (user-agent) нашего краулера: архив.org_bot
- Диапазон IP-адресов наших поисковых роботов предоставляется по запросу.
Вы можете сообщить веб-мастеру, что наш сканер очень «вежлив», что означает, что разрешение ему сканировать их сайт не должно каким-либо образом влиять на производительность или безопасность сайта.
В случае, если веб-мастер не отвечает или отклоняет ваш запрос, вы можете использовать приведенные ниже инструкции для , игнорируя исключения для роботов .
Независимо от того, сделает ли веб-мастер исключение для нашего сканера описанным выше способом, вы можете игнорировать исключения для роботов и, таким образом, сканировать материалы, заблокированные роботами. txt, запросив включение этой специальной функции для вашей учетной записи. Чтобы начать работу, свяжитесь с нашими веб-архивистами напрямую, укажите любые конкретные хосты или типы материалов, заблокированных роботами-исключениями, которые вы хотите сканировать, и попросите включить эту функцию для вашей учетной записи.
txt, запросив включение этой специальной функции для вашей учетной записи. Чтобы начать работу, свяжитесь с нашими веб-архивистами напрямую, укажите любые конкретные хосты или типы материалов, заблокированных роботами-исключениями, которые вы хотите сканировать, и попросите включить эту функцию для вашей учетной записи.
Игнорирование robots.txt по семейству или по хосту, в чем разница?
Вы можете выбрать, хотите ли вы игнорировать исключения роботов для всех хостов в пределах определенного начального числа (правила начального уровня) или всех экземпляров определенного хоста в коллекции (правила уровня сбора).Для получения дополнительной информации о том, когда использовать правила начального уровня по сравнению с правилами уровня сбора, посетите наше руководство «В чем разница».
Игнорировать robots.txt с помощью семени
После включения для вашей учетной записи функции «Игнорировать robots.txt» вы можете переопределить исключения роботов при сканировании по отдельности. Чтобы игнорировать все блоки robots.txt на хостах, захваченных из определенного семени (включая первичный хост и любой встроенный контент хоста, исходящий от), щелкните конкретное семя из списка семени вашей коллекции, а затем перейдите на вкладку «Объем семени», выберите «Игнорировать роботов».txt «в раскрывающемся меню и нажмите кнопку» Добавить правило «, чтобы применить его к будущим обходам вашего сид:
Чтобы игнорировать все блоки robots.txt на хостах, захваченных из определенного семени (включая первичный хост и любой встроенный контент хоста, исходящий от), щелкните конкретное семя из списка семени вашей коллекции, а затем перейдите на вкладку «Объем семени», выберите «Игнорировать роботов».txt «в раскрывающемся меню и нажмите кнопку» Добавить правило «, чтобы применить его к будущим обходам вашего сид:
Игнорировать robots.txt хостом
После включения функции «Игнорировать robots.txt» для вашей учетной записи вы также можете переопределить исключения роботов в своей коллекции для каждого хоста. Чтобы игнорировать все блоки robots.txt на хостах, которые появляются в любом месте в ходе сканирования, перейдите на вкладку «Область сбора» в области управления вашей коллекцией и выберите «Игнорировать роботов».txt «в раскрывающемся меню, добавьте хосты, к которым вы хотите применить это новое правило (точно так, как они отображаются в отчете о хостах), и нажмите кнопку« Добавить правило », чтобы применить его к будущим обходам вашего сид:
Обратите внимание, что вы также можете применить это правило, зависящее от хоста, непосредственно из наших отчетов по хостам с действиями.
Для получения более общей информации об исключениях для роботов см .: http://www.robotstxt.org/
Роботы.txt файлы | W3pedia
В этой статье объясняется использование файлов robot.txt в вашем w3shop.
На главной странице w3shop вы найдете панель robots.txt в разделе SEO. Это будет отображаться только в том случае, если у вас есть собственный домен.
Что такое файл robots.txt?
Сообщает сканерам поисковых систем (Google, Bing, Yahoo и т. Д.), Как посетить ваш сайт. Важно то, какие страницы или контент вы НЕ хотите индексировать и, следовательно, куда НЕ должны заходить сканеры.
Это очень простой файл .txt. Стандартно ваш файл w3shop robots.txt будет настроен следующим образом:
Пользовательский агент: * Disallow: / product-price-grid Disallow: / template-details Disallow: / корзина Disallow: / account / register Запретить: / аккаунт / логин
«User-agent: *» означает, что этот раздел применим ко всем роботам. «Disallow: /» сообщает роботу, что он не должен посещать эти страницы сайта.
«Disallow: /» сообщает роботу, что он не должен посещать эти страницы сайта.
/ Product-price-grid (URL-адрес может отличаться от сайта к сайту) — это тип страницы «Сетка цен на продукты».Например, этих страниц:
/ template-details (URL-адрес может отличаться от сайта к сайту) — это тип страницы «Шаблон: сведения». Например, этих страниц:
Почему мне не нужно индексировать определенные страницы?
У поисковых роботов есть ограниченное время для сканирования вашего сайта. Если веб-сайт имеет идентичный контент в нескольких местах, это оставляет меньше времени для основных страниц. Этот идентичный контент может привести к тому, что ссылки будут распределены по двум страницам и заставят поисковую систему выбрать одну для отображения поверх другой.Это значение общей ссылки приведет к тому, что обе страницы будут слабее, чем если бы была только одна основная страница.
Идентичный контент может быть вызван множеством проблем, например:
- Дубликаты страниц из-за фильтров
- версии с www и без www
- Динамически генерируемые страницы
Таким образом, использование файла robots. txt сообщает поисковым системам, на чем следует сосредоточить свое время. Обеспечение того, чтобы поисковые системы избегали потенциально дублирующегося контента, повышает вероятность того, что ваши основные «целевые страницы» будут ранжироваться на страницах результатов поиска (SERP).
txt сообщает поисковым системам, на чем следует сосредоточить свое время. Обеспечение того, чтобы поисковые системы избегали потенциально дублирующегося контента, повышает вероятность того, что ваши основные «целевые страницы» будут ранжироваться на страницах результатов поиска (SERP).
Целевые страницы должны быть основной точкой входа вашего веб-сайта и, следовательно, тем, что вы хотите ранжировать (вместе с вашим основным доменом).
Редактирование файла robots.txt
Вы можете добавлять, редактировать или удалять элементы из стандартного файла robots.txt. Просто отредактируйте текст файла роботов, чтобы добавить, изменить или удалить перечисленные URL-адреса. Для каждого префикса URL, который вы хотите исключить, вам понадобится отдельная строка «Disallow».
Мета ‘noindex’
Добавляйте это только на определенные соответствующие страницы.НЕ добавляйте это в поле «фрагмент заголовка» основной категории.
Кроме того, вы можете использовать мета ‘noindex’ — тег, добавляемый к странице. Это говорит поисковым системам не индексировать эту страницу. Однако в идеале вы должны использовать файл robots.txt, потому что он хранит все в одном центральном месте.
Это говорит поисковым системам не индексировать эту страницу. Однако в идеале вы должны использовать файл robots.txt, потому что он хранит все в одном центральном месте.
Однако вы можете добавить мета ‘noindex’:
в поле фрагмента заголовка страницы, которую вы хотите заблокировать:
- noindex = Не показывать эту страницу в результатах поиска и не показывать ссылку «Сохранено в кеше» в результатах поиска.
- nofollow = Не переходите по ссылкам на этой странице
Но мой сайт уже проиндексирован!
Если ваш сайт уже был проиндексирован и вы не хотите, чтобы его элементы были проиндексированы, вам необходимо удалить любой запрещающий контент из файла robots.txt. Затем добавьте мета-индекс noindex к страницам, которые нужно деиндексировать.
Это позволяет поисковым системам сканировать эти страницы и видеть теги «noindex, nofollow». Как только Google снова просканирует ваш сайт и деиндексирует соответствующие страницы, вы можете снова добавить запрещенный контент в файл robots. txt файл.
Нужен ли мне файл Robots.txt для моего сайта?
Файл robots.txt — это как забор вокруг вашей собственности. Заборы предназначены для защиты от опасности, но они также могут позволить другим видеть сквозь них. Для веб-сайта файл robots.txt находится в корневой папке вашего веб-сайта и указывает те части вашего веб-сайта, которые вы хотите или не хотите, чтобы поисковые роботы видели или получали доступ. Вы можете настроить таргетинг на отдельные файлы, типы файлов, папки, а также на какие IP-адреса и ботов не допускать попадания на ваш сайт.
Зачем вам нужны роботы.txt файл?
- Неправильное использование файла robots.txt может повредить вашему рейтингу в поисковой системе *
- Файл robots.txt контролирует, как некоторые боты и пауки видят ваш веб-сайт и взаимодействуют с ним.
- Этот файл содержит инструкции для ботов по взаимодействию с вашим сайтом. сайт и является фундаментальной частью работы поисковых систем.

* Google прекращает поддержку Robots.txt NoIndex в сентябре 2019 года.
Что такое файл robots.txt?
Роботы.txt — это отдельный файл, в котором используется стандарт исключения роботов, который представляет собой протокол с небольшим набором команд, которые можно использовать для указания доступа к вашему сайту по разделам и определенным видам поисковых роботов (например, мобильные сканеры или сканеры для настольных компьютеров). . Robots.txt позволяет вам попытаться заблокировать области вашего веб-сайта, которые вы, возможно, не хотите, чтобы поисковые роботы находили (например, области только для участников). Использование файла Robots.txt — это шаг, но не единственный шаг, который вы должны предпринять, чтобы выделить области вашего сайта, в которые могут не входить сканеры.
Веб-страницы (HTML / PHP)
Для файлов без изображений (то есть веб-страниц) robots.txt используется для управления сканированием трафика, обычно потому, что вы не хотите, чтобы ваш сервер был перегружен поисковым роботом.
Файлы изображений
Файл robots.txt предотвращает появление файлов изображений в результатах поиска Google. Это может быть хорошим способом уберечь ваши изображения от поиска изображений Google, если вы, например, фотограф, продающий свои работы в Интернете.Это не мешает другим страницам или пользователям ссылаться на ваше изображение. Это хорошо, потому что вы действительно хотите, чтобы люди делились вашими страницами и работали с друзьями в социальных сетях.
Файлы ресурсов
Вы можете использовать robots.txt для блокировки файлов ресурсов, таких как неважные файлы изображений, сценариев или стилей. Помните, что если эти файлы необходимы для отображения вашего веб-сайта, это может повлиять на его возможности поиска. Если файлы заблокированы, поисковый робот не загрузит их, даже если страница будет вызвана.Будет ли ваш сайт выглядеть так же на мобильных устройствах, если вы удалите CSS, предназначенный для мобильных устройств? Как Google будет думать о вашем сайте, если он не видит CSS?
Примечание от Google
Вы не должны использовать robots. txt как средство, чтобы скрыть свои веб-страницы от результатов поиска Google. Это связано с тем, что другие страницы могут указывать на вашу страницу, и ваша страница может быть проиндексирована таким образом, минуя файл robots.txt. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, такой как защита паролем, метатеги или директивы noindex непосредственно на каждой странице.
txt как средство, чтобы скрыть свои веб-страницы от результатов поиска Google. Это связано с тем, что другие страницы могут указывать на вашу страницу, и ваша страница может быть проиндексирована таким образом, минуя файл robots.txt. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, такой как защита паролем, метатеги или директивы noindex непосредственно на каждой странице.
Основные примеры robots.txt
Вот несколько распространенных настроек robots.txt.
Разрешить полный доступ
Пользовательский агент: *
Disallow:
Блокировать полный доступ
Пользовательский агент: *
Disallow: *
Заблокировать одну папку
Пользовательский агент: *
Disallow: / folder /
Блокировать один файл
Пользовательский агент: *
Disallow: /file.html
Есть ли на вашем сайте файл robots.txt файл?
Проверить наличие файла robots. txt можно из любого веб-браузера, подключенного к сети. Файл robots.txt всегда находится в одном и том же месте на любом веб-сайте, поэтому легко определить, есть ли он на сайте. Просто добавьте «/robots.txt» в конец имени домена, как показано ниже.
txt можно из любого веб-браузера, подключенного к сети. Файл robots.txt всегда находится в одном и том же месте на любом веб-сайте, поэтому легко определить, есть ли он на сайте. Просто добавьте «/robots.txt» в конец имени домена, как показано ниже.
https://www.yourwebsite.com/robots.txt
Если у вас есть файл, то это ваш файл robots.txt. Вы либо найдете файл со словами в нем, либо найдете файл без слов, либо вернете страницу с ошибкой 404.
Тестирование файла robots.txt
Если у вас есть доступ и разрешение, вы можете использовать консоль поиска Google для проверки файла robots.txt. Инструкции по тестированию файла Robots.txt находятся здесь.
Чтобы полностью понять, не блокирует ли ваш файл robots.txt то, что вы не хотите, чтобы он блокировал, вам необходимо понять, о чем он говорит. Я расскажу об этом ниже.
Вам нужен файл robots.txt?
Возможно, вам даже не понадобится файл robots.txt на вашем сайте. На самом деле, зачастую он вам не нужен.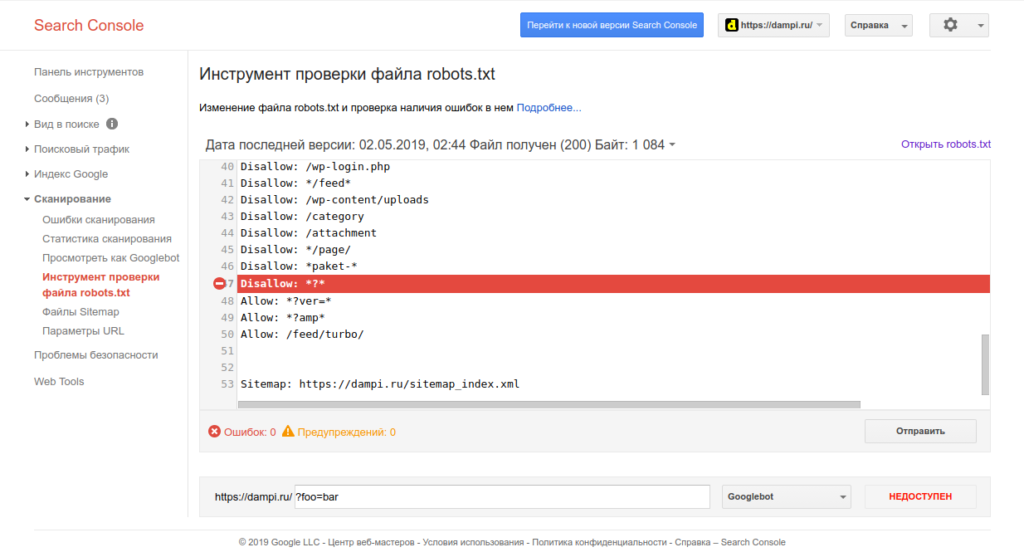
Причины, по которым вам может понадобиться файл robots.txt:
- У вас есть контент, который вы хотите заблокировать для поисковых систем
- Вы разрабатываете действующий сайт, но не хотите, чтобы поисковые системы индексировали новые страницы
- Вы хотите настроить доступ к своему сайту из авторитетных боты и сканеры
- Вы используете платные ссылки или рекламные объявления, требующие специальных инструкций для ботов.
- Они помогают вам в некоторых ситуациях следовать некоторым рекомендациям Google.
Причины, по которым вы можете не захотеть иметь файл robots.txt файл:
- Ваш сайт простой и безошибочный, и вы хотите, чтобы все было проиндексировано.
- У вас нет файлов, которые вы хотите или которые нужно заблокировать для поисковых систем.
- Вы не попали ни в одну из ситуаций, перечисленных в приведенных выше причинах. иметь файл robots.txt
- Нет файла robots.
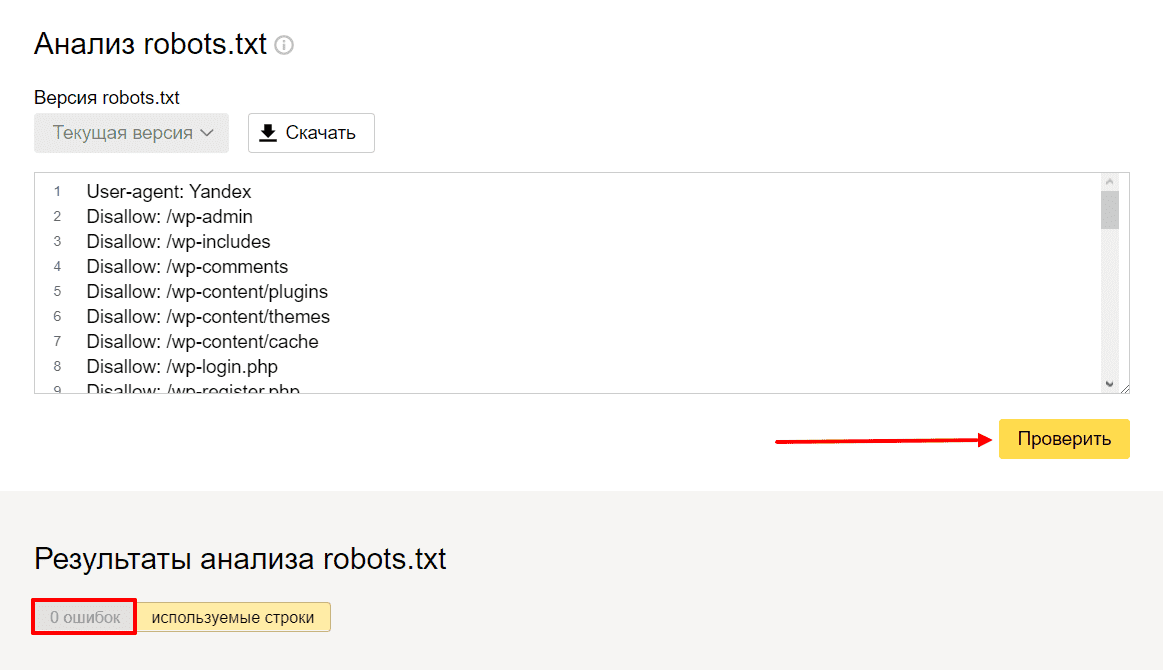 txt — это нормально.
txt — это нормально.
Если у вас нет файла robots.txt, роботы поисковых систем, такие как Googlebot, будут иметь полный доступ к вашему сайту.Это нормальный и простой метод, который очень распространен.
Ключи к robots.txt
- Если вы используете файл robots.txt, убедитесь, что он используется правильно.
- Неправильный файл robots.txt может заблокировать ботам и поисковым роботам обнаруживать все страницы вашего сайта
- Убедитесь, что вы не блокируете страницы или элементы, которые Google необходимо читать, обрабатывать и оценивать ваши страницы
О robots.txt
Использование Robotstxt
Использование RobotstxtПитер Мейснер
2020-09-03
Пакет предоставляет простой класс robotstxt и сопутствующие методы для синтаксического анализа и проверки robots.txt ’. Поля данных представлены в виде фреймов данных и векторов. Разрешения можно проверить, указав векторы символов пути и необязательные имена ботов.
Robots.txt — это способ любезно попросить веб-ботов, пауков, сканеров, странников и т.п. получить или не получить доступ к определенным частям веб-страницы. Де-факто «стандарт» никогда не выходил за рамки неофициального «ИНТЕРНЕТ-ПРОЕКТА сетевой рабочей группы». Тем не менее, использование файлов robots.txt широко распространено (например, https://en.wikipedia.org/robots.txt, https://www.google.com/robots.txt), а боты из Google, Yahoo и т. п. будут придерживаться правил, определенных в файлах robots.txt, хотя их интерпретация этих правил может отличаться (например, правила для googlebot).
Как видно из названия файлов, файлы robots.txt представляют собой обычный текст и всегда находятся в корне домена. Синтаксис файлов по существу следует схеме fieldname: value с необязательными предшествующими user-agent: ... строками, чтобы указать область действия следующего блока правил.Блоки разделяются пустыми строками, а отсутствие поля пользовательского агента (которое напрямую соответствует полю пользовательского агента HTTP) рассматривается как относящееся ко всем ботам.
# служит для комментирования строк и частей строк. Все после # до конца строки считается комментарием. Возможные имена полей: user-agent, disallow, allow, crawl-delay, sitemap и host.
У нас есть пример файла, чтобы понять, как может выглядеть файл robots.txt. Файл ниже начинается со строки комментария, за которой следует строка, запрещающая доступ к любому содержимому — всему, что содержится в корневом каталоге («/») — для всех ботов.Следующий блок касается GoodBot и NiceBot. У этих двоих отменяются предыдущие разрешения, поскольку ничего не запрещается. Третий блок — для PrettyBot. PrettyBot любит блестящие вещи и поэтому получает специальное разрешение на все, что содержится в папке « / shinystuff / », в то время как все остальные ограничения остаются в силе. В последнем блоке всем ботам предлагается сделать паузу не менее 5 секунд между двумя посещениями.
# это комментарий
# вымышленный пример файла robots. txt
Запретить: /
User-agent: GoodBot # еще один комментарий
Пользовательский агент: NiceBot
Запретить:
Пользовательский агент: PrettyBot
Разрешить: / shinystuff /
Задержка сканирования: 5
txt
Запретить: /
User-agent: GoodBot # еще один комментарий
Пользовательский агент: NiceBot
Запретить:
Пользовательский агент: PrettyBot
Разрешить: / shinystuff /
Задержка сканирования: 5 Для получения дополнительной информации посетите: http: // www.robotstxt.org/norobots-rfc.txt, где «стандартный» файл robots.txt описан формально. Ценные введения можно найти на http://www.robotstxt.org/robotstxt.html, а также на https://en.wikipedia.org/wiki/Robots_exclusion_standard — разумеется.
библиотека (robotstxt)
paths_allowed ("http://google.com/") ## [1] ИСТИНА paths_allowed ("http://google.com/search") ## [1] ЛОЖЬ Сначала загрузим пакет.Кроме того, мы загружаем пакет dplyr, чтобы иметь возможность использовать оператор канала magrittr %>% и некоторые простые для чтения и запоминания функции манипулирования данными.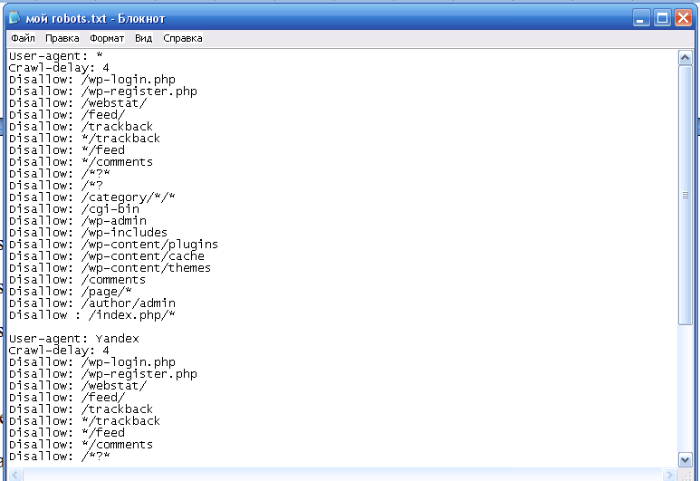
библиотека (robotstxt)
библиотека (dplyr) объектно-ориентированный стиль
Первым шагом является создание экземпляра класса robotstxt, предоставленного пакетом. Экземпляр должен быть инициирован путем предоставления домена или фактического текста файла robots.txt. Если указан только домен, то файл robots.txt будет загружен автоматически. Взгляните на ? Robotstxt для описания всех полей данных и методов, а также их параметров.
rtxt <- robotstxt (domain = "wikipedia.org") rtxt относится к классу robotstxt .
## [1] "robotstxt" Печать объекта позволяет нам взглянуть на все поля данных и методы в rtxt - у нас есть доступ к тексту, а также ко всем общим полям.Нестандартные поля собраны в других .
## $ text
## [1] "# \ n # robots.txt для http://www.wikipedia.org/ и друзей \ n # \ n # Обратите внимание: на этом сайте много страниц, и есть \ n # какие-то непослушные пауки, которые ходят _постоянно_ слишком быстро.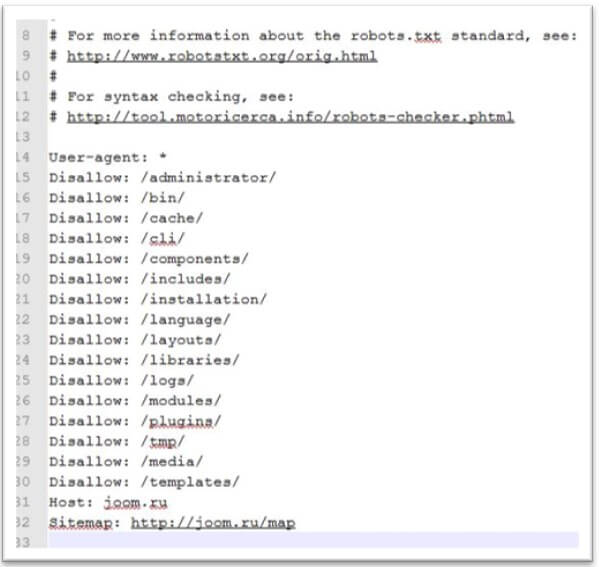 Если вы \ n # безответственны, ваш доступ к сайту может быть заблокирован. \ n # \ n \ n # боты, связанные с рекламой: \ nUser-agent: Mediapartners- Google * \ n \ n [... 653 строки пропущены ...] "
##
## $ домен
## [1] "википедия.org "
##
## $ robexclobj
## <Объект протокола исключения роботов>
## $ боты
## [1] "Медиапартнеры-Google *" "IsraBot"
## [3] "Ортогаффе" "UbiCrawler"
## [5] "ДОК" "Зао"
## [7] "" "[... 28 элементов опущены ...]"
##
## $ комментарии
## строчный комментарий
## 1 1 #
## 2 2 # роботов.txt для http://www.wikipedia.org/ и друзей
## 3 3 #
## 4 4 # Обратите внимание: на этом сайте много страниц, и есть
## 5 5 # там какие-то непослушные пауки, которые бегают слишком быстро. Если ты
## 6 6 # безответственно, ваш доступ к сайту может быть заблокирован.
## 7
## 8 [... 173 элемента опущены ...]
##
## $ разрешения
## поле useragent значение
## 1 Disallow Mediapartners-Google * /
## 2 Запретить IsraBot
## 3 Запретить ортогаффе
## 4 Запретить UbiCrawler /
## 5 Запретить DOC /
## 6 Запретить Zao /
## 7
## 8 [.
Если вы \ n # безответственны, ваш доступ к сайту может быть заблокирован. \ n # \ n \ n # боты, связанные с рекламой: \ nUser-agent: Mediapartners- Google * \ n \ n [... 653 строки пропущены ...] "
##
## $ домен
## [1] "википедия.org "
##
## $ robexclobj
## <Объект протокола исключения роботов>
## $ боты
## [1] "Медиапартнеры-Google *" "IsraBot"
## [3] "Ортогаффе" "UbiCrawler"
## [5] "ДОК" "Зао"
## [7] "" "[... 28 элементов опущены ...]"
##
## $ комментарии
## строчный комментарий
## 1 1 #
## 2 2 # роботов.txt для http://www.wikipedia.org/ и друзей
## 3 3 #
## 4 4 # Обратите внимание: на этом сайте много страниц, и есть
## 5 5 # там какие-то непослушные пауки, которые бегают слишком быстро. Если ты
## 6 6 # безответственно, ваш доступ к сайту может быть заблокирован.
## 7
## 8 [... 173 элемента опущены ...]
##
## $ разрешения
## поле useragent значение
## 1 Disallow Mediapartners-Google * /
## 2 Запретить IsraBot
## 3 Запретить ортогаффе
## 4 Запретить UbiCrawler /
## 5 Запретить DOC /
## 6 Запретить Zao /
## 7
## 8 [. .. 370 элементов опущено ...]
##
## $ crawl_delay
## [1] поле useragent значение
## <0 строк> (или имена строк с нулевой длиной)
##
## $ host
## [1] поле значение агента пользователя
## <0 строк> (или имена строк с нулевой длиной)
##
## $ sitemap
## [1] поле значение агента пользователя
## <0 строк> (или имена строк с нулевой длиной)
##
## $ other
## [1] поле значение агента пользователя
## <0 строк> (или строка нулевой длины.имена)
##
## $ check
## function (paths = "/", bot = "*")
## {
## spiderbar :: can_fetch (obj = self $ robexclobj, path = paths,
## user_agent = bot)
##}
## <байт-код: 0x000000001bac20f0>
## <среда: 0x000000001bac1478>
##
## attr (, "класс")
## [1] "robotstxt"
.. 370 элементов опущено ...]
##
## $ crawl_delay
## [1] поле useragent значение
## <0 строк> (или имена строк с нулевой длиной)
##
## $ host
## [1] поле значение агента пользователя
## <0 строк> (или имена строк с нулевой длиной)
##
## $ sitemap
## [1] поле значение агента пользователя
## <0 строк> (или имена строк с нулевой длиной)
##
## $ other
## [1] поле значение агента пользователя
## <0 строк> (или строка нулевой длины.имена)
##
## $ check
## function (paths = "/", bot = "*")
## {
## spiderbar :: can_fetch (obj = self $ robexclobj, path = paths,
## user_agent = bot)
##}
## <байт-код: 0x000000001bac20f0>
## <среда: 0x000000001bac1478>
##
## attr (, "класс")
## [1] "robotstxt" Проверка разрешений работает с помощью метода rtxt ' check , указав один или несколько путей. Если имя бота не указано, предполагается "*" - означает любой бот.
# проверка прав доступа
rtxt $ check (paths = c ("/", "api /"), bot = "*") ## [1] ИСТИНА ЛОЖЬ rtxt $ check (paths = c ("/", "api /"), bot = "Orthogaffe") ## [1] ИСТИНА ИСТИНА rtxt $ check (paths = c ("/", "api /"), bot = "Mediapartners-Google *") ## [1] ИСТИНА ЛОЖЬ функциональный стиль
При работе с классом robotstxt рекомендуется проверять также только функции. Далее мы (1) загружаем файл robots.txt; (2) проанализировать его и (3) проверить разрешения.
Далее мы (1) загружаем файл robots.txt; (2) проанализировать его и (3) проверить разрешения.
r_text <- get_robotstxt ("nytimes.com") r_parsed <- parse_robotstxt (r_text)
r_parsed ## $ useragents
## [1] "*" "Mediapartners-Google" "AdsBot-Google"
## [4] "adidxbot"
##
## $ комментарии
## [1] строчный комментарий
## <0 строк> (или строка нулевой длины.имена)
##
## $ разрешения
## поле useragent значение
## 1 Разрешить * / ads / public /
## 2 Разрешить * /svc/news/v3/all/pshb.rss
## 3 Disallow * / ads /
## 4 Запретить * / adx / bin /
## 5 Запретить * / archives /
## 6 Запретить * / auth /
## 7 Disallow * / cnet /
## 8 Disallow * / College /
## 9 Disallow * / external /
## 10 Disallow * / financialtimes /
## 11 Запретить * / idg /
## 12 Disallow * / indexes /
## 13 Запретить * / library /
## 14 Disallow * / nytimes-partners /
## 15 Disallow * / packages / flash / multimedia / TEMPLATES /
## 16 Disallow * / pages / college /
## 17 Disallow * / paycontent /
## 18 Disallow * / partners /
## 19 Disallow * / Restaurants / search *
## 20 Disallow * / reuters /
## 21 Запрещение * / регистрация
## 22 Disallow * / thestreet /
## 23 Запретить * / svc
## 24 Запретить * / video / embedded / *
## 25 Disallow * / web-services /
## 26 Disallow * / gst / travel / travsearch *
## 27 Запретить Mediapartners-Google / Restaurants / search *
## 28 Disallow AdsBot-Google / Restaurants / search *
## 29 Запретить adidxbot / Restaurants / search *
##
## $ crawl_delay
## [1] поле значение агента пользователя
## <0 строк> (или строка нулевой длины. имена)
##
## $ sitemap
## поле useragent
## 1 Sitemap *
## 2 Карта сайта *
## 3 Карта сайта *
## значение
## 1 http://spiderbites.nytimes.com/sitemaps/www.nytimes.com/sitemap.xml.gz
## 2 http://www.nytimes.com/sitemaps/sitemap_news/sitemap.xml.gz
## 3 http://spiderbites.nytimes.com/sitemaps/sitemap_video/sitemap.xml.gz
##
## $ host
## [1] поле значение агента пользователя
## <0 строк> (или строка нулевой длины.имена)
##
## $ other
## [1] поле значение агента пользователя
## <0 строк> (или имена строк с нулевой длиной)
имена)
##
## $ sitemap
## поле useragent
## 1 Sitemap *
## 2 Карта сайта *
## 3 Карта сайта *
## значение
## 1 http://spiderbites.nytimes.com/sitemaps/www.nytimes.com/sitemap.xml.gz
## 2 http://www.nytimes.com/sitemaps/sitemap_news/sitemap.xml.gz
## 3 http://spiderbites.nytimes.com/sitemaps/sitemap_video/sitemap.xml.gz
##
## $ host
## [1] поле значение агента пользователя
## <0 строк> (или строка нулевой длины.имена)
##
## $ other
## [1] поле значение агента пользователя
## <0 строк> (или имена строк с нулевой длиной) paths_allowed (
paths = c ("изображения /", "/ поиск"),
domain = c ("wikipedia.org", "google.com"),
bot = "Ортогаффе"
) ##
wikipedia.org
google.com ## [1] ИСТИНА ЛОЖЬ .