ТОП-5 способов выполнения SQL-запрос в PySpark
Если вы знаете SQL, но еще не освоились с фреймворком Apache Spark, то вы можете выполнять запросы различными способами. В этой статье вы узнаете, как писать SQL-выражения в PySpark, какие способы выполнения запросов существуют, как конкатенировать строки, фильтровать данные и работать с датами.
Способы выполнения в SQL-запросов в Apache Spark
Выполнять SQL-запросы можно выполнять различным образом, но все они в итоге дают тот же результат. Причем только один из них является полноценным запросом, все остальные является вызов функции, принимающей SQL-выражение. Вот некоторые из них:
- напрямую через
spark.sql("QUERY"); - выборка столбцов через метод
selectв связке с функциейexprизpyspark.sql.functions; - выборка столбцов через метод
selectExpr; - добавление результата вычисления SQL-выражения к исходной таблице через метод
withColumn; - фильтрация данных через методы
whereилиfilterв связке с функциейexprизpyspark.;. sql.functions
sql.functions
 sql.functions
sql.functionsДопустим, имеется следующий DataFrame:
df = spark.createDataFrame([
('py', 'Anton', 'Moscow', 23),
('c', 'Anna', 'Omsk', 27),
('py', 'Andry', 'Moscow', 24),
('cpp', 'Alex', 'Moscow', 32),
('cpp', 'Boris', 'Omsk', 55),
('py', 'Vera', 'Moscow', 89), ],
['lang', 'name', 'city', 'salary'])
Тогда чтобы напрямую выполнить SQL-запрос (1-способ), нужно создать так называемое представление (view). Это делается для того чтобы Spark знал о созданной таблице. Представление создается вызовом метода, в который нужно передать желаемое имя таблицы:
df.createOrReplaceTempView("prog_info")
Теперь можно выполнять запросы, так же, как это делается при работе с базами данных:
spark.sql("select lang from prog_info").show()
"""
+----+
|lang|
+----+
| py|
| c|
| py|
| cpp|
| cpp|
| py|
+----+
"""
Этот способ наиболее универсален, поскольку не нужно знать о различных функциях, а просто нужно дать необходимый запрос.
Второй способ заключается в использовании метода select в связке с функцией expr. Она уже не требует создания представления. Однако она применяется к конкретному DataFrame, поэтому операторы SELECT FROM должны быть опущены. В этом случае следует говорить о SQL-выражении, ведь не является полным запросом. Например, вот так выглядит тот же самый запрос, что и выше, но только с использованием функции
# На самом деле именно для этого случая, `expr` может быть опушен,
# но далее вы увидите, что его обязательно нужно использовать
import pyspark.sql.functions as F
df.select(F.expr('lang')).show()
"""
+----+
|lang|
+----+
| py|
| c|
| py|
| cpp|
| cpp|
| py|
+----+
"""
Далее следуют метод selectExpr. Второй метод точно такой же, как и select
expr.
df.selectExpr('lang').show()
# Или что то же самое:
df.select('lang').show()
+----+
|lang|
+----+
| py|
| c|
| py|
| cpp|
| cpp|
| py|
+----+
Различие заключается в том, что в select передаются именно столбцы, поэтому такая запись неправильная:
# Ошибка selectExpr(df.lang).show() # А вот так можно: select(df.lang).show()
Самый последний способ использования SQL-выражений — это метод withColumn в связке с функцией expr. В отличие от предыдущих он добавляет к имеющейся таблице новый столбец, полученный на основе SQL-выражения. Его можно рассматривать как оператор SELECT * FROM.
Анализ данных с Apache Spark
Конечно, на примере операции выборки столбца всю силу SQL-выражений не показать, поэтому рассмотрим более интересные операции, включая фильтрацию данных, о которой мы еще не поговорили.
Конкатенация строк с использованием ||
Самый простой способ объединения нескольких строк в одну — это использование SQL-выражения со знаком ||. Такая операция называется конкатенация строк. Итак, чтобы конкатенировать строки используйте один из вышеперечисленных способов.
spark.sql('SELECT name || "_" || lang AS name_lang FROM lang_info').show()
df.select(F.expr('name || "_" || lang AS name_lang')).show()
df.selectExpr('name || "_" || lang AS name_lang').show()
"""
+---------+
|name_lang|
+---------+
| Anton_py|
| Anna_c|
| Andry_py|
| Alex_cpp|
|Boris_cpp|
| Vera_py|
+---------+
"""
# Возвращает всю таблицу
df.withColumn('name_lang', F.expr('name || "_" || lang')).show()
"""
+----+-----+------+------+---------+
|lang| name| city|salary|name_lang|
+----+-----+------+------+---------+
| py|Anton|Moscow| 23| Anton_py|
| c| Anna| Omsk| 27| Anna_c|
| py|Andry|Moscow| 24| Andry_py|
| cpp| Alex|Moscow| 32| Alex_cpp|
| cpp|Boris| Omsk| 55|Boris_cpp|
| py| Vera|Moscow| 89| Vera_py|
+----+-----+------+------+---------+
"""
Фильтрация данных в PySpark
Для фильтрации существуют методы filter и where (это синонимы, они делают то же самое). Фильтрация данных может быть выражена двумя способами: в виде SQL-выражения или так, как это делается в библиотеке Pandas. Например, найдем те записи, которые содержат одинаковые значения.
Фильтрация данных может быть выражена двумя способами: в виде SQL-выражения или так, как это делается в библиотеке Pandas. Например, найдем те записи, которые содержат одинаковые значения.
# В виде SQL-выражения
df.filter('salary > 30 AND city like "Moscow"').show()
# Как в Pandas:
df.filter((df.salary > 30) & (df.city == 'Moscow')).show()
"""
+----+----+------+------+
|lang|name| city|salary|
+----+----+------+------+
| cpp|Alex|Moscow| 32|
| py|Vera|Moscow| 89|
+----+----+------+------+
"""
При использовании Pandas-стиля выражения заключается в скобки; если требуется произвести логические операции между ними, то ставится знак & (AND, побитовое И) или | (OR, побитовое ИЛИ). В нашем примере мы использовали знак И. Также стоит отметить, что его использование ограничено использованием имен с латинскими буквами и цифрами (как например, обратиться к имени столбца, содержащий пробел).
Также можно использовать обычный SQL-запрос в spark.sql.
spark.sql('SELECT * FROM lang_info WHERE salary > 30 AND city like "Moscow"')
Использование CASE WHEN в PySpark
В PySpark эквивалентом оператор CASE WHEN является использование функций when().otherwise(). Он необходим для выбора того или иного результата в зависимости от выполнения условия. Аналогичный оператор можно встретить в Python, который состоит if\elif\eles. Синтаксис у оператора `CASE WHEN в SQL такой:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
Допустим из неполных названий языков мы хотим получить полные. В этом случае можно поступить таким образом:
sql = """
CASE
WHEN (lang LIKE 'c') OR (lang LIKE 'cpp') THEN 'C/C++'
WHEN (lang LIKE 'py') THEN 'Python'
ELSE 'unknown'
END"""
df. withColumn('FullLang', F.expr(sql)).show()
"""
+----+-----+------+------+--------+
|lang| name| city|salary|FullLang|
+----+-----+------+------+--------+
| py|Anton|Moscow| 23| Python|
| c| Anna| Omsk| 27| C/C++|
| py|Andry|Moscow| 24| Python|
| cpp| Alex|Moscow| 32| C/C++|
| cpp|Boris| Omsk| 55| C/C++|
| py| Vera|Moscow| 89| Python|
+----+-----+------+------+--------+
"""
withColumn('FullLang', F.expr(sql)).show()
"""
+----+-----+------+------+--------+
|lang| name| city|salary|FullLang|
+----+-----+------+------+--------+
| py|Anton|Moscow| 23| Python|
| c| Anna| Omsk| 27| C/C++|
| py|Andry|Moscow| 24| Python|
| cpp| Alex|Moscow| 32| C/C++|
| cpp|Boris| Omsk| 55| C/C++|
| py| Vera|Moscow| 89| Python|
+----+-----+------+------+--------+
"""
Опять же мы могли бы вызвать select, но получили бы только один столбец, также в этом случае следует добавить оператор AS или метод alias, иначе название столбца будет состоять из всего оператора CASE WHEN. Например, так:
df.select(F.expr(sql).alias('FullLang')).show()
"""
+--------+
|FullLang|
+--------+
| Python|
| C/C++|
| Python|
| C/C++|
| C/C++|
| Python|
+--------+
"""
Либо, как уже говорили, и вовсе сделать с помощью функций when-otherwise.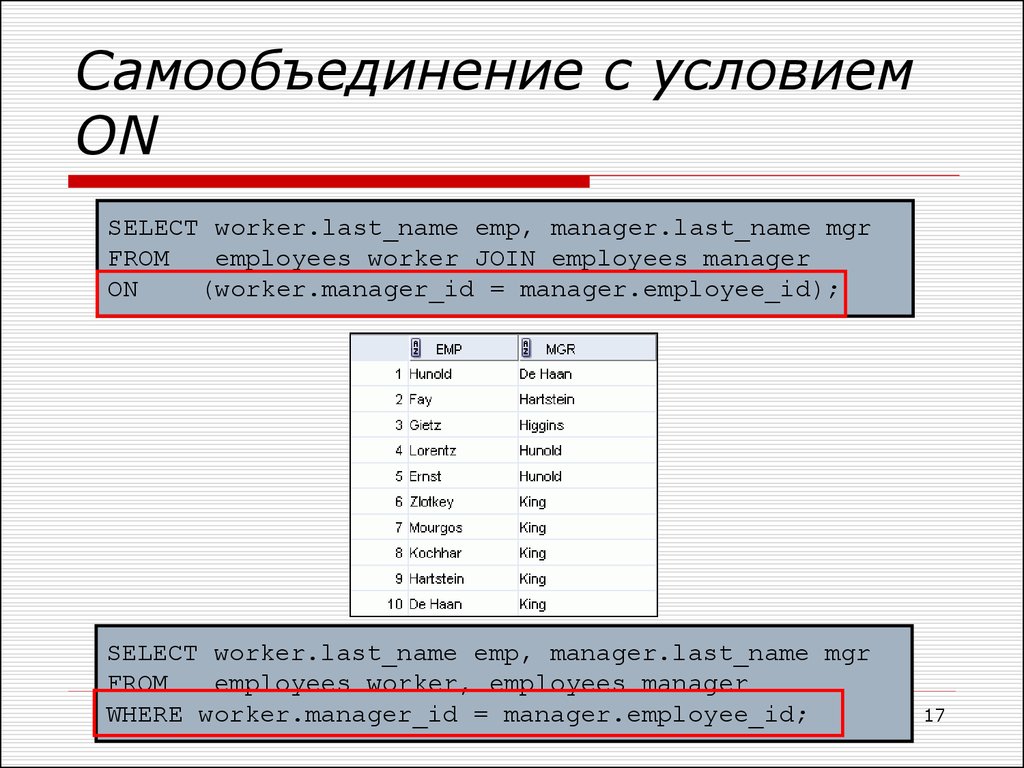 Советуем при этом соблюдать структурные отступы для читабельности кода:
Советуем при этом соблюдать структурные отступы для читабельности кода:
case_when = (
F.when(F.expr('lang LIKE "c" OR lang LIKE "cpp"'), 'C/C++')
.when(F.expr('lang LIKE "py"'), 'Python')
.otherwise('uknown')
)
df.withColumn('FullLang', case_when)
Работаем с датой и временем
df2 = spark.createDataFrame([
('2020-01-01', '2022-10-25'),
('2021-05-12', '2022-05-12'),],
['before', 'after'])
df2.withColumn('diff', F.expr('DATEDIFF(after, before)')).show()
"""
+----------+----------+----+
| before| after|diff|
+----------+----------+----+
|2020-01-01|2022-10-25|1028|
|2021-05-12|2022-05-12| 365|
+----------+----------+----+
"""
Заметим, что мы могли бы не писать так, как это делается в SQL, а могли бы использовать функции из pyspark.. Более того, это хороший способ узнать, есть ли такая-то функция, заглянув в документацию. Однако полностью полагаться на документацию не стоит, так как есть еще незадокументированные функции, которые нет в языке SQL, но могут в некоторых случаях пригодится(например,  sql.functions
sql.functionsstack — обратная операция функции pivot, см. [5]).
Еще больше подробностей об SQL-операциях в PySpark вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Записаться на курс
Смотреть раcписание
Источники
- expr
- select
- selectExpr
- withColumn
- Как развернуть таблицу
Получение данных из таблицы c помощью SQL запроса
Получение данных из таблицы c помощью SQL запроса1.
 Введение
Введение1.1 Синтаксис SQL запроса
1.2 Получение данных из таблицы
1.3 Вызов функции
1.4 Конкатенация строк
1.5 Арифметические операции
1.6 Исключение дубликатов
2. Отсечение строк и сортировка
2.1 Выражение WHERE
2.2 Логические операторы
2.3 Порядок условий
2.4 Операции сравнения
2.5 BETWEEN
2.6 IN
2.7 Поиск по шаблону
2.8 Обработка NULL значений
2.9 Сортировка
2.10 Ограничение количества строк LIMIT
2.11 Пропуск первых строк результата
3. Соединения
3.1 Соединение двух таблиц
3.2 Псевдонимы таблиц
3.3 Добавляем WHERE
3.4 Несколько условий соединения
3.5 Использование таблицы несколько раз
3.6 Типы соединения
3.
 7 RIGHT JOIN
7 RIGHT JOIN3.8 FULL JOIN
3.9 Декартово произведение
3.10 Синтаксис через WHERE
4. Агрегатные функции
4.1 Агрегатные функции
4.2 NULL значения в агрегатных функциях
4.3 Количество уникальных значений
4.4 Отсутствие строк
4.5 GROUP BY
4.6 Дополнительные столбцы в списке выборки с GROUP BY
4.7 GROUP BY и WHERE
4.8 GROUP BY по нескольким выражениям
4.9 NULL значения в GROUP BY
4.10 HAVING
4.11 ROLLUP
4.12 CUBE
4.13 GROUPING SETS
5. Операции над множествами
5.1 Доступные операции над множествами
5.2 Из какого запроса строка?
5.3 Пересечение строк
5.4 Исключение строк
5.5 Дубликаты строк
5.6 Совпадение типов данных столбцов
5.
 7 Сортировка
7 Сортировка5.8 Несколько операций
6. Подзапросы
6.1 Подзапрос одиночной строки
6.2 Коррелированный подзапрос
6.3 Подзапрос вернул более одной строки
6.4 Подзапрос не вернул строк
6.5 Попадание в список значений
6.6 Отсутствие в списке значений
6.7 NULL значения в NOT IN
6.8 Проверка существования строки
6.9 Проверка отсутствия строки
7. Строковые функции
7.1 CONCAT — конкатенация строк
7.2 Преобразование регистра букв
7.3 LENGTH — определение длины строки
7.4 Извлечение подстроки
7.5 POSITION — поиск подстроки
7.6 Дополнение до определенной длины
7.7 TRIM — удаление символов с начала и конца строки
7.8 REPLACE — замена подстроки
7.9 TRANSLATE — замена набора символов
8.
 !)
!)8.5 Получение числа из строки
8.6 ROUND — округление числа
8.7 TRUNC — усечение числа
8.8 CEIL — следующее целое число
8.9 FLOOR — предыдущее целое число
8.10 GREATEST — определение большего числа
8.11 LEAST — определение меньшего числа
8.12 ABS — модуль числа
8.13 TO_CHAR — форматирование числа
9. Рекурсивные подзапросы
9.1 Подзапрос во фразе FROM
9.2 Введение в WITH
9.3 Несколько подзапросов в WITH
9.4 Простейший рекурсивный запрос
9.5 Рекурсивный запрос посложнее
9.6 Строим иерархию объектов
9.7 Путь до элемента
9.8 Сортировка (плохая)
9.9 Сортировка (надежная)
9.10 Форматирование иерархии
9.11 Нумерация вложенных списков
9.12 Листовые строки CONNECT_BY_ISLEAF
10. Оконные функции
Оконные функции
10.1 Получение номера строки
10.2 Номер строки в рамках группы
10.3 Составляем рейтинг — RANK
10.4 Несколько человек на место — DENSE_RANK
10.5 Разделение на группы — NTILE
10.6 Агрегатные оконные функции
10.7 Обработка NULL значений
10.8 Нарастающий итог SUM + ORDER BY
10.9 Неуникальные значения в нарастающем итоге SUM + ORDER BY
10.10 Собираем строки через разделитель — STRING_AGG
10.11 WITHIN GROUP
- Оглавление
- Введение
Наступила пора сделать что-нибудь полезное, например получить все данные из таблицы. Для получения всех данных из таблицы с названием table1 достаточно выполнить запрос:
SELECT * FROM table1
Из какой таблицы выбирать данные указывается после ключевого слова FROM. О необходимости выбора всех полей из таблицы говорит
О необходимости выбора всех полей из таблицы говорит *.
Зачастую нужно получить не все столбцы таблицы, а какую-то их часть. Чтобы выбрать определенные столбцы, нужно перечислить их через запятую после ключевого слова SELECT. Например, чтобы получить столбцы col1, col2 и col3 из таблицы table1, нужно написать следующий запрос:
SELECT col1, col2, col3 FROM table1
Столбцам в запросе можно назначить псевдоним (по сути переименовать столбец). Это необходимо делать как минимум при выполнении в списке выборки операций над столбцами таблицы, конкатенации строк, вызове функции и т.д.
Для назначение столбцу псевдонима, следует после выражения написать ключевое слово AS и за ним новое название, например:
SELECT 1 AS one, 'Бим' AS dog_name
Слово AS является необязательным и его можно опустить. Вышеуказанный пример можно переписать в следующей форме:
SELECT 1 one, 'Бим' dog_name
Псевдонимы как и все идентификаторы и ключевые слова SQL должны начинаться с буквы (a-z) или подчёркивания (_). Последующими символами могут быть буквы, цифры (0-9), знаки доллара ($) или подчёркивания.
Последующими символами могут быть буквы, цифры (0-9), знаки доллара ($) или подчёркивания.
Псевдонимы без кавычек воспринимаются системой без учёта регистра. Таким образом dog_name, DOG_NAME, Dog_Name являются идентичными.
Если заключить псевдоним в двойные кавычки, то он становится регистрочувствительным и может состоять из произвольной последовательности символов, например «имя собаки», «1», «dogName».
Максимальная длина псевдонима равна 63 символам, хотя ее можно изменить в настройках сервера.
Практическое задание
Выбор всех полей из таблицы
Практическое задание
Выбор списка полей
Практическое задание
Псевдонимы столбцов
1.1 Синтаксис SQL запроса
1.3 Вызов функции
Сделано ребятами из Сибири© 2023 LearnDB
sql-запрос, что такое «C» в этом запросе
спросил
Изменено 4 года, 10 месяцев назад
Просмотрено 3к раз
выбрать
C. CMPNAME,
C. МИНИМАЛЬНОЕ ЗНАЧЕНИЕ,
К.ПРЖИД,
C.ALLOTDATE
от
(
выбирать
min(A.bidvalue) как MINBIDVALUE,
А.пржид,
П.аллотдата,
A.cmpname
от
выделено А,
проекты П
где
A.prjid = P.projectid
группа по
prjid
) С
CMPNAME,
C. МИНИМАЛЬНОЕ ЗНАЧЕНИЕ,
К.ПРЖИД,
C.ALLOTDATE
от
(
выбирать
min(A.bidvalue) как MINBIDVALUE,
А.пржид,
П.аллотдата,
A.cmpname
от
выделено А,
проекты П
где
A.prjid = P.projectid
группа по
prjid
) С
что ‘C’ (я знаю, что он используется как псевдоним, но для него не объявлено имя таблицы). ->здесь A начинает использоваться в качестве псевдонима для выделенного n P начинает использоваться для проекта.
1
C — псевдоним для результатов подзапроса (выберите min(A.bidvalue) как ….). Этот подзапрос создаст набор результатов, который ведет себя как таблица на протяжении всего запроса. Чтобы сослаться на этот набор результатов и его столбцы, ему был присвоен псевдоним «C», и все C.stuff являются столбцами из подзапроса.
Это подзапрос. Подзапросы являются анонимными, поэтому им должен быть присвоен псевдоним с использованием ключевого слова AS . SQL позволяет опустить ключевое слово
SQL позволяет опустить ключевое слово AS .
В этом конкретном запросе подзапрос не добавляет никакой пользы: внутренний подзапрос можно использовать сразу после перестановки столбцов в соответствии с внешним запросом.
1
«C» — псевдоним для «набора результатов» подзапроса, определенного
выбрать
min(A.bidvalue) как MINBIDVALUE,
А.пржид,
П.аллотдата,
A.cmpname
от
выделено А,
проекты П
где
A.prjid = P.projectid
группа по
prjid
Подзапрос
выбрать
min(A.bidvalue) как MINBIDVALUE,
А.пржид,
П.аллотдата,
A.cmpname
от
выделено А,
проекты П
где
A.prjid = P.projectid
группа по
prjid
имеет псевдоним «C».
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Изучение SQL: Учебник по SQL для начинающих
КОДИРОВАНИЕ
PRO
СКИДКА 36%
Попробуйте SQL на практике с Programiz PRO
Получите скидку сейчас
Указатель страниц
- Введение
- SQL ВЫБРАТЬ (I)
- SQL ВЫБРАТЬ (II)
- SQL СОЕДИНЕНИЕ
- База данных SQL
- Вставка и удаление SQL
- Ограничения SQL
- Дополнительные темы SQL
- О SQL
- Зачем изучать SQL?
- Как выучить SQL?
Введение
- Введение в SQL
SQL SELECT (I)
- SQL SELECT и SELECT WHERE
- SQL И, ИЛИ и НЕ
- SQL ВЫБЕРИТЕ ОТЛИЧНЫЙ
- SQL ВЫБРАТЬ КАК
- SQL LIMIT, TOP и FETCH FIRST
- Оператор SQL IN
- Оператор SQL МЕЖДУ
- SQL IS NULL, а НЕ NULL
- SQL МИН() и МАКС()
- СЧЕТЧИК SQL()
- SQL SUM() и AVG()
SQL SELECT (II)
- SQL ORDER BY
- SQL ГРУППА ПО
- SQL КАК
- Подстановочные знаки SQL
- ОБЪЕДИНЕНИЕ SQL
- Подзапрос SQL
- SQL ЛЮБОЙ и ВСЕ
- СЛУЧАЙ SQL
- SQL, ИМЕЮЩИЙ
- SQL СУЩЕСТВУЕТ
SQL СОЕДИНЯЕТ
- SQL СОЕДИНЯЕТ
- ВНУТРЕННЕЕ СОЕДИНЕНИЕ SQL
- SQL ЛЕВОЕ СОЕДИНЕНИЕ
- SQL ПРАВОЕ СОЕДИНЕНИЕ
- SQL ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
База данных SQL и таблица
- Создание базы данных SQL
- Создание таблицы SQL
- База данных SQL Drop
- Таблица удаления SQL
- Изменить таблицу SQL
- База данных резервного копирования SQL
Вставка, обновление и удаление SQL
- Вставка SQL в
- Обновление SQL
- Выбор SQL в
- Выбор SQL для вставки
- SQL Удаление и усечение строк
Ограничения SQL
- Ограничения SQL
- Ограничение SQL Not Null
- Уникальные ограничения SQL
- Первичный ключ SQL
- Внешний ключ SQL
- Проверка SQL
- SQL по умолчанию
- Создание индекса SQL
Дополнительные темы SQL
- Типы данных SQL
- Дата и время SQL
- Операторы SQL
- Комментарии SQL
- Представления SQL
- Хранимые процедуры SQL
- SQL-инъекция
Что такое SQL?
SQL — это стандартизированный язык программирования, который используется для взаимодействия с системами баз данных.
SQL используется для
- создания баз данных
- создавать таблицы в базе данных
- прочитать данные из таблицы
- вставить данные в таблицу
- обновить данные в таблице
- удалить данные из таблицы
- удалить таблицы базы данных
- удалить базы данных
- предоставлять и отзывать разрешения
- резервное копирование и восстановление баз данных
- и многие другие операции с базой данных
Зачем изучать SQL?
- SQL используется для связи с популярными системами реляционных баз данных. Он используется в таких системах данных, как MySQL, PostgreSQL, Oracle и многих других.
- Знание SQL предпочтительно для ответственных должностей, таких как инженер-программист , бизнес-аналитик , специалист по данным и т. д.
Как выучить SQL?
- Учебник по SQL от Programiz — Мы предоставляем пошаговые руководства вместе с предложениями, операторами, функциями и примерами.
