Как создать PDF файл на компьютере
Руководства | Форматы файлов
Portable Document Format был создан Adobe для того, чтобы пользователи и компании могли создавать точные цифровые версии бумажных документов. С помощью этого формата можно передавать файлы на разные устройства, отправлять их другим пользователям по электронной почте или размещать на сайтах для чтения. Для чего еще нужен PDF и как создать такой файл?
ПреимуществаPDF используется для отображения графического и текстового контента. Основное преимущество в том, что он сохраняет полный вид документа после печати и позволяет зашифровать файл, что является дополнительной защитой. В этом случае, чтобы открыть полученное сообщение в формате PDF, необходимо знать пароль, который задает отправитель. Также можно ограничить действия, которые может совершать получатель, например, отключить копирование или редактирование.
PDF используется для публикации электронных книг и руководств, чтения текстовых файлов, предварительного просмотра изображений и даже воспроизведения видео. Сохранение в формате PDF позволяет просматривать документ даже в веб-браузере без необходимости установки программы-ридера на компьютер.
Более того, независимо от того, откроете ли вы файл в браузере или в приложении, он будет выглядеть одинаково. Преобразование элементов также позволит открывать их на устройстве с любой операционной системой. Получается, что не придется беспокоиться о том, какое программное обеспечение установлено у получателя.
Как создать?Adobe Acrobat бесплатно позволяет только открывать и просматривать PDF, а для использования других функций, включая добавление комментариев, редактирование, экспорт, создание новых файлов, придется купить лицензию.
Однако существует множество способов создать собственный PDF-файл с помощью другого софта.
Из WordКогда вы закончите редактировать документ:
- Нажмите «Файл» в верхнем левом углу экрана.

- Затем кликните по «Сохранить как».
- Выберите папку, куда будет помещен документ. Когда появится окно сохранения, найдите внизу пункт «Тип файла» и выберите вариант «PDF». Нажать «Сохранить».
Процесс аналогичен для других программ, таких как Microsoft Excel или PowerPoint.
Из Google DocsЧтобы создать PDF из документа Google Docs, выполните следующие действия:
- На верхней панели управления выберите «Файл».
- В выпадающем меню найдите вариант «Скачать» – «PDF».
Если вы просматриваете документ в Интернете и хотите сохранить его в формате PDF, сделать это просто как в Chrome, так и в другом браузере:
- Нажмите на три точки в правом верхнем углу для вызова меню.
- Щелкните по пункту «Печать».
- Появится окно печати с предварительным просмотром слева и набором функций справа.

- Когда документ многостраничный и вы хотите создать PDF-файл, используя только определенную страницу или диапазон, щелкните по раскрывающемуся меню рядом с пунктом «Страницы», выберите вариант «Персонализированные».
- Под вариантом «Персонализированные» отобразится поле, в котором укажите, какие страницы нужно сохранить.
- Нажав «Сохранить», появится окно, где нужно выбрать папку места назначения.
Обратите внимание, что будет напечатана вся веб-страница, а не только то, что в данный момент отображается в браузере. Поэтому рекомендуется проверить в окне предварительного просмотра, что будет сохранено.
Из рисункаСоздать файл PDF возможно из одного или сразу нескольких изображений прямо из Проводника:
- Кликом левой кнопки мышки выберите все картинки, которые нужно объединить.
- Теперь щелкните правой кнопкой мышки для вызова меню и выберите пункт «Печать».
- Убедитесь, что в списке доступных принтеров выбран вариант «Microsoft Print to PDF».
- Затем нажмите «Печать», чтобы сохранить файл на диске.
Порядок отображения картинки в Проводнике совпадает с порядком, в котором они будут отображаться в сохраненном файле. Если вы хотите, чтобы они располагались в другом порядке, переименуйте рисунки перед печатью.
Сторонний софтНа рынке доступно множество программ, позволяющих создавать PDF-файлы, читать их и конвертировать из различных форматов. Все они работают по одному принципу.
Например, PDFCreator – бесплатный и популярный инструмент, добавляется в систему в виде виртуального принтера, благодаря чему вы сможете создавать PDF в любой программе. Выполняет обширную настройку параметров печати, что позволяет настроить процесс преобразования в соответствии со своими индивидуальными потребностями.
Программа позволяет объединять несколько документов в один и защищать их от открытия, печати и изменения. Шифрование осуществляется с помощью 128-битного ключа AES. PDFCreator также может подписывать файл цифровой подписью, чтобы вы могли подтвердить свое авторство или защитить его от изменений.
В настройках профиля настраивается множество параметров, связанных с генерацией текстовых и графических документов в одном из наиболее популярных форматов. Вы сможете на постоянной основе присвоить автора (имя и фамилию) публикации, ставить штампы (как водяной знак).
PDFCreator также предлагает возможность настройки дополнительных параметров для более опытных пользователей. Есть возможность выбирать форматы PDF, PDF/A и PDF/X по умолчанию, управлять цветовым профилем и задавать сжатие графических файлов, содержащихся в документе. Вы даже можете настроить выполнение операции после того, как будет создан документ.
Можем порекомендовать еще несколько похожих программ:
- CutePDF Writer.
- PDF24 Creator.
- Doro PDF Writer
- Foxit Reader.
Метки записи: #PDF#файлы на ПК
Похожие записи
Android | Приложения | Руководства
Как добавить функции Отменить, Повторить, Найти и Заменить в Android
Представьте себе — вы набираете что-то на телефоне (скажем, длинный e-mail), и вы теряете данные из-за сбоя в приложении или случайного нажатия кнопки. Думается, что это довольно распространенное явление. На компьтерах у нас есть опция отмены ошибки, но что происходит в Android телефонах? ОС Android очень трансформировалась за эти годы, но даже через 7 лет…
Читать далее Как добавить функции Отменить, Повторить, Найти и Заменить в AndroidПродолжить
Интересное
Что такое файлы TAR?
TAR-файлы — это своего рода лента архива, часто называемая тарбол. Эти файлы используют формат консолидированного архива Unix и, таким образом, содержат несколько файлов в одном. Файлы TAR хранят данные, но не сжимают их автоматически — этот тип файлов идеально подходит для архивирования или отправки файлов через Интернет.
Читать далее Что такое файлы TAR?Продолжить
Android | Руководства
Как найти приложения, которые сажают батарею телефона или планшета андроид
В том случае, если ваш андроид-телефон теряет заряд батареи быстрее, чем обычно, тогда вам стоит посмотреть на экран использования батареи вашего устройства для того, чтобы найти приложения, которые сажают батарею телефона или планшета андроид.
Читать далее Как найти приложения, которые сажают батарею телефона или планшета андроидПродолжить
Создание и изменение PDF-файлов в Python.
 Часть 2
Часть 2Оглавление
- Объединение и слияние PDF-файлов
- Используем класс
PdfFileMerger - Объединяем PDF-файлы при помощи метода
.append() - Слияние PDF-файлов при помощи метода
.merge() - Проверка ваших знаний
- Используем класс
- Создание PDF-файла с нуля
- Устанавливаем reportlab
- Используем класс Canvas
- Устанавливаем размер страницы
- Устанавливаем свойства шрифтов
- Проверка ваших знаний
Объединение и слияние PDF-файлов
Существуют две похожие задачи — слияние и объединение нескольких PDF-файлов в один.
Когда вы объединяете (concatenate) два или более PDF-файла, вы добавляете файлы один за другим и получаете из них один документ. Например, компания может объединять множество ежедневных отчетов в один ежемесячный отчет в конце месяца.
В результате операции слияния (merging) также из нескольких файлов получается один. Но, в отличии от операции объединения (concatenate), вы можете добавить новый файл не только в конец последнего, но и в любое другое место в файле после определенной страницы.
В этой секции мы изучим, как объединять и сливать PDF-файлы, используя класс PdfFileMerger из пакета PyPDF2.
Используем класс PdfFileMerger
Класс PdfFileMerger во многом очень похож на класс PdfFileWriter, который мы изучили в предыдущем разделе. Для записи PDF-файлов можно использовать оба эти класса. В обоих случаях мы добавляем страницы к экземплярам класса, а затем записываем их в файл.
Основное отличие между этими двумя классами состоит в следующем: класс PdfFileMerger может вставлять их в любое место.
Что же, двинемся дальше и создадим наш первый экземпляр класса PdfFileMerger. Для этого вначале импортируем этот класс, а потом создадим его экземпляр класса, сохранив его в переменную pdf_merger:
from PyPDF2 import PdfFileMerger pdf_merger = PdfFileMerger()
Объекты класса  Прежде чем с этими объектами можно будет что-то делать, к ним надо добавить одну или несколько страниц.
Прежде чем с этими объектами можно будет что-то делать, к ним надо добавить одну или несколько страниц.
Есть два способа добавить страницы в объект pdf_merger, и какой из них выбрать, зависит от того, что нам нужно сделать:
- Метод
.append()добавляет все страницы, находящиеся в PDF-файле, после последней страницы в нашем объекте классаPdfFileMerger - Метод
.merge()вставляет все страницы, находящиеся в PDF-файле, после определенной странице в объекте класса
В данной секции мы рассмотрим оба этих способа, начав с метода .append().
Объединяем PDF-файлы при помощи метода .append()
В папке practice_files/ нашего репозитория есть еще одна папка под названием expense_reports. В ней содержатся три файла, каждый из которых представляет собой отчет о расходах сотрудника по имени Peter Python.
Питер должен объединить эти три PDF-файла в один и представить их своему работодателю в качестве отчета для получения компенсации за некоторые связанные с работой расходы.
Начнем, как обычно, с модуля pathlib и получим список объектов класса Path для каждого из трех отчетов о расходах, лежащих в папке expense_reports:
from pathlib import Path
reports_dir = (
Path.home()
/ "creating-and-modifying-pdfs"
/ "practice_files"
/ "expense_reports"
)После импорта класса Path мы построили путь до наших файлов в папке expense_reports. Обратите внимание, что вам возможно придется скорректировать этот путь в соответствии с расположением файлов на вашем компьютере.
Как только мы создали путь к каталогу cost_reports/ и сохранили его в переменную reports_dir, мы можем использовать метод .glob () для получения итерируемой последовательности путей ко всем PDF-файлам в этом каталоге.
Давайте посмотрим, что есть в этой директории:
for path in reports_dir.glob("*.pdf"):
print(path.name)
...
Expense report 1.pdf
Expense report 3.pdf
Expense report 2.pdfИмена всех трех файлов выведены на экран, но, как можно заметить, не по порядку. Более того, их порядок на вашем компьютере также может отличаться от того, что вы видите здесь.
Таким образом, метод .glob() не обеспечивает порядок данных, которые мы сохранили в список. Но мы можем упорядочить их самостоятельно, использовав стандартный метод списков .sort().
expense_reports = list(reports_dir.glob("*.pdf")) expense_reports.sort()
Заметим, что метод .sort() изменяет список по месту (in-place метод), и поэтому не нужно сохранять результат в отдельную переменную. После вызова метода .sort() список expense_reports будет отсортирован в алфавитном порядке.
Чтобы убедиться в этом, выведем опять этот список на экран:
for path in expense_reports:
print(path.name)
...
Expense report 1.pdf
Expense report 2.pdf
Expense report 3.pdfВыглядит отлично!
Теперь мы можем приступить к объединению всех трех файлов. Для этого будем использовать метод PdfFileMerger.append(). Он требует всего один строковый аргумент, в котором содержится путь к PDF-файлу. Когда мы вызываем метод .append (), все страницы в PDF-файле добавляются к набору страниц, которые уже хранятся в объекте класса PdfFileMerger.
Теперь проверим это в действии. Для начала импортируем класс PdfFileMerger и создадим его новый экземпляр:
from PyPDF2 import PdfFileMerger pdf_merger = PdfFileMerger()
Теперь переберем все пути в отсортированном списке expense_reports и добавим их в pdf_merger:
for path in expense_reports:
pdf_merger.append(str(path))Обратите внимание, что каждый объект Path в списке expense_reports преобразуется в строку при помощи встроенной функции str() перед передачей в метод pdf_merger.append ().
Когда все PDF-файлы из директории expense_reports/ объединены в объекте pdf_merger, нам остается только записать этот объект в PDF-файл. У экземпляра класса PdfFileMerger имеется метод .write(), который работает также как метод PdfFileWriter.write().
Открываем новый файл в режиме записи и передаем его в метод pdf_merge.write():
with Path("expense_reports.pdf").open(mode="wb") as output_file:
pdf_merger.write(output_file)Теперь у нас в нашей текущей директории есть файл под названием expense_reports.pdf. Открыв его, можно убедится, что все три отчета о затратах объединены в одном PDF-файле.
Слияние PDF-файлов при помощи метода .merge()
Чтобы объединить два или более PDF-файла произвольным образом, используется метод .. Этот метод похож на метод 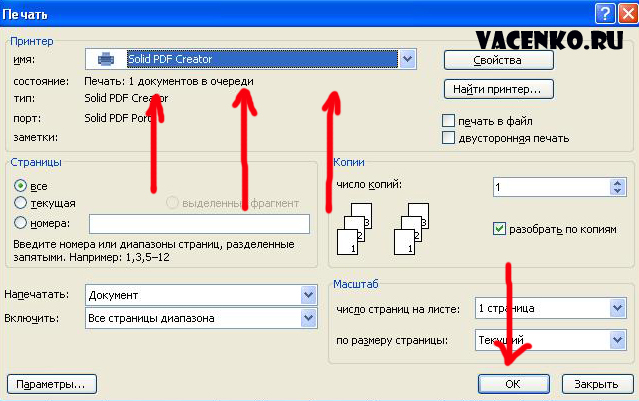 merge()
merge()append(), за исключением того, что в нем вы обязаны определить, в какое место итогового файла будет помещено содержимое объединяемых файлов.
Рассмотрим следующий пример. В компании Goggle, Inc. был подготовлен квартальный отчет, но в него забыли включить оглавление. Peter Python быстро заметил эту ошибку и создал PDF-файл с недостающим оглавлением. Теперь нужно объединить этот файл с файлом отчета правильным образом.
Оба этих файла находятся в нашем репозитории в папке quarterly_report/, которая в свою очередь находится в папке practice_files. Отчет находится в файле с именем report.pdf, а оглавление — в файле с именем toc.pdf.
Итак, импортируем класс PdfFileMerger и создадим объект Path для двух наших файлов:
from pathlib import Path
from PyPDF2 import PdfFileMerger
report_dir = (
Path.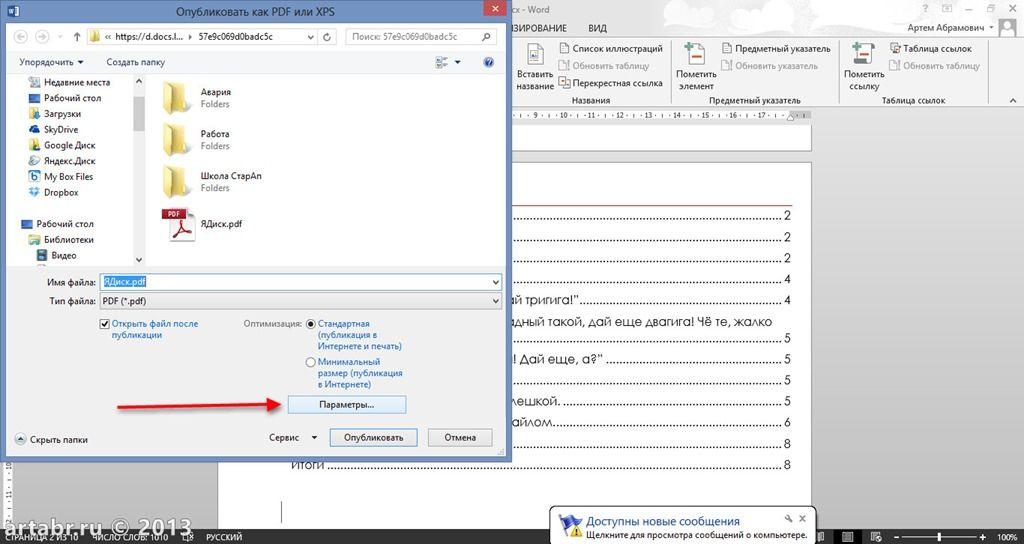 home()
/ "creating-and-modifying-pdfs"
/ "practice_files"
/ "quarterly_report"
)
report_path = report_dir / "report.pdf"
toc_path = report_dir / "toc.pdf"
home()
/ "creating-and-modifying-pdfs"
/ "practice_files"
/ "quarterly_report"
)
report_path = report_dir / "report.pdf"
toc_path = report_dir / "toc.pdf"Первым делом давайте присоединим файл с отчетом к только что созданному экземпляру класса PdfFileMerger, используя метод .append():
pdf_merger = PdfFileMerger() pdf_merger.append(str(report_path))
Теперь, когда в pdf_merger есть все страницы отчета, мы можем вставить оглавление в нужное место. Если вы откроете файл report.pdf с помощью любой программы чтения PDF, то увидите, что первая страница отчета является титульной страницей. Вторая — введение, а остальные страницы содержат различные разделы отчета.
Мы хотим вставить оглавление после титульной страницы, прямо перед введением. Поскольку индексация страниц PDF-файлов в пакете PyPDF2 начинаются с 0, нам необходимо вставить оглавление после страницы с индексом 0 и перед страницей с индексом 1.
Чтобы это сделать, вызовем метод pdf_merger.merge() с двумя аргументами:
- В первом — целое число 1 указывает индекс страницы, в которую мы хотим вставить наше оглавление.
- Второй аргумент содержит путь, по которому можно найти файл с оглавлением.
Вот как это выглядит:
pdf_merger.merge(1, str(toc_path))
Все страницы из файла toc.pdf будут вставлены перед страницей с индексом 1. Так как этот файл состоит только из одной страницы, она будет иметь в новом файле индекс 1. Соответственно, страница, у которой был индекс 1 до этого, получит индекс 2. Индекс последующих страниц также увеличится на единицу.
Теперь сохраним получившийся PDF-файл:
with Path("full_report. pdf").open(mode="wb") as output_file:
pdf_merger.write(output_file)
pdf").open(mode="wb") as output_file:
pdf_merger.write(output_file)
Теперь в нашей рабочей директории есть файл под названием ull_report.pdf. Открыв его в любом редакторе PDF, можно убедится, что оглавление вставлено на свое место.
Объединение и слияние PDF-файлов — обычные операции. Хотя примеры в этом разделе, по общему признанию, несколько надуманы, вы можете себе представить, насколько полезной была бы программа для объединения тысяч PDF-файлов или для автоматизации рутинных задач, которые в противном случае заняли бы очень много времени.
Проверка ваших знаний
Упражнение: объедините два PDF-файла
В директории practice_files/ нашего репозитория есть два файла merge1.pdf и merge2.pdf.
Используя экземпляр класса PdfFileMerge, объедините два этих файла при помощи метода.append(). Результат запишите в новый файл под названием concatenated.pdf.
Решение: объединение двух PDF-файлов
Устанавливаем путь к нашему PDF-файлу:
# Сначала импортируем необходимые классы и библиотеки from pathlib import Path from PyPDF2 import PdfFileMerger # Создаем объект Path, который содержит путь до нужного файла.# На вашем компьютере он может быть другим BASE_PATH = ( Path.home() / "creating-and-modifying-pdfs" / "practice_files" ) pdf_paths = [BASE_PATH / "merge1.pdf", BASE_PATH / "merge2.pdf"]
Теперь создаем экземпляр класса PdfFileMerger:
pdf_merger = PdfFileMerger()
Далее мы при помощи цикла переберем все значения переменной pdf_paths и при помощи метода .append() добавим каждый файл в объект pdf_merger:
for path in pdf_paths:
pdf_merger.append(str(path))И наконец, запишем содержимое pdf_merger в новый файл под названием concatenated. pdf:
pdf:
output_path = Path.home() / "concatenated.pdf"
with output_path.open(mode="wb") as output_file:
pdf_merger.write(output_file)Создание PDF-файла с нуля
Пакет PyPDF2 отлично подходит для чтения и изменения существующих PDF-файлов, но у него есть одно серьезное ограничение: его нельзя использовать для создания нового файла формата PDF. Поэтому в этом разделе для создания PDF-файлов мы будем использовать ReportLab Toolkit.
ReportLab — это полнофункциональное решение для создания PDF-файлов. Существует платная коммерческая версия, но также доступна версия с открытым исходным кодом с ограниченными возможностями.
Устанавливаем reportlab
Для начала установим пакет reportlab при помощи менеджера pip.
$ python3 -m pip install reportlab
Проверим установку при помощи команды pip show:
$ python3 -m pip show reportlab Name: reportlab Version: 3.5.34 Summary: The Reportlab Toolkit Home-page: http://www.reportlab.com/ Author: Andy Robinson, Robin Becker, the ReportLab team and the community Author-email: [email protected] License: BSD license (see license.txt for details), Copyright (c) 2000-2018, ReportLab Inc. Location: c:\users\davea\venv\lib\site-packages Requires: pillow Required-by:
На момент написания статьи последней версией пакета reportlab была 3.5.34. Если вы используете IDE IDLE, для работы с только что установленным пакетом ее надо перезапустить.
Используем класс Canvas
Основным интерфейсом для создания PDF-файлов при помощи пакета reportlab является класс Canvas, который находится в модуле reportlab.pdfgen.canvas.
Импортируем этот класс:
from reportlab.pdfgen.canvas import Canvas
Когда мы создаем новый экземпляр класса Canvas, нам нужно указать строку с именем файла PDF, который мы создаем. Например, создадим новый экземпляр класса Canvas для файла hello.pdf:
canvas = Canvas("hello.pdf")Теперь у нас есть экземпляр класса Canvas, который мы сохранили в переменную canvas. Этот экземпляр класса связан с файлом в текущем рабочем каталоге hello.pdf. Однако сам файл hello.pdf еще не существует.
Давайте добавим текст в этот PDF-файл. Для этого воспользуемся методом drawString ():
canvas.drawString(72, 72, "Hello, World")
Первые два аргумента, переданные в метод ., определяют расположение текста на странице. Первый аргумент указывает расстояние от левого края страницы, а второй — расстояние от нижнего края. drawString ()
drawString ()
Значения, передаваемые в метод .drawString (), измеряются в точках. Поскольку точка равна 1/72 дюйма, .drawString (72, 72, «Hello, World») рисует строку «Hello, World» на расстоянии одного дюйма слева и одного дюйма от нижней части страницы.
Чтобы сохранить наш PDF-файл, используем метод .save():
canvas.save()
Теперь в нашей рабочей директории есть файл под названием hello.pdf. Его можно открыть и увидеть внизу страницы надпись «Hello, World»!
Есть два момента, которые хотелось бы отметить:
- Формат страницы по умолчанию — А4.
- По умолчанию используется шрифт Helvetica c размером 12.

Но разумеется, вы не обязаны эти настройки оставлять.
Устанавливаем размер страницы
При создании экземпляра класса Canvas можно изменить размер страницы с помощью необязательного параметра pagesize. Этот параметр принимает кортеж из двух чисел типа float, представляющих ширину и высоту страницы в точках.
Например, чтобы установить размер страницы 8,5 дюймов в ширину и 11 дюймов в высоту, нужно создать следующий объект canvas:
canvas = Canvas("hello.pdf", pagesize=(612.0, 792.0))612 — это 8.5*72, а 792 — это 11*72.
Если перевод точек в дюймы или сантиметры — не ваш конек, в этой библиотеке есть модуль reportlab.lib.units, который может вам помочь. Он содержит несколько вспомогательных объектов, таких как inch и cm, которые упростят ваши вычисления.
Давайте их импортируем:
from reportlab.lib.units import inch, cm
Теперь мы можем посмотреть, что они из себя представляют:
cm # результат: 28.346456692913385 inch # результат: 72.0
И cm, и inch принимают значения с плавающей точкой. Они представляют собой количество точек, содержащихся в них. Соответственно, в сантиметре 28.346456692913385 точки, а в дюйме ровно 72.
Чтобы это использовать, их надо просто умножать на то, что мы хотим преобразовать в точки. Например, вот как использовать дюйм, чтобы установить размер страницы 8,5 дюймов в ширину и 11 дюймов в высоту:
canvas = Canvas("hello. pdf", pagesize=(8.5 * inch, 11 * inch))
pdf", pagesize=(8.5 * inch, 11 * inch))Передавая кортеж в параметр pagesize, можно создать абсолютно любой размер страницы. Однако в пакете reportlab есть несколько стандартных встроенных размеров, с которыми проще работать.
Размеры страниц находятся в модуле reportlab.lib.pagesizes. Например, чтобы установить размер страницы letter, можно импортировать объект LETTER из модуля reportlab.lib.pagesizes и передать его параметру pagesize при создании экземпляра класса Canvas:
from reportlab.lib.pagesizes import LETTER
canvas = Canvas("hello.pdf", pagesize=LETTER)Изучив объект LETTER, можно увидеть, что он хранит в себе кортеж из двух чисел с плавающей точкой:
LETTER # результат: (612.0, 792.0)
Модуль reportlab.lib.pagesize содержит много стандартных размеров страниц. Вот несколько примеров с их размерами:
| Страница | Размеры |
| A4 | 210 mm x 297 mm |
| LETTER | 8.5 in x 11 in |
| LEGAL | 8.5 in x 14 in |
| TABLOID | 11 in x 17 in |
В завершение заметим, что данный модуль содержит в себе все размеры, которые есть в стандарте ISO 216.
Устанавливаем свойства шрифтов
При работе с текстом в Canvas можно менять сам шрифт, размер шрифта и цвет шрифта.
Чтобы изменить шрифт и размер шрифта, можно использовать метод .setFont (). Для начала создадим новый экземпляр класса Canvas с именем файла font-example.pdf и размером страницы LETTER:
canvas = Canvas("font-example. pdf", pagesize=LETTER)
pdf", pagesize=LETTER)Затем установиv шрифт Times New Roman размером в 18 точек:
canvas.setFont("Times-Roman", 18)Наконец, напишем на странице строку «Times New Roman (18 pt)» и сохраним ее:
canvas.drawString(1 * inch, 10 * inch, "Times New Roman (18 pt)") canvas.save()
С этими настройками текст будет написан на расстоянии одного дюйма с левой стороны страницы и десяти дюймов снизу. Можно открыть файл font-example.pdf в текущем рабочем каталоге и убедиться в этом!
По умолчанию доступно три шрифта:
- «Courier»
- «Helvetica»
- «Times-Roman»
Каждый может быть в виде жирного шрифта либо курсива. Вот список всех возможных вариантов:
Вот список всех возможных вариантов:
- «Courier»
- «Courier-Bold
- «Courier-BoldOblique»
- «Courier-Oblique»
- «Helvetica»
- «Helvetica-Bold»
- «Helvetica-BoldOblique»
- «Helvetica-Oblique»
- «Times-Bold»
- «Times-BoldItalic
- «Times-Italic»
- «Times-Roman»
Установить цвет шрифта можно при помощи метода .setFillColor(). В следующем примере мы создаем PDF-файл под названием font-colors.pdf и пишем в нем текст синим цветом:
from reportlab.lib.colors import blue
from reportlab.lib.pagesizes import LETTER
from reportlab.lib.units import inch
from reportlab.pdfgen.canvas import Canvas
canvas = Canvas("font-colors.pdf", pagesize=LETTER)
# Устанавливаем шрифт Times New Roman с 12 размером
canvas.setFont("Times-Roman", 12)
# Пишем синий текст на расстоянии 1 дюйма слева и
# 10 дюймов снизу
canvas. setFillColor(blue)
canvas.drawString(1 * inch, 10 * inch, "Blue text")
# Сохраняем PDF-файл
canvas.save()
setFillColor(blue)
canvas.drawString(1 * inch, 10 * inch, "Blue text")
# Сохраняем PDF-файл
canvas.save()blue — это объект, импортированный из модуля reportlab.lib.colors. Этот модуль содержит несколько обычных цветов. Полный список цветов можно найти в исходном коде пакета reportLab.
В примерах этого раздела освещены основы работы с объектами класса Canvas. Но мы затронули только то, что лежит на поверхности. С помощью reportlab можно с нуля создавать таблицы, формы и даже высококачественную графику!
Руководство пользователя ReportLab содержит множество примеров создания документов PDF с нуля. Это самое правильное место для начала изучения данного пакета.
Проверка ваших знаний
Упражнение: создайте PDF-файл с нуля
Создайте PDF-файл в рабочей директории вашего компьютера под названием realpython.pdf с размером страницы LETTER. Страница файла должна содержать текст «Hello, Real Python!», размещённый в двух дюймах от левого края и в восьми дюймах от нижнего края страницы.
Решение:
Создадим экземпляр класса Canvas с размеров страниц LETTER:
from reportlab.lib.pagesizes import LETTER
from reportlab.lib.units import inch
from reportlab.pdfgen.canvas import Canvas
canvas = Canvas("font-colors.pdf", pagesize=LETTER)Теперь напишем строку «Hello, Real Python!» на расстоянии два дюйма слева и восемь дюймов снизу:
canvas.drawString(2 * inch, 8 * inch, "Hello, Real Python!")
И, наконец, сохраняем все это для записи в PDF-файл:
canvas.save()
Как создать PDF-файл из вашего веб-приложения — Smashing Magazine
- 10 минут чтения
- CSS, Браузеры
- Поделиться в Twitter, LinkedIn
Об авторе
Рэйчел Эндрю — веб-разработчик, писатель и спикер. Она является автором ряда книг, в том числе The New CSS Layout. Она одна из тех, кто стоит за… Больше о Рэйчел ↬
Существует множество вариантов создания PDF-файла из веб-приложения. В этой статье Рэйчел Эндрю рассматривает доступные инструменты и делится своими рекомендациями, которые помогут вам найти инструмент, который лучше всего подходит для вас.Многие веб-приложения требуют предоставления пользователю возможности загружать что-либо в формате PDF. В случае приложений (таких как магазины электронной коммерции) эти PDF-файлы должны создаваться с использованием динамических данных и быть немедленно доступными для пользователя.
В этой статье я рассмотрю способы создания PDF-файла непосредственно из веб-приложения на лету. Это не исчерпывающий список инструментов, вместо этого я постараюсь продемонстрировать различные подходы. Если у вас есть любимый инструмент или собственный опыт, которым вы хотите поделиться, добавьте его в комментарии ниже.
Это не исчерпывающий список инструментов, вместо этого я постараюсь продемонстрировать различные подходы. Если у вас есть любимый инструмент или собственный опыт, которым вы хотите поделиться, добавьте его в комментарии ниже.
Начиная с HTML и CSS
Наше веб-приложение, скорее всего, уже создает HTML-документ, используя информацию, которая будет добавлена в наш PDF-файл. В случае счета-фактуры пользователь может просмотреть информацию в Интернете, а затем щелкнуть, чтобы загрузить PDF-файл для своих записей. Возможно, вы создаете упаковочные листы; еще раз, информация уже хранится в системе. Вы хотите отформатировать это в удобном для загрузки и печати виде. Поэтому для начала было бы неплохо подумать, можно ли использовать эти HTML и CSS для создания PDF-версии.
У CSS есть спецификация, касающаяся CSS для печати, и это модуль Paged Media. У меня есть обзор этой спецификации в моей статье «Проектирование для печати с помощью CSS», и многие издатели книг используют CSS для всей своей печатной продукции. Следовательно, поскольку сам CSS имеет спецификации для печатных материалов, мы, конечно же, должны иметь возможность его использовать?
Следовательно, поскольку сам CSS имеет спецификации для печатных материалов, мы, конечно же, должны иметь возможность его использовать?
Самый простой способ создать PDF-файл — через браузер. Если выбрать печать в PDF, а не на принтер, будет создан PDF-файл. К сожалению, этот PDF обычно не совсем удовлетворительный! Для начала у него будут верхние и нижние колонтитулы, которые автоматически добавляются при печати чего-либо с веб-страницы. Он также будет отформатирован в соответствии с вашей таблицей стилей печати — при условии, что она у вас есть.
Проблема, с которой мы здесь сталкиваемся, заключается в плохой поддержке спецификации фрагментации в браузерах; это может означать, что содержимое ваших страниц прерывается необычным образом. Поддержка фрагментации неоднородна, как я обнаружил, изучая свою статью «Разрушение блоков с помощью фрагментации CSS». Это означает, что вы, возможно, не сможете предотвратить неоптимальное прерывание содержимого, когда заголовки остаются последним элементом на странице и т. д.
д.
Кроме того, у нас нет возможности контролировать содержимое полей на полях страницы, т.е. добавление заголовка по нашему выбору к каждой странице или нумерация страниц, чтобы показать, сколько страниц имеет сложный счет. Эти вещи являются частью спецификации Paged Media, но не реализованы ни в одном браузере.
Моя статья «Путеводитель по таблицам стилей печати в 2018 году» по-прежнему точна с точки зрения типа поддержки, которую браузеры имеют для печати непосредственно из браузера с использованием таблицы стилей печати.
Больше после прыжка! Продолжить чтение ниже ↓Печать с использованием механизмов рендеринга в браузере
Существуют способы печати в PDF с использованием механизмов рендеринга в браузере, не заходя в меню печати в браузере и получая верхние и нижние колонтитулы, как если бы вы распечатали документ. Самыми популярными вариантами в ответ на мой твит были wkhtmltopdf и печать с использованием безголового Chrome и Puppeteer.
wkhtmltopdf
Решение, которое несколько раз упоминалось в Твиттере, — это инструмент командной строки под названием wkhtmltopdf.
Мы используем wkhtmltopdf. Это не идеально, хотя, вероятно, это была ошибка пользователя, но вполне достаточно для производственного приложения.
— Paul Cardno (@pcardno) 15 февраля 2019 г.
Таким образом, этот инструмент делает то же самое, что и печать из браузера, однако вы не получите автоматически добавленных верхних и нижних колонтитулов. С этой положительной стороны, если у вас есть рабочая таблица стилей печати для вашего контента, она также должна хорошо выводиться в PDF с помощью этого инструмента, и поэтому простой макет вполне может печатать очень хорошо.
Однако, к сожалению, вы по-прежнему будете сталкиваться с теми же проблемами, что и при печати непосредственно из веб-браузера, с точки зрения отсутствия поддержки спецификации Paged Media и свойств фрагментации, поскольку вы по-прежнему печатаете с использованием механизма рендеринга браузера. Есть несколько флагов, которые вы можете передать в wkhtmltopdf, чтобы добавить обратно некоторые недостающие функции, которые были бы у вас по умолчанию при использовании спецификации Paged Media. Однако это требует дополнительной работы помимо написания хороших HTML и CSS.
Есть несколько флагов, которые вы можете передать в wkhtmltopdf, чтобы добавить обратно некоторые недостающие функции, которые были бы у вас по умолчанию при использовании спецификации Paged Media. Однако это требует дополнительной работы помимо написания хороших HTML и CSS.
Headless Chrome
Еще одна интересная возможность — использование Headless Chrome и Puppeteer для печати в PDF.
Кукольник. Это удивительно для этого.
— Алекс Рассел (@slightlylate) 15 февраля 2019 г.
Однако в очередной раз вы ограничены браузерной поддержкой Paged Media и фрагментацией. Есть несколько параметров, которые можно передать в функцию page.pdf() . Как и в случае с wkhtmltopdf, они добавляют некоторые функциональные возможности, которые были бы возможны из CSS, если бы была поддержка браузера.
Вполне может быть, что одно из этих решений сделает все, что вам нужно, однако, если вы обнаружите, что ведете какую-то битву, вполне вероятно, что вы достигаете пределов того, что возможно с текущими механизмами рендеринга браузера, и вам нужно будет искать лучшее решение.
Полифиллы JavaScript для Paged Media
Есть несколько попыток по существу воспроизвести спецификацию Paged Media в браузере с помощью JavaScript — по сути, создать Polyfill Paged Media. Это может дать вам поддержку Paged Media при использовании Puppeteer. Взгляните на paged.js и Vivliostyle.
Да. Для простых документов, таких как сертификаты курсов, мы можем использовать Chrome, который имеет минимальную поддержку @ page. Для всего остального мы используем PrinceXML или полифил paged.js в Chrome. Вот подтверждение концепции WIP с использованием paged.js для книг: https://t.co/AZ9fO94PT2
— Electric Book Works (@electricbook) 15 февраля 2019 г.
Использование пользовательского агента печати
API для создания PDF из ваших файлов. Эти пользовательские агенты реализуют спецификацию Paged Media и гораздо лучше поддерживают свойства CSS Fragmentation; это даст вам больший контроль над выводом. Основные варианты включают в себя:
- Prince
- Antenna House
- PDFReactor
UA для печати будет форматировать документы с помощью CSS — так же, как это делает веб-браузер. Как и в случае с браузерной поддержкой CSS, вам нужно проверить документацию этих UA, чтобы узнать, что они поддерживают. Например, Prince (с которым я лучше всего знаком) на момент написания статьи поддерживает Flexbox, но не поддерживает CSS Grid Layout. При отправке ваших страниц в инструмент, который вы используете, обычно это будет с определенной таблицей стилей для печати. Как и в случае с обычной таблицей стилей для печати, не все CSS, которые вы используете на своем сайте, подходят для версии в формате PDF.
Как и в случае с браузерной поддержкой CSS, вам нужно проверить документацию этих UA, чтобы узнать, что они поддерживают. Например, Prince (с которым я лучше всего знаком) на момент написания статьи поддерживает Flexbox, но не поддерживает CSS Grid Layout. При отправке ваших страниц в инструмент, который вы используете, обычно это будет с определенной таблицей стилей для печати. Как и в случае с обычной таблицей стилей для печати, не все CSS, которые вы используете на своем сайте, подходят для версии в формате PDF.
Создание таблицы стилей для этих инструментов очень похоже на создание обычной таблицы стилей для печати, принимая решения относительно того, что отображать или скрывать, возможно, используя другой размер шрифта или цвета. После этого вы сможете воспользоваться преимуществами спецификации Paged Media, добавляя сноски, номера страниц и т. д.
Что касается использования этих инструментов из вашего веб-приложения, вам нужно будет установить их на свой сервер (конечно, купив для этого лицензию). Основная проблема с этими инструментами заключается в том, что они дороги. Тем не менее, учитывая легкость, с которой вы затем можете создавать с их помощью печатные документы, они вполне могут окупить себя за сэкономленное время разработчиков.
Основная проблема с этими инструментами заключается в том, что они дороги. Тем не менее, учитывая легкость, с которой вы затем можете создавать с их помощью печатные документы, они вполне могут окупить себя за сэкономленное время разработчиков.
Можно использовать Prince через API, с оплатой за каждый документ, через сервис под названием DocRaptor. Это, безусловно, было бы хорошим местом для запуска многих приложений, поскольку казалось бы, что размещение собственных приложений станет более рентабельным, стоимость разработки переключения будет минимальной.
Бесплатная альтернатива, которая не так универсальна, как вышеупомянутые инструменты, но вполне может дать нужные вам результаты, — это WeasyPrint. Он не полностью реализует весь Paged Media, однако реализует больше, чем движок браузера. Однозначно, стоит попробовать!
Другие инструменты, которые утверждают, что поддерживают преобразование из HTML и CSS, включают PDFCrowd, который смело заявляет о поддержке HTML5, CSS3 и JavaScript. Однако я не смог найти никаких подробностей о том, что именно поддерживалось, и поддерживалась ли какая-либо спецификация Paged Media. Также в ответах на мой твит упоминается mPDF.
Однако я не смог найти никаких подробностей о том, что именно поддерживалось, и поддерживалась ли какая-либо спецификация Paged Media. Также в ответах на мой твит упоминается mPDF.
Отказ от HTML и CSS
Существует ряд других решений, которые отходят от использования HTML и CSS и требуют от вас создания специального вывода для инструмента. Пара претендентов на JavaScript выглядит следующим образом:
- jsPDF
- pdfmake
Безголовый браузер + сохранение в PDF когда-то был моим первым выбором, но всегда давал некачественные результаты для всего, кроме одностраничного документа. Мы перешли на https://t.co/3o8Ce23F1t для многостраничных отчетов, что потребовало гораздо больше усилий, но в итоге оно того стоило!
— JimmyJoy (@jimle_uk) 15 февраля 2019 г.
Помимо подходов на основе JavaScript, которые требуют от вас создания совершенно другого представления вашего контента для печати, красота многих из этих решений заключается в том, что они взаимозаменяемы. Если ваше решение основано на вызове инструмента командной строки и передаче этому инструменту вашего HTML, CSS и, возможно, некоторого JavaScript, переключаться между инструментами довольно просто.
Если ваше решение основано на вызове инструмента командной строки и передаче этому инструменту вашего HTML, CSS и, возможно, некоторого JavaScript, переключаться между инструментами довольно просто.
В ходе написания этой статьи я также обнаружил оболочку Python, которая может запускать ряд различных инструментов. (Обратите внимание, что сами инструменты должны быть уже установлены, однако это может быть хорошим способом протестировать различные инструменты на образце документа.)
Что касается поддержки Paged Media и фрагментации, Prince, Antenna House и PDFReactor выходят на первое место. Как коммерческие продукты, они также поставляются с поддержкой. Если у вас есть бюджет, сложные страницы для печати в PDF и ваше ограничение — время разработчика, то вы, скорее всего, обнаружите, что это самый быстрый путь к тому, чтобы ваше создание PDF работало хорошо.
Однако во многих случаях вам подойдут бесплатные инструменты. Если ваши требования очень просты, то wkhtmltopdf или базовое безголовое решение для Chrome и Puppeteer может помочь. Это определенно сработало для многих людей, которые ответили на мой первоначальный твит.
Это определенно сработало для многих людей, которые ответили на мой первоначальный твит.
Однако, если вы обнаружите, что не можете получить желаемый результат, имейте в виду, что это может быть ограничение печати браузера, а не то, что вы делаете неправильно. В случае, если вам нужна дополнительная поддержка Paged Media, но вы не в состоянии перейти на коммерческий продукт, возможно, обратите внимание на WeasyPrint.
Я надеюсь, что это полезный обзор инструментов, доступных для создания PDF-файлов из вашего веб-приложения. По крайней мере, это демонстрирует, что существует широкий выбор вариантов, если ваш первоначальный выбор не работает.
Пожалуйста, поделитесь своим опытом и предложениями в комментариях, это одна из тех вещей, с которыми многие из нас сталкиваются, и обмен личным опытом может быть невероятно полезным.
Дополнительная литература
Обзор различных ресурсов и инструментов, упомянутых в этой статье, а также некоторых других полезных ресурсов для работы с файлами PDF из веб-приложений.
Технические характеристики
- Медиа-модуль Paged
- Фрагментация
Статьи и ресурсы
- Проектирование для печати с помощью CSS
- CSS3 Разделение блоков с помощью фрагментации 9 0004
- Руководство по состоянию таблиц стилей для печати в 2018 году 03 paged.js
- Вивлиостиль
- Prince
- Антенный дом
- PDFReactor
- DocRaptor
- WeasyPrint
- PDFCrowd
- mPDF
- jsPDF 9000 4
- pdfmake
- Produce & Publish Server
Создание PDF-файла — Первый окружной апелляционный суд
Создание PDF-файла, если у вас есть программное обеспечение Adobe Acrobat
Если у вас уже есть все установленной версии Adobe Acrobat (а не бесплатного Acrobat Reader, установленного на большинстве компьютеров), для создания файлов PDF достаточно просто выбрать «Adobe PDF» в качестве принтера и, по сути, распечатать в файл PDF. Когда вы печатаете на принтере Adobe PDF, вам будет предложено указать имя файла и место сохранения. После того, как вы выберете оба варианта и нажмете «распечатать», ваш PDF-файл будет создан.
После того, как вы выберете оба варианта и нажмете «распечатать», ваш PDF-файл будет создан.
Создание PDF-файла из Microsoft Word
Microsoft предлагает бесплатное дополнение, которое позволит вам сохранять PDF-файлы прямо из Word .
После загрузки и установки надстройки выполните следующие действия, чтобы создать файл PDF в Word:
- Нажмите кнопку Office
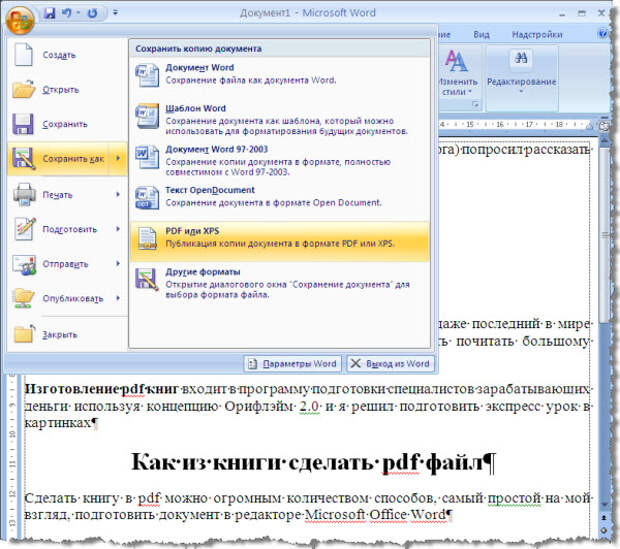
- Нажмите «Сохранить как», затем нажмите «PDF или XPS» 04
- В диалоговом окне «Сохранить как» выберите PDF в качестве предпочтительного формата файла и выберите подходящее имя файла.
- Нажмите «Сохранить».
Создание PDF-файла из WordPerfect
Функция WordPerfect «Публикация в PDF» появилась в версии 9. Эта функция улучшалась с каждым обновлением версии и теперь значительно улучшена в версиях 12 и X3. В зависимости от того, какая у вас версия, процесс может незначительно отличаться. Ниже вы найдете инструкции по преобразованию документа WordPerfect в PDF из WordPerfect v. 9 – WordPerfect v.X3
9 – WordPerfect v.X3
Создание PDF-файлов с помощью WordPerfect 12 и X3
- Открыв документ, выберите «Файл» > «Опубликовать в» > PDF.
- В диалоговом окне «Опубликовать в PDF» в текстовом поле «Имя файла» на вкладке «Общие» отображается имя вашего файла. По умолчанию файл PDF сохраняется в той же папке, что и исходный файл WordPerfect. Вы можете изменить расположение файла, чтобы сохранить его в папке с другими веб-документами. Для этого нажмите кнопку «Обзор» (папка) и выберите нужную папку.
- Затем параметр совместимости должен быть изменен на «Acrobat 5», а стиль PDF должен быть установлен на «Самый маленький файл». Этот параметр означает, что шрифты НЕ будут встроены в файл; поэтому использование Times New Roman обеспечит наилучшие результаты при печати. С этими настройками у вас автоматически будут все настройки для лучшего PDF-файла, которым можно поделиться в Интернете или отправить по электронной почте. Например, разрешение изображений в файле PDF будет оптимизировано для Всемирной паутины.

- Нажмите кнопку OK, чтобы сохранить файл PDF.
Чтобы проверить файл на правильность преобразования и макета, откройте файл PDF в программе Adobe Reader.
Дополнительную информацию обо всех параметрах, доступных в 12 и X3, а также подробности об улучшениях X3 см. на странице Использование функции публикации в PDF в Corel® WordPerfect® на веб-сайте Corel.
ПРИМЕЧАНИЕ. Этот файл PDF можно просматривать только в Adobe Reader.
Как создавать файлы PDF с возможностью поиска
Ниже приведен неисключительный список примеров создания PDF-файлов с возможностью поиска. Для получения информации о других версиях/приложениях для обработки текстов и PDF обратитесь к производителю программного обеспечения или специалисту по ИТ-поддержке.
Сохранить Microsoft Word 2013 в формате PDF:
- Перейдите на вкладку Файл .
- Нажмите Сохранить как . Чтобы увидеть диалоговое окно «Сохранить как » в Word 2013, необходимо выбрать место и папку.

- В Имя файла введите имя файла, если вы еще этого не сделали.
- В списке Сохранить как тип щелкните PDF (*.pdf) .
- Щелкните Сохранить .
- Нет необходимости запускать OCR, если файл сохранен из Microsoft Word в PDF.
Сканирование в PDF в Adobe Acrobat и применение OCR:
- В Acrobat выберите Файл > Создать > PDF из сканера . Если у вас уже есть отсканированное изображение, выберите Файл > Создать > PDF из файла и выберите файл, который хотите преобразовать.
- Выберите Вид > Инструменты > Распознавание текста .
- Выберите параметр В этом файле на панели распознавания текста, которая открывается справа.
- Назначьте нужные страницы и нажмите OK .
 Acrobat автоматически применяет распознавание символов к отсканированному документу или изображению.
Acrobat автоматически применяет распознавание символов к отсканированному документу или изображению.
Проверить и исправить предполагаемые ошибки OCR:
- Откройте файл PDF.
- В Acrobat выберите Вид > Инструменты > Распознавание текста . Откроется панель «Распознавание текста» на панели «Инструменты».
- Нажмите Найти первого подозреваемого . Acrobat идентифицирует подозрительные символы или слова для вашей оценки.
- Чтобы внести исправления, нажмите на выделенный объект в документе и введите исправленный текст. Щелкните Найти следующий . Если текст уже правильный, нажмите Принять и найти , чтобы перейти к следующему. Если подозреваемого нет в слове, нажмите Not Text .
- По завершении нажмите Закрыть .
Создание PDF-файла с использованием других программных пакетов
Если предыдущие примеры не удовлетворяют ваши потребности в создании PDF-файла.