Директива Clean-param — Вебмастер. Справка
Используйте директиву Clean-param, если адреса страниц сайта содержат GET-параметры (например, идентификаторы сессий, пользователей) или метки (например, UTM), которые не влияют на их содержимое.
Примечание. Иногда для закрытия таких страниц используется директива Disallow. Рекомендуем использовать Clean-param, так как эта директива позволяет передавать основному URL или сайту некоторые накопленные показатели, например ссылочные.
Заполняйте директиву Clean-param максимально полно и поддерживайте ее актуальность. Новый параметр, не влияющий на контент страницы, может привести к появлению страниц-дублей, которые не должны попасть в поиск. Из-за большого количества таких страниц робот медленнее обходит сайт. А значит, важные изменения дольше не попадут в результаты поиска.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.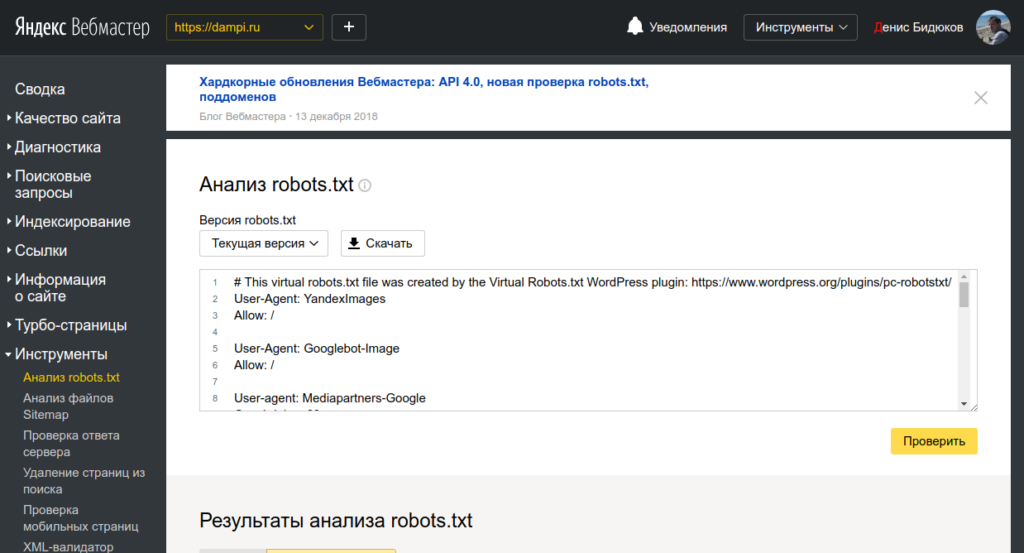
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Clean-param: p0[&p1&p2&..&pn] [path]В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Примечание. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.php
означает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.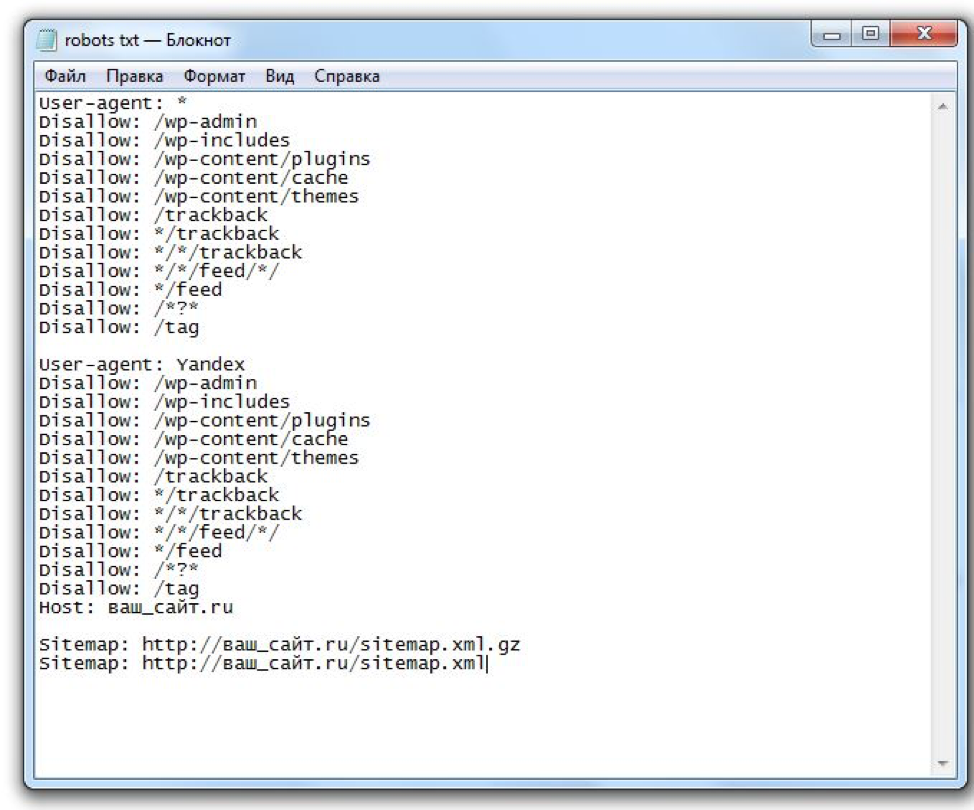 php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc /forum/showthread.php Clean-param: sid&sort /forum/*.php Clean-param: someTrash&otherTrash
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.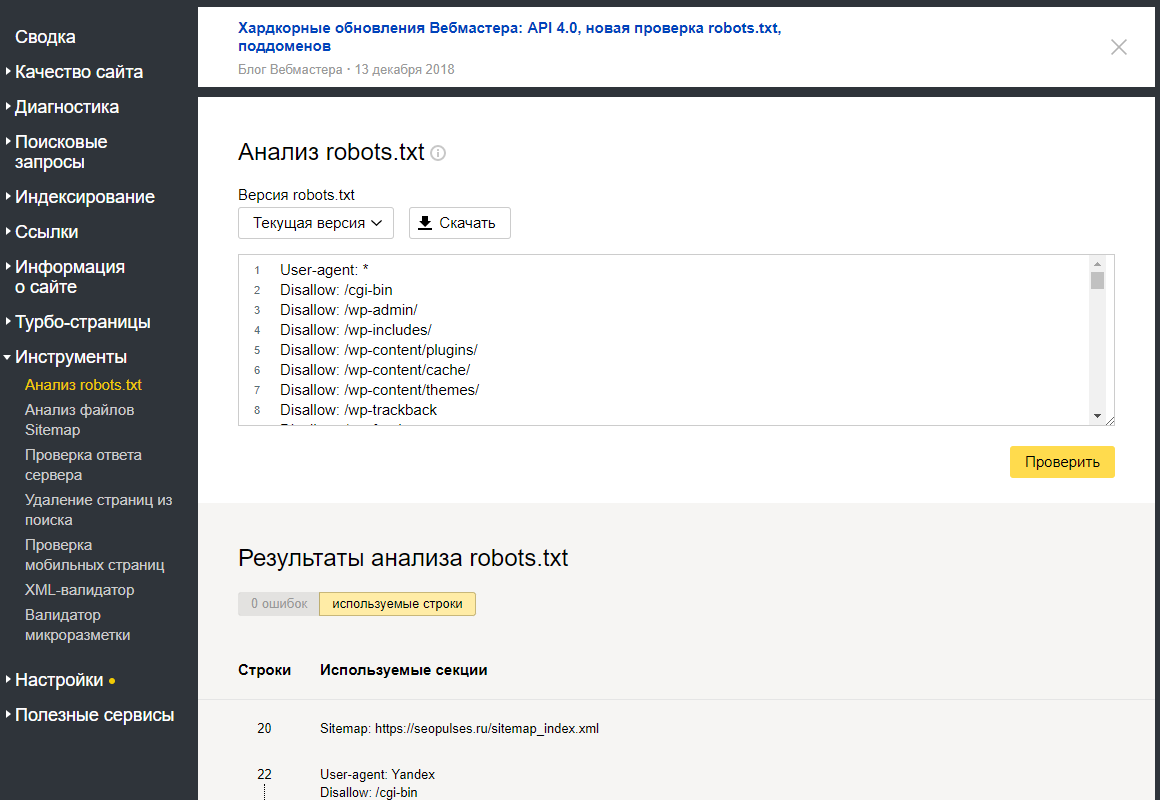
txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php#если таких параметров несколько:
www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311
www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s&ref /forum*/showthread.php#если параметр используется в нескольких скриптах: www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243 www.example1.com/forum/index.php?s=1e71c4427317a117a&t=8243 #robots.txt будет содержать: User-agent: Yandex Disallow: Clean-param: s /forum/index.php Clean-param: s /forum/showthread.php
правила составления и основные директивы
Эффективная оптимизация сайта неизбежно включает в себя создание и правильную настройку файла robots.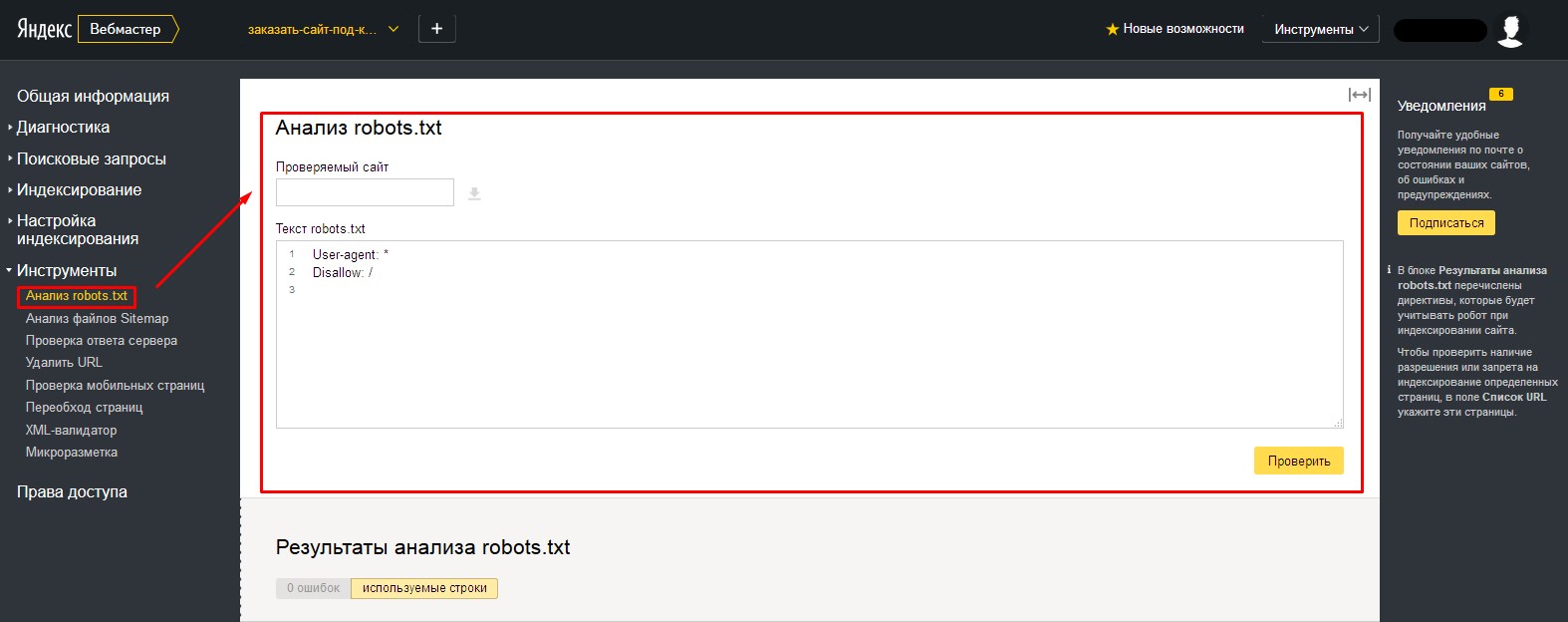 txt. Создать этот файл можно в обычном «блокноте», а для того, чтобы он начал использоваться, его нужно поместить в корневую папку сайта (туда же, где расположен файл index.php). Этот файл содержит в себе перечень инструкций, или директив, которыми будут пользоваться поисковые роботы. Это не значит, что в случае отсутствия файла роботс они не станут индексировать ваш сайт – это значит, что при наличии такого файла они будут делать это гораздо более эффективно и быстро.
txt. Создать этот файл можно в обычном «блокноте», а для того, чтобы он начал использоваться, его нужно поместить в корневую папку сайта (туда же, где расположен файл index.php). Этот файл содержит в себе перечень инструкций, или директив, которыми будут пользоваться поисковые роботы. Это не значит, что в случае отсутствия файла роботс они не станут индексировать ваш сайт – это значит, что при наличии такого файла они будут делать это гораздо более эффективно и быстро.
Это важно по многим причинам. Во-первых, задав роботам определенные правила взаимодействия с вашим порталом, вы уменьшите нагрузку на свой сервер, создаваемую из-за их работы. Во-вторых, вы сможете задать перечень файлов, страниц и разделов, к которым роботы не будут обращаться в принципе. И, наконец, в-третьих, вы сможете оптимизировать индексацию страниц вашего сайта.
Основные директивы файла robots.
 txt
txtСуществует несколько основных директив, которые должен содержать файл роботс, и от которых непосредственно зависит, каким образом поисковые системы и роботы будут взаимодействовать с вашим сайтом:
-
User-agent. Эта директива говорит о том, инструкции для каких роботов будут следовать за ней. Это может быть робот Mail.Ru, StackRambler, Bingbot, любой из многочисленных роботов Яндекса(YandexBot, YandexDirect, YandexMetrika, YandexImages, YandexNews и так далее), любой из многочисленных роботов Google (Googlebot, Mediapartners, AdsBot-Google, Googlebot-Image, GoogleBot-Video и так далее). Юзер агент – ключевая директива, без которой все, что следует дальше, не будет иметь какого-либо смысла.
-
Disallow. Главное назначение этой директивы заключается в том, чтобы закрыть определенные файлы, страницы или даже разделы сайта от индексирования поисковыми роботами. Это самая востребованная директива, только из-за возможности пользоваться которой многие вебмастера в принципе заводят файл robots.
txt. При указании адресов файлов, страниц, групп страниц и разделов, которые не должны индексироваться, можно использовать дополнительные символы. Так, «*» предполагает любое количество символов (включая нулевое) и по умолчанию подразумевается в конце каждой строки. А знак «$» говорит о том, что предшествующий символ был последним.
-
Allow. Это гораздо менее популярная директива, которая формально разрешает роботу заниматься индексацией того или иного раздела. Не востребована она потому, что поисковики в принципе имеют свойство индексировать все данные интернет-ресурса, которые теоретически могут быть полезны пользователям (за исключением тех, что прописаны под директивой Disallow).
Host. Такая директива позволяет задать адрес главного зеркала сайта. Отличие, как правило, заключается в наличии или отсутствии трех букв «w». Если ваш портал еще не индексировался поисковыми системами, то вы можете сами задать его зеркало.
 В противном случае введите адрес своего сайта, например, в Яндексе. И если в первом результате выдачи не будет «www», то это будет означать, что в главном зеркале эти три буквы есть, и наоборот. Обратите внимание на то, что эту директиву поддерживают только роботы Mail.Ru и Яндекса, а вводить ее необходимо исключительно однократно.
В противном случае введите адрес своего сайта, например, в Яндексе. И если в первом результате выдачи не будет «www», то это будет означать, что в главном зеркале эти три буквы есть, и наоборот. Обратите внимание на то, что эту директиву поддерживают только роботы Mail.Ru и Яндекса, а вводить ее необходимо исключительно однократно.
Sitemap. Эта директива должна подсказывать роботам путь к одноименному XML-файлу, в котором содержится карта индексируемых страниц, информация о датах их изменения и приоритете при просмотре и индексации.
-
Crawl-delay. С помощью такой директивы можно назначить временной интервал между теми моментами, когда поисковый робот заканчивает скачивание предыдущей страницы сайта и начинает загрузку следующей. Измеряется этот временной интервал в секундах. Директива Crawl delay применяется для того, чтобы сократить нагрузку на сайт со стороны поисковых роботов и избежать неполадок в работе сервера.
 Не рекомендуется сразу начинать с больших значений (например, с Crawl-delay 2), лучше вводить задержки продолжительностью в десятые доли секунды и, при необходимости, постепенно их удлинять. При этом более продолжительные временные интервалы можно использовать для менее важных роботов (Yahoo, Bing, Mail.Ru), а для Яндекса лучше делать их минимальными. Роботы Google игнорируют эту директиву.
Не рекомендуется сразу начинать с больших значений (например, с Crawl-delay 2), лучше вводить задержки продолжительностью в десятые доли секунды и, при необходимости, постепенно их удлинять. При этом более продолжительные временные интервалы можно использовать для менее важных роботов (Yahoo, Bing, Mail.Ru), а для Яндекса лучше делать их минимальными. Роботы Google игнорируют эту директиву.
-
Clean param. Это директива, способная существенно рационализировать прохождение поискового робота по сайту. С помощью Clean param вы можете описать динамические составляющие URL, не оказывающие никакого влияния на содержимое страницы. Это идентификаторы пользователей, сессий, индивидуальные префиксы и другие части подобного плана. Указание их в Clean param даст поисковому роботу понять, что он уже загружал этот материал (только с другими динамическими элементами, не меняющими содержание), и скачивать его повторно он не будет. Это очень полезная директива, которая, тем не менее, используется владельцами сайтов не так часто, как стоило бы.
 Поэтому если вы хотите сделать взаимодействие своего портала с роботами как можно более эффективным – не забудьте указать в файле роботс Clean param.
Поэтому если вы хотите сделать взаимодействие своего портала с роботами как можно более эффективным – не забудьте указать в файле роботс Clean param.
Какие бы директивы вы ни прописывали, будь то Crawl-Delay, Clean param, Disallow или что-либо еще, крайне желательно снабжать их комментариями (под символом «#», текст после которого робот не читает). В противном случае даже вы сами через полгода можете не вспомнить, почему, например, закрыли от индексации ту или иную страницу, а уж если за дело возьмется другой человек – то ему и подавно будет сложно в этом разобраться. Тем временем, спустя какое-то время в файле, вполне возможно, понадобится что-то изменить, поэтому лучше бы сохранить возможность беспроблемно в нем ориентироваться.
Ключевые правила настройки файла robots.
 txt
txtНеобязательно самостоятельно создавать файл robots.txt: Яндекс, Google и другие поисковые системы смогут довольно эффективно использовать на вашем сайте своих роботов, даже если вы скачаете шаблонный вариант этого файла. Однако если вы хотите, чтобы их работа была наиболее оптимизированной, быстрой и результативной, стоит все же позаботиться о самостоятельной настройке файла роботс. При этом стоит учесть следующие ключевые правила:
-
Все страницы, связанные с администрированием сайта, личными кабинетами, процедурами регистрации-авторизации, оформлением заказов, а также технические дубли страниц и служебные разделы должны быть закрыты от индексирования. Это касается всех поисковых систем, будь то User-agent Yandex bot, или, например, User-agent Mail.Ru.
-
Имеет смысл также закрыть от индексации json- и ajax-скрипты, папку cgi, страницы с параметрами сессий и UTM-меток, сортировки, фильтров, сравнения.

-
Чтобы убедиться, что вы сделали подходящие настройки robots.txt, можно воспользоваться соответствующими инструментами систем Яндекс и Google.
-
Спустя полмесяца после добавления новых страниц на сайт и включения их в директиву Disallow имеет смысл проверить через поисковые системы, не были ли они проиндексированы. Если да – то потребуется пересмотреть и откорректировать настройки.
Файл robots.txt дает возможность оптимизировать работу сайта с поисковыми роботами, которая доступна даже при отсутствии глубоких узкоспециализированных знаний. Главное – правильно настроить этот файл и периодически проверять, корректно ли он считывается роботами Google, Яндекса и других поисковых систем.
Материал подготовила Светлана Сирвида-Льорентэ.
Файл robots.
 txt — способы анализа и проверки robots.txt
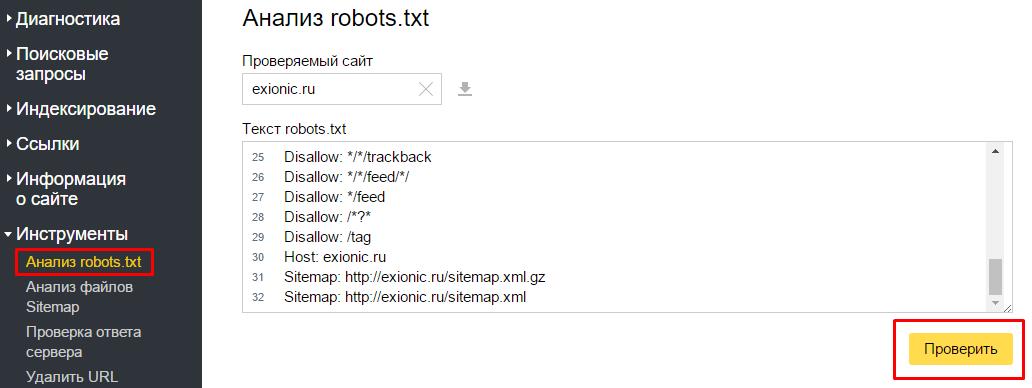
txt — способы анализа и проверки robots.txtПоисковые роботы — краулеры начинают знакомство с сайтом с чтения файла robots.txt. В нем содержится вся важная для них информация. Владельцам сайтов следует создать и периодически проводить анализ robots.txt. От корректности его работы зависит скорость индексации страниц и место в поисковой выдачи.
Создание файла
Описание. Файл robots.txt — это документ со служебной информацией. Он предназначен для поисковых роботов. В нем записывают, какие страницы можно индексировать, какие — нет и каким именно краулерам. Например, англоязычный Facebook разрешает доступ только боту Google. Файл robots.txt любого сайта можно посмотреть в браузере по ссылке
www. site.ru/robots.txt.
Он не является обязательным элементом сайта, но его наличие желательно, потому что с его помощью владельцы сайта управляют поисковыми роботами. Задавайте разные уровни доступа к сайту, запрет на индексацию всего сайта, отдельных страниц, разделов или файлов. Для ресурсов с высокой посещаемостью ограничивайте время индексации и запрещайте доступ роботам, которые не относятся к основным поисковым системам. Это уменьшит нагрузку на сервер.
Создание. Создают файл в текстовом редакторе Notepad или подобных. Следите за тем, чтобы размер файла не превышал 32 КБ. Выбирайте для файла кодировку ASCII или UTF-8. Учтите, что файл должен быть единственным. Если сайт создан на CMS, то он будет генерироваться автоматически.
Разместите созданный файл в корневой директории сайта рядом с основным файлом index.html. Для этого используют FTP доступ. Если сайт сделан на CMS, то с файлом работают через административную панель.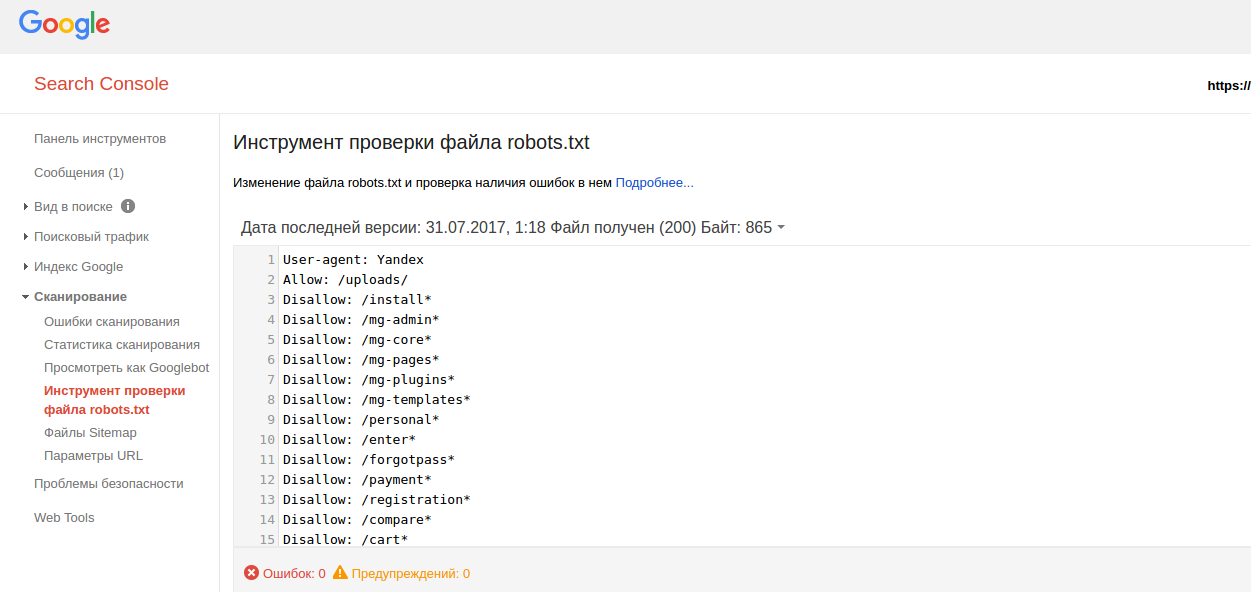 Когда файл создан и работает корректно, он доступен в браузере.
Когда файл создан и работает корректно, он доступен в браузере.
При отсутствии robots.txt поисковые роботы собирают всю информацию, относящуюся к сайту. Не удивляйтесь, когда увидите в выдаче незаполненные страницы или служебную информацию. Определите, какие разделы сайта будут доступны пользователям, остальные — закройте от индексации.
Проверка. Периодически проверяйте, все ли работает корректно. Если краулер не получает ответ 200 ОК, то он автоматически считает, что файла нет, и сайт открыт для индексации полностью. Коды ошибок бывают такими:
-
3хх — ответы переадресации. Робота направляют на другую страницу или на главную. Создавайте до пяти переадресаций на одной странице. Если их будет больше, робот пометит такую страницу как ошибку 404. То же самое относится и к переадресации по принципу бесконечного цикла;
-
4хх — ответы ошибок сайта. Если краулер получает от файла robots.
 txt 400-ую ошибку, то делается вывод, что файла нет и весь контент доступен. Это также относится к ошибкам 401 и 403;
txt 400-ую ошибку, то делается вывод, что файла нет и весь контент доступен. Это также относится к ошибкам 401 и 403;
-
5хх — ответы ошибок сервера. Краулер будет «стучаться», пока не получит ответ, отличный от 500-го.
Правила создания
Начинаем с приветствия. Каждый файл должен начинаться с приветствия User-agent. С его помощью поисковики определят уровень открытости.
| Код | Значение |
| User-agent: * | Доступно всем |
| User-agent: Yandex | Доступно роботу Яндекс |
| User-agent: Googlebot | Доступно роботу Google |
|
User-agent: Mail. |
Доступно роботу Mail.ru |
Добавляем отдельные директивы под роботов. При необходимости добавляйте директивы для специализированных поисковых ботов Яндекса.
Однако в этом случае директивы * и Yandex не будут учитываться.
| YandexBot | Основной робот |
| YandexImages | Яндекс.Картинки |
| YandexNews | Яндекс.Новости |
| YandexMedia | Индексация мультимедиа |
| YandexBlogs | Индексация постов и комментариев |
| YandexMarket |
Яндекс. Маркет Маркет
|
| YandexMetrika | Яндекс.Метрика |
| YandexDirect | Рекламная сеть Яндекса |
| YandexDirectDyn | Индексация динамических баннеров |
| YaDirectFetcher | Яндекс.Директ |
| YandexPagechecker | Валидатор микроразметки |
| YandexCalendar | Яндекс.Календарь |
У Google собственные боты:
| Googlebot | Основной краулер |
| Google-Images | Google.Картинки |
| Mediapartners-Google | AdSense |
| AdsBot-Google | Проверка качества рекламы |
|
AdsBot-Google-Mobile |
Проверка качества рекламы на мобильных устройствах |
| Googlebot-News | Новости Google |
Сначала запрещаем, потом разрешаем.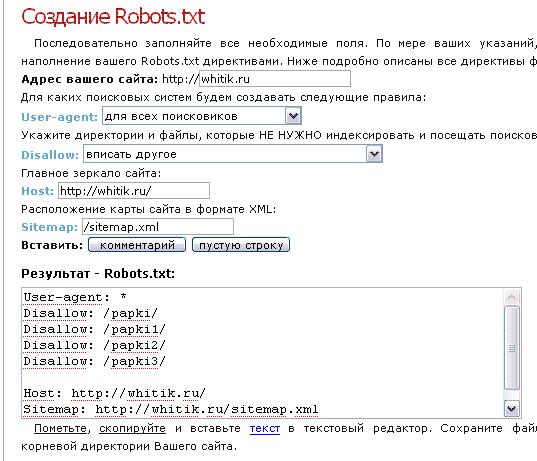 Оперируйте двумя директивами: Allow — разрешаю, Disallow — запрещаю. Обязательно укажите директиву disallow, даже если доступ разрешен ко всему сайту. Такая директива является обязательной. В случае ее отсутствия краулер может не верно прочитать остальную информацию. Если на сайте нет закрытого контента, оставьте директиву пустой.
Оперируйте двумя директивами: Allow — разрешаю, Disallow — запрещаю. Обязательно укажите директиву disallow, даже если доступ разрешен ко всему сайту. Такая директива является обязательной. В случае ее отсутствия краулер может не верно прочитать остальную информацию. Если на сайте нет закрытого контента, оставьте директиву пустой.
Работайте с разными уровнями. В файле можно задать настройки на четырех уровнях: сайта, страницы, папки и типа контента. Допустим, вы хотите закрыть изображения от индексации. Это можно сделать на уровне:
- папки — disallow: /images/
- типа контента — disallow: /*.jpg
| Нет | Да |
| Disallow: Yandex |
User-agent: Yandex Disallow: / |
| Disallow: /css/ /images/ |
Disallow: /css/ Disallow: /images/ |
Пишите с учетом регистра. Имя файла укажите строчными буквами. Яндекс в пояснительной документации указывает, что для его ботов регистр не важен, но Google просит соблюдать регистр. Также вероятна ошибка в названиях файлов и папок, в которых учитывается регистр.
Имя файла укажите строчными буквами. Яндекс в пояснительной документации указывает, что для его ботов регистр не важен, но Google просит соблюдать регистр. Также вероятна ошибка в названиях файлов и папок, в которых учитывается регистр.
Укажите 301 редирект на главное зеркало сайта. Раньше для этого использовалась директива Host, но с марта 2018 г. она больше не нужна. Если она уже прописана в файле robots.txt, удалите или оставьте ее на свое усмотрение; роботы игнорируют эту директиву.
Для указания главного зеркала проставьте 301 редирект на каждую страницу сайта. Если редиректа стоят не будет, поисковик самостоятельно определит, какое зеркало считать главным. Чтобы исправить зеркало сайта, просто укажите постраничный 301 редирект и подождите несколько дней.
Пропишите директиву Sitemap (карту сайта). Файлы sitemap.xml и robots.txt дополняют друг друга. Проверьте, чтобы:
- файлы не противоречили друг другу;
- страницы были исключены из обоих файлов;
- страницы были разрешены в обоих файлах.

Указывайте комментарии через символ #. Все, что написано после него, краулер игнорирует.
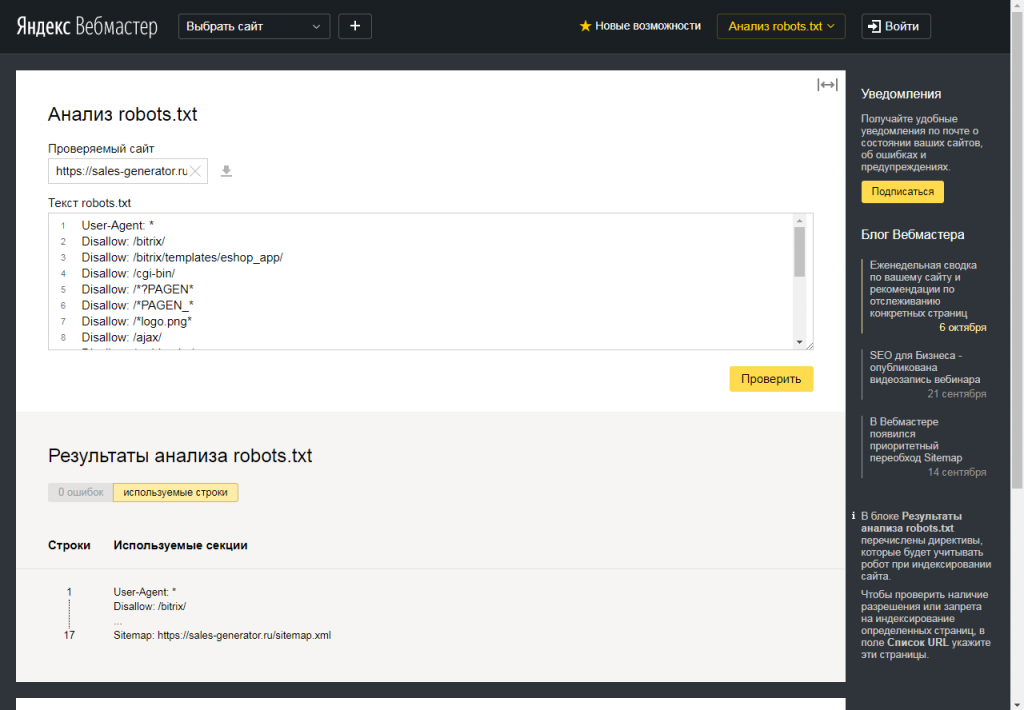
Проверка файла
Проводите анализ robots.txt с помощью инструментов для разработчиков: через Яндекс.Вебмастер и Google Robots Testing Tool. Обратите внимание, что Яндекс и Google проверяют только соответствие файла собственным требованиям. Если для Яндекса файл корректный, это не значит, что он будет корректным для роботов Google, поэтому проверяйте в обеих системах.
Если вы найдете ошибки и исправите robots.txt, краулеры не считают изменения мгновенно. Обычно переобход страниц осуществляется один раз в день, но часто занимает гораздо большее время. Проверьте через неделю файл, чтобы убедиться, что поисковики используют новую версию.
Проверьте через неделю файл, чтобы убедиться, что поисковики используют новую версию.
Проверка в Яндекс.Вебмастере
Сначала подтвердите права на сайт. После этого он появится в панели Вебмастера. Введите название сайта в поле и нажмите проверить. Внизу станет доступен результат проверки.
Дополнительно проверяйте отдельные страницы. Для этого введите адреса страниц и нажмите «проверить».
Проверка в Google Robots Testing Tool
Позволяет проверять и редактировать файл в административной панели. Выдает сообщение о логических и синтаксических ошибках. Исправляйте текст файла прямо в редакторе Google. Но обратите внимание, что изменения не сохраняются автоматически. После исправления robots.txt скопируйте код из веб-редактора и создайте новый файл через блокнот или другой текстовый редактор. Затем загрузите его на сервер в корневой каталог.
Запомните
-
Файл robots.
 txt помогает поисковым роботам индексировать сайт. Закрывайте сайт во время разработки, в остальное время — весь сайт или его часть должны быть открыты. Корректно работающий файл должен отдавать ответ 200.
txt помогает поисковым роботам индексировать сайт. Закрывайте сайт во время разработки, в остальное время — весь сайт или его часть должны быть открыты. Корректно работающий файл должен отдавать ответ 200.
-
Файл создается в обычном текстовом редакторе. Во многих CMS в административной панели предусмотрено создание файла. Следите, чтобы размер не превышал 32 КБ. Размещайте его в корневой директории сайта.
-
Заполняйте файл по правилам. Начинайте с кода “User-agent:”. Правила прописывайте блоками, отделяйте их пустой строкой. Соблюдайте принятый синтаксис.
-
Разрешайте или запрещайте индексацию всем краулерам или избранным. Для этого укажите название поискового робота или поставьте значок *, который означает «для всех».
-
Работайте с разными уровнями доступа: сайтом, страницей, папкой или типом файлов.

-
Включите в файл указание на главное зеркало с помощью постраничного 301 редиректа и на карту сайта с помощью директивы sitemap.
-
Для анализа robots.txt используйте инструменты для разработчиков. Это Яндекс.Вебмастер и Google Robots Testing Tools. Сначала подтвердите права на сайт, затем сделайте проверку. В Google сразу отредактируйте файл в веб-редакторе и уберите ошибки. Отредактированные файлы не сохраняются автоматически. Загружайте их на сервер вместо первоначального robots.txt. Через неделю проверьте, используют ли поисковики новую версию.
Материал подготовила Светлана Сирвида-Льорентэ.
Как создать правильный robots.txt для Google, Яндекс и других поисковых систем | by Ruslan Fatkhutdinov
Если робот Google уже нашел какие-либо параметры на сайте, то вы увидите список этих параметров в таблице и сможете посмотреть примеры таких страниц.
Рассмотрев основные директивы для работы с файлом robots.txt перейдем к составлению robots.txt для сайта.
Во-первых, мы не рекомендуем брать и в слепую использовать шаблонные robots.txt, которые можно найти в интернете, так как они просто не могут учитывать всех тонкостей работы вашего сайта.
1. Первым делом добавим в robots.txt три User-Agent с одной пустой строкой между каждой директивой
User-agent: Yandex
User-agent: Googlebot
User-agent: *
Третий User-Agent добавляется по причине того, что для роботов каждой поисковой системы наборы директив будут различаться.
2. Каждому User-agent’у рекомендуется добавить директивы запрета индексации самых распространенных форматов документов
Disallow: /*.pdf
Disallow: /*.xls
Disallow: /*.doc
Disallow: /*.ppt
Disallow: /*.txt
Документы закрываются от индексации по той причине, что они могут «перетянуть» на себя релевантность и попадать в выдачу вместо продвигаемых целевых страниц.
Даже если сейчас на вашем сайте пока нет документов в вышеперечисленных форматах, рекомендуем не удалять эти строки, а оставить их на перспективу.
3. Каждому User-agent’у добавляем директиву разрешения индексации JS и CSS файлов
Allow: /*/<папка содержащая css>/*.css
Allow: /*/<папка содержащая js>/*.js
JS и CSS файлы открываются для индексации, так как часто они находятся в каталогах системных папок, но они требуются для правильного индексирования сайта роботами поисковых систем.
4. Каждому User-agent’у добавляем директиву разрешения индексации самых распространенных форматов изображений
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpeg
Allow: /*/<папка содержащая медиа файлы>/*.png
Allow: /*/<папка содержащая медиа файлы>/*.gif
Картинки открываем для исключения возможности случайного запрета их для индексации.
Так же как и с документами, если сейчас у вас на сайте нет графических изображений в каком-либо из перечисленных форматах, все равно лучше оставить эти строки.
5. Для User-agent’а Yandex добавляем директиву удаления меток отслеживания, чтобы исключить возможность появления дублей страниц в индексе поисковых систем
Clean-param: utm_source&utm_medium&utm_term&utm_content&utm_campaign&yclid&gclid&_openstat&from /
6. Эти же параметры закрываем в GSC в разделе «Параметры URL»
Внимание! Если закрыть от индексации роботами Google метки при помощи директивы запрета, есть вероятность того, что вы не сможете запустить на такие страницы рекламу в Google Adwords.
7. Для User-agent’а «*» закрываем метки отслеживания стандартной директивой запрета
Disallow: /*utm
Disallow: /*clid=
Disallow: /*openstat
Disallow: /*from
8. Далее задача закрыть от индексации все служебные документы, документы бесполезные для поиска и дубли других страниц. Директивы запрета копируются для каждого User-agent’а. Пример таких страниц:
Директивы запрета копируются для каждого User-agent’а. Пример таких страниц:
- Администраторская часть сайта
- Персональные разделы пользователей
- Корзины и этапы оформления
- Фильтры и сортировки в каталогах
9. Последней директивой для User-agent’а Yandex указывается главное зеркало
Host: site.ru
10. Последней директивой, после всех директив, через пустую строку указываются директивы xml-карт сайта, если таковые используются на сайте
Sitemap: http://site.ru/sitemap.xml
После всех манипуляций должен получится готовый файл robots.txt, который можно использовать на сайте.
Шаблон, который можно взять за основу при составлении robots.txt
User-agent: Yandex
# Наиболее часто встречаемые расширения документов
Disallow: /*.pdf
Disallow: /*.xls
Disallow: /*.doc
Disallow: /*.ppt
Disallow: /*.txt
# Требуется для правильно обработки ПС
Allow: /*/<папка содержащая css>/*.
css
Allow: /*/<папка содержащая js>/*.js
# Картинки
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpeg
Allow: /*/<папка содержащая медиа файлы>/*.png
Allow: /*/<папка содержащая медиа файлы>/*.gif
# Наиболее часто встречаемые метки для отслеживания рекламы
Clean-param: utm_source&utm_medium&utm_term&utm_content&utm_campaign&yclid&gclid&_openstat&from /
# При наличии фильтров и параметров добавляем и их в Clean-param
Host: site.ru
User-agent: Googlebot
Disallow: /*.pdf
Disallow: /*.xls
Disallow: /*.doc
Disallow: /*.ppt
Disallow: /*.txt
Allow: /*/<папка содержащая css>/*.css
Allow: /*/<папка содержащая js>/*.js
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpeg
Allow: /*/<папка содержащая медиа файлы>/*.
png
Allow: /*/<папка содержащая медиа файлы>/*.gif
# У google метки, фильтры и параметры закрываются в GSC-Сканирование-Параметры URL
User-agent: *
# Метки, фильтры и параметры для других ПС закрываем по классическому стандарту
Disallow: /*utm
Disallow: /*clid=
Disallow: /*openstat
Disallow: /*from
Disallow: /*.pdf
Disallow: /*.xls
Disallow: /*.doc
Disallow: /*.ppt
Disallow: /*.txt
Allow: /*/<папка содержащая css>/*.css
Allow: /*/<папка содержащая js>/*.js
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpeg
Allow: /*/<папка содержащая медиа файлы>/*.png
Allow: /*/<папка содержащая медиа файлы>/*.gif
Sitemap: http://site.ru/sitemap.xml
* Напомним, что в указанном шаблоне присутствует спецсимвол комментария «#», и все что находится справа от него предназначается не для роботов, а является подсказками для людей.
Важно! Когда копируете шаблон в текстовый файл, не забудьте убрать лишние пустые строки.
Пустые строки в robots.txt должны быть только:
- Между последней директивой одного User-agent’а и следующим User-agent’ом.
- Последней директивой последнего User-agent’а и директивой Sitemap.
Но прежде чем добавлять его на сайт, мы рекомендуем проверить его в сервисах анализа, например, для Яндекса, нет ли в нем ошибок. А заодно проверить несколько документов из каталогов, которые запрещены к индексации, и несколько документов, которые должны быть открыты для индексации, и проверить, нет ли каких-либо ошибок.
Хоть составление правильного robots.txt задача не самая сложная, но есть распространенные ошибки, которые многие допускают, и от которых мы хотим вас предупредить.
4.1. Полное закрытие сайта от индексации
User-agent: *
Disallow: /
Такая ошибка приводит к исключению всех страниц из индекса поисковых систем и полной потери поискового трафика.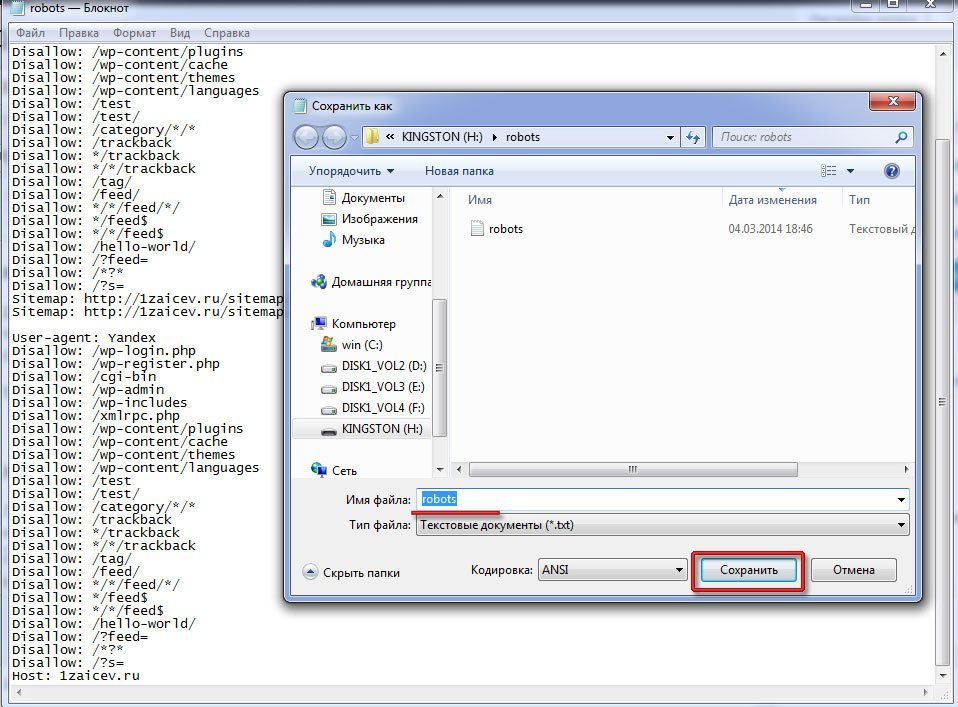
4.2. Не закрытие от индексации меток отслеживания
Эта ошибка может привести к появлению большого количества дублей страниц, что негативно скажется на продвижении сайта
4.3. Неправильное зеркало сайта
User-agent: *
Host: site.ru # В то время, как правильное зеркало sub.site.ru
Скорее всего в большинстве случаев Яндекс просто проигнорирует эту директиву, но если, например, у вас есть несколько судбоменов для разных регионов, то есть вероятность того, что зеркала просто «склеятся».
Кроме файла robots.txt существует множество других способов управления индексацией сайта. Но по нашему опыту, правильный robots.txt помогает продвинуть сайт и защитить его от многих серьезных ошибок.
Надеемся, наш опыт, изложенный в данной статье, поможет вам разобраться с основными принципами составления robots.txt.
Как составить robots.txt самостоятельно
Как правильно составить robots.txt и зачем он нужен, как закрыть индексацию через robots. txt и бесплатно проверить robots.txt с помощью онлайн-инструментов.
txt и бесплатно проверить robots.txt с помощью онлайн-инструментов.
Как поисковики сканируют страницу
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено
краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots. txt.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта —
Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI). - Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. - Быстро загружаются.
Проверьте скорость загрузки инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Посмотреть на сайт глазами поискового бота
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt. Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt«, название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web..jpg) site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots. txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Как составить robots.txt правильно
Файл можно составить в любом текстовом редакторе и сохранить в формате txt. В нем нужно прописать инструкцию для роботов: указание, каким роботам реагировать, и разрешение или запрет на сканирование файлов.
Инструкции отделяют друг от друга переносом строки.
Символы robots.
 txt
txt
«*» — означает любую последовательность символов в файле.
«$» — ограничивает действия «*», представляет конец строки.
«/» — показывает, что закрывают для сканирования.
«/catalog/» — закрывают раздел каталога;
«/catalog» — закрывают все ссылки, которые начинаются с «/catalog».
«#» — используют для комментариев, боты игнорируют текст с этим символом.
User-agent: * Disallow: /catalog/ #запрещаем сканировать каталог
Директивы robots.txt
Директивы, которые распознают все краулеры:
User-agent
На первой строчке прописывают правило User-agent — указание того, какой робот должен реагировать на рекомендации. Если запрещающего правила нет, считается, что доступ к файлам открыт.
Для разного типа контента поисковики используют разных ботов:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.
Маркета и другие.
Для отдельных ботов можно указать свою директиву, если есть необходимость в рекомендациях по типу контента.
User-agent: * — правило для всех поисковых роботов;
User-agent: Googlebot — только для основного поискового бота Google;
User-agent: YandexBot — только для основного бота Яндекса;
User-agent: Yandex — для всех ботов Яндекса. Если любой из ботов Яндекса обнаружит эту строку, то другие правила User-agent: * учитывать не будет.
Sitemap
Указывает ссылку на карту сайта — файл со структурой сайта, в котором перечислены страницы для индексации:
User-agent: * Sitemap: http://site.com/sitemap.xml
Некоторые веб-мастеры не делают карты сайтов, это не обязательное требование, но лучше составить Sitemap — этот файл краулеры воспринимают как структуру страниц, которые не можно, а нужно индексировать.
Disallow
Правило показывает, какую информацию ботам сканировать не нужно.
Если вы еще работаете над сайтом и не хотите, чтобы он появился в незавершенном виде, можно закрыть от сканирования весь сайт:
User-agent: * Disallow: /
После окончания работы над сайтом не забудьте снять блокировку.
Разрешить всем ботам сканировать весь сайт:
User-agent: * Disallow:
Для этой цели можно оставить robots.txt пустым.
Чтобы запретить одному боту сканировать, нужно только прописать запрет с упоминанием конкретного бота. Для остальных разрешение не нужно, оно идет по умолчанию:
Пользователь-агент: BadBot Disallow: /
Чтобы разрешить одному боту сканировать сайт, нужно прописать разрешение для одного и запрет для остальных:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Запретить ботам сканировать страницу:
User-agent: * Disallow: /page.html
Запретить сканировать конкретную папку с файлами:
User-agent: * Disallow: /name/
Запретить сканировать все файлы, которые заканчиваются на «.pdf»:
User-agent: * Disallow: /*.pdf$
Запретить сканировать раздел http://site.com/about/:
User-agent: * Disallow: /about/
Запись формата «Disallow: /about» без закрывающего «/» запретит доступ и к разделу
http://site.com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с «/about».
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Директива определяет те пути, которые доступны для указанных поисковых ботов. По сути, это Disallow-наоборот — директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл «photo.html» разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.html Disallow: /album1/
Заблокировать доступ к каталогам «site.com/catalog1/» и «site.com/catalog2/» но разрешить к «catalog2/subcatalog1/»:
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.
К примеру, если в каталоге товаров использовали сортировку или разные id.
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
«www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123″
«www.site. com/some_dir/get_book.pl?ref=site_2& book_id=123″
«www.site. com/some_dir/get_book.pl?ref=site_3& book_id=123″
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref/some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
«www.example. com/some_dir/get_book.pl? book_id=123″
Для адресов вида:
«www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df»
«www. example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae»
example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid/index.php
Для адресов вида
«www.example1. com/forum/showthread.php? s=681498b9648949605&t=8243″
«www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s/forum/showthread.php
Если переходных параметров несколько:
«www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311″
«www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref/forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации.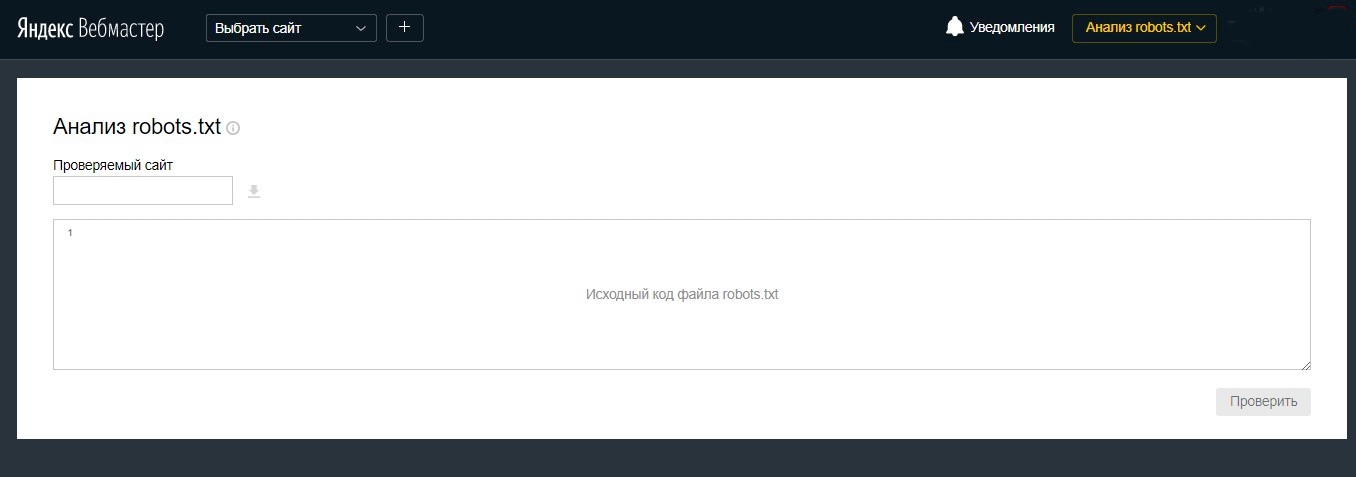 URL нужно писать без «http://» и без закрывающего слэша «/».
URL нужно писать без «http://» и без закрывающего слэша «/».
User-agent: Yandex Disallow: /about Host: www.site.com
Сейчас эту директиву уже
не используют, если в ваших robots.txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
Crawl-delay
Раньше частая загрузка страниц нагружала сервер, поэтому для ботов устанавливали Crawl-delay — время ожидания робота в секундах между загрузками. Эту директиву можно не использовать, мощным серверам она не требуется.
Время ожидания — 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Напомним, что все кириллические ссылки нужно перевести в Punycode с помощью любого конвертера.
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3a
Пример robots.
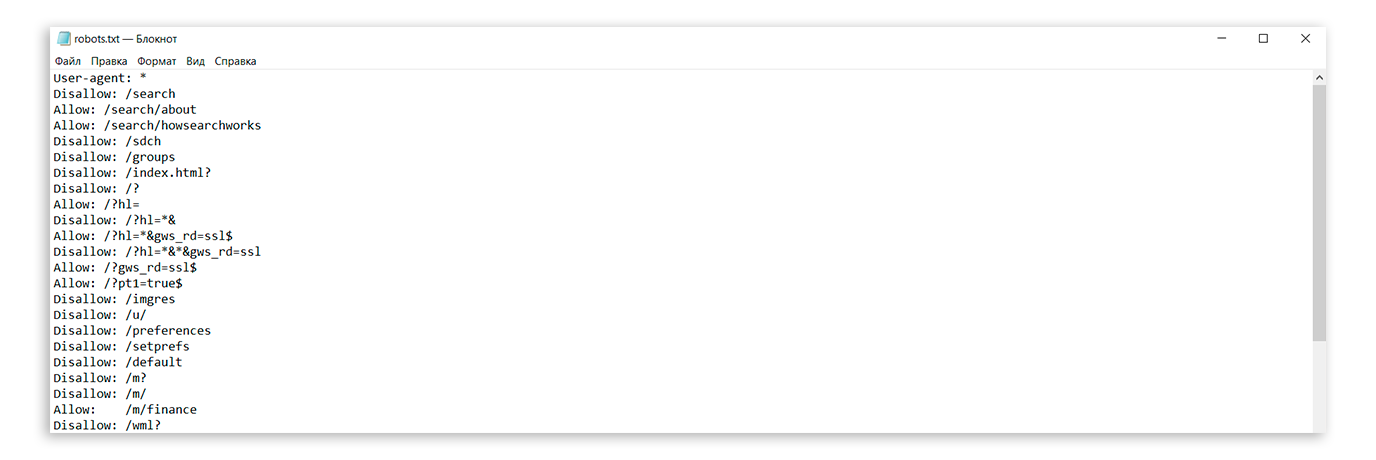 txt
txtЗапись означает, что правило справедливо для всех роботов: запрещено сканировать ссылки из корзины, из встроенного поиска и админки, карта сайта находится по ссылке http://site.com/sitemap, ref не меняет содержание страницы get_book:
User-agent: * Disallow: /bin/ Disallow: /search/ Disallow: /admin/ Sitemap: http://site.com/sitemap Clean-param: ref/some_dir/get_book.pl
Составить robots.txt бесплатно поможет
инструмент для генерации robots.txt от PR-CY, он позволит закрыть или открыть весь сайт для ботов, указать путь к карте сайта, настроить ограничение на посещение страниц, закрыть доступ некоторым роботам и установить задержку:
Для проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Файл robots.txt не подходит для блокировки доступа к приватным файлам, но направляет краулеров к карте сайта и дает рекомендации для быстрого сканирования важных материалов ресурса.
Настройка robots.txt – как узнать, какие страницы необходимо закрывать от индексации
Файл robots.txt представляет собой набор директив (набор правил для роботов), с помощью которых можно запретить или разрешить поисковым роботам индексирование определенных разделов и файлов вашего сайта, а также сообщить дополнительные сведения. Изначально с помощью robots.txt реально было только запретить индексирование разделов, возможность разрешать к индексации появилась позднее, и была введена лидерами поиска Яндекс и Google.
Структура файла robots.txt
Сначала прописывается директива User-agent, которая показывает, к какому поисковому роботу относятся инструкции.
Небольшой список известных и частоиспользуемых User-agent:
- User-agent:*
- User-agent: Yandex
- User-agent: Googlebot
- User-agent: Bingbot
- User-agent: YandexImages
- User-agent: Mail.RU
Далее указываются директивы Disallow и Allow, которые запрещают или разрешают индексирование разделов, отдельных страниц сайта или файлов соответственно. Затем повторяем данные действия для следующего User-agent. В конце файла указывается директива Sitemap, где задается адрес карты вашего сайта.
Прописывая директивы Disallow и Allow, можно использовать специальные символы * и $. Здесь * означает «любой символ», а $ – «конец строки». Например, Disallow: /admin/*.php означает, что запрещается индексация индексацию всех файлов, которые находятся в папке admin и заканчиваются на .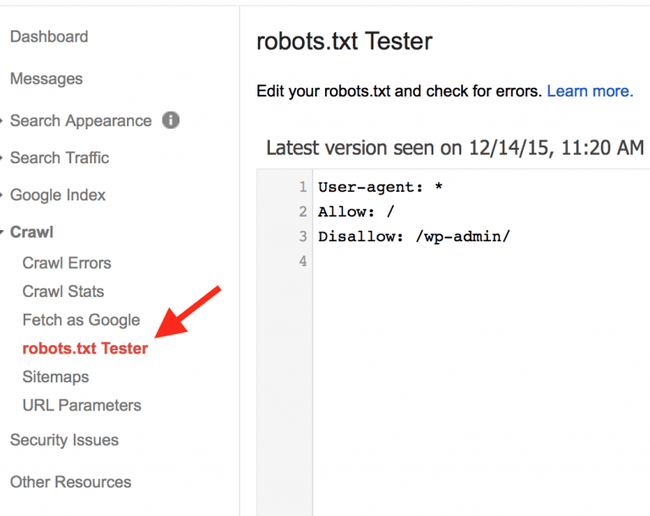 php, Disallow: /admin$ запрещает адрес /admin, но не запрещает /admin.php, или /admin/new/ , если таковой имеется.
php, Disallow: /admin$ запрещает адрес /admin, но не запрещает /admin.php, или /admin/new/ , если таковой имеется.
Если для всех User-agent использует одинаковый набор директив, не нужно дублировать эту информацию для каждого из них, достаточно будет User-agent: *. В случае, когда необходимо дополнить информацию для какого-то из user-agent, следует продублировать информацию и добавить новую.
Пример robots.txt для WordPress:
*Примечание для User agent: Yandex
-
Для того чтобы передать роботу Яндекса Url без Get параметров (например: ?id=, ?PAGEN_1=) и utm-меток (например: &utm_source=, &utm_campaign=), необходимо использовать директиву Clean-param.
-
Ранее роботу Яндекса можно было сообщить адрес главного зеркала сайта с помощью директивы Host. Но от этого метода отказались весной 2018 года.
-
Также ранее можно было сообщить роботу Яндекса, как часто обращаться к сайту с помощью директивы Crawl-delay.
 Но как сообщается в блоге для вебмастеров Яндекса:
Но как сообщается в блоге для вебмастеров Яндекса:- Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay.
- Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Вместо этой директивы в Яндекс. Вебмастер добавили новый раздел «Скорость обхода».
Проверка robots.txt
Старая версия Search console
Для проверки правильности составления robots.txt можно воспользоваться Вебмастером от Google – необходимо перейти в раздел «Сканирование» и далее «Просмотреть как Googlebot», затем нажать кнопку «Получить и отобразить». В результате сканирования будут представлены два скриншота сайта, где изображено, как сайт видят пользователи и как поисковые роботы. А ниже будет представлен список файлов, запрет к индексации которых мешает корректному считыванию вашего сайта поисковыми роботами (их необходимо будет разрешить к индексации для робота Google).
А ниже будет представлен список файлов, запрет к индексации которых мешает корректному считыванию вашего сайта поисковыми роботами (их необходимо будет разрешить к индексации для робота Google).
Обычно это могут быть различные файлы стилей (css), JavaScript, а также изображения. После того, как вы разрешите данные файлы к индексации, оба скриншота в Вебмастере должны быть идентичными. Исключениями являются файлы, которые расположены удаленно, например, скрипт Яндекс.Метрики, кнопки социальных сетей и т.д. Их у вас не получится запретить/разрешить к индексации. Более подробно о том, как устранить ошибку «Googlebot не может получить доступ к файлам CSS и JS на сайте», вы читайте в нашем блоге.
Новая версия Search console
В новой версии нет отдельного пункта меню для проверки robots.txt. Теперь достаточно просто вставить адрес нужной страны в строку поиска.
В следующем окне нажимаем «Изучить просканированную страницу».
Далее нажимаем ресурсы страницы
В появившемся окне видно ресурсы, которые по тем или иным причинам недоступны роботу google. В конкретном примере нет ресурсов, заблокированных файлом robots.txt.
В конкретном примере нет ресурсов, заблокированных файлом robots.txt.
Если же такие ресурсы будут, вы увидите сообщения следующего вида:
Рекомендации, что закрыть в robots.txt
Каждый сайт имеет уникальный robots.txt, но некоторые общие черты можно выделить в такой список:
- Закрывать от индексации страницы авторизации, регистрации, вспомнить пароль и другие технические страницы.
- Админ панель ресурса.
- Страницы сортировок, страницы вида отображения информации на сайте.
- Для интернет-магазинов страницы корзины, избранное. Более подробно вы можете почитать в советах интернет-магазинам по настройкам индексирования в блоге Яндекса.
- Страница поиска.
Это лишь примерный список того, что можно закрыть от индексации от роботов поисковых систем. В каждом случае нужно разбираться в индивидуальном порядке, в некоторых ситуациях могут быть исключения из правил.
Заключение
Файл robots. txt является важным инструментом регулирования отношений между сайтом и роботом поисковых систем, важно уделять время его настройке.
txt является важным инструментом регулирования отношений между сайтом и роботом поисковых систем, важно уделять время его настройке.
В статье большое количество информации посвящено роботам Яндекса и Google, но это не означает, что нужно составлять файл только для них. Есть и другие роботы – Bing, Mail.ru, и др. Можно дополнить robots.txt инструкциями для них.
Многие современные cms создают файл robots.txt автоматически, и в них могут присутствовать устаревшие директивы. Поэтому рекомендую после прочтения этой статьи проверить файл robots.txt на своем сайте, а если они там присутствуют, желательно их удалить. Если вы не знаете, как это сделать, обращайтесь к нам за помощью.
Robots.txt и его оптимизация и поиск ошибок. 100 советов от профи.
3. Перепутанные инструкции
Одна из самых распространённых ошибок в robots.txt – перепутанные между собой инструкции. Например:
Disallow: Yandex
Правильно писать вот так:
User-agent: Yandex
Disallow: /
4.
Многие владельцы сайтов пытаются поместить все запрещаемые к индексации каталоги в одну инструкцию Disallow:
Disallow: /css/ /cgi-bin/ /images/
Такая запись нарушает стандарт, и невозможно угадать, как ее обработают разные роботы. Правильно надо писать так:
Disallow: /css/
Disallow: /cgi-bin/
Disallow: /images/
5. Пустая строка в user-agent
Так неправильно:
User-agent:
Disallow:
Так правильно:
User-agent: *
Disallow:
6. Зеркала сайта и URL в директиве Host
Чтобы указать, какой сайт является главным, а какой — зеркалом (дублем), для Google используются 301 редирект и внесение информации в Google Search Console, а для Яндекса — директива host. Правда эта директива была отменена весной 2018 года, но многие продолжают её использовать.
С точки зрения поисковых систем http://www.site.ru , http://site.ru , https://www.site.ru и https://site.ru — четыре разных сайта. Несмотря на то что визуально для людей это одно и то же, поисковая система принимает решение самостоятельно, какой сайт отображать в результатах выдачи, а какой — нет. Казалось бы, в чем проблема? Их может быть несколько:
Несмотря на то что визуально для людей это одно и то же, поисковая система принимает решение самостоятельно, какой сайт отображать в результатах выдачи, а какой — нет. Казалось бы, в чем проблема? Их может быть несколько:
- поисковик Яндекс принял решение оставить у себя в индексе сайт с www, a Google решил оставить без www;
- ссылки с других ресурсов, которые имеют влияние на ранжирование, ссылаются на сайт с www, а в индексе поисковика остался сайт без www.
Чтобы таких проблем не возникло, на этапе технической оптимизации принудительно сообщаем поисковикам, какой вариант сайта — с www или без, с https или без него — для нас предпочтительнее, и избавляем себя от возможных проблем в дальнейшем.
Итак, для протокола http следует писать без аббревиатуры протокола передачи гипертекста, то есть без http:// и без закрывающего слеша /
Неправильно:
User-agent: Yandex
Disallow: /cgi-bin
Host: http://www.site.ru/
Правильно:
User-agent: Yandex
Disallow: /cgi-bin
Host: www. site.ru
site.ru
Однако, если ваш сайт с https, то правильно писать вот так:
User-agent: Yandex
Disallow: /cgi-bin
Host:https:// www.site.ru
Директива host Является корректной только для робота Яндекса, межсекционной. Поэтому, желательно, секцию Яндекса описывать после всех других секций.
Напомню еще раз, директива host стала необязательной. Теперь главное зеркало можно установить в Яндекс вебмастере.
7. Использование в Disallow символов подстановки
Иногда хочется написать что-то вроде:
User-agent: *
Disallow: file*.html
для указания все файлов file1.html, file2.html, file3.html и т.д. На сегодняшний день — это вполне допустимо как для робота Яндекс так и Google.
Более того, Яндекс по умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *. Пример:
User-agent: Yandex
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с ‘/cgi-bin’
Disallow: /cgi-bin # то же самое
Чтобы отменить * на конце правила, можно использовать спецсимвол $, например:
User-agent: Yandex
Disallow: /example$ # запрещает ‘/example’,
# но не запрещает ‘/example. html’
html’
User-agent: Yandex
Disallow: /example # запрещает и ‘/example’,
# и ‘/example.html’
Спецсимвол $ не запрещает указанный * на конце, то есть:
User-agent: Yandex
Disallow: /example$ # запрещает только ‘/example’
Disallow: /example*$ # так же, как ‘Disallow: /example’
# запрещает и /example.html и /example
8. Редирект на страницу 404-й ошибки
Довольно часто, на сайтах без файла robots.txt при запросе этого файла делается переадресация на другую страницу.
Иногда такая переадресация происходит без отдачи статуса 404 Not Found. Пауку самому приходится разбираться, что он получил – robots.txt или обычный html-файл. Эта ситуация вряд ли создаст какие-то проблемы, но все-таки лучше всегда класть в корень сайта пустой файл robots.txt.
9. Заглавные буквы — это плохой стиль
USER-AGENT: GOOGLEBOT
DISALLOW:
Хотя по стандарту robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий. Кроме того, написание robots.txt сплошь заглавными буквами считается плохим стилем.
10. Перечисление всех файлов
Еще одной ошибкой является перечисление каждого файла в директории:
User-agent: *
Disallow: /AL/Alabama.html
Disallow: /AL/AR.html
Disallow: /Az/AZ.html
Disallow: /Az/bali.html
Disallow: /Az/bed-breakfast.html
Вместо этого можно просто закрыть от индексации директорию целиком:
User-agent: *
Disallow: /AL/
Disallow: /Az/
11.Использование дополнительных директив в секции *
Некоторые роботы могут неправильно отреагировать на использование дополнительных директив. Это значит, что не стоит использовать дополнительные директивы в секции «*».
То есть рекомендуется создавать специальные секции для нестандартных директив, таких как host.
Так неправильно:
User-agent: *
Disallow: /css/
Host: www.example.com
А вот так – правильно:
User-agent: *
Disallow: /css/
User-agent: Yandex
Disallow: /css/
Host: www. example.com
example.com
12. Отсутствие инструкции Disallow
Даже если мы хотим просто использовать дополнительную директиву и не хотим ничего запрещать, лучше всего указать пустой Disallow. По стандарту инструкция Disallow является обязательной, и робот может «неправильно вас понять».
Так неправильно:
User-agent: Yandex
Host: www.example.com
Так правильно:
User-agent: Yandex
Disallow:
Host: www.example.com
13. Отсутствие слешей при указании директории
Как в этом случае поступит робот?
User-agent: Yandex
Disallow: john
По стандарту, он не будет индексировать файл с именем «john» и директорию с именем «john». Для указания только директории надо писать так:
User-agent: Yandex
Disallow: /john/
14. Неправильный HTTP-заголовок
Сервер должен возвращать в HTTP-заголовке для robots.txt «Content-Type: text/plain» а, например, не «Content-Type: text/html». Неправильный заголовок может привести к тому, что некоторые роботы не обработают файл.
15. Логические ошибки
Зачастую при разветвленной структуре сайта возникают логические ошибки в определении того, что и как нужно блокировать от индексации.
Для Google: На уровне группы, в частности для директив allow и disallow, самое строгое правило, учитывающее длину записи [путь], будет важнее менее строгого и более короткого правила. Порядок очередности правил с подстановочными знаками не определен.
Яндекс: Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом.
Исходный robots.txt:
User-agent: Yandex
Allow: /catalog
Disallow: /
Сортированный robots.txt:
User-agent: Yandex
Disallow: /
Allow: /catalog
# разрешает скачивать только страницы, начинающиеся с ‘/catalog’
Исходный robots. txt:
txt:
User-agent: Yandex
Allow: /
Allow: /catalog/auto
Disallow: /catalog
Сортированный robots.txt:
User-agent: Yandex
Allow: /
Disallow: /catalog
Allow: /catalog/auto
# запрещает скачивать страницы, начинающиеся с ‘/catalog’,
# но разрешает скачивать страницы, начинающиеся с ‘/catalog/auto’.
При конфликте между двумя директивами с префиксами одинаковой длины в Яндексе приоритет отдается директиве Allow, в Google — Disallow.
В любом случае протестируйте ваш robots.txt на конфликты в обоих вебмастерах.
# yandex.com
Пользовательский агент: *
Запретить: /?
Disallow: /403.html
Disallow: /404.html
Disallow: /500.html
Запретить: /about.html
Запретить: / adddata
Disallow: / adresa-segmentator
Запрещено: /advanced_engl.html
Disallow: / реклама
Запретить: / все-поддерживаемые-параметры
Disallow: / статьи Запретить: / blog / *? Text =
Запретить: / blog / *? Tag =
Запретить: / blog / * / * / *
Запретить: / blog / punto Disallow: / blogs *
Разрешить: / blogs / $
Разрешить: / blogs / pad / $
Разрешить: / blogs / pad $ Запретить: / catalog /? Text =
Запретить: / чат
Disallow: / cgi-bin /
Disallow: / cgi /
Disallow: / chisla. html
Запретить: / clck Запретить: / collections / feed
Запретить: / collections / search /
Запретить: / collections / * / search / *
Disallow: / collections / iznanka /
Запретить: / collections / * / _ подписчиков *
Запретить: / collections / * / _ подписок *
Запретить: / collections / share
Запретить: / коллекции / избранное
Запретить: / collections / embed
Запретить: / коллекции / изображение / Disallow: /company/*.rss
Запретить: / компания / поиск Запретить: / комментарии / * Запретить: / conflagexp
Запретить: / cy
Запретить: / cycounter
Disallow: / dzen
Запретить: / edu / ping
Запретить: / edu / tasks
Запрещено: / edu / Teachers
Запретить: / edu / test
Запретить: / эксперименты.xml
Запретить: / formfeedback Запрещено: / gorsel / *
Разрешить: / gorsel / $
Разрешить: / gorsel /? *
Разрешить: / gorsel / smart / $
Разрешить: / gorsel / touch / $
Разрешить: / gorsel / touch /? * Запретить: / goto_issue /
Запретить: / goto_rubric /
Запретить: / i / Запретить: / изображения-данные
Запретить: /images.
html
Запретить: / clck Запретить: / collections / feed
Запретить: / collections / search /
Запретить: / collections / * / search / *
Disallow: / collections / iznanka /
Запретить: / collections / * / _ подписчиков *
Запретить: / collections / * / _ подписок *
Запретить: / collections / share
Запретить: / коллекции / избранное
Запретить: / collections / embed
Запретить: / коллекции / изображение / Disallow: /company/*.rss
Запретить: / компания / поиск Запретить: / комментарии / * Запретить: / conflagexp
Запретить: / cy
Запретить: / cycounter
Disallow: / dzen
Запретить: / edu / ping
Запретить: / edu / tasks
Запрещено: / edu / Teachers
Запретить: / edu / test
Запретить: / эксперименты.xml
Запретить: / formfeedback Запрещено: / gorsel / *
Разрешить: / gorsel / $
Разрешить: / gorsel /? *
Разрешить: / gorsel / smart / $
Разрешить: / gorsel / touch / $
Разрешить: / gorsel / touch /? * Запретить: / goto_issue /
Запретить: / goto_rubric /
Запретить: / i / Запретить: / изображения-данные
Запретить: /images. html
Запретить: / images / *
Запретить: / images-apphost / * Разрешить: / images / $
Разрешить: / images /? *
Разрешить: / images / smart / $
Разрешить: / images / touch / $
Разрешить: / images / touch /? Запретить: / index_m
Disallow: / инфицированный
Disallow: / изнанка /
Запретить: / keyboard_qwerty.html
Disallow: / logotypes Запретить: / map-constructor / loader *
Disallow: / more_samples
Запретить: / msearch
Disallow: / msearchpart
Запретить: / maps?
Запретить: / maps / *?
Запретить: / maps / — / *
Запретить: / maps / print / *
Разрешить: / maps / *? Lang = kk $
Разрешить: / maps / *? Lang = uz $
Запретить: / nmaps / *?
Запретить: / mapeditor / *? Запретить: / метро / *? От Запретить: / norobot
Запретить: /opensearch.xml
Запретить: / padsearch
Disallow: / люди *
Disallow: / человек
Disallow: /podpiska/login.pl
Запретить: / опрос
Disallow: / Promo / diskelement
Disallow: / promo / * до свидания *
Disallow: / promo / skype *? *
Запретить: / promo / skype / * / *
Запретить: / promo / launcher / feedback
Disallow: / Promo / launcher / mgoodbye / *
Disallow: / promo / * добро пожаловать *
Запретить: / Promo / yobject / changelog *
Disallow: / soft / bm / до свидания
Запретить: / soft / chrome / ext-install / *
Запретить: / soft / chrome / searchline-install / *
Disallow: / soft / * до свидания *
Запретить: / soft / punto / mac / uninstall / *
Запретить: / soft / punto / win / uninstall / *
Disallow: / soft / * добро пожаловать *
Disallow: / soft / win /? *
Disallow: / котировки
Disallow: / redir
Запретить: / region_map
Запретить: / список_регионов.
html
Запретить: / images / *
Запретить: / images-apphost / * Разрешить: / images / $
Разрешить: / images /? *
Разрешить: / images / smart / $
Разрешить: / images / touch / $
Разрешить: / images / touch /? Запретить: / index_m
Disallow: / инфицированный
Disallow: / изнанка /
Запретить: / keyboard_qwerty.html
Disallow: / logotypes Запретить: / map-constructor / loader *
Disallow: / more_samples
Запретить: / msearch
Disallow: / msearchpart
Запретить: / maps?
Запретить: / maps / *?
Запретить: / maps / — / *
Запретить: / maps / print / *
Разрешить: / maps / *? Lang = kk $
Разрешить: / maps / *? Lang = uz $
Запретить: / nmaps / *?
Запретить: / mapeditor / *? Запретить: / метро / *? От Запретить: / norobot
Запретить: /opensearch.xml
Запретить: / padsearch
Disallow: / люди *
Disallow: / человек
Disallow: /podpiska/login.pl
Запретить: / опрос
Disallow: / Promo / diskelement
Disallow: / promo / * до свидания *
Disallow: / promo / skype *? *
Запретить: / promo / skype / * / *
Запретить: / promo / launcher / feedback
Disallow: / Promo / launcher / mgoodbye / *
Disallow: / promo / * добро пожаловать *
Запретить: / Promo / yobject / changelog *
Disallow: / soft / bm / до свидания
Запретить: / soft / chrome / ext-install / *
Запретить: / soft / chrome / searchline-install / *
Disallow: / soft / * до свидания *
Запретить: / soft / punto / mac / uninstall / *
Запретить: / soft / punto / win / uninstall / *
Disallow: / soft / * добро пожаловать *
Disallow: / soft / win /? *
Disallow: / котировки
Disallow: / redir
Запретить: / region_map
Запретить: / список_регионов. xml
Запретить: /regions.html?
Disallow: / rubric2sport
Запретить: / s /
Запретить: / сохранить
Disallow: / безопасность /? *
Запретить: / поиск
Запретить: / setup
Запретить: / showcaptcha
Запретить: / sitesearch
Disallow: / сказки
Запретить: /sl/*.html
Disallow: / soft / extensions / до свидания
Disallow: / sportagent
Запретить: / storeclick
Запретить: / storerequest
Запретить: /subscribe/confirm.pl
Запретить: /subscribe/view.pl Запретить: / support / direct-images
Запретить: / support / direct-tooltips
Запретить: / support / distr
Запретить: / support / dsp
Запрещено: / support / fe4be44a295cc679e19bf0b8f133083d
Запретить: / support / maps-beta
Запретить: / support / market-images
Запретить: / поддержка / безопасность
Запретить: / support / webmaster-images
Запретить: / support / * zout_
Запретить: / support / search-results /
Disallow: / support / praktikum / flow.html Запретить: / telsearch
Запретить: / themes
Запретить: / toggle-эксперимент
Запретить: / touchsearch
Запретить: / tune * retpath =
Запретить: / версии Disallow: / v $
Запретить: / viewconfig $
Запретить: / video / v $
Запретить: / video / viewconfig $
Запретить: / images / v $
Запретить: / images / viewconfig $ Разрешить: / uslugi / $
Disallow: / uslugi / * Запретить: / видео / *
Запретить: / video / * filmId = *
Запретить: / видео / поиск
Запретить: / видео / предварительный просмотр
Запретить: / видео / * / поиск
Запретить: / video / * / preview
Разрешить: / video / $
Разрешить: / видео /?
Разрешить: / видео / карта сайта
Разрешить: / video /% D0% B7% D0% B0% D0% BF% D1% 80% D0% BE% D1% 81 /
Разрешить: / video / dizi-izle /
Разрешить: / видео / дизи-изле /?
Разрешить: / video / yerli-dizi-izle /
Разрешить: / video / yabanci-dizi-izle /
Разрешить: / видео / касание /
Разрешить: / video / pad / Запретить: / xmlsearch
Disallow: / yaca
Запретить: / yandsearch
Disallow: / yca / cy Disallow: / soft / distribution
Disallow: / soft /? *
Запретить: / promo / launcher /? *
Disallow: / opera /? *
Запретить: / firefox /? *
Запрещать: / soft / bm /? *
Запретить: / soft / browsers /? *
Запретить: / soft / punto /? *
Запретить: / ie /? *
Запретить: / element /? *
Disallow: / element / * до свидания *
Disallow: / soft / * до свидания *
Disallow: / взрослый Запретить: / sport *? * Parent-reqid *
Запретить: / зеркало *? * Родитель-reqid *
Запретить: / turbo *? * Parent-reqid *
Запретить: / зеркало / скрыть Запретить: / turbo *? * Ajax = 1 *
Запретить: / sport *? * Ajax = 1 *
Запретить: / зеркало *? * Ajax = 1 * Clean-Param: ncrnd & redircnt & clid & _ & win /
Clean-Param: random_cgi и знак / турбо * Карта сайта: https: // яндекс.
xml
Запретить: /regions.html?
Disallow: / rubric2sport
Запретить: / s /
Запретить: / сохранить
Disallow: / безопасность /? *
Запретить: / поиск
Запретить: / setup
Запретить: / showcaptcha
Запретить: / sitesearch
Disallow: / сказки
Запретить: /sl/*.html
Disallow: / soft / extensions / до свидания
Disallow: / sportagent
Запретить: / storeclick
Запретить: / storerequest
Запретить: /subscribe/confirm.pl
Запретить: /subscribe/view.pl Запретить: / support / direct-images
Запретить: / support / direct-tooltips
Запретить: / support / distr
Запретить: / support / dsp
Запрещено: / support / fe4be44a295cc679e19bf0b8f133083d
Запретить: / support / maps-beta
Запретить: / support / market-images
Запретить: / поддержка / безопасность
Запретить: / support / webmaster-images
Запретить: / support / * zout_
Запретить: / support / search-results /
Disallow: / support / praktikum / flow.html Запретить: / telsearch
Запретить: / themes
Запретить: / toggle-эксперимент
Запретить: / touchsearch
Запретить: / tune * retpath =
Запретить: / версии Disallow: / v $
Запретить: / viewconfig $
Запретить: / video / v $
Запретить: / video / viewconfig $
Запретить: / images / v $
Запретить: / images / viewconfig $ Разрешить: / uslugi / $
Disallow: / uslugi / * Запретить: / видео / *
Запретить: / video / * filmId = *
Запретить: / видео / поиск
Запретить: / видео / предварительный просмотр
Запретить: / видео / * / поиск
Запретить: / video / * / preview
Разрешить: / video / $
Разрешить: / видео /?
Разрешить: / видео / карта сайта
Разрешить: / video /% D0% B7% D0% B0% D0% BF% D1% 80% D0% BE% D1% 81 /
Разрешить: / video / dizi-izle /
Разрешить: / видео / дизи-изле /?
Разрешить: / video / yerli-dizi-izle /
Разрешить: / video / yabanci-dizi-izle /
Разрешить: / видео / касание /
Разрешить: / video / pad / Запретить: / xmlsearch
Disallow: / yaca
Запретить: / yandsearch
Disallow: / yca / cy Disallow: / soft / distribution
Disallow: / soft /? *
Запретить: / promo / launcher /? *
Disallow: / opera /? *
Запретить: / firefox /? *
Запрещать: / soft / bm /? *
Запретить: / soft / browsers /? *
Запретить: / soft / punto /? *
Запретить: / ie /? *
Запретить: / element /? *
Disallow: / element / * до свидания *
Disallow: / soft / * до свидания *
Disallow: / взрослый Запретить: / sport *? * Parent-reqid *
Запретить: / зеркало *? * Родитель-reqid *
Запретить: / turbo *? * Parent-reqid *
Запретить: / зеркало / скрыть Запретить: / turbo *? * Ajax = 1 *
Запретить: / sport *? * Ajax = 1 *
Запретить: / зеркало *? * Ajax = 1 * Clean-Param: ncrnd & redircnt & clid & _ & win /
Clean-Param: random_cgi и знак / турбо * Карта сайта: https: // яндекс. ru / support / sitemap.xml
Карта сайта: https://yandex.com/blog/sitemap.xml
Карта сайта: https://yandex.com/turbo/public/sitemap.xml
Карта сайта: https://yandex.com/games/sitemaps/sitemap.index.xml Пользовательский агент: Twitterbot
Разрешить: / изображения
Разрешить: / gorsel
Разрешить: / видео
Разрешить: / коллекции / изображение /
Disallow: / взрослый Карта сайта: https://yandex.com/support/sitemap.xml
Карта сайта: https://yandex.com/blog/sitemap.xml
Карта сайта: https://yandex.com/turbo/public/sitemap.xml
Карта сайта: https://yandex.com/games/sitemaps/sitemap.index.xml Пользовательский агент: Applebot
Запретить: /?
Disallow: /403.html
Disallow: /404.html
Disallow: /500.html
Запретить: /about.html
Запретить: / adddata
Disallow: / adresa-segmentator
Запрещено: /advanced_engl.html
Disallow: / реклама
Запретить: / все-поддерживаемые-параметры
Disallow: / статьи Запретить: / blog / *? Text =
Запретить: / blog / *? Tag =
Запретить: / blog / * / * / *
Запретить: / blog / punto Disallow: / blogs *
Разрешить: / blogs / $
Разрешить: / blogs / pad / $
Разрешить: / blogs / pad $ Запретить: / catalog /? Text =
Запретить: / чат
Disallow: / cgi-bin /
Disallow: / cgi /
Disallow: / chisla.html
Запретить: / clck Запретить: / collections / feed
Запретить: / collections / search /
Запретить: / collections / * / search / *
Disallow: / collections / iznanka /
Запретить: / collections / * / _ подписчиков *
Запретить: / collections / * / _ подписок *
Запретить: / collections / share
Запретить: / коллекции / избранное
Запретить: / collections / embed
Запретить: / коллекции / изображение / Disallow: /company/*.rss
Запретить: / компания / поиск Запретить: / комментарии / * Запретить: / conflagexp
Запретить: / cy
Запретить: / cycounter
Disallow: / dzen
Запретить: / edu / ping
Запретить: / edu / tasks
Запрещено: / edu / Teachers
Запретить: / edu / test
Запретить: / эксперименты.xml
Запретить: / formfeedback Запрещено: / gorsel / *
Разрешить: / gorsel / $
Разрешить: / gorsel /? *
Разрешить: / gorsel / smart / $
Разрешить: / gorsel / touch / $
Разрешить: / gorsel / touch /? * Запретить: / goto_issue /
Запретить: / goto_rubric /
Запретить: / i / Запретить: / изображения-данные
Запретить: /images.html
Запретить: / images / *
Разрешить: / images / $
Разрешить: / images /? *
Разрешить: / images / smart / $
Разрешить: / images / touch / $
Разрешить: / images / touch /? Запретить: / index_m
Disallow: / инфицированный
Disallow: / изнанка /
Запретить: /keyboard_qwerty.html
Disallow: / logotypes Запретить: / map-constructor / loader *
Disallow: / more_samples
Запретить: / msearch
Disallow: / msearchpart
Запретить: / nmaps / *?
Запретить: / maps / print / *
Разрешить: / maps / *? Ll = *
Разрешить: / maps / org /
Запретить: / maps / — / *
Запретить: / mapeditor / *? Запретить: / метро / *? От Запретить: / norobot
Запретить: / opensearch.xml
Запретить: / padsearch
Disallow: / люди *
Disallow: / человек
Disallow: /podpiska/login.pl
Запретить: / опрос
Disallow: / Promo / diskelement
Disallow: / promo / * до свидания *
Disallow: / promo / skype *? *
Запретить: / promo / skype / * / *
Запретить: / promo / launcher / feedback
Disallow: / Promo / launcher / mgoodbye / *
Disallow: / promo / * добро пожаловать *
Запретить: / Promo / yobject / changelog *
Disallow: / soft / bm / до свидания
Запретить: / soft / chrome / ext-install / *
Запретить: / soft / chrome / searchline-install / *
Disallow: / soft / * до свидания *
Запретить: / soft / punto / mac / uninstall / *
Запретить: / soft / punto / win / uninstall / *
Disallow: / soft / * добро пожаловать *
Disallow: / soft / win /? *
Disallow: / котировки
Disallow: / redir
Запретить: / region_map
Запретить: / список_регионов.xml
Запретить: /regions.html?
Disallow: / rubric2sport
Запретить: / s /
Запретить: / сохранить
Disallow: / безопасность /? *
Запретить: / поиск
Запретить: / setup
Запретить: / showcaptcha
Запретить: / sitesearch
Disallow: / сказки
Запретить: /sl/*.html
Disallow: / soft / extensions / до свидания
Disallow: / sportagent
Запретить: / storeclick
Запретить: / storerequest
Запретить: /subscribe/confirm.pl
Запретить: /subscribe/view.pl Запретить: / support / direct-images
Запретить: / support / direct-tooltips
Запретить: / support / distr
Запретить: / support / dsp
Запрещено: / support / fe4be44a295cc679e19bf0b8f133083d
Запретить: / support / maps-beta
Запретить: / support / market-images
Запретить: / поддержка / безопасность
Запретить: / support / webmaster-images
Запретить: / support / * zout_
Запретить: / support / search-results /
Disallow: / support / praktikum / flow.html Запретить: / telsearch
Запретить: / themes
Запретить: / toggle-эксперимент
Запретить: / touchsearch
Запретить: / tune * retpath =
Запретить: / версии Disallow: / v $
Запретить: / viewconfig $
Запретить: / video / v $
Запретить: / video / viewconfig $
Запретить: / images / v $
Запретить: / images / viewconfig $ Разрешить: / uslugi / $
Disallow: / uslugi / * Разрешить: / репетитор
Запретить: / tutor / admin
Запретить: / наставник / поиск / проблемы Запретить: / видео / *
Запретить: / video / * filmId = *
Разрешить: / video / $
Разрешить: / видео /?
Разрешить: / видео / карта сайта
Разрешить: / video /% D0% B7% D0% B0% D0% BF% D1% 80% D0% BE% D1% 81 /
Разрешить: / video / dizi-izle /
Разрешить: / видео / дизи-изле /?
Разрешить: / video / yerli-dizi-izle /
Разрешить: / video / yabanci-dizi-izle /
Разрешить: / видео / касание /
Разрешить: / video / pad / Запретить: / xmlsearch
Disallow: / yaca
Запретить: / yandsearch
Disallow: / yca / cy Disallow: / soft / distribution
Disallow: / soft /? *
Запретить: / promo / launcher /? *
Disallow: / opera /? *
Запретить: / firefox /? *
Запрещать: / soft / bm /? *
Запретить: / soft / browsers /? *
Запретить: / soft / punto /? *
Запретить: / ie /? *
Запретить: / element /? *
Disallow: / element / * до свидания *
Disallow: / soft / * до свидания *
Disallow: / взрослый Clean-Param: ncrnd & redircnt & clid & _ & win /
Clean-Param: random_cgi и знак / турбо * Карта сайта: https: // яндекс.ru / support / sitemap.xml
Карта сайта: https://yandex.com/blog/sitemap.xml
Карта сайта: https://yandex.com/turbo/public/sitemap.xml
Карта сайта: https://yandex.com/games/sitemaps/sitemap.index.xml
ru / support / sitemap.xml
Карта сайта: https://yandex.com/blog/sitemap.xml
Карта сайта: https://yandex.com/turbo/public/sitemap.xml
Карта сайта: https://yandex.com/games/sitemaps/sitemap.index.xml Пользовательский агент: Twitterbot
Разрешить: / изображения
Разрешить: / gorsel
Разрешить: / видео
Разрешить: / коллекции / изображение /
Disallow: / взрослый Карта сайта: https://yandex.com/support/sitemap.xml
Карта сайта: https://yandex.com/blog/sitemap.xml
Карта сайта: https://yandex.com/turbo/public/sitemap.xml
Карта сайта: https://yandex.com/games/sitemaps/sitemap.index.xml Пользовательский агент: Applebot
Запретить: /?
Disallow: /403.html
Disallow: /404.html
Disallow: /500.html
Запретить: /about.html
Запретить: / adddata
Disallow: / adresa-segmentator
Запрещено: /advanced_engl.html
Disallow: / реклама
Запретить: / все-поддерживаемые-параметры
Disallow: / статьи Запретить: / blog / *? Text =
Запретить: / blog / *? Tag =
Запретить: / blog / * / * / *
Запретить: / blog / punto Disallow: / blogs *
Разрешить: / blogs / $
Разрешить: / blogs / pad / $
Разрешить: / blogs / pad $ Запретить: / catalog /? Text =
Запретить: / чат
Disallow: / cgi-bin /
Disallow: / cgi /
Disallow: / chisla.html
Запретить: / clck Запретить: / collections / feed
Запретить: / collections / search /
Запретить: / collections / * / search / *
Disallow: / collections / iznanka /
Запретить: / collections / * / _ подписчиков *
Запретить: / collections / * / _ подписок *
Запретить: / collections / share
Запретить: / коллекции / избранное
Запретить: / collections / embed
Запретить: / коллекции / изображение / Disallow: /company/*.rss
Запретить: / компания / поиск Запретить: / комментарии / * Запретить: / conflagexp
Запретить: / cy
Запретить: / cycounter
Disallow: / dzen
Запретить: / edu / ping
Запретить: / edu / tasks
Запрещено: / edu / Teachers
Запретить: / edu / test
Запретить: / эксперименты.xml
Запретить: / formfeedback Запрещено: / gorsel / *
Разрешить: / gorsel / $
Разрешить: / gorsel /? *
Разрешить: / gorsel / smart / $
Разрешить: / gorsel / touch / $
Разрешить: / gorsel / touch /? * Запретить: / goto_issue /
Запретить: / goto_rubric /
Запретить: / i / Запретить: / изображения-данные
Запретить: /images.html
Запретить: / images / *
Разрешить: / images / $
Разрешить: / images /? *
Разрешить: / images / smart / $
Разрешить: / images / touch / $
Разрешить: / images / touch /? Запретить: / index_m
Disallow: / инфицированный
Disallow: / изнанка /
Запретить: /keyboard_qwerty.html
Disallow: / logotypes Запретить: / map-constructor / loader *
Disallow: / more_samples
Запретить: / msearch
Disallow: / msearchpart
Запретить: / nmaps / *?
Запретить: / maps / print / *
Разрешить: / maps / *? Ll = *
Разрешить: / maps / org /
Запретить: / maps / — / *
Запретить: / mapeditor / *? Запретить: / метро / *? От Запретить: / norobot
Запретить: / opensearch.xml
Запретить: / padsearch
Disallow: / люди *
Disallow: / человек
Disallow: /podpiska/login.pl
Запретить: / опрос
Disallow: / Promo / diskelement
Disallow: / promo / * до свидания *
Disallow: / promo / skype *? *
Запретить: / promo / skype / * / *
Запретить: / promo / launcher / feedback
Disallow: / Promo / launcher / mgoodbye / *
Disallow: / promo / * добро пожаловать *
Запретить: / Promo / yobject / changelog *
Disallow: / soft / bm / до свидания
Запретить: / soft / chrome / ext-install / *
Запретить: / soft / chrome / searchline-install / *
Disallow: / soft / * до свидания *
Запретить: / soft / punto / mac / uninstall / *
Запретить: / soft / punto / win / uninstall / *
Disallow: / soft / * добро пожаловать *
Disallow: / soft / win /? *
Disallow: / котировки
Disallow: / redir
Запретить: / region_map
Запретить: / список_регионов.xml
Запретить: /regions.html?
Disallow: / rubric2sport
Запретить: / s /
Запретить: / сохранить
Disallow: / безопасность /? *
Запретить: / поиск
Запретить: / setup
Запретить: / showcaptcha
Запретить: / sitesearch
Disallow: / сказки
Запретить: /sl/*.html
Disallow: / soft / extensions / до свидания
Disallow: / sportagent
Запретить: / storeclick
Запретить: / storerequest
Запретить: /subscribe/confirm.pl
Запретить: /subscribe/view.pl Запретить: / support / direct-images
Запретить: / support / direct-tooltips
Запретить: / support / distr
Запретить: / support / dsp
Запрещено: / support / fe4be44a295cc679e19bf0b8f133083d
Запретить: / support / maps-beta
Запретить: / support / market-images
Запретить: / поддержка / безопасность
Запретить: / support / webmaster-images
Запретить: / support / * zout_
Запретить: / support / search-results /
Disallow: / support / praktikum / flow.html Запретить: / telsearch
Запретить: / themes
Запретить: / toggle-эксперимент
Запретить: / touchsearch
Запретить: / tune * retpath =
Запретить: / версии Disallow: / v $
Запретить: / viewconfig $
Запретить: / video / v $
Запретить: / video / viewconfig $
Запретить: / images / v $
Запретить: / images / viewconfig $ Разрешить: / uslugi / $
Disallow: / uslugi / * Разрешить: / репетитор
Запретить: / tutor / admin
Запретить: / наставник / поиск / проблемы Запретить: / видео / *
Запретить: / video / * filmId = *
Разрешить: / video / $
Разрешить: / видео /?
Разрешить: / видео / карта сайта
Разрешить: / video /% D0% B7% D0% B0% D0% BF% D1% 80% D0% BE% D1% 81 /
Разрешить: / video / dizi-izle /
Разрешить: / видео / дизи-изле /?
Разрешить: / video / yerli-dizi-izle /
Разрешить: / video / yabanci-dizi-izle /
Разрешить: / видео / касание /
Разрешить: / video / pad / Запретить: / xmlsearch
Disallow: / yaca
Запретить: / yandsearch
Disallow: / yca / cy Disallow: / soft / distribution
Disallow: / soft /? *
Запретить: / promo / launcher /? *
Disallow: / opera /? *
Запретить: / firefox /? *
Запрещать: / soft / bm /? *
Запретить: / soft / browsers /? *
Запретить: / soft / punto /? *
Запретить: / ie /? *
Запретить: / element /? *
Disallow: / element / * до свидания *
Disallow: / soft / * до свидания *
Disallow: / взрослый Clean-Param: ncrnd & redircnt & clid & _ & win /
Clean-Param: random_cgi и знак / турбо * Карта сайта: https: // яндекс.ru / support / sitemap.xml
Карта сайта: https://yandex.com/blog/sitemap.xml
Карта сайта: https://yandex.com/turbo/public/sitemap.xml
Карта сайта: https://yandex.com/games/sitemaps/sitemap.index.xml
Как добавить свой сайт на WordPress в Яндекс Инструменты для веб-мастеров
Хотите подключить свой сайт к инструментам Яндекс для веб-мастеров? Инструменты для веб-мастеров, такие как консоль поисковой системы от Google и Bing для веб-мастеров, помогут вам оптимизировать ваш сайт, отслеживать трафик, управлять robots.txt, проверять ошибки сайта и многое другое.В этой статье мы расскажем, как добавить свой сайт на WordPress в инструменты Яндекс для веб-мастеров, чтобы отслеживать трафик поисковых систем.
Что такое Яндекс?
Яндекс — популярная поисковая система, такая как Google и Bing, базирующаяся в России. Вы можете оптимизировать свой сайт для SEO в Яндексе, чтобы привлечь больше посетителей из России.
Яндекс имеет ряд инструментов, таких как универсальная поисковая система, поиск изображений, электронная почта, видео, карты и многое другое. В нем также есть инструменты для веб-мастеров, которые помогут вам ранжировать свой сайт, отслеживать статистику трафика, поисковые запросы, ключевые слова и многое другое.
Вы можете связать свой сайт WordPress с Яндексом с помощью плагина Yoast SEO. Он работает аналогично консоли поиска Google и инструментам Bing для веб-мастеров.
Добавление сайта WordPress в Яндекс Инструменты для веб-мастеров
Перед тем, как мы начнем, вам понадобится учетная запись Яндекс. Инструменты для веб-мастеров для подключения вашего сайта. Создав учетную запись, вы можете войти на свой сайт WordPress, чтобы настроить инструменты Яндекс для веб-мастеров с помощью плагина Yoast SEO.
Давайте посмотрим, как добавить свой сайт в инструменты Яндекс для веб-мастеров и сразу приступить к его оптимизации.
Шаг 1. Создайте аккаунт на Яндексе
Первое, что вам нужно сделать, это войти в свой аккаунт Яндекс. Если у вас нет аккаунта на Яндексе, вы можете создать его по этой ссылке.
После создания аккаунта вы попадете на страницу Яндекса для веб-мастеров. На этой странице вам нужно нажать кнопку « + » в верхней панели, чтобы добавить свой сайт в Яндекс.
В поле адреса сайта вам нужно добавить полное доменное имя вашего сайта и нажать кнопку Добавить .
Примечание: Если ваш основной домен использует «www» в URL-адресе, вам необходимо добавить его перед доменом (например, www.wpbeginner.com)
На следующей странице вам будет предложено подтвердить право собственности на сайт, добавив мета-контент на свой сайт WordPress. Скопируйте код содержимого с этой страницы, потому что он понадобится вам на шаге 2.
Шаг 2: Войдите в админку WordPress и добавьте код
Теперь вам нужно войти в админку WordPress и добавить проверочный код в настройки веб-мастера Yoast SEO.
Просто перейдите в область SEO »Общие и щелкните вкладку Инструменты для веб-мастеров .
Далее необходимо вставить код в поле кода подтверждения Яндекса и нажать на кнопку Сохранить изменения .
После добавления кода на свой сайт WordPress вам нужно вернуться на страницу инструментов Яндекс для веб-мастеров, с которой вы скопировали код, и нажать кнопку Проверить , чтобы подтвердить право собственности.
После успешной проверки будет отображаться ваш логин, имеющий права на управление вашим сайтом в инструментах Яндекс для веб-мастеров. Вы также можете делегировать права другим пользователям, добавив их имя пользователя и нажав кнопку Делегировать права .
Теперь, когда ваш сайт проверен и добавлен в инструменты Яндекс для веб-мастеров, вы можете просматривать статистику трафика, ошибки поиска, поисковые запросы, внутренние и внешние ссылки, информацию о сайте, анализ robots.txt, страницы аудита для мобильных устройств и многое другое на панели инструментов Яндекса. .Вы можете использовать меню в левой части экрана, чтобы найти любую информацию, которая может вам понадобиться.
В инструментахЯндекс для веб-мастеров есть параметры оптимизации сайта, которые отфильтрованы от устранения неполадок до важных настроек, таких как robots.txt и .htaccess. Вы можете дополнительно оптимизировать свой robots.txt для SEO отдельно и регулярно выполнять задачи по обслуживанию WordPress, чтобы поддерживать свой сайт в актуальном состоянии.
Надеемся, эта статья помогла вам узнать, как добавить свой сайт WordPress в инструменты Яндекс для веб-мастеров.Вы также можете увидеть наш список лучших плагинов и инструментов WordPress для SEO, которые вы должны использовать для ранжирования своего сайта в поисковых системах.
Если вам понравилась эта статья, то подпишитесь на наш канал YouTube для видеоуроков по WordPress. Вы также можете найти нас в Twitter и Facebook.
Пост «Как добавить свой сайт на WordPress в Яндекс. Инструменты для веб-мастеров» впервые появился на WPBeginner.
Оригинальный артикул
критических ошибок в вашем файле robots.txt нарушат ваш рейтинг, и вы даже не узнаете об этом
Использование роботов.txt уже давно обсуждается веб-мастерами, поскольку он может оказаться сильным инструментом, если он хорошо написан или с его помощью можно прострелить себе ногу. В отличие от других концепций SEO, которые можно считать более абстрактными и для которых у нас нет четких рекомендаций, файл robots.txt полностью задокументирован Google и другими поисковыми системами.
Вам нужен файл robots.txt
только, если у вас есть определенные части вашего веб-сайта, которые вы не хотите индексировать, и / или вам нужно блокировать или управлять различными сканерами.
* спасибо Ричарду за исправление текста выше. (см. комментарии для получения дополнительной информации) Что важно понимать в случае файла robots, так это то, что он не служит законом для выполнения поисковыми роботами, это скорее указатель с несколькими указаниями. Соблюдение этих рекомендаций может привести к более быстрой и лучшей индексации поисковыми системами, а ошибки, скрывающие важный контент от поисковых роботов, в конечном итоге приведут к потере трафика и проблемам с индексацией.
История Robots.txtМы уверены, что большинство из вас уже знакомы с robots.txt, но на тот случай, если вы слышали о нем некоторое время назад и забыли о нем, Стандарты исключения роботов, как они официально известны, — это способ взаимодействия веб-сайтов. с помощью поисковых роботов или других веб-роботов. По сути, это текстовый файл, содержащий короткие инструкции, направляющие поисковые роботы к определенным частям веб-сайта или прочь от них. Обычно роботов обучают искать этот документ, когда они заходят на веб-сайт и подчиняются его директивам.Некоторые роботы не соответствуют этому стандарту, например роботы-сборщики электронной почты, спам-боты или вредоносные программы, у которых не самые лучшие намерения, когда они попадают на ваш сайт.
Все началось в начале 1994 года, когда Мартин Костер создал веб-сканер, который вызвал серьезный случай DDOS на его серверах. В ответ на это был создан стандарт, который направляет поисковые роботы и блокирует их доступ к определенным областям. С тех пор файл robots эволюционировал, содержит дополнительную информацию и имеет еще несколько применений, но мы вернемся к этому позже.
Насколько важен Robots.txt для вашего сайта?Чтобы лучше понять это, подумайте о robots.txt как о путеводителе для поисковых роботов и ботов. Он переносит посетителей, не являющихся людьми, в удивительные области сайта, где находится контент, и показывает им, что важно, а что не должно индексироваться. Все это делается с помощью нескольких строк в формате файла txt. Наличие опытного гида-робота может увеличить скорость индексации веб-сайта, сократив время, которое роботы просматривают по строкам кода, чтобы найти контент, который пользователи ищут в поисковой выдаче.
За все время в файл роботов была включена дополнительная информация, которая помогает веб-мастерам быстрее сканировать и индексировать свои веб-сайты.
В настоящее время большинство файлов robots.txt содержат адрес sitemap.xml, который увеличивает скорость сканирования ботов. Нам удалось найти файлы роботов, содержащие объявления о найме на работу, оскорбляющие чувства людей и даже инструкции по обучению роботов, когда они начинают стесняться. Имейте в виду, что даже несмотря на то, что файл robots предназначен исключительно для роботов, он по-прежнему общедоступен для всех, кто выполняет / robots.txt в свой домен. Пытаясь скрыть от поисковых систем личную информацию, вы просто показываете URL всем, кто открывает файл robots.
Как проверить файл robots.txtПервое, что нужно сделать после того, как у вас есть файл robots, — это убедиться, что он хорошо написан, и проверить на наличие ошибок. Одна ошибка здесь может и причинит вам большой вред, поэтому после того, как вы заполнили файл robots.txt, будьте особенно внимательны, проверяя в нем ошибки.Большинство поисковых систем предоставляют свои собственные инструменты для проверки файлов robots.txt и даже позволяют вам увидеть, как сканеры видят ваш сайт.
Инструменты Google для веб-мастеров предлагают тестер robots.txt, инструмент, который сканирует и анализирует ваш файл. Как вы можете видеть на изображении ниже, вы можете использовать тестер роботов GWT, чтобы проверить каждую строку и увидеть каждого сканера и его доступ к вашему веб-сайту. Инструмент отображает дату и время, когда робот Googlebot загрузил файл роботов с вашего веб-сайта, обнаруженный HTML-код, а также области и URL-адреса, к которым у него не было доступа.Любые ошибки, обнаруженные тестером, необходимо исправить, поскольку они могут привести к проблемам с индексацией вашего сайта, и ваш сайт не может отображаться в поисковой выдаче.
Инструмент, предоставляемый Bing, отображает данные в том виде, в каком их видит BingBot. При загрузке как Bingbot даже ваши HTTP-заголовки и источники страниц отображаются так, как они выглядят для Bingbot. Это отличный способ узнать, действительно ли ваш контент виден поисковому роботу, а не скрыт ли он по какой-то ошибке в robots.txt файл. Более того, вы можете проверить каждую ссылку, добавив ее вручную, и если тестер обнаружит какие-либо проблемы с ней, он отобразит строку в вашем файле robots, которая ее блокирует.
Не торопитесь и внимательно проверяйте каждую строку файла robots. Это первый шаг в создании хорошо написанного файла robots, и с имеющимися в вашем распоряжении инструментами вам действительно нужно очень постараться, чтобы сделать здесь какие-либо ошибки. Большинство поисковых систем предоставляют опцию «получить как * бот», поэтому после того, как вы проверили файл robots.txt самостоятельно, обязательно запустите его через предоставленные автоматические тестеры.
Убедитесь, что вы не исключаете важные страницы из индекса GoogleНаличие проверенного файла robot.txt недостаточно, чтобы гарантировать, что у вас есть отличный файл robots. Мы не можем достаточно подчеркнуть это, но наличие одной строчки в ваших роботах, которая блокирует сканирование важной части содержания вашего сайта, может навредить вам. Поэтому, чтобы убедиться, что вы не исключили важные страницы из индекса Google, вы можете использовать те же инструменты, которые вы использовали для проверки роботов.txt файл.
Загрузите веб-сайт как бот и перейдите по нему, чтобы убедиться, что вы не исключили важный контент.
Перед тем, как вставлять страницы, которые должны быть исключены из поля зрения ботов, убедитесь, что они находятся в следующем списке элементов, которые практически не представляют ценности для поисковых систем:
- Кодовые и скриптовые страницы
- Частные страницы
- Временные страницы
- Любая страница, которую вы считаете бесполезной для пользователя.
Мы рекомендуем иметь четкий план и видение при создании архитектуры веб-сайта, чтобы упростить запрет на использование папок, не представляющих ценности для поисковых роботов.
Как отслеживать несанкционированные изменения в вашем файле robots.txtТеперь все на месте, файл robots.txt заполнен, проверен, и вы убедились, что у вас нет ошибок или важных страниц, исключенных из сканирования Google. Следующий шаг — убедиться, что никто не вносит никаких изменений в документ без вашего ведома. Речь идет не только об изменениях в файле, вам также необходимо знать обо всех ошибках, возникающих при использовании документа robots.txt.
1.Уведомления об обнаружении изменений — бесплатный инструментПервый инструмент, который мы хотим порекомендовать, — это changedetection.com. Этот полезный инструмент отслеживает любые изменения, внесенные на страницу, и автоматически отправляет электронное письмо, когда обнаруживает их. Первое, что вам нужно сделать, это вставить адрес robots.txt и адрес электронной почты, на который вы хотите получать уведомления. На следующем шаге вы можете настроить свои уведомления. Вы можете изменять частоту уведомлений и устанавливать предупреждения только в том случае, если были изменены определенные ключевые слова из файла.
2. Уведомления Инструментов Google для веб-мастеровИнструменты Google для веб-мастеров предоставляют дополнительный инструмент оповещения. Разница в использовании этого инструмента заключается в том, что он работает, отправляя вам уведомления о любой ошибке в вашем коде каждый раз, когда поисковый робот достигает вашего веб-сайта. Ошибки Robots.txt также отслеживаются, и вы будете получать электронное письмо каждый раз, когда возникает проблема. Вот подробное руководство по настройке оповещений Инструментов Google для веб-мастеров.
3.Уведомления об ошибках HTML — бесплатный и платный инструментЧтобы не прострелить себе ногу при создании файла robots.txt, должны отображаться только эти коды ошибок html.
Код 200 в основном означает, что страница была найдена и прочитана;
Коды 403 и 404 означают, что страница не была найдена, и, следовательно, боты будут думать, что у вас нет файла robots.txt. Это заставит ботов сканировать весь ваш сайт и соответствующим образом проиндексировать его.
Инструмент SiteUptime периодически проверяет ваш URL-адрес robots.txt и может немедленно уведомить вас, если обнаружит нежелательные ошибки. Критическая ошибка, которую вы хотите отслеживать, — это ошибка 503.
Ошибка 503 означает, что на стороне сервера есть ошибка, и если робот обнаружит ее, ваш веб-сайт не будет сканироваться вообще.
Инструменты Google для веб-мастеров также обеспечивают постоянный мониторинг и показывают временную шкалу каждого раза, когда был получен файл роботов.На диаграмме Google отображает ошибки, обнаруженные при чтении файла; мы рекомендуем вам время от времени просматривать его, чтобы проверить, не отображаются ли в нем какие-либо другие ошибки, кроме перечисленных выше. Как мы видим ниже, инструменты Google для веб-мастеров предоставляют диаграмму с подробным описанием частоты получения роботом Googlebot файла robots.txt, а также любых ошибок, с которыми он столкнулся при его загрузке.
Критические, но распространенные ошибки 1. Блокирование файлов CSS или изображений при сканировании GoogleВ октябре прошлого года Google заявил, что запрет на использование CSS, Javascript и даже изображений (мы написали об этом интересную статью) учитывается в общем рейтинге вашего сайта.Алгоритм Google становится все лучше и лучше, и теперь он может читать код CSS и JS вашего сайта и делать выводы о том, насколько полезен контент для пользователя. Блокирование этого контента в файле robots может причинить вам некоторый вред и не позволит вам занять такое высокое место, как вам, вероятно, следовало бы.
2. Неправильное использование подстановочных знаков может деиндексировать ваш сайтПодстановочные знаки, такие как «*» и «$», являются допустимым вариантом для блокировки пакетов URL-адресов, которые, по вашему мнению, не представляют ценности для поисковых систем.Большинство больших роботов поисковых систем наблюдают и подчиняются, используя его в файле robots.txt. Кроме того, это хороший способ заблокировать доступ к некоторым глубоким URL-адресам, не перечисляя их все в файле robots.
Итак, если вы хотите заблокировать, скажем, URL-адреса с расширением PDF, вы можете записать строку в своем файле роботов с помощью User-agent: googlebot
Disallow: /*.pdf$
Подстановочный знак * представляет все доступные ссылки, оканчивающиеся на .pdf, а знак $ закрывает расширение.Подстановочный знак $ в конце расширения сообщает ботам, что сканировать нельзя только URL-адреса, заканчивающиеся на pdf, в то время как любой другой URL-адрес, содержащий слово «pdf» (например, pdf.txt), должен сканироваться.
Снимок экрана с сайта developers.google.com
* Примечание. Как и любой другой URL-адрес, файл robots.txt чувствителен к регистру, поэтому примите это во внимание при написании файла.
Другие варианты использования Robots.txtС момента первого появления файл robots.txt было обнаружено, что некоторые веб-мастера могут использовать его и в других целях. Давайте рассмотрим другие полезные способы использования этого файла.
1. Нанять крутых гиков Файл robotos.txt на сайтеTripadvisor.com был преобразован в скрытый файл найма. Это интересный способ отфильтровать из группы только «самых увлеченных» и найти именно тех людей, которые подходят для вашей компании. Посмотрим правде в глаза, в настоящее время ожидается, что люди, которые интересуются вашей компанией, будут уделять дополнительное время изучению ее, но люди, которые даже ищут скрытые сообщения в ваших роботах.txt великолепны.
2. Предотвратите проникновение на сайт ползуновЕще одно применение файла robots — не дать этим надоедливым сканерам съесть всю полосу пропускания. Командная строка Crawl-delay может быть полезна, если на вашем веб-сайте много страниц. Например, если на вашем веб-сайте около 1000 страниц, поисковый робот может просканировать весь ваш сайт за несколько минут. Размещение в командной строке Crawl-delay: 30 скажет им, что нужно немного расслабиться, использовать меньше ресурсов, и ваш веб-сайт просканируется через пару часов вместо нескольких минут.
Мы не рекомендуем это использование, так как Google не принимает во внимание команду crawl-delay, поскольку в Google Webmaster Tools есть встроенная функция настройки скорости сканирования. Использование функции задержки сканирования лучше всего подходит для других ботов, таких как Ask, Yandex и Bing.
3. Запретить конфиденциальную информациюЗапрет на конфиденциальную информацию — это палка о двух концах. Замечательно не предоставлять Google доступ к конфиденциальной информации и показывать ее во фрагментах тем людям, которым вы не хотите иметь к ней доступ.Но главным образом потому, что не все роботы подчиняются командам robots.txt, некоторые сканеры все еще могут иметь к нему доступ. Точно так же, если человек с неправильными намерениями выполнит поиск в вашем файле robots.txt, он сможет быстро найти области веб-сайта, содержащие ценную информацию. Мы советуем использовать его с умом и проявлять особую осторожность с размещаемой там информацией и помнить, что не только роботы имеют доступ к файлу robots.txt.
ЗаключениеЭто отличный пример того, что «большая сила дает большую ответственность», возможность направлять робота Googlebot с помощью хорошо написанного файла робота является соблазнительной.Как указано ниже, наличие хорошо написанного файла robots дает большие преимущества, лучшую скорость сканирования, отсутствие бесполезного контента для поисковых роботов и даже сообщений о найме на работу. Просто имейте в виду, что одна маленькая ошибка может причинить вам много вреда. Создавая файл robots, чтобы иметь четкое изображение пути, по которому роботы идут на вашем сайте, запретите их использование на определенных частях вашего веб-сайта и не блокируйте важные области контента. Также следует помнить, что файл robots.txt не является законным хранителем, роботы не обязаны подчиняться ему, а некоторые роботы и сканеры даже не пытаются найти файл и просто сканируют весь ваш веб-сайт.
Что такое файл Robots.txt в домене?
Если вы являетесь владельцем веб-сайта и заботитесь о его SEO-состоянии, вам следует хорошо ознакомиться с файлом robots.txt в своем домене. Вы не поверите, но очень большое количество людей быстро запускают домен, быстро устанавливают веб-сайт WordPress и никогда не делают ничего со своим файлом robots.txt.
Это опасно. Плохо настроенный файл robots.txt может фактически подорвать SEO вашего сайта и повредить любые ваши шансы на увеличение трафика.
Что такое файл Robots.txt?
Файл Robots.txt назван удачно, потому что это, по сути, файл, в котором перечислены директивы для веб-роботов (например, роботов поисковых систем) о том, как и что они могут сканировать на вашем веб-сайте. Это веб-стандарт, которому следуют веб-сайты с 1994 года, и все основные поисковые роботы придерживаются этого стандарта.
Файл хранится в текстовом формате (с расширением .txt) в корневой папке вашего веб-сайта. Фактически, вы можете просмотреть робота любого веб-сайта.txt, просто введя домен, а затем /robots.txt. Если вы попробуете это с помощью groovyPost, вы увидите пример хорошо структурированного файла robot.txt.
Файл простой, но эффективный. В этом примере файла отсутствуют различия между robots. Команды выдаются всем роботам с помощью директивы User-agent: * . Это означает, что все команды, следующие за ним, применяются ко всем роботам, которые посещают сайт для его сканирования.
Указание веб-сканеров
Вы также можете указать определенные правила для определенных веб-сканеров.Например, вы можете разрешить роботу Googlebot (поисковому роботу Google) сканировать все статьи на вашем сайте, но вы можете запретить русскому поисковому роботу Yandex Bot сканировать статьи на вашем сайте, содержащие пренебрежительную информацию о России.
Существуют сотни поисковых роботов, которые просматривают Интернет в поисках информации о веб-сайтах, но 10 наиболее распространенных, о которых следует беспокоиться, перечислены здесь.
- Googlebot : поисковая система Google
- Bingbot : поисковая система Microsoft Bing
- Slurp : поисковая система Yahoo
- DuckDuckBot : поисковая система DuckDuckGo
- поисковая машина Baiduspider
- Baiduspider 9032: китайский поисковик YandexBot : российская поисковая система Яндекс
- Exabot : французская поисковая система Exalead
- Facebot : сканирующий бот Facebook
- ia_archiver : поисковый робот Alexa
- MJ12bot 2
User-agent: googlebot
Disallow: Disallow: / wp-admin /
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: / wp-admin /
Disallow /wp-login.php
Disallow: / russia /
Как видите, первый раздел блокирует только сканирование вашей страницы входа в WordPress и административных страниц в Google. Второй раздел блокирует доступ Яндекса к той же, но и ко всей области вашего сайта, где вы публиковали статьи с антироссийским содержанием.
Это простой пример того, как вы можете использовать команду Disallow для управления определенными поисковыми роботами, которые посещают ваш веб-сайт.
Другие команды Robots.txt
Disallow — не единственная команда, к которой у вас есть доступ в файле robots.txt. Вы также можете использовать любые другие команды, которые будут указывать, как робот может сканировать ваш сайт.
- Disallow : Указывает агенту пользователя избегать сканирования определенных URL-адресов или целых разделов вашего сайта.
- Разрешить : Позволяет настраивать определенные страницы или подпапки на вашем сайте, даже если вы запретили родительскую папку. Например, вы можете запретить: / about /, но затем разрешить: / about / ryan /.
- Crawl-delay : указывает сканеру подождать xx секунд перед тем, как начать сканирование содержания сайта.
- Карта сайта: Предоставьте поисковым системам (Google, Ask, Bing и Yahoo) расположение ваших XML-карт сайта.
Помните, что боты будут только слушать команды, которые вы указали при указании имени бота.
Распространенная ошибка, которую делают люди, — запрещает использование таких областей, как / wp-admin / для всех ботов, но затем указывает раздел googlebot и запрещает только другие области (например, / about /).
Поскольку боты следуют только командам, указанным вами в их разделе, вам необходимо повторно ввести все те другие команды, которые вы указали для всех ботов (с помощью * user-agent).
- Disallow : команда, используемая для указания агенту пользователя не сканировать определенный URL. Для каждого URL разрешена только одна строка «Disallow:».
- Разрешить (применимо только для робота Googlebot) : команда, сообщающая роботу Googlebot, что он может получить доступ к странице или подпапке, даже если его родительская страница или подпапка могут быть запрещены.
- Задержка сканирования : сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что робот Googlebot не подтверждает эту команду, но скорость сканирования можно установить в консоли поиска Google.
- Карта сайта : Используется для вызова местоположения XML-карты (-ов) сайта, связанной с этим URL-адресом.Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
Помните, что файл robots.txt предназначен для более эффективного сканирования вашего сайта законными ботами (например, ботами поисковых систем).
Есть много гнусных поисковых роботов, которые сканируют ваш сайт, чтобы делать такие вещи, как очистка адресов электронной почты или кража вашего контента. Если вы хотите попробовать использовать свой файл robots.txt, чтобы заблокировать этим сканерам сканирование чего-либо на вашем сайте, не беспокойтесь. Создатели этих поисковых роботов обычно игнорируют все, что вы вложили в своих роботов.txt файл.
Почему что-то запрещать?
Заставить поисковую систему Google сканировать как можно больше качественного содержания на вашем веб-сайте — это основная задача большинства владельцев веб-сайтов.
Однако Google расходует только ограниченный бюджет сканирования и скорость сканирования на отдельных сайтах. Скорость сканирования — это количество запросов в секунду, которые робот Googlebot отправит вашему сайту во время сканирования.
Более важным является бюджет сканирования, который представляет собой общее количество запросов, которые робот Googlebot сделает для сканирования вашего сайта за один сеанс.Google «тратит» свой краулинговый бюджет, сосредотачиваясь на тех областях вашего сайта, которые очень популярны или изменились в последнее время.
Вы не закрываете глаза на эту информацию. Если вы зайдете в Инструменты Google для веб-мастеров, вы увидите, как сканер обрабатывает ваш сайт.
Как видите, поисковый робот поддерживает постоянную активность на вашем сайте каждый день. Он сканирует не все сайты, а только те, которые считает наиболее важными.
Зачем оставлять Googlebot решать, что важно на вашем сайте, если вы можете использовать своих роботов.txt, чтобы указать, какие страницы наиболее важны? Благодаря этому робот Googlebot не будет тратить время на малоценные страницы вашего сайта.
Оптимизация бюджета сканирования
Инструменты Google для веб-мастеров также позволяют проверить, правильно ли Googlebot читает ваш файл robots.txt и нет ли ошибок.
Это поможет вам убедиться, что вы правильно структурировали файл robots.txt.
Какие страницы следует запретить роботу Googlebot? Для SEO вашего сайта полезно запретить следующие категории страниц.
- Дубликаты страниц (например, страницы для печати)
- Страницы с благодарностями после заказов на основе форм
- Формы заказов или информационных запросов
- Страницы контактов
- Страницы входа в систему
- Страницы «продаж» для лид-магнита
Дон ‘ t Не обращайте внимания на файл robots.txt
Самая большая ошибка новых владельцев веб-сайтов — это то, что они никогда не смотрят свой файл robots.txt. Худшая ситуация может заключаться в том, что файл robots.txt фактически блокирует сканирование вашего сайта или его частей.
Обязательно просмотрите файл robots.txt и убедитесь, что он оптимизирован. Таким образом, Google и другие важные поисковые системы «видят» все невероятные вещи, которые вы предлагаете миру на своем веб-сайте.
Как правильно создать robots.txt для Google и Яндекс
Разрешить — Директива разрешает индексацию документов. Это директива по умолчанию для всех документов на сайте, если не указано иное.
Вы можете разрешить индексирование документов в URL, содержащих определенные символы.Стоит обратить внимание на правила директив application-Disallow Allow: «Директивы Allow и Disallow из соответствующего модуля User-agent отсортированы по длине префикса URL (от наименьшего к наибольшему) и применяются последовательно».
Sitemap — это директива для указания пути к файлу xml-sitemaps. Если на сайте более одного XML-документа, можно указать несколько путей.
Агент пользователя: *
Карта сайта: http://samplesite.com/sitemap1.xml
Карта сайта: http://samplesite.com/sitemap2.xml
Специальные символы
- * означает любую последовательность символов. Добавлен default в конце каждой директивы
- $ используется для удаления символа «*» в конце директивы
- # — это описывающий знак комментария. Все, что указано справа от этого знака, будет игнорироваться роботами.
Хост — это директива, определяющая главный зеркальный сайт.Учитывается только Яндексом. Google и другие просто игнорируют это.
Эта директива обеспечивает «склейку» зеркала www.site.com и site.com, а также других сайтов, основной хост которых указан в robots.txt.
Если зеркало доступно только через защищенный протокол, необходимо использовать адрес с протоколом https. В остальных случаях протокол не указывается. Чтобы настроить главное зеркало в поисковой системе Google, используйте «Настройки сайта» в консоли поиска Google.
Crawl-delay — минимальное время (в секундах) между загрузкой нескольких страниц. Эта директива используется пауками поисковых систем и не позволяет веб-сайту быть перегруженным. Чтобы ограничить это время в поисковой системе Google, используйте «Настройки сайта» в Google Search Console.
Clean-param используется для удаления параметров с url-адресов сайта. Учитывается только роботами Яндекса.
Может использоваться для удаления меток, фильтров, идентификаторов сеансов и других параметров.
Для правильной обработки тегов роботов Google используйте «URL настроек» в консоли поиска Google.
2. Руководство Google Search Console (GSC)
Как упоминалось ранее, некоторые функции, которые могут быть указаны для Яндекса в robots.txt, должны быть указаны в Google Search Console для роботов Google.
Чтобы указать основное зеркало в Google, вы должны подтвердить два зеркала (www.samplesite.com и samplesite.com) в GSC. Просмотрите настройки сайта (значок шестеренки), затем выберите ссылку «Конфигурация сайта» и поле «Основной домен», чтобы выбрать главное зеркало и сохранить изменения.
Для ограничения скорости сканирования сайта роботами Google необходимо подтвердить сайт в GSC. Просмотрите настройки сайта (знак шестеренки), там выберите ссылку «Конфигурация сайта» в поле «Скорость сканирования» выберите «Ограничить максимальную скорость сканирования Google» и установите приемлемое значение, затем сохраните изменения.
Чтобы указать, как Google будет обрабатывать настройки в url-адресе сайта, вам необходимо подтвердить свой сайт в GSC. Просмотрите раздел «Сканировать» — «Параметры URL», нажмите «Добавить параметр», заполните соответствующие поля и сохраните изменения.
3. Создание файла robots.txt
Ознакомившись с основными рекомендациями для файла robots.txt, приступим к компиляции файла robots.txt.
Во-первых, мы не рекомендуем слепо копировать содержимое шаблона robots.txt, которое вы можете найти в Интернете, потому что они просто не могут учесть все детали вашего сайта.
1. Первым шагом является добавление трех User-Agent robots.txt с одной пустой строкой между директивами
User-agent: Яндекс
Пользовательский агент: Googlebot
Пользовательский агент: *
Добавлен пользовательский агент *, если директивы будут различаться в зависимости от ботов поисковых систем.
2. Мы не рекомендуем индексировать файлы с разными расширениями.
Запрещено: * .pdf
Запрещено: * .xls
Запрещено: * .doc
Запрещено: * .ppt
Disallow: * .txt
Документы закрыты от индексации, потому что они могут показаться более релевантными, чем целевые страницы, специально оптимизированные для запроса.
Даже если на вашем сайте нет документов в указанных форматах, не удаляйте эти строки и оставьте их на будущее.
3. Добавьте все директивы User-agent, разрешающие индексацию файлов JS и CSS
Разрешить: * / <папка, содержащая css> / * css.
Разрешить: * / <папка, содержащая js> / * js.
JS и CSS открываются для индексации, потому что часто они находятся в системной папке, но они необходимы для правильной индексации.
4. Добавьте каждую директиву User-agent, разрешающую индексирование наиболее распространенных форматов изображений
Разрешить: * / <папка с медиафайлами> / * jpg.
Разрешить: * / <папка с медиафайлами> / * jpeg.
Разрешить: * / <папка с медиафайлами> / * png.
Разрешить: * / <папка с медиафайлами> / * gif.
Картинки открыты, чтобы избежать случайного отказа от индексации.
5. Чтобы избежать индексации utm-тегов и прочего, укажите это для роботов Яндекса.
Clean-param: utm_source & utm_medium & utm_term & utm_content & utm_campaign & yclid & gclid & _openstat & from /
6.Эти же параметры нужно закрыть из Google в разделе GSC «URL параметров» /
.Внимание! Если вы закроете Google от индексации тегов с помощью директивы запрета, вполне вероятно, что вы не сможете размещать рекламу на этих страницах в Google Adwords.
7. Запрет тегов индексации из * пользовательского агента
Запрещено: * utm
Запрещено: * clid =
Disallow: * openstat
Disallow: * от
8. Затем ограничьте индексирование всех системных документов и дубликатов.Вот пример таких страниц:
Администратор сайта
Персональные форумы пользователей
Корзины и стадии проектирования
Фильтры и сортировка в каталогах
9. Хост стоит в файле последним и понятен только Яндекс.
Хост: samplesite.com
10. Директива последняя, после всех директив через пустую строку указываются директивы xml-sitemaps, если используются на сайте
Карта сайта: http: // samplesite.ru / sitemap.xml
Шаблон файла robots.txt
Вот шаблон, который можно использовать как основу для компиляции файла robots.txt.
Пользовательский агент: Яндекс
Disallow: /*.pdf
Disallow: /*.xls
Disallow: /*.doc
Disallow: /*.ppt
Disallow: /*.txt
Разрешить: / * / <папка, содержащая css> / *. Css
Разрешить: / * / <папка, содержащая js> / *. Js
Разрешить: / * / <папка, содержащая медиафайлы> / *.jpg
Разрешить: / * / <папка с медиафайлами> / *. Jpeg
Разрешить: / * / <папка с медиафайлами> / *. Png
Разрешить: / * / <папка с медиафайлами> / *. Gif
Clean-param: utm_source & utm_medium & utm_term & utm_content & utm_campaign & yclid & gclid & _openstat & от
Хост: site.comПользовательский агент: Googlebot
Disallow: /*.pdf
Disallow: /*.xls
Запретить: / *.doc
Disallow: /*.ppt
Disallow: /*.txt
Разрешить: / * / <папка, содержащая css> / *. Css
Разрешить: / * / <папка, содержащая js> / *. Js
Разрешить: / * / <папка с медиафайлами> / *. Jpg
Разрешить: / * / <папка с медиафайлами> / *. Jpeg
Разрешить: / * / <папка с медиафайлами> / *. Png
Разрешить: / * / <папка с медиафайлами> / *. GifПользовательский агент: *
Disallow: / * utm
Disallow: / * clid =
Disallow: / * openstat
Disallow: / * от
Запретить: / *.pdf
Disallow: /*.xls
Disallow: /*.doc
Disallow: /*.ppt
Disallow: /*.txt
Разрешить: / * / <папка, содержащая css> / *. Css
Разрешить: / * / <папка, содержащая js> / *. Js
Разрешить: / * / <папка с медиафайлами> / *. Jpg
Разрешить: / * / <папка с медиафайлами> / *. Jpeg
Разрешить: / * / <папка с медиафайлами> / *. Png
Разрешить: / * / <папка с медиафайлами> / *. Gif
Карта сайта: http: // site.ru / sitemap.xml
Заключение
Помимо файла robots.txt существует множество других способов управления индексированием сайта. Но, по нашему опыту, действующий файл robots.txt помогает продвигать веб-сайт и защищать его от многих серьезных ошибок.
Мы надеемся, что наш опыт, изложенный в этой статье, поможет вам понять основные принципы создания файла robots.txt для Google и Яндекс.
Прощай, краулер: блокировка паразитов
Доводилось ли вам когда-нибудь сталкиваться с напористым количеством непослушных, гипер-агрессивных пауков, поражающих ваши серверы с частотой запросов до нескольких тысяч в секунду?
Как бы мы ни хотели, чтобы все поисковые системы мира обращали внимание на нашу ценность в Интернете — когда им действительно удавалось несколько раз вывести из строя вашу систему, вас могут простить за то, что вы сомневаетесь.Точно так же, когда они загружают ваши серверы с такой нагрузкой, у ваших посетителей может легко сложиться впечатление, что просмотр ваших страниц сродни продвижению через патоку — это препятствует продажам и репутации вашей компании, не говоря уже о том, что это что угодно, только не отличный пользовательский опыт.
Так что с этим делать? А как насчет того, чтобы просто заблокировать их? В конце концов, как всегда в бизнесе, вопрос заключается в том, на какой компромисс вы на самом деле застряли.
Не все пауки созданы равными, и только ваша конкретная онлайн-бизнес-модель должна определять ваше решение: либо терпеть, чтобы они регулярно посещали ваши страницы, либо приказывали им заблудиться.В конце концов, пропускная способность обходится недешево, и потеря продаж из-за плохой производительности сервера тоже не особенно забавна.
Вы вообще ориентируетесь на российский рынок? В противном случае вы вполне можете обойтись без всего этого трафика, создаваемого сканерами поисковых систем Яндекса.
А как насчет Китая? Япония? Корея? Китайские поисковые системы, такие как Baidu, SoGou и Youdao, весело спустят ваши сайты в небытие, если вы им позволите. В Японии это Goo, а в Южной Корее — Naver, который может превратиться в торпеду производительности, как только им понравится ваш сайт.
И это еще не все, потому что поисковые системы — не единственные виновники в этой области.
Довольны ли вы тем, что ваши конкуренты выясняют всю вашу стратегию создания ссылок (как входящих, так и исходящих)? В этом им поможет ряд сервисов. К счастью, по крайней мере один из основных претендентов, а именно Majestic-SEO, совершенно открыто говорит о вещах и позволяет вам изящно блокировать их сканеры. (Нет такой удачи с большинством других настроек…)
Помимо отслеживания ссылок, вы можете внимательно изучить такую службу, как Copyscape, которая будет беспечно сканировать весь ваш сайт * — для чего? Просто чтобы позволить конкурентам преследовать вас исками о нарушении авторских прав, если они найдут доказательства этого на любой из ваших страниц.Не поймите меня неправильно: я ни в коей мере не призываю к нарушению прав интеллектуальной собственности, как раз наоборот. (Имея опыт работы в офлайн-издательстве и розничной торговле книгами и имея в своем активе более 30 изданных книг, я являюсь ярым сторонником защиты авторских прав.)
Но если нарушение авторских прав — это именно то, что вы совершаете, , а не , какой смысл позволять какой-то самообслуживающейся коммерческой установке сторожевого пса в первую очередь съедать вашу пропускную способность и ресурсы сервера? Не то чтобы вы получали от них что-то взамен, правда?
В конце концов, это исключительно ваш выбор, блокировать определенных пауков или нет.Однако вот как это сделать, если вам действительно нужно.
Как запретить определенным паукам сканировать ваши страницы
Давайте кратко обсудим три различных способа блокировки пауков. Однако перед тем, как мы начнем, вам понадобятся некоторые фундаментальные данные для работы, чтобы надежно идентифицировать конкретных пауков. В основном это поле заголовка пользовательского агента (также известное как идентификатор) и, в случае Copyscape, исходный IP-адрес паука.
Базовые данные паука: пользовательские агенты
Яндекс (RU)
Российская поисковая система Яндекс имеет следующие пользовательские агенты:
Mozilla / 5.0 (совместимый; ЯндексБлоги / 0.99; робот; B; + http: //yandex.com/bots)
Mozilla / 5.0 (совместимый; YandexBot / 3.0; + http: //yandex.com/bots)
Mozilla /5.0 (совместимый; ЯндексБот / 3.0; MirrorDetector; + http: //yandex.com/bots)
Mozilla / 5.0 (совместимый; ЯндексМедиа / 3.0; + http: //yandex.com/bots)
YandexSomething / 1.0
Goo (JP)
Японская поисковая система Goo включает следующие пользовательские агенты:
DoCoMo / 2.0 P900i (c100; TB; W24h21) (совместимый; ichiro / mobile goo; + http: //help.goo.ne.jp/help/article/1142/)
ichiro / 2.0 (http: // help .goo.ne.jp / door / crawler.html)
moget / 2.0 ([адрес электронной почты защищен])
Naver (KR)
Корейская поисковая система Naver имеет следующие пользовательские агенты:
Mozilla / 4.0 (совместимый; NaverBot / 1.0; http://help.naver.com/customer_webtxt_02.jsp)
Baidu (CN)
Поисковая система номер один в Китае, Baidu, включает в себя следующих пользовательских агентов:
Baiduspider + (+ http: //www.baidu.com/search/spider.htm)
Baiduspider + (+ http: //www.baidu.jp/spider/)
SoGou (CN)
Китайская поисковая система SoGou имеет следующие пользовательские агенты:
Sogou Pic Spider / 3.0 (http://www.sogou.com/docs/help/webmasters.htm#07)
Головной паук Sogou / 3.0 (http://www.sogou.com/docs/help/webmasters.htm#07)
Веб-паук Согоу / 4.0 (+ http: //www.sogou.com/docs/help/webmasters.htm#07)
Паук Согоу Орион / 3.0 (http://www.sogou.com/docs/help/webmasters. htm # 07)
Sogou-Test-Spider / 4.0 (совместимый; MSIE 5.5; Windows 98)
sogou spider
Sogou Pic Agent
Youdao (CN)
Китайская поисковая система Youdao (которая иногда называет себя «Йодао») имеет следующих пользовательских агентов:
Mozilla / 5.0 (совместимый; YoudaoBot / 1.0; http://www.youdao.com/help/webmaster/spider/;)
Mozilla / 5.0 (совместимый; YodaoBot-Image / 1.0; http://www.youdao.com/help / webmaster / spider /;)
Majestic-SEO
Служба анализа ссылок Majestic-SEO http://www.majesticseo.com/ использует распределенную поисковую систему Majestic-12:
Majestic-12
UA: Mozilla / 5.0 (совместимый; MJ12bot / v1.3.3; http://www.majestic12.co.uk/bot.php?+)
Copyscape
Copyscape Plagiarism Checker — программа для обнаружения дублированного контента
Информация о сайте: http: // www.copyscape.com
Copyscape
Пользовательский агент: Mozilla / 4.0 (совместимый; MSIE 6.0; Windows NT 5.1)
IP: 212.100.254.105
Хост: googlealert.com
Copyscape работает закулисно, скрывая своего паука за общим пользовательским агентом и доменным именем, которое дает вам совершенно ложное впечатление о том, что он каким-то образом связан с Google, хотя на самом деле он принадлежит самому Copyscape.
Это означает, что вы не можете идентифицировать их подлого паука через поле заголовка User Agent.Единственный надежный способ заблокировать это — через их IP.
Блокирующие пауки через robots.txt
Общие сведения о протоколе robots.txt см. По адресу: http://www.robotstxt.org/
Поисковые системы призваны сообщать, какой код следует развернуть в данном файле robots.txt, чтобы запретить своим паукам доступ к страницам сайта. Более того, страницу с описанием этого процесса должно быть легко найти.
К сожалению, у большинства перечисленных выше пауков есть свои роботы.txt только на китайском, японском, русском или корейском языках — не очень полезны для среднего англоговорящего веб-мастера.
В следующем списке представлены информационные ссылки для веб-мастеров и код, который вам следует развернуть для блокировки определенных пауков.
Яндекс (RU)
Информация: http://yandex.com/bots не дает нам информации об использовании robots.txt, специфичных для Яндекса.
Требуемый код robots.txt:
User-agent: Яндекс
Disallow: /
Goo (JP)
Информация (японский): http: // help.goo.ne.jp/help/article/704/
Информация (на английском языке): http://help.goo.ne.jp/help/article/853/
Требуемый код robots.txt:
Агент пользователя: moget
Агент пользователя: ichiro
Запрещение: /
Naver (KR)
Информация: http://help.naver.com/customer/etc/webDocument02.nhn
Требуемый код robots.txt:
Агент пользователя: NaverBot
Агент пользователя: Yeti
Запрещение: /
Baidu (CN)
Информация: http: // www.baidu.com/search/spider.htm
Требуемый код robots.txt:
User-agent: Baiduspider
User-agent: Baiduspider-video
User-agent: Baiduspider-image
Disallow: /
SoGou (CN)
Информация: http://www.sogou.com/docs/help/webmasters.htm#07
Требуемый код robots.txt:
Агент пользователя: sogou spider
Disallow: /
Youdao (CN)
Информация: http: // www.youdao.com/help/webmaster/spider/
Требуемый код robots.txt:
Пользовательский агент: YoudaoBot
Disallow: /
Поскольку протокол robots.txt не позволяет блокировать IP-адреса, вам придется прибегнуть к одному из двух следующих методов, чтобы заблокировать пауков Copyscape..»Означает, что пользовательский агент должен начинаться с указанной строки (например,« Baiduspider »).
Таким образом, если вы хотите, например, заблокировать пауков Яндекса, вы можете использовать следующий код:
RewriteCond% {HTTP_USER_AGENT} Яндекс
В данном конкретном случае блокировка будет происходить всякий раз, когда в идентификаторе User Agent встречается строка «Яндекс».
Как упоминалось выше, Copyscape можно заблокировать только через их IP.212.100.254.105 $
Блокировка пауков через файл конфигурации Apache httpd.conf
Альтернативный метод блокировки пауков может быть запущен из файла конфигурации веб-сервера Apache, указав в нем соответствующие поля заголовка User Agent. Основное преимущество этого подхода в том, что он будет применяться ко всему серверу (то есть не ограничен отдельными доменами). Это может сэкономить вам много времени и усилий, при условии, что вы действительно хотите применять эти блоки-пауки единообразно во всей вашей системе.Sogou »bad_bots
SetEnvIf Remote_Addr« 212.100.254.105 »bad_bot
Разрешить заказ, отказать
Разрешить со всех
Запретить от env = bad_bots
…
* Технический директор и основатель Copyscape утверждает, что это утверждение неверно.
Пользовательский агент: * Запретить: / wp-admin / Разрешить: / wp-admin / admin-ajax.php Disallow: / *? * Разрешить: /*.css$ Разрешить: /*.js$ Карта сайта: https://www.coverlambygrespania.com/sitemap_index.xml Карта сайта: https://www.coverlambygrespania.com/page-sitemap.xml Карта сайта: https://www.coverlambygrespania.com/post-sitemap.xml Карта сайта: https://www.coverlambygrespania.com/portfolio-sitemap.xml Карта сайта: https://www.coverlambygrespania.com/product-sitemap1.xml Карта сайта: https://www.coverlambygrespania.com/product-sitemap2.xml #Bloqueo de bots y crawlers poco utiles Пользовательский агент: «Net Probe» Пользовательский агент: «Агент SSM» Пользовательский агент: «Том бот» Пользовательский агент: «TSW Bot» Пользовательский агент: «Веб-загрузчик» Пользовательский агент: Acrobat Пользовательский агент: AISearchBot Пользовательский агент: baidu * Пользовательский агент: Baiduspider Пользовательский агент: Baiduspider + (+ http: // www.baidu.com/search/spider.htm) Пользовательский агент: Baiduspider + (+ http: //www.baidu.jp/spider/) Пользовательский агент: Baiduspider-image Пользовательский агент: Baiduspider-video Пользовательский агент: Черная дыра Пользовательский агент: BlackWidow Пользовательский агент: BlackWidow 4.40 Пользовательский агент: cfetch / 1.0 Пользовательский агент: CheeseBot Пользовательский агент: CherryPicker Пользовательский агент: Comodo + HTTP (S) + Crawler Пользовательский агент: ConveraMultiMediaCrawler / 0.1 Пользовательский агент: dloader (NaverRobot) Пользовательский агент: dloader (Speedy Spider) Пользовательский агент: dotbot Пользовательский агент: EmailCollector Пользовательский агент: EmailSiphon Пользовательский агент: EmailWolf Пользовательский агент: EverbeeCrawler Пользовательский агент: ExtractorPro Пользовательский агент: флеш-процессор User-agent: flash + процессор Пользовательский агент: flatlandbot Пользовательский агент: flatlandbot / baypup Пользовательский агент: grub-client Пользовательский агент: HLoader User-agent: home.thenewweb.com Пользовательский агент: htdig / 3.1.5 Пользовательский агент: HTTrack Пользовательский агент: ia_archiver Пользовательский агент: Ичиро Пользовательский агент: Ичиро Пользовательский агент: iCollect Пользовательский агент: iGetter Пользовательский агент: ImageWalker Пользовательский агент: Отраслевая программа Пользовательский агент: Indy Пользовательский агент: Indy Library Пользовательский агент: Innerprise Пользовательский агент: InstallShield Пользовательский агент: InternetLinkAgent / Пользовательский агент: IntScanner Пользовательский агент: ipd Пользовательский агент: IPiumBot Пользовательский агент: Ирия Пользовательский агент: IUPUI Research Bot Пользовательский агент: Java Пользовательский агент: Java1 Пользовательский агент: Java1.3.0 Пользовательский агент: Java1.3.1 Пользовательский агент: Java2 Пользовательский агент: JoBo Пользовательский агент: JOC Web Spider Пользовательский агент: johnhasbeenhere Пользовательский агент: jscript + процессор Пользовательский агент: Капере Пользовательский агент: Lachesis Пользовательский агент: Ларбин Пользовательский агент: larbin_2.6.1 Пользовательский агент: larbin_2.6.1 [email protected] Пользовательский агент: larbin_2.6.2 Пользовательский агент: larbin_2.6.2 [email protected] Пользовательский агент: LeechGet Пользовательский агент: libwww-perl Пользовательский агент: LightningDownload Пользовательский агент: LinkAlarm Пользовательский агент: LinkChecker Пользовательский агент: LinkLint-checkonly Пользовательский агент: Linkman Пользовательский агент: LLUPDATECTRL Пользовательский агент: Mac Finder Пользовательский агент: Mail Sweeper Пользовательский агент: Mass Пользовательский агент: Массовый загрузчик Пользовательский агент: McBot Пользовательский агент: MetaProducts Пользовательский агент: MetaProducts Download Express Пользовательский агент: MFC_Tear_Sample Пользовательский агент: MFHttpScan Пользовательский агент: moget Пользовательский агент: moget Пользовательский агент: Mozilla / 4.0 (совместимый; NaverBot / 1.0; http://help.naver.com/customer_webtxt_02.jsp) User-agent: Mozilla / 5.0 (совместимый; ЯндексБлоги / 0.99; робот; B; + http: //yandex.com/bots) Пользовательский агент: Mozilla / 5.0 (совместимый; ЯндексБот / 3.0; + http: //yandex.com/bots) User-agent: Mozilla / 5.0 (совместимый; YandexBot / 3.0; MirrorDetector; + http: //yandex.com/bots) Пользовательский агент: Mozilla / 5.0 (совместимый; ЯндексМедиа / 3.0; + http: //yandex.com/bots) Пользовательский агент: MyGetRight Пользовательский агент: Naver Пользовательский агент: NaverBot Пользовательский агент: NaverRobot Пользовательский агент: NetPumper Пользовательский агент: NEWT Пользовательский агент: NextGenSearchBot Пользовательский агент: NICErsPRO Пользовательский агент: Nitro Пользовательский агент: Nitro Downloader Пользовательский агент: Nudelsalat Пользовательский агент: Nutch Пользовательский агент: oBot Пользовательский агент: Offline Пользовательский агент: Offline Explorer Пользовательский агент: page_prefetcher Пользовательский агент: PagmIEDownload Пользовательский агент: павук Пользовательский агент: PixGrabber Пользовательский агент: PlantyNet_WebRobot Пользовательский агент: Plucker Пользовательский агент: Pockey Пользовательский агент: Popdexter Пользовательский агент: Программа Пользователь-агент: Программа Условно-бесплатная Пользовательский агент: Прогрессивный Пользовательский агент: прогрессивная загрузка Пользовательский агент: ProWebWalker Пользовательский агент: ProxyTester Пользовательский агент: psbot Пользовательский агент: puf Пользовательский агент: PuxaRapido Пользовательский агент: Python-urllib Пользовательский агент: Python-webchecker Пользовательский агент: RealDownload Пользовательский агент: RepoMonkey Пользовательский агент: RepoMonkey Bait & Tackle Пользовательский агент: RobotMidareru Пользовательский агент: RPT-HTTPClient Пользовательский агент: Scat Пользовательский агент: ScoutAbout Пользовательский агент: семантическое открытие Пользовательский агент: Сифон Пользовательский агент: SiteSnagger Пользовательский агент: SiteSnagger Пользовательский агент: SiteWinder Пользовательский агент: Slurp Пользовательский агент: SlySearch Пользовательский агент: SmartDownload Пользовательский агент: SOFTWING_TEAR_AGENT Пользовательский агент: Согоу голова паука / 3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Пользовательский агент: Sogou Orion spider / 3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Пользовательский агент: Sogou Pic Agent Пользовательский агент: Sogou Pic Spider / 3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Пользовательский агент: sogou spider Пользовательский агент: sogou spider Пользовательский агент: Sogou web spider / 4.0 (+ http: //www.sogou.com/docs/help/webmasters.htm#07) Пользовательский агент: Sogou-Test-Spider / 4.0 (совместимый; MSIE 5.5; Windows 98) Пользовательский агент: Sonic Пользовательский агент: Sosospider Пользовательский агент: SpeedDownload Пользовательский агент: Speedy Пользовательский агент: звездочка Пользовательский агент: SQ Пользовательский агент: SQ Webscanner Пользовательский агент: Stamina Пользовательский агент: Star Пользовательский агент: Star Downloader Пользовательский агент: Стилер Пользовательский агент: SuperHTTP Пользовательский агент: SurveyBot Пользовательский агент: SynoBot User-agent: телепорт Пользовательский агент: Телепорт Пользовательский агент: телепорт про Пользовательский агент: thunderstone Пользовательский агент: TurnitinBot Пользовательский агент: TurnitinBot Пользовательский агент: TweakMASTER Пользовательский агент: Twiceler Пользовательский агент: UdmSearch User-agent: не разглашается Пользовательский агент: URLGetFile Пользовательский агент: UtilMind Пользовательский агент: UtilMind HTTPGet Пользовательский агент: VCIKJZDDLS Пользовательский агент: vobsub Пользовательский агент: voyager / 2.0 Пользовательский агент: voyager-hc / 1.0 Пользовательский агент: веб-загрузчик Пользовательский агент: WebAlta Пользовательский агент: WebAuto Пользовательский агент: WebCapture Пользовательский агент: Webclipping.com Пользовательский агент: webcollage Пользовательский агент: WebCopier Пользовательский агент: WebCopier Пользовательский агент: Webinator Пользовательский агент: WebLeacher Пользовательский агент: WEBMOLE Пользовательский агент: WebReaper Пользовательский агент: WebSauger Пользовательский агент: Website eXtractor Пользовательский агент: Вебстер Пользовательский агент: WebStripper Пользовательский агент: WebStripper Пользовательский агент: WebZIP Пользовательский агент: WebZIP Пользовательский агент: WEP Search Пользовательский агент: WEP Search 00 Пользовательский агент: Wget Пользовательский агент: WhizBang Пользовательский агент: whsearch Пользовательский агент: Wildsoft Пользовательский агент: Wildsoft Surfer Пользовательский агент: WinHttp.WinHttpRequest Пользовательский агент: woriobot Пользовательский агент: www4mail Пользовательский агент: WWWOFFLE Пользовательский агент: Xaldon Пользовательский агент: Xaldon WebSpider Пользовательский агент: xEdit Пользовательский агент: Xenu User-agent: Яндекс Пользовательский агент: яндекс * Пользовательский агент: YandexSomething / 1.