Что такое robots.txt и как правильно его заполнять | Шпаргалка
Поисковые системы постоянно бродят по сети для осуществления проверки «старых» и обнаружения новых веб-сайтов, в результате чего им удаётся обновить или пополнить свою базу данных.
К счастью, поисковики управляются не вручную, а с использованием специальных инструментов. Чтобы боты-поисковики самостоятельно не хозяйничали на вашем интернет-ресурсе, требуется грамотно прописанный robots.txt.
Что такое robots.txt?
Robots.txt (ещё его называют стандарт исключений) — текстовый файл, содержащий в себе свод правил (требований), адресованных к ботам-поисковикам. Простыми словами: в нём прописываются указания — какие страницы рекомендованы к обработке, а какие не рекомендованы.
Важно понимать, что это руководство не воспринимается в качестве обязательной к выполнению команды, а в большей степени носит рекомендательный характер.
Файл кодируется в UTF-8, функционирует для протоколов FTP, http, https. Его нужно вставить в корневой каталог веб-ресурса. Попадая на сайт, бот разыскивает robots.txt, считывает его и в дальнейшем, как правило, действует согласно прописанным рекомендациям.
А если робот не найдёт данный файл? Он продолжит свою работу на ресурсе, но начнёт скачивание и анализ всех его страниц. В ряде случаев это совершенно не нужно.
Для чего нужен robots.txt?
- Увеличение скорости обработки ресурса. Опираясь на изложенные рекомендации, поисковой бот работает с требуемыми для вас страницами, а не со всеми подряд. Соответственно, вам удаётся обратить его внимание на первоочередную информацию.
- Повышение скорости индексации. В связи с тем, что за 1 визит робот обрабатывает определённое количество веб-страниц, возникает необходимость в быстрой индексации, особенно нового контента.
Так вы сможете защитить контент от кражи и проследить, как он повлиял на позиции сайта в поисковой выдаче.
- Уменьшение нагрузки на сайт. Нежелательно, чтобы робот постоянно скачивал большой объём информации, потому что из-за этого работа ресурса может существенно замедлиться.
- Сокрытие «поискового мусора»
Что закрывать в robots.txt?
- страницы поиска — при условии, когда вы не строите планы на их проработку и модерацию;
- корзину онлайн-магазина, страницу оформления заказа, сравнение, сортировку и фильтры товаров/услуг;
- веб-страницы для регистрации/авторизации и личный кабинет пользователей, списки желаний, профили, фиды и тому подобное;
- landing page, сформированные специально для акционных предложений, скидок, распродаж;
- системные каталоги/файлы, пустые страницы, версии для печати и языковые версии, не подлежащие оптимизации.
В общем, необходимо закрывать сведения, бесполезные для пользователей, а также ещё недоработанные страницы и дубли.
Структура robots.txt
Строение файла выглядит просто. Он включает ряд блоков, адресованных конкретным ботам-поисковикам. В этих блоках прописываются директивы (команды) для управления ходом индексации.
Дополнительно можно проставлять комментарии. Чтобы они игнорировались поисковиком, нужно использовать знак #. Каждый комментарий начинается и заканчивается этим символом. Кроме того, не рекомендуется вставлять символ комментария внутри директивы.
Robots.txt создаётся одним из удобных для вас методов:
- вручную с использованием текстового редактора, после чего он сохраняется с расширением *. txt.
- автоматически с применением онлайн-программ.
Большинство специалистов работают с файлом вручную — процесс достаточно прост, занимает немного времени, но при этом вы будете уверены в правильности его написания.
В любом случае, автоматически сформированные файлы обязательно подлежат проверке, ведь от этого зависит, насколько хорошо будет функционировать ваш сайт.
Операторы в robots.txt
Прежде, чем мы перейдём к обзору директив, ознакомимся с дополнительными операторами. Про символ # мы поговорили выше. Кроме него вам могут потребоваться следующие операторы:
«*» сообщает, что допускается любое число символов или таковые отсутствуют;
«$» поясняет, что находящийся перед ним символ является последним.
Директива User-agent
Адресует ваши команды определённому боту-поисковику. Именно с неё вы начинаете прописывать robots.txt.
User-agent: Yandex
(правила задаются для всех роботов Яндекса)
User-agent: Google
(правила задаются для всех роботов Google)
User-agent: *
(правила задаются для всех поисковых систем)
Обращаю ваше внимание: когда поисковой робот обнаруживает своё имя после User-agent, то он не воспринимает все команды, которые вы зададите в блоке User-agent: *.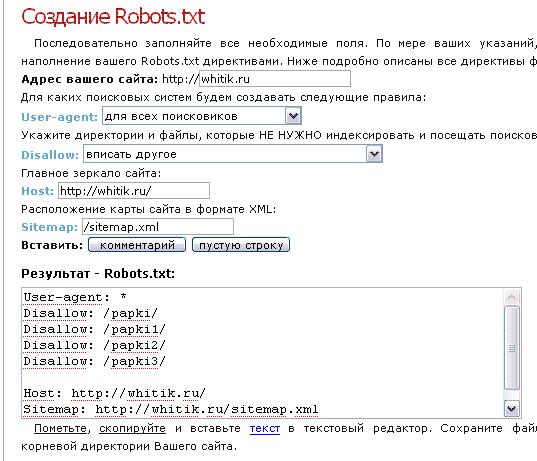
И ещё, у отдельных поисковых систем существует целая группа ботов, команды для которых можно задавать в индивидуальном порядке. При этом блоки с рекомендациями для таких ботов разбиваются путём оставления пустой строки.
Поисковые роботы Google:
- Googlebot — основной бот системы;
- Googlebot-Image — обрабатывает изображения;
- Googlebot-Video — отслеживает видео-контент;
- Googlebot-Mobile — работает со страницами для мобильных девайсов;
- Adsbot-Google — анализирует качество рекламы на веб-страницах для персональных компьютеров;
- Googlebot-News — определяет веб-страницы, которые следует внести в Новости Google.
Поисковые роботы Yandex:
- YandexBot — основной бот системы;
- YandexImages — обрабатывает изображения;
- YandexNews — определяет веб-страницы для добавления в Яндекс.
- YandexMedia — отслеживает мультимедиа контент;
- YandexMobileBot — работает со страницами для мобильных девайсов.
Директива Disallow
Самая популярная команда — выдаёт запрет на индексацию страниц.
Примеры:
Disallow: /
(закрытие доступа ко всему веб-ресурсу)
Disallow: /admin/
(закрытие доступа к панели администратора)
Disallow: /*png*
(закрытие доступа на обработку документов заданного типа)
Директива Allow
Даёт право обрабатывать поисковикам заданные вами веб-страницы. Это особенно актуально в процессе ведения техработ на сайте.
Например, вы модернизируете веб-ресурс, но каталог с товарами не подлежит изменениям. Вы закрываете доступ к своему сайту, а ботов направляете только к нужному вам разделу.
Пример:
Allow: /product
Директива Host
До недавнего времени применялась для показа роботам Яндекса основного зеркала веб-сайта — с www или без.
Весной 2018 г. российская ИТ-компания проинформировала пользователей, что директива заменяется на редирект 301 — универсальный метод для всех работающих поисковиков, который указывает на основной сайт.
На сегодняшний день эта команда бесполезна. Но если она проставлена в файле, то ничего страшного — поисковые боты её просто игнорируют.
Директива Sitemap
Предназначена для указания пути к Карте вашего ресурса. По-хорошему, sitemap.xml должен храниться в корне веб-сайта. В случае, когда путь отличается, эта команда позволяет найти поисковикам Карту.
Sitemap: https://site.ru/site_structure/my_sitemaps1.xml
Директива Clean-param
Её задача — пояснить боту, что нет необходимости в индексировании страницы с определёнными параметрами. Это относится к динамическим ссылкам, ведь они периодически формируются в ходе работы веб-сайта и образуют дубли — то есть одинаковая страница становится доступна на нескольких адресах.
Тогда применяется «ref» — параметр, позволяющий выявить источник ссылки.
Пример:
www.site.ru/some_dir/get_book.pl?ref=site_1&book_id=1
www. site.ru/some_dir/get_book.pl?ref=site_2&book_id=1
www. site.ru/some_dir/get_book.pl?ref=site_3&book_id=1
Результат:
User-agent: Yandex
Clean-param: ref /some_dir/get_book.pl
Таким образом поисковик сведёт все URL к одной странице. Она будет участвовать в поисковой выдаче при условии её наличия на веб-сайте:
www.site.ru/some_dir/get_book.pl?book_id=123
Директива Crawl-Delay
Команда предназначена, чтобы уведомить бота-поисковика о продолжительности загрузки страницы (в секундах). Она позволяет снизить нагрузку на веб-ресурс. Это актуально, когда веб-сайт размещён на слабом сервере.
Выглядит это так:
Crawl-delay: 3.5
(вы уведомили поисковика, что можно скачивать данные каждые 3. 5 секунд)
5 секунд)
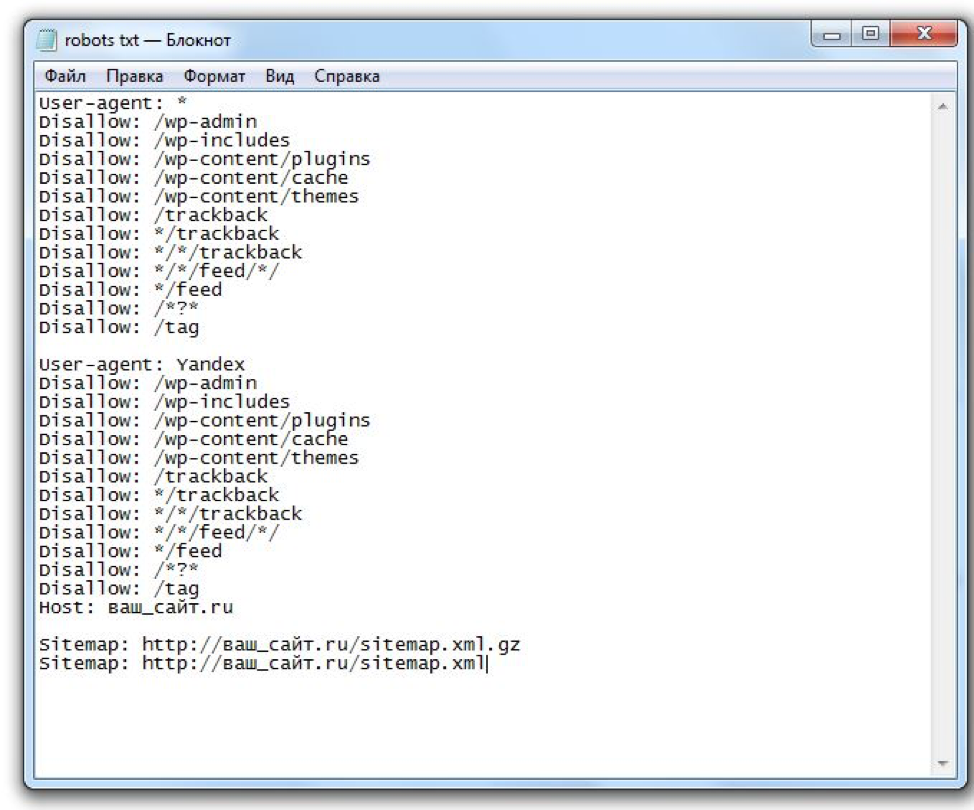
Написание и проверка robots.txt
Теперь вы знаете, какими директивами и как пользоваться. Переходите к написанию файла:
- Откройте текстовый редактор, к примеру, Блокнот.
- Пропишите содержимое.
- Сохраните документ с именем robots в формате txt.
- Опубликуйте файл в корневой каталог.
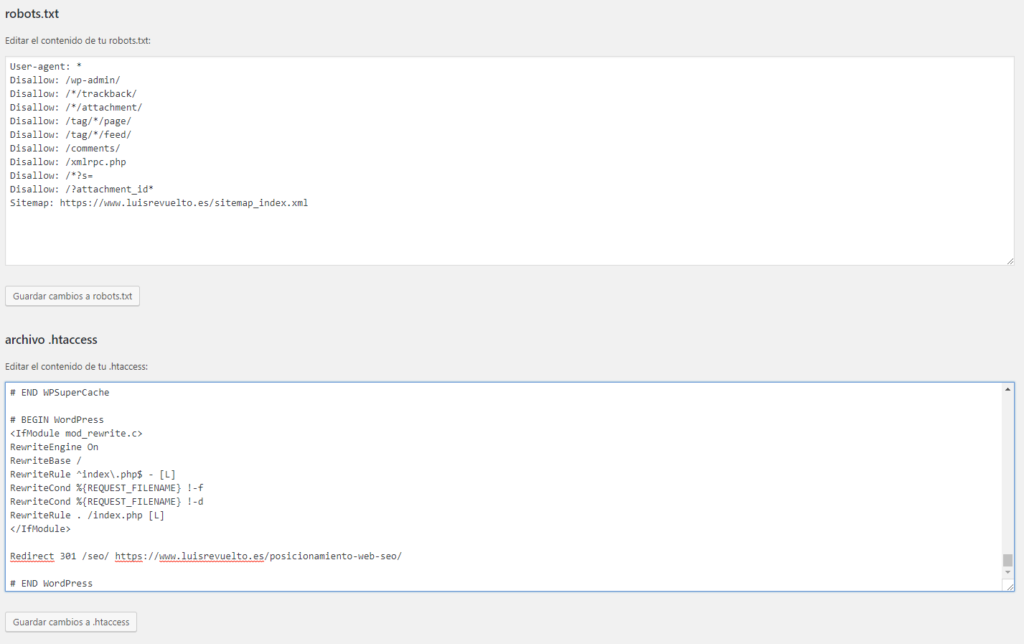
Не загружайте готовый robots.txt сразу на веб-сайт. Сначала сделайте его проверку одним из методов:
- В Google Search Console.
Для этого нужно открыть «Сканирование» — «Инструмент проверки файла robots.txt». Потом вставляем содержимое robots.txt в указанное поле и задаём адрес веб-сайта. Кликаем «Проверить».
Google автоматически укажет вам на имеющиеся ошибки и покажет предупреждения. При наличии таковых нужно внести корректировки.
Кроме того, пользуясь инструментами системы, вы можете получать уведомления о появившихся ошибках — они будут доступны в админке Console.
- В Яндекс.
 Вебмастер.
Вебмастер.
Откройте «Инструменты» — «Анализ robots.txt». Всё происходит аналогично предыдущему способу — вводим адрес веб-сайта, копируем и вставляем содержимое написанного файла.
Кликаем «Проверить» и получаем результаты — ошибки и предупреждения.
Распространённые ошибки robots.txt
- Отсутствие значений после Disallow. Оставив команду пустой, вы автоматически разрешаете индексацию всего веб-сайта.
Disallow:
- Указание нескольких папок в Disallow. Запрещено перечислять их с помощью запятых/пробелов. Каждая последующая рекомендация прописывается в новой строке.
Disallow: /category-10
Disallow: /category-11
- Неверно указано имя.
robots.txt — правильно, Robots.txt — неправильно.
- В User-agent указан более, чем один робот. Для каждого бота директива проставляется отдельно.
User-agent: Yandex
- В директиве отображён адрес страницы.

Disallow: http://site.ru/ivanov
Неправильно!
Disallow: /ivanov
Правильно!
Вывод
Написать файл совершенно несложно — нужно быть предельно внимательным, внося директивы и операторы. Однако при выполнении задачи следует проявить творческий подход.
Размещение robots.txt не должно ухудшать позиции веб-сайта в результатах выдачи поисковых систем, но при этом его наличие должно стать ограничением для бесполезных хождений роботов по страницам ресурса.
Как писать robots.txt
Файл robots.txt — это обычный текстовый файл. Вы можете его создать, открыв Блокнот в Windows или TextEdit на Mac. Файлы роботс существуют для того, чтобы рекомендовать поисковому движку или какому-то конкретному роботу, как проходить сайт по ссылкам.
Что писать в файле?
Блоки агентов
Robots. txt содержит инструкции, которые должны быть написаны по определенным правилам. Большинство инструкций находится в блоке агента. Агент (поисковый робот) описывается так:
txt содержит инструкции, которые должны быть написаны по определенным правилам. Большинство инструкций находится в блоке агента. Агент (поисковый робот) описывается так:
Для конкретного робота: User-agent: название бота
Для группы роботов (например для всех роботов яндекса): User-agent: название группы ботов
Для всех роботов: User-agent: *
Все, что находится между двумя записями user-agent (или от последнего user-agent до конца файла), относится к этому боту или этой группе ботов.
Например:
User-agent: yandex Disallow: / User-agent: googlebot Allow: /
Означает, что всем ботам Яндекса (User-agent для группы ботов Yandex) запрещено проходить по ссылкам на любые страницы сайта (инструкция Disallow: /), а ботам Гугла, наоборот, разрешено переходить по любым ссылкам (инструкция Allow: /).
Приоритеты блоков агентов
Любой робот сначала ищет блок со своим именем (инструкции именно для этого робота), если он находит такой блок — он использует инструкции из этого блока, остальные игнорирует; если не находит — ищет блок для своей группы и использует только его инструкции; если не находит — использует блок для всех роботов; если и этого блока нет, робот считает, что разрешен проход по всем ссылкам на сайте.
Например:
User-agent: * Disallow: /
User-agent: googlebot Disallow: /not-for-google
User-agent: googlebot-mobile Disallow: /not-for-google Disallow: /not-mobile
Мобильный робот Гугл (googlebot-mobile) будет использовать строки: Disallow: /not-for-google Disallow: /not-mobile
Бот гугл картинок (googlebot-image) использует: Disallow: /not-for-google
Бот яндекса использует: Disallow: /
Инструкции, запрещающие переходы на страницы
Чтобы запретить проходить страницы на сайте, используется инструкция Disallow: что именно запретить.
Например, чтобы запретить все страницы в папке https://example.com/category/, мы пишем Disallow: /category/,
т.е. мы пишем адрес страницы, которую надо закрыть от переходов робота. При этом закроются все страницы, адрес которых начинается с /category/.
Специальные символы * и $
Любые символы *
Символ * означает “любой набор символов” Например Disallow: *.html Запретит переходить на все ссылки сайта, в которых встречается .htm: https://example.com/smth.htm https://example.com/index.html
Обратите внимание, что любой адрес в Disallow… начинается либо с / либо с *.
Символ конца строки $
Символ $ означает конец адреса например, если нам надо, чтобы https://example.com/category/ не должно проходиться роботом, а все что в него вложено,
Например https://example.com/category/123 должно,
Тогда пишем Disallow: /category/$
Инструкции, разрешающие переходы по ссылкам
Есть инструкция Allow, которая работает также, как и Disallow, только имеет обратный эффект — страницы, соответствующие адресу в Allow будут разрешены к переходам по ссылкам.
Если для одного и того же адреса присутствуют и инструкции Allow, и инструкции Disallow, то будет применяться та, в которой адрес страницы (то что идет после двоеточия после Allow или Disallow) будет длиннее.
Например
User-agent: Somebot
Disallow: / Allow: /cat/ Disallow: /cat/123
Страница https://example.com/123 будет запрещена (подходит только правило Disallow: /) Страница https://example.com/cat/ будет разрешена (подходят Disallow: / и Allow: /cat/, но /cat/ длиннее чем /) Страница https://example.com/cat/12345 будет запрещена, т.к. Подходят все три правила, но /cat/123 длиннее всех остальных
Инструкции карт сайта
Чтобы указать путь к карте сайта в стандарте sitemap.xml, используется инструкция Sitemap: адрес карты сайта
Если карт сайта несколько, при этом есть файл списка sitemap — указывается только его адрес. Если карт сайта несколько, но индексного файла нет — пишется отдельная инструкция для каждой карты сайта,
Если карт сайта несколько, но индексного файла нет — пишется отдельная инструкция для каждой карты сайта,
например: Sitemap: https://example.com/sitemap1.xml Sitemap: https://example.com/sitemap2.xml Sitemap: https://example.com/sitemap3.xml
Обратите внимание, путь к файлу указывается вместе с протоколом (http:// или https://) и адресом сайта.
Инструкция Sitemap не относится к спискам агентов и будет использована всеми роботами независимо от того, где она написана.
Инструкция задержки обхода
Сейчас такая инструкция почти нигде не используется, но все-таки мы её опишем. Иногда, если хостинг сайта очень слабый, и обход роботом может затормозит работу сайта, используется инструкция Crawl-delay: время в секундах между запросами робота
Например: Crawl-delay: 0.5
Сделает так, что робот будет запрашивать страницы сайта не чаще, чем раз в полсекунды.
Инструкция Crawl-delay относится к секциям агентов т.е. можно задать разный Crawl-delay для разных роботов.
Инструкция указания основного зеркала (только Яндекс)
Эта инструкция не входит в стандарт robots.txt и придумана Яндексом. Она служит для определения основного зеркала с www или без www. Для остальных поисковиков она будет отображаться как ошибка.
Записывается она так: Host: адрес основного зеркала
Например:
Host: example.com или Host: www.example.com или Host: https://example.com
Обратите внимание, что для сайтов, использующих https:// надо обязательно указывать протокол.
Инструкция склейки параметров (только Яндекс)
Эта инструкция также придумана Яндексом. Она используется, когда у страницы есть множество копий, отличающихся одним или несколькими GET параметрами.
Clean-param: название параметра ПРОБЕЛ для каких страниц применяется
Лучший пример — всегда некорректный, поэтому как вариант: если пользователь залогинен, мы храним его сессию в параметре GET session_ID. Например для залогиненного пользователя главной страницей будет https://example.com/?session=1231224. Но она ничем значимым от страницы https://example.com не отличается. Чтобы эти страницы воспринимались, как одна, пишем
Например для залогиненного пользователя главной страницей будет https://example.com/?session=1231224. Но она ничем значимым от страницы https://example.com не отличается. Чтобы эти страницы воспринимались, как одна, пишем
Clean-param: session * session — название нашего параметра
* — любая страница.
Если параметры надо склеивать только в папке /cat/, Тогда Clean-param: session /cat/
Если нам нужно склеивать, допустим параметр session и параметр sort, тогда мы можем или написать 2 инструкции Clean-param, или записать параметры через амперсанд: Clean-param: session&sort /cat/
Как использовать готовый файл?
Чтобы поисковый робот нашел этот файл, он должен находиться в корне сайта: если ваш сайт https://example.com/. По адресу https://example.com/robots.txt должно отображаться содержимое файла.
Вот, собственно, и все, что хотелось рассказать про синтаксис robots.txt. Возможно, вам также будет полезно почитать примеры использования файлов роботс. Если вы не уверены, что все поняли правильно, или не знаете как правильно записать какую-то инструкцию, вы всегда можете проверить свой файл роботс в валидаторе Яндекса — https://webmaster.yandex.ru/tools/robotstxt/
Если вы не уверены, что все поняли правильно, или не знаете как правильно записать какую-то инструкцию, вы всегда можете проверить свой файл роботс в валидаторе Яндекса — https://webmaster.yandex.ru/tools/robotstxt/
#HowTo #robotstxt #SEO
robots.txt — настройка индексирования сайта
Файл robots.txt — текстовый файл в формате .txt, ограничивающий поисковым роботам доступ к содержимому на http-сервере. Как определение, Robots.txt — это стандарт исключений для роботов, который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте.
Файл должен содержать обычный текст в кодировке UTF-8, состоящий из записей (строк), разделенных символами возврата каретки, возврата каретки/перевода строки или перевода строки.
Директивы:
Директива User-agent.
Создает указание конкретному роботу.
Примеры:
User-agent: YandexBot # будет использоваться только основным индексирующим роботом Яндекса
Disallow: /*id=
User-agent: Yandex # будет использована всеми роботами Яндекса
Disallow: /*sid= # кроме основного индексирующего робота Яндекса
User-agent: Googlebot-Image # запрещает агенту пользователя Googlebot-Image сканировать файлы в каталоге /personal
Disallow: /personal
User-agent: Googlebot # будет использована всеми роботами Google
Disallow: /dir
User-agent: * # используется всеми роботами, за исключением выше перчисленных
Disallow: /cgi-bin
Проще говоря, директивы для всех роботов уточняются директивами для общего робота поисковой системы (Yandex, Googlebot, StackRambler и т.п.), которые, в свою очередь, могут уточнятся директивами для общего робота конкретной поисковой системы (например для Googlebot-Imag для Googlebot).
В соответствии со стандартом перед каждой директивой User-agent рекомендуется вставлять пустой перевод строки.
Директивы Disallow и Allow.
Disallow — запрещающая директива.
Allow — разрешающая директива.
Пример:
User-agent: *
Allow: /main
Disallow: /
# запрещает скачивать все, кроме страниц
# начинающихся с ‘/main’
Директива Host.
Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта.
Если у вашего сайта есть зеркала, специальный робот зеркальщик (Mozilla/5.0 (compatible; YandexBot/3.0; MirrorDetector; +http://yandex.com/bots)) определит их и сформирует группу зеркал вашего сайта. В поиске будет участвовать только главное зеркало. Вы можете указать его для всех зеркал в файле robots.txt: имя главного зеркала должно быть значением директивы Host.
Директива ‘Host’ не гарантирует выбор указанного главного зеркала, тем не менее, алгоритм при принятии решения учитывает ее с высоким приоритетом.
Пример:
User-agent: Yandex
Host: glavnoye-zerkalo.ru
Директива Clean-param.
Позволяет исключить из индексации страницы с динамическими параметрами.
Синтаксис:
Clean-param: parm1[&parm2&parm3&parm4&..&parmn] [Путь]
Пример:
Для страницы www.mysite.ru/page.html?&parm1=1&parm2=2&parm3=3 убрать из индексации все динамические адреса для page.html
Clean-param: parm1&parm2&parm3 /page.html
Директива Crawl-delay.
Позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Поисковый робот Яндекса поддерживает дробные значения Crawl-Delay, например, 0.5. Это не гарантирует, что поисковый робот будет заходить на ваш сайт каждые полсекунды, но позволяет ускорить обход сайта.
Google игнорирует Crawl-delay.
Директива Sitemap.
Указывает на карту сайта — файл Sitemap.
Файл Sitemap — это файл с информацией о страницах сайта, подлежащих индексированию. Разместив этот файл на сайте, можно сообщить роботу Яндекса:
— какие страницы вашего сайта нужно индексировать;
— как часто обновляется информация на страницах;
— индексирование каких страниц наиболее важно.
Файл Sitemap учитывается при индексировании сайта роботом, однако не гарантирует, что все URL, указанные в файле, будут добавлены в поисковый индекс.
Пример:
Sitemap: http://site.ru/sitemap.xml
Комментарии в robots.txt.
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.
Пример robots.txt для Joomla:
User-agent: Yandex
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /modules/
Disallow: /plugins/
Disallow: /tmp/
Host: site. ru
ru
Sitemap: http://site.ru/component/osmap/?view=xml&id=1
Crawl-delay: 0.5
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /modules/
Disallow: /plugins/
Disallow: /tmp/
Sitemap: http://site.ru/component/osmap/?view=xml&id=1
Crawl-delay: 1
Поисковые роботы:
1. Яндекс:
— ‘YandexBot’ — основной индексирующий робот;
— ‘YandexDirect’ — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы, интерпретирует robots.txt особым образом;
— ‘YandexDirectDyn’ — робот генерации динамических баннеров, интерпретирует robots.txt особым образом;
— ‘YandexMedia’ — робот, индексирующий мультимедийные данные;
— ‘YandexImages’ — индексатор Яндекс. Картинок;
Картинок;
— ‘YaDirectFetcher’ — робот Яндекс.Директа, интерпретирует robots.txt особым образом;
— ‘YandexBlogs’поиска по блогам — робот , индексирующий посты и комментарии;
— ‘YandexNews’ — робот Яндекс.Новостей;
— ‘YandexPagechecker’ — валидатор микроразметки;
— ‘YandexMetrika’ — робот Яндекс.Метрики;
— ‘YandexMarket’— робот Яндекс.Маркета;
— ‘YandexCalendar’ — робот Яндекс.Календаря.
Если обнаружены директивы для конкретного робота, директивы User-agent: Yandex и User-agent: * не используются.
2. Google:
— Googlebot
— Googlebot-News
— Googlebot-Image
— Googlebot-Video
— Mediapartners-Google или Mediapartners
— AdsBot-Google
— AdsBot-Google-Mobile-Apps
Ссылки:
1. http://www.robotstxt.org/ и http://robotstxt.org.ru
2. Спецификации файла robots.txt — https://developers.google.com/webmasters/control-crawl-index/docs/robots_txt?hl=ru
(методы обработки файла robots. txt роботами Google).
txt роботами Google).
3. Использование robots.txt — https://yandex.ru/support/webmaster/controlling-robot/robots-txt.xml
(методы обработки файла robots.txt роботами Яндекса).
4. Анализ robots.txt — Яндекс — https://webmaster.yandex.ru/tools/robotstxt/
5. Анализ robots.txt — Google — https://www.google.com/webmasters/tools/robots-testing-tool
6. Поисковые роботы Google — https://support.google.com/webmasters/answer/1061943?hl=ru
7. Поисковые роботы Яндекс — https://yandex.ru/support/webmaster/controlling-robot/robots-txt.html#user-agent
8. Robots Database — http://www.robotstxt.org/db.html
Файл robots.txt — управляем поведением поисковых роботов
Robots.txt — это обычный текстовый файл, который содержит инструкции для роботов поисковых систем о том как нужно индексировать сайт. Содержимое файла стандартизировано консорциумом W3C в 1994 году, большинство поисковых систем поддерживает работу с этим файлом на добровольной основе, но некоторые директивы действуют только для определенных поисковых систем.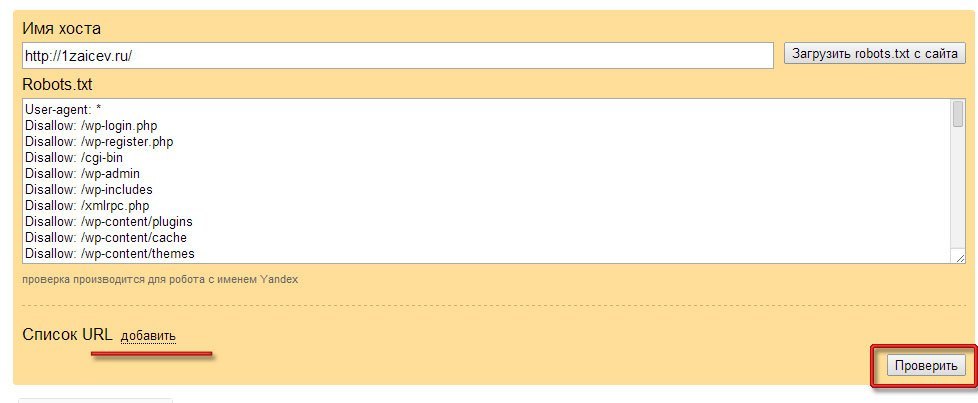
Что дает использование robots.txt
Использование этого файла, один из важных элементов комплексной оптимизации сайта. Он позволяет исключить из индекса поисковиков служебные страницы, которые не содержат контента, но нужны для пользователей. Ответ на вопрос: «Нужен ли robots.txt всем сайтам?», скорее утвердительный, потому что кроме запрета на индексирование (что не всегда оправданно в случае небольших сайтов) можно использовать рекомендательные директивы Host или Sitemap.
В основном robots.txt содержит запреты на индексацию определенных страниц сайта, но даже если Вы ничего не хотите запрещать к индексации, файл все равно желательно разместить в корне сервера с таким содержимым:
User-agent: *
Allow: /
Эти директивы разрешают роботам любых поисковых систем, индексировать все страницы и директории на сайте. Расположение файла стандартизировано и он должен открываться по адресу: http://mysite.com/robots.txt, где mysite.com — адрес Вашего сайта. Загрузить файл на сервер можно по FTP, через менеджер файлов в панели управления хостингом и некоторые системы управления контентом имеют соответствующую функцию.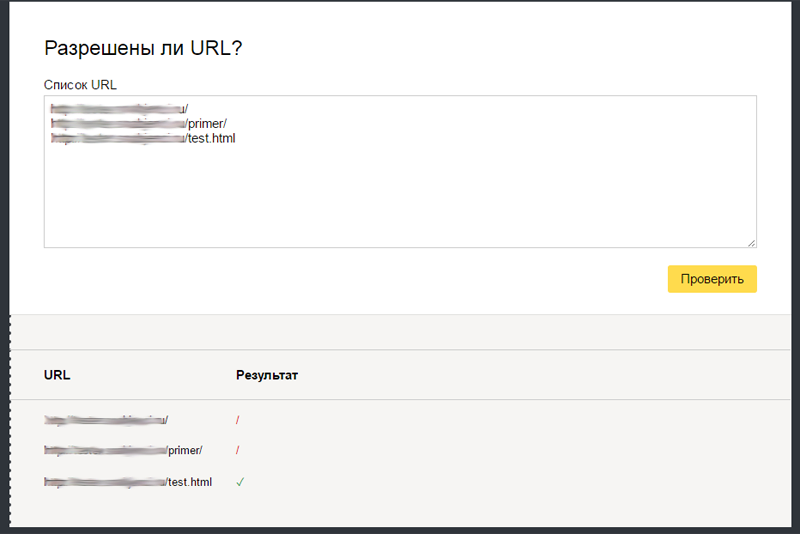 Если все сделано правильно, то при открытии ссылки содержимое файла отобразится в браузере.
Если все сделано правильно, то при открытии ссылки содержимое файла отобразится в браузере.
Создание robots.txt
Создание файла под силу даже новичкам, можно использовать любой текстовый редактор в котором нужно набрать или скопировать уже готовые директивы. Подробно о содержимом будет написано ниже, готовый файл нужно сохранить под именем robots.txt. Если на сайте используется одна из популярных CMS, то вероятно к ней есть соответствующий плагин, который может сделать всю работу за Вас.
Изменение robots.txt
После создания файла в текстовом редакторе или скачивания уже готового с онлайн-сервиса, его нужно отредактировать. Это не сложный процесс, достаточно соблюдать несколько простых правил и не совершать синтаксических ошибок. После внесения правок не забывайте обновлять robots.txt на сайте, поддержка файла в актуальном состоянии позволит быстрее применять правки и ощутить эффект. Ниже Вы можете найти примеры и познакомиться с правилами, которые помогут создать эффективный и оптимизированный файл с директивами для роботов поисковых систем.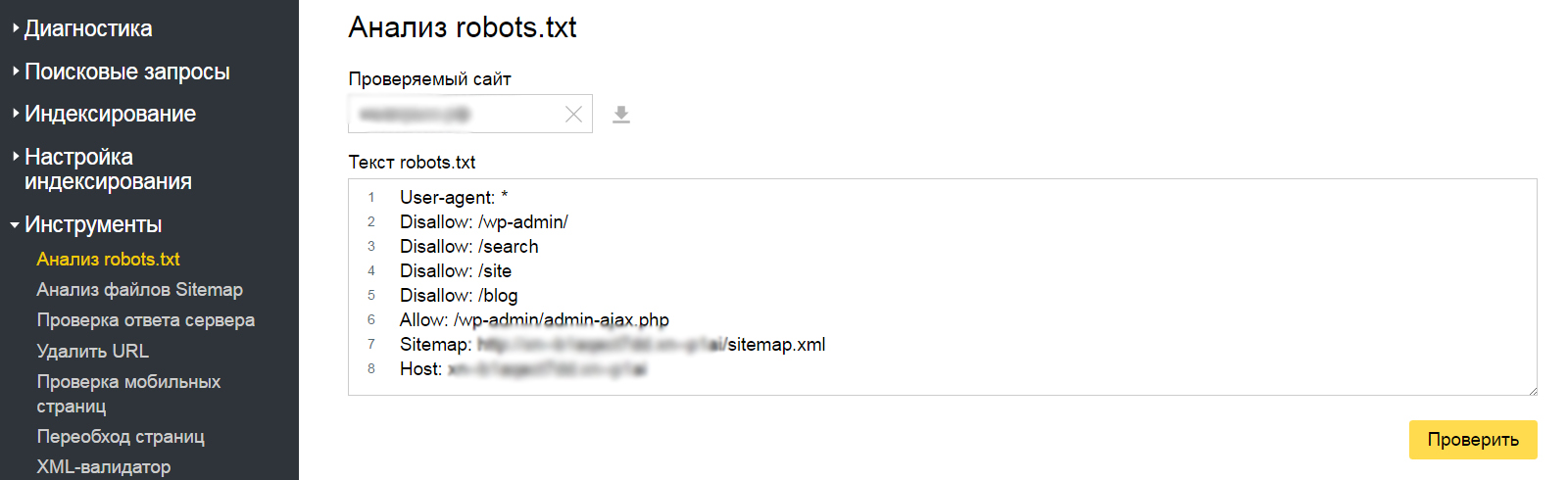
Онлайн сервисы для создания robots.txt
Позволяют автоматически генерировать robots.txt, такой вариант тоже имеет право на жизнь, но подходит не для всех. Онлайн-сервисов достаточного много, использовать их нужно осторожно, готовый файл желательно проверить, не запрещено ли индексировать нужные страницы. Ошибки в robots.txt могут дорого обойтись и их может быть сложно исправить, из-за того, что индексация растянутый во времени процесс и может длиться месяцы. Рекомендуем потратить немного времени на изучение структуры и составление собственного файла robots.txt.
Как правильно заполнить robots.txt
Этот файл используется для указанию поисковому роботу что некоторые страницы не нужно индексировать, но все директивы в файле носят рекомендательный характер, и робот может их проигнорировать, поэтому если у Вас есть конфиденциальный контент — для его защиты нужно использовать другие методы. Роботы крупных и авторитетных поисковых систем руководствуются директивами в robots.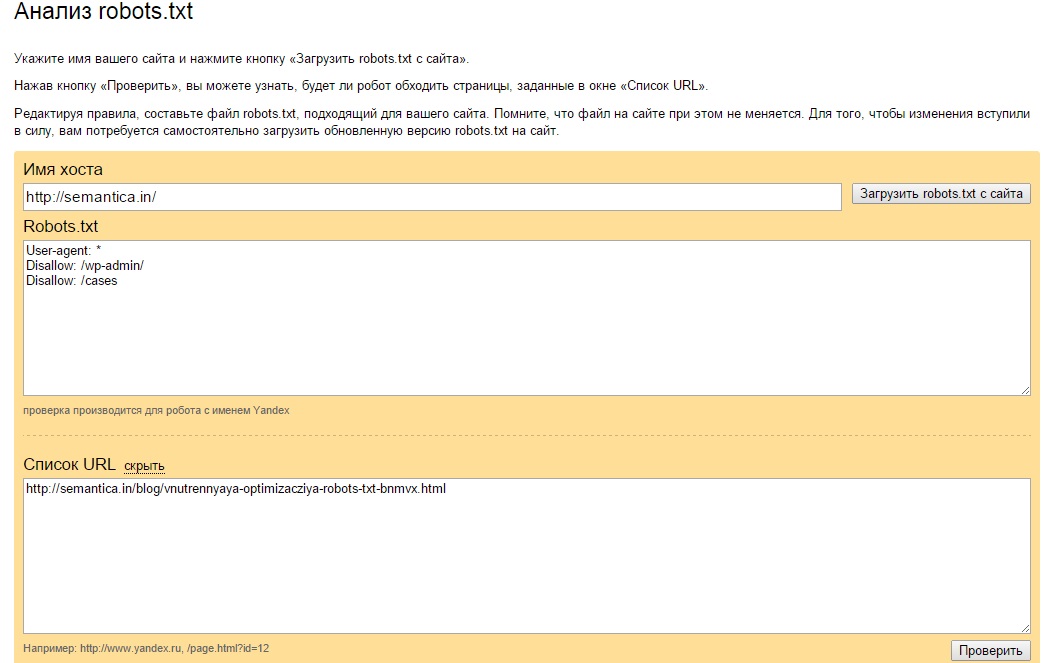 txt, но другие могут их игнорировать, этот факт то же стоит учитывать. Понимание функций и возможностей по управлению индексированием, позволит повысить эффективность оптимизации.
txt, но другие могут их игнорировать, этот факт то же стоит учитывать. Понимание функций и возможностей по управлению индексированием, позволит повысить эффективность оптимизации.
Есть общие правила и директивы, которые действуют на всех роботов, но действие некоторых распространяется только на роботов определенных поисковых систем. Для начала рассмотрим общие директивы и базовый синтаксис robots.txt.
Первой в файле должна быть команда User-agent, она нужна для указания к какому именно роботу относятся директивы ниже. Например User-agent в robots.txt может иметь вид:
В таком варианте, директивы будут распространяться на всех роботов:
User-agent: *
Эти директивы подействуют на всех роботов Yandex
User-agent: Yandex
В таком виде директивы распространяются только на YandexBot (отвечает за индексирование сайтов)
User-agent: YandexBot
Директивы для ботов Google
User-agent: Googlebot
Для правильной работы, нужно указать общие директивы для всех роботов, а затем если нужно дописать отдельные для конкретных роботов.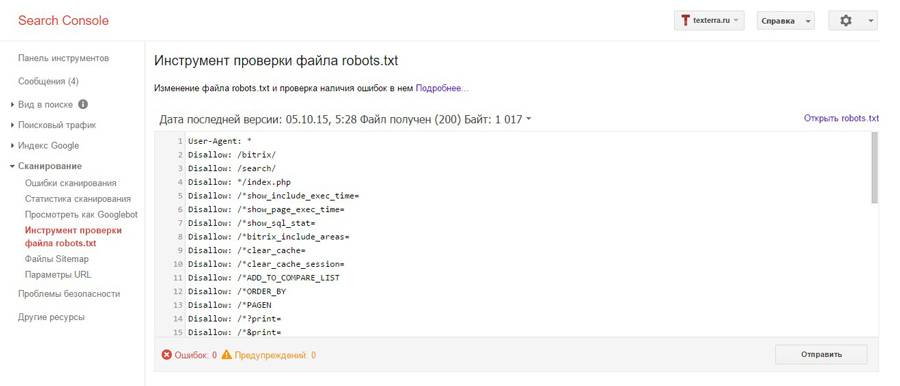
Например, в этом случае robots.txt содержит несколько указаний User-agent и может выглядеть так:
Директивы для всех роботов Google
User-agent: Googlebot
Disallow: /*post_
Директивы для всех роботов Яндекс
User-agent: Yandex
Disallow: /*post_
Директивы для всех роботов кроме указанных выше
User-agent: *
Allow: /*post_
По сути User-agent является указанием для поискового робота и после нее должна указываться команда, которую выполнит робот. В предыдущем примере мы запрещаем индексировать все страницы содержащие в названии «/*post_», для запрета чего-либо используется «Disallow». В файле не должно быть лишних переводов строк между User-agent и командой в следующей строке, в противном случае robots.txt будет проигнорирован.
В правильном robots.txt, нет лишних переводов строк:
User-agent: Yandex
Disallow: /*post_
Allow: /*ads=
User-agent: *
Disallow: /*post_
Allow: /*ads=
Неправильное написание директив (лишние переводы строк):
User-agent: Yandex
Disallow: /*post_
Allow: /*ads=
User-agent: *
Disallow: /*post_
Allow: /*ads=
Из примеров понятно, как следует размещать директивы, для удобства блоки можно разделять пустой строкой, но в самом блоке пустых строк быть не должно. Помимо этого, нужно четко следовать правилам по размещению и сортировке команд и указаний в robots.txt, в случаях когда используются разрешающие и запрещающие команды (Disallow и Allow) совместно, есть несколько вариантов написания и сортировки, использовать можно любой, главное понимать логику работы.
Помимо этого, нужно четко следовать правилам по размещению и сортировке команд и указаний в robots.txt, в случаях когда используются разрешающие и запрещающие команды (Disallow и Allow) совместно, есть несколько вариантов написания и сортировки, использовать можно любой, главное понимать логику работы.
Использование Disallow и Allow вместе:
В этом примере запрещена индексация всех страниц адрес который начинается с /shop, а страниц с адресом начинающимся с /shop/dir — разрешена, но они не будут проиндексированы роботом, потому что ниже идет запрещающая команда и она имеет более высокий приоритет.
User-agent: *
Allow: /shop/dir
Disallow: /shop
Что бы правило сработало, нужно разместить разрешения и запреты в правильном порядке:
User-agent: *
Disallow: /shop
Allow: /shop/dir
Тут мы сперва запрещаем индексировать раздел, а затем разрешаем индексацию некоторых подразделов, в этом случае робот будет индексировать только то что разрешено.
Директивы разрешения и запрета можно сочетать, главное в результате понимать логику запретов и разрешений:
User-agent: *
Allow: /
Disallow: /shop
Allow: /shop/dir
В этом примере, разрешаем индексировать все, запрещаем радел /shop, но в нем разрешаем индексацию одного подраздела — /shop/dir.
Можно использовать команды запрета/разрешения индексации без параметров, в этом случае они будут распространяться на весь сайт.
Пример Disallow/Allow без указания области действия:
User-agent: *
Disallow: # равнозначно Allow: / (разрешить все)
Disallow: /shop
Allow: /shop/dir
Можете использовать любой из представленных вариантов, они все рабочие и правильные, для удобства рекомендуем за основу брать тот, который более понятен. В корректном файле должны быть точно указаны параметры директив и приоритеты для запрещения или разрешения индексации разделов сайта. Ниже мы вернемся к использованию Disallow/Allow и рассмотрим несколько примеров.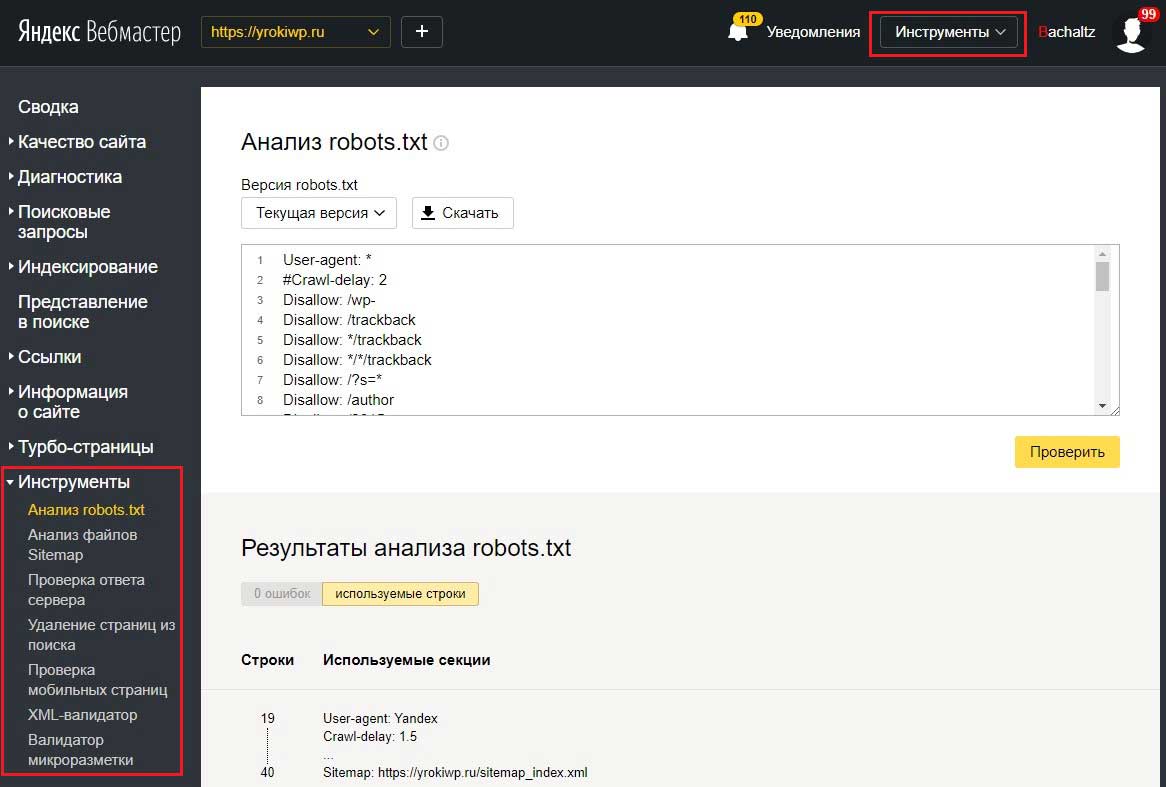
Синтаксис robots.txt
Соблюдение директив роботами дело добровольное, одна из проблем тех кто составляет файл вручную, это необходимость знать некоторые тонкости, потому что синтаксис может трактоваться по разному. Структура robots.txt стандартизирована и поэтому зная нюансы составить этот файл не сложно, все достаточно просто и понятно.
Достаточно соблюдать простые правила из списка ниже, и Вы минимизируете возможные ошибки:
- Все директивы должны начинаться с новой строки
- В одной строке должна быть только одна директива
- Команды указываются в формате: Директива: Значение; (Вокруг значения можно использовать пробелы, это повышает читаемость файла, но не является обязательным условием)
- Комментарии пишутся после символа # b могут начинаться с новой строки или дописываться в конец строк с командами или директивами.
- Недоступный или пустой robots.txt, так же считается разрешающим
- Если не завершать директивы пустой строкой, то в большинстве случаев поисковый робот обработает только первую директиву User-agent, все последующие обработаны не будут
- В файле нельзя использовать кириллицу или другие национальные алфавиты
- Перевод строки трактуется как завершение действия директивы User-agent
- Использование Disallow без значения, равнозначно разрешению индексировать весь сайт
- Не допускается в Allow и Disallow указывать более одного значения
- Имя файла стандартизировано и не должно отличаться от robots.
 txt, другие варианты имени файла считаются ошибочными и игнорируются.
txt, другие варианты имени файла считаются ошибочными и игнорируются. - Внутри файла в названии директив и команд можно использовать заглавные буквы, но это не рекомендуется, названия файлов и директорий в файле должны совпадать с таковыми на сервере.
- Есть в качестве значения параметра нужно указать папку, то перед ней ставится знак “/”, Disallow: /Shop
- Файл robots.txt с размером более 32 кб, будет проигнорирован и в таком случае поисковый робот игнорирует все запреты
- Строки нельзя начинать с пробела или других спец символов, исключение знак # — означает комментарий
- Параметры директивы нельзя переносить по строкам, они должны быть одно-строчными
- Директивы пишутся как есть, не нужно их обрамлять кавычками, заключать в скобки или использовать закрывающие символы в конце (точка с запятой, двоеточие или любые другие)
Некоторые правила не строгие и допускают нарушения, из-за того что роботы каждой поисковой системы обрабатывают файл по-разному. Например, роботы Яндекса могут корректно обработать файл с несколькими указаниями User-agent без пустой строки между ними. Это из-за того что робот Яндекса корректно определяет начало и конец директив без дополнительных разделителей. Старайтесь не указывать в файле ничего лишнего или команд действие которых для Вас до конца не ясно. Короткий и понятный robots txt, с большой вероятностью будет правильно интерпретирован подавляющим большинством поисковых роботов.
Например, роботы Яндекса могут корректно обработать файл с несколькими указаниями User-agent без пустой строки между ними. Это из-за того что робот Яндекса корректно определяет начало и конец директив без дополнительных разделителей. Старайтесь не указывать в файле ничего лишнего или команд действие которых для Вас до конца не ясно. Короткий и понятный robots txt, с большой вероятностью будет правильно интерпретирован подавляющим большинством поисковых роботов.
Проверка robots txt на ошибки синтаксиса
Яндекс и Google, предоставляют для веб-мастеров специальный сервис, который анализирует структуру и проверяет файл на ошибки с указанием их расположения. Использование онлайн-сервис существенно сокращает количество ошибок и позволяет загружать на сайт только корректные версии robots txt.
Ссылки по которым можно проверить файл на ошибки:
Google webmaster tools: https://www.google.com/webmasters/tools/siteoverview?hl=ru
Яндекс.Вебмастер: http://webmaster. yandex.ru/robots.xml
yandex.ru/robots.xml
Процесс проверки не сложный, загружаете robots.txt на свой сайт и переходите по ссылке. После нажатия кнопки проверить, Вы получите отчет. В случае ошибок или если файл недоступен — сервис сообщит об ошибках или недоступности файла. Если Вы уверены что файл загружен и доступен, убедитесь в этом перейдя по ссылке адрес_вашего_сайта/robots.txt Если эти сервисы по каким-то причинам Вам не подходят в сети есть масса аналогичных сервисов для проверки, используйте их.
Использование директив которые действуют только на конкретных роботов
Существует мнение что указание отдельных директив для Яндекса, оказывает какое-то позитивное влияние на отношение поискового робота к сайту и даже улучшает индексацию. Похожие мнения есть и о роботе Google. В реальности такое влияние очень трудно обнаружить, хотя бы потому что инструкции robots.txt носят рекомендательный характер, а указание отдельных директив для поисковых систем просто позволяет им рекомендовать какой-либо контент к индексации, но не обязывает их его индексировать.
Большинство файлов robots.txt будут содержать стандартный набор блоков User-agent и иметь одинаковую структуру, используя конкретные значения можно например запретить боту Google индексировать весь или часть сайта, но разрешить полную индексацию роботам других поисковиков. Хотя такая возможность и есть, пользуются ею очень редко. Но указание отдельных директив имеет смысл, например для Yandex желательно использовать “Host”, чтоб указать какой из доменов основной, а какой зеркало.
Если у Вашего сайта есть зеркала, то для правильной индексации важно что бы поисковый робот мог определить главное, поможет в этом директива Host. Google использует интеллектуальный алгоритм распознавания и обычно верно определяет главное зеркало, робот Яндекса часто ошибается, поэтом для него нужно указывать приоритет зеркал, роботы других поисковых систем директиву Host игнорируют.
Например, сайт может быть доступен в разных доменных зонах
site.org
site.com
Или c www и без
site. com
com
www.site.com
Host добавляется в блок «User-agent: Yandex» и в качестве параметра, нужно указать адрес главного зеркала без указания протокола — https или http, в примере ниже показано использование:
User-agent: Yandex
Disallow: /dir
Host: site.com
В примере site.com (без www) — будет главным зеркалом и именно оно попадет в выдачу, остальные варианты тоже будут проиндексированы, но в результаты поиска не попадут. Или наоборот, можно сделать главным зеркалом site.com с www:
User-agent: Yandex
Disallow: /dir
Host: www.mysite.com
Host указывается один раз, повторные указания будут проигнорированы. Для Google указать главное зеркало можно в панели управления сайтом для веб-мастеров.
На сайтах, где контент генерируется автоматически, может иметь смысл убрать из списка индексации некоторые страницы, для этого используется Clean-param. Получается что у одной страницы будет куча дубликатов и каждый из них проиндексируется роботом. Наличие дублей снижает ценность страницы, поэтому имеет смысл удалить динамические параметры и дать понять роботу что это одна страница.
Наличие дублей снижает ценность страницы, поэтому имеет смысл удалить динамические параметры и дать понять роботу что это одна страница.
В общем случае синтаксис выглядит так: Clean-param: parm1&parm2..&parmn Путь
Например, на сайте может быть такая страница с таким адресом:
www.mysite.ru/dir.html?&par1=1&par2=2&par3=333
В robots.txt нужно добавить следующее:
Clean-param: parm1&parm2&parm3 /dir.html # обрабатываться будет только dir.html
Если страниц несколько:
Clean-param: parm1&parm2&parm3 / # обработаются все подходящие под условие страницы
Разрешение индексации
Для этого используется команда Allow, ее синтаксис схож в директивой Disallow. Например, запретим индексировать сайт, кроме некоторых папок:
User-agent: *
Disallow: /
Allow: /dir
В этом примере разрешена индексация папок которые начинаются на /dir, все остальные запрещены к индексации. Если использовать директивы с пустыми параметрами или вообще без них, их действие меняется на противоположное. Директива Disallow без параметров, ничего не запрещает, то есть разрешено индексировать все:
Директива Disallow без параметров, ничего не запрещает, то есть разрешено индексировать все:
User-agent: *
Disallow:
Аналогичное действие будет и в этом случае:
User-agent: *
Allow: /
Директива Allow без параметров, ничего не разрешает, то есть имеет обратное действие и запрещает индексировать любые страницы сайта:
User-agent: *
Allow:
Аналогичный эффект можно получить использовав Disallow:
User-agent: *
Disallow: /
Запрет индексирования страниц
Для запрета используется директива Disallow, в зависимости от параметров можно настроить запрет как на весь сайт так и на отдельные страницы и папки.
Запрещаем любым роботам индексировать все страницы вместе с директориями на сайте:
User-agent: *
Disallow: /
При задании параметров можно использовать маски, это специальные символы позволяющие закрывать от индексации не все страницы, а только те которые удовлетворяют правилам. Используется символ звездочка * — она означает соответствие любому количеству любых символов, например под указание /dir* попадут все папки и страницы начинающиеся с символов dir — /dir1, /dirbeyupi и другие. Иногда звездочку можно опускать, примеры ниже тождественны и обрабатываются одинаково:
Иногда звездочку можно опускать, примеры ниже тождественны и обрабатываются одинаково:
User-agent: Googlebot
Disallow: /dir
User-agent: Googlebot
Disallow: /dir*
Знак доллара $ — указывает на точное соответствие конкретным символам.
User-agent: Googlebot
Disallow: /dir$
В этом примере Disallow запрещает индексировать только папку «/dir», но разрешает индексировать другие варианты — /dir1, /dirbeyupi. Если закрыть индексацию через robots.txt, то в панели веб-мастера можно будет увидеть соответствующую ошибку, поэтому когда надо запретить индексацию только одной или нескольких страниц можно использовать соответствующие мета-теги:
запрет на индексирование страницы
запрет на переход по ссылкам с этой страницы, считается что это не передает вес исходной страницы на страницы по ссылкам.
двойной запрет и на индексацию и на переход по ссылкам
тоже самое что и в предыдущем варианте, полный запрет
В robots.txt можно добавить ссылку на sitemap. xml — файл с картой сайта, например:
xml — файл с картой сайта, например:
User-agent: *
Disallow: /dir
Sitemap: http://www.mysite.ru/sitemap.xml
Обычно карту сайта поисковые роботы находят автоматически, так же можно указать ее расположение в панелях веб-мастера в большинстве крупных поисковиков. Иногда роботы поисковых систем посещают сайт слишком часто и создают заметную нагрузку на сервер, для ее снижения можно использовать Crawl-delay, в примере мы рекомендуем роботу Google обращаться к страницам сайта один раз в 10 секунд:
User-agent: Google
Disallow: /dir
Crawl-delay: 10
Для удобства и упрощения поддержки сайта, рекомендуется добавлять комментарии, они помогут быстро понять и разобраться в командах, когда нужно будет обновить или изменить файл. Комментарии начинаются с «#» и игнорируются роботами, комментарий должен размещаться на одной строке, в противном случае вторую и следующие строки нужно начинать с #.
Например:
User-agent: *
# Это одно-строчный комментарий, он может продолжаться до конца строки
Disallow: /dir # Так же можно добавить комментарий в конец строки
Использование robots.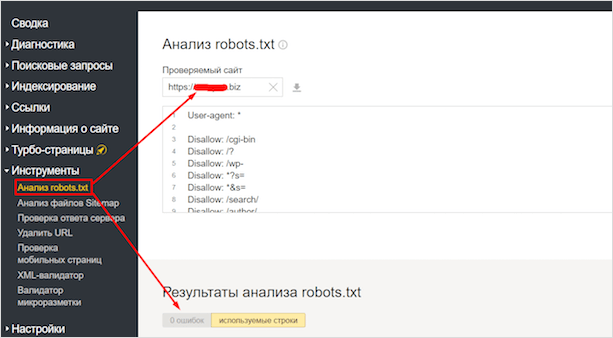 txt, упрощает взаимодействие с роботами поисковых систем и при правильном использовании является важным инструментом оптимизации сайта.
txt, упрощает взаимодействие с роботами поисковых систем и при правильном использовании является важным инструментом оптимизации сайта.
Составляем корректный robots.txt для сайта » Блог. ArtKiev Design Studio
Если в файле robots.txt не указать определенные правила для поисковых роботов, то поисковые пауки обязательно проиндексируют много мусорных страниц, и может произойти многократное дублирование информации вашего проекта (одна и та же статья доступна по разным ссылкам), что очень плохо. Для составления правильного robots.txt вы должны знать основные директивы этого файла.
Главные директивы и правила написания файла robots.txt.
Первая и наиболее важная директива, это «User-agent» – она должна содержать название поискового робота.
Если вы не укажете название поискового робота в директиве User-agent, то это правила будут понимать все поисковые системы.
А предположим, что вы хотите задать правила поведения у вас на сайте именно поисковому роботу Яндекса, то в «User-agent» задаем название Yandex, это будет выглядеть так:User-agent: Yandex
И правила которые будут указаны после «User-agent» для Яндекса будет понимать именно эта поисковая система.
Соответственно бот каждой поисковой системы имеет своё уникальное название:Google - Googlebot
Яндекс - Yandex
Рамблер - StackRambler
Мэйл.ру - Mail.Ru
Конечно, можно было собрать более большой список, но хватило бы только Google и Яндекса, траффик с остальных поисковых систем очень маленький по сравнению с этими двумя гигантами, и работать нужно именно на них.
Следующие директивы правильного robots.txt о которых нужно сказать это Allow и Disallow, первая разрешающая а вторая запрещающая индексацию поисковым роботам.
Ваш правильный файл robots.txt должен содержать как минимум одну директиву «Disallow» соответственно после каждой записи «User-agent».
А вот если вы оставите совсем пустой файл robots.txt, то поисковые машины будут индексировать ваш ресурс полностью, и в индекс попадет много мусорных и дублированных страниц.
Приведу простые примеры составления правильного robots.txt, с участием директивы User-agent, Disallow и Allow:User-agent: *
Disallow:
Как видете в данном примере я разрешаю всем поисковым роботам индексировать весь веб-ресурс целиком, без ограничений.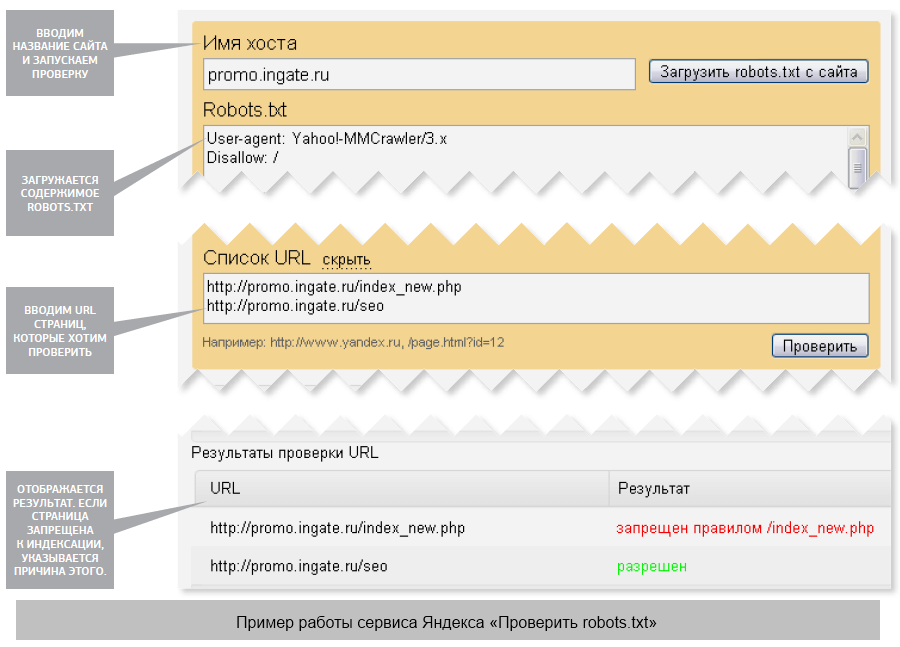
А если вам нужно запретить индексацию всего сайта всем поисковым роботам, то в файле robots.txt нужно прописать следующее:User-agent: *
Disallow: /
Из всего выше сказанного можно составить файл который мы обсуждаем в данной статье такого вида:User-agent: *
Disallow: /
User-agent: Yandex
Disallow:
В этом примере я запретил индексацию всего блога, всем поисковым роботам, кроме робота Яндекса, таким образом вы можете разрешать или запрещать индексацию определенным ботам.
В следующем примере мы с вами запретим индексацию каталога index, вот путь к этому каталогу http://mysite.ru/index/:User-agent: *
Disallow: /index/
То есть, все поисковые системы будут игнорировать каталог index.
Далее я приведу пример в котором будет запрещена индексация директории «index», и не будут индексироваться все файлы и страницы, которые начинаются с символами index, к примеру файлы и страницы index.html, index, index1, index34 и т.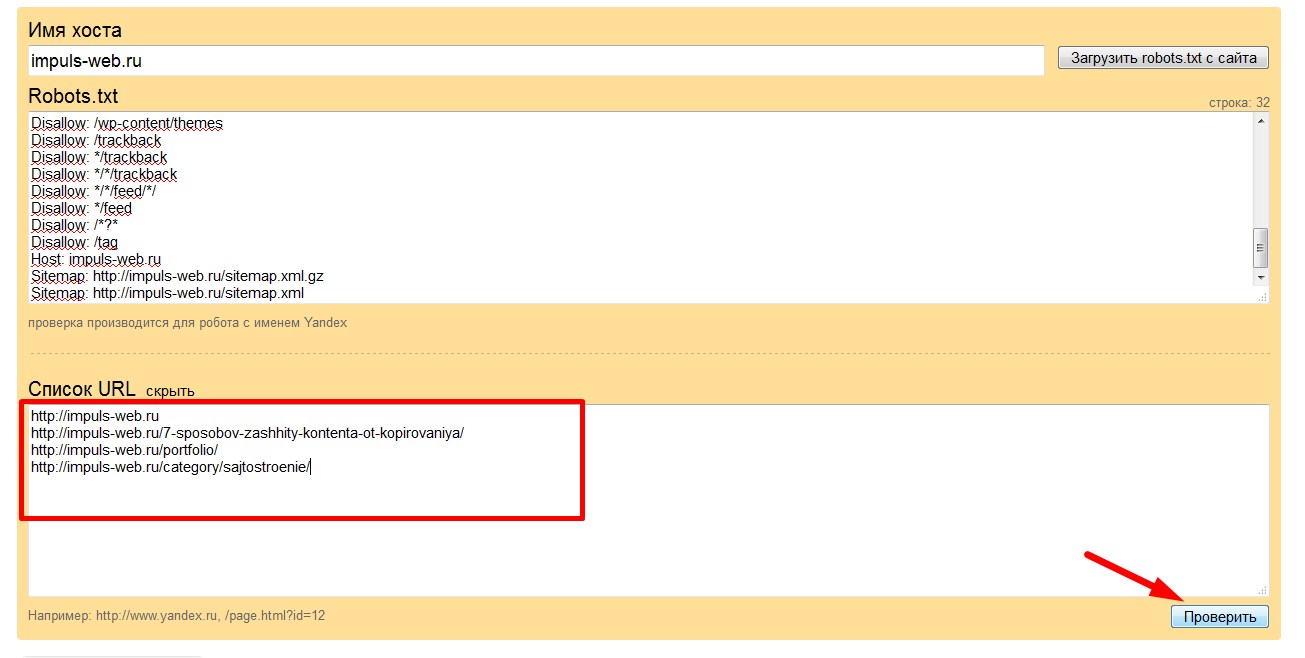 д.:
д.:User-agent: *
Disallow: /index
Ну вот, я думаю что на приведенных выше примерах вам стало понятны как работают директивы User-agent, Disallow и Allow.
Также имеется директива Host – которую понимает только поисковая система Яндекс, она служит, для определения основного зеркала вашего сайта, то есть ваш ресурс может быть доступен по нескольким адресам, допустим с www и без, помните что для поисковых систем это два разных сайта.
И ваш ресурс может быть в индексе поисковиков с www и без, и даже эти два разных сайта, с точки зрения поисковиков, могут иметь разные показатели тиц и пр, это очень плохо скажется на раскрутке вашего интернет проекта и конечно же, этот момент отрицательно скажется на поисковой выдаче, более подробно я рассказа в статье: Склеиваем дубли с www и без.
Про директиву Host и проблемы дублирования блога более подробно вы узнаете в статье, ссылку на которую я привел выше, здесь я при приведу маленький пример составления файла роботс с директивой Host:User-agent: Yandex
Disallow:
Host: www.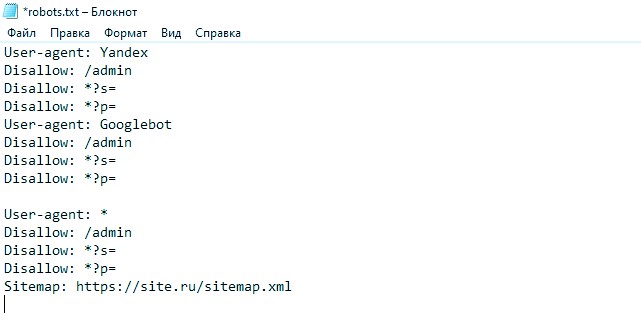 site.ru
site.ru
или
User-agent: Yandex
Disallow:
Host: site.ru
Обязательно помните, что директиву Host понимает только Яндекс, и специально для этого нужно использовать User-agent: Yandex, а для указания действий к индексации другим поисковым роботам нужно использовать другую директиву User-agent.
Вы можете добавлять свои правила в файл robots.txt, но после этого обязательно протестируйте — достигли ли вы желаемого результата.
Для это используйте соответствующие инструменты панелей вебмастеров поисковиков, об которых я подробно расказывал в статьях: панель инструментов Яндекса и панель инструментов Google.
Что такое robots.txt для сайта, правильная настройка, синтаксис составления, что должно быть сделано в файле роботс для яндекса
Правильное составление и настройка файла robots txt для сайта – это сокровенные знания веб-мастера. Без них боты поисковых систем начнут вести работы по своему усмотрению. А это не самые умные машины, и чтобы индексация была действительно качественной и грамотной, их приходится водить чуть ли не за ручку.
Поэтому в этом обзоре мы разберемся в этой проблеме детально. Узнаем все особенности создания этого документа, а также разберемся с его значением. Ведь многие ошибочно полагают, что практической пользы от него почти нет. И игнорируют рекомендации по его наличию. И это становится серьезной ошибкой, снижающий и позиции в поисковике, и входящий трафик.
Если seo-специалисты провели аудит вашего интернет-ресурса и уже выставили на вас задачи по исправлению технических ошибок, внедрению новой структуры контента и изменению структуры сайта, но вы не знаете с какой стороны к ним подойти и у вас некому эти задачи реализовывать, вы можете обратиться к специалистам “Студии 17”. Мы занимаемся не только разработкой, но и оказываем качественную техническую поддержку.
Что же это такое
Один из самых частых вопросов – как создать файл robots txt для HTML сайта. И это крайне забавно, ведь по сути такому типу ресурсов подобный документ и не нужен. Это практически единственное исключение. Небольшие ресурсы без динамических страниц – это системы, которые и не могут содержать множество вкладок с информацией. Если робот поисковика пройдется по всем, вряд ли случится что-то страшное.
Смысл метода в принципе ограничения исследований ботов, чтобы направить их силы в нужное русло. Тут у вас просто нерелевантная техническая информация, индексация не нужна. Закрываем доступ. А вот здесь скрывается новый контент с уникальными текстами, строго оптимизированный под тематику ресурса. Как раз сюда и нужно направить силы поисковиков. Общий смысл понятен.
Есть и иной аспект с не меньшей важностью. Почти каждому сайту с дублированным контентом нужен правильный файл роботс тхт (txt), настройка его позволяет исключить проверку таких участков. Вы, например, просто показываете пользователям текстовые части с иных ресурсов, описываете общие понятия, вставляете вырезки из авторитетных источников. И все это снижает уникальность. А за такое можно и санкции от поисковых систем получить. Вот тут и понадобится запрет на исследование.
Поэтому не стоит недооценивать его значения. В современных реалиях почти нет веб-ресурсов, которые могут обойтись без этого маленького помощника. Тем более, обзавестись им можно в считаные минуты. Главное понимать, как именно решить задачу.
Как создать
Прежде всего, начнем с основ. Для того чтобы понять, как написать, сделать файл robots txt для сайта, что должно быть в нем, достаточно уяснить, что это текстовый документ. Обычный и тривиальный. Открыли блокнот, сохранили под соответствующим именем – все, задача выполнена. Правда, неправильно. Ни команд, ни директив там не будет. Но теоретически документ создан.
Всего-то нам и нужно вооружиться блокнотом и поместить результат в правильное место. А конкретно, в корневой каталог. То есть, наш сайт/наш документ.
Есть и аналогичные методики. Просто скачать необходимый вариант из сети. Или даже сгенерировать его. Сейчас различные онлайн-сервисы предоставляет возможности по автоматическому созданию. Но тут тоже могут быть свои палки в колесах.
- Сервис может работать в принципе неправильно. И такое случается.
- Полученный вариант будет не персонализированным. Не заточен под конкретные аспекты вашего ресурса. Его все равно придется дорабатывать и переделывать. Если у вас не супертиповой сайт, разумеется. Что в реальности не случается. Даже клонированные блоги на WordPress имеют массу отличий.
- В этом нет особого смысла, ведь подобный процесс без проблем можно провести своими собственными силами.
Настройка
Правильный файл robots txt что это такое – текстовый документ, который следует корректному синтаксису и обеспечивает изоляцию всех внутренних страниц, где роботом нет смысла тратить время или даже вредно находиться.
В какой-то мере – это инструкция для ботов. Они ей следуют. Не будем оставлять их без присмотра. Вот подобный маневр значительно увеличивает поисковую позицию, а также повышает внутренний рейтинг площадки в глазах поисковиков. Простейший метод оптимизации, достигаемый не вливанием массивных денежных пластов, не покупкой профессиональных услуг, а всего лишь небольшой редактурой на пару минут. Вариант звучит выгодно.
Структура
Важнейшие команды – это User-agent и robots txt disallow. Первая сообщает, какой конкретно поисковый робот должен следовать указаниям. А вторая говорит, куда ходить не следует.
Структура становится примерно следующей.
User-agent: Yandex
Disallow: /PPP – произвольное название нашей страницы.
Disallow: /admin – закрытая для исследований админка.
Такую же манипуляцию можно провести с Гуглом. Только сменится агент.
User-agent: Googlebot
Disallow: /
В данном варианте будет запрещена полностью индексация для Гугла. Но для Яндекса сохранена возможность изучения, кроме двух страниц. А именно PPP и admin. Все остальные точки свободны для посещения ботов. То есть, это пример, как настроить файл robots txt для Яндекса, запрещая при этом поиск оппоненту. Но зачастую, разумеется, абстрагироваться от ключевых поисковиков все же не стоит.
Синтаксис и правила
Их, в отличие от смежных областей, немного.
- Используются только строчные буквы в названии документа.
- Пробелы не имеют значения, но пустые строки имеют. Одно необходимо ставить лишь после позиции User-agent.
- Символы * в какой-то мере являются закрывающими. Но их допустимо пропускать и итог от этого не изменится.
- Каждое указание пишется с новой строки.
- На одной строчке допустимо поставить единственную директиву.
- Комментарии ставятся только после знака #. И они не учитываются ботом.
Спецсимволы
Пройдемся по ним.
- *. Символ означает произвольное, любое количество символов. Также подходит и нулевое. Этот знак по логике всегда стоит вначале, даже если его не прописать руками.
- $. Отображает факт, что предыдущий символ является последним в строке. То есть, закрываем ее.
- #. Комментарий отключен от индексации.
Директивы
Двигаемся дальше. Теперь разберем, какие конкретно указания мы способны передать ботам. И какие действия заставить их выполнять.
Агенты
Команда для всех роботов одинаковая – User-agent. Дальше уже после двоеточия ставится конкретное имя. Стоит понимать, что настройка robots txt синтаксис, директивы – все это точные значения. Не укажете команду для конкретного бота, он будет следовать общей. При этом допустимо заблокировать вход всем исследователям кроме выбранных. Но это тоже не самый логичный вариант.
Разумеется, чаще всего приходится ориентироваться только на Яндекс и Гугл.
Запрет индексации
Директива Disallow. Она запрещает исследование отдельных страницы или определенного набора. Перекрыть допустимо как путь, чтобы все разветвления были заблокированы, так и конечную точку, имеющую адрес.
Сюда логично будет помещать динамическую выдачу поиска, дублированный контент, потерявший свою уникальность. Причем при указании ссылки на источник, для самого Яндекса или Гугла по факту не меняется наличие плагиата. Технические страницы тоже изучать роботом не следует, закрываем им доступ. Логи, сформированные в результате ошибок и отчетности интерес также не вызывают.
Разрешение индексации
Команда Allow. Это антагонист, директива дает право на доскональное изучение всей представленной на странице информации. Существует параметр – /. После него идет сам адрес точки. И если его оставить пустым, как Allow/ – это означает, что допустимо полное исследование зоны площадки. Ни одна из страниц не будет скрыта. Такой же прочерк, но с запрещающей директивой не позволит проникать на ресурс никому. В итоге мы, используя пометку агента, вполне способны части ботов запретить посещать веб-ресурс полностью, а другим дать все возможности для индексации. Подходит, если работать под конкретный набор поисковых машин.
Это основные директивы роботс.
Карта сайта
Команда Sitemap позволяет точно указать путь на xml навигатор. Это важнейший аспект. Любая система в первую очередь пытается направить своих кравлеров именно туда. Ведь там содержатся основные ссылки, пометки, размещение страниц в пространстве. И поисковик положительно оценивает сайт, если на нем есть грамотная карта, развернутая и со всеми обозначениями. И снижает его в выдаче, если искомого элемента нет на месте. Поэтому следует указать к нему путь. Делается это просто.
User-agent: *
Sitemap: https://нашсайт.рф/sitemal.xml
Соответственно, у вас адрес будет собственный.
Центральное зеркало, robots host
С помощью этой команды допустимо было указать дубликат сайта, если основной адрес заблокирован по веским причинам. Самый частый случай использования – это появление в свое время Secure протокола. Когда большая часть ресурсов массово переходила с HTTP на HTTPS. И если честно, вариант оказался не слишком удобным. Так от него было решено отказаться еще в 2018 году. На смену пришел сервис переезда от Яндекса или новый директ под номером 301. В данный момент заполнять HOST не нужно.
Команда Crawl-delay
Из названия становится понятно, что с помощью директивы создаются задержки по времени посещения. Сессии с тайм-аутом. Указав этот параметр и цифру, как вариант, 4, вы поставите задержку в 4 секунды. Такая практика оказывается весьма полезной, если боты просто нагло грузят площадку, создают повышенный перевес частыми посещениями, а сервер и так не самый мощный. Тогда скорость загрузки страниц и общая динамика начнут сильно падать. Что создать негативное впечатление уже у пользователей. А как бы важны ни были поисковые машины, все же пользователи – это самое главное.
Также это и неплохой способ диагностики. Смысл прост: если сервер постоянно падает, в наблюдаем перезагрузку, пора создавать новый робот тхт (txt) для сайта. Там мы указываем задержку в 1-2-6 секунд для кравлеров. И если после этого неполадки остались, значит, проблема лежит в другой плоскости. Но на практике – это часто решение ситуации с перевесом.
Команда Clean-param
Это лучший друг почти всех интернет-магазинов на просторах Рунета. Ведь директива запрещает изучение динамических страниц с аналоговым содержанием – то есть когда динамическая выдача (подбор товаров по категориям) будет точно копировать отдельные страницы ресурса, просто собранные в новом формате. В таком случае будет создавать искусственная нагрузка. Причем она может достигать катастрофических размеров, зависит от оптимизации.
Зачастую в директиве нужно указать сведения, по которым и собираются динамические участки. Идентификаторы пользователя и иные ресурсы.
Остальные параметры
Ранее использовался еще один вариант команд. Это Request-rate. Он предоставлял возможность поставить максимальное количество страниц для изучения за определенный диапазон времени. Опять же, чтобы свести нагрузку к минимальным значениям. Но сейчас технологии находятся на высоком уровне, директива утратила актуальность и не используется. Как и Visit-time. Эта команда позволяла посещать саму площадку только в определенное время. Например, пару часов по утрам, а также вечером. Чтобы отделить время посещения пользователей и ботов. Ведь вместе они создавали сильный перекос на сервере, и он мог просто упасть. Неудобно, но альтернатив раньше не было.
Комментарии
Как мы уже уточнили, для прописывания собственных пометок понадобится знак #. Он будет свидетельствовать о том, что дальнейшее изучение слов после символа не требуется. То есть, запрет на индексацию. А да, смысл пока не понятен. На самом деле все примитивно. Это пометки для себя, для помощников, сотрудников, оптимизаторов и кодеров. Чтобы натолкнувшись на определенный элемент, они могли понять, почему тут стоит disallow или, напротив, проверка полностью разрешена. Когда есть небольшие аспекты, необходимые для упоминания.
Проверка
Завершающим этапом после создания документа будет его диагностика. Нельзя запускать в работу вариант, если вы не уверены в его корректности. Создав, как вариант, файл роботс тхт для Яндекс, может оказаться, что он сильно мешает другим системам. Или даже для самого целевого поисковика оптимизирован не лучшим образом.
Проверка – это последняя стадия в любой работе, и эта сфера не является исключением. Проблема даже не в знаниях, а в банальном человеческом факторе. Парочка нелепых ошибок способна сильно сказаться на посещаемости ресурса.
Проверка на сайте
Как мы помним, документ грузится в корневую папку. А значит, у него есть собственный адрес, с помощью которого его допустимо найти. И что более интересно, все сведения, связанные с этими аспектами – публичные. Вы можете проверить не только собственный файл, но также и любой в интернете. Так и начать следует с вашей работы. Напрямую вводите адрес, смотрите, получилось ли найти загруженный документ.
Выявляем ошибки
Существует два варианта. В первом случае следует проверить все моменты самостоятельно. Просто пройтись глазам, не напутали ли мы адреса, директивы, не забыли ли важный аспект. Это отличный способ, если по итогу у нас получился небольшой размер. 3-4 десятка строк, не более. А вот когда документ вышел несравнимо крупнее, придется обращаться к сервисам. Хотя они в любом случае понадобятся. Это панель веб-мастера Яндекса или аналог у Гугла. В автоматическом режиме эти утилиты изучат полученный Вами файл, посмотрят, есть ли серьезные ошибки, неточности, разночтения. И укажут Вам на них, снабдив своими комментариями.
Работа под Яндекс и Google
Возникает закономерный вопрос. А почему бы не прописать команды сразу для всех поисковиков. Зачем указывать отдельно каждого агента. Ответ лежит на поверхности. В первую очередь, эти две системы реагируют по-разному. Одни любят большие тексты, другие поменьше. Отношение к спаму, расположения страниц, ко всему – разное. И направлять их нужно туда, где лучше оптимизация по их мнению.
Но это не главное, условности. А вот тот факт, что поисковики лучше реагируют на сайт, если в документе конкретно прописан их агент – неоспорим. Поэтому придется команды писать под конкретного бота, если хотите нормальные позиции в выдаче.
Заключение и советы
В эпилоге пройдемся по краткому списку рекомендаций:
- Всегда создавайте указания для ботов. Какой бы сайт у вас ни был.
- При любых неполадках с посещаемостью перепроверьте на ошибки.
- Заходите на Яндекс индексацию раз в неделю-две. Проверяйте позиции.
На этом наша инструкция как создать, правильно составить robots txt для сайта считается законченной. Пробуйте и экспериментируйте, отслеживайте результат. Если он окажется неудовлетворительным, всегда можно провести работу над ошибками. Благо, это занимает не так много времени.
Работа с файлом robots.txt
Когда происходит создание сайта, то оптимизация его содержания происходит в двух направлениях :
- Оптимизируют дизайн и тексты для посетителей веб-ресурса
- Оптимизации подвергается программная часть сайта, которая важна для поисковых систем
Файл robots.txt имеет неоднозначную оценку в среде веб-программистов и специалистов по продвижению веб-сайтов. Этот файл существует во всех сайтах, его готовят специалисты для поисковых систем в ходе оптимизации веб-ресурса для раскрутки. Но все же не до конца понятно то, важен ли в наше время этот файл. Нужно заметить, что файл robots.txt представляет собой неисполняемый файл, который имеет содержание сугубо для поисковых систем. Причем те инструкции, которые указываются в файле robots.txt могут быть применены и без него, если установить в CMS сайта нужные функциональные плагины.
Например, через файл robots.txt имеется возможность запретить индексирование сайта, однако та же функция имеется и в специальных плагинов для seo, которые можно установить бесплатно через магазин плагинов для любой CMS, а также запретить индексировать сайт или отдельные страницы сайта можно и через панель управления служб Яндекс Вебмастер и Google Вебмастер. Также через эти службы, как и через файл robots.txt, можно запретить индексирование, например, версий страниц сайта для печати.
Когда начинается процесс индексирования контента сайта поисковыми системами, те в первую очередь ищут в корневом каталоге файл robots.txt, который должен с самого начала указать поисковым ботом то, какие страницы разрешено индексировать, а какие все же нет. Но, как указывают специалисты, поисковые боты индексируют все страницы сайтов, даже если их запрещает владелец сайта через файл robots.txt, только запрещенные к индексации страницы не попадут в поисковую выдачу. И вот опять можно задать вопрос- зачем тогда нужен файл robots.txt? Его функции заменяют панель управления сайтами через службы вебмастера от крупнейших поисковиков, и даже при запрещении индексирования некоторого контента через этот файл, все равно поисковики индексируют весь контент сайта.
Не стоит забывать, что файл robots.txt не исполняемый, то есть его можно только читать. Править этот файл можно разными способами. И через обычный бесплатный редактор Notepad, установленный на компьютер, либо через панель управления контентом CMS, где также есть возможность управлять записями этого файла. Конечно, не стоит забывать, что хоть файл robots.txt это всего лишь читаемый файл, содержание его обращено к поисковым ботам, а значит информация в этом файле должна быть написана на понятном языке для всех поисковых ботов в мире, и иметь ясную и четкую структуру.
Структура файла robots.txt
Начинается записать в файле robots.txt всегда с упоминания того поискового бота, к которому будет обращены команды. Обращаться к поисковому боту можно с помощью директивы User-agent. Стоит отметить и то, что если после директивы User-agent стоит звездочка *, то значит команда директивы обращена ко всем поисковым ботам. Также не стоит забывать и о том, что текст в файле robots.txt не чувствителен к регистру, то есть можно писать как с большой буквы. Так и большими буквами. Но лучше всего, раз уж этот традиционный файл используется на сайте, лучше соблюдать все традиции. После директивы user-agent используется название поискового бота, к которому и обращено послание. Если к поисковому боту от Google, то после директивы первой стоит добавить googlebot, если к поисковой системе Яндекс, то Yandex. Таким образом, первая запись всегда в файле robots.txt имеет первую строку :
User-agent: googlebot
После обращению к поисковому боту стоит указать те папки или файлы, которые запрещено индексировать. Используется для этого простая директива Disallow. После ее объявления, нужно указать запрещенные к индексированию папки или файлы, как указано в примере ниже:
Disallow: /feedback.php Disallow: /cgi-bin/
В данном примере показано, что в файле robots.txt были запрещены к индексированию файл feedback.php и папка cgi-bin/ , которые находятся в корневом каталоге сайта. Для особо ленивых предусмотрена возможность блокировки по начальным символам, поэтому стоит всегда быть аккуратней с директивой Disallow, а также с упоминанием в ней различных файлов и папок. Если указать в файле robots.txt :
Disallow : prices
То поисковой бот не будет индексировать и имеющиеся файлы http://site.ru/prices.php и даже папку http://site.ru/prices/
Также не стоит забывать, что после директивы Disallow ничего не находится, то полностью все содержание сайта будет проиндексировано. Если же после директивы Disallow стоит символ /, то абсолютно полностью все содержимое сайта запрещено индексировать.
Если вдруг возникла свободная минутка и есть желание пообщаться с поисковыми ботами, но нет желание ничего запрещать для индексирования, то можно создать файл robots.txt с командой :
User-agent: * Disallow:
Поисковой бот любой поймет, что владелец сайта имеет много свободного времени, раз тратить свое время на создание файла robots.txt, в котором разрешает всем ботам индексировать все содержание сайта. Если не будет такой записи или даже вообще будет отсутствовать файл robots.txt, то любой поисковик так и сделает.
Директива Allow и ее магические свойства
Не все волшебство файла robots.txt заключено в запрете индексирования файлов сайта, также можно разрешать индексировать. Все точно также, как и с директивой Disallow, только используется директива Allow, которая разрешает индексацию всего, что указано. Вот пример :
User-agent: Yandex Allow: /prices Disallow: /
Все ясно и понятно – Поисковому боту от Яндекса запрещается индексировать на сайте все, кроме папки prices. Стоит отметить, что директиву Allow используют всегда перед директивой Disallow. Если после Allow в файле robots.txt будет пусто , то это означает, что поисковому боту Яндекса запрещена индексация всех файлов :
User-agent: Yandex Allow:
Иными словами, в файле robots.txt директивы Disallow / и Allow равнозначны, запрещающие индексацию.
Все поисковые системы, по крайней мере речь если идет о крупнейших, понимают содержание записей файла robots.txt одинаково. Если есть опасения запутаться в директивах данного файла, то лучше всего использовать службы Яндекс Вебмастер и Google Вебмастер, через которые можно начать индексацию страниц сайта, а также без труда управлять индексацией страниц, разрешая или запрещая те или иные страницы для поисковых ботов. Эти службы помогают также загрузить карту сайта.
Специальные регулярные выражения для robots.txt
С помощью всемогущего файла robots.txt можно запретить индексировать не только отдельные страницы сайта или какие-то папки с файлами, но и отдельно файлы. Это очень удобно бывает в том случае, если сайт достаточно крупный, и в нем находится большое количество файлов различного содержания. Тут нужно отдельно указать, что регулярные выражение $ означает окончание ссылки, указанной в файле, а звездочка * на любой адрес ссылки или название файла в указанном формате. Вот пример :
User-agent: Yandex Allow: /prices/*.html$ Disallow: /
Ценителям магии файла robots.txt все понятно с этой записью, точно также, как и поисковому боту от Яндекса. Поисковик должен индексировать все файлы в папке prices в html формате, но запрещена индексация любых других файлов на сайте. Или еще один пример с регулярными выражениями для robots.txt :
User-agent: Yandex Disallow: *.pdf$
Запись говорит, что Яндекс-боту запрещена индексация всех файлов в формате pdf.
Путь к карте сайта
Файл robots.txt многофункциональный читаемый файл, которые также указывает и направление поисков поисковыми ботами карты сайта. Стоит отметить, что карта сайта, если веб-ресурс действительно обширен, очень важна для того, чтобы поисковые системы могли проиндексировать все нужные страницы и файлы сайта. Послать поисковой бот можно с помощью директивы Sitemap :
User-agent: googlebot Disallow: Sitemap: http://site.ru/sitemap.xml
Загрузить карту сайта можно и с помощью служб Яндекс Вебмастер и Google Вебмастер, не работая с директивами robots.txt.
Работа с зеркалами сайта в файле robots.txt
Не так давно поисковой гигант Google решил начать борьбу за повышенную защищенность посетителей сайтов в интернете, и решил оценивать сайты с шифрованном трафиком с https протоколом выше сайтов, которые были всегда с стандартным http протоколом. И многие владельцы сайтов, даже если они не работали с платежными системами, должны были перейти на https протокол для того, чтобы поднять свой рейтинг в поисковой выдачи. Но как это сделать?
Начать нужно с того, что для поисковых систем сайты http://site.ru/ и https://site.ru/ являются различными, хотя имеют одинаковое название, и являются по сути зеркалами друг друга, но поисковые системы будут их по-разному индексировать и оценивать. Чтобы указать поисковым ботам, что нужно индексировать только одно главное зеркало сайта, требуется использовать директиву Hosts в файле robots.txt. Выглядеть это будет так :
User-agent: googlebot Disallow: /prices.php Host: https://site.(.*)$ http://www.site.ru/$1 [R=301,L]
Использование комментариев в robots.txt
Зачем комментировать что-то для поисковых ботов в файле robots.txt? Сложно сказать, но если кому-то захочется это делать, стоит использовать символ #. Вот пример :
User-agent: googlebot Disallow: /prices/ # тут нет ничего интересного
Краткое описание работы с файлом robots.txt
1.Как разрешить всем поисковым ботам индексацию всех файлов на сайте?
User-agent: * Disallow:
2.Как запретить всем поисковым ботам индексацию всех файлов на сайте?
User-agent: * Disallow: /
3.Как запретить поисковому боту от Google индексировать файл prices.html?
User-agent: googlebot Disallow: prices.html
4.Как разрешить всем поисковым ботам индексировать весь сайта, а боту от Google запрещаем индексацию папки prices?
User-agent: googlebot Disallow: /prices/ User-agent: * Disallow:
Какие ошибки могут возникнуть при работе с файлом robots.txt?
Нужно сказать, что поисковые боты не чувствительны к регистру букв при написании директив, но с названием файлов и папок нужно быть осторожнее. Также проблем между директивами не стоит делать просто так для красоты, ведь для файла robots.txt проблем означает разделение команд для разных поисковых ботов.
Для каждого поискового бота нужно создавать свою директиву user-agent, а не пытаться в одну вписать несколько ботов. Очень часто забывают использовать символ / перед названием папок, что приведет к недопониманию поисковым ботом директивы. Также админка сайта исключается всегда поисковыми ботами из индексации и ее не следует указывать в файле. Есть мнение специалистов, что большой размер файла robots.txt с огромным списком страниц сайта и файлов, исключаемых из индексации, просто игнорируются поисковыми системами.
Поэтому надежней всего удалять ненужные файлы, а не указывать запрет на их индексацию.
Как проверить файл robots.txt на фатальные ошибки?
Если файл robots.txt отличается многословием, то есть в нем указаны команды для поисковых ботов для множества файлов и страниц сайта, то лучше провести проверку качества файла robots.txt с помощью ресурсов Яндекс Вебмастер и Google Вебмастер.
Пользовательский агент: * Позволять: / # Конкретные команды Spider на 2010 год # Яндекс Пользовательский агент: яндекс * Запретить: / # Яндекс User-agent: Яндекс * Запретить: / # Baidu Пользовательский агент: baidu * Запретить: / # рекламных ботов: Пользовательский агент: Mediapartners-Google * Запретить: / # Сканеры, которые достаточно любезны, чтобы подчиняться, но которых мы не хотели бы иметь # если они не подпитывают поисковые системы. Пользовательский агент: UbiCrawler Запретить: / Пользовательский агент: DOC Запретить: / Пользовательский агент: Zao Запретить: / # Известно, что некоторые боты вызывают проблемы, особенно те, которые предназначены для копирования # целые сайты.Пожалуйста, соблюдайте robots.txt. Пользовательский агент: sitecheck.internetseer.com Запретить: / Пользовательский агент: Zealbot Запретить: / Пользовательский агент: MSIECrawler Запретить: / Пользовательский агент: SiteSnagger Запретить: / Пользовательский агент: WebStripper Запретить: / Пользовательский агент: WebCopier Запретить: / Пользовательский агент: Fetch Запретить: / Пользовательский агент: Offline Explorer Запретить: / Пользовательский агент: Телепорт Запретить: / Пользователь-агент: TeleportPro Запретить: / Пользовательский агент: WebZIP Запретить: / Пользовательский агент: linko Запретить: / Пользовательский агент: HTTrack Запретить: / Пользовательский агент: Microsoft.URL.Control Запретить: / Пользовательский агент: Xenu Запретить: / Пользовательский агент: ларбин Запретить: / Пользовательский агент: libwww Запретить: / Пользовательский агент: ZyBORG Запретить: / Пользовательский агент: Скачать Ninja Запретить: / # # Извините, wget в рекурсивном режиме — частая проблема. # Пожалуйста, прочтите страницу руководства и используйте ее правильно; Eсть # параметр —wait, который можно использовать для установки задержки между попаданиями, # например. # Пользовательский агент: wget Запретить: / # # Распределенный клиент ‘grub’ ведет себя * очень * плохо.# Пользовательский агент: grub-client Запретить: / # # Все равно не следует за robots.txt, но … # Пользовательский агент: k2spider Запретить: / # # Ударов много раз в секунду, неприемлемо # http://www.nameprotect.com/botinfo.html Пользовательский агент: NPBot Запретить: / # Бот для захвата, скачивает миллионы страниц без общественной пользы # http://www.webreaper.net/ Пользовательский агент: WebReaper Запретить: / # Все остальные пауки Пользовательский агент: * Запретить: / *.axd $ Задержка сканирования: 1
####### # Блокировать поисковые системы из зарубежных стран # http://searchenginewatch.com/article/2067357/Bye-bye-Crawler-Blocking-the-Parasites ####### # Яндекс (RU) # Информация: http://yandex.com/bots не дает нам информации об использовании файла robots.txt, специфичного для Яндекса. User-agent: Яндекс Запретить: / # Гу (JP) # Информация (японский): http://help.goo.ne.jp/help/article/704/ # Информация (на английском языке): http://help.goo.ne.jp/help/article/853/ Пользовательский агент: moget Пользовательский агент: Ичиро Запретить: / # Naver (КР) # Информация: http: // help.naver.com/customer/etc/webDocument02.nhn Пользовательский агент: NaverBot Пользовательский агент: Yeti Запретить: / # Baidu (CN) # Информация: http://www.baidu.com/search/spider.htm Пользовательский агент: Baiduspider Пользовательский агент: Baiduspider-video Пользовательский агент: Baiduspider-image Запретить: / # SoGou (CN) # Информация: http://www.sogou.com/docs/help/webmasters.htm#07 Пользовательский агент: sogou spider Запретить: / # Youdao (CN) # Информация: http://www.youdao.com/help/webmaster/spider/ Пользовательский агент: YoudaoBot Запретить: / # Если сайт Joomla установлен в папке, например в # е.грамм. www.example.com/joomla/ файл robots.txt ДОЛЖЕН быть # перемещен в корень сайта, например, www.example.com/robots.txt # И имя папки joomla ДОЛЖНО быть префиксом запрещенного # путь, например правило запрета для папки / administrator / # ДОЛЖЕН быть изменен на Disallow: / joomla / administrator / # # Дополнительную информацию о стандарте robots.txt см. В следующих статьях: # http://www.robotstxt.org/orig.html # # Для проверки синтаксиса см .: # http://www.sxw.org.uk/computing/robots/check.html Пользовательский агент: * Запретить: / администратор / Запретить: / cache / Запретить: / cli / Disallow: / components / Запретить: / images / Disallow: / включает / Запретить: / установка / Запретить: / язык / Запретить: / библиотеки / Запретить: / журналы / Запретить: / media / Запретить: / modules / Запретить: / плагины / Запретить: / templates / Запретить: / DMDocuments / Запрещение: / tmp / Запретить: / ProcFileRepository / Запретить: / BCFileRepository / Запрещено: / Наследие * Disallow: / HeritageScripts *
Как запретить поисковым системам сканировать ваш веб-сайт
Чтобы ваш веб-сайт могли найти другие люди, сканеры поисковой системы , также иногда называемые ботами или пауками, будут сканировать ваш веб-сайт ищет обновленный текст и ссылки для обновления своих поисковых индексов.
Как управлять сканерами поисковых систем с помощью файла robots.txt
Владельцы веб-сайтов могут указать поисковым системам, как им следует сканировать веб-сайт, с помощью файла robots.txt .
Когда поисковая система просматривает веб-сайт, она сначала запрашивает файл robots.txt , а затем следует внутренним правилам.
Измените или создайте файл robots.txt
Файл robots.txt должен находиться в корне вашего сайта. Если ваш домен был например.com необходимо найти:
На вашем сайте :
https://example.com/robots.txt
На вашем сервере :
/home/userna5/public_html/robots.txt
Вы также можете создать новый файл и называть его robots.txt как обычный текстовый файл, если у вас его еще нет.
Поисковая машина Агенты пользователя
Наиболее распространенное правило, которое вы используете в файле robots.txt , основано на User-agent сканера поисковой системы.
Сканеры поисковых систем используют User-agent , чтобы идентифицировать себя при сканировании, вот несколько распространенных примеров:
Топ-3 поисковых систем США Пользовательские агенты :
Googlebot Yahoo! Slurp bingbot
Обычная поисковая система Заблокированы пользовательские агенты :
AhrefsBot Байдуспайдер Ezooms MJ12bot ЯндексБот
Доступ сканера поисковой системы через файл robots.txt
Существует довольно много вариантов, когда дело доходит до управления сканированием вашего сайта роботами .txt файл.
Правило User-agent: указывает, к какому User-agent применяется правило, а * — это подстановочный знак, соответствующий любому User-agent.
Запретить: устанавливает файлы или папки, которые не разрешено сканировать.
Установите задержку сканирования для всех поисковых систем. :
. Если бы на вашем веб-сайте было 1000 страниц, поисковая система потенциально могла бы проиндексировать ваш сайт за несколько минут.
Однако это может привести к высокому использованию системных ресурсов, поскольку все эти страницы загружаются за короткий период времени.
A Задержка сканирования: из 30 секунд позволит сканерам проиндексировать весь ваш 1000-страничный веб-сайт всего за 8,3 часа
A Задержка сканирования: из 500 секунд позволит сканерам проиндексировать ваш весь сайт на 1000 страниц за 5,8 дней
Вы можете установить Crawl-delay: для всех поисковых систем одновременно с:
User-agent: * Crawl-delay: 30
Разрешить всем поисковым системам сканировать веб-сайт :
По умолчанию поисковые системы должны иметь возможность сканировать ваш веб-сайт, но вы также можете указать, что им разрешено с:
Пользователь -агент: * Запретить:
Запретить всем поисковым системам сканировать веб-сайт :
Вы можете запретить любой поисковой системе сканировать ваш веб-сайт со следующими правилами:
User-agent: * Disallow: /
Запретить сканирование веб-сайта одной конкретной поисковой системе :
Вы можете запретить сканирование вашего веб-сайта только одной конкретной поисковой системе, используя следующие правила:
User-agent: Baiduspider Disallow: /
Запретить все поисковые системы из определенных папок :
Если бы у нас было несколько каталогов, таких как / cgi-bin / , / private / и / tmp / , мы не хотели, чтобы боты сканировали, мы могли бы использовать это:
User-agent: * Disallow: / cgi-bin / Запрещено: / частный / Disallow: / tmp /
Запретить всем поисковым системам использовать определенные файлы :
Если бы у нас были такие файлы, как contactus.htm , index.htm и store.htm мы не хотели, чтобы боты сканировали, мы могли бы использовать это:
User-agent: * Disallow: /contactus.htm Disallow: /index.htm Disallow: /store.htm
Запретить все поисковые системы, кроме одной :
Если бы мы только хотели разрешить Googlebot доступ к нашему каталогу / private / и запретить всем другим ботам, которые мы могли бы использовать :
Пользовательский агент: * Запрещено: / частный / Агент пользователя: Googlebot Disallow:
Когда Googlebot считывает наши robots.txt , он увидит, что сканирование каталогов не запрещено.
Как использовать Robots.txt | HostGator Поддержка
Для чего нужен файл роботов?
Когда поисковая система просматривает (индексирует) ваш веб-сайт, первое, что они ищут, — это ваш файл robots.txt. Однако есть некоторые исключения. Этот файл сообщает поисковым системам, что они должны и не должны индексировать (сохранять и делать общедоступными в качестве результатов поиска). Он также может указывать на расположение вашей XML-карты сайта.Затем поисковая система отправляет своего «бота», или «робота», или «паука» для сканирования вашего сайта, как указано в файле robots.txt (или не отправлять его, если вы сказали, что они не могут).
Бот Google называется Googlebot, а бот сети Bing — Bingbot. Многие другие поисковые системы, такие как Excite, Lycos, Alexa и Ask Jeeves, также имеют своих собственных ботов. Большинство ботов поступают из поисковых систем, хотя иногда другие сайты рассылают ботов по разным причинам. Например, некоторые сайты могут попросить вас разместить код на своем веб-сайте, чтобы подтвердить, что вы являетесь его владельцем, а затем они отправят бота, чтобы узнать, разместили ли вы код на своем сайте.
Куда идет Robots.txt?
Файл robots.txt находится в корневой папке вашего документа.
Вы можете просто создать пустой файл и назвать его robots.txt. Это уменьшит количество ошибок сайта и позволит всем поисковым системам ранжировать все, что они хотят.
Блокировка роботов и поисковых систем от сканирования
Если вы хотите, чтобы не позволяли ботам посещать ваш сайт, а не позволяли поисковым системам ранжировать вас, используйте этот код:
# Код, запрещающий поисковые системы!
Пользовательский агент: *
Disallow: / Вы также можете запретить роботам сканировать части вашего сайта, разрешив им сканировать другие разделы.В следующем примере поисковым системам и роботам предлагается не сканировать папку cgi-bin , папку tmp и папку нежелательной почты и все, что находится в этих папках на вашем веб-сайте.
# Блокирует роботов из определенных папок / каталогов
Пользовательский агент: *
Disallow: / cgi-bin /
Запрещение: / tmp /
Disallow: / junk / В приведенном выше примере http://www.yoursitesdomain.com/junk/index.html будет одним из заблокированных URL-адресов; но http: // www.yoursitesdomain.com/index.html и http://www.yoursitesdomain.com/someotherfolder/ можно будет сканировать.
Имейте в виду, что robot.txt работает как знак «Вход воспрещен». Он сообщает роботам, хотите ли вы, чтобы они сканировали ваш сайт или нет. Фактически он не блокирует доступ. Достопочтенные и законные боты будут соблюдать вашу директиву относительно того, могут они посещать или нет. Боты-мошенники могут просто игнорировать robots.txt. Как объясняется ниже, вы ДОЛЖНЫ использовать инструменты для веб-мастеров для Bingbot и Googlebot, поскольку они не уважают роботов.txt файл.
Google и сеть Bing
Google и сеть Bing НЕ соблюдают стандарт robots.txt. Вы можете создать учетные записи Google и Bing Network для веб-мастеров и настроить свои домены на меньшую задержку сканирования. Прочтите официальную позицию Google по файлу robots.txt. Вы ДОЛЖНЫ использовать инструменты Google для веб-мастеров, чтобы установить большинство параметров для GoogleBot.
Мы по-прежнему рекомендуем настроить файл robots.txt. Это снизит скорость, с которой сканеры будут инициировать запросы к вашему сайту, и сократит ресурсы, которые требуются от системы, что позволит обслуживать больше легитимного трафика.
Если вы хотите уменьшить трафик от поисковых роботов, таких как Яндекс или Baidu, это обычно нужно делать с помощью чего-то вроде блока .htaccess.
Для получения более подробной информации по этим темам перейдите по ссылкам, перечисленным ниже:
веб-сканеров и пользовательских агентов — 10 самых популярных
Брайан Джексон
Обновлено 6 июня 2017 г.
Когда дело доходит до всемирной паутины, есть как плохие, так и хорошие боты. Плохие боты, которых вы определенно хотите избежать, поскольку они потребляют пропускную способность вашей CDN, занимают ресурсы сервера и крадут ваш контент.С другой стороны, с хорошими ботами (также известными как веб-сканеры) следует обращаться осторожно, поскольку они являются жизненно важной частью индексации вашего контента в таких поисковых системах, как Google, Bing и Yahoo. Прочтите ниже о некоторых из 10 лучших веб-сканеров и пользовательских агентах , чтобы убедиться, что вы правильно с ними обращаетесь.
Веб-сканеры
Веб-сканеры, также известные как веб-пауки или Интернет-боты, представляют собой программы, которые просматривают Интернет в автоматическом режиме с целью индексации контента.Сканеры могут просматривать все виды данных, такие как контент, ссылки на странице, неработающие ссылки, карты сайта и проверку HTML-кода.
Поисковые системы, такие как Google, Bing и Yahoo, используют сканеры для правильной индексации загруженных страниц, чтобы пользователи могли находить их быстрее и эффективнее при поиске. Без поисковых роботов ничто не могло бы сказать им, что на вашем веб-сайте есть новый и свежий контент. Карты сайта также могут сыграть свою роль в этом процессе. Так что поисковые роботы по большей части — это хорошо.Однако иногда возникают проблемы, когда дело доходит до планирования и загрузки, поскольку поисковый робот может постоянно опрашивать ваш сайт. И здесь в игру вступает файл robots.txt. Этот файл может помочь контролировать сканирование трафика и гарантировать, что он не приведет к перегрузке вашего сервера.
Веб-сканеры идентифицируют себя для веб-сервера с помощью заголовка запроса User-Agent в HTTP-запросе, и каждый поисковый робот имеет свой собственный уникальный идентификатор. В большинстве случаев вам нужно будет исследовать журналы реферера вашего веб-сервера, чтобы просмотреть трафик поискового робота.
Robots.txt
Поместив файл robots.txt в корень своего веб-сервера, вы можете определить правила для поисковых роботов, например разрешить или запретить сканирование определенных ресурсов. Поисковые роботы должны следовать правилам, определенным в этом файле. Вы можете применить общие правила, которые применяются ко всем ботам, или получить более детальную информацию и указать их конкретную строку User-Agent .
Пример 1
В этом примере всем роботам поисковых систем предписывается не индексировать какой-либо контент веб-сайта.Это определяется запретом корневого каталога / вашего веб-сайта.
Агент пользователя: *
Запретить: /
Пример 2
В этом примере достигается противоположность предыдущему. В этом случае инструкции по-прежнему применяются ко всем пользовательским агентам, однако в инструкции Disallow ничего не определено, что означает, что все может быть проиндексировано.
Агент пользователя: *
Запретить:
Чтобы увидеть больше примеров, обязательно ознакомьтесь с нашим подробным постом о том, как использовать robots.txt файл.
Топ-10 поисковых роботов и роботов
В Интернете просматриваются сотни поисковых роботов и роботов, но ниже приведен список из 10 популярных веб-сканеров и ботов, которые мы собрали на основе тех, которые мы регулярно видим в нашем журналы веб-сервера.
1. GoogleBot
Googlebot, безусловно, является одним из самых популярных поисковых роботов в Интернете сегодня, поскольку он используется для индексации контента для поисковой системы Google. Патрик Секстон написал отличную статью о том, что такое робот Google и как он влияет на индексацию вашего веб-сайта.Одна замечательная особенность поискового робота Google заключается в том, что они предоставляют нам множество инструментов и контроль над процессом.
User-Agent Googlebot
Полный
User-Agent string Mozilla / 5.0 (совместимый; Googlebot / 2.1; + http: //www.google.com/bot.html)
Пример робота Googlebot в robots.txt
Этот пример демонстрирует немного большую детализацию, относящуюся к определенным инструкциям. Здесь инструкции относятся только к роботу Googlebot.В частности, он сообщает Google не индексировать определенную страницу ( /no-index/your-page.html ).
Пользовательский агент: Googlebot
Запретить: /no-index/your-page.html
Помимо поискового робота Google, у них есть еще 9 поисковых роботов:
| Поисковый робот | User-Agent string | |||||
|---|---|---|---|---|---|---|
| Googlebot News | Googlebot | Новости | Googlebot | Новости Googlebot | Изображения | Googlebot-Image / 1.0 |
| Googlebot Video | Googlebot-Video / 1.0 | |||||
| Google Mobile (рекомендуемый телефон) | SAMSUNG-SGH-E250 / 1.0 Profile / MIDP-2.0 Configuration / CLDC-1.1 UP Browser / 6.2.3.3 .c.1.101 (GUI) MMP / 2.0 (совместимый; Googlebot-Mobile / 2.1; + http: //www.google.com/bot.html) | |||||
| Google Smartphone | Mozilla / 5.0 (Linux; Android 6.0 .1; Nexus 5X Build / MMB29P) AppleWebKit / 537.36 (KHTML, например Gecko) Chrome / 41.0.2272.96 Mobile Safari / 537.36 (совместимый; Googlebot / 2.1; + http: //www.google.com/bot.html) | |||||
| Google Mobile Adsense | (совместимый; Mediapartners-Google / 2.1; + http: //www.google. com / bot.html) | |||||
| Google Adsense | Mediapartners-Google | |||||
| Google AdsBot (качество целевой страницы PPC) | AdsBot-Google (+ http: //www.google.com/adsbot.html) | |||||
| Сканер приложений Google (получение ресурсов для мобильных устройств) | AdsBot-Google-Mobile-Apps |
Вы можете использовать инструмент Fetch в консоли поиска Google, чтобы проверить, как Google сканирует или отображает URL на вашем сайте.Узнайте, может ли робот Googlebot получить доступ к странице вашего сайта, как он отображает страницу и не заблокированы ли какие-либо ресурсы страницы (например, изображения или сценарии) для робота Googlebot.
Вы также можете увидеть статистику сканирования роботом Googlebot за день, количество загруженных килобайт и время, потраченное на загрузку страницы.
См. Документацию робота Googlebot robots.txt.
2. Bingbot
Bingbot — это веб-сканер, развернутый Microsoft в 2010 году для предоставления информации их поисковой системе Bing. Это замена того, что раньше было ботом MSN.
User-Agent Bingbot
Полный
User-Agent string Mozilla / 5.0 (совместимый; Bingbot / 2.0; + http: //www.bing.com/bingbot.htm)
Bing также имеет очень похожий на Google инструмент, который называется Fetch as Bingbot, в составе Bing Webmaster Tools. Робот Fetch As Bingbot позволяет запросить сканирование страницы и ее отображение в том виде, в каком ее видит наш сканер. Вы увидите код страницы так, как его увидит Bingbot, что поможет вам понять, видят ли они вашу страницу так, как вы планировали.
См. Документацию Bingbot robots.txt.
3. Бот Slurp
Результаты поиска Yahoo поступают от поискового робота Yahoo Slurp и поискового робота Bing, так как большая часть Yahoo теперь работает на Bing. Сайты должны разрешать доступ Yahoo Slurp, чтобы они появлялись в результатах поиска Yahoo Mobile Search.
Кроме того, Slurp выполняет следующие функции:
- Собирает контент с партнерских сайтов для включения в такие сайты, как Yahoo News, Yahoo Finance и Yahoo Sports.
- Доступ к страницам сайтов в Интернете, чтобы подтвердить точность и улучшить персонализированный контент Yahoo для наших пользователей.
User-Agent Slurp
Полный
User-Agent string Mozilla / 5.0 (совместимый; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)
См. Документацию Slurp robots.txt.
4. DuckDuckBot
DuckDuckBot — это веб-сканер для DuckDuckGo, поисковой системы, которая в последнее время стала довольно популярной, поскольку известна своей конфиденциальностью и не отслеживает вас. Сейчас он обрабатывает более 12 миллионов запросов в день.DuckDuckGo получает результаты из более чем четырехсот источников. К ним относятся сотни вертикальных источников, доставляющих нишевые мгновенные ответы, DuckDuckBot (их поисковый робот) и краудсорсинговые сайты (Википедия). У них также есть более традиционные ссылки в результатах поиска, которые они получают из Yahoo !, Яндекс и Bing.
User-Agent DuckDuckBot
Полный
User-Agent string DuckDuckBot / 1.0; (+ http: //duckduckgo.com/duckduckbot.html)
Он уважает правила WWW :: RobotRules и исходит от следующих IP-адресов:
- 72.94.249.34
- 72.94.249.35
- 72.94.249.36
- 72.94.249.37
- 72.94.249.37
6 72.94.249.38 Baiduspider — официальное название паука, сканирующего веб-страницы китайской поисковой системы Baidu. Он сканирует веб-страницы и возвращает обновления в индекс Baidu. Baidu — ведущая китайская поисковая система, занимающая 80% рынка поисковых систем материкового Китая.
User-AgentBaiduspiderПолный
User-AgentstringMozilla / 5.0 (совместимый; Baiduspider / 2.0; + http: //www.baidu.com/search/spider.html)Помимо поискового робота Baidu, у них на самом деле есть 6 дополнительных поисковых роботов:
Веб-сканер User-AgentstringПоиск изображений 434434 видео Поиск Baiduspider-video Поиск новостей Baiduspider-news Списки желаний Baidu Baiduspider-favo Baidu Union Baidu Union Поиск объявленийДругие страницы поиска Baiduspider См. Baidu robots.txt документация.
6. Яндекс-бот
Яндекс-бот — это поисковый робот одной из крупнейших российских поисковых систем Яндекс. По данным LiveInternet, за три месяца, закончившихся 31 декабря 2015 года, они генерировали 57,3% всего поискового трафика в России.
User-AgentЯндексБотПолный
User-AgentstringMozilla / 5.0 (совместимый; YandexBot / 3.0; + http: //yandex.com/bots)Есть много разных строк User-Agent, которые Яндекс-бот может отображать в журналах вашего сервера.Смотрите полный список роботов Яндекса и документацию Яндекс robots.txt.
7. Sogou Spider
Sogou Spider — это веб-сканер для Sogou.com, ведущей китайской поисковой системы, которая была запущена в 2004 году. По состоянию на апрель 2016 года она занимает 103 место в рейтинге Alexa в Интернете.
Примечание: Веб-паук Sogou не соблюдает стандарт исключения роботов и поэтому ему запрещен доступ ко многим веб-сайтам из-за чрезмерного сканирования.User-AgentSogou Pic Spider / 3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Голова паука Сого / 3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Веб-паук Sogou / 4.0 (+ http: //www.sogou.com/docs/help/webmasters.htm#07) Sogou Orion spider / 3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Sogou-Test-Spider / 4.0 (совместимый; MSIE 5.5; Windows 98)8. Exabot
Exabot — это веб-сканер для Exalead, поисковой системы, базирующейся во Франции. Он был основан в 2000 году, и в настоящее время в нем проиндексировано более 16 миллиардов страниц.
User-AgentMozilla / 5.0 (совместимый; Konqueror / 3.5; Linux) KHTML / 3.5.5 (например, Gecko) (Exabot-Thumbnails) Mozilla / 5.0 (совместимый; Exabot / 3.0; + http: //www.exabot.com/go/robot)См. Документацию Exabot robots.txt.
9. Внешнее обращение Facebook
Facebook позволяет своим пользователям отправлять ссылки на интересный веб-контент другим пользователям Facebook. Часть того, как это работает в системе Facebook, включает временное отображение определенных изображений или деталей, относящихся к веб-контенту, таких как заголовок веб-страницы или тег для встраивания видео.Система Facebook получает эту информацию только после того, как пользователь предоставит ссылку.
Один из их основных роботов для сканирования — Facebot, предназначенный для повышения эффективности рекламы.
User-Agentfacebot facebookexternalhit / 1.0 (+ http: //www.facebook.com/externalhit_uatext.php) facebookexternalhit / 1.1 (+ http: //www.facebook.com/externalhit_uatext.php)См. Документацию Facebot robots.txt.
10. Поисковый робот Alexa
ia_archiver— это поисковый робот для интернет-рейтинга Amazon Alexa.Как вы, наверное, знаете, они собирают информацию, чтобы показать рейтинги как местных, так и международных сайтов.User-Agentia_archiverПолный
User-Agentstringia_archiver (+ http: //www.alexa.com/site/help/webmasters; [email protected])См. Документацию Ia_archiver robots.txt.
Плохие боты
Как мы упоминали выше, большинство из них на самом деле являются хорошими поисковыми роботами. Обычно вы не хотите блокировать Google или Bing от индексации вашего сайта, если у вас нет веской причины.Но как насчет тысяч плохих ботов? KeyCDN выпустил новую функцию еще в феврале 2016 года, которую вы можете включить на своей панели инструментов, под названием Блокировать плохих ботов. KeyCDN использует исчерпывающий список известных плохих ботов и блокирует их на основе строки
User-Agent.Когда добавляется новая зона, для функции Блокировать плохих ботов устанавливается значение
отключено. Для этого параметра можно установить значениевключено, если вы хотите, чтобы плохие боты автоматически блокировались.Ресурсы ботов
Возможно, вы видите в своих журналах строки пользовательского агента, которые вас беспокоят.Вот несколько хороших ресурсов, в которых вы можете найти популярных плохих ботов, сканеров и парсеров.
У Кайо Алмейды также есть неплохой список в своем проекте поисковых роботов-пользователей на GitHub.
Резюме
Существуют сотни различных поисковых роботов, но, надеюсь, теперь вы знакомы с парой наиболее популярных из них. Опять же, вы должны быть осторожны при блокировке любого из них, поскольку они могут вызвать проблемы с индексацией. Всегда полезно проверять журналы вашего веб-сервера, чтобы узнать, как часто они действительно сканируют ваш сайт.
Пропустили важные? Если да, сообщите нам об этом ниже, и мы добавим их.
Подробное руководство по /robots.txt для специалистов по поисковой оптимизации
Это руководство по /robots.txt «от новичка до продвинутого». Каждая инструкция содержит советы по типичным ошибкам и подводным камням. Написано для начинающих SEO-специалистов и маркетологов, но содержит полезную информацию для людей с любым уровнем знаний.
Введение в /robots.txt
Стандарт /robots.txt позволяет владельцам веб-сайтов давать инструкции роботам, посещающим их веб-сайты.Это может быть запрос не сканировать определенную часть веб-сайта или указание, где найти XML-карту сайта.
/robots.txt — это простой текстовый файл с простыми инструкциями, всегда размещаемый в одном месте на веб-сайте:
Как это работает?
Роботы, например, из Google, проверяют, есть ли на веб-сайте файл /robots.txt, прежде чем они сначала сканируют веб-сайт. Он ищет правила, специфичные для их User-agent (Googlebot). Если ничего не найдено, он следует общим правилам User-agent.
Действующие правила /robots.txt
User-agent:
У каждого робота есть свой user-agent. По сути, это имя робота, позволяющее предоставлять одним ботам доступ к файлам, а другим — нет.
-
User-agent: *= Any robot -
User-agent: Google= Google search -
User-agent: Googlebot-Image= Google images -
User-agent: AhrefsBot= Ahrefs webcrawler
Важно : Робот будет обращать внимание только на наиболее конкретную группу инструкций.В приведенном ниже примере есть две инструкции User-agent. Один для «любого робота» и один для «DuckDuckBot». DuckDuckBot будет смотреть только на свои собственные инструкции (и игнорировать другие правила), а будет искать в других папках, таких как
/ api /.Пользовательский агент: * Disallow: / cgi-bin / Запрещение: / tmp / Запретить: / api / Пользовательский агент: DuckDuckBot Disallow: / duckhunt /
Disallow:
С помощью правила Disallow вы можете легко заблокировать целые разделы вашего сайта от индексации в поисковых системах.Вы также можете заблокировать доступ ко всему сайту для всех или определенных ботов. В зависимости от ваших потребностей это может быть полезно для динамических, временных или защищенных от входа разделов вашего сайта.
Пользовательский агент: * # Блок / cms и любые файлы в нем Disallow: / cms # Блокировать / изображения / изменить размер (/ изображения по-прежнему разрешены) Disallow: / images / resized /
Чтобы упростить эту задачу, вы можете использовать сопоставление с шаблоном для блокировки сложных URL-адресов.
-
*= любая последовательность символов -
$= Соответствует концу URL-адреса
User-agent: * # Блокировать URL-адреса, начинающиеся с / photo like # /фотографии # / фото / обзор Запретить: / фото # Блокировать URL-адреса, начинающиеся с / blog / и заканчивающиеся / stats / Disallow: / blog / * / stats $
(символ решетки — это способ добавления комментариев.Роботы их проигнорируют.)
Важно: Не блокируйте файлы CSS или JavaScript. Это необходимо поисковым системам для правильного отображения вашего сайта.
Разрешить:
С помощью правила Разрешить можно разблокировать подкаталог, который заблокирован правилом запрета. Это может быть полезно, если вы запретили часть (или весь) сайт, но хотите разрешить определенные файлы / папки.
Пользовательский агент: * # Заблокировать доступ ко всему в папке администратора Запретить: / admin # Кроме / admin / css / style.css Разрешить: /admin/css/style.css # И все в папке / admin / js. Нравиться: # /admin/js/global.js # /admin/js/ajax/update.js Разрешить: / admin / js /
Другое использование — предоставление доступа определенным роботам.
# Запретить доступ всем роботам Пользовательский агент: * Запретить: / # Кроме Googlebot Пользовательский агент: Googlebot Allow: /
Crawl-delay:
Если робот использует слишком много ресурсов на веб-сайте, вы можете замедлить его сканирование с помощью правила Crawl-delay.
Пользовательский агент: * Crawl-delay: 5
Поскольку это не официальная часть стандарта, реализация меняется в зависимости от робота.В целом: чем больше число, тем меньше сканирований будет сканировать ваш сайт.
- Google (робот Google) игнорирует эту команду. Вы можете изменить скорость сканирования в Search Console.
- Baidu игнорирует эту команду. Его можно изменить с помощью функции Инструментов для веб-мастеров, но в настоящее время она недоступна на английском языке.
- Bing (BingBot) рассматривает это как «временное окно», в течение которого BingBot просканирует ваш веб-сайт только один раз.
- Яндекс (ЯндексБот) количество секунд ожидания между сканированиями.
Внимание! : Если файл Robots.txt содержит высокую задержку сканирования, проверьте, своевременно ли индексируется ваш сайт. Поскольку в сутках 86400 секунд,
Crawl-Delay: 30— это 2880 страниц, просканированных в день, что может быть слишком мало для больших сайтов.Карта сайта:
Одно из основных применений файла /robots.txt (для оптимизаторов поисковых систем) — это объявление карты (ов) сайта. Это делается путем добавления следующей строки, за которой следует полный URL-адрес.
Карта сайта: https: // www.example.com/sitemap.xml Карта сайта: https://www.example.com/blog-sitemap.xml
Если у вас несколько карт сайта, вы можете добавить их с новым правилом.
О чем следует помнить
- Карта сайта должна начинаться с заглавной буквы S.
- Карта сайта не зависит от инструкций агента пользователя.
- Ссылка должна быть полным URL. Вы не можете использовать относительный путь.
Убедитесь, что ссылка возвращает заголовок HTTP
200 OK(без перенаправлений).Общий /robots.txt
Это некоторые общие шаблоны /robots.txt, которые вы можете использовать для своих веб-сайтов.
Разрешить полный доступ
Не блокируйте доступ роботов к вашему сайту, оставив пустое правило Disallow.
Пользовательский агент: * Запретить:
Блокировать весь доступ
Агент пользователя: * Запретить: /
Запретить определенную папку
Агент пользователя: * Запретить: / admin /
Запретить определенный файл
Агент пользователя: * Запретить: / images / my-embarrassing-photo.png
Добавить карту сайта
Карта сайта: https://www.example.com/sitemap.xml
Распространенные ошибки
Установка пользовательских правил для агента без повторения правил запрета
Из-за способа работы /robots.txt Если вы установите для бота собственный User-agent, он будет следовать только тем правилам, которые вы для него установили. Часто совершаемая ошибка — использовать расширенные правила запрета для подстановочного знака (`*`), а затем добавлять новое правило без повторения этих правил запрета.
# (Отредактированная версия IMDb / robots.текст) # # Ограничить скорость сканирования ScoutJet # Пользовательский агент: ScoutJet Задержка сканирования: 3 # # # # Все остальные # Пользовательский агент: * Запретить: / tvschedule Запретить: / ActorSearch Запретить: / ActressSearch Запретить: / AddRecommendation Запретить: / ads / Запретить: / Альтернативные версии Запретить: / AName Disallow: / Награды Disallow: / BAgent Запретить: / Голосование / # # Карта сайта: http://www.imdb.com/sitemap_US_index.xml.gz
В /robots.txt для IMDb есть обширные правила запрета, но они не повторяются для ScoutJet .Предоставление этому боту доступа ко всем папкам.
Common User-agent’s
Ищете конкретного робота? Это наиболее часто используемые пользовательские агенты /robots.txt.
User-agent # Google [подробнее] Googlebot Обычный поисковый бот Google Googlebot-Image Робот Google Images Робот Google Images подробнее] Bingbot Обычный поисковый бот Bing MSNBot Старый сканер для Bing, но все еще используется MSNBot-Media Crawler для Bing Image создатель [подробнее]Яндекс [подробнее] ЯндексБот Обычный поисковый бот Яндекс YandexImages Краулер для Яндекс изображений Baid435 Главный поисковый паук для Baidu Baiduspid er-image Краулер для изображений Baidu Applebot Краулер для Apple.Используется для предложений Siri и Spotlight. SEO инструменты AhrefsBot Webcrawler для Ahrefs MJ12Bot Webcrawler для Majestic rogerbot Webcrawler для Мос Разное DuckDuckBot Webcrawler для DuckDuckGo Расширенные уловки с подстановочными знаками
Широко поддерживаются два подстановочных символа.Звездочки
*для соответствия любой последовательности символов и$, которые соответствуют концу URL-адреса.Блокировать определенные типы файлов
Пользовательский агент: * # Блокировать файлы с расширением .json # Звездочки позволяют любое имя файла # Знак доллара гарантирует, что он соответствует только концу URL-адреса, а не URL-адресу в странном формате (например, /locations.json.html) Disallow: /*.json$
Блокировать любой URL-адрес с?
Агент пользователя: * # Блокировать все URL-адреса, содержащие вопросительный знак Disallow: / *?
Блокировать страницы результатов поиска (но не саму страницу поиска)
User-agent: * # Заблокировать страницу результатов поиска Запретить: / search.php? query = *
Часто задаваемые вопросы о /robots.txt
Действительно ли мне нужен файл /robots.txt?
Да. Хотя вы можете обойтись без файла /robots.txt, разумно всегда его создавать. Хорошие боты всегда будут пытаться посетить ваш файл /robots.txt. Если у вас его нет, журналы вашего сервера будут заполнены ошибками 404. Если хотите, можете просто создать пустой файл.
В моем /robots.txt нет файла Sitemap. Могу ли я его добавить?
Да. Хотя вам определенно следует отправить карту сайта через Google Search Console, неплохо также добавить ее в файл robots.текст. Это просто сделать и избавляет вас от необходимости отправлять карту сайта в все поисковые системы (у всех Google, Bing, Yandex, Baidu есть собственные инструменты для веб-мастеров). Это также помогает другим сканерам (не поисковым системам) находить вашу карту сайта.
Учитываются ли регистры в каталогах?
Как и большинство URL-адресов, правила Disallow и Allow чувствительны к регистру. Убедитесь, что ваши правила такие же, как и ваши URL-адреса.
Пользовательский агент: * # / users будут сканироваться, так как регистр не соответствует Disallow: / Users
Учитываются ли регистры в полях / инструкциях?
Сами инструкции не чувствительны к регистру.Вы можете указать правило как
Disallow:илиdisallow:.Как я могу проверить изменения в файлах /robots.txt?
Тестер /robots.txt в Google Search Console позволяет проверить, доступна ли сканирование определенной странице.В сети есть несколько бесплатных парсеров /robots.txt, но самый надежный способ — через Google Search Console. Он содержит расширенный инструмент, в котором вы можете ввести URL-адрес и проверить, разрешено ли Google сканировать его.
Что такое файл Robots.txt и его значение для SEO?
Примеры использования регулярных выражений в robots.txt
При создании правил в файле robots.txt вы можете использовать сопоставление с шаблоном, чтобы заблокировать диапазон URL-адресов в одном запрещающем правиле. Регулярные выражения могут использоваться для сопоставления с образцом, и два основных символа, которые соблюдаются как Google, так и Bing, включают:
- Знак доллара ($), который соответствует концу URL-адреса
- Звездочка (*), который является правило с подстановочными знаками, представляющее любую последовательность символов.
Примеры сопоставления с образцом в Semetrical:
Disallow: * / searchjobs / *Это заблокирует любой URL-адрес, содержащий путь к / searchjobs /, например www.example.com/searchjobs/construction. Это было необходимо для клиента, поскольку раздел поиска на его сайте необходимо было заблокировать, чтобы поисковые системы не сканировали и не индексировали этот раздел сайта.
Disallow: / jobs * / full-time / *Это заблокирует URL-адреса, которые включают путь после / jobs /, за которым следует / full-time /, например www.example.com/jobs/admin- секретарский-па / полный рабочий день /. В этом сценарии нам нужна полная занятость в качестве фильтра для UX, но для поисковых систем нет необходимости индексировать страницу, чтобы обслуживать «название должности» + «полный рабочий день».
Disallow: / jobs * / * - 000 - * - 999 / *При этом будут заблокированы URL-адреса, содержащие фильтры заработной платы, такие как www.example.com/jobs/city-of-bristol/-50- 000-59-999 /. В этом сценарии нам нужны фильтры зарплат, но поисковым системам не нужно было сканировать страницы с зарплатами и индексировать их.
Disallow: / jobs / * / * / flexible-hours /Это заблокирует URL-адреса, которые включают гибкие часы и включают два промежуточных пути фасетов.В этом сценарии мы обнаружили с помощью исследования ключевых слов, что пользователи могут искать местоположение + гибкий график или работа + гибкий график, но пользователи не будут искать «название должности» + «местоположение» + «гибкий график». Пример URL-адреса выглядит так: www.example.com/jobs/admin-secretarial-and-pa/united-kingdom/f flexible-hours/.
Disallow: * / company / * / * / * / people $Это заблокирует URL-адрес, который включает три пути между компанией и людьми, а также URL-адрес, заканчивающийся на людей.Примером может быть www.example.com/company/gb/047/company-check-ltd/people.
Disallow: *? CostLowerAsNumber = *Это правило блокирует фильтр параметров, который упорядочивает цены.
Запретить: *? Radius = *Запретить: *? Radius = *Эти два правила запрещали ботам сканировать URL-адрес параметра, который изменял радиус поиска пользователей. Было добавлено правило как в верхнем, так и в нижнем регистре, поскольку сайт включал обе версии.
Что нужно знать о robots.txt
- Файл robots.txt чувствителен к регистру, поэтому вам нужно использовать правильный регистр в ваших правилах, например, / hello / будет обрабатываться иначе, чем / Hello / .
- Чтобы поисковые системы, такие как Google, быстрее повторно кэшировали ваш robots.txt для поиска новых правил, вы можете проверить URL-адрес robots.txt в Search Console и запросить индексацию.
- Если ваш веб-сайт использует файл robots.txt с рядом правил и ваш файл robots.txt в течение длительного периода времени обслуживает код состояния 4xx, правила будут игнорироваться, а заблокированные страницы станут индексируемыми. Важно убедиться, что он всегда обслуживает код состояния 200.
- Если ваш веб-сайт не работает, убедитесь, что robots.txt возвращает код состояния 5xx, так как поисковые системы поймут, что сайт не работает на техническое обслуживание, и вернутся для повторного сканирования веб-сайта позже.
- Если URL-адреса уже проиндексированы и затем на ваш веб-сайт добавлено запрещение для удаления этих URL-адресов из индекса, для удаления и удаления этих URL-адресов может потребоваться некоторое время.Кроме того, URL-адреса могут еще какое-то время оставаться в индексе, но в метаописании будет отображаться сообщение типа «Описание этого результата недоступно из-за файла robots.txt этого сайта — подробнее».
- Правило запрета файла robots.txt не всегда гарантирует, что страница не будет отображаться в результатах поиска, поскольку Google может решить, основываясь на внешних факторах, таких как входящие ссылки, что она актуальна и должна быть проиндексирована.
- Если у вас есть правило запрета, а также поместите тег «без индекса» в исходный код страницы, то «без индекса» будет проигнорировано, поскольку поисковые системы не могут получить доступ к странице для обнаружения тега «без индекса». .
- Правило запрета на проиндексированных страницах, особенно на тех, которые содержат входящие ссылки, означает, что вы потеряете ссылочный вес тех обратных ссылок, которые в противном случае были бы переданы другим страницам.
-