Как создать файл robots.txt • Full-Arts
Содержание статьи
ToggleRobots.txt – имеет определенные стандарты исключений для поисковых агентов (ботов), который был принят в январе 1944 года. Правилам этого файла добровольно следуют самые распространенные PS. Файл может состоять из одного или нескольких правил, каждое из которых блокирует или разрешает поисковому роботу доступ к определенным путям на сайте.
По умолчанию этого файла нет на сайте – что дает всем PS полное разрешение на индексирование всего содержимого сайта. Такое разрешение может привести к попаданию в индекс поисковиков важных технических страниц сайта, которых там быть не должно.
Для чего нужен Robots.txt на сайте — его влияние на продвижение в поисковиках
Robots.txt — это наиважнейший фактор поисковой оптимизации сайта. Благодаря правильно прописанному набору правил для поисковых ботов, можно достичь определенного повышения ранжирования сайта в поиске. Что дают такие инструкции:
Что дают такие инструкции:
- Заперты на индексирование определенных страниц, разделов, каталогов сайта;
- Исключение страниц не содержащих полезного контента;
- Исключение дублей страниц и прочее.
Для большинства сайтов, такие ограничения на индексирование просто необходимы для небольших полностраничных необязательны. Тем не менее определенные директивы, необходимо добавлять каждому сайту. К примеру запреты на индексацию:
- Страниц регистрации, входа в админку, восстановления пароля;
- Технических каталогов;
- Rss – ленты сайта;
- Replytocom и прочего.
Как создать файл Robors.txt самостоятельно плюс примеры
Затруднений при создании файла Robots.txt не может возникнуть даже у начинающих. Достаточно следовать определенной последовательности действий:
- Robots.
 txt — текстовый документ и создается любым доступным текстовым редактором;
txt — текстовый документ и создается любым доступным текстовым редактором; - Расширение файла должно быть обязательно .txt;
- Название обязательно robots;
- На одном сайте, разрешен только один такой файл;
- Размещается только в корневом каталоге сайта;
Вам необходимо воспользоваться обыкновенным текстовым редактором (блокнотом как альтернативой). Создаем документ формата .txt и названием robots. Затем сохраняем и переносим этот документ с помощью FTP клиента в корневой каталог сайта. Это основные действия которые необходимо выполнить.
Примеры стандартных Robots.txt для популярных CMS
Пример robots.txt для amiro.cms:
Пример robots.txt для bitrix:
Пример robots.txt для dle:
Пример robots.txt для drupal:
Пример robots.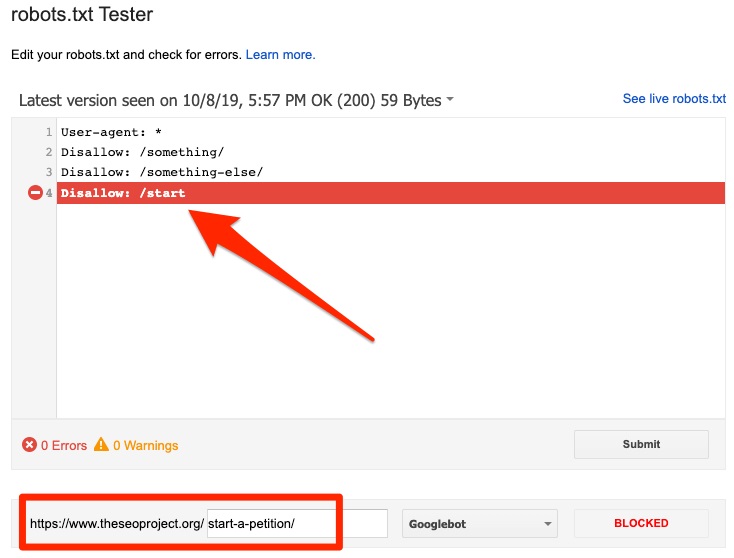 txt для hostcms:
txt для hostcms:
Пример robots.txt для joomla3:
Пример robots.txt для joomla:
Пример robots.txt для modx evo:
Пример robots.txt для modx:
Пример robots.txt для netcat:
Пример robots.txt для opencat:
Пример robots.txt для typo3:
Пример robots.txt для umi:
Пример robots.txt для wordpress:
Далее пример файла моего сайта CMS WordPress:
# robots.txt
User-Agent: *
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /template.html
Disallow: /wp-admin
Disallow: */trackback
Disallow: */comments*
Disallow: *comments_*
Disallow: /search
Disallow: /author/*
Disallow: /users/
Disallow: /*?replytocom
Disallow: /*?replytocom*
Disallow: /comment-page*
Disallow: */tag/*
Disallow: /tag/*
Disallow: /?s=*
Disallow: /?s=
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /?p=
Disallow: *. php
php
Disallow: /ads.txt
Disallow: */stylesheet
Disallow: */stylesheet*
Allow: /wp-content/uploads/
Allow: /wp-includes
Allow: /wp-content
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: Yandex
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /template.html
Disallow: /wp-admin
Disallow: */trackback
Disallow: */comments*
Disallow: *comments_*
Disallow: /search
Disallow: /author/*
Disallow: /users/
Disallow: /*?replytocom
Disallow: /*?replytocom*
Disallow: /comment-page*
Disallow: */tag/*
Disallow: /tag/*
Disallow: /?s=*
Disallow: /?s=
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /?s=
Disallow: /?p=
Disallow: *.php
Disallow: /ads.txt
Disallow: */amp
Disallow: */amp?
Disallow: */amp/
Disallow: */stylesheet
Disallow: */stylesheet*
Allow: /wp-content/uploads/
Allow: /wp-includes
Allow: /wp-content
Allow: */uploads
Allow: /*/*. js
js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: Mail.Ru
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /template.html
Disallow: /wp-admin
Disallow: */trackback
Disallow: */comments*
Disallow: *comments_*
Disallow: /search
Disallow: /author/*
Disallow: /users/
Disallow: /*?replytocom
Disallow: /*?replytocom*
Disallow: /comment-page*
Disallow: */tag/*
Disallow: /tag/*
Disallow: /?s=*
Disallow: /?s=
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /?s=
Disallow: /?p=
Disallow: *.php
Disallow: /ads.txt
Disallow: */stylesheet
Disallow: */stylesheet*
Allow: /wp-content/uploads/
Allow: /wp-includes
Allow: /wp-content
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*. png
png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: ia_archiver
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /template.html
Disallow: /wp-admin
Disallow: */trackback
Disallow: */comments*
Disallow: *comments_*
Disallow: /search
Disallow: /author/*
Disallow: /users/
Disallow: /*?replytocom
Disallow: /*?replytocom*
Disallow: /comment-page*
Disallow: */tag/*
Disallow: /tag/*
Disallow: /?s=*
Disallow: /?s=
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /?s=
Disallow: /?p=
Disallow: *.php
Disallow: /ads.txt
Disallow: */stylesheet
Disallow: */stylesheet*
Allow: */?amp
Allow: /wp-content/uploads/
Allow: /wp-includes
Allow: /wp-content
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*. jpg
jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: SputnikBot
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /template.html
Disallow: /wp-admin
Disallow: */trackback
Disallow: */comments*
Disallow: *comments_*
Disallow: /search
Disallow: /author/*
Disallow: /users/
Disallow: /*?replytocom
Disallow: /*?replytocom*
Disallow: /comment-page*
Disallow: */tag/*
Disallow: /tag/*
Disallow: /?s=*
Disallow: /?s=
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /?s=
Disallow: /?p=
Disallow: *.php
Disallow: /ads.txt
Disallow: */stylesheet
Disallow: */stylesheet*
Allow: */?amp
Allow: /wp-content/uploads/
Allow: /wp-includes
Allow: /wp-content
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*. jpeg
jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: Bingbot
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /template.html
Disallow: /wp-admin
Disallow: */trackback
Disallow: */comments*
Disallow: *comments_*
Disallow: /search
Disallow: /author/*
Disallow: /users/
Disallow: /*?replytocom
Disallow: /*?replytocom*
Disallow: /comment-page*
Disallow: */tag/*
Disallow: /tag/*
Disallow: /?s=*
Disallow: /?s=
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /?s=
Disallow: /?p=
Disallow: *.php
Disallow: /ads.txt
Disallow: */stylesheet
Disallow: */stylesheet*
Allow: */?amp
Allow: /wp-content/uploads/
Allow: /wp-includes
Allow: /wp-content
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.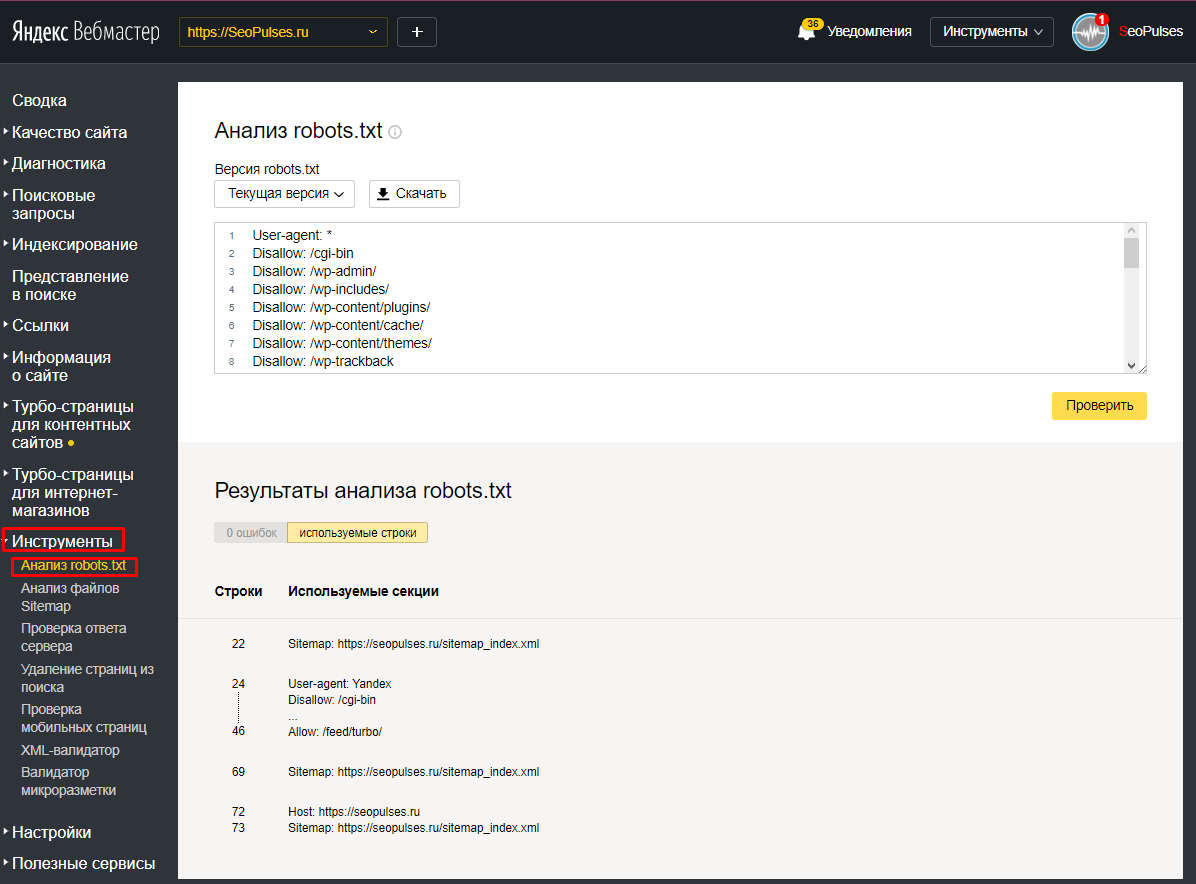 gif
gif
Allow: /wp-admin/admin-ajax.php
User-agent: Googlebot
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /template.html
Disallow: /wp-admin
Disallow: */trackback
Disallow: */comments*
Disallow: *comments_*
Disallow: /search
Disallow: /author/*
Disallow: /users/
Disallow: /*?replytocom
Disallow: /*?replytocom*
Disallow: /comment-page*
Disallow: */tag/*
Disallow: /tag/*
Disallow: /?s=*
Disallow: /?s=
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /?s=
Disallow: /?p=
Disallow: *.php
Disallow: */stylesheet
Disallow: */stylesheet*
Allow: */?amp
Allow: */*/?amp
Allow: */tag/?amp
Allow: */page/?amp
Allow: /wp-content/uploads/
Allow: /wp-includes
Allow: /wp-content
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*. jpeg
jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: Yandex-Images
Allow: /wp-content/uploads/
User-agent: Mail.Ru-Images
Allow: /wp-content/uploads/
User-agent: ia_archiver-Images
Allow: /wp-content/uploads/
User-agent: Bingbot-Images
Allow: /wp-content/uploads/
Host: https://nicola.top
Sitemap: https://nicola.top/sitemap_index.xml
Sitemap: https://nicola.top/?feed=googleimagesitemap
Надеюсь, что он будет Вам полезен. Пожалуйста применяйте правила исходя из соображений касательно ваших сайтов. К каждому ресурсу должен быть свой подход.
Как создать файл Robots.txt с помощью онлайн сервисов
Этот метод самый простой и быстрый, подойдет тем кто боится самостоятельно создавать Robots.txt или просто ленится. Сервисов предлагающих создание этого файла огромное множество. Но стоит учитывать некоторые нюансы касательно этого способа. К примеру:
К примеру:
— Необходимо заранее учесть, что именно Вы желаете запретить, либо разрешить агенту.
— Необходима обязательная проверка готового файла перед загрузкой его на сайт.
— Будьте внимательны, ведь некорректно созданный файл Robots.txt online, приведет к плачевной ситуации. Таким образом в поиск могут попасть, технические и прочие страницы сайта, которых там быть в априори не должно.
— Все таки, лучше потратить время и усилия для создания корректного пользовательского роботса. Таким образом можно воссоздать четко обоснованную структуру запретов и разрешений соответствующую вашему сайту.
Редактирование и правильный синтаксис файла Robots.txt
После успешно созданного Robots.txt, его можно спокойно редактировать и изменять как Вам будет угодно. При этом следует учесть некоторые правила и грамотный синтаксис. По прошествии некоторого времени вы неоднократно будете изменять этот файл. Но не забывайте, после проведения работ по редактированию, Вам необходимо будет выгрузить этот файл на сайт. Тем самым обновив его содержимое для поисковых роботов.
Тем самым обновив его содержимое для поисковых роботов.
Написать Robots.txt очень просто, причина этому достаточно простая структура оформления данного файла. Главное при написании правил, использовать строго определенный синтаксис. Данным правилам добровольно следуют, практически все основные ПС. Вот список некоторых правил, для избежания большинства ошибок в файле Robots.txt:
- В одной строке не должно быть более одной указанной директивы;
- Каждое правило начинается с новой строки;
- Исключен пробел в начале строки;
- Допустимы комментарии после символа #;
- Пустой Роботс будет считаться как полное разрешение на индексацию;
- Название этого файла возможно только в допустимом формате “robots”;
- Размер файла не должен превышать 32кб;
- В директивах Allow и Disallow допустимо только одно правило.
 Пустое значение после Allow: или Disallow: равносильны полному разрешению;
Пустое значение после Allow: или Disallow: равносильны полному разрешению; - Все правила должны быть прописаны в нижнем регистре;
- Файл должен быть доступен всегда;
- Пустая строка после указанных правил, указывает на полное окончание правил директивы User-agent;
- Желательно прописывать правила, каждой ПС по отдельности;
- Если правило это директория сайта, то обязательно ставьте слеш (/) перед ее началом;
- Кавычек в строке или в правиле быть не должно;
- Необходимо учитывать строгую структуру правил, соответствующую Вашему сайту не более;
- Robots.txt должен быть минималистичен и четко отображать передаваемый смысл;
Грамотная настройка файла Robots.txt — правильное написание команд
Чтобы получить позитивный результат при использовании роботс, необходимо правильно его настроить. Всем основным командам данного файла с инструкциями, следуют самые масштабные поисковые системы Google and Yandex. Остальные PS могут игнорировать некоторые инструкции. Как сделать robots.txt наиболее отзывчивым большинству поисковиков? Здесь необходимо понимание основных правил работы с этим файлом о которых говорилось выше.
Всем основным командам данного файла с инструкциями, следуют самые масштабные поисковые системы Google and Yandex. Остальные PS могут игнорировать некоторые инструкции. Как сделать robots.txt наиболее отзывчивым большинству поисковиков? Здесь необходимо понимание основных правил работы с этим файлом о которых говорилось выше.
Рассмотрим основные команды:
- User-Agent: * — инструкции будут касаться абсолютно всех ps ботов. Также возможно указание определенных поисковых систем по отдельности к примеру: User-Agent: GoogleBot и User-Agent: YandexBot. Таким образом корректно обозначаются правила для важных ПС.
- Disallow: — полностью запрещает обход и индексацию (страницы, каталога или файлов).
- Allow: — полностью разрешает обход и индексацию (страницы, каталога или файлов).
- Clean-param: — нужен для исключения страниц сайта с динамическим контентом. Благодаря этому правилу можно избавиться от дублей контента на сайте.
- Crawl-delay: — правило указывает интервал времени п-ботам для выгрузки документов с сайта. Позволяет значительно уменьшить нагрузки на сервер. К примеру: “Crawl-delay: 5” – скажет п-роботу, что скачивание документов с сайта возможно не чаще 1-го раза в 5 секунд.
- Host: ваш_сайт.ru — отвечает за главное зеркало сайта. В этой директиве необходимо прописать приоритетную версию сайта.
- Sitemap: http://ваш_сайт.ru/sitemap.xml — как Вы могли догадаться данная директива подсказывает п-боту о наличие Sitemap на сайте.
- # — позволяет оставлять комментарии. Комментировать можно, только после знака решетки. Размещать ее можно как в новой строке, так и продолжением директивы. Все эти варианты будут игнорироваться ботами при проходе инструкций.
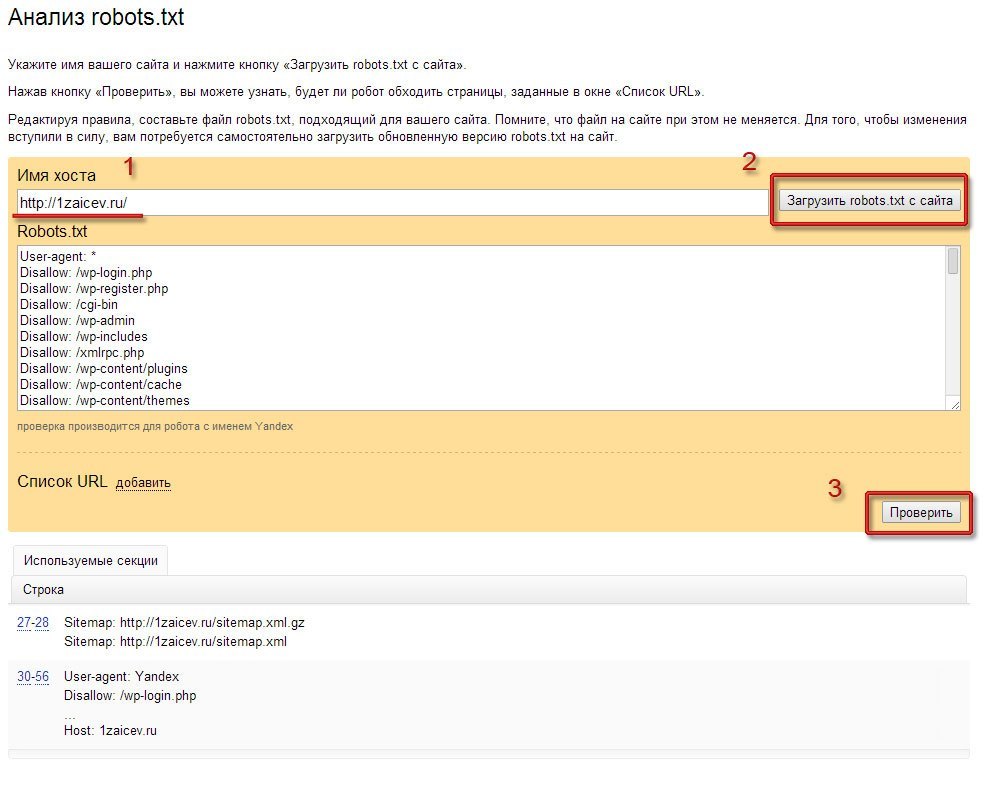
Как проверить Robots.txt с помощью Google или Yandex
Как не странно для проверки этого файла необходимы только панели вебмастера Google или Yandex. Что в свою очередь значительно облегчает поиск ошибок.
Что в свою очередь значительно облегчает поиск ошибок.
- Вебмастер Google — выбираем в левом меню “Сканирование” и затем вкладку “Инструмент проверки файла Robots.txt”. Затем в нижней строке появившегося окна допишите название файла. Затем нажмите на “Проверить” и посмотрите как бот гугла видит Ваш роботс.
- Вебмастер Yandex — в левом меню выбираем “Инструменты” и “Анализ Robots.txt”. После этого в появившимся окне просто нажмите на кнопку “Проверить”.
Стоит отметить, что онлайн валидаторов для проверки этого файла очень много.
Список цен на услуги
26 просмотров
Отказ от ответственности: Вся размещенная информация была взята из открытых источников и представлена исключительно в ознакомительных целях а также не несет призыва к действию. Создано лишь в образовательных и развлекательных целях. | Так же, если вы являетесь правообладателем размещенного на страницах портала материала, просьба написать нам через контактную форму жалобу на удаление определенной страницы, а также ознакомиться с инструкцией для правообладателей материалов. Спасибо за понимание.
Спасибо за понимание.
Если вам понравились материалы сайта, вы можете поддержать проект финансово, переведя некоторую сумму с банковской карты, счёта мобильного телефона или из кошелька ЮMoney.
как его создать и правильно настроить
Robots.txt – это текстовый файл, в котором указаны рекомендации для роботов поисковых систем относительно индексации сайта. Расположен данный файл в корневом каталоге сайта и среди его основных функций мы можем выделить следующие:
- Указание главного зеркала сайта;
- Указание пути к карте сайта для роботов;
- Создание необходимых правил обхода страниц поисковым краулером.
Помимо возможности давать рекомендации поисковыми системам по индексации сайта, роботс тхт максимально удобен в редактировании. Для этого через доступ FTP файл можно открыть через любой текстовый редактор, внести необходимые правки и загрузить обновленный файл в корень сайта с заменой старого документа. При этом некоторые CMS обеспечивают возможность редактирования без необходимости скачивать файл.
Важно отметить, что директивы robots txt могут не работать даже при правильном их составлении. Зачастую это связано со следующими синтаксическими ошибками:
- Итоговый размер файла превышает максимально допустимое значение для Яндекса в 500 килобайт и Гугла в 500 кибибайт;
- В процессе создания вы использовали кодировку, которая отличается от UTF-8, что актуально именно для Google;
- Расширение файла не txt или в его названии содержатся недопустимые символы;
- К файлу по определенным причинам нет доступа на сервере.
Исходя из всех вышеперечисленных пунктов можно отметить необходимость регулярно делать анализ robots txt, проверяя его на работоспособность.
Синтаксис и директивы файла Robots.txt для сайта
 Стандартно первой директивой должна быть User Agent, после следует запрет на индексацию Disallow, затем разрешение индексации Allow и окончательным этапом указывается основное зеркало сайта через директиву Host. Во избежания ошибок в процессе настройки Robots.txt мы рекомендуем обратить внимание на следующие правила работы с синтаксисом:
Стандартно первой директивой должна быть User Agent, после следует запрет на индексацию Disallow, затем разрешение индексации Allow и окончательным этапом указывается основное зеркало сайта через директиву Host. Во избежания ошибок в процессе настройки Robots.txt мы рекомендуем обратить внимание на следующие правила работы с синтаксисом:- Любая новая директива прописывается с новой строки;
- В начале строки и между строками не допускаются пробелы;
- Описываемый параметр нельзя переносить в новую строку;
- Перед всеми страницами сайта в директории обязательно нужно ставить слэш (/).
Важно отметить, что все директивы должны быть прописаны только латинскими символами. Правильный robots txt содержит в себе ряд директив, которые стоит рассмотреть более детально.
User-agent
Это обязательная директива файла, которая прописывается в первой строке. Основная цель данной директивы – это обращение к поисковому роботу, соответственно, существуют следующие ее варианты:
- User-agent: *
- User-agent: Yandex
- User-agent: Googlebot
Первый вариант предполагает обращение ко всем поисковым роботам, а остальные к конкретной поисковой системе.
Disallow
Директива указывает поисковому роботу на запрет индексации конкретной части сайта. При сочетании с директивой User-agent можно обеспечить запрет индексации для всех роботов или для конкретного поискового краулера.
Allow
Директива разрешает поисковым роботам индексацию всех страниц сайта или разделов, которые включают в себя данные страницы.
Crawl-Delay
Директива позволяет задать временной период, через который робот будет индексировать страницы. При заданном параметре Crawl-delay: 5 краулер будет индексировать следующую страницу через 5 секунд.
Host
Благодаря данной директиве можно указать главное зеркало сайта с www или без www.
Sitemap
Можно указать путь к карте сайта, а сама директива выглядит следующим образом Sitemap: mysite.com/sitemap.xml.
Как сделать Robots.txt
Правильный файл robots txt можно создать вручную, используя необходимые вам вышеперечисленные директивы в зависимости от особенностей вашего сайта.
- PR-CY;
- Seolib;
- Media Sova.
Любой из вышеперечисленных сервисов обеспечивает автоматическую генерацию файла, поэтому проблем с тем, как как сделать robots txt для сайта у вас не возникнет. Важно отметить, что содержимое файла robots txt отличается не только в зависимости от конкретного сайта, но и в зависимости от CMS.
Проверка файла robots.txt
Когда мы уже рассмотрели как создать robots txt и сгенерировали текстовый файл, его необходимо проверить на работоспособность. Для этого мы рекомендуем воспользоваться одним из множества онлайн сервисов.
Google Search Console и Яндекс.Вебмастер
Стандартные сервисы поисковых систем, которые в своем функционале предлагают возможность проверки файла роботс на правильность и отсутствие ошибок.
Website Planet
На главной странице сайта доступны все инструменты сервиса, среди которых есть проверка файла robots. После ввода адреса сайта мы получаем не только наличие ошибок или их отсутствие, но и любые предупреждения по файлу.
После ввода адреса сайта мы получаем не только наличие ошибок или их отсутствие, но и любые предупреждения по файлу.
Данный сервис можно с уверенностью назвать самым информативным для анализа роботс.
Tools.descript.ru
Проверка осуществляется стандартным методом через инструменты, которые предлагает Tools.descript. В окне для проверки просто вводим URL сайта и получаем детальный отчет.
Ключевой особенностью сервиса можно отметить возможность выбора не только целевого краулера определенной поисковой системы, но и выбор конкретной CMS. Это позволяет проверить правильность создания Robots для любого движка сайта.
Возьмем на себя все заботы по продвижению и раскрутке сайта:
> Создание сайта > SEO продвижение > Контекстная реклама в Яндекс и Google
Подпишись на рассылку, чтобы не пропустить ничего интересного!
Бесплатная консультация
Создание и настройка файла robots.txt
Файл robots.txt сообщает веб-роботам, как сканировать веб-страницы на вашем веб-сайте. Вы можете использовать веб-интерфейс Fastly для создания и настройки файла robots.txt. Если вы будете следовать инструкциям в этом руководстве, Fastly будет обслуживать файл robots.txt из кеша, чтобы запросы не попали в ваш источник.
Вы можете использовать веб-интерфейс Fastly для создания и настройки файла robots.txt. Если вы будете следовать инструкциям в этом руководстве, Fastly будет обслуживать файл robots.txt из кеша, чтобы запросы не попали в ваш источник.
Создание файла robots.txt
Чтобы создать и настроить файл robots.txt, выполните следующие действия:
- Войдите в веб-интерфейс Fastly.
- На домашней странице выберите соответствующую службу. Вы можете использовать поле поиска для поиска по идентификатору, имени или домену.
- Нажмите кнопку Изменить конфигурацию и выберите параметр для клонирования активной версии. Появится страница Домены.
- Щелкните ссылку Content . Появится страница содержимого.
Щелкните переключатель robots.txt , чтобы включить ответ robots.txt.
В TXT Response В поле настройте ответ для файла robots.
 txt.
txt.Нажмите кнопку Сохранить , чтобы сохранить ответ.
- Нажмите кнопку Активировать , чтобы применить изменения конфигурации.
Создание и настройка файла robots.txt вручную
Если вам нужно настроить ответ robots.txt, вы можете выполнить следующие шаги, чтобы вручную создать синтетический ответ и условие:
- Войдите в веб-интерфейс Fastly.
- На странице Home выберите соответствующую услугу. Вы можете использовать поле поиска для поиска по идентификатору, имени или домену.
- Нажмите кнопку Изменить конфигурацию и выберите параметр для клонирования активной версии. Появится страница Домены.
- Щелкните ссылку Content . Появится страница содержимого.
Нажмите кнопку Настроить расширенный ответ . Появится страница Создать синтетический ответ.
Заполните поля Создайте синтетический ответ следующим образом:
- В поле Имя введите соответствующее имя.
 Например
Например robots.txt. - Оставьте в меню Статус значение по умолчанию
200 OK. - В поле MIME Type введите
text/plain. - В поле Response введите хотя бы одну строку User-agent и одну строку Disallow. Например, приведенный выше пример сообщает всем пользовательским агентам (через
User-agent: *строка) им не разрешено сканировать что-либо после каталога/tmp/или файла/foo.html(черезDisallow: /tmp/*иDisallow: /foo. htmlстрок соответственно).
- В поле Имя введите соответствующее имя.
Нажмите кнопку Создать . Ваш новый ответ появится в списке ответов.
Щелкните ссылку Прикрепить условие справа от только что созданного ответа. Появится окно Создать новое условие.
Заполните поля Создать условие следующим образом:
- В меню Введите выберите нужное условие (например,
Запрос).
- В поле Name введите значимое имя для вашего состояния (например,
Robots). - В поле Применить, если введите логическое выражение для выполнения в VCL, чтобы определить, разрешается ли условие как истинное или ложное. В этом случае логичным выражением будет расположение вашего файла robots.txt (например,
req.url.path == "/robots.txt").
- В меню Введите выберите нужное условие (например,
Нажмите кнопку Сохранить .
- Нажмите кнопку Активировать , чтобы применить изменения конфигурации.
ПРИМЕЧАНИЕ
Подробное описание создания пользовательских ответов см. в нашем Учебном руководстве по ответам.
Почему я не могу настроить файл robots.txt с помощью global.prod.fastly.net?
Добавление расширения .global.prod.fastly.net в ваш домен (например, www.example.com.global.prod.fastly.net ) через браузер или команду curl можно использовать для проверки того, как ваш рабочий сайт будет работать с использованием сервисов Fastly.
Чтобы предотвратить случайное сканирование Google этого тестового URL-адреса, мы предоставляем внутренний файл robots.txt, в котором веб-сканеры Google предписывают игнорировать все страницы для всех имен хостов, которые заканчиваются на .prod.fastly.net .
Этот внутренний файл robots.txt нельзя настроить через веб-интерфейс Fastly до тех пор, пока вы не настроите DNS-запись CNAME для своего домена так, чтобы она указывала на 9.0084 global.prod.fastly.net .
Не используйте эту форму для отправки конфиденциальной информации. Если вам нужна помощь, обратитесь в службу поддержки. Эта форма защищена reCAPTCHA, и к ней применяются Политика конфиденциальности и Условия использования Google.
Как создать файл Robots.txt (4 основных шага)
Содержание
Переключатель Файл robots.txt делает роботов поисковых систем более эффективными при анализе SEO вашего сайта. Хорошая метафора заключается в том, что файл robots. txt помогает указать Google, куда вы хотите, чтобы они направлялись, как указатель к вашему контенту. Эта статья покажет вам, как создавать файлы robots.txt для оптимизации SEO вашего сайта и увеличения трафика. Исторически сложилось так, что сайты robots.txt имеют немного лучший SEO и веб-трафик, чем сайты, не использующие файлы robots.txt.
txt помогает указать Google, куда вы хотите, чтобы они направлялись, как указатель к вашему контенту. Эта статья покажет вам, как создавать файлы robots.txt для оптимизации SEO вашего сайта и увеличения трафика. Исторически сложилось так, что сайты robots.txt имеют немного лучший SEO и веб-трафик, чем сайты, не использующие файлы robots.txt.
1. Создайте файл
Начните с создания файла .txt с помощью блокнота или любого текстового редактора, сохранив новый файл как «роботы» в нижнем регистре.
2. Добавьте строки текста в файл
Введите следующие две строки текста в файл robots.txt, который вы только что сохранили:
User-agent: *
Disallow:
сайт, что эта строка текста относится ко всем из них.
3. Используйте линии запрета для управления поиском бота
Используя строки запрета для ограничения частей вашего сайта, которые боты Google могут сканировать, вы можете сделать SEO более эффективным, вырезав любые страницы, на которых вы не хотите, чтобы они фокусировались, оставив их для прямого доступа. к вашему контенту. Примером строки запрета может быть:
Запретить: /database/
Вырезание раздела базы данных вашего сайта и упрощение поиска по вашему сайту.
4. Сохраните файл robots.txt на своем веб-сайте
Последний шаг — сохранить только что созданный файл robots.txt в корневой каталог вашего веб-сайта. Перейдите в корневую директорию сервера хостинга веб-сайта и сохраните там файл robots.txt.
Структура и содержимое файла robots.txt
Файл robots.txt состоит из двух элементов. Во-первых, вы должны назвать пользовательский агент. После этого вы даете команды, какие каталоги на вашем сайте следует читать или игнорировать.
- Команда, которая обращается к боту, идет первой.
User-agent:
- После User-agent: вы можете назвать каждого бота отдельно или использовать звездочку * для включения всех ботов.
- Далее идет командная строка. Запретить: это для предотвращения доступа ботов к определенным областям. В то время как команда Разрешить: разрешает доступ к перечисленным областям.
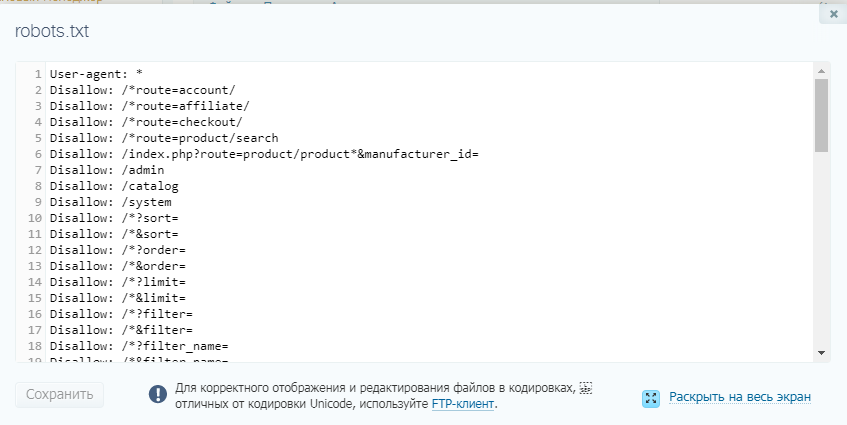
Ниже приведены несколько примеров файлов robots.txt:
Пример 1:
Агент пользователя: seobot
Disallow: /nothere/
В этом примере бот с именем «seobot» не будет сканировать папку http://www.test.com/nothere/ и все последующие подкаталоги.
Пример 2:
Агент пользователя: *
Разрешить: /
В этом примере все агенты пользователя могут получить доступ ко всему сайту. Однако боты все равно будут искать по всему сайту, если нет команды disallow, поэтому команда Allow:/ не нужна.
Однако боты все равно будут искать по всему сайту, если нет команды disallow, поэтому команда Allow:/ не нужна.
Образец 3:
Агент пользователя: seobot
ПОСЛЕДНИЕ ПОСТЫ
Ошибка 502 Bad Gateway является довольно распространенной, но раздражающей проблемой для большинства пользователей Интернета. Это один из кодов состояния HTTP, указывающих на наличие …
. SMTP-серверможет сбивать с толку, но вы должны научиться использовать его для своего бизнеса. Вместо использования переносного SMTP-сервера или стороннего почтового клиента…
Запретить: /directory2/
Запретить: /directory3/
В этом примере имя бота ‘seobot’ сообщает, что он не может просматривать каталоги 2 и 3. Обратите внимание, что каждая команда Disallow: должна располагаться на отдельной строке.
Другие инструкции, которые может использовать файл robots.txt
Выше мы упомянули несколько командных инструкций. Вот описательный список инструкций;
- User-agent: Используется для присвоения имен ботам, которым вы хотите отдавать команды.
 Использование *, чтобы позволить всем агентам следовать командам.
Использование *, чтобы позволить всем агентам следовать командам. - Disallow: запрещает ботам доступ к каким-либо каталогам, расположенным по указанному пути к файлу. / косая черта относится ко всем страницам сайта, поэтому Disallow: / предотвратит доступ ботов к любой странице.
- Разрешить: по умолчанию каждая страница на сайте помечена как разрешенная. Однако его можно использовать для предоставления доступа к определенным путям к файлам, даже если они ранее были заблокированы командой Disallow:. Эта функция полезна, если вы хотите заблокировать доступ к поддомену и получить доступ к определенной странице в этом заблокированном поддомене.
- Карта сайта: используется для предоставления местоположения вашей карты сайта ботам поисковых систем.
Как файл robots.txt влияет на поисковую оптимизацию?
При правильном использовании файл robots.txt может существенно повлиять на поисковую оптимизацию (SEO). Крайне важно не ограничивать ботов поисковых систем слишком сильно с помощью команды disallow. Если они слишком ограничены, это отрицательно скажется на рейтинге ваших веб-страниц. Прежде чем сохранять файл в корневой каталог, обязательно проверьте его на наличие ошибок. Если есть ошибка, это может означать, что важные области вашего сайта не включены или включены области, которые должны быть проигнорированы.
Если они слишком ограничены, это отрицательно скажется на рейтинге ваших веб-страниц. Прежде чем сохранять файл в корневой каталог, обязательно проверьте его на наличие ошибок. Если есть ошибка, это может означать, что важные области вашего сайта не включены или включены области, которые должны быть проигнорированы.
У Google есть удобный инструмент для проверки правильности работы файла robots.txt. Используйте консоль поиска Google, так как она перечислит все заблокированные страницы из ваших инструкций по запрету под заголовками «текущее состояние» и «ошибки сканирования». поисковые системы, которые его посещают.
Преимущества использования файла robots.txt на вашем веб-сайте
Поисковые роботы, которые индексируют веб-сайты в Интернете, имеют заранее определенное количество страниц, которые они могут сканировать, известное как краулинговый бюджет. Основное преимущество файла robots.txt заключается в том, что он позволяет заблокировать их в различных частях сайта и сосредоточиться на более дружественных к SEO разделах. Например, если на вашем сайте продаются футболки разных цветов и размеров, у каждой из них есть действительный URL-адрес для сканирования ботом. Заблокировав их, бот может сосредоточиться на основных важных страницах и пропустить разделы с несколькими цветами и размерами, если вы запретите эту область. Поэтому, если вы создадите файл robots.txt для своего сайта, вы сможете воспользоваться этими преимуществами.
Например, если на вашем сайте продаются футболки разных цветов и размеров, у каждой из них есть действительный URL-адрес для сканирования ботом. Заблокировав их, бот может сосредоточиться на основных важных страницах и пропустить разделы с несколькими цветами и размерами, если вы запретите эту область. Поэтому, если вы создадите файл robots.txt для своего сайта, вы сможете воспользоваться этими преимуществами.
Недостатки использования файла robots.txt
Поисковые системы не обязаны следовать командам, содержащимся в файле robots.txt. Так что в будущем файл robots.txt может полностью игнорироваться. Другим недостатком является то, что даже если вы запретите раздел своего сайта, он будет проиндексирован в результатах поиска независимо от файла robots.txt, если будет найдено достаточно ссылок на этот раздел. Это означает, что результат Google для этой страницы будет выглядеть пустым, потому что ботам не разрешено просматривать ее, но они знают, что она есть. Файл robots.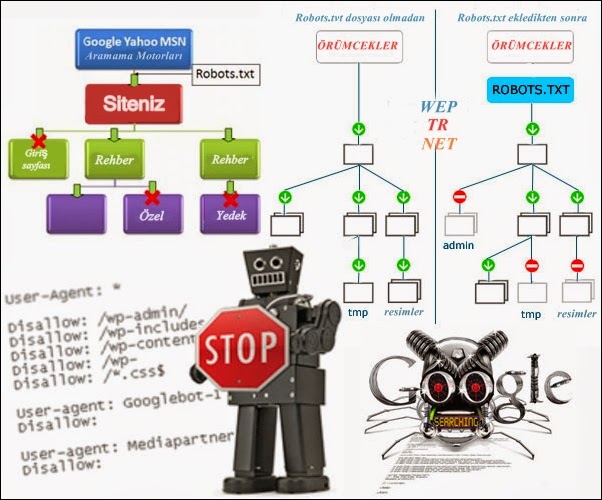 txt также не обеспечивает никакой защиты от других людей, хотя настоятельно рекомендуется использовать защиту паролем на веб-сервере. Если вы беспокоитесь об этом, вы не можете создать файл robots.txt для своего сайта.
txt также не обеспечивает никакой защиты от других людей, хотя настоятельно рекомендуется использовать защиту паролем на веб-сервере. Если вы беспокоитесь об этом, вы не можете создать файл robots.txt для своего сайта.
Завершение файла robots.txt
Мы объяснили, как создать файл robots.txt. В целом, файл robots.txt легко создать и внедрить, и он может помочь повысить удобство SEO, а также увеличить веб-трафик для вашего сайта. Тот факт, что поисковые системы могут полностью игнорировать этот файл в будущем, не умаляет преимуществ реализации файла сегодня. Тот факт, что крошечный файл может помочь направить поисковые системы в определенные области вашего сайта, является слишком большой возможностью, чтобы его игнорировать. Надеюсь, вам понравилось читать эту статью, и вы узнали кое-что о файлах robots.txt и о том, как их использовать. Если вы хотите узнать, что такое файл robots.txt, у нас есть более подробная статья о нем.
Часто задаваемые вопросы
Нужен ли мне файл robots.txt для моего сайта WordPress?
Нет, файл robots.txt использовать не нужно. Тем не менее, это может помочь вашему сайту стать более оптимизированным для SEO и увеличить посещаемость сайта.
Где сохранить файл robots.txt?
Файл robots.txt всегда следует сохранять в корневом каталоге вашего домена. В нашем предыдущем примере вы должны найти файл robots.txt по адресу https://www.test.com/robots.txt. Имя файла чувствительно к регистру и всегда должно быть строчным; в противном случае это не сработает.
Как включить карту сайта в robots.txt?
Вы должны включить файл sitemap.xml в файл robots.txt, так как это считается хорошей практикой. Вы можете использовать команду sitemap: для ссылки на вашу карту сайта.