Правильная настройка robots.txt для Google и Яндекс
Основные правила настройки robots.txt
Перед тем, как приступить к настройке роботса для вашего сайта, неплохо ознакомиться с официальными рекомендациями Яндекс и Google.
Теперь о том, что должно быть в файле robots.txt. В нем необходимо создавать 3 отдельных набора директив — для Яндекс, для Google, и для остальных роботов-краулеров. Почему отдельно? Да потому что есть директивы, предназначенные только для определенных ПС, а также можете считать это неким проявлением уважения к основным поисковикам рунета
Следовательно, роботс должен состоять из таких секций:
User-agent: * User-agent: Yandex User-agent: Googlebot
Между наборами директив для разных роботов необходимо оставлять пустую строку.
В robots.txt необходимо указать путь к XML карте сайта. Директива является межсекционной, поэтому она может быть размещена в любом месте файла, однако перед ней рекомендуется вставить пустой перевод строки. Запись должна выглядеть так:
Запись должна выглядеть так:
Sitemap: http://site.com/sitemap.xml
Адрес сайта и сам путь к карте необходимо заменить на те, которые являются актуальными для вашего сайта. Также следует помнить, что для сайтов с большим количеством страниц (более 50 000) необходимо создать несколько карт и все их прописать в роботсе.
Настройка robots.txt для Яндекс
Для того, чтобы наглядно показать правильную настройку директив для Яши, я возьму в качестве примера стандартный robots.txt для WordPress.
User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: */trackback Disallow: */feed Host: site.com
Обратите внимание на директиву Host. Она указывает пауку-роботу Яндекса, какое из зеркал сайта является главным. Наиболее распространенная группа зеркал — site.com и www.site.com. Тут есть еще один тонкий нюанс, о котором редко упоминают. Дело в том, что директива Host не является прямой командой роботам считать зеркало главным. Сначала Яндекс должен найти и идентифицировать сайты именно как зеркала, и только тогда данная директива сработает. Тем не менее, прописывать Host рекомендую в любом случае.
Дело в том, что директива Host не является прямой командой роботам считать зеркало главным. Сначала Яндекс должен найти и идентифицировать сайты именно как зеркала, и только тогда данная директива сработает. Тем не менее, прописывать Host рекомендую в любом случае.
Проверить корректность настройки robots.txt для Яндекса можно при помощи данного сервиса.
Настройка robots.txt для Google
Для Google настройка роботса мало чем отличается от уже написанного выше. Однако, есть пара моментов, на которые следует обратить внимание.
User-agent: Googlebot Allow: *.css Allow: *.js Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: */trackback Disallow: */feed
Как видно из примера, отсутствует директива Host — она распознается исключительно ботами Яндекса. Кроме этого, появились две директивы, разрешающие индексировать JS скрипты и CSS таблицы.
файлы шаблона (темы) сайта. Естественно, скрипты и таблицы в поиск не попадут, однако это позволит роботам корректнее индексировать сайт и отображать его в результатах выдачи.
Ну а корректность настройки директив для Google вы можете проверить инструментом проверки файла robots.txt, который находится в Google Webmaster Tools.
Что еще стоит закрывать в роботсе?
Страницы поиска
Тут кое-кто может поспорить, так как бывают случаи, когда на сайте используют внутренний поиск именно для создания релевантных страниц. Однако, так поступают далеко не всегда и в большинстве случаев открытые результаты поиска могут наплодить невероятное количество дублей. Поэтому вердикт — закрыть.
Корзина и страница оформления/подтверждения заказа
Данная рекомендация актуальна для интернет-магазинов и других коммерческих сайтов, где есть форма заказа. Данные страницы ни в коем случае не должны попадать в индекс ПС.
Страницы пагинации. Обычно для таких страниц автоматически прописываются одинаковые мета-теги плюс на них размещен динамический контент, что приводит к дублям в выдаче. Поэтому пагинацию необходимо закрывать от индексации.
Фильтры и сравнение товаров. Рекомендация относится к интернет-магазинам и сайтам-каталогам.
Страницы регистрации и авторизации. Информация, которая вводится при регистрации или входе на сайт, является конфиденциальной. Поэтому следует избегать индексации подобных страниц, Google это оценит.
Системные каталоги и файлы. Каждый сайт состоит из множества данных — скриптов, таблиц CSS, административной части. Такие файлы следует также ограничить для просмотра роботам.
Замечу, что для выполнения некоторых из вышеописанных пунктов можно использовать и другие инструменты, например, rel=canonical, про который я позже напишу в отдельной статье.
Robots.txt для WordPress и Joomla
robots.txt для WordPress
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: */trackback Disallow: */feed Disallow: /*? Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: */trackback Disallow: */feed Disallow: /*? Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php Host: site.com User-agent: Googlebot Allow: *.css Allow: *.js Allow: /wp-includes/*.js Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/cache Disallow: */trackback Disallow: */feed Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php Disallow: /*? Sitemap: http://site.com/sitemap.xml

Обратите внимание, что директивы Sitemap и Host в вашем роботсе нужно заменить на необходимые вам.
robots.txt для Joomla
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /language/ Disallow: /libraries/ Disallow: /logs/ Disallow: /media/ Disallow: /system/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /component/ Disallow: /*start Disallow: /*searchword User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /language/ Disallow: /libraries/ Disallow: /logs/ Disallow: /system/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /component/ Disallow: /*start Disallow: /*searchword Host: site.com User-agent: Googlebot Allow: *.css Allow: *.js Disallow: /administrator/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /language/ Disallow: /libraries/ Disallow: /logs/ Disallow: /system/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/ Disallow: /component/ Disallow: /*start Disallow: /*searchword Sitemap: http://site.com/sitemap.xml

Замечу, что в наборе поисковых правил для Joomla я закрыл пагинацию страниц в разделах, а также страницу поиска по сайту. Если вам необходимы данные страницы в поиске — можете убрать из robots.txt эти две строчки:
Disallow: /*start Disallow: /*searchword
Немного о нестандартном использовании robots.txt
С учетом написанного выше, тему правильной настройки robots.txt можно считать раскрытой, однако есть еще кое-что, о чем я бы хотел рассказать. Роботс можно с пользой применять помимо назначения и без вреда для сайта. Дело в том, что в файле можно использовать такой знак, как «#» — он обозначает комментарии, не учитываемые роботами.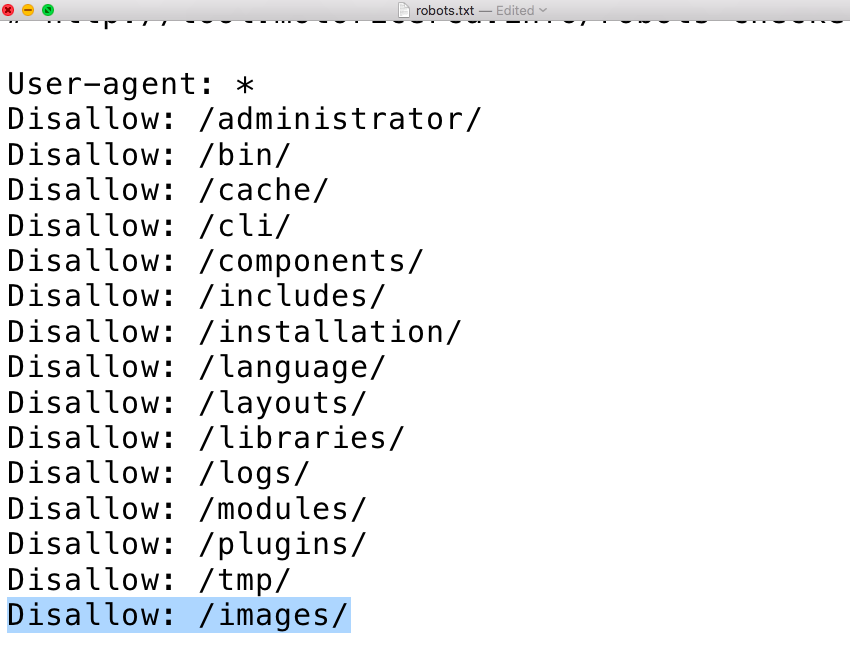 Данный знак действителен в пределах одной строки, там, где он используется. Его можно использовать для пометок, чтобы не забыть, что и зачем было закрыто от поисковых систем.
Данный знак действителен в пределах одной строки, там, где он используется. Его можно использовать для пометок, чтобы не забыть, что и зачем было закрыто от поисковых систем.
Но есть и другое применение. Например, после знака комментария, вы можете разместить полезную информацию: контакты сайта, вакансию для оптимизатора, ссылку на важную информацию, и даже рекламу. Не буду заниматься плагиатом, так как идея не моя, поэтому предлагаю ознакомиться с различными вариантами на блоге Devaka. Уверен, вы будете удивлены, узнав, насколько разнообразным может быть использование роботса не по назначению.
На этом все, правильная настройка robots.txt описана в полной мере, надеюсь, вы узнали что-то новое. Если же после прочтения статьи у вас остались вопросы — задавайте их в комментариях, и я постараюсь на них ответить.
Исследование файла robots.txt сайтов Яндекс.Каталога
В марте прошлого года (запись в блоге автора от 03.12.2007, [1]) программный инженер компании Apple, Эндрю Вустер, провёл исследование файлов управления поисковыми роботами (robots.
Исследований русскоязычного сегмента Интернет на предмет корректности файла robots.txt ранее не проводилось. В качестве источника сайтов мы выбрали самый большой русскоязычный каталог – каталог сайтов поисковой системы Яндекс.
Цели исследования
Определить качественный уровень грамотности вебмастеров сайтов, размещенных в каталоге Яндекса.
Определить, насколько профессионально используется файл управления индексацией сайта robots.txt.
Сравнить полученные результаты с аналогичными для сайтов, описанных в каталоге DMOZ.
Методы и средства
На момент исследования в каталоге Яндекса было зарегистрировано 86534 сайта. Посредством автоматического сбора был составлен список из 77643 уникальных доменных имён из 75 доменных зон.
Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации некоторые разделы или страницы на сайте, указывать главный домен, рекомендовать поисковому роботу соблюдать определенный временной интервал между скачиванием документов с сервера и т.д. ([3]).
Исследовались следующие параметры файла robots.txt:
— статус коды ответов серверов,
— mime типы для файлов robots.txt,
— наличие и правильность указания кодировки в заголовке ответа сервера,
— проверка корректности синтаксиса и орфографии при написании директив,
— использование специализированных команд.
Статус-коды
HTTP коды статуса (возвращаемые сервером заголовки) говорят веб-браузерам и роботам поисковых систем, какого рода ответ они получают при загрузке страницы. Например, код 200 (ОК) значит, что все нормально, а 404 (file not found) — что веб-сервер не смог найти файл по заданному адресу.
Для оценки того, насколько активно вебмастера используют возможность управлением индексацией своего сайта, соберём статус-коды для файлов robots.txt для обозначенного выше списка сайтов.
Для сайтов нашей выборки распределение выглядит следующим образом:
|
Класс |
Число сайтов |
|
|
5xx |
119 |
0,15 |
|
4xx |
45732 |
59,00 |
|
3xx |
72 |
0,09 |
|
2xx |
|
40,76 |
|
1xx |
0 |
0,00 |
В исследовании [1] статистика распределения статус-кодов для файлов robots. txt имеет следующий вид:
txt имеет следующий вид:
|
Класс |
Число сайтов |
В % от всех |
|
5xx |
4,338 |
0,09 |
|
4xx |
3,035,454 |
65,86 |
|
3xx |
350,946 |
7,61 |
|
2xx |
1,217,559 |
26,42 |
|
1xx |
12 |
0,00 |
Доля сайтов в Яндекс. Каталоге, ответивших 2xx ответом сервера, значительно выше, чем у сайтов в каталоге DMOZ: 41% в сравнении с 27%. При этом разница достигается не за счёт сокращения числа файлов, ответивших 4xx кодом, а сокращением количества сайтов с заголовком перенаправления на другой домен(3xx). При разнице 2xx кодов на 14%, разница 4xx кодов всего 7%.
Каталоге, ответивших 2xx ответом сервера, значительно выше, чем у сайтов в каталоге DMOZ: 41% в сравнении с 27%. При этом разница достигается не за счёт сокращения числа файлов, ответивших 4xx кодом, а сокращением количества сайтов с заголовком перенаправления на другой домен(3xx). При разнице 2xx кодов на 14%, разница 4xx кодов всего 7%.
Иногда сервер настроен таким образом, что и для страницы с ошибкой отдаёт код 200( 1, 2, 3). Однако вероятности возникновения этого события приблизительно равны, в связи с чем данные можно считать сопоставимыми.
MIME типы
MIME типы (типы содержания) возвращаются веб-серверами в HTTP заголовках, чтобы сообщить клиентам, какой документ передается. Они состоят из типов (text, image и так далее), подтипов (html или jpeg) и некоторых необязательных параметров, таких как кодировка документа. Единственный MIME тип, который должен возвращать файл robots.txt — это текст (text/plain).
В каталоге Яндекса после сбора статус-кодов, осталось 31593 сайтов, ответивших заголовком 2xx, у 29055 из которых MIME тип соответствует «text/plain». Соответственно, 2538 (8,03%) сайтов возвращают MIME тип, отличный от верного (в исследовании [1] — 109 780 (9,01%) сайтов имели MIME тип, отличный от text/plain).
Соответственно, 2538 (8,03%) сайтов возвращают MIME тип, отличный от верного (в исследовании [1] — 109 780 (9,01%) сайтов имели MIME тип, отличный от text/plain).
Исследуемые серверы ответили следующими различными значениями MIME типов:
application/octet-stream
application/x-empty
application/x-httpd-php
download/octet-stream
plain/text
text
text/html
text/plain
text/plane
text/text
text/txt
Кодировка
Кодировка символов определяет, какие знаки соответствуют определенным наборам бит. Сайты определяют кодировку, устанавливая ее в переменной content-type в заголовке ответа сервера.
Мало сайтов возвращают в заголовке кодировку документа. При этом, в связи со специфичностью каталога Яндекса (в нём расположены только русскоязычные сайты), проблемы с кодировкой возникают достаточно редко. Список различных кодировок выглядит следующим образом:
charset=
charset=iso-8859-1
charset=koi8-r
charset=ru
charset=utf -8
charset=utf8
charset=utf-8
charset=win
charset=windows-1251
Явных ляпов не замечено, однако стоит отметить, что многие вебмастера не могут договориться, как правильно писать название универсальной кодировки UTF-8.
Комментарии
В robots.txt для Яндекса и других поисковых систем можно использовать только один вид комментариев. Комментарием считается строка после знака “#”. При этом среди исследованных файлов были найдены HTML комментарии ““(16 файлов), комментарии в стиле C++ “//”(20 файлов).
Обычные синтаксические ошибки
Спецификация говорит о том, что записи должны разделяться пустыми строками, и большинство ошибок вращаются вокруг этого.
Во-первых, многие вебмастера вставляют дополнительную пустую строку между строкой User-agent и правилами для этого робота. Для нашей выборки эта доля равна 1,6% (498 сайтов), в исследовании [1] таких сайтов 6,1% (74 043).
Второй частой ошибкой является то, что между User-Agent и правилами для индексации пропущен символ начала новой строки. Сайтов, содержащих подобную ошибку, — 1,07% (340), сайтов с аналогичной ошибкой в каталоге DMOZ — 5,33% (64921).
Третий тип ошибок: часто пишут строку с агентом после правила Disallow, не разделяя их пустой строкой. В каталоге Яндекса 1,45% (457) таких сайтов. При этом доля аналогичных ошибок в исследовании [1] в 2 раза больше: 2,68% (32 656 файлов).
В каталоге Яндекса 1,45% (457) таких сайтов. При этом доля аналогичных ошибок в исследовании [1] в 2 раза больше: 2,68% (32 656 файлов).
Задержка сканирования
Роботы некоторых поисковых систем обращают внимание на директивы управления, например, Crawl-delay (задержка сканирования, чтобы робот не положил сервер). MSN, Yahoo! и Ask поддерживают эту директиву. Файлов, в которых встречается данная директива, всего 725.
Небольшое количество файлов, содержащих такую директиву, обуславливается тем, что 3 крупнейшие поисковые системы в российском интернете (Яндекс, Рамблер и Google) не поддерживают эту директиву. Поэтому вебмастера не придают значения этой настройке.
Опечатки
Очень часто причиной того, что робот поисковой системы игнорирует инструкции в файле robots.txt, являются банальные опечатки. В указанном списке сайтов встречается 18 различных написаний директивы Disallow:
1disallow
diasllow
disaalow
disalljw
disallos
disallov
disallowed
disallowing
disallows
disalow
disaoolw
dissallow
dissalow
dosallow
nodisallow
ppdisallow
robotsdisallow
При этом написание директивы user-agent вызывает значительно меньше сложностей.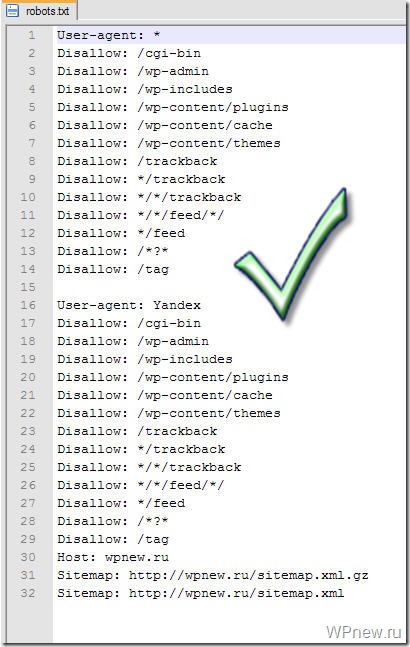 Найдено 7 различных вариантов:
Найдено 7 различных вариантов:
user_agent
useragent
user-agent=»yandex»
user-agents
user-agernt
user-aget
user-аgent (кирилическая буква а)
Другие ошибки и курьёзы
Многие вебмастера, вероятно, слышали о том, что необходим файл robots.txt, но не совсем понимают, для чего он нужен. Поэтому появилось множество курьёзов.
Разработчики сайта blog.kp.ru искренне приветствуют роботов поисковых систем, причём делают это современно:
Превед роботы
Возникает сомнение, что роботы поисковых систем по достоинству оценят искромётный юмор разработчиков. Не отстают и разработчики сайта www.modernglass.ru. Они поступили ещё проще, путём нехитрых нажатий на клавиши получив совершенно бесполезный файл:
sdfsdf
Эта комбинация букв совершенно бесполезна, в отличие от первого примера, при просмотре которого хотя бы возникает улыбка.
Некоторые вебмастера оказались очень радушными хозяевами (1.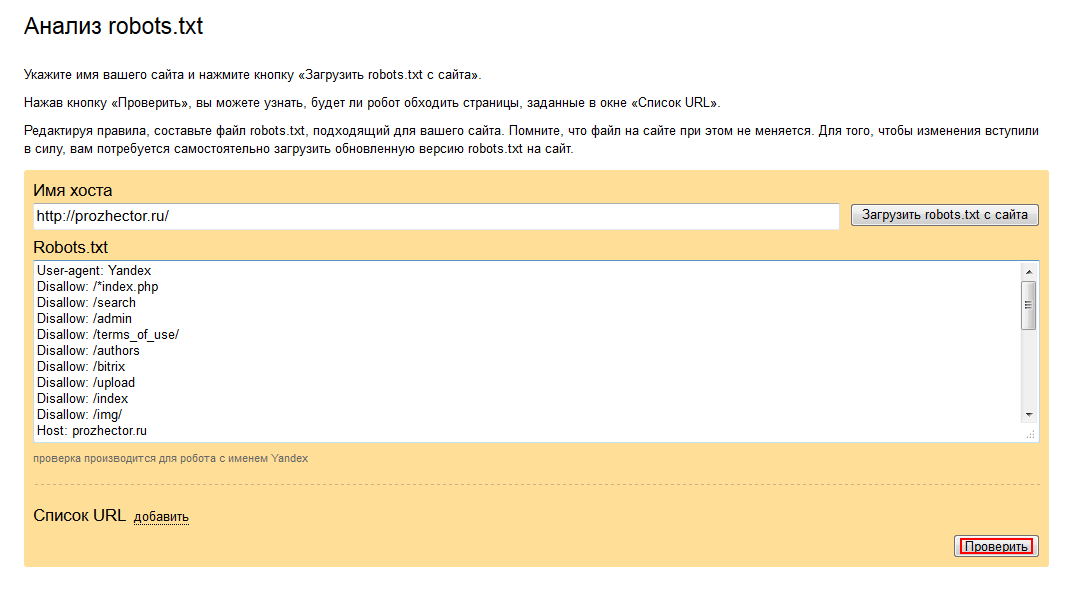 optics.sgu.ru/robots.txt, 2. www.anatomyatlases.org/robots.txt). Мало того, что они здороваются с роботом, они предлагают ему чувствовать себя как дома, и индексировать документы как скрипт на душу положит:
optics.sgu.ru/robots.txt, 2. www.anatomyatlases.org/robots.txt). Мало того, что они здороваются с роботом, они предлагают ему чувствовать себя как дома, и индексировать документы как скрипт на душу положит:
1. # Welcome!
2. # Robots.txt file, robots welcome
Надо отдать должное, что вебмастер не стал нагружать парсер файлов robots.txt и закрыл приветствие в комментарии. Но есть и такие вебмастера (pravo-levo.ru/robots.txt), которые, желая похохмить, задают парсеру действительно нетривиальные задачи:
U s e r — a g e n t : *
D i s a l l o w :
Совершенно не понятно, чем руководствовался вебмастер, когда писал директивы именно таким образом. Боюсь, что и для автора этого файла это останется загадкой.
Выводы анализа robots.txt сайтов в Яндекс.Каталоге:
1. Общий уровень грамотности вебмастеров русскоязычной части интернета выше по сравнению с западными вебмастерами (доля сайтов, имеющих robots.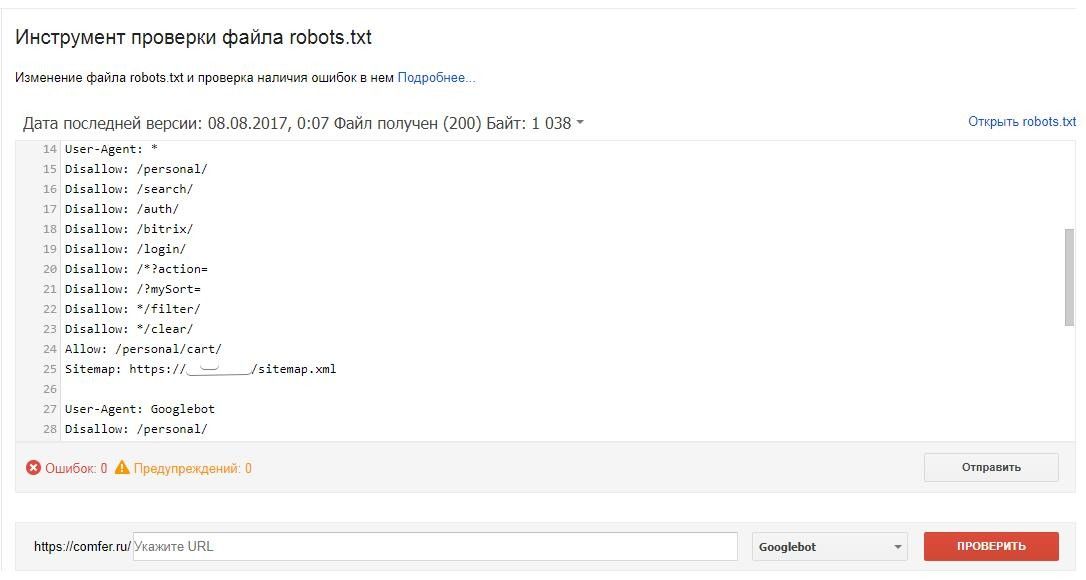 txt, больше (49%), чем у сайтов из каталога DMOZ (27%)).
txt, больше (49%), чем у сайтов из каталога DMOZ (27%)).
2. Количество сайтов, имеющих код 3xx (перенаправление на другое доменное имя), ниже у сайтов в каталоге Яндекса(0.09%), чем в каталоге DMOZ (7,61%).
3. Количество файлов с неверно указанным значением MIME типов содержимого близко в обоих исследованиях, это говорит о том, что такой тип ошибок интернационален и не зависит от языковой особенности списка файлов.
4. Владельцы сайтов в каталоге Яндекса не утруждают себя указанием кодировки документа, передаваемого роботу поисковой системы. У тех же, кто прописывает этот параметр, часто возникают проблемы с правильным написанием кодировки utf-8.
5. Часто вебмастера вместо указанных в спецификации комментариев «#» используют комментирующие символы из других языков: HTML, C++.
6. У сайтов в каталоге Яндекса значительно реже встречаются ошибки в структуре самого фала robots.txt: наличие дополнительного символа переноса строки между User-Agent и Disallow, пропуск символа переноса строки между директивами для разных секций.
7. Многие отечественные вебмастера, как и зарубежные, допускают орфографические ошибки при написании директив (Disallow и User-Agent).
Источники:
1. robots.txt Adventure
2. Dmoz: Каждый четвертый сайт имеет ошибки в robots.txt
3. Все о файле robots.txt по-русски
Олег Сахно, Евгений Селин, www.interlabs.ru
Использование robots.txt для оптимизации производительности вашего сайта и снижения нагрузки на него — База знаний
Поисковые роботы или так называемые веб-пауки/роботы могут вызвать значительную нагрузку на ваш сайт, особенно если вы используете такие платформы, как WordPress.
В этой статье содержится несколько быстрых способов уменьшить нагрузку от поисковых роботов, но мы рекомендуем вам проконсультироваться с веб-дизайнером/профессионалом для получения дополнительной информации о том, как их эффективно реализовать.
Вот образец robots.txt, который подходит для WP (аналогично можно применить для любого веб-сайта и платформы).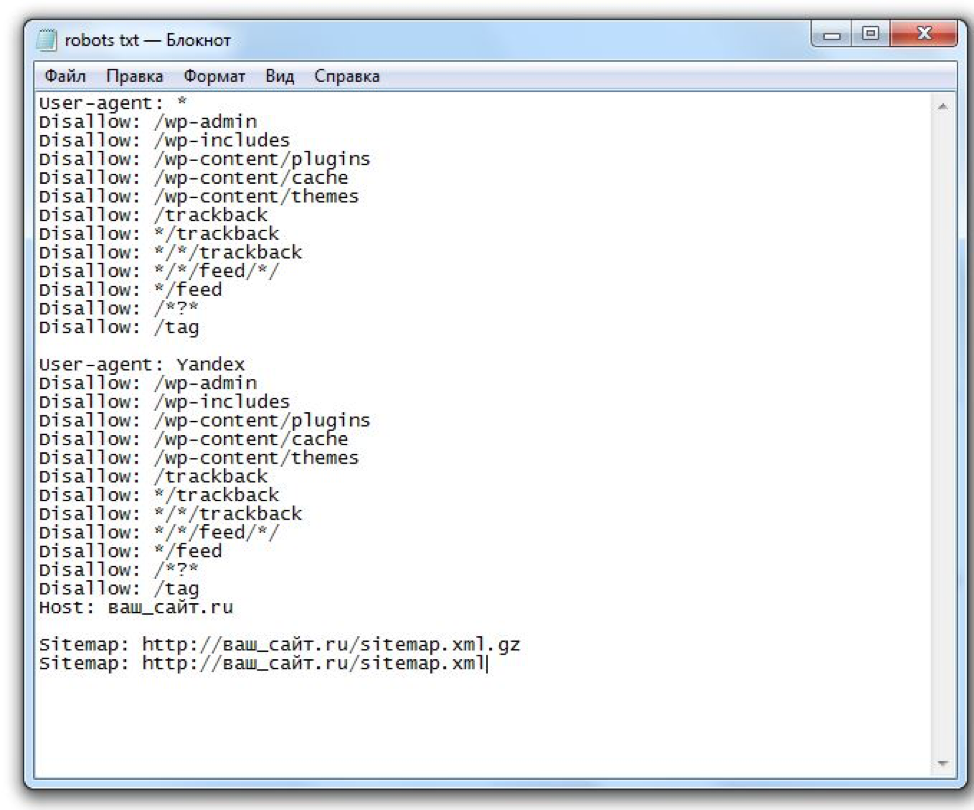
Вам необходимо создать этот файл на своем компьютере и загрузить его через FTP или файловый менеджер панели управления (в cPanel вы можете создать этот файл, используя файловый менеджер cPanel напрямую), и поместить в корневую папку каждого из ваших доменных имен (та же папка, где находится ваш основной файл index.php / index.html).
Просто скопируйте/вставьте между строками «—» ниже:
—
Задержка сканирования: 30 Пользовательский агент: * Запретить: /cgi-bin/ Запретить: /wp-admin/ Запретить: /wp-includes/ Запретить: /wp-контент/ Запретить: /трекбэк/ Запретить: /index.php Запретить: /xmlrpc.com Запретить: /wp-login.php Запретить: /wp-content/plugins/ Запретить: /comments/feed/ Запретить: /администратор/ Запретить: /bin/ Запретить: /кеш/ Запретить: /кли/ Запретить: /компоненты/ Запретить: /включает/ Запретить: /установка/ Запретить: /язык/ Запретить: /макеты/ Запретить: /библиотеки/ Запретить: /журналы/ Запретить: /модули/ Запретить: /плагины/ Запретить: /tmp/ User-agent: Яндекс Запретить: / Агент пользователя: Baiduspider Запретить: / Агент пользователя: Googlebot-Image Запретить: / Агент пользователя: bingbot Задержка сканирования: 10 Запретить: Агент пользователя: Slurp Задержка сканирования: 10 Запретить:
—
Приведенный выше пример замедляет работу поисковых систем, чтобы они не сканировали ваш сайт агрессивно по очереди (это не влияет на частоту сканирования вашего сайта поисковой системой), код также блокирует некоторых пауков, таких как Baiduspider (китайская поисковая система, которую следует отключить, если ваш сайт не должен быть проиндексирован на китайском языке), Яндекс (российские поисковые системы, оставьте включенной, если у вас русский веб-сайт или посетители из России), а также не позволит боту Google Image сканировать ваш сайт. Если вам нужен какой-либо из этих движков, просто удалите часть между «User-agent» и «Disallow» и оставьте оставшийся код.
Если вам нужен какой-либо из этих движков, просто удалите часть между «User-agent» и «Disallow» и оставьте оставшийся код.
Кроме того, вы можете управлять тем, как Google и Bing индексируют ваш сайт, и принимать меры для индивидуального замедления их работы.
Для получения дополнительной информации о Google вам необходимо настроить учетную запись с помощью инструментов Google Web Master https://search.google.com/search-console/about и следовать их указаниям о том, как оптимизировать скорость и скорость сканирования.
Для Bing: зарегистрируйтесь или войдите в свои инструменты для веб-мастеров по адресу https://www.bing.com/webmasters/about и следуйте их указаниям по оптимизации настроек сканирования.
Существует множество других оптимизаций, которые вы можете применить к файлу robots.txt, но мы рекомендуем обращаться к профессионалам, чтобы получить наилучшие результаты и не нарушить работу вашего веб-сайта.
Для опытных пользователей:
В дополнение к реализации robots. txt вы можете заблокировать нежелательных поисковых роботов (особенно тех, которые полностью игнорируют ваш файл robots.txt), используя следующий код .htaccess:
txt вы можете заблокировать нежелательных поисковых роботов (особенно тех, которые полностью игнорируют ваш файл robots.txt), используя следующий код .htaccess:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Baiduspider [ИЛИ]
RewriteCond %{HTTP_USER_AGENT} Baiduspider/2.0 [ИЛИ]
RewriteCond %{HTTP_USER_AGENT} Baiduspider/3.0 [ИЛИ]
RewriteCond %{HTTP_USER_AGENT} MJ12bot/v1.4.5 [ИЛИ]
RewriteCond %{HTTP_USER_AGENT} MJ12 [ИЛИ]
RewriteCond %{HTTP_USER_AGENT} AhrefsBot/5.1 [ИЛИ]
RewriteCond %{HTTP_USER_AGENT} ЯндексБот/3.0 [ИЛИ]
RewriteCond %{HTTP_USER_AGENT} YandexImages/3.0 [ИЛИ]
RewriteCond %{HTTP_USER_AGENT} ЯндексБот 9yandex.com$» bad_bot_block
С якорями start и end-of-string в регулярном выражении вы в основном проверяете, что строка User-Agent точно равна «yandex.com» (за исключением того, что . — это любой символ ), что явно не соответствует указанному user-agent строка.
Необходимо проверить, что User-Agent заголовок содержит «ЯндексБот» (или «yandex.com»). Здесь также можно использовать регистрозависимое соответствие, так как настоящий бот Яндекса не меняет регистр.
Например, вместо этого попробуйте следующее:
SetEnvIf User-Agent "YandexBot" bad_bot_block
Вместо этого рассмотрите возможность использования директивы BrowserMatch , которая является ярлыком для SetEnvIf User-Agent .
Если вы используете Apache 2.4, вам следует использовать вариант Require (второй) двух ваших блоков кода. Директивы Order , Deny и Allow относятся к Apache 2.2 и ранее устарели в Apache 2.4.
Однако рассмотрите возможность использования robots.txt вместо блокировки при сканировании в первую очередь. Яндекс якобы поддерживает robots.txt .
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.