Robots.txt как создать и правильно настроить
Последнее обновление: 08 ноября 2022 года
26327
Время прочтения: 6 минут
Тэги: Яндекс, Google
О чем статья?
- Зачем нужен robots.txt?
- Основные директивы файла robots.txt
- Как создать robots.txt?
- Как проверить файл?
Кому будет полезна статья?
- Веб-разработчикам.
- Техническим специалистам.
- Оптимизаторам.
- Администраторам и владельцам сайтов.
Поисковые роботы или веб-краулеры постоянно индексируют страницы сайтов, собирают информацию и заносят ее в базы данных поисковых систем. Первый файл, с которого начинается проверка, — это robots.txt. Именно в нем содержится вся необходимая и важная для краулеров информация. В статье мы расскажем, как создать, настроить и проверить robots.
Зачем нужен robots.txt?
Файл robots.txt — служебный файл, который содержит информацию о том, какие страницы сайта доступны для сканирования поисковыми роботами, а какие им посещать нельзя. Он не является обязательным элементом, но от его наличия зависит скорость индексации страниц и позиции ресурса в поисковой выдаче.
С помощью robots.txt вы можете задать уровень доступа краулеров к сайту и его разделам: полностью запретить индексацию или ограничить сканирование отдельных папок, страниц, файлов, а также закрыть ресурс для роботов, которые не относятся к основным поисковым системам.
Таким образом, создание и правильная настройка robots.txt помогут ускорить процесс индексации сайта, снизить нагрузку на сервер, положительно отразятся на ранжировании сайта в поисковой выдаче.
Мнение эксперта
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры»:
«Некоторым сайтам файл robots. txt не нужен совсем или может ограничиваться малым набором директив. Например, при одностраничной структуре ресурса-лендинга зачастую файл robots.txt не требуется — поисковые системы проиндексируют одну страницу, лишние служебные файлы с малой вероятностью будут добавлены в индекс. Небольшое количество правил в robots.txt также можно наблюдать и у больших сайтов с простой структурой, например, у информационных ресурсов. Так, например, один из крупнейших зарубежных блогов по SEO https://backlinko.com/ имеет в robots.txt только две простые директивы:
txt не нужен совсем или может ограничиваться малым набором директив. Например, при одностраничной структуре ресурса-лендинга зачастую файл robots.txt не требуется — поисковые системы проиндексируют одну страницу, лишние служебные файлы с малой вероятностью будут добавлены в индекс. Небольшое количество правил в robots.txt также можно наблюдать и у больших сайтов с простой структурой, например, у информационных ресурсов. Так, например, один из крупнейших зарубежных блогов по SEO https://backlinko.com/ имеет в robots.txt только две простые директивы:
Disallow: /tag/
Disallow: /wp-admin/».
Основные директивы файла robots.txt
Чтобы поисковые роботы могли корректно прочитать robots.txt, он должен быть составлен по определенным правилам. Структура служебного файла содержит следующие директивы:
- User-agent. Директива User-agent определяет уровень открытости сайта для поисковых роботов.

Пример:
User-agent: * — сайт доступен для индексации всем краулерам
User-agent: Yandex — доступ открыт только для роботов Яндекса
User-agent: Googlebot — доступ открыт только для роботов Google - Disallow. Директива Disallow определяет, какие страницы сайта необходимо закрыть для индексации. Как правило, для сканирования закрывают весь служебный контент, но при желании вы можете скрыть и любые другие разделы проекта. Подробнее о том, каким страницам и сайтам не нужно индексирование, вы можете прочитать в статье: «Как закрыть сайт от индексации в robots.txt». Обратите внимание, что даже если на сайте нет страниц, которые вы хотите закрыть, директиву все равно нужно прописать, но без указания значения.

Пример 1:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: /wp-admin — служебная папка со всеми вложениями закрыта для индексации
User-agent: Yandex — правила, размещенные ниже, действуют для роботов Яндекса
Disallow: / — все разделы сайта доступны для индексации - Allow. Директива Allow определяет, какие разделы сайта доступны для сканирования поисковыми роботами. Поскольку все, что не запрещено директивой Disallow, индексируется автоматически, здесь достаточно прописать только исключения из правил. Указывать все доступные краулерам разделы сайта не нужно.
Пример 1:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: / — сайт полностью закрыт для всех поисковых роботов
Пример 2:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: / — сайт полностью закрыт для всех поисковых роботов
User-agent: Googlebot — правила, размещенные ниже, действуют для роботов Google
Allow: / — сайт полностью открыт для роботов Google - Sitemap.
 Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Sitemap: https://site.ru/sitemap.xml
Как создать robots.txt?
Служебный файл robots.txt можно создать в текстовом редакторе Notepad++ или другой аналогичной программе. Весь текст внутри файла должен быть записан латиницей, русские названия можно перевести с помощью любого Punycode-конвертера. Для кодировки файла выбирайте стандарты ASCII или UTF-8.
Чтобы robots.txt корректно индексировался поисковыми роботами, при создании файла следуйте данным ниже рекомендациям:
- Объединяйте директивы в группы. Чтобы избежать путаницы и сократить время индексации, сгруппируйте директивы блоками для каждого поискового робота и разделите блоки пустой строкой.

- Учитывайте регистр. Прописывайте имя файла строчными буквами. Если Яндекс информирует, что для его поисковых роботов регистр не имеет значения, то Google рекомендует соблюдать регистр.
- Не указывайте несколько папок в одной директиве.
- Работайте с разными уровнями. В robots.txt вы можете задавать настройки на трех уровнях: сайта, страницы, папки. Используйте эту возможность, если хотите закрыть часть материалов для поисковиков.
- Удаляйте неактуальные директивы. Некоторые директивы robots.
 txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента).
txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента). - Проверьте соответствие sitemap.xml и robots.txt. Файлы sitemap.xml и robots.txt дополняют друг друга. Проверьте, чтобы информация в них совпадала, и sitemap был включен в одноименную директиву.
После создания robots.txt, обратите внимание, чтобы его размер не превышал 32 КБ. При большом объеме файла, он не будет восприниматься поисковыми роботами Яндекс.
Разместите robots.txt в корневой директории сайта рядом с основным файлом index.html. Для этого используйте FTP доступ. Если сайт сделан на CMS, то с файлом можно работать через административную панель.
Как проверить файл?
Удостовериться в том, что файл составлен корректно, можно с помощью инструментов Яндекс. Вебмастер и Google Robots Testing Tool. Поскольку каждая система проверяет robots.txt, основываясь только на собственных критериях, проверку необходимо выполнить в обоих сервисах.
Вебмастер и Google Robots Testing Tool. Поскольку каждая система проверяет robots.txt, основываясь только на собственных критериях, проверку необходимо выполнить в обоих сервисах.
Проверка robots.txt в Яндекс.Вебмастер
При первом запуске Яндекс.Вебмастер необходимо создать личный кабинет, добавить сайт и подтвердить свои права на него. После этого вы получите доступ к инструментам сервиса. Для проверки файла нужно зайти в раздел «Инструменты» подраздел «Анализ robots.txt» и запустить тестирование. Если в ходе проверки сервис обнаружит ошибки, он покажет, какие строки требуют корректировки, и что нужно исправить.
Мнение эксперта
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры»:
«В пункте «Анализ robots.txt» вы также можете «протестировать» написание директив и их влияние на статус индексации. Если Вы сомневаетесь в правильности написания директив, то укажите в поле «Разрешены ли URL?» нужные Вам URL, после чего Вебмастер покажет вам статус индексации этих адресов при указанном robots. txt.».
txt.».
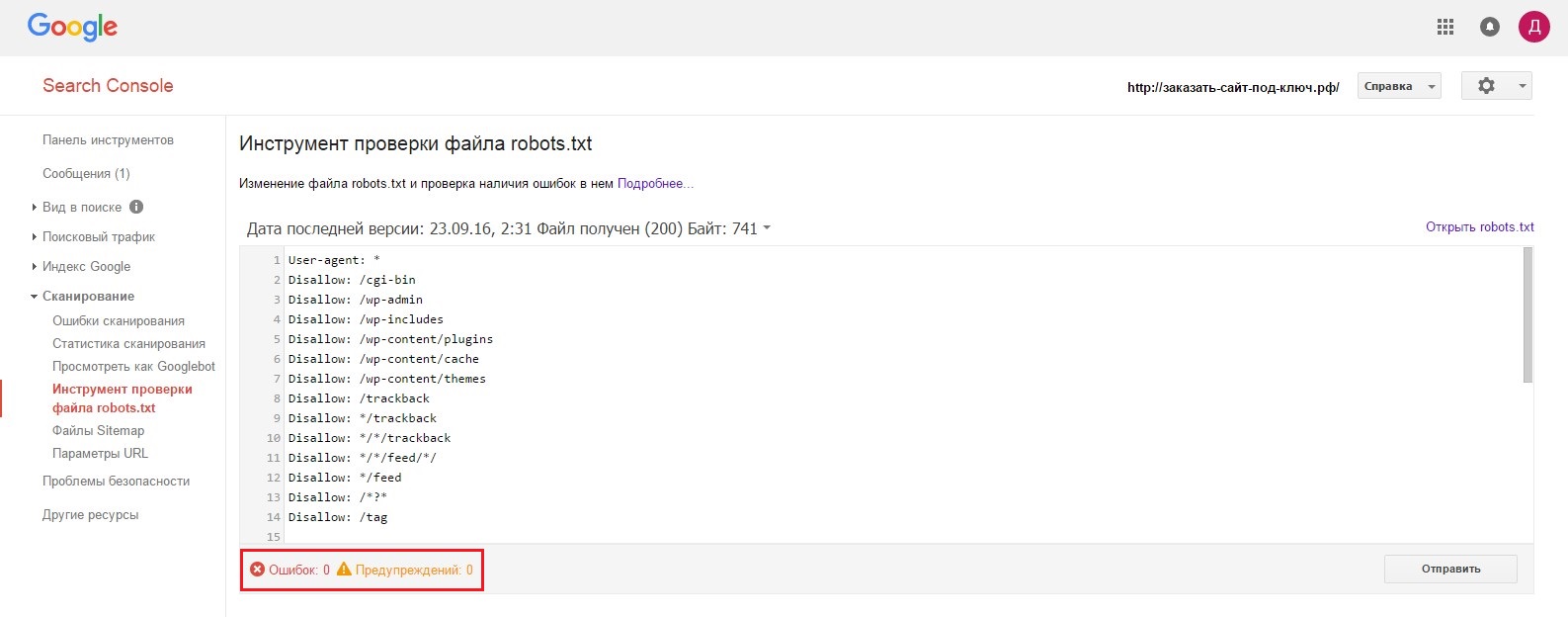
Проверка robots.txt в Google Robots Testing Tool
Проверять robots.txt в Google можно в административной панели Search Console. Просто перейдите на страницу проверки, и система автоматически протестирует файл. Если на странице вы увидите неактуальную версию robots.txt, нажмите кнопку «Отправить» и действуйте согласно инструкциям поисковой системы. Если Google найдет ошибки, вы можете исправить их в сервисе проверки. Однако учтите, что система не сохраняет правки автоматически. Чтобы исправления не пропали, их нужно внести вручную на хостинге или в административной панели CMS и сохранить.
Выводы
- Файл robots.txt — это служебный документ, который создается для корректной индексации сайта поисковыми роботами. Он не является обязательным элементом, но от его наличия зависит скорость индексации страниц и позиции ресурса в поисковой выдаче.
- Файл создается в Notepad++ или любом другом текстовом редакторе. Структура robots.
 txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.txt, они должны быть прописаны правильно.
txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.txt, они должны быть прописаны правильно. - Заполнять файл следует по правилам, начиная с кода User-agent. Директивы необходимо объединять в группы, отделяя блоки пустой строкой. С помощью директив Disallow и Allow можно запрещать и разрешать индексацию страниц, папок и отдельных файлов.
- Размер robots.txt не должен превышать 32 КБ. Размещать файл необходимо в корневой директории сайта рядом с основным файлом index.html.
- Проверить robots.txt на наличие ошибок можно с помощью инструментов Яндекс.Вебмастер и Google Robots Testing Tools.
Статья
Яндекс обновил алгоритмы: как улучшить ранжирование сайта?
#SEO, #Яндекс
СтатьяКак закрыть сайт от индексации в robots. txt
txt
#SEO, #Яндекс, #Google
СтатьяКак пользоваться Яндекс.Вордстат: инструкция с примерами
#SEO, #Яндекс
Статью подготовили:
Прокопьева Ольга. Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры».
Теги: SEO, Яндекс, Google
Проверка файла robots.txt | REG.RU
Файл robots.txt — это инструкция для поисковых роботов. В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
Зачем нужен robots.txt
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Яндекс, Google и других систем. Этот процесс называется индексацией.
robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots.txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов. Ниже кратко рассмотрим основные директивы для robots.txt.
Основные директивы robots.txt
Структура файла robots.txt выглядит так:
- Директива User-agent. Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
- Директива Disallow (запрет индексации). Указывает, какие разделы не должны сканировать роботы. Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.

- Директива Allow (разрешение). Указывает, какие разделы или файлы должны просканировать поисковые роботы. Здесь не нужно указывать все разделы сайта: все, что не запрещено к обходу, индексируется автоматически. Поэтому следует задавать только исключения из правила Disallow.
- Sitemap (карта сайта). Полная ссылка на файл в формате .xml. Sitemap содержит список всех страниц, доступных для индексации, а также время и частоту их обновления.
Пример простого файла robots.txt (после # указаны пояснительные комментарии к директивам):
User-agent: * # правила ниже предназначены для всех поисковых роботов Disallow: /wp-admin # запрет индексации служебной папки со всеми вложениями Disallow: /*? # запрет индексации результатов поиска на сайте Allow: /wp-admin/admin-ajax.php # разрешение индексации JS-скрипты темы WordPress Allow: /*.jpg # разрешение индексации всех файлов формата .jpg Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайта
Советы по созданию robots.txt
Для того чтобы файл читался поисковыми программами корректно, он должен быть составлен по определенным правилам. Даже детали (регистр, абзацы, написание) играют важную роль. Рассмотрим несколько основных советов по оформлению текстового документа.
Группируйте директивы
Если требуется задать различные правила для отдельных поисковых роботов, в файле нужно сделать несколько блоков (групп) с правилами и разделить их пустой строкой. Это необходимо, чтобы не возникало путаницы и каждому роботу не нужно было сканировать весь документ в поисках подходящих инструкций. Если правила сгруппированы и разделены пустой строкой, робот находит нужную строку User-agent и следует директивам. Пример:
User-agent: Yandex # правила только для ПС Яндекс Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов # пустая строка User-agent: Googlebot # правила только для ПС Google Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов Sitemap: # адрес файла
Учитывайте регистр в названии файла
Для некоторых поисковых систем не имеет значение, какими буквами (прописными или строчными) будет обозначено название файла robots. txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
Не указывайте несколько каталогов в одной директиве
Для каждого раздела/файла нужно указывать отдельную директиву Disallow. Это значит, что нельзя писать Disallow: /cgi-bin/ /authors/ /css/ (указаны три папки в одной строке). Для каждой нужно прописывать свою директиву Disallow:
Disallow: /cgi-bin/ Disallow: /authors/ Disallow: /css/
Убирайте лишние директивы
Часть директив robots.txt считается устаревшими и необязательными: Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующегося контента). Вы можете удалить эти директивы, чтобы не «засорять» файл.
Как проверить robots.txt онлайн
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Яндекс, Google или онлайн-сервисы (PR-CY, Website Planet и т. п.). В Яндекс и Google есть собственные правила для проверки robots. txt. Поэтому файл необходимо проверять дважды: и в Яндекс, и в Google.
txt. Поэтому файл необходимо проверять дважды: и в Яндекс, и в Google.
Яндекс.Вебмастер
Если вы впервые пользуетесь сервисом Яндекс.Вебмастер, сначала добавьте свой сайт и подтвердите права на него. После этого вы получите доступ к инструментам для анализа SEO-показателей сайта и продвижения в ПС Яндекс.
Чтобы проверить robots.txt с помощью валидатора Яндекс:
- 1.
Зайдите в личный кабинет Яндекс.Вебмастер.
- 2.
Выберите в левом меню раздел Инструменты → Анализ robots.txt.
- 3.
Содержимое нужного файла подставиться автоматически. Если по какой-то причине этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:
 org/HowToStep»>
4.
org/HowToStep»>
4.Ниже будут указаны результаты проверки. Если в директивах есть ошибки, сервис покажет, какую строку нужно поправить, и опишет проблему:
Google Search Console
Чтобы сделать проверку с помощью Google:
- 1.
Перейдите на страницу инструмента проверки.
- 2.
Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку Отправить и следуйте инструкциям Google:
- 3.
Через несколько минут вы можете обновить страницу. В поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.
Проверка robots.txt Google не выявила ошибок
Обратите внимание: правки, которые вы вносите в сервисе проверки, не будут автоматически применяться в robots. txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
Помогла ли вам статья?
Да
раз уже
помогла
Как исправить «Проиндексировано, но заблокировано robots.txt» в Google Search Console
26 ноябрь
26 ноябрь
Содержание
Краткий обзор
Укажите затрагиваемые страницы или URL-адреса
Укажите причину уведомления
Неверный формат URL-адреса
Страницы, которые следует проиндексировать проверить своих роботов .txt корректен в WordPress?
Страницы, которые не следует индексировать
Старые URL-адреса
Виртуальные файлы robots.txt
В заключение
Краткий обзор
Если вы получили предупреждение Уведомление «Проиндексировано, хотя и заблокировано robots.txt» в Google Search Console, вы Я хочу исправить это как можно скорее, так как это может повлиять на способность ваших страниц вообще ранжироваться на страницах результатов поисковой системы (SERPS).
Файл robots.txt — это файл, который находится в каталоге вашего веб-сайта и содержит некоторые инструкции для сканеров поисковых систем, таких как бот Google, относительно того, какие файлы они должны и не должны просматривать.
«Проиндексировано, хотя и заблокировано robots.txt» означает, что Google нашел вашу страницу, но также обнаружил указание игнорировать ее в вашем файле robots (что означает, что она не будет отображаться в результатах).
Иногда это делается намеренно, а что-то случайно, по ряду причин, изложенных ниже, и их можно исправить.
Вот снимок экрана с уведомлением:
Укажите затрагиваемые страницы или URL-адреса
Если вы получили уведомление от Google Search Console (GSC), вам необходимо указать конкретные страницы или URL-адреса, о которых идет речь.
Вы можете просматривать страницы с пометкой «Проиндексировано, но заблокировано robots. txt» в Google Search Console>>Coverage. Если вы не видите предупреждающую метку, то вы свободны и чисты.
txt» в Google Search Console>>Coverage. Если вы не видите предупреждающую метку, то вы свободны и чисты.
Проверить файл robots.txt можно с помощью нашего тестера robots.txt. Вы можете обнаружить, что у вас все в порядке с тем, что все, что блокируется, остается «заблокированным». Поэтому никаких действий предпринимать не нужно.
Вы также можете перейти по этой ссылке GSC. Далее вам необходимо:
- Откройте список заблокированных ресурсов и выберите домен.
- Щелкните по каждому ресурсу. Вы должны увидеть это всплывающее окно:
Укажите причину уведомления
Уведомление может быть вызвано несколькими причинами. Вот наиболее распространенные из них:
Но, во-первых, это не обязательно проблема, если есть страницы, заблокированные robots.txt. Он может быть разработан по причинам, таким как желание разработчика заблокировать ненужные страницы / страницы категорий или дубликаты. Итак, в чем расхождения?
Итак, в чем расхождения?
Неверный формат URL-адреса
Иногда проблема может возникать из-за того, что URL-адрес на самом деле не является страницей. Например, если URL-адрес https://www.seoptimer.com/?s=digital+marketing, вам необходимо знать, на какую страницу он указывает.
Если это страница с важным содержанием, которое вам действительно нужно, чтобы ваши пользователи увидели, вам необходимо изменить URL-адрес. Это возможно в системах управления контентом (CMS), таких как WordPress, где вы можете редактировать ярлык страницы.
Если страница не важна, или в нашем примере /?s=digital+marketing это поисковый запрос из нашего блога, то ошибку GSC исправлять не нужно.
Не имеет значения, проиндексирован он или нет, так как это даже не настоящий URL, а поисковый запрос. Кроме того, вы можете удалить страницу.
Страницы, которые должны быть проиндексированы
Существует несколько причин, по которым страницы, которые должны быть проиндексированы, не индексируются. Вот некоторые из них:
Вот некоторые из них:
- Вы проверили свои директивы для роботов? Возможно, вы включили в файл robots.txt директивы, запрещающие индексацию страниц, которые действительно должны быть проиндексированы, например теги и категории. Теги и категории — это фактические URL-адреса на вашем сайте.
- Вы указываете роботу Googlebot цепочку переадресации? Робот Google просматривает все ссылки, которые может найти, и делает все возможное, чтобы прочитать их для индексации. Однако, если вы настроите многократную длинную глубокую переадресацию или если страница просто недоступна, робот Googlebot перестанет искать.
- Правильно ли реализована каноническая ссылка? Тег canonical используется в заголовке HTML, чтобы сообщить роботу Googlebot, какая страница является предпочтительной и канонической в случае дублирования контента. Каждая страница должна иметь канонический тег. Например, у вас есть страница, переведенная на испанский язык.
 Вы сами сделаете каноническим URL-адрес на испанском языке и захотите вернуть страницу к английской версии по умолчанию.
Вы сами сделаете каноническим URL-адрес на испанском языке и захотите вернуть страницу к английской версии по умолчанию.
Как проверить правильность файла Robots.txt в WordPress?
Для WordPress: если ваш файл robots.txt является частью установки сайта, используйте плагин Yoast для его редактирования. Если вызывающий проблемы файл robots.txt находится на другом сайте, который не принадлежит вам, вам необходимо связаться с владельцами сайта и попросить их отредактировать файл robots.txt.
Страницы, которые не следует индексировать
Существует несколько причин, по которым страницы, которые не следует индексировать, индексируются. Вот некоторые из них:
Директивы robots.txt, которые «говорят», что страницу не следует индексировать . Обратите внимание, что вам нужно разрешить сканирование страницы с директивой noindex, чтобы роботы поисковых систем «знали», что ее нельзя индексировать.
В файле robots.txt убедитесь, что:
- Строка «disallow» не следует сразу за строкой «user-agent».
- Существует не более одного блока «агент пользователя».
- Невидимые символы Unicode — вам нужно запустить файл robots.txt через текстовый редактор, который преобразует кодировки. Это удалит все специальные символы.
Страницы, на которые есть ссылки с других сайтов . Страницы могут быть проиндексированы, если на них есть ссылки с других сайтов, даже если это запрещено в файле robots.txt. Однако в этом случае в результатах поиска отображаются только URL-адрес и текст привязки. Вот как эти URL-адреса отображаются на странице результатов поисковой системы (SERP):
источник изображения Веб-мастера StackExchange
Одним из способов решения проблемы блокировки robots.txt является защита паролем файлов на вашем сервере. .
Либо удалите страницы из robots. txt или используйте следующий метатег, чтобы заблокировать
txt или используйте следующий метатег, чтобы заблокировать
их:
Старый URL-адреса
Если вы создали новый контент или новый сайт и использовали директиву noindex в файле robots.txt, чтобы убедиться, что он не проиндексирован, или недавно зарегистрировались в GSC, есть два варианта устранения заблокированного Ошибка robots.txt:
- Дайте Google время удалить старые URL из своего индекса
- 301 перенаправить старые URL-адреса на текущие
В первом случае Google в конечном итоге удаляет URL-адреса из своего индекса, если все, что они делают, — это возвращает 404 (это означает, что страницы не существуют). Не рекомендуется использовать плагины для перенаправления ошибок 404. Плагины могут вызвать проблемы, которые могут привести к тому, что GSC отправит вам предупреждение «заблокировано robots.txt».
Виртуальные файлы robots.
 txt
txt
Есть возможность получения уведомления, даже если у вас нет файла robots.txt. Это связано с тем, что сайты на основе CMS (Customer Management Systems), например WordPress, имеют виртуальные файлы robots.txt. Плагины также могут содержать файлы robots.txt. Это могут быть те, которые вызывают проблемы на вашем сайте.
Эти виртуальные файлы robots.txt необходимо перезаписать вашим собственным файлом robots.txt. Убедитесь, что в файле robots.txt есть директива, позволяющая всем ботам поисковых систем сканировать ваш сайт. Это единственный способ указать URL-адресам индексировать их или нет.
Вот директива, позволяющая всем ботам сканировать ваш сайт:
User-agent: *
Disallow: /
Это означает «ничего не запрещать». .
В заключение
Мы рассмотрели предупреждение «Проиндексировано, но заблокировано robots.txt», что оно означает, как определить затронутые страницы или URL-адреса, а также причину предупреждения. Мы также рассмотрели, как это исправить. Обратите внимание, что предупреждение не означает ошибку на вашем сайте. Однако если вы не исправите это, ваши самые важные страницы могут не индексироваться, что не очень хорошо для пользователей.
Мы также рассмотрели, как это исправить. Обратите внимание, что предупреждение не означает ошибку на вашем сайте. Однако если вы не исправите это, ваши самые важные страницы могут не индексироваться, что не очень хорошо для пользователей.
Как исправить ошибку «Заблокировано robots.txt» в Google Search Console? » Rank Math
Если вы когда-либо видели ошибку «Заблокировано robots.txt» в своей консоли поиска Google и в отчете о статусе индекса аналитики Rank Math, вы знаете, что это может быть довольно неприятно. В конце концов, вы соблюдали все правила и позаботились о том, чтобы ваш сайт был оптимизирован для поисковых систем, таких как Google или Bing. Так почему это происходит?
В этой статье базы знаний мы покажем вам, как исправить ошибку «Заблокировано robots.txt», а также объясним, что означает эта ошибка и как предотвратить ее повторение в будущем.
Начнем!
Содержание
- Что означает ошибка?
- Как найти ошибку «Заблокировано robots.
 txt»?
txt»? - Как исправить ошибку «Заблокировано robots.txt»?
- Как предотвратить повторение ошибки
- Заключение
1 Что означает ошибка?
Ошибка «Заблокировано robots.txt» означает, что файл robots.txt вашего веб-сайта блокирует сканирование страницы роботом Googlebot. Другими словами, Google пытается получить доступ к странице, но ему мешает файл robots.txt.
Это может произойти по ряду причин, но наиболее распространенной причиной является неправильная настройка файла robots.txt. Например, вы могли случайно заблокировать роботу Googlebot доступ к странице или включить директиву disallow в файл robots.txt, которая не позволяет роботу Googlebot сканировать страницу.
2 Как найти ошибку «Заблокировано robots.txt»?
К счастью, ошибку «Заблокировано robots.txt» довольно легко найти. Вы можете использовать консоль поиска Google или отчет о статусе индекса в аналитике Rank Math, чтобы найти эту ошибку.
2.1 Используйте консоль поиска Google, чтобы найти ошибку
Чтобы проверить, есть ли эта ошибка в вашей консоли поиска Google, просто перейдите на Страницы и щелкните раздел Не проиндексировано .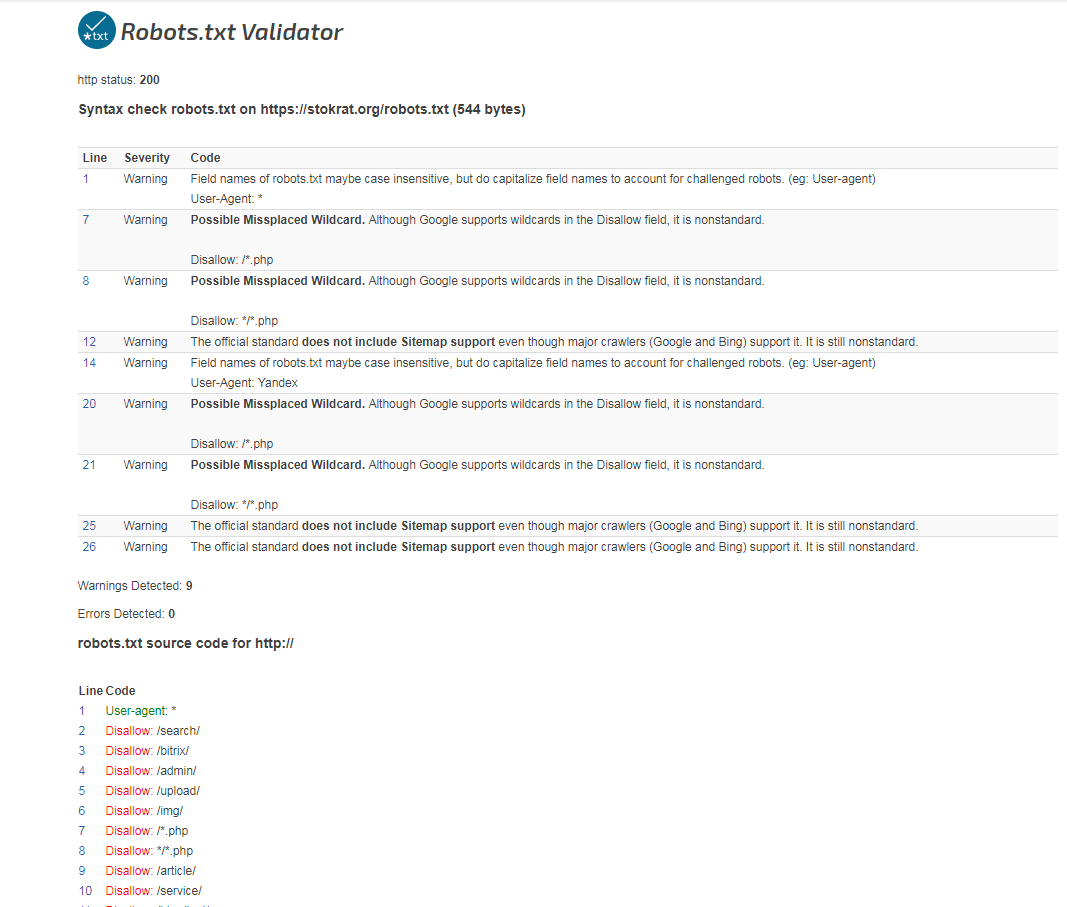
Затем нажмите на ошибку Blocked by robots.txt , как показано ниже:
Если вы нажмете на ошибку, вы увидите список страниц, которые заблокированы вашим файлом robots.txt.
2.2 Использование аналитики Rank Math для выявления проблемных страниц
Вы также можете использовать отчет о состоянии индекса в Rank Math Analytics, чтобы определить страницы с проблемой.
Для этого перейдите к Rank Math > Analytics на панели управления WordPress. Затем щелкните вкладку Состояние индекса . На этой вкладке вы получите реальные данные/статус ваших страниц, а также их присутствие в Google.
Кроме того, вы можете отфильтровать статус индекса сообщения, используя раскрывающееся меню. Когда вы выберете определенный статус, скажем, «Заблокировано robot.txt», вы сможете увидеть все сообщения, которые имеют один и тот же статус индекса.
Получив список страниц, которые возвращают этот статус, вы можете приступить к устранению неполадок и устранению проблемы.
3 Как исправить ошибку «Заблокировано robots.txt»?
Чтобы исправить это, вам нужно убедиться, что файл robots.txt вашего веб-сайта настроен правильно. Вы можете использовать инструмент тестирования robots.txt от Google, чтобы проверить свой файл и убедиться, что нет никаких директив, которые блокируют доступ робота Googlebot к вашему сайту.
Если вы обнаружите, что в вашем файле robots.txt есть директивы, которые блокируют доступ робота Googlebot к вашему сайту, вам нужно будет удалить их или заменить более либеральными.
Давайте посмотрим, как вы можете протестировать файл robots.txt и убедиться, что никакие директивы не блокируют доступ робота Googlebot к вашему сайту.
3.1 Откройте тестер robots.txt
Сначала перейдите к тестеру robots.txt. Если ваша учетная запись Google Search Console связана с несколькими веб-сайтами, выберите свой веб-сайт из списка сайтов, показанного в правом верхнем углу. Теперь Google загрузит файл robots.txt вашего сайта.
Вот как это будет выглядеть.
3.2 Введите URL-адрес вашего сайта
В нижней части инструмента вы найдете возможность ввести URL-адрес вашего веб-сайта для тестирования.
3.3 Выберите агент пользователя
В раскрывающемся списке справа от текстового поля выберите агент пользователя, который вы хотите имитировать (в нашем случае Googlebot).
3.4 Проверить Robots.txt
Наконец, нажмите кнопку Проверить .
Сканер немедленно проверит, есть ли у него доступ к URL-адресу на основе конфигурации robots.txt, и, соответственно, тестовая кнопка окажется ПРИНЯТ или ЗАБЛОКИРОВАН .
Редактор кода, доступный в центре экрана, также выделит правило в файле robots.txt, которое блокирует доступ, как показано ниже.
3.5 Редактирование и отладка
Если тестер robots.txt обнаружит какое-либо правило, запрещающее доступ, вы можете попробовать отредактировать правило прямо в редакторе кода, а затем снова запустить тест.
Вы также можете обратиться к нашей специальной статье базы знаний о robots.txt, чтобы узнать больше о принятых правилах, и было бы полезно отредактировать правила здесь.
Если вам удастся исправить правило, то это здорово. Но обратите внимание, что это инструмент отладки, и любые внесенные вами изменения не будут отражены в robots.txt вашего веб-сайта, если вы не скопируете и не вставите содержимое в robots.txt своего веб-сайта.
3.6 Редактирование файла robots.txt с помощью Rank Math
Для этого перейдите к файлу robots.txt в Rank Math, который находится в разделе Панель управления WordPress > Rank Math > Общие настройки > Редактировать robots.txt , как показано ниже:
Примечание: Если этот параметр недоступен для вас, убедитесь, что вы используете расширенный режим в Rank Math.
В редакторе кода, расположенном посередине экрана, вставьте код, скопированный из robots.txt. Tester, а затем нажмите кнопку Сохранить изменения , чтобы отразить изменения.
Предупреждение: Будьте осторожны, внося какие-либо существенные или незначительные изменения на свой веб-сайт с помощью файла robots.txt. Хотя эти изменения могут улучшить ваш поисковый трафик, они также могут принести больше вреда, чем пользы, если вы не будете осторожны.
Чтобы узнать больше, смотрите скриншоты ниже:
Вот и все! После внесения этих изменений Google сможет получить доступ к вашему веб-сайту, а ошибка «Заблокировано robots.txt» будет исправлена.
4 Как предотвратить повторное появление ошибки
Чтобы предотвратить повторение ошибки «Заблокировано robots.txt» в будущем, мы рекомендуем регулярно проверять файл robots.txt вашего веб-сайта. Это поможет убедиться, что все директивы точны и что ни одна страница не будет случайно заблокирована для сканирования роботом Googlebot.
Мы также рекомендуем использовать такие инструменты, как Инструменты Google для веб-мастеров, которые помогут вам управлять файлом robots.