Индексация сайта robots.txt, способы закрыть от индексации
Последнее обновление: 08 ноября 2022 года
30903
Время прочтения: 6 минут
Тэги: Яндекс, Google
О чем статья?
- Зачем закрывать сайт от поисковых роботов?
- Как проверить, закрыт сайт от индексации или нет? robots.txt
- Как закрыть сайт от индексации?
- Какие ошибки встречаются при записи файла robots.txt?
Кому будет полезна статья?
- Веб-разработчикам.
- Контент-редакторам.
- Оптимизаторам.
- Администраторам и владельцам сайтов.
Несмотря на то, что все ресурсы стремятся попасть в топ поисковой выдачи, в процессе работы возникают ситуации, когда требуется сделать прямо противоположное — закрыть сайт от поисковых роботов. В каких случаях может понадобиться запрет на индексацию, и как это сделать, мы расскажем в этой статье.
Зачем закрывать сайт от поисковых роботов?
Первое время после запуска проекта о нем знают только разработчики и те пользователи, которые получили ссылку на ресурс. В базы поисковых систем и, соответственно, в выдачу сайт попадает только после того, как его найдут и проанализируют краулеры (поисковые работы). С этого момента он становится доступным для пользователей Яндекс и Google.
Но всю ли информацию, содержащуюся на страницах ресурса, должны видеть пользователи? Конечно, нет. Им, прежде всего, интересны полезные материалы: статьи, информация о компании, товарах, услугах, развлекательный контент. Временные файлы, документация для ПО и другая служебная информация пользователям неинтересна, и поэтому не нужна. Если лишние страницы будут отображаться вместе с полезным контентом, это затруднит поиск действительно нужной информации и негативно отразится на позициях ресурса в поисковой выдаче. Вывод — служебную информацию следует закрывать от индексации.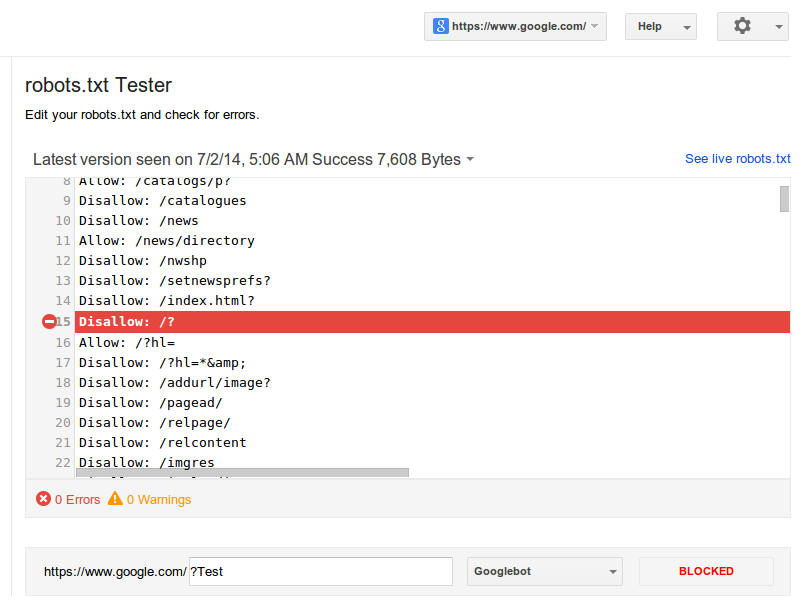
В процессе работы сайта также возникают ситуации, когда требуется полностью закрыть ресурс от поисковиков. Например, во время технических работ, внесения существенных правок, изменения структуры и дизайна проекта. Если этого не сделать, сайт может быть проиндексирован с ошибками, что негативно отразиться на его рейтинге.
Мнение эксперта
Анастасия Курдюкова, руководитель группы оптимизаторов в компании «Ашманов и партнеры»:
«Чтобы сайт быстрее индексировался, рекомендуется закрывать от поисковых роботов мусорные страницы: устаревшие материалы, информацию о прошедших акциях и мероприятиях, а также всплывающие окна и баннеры. Это не только сократит время индексации, но уменьшит нагрузку на сервер, а поисковые роботы смогут проиндексировать более количество качественных страниц».
Как проверить, закрыт сайт от индексации или нет?
Если вы не уверены, индексируется ли сайт поисковыми роботами, какие разделы, страницы и файлы доступны для сканирования, а какие нет, можно проверить ресурс с помощью сервисов Яндекс.
В качестве альтернативы можно использовать бесплатный инструмент «Определение возраста сайта» от «Пиксель Тулс». С помощью этого сервиса вы узнаете возраст домена, отдельных страницы, дату индексации и кэша. Данные проверки можно отправить в Яндекс.Вебмастер и выгрузить в формате CSV.
Как закрыть сайт от индексации?
Запретить доступ к сайту можно с помощью служебного файла robots.txt. Он находится в корневой папке. Если файла нет, создайте документ в Notepad++ или любом другом текстовом редакторе. Далее следуйте рекомендациям ниже.
Запрет индексации всего сайта
Управление доступом к ресурсу, его разделам и страницам осуществляется с помощью директив User-agent, Disallow и Allow. Директива User-agent указывает на робота, для которого действуют перечисленные ниже правила, Disallow — запрещает индексацию, Allow — разрешает индексацию.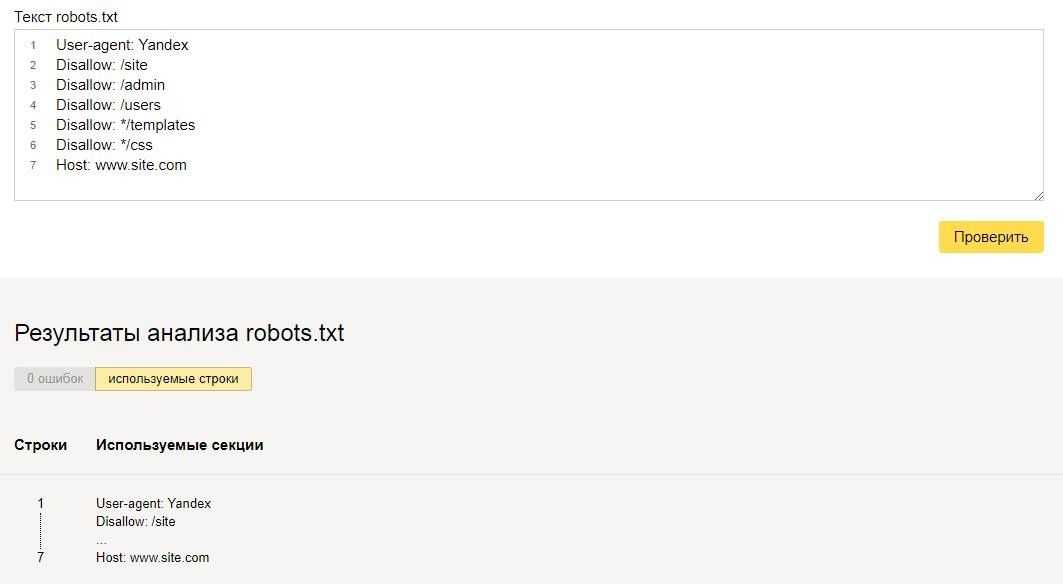
Если вы хотите установить запрет для всех краулеров, в файле robots.txt следует указать:
Disallow: /
Запрет для всех поисковых роботов, кроме краулеров Яндекса, будет выглядеть так:
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Запрет для всех поисковиков, кроме Google, так:
User-agent: *
Disallow: /
User-agent: Googlebot
Allow: /
Вы также можете ограничить доступ для отдельных поисковых роботов, разрешив всем остальным краулерам сканировать без ограничений. Например, запрет для робота YandexImages, который индексирует изображения для показа на Яндекс.Картинках, будет выглядеть так:
User-agent: YandexImages
Таким образом, с помощью всего трех директив вы можете управлять доступом к сайту для краулеров любых поисковых систем: запрещать или разрешать индексацию всем поисковикам, закрывать доступ одним и открывать другим роботам.
Запрет на индексацию разделов и страниц
Если вы не хотите закрывать от индексации весь сайт, а только некоторые его разделы или страницы, это можно сделать с помощью тех же директив. Для понимания приведем несколько примеров.
- Поисковым роботам доступны все разделы, кроме каталога:
User-agent: *
Disallow: /catalog - Поисковым роботам доступны все страницы, кроме контактов:
User-agent: *
Disallow: /contact.html - Поисковым роботам закрыт весь сайт, кроме одного раздела:
User-agent: *
Disallow: /
Allow: /catalog - Поисковым роботам закрыт весь раздел, кроме одного подраздела:
User-agent: *
Disallow: /product
Allow: /product/auto
Несмотря на простоту управления, файл robots.txt позволяет выполнять достаточно гибкие настройки индексации для краулеров поисковых систем и изменять уровень доступа в зависимости от текущей ситуации.
Как скрыть от индексации ссылки?
Закрыть от краулеров можно не только сайт или его разделы, но и отдельные элементы, например, ссылки. Сделать это можно двумя способами:
- в html-коде страницы указать метатег robots с директивой nofollow;
- вставить атрибут rel=”nofollow” в саму ссылку: <a href=”url” rel=”nofollow”>текст ссылки</а>.
Второй вариант предпочтительнее, так как атрибут rel=”nofollow” запрещает краулерам переходить по ссылке даже в том случае, если поисковая система находит ее через другие материалы вашего сайта или сторонних ресурсов.
Проверь своего подрядчика
Если работа SEO-подрядчика не дает ожидаемых результатов, мы предлагаем провести аудит текущего поискового продвижения. Наша экспертиза поможет выявить существующие проблемы.
Какие ошибки встречаются при записи файла robots.txt?
Если robots. txt будет записан с ошибками, краулеры не смогут корректно проиндексировать файл и полезная для пользователей информация не попадет в поисковую выдачу. Наиболее часто разработчики допускают следующие ошибки:
txt будет записан с ошибками, краулеры не смогут корректно проиндексировать файл и полезная для пользователей информация не попадет в поисковую выдачу. Наиболее часто разработчики допускают следующие ошибки:
- Неверные (перепутанные) значения директив.
User-agent: /
Disallow: Yandex
Правильно:
User-agent: Yandex
Disallow: / - Указание нескольких URL в одной директиве.
Неправильно:
Disallow: /admin/ /tags/ /images/
Правильно:
Disallow: /admin/
Disallow: /tags/
Disallow: /images/ - Пустое значение User-agent.
Неправильно:
User-agent:
Disallow: /
Правильно:
User-agent: *
Disallow: / - Некорректный формат директивы Disallow.
Неправильно:
Disallow: admin
Правильно:
User-agent: Yandex
Disallow: /admin/
Проверить файл robots. txt на наличие ошибок можно с помощью Яндекс.Вебмастер и Google Search Console. Порядок проверки мы подробно описали в статье «Проверка файла robot.txt».
txt на наличие ошибок можно с помощью Яндекс.Вебмастер и Google Search Console. Порядок проверки мы подробно описали в статье «Проверка файла robot.txt».
Выводы
- Запрет на индексацию позволяет скрыть от поисковых роботов временные и служебные документы, неактуальный контент, ссылки, всплывающие окна и баннеры, полностью ограничить доступ к сайту на время технических работ.
- Проверить, какие страницы сайта индексируются, можно с помощью Яндекс.Вебмастер, Google Search Console и бесплатных инструментов, предоставляемых сторонними ресурсами.
- Закрыть сайт или отдельные его разделы и страницы от краулеров можно через robots.txt, который находится в корневом каталоге.
- Гибкие настройки позволяют изменять уровень доступа в зависимости от текущей ситуации.
- После внесения изменений файл robots.txt необходимо проверить на наличие ошибок. Это можно сделать с помощью сервисов поисковых систем Яндекс.Вебмастер и Google Search Console.

Статья
Что из англоязычного SEO можно применять в Рунете?
#SEO, #Google
СтатьяКейс RU-CENTER: выстроили работу с упоминаниями и снизили долю негатива в выдаче
#Яндекс, #Google
СтатьяЯндекс обновил алгоритмы: как улучшить ранжирование сайта?
#SEO, #Яндекс
Статью подготовили:
Прокопьева Ольга. Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Анастасия Курдюкова, руководитель группы оптимизаторов «Ашманов и партнеры», опытный специалист по SEO-оптимизации, ведущая вебинаров для клиентов компании.
Теги: SEO, Яндекс, Google
Robots.txt — Как создать правильный robots.txt
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:
Исключения Яндекса
Стандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:User-agent: *
Для конкретного бота:User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс. Картинки Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Следующие ссылки будут закрыты от индексации:
http://site.ru/?s=
http://site. ru/?s=keyword
ru/?s=keyword
http://site.ru/page/?s=keyword
http://site.ru/category/
Следующие ссылки будут открыты для индексации:
http://site.ru/category/cat1/
http://site.ru/category-folder/
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site.ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Host
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:Host: site.ru
Пример 2:Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:Crawl-delay: 3
Пример 2:Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Пример 1:
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Пример 2:
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: *
Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
- Закройте от индексирования админку сайта
- Закройте от индексирования личный кабинет, авторизацию, регистрацию
- Закройте от индексирования корзину, формы заказа, данные по доставке и заказам
- Закройте от индексирования ajax, json-скрипты
- Закройте от индексирования папку cgi
- Закройте от индексирования плагины, темы оформления, js, css для всех роботов, кроме Яндекса и Google
- Закройте от индексирования функционал поиска
- Закройте от индексирования служебные разделы, которые не несут никакой ценности для сайта в поиске (ошибка 404, список авторов)
- Закройте от индексирования технические дубли страниц, а также страницы, на которых весь контент в том или ином виде продублирован с других страниц (календари, архивы, RSS)
- Закройте от индексирования страницы с параметрами фильтров, сортировки, сравнения
- Закройте от индексирования страницы с параметрами UTM-меток и сессий
- Проверьте, что проиндексировано Яндексом и Google с помощью параметра «site:» (в поисковой строке наберите «site:site.
 ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt - Укажите Sitemap и Host
- По необходимости пропишите Crawl-Delay и Clean-Param
- Проверьте корректность robots.txt через инструменты Google и Яндекса (описано ниже)
- Через 2 недели перепроверьте, появились ли в поисковой выдаче новые страницы, которые не должны индексироваться. В случае необходимости повторить выше перечисленные шаги.
Пример robots.txt
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif User-agent: Yandex Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif Clean-Param: utm_source&utm_medium&utm_campaign Crawl-Delay: 0.5 Sitemap: https://site.ru/sitemap.xml Host: https://site.ru
Как добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
- В Яндекс.Вебмастере — на вкладке Инструменты>Анализ robots.
 txt
txt - В Google Search Console — на вкладке Сканирование>Инструмент проверки файла robots.txt
Типичные ошибки в robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
- robots.txt отсутствует
- в robots.txt сайт закрыт от индексирования (Disallow: /)
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий
- в файле указаны только директивы
Allow: *.css
Allow: *.js
Allow: *.png
Allow: *.jpg
Allow: *.gif
при этом файлы css, js, png, jpg, gif закрыты другими директивами в ряде директорий - директива Host прописана несколько раз
- в Host не указан протокол https
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта
P.S.
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots. txt для WordPress».
txt для WordPress».
P.S.2
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
Что такое robots.txt в WordPress?
акции 70 Делиться Твитнуть Делиться Facebook-мессенджер WhatsApp Эл. адрес
Robots.txt — это текстовый файл, который позволяет веб-сайту давать инструкции роботам, сканирующим веб-страницы.
Поисковые системы, такие как Google, используют эти поисковые роботы, иногда называемые веб-роботами, для архивирования и категоризации веб-сайтов. Большинство ботов настроены на поиск файла robots.txt на сервере, прежде чем он прочитает любой другой файл с веб-сайта. Это делается для того, чтобы узнать, есть ли у владельца веб-сайта какие-либо специальные инструкции о том, как сканировать и индексировать его сайт.
Файл robots.txt содержит набор инструкций, которые требуют от бота игнорировать определенные файлы или каталоги. Это может быть сделано в целях конфиденциальности или потому, что владелец веб-сайта считает, что содержимое этих файлов и каталогов не имеет отношения к классификации веб-сайта в поисковых системах.
Если веб-сайт имеет более одного субдомена, для каждого субдомена должен быть свой файл robots.txt. Важно отметить, что не все боты поддерживают файл robots.txt. Некоторые вредоносные боты даже читают файл robots.txt, чтобы определить, какие файлы и каталоги им следует атаковать в первую очередь.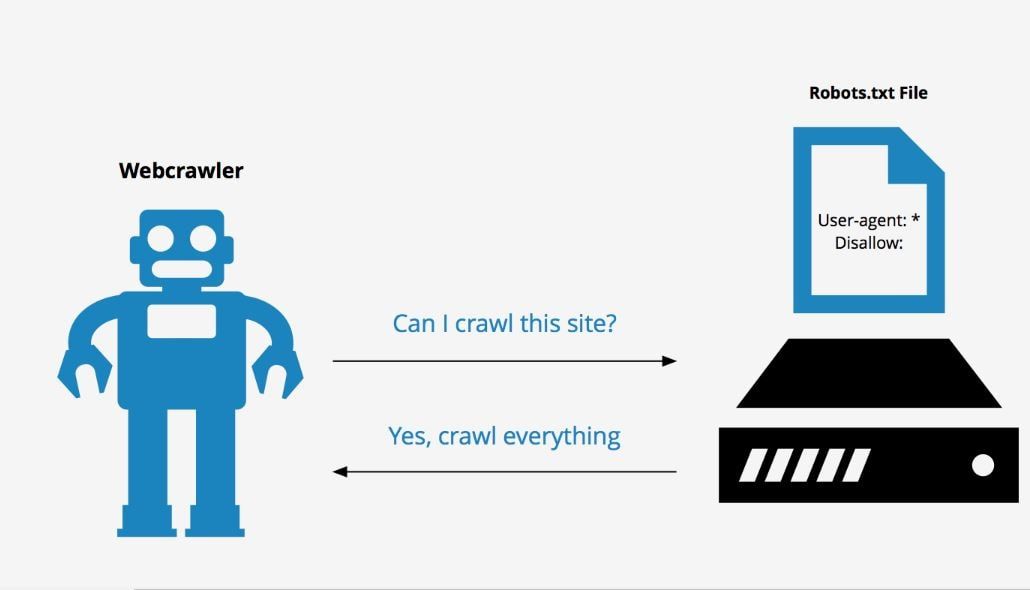 Кроме того, даже если файл robots.txt предписывает ботам игнорировать определенные страницы сайта, эти страницы все равно могут отображаться в результатах поиска, если на них есть ссылки с других сканируемых страниц.
Кроме того, даже если файл robots.txt предписывает ботам игнорировать определенные страницы сайта, эти страницы все равно могут отображаться в результатах поиска, если на них есть ссылки с других сканируемых страниц.
Дополнительные показания
- Как добавить свой сайт WordPress в Google Search Console
- SEO
Акции
70
Делиться
Твитнуть
Делиться
Facebook-мессенджер
WhatsApp
Эл. адрес
адрес
О редакции
Редакция WPBeginner — это команда экспертов WordPress во главе с Сайедом Балхи. Мы создаем учебные пособия по WordPress с 2009 года, и WPBeginner стал крупнейшим в отрасли сайтом с бесплатными ресурсами WordPress.
Файлы robots.txt | Search.gov
Файл /robots.txt — это текстовый файл, который инструктирует автоматических веб-ботов о том, как сканировать и/или индексировать веб-сайт. Веб-команды используют их для предоставления информации о том, какие каталоги сайта следует или не следует сканировать, как быстро следует получать доступ к контенту и какие боты приветствуются на сайте.
Как должен выглядеть мой файл robots.txt?
Подробную информацию о том, как и где создать файл robots.txt, см. в протоколе robots.txt. Ключевые моменты, о которых следует помнить:
- Файл должен находиться в корне домена, и для каждого поддомена нужен свой файл.
- Протокол robots.
 txt чувствителен к регистру.
txt чувствителен к регистру. - Легко случайно заблокировать сканирование всего:
-
Запретить: /означает запретить все. -
Disallow:означает ничего не запрещать, то есть разрешать все. -
Разрешить: /означает разрешить все. -
Разрешить:означает ничего не разрешать, что запрещает все.
-
- Инструкции в файле robots.txt являются руководством для ботов, а не обязательными требованиями — вредоносные боты могут игнорировать ваши настройки.
Как оптимизировать файл robots.txt для Search.gov?
Задержка сканирования
В файле robots.txt может быть указана директива «задержка сканирования» для одного или нескольких пользовательских агентов, которая сообщает боту, как быстро он может запрашивать страницы с веб-сайта. Например, задержка сканирования, равная 10, означает, что сканер не должен запрашивать новую страницу чаще, чем каждые 10 секунд.
500 000 URL-адресов
x 10 секунд между запросами
5 000 000 секунд на все запросы
5 000 000 секунд = 58 дней, чтобы проиндексировать сайт один раз.
Мы рекомендуем задержку сканирования в 2 секунды для нашего пользовательский агент usasearch и установка более высокой задержки сканирования для всех остальных ботов. Чем меньше задержка сканирования, тем быстрее Search.gov сможет проиндексировать ваш сайт. В файле robots.txt это будет выглядеть так:
Агент пользователя: usasearch Задержка сканирования: 2 Пользовательский агент: * Задержка сканирования: 10
XML-карты сайта
В файле robots.txt также должны быть перечислены одна или несколько ваших XML-карт сайта. Например:
Карта сайта: https://www.example.gov/sitemap.xml Карта сайта: https://www.example.gov/independent-subsection-sitemap.xml
- Список карт сайта только для домена, в котором находится файл robots.txt. Карта сайта другого субдомена должна быть указана в файле robots.
 txt этого субдомена.
txt этого субдомена.
Разрешить только тот контент, который вы хотите найти
Мы рекомендуем запретить любые каталоги или файлы, которые не должны быть доступны для поиска. Например:
Запретить: /архив/ Запретить: /news-1997/ Запретить: /reports/duplicative-page.html
- Обратите внимание: если вы запретите каталог после того, как он был проиндексирован поисковой системой, это может не привести к удалению этого содержимого из индекса. Вам нужно будет зайти в инструменты поисковой системы для веб-мастеров, чтобы запросить удаление.
- Также обратите внимание, что поисковые системы могут индексировать отдельные страницы в запрещенной папке, если поисковая система узнает об URL-адресе из метода, не связанного со сканированием, например, по ссылке с другого сайта или из вашей карты сайта. Чтобы данная страница не была доступна для поиска, установите на этой странице метатег robots.
Настройка параметров для разных ботов
Вы можете установить разные разрешения для разных ботов.