Правильный robots.txt для WordPress | Как сделать robots.txt
Содержание:
- Что такое robots.txt
- Для чего нужен robots.txt
- Как редактировать robots txt
- Правильный robots.txt для CMS WordPress
- Проверка robots.txt
Вебмастера и маркетологи знают насколько важна индексация сайта поисковыми системами. Именно поэтому они делают все возможное, чтобы помочь поисковикам типа Google и Yandex правильно сканировать и индексировать свои сайты.
Большое количество времени и ресурсов тратятся на внутреннюю и внешнюю оптимизацию, такую как контент, ссылки, теги, оптимизация изображений и структуры сайта.
Всё это играет огромную роль в продвижении. Однако если вы забыли сделать техническую оптимизацию сайта, если вы не слышали о файлах robots.txt и sitemap.xml могут возникнуть проблемы с правильным сканированием и индексацией вашего сайта.
к содержанию ↑
Что такое robots.txt
Robots.txt – это текстовый файл, который используется в качестве инструкции для роботов поисковых систем (также известных как сканеры, боты или пауки), как сканировать и индексировать страницы сайта.
Простыми словами, robots.txt говорит роботам, какие страницы или файлы сайта мы хотим видеть в поиске, а какие нет.
В идеале файл robots.txt размещается в корневом каталоге вашего веб-сайта (https://site.com/robots.txt), чтобы роботы могли сразу получить доступ к его инструкциям.
Если вы используете CMS WordPress, то вы сможете увидеть ваш файл по вышеуказанному адресу, однако вы не найдете сам файл в общей папке с вашим сайтом. Это потому что WordPress автоматически создает виртуальный файл robots.txt (с параметрами по-умолчанию), если не находит данный файл в корневом каталоге сайта.
Это потому что WordPress автоматически создает виртуальный файл robots.txt (с параметрами по-умолчанию), если не находит данный файл в корневом каталоге сайта.
Виртуальный файл robots.txt CMS WordPress не решает всех необходимых задач, в связи с этим крайне желательно написать свой.
к содержанию ↑
Для чего нужен robots.txt
Файл robots.txt нужен, для того чтобы запретить поисковым роботам посещать определенные разделы вашего сайта, например:
- страницы пагинации;
- страницы с результатами поиска на сайте;
- административные файлы;
- служебные страницы;
- ссылки с utm-метками;
- данные о параметрах сортировки, фильтрации, сравнении;
- страница личного кабинета и т.п.
Важно! Файл robots.txt не является обязательным к исполнению поисковыми роботами. В связи с этим, если вы хотите на 100% быть уверенными в том что какая-либо из страниц вашего сайта не появится в поисковой выдаче – используйте мета-тег robots.![]()
Согласно Cправке Google файл robots.txt не предназначен для того, чтобы запрещать показ веб-страниц в результатах поиска Google.
Если вы не хотите чтобы какая-то страница вашего сайта появилась в поиске вставьте в <head> страницы атрибут noindex:
<meta name=“robots” content=“noindex,nofollow”>
к содержанию ↑
Как редактировать robots txt
Редактировать файл robots.txt в CMS WordPress можно двумя способами. Добавить необходимый код в файл functions.php, или при помощи плагина.
В нашей компании мы предпочитаем второй способ.
Устанавливаем плагин Virtual Robots.txt из репозитория CMS WordPress, открываем его в админ. панеле во вкладке Настройки. В открывшееся поле плагина вносим необходимый код, жмем кнопку Save и вуаля – ваш файл robots.txt готов.
к содержанию ↑
Правильный robots.txt для CMS WordPress
Взял с сайта seogio.ru и немного подкорректировал. Вот что получилось:
Вот что получилось:
User-agent: * # общие правила для роботов всех поисковых систем
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск по сайту
Disallow: *&s= # поиск по сайту
Disallow: /search/ # поиск по сайту
Disallow: /author/ # архив автора
Disallow: /users/ # архив пользователей
Disallow: */trackback # трекбеки, уведомления в комментариях о ссылке на веб-документ
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Allow: /*/*.js # открываем файлы скриптов js
Allow: /*/*.css # открываем фалы css
Allow: /wp-*.png # разрешаем индексировать изображения
Allow: /wp-*.jpg # разрешаем индексировать изображения
Allow: /wp-*.jpeg # разрешаем индексировать изображения
Allow: /wp-*.gif # разрешаем индексировать гифки
Allow: /wp-admin/admin-ajax.php # разрешаем ajax
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.
RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
к содержанию ↑
Проверка robots.txt
Если файл robots.txt настроен неправильно это может привести к множественным ошибкам в индексации сайта. Проверить правильность настройки вашего robots.txt можно с помощью бесплатного инструмента Google Robots Testing Tool
Выбираем наш сайт:
Вводим в строку путь к нашему файлу robots.txt и жмем кнопку Проверить:
В результате не должно быть ошибок и предупреждений и файл должен быть Доступен для роботов:
Если файл robots.txt настроен правильно, это значительно ускорит процесс индексации вашего сайта.
Правильный файл robots.
 txt для сайта на WordPress в 2022
txt для сайта на WordPress в 2022Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
- Пример;
- Где найти;
- Как создать;
- Инструкция по работе;
- Синтаксис;
- Директивы;
- Как проверить.
Пример правильного файла robots.txt для сайта на WordPress
- User-agent: *
- Disallow: /cgi-bin
- Disallow: /wp-admin/
- Disallow: /wp-includes/
- Disallow: /wp-content/plugins/
- Disallow: /wp-content/cache/
- Disallow: /wp-content/themes/
- Disallow: /wp-trackback
- Disallow: /wp-feed
- Disallow: /wp-comments
- Disallow: /author/
- Disallow: */embed*
- Disallow: */wp-json*
- Disallow: */page/*
- Disallow: /*?
- Disallow: */trackback
- Disallow: */comments
- Disallow: /*.php
- Host: https://seopulses.
 ru
ru - Sitemap: https://seopulses.ru/sitemap_index.xml
Где можно найти файл robots.txt и как его создать или редактировать
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
- Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
- WordPress;
https://ru. wordpress.org/plugins/pc-robotstxt/
wordpress.org/plugins/pc-robotstxt/
- Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
- Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.

Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site. ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами./cdn.vox-cdn.com/uploads/chorus_asset/file/23952392/HT022_slack_0001.jpg) Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Создаем правильный Robots.txt для WordPress
В этом руководстве я поделюсь методикой составления правильного robots.txt для сайтов на базе WordPress. Вы узнаете все об основных параметрах и допустимых значениях этого файла, а так же способах манипулирования поведением поисковых роботов для ускорения индексации сайта.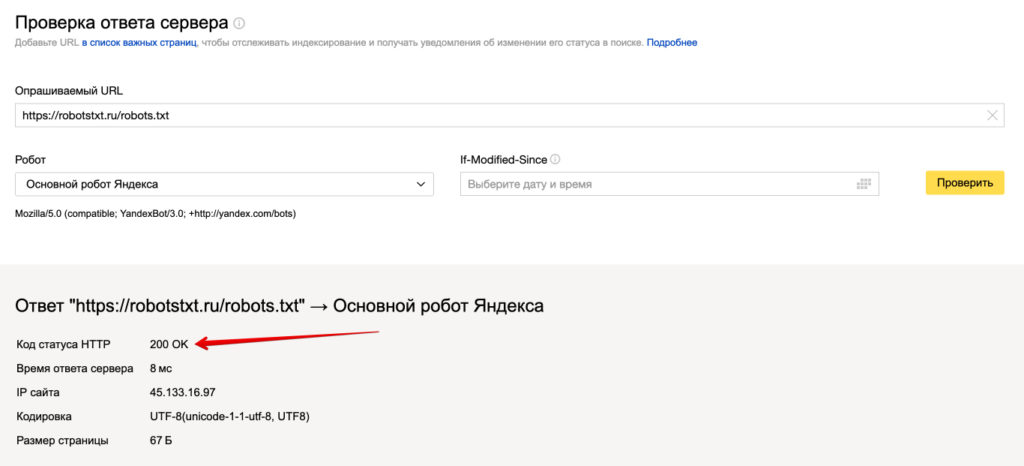
Robots.txt — это текстовый файл, который содержит директивы и их значения для управления индексированием сайта в поисковых системах.
В базовый набор директив (параметров) для поисковой системы Яндекс входят:
| Директива | Описание |
|---|---|
| User-agent | Указывает на робота, для которого действуют правила (например, Yandex). |
| Allow | Разрешает обход и индексирование разделов, страниц, файлов. |
| Disallow | Запрещает обход и индексирование разделов, страниц, файлов. |
| Clean-param | Указывает роботу, какие параметры URL (например, UTM-метки) не следует учитывать при индексировании. |
| Sitemap | Указывает путь к файлу Sitemap, который размещен на сайте. |
Все директивы, кроме Clean-param одинаково интерпретируются в других поисковых системах и помогают решить 90% задач связанных с индексированием сайтов на WordPress.
Краулинговый бюджет: что это и как им управлять
Важно понимать, что файл robots.txt не является инструментом для запрета индексирования сайта. Поисковая система Google может не учитывать значения директив и индексировать страницы по своему усмотрению.
Crawler (веб-паук, краулер) или поисковой бот. Его задачи: найти, прочитать и внести в поисковую базу данных веб-страницы найденные в Интернете.
Владельцы сайтов могут управлять поведением краулера. Для этого достаточно разместить инструкции в robots.txt с помощью указанных директив в исходном коде страниц.
От правильности настройки будет зависеть частота сканирования вашего сайта. Основная цель такого управления — это снижение нагрузки на краулер и экономия квоты обхода страниц.
Где находится robots.txt в WordPress
Согласно требованиям поисковых систем файл robots.txt должен быть расположен в корневой директории. Если у вас он отсутствует, убедитесь, что вы не используете SEO-плагины.
Плагины позволяют редактировать robots.txt из панели администратора WordPress и не создают копию файла в корневой папке сайта (например, в режиме Multisite).
Если вы не используете плагин, создайте файл заново и проверьте его доступность. Ручная проверка доступности должна выявить:
- Наличие файла в корневой директории,
- Правильный ответ сервера (код 200 ОК),
- Допустимый размер файла (не более 500 Кб).
После проверки сообщите поисковым системам о внесении изменений.
Стандартный robots.txt для WordPress
После инсталляции WordPress 5.9.3 по умолчанию robots.txt выглядит так:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://example.com/wp-sitemap.xml
Из содержания следует, что разработчики рекомендуют закрывать от поисковых машин раздел административной панели, кроме сценария admin-ajax.php из этой же директории. При составлении файла robots. txt для любого проекта под управлением WordPress это необходимо учитывать.
txt для любого проекта под управлением WordPress это необходимо учитывать.
Правильный robots.txt для WordPress
В WordPress имеется набор системных директорий, файлов и параметров, которые любят сканировать поисковые системы. Все они должны быть запрещены к индексированию за исключением редких случаев.
Системные директории и файлы
| Директория / Файл | Описание |
|---|---|
| /wp-admin | Панель администратора |
| /wp-json | JSON REST API |
| /xmlrpc.php | Протокол XML-RPC |
Параметры URL
| Параметр | Описание |
|---|---|
| s | Стандартная функция поиска |
| author | Личная страница пользователя |
| p&preview | Просмотр черновика записи |
| customize_theme | Изменение внешнего вида темы оформления |
| customize_autosaved | Автосохранение состояния кастомайзера |
Для более гибкой настройки мы рекомендуем разделять robots. txt на две секции. Первая секция будет содержать инструкции для всех поисковых систем, кроме Яндекса. Вторая — только для Яндекса.
txt на две секции. Первая секция будет содержать инструкции для всех поисковых систем, кроме Яндекса. Вторая — только для Яндекса.
Примечательно, что системные каталоги, файлы и параметры URL можно запретить с помощью директивы Disallow без использования Clean-param. В результате правильный robots.txt для WordPress выглядит так:
User-agent: * Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php User-agent: Yandex Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php Sitemap: https://example.com/wp-sitemap.xml
Это универсальная конфигурация robots.txt для сайтов под управлением WordPress.
Значение /*? директивы Disallow запрещает к индексированию все параметры URL для главной страницы, записей и категорий. В том числе: рекламные UTM-метки, параметры плагинов, поисковых систем, сервисов коллтрекинга и CRM-платформ.
В том числе: рекламные UTM-метки, параметры плагинов, поисковых систем, сервисов коллтрекинга и CRM-платформ.
Отлично! Теперь перейдем к индивидуальной настройке.
Несколько примеров из практики
Запрет индексирования AMP страниц в поиске Яндекса
Сайт использует плагин для генерации мобильных страниц в формате AMP для поисковой системы Google. Яндекс их не поддерживает, но умеет сканировать. Для экономии квоты, запрещаем обход AMP страниц для Яндекса с помощью директивы Disallow:
User-agent: * Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php User-agent: Yandex Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /amp Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php Sitemap: https://example.com/wp-sitemap.xml
Не забудьте изменить значение директивы Sitemap.
Запрет индексирования служебных URL
Сайт использует плагин кастомной авторизации.
- https://example.com/login,
- https://example.com/register,
- https://example.com/reset-password.
Предварительно, исключим страницы из wp-sitemap.xml и добавим запрет на их сканирование с помощью директивы Disallow в файле robots.txt:
User-agent: * Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /login Disallow: /register Disallow: /reset-password Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php User-agent: Yandex Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /amp Disallow: /login Disallow: /register Disallow: /reset-password Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php Sitemap: https://example.com/wp-sitemap.xml
Не забудьте изменить значение директивы Sitemap.
Использование директивы Clean-param
Директива Clean-param позволяет гибко настроить индексирование страниц с параметрами URL, которые влияют на содержание страниц.
Она поддерживается только поисковой системой Яндекса. Поисковые роботы Google теперь работают с параметрами URL автоматически.
Например, в торговом каталоге WooCommerce имеется фильтр, который сортирует товары по различным характеристикам: цвету, бренду, размеру.
| Параметр | Описание |
|---|---|
| orderby | Функция сортировки |
| add-to-cart | Функция добавления товара в корзину |
| removed_item | Функция удаления товара из корзины |
Чтобы разрешить индексирование каталога с сортировками в Яндексе без ущерба квоте на переобход сайта, потребуется сделать несколько корректировок.
Разрешим сканирование параметров URL в каталоге, где установлен Woocommerce. Определим лишние параметры — это add-to-cart и removed_item. Воспользуемся директивой Clean-param и внесем изменения:
User-agent: * Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /login Disallow: /register Disallow: /reset-password Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php User-agent: Yandex Allow: /catalog/? Allow: /wp-admin/admin-ajax.php Disallow: /*? Disallow: /amp Disallow: /login Disallow: /register Disallow: /reset-password Disallow: /wp-admin Disallow: /wp-json Disallow: /xmlrpc.php Clean-param: add-to-cart Clean-param: removed_item Sitemap: https://example.com/wp-sitemap.xml
Не забудьте изменить значение директивы Sitemap.
Сканирование сортировок товара разрешено в рамках экономии квоты переобхода страниц. Поисковой бот Яндекса не будет сканировать параметры URL предназначенные для манипуляций с корзиной товаров.
Отслеживание лишних страниц в поисковой консоли
Для получения максимального эффекта регулярно отслеживайте сканирование страниц в поисковой консоли Яндекса (разд. Статистика обхода) и запрещайте обход лишних страниц в robots.txt.
При настройке robots.txt я не рекомендую:
- Запрещать обход страниц пагинации записей и разделов (используйте атрибут
rel="canonical"), - Исключать из поиска комментарии пользователей к записям,
- Запрещать сканирование системных папок, где хранятся изображения, скрипты и стили тем оформления WordPress: wp-content, wp-includes и пр.
Как сообщить об изменениях поисковикам
Для отправки изменений используйте инструменты для анализа robots.txt в Яндекс.Вебмастер и Google Search Console.
robots.txt для WordPress — что это и как его использовать
Искусство и науку повышения рейтинга вашего сайта в различных поисковых системах обычно называют SEO (поисковая оптимизация). И когда дело доходит до SEO, существует множество различных аспектов, возможно, слишком много, чтобы охватить их в одной статье. Вот почему мы сосредоточимся только на одном – robots.txt WordPress. В этой статье подробнее рассмотрим, что такое robots.txt и как его использовать, обсудим различные способы создания файла и рассмотрим лучшие практики в отношении его директив.
Robots.txt – это текстовый файл, расположенный в корневом каталоге WordPress. К нему можно получить доступ из браузера, открыв URL-адрес your-website.com/robots.txt. Он позволяет ботам поисковых систем знать, какие страницы сайта следует сканировать, а какие нет. Строго говоря, веб-сайту не нужен robots.txt. Если вы находитесь в процессе создания своего веб-сайта, лучше сначала сосредоточиться на создании качественного контента. Боты поисковых систем будут сканировать вебсайт независимо от того, есть ли у вас robots.txt или нет.
Строго говоря, веб-сайту не нужен robots.txt. Если вы находитесь в процессе создания своего веб-сайта, лучше сначала сосредоточиться на создании качественного контента. Боты поисковых систем будут сканировать вебсайт независимо от того, есть ли у вас robots.txt или нет.
Однако есть немало преимуществ наличия robots.txt с соответствующими директивами после завершения создания веб-сайта WordPress. Помимо предотвращения сканирования ненужного контента сканерами, оптимизированные директивы robots.txt гарантируют, что ваша квота на сканирование (максимальное количество раз, которое сканер может сканировать сайт в течение определенного времени) не будет потрачена впустую.
Более того, хорошо написанные директивы WordPress robots.txt могут уменьшить негативные последствия плохих ботов, запретив им доступ. Это, в свою очередь, улучшит общую скорость загрузки сайта. Но имейте в виду, что директивы robots.txt не должны быть единственной защитой. Плохие боты часто игнорируют их, поэтому настоятельно рекомендуется использовать хороший плагин безопасности, особенно если на веб-сайте возникают проблемы, вызванные плохими ботами.
Наконец, распространено заблуждение, что robots.txt предотвратит индексацию некоторых страниц веб-сайта. Файл robots.txt может содержать директивы, запрещающие сканирование, но не индексирование. И даже если страница не просканирована, ее все равно можно проиндексировать с помощью внешних ссылок, ведущих на нее. Если вы хотите избежать индексации определенной страницы, следует использовать метатег noindex вместо директив в robots.txt для WordPress.
Как использовать «robots.txt»
Уяснив, что такое robots.txt в WordPress и что он делает, рассмотрим, как он используется. Из этого раздела вы узнаете, как создать и отредактировать robots.txt, некоторые передовые практики в отношении его содержания и как проверить его на наличие ошибок.
По умолчанию WordPress создает виртуальный robots.txt для любого веб-сайта. Он может выглядеть примерно так:
Смотрите также:
Как закрыть сайт от индексации и что это означает
Но если вы захотите его отредактировать, нужно создать настоящий robots. txt. Ниже описаны три способа, как это сделать. Два из них предполагают использование плагинов WordPress, а третий полагается на использование FTP.
txt. Ниже описаны три способа, как это сделать. Два из них предполагают использование плагинов WordPress, а третий полагается на использование FTP.
Yoast SEO
Плагин Yoast SEO – один из самых популярных доступных плагинов для SEO с более чем 5 миллионами активных установок. Он включает множество инструментов для оптимизации сайта, в том числе функцию для создания и редактирования robots.txt для WordPress.
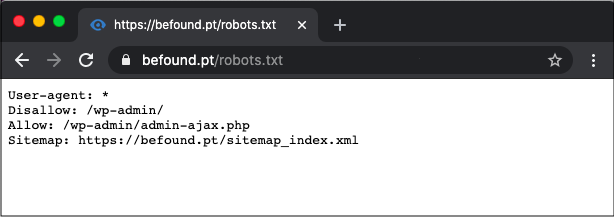
После установки плагина, нажмите на вновь созданный SEO раздел, а затем кликните на подраздел Инструменты. На открывшейся странице щелкните ссылку Редактор файлов вверху.
На следующей странице найдите раздел robots.txt. Оттуда, если не создали файл раньше, следует нажать кнопку Создать robots.txt.
Это действие создаст файл, и теперь можно увидеть его содержимое в текстовой области. Используя ту же текстовую область, можно редактировать содержание нового robots.txt. Закончив редактирование, нажмите кнопку Сохранить изменения в robots. txt ниже.
txt ниже.
All in one SEO
После установки плагина нажмите новый раздел All in One SEO в меню панели инструментов, а затем кликните на опцию Feature Manager. На странице Feature Manager найдите функцию Robots.txt и нажмите кнопку Активировать.
Файл robots.txt создан. После этого появится сообщение об успешном выполнении, в котором говорится, что параметры обновлены. И появится новый подраздел под названием Robots.txt.
Нажав на опцию Robots.txt, откроется новый раздел. Там вы сможете добавить новые правила в robots.txt, а также посмотреть, как он выглядит в настоящее время.
Помимо использования плагина WordPress, можно создать robots.txt вручную. Сначала создайте на своем компьютере пустой файл типа .txt и сохраните его как robots. txt.
txt.
Затем подключитесь к серверу, используя свои учетные данные FTP. Затем в правом разделе перейдите в корневой каталог WordPress, который часто называется public_html. В левой части вашего FTP-клиента (в примере используем Filezilla) найдите robots.txt, который вы ранее создали и сохранили на своем компьютере. Щелкните на него правой кнопкой мыши и выберите Загрузить вариант.
Через несколько секунд файл будет загружен, и его можно увидеть среди других в корневом каталоге WordPress.
Если вы хотите впоследствии отредактировать загруженный robots.txt, найдите его в корневом каталоге WordPress, щелкните по нему правой кнопкой мыши и выберите параметр «Просмотр / редактирование».
Добавление правил в robots.txt
Теперь, когда вы знаете, как создавать и редактировать robots.txt, можем подробнее поговорить о правилах, которые может содержать этот файл. В robots.txt чаще всего присутствуют две директивы: User-agent и Disallow.
Правило User-agent указывает, к какому боту применяются директивы, перечисленные под User-agent. Вы можете указать одного бота (например, User-agent: Bingbot) или применить директивы ко всем ботам, поставив звездочку (User-agent: *).
Правило Disallow запрещает боту доступ к определенной части сайта. А еще есть правило Allow, которое делает прямо противоположное. Ее не нужно использовать так часто, как Disallow, потому что ботам по умолчанию предоставляется доступ к сайту. Allow обычно используется в сочетании с директивой Disallow. Точнее, она служит для разрешения доступа к файлу или подпапке, принадлежащей запрещенной папке.
Кроме того, есть еще две директивы: Crawl-delay и Sitemap.
Правило Crawl-delay используется для предотвращения перегрузки сервера из-за чрезмерных запросов сканирования. Однако эту директиву следует использовать с осторожностью, поскольку она не поддерживается некоторыми сканерами (например, Googlebot) и по-разному интерпретируется поисковыми роботами, которые ее поддерживают (например, BingBot).
Правило Sitemap указывает поисковым системам на ваш XML-файл карты сайта. Настоятельно рекомендуем использовать эту директиву, так как она поможет с отправкой созданной вами XML-карты сайта в Google Search Console или Bing Webmaster Tools. Но имейте в виду, что при использовании этой директивы нужно использовать абсолютный URL-адрес для ссылки на свою карту сайта (например, Sitemap: https://www.example.com/sitemap_index.xml).
Примеры фрагментов robots.txt
Ниже рассмотрим два примера фрагментов, иллюстрирующие использование директив robots.txt, упомянутых выше. Однако это только примеры; в зависимости от вашего веб-сайта может потребоваться другой набор правил. С учетом сказанного, давайте взглянем на фрагменты.
- Этот фрагмент примера запрещает доступ ко всему каталогу / wp-admin / для всех ботов, за исключением файла /wp-admin/admin-ajax.php, находящегося внутри.
User-agent: *
Disallow: / wp-admin /
Allow: /wp-admin/admin-ajax.php
- Этот фрагмент обеспечивает доступ к папке / wp-content / uploads / для всех ботов.
 При этом запрещает доступ к папке / wp-content / plugins /, / wp-admin / и / refer /, а также к файлу /readme.html для всех ботов. В приведенном ниже примере показан правильный способ написания нескольких правил; независимо от того, относятся они к одному или к разным типам, обязательно указывайте по одному в каждой строке. Кроме того, этот пример фрагмента позволяет ссылаться на файл карты сайта, указав его абсолютный URL. Если решите использовать его, не забудьте заменить часть www.example.com фактическим URL-адресом вашего веб-сайта.
При этом запрещает доступ к папке / wp-content / plugins /, / wp-admin / и / refer /, а также к файлу /readme.html для всех ботов. В приведенном ниже примере показан правильный способ написания нескольких правил; независимо от того, относятся они к одному или к разным типам, обязательно указывайте по одному в каждой строке. Кроме того, этот пример фрагмента позволяет ссылаться на файл карты сайта, указав его абсолютный URL. Если решите использовать его, не забудьте заменить часть www.example.com фактическим URL-адресом вашего веб-сайта.
User-agent: *
Allow: / wp-content / uploads /
Disallow: / wp-content / plugins /
Disallow: / wp-admin /
Disallow: /readme.html
Disallow: / refer /
Sitemap: https://www.example.com/sitemap_index.xml
Тестирование «robots.txt»
После добавления директив, соответствующих требованиям вашего веб-сайта, вам следует протестировать robots.txt WordPress. Таким образом, вы одновременно проверяете, что в файле нет никаких синтаксических ошибок, и убедитесь, что соответствующие области вашего веб-сайта были правильно разрешены или запрещены.
Чтобы протестировать robots.txt своего веб-сайта, перейдите на веб-сайт, посвященный SEO-тестированию. Затем вставьте любой URL вашего сайта (URL домашней страницы, например), выберите User-agent (Googlebot, например), и нажмите кнопку Test.
Если URL-адрес доступен для сканирования, то увидите зеленый результат с надписью Разрешено. В противном случае будет отображаться сообщение «Запрещено». Чтобы подтвердить правильность директив сканирования на своем веб-сайте, можете повторить тот же процесс для любого количества разных URL-адресов.
robots.txt – это текстовый файл, расположенный в корневом каталоге каждого сайта WordPress. Он содержит директивы для поисковых роботов, сообщающие им, какие части веб-сайта следует сканировать, а какие нет. Хотя этот файл по умолчанию является виртуальным, знание того, как создать его самостоятельно, будет полезным для поисковой оптимизации.
Поэтому мы рассмотрели различные способы создания физической версии и поделились инструкциями по ее редактированию, коснулись основных директив, которые должен содержать robots.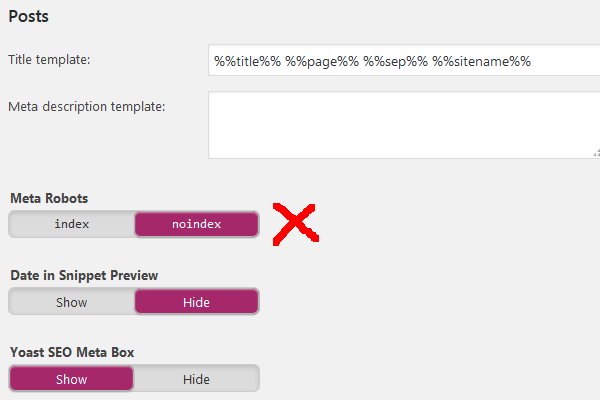 txt WordPress, и того, как проверить правильность их установки.
txt WordPress, и того, как проверить правильность их установки.
Источник: qodeinteractive.com
Смотрите также:
Изучает сайтостроение с 2008 года. Практикующий вебмастер, специализирующий на создание сайтов на WordPress. Задать вопрос Алексею можно на https://profiles.wordpress.org/wpthemeus/
Virtual Robots.txt — Плагин для WordPress
- Детали
- Отзывы
- Установка
- Поддержка
- Разработка
Virtual Robots.txt is an easy (i.e. automated) solution to creating and managing a robots.txt file for your site. Instead of mucking about with FTP, files, permissions ..etc, just upload and activate the plugin and you’re done.
By default, the Virtual Robots.txt plugin allows access to the parts of WordPress that good bots like Google need to access. Other parts are blocked.
If the plugin detects an existing XML sitemap file, a reference to it will be automatically added to your robots. txt file.
txt file.
- Upload pc-robotstxt folder to the
/wp-content/plugins/directory - Активируйте плагин используя меню ‘Плагины’ в WordPress.
- Once you have the plugin installed and activated, you’ll see a new Robots.txt menu link under the Settings menu. Click that menu link to see the plugin settings page. From there you can edit the contents of your robots.txt file.
Will it conflict with an existing robots.txt file?
If a physical robots.txt file exists on your site, WordPress won’t process any request for one, so there will be no conflict.
Will this work for sub-folder installations of WordPress?
Out of the box, no. Because WordPress is in a sub-folder, it won’t «know» when someone is requesting the robots.txt file which must be at the root of the site.
Does this plugin modify individual posts, pages, or categories?
No it doesn’t.
Why does the default plugin block certain files and folders?
By default, the virtual robots.
 txt is set to block WordPress files and folders that don’t need to be accessed by search engines. Of course, if you disagree with the defaults, you can easily change them.
txt is set to block WordPress files and folders that don’t need to be accessed by search engines. Of course, if you disagree with the defaults, you can easily change them.
Simple and easy. Works perfectly.
Works great and easy to use and customise. It already set by default the directories that need to be left out of Search Engines scanning/indexing… Very happy with it!
What I saw wasn’t what I got. The XML sitemap wasn’t included in the robots.txt file, even thought this was described as a feature that should work out of the box. In addition to that, upon installing this plugin, it blocked certain directories without asking. Lastly, it inserts a line at the top of the file, promoting the plugin. That should be an optional feature that users are empowered to turn off. All in all, it offers the functionality, but falls short and disappoints in other areas.
It was good
I thought this would be simple. Sure sounds simple.
But after I saved your suggested text to my brand new «virtual robots.txt», I clicked the link where it says «You can preview your robots.txt file here (opens a new window). If your robots.txt file doesn’t match what is shown below, you may have a physical file that is being displayed instead.»
That new window shows text that is indeed different from the plugin’s. So I understand that to mean there’s a physical robots.txt file on my server.
So which one is actually going to be used?
Your FAQ offers this:
Q: Will it conflict with any existing robots.txt file?
A: If a physical robots.txt file exists on your site, WordPress won’t process any request for one, so there will be no conflict.
If a physical file exists, WP won’t process ANY request for one?
This SOUNDS like WP will ignore BOTH the physical file AND your virtual one. In which case, what’s the point? Might as well not have one, it seems to me.
When I manually go to mydomain.com/robots.txt, I see what’s in the physical file, not what the plugin saved.
Sure sounds simple.
But after I saved your suggested text to my brand new «virtual robots.txt», I clicked the link where it says «You can preview your robots.txt file here (opens a new window). If your robots.txt file doesn’t match what is shown below, you may have a physical file that is being displayed instead.»
That new window shows text that is indeed different from the plugin’s. So I understand that to mean there’s a physical robots.txt file on my server.
So which one is actually going to be used?
Your FAQ offers this:
Q: Will it conflict with any existing robots.txt file?
A: If a physical robots.txt file exists on your site, WordPress won’t process any request for one, so there will be no conflict.
If a physical file exists, WP won’t process ANY request for one?
This SOUNDS like WP will ignore BOTH the physical file AND your virtual one. In which case, what’s the point? Might as well not have one, it seems to me.
When I manually go to mydomain.com/robots.txt, I see what’s in the physical file, not what the plugin saved. So… is it working? I don’t know!
Should I delete the physical file and assume the virtual one will work? I don’t know!
Should I delete this plugin and edit the physical file manually? Most likely.
2 stars instead of 1 because I appreciate getting the suggested lines to include in my file.
So… is it working? I don’t know!
Should I delete the physical file and assume the virtual one will work? I don’t know!
Should I delete this plugin and edit the physical file manually? Most likely.
2 stars instead of 1 because I appreciate getting the suggested lines to include in my file.
I like the fact that it’s so clean. Thanks for building it!
Посмотреть все 9 отзывов
«Virtual Robots.txt» — проект с открытым исходным кодом. В развитие плагина внесли свой вклад следующие участники:
Участники
- Marios Alexandrou
«Virtual Robots.txt» переведён на 1 язык. Благодарим переводчиков за их работу.
Перевести «Virtual Robots.txt» на ваш язык.
Заинтересованы в разработке?
Посмотрите код, проверьте SVN репозиторий, или подпишитесь на журнал разработки по RSS.
1.10
- Fix to prevent the saving of HTML tags within the robots.
 txt form field. Thanks to TrustWave for identifying this issue.
txt form field. Thanks to TrustWave for identifying this issue.
1.9
- Fix for PHP 7. Thanks to SharmPRO.
1.8
- Undoing last fixes as they had unintended side-effects.
1.7
- Further fixes to issue with newlines being removed. Thanks to FAMC for reporting and for providing the code fix.
- After upgrading, visit and re-save your settings and confirm they look correct.
1.6
- Fixed bug where newlines were being removed. Thanks to FAMC for reporting.
1.5
- Fixed bug where plugin assumed robots.txt would be at http when it may reside at https. Thanks to jeffmcneill for reporting.
1.4
- Fixed bug for link to robots.txt that didn’t adjust for sub-folder installations of WordPress.
- Updated default robots.txt directives to match latest practices for WordPress.
- Plugin development and support transferred to Marios Alexandrou.
1.
 3
3- Now uses do_robots hook and checks for is_robots() in plugin action.
1.2
- Added support for existing sitemap.xml.gz file.
1.1
- Added link to settings page, option to delete settings.
1.0
- Первая версия.
Мета
- Версия: 1.10
- Обновление: 7 месяцев назад
- Активных установок: 40 000+
- Версия WordPress: 5.0 или выше
- Совместим вплоть до: 5.9.4
- Языки:
English (US) и Swedish.
Перевести на ваш язык
- Метки:
crawlerrobotrobotsrobots.txt
- Дополнительно
Оценки
Посмотреть все
- 5 звёзд 6
- 4 звезды 0
- 3 звезды 0
- 2 звезды 1
- 1 звезда 1
Войдите, чтобы оставить отзыв.
Участники
- Marios Alexandrou
Поддержка
Решено проблем за последние 2 месяца:
1 из 2
Перейти в форум поддержки
Пожертвование
Would you like to support the advancement of this plugin?
Пожертвовать на развитие плагина
Правильный robots.txt для WordPress — 2021
- 1. Оптимальный robots.txt
- 2. Расширенный вариант (разделенные правила для Google и Яндекса)
- 3. Оптимальный Robots.txt для WooCommerce
- 4. Где находится файл robots.txt в WordPress
- 5. Часто задаваемые вопросы
Robots.txt – текстовой файл, который сообщает поисковым роботам, какие файлы и папки следует сканировать (индексировать), а какие сканировать не нужно.
Поисковые системы, такие как Яндекс и Google сначала проверяют файл robots.txt, после этого начинают обход с помощью веб-роботов, которые занимаются архивированием и категоризацией веб сайтов.
Файл robots.txt содержит набор инструкций, которые просят бота игнорировать определенные файлы или каталоги. Это может быть сделано в целях конфиденциальности или потому что владелец сайта считает, что содержимое этих файлов и каталогов не должны появляться в выдаче поисковых систем.
Если веб-сайт имеет более одного субдомена, каждый субдомен должен иметь свой собственный файл robots.txt. Важно отметить, что не все боты будут использовать файл robots.txt. Некоторые злонамеренные боты даже читают файл robots.txt, чтобы найти, какие файлы и каталоги Вы хотели скрыть. Кроме того, даже если файл robots.txt указывает игнорировать определенные страницы на сайте, эти страницы могут по-прежнему появляться в результатах поиска, если на них ссылаются другие просканированные страницы. Стандартный роботс тхт для вордпресс открывает весь сайт для интдекса, поэтому нам нужно закрыть не нужные разделы WordPress от индексации.
Кроме того, даже если файл robots.txt указывает игнорировать определенные страницы на сайте, эти страницы могут по-прежнему появляться в результатах поиска, если на них ссылаются другие просканированные страницы. Стандартный роботс тхт для вордпресс открывает весь сайт для интдекса, поэтому нам нужно закрыть не нужные разделы WordPress от индексации.
Оптимальный robots.txt
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # системная папка на хостинге, закрывается всегда
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # запрос поиска
Disallow: *&s= # запрос поиска
Disallow: /search/ # запрос поиска
Disallow: /author/ # архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть
# архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.Скачать оптимальную версию robots.txt
Расширенный вариант (разделенные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*. jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно).
jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.
Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.Скачать Расширенный вариант robots.txt
Оптимальный Robots.txt для WooCommerce
Владельцы интернет-магазинов на WordPress – WooCommerce также должны позаботиться о правильном robots.txt. Мы закроем от индексации корзину, страницу оформления заказа и ссылки на добавление товара в корзину.
User-agent: * Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Sitemap: https://site.ru/sitemap_index.xml
Скачать robots.txt для WooCommerce
Где находится файл robots.txt в WordPress
Обычно robots.txt располагается в корне сайта. Если его нет, то потребуется создать текстовой файл и загрузить его на сайт по FTP или панель управления на хостинге. Если Вы не смогли найти robots.txt в корне сайта, но при переходе по ссылке вашсайт.ру/robots.txt он открывается, значит какой то из SEO плагинов сам генерирует его.
К примеру плагин Yoast SEO создает виртуальный файл, которого нет в корне сайта.
Как редактировать robots.txt с помощью Yoast SEO
- Зайдите в админ панель сайта
Админа панель находится по следующему адресу вашсайт.ру/wp-admin/
- Слева в консоли наведите на кнопку SEO и в выпадающем окне выберите “Инструменты”. Перейдите в раздел, как указано на картинке.
- Зайдите в редактор файлов
Этот инструмент позволит быстро отредактировать такие важные для вашего SEO файлы, как robots.
 txt и .htaccess (при его наличии).
txt и .htaccess (при его наличии). - Если файла robots.txt нет, нажмите на кнопку создать, либо вставьте нужное содержимое.
Содержимое файла для WordPress и WooCommerce можно взять из примеров выше.
- Сохраните изменения в robots.txt
После сохранения файла вы можете проверить правильность через сервисы проверки.
Чтобы установить плагин Yoast SEO воспользуйтесь данной статьей – ссылка.
Часто задаваемые вопросы
Как проверить правильность работы robots.txt?
У Google и Яндекс есть средства для проверки файла robots.txt:
Яндекс – https://webmaster.yandex.ru/tools/robotstxt/
Google – https://support.google.com/webmasters/answer/6062598?hl=ru
Закрывать ли feed в robots.txt?
По умолчанию мы рекомендуем закрывать feed от индексации в robots.txt. Открытие feed может потребоваться, если вы например настраиваете Турбо-страницы от Яндекса или выгружаете свою ленту в другой сервис.
Как разрешить индексировать feed Турбо-страниц
Добавьте директиву: Allow: /feed/turbo/, тогда Яндекс сможет проверять ваши турбо-страницы и обновлять их.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Robots.txt и WordPress — Центр поддержки
Последнее обновление: 11 апреля 2022 г. Однако есть некоторые страницы, такие как повторяющийся контент или промежуточные области, которые вы не хотите, чтобы пользователи находили через поисковые системы. К счастью, есть способ запретить поисковым системам, таким как Google, доступ к определенным страницам и их отображение пользователям. Редактируя свой сайт robots.txt , вы можете контролировать, какой контент отображается на страницах результатов поисковой системы (SERP).
ПРИМЕЧАНИЕ
По умолчанию WP Engine ограничивает трафик поисковых систем любым сайтом, использующим домен среды .. Это означает, что поисковые системы не смогут посещать сайты , а не , которые в настоящее время находятся в разработке, используя пользовательский домен. wpengine.com
wpengine.com
О программе
Robots.txt A robots.txt содержит инструкции для поисковых систем о том, как обнаруживать и извлекать информацию с вашего веб-сайта. Этот процесс называется «сканированием». После сканирования страницы она будет проиндексирована, чтобы поисковая система могла быстро найти и отобразить ее позже.
Первое, что делает сканер поисковой системы, когда он достигает сайта, это ищет файл robots.txt . Если его нет, он продолжит сканирование остальной части сайта в обычном режиме. Если он найдет этот файл, сканер будет искать в нем какие-либо команды, прежде чем двигаться дальше.
В файле robots.txt содержатся четыре общие команды:
-
Disallowзапрещает сканерам поисковых систем проверять и индексировать указанные файлы сайта. Это может помочь вам предотвратить появление дублированного контента, промежуточных областей или других личных файлов в поисковой выдаче.
Это может помочь вам предотвратить появление дублированного контента, промежуточных областей или других личных файлов в поисковой выдаче. -
Разрешитьразрешает доступ к подпапкам, в то время как родительские папки запрещены. -
Crawl-delayпредписывает сканерам ждать определенное время перед загрузкой файла. -
Карта сайтауказывает местоположение любых карт сайта, связанных с вашим сайтом.
Файлы Robots.txt всегда форматируются одинаково, чтобы сделать их директивы понятными:
Каждая директива начинается с идентификации пользовательского агента , который обычно является поисковым роботом. Если вы хотите, чтобы команда применялась ко всем потенциальным пользовательским агентам, вы можете использовать звездочку * . Вместо этого, чтобы настроить таргетинг на определенный пользовательский агент, вы можете добавить его имя. Например, мы могли бы заменить звездочку выше на Googlebot , чтобы Google не сканировал страницу администратора.
Очень важно знать, как использовать и редактировать файл robots.txt . Директивы, которые вы включите в него, будут определять, как поисковые системы взаимодействуют с вашим сайтом. Они могут помочь вам, скрывая контент, от которого вы хотите отвлечь пользователей, что принесет пользу вашему сайту в целом.
Протестируйте файл
Robots.txt Вы можете проверить, есть ли у вас файл robots.txt , добавив /robots.txt в конец URL-адреса вашего сайта в браузере (пример: https://wpengine.com/robots.txt ). Это вызовет файл, если он существует. Однако то, что ваш файл есть, не обязательно означает, что он работает правильно.
К счастью, проверить файл robots.txt несложно. Вы можете просто скопировать и вставить файл в тестер robots.txt. Инструмент выделит любые ошибки в файле. Важно отметить, что изменения, которые вы вносите в robots.txt Редактор тестировщика не будет применяться к реальному файлу — вам все равно придется редактировать файл на своем сервере.
Некоторые распространенные ошибки включают запрет файлов CSS или JavaScript, неправильное использование подстановочных знаков, таких как * и $ , а также случайное запрещение важных страниц. Также важно помнить, что сканеры поисковых систем чувствительны к регистру, поэтому все URL-адреса в вашем файле robots.txt должны отображаться так же, как и в вашем браузере.
Создайте файл
Robots.txt с помощью плагина Если на вашем сайте отсутствует файл robots.txt , вы можете легко добавить его в WordPress с помощью плагина Yoast SEO. Это избавит вас от необходимости создавать обычный текстовый файл и загружать его на сервер вручную. Если вы предпочитаете создавать его вручную, перейдите к разделу «Создание файла Robots.txt вручную» ниже.
Перейдите к Yoast SEO Tools
Для начала вам необходимо установить и активировать плагин Yoast SEO. Затем вы можете перейти к панели администратора WordPress и выбрать SEO > Инструменты на боковой панели :
Это приведет вас к списку полезных инструментов, к которым пользователи Yoast могут получить доступ для эффективного улучшения своей SEO.
Использование редактора файлов для создания файла
Robots.txt Одним из инструментов, доступных в списке, является редактор файлов. Это позволяет вам редактировать файлы, связанные с SEO вашего веб-сайта, включая файл robots.txt :
Поскольку на вашем сайте его еще нет, вам нужно выбрать «Создать 9».0007 robots.txt файл:
Это приведет вас к редактору файлов, где вы сможете отредактировать и сохранить новый файл.
Отредактируйте файл
Robots.txt по умолчанию и сохраните его По умолчанию новый файл robots.txt , созданный с помощью Yoast, включает директиву, чтобы скрыть вашу папку wp-admin и разрешить доступ к вашему администратору -ajax.php файл для всех юзер-агентов. Рекомендуется оставить эту директиву в файле:
Перед сохранением файла вы также можете добавить любые другие директивы, которые хотите включить. В этом примере мы запретили сканерам Bing доступ ко всем нашим файлам, добавили задержку сканирования в десять миллисекунд для сканера Yahoo 9. 0007 Slurp и направил поисковых роботов на нашу карту сайта. Когда вы закончите вносить свои собственные изменения, не забудьте их сохранить!
0007 Slurp и направил поисковых роботов на нашу карту сайта. Когда вы закончите вносить свои собственные изменения, не забудьте их сохранить!
Руководство
Robots.txt Создание файла Если вам нужно создать файл robots.txt вручную, процесс так же прост, как создание и загрузка файла на ваш сервер.
- Создайте файл с именем
robots.txt- Убедитесь, что имя в нижнем регистре
- Убедитесь, что расширение
.txt, а не.html
- Добавьте в файл любые необходимые директивы и сохраните
- Загрузите файл с помощью шлюза SFTP или SSH в корневой каталог вашего сайта физический файл в корне вашего сайта с именем
robots.txt, он перезапишет любой динамически сгенерированный файлrobots.txt, созданный плагином или темой.Использование файла robots.txt
Файл robots.txtразбит на блоки пользовательским агентом. Внутри блока каждая директива указана с новой строки. Например:
Внутри блока каждая директива указана с новой строки. Например:Агент пользователя: * Запретить: / Агент пользователя: Googlebot Запретить: Агент пользователя: bingbot Запретить: /no-bing-crawl/ Disallow: wp-admin
Пользовательские агенты обычно сокращаются до более общего имени, но это не требуется .
-
Mozilla/5.0 (совместимый; Googlebot/2.1; +http://www.google.com/bot.html)становится простоGooglebot - Базу данных роботов можно найти здесь.
Значения директив чувствительны к регистру.
- URL-адреса
no-bing-crawlиNo-Bing-Crawlразные .
Подстановка и регулярные выражения поддерживаются не полностью.
-
*в поле User-agent — это специальное значение, означающее «любой робот».
Ограничить доступ всех ботов к вашему сайту
(Все сайты в среде
URL-адрес .автоматически применяют следующий файл wpengine.com
wpengine.com robots.txt.)Агент пользователя: * Запретить: /
Запретить одного робота со всего сайта
User-agent: BadBotName Disallow: /
Ограничить доступ ботов к определенным каталогам и файлам
Пример запрещает ботам на всех
страницах wp-adminиwp-login.phpстраница. Это хороший файл по умолчанию или начальный файлrobots.txt.Агент пользователя: * Запретить: /wp-admin/ Запретить: /wp-login.php
Ограничить доступ бота ко всем файлам определенного типа
Пример использует тип файла
.pdfUser-agent: * Запретить: /*.pdf$
Ограничить конкретную поисковую систему
Пример использования Googlebot-Image в каталог /wp-content/
загрузокАгент пользователя: Googlebot-Image Запретить: /wp-content/uploads/
Запретить всех ботов, кроме одного
Пример разрешает только Google
Агент пользователя: Google Запретить: Пользовательский агент: * Disallow: /
Добавление правильных комбинаций директив может быть сложным.
 К счастью, есть плагины, которые также создадут (и протестируют) файл
К счастью, есть плагины, которые также создадут (и протестируют) файл robots.txtдля вас. Примеры плагинов:- All-in-One SEO plugin
- Yoast SEO
Если вам нужна дополнительная помощь в настройке правил в файле robots.txt, мы рекомендуем посетить Google Developers или The Web Robots Pages для получения дополнительных инструкций.
Задержка сканирования
Если вы видите слишком высокий трафик ботов и это влияет на производительность сервера, задержка сканирования может быть хорошим вариантом. Задержка сканирования позволяет ограничить время, которое должно пройти боту перед сканированием следующей страницы.
Чтобы настроить задержку сканирования, используйте следующую директиву, значение настраивается и обозначается в секундах:
crawl-delay: 10
Например, чтобы запретить всем ботам сканировать
wp-admin,wp-login.phpи установить задержку сканирования для всех ботов в 600 секунд (10 минут):User -агент: * Запретить: /wp-login.
 php
Запретить: /wp-admin/
Crawl-delay: 600
php
Запретить: /wp-admin/
Crawl-delay: 600 ПРИМЕЧАНИЕ
У служб сканирования могут быть собственные требования для установки задержки сканирования. Как правило, лучше всего напрямую связаться со службой для получения требуемого метода.
Настройка задержки сканирования для SEMrush
- SEMrush — отличный сервис, но он может сильно сканировать, что в конечном итоге снижает производительность вашего сайта. По умолчанию боты SEMrush будут игнорировать директивы о задержке сканирования в файле robots.txt, поэтому обязательно войдите в их панель управления и включите параметр Уважать задержку сканирования robots.txt .
- Дополнительную информацию о SEMrush можно найти здесь.
Настройка задержки сканирования Bingbot
- Bingbot должен учитывать
задержку сканирования, однако они также позволяют вам установить шаблон управления сканированием.
Настройте задержку сканирования для Google
Подробнее читайте в документации службы поддержки Google)
Откройте страницу настроек скорости сканирования для вашего ресурса.

- Если ваша скорость сканирования указана как и рассчитана как оптимальная , единственный способ снизить скорость сканирования — это подать специальный запрос. Вы не можете увеличить скорость сканирования.
- В противном случае выберите нужный вариант, а затем ограничьте скорость сканирования по желанию. Новая скорость сканирования будет действовать в течение 90 дней.
ПРИМЕЧАНИЕ
Хотя эта конфигурация запрещена на нашей платформе, стоит отметить, что
Задержка сканирования Googlebotне может быть настроена для сайтов, размещенных в подкаталогах, таких какdomain.com/blog.Передовой опыт
Первое, о чем следует помнить: нерабочие сайты должны запрещать использование всех пользовательских агентов. WP Engine автоматически делает это для любых сайтов, использующих
имя среды .wpengine.comдомен. Только когда вы будете готовы «запустить» свой сайт, вы должны добавить файлrobots.. txt
txt Во-вторых, если вы хотите заблокировать определенного User-Agent, помните, что роботы не обязаны следовать правилам, установленным в вашем файле
robots.txt. Лучшей практикой будет использование брандмауэра, такого как Sucuri WAF или Cloudflare, который позволяет блокировать злоумышленников до того, как они попадут на ваш сайт. Или вы можете обратиться в службу поддержки за дополнительной помощью по блокировке трафика.Наконец, если у вас очень большая библиотека постов и страниц на вашем сайте, Google и другие поисковые системы, индексирующие ваш сайт, могут вызвать проблемы с производительностью. Увеличение срока действия кэша или ограничение скорости обхода поможет компенсировать это влияние.
СЛЕДУЮЩИЙ ШАГ: Диагностика ошибок 504
Robots.txt и WordPress — Центр поддержки свой путь. Однако есть некоторые страницы, такие как повторяющийся контент или промежуточные области, которые вы не хотите, чтобы пользователи находили через поисковые системы.
 К счастью, есть способ запретить поисковым системам, таким как Google, доступ к определенным страницам и их отображение пользователям. Редактируя свой сайт
К счастью, есть способ запретить поисковым системам, таким как Google, доступ к определенным страницам и их отображение пользователям. Редактируя свой сайт robots.txt, вы можете контролировать, какой контент отображается на страницах результатов поисковой системы (SERP).ПРИМЕЧАНИЕ
По умолчанию WP Engine ограничивает трафик поисковых систем любым сайтом, использующим домен среды
.wpengine.com. Это означает, что поисковые системы не смогут посещать сайты , а не , которые в настоящее время находятся в разработке, используя пользовательский домен.О программе
Robots.txtA
robots.txtсодержит инструкции для поисковых систем о том, как обнаруживать и извлекать информацию с вашего веб-сайта. Этот процесс называется «сканированием». После сканирования страницы она будет проиндексирована, чтобы поисковая система могла быстро найти и отобразить ее позже.Первое, что делает сканер поисковой системы, когда он достигает сайта, это ищет файл
robots.. Если его нет, он продолжит сканирование остальной части сайта в обычном режиме. Если он найдет этот файл, сканер будет искать в нем какие-либо команды, прежде чем двигаться дальше. txt
txt В файле
robots.txtсодержатся четыре общие команды:-
Disallowзапрещает сканерам поисковых систем проверять и индексировать указанные файлы сайта. Это может помочь вам предотвратить появление дублированного контента, промежуточных областей или других личных файлов в поисковой выдаче. -
Разрешитьразрешает доступ к подпапкам, в то время как родительские папки запрещены. -
Crawl-delayпредписывает сканерам ждать определенное время перед загрузкой файла. -
Карта сайтауказывает местоположение любых карт сайта, связанных с вашим сайтом.
Файлы Robots.txtвсегда форматируются одинаково, чтобы сделать их директивы понятными:Каждая директива начинается с идентификации
пользовательского агента, который обычно является поисковым роботом. Если вы хотите, чтобы команда применялась ко всем потенциальным пользовательским агентам, вы можете использовать звездочку
Если вы хотите, чтобы команда применялась ко всем потенциальным пользовательским агентам, вы можете использовать звездочку *. Вместо этого, чтобы настроить таргетинг на определенный пользовательский агент, вы можете добавить его имя. Например, мы могли бы заменить звездочку выше наGooglebot, чтобы Google не сканировал страницу администратора.Очень важно знать, как использовать и редактировать файл
robots.txt. Директивы, которые вы включите в него, будут определять, как поисковые системы взаимодействуют с вашим сайтом. Они могут помочь вам, скрывая контент, от которого вы хотите отвлечь пользователей, что принесет пользу вашему сайту в целом.Протестируйте файл
Robots.txtВы можете проверить, есть ли у вас файл
robots.txt, добавив/robots.txtв конец URL-адреса вашего сайта в браузере (пример:https://wpengine.com/robots.txt). Это вызовет файл, если он существует. Однако то, что ваш файл есть, не обязательно означает, что он работает правильно.
Однако то, что ваш файл есть, не обязательно означает, что он работает правильно.К счастью, проверить файл
robots.txtнесложно. Вы можете просто скопировать и вставить файл в тестер robots.txt. Инструмент выделит любые ошибки в файле. Важно отметить, что изменения, которые вы вносите вrobots.txtРедактор тестировщика не будет применяться к реальному файлу — вам все равно придется редактировать файл на своем сервере.Некоторые распространенные ошибки включают запрет файлов CSS или JavaScript, неправильное использование подстановочных знаков, таких как
*и$, а также случайное запрещение важных страниц. Также важно помнить, что сканеры поисковых систем чувствительны к регистру, поэтому все URL-адреса в вашем файлеrobots.txtдолжны отображаться так же, как и в вашем браузере.Создайте файл
Robots.txt с помощью плагинаЕсли на вашем сайте отсутствует файл
robots., вы можете легко добавить его в WordPress с помощью плагина Yoast SEO. Это избавит вас от необходимости создавать обычный текстовый файл и загружать его на сервер вручную. Если вы предпочитаете создавать его вручную, перейдите к разделу «Создание файла Robots.txt вручную» ниже. txt
txt Перейдите к Yoast SEO Tools
Для начала вам необходимо установить и активировать плагин Yoast SEO. Затем вы можете перейти к панели администратора WordPress и выбрать SEO > Инструменты на боковой панели :
Это приведет вас к списку полезных инструментов, к которым пользователи Yoast могут получить доступ для эффективного улучшения своей SEO.
Использование редактора файлов для создания файла
Robots.txtОдним из инструментов, доступных в списке, является редактор файлов. Это позволяет вам редактировать файлы, связанные с SEO вашего веб-сайта, включая файл
robots.txt:Поскольку на вашем сайте его еще нет, вам нужно выбрать «Создать 9».
 0007 robots.txt файл:
0007 robots.txt файл:Это приведет вас к редактору файлов, где вы сможете отредактировать и сохранить новый файл.
Отредактируйте файл
Robots.txt по умолчанию и сохраните егоПо умолчанию новый файл
robots.txt, созданный с помощью Yoast, включает директиву, чтобы скрыть вашу папкуwp-adminи разрешить доступ к вашемуадминистратору -ajax.phpфайл для всех юзер-агентов. Рекомендуется оставить эту директиву в файле:Перед сохранением файла вы также можете добавить любые другие директивы, которые хотите включить. В этом примере мы запретили сканерам Bing доступ ко всем нашим файлам, добавили задержку сканирования в десять миллисекунд для сканера Yahoo 9.0007 Slurp и направил поисковых роботов на нашу карту сайта. Когда вы закончите вносить свои собственные изменения, не забудьте их сохранить!
Руководство
Robots.txt Создание файлаЕсли вам нужно создать файл
robots.вручную, процесс так же прост, как создание и загрузка файла на ваш сервер. txt
txt - Создайте файл с именем
robots.txt- Убедитесь, что имя в нижнем регистре
- Убедитесь, что расширение
.txt, а не.html
- Добавьте в файл любые необходимые директивы и сохраните
- Загрузите файл с помощью шлюза SFTP или SSH в корневой каталог вашего сайта физический файл в корне вашего сайта с именем
robots.txt, он перезапишет любой динамически сгенерированный файлrobots.txt, созданный плагином или темой.Использование файла robots.txt
Файл robots.txtразбит на блоки пользовательским агентом. Внутри блока каждая директива указана с новой строки. Например:Агент пользователя: * Запретить: / Агент пользователя: Googlebot Запретить: Агент пользователя: bingbot Запретить: /no-bing-crawl/ Disallow: wp-admin
Пользовательские агенты обычно сокращаются до более общего имени, но это не требуется .

-
Mozilla/5.0 (совместимый; Googlebot/2.1; +http://www.google.com/bot.html)становится простоGooglebot - Базу данных роботов можно найти здесь.
Значения директив чувствительны к регистру.
- URL-адреса
no-bing-crawlиNo-Bing-Crawlразные .
Подстановка и регулярные выражения поддерживаются не полностью.
-
*в поле User-agent — это специальное значение, означающее «любой робот».
Ограничить доступ всех ботов к вашему сайту
(Все сайты в среде
URL-адрес .wpengine.comавтоматически применяют следующий файлrobots.txt.)Агент пользователя: * Запретить: /
Запретить одного робота со всего сайта
User-agent: BadBotName Disallow: /
Ограничить доступ ботов к определенным каталогам и файлам
Пример запрещает ботам на всех
страницах wp-adminиwp-login.страница. Это хороший файл по умолчанию или начальный файл php
php robots.txt.Агент пользователя: * Запретить: /wp-admin/ Запретить: /wp-login.php
Ограничить доступ бота ко всем файлам определенного типа
Пример использует тип файла
.pdfUser-agent: * Запретить: /*.pdf$
Ограничить конкретную поисковую систему
Пример использования Googlebot-Image в каталог /wp-content/
загрузокАгент пользователя: Googlebot-Image Запретить: /wp-content/uploads/
Запретить всех ботов, кроме одного
Пример разрешает только Google
Агент пользователя: Google Запретить: Пользовательский агент: * Disallow: /
Добавление правильных комбинаций директив может быть сложным. К счастью, есть плагины, которые также создадут (и протестируют) файл
robots.txtдля вас. Примеры плагинов:
Примеры плагинов:- All-in-One SEO plugin
- Yoast SEO
Если вам нужна дополнительная помощь в настройке правил в файле robots.txt, мы рекомендуем посетить Google Developers или The Web Robots Pages для получения дополнительных инструкций.
Задержка сканирования
Если вы видите слишком высокий трафик ботов и это влияет на производительность сервера, задержка сканирования может быть хорошим вариантом. Задержка сканирования позволяет ограничить время, которое должно пройти боту перед сканированием следующей страницы.
Чтобы настроить задержку сканирования, используйте следующую директиву, значение настраивается и обозначается в секундах:
crawl-delay: 10
Например, чтобы запретить всем ботам сканировать
wp-admin,wp-login.phpи установить задержку сканирования для всех ботов в 600 секунд (10 минут):User -агент: * Запретить: /wp-login.php Запретить: /wp-admin/ Crawl-delay: 600
ПРИМЕЧАНИЕ
У служб сканирования могут быть собственные требования для установки задержки сканирования.
 Как правило, лучше всего напрямую связаться со службой для получения требуемого метода.
Как правило, лучше всего напрямую связаться со службой для получения требуемого метода.Настройка задержки сканирования для SEMrush
- SEMrush — отличный сервис, но он может сильно сканировать, что в конечном итоге снижает производительность вашего сайта. По умолчанию боты SEMrush будут игнорировать директивы о задержке сканирования в файле robots.txt, поэтому обязательно войдите в их панель управления и включите параметр Уважать задержку сканирования robots.txt .
- Дополнительную информацию о SEMrush можно найти здесь.
Настройка задержки сканирования Bingbot
- Bingbot должен учитывать
задержку сканирования, однако они также позволяют вам установить шаблон управления сканированием.
Настройте задержку сканирования для Google
Подробнее читайте в документации службы поддержки Google)
Откройте страницу настроек скорости сканирования для вашего ресурса.

- Если ваша скорость сканирования указана как и рассчитана как оптимальная , единственный способ снизить скорость сканирования — это подать специальный запрос. Вы не можете увеличить скорость сканирования.
- В противном случае выберите нужный вариант, а затем ограничьте скорость сканирования по желанию. Новая скорость сканирования будет действовать в течение 90 дней.
ПРИМЕЧАНИЕ
Хотя эта конфигурация запрещена на нашей платформе, стоит отметить, что
Задержка сканирования Googlebotне может быть настроена для сайтов, размещенных в подкаталогах, таких какdomain.com/blog.Передовой опыт
Первое, о чем следует помнить: нерабочие сайты должны запрещать использование всех пользовательских агентов. WP Engine автоматически делает это для любых сайтов, использующих
имя среды .wpengine.comдомен. Только когда вы будете готовы «запустить» свой сайт, вы должны добавить файлrobots.. txt
txt Во-вторых, если вы хотите заблокировать определенного User-Agent, помните, что роботы не обязаны следовать правилам, установленным в вашем файле
robots.txt. Лучшей практикой будет использование брандмауэра, такого как Sucuri WAF или Cloudflare, который позволяет блокировать злоумышленников до того, как они попадут на ваш сайт. Или вы можете обратиться в службу поддержки за дополнительной помощью по блокировке трафика.Наконец, если у вас очень большая библиотека постов и страниц на вашем сайте, Google и другие поисковые системы, индексирующие ваш сайт, могут вызвать проблемы с производительностью. Увеличение срока действия кэша или ограничение скорости обхода поможет компенсировать это влияние.
СЛЕДУЮЩИЙ ШАГ: Диагностика ошибок 504
Robots.txt и WordPress — Центр поддержки свой путь. Однако есть некоторые страницы, такие как повторяющийся контент или промежуточные области, которые вы не хотите, чтобы пользователи находили через поисковые системы.
 К счастью, есть способ запретить поисковым системам, таким как Google, доступ к определенным страницам и их отображение пользователям. Редактируя свой сайт
К счастью, есть способ запретить поисковым системам, таким как Google, доступ к определенным страницам и их отображение пользователям. Редактируя свой сайт robots.txt, вы можете контролировать, какой контент отображается на страницах результатов поисковой системы (SERP).ПРИМЕЧАНИЕ
По умолчанию WP Engine ограничивает трафик поисковых систем любым сайтом, использующим домен среды
.wpengine.com. Это означает, что поисковые системы не смогут посещать сайты , а не , которые в настоящее время находятся в разработке, используя пользовательский домен.О программе
Robots.txtA
robots.txtсодержит инструкции для поисковых систем о том, как обнаруживать и извлекать информацию с вашего веб-сайта. Этот процесс называется «сканированием». После сканирования страницы она будет проиндексирована, чтобы поисковая система могла быстро найти и отобразить ее позже.Первое, что делает сканер поисковой системы, когда он достигает сайта, это ищет файл
robots.. Если его нет, он продолжит сканирование остальной части сайта в обычном режиме. Если он найдет этот файл, сканер будет искать в нем какие-либо команды, прежде чем двигаться дальше.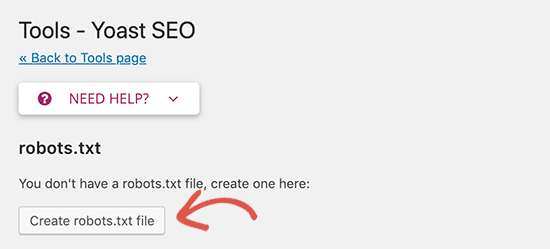 txt
txt В файле
robots.txtсодержатся четыре общие команды:-
Disallowзапрещает сканерам поисковых систем проверять и индексировать указанные файлы сайта. Это может помочь вам предотвратить появление дублированного контента, промежуточных областей или других личных файлов в поисковой выдаче. -
Разрешитьразрешает доступ к подпапкам, в то время как родительские папки запрещены. -
Crawl-delayпредписывает сканерам ждать определенное время перед загрузкой файла. -
Карта сайтауказывает местоположение любых карт сайта, связанных с вашим сайтом.
Файлы Robots.txtвсегда форматируются одинаково, чтобы сделать их директивы понятными:Каждая директива начинается с идентификации
пользовательского агента, который обычно является поисковым роботом. Если вы хотите, чтобы команда применялась ко всем потенциальным пользовательским агентам, вы можете использовать звездочку
Если вы хотите, чтобы команда применялась ко всем потенциальным пользовательским агентам, вы можете использовать звездочку *. Вместо этого, чтобы настроить таргетинг на определенный пользовательский агент, вы можете добавить его имя. Например, мы могли бы заменить звездочку выше наGooglebot, чтобы Google не сканировал страницу администратора.Очень важно знать, как использовать и редактировать файл
robots.txt. Директивы, которые вы включите в него, будут определять, как поисковые системы взаимодействуют с вашим сайтом. Они могут помочь вам, скрывая контент, от которого вы хотите отвлечь пользователей, что принесет пользу вашему сайту в целом.Протестируйте файл
Robots.txtВы можете проверить, есть ли у вас файл
robots.txt, добавив/robots.txtв конец URL-адреса вашего сайта в браузере (пример:https://wpengine.com/robots.txt). Это вызовет файл, если он существует. Однако то, что ваш файл есть, не обязательно означает, что он работает правильно.
Однако то, что ваш файл есть, не обязательно означает, что он работает правильно.К счастью, проверить файл
robots.txtнесложно. Вы можете просто скопировать и вставить файл в тестер robots.txt. Инструмент выделит любые ошибки в файле. Важно отметить, что изменения, которые вы вносите вrobots.txtРедактор тестировщика не будет применяться к реальному файлу — вам все равно придется редактировать файл на своем сервере.Некоторые распространенные ошибки включают запрет файлов CSS или JavaScript, неправильное использование подстановочных знаков, таких как
*и$, а также случайное запрещение важных страниц. Также важно помнить, что сканеры поисковых систем чувствительны к регистру, поэтому все URL-адреса в вашем файлеrobots.txtдолжны отображаться так же, как и в вашем браузере.Создайте файл
Robots.txt с помощью плагинаЕсли на вашем сайте отсутствует файл
robots., вы можете легко добавить его в WordPress с помощью плагина Yoast SEO. Это избавит вас от необходимости создавать обычный текстовый файл и загружать его на сервер вручную. Если вы предпочитаете создавать его вручную, перейдите к разделу «Создание файла Robots.txt вручную» ниже. txt
txt Перейдите к Yoast SEO Tools
Для начала вам необходимо установить и активировать плагин Yoast SEO. Затем вы можете перейти к панели администратора WordPress и выбрать SEO > Инструменты на боковой панели :
Это приведет вас к списку полезных инструментов, к которым пользователи Yoast могут получить доступ для эффективного улучшения своей SEO.
Использование редактора файлов для создания файла
Robots.txtОдним из инструментов, доступных в списке, является редактор файлов. Это позволяет вам редактировать файлы, связанные с SEO вашего веб-сайта, включая файл
robots.txt:Поскольку на вашем сайте его еще нет, вам нужно выбрать «Создать 9».
 0007 robots.txt файл:
0007 robots.txt файл:Это приведет вас к редактору файлов, где вы сможете отредактировать и сохранить новый файл.
Отредактируйте файл
Robots.txt по умолчанию и сохраните егоПо умолчанию новый файл
robots.txt, созданный с помощью Yoast, включает директиву, чтобы скрыть вашу папкуwp-adminи разрешить доступ к вашемуадминистратору -ajax.phpфайл для всех юзер-агентов. Рекомендуется оставить эту директиву в файле:Перед сохранением файла вы также можете добавить любые другие директивы, которые хотите включить. В этом примере мы запретили сканерам Bing доступ ко всем нашим файлам, добавили задержку сканирования в десять миллисекунд для сканера Yahoo 9.0007 Slurp и направил поисковых роботов на нашу карту сайта. Когда вы закончите вносить свои собственные изменения, не забудьте их сохранить!
Руководство
Robots.txt Создание файлаЕсли вам нужно создать файл
robots.вручную, процесс так же прост, как создание и загрузка файла на ваш сервер. txt
txt - Создайте файл с именем
robots.txt- Убедитесь, что имя в нижнем регистре
- Убедитесь, что расширение
.txt, а не.html
- Добавьте в файл любые необходимые директивы и сохраните
- Загрузите файл с помощью шлюза SFTP или SSH в корневой каталог вашего сайта физический файл в корне вашего сайта с именем
robots.txt, он перезапишет любой динамически сгенерированный файлrobots.txt, созданный плагином или темой.Использование файла robots.txt
Файл robots.txtразбит на блоки пользовательским агентом. Внутри блока каждая директива указана с новой строки. Например:Агент пользователя: * Запретить: / Агент пользователя: Googlebot Запретить: Агент пользователя: bingbot Запретить: /no-bing-crawl/ Disallow: wp-admin
Пользовательские агенты обычно сокращаются до более общего имени, но это не требуется .

-
Mozilla/5.0 (совместимый; Googlebot/2.1; +http://www.google.com/bot.html)становится простоGooglebot - Базу данных роботов можно найти здесь.
Значения директив чувствительны к регистру.
- URL-адреса
no-bing-crawlиNo-Bing-Crawlразные .
Подстановка и регулярные выражения поддерживаются не полностью.
-
*в поле User-agent — это специальное значение, означающее «любой робот».
Ограничить доступ всех ботов к вашему сайту
(Все сайты в среде
URL-адрес .wpengine.comавтоматически применяют следующий файлrobots.txt.)Агент пользователя: * Запретить: /
Запретить одного робота со всего сайта
User-agent: BadBotName Disallow: /
Ограничить доступ ботов к определенным каталогам и файлам
Пример запрещает ботам на всех
страницах wp-adminиwp-login.страница. Это хороший файл по умолчанию или начальный файл php
php robots.txt.Агент пользователя: * Запретить: /wp-admin/ Запретить: /wp-login.php
Ограничить доступ бота ко всем файлам определенного типа
Пример использует тип файла
.pdfUser-agent: * Запретить: /*.pdf$
Ограничить конкретную поисковую систему
Пример использования Googlebot-Image в каталог /wp-content/
загрузокАгент пользователя: Googlebot-Image Запретить: /wp-content/uploads/
Запретить всех ботов, кроме одного
Пример разрешает только Google
Агент пользователя: Google Запретить: Пользовательский агент: * Disallow: /
Добавление правильных комбинаций директив может быть сложным. К счастью, есть плагины, которые также создадут (и протестируют) файл
robots.txtдля вас.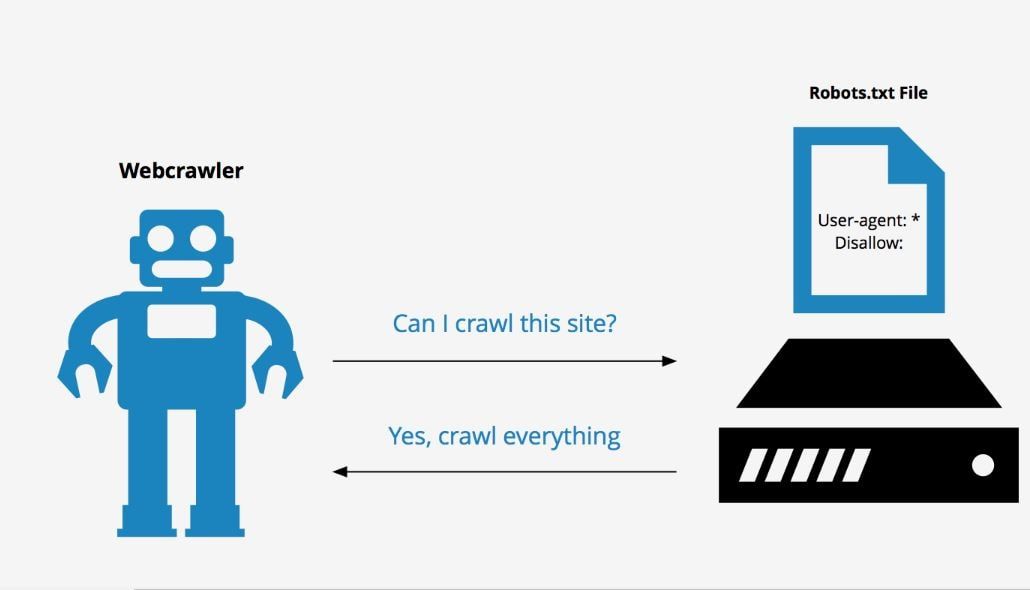 Примеры плагинов:
Примеры плагинов:- All-in-One SEO plugin
- Yoast SEO
Если вам нужна дополнительная помощь в настройке правил в файле robots.txt, мы рекомендуем посетить Google Developers или The Web Robots Pages для получения дополнительных инструкций.
Задержка сканирования
Если вы видите слишком высокий трафик ботов и это влияет на производительность сервера, задержка сканирования может быть хорошим вариантом. Задержка сканирования позволяет ограничить время, которое должно пройти боту перед сканированием следующей страницы.
Чтобы настроить задержку сканирования, используйте следующую директиву, значение настраивается и обозначается в секундах:
crawl-delay: 10
Например, чтобы запретить всем ботам сканировать
wp-admin,wp-login.phpи установить задержку сканирования для всех ботов в 600 секунд (10 минут):User -агент: * Запретить: /wp-login.php Запретить: /wp-admin/ Crawl-delay: 600
ПРИМЕЧАНИЕ
У служб сканирования могут быть собственные требования для установки задержки сканирования.
 Как правило, лучше всего напрямую связаться со службой для получения требуемого метода.
Как правило, лучше всего напрямую связаться со службой для получения требуемого метода.Настройка задержки сканирования для SEMrush
- SEMrush — отличный сервис, но он может сильно сканировать, что в конечном итоге снижает производительность вашего сайта. По умолчанию боты SEMrush будут игнорировать директивы о задержке сканирования в файле robots.txt, поэтому обязательно войдите в их панель управления и включите параметр Уважать задержку сканирования robots.txt .
- Дополнительную информацию о SEMrush можно найти здесь.
Настройка задержки сканирования Bingbot
- Bingbot должен учитывать
задержку сканирования, однако они также позволяют вам установить шаблон управления сканированием.
Настройте задержку сканирования для Google
Подробнее читайте в документации службы поддержки Google)
Откройте страницу настроек скорости сканирования для вашего ресурса.

- Если ваша скорость сканирования указана как и рассчитана как оптимальная , единственный способ снизить скорость сканирования — это подать специальный запрос. Вы не можете увеличить скорость сканирования.
- В противном случае выберите нужный вариант, а затем ограничьте скорость сканирования по желанию. Новая скорость сканирования будет действовать в течение 90 дней.
ПРИМЕЧАНИЕ
Хотя эта конфигурация запрещена на нашей платформе, стоит отметить, что
Задержка сканирования Googlebotне может быть настроена для сайтов, размещенных в подкаталогах, таких какdomain.com/blog.Передовой опыт
Первое, о чем следует помнить: нерабочие сайты должны запрещать использование всех пользовательских агентов. WP Engine автоматически делает это для любых сайтов, использующих
имя среды .wpengine.comдомен. Только когда вы будете готовы «запустить» свой сайт, вы должны добавить файлrobots.. txt
txt Во-вторых, если вы хотите заблокировать определенного User-Agent, помните, что роботы не обязаны следовать правилам, установленным в вашем файле
robots.txt. Лучшей практикой будет использование брандмауэра, такого как Sucuri WAF или Cloudflare, который позволяет блокировать злоумышленников до того, как они попадут на ваш сайт. Или вы можете обратиться в службу поддержки за дополнительной помощью по блокировке трафика.Наконец, если у вас очень большая библиотека постов и страниц на вашем сайте, Google и другие поисковые системы, индексирующие ваш сайт, могут вызвать проблемы с производительностью. Увеличение срока действия кэша или ограничение скорости обхода поможет компенсировать это влияние. СЛЕДУЮЩИЙ ШАГ: Диагностика ошибок 504 прямой ответ?
Нелегко, не так ли? Кроме того, вы, сами того не подозревая, наверняка уже имеете его на своем веб-сайте.
Дело в том, что мы не всегда понимаем этот знаменитый файл. Для чего это используется? Что вы в него кладете? Почему его код выглядит трудным для понимания?
Если вы когда-нибудь изучали эту тему, держу пари, вы задавали себе эти вопросы.

С этим файлом, похожим на динамит, нужно обращаться очень осторожно .
Если вы не настроите его должным образом, вы рискуете повредить SEO вашего сайта. Так что берегитесь взрыва!
В этом посте я покажу вам, как избежать катастрофы и как оптимизировать файл robots.txt WordPress
. Вы узнаете, для чего он используется, как он работает, два способа его создания и что положить внутрь.Обзор
- Что такое файл WordPress robots.txt?
- Как создать файл robots.txt для WordPress?
- Как проверить правильность работы файла robots.txt?
- Как оптимизировать файл robots.txt в WordPress?
- Заключение
Вашим лучшим проектам WordPress нужен лучший хостинг!
WPMarmite рекомендует Bluehost: отличная производительность, отличная поддержка. Все, что нужно для отличного старта.
Попробуйте Bluehost
Что такое файл WordPress robots.
 txt?
txt?Презентация
Файл WordPress
robots.txt— это текстовый файл, расположенный в корневом каталоге вашего сайта, который «сообщает поисковым роботам, к каким URL-адресам вашего сайта сканер может получить доступ» в соответствии с определением, данным Google на своем справочном сайте для веб-мастеров.Также называемый «Стандартом/протоколом исключения роботов», он позволяет поисковым системам избегать индексации определенного бесполезного и/или личного контента (например, вашей страницы входа, конфиденциальных папок и файлов).
Короче говоря, этот протокол сообщает роботам поисковой системы, что они могут или не могут делать на вашем сайте.
Вот как это работает. Когда робот собирается просканировать URL-адрес вашего сайта (т. е. он собирается изучить и получить информацию, чтобы иметь возможность ее проиндексировать), он сначала просмотрит ваши
файл robots.txt.Если найдет, то прочитает, а потом будет следовать указаниям, которые вы ему дали (он не сможет просканировать такой-то файл, если вы ему запретили).

Если он не найдет его, он будет сканировать ваш сайт в обычном режиме, не исключая какой-либо контент.
Посмотрите на этот пример файла robots.txt WordPress
, чтобы увидеть, как он выглядит:Не обязательно останавливаться на его содержимом. Как вы увидите позже, не существует стандартного файла, который можно было бы адаптировать к любому сайту. В любом случае не рекомендуется.
Если вам нужно было вспомнить еще 4 вещи по нашей теме дня, запомните это:
- Как объясняет Google, информация, которую вы предоставляете в файле
robots.txt, «не может заставить поисковый робот, чтобы следовать правилам вашего сайта» . Если «серьезные» поисковые роботы (Google, Bing, Yahoo, Yandex, Baidu и т. д.) будут уважать их, то не в случае со злонамеренными роботами, стремящимися подорвать безопасность вашего сайта.
Более того, не все роботы одинаково интерпретируют инструкции, поэтому обязательно соблюдайте синтаксис, указанный Google.
- Файл
robots.txtявляется общедоступным файлом . Любой может получить к нему доступ, введя следующий шаблон:yoursite.com/robots.txt. Поэтому не используйте его для сокрытия контента, вы быстро найдете, где он спрятан… Если вы хотите, чтобы какой-то контент оставался приватным, не помещайте его в этот файл, а защитите, например, паролем. - Если вы не хотите, чтобы определенные страницы отображались в результатах поиска, «не используйте файл
robots.txt, чтобы скрыть вашу веб-страницу» говорит Google. Действительно, если несколько ссылок указывают на эту страницу, возможно, что Google индексирует и отображает ее в своих результатах поиска, не зная, что она содержит, даже если вы заблокировали ее в своем файлеrobots.txt.
Чтобы страница не отображалась в результатах поиска, Google рекомендует использовать так называемый тегnoindex(его можно легко активировать в Yoast SEO, сняв флажок «Разрешить поисковым системам показывать этот пост в результатах поиска?» находится под каждой записью/страницей на вкладке настроек).
- Файл
robots.txtимеет родственника с именем human.txt .
Это файл TXT, который также находится в корне вашего сайта и содержит информацию о разных людях, принимавших участие в его разработке.
Например, разработчики, веб-дизайнеры, редакторы и т. д. Это не обязательно, но если вы считаете полезным интегрировать его на свой сайт WordPress, вам придется добавить его в корень вашего сайта, рядом сФайл robots.txt(посмотрите, например, на файл от WPMarmite).
Вам действительно нужен файл
robots.txt?По умолчанию веб-сайт будет нормально сканироваться и индексироваться поисковой системой, даже без наличия файла
robots.txt.Последнее, следовательно, не является обязательным. Как объясняет Дэниел Рох, SEO-специалист WordPress, «если вы хотите проиндексировать все свои страницы, контент и медиа, не используйте файл
robots.txt: это не принесет вам никакой пользы» .
Но тогда какая польза от этого файла в остальное время?
Основная выгода заключается в том, что ваша поисковая оптимизация . На самом деле файл
robots.txtпозволяет экономить то, что называется краулинговым бюджетом, говорится в этом посте из блога Yoast SEO.Это довольно технический вопрос, но проще говоря, деиндексируя страницы вашего сайта, которые не представляют интереса для SEO, вы оставляете Google больше времени и энергии для сканирования остальных.
Если вы хотите углубиться в тему, Брайан Дин из Backlinko расскажет об этом здесь.
Присоединяйтесь к подписчикам WPMarmite
Получайте последние посты WPMarmite (а также эксклюзивные ресурсы).
ПОДПИСАТЬСЯ СЕЙЧАС
Теперь пришло время перейти к настройке вашего файла. И это важно, поверьте. Если он не оптимизирован должным образом, вы рискуете серьезно оштрафовать свое присутствие в поисковых системах.
Как создать файл WordPress
robots.? txt
txt По умолчанию WordPress создает виртуальный
robots.txtфайл . Он недоступен на вашем сервере, но вы можете просмотреть его онлайн.Возьмите тот, что на сайте Усэйна Болта, бывшей звезды ямайского спринта.
Да, даже сайт Усэйна Болта построен на WordPress.Чтобы увидеть это, вам просто нужно ввести в браузере
http://usainbolt.com/robots.txt.Вот что вы получите:
Агент пользователя: * Запретить: /wp-admin Разрешить: /wp-admin/admin-ajax.php
Этот виртуальный файл работает. Но как изменить это
robots.txtна вашем сайте WordPress?Ну, вам придется создать свой собственный файл, чтобы заменить его.
Есть два способа сделать это:
- Использовать плагин
- Создать вручную
Я подробно покажу, как это сделать.
Как создать файл
robots.на WordPress с помощью Yoast SEO txt
txt Готов поспорить, вы знаете Yoast SEO, верно? Вы знаете, это SEO-плагин, один из самых загружаемых за все время.
WPMarmite использует его, и я также собираюсь использовать его, чтобы показать вам, как он может помочь вам создать файл WordPress
robots.txt.Конечно, предварительным условием является то, что вы установили и активировали этот плагин.
Начните с панели управления WordPress и выберите Yoast SEO > Инструменты .
Продолжить, нажав «Редактор файлов».
Если у вас еще нет специального файла, нажмите кнопку, чтобы создать его. У меня уже был один на моем сайте, поэтому я мог только редактировать его. И не забудьте сохраниться, когда закончите.
Вот и все.
Не беспокойтесь, в конце этой части я объясню, какую информацию нужно поместить в этот файл.
А пока давайте перейдем ко второму способу: вам придется использовать свои маленькие руки.
Ручной метод
Независимо от того, используете ли вы специальный плагин или нет, также можно вручную добавить файл
robots.на ваш веб-сайт WordPress. Это очень просто, вот увидите.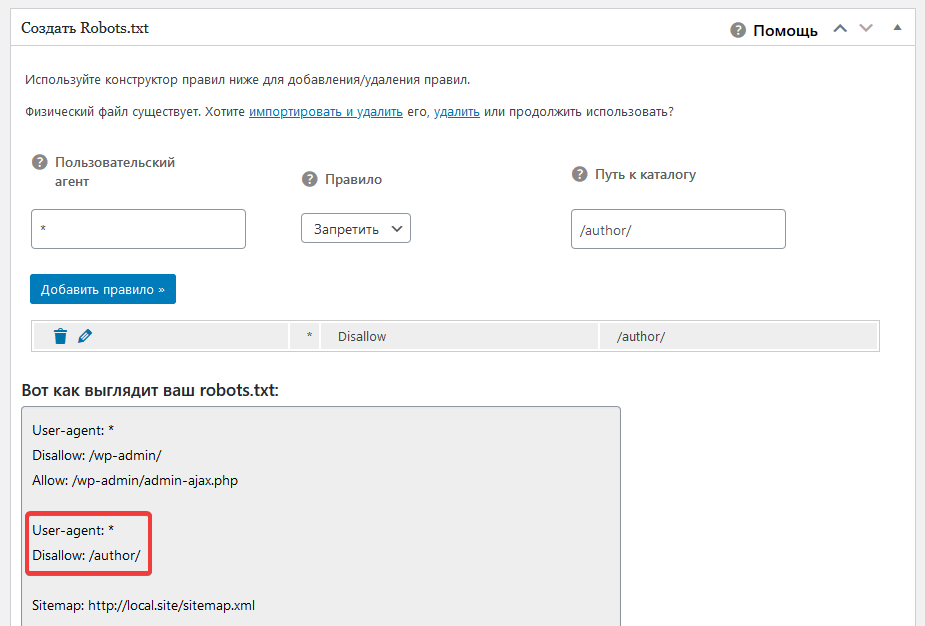 txt
txt Во-первых, вам понадобится текстовый редактор. Среди них могу порекомендовать:
- Скобки
- Notepad++
- Sublime Text
В остальном ваш старый добрый Блокнот тоже будет работать очень хорошо.
Создайте новый документ и сохраните его на своем компьютере под именем
robots.txt.Его имя всегда должно быть в нижнем регистре, и не забывайте ставить «s» в слове robots (не пишите
robot.txt).Затем подключитесь к FTP-клиенту. Это программное обеспечение, которое позволяет вам общаться с вашим сервером.
Лично я использую Filezilla. Но вы также можете использовать Cyberduck. Для получения дополнительной информации о том, как использовать FTP, ознакомьтесь с нашей статьей: Как использовать FTP для доступа к вашим файлам WordPress.
Также FTP пригодится вам в процессе установки WordPress.
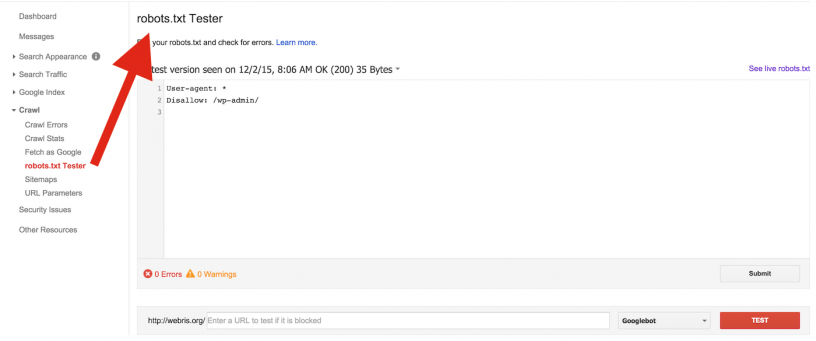 Прочтите наше руководство об этом: Как установить WordPress: пошаговое руководство.
Прочтите наше руководство об этом: Как установить WordPress: пошаговое руководство. Третий и последний шаг: добавить файл в корень вашего сайта . Повторюсь, в корне вашего сайта, а не в подкаталоге. В противном случае поисковые системы не примут его во внимание.
Например, если ваш сайт доступен через
https://www.yoursite.com/, файлrobots.txtдолжен находиться по адресуhttps://www.yoursite.com/robots.txt.Это местоположение (корень) может варьироваться от одного хоста к другому. На Bluehost (партнерская ссылка) он называется
public_html. В OVH вы найдете его под названиемwww.Окончательная реализация на вашем сайте должна выглядеть так:
Основные правила, которые необходимо знать
Поздравляем, ваш файл
robots.txtтеперь находится на вашем сервере. На данный момент он пуст, но вы можете редактировать его, когда захотите.
По логике нужно спросить себя, какие инструкции туда вставлять.
Прежде чем мы перейдем к этому, необходимо понять особый синтаксис этого файла.
«Каждое правило блокирует или разрешает доступ для данного поискового робота к указанному пути к файлу на этом веб-сайте» , как объясняет Google в своей справке Search Console.
Два основных правила называются:
-
User-agent: Относится к имени робота поисковой системы, к которому применяется правило. -
Запретить: Назначает каталог или страницу относительно корневого домена, которые не должны сканироваться агентом пользователяDisallow 9.Правило 0008.
Давайте изучим простой пример, чтобы вы поняли.
User-agent: * Disallow: /
В первой строке звездочка
*— это то, что мы называем подстановочным знаком. Он относится ко всем роботам поисковых систем (
Он относится ко всем роботам поисковых систем ( user-agent).Во второй строке вы
запрещаетедоступ этим поисковым системам ко всем каталогам и страницам вашего сайта, через косую черту/.Вам не нужно вводить свое доменное имя (например,
mysite.com/) перед косой чертой, поскольку в файлеrobots.txtиспользуются относительные URL-адреса. Проще говоря, он знает, что косая черта относится к корню вашего доменного имени.Очевидно, что приведенный выше код бесполезен, если вы хотите, чтобы ваш сайт сканировался и индексировался. Но это может быть полезно, когда вы находитесь на этапе создания своего сайта.
Если вы не хотите, чтобы ваш сайт сканировал определенный тип робота, например, Yahoo (Slurp — это имя, связанное с роботом Yahoo), вам необходимо сделать следующее:
Агент пользователя: Slurp Disallow: /
Для получения дополнительной информации об именах роботов я отсылаю вас к этому снимку экрана с сайта Yoast SEO.

Некоторые дополнительные правила
Я рассказал вам о наиболее часто используемых
User-agentиDisallow. Вы должны знать, что есть и другие правила синтаксиса, но они учитываются не всеми роботами (да, Google). Среди них:-
Разрешить: Разрешить исследование подкаталога или страницы в каталоге, который не разрешен (Запретить). -
Карта сайта: сообщает роботам, где находится ваша карта сайта. Эта строка не является обязательной. Я рекомендую вам отправлять карту сайта в поисковые системы с помощью специального инструмента, такого как Google Search Console. Я объясню вам, как это сделать в этом посте.
Чтобы убедиться, что вы поняли, давайте пойдем немного дальше и приведем вам 3 новых примера.
Как заблокировать доступ к каталогу
User-agent: * Disallow: /wp-admin/
Прошу всех роботов не исследовать все содержимое каталога
wp-admin.
Как заблокировать доступ к странице или файлу
User-agent: * # Без индексации страницы входа Disallow: /wp-login.php # Без индексации фото Disallow: /myphoto.jpg
В этом Например, я прошу всех роботов не индексировать страницу входа в WordPress, а также фотографию.
Вы также можете увидеть 9Появится символ 0007 # . Он вводит комментарий. Текст за ним не будет учитываться.
Также имейте в виду, что правила чувствительны к регистру.
Например,
Disallow: /myphoto.jpgсоответствуетhttp://www.mysite.com/myphoto.jpg, но неhttp://www.mysite.com/Myphoto.jpg.Как создать разные правила для разных роботов
User-agent: * Disallow: /wp-login.php User-agent: Googlebot Disallow: /
Правила всегда обрабатываются сверху вниз. Помните, что они всегда начинаются с оператора
User-agent, указывающего на робота, к которому применяется правило.
В первом прошу всех роботов не индексировать страницу входа (
wp-login.php).Во втором случае я специально прошу поисковый робот Google (Googlebot) не сканировать весь мой сайт.
Как разрешить доступ к файлу в заблокированном каталоге
User-agent: * Disallow: /wp-admin Allow: wp-admin/widgets.php
Мы используем инструкцию
Allow. В этом примере заблокирован весь каталогwp-admin, кроме файлаwidgets.php.Найдите лучших экспертов по WordPress
Компания Codeable поможет вам с экспертами, которые помогут вам во всем: от дизайна или установки темы WordPress до разработки пользовательских плагинов.
Попробуйте кодировать
Как проверить правильность работы файла robots.txt?
Чтобы убедиться, что ваш файл настроен правильно, вы можете проверить его в Google Search Console, бесплатном и важном инструменте для управления SEO вашего сайта (среди прочего).

Откройте средство тестирования файла robots.txt (предварительно необходимо зарегистрировать там свой сайт).
После того, как вы ввели необходимые инструкции в предоставленном редакторе, вы можете протестировать свой файл.
Если все хорошо, вы должны увидеть следующее сообщение в нижней части редактора.
Если нет, ваш файл содержит логические ошибки или синтаксические предупреждения. Наконец, не забудьте отправить файл, нажав кнопку «Отправить».
Как оптимизировать файл robots.txt в WordPress?
Что следует или не следует добавлять в файл
robots.txt?Существует ли предопределенный шаблон, который можно адаптировать для каждого сайта?
Ответ: и да, и нет.
Действительно, каждый сайт уникален, и было бы трудно скопировать и вставить то, что Питер, Пол или Джеймс предлагают на их сайтах. Их проблемы, скорее всего, будут отличаться от ваших.
Тем не менее, мы можем дать вам базовый файл
robots., который подойдет большинству сайтов: txt
txt User-agent: * # Предотвращено индексирование конфиденциальных файлов Disallow: /wp-admin Disallow: /wp-includes Disallow: /wpcontent/cache Disallow: /trackback Disallow: /*.php$ Disallow: /*.inc$ Disallow: /*.gz$ # Деиндексируем страницу входа (ненужный контент) Disallow: /wp-login.php
Честно говоря, даже в сообществе WordPress невозможно добиться согласия всех. Мнения расходятся.
Некоторые, например Йоост де Валк, основатель Yoast, выступают за минимализм. На самом деле это текущая тенденция .
По сути, они считают, что, поскольку Google может полностью интерпретировать ваш сайт (включая код CSS и JavaScript, а не только HTML), он не должен блокировать доступ к файлам CSS и JavaScript, чтобы он мог видеть ваши страницы целиком. В противном случае это может повлиять на ваше SEO.
Чтобы убедиться, что у Google есть доступ ко всем ресурсам, необходимым для правильного отображения вашей страницы, вы можете вернуться в Google Search Console.
 Перейдите на вкладку «Проверка URL», нажмите «Просмотреть проверенную страницу», а затем нажмите «Снимок экрана».
Перейдите на вкладку «Проверка URL», нажмите «Просмотреть проверенную страницу», а затем нажмите «Снимок экрана».Если ваш сайт выглядит не так, как должен (например, некоторые стили не применяются), возможно, это связано с тем, что некоторые правила в вашем файле
robots.txtнеобходимо пересмотреть.Но вернемся к Йоасту. Посмотрите на их файл
robots.txt:# Это место намеренно оставлено пустым # Если вы хотите узнать, почему наш robots.txt выглядит так, прочитайте этот пост: https://yoa.st/robots-txt User -agent: *
Как видите ничего не блокируется!
Другие выступают за более широкий, «безопасный» подход к вашему сайту. Среди прочего, они советуют:
- Запретить доступ к двум ключевым каталогам WordPress , таким как папка
wp-admin(где расположены административные элементы вашего веб-сайта) и папкаwp-includes(в которой находится все файлы WordPress).
- Деиндексировать страницу входа
(wp-login.php). - Или для деиндексации
readme.html, потому что он содержит версию WordPress, которую вы используете.
Короче говоря, разобраться во всех этих рекомендациях непросто!
Подводя итог, я советую вам:
- Придерживайтесь минимума, если вы не уверены в том, что делаете . В противном случае последствия для вашего SEO могут быть плачевными.
- Прежде чем отправлять файл, убедитесь, что он не содержит ошибок в Search Console .
Заключение
Как вы видели, файл
robots.txt— интересный инструмент для вашего SEO. Это позволяет указать роботам поисковых систем, что они должны и не должны сканировать.Но с ним нужно обращаться осторожно. Неправильная конфигурация может привести к полной деиндексации вашего сайта (например, если вы используете
Disallow: /). Так что будьте осторожны!
Так что будьте осторожны!Чтобы закончить этот пост, давайте подведем итоги. В этих строках я подробно описал:
- Что такое файл
robots.txt. - Как установить на WordPress .
- Как оптимизировать файл
robots.txtв WordPress для SEO.
Теперь ваша очередь. Скажите, используете ли вы этот тип файла и как вы его настраиваете.
Делитесь своими мыслями и отзывами в комментариях.
Об авторе
WPMarmite Team
WPMarmite помогает новичкам получить максимальную отдачу от WordPress с помощью подробных руководств и честных обзоров. Познакомьтесь с основателем Алексом и его командой прямо здесь.
Хотите пойти дальше с WordPress?
Присоединяйтесь к 40 000+ подписчиков, чтобы получать подробные руководства по WordPress
и честные обзоры (без жаргона).
Имя
Электронная почта
Подписавшись на информационный бюллетень, вы соглашаетесь с тем, что WPMarmite в качестве контролера данных собирает ваши данные для отправки вам сообщений в электронном виде. Вы можете отменить подписку в любое время. Чтобы воспользоваться своим правом на доступ, исправление или удаление, ознакомьтесь с нашей Политикой конфиденциальности.
Нет, спасибо. Я передумал.
WordPress Robots.txt — Как создать и оптимизировать для SEO
Что такое robots.txt? Как создать файл robots.txt? Зачем нужно создавать файл robots.txt? Помогает ли оптимизация файла robots.txt улучшить ваш поисковый рейтинг?
Мы расскажем обо всем этом и многом другом в этой подробной статье о robots.txt!
Вы когда-нибудь хотели запретить поисковым системам сканировать определенный файл? Хотели, чтобы поисковые системы не сканировали определенную папку на вашем сайте?
Здесь на помощь приходит файл robots.txt. Это простой текстовый файл, который сообщает поисковым системам, где и где не сканировать ваш сайт при индексировании.
Хорошей новостью является то, что вам не нужно иметь никакого технического опыта, чтобы раскрыть всю мощь файла robots.txt.
Robots.txt — это простой текстовый файл, создание которого занимает несколько секунд. Это также один из самых простых файлов, который можно испортить. Всего один неуместный символ, и вы испортите SEO всего своего сайта и запретите поисковым системам доступ к вашему сайту.
При работе над SEO сайта важную роль играет файл robots.txt. Хотя он позволяет запретить поисковым системам доступ к различным файлам и папкам, часто это не лучший способ оптимизировать ваш сайт.
В этой статье мы объясним, как использовать файл robots.txt для оптимизации вашего веб-сайта. Мы также покажем вам, как его создать, и поделимся некоторыми плагинами, которые нам нравятся, которые могут сделать тяжелую работу за вас.
Содержание
- Что такое robots.txt?
- Как выглядит файл robots.txt?
- Что такое бюджет сканирования?
- Как создать файл robots.
 txt в WordPress?
txt в WordPress?- Способ 1. Создание файла Robots.txt с помощью плагина Yoast SEO
- Способ 2. Создание файла Robots.txt вручную с помощью FTP
- Как проверить файл robots.txt
- Нужен ли вам файл robots.txt для вашего сайта WordPress?
- Заключительные мысли
Что такое robots.txt?
Robots.txt — это простой текстовый файл, который сообщает роботам поисковых систем, какие страницы вашего сайта сканировать. Он также сообщает роботам, какие страницы не сканировать.
Прежде чем мы углубимся в эту статью, важно понять, как работает поисковая система.
Поисковые системы выполняют три основные функции: сканирование, индексирование и ранжирование.
(Источник: Moz.com)
Поисковые системы начинают с того, что рассылают по сети своих поисковых роботов, также называемых пауками или ботами. Эти боты представляют собой часть интеллектуального программного обеспечения, которое перемещается по всей сети в поисках новых ссылок, страниц и веб-сайтов.
 Этот процесс поиска в сети называется сканированием .
Этот процесс поиска в сети называется сканированием .Как только боты обнаружат ваш веб-сайт, ваши страницы будут организованы в удобную структуру данных. Этот процесс называется индексированием .
И, наконец, все сводится к рейтинг . Где поисковая система предоставляет своим пользователям лучшую и наиболее актуальную информацию на основе их поисковых запросов.
Как выглядит robots.txt?
Допустим, поисковая система собирается посетить ваш сайт. Прежде чем он просканирует сайт, он сначала проверит robots.txt на наличие инструкций.
Например, предположим, что робот поисковой системы собирается просканировать наш сайт WPAstra и получить доступ к нашему файлу robots.txt, доступ к которому осуществляется с https://wpastra.com/robots.txt.
Пока мы обсуждаем эту тему, вы можете получить доступ к файлу robots.txt для любого веб-сайта, введя «/ robots.txt» после имени домена.
ОК.
 Возвращение на правильный путь.
Возвращение на правильный путь.Выше приведен типичный формат файла robots.txt.
И прежде чем вы подумаете, что все это слишком технично, хорошая новость заключается в том, что это все, что есть в файле robots.txt. Ну, почти.
Давайте разберем каждый элемент, упомянутый в файле.
Первый User-agent: * .
Звездочка после User-agent означает, что файл применяется ко всем роботам поисковых систем, которые посещают сайт.
У каждой поисковой системы есть собственный пользовательский агент, который сканирует Интернет. Например, Google использует Googlebot для индексации контента вашего сайта для поисковой системы Google.
Некоторые другие пользовательские агенты, используемые популярными поисковыми системами:
- Google: Googlebot
- Googlebot News: Googlebot-News
- Googlebot Images: Googlebot-Image
- Googlebot Video: Googlebot-Video
- Bing: Bingbot
- Yahoo: Slurp Bot
- Duckduckgo: Duckduckbot
- Baidu: Baiduspider
- yandex: yandexbot 38 8.
- 8.100.10038.100.10038.1.1.1.male
- 8.10038 8.10038. сотни таких юзер-агентов.
Вы можете установить пользовательские инструкции для каждого пользовательского агента. Например, если вы хотите указать конкретные инструкции для робота Googlebot, первая строка вашего файла robots.txt будет такой:
Агент пользователя: Googlebot
Вы назначаете директивы всем агентам пользователя, используя звездочку (*) рядом с Агентом пользователя.
Допустим, вы хотите запретить всем ботам, кроме робота Google, сканировать ваш сайт. Ваш файл robots.txt будет иметь следующий вид:
User-agent: * Запретить: / Агент пользователя: Googlebot Разрешить: /
Косая черта ( / ) после Запретить указывает боту не индексировать какие-либо страницы на сайте. И хотя вы назначили директиву, которая будет применяться ко всем ботам поисковых систем, вы также явно разрешили роботу Google проиндексировать ваш веб-сайт, добавив ‘ Разрешить: / .
 ’
’Точно так же вы можете добавить директивы для любого количества пользовательских агентов.
Подводя итоги, давайте вернемся к нашему примеру Astra robots.txt, т. е.
User-agent: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
Для всех поисковых роботов была установлена директива не сканировать что-либо в папке « /wp-admin/», но следовать « admin-ajax». php ' в той же папке.
Просто, правда?
Здравствуйте! Меня зовут Суджей, и я генеральный директор Astra.
Наша миссия — помочь малым предприятиям расти в Интернете с помощью доступных программных продуктов и образования, необходимого для достижения успеха.
Оставьте комментарий ниже, если хотите присоединиться к беседе, или нажмите здесь, если хотите получить личную помощь или пообщаться с нашей командой в частном порядке.
Что такое краулинговый бюджет?
Добавив косую черту после Disallow , вы запрещаете роботу посещать какие-либо страницы сайта.
Итак, ваш следующий очевидный вопрос: зачем кому-то мешать роботам сканировать и индексировать ваш сайт? В конце концов, когда вы работаете над SEO веб-сайта, вы хотите, чтобы поисковые системы сканировали ваш сайт, чтобы помочь вам в рейтинге.
Именно поэтому вам следует подумать об оптимизации файла robots.txt.
Вы представляете, сколько страниц у вас на сайте? От реальных страниц до тестовых страниц, страниц дублированного контента, страниц благодарности и других. Много, полагаем.
Когда бот сканирует ваш сайт, он будет сканировать каждую страницу. А если у вас несколько страниц, поисковому роботу потребуется некоторое время, чтобы просканировать их все.
(Источник: Seo Hacker)
Знаете ли вы, что это может негативно повлиять на рейтинг вашего сайта?
И это из-за краулингового бюджета поисковой системы .
ОК. Что такое краулинговый бюджет?
Бюджет обхода — это количество URL-адресов, которое поисковый робот может просканировать за сеанс.
Для каждого сайта будет выделен определенный краулинговый бюджет. И вам нужно убедиться, что краулинговый бюджет расходуется наилучшим образом для вашего сайта.Если у вас есть несколько страниц на вашем веб-сайте, вам определенно нужно, чтобы бот сначала сканировал наиболее ценные страницы. Таким образом, необходимо явно указать это в файле robots.txt.
Ознакомьтесь с ресурсами, доступными в Google, чтобы узнать, что означает краулинговый бюджет для робота Googlebot.
Как создать файл robots.txt в WordPress?
Теперь, когда мы рассмотрели, что такое файл robots.txt и насколько он важен, давайте создадим его в WordPress.
У вас есть два способа создать файл robots.txt в WordPress. Один использует плагин WordPress, а другой вручную загружает файл в корневую папку вашего сайта.
Способ 1. Создайте файл Robots.txt с помощью плагина Yoast SEO
Чтобы оптимизировать свой веб-сайт WordPress, вы можете использовать плагины SEO. Большинство этих плагинов поставляются с собственным генератором файлов robots.
txt.В этом разделе мы создадим его с помощью плагина Yoast SEO. С помощью плагина вы можете легко создать файл robots.txt на панели управления WordPress.
Шаг 1. Установите плагин
Перейдите к Плагины > Добавить новый . Затем найдите, установите и активируйте плагин Yoast SEO, если у вас его еще нет.
Шаг 2. Создайте файл robots.txt
После активации плагина перейдите Yoast SEO > Инструменты и нажмите Редактор файлов .
Поскольку мы создаем файл впервые, нажмите Создать файл robots.txt .
Вы заметите файл, созданный с некоторыми директивами по умолчанию.
По умолчанию генератор файла robots.txt Yoast SEO добавит следующие директивы:
User-agent: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
При желании вы можете добавить дополнительные директивы в robots.txt. Когда вы закончите, нажмите Сохранить изменения в robots.
txt .Введите имя своего домена, а затем « /robots.txt ». Если вы обнаружите директивы по умолчанию, отображаемые в браузере, как показано на изображении ниже, вы успешно создали файл robots.txt.
Мы также рекомендуем добавить URL-адрес карты сайта в файл robots.txt.
Например, если URL-адрес карты сайта вашего веб-сайта https://yourdomain.com/sitemap.xml, рассмотрите возможность включения Карта сайта: https://yourdomain.com/sitemap.xml в файле robots.txt.
Другой пример: если вы хотите создать директиву, запрещающую боту сканировать все изображения на вашем веб-сайте. И допустим, мы хотели бы ограничить это только GoogleBot.
В этом случае наш robots.txt будет выглядеть следующим образом:
User-agent: Googlebot Запретить: /загрузки/ Пользовательский агент: * Разрешить: /загрузки/
И на всякий случай, если вам интересно, как узнать имя папки с изображениями, просто щелкните правой кнопкой мыши любое изображение на вашем веб-сайте, выберите «Открыть в новой вкладке» и запишите URL-адрес в браузере.
Вуаля!Способ 2. Создание файла robots.txt вручную с помощью FTP
Следующий способ — создать файл robots.txt на локальном компьютере и загрузить его в корневую папку веб-сайта WordPress.
Вам также потребуется доступ к вашему хостингу WordPress с помощью FTP-клиента, такого как Filezilla. Учетные данные, необходимые для входа, будут доступны в панели управления хостингом, если у вас их еще нет.
Помните, что файл robots.txt должен быть загружен в корневую папку вашего сайта. То есть он не должен находиться ни в одном подкаталоге.
Итак, как только вы войдете в систему с помощью FTP-клиента, вы сможете увидеть, существует ли файл robots.txt в корневой папке вашего веб-сайта.
Если файл существует, просто щелкните его правой кнопкой мыши и выберите параметр редактирования.
Внесите изменения и нажмите «Сохранить».
Если файл не существует, вам необходимо его создать. Вы можете создать его с помощью простого текстового редактора, такого как Блокнот, и добавить директивы в файл.
Например, включите следующие директивы,
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
… и сохранить файл как robots.txt.
Теперь, используя FTP-клиент, нажмите « File Upload » и загрузите файл в корневую папку веб-сайта.
Чтобы убедиться, что ваш файл был успешно загружен, введите имя своего домена, а затем «/robots.txt».
Плюсы и минусы Robots.txt
Плюсы файла robots.txt
- Он помогает оптимизировать краулинговые бюджеты поисковых систем, говоря им не тратить время на страницы, которые вы не хотите индексировать. Это помогает поисковым системам сканировать наиболее важные для вас страницы.
- Это помогает оптимизировать ваш веб-сервер, блокируя ботов, которые тратят ресурсы впустую.
- Помогает скрыть страницы благодарности, целевые страницы, страницы входа и многое другое, что не нужно индексировать поисковыми системами.
Минусы файла robots.
txt - Теперь вы знаете, как получить доступ к файлу robots.txt для любого веб-сайта. Это довольно просто. Просто введите доменное имя, а затем «/ robots.txt». Это, однако, также сопряжено с определенным риском. Файл robots.txt может содержать URL-адреса некоторых ваших внутренних страниц, которые вы не хотели бы индексировать поисковыми системами.
Например, может быть страница входа, которую вы не хотели бы индексировать. Однако его упоминание в файле robots.txt позволяет злоумышленникам получить доступ к странице. То же самое происходит, если вы пытаетесь скрыть некоторые личные данные. - Хотя создать файл robots.txt довольно просто, если вы ошибетесь хотя бы в одном символе, это испортит все ваши усилия по SEO.
Куда поместить файл robots.txt
Мы полагаем, что теперь вы хорошо знаете, куда следует добавить файл robots.txt.
Файл robots.txt всегда должен находиться в корне вашего сайта. Если ваш домен — yourdomain.com, то URL-адрес вашего файла robots.
txt будет https://yourdomain.com/robots.txt.В дополнение к включению файла robots.txt в корневой каталог, необходимо следовать некоторым рекомендациям. Так что делайте это правильно, иначе это не будет работать
- Каждая директива должна быть на новой строке
- Включите символ «$», чтобы отметить конец URL-адреса
- Используйте отдельные пользовательские агенты только один раз
- Используйте комментарии для объясните людям свой файл robots.txt, начав строку с решётки (#)
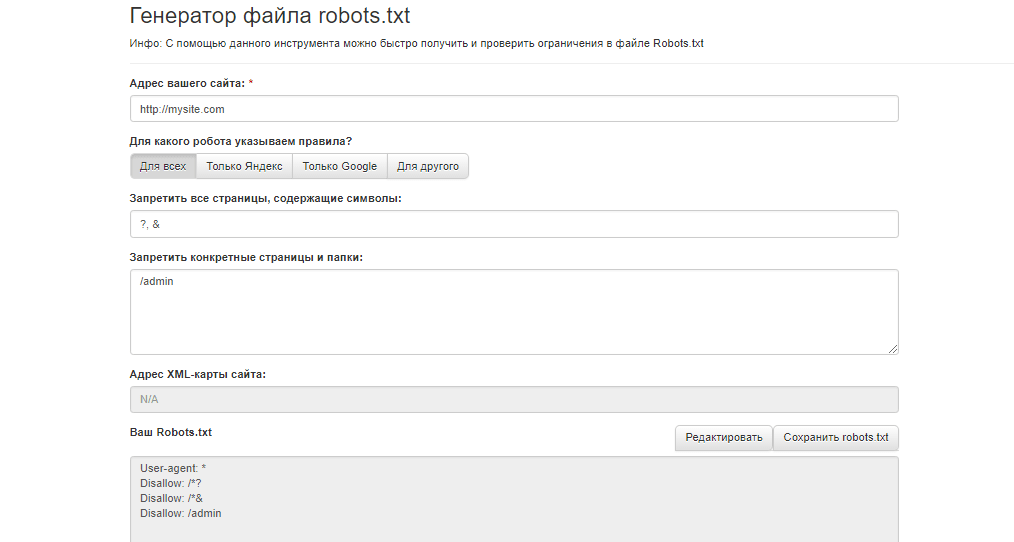 1.10.1.101.1.101.100 x.lastead
1.10.1.101.1.101.100 x.lastead -
Как протестировать файл robots.txt
Теперь, когда вы создали файл robots.txt, пришло время протестировать его с помощью инструмента для тестирования robots.txt.
Мы рекомендуем инструмент внутри Google Search Console.
Чтобы получить доступ к этому инструменту, щелкните Открыть тестер robots.txt.
Мы предполагаем, что ваш веб-сайт добавлен в Google Search Console. Если это не так, нажмите « Добавить свойство сейчас » и выполните простые шаги, чтобы включить свой веб-сайт в Google Search Console.
После этого ваш веб-сайт появится в раскрывающемся списке под « Пожалуйста, выберите свойство ».
Нужен ли вам файл robots.txt для вашего сайта WordPress?
Да, вам нужен файл robots.txt на вашем сайте WordPress. Независимо от того, есть у вас файл robots.txt или нет, поисковые системы все равно будут сканировать и индексировать ваш сайт. Но после того, как вы узнали, что такое robots.txt, как он работает и какой у него краулинговый бюджет, почему бы вам не включить его?
Файл robots.txt сообщает поисковым системам, что сканировать и, что более важно, что не сканировать.
Основной причиной для включения файла robots.txt является рассмотрение неблагоприятных последствий краулингового бюджета.
Как указывалось ранее, каждый веб-сайт имеет определенный краулинговый бюджет. Это сводится к количеству страниц, которые бот просматривает за сеанс. Если бот не завершит сканирование всех страниц вашего сайта во время сеанса, он вернется и возобновит сканирование в следующем сеансе.
И это замедляет индексацию вашего сайта.
Чтобы быстро исправить это, запретите поисковым ботам сканировать ненужные страницы, медиафайлы, плагины, папки тем и т. д., тем самым сэкономив квоту сканирования.
Заключительные мысли
При работе над SEO вашего веб-сайта мы придаем большое значение оптимизации контента, поиску правильных ключевых слов, работе с обратными ссылками, созданию файла sitemap.xml и другим факторам. Элементом SEO, на который некоторые веб-мастера обращают меньше внимания, является файл robots.txt.
Файл robots.txt может не иметь большого значения при запуске веб-сайта. Но по мере роста вашего веб-сайта и увеличения количества страниц он принесет богатые дивиденды, если мы начнем следовать передовым методам в отношении файла robots.txt.
Мы надеемся, что эта статья помогла вам получить полезную информацию о том, что такое robots.txt и как создать его на своем веб-сайте. Итак, какие директивы вы установили в файле robots.
txt?Полное руководство по оптимизации WordPress Robots.txt
Советы
Последнее обновление:
Когда вы создаете блог или веб-сайт на WordPress, файл robots.txt автоматически создается для каждой из ваших целевых страниц и сообщений. Это важный аспект SEO вашего сайта, так как он будет использоваться поисковыми системами при сканировании контента вашего сайта.
Если вы хотите поднять SEO своего веб-сайта на новый уровень, оптимизация файла robots.txt на вашем сайте WordPress важна, но, к сожалению, не так проста, как добавление ключевых слов к вашему контенту. Вот почему мы составили это руководство по WordPress robots.txt, чтобы вы могли начать совершенствовать его и улучшить свой поисковый рейтинг.
Что такое файл robots.txt?
При размещении веб-сайтов на страницах результатов поисковых систем (SERP) поисковые системы, такие как Google, «сканируют» страницы веб-сайтов и анализируют их содержимое.
Файл robots.txt любого веб-сайта сообщает роботам-роботам, какие страницы сканировать, а какие нет — по сути, это форма роботизированной автоматизации процессов (RPA).Вы можете просмотреть файл robots.txt любого веб-сайта, введя /robots.txt после имени домена. Это будет выглядеть примерно так:
Давайте разберем каждый из элементов на изображении выше.
User-agent
User-agent в файле robots.txt — это поисковая система, которой должен быть прочитан файл robots.txt. В приведенном выше примере пользовательский агент помечен звездочкой, что означает, что он применяется ко всем поисковым системам.
Большинство веб-сайтов согласны с тем, что все поисковые системы сканируют их сайт, но иногда вам может потребоваться заблокировать сканирование вашего сайта всеми поисковыми системами, кроме Google, или дать конкретные инструкции о том, как поисковые системы, такие как Новости Google или Google Картинки, сканируют ваш сайт.
В этом случае вам необходимо узнать идентификатор агента пользователя поисковых систем, которым вы хотите дать инструкции.
Это достаточно просто найти в Интернете, но вот некоторые из основных:- Google: Googlebot
- Новости Google: Googlebot-Новости
- Изображения Google: Googlebot-изображение
- Видео Google: Googlebot-Video
- Бинг: Бингбот
- Yahoo: Slurp Bot
Разрешить и запретить
В файлах robots.txt разрешения и запреты сообщают ботам, какие страницы и контент они могут сканировать, а какие нет. Если, как упоминалось выше, вы хотите запретить всем поисковым системам, кроме Google, сканировать ваш сайт, вы можете использовать следующий файл robots.txt:0003
Косая черта (/) после «Запретить» и «Разрешить» сообщает боту, что ему разрешено или запрещено сканировать все страницы. Вы также можете поместить определенные страницы между косой чертой, чтобы разрешить или запретить боту их сканирование.
Карта сайта
«Карта сайта» в файле robots.txt представляет собой XML-файл, содержащий список и сведения обо всех страницах вашего веб-сайта.
Это выглядит так:Карта сайта содержит все веб-страницы, которые вы хотите, чтобы бот обнаружил. Карта сайта особенно полезна, если у вас есть веб-страницы, которые вы хотите отображать в результатах поиска, но они не являются типичными целевыми страницами, например сообщения в блогах.
Файлы Sitemap особенно важны для пользователей WordPress, которые хотят оживить свой веб-сайт с помощью сообщений в блогах и страниц категорий. Многие из них могут не отображаться в поисковой выдаче, если у них нет собственной карты сайта robots.txt.
Это основные аспекты файла robots.txt. Однако следует отметить, что ваш файл robots.txt не является верным способом заблокировать роботов поисковых систем от сканирования определенных страниц. Например, если другой сайт использует якорные тексты для ссылки на страницу, которую вы «запретили» в файле robots.txt, роботы поисковых систем все равно смогут сканировать эту страницу.
Нужен ли вам файл robots.txt в WordPress?
Если у вас есть веб-сайт или блог на базе WordPress, у вас уже будет автоматически сгенерированный файл robots.
txt. Вот несколько причин, по которым важно рассмотреть файл robots.txt, если вы хотите убедиться, что ваш сайт WordPress оптимизирован для SEO.Вы можете оптимизировать свой бюджет сканирования
Бюджет сканирования или квота сканирования — это количество страниц, которые роботы поисковых систем будут сканировать на вашем веб-сайте в любой день. Если у вас нет оптимизированного файла robots.txt, возможно, вы зря тратите свой краулинговый бюджет и не позволяете ботам сканировать страницы вашего сайта, которые вы хотите показывать первыми в поисковой выдаче.
Если вы продаете товары или услуги через свой сайт WordPress, в идеале вы хотите, чтобы поисковые роботы отдавали приоритет страницам с наилучшей конверсией продаж.
Вы можете расставить приоритеты для важных целевых страниц
Оптимизировав файл robots.txt, вы можете сделать так, чтобы целевые страницы, которые вы хотите показывать первыми в поисковой выдаче, легко и быстро находили поисковые роботы.
Разделение индекса вашего сайта на индекс «страниц» и «сообщений» особенно полезно для этого, так как вы можете убедиться, что сообщения блога появляются в поисковой выдаче, а не только на ваших стандартных целевых страницах.Например, если на вашем веб-сайте много страниц, а ваши данные о клиентах показывают, что ваши сообщения в блоге генерируют много покупок, вы можете использовать карты сайта в файле robots.txt, чтобы убедиться, что ваши сообщения в блоге появляются в поисковой выдаче.
Вы можете улучшить общее качество SEO вашего веб-сайта
Маркетологи хорошо осведомлены о высокой рентабельности инвестиций в поисковую оптимизацию. Направление органического поиска на ваш веб-сайт с упором на его SEO дешевле и часто более эффективно, чем платная реклама и партнерские ссылки, хотя и то, и другое по-прежнему помогает. Посмотрите эти статистические данные о рентабельности маркетинговых каналов.
Оптимизация файла robots.txt — не единственный способ повысить рейтинг вашего веб-сайта или блога в результатах поиска.
Вам по-прежнему необходимо иметь оптимизированный для SEO контент на самих страницах, и вам может понадобиться помощь поставщика SEO SaaS. Однако вы можете легко отредактировать файл robots.txt самостоятельно.Как редактировать файл robots.txt в WordPress
Если вы хотите отредактировать файл robots.txt в WordPress, это можно сделать несколькими способами. Лучший и самый простой вариант — добавить плагин в вашу систему управления контентом — панель инструментов WordPress.
Добавить SEO-плагин в ваш WordPress
Это самый простой способ отредактировать файл robots.txt WordPress. Существует множество хороших SEO-плагинов, которые позволят вам редактировать файл robots.txt. Одними из самых популярных являются Yoast, Rank Math и All In One SEO.
Добавьте плагин Robots.txt в свой WordPress
Существуют также плагины WordPress, специально разработанные путем редактирования файла robots.txt. Популярными плагинами robots.txt являются Virtual Robots.
txt, WordPress Robots.txt Optimization и Robots.txt Editor.Как протестировать файл robots.txt WordPress
Если вы редактировали файл robots.txt, важно протестировать его, чтобы убедиться, что вы не допустили ошибок. Ошибки в вашем файле robots.txt могут привести к тому, что ваш сайт будет полностью исключен из поисковой выдачи.
У Google Webmaster есть инструмент для тестирования robots.txt, который вы можете использовать бесплатно для проверки вашего файла. Чтобы использовать его, вы просто добавляете URL-адрес своей домашней страницы. Появится файл robots.txt, и вы увидите «синтаксическое предупреждение» и «логическую ошибку» во всех неработающих строках файла.
Затем вы можете войти на определенную страницу своего веб-сайта и выбрать пользовательский агент для запуска теста, который покажет, является ли эта страница «принятой» или «заблокированной». Вы можете отредактировать файл robots.txt в инструменте тестирования и при необходимости снова запустить тест, но обратите внимание, что это не изменит ваш фактический файл, вам нужно будет скопировать и вставить отредактированную информацию в редактор robots.
txt и сохранить его там.Как оптимизировать файл robots.txt WordPress для SEO
Самый простой способ оптимизировать файл robots.txt — выбрать, какие страницы вы хотите запретить. В WordPress типичными страницами, которые вы можете запретить, являются /wp-admin/ , /wp-content/plugins/ , /readme.html , /trackback/ .
Например, поставщик маркетинговых услуг SaaS имеет множество различных страниц и сообщений на своем сайте WordPress. Запрещая такие страницы, как /wp-admin/ и /wp-content/plugins/ , они могут гарантировать, что страницы, которые они ценят, будут иметь приоритет для поисковых роботов.
Создание карт сайта и добавление их в файл robots.txt
WordPress создает собственную общую карту сайта, когда вы создаете с ее помощью блог или веб-сайт. Обычно это можно найти на странице example.wordpress.com/sitemap.xml. Если вы хотите настроить свою карту сайта и создать дополнительные карты сайта, вам следует использовать плагин robots.
txt или SEO WordPress.Вы можете получить доступ к своему плагину на панели инструментов WordPress, и в нем должен быть раздел для включения и редактирования вашей карты сайта. Хорошие плагины позволят вам с легкостью создавать и настраивать дополнительные карты сайта, такие как карта сайта «страницы» и карта сайта «сообщения».
Когда вы настроили карты сайта, просто добавьте их в файл robots.txt следующим образом:
Используйте минималистический подход
Хотя редактирование и оптимизация файла robots.txt для WordPress может быть интересным, это важно иметь минималистский подход «меньше значит больше». Это связано с тем, что если вы запретите страницы на своем сайте, поисковые роботы не смогут искать на этих страницах другие страницы. Это может означать, что ключевые страницы не будут обнаружены, а структурная целостность вашего сайта будет ослаблена с точки зрения ботов поисковых систем.
Также нет необходимости «разрешать» доступ к каждой странице вашего сайта в файле robots.
-
-