Как использовать robots.txt для разрешения или запрета всего
Файл robots.txt — это файл, расположенный в корневом домене.
Это простой текстовый файл, основной целью которого является указание поисковым роботам и поисковым роботам файлов и папок, от которых следует держаться подальше.
Роботы поисковых систем — это программы, которые посещают ваш сайт и переходят по ссылкам на нем, чтобы узнать о ваших страницах. Примером может служить поисковый робот Google, который называется Googlebot.
Обычно боты проверяют файл robots.txt перед посещением вашего сайта. Они делают это, чтобы узнать, разрешено ли им сканировать сайт и есть ли вещи, которых следует избегать.
Файл robots.txt следует поместить в каталог верхнего уровня вашего домена, например, example.com/robots.txt.
Лучший способ отредактировать его — войти на свой веб-хост через бесплатный FTP-клиент, такой как FileZilla, а затем отредактировать файл с помощью текстового редактора, такого как Блокнот (Windows) или TextEdit (Mac).
Если вы не знаете, как войти на свой сервер через FTP, обратитесь в свою хостинговую компанию за инструкциями.
Некоторые плагины, такие как Yoast SEO, также позволяют редактировать файл robots.txt из панели управления WordPress.
Как запретить всем использовать robots.txt
Если вы хотите, чтобы все роботы держались подальше от вашего сайта, то этот код вы должны поместить в свой robots.txt, чтобы запретить все:
User-agent: * Disallow: /
Часть «User-agent: *» означает, что применяется ко всем роботам. Часть «Запретить: /» означает, что она применяется ко всему вашему сайту.
По сути, это сообщит всем роботам и поисковым роботам, что им не разрешен доступ к вашему сайту или его сканирование.
Важно: Запрет всех роботов на действующем веб-сайте может привести к удалению вашего сайта из поисковых систем и потере трафика и доходов. Используйте это, только если вы знаете, что делаете!
Как разрешить все
Robots. txt работает преимущественно путем исключения. Вы исключаете файлы и папки, к которым не хотите получать доступ, все остальное считается разрешенным.
txt работает преимущественно путем исключения. Вы исключаете файлы и папки, к которым не хотите получать доступ, все остальное считается разрешенным.
Если вы хотите, чтобы боты могли сканировать весь ваш сайт, вы можете просто иметь пустой файл или вообще не иметь файла.
Или вы можете поместить это в свой файл robots.txt, чтобы разрешить все:
Агент пользователя: * Disallow:
Это интерпретируется как запрещение ничего, поэтому фактически разрешено все.
Как запретить определенные файлы и папки
Вы можете использовать команду «Запретить:», чтобы заблокировать отдельные файлы и папки.
Вы просто помещаете отдельную строку для каждого файла или папки, которые хотите запретить.
Вот пример:
User-agent: * Запретить: /topsy/ Запретить: /crets/ Запретить: /hidden/file.html
В этом случае разрешено все, кроме двух подпапок и одного файла.
Как запретить определенным ботам
Если вы просто хотите заблокировать сканирование одного конкретного бота, сделайте это следующим образом:
Агент пользователя: Bingbot Запретить: / Пользовательский агент: * Disallow:
Это заблокирует поисковый робот Bing от сканирования вашего сайта, но другим ботам будет разрешено сканировать все.
Вы можете сделать то же самое с Googlebot, используя «User-agent: Googlebot».
Вы также можете запретить определенным ботам доступ к определенным файлам и папкам.
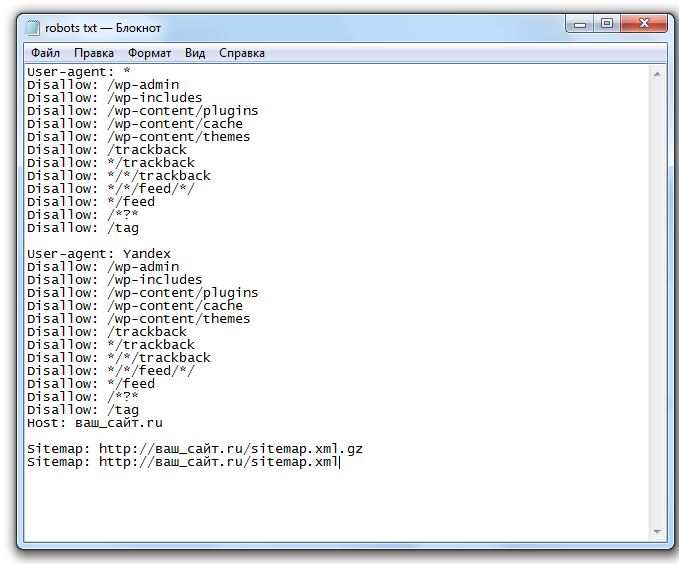
Хороший файл robots.txt для WordPress
Следующий код — это то, что я использую в своем файле robots.txt. Это хорошая настройка по умолчанию для WordPress.
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php Карта сайта: https://searchfacts.com/sitemap.xml
Этот файл robots.txt сообщает ботам, что они могут сканировать все, кроме папки /wp-admin/. Однако им разрешено сканировать один файл в папке /wp-admin/ с именем admin-ajax.php.
Причиной этого параметра является то, что Google Search Console раньше сообщала об ошибке, если не могла просканировать файл admin-ajax.php.
Googlebot — единственный бот, который понимает «Разрешить:» — он используется для разрешения обхода определенного файла внутри запрещенной папки.
Вы также можете использовать строку «Карта сайта:», чтобы сообщить ботам, где найти вашу XML-карту сайта.
Когда использовать noindex вместо robots
Если вы хотите заблокировать показ всего сайта или отдельных страниц в поисковых системах, таких как Google, то robots.txt — не лучший способ сделать это.
Поисковые системы по-прежнему могут индексировать файлы, заблокированные роботами, просто они не будут показывать некоторые полезные метаданные.
Вместо этого в описании результатов поиска будет указано: «Описание этого результата недоступно из-за файла robots.txt этого сайта».
Источник: Круглый стол поисковой системыЕсли вы скрываете файл или папку с robots.txt, но потом кто-то ссылается на него, Google с большой долей вероятности покажет его в результатах поиска только без описания.
В этих случаях лучше использовать тег noindex, чтобы запретить поисковым системам отображать его в результатах поиска.
В WordPress, если вы перейдете в «Настройки» -> «Чтение» и отметите «Запретить поисковым системам индексировать этот сайт», на все ваши страницы будет добавлен тег noindex.
Выглядит так:
Вы также можете использовать бесплатный SEO-плагин, такой как Yoast или The SEO Framework, чтобы не индексировать определенные сообщения, страницы или категории на вашем сайте.
В большинстве случаев noindex лучше блокирует индексирование, чем robots.txt.
Когда вместо этого заблокировать весь сайт
В некоторых случаях может потребоваться заблокировать доступ ко всему сайту как для ботов, так и для людей.
Лучше всего для этого установить пароль на свой сайт. Это можно сделать с помощью бесплатного плагина WordPress под названием «Защищено паролем».
Важные факты о файле robots.txt
Имейте в виду, что роботы могут игнорировать ваш файл robots.txt, особенно вредоносные боты, такие как те, которыми управляют хакеры, ищущие уязвимости в системе безопасности.
Кроме того, если вы пытаетесь скрыть папку со своего веб-сайта, просто поместить ее в файл robots. txt может быть неразумным подходом.
txt может быть неразумным подходом.
Любой может увидеть файл robots.txt, если введет его в свой браузер, и может понять, что вы пытаетесь скрыть таким образом.
На самом деле, вы можете посмотреть на некоторых популярных сайтах, как настроены их файлы robots.txt. Просто попробуйте добавить /robots.txt к URL-адресу домашней страницы ваших любимых веб-сайтов.
Если вы хотите убедиться, что ваш файл robots.txt работает, вы можете протестировать его с помощью Google Search Console. Вот инструкции.
Сообщение на вынос
Файл robots.txt сообщает роботам и поисковым роботам, какие файлы и папки они могут и не могут сканировать.
Его использование может быть полезно для блокировки определенных областей вашего веб-сайта или для предотвращения сканирования вашего сайта определенными ботами.
Если вы собираетесь редактировать файл robots.txt, то будьте осторожны, ведь небольшая ошибка может иметь катастрофические последствия.
Например, если вы неправильно поместите одну косую черту, она может заблокировать всех роботов и буквально удалить весь ваш поисковый трафик, пока это не будет исправлено.
Я работал с большим сайтом до того, как однажды случайно поставил «Disallow: /» в их живой файл robots.txt. Из-за этой маленькой ошибки они потеряли много трафика и доходов.
Файл robots.txt очень мощный, поэтому обращайтесь с ним с осторожностью.
Как запретить всем использовать robots.txt?
Если вы хотите, чтобы все роботы держались подальше от вашего сайта, то этот код вы должны поместить в свой robots.txt, чтобы запретить все:
User-agent: *
Disallow: /
Как разрешить все с помощью robots.txt?
Если вы хотите, чтобы боты могли сканировать весь ваш сайт, вы можете просто иметь пустой файл или вообще не иметь файла.
Или вы можете поместить это в свой файл robots.txt, чтобы разрешить все:
User-agent: *
Disallow:
Как запретить определенные файлы и папки с robots.txt?
Вы просто помещаете отдельную строку для каждого файла или папки, которые хотите запретить.
Вот пример:
User-agent: *
Disallow: /topsy/
Disallow: /crets/
Disallow: /hidden/file. html
html
Как запретить определенных ботов с помощью robots.txt?
Если вы просто хотите заблокировать сканирование одного конкретного бота, например Bing, то вы делаете это так:
User-agent: Bingbot
Disallow: /
Какой файл robots.txt подходит для WordPress?
Следующий код — это то, что я использую в своем файле robots.txt. Это хорошая настройка по умолчанию для WordPress.
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Карта сайта: https://searchfacts.com/sitemap.xml
Как использовать Robots.txt для Разрешить или запретить все
На первый взгляд, файл robots.txt может показаться чем-то, предназначенным только для самых текстовых из нас. Но на самом деле научиться пользоваться файлом robots.txt может и должен освоить каждый.
И если вы заинтересованы в точном контроле над тем, какие области вашего веб-сайта разрешены для роботов поисковых систем (а какие вы можете запретить), то этот ресурс вам нужен.
В этом руководстве мы рассмотрим основные основы, в том числе:
- Что такое файл robots.txt
- Когда использовать файл robots.txt
- Как создать файл robots.txt
- Почему и как реализовать файл robots.txt «Запретить все» (или «Разрешить все»)
Проще говоря, robots.txt — это специальный текстовый файл, расположенный в корневом домене вашего веб-сайта и используемый для связи с роботами поисковых систем. В текстовом файле указывается, к каким веб-страницам/папкам на данном веб-сайте им разрешен доступ.
Возможно, вы захотите заблокировать URL-адреса в robots.txt, чтобы поисковые системы не индексировали определенные веб-страницы, к которым вы не хотите, чтобы онлайн-пользователи имели доступ. Например, файл robots.txt «Запретить» может запретить доступ к веб-страницам, содержащим специальные предложения с истекшим сроком действия, невыпущенные продукты или частный контент только для внутреннего пользования.
Когда дело доходит до решения проблем с дублированием контента или других подобных проблем, использование файла robots.txt для запрета доступа также может поддержать ваши усилия по SEO.
Как именно работает файл robots.txt? Когда робот поисковой системы начинает сканировать ваш веб-сайт, он сначала проверяет наличие файла robots.txt. Если он существует, робот поисковой системы может «понимать», к каким страницам ему не разрешен доступ, и он будет просматривать только разрешенные страницы.
Когда использовать файл robots.txtОсновной причиной использования файла robots.txt является запрет поисковым системам (Google, Bing и т. д.) индексировать определенные веб-страницы или контент.
Эти типы файлов могут быть идеальным вариантом, если вы хотите:
- Управлять сканирующим трафиком (если вас беспокоит, что ваш сервер перегружен)
- Убедитесь, что некоторые части вашего веб-сайта остаются закрытыми (например, страницы администратора или страницы «песочницы», принадлежащие команде разработчиков)
- Избегайте проблем с индексацией
- Заблокировать URL-адрес
- Предотвращение включения дублированного контента в результаты поиска (и отрицательного влияния на SEO)
- Запретить поисковым системам индексировать определенные файлы, например PDF-файлы или изображения
- Удалить медиафайлы из SERP (страниц результатов поисковой системы)
- Запускайте платную рекламу или ссылки, требующие выполнения определенных требований для роботов
Как видите, существует множество причин для использования файла robots.txt. Однако, если вы хотите, чтобы поисковые системы имели доступ к вашему веб-сайту и индексировали его целиком, вам не нужен файл robots.txt.
Как настроить файл robots.txt 1. Убедитесь, что на вашем сайте уже есть файл robots.txt.Во-первых, давайте удостоверимся, что для вашего веб-сайта не существует файла robots.txt. В адресной строке веб-браузера добавьте «/robots.txt» в конце имени вашего домена (например, www.example.com/robots.txt ).
Если отображается пустая страница, у вас нет файла robots.txt. А вот если файлик со списком инструкций обнаружится, то там это одно.
2. Если вы создаете новый файл robots.txt, определите свою общую цель. Одним из наиболее значительных преимуществ файлов robots.txt является то, что они упрощают разрешение или запрет нескольких страниц одновременно, не требуя ручного доступа к коду каждой страницы.
- Полное разрешение: Роботам поисковых систем разрешено сканировать все содержимое (обратите внимание, что, поскольку все URL-адреса разрешены по умолчанию, полное разрешение вообще не нужно)
- Полный запрет: Роботам поисковых систем не разрешено сканировать любой контент (вы хотите запретить поисковым роботам Google доступ к любой части вашего сайта)
- Условное разрешение: Файл устанавливает правила для заблокированного контента, который открыт для поисковых роботов (вы хотите запретить определенные URL-адреса, но не весь веб-сайт)
Как только вы определите желаемую цель, вы готовы настроить файл.
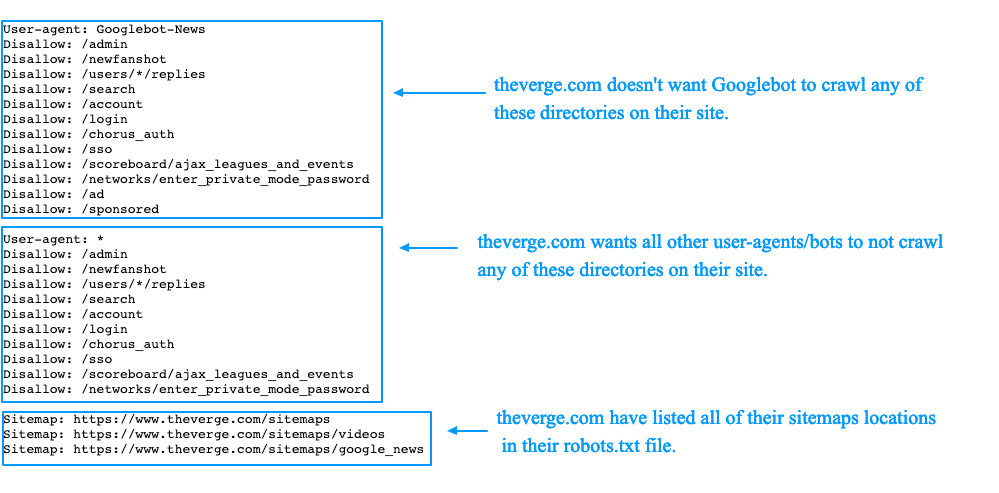
3. Используйте файл robots.txt, чтобы заблокировать выбранные URL-адреса.При создании файла robots.txt вы будете работать с двумя ключевыми элементами:
- Пользовательский агент – это конкретный робот поисковой системы, к которому применяется блокировка URL.
- Строка disallow указывает URL-адреса или файлы, которые вы хотите заблокировать от робота поисковой системы.
Эти строки содержат одну запись в файле robots.txt, что означает, что один файл robots.txt может содержать несколько записей.
Вы можете использовать строку user-agent, чтобы назвать конкретный бот поисковой системы (например, Googlebot Google), или вы можете использовать звездочку (*), чтобы указать, что блокировка должна применяться ко всем поисковым системам: User-agent: *
Затем в строке запрета будет указано, какой именно доступ ограничен. Косая черта ( Disallow: / ) блокирует весь сайт. Или вы можете использовать косую черту, за которой следует конкретная страница, изображение, тип файла или каталог. Например, Disallow: /bad-directory/ заблокирует каталог веб-сайта и его содержимое, а
Соберите все вместе, и вы можете получить запись, которая выглядит примерно так:
User-agent: *
Disallow: /bad-directory/
Каждый URL-адрес, который вы хотите разрешить или запретить, должен располагаться на отдельной строке. Если вы включаете несколько URL-адресов в одну строку, вы можете столкнуться с проблемами, когда сканеры не могут их разделить.
Если вы включаете несколько URL-адресов в одну строку, вы можете столкнуться с проблемами, когда сканеры не могут их разделить.
Вы можете найти множество примеров записей в этом ресурсе от Google, если вы хотите увидеть другие потенциальные варианты.
После того, как вы закончите ввод данных, вам нужно правильно сохранить файл.
Вот как:
- Скопируйте его в текстовый файл или файл блокнота, а затем сохраните как «robots.txt». Используйте только строчные буквы.
- Сохраните файл в каталоге верхнего уровня вашего веб-сайта. Убедитесь, что он размещен в корневом домене и его имя соответствует «robots.txt».
- Добавьте файл в каталог верхнего уровня кода вашего веб-сайта, чтобы его можно было легко сканировать и индексировать.
- Убедитесь, что ваш код имеет правильную структуру (User-agent -> Disallow/Allow -> Host -> Sitemap). Таким образом, роботы поисковых систем будут обращаться к страницам в правильном порядке.
- Вам нужно настроить отдельные файлы для разных субдоменов. Например, для «blog.domain.com» и «domain.com» требуются отдельные файлы.
Наконец, запустите быстрый тест в Google Search Console, чтобы убедиться, что ваш файл robots.txt работает должным образом.
- Откройте инструмент «Тестер», затем выполните быстрое сканирование, чтобы увидеть, не обнаружены ли какие-либо ошибки или предупреждающие сообщения.
- Если все выглядит хорошо, введите URL для проверки в поле внизу страницы.
- Выберите пользовательский агент, который вы хотите протестировать (из раскрывающегося меню).
- Нажмите «ТЕСТ».
- После этого кнопка «ПРОВЕРКА» будет выглядеть как «ПРИНЯТО» или «БЛОКИРОВАНО», что говорит о том, заблокирован ли доступ сканера к этому файлу.
- При необходимости вы можете отредактировать файл и повторно протестировать его.
 Не забывайте, что любые изменения, сделанные в инструменте, должны быть скопированы в код вашего сайта и сохранены там.
Не забывайте, что любые изменения, сделанные в инструменте, должны быть скопированы в код вашего сайта и сохранены там.
Теперь вы знаете, как использовать robots.txt, чтобы запретить доступ, но когда его следует избегать?
Согласно Google, robots.txt не должен быть вашим методом блокировки URL-адресов без рифмы или причины. Этот метод блокировки не заменяет надлежащую разработку и структуру веб-сайта и, безусловно, не является приемлемой заменой мер безопасности. Google предлагает несколько причин для использования различных методов блокировки поисковых роботов, чтобы вы могли решить, какой из них лучше всего соответствует вашим потребностям.
Усовершенствуйте свою SEO-стратегию и дизайн веб-сайта с помощью V Digital Services Вы узнали, что в некоторых ситуациях файл robots.txt может быть невероятно полезен. Однако есть также несколько сценариев, которые не требуют файла robots.