Robots.txt для WordPress
Очищая свои файлы во время последнего редизайна, я понял, что прошло уже несколько лет когда я смотрел файл robots.txt. Я думаю что это не плохо, но когда все изменения структуры сайта и контента проходят через файл robots.txt — его надо смотреть чаще.
Robots.txt за 30 секунд
Во-первых, директива disallow запрещает доступ к определенным частям вашего сайта. А директива allow — разрешает доступ поисковых пауков к определенным файлам и директориям. Поэтому, в основном они используются для того, чтобы поисковые системы (Яндекс, Гугл) могли знать что индексировать а что не при посещении вашего сайта. Вы можете задать специфику индексации в Яндексе и Гугле, а также прописать карту сайта. Robots.txt — простой текстовый файл, но он обладает значительными полномочиями. И мы можем использовать его чтобы получить большое преимущество.
Robots.txt и WordPress
Сайт под управлением WordPress, где вы показываете роботам поисковых систем какие посты и страницы вашего сайта сканировать и индексировать, но не само ядро WP — файлы и каталоги. Также, вы можете быть спокойными что фиды (feeds) и трекбеки (trackbacks) не будут учитываться в результатах поиска. Это также хорошая практика, чтобы объявить здесь карту сайта. Вот хорошая отправная точка для вашей следующей сессии WP на основе robots.txt.
Также, вы можете быть спокойными что фиды (feeds) и трекбеки (trackbacks) не будут учитываться в результатах поиска. Это также хорошая практика, чтобы объявить здесь карту сайта. Вот хорошая отправная точка для вашей следующей сессии WP на основе robots.txt.
Некоторые испытанные и надежные правила были удалены из robots.txt, чтобы удовлетворить новые требования Google, что все JavaScript и CSS файлы не блокируются:
Ко мне часто поступают вопросы про хостинг, которым я пользуюсь и поэтому решил указать хостинг в статье https://sprinthost.ru. Вы можете попробовать попользоваться хостингом 30 дней бесплатно. Чтобы понять, как будет работать Ваш сайт на этом хостинге просто перенести свой сайт (в этом поможет поддержка хостинга бесплатно) и и таким образом сможете понять подходит хостинг Вам или нет. На этом хостинге находятся сайты с 20 000 тысяч посещаемость и сайты чувствуют себя отлично. Рекомендую! Да, если делать оплату на 1 год то получаете скидку 25%. И что мне нравится — тех.
Disallow: /wp-content/ Disallow: /wp-includes/
Это не может быть необходимым, разрешая доступ Гуглу и другим поисковикам к включающим в себя папки, которые содержат некоторые JS и CSS файлы, так что лучше перестраховаться. Видимо, Google настолько непреклонный в этом новом требовании, что он на самом деле наказывает сайты за их не соблюдение. Плохие новости для сотен тысяч владельцев сайтов, которые имеют более важные дела, чем идти в ногу с постоянными изменениями в Google. Обратите внимание, что это все-таки хорошо, чтобы заблокировать /wp-content/ и /wp-includes/ для других ботов — на момент написания этой статьи только Google требует доступ ко всем JS и CSS файлам.
Тем не менее, вот новые и улучшенные правила robots.txt для WordPress:
User-agent: * Disallow: /wp-admin/ Disallow: /trackback/ Disallow: /xmlrpc.php Disallow: /feed/ Sitemap: https://zacompom.ru/sitemap.xml

Это технология «включай и работай», что вы можете настроить, чтобы соответствовать конкретной структуре сайта, а также в качестве собственной стратегии SEO. Чтобы использовать этот код для вашего сайта на WordPress, просто скопируйте и вставьте в пустой файл с именем robots.txt, расположенный в корневом каталоге сайта, например:
https://zacompom.ru/robots.txt
Если посмотреть на содержимое файла robots.txt для сайта zacompom.ru, вы заметите некоторые дополнительные директивы для роботов поисковых систем, которые используются, чтобы запретить доступ к индексированию некоторых плохих ботов. Давайте посмотрим:
User-agent: * Disallow: /wp-admin/ Disallow: /trackback/ Disallow: /xmlrpc.php Disallow: /blackhole/ Disallow: /mint/ Disallow: /feed/ Allow: /tag/mint/ Allow: /tag/feed/ Sitemap: https://zacompom.ru/sitemap.xml
Поисковые пауки не будут заходить в папку /wp-admin/, потому что это им запрещено. А также еще и в trackback, xmlrpc, и feed — они тоже закрыты для них. Затем я добавляю несколько разрешающих директив Allow, чтобы разблокировать доступ к определенным URL-адресам, которые в противном случае запрещены существующими правилами. Я также прописываю местоположение файла sitemap, просто чтобы сделать его доступным по этому адресу.
А также еще и в trackback, xmlrpc, и feed — они тоже закрыты для них. Затем я добавляю несколько разрешающих директив Allow, чтобы разблокировать доступ к определенным URL-адресам, которые в противном случае запрещены существующими правилами. Я также прописываю местоположение файла sitemap, просто чтобы сделать его доступным по этому адресу.
Ранее в robots.txt
Как я уже упоминал, мой первый файл robots.txt, был без изменений в течение нескольких лет (которые просто исчезли в мгновение ока), но они были достаточно эффективны, особенно совместимым с таким пауком как Googlebot. К сожалению, он содержит язык, что лишь немногие из более крупных поисковых систем его понимают (и, следовательно, подчиняются):
User-agent: * Disallow: /mint/ Disallow: /labs/ Disallow: /*/wp-* Disallow: /*/feed/* Disallow: /*/*?s=* Disallow: /*/*.js$ Disallow: /*/*.inc$ Disallow: /transfer/ Disallow: /*/cgi-bin/* Disallow: /*/blackhole/* Disallow: /*/trackback/* Disallow: /*/xmlrpc.php Allow: /*/20*/wp-* Allow: /press/feed/$ Allow: /press/tag/feed/$ Allow: /*/wp-content/online/* Sitemap: https://zacompom.ru/sitemap.xml User-agent: ia_archiver

Видимо, специальный символ в конце (знак доллара $) не распознается роботами, хотя как мне кажется Google понимает его.
Эти структуры может будут поддерживаться в будущем, но сейчас включать их впереди всех нет никаких оснований. Как в примерах приведенных выше, на основе сопоставления с шаблоном можно использовать без подстановочных знаков и знаков доллара ($) позволяет всех совместимых ботов понять Ваши предпочтения.
Юрич:
Занимаюсь созданием сайтов на WordPress более 6 лет. Ранее работал в нескольких веб-студиях и решил делиться своим опытом на данном сайте. Пишите комментарии, буду рад общению.
составляем правильный роботс для WordPress и других систем
Содержание статьи
- Что такое robots.txt
- Зачем закрывают какие-то страницы? Не проще ли открыть всё?
- Где находится Robots
- Для чего нужен этот файл
- Как работают поисковые роботы и как они обрабатывают данный файл
- По-разному ли Яндекс и Google воспринимают этот файл
- Чем может грозить неправильно составленный роботс
- Как создать файл robots.
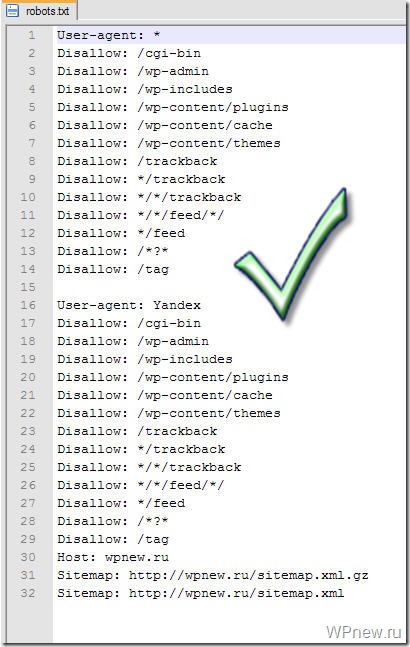 txt
txt - Пример правильного robots.txt для WordPress
- «Универсальный» роботс
- Роботс для Joomla
- Robots для Битрикса
- Как правильно составить роботс
- Что нужно закрывать в нем
- Как закрыть страницы от индексации и использовать Disallow
- Нужно ли использовать директиву Allow?
- Регулярные выражения
- Для чего нужна директива Host
- Что такое Crawl-delay
- Нужно ли указывать Sitemap в роботсе
- Прочие рекомендации к составлению
- Как запретить индексацию всего сайта
- Как проверить, правильно ли составлен файл
Вы знаете, насколько важна индексация — это основа основ в продвижении сайтов. Потому что если ваш сайт не индексируется, то хрен вы какой трафик из поиска получите. Если он индексируется некорректно — то у вас даже при прочих идеальных условиях будет обрубаться часть трафика. Тут все просто — если вы, например, запретили к индексации папку с изображениями, то у вас почти не будет по ним трафа (хотя многие сознательно идут на такой шаг).
Индексация сайта — это процесс, в ходе которого страницы вашего сайта попадают в Яндекс, Гугл или другой поисковик. И после этого пользователь может найти страницу вашего сайта по какому-нибудь запросу.
Управляете вы такой важной штукой, как индексация, именно посредством файла robots.txt. Начну с азов.
Что такое robots.txt
Robots.txt — файл, который говорит поисковой системе, какие разделы и страницы вашего сайта нужно включать в поиск, а какие — нельзя. Ну то есть он говорит не поисковой системе напрямую, а её роботу, который обходит все сайты интернета. Вот что такое роботс. Этот файл всегда создается в универсальном формате .txt, который сможет открыть даже компьютер вашего деда.
Основное назначение – контроль за доступом к публикуемой информации. При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
Использование стандарта осуществляется на добровольной основе владельцами сайтов. Файл должен включать в себя специальные инструкции, на основе которых проводится проверка сайта поисковыми роботами.
Самый простой пример robots:
User-agent: * Allow: /
Данный код открывает весь сайт, структура которого должна быть безупречной.
Зачем закрывают какие-то страницы? Не проще ли открыть всё?
Смотрите — у каждого сайта есть свой лимит, который называется краулинговый бюджет. Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Где находится Robots
Robots традиционно загружают в корневой каталог сайта.
Это корневой каталог, и в нем лежит роботс.
Для загрузки текстового файла обычно используется FTP доступ. Некоторые CMS, например WordPress или Joomla, позволяют создавать robots из админпанели.
Для чего нужен этот файл
А вот для чего:
- запрета на индексацию мусора — страниц и разделов, которые не содержат в себе полезный контент;
- разрешение индексации нужных страниц и разделов;
- чтобы давать разные задачи роботам разных поисковиков — то есть, например, Яндексу разрешить индексировать всё, а Рамблеру — ничего;
- можно также задавать роботам разные категории. Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;
- чтобы показать через директиву Host Яндексу, какое у сайта главное зеркало;
- еще некоторые вебмастера запрещают всяким нехорошим парсерам сканировать сайт с помощью этого файла;
То есть большую часть проблем по индексации он решает. Есть конечно помимо роботса еще и такие инструменты, как метатег роботс (не путайте!), заголовок Last-Modified и другие, но это уже для профессионалов и нужны они лишь в особых случаях. Для решения большинства базовых проблем с индексацией хватает манипуляций с роботсом.
Есть конечно помимо роботса еще и такие инструменты, как метатег роботс (не путайте!), заголовок Last-Modified и другие, но это уже для профессионалов и нужны они лишь в особых случаях. Для решения большинства базовых проблем с индексацией хватает манипуляций с роботсом.
Как работают поисковые роботы и как они обрабатывают данный файл
В большинстве случаев, очень упрощенно, они работают так:
- Обходят Интернет;
- Проверяют, какие документы разрешено индексировать, а какие запрещено;
- Включает разрешенные документы в базу;
- Затем уже другие механизмы решают, какие страницы достаточно полезны для включения в индекс.
Вот ссылка на справку Яндекса о работе поисковых роботов, но там все довольно отдаленно описано.
Справка Google свидетельствует: robots – рекомендация. Файл создается для того, чтобы страница не добавлялась в индекс поисковой системы, а не чтобы она не сканировалась поисковыми системами. Гугл позволяет запрещенной странице попасть в индекс, если на нее направляется ссылка внутри ресурса или с внешнего сайта.

По-разному ли Яндекс и Google воспринимают этот файл
Многие прописывают для роботов разных поисковиков разные директивы. Даже если список этих директив ничем не отличается.
Наверное, это для того, чтобы выразить уважение к Господину Поисковику. Как там раньше делали — «великий князь челом бьет… и просит выдать ярлык на княжение». Других соображений по поводу того, зачем разным юзер-агентам прописывают одни и те же директивы, у меня нет, да и вебмастера, так делающие, дать нормальных объяснений своим действиям не могут.
А те, кто может ответить, аргументируют это так: мол, Google не воспринимает директиву Host и поэтому её нужно указывать только для Яндекса, и вот почему, мол, для яндексовского юзер-агента нужны отдельные директивы. Но я скажу так: если какой-то робот не воспринимает какую-то директиву, то он её просто проигнорирует. Так что лично я не вижу смысла указывать одни и те же директивы для разных роботов отдельно. Хотя, отчасти понимаю перестраховщиков.
Хотя, отчасти понимаю перестраховщиков.
Чем может грозить неправильно составленный роботс
Некоторые при создании сайта на WordPress ставят галочку, чтобы система закрывала сайт от индексации (и забывают потом убрать её). Тогда Вордпресс автоматом ставит вам такой роботс, чтобы поисковики не включали ваш сайт в индекс, и это — самая страшная ошибка. Те страницы, на которые вы намерены получать трафик, обязательно должны быть открыты для индексации.
Потом, если вы не закрыли ненужные страницы от индексации, в индекс может попасть, как я уже говорил выше, очень много мусора (ненужных страниц), и они могут занять в индексе место нужных страниц.
Вообще, если вкратце, неправильный роботс грозит вам тем, что часть страниц не попадет в поиск и вы лишитесь части посетителей.
Как создать файл robots.txt
В Блокноте или другом редакторе создаем файл с расширением .txt, чтобы он в итоге назывался robots.txt. Заполняем его правильно (дальше расскажу, как) и загружаем в корень сайта. Готово!
Готово!
Вот тут разработчик сайта Loftblog создает файл с нуля в режиме реального времени и делает настройку роботс:
Пример правильного robots.txt для WordPress
Составить правильный robots.txt для сайта WordPress проще всего. Я сам видел очень много таких роботсов (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Host: znet.ru User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc. php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Sitemap: https://znet.ru/sitemap.xml

Этот роботс для WordPress довольно проверенный. Большую часть задач он выполняет — закрывает версию для печати, файлы админки, результаты поиска и так далее.
«Универсальный» роботс
Если вы ищете какое-то решение, которое подойдет для всех сайтов на всех CMS (или для лендинга), «волшебную таблетку» — такой нет. Для всех CMS одинаково хорошо подойдет лишь решение, при котором вы говорите разрешить все для индексации:
User-agent: * Allow: /
В остальном — нужно отталкиваться от системы, на которой написан ваш сайт. Потому что у каждой из них уникальная структура и разные разделы/служебные страницы.
Роботс для Joomla
Joomla — ужасный движок, вы ужасный человек, если до сих пор им пользуетесь. Дублей страниц там просто дофига. В основном нормально работает такой код (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
Дублей страниц там просто дофига. В основном нормально работает такой код (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: https://znet.ru/sitemap.xml User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml
Но я вам настоятельно советую отказаться от этого жестокого движка и перейти на WordPress (а если у вас интернет-магазин — на Opencart или Bitrix). Потому что Joomla — это жесть.
Потому что Joomla — это жесть.
Robots для Битрикса
Как составить robots.txt для Битрикс (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /bitrix/ Disallow: /upload/ Disallow: /search/ Allow: /search/map.php Disallow: /club/search/ Disallow: /club/group/search/ Disallow: /club/forum/search/ Disallow: /communication/forum/search/ Disallow: /communication/blog/search.php Disallow: /club/gallery/tags/ Disallow: /examples/my-components/ Disallow: /examples/download/download_private/ Disallow: /auth/ Disallow: /auth.php Disallow: /personal/ Disallow: /communication/forum/user/ Disallow: /e-store/paid/detail.php Disallow: /e-store/affiliates/ Disallow: /club/$ Disallow: /club/messages/ Disallow: /club/log/ Disallow: /content/board/my/ Disallow: /content/links/my/ Disallow: /*/search/ Disallow: /*PAGE_NAME=search Disallow: /*PAGE_NAME=user_post Disallow: /*PAGE_NAME=detail_slide_show Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?print= Disallow: /*&print= Disallow: /*register=yes Disallow: /*forgot_password=yes Disallow: /*change_password=yes Disallow: /*login=yes Disallow: /*logout=yes Disallow: /*auth=yes Disallow: /*action=ADD_TO_COMPARE_LIST Disallow: /*action=DELETE_FROM_COMPARE_LIST Disallow: /*action=ADD2BASKET Disallow: /*action=BUY Disallow: /*print_course=Y Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*index.php$ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml
Как правильно составить роботс
У каждой поисковой системы есть свой User-Agent. Когда вы прописываете юзер-эйджент, то вы обращаетесь к какой-то определенной поисковой системе. Вот названия ботов поисковых систем:
Google: Googlebot
Яндекс: Yandex
Мэйл.ру: Mail.Ru
Yahoo!: Slurp
MSN: MSNBot
Рамблер: StackRambler
Это основные, которые включают ваш сайт в текстовые индексы поисковиков. А вот их вспомогательные роботы:
Googlebot-Mobile — это юзер-агент для мобильных
Googlebot-Image — это для картинок
Mediapartners-Google — этот робот сканирует содержание обьявлений AdSense
Adsbot-Google — это для качества целевых страниц AdWords
MSNBot-NewsBlogs – это для новостей MSN
Сначала в любом нормальном роботсе идет указание юзер-агента, а потом директивы ему. Юзер-агента мы указываем в первой строке, вот так:
User-agent: Yandex
Это будет обращение к роботу Яндекса. А вот обращение ко всем роботам всех систем сразу:
А вот обращение ко всем роботам всех систем сразу:
User-agent: *
После юзер-агента идут указания, относящиеся именно к нему. Пример:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
Сначала мы прописываем директивы для всех интересующих нас юзер-агентов. Затем дополняем их тем, что нас интересует, и заканчиваем обычно ссылкой на XML-карту сайта:
Sitemap: https://znet.ru/sitemap.xml
А вот что прописывать в директивах — это для каждой CMS, как я уже писал выше, по-разному. Но в принципе можно выделить основные типы страниц, которые нужно закрывать во всех роботсах.
Но в принципе можно выделить основные типы страниц, которые нужно закрывать во всех роботсах.
Что нужно закрывать в нем
Всю эту хрень нужно закрыть от индексации:
- Страницы поиска. Обычно поиск генерирует очень много страниц, которые нам не будут нести трафика;
- Корзина и страница оформления заказа. Обычно они не должны попадать в индекс;
- Страницы пагинации. Некоторые мастера знают, как получать с них трафик, но если вы не профессионал, лучше закройте их;
- Фильтры и сравнение товаров могут генерировать мусорные страницы;
- Страницы регистрации и авторизации. На этих страницах вводится только конфиденциальная информация;
- Системные каталоги и файлы. Каждый ресурс включает в себя административную часть, таблицы CSS, скрипты. В индексе нам это все не нужно;
- Языковые версии, если вы не продвигаетесь в других странах и они нужны вам чисто для информации;
- Версии для печати.
Как закрыть страницы от индексации и использовать Disallow
Вот чтобы закрыть от индексации какой-то тип страниц, нам потребуется она. Disallow – директива для запрета индексации. Чтобы закрыть, допустим, страницу znet.ru/page.html на своем блоге, я должен добавить в роботс:
Disallow – директива для запрета индексации. Чтобы закрыть, допустим, страницу znet.ru/page.html на своем блоге, я должен добавить в роботс:
Disallow: /page.html
А если мне нужно закрыть все страницы, которые начинаются с https://znet.ru/instrumenty/? То есть страницы https://znet.ru/instrumenty/1.html, https://znet.ru/instrumenty/2.html и другие? Тогда я добавляю такую строку в роботс:
Disallow: /instrumenty/
Короче, это самая нужная директива.
Нужно ли использовать директиву Allow?
Крайне редко ей пользуюсь. Вообще, она нужна для того, чтобы разрешать роботу индексировать определенные страницы. Но он индексирует все, что не запрещено. Так что Allow я почти не использую. За исключением редких случаев, например, таких:
Допустим, у меня в роботсе закрыта категория /instrumenty/. Но страницу https://znet.ru/instrumenty/44.html я должен открыть для индексации. Тогда у меня в роботс тхт будет написано так:
Disallow: /instrumenty/ Allow: /instrumenty/44.html
В таком случае проблема будет решена. Как пишет Яндекс, «При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow». Короче, Allow я использую тогда, когда нужно перебить требования какой-то из директив Disallow.
Регулярные выражения
Когда прописываем директивы, мы можем использовать спецсимволы * и $ для создания регулярных выражений. Для чего они нужны? Давайте на практике рассмотрим:
User-agent: Yandex Disallow: /cgi-bin/*.aspx
Такая директива запретит Яндексу индексировать страницы, которые начинаются на /cgi-bin/ и заканчиваются на .aspx, то есть вот эти страницы:
/cgi-bin/loh.aspx
/cgi-bin/pidr.aspx
И подобные им будут закрыты.
А вот спецсимвол $ «фиксирует» запрет какой-то конкретной страницы. То есть такой код:
User-agent: Yandex Disallow: /example$
Запретит индексировать страницу /example, но не запрещает индексировать страницы /example-user, /example. html и другие. Только конкретную страницу /example.
html и другие. Только конкретную страницу /example.
Для чего нужна директива Host
Если сайт доступен сразу по нескольким адресам, директива Host указывает главное зеркало одного ресурса. Эту директиву распознают только роботы Яндекса, остальные поисковики забивают на нее болт. Пример:
User-agent: Yandex Disallow: /page Host: znet.ru
Host используется в robots только один раз. Если же их будет указано несколько, учитываться будет только первая директива.
Что такое Crawl-delay
Директива Crawl-delay устанавливает минимальное время между завершением загрузки роботом страницы 1 и началом загрузки страницы 2. То есть если у вас в роботсе добавлено такое:
User-agent: Yandex Crawl-delay: 2
То таймаут между загрузками двух страниц составит две секунды.
Это нужно, если ваш сервер плохо выдерживает запросы на загрузку страниц. Но я скажу так: если это так и есть, то ваш сервер — говно, и тут не Crawl-delay нужно устанавливать, а менять сервер.
Нужно ли указывать Sitemap в роботсе
В конце роботса нужно указывать ссылку на сайтмап, да. Я вам скажу, что это очень круто помогает индексации.
Был у меня один сайт, который хреново индексировался месяца полтора, когда я еще только начинал в SEO. Я не мог никак понять, в чем причина. Оказалось, я просто не указал путь к сайтмапу. Когда я это сделал — все нужные страницы через 1 апдейт уже попали в индекс.
Указывается путь к сайтмапу так:
Sitemap: https://znet.ru/sitemap.xml
Это если ваша карта сайта открывается по этому адресу. Если она открывается по другому адресу — прописывайте другой.
Прочие рекомендации к составлению
Рекомендую соблюдать:
- В одной строке — одна директива;
- Без пробелов в начале строк;
- Директива будет работать, только если написана целиком и без лишних знаков;
- Как пишет сам Яндекс, «Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке»;
- Правильный код роботс должен содержать как минимум одну директиву Dissallow.

А вот еще видео для продвинутых с вебмастерской Яндекса:
Как запретить индексацию всего сайта
Вот этот код поможет закрыть сайт от индексации:
User-agent: * Disallow: /
Пригодиться это может, если вы делаете новый сайт, но он еще не готов, и поэтому его лучше закрыть, чтобы он во время доработки не попал под какой-нибудь фильтр АГС.
Как проверить, правильно ли составлен файл
В Яндекс Вебмастере и Гугл Вебмастере есть инструмент, который поможет вам понять, правильно ли составлен роботс. Рекомендую обязательно проверять файл в этих сервисах перед размещением. В Яндекс Вебмастере вы также сможете добавить список страниц, чтобы проверить, разрешены ли они к индексации роботом.
Robots.txt для WordPress | Лучший генератор robots.txt
Генератор robots.txt
| По умолчанию — все роботы: | РазрешеноОтклонено | |
| Задержка сканирования: | По умолчанию — без задержки5 секунд10 секунд20 секунд60 секунд120 секунд | |
| Карта сайта: (оставьте поле пустым, если у вас его нет) | ||
| Поисковые роботы: | Гугл | То же, что и DefaultAllowedRefused |
| Изображение Google | То же, что и DefaultAllowedRefused | |
| Google Мобильный | То же, что и DefaultAllowedRefused | |
| MSN-поиск | То же, что и DefaultAllowedRefused | |
| Яху | То же, что и DefaultAllowedRefused | |
| Яху ММ | То же, что и DefaultAllowedRefused | |
| Блоги Yahoo | То же, что и DefaultAllowedRefused | |
| Аск/Теома | То же, что и DefaultAllowedRefused | |
| Гигавзрыв | То же, что и DefaultAllowedRefused | |
| Проверка ДМОЗ | То же, что и DefaultAllowedRefused | |
| Натч | То же, что и DefaultAllowedRefused | |
| Алекса/Путь назад | То же, что и DefaultAllowedRefused | |
| Байду | То же, что и DefaultAllowedRefused | |
| Навер | То же, что и DefaultAllowedRefused | |
| MSN PicSearch | То же, что и DefaultAllowedRefused | |
| Ограниченные каталоги: | Путь указан относительно корня и должен содержать завершающую косую черту «/» | |
Теперь создайте файл robots. txt в корневом каталоге. Скопируйте текст выше и вставьте в текстовый файл.
txt в корневом каталоге. Скопируйте текст выше и вставьте в текстовый файл.
О генераторе Robots.txt
Беспокоитесь о своем онлайн-контенте, который не хочет индексироваться поисковой системой, но индексируется поисковыми системами? Ну, robots.txt генератор – это удобный инструмент, который впечатляет, если поисковые системы посещают и индексируют ваш сайт. Но в некоторых случаях поисковая система индексирует неверные данные, которые вы не хотите, чтобы люди видели.
Предположим, вы сделали специальные данные для людей, которые подписались на ваш сайт, но из-за некоторых ошибок эти данные доступны и для обычных людей. И иногда ваши конфиденциальные данные, которые вы не хотите, чтобы кто-либо видел, становятся видимыми для многих людей. Чтобы решить эту проблему, вы должны сообщить веб-сайтам о некоторых конкретных файлах и папках, которые необходимо хранить в безопасности, используя метатег. Но большинство поисковых систем не читают все метатеги, поэтому, чтобы быть вдвойне уверенным, вам нужно использовать файл robots. txt.
txt.
Robots.txt — это текстовый файл, который сообщает поисковым роботам, какие страницы следует сохранять конфиденциальными и не просматривать другими людьми. Это текстовый файл, поэтому не сравнивайте его с html-файлом. Иногда robots.txt ошибочно принимают за брандмауэр или любую другую функцию защиты паролем. Robots.txt гарантирует, что необходимые данные, которые веб-владелец хочет сохранить в тайне, будут скрыты. Один из часто задаваемых вопросов о файле robots.txt: , как создать файл robots.txt для SEO 9.0047 ? В этой статье мы ответим вам на этот вопрос.
Пример файла Robots.txt или базовый формат:Robots.txt имеет правильный формат, о котором следует помнить. Если в формате будет допущена какая-либо ошибка, поисковые роботы не будут выполнять никаких задач. Ниже приведен формат файла robots.txt:
.Агент пользователя: [имя агента пользователя]
Запретить: [строка URL не сканируется]
Только учтите, что файл должен быть в текстовом формате.
Пользовательский генератор robots.txt для blogger — это инструмент, который помогает веб-мастерам защитить конфиденциальные данные своих сайтов для индексации в поисковых системах. Другими словами, это помогает в создании файла robots.txt. Это значительно облегчило жизнь владельцам веб-сайтов, поскольку им не нужно самостоятельно создавать весь файл robots.txt. Они могут легко создать файл, выполнив следующие шаги:
- Сначала выберите, хотите ли вы запретить всем роботам или некоторым роботам доступ к вашим файлам.
- Во-вторых, выберите требуемую задержку сканирования. Вы можете выбрать от 5 секунд до 120 секунд.
- Вставьте карту сайта в генератор, если она у вас есть.
- Выберите, какого бота вы хотите сканировать, а какого бота не хотите сканировать на своем сайте.
- Наконец, ограничьте каталоги. Путь должен содержать косую черту «/».
С помощью этих простых шагов вы легко создадите файл robots.txt для своего веб-сайта.
Как оптимизировать файл Robots.txt для улучшения SEO?Если у вас уже есть файл robots.txt, то для обеспечения надлежащей безопасности ваших файлов вам необходимо создать правильно оптимизированный файл robots.txt без ошибок. Файл Robots.txt следует тщательно изучить. Чтобы файл robots.txt был оптимизирован для поисковых систем, вы должны четко решить, что должно сопровождаться разрешающим тегом, а что — запрещающим. Папка с изображениями, папка с содержимым и т. д. должны иметь тег «Разрешить», если вы хотите, чтобы ваши данные были доступны поисковым системам и другим людям. А для тега «Запретить» должны быть указаны такие папки, как «Дубликаты веб-страниц», «Дублированный контент», «Дубликаты папок», «Архивные папки» и т. д.
Как использовать генератор файлов robots.txt для WordPress? Хотя создавать файл Robots. txt в WordPress не требуется. Но для достижения более высокого SEO вам необходимо создать файл robots.txt, чтобы поддерживать стандарты. Вы можете легко создать файл WordPress robots.txt, чтобы запретить поисковым системам доступ к некоторым вашим данным, выполнив следующие действия:
txt в WordPress не требуется. Но для достижения более высокого SEO вам необходимо создать файл robots.txt, чтобы поддерживать стандарты. Вы можете легко создать файл WordPress robots.txt, чтобы запретить поисковым системам доступ к некоторым вашим данным, выполнив следующие действия:
- Сначала войдите в свою панель управления хостингом, например Cloudways. Cloudways — это генератор robots.txt для WordPress.
- После входа в панель управления выберите вкладку « Серверы », расположенную в правом верхнем углу экрана.
- После этого откройте « FileZilla », приложение FTP-сервера, используемое для доступа к документу WordPress. После этого подключите FileZilla к серверу, используя «Master Credentials».
- После подключения к серверу перейдите на вкладку « Приложения ».
- Вернитесь в Cloudways и слева вверху перейдите к « Applications ” вкладка.
- Выберите WordPress из приложений.

- После входа в панель WordPress выберите « Файловый менеджер » на левой вкладке.
- После этого вернитесь в FileZilla и выполните поиск « /applications/[Имя вашей папки]/public_html ».
- Создайте новый текстовый файл и назовите его « Robots.txt ».
- После этого откройте этот файл в любом инструменте для набора текста, таком как Блокнот, Блокнот ++ и т. Д. Поскольку Блокнот встроен, вы можете его использовать.
- Ниже приведен пример создания файла robots.txt для Cloudways:
Агент пользователя: *
Запретить: /admin/
Запретить: /admin/*?*
Запретить: /admin/*?
Запретить: /блог/*?*
Запретить: /блог/*?
Если у вас есть карта сайта, добавьте ее URL-адрес:
«карта сайта: http://www. yoursite.com/sitemap.xml»
yoursite.com/sitemap.xml»
Так как у блоггера в системе есть файл robots.txt, то вам не придется так сильно с этим заморачиваться. Но, некоторых его функций недостаточно. Для этого вы можете легко изменить файл robots.txt в blogger в соответствии с вашими потребностями, выполнив следующие шаги:
- Сначала посетите свой блог blogger.
- После этого перейдите в настройки и нажмите « настройки поиска ».
- На вкладке «Настройки поиска» нажмите « сканеры и индексирование ».
4. Отсюда перейдите на вкладку « Custom robots.txt » и нажмите «Изменить», а затем «Да».
5. После этого вставьте туда свой файл Robots.txt, чтобы добавить дополнительные ограничения в блог. Вы также можете использовать собственный генератор блоггера robots.txt.
6. Затем сохраните настройку. Готово.
Затем сохраните настройку. Готово.
Ниже приведены некоторые шаблоны robots.txt:
- Разрешить все:
Пользователь-агент: *
Запретить:
ИЛИ
Агент пользователя: *
Разрешить: /
- Запретить все:
Агент пользователя: *
Запретить: /
- Запретить определенную папку:
Как создать файл robots.txt с помощью SEO Magnifier?Агент пользователя: *
Запретить: /папка/
Нет ничего сложного в использовании инструмента для создания файлов роботов SEO Magnifier. Просто выполните следующие действия, чтобы создать файл.
- Выберите « разрешить всех » или « заблокировать всех » роботов из опции.
- Выберите « время задержки сканирования ».
- Введите адрес вашего сайта « карта сайта «, например https://yoursite.com/sitemap.xml
- Выберите ваши любимые поисковые роботы, которые вы хотите « разрешить » или « блокировать » отдельно.
- Добавьте любой каталог, который вы хотите ограничить, например, /admin, /uploads и т. д.
- После добавления всей информации просто нажмите » создайте robots.txt » или « создайте и сохраните как robots.txt », и вы сделали это, и просто загрузите этот файл в « корневой каталог веб-сайта ».
Создайте файл robots.txt и активируйте его в WordPress
ЖИВОЙ ЧАТ
Последнее обновление: 8 сентября 2022 г.
Расчетное время чтения: 2 мин.
Основная задача веб-робота — сканирование веб-сайтов и страниц в поисках информации. Они неустанно работают над сбором данных от имени поисковых систем и других приложений. Для некоторых есть веская причина держать страницы подальше от поисковых систем. Хотите ли вы точно настроить доступ к вашему сайту. Или хотите работать над сайтом разработки, не показывая результаты Google. После внедрения файл robots.txt позволяет поисковым роботам знать, какие части они могут собирать информацию.
Создание файла robots.txt
Как один из первых аспектов, проанализированных поисковыми роботами, файл robots.txt может быть реализован на странице (страницах) или на всем сайте. Чтобы поисковые системы не отображали информацию о вашем сайте. В этой статье мы расскажем, как использовать файл robots.txt, а также синтаксис, необходимый для того, чтобы держать этих ботов в страхе.
User-agent: *
Disallow: /
Давайте разберем приведенный ниже код: «user-agent» относится к поисковым роботам, а знак * означает все поисковые роботы. Следовательно, первая строка привлекает внимание, говоря: «Слушайте все поисковые роботы!». Мы переходим ко второй строке, которая позволяет поисковому роботу узнать свое направление. Косая черта (/) не позволяет ботам искать все страницы вашего сайта. В этом случае вы также можете отказаться от сбора информации для одной конкретной страницы. это карта планировки нашего здания. Поскольку дизайн нашего здания не нуждается в поиске, с помощью команды ниже. Я могу сказать всем ботам не указывать индекс фотографии buildinglayout.png, оставив ее доступной для просмотра любому гостю, который захочет ее просмотреть.
Следовательно, первая строка привлекает внимание, говоря: «Слушайте все поисковые роботы!». Мы переходим ко второй строке, которая позволяет поисковому роботу узнать свое направление. Косая черта (/) не позволяет ботам искать все страницы вашего сайта. В этом случае вы также можете отказаться от сбора информации для одной конкретной страницы. это карта планировки нашего здания. Поскольку дизайн нашего здания не нуждается в поиске, с помощью команды ниже. Я могу сказать всем ботам не указывать индекс фотографии buildinglayout.png, оставив ее доступной для просмотра любому гостю, который захочет ее просмотреть.
User-agent: *
Disallow: /buildinglayout.png
И наоборот, если вы хотите, чтобы все поисковые системы собирали информацию обо всех страницах вашего сайта, вы можете оставить раздел Disallow пустым.
User-agent: *
Disallow:
Существует много типов поисковых роботов (они же user-agent), которые можно указать. Ниже приведена диаграмма самых популярных поисковых роботов, за которыми следуют их ассоциации. Кроме того, вы также можете указать этим ботам индексировать определенную страницу, используя Разрешить. показано в примере ниже. Вы можете внедрить эти поисковые роботы в свой файл robots.txt следующим образом:
Кроме того, вы также можете указать этим ботам индексировать определенную страницу, используя Разрешить. показано в примере ниже. Вы можете внедрить эти поисковые роботы в свой файл robots.txt следующим образом:
User-agent:Googlebot
Разрешить: /parkinglotmap.png
Запретить: /buildinglayout.png
Таблица сканеров
В большинстве случаев сайты не поставляются с файлом robots.txt автоматически (и это не требуется) поэтому вы можете создать его с помощью текстового редактора и загрузить файл в свой корневой каталог или любой другой каталог. К счастью, если вы используете популярную CMS, WordPress и его полезный SEO-плагин Yoast, вы увидите раздел в окне администратора для создания файла robots.txt.
Файл Robots.txt в WordPress
После входа в бэкенд WordPress (yourdomain.com/wp-login.php) найдите раздел SEO и выберите Инструменты.
Выберите Редактор файлов в разделе «Инструменты»
После нажатия на ссылку редактора файлов вы увидите страницу, похожую на код, использованный в первой части нашей статьи.