настройки сканирования без бубна — SEO на vc.ru
Как показывает практика, база технического SEO – файл robots.txt, – многими вебмастерами не только заполняется неправильно, но и без понимания, зачем этот файл и как он работает. Статей на эту тему – объективно, тонны, но есть смысл расставить некоторые акценты.
3995 просмотров
Для чего вообще нужен robots.txt
В интернете можно найти много глупых советов по настройкам robots.txt. Люди советуют управлять с его помощью доступами, предлагают какие-то типовые шаблонные списки инструкций, пытаются что-то удалять таким образом из индекса.
robots.txt предназначен для единственной цели: управлять сканированием сайта на базе «Стандарта исключений для роботов». Это не инструмент для управления индексацией, и если вы попытаетесь управлять с его помощью попаданием ваших страниц в индекс, неизбежно получите ошибки и проблемы. И чем больше и сложнее ваш сайт – тем больше будет ошибок. Для управления индексацией используйте предназначенные для этого инструменты:
С его помощью можно указать поисковым роботам, какие URL не должны сканироваться, а какие сканировать можно и нужно. Это не команды: поисковые роботы могут проигнорировать запрещающие и разрешающие директивы, если получат более весомые сигналы это сделать. Простой пример: если на страницу ведёт достаточное количество ссылок, она появится в выдаче – хотя саму страницу поисковик скачивать и не будет.
Это не команды: поисковые роботы могут проигнорировать запрещающие и разрешающие директивы, если получат более весомые сигналы это сделать. Простой пример: если на страницу ведёт достаточное количество ссылок, она появится в выдаче – хотя саму страницу поисковик скачивать и не будет.
Важно понимать: robots.txt – не закон для роботов, а просто список пожеланий с достаточно противоречивой историей. Несмотря на необязательность директив, например, гуглобот не станет сканировать ваш сайт, если сервер ответит технической ошибкой на запрос «роботс». И вместе с тем, легко проигнорирует запреты, если получит сигналы о важности какого-то URL в рамках сайта (наличие ссылок, настройка перенаправлений, постоянный пользовательский трафик и т.п.).
Что не нужно сканировать
Системные папки на сервере
Дубли: сортировки, UTM-метки, фильтры и прочие URL с параметрами
- Страницы пользовательских сессий, результаты поиска по сайту, динамические URL
- Служебные URL
- Административная часть сайта
К чему должен быть обязательный доступ
- Служебные файлы, отвечающие за рендеринг страницы (js, css, шрифты, графика)
Особое внимание обращу на обязательное наличие разрешений на сканирование JS и CSS. Если поисковые системы не смогут отрисовать страницы сайта в том виде, в каком их получает посетитель-человек, это приведёт к следующим проблемам:
Если поисковые системы не смогут отрисовать страницы сайта в том виде, в каком их получает посетитель-человек, это приведёт к следующим проблемам:
Зачем нужны отдельные секции для поисковых роботов
Оставлять единый блок директив для всех поисковых роботов – плохая идея, и вот почему.
Поисковые роботы Яндекса и Гугла в ряде случаев совершенно по-разному воспринимают директивы, потому и что и правила сканирования у них разные. Вот лишь несколько главных отличий.
Яндекс плохо работает с метатегами robots и каноническими адресами. Директивы в robots.txt для него важнее. Если вы разрешите ему сканировать то, что не должно попасть в индекс, он с большой степенью вероятности проигнорирует всё остальное, и может начать ранжировать вовсе не то, что вам надо. Скажем, нецелевую страницу пагинации — просто потому, что ему что-то не понравилось на целевой странице.
- Яндекс использует директивы, которые не признаёт Google, например, Clean-param.

- Хорошая идея — минимально блокировать сканирование для гуглобота, индексацией управляя только на уровне страницы. Таким образом Гугл будет лучше понимать ваш сайт, а алгоритмы там достаточно умные, чтобы и без вашего участия разобраться, что к чему. Если же по логам вы отмечаете ненормальную активность гуглобота там, где не надо – это повод подумать, что не так с сайтом.
- Если гуглобот зайдёт на сайт и не сможет скачать robots.txt, он уйдёт. Яндекс-бот в такой придирчивости не замечен.
Общий принцип: открывайте для Яндекса по необходимости. Для Гугл – по необходимости закрывайте.
Для Яндекса вы должны понимать, что у вас должно быть в индексе. Для Гугл – наоборот, чего в индексе быть не должно.
Активность Яндекс-бота в рунете кратно превышает активность гуглобота, которая в принципе лимитирована. Это ещё одно условие, которое надо учитывать при составлении директив для robots.txt.
Это ещё одно условие, которое надо учитывать при составлении директив для robots.txt.
Можно ли блокировать на уровне robots.txt зловредных ботов и парсеры
Каждый сайт посещает множество роботов, и не все они вам нужны. Это могут быть роботы-парсеры, которые используют ваши конкуренты для извлечения информации, многочисленные SEO-сервисы, которые могут предоставлять информацию о вашем сайте конкурентам и т.п. Пользы для сайта от них нет, а нагрузку на сервер они создают. Стоит ли пытаться запрещать им сканирование в robots.txt?
Нет. Набор инструкций на базе стандарта исключений имеет рекомендательный характер, и фактически ограничить ничего не может. Если вы хотите заблокировать посторонних роботов – делать это надо на уровне сервера. Чаще всего в robots.txt пытаются заблокировать самых известных официальных ботов типа AhrefsBot, MJ12bot, Slurp, SMTBot, SemrushBot, DotBot, BLEXBot и т.п. Смысла это не имеет, но вы можете попробовать.
Что будет, если robots.
Недоступность файла с директивами по техническим причинам (ошибки 5**) может привести к тому, что гуглобот не станет сканировать сайт. Отсутствие же файла приведет к тому, что роботы будут обходить всё подряд и накидают в индекс тонны мусора. Чаще всего это не очень страшно. А вот ошибки в директивах могут привести к достаточно широкому спектру проблем. Вот типовые:
Поисковая система не сможет отрисовать адаптивную вёрстку вашего сайта, потому что не может получить доступ к файлам шаблона, и решит, что сайт не подходит для просмотра на смартфонах.
- Часть контента или оформления не будет просканирована или учтена, если выводится она средствами JS, а доступ к ним заблокирован.
- Если в robots.txt запрещено сканирование страниц, которые вы хотели бы удалить из индекса, деиндексированы они не будут – робот просто не увидит ваших указаний в рамках страницы, а в панели вебмастеров вы увидите соответствующее уведомление («Проиндексировано, несмотря на блокировку в файле robots.

- Без запрета на сканирование определенных страниц (пользовательских, с параметрами) поисковая система будет вносить в индекс явный мусор, который через время будет выбрасывать. В случае Яндекса это может быть чревато переклейкой запросов на нецелевые страницы, рост страниц, рассматриваемых как некачественные, и как следствие – снижения доверия к сайту на уровне хоста.
Ошибки в настройках сканирования – и вот уже поисковому роботу недоступен целый блок, куда выводится портфолио веб-студии.
Простенькие сайты на той же «Тильде» чаще всего вообще не нуждаются в правках robots.txt – там разрешено всё, и нет никаких проблем ни с отрисовкой сайта, ни с попаданием в индекс поискового мусора. Интерпретаторы современных ПС довольно снисходительно относятся к возможным ошибкам, однако надеяться на это не стоит.
Основные правила
Заполнение файла директив должно соответствовать правилам, игнорирование которых может привести к критическим ошибкам сканирования и непредсказуемым багам обхода сайта. Перечислим основные.
Перечислим основные.
Файл может называться только «robots.txt» с названием в нижнем регистре, быть в кодировке UTF-8 без BOM, и находиться в корне сайта.
Sitemap: http://xn--80aswg.xn--p1ai/sitemap.xml- Каждая новая директива начинается с новой строки.
- Блок директив для каждого User-agent отделяется от других блоков пустой строкой. Пустая строка между директивами обрывает список, после пустой строки начинается новый блок.
- Все запрещающие или разрешающие директивы относятся только к боту, указанному для заданного блока.
- Порядок размещения разрешающих и запрещающих директив особого значения не имеет.
 В настоящий момент это свойственно и роботам Яндекса, и Google.
В настоящий момент это свойственно и роботам Яндекса, и Google.
Регулярные выражения и подстановочные знаки
Регулярные выражения и подстановочные знаки значительно упрощают процесс настройки сканирования. Официально они не поддерживаются стандартами, и тем не менее, понимают их все роботы. Ваша задача – составить регулярное выражение, блокирующее сканирование всего поискового мусора и разрешить необходимые URL, а не вносить туда десятки и даже сотни URL (как иногда пытаются делать). Отдельные URL, ненужные в выдаче по каким-то причинам, нужно просто запрещать индексировать метатегом.
Пример заполнения robots.txt в стиле «Знай наших» школы SEO-кунгфу «Раззудись плечо» — и это ещё не весь список
Для формирования регулярных выражений в рамках «роботс» используется всего два знака: * и $.
Знак * означает любую последовательность символов, «что угодно». Примеры.
User-agent: * Disallow: /*?
Это означает, что для любого робота (если для него нет отдельного набора директив) запрещено сканирование любых страниц фильтров.
User-agent: * Allow: */*.jpg*
Разрешено сканирование файлов JPG с любым названием в любой доступной папке сайта, включая кэшированные файлы.
Знак $ соответствует концу заданного URL. Те URL, что содержат какие-то знаки после знака $, могут быть просканированы. Пример:
User-agent: * Disallow: */*.pdf$
Эта директива запрещает сканировать любой файл в формате PDF в рамках сайта. Ещё один пример:
Disallow: */ofis$
Будет заблокирован URL https://сайт-ру/catalog/muzhchinam/ofis
Но URL https://сайт-ру/catalog/muzhchinam/ofis?sort=rate&page=1 будет доступен.
Как составить правильный robots.txt для своего сайта
Как уже было сказано выше, гуглобот не станет сканировать сайт, если не найдёт robots.txt, поэтому для начала можно использовать даже шаблонный «роботс» (как многие и поступают). Однако это явно не оптимальный вариант.
Чтобы составить правильный robots.txt для своего сайта, вы должны чётко понимать два момента:
На первый вопрос вам поможет ответить семантическое ядро и структура сайта, созданная на его основе. Мы не будем разбирать здесь вопросы структурирования.
Мы не будем разбирать здесь вопросы структурирования.
На второй же вопрос вам поможет ответить парсер сайта, способный эмулировать заданных поисковых роботов, показать наглядно, как поисковых робот отрисовывает страницу по актуальным правилам, справляется ли он с рендерингом адаптивной версии сайта и т.п. С этой целью я использую Screaming Frog SEO Spider. Думаю, эти возможности есть и у его конкурентов.
Полноценный рендеринг сайта позволит вам увидеть его глазами поискового робота
Можно начинать парсинг. По окончании запустите Crawl Analysis, и можно приступать к изучению результатов.
Поскольку нас в данном случае интересует список проблем с файлом robots.txt начнём с вкладки Rendered Page — там можно посмотреть, как видит робот выбранную страницу.
Если всё совсем плохо, вы увидите тлен и безнадёжность: отсутствие внятной вёрстки, пустые блоки, абсолютно нечитабельный контент.
Как вариант – контент может быть в основном доступен, просто без ожидаемого дизайна, дырками на месте картинок и т. п. Здесь же можно сразу посмотреть, что именно заблокировано и мешает роботу увидеть сайт так, как видите его вы. Если в списке заблокированных ресурсов вы видите js, css, файлы изображений, веб-шрифты – вносите их в список разрешающих директив.
п. Здесь же можно сразу посмотреть, что именно заблокировано и мешает роботу увидеть сайт так, как видите его вы. Если в списке заблокированных ресурсов вы видите js, css, файлы изображений, веб-шрифты – вносите их в список разрешающих директив.
В левом окне мы видим заблокированные папки, содержащие файлы шаблона. Их отсутствие приводит к тому, что робот видит сайт так, как показано в правом окне.
Внимательно изучите все страницы, которые так или иначе помечены как дубли – по тайтлам, по сходству контента и т.п. Вероятно, среди них действительно могут оказаться дубли и поисковый мусор. Дубли могут быть как чисто техническими (например, товары могут выводиться плиткой, а могут списком), а могут быть и качественными, когда полезного контента на странице недостаточно, и она похожа на другие страницы, такие же некачественные с точки зрения ПС. В данном случае вам предстоит решить, что делать: закрыть мусор от сканирования, запретить индексацию метатегом, или оперативно внести правки и отправить URL на переобход.
На следующем шаге вам предстоит изучить данные из панелей вебмастеров. Достаточно удобно и наглядно это реализовано в Яндекс-Вебмастере. Заходим в «Индексирование», «Страницы в поиске», вкладка «Исключенные» – и внимательно оцениваем URL, помеченные как неканонические, дубли, а также МПК. Среди них, как правило, большую часть представляют страницы сортировок, фильтров, пагинации и т.п. Их чаще всего можно смело вносить в список для запрета на сканирование.
Инструменты для тестирования
Любые внесенные правки должны проверяться с помощью соответствующих инструментов поисковых систем.
В Гугл – https://www.google.com/webmasters/tools/robots-testing-tool
В Яндексе – https://webmaster.yandex.ru/tools/robotstxt/
Принцип действия прост: вы видите актуальную кэшированную версию файла, анализатор, инструмент проверки заданных URL. Если URL заблокирован – вы увидите строку, которая его блокирует.
Заключение
Подытожим основные тезисы.
UPD. Для настроек индексирования сайта рекомендую использовать метатег Robots, HTTP-заголовок X-Robots-Tag, настройки тега Canonical, а также вполне традиционные средства – редиректы, sitemap.xml и т.п.
Robots.txt как создать и правильно настроить
Последнее обновление: 03 ноября 2022 года
24245
Время прочтения: 6 минут
Тэги: Яндекс, Google
О чем статья?
- Зачем нужен robots.txt?
- Основные директивы файла robots.txt
- Как создать robots.txt?
- Как проверить файл?
Кому будет полезна статья?
- Веб-разработчикам.
- Техническим специалистам.
- Оптимизаторам.
- Администраторам и владельцам сайтов.
Поисковые роботы или веб-краулеры постоянно индексируют страницы сайтов, собирают информацию и заносят ее в базы данных поисковых систем. Первый файл, с которого начинается проверка, — это robots.txt. Именно в нем содержится вся необходимая и важная для краулеров информация. В статье мы расскажем, как создать, настроить и проверить robots.txt с помощью доступных инструментов Яндекс и Google.
Первый файл, с которого начинается проверка, — это robots.txt. Именно в нем содержится вся необходимая и важная для краулеров информация. В статье мы расскажем, как создать, настроить и проверить robots.txt с помощью доступных инструментов Яндекс и Google.
Зачем нужен robots.txt?
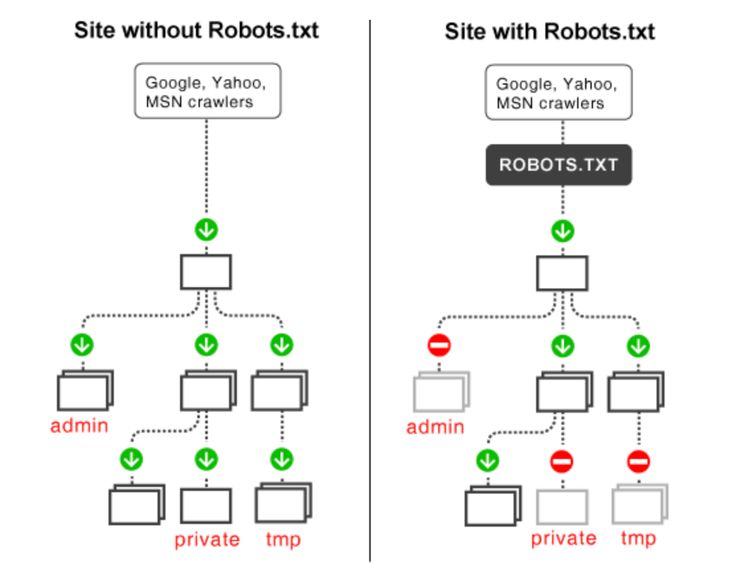
Файл robots.txt — служебный файл, который содержит информацию о том, какие страницы сайта доступны для сканирования поисковыми роботами, а какие им посещать нельзя. Он не является обязательным элементом, но от его наличия зависит скорость индексации страниц и позиции ресурса в поисковой выдаче.
С помощью robots.txt вы можете задать уровень доступа краулеров к сайту и его разделам: полностью запретить индексацию или ограничить сканирование отдельных папок, страниц, файлов, а также закрыть ресурс для роботов, которые не относятся к основным поисковым системам.
Таким образом, создание и правильная настройка robots.txt помогут ускорить процесс индексации сайта, снизить нагрузку на сервер, положительно отразятся на ранжировании сайта в поисковой выдаче.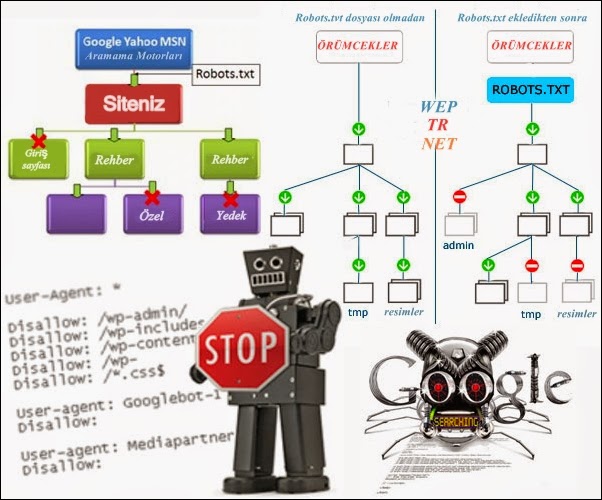
Мнение эксперта
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры»:
«Некоторым сайтам файл robots.txt не нужен совсем или может ограничиваться малым набором директив. Например, при одностраничной структуре ресурса-лендинга зачастую файл robots.txt не требуется — поисковые системы проиндексируют одну страницу, лишние служебные файлы с малой вероятностью будут добавлены в индекс. Небольшое количество правил в robots.txt также можно наблюдать и у больших сайтов с простой структурой, например, у информационных ресурсов. Так, например, один из крупнейших зарубежных блогов по SEO https://backlinko.com/ имеет в robots.txt только две простые директивы:
User-agent: *
Disallow: /tag/
Disallow: /wp-admin/».
Основные директивы файла robots.txt
Чтобы поисковые роботы могли корректно прочитать robots.txt, он должен быть составлен по определенным правилам. Структура служебного файла содержит следующие директивы:
Структура служебного файла содержит следующие директивы:
- User-agent. Директива User-agent определяет уровень открытости сайта для поисковых роботов. Здесь вы можете открыть доступ всем поисковикам или разрешить сканирование только определенным краулерам. Для неограниченного доступа достаточно поставить символ «*», для конкретных роботов нужно добавить отдельные директивы.
Пример:
User-agent: * — сайт доступен для индексации всем краулерам
User-agent: Yandex — доступ открыт только для роботов Яндекса
User-agent: Googlebot — доступ открыт только для роботов Google - Disallow. Директива Disallow определяет, какие страницы сайта необходимо закрыть для индексации. Как правило, для сканирования закрывают весь служебный контент, но при желании вы можете скрыть и любые другие разделы проекта. Подробнее о том, каким страницам и сайтам не нужно индексирование, вы можете прочитать в статье: «Как закрыть сайт от индексации в robots.
 txt». Обратите внимание, что даже если на сайте нет страниц, которые вы хотите закрыть, директиву все равно нужно прописать, но без указания значения. В противном случае поисковые роботы могут некорректно прочитать файл robots.txt.
txt». Обратите внимание, что даже если на сайте нет страниц, которые вы хотите закрыть, директиву все равно нужно прописать, но без указания значения. В противном случае поисковые роботы могут некорректно прочитать файл robots.txt.
Пример 1:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: /wp-admin — служебная папка со всеми вложениями закрыта для индексации
Пример 2:
User-agent: Yandex — правила, размещенные ниже, действуют для роботов Яндекса
Disallow: / — все разделы сайта доступны для индексации - Allow. Директива Allow определяет, какие разделы сайта доступны для сканирования поисковыми роботами. Поскольку все, что не запрещено директивой Disallow, индексируется автоматически, здесь достаточно прописать только исключения из правил. Указывать все доступные краулерам разделы сайта не нужно.
Пример 1:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: / — сайт полностью закрыт для всех поисковых роботов
Allow: /catalog — раздел «Каталог» открыт для всех краулеров
Пример 2:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: / — сайт полностью закрыт для всех поисковых роботов
User-agent: Googlebot — правила, размещенные ниже, действуют для роботов Google
Allow: / — сайт полностью открыт для роботов Google - Sitemap.
 Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Пример:
Sitemap: https://site.ru/sitemap.xml
Как создать robots.txt?
Служебный файл robots.txt можно создать в текстовом редакторе Notepad++ или другой аналогичной программе. Весь текст внутри файла должен быть записан латиницей, русские названия можно перевести с помощью любого Punycode-конвертера. Для кодировки файла выбирайте стандарты ASCII или UTF-8.
Чтобы robots.txt корректно индексировался поисковыми роботами, при создании файла следуйте данным ниже рекомендациям:
- Объединяйте директивы в группы. Чтобы избежать путаницы и сократить время индексации, сгруппируйте директивы блоками для каждого поискового робота и разделите блоки пустой строкой. Так, краулеру не придется сканировать весь файл в поисках нужной инструкции, робот быстро найдет предназначенную для него строку User-agent и, следуя директивам, проверит указанные разделы сайта.

- Учитывайте регистр. Прописывайте имя файла строчными буквами. Если Яндекс информирует, что для его поисковых роботов регистр не имеет значения, то Google рекомендует соблюдать регистр.
- Не указывайте несколько папок в одной директиве. Не объединяйте в одной директиве Disallow несколько папок/файлов. Создавайте отдельную директиву на каждый раздел и файл. Это позволит избежать ошибок при проверке и ускорит процесс индексации.
- Работайте с разными уровнями. В robots.txt вы можете задавать настройки на трех уровнях: сайта, страницы, папки. Используйте эту возможность, если хотите закрыть часть материалов для поисковиков.
- Удаляйте неактуальные директивы. Некоторые директивы robots.txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента).

- Проверьте соответствие sitemap.xml и robots.txt. Файлы sitemap.xml и robots.txt дополняют друг друга. Проверьте, чтобы информация в них совпадала, и sitemap был включен в одноименную директиву.
После создания robots.txt, обратите внимание, чтобы его размер не превышал 32 КБ. При большом объеме файла, он не будет восприниматься поисковыми роботами Яндекс.
Разместите robots.txt в корневой директории сайта рядом с основным файлом index.html. Для этого используйте FTP доступ. Если сайт сделан на CMS, то с файлом можно работать через административную панель.
Как проверить файл?
Удостовериться в том, что файл составлен корректно, можно с помощью инструментов Яндекс.Вебмастер и Google Robots Testing Tool. Поскольку каждая система проверяет robots.txt, основываясь только на собственных критериях, проверку необходимо выполнить в обоих сервисах.
Проверка robots.txt в Яндекс.
 Вебмастер
ВебмастерПри первом запуске Яндекс.Вебмастер необходимо создать личный кабинет, добавить сайт и подтвердить свои права на него. После этого вы получите доступ к инструментам сервиса. Для проверки файла нужно зайти в раздел «Инструменты» подраздел «Анализ robots.txt» и запустить тестирование. Если в ходе проверки сервис обнаружит ошибки, он покажет, какие строки требуют корректировки, и что нужно исправить.
Мнение эксперта
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры»:
«В пункте «Анализ robots.txt» вы также можете «протестировать» написание директив и их влияние на статус индексации. Если Вы сомневаетесь в правильности написания директив, то укажите в поле «Разрешены ли URL?» нужные Вам URL, после чего Вебмастер покажет вам статус индексации этих адресов при указанном robots.txt.».
Проверка robots.txt в Google Robots Testing Tool
Проверять robots.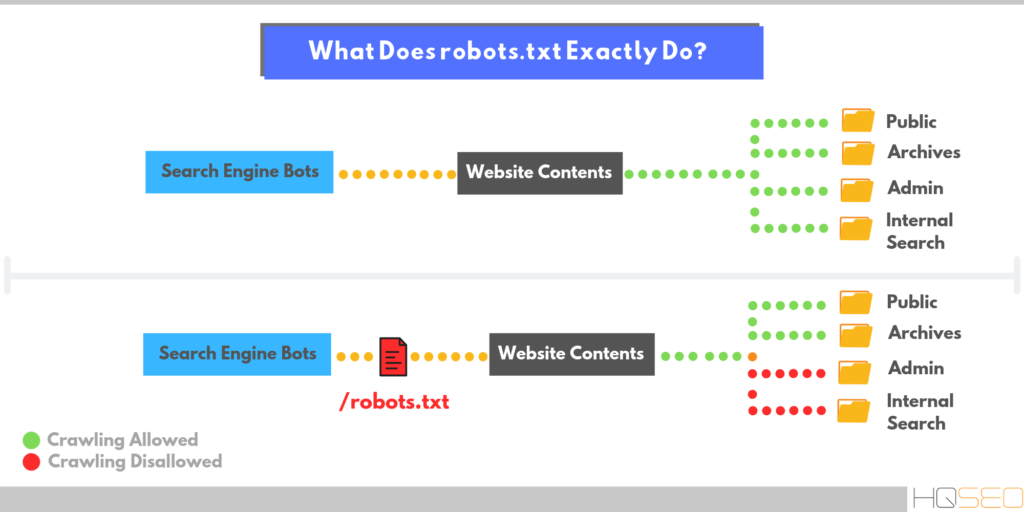 txt в Google можно в административной панели Search Console. Просто перейдите на страницу проверки, и система автоматически протестирует файл. Если на странице вы увидите неактуальную версию robots.txt, нажмите кнопку «Отправить» и действуйте согласно инструкциям поисковой системы. Если Google найдет ошибки, вы можете исправить их в сервисе проверки. Однако учтите, что система не сохраняет правки автоматически. Чтобы исправления не пропали, их нужно внести вручную на хостинге или в административной панели CMS и сохранить.
txt в Google можно в административной панели Search Console. Просто перейдите на страницу проверки, и система автоматически протестирует файл. Если на странице вы увидите неактуальную версию robots.txt, нажмите кнопку «Отправить» и действуйте согласно инструкциям поисковой системы. Если Google найдет ошибки, вы можете исправить их в сервисе проверки. Однако учтите, что система не сохраняет правки автоматически. Чтобы исправления не пропали, их нужно внести вручную на хостинге или в административной панели CMS и сохранить.
Выводы
- Файл robots.txt — это служебный документ, который создается для корректной индексации сайта поисковыми роботами. Он не является обязательным элементом, но от его наличия зависит скорость индексации страниц и позиции ресурса в поисковой выдаче.
- Файл создается в Notepad++ или любом другом текстовом редакторе. Структура robots.txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.
 txt, они должны быть прописаны правильно.
txt, они должны быть прописаны правильно. - Заполнять файл следует по правилам, начиная с кода User-agent. Директивы необходимо объединять в группы, отделяя блоки пустой строкой. С помощью директив Disallow и Allow можно запрещать и разрешать индексацию страниц, папок и отдельных файлов.
- Размер robots.txt не должен превышать 32 КБ. Размещать файл необходимо в корневой директории сайта рядом с основным файлом index.html.
- Проверить robots.txt на наличие ошибок можно с помощью инструментов Яндекс.Вебмастер и Google Robots Testing Tools.
Статья
Изменения в Яндексе на 2022 год: новые метрики качества
#SEO, #Яндекс
СтатьяПродвижение сайта в Яндексе
#SEO, #Яндекс
СтатьяБарри Шварц: «Google Page Experience вряд ли повлияют на ранжирование, но внедрить их стоит». Главное из интервью
Главное из интервью
#SEO, #Google
Статью подготовили:
Прокопьева Ольга. Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры».
Теги: SEO, Яндекс, Google
Best 10 Robots.txt Generator Tools
Когда дело доходит до вашего веб-сайта, важно сделать все возможное (цифровое) вперед. Это может означать, что некоторые страницы будут скрыты от робота Googlebot, пока он сканирует ваш сайт. К счастью, файлы robots.txt позволяют это сделать.
Ниже мы обсудим важность файлов robots.txt и то, как просто сгенерировать robots.txt с помощью бесплатных инструментов.
Что такое файл robots.
 txt?
txt?Прежде чем мы перейдем к супер полезному (не говоря уже о бесплатно !) Инструменты генератора robots.txt, которые вы должны проверить, давайте поговорим о том, что на самом деле представляет собой файл robots.txt и почему он важен.
На вашем веб-сайте могут быть страницы, которые вам не нужны или для сканирования которых требуется робот Googlebot. Файл robots.txt сообщает Google, какие страницы и файлы следует сканировать, а какие пропускать на вашем веб-сайте. Думайте об этом как о инструкции для Googlebot, чтобы сэкономить время.
Вот как это работает.
Робот хочет просканировать URL-адрес веб-сайта, например http://www.coolwebsite.com/welcome.html . Сначала он сканирует http://www.coolwebsite.com/robots.txt и находит:
Раздел запрета указывает Google (или другому указанному роботу поисковой системы) пропустить сканирование определенных элементов или страниц веб-сайта.
Хотите узнать больше? Прочтите наше полезное руководство по Robots.
 txt.
txt.Вот несколько примеров файлов robots.txt некоторых популярных сайтов:
Apple
Файлы robots.txt от Apple включают ряд страниц, посвященных розничным и мобильным покупкам.
Старбакс
В этом примере Starbucks внедрила задержку сканирования. Это показывает, сколько секунд робот должен ждать, прежде чем просканировать страницу. Вы можете настроить скорость сканирования через Google Search Console, но часто в этом нет необходимости.
Disney Plus
Когда бот попадает на веб-сайт Disney Plus, он не будет сканировать ни одну из этих страниц выставления счетов, учетной записи или настроек. Сообщение о запрете дает понять, что бот должен пропустить эти URL-адреса.
Теперь, когда вы знаете, что такое файл robots.txt, давайте поговорим о том, почему он важен.
Почему важен файл robots.txt?
Файл robots.txt служит многим целям SEO. Во-первых, это быстро и четко помогает Google понять, какие страницы на вашем сайте более важны, а какие менее важны.
Файлы robots.txt можно использовать для скрытия таких элементов веб-сайта, как аудиофайлы, от появления в результатах поиска. Обратите внимание: вы не должны использовать файл robots.txt, чтобы скрыть страницы от Google, но его можно использовать для контроля трафика поисковых роботов.
В руководстве по краулинговому бюджету Google четко указано, что вы не хотите, чтобы ваш сервер:
- был перегружен поисковым роботом Google или
- тратил краулинговый бюджет на сканирование неважных или похожих страниц на вашем сайте.
Как создать файл robots.txt? Рад, что вы спросили.
Как создать файл robots.txt
Существует очень специфический способ форматирования файлов robots.txt для Google. На любом веб-сайте разрешено иметь только один файл robots.txt. Первое, что нужно знать, это то, что файл robots.txt необходимо поместить в корень вашего домена.
Подробные инструкции о том, как создавать файлы robots.txt вручную, см. в Центре поиска Google. Мы облегчим вам задачу, предоставив 10 лучших инструментов для создания robots.txt, которые вы можете использовать бесплатно !
в Центре поиска Google. Мы облегчим вам задачу, предоставив 10 лучших инструментов для создания robots.txt, которые вы можете использовать бесплатно !
10 бесплатных инструментов для создания Robots.txt
Давайте начнем с бесплатных генераторов в произвольном порядке!
1. SEO Optimer
Инструмент Seo Optimer предлагает чистый интерфейс для бесплатного создания файла robots.txt. Вы можете установить период задержки сканирования и указать, каким ботам разрешено или запрещено сканировать ваш сайт.
2. Ryte
Бесплатный генератор Ryte имеет три варианта создания файла robots.txt: разрешить все, запретить все и настроить. Опция настройки позволяет вам указать, на каких ботов вы хотите повлиять, и включает пошаговые инструкции.
3. Better Robots.txt (WordPress)
Плагин Better Robots.txt для WordPress помогает улучшить SEO и возможности загрузки вашего сайта. Он поддерживается на 7 языках и может защитить ваши данные и контент от вредоносных ботов. Загрузите этот замечательный плагин для своего сайта WordPress!
Загрузите этот замечательный плагин для своего сайта WordPress!
4. Virtual Robots.txt (WordPress)
Плагин Virtual Robots.txt для WordPress — это автоматизированное решение для создания файла robots.txt для вашего веб-сайта WordPress. По умолчанию плагин блокирует некоторые части вашего веб-сайта и разрешает доступ к частям WordPress, к которым нужны хорошие боты.
5. Small SEO Tools
Бесплатный генератор Small SEO Tools — еще один простой инструмент, который вы можете использовать для создания файла robot.txt. Он использует раскрывающиеся панели для настроек каждого отдельного бота. Вы можете выбрать разрешенный или запрещенный для каждого бота.
6. Web Nots
Инструмент генератора robots.txt Web Nots похож на генератор Small SEO Tools из-за его упрощенного дизайна. Он также использует раскрывающиеся панели и имеет раздел для ограниченных каталогов. Вы можете скачать файл robots.txt, когда закончите.
7.
Генератор отчетов поисковых систем имеет разделы для размещения карты вашего сайта и любых каталогов с ограниченным доступом. Этот бесплатный инструмент — отличный вариант для простого создания файла robots.txt.
8. Инструменты SEO
Бесплатный генератор инструментов SEO — это простое и быстрое решение для создания файла robots.txt для вашего веб-сайта. Вы можете установить задержку сканирования, если хотите, и ввести карту своего сайта. Нажмите «Создать и сохранить как Robots.txt», когда закончите выбирать нужные параметры.
9. SEO To Checker
Генератор SEO To Checker robot.txt — еще один отличный инструмент для создания файла robots.txt. Вы можете добавить карту сайта и обновить настройки для всех поисковых роботов.
10. Google Search Console Robots.txt Tester
В Google Search Console есть отличный тестер robots.txt, который вы можете использовать после создания файла robots. txt. Отправьте свой URL-адрес в инструмент тестирования, чтобы проверить, правильно ли он отформатирован, чтобы заблокировать робота Googlebot от определенных элементов, которые вы хотите скрыть.
txt. Отправьте свой URL-адрес в инструмент тестирования, чтобы проверить, правильно ли он отформатирован, чтобы заблокировать робота Googlebot от определенных элементов, которые вы хотите скрыть.
Повысьте уровень своего веб-сайта с помощью технических советов от Markitors!
Приведенные выше инструменты позволяют легко и быстро создать файл robots.txt. Но здоровый, хорошо работающий сайт — это не только файл robots.txt. Чтобы сделать ваш веб-сайт видимым, необходимо улучшить техническое SEO.
От оценки и повышения скорости сайта до обеспечения правильной индексации — существует множество способов оптимизации вашего сайта. Markitors здесь, чтобы помочь вашему малому бизнесу с техническим SEO. Запишитесь на консультацию сегодня!
Robots.txt — полное руководство
26 сен
26 сен
Содержание
- Определение
- Зачем вам нужен Robots.txt
- Вот некоторые вещи, которые robots.txt будет и не будет делать:
- Понимание синтаксиса robots.
 txt
txt - Результаты инструкции robots.txt
- Полное разрешение
- Полный запрет
- Условное разрешение
- Может ли робот по-прежнему сканировать и игнорировать мой файл robots.txt?
- Могу ли я заблокировать только плохих роботов?
- Каковы лучшие методы SEO при использовании robots.txt?
- Основные правила robots.txt
- Формат и расположение
- Как тогда убедиться, что файл robots.txt не отображает конфиденциальные данные в результатах поиска?
- Не приводит ли перечисление страниц или каталогов в файле robots.txt к непреднамеренному доступу?
- Можете ли вы оптимизировать файл robots.txt для SEO?
- Какие страницы вы можете исключить из индексации?
- Без индекса и без следования
- Директива noindex
- Директива nofollow
- Генерация robots.txt
- Проверка файла robots.txt
- Как добавить robots.
 txt на ваш сайт WordPress
txt на ваш сайт WordPress - Как отредактировать файл robots.txt на Wix
- Как отредактировать файл robots.txt на Shopify
Определение
Robots.txt — это файл в текстовой форме, который указывает поисковым роботам индексировать или не индексировать определенные страницы. Он также известен как привратник для всего вашего сайта. Первая цель сканеров ботов — найти и прочитать файл robots.txt, прежде чем получить доступ к вашей карте сайта или любым страницам или папкам.
С помощью robots.txt вы можете более конкретно:
- Регулировать, как роботы поисковых систем сканируют ваш сайт
- Предоставить определенный доступ
- Помогите поисковым роботам проиндексировать содержимое страницы
- Показать, как предоставлять контент пользователям
Robots.txt является частью протокола исключения роботов (R.E.P), состоящего из директив уровня сайта/страницы/URL. Хотя роботы поисковых систем все еще могут сканировать весь ваш сайт, вы должны помочь им решить, стоят ли определенные страницы времени и усилий.
Зачем вам нужен файл robots.txt
Вашему сайту не нужен файл robots.txt для правильной работы. Основная причина, по которой вам нужен файл robots.txt, заключается в том, что когда боты сканируют вашу страницу, они запрашивают разрешение на сканирование, чтобы они могли попытаться получить информацию о странице для индексации. Кроме того, веб-сайт без файла robots.txt в основном просит поисковые роботы проиндексировать сайт по своему усмотрению. Важно понимать, что боты все равно будут сканировать ваш сайт без файла robots.txt.
Расположение файла robots.txt также важно, поскольку все боты будут искать www.123.com/robots.txt. Если там ничего не найдут, то будут считать, что на сайте нет файла robots.txt и все проиндексируют. Файл должен быть текстовым файлом ASCII или UTF-8. Также важно отметить, что правила чувствительны к регистру.
Вот некоторые вещи, которые robots.txt будет и не будет делать:
- Файл может контролировать доступ поисковых роботов к определенным областям вашего веб-сайта.
 Вы должны быть очень осторожны при настройке robots.txt, так как можно заблокировать индексацию всего веб-сайта.
Вы должны быть очень осторожны при настройке robots.txt, так как можно заблокировать индексацию всего веб-сайта. - Предотвращает индексирование дублированного контента и его появление в результатах поиска.
- В этом файле указывается задержка обхода, чтобы предотвратить перегрузку серверов, когда сканеры загружают несколько фрагментов содержимого одновременно.
Вот некоторые роботы Google, которые могут время от времени сканировать ваш сайт:
| Веб-краулер | Строка агента пользователя |
| Googlebot Новости | Googlebot-Новости |
| Googlebot Изображения | Googlebot-изображение/1.0 |
| Робот Googlebot Видео | Googlebot-Видео/1.0 |
| Google Mobile (рекомендуемый телефон) | SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (совместимый; Googlebot-Mobile/2. 1; +http://www .google.com/bot.html) 1; +http://www .google.com/bot.html) |
| Смартфон Google | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (совместимо; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile AdSense | (совместимо; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Гугл Адсенс | Медиапартнеры-Google |
| Google AdsBot (качество целевой страницы PPC) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Сканер приложений Google (извлечение ресурсов для мобильных устройств) | AdsBot-Google-Mobile-Apps |
Список дополнительных ботов можно найти здесь.
- Файлы помогают указать расположение карт сайта.
- Это также предотвращает индексацию различных файлов на веб-сайте ботами поисковых систем, таких как изображения и PDF-файлы.

Когда бот хочет посетить ваш сайт (например, www.123.com), он сначала проверяет www.123.com/robots.txt и находит:
User-agent: *
Disallow: /
Если вы удалили переднюю черту от Dishow, как в примере ниже,
Пользовательский агент: *
Diswally:
. Боты будут способны и все-таки на сайте. Вот почему важно понимать синтаксис файла robots.txt.
Понимание синтаксиса robots.txt
Синтаксис robots.txt можно рассматривать как «язык» файлов robots.txt. В файле robots.txt вы, скорее всего, встретите 5 распространенных терминов. Это:
- Агент пользователя: Конкретный поисковый робот, которому вы даете инструкции по сканированию (обычно это поисковая система). Список большинства пользовательских агентов можно найти здесь.

- Disallow: Команда, используемая для указания пользовательскому агенту не сканировать определенный URL-адрес. Для каждого URL разрешена только одна строка «Disallow:».
- A llow (применимо только для робота Googlebot): Команда сообщает роботу Googlebot, что он может получить доступ к странице или вложенной папке, даже если ее родительская страница или вложенная папка могут быть запрещены.
- Crawl-delay: Количество миллисекунд, в течение которых сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что Googlebot не подтверждает эту команду, но скорость сканирования можно установить в Google Search Console.
- Карта сайта: Используется для вызова местоположения любой карты сайта в формате XML, связанной с URL-адресом. Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
Результаты инструкций robots.
 txt
txt
Вы ожидаете три результата при вводе инструкций robots.txt:
- Полное разрешение
- Полный запрет
- Условное разрешение
Давайте рассмотрим каждую из них ниже.
Полное разрешение
Этот результат означает, что все содержимое вашего веб-сайта может быть просканировано. Файлы robots.txt предназначены для блокировки сканирования ботами поисковых систем, поэтому эта команда может быть очень важной.
Такой результат может означать, что на вашем веб-сайте вообще нет файла robots.txt. Даже если у вас его нет, поисковые роботы все равно будут искать его на вашем сайте. Если они этого не получат, то будут сканировать все части вашего сайта.
Другой вариант в этом случае — создать файл robots.txt, но оставить его пустым. Когда паук начнет ползать, он идентифицирует и даже прочитает файл robots.txt. Поскольку он ничего там не найдет, он продолжит сканирование остальной части сайта.
Если у вас есть файл robots.txt, и у него есть следующие две строки в нем,
Пользовательский агент:*
Diswalk , найдите файл robots.txt и прочитайте его. Он доберется до второй строки, а затем продолжит сканирование остальной части сайта.
Полный запрет
Здесь содержимое не будет сканироваться и индексироваться. Эта команда выдается этой строкой:
User-agent:*
Disallow:/
Когда мы говорим об отсутствии контента, мы имеем в виду, что ничто с веб-сайта (контент, страницы и т. д.) не может быть просканировано. Это никогда не бывает хорошей идеей.
Разрешение с условием
Это означает, что сканировать можно только определенный контент на веб-сайте.
Условное разрешение имеет следующий формат:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Allow:/
Полный синтаксис robots.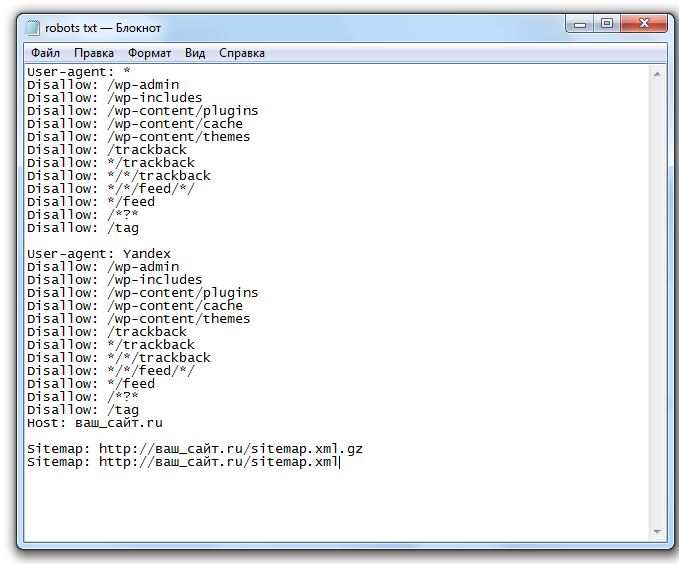 txt можно найти здесь.
txt можно найти здесь.
Обратите внимание, что заблокированные страницы все еще могут быть проиндексированы, даже если вы запретили URL-адрес, как показано на изображении ниже:
Вы можете получить электронное письмо от поисковых систем о том, что ваш URL-адрес был проиндексирован, как показано на снимке экрана выше. Если ваш запрещенный URL-адрес связан с другими сайтами, например якорным текстом в ссылках, он будет проиндексирован. Решение этой проблемы состоит в том, чтобы 1) защитить файлы на сервере паролем, 2) использовать метатег noindex или 3) полностью удалить страницу.
Может ли робот сканировать и игнорировать мой файл robots.txt?
Да. возможно, что робот может обойти robots.txt. Это связано с тем, что Google использует другие факторы, такие как внешняя информация и входящие ссылки, чтобы определить, следует ли индексировать страницу или нет. Если вы не хотите, чтобы страница вообще индексировалась, используйте метатег noindex robots. Другой вариант — использовать HTTP-заголовок X-Robots-Tag.
Другой вариант — использовать HTTP-заголовок X-Robots-Tag.
Могу ли я заблокировать только плохих роботов?
Теоретически можно заблокировать плохих роботов, но на практике это может быть сложно. Давайте рассмотрим несколько способов сделать это:
- Вы можете заблокировать плохого робота, исключив его. Однако вам необходимо знать имя, которое конкретный робот сканирует в поле User-Agent. Затем вам нужно добавить в файл robots.txt раздел, исключающий неверный робот.
- Конфигурация сервера. Это будет работать только в том случае, если плохой робот работает с одного IP-адреса. Конфигурация сервера или сетевой брандмауэр заблокируют доступ вредоносного робота к вашему веб-серверу.
- Использование расширенных конфигураций правил брандмауэра. Они автоматически блокируют доступ к различным IP-адресам, на которых существуют копии вредоносного робота. Хорошим примером ботов, работающих с разными IP-адресами, являются захваченные компьютеры, которые могут даже быть частью более крупной ботнета (узнать больше о ботнете можно здесь).

Если плохой робот работает с одного IP-адреса, вы можете заблокировать его доступ к вашему веб-серверу с помощью конфигурации сервера или сетевого брандмауэра.
Если копии робота работают с несколькими разными IP-адресами, то их становится сложнее заблокировать. Наилучший вариант в этом случае — использовать расширенные конфигурации правил брандмауэра, которые автоматически блокируют доступ к IP-адресам, которые осуществляют много подключений; к сожалению, это может повлиять и на доступ хороших ботов.
Каковы лучшие методы SEO при использовании robots.txt?
В этот момент вам может быть интересно, как ориентироваться в этих очень сложных водах robots.txt. Рассмотрим это подробнее:
- Убедитесь, что вы не блокируете какой-либо контент или разделы вашего сайта, которые вы хотите просканировать.
- Используйте механизм блокировки, отличный от robots.txt, если вы хотите, чтобы вес ссылки передавался со страницы с robots.
 txt (что означает, что она практически заблокирована) в место назначения ссылки.
txt (что означает, что она практически заблокирована) в место назначения ссылки. - Не используйте robots.txt, чтобы предотвратить появление конфиденциальных данных, таких как личная информация пользователя, в результатах поиска. Это может позволить другим страницам ссылаться на страницы, содержащие личную информацию пользователя, что может привести к индексации страницы. В данном случае файл robots.txt был обойден. Другие варианты, которые вы можете изучить здесь, — это защита паролем или мета-директива noindex.
- Нет необходимости указывать директивы для каждого сканера поисковой системы, поскольку большинство пользовательских агентов, если они принадлежат одной и той же поисковой системе, следуют одним и тем же правилам. Google использует Googlebot для поисковых систем и Googlebot Image для поиска изображений. Единственное преимущество знания того, как указать каждый поисковый робот, заключается в том, что вы можете точно настроить, как будет сканироваться контент на вашем сайте.

- Если вы изменили файл robots.txt и хотите, чтобы Google обновил его быстрее, отправьте его непосредственно в Google. Чтобы узнать, как это сделать, нажмите здесь. Важно отметить, что поисковые системы кешируют содержимое robots.txt и обновляют кешированный контент не реже одного раза в день.
Основные рекомендации по robots.txt
Теперь, когда у вас есть общее представление о поисковой оптимизации применительно к robots.txt, о чем следует помнить при использовании robots.txt? В этом разделе мы рассмотрим некоторые рекомендации, которым необходимо следовать при использовании robots.txt, хотя на самом деле важно прочитать весь синтаксис.
Формат и расположение
Текстовый редактор, который вы выбрали для создания файла robots.txt, должен иметь возможность создавать стандартные текстовые файлы ASCII или UTF-8. Использование текстового процессора не является хорошей идеей, так как могут быть добавлены некоторые символы, которые могут повлиять на сканирование.
Хотя для создания файла robots.txt можно использовать практически любой текстовый редактор, настоятельно рекомендуется использовать этот инструмент, поскольку он позволяет проводить тестирование на вашем сайте.
Вот дополнительные рекомендации по формату и местоположению:
- Создаваемый файл должен называться robots.txt, поскольку он чувствителен к регистру. Заглавные буквы не используются.
- На всем сайте может быть только один файл robots.txt.
- Файл robots.txt находится только в одном месте: в корне хоста веб-сайта, к которому он применим. Обратите внимание, что его нельзя поместить в подкаталог. Если ваш веб-сайт http://www.123.com/, то расположение файла robots.txt — http://www.123.com/robots.txt, а не http://www.123.com/pages/. robots.txt. Обратите внимание, что файл robots.txt может применяться к поддоменам (http://website.123.com/robots.txt) и даже к нестандартным портам, таким как http://www.123.
 com: 8181/robots.txt. .
com: 8181/robots.txt. .
Как упоминалось выше, файл robots.txt — не лучший способ предотвратить индексацию конфиденциальной личной информации. Это серьезная проблема, особенно сейчас, когда недавно был введен GDPR. Конфиденциальность данных не должна быть нарушена. Период.
Как в таком случае убедиться, что файл robots.txt не отображает конфиденциальные данные в результатах поиска?
Использование отдельного подкаталога, который не указан в Интернете, предотвратит распространение конфиденциальных материалов. Вы можете убедиться, что он «не включен в список», используя конфигурацию сервера. Просто сохраните все файлы, которые вы не хотите, чтобы robot.txt посещал и индексировал в этом подкаталоге.
Не приводит ли перечисление страниц или каталогов в файле robots.txt к непреднамеренному доступу?
Как упоминалось выше, размещение всех файлов, которые вы не хотите индексировать, в отдельный подкаталог, а затем удаление его из списка с помощью конфигураций сервера должно гарантировать, что они не будут отображаться в результатах поиска. Единственный список, который вы затем сделаете в файле robots.txt, — это имя каталога. Единственный способ получить доступ к этим файлам — это прямая ссылка на один из файлов.
Единственный список, который вы затем сделаете в файле robots.txt, — это имя каталога. Единственный способ получить доступ к этим файлам — это прямая ссылка на один из файлов.
Вот пример:
вместо
Пользовательский агент:*
DISLINGE Используйте
User-Agent:*
Disallow:/norobots/
Затем вам нужно создать каталог «norobots», который включает foo.html и bar.html Обратите внимание, что в конфигурации вашего сервера должно быть четко указано, что не нужно создавать список каталогов для каталога «norobots».
Это может быть не очень безопасный подход, потому что человек или бот, атакующий ваш сайт, все еще может видеть, что у вас есть каталог «norobots», даже если они не могут просматривать файлы внутри каталога. Однако кто-то может опубликовать ссылку на эти файлы на своем веб-сайте или, что еще хуже, ссылка может появиться в общедоступном файле журнала (например, в журнале веб-сервера в качестве реферера). Также возможна неправильная конфигурация сервера, что приводит к отображению списка каталогов.
Также возможна неправильная конфигурация сервера, что приводит к отображению списка каталогов.
Что это значит? Robots.txt не может помочь вам с контролем доступа по той простой причине, что он для этого не предназначен. Хороший пример — знак «Вход запрещен». Есть люди, которые все равно нарушат инструкцию.
Если есть файлы, доступ к которым должен иметь только авторизованный пользователь, конфигурация сервера поможет с аутентификацией. Если вы используете CMS (систему управления контентом), у вас есть элементы управления доступом к отдельным страницам и коллекции ресурсов.
Можете ли вы оптимизировать файл robots.txt для SEO?
Абсолютно. Лучшее руководство по оптимизации robots.txt — это контент сайта. Небольшое напоминание: Robots.txt никогда не следует использовать для блокировки страниц от сканирования ботами поисковых систем. Используйте его только для блокировки разделов вашего сайта, недоступных для публики, например, страницы входа, такие как wp-admin.
Это строка запрета для страницы входа Нила Пателя на один из его веб-сайтов:
Пользовательский агент:*
DISLAIN ваш логин от индексации.
Если есть определенные страницы, которые вы не хотите индексировать, используйте ту же команду, что и выше. Пример:
User-agent:*
Disallow:/page/
Укажите страницу, которую вы не хотите индексировать, после косой черты и закройте ее другой косой чертой. Например:
User-agent:*
Disallow:/page/thank-you/
Какие страницы вы можете исключить из индексации?
- Преднамеренное дублирование контента. Что это значит? Иногда вы намеренно создаете дублированный контент для достижения определенной цели. Хорошим примером является версия определенной веб-страницы для печати. Вы можете использовать robots.
 txt, чтобы заблокировать индексацию печатной версии идентичного контента.
txt, чтобы заблокировать индексацию печатной версии идентичного контента. - Страницы благодарности. Причина, по которой вы хотите заблокировать эту страницу от индексации, проста: предполагается, что это последний шаг в воронке продаж. К тому времени, когда ваши посетители попадают на эту страницу, они должны пройти всю воронку продаж. Если эта страница будет проиндексирована, это означает, что вы можете упустить лидов или получить ложные лиды.
Команда для блокировки такой страницы:
Disallow:/thank-you/
Noindex и NoFollow
Как мы уже говорили в этой статье, использование robots.txt не является 100% гарантией того, что ваша страница не будет проиндексирована. Давайте рассмотрим два способа убедиться, что ваша заблокированная страница действительно не проиндексирована.
Директива noindex
Работает в сочетании с командой disallow. Используйте оба в своей директиве, например:
Disallow:/thank-you/
Noindex:/thank-you/
Директива nofollow
Это специально указывает ботам Google не сканировать ссылки на странице. Это не часть файла robots.txt. Чтобы использовать команду nofollow для блокировки сканирования и индексации страниц, вам необходимо найти исходный код конкретной страницы, которую вы не хотите индексировать.
Это не часть файла robots.txt. Чтобы использовать команду nofollow для блокировки сканирования и индексации страниц, вам необходимо найти исходный код конкретной страницы, которую вы не хотите индексировать.
Вставьте это между открывающим и закрывающим тегами заголовка:
Вы можете использовать как «nofollow», так и «noindex» одновременно. Используйте следующую строку кода:
Генерация robots.txt
необходимые форматы и синтаксис, которые необходимо понимать и соблюдать, можно использовать инструменты, упрощающие процесс. Хороший пример — наш бесплатный генератор robots.txt.
Этот инструмент позволяет вам выбрать тип результата, который вам нужен на вашем веб-сайте, а также файл или каталоги, которые вы хотите добавить. Вы даже можете протестировать свой файл и посмотреть, как обстоят дела у ваших конкурентов.
Проверка файла robots.txt
Вам необходимо протестировать файл robots.txt, чтобы убедиться, что он работает должным образом.
Используйте тестер Google robots.txt.
Для этого войдите в свою учетную запись веб-мастера.
- Затем выберите свой ресурс. В данном случае это ваш сайт.
- Нажмите «сканировать» на левой боковой панели.
- Нажмите «тестер robots.txt».
- Замените любой существующий код новым файлом robots.txt.
- Нажмите «Проверить».
Вы должны увидеть текстовое поле «разрешено», если файл действителен. Для получения дополнительной информации ознакомьтесь с этим подробным руководством по тестированию Google robots.txt.
Если ваш файл действителен, пришло время загрузить его в корневой каталог или сохранить как другой файл robots.txt.
Как добавить robots.txt на ваш сайт WordPress
Чтобы добавить файл robots. txt в ваш файл WordPress, мы рассмотрим плагин и параметры FTP.
txt в ваш файл WordPress, мы рассмотрим плагин и параметры FTP.
Для опции плагина вы можете использовать плагин, такой как All in One SEO Pack
Для этого войдите в свою панель управления WordPress
Прокрутите вниз до тех пор, пока не дойдете до «Плагинов»
Нажмите «Добавить новый»
Перейти на «Поиск плагинов»
Тип «Все в одном пакете SEO»
. Установите его. и активируйте
В разделе «Общие настройки» плагина All in One SEO вы можете настроить правила noindex и nofollow, которые будут включены в файл robots.txt.
Вы можете указать, какие URL-адреса должны быть NOINDEX, NOFOLLOW. Если оставить их неотмеченными, по умолчанию будет проиндексировано:
Чтобы создать расширенные правила в файле robots.txt, щелкните диспетчер функций, а затем нажмите кнопку активации сразу под файлом robots.txt.
Robots. txt теперь отображается сразу под диспетчером функций. Нажмите здесь. Вы увидите раздел «Создать файл robots.txt».
txt теперь отображается сразу под диспетчером функций. Нажмите здесь. Вы увидите раздел «Создать файл robots.txt».
Существует раздел построителя правил, который позволяет вам выбирать и заполнять правила, которые вы хотите для своего сайта, в зависимости от того, что вы хотите не индексировать.
Завершив создание правила, нажмите «Добавить правило».
Правило будет указано в созданной папке robots.txt.
Вы увидите сообщение о том, что «Параметры «Все в одном»» обновлены.
Другой метод, который вы можете использовать, — это загрузить файл robots.txt непосредственно на FTP-клиент (протокол передачи файлов), например FileZilla.
Создав файл robots.txt, вы можете найти и заменить его. Ваш файл robots.txt будет находиться в папке: «/applications/[ИМЯ ПАПКИ]/public_html».
Как редактировать файл robots.txt на Wix
Wix создает файл robots. txt для веб-сайтов, использующих платформу веб-строительства. Чтобы просмотреть его, добавьте «/robots.txt» в свой домен. Файлы, добавленные в robots.txt, связаны со структурой сайтов Wix, например, ссылки noflashhtml, которые не влияют на ценность SEO вашего сайта на базе Wix.
txt для веб-сайтов, использующих платформу веб-строительства. Чтобы просмотреть его, добавьте «/robots.txt» в свой домен. Файлы, добавленные в robots.txt, связаны со структурой сайтов Wix, например, ссылки noflashhtml, которые не влияют на ценность SEO вашего сайта на базе Wix.
Вы не можете редактировать файл robots.txt, если ваш сайт работает на Wix. Вы можете использовать только другие параметры, такие как добавление «тега noindex» к страницам, которые вы не хотите индексировать.
Чтобы создать тег noindex для конкретной страницы:
- Нажмите Меню сайта
- Нажмите на параметр Настройка для этой конкретной страницы
- Выберите Тег SEO (Google)
- Включить Скрыть эту страницу из результатов поиска
Как редактировать файл robots.txt на вашем Shopify
Как и в случае с Wix, Shopify автоматически добавляет нередактируемый файл robots.