настройки сканирования без бубна — SEO на vc.ru
Как показывает практика, база технического SEO – файл robots.txt, – многими вебмастерами не только заполняется неправильно, но и без понимания, зачем этот файл и как он работает. Статей на эту тему – объективно, тонны, но есть смысл расставить некоторые акценты.
9269 просмотров
Для чего вообще нужен robots.txt
В интернете можно найти много глупых советов по настройкам robots.txt. Люди советуют управлять с его помощью доступами, предлагают какие-то типовые шаблонные списки инструкций, пытаются что-то удалять таким образом из индекса.
robots.txt предназначен для единственной цели: управлять сканированием сайта на базе «Стандарта исключений для роботов». Это не инструмент для управления индексацией, и если вы попытаетесь управлять с его помощью попаданием ваших страниц в индекс, неизбежно получите ошибки и проблемы. И чем больше и сложнее ваш сайт – тем больше будет ошибок. Для управления индексацией используйте предназначенные для этого инструменты:
С его помощью можно указать поисковым роботам, какие URL не должны сканироваться, а какие сканировать можно и нужно. Это не команды: поисковые роботы могут проигнорировать запрещающие и разрешающие директивы, если получат более весомые сигналы это сделать. Простой пример: если на страницу ведёт достаточное количество ссылок, она появится в выдаче – хотя саму страницу поисковик скачивать и не будет.
Это не команды: поисковые роботы могут проигнорировать запрещающие и разрешающие директивы, если получат более весомые сигналы это сделать. Простой пример: если на страницу ведёт достаточное количество ссылок, она появится в выдаче – хотя саму страницу поисковик скачивать и не будет.
Важно понимать: robots.txt – не закон для роботов, а просто список пожеланий с достаточно противоречивой историей. Несмотря на необязательность директив, например, гуглобот не станет сканировать ваш сайт, если сервер ответит технической ошибкой на запрос «роботс». И вместе с тем, легко проигнорирует запреты, если получит сигналы о важности какого-то URL в рамках сайта (наличие ссылок, настройка перенаправлений, постоянный пользовательский трафик и т.п.).
Что не нужно сканировать
Системные папки на сервере
Дубли: сортировки, UTM-метки, фильтры и прочие URL с параметрами
- Страницы пользовательских сессий, результаты поиска по сайту, динамические URL
- Служебные URL
- Административная часть сайта
К чему должен быть обязательный доступ
- Служебные файлы, отвечающие за рендеринг страницы (js, css, шрифты, графика)
Особое внимание обращу на обязательное наличие разрешений на сканирование JS и CSS. Если поисковые системы не смогут отрисовать страницы сайта в том виде, в каком их получает посетитель-человек, это приведёт к следующим проблемам:
Если поисковые системы не смогут отрисовать страницы сайта в том виде, в каком их получает посетитель-человек, это приведёт к следующим проблемам:
Зачем нужны отдельные секции для поисковых роботов
Оставлять единый блок директив для всех поисковых роботов – плохая идея, и вот почему.
Поисковые роботы Яндекса и Гугла в ряде случаев совершенно по-разному воспринимают директивы, потому и что и правила сканирования у них разные. Вот лишь несколько главных отличий.
Яндекс плохо работает с метатегами robots и каноническими адресами. Директивы в robots.txt для него важнее. Если вы разрешите ему сканировать то, что не должно попасть в индекс, он с большой степенью вероятности проигнорирует всё остальное, и может начать ранжировать вовсе не то, что вам надо. Скажем, нецелевую страницу пагинации — просто потому, что ему что-то не понравилось на целевой странице.
- Яндекс использует директивы, которые не признаёт Google, например, Clean-param.

- Хорошая идея — минимально блокировать сканирование для гуглобота, индексацией управляя только на уровне страницы. Таким образом Гугл будет лучше понимать ваш сайт, а алгоритмы там достаточно умные, чтобы и без вашего участия разобраться, что к чему. Если же по логам вы отмечаете ненормальную активность гуглобота там, где не надо – это повод подумать, что не так с сайтом.
- Если гуглобот зайдёт на сайт и не сможет скачать robots.txt, он уйдёт. Яндекс-бот в такой придирчивости не замечен.
Общий принцип: открывайте для Яндекса по необходимости. Для Гугл – по необходимости закрывайте.
Для Яндекса вы должны понимать, что у вас должно быть в индексе. Для Гугл – наоборот, чего в индексе быть не должно.
Активность Яндекс-бота в рунете кратно превышает активность гуглобота, которая в принципе лимитирована. Это ещё одно условие, которое надо учитывать при составлении директив для robots.txt.
Это ещё одно условие, которое надо учитывать при составлении директив для robots.txt.
Можно ли блокировать на уровне robots.txt зловредных ботов и парсеры
Каждый сайт посещает множество роботов, и не все они вам нужны. Это могут быть роботы-парсеры, которые используют ваши конкуренты для извлечения информации, многочисленные SEO-сервисы, которые могут предоставлять информацию о вашем сайте конкурентам и т.п. Пользы для сайта от них нет, а нагрузку на сервер они создают. Стоит ли пытаться запрещать им сканирование в robots.txt?
Нет. Набор инструкций на базе стандарта исключений имеет рекомендательный характер, и фактически ограничить ничего не может. Если вы хотите заблокировать посторонних роботов – делать это надо на уровне сервера. Чаще всего в robots.txt пытаются заблокировать самых известных официальных ботов типа AhrefsBot, MJ12bot, Slurp, SMTBot, SemrushBot, DotBot, BLEXBot и т.п. Смысла это не имеет, но вы можете попробовать.
Что будет, если robots. txt не заполнен или заполнен неправильно
txt не заполнен или заполнен неправильно
Недоступность файла с директивами по техническим причинам (ошибки 5**) может привести к тому, что гуглобот не станет сканировать сайт. Отсутствие же файла приведет к тому, что роботы будут обходить всё подряд и накидают в индекс тонны мусора. Чаще всего это не очень страшно. А вот ошибки в директивах могут привести к достаточно широкому спектру проблем. Вот типовые:
Поисковая система не сможет отрисовать адаптивную вёрстку вашего сайта, потому что не может получить доступ к файлам шаблона, и решит, что сайт не подходит для просмотра на смартфонах.
- Часть контента или оформления не будет просканирована или учтена, если выводится она средствами JS, а доступ к ним заблокирован.
- Если в robots.txt запрещено сканирование страниц, которые вы хотели бы удалить из индекса, деиндексированы они не будут – робот просто не увидит ваших указаний в рамках страницы, а в панели вебмастеров вы увидите соответствующее уведомление («Проиндексировано, несмотря на блокировку в файле robots.

- Без запрета на сканирование определенных страниц (пользовательских, с параметрами) поисковая система будет вносить в индекс явный мусор, который через время будет выбрасывать. В случае Яндекса это может быть чревато переклейкой запросов на нецелевые страницы, рост страниц, рассматриваемых как некачественные, и как следствие – снижения доверия к сайту на уровне хоста.
Ошибки в настройках сканирования – и вот уже поисковому роботу недоступен целый блок, куда выводится портфолио веб-студии.
Простенькие сайты на той же «Тильде» чаще всего вообще не нуждаются в правках robots.txt – там разрешено всё, и нет никаких проблем ни с отрисовкой сайта, ни с попаданием в индекс поискового мусора. Интерпретаторы современных ПС довольно снисходительно относятся к возможным ошибкам, однако надеяться на это не стоит.
Основные правила
Заполнение файла директив должно соответствовать правилам, игнорирование которых может привести к критическим ошибкам сканирования и непредсказуемым багам обхода сайта. Перечислим основные.
Перечислим основные.
Файл может называться только «robots.txt» с названием в нижнем регистре, быть в кодировке UTF-8 без BOM, и находиться в корне сайта.
- Никакой кириллицы в robots.txt быть не должно! Если вы используете домен в зоне РФ или кириллические адреса – для настроек robots.txt используйте конвертацию таких URL в пуникод. Например, директива Sitemap в данном случае будет выглядеть примерно так:
- Каждая новая директива начинается с новой строки.
- Блок директив для каждого User-agent отделяется от других блоков пустой строкой. Пустая строка между директивами обрывает список, после пустой строки начинается новый блок.
- Все запрещающие или разрешающие директивы относятся только к боту, указанному для заданного блока.
- Порядок размещения разрешающих и запрещающих директив особого значения не имеет.

Регулярные выражения и подстановочные знаки
Регулярные выражения и подстановочные знаки значительно упрощают процесс настройки сканирования. Официально они не поддерживаются стандартами, и тем не менее, понимают их все роботы. Ваша задача – составить регулярное выражение, блокирующее сканирование всего поискового мусора и разрешить необходимые URL, а не вносить туда десятки и даже сотни URL (как иногда пытаются делать). Отдельные URL, ненужные в выдаче по каким-то причинам, нужно просто запрещать индексировать метатегом.
Пример заполнения robots.txt в стиле «Знай наших» школы SEO-кунгфу «Раззудись плечо» — и это ещё не весь список
Для формирования регулярных выражений в рамках «роботс» используется всего два знака: * и $.
Знак * означает любую последовательность символов, «что угодно». Примеры.
User-agent: * Disallow: /*?
Это означает, что для любого робота (если для него нет отдельного набора директив) запрещено сканирование любых страниц фильтров.![]()
User-agent: * Allow: */*.jpg*
Разрешено сканирование файлов JPG с любым названием в любой доступной папке сайта, включая кэшированные файлы.
Знак $ соответствует концу заданного URL. Те URL, что содержат какие-то знаки после знака $, могут быть просканированы. Пример:
User-agent: * Disallow: */*.pdf$
Эта директива запрещает сканировать любой файл в формате PDF в рамках сайта. Ещё один пример:
Disallow: */ofis$
Будет заблокирован URL https://сайт-ру/catalog/muzhchinam/ofis
Но URL https://сайт-ру/catalog/muzhchinam/ofis?sort=rate&page=1 будет доступен.
Как составить правильный robots.txt для своего сайта
Как уже было сказано выше, гуглобот не станет сканировать сайт, если не найдёт robots.txt, поэтому для начала можно использовать даже шаблонный «роботс» (как многие и поступают). Однако это явно не оптимальный вариант.
Чтобы составить правильный robots.txt для своего сайта, вы должны чётко понимать два момента:
На первый вопрос вам поможет ответить семантическое ядро и структура сайта, созданная на его основе. Мы не будем разбирать здесь вопросы структурирования.
Мы не будем разбирать здесь вопросы структурирования.
На второй же вопрос вам поможет ответить парсер сайта, способный эмулировать заданных поисковых роботов, показать наглядно, как поисковых робот отрисовывает страницу по актуальным правилам, справляется ли он с рендерингом адаптивной версии сайта и т.п. С этой целью я использую Screaming Frog SEO Spider. Думаю, эти возможности есть и у его конкурентов.
Полноценный рендеринг сайта позволит вам увидеть его глазами поискового робота
Можно начинать парсинг. По окончании запустите Crawl Analysis, и можно приступать к изучению результатов.
Поскольку нас в данном случае интересует список проблем с файлом robots.txt начнём с вкладки Rendered Page — там можно посмотреть, как видит робот выбранную страницу.
Если всё совсем плохо, вы увидите тлен и безнадёжность: отсутствие внятной вёрстки, пустые блоки, абсолютно нечитабельный контент.
Как вариант – контент может быть в основном доступен, просто без ожидаемого дизайна, дырками на месте картинок и т. п. Здесь же можно сразу посмотреть, что именно заблокировано и мешает роботу увидеть сайт так, как видите его вы. Если в списке заблокированных ресурсов вы видите js, css, файлы изображений, веб-шрифты – вносите их в список разрешающих директив.
п. Здесь же можно сразу посмотреть, что именно заблокировано и мешает роботу увидеть сайт так, как видите его вы. Если в списке заблокированных ресурсов вы видите js, css, файлы изображений, веб-шрифты – вносите их в список разрешающих директив.
В левом окне мы видим заблокированные папки, содержащие файлы шаблона. Их отсутствие приводит к тому, что робот видит сайт так, как показано в правом окне.
Внимательно изучите все страницы, которые так или иначе помечены как дубли – по тайтлам, по сходству контента и т.п. Вероятно, среди них действительно могут оказаться дубли и поисковый мусор. Дубли могут быть как чисто техническими (например, товары могут выводиться плиткой, а могут списком), а могут быть и качественными, когда полезного контента на странице недостаточно, и она похожа на другие страницы, такие же некачественные с точки зрения ПС. В данном случае вам предстоит решить, что делать: закрыть мусор от сканирования, запретить индексацию метатегом, или оперативно внести правки и отправить URL на переобход.
На следующем шаге вам предстоит изучить данные из панелей вебмастеров. Достаточно удобно и наглядно это реализовано в Яндекс-Вебмастере. Заходим в «Индексирование», «Страницы в поиске», вкладка «Исключенные» – и внимательно оцениваем URL, помеченные как неканонические, дубли, а также МПК. Среди них, как правило, большую часть представляют страницы сортировок, фильтров, пагинации и т.п. Их чаще всего можно смело вносить в список для запрета на сканирование.
Инструменты для тестирования
Любые внесенные правки должны проверяться с помощью соответствующих инструментов поисковых систем.
В Гугл – https://www.google.com/webmasters/tools/robots-testing-tool
В Яндексе – https://webmaster.yandex.ru/tools/robotstxt/
Принцип действия прост: вы видите актуальную кэшированную версию файла, анализатор, инструмент проверки заданных URL. Если URL заблокирован – вы увидите строку, которая его блокирует.
Заключение
Подытожим основные тезисы.
UPD. Для настроек индексирования сайта рекомендую использовать метатег Robots, HTTP-заголовок X-Robots-Tag, настройки тега Canonical, а также вполне традиционные средства – редиректы, sitemap.xml и т.п.
Настройка файла robots.txt — Виртуальный хостинг
robots.txt — это служебный файл с инструкциями для поисковых роботов, размещаемый в корневой директории сайта (/public_html/robots.txt). С его помощью можно запретить индексирование отдельных страниц (или всего сайта), ограничить доступ для определенных роботов, настроить частоту запросов роботов к сайту и др. Корректная настройка robots.txt позволит снизить нагрузку на сайт, создаваемую поисковыми роботами.
Формат robots.txt
- Файл содержит набор правил (директив), каждое из которых записывается с новой строки в формате
имя_директивы: значение(пробел после двоеточия необязателен, но допустим).
- Каждый блок правил начинается с директивы
User-agent. - Внутри блока правил не должно быть пустых строк.
- Новый блок правил отделяется от предыдущего пустой строкой.
- В файле можно использовать примечания, отделяя их знаком
#. - Файл должен называться именно
robots.txt; написание Robots.txt или ROBOTS.TXT будет ошибочным.
Некоторые роботы могут игнорировать отдельные директивы. Например, GoogleBot не учитывает директивы Host и Crawl-Delay; YandexDirect игнорирует общие директивы (заданные как User-agent: *), но учитывает правила, заданные специально для него.
Проверить созданный robots.txt можно в вебмастер-сервисах Yandex или Google или в других подобных сервисах в сети.
Используемые директивы
User-agent
Все блоки правил начинаются с директивы User-agent, в которой указывается название робота, для которого задается правило. Запись вида
Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например, при следующей записи правило будет применено только к основному индексирующему боту Яндекса:
User-agent: YandexBot
Правило будет применено ко всем роботам Яндекса и Google:
User-agent: Yandex
User-agent: Googlebot
Правило будет применено вообще ко всем роботам:
User-agent: *
Disallow и Allow
Директивы используются, чтобы запретить и разрешить доступ к определенным разделам сайта.
Например, можно запретить индексацию всего сайта (Disallow: /), кроме определенного каталога (Allow: /catalog):
User-agent: имя_бота
Disallow: /
Allow: /catalog
Запретить индексацию страниц, начинающихся с /catalog, но разрешить для страниц, начинающихся с /catalog/auto и /catalog/new:
User-agent: имя_бота
Disallow: /catalog
Allow: /catalog/auto
Allow: /catalog/new
В каждой строке указывается только одна директория. Для запрещения (или разрешения) доступа к нескольким каталогам, для каждого требуется отдельная запись.
Для запрещения (или разрешения) доступа к нескольким каталогам, для каждого требуется отдельная запись.
С помощью Disallow можно ограничить доступ к сайту для нежелательных ботов, тем самым снизив создаваемую ими нагрузку. Например, чтобы запретить доступ ко всему сайту для MJ12bot и AhrefsBot — ботов сервиса majestic.com и ahrefs.com — используйте:
User-agent: MJ12bot
User-agent: AhrefsBot
Disallow: /
Аналогичным образом устанавливается блокировка и для других ботов (скажем, DotBot, SemrushBot и других).
Примечания:
- Пустая директива
Disallow:равнозначнаAllow: /, то есть «не запрещать ничего». - В директивах может использоваться символ
$для обозначения точного соответствия указанному параметру. Например, записьDisallow: /catalogаналогичнаDisallow: /catalog *и запретит доступ ко всем страницам с/catalog(/catalog, /catalog1, /catalog-new, /catalog/clothes и др. ).
).
Использование$это изменит.Disallow: /catalog$запретит доступ к/catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
Sitemap
При использовании файла sitemap.xml для описания структуры сайта, можно указать путь к нему с помощью соответствующей директивы:
User-agent: *
Disallow:
Sitemap: https://mydomain.com/путь_к_файлу/mysitemap.xml
Можно перечислить несколько файлов Sitemap, каждый в отдельной строке.
Host
Директива используется для указания роботам Яндекса основного зеркала сайта и полезна, когда сайт доступен по нескольким доменам.
User-agent: Yandex
Disallow: /catalog1$
Host: https://mydomain.com
Примечания:
- Директива
Hostможет быть только одна; если в файле указано несколько, роботом будет учтена только первая. - Необходимо указывать протокол HTTPS, если он используется.
 Если вы используете HTTP, зеркало можно записать в виде mydomain.com
Если вы используете HTTP, зеркало можно записать в виде mydomain.com - Для корректного прочтения директивы, ее нужно указывать в блоке правил
User-agentпосле директивDisallowиAllow.
Crawl-delay
Директива устанавливает минимальный интервал в секундах между обращениями робота к сайту, что может быть полезно для снижения создаваемой роботами нагрузки. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами (разделитель — точка).
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Примечания:
- Для корректного прочтения директивы, ее нужно указывать в блоке правил
User-agentпосле директивDisallowиAllow. - Для Яндекса максимальное значение в
Crawl-delay— 2. Более высокое значение можно установить инструментами Яндекс. Вебмастер.
Вебмастер. - Для Google-бота установить частоту обращений можено в панели вебмастера Search Console.
Clean-param
Директива используется для робота Яндекса. Она позволяет исключить из индексации страницы с динамическими параметрами в URL-адресах (это могут быть идентификаторы сессий, пользователей, рефереров), чтобы робот не индексировал одно и то же содержимое повторно, повышая тем самым нагрузку на сервер.
Например, на сайте есть страницы:
www.mydomain.ru/news.html?&parm1=1&parm2=2
www.mydomain.ru/news.html?&parm2=2&parm3=3
По факту по обоим адресам отдается одна и та же страница — www.mydomain.ru/news.html, при этом в URL присутствуют дополнительные динамические параметры.
Чтобы робот не индексировал каждую подобную страницу, можно использовать директиву:
User-agent: Yandex
Disallow:
Clean-param: parm1&parm2&parm3 /news.html
Через знак & указываются параметры, которые робот должен игнорировать.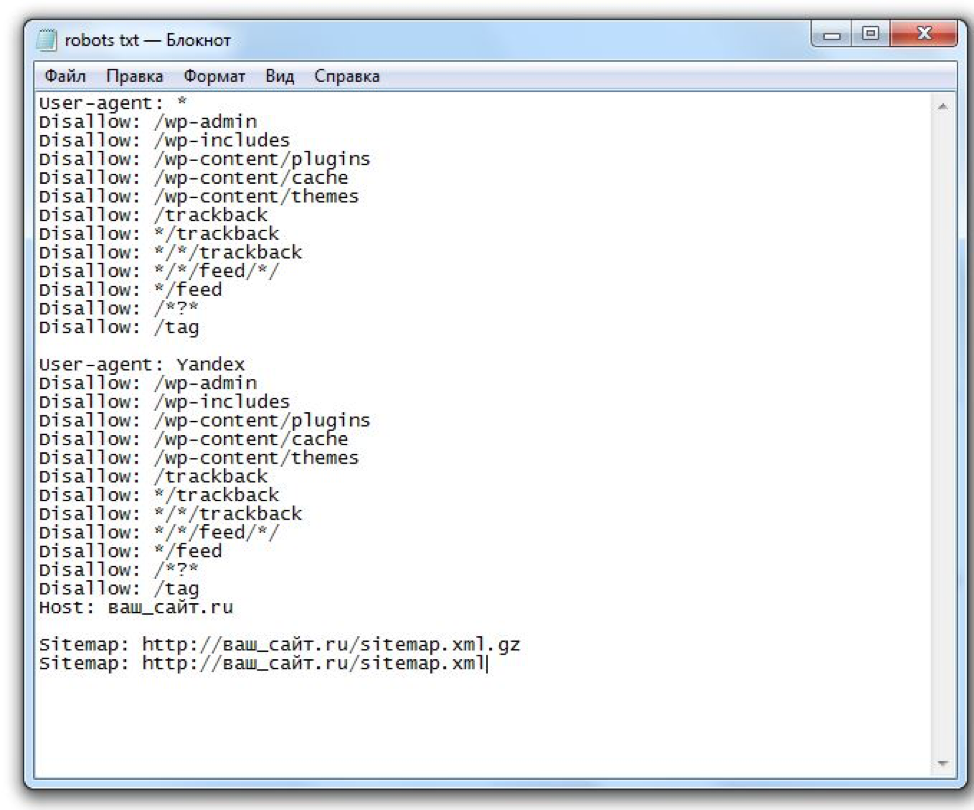 Далее указывается страница, для которой применяется данное правило
Далее указывается страница, для которой применяется данное правило
С более подробной информацией о настройке директивы Clean-param рекомендуем ознакомиться в справочнике Яндекса.
Редактирование файла robots.txt вашего сайта | Справочный центр
Файл robots.txt сообщает поисковым системам, какие страницы вашего сайта включать или пропускать в результатах поиска. Поисковые системы проверяют файл robots.txt вашего сайта, когда сканируют и индексируют ваш сайт. Это не гарантирует, что поисковые системы будут или не будут сканировать страницу или файл, но может помочь предотвратить менее точные попытки индексации.Если вы хотите лучше контролировать запросы на сканирование вашего сайта, вы можете отредактировать файл robots.txt.
Из этой статьи вы узнаете больше о:
Что такое файл robots.txt
Файл robots.txt содержит инструкции по разрешению или запрещению определенных запросов от поисковых систем. Команда «разрешить» сообщает сканерам ссылки, по которым они могут переходить, а команда «запретить» сообщает сканерам ссылки, по которым они не могут переходить. Он также включает URL-адрес файла карты сайта вашего сайта.
Команда «разрешить» сообщает сканерам ссылки, по которым они могут переходить, а команда «запретить» сообщает сканерам ссылки, по которым они не могут переходить. Он также включает URL-адрес файла карты сайта вашего сайта.
Вы можете просмотреть файл robots.txt своего сайта, добавив «/robots.txt» к корневому домену. Например: https://www.mystunningwebsite.com/robots.txt .
Редактирование файла robots.txt
Вы можете редактировать файл robots.txt своего сайта с помощью редактора Robots.txt на панели SEO вашего сайта. Файл robots.txt вашего сайта по умолчанию позволяет роботам поисковых систем получать доступ ко всем страницам вашего сайта. Боты могут не иметь доступа к определенным страницам, если они:
Прежде чем вносить изменения в файл robots.txt, рекомендуем ознакомиться с рекомендациями и ограничениями Google для файлов robots.txt.
Чтобы отредактировать файл robots.txt:
- Перейдите на панель инструментов SEO.

- Выберите Перейдите в редактор Robots.txt в разделе Инструменты и настройки .
- Нажмите Просмотреть файл .
- Добавьте информацию о файле robots.txt, написав директивы под Это ваш текущий файл .
- Нажмите Сохранить изменения .
- Щелкните Сохранить .
Сброс файла robots.txt
Если вы изменили файл robots.txt своего сайта и хотите вернуть его обратно, вы можете восстановить его состояние по умолчанию с помощью редактора Robots.txt на панели инструментов SEO вашего сайта.
Чтобы сбросить файл robots.txt:
- Перейдите на панель инструментов SEO.
- Выберите Перейдите в редактор Robots.txt в разделе Инструменты и настройки .
- Нажмите Просмотреть файл .
- Нажмите Восстановить настройки по умолчанию .

- Нажмите Сброс .
Ошибка robots.txt в Wix Site Inspection или Google Search Console
Иногда вы можете видеть такие ошибки, как Blocked by robots.txt , в своем отчете Wix Site Inspection или в своей учетной записи Google Search Console.
Если вы видите подобную ошибку, вам не нужно редактировать файл robots.txt, особенно если вы никогда не редактировали его раньше. Вместо этого вы должны проверить свои страницы на наличие следующих настроек:
Если вам нужно обновить страницу, Wix автоматически обновит файл robots.txt после публикации страницы. Если вы измените настройки своего сайта, ваш файл robots.txt будет немедленно обновлен.
После внесения изменений поисковые системы обновят свою кешированную версию файла robots.txt при следующем сканировании вашего сайта. Если вам нужно обновить ее раньше, вы можете попробовать отправить свою домашнюю страницу в поисковые системы для переиндексации.
Robots.txt: Руководство для начинающих
Содержание
Contents
Contents
Robots.txt:
Простой файл, содержащий компоненты, используемые для указания страниц веб-сайта, которые не должны (или в некоторых случаях должны быть просканированы) сканироваться роботами поисковых систем. Этот файл необходимо поместить в корневой каталог вашего сайта. Стандарт для этого файла был разработан в 1994 году и известен как стандарт исключения роботов или протокол исключения роботов.
Некоторые распространенные заблуждения о robots.txt:
- Блокирует индексацию контента и его отображение в результатах поиска.
Если вы указываете определенную страницу или файл в файле robots.txt, но URL-адрес этой страницы находится во внешних ресурсах, роботы поисковых систем все равно могут сканировать и индексировать этот внешний URL-адрес и отображать страницу в результатах поиска. Кроме того, не все роботы следуют инструкциям, данным в файлах robots. txt, поэтому некоторые боты все равно могут сканировать и индексировать страницы, упомянутые в файле robots.txt. Если вам нужен дополнительный блок индексации, метатег robots со значением «noindex» в атрибуте контента будет служить таковым при использовании на этих конкретных веб-страницах, как показано ниже:
txt, поэтому некоторые боты все равно могут сканировать и индексировать страницы, упомянутые в файле robots.txt. Если вам нужен дополнительный блок индексации, метатег robots со значением «noindex» в атрибуте контента будет служить таковым при использовании на этих конкретных веб-страницах, как показано ниже:
Подробнее об этом читайте здесь.
- Защищает частное содержимое.
Если у вас есть частный или конфиденциальный контент на сайте, который вы хотите заблокировать от ботов, пожалуйста, не полагайтесь только на robots.txt. Желательно использовать защиту паролем для таких файлов или вообще не публиковать их в сети.
- Гарантирует отсутствие дублирования индексации контента.
Поскольку файл robots.txt не гарантирует, что страница не будет проиндексирована, использовать его для блокировки дублирующегося контента на вашем сайте небезопасно. Если вы используете robots.txt для блокировки дублированного контента, убедитесь, что вы также используете другие надежные методы, такие как тег rel=canonical.
Если вы используете robots.txt для блокировки дублированного контента, убедитесь, что вы также используете другие надежные методы, такие как тег rel=canonical.
- Гарантирует блокировку всех роботов.
В отличие от ботов Google, не все боты являются законными и поэтому могут не следовать инструкциям файла robots.txt, чтобы заблокировать определенный файл от индексации. Единственный способ заблокировать этих нежелательных или вредоносных ботов — заблокировать их доступ к вашему веб-серверу с помощью конфигурации сервера или сетевого брандмауэра, при условии, что бот работает с одного IP-адреса.
Использование robots.txt:
В некоторых случаях использование robots.txt может показаться неэффективным, как указано в предыдущем разделе. Однако у этого файла есть причина, и это его важность для SEO на странице.
Ниже приведены некоторые практические способы использования файла robots.txt:
- Для предотвращения посещения краулерами личных папок.
- Чтобы роботы не сканировали менее примечательный контент на веб-сайте. Это дает им больше времени для сканирования важного контента, который должен отображаться в результатах поиска.
- Чтобы разрешить сканирование вашего сайта только определенным ботам. Это экономит пропускную способность. Поисковые боты по умолчанию запрашивают файлы robots.txt. Если они не найдут его, они сообщат об ошибке 404, которую вы найдете в файлах журнала. Чтобы избежать этого, вы должны как минимум использовать файл robots.txt по умолчанию, то есть пустой файл robots.txt.
- Для предоставления ботам местоположения вашего файла Sitemap. Для этого введите в файле robots.txt директиву, в которой указано местоположение вашего файла Sitemap:
- Карта сайта: http://yoursite.com/sitemap-location.xml
Вы можете добавить это в любом месте файла robots.txt, потому что директива не зависит от строки пользовательского агента. Все, что вам нужно сделать, это указать местоположение вашего файла Sitemap в части sitemap-location. xml URL-адреса. Если у вас несколько файлов Sitemap, вы также можете указать расположение файла индекса Sitemap. Узнайте больше о файлах Sitemap в нашем блоге XML Sitemaps.
xml URL-адреса. Если у вас несколько файлов Sitemap, вы также можете указать расположение файла индекса Sitemap. Узнайте больше о файлах Sitemap в нашем блоге XML Sitemaps.
Ознакомьтесь с нашим Руководством по поисковой оптимизации Robots.txt, чтобы узнать, как работают файлы robots.txt и как их можно использовать для SEO.
Примеры файлов robots.txt:
В файле robots.txt есть два основных элемента: User-agent и Disallow.
Агент пользователя: Агент пользователя чаще всего представляется подстановочным знаком (*), который представляет собой знак звездочки, означающий, что инструкции по блокировке предназначены для всех ботов. Если вы хотите, чтобы определенные боты были заблокированы или разрешены на определенных страницах, вы можете указать имя бота в директиве пользовательского агента.
Disallow: если ничего не указано в disallow, это означает, что боты могут сканировать все страницы на сайте. Чтобы заблокировать определенную страницу, вы должны использовать только один префикс URL для каждого запрета. Вы не можете включать несколько папок или префиксов URL-адресов в элемент disallow в файле robots.txt.
Вы не можете включать несколько папок или префиксов URL-адресов в элемент disallow в файле robots.txt.
Ниже приведены некоторые распространенные варианты использования файлов robots.txt.
Чтобы разрешить всем ботам доступ ко всему сайту (по умолчанию robots.txt) используется следующее:
User-agent:* Disallow:
Чтобы заблокировать весь сервер от ботов, используется этот robots.txt:
User-agent:* Disallow: /
Разрешить одного робота и запретить другим роботам:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Чтобы заблокировать сайт от одного робота:
Агент пользователя: XYZbot Запретить: /
Чтобы заблокировать некоторые части сайта:
Агент пользователя: * Запретить: /tmp/ Запретить: /junk/
Используйте этот файл robots.txt для блокировки всего содержимого определенный тип файла. В этом примере мы исключаем все файлы, которые являются файлами Powerpoint. (ПРИМЕЧАНИЕ: Знак доллара ($) указывает на конец строки):
User-agent: * Disallow: *. ppt$
ppt$
Для блокировки ботов из определенного файла:
User-agent: * Disallow: / каталог/файл.html
Для обхода определенных HTML-документов в каталоге, который заблокирован от ботов, вы можете использовать директиву Allow. Некоторые основные поисковые роботы поддерживают директиву Allow в файле robots.txt. Пример показан ниже:
User-agent: * Disallow: /folder/ Allow: /folder1/myfile.html
Чтобы заблокировать URL-адреса, содержащие определенные строки запроса, которые могут привести к дублированию содержимого, используется приведенный ниже файл robots.txt. В этом случае любой URL, содержащий вопросительный знак (?), блокируется:
User-agent: * Disallow: /*?
Иногда страница будет проиндексирована, даже если вы включите ее в файл robots.txt по таким причинам, как внешняя ссылка. Чтобы полностью заблокировать отображение этой страницы в результатах поиска, вы можете добавить метатеги robots noindex на эти страницы по отдельности. Вы также можете включить тег nofollow и указать ботам не переходить по исходящим ссылкам, вставив следующие коды:
Чтобы страница не индексировалась:
Для того, чтобы страница не индексировалась и по ссылкам не переходили:
ПРИМЕЧАНИЕ: Если вы добавите эти страницы в файл robots. txt, а также добавить указанный выше метатег на страницу, она не будет сканироваться, но страницы могут отображаться в списках результатов поиска только по URL-адресам, поскольку ботам было специально заблокировано чтение метатегов на странице.
txt, а также добавить указанный выше метатег на страницу, она не будет сканироваться, но страницы могут отображаться в списках результатов поиска только по URL-адресам, поскольку ботам было специально заблокировано чтение метатегов на странице.
Еще один важный момент: вы не должны включать URL-адреса, заблокированные в файле robots.txt, в карту сайта XML. Это может произойти, особенно если вы используете отдельные инструменты для создания файла robots.txt и XML-карты сайта. В таких случаях вам, возможно, придется вручную проверить, включены ли эти заблокированные URL-адреса в карту сайта. Вы можете проверить это в своей учетной записи Google Webmaster Tools, если ваш сайт отправлен и проверен в инструменте, а также отправлена ваша карта сайта.
Перейдите на страницу Инструменты для веб-мастеров > Оптимизация > Карты сайта , и если инструмент покажет какую-либо ошибку сканирования в отправленных картах сайта, вы можете дважды проверить, включена ли эта страница в robots. txt.
txt.
Кроме того, в GWT есть инструмент тестирования robots.txt. Он находится в разделе Инструменты для веб-мастеров > Здоровье > Заблокированные URL-адреса .
Этот инструмент — отличный способ научиться пользоваться файлом robots.txt. Вы можете увидеть, как роботы Google будут обрабатывать URL-адреса после того, как вы введете URL-адрес, который хотите протестировать.
Наконец, есть несколько важных моментов, которые следует помнить, когда речь заходит о robots.txt:
- Если вы используете косую черту после каталога или папки, это означает, что robots.txt заблокирует каталог или папку и все, что в ней , как показано ниже:
- Запретить: /junk-directory/
- Убедитесь, что файлы CSS и коды JavaScript, которые отображают расширенное содержимое, не заблокированы в файле robots.txt, так как это будет препятствовать предварительному просмотру фрагментов.
- Проверьте свой синтаксис с помощью Google Webmaster Tool или обратитесь к специалисту, хорошо разбирающемуся в robots.