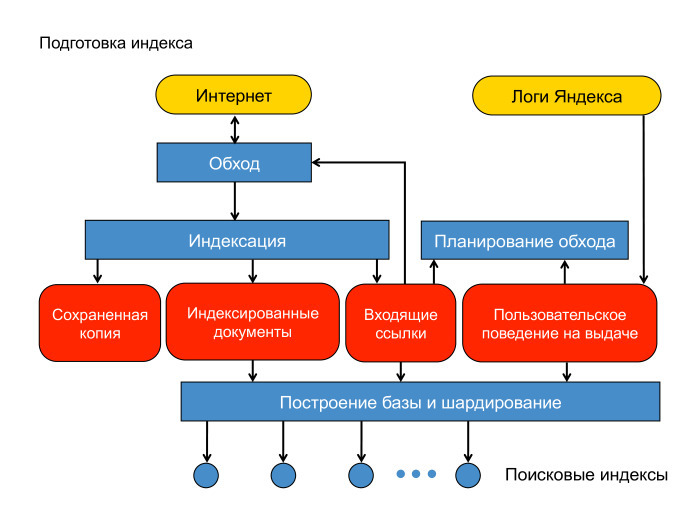
Компания Яндекс — Принципы — Принципы ранжирования поиска Яндекса
Интернет состоит из миллионов сайтов и содержит экзабайты информации. Чтобы люди могли узнать о существовании этой информации и воспользоваться ей, существуют поисковые системы. Они реализуют право человека на доступ к информации — любой информации, которая нужна в данный момент. Поисковая система — это техническое средство, с помощью которого пользователь интернета может найти данные, уже размещенные в сети.
Пользователи ищут в интернете самые разные вещи — от научных работ до эротического контента. Мы считаем, что поисковая система в каждом случае должна показывать подходящие страницы — от статей по определенной теме до сайтов для взрослых. При этом она просто находит ту информацию, которая уже есть в интернете и открыта для всех.
Яндекс не является цензором и не отвечает за содержание других сайтов, которые попадают в поисковый индекс. Об этом было написано в одном из первых документов компании «Лицензия на использование поисковой системы Яндекса», созданном еще в 1997 году, в момент старта www. yandex.ru: «Яндекс индексирует сайты, созданные независимыми людьми и организациями. Мы не отвечаем за качество и содержание страниц, которые вы можете найти при помощи нашей поисковой машины. Нам тоже многое не нравится, однако Яндекс — зеркало Рунета, а не цензор».
yandex.ru: «Яндекс индексирует сайты, созданные независимыми людьми и организациями. Мы не отвечаем за качество и содержание страниц, которые вы можете найти при помощи нашей поисковой машины. Нам тоже многое не нравится, однако Яндекс — зеркало Рунета, а не цензор».
Информация, которая удаляется из интернета, удаляется и из поискового индекса. Поисковые роботы регулярно обходят уже проиндексированные сайты. Когда они обнаруживают, что какая-то страница больше не существует или закрыта для индексирования, она удаляется и из поиска. Для ускорения этого процесса можно воспользоваться формой «Удалить URL».
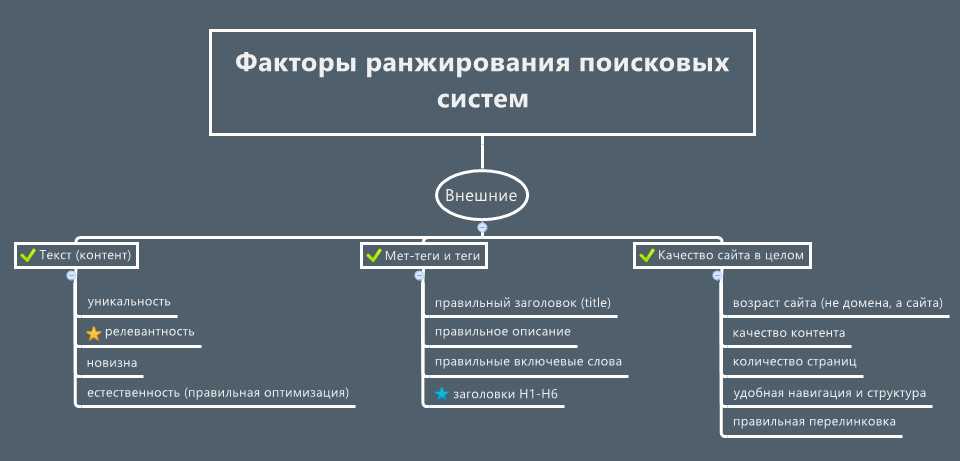
В ответ на запрос, который пользователь ввел в поисковой строке, поисковая система показывает ссылки на известные ей страницы, в тексте которых (а также в метатегах или в ссылках на эти сайты) содержатся слова из запроса. В большинстве случаев таких страниц очень много — настолько, что пользователь не сможет просмотреть их все. Поэтому важно не просто найти их, но и упорядочить таким образом, чтобы сверху оказались те, которые лучше всего подходят для ответа на заданный запрос — то есть, наиболее релевантные запросу. Релевантность — это наилучшее соответствие интересам пользователей, ищущих информацию. Релевантность найденных страниц заданному запросу Яндекс определяет полностью автоматически — с помощью сложных формул, учитывающих тысячи свойств запроса и документа. Процесс упорядочивания найденных результатов по их релевантности называется ранжированием. Именно от ранжирования зависит качество поиска — то, насколько поисковая система умеет показать пользователю нужный и ожидаемый результат. Формулы ранжирования строятся также автоматически — с помощью машинного обучения — и постоянно совершенствуются.
Релевантность — это наилучшее соответствие интересам пользователей, ищущих информацию. Релевантность найденных страниц заданному запросу Яндекс определяет полностью автоматически — с помощью сложных формул, учитывающих тысячи свойств запроса и документа. Процесс упорядочивания найденных результатов по их релевантности называется ранжированием. Именно от ранжирования зависит качество поиска — то, насколько поисковая система умеет показать пользователю нужный и ожидаемый результат. Формулы ранжирования строятся также автоматически — с помощью машинного обучения — и постоянно совершенствуются.
Качество поиска — это самый важный аспект для любой поисковой системы. Если она будет плохо искать, люди просто перестанут ей пользоваться.
Поэтому нам важно постоянно совершенствовать алгоритмы ранжирования и делать их устойчивыми к внешнему влиянию (например, к попыткам некоторых вебмастеров обмануть поисковую систему).
Поэтому мы не продаем места в результатах поиска.
Поэтому на результаты поиска никак не влияют политические, религиозные и любые другие взгляды сотрудников компании.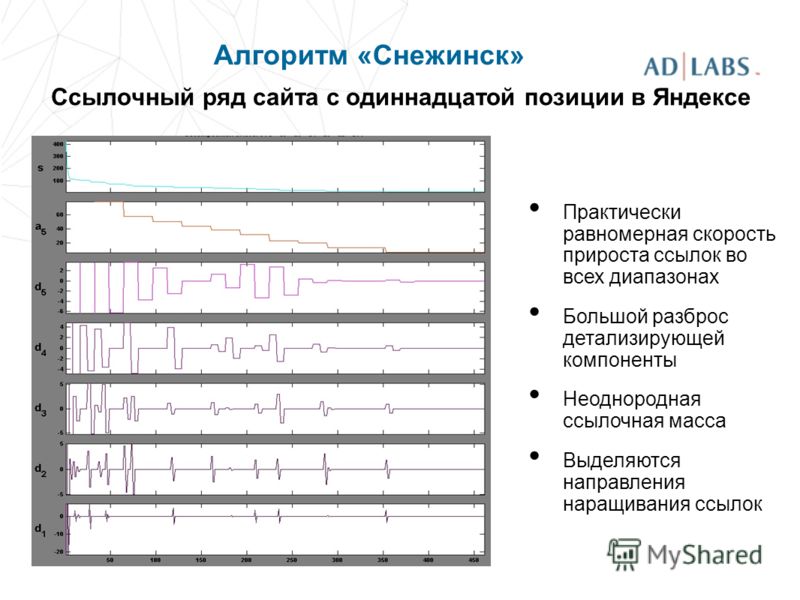
Пользователи просматривают страницу результатов поиска сверху вниз. Поэтому Яндекс показывает сверху, среди первых результатов, те документы, которые содержат наиболее подходящие пользователю ответы — то есть наиболее релевантные заданному запросу. Из всех возможных релевантных документов Яндекс всегда старается выбрать наилучший вариант.
С этим принципом связано несколько правил, которые Яндекс применяет к некоторым типам сайтов. Все эти правила работают полностью автоматически, их выполняют алгоритмы, а не люди.
1. Существуют страницы, которые явно ухудшают качество поиска. Они специально созданы с целью обмануть поисковую систему. Для этого, например, на странице размещают невидимый или бессмысленный текст. Или создают дорвеи — промежуточные страницы, которые перенаправляют посетителей на сторонние сайты. Некоторые сайты умеют замещать страницу, с которой перешел пользователь, на какую-нибудь другую. То есть когда пользователь переходит на такой сайт по ссылке из результатов поиска, а потом хочет снова вернуться к ним и посмотреть другие результаты, он видит какой-то другой ресурс.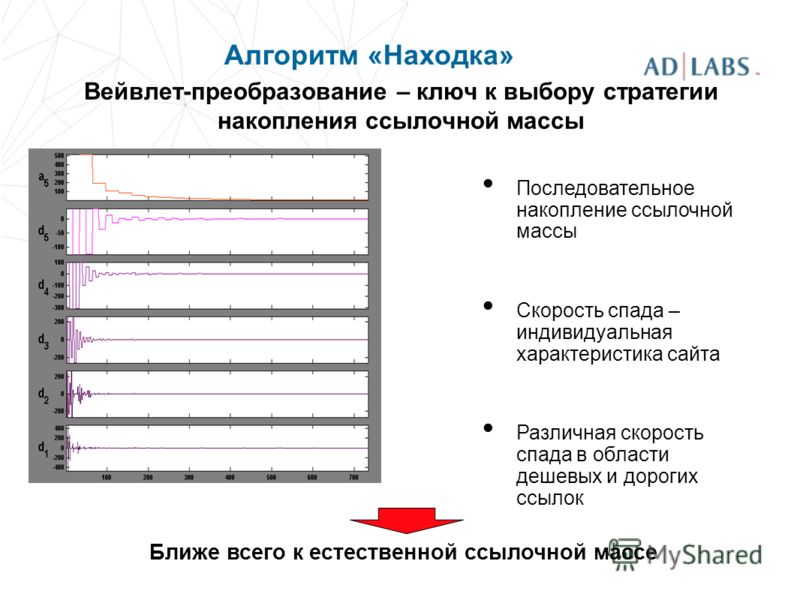
Такие ресурсы не представляют интереса для пользователей и вводят их в заблуждение — и, соответственно, ухудшают качество поиска. Яндекс автоматически исключает их из поиска или понижает в ранжировании.
2. Бывает, что в том или ином документе есть полезная информация, но воспринимать ее сложно. Например, есть сайты, которые содержат popunder-баннеры (они перемещаются по экрану вслед за прокруткой страницы и закрывают ее содержание, а при попытке закрытия такого баннера открывается новое окно) и clickunder-рекламу (она неожиданно для пользователя открывает рекламную страницу при любом клике по сайту, в том числе — по ссылкам). С нашей точки зрения, оба этих вида рекламы мешают навигации по сайту и нормальному восприятию информации. Поэтому сайты с такой рекламой располагаются в поисковой выдаче ниже, чем сайты, на которых пользователь может найти ответ на свой вопрос без лишних проблем.
3. По запросам, которые не подразумевают явно потребность в эротическом контенте, Яндекс ранжирует сайты для взрослых ниже или вообще не показывает их в результатах поиска. Дело в том, что ресурсы с эротическим контентом часто используют достаточно агрессивные методы продвижения — в частности, они могут появляться в результатах поиска по самым разнообразным запросам. С точки зрения пользователя, который не искал эротики и порнографии, «взрослые» результаты поиска нерелевантны, и, к тому же, могут шокировать. Более подробно об этом принципе можно почитать здесь.
Дело в том, что ресурсы с эротическим контентом часто используют достаточно агрессивные методы продвижения — в частности, они могут появляться в результатах поиска по самым разнообразным запросам. С точки зрения пользователя, который не искал эротики и порнографии, «взрослые» результаты поиска нерелевантны, и, к тому же, могут шокировать. Более подробно об этом принципе можно почитать здесь.
4. Яндекс проверяет индексируемые веб-страницы на наличие вирусов. Если обнаружилось, что сайт заражен, в результатах поиска рядом с ним появляется предупреждающая пометка. При этом зараженные сайты не исключаются из поиска и не понижаются в результатах поиска — может быть, на таком ресурсе находится нужный пользователю ответ, и он все равно захочет туда перейти. Однако Яндекс считает важным предупредить его о возможном риске.
Основная метрика качества поиска Яндекса — это то, насколько пользователю пригодились найденные результаты. Иногда по запросам пользователей невозможно определить, какой ответ ему подойдет. Например, человек, задавший запрос [пушкин], возможно, ищет информацию о поэте, а возможно — о городе. Точно так же человек, который набрал запрос [iphone 4], может быть, хочет почитать отзывы и ищет форумы, а может быть, хочет купить и ищет магазины. Среди первых результатов поиска должны найтись ответы для всех случаев. Поэтому Яндекс старается сделать страницу результатов поиска разнообразной. Поиск Яндекса умеет определять многозначные запросы и показывает разнообразные ответы. Для этого используется технология «Спектр».
Например, человек, задавший запрос [пушкин], возможно, ищет информацию о поэте, а возможно — о городе. Точно так же человек, который набрал запрос [iphone 4], может быть, хочет почитать отзывы и ищет форумы, а может быть, хочет купить и ищет магазины. Среди первых результатов поиска должны найтись ответы для всех случаев. Поэтому Яндекс старается сделать страницу результатов поиска разнообразной. Поиск Яндекса умеет определять многозначные запросы и показывает разнообразные ответы. Для этого используется технология «Спектр».
Урок 35. Эволюция алгоритмов ранжирования Яндекса и история поисковой системы
Веб-студия «Visual Group»
Создание и продвижение сайтов профессионально
+7 (812) 987-02-02 Заказать обратный звонок
 org/ListItem»>Главная
org/ListItem»>Главная- Книга «Эффективное продвижение сайтов» Online-версия
- Урок 35. Эволюция алгоритмов ранжирования Яндекса и история поисковой системы
Когда мы только начинали говорить о поисковом продвижении, мы уже касались темы истории крупнейшего российского поисковика. Однако в свете всей приведенной информации, важным будет рассказать и об истории развития основных алгоритмов системы.
В этом уроке мы наглядно отразим основные изменения в системе, которые во многом сформировали и продолжают формировать её нынешний облик и главные принципы работы. Для каждого алгоритма мы приведем краткую характеристику и расскажем об особенностях его внедрения.
Основные алгоритмы Яндекса: история с 2008 года
Сегодня алгоритмы Яндекса регулярно обновляются, с целью того, чтобы каждый пользователь имел возможность получать в выдаче ссылки на сайты с самой точной и полной информацией.
- Магадан. Один из первых алгоритмов, введенных Яндексом. Это событие состоялось в 2008 году и стало весомым вкладом в систему ранжирования с региональной привязкой. Алгоритм принес с собой целый ряд значимых изменений. Уже к маю 2008 года «Магадан» научился искать информацию на иностранных сайтах.
Помимо этого было увеличено и количество факторов ранжирования, что позволило улучшить показатели качества выдачи. Всего число факторов ранжирования увеличилось почти в 2 раза. Также поисковик стал лучше работать с ссылками, а специальный классификатор позволил определять тип различных страниц. Также с появлением алгоритма «Магадан», в Яндексе вводится такое понятие как «коммерционализированность». Одна из важнейших функций, принесенных алгоритмом – учет уникальности контента на конкретном ресурсе.
Создатели научили поисковик работать с запросами, ведёнными транслитом, а также понимать и расшифровывать различные аббревиатуры.
 Помимо этого, алгоритм «Магадан» заложил основы присвоения запросам характеристик относительно геолокации.
Помимо этого, алгоритм «Магадан» заложил основы присвоения запросам характеристик относительно геолокации.Во всех отношениях «Магадан» стал для поисковика очень значимым нововведением, которое заложило фундамент для дальнейшей активной модернизации.
- Магадан 2.0. Это более продвинутая версия алгоритма, о котором мы рассказывали выше. В ходе длительного тестирования и анализа обратной связи специалисты Яндекса смогли учесть все пожелания и отзывы пользователей. В соответствии с этим, в алгоритм выл внесен целый ряд значимых изменений. Поисковик научился лучше определять уникальность, была усовершенствована система геоклассификации. Классификатор коммерционализорованности также был существенно улучшен.
- Находка. Этот алгоритм появляется в системе в сентябре 2008 года. Главная цель находки – сформировать и внедрить принципиально новый подход к машинному обучению. Помимо этого поисковик также внедрил целый ряд дополнительных новшеств, среди которых улучшение работы со стоп-словами и многословными запросами.

- Арзамас. Один из знаковых алгоритмов Яндекса, появившийся в апреле 2009 года. Алгоритм принес изменения в области классификации и учёта омонимов. Слова с несколькими значениями стали лучше классифицироваться в поиске, а пользователи смогли получать сразу нескольких информационных ссылок.
- Арзамас 1.2. Более продвинутая версия алгоритма, которая существенно улучшила классификатор геозависимых запросов.
- Арзамас +16. Продвинутая версия алгоритма, появившаяся в конце августа 2009 года. Название обусловлено появлением поиска с геопривязкой по 16 городам России.

- Арзамас 1.5. Алгоритм принес с собой изменение формулы ранжирования, а также дополнительно модернизировал составление выдачи по геазовисимым запросам. При работе с таким алгоритмом, поисковик улучшил выдачу для тех городов, которые пока не учитывались при геопривязке.
- Арзамас 1.5 SP1. Финальная версия алгоритма, которая смогла существенно улучшить все достигнутые им показатели. Именно с введением этой версии поисковик стал активно продвигать собственные принципы работы с геозависимыми запросами. Список городов был существенно расширен, а классификатор геозависимости претерпел изменения. Помимо этого была проведена колоссальная работа с омонимами. Все изменения позволили достичь улучшения качества выдачи для жителей различных регионов страны.
- АГС-17 и АГС-30. С выпуском этого алгоритма в 2009 году начинается активная борьба сайта с низкокачественными страницами.
 Такая работа была направлена на повышение качества выдачи и позволила перевести под фильтры некачественные сайты или те страницы, которые не содержат никакой полезной информации для конкретного пользователя.
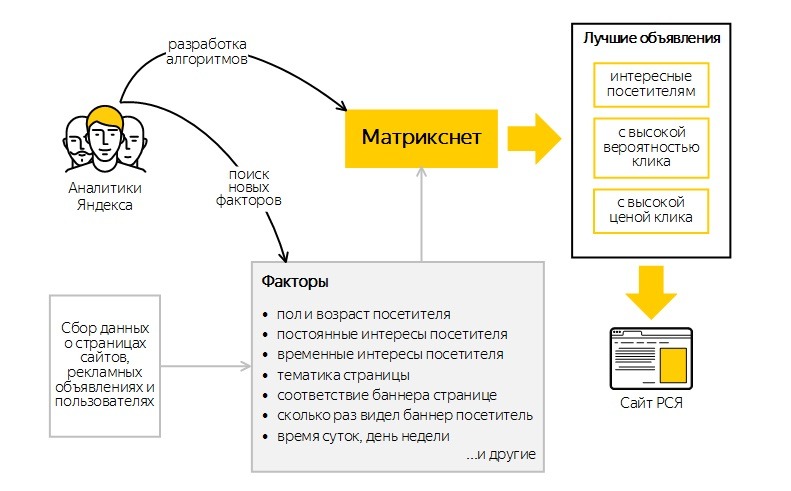
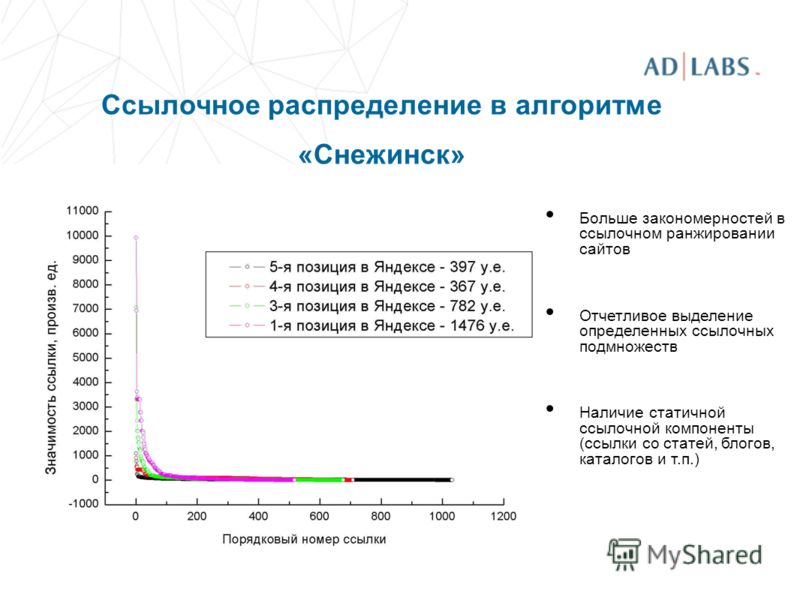
Такая работа была направлена на повышение качества выдачи и позволила перевести под фильтры некачественные сайты или те страницы, которые не содержат никакой полезной информации для конкретного пользователя. - Снежинск. 2009 год принес пользователям и веб-мастерам и алгоритм «Снежинск». Большинству он запомнился по введению нового алгоритма машинного обучения под названием Матрикснет. Продолжилось улучшение формирования списка выдачи, а документы стали анализироваться по большому количеству факторов. Специально для более точного анализа документов специалистами Яндекс была создана по-настоящему сложная и многофакторная модель. Продолжилась и работа с геозависимыми запросами, были подключены новые региональные факторы. Еще одна важная особенность алгоритма – активное начало учета поведенческих факторов при ранжировании сайтов в выдаче.
- Конаково
 Особенность введения алгоритма – расширение функций локального ранжирования. Теперь в базе системы появилось 1250 городов, с привязкой к которым создавалась выдача. Можно понять, насколько значимым был этот скачок, ведь ранее привязка осуществлялась только к 19 городам.
Особенность введения алгоритма – расширение функций локального ранжирования. Теперь в базе системы появилось 1250 городов, с привязкой к которым создавалась выдача. Можно понять, насколько значимым был этот скачок, ведь ранее привязка осуществлялась только к 19 городам. - Снежинск 1.1. Введение этого алгоритма принесло с собой существенное расширение возможностей Матрикснет, улучшение работы с геозависимыми запросами для российских городов. Яндекс продолжил наращивание показателей ранжирования сайтов в соответствии с определенным регионом, что позволило повысить качество формирования списка выдачи.
- Мировой интернет. Алгоритм был запущен в середине лета 2010 года и для отечественного поисковика стал настоящим событием. 7 июля – именно этот день большинство пользователей запомнит в связи с возможностью поиска в Яндексе по иностранным ресурсам. При этом поисковик расширил и возможности фильтрации – теперь каждый пользователь мог включить специальный фильтр, который бы отсекал результаты выдачи из определённого региона.
 Таким образом, каждый пользователь системы мог выбирать, в каком сегменте интернета ему проводить поиск.
Таким образом, каждый пользователь системы мог выбирать, в каком сегменте интернета ему проводить поиск. - Полтава. Еще один немаловажной алгоритм, разработанный специально для пользователей с Украины. Учет национальной специфики в работе стал краеугольным камнем успеха этого детища отечественных программистов. Алгоритм мог быстро переводить запросы украинского на русский и наоборот и осуществлять эффективную региональную привязку.
- Обнинск. С этим алгоритмом продолжилось активное введение новых методов распознавания и выдачи геозависимых запросов. Алгоритм ввел новые принципы ранжирования, существенно усложнив их. В результате многие пользователи запомнили август 2010 года за счет изменения положения популярных сайтов в выдаче.
- SEO-ссылки. Этот алгоритм появился осенью 2010 года. В нем Яндекс вплотную занялся рассмотрением вопроса качества ссылок и их влияния на положение сайта в ТОПе.
 Благодаря пересмотру отношения к ссылкам и введению новых параметров определения уровня доверия к ресурсу, специалистам поисковика удалось вновь улучшить выдачу.
Благодаря пересмотру отношения к ссылкам и введению новых параметров определения уровня доверия к ресурсу, специалистам поисковика удалось вновь улучшить выдачу. - Авторский контент. Как можно понять из названия, этот алгоритм увеличил роль в ранжировании уникального контента. Повысилась точность распознавания основного сайта-донора. Сайты с высокими показателями витальности стали получать лучшие позиции в выдаче, что стало для веб-мастеров дополнительным стимулом к улучшению качества сайтов, занесенных в выдачу.
- Запросы на латинице. Как мы уже упоминали в одном из предыдущих уроков, в классификации языковых запросов существует также дополнительная категория на латинице. Долгое время качество выдачи по таким запросам оставляло желать лучшего. Но в декабре 2010 Яндекс ввел алгоритм, позволяющий существенно улучшить выдачу по запросам, написанным на латинице.
- Краснодар. Введение этого алгоритма ознаменовалось запуском системы «Спектр», которая уже знакома вам по предыдущим урокам.
 С введением такого алгоритма увеличилось качество выдачи по геозависмым запросам, а также работа с многозначными запросами. Благодаря использованию специальных принципов учета неявных категорий в запросах, пользователи получили намного более качественную выдачу.
С введением такого алгоритма увеличилось качество выдачи по геозависмым запросам, а также работа с многозначными запросами. Благодаря использованию специальных принципов учета неявных категорий в запросах, пользователи получили намного более качественную выдачу. - Поведенческая накрутка. Это первый алгоритм, запущенный в 2011 году. Работа с поведенческими факторами продолжилась и очередным шагом в этом направлении стало определение параметров накрутки. Как выяснилось, на первых позициях оказалось большое количество сайтов, использующих не самые честные методы продвижения. Как итог – существенное повышение качества выдачи и изменение позиций многих лидеров рынка. Вывод сайта в ТОП стал сложнее, но и конкуренция начала складываться на более честных условиях.
- Рейкьявик. Этот алгоритм принес большое количество изменений, среди которых особенно выделяется работа с определением языковых предпочтений пользователей. Были обновлены колдунщики – математический и созданный для онлайн игр.
 Помимо этого, новшеством в использовании алгоритма стало дальнейшее совершенствование распознавания запросов. Теперь поисковик нуачился лучше работать с запросами, содержащими опечатки. Также был отработан пришедшийся по вкусу большинству пользователей механизм вывода удобных подсказок в поиске.
Помимо этого, новшеством в использовании алгоритма стало дальнейшее совершенствование распознавания запросов. Теперь поисковик нуачился лучше работать с запросами, содержащими опечатки. Также был отработан пришедшийся по вкусу большинству пользователей механизм вывода удобных подсказок в поиске. - Переоптимизированные тексты. Мы уже не раз говорили вам о том, что тексты на сайте нужно создавать не только для поисковых роботов, но и для людей. И особенно актуальным это утверждение стало именно в сентябре 2011 года, с усложнением использованных фильтров. Поисковик научились хорошо определять те сайты, контент которых создан исключительно с упором на ключевые слова. Как итог – выдача улучшилась, а оптимизаторам пришлось позаботиться о наполнении ресурсов действительно интересными для пользователей текстами. Также стало еще более необходимо следить за количество ключевых слов.
- Юзабилити. Выпуск алгоритма, который ужесточил контроль ранжирования по факторам юзабилити сайта произошел в 2011 году.
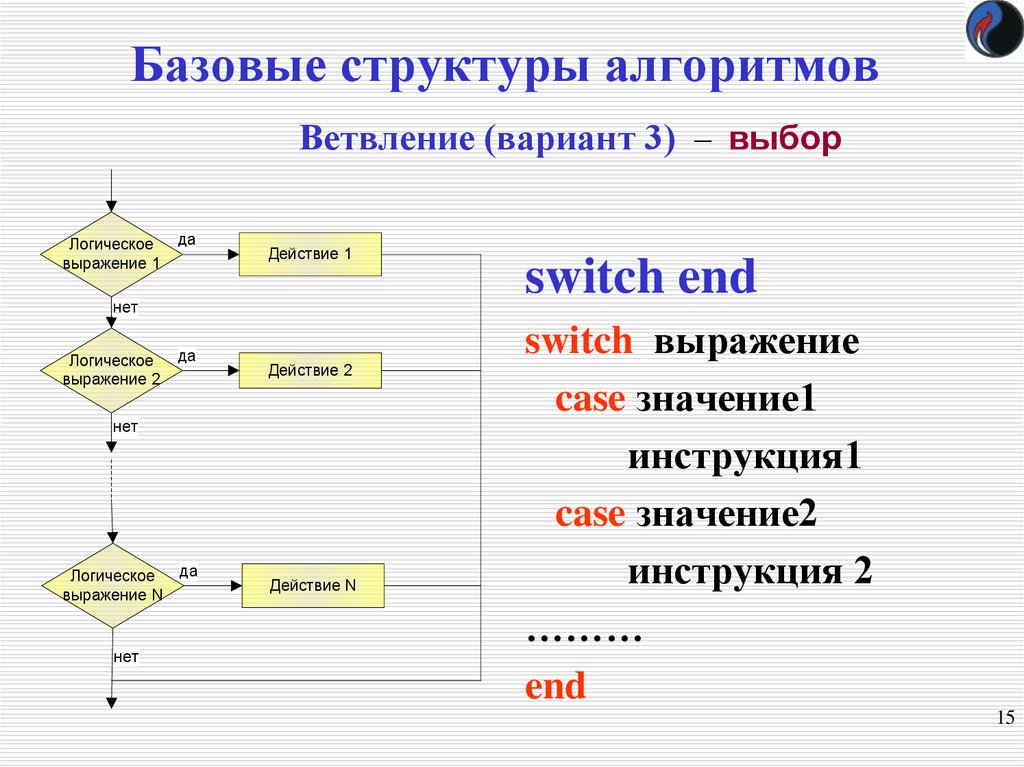 Благодаря усовершенствованию индексации и работы поисковых роботов, система получила возможность определять, удобно ли пользователю работать с конкретным сайтом, нет ли на ресурсе факторов, которые мешают этому. В соответствии с новым алгоритмом также произошло изменение позиций ранжирования.
Благодаря усовершенствованию индексации и работы поисковых роботов, система получила возможность определять, удобно ли пользователю работать с конкретным сайтом, нет ли на ресурсе факторов, которые мешают этому. В соответствии с новым алгоритмом также произошло изменение позиций ранжирования. - Коммерческая выдача. Еще один важный и известный алгоритм, который был реализован в 2011 году. Этот алгоритм улучшил качество работы с различными показателями, важными для конкретных запросов. После введения алгоритма при ранжировании стали учитываться уровень доверия к сайту, удобство дизайна и созданного для пользователя интерфейса. Все основы ранжирования коммерческих запросов, которые мы перечислили в одном из прошлых уроков также были заложены именно этим алгоритмом. С его внедрением для продвижения сайта по коммерческому запросу начала играть особую роль конкретная информация, наличие указания цены и других полезных данных для конкретного покупателя.
- Минусинск.
 Алгоритм, призванный фильтровать все сайты закупающие ссылки и писсимизировать их в выдаче. В среднем, сайты, злоупотребляющие покупной ссылочной массой, отбрасываются на 20 позиций вниз. Запущен он 15 мая 2015 года и уже в значительной степени дал о себе знать владельцам многих крупных площадок.
Алгоритм, призванный фильтровать все сайты закупающие ссылки и писсимизировать их в выдаче. В среднем, сайты, злоупотребляющие покупной ссылочной массой, отбрасываются на 20 позиций вниз. Запущен он 15 мая 2015 года и уже в значительной степени дал о себе знать владельцам многих крупных площадок.
Основные выводы
Теперь вы знаете о том, что современные условия ранжирования – это результат длительной работы поисковой системы по улучшению качества выдачи. Важно понимать, что работа по совершенствованию алгоритмов выдачи не прекращается и сегодня поисковая система по-прежнему дорабатывает многие из своих возможностей.
Для того, чтобы ваш сайт правильно индексировался и получал при ранжировании высокие позиции, стоит учитывать все особенности – от требований к юзабилити и авторскому контенту, до правильной работы с геозависимыми запросами. Комплексный подход к улучшению качественных показателей, позволит сделать продвижение сайта эффективным, а самое главное безопасным.
(см. также «Продвижение интернет-магазина»)
Урок 34. Особенности ранжирования при работе с коммерческими запросами
Оглавление
Урок 36. Поисковые фильтры как главное ограничение в продвижении сайта
Получите бесплатную консультацию
и особое ценовое предложение
Взгляд на факторы ранжирования в поиске Яндекса
Сообщество поискового маркетинга пытается разобраться в просочившемся репозитории Яндекса, который содержит файлы, содержащие список факторов ранжирования в поиске.
Некоторые могут искать действенные советы по SEO, но вряд ли это истинная ценность.
Принято считать, что это будет полезно для общего понимания того, как работают поисковые системы.
Есть что открыть
Райан Джонс (@RyanJones) считает, что эта утечка имеет большое значение.
Он уже протестировал некоторые модели машинного обучения Яндекса на своей машине.
Райан убежден, что есть чему поучиться, но для этого потребуется гораздо больше, чем просто просмотр списка факторов ранжирования.
Райан уточняет:
«Хотя Яндекс — это не Google, мы можем многому научиться из этого с точки зрения сходства.
Яндекс широко использует технологию, разработанную Google. Они особо упоминают PageRank, а также Среди прочего, Map Reduce и BERT.
Факторы, очевидно, будут различаться, как и присваиваемые им веса, но методы информатики, используемые для анализа релевантности текста, создания ссылок и выполнения вычислений, будут очень похожи в разных поисковых системах.
Я считаю, что факторы ранжирования могут дать ценную информацию, но недостаточно просто взглянуть на просочившийся список.
При просмотре весов по умолчанию (до машинного обучения) есть некоторые отрицательные веса, которые SEO-специалисты считают положительными, и наоборот.
Существует также НАМНОГО больше факторов ранжирования, рассчитанных в коде, чем указано в списках факторов ранжирования, которые были распространены.
Этот список, по-видимому, состоит только из статических факторов, без упоминания о том, как они вычисляют релевантность запроса, или многих динамических факторов, связанных с набором результатов для этого запроса».
Более 200 факторов ранжирования
использует 1923 фактора ранжирования (некоторые говорят, что меньше).0003
Кристоф упомянул:
«Друзья стали свидетелями:
- Существует 275 факторов персонализации.
- Существует 220« Факторы свежести ». Факторы
- 3186.
- Еще многое предстоит открыть.
Тот факт, что у Яндекса сотни факторов для ссылок, наверное, больше всего удивляет многих.»
Дело в том, что это намного больше, чем 200+ факторов ранжирования, заявленных Google.
Даже Джон Мюллер из Google заявил, что компания отказалась от более чем 200 факторов ранжирования.
Так что, возможно, это поможет индустрии поиска перестать думать об алгоритме Google в этих терминах.
Никто не знает весь алгоритм Google?
Что поражает в утечке данных, так это то, как легко были собраны и организованы факторы ранжирования.
Утечка ставит под сомнение идею о том, что алгоритм Google тщательно охраняется и что никто, включая сотрудников Google, не знает всего алгоритма.
Возможно ли, что у Google есть электронная таблица с более чем тысячей факторов ранжирования?
Кристоф Цемпер оспаривает представление о том, что никто не знает алгоритма Google.
Кристоф сделал следующий комментарий для Search Engine Journal:
«В LinkedIn кто-то прокомментировал, что он не может себе представить, чтобы Google «документировал» факторы ранжирования таким образом.
которые должны быть построены.Эта информация была получена от надежного инсайдера.
У Google также есть код, который может стать предметом утечки.
Для такого технаря, как я, часто повторяющееся утверждение о том, что даже сотрудники Google не знают о факторах ранжирования, казалось абсурдным.
Людей, владеющих всей информацией, будет очень мало.
Но это должно быть в коде, потому что именно код управляет поисковой системой.»
Какие функции Яндекса похожи на Google?
Утекшие файлы Яндекса намекают на то, как работают поисковые системы.
Данные не показывают, как работает Google. Тем не менее, он позволяет вам увидеть часть того, как поисковая система (Яндекс) ранжирует результаты поиска.
То, что содержится в данных, не следует путать с тем, что может сделать с ними Google.
Тем не менее, есть некоторые интересные параллели между двумя поисковыми системами.
MatrixNet — это не то же самое, что RankBrain
Одно из интригующих открытий связано с нейронной сетью Яндекса под названием MatrixNet.
MatrixNet — более старая технология, впервые представленная в 2009 г. (ссылка на объявление на сайте archive.org).
Вопреки распространенному мнению, MatrixNet не является эквивалентом Google RankBrain от Яндекса.
Google RankBrain — это ограниченный алгоритм, который фокусируется на понимании 15% поисковых запросов, которые Google никогда раньше не видел.
Согласно статье Bloomberg, назначение RankBrain ограничено:
«Если RankBrain встречает незнакомое слово или фразу, машина может угадать, какие слова или фразы могут иметь сходное значение, и соответствующим образом отфильтровать результат, делая он более эффективен при обработке невиданных ранее поисковых запросов».
MatrixNet, с другой стороны, представляет собой многоцелевой алгоритм машинного обучения.
Он классифицирует поисковые запросы, а затем применяет к этим запросам соответствующие алгоритмы ранжирования.
Это часть объявления алгоритма 2009 года на английском языке 2016 года:
«MatrixNet может генерировать очень длинную и сложную формулу ранжирования, которая учитывает множество различных факторов и их комбинаций.
Еще одна полезная функция MatrixNet: возможность адаптировать формулу ранжирования к определенному классу поисковых запросов.
Кроме того, настройка алгоритма ранжирования, скажем, для поиска музыки не ухудшит качество ранжирования для других типов запросов.
Алгоритм ранжирования аналогичен сложному механизму с десятками кнопок, переключателей, рычагов и датчиков. В большинстве случаев поворот одного переключателя в механизме вызывает глобальные изменения во всей машине.
MatrixNet, с другой стороны, позволяет настраивать определенные параметры для определенных классов запросов, не требуя капитального ремонта всей системы.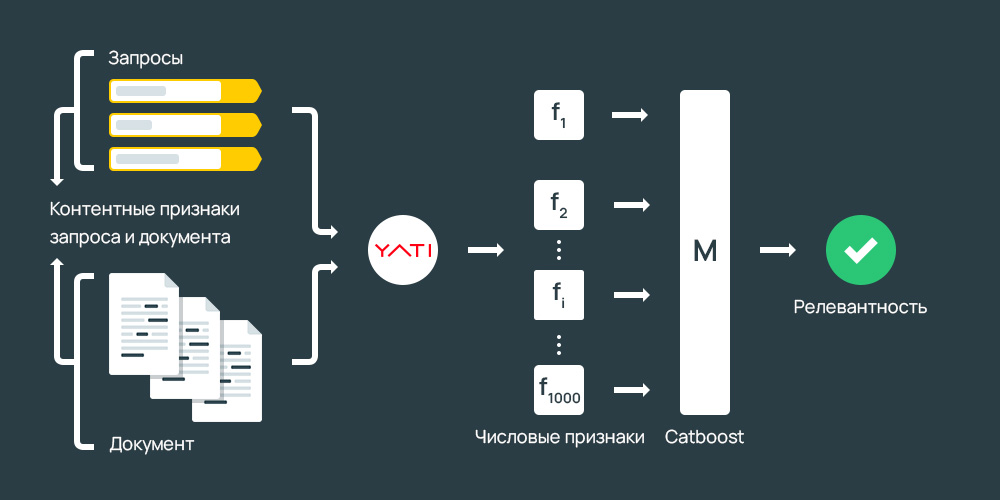
MatrixNet также может автоматически выбирать чувствительность для определенных диапазонов факторов ранжирования».
MatrixNet делает гораздо больше, чем RankBrain; они явно не одинаковы. он классифицирует поисковые запросы и применяет к ним различные факторы.
MatrixNet упоминается в нескольких документах по факторам ранжирования, поэтому важно поместить MatrixNet в надлежащий контекст, чтобы факторы ранжирования имели смысл.
Чтобы разобраться в утечке Яндекса, может быть полезно узнать больше об алгоритме Яндекса.
Некоторые факторы Яндекса соответствуют практикам SEO.
У Доминика Вудмана (@domwoodman) есть несколько проницательных комментариев по поводу утечки.
Алекс Буракс (@alex buraks) опубликовал обширную ветку Twitter на эту тему, которая содержит отголоски практики SEO.
Одним из таких факторов, о котором упоминает Алекс, является оптимизация внутренних ссылок для уменьшения глубины сканирования важных страниц.
Джон Мюллер из Google уже давно призывает издателей размещать на видном месте ссылки на важные страницы.
Мюллер советует не хоронить важные страницы глубоко в архитектуре сайта.
В 2020 году Джон Мюллер заявил:
«Что произойдет, так это то, что мы увидим, что домашняя страница очень важна, и что ссылки на главной странице также очень важны.
А потом… поскольку он удаляется от главной страницы, мы, вероятно, будем думать, что это менее важно».
Крайне важно, чтобы важные страницы располагались рядом с главными страницами, на которые заходят посетители сайта.
Таким образом, если ссылки ведут на домашнюю страницу, страницы, на которые есть ссылки с домашней страницы, считаются более важными.
Глубина сканирования не упоминалась Джоном Мюллером в качестве фактора ранжирования. Он просто заявил, что информирует Google о том, какие страницы важны.
Алекс цитирует правило Яндекса, которое использует глубину сканирования с главной страницы в качестве фактора ранжирования.
Имеет смысл рассматривать домашнюю страницу в качестве отправной точки важности, а затем вычислять меньшую важность по мере того, как пользователь переходит вглубь сайта, удаляясь от нее.
Аналогичные идеи можно найти в исследовательских работах Google (Reasonable Surfer Model, Random Surfer Model), в которых рассчитывалась вероятность того, что случайный посетитель окажется на данной веб-странице, просто перейдя по ссылкам.
В течение многих лет эмпирическим правилом SEO было размещение важного контента в нескольких кликах от главной страницы (или от внутренних страниц, которые привлекают внешние ссылки).
Обновление Яндекса Веги… Что касается экспертизы и авторитета?
Поисковик Яндекса обновился в 2019 годус обновлением Веги. В обновлении Яндекс Веги появились нейронные сети, обученные с профильными экспертами.
Целью этого обновления 2019 года было включение экспертных и авторитетных страниц в результаты поиска. Тем не менее, поисковые маркетологи, просматривающие документы, еще не обнаружили ничего, что коррелировало бы с такими вещами, как биографии авторов, которые, по мнению некоторых, связаны с опытом и авторитетом, которые ищет Google.
Hocalwire CMS включает в себя фантастические функции автоматизации, которые помогают сосредоточить трафик из различных источников на вашем веб-сайте. Вы можете значительно увеличить свой трафик с помощью Google Analytics и потенциальных возможностей Hocalwire. Чтобы узнать больше о безграничном потенциале Hocalwire CMS, запланируйте демонстрацию.
Яндекс и Google, платформа «Enshittification», приятная экономика
Факторы ранжирования Яндекса и Google
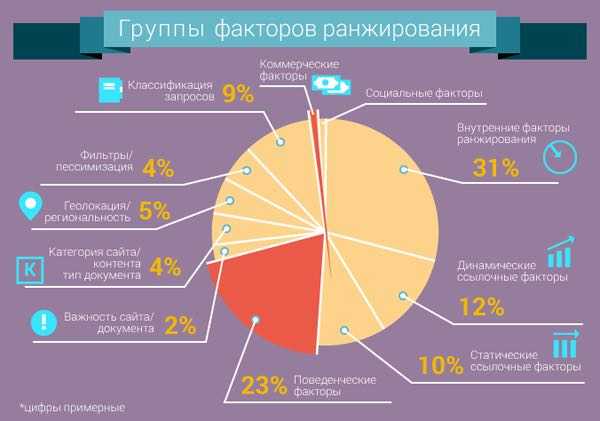
С тех пор как алгоритм ранжирования российской поисковой системы Яндекс был «слит» или взломан на прошлой неделе, SEO-специалисты изливали его в поисках информации об алгоритме Google. Сообщается, что Яндекс был создан «как клон Google», и многие бывшие сотрудники Google работают / работали там. Существует около 1900 факторов ранжирования, многие из которых больше не действуют, что вызывает вопросы о том, насколько актуальны данные. В сети много анализов (здесь, здесь, здесь). Среди выявленных основных переменных: обратные ссылки и их возраст, трафик сайта (включая платную рекламу), сигналы поведения пользователей (CTR, показатель отказов, время на сайте, повторные посещения), качество/возраст контента, трафик Википедии, ключевые слова в URL, количество рекламы на странице и различные другие сигналы доверия. Наличие карты на странице, по-видимому, является еще одним фактором ранжирования. Алгоритм Google более сложен и, вероятно, использует больше переменных, чем Яндекс. Однако многие факторы, выявленные в утечке из Яндекса, несомненно, относятся и к Google.
Наличие карты на странице, по-видимому, является еще одним фактором ранжирования. Алгоритм Google более сложен и, вероятно, использует больше переменных, чем Яндекс. Однако многие факторы, выявленные в утечке из Яндекса, несомненно, относятся и к Google.
Наш вывод:
- В переводе факторов, которые я видел, много упоминаний о «местных». Факторами являются соответствие между местоположением IP-адреса пользователя, местоположением документа и местоположением в URL-адресе. Приставка «гео» также имеет 65 упоминаний.
- Я опросил людей в Twitter и LinkedIn о гипотетическом влиянии подобной утечки Google; в среднем 68% сказали, что это вызовет больше спама.
- Мы увидим еще больше анализа; неясно, изменят ли какие-либо SEO-специалисты свое поведение на основе выводов об алгоритме Google.
Что такое «эншиттификация»?
Автор Кори Доктороу написал грандиозную тираду о жизненном цикле и упадке платформ, которую он называет «эншиттификацией». Он говорит: «Во-первых, [платформы] хороши для своих пользователей; затем они злоупотребляют своими пользователями, чтобы улучшить положение своих бизнес-клиентов; наконец, они злоупотребляют этими бизнес-клиентами, чтобы вернуть себе всю ценность». Он утверждает, что растущие платформы субсидируют использование (например, продают ниже себестоимости), а затем переносят эту субсидию на приобретение B2B. Как только возникает блокировка, пользовательская и B2B-ценность сжимается в пользу акционеров. Доктороу говорит, что такая же картина наблюдалась в Amazon, Facebook и Google («Сегодняшние результаты Google представляют собой все более бесполезную трясину ссылок на собственные продукты, рекламу продуктов, которые недостаточно хороши, чтобы всплывать в верхней части списка на свой собственный и паразитический SEO-мусор»). Он утверждает, что TikTok находится в процессе «эншитификации», потому что он все чаще манипулирует алгоритмом в коммерческих целях. Хотя в некоторых отношениях это вульгарно, прочитать стоит.
Он говорит: «Во-первых, [платформы] хороши для своих пользователей; затем они злоупотребляют своими пользователями, чтобы улучшить положение своих бизнес-клиентов; наконец, они злоупотребляют этими бизнес-клиентами, чтобы вернуть себе всю ценность». Он утверждает, что растущие платформы субсидируют использование (например, продают ниже себестоимости), а затем переносят эту субсидию на приобретение B2B. Как только возникает блокировка, пользовательская и B2B-ценность сжимается в пользу акционеров. Доктороу говорит, что такая же картина наблюдалась в Amazon, Facebook и Google («Сегодняшние результаты Google представляют собой все более бесполезную трясину ссылок на собственные продукты, рекламу продуктов, которые недостаточно хороши, чтобы всплывать в верхней части списка на свой собственный и паразитический SEO-мусор»). Он утверждает, что TikTok находится в процессе «эншитификации», потому что он все чаще манипулирует алгоритмом в коммерческих целях. Хотя в некоторых отношениях это вульгарно, прочитать стоит.
Наш вариант:
- Стиль и тон могут кого-то очень раздражать, но они содержат много пищи для размышлений.
- По словам Доктороу, это серьезное обсуждение упадка публичных интернет-компаний, которые сначала сосредоточились на UX, а затем сместили акцент на получение доходов, что привело к их упадку.
- Справедливо сказать, что UX в Amazon, Google и Facebook пострадал, поскольку они стремились угодить инвесторам. Но является ли эншиттификация неизбежным следствием публичной интернет-компании?
Конец «хорошей экономики»?
В разгар пандемии многие люди сосредоточили расходы на «предметах первой необходимости». Однако то, что было определено как необходимое, часто включало вещи, которые фактически были роскошью, но подходили для жизни в условиях изоляции: доставка еды, категории онлайн-расходов, потоковые сервисы и (для некоторых) Peloton. Когда в 2022 году вернулась квазинормальная жизнь и воцарилась инфляция, потребители избегали многих онлайн-сервисов, которые определяли образ жизни во время пандемии. Слияние экономических встречных ветров теперь угрожает уничтожить многие из этих стартапов, что Wall Street Journal называет концом «экономики, которую приятно иметь». К уязвимым относятся приготовление еды, доставка еды, потоковое вещание (множество сервисов), домашний фитнес и многие другие развлечения, доступные непосредственно потребителю. Carvana является примером в статье с огромными долгами, обрушившейся оценкой и продолжающимися увольнениями. Технически экономика США не находится в рецессии, но большинство (70%) потребителей считают, что это так. Восприятие есть реальность.
Слияние экономических встречных ветров теперь угрожает уничтожить многие из этих стартапов, что Wall Street Journal называет концом «экономики, которую приятно иметь». К уязвимым относятся приготовление еды, доставка еды, потоковое вещание (множество сервисов), домашний фитнес и многие другие развлечения, доступные непосредственно потребителю. Carvana является примером в статье с огромными долгами, обрушившейся оценкой и продолжающимися увольнениями. Технически экономика США не находится в рецессии, но большинство (70%) потребителей считают, что это так. Восприятие есть реальность.
Наше мнение:
- Многие из этих «хороших» стартапов, которые обычно субсидировали усыновление клиентов, теперь вынуждены перекладывать расходы на пользователей.
- Но повышение цен (например, Amazon Fresh) для получения большего дохода и удовлетворения инвесторов может привести к оттоку. Они находятся в своего рода двойной связи.

- Потребительские расходы должны оставаться ограниченными, а денег инвесторов должно быть мало (за исключением ИИ) в 2024 году. Многие стартапы просто не выживут.
Недавний анализ
- Ближайшая заметка 98: Менеджер кампании Mailchimp, генеративный ИИ и авторское право, жалобы на форуме в фунтах стерлингов и информация об ошибках Google.
Короткие дубли
- Google создал ИИ, который генерирует музыку из подсказок (послушайте здесь).
- Далее: китайский SE Baidu , интегрирующий бота в стиле ChatGPT.
- Законопроекты о реформе антимонопольного законодательства кажутся мертвыми после смены руководства Палаты представителей США.
- AI-контент более широко распространен в массовой журналистике, чем вы думаете.
- TikTok видео «день из жизни» посвящены увольнениям и безработице.
- Twitter заново открывает модерацию контента, предлагает разъяснения.