Проверка текста на плагиат? — Хабр Q&A
Не совсем понял, может быть advego.ru/plagiatus/
Ответ написан
Тысячи, рерайтеров совершенствуются в этом нелегком деле, а Вы хотите так просто взять и выявлять плагиат.
Ответ написан
Вы не ту проблему решаете. Иначе говоря, вы тушите пожары когда нужно найти тех, кто поджигает.
Чтобы не сдавали дипломы десятилетней давности нужно утверждать темы, актуальные и нужные сегодня и сейчас. А не давать темы десятилетней давности. Вы же тратите труд студентов непонятно на что, когда студенты в процессе написания диплома могли бы помочь решить реальную задачу и принести пользу.
Ответ написан
Есть несколько вариантов проверок, вот 2 из самых простых:
1. Случайный кусок текста (с размером куска нужно будет определиться самому) кидать в поисковик (ya.ru/google.com) в кавычках и смотреть на результаты поиска, а именно на 100%-ое совпадение.
2. Если есть предположение, что текст состоит из кусков чужих работ, то самый простой, но не очень надёжный способ — это подсчитать количество слов в каждом предложении, подсчитать средне арифметическое каждого абзаца и если будет большое отклонение от среднего в одном из абзацев, то этот кусок предположительно украден, тогда и проверяем его по пункту №1.
А вообще есть волшебные математические способы проверки стилистики изложения автора (правда давно это было и название уже не вспомню с ходу), если от главы к главе, от абзаца к абзацу, от предложения к предложению стиль резко изменяется, то можно предположить о том что текст представляет из себя монстра Франкенштейна куски чужих работ.
Надеюсь, что-то, из выше описанного, поможет Вам в поисках истины и авторского права.
Ответ написан
Проверка уникальности текста на сайтах.
Advego Plagiatus — free
Yazzle: можно проверять много текстов сразу
Ответ написан
Не совсем антиплагиатный инструмент, но может быть Вам поможет программа-конкордансер. Есть настольные версии, которые индексируют пачку txt-файлов, а потом по введённому слову показывают все найденные контексты его использования. В статье на Грамоте приводится пример с «Евгением Онегиным» в качестве базы, и искомого слова «Москва»:
Москва, России дочь любима, — Эп.Г7.1
Как и надменная Москва. — Г4XVII.14
Москва, я думал о тебе! — Г7XXXVI.12
Москва… как много в этом звуке — Г7.XXXVI.12
Нет, не пошла Москва моя — Г7.XXXVII.8
Ответ написан
Сервис антиплагиат.ру поддерживает возможность создания своей базы текстов и поиска по этой базе. Правда, это платная фича.
Причём есть возможность держать базу как у них на серваке, так и у себя.
Ответ написан
Вот, нашел приложение, которое делает то, что нужно! Это не пиар, поэтому ссылка через сокращалку и не ссылка вообще u. to/HVdOAQ
to/HVdOAQ
Ответ написан
И вторая статья того же автора уже с его системой: ceur-ws.org/Vol-803/paper16.pdf
Ответ написан
Комментировать
1 От заката до рассвета у студента нет просвета
Пишет бедный рефераты, как уйти от плагиата!
Ведь работу проверяют, вот он голову ломает
Почему не уникально, приуныл сидит печально,
После, малость поработав, рефератик обработав,
Получаешь результат- 100 процентов: счастлив, рад!
Польза есть от АнтиПЛАГА, для студентов- только благо!
Пишите: [email protected]
Сайт antiplag. com.ua antiplag.ru
com.ua antiplag.ru
7 (499) 686-06-56 Россия +38 (063) 657
Комментировать
Я пробовал, пропустил курсак через эту систему. Обошел программы Antiplagiat.ru, Etxt-антиплагиат, как они пишут, хотел сделать из 10% 95%, а получилось всего 80% , самое главное быстро и всегда онлайн. Пользуйтесь antiplag.ru + 7 (499) 686-06-56 Россия, +38 (063)657-99-96 Украина и экономьте!
Ответ написан
Комментировать
Есть отличны вариант: https://antiplagiat.org/.
Ресурс помогает проверять и поднимать уникальность любого текстового документа. Делают автоматический и ручной рерайтинг.
Делают автоматический и ручной рерайтинг.
Ответ написан
Как проверить текст на уникальность
Поисковые системы не любят повторений – в текстах, в мета-описаниях и остальных текстовых полях. Как проверить текст на уникальность и на что обращать внимание при проверке?
DepositphotosСтремиться к 100% уникальности не всегда необходимо: если в тексте есть цитаты или отсылки к авторитетным источникам, тот же Google возражать не станет.
Далеко не всегда текст в принципе может быть абсолютно уникален: описание товарных позиций предполагает использование одного и того же набора слов. Цвет, форма, указание о гарантийных обязательствах, особенности использования, описание материала и название модели – то, без чего не обходится ни одна правильно и полностью заполненная карточка товарной позиции в разных онлайн-магазинах.
Однако в среднем работает правило “Чем более уникален ваш контент, тем лучше будет чувствовать себя сайт в поисковой выдаче”. И хорошему копирайтеру под силу внести максимум оригинальности даже в банальные описания, не говоря уже о специально для вашего сайта созданных текстах.
Сервисы для проверки текста на уникальность помогут в том случае, если работу для вас выполняет наёмный копирайтер: вы сможете проконтролировать качество его работы.
Стоит прогонять через проверяющие сервисы и собственные тексты: мы часто пишем устоявшимися штампами, даже не осознавая этого. Взглянув на собственное описание товарной позиции со стороны, вы наверняка сможете его улучшить.
Еще один способ использования сервисов, проверяющих уникальность текстов, – поиск тех, кто заимствует у вас описания (многие сервисы выдают ссылки на ресурсы, где есть такой же или подобный текст).
Сервисов, которые позволяют проверить текст на уникальность, немало. Практически у всех схожий функционал, однако показать они могут различный результат.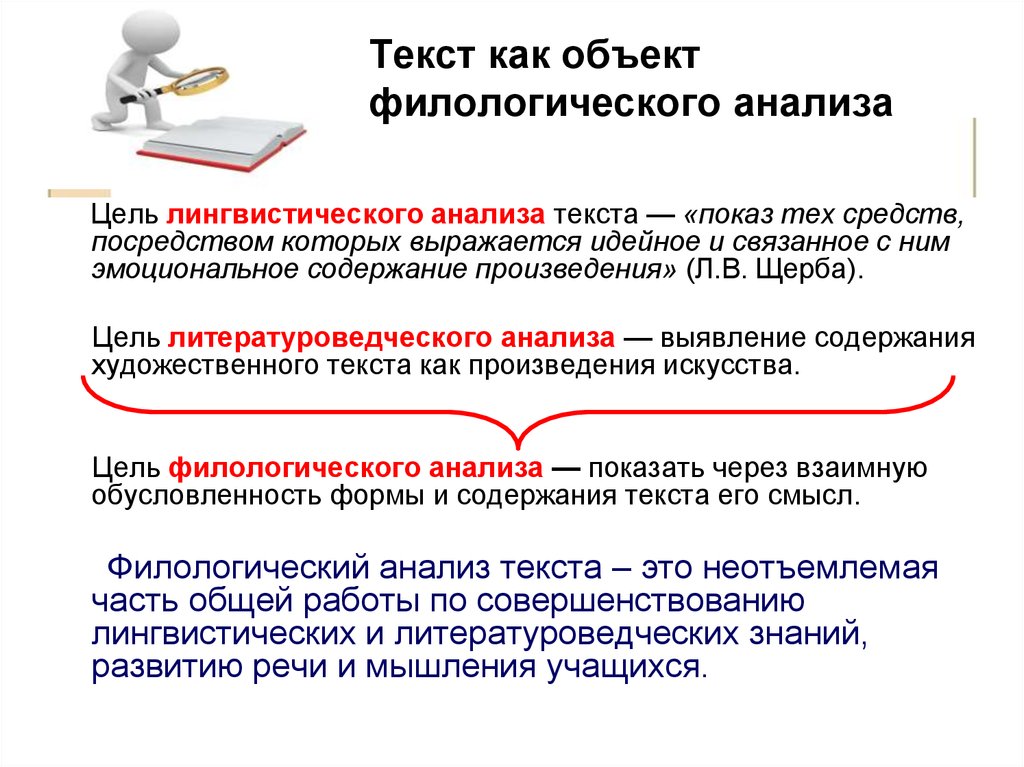
1
Advego Plagiatus
Программа для проверки текста на уникальность, которая при проверке определяет степень оригинальности текстов, а также ссылки, где определенные фрагменты встречаются. Плагиатус показывает процент совпадения текста, а также проверяет уникальность указанного URL.
2
Проверка на уникальность PR-CY
Сервис помогает в онлайн-режиме проверить текст на уникальность, а также узнать, где встречаются те или иные фрагменты текста в глобальной сети.
3
Антиплагиат онлайн на TEXT.RU
Антиплагиат позволяет выявлять как откровенный копипаст, так и очень плохой рерайт – где просто были заменены слова на синонимы. Таким образом можно выловить тексты, которые были подготовлены не особо тщательно. Разработчики Антиплагиата акцентируют внимание на том, что для получения 100% уникальности надо очень хорошо поработать над текстом. Халтура не пройдет.
Кроме проверки на уникальность, сервис проверяет грамматику и орфографию, а также SEO-показатели текста.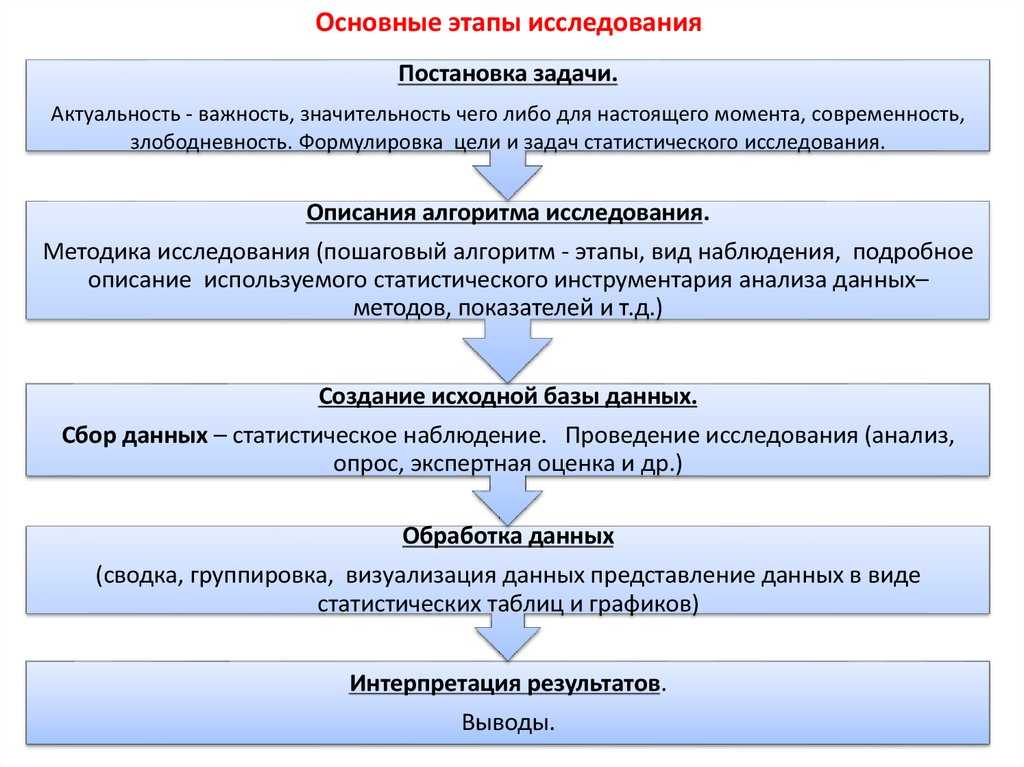
При регистрации на сайте снимаются ограничения на количество символов для проверки.
4
Антиплагиат-проверка от Content Watch
Сервис в онлайн-режиме проверяет текст на совпадения. Он умеет определять рерайт и другие способы уникализации текста, правда, считает в «неуникальное использование» не только предложения и фразы, но и отдельные слова, что искажает результат.
Договариваясь с копирайтером, который, возможно, будет писать тексты для вашего сайта, необходимо определить, на какой сервис проверки вы будете ориентироваться, так как они все показывают абсолютно разные показатели для только что написанного текста, без копирования из других источников.
python — Концепции для измерения «релевантности» текста теме?
спросил
Изменено 3 года, 8 месяцев назад
Просмотрено 503 раза
Я подрабатываю, пишу/улучшаю веб-приложение исследовательского проекта для некоторых политологов. Это приложение собирает статьи, относящиеся к Верховному суду США, и проводит их анализ, и спустя почти полтора года у нас есть база данных, насчитывающая около 10 000 статей (и она растет) для работы.
Это приложение собирает статьи, относящиеся к Верховному суду США, и проводит их анализ, и спустя почти полтора года у нас есть база данных, насчитывающая около 10 000 статей (и она растет) для работы.
Одной из основных задач проекта является возможность определить «релевантность» статьи, то есть основное внимание уделяется федеральному Верховному суду США (и/или его судьям), а не местному или иностранному верховному суду. корт. С самого начала мы решали эту проблему, прежде всего, анализируя заголовок на наличие различных явных ссылок на федеральный суд, а также проверяя, что «верховный» и «суд» являются ключевыми словами, взятыми из текста статьи. Простой и небрежный, но на самом деле работает довольно хорошо. При этом нерелевантные статьи могут попасть в базу данных — обычно это статьи с заголовками, в которых явно не упоминается штат или иностранная страна (обычно нарушителем является Верховный суд Индии).
Я достиг точки в разработке, когда я могу больше сосредоточиться на этом аспекте проекта, но я не совсем уверен, с чего начать. Все, что я знаю, это то, что я ищу метод анализа текста статьи, чтобы определить его отношение к федеральному суду, и ничего больше. Я предполагаю, что это повлечет за собой некоторое машинное обучение, но у меня практически нет опыта в этой области. Я немного почитал о таких вещах, как взвешивание tf-idf, моделирование векторного пространства и word2vec (+ модели CBOW и Skip-Gram), но пока не вижу «общей картины», которая показывает мне, как именно применимы эти концепции могут быть к моей проблеме. Может кто-то указать мне верное направление?
Все, что я знаю, это то, что я ищу метод анализа текста статьи, чтобы определить его отношение к федеральному суду, и ничего больше. Я предполагаю, что это повлечет за собой некоторое машинное обучение, но у меня практически нет опыта в этой области. Я немного почитал о таких вещах, как взвешивание tf-idf, моделирование векторного пространства и word2vec (+ модели CBOW и Skip-Gram), но пока не вижу «общей картины», которая показывает мне, как именно применимы эти концепции могут быть к моей проблеме. Может кто-то указать мне верное направление?
- python
- машинное обучение
- nlp
- наука о данных
формулирование проблемы
проблема и освещенный обзор + эксперимент более эффективно.
У вас есть данные для построения модели? У вас есть около 10 000 статей, которые будут входными данными для вашей модели, однако, чтобы использовать подход к обучению с учителем, вам потребуются надежные метки для всех статей, которые будут использоваться при обучении модели.
 Похоже, вы уже сделали это.
Похоже, вы уже сделали это.Какие показатели использовать для количественной оценки успеха. Как вы можете измерить, делает ли ваша модель то, что вы хотите? В вашем конкретном случае это звучит как проблема бинарной классификации — вы хотите иметь возможность помечать статьи как релевантные или нет. Вы можете измерить свой успех, используя стандартную метрику бинарной классификации, например площадь под ROC. Или, поскольку у вас есть конкретная проблема с ложными срабатываниями, вы можете выбрать такую метрику, как точность.
Насколько хорошо вы справитесь со случайным или наивным подходом. После того, как набор данных и метрика будут установлены, вы можете количественно оценить, насколько хорошо вы можете справиться со своей задачей с помощью базового подхода. Это может быть просто вычисление вашей метрики для модели, которая выбирает случайным образом, но в вашем случае у вас есть модель анализатора ключевых слов, которая является идеальным способом установить контрольную точку.
 Оцените, насколько хорошо ваш подход к синтаксическому анализу ключевых слов подходит для вашего набора данных, чтобы вы могли определить, когда модель машинного обучения работает хорошо.
Оцените, насколько хорошо ваш подход к синтаксическому анализу ключевых слов подходит для вашего набора данных, чтобы вы могли определить, когда модель машинного обучения работает хорошо.
Извините, если это было очевидно и банально для вас, но я хотел убедиться, что это было в ответе. В таком инновационном открытом проекте, как этот, погружение прямо в эксперименты по машинному обучению без обдумывания этих основ может быть неэффективным.
Подходы к машинному обучению
Как предложили Эван Мата и Стефан Г., лучший подход — сначала преобразовать ваши статьи в функции. Это можно сделать без машинного обучения (например, модель векторного пространства) или с помощью машинного обучения (word2vec и другие приведенные вами примеры). Для вашей проблемы я думаю, что что-то вроде BOW имеет смысл попробовать в качестве отправной точки.
Когда у вас есть представление ваших статей в виде функций, вы почти закончили, и есть ряд моделей бинарной классификации, которые хорошо себя зарекомендовали. Поэкспериментируйте отсюда, чтобы найти лучшее решение.
Поэкспериментируйте отсюда, чтобы найти лучшее решение.
В Википедии есть хороший пример простого способа использования этого двухэтапного подхода в фильтрации спама, аналогичной проблемы (см. раздел Пример использования статьи).
Удачи, звучит как интересный проект!
Если у вас достаточно размеченных данных — не только для «да, эта статья актуальна», но также и для «нет, эта статья неактуальна» (вы в основном создаете бинарную модель между релевантными да/нет — поэтому я бы исследовал спам фильтры), то вы можете обучить справедливую модель. Я не знаю, есть ли у вас приличное количество данных без данных. Если вы это сделаете, вы можете обучить относительно простую модель с учителем, выполнив (песудокод) следующее:0005
Корпус = предварительная обработка(Корпус) #(удалить стоп-слова и т.д.) Векторы = BOW (Корпус) # Или TFIDF или любая другая модель, которую вы хотите использовать SomeModel.train(Vectors[~3/4 из них], Labels[соответствующие 3/4]) #Labels = 1, если применимо, 0, если нет SomeModel.evaluate(Vectors[remainder], Labels[remainder]) #Убедитесь, что модель не подходит больше SomeModel.Predict(new_document)
Точная модель будет зависеть от ваших данных. Простой метод Наивного Байеса может (вероятно, будет) работать нормально, если вы сможете получить приличное количество документов без документов. Одно замечание: вы подразумеваете, что у вас есть два вида бездокументов — те, которые достаточно близки (Верховный суд Индии), или те, которые совершенно не имеют значения (скажем, Налоги). Вы должны протестировать обучение с «близкими» ошибочными случаями с отфильтрованными «дальними» ошибочными случаями, как вы это делаете сейчас, по сравнению с «близкими» ошибочными случаями и «дальними» ошибочными случаями и посмотреть, какой из них выходит лучше.
1
Есть много способов сделать это, и лучший метод меняется в зависимости от проекта. Возможно, самый простой способ сделать это — выполнить поиск по ключевым словам в ваших статьях, а затем эмпирическим путем выбрать пороговую оценку. Хотя это просто, на самом деле это работает довольно хорошо, особенно в такой теме, как эта, где вы можете придумать небольшой список слов, которые с большой вероятностью появятся где-нибудь в соответствующей статье.
Хотя это просто, на самом деле это работает довольно хорошо, особенно в такой теме, как эта, где вы можете придумать небольшой список слов, которые с большой вероятностью появятся где-нибудь в соответствующей статье.
Когда тема более широкая, например, «бизнес» или «спорт», поиск по ключевым словам может быть запретительным и отсутствовать. Именно тогда подход машинного обучения может стать лучшей идеей. Если машинное обучение — это то, к чему вы стремитесь, то есть два шага: 9.0005
- Встраивайте свои статьи в векторы признаков
- Тренируйте свою модель
Шаг 1 может быть чем-то простым, например вектором TFIDF. Тем не менее, встраивание ваших документов само по себе может быть глубоким обучением. Здесь в игру вступают CBOW и Skip-Gram. Популярный способ сделать это — Doc2Vec (PV-DM). Прекрасная реализация находится в библиотеке Python Gensim. Современные и более сложные встраивания символов, слов и документов представляют собой гораздо более сложную задачу для начала, но они очень полезны. Примерами этого являются вложения ELMo или BERT.
Примерами этого являются вложения ELMo или BERT.
Шаг 2 может быть типичной моделью, так как теперь это просто бинарная классификация. Вы можете попробовать многослойную нейронную сеть, либо полносвязную, либо сверточную, или вы можете попробовать более простые вещи, такие как логистическая регрессия или Наивный Байес.
Мое личное предложение состояло бы в том, чтобы придерживаться векторов TFIDF и наивного Байеса. Исходя из опыта, я могу сказать, что это работает очень хорошо, его проще всего реализовать, и в зависимости от ваших данных он может даже превзойти такие подходы, как CBOW или Doc2Vec.
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
mysql — В чем измеряется релевантность полнотекстового поиска?
спросил
Изменено 10 лет, 1 месяц назад
Просмотрено 4к раз
Я создаю систему викторин, и когда создатели викторин вставляют вопросы в банк вопросов, я должен проверять БД на наличие дубликатов/очень похожих вопросов.
Тестирование MySQL MATCH() … AGAINST(), самая высокая релевантность, которую я получаю, составляет 30+, когда я тестирую 100% похожую строку.
Так в чем именно заключается актуальность? Цитировать руководство:
Значения релевантности — неотрицательные числа с плавающей запятой. Нулевая релевантность означает отсутствие сходства. Релевантность вычисляется на основе количества слов в строке, количества уникальных слов в этой строке, общего количества слов в коллекции и количества документов (строк), содержащих определенное слово.
Моя проблема заключается в том, как проверить значение релевантности, если строка является дубликатом. Если это 100% дубликат, не допускайте его вставки в банк вопросов. Но если это только так похоже, подскажите викторине проверить, вставить или нет. Итак, как мне это сделать? 30+ для 100% идентичной строки это не процент, так что я пень.
Заранее спасибо.
- mysql
- производительность
- релевантность
- полнотекстовый поиск
Основной структурой данных для системы поиска текста является инвертированный индекс. По сути, это список слов, найденных в коллекции документов, со списком документов, в которых они встречаются. Он также может содержать метаданные о встречаемости для каждого документа, например, количество раз появления слова.
По сути, это список слов, найденных в коллекции документов, со списком документов, в которых они встречаются. Он также может содержать метаданные о встречаемости для каждого документа, например, количество раз появления слова.
Документы, содержащие слова, могут быть запрошены путем сопоставления условий поиска. Чтобы определить релевантность, для совпадений рассчитывается эвристика, известная как ранжирование косинусов. Это работает путем построения n-мерного вектора с одним компонентом для каждого из n условий поиска. Вы также можете взвесить условия поиска, если хотите. Этот вектор дает точку в n-мерном пространстве, соответствующую условиям поиска.
Аналогичный вектор на основе взвешенных вхождений в каждом документе может быть построен из инвертированного индекса с каждой осью в векторе, соответствующей оси для каждого условия поиска. Если вы вычислите скалярное произведение этих векторов, вы получите косинус угла между ними. 1.0 эквивалентно cos (0), что предполагает, что векторы занимают общую линию от начала координат. Чем ближе векторы друг к другу, тем меньше угол и тем ближе косинус к 1,0.
Чем ближе векторы друг к другу, тем меньше угол и тем ближе косинус к 1,0.
Если вы отсортируете результаты поиска по косинусу (или поместите их в приоритетную очередь, как это делает мг), вы получите наиболее релевантные. Более умные алгоритмы релевантности имеют тенденцию возиться с весами поисковых терминов, искажая скалярное произведение в пользу терминов с высокой релевантностью.
Если вы хотите немного покопаться, в книге «Управление гигабайтами» Белла и Моффета обсуждается внутренняя архитектура систем поиска текста.
andygeers находится на правильном пути: эти числа не имеют никакого эмпирического значения, кроме их отношения друг к другу, и не могут использоваться сами по себе для определения того, что является или не является «точным совпадением». Вы должны определить это сами. Даже помимо ограничений ранжирования полнотекстового поиска, остается открытым вопрос о том, что именно вы считаете «точным соответствием». (Только фактический текст или учитываются совпадения soundex? Считаются ли синонимы (например, «диван» и «диван») совпадающими или отдельными? Следует ли попытаться компенсировать орфографические ошибки? И т.