Как проверить научную статью на Плагиат? ? Читайте
Содержание
Плагиат – неэтичный, но короткий и дешевый путь достижения учеными своих целей. О его масштабах говорят цифры. Несоблюдение научной этики – главная причина отзыва научных статей из журналов. Причем, из них 10% – это откровенный плагиат, а 15% – самоплагиат. Committee of Publication Ethics (COPE) не случайно ужесточает методы борьбы. Поэтому проверка на плагиат возглавляет все критерии оценки научных статей.
Какой процент плагиата допустим в научных статьях?
Уникальность научных статей – от 85% для гуманитарных направлений и от 75% для технических и точных дисциплин. Эти цифры ориентировочные и усредненные, потому что ни один документ в мире не закрепил единое для всех значение. Редакции журналов устанавливают более четкие требования.
Дословное копирование, клонирование, перефразирование чужих работ без ссылки на источник не может превышать 10%. То есть эта цифра – лимит, верхний предел допустимого плагиата. На практике лучше не ходить «по краю» и свести этот показатель хотя бы к 5%.
На практике лучше не ходить «по краю» и свести этот показатель хотя бы к 5%.
Нюансы:
- Нельзя дословно цитировать более 10% работы чужого автора, не ссылаясь на него. Даже если общая уникальность статьи достаточная (например, первоисточник небольшой, и его десятая часть – это пара абзацев новой статьи) – требуется оформление ссылки. Это называется существенным некорректным перефразированием.
- Нельзя нарушать авторские права не только на текст, но и на графики, изображения, иллюстрации, рисунки, таблицы. Даже если заимствуется отдельный фрагмент, необходима ссылка на авторства, выражения слов признательности, ссылки. В отдельных случаях требуется получить разрешение владельца авторских прав, чтоб использовать его произведение.
- Нельзя выдавать собственные ранее опубликованные материалы или их фрагменты за впервые используемые. Это самоплагиат. Если работа уже публиковалась, нужно оформить ссылку на более раннюю публикацию. А также прокомментировать существенные отличия, сопоставить выводы, обосновать, почему нужно было обратиться к собственному труду.

Кроме плагиата есть требование соблюдения нормы цитирования и самоцитирования. Нельзя выстроить весь научный труд на чужих материалах, даже при правильном оформлении заимствований. Норма цитирования чужих и своих работ в научной статье – 15-20%. Остальное – собственный материал.
Если игнорировать требования к уникальности, смысл научной деятельности утрачивается. Процесс будет напоминать собаку, которая гоняется по кругу за собственным хвостом. Или, выразимся более научно, – вечное движение уроборос, символом которого является изображение змеи, заглатывающей собственный хвост
На каких онлайн-сервисах можно проверить уникальность?
Самый доступный и эффективный вариант проверки научных работ – система Антиплагиат.ру. Это сервис, «заточенный» на научные и студенческие тексты. Есть бесплатная поверхностная версия проверки – дает общее представление и процент заимствования. Регистрация простая, объем проверяемого текста может быть каким угодно (в рамках реалистичности, конечно)..png)
Full версия Антиплагиат.ру позволяет предметно проанализировать оригинальность, заимствования и самоцитирования, со ссылками на все источники по неуникальным фрагментам. Как правило, такой проверки достаточно, чтоб получить более-менее правдивую картину. Тарифы – разные, можно воспользоваться разовым пакетом.
Среди других доступных онлайн-сервисов проверки на антиплагиат:
- Etxt – проверка на рерайт, сравнение текстов, обнаружение копий;
- Text.ru – проверка уникальности, сео-анализ;
- Advego – проверка уникальности текста и процент оригинальности по фразам, сео анализ;
- ContentWhatch – система проверки копий и рерайта. Алгоритм похож на Антиплагиат.ру.
Поскольку эти сервисы не специализируются на научных работах, их алгоритмы проверки не гарантируют абсолютные данные об уникальности научной статьи. Более того, нужный процент на одном ресурсе вовсе не означает, что работа пройдет Антиплагиат.
Здесь работает принцип – чем выше уникальность по всем программам одновременно – тем лучше.
Поэтому будет нелишним прогнать текст везде. Тем более, это занимает мало времени – буквально, несколько минут
Главным и самым применяемым ресурсом проверки научных работ считается сервис Антиплагиат.ВУЗ. Его алгоритм проверки достаточно хорошо зарекомендовал себя в работе с научными текстами. Однако, есть одно «но» – доступ к сайту не у всех, а только у преподавателей и некоторых сотрудников. Однако программа Антиплагиат.ру очень схожа с этой версией.
Проверку иностранных научных работ можно провести на ресурсе Unicheck.com. Это международная программа с авторитетным бэкграундом. Однако, в бесплатном доступе проверка только нескольких страниц. Для полноценного анализа объемной научной статьи или диссертации потребуется платный пакет услуг.
Как проверяют на плагиат статьи Scopus?
Проверка материалов для публикации в Scopus не ограничивается только системами Антиплагиат. Это комплексный анализ, в рамках которого большую работу проделывает экспертный совет или даже комитет по этике. Проверка на плагиат статей Scopus включает:
Проверка на плагиат статей Scopus включает:
- общий процент уникальности;
- наличие некорректных заимствований;
- академическую добропорядочность;
- правильное оформление цитат и заимствований;
- соблюдение авторских прав;
- нерушимость интеллектуальной собственности;
- отсутствие конфликта интересов, связанных с авторским правом;
- факт не публикации этого материала в других изданиях.
В зависимости от тематики и содержания научной статьи проверка может включать оценку патентной чистоты изобретения (если оно берется в основу исследования как наработка автора). При выявлении подобных нарушении издатель вправе компенсировать убытки.
Проверка статей для Скопус предполагает оценку плагиата со всех ракурсов. То есть исключается клонирование, ненамеренный плагиат, некорректное дублирование, смысловой, мозаичный, дословный плагиат, перевод с другого языка
Научная статья сомнительно уникальная, если выявлены «авторы-призраки». Особенно этот формат характерен для соавторства. Практика знает случаи, когда ученый заявлен как автор или соавтор в более чем 5 тысячах публикаций. И как-то же они прошли проверки. Значит, алгоритм явно несовершенен.
Особенно этот формат характерен для соавторства. Практика знает случаи, когда ученый заявлен как автор или соавтор в более чем 5 тысячах публикаций. И как-то же они прошли проверки. Значит, алгоритм явно несовершенен.
Тем не менее, Scopus демонстрирует высокое качество публикаций и регулярно исключает журналы-хищники, и автоматически аннулирует статус уже опубликованных статей. По Украине этот процент составляет около 4% от всех опубликованных статей. И вроде небольшой процент, но в количественном выражении это около 2,5 тысяч.
Вывод
Плагиат – главный критерий оценки научной публикации. Без уникальности даже лучшие материалы не будут размещены ни в одном приличном журнале. Парадокс в том, что самостоятельное написание не гарантирует оригинальный текст. Изложить собственные мысли уникально – искусство.
Если вы не можете достичь нужной отметки в 80-85%, не хотите рисковать, не знаете, как полноценно проверить научную работу или уже получили отказ в публикации – обращайтесь в компанию «SOER Publishing».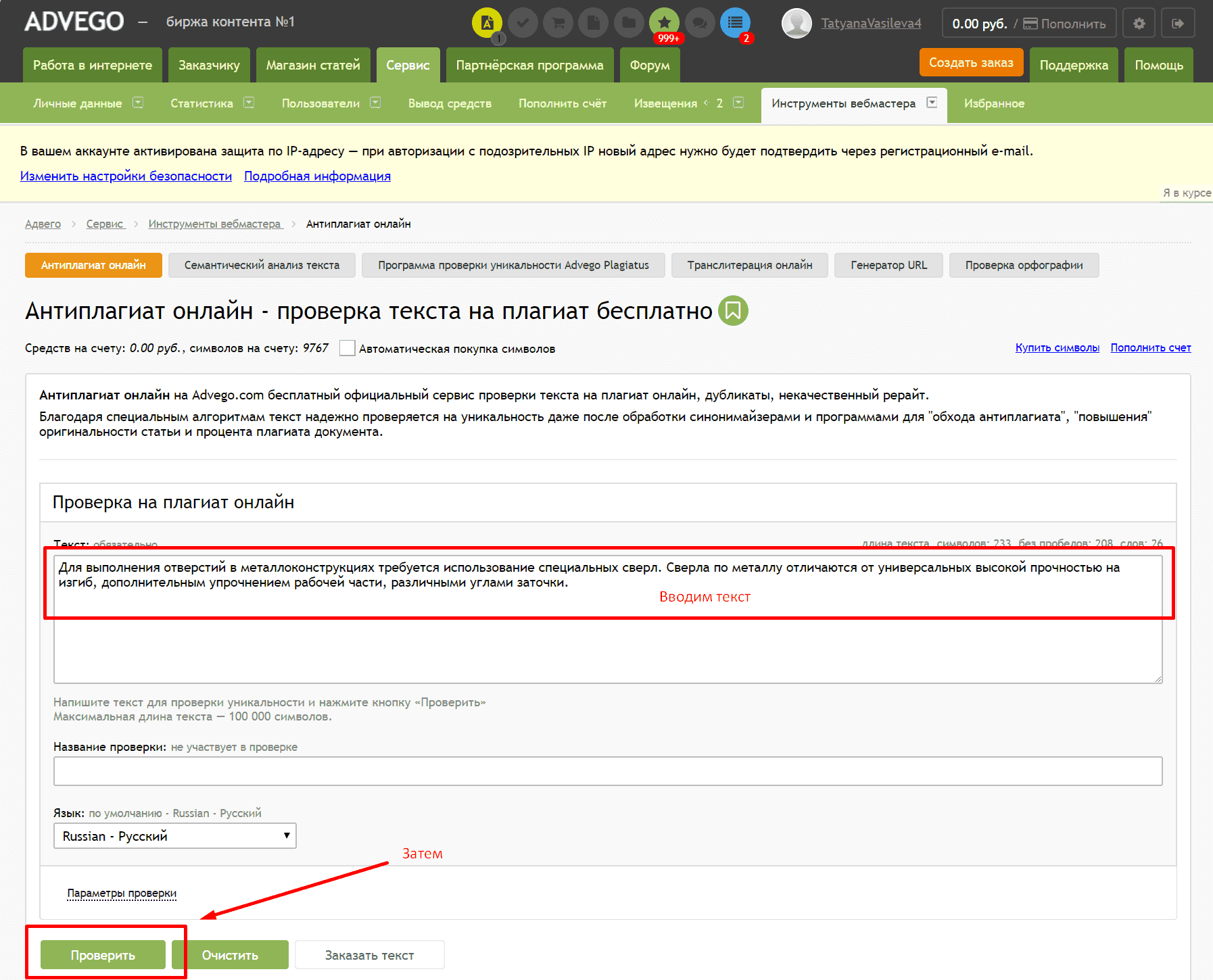 Наши авторы подготавливают научные статьи для размещения в журналах Scopus на любые темы «под ключ» и не только. Мы гарантируем результат и бесплатные доработки, потому что уверенны в качестве своей работы.
Наши авторы подготавливают научные статьи для размещения в журналах Scopus на любые темы «под ключ» и не только. Мы гарантируем результат и бесплатные доработки, потому что уверенны в качестве своей работы.
Создайте средство проверки на плагиат с помощью машинного обучения / Хабр
Используя машинное обучение, мы можем создать нашу собственную программу проверки на плагиат, которая выполняет поиск украденного контента в огромной базе данных. В этой статье мы сделаем демонстрационное приложение для этой цели.
Плагиат широко распространен в Интернете и в процессе обучения. При большом количестве контента иногда трудно определить, когда что-то стало плагиатом.
Авторы, пишущие сообщения в блогах, могут захотеть проверить, не украл ли кто-то их работу и не разместил ли ее в другом месте. Учителя могут захотеть сравнить работы студентов с другими научными статьями на предмет скопированных работ. Новостные агентства могут захотеть проверить, не украла ли контент-ферма их новостные статьи и не презентовала ли на это содержание как на свое.
Итак, как нам защититься от плагиата? Разве не было бы хорошо, если бы у нас было программное обеспечение, которое делало бы за нас всю тяжелую работу? Используя машинное обучение, мы можем создать нашу собственную программу проверки на плагиат, которая выполняет поиск украденного контента в огромной базе данных. В этой статье мы сделаем именно это.
Мы создадим Python Flask приложение, которое использует Pinecone — службу поиска сходства — для поиска возможного плагиата.
Обзор демонстрационного приложения
Давайте посмотрим на демонстрационное приложение, которое мы создадим сегодня. Ниже вы можете увидеть краткую анимацию приложения в действии.
Пользовательский интерфейс имеет простое текстовое поле для ввода, в которое пользователь может вставить текст из статьи. Когда пользователь нажимает кнопку «Отправить», этот ввод используется для запроса в базе данных статей. Затем пользователю отображаются результаты поиска и их проценты совпадения. Чтобы уменьшить количество шума, приложение также включает ползунок, в котором пользователь может указать порог схожести, чтобы показывать только очень сильные совпадения.
Как видите, когда исходный контент используется в качестве входных данных для поиска, оценки совпадений для статей, возможно, являющихся плагиатом, относительно низкие. Однако, если бы мы скопировали и вставили текст из одной из статей в нашей базе данных, результаты для статьи с плагиатом вернутся с совпадением 99,99%!
Итак, как мы это сделали?
При создании приложения мы начинаем с набора данных новостных статей от Kaggle. Этот набор данных содержит 143 000 новостных статей из 15 крупных публикаций, но мы используем только первые 20 000. (Полный набор данных, из которого создан этот, содержит более двух миллионов статей!)
Затем мы очищаем набор данных, переименовав пару столбцов и удалив несколько ненужных. Затем мы пропускаем статьи через модель вложения для создания vector embeddings (сопоставлений векторов) — это метаданные для алгоритмов машинного обучения для определения сходства между различными входными данными.
Подробнее см.
статью на Хабре: «Чудесный мир Word Embeddings: какие они бывают и зачем нужны?»
Мы используем модель Average Word Embeddings Model (модель среднего количества сопоставлений слов). Наконец, мы вставляем эти сопоставления векторов в векторную базу данных, управляемую Pinecone.
Когда векторные сопоставления добавлены в базу данных и проиндексированы, мы готовы начать поиск аналогичного контента. Когда пользователи отправляют текст своей статьи в качестве входных данных, делается запрос к конечной точке API, использующей SDK Pinecone для запроса индекса сопоставлений векторов. Конечная точка API возвращает 10 похожих статей, которые, возможно, были плагиатом, и отображает их в пользовательском интерфейсе приложения. Вот и все! Достаточно просто, правда?
Если вы хотите попробовать это сами, вы можете найти код этого приложения на GitHub. README содержит инструкции по локальному запуску приложения на вашем компьютере.
Пошаговое ревью кода демонстрационного приложения
Мы рассмотрели внутреннюю работу приложения, но как мы на самом деле его создали? Как отмечалось ранее, это Python Flask приложение, которое использует Pinecone SDK. HTML использует файл шаблона, а остальная часть интерфейса создается с использованием статических ресурсов CSS и JS. Для простоты весь внутренний код находится в файле app.py, который мы полностью воспроизвели ниже:
HTML использует файл шаблона, а остальная часть интерфейса создается с использованием статических ресурсов CSS и JS. Для простоты весь внутренний код находится в файле app.py, который мы полностью воспроизвели ниже:
from dotenv import load_dotenv
from flask import Flask
from flask import render_template
from flask import request
from flask import url_for
import json
import os
import pandas as pd
import pinecone
import re
import requests
from sentence_transformers import SentenceTransformer
from statistics import mean
import swifter
app = Flask(__name__)
PINECONE_INDEX_NAME = "plagiarism-checker"
DATA_FILE = "articles.csv"
NROWS = 20000
def initialize_pinecone():
load_dotenv()
PINECONE_API_KEY = os.environ["PINECONE_API_KEY"]
pinecone.init(api_key=PINECONE_API_KEY)
def delete_existing_pinecone_index():
if PINECONE_INDEX_NAME in pinecone.list_indexes():
pinecone.delete_index(PINECONE_INDEX_NAME)
def create_pinecone_index():
pinecone.create_index(name=PINECONE_INDEX_NAME, metric="cosine", shards=1)
pinecone_index = pinecone.
Index(name=PINECONE_INDEX_NAME)
return pinecone_index
def create_model():
model = SentenceTransformer('average_word_embeddings_komninos')
return model
def prepare_data(data):
# rename id column and remove unnecessary columns
data.rename(columns={"Unnamed: 0": "article_id"}, inplace = True)
data.drop(columns=['date'], inplace = True)
# combine the article title and content into a single field
data['content'] = data['content'].fillna('')
data['content'] = data.content.swifter.apply(lambda x: ' '.join(re.split(r'(?<=[.:;])\s', x)))
data['title_and_content'] = data['title'] + ' ' + data['content']
# create a vector embedding based on title and article content
encoded_articles = model.encode(data['title_and_content'], show_progress_bar=True)
data['article_vector'] = pd.Series(encoded_articles.tolist())
return data
def upload_items(data):
items_to_upload = [(row.id, row.article_vector) for i, row in data.iterrows()]
pinecone_index.
upsert(items=items_to_upload)
def process_file(filename):
data = pd.read_csv(filename, nrows=NROWS)
data = prepare_data(data)
upload_items(data)
pinecone_index.info()
return data
def map_titles(data):
return dict(zip(uploaded_data.id, uploaded_data.title))
def map_publications(data):
return dict(zip(uploaded_data.id, uploaded_data.publication))
def query_pinecone(originalContent):
query_content = str(originalContent)
query_vectors = [model.encode(query_content)]
query_results = pinecone_index.query(queries=query_vectors, top_k=10)
res = query_results[0]
results_list = []
for idx, _id in enumerate(res.ids):
results_list.append({
"id": _id,
"title": titles_mapped[int(_id)],
"publication": publications_mapped[int(_id)],
"score": res.scores[idx],
})
return json.dumps(results_list)
initialize_pinecone()
delete_existing_pinecone_index()
pinecone_index = create_pinecone_index()
model = create_model()
uploaded_data = process_file(filename=DATA_FILE)
titles_mapped = map_titles(uploaded_data)
publications_mapped = map_publications(uploaded_data)
@app.
route("/")
def index():
return render_template("index.html")
@app.route("/api/search", methods=["POST", "GET"])
def search():
if request.method == "POST":
return query_pinecone(request.form.get("originalContent", ""))
if request.method == "GET":
return query_pinecone(request.args.get("originalContent", ""))
return "Only GET and POST methods are allowed for this endpoint"Давайте пройдемся по важным частям файла app.py, чтобы понять его.
В строках 1–14 мы импортируем зависимости нашего приложения. Наше приложение использует следующее зависимости:
dotenvдля чтения переменных среды из файла .envflaskдля настройки веб-приложенияjsonдля работы с JSONosтакже для получения переменных средыpandasдля работы с набором данныхpineconeдля работы с Pinecone SDKreдля работы с регулярными выражениями (RegEx)requestsдля выполнения запросов API для загрузки нашего набора данныхstatisticsдля некоторых удобных методов статистикиsentence_transformersдля нашей модели встраиванияswifterдля работы с фреймом данных pandas
В строке 16 мы предоставляем шаблонный код, чтобы сообщить Flask имя нашего приложения.
В строках 18-20 мы определяем некоторые константы, которые будут использоваться в приложении. К ним относятся имя нашего индекса Pinecone, имя файла набора данных и количество строк для чтения из файла CSV.
В строках 22-25, метод initialize_pinecone получает наш ключ API из файла .env и использует его для инициализации Pinecone.
В строках 27-29, наш метод delete_existing_pinecone_indexищет в нашем экземпляре Pinecone индексы с тем же именем, что и тот, который мы используем («проверка на плагиат»). Если найден существующий индекс, мы его удаляем.
В строках 31-35, наш метод create_pinecone_index создает новый индекс, используя выбранное нами имя («проверка на плагиат»), метрику близости «косинус» и только одну shard.
В строках 37-40, наш метод create_model использует библиотеку offer_transformers для работы с моделью среднего количества сопоставлений слов. Позже мы закодируем наши сопоставлений векторов, используя эту модель.
В строках 62-68, наш метод prepare_data и upload_items. Эти два метода описаны ниже.
В строках 42-56 наш метод prepare_data корректирует набор данных, переименовывая первый столбец «id» и удаляя столбец «date». Затем он объединяет заголовок статьи с содержанием статьи в одно поле. Мы будем использовать это комбинированное поле при создании сопоставлений векторов.
В строках 58-60 наш upload_itemsметод создает сопоставление векторов для каждой статьи, кодируя его с помощью нашей модели. Затем мы вставляем сопоставления векторов в индекс Pinecone.
В строках 70-74, наши методы map_publications создают некоторые словари названий и имен публикаций, чтобы позже легче найти статьи по их идентификаторам.
Каждый из описанных методов вызывается в строках 95-101 при запуске серверной части приложения. Ее работа подготавливает нас к последнему этапу фактического запроса индекса Pinecone на основе пользовательского ввода.
В строках 103–113 мы определяем два маршрута для нашего приложения: один для домашней страницы и один для конечной точки API. Домашняя страница обслуживает файл шаблона index.html вместе с активами JS и CSS, а конечная точка API предоставляет функции поиска для запроса индекса Pinecone.
Наконец, в строках 76-93 наш метод query_pinecone принимает вводимое пользователем содержимое статьи, преобразует его в сопоставления векторов, а затем запрашивает индекс Pinecone, чтобы найти похожие статьи. Этот метод вызывается при переходе на конечную точку /api/search, что происходит каждый раз, когда пользователь отправляет новый поисковый запрос.
Для визуализации процесса, вот схема, показывающая, как работает приложение:
Архитектура приложения и пользовательский интерфейсПримеры сценариев
Итак, суммируя сказанное, как выглядит пользовательский сценарий? Давайте рассмотрим три сценария: оригинальный контент, точная копия плагиата и контент с «исправлением написанного».
Когда отправляется оригинальный контент, приложение отвечает некоторыми, возможно, связанными статьями, но оценки соответствия довольно низкие. Это хороший знак, поскольку контент не является плагиатом, поэтому мы ожидаем низких оценок соответствия.
Когда отправляется точная копия плагиата, приложение выдает почти идеальную оценку совпадения для одной статьи. Это потому, что контент идентичен. Хорошая проверка на плагиат!
Теперь, для третьего сценария, мы должны определить, что мы подразумеваем под «исправлением написанного». Исправление написанного — это форма плагиата, при которой кто-то копирует и вставляет украденный контент, но затем пытается замаскировать факт плагиата, изменяя некоторые слова здесь и там. Если в предложении из исходной статьи говорится: «Он был вне себя от радости найдя свою потерянную собаку», кто-то может написать исправление, чтобы вместо этого сказать: «Он был счастлив вернуть свою пропавшую собаку». Это несколько отличается от перефразирования, потому что основная структура предложения содержания часто остается неизменной на протяжении всей статьи, подвергшейся плагиату.
Вот что самое интересное: наша программа проверки на плагиат действительно хорошо распознает контент с «исправлением написанного»! Если вы скопируете и вставите одну из статей в базе данных, а затем измените несколько слов здесь и там, и, возможно, даже удалите несколько предложений или абзацев, оценка совпадения все равно вернется как почти идеальное совпадение! Когда я попытался сделать это со скопированной и вставленной статьей, у которой была оценка совпадения 99,99%, содержание «записанного исправления» по-прежнему давало оценку совпадения 99,88% после моих изменений!
Не слишком испорчена оценка! Похоже, наша программа проверки на плагиат работает нормально.
Заключение и следующие шаги
Мы создали простое приложение Python для решения реальной проблемы. Подражание может быть высшей формой лести, но никому не нравится, когда его работы крадут. В мире растущего контента подобная программа для проверки плагиата будет очень полезна как авторам, так и учителям.
У этого демонстрационного приложения есть некоторые ограничения, так как это всего лишь демонстрация. База данных статей, загруженных в наш индекс, содержит всего 20 000 статей из 15 крупных новостных изданий. Однако существуют миллионы или даже миллиарды статей и сообщений в блогах. Подобная программа проверки на плагиат полезна только в том случае, если она проверяет ваш ввод на предмет всех мест, где ваша работа могла быть плагиатом. Это приложение было бы лучше, если бы в нашем индексе было больше статей и если бы мы постоянно добавляли в него.
Тем не менее, на данный момент мы продемонстрировали важное подтверждение концепции. Pinecone, как сервис поиска сходства, сделала за нас тяжелую работу, когда дело дошло до аспекта машинного обучения. С его помощью мы смогли создать полезное приложение, которое довольно легко использует обработку естественного языка и семантический поиск, и теперь мы можем быть спокойны, зная, что наша работа не является плагиатом.
Простые и эффективные подходы к написанию уникальных статей
Написание статей — это большое ремесло, которое в настоящее время очень востребовано.
Уникальность противоположна плагиату. Если ваш контент имеет такую же формулировку, что и другой, или в нем обсуждаются идеи и концепции, представленные другими, без их признания, то это называется плагиатом.
Плагиат строго наказывается издателями и поисковыми системами. Издатели просто отказываются публиковать такой контент, а также могут занести автора в черный список. Поисковые системы снижают рейтинг копируемого контента или полностью удаляют страницу, на которой он был размещен, из своего индекса.
Чтобы избежать подобных последствий, авторам статей необходимо сделать свой контент уникальным. Итак, вот несколько простых и эффективных способов сделать это.
1. Проведите тщательное исследование
Большинство людей сознательно не занимаются плагиатом. Они непреднамеренно копируют других во время письма. Итак, как это происходит? Наиболее распространенная причина заключается в том, что автору не хватает информации по своей теме.
Они непреднамеренно копируют других во время письма. Итак, как это происходит? Наиболее распространенная причина заключается в том, что автору не хватает информации по своей теме.
Это делает их склонными к копированию других.
Единственный способ справиться с этим — иметь много знаний и понимания темы. Для этого нужно провести исследование. Исследование является краеугольным камнем написания статьи. Вы не можете создать что-то из ничего, и то же самое касается письма. Чтобы писать, нужно иметь некоторые знания.
Вот несколько советов по проведению исследований:
• Прочитайте исследовательские работы по вашей теме. Исследовательские работы являются лучшим источником для получения новой и исчерпывающей информации по большинству тем. Они предоставляют достаточно справочной информации, чтобы большинство людей могли их понять.
• Читайте книги по интересующим вас темам. Подобно исследовательским работам, книги могут предоставить много всесторонних знаний наряду с справочной информацией.
• Читайте статьи и новостные колонки по интересующей вас теме.
Изменяя источники и много читая о предмете, вы сможете лучше понять его. С пониманием приходит уверенность в том, что вы можете написать об этом, и с уверенностью вы не будете бессознательно копировать других.
2. Пишите в своем собственном стиле
Иногда новые писатели имеют привычку подражать стилям других авторов. Это естественная вещь, и это не так уж плохо. Однако это создает одну проблему; это может привести к плагиату, т.е. к неуникальным статьям.
Таким образом, единственный способ справиться с этим — отказаться от стилей других авторов и развивать свой собственный. Выработать свой личный стиль письма может быть сложно или очень легко, это зависит от человека. Но есть некоторые шаги, которые вы можете предпринять независимо от сложности.
Итак, вот что вы можете сделать:
• Всегда формулируйте вещи так, как вы хотели бы, а не словами других людей.
• Читайте больше и улучшайте свой словарный запас. Это даст вам больше возможностей и поможет вам найти свой стиль.
Это даст вам больше возможностей и поможет вам найти свой стиль.
• Не зацикливайтесь на одном тоне. Попробуйте создать разные голоса, которые подходят для разных ситуаций. Вы бы не использовали тот же тон в официальном письме, что и в описательном эссе, не так ли?
• Используйте собственный опыт (когда этого требует ситуация), чтобы представить свою уникальную точку зрения.
Практикуя эти вещи, вы можете быть уверены, что ваш стиль письма будет отличным и уникальным.
3. Всегда проверяйте черновики на плагиат
Даже если вы проведете обширное исследование и создадите свой собственный стиль письма, вы все равно можете случайно совершить плагиат, что снизит уникальность вашей статьи.
Случайный плагиат может произойти случайно или по ошибке. В статьях, где вы должны указать кого-то еще, потому что вы использовали их работу, ошибка в цитировании приводит к плагиату. Иногда плагиат возникает просто из-за того, что вы написали что-то сверхъестественно похожее на кого-то другого, даже не подозревая об этом.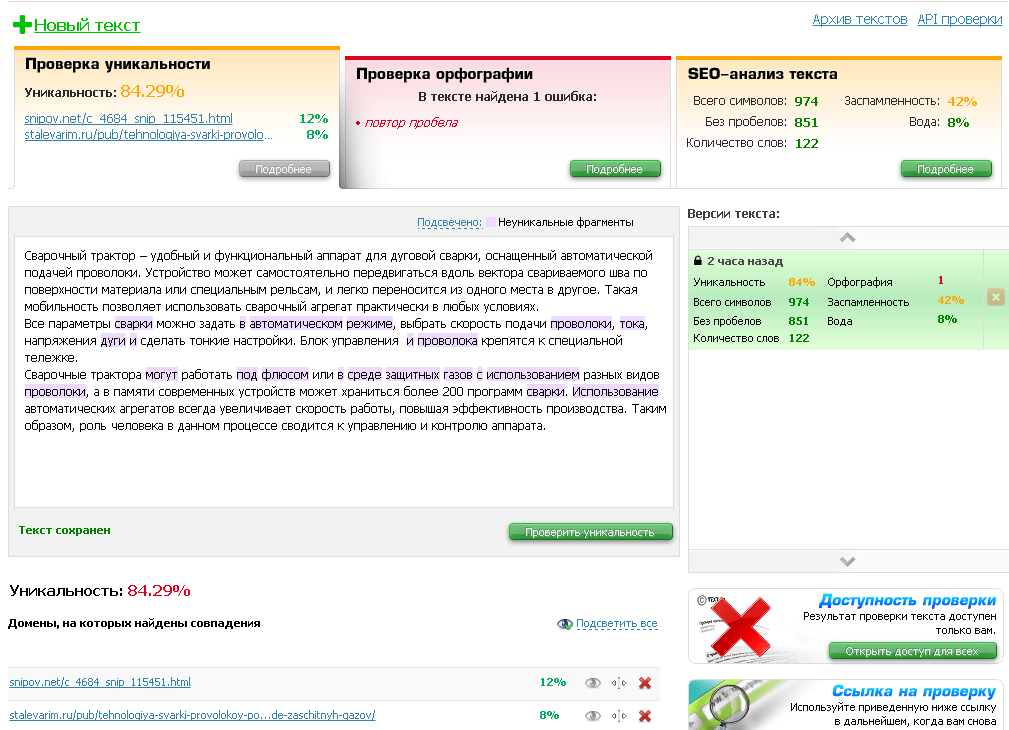
Все эти вещи считаются плагиатом и наказываются так, как мы упоминали в начале этого поста. Поэтому важно проверять свою работу на плагиат. Есть только один реальный способ сделать это — полагаться на онлайн-проверки на плагиат.
Бесплатная программа проверки на плагиат с достаточно большим количеством слов идеально подходит для проверки статей. В настоящее время статьи не такие длинные из-за постоянно сокращающейся концентрации человеческого внимания. Как правило, они составляют от 500 до 1000 слов. Это число, которое может легко вместить большинство инструментов.
Проверив свою работу с помощью бесплатной программы проверки на плагиат, вы можете получить отчет, показывающий, какой контент является плагиатом. Также показаны части, которые являются плагиатом, поэтому вы можете использовать эту информацию, чтобы справиться с этим. Это сделает ваш контент уникальным.
4. Удалите любой обнаруженный плагиат из вашей работы
Обнаружение плагиата в вашем содержании — это одно, а удаление — другое. Удаление плагиата может быть выполнено несколькими способами в зависимости от типа плагиата.
Удаление плагиата может быть выполнено несколькими способами в зависимости от типа плагиата.
Для любого вида скопированного контента, имеющего надлежащий источник, принято ссылаться на него. Итак, если вы случайно скопировали из какого-то источника, то просто укажите источник и вперед.
Если плагиат произошел из-за схожей формулировки, но сама идея не связана с источником, то перефразирование подойдет.
Однако перефразировать немного сложнее, чем цитировать, что относительно просто. Перефразирование требует, чтобы у писателя был большой словарный запас и присутствие духа, чтобы использовать его. Но есть и более простой способ. Вместо этого вы можете перефразировать онлайн.
Чтобы перефразировать онлайн, вам нужно всего лишь найти инструмент в Интернете, предоставить ему ваш плагиат, и он автоматически изменит его. Вы получите уникальное предложение/отрывок, не затрачивая при этом никаких усилий.
Заключение
Вот несколько простых, легких, эффективных и действенных советов по созданию уникального контента без плагиата. Два из этих советов настолько просты, что вы можете начать применять их прямо сейчас, а два из них требуют некоторого времени и усилий, чтобы принести свои плоды.
Два из этих советов настолько просты, что вы можете начать применять их прямо сейчас, а два из них требуют некоторого времени и усилий, чтобы принести свои плоды.
Вы должны знать, что, применяя эти советы к своим рецензиям, вы можете избежать многих проблем, связанных с плагиатом. Большинство профессиональных писателей применяют все эти приемы и в своих работах (за исключением того, что у них есть редакторы), так что вам следует поступать так же.
Проверка значений серии Pandas уникальна
Распространение любви
Pandas Атрибут Series.is_unique используется для проверки каждого элемента или значения, присутствующего в объекте серии pandas, имеет уникальные значения или нет. Он возвращает True , если элементы, присутствующие в данном объекте серии, уникальны, в противном случае возвращается False . В этой статье я объясню Series.is_unique и использую эту функцию, чтобы проверить, содержит ли серия панд все уникальные значения или нет.
Учебное пособие по PySpark для начинающих (Spa…
Пожалуйста, включите JavaScript
Учебное пособие по PySpark для начинающих (Spark с Python)1. Краткие примеры проверки уникальности каждого значения серии
Если вы спешите, ниже приведены краткие примеры того, как проверить уникальность каждого значения в серии pandas.
# Ниже приведены краткие примеры # Пример 1: Использование Series.is_unique ser2 = ser.is_unique # Пример 2: Проверить уникальность серии pandas или нет ser = pd.Series(['Spark','PySpark','Pandas','NumPy']).is_unique # Пример 3: Используйте функцию pandas.series() для применения свойства is_unique ser = pd.Series(['Spark','PySpark','Pandas','PySpark']).is_unique # Пример 4: Использование атрибута is_unique со значениями nan # Чтобы проверить уникальные значения ser = pd.Series(['Spark','PySpark','Pandas','NumPy',np.nan,np.nan]).is_unique # Пример 5: Использование атрибута dropna() и is_unique # Со значениями nan для проверки уникальных значений ser = pd.Series(['Spark','PySpark','Pandas', np.nan, np.nan]).dropna().is_unique # Пример 6: Использование функции nunic() # Чтобы проверить уникальность серии ser = pd.Series([1, 2, 3]).nunique()==len(pd.Series([1, 2, 3]))
2. Синтаксис Pandas Series.is_unique
Ниже приведен синтаксис атрибута Series.is_unique .
# Синтаксис Series.is_unique Series.is_unique
Возвращает логическое значение.
3. Проверка серии Pandas содержит уникальные значения
Используйте атрибут pandas Series.is_unique , чтобы проверить, являются ли все данные или элементы в данном объекте Series уникальным значением или нет. Если этот атрибут возвращает True , это будет означать, что данный объект серии уникален.
Серия Pandas — это одномерная структура данных с индексной меткой, доступная только в библиотеке Pandas. Он может хранить все типы данных, такие как строки, целые числа, числа с плавающей запятой и другие объекты Python. Мы можем получить доступ к каждому элементу в серии с помощью соответствующих индексов по умолчанию. Теперь давайте создадим ряд панд, используя список значений.
Мы можем получить доступ к каждому элементу в серии с помощью соответствующих индексов по умолчанию. Теперь давайте создадим ряд панд, используя список значений.
импортировать панд как pd импортировать numpy как np # Создать серию ser = pd.Series(['Spark','PySpark','Pandas','NumPy']) печать (сер)
Выход ниже выходного.
# Выход: 0 Искра 1 PySpark 2 панды 3 числовой код тип: объект
Теперь воспользуемся атрибутом Series.is_unique , чтобы проверить, содержит ли ti уникальные значения.
# Использование Series.is_unique ser2 = ser.is_unique печать (сер2) # Выход: # Истинный
5. Проверить уникальность серии Pandas
Создал серию pandas, используя список строк Python, затем применил атрибут is_unique к данному объекту серии. Он вернет логическое значение (либо True, либо False). Давайте проверим, являются ли данные данного объекта серии уникальными или нет.
# Проверить уникальность серии панд или нет ser = pd.Series(['Spark','PySpark','Pandas','NumPy']).is_unique печать (сер) # Выход: # Истинный # Используйте функцию pandas.series() для применения свойства is_unique ser = pd.Series(['Spark','PySpark','Pandas','PySpark']).is_unique печать (сер) # Выход # ЛОЖЬ
6. Используйте атрибут is_unique со значениями NaN для проверки уникальных значений
Создал объект серии pandas с несколькими значениями NaN, затем вызовите атрибут is_unique , он возвращает логическое значение Ложь ,
# Используйте атрибут is_unique со значениями nan для проверки уникальных значений ser = pd.Series(['Spark','PySpark','Pandas','NumPy',np.nan,np.nan]).is_unique печать (сер) # Выход: # ЛОЖЬ
Чтобы игнорировать значения NaN, сначала вызовите функцию dropna() , чтобы удалить все значения NaN, а затем вызовите метод is_unique.
# Используйте атрибут dropna() и is_unique со значениями nan для проверки уникальных значений ser = pd.Series(['Spark','PySpark','Pandas', np.
