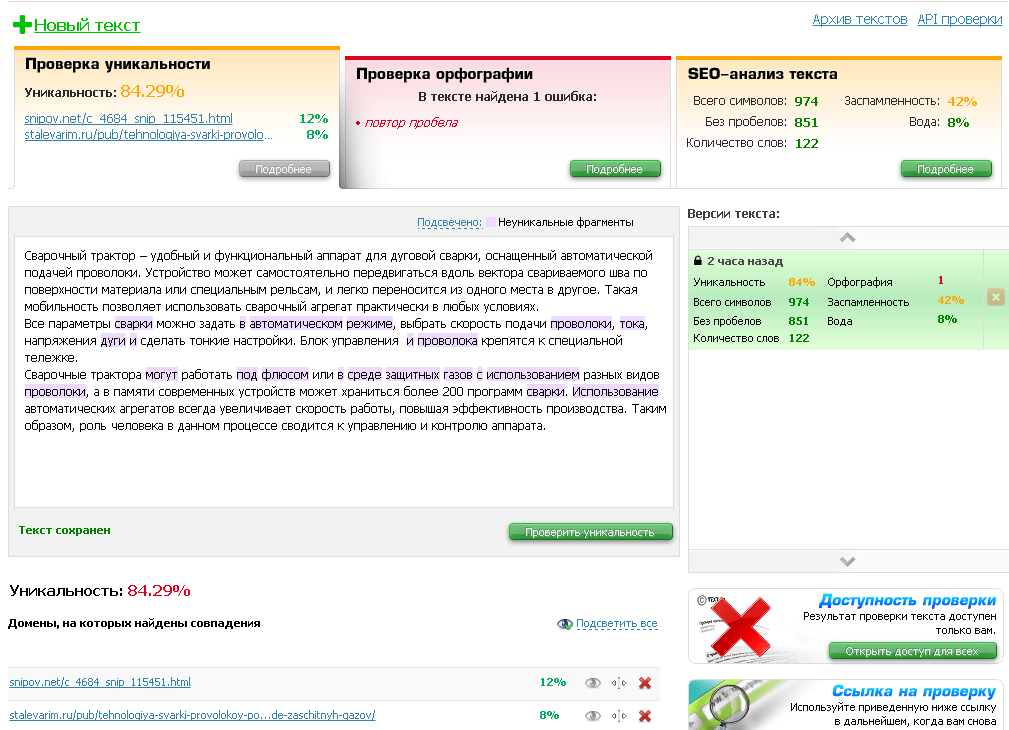
Как найти более актуальную информацию! – Text Mining
Дж. К. Шолтес
8 способов реализовать настоящий исследовательский поиск.
В некоторых поисковых задачах достаточно найти несколько «лучших совпадений», чтобы найти ответ на вопрос или решение проблемы. Хороший пример — поиск отеля в чужом городе, например, в Амстердаме. Достаточно найти лучший сайт отеля с лучшими предложениями; никому не интересно найти все веб-сайтов, посвященных предложениям отелей в Амстердаме. Этот тип поиска часто называют фокальным или веб-поиском, и он обеспечивает высокую точность, а не высокий отзыв.
Но когда полицейский, следователь, адвокат или аналитик разведки проводят поиски, им нужно выйти за рамки простого поиска «лучших результатов». Им необходимо просмотреть все потенциально важные документы, чтобы не столкнуться с неожиданной информацией.
Есть еще несколько проблем, которые они должны решить: когда люди совершают мошенничество, они не хотят, чтобы их нашли, в отличие от обычного веб-поиска, где все хотят быть в начале списка. Кроме того, поисковики не всегда знают точные ключевые слова для поиска: могут использоваться неизвестные (кодовые) имена или синонимы. В результате поисковикам нужен более широкий и исследовательский тип поиска. Этот поиск должен позволить им исследуйте данные очень интерактивным образом. Поиск должен обеспечивать высокий уровень отзыва (например, находить все потенциально релевантные документы), но в то же время подавлять шум нерелевантных документов.
Точность и полнота обратно пропорциональны: если вы используете инструменты для увеличения одной, другая уменьшится. Например, нечеткий поиск даст вам больше релевантных результатов, но вы также найдете несколько ложных срабатываний. Поиск по близости (найти слово A среди X слов слова B), с другой стороны, даст меньше ложных срабатываний, но вы также можете пропустить соответствующие документы.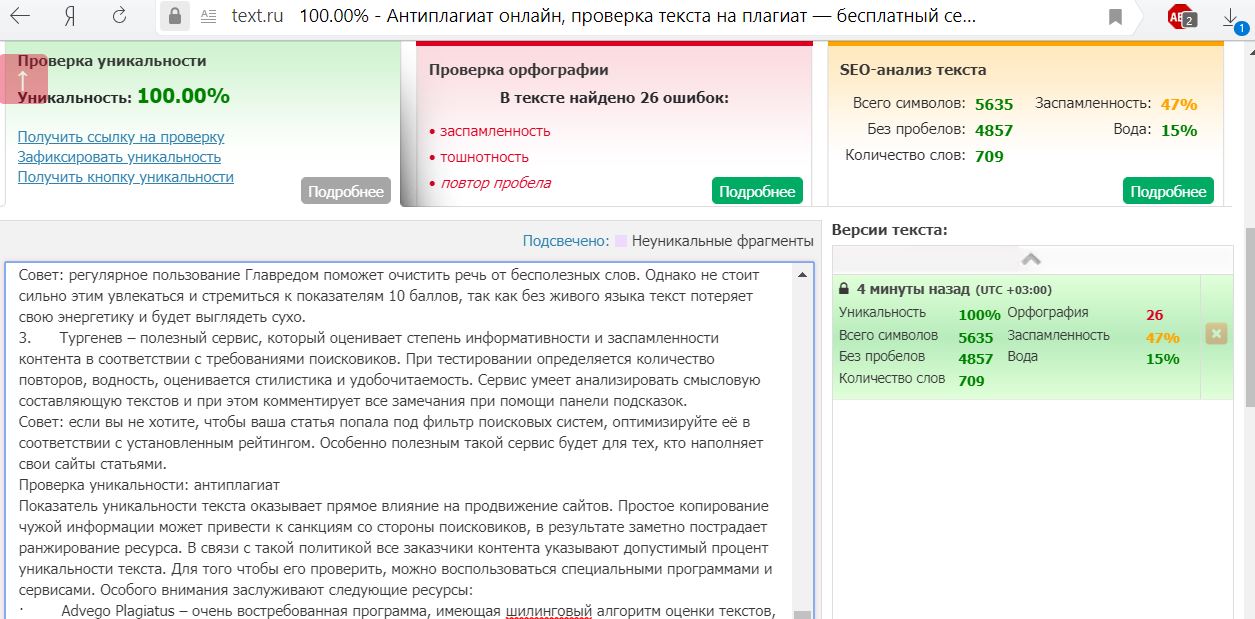
Профессиональный исследовательский поиск должен предоставлять пользователю не только инструменты поиска, чтобы найти больше, но и интерактивные инструменты для исключения нерелевантных документов за счет возможности быстрой навигации в интерактивном режиме и использования различных углов (фасетов) для просмотра списков результатов. .
Вот 8 основных методов, которые вам следует искать:
- Реальный нечеткий поиск и поиск с использованием подстановочных знаков: это важно для поиска слов и фраз, которые выглядят как запрос, но не являются точно такими же. Важно иметь возможность изменить не только конец слова, но и его начало, середину или конец (или их комбинацию). В то же время система не должна зависеть от словарей (поскольку это ограничит возможности поиска) и должна по-прежнему работать с огромными наборами данных. Это требует, чтобы поисковый индекс был реализован таким образом, чтобы поддерживать эти типы поиска. Это потребует некоторых дополнительных усилий при индексации времени, поэтому почти все 9Движки 0009 web
 В результате сканирование, OCR, транслитерация и орфографические ошибки и варианты не могут быть найдены такими поисковыми системами.
В результате сканирование, OCR, транслитерация и орфографические ошибки и варианты не могут быть найдены такими поисковыми системами. - Быстрое выделение совпадений, навигация по совпадениям и использование ключевых слов в контексте: это важные инструменты для быстрой навигации по большим документам от попадания к попаданию. Только тогда пользователи смогут эффективно определить, почему документ был извлечен и где находятся соответствующие слова. Это должно работать во всех форматах файлов, а также быть быстрым: вы не хотите ждать, пока 500 страниц будут загружены по отдельности, прежде чем увидеть страницу с хитом. Ключевое слово в контексте (так называемое представление KWIC) позволяет пользователям видеть слова до и после совпадения в списке результатов. Это очень полезно для просмотра содержимого документа из списка результатов. Если имеется более одного совпадения, то несколько записей из этого документа будут перечислены в записи списка результатов.
- Настраиваемое ранжирование релевантности: все веб-движки настроены только на один тип ранжирования релевантности: в основном алгоритм популярности или ссылок на страницы.

- Гибкий поиск близости и поддержка сложных вложенных логических операторов: (согласовано) Логические запросы часто бывают большими и сложными, чтобы включать как включающие, так и исключающие ключевые слова, которые можно комбинировать с И, ИЛИ и НЕ. Особенно в длинных документах нужна возможность вкладывать их в скобки, а также нужен оператор близости, рядом или предшествующий оператор, который дает возможность определить, что определенные ключевые слова должны встречаться в одном предложении, абзаце или в X словах друг от друга. Это особенно важно в длинных документах с множеством различных разделов и глав.

- Поиск кворума: это идеальное сочетание точности и полноты. Такой возможностью обладают не многие производители. При поиске кворума можно определить набор слов (компонент отзыва) и установить, что в документе должно быть не менее X этих слов (компонент точности). Обычно это выглядит как 2 {дерево, растение, цветок, роза, тюльпан}. Чем выше значение X, тем выше точность. Большие ведра слов приведут к лучшему отзыву. Поиск кворума идеально подходит для определения сложных понятий.
- Текстовая и контент-аналитика: поиски будущего. В наши дни существует так много новых инструментов для добавления дополнительных поисковых метаданных в документы, что, к сожалению, не многие поисковые системы используют их. Некоторыми примерами являются извлечение свойств документа, свойств файла, сущностей, фактов, событий и понятий.
 Другие инструменты включают автоматические сводки, машинный перевод, определение языка и многое другое. Вся эта дополнительная информация предоставит больше возможностей для поиска, а также возможность экспортировать, например, все названия компаний или отдельных лиц, которые упоминаются в наборе документов. Дополнительные возможности ранжирования релевантности и расширенной визуализации за счет более заполненных списков результатов также являются дополнительным преимуществом.
Другие инструменты включают автоматические сводки, машинный перевод, определение языка и многое другое. Вся эта дополнительная информация предоставит больше возможностей для поиска, а также возможность экспортировать, например, все названия компаний или отдельных лиц, которые упоминаются в наборе документов. Дополнительные возможности ранжирования релевантности и расширенной визуализации за счет более заполненных списков результатов также являются дополнительным преимуществом. - Фасетный поиск (также известный как уточнение результатов или ранжирование семантической релевантности):. Дополнительный контент, созданный аналитикой контента, предоставит нам дополнительные аспекты, которые мы можем использовать для уточнения наших результатов. Например, мы можем определить такой фасет, как Country или Person , который будет включать все страны или лица, названные в наборе документов, извлеченных с помощью полнотекстового запроса. Простая операция щелчка по одному из значений фасета приведет к получению документов, содержащих это конкретное значение.

- Расширенная визуализация данных и обнаружение аномалий: анализ текста часто упоминается в том же предложении, что и визуализация информации (или данных); в значительной степени потому, что визуализация является одним из жизнеспособных технических инструментов для анализа информации после того, как неструктурированная информация была структурирована.
Вместо того, чтобы отображать все результаты в виде (большого) табличного списка результатов, их также можно нанести на карту Google, например, чтобы показать их географическое положение. Также возможно отобразить результаты в виде интерактивного гиперболического дерева. Пользователь может щелкнуть и перетащить звездочку, чтобы показать различные взаимосвязи между результатами поиска, ее свойствами и ее местоположением. Такие методы дадут лучшее понимание иерархических отношений между набором данных на основе метаинформации. Было доказано, что несоответствия данных и сложные закономерности могут быть обнаружены очень легко с помощью таких методов и часто намного быстрее, чем без них.
Было доказано, что несоответствия данных и сложные закономерности могут быть обнаружены очень легко с помощью таких методов и часто намного быстрее, чем без них.
Если вы не знакомы с расширенным поиском, то это может быть, так сказать, «слишком много информации». Если у вас сейчас немного кружится голова, это понятно. Главный вывод заключается в том, что если вы занимаетесь бизнесом, требующим исследовательского поиска, вам следует выйти за рамки простого окна поиска «Google». Вы должны использовать все технологии, доступные в настоящих поисковых решениях. Вы получите профессиональную панель поиска, которая поможет вам изучить и найти всю информацию, даже если вы точно не знаете, что ищете!
Нравится:
Нравится Загрузка…
Просмотреть все сообщения J.C. Scholtes
mysql — В чем измеряется релевантность полнотекстового поиска?
спросил
Изменено 10 лет, 8 месяцев назад
Просмотрено 4к раз
Я создаю систему викторин, и когда создатели викторин вставляют вопросы в Банк вопросов, я должен проверять БД на наличие дубликатов/очень похожих вопросов.
Тестирование MySQL MATCH() … AGAINST(), самая высокая релевантность, которую я получаю, составляет 30+, когда я тестирую 100% похожую строку.
Так в чем именно актуальность? Цитировать руководство:
Значения релевантности — неотрицательные числа с плавающей запятой. Нулевая релевантность означает отсутствие сходства. Релевантность вычисляется на основе количества слов в строке, количества уникальных слов в этой строке, общего количества слов в коллекции и количества документов (строк), содержащих определенное слово.
Моя проблема заключается в том, как проверить значение релевантности, если строка является дубликатом. Если это 100% дубликат, не допускайте его вставки в банк вопросов. Но если это только так похоже, подскажите викторине проверить, вставить или нет. Итак, как мне это сделать? 30+ для 100% идентичной строки это не процент, так что я пень.
Заранее спасибо.
- mysql
- производительность
- релевантность
- полнотекстовый поиск
Основной структурой данных для системы поиска текста является инвертированный индекс. По сути, это список слов, найденных в коллекции документов, со списком документов, в которых они встречаются. Он также может содержать метаданные о встречаемости для каждого документа, например, сколько раз встречается слово.
По сути, это список слов, найденных в коллекции документов, со списком документов, в которых они встречаются. Он также может содержать метаданные о встречаемости для каждого документа, например, сколько раз встречается слово.
Документы, содержащие слова, могут быть запрошены путем сопоставления условий поиска. Чтобы определить релевантность, для совпадений рассчитывается эвристика, известная как ранжирование по косинусу. Это работает путем построения n-мерного вектора с одним компонентом для каждого из n условий поиска. Вы также можете взвесить условия поиска, если хотите. Этот вектор дает точку в n-мерном пространстве, соответствующую условиям поиска.
Аналогичный вектор на основе взвешенных вхождений в каждом документе может быть построен из инвертированного индекса с каждой осью в векторе, соответствующей оси для каждого условия поиска. Если вы вычислите скалярное произведение этих векторов, вы получите косинус угла между ними. 1.0 эквивалентно cos (0), что предполагает, что векторы занимают общую линию от начала координат. Чем ближе векторы друг к другу, тем меньше угол и тем ближе косинус к 1,0.
Чем ближе векторы друг к другу, тем меньше угол и тем ближе косинус к 1,0.
Если вы отсортируете результаты поиска по косинусу (или поместите их в приоритетную очередь, как это делает mg), вы получите наиболее релевантные. Более умные алгоритмы релевантности имеют тенденцию возиться с весами поисковых терминов, искажая скалярное произведение в пользу терминов с высокой релевантностью.
Если вы хотите немного покопаться, в книге «Управление гигабайтами» Белла и Моффета обсуждается внутренняя архитектура систем поиска текста.
andygeers находится на правильном пути: эти числа не имеют никакого эмпирического значения, кроме их отношения друг к другу, и не могут использоваться сами по себе для определения того, что является или не является «точным совпадением». Вы должны определить это сами. Даже помимо ограничений ранжирования полнотекстового поиска, остается открытым вопрос о том, что именно вы считаете «точным соответствием». (Только фактический текст или учитываются совпадения soundex? Считаются ли синонимы (например, «диван» и «диван») совпадающими или отдельными? Следует ли попытаться компенсировать орфографические ошибки? И т.