Профилирование кода на C/С++ в *nix-системах / Хабр
Отличный обзорный доклад конференции HighLoad++ 2016 о том, как надо проводить профилирование программного кода. О типичных ошибках, происходящих при измерениях. И, конечно, об инструментах:
— gettimeofday
— strace, ltrace, truss
— gprof
— gdb / lldb
— perf
— pmcstat
— SystemTap
— DTrace
— HeapTrack
— BPF / bcc
В начале у меня будет не слишком техническая часть, о том, как не надо делать benchmark’и.
Я наблюдаю, что люди часто делают типичные ошибки, когда делают benchmark’и. И вот первая из них…
Если вы не знаете, то у всех докладчиков HighLoad++ проходит суровый коучинг, многократный, по разным векторам. Один коучинг обязательный, остальные — опциональные. Опциональный коучинг — это как побороть боязнь сцены, например. То есть очень суровый подход к организации всего этого дела.И когда я подавал доклад на HighLoad++, организаторы предложили убрать всю эту техническую часть и добавить больше кулстори, красивых скриншотов и так далее. А те, кому интересно, как это запустить, какие команды набрать, могут обратиться к документации — и вот поэтому — ссылка на мой бложик, потому что все там есть. Если вас интересует, к примеру, как SystemTap сложно собирается на Linux, то открываем ссылку на блог и там будет прямо все. А в этом докладе будет скорее такой обзор, чтобы вы представляли, какие инструменты вообще есть, что они дают и когда какой использовать.
В начале у меня будет не слишком техническая часть, о том, как не надо делать benchmark’и.
Я наблюдаю, что люди часто делают типичные ошибки, когда делают benchmark’и.
- Во-первых, это неповторяемость. Когда вы открываете какой-нибудь бложик, и там такая классная статья, что мы «померяли что-то, получили такие красивые графики, и наше решение, которое стоит так, делает это в 500 раз быстрее».
 При этом не приводится никаких данных для повторения этого эксперимента, никаких скриптов и ничего. Ну, это хреновый benchmark, и нужно это сразу страницу закрыть. Если вы не можете его повторить, как можно ему верить?
При этом не приводится никаких данных для повторения этого эксперимента, никаких скриптов и ничего. Ну, это хреновый benchmark, и нужно это сразу страницу закрыть. Если вы не можете его повторить, как можно ему верить?
Вы должны хотя бы примерно такие же результаты мочь воспроизвести.
- Вы измеряете не то, что думаете. Типичный пример: мы хотим померить, как у нас жесткий диск работает. Мы весело набираем dd if что-нибудь куда-нибудь. Пишем в диск и меряем, а как быстро он, собственно, пишет. Кто-нибудь из зала может сказать, почему это не измерение скорости диска?
Правильно — потому что на самом деле вы померяли скорость, с которой у вас кэш файловой системы работает. Как это обойти — это тоже интереснаяпроблема.
- Взятие среднего. Это меня всегда бесило на наших митингах, и я вижу в первом ряду слушателя, который меня понимает. Нам нужно понимать, как быстро мы отвечаем пользователю на запросы — давайте построим график среднего времени ответа.
- Кто будет бенчмаркать бенчмарки? Это такая проблема. Например, вы написали клевый тест, который меряет, сколько ответов в секунду генерит ваше приложение. Померили, получили, скажем, 4000 запросов в секунду. Думаете: «Как-то маловато, надо оптимайзить». Проблема в том, что ваш benchmark однопоточный. А под реальной нагрузкой ваше приложение работает в сотнях, в тысячи потоков. И, собственно, вы не учли, что ваш собственный benchmark — это bottleneck в данном случае. Это нужно понимать.

- Отсутствие анализа. Это когда вы померяли, говорите: «Что-то тупит, надо все отрефачить, все переписать». То есть нужно понимать, почему оно тупит.
- Игнорирование ошибок. Опять же, вернемся к примеру с вашим бенчмарком. Допустим, это не ваш benchmark, это A/B, и вы его натравили на свой сервис, померили, получили 5 млн. запросов в секунду и радуетесь: «У нас все очень быстро». Но вы не посмотрели, что все это ответы 404, например. То есть нужно ошибки тоже высчитывать.
- Неправильные настройки. В моей сфере, в базах данных, это частая проблема, потому что настройки Postgres по умолчанию предполагают, что вы пытаетесь запустить его на микроволновке. Сейчас сервера мощные, поэтому все настройки по умолчанию надо очень сильно менять. Побольше шарить buffers, побольше work_mem. И понимать, что эти настройки делают. Если вы видите бенчмарк, даже с данными, на которых тестировалось, и даже со скриптами, но там сказано, что «мы тестировали с настройками по умолчанию» — по умолчанию MongoDB и Postgres — все, можно закрывать.

- Нетипичная нагрузка. У вас 90% времени что-то читает, 10% что-то пишет, а вы решили: напишем benchmark, который фифти/фифти — и так, и так делает. Зачем такое тестировать? То есть вы что-то соптимизируете, просто это вам в продакте не сильно поможет.
- Маркетинг и подгон. Тут у меня есть небольшая кулстори. Я достоверно знаю, что были лет …дцать назад такие производители железа, которые знали бенчмарки, по которым некий журнал тестирует компьютеры. Они свое железо собирали так, чтобы на этих бенчмарках выглядело хорошо. В результате все очень здорово продавалось. Это первый способ подгона.
То есть нужно понимать, что это существует, это не иллюзорная вещь.

- Ну, и другие свойства. Близкий мне пример: Oracle против Postgres — что быстрее? Может быть, Oracle быстрее в 10 раз, но он и стоит как не в себя. Это надо тоже учитывать. А, может, и нет — я не бенчмаркал Oracle ни разу и вообще его никогда не видел, если честно.
Для создания полноты картины начну с того, как не надо бенчмаркать код. Самый простой способ — gettimeofday(). Дедовский метод, когда у нас есть кусочек кода, мы хотим узнать, насколько он быстрый или медленный — мы померили время в начале, выполнили код, померили время в конце, посчитали дельту и сделали вывод, что код выполняется столько времени.
На самом деле не самый идиотский способ, он удобен, например, когда у вас этот код  По сути, у вас есть страница в ядре, которая мапится в адресное пространство всех процессов, и ваш gettimeofday() превращается в обращение к оперативной памяти, никакого syscall’а не происходит.
По сути, у вас есть страница в ядре, которая мапится в адресное пространство всех процессов, и ваш gettimeofday() превращается в обращение к оперативной памяти, никакого syscall’а не происходит.
Не стоит его использовать, несмотря на то, что он дешевый, если вы делаете что-то со спинлоками. Потому что спинлоки сами по себе довольно быстро работают. То есть то, что вы меряете, должно хотя бы миллисекунды выполняться, иначе у вас погрешность будет на уровне измерений.
Инструменты, такие как strace, ltrace, truss — прикольные инструменты, у них есть флажок -с, который показывает, сколько времени у вас какие syscall’ы выполнялись. Ну, ltrace измеряет библиотечные процедуры, а strace — syscall’ы, но тоже, в принципе, могут быть удобны где-то в каких-то задачах. Не могу сказать, что я этим часто пользуюсь.
Gprof, есть такой прикольный инструмент, на слайде приводится пример его текстового отчета. Тоже понятно — вот у нас есть процедуры в программе, вот столько раз они были вызваны, столько времени это в процентах выполнялось.
С помощью gprof еще можно генерировать такие картинки:
Это, скорее, пример того, как не надо делать. Запомните эту картинку, здесь 6 квадратиков. Обратите внимание, как много места они занимают, тут имена процедур, над стрелками все время что-то написано, ничего не понятно — очень много места занимает. Мы увидим намного более наглядные отчеты, чем этот. Но, в принципе, красивая картинка, можно начальству показать, понтануться.
Отладчики. На самом деле, это уже пример инструментов, которые приходится использовать на практике при профайлинге, потому что у них есть клевые свойства выполнять команды batch’ем и можно написать в этот набор batch-команд (bt) получение бэктрейса. Это очень удобно при отладке lock contention, когда у вас происходит борьба за локи.
http://habr.ru/p/310372/
Здесь у меня есть небольшая кулстори. Это, по-моему, был самый первый патч, который я написал для Postgres. Или второй, не помню. У Postgres есть своя реализация хэш-таблиц, сильно заточенных под задачи Postgres. И она, в том числе, может быть создана с такими флагами, чтобы использоваться разными процессами. Пришел клиент с проблемой, что «вот у меня на таких-то запросах, в такой-то схеме все тупит, помогите». Интересно, что сначала с помощью приема с бэктрейсом это выглядело так, что вы запускаете gdb 10 раз, в 5 случаях у вас бэктрейс висит на взятии лока, а еще в половине случаев — на чем-то другом, то есть явно у вас процесс часто висит на локе, что-то не так.
Или второй, не помню. У Postgres есть своя реализация хэш-таблиц, сильно заточенных под задачи Postgres. И она, в том числе, может быть создана с такими флагами, чтобы использоваться разными процессами. Пришел клиент с проблемой, что «вот у меня на таких-то запросах, в такой-то схеме все тупит, помогите». Интересно, что сначала с помощью приема с бэктрейсом это выглядело так, что вы запускаете gdb 10 раз, в 5 случаях у вас бэктрейс висит на взятии лока, а еще в половине случаев — на чем-то другом, то есть явно у вас процесс часто висит на локе, что-то не так.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
По бэктрейсу удалось найти, что это за код такой, который то берет, то освобождает лок. Это долгая история, можете по ссылке прочитать статью на Хабре. Там же есть ссылка на обсуждение в hackers, где есть технические детали.
На слайде выше — кусочек кода, между взятием и освобождением лока, он в свою очередь там проваливался куда-то в dynahash, где крутился на взятии спинлока. Это удалось с помощью отладчиков найти, исправить, предложить патч. И тот спинлок, который в dynahash (это хэш-табличка в Postgres), превратили в 8 или 16 спинлоков, которые при определенных условиях берутся разные. Удалось его пошардить и это уже есть в 9.6.
Perf — замечательный инструмент, потому что perf top показывает топ процедур. В данном случае в указанном процессе, сколько времени они выполняются. Вверху мы видим 30%, 20% и мы видим ResourceOwner — это неспроста в именах процедур, потому что следующая кулстори тоже про реальный патч.
Пришел клиент, сказал: «У меня такие запросы и такая схема. Все тупит. Что делать?». Начали отладку. А у него энтерпрайзное приложение, у него есть таблицы, тысяча дочерних таблиц (в Postgres, если кто не знает, есть наследование таблиц). И с помошью perf top мы видим, что в ResourceOwner все тупит. ResourceOwner — это такой объект (насколько слово объект применимо для языка С), который хранит в себе разные ресурсы, файлы, шареную память и что-то еще. И он написан в предположении, что обычно мы ресурсы выделяем и кладем в массив, а освобождаем в обратном порядке. Поэтому при удалении ресурсов, он начинает их искать с конца. Размер массива он знает, ну, в смысле — у него есть индекс последнего элемента. Оказалось, что это условие выполняется не всегда и ему приходится во все стороны искать по этому массиву, поэтому он тупит. Патч заключается в том, что при определенном количестве ресурсов (около 16 или число порядка этого) этот массив превращается в хэш-таблицу. Когда вы конфликт разрешаете, вы по хэшу пришли в заданный индекс массива, а потом идете в одну из сторон.
ResourceOwner — это такой объект (насколько слово объект применимо для языка С), который хранит в себе разные ресурсы, файлы, шареную память и что-то еще. И он написан в предположении, что обычно мы ресурсы выделяем и кладем в массив, а освобождаем в обратном порядке. Поэтому при удалении ресурсов, он начинает их искать с конца. Размер массива он знает, ну, в смысле — у него есть индекс последнего элемента. Оказалось, что это условие выполняется не всегда и ему приходится во все стороны искать по этому массиву, поэтому он тупит. Патч заключается в том, что при определенном количестве ресурсов (около 16 или число порядка этого) этот массив превращается в хэш-таблицу. Когда вы конфликт разрешаете, вы по хэшу пришли в заданный индекс массива, а потом идете в одну из сторон.
Кстати, если кого-то интересует вопрос, кому в третьем тысячелетии приходится писать свои хэш-таблицы, то вот я сижу и в двух патчах пишу свои хэш-таблицы, потому что не подходят нам стандартные реализации. Это тоже уже есть в 9. 6, там ResourceOwner не тупит, если у вас партицированная сильно таблица. В смысле, он все еще тупит, но слабее.
6, там ResourceOwner не тупит, если у вас партицированная сильно таблица. В смысле, он все еще тупит, но слабее.
С помощью perf можно строить такие красивые картинки, они называются флеймграфы. Это читается снизу вверх. Внизу у нас есть процедура, потом — пропорционально тому, сколько времени где она проводит и в свою очередь вызывает — у нас поделено на другие процедуры. Потом вверх идем, у нас так же пропорционально делится, сколько времени она где проводит. И далее вверх. Это очень наглядно, но может быть непривычно, если вы первый раз такое видите. На самом деле, это очень наглядный отчет, намного нагляднее примера с графом, который Gprof строит. Обратите внимание, как экономно используется место, на слайдах это нельзя показать, но во все это можно кликать. И у него есть подсказка, которая показывает проценты.
Вот увеличенный кусок, это где-то из середины часть:
Собственно это, наверное, все. Мы этим часто пользуемся. На предыдущей работе мы таким же образом анализировали логи. Там была другая история — был АК-кластер, распределенное приложение, и мы по логам строили такие вещи, пытаясь понять, где же у нас тормозит код. Логи, разумеется, нужно было со всех бэкендов агрегировать. В общем, удобная штука, всем рекомендую.
Там была другая история — был АК-кластер, распределенное приложение, и мы по логам строили такие вещи, пытаясь понять, где же у нас тормозит код. Логи, разумеется, нужно было со всех бэкендов агрегировать. В общем, удобная штука, всем рекомендую.
Это Брендон Грегг. Он изобрел flame graphs и чуть ли не сам perf. Наверное, он не совсем один писал, но существенно в него вложился. Также он известен в видео на YouTube, где он орет на жесткие диски в дата-центре, и у него увеличивается latency при обращении к этим дискам — замечательное видео. Если кому интересно, это реальная тема, правда, с SSD работает это или нет — не знаю.
Недавно было похожая история, про то, как во время пожарных учений в банке вырубило весь дата-центр, потому что слишком громко свистели трубы, которые подают газ, который тушит огонь. То есть вибрация воздуха вырубила все диски.
К Брендону мы еще вернемся, потому что он знает все про профайлинг и очень много в это все вложил, сейчас он этим занимается в Netflix.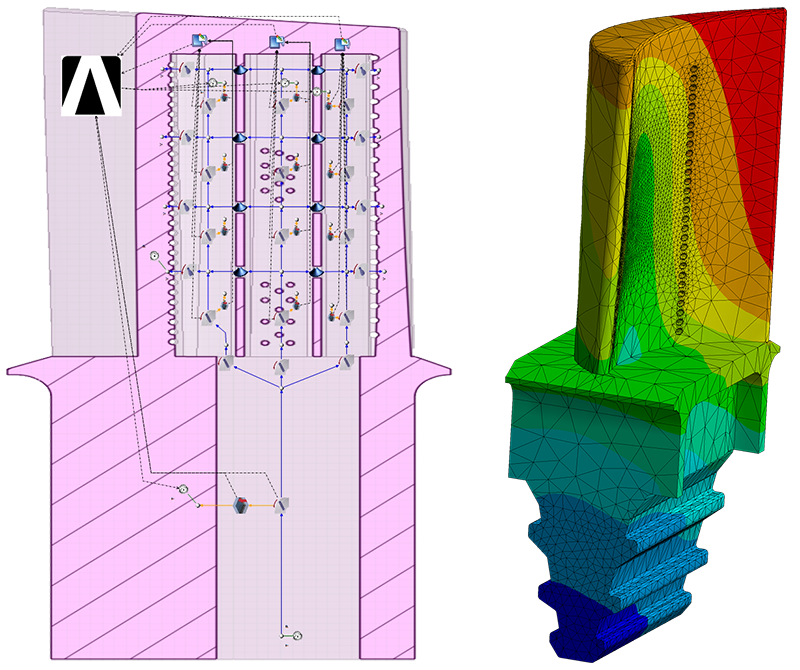
http://eax.me/freebsd-pmcstat/
Pmcstat — это инструмент исключительно под FreeBSD. Когда я делал эти слайды, я думал что ни у кого не будет FreeBSD, поэтому здесь нет особых подробностей про pmcstat, т.к. остальным это не очень интересно. Но краткое содержание такое, что с его помощью можно делать все то же самое, что с помощью perf. Он также делает top, тоже строит flame graphs и он ничем не хуже, просто команды другие. Кому интересно, вот ссылка на конкретную статью.
Переходим к более серьезным инструментам. SystemTap. Выше до этого был профайлинг CPU, где что-то тормозит, а SystemTap позволяет делать еще больше — вы можете посмотреть буквально на все, что угодно, в ядре, померить, сколько у вас пакетов по сети уходит, обращение к диску померить и все что угодно, ограничено только вашей фантазией. SystemTap позволяет писать вот такие скрипты, в данном случае трейсится вызов ip_rcv, то есть получение какого-то iP пакета.
Плюсы и минусы. Главных минусов 2. Во-первых, это не какой-то официальный инструмент для Linux, это чуваки из Red Hat запилили в основном для себя, для отладки своего кода, как я это понимаю. Его очень неудобно устанавливать, нужно скачивать пакет с отладочными символами ядра, потом его устанавливать, потом очень долго компилить сам SystemTap, он тоже так не просто компилируется, нужны версии. Но в конечном счете оно начинает работать. Второй недостаток — то, что вам нужно хорошо понимать базу того, что вы хотите проанализировать, потрейсить. Не все знают наизусть ядро Linux. Но если вы хорошо знаете свой код, вы можете это использовать.
Во-первых, это не какой-то официальный инструмент для Linux, это чуваки из Red Hat запилили в основном для себя, для отладки своего кода, как я это понимаю. Его очень неудобно устанавливать, нужно скачивать пакет с отладочными символами ядра, потом его устанавливать, потом очень долго компилить сам SystemTap, он тоже так не просто компилируется, нужны версии. Но в конечном счете оно начинает работать. Второй недостаток — то, что вам нужно хорошо понимать базу того, что вы хотите проанализировать, потрейсить. Не все знают наизусть ядро Linux. Но если вы хорошо знаете свой код, вы можете это использовать.
Есть интересное свойство — код транслируется в С, потом это компилируется в модуль ядра, который подгружается и собирает всю статистику, все трейсит. При этом вы можете не бояться делить на ноль, разыменовывать указатели неправильные. Если это написать в скриптовом языке, это не приведет к крэшу ядра, оно просто аккуратно свернет лапки и выгрузится, но ваше ядро продолжит работать.
Есть автоматический вывод типов. Правда, там всего два или три типа, зато они автоматически выводятся.
Лично мне страшно было бы использовать это в продакшне, потому что он не производит впечатления стабильного инструмента. Один тот факт — у вас скрипт секунд 10 компилируется и загружается, а что в это время будет там тормозить, не тормозить, не очень понятно. Я бы не рискнул, но, может, вы смелее.
DTrace — это тоже прикольный инструмент, не только для FreeBSD, в Linux тоже есть, все хорошо. Он похож на SystemTap, в этом примере мы трейсим системный вызов poll, притом для процессов, которые называются postgres. Здесь трейсится, с какими аргументами он вызывается и что возвращается.
Плюсы и минусы. Во-первых, он, в отличие от SystemTap, прямо есть в системе из коробки, ничего не надо устанавливать, компилировать. Есть во FreeBSD, в Mac OS. Для Linux он тоже есть, если вы каким-то образом используете Oracle Linux. Кроме того, есть проект dtrace4linux на GitHub, он компилируется, работает, я проверял. В принципе, можно пользоваться.
В принципе, можно пользоваться.
В отличие от SystemTap, DTrace не страшно использовать в продакшне — заходите на ваш Mac в боевом окружении и трейсите все, что угодно. По моим субъективным ощущениям, DTrace больше для админов, потому что у вас в ядре есть куча пробов на все что угодно, вам не нужно знать кодовую базу, вы просто говорите: «Хочу собрать статистику по IP-пакетам — сколько пришло, сколько ушло». Кстати, есть наборы готовых утилит, вам не нужно обязательно скриптами все самим писать. DTrace Toolkit называется.
А SystemTap скорее не для админов, а для разработчиков: «Я знаю код ядра, я хочу вот в этом месте потрейсить, без написания какого-то кода, не патча его».
До сих пор мы говорили про профайлинг в плане использования ЦПУ, но еще частая проблема — это «а что, если у меня отжирается много памяти?». Лично мне нравится инструмент HeapTrack, если вы когда-нибудь использовали Valgrind Massif, то он такой же, только быстрый, но с ограничением — работает только на Linux.
Здесь (на слайде выше) пример текстового отчета, найдено место, которое отъедает больше всего памяти, есть конкретные номера строк, имена файлов с исходниками и так далее.
Кроме того, он может строить вот такие красивые отчеты в инструменте Massif Visualizer. В нем можно все открывать, это все в динамике. Там память росла, потом достигла своего пика, потом она начала падать, освобождаться, выделяться, справа есть трейсы. Все очень наглядно и красиво.
Плюсы и минусы. Он быстрый, в отличие от Valgrind. Может цепляться к запущенным процессам, можно запускать под ним процессы. Красивые отчеты. Он умеет находить мемори лики. Немного криво их находит, если у вас стандартная библиотека языка выделила 16 кБ под какие-то свои внутренние нужды и потом их не освободила, потому что «ну, зачем?», он скажет, что это мемори лик. Но, в принципе, довольно полезный инструмент, несмотря на все это.
Можно построить гистограмму, что у меня кусочки размером в 8 байт выделяются больше всего, а кусочки памяти размером 32 байта выделяются чуть реже. Такая красивая гистограмма получается.
Такая красивая гистограмма получается.
Про стек он ничего не знает, если вам нужен стек или нужно что-то за пределами Linux, то используйте Valgrind. Я Linux’оид, поэтому ничего не знаю про Valgrind.
Есть такая тема в Linux, называется BPF, изначально это был Berkeley Packet Filter и, как можно догадаться по названию, имеет отношение к Berkeley и какой-то там фильтрации пакетов, но BPF он где-то в 2.6 ветку приземлил в свое время. Но в результате его доработали и, по сути, он превратился, не без помощи уже упомянутого Брендона Грегга, в DTrace в Linux.
Он позволяет делать абсолютно все то же самое. Недавно у Брендона был пост в блоге, где он пишет, что в ядро 4.9, которое сейчас все еще релиз-кандидат, но скоро будет, туда приземлились окончательно изменения в BPF. Больших, крупных изменений не будет, может, они что-то зарефачат, может, немного поправят, но чтобы активно добавлять — такого уже не будет.
Bcc — это набор утилит, который использует BPF для профайлинга разных мест ядра. На картинке это все названия утилит. Вы фактически любое место в ядре можете потрейсить, попрофайлить в ядре.
На картинке это все названия утилит. Вы фактически любое место в ядре можете потрейсить, попрофайлить в ядре.
Недостаток у BPF в том, что у него нет еще своего скриптового языка, как есть у DTrace, SystemTap, но в этом направлении уже есть наработки. В частности, парни из Red Hat подключились, они взяли свой SystemTap и сделали его сборку для BPF. То есть используется язык SystemTap, но работает оно на BPF. Оно пока какое-то ограниченное, вообще не поддерживает строковый тип, но они работают над этим.
Суть в том, что BPF — это, похоже, наше далекое светлое будущее, и он является наибольшим общим знаменателем, к которому в итоге пришли все компании, потому что там были какие-то скрипты у Facebook, был SystemTap у Red Hat, потому что им нужно было для разработки что-то такое трейсить. Они свою задачу решили и им больше ничего не надо. А BPF — это то, что должно в результате решать нужды всех, и оно уже прямо в ядре из коробки готовое и, похоже, в итоге все к этому придут и через пару лет наступит большое счастье.
Главный вопрос, который будоражит умы миллионов: «Хорошо, много инструментов, что и когда использовать?». Что лично я использую. Отладчики. Если вы подозреваете lock contention, его легко довольно заподозрить, вы в perf top не будете видеть, что кто-то жрет большое количество времени, наверное, оно висит в локах. Perf, если вы думаете, что уперлись в СPU, это в обычном htop видно — вот процесс, он жрет много СPU. Pmcstat, если у вас FreeBSD, SystemTap, мне кажется, бесполезный инструмент по той причине, что есть perf — он удобнее. Имеется в виду в контексте именно профайлинга, то есть профайлить я могу perf’ом, а для трейсировки SystemTap он ничего, он только не про профайлинг.
DTrace — это, если вы сидите под Mac, то он — ваше все, потому что он умеет все.
HeapTrack для памяти, Vagrant Massif — если вы на Linux, и BPF — это светлое будущее, но сейчас я бы не стал ставить 4. 9 в продакт, но, может, вы смелее, опять же.
Хочу порекомендовать книги с соавторством Брендона Грегга.
Первая — Systems Performance: Enterprise and the Cloud — потрясающая книга, ее обязательно нужно читать всем поголовно. Это одна из лучших книг, которую я читал и которая связана с программированием. Она взорвала мозг мне, потом шрапнелью задела мозги коллег, в общем, просто прочитайте.
Вторая книга про DTrace — тоже книга Брендона Грегга в соавторстве с парнем, который я не знаю, чем примечателен. Ее я не читал, полистал, это такой большой сборник рецептов про DTrace. Там дается команда, и что она делает, примеры скриптов. И так на тысячу страниц. Мне кажется, это не очень интересное чтиво, но если вы сильно интересуетесь DTrace, вечером полистать вредно не будет.
Куча онлайн-ресурсов:
- Это ссылка на мой бложик;
- http://www.brendangregg.com/blog/index.html — блог Брендона Грегга — подписаться обязательно, он там постит умопомрачительные вещи.
- http://dtrace.org/blogs/ — блог DTrace я тоже читаю, там есть интересные статьи.

- Дальше. https://sourceware.org/systemtap/ — сайт SystemTap’а.
- FreeBSD в wiki — https://wiki.freebsd.org/DTrace
- И в handbook’е можно прочитать про DTrace. Даже если вы пользуетесь Mac, все равно полистайте handbook, там есть хорошие примеры — https://www.freebsd.org/doc/handbook/dtrace.html
- И в конце мануал Intel — http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html. Там можно почитать, собственно, на чем паразитирует perf, что такое РMC, прямо в процессорах есть инструкции, которые позволяют все это мерить.
У меня все.
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. До конференции HighLoad++ 2017 осталось меньше месяца.У нас уже готова Программа конференции, сейчас активно формируется расписание.
В этом году доклады по тегу «Правильные ручки«:
- Хочу всё сжать / Андрей Аксенов
- Защищаемость от DDoS на этапе проектирования системы / Рамиль Хантимиров
- Чем заняться вечером, если я знаю, сколько будет ++i + ++i / Андрей Бородин
- Как развивать библиотеку компонентов, не ломая её / Артур Удалов
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.
Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Профилирование кода — Как найти слабое звено?
Профилирование кода это попытка найти узкие места в вашем коде. Профилирование может найти самые долго выполняющиеся части вашего кода. Найдя их, вы можете оптимизировать эти части удобным вам способом. Python содержит три встроенных профайлера: cProfile, profile и hotshot. В соответствии с документацией Python, hotshot «не поддерживается, и может быть удален из Python». Модуль profile это в корне своем модуль Python, но добавляет много чего сверху в профилированные программы. Поэтому мы сфокусируемся на cProfile, который содержит интерфейс, который имитирует модуль profile.
Профилирование кода при помощи cProfile
Профилирование кода с cProfile это достаточно просто. Все что вам нужно сделать, это импортировать модуль и вызвать его функцию run. Давайте посмотрим на простой пример:
Все что вам нужно сделать, это импортировать модуль и вызвать его функцию run. Давайте посмотрим на простой пример:
Python
import hashlib import cProfile cProfile.run(«hashlib.md5(b’abcdefghijkl’).digest()»)
import hashlib import cProfile
cProfile.run(«hashlib.md5(b’abcdefghijkl’).digest()») |
Здесь мы импортировали модуль hashlib и использовали cProfile для профилирования того, что создал хеш MD5. Первая строка показывает, что в ней 4 вызова функций. Следующая строка говорит нам, в каком порядке результаты выдачи. Здесь есть несколько столбцов.
- ncalls – это количество совершенных вызовов;
- tottime – это все время, потраченное в данной функции;
- percall – ссылается на коэффициент tottime, деленный на ncalls;
- cumtime – совокупное время, потраченное как в данной функции, так и наследуемых функциях.
 Это работает также и с рекурсивными функциями!
Это работает также и с рекурсивными функциями! - Второй столбец percall – это коэффициент cumtime деленный на примитивные вызовы;
- filename:lineno(function) предоставляет соответствующие данные о каждой функции.
Примитивный вызов – это вызов, который не был совершен при помощи рекурсии. Это очень интересный пример, так как здесь нет очевидных узких мест. Давайте создадим часть кода с узкими местами, и посмотрим, обнаружит ли их профайлер.
Python
# -*- coding: utf-8 -*- import time def fast(): print(«Я быстрая функция») def slow(): time.sleep(3) print(«Я очень медленная функция») def medium(): time.sleep(0.5) print(«Я средняя функция…») def main(): fast() slow() medium() if __name__ == ‘__main__’: main()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | # -*- coding: utf-8 -*- import time
def fast(): print(«Я быстрая функция»)
def slow(): time. print(«Я очень медленная функция»)
def medium(): time.sleep(0.5) print(«Я средняя функция…»)
def main(): fast() slow() medium()
if __name__ == ‘__main__’: main() |
 sleep(3)
sleep(3)Сохраняем программу как ptest.py. В этом примере мы создали четыре функции. Первые три работают с разными темпами. Быстрая функция запустится с нормальной скоростью, средняя функция потратит примерно полсекунды на запуск, медленная функция потратит примерно три секунды для запуска. Главная функция вызывает остальные три. Давайте запустим cProfile в этой маленькой глупой программе:
Python
import cProfile import ptest cProfile.run(‘ptest.main()’)
import cProfile import ptest
cProfile.run(‘ptest. |
 main()’)
main()’)На этот раз мы видим, что у программы ушло 3.5 секунды на запуск. Если вы изучите результаты, то увидите, что cProfile выявил медленную функцию, которая тратит 3 секунды на запуск. Это и есть самая «слабая» часть основной функции. Обычно, когда вы обнаруживаете такие места, вы можете попытаться найти самый быстрый способ выполнения вашего кода, или прийти к выводу, что такая задержка приемлема. В этом примере, мы знаем, что лучший способ ускорить функцию, то убрать вызов time.sleep, или, по крайней мере, снизить продолжительность сна. Вы можете также вызвать cProfile в командной строке, вместо применения в интерпретаторе. Как это сделать:
python -m cProfile ptest.py
python -m cProfile ptest.py |
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Python Форум Помощи
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Видео уроки и книги для вас!
Подписаться
Таким образом, будет запущен cProfile в вашем скрипте по аналогии с тем, как мы делали это ранее. Но что если вам нужно сохранить выдачу профайлера? Что-ж, это очень просто с cProfile! Все что вам нужно, это передать ему команду –o, за которой следует название (или путь) файла выдачи. Вот пример:
python -m cProfile -o output.txt ptest.py
python -m cProfile -o output.txt ptest.py |
К сожалению, выдаваемый файл едва ли можно назвать читаемым. Если вы хотите прочесть файл, тогда вам нужно использовать модуль Python pstats. Вы можете использовать pstats для форматирования выдачи разными способами. Вот небольшой код, который показывает, как получить выдачу, по аналогии с тем, как мы делали это раньше:
Python
import pstats
p = pstats. Stats(«output.txt»)
p.strip_dirs().sort_stats(-1).print_stats()
Stats(«output.txt»)
p.strip_dirs().sort_stats(-1).print_stats()
import pstats p = pstats.Stats(«output.txt»)
p.strip_dirs().sort_stats(-1).print_stats() |
Вызов strip_dirs вырезает все пути к модулям из вывода, пока вызов sort_stats делает сортировку, которая нужна нам для виденья картины. Существует множества очень интересных примеров в документации cProfile, которые наглядно демонстрируют различные пути извлечения информации с использованием модуля pstats.
Выясняем скорость загрузки сайтов
Давайте немного развлечемся. Сделаем небольшой марафон и узнаем какой сайт быстрее всех откроется из нашей программы. Узнать больше насчет производительности requests можно узнать в данной статье.
Python
# -*- coding: utf-8 -*-
import requests
import cProfile
def facebook():
requests.get(‘https://facebook. com’)
def google():
requests.get(‘https://google.com’)
def twitter():
requests.get(‘https://twitter.com’)
def vk():
requests.get(‘https://vk.com’)
def main():
facebook()
google()
twitter()
vk()
cProfile.run(‘main()’)
com’)
def google():
requests.get(‘https://google.com’)
def twitter():
requests.get(‘https://twitter.com’)
def vk():
requests.get(‘https://vk.com’)
def main():
facebook()
google()
twitter()
vk()
cProfile.run(‘main()’)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | # -*- coding: utf-8 -*- import requests import cProfile
def facebook(): requests.get(‘https://facebook.com’)
def google(): requests.get(‘https://google.com’) def twitter(): requests.get(‘https://twitter.com’) def vk(): requests.get(‘https://vk.com’)
def main(): facebook() google() twitter() vk() cProfile. |
 run(‘main()’)
run(‘main()’)Результат
Python
python3 site_speed_test.py 61356 function calls (61000 primitive calls) in 2.683 seconds ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 0.743 0.743 ptest.py:10(google) 1 0.001 0.001 0.521 0.521 ptest.py:14(twitter) 1 0.000 0.000 0.876 0.876 ptest.py:18(vk) 1 0.000 0.000 2.683 2.683 ptest.py:22(main) 1 0.002 0.002 0.543 0.543 ptest.py:6(facebook)
1 2 3 4 5 6 7 8 9 10 11 | python3 site_speed_test.py
61356 function calls (61000 primitive calls) in 2.683 seconds
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.743 0.743 ptest.py:10(google) 1 0.001 0.001 0.521 0.521 ptest.py:14(twitter) 1 0. 1 0.000 0.000 2.683 2.683 ptest.py:22(main) 1 0.002 0.002 0.543 0.543 ptest.py:6(facebook) |
 000 0.000 0.876 0.876 ptest.py:18(vk)
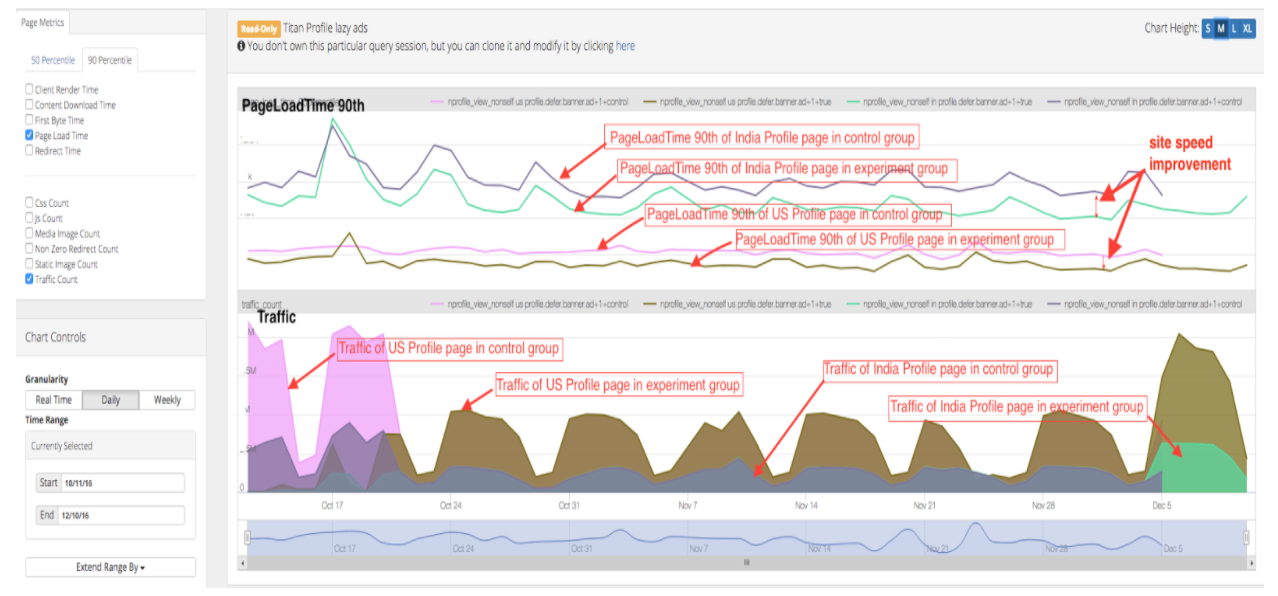
000 0.000 0.876 0.876 ptest.py:18(vk)Мы получим большой список результатов, давайте найдем только наши функции. Запуск всех сайтов выполнился в 2.68 секунды. Быстрее всех открылся Twitter, самый медленный стал VK. Это конечно не идеальный тест скорости, но наша задача была выполнена. Мы выясняли скорость открытия сайтов используя cProfile.
Подведем итоги
С этого момента вы должны знать, как использовать модуль cProfile для диагностики того, что делает ваш код таким медленным. Вы также можете взглянуть на модуль Python timeit. Он позволяет вам отсчитывать маленькие части вашего кода, если вы не хотите иметь дела со сложностями, которые может повлечь за собой профилирование. Также существует несколько других сторонних модулей, которые также хороши в профилировании как проекты line_profiler и memory_profiler.
Vasile Buldumac
Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: [email protected]
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
Профилировщики Python | Python 3
- /
- Переводы документации /
- Документация Python 3.8.8 /
- Стандартная библиотека Python /
- Отладка и профилирование /
- Профилировщики Python
Знакомство с профилировщиками
cProfile и profile предоставляют детерминированное профилирование программ Python. Профиль — это множество статистических данных,
описывающих, как часто и как долго выполняются различные части программы. Эту
статистику можно форматировать в отчёты через модуль
Профиль — это множество статистических данных,
описывающих, как часто и как долго выполняются различные части программы. Эту
статистику можно форматировать в отчёты через модуль pstats.
Стандартная библиотека Python предоставляет две разные реализации одного и того же интерфейса профилирования:
cProfileрекомендуется большинству пользователей; это C расширение с разумными накладными расходами, что делает его подходящим для профилирования долго работающих программ. Основан наlsprof, предоставленным Бреттом Розеном и Тедом Чоттером.profile, чистый Python модуль, интерфейс которого имитируетcProfile, но который значительно увеличивает нагрузку на профилированные программы. Если вы пытаетесь каким-то образом расширить профилировщик, с этим модулем задача может быть проще. Первоначально разработан и написан Джимом Роскиндом.
Примечание
Модули профилировщика предназначены для предоставления профиля выполнения
для данной программы, а не для целей бенчмаркинга (для этого есть timeit для получения достаточно точных результатов). В частности, это
относится к сравнению кода Python с кодом C: профилировщики вносят накладные
расходы для кода Python, но не для функций уровня C, поэтому код C кажется
более быстрым, чем любой Python код.
В частности, это
относится к сравнению кода Python с кодом C: профилировщики вносят накладные
расходы для кода Python, но не для функций уровня C, поэтому код C кажется
более быстрым, чем любой Python код.
Быстрое руководство пользователя
Данный раздел предназначен для пользователей, которые «не хотят читать руководство». Оно предоставляет очень краткий обзор и позволяет пользователю быстро выполнить профилирование существующего приложения.
Чтобы профилировать функцию, которая принимает один аргумент, вы можете сделать:
import cProfile
import re
cProfile.run('re.compile("foo|bar")')
(Используйте profile вместо cProfile, если последний недоступен в
вашей системе.)
Приведённое выше действие будет запускать re.compile() и печатать
результаты профиля, как показано ниже:
197 function calls (192 primitive calls) in 0.002 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0. 000 0.000 0.001 0.001 <string>:1(<module>)
1 0.000 0.000 0.001 0.001 re.py:212(compile)
1 0.000 0.000 0.001 0.001 re.py:268(_compile)
1 0.000 0.000 0.000 0.000 sre_compile.py:172(_compile_charset)
1 0.000 0.000 0.000 0.000 sre_compile.py:201(_optimize_charset)
4 0.000 0.000 0.000 0.000 sre_compile.py:25(_identityfunction)
3/1 0.000 0.000 0.000 0.000 sre_compile.py:33(_compile)
000 0.000 0.001 0.001 <string>:1(<module>)
1 0.000 0.000 0.001 0.001 re.py:212(compile)
1 0.000 0.000 0.001 0.001 re.py:268(_compile)
1 0.000 0.000 0.000 0.000 sre_compile.py:172(_compile_charset)
1 0.000 0.000 0.000 0.000 sre_compile.py:201(_optimize_charset)
4 0.000 0.000 0.000 0.000 sre_compile.py:25(_identityfunction)
3/1 0.000 0.000 0.000 0.000 sre_compile.py:33(_compile)
В первой строке указано, что было отслежено 197 вызовов. Из данных вызовов 192
были примитивными, что означает, что вызов не был вызван рекурсией.
Следующая строка: Ordered by: standard name указывает, что текстовая строка
в крайнем правом столбце использовалась для сортировки вывода. Заголовки
столбцов включают:
- ncalls
- на количество вызовов.
- tottime
- за общее время, проведенное в данной функции (без учета времени, проведенного в вызовы подфункций)
- percall
- представляет собой частное
tottime, делённое наncalls - cumtime
- это совокупное время, затраченное на эту и все подфункции (с момента вызова
до выхода).
 Данный рисунок точен даже для рекурсивных функций.
Данный рисунок точен даже для рекурсивных функций. - percall
- является частным
cumtime, разделённым на примитивные вызовы - filename:lineno(function)
- предоставляет соответствующие данные каждой функции
Когда в первом столбце два числа (например, 3/1), это означает, что функция
рекурсивна. Второе значение — это количество примитивных вызовов, а первое —
общее количество вызовов. Обратите внимание, что когда функция не рекурсивна,
данные два значения совпадают, и печатается только одна цифра.
Вместо того, чтобы печатать выходные данные в конце выполнения профиля, вы
можете сохранить результаты в файл, указав имя файла для функции run():
import cProfile
import re
cProfile.run('re.compile("foo|bar")', 'restats')
Класс pstats.Stats считывает результаты профиля из файла и форматирует
их различными способами.
Файлы cProfile и profile также можно вызывать как сценарий для
профилирования другого сценария. Например:
Например:
python -m cProfile [-o output_file] [-s sort_order] (-m module | myscript.py)
-o записывает результаты профиля в файл, а не в стандартный вывод
-s указывает одно из значений сортировки sort_stats() для сортировки вывода. Это применимо только в том случае, если -o не
поставляется.
-m указывает, что профилируется модуль, а не сценарий.
Добавлено в версии 3.7: Добавлен параметр
-mвcProfile.Добавлено в версии 3.8: Добавлен параметр
-mвprofile.
Класс Stats модуля pstats имеет множество методов для
обработки и печати данных, сохранённых в файле результатов профиля:
import pstats
from pstats import SortKey
p = pstats.Stats('restats')
p.strip_dirs().sort_stats(-1).print_stats()
Метод strip_dirs() удалил посторонний путь из всех имён
модулей. Метод
Метод sort_stats() отсортировал все записи в
соответствии со стандартной строкой модуля/строки/имени, которая печатается.
Метод print_stats() распечатывает всю статистику. Вы можете
попробовать следующие вызовы сортировки:
p.sort_stats(SortKey.NAME) p.print_stats()
Первый вызов фактически отсортирует список по имени функции, а второй вызов распечатает статистику. Ниже приведены некоторые интересные вызовы для экспериментов:
p.sort_stats(SortKey.CUMULATIVE).print_stats(10)
Это сортирует профиль по совокупному времени в функции, а затем печатает только десять наиболее значимых строк. Если вы хотите понять, какие алгоритмы требуют времени, вы бы использовали приведенную выше строку.
Если бы вы хотели увидеть, какие функции часто зацикливаются и занимают много времени, то выполните
p.sort_stats(SortKey.TIME).print_stats(10)
для сортировки по времени, затраченному на каждую функцию, а затем распечатать
статистику для первых десяти функций.
Вы также можете выполнить
p.sort_stats(SortKey.FILENAME).print_stats('__init__')
Это отсортирует всю статистику по имени файла, а затем распечатает статистику
только для методов инициализации класса (поскольку в них они пишутся с __init__). В качестве последнего примера вы можете
p.sort_stats(SortKey.TIME, SortKey.CUMULATIVE).print_stats(.5, 'init')
Эта строка сортирует статистику по первичному ключу времени и вторичному ключу
совокупного времени, а затем выводит часть статистики. Чтобы быть конкретным,
список сначала отбраковывается до 50% (re: .5) от его исходного размера,
затем сохраняются только строки, содержащие init, и данный под-подсписок
печатается.
Если вам интересно, какие функции называются вышеперечисленными функциями, вы
можете сейчас (p все ещё сортируется по последнему критерию) сделать:
p.print_callers(.5, 'init')
и вы получить список вызывающих для каждой из перечисленных функций.
Если вам нужна дополнительная функциональность, вам придется прочитать руководство или угадать, что делают следующие функции:
p.print_callees()
p.add('restats')
Модуль pstats, вызываемый как сценарий, представляет собой браузер
статистики для чтения и изучения дампов профилей. Он имеет простой линейный
интерфейс (реализованный с использованием cmd) и интерактивную справку.
Оба модуля profile и cProfile предоставляют следующие функции:
-
profile.run(command, filename=None, sort=-1) Данная функция принимает один аргумент, который можно передать функции
exec(), и необязательное имя файла. Во всех случаях эта процедура выполняется:exec(command, __main__.__dict__, __main__.__dict__)
и собирает статистику профилирования от выполнения. Если имя файла отсутствует, данная функция автоматически создаёт экземпляр
Statsи печатает простой отчёт о профилировании. Если
указано значение сортировки, оно передаётся этому экземпляру
Если
указано значение сортировки, оно передаётся этому экземпляру Statsдля управления сортировкой результатов.
-
profile.runctx(command, globals, locals, filename=None, sort=-1) Данная функция похожа на
run(), но с добавленными аргументами для предоставления словарей глобальных и локальных переменных для строки command. Эта функция выполняетexec(command, globals, locals)
и собирает статистику профилирования, как в функции
run()выше.
- class
profile.Profile(timer=None, timeunit=0.0, subcalls=True, builtins=True) Данный класс обычно используется только в том случае, если требуется более точное управление профилированием, чем то, что обеспечивает функция
cProfile.run().Пользовательский таймер может быть предоставлен для измерения времени выполнения кода с помощью аргумента timer.
 Это должна быть функция,
которая возвращает одно число, представляющее текущее время. Если число
является целым числом, timeunit задаёт множитель, определяющий
продолжительность каждой единицы времени. Например, если таймер возвращает
время в тысячах секунд, единицей времени будет
Это должна быть функция,
которая возвращает одно число, представляющее текущее время. Если число
является целым числом, timeunit задаёт множитель, определяющий
продолжительность каждой единицы времени. Например, если таймер возвращает
время в тысячах секунд, единицей времени будет .001.Непосредственное использование класса
Profileпозволяет форматировать результаты профиля без записи данных профиля в файл:import cProfile, pstats, io from pstats import SortKey pr = cProfile.Profile() pr.enable() # ... сделать что-нибудь ... pr.disable() s = io.StringIO() sortby = SortKey.CUMULATIVE ps = pstats.Stats(pr, stream=s).sort_stats(sortby) ps.print_stats() print(s.getvalue())
Класс
Profileтакже можно использовать в качестве менеджера контекста (поддерживается только в модулеcProfile, см. Типы менеджера контекста):import cProfile with cProfile.Profile() as pr: # ... сделать что-нибудь ... pr.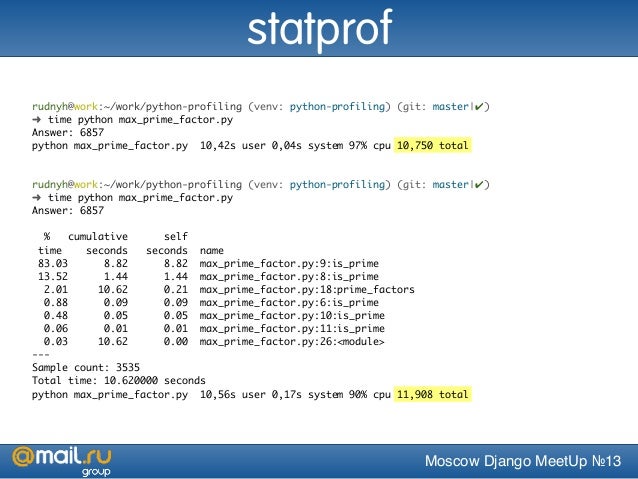 print_stats()
print_stats()
Изменено в версии 3.8: Добавлена поддержка контекстного менеджера.
-
enable() Начать собирать данные профилирования. Только в
cProfile.
-
disable() Прекратить сбор данных профилирования. Только в
cProfile.
-
create_stats() Прекратить сбор данных профилирования и записать результаты внутри как текущий профиль.
-
print_stats(sort=-1) Создать объект
Statsна основе текущего профиля и распечатать результаты в стандартный вывод.
-
dump_stats(filename) Записать результаты текущего профиля в filename.
-
run(cmd) Профилировать cmd через
exec().
-
runctx(cmd, globals, locals) Профилировать cmd через
exec()с указанным глобальным и локальным окружением.
-
runcall(func, *args, **kwargs) Профилирование
func(*args, **kwargs)
-
Обратите внимание, что профилирование будет работать только в том случае, если
вызванная команда/функция действительно возвращает значение. Если интерпретатор
завершается (например, через вызов sys.exit() во время выполнения
вызванной команды/функции), результаты профилирования не будут напечатаны.
Что такое детерминированное профилирование
Детерминированное профилирование предназначено для отражения того
факта, что все события вызова функции, возврата функции и исключение отслеживаются, и
устанавливаются точные временные интервалы между этими событиями (в течение
которых выполняется код пользователя). Напротив, статистическое профилирование (который не выполняется этим модулем) случайным образом выбирает действующий
указатель инструкции и определяет, где тратится время. Последний метод
традиционно требует меньших накладных расходов (поскольку код не требует
инструментальной обработки), но даёт лишь относительные указания на то, на что
тратится время.
Последний метод
традиционно требует меньших накладных расходов (поскольку код не требует
инструментальной обработки), но даёт лишь относительные указания на то, на что
тратится время.
В Python, поскольку во время выполнения активен интерпретатор, наличие инструментированного кода не требуется для выполнения детерминированного профилирования. Python автоматически предоставляет хук (необязательный обратный вызов) для каждого события. Кроме того, интерпретируемый характер Python имеет тенденцию увеличивать нагрузку на выполнение, поэтому детерминированное профилирование имеет тенденцию добавлять только небольшие накладные расходы на обработку в типичных приложениях. В результате детерминистическое профилирование не так уж и дорого, но при этом предоставляет обширную статистику времени выполнения Python программы.
Статистика подсчёта вызовов может использоваться для выявления ошибок в коде
(неожиданные подсчёты) и выявления возможных встроенных точек расширения
(большое количество вызовов). Внутреннюю статистику времени можно использовать
для выявления «горячих циклов», которые следует тщательно оптимизировать.
Накопленную статистику по времени следует использовать для выявления ошибок
высокого уровня при выборе алгоритмов. Обратите внимание, что необычная
обработка совокупного времени в этом профилировщике позволяет напрямую
сравнивать статистику рекурсивных реализаций алгоритмов с итеративными
реализациями.
Внутреннюю статистику времени можно использовать
для выявления «горячих циклов», которые следует тщательно оптимизировать.
Накопленную статистику по времени следует использовать для выявления ошибок
высокого уровня при выборе алгоритмов. Обратите внимание, что необычная
обработка совокупного времени в этом профилировщике позволяет напрямую
сравнивать статистику рекурсивных реализаций алгоритмов с итеративными
реализациями.
Ограничения
Одно ограничение связано с точностью информации о времени. Существует фундаментальная проблема с детерминированными профилировщиками, связанная с точностью. Наиболее очевидным ограничением является то, что базовые «часы» тикают только со скоростью (обычно) около 0.001 секунды. Следовательно, никакие измерения не будут более точными, чем базовые часы. Если будет проведено достаточно измерений, то «ошибка» будет иметь тенденцию к усреднению. К сожалению, удаление этой первой ошибки вызывает второй источник ошибки.
Вторая проблема заключается в том, что «требуется некоторое время» с момента
отправки события до вызова профилировщика, чтобы получить время на самом деле получает состояние часов. Точно так же существует определённая задержка при
выходе из обработчика событий профилировщика с момента, когда значение часов
было получено (и затем убрано), до тех пор, пока код пользователя снова не
будет выполнен. В результате функции, которые вызываются много раз или вызывают
много функций, обычно накапливают эту ошибку. Ошибка, которая накапливается
таким образом, обычно меньше точности часов (менее одного тактового импульса),
но она накапливается и становится очень значительной.
Точно так же существует определённая задержка при
выходе из обработчика событий профилировщика с момента, когда значение часов
было получено (и затем убрано), до тех пор, пока код пользователя снова не
будет выполнен. В результате функции, которые вызываются много раз или вызывают
много функций, обычно накапливают эту ошибку. Ошибка, которая накапливается
таким образом, обычно меньше точности часов (менее одного тактового импульса),
но она накапливается и становится очень значительной.
Проблема более серьезна с profile, чем с cProfile с меньшими
накладными расходами. По этой причине profile предоставляет средства
калибровки для данной платформы, чтобы эта ошибка могла быть вероятностно (в
среднем) устранена. После того, как профайлер откалиброван, он будет более
точным (в смысле наименьших квадратов), но иногда будет давать отрицательные
числа (когда количество вызовов исключительно мало, и боги вероятности работают
против вас :-). ) Не пугайтесь отрицательных цифр в профиле. Они должны
появиться только в том случае, если вы откалибровали свой профилировщик,
и результаты на самом деле лучше, чем без калибровки.
Они должны
появиться только в том случае, если вы откалибровали свой профилировщик,
и результаты на самом деле лучше, чем без калибровки.
Калибровка
Профилировщик модуля profile вычитает константу из времени обработки
каждого события, чтобы компенсировать накладные расходы на вызов функции
времени и сохранение результатов. По умолчанию константа равна 0. Для получения
лучшей константы для данной платформы можно использовать следующий код
(см. Ограничения).
import profile
pr = profile.Profile()
for i in range(5):
print(pr.calibrate(10000))
Код выполняет количество вызовов Python, заданное аргументом, напрямую и
снова под профилировщиком, измеряя время для обоих. Затем он вычисляет скрытые
служебные данные для каждого события профилировщика и возвращает его в виде
числа с плавающей запятой. Например, на процессоре Intel Core i5 с тактовой
частотой 1,8 ГГц под управлением Mac OS X и использовании в качестве таймера
Python time.process_time() магическое число составляет около 4,04e-6.
Цель этого действия — получить достаточно последовательный результат. Если ваш компьютер работает очень быстро или ваша функция таймера имеет низкое разрешение, вам, возможно, придется пройти 100000 или даже 1000000, чтобы получить стабильные результаты.
Когда у вас есть последовательный ответ, вы можете использовать его тремя способами:
import profile # 1. Применить вычисленное смещение ко всем экземплярам Profile, созданным ниже. profile.Profile.bias = your_computed_bias # 2. Применить вычисленное смещение к конкретному экземпляру Profile. pr = profile.Profile() pr.bias = your_computed_bias # 3. Указать вычисленное смещение в конструкторе экземпляра. pr = profile.Profile(bias=your_computed_bias)
Если у вас есть выбор, вам лучше выбрать меньшую константу, и тогда ваши результаты будут «реже» отображаться как отрицательные в статистике профиля.
Использование пользовательского таймера
Если вы хотите изменить способ определения текущего времени (например,
принудительно использовать время настенных часов или прошедшее время процесса),
передайте нужную функцию синхронизации конструктору класса Profile:
pr = profile.Profile(your_time_func)
Полученный профилировщик вызовет your_time_func. В зависимости от того,
используете ли вы profile.Profile или cProfile.Profile,
возвращаемое значение your_time_func будет интерпретироваться по-разному:
profile.Profileyour_time_funcдолжен возвращать один номер или список номеров, чьи sum — это текущее время (например, то, что возвращаетos.times()). Если функция возвращает одно число времени или список возвращаемых чисел длины 2, то вы получить особо быструю версию диспетчеризации рутина.Имейте в виду, что вы должны откалибровать класс профилировщика для выбранной вами функции таймера (см. Калибровка). Для большинства машин таймер, возвращающий одиночное целочисленное значение, обеспечит наилучшие результаты с точки зрения низких накладных расходов при профилировании. (
os.times()— симпатичная, т. к. она возвращает кортеж значений с плавающей запятой).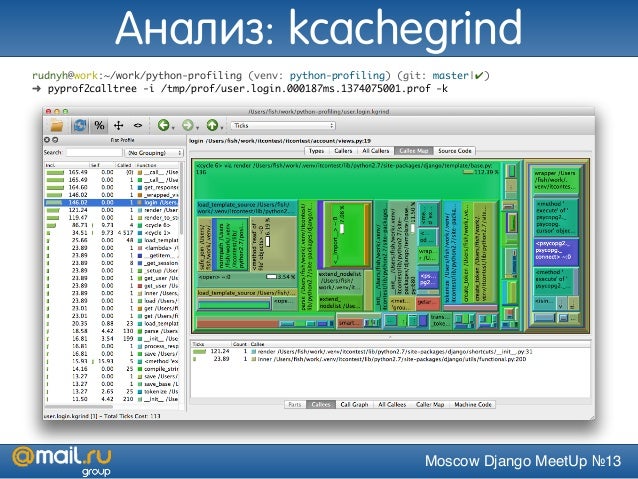 Если вы хотите заменить лучший таймер самым
чистым способом, создайте класс и задайте метод отправки замены, который лучше
всего обрабатывает ваш вызов таймера, вместе с соответствующей константой
калибровки.
Если вы хотите заменить лучший таймер самым
чистым способом, создайте класс и задайте метод отправки замены, который лучше
всего обрабатывает ваш вызов таймера, вместе с соответствующей константой
калибровки.cProfile.Profileyour_time_funcдолжен возвращать одно число. Если он возвращает целые числа, вы также можете вызвать конструктор класса с указанием второго аргумента реальная продолжительность одной единицы времени. Например, еслиyour_integer_time_funcвозвращает время в тысячах секунд вы должны построить экземплярProfileследующим образом:pr = cProfile.Profile(your_integer_time_func, 0.001)
Поскольку класс
cProfile.Profileне может быть откалиброван, пользовательские функции таймера следует использовать с осторожностью, и они должны работать как можно быстрее. Для достижения наилучших результатов с пользовательским таймером может потребоваться жестко закодировать его в исходном коде C внутреннего модуля_lsprof.
Python 3.3 добавляет несколько новых функций в time, которые можно
использовать для точного измерения времени процесса или настенных часов.
Например, см. time.perf_counter().
« предыдущий | следующий »
Общие сведения о профилировании — .NET Framework
- Статья
- Чтение занимает 9 мин
Профилировщик — это инструмент, который наблюдает за выполнением другого приложения. Профилировщик среды CLR — это библиотека DLL, содержащая функции, которые получают сообщения из среды CLR и отправляют сообщения в среду CLR с помощью API профилирования. Библиотека DLL профилировщика загружается средой CLR во время выполнения.
Традиционные средства профилирования основное внимание уделяют измерению выполнения приложения. То есть они измеряют время, затраченное на каждую функцию, или использование памяти приложением за период времени. API профилирования предназначен для более широкого класса диагностических средств, таких как служебные программы с покрытием кода и расширенные средства отладки. Сфера их применения — вся диагностика в природе. API профилирования не только измеряет, но также наблюдает за выполнением приложения. По этой причине API профилирования никогда не должен использоваться самим приложением, и выполнение приложения не должно ни зависеть от профилировщика, ни подвергаться его влиянию.
Для профилирования приложения среды CLR требуется дополнительная поддержка по сравнению с профилированием стандартно скомпилированного машинного кода. Это объясняется тем, что в среде CLR вводятся такие понятия, как домены приложений, сборка мусора, обработка управляемых исключений, JIT-компиляция кода (преобразование кода MSIL в машинный код) и другие аналогичные возможности.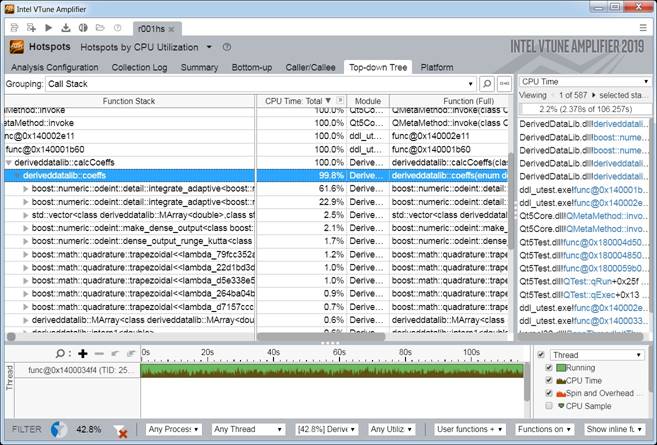 Механизмы традиционного профилирования не могут обнаруживать эти возможности или предоставлять полезные сведения о них. API профилирования эффективно предоставляет эти отсутствующие сведения с минимальным влиянием на производительность среды CLR и профилируемого приложения.
Механизмы традиционного профилирования не могут обнаруживать эти возможности или предоставлять полезные сведения о них. API профилирования эффективно предоставляет эти отсутствующие сведения с минимальным влиянием на производительность среды CLR и профилируемого приложения.
JIT-компиляция во время выполнения обеспечивает прекрасные возможности для профилирования. API профилирования позволяет профилировщику вносить изменения потока кода MSIL в памяти для подпрограммы перед ее JIT-компиляцией. Таким образом, профилировщик может динамически добавлять код инструментирования в определенные подпрограммы, требующие более глубокого анализа. Хотя такой подход возможен в обычных сценариях, его гораздо проще реализовать для среды CLR с помощью API профилирования.
API профилирования
Как правило, API профилирования используется для написания профилировщика кода, который является программой, отслеживающей выполнение управляемого приложения.
API профилирования используется библиотекой DLL профилировщика, которая загружается в один процесс с профилируемым приложением. библиотека DLL профилировщика реализует интерфейс обратного вызова (ICorProfilerCallback в платформа .NET Framework версии 1,0 и 1,1, ICorProfilerCallback2 в версии 2,0 и более поздних). Среда CLR вызывает методы этого интерфейса для уведомления профилировщика о событиях в процессе профилирования. Профилировщик может выполнить обратный вызов в среду выполнения, используя методы в интерфейсах ICorProfilerInfo и ICorProfilerInfo2 для получения сведений о состоянии профилированного приложения.
библиотека DLL профилировщика реализует интерфейс обратного вызова (ICorProfilerCallback в платформа .NET Framework версии 1,0 и 1,1, ICorProfilerCallback2 в версии 2,0 и более поздних). Среда CLR вызывает методы этого интерфейса для уведомления профилировщика о событиях в процессе профилирования. Профилировщик может выполнить обратный вызов в среду выполнения, используя методы в интерфейсах ICorProfilerInfo и ICorProfilerInfo2 для получения сведений о состоянии профилированного приложения.
Примечание
В одном процессе с профилируемым приложением должна запускаться только часть решения профилировщика, отвечающая за сбор данных. Весь анализ пользовательского интерфейса и данных должен выполняться в отдельном процессе.
На следующем рисунке показано, как библиотека DLL профилировщика взаимодействует с профилируемым приложением и средой CLR.
Интерфейсы уведомлений
ICorProfilerCallback и ICorProfilerCallback2 могут считаться интерфейсами уведомления. Эти интерфейсы состоят из таких методов, как класслоадстартед, класслоадфинишеди JITCompilationStarted. Каждый раз, когда среда CLR загружает или выгружает класс, компилирует функцию и т. д., она вызывает соответствующий метод в интерфейсе
Каждый раз, когда среда CLR загружает или выгружает класс, компилирует функцию и т. д., она вызывает соответствующий метод в интерфейсе ICorProfilerCallback или ICorProfilerCallback2 профилировщика.
Например, профилировщик может измерять производительность кода с помощью двух функций уведомления: FunctionEnter2 и FunctionLeave2. Он просто устанавливает метки времени для каждого уведомления, собирает результаты и выводит список, в котором указывается, на какие функции было затрачено больше ресурсов ЦП или физического времени во время выполнения приложения.
Интерфейсы для извлечения сведений
Другими основными интерфейсами, участвующими в профилировании, являются ICorProfilerInfo и ICorProfilerInfo2. Профилировщик вызывает эти интерфейсы по мере необходимости для получения дополнительных сведений, помогающих выполнить анализ. Например, всякий раз, когда среда CLR вызывает функцию FunctionEnter2 , она предоставляет идентификатор функции. Профилировщик может получить дополнительные сведения об этой функции, вызвав метод ICorProfilerInfo2:: GetFunctionInfo2 , чтобы обнаружить родительский класс функции, его имя и т. д.
д.
Поддерживаемые компоненты
API профилирования предоставляет сведения о различных событиях и действиях, которые происходят в среде CLR. Эти сведения можно использовать для мониторинга внутренней работы процессов и анализа производительности приложения .NET Framework.
API профилирования извлекает сведения о следующих действиях и событиях, происходящих в среде CLR.
События запуска и завершения работы среды CLR.
События создания и завершения работы домена приложения.
События загрузки и выгрузки сборки.
События загрузки и выгрузки модуля.
События создания и удаления таблицы VTable COM.
События JIT-компиляции и пошагового выполнения кода.
События загрузки и выгрузки класса.
События создания и удаления потока.
События входа и выхода функции.
Исключения.
Переходы между выполнением управляемого и неуправляемого кода.

Переходы между различными контекстами среды выполнения.
Сведения о приостановках среды выполнения.
Сведения о действиях сборки мусора и кучи в памяти времени выполнения.
API профилирования можно вызывать из любого (неуправляемого) языка, совместимого с COM.
Этот API является эффективным с точки зрения потребления ресурсов ЦП и памяти. Профилирование не влечет за собой изменения профилируемого приложения, которые могут привести к недостоверным результатам.
API профилирования полезен для профилировщиков как с выборкой, так и без выборки. Профилировщик с выборкой проверяет профиль по регулярным тактовым импульсам, скажем, через 5 миллисекунд. Профилировщик без выборки уведомляется о событии синхронно с потоком, вызвавшим событие.
Неподдерживаемые функциональные возможности
API профилирования не поддерживает следующие функциональные возможности.
Неуправляемый код, который необходимо профилировать с помощью стандартных методов Win32.
 Однако профилировщик среды CLR включает события переходов для определения границ между управляемым и неуправляемым кодом.
Однако профилировщик среды CLR включает события переходов для определения границ между управляемым и неуправляемым кодом.Самоизменяющиеся приложения, которые изменяют собственный код приложения, которые изменяют собственный код, например в целях аспектно-ориентированного программирования.
Проверка привязок, поскольку API профилирования не предоставляет эти сведения. Среда CLR предоставляет существенную поддержку для проверки границ всего управляемого кода.
Удаленное профилирование, которое не поддерживается по следующим причинам.
Удаленное профилирование увеличивает время выполнения. При использовании интерфейсов профилирования необходимо минимизировать время выполнения, чтобы оно не слишком сильно сказывалось на результатах профилирования. Это особенно важно при мониторинге производительности. Тем не менее удаленное профилирование не является ограничением при использовании интерфейсов профилирования для мониторинга использования памяти или для получения сведений времени выполнения о кадрах стека, объектах и т.
 п.
п.Профилировщик кода среды CLR должен зарегистрировать один или несколько интерфейсов обратного вызова в среде выполнения на локальном компьютере, на котором выполняется профилируемое приложение. Это ограничивает возможность создания удаленного профилировщика кода.
Потоки уведомлений
В большинстве случаев поток, который создает событие, также выполняет уведомления. Такие уведомления (например, FunctionEnter и FunctionLeave) не требуют явного указания. Кроме того, профилировщик может использовать локальное хранилище потока для хранения и обновления своих блоков анализа вместо индексирования этих блоков в глобальном хранилище на основе ThreadID затронутого потока.
Обратите внимание, что эти обратные вызовы не сериализуются. Пользователи должны защищать свой код, путем создания потокобезопасных структур данных и путем блокировки кода профилировщика в тех случаях, когда необходимо предотвратить параллельный доступ из нескольких потоков. Таким образом, в некоторых случаях можно получить необычную последовательность обратных вызовов. Например, предположим, что управляемое приложение порождает два потока, выполняющие идентичный код. В этом случае можно получить событие ICorProfilerCallback:: JITCompilationStarted для некоторой функции из одного потока и обратный вызов из другого потока перед получением обратного вызова ICorProfilerCallback:: JITCompilationFinished . В этом случае пользователь получит обратный вызов
Таким образом, в некоторых случаях можно получить необычную последовательность обратных вызовов. Например, предположим, что управляемое приложение порождает два потока, выполняющие идентичный код. В этом случае можно получить событие ICorProfilerCallback:: JITCompilationStarted для некоторой функции из одного потока и обратный вызов из другого потока перед получением обратного вызова ICorProfilerCallback:: JITCompilationFinished . В этом случае пользователь получит обратный вызов FunctionEnter для функции, которая могла быть не полностью JIT-скомпилирована.
Безопасность
Библиотека DLL профилировщика — это неуправляемая библиотека DLL, которая выполняется в рамках подсистемы выполнения среды CLR. В результате на код в библиотеке DLL профилировщика DLL не налагаются ограничения управления доступом для управляемого кода. Для библиотеки DLL профилировщика действуют только ограничения, накладываемые операционной системой на пользователя, запускающего профилируемое приложение.
Разработчики профилировщика должны принять соответствующие меры предосторожности, чтобы избежать проблем, связанных с безопасностью. Например, во время установки библиотека DLL профилировщика должна добавляться в список управления доступом (ACL), чтобы злоумышленник не мог изменить ее.
Объединение управляемого и неуправляемого кода в коде профилировщика
Неправильно написанный профилировщик может вызвать циклические ссылки на себя, что приводит к непредсказуемому поведению.
Обзор API профилирования среды CLR может создать впечатление, что можно написать профилировщик, содержащий управляемые и неуправляемые компоненты, которые вызывают друг друга посредством COM-взаимодействия или непрямых вызовов.
Хотя это возможно с точки зрения проектирования, API профилирования не поддерживает управляемые компоненты. Профилировщик среды CLR должен быть полностью неуправляемым. Попытки объединить управляемый и неуправляемый код в профилировщике среды CLR могут привести к нарушениям прав доступа, сбоям программы или взаимоблокировкам. Управляемые компоненты профилировщика будут возвращать события обратно их неуправляемым компонентам, что будет затем вызывать управляемые компоненты снова, и таким образом будут создаваться циклические ссылки.
Управляемые компоненты профилировщика будут возвращать события обратно их неуправляемым компонентам, что будет затем вызывать управляемые компоненты снова, и таким образом будут создаваться циклические ссылки.
Единственное место, где профилировщик CLR может безопасно вызывать управляемый код, это текст MSIL в теле метода. Рекомендуемым методом изменения тела MSIL является использование методов JIT-компиляции в интерфейсе ICorProfilerCallback4 .
Кроме того, для изменения MSIL можно использовать старые методы инструментирования. Перед завершением JIT-компиляции функции профилировщик может вставить управляемые вызовы в текст MSIL метода, а затем выполнить JIT-компиляцию (см. метод ICorProfilerInfo:: GetILFunctionBody ). Этот способ можно успешно использовать для выборочного инструментирования управляемого кода или для сбора статистики и данных производительности касательно JIT.
Кроме того, профилировщик кода может вставлять собственные обработчики в текст MSIL любой управляемой функции, которая вызывает неуправляемый код. Этот способ можно использовать для инструментирования и покрытия. Например, профилировщик кода может вставить обработчики инструментирования после каждого блока MSIL для обеспечения выполнения блока. Изменение текста MSIL метода следует выполнять очень аккуратно и принимать во внимание множество факторов.
Этот способ можно использовать для инструментирования и покрытия. Например, профилировщик кода может вставить обработчики инструментирования после каждого блока MSIL для обеспечения выполнения блока. Изменение текста MSIL метода следует выполнять очень аккуратно и принимать во внимание множество факторов.
Профилирование неуправляемого кода
API профилирования среды CLR предоставляет минимальную поддержку профилирования неуправляемого кода. Предоставляются следующие функциональные возможности.
Перечисление цепочек стека. Эта возможность позволяет профилировщику кода определить границу между управляемым и неуправляемым кодом.
Определение, соответствует ли цепочка стека управляемому коду или машинному коду.
В .NET Framework версий 1.0 и 1.1 эти методы доступны через внутрипроцессное подмножество API отладки среды CLR. Они определяются в файле CorDebug.idl.
в платформа .NET Framework 2,0 и более поздних версиях для этой функции можно использовать метод ICorProfilerInfo2::D остаккснапшот .
Использование модели COM
Хотя интерфейсы профилирования определяются как COM-интерфейсы, среда CLR в действительности не инициализирует модель COM для использования этих интерфейсов. Причина заключается в том, чтобы не задавать модель потоков с помощью функции CoInitialize , прежде чем управляемое приложение сможет указать требуемую потоковую модель. Аналогично, сам профилировщик не должен вызывать CoInitialize, поскольку он может выбрать потоковую модель, несовместимую с профилируемым приложением, что может привести к сбою приложения.
Стеки вызовов
API профилирования предоставляет два способа получения стеков вызова: метод моментальных снимков стека, который позволяет реже выполнять сбор стеков вызовов, и метод теневого стека, который отслеживает стек вызовов в каждый момент времени.
Моментальный снимок стека
Моментальный снимок стека — это трассировка стека потока в момент времени. API профилирования поддерживает трассировку управляемых функций в стеке, но оставляет трассировку неуправляемых функций собственному обходчику стека профилировщика.
дополнительные сведения о программировании профилировщика для прохода по управляемым стекам см. в описании метода ICorProfilerInfo2::D остаккснапшот в этом наборе документации и в стеке профилировщика в платформа .NET Framework 2,0: основы и за пределами.
Теневой стек
Слишком частое использование метода моментального снимка может быстро создавать проблемы производительности. Если вы хотите часто получать трассировки стека, профилировщик должен создать теневой стек с помощью обратных вызовов исключений FunctionEnter2, FunctionLeave2, FunctionTailcall2и ICorProfilerCallback2 . Теневой стек всегда является текущим, и его можно быстро скопировать в хранилище каждый раз, когда требуется моментальный снимок стека.
Теневой стек может получать аргументы функций, возвращать значения и сведения об универсальных экземплярах. Эти сведения доступны только посредством теневого стека и могут быть получены, когда управление передается в функцию. Однако эти сведения могут оказаться недоступны позднее, во время выполнения функции.
Обратные вызовы и глубина стека вызовов
Обратные вызовы профилировщика могут осуществляться в условиях очень ограниченного стека, и переполнение стека в обратном вызове профилировщика приведет к немедленному завершению выполнения процесса. В ответ на обратные вызовы профилировщик должен гарантированно использовать минимально возможный стек. Если профилировщик предназначен для использования в процессах, устойчивых к переполнению стека, сам профилировщик должен также избегать активации переполнения стека.
| Заголовок | Описание |
|---|---|
| Установка профилирующей среды | В этом разделе объясняется, как можно инициализировать профилировщик, установить уведомления о событиях и профилировать службу Windows. |
| Профилирующие интерфейсы | В этом разделе описываются неуправляемые интерфейсы, которые использует API профилирования. |
| Глобальные статические функции профилирования | В этом разделе описываются неуправляемые глобальные статистические функции, которые использует API профилирования. |
| Перечисления профилирования | В этом разделе описываются неуправляемые перечисления, которые использует API профилирования. |
| Структуры профилирования | В этом разделе описываются неуправляемые структуры, которые использует API профилирования. |
Введение в профилирование приложений Java в IDE NetBeans
Среда IDE предоставляет ряд внутренних параметров, позволяющих настраивать профилирования в соответствии с вашими требованиями. Например, можно уменьшить дополнительный расход ресурсов на профилирование за счет уменьшения объема созданной информации. Однако ознакомление со множеством доступных параметров может занять некоторое время. Для большинства приложений параметров по умолчанию, указанных для задач профилирования, достаточно для большинства ситуаций.
При профилировании проекта используется диалоговое окно «Выбор задачи профилирования» для выбора задачи в соответствии с необходимо информацией профилирования. В следующей таблице описываются задачи профилирования и результаты, получаемые в результате выполнения задачи.
В следующей таблице описываются задачи профилирования и результаты, получаемые в результате выполнения задачи.
| Задача профилирования | Результаты |
|---|---|
Наблюдение за приложением | Выберите для получения высокоуровневой информации о свойствах целевой JVM, включая активность потоков и распределение памяти. |
Анализ производительности ЦП | Выберите для получения подробных данных о производительности приложения, включая время выполнения методов и число вызовов метода. |
Анализ использования памяти | Выберите для получения подробной информации о выделении объектов и сборке мусора. |
Диалоговое окно «Выбор задачи профилирования» — основной интерфейс для выполнения задач профилирования. После выбора задачи можно изменить ее параметры для точной настройки получаемых результатов. Для каждой задачи профилирования также можно создать и сохранить пользовательские задачи профилирования на основе данной задачи. При создании пользовательской задачи профилирования она будет указана в диалоговом окне «Выбрать задачу профилирования», что позволяет позже просто найти и выполнить пользовательские параметры. При создании пользовательской задачи профилирования можно изменить дополнительные параметры профилирования, нажав кнопку Дополнительные параметры в диалоговом окне «Выбрать задачу профилирования».
При создании пользовательской задачи профилирования она будет указана в диалоговом окне «Выбрать задачу профилирования», что позволяет позже просто найти и выполнить пользовательские параметры. При создании пользовательской задачи профилирования можно изменить дополнительные параметры профилирования, нажав кнопку Дополнительные параметры в диалоговом окне «Выбрать задачу профилирования».
Наблюдение за приложением
При выборе задачи наблюдения целевое приложение запускается без каких-либо инструментов. При наблюдении за приложением вы получаете высокоуровневую информацию о нескольких важных свойствах целевой JVM. Поскольку наблюдение за приложением не требует большого дополнительного расхода ресурсов, можно запускать приложение в этом режиме в течение длительного времени.
Для наблюдения за приложением Anagram Game выполните следующие действия.
Убедитесь, что проект AnagramGame установлен как главный проект.
Выберите «Профиль > Профилировать главный проект» в главном меню.
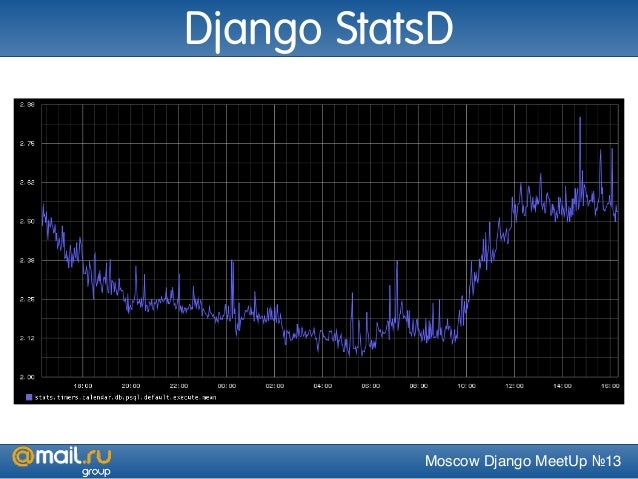
Также можно щелкнуть правой кнопкой мыши узел проекта в окне ‘Проекты’ и выбрать ‘Профиль’.
Выберите «Наблюдение» в диалоговом окне «Выбор задачи профилирования».
При необходимости выберите дополнительные параметры монитора. Нажмите кнопку «Выполнить».
Figure 5. Выбор задачи профилирования приложения монитора
Можно подвести курсор к параметру для просмотра всплывающей подсказки со сведениями о параметре.
При нажатии кнопки «Выполнить» среда IDE запускает приложение, и открывается окно «Средство профилирования» в левой панели среды IDE. В окне «Средство профилирования» содержатся элементы управления, позволяющие выполнять следующие действия.
Контроль за задачей профилирования
Просмотр состояния текущей задачи профилирования
Отображение результатов профилирования
Управление моментальными снимками результатов профилирования
Просмотр статистики основной телеметрии
Можно использовать элементы управления в окне «Средство профилирования» или главном меню для открытия окон, в которых можно просматривать данные наблюдения. Окно «Обзор телеметрии» можно использовать для быстрого получения обзора данных наблюдения в реальном времени. Если поместить курсор на график, можно просмотреть более подробную статистику отображающихся в графике данных. Можно дважды щелкнуть любой график в окне «Обзор телеметрии» для открытия более крупной и подробной версии графика.
Окно «Обзор телеметрии» можно использовать для быстрого получения обзора данных наблюдения в реальном времени. Если поместить курсор на график, можно просмотреть более подробную статистику отображающихся в графике данных. Можно дважды щелкнуть любой график в окне «Обзор телеметрии» для открытия более крупной и подробной версии графика.
Figure 6. Окно ‘Обзор телеметрии’
Если обзор не открывается автоматически, можно выбрать «Окно > Профилирование > Обзор телеметрии», чтобы открыть окно вывода. Можно открыть окно «Обзор телеметрии VM» и просмотреть данные наблюдения в любое время во время сеанса профилирования.
Анализ производительности ЦП
При выборе задачи ЦП среда IDE профилирует производительность ЦП уровня метода (время выполнения) приложения и обрабатывает результаты в реальном времени. Можно выбрать анализ производительности путем периодического выполнения трассировки стека или инструментирования методов в приложении. Можно выбрать инструментирование всех методов или ограничить инструментирование частью кода приложения, даже определенным фрагментом кода.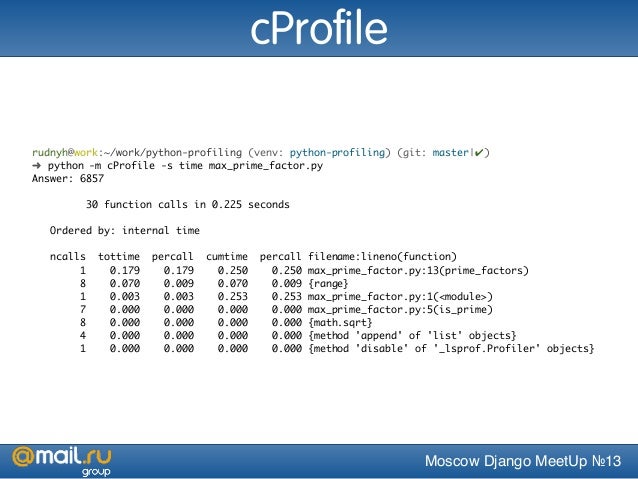
Для анализа производительности ЦП можно выбрать способ профилирования приложения, выбрав один из следующих вариантов.
Быстрый (образец). В этом режиме IDE создает образец приложения и периодически создает трассировку стека. Этот вариант менее точен, чем методы инструментирования, но вызывает меньший дополнительный расход ресурсов. Этот вариант может помочь выбрать методы для инструментирования.
Расширенный (инструментация). В этом режиме методы профилируемого приложения инструментируются. Среда IDE регистрирует вход и выход потоков в методы проекта, позволяя отслеживать время, затрачиваемое на каждый метод. При входе в метод потоки создают событие «вход в метод». При выходе из метода потоки создают соответствующее событие «выход из метода». Записываются метки времени обоих событий. Эти данные обрабатываются в реальном времени.
Можно выбрать инструментирование всех методов приложения или ограничить инструментирование поднабором кода приложения, указав один или несколько корневых методов.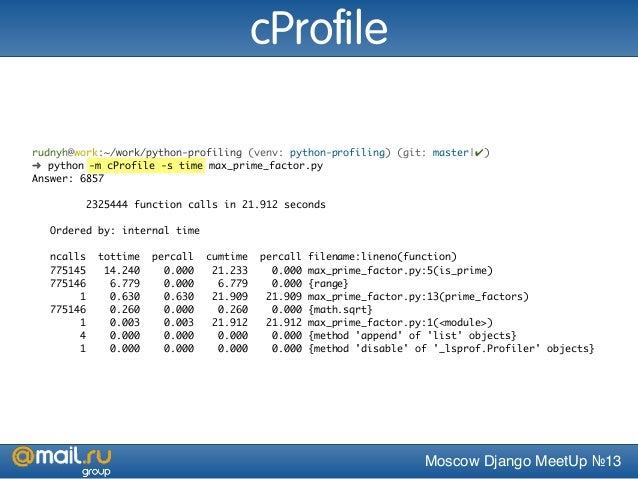 Корневой метод можно указать, используя всплывающее меню в исходном коде, или щелкнув настроить, чтобы открыть диалоговое окно «Изменить корневые методы профилирования».
Корневой метод можно указать, используя всплывающее меню в исходном коде, или щелкнув настроить, чтобы открыть диалоговое окно «Изменить корневые методы профилирования».
Корневой метод — это метод, класс или пакет в исходном коде, который можно указать как корень обработки. Данные профилирования собираются при входе и выходе одного из потоков приложения из корня обработки. До входа одного из потоков приложения в корневой метод данные профилирования не собираются. Указание корневого метода может значительно снизить дополнительный расход ресурсов на профилирование. Для некоторых приложений указание корневого метода может быть единственным способом получения подробных и/или реалистичных данных производительности, поскольку профилирование всего приложения может создать так много данных профилирования, что приложение станет непригодным к использованию, или даже произойдет отказ приложения.
Примечание. Режим профиля Quick недоступен в IDE NetBeans 7.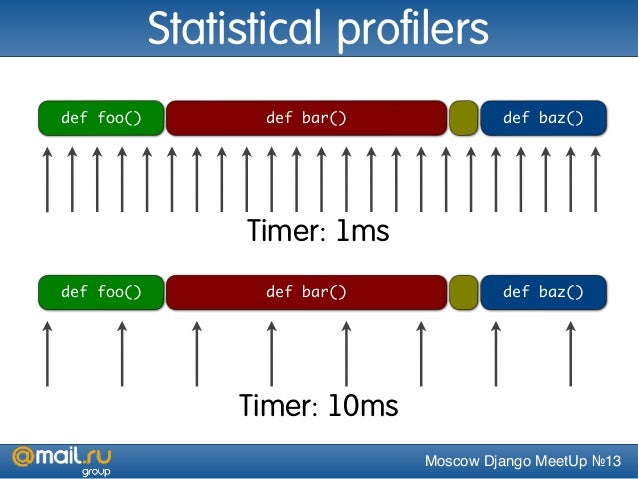 0 и более ранних версиях. Можно использовать только инструментирование для получения результатов профилирования, но можно выбрать инструментирование всего приложения или ограничить инструментирование частью приложения, указав один или несколько корневых методов.
0 и более ранних версиях. Можно использовать только инструментирование для получения результатов профилирования, но можно выбрать инструментирование всего приложения или ограничить инструментирование частью приложения, указав один или несколько корневых методов.
Можно еще больше уточнить код для профилирования, используя фильтр для ограничения исходного кода для инструментирования.
Теперь среда IDE будет использоваться для анализа производительности ЦП приложения Anagram Game. Необходимо выбрать вариант «Часть приложения», а затем WordLibrary.java в качестве корневого метода профилирования. При выборе этого класса в качестве корневого метода профилирования последнее ограничивается методами в этом классе.
Нажмите кнопку «Остановить» в окне «Средство профилирования», чтобы остановить предыдущий сеанс профилирования (если он еще запущен).
Выберите «Профиль > Профилировать главный проект» в главном меню.
Выберите «ЦП» в диалоговом окне «Выбор задачи профилирования».

Выберите Расширенный (инструментарий).
Для использования этого варианта также необходимо указать корневой метод профилирования.
Нажмите кнопку настроить, чтобы открыть диалоговое окно «Изменение корневых методов профилирования».
Figure 7. Выбор задачи профилирования ЦП
В диалоговом окне ‘Изменение корневых методов профилирования’ разверните узел AnagramGame и выберите
Sources/com.toy.anagrams.lib/WordLibrary. При профилировании проекта можно указать несколько корневых методов профилирования.
Figure 8. Диалоговое окно для выбора корневых методов
Нажмите кнопку «Дополнительно», чтобы открыть диалоговое окно «Изменение корневых методов профилирования (Дополнительно)», в котором доступны дополнительные параметры для добавления, изменения и удаления корневых методов.
Figure 9. Диалоговое окно для указания корневых методов
Можно видеть, что WordLibrary указан как корневой метод. Нажмите «ОК», чтобы закрыть диалоговое окно «Изменение корневых методов профилирования (Расширенное)».
Нажмите «ОК», чтобы закрыть диалоговое окно «Изменение корневых методов профилирования (Расширенное)».
Нажмите «ОК», чтобы закрыть диалоговое окно «Изменение корневых методов профилирования».
После выбора корневых методов профилирования можно щелкнуть правка в диалоговом окне ‘Выбор задачи профилирования’ дл изменения выбранного корневого метода.
Выберите Профилировать только классы проекта для значения «Фильтр».
Фильтр позволяет ограничить инструментируемые классы. Можно выбрать один из предварительно определенных фильтров профилирования IDE или создать собственные пользовательские фильтры. Щелкните Показать значение фильтра для просмотра списка классов, которые будут профилированы при применении выбранного фильтра.
Figure 10. Диалоговое окно ‘Показать значени фильтра’
Нажмите кнопку «Выполнить» в диалоговом окне «Выбрать задачу профилирования» для начала сеанса профилирования.
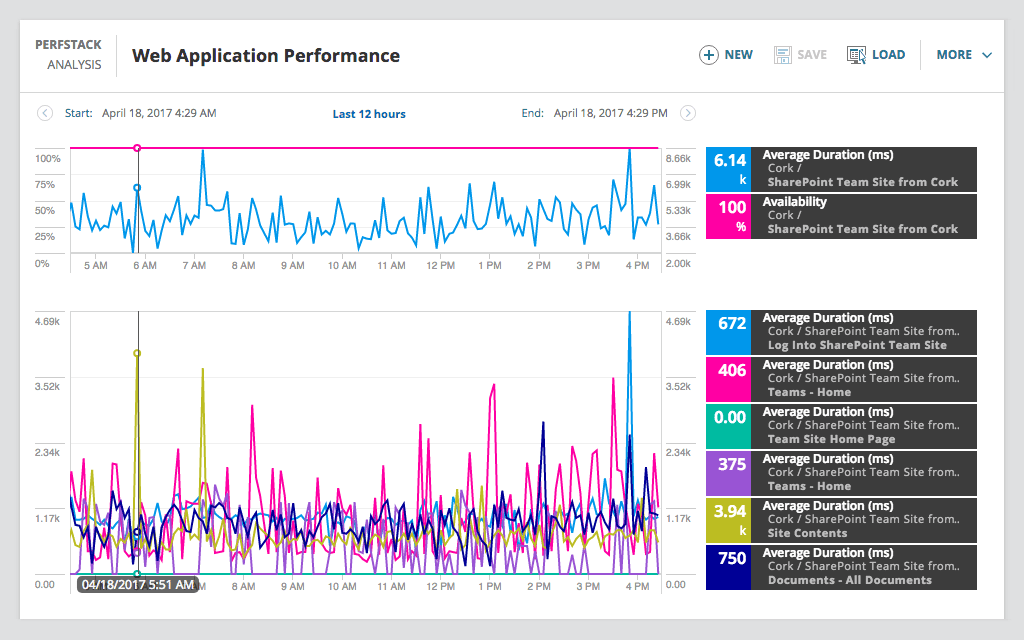
При нажатии кнопки «Выполнить» среда IDE запускает приложение Anagram Game и запускает сеанс профилирования. Чтобы просмотреть результаты профилирования, нажмите кнопку «Текущие результаты» в окне «Средство профилирования», при этом откроется окно «Текущие результаты». В окне «Текущие результаты» отображаются собранные на этот момент данные профилирования. По умолчанию отображаемые данные обновляются каждые несколько секунд. При анализе производительности ЦП в окне «Текущие результаты» отображаются сведения о времени, затраченным для каждого метода, и число вызовов каждого метода. Можно видеть, что в приложении Anagram Game изначально вызываются только выбранные корневые методы.
Figure 11. Текущие результаты ЦП
Вы можете быстро перейти к исходному коду, содержащему любой из перечисленных методов, щелкнув правой кнопкой мыши имя метода и выбрав ‘Перейти к источнику’. При щелчке ‘Перейти к исходному коду’ класс открывается в редакторе исходного кода.
Анализ использования памяти
Задач «Анализ использования памяти» предоставляет данные об объектах, выделенных в целевом приложении, таких как число, тип и расположение выделенных объектов.
Для анализа производительности памяти следует выбрать объем данных, который необходимо получить, выбрав один из следующих вариантов.
Быстро. Если выбран этот вариант, профилировщик создаст образец приложения для предоставления данных, которые ограничены живыми объектами. Этот параметр отслеживает только живые объекты и не отслеживает распределение при использовании запасов. Если выбран этот вариант, невозможно регистрировать трассировки стеков или использовать точки профилирования. Этот вариант требует значительно меньших затрат, чем ‘Дополнительно’.
Дополнительно. При выборе этого варианта приложение может получить информацию о количестве, типе и расположении выделенных объектов. Все классы, которые в настоящее время загружены целевым JVM (и каждый новый класс после его загрузки), являются инструментами для получения информации о распределении объектов. Этот вариант необходимо выбрать, если нужно использовать точки профилирования при анализе памяти или если нужно выполнить запись стека вызовов.
 Этот вариант требует больших затрат на профилирование по сравнению с вариантом ‘Быстро’.
Этот вариант требует больших затрат на профилирование по сравнению с вариантом ‘Быстро’.
Если вы выберете вариант ‘Дополнительно’, вы также можете установить следующие параметры.
Запись полного образа жизни объекта. Выберите этот вариант, чтобы записать всю информацию по каждому объекту, в том числе количество выживших поколений.
Запись трассировки стека для распределения. Выберите этот вариант, чтобы записать полный стек вызовов. Этот вариант позволяет просматривать дерево обратных вызовов для вызовов методов при просмотре снимка памяти.
Использование определенных точек профилирования. Выберите этот вариант, чтобы включить поддержку точек профилирования. Отключенные точки профилирования игнорируются. При отмене этого параметра все точки профилирования в проекте игнорируется.
Показатель «Накладные расходы» в окне «Выбрать задачу профилирования» предоставляет примерное увеличение или уменьшение дополнительного расхода ресурсов на профилирование в соответствии с выбранными вариантами профилирования.
В этом упражнении среда IDE будет использоваться для анализа производительности памяти приложения Anagram Game. Рекомендуется выбрать вариант Дополнительно и выбрать параметр Запись трассировки стека для распределения, чтобы в IDE выполнялась запись полного стека вызовов. При выборе этого варианта при работе со снимком памяти вы сможетепросмотреть дерево обратных вызовов.
Нажмите кнопку «Остановить» в окне «Средство профилирования», чтобы остановить предыдущий сеанс профилирования (если он еще запущен) и приложение Anagram Game.
Выберите «Профиль > Профилировать главный проект» в главном меню.
Выберите «Память» в диалоговом окне «Выбрать задачу профилирования».
Выберите Дополнительно.
Выберите Регистрировать трассировку стека для операций выделения. Нажмите кнопку «Выполнить» для начала сеанса профилирования.
Обратите внимание, что при выборе этого варианта значение показателя «Накладные расходы» значительно увеличивается, но приложение достаточно мало для того, чтобы снижение производительности было приемлемым.
Figure 12. Выбор задачи профилирования памяти
При нажатии кнопки «Выполнить» среда IDE запускает приложение Anagram Game и запускает сеанс профилирования. Чтобы просмотреть результаты профилирования, нажмите кнопку «Текущие результаты» в окне «Средство профилирования», при этом откроется окно «Текущие результаты». В окне «Текущие результаты» отображается информация о размере и числе объектов, выделенных в нашем проекте.
По умолчанию результаты сохраняются и отображаются как число выделенных байтов, но можно щелкнуть заголовок столбца, чтобы изменить способ отображения результатов. Также можно выполнить фильтрацию результатов, введя имя класса в поле фильтра под списком.
Figure 13. Результаты профилирования памяти
Профилирование кода Python с Py-Spy
Если у вас есть программа Python, которая в настоящее время работает, вы можете понять, каково реальное профиль производительности кода. Эта программа может быть в производственной среде или просто на вашей местной машине. Вы захотите понять, где проведенная программа тратит свое время, и существуют ли какие -либо «горячие точки», которые следует исследовать для улучшения. Возможно, вы имеете дело с производственной системой, которая плохо себя ведет, и вы можете профилировать ее ненавязчивым способом, который не влияет на производительность производства или требует модификаций кода. Как это хороший способ сделать это? Эта статья расскажет о py-spy , инструмент, который позволяет вам профилировать программы Python, которые уже работают.
Вы захотите понять, где проведенная программа тратит свое время, и существуют ли какие -либо «горячие точки», которые следует исследовать для улучшения. Возможно, вы имеете дело с производственной системой, которая плохо себя ведет, и вы можете профилировать ее ненавязчивым способом, который не влияет на производительность производства или требует модификаций кода. Как это хороший способ сделать это? Эта статья расскажет о py-spy , инструмент, который позволяет вам профилировать программы Python, которые уже работают.
Детерминированные и профилировщики отбора проб
В более ранних статьях я написал о двух детерминированных профилирующих, cProfile и line_profiler Анкет Эти профилировщики полезны, когда вы разрабатываете код и хотите профилировать разделы кода или всего процесса. Поскольку они детерминированные, они будут точно сказывать вам, сколько раз выполняется функция (или в случае line_profiler , строка) и сколько времени она относительно берет, чтобы выполнить по сравнению с остальной частью вашего кода. Поскольку эти профилировщики работают в рамках наблюдаемого процесса, они несколько замедляют его, потому что им приходится делать бухгалтерский уст и расчет в разгар программы. Для производственного кода, изменение кода или перезапуск его с помощью включенного профилировщика часто не является вариантом.
Поскольку эти профилировщики работают в рамках наблюдаемого процесса, они несколько замедляют его, потому что им приходится делать бухгалтерский уст и расчет в разгар программы. Для производственного кода, изменение кода или перезапуск его с помощью включенного профилировщика часто не является вариантом.
Здесь могут быть полезные профилировщики отбора проб. Профилировщик отбора проб рассматривает существующий процесс и использует различные трюки, чтобы определить, что делает процесс выполнения. Вы можете вручную попробовать это самостоятельно. Например, на Linux вы можете использовать PSTACK (или gstack ) Команда, чтобы увидеть, что делает ваш процесс. На Mac вы можете выполнить Echo "Thread Backtrace All" | lldb -p увидеть что -то подобное. Вывод будет стопкой всех потоков в вашем процессе. Это работает для любого процесса, а не только для программ Python. Для ваших программ Python вы увидите основные функции C, а не ваши функции Python. В некоторых случаях проверка стека несколько раз таким образом может сказать вам, застрял ли ваш процесс или где он медленный, при условии, что вы можете сделать перевод в свой собственный код. Но это обеспечивает только один образец во времени. Поскольку процесс постоянно выполняется, ваш образец может меняться каждый раз, когда вы запускаете команду (если он не заблокирован или вам просто очень повезло).
В некоторых случаях проверка стека несколько раз таким образом может сказать вам, застрял ли ваш процесс или где он медленный, при условии, что вы можете сделать перевод в свой собственный код. Но это обеспечивает только один образец во времени. Поскольку процесс постоянно выполняется, ваш образец может меняться каждый раз, когда вы запускаете команду (если он не заблокирован или вам просто очень повезло).
Профилировщик выборки и окружающие инструменты с течением времени делают несколько снимков системы, а затем предоставляют вам возможность просматривать эти данные и понимать, где ваш код медленно.
пио- шпион
Py-Spy использует системные вызовы ( process_vm_readv on linux, vm_read on osx, readprocessmemory на Windows), чтобы получить стек вызовов, а затем переводит эту информацию в функцию Python, которые вы видите в Ваш исходный код. Он выбирает несколько раз в секунду, поэтому у него есть хорошие шансы увидеть вашу программу в различных состояниях, что она будет со временем. Это написано в ржавчине для скорости.
Это написано в ржавчине для скорости.
Получить Py-Spy в ваш проект очень просто, он можно установить через Pip Анкет Чтобы показать вам, как его использовать, я создал какой-то образец кода для профиля и наблюдения, как PY-Spy может рассказать нам о запущенном процессе Python. Если вы хотите следовать, вы можете легко воспроизвести эти шаги.
Сначала я настраиваю новую виртуальную среду, используя py-env и Pyenv-virtualenv plugin для этого проекта. Вы можете сделать это или настроить виртуальную среду, используя ваш предпочтительный инструмент.
# whichever Python version you prefer pyenv install 3.8.7 # make our virtualenv (with above version) pyenv virtualenv 3.8.7 py-spy # activate it pyenv activate py-spy # install py-spy pip install py-spy # make sure we pick up the commands in our path pyenv rehash
Это все, что нужно, у нас теперь есть инструменты. Если вы запускаете Py-Spy, вы можете увидеть общее использование.
$ py-spy
py-spy 0.3.4
Sampling profiler for Python programs
USAGE:
py-spy
OPTIONS:
-h, --help Prints help information
-V, --version Prints version information
SUBCOMMANDS:
record Records stack trace information to a flamegraph, speedscope or raw file
top Displays a top like view of functions consuming CPU
dump Dumps stack traces for a target program to stdout
help Prints this message or the help of the given subcommand(s)
Пример
Чтобы продемонстрировать Py-Spy, я написал простой продолжительный процесс, который будет потреблять цены на потоковую передачу от обмена криптовалютами и генерировать записи каждую минуту (это также известно как бар). Бар содержит различную информацию с последней минуты. Бар включает в себя высокую, низкую и последнюю цену, объем и средневзвешенную цену (VWAP). Прямо сейчас код регистрирует только эти значения, но может быть расширен для обновления базы данных. Хотя это просто, это полезный пример для использования, так как криптовалюты торгуются по часам и даст нам данные реального мира для работы.
Бар содержит различную информацию с последней минуты. Бар включает в себя высокую, низкую и последнюю цену, объем и средневзвешенную цену (VWAP). Прямо сейчас код регистрирует только эти значения, но может быть расширен для обновления базы данных. Хотя это просто, это полезный пример для использования, так как криптовалюты торгуются по часам и даст нам данные реального мира для работы.
Я использую Coinbase Pro Api для Python Чтобы получить доступ к данным из подачи WebSocket. Вот первый сокращение, в котором остался код отладки (вместе с двумя способами генерирования VWAP, один неэффективный ( _ VWAP Метод) и один более эффективный). Посмотрим, показывает ли Py-Spy, сколько времени использует этот код.
Этот код в конечном итоге генерирует поток для клиента WebSocket. Loop Asyncio установит таймер для границы следующей минуты, чтобы сообщить клиенту регистрировать данные панели. Он будет работать до тех пор, пока вы не убьете его (например, CTRL-C).
#!/usr/bin/env python import argparse import functools import datetime import asyncio import logging import arrow import cbpro class BarClient(cbpro.WebsocketClient): def __init__ (self, **kwargs): super(). __init__ (**kwargs) self._bar_volume = 0 self._weighted_price = 0.0 self._ticks = 0 self._bar_high = None self._bar_low = None self.last_msg = {} self._pxs = [] self._volumes = [] def next_minute_delay(self): delay = (arrow.now().shift(minutes=1).floor('minutes') - arrow.now()) return (delay.seconds + delay.microseconds/1e6) def _vwap(self): if len(self._pxs): wp = sum([x*y for x,y in zip(self._pxs, self._volumes)]) v = sum(self._volumes) return wp/v def on_message(self, msg): if 'last_size' in msg and 'price' in msg: last_size = float(msg['last_size']) price = float(msg['price']) self._bar_volume += last_size self._weighted_price += last_size * price self._ticks += 1 if self._bar_high is None or price > self.
_bar_high: self._bar_high = price if self._bar_low is None or price < self._bar_low: self._bar_low = price self._pxs.append(price) self._volumes.append(last_size) logging.debug("VWAP: %s", self._vwap()) self.last_msg = msg logging.debug("Message: %s", msg) def on_bar(self, loop): if self.last_msg is not None: if self._bar_volume == 0: self.last_msg['vwap'] = None else: self.last_msg['vwap'] = self._weighted_price/self._bar_volume self.last_msg['bar_bar_volume'] = self._bar_volume self.last_msg['bar_ticks'] = self._ticks self.last_msg['bar_high'] = self._bar_high self.last_msg['bar_low'] = self._bar_low last = self.last_msg.get('price') if last: last = float(last) self._bar_high = last self._bar_low = last logging.
info("Bar: %s", self.last_msg) self._bar_volume = 0 self._weighted_price = 0.0 self._ticks = 0 self._pxs.clear() self._volumes.clear() // reschedule loop.call_at(loop.time() + self.next_minute_delay(), functools.partial(self.on_bar, loop)) def main(): argparser = argparse.ArgumentParser() argparser.add_argument("--product", default="BTC-USD", help="coinbase product") argparser.add_argument('-d', "--debug", action='store_true', help="debug logging") args = argparser.parse_args() cfg = {"format": "%(asctime)s - %(levelname)s - %(message)s"} if args.debug: cfg["level"] = logging.DEBUG else: cfg["level"] = logging.INFO logging.basicConfig(**cfg) client = BarClient(url="wss://ws-feed.pro.coinbase.com", products=args.product, channels=["ticker"]) loop = asyncio.get_event_loop() loop.
call_at(loop.time() + client.next_minute_delay(), functools.partial(client.on_bar, loop)) loop.call_soon(client.start) try: loop.run_forever() finally: loop.close() if __name__ == ' __main__': main()
Запуск примера
Чтобы запустить этот код, вам нужно установить несколько дополнительных модулей. Модуль CBPRO – это простая обертка Python API Coinbase. Стрелка Хорошая библиотека для выполнения логики DateTime.
pip install arrow cbpro
Теперь вы можете запустить код с журналом отладки и, надеюсь, увидеть некоторые сообщения, в зависимости от того, насколько занят обмен.
./coinbase_client.py -d 2021-03-14 17:20:12,828 - DEBUG - Using selector: KqueueSelector -- Subscribed! -- 2021-03-14 17:20:13,059 - DEBUG - Message: {'type': 'subscriptions', 'channels': [{'name': 'ticker', 'product_ids': ['BTC-USD']}]} 2021-03-14 17:20:13,060 - DEBUG - VWAP: 60132.57
Профилирование примера
Теперь давайте рассмотрим команды Py-Spy. Во -первых, использование команды дампа даст нам быстрый вид стека, переведенный на функции Python.
Быстрое примечание здесь, если вы используете Mac, вам нужно будет запустить Py-Spy в качестве Sudo. На Linux это зависит от ваших настроек безопасности. Кроме того, так как я использовал Pyenv, мне нужно было передать свою среду в Sudo, используя -E Флаг, чтобы он поднимает правый интерпретатор Python и сценарий Py-Spy на пути. Я получил идентификатор процесса для моего процесса, используя ps командование в моей оболочке (в моем случае это было 97520).
Py-Spy Damp
sudo -E py-spy dump -p 97520 Process 97520: /Users/mcw/.pyenv/versions/py-spy/bin/python ./coinbase_client.py -d Python v3.8.7 (/Users/mcw/.pyenv/versions/3.8.7/bin/python3.8) Thread 0x113206DC0 (idle): "MainThread" select (selectors.py:558) _run_once (asyncio/base_events.py:1823) run_forever (asyncio/base_events.py:570) main (coinbase_client.py:107) (coinbase_client.py:113) Thread 0x700009CAA000 (idle): "Thread-1" read (ssl.py:1101) recv (ssl.py:1226) recv (websocket/_socket.py:80) _recv (websocket/_core.py:427) recv_strict (websocket/_abnf.py:371) recv_header (websocket/_abnf.py:286) recv_frame (websocket/_abnf.py:336) recv_frame (websocket/_core.py:357) recv_data_frame (websocket/_core.py:323) recv_data (websocket/_core.py:310) recv (websocket/_core.py:293) _listen (cbpro/websocket_client.py:84) _go (cbpro/websocket_client.py:41) run (threading.py:870) _bootstrap_inner (threading.py:932) _bootstrap (threading.py:890)
Вы можете видеть, что работает две темы. Один из них читает данные, другой – в
Один из них читает данные, другой – в Выберите В петле бега. Это полезно только для профилирования, если наша программа застряла. Одна действительно хорошая особенность, хотя, если вы дадите ей -Локал Вариант, он покажет вам любые локальные переменные, которые могут быть очень полезны для отладки!
Py-Spy Top
Следующая команда, чтобы попробовать, это Верх Анкет
sudo -E py-spy top -p 97520
Это вызовет интерфейс, который выглядит очень похоже на Unix Верх командование Когда ваша программа работает, и Py-Spy собирает образцы, она покажет вам, где она проводит время. Вот скриншот того, как это выглядело для меня примерно через 30 секунд.
py-spy Верхний вывод
Py-Spy Record
Наконец, вы можете записать данные, используя Py-Spy для последующего анализа или вывода. Существует необработанный формат, формат SpeedScope и вывод фламеграфа. Вы можете указать количество времени, которое вы хотите собирать данные (в секунды), или просто позволить ему собирать данные, пока вы не выйдете из программы, используя CTRL-C. Например, эта команда будет генерировать полезный маленький фламеграф SVG, с которым вы можете взаимодействовать в веб -браузере.
sudo -E py-spy record -p 97520 --output py-spy.svg
Вы также можете экспортировать данные в SpeedScope Формат, а затем загрузите его в веб -инструмент SpeedScope для дальнейшего анализа. Это отличный инструмент для интерактивного вида, как выполняется ваш код.
Это отличный инструмент для интерактивного вида, как выполняется ваш код.
Я бы посоветовал вам запустить этот код самостоятельно и играть как с инструментом SpeedScope, так и с выходом SVG, но вот два снимка экрана, которые помогают объяснить, как он работает. Это первое представление – общий выход SVG. Если вы будете зависать над ячейками, это покажет вам детали функции. Вы можете видеть, что большую часть времени проводится в клиенте WebSocket _Listen метод Но on_message Метод отображается справа от этого (обозначается стрелкой)
py-spy svg вывод
Если мы нажмем на него, мы получим подробный вид.
Py-Spy Svg Подробный выход
В моем случае я вижу, что мой список понимания и регистрация в нединешнем _VWAP Метод появляется довольно высоко в профиле. Я могу легко удалить этот метод (и дополнительные цены и объемы, которые я отслеживал), так как VWAP можно рассчитать только с помощью работающего продукта и общего объема (как я уже делаю в коде). Также интересно посмотреть, когда сценарий запускается в режиме отладки, сколько времени в журнале регистрации принимает
Также интересно посмотреть, когда сценарий запускается в режиме отладки, сколько времени в журнале регистрации принимает
Резюме
Таким образом, я бы посоветовал вам попробовать Py-Spy на некоторых из вашего кода. Если вы попытаетесь предсказать, где ваш код будет тратить свое время, насколько вы верны? Есть ли вы выводы, которые вас удивляют? Возможно, сравните вывод PY-Spy с детерминированным профилировщиком, таким как LINE_PROFILER.
Я надеюсь, что этот обзор Py-Spy был полезен, и вы можете развернуть этот инструмент в диагностике проблем с производительностью в своем собственном коде.
Пост Профилирование кода Python с py-spy появился первым на wrighters.io Анкет
Оригинал: “https://dev.to/wrighter/profiling-python-code-with-py-spy-17oj”
Все о профилировании кода | Как правильно выбрать инструмент
Создание приложения, его тестирование и запуск в производство — это только полдела. Настоящее испытание — это когда пользователи испытывают приложение.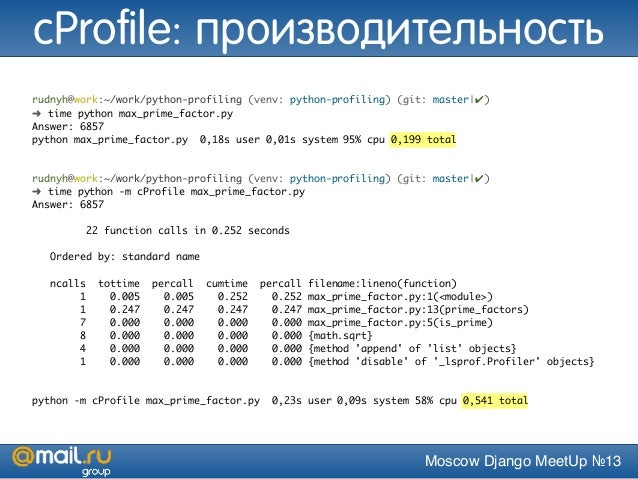 Ваше приложение может быть очень сложным и непревзойденным по своим возможностям, но если выполнение следующего желаемого действия займет на пару секунд больше, ваши пользователи могут уйти.
Ваше приложение может быть очень сложным и непревзойденным по своим возможностям, но если выполнение следующего желаемого действия займет на пару секунд больше, ваши пользователи могут уйти.
Непрерывно отслеживайте цифровой опыт по различным каналам доставки на реальных устройствах. Узнать больше .
Производительность приложения зависит от того, насколько эффективен его код. Быстрый, чистый код, свободный от ненужных циклов или регрессий, делает приложение гораздо более отзывчивым и надежным. Здесь помогает код профилирования.
Что такое профилирование кода?
Профилирование кода проверяет код приложения, чтобы убедиться, что он оптимизирован, что приводит к высокой производительности приложения. Он анализирует память, ЦП и сеть, используемые каждым программным компонентом или подпрограммой.
Путем профилирования кода разработчики, тестировщики и инженеры по обеспечению качества могут определить, потребляет ли какая-либо процедура непропорциональный объем памяти или ресурсов ЦП, и оптимизировать ее для повышения производительности.
Какие преимущества дает профилирование кода разработчикам и инженерам по контролю качества?
Давайте разберемся, какую пользу могут извлечь разработчики и тестировщики из профилирования кода.
Сокращает циклы разработки программного обеспечения и делает его более гибким.
Разработчики могут постепенно улучшать код, профилируя его на каждом этапе разработки. Таким образом, им не нужно выполнять какой-либо значительный рефакторинг кода позже в процессе разработки, который требует много времени и усилий.
Читайте также: Рекомендации по тестированию производительности приложений
Обеспечивает надежную работу приложения при любых обстоятельствах.
Оптимизация кода имеет основополагающее значение для достижения высокой производительности приложений. Когда его код профилирован и оптимизирован, приложение может работать хорошо независимо от внешних факторов, таких как внезапные скачки трафика.
Выдача: Показатели тестирования производительности на стороне клиента, которые следует учитывать
Улучшает работу конечного пользователя, позволяя разработчикам исправлять аномалии в режиме реального времени.
Часто приложение может пройти все тесты и проверки качества в промежуточной среде, но по-прежнему создает проблемы для конечных пользователей во время выполнения. Профилирование кода позволяет разработчикам выявлять и устранять такие проблемы «на лету», обеспечивая максимальное удобство работы с приложениями для клиентов.
Типы профилирования кода
Существует два метода профилирования кода — выборка и инструментирование.
Профилировщик выборки
Профилировщик выборки работает, анализируя, какая инструкция сборки выполняется в данный момент и какие подпрограммы вызывают текущую функцию для профилируемого приложения.
Идентифицирует выполняющуюся в данный момент команду, определяя, когда операционная система прерывает ЦП для выполнения переключений процесса. Затем он использует символы отладки, связанные с исполняемым файлом приложения, для сопоставления точек реализации, записанных с соответствующей подпрограммой и строкой исходного кода.
Затем он использует символы отладки, связанные с исполняемым файлом приложения, для сопоставления точек реализации, записанных с соответствующей подпрограммой и строкой исходного кода.
Выходные данные профилировщика выборки — это количество раз, когда подпрограмма или строка исходного кода выполняется во время выполнения приложения. С помощью профилировщика кода выборки разработчики могут определить, является ли подпрограмма слишком большой, что является потенциальным узким местом в производительности, и оптимизировать ее, чтобы завершить выполнение быстрее.
Преимущества
Профили выборки проверяют только частоту обычных вызовов и, следовательно, не мешают приложению во время выполнения и не влияют на его производительность. Он также никоим образом не изменяет исходный код, избегая возможного повреждения.
Недостатки
Результаты, полученные профилировщиками выборки, являются приблизительными и неточными, поскольку они профилируют код только посредством обращений к ЦП.
Например, небольшая подпрограмма может вызываться несколько раз во время профилирования и каждый раз завершать выполнение в пределах интервалов выборки. Профилировщик выборки сочтет это большой процедурой и пометит как узкое место, если это не реально.
Инструментальный профилировщик
Инструментальный профилировщик работает путем вставки кода в начале и в конце подпрограммы. Он определяет важные контрольные точки и вставляет в них код для записи рутинных последовательностей, времени или даже переменного содержимого.
Существует два типа инструментальных профилировщиков — профилировщик, изменяющий исходный код, и бинарный профайлер.
Профилировщик, изменяющий исходный код:Эти профилировщики вставляют инструментальный код в исходный код в начале и в конце подпрограммы.
Двоичный профилировщик: Они работают во время выполнения, вставляя инструментальный код в исполняемый код приложения. Это не касается исходного кода.
Это не касается исходного кода.
Преимущества
Поскольку они работают путем перекомпиляции фактической программы, профилировщики инструментов могут записывать точное время выполнения подпрограммы для каждого вызова.
Инструментальные профилировщики предлагают точные данные с гораздо большей детализацией. Они могут предоставить информацию о последовательности подпрограмм и других подпрограмм, вызываемых из записанной.
Недостатки
Инструментальные профилировщики работают, изменяя исходный код, поэтому высока вероятность его повреждения.
Поскольку они вставляют дополнительный код в исходный код (или в исполняемый код в случае бинарных профилировщиков), они добавляют значительные накладные расходы во время выполнения и снижают производительность приложения.
Рекомендуемая публикация : Тестирование производительности на стороне клиента: метрики для рассмотрения
Несколько различных профилировщиков кода и то, что они измеряют: сбор мусора и сохранение памяти.

Выбор профилировщика кода, который наилучшим образом соответствует вашим потребностям
В идеале это поможет выбрать профилировщик кода, который позволит вам измерять то, что вы хотите, не навязчивый и экономичный.
Этот аспект может показаться невозможным из того, что мы обсуждали выше — выбор одного профилировщика кода над другим может показаться компромиссом между скоростью и точностью, неинвазивностью и глубиной данных.
Однако это не так. Некоторые решения предлагают вам лучшее из обоих миров, то есть точные, подробные данные с минимальным вмешательством и без влияния на производительность приложений.
Рекомендуемое сообщение : Бесплатные инструменты для тестирования производительности мобильных приложений с Appium
Тем не менее, вот еще несколько вещей, которые вам нужно искать в профилировщике кода:
3
40 Различные performance metrics:
Профилировщик кода должен позволять разработчикам профилировать свой код по различным метрикам, таким как использование памяти и ОС, время выполнения и общая производительность приложения.
Простота
из использование: Профиль не должен быть сложным. Он должен быть интуитивно понятным, простым и включать минимальную настройку. Разработчики используют инструменты профилирования кода для повышения производительности приложений, поэтому усложнение кода приложения не принесет пользы.
Он должен быть интуитивно понятным, простым и включать минимальную настройку. Разработчики используют инструменты профилирования кода для повышения производительности приложений, поэтому усложнение кода приложения не принесет пользы.
1. Какие существуют методы профилирования распределения памяти и уровней?Ответ: Профилирование памяти: Профилирование памяти позволяет тестировщикам понять распределение памяти и поведение сборки мусора в приложениях с течением времени.
Профилирование распределения уровней: Это метод сбора статистики о синхронных вызовах функций базы данных SQL-сервера.
2. Что такое профилирование API?Ответ: API профилирования — это инструмент, используемый для написания профилировщика кода, программы, которая отслеживает выполнение управляемого приложения.
3. Что вы подразумеваете под пассивным профайлером?
Что вы подразумеваете под пассивным профайлером? Ответ: Пассивный профилировщик собирает информацию о выполнении приложения без изменения этого приложения. Пассивные профилировщики остаются вне приложения и наблюдают за его работой на расстоянии.
4. Что такое профилирование на основе событий? Ответ: Профилирование на основе событий (EBP) использует счетчики событий производительности оборудования для подсчета количества определенных типов событий, происходящих во время выполнения. Примерами событий являются тактовые циклы процессора, устаревшие инструкции, доступ к кэшу данных и промахи в кэше данных.
Что такое профилирование кода? Изучите 3 типа профилировщиков кода
Александра Альтватер Советы, рекомендации и ресурсы для разработчиков
В Stackify мы стремимся помочь вам повысить производительность вашего приложения. На самом деле мы сами разработали два профилировщика кода. Из-за этого нам нравится думать, что мы кое-что знаем о профилировании кода.
На самом деле мы сами разработали два профилировщика кода. Из-за этого нам нравится думать, что мы кое-что знаем о профилировании кода.
Сегодня я хочу поговорить о трех различных типах профилировщиков кода, описать различия между ними и порекомендовать некоторые инструменты для вашего набора инструментов.
Итак, что именно делает профилирование кода?
Обычно профилировщики кода используются разработчиками для выявления проблем с производительностью, не затрагивая их код. Профилировщики могут ответить на такие вопросы, как «Сколько раз вызывается каждый метод в моем коде?» и «Сколько времени занимает каждый из этих методов?» Профилировщики также отслеживают такие вещи, как выделение памяти и сборка мусора. Некоторые профилировщики могут даже отслеживать ключевые методы в вашем коде, чтобы вы могли понять, как часто вызываются операторы SQL и веб-службы. Кроме того, некоторые профилировщики могут отслеживать веб-запросы и обучать эти транзакции, чтобы понять производительность транзакций в вашем коде.
Профилировщики кода могут отслеживать все до каждой отдельной строки кода. Однако большинство разработчиков используют профилировщики только при поиске проблем с ЦП или памятью, и им нужно приложить все усилия, чтобы попытаться найти эти проблемы. Это связано с тем, что многие профилировщики заставляют приложения работать в сто раз медленнее, чем обычно. Хотя большинство считает профилировщики ситуационным инструментом, не предназначенным для повседневного использования, профилирование кода может стать настоящим спасением, когда вам это нужно.
Профилировщики отлично подходят для поиска горячих путей в вашем коде. Выяснение того, что использует двадцать процентов общего использования ЦП вашего кода, а затем определение того, как это улучшить, было бы отличным примером того, когда следует использовать профилировщик кода. Кроме того, профилировщики также отлично подходят для раннего обнаружения утечек памяти, а также для понимания производительности вызовов зависимостей и транзакций. Профилировщики помогают вам искать методы, которые со временем могут привести к улучшению. Один бывший наставник однажды сказал мне: «Если ты можешь улучшать что-то на один процент каждый день, то в течение месяца ты улучшишься на тридцать процентов». Что действительно имеет значение, так это постоянное улучшение с течением времени.
Профилировщики помогают вам искать методы, которые со временем могут привести к улучшению. Один бывший наставник однажды сказал мне: «Если ты можешь улучшать что-то на один процент каждый день, то в течение месяца ты улучшишься на тридцать процентов». Что действительно имеет значение, так это постоянное улучшение с течением времени.
Типы профилировщиков кода
Существует два разных типа профилировщиков кода: серверные и настольные. Профилировщик на стороне сервера отслеживает производительность ключевых методов в предпроизводственной или производственной среде. Эти профилировщики измеряют время транзакций, например, отслеживают, сколько времени занимает веб-запрос, а также дают вам больше информации об ошибках и журналах. Примером профилировщика на стороне сервера может быть инструмент управления производительностью приложений, или сокращенно APM.
Профилирование кода рабочего стола выполняется медленнее и требует больших накладных расходов, что может сделать ваше приложение намного медленнее, чем должно быть. Этот тип профилировщика обычно отслеживает производительность каждой строки кода в каждом отдельном методе. Эти типы профилировщиков также отслеживают выделение памяти и сборку мусора, чтобы помочь с утечками памяти. профилировщики настольных компьютеров очень хорошо находят этот горячий путь, выясняя каждый метод, который вызывается, и определяя, какой из них использует больше всего ЦП.
Этот тип профилировщика обычно отслеживает производительность каждой строки кода в каждом отдельном методе. Эти типы профилировщиков также отслеживают выделение памяти и сборку мусора, чтобы помочь с утечками памяти. профилировщики настольных компьютеров очень хорошо находят этот горячий путь, выясняя каждый метод, который вызывается, и определяя, какой из них использует больше всего ЦП.
Но есть и другое решение. Для простоты назовем его гибридным профилировщиком.
Эти гибридные профилировщики кода объединяют ключевые данные из серверного профилирования с деталями на уровне кода на вашем рабочем столе для ежедневного использования. Эти профилировщики предоставляют информацию на уровне сервера в сочетании с возможностью отслеживать ключевые методы, каждую транзакцию, вызовы зависимостей, ошибки и журналы.
Инструменты, соответствующие этим трем различным типам профилировщиков
Для профилирования кода на стороне сервера большинство компаний используют APM. В Stackify мы разработали продукт под названием Retrace.
В Stackify мы разработали продукт под названием Retrace.
Некоторые варианты профилировщиков кода для настольных компьютеров включают Visual Studio, NProfiler и другие.
Настоящих гибридных решений для профилирования кода очень мало. Среди них наш собственный гибридный профилировщик, который мы называем Prefix, который можно использовать бесплатно.
При сравнении серверных и гибридных профилировщиков кода имейте в виду несколько вещей. Многие профилировщики должны быть встроены в сам код. Это то, что заставляет большинство профилировщиков замедлять работу приложений, а также поэтому они, как правило, используются в определенных обстоятельствах.
Очень немногие профилировщики, такие как Prefix, способны собирать данные извне.
Немногие APM можно установить на ваш сервер без каких-либо изменений в коде. Большинство APM требуют изменения кода и/или нескольких изменений конфигурации.
- Об авторе
- Последние посты
О Александре Альтватер
- Top .
 net Developer Skills Согласно Tech Leaders и Experts. , исправления и многое другое — 3 сентября 2021 г.
net Developer Skills Согласно Tech Leaders и Experts. , исправления и многое другое — 3 сентября 2021 г. - Что такое нагрузочное тестирование? Как это работает, инструменты, учебные пособия и многое другое — 5 февраля 2021 г.
- Americaneagle.com и ROC Commerce остаются впереди благодаря Retrace — 25 сентября 2020 г.
- Новые цены Stackify: все, что вам нужно знать — 9 сентября 2020 г.
Что такое профилирование кода? – Подробное объяснение
Несколько строк кода, независимо от того, насколько велика ваша команда разработчиков, работают с максимальной производительностью, когда они изначально разработаны. Чтобы найти наиболее эффективный метод ускорения работы кода, его необходимо оценить, отладить и просмотреть.
Как инженеры-программисты и инженеры по обеспечению качества могут гарантировать, что их код будет быстрым, эффективным и, в конечном счете, ценным?
Подход заключается в оценке кода приложения, обнаружении и устранении узких мест производительности с помощью профилирования кода.
Мы покроем следующее:
- Что такое профилирование?
- Методы сбора профилирования
- Как работает профилирование?
- Что именно делает профилирование кода?
- Типы профилирования кода
- Почему следует использовать инструмент профилирования?
- Проблемы профилирования
- Зачем нам нужен инструмент профилирования?
Что такое профилирование?
Профилирование — это процесс сбора параметров программы во время ее работы. При профилировании измеряется продолжительность выполнения и количество вызовов конкретных функций и строк программного кода. Программист может использовать этот инструмент для поиска и оптимизации самых медленных частей кода.
Многие программы, особенно индикаторы, производят расчеты только при появлении нового тика. В результате вы должны ждать новых тиков в режиме реального времени, чтобы оценить производительность. Обеспечить соответствующую нагрузку и оценить работу программы можно даже в выходные дни, когда рынки закрыты, при профилировании по историческим данным.
В результате вы должны ждать новых тиков в режиме реального времени, чтобы оценить производительность. Обеспечить соответствующую нагрузку и оценить работу программы можно даже в выходные дни, когда рынки закрыты, при профилировании по историческим данным.
Методы сбора данных о профилировании
Производительность приложения можно измерить различными способами. Результаты профилировщика будут различаться в зависимости от используемого метода сбора.
На высоком уровне профилирование в Visual Studio можно разделить на следующие методы сбора:
- Инструментирование
Подход с инструментальным профилированием собирает обширную информацию о работе приложения во время выполнения профилирования. Это достигается путем внедрения кода в начале и в конце каждой подпрограммы, чтобы отслеживать, когда подпрограмма начинается и заканчивается. Когда функция, например запись в файл, вызывает операционную систему, этот метод также может ее обнаружить.
- Выборка
Во время выполнения профилирования метод выборочного профилирования собирает статистические данные о работе, которую выполняет приложение. Он работает, собирая данные о приложении через регулярные промежутки времени или частоту выборки, а затем анализируя данные для разработки модели того, сколько времени было потрачено в приложении. - Параллелизм
Многопоточные приложения профилируются с использованием метода профилирования параллелизма. Когда конкурирующие потоки в приложении вынуждены ждать доступа к общему ресурсу, , например , он собирает обширную информацию о стеке вызовов. - Память
Профилирование памяти собирает подробную информацию о распределении памяти и сборе мусора. Он собирает данные о типе, размере и количестве объектов, созданных при распределении или уничтоженных во время сборки мусора, например . - Tier Allocation
Метод профилирования Tier Allocation собирает статистику о синхронных вызовах функций базы данных SQL Server. Эта информация профилирования может быть объединена с информацией, собранной с помощью подходов инструментирования, выборки, параллелизма или памяти.
Эта информация профилирования может быть объединена с информацией, собранной с помощью подходов инструментирования, выборки, параллелизма или памяти.
Как работает профилирование?
Для профилирования используется подход «Выборка». Профилировщик замораживает MQL-программу (1000 раз в секунду) и записывает, сколько раз пауза возникает в каждой области кода. Это включает просмотр стеков вызовов, чтобы увидеть, какой вклад каждая функция вносит в общее время выполнения кода.
Вы получите информацию о том, сколько раз выполнение было прервано и сколько раз каждая из функций встречалась в стеке вызовов в конце профилирования:
- Total CPU [unit, %]
Количество вызовов функции в стеке вызовов. - Self-CPU [единица измерения, %]
Общее количество «пауз», произошедших в рамках предоставленной функции. Эта переменная имеет решающее значение для поиска узких мест: статистика показывает, что паузы возникают чаще, когда требуется больше процессорного времени.
(Примечание. Выборка — это простой и точный подход. В отличие от других подходов, выборка не вносит никаких изменений в изучаемый код, что может замедлить его работу.)
Что именно делает профилирование кода?
Разработчики обычно используют профилировщики кода для выявления проблем с производительностью, не затрагивая свой код.
Вот вопросы, на которые могут ответить профилировщики:
- Сколько раз вызывается каждая функция в моем коде?
- Сколько времени занимает каждая из этих процедур?
- Сколько времени занимает каждый из этих подходов?
Выделение памяти и сбор мусора также отслеживаются профилировщиками.
Некоторые профилировщики могут даже отслеживать критические методы в вашем коде, позволяя вам видеть, как часто используются операторы SQL и веб-службы. Кроме того, некоторые профилировщики могут отслеживать веб-запросы и обучать эти транзакции, чтобы лучше понять производительность транзакций в вашем коде.
Профилировщики кода могут пройти весь путь до одной строки кода. С другой стороны, большинство разработчиков используют профилировщики только тогда, когда они ищут проблемы с ЦП или памятью, и им приходится изо всех сил стараться найти их.
Это связано с тем, что многие профилировщики заставляют приложения работать в сто раз медленнее, чем в противном случае. Хотя большинство людей считают профилировщики ситуационным инструментом, который не предназначен для ежедневного использования, когда он вам нужен, профилирование кода может спасти вам жизнь.
Профилировщики отлично подходят для определения горячего маршрута кода. Хороший пример того, когда использовать профилировщик кода, — выяснить, что использует 20% общего потребления ЦП вашего кода, а затем выяснить, как это улучшить.
Профилировщики также полезны для раннего обнаружения утечек памяти и анализа скорости зависимых вызовов и транзакций. Профилировщики помогают вам определить стратегии, которые могут привести к долгосрочному прогрессу.
Типы профилирования кода
Профилировщики кода делятся на три типа:
#1 Серверные профилировщики
В предварительных или производственных средах профилировщик на стороне сервера отслеживает производительность ключевых методов. Эти профилировщики отслеживают время транзакции, например, сколько времени требуется для выполнения веб-запроса, сколько времени занимает запрос, а также обеспечивают улучшенную видимость ошибок и журналов. Инструмент управления производительностью приложений, или сокращенно APM, является примером профилировщика на стороне сервера.
#2 Профилировщики рабочих столов
Эти профилировщики работают медленно и имеют много накладных расходов, из-за чего ваше программное обеспечение работает намного медленнее, чем должно. Этот тип профилировщика часто отслеживает производительность каждой строки кода в каждой процедуре.
Выделение памяти и сбор мусора также отслеживаются этими профилировщиками, чтобы помочь с утечками памяти. Профилировщики рабочего стола превосходно находят горячие пути, определяют, какие методы вызываются, и определяют, какие процессы используют больше всего ресурсов ЦП.
Профилировщики рабочего стола превосходно находят горячие пути, определяют, какие методы вызываются, и определяют, какие процессы используют больше всего ресурсов ЦП.
#3 Гибридные профилировщики
Эти профилировщики объединяют важную статистику профилирования на сервере с данными на уровне кода на вашем рабочем столе для ежедневного использования. Эти профилировщики предоставляют вам информацию на уровне сервера, а также возможность отслеживать важные методы, транзакции, вызовы зависимостей, ошибки и журналы.
Зачем использовать инструмент профилирования?
Существует ряд причин для использования инструмента профилирования. Возможно, вы входите в число 81% компаний, опрошенных Digital Focus, которые используют (или планируют использовать) гибкий процесс разработки программного обеспечения.
Короткие циклы разработки, обычно длящиеся от двух до восьми недель, являются одним из определяющих качеств гибкой разработки. Эти короткие циклы дают ограниченное пространство для реструктуризации кода или повышения производительности. В результате программисты должны убедиться, что код работает эффективно с самого начала проекта.
В результате программисты должны убедиться, что код работает эффективно с самого начала проекта.
Возможно, вы также пытаетесь не отставать от сокращающейся концентрации внимания ваших клиентов. По данным Business Week за 19 лет, пользователи могут ждать загрузки веб-сайта до 8 секунд.99.
К 2006 году Akamai обнаружил, что серферы ждали всего 4 секунды. По данным Akamai, более трети онлайн-покупателей, у которых был плохой опыт, полностью покинули сайт, а 75% заявили, что вряд ли будут делать там покупки снова. Такая негативная реклама недоступна для любого бизнеса.
Возможно, вы столкнулись с ростом клиентского трафика и вам нужно убедиться, что ваша система сможет с этим справиться. Например, , в период с 2005 по 2006 год продажи на Amazon выросли на 26%. Такое увеличение демонстрирует, насколько важна оптимизация в повседневных операциях успешных онлайн-продавцов.
Когда один пользователь выполняет функцию или подпрограмму, он может быстро ответить, но что происходит, когда ее одновременно выполняют сотни или даже тысячи пользователей?
Даже для огромных приложений код, который не был оптимизирован, может быстро превратиться в кошмар производительности, когда он подвергается нагрузке.
Проблемы профилирования
Несмотря на преимущества инструментов профилирования, программисты не решаются их использовать. Они утверждают, что традиционные профилировщики навязчивы и сложны в использовании. В некоторых случаях программисты обнаружили, что некоторые профилировщики влияли на данные о производительности, увеличивая нагрузку на выполнение приложения. Вместо того, чтобы решить проблему, профайлеры ее усугубили.
Low Impact
Однако недавно начало появляться новое поколение технологий профилирования. Это поколение профилировщиков позволяет избежать многих недостатков, присущих предыдущим поколениям, и фактически ускоряет процесс оптимизации.
Идеальный инструмент для профилирования органично вписывается в ваш процесс разработки и позволяет измерять производительность вашего кода с точностью и достоверностью.
Простота использования
Разработчики должны выбрать подходящий профилировщик для быстрой и простой диагностики проблем с производительностью приложений в своем коде. Если пользователю нужен длинный список команд для выполнения простой задачи, он пойдет в другое место за более простым решением. У разработчиков также нет времени на настройку чрезмерно сложных инструментов из-за растущих требований к созданию высокопроизводительных приложений за меньшее время.
Если пользователю нужен длинный список команд для выполнения простой задачи, он пойдет в другое место за более простым решением. У разработчиков также нет времени на настройку чрезмерно сложных инструментов из-за растущих требований к созданию высокопроизводительных приложений за меньшее время.
Профилировщик должен помочь ускорить процесс разработки программного обеспечения, а не замедлить его еще больше. Такой инструмент должен иметь короткую кривую обучения и позволять разработчикам сразу же начать его использовать.
Множественные измерения
Идеальный профилировщик позволит разработчику профилировать свой код несколькими способами. С таким разнообразным инструментом профилирования разработчик может быть уверен, что его код хорошо работает в различных областях, таких как выделение памяти, использование ресурсов операционной системы и общая производительность приложения. Переключение между этими различными измерениями также должно быть быстрым, простым и понятным, чтобы у инженеров было достаточно времени для их выполнения.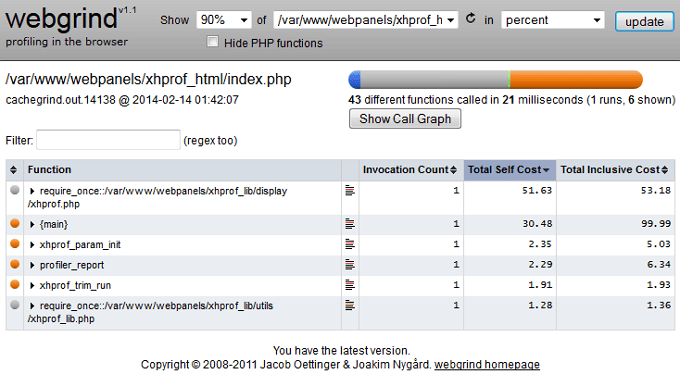
Подробная отчетность
Знания специалиста по профилированию бесполезны, если он не может описать их подробно и легко для понимания. Данные от профилировщика, будь то HTML-страницы или документы Microsoft Word, должны быть простыми для понимания. Кроме того, система отчетности должна быть надежной, предоставляя всю необходимую разработчику информацию, оставаясь при этом достаточно гибкой, чтобы можно было фильтровать данные для отображения только релевантной информации.
Зачем нам инструмент профилирования?
Оптимизация кода затруднена; это требует усилий, размышлений и исследований со стороны разработчиков. Без нужных инструментов программисты вынуждены прибегать к более медленным и менее эффективным методам оптимизации своих приложений.
Некоторые разработчики выполняют «предварительную оптимизацию», при которой они предсказывают, где могут возникнуть проблемы с производительностью, и изменяют свой код, чтобы устранить их до того, как они возникнут. Этот метод проблематичен, потому что разработчик часто неточно оценивает возможное узкое место.
Этот метод проблематичен, потому что разработчик часто неточно оценивает возможное узкое место.
Они могут просматривать только свой собственный код, а не всю кодовую базу, и поэтому упускают из виду проблемы интеграции. Им может не хватать понимания ожидаемого поведения их целевых пользователей, или они могут сосредоточиться на редко используемом участке кода.
Несмотря на благие намерения, этот подход часто не позволяет выявить фактические узкие места в производительности. Слепая оптимизация теряет время без инструмента профилирования, помогающего найти узкие места, как показано на диаграмме ниже.
Также ужасная идея отказаться от оптимизации кода. Ни один конечный пользователь не захочет регулярно использовать медленное приложение. Они начнут искать альтернативное приложение, если будут достаточно разочарованы.
Недовольные клиенты часто выражают свое недовольство в блогах и других форумах, отталкивая потенциальных клиентов от продуктов одной компании к продуктам другой. Такой ущерб репутации компании может быть необратимым и стоить организации упущенной выгоды в десятки тысяч долларов.
Такой ущерб репутации компании может быть необратимым и стоить организации упущенной выгоды в десятки тысяч долларов.
«Если вы будете улучшаться на один процент каждый день, в течение месяца вы улучшитесь на тридцать процентов», однажды сказал мне один из предыдущих наставников. Непрерывное улучшение с течением времени — вот что на самом деле имеет значение.
Успех компании-разработчика программного обеспечения зависит от производительности ее приложений. Клиенты воспринимают приложение как отзывчивое и надежное, когда код выполняется быстро и эффективно; они видят в этом возможность сэкономить время.
Клиенты, с другой стороны, совершенно по-другому реагируют, когда код зацикливается, вызывает ненужные функции или иным образом спотыкается сам о себя. Приложение может показаться им медленным или не отвечающим, и они посчитают его использование пустой тратой времени. Если не остановить это, это приведет к недовольству пользователей, запятнанной корпоративной репутации и потере миллионов долларов дохода.
Профилирование кода — это мощный инструмент для определения того, где компонент, метод или строка кода потребляют больше всего ресурсов, таких как ЦП и память. Это позволяет разработчикам понять поведение профилированного приложения во время выполнения и предоставить практические рекомендации по повышению производительности.
Контролируйте все свое приложение с помощью Ататус
Atatus — это полнофункциональная платформа наблюдения, которая позволяет вам просматривать проблемы так, как если бы они возникли в вашем приложении. Вместо того, чтобы гадать, почему возникают ошибки, или запрашивать у пользователей скриншоты и дампы журналов, Atatus позволяет воспроизвести сеанс, чтобы быстро понять, что пошло не так.
Мы предлагаем мониторинг производительности приложений, мониторинг реальных пользователей, мониторинг серверов, мониторинг журналов, синтетический мониторинг, мониторинг работоспособности и аналитику API. Он отлично работает с любым приложением, независимо от фреймворка, и имеет плагины.
Он отлично работает с любым приложением, независимо от фреймворка, и имеет плагины.
Ататус может быть полезным для вашего бизнеса, поскольку обеспечивает комплексное представление о вашем приложении, в том числе о том, как оно работает, где существуют узкие места в производительности, какие пользователи больше всего страдают и какие ошибки нарушают ваш код для вашего внешнего интерфейса, внутреннего интерфейса и инфраструктуры.
Если вы еще не являетесь клиентом Atatus, вы можете зарегистрируйтесь на 14-дневную бесплатную пробную версию .
Как выбрать инструмент для профилирования кода
Независимо от того, насколько талантлива ваша команда разработчиков, очень немногие строки кода работают с максимальной производительностью, когда они впервые написаны. Код необходимо анализировать, отлаживать и проверять, чтобы определить наиболее эффективный способ ускорить его работу. Как разработчики программного обеспечения и инженеры по качеству могут гарантировать, что их код будет быстрым, эффективным и, в конечном итоге, ценным? Решение заключается в использовании инструмента профилирования для изучения кода приложения, обнаружения и устранения узких мест в производительности. Эти инструменты могут быстро диагностировать, как работает приложение, и позволяют программистам выявить области низкой производительности. Результатом является оптимизированная кодовая база, которая работает в соответствии с ожиданиями клиентов или превосходит их.
Эти инструменты могут быстро диагностировать, как работает приложение, и позволяют программистам выявить области низкой производительности. Результатом является оптимизированная кодовая база, которая работает в соответствии с ожиданиями клиентов или превосходит их.
Зачем вам иметь инструмент профилирования?
Существует множество причин инвестировать в инструмент профилирования. Возможно, вы входите в число 81 % компаний, опрошенных Digital Focus, которые используют (или планируют использовать) гибкий процесс разработки программного обеспечения1. Одной из отличительных черт гибкой разработки являются короткие циклы разработки, которые обычно составляют от двух до восьми недель3. Эти короткие циклы практически не оставляют места для рефакторинга кода или настройки производительности. Таким образом, программисты должны убедиться, что код работает эффективно с самого начала проекта.
Возможно, вы также пытаетесь идти в ногу с быстро уменьшающейся концентрацией внимания ваших конечных пользователей. В 1999 году Business Week сообщил, что посетители будут ждать загрузки веб-сайта до 8 секунд3. К 2006 году Akamai обнаружил, что серферы будут ждать всего 4 секунды. Akamai также обнаружил, что более трети онлайн-покупателей с плохим опытом полностью покинули сайт, а 75%, вероятно, больше не будут совершать покупки на этом сайте4. Ни одна компания не может позволить себе такое негативное внимание.
В 1999 году Business Week сообщил, что посетители будут ждать загрузки веб-сайта до 8 секунд3. К 2006 году Akamai обнаружил, что серферы будут ждать всего 4 секунды. Akamai также обнаружил, что более трети онлайн-покупателей с плохим опытом полностью покинули сайт, а 75%, вероятно, больше не будут совершать покупки на этом сайте4. Ни одна компания не может позволить себе такое негативное внимание.
Или, возможно, у вас большое количество клиентов, и вам нужно убедиться, что вы можете справиться с возросшим трафиком. Продажи Amazon.com, например, выросли на 26% в период с 2005 по 2006 год. Столь резкое увеличение показывает, насколько успешные интернет-магазины нуждаются в оптимизации своих повседневных операций. Функция или подпрограмма могут быстро реагировать, когда ее выполняет один пользователь, но что происходит, когда ее одновременно выполняют сотни или даже тысячи пользователей? Код, который не был оптимизирован, может быстро превратиться в кошмар производительности, когда он подвергается нагрузке, даже для больших приложений.
Или, возможно, у вас большой поток клиентов, и вам нужно убедиться, что вы можете справиться с возросшим трафиком. Продажи Amazon.com, например, выросли на 26% в период с 2005 по 2006 год5. Столь резкое увеличение показывает, насколько успешные интернет-магазины нуждаются в оптимизации своих повседневных операций. Функция или подпрограмма могут быстро реагировать, когда ее выполняет один пользователь, но что происходит, когда ее одновременно выполняют сотни или даже тысячи пользователей? Код, который не был оптимизирован, может быстро превратиться в кошмар производительности, когда он подвергается нагрузке.
Рис. 1. Слепая оптимизация — пустая трата времени
Жизнь без инструмента профилирования
Оптимизация кода — сложная задача; это требует времени, размышлений и исследований со стороны разработчиков. Без надлежащих инструментов программистам приходится прибегать к более медленным и менее эффективным способам оптимизации своих приложений. Некоторые разработчики занимаются «предварительной оптимизацией» кода; они угадывают, где могут возникнуть проблемы с производительностью, и реорганизуют свой код, пытаясь устранить проблемы до их появления. Этот подход проблематичен, потому что разработчик часто неправильно диагностирует потенциальное узкое место. Она может смотреть только на свой собственный код, а не на полную кодовую базу, таким образом пропуская проблемы с интеграцией. Он может не иметь представления об ожидаемом поведении своих целевых пользователей или может сосредоточиться на области кода, которая редко используется.
Этот подход проблематичен, потому что разработчик часто неправильно диагностирует потенциальное узкое место. Она может смотреть только на свой собственный код, а не на полную кодовую базу, таким образом пропуская проблемы с интеграцией. Он может не иметь представления об ожидаемом поведении своих целевых пользователей или может сосредоточиться на области кода, которая редко используется.
Несмотря на то, что этот подход имел хорошие намерения, он, как правило, не позволяет найти какие-либо узкие места в производительности. Без инструмента профилирования, помогающего найти узкие места, слепая оптимизация только тратит время, как показано на рисунке ниже.
Просто отказаться от оптимизации кода — тоже плохая идея. Ни один конечный пользователь не захочет делать медленное приложение частью своей повседневной жизни. Если они достаточно разочаруются, они начнут искать альтернативное приложение. Недовольные пользователи часто высказывают свое мнение в блогах и других форумах, отвлекая потенциальных клиентов от продуктов одной компании к продуктам другой. Такой ущерб репутации компании может быть непоправимым и может стоить компании бесчисленных долларов упущенной выгоды.
Такой ущерб репутации компании может быть непоправимым и может стоить компании бесчисленных долларов упущенной выгоды.
Проблемы использования Profiler
Несмотря на явные преимущества, программисты не спешили внедрять инструменты профилирования. Они жалуются, что традиционные профилировщики агрессивны и сложны в использовании. В некоторых случаях программисты обнаруживали, что некоторые профилировщики так сильно увеличивали нагрузку на выполнение приложения, что данные о производительности искажались. Эти профилировщики на самом деле внесли свой вклад в проблему, а не решили ее.
Низкоэффективное интегрированное средство профилирования
Однако недавно появилось новое поколение инструментов профилирования. Это последнее поколение профилировщиков не подвержено многим ограничениям своих предшественников и действительно ускоряет процесс оптимизации.
Идеальный инструмент профилирования плавно интегрируется в ваш процесс разработки и позволяет точно и точно измерять производительность вашего кода.
Профилирование с минимальным воздействием
Важно выбрать максимально неинвазивный профилировщик. Некоторые инструменты профилирования сильно вторгаются в код приложения; на самом деле они могут потребовать модификации кода, чтобы профилировщик мог выполнять точные измерения. Поскольку это может привести к сотням или тысячам изменений в коде, это должно быть сделано с помощью автоматизированного инструмента модификации исходного кода. Как только это происходит, разработчик больше не может контролировать свой код. Когда это происходит, многие люди склонны задаваться вопросом, может ли сам инструмент профилирования создавать проблемы в приложении.
Выбранный вами профилировщик не должен требовать каких-либо изменений в исходном коде и не должен вводить столько накладных расходов, которые влияют на время отклика приложения.
Простота использования
Разработчики должны выбрать профилировщик, который позволит им быстро и легко диагностировать проблемы производительности в своем коде. Если пользователю нужен сложный набор команд для выполнения простого действия, он будет искать в другом месте, чтобы увидеть, существует ли более простое решение. Кроме того, из-за возросшего спроса на создание высокопроизводительных приложений за меньшее время у разработчиков нет времени на настройку слишком сложных инструментов.
Если пользователю нужен сложный набор команд для выполнения простого действия, он будет искать в другом месте, чтобы увидеть, существует ли более простое решение. Кроме того, из-за возросшего спроса на создание высокопроизводительных приложений за меньшее время у разработчиков нет времени на настройку слишком сложных инструментов.
Профилировщик предназначен для ускорения жизненного цикла программного обеспечения, а не для дальнейшего его усложнения. Такой инструмент должен иметь минимальную кривую обучения и позволять разработчикам сразу же начать его использовать.
Множественные измерения
Идеальный профилировщик позволит разработчику профилировать свой код несколькими различными способами. Наличие такого универсального инструмента профилирования гарантирует, что разработчик может быть уверен, что его код работает хорошо с учетом ряда факторов; таких как выделение памяти, использование ресурсов операционной системы и общая производительность приложения. Также важно, чтобы переключение между этими различными измерениями было быстрым, простым и интуитивно понятным, чтобы у разработчиков было достаточно времени для их выполнения.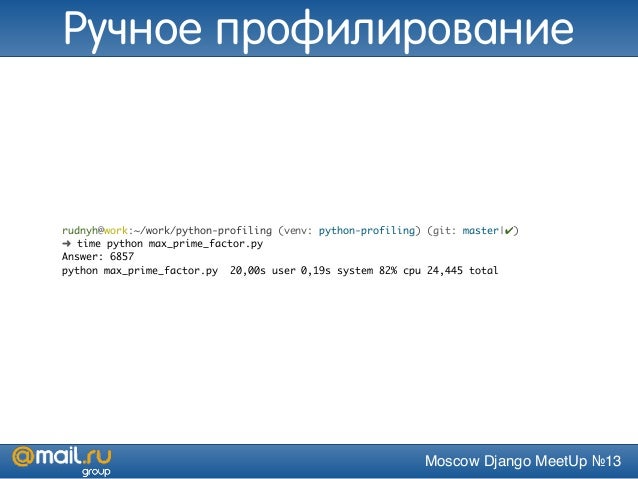
Подробная отчетность
Вся информация, сгенерированная профилировщиком, бесполезна, если он не может сообщить эту информацию в подробной и легкой для понимания форме. Независимо от того, выводит ли профилировщик HTML-страницы или документы Microsoft Word, данные должны легко интерпретироваться. Более того, система отчетности должна быть надежной, предоставляя всю необходимую разработчику информацию, но при этом быть достаточно гибкой, чтобы данные можно было фильтровать, чтобы показывать только то, что актуально.
AQtime: решение SmartBear для оптимизации профилирования
AQtime — это отмеченный наградами набор инструментов SmartBear для профилирования производительности и отладки памяти и ресурсов для компиляторов Microsoft, Borland, Java, Intel, Compaq и GNU. AQtime включает в себя десятки инструментов повышения производительности, которые помогают пользователям легко изолировать и устранять проблемы с производительностью, памятью и ресурсами в своем коде.
AQtime создан с одной ключевой целью — помочь пользователям полностью понять, как работают их программы во время выполнения. Используя встроенный набор профилировщиков производительности и отладки, AQtime собирает важную информацию о производительности и распределении памяти/ресурсов во время выполнения. Затем он предоставляет результаты своих профилировщиков как в обобщенной, так и в подробной форме. Короче говоря, AQtime предоставляет вам все инструменты, необходимые для начала процесса оптимизации, и дает следующие преимущества:
Мощный и экономичный
Модель ценообразования AQtime невероятно экономична. Некоторые другие поставщики берут в пять раз больше за продукты с меньшим количеством функций, чем AQtime. Это означает, что целая команда программистов может быть оснащена AQtime по той же цене, что и одна лицензия на продукт конкурента. Ни одно другое приложение для профилирования не может претендовать на такую большую функциональность при такой небольшой цене.
- Профилировщик производительности — Этот профилировщик помогает находить плохо работающие функции и помогает в их отладке. Он отслеживает все вызовы методов в приложении, подсчитывает вызовы и отслеживает иерархию вызовов для каждого потока.
- Allocation Profiler — помогает определить, правильно ли приложение освобождает память. Это достигается путем отслеживания использования памяти в 32-разрядных и 64-разрядных приложениях во время выполнения.
- Coverage Profiler — Позволяет узнать, какая часть вашего кода фактически выполняется и тестируется. Он определяет, выполнялась ли подпрограмма или строка во время запуска профилировщика и сколько раз она выполнялась.
- Профилировщик трассировки исключений — позволяет подтвердить, что для данных обстоятельств отображаются соответствующие сообщения об ошибках. Он отслеживает выполнение приложения и (если применимо) выводит информацию о трассировке исключений.
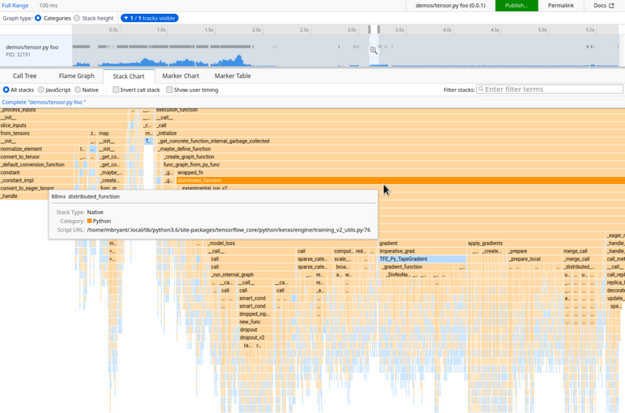
- Профилировщик трассировки функций — показывает, какой код вызывается и когда, что позволяет убедиться, что используется наиболее эффективный путь выполнения кода. Он исследует маршрут и порядок вызова подпрограмм во время выполнения приложения.
- Загрузка библиотеки Tracer Profiler — Многократная загрузка и выгрузка dll может значительно замедлить работу приложения. Этот профилировщик определяет, какие библиотеки динамической компоновки были загружены и выгружены профилируемым приложением и сколько раз они были загружены и выгружены.
- Профилировщик отказов эмулятора — проверяет, содержит ли ваше приложение код, правильно обрабатывающий различные сбои приложений.
- Профилировщик соответствия платформ — позволяет определить, может ли профилируемое приложение работать в конкретной операционной системе.
- Resource Profiler — проверяет, правильно ли приложение создает ресурсы Windows и освобождает ли эти ресурсы соответствующим образом.
 Он отслеживает выделение и освобождение ресурсов, а также вызовы процедур управления ресурсами.
Он отслеживает выделение и освобождение ресурсов, а также вызовы процедур управления ресурсами. - Reference Count Profiler — отслеживает количество ссылок на объекты интерфейса в профилируемом приложении.
- Sequence Diagram Link Profiler — Создает графическую карту того, как выполняются вызовы функций, что позволяет ускорить отладку кода. Он анализирует последовательность вызовов функций в вашем приложении, а затем строит диаграмму вызовов функций в стиле UML. Это позволяет отслеживать связи между методами и функциями без запуска приложения.
- Static Analysis Profiler — выявляет подпрограммы, которые не могут быть написаны для обеспечения оптимальной производительности, путем анализа отладочной информации или метаданных. При этом раскрывается огромное количество информации, такой как количество циклов в подпрограмме, размер подпрограмм в байтах, все возможные ответвления кода в приложении и многое другое.

- BDE SQL Profiler — Измеряет производительность SQL-запросов или хранимых процедур SQL, вызываемых через Borland Database Engine (BDE).
- Профилировщик неиспользуемых модулей VCL — помогает определить, какие модули VCL на самом деле не используются в вашем приложении.
Минимальное вмешательство
AQtime никогда не изменяет исходный код. На самом деле он всегда использует наименее навязчивый метод для достижения требуемых результатов. Поскольку обычно ожидается, что результаты будут относиться к функциям или разделам кода, большинству профилировщиков AQtime требуется только, чтобы приложение было скомпилировано с информацией отладчика, чтобы кодовые точки можно было связать с именами функций или модулей.
Простой в использовании интерфейс
Разработчикам не нужно изучать сложные команды оболочки или проприетарные языки программирования для профилирования кода с помощью AQtime. Он имеет интуитивно понятный интерфейс, разработанный с учетом потребностей занятых программистов. Всего несколькими щелчками мыши разработчик может изолировать проблемы с производительностью или ресурсами за долю времени, которое требуется другим инструментам. Более того, AQtime может работать автономно или интегрироваться непосредственно в Microsoft Visual Studio или Embarcadero RAD Studio (и более ранние версии RAD Studio от CodeGear и Borland). Эта функция предоставляет вам полную функциональность AQtime, не выходя из выбранной IDE. Вы можете создавать проекты AQtime и управлять ими, профилировать свои приложения и просматривать результаты профилирования непосредственно из IDE.
Всего несколькими щелчками мыши разработчик может изолировать проблемы с производительностью или ресурсами за долю времени, которое требуется другим инструментам. Более того, AQtime может работать автономно или интегрироваться непосредственно в Microsoft Visual Studio или Embarcadero RAD Studio (и более ранние версии RAD Studio от CodeGear и Borland). Эта функция предоставляет вам полную функциональность AQtime, не выходя из выбранной IDE. Вы можете создавать проекты AQtime и управлять ими, профилировать свои приложения и просматривать результаты профилирования непосредственно из IDE.
AQtime расширяет IDE Visual Studio и RAD Studio следующими способами:
- Контекстно-зависимое профилирование . Щелкните правой кнопкой мыши в редакторе Visual Studio и выберите «Профилировать этот метод» или «Профилировать этот класс», чтобы начать новый сеанс профилирования. Это легко и естественно.
- Встроенные панели AQtime . Все панели AQtime — «Настройка», «Отчет», «Сводка», «График вызовов», «Помощник» и другие — становятся настоящими панелями Visual Studio/RAD Studio.

- Добавить новый проект AQtime Тип . Вы можете создавать проекты AQtime или добавлять их в существующее решение Visual Studio так же, как вы создаете или добавляете другие проекты VS/BDS; с помощью диалоговых окон «Создать проект» и «Добавить новый проект» Visual Studio или диалогового окна «Новые элементы» RAD Studio.
- Интеграция меню AQtime и панели инструментов . AQtime добавляет меню «Профиль» в главное меню IDE. Это меню содержит команды, которые позволяют запускать, приостанавливать и возобновлять профилирование, а также выбирать режим профилирования, изменять параметры профилировщика и панели и т. д. В Visual Studio команды для конкретных проектов, такие как «Добавить модуль», «Добавить вывод» или «Добавить сборку». , добавляются в меню «Проект», а также доступны через контекстное меню узла проекта AQtime в обозревателе решений. В RAD Studio в меню «Выполнить» добавлена команда «Выполнить с профилированием». AQtime также добавляет панель инструментов AQtime в обе IDE.
 Эта панель инструментов содержит наиболее часто используемые элементы, такие как «Выполнить», «Выбрать профилировщик» и т. д.
Эта панель инструментов содержит наиболее часто используемые элементы, такие как «Выполнить», «Выбрать профилировщик» и т. д. - Участие в модели автоматизации Visual Studio. Модель автоматизации Visual Studio предоставляет пользователям возможность создавать собственные надстройки, мастера и работать с макросами. Как настоящий интегрированный в Visual Studio продукт, AQtime предоставляет программные интерфейсы для своих внутренних компонентов (например, для интерфейса Projects). Это позволяет сторонним разработчикам создавать надстройки, мастера и макросы Visual Studio, использующие объектную модель AQtime.
- Полностью интегрирован в справочную систему IDE. Справочная система AQtime полностью интегрирована в справочные системы VS и RAD. Контекстно-зависимая справка F1 предоставляется для всех панелей, диалоговых окон и элементов проекта AQtime.
Рисунок 2: Меню AQtime, интегрированные в Visual Studio
Рисунок 3: Меню AQtime, интегрированные в Borland Developer Studio
Простые для понимания отчеты
После завершения сеанса профилирования AQtime отображает сводный отчет о результатах . В этой сводке четко указаны разделы кода, которые необходимо оптимизировать, что позволяет разработчикам быстро выявить болевые точки в своем коде. Отображаемая информация относится к запущенному профилировщику, поэтому отображаются только релевантные данные. Также доступен более подробный отчет, позволяющий пользователям просматривать подробную информацию по отдельным методам. После создания эти отчеты могут быть сохранены в формате XML, HTML или TXT.
В этой сводке четко указаны разделы кода, которые необходимо оптимизировать, что позволяет разработчикам быстро выявить болевые точки в своем коде. Отображаемая информация относится к запущенному профилировщику, поэтому отображаются только релевантные данные. Также доступен более подробный отчет, позволяющий пользователям просматривать подробную информацию по отдельным методам. После создания эти отчеты могут быть сохранены в формате XML, HTML или TXT.
Поддержка множества сред
AQtime поддерживает широкий спектр версий Windows, включая Windows 98, ME, 2000, NT 4.0, XP, Windows 2003 Server и Vista. Кроме того, AQtime поддерживает 32- и 64-битные чипсеты как AMD, так и Intel.
Поддержка большого количества языков
AQtime может профилировать код, написанный на самых разных языках, включая:
- Microsoft Visual C#
- Microsoft Visual Basic
- Microsoft Visual J#
- Microsoft С++
- Borland C# Builder
- Microsoft JScript .
 NET
NET - Microsoft F#, Microsoft Visual F#
- Embarcadero Delphi 2010, XE, XE2 и XE3
- CodeGear Delphi 2007 и 2009
- Borland Delphi для .NET
- Борланд Делфи 2005
- Ява
- Intel С++
- Сборник компиляторов GNU
- Визуальный Фортран Compaq
- Разнообразие показателей
AQtime может похвастаться десятью различными механизмами профилирования, которые можно настроить несколькими способами. Конечным результатом является гибкое решение, которое позволяет пользователям легко определять те области, которые вызывают наибольшую озабоченность. Поддерживаются следующие механизмы профилировщика:
Быстрая окупаемость инвестиций
В отличие от некоторых инструментов, которые имеют крутую кривую обучения и требуют обширного обучения, AQtime можно сразу же запустить в работу. Многие пользователи говорят, что им удалось выявить и устранить проблемы с производительностью в течение нескольких минут после запуска AQtime. Благодаря интуитивно понятному интерфейсу и понятным отчетам процесс оптимизации может сразу превратиться из болезненного в безболезненный. Нет длительного времени ввода в эксплуатацию, нет неуклюжих шагов настройки, просто чистый пользовательский интерфейс и ряд простых шагов, чтобы обеспечить спокойствие для команды разработчиков, заботящейся о производительности.
Благодаря интуитивно понятному интерфейсу и понятным отчетам процесс оптимизации может сразу превратиться из болезненного в безболезненный. Нет длительного времени ввода в эксплуатацию, нет неуклюжих шагов настройки, просто чистый пользовательский интерфейс и ряд простых шагов, чтобы обеспечить спокойствие для команды разработчиков, заботящейся о производительности.
Краткое и простое руководство по профилированию кода в Python | by Sarah Beshr
ПРОГРАММИРОВАНИЕ
Поиск узких мест в функциях с помощью профилировщика линий
Источник: unDraw.co /или обучение ваших моделей машинного обучения. Однако вы можете обнаружить, что это быстро перестает быть таковым, когда ваш код выполняется, казалось бы, целую вечность. По этой причине профилирование кода приходит на помощь, когда вам нужно оценить узкие места в вашем приложении и сэкономить ваше драгоценное время. Главным героем нашей сегодняшней статьи будет пакет line_profiler, и мы будем использовать его для построчного профилирования среды выполнения функции, чтобы мы могли сделать вас на шаг ближе к небесам эффективности кода. Займемся профилированием!
Займемся профилированием!Обратите внимание, что в этой статье я буду работать с записной книжкой Python (.ipynb), так как я считаю, что они хорошо подходят для экспериментов, что делает их отличным инструментом для профилирования кода, поскольку вы часто вносите изменения в более эффективный код. .
Что такое профилирование кода?
Проще говоря, профилирование кода — это метод, который используется для определения времени выполнения каждой функции или строки кода и частоты их выполнения. Это важный шаг к поиску узких мест в вашем коде и, следовательно, к пониманию того, как ваш код можно оптимизировать. Наш метод носит количественный характер, поскольку он позволяет получить сводную статистику по отдельным строкам кода. В результате он дает полезную информацию о том, какие части вашего кода требуют дальнейшей оптимизации.
Как профилировать функцию
Лучший способ изучить, как мы можем профилировать наш код, — это пример. Предположим, у нас есть простая функция, которая преобразует фунты в килограммы и граммы следующим образом:
def фунты_в_метрику(фунты):
килограммов = фунтов / 2,2
граммов = килограммов * 1000
return 'Введенное вами количество равно {} килограммам и {} грамм.'.format(int(килограммы), граммы)
Быстрый и грязный подход: %timeit
Если мы хотим получить приблизительное время выполнения этой функции, мы можем использовать волшебную функцию IPython timeit, которая даст нам общее время выполнения.
%timeitpounds_to_metric(115)
Самый медленный забег занял в 11,57 раз больше времени, чем самый быстрый. Это может означать, что промежуточный результат кэшируется. 1000000 циклов, лучшее из 5: 1,27 мкс на цикл
Из вывода видно, что было выполнено несколько запусков и циклов. %timeit выполняет пример кода несколько раз и предоставляет оценку времени выполнения кода, что делает его более точным представлением фактического времени выполнения, чем полагаясь только на одну итерацию. Среднее значение, отображаемое в выходных данных, представляет собой сводку времени выполнения с учетом каждого из нескольких запусков.
Строгий подход: Line Profiler
Поскольку %timeit умножает только на одну строку кода, это удобно, когда мы хотим получить быструю оценку производительности функции во время выполнения. Однако нетрудно понять, почему это плохо масштабируется для больших фрагментов кода. Поэтому, если мы хотим увидеть, сколько времени потребовалось для выполнения каждой строки внутри функции, именно здесь нам пригодится пакет профилировщика линий.
Однако нетрудно понять, почему это плохо масштабируется для больших фрагментов кода. Поэтому, если мы хотим увидеть, сколько времени потребовалось для выполнения каждой строки внутри функции, именно здесь нам пригодится пакет профилировщика линий.
Поскольку этот пакет не является частью стандартной библиотеки Python, нам необходимо установить его отдельно. Это легко сделать с помощью команды pip install. Затем мы загружаем его в нашу сессию следующим образом.
%load_ext line_profiler
Теперь мы можем использовать волшебную команду профилировщика линий %lprun для оценки времени выполнения определенных строк кода в нашей функции pound_to_metric. Для начала мы используем флаг -f, чтобы указать, что мы хотим профилировать функцию, за которой следует функция, которую мы хотим профилировать. Обратите внимание, имя функции передается без скобок. Наконец, мы указываем точный вызов функции, которую мы хотим профилировать, вместе с любыми необходимыми аргументами. Я буду использовать 115 в качестве аргумента в фунтах, как и раньше.
%lprun -f фунты_в_метрике фунты_в_метрике(115)
Статистика профилирования
Выполнение предыдущей строки кода дает таблицу, которая обобщает статистику профилирования, как показано ниже.
Изображение автораТеперь давайте пройдемся по столбцам нашей сводной таблицы!
Сначала отображается столбец, определяющий номер строки функции , за которым следует столбец Hits , в котором отображается количество выполнений этой строки. Далее 9Столбец 0080 Time показывает общее количество времени, которое потребовалось для выполнения каждой строки. В этом столбце используется конкретный таймер, который можно найти в первой строке вывода. Здесь единица измерения таймера указана в микросекундах с использованием экспоненциального представления (1e-06). Например, мы можем видеть, что для выполнения пятой строки потребовалось 12 единиц таймера или примерно 13 микросекунд.
Кроме того, в столбце Per Hit указано среднее время, затрачиваемое на выполнение одной строки, рассчитанное путем деления столбца Time на столбец Hits. Учитывая, что все наши попадания равны 1 в этой функции, столбцы «Время» и «За попадание» показывают аналогичные результаты. 9Столбец 0080 % Time показывает процент времени, проведенного в строке, по отношению к общему количеству времени, проведенному в функции. Это может помочь нам обнаружить строки кода, которые занимают больше всего времени внутри функции. Наконец, исходный код отображается для каждой строки в столбце Line Contents . Довольно аккуратно, да?
Учитывая, что все наши попадания равны 1 в этой функции, столбцы «Время» и «За попадание» показывают аналогичные результаты. 9Столбец 0080 % Time показывает процент времени, проведенного в строке, по отношению к общему количеству времени, проведенному в функции. Это может помочь нам обнаружить строки кода, которые занимают больше всего времени внутри функции. Наконец, исходный код отображается для каждой строки в столбце Line Contents . Довольно аккуратно, да?
Заключение
На этом мы завершаем наше краткое и простое руководство по профилированию кода в Python. Напомним, мы рассмотрели, как мы можем оценить производительность функции с помощью модуля line-profiler и почему этот подход лучше по сравнению с использованием %timeit. Надеюсь, эта статья оказалась для вас полезной, не стесняйтесь задавать любые вопросы в комментариях. Если вам понравилась эта статья, обязательно ознакомьтесь с другими моими статьями здесь, на Medium. Удачного профилирования!
9 отличных библиотек для профилирования кода Python
От простых таймеров и модулей сравнительного анализа до сложных основанных на статистике платформ — обратите внимание на эти инструменты, чтобы получить представление о производительности вашей программы Python.

Сердар Егулалп
старший писатель, Информационный Мир |
Thinkstock Содержание- Время и Timeit
- cПрофиль
- Функционал Трайс
- Палантеер
- Пинструмент
- Шпион-шпион
- Снакевиз
- Яппи
Показать больше
Каждый язык программирования имеет два вида скорости: скорость разработки и скорость исполнения. Python всегда предпочитал быстрое написание, а не быстрое выполнение. Хотя код Python почти всегда достаточно быстр для выполнения задачи, иногда это не так. В этих случаях вам нужно выяснить, где и почему он отстает, и что-то с этим сделать.
В этих случаях вам нужно выяснить, где и почему он отстает, и что-то с этим сделать.
Известная поговорка разработчиков программного обеспечения и техники в целом гласит: «Измеряй, а не угадывай». С программным обеспечением легко предположить, что не так, но никогда не стоит этого делать. Статистические данные о фактической производительности программы всегда являются вашим лучшим первым инструментом в стремлении сделать приложения быстрее.
Хорошей новостью является то, что Python предлагает целый ряд пакетов, которые вы можете использовать для профилирования своих приложений и изучения того, где они работают медленнее всего. Эти инструменты варьируются от простых однострочников, включенных в стандартную библиотеку, до сложных фреймворков для сбора статистики из запущенных приложений. Здесь я расскажу о девяти наиболее важных из них, большинство из которых работают на разных платформах и легко доступны либо в PyPI, либо в стандартной библиотеке Python.
Время и Timeit
Иногда все, что вам нужно, это секундомер.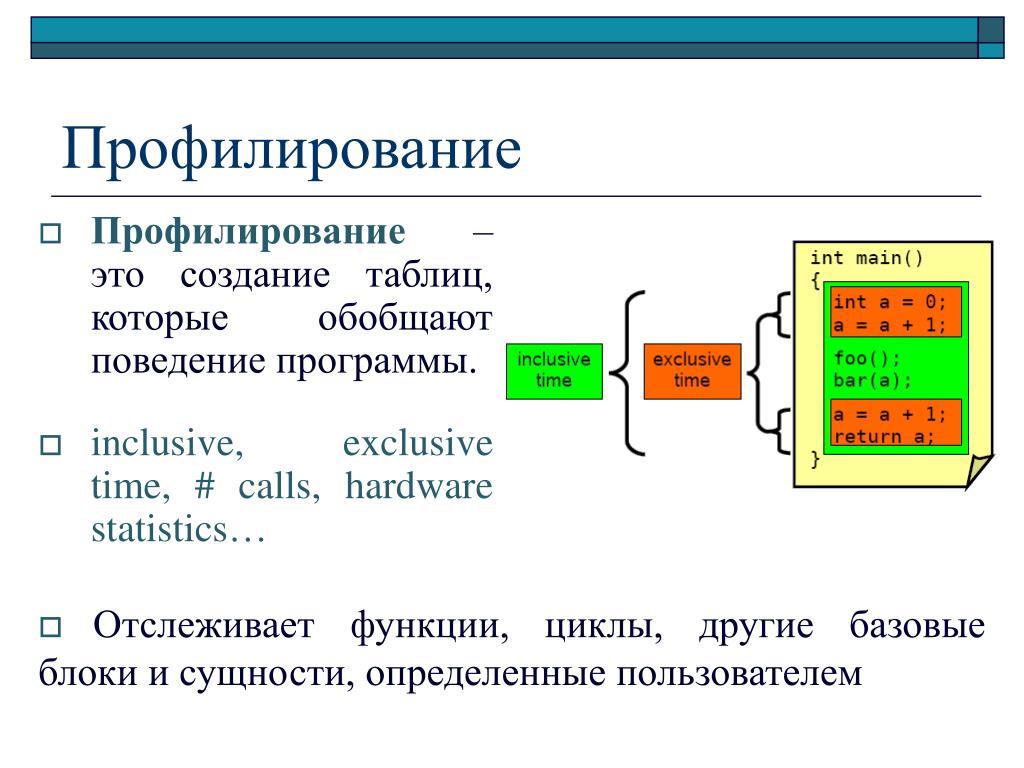 Если все, что вы делаете, — это профилируете время между двумя фрагментами кода, выполнение которых занимает секунды или минуты подряд, то секундомера будет более чем достаточно.
Если все, что вы делаете, — это профилируете время между двумя фрагментами кода, выполнение которых занимает секунды или минуты подряд, то секундомера будет более чем достаточно.
Стандартная библиотека Python поставляется с двумя функциями, которые работают как секундомеры. Модуль Time имеет функцию perf_counter , которая вызывает таймер с высоким разрешением операционной системы для получения произвольной метки времени. Вызовите time.perf_counter один раз перед действием, один раз после и получите разницу между ними. Это дает вам ненавязчивый, малозатратный — хотя и несложный — способ тайм-кода.
Модуль Timeit пытается выполнить что-то вроде фактического бенчмаркинга кода Python. timeit.timeit берет фрагмент кода, запускает его много раз (по умолчанию — 1 миллион проходов) и получает общее время, необходимое для этого. Его лучше всего использовать для определения того, как одиночная операция или вызов функции выполняются в тесном цикле — например, если вы хотите определить, что будет быстрее: понимание списка или обычное построение списка для чего-то, что выполняется много раз. (Обычно побеждает списковое понимание.)
(Обычно побеждает списковое понимание.)
Недостатком Time является то, что это не более чем секундомер, а недостатком Timeit является то, что его основным вариантом использования являются микротесты на отдельных строках или блоках кода. Эти модули работают, только если вы имеете дело с изолированным кодом. Ни одного из них недостаточно для анализа всей программы — выяснения, где из тысяч строк кода ваша программа проводит большую часть своего времени.
cProfile
Стандартная библиотека Python также поставляется с профилировщиком анализа всей программы, cProfile. При запуске cProfile отслеживает каждый вызов функции в вашей программе и генерирует список наиболее часто вызываемых функций и средней продолжительности вызовов.
cProfile имеет три сильных стороны. Во-первых, он включен в стандартную библиотеку, поэтому он доступен даже в стандартной установке Python. Во-вторых, он профилирует ряд различных статистических данных о поведении вызовов — например, он отделяет время, затраченное на собственные инструкции вызова функции, от времени, затраченного всеми других вызовов, вызванных функцией. Это позволяет вам определить, является ли функция медленной сама по себе или она вызывает других медленных функций.
Это позволяет вам определить, является ли функция медленной сама по себе или она вызывает других медленных функций.
В-третьих, и, возможно, лучше всего, вы можете свободно ограничивать cProfile. Вы можете сэмплировать выполнение всей программы или включать профилирование только тогда, когда запускается функция выбора, чтобы лучше сосредоточиться на том, что эта функция делает и что она вызывает. Этот подход работает лучше всего только после того, как вы немного сузили круг, но избавляет вас от необходимости пробираться сквозь шум трассировки полного профиля.
Это подводит нас к первому из недостатков cProfile: по умолчанию он генерирует лотов статистики. Попытка найти нужную иголку во всем этом сене может быть ошеломляющей. Другим недостатком является модель выполнения cProfile: она перехватывает при каждом отдельном вызове функции , создавая значительные накладные расходы. Это делает cProfile непригодным для профилирования приложений в продакшне с данными в реальном времени, но прекрасно подходит для их профилирования во время разработки.
Более подробное описание cProfile см. в нашей отдельной статье.
FunctionTrace
FunctionTrace работает как cProfile в общих чертах: вы передаете ему имя сценария, который хотите профилировать, без необходимости добавления инструментов в код, и он генерирует подробную трассировку вызовов функций и использование памяти со временем. FunctionTrace также работает с многопоточными/многопроцессорными приложениями без необходимости делать что-либо дополнительно. См. эту статью для получения технических сведений о том, как работает FunctionTrace.
Подобно cProfile, FunctionTrace не использует выборку; каждое действие записывается. Компоненты профилирования написаны на Rust для ускорения. Разработчики FunctionTrace утверждают, что накладные расходы приложений на профилирование составляют менее 10%.
Данные трассировки сохраняются в формате JSON, поэтому теоретически для их анализа можно использовать любое приложение. Но большим преимуществом FunctionTrace является то, что он использует профилировщик Firefox, который будет работать в любом браузере с поддержкой JavaScript, а не только в Firefox, для отображения результатов на интерактивном графике.
Обратите внимание, что компоненты профилирования FunctionTrace пока недоступны в Windows; профилирование можно выполнять только в системах Linux или Mac.
ИДГFunctionTrace использует Firefox Profiler (который может работать в любом браузере с поддержкой JavaScript), чтобы сделать статистику трассировки интерактивной и доступной для изучения.
Palanteer
Относительно новое дополнение к арсеналу профилирования Python, Palanteer может использоваться для профилирования программ Python и C++. Это делает его очень полезным, если вы пишете приложение Python, включающее созданные вами библиотеки C++, и вам требуется наиболее детальное представление об обоих компонентах вашего приложения. Лучше всего то, что Palanteer отображает результаты в приложении с графическим интерфейсом, которое работает на рабочем столе, и обновляется в режиме реального времени по мере запуска вашей программы.
Инструментирование приложений Python так же просто, как запуск приложения через Palanteer, точно так же, как при использовании cProfile. Отслеживаются вызовы функций, исключения, сборка мусора и выделение памяти на уровне ОС. Последние два особенно полезны, если проблемы с производительностью вашего приложения связаны с использованием памяти или размещением объектов.
Отслеживаются вызовы функций, исключения, сборка мусора и выделение памяти на уровне ОС. Последние два особенно полезны, если проблемы с производительностью вашего приложения связаны с использованием памяти или размещением объектов.
Один большой недостаток Palanteer, по крайней мере сейчас, заключается в том, что вы должны создавать его полностью из исходного кода. Предварительно скомпилированные двоичные файлы пока не доступны в качестве устанавливаемых колес Python, поэтому вам нужно будет разобрать свой компилятор C++ и также иметь под рукой копию исходного кода CPython.
Pyinstrument
Pyinstrument работает как cProfile в том смысле, что он отслеживает вашу программу и генерирует отчеты о коде, который занимает большую часть ее времени. Но у Pyinstrument есть два основных преимущества перед cProfile, которые делают его достойным внимания.
Во-первых, Pyinstrument не пытается перехватывать каждый экземпляр вызова функции. Он производит выборку стека вызовов программы каждую миллисекунду, поэтому он менее навязчив, но все же достаточно чувствителен, чтобы определить, что занимает большую часть времени выполнения вашей программы.
Во-вторых, отчеты Pyinstrument гораздо лаконичнее. Он показывает вам основные функции в вашей программе, которые занимают больше всего времени, поэтому вы можете сосредоточиться на анализе самых больших виновников. Это также позволяет вам быстро находить эти результаты без особых церемоний.
Pyinstrument также обладает многими удобствами cProfile. Вы можете использовать профилировщик как объект в своем приложении и записывать поведение выбранных функций, а не всего приложения. Вывод может быть представлен любым количеством способов, в том числе в виде HTML. Если вы хотите увидеть полную хронологию звонков, вы также можете потребовать это.
Также на ум приходят два предостережения. Во-первых, некоторые программы, использующие расширения, скомпилированные на C, например созданные с помощью Cython, могут работать неправильно при вызове с помощью Pyinstrument через командную строку. Но они работают, если используется Pyinstrument в самой программе — например, обернув функцию main() вызовом профилировщика Pyinstrument.
Второе предостережение: Pyinstrument плохо справляется с кодом, который выполняется в несколько потоков. Py-spy, подробно описанный ниже, может быть лучшим выбором.
Py-spy
Py-spy, как и Pyinstrument, работает путем выборки состояния стека вызовов программы через регулярные промежутки времени, вместо того, чтобы пытаться записывать каждый отдельный вызов. В отличие от PyInstrument, Py-spy имеет основные компоненты, написанные на Rust (Pyinstrument использует расширение C) и работает вне процесса с профилированной программой, поэтому его можно безопасно использовать с кодом, работающим в рабочей среде.
Эта архитектура позволяет Py-spy легко делать то, что многие другие профилировщики не могут: профилировать многопоточные или подпроцессорные приложения Python. Py-spy также может профилировать расширения C, но они должны быть скомпилированы с символами, чтобы быть полезными. А в случае расширений, скомпилированных с помощью Cython, сгенерированный файл C должен присутствовать для сбора правильной информации о трассировке.
Существует два основных способа проверки приложения с помощью Py-spy. Вы можете запустить приложение с помощью команды Py-spy record , которая генерирует график пламени после завершения запуска. Или вы можете запустить приложение с помощью Py-spy’s 9.Команда 0892 top , которая вызывает интерактивное отображение внутренней части вашего приложения Python, отображаемое так же, как и утилита Unix top . Отдельные стеки потоков также можно вывести из командной строки.
Py-spy имеет один большой недостаток: он в основном предназначен для профилирования всей программы или некоторых ее компонентов из вне . Это не позволяет вам украшать и пробовать только определенную функцию.
Snakeviz
Наиболее распространенный способ визуализации данных из трассировки cProfile — использование другого модуля стандартной библиотеки, pstats. Дело в том, что pstats создает отчеты в виде простого текста, которые не всегда обеспечивают визуализацию, необходимую для статистики профиля.
Snakeviz использует данные, сгенерированные cProfile, и создает легко читаемую интерактивную графику, отображаемую с помощью HTML. Доступны два типа графиков: «сосулька» и «солнечные лучи», каждый из которых сразу показывает, где ваша программа занимает больше всего времени. Каждый сегмент диаграммы представляет время вызова функции. Просто щелкните сегмент, чтобы увеличить масштаб функции, и вы также сможете проверить время, затрачиваемое всем в стеке под ним.
Snakeviz также создает табличное HTML-представление данных трассировки с возможностью поиска и сортировки; это похоже на более интерактивную версию трассировок, созданных pstats. Даже если вы не возитесь с диаграммами, табличное представление трассировки само по себе является чрезвычайно мощным способом разобраться в данных cProfile.
IDGSnakeviz создает интерактивные диаграммы на основе статистики для трассировки cProfile программы Python.
Yappi
Yappi («еще один Python Profiler») обладает многими из лучших функций других обсуждаемых здесь профилировщиков, а некоторые из них не предоставляются ни одним из них. PyCharm по умолчанию устанавливает Yappi в качестве предпочтительного профилировщика, поэтому пользователи этой IDE уже имеют встроенный доступ к Yappi.
Чтобы использовать Yappi, вы дополняете свой код инструкциями по вызову, запуску, остановке и созданию отчетов для механизмов профилирования. Yappi позволяет вам выбирать между «временем стены» или «время процессора» для измерения затраченного времени. Первый — просто секундомер; последний отсчитывает с помощью системных API-интерфейсов, как долго ЦП фактически был занят выполнением кода, исключая паузы для ввода-вывода или спящего потока. Процессорное время дает наиболее точное представление о том, сколько времени на самом деле занимают определенные операции, например выполнение числового кода.
Одно очень приятное преимущество того, как Yappi обрабатывает получение статистики из потоков, заключается в том, что вам не нужно декорировать код потока. Yappi предоставляет функцию yappi.get_thread_stats() , которая извлекает статистику из любой записанной активности потока, которую затем можно анализировать отдельно.