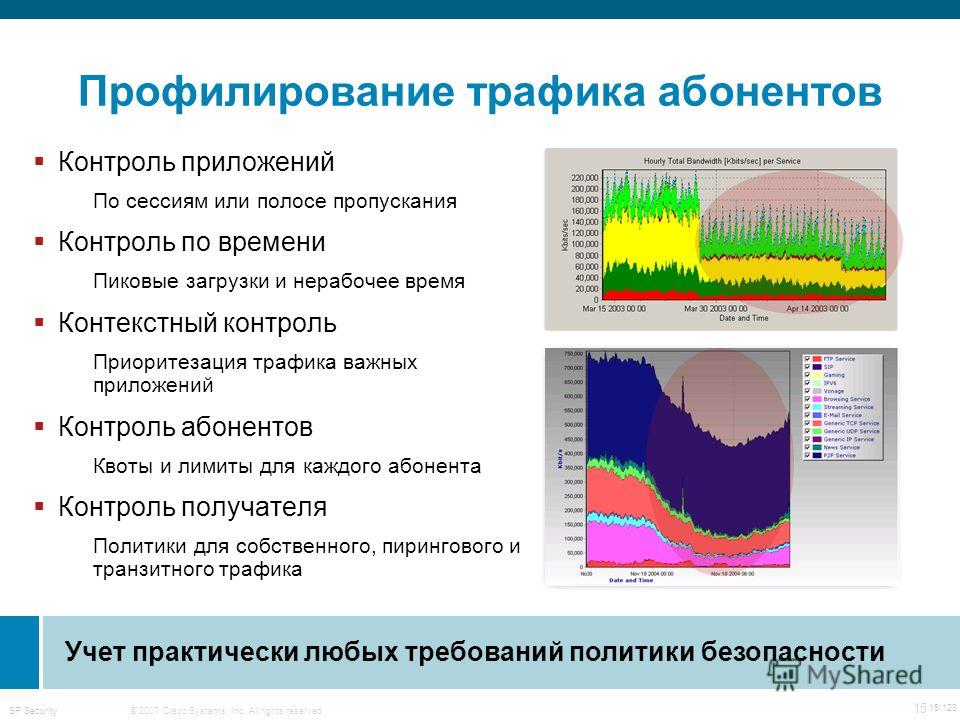
Профилирование кода на C/С++ в *nix-системах / Хабр
Отличный обзорный доклад конференции HighLoad++ 2016 о том, как надо проводить профилирование программного кода. О типичных ошибках, происходящих при измерениях. И, конечно, об инструментах:
— gettimeofday
— strace, ltrace, truss
— gprof
— gdb / lldb
— perf
— pmcstat
— SystemTap
— DTrace
— HeapTrack
— BPF / bcc
В начале у меня будет не слишком техническая часть, о том, как не надо делать benchmark’и.
Я наблюдаю, что люди часто делают типичные ошибки, когда делают benchmark’и. И вот первая из них…
Если вы не знаете, то у всех докладчиков HighLoad++ проходит суровый коучинг, многократный, по разным векторам. Один коучинг обязательный, остальные — опциональные. Опциональный коучинг — это как побороть боязнь сцены, например. То есть очень суровый подход к организации всего этого дела.И когда я подавал доклад на HighLoad++, организаторы предложили убрать всю эту техническую часть и добавить больше кулстори, красивых скриншотов и так далее. А те, кому интересно, как это запустить, какие команды набрать, могут обратиться к документации — и вот поэтому — ссылка на мой бложик, потому что все там есть. Если вас интересует, к примеру, как SystemTap сложно собирается на Linux, то открываем ссылку на блог и там будет прямо все. А в этом докладе будет скорее такой обзор, чтобы вы представляли, какие инструменты вообще есть, что они дают и когда какой использовать.

В начале у меня будет не слишком техническая часть, о том, как не надо делать benchmark’и.
Я наблюдаю, что люди часто делают типичные ошибки, когда делают benchmark’и.
- Во-первых, это неповторяемость. Когда вы открываете какой-нибудь бложик, и там такая классная статья, что мы «померяли что-то, получили такие красивые графики, и наше решение, которое стоит так, делает это в 500 раз быстрее».
 При этом не приводится никаких данных для повторения этого эксперимента, никаких скриптов и ничего. Ну, это хреновый benchmark, и нужно это сразу страницу закрыть. Если вы не можете его повторить, как можно ему верить?
При этом не приводится никаких данных для повторения этого эксперимента, никаких скриптов и ничего. Ну, это хреновый benchmark, и нужно это сразу страницу закрыть. Если вы не можете его повторить, как можно ему верить?
Вы должны хотя бы примерно такие же результаты мочь воспроизвести.
- Вы измеряете не то, что думаете. Типичный пример: мы хотим померить, как у нас жесткий диск работает. Мы весело набираем dd if что-нибудь куда-нибудь. Пишем в диск и меряем, а как быстро он, собственно, пишет. Кто-нибудь из зала может сказать, почему это не измерение скорости диска?
Правильно — потому что на самом деле вы померяли скорость, с которой у вас кэш файловой системы работает. Как это обойти — это тоже интереснаяпроблема.
- Взятие среднего. Это меня всегда бесило на наших митингах, и я вижу в первом ряду слушателя, который меня понимает. Нам нужно понимать, как быстро мы отвечаем пользователю на запросы — давайте построим график среднего времени ответа.

- Кто будет бенчмаркать бенчмарки? Это такая проблема. Например, вы написали клевый тест, который меряет, сколько ответов в секунду генерит ваше приложение. Померили, получили, скажем, 4000 запросов в секунду. Думаете: «Как-то маловато, надо оптимайзить». Проблема в том, что ваш benchmark однопоточный. А под реальной нагрузкой ваше приложение работает в сотнях, в тысячи потоков. И, собственно, вы не учли, что ваш собственный benchmark — это bottleneck в данном случае. Это нужно понимать.
- Отсутствие анализа. Это когда вы померяли, говорите: «Что-то тупит, надо все отрефачить, все переписать». То есть нужно понимать, почему оно тупит.
- Игнорирование ошибок. Опять же, вернемся к примеру с вашим бенчмарком. Допустим, это не ваш benchmark, это A/B, и вы его натравили на свой сервис, померили, получили 5 млн. запросов в секунду и радуетесь: «У нас все очень быстро». Но вы не посмотрели, что все это ответы 404, например. То есть нужно ошибки тоже высчитывать.
- Неправильные настройки. В моей сфере, в базах данных, это частая проблема, потому что настройки Postgres по умолчанию предполагают, что вы пытаетесь запустить его на микроволновке. Сейчас сервера мощные, поэтому все настройки по умолчанию надо очень сильно менять. Побольше шарить buffers, побольше work_mem. И понимать, что эти настройки делают. Если вы видите бенчмарк, даже с данными, на которых тестировалось, и даже со скриптами, но там сказано, что «мы тестировали с настройками по умолчанию» — по умолчанию MongoDB и Postgres — все, можно закрывать.

- Нетипичная нагрузка. У вас 90% времени что-то читает, 10% что-то пишет, а вы решили: напишем benchmark, который фифти/фифти — и так, и так делает. Зачем такое тестировать? То есть вы что-то соптимизируете, просто это вам в продакте не сильно поможет.
- Маркетинг и подгон. Тут у меня есть небольшая кулстори. Я достоверно знаю, что были лет …дцать назад такие производители железа, которые знали бенчмарки, по которым некий журнал тестирует компьютеры. Они свое железо собирали так, чтобы на этих бенчмарках выглядело хорошо. В результате все очень здорово продавалось. Это первый способ подгона.
То есть нужно понимать, что это существует, это не иллюзорная вещь.

- Ну, и другие свойства. Близкий мне пример: Oracle против Postgres — что быстрее? Может быть, Oracle быстрее в 10 раз, но он и стоит как не в себя. Это надо тоже учитывать. А, может, и нет — я не бенчмаркал Oracle ни разу и вообще его никогда не видел, если честно.
Для создания полноты картины начну с того, как не надо бенчмаркать код. Самый простой способ — gettimeofday(). Дедовский метод, когда у нас есть кусочек кода, мы хотим узнать, насколько он быстрый или медленный — мы померили время в начале, выполнили код, померили время в конце, посчитали дельту и сделали вывод, что код выполняется столько времени.
На самом деле не самый идиотский способ, он удобен, например, когда у вас этот код  По сути, у вас есть страница в ядре, которая мапится в адресное пространство всех процессов, и ваш gettimeofday() превращается в обращение к оперативной памяти, никакого syscall’а не происходит.
По сути, у вас есть страница в ядре, которая мапится в адресное пространство всех процессов, и ваш gettimeofday() превращается в обращение к оперативной памяти, никакого syscall’а не происходит.
Не стоит его использовать, несмотря на то, что он дешевый, если вы делаете что-то со спинлоками. Потому что спинлоки сами по себе довольно быстро работают. То есть то, что вы меряете, должно хотя бы миллисекунды выполняться, иначе у вас погрешность будет на уровне измерений.
Инструменты, такие как strace, ltrace, truss — прикольные инструменты, у них есть флажок -с, который показывает, сколько времени у вас какие syscall’ы выполнялись. Ну, ltrace измеряет библиотечные процедуры, а strace — syscall’ы, но тоже, в принципе, могут быть удобны где-то в каких-то задачах. Не могу сказать, что я этим часто пользуюсь.
Gprof, есть такой прикольный инструмент, на слайде приводится пример его текстового отчета. Тоже понятно — вот у нас есть процедуры в программе, вот столько раз они были вызваны, столько времени это в процентах выполнялось.
С помощью gprof еще можно генерировать такие картинки:
Это, скорее, пример того, как не надо делать. Запомните эту картинку, здесь 6 квадратиков. Обратите внимание, как много места они занимают, тут имена процедур, над стрелками все время что-то написано, ничего не понятно — очень много места занимает. Мы увидим намного более наглядные отчеты, чем этот. Но, в принципе, красивая картинка, можно начальству показать, понтануться.
Отладчики. На самом деле, это уже пример инструментов, которые приходится использовать на практике при профайлинге, потому что у них есть клевые свойства выполнять команды batch’ем и можно написать в этот набор batch-команд (bt) получение бэктрейса. Это очень удобно при отладке lock contention, когда у вас происходит борьба за локи.
http://habr.ru/p/310372/
Здесь у меня есть небольшая кулстори. Это, по-моему, был самый первый патч, который я написал для Postgres. Или второй, не помню. У Postgres есть своя реализация хэш-таблиц, сильно заточенных под задачи Postgres. И она, в том числе, может быть создана с такими флагами, чтобы использоваться разными процессами. Пришел клиент с проблемой, что «вот у меня на таких-то запросах, в такой-то схеме все тупит, помогите». Интересно, что сначала с помощью приема с бэктрейсом это выглядело так, что вы запускаете gdb 10 раз, в 5 случаях у вас бэктрейс висит на взятии лока, а еще в половине случаев — на чем-то другом, то есть явно у вас процесс часто висит на локе, что-то не так.
Или второй, не помню. У Postgres есть своя реализация хэш-таблиц, сильно заточенных под задачи Postgres. И она, в том числе, может быть создана с такими флагами, чтобы использоваться разными процессами. Пришел клиент с проблемой, что «вот у меня на таких-то запросах, в такой-то схеме все тупит, помогите». Интересно, что сначала с помощью приема с бэктрейсом это выглядело так, что вы запускаете gdb 10 раз, в 5 случаях у вас бэктрейс висит на взятии лока, а еще в половине случаев — на чем-то другом, то есть явно у вас процесс часто висит на локе, что-то не так.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
По бэктрейсу удалось найти, что это за код такой, который то берет, то освобождает лок. Это долгая история, можете по ссылке прочитать статью на Хабре. Там же есть ссылка на обсуждение в hackers, где есть технические детали.
На слайде выше — кусочек кода, между взятием и освобождением лока, он в свою очередь там проваливался куда-то в dynahash, где крутился на взятии спинлока. Это удалось с помощью отладчиков найти, исправить, предложить патч. И тот спинлок, который в dynahash (это хэш-табличка в Postgres), превратили в 8 или 16 спинлоков, которые при определенных условиях берутся разные. Удалось его пошардить и это уже есть в 9.6.
Perf — замечательный инструмент, потому что perf top показывает топ процедур. В данном случае в указанном процессе, сколько времени они выполняются. Вверху мы видим 30%, 20% и мы видим ResourceOwner — это неспроста в именах процедур, потому что следующая кулстори тоже про реальный патч.
Пришел клиент, сказал: «У меня такие запросы и такая схема. Все тупит. Что делать?». Начали отладку. А у него энтерпрайзное приложение, у него есть таблицы, тысяча дочерних таблиц (в Postgres, если кто не знает, есть наследование таблиц). И с помошью perf top мы видим, что в ResourceOwner все тупит. ResourceOwner — это такой объект (насколько слово объект применимо для языка С), который хранит в себе разные ресурсы, файлы, шареную память и что-то еще. И он написан в предположении, что обычно мы ресурсы выделяем и кладем в массив, а освобождаем в обратном порядке. Поэтому при удалении ресурсов, он начинает их искать с конца. Размер массива он знает, ну, в смысле — у него есть индекс последнего элемента. Оказалось, что это условие выполняется не всегда и ему приходится во все стороны искать по этому массиву, поэтому он тупит. Патч заключается в том, что при определенном количестве ресурсов (около 16 или число порядка этого) этот массив превращается в хэш-таблицу. Когда вы конфликт разрешаете, вы по хэшу пришли в заданный индекс массива, а потом идете в одну из сторон.
ResourceOwner — это такой объект (насколько слово объект применимо для языка С), который хранит в себе разные ресурсы, файлы, шареную память и что-то еще. И он написан в предположении, что обычно мы ресурсы выделяем и кладем в массив, а освобождаем в обратном порядке. Поэтому при удалении ресурсов, он начинает их искать с конца. Размер массива он знает, ну, в смысле — у него есть индекс последнего элемента. Оказалось, что это условие выполняется не всегда и ему приходится во все стороны искать по этому массиву, поэтому он тупит. Патч заключается в том, что при определенном количестве ресурсов (около 16 или число порядка этого) этот массив превращается в хэш-таблицу. Когда вы конфликт разрешаете, вы по хэшу пришли в заданный индекс массива, а потом идете в одну из сторон.
Кстати, если кого-то интересует вопрос, кому в третьем тысячелетии приходится писать свои хэш-таблицы, то вот я сижу и в двух патчах пишу свои хэш-таблицы, потому что не подходят нам стандартные реализации. Это тоже уже есть в 9. 6, там ResourceOwner не тупит, если у вас партицированная сильно таблица. В смысле, он все еще тупит, но слабее.
6, там ResourceOwner не тупит, если у вас партицированная сильно таблица. В смысле, он все еще тупит, но слабее.
С помощью perf можно строить такие красивые картинки, они называются флеймграфы. Это читается снизу вверх. Внизу у нас есть процедура, потом — пропорционально тому, сколько времени где она проводит и в свою очередь вызывает — у нас поделено на другие процедуры. Потом вверх идем, у нас так же пропорционально делится, сколько времени она где проводит. И далее вверх. Это очень наглядно, но может быть непривычно, если вы первый раз такое видите. На самом деле, это очень наглядный отчет, намного нагляднее примера с графом, который Gprof строит. Обратите внимание, как экономно используется место, на слайдах это нельзя показать, но во все это можно кликать. И у него есть подсказка, которая показывает проценты.
Вот увеличенный кусок, это где-то из середины часть:
Собственно это, наверное, все. Мы этим часто пользуемся. На предыдущей работе мы таким же образом анализировали логи. Там была другая история — был АК-кластер, распределенное приложение, и мы по логам строили такие вещи, пытаясь понять, где же у нас тормозит код. Логи, разумеется, нужно было со всех бэкендов агрегировать. В общем, удобная штука, всем рекомендую.
Там была другая история — был АК-кластер, распределенное приложение, и мы по логам строили такие вещи, пытаясь понять, где же у нас тормозит код. Логи, разумеется, нужно было со всех бэкендов агрегировать. В общем, удобная штука, всем рекомендую.
Это Брендон Грегг. Он изобрел flame graphs и чуть ли не сам perf. Наверное, он не совсем один писал, но существенно в него вложился. Также он известен в видео на YouTube, где он орет на жесткие диски в дата-центре, и у него увеличивается latency при обращении к этим дискам — замечательное видео. Если кому интересно, это реальная тема, правда, с SSD работает это или нет — не знаю.
Недавно было похожая история, про то, как во время пожарных учений в банке вырубило весь дата-центр, потому что слишком громко свистели трубы, которые подают газ, который тушит огонь. То есть вибрация воздуха вырубила все диски.
К Брендону мы еще вернемся, потому что он знает все про профайлинг и очень много в это все вложил, сейчас он этим занимается в Netflix.
http://eax.me/freebsd-pmcstat/
Pmcstat — это инструмент исключительно под FreeBSD. Когда я делал эти слайды, я думал что ни у кого не будет FreeBSD, поэтому здесь нет особых подробностей про pmcstat, т.к. остальным это не очень интересно. Но краткое содержание такое, что с его помощью можно делать все то же самое, что с помощью perf. Он также делает top, тоже строит flame graphs и он ничем не хуже, просто команды другие. Кому интересно, вот ссылка на конкретную статью.
Переходим к более серьезным инструментам. SystemTap. Выше до этого был профайлинг CPU, где что-то тормозит, а SystemTap позволяет делать еще больше — вы можете посмотреть буквально на все, что угодно, в ядре, померить, сколько у вас пакетов по сети уходит, обращение к диску померить и все что угодно, ограничено только вашей фантазией. SystemTap позволяет писать вот такие скрипты, в данном случае трейсится вызов ip_rcv, то есть получение какого-то iP пакета.
Плюсы и минусы. Главных минусов 2. Во-первых, это не какой-то официальный инструмент для Linux, это чуваки из Red Hat запилили в основном для себя, для отладки своего кода, как я это понимаю. Его очень неудобно устанавливать, нужно скачивать пакет с отладочными символами ядра, потом его устанавливать, потом очень долго компилить сам SystemTap, он тоже так не просто компилируется, нужны версии. Но в конечном счете оно начинает работать. Второй недостаток — то, что вам нужно хорошо понимать базу того, что вы хотите проанализировать, потрейсить. Не все знают наизусть ядро Linux. Но если вы хорошо знаете свой код, вы можете это использовать.
Во-первых, это не какой-то официальный инструмент для Linux, это чуваки из Red Hat запилили в основном для себя, для отладки своего кода, как я это понимаю. Его очень неудобно устанавливать, нужно скачивать пакет с отладочными символами ядра, потом его устанавливать, потом очень долго компилить сам SystemTap, он тоже так не просто компилируется, нужны версии. Но в конечном счете оно начинает работать. Второй недостаток — то, что вам нужно хорошо понимать базу того, что вы хотите проанализировать, потрейсить. Не все знают наизусть ядро Linux. Но если вы хорошо знаете свой код, вы можете это использовать.
Есть интересное свойство — код транслируется в С, потом это компилируется в модуль ядра, который подгружается и собирает всю статистику, все трейсит. При этом вы можете не бояться делить на ноль, разыменовывать указатели неправильные. Если это написать в скриптовом языке, это не приведет к крэшу ядра, оно просто аккуратно свернет лапки и выгрузится, но ваше ядро продолжит работать.
Есть автоматический вывод типов. Правда, там всего два или три типа, зато они автоматически выводятся.
Лично мне страшно было бы использовать это в продакшне, потому что он не производит впечатления стабильного инструмента. Один тот факт — у вас скрипт секунд 10 компилируется и загружается, а что в это время будет там тормозить, не тормозить, не очень понятно. Я бы не рискнул, но, может, вы смелее.
DTrace — это тоже прикольный инструмент, не только для FreeBSD, в Linux тоже есть, все хорошо. Он похож на SystemTap, в этом примере мы трейсим системный вызов poll, притом для процессов, которые называются postgres. Здесь трейсится, с какими аргументами он вызывается и что возвращается.
Плюсы и минусы. Во-первых, он, в отличие от SystemTap, прямо есть в системе из коробки, ничего не надо устанавливать, компилировать. Есть во FreeBSD, в Mac OS. Для Linux он тоже есть, если вы каким-то образом используете Oracle Linux. Кроме того, есть проект dtrace4linux на GitHub, он компилируется, работает, я проверял. В принципе, можно пользоваться.
В принципе, можно пользоваться.
В отличие от SystemTap, DTrace не страшно использовать в продакшне — заходите на ваш Mac в боевом окружении и трейсите все, что угодно. По моим субъективным ощущениям, DTrace больше для админов, потому что у вас в ядре есть куча пробов на все что угодно, вам не нужно знать кодовую базу, вы просто говорите: «Хочу собрать статистику по IP-пакетам — сколько пришло, сколько ушло». Кстати, есть наборы готовых утилит, вам не нужно обязательно скриптами все самим писать. DTrace Toolkit называется.
А SystemTap скорее не для админов, а для разработчиков: «Я знаю код ядра, я хочу вот в этом месте потрейсить, без написания какого-то кода, не патча его».
До сих пор мы говорили про профайлинг в плане использования ЦПУ, но еще частая проблема — это «а что, если у меня отжирается много памяти?». Лично мне нравится инструмент HeapTrack, если вы когда-нибудь использовали Valgrind Massif, то он такой же, только быстрый, но с ограничением — работает только на Linux.
Здесь (на слайде выше) пример текстового отчета, найдено место, которое отъедает больше всего памяти, есть конкретные номера строк, имена файлов с исходниками и так далее.
Кроме того, он может строить вот такие красивые отчеты в инструменте Massif Visualizer. В нем можно все открывать, это все в динамике. Там память росла, потом достигла своего пика, потом она начала падать, освобождаться, выделяться, справа есть трейсы. Все очень наглядно и красиво.
Плюсы и минусы. Он быстрый, в отличие от Valgrind. Может цепляться к запущенным процессам, можно запускать под ним процессы. Красивые отчеты. Он умеет находить мемори лики. Немного криво их находит, если у вас стандартная библиотека языка выделила 16 кБ под какие-то свои внутренние нужды и потом их не освободила, потому что «ну, зачем?», он скажет, что это мемори лик. Но, в принципе, довольно полезный инструмент, несмотря на все это.
Можно построить гистограмму, что у меня кусочки размером в 8 байт выделяются больше всего, а кусочки памяти размером 32 байта выделяются чуть реже. Такая красивая гистограмма получается.
Такая красивая гистограмма получается.
Про стек он ничего не знает, если вам нужен стек или нужно что-то за пределами Linux, то используйте Valgrind. Я Linux’оид, поэтому ничего не знаю про Valgrind.
Есть такая тема в Linux, называется BPF, изначально это был Berkeley Packet Filter и, как можно догадаться по названию, имеет отношение к Berkeley и какой-то там фильтрации пакетов, но BPF он где-то в 2.6 ветку приземлил в свое время. Но в результате его доработали и, по сути, он превратился, не без помощи уже упомянутого Брендона Грегга, в DTrace в Linux.
Он позволяет делать абсолютно все то же самое. Недавно у Брендона был пост в блоге, где он пишет, что в ядро 4.9, которое сейчас все еще релиз-кандидат, но скоро будет, туда приземлились окончательно изменения в BPF. Больших, крупных изменений не будет, может, они что-то зарефачат, может, немного поправят, но чтобы активно добавлять — такого уже не будет.
Bcc — это набор утилит, который использует BPF для профайлинга разных мест ядра. На картинке это все названия утилит. Вы фактически любое место в ядре можете потрейсить, попрофайлить в ядре.
На картинке это все названия утилит. Вы фактически любое место в ядре можете потрейсить, попрофайлить в ядре.
Недостаток у BPF в том, что у него нет еще своего скриптового языка, как есть у DTrace, SystemTap, но в этом направлении уже есть наработки. В частности, парни из Red Hat подключились, они взяли свой SystemTap и сделали его сборку для BPF. То есть используется язык SystemTap, но работает оно на BPF. Оно пока какое-то ограниченное, вообще не поддерживает строковый тип, но они работают над этим.
Суть в том, что BPF — это, похоже, наше далекое светлое будущее, и он является наибольшим общим знаменателем, к которому в итоге пришли все компании, потому что там были какие-то скрипты у Facebook, был SystemTap у Red Hat, потому что им нужно было для разработки что-то такое трейсить. Они свою задачу решили и им больше ничего не надо. А BPF — это то, что должно в результате решать нужды всех, и оно уже прямо в ядре из коробки готовое и, похоже, в итоге все к этому придут и через пару лет наступит большое счастье.
Главный вопрос, который будоражит умы миллионов: «Хорошо, много инструментов, что и когда использовать?». Что лично я использую. Отладчики. Если вы подозреваете lock contention, его легко довольно заподозрить, вы в perf top не будете видеть, что кто-то жрет большое количество времени, наверное, оно висит в локах. Perf, если вы думаете, что уперлись в СPU, это в обычном htop видно — вот процесс, он жрет много СPU. Pmcstat, если у вас FreeBSD, SystemTap, мне кажется, бесполезный инструмент по той причине, что есть perf — он удобнее. Имеется в виду в контексте именно профайлинга, то есть профайлить я могу perf’ом, а для трейсировки SystemTap он ничего, он только не про профайлинг.
DTrace — это, если вы сидите под Mac, то он — ваше все, потому что он умеет все.
HeapTrack для памяти, Vagrant Massif — если вы на Linux, и BPF — это светлое будущее, но сейчас я бы не стал ставить 4. 9 в продакт, но, может, вы смелее, опять же.
Хочу порекомендовать книги с соавторством Брендона Грегга.
Первая — Systems Performance: Enterprise and the Cloud — потрясающая книга, ее обязательно нужно читать всем поголовно. Это одна из лучших книг, которую я читал и которая связана с программированием. Она взорвала мозг мне, потом шрапнелью задела мозги коллег, в общем, просто прочитайте.
Вторая книга про DTrace — тоже книга Брендона Грегга в соавторстве с парнем, который я не знаю, чем примечателен. Ее я не читал, полистал, это такой большой сборник рецептов про DTrace. Там дается команда, и что она делает, примеры скриптов. И так на тысячу страниц. Мне кажется, это не очень интересное чтиво, но если вы сильно интересуетесь DTrace, вечером полистать вредно не будет.
Куча онлайн-ресурсов:
- Это ссылка на мой бложик;
- http://www.brendangregg.com/blog/index.html — блог Брендона Грегга — подписаться обязательно, он там постит умопомрачительные вещи.
- http://dtrace.org/blogs/ — блог DTrace я тоже читаю, там есть интересные статьи.

- Дальше. https://sourceware.org/systemtap/ — сайт SystemTap’а.
- FreeBSD в wiki — https://wiki.freebsd.org/DTrace
- И в handbook’е можно прочитать про DTrace. Даже если вы пользуетесь Mac, все равно полистайте handbook, там есть хорошие примеры — https://www.freebsd.org/doc/handbook/dtrace.html
- И в конце мануал Intel — http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html. Там можно почитать, собственно, на чем паразитирует perf, что такое РMC, прямо в процессорах есть инструкции, которые позволяют все это мерить.
У меня все.
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. До конференции HighLoad++ 2017 осталось меньше месяца.У нас уже готова Программа конференции, сейчас активно формируется расписание.
В этом году доклады по тегу «Правильные ручки«:
- Хочу всё сжать / Андрей Аксенов
- Защищаемость от DDoS на этапе проектирования системы / Рамиль Хантимиров
- Чем заняться вечером, если я знаю, сколько будет ++i + ++i / Андрей Бородин
- Как развивать библиотеку компонентов, не ломая её / Артур Удалов
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.
Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Профилирование Python-программ и анализ их производительности / Хабр
Профилирование — это неотъемлемая часть любых работ по оптимизации кода или производительности программ. Любой опыт, любые знания в сфере оптимизации производительности, которые уже у вас есть, не принесут особой пользы в том случае, если вы не знаете о том, где их применить. В результате оказывается, что поиск узких мест приложений может помочь в деле решения проблем производительности, поможет сделать это быстро и приложив не слишком много усилий.
В этом материале мы обсудим инструменты и методы работы, которые способны обнаруживать и конкретизировать проблемы с производительностью кода, связанные и с ресурсами процессора, и с потреблением памяти. Здесь же мы поговорим о том, как реализовывать (почти безо всяких усилий) простые механизмы, позволяющие бороться с проблемами производительности. Эти механизмы используются в тех случаях, когда даже точно просчитанные изменения кода больше не позволяют улучшить ситуацию.
Эти механизмы используются в тех случаях, когда даже точно просчитанные изменения кода больше не позволяют улучшить ситуацию.
Идентификация узких мест
В деле оптимизации производительности программ лениться — это хорошо. Вместо того чтобы пытаться понять то, какая именно часть кодовой базы замедляет приложение, можно просто воспользоваться инструментами профилирования кода. Они позволят найти те места приложения, на которые стоит обратить внимание, такие, которые нуждаются в более глубоком исследовании.
Самый распространённый инструмент, который используют для этих целей Python-разработчики — это cProfile. Это — стандартный модуль, который способен измерять время выполнения функций.
Рассмотрим следующую функцию, которая возводит (медленно) e в степень X:
# some-code.py from decimal import * def exp(x): getcontext().prec += 2 i, lasts, s, fact, num = 0, 0, 1, 1, 1 while s != lasts: lasts = s i += 1 fact *= i num *= x s += num / fact getcontext().prec -= 2 return +s exp(Decimal(3000))
Исследуем этот медленный код с помощью cProfile:
python -m cProfile -s cumulative some-code.py
1052 function calls (1023 primitive calls) in 2.765 seconds
Ordered by: cumulative timek
ncalls tottime percall cumtime percall filename:lineno(function)
5/1 0.000 0.000 2.765 2.765 {built-in method builtins.exec}
1 0.000 0.000 2.765 2.765 some-code.py:1(<module>)
1 2.764 2.764 2.764 2.764 some-code.py:3(exp)
4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:986(_find_and_load)
4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:956(_find_and_load_unlocked)
4/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap>:650(_load_unlocked)
3/1 0.000 0.000 0.001 0.001 <frozen importlib._bootstrap_external>:842(exec_module)
5/1 0.000 0. 000 0.001 0.001 <frozen importlib._bootstrap>:211(_call_with_frames_removed)
1 0.000 0.000 0.001 0.001 decimal.py:2(<module>)
...
000 0.001 0.001 <frozen importlib._bootstrap>:211(_call_with_frames_removed)
1 0.000 0.000 0.001 0.001 decimal.py:2(<module>)
...Тут мы воспользовались опцией -s cumulative для сортировки выходных данных по суммарному времени, затраченному на выполнение каждой из функций. Это упрощает поиск проблемных участков кода. Видно, что почти всё время (примерно 2,764 секунды) в ходе одного сеанса выполнения программы было потрачено в функции exp.
Профилирование подобного рода может принести пользу, но его, к сожалению, не всегда достаточно. cProfile снабжает нас информацией лишь о вызовах функций, но не об отдельных строках кода. Если вызвать какую-то особую функцию, вроде append, в разных местах, то сведения обо всех её вызовах будут собраны в одной строке отчёта cProfile. То же самое относится и к скриптам, вроде того, который мы исследовали выше. Он содержит единственную функцию, которая вызывается лишь один раз, в результате у cProfile оказывается не особенно много данных для формирования отчёта.
Иногда такая роскошь, как локальная отладка проблемного кода, программисту не доступна. Или бывает так, что нужно проанализировать проблему с производительностью, что называется, «на лету», когда она возникает в продакшн-окружении. В таких ситуациях можно воспользоваться пакетом py-spy. Это — профилировщик, способный исследовать программы, которые уже запущены. Например — приложения, работающие в продакшне, или на любой удалённой системе:
pip install py-spy python some-code.py & [1] 1129587 ps -A -o pid,cmd | grep python ... 1129587 python some-code.py 1130365 grep python sudo env "PATH=$PATH" py-spy top --pid 1129587
В этом фрагменте кода мы сначала устанавливаем py-spy, а потом, в фоне, запускаем программу, которая выполняется длительное время. Это приводит к автоматическому показу идентификатора процесса (PID), но если мы его не знаем, можно, для его выяснения, воспользоваться командой ps. И, наконец, мы запускаем py-spy в режиме top, передавая ему PID. Это ведёт к выводу данных, очень похожих на те, что выводит Linux-утилита
Это ведёт к выводу данных, очень похожих на те, что выводит Linux-утилита top.
Тут, правда, в нашем распоряжении оказывается не так много данных, так как скрипт представляет собой всего лишь одну функцию, выполняющуюся длительное время. Но в реальных случаях, вероятнее всего, подобный отчёт будет содержать сведения о многих функциях, совместно использующих процессорное время. А это может помочь несколько прояснить ситуацию с существующими проблемами производительности программы.
Более глубокое исследование кода
Профилировщики, о которых мы только что говорили, должны помочь вам в деле обнаружения функций, которые вызывают проблемы, связанные с производительностью. Но если это не приведёт к обнаружению конкретных строк кода, которые надо доработать, это значит, что мы можем обратиться к профилировщикам, которые позволяют исследовать программы на более глубоком уровне.
Первый из таких инструментов представлен пакетом line_profiler. Он, как можно судить по его названию, может использоваться для выяснения того, сколько времени уходит на выполнение каждой конкретной строки кода:
Он, как можно судить по его названию, может использоваться для выяснения того, сколько времени уходит на выполнение каждой конкретной строки кода:
# https://github.com/pyutils/line_profiler pip install line_profiler kernprof -l -v some-code.py # Это может занять некоторое время... Wrote profile results to some-code.py.lprof Timer unit: 1e-06 s Total time: 13.0418 s File: some-code.py Function: exp at line 3 Line # Hits Time Per Hit % Time Line Contents 3 @profile 4 def exp(x): 5 1 4.0 4.0 0.0 getcontext().prec += 2 6 1 0.0 0.0 0.0 i, lasts, s, fact, num = 0, 0, 1, 1, 1 7 5818 4017.0 0.7 0.0 while s != lasts: 8 5817 1569.0 0.3 0.0 lasts = s 9 5817 1837.0 0.3 0.0 i += 1 10 5817 6902.0 1.2 0.1 fact *= i 11 5817 2604.0 0.4 0.0 num *= x 12 5817 13024902.0 2239.1 99.9 s += num / fact 13 1 5.0 5.0 0.0 getcontext().prec -= 2 14 1 2.0 2.0 0.0 return +s
Библиотека line_profiler распространяется вместе с интерфейсом командной строки kernprof (названным так в честь Роберта Керна), который используется для организации эффективного анализа результатов тестовых прогонов программ. Передача нашего кода этой утилите приводит к созданию .lprof-файла со сведениями об анализе кода. В нашем распоряжении, кроме того, оказывается отчёт, выводимый на экран (при использовании опции -v), подобный показанному выше. Тут чётко видны места функции, на выполнение которых уходит больше всего времени. Это очень сильно помогает в деле поиска и исправления проблем с производительностью. В выходных данных можно заметить декоратор @profile, добавленный к функции exp.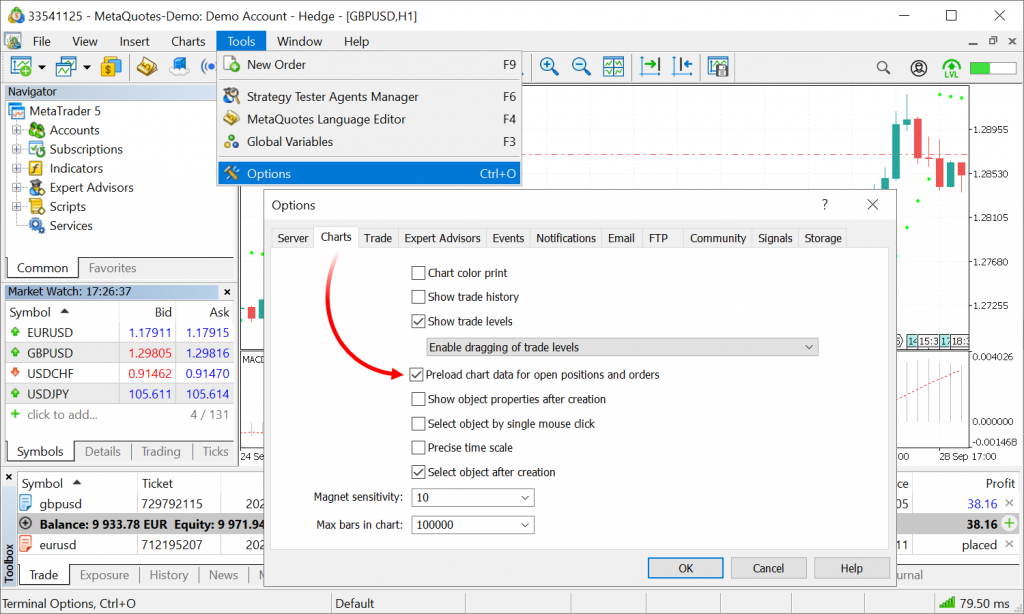 Это — необходимое дополнение, которое позволяет
Это — необходимое дополнение, которое позволяет line_profiler узнать о том, какую именно функцию в файле мы хотим изучить.
Но даже если построчно проанализировать функцию, первоисточник проблем с производительностью можно и не обнаружить. Например, такое бывает в том случае, если в конструкциях while или if используются условия, составленные из множества выражений. В подобных случаях имеет смысл переписать проблемные фрагменты, разбить одну строку кода на несколько. Это позволит получить более полные и понятные результаты анализа.
Если же вы — по-настоящему ленивый разработчик (как я), и чтение текстового вывода в интерфейсе командной строки — это для вас уже слишком — тогда вот вам ещё один инструмент — pyheat. Это — профилировщик, основанный на pprofile, ещё одном построчном профилировщике, создатели которого черпали вдохновение из кода line_profiler. Этот профилировщик генерирует тепловую карту для строк/областей кода, выполнение которых занимает основную долю времени выполнения программы:
pip install py-heat pyheat some-code.Тепловая карта, построенная с помощью pyheatpy --out image_file.png
Учитывая простоту кода нашего примера, отчёт, выводимый на экран с помощью kernprof, который мы видели, выглядит достаточно понятным. Но вышеприведённая тепловая карта ещё лучше идентифицирует узкое место нашей функции.
До сих пор мы говорили лишь о профилировании, имеющем отношение к ресурсам процессора. Но то, как программа пользуется CPU, не всегда является тем, что волнует разработчика. Оперативная память — дешёвый ресурс, поэтому программисты обычно не задумываются о её использовании. По крайней мере — до тех пор, пока программа не исчерпает доступную память.
Даже если ваша программа не попала в ситуацию, когда ей не хватает памяти, всё равно, то, как приложение пользуется памятью, стоит исследовать. Сделать это можно для того чтобы узнать, можно ли оптимизировать код с прицелом на экономию памяти, или можно ли дать программе больше памяти ради повышения её производительности. Для анализа использования памяти можно воспользоваться инструментом memory_profiler. Он похож на уже известный вам
Он похож на уже известный вам line_profiler:
# https://github.com/pythonprofilers/memory_profiler pip install memory_profiler psutil psutil is needed for better memory_profiler performance python -m memory_profiler some-code.py Filename: some-code.py Line # Mem usage Increment Occurrences Line Contents 15 39.113 MiB 39.113 MiB 1 @profile 16 def memory_intensive(): 17 46.539 MiB 7.426 MiB 1 small_list = [None] * 1000000 18 122.852 MiB 76.312 MiB 1 big_list = [None] * 10000000 19 46.766 MiB -76.086 MiB 1 del big_list 20 46.766 MiB 0.000 MiB 1 return small_list
Это испытание мы проводим на другом фрагменте кода.
Функция memory_intensive создаёт и уничтожает большие Python-списки. На её примере мы способны оценить ту пользу, которую может принести нам memory_profiler в деле анализа использования памяти. Так же, как и при
Так же, как и при kernprof-профилировании, функцию надо оснастить декоратором @profile. Он позволит memory_profiler узнать о том, какой именно код мы хотим профилировать.
Тут видно, что для обычного списка, содержащего значения None, было выделено более 100 МиБ памяти. Анализируя эти данные, правда, надо учитывать то, что они отражают не реальное использование памяти, а то, сколько памяти было выделено при выполнении каждой из строк функции. В данном случае это значит, что переменные, хранящие списки, на самом деле, не занимают столько памяти. Здесь отражён лишь тот факт, что Python-объекты list, вероятнее всего, выделяют память с запасом, чтобы подстроиться под ожидаемый рост объёма данных, которые могут попасть в список.
Как мы уже видели, Python-списки часто потребляют сотни мегабайт или даже гигабайты памяти. Быстро улучшить ситуацию можно, прибегнув к оптимизации, которая заключается в переходе на обычные объекты array. Они эффективнее хранят данные примитивных типов, вроде
Они эффективнее хранят данные примитивных типов, вроде int или float. Кроме того, можно ограничить использование памяти, выбирая типы с меньшей точностью, применяя параметр typecode. Воспользуйтесь командой help(array) чтобы посмотреть таблицу, в которой перечислены доступные варианты типов и их требования к памяти.
Если же даже подобные инструменты, дающие точную и детализированную информацию, не позволяют найти узкие места кода, можно попытаться дизассемблировать код и выйти на реальный байт-код, используемый интерпретатором Python. А если и дизассемблирование не помогает решить имеющуюся проблему — тогда полезным может оказаться выяснение и понимание того, какие операции выполняются в недрах Python при вызове некоей функции. Вооружившись знаниями, полученными в ходе таких исследований, в будущем вы сможете писать более производительный код.
Дизассемблированный вариант кода можно сгенерировать, воспользовавшись встроенным модулем dis, передав функцию методу dis.. Он сгенерирует и выведет список инструкций байт-кода, выполняемого при вызове функции. dis(...)
dis(...)
from math import e def exp(x): return e**x # math.exp(x) import dis dis.dis(exp)
В этом материале мы всё время исследовали очень медленную реализацию возведения e в степень X. Выше же представлена простейшая функция, которая решает эту задачу с высокой скоростью. Теперь мы можем сравнить результаты дизассемблирования быстрой и медленной функций. Результаты их дизассемблирования окажутся совершенно различными. Их изучение делает ещё более очевидным тот факт, что одна функция гораздо медленнее другой.
Вот как выглядит быстрая функция:
2 0 LOAD_GLOBAL 0 (e)
2 LOAD_FAST 0 (x)
4 BINARY_POWER
6 RETURN_VALUEА вот — наша старая функция, которая работает медленно:
4 0 LOAD_GLOBAL 0 (getcontext)
2 CALL_FUNCTION 0
4 DUP_TOP
6 LOAD_ATTR 1 (prec)
8 LOAD_CONST 1 (2)
10 INPLACE_ADD
12 ROT_TWO
14 STORE_ATTR 1 (prec)
5 16 LOAD_CONST 2 ((0, 0, 1, 1, 1))
18 UNPACK_SEQUENCE 5
20 STORE_FAST 1 (i)
22 STORE_FAST 2 (lasts)
24 STORE_FAST 3 (s)
26 STORE_FAST 4 (fact)
28 STORE_FAST 5 (num)
6 >> 30 LOAD_FAST 3 (s)
32 LOAD_FAST 2 (lasts)
34 COMPARE_OP 3 (!=)
36 POP_JUMP_IF_FALSE 80
. ..
100 RETURN_VALUE
..
100 RETURN_VALUEДля того чтобы лучше разобраться в том, что именно тут происходит — рекомендую взглянуть на этот ответ со StackOverflow, в котором раскрывается смысл столбцов, по которым распределены эти данные.
Подходы к решению проблем
Тот, кто занимается оптимизацией программы, рано или поздно доведёт её до такого состояния, когда изменения в коде или в алгоритмах начнут давать совсем небольшие улучшения. В этот момент хорошо будет обратить внимание на внешние инструменты, способные дать дополнительный прирост производительности.
Верный способ улучшить скорость работы кода заключается в компиляции его в виде C-программы. Это можно сделать, воспользовавшись различными инструментами. Например — PyPy или Cython. Первый из них — это JIT-компилятор, который можно использовать как непосредственную замену CPython. Он может дать, не требуя никаких усилий от программиста, значительный рост производительности кода. Его применение вполне может стать достойным решением некоей проблемы с производительностью. Для того чтобы воспользоваться PyPy — достаточно загрузить соответствующий архив, распаковать его и запустить с помощью PyPy свой код:
Для того чтобы воспользоваться PyPy — достаточно загрузить соответствующий архив, распаковать его и запустить с помощью PyPy свой код:
# Загрузить архив можно с https://www.pypy.org/download.html tar -xjf pypy3.8-v7.3.7-linux64.tar.bz2 cd pypy3.8-v7.3.7-linux64/bin ./pypy some-code.py
Просто чтобы доказать то, что благодаря PyPy можно, не прилагая особых усилий, сразу же улучшить производительность программы, устроим небольшое испытание скрипта, запущенного с помощью CPython и PyPy:
time python some-code.py real 0m2,861s user 0m2,841s sys 0m0,016s time pypy some-code.py real 0m1,450s user 0m1,422s sys 0m0,009s
PyPy, помимо вышеозначенных плюсов, отличается ещё и тем, что для его использования не нужно вносить в код никаких изменений. Он, кроме того, поддерживает все встроенные модули и функции Python.
Всё это звучит просто замечательно, но использование PyPy означает необходимость идти на кое-какие компромиссы. Этот инструмент поддерживает проекты, нуждающиеся в C-привязках, такие, как numpy, но это создаёт значительную дополнительную нагрузку на систему, что сильно замедляет соответствующие библиотеки, сводя на нет другие улучшения производительности. PyPy, кроме того, не решает проблем с производительностью в ситуациях, когда применяются внешние библиотеки, или в случаях, когда речь идёт о работе с базами данных. И, аналогично, если речь идёт о программах, производительность которых привязана к подсистеме ввода/вывода, не стоит ожидать значительной выгоды от применения PyPy.
PyPy, кроме того, не решает проблем с производительностью в ситуациях, когда применяются внешние библиотеки, или в случаях, когда речь идёт о работе с базами данных. И, аналогично, если речь идёт о программах, производительность которых привязана к подсистеме ввода/вывода, не стоит ожидать значительной выгоды от применения PyPy.
Если PyPy вам не помогает — можете попробовать Cythoh. Это — компилятор, который использует C-подобные аннотации типов (не подсказки по типам, применяемые в Python) для создания компилируемых модулей расширения Python. Cython, кроме прочего, использует AOT-компиляцию, что может дать значительный прирост производительности благодаря уходу от холодного запуска приложений. Но использование Cython требует переработки существующего кода с использованием особого синтаксиса, что приводит к усложнению программ.
Если вы не против перейти на Python-синтаксис, немного отличающийся от обычного, тогда вам, возможно, интересно будет взглянуть на prometeo — встраиваемый язык, отражающий специфику конкретной предметной области, основанный на Python. Он, в частности, ориентирован на научные вычисления. Программы, написанные на
Он, в частности, ориентирован на научные вычисления. Программы, написанные на prometeo, транспилируются в чистый C-код. Их производительность сравнима со скоростью работы программ, изначально написанных на C.
Если же ни одно из представленных тут решений не позволит вам выйти на нужный уровень производительности, тогда вам, возможно, стоит писать свой оптимизированный код на C или Fortran, а для вызова этого кода из Python использовать EFI. Среди библиотек, которые способны вам в этом помочь, можно отметить ctypes и cffi для языка C, и f2py для Fortran.
Итоги
Первое правило оптимизации заключается в том, чтобы ничего не оптимизировать. Если же вам действительно это нужно — оптимизируйте то, что имеет смысл оптимизировать. Используйте инструменты для профилирования кода, о которых мы говорили — это позволит вам избежать пустой траты времени на улучшение малозначимых фрагментов программ. Ещё, занимаясь оптимизацией, полезно создавать воспроизводимые тесты производительности для улучшаемого фрагмента кода. Это позволит оценить реальное воздействие оптимизаций на производительность.
Это позволит оценить реальное воздействие оптимизаций на производительность.
Эта статья нацелена на то, чтобы помочь всем желающим в поиске источников проблем с производительностью. Но вот исправление таких проблем — это уже совсем другая история. Кое-какие идеи на эту тему можно найти в одной из моих предыдущих статей, посвящённой методам значительного ускорения Python-кода.
О, а приходите к нам работать? 😏Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
Присоединяйтесь к нашей команде.
Все о профилировании кода | Как правильно выбрать инструмент
Создание приложения, его тестирование и запуск в производство — это только полдела. Настоящее испытание — это когда пользователи испытывают приложение. Ваше приложение может быть очень сложным и непревзойденным по своим возможностям, но если выполнение следующего желаемого действия займет на пару секунд больше, ваши пользователи могут уйти.
Непрерывно отслеживайте цифровой опыт по различным каналам доставки на реальных устройствах. Узнать больше .
Производительность приложения зависит от того, насколько эффективен его код. Быстрый, чистый код, свободный от ненужных циклов или регрессий, делает приложение гораздо более отзывчивым и надежным. Здесь помогает код профилирования.
Что такое профилирование кода?
Профилирование кода проверяет код приложения, чтобы убедиться, что он оптимизирован, что приводит к высокой производительности приложения. Он анализирует память, ЦП и сеть, используемые каждым программным компонентом или подпрограммой.
Он анализирует память, ЦП и сеть, используемые каждым программным компонентом или подпрограммой.
Путем профилирования кода разработчики, тестировщики и инженеры по обеспечению качества могут определить, потребляет ли какая-либо процедура непропорциональный объем памяти или ресурсов ЦП, и оптимизировать ее для повышения производительности.
Какие преимущества дает профилирование кода разработчикам и инженерам по контролю качества?
Давайте разберемся, какую пользу могут извлечь разработчики и тестировщики из профилирования кода.
Сокращает циклы разработки программного обеспечения и делает его более гибким.
Разработчики могут постепенно улучшать код, профилируя его на каждом этапе разработки. Таким образом, им не нужно выполнять какой-либо значительный рефакторинг кода позже в процессе разработки, который требует много времени и усилий.
Читайте также: Рекомендации по тестированию производительности приложений
Обеспечивает надежную работу приложения при любых обстоятельствах.

Оптимизация кода имеет основополагающее значение для достижения высокой производительности приложений. Когда его код профилирован и оптимизирован, приложение может работать хорошо независимо от внешних факторов, таких как внезапные скачки трафика.
Выдача: Показатели тестирования производительности на стороне клиента, которые следует учитывать
Улучшает работу конечного пользователя, позволяя разработчикам исправлять аномалии в режиме реального времени.
Часто приложение может пройти все тесты и проверки качества в промежуточной среде, но по-прежнему создает проблемы для конечных пользователей во время выполнения. Профилирование кода позволяет разработчикам выявлять и устранять такие проблемы «на лету», обеспечивая максимальное удобство работы с приложениями для клиентов.
Типы профилирования кода
Существует два метода профилирования кода — выборка и инструментирование.
Профилировщик выборки
Профилировщик выборки работает, анализируя, какая инструкция сборки выполняется в данный момент и какие подпрограммы вызывают текущую функцию для профилируемого приложения.
Идентифицирует выполняющуюся в данный момент команду, определяя, когда операционная система прерывает ЦП для выполнения переключений процесса. Затем он использует символы отладки, связанные с исполняемым файлом приложения, для сопоставления точек реализации, записанных с соответствующей подпрограммой и строкой исходного кода.
Чтение: Сохранение тестовых данных для упрощения отладки
Выходные данные профилировщика выборки — это количество раз, когда подпрограмма или строка исходного кода выполняется во время выполнения приложения. С помощью профилировщика кода выборки разработчики могут определить, является ли подпрограмма слишком большой, что является потенциальным узким местом в производительности, и оптимизировать ее, чтобы завершить выполнение быстрее.
Преимущества
Профили выборки проверяют только частоту обычных вызовов и, следовательно, не мешают приложению во время выполнения и не влияют на его производительность.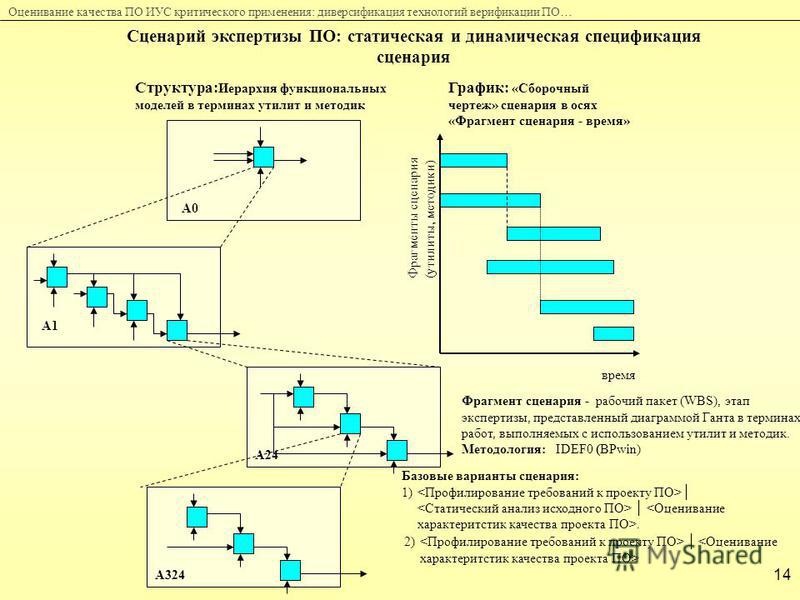 Он также никоим образом не изменяет исходный код, избегая возможного повреждения.
Он также никоим образом не изменяет исходный код, избегая возможного повреждения.
Недостатки
Результаты, полученные профилировщиками выборки, являются приблизительными и не точными, поскольку они профилируют код только посредством обращений к ЦП.
Например, небольшая подпрограмма может вызываться несколько раз во время профилирования и каждый раз завершать выполнение в пределах интервалов выборки. Профилировщик выборки сочтет это большой процедурой и пометит как узкое место, если это не реально.
Выписка: Полное руководство по TestNG
Инструментальный профилировщик
Инструментальный профилировщик работает, вставляя код в начале и в конце подпрограммы. Он определяет важные контрольные точки и вставляет в них код для записи рутинных последовательностей, времени или даже переменного содержимого.
Существует два типа инструментальных профилировщиков — профилировщик, изменяющий исходный код, и бинарный профайлер.
Эти профилировщики вставляют инструментальный код в исходный код во время запуска и завершения подпрограммы.
Двоичный профилировщик:Они работают во время выполнения, вставляя инструментальный код в исполняемый код приложения. Это не касается исходного кода.
Преимущества
Поскольку они работают путем перекомпиляции фактической программы, профилировщики инструментов могут записывать точное время выполнения подпрограммы для каждого вызова.
Инструментальные профилировщики предлагают точные данные с гораздо большей детализацией. Они могут предоставить информацию о последовательности подпрограмм и других подпрограмм, вызываемых из записанной.
Недостатки
Инструментальные профилировщики работают, изменяя исходный код, поэтому высока вероятность его повреждения.
Поскольку они вставляют дополнительный код в исходный код (или в исполняемый код в случае бинарных профилировщиков), они добавляют значительные накладные расходы во время выполнения и снижают производительность приложения.
Рекомендуемая публикация: Тестирование производительности на стороне клиента: метрики для рассмотрения
Несколько разных профилировщиков кода и то, что они измеряют:
- Профилировщик распределения: помогает находить объекты, которые не подвергаются сборке мусора, и сохранять память.
- Профилировщик покрытия: оценивает, сколько кода приложения было выполнено.
- Профилировщик трассировки функций: показывает, какие функции вызываются, когда и в какой последовательности во время выполнения приложения.
- Профилировщик эмулятора отказов: позволяет имитировать сбои в коде, чтобы оценить, может ли ваше приложение справиться с ними.
- Профилировщик производительности: помогает определить области кода, снижающие производительность приложения, и помогает оптимизировать код.
- Профилировщик ресурсов: отслеживает выделение ресурсов приложениям и проверяет, правильно ли объекты освобождают эти ресурсы.

Выбор профилировщика кода, который наилучшим образом соответствует вашим потребностям
В идеале это поможет выбрать профилировщик кода, который позволит вам измерять то, что вы хотите, не навязчивый и экономичный.
Этот аспект может показаться невозможным из того, что мы обсуждали выше — выбор одного профилировщика кода над другим может показаться компромиссом между скоростью и точностью, неинвазивностью и глубиной данных.
Однако это не так. Некоторые решения предлагают вам лучшее из обоих миров, то есть точные, подробные данные с минимальным вмешательством и без влияния на производительность приложений.
Проверить: Бесплатные инструменты для тестирования производительности мобильных приложений с помощью Appium 9 производительность таких как использование памяти и ОС, время выполнения и общая производительность приложения.Простота
из использование:Профиль не должен быть сложным.
Часто задаваемые вопросыОн должен быть интуитивно понятным, простым и включать минимальную настройку. Разработчики используют инструменты профилирования кода для повышения производительности приложений, поэтому усложнение кода приложения не принесет пользы.
1. Какие существуют методы профилирования распределения памяти и уровней?Ответ: Профилирование памяти: Профилирование памяти позволяет тестировщикам понять распределение памяти и поведение сборки мусора в приложениях с течением времени.
Профилирование распределения уровней: Это метод сбора статистики о синхронных вызовах функций базы данных SQL-сервера.
2. Что такое профилирование API?Ответ: API профилирования — это инструмент, используемый для написания профилировщика кода, программы, которая отслеживает выполнение управляемого приложения.
3.Что вы подразумеваете под пассивным профайлером?
Ответ: Пассивный профилировщик собирает информацию о выполнении приложения без изменения этого приложения. Пассивные профилировщики остаются вне приложения и наблюдают за его работой на расстоянии.
4. Что такое профилирование на основе событий? Ответ: Профилирование на основе событий (EBP) использует счетчики событий производительности оборудования для подсчета количества определенных типов событий, происходящих во время выполнения. Примерами событий являются тактовые циклы процессора, устаревшие инструкции, доступ к кэшу данных и промахи в кэше данных.
Что такое профилирование кода? Изучите 3 типа профилировщиков кода
Александра Альтватер Советы, рекомендации и ресурсы для разработчиков
В Stackify мы стремимся помочь вам повысить производительность вашего приложения.
На самом деле мы сами разработали два профилировщика кода. Из-за этого нам нравится думать, что мы кое-что знаем о профилировании кода.
Сегодня я хочу поговорить о трех различных типах профилировщиков кода, описать различия между ними и порекомендовать некоторые инструменты для вашего набора инструментов.
Итак, что именно делает профилирование кода?
Обычно профилировщики кода используются разработчиками для выявления проблем с производительностью, не затрагивая их код. Профилировщики могут ответить на такие вопросы, как «Сколько раз вызывается каждый метод в моем коде?» и «Сколько времени занимает каждый из этих методов?» Профилировщики также отслеживают такие вещи, как выделение памяти и сборка мусора. Некоторые профилировщики могут даже отслеживать ключевые методы в вашем коде, чтобы вы могли понять, как часто вызываются операторы SQL и веб-службы. Кроме того, некоторые профилировщики могут отслеживать веб-запросы и обучать эти транзакции, чтобы понять производительность транзакций в вашем коде.
Профилировщики кода могут отслеживать все до каждой отдельной строки кода. Однако большинство разработчиков используют профилировщики только при поиске проблем с ЦП или памятью, и им нужно приложить все усилия, чтобы попытаться найти эти проблемы. Это связано с тем, что многие профилировщики заставляют приложения работать в сто раз медленнее, чем обычно. Хотя большинство считает профилировщики ситуационным инструментом, не предназначенным для повседневного использования, профилирование кода может стать настоящим спасением, когда вам это нужно.
Профилировщики отлично подходят для поиска горячих путей в вашем коде. Выяснение того, что использует двадцать процентов общего использования ЦП вашего кода, а затем определение того, как это улучшить, было бы отличным примером того, когда следует использовать профилировщик кода. Кроме того, профилировщики также отлично подходят для раннего обнаружения утечек памяти, а также для понимания производительности вызовов зависимостей и транзакций.
Профилировщики помогают вам искать методы, которые со временем могут привести к улучшению. Один бывший наставник однажды сказал мне: «Если ты можешь улучшать что-то на один процент каждый день, то в течение месяца ты улучшишься на тридцать процентов». Что действительно имеет значение, так это постоянное улучшение с течением времени.
Типы профилировщиков кода
Существует два разных типа профилировщиков кода: серверные и настольные. Профилировщик на стороне сервера отслеживает производительность ключевых методов в предпроизводственной или производственной среде. Эти профилировщики измеряют время транзакций, например, отслеживают, сколько времени занимает веб-запрос, а также дают вам больше информации об ошибках и журналах. Примером профилировщика на стороне сервера может быть инструмент управления производительностью приложений, или сокращенно APM.
Профилирование кода рабочего стола выполняется медленнее и требует больших накладных расходов, что может сделать ваше приложение намного медленнее, чем должно быть.
Этот тип профилировщика обычно отслеживает производительность каждой строки кода в каждом отдельном методе. Эти типы профилировщиков также отслеживают выделение памяти и сборку мусора, чтобы помочь с утечками памяти. профилировщики настольных компьютеров очень хорошо находят этот горячий путь, выясняя каждый метод, который вызывается, и определяя, какой из них использует больше всего ЦП.
Но есть и другое решение. Для простоты назовем его гибридным профилировщиком.
Эти гибридные профилировщики кода объединяют ключевые данные из серверного профилирования с деталями на уровне кода на вашем рабочем столе для ежедневного использования. Эти профилировщики предоставляют информацию на уровне сервера в сочетании с возможностью отслеживать ключевые методы, каждую транзакцию, вызовы зависимостей, ошибки и журналы.
Инструменты, соответствующие этим трем различным типам профилировщиков
Для профилирования кода на стороне сервера большинство компаний используют APM.
В Stackify мы разработали продукт под названием Retrace.
Некоторые варианты профилировщиков кода для настольных компьютеров включают Visual Studio, NProfiler и другие.
Настоящих гибридных решений для профилирования кода очень мало. Среди них наш собственный гибридный профилировщик, который мы называем Prefix, который можно использовать бесплатно.
При сравнении серверных и гибридных профилировщиков кода имейте в виду несколько вещей. Многие профилировщики должны быть встроены в сам код. Это то, что заставляет большинство профилировщиков замедлять работу приложений, а также поэтому они, как правило, используются в определенных обстоятельствах.
Очень немногие профилировщики, такие как Prefix, способны собирать данные извне.
Немногие APM можно установить на ваш сервер без каких-либо изменений в коде. Большинство APM требуют изменения кода и/или нескольких изменений конфигурации.
- Об авторе
- Последние сообщения
Об Александре Альтватер
- Что такое методология Agile? Как это работает, передовой опыт, инструменты — 5 марта 2023 г.