примеры для различных CMS, правила, рекомендации
Правильная индексация страниц сайта в поисковых системах одна из важных задач, которая стоит перед владельцем ресурса. Попадание в индекс ненужных страниц может привести к понижению документов в выдаче. Для решения таких проблем и был принят стандарт исключений для роботов консорциумом W3C 30 января 1994 года — robots.txt.
Что такое Robots.txt?
Robots.txt — текстовый файл на сайте, содержащий инструкции для роботов какие страницы разрешены для индексации, а какие нет. Но это не является прямыми указаниями для поисковых машин, скорее инструкции несут рекомендательный характер, например, как пишет Google, если на сайт есть внешние ссылки, то страница будет проиндексирована.
На иллюстрации можно увидеть индексацию ресурса без файла Robots.txt и с ним.
Что следует закрывать от индексации:
- служебные страницы сайта
- дублирующие документы
- страницы с приватными данными
- результат поиска по ресурсу
- страницы сортировок
- страницы авторизации и регистрации
- сравнения товаров
Как создать и добавить Robots.
 txt на сайт?
txt на сайт?Robots.txt обычный текстовый файл, который можно создать в блокноте, следуя синтаксису стандарта, который будет описан ниже. Для одного сайта нужен только один такой файл.
Файл нужно добавить в корневой каталог сайта и он должен быть доступен по адресу: http://www.site.ru/robots.txt
Синтаксис файла robots.txt
Инструкции для поисковых роботов задаются с помощью директив с различными параметрами.
Директива User-agent
С помощью данной директивы можно указать для какого робота поисковой системы будут заданы нижеследующие рекомендации. Файл роботс должен начинаться с этой директивы. Всего официально во всемирной паутине таких роботов 302. Но если не хочется их все перечислять, то можно воспользоваться следующей строчкой:
User-agent: *
Где * является спецсимволом для обозначения любого робота.
Список популярных поисковых роботов:
- Googlebot — основной робот Google;
- YandexBot — основной индексирующий робот;
- Googlebot-Image — робот картинок;
- YandexImages — робот индексации Яндекс.
 Картинок;
Картинок; - Yandex Metrika — робот Яндекс.Метрики;
- Yandex Market— робот Яндекс.Маркета;
- Googlebot-Mobile —индексатор мобильной версии.
Директивы Disallow и Allow
С помощью данных директив можно задавать какие разделы или файлы можно индексировать, а какие не следует.
Disallow — директива для запрета индексации документов на ресурсе. Синтаксис директивы следующий:
Disallow: /site/
В данном примере от поисковиков были закрыты от индексации все страницы из раздела site.ru/site/
Примечание: Если данная директива будет указана пустой, то это означает, что весь сайт открыт для индексации. Если же указать Disallow: / — это закроет весь сайт от индексации.
Директива Sitemap
Если на сайте есть файл описания структуры сайта sitemap.xml, путь к нему можно указать в robots.txt с помощью директивы Sitemap. Если файлов таких несколько, то можно их перечислить в роботсе:
User-agent: *
Disallow: /site/
Allow: /
Sitemap: http://site. com/sitemap1.xml
com/sitemap1.xml
Sitemap: http://site.com/sitemap2.xml
Директиву можно указать в любой из инструкций для любого робота.
Директива Host
Host является инструкцией непосредственно для робота Яндекса для указания главного зеркала сайта. Данная директива необходима в том случае, если у сайта есть несколько доменов, по которым он доступен. Указывать Host необходимо в секции для роботов Яндекса:
User-agent: Yandex
Disallow: /site/
Host: site.ru
В роботсе директива Host учитывается только один раз. Если в файле есть 2 директивы HOST, то роботы Яндекса будут учитывать только первую.
Директива Clean-param
Clean-param дает возможность запретить для индексации страницы сайта, которые формируются с динамическими параметрами. Такие страницы могут содержать один и тот же контент, что будет являться дублями для поисковых систем и может привести к понижению сайта в выдаче.
Директива Clean-param имеет следующий синтаксис:
Clean-param: p1[&p2&p3&p4&.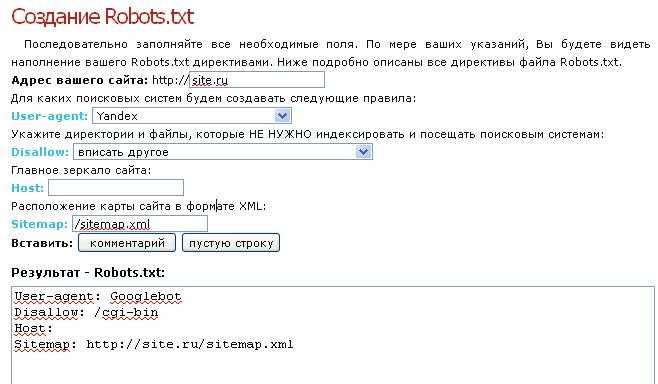 .&pn] [Путь к динамическим страницам]
.&pn] [Путь к динамическим страницам]
Рассмотрим пример, на сайте есть динамические страницы:
- https://site.ru/promo-odezhda/polo.html?kol_from=&price_to=&color=7
- https://site.ru/promo-odezhda/polo.html?kol_from=100&price_to=&color=7
Для того, чтобы исключить подобные страницы из индекса следует задать директиву таким образом:
Clean-param: kol_from1&price_to2&pcolor /polo.html # только для polo.html
или
Clean-param: kol_from1&price_to2&pcolor / # для всех страниц сайта
Директива Crawl-delay
Если роботы поисковиков слишком часто заходят на ресурс, это может повлиять на нагрузку на сервер (актуально для ресурсов с большим количеством страниц). Чтобы снизить нагрузку на сервер, можно воспользоваться директивой Crawl-delay.
Параметром для Crawl-delay является время в секундах, которое указывает роботам, что страницы следует скачивать с сайта не чаще одного раза в указанный период.
Пример использования директивы Crawl-delay:
User-agent: *
Disallow: /site
Crawl-delay: 4
Особенности файла Robots.txt
- Все директивы указываются с новой строки и не следует перечислять директивы в одной строке
- Перед директивой не должно быть указано каких-либо других символов (в том числе пробела)
- Параметры директив необходимо указывать в одну строку
- Правила в роботс указываются в следующей форме: [Имя_директивы]:[необязательный пробел][значение][необязательный пробел]
- Параметры не нужно указывать в кавычках или других символах
- После директив не следует указывать “;”
- Пустая строка трактуется как конец директивы User-agent, если нет пустой строки перед следующим User-agent, то она может быть проигнорирована
- В роботс можно указывать комментарии после знака решетки # (даже если комментарий переносится на следующую строку, на след строке тоже следует поставить #)
- Robots.txt нечувствителен к регистру
- Если файл роботс имеет вес более 32 Кб или по каким-то причинам недоступен или является пустым, то он воспринимается как Disallow: (можно индексировать все)
- В директивах «Allow», «Disallow» можно указывать только 1 параметр
- В директивах «Allow», «Disallow» в параметре директории сайта указываются со слешем (например, Disallow: /site)
- Использование кириллицы в роботс не допускаются
Спецсимволы robots.
 txt
txtПри указании параметров в директивах Disallow и Allow разрешается использовать специальные символы * и $, чтобы задавать регулярные выражения. Символ * означает любую последовательность символов (даже пустую).
Пример использования:
User-agent: *
Disallow: /store/*.php # запрещает ‘/store/ex.php’ и ‘/store/test/ex1.php’
Disallow: /*tpl # запрещает не только ‘/tpl’, но и ‘/tpl/user’
По умолчанию у каждой инструкции в роботсе в конце подставляется спецсимвол *. Для того, чтобы отменить * на конце, используется спецсимвол $ (но он не может отменить явно поставленный * на конце).
Пример использования $:
User-agent: *
Disallow: /site$ # запрещено для индексации ‘/site’, но не запрещено’/ex.css’
User-agent: *
Disallow: /site # запрещено для индексации и ‘/site’, и ‘/site.css’
User-agent: *
Disallow: /site$ # запрещен к индексации только ‘/site’
Disallow: /site*$ # так же, как ‘Disallow: /site’ запрещает и /site.
 css и /site
css и /siteОсобенности настройки robots.txt для Яндекса
Особенностями настройки роботса для Яндекса является только наличие директории Host в инструкциях. Рассмотрим корректный роботс на примере:
User-agent: Yandex
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Disallow: */css
Host: www.site.com
В данном случаем директива Host указывает роботам Яндекса, что главным зеркалом сайта является www.site.com (но данная директива носит рекомендательный характер).
Особенности настройки robots.txt для Google
Для Google особенность лишь состоит в том, что сама компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. В таком случае, робот примет такой вид:
User-agent: Googlebot
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Allow: *.css
Allow: *. js
js
Host: www.site.com
С помощью директив Allow роботам Google доступны файлы стилей и скриптов, они не будут проиндексированы поисковой системой.
Проверка правильности настройки роботс
Проверить robots.txt на ошибки можно с помощью инструмента в панели Яндекс.Вебмастера:
Также при помощи данного инструмента можно проверить разрешены или запрещены к индексации страницы:
Еще одним инструментом проверки правильности роботс является “Инструмент проверки файла robots.txt” в панели Google Search Console:
Но данный инструмент доступен только в том случае, если сайт добавлен в панель Вебмастера Google.
Заключение
Robots.txt является важным инструментом управления индексацией сайта поисковыми системами. Очень важно держать его актуальным, и не забывать открывать нужные документы для индексации и закрывать те страницы, которые могут повредить хорошему ранжированию ресурса в выдаче.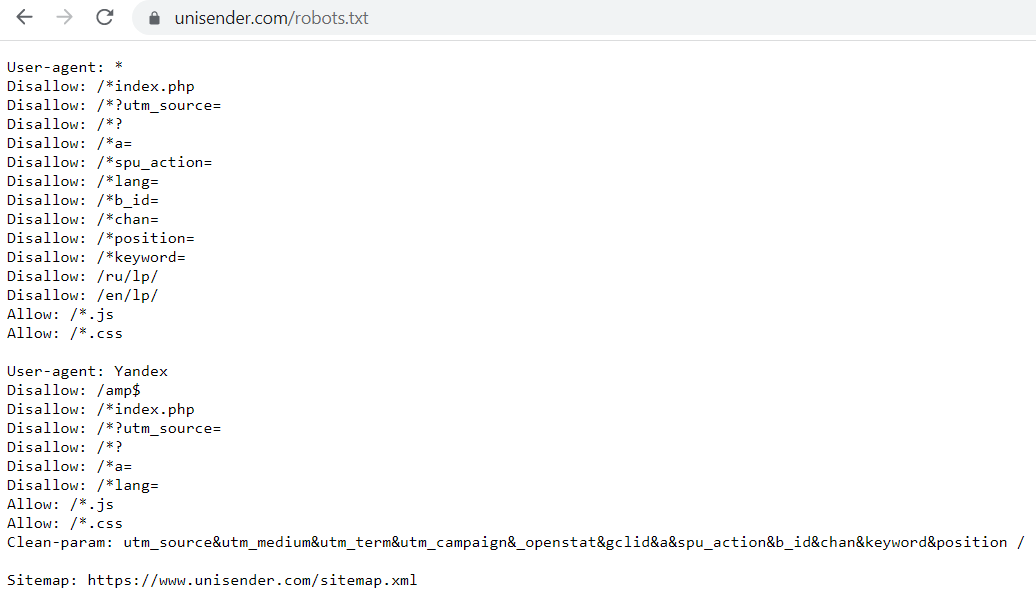
Пример настройки роботс для WordPress
Правильный robots.txt для WordPress должен быть составлен таким образом (все, что указано в комментариях не обязательно размещать):
User-agent: Yandex
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Host: www.site.ru
User-agent: Googlebot
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Allow: *. css # открыть все файлы стилей
css # открыть все файлы стилей
Allow: *.js # открыть все с js-скриптами
User-agent: *
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap1.xml
Пример настройки роботс для Bitrix
Если сайт работает на движке Битрикс, то могут возникнуть такие проблемы:
- попадание в выдачу большого количества служебных страниц;
- индексация дублей страниц сайта.
Чтобы избежать подобных проблем, которые могут повлиять на позицию сайта в выдаче, следует правильно настроить файл robots.txt. Ниже приведен пример robots. txt для CMS 1C-Bitrix:
txt для CMS 1C-Bitrix:
User-Agent: Yandex
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
HOST: https://site.ru
User-Agent: *
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
Sitemap: https://site.ru/sitemap.xml
User-Agent: Googlebot
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/tools/conversion/ajax_counter.php
Allow: /bitrix/components/main/
Allow: /bitrix/css/
Allow: /bitrix/templates/comfer/img/logo. png
png
Allow: /personal/cart/
Sitemap: https://site.ru/sitemap.xml
Пример настройки роботс для OpenCart
Правильный robots.txt для OpenCart должен быть составлен таким образом:
User-agent: Yandex
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Host: site. ru
ru
User-agent: Googlebot
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index. php
php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Umi.CMS
Правильный robots.txt для Umi CMS должен быть составлен таким образом (проблемы с дублями страниц в таком случае не должно быть):
User-Agent: Yandex
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.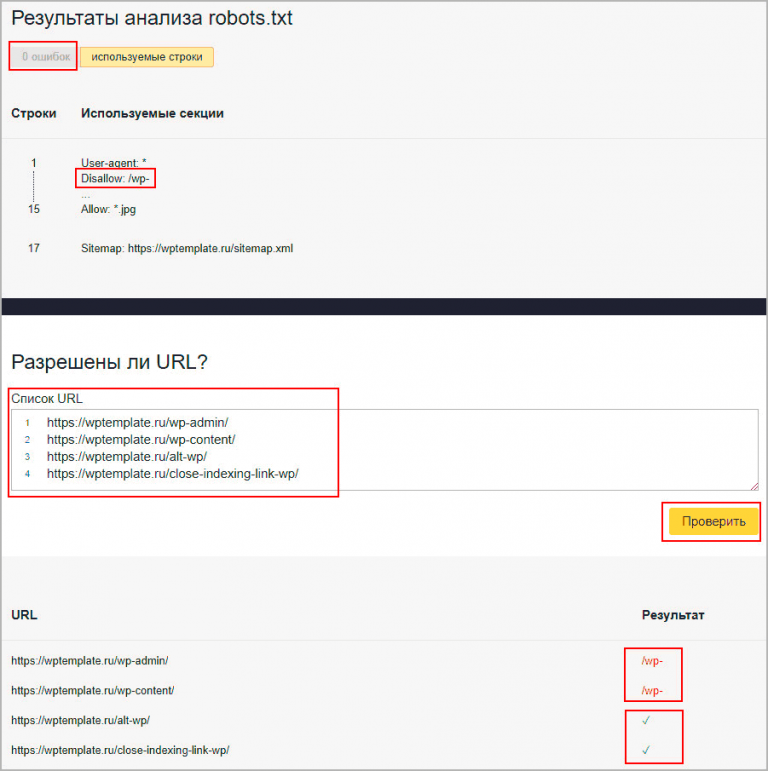 php
php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Host: site.ru
User-Agent: Googlebot
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Allow: *.css
Allow: *.js
User-Agent: *
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Joomla
Правильный robots. txt для Джумлы должен быть составлен таким образом:
txt для Джумлы должен быть составлен таким образом:
User-agent: Yandex
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Host: www.site.ru
User-agent: Googlebot
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Sitemap: http://www. site.ru/sitemap.xml
site.ru/sitemap.xml
Файл robots txt для сайта
Robots.txt – это служебный файл, инструкция для поисковых роботов для индексации сайта. В файле указываются каталоги, которые не требуется индексировать. Обычно это администраторская панель, кеш, служебные файлы. Размещается в корневой папке веб-ресурса. Его использование необходимо для лучшей индексации страниц, защиты приватной информации и повышения безопасности сайта.
Часто используется веб-мастерами вместе с другим служебным файлом, предусмотренным протоколом sitemap ( написанном на языке XML), который действует наоборот, предоставляя карту сайта с разрешенными к чтению роботами страницами.
Robots.txt и его влияние на индексацию сайта
На индексацию сайта также влияют скорость и надежность хостинга. Быстрый и надежный хостинг со скидкой до 30%!
После создания сайта его корневая папка на хосте становится доступной для поисковых систем. Роботы читают все, что найдут, без разбора.
В каталогах динамических сайтов, находящихся под управлением CMS, они не найдут никакой информации, ведь она хранится в базах данных MYSQL. Роботы, если им этого не запретить, беспрепятственно перебирают файлы в директориях, которые закрыты для посещения всем, кроме администратора. Это опасно для сайта и отнимает время у поисковиков, снижая скорость индексации веб-ресурса.
Роботы, если им этого не запретить, беспрепятственно перебирают файлы в директориях, которые закрыты для посещения всем, кроме администратора. Это опасно для сайта и отнимает время у поисковиков, снижая скорость индексации веб-ресурса.
Для хакеров и прочих компьютерных злоумышленников доступные к чтению служебные файлы – это еще не дверь, но замочная скважина, в которую они обязательно залезут с электронной отмычкой для получения контроля над всем сайтом. Если в файле robots.txt указать, что читать надо только индексные файлы, то знакомство поисковой системы с динамическим сайтом произойдет быстрее, а его безопасность повысится.
Для статических веб-ресурсов этот файл станет небольшой гарантией, что хранящиеся конфиденциальные данные (телефоны, адреса электронной почты и другие) не окажутся в открытом доступе.
Веб-мастер, создавая файл robots.txt, может запретить роботам поисковых систем посещение всего сайта или дать доступ к его индексации только одной из категорий или страниц сайта.
Какие страницы стоит запретить и закрыть в robots.txt?
Если на хосте, где размещен сайт, есть панель управления, то этот файл можно создать, открыв корневую папку и нажав кнопку «новый файл» (бывают варианты в названиях). Но лучше создать файл на домашнем компьютере, а для загрузки воспользоваться каналом FTP.
Самой удобной программой для создания файла robots.txt является Notepad++. Но не возбраняется использовать обычный блокнот из набора Windows или текстовый редактор Word. Сохранять файл надо с расширением .txt.
Даже если он написан неправильно, это не приведет к потере работоспособности сайта, как это происходит с неправильным файлом .htaccess.
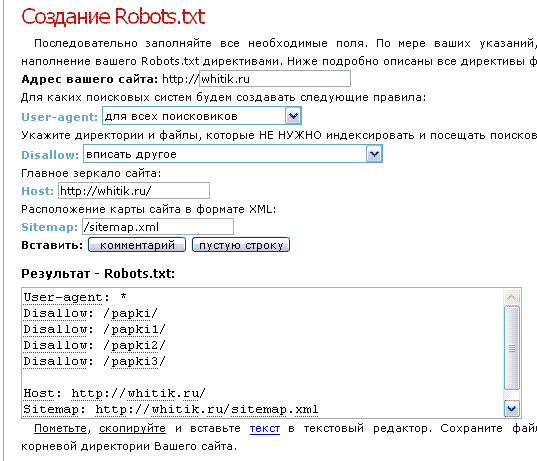
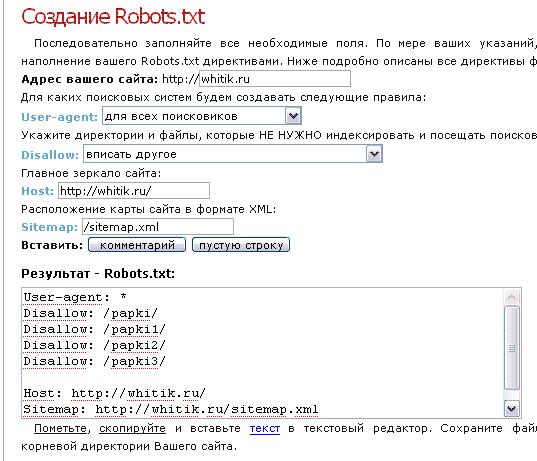
— Если не хочется ни изучать синтаксис файла, ни создавать его самостоятельно, то можно обратиться, например на http://pr-cy.ru/robots/, где его сгенерируют автоматически.
Директивы файла — user agent, host и т.д.
Директивы (команды) файла пишутся на латинице, после каждой из них ставится двоеточие и указывается объект управления.
Директивы бывают стандартные:
- User-agent – имя поискового робота;
- Allow – разрешить;
- Disallow – запретить;
- Sitemap – адрес, где находится sitemap.xml;
- * – для всех.
И расширенные:
- Craw-delay– промежуток времени между чтением директорий;
- Request-rate – количество страниц, просмотренных за одну секунду;
- Visit-time – желаемое время посещения сайта роботом.
Расширенные директивы снижают нагрузку на сервер и защищают сайт от слишком назойливых парсеров.
Google, Яндекс и настройка роботс
Поисковые системы Гугл и Яндекс одинаково хорошо читают этот файл, но рассчитывать, что его наличие послужит установлению каких-либо особенных отношений поисковых систем с сайтом – это ненужный романтизм, лишенный оснований. Есть некоторые отличия в том как можно обратиться к поисковому роботу, ведь у каждой системы их целый набор:
- YandexBot и Googlebot – это обращение к основным поисковым роботам;
- YandexNews и Googlebot-news – роботы, специализирующиеся на новостном контенте;
- YandexImages и Googlebot-image – индексаторы картинок.
У Яндекса поисковых роботов девять, а у Google восемь. Если требуется общая индексация, то после директивы User-agent пишется Yandex или Googlebot.
У Яндекса есть еще одна особенность: его роботы читают директиву Host, указывающую на «зеркало» сайта. Гугл ее не понимает.
Нужен красивый домен для Вашего проекта? Проверить и купить домен дешево болеее чем в 300 зонах!
Как составить robots.txt для Joomla
Вот как может выглядеть этот файл для новостного сайта на CMS Joomla.
User-agent: YandexNews
Disallow: /administrator
Disallow: /components
Disallow: /libraries
Allow: /index1.php
Allow: /index2.php
Request-rate: 1/20
Visit-time: 0200-0600
В нем для индексации «приглашен» новостной бот Яндекса, которому запрещено читать директории administrator, components и libraries (папка, где собственно и содержится «движок»). Индексировать можно 1 страницу за 20 секунд, а посещать сайт с двух ночи до шести утра по Гринвичу.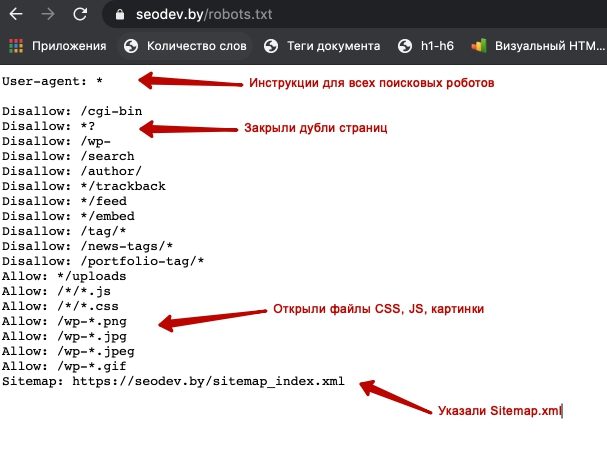
Проверить правильность написания файла robots.txt можно обратившись в Яндексе к сервису «Вебмастеру». Такой же Центр Веб-мастеров есть и у Google.
Не нужно использовать этот файл как основу – в нем просто показано использование директив.
Пример правильного файла robots.txt для WordPress — как запретить все лишнее
А это – рабочий файл robots.txt для CMS WordPress.
User-agent: *
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /archives/
Disallow: /*?*
Disallow: *?replytocom
Disallow: /wp-*
Disallow: /comments/feed/
User-agent: Yandex
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /archives/
Disallow: /*?*
Disallow: *?replytocom
Disallow: /wp-*
Disallow: /comments/feed/
Host: http://вашсайт.ру
Sitemap: http://вашсайт.ру/sitemap. xml
В первом блоке написаны директивы для всех поисковых роботов, они же дублируются для Яндекса, только с уточнением основной версии сайта. Как видно, из индекса исключена пагинация, служебные файлы и каталоги.
iPipe – надёжный хостинг-провайдер с опытом работы более 15 лет.
Мы предлагаем:
- Виртуальные серверы с NVMe SSD дисками от 299 руб/мес
- Безлимитный хостинг на SSD дисках от 142 руб/мес
- Выделенные серверы в наличии и под заказ
- Регистрацию доменов в более 350 зонах
Файл robots.txt для сайта в 2022: пошаговая инструкция
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет. В данной статье рассмотрим, где можно найти robots.txt, как его редактировать и какие правила по его использовать в SEO-продвижении.
- Где найти;
- Как создать;
- Инструкция по работе;
- Синтаксис;
- Директивы;
- Как проверить.

Где можно найти файл robots.txt и как его создать или редактировать
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
- Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
- WordPress;
Virtual Robots.txt
- Для Opencart;
https://opencartforum.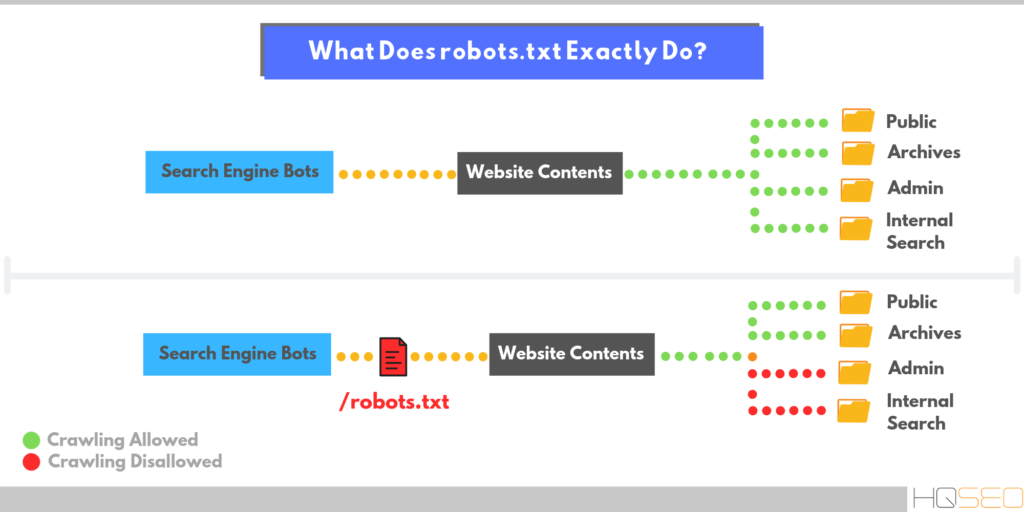 com/files/file/5141-edit-robotstxt/
com/files/file/5141-edit-robotstxt/
- Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.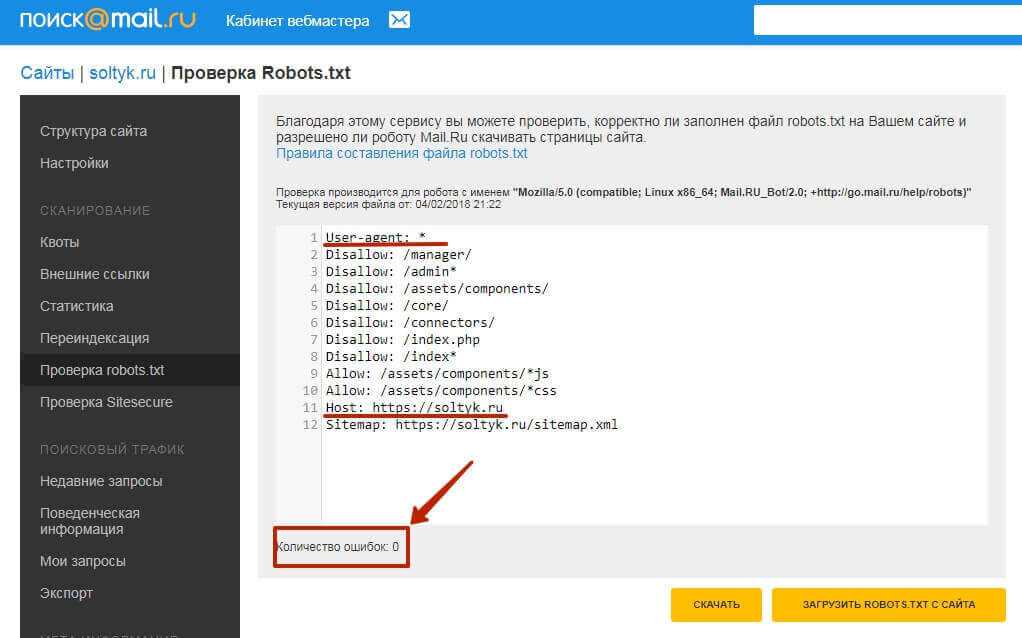 ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
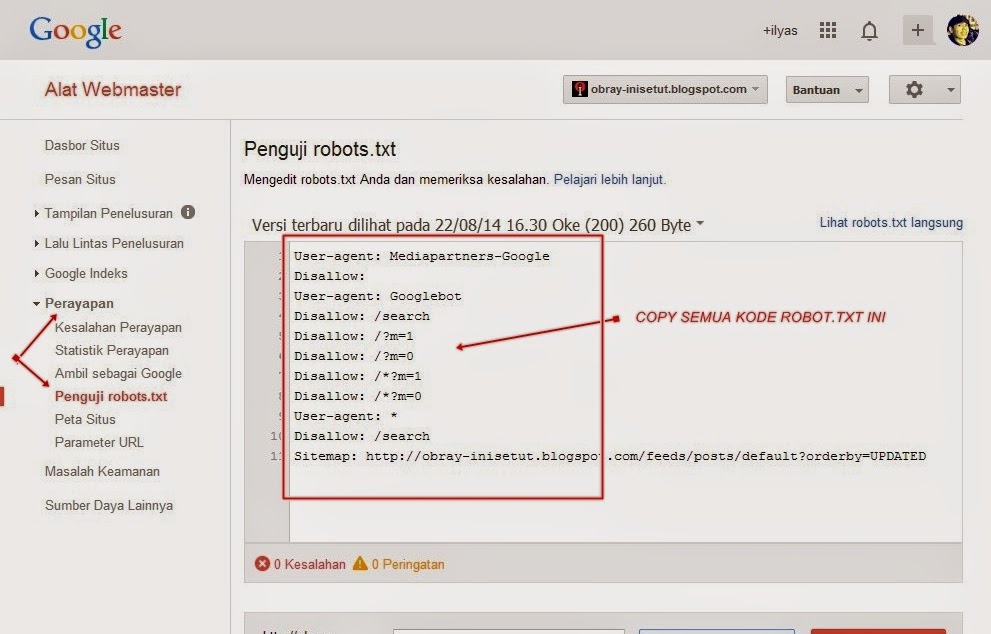
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
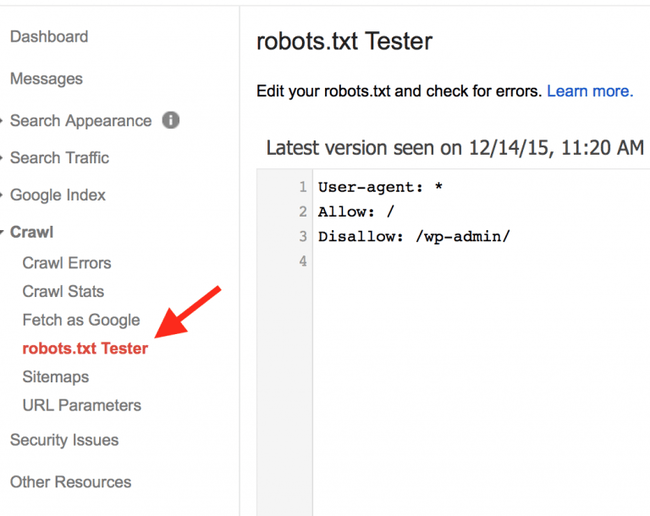
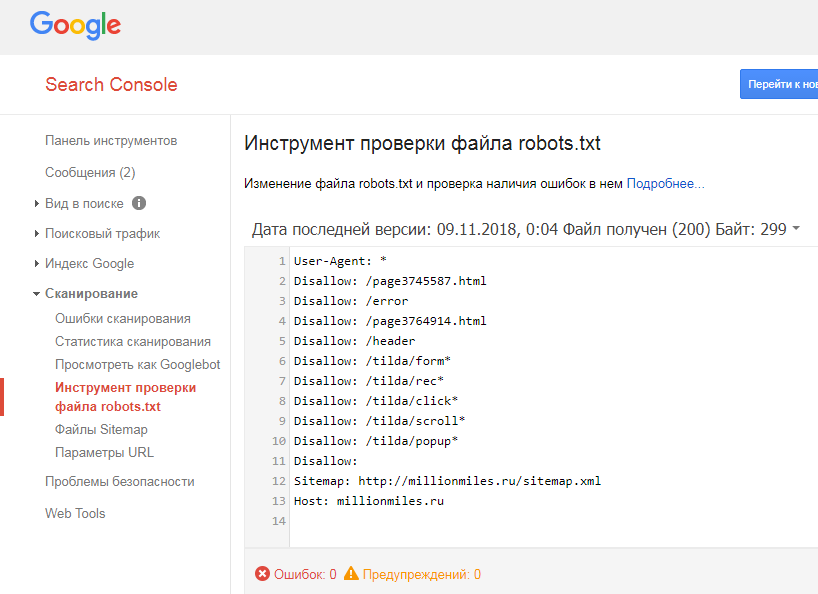
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Что такое файл robots.txt?
Файл robots.txt — это простой способ сообщить роботам, таким как Google, Bing и Yahoo, какие данные вы хотите, чтобы они показывали о вашем сайте. Это не лучший способ сообщить определенные вещи, но он может помочь им лучше понять ваш сайт.
Robots.
 txt Основы
txt ОсновыЭтот файл создан специально для поисковых систем и других роботов, чтобы сообщить им, как взаимодействовать с вашим сайтом. Это не обязательно, однако рекомендуется иметь хотя бы минимальную версию. Каждая команда должна находиться на новой строке, а пустая строка указывает на конец раздела. Файл должен находиться в корневой папке вашего сайта, иначе есть большая вероятность, что роботы его не увидят, и он не будет иметь никакого эффекта. Если все сделано правильно, вы можете перейти на адрес своего веб-сайта, за которым следует /robots.txt, например, examplewebsite.com/robots.txt
В файле вы специально сообщаете роботам три вещи:
- Где находится ваша карта сайта.
- Какие страницы они должны индексировать.
- Какие страницы не должны индексироваться.
По умолчанию файл WordPress robots.txt указывает поисковым системам сканировать ваш сайт, но исключать страницу входа и папку, содержащую библиотеку WordPress и основные файлы.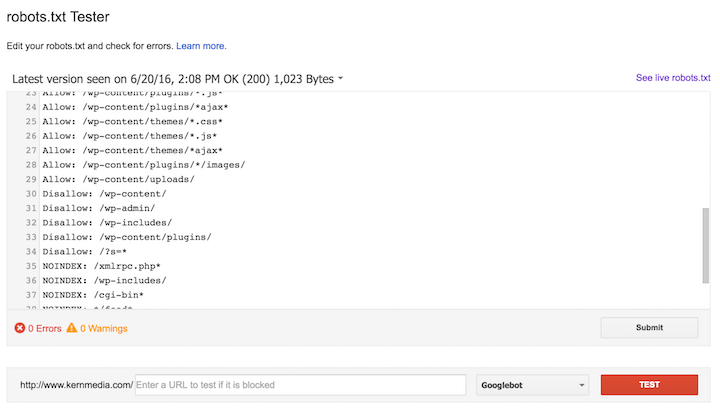
Агент пользователя: * Запретить: /wp-admin/ Запретить: /wp-includes/
Это хорошее начало, так как вы не хотите, чтобы эти файлы отображались в поисковых системах (однако есть лучший способ заблокировать их, но об этом позже). Однако есть ряд других страниц, которые вы хотите добавить, включая папку плагинов, папку тем и cgi-bin.
Агент пользователя: * Разрешать: / Запретить: /cgi-bin Запретить: /wp-admin Запретить: /wp-includes Запретить: /wp-content/plugins Запретить: /wp-content/themes
Приведенный выше код является рекомендуемым для начала, хотя вы, вероятно, захотите настроить его в соответствии со своей стратегией. Далее мы рассмотрим, как работает файл и как добавить дополнительные страницы.
Как использовать файл robots.txt
Агент пользователя: Разрешать: Запретить: Карта сайта:
Код «User-agent:» определяет, для какого бота предназначен следующий код. По умолчанию для пользовательского агента установлено значение *, которое охватывает всех роботов. Вы можете индивидуально выбрать, для каких ботов предназначен код, используя их пользовательский агент, вот несколько примеров:
По умолчанию для пользовательского агента установлено значение *, которое охватывает всех роботов. Вы можете индивидуально выбрать, для каких ботов предназначен код, используя их пользовательский агент, вот несколько примеров:
Агент пользователя: Googlebot Агент пользователя: Bingbot Агент пользователя: msnbot User-agent: Яндекс Агент пользователя: Slurp
В приведенном выше тексте говорится о роботах Google, Bing, MSN, Yandex и Yahoo (обозначенных как «Slurp»). Как правило, люди создают файл robots.txt, который общается со всеми роботами, однако, если вы хотите, чтобы они просматривали другую информацию, или вы просто хотите быть уверены, что можете вызвать их по имени. Убедитесь, что вы указали пользовательский агент, за которым сразу следуют его инструкции, вы не можете перечислить их все подряд, как в приведенном выше примере.
Код «Разрешить:» определяет, какие страницы поисковым системам разрешено сканировать. Как правило, вам не понадобится этот код, потому что они будут сканировать каждую страницу вашего сайта по умолчанию, однако, если у вас есть папка, которую вы хотите исключить, за исключением одного файла, вы должны использовать ее следующим образом:
Агент пользователя: Googlebot Запретить: /файлы/ Разрешить: /files/album.php
Код «Запретить:» определяет страницы, которые вы хотите исключить, однако поисковые системы могут решить ответить или проигнорировать его. Лучший способ предотвратить индексацию определенных страниц — добавить метатег nofollow на каждую отдельную страницу. 9В 99 случаях из 1000 это сработает, однако иногда роботы будут игнорировать оба тега. В этом случае единственным решением является скрытие контента за логином. Помните, что роботы могут делать все, что захотят, поэтому ваша задача — скрыть конфиденциальную информацию.
Кроме того, это ненадежный способ скрыть страницы или файлы, поскольку файл robots.txt общедоступен, поэтому любой может прочитать его содержание. Вместо этого вы должны скрыть конфиденциальную информацию за логином, чтобы обеспечить ее безопасность.
Наконец, код «Sitemap:» сообщает ботам, где находится ваша карта сайта. Всегда полезно иметь ее в файле robots.txt, поскольку это увеличивает шансы поисковых систем проиндексировать весь ваш сайт.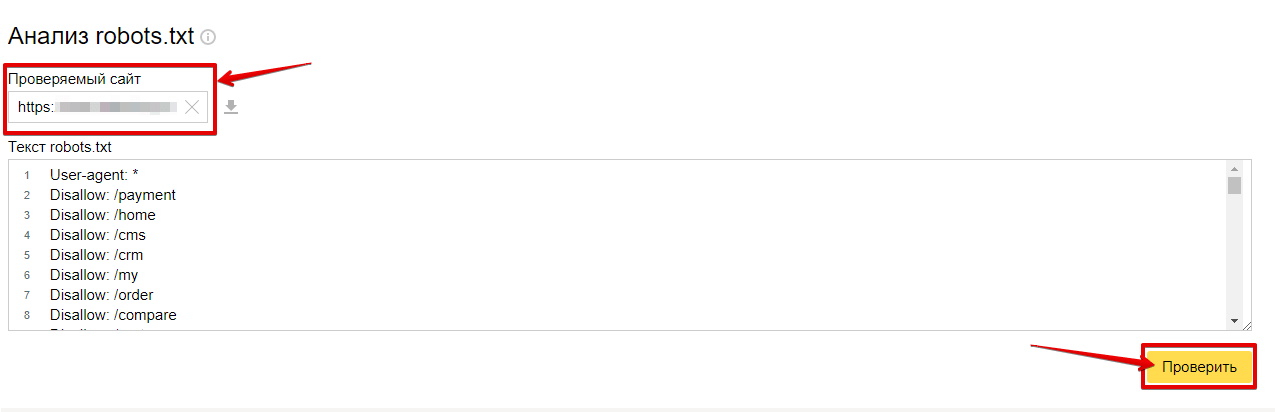
Советы и рекомендации
В целом файл довольно прост, однако есть несколько приемов, облегчающих его использование.
Чтобы заблокировать все URL-адреса, содержащие .pdf, добавьте этот код:
Агент пользователя: * Запретить: /*.pdf$
Чтобы заблокировать все URL-адреса, содержащие вопросительный знак, используйте следующий код:
.Агент пользователя: * Запретить: /*?
Чтобы заблокировать определенную папку, используйте следующий код:
Агент пользователя: * Запретить: /2015/
Чтобы заблокировать определенную папку, но включить один файл в эту папку, будет использоваться следующий код:
Агент пользователя: * Запретить: /2015/ Разрешить: /2015/important-file.php
Чтобы заблокировать весь ваш сайт:
Агент пользователя: * Запретить: /
Чтобы заблокировать весь ваш сайт для определенной поисковой системы, просто используйте пользовательский агент этой системы:
Агент пользователя: baiduspider Запретить: /
Поделитесь этой статьей:
Как использовать роботов поисковых систем
Как настроить и использовать сканеры поисковых систем с помощью файла robots. txt или файла .htaccess.
txt или файла .htaccess.
Что вам нужно
- FTP-доступ к вашему серверу Nexcess. Подробнее об использовании FileZilla, популярного FTP-клиента, см. в разделе Как использовать FileZilla.
- Учетная запись Nexcess в физической (не облачной) среде.
Роботы поисковых систем в robots.txt
Поиск
- С помощью предпочитаемого FTP-клиента введите каталог вашего сайта и каталог /html.
- В этом каталоге найдите файл robots.txt. Если вы не можете найти этот файл, создайте текстовый файл с именем robots.txt.
Добавление функций
В следующих разделах описывается форматирование, позволяющее или запрещающее поисковым роботам получать доступ к определенным папкам на вашем веб-сайте.
ВНИМАНИЕ: Сканеры поисковых систем не сканируют файл robots.txt каждый раз, когда они сканируют ваш сайт, поэтому изменения в вашем файле robots.txt могут не считываться поисковой системой в течение недели.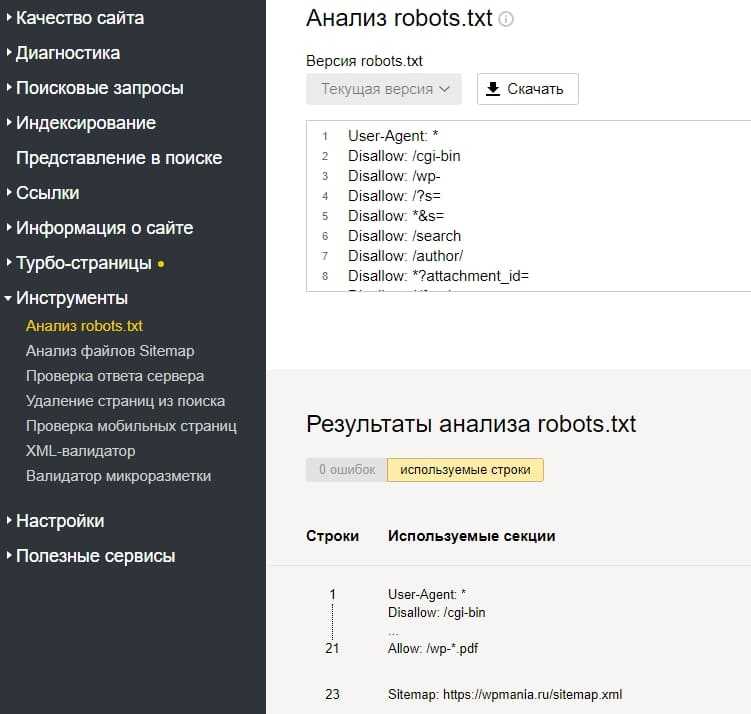
Блокировка поисковых роботов
Если вы занимаетесь разработкой своего сайта и предпочитаете, чтобы Google или Bing не сканировали ваш сайт, можно заблокировать ваш сайт от поисковых систем.
- В первой строке файла robots.txt будет User-agent: за которым следует название поисковой системы, которую вы хотите заблокировать.
- В следующей строке введите Disallow: , а затем папки и файлы, сканирование которых вы хотите запретить боту. Например:
User-agent: googlebot
Disallow: /photos
Разрешение поисковым системам сканировать определенные папки вашего сайта
Если вы хотите заблокировать все свои папки от сканеров поисковых систем, настройте разрешающее правило.
- Первая строка файла robots.txt будет User-agent:, за которой следует имя поискового робота.
- В следующей строке введите Разрешить:, , а затем имя папки, которую вы хотите разрешить боту сканировать.

Добавление задержек сканирования для роботов поисковых систем
Если ваш сайт испытывает большой объем трафика и кажется, что это вызвано одновременным посещением вашего сайта несколькими сканерами поисковых систем, настройте задержку для сканеров поисковых систем.
ВНИМАНИЕ: Добавление задержки сканирования в файл robots.txt считается нестандартной записью, и некоторые поисковые системы не соблюдают это правило. Вам нужно будет проверить конкретную поисковую систему, которую вы хотите отложить, для получения конкретных деталей.
- Первой строкой вашего robots.txt будет дополнение User-agent: и название поисковой системы.
- Вторая строка будет иметь вид Crawl-delay: , за которым следует число от 1 до 30. Это вторая задержка, когда поисковая система может просканировать ваш сайт. Если ваш сайт сканируется несколькими ботами одновременно, добавляется задержка сканирования на 10 секунд и более.

The following table is a list of search engines and their corresponding bot names:
| Search Engines | Search Bot Name | ||
| googlebot | |||
| Bing | bingbot | ||
| Baidu | baiduspider | ||
| MSN Bot | msnbot | ||
| Яндекс.ру 7 | 10167 | Все поисковые системы | * |
Например, чтобы запретить роботу Google просматривать вашу папку /photos , в файле robots.txt нужно настроить следующую строку:
Агент пользователя: googlebot Disallow: /photos
Роботы поисковых систем в .htaccess
В зависимости от того, как настроен ваш веб-сайт, ваш файл robots.txt может неправильно работать со сканерами поисковых систем. Вместо этого вы можете внести изменения в файл . htaccess.
htaccess.
ВНИМАНИЕ: Сканеры поисковых систем не сканируют файл robots.txt каждый раз, когда они сканируют ваш сайт, поэтому изменения в вашем файле robots.txt могут не считываться поисковой системой в течение недели.
Поиск .htaccess
- С помощью предпочитаемого FTP-навигатора введите каталог и файл /html.
- В этом каталоге найдите файл .htaccess. Если файлы не существуют, создайте текстовый файл с именем .htaccess.
Добавление функций
- После того, как вы нашли или создали файл .htaccess, откройте его в предпочитаемом вами текстовом редакторе.
- Если вы создаете новый файл. наверху.
- Следующая строка считывает имя пользовательского агента пользователя или бота и сопоставляет его с тем, что было предоставлено в файле .htaccess. Ваши пользователи не будут сопоставлены с этой переменной, поэтому не будут заблокированы. Замените [краулер] на название поисковой системы. 9Яндекс$ [NC,OR]
RewriteRule .
 * — [R=403,L]
* — [R=403,L] Добавление задержки сканирования для роботов поисковых систем
Если добавление задержки сканирования в файл robots.txt не удалось, добавьте в файл .htaccess следующее:
SetEnvIf User- Агент [имя_бота] GoAway=1 Порядок разрешить, запретить Разрешить от всех Deny from env=GoAway
- Первая строка проверяет идентификатор пользователя, где [botname] – имя бота:
SetEnvIf User-Agent [botname] GoAway=1
- Вторая и третья строки разрешают весь трафик соответствует первой строке:
Приказ разрешить, запретить Разрешить от всех
- Четвертая строка запрещает весь трафик, соответствующий переменной GoAway.
Deny from env=GoAway
Для получения круглосуточной помощи в любой день года обратитесь в нашу службу поддержки по электронной почте или через свой клиентский портал.
Что такое файл robots.txt в домене?
Одной из самых больших ошибок новых владельцев веб-сайтов является то, что они не заглядывают в свой файл robots.
 txt. Так что же это такое и почему так важно? У нас есть ваши ответы.
txt. Так что же это такое и почему так важно? У нас есть ваши ответы.Если у вас есть веб-сайт и вы заботитесь о его SEO-здоровье, вам следует хорошо ознакомиться с файлом robots.txt в вашем домене. Хотите верьте, хотите нет, но это тревожно большое количество людей, которые быстро запускают домен, устанавливают быстрый веб-сайт WordPress и никогда ничего не делают со своим файлом robots.txt.
Это опасно. Плохо настроенный файл robots.txt может разрушить SEO-здоровье вашего сайта и подорвать любые ваши шансы на увеличение трафика.
Что такое файл robots.txt?
Файл Robots.txt имеет подходящее название, потому что это, по сути, файл, в котором перечислены директивы для веб-роботов (например, роботов поисковых систем) о том, как и что они могут сканировать на вашем веб-сайте. Это веб-стандарт, которому следуют веб-сайты с 1994 года, и все основные поисковые роботы придерживаются этого стандарта.
Файл хранится в текстовом формате (с расширением .
 txt) в корневой папке вашего сайта. Вы можете просмотреть файл robot.txt любого веб-сайта, просто введя домен, а затем /robots.txt. Если вы попробуете это с groovyPost, вы увидите пример хорошо структурированного файла robot.txt.
txt) в корневой папке вашего сайта. Вы можете просмотреть файл robot.txt любого веб-сайта, просто введя домен, а затем /robots.txt. Если вы попробуете это с groovyPost, вы увидите пример хорошо структурированного файла robot.txt.Файл простой, но эффективный. В этом примере файл не делает различий между файлами robots. Команды выдаются всем роботам с помощью директивы User-agent: * . Это означает, что все команды, которые следуют за ним, применяются ко всем роботам, которые посещают сайт для его сканирования.
Указание поисковых роботов
Можно также указать определенные правила для определенных поисковых роботов. Например, вы можете разрешить роботу Googlebot (сканеру Google) сканировать все статьи на вашем сайте. Тем не менее, вы можете запретить российскому поисковому роботу Yandex Bot сканировать статьи на вашем сайте, содержащие пренебрежительную информацию о России.
Сотни поисковых роботов прочесывают Интернет в поисках информации о веб-сайтах, но 10 наиболее распространенных, о которых вам следует беспокоиться, перечислены здесь.

- Googlebot : Google search engine
- Bingbot : Microsoft’s Bing search engine
- Slurp : Yahoo search engine
- DuckDuckBot : DuckDuckGo search engine
- Baiduspider : Chinese Baidu search engine
- ЯндексБот : Russian Yandex search engine
- Exabot : French Exalead search engine
- Facebot : Facebook’s crawling bot
- ia_archiver : Alexa’s web ranking crawler
- MJ12bot : Large link indexing database
Taking the В приведенном выше примере сценария, если вы хотите разрешить роботу Googlebot индексировать все на вашем сайте, но хотите запретить Яндексу индексировать содержимое вашей статьи на русском языке, вы должны добавить следующие строки в файл robots.txt.
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.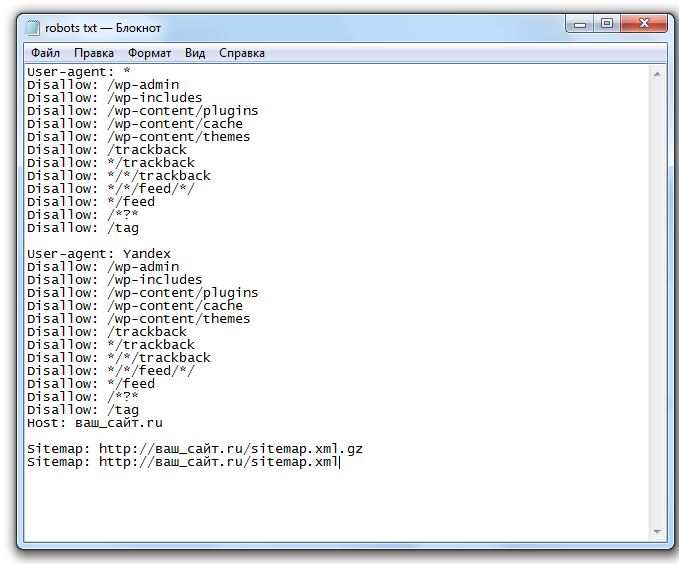 php
php User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/Как видите, первый раздел блокирует Google только от сканирования вашей страницы входа в WordPress и административных страниц. Второй раздел останавливает Яндекс от той же, но и от всей области вашего сайта, где вы публиковали статьи антироссийского содержания.
Это простой пример того, как вы можете использовать команду Disallow для управления определенными поисковыми роботами, которые посещают ваш веб-сайт.
Другие команды Robots.txt
Disallow — не единственная команда, к которой у вас есть доступ в файле robots.txt. Вы также можете использовать любые другие команды, которые определяют, как робот может сканировать ваш сайт.
- Запретить : Указывает агенту пользователя избегать сканирования определенных URL-адресов или целых разделов вашего сайта.
- Разрешить : позволяет точно настроить определенные страницы или подпапки на вашем сайте, даже если вы запретили родительскую папку.
 Например, вы можете запретить: /about/, но затем разрешить: /about/ryan/.
Например, вы можете запретить: /about/, но затем разрешить: /about/ryan/. - Crawl-delay : Это говорит сканеру подождать xx секунд, прежде чем начать сканирование содержимого сайта.
- Карта сайта: Предоставьте поисковым системам (Google, Ask, Bing и Yahoo) расположение ваших XML-карт сайта.
Имейте в виду, что боты будут только слушайте команды, которые вы предоставили, когда вы указываете имя бота.
Люди совершают распространенную ошибку, запрещая такие области, как /wp-admin/, для всех ботов, но затем указывают раздел Googlebot и запрещают только другие области (например, /about/).
Поскольку боты следуют только тем командам, которые вы указали в своем разделе, вам необходимо переформулировать все те другие команды, которые вы выбрали для всех ботов (используя * user-agent).
- Disallow : Команда, используемая для указания пользовательскому агенту не сканировать определенный URL-адрес.
 Для каждого URL разрешена только одна строка «Disallow:».
Для каждого URL разрешена только одна строка «Disallow:». - Разрешить (только для робота Googlebot) : Команда, сообщающая роботу Googlebot, что он может получить доступ к странице или вложенной папке, даже если ее родительская страница или вложенная папка могут быть запрещены.
- Crawl-delay : Сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что Googlebot не подтверждает эту команду, но скорость сканирования можно установить в Google Search Console.
- Карта сайта : Используется для вызова местоположения карты сайта в формате XML, связанной с этим URL-адресом. Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
Помните, что файл robots.txt предназначен для того, чтобы помочь легитимным ботам (например, ботам поисковых систем) более эффективно сканировать ваш сайт.
Существует множество гнусных поисковых роботов, которые сканируют ваш сайт, чтобы делать такие вещи, как очищать адреса электронной почты или красть ваш контент.
 Не беспокойтесь, если вы хотите попробовать использовать файл robots.txt, чтобы запретить поисковым роботам сканировать что-либо на вашем сайте. Создатели этих сканеров обычно игнорируют все, что вы добавили в файл robots.txt.
Не беспокойтесь, если вы хотите попробовать использовать файл robots.txt, чтобы запретить поисковым роботам сканировать что-либо на вашем сайте. Создатели этих сканеров обычно игнорируют все, что вы добавили в файл robots.txt.Зачем что-то запрещать?
Заставить поисковую систему Google сканировать как можно больше качественного контента на вашем веб-сайте — основная задача большинства владельцев веб-сайтов.
Однако Google расходует ограниченный бюджет сканирования и скорость сканирования на отдельных сайтах. Скорость сканирования — это количество запросов в секунду, которые робот Googlebot будет отправлять на ваш сайт во время сканирования.
Более важным является краулинговый бюджет, то есть общее количество запросов, которые робот Googlebot сделает для сканирования вашего сайта за один сеанс. Google «тратит» свой краулинговый бюджет, сосредотачиваясь на областях вашего сайта, которые очень популярны или недавно изменились.

Вы знаете эту информацию. Если вы посетите Инструменты Google для веб-мастеров, вы увидите, как сканер обрабатывает ваш сайт.
Как видите, краулер каждый день поддерживает постоянную активность на вашем сайте. Он не сканирует все сайты, а только те, которые считает наиболее важными.
Зачем оставлять Googlebot решать, что важно на вашем сайте, когда вы можете использовать файл robots.txt, чтобы сообщить ему, какие страницы являются наиболее важными? Это предотвратит трату времени роботом Googlebot на малоценные страницы вашего сайта.
Оптимизация бюджета сканирования
Инструменты Google для веб-мастеров также позволяют проверить, правильно ли робот Google читает ваш файл robots.txt и нет ли ошибок.
Это поможет вам убедиться, что вы правильно структурировали файл robots.txt.
Какие страницы следует запретить роботу Googlebot? Для SEO вашего сайта полезно запретить следующие категории страниц.
- Дублирование страниц (например, страницы для печати)
- Страницы с благодарностью после заказов на основе формы
- Формы заказа или информационного запроса
- Контактные страницы
- Страницы входа
- Страницы продаж лид-магнитов
Не игнорируйте файл robots.

- Первая строка проверяет идентификатор пользователя, где [botname] – имя бота: