Правильный robots.txt для Вордпресс
Наверное, только ленивый не писал про то, как должен выглядеть правильный Robots.txt для Вордпресс. Я попробую объяснить, почему многие старые способы больше не работают.
Прежде напомню, на дворе 2017-й год — прогресс не стоит на месте, технологии развиваются. Кто давно в теме — знают, что поисковые системы за последнее десятилетие сильно эволюционировали. Поисковые алгоритмы стали более сложными. Сложными стали и факторы ранжирования, их количество существенно увеличилось. Естественно, всё это не могло не отразиться на методах поисковой оптимизации сайтов и отрасли в целом.
Robots.txt — это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции для поисковых роботов, разработан Мартином Костером и принят в качестве стандарта 30 июня 1994 года.
Robots.txt — мощное оружие SEO-оптимизации, грамотная настройка которого может существенно помочь в индексации.
В то же время, кривая настройка robots.txt может нанести проекту огромный вред. Рассуждать о правильности того или иного примера robots.txt можно бесконечно долго. Предлагаю остановиться на фактах.
Еще недавно Google был настолько примитивен, что видел сайты лишь в виде HTML-кода. В прошлом году, с приходом алгоритма Panda 4, Google стал видеть сайты такими же, какими их видят пользователи. Вместе с CSS и исполненным JavaScript.
Это изменение коснулось и Вордпресс.
На многих сайтах используются старые приёмы, которые блокируют индексацию системной директории /wp-includes/, в которой часто хранятся JS-библиотеки и стили, необходимые для работы сайта. А это значит, Google увидит сайт уже не таким, каким его видят посетители.
Получается, что старая практика больше не работает.
На многих Вордпресс-сайтах закрывалась от индексации и другая системная директория /wp-admin/.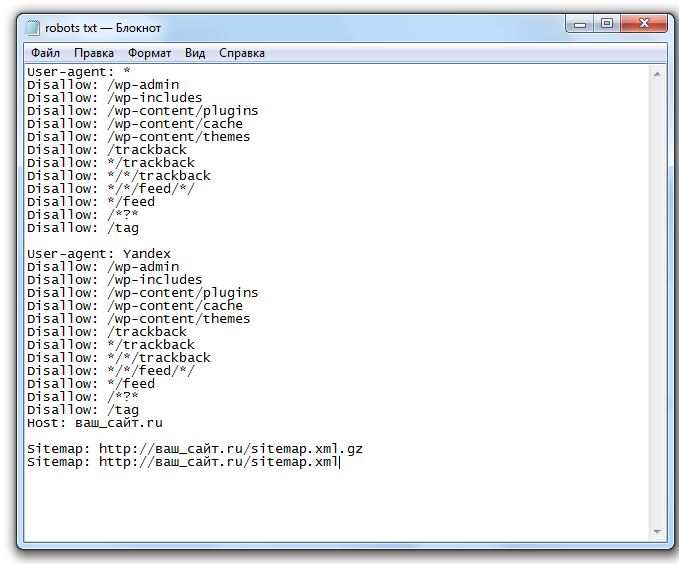 Что правильно, по-сути. Но если на сайте используется асинхронная загрузка страниц (AJAX), это может блокировать загрузку внутренних страниц. Потому что admin-ajax.php, который за всё это отвечает, расположен в /wp-admin/.
Что правильно, по-сути. Но если на сайте используется асинхронная загрузка страниц (AJAX), это может блокировать загрузку внутренних страниц. Потому что admin-ajax.php, который за всё это отвечает, расположен в /wp-admin/.
Директорию /wp-admin/ можно оставить закрытой от индексации, но тогда необходимо отдельно разрешить индексацию admin-ajax.php.
Allow: /wp-admin/admin-ajax.php
Если в вашем Вордпресс используется один из старых способов оформления robots.txt, нужно обязательно проверить какие конкретно директории скрываются от индексации и удалить все запреты, блокирующие загрузку страниц.
Для проверки рекомендую использовать Google Search Console, в котором необходимо предварительно зарегистрироваться, добавить проверяемый сайт и подтвердить права на него. Это делается очень просто.
Как проверить Robots.txt
Проверить robots.txt на ошибки можно с помощью инструмента проверки файла robots. txt — именно так и называется этот инструмент в разделе «Сканирование» Google для веб-мастеров.
txt — именно так и называется этот инструмент в разделе «Сканирование» Google для веб-мастеров.
Кстати, проверить robots.txt на ошибки можно и в Яндекс Вебмастере. Но в Google Search Console все равно нужно зарегистрироваться, потому что только там можно проверить видимость сайта поисковыми пауками Гугла. Конкретно это делается в разделе «Сканирование» с помощью инструмента «Просмотреть как Googlebot».
Если сайт выглядит таким же как и в браузере, значит все в порядке, robots.txt ничего не блокирует. Если же имеются какие-то отличия, что-то не отображается или сайт не виден вообще, значит придется выяснить, где происходит блокировка и ликвидировать её.
Как же должен выглядеть правильный Robots.txt для Вордпресс
Я все больше убеждаюсь, что лучше делать сразу минимальный robots.txt и закрывать только /wp-admin/. Естественно, открыв admin-ajax.php, если есть AJAX-запросы. И обязательно указываем Host и Sitemap.
Мой robots.txt чаще всего выглядит так:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Host: https://danilin.biz Sitemap: https://danilin.biz/sitemap.xml
В заключение
Создать универсальный правильный robots.txt для всех сайтов на Вордпресс невозможно.
На каждом сайте работает конкретная тема, набор плагинов и типов данных (CPT), которые генерируют свой уникальный пул URL.
Robots.txt часто корректируется уже в процессе эксплуатации сайта. Для этого осуществляется постоянный мониторинг индекса сайта. И если в него попадают какие-то ненужные страницы, они исключаются. Например, в индекс иногда попадают страницы с параметрами
Их можно исключить.
Disallow: /?p= Disallow: /?s=
Иногда даже попадают фиды, которые тоже можно закрыть.
Disallow: */feed
Вообще, задачи по исключению страниц из индекса правильнее решать на уровне кода, закрывая страницы от сканирования с помощью метатега «noindex».
Для Яндекса инструкции в robots. txt и метатег «noindex» работают одинаково — страница удаляется из индекса. А вот для Гугла robots.txt — это запрет на индексирование, а метатег «
txt и метатег «noindex» работают одинаково — страница удаляется из индекса. А вот для Гугла robots.txt — это запрет на индексирование, а метатег «
Как видим, Robots.txt может быть очень опасен для сайта.
Бездумные действия с этим файлом могут привести к печальным последствиям. Не спешите с помощью него закрывать все подряд директории. Пользуйтесь плагином Yoast SEO — он позволяет настроить правильные запреты с помощью метатегов.
Правильный robots.txt для WordPress — HD-24
Что такое robots.txt и какая от него польза
Все мы знаем что roborts.txt нужен для SEO, но в чем именно заключается его работа и благодаря чему он улучшает качество сайта, знают немногие.
Какие задачи решает roborts.txt? Да по большому счету задач немного, их по сути две:
- Сокрытие от поисковиков малоинформативных страниц.
- Экономия краулингового бюджета.
Задачи две, но решаются они одним действием. Закрывая от поисковиков некачественные страницы, мы автоматически экономим краулинговый бюджет. Для чего необходима экономить краулинговый бюджет? Ответ довольно прост, для оперативного индексирования новых страниц на вашем сайте. Давайте рассмотрим это на простом примере:
Как-то мне в руки попался интернет-магазин, у которого было около 800 товаров и несколько десятков статей в блоге плюс кучка технических страниц. В общей сложности полезных страниц на сайте было чуть больше 1000. Предположим вы решили внести изменения на некоторые страницы, несколько товаров удалили, а несколько добавили. Допустим у вас получилось 1043 страницы. Давайте посчитаем сколько времени понадобится роботу того же Яндекса чтобы обойти весь сайт и найти измененные страницы, узнать об удаленных и добавить в индекс новые. При максимальной скорости обхода (30 запросов в секунду) Яндексу потребуется всего 34,8 сек для обхода сайта, а при минимальной (0,6 запроса в секунду) уже 29 минут. Но проблема этого интернет-магазина была в том, что у него был неправильно заполненный robots.txt и в индексе было свыше 7000 страниц при свыше 4 млн загруженных. То есть чтобы выискать нормальные страницы на сайте, ботам поисковиков нужно было обойти свыше 4 миллионов страниц. По времени это займет:
Допустим у вас получилось 1043 страницы. Давайте посчитаем сколько времени понадобится роботу того же Яндекса чтобы обойти весь сайт и найти измененные страницы, узнать об удаленных и добавить в индекс новые. При максимальной скорости обхода (30 запросов в секунду) Яндексу потребуется всего 34,8 сек для обхода сайта, а при минимальной (0,6 запроса в секунду) уже 29 минут. Но проблема этого интернет-магазина была в том, что у него был неправильно заполненный robots.txt и в индексе было свыше 7000 страниц при свыше 4 млн загруженных. То есть чтобы выискать нормальные страницы на сайте, ботам поисковиков нужно было обойти свыше 4 миллионов страниц. По времени это займет:
- 37 часов на максимальной скорости обхода
- 77,1 суток, то есть больше двух месяцев
Само собой максимальную скорость обхода сможет выдержать далеко не каждый сайт и само собой поисковики стараются использовать низкую скорость обхода. В итоге любое изменение на сайте замечалось поисковиками через продолжительное время, а обилие страниц низкого качества в поиске, ухудшало и качество сайта.
Таким образом robots.txt – это инструмент управления индексацией сайта. Настроили грамотно – новые странички будут оперативно залетать в индекс, а отредактированные быстро переиндексироваться. Если напихали директив от балды – прощай позиции, трафик и оперативное обновление индекса.
Почему стандартный robots.txt бесполезен
У WordPress нет стандартного robots.txt, но его создает в частности плагин YoastSEO (за другие не знаю). В этом, автоматически созданном, robots.txt имеется всего две директивы для всех роботов:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Удивительно что создатели плагина для SEO-оптимизации не смогли подготовить универсальный robots.txt. Я не понимаю зачем закрывать от индексации эти две директории, если там нечего индексировать.
Наша с вами задача не описать в robots.txt куда можно, а куда нельзя поисковику используя директивы «disallow» и «allow» налево и направо, а исключить из индекса страницы, которых там быть не должно. Для этого вам самим кроме копипаста придется ещё и информацию из кабинетов для веб-мастеров поизучать на предмет ненужных страниц в индексе поисковиков.
Я вам дам совет исходя из своего опыта на базе моего сайта, по-этому скопировав мой пример, дополните его своими директивами, наверняка у вас есть на сайте не совсем стандартные для WrdPress страницы, которые поисковикам нет смысла индексировать.
Кто стучится в дверь ко мне
Прежде чем нафаршировать свой robots. txt директивами, давайте сначала разберемся с тем, кто вообще ползает по нашему сайту. На самом деле роботов, кои топчутся по нашим с вами сайтам, превеликое множество. Среди них есть несколько известных, а ещё больше неизвестных, которым плевать на robots.txt. Давайте разберемся что это за роботы и как с ними быть.
txt директивами, давайте сначала разберемся с тем, кто вообще ползает по нашему сайту. На самом деле роботов, кои топчутся по нашим с вами сайтам, превеликое множество. Среди них есть несколько известных, а ещё больше неизвестных, которым плевать на robots.txt. Давайте разберемся что это за роботы и как с ними быть.
Роботы Яндекса
Обратите внимание на то, что многие вебмастеры добавляют в robots.txt для Яндекса user-agent: Yandex, но мало кто понимает разницу между Yandex и YandexBot, а разница весьма существенна.
User-agent: YandexBot # будет использоваться только основным индексирующим роботом
User-agent: Yandex # будет использована всеми роботами Яндекса
Какие вообще бывают боты у Яндекса? Их множество, вот некоторые из них:
- YandexBot — основной индексирующий робот.
- YandexImages — индексатор Яндекс.Картинок.
- YandexMedia — робот, индексирующий мультимедийные данные.
- YandexPagechecker — валидатор микроразметки.
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы, особым образом интерпретирует robots.txt.
Полный список роботов Яндекса смотрите на этой странице.
Роботы Google
- Googlebot – основной индексирующий робот
- Googlebot-Image – робот индексирующий изображения.
- Mediapartners-Google – робот отвечающий за размещение рекламы на сайте. Важен для тех, у кого крутится реклама от AdSense. Благодаря этому user-agent вы можете управлять размещение рекламы запрещая или разрешая её на тех или иных страницах.
Полный список роботов Google смотрите на этой странице.
Робот Twitter
Полезный робот, который ходит на наш сайт за расширенной информацией когда кто-либо в твиттере делится ссылкой на наш сайт.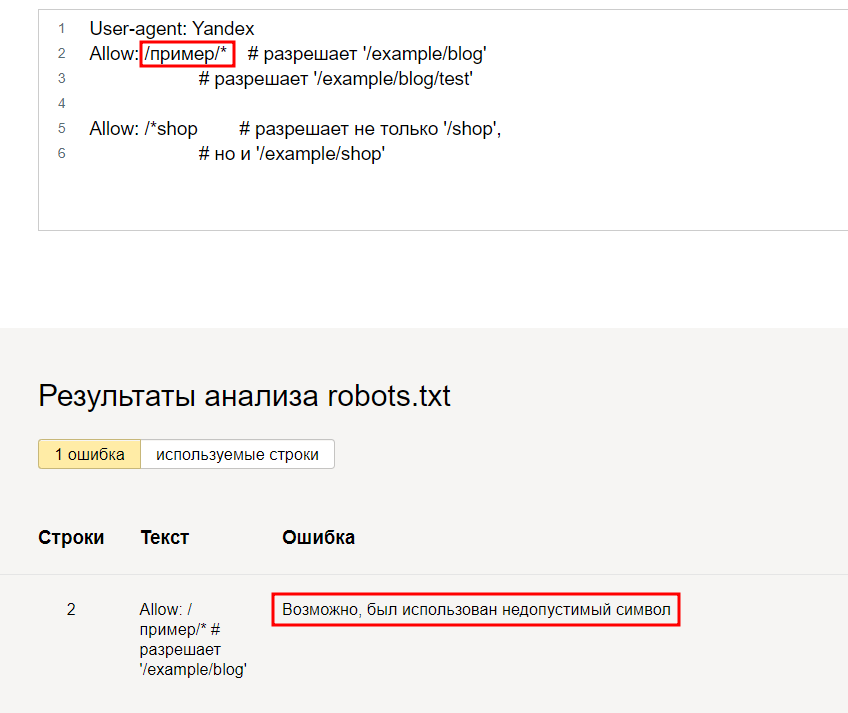 Чтобы вместо ссылки появлялся красивый пост, то надо явно в robots.txt разрешить доступ к сайту роботу твиттера.
Чтобы вместо ссылки появлялся красивый пост, то надо явно в robots.txt разрешить доступ к сайту роботу твиттера.
Директивы robots.txt, параметры и логика работы
Несмотря на свою простоту и элементарность, даже у опытных сеошников порой возникают трудности с составлением параметров для директив. Что там говорить, я сам не исключение и иногда допускаю ошибки при закрытии URL от индексации и потом приходится разгребать последствия.
В нашем распоряжении по сути несколько директив
User-Agent
С этой директивы начинается блок правил, а её значение указывает на то, для какого поисковика предназначается данный набор правил. Например, значение «YandexBot» обозначает что этот блок предназначен исключительно для основного Яндекс бота, а значение директивы «*» говорит что этот блок для всех роботов.
Причем необходимо понимать логику интерпретации директивы «User-agent» ботами Яндекса, если в файле robots.txt присутствует две директивы «User-agent: *» и «User-agent: Yandex», то блок директив после «User-agent: *» будет проигнорирован ботами Яндекса. По этой причине для основного бота Яндекса я выделяю отдельный блок, второй для всех остальных. Почему именно так, вы поймете ниже, когда я объясню назначение директив.
По этой причине для основного бота Яндекса я выделяю отдельный блок, второй для всех остальных. Почему именно так, вы поймете ниже, когда я объясню назначение директив.
Disallow и Allow
Собственно основные директивы файла robots.txt. Данные директивы запрещают или разрешают поисковикам индексировать страницу или раздел указанный в значении данной директивы. В качестве параметра этим директивам мы передаем часть URL страниц, которые необходимо запретить индексировать или разрешить к индексации.
Иногда меня спрашивают зачем нужна Allow? Логика вопрошающего очевидна, если с помощью Disallow мы запретили некоторые вещи, то получается все остальное доступно, а значит не запрещено. Но давайте рассмотрим простой пример:
- Disallow: *?* – запретит к индексации все страницы ссылки на которые содержат «?».
Каковы последствия работы такой директивы? Последствия такой директивы вот такие:
Спросите в чем связь? Ответ не очевиден, но он прост. Вышеуказанной директивой мы запрещаем роботам загружать файлы стилей, ссылка на которые содержит «?ver=5. 1.1». А стили темы оформления отвечают за адаптивность дизайна, которая как раз и определяет оптимизацию сайта под мобильные устройства. Тут нас как раз спасает директива Allow:
1.1». А стили темы оформления отвечают за адаптивность дизайна, которая как раз и определяет оптимизацию сайта под мобильные устройства. Тут нас как раз спасает директива Allow:
- Allow: *.css?ver=*
Таким образом мы вернем доступ роботам к файлам стилей и наш сайт станет снова оптимизированным под мобильные устройства.
Знак «*» заменяет нам один или несколько символов, но его использование не всегда очевидно. Давайте поиграемся с примерами.
- Disallow: /news
Данная директива запретит к индексации все страницы, ссылки которых начинаются с /news. Например:
- /news/hello-world
- /news/finance
- /news/auto
А вот ссылки такого плана:
- /blog/news/hello-world
Такая директива уже не закроет. А что будет, если мы добавим вот такую директиву:
- Disallow: *news*
Тогда мы запретим доступ роботам ко всем ссылкам, коиторые имеют в себе вхождение «news». Например:
- /news/hwllo-world
- /its-fake-news
Как видите с директивами нужно быть крайне осторожным в их формулировке.
Также стоит особо отметить один немаловажный нюанс – это порядок обработки директив. Да, да, вне зависимости от того, как вы их расположите в файле robots.txt, они будут отсортированы и применены в порядке возрастания. То есть первыми будут применены короткие,, а самые длинные последними.
Является ли это важным? Весьма. Чем длиньше параметр директивы, тем больше её приоритет. Допустим у нас с вами в robots.txt есть несколько директив, выстроим их в порядок возрастания и посмотрим на логику робота:
- Disallow: /
- Allow: /news
- Allow: /catalog
Таким образом получается так, первым делом робот видит что первая директива запрещает ему индексировать весь сайт, но вторая и третья открывают ему раздели новостей и каталог. Таким образом мы можем сначала запретить весь сайт, а потом открывать только те части, которые необходимо индексировать. Обычно при составлении директив robots.txt мы руководствуемся другой логикой, поскольку обычно запрещаем те вещи, на которые ругается Яндекс или Google.
Одинм из важных моментов является наличие кириллицы в URL, который мы хотим запретить или открыть. Поскольку я категорически не приемлю кириллицу в URL, я не сталкивался с проблемами связанными с кириллицей, но некоторые сайты в принципе не парятся по этому поводу. Допустим на сайте надо скрыть страницу, доступную по ссылке «/каталог»:
- Disallow: /каталог – не правильно.
- Disallow: /%D0%BA%D0%B0%D1%82%D0%B0%D0%BB%D0%BE%D0%B3 – правильно.
Host
Устаревшая директива, которая указывала ботам Яндекса, какое зеркало делать основным. Вот что Яндекс говорит по поводу этой директивы:
Как мы писали ранее, мы отказываемся от директивы Host. Теперь эту директиву можно удалять из robots.txt, но важно, чтобы на всех не главных зеркалах вашего сайта теперь стоял 301-й постраничный редирект. Вебмастерам, которые, по нашим данным, ещё не установили перенаправление, мы отправили соответствующее уведомление.
Источник

Sitemap
Соответственно эта директива указывает путь к файлу sitemap. Эта директива является межсекционной, то есть её достаточно указать всего лишь один раз. Обычено она указывается в самом конце файла robots.txt. Добавление директивы Sitemap в каждую секцию «User-agent» является ошибкой.
Где взять sitemap? За генерацию этой штуки отвечает SEO-плагин, в моем случае это Yoast SEO. Содержимое этого файла зависит от настроек отображения в поисковой выдаче, которые располагаются в одноименном разделе плагина.
Crawl-delay
Указывает поисковому роботу промежуток времени в секундах, который должен пройти с момента окончания загрузки одной страницы и началом загрузки другой. Значением директивы может быть любое число как целое, так и дробное.
На текущий момент по сути бесполезная директива, поскольку роботы Google и Яндекс не отказались от учета директивы Crawl-delay. Таймаут роботам можно указать в панели вебмастера.
Clean-param
Если на Вашем сайте используются параметры, которые не влияют на отображение страницы, то в значении этой директивы Вы можете указать эти параметры. Допустим у Вас на сайте есть каталог, в котором пользователю доступны некоторые возможности, такие как сортировка, допустим ссылка выглядит так:
Допустим у Вас на сайте есть каталог, в котором пользователю доступны некоторые возможности, такие как сортировка, допустим ссылка выглядит так:
- http://site.ru/catalog.php?sort_by=price&sort=desc
Что бы указать роботу на параметры, которые необходимо исключить, то нам потребуется указать директиву с соответствующими параметрами:
- Clean-param: sort_by /catalog.php # если необходимо исключить только sort_by
- Clean-param: sort_by&sort /catalog.php # если необходимо исключить sort_by и sort
Лично я не пользуюсь подобной директивой, поскольку её логика работы не очевидна. На мой взгляд проще всего страницы с параметрами проще закрыть директивой «Disallow», тем самым явно сэкономив краулинговый бюджет.
Что нужно закрыть от индексации в WordPress
Предлагаю не просто скопировать готовый robots.txt, а попытаемся понять, почему мы закрыли от индексации именно эти страницы.
- Disallow: /cgi-bin – по сути такая же бесполезная директива как и «Disallow: /wp-admin», но до тех пор, пока не начнете работать с Cloudflare, например ради халявного SSL, тогда на сайте появляется куча ссылок, которые начинаются с «/cgi-bin».

- Disallow: /xmlrpc.php – закрываем из-за пустой страницы при обращении к этому файлу.
- Disallow: /author – с точки зрения поиска, это бесполезная страница.
- Disallow: /wp-json – закрываем ибо возвращает пустую страницу.
- Disallow: /wp-login.php – закрываем ибо эта страница является малоинформативной и не несет в себе смысловой нагрузки выполняя чисто техническую роль.
- Disallow: */feed* – RSS-лента, очевидно не несет в себе пользы для поисковиков.
- Disallow: /wp-content/uploads – закрываем именно эту папку, поскольку она может содержать разного рода документы, например, PDF, DOC и т.д., которые не стоит пускать в индекс. Закрывать «wp-content» полностью чревато проблемами.
- Disallow: /category – страница категорий, естественно при определенных настройках постоянных ссылок. Категории также являются малоинформативными страницами, если конечно вы не уделили этому внимания и не наполнили каждую категорию полезной информацией, в ином случае лучше прикрыть, поисковикам там делать нечего.
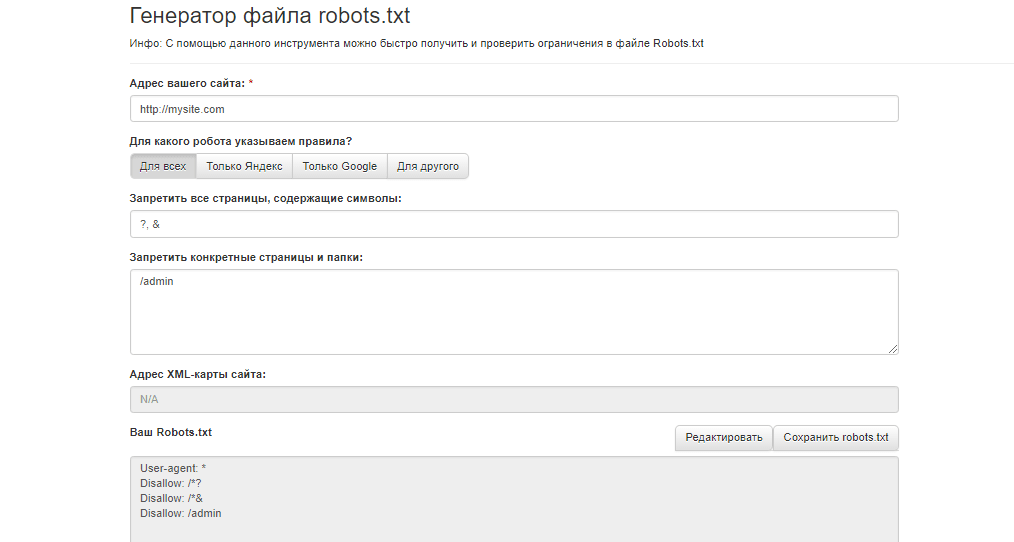
- Disallow: /attachment – закрываем страницы вложений. Не всегда они бывают доступны по ссылке, но лучше перебдеть. Один раз мне эти странички, высыпавшись в индекс, не хило так посещалку обвалили.
- Disallow: */page/ – закрываем пагинацию. В сети существует много споров закрывать или не закрывать страницы пагинации, но я закрываю. Некоторые SEOшники говорят что таким образом мы лишаемся некоторых внутренних факторов в виде анкоров во внутренних ссылках. Но я считаю эти страницы малоинформативными, а внутренние факторы не такими важными. В моем случае пользы от прикрытия пагинации больше чем от открытия, при 100+ страницах в индексе мой сайт посещает почти 2 000 человек в сутки и этот показатель растет.
Ну вот по сути это основные моменты, которые стоит прикрыть от поисковых роботов на сайте с CMS WordPress.
Мой вариант robots.txt
#Разрешаем роботу Яндекса, который индексирует изображения, доступ к папке с вложениями.
User-Agent: YandexImages
Allow: /wp-content/uploads
#Делаем тоже самое для гугловского бота, которые индексирует изображения
User-Agent: Googlebot-Image
Allow: /wp-content/uploads
#Говорим рекламе что сайт весь в её распоряжении
User-agent: Mediapartners-Google
Allow: /
#Открываем доступ твиттеру
User-agent: Twitterbot
Allow: /
#Поскольку Яндекс проигнорирует секцию с User-agent: *, то придется перечислить все для него
User-Agent: YandexBot
Disallow: /cgi-bin
Disallow: /xmlrpc.php
Disallow: /author
Disallow: /blog
Disallow: /wp-json
Disallow: /wp-login.php
Disallow: */feed*
Allow: /feed/turbo/ #открываем доступ к RSS для турбостраниц ибо чуть выше мы запретили к ним доступ.
Disallow: /wp-content/uploads
Disallow: /category
Disallow: /attachment
Disallow: */page/
Disallow: *?*
Disallow: */amp #закрываем доступ к AMP-страницам
Allow: *.css?ver=*
User-Agent: *
Disallow: /cgi-bin
Disallow: /xmlrpc. php
php
Disallow: /author
Disallow: *readme.txt
Disallow: /blog
Disallow: /wp-json
Disallow: /wp-login.php
Disallow: */feed*
Disallow: /wp-content/uploads
Disallow: /category
Disallow: /attachment
Disallow: */page/
Disallow: *?*
Allow: *?ver=*
Sitemap: https://dampi.ru/sitemap_index.xml
Некоторые директивы я прокомментировал, которые не описал в главе выше.
Добавление robots.txt в WordPress
По сути в случае с сайтом на WordPress существует три способа редактирования и соответственно загрузки robots.txt на наш сайт, но рассмотрю я только два, характерных именно для WordPress, поскольку третий – это загрузка файла по FTP и этот способ универсален. Давайте рассмотрим эти два способа.
Способ первый: с помощью специального плагина
Не надо качать FTP-киент, лезть на сервер, создавать текстовый файл, а потом каждый раз из-за каждой мелочи снова и снова соваться туда. Есть вполне себе изящное решение в виде простого плагина, который создает «виртуальный» robots. txt.
txt.
- Собственно ссылка на плагин: https://ru.wordpress.org/plugins/pc-robotstxt/
С установкой разберетесь сами, там ничего сложного. После установки и активации плагина необходимо пройти на страницу с настройками этого плагина
Страница настроек предельно проста, там всего лишь текстовое поле, куда надо поместить наши директивы и один чекбокс, отметив который мы указываем плагину что необходимо подтереть свои настроки при деактивации.
Как видите ничего сверх естественного. Подтираем дефолтный текст и вбиваем наши директивы.
Способ второй: с помощью SEO-плагинов
Поскольку я пользуюсь плагином Yoast SEO, то расскажу на его примере. Для создания и редактирования файла robots.txt необходимо пройти в раздел «Инструменты» плагина:
Нас интересует «Редактор файлов», переходим туда и уже там видим следующее:
У меня файл robots.txt физически отсутствует ибо он создается плагином «на лету», иначе тут было бы видно его содержимое. Вам остается выбрать подходящий способ редактирования, скопировать директивы нашего robots.txt и сохранить. Дальше вам потребуется отслеживать поведение вашего сайта в поиске.
Вам остается выбрать подходящий способ редактирования, скопировать директивы нашего robots.txt и сохранить. Дальше вам потребуется отслеживать поведение вашего сайта в поиске.
Проверка robots.txt в панели вебмастера
Для проверки правильности robots.txt у Яндекс и Google предусмотрены специальные инструменты. Использование данных инструментов довольно элементарный процесс. Давайте рассмотрим оба варианта.
Search Console от Google
В соответствующем разделе мы видим содержимое нашего robots.txt
Кроме содержимого robots.txt мы видим сообщения с ошибками и предупреждениями. В моем случае их счетчики по нолям. В поле ниже мы можем указать URL, который хотим проверить. Если введенный нами URL запрещен в файле robots.txt, то вы увидите сообщение справа и выделенную директиву, которая запрещает индексирование данного URL. Вполне удобно.
Яндекс Вебмастер
Проходим в «Инструменты»->«Анализ robots.txt» и видим вот такую картину.
Эта страница устроена чуть сложнее. Страница разделена на три части, в первой все содержимое robots.txt, вторая часть показывает какие директивы использует основной робот, а третья часть отвечает за проверку URL. Обратите внимание на то, что тут поле позволяет проверять URL пачками, что гораздо удобнее чем в инструменте проверки от Google.
Страница разделена на три части, в первой все содержимое robots.txt, вторая часть показывает какие директивы использует основной робот, а третья часть отвечает за проверку URL. Обратите внимание на то, что тут поле позволяет проверять URL пачками, что гораздо удобнее чем в инструменте проверки от Google.
Как добавить robots.txt в Яндекс и Google
В отличии от sitemap, адрес которого необходимо указывать в robots.txt или в панели вебмастера, robots.txt не нужно никуда загружать. Его наличие поисковые роботы проверяют каждый раз обращаясь к сайту. По этой причине для «загрузки robots.txt» в Яндекс и Google достаточно просто создать его на своем сайте.
Имя этого файла и его расположение является жестким требованием и соответственно все знают что robots.txt лежит в корне сайта. По этому кроме его создания и заполнения никаких действий больше не требуется, разве что проверить его на ошибки, с помощью описанных выше инструментов.
0Правильный robots.
txt для WordPressПравильно созданный файл robots.txt способствует быстрой индексации страниц сайта. Этот файл является служебным и призван улучшать поисковую оптимизацию сайта. Внутренняя оптимизация страниц сайта на WordPress также немаловажна для проекта и ею нужно заниматься.
Файл robots.txt позволяет ограничить индексацию тех страниц, которые индексировать не нужно. Поисковые роботы обращают внимание на этот служебный файл с целью запрета показа страниц в поисковых системах, которые закрыты от индексации. Кстати, в файле также указываются карта сайта и его зеркало.
Как создать robots.txt для WordPress
Чтобы приступить к созданию правильного файла, для начала давайте поймем, где находится robots.txt WordPress. Он располагается в корне сайта. Чтобы просмотреть корневые папки и файлы вашего проекта, необходимо воспользоваться любым FTP-клиентом, для этого просто нужно нажать на настроенное «Соединение».
Чтобы посмотреть содержимое нашего служебного файла, достаточно просто набрать в адресной строке после имени сайта robots. txt. Пример: https://mysite.com/robots.txt
WordPress robots.txt где лежит вы знаете, осталось взглянуть, как должен выглядеть идеальный служебный файл для указанного выше движка.
- В первую очередь в файле необходимо указать пусть к карте сайта:
Sitemap: http://web-profy.com/sitemap.xml
- А теперь непосредственно правильная структура файла robots.txt для WordPress:
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: mysite. com
Sitemap: http://mysite.com/sitemap.xml.gz
Sitemap: http://mysite.com/sitemap.xml
Достаточно просто скопировать эти данные в свой файл. Так выглядит правильный robots.txt для WordPress.
Теперь рассмотрим, что означает каждая из строк в структуре служебного файла:
User-agent: * — строка, которая показывает, что все введенные ниже данные будут применимы относительно всех поисковых систем.
Однако для Яндекса правило будет выглядеть следующим образом: User-agent: Yandex.
Allow: — страницы, которые поисковые роботы могут индексировать.
Disallow: — страницы, которые поисковым роботам индексировать запрещено.
Host: mysite.com — зеркало сайта, которое нужно указывать в данном служебном файле.
Sitemap: — путь к карте сайта.
robots.txt для сайта WordPress, на котором не настроены ЧПУ
robots.txt для сайта WordPress, где находится список правил будет выглядеть несколько иначе в случае, если на сайте не настроены ЧПУ.
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Host: mysite. com
com
Sitemap: http://mysite.com /sitemap.xml.gz
Sitemap: http://mysite.com /sitemap.xml
Какие могут возникнуть проблемы на WordPress сайте, если нет настроены ЧПУ. Строка в служебном файле robots.txt Disallow: /*?* не позволяет индексировать страницы сайта, а именно так выглядят адреса страниц проекта при отсутствии настроек ЧПУ. Это может негативно отражаться на рейтинге интернет-проекта в поисковиках, поскольку нужный пользователям контент просто не будет им показываться в результатах выдачи.
Конечно, эту строку можно в файле можно легко удалить. Тогда сайт будет работать в нормальном режиме.
Как убедиться в том, что robots.txt составлен правильно
Сделать это можно при помощи специального инструмента от Яндекс — Яндекс.Вебмастер.
Необходимо зайти в Настройки индексирования — Анализ robots.txt
Внутри все интуитивно понятно. Необходимо нажать на «Загрузить robots.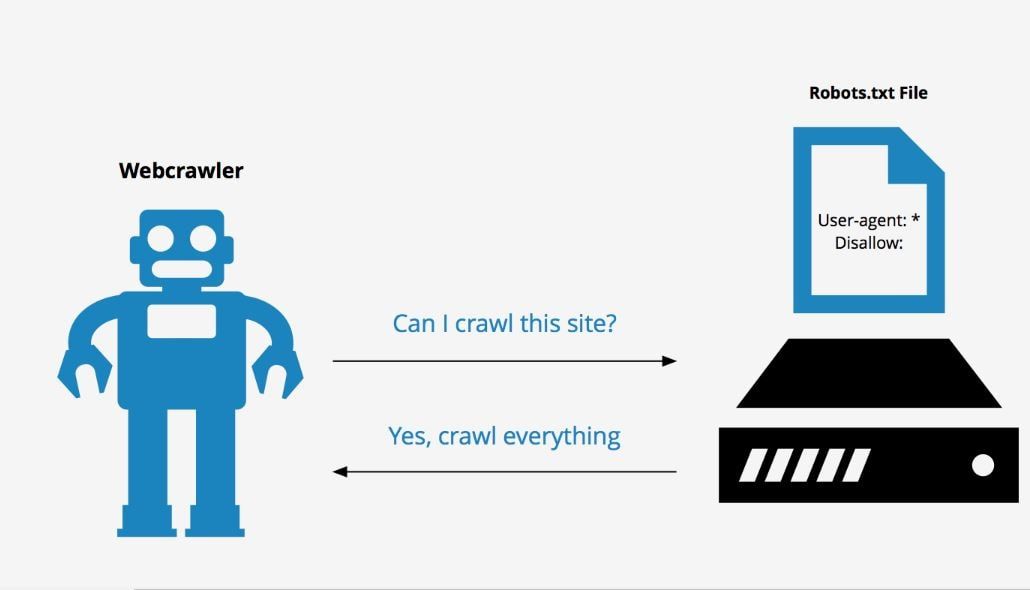 txt с сайта». Также вы можете каждую страницу отдельно просмотреть на наличие возможности ее индексации. В «Список URL» можно просто ввести адрес интересующих вас страниц, система покажет все сама.
txt с сайта». Также вы можете каждую страницу отдельно просмотреть на наличие возможности ее индексации. В «Список URL» можно просто ввести адрес интересующих вас страниц, система покажет все сама.
Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь несколько месяцев.
Как правильно сохранять файл robots.txt
Чтобы наш служебный файл был доступен в такой поисковой системе, как Google, его необходимо сохранить следующим образом:
- Файл в обязательном порядке должен иметь текстовый формат;
- Разместить его необходимо корне вашего сайта;
- Файл должен иметь имя robots.txt и никакое другое больше.
Адрес, по которому поисковые роботы находят robots.txt должен иметь следующий вид — https://mysite.com/robots.txt
Полный обзор WordPress Robots.txt — как его использовать?
Введение
Если вы являетесь веб-мастером, термин «robots. txt» наверняка попадался вам на глаза то здесь, то там. Вы когда-нибудь задумывались, что это значит? Как это применимо к вашему веб-контенту и какую роль оно играет?
txt» наверняка попадался вам на глаза то здесь, то там. Вы когда-нибудь задумывались, что это значит? Как это применимо к вашему веб-контенту и какую роль оно играет?
Почти на каждом веб-сайте файл robots.txt является обязательным, но некоторые владельцы знают, для чего он используется. Цель написания этой статьи — предоставить вам необходимую информацию, чтобы вы могли использовать ее для дальнейшего повышения качества вашего сайта.
Приготовьтесь и пристегните ремни безопасности, потому что мы собираемся взять вас в интересное приключение о знании файла WordPress robots.txt . Вы также сможете лучше управлять доступом к своему сайту. Как только вы узнаете о функционировании файла, вам будет проще использовать его в своих интересах и выделиться из пула веб-сайтов
Что такое WordPress Robots.txt?
До начала останавливаться на термине Robots.txt WordPress , нам нужно понимать довольно широкий термин, то есть робот. В мире Интернета это слово используется в контексте любого вида «бота», который посещает веб-сайты.
Вы можете рассмотреть пример поисковых роботов Google, которые бродят по сети и помогают Google индексировать миллиарды веб-страниц с огромного количества веб-сайтов по всему миру.
Боты — удобный инструмент, и они довольно эффективно заменяют рабочую силу, необходимую для выполнения своих задач. Их можно назвать «цифровыми помощниками». Они имеют решающее значение для существования интернет-структуры и ее надлежащего функционирования.
Однако, если вы являетесь владельцем веб-сайта, вы не хотите, чтобы эти мошенники бродили по вашему веб-сайту для проверки качества. Вы хотите контролировать внешний вид и статистику вашего веб-сайта. Это непростой бизнес, который породил стандарт исключения роботов в конце 90-х.
Теперь, переходя к нашему предметному термину, то есть к файлу Robots.txt, вы можете назвать его реализацией вышеупомянутого стандарта. С помощью файла WordPress Robots.txt вы можете контролировать, как эти боты перемещаются по веб-страницам.
Используя этот файл, вы можете регулировать и даже прекращать участие ботов на вашем сайте. Да, это стоит за той человеческой проверкой на многих веб-сайтах, которые вы так ненавидите, — тайна раскрыта.
Однако регулирование участия ботов не так просто контролировать. Боты «злых гениев» могут легко обойти файл robots.txt и все равно попасть на ваш сайт. И как только они вошли, их нельзя заставить взаимодействовать так, как вы хотите, даже с помощью robots.txt.
Кроме того, многие крупные предприятия не осознают преимущества добавления команд в robots.txt, которые даже не распознаются Google. Примите во внимание любые правила относительно количества ботов, которые могут войти на ваш сайт, и он не будет скомпрометирован. Однако, если вы все еще не можете справиться с этими вредными существами, вы можете воспользоваться онлайн-средством, доступным в Интернете.
Зачем беспокоиться о получении файла Robots.txt для вашего веб-сайта?
Как владелец веб-сайта, этот вопрос должен возникать у вас в голове. Зачем эти дополнительные усилия и инвестиции? Вы хотите, чтобы ваш бизнес работал максимально рентабельно, сто раз подумаете, прежде чем добавлять?
Зачем эти дополнительные усилия и инвестиции? Вы хотите, чтобы ваш бизнес работал максимально рентабельно, сто раз подумаете, прежде чем добавлять?
Вам может быть интересно, как останов вторжений ботов на веб-сайт изменит работу вашего веб-сайта. Ну, вы знаете, пока еще капля, и остался океан.
Но не волнуйтесь, мы здесь именно по этой причине. К концу этой статьи вы сможете сами увидеть, что лучше для вас. Короче говоря, Robots.txt WordPress помогает вашему сайту двумя способами:
- Оптимизация использования ресурсов за счет блокировки ботов. Эти посещения ботов приводят к ненужной трате полезных ресурсов.
- Улучшите ресурсы сканирования поисковых систем, дав им указание не тратить время на страницы, которые не нужно проверять на предмет индексации. Таким образом, вы можете контролировать свой сайт, индексируя только те страницы, которые считаете лучшими.
Следовательно, вы в конечном итоге достигнете лучшего рейтинга вашего веб-сайта, поскольку ваши результаты оптимизированы для того, чтобы они были такими, какими вы хотите их видеть. Это умное сотрудничество ума и технологий приводит к общей пользе вашего сайта. Любой здравомыслящий веб-мастер хотел бы этого.
Это умное сотрудничество ума и технологий приводит к общей пользе вашего сайта. Любой здравомыслящий веб-мастер хотел бы этого.
- WordPress Robots.txt не предназначен специально для управления индексацией страниц.
Robots.txt на самом деле не мешает поисковым системам проверять определенные страницы вашего веб-сайта. Если это ваша основная цель, вам лучше выбрать метатег без индекса. Это более прямой способ решения этой конкретной проблемы.
Основная цель WordPress Robot.txt — не мешать поисковым системам индексировать страницу. Скорее это просто инструктирует ботов ползать. Хотя Google не сканирует отмеченную вами страницу напрямую, в нем четко указано, что внешняя ссылка на страницу позволит ему сканировать ее.
На это указал аналитик Google для веб-мастеров в видеовстрече Webmaster Central. Он воскликнул, что если люди хотят запретить ботам индексировать определенную страницу, им следует использовать неиндексирующий тег, а не файл robots. txt, поскольку внешние ссылки будут отображать движок, не зная, что страницы не нужно индексировать.
txt, поскольку внешние ссылки будут отображать движок, не зная, что страницы не нужно индексировать.
Итак, если вы читаете эту статью, сделайте шаг назад, если вы планируете использовать файл для указанной выше цели. В конечном итоге это приведет к вашей потере, поскольку вы не получите того, что ожидаете.
- Как создать и отредактировать файл WordPress Robots.txt
Теперь, когда вы получили необходимые знания о том, что такое Robots.txt WordPress и как вы можете использовать его в своих интересах, вам должно быть интересно, как создать и редактировать файлы Robots.txt WordPress .
В WordPress вы получаете файл robots.txt с инициалами. Таким образом, несмотря на то, что вы не предпринимаете никаких внешних усилий для файла robots.txt в своем файле WordPress, он уже должен быть там. Чтобы проверить, есть ли он, можно использовать определенный метод тестирования. Введите «/robots.txt» в конце вашего домена и нажмите кнопку поиска.
Поскольку файл по сути является виртуальным, его нельзя изменить. Если вы хотите изменить файл по своему усмотрению, вам придется создать документ на своем компьютере, который вы сможете редактировать по своему вкусу. Ознакомьтесь с тремя простыми способами сделать это:
Лучший в своем классе управляемый облачный хостинг WordPress с неограниченным количеством правок на уровне приложений.
Запустите свой первый сайт бесплатно
Зарегистрируйтесь
- С помощью Yoast SEO
Если вы используете знаменитый плагин Yoast SEO, есть возможность создать файл robots.txt, который позже будет редактироваться просто из основного интерфейса. Для этого вам сначала нужно авторизовать расширенные функции Yoast SEO, выполнив путь 9.0011 SEO> Панель инструментов> Функции , а затем переключитесь на страницу дополнительных настроек .
После того, как вы выполнили указанную выше задачу, вам нужно перейти к SEO> Инструменты и нажать Редактор файлов . Расположение WordPress robots.txt обычно является корневой папкой сайта.
Расположение WordPress robots.txt обычно является корневой папкой сайта.
Предположим, что на вашем веб-сайте его еще нет. Yoast позволяет вам создать файл, используя его интерфейс:
После нажатия кнопки вы можете легко редактировать файл robots.txt WordPress легко из интерфейса.
Далее мы также обсудим, какие типы команд вы можете ввести в свой файл robots.txt, которые помогут вам сделать ваш веб-сайт более оптимизированным и регулируемым.
- Использование все в одном SEO
All in One SEO так же популярен среди пользователей, как и Yoast. Это достойная платформа. Если вы используете этот плагин, вы можете создавать и также отредактируйте файл robots.txt WordPress из его интерфейса.
Для выполнения этой задачи вам нужно перейти на страницу All in One SEO и выбрать диспетчер функций , а затем активировать функцию robots.txt.
После того, как вы активировали функцию файла, как вы видели на картинке выше, вы можете легко отредактировать ее, открыв All in One SEO> Robots. txt .
txt .
- Использование FTP
Если вы не используете ни один из вышеперечисленных плагинов, вам необходимо использовать стороннюю программу. Для этой задачи вам нужно знать, где находится файл robots.txt. Он должен находиться в корневой папке сайта. Для подключения к нему можно использовать FTP-клиент.
Для этого сначала создайте в папке текстовый файл, назовите его robots.txt.
Затем вам нужно будет подключиться к вашему веб-сайту с помощью SFTP и перенести документ в корневую папку сайта.
В файл также можно внести дополнительные изменения, используя SFTP или загрузив последние версии файла. Это один из хороших способов редактирования файла WordPress Robots.txt .
Что вы можете ввести в свой файл robots.txt?
Очень важно задать этот вопрос перед настройкой файла robots.txt WordPress . Вы должны четко осознавать, что вы делаете и как вы собираетесь это делать.
У вас есть физический файл robots.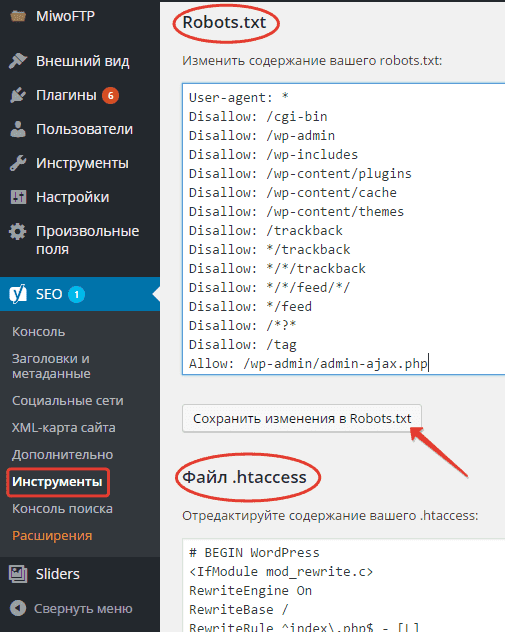 txt в вашем WordPress, и теперь вы можете изменить его по своему желанию. Но вы должны знать домен, который вы должны указать в файле. Robots.txt управляет тем, как поисковые роботы ссылаются на веб-сайт, используя два метода:
txt в вашем WordPress, и теперь вы можете изменить его по своему желанию. Но вы должны знать домен, который вы должны указать в файле. Robots.txt управляет тем, как поисковые роботы ссылаются на веб-сайт, используя два метода:
- Метод Disallow , который специально используется, чтобы запретить роботам доступ к определенным определенным страницам вашего веб-сайта.
- Метод User-agent предназначен для нацеливания на определенный тип ботов. Боты используют пользовательские агенты, чтобы узнавать себя. С их помощью вы можете установить директиву, которая применяется к Yahoo, но не к Google.
Вы будете использовать команду «Разрешить» в своей нише. Все на сайте по умолчанию разрешено, и вам нужно только отменить выбор областей, которые вы хотите запретить. Вы можете заблокировать доступ к одной конкретной папке и ее подпапкам, разрешив при этом доступ к определенной подпапке.
В основном вы добавляете правила, сначала выбирая, какое правило пользовательского агента будет применяться, а затем выбирая, какие правила реализовать с помощью разрешения и запрета. Crawl-delay и sitemap — это второстепенные команды, которые также доступны. Они бесполезны для:
Crawl-delay и sitemap — это второстепенные команды, которые также доступны. Они бесполезны для:
- больших поисковых роботов, так как они их игнорируют.
- Такие инструменты, как консоль поиска Google, могут сделать их излишними.
Вы можете лучше понять упражнение, ознакомившись с особыми случаями:
- Использование файла Robots.txt WordPress для блокировки доступа ко всему сайту
Этот метод используется при условии, что на вашем веб-сайте не должно быть поисковых роботов. Полная блокировка поместит ваш сайт в принудительный карантин от внешних сканеров. Для этого вы можете написать следующий код в файле WordPress robots.txt :
User-agent: *
Disallow: /
Знак ‘*’ рядом с user agent дает сообщение файлу, что все пользовательские агенты должны быть заблокированы. «/» после запрета означает, что доступ ко всем страницам должен быть ограничен. Однако этот метод вряд ли применим на действующем сайте. Лучше применять для сайта разработки.
Лучше применять для сайта разработки.
- Блокировка конкретного бота на вашем сайте
Этот метод часто более желателен, чем рассмотренный выше, и чаще всего применяется. Рассмотрим пример, скажем, вы не хотите, чтобы Bing-bot ползал по вашему сайту.
Чтобы заблокировать только Bing от входа на ваш сайт, вам нужно будет ввести этот код в файл:
User-agent: Bingbot
Disallow: /
Этот код сообщает robots.txt Файл WordPress , чтобы запретить только определенным ботам, имеющим пользовательский агент Bing-bot. этот метод будет очень полезен, когда вам нужен определенный жучок на ваших страницах. Посетите этот сайт, чтобы узнать об известных именах пользовательских агентов некоторых служб.
Лучший в своем классе управляемый облачный хостинг WordPress с неограниченным количеством правок на уровне приложений.
Запустите свой первый сайт бесплатно
Зарегистрируйтесь
- Блокировка входа в одну папку
Возможно, вы захотите запретить ботам блуждать по одной папке. В таком случае вы будете делиться знаниями из этого раздела. Допустим, вы хотите заблокировать доступ к следующим папкам:
В таком случае вы будете делиться знаниями из этого раздела. Допустим, вы хотите заблокировать доступ к следующим папкам:
- Полная папка wp-admin
- wp-login.php
Используйте следующий код для этой команды:
Запретить: /wp-login.php
- Чтобы разрешить вход в определенную папку внутри заблокированной папки
Теперь перейдем к случаю, когда вы хотите остановить доступ ко всему документу, но внутри есть определенный файл, который вы хотите проиндексировать. Это время показа команды «Разрешить». Это очень полезно для WordPress.
Вы можете получить идеальную иллюстрацию этой команды с помощью виртуального файла WordPress Robotx.txt :
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax .php
Это означает, что вы блокируете доступ ко всей папке «wp-admin», но исключаете «admin-ajax. php» из списка. Это действительно очень полезная команда.
php» из списка. Это действительно очень полезная команда.
- Использование файла robots.txt для запрета ботам сканировать результаты поиска WordPress
Это привилегия для пользователей WordPress. Вы можете контролировать доступ ботов к результатам поиска на вашей веб-странице. Чтобы они не сканировали ваши страницы результатов поиска, WordPress по умолчанию использует параметр запроса, то есть «?S=». для этого вы можете добавить следующее правило в пользовательский агент:
User-agent: *
Запретить: /?s=
Запретить: /search/
Метод также полезен при программных ошибках 404. Это также ускорит ваши поиски в WordPress, что приведет к более качественным и оптимизированным страницам.
- Создание разных правил для разных ботов
Это более общий сценарий, в котором вы хотите реализовать различные команды для ряда ботов. Для этого вы добавите правила для каждого бота в пользовательском агенте и создадите правила для каждого из них отдельно. Предположим, вы хотите создать общее правило для всех ботов и специальные правила, которые должны применяться только к Bing-боту. Введите этот код:
Предположим, вы хотите создать общее правило для всех ботов и специальные правила, которые должны применяться только к Bing-боту. Введите этот код:
Агент пользователя: *
Запретить: /wp-admin/
Агент пользователя: Bingbot
Запретить: /
С помощью этой команды вы заблокируете всех ботов от перехода к папке «wp-admin», но «Bing-bot» не будет разрешен на всем веб-сайте.
Проверка файла robots.txt
Небольшое техническое обслуживание всегда оказывается полезным и выгодным в долгосрочной перспективе. Частое тестирование обеспечивает максимальную производительность файла Robots.txt WordPress . Консоль поиска Google может выполнить проверку вашей папки.
Перейдите на сайт и нажмите «тестер robots.txt» под «Crawler». После этого вам нужно отправить URL-адрес страницы, на которой вы хотите протестировать файл. Если все доступно для сканирования, вы должны увидеть зеленое «разрешено». Вы также можете проверить заблокированные URL-адреса, чтобы убедиться, что они правильно заблокированы.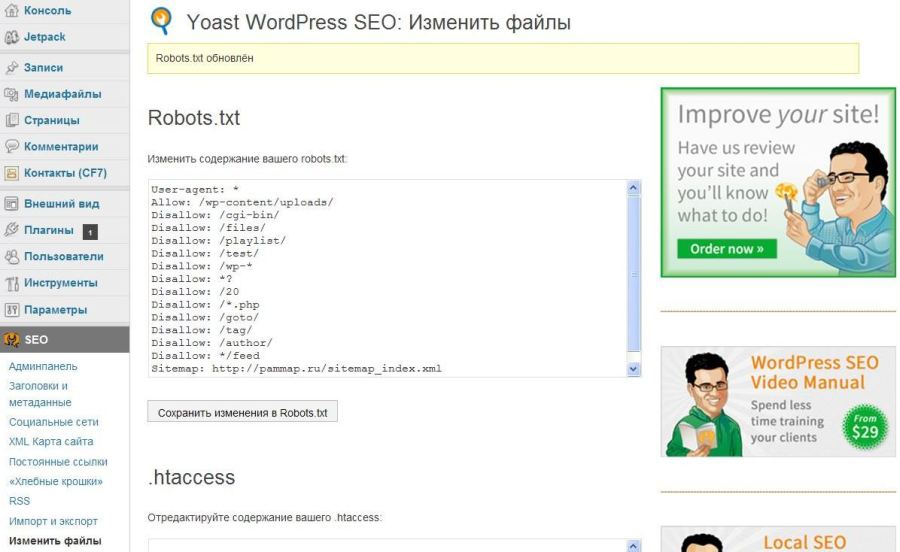
Берегите себя от спецификации UTF-8
Метка порядка байтов или спецификация по сути является невидимым символом, который иногда помещают в файлы из-за некоторых старых текстовых редакторов. Google не будет читать ваши WordPress Robots.txt файл правильно, если он является жертвой этого колдовства.
По этой причине вам следует часто проверять свои файлы на наличие ошибок для лучшей и своевременной диагностики. Возьмем пример, показанный ниже. В файле есть невидимый символ, из-за которого Google не может понять синтаксис.
Следовательно, первая строка вашего файла недействительна и вообще не годится. UTF-8 может стать кошмаром для многих.
Google Bot преимущественно базируется в США
Вы никогда не должны блокировать бота Google из Соединенных Штатов, даже если вы хотите нацелиться на местный регион, соседний с США. Иногда происходит локальное сканирование, но в основном оно происходит в США.
Как максимально эффективно использовать файл WordPress Robots.
 txt
txtМы уверены, что к настоящему времени вы усвоили большой объем знаний и даже применили некоторые из них в свою пользу. Мы стремимся сделать ваш сайт больше и лучше с помощью наших информативных и всеобъемлющих статей.
В заключение, само собой разумеется, что вы всегда должны быть осторожны со своими действиями. В случае нашей нынешней проблемы вам нужно очень хорошо решить, какова ваша основная цель создания файла Robots.txt. Вы хотите запретить ботам заходить на ваш сайт? Тогда вы должны использовать неиндексный тег. Это лучшее решение для полного предотвращения индексации.
Если вы случайный пользователь WordPress, вы действительно не хотите изменять свой файл Robots.txt WordPress . Однако, если вы столкнулись с проблемами с ботом или хотите оптимизировать взаимодействие с поисковой системой, вам пригодится файл robots.txt.
Надеюсь, эта статья предоставила вам достаточно информации о файле Robots.txt. Вы можете связаться с нами в случае возникновения каких-либо вопросов. Пусть ваши усилия облегчатся.
Пусть ваши усилия облегчатся.
Как оптимизировать файл WordPress Robots.txt для SEO?
Вы оптимизировали файл WordPress Robots.txt для SEO? Если нет, вы игнорируете важный аспект SEO, который играет важную роль 9.0005
Вы оптимизировали файл WordPress Robots.txt для SEO? Если вы этого не сделали, вы игнорируете важный аспект SEO. Файл robots.txt играет важную роль в SEO вашего сайта. Вам повезло, что WordPress автоматически создает для вас файл Robots.txt. Иметь этот файл — половина дела. Вы должны убедиться, что файл Robots.txt оптимизирован для получения всех преимуществ.
Файл Robots.txt сообщает роботам поисковых систем, какие страницы следует сканировать, а какие избегать. Этот пост покажет вам, как редактировать и оптимизировать файлы Robots.txt в WordPress.
Оптимизация файла WordPress Robots.txt для SEO
Как оптимизировать файл WordPress Robots.txt для SEO? Что такое файл robots.txt? Начнем с основ. Файл Robots.txt — это текстовый файл, который указывает ботам поисковых систем сканировать и индексировать сайт. Всякий раз, когда роботы поисковых систем заходят на ваш сайт, они читают файл robots.txt и следуют инструкциям. Используя этот файл, вы можете указать, какую часть вашего сайта следует сканировать, а какую функцию следует избегать. Однако отсутствие файла robots.txt не помешает роботам поисковых систем сканировать и индексировать ваш сайт.
Файл Robots.txt — это текстовый файл, который указывает ботам поисковых систем сканировать и индексировать сайт. Всякий раз, когда роботы поисковых систем заходят на ваш сайт, они читают файл robots.txt и следуют инструкциям. Используя этот файл, вы можете указать, какую часть вашего сайта следует сканировать, а какую функцию следует избегать. Однако отсутствие файла robots.txt не помешает роботам поисковых систем сканировать и индексировать ваш сайт.
Я уже говорил, что каждый сайт WordPress имеет файл robots.txt по умолчанию в корневом каталоге. Вы можете проверить файл robots.txt, перейдя по адресу http://yourdomain.com/robots.txt. Например, вы можете просмотреть наш файл robots.txt здесь: https://visualmodo.com/robots.txt
Если у вас нет файла robots.txt, вам придется его создать. Это очень легко сделать. Просто создайте текстовый файл на своем компьютере, сохраните его как robots.txt и загрузите в корневой каталог. Вы можете загрузить его через FTP-менеджер или файловый менеджер cPanel.
Вы можете загрузить его через FTP-менеджер или файловый менеджер cPanel.
Редактирование файлов
Теперь давайте посмотрим, как редактировать файл robots.txt.
Вы можете редактировать файл robots.txt с помощью диспетчера FTP или файлового менеджера cPanel. Но это долго и немного сложно.
Лучший способ редактировать файлы Robots.txt — использовать подключаемый модуль. Существует несколько плагинов WordPress robots.txt. Я предпочитаю Yoast SEO. Это лучший SEO-плагин для WordPress. Я уже рассказывал, как настроить Yoast SEO.
Yoast SEO позволяет вам изменять файл robots.txt из области администрирования WordPress. Однако, если вы не хотите использовать плагин Yoast, вы можете использовать другие плагины, такие как WP Robots Txt.
Видеоруководство
Установив и активировав плагин Yoast SEO, перейдите в Панель администратора WordPress > SEO > Инструменты.
Затем нажмите «Редактор файлов».
Во-вторых, нажмите «Редактор файлов».
Затем нужно нажать «Создать файл robots.txt».
Редактирование файла robots.txtПосле этого вы получите редактор файла Robots.txt. Здесь вы можете настроить файл robots.txt.
ФайлыПеред редактированием файла необходимо понять команды файла. В основном это три команды.
- User-agent — определяет имя ботов поисковых систем, таких как Googlebot или Bingbot. Вы можете использовать звездочку (*) для обозначения всех ботов поисковых систем.
- Запретить – указывает поисковым системам не сканировать и не индексировать некоторые части вашего сайта.
- Разрешить – указывает поисковым системам сканировать и индексировать, какие части вы хотите индексировать.
Вот пример файла Robots.txt.
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /
Этот файл robots.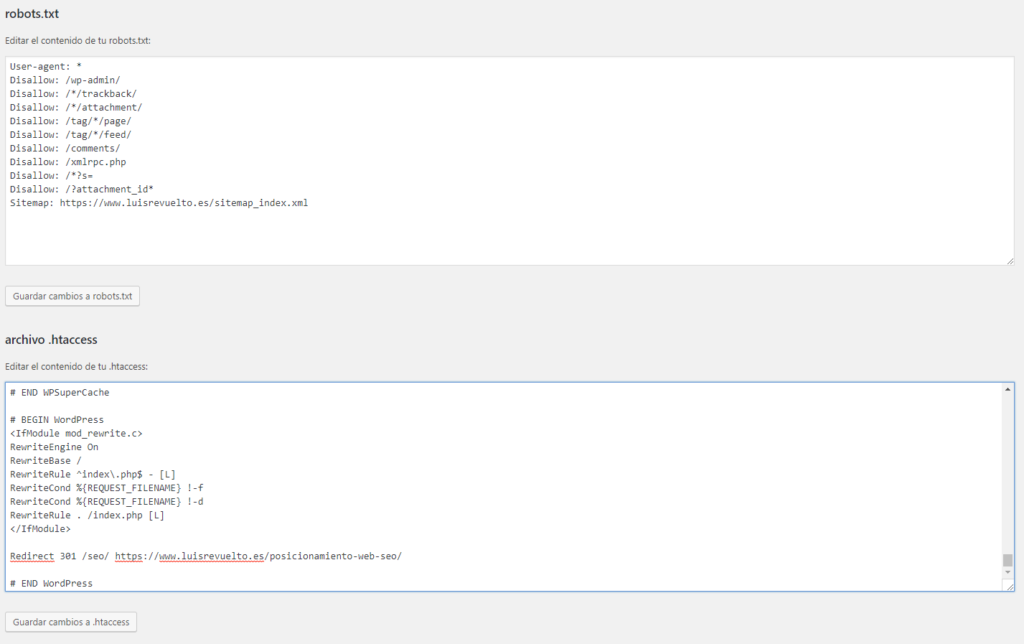 txt указывает всем ботам поисковых систем сканировать сайт. Вторая строка указывает ботам поисковых систем не сканировать часть /wp-admin/. В 3-й строке он указывает ботам поисковых систем сканировать и индексировать весь веб-сайт.
txt указывает всем ботам поисковых систем сканировать сайт. Вторая строка указывает ботам поисковых систем не сканировать часть /wp-admin/. В 3-й строке он указывает ботам поисковых систем сканировать и индексировать весь веб-сайт.
Простая ошибка в настройке файла Robots.txt может привести к полной деиндексации вашего сайта поисковыми системами. Например, если вы используете команду «Запретить: /» в файле Robots.txt, ваш сайт будет деиндексирован поисковыми системами. Так что нужно быть осторожным при настройке.
Еще одна важная вещь — оптимизация файла Robots.txt для SEO. Прежде чем перейти к лучшим практикам SEO для Robots.txt, я хотел бы предупредить вас о некоторых плохих практиках.
- Не используйте файл Robots.txt для сокрытия некачественного контента. Лучше всего использовать метатеги noindex и nofollow. Вы можете сделать это с помощью плагина Yoast SEO.
- Не используйте файл Robots.
 txt, чтобы запретить поисковым системам индексировать ваши категории, теги, архивы, страницы авторов и т. д. Вы можете добавить на эти страницы метатеги nofollow и noindex с помощью плагина Yoast SEO.
txt, чтобы запретить поисковым системам индексировать ваши категории, теги, архивы, страницы авторов и т. д. Вы можете добавить на эти страницы метатеги nofollow и noindex с помощью плагина Yoast SEO. - Не используйте файл Robots.txt для обработки повторяющегося содержимого. Есть и другие способы.
Теперь давайте посмотрим, как сделать файл Robots.txt оптимизированным для SEO.
- Во-первых, вам нужно определить, какие части вашего сайта не должны сканироваться роботами поисковых систем. Я предпочитаю запрещать /wp-admin/, /wp-content/plugins/, /readme.html, /trackback/.
- Во-вторых, добавление производных «Разрешить: /» в файл Robots.txt не имеет решающего значения, так как боты все равно будут сканировать ваш сайт. Но вы можете использовать его для конкретного бота.
- Наконец, добавление файлов Sitemap в файл Robots.txt также является хорошей практикой. Читайте: Как создать карту сайта
Вот пример идеального файла Robots.
 txt для WordPress.
txt для WordPress.Агент пользователя: * Запретить: /wp-admin/ Запретить: /wp-content/plugins/ Запретить: /readme.html Запретить: /трекбэк/ Запретить: /иди/ Разрешить: /wp-admin/admin-ajax.php Разрешить: /wp-content/uploads/ Карта сайта: https://roadtoblogging.com/post-sitemap.xml Карта сайта: https://roadtoblogging.com/page-sitemap.xml
Вы можете проверить файл Robots.txt RTB здесь: https://visualmodo.com/robots.txt
Тестирование файла Robots.txt в Инструментах Google для веб-мастеровПосле обновления файла Robots.txt вам необходимо протестируйте файл Robots.txt, чтобы проверить, влияет ли обновление на какой-либо контент.
Вы можете использовать Google Search Console, чтобы проверить, есть ли какие-либо «Ошибки» или «Предупреждения» для вашего файла Robots.txt. Просто войдите в Google Search Console и выберите сайт. Затем перейдите в Crawl > robots.txt Tester и нажмите кнопку «Отправить».
Google Search Console Появится всплывающее окно. Просто нажмите на кнопку «Отправить».
Просто нажмите на кнопку «Отправить».
Затем перезагрузите страницу и проверьте, обновлен ли файл. Таким образом, обновление файла Robots.txt может занять некоторое время.
Если он не был обновлен, вы можете ввести код файла Robots.txt в поле, чтобы проверить наличие ошибок или предупреждений. Более того, он покажет ошибки и предупреждения там.
Код файла robots.txtИтак, если вы заметили какие-либо ошибки или предупреждения в файле robots.txt, вы должны исправить их, отредактировав файл robots.txt.
Заключительные мыслиВ заключение, я надеюсь, что этот пост помог вам оптимизировать файл robots.txt WordPress. Если вы не уверены в этом, не стесняйтесь спрашивать нас в комментариях.
Однако, чтобы сделать ваш блог WordPress оптимизированным для SEO, вы можете прочитать нашу статью о том, как настроить плагин WordPress Yoast SEO.
Наконец, если вы найдете этот пост полезным, пожалуйста, помогите мне, поделившись этим постом на Facebook и Twitter.
Понимание и оптимизация robots.txt WordPress
Когда дело доходит до SEO, большинство людей хорошо разбираются в основах. Они знают о ключевых словах и о том, как они должны отображаться в разных местах контента. Они слышали о поисковой оптимизации на странице и, возможно, даже попробовали SEO-плагины для WordPress.
Если вы углубитесь в мельчайшие детали поисковой оптимизации, то обнаружите несколько довольно неясных фрагментов головоломки, о которых знают не все. Одним из них являются файлы robots.txt.
Что такое файлы robots.txt и для чего они используются?
Файл robots.txt — это текстовый файл, который находится на вашем сервере. Он содержит правила индексации вашего веб-сайта и является инструментом для прямого общения с поисковыми системами.
По сути, в файле указано , какие части вашего сайта Google разрешил индексировать, а какие следует оставить в покое.
Однако, зачем вообще указывать Google , а не сканировать что-то на вашем сайте? Разве это не вредно с точки зрения SEO? На самом деле есть много причин, по которым вы бы посоветовали Google не сканировать что-либо на вашем сайте.
Одним из наиболее распространенных способов использования файла robots.txt является исключение веб-сайта из результатов поиска, который все еще находится в стадии разработки.
То же самое касается промежуточной версии вашего сайта, где вы тестируете изменения, прежде чем вносить их в действующую версию.
Или, может быть, у вас на сервере есть файлы, которые вы не хотите показывать в Интернете, потому что они предназначены только для ваших пользователей.
Обязательно ли иметь файл robots.txt?
Вы абсолютно есть , чтобы иметь файл robots.txt? Нет, ваш сайт WordPress будет проиндексирован поисковыми системами даже без этого файла.
На самом деле WordPress сам по себе уже содержит виртуальный robots.txt. Тем не менее, я бы по-прежнему рекомендовал создать физическую копию на вашем сервере. Это сделает вещи намного проще.
Одна вещь, о которой вы должны знать, это то, что подчинение robots.txt не может быть принудительно выполнено. Файл будет распознаваться и уважаться основными поисковыми системами, но вредоносные сканеры и поисковые роботы низкого качества могут полностью игнорировать его.
Файл будет распознаваться и уважаться основными поисковыми системами, но вредоносные сканеры и поисковые роботы низкого качества могут полностью игнорировать его.
Как его создать и где разместить?
Создать собственный файл robots.txt так же просто, как создать текстовый файл в выбранном вами редакторе и назвать его robots.txt. Просто сохраните, и все готово. Серьезно, это так просто.
Хорошо, есть второй шаг: загрузка через FTP. Файл обычно помещается в вашу корневую папку, даже если вы переместили WordPress в отдельный каталог. Хорошее эмпирическое правило — поместить его в то же место, что и ваш index.php, дождаться завершения загрузки, и все готово.
Имейте в виду, что вам потребуется отдельный файл robots.txt для каждого субдомена вашего сайта и для различных протоколов, таких как HTTPS.
Как установить правила внутри robots.txt
Теперь поговорим о содержании.
Файл robots.txt имеет собственный синтаксис для определения правил. Эти правила также называются «директивами». Далее мы рассмотрим, как вы можете использовать их, чтобы сообщить поисковым роботам, что они могут и чего не могут делать на вашем сайте.
Эти правила также называются «директивами». Далее мы рассмотрим, как вы можете использовать их, чтобы сообщить поисковым роботам, что они могут и чего не могут делать на вашем сайте.
Базовый синтаксис robots.txt
Если вы закатили глаза при слове «синтаксис», не волнуйтесь, вам не нужно изучать новый язык программирования. Доступных команд для директив немного. На самом деле, для большинства целей достаточно знать только два из них:
- User-Agent – определяет поисковый робот .
- Запретить — указывает сканеру держаться подальше от определенных файлов, страниц или каталогов
Если вы не собираетесь устанавливать разные правила для разных сканеров или поисковых систем, можно использовать звездочку (*), чтобы определить универсальные директивы для всех них. Например, чтобы заблокировать всех со всего вашего веб-сайта, вы должны настроить файл robots.txt следующим образом:
Агент пользователя: * Disallow: /
Это в основном говорит о том, что все каталоги запрещены для всех поисковых систем.
Важно отметить, что файл использует относительные (а не абсолютные) пути. Поскольку robots.txt находится в вашем корневом каталоге, косая черта означает запрет на это место и все, что в нем содержится. Чтобы определить отдельные каталоги, такие как папка мультимедиа, как закрытые, вам нужно будет написать что-то вроде /wp-content/uploads/ . Также имейте в виду, что пути чувствительны к регистру.
Если это имеет смысл для вас, вы также можете разрешать и запрещать части вашего сайта для определенных ботов. Например, следующий код в файле robots.txt предоставит полный доступ к вашему веб-сайту только Google, не допуская при этом всех остальных:
User-agent: Googlebot Запретить: Пользовательский агент: * Disallow: /
Имейте в виду, что правила для определенных поисковых роботов должны быть определены в начале файла robots.txt. После этого вы можете включить User-agent:* подстановочный знак в качестве универсальной директивы для всех пауков, у которых нет явных правил.
Примечательные имена пользовательских агентов включают:
- Googlebot – Google
- Googlebot-Изображение – Изображение Google
- Googlebot-Новости – Новости Google
- Бингбот – Бинг
- Yahoo! Slurp — Yahoo (отличный выбор имени, Yahoo!)
Больше можно найти здесь:
- UserAgentString.com
- User-Agents.org
Опять же, позвольте мне напомнить вам, что Google, Yahoo, Bing и подобные обычно соблюдают директивы в вашем файле, однако не все поисковые роботы там будут.
Дополнительный синтаксис
Запретить и User-agent — не единственные доступные правила. Вот еще несколько:
- Разрешить — явно разрешает сканирование объекта на вашем сервере .
- Карта сайта – Сообщите поисковым роботам, где находится ваша карта сайта
- Хост — определяет предпочтительный домен для сайта с несколькими зеркалами
- Crawl-delay — Устанавливает интервал времени ожидания поисковых систем между запросами на ваш сервер
Сначала поговорим о , разрешив . Распространенным заблуждением является то, что это правило используется для того, чтобы заставить поисковые системы проверить ваш сайт, и поэтому оно важно для SEO. По этой причине в некоторых файлах robots.txt вы найдете следующее:
Распространенным заблуждением является то, что это правило используется для того, чтобы заставить поисковые системы проверить ваш сайт, и поэтому оно важно для SEO. По этой причине в некоторых файлах robots.txt вы найдете следующее:
Агент пользователя: * Разрешить: /
Эта директива избыточна. Почему? Потому что поисковые системы считают все, что конкретно не запрещено на вашем сайте, честной игрой. Если вы сообщите им, что вы разрешаете сканирование всего вашего сайта, это мало что изменит.
Вместо этого директива allow используется для противодействия disallow . Это полезно, если вы хотите заблокировать весь каталог, но предоставить поисковым системам доступ к одному или нескольким определенным файлам внутри него, например:0005
Агент пользователя: * Разрешить: /my-directory/my-file.php Disallow: /my-directory/
Поисковые системы будут держаться подальше от my-directory в целом, но по-прежнему будут обращаться к my-file. . Однако важно отметить, что для того, чтобы это работало, сначала необходимо разместить директиву 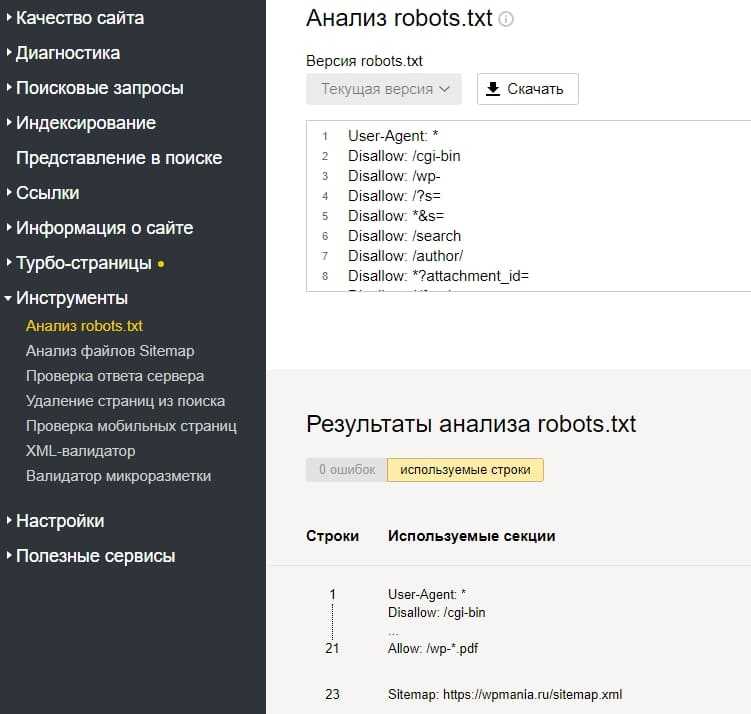 php
php allow .
Некоторые сканеры поддерживают директиву Sitemap . Вы можете использовать его, чтобы сообщить им, где найти карту сайта вашего веб-сайта, и это будет выглядеть так:
Карта сайта: http://mysite.com/sitemap_index.xml Карта сайта: http://mysite.com/post-sitemap.xml Карта сайта: http://mysite.com/page-sitemap.xml Карта сайта: http://mysite.com/category-sitemap.xml Карта сайта: http://mysite.com/post_tag-sitemap.xml
Директива может находиться в любом месте файла robots.txt. Обычно владельцы веб-сайтов предпочитают размещать его либо в начале, либо в конце. Однако его полезность является спорной. Например, у Yoast есть следующие мысли по этому поводу:
«Мне всегда казалось, что ссылка на карту сайта в формате XML из файла robots.txt — это немного глупо. Вы должны добавить их вручную в свои инструменты для веб-мастеров Google и Bing и убедиться, что вы просматриваете их отзывы о вашей XML-карте сайта».
– Joost de Valk
Поэтому вам решать, добавлять его в свой файл или нет.
Host и Crawl-delay — это две директивы, которые я лично никогда не использовал. Первый сообщает поисковым системам, какой домен является вашим любимым, если у вас есть несколько зеркал вашего сайта. Последний устанавливает количество секунд, в течение которых сканеры должны ждать между проверками.
Поскольку оба варианта не так уж распространены, я не буду вдаваться в них слишком глубоко, но я хотел включить их для полноты картины.
Дополнительные возможности
Все еще со мной? Отличная работа. Теперь это становится немного сложнее.
Мы уже знаем, что можем установить подстановочные знаки через звездочку для User-agent . Однако то же самое верно и для других директив.
Например, если вы хотите заблокировать доступ ко всем папкам, имена которых начинаются с wp-, вы можете сделать это так:
Агент пользователя: * Disallow: /wp-*/
Имеет смысл, не так ли? То же самое работает и с файлами. Например, если бы моей целью было исключить все PDF-файлы в моей медиа-папке из поисковой выдачи, я бы использовал этот код:
Например, если бы моей целью было исключить все PDF-файлы в моей медиа-папке из поисковой выдачи, я бы использовал этот код:
User-agent: * Запретить: /wp-content/uploads/*/*/*.pdf
Обратите внимание, что я заменил каталоги месяца и дня, которые WordPress автоматически устанавливает подстановочными знаками, чтобы убедиться, что все файлы с таким окончанием перехватываются независимо от того, когда они были загружены.
Хотя в большинстве случаев этот метод работает хорошо, иногда необходимо определить строку через ее конец, а не начало. Здесь пригодится подстановочный знак доллара:
User-agent: * Disallow: /page.php$
Вышеупомянутое правило гарантирует, что будет заблокирован только page.php , а не page.php?id=12 . Знак доллара сообщает поисковым системам, что page.php — это самый конец строки. Аккуратно, да?
Хорошо, но что мне теперь поместить в файл robots.txt?!
Я вижу, ты теряешь терпение. Где код? Могу ли я опубликовать здесь несколько оптимизированных директив, которые вы можете просто скопировать и вставить, и покончить с этой темой?
Где код? Могу ли я опубликовать здесь несколько оптимизированных директив, которые вы можете просто скопировать и вставить, и покончить с этой темой?
Как бы мне этого не хотелось, но, к сожалению, нет.
Почему? Ну, одна из причин заключается в том, что содержимое вашего robots.txt действительно зависит от вашего сайта. Возможно, у вас есть несколько вещей, которые вы предпочли бы держать подальше от поисковых систем, до которых другим нет дела.
Во-вторых, что более важно, не существует согласованного стандарта для лучших практик и оптимальных способов настройки файла robots.txt с точки зрения SEO. Вся тема представляет собой дискуссию.
Что делают эксперты
Например, ребята из Yoast имеют в файле robots.txt только следующее:
User-Agent: * Disallow: /out/
Как видите, единственное, что они запрещают, — это их каталог «out», в котором находятся их партнерские ссылки. Все остальное — честная игра. Причина в следующем:
«Google больше не тупой маленький ребенок, который просто извлекает HTML-код вашего сайта и игнорирует ваш стиль и JavaScript.
Он извлекает все и полностью отображает ваши страницы. Это означает, что когда вы отказываете Google в доступе к своим файлам CSS или JavaScript, ему это совсем не нравится». – Yoast
К настоящему времени Google рассматривает ваш сайт в целом. Если вы заблокируете компоненты стиля, он решит, что ваш сайт выглядит как дерьмо, и накажет вас за это разрушительными последствиями.
Чтобы проверить, как Google видит ваш сайт, используйте «Просмотреть как Google», а затем «Получить и обработать» в разделе «Сканирование» инструментов Google для веб-мастеров. Если ваш файл robots.txt содержит слишком много ограничений, ваш сайт, вероятно, не будет выглядеть так, как вы хотите, и вам потребуется внести некоторые коррективы.
Yoast также настоятельно рекомендует не использовать директивы robots.txt для скрытия некачественного контента, такого как категория, дата и другие архивы, а работать с noindex, вместо этого использовать метатеги . Также обратите внимание, что в их файле нет ссылки на карту сайта по причине, указанной выше.
Основатель WordPress Мэтт Малленвег использует аналогичный минималистичный подход:
User-agent: * Запретить: Агент пользователя: Mediapartners-Google* Запретить: Пользовательский агент: * Запретить: /dropbox Запретить: /контакт Запретить: /blog/wp-login.php Disallow: /blog/wp-admin
Вы можете видеть, что он блокирует только свой почтовый ящик и папку контактов, а также важные файлы и папки администратора и входа в систему для WordPress. Хотя некоторые люди делают последнее из соображений безопасности, скрытие папки wp-admin — это то, против чего Yoast на самом деле не советует.
Наш следующий пример исходит от WPBeginner:
User-Agent: * Разрешить: /?display=широкий Разрешить: /wp-content/uploads/ Запретить: /wp-content/plugins/ Запретить: /readme.html Запретить: /см./ Карта сайта: http://www.wpbeginner.com/post-sitemap.xml Карта сайта: http://www.wpbeginner.com/page-sitemap.xml Карта сайта: http://www.wpbeginner.com/deals-sitemap.xml Карта сайта: http://www.wpbeginner.com/hosting-sitemap.xml
Вы можете видеть, что они блокируют свои партнерские ссылки (см. папку «Refer»), а также плагины и файл readme.html. Как объясняется в этой статье, последнее позволяет избежать вредоносных запросов, направленных на определенные версии WordPress. Запретив файл, вы сможете защитить себя от массовых атак.
Блокировка папки плагинов также направлена на то, чтобы хакеры не могли использовать уязвимые плагины. Здесь они используют другой подход, чем Yoast, который не так давно изменил это, чтобы стили в папках плагинов не терялись.
Одна вещь, которую WPBeginner делает иначе, чем в двух других примерах, — это установка wp-content/uploads в явное значение «разрешить», даже если это не заблокировано какой-либо другой директивой. Они заявляют, что это сделано для того, чтобы все поисковые системы включали эту папку в свой поиск.
Однако я не вижу в этом особого смысла, так как по умолчанию поисковые системы индексируют все, до чего могут дотянуться. Поэтому я не думаю, что разрешение им сканировать что-то конкретное сильно поможет.
Поэтому я не думаю, что разрешение им сканировать что-то конкретное сильно поможет.
Окончательный вердикт
Я с Yoast, когда дело доходит до настройки robots.txt.
С точки зрения поисковой оптимизации имеет смысл дать Google как можно больше, чтобы они могли понять ваш сайт. Однако, если есть части, которые вы хотели бы оставить для себя (например, партнерские ссылки), запретите их по желанию.
Это также идет рука об руку с соответствующим разделом в Кодексе WordPress:
«Добавление записей в robots.txt для помощи SEO — популярное заблуждение. Google говорит, что вы можете использовать robots.txt для блокировки частей вашего сайта, но в наши дни предпочитает, чтобы вы этого не делали. Вместо этого используйте теги noindex на уровне страницы, чтобы бороться с некачественными частями вашего сайта. С 2009 года Google все чаще советует избегать блокировки файлов JS и CSS, а команда Google по обеспечению качества поиска все активнее продвигает политику прозрачности веб-мастерами, чтобы помочь Google убедиться, что мы не «маскируем» или не связываем неприглядный спам на заблокированных страницах.
Таким образом, идеальный файл robots ничего не запрещает и может ссылаться на XML-карту сайта, если она была создана (что само по себе редко!).
WordPress по умолчанию блокирует только пару JS-файлов, но почти соответствует рекомендациям Google».
Довольно ясно, не правда ли? Имейте в виду, что если вы решите разместить ссылку на карту сайта, вы обязательно должны отправить ее поисковым системам напрямую через их наборы для веб-мастеров.
Что бы вы ни решили сделать, не забудьте протестировать карту сайта ! Это можно сделать следующими способами:
- Перейдите на сайт yoursite.com/robots.txt, чтобы узнать, отображается ли он 9.0052
- Прогоните через тестер, чтобы найти синтаксические ошибки (например, эту)
- Получить и отобразить, чтобы проверить, видит ли Google то, что вы хотите, чтобы он увидел
- Следите за возможными сообщениями об ошибках из Инструментов Google для веб-мастеров
Robots.
