Как создать файл Robots.txt: настройка, проверка, индексация
В SEO мелочей не бывает. Иногда на продвижение сайта может оказать влияние всего лишь один небольшой файл — Robots.txt. Если вы хотите, чтобы ваш сайт зашел в индекс, чтобы поисковые роботы обошли нужные вам страницы, нужно прописать для них рекомендации.
«Разве это возможно?», — спросите вы. Возможно. Для этого на вашем сайте должен быть файл robots.txt. Как правильно составить файл роботс, настроить и добавить на сайт – разбираемся в этой статье.
Реклама: 2VtzqvSTRwm
Читайте также: Как проиндексировать сайт в Яндексе и Google
Что такое robots.txt и для чего нужен
Robots.txt – это обычный текстовый файл, который содержит в себе рекомендации для поисковых роботов: какие страницы нужно сканировать, а какие нет.
Важно: файл должен быть в кодировке UTF-8, иначе поисковые роботы могут его не воспринять.
Зайдет ли в индекс сайт, на котором не будет этого файла? Зайдет, но роботы могут «выхватить» те страницы, наличие которых в результатах поиска нежелательно: например, страницы входа, админпанель, личные страницы пользователей, сайты-зеркала и т.п. Все это считается «поисковым мусором»:
Если в результаты поиска попадёт личная информация, можете пострадать и вы, и сайт. Ещё один момент – без этого файла индексация сайта будет проходить дольше.
В файле Robots.txt можно задать три типа команд для поисковых пауков:
- сканирование запрещено;
- сканирование разрешено;
- сканирование разрешено частично.
Все это прописывается с помощью директив.
Как создать правильный файл Robots.txt для сайта
Файл Robots.txt можно создать просто в программе «Блокнот», которая по умолчанию есть на любом компьютере. Прописывание файла займет даже у новичка максимум полчаса времени (если знать команды).
Также можно использовать другие программы – Notepad, например. Есть и онлайн сервисы, которые могут сгенерировать файл автоматически. Например, такие как CY-PR.com или Mediasova.
Есть и онлайн сервисы, которые могут сгенерировать файл автоматически. Например, такие как CY-PR.com или Mediasova.
Вам просто нужно указать адрес своего сайта, для каких поисковых систем нужно задать правила, главное зеркало (с www или без). Дальше сервис всё сделает сам.
Лично я предпочитаю старый «дедовский» способ – прописать файл вручную в блокноте. Есть ещё и «ленивый способ» — озадачить этим своего разработчика 🙂 Но даже в таком случае вы должны проверить, правильно ли там всё прописано. Поэтому давайте разберемся, как составить этот самый файл, и где он должен находиться.
Это интересно: Как увеличить посещаемость сайта
Где должен находиться файл Robots
Готовый файл Robots.txt должен находиться в корневой папке сайта. Просто файл, без папки:
Хотите проверить, есть ли он на вашем сайте? Вбейте в адресную строку адрес: site.ru/robots.txt. Вам откроется вот такая страничка (если файл есть):
Файл состоит из нескольких блоков, отделённых отступом. В каждом блоке – рекомендации для поисковых роботов разных поисковых систем (плюс блок с общими правилами для всех), и отдельный блок со ссылками на карту сайта – Sitemap.
В каждом блоке – рекомендации для поисковых роботов разных поисковых систем (плюс блок с общими правилами для всех), и отдельный блок со ссылками на карту сайта – Sitemap.
Внутри блока с правилами для одного поискового робота отступы делать не нужно.
Каждый блок начинается директивой User-agent.
После каждой директивы ставится знак «:» (двоеточие), пробел, после которого указывается значение (например, какую страницу закрыть от индексации).
Нужно указывать относительные адреса страниц, а не абсолютные. Относительные – это без «www.site.ru». Например, вам нужно запретить к индексации страницу www.site.ru/shop. Значит после двоеточия ставим пробел, слэш и «shop»:
Disallow: /shop.
Звездочка (*) обозначает любой набор символов.
Знак доллара ($) – конец строки.
Вы можете решить – зачем писать файл с нуля, если его можно открыть на любом сайте и просто скопировать себе?
Для каждого сайта нужно прописывать уникальные правила. Нужно учесть особенности CMS. Например, та же админпанель находится по адресу /wp-admin на движке WordPress, на другом адрес будет отличаться. То же самое с адресами отдельных страниц, с картой сайта и прочим.
Нужно учесть особенности CMS. Например, та же админпанель находится по адресу /wp-admin на движке WordPress, на другом адрес будет отличаться. То же самое с адресами отдельных страниц, с картой сайта и прочим.
Читайте также: Как найти и удалить дубли страниц на сайте
Настройка файла Robots.txt: индексация, главное зеркало, диррективы
Как вы уже видели на скриншоте, первой идет директива User-agent. Она указывает, для какого поискового робота будут идти правила ниже.
User-agent: * — правила для всех поисковых роботов, то есть любой поисковой системы (Google, Yandex, Bing, Рамблер и т.п.).
User-agent: Googlebot – указывает на правила для поискового паука Google.
User-agent: Yandex – правила для поискового робота Яндекс.
Для какого поискового робота прописывать правила первым, нет никакой разницы. Но обычно сначала пишут рекомендации для всех роботов.
Рекомендации для каждого робота, как я уже писала, отделяются отступом.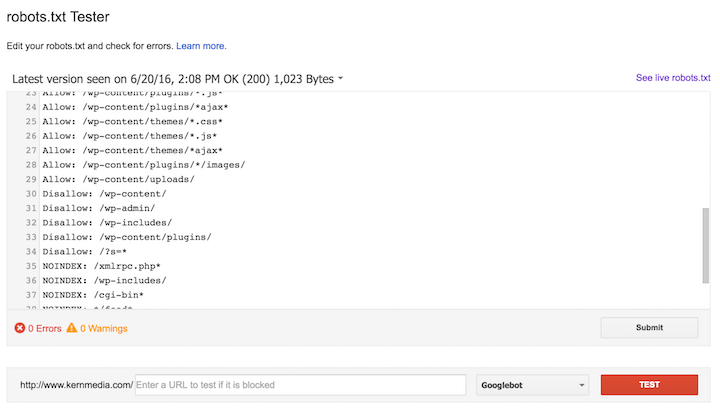
Disallow: Запрет на индексацию
Чтобы запретить индексацию сайта в целом или отдельных страниц, используется директива Disallow.
Например, вы можете полностью закрыть сайт от индексации (если ресурс находится на доработке, и вы не хотите, чтобы он попал в выдачу в таком состоянии). Для этого нужно прописать следующее:
User-agent: *
Disallow: /
Таким образом всем поисковым роботам запрещено индексировать контент на сайте.
А вот так можно открыть сайт для индексации:
User-agent: *
Disallow:
Потому проверьте, стоит ли слеш после директивы Disallow, если хотите закрыть сайт. Если хотите потом его открыть – не забудьте снять правило (а такое часто случается).
Чтобы закрыть от индексации отдельные страницы, нужно указать их адрес. Я уже писала, как это делается:
User-agent: *
Disallow: /wp-admin
Таким образом на сайте закрыли от сторонних взглядов админпанель.
Что нужно закрывать от индексации в обязательном порядке:
- административную панель;
- личные страницы пользователей;
- корзины;
- результаты поиска по сайту;
- страницы входа, регистрации, авторизации.
Можно закрыть от индексации и отдельные типы файлов. Допустим, у вас на сайте есть некоторые .pdf-файлы, индексация которых нежелательна. А поисковые роботы очень легко сканируют залитые на сайт файлы. Закрыть их от индексации можно следующим образом:
User-agent: *
Disallow: /*. pdf$
Как отрыть сайт для индексации
Даже при полностью закрытом от индексации сайте можно открыть роботам путь к определённым файлам или страницам. Допустим, вы переделываете сайт, но каталог с услугами остается нетронутым. Вы можете направить поисковых роботов туда, чтобы они продолжали индексировать раздел. Для этого используется директива Allow:
User-agent: *
Allow: /uslugi
Disallow: /
Главное зеркало сайта
До 20 марта 2018 года в файле robots. txt для поискового робота Яндекс нужно было указывать главное зеркало сайта через директиву Host. Сейчас этого делать не нужно – достаточно настроить постраничный 301-редирект.
txt для поискового робота Яндекс нужно было указывать главное зеркало сайта через директиву Host. Сейчас этого делать не нужно – достаточно настроить постраничный 301-редирект.
Что такое главное зеркало? Это какой адрес вашего сайта является главным – с www или без. Если не настроить редирект, то оба сайта будут проиндексированы, то есть, будут дубли всех страниц.
Карта сайта: robots.txt sitemap
После того, как прописаны все директивы для роботов, необходимо указать путь к Sitemap. Карта сайта показывает роботам, что все URL, которые нужно проиндексировать, находятся по определённому адресу. Например:
Sitemap: site.ru/sitemap.xml
Когда робот будет обходить сайт, он будет видеть, какие изменения вносились в этот файл. В итоге новые страницы будут индексироваться быстрее.
Читайте по теме: Как сделать карту сайта
Директива Clean-param
В 2009 году Яндекс ввел новую директиву – Clean-param. С ее помощью можно описать динамические параметры, которые не влияют на содержание страниц. Чаще всего данная директива используется на форумах. Тут возникает много мусора, например id сессии, параметры сортировки. Если прописать данную директиву, поисковый робот Яндекса не будет многократно загружать информацию, которая дублируется.
С ее помощью можно описать динамические параметры, которые не влияют на содержание страниц. Чаще всего данная директива используется на форумах. Тут возникает много мусора, например id сессии, параметры сортировки. Если прописать данную директиву, поисковый робот Яндекса не будет многократно загружать информацию, которая дублируется.
Прописать эту директиву можно в любом месте файла robots.txt.
Параметры, которые роботу не нужно учитывать, перечисляются в первой части значения через знак &:
Clean-param: sid&sort /forum/viewforum.php
Эта директива позволяет избежать дублей страниц с динамическими адресами (которые содержат знак вопроса).
Директива Crawl-delay
Эта директива придёт на помощь тем, у кого слабый сервер.
Приход поискового робота – это дополнительная нагрузка на сервер. Если у вас высокая посещаемость сайта, то ресурс может попросту не выдержать и «лечь». В итоге робот получит сообщение об ошибке 5хх. Если такая ситуация будет повторяться постоянно, сайт может быть признан поисковой системой нерабочим.
Представьте, что вы работаете, и параллельно вам приходится постоянно отвечать на звонки. Ваша продуктивность в таком случае падает.
Так же и с сервером.
Вернемся к директиве. Crawl-delay позволяет задать задержку сканирования страниц сайта с целью снизить нагрузку на сервер. Другими словами, вы задаете период, через который будут загружаться страницы сайта. Указывается данный параметр в секундах, целым числом:
Crawl-delay: 2
Комментарии в robots.txt
Бывают случаи, когда вам нужно оставить в файле комментарий для других вебмастеров. Например, если ресурс передаётся в работу другой команде или если над сайтом работает целая команда.
В этом файле, как и во всех других, можно оставлять комментарии для других разработчиков.
Делается это просто – перед сообщением нужно поставить знак решетки: «#». Дальше вы можете писать свое примечание, робот не будет учитывать написанное:
User-agent: *
Disallow: /*. xls$
#закрыл прайсы от индексации
Как проверить файл robots.
 txt
txtПосле того, как файл написан, нужно узнать, правильно ли. Для этого вы можете использовать инструменты от Яндекс и Google.
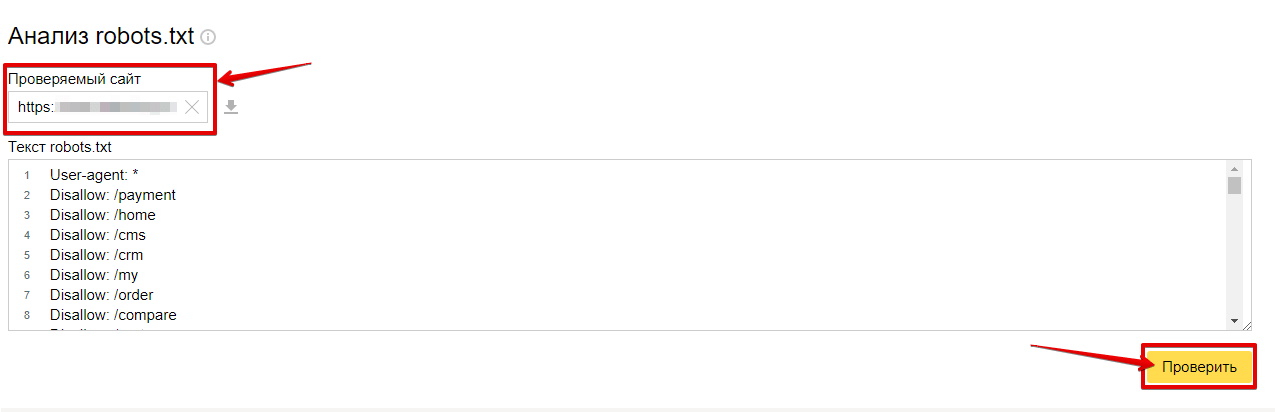
Через Яндекс.Вебмастер robots.txt можно проверить на вкладке «Инструменты – Анализ robots.txt»:
На открывшейся странице указываем адрес проверяемого сайта, а в поле снизу вставляем содержимое своего файла. Затем нажимаем «Проверить». Сервис проверит ваш файл и укажет на возможные ошибки:
Также можно проверить файл robots.txt через Google Search Console, если у вас подтверждены права на сайт.
Для этого в панели инструментов выбираем «Сканирование – Инструмент проверки файла robots.txt».
На странице проверки вам тоже нужно будет скопировать и вставить содержимое файла, затем указать адрес сайта:
Потом нажимаете «Проверить» — и все. Система укажет ошибки или выдаст предупреждения.
Останется только внести необходимые правки.
Если в файле присутствуют какие-то ошибки, или появятся со временем (например, после какого-то очередного изменения), инструменты для вебмастеров будут присылать вам уведомления об этом. Извещение вы увидите сразу, как войдете в консоль.
Извещение вы увидите сразу, как войдете в консоль.
Это интересно: 20 самых распространённых ошибок, которые убивают ваш сайт
Частые ошибки в заполнении файла robots.txt
Какие же ошибки чаще всего допускают вебмастера или владельцы ресурсов?
1. Файла вообще нет. Это встречается чаще всего, и выявляется при SEO-аудите ресурса. Как правило, на тот момент уже заметно, что сайт индексируется не так быстро, как хотелось бы, или в индекс попали мусорные страницы.
2. Перечисление нескольких папок или директорий в одной инструкции. То есть вот так:
Allow: /catalog /uslugi /shop
Называется «зачем писать больше…». В таком случае робот вообще не знает, что ему можно индексировать. Каждая инструкция должна иди с новой строки, запрет или разрешение на индексацию каждой папки или страницы – это отдельная рекомендация.
3. Разные регистры. Название файла должно быть с маленькой буквы и написано маленькими буквами – никакого капса. То же самое касается и инструкций: каждая с большой буквы, все остальное – маленькими. Если вы напишете капсом, это будет считаться уже совсем другой директивой.
То же самое касается и инструкций: каждая с большой буквы, все остальное – маленькими. Если вы напишете капсом, это будет считаться уже совсем другой директивой.
4. Пустой User-agent. Нужно обязательно указать, для какой поисковой системы идет набор правил. Если для всех – ставим звездочку, но никак нельзя оставлять пустое место.
5. Забыли открыть ресурс для индексации после всех работ – просто не убрали слеш после Disallow.
6. Лишние звездочки, пробелы, другие знаки. Это просто невнимательность.
Регулярно заглядывайте в инструменты для вебмастеров и вовремя исправляйте возможные ошибки в своем файле robots.txt.
Удачного вам продвижения!
примеры для различных CMS, правила, рекомендации
Правильная индексация страниц сайта в поисковых системах одна из важных задач, которая стоит перед владельцем ресурса. Попадание в индекс ненужных страниц может привести к понижению документов в выдаче. Для решения таких проблем и был принят стандарт исключений для роботов консорциумом W3C 30 января 1994 года — robots.txt.
Для решения таких проблем и был принят стандарт исключений для роботов консорциумом W3C 30 января 1994 года — robots.txt.
Что такое Robots.txt?
Robots.txt — текстовый файл на сайте, содержащий инструкции для роботов какие страницы разрешены для индексации, а какие нет. Но это не является прямыми указаниями для поисковых машин, скорее инструкции несут рекомендательный характер, например, как пишет Google, если на сайт есть внешние ссылки, то страница будет проиндексирована.
На иллюстрации можно увидеть индексацию ресурса без файла Robots.txt и с ним.
Что следует закрывать от индексации:
- служебные страницы сайта
- дублирующие документы
- страницы с приватными данными
- результат поиска по ресурсу
- страницы сортировок
- страницы авторизации и регистрации
- сравнения товаров
Как создать и добавить Robots.txt на сайт?
Robots.txt обычный текстовый файл, который можно создать в блокноте, следуя синтаксису стандарта, который будет описан ниже.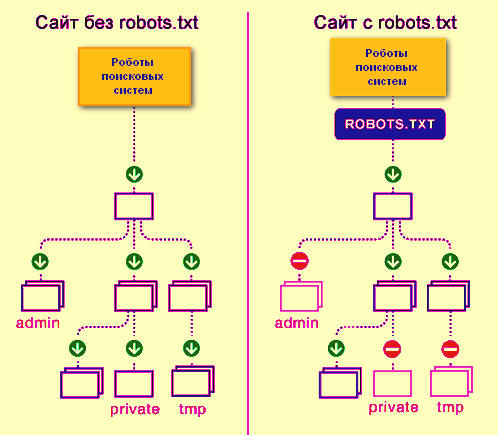 Для одного сайта нужен только один такой файл.
Для одного сайта нужен только один такой файл.
Файл нужно добавить в корневой каталог сайта и он должен быть доступен по адресу: http://www.site.ru/robots.txt
Синтаксис файла robots.txt
Инструкции для поисковых роботов задаются с помощью директив с различными параметрами.
Директива User-agent
С помощью данной директивы можно указать для какого робота поисковой системы будут заданы нижеследующие рекомендации. Файл роботс должен начинаться с этой директивы. Всего официально во всемирной паутине таких роботов 302. Но если не хочется их все перечислять, то можно воспользоваться следующей строчкой:
User-agent: *
Где * является спецсимволом для обозначения любого робота.
Список популярных поисковых роботов:
- Googlebot — основной робот Google;
- YandexBot — основной индексирующий робот;
- Googlebot-Image — робот картинок;
- YandexImages — робот индексации Яндекс.Картинок;
- Yandex Metrika — робот Яндекс.Метрики;
- Yandex Market— робот Яндекс.
 Маркета;
Маркета; - Googlebot-Mobile —индексатор мобильной версии.
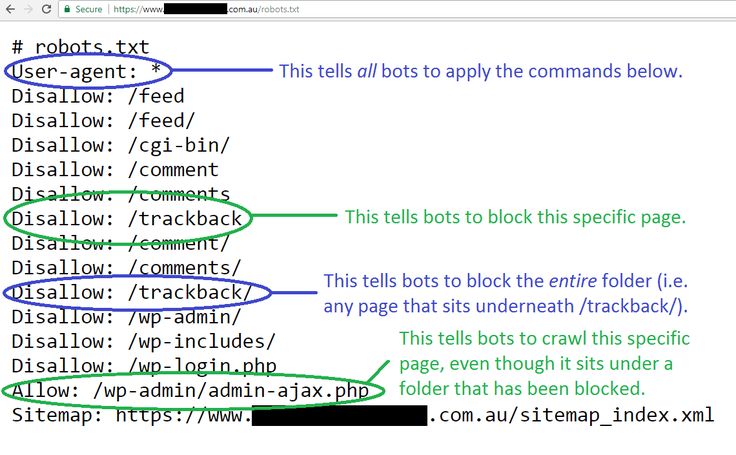
Директивы Disallow и Allow
С помощью данных директив можно задавать какие разделы или файлы можно индексировать, а какие не следует.
Disallow — директива для запрета индексации документов на ресурсе. Синтаксис директивы следующий:
Disallow: /site/
В данном примере от поисковиков были закрыты от индексации все страницы из раздела site.ru/site/
Примечание: Если данная директива будет указана пустой, то это означает, что весь сайт открыт для индексации. Если же указать Disallow: / — это закроет весь сайт от индексации.
Директива Sitemap
Если на сайте есть файл описания структуры сайта sitemap.xml, путь к нему можно указать в robots.txt с помощью директивы Sitemap. Если файлов таких несколько, то можно их перечислить в роботсе:
User-agent: *
Disallow: /site/
Allow: /
Sitemap: http://site. com/sitemap1.xml
com/sitemap1.xml
Sitemap: http://site.com/sitemap2.xml
Директиву можно указать в любой из инструкций для любого робота.
Директива Host
Host является инструкцией непосредственно для робота Яндекса для указания главного зеркала сайта. Данная директива необходима в том случае, если у сайта есть несколько доменов, по которым он доступен. Указывать Host необходимо в секции для роботов Яндекса:
User-agent: Yandex
Disallow: /site/
Host: site.ru
В роботсе директива Host учитывается только один раз. Если в файле есть 2 директивы HOST, то роботы Яндекса будут учитывать только первую.
Директива Clean-param
Clean-param дает возможность запретить для индексации страницы сайта, которые формируются с динамическими параметрами. Такие страницы могут содержать один и тот же контент, что будет являться дублями для поисковых систем и может привести к понижению сайта в выдаче.
Директива Clean-param имеет следующий синтаксис:
Clean-param: p1[&p2&p3&p4&. .&pn] [Путь к динамическим страницам]
.&pn] [Путь к динамическим страницам]
Рассмотрим пример, на сайте есть динамические страницы:
- https://site.ru/promo-odezhda/polo.html?kol_from=&price_to=&color=7
- https://site.ru/promo-odezhda/polo.html?kol_from=100&price_to=&color=7
Для того, чтобы исключить подобные страницы из индекса следует задать директиву таким образом:
Clean-param: kol_from1&price_to2&pcolor /polo.html # только для polo.html
или
Clean-param: kol_from1&price_to2&pcolor / # для всех страниц сайта
Директива Crawl-delay
Если роботы поисковиков слишком часто заходят на ресурс, это может повлиять на нагрузку на сервер (актуально для ресурсов с большим количеством страниц). Чтобы снизить нагрузку на сервер, можно воспользоваться директивой Crawl-delay.
Параметром для Crawl-delay является время в секундах, которое указывает роботам, что страницы следует скачивать с сайта не чаще одного раза в указанный период.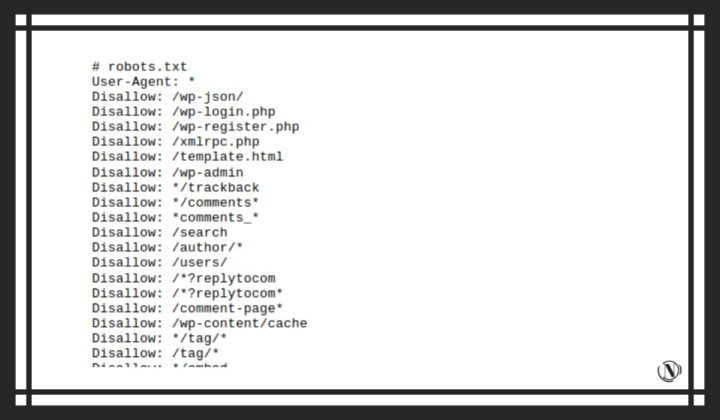
Пример использования директивы Crawl-delay:
User-agent: *
Disallow: /site
Crawl-delay: 4
Особенности файла Robots.txt
- Все директивы указываются с новой строки и не следует перечислять директивы в одной строке
- Перед директивой не должно быть указано каких-либо других символов (в том числе пробела)
- Параметры директив необходимо указывать в одну строку
- Правила в роботс указываются в следующей форме: [Имя_директивы]:[необязательный пробел][значение][необязательный пробел]
- Параметры не нужно указывать в кавычках или других символах
- После директив не следует указывать “;”
- Пустая строка трактуется как конец директивы User-agent, если нет пустой строки перед следующим User-agent, то она может быть проигнорирована
- В роботс можно указывать комментарии после знака решетки # (даже если комментарий переносится на следующую строку, на след строке тоже следует поставить #)
- Robots.txt нечувствителен к регистру
- Если файл роботс имеет вес более 32 Кб или по каким-то причинам недоступен или является пустым, то он воспринимается как Disallow: (можно индексировать все)
- В директивах «Allow», «Disallow» можно указывать только 1 параметр
- В директивах «Allow», «Disallow» в параметре директории сайта указываются со слешем (например, Disallow: /site)
- Использование кириллицы в роботс не допускаются
Спецсимволы robots.
 txt
txtПри указании параметров в директивах Disallow и Allow разрешается использовать специальные символы * и $, чтобы задавать регулярные выражения. Символ * означает любую последовательность символов (даже пустую).
Пример использования:
User-agent: *
Disallow: /store/*.php # запрещает ‘/store/ex.php’ и ‘/store/test/ex1.php’
Disallow: /*tpl # запрещает не только ‘/tpl’, но и ‘/tpl/user’
По умолчанию у каждой инструкции в роботсе в конце подставляется спецсимвол *. Для того, чтобы отменить * на конце, используется спецсимвол $ (но он не может отменить явно поставленный * на конце).
Пример использования $:
User-agent: *
Disallow: /site$ # запрещено для индексации ‘/site’, но не запрещено’/ex.css’
User-agent: *
Disallow: /site # запрещено для индексации и ‘/site’, и ‘/site.css’
User-agent: *
Disallow: /site$ # запрещен к индексации только ‘/site’
Disallow: /site*$ # так же, как ‘Disallow: /site’ запрещает и /site.
 css и /site
css и /siteОсобенности настройки robots.txt для Яндекса
Особенностями настройки роботса для Яндекса является только наличие директории Host в инструкциях. Рассмотрим корректный роботс на примере:
User-agent: Yandex
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Disallow: */css
Host: www.site.com
В данном случаем директива Host указывает роботам Яндекса, что главным зеркалом сайта является www.site.com (но данная директива носит рекомендательный характер).
Особенности настройки robots.txt для Google
Для Google особенность лишь состоит в том, что сама компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. В таком случае, робот примет такой вид:
User-agent: Googlebot
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Allow: *.css
Allow: *. js
js
Host: www.site.com
С помощью директив Allow роботам Google доступны файлы стилей и скриптов, они не будут проиндексированы поисковой системой.
Проверка правильности настройки роботс
Проверить robots.txt на ошибки можно с помощью инструмента в панели Яндекс.Вебмастера:
Также при помощи данного инструмента можно проверить разрешены или запрещены к индексации страницы:
Еще одним инструментом проверки правильности роботс является “Инструмент проверки файла robots.txt” в панели Google Search Console:
Но данный инструмент доступен только в том случае, если сайт добавлен в панель Вебмастера Google.
Заключение
Robots.txt является важным инструментом управления индексацией сайта поисковыми системами. Очень важно держать его актуальным, и не забывать открывать нужные документы для индексации и закрывать те страницы, которые могут повредить хорошему ранжированию ресурса в выдаче.
Пример настройки роботс для WordPress
Правильный robots.txt для WordPress должен быть составлен таким образом (все, что указано в комментариях не обязательно размещать):
User-agent: Yandex
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Host: www.site.ru
User-agent: Googlebot
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Allow: *. css # открыть все файлы стилей
css # открыть все файлы стилей
Allow: *.js # открыть все с js-скриптами
User-agent: *
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap1.xml
Пример настройки роботс для Bitrix
Если сайт работает на движке Битрикс, то могут возникнуть такие проблемы:
- попадание в выдачу большого количества служебных страниц;
- индексация дублей страниц сайта.
Чтобы избежать подобных проблем, которые могут повлиять на позицию сайта в выдаче, следует правильно настроить файл robots.txt. Ниже приведен пример robots. txt для CMS 1C-Bitrix:
txt для CMS 1C-Bitrix:
User-Agent: Yandex
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
HOST: https://site.ru
User-Agent: *
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
Sitemap: https://site.ru/sitemap.xml
User-Agent: Googlebot
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/tools/conversion/ajax_counter.php
Allow: /bitrix/components/main/
Allow: /bitrix/css/
Allow: /bitrix/templates/comfer/img/logo. png
png
Allow: /personal/cart/
Sitemap: https://site.ru/sitemap.xml
Пример настройки роботс для OpenCart
Правильный robots.txt для OpenCart должен быть составлен таким образом:
User-agent: Yandex
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Host: site. ru
ru
User-agent: Googlebot
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index. php
php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Umi.CMS
Правильный robots.txt для Umi CMS должен быть составлен таким образом (проблемы с дублями страниц в таком случае не должно быть):
User-Agent: Yandex
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out. php
php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Host: site.ru
User-Agent: Googlebot
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Allow: *.css
Allow: *.js
User-Agent: *
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Joomla
Правильный robots. txt для Джумлы должен быть составлен таким образом:
txt для Джумлы должен быть составлен таким образом:
User-agent: Yandex
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Host: www.site.ru
User-agent: Googlebot
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Sitemap: http://www. site.ru/sitemap.xml
site.ru/sitemap.xml
Руководство для новичков по блокировке URL-адресов в файле Robots.txt
Robots.txt, также известный как исключение роботов, является ключом к предотвращению сканирования роботами поисковых систем ограниченных областей вашего сайта.
В этой статье я расскажу об основах блокировки URL-адресов в файле robots.txt.
Что мы рассмотрим:
- Что такое файл robtos.txt
- Примеры использования robots.txt
- Когда вы должны использовать это
- Начало работы
- Как создать файл robots.txt
- Как запретить файл
- Как сохранить файл robots.txt
- Как проверить свои результаты
- Часто задаваемые вопросы
Что такое файл robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы научить роботов сканировать страницы веб-сайта и сообщать поисковым роботам, следует ли обращаться к файлу или нет.
Вы можете заблокировать URL-адреса в robots txt, чтобы Google не индексировал личные фотографии, специальные предложения с истекшим сроком действия или другие страницы, к которым вы не готовы предоставить пользователям доступ. Использование его для блокировки URL-адреса может помочь в усилиях по SEO.
Это может решить проблемы с дублирующимся контентом (однако могут быть лучшие способы сделать это, которые мы обсудим позже). Когда робот начинает сканирование, он сначала проверяет наличие файла robots.txt, препятствующего просмотру определенных страниц.
Примеры того, как заблокировать URL-адреса в robots.txtВот несколько примеров того, как заблокировать URL-адреса в robots.txt:
Блокировать всеЕсли вы хотите заблокировать сканирование всех роботов поисковых систем части вашего веб-сайта, вы можете добавить следующую строку в файл robots.txt:
User-agent: *
Disallow: /
Блокировка определенного URL-адреса Если вы хотите заблокировать определенную страницу или каталог, вы можете сделать это, добавив эту строку в файл robots. txt.
txt.
User-agent: *
Disallow: /private.html
Если вы хотите заблокировать несколько URL:
User-agent: *
Disallow: /private.html
Disallow: /special-offers.html
Запретить: /expired-offers.html
Блокировать файл определенного типаЕсли вы хотите заблокировать индексирование файла определенного типа, вы можете добавить следующую строку в файл robots.txt:
Агент пользователя: *Disallow: /*.html
Использование канонического тегаЕсли вы хотите, чтобы роботы поисковых систем не индексировали повторяющийся контент, вы можете добавить следующий канонический тег на страницу-дубликат.
rel=»canonical» href=»https://www.example.com/original-url»
Когда следует использовать файл Robots.txt?
Вам нужно будет использовать его, если вы не хотите, чтобы поисковые системы индексировали определенные страницы или контент. Если вы хотите, чтобы поисковые системы (например, Google, Bing и Yahoo) имели доступ и индексировали весь ваш сайт, вам не нужен файл robots.
Однако, если другие сайты ссылаются на страницы вашего веб-сайта заблокированы, поисковые системы могут по-прежнему индексировать URL-адреса, и в результате они могут по-прежнему отображаться в результатах поиска. Чтобы этого не произошло, используйте x-robots-tag , метатег noindex или rel canonical на соответствующую страницу.
Эти типы файлов помогают веб-сайтам в следующем:
- Обеспечьте конфиденциальность частей сайта — например, страницы администратора или песочницу вашей команды разработчиков.
- Предотвратить дублирование контента в результатах поиска.
- Избегайте проблем с индексацией
- блокировка URL-адреса
- Запретить поисковым системам индексировать определенные файлы, такие как изображения или PDF-файлы
- Управляйте сканирующим трафиком и предотвращайте появление медиафайлов в поисковой выдаче.
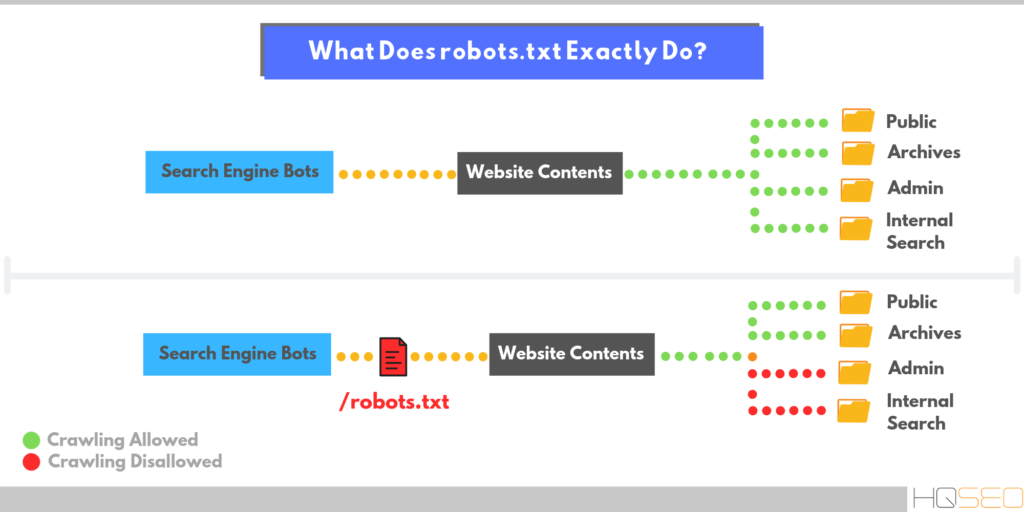
- Используйте его, если вы размещаете платную рекламу или ссылки, требующие специальных инструкций для роботов.
Тем не менее, если на вашем сайте нет областей, которые вам не нужно контролировать, то они вам и не нужны. В рекомендациях Google также упоминается, что вы не должны использовать robots.txt для блокировки веб-страниц из результатов поиска.
Причина в том, что если другие страницы ссылаются на ваш сайт с описательным текстом, ваша страница все равно может быть проиндексирована в силу ее появления на этом стороннем канале. Директивы Noindex или страницы, защищенные паролем, являются лучшим выбором.
Приступаем к работе с Robots.txt
Прежде чем приступить к сборке файла, убедитесь, что у вас его еще нет. Чтобы найти его, просто добавьте «/robots.txt» в конце любого доменного имени — www.examplesite.com/robots.txt. Если он у вас есть, вы увидите файл со списком инструкций. В противном случае вы увидите пустую страницу.
Затем проверьте, не блокируются ли какие-либо важные файлы
Перейдите в консоль поиска Google, чтобы узнать, блокирует ли ваш файл какие-либо важные файлы. Тестер robots.txt покажет, мешает ли ваш файл поисковым роботам Google получить доступ к определенным частям вашего веб-сайта.
Тестер robots.txt покажет, мешает ли ваш файл поисковым роботам Google получить доступ к определенным частям вашего веб-сайта.
Стоит также отметить, что файл robots.txt может вам вообще не понадобиться. Если у вас относительно простой веб-сайт и вам не нужно блокировать определенные страницы для тестирования или защиты конфиденциальной информации, вы можете обойтись без него. И — туториал останавливается.
Настройка файла Robots.Txt
Эти файлы можно использовать по-разному. Однако их основное преимущество заключается в том, что маркетологи могут разрешить или запретить несколько страниц одновременно без необходимости доступа к коду каждой страницы вручную.
Все файлы robots.txt приведут к одному из следующих результатов:
- Полное разрешение — весь контент может быть просканирован
- Полный запрет — сканирование контента невозможно. Это означает, что вы полностью блокируете доступ поисковых роботов Google к любой части вашего веб-сайта.
- Условное разрешение — правила, изложенные в файле, определяют, какой контент открыт для сканирования, а какой заблокирован. Если вам интересно, как запретить URL-адрес, не блокируя сканеры на всем сайте, вот оно.
Если вы хотите настроить файл, процесс на самом деле довольно прост и включает в себя два элемента: «пользовательский агент», который является роботом, к которому применяется следующий блок URL-адресов, и «запретить», который является URL-адресом. вы хотите заблокировать. Эти две строки рассматриваются как одна запись в файле, а это означает, что в одном файле может быть несколько записей.
Форматирование файла robots.txtПосле того, как вы определили, какие URL-адреса вы хотите включить в файл robots.txt, вам необходимо правильно его отформатировать.
При настройке файла вы должны добавить следующие компоненты:
User-AgentЭто робот, к которому вы хотите применить следующие правила. Часто записывается в следующем формате:
User-agent: [имя робота]
Наиболее распространенные роботы, которых вы здесь найдете, это Googlebot и Bingbot
Disallow Это часть файла, где вы укажете, какие URL должны быть заблокированы. Синтаксис для этого обычно выглядит так:
Синтаксис для этого обычно выглядит так:
Запретить: [URL или каталог]
Итак, если вы хотите заблокировать каталог «/privacy-policy/», вам нужно добавить «/privacy-policy/» в качестве записи о запрете.
Вы также можете использовать подстановочные знаки в файле robots.txt, что позволит заблокировать несколько URL-адресов за один раз.
Карта сайтаЭлемент карты сайта является необязательным. Однако поисковые системы могут воспринять это как признак того, что вы пытаетесь сделать свой сайт удобным и надежным. Это может помочь вашему рейтингу в поисковой выдаче.
Ваша запись в карте сайта должна выглядеть примерно так:
Карта сайта: https://www.example.com/sitemap.xml
После настройки файла все, что вам нужно сделать, это сохранить его как « robots.txt», загрузите его в корневой домен, и все готово.
Теперь ваш файл будет виден по адресу http://[ yoursite.com ]/robots. txt .
txt .
Файл robots.txt всегда следует размещать в корневом домене вашего веб-сайта.
Обратите внимание, что адрес чувствителен к регистру, поэтому не следует использовать заглавные буквы. Он всегда должен начинаться с «/».
Например, файл можно найти по адресу http://www.example.com/robots.txt, но не по адресу http://www.example.com/ROBOTS.TXT.
Как заблокировать URL-адреса в Robots txt:
В строке агента пользователя вы можете указать конкретного бота (например, Googlebot) или применить блокировку URL-адреса txt ко всем ботам, используя звездочку. Ниже приведен пример пользовательского агента, блокирующего всех ботов.
Агент пользователя: *
Во второй строке записи, disallow, перечислены конкретные страницы, которые вы хотите заблокировать. Чтобы заблокировать весь сайт, используйте косую черту. Для всех остальных записей сначала используйте косую черту, а затем укажите страницу, каталог, изображение или тип файла.
Запретить: /bad-directory/ блокирует как каталог, так и все его содержимое.
Запретить: /secret.html блокирует страницу.
После выбора пользовательского агента и запрета одна из ваших записей может выглядеть так:
Пользовательский агент: *
Запретить: /bad-directory/
Посмотреть другие примеры записей из Google Search Console .
Как сохранить файл
- Сохраните файл, скопировав его в текстовый файл или блокнот и сохранив как «robots.txt».
- Обязательно сохраните файл в каталог самого высокого уровня вашего сайта и убедитесь, что он находится в корневом домене с именем, точно совпадающим с «robots.txt».
- Добавьте файл в каталог верхнего уровня кода вашего веб-сайта для простого сканирования и индексации.
- Убедитесь, что ваш код имеет правильную структуру: Агент пользователя → Запретить → Разрешить → Хост → Карта сайта.
 Это позволяет поисковым системам получать доступ к страницам в правильном порядке.
Это позволяет поисковым системам получать доступ к страницам в правильном порядке. - Сделайте так, чтобы все URL-адреса, которые вы хотите «Разрешить:» или «Запретить:», располагались на отдельной строке. Если в одной строке появится несколько URL-адресов, поисковым роботам будет сложно их разделить, и у вас могут возникнуть проблемы.
- Всегда используйте строчные буквы для сохранения файла, так как имена файлов чувствительны к регистру и не содержат специальных символов.
- Создайте отдельные файлы для разных субдоменов. Например, «example.com» и «blog.example.com» имеют отдельные файлы с собственным набором директив.
- Если вы должны оставить комментарий, начните с новой строки и предварите комментарий символом #. # сообщает поисковым роботам, что не следует включать эту информацию в свою директиву.
Как проверить свои результаты
Проверьте свои результаты в своей учетной записи Google Search Console, чтобы убедиться, что боты сканируют нужные вам части сайта и блокируют URL-адреса, которые вы не хотите, чтобы поисковики видели.
- Сначала откройте инструмент тестирования и просмотрите файл на наличие предупреждений или ошибок.
- Затем введите URL-адрес страницы вашего веб-сайта в поле внизу страницы.
- Затем в раскрывающемся меню выберите пользовательский агент , который вы хотите имитировать.
- Нажмите ТЕСТ.
- Кнопка ПРОВЕРКА должна быть следующей: ПРИНЯТО или ЗАБЛОКИРОВАНО, , что указывает на то, заблокирован ли файл поисковыми роботами или нет.
- При необходимости отредактируйте файл и повторите проверку.
- Помните, что любые изменения, которые вы делаете в инструменте тестирования GSC, не будут сохранены на вашем веб-сайте (это симуляция).
- Если вы хотите сохранить изменения, скопируйте новый код на свой веб-сайт.
Имейте в виду, что это будет тестировать только Googlebot и другие пользовательские агенты, связанные с Google. Тем не менее, использование тестера очень важно, когда дело доходит до SEO.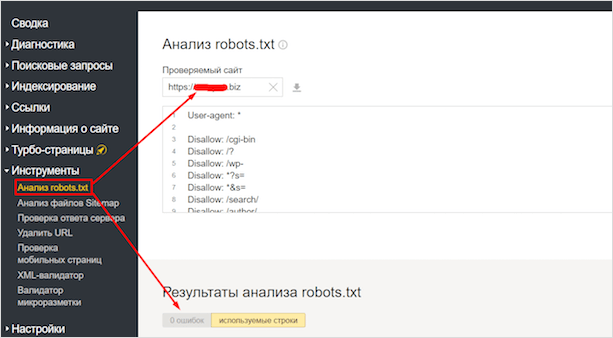 Видите ли, если вы решите использовать файл, обязательно правильно его настройте. Если в вашем коде есть какие-либо ошибки, робот Googlebot может не проиндексировать вашу страницу или вы можете непреднамеренно заблокировать важные страницы из поисковой выдачи.
Видите ли, если вы решите использовать файл, обязательно правильно его настройте. Если в вашем коде есть какие-либо ошибки, робот Googlebot может не проиндексировать вашу страницу или вы можете непреднамеренно заблокировать важные страницы из поисковой выдачи.
Наконец, убедитесь, что вы не используете его вместо реальных мер безопасности. Пароли, брандмауэры и зашифрованные данные — лучшие варианты защиты вашего сайта от хакеров, мошенников и посторонних глаз.
Robots.txt Часто задаваемые вопросыВ: Где мне сохранить файл robots.txt?
О: Ваш файл robots.txt должен быть сохранен в корневом домене вашего веб-сайта. Адрес должен быть в нижнем регистре и начинаться с «/».
Например, файл можно найти по адресу http://www.example.com/robots.txt, но не по адресу http://www.example.com/ROBOTS.TXT
В: Должен ли я всегда использовать подстановочные знаки в строках запрета?
О: Использование подстановочных знаков не всегда необходимо и может вызвать проблемы, если вы не будете осторожны. При указании конкретных URL-адресов всегда следует указывать их полностью, даже если вы считаете, что может подойти подстановочный знак.
При указании конкретных URL-адресов всегда следует указывать их полностью, даже если вы считаете, что может подойти подстановочный знак.
О: Да, можно. Чтобы заблокировать конкретное изображение, вы можете использовать команду «Запретить» и указать тип файла изображения (например, «Запретить: /*.png»).
В: Должен ли файл robots.txt быть идеальным, чтобы он работал?
О: Хотя очень важно убедиться, что файл robots.txt точен, незначительные ошибки не должны препятствовать работе вашего файла. Вы можете использовать инструмент тестера в Google Search Console, чтобы протестировать файл.
В: Что делать, если я хочу заблокировать определенных ботов?
О: Вы можете использовать строку «User-agent», чтобы указать, каких ботов блокировать. Например, если вы хотите заблокировать всех ботов, кроме Googlebot, вы можете использовать это:
Агент пользователя: *
Запретить: /
Агент пользователя: Googlebot
Разрешить: /
Подведение итогов
Готовы начать работу с robots.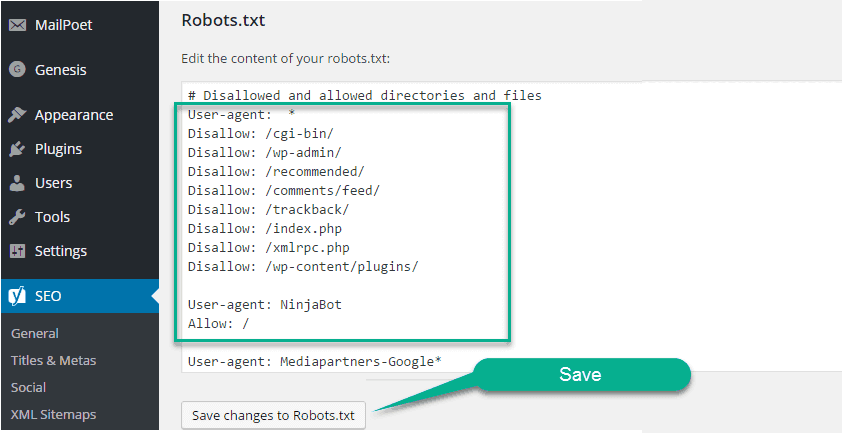 txt? Большой!
txt? Большой!
Если у вас есть вопросы или вам нужна помощь в начале работы, дайте нам знать!
Что такое robots.txt — руководство для начинающих
Файл robots.txt и sitemap.xml содержат наиболее важную информацию о ресурсе; он показывает ботам поисковых систем, как именно «читать» сайт, какие страницы важны, а какие следует пропустить. robots.txt также является первой страницей, на которую следует обратить внимание, если посещаемость вашего сайта внезапно падает.
Что такое файл robots.txt?
Файл robots.txt представляет собой текстовый документ в кодировке UTF-8, допустимый для протоколов http, https, а также FTP. Файл дает рекомендации поисковым роботам, какие страницы или файлы следует сканировать. Если файл содержит символы в кодировке, отличной от UTF-8, поисковые роботы могут неправильно их обработать. Инструкции в файле robots.txt работают только с хостом, протоколом и номером порта, на котором находится файл.
Файл находится в корневом каталоге в виде обычного текстового документа и находится по адресу https://mysite.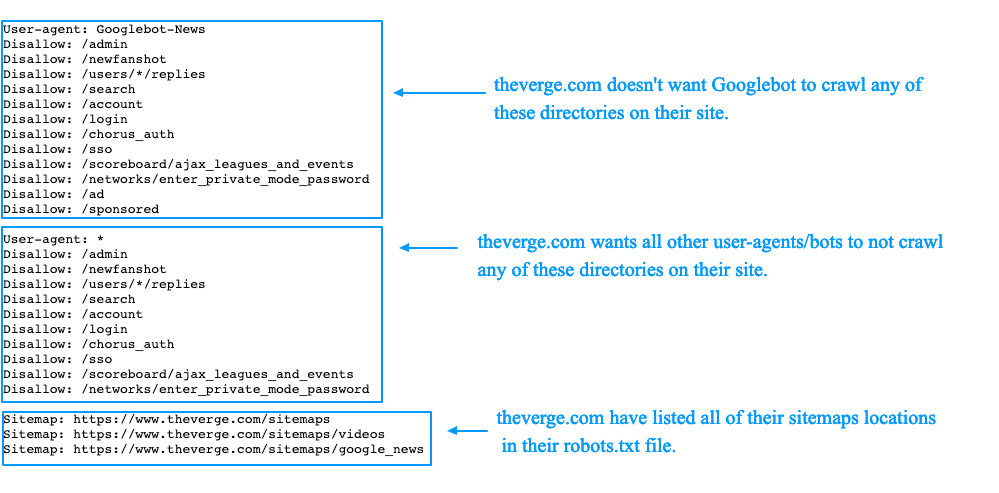 com/robots.txt .
com/robots.txt .
В других файлах принято размещать метку порядка байтов (BOM). Это символ Unicode, который используется для определения последовательности байтов при чтении информации. Кодовый символ U+FEFF. Метка порядка следования байтов в начале файла robots.txt игнорируется.
Google установил ограничение на размер файла robots.txt — он не должен превышать 500 КБ.
Итак, если вас интересуют более подробные технические подробности, файл robots.txt представляет собой описание в форме Бэкуса-Навра (БНФ). В этом случае используются директивы RFC 822.
При обработке директив в файле robots.txt поисковые роботы получают одну из следующих трех инструкций:
- Частичный доступ: отдельные элементы сайта могут быть просканированы.
- Полный доступ: все можно просканировать.
- Полный отказ: роботы ничего не сканируют.
При сканировании файла robots.txt боты поисковых систем получают следующие ответы:
- 2xx – сканирование прошло успешно.

- 3xx — поисковый робот выполняет перенаправление, пока не получит другой ответ. Обычно у поискового бота есть пять попыток получить ответ, отличный от 3xx, прежде чем будет зарегистрирована ошибка 404.
- 4xx — поисковый робот считает, что может просканировать весь контент сайта.
- 5xx — оценивается как временная ошибка сервера, сканирование полностью запрещено. Бот продолжит доступ к файлу, пока не получит другой ответ. Поисковый бот Google может определить, правильно или неправильно настроен ответ на отсутствующие страницы сайта. Это означает, что если страница выдает ответ 5xx вместо ошибки 404, страница будет считаться с кодом ответа 404.
Пока неясно, как обрабатывается файл robots.txt, когда он недоступен из-за проблем сервера с доступом в интернет.
Загрузите бесплатный контрольный список.
Продажи вашего сайта падают?
Вот что делать!
Получить контрольный список
Почему файл robots.txt важен?
Иногда существуют страницы, которые поисковые роботы не должны посещать. Например,
Например,
- страницы сайта с личной информацией пользователей;
- страниц с множеством форм для отправки информации;
- зеркальных сайтов;
- страниц с результатами поиска;
- дубликатов страниц.
Важно: Даже если страница есть в файле robots.txt, есть шанс, что она появится в выдаче, если на нее будет найдена ссылка внутри сайта или где-то на внешнем ресурсе.
Но так ли необходим файл robots.txt?
Если вы уверены, что хотите, чтобы сканеры просматривали все содержимое вашего веб-сайта, вам не нужно создавать даже пустой файл robots.txt.
Но без файла robots.txt в результатах поиска могла появиться информация, которая должна быть скрыта от посторонних глаз. В результате могут быть затронуты как вы, так и веб-сайт.
Как бот поисковой системы видит файл robots.txt:
Google обнаружил на сайте файл robots.txt и определил директивы для обхода страниц сайта.
Синтаксис robots.txt
Синтаксис robots.txt основан на регулярных выражениях.
В файле robots.txt используются следующие основные символы: /, *, $ и #.
Косая черта «/» используется для обозначения того, что мы хотим скрыть от сканеров. Например, одна косая черта в директиве Disallow заблокирует сканирование всего сайта.
Можно использовать две косые черты, чтобы запретить сканирование одного каталога, например: /catalog/.
Такая запись означает, что мы запрещаем сканирование всего содержимого каталога «каталог». Однако, если мы напишем «/catalog», мы запретим любые ссылки на веб-сайты, начинающиеся с /catalog.
Звездочка «*» означает любую последовательность символов в файле. Он используется после каждой директивы.
Эта запись предписывает всем поисковым роботам не сканировать файлы с расширением .gif в каталоге /catalog/.
Знак доллара «$» ограничивает действие «*». Если вы хотите запретить весь контент в каталоге «catalog», но в то же время не хотите запрещать URL-адреса, содержащие «/catalog», запись в вашем файле robots. txt будет выглядеть следующим образом:
txt будет выглядеть следующим образом:
Сетка «#» используется для комментариев, оставленных веб-мастером для себя или других веб-мастеров. Поисковый бот не будет учитывать их при сканировании сайта.
Например:
Как создать файл robots.txt
Чтобы создать файл robots.txt, вы можете использовать Блокнот, Sublime или любой другой текстовый редактор. Но если вы хотите сделать этот процесс более автоматизированным, вы можете использовать бесплатный генератор robots.txt. Такие сервисы помогают создать правильный robots.txt на основе информации вашего сайта.
Основными директивами robots.txt являются «User-agent» и «Disallow». Есть также некоторые второстепенные директивы.
User-agent – визитная карточка поисковых ботов
User-agent – это директива для краулеров, которые будут видеть инструкции, описанные в файле robots.txt. В настоящее время известно 302 поисковых робота. Чтобы не прописывать их всех по отдельности, стоит использовать запись:
Это значит, что мы задали директивы в файле robots. txt для всех краулеров.
txt для всех краулеров.
Для Google основным поисковым роботом является Googlebot. Если мы хотим рассматривать только Googlebot, запись в файле должна быть такой:
В этом случае все остальные боты будут сканировать контент в соответствии со своими директивами для обработки пустого файла robots.txt.
Другие специальные поисковые роботы:
- Mediapartners-Google – для сервисов AdSense.
- AdsBot-Google — для проверки качества целевой страницы.
- Googlebot-Image — для картинок.
- Googlebot-Video — для видео.
- Googlebot-Mobile — для мобильной версии.
Что означает «Запретить» в файле robots.txt?
Disallow рекомендует информацию, которую не следует сканировать.
Эта запись открывает для сканирования весь сайт:
Тогда как эта запись говорит, что абсолютно все содержимое сайта запрещено для сканирования:
Это может быть полезно, если сайт находится в разработке и вы не хотите, чтобы он отображался в поисковой выдаче в его текущей конфигурации.
Однако важно удалить эту директиву, как только сайт будет готов для посещения пользователями. К сожалению, об этом иногда забывают многие веб-мастера.
Например, вот как написать директиву Disallow, чтобы запретить роботам сканировать содержимое каталога /folder/ :
запретить поисковым роботам сканировать определенный файл:
запретить поисковым ботам сканировать все файлы определенного типа:
Эта директива запрещает сканирование всех файлов .gif
Разрешить – руководство для роботов поисковых систем
«Разрешить» позволяет сканировать любой файл/каталог/страницу. Например, вы хотите, чтобы поисковые роботы посещали страницы, начинающиеся с «/catalog», и отключили весь остальной контент. В этом случае используется следующая комбинация:
Директивы Allow и Disallow сортируются по длине префикса URL (от самого короткого до самого длинного) и применяются по очереди. Если для страницы релевантно более одной директивы, бот поисковой системы выберет последнее правило в отсортированном списке.
Sitemap.xml — для навигации по веб-сайту
Карта сайта сообщает поисковым роботам, что все URL-адреса, необходимые для индексации, расположены по адресу https://site.com/sitemap.xml . При каждом сканировании роботы поисковых систем будут видеть изменения, которые были внесены в этот файл, и быстро обновлять информацию о сайте в базах данных поисковых систем.
Инструкции должны быть правильно прописаны в файле:
Crawl-delay — таймер для медленных серверов
Crawl-delay — директива, используемая для установки периода времени, по истечении которого страницы сайта будут сканироваться. Это правило полезно, если у вас медленный сервер. В этом случае возможны длительные задержки в доступе краулеров к страницам сайта. Этот параметр измеряется в секундах.
Как создать идеальный файл robots.txt?
Такой файл robots.txt можно разместить практически на любом веб-сайте:
Файл открывает содержимое веб-сайта для сканирования, включена карта сайта, которая позволит поисковым системам всегда видеть URL-адреса, которые необходимо проиндексировать.
Но не спешите копировать содержимое файла себе — для каждого сайта нужно писать уникальные инструкции, которые зависят от типа сайта и CMS. На этом этапе неплохо запомнить все правила заполнения файла robots.txt.
Как проверить файл robots.txt
Если вы хотите узнать, правильно ли заполнен ваш файл robots.txt, проверьте его в Google Search Console. Введите исходный код файла robots.txt в форму ссылки и выберите сайт, который хотите проверить.
Распространенные ошибки в robots.txt, которых следует избегать
Часто при заполнении файла robots.txt допускаются определенные ошибки, обычно вызванные невнимательностью или спешкой. Вот таблица, в которой перечислены распространенные ошибки robots.txt.
1. Неправильные инструкции:
Правильные:
2. Запись более одной папки/каталога в одной директиве Disallow:
Это может сбить с толку поисковых роботов о том, должны ли они сканировать первую папку или последний.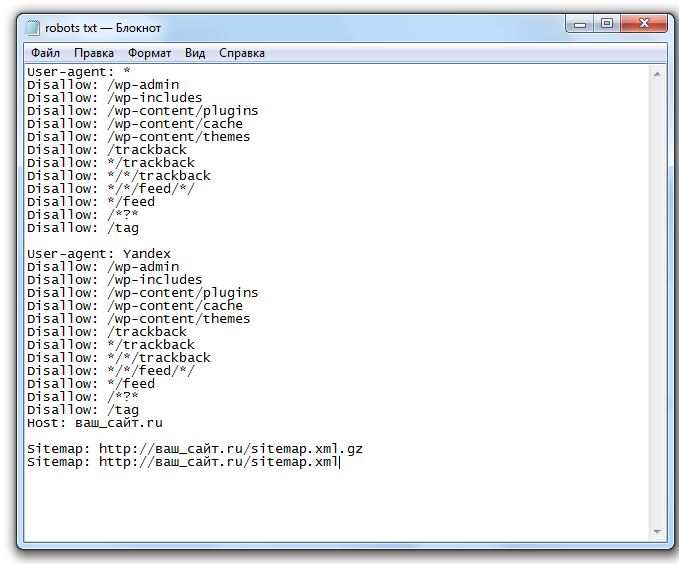 Итак, обязательно пропишите каждую инструкцию отдельно:
Итак, обязательно пропишите каждую инструкцию отдельно:
3. Файл должен называться только robots.txt, а не Robots.txt, ROBOTS.TXT или как-то еще.
4. Директиву User-agent нельзя оставлять пустой – нужно указать поисковых ботов, которые должны следовать инструкциям в файле.
5. Лишние символы в файле (например, косые черты, звездочки).
6. Добавление в файл страниц, которые не следует индексировать.
Не сканировать не означает не индексировать
Директивы в файле robots.txt ограничивают только сканирование содержимого веб-сайта. Они не относятся к индексации.
Чтобы убедиться, что URL-адрес не проиндексирован, вместо этого рекомендуется использовать метатег robots или HTTP-заголовок X-Robots-Tag.
- Метатеги Robots можно использовать для управления тем, как определенная HTML-страница отображается (или не отображается) в поисковой выдаче.
- HTTP-заголовок X-Robots-Tag можно использовать для управления тем, как не-HTML-контент отображается (или не отображается) в результатах поиска.

Наиболее полезные метатеги robots:
- Индекс : страница может быть проиндексирована.
- Follow : сканер может просматривать ссылки на этой странице.
- Noindex : эта страница не может быть проиндексирована.
- Nofollow : запретить роботам поисковых систем переходить по ссылкам на этой странице.
- Нет : Noindex + Nofollow.
- Noimageindex : отключить индексацию изображений.
- Без архива : не показывать кешированную версию этой веб-страницы.
- Nosnippet : не показывать метаданные в поисковой выдаче.
Необычное использование файла robots.txt
Помимо своих прямых функций, файл robots.txt может быть площадкой для творчества и способом поиска новых сотрудников.
Многие бренды используют robots.txt, чтобы выразить свою индивидуальность и подчеркнуть свой брендинг:
В качестве платформы для поиска специалистов robots. txt в основном используется SEO-агентствами. Кто еще мог знать о его существовании? 🙂
txt в основном используется SEO-агентствами. Кто еще мог знать о его существовании? 🙂
Когда у веб-мастеров появляется свободное время, они часто тратят его на обновление robots.txt:
Summary
С помощью Robots.txt можно давать инструкции поисковым ботам, какие страницы сканировать, продвигать. себя и свой бренд, а также поиск специалистов. Это отличное поле для экспериментов. Главное – помнить о правильном заполнении файла и избегать типичных ошибок.
Основные директивы файла robots.txt следующие.
- User-agent — директива о том, какие роботы должны видеть инструкции, описанные в robots.txt.
- Disallow сообщает, какую информацию не следует сканировать.
- Карта сайта сообщает роботам, что все URL-адреса, необходимые для индексации, расположены по адресу https://site.com/sitemap.xml.
- Crawl-delay — параметр, с помощью которого можно указать период времени, по истечении которого страницы сайта будут загружаться.
