Анализ robots.txt — Вебмастер. Справка
- Как проверить файл
- Как узнать, обойдет ли робот определенный URL
- Как отслеживать изменения файла
- Вопросы и ответы
Инструмент Анализ robots.txt помогает проверить, правильно ли составлен файл robots.txt или написать содержимое файла и после проверки скопировать его в robots.txt.
Также инструмент поможет отследить изменения в файле и скачать определенную версию.
- Как проверить файл
- Как узнать, обойдет ли робот определенный URL
- Как отслеживать изменения файла
- Вопросы и ответы
- Если сайт добавлен в Яндекс Вебмастер и права на его управление подтверждены
Содержимое файла появится на странице Инструменты → Анализ robots.txt после подтверждения прав на управление сайтом.
Если содержимое отображается на странице Анализ robots.txt, нажмите кнопку Проверить.
- Если сайт не добавлен в Яндекс Вебмастер
Перейдите на страницу Анализ robots.
 txt.
txt.В поле Проверяемый сайт укажите адрес вашего сайта. Например, https://example.com.
Нажмите значок . Содержимое robots.txt и результаты анализа отобразятся ниже.
 txt.
txt.В предназначенных для робота Яндекса (User-agent: Yandex или User-agent:*) разделах инструмент проверяет директивы, руководствуясь правилами использования robots.txt. Остальные разделы проверяются в соответствии со стандартом.
После проверки могут отобразиться:
Предупреждения. Они сообщают об отклонении от правил, которое инструмент может исправить самостоятельно. Также предупреждения указывают на потенциальную проблему, связанную с опечаткой или неточностью в написании правил.
Ошибки в файле. Это значит, что инструмент не может обработать строку, секцию или весь файл из-за серьезных ошибок в синтаксисе, допущенных при составлении директив.
Подробное описание см.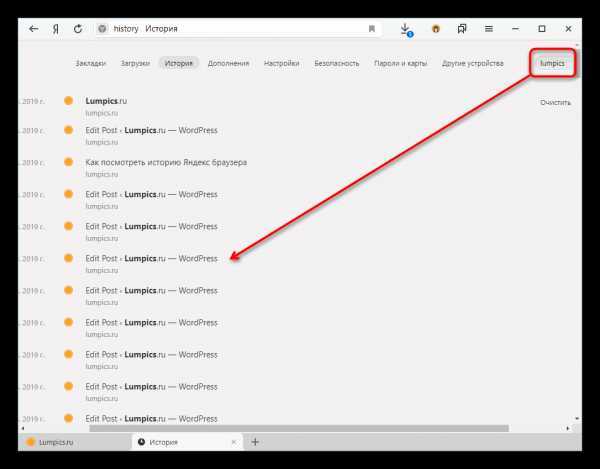 в разделе Справочник по ошибкам анализа robots.txt.
в разделе Справочник по ошибкам анализа robots.txt.
Когда ваш файл robots.txt загружен в Яндекс Вебмастер, на странице Анализ robots.txt отображается блок Разрешены ли URL?.
В поле Список URL укажите адрес страницы, которую хотите проверить. Можно указать полный URL или адрес относительно корневого каталога сайта. Например, https://example.com/page/ или /page/.
Нажмите кнопку Проверить.
Если URL разрешен для индексирования роботами Яндекса, напротив адреса появится значок , если запрещен — отобразится адрес, выделенный красным.
Примечание. Доступна история изменений за шесть месяцев. Максимальное количество сохраненных версий — 100.
Чтобы своевременно узнавать об изменениях файла robots.txt, настройте уведомления.
Яндекс Вебмастер регулярно проверяет обновления файла и сохраняет версии с учетом даты и времени изменения. Чтобы их посмотреть, перейдите на страницу Инструменты → Анализ robots.txt.
Список версий отображается, если одновременно выполнены следующие условия:
вы добавили сайт в Яндекс Вебмастер и подтвердили права на управление сайтом;
в Яндекс Вебмастере есть информация об изменениях robots.
 txt.
txt.
Вы можете:
- Просмотреть текущую и предыдущие версии файла
Выберите из списка Версия robots.txt версию файла. В поле ниже отобразится содержимое robots.txt, а также результаты анализа.
- Скачать выбранную версию файла
Выберите из списка Версия robots.txt версию файла.
Нажмите кнопку Скачать. Файл сохранится на вашем устройстве в формате TXT.
Ошибка «Этот URL не принадлежит вашему домену»
Скорее всего, в списке URL вы указали адрес одного из зеркал вашего сайта, например http://example.com вместо http://www.example.com. Формально это два различных URL. Проверяемые URL должны принадлежать сайту, для которого производится анализ robots.txt.
Укажите инструмент, в работе которого вы нашли ошибку, опишите ситуацию как можно подробнее, а при необходимости приложите скриншот, иллюстрирующий ситуацию.
Почему страницы исключены из поиска
Страницы сайта могут пропадать из результатов поиска Яндекса по нескольким причинам. Чтобы узнать, по какой именно причине страница исключена, перейдите в Вебмастер на страницу Индексирование → Страницы в поиске и выберите Исключённые страницы. Подробно о блоке Исключённые страницы
| Причина исключения страницы | Решение |
|---|---|
| Страница признана малоценной или маловостребованной | Алгоритм принял решение не включать страницу в поиск, поскольку у нее мало шансов оказаться востребованной пользователями. Так может произойти, например, если страница не содержит контента, дублирует уже известные роботу страницы или ее контент не вполне отвечает интересам пользователей. Это автоматический регулярный процесс, поэтому решение алгоритма может измениться. Подробно в разделе Малоценные или маловостребованные страницы. |
| Ошибка при загрузке или обработке страницы роботом — если ответ сервера содержал HTTP-статус 3XX, 4XX или 5XX | Выявить ошибку поможет инструмент Проверка ответа сервера. Если страница доступна для робота, проверьте, что:
|
| Индексирование страницы запрещено в файле robots.txt или с помощью метатега с директивой noindex | Удалите запрещающие директивы. Если вы самостоятельно не размещали запрет в файле robots.txt, обратитесь к хостинг-провайдеру или регистратору доменного имени для выяснения подробностей. Также проверьте, не было ли блокировки доменного имени в связи с истечением срока регистрации. |
| Страница перенаправляет робота на другие страницы | Убедитесь, что исключенная страница действительно должна перенаправлять пользователей. Для этого используйте инструмент Проверка ответа сервера. |
| Страница дублирует содержание другой страницы | Если страница определена как дубль по ошибке, следуйте указаниям в разделе Дублирование страниц. |
| Страница не является канонической | Проверьте, что страницы действительно должна перенаправлять робота на URL, указанный в атрибуте rel=»canonical». |
| Сайт признан неглавным зеркалом | Если сайты объединены в группу по ошибке, следуйте рекомендациям в разделе Расклейка зеркал сайта. |
| На сайте обнаружены нарушения | Чтобы проверить это, перейдите в Вебмастере на страницу Диагностика → Безопасность и нарушения. |

Робот продолжает посещать исключенные из поиска страницы, а специальный алгоритм проверяет вероятность их показа в выдаче перед каждым обновлением поисковой базы. Таким образом, страница может появится в поиске в течение двух недель после того, как робот узнает о ее изменении.
Если вы устранили причину удаления страницы, отправьте страницу на переобход. Так вы сообщите роботу об изменениях.
Нажмите, чтобы решить проблему
Заголовки, которые запрашивает робот у сервера, отличаются от заголовков, запрашиваемых браузером. Поэтому исключенные страницы могут открываться в браузере корректно.
Если страница исключена из поиска из-за ошибки при ее загрузке, она исчезнет из списка исключенных только в том случае, если при новом обращении робота станет доступна.
 Проверьте ответ сервера по интересующему вас URL. Если ответ содержит HTTP-статус 200 OK, дождитесь нового посещения робота.
Проверьте ответ сервера по интересующему вас URL. Если ответ содержит HTTP-статус 200 OK, дождитесь нового посещения робота.она недоступна для робота в течение некоторого времени;
на нее не ссылаются другие страницы сайта и внешние источники.
На странице правильно заполнены метатеги description, Keywords и элемент title, страница соответствует всем требованиям. Почему она не в поиске?
Алгоритм проверяет на страницах сайта не только наличие всех необходимых тегов, но и уникальность, полноту материала, его востребованность и актуальность, а также многие другие факторы. При этом метатегам стоит уделять внимание. Например, метатег description и элемент title могут создаваться автоматически, повторять друг друга.
При этом метатегам стоит уделять внимание. Например, метатег description и элемент title могут создаваться автоматически, повторять друг друга.
Если на сайте большое количество практически одинаковых товаров, которые отличаются только цветом, размером или конфигурацией, они тоже могут не попасть в поиск. В этот список можно также добавить страницы пагинации, подбора товара или сравнений, страницы-картинки, на которых совсем нет текстового контента.
Страницы, которые отображаются как исключенные, в браузере открываются нормально. Что это значит?
Это может происходить по нескольким причинам:
В списке «Исключенные страницы» показываются страницы, которых уже нет на сайте. Как их удалить?
На странице Страницы в поиске, в списке Исключенные страницы, отображаются страницы, к которым робот обращался, но не проиндексировал (это могут быть уже несуществующие страницы, если ранее они были известны роботу).
Страница удаляется из списка исключенных, если:
Наличие и количество исключенных страниц в сервисе не должно влиять на положение сайта в результатах поиска.
Чтобы ваш вопрос быстрее попал к нужному специалисту, уточните тему:
Страницы с разным содержанием могут считаться дублями, если отвечали роботу сообщением об ошибке (например, на сайте была установлена заглушка). Проверьте, как отвечают страницы сейчас. Если страницы отдают разное содержимое, отправьте их на переобход — так они смогут быстрее вернуться в результаты поиска.
Проверьте, как отвечают страницы сейчас. Если страницы отдают разное содержимое, отправьте их на переобход — так они смогут быстрее вернуться в результаты поиска.
Чтобы избежать исключения страниц из поиска в случае кратковременной недоступности сайта, настройте HTTP-код ответа 503.
Исключение страниц из поиска не является ошибкой со стороны сайта или индексирующего робота: исключаются страницы, которые пользователи не смогут обнаружить по запросам, поэтому их исключение не должно повлиять на видимость проиндексированных страниц сайта. Подробно см. в разделе Малоценные или маловостребованные страницы.
Напишите в службу поддержки, если:
страницы занимали высокие позиции в результатах поиска до момента их исключения;
позиции сайта после исключения страниц существенно понизились;
количестве переходов из поисковой системы значительно сократилось после исключения страниц.
Заполнить форму
Цель «Просмотр страницы» — Яндекс.
 Метрика. Справка
Метрика. СправкаЭтот тип цели позволяет отслеживать:
Трафик на определенную страницу или несколько страниц.
Трафик по исходящей ссылке.
Загрузка файлов.
Совет. Пользователи могут достичь цели не на сайте, а где-то еще, например, по телефону. Для подсчета таких пользователей настройте передачу данных коллтрекера в Яндекс.Метрику. Далее вы можете добавлять звонки в отчеты Яндекс.Метрики, а также использовать специальную группу отчетов.
Как создать цель «Просмотр страницы»
Ограничения
Примеры:
В Яндекс.Метрике заходим в меню слева на страницу Целиa,
Нажмите Добавить цель.
В поле Имя введите имя создаваемой цели.
Выберите тип цели Просмотр страницы.
Укажите желаемое условие. Вы можете добавить до 10 условий.

Нажмите Добавить цель. Созданная цель появится в списке целей. Яндекс.Метрика начнет собирать по нему статистику в течение нескольких минут.
Проверить правильность работы цели.
Существует несколько типов условий, доступных при создании цели. Условия объединяются оператором ИЛИ, поэтому цель считается выполненной, если выполняется хотя бы одно из поставленных условий.
| Условие | Описание |
|---|---|
| url: соответствует | Укажите полный URL целевой страницы. |
| URL: содержит | Укажите часть URL. Используйте этот вариант, если целевых страниц несколько и их можно объединить одним условием. Пример Если указано условие /abc, цель будет достигнута на страницах example.com/abc-1, example.com/abc/2 и example.com/abcd. |
| URL: начинается с… | Указывается только первая часть URL. Используйте это условие, если хотите отслеживать просмотры в подкаталогах. Пример Если установлено условие https://example.com/abc/, цель будет выполнена на страницах https://example.com/abc/1, https://example.com /abc/2 и https://example.com/abc/1/2/3. |
| URL-адрес: регулярное выражение | Используется для отслеживания URL-адресов, соответствующих пользовательскому шаблону. |
 Укажите как можно большую часть URL-адреса, чтобы цель выполнялась только на нужных страницах.
Укажите как можно большую часть URL-адреса, чтобы цель выполнялась только на нужных страницах.При обработке условия такие символы, как ?, #, & и точки (.), удаляются из конца URL-адреса. Например, для URL-адресов http://example.com/?, http://example.com/# и http://example.com/?var=1& сравнение будет производиться с http:// example.com/, http://example.com/, http://example.com/?var=1 соответственно. Чтобы добавить эти символы, кроме точки, в URL-адрес, используйте условие регулярного выражения url:.
Если вы хотите, чтобы цель была достигнута для просмотров страниц с URL-адресами, содержащими знак плюс, поместите в шаблоне %2B вместо символа +.
Пример
Для каждого тега можно установить не более 200 целей.
Сервис регистрирует пользователя, выполняющего одну и ту же цель по одному и тому же тегу не чаще одного раза в секунду.
За один сеанс пользователя сервис может зарегистрировать до 400 выполнений всех целей, созданных для тега.
Если вы отредактируете тег или цель, ранее собранная информация не изменится.

Если вы удалите цель, информация, собранная для нее, больше не будет доступна в отчетах.
Установите тип условия «URL: содержит».
Введите в качестве условия полный или частичный путь к файлу (или его имени) на вашем сайте. Например, https://example.com/files/name.pdf или name.pdf. Если вы указываете имя в качестве условия, убедитесь, что оно не пересекается с другими именами файлов или страниц на веб-сайте.
Отслеживание загрузок файлов
Выберите вопрос, чтобы найти решение.
Цели в Яндекс.Метрике работают одинаково для любого источника. Возможно, еще нет пользователей, которые выполнили цель из этого источника.
Данные рекомендации не помогли
Это могло произойти по следующим причинам:
Условие цели в Яндекс.Метрике не охватывает всех возможностей.
 Например, цель поставлена как переход на страницу подтверждения заказа, но сайт также позволяет моментальную оплату без посещения этой страницы.
Например, цель поставлена как переход на страницу подтверждения заказа, но сайт также позволяет моментальную оплату без посещения этой страницы.У пользователя сайта установлен плагин для браузера, который блокирует метку Яндекс.Метрики, поэтому этот пользователь не учитывается.
У пользователя установлена антивирусная система со строгими настройками конфиденциальности.
У пользователя медленное интернет-соединение, поэтому на целевой странице не загрузилась метка Яндекс.Метрики.
Эти рекомендации не помогли
🪐 Leonardo Pizarro sur LinkedIn : #seo #rankingfactors #yandex
🪐 Леонардо Писарро
Глава отдела формирования спроса @ Лунио • Реклама предназначена для людей, а не для ботов — превратите потраченные впустую расходы в рост доходов ⚡🤖
SEO-специалистов анализируют более 1922 просочившихся факторов ранжирования Яндекса. Вот 5 главных вещей, на которых вы должны сосредоточиться:
• Индексация платных целевых страниц (по ситуации)
• Повысьте CTR, написав привлекательные метазаголовки.
• Сосредоточьтесь на тематических кластерах, а не на отдельных ключевых словах.
• Создание релевантных ссылок для повышения PageRank
• Используйте принципы UX/UI
______
1. Индексация платных целевых страниц
Судя по просочившимся записям Яндекса, количество уникальных посетителей ваших страниц влияет на поисковую выдачу. Это не означает, что Google применяет тот же вес к общему трафику.
Однако, если вы прикладываете усилия для диверсификации своих платных целевых страниц с высоким показателем качества, их индексация поможет вам быстро увеличить свой органический след.
2. Повысьте CTR, написав привлекательные мета-заголовки
Это не должно быть сюрпризом. Хотя Google заявил, что CTR не является прямым фактором ранжирования, бесчисленные SEO-исследования доказывают обратное.
Поисковые системы отдают предпочтение контенту, который интересен пользователям.
Вот 5 главных вещей, на которых вы должны сосредоточиться:
• Индексация платных целевых страниц (по ситуации)
• Повысьте CTR, написав привлекательные метазаголовки.
• Сосредоточьтесь на тематических кластерах, а не на отдельных ключевых словах.
• Создание релевантных ссылок для повышения PageRank
• Используйте принципы UX/UI
______
1. Индексация платных целевых страниц
Судя по просочившимся записям Яндекса, количество уникальных посетителей ваших страниц влияет на поисковую выдачу. Это не означает, что Google применяет тот же вес к общему трафику.
Однако, если вы прикладываете усилия для диверсификации своих платных целевых страниц с высоким показателем качества, их индексация поможет вам быстро увеличить свой органический след.
2. Повысьте CTR, написав привлекательные мета-заголовки
Это не должно быть сюрпризом. Хотя Google заявил, что CTR не является прямым фактором ранжирования, бесчисленные SEO-исследования доказывают обратное.
Поисковые системы отдают предпочтение контенту, который интересен пользователям.