Алгоритм поисковой системы Яндекса и Google
- Алгоритм поисковой системы
- Поисковые алгоритмы Яндекса
- Магадан
- Находка
- Арзамас
- Снежинск
- Конаково
- Обнинск
- Краснодар
- Рейкьявик
- Калининград
- Дублин
- Поисковые алгоритмы Google
- PageRank
- Hilltop
- Флорида
- Орион
- Austin
- Caffeine
- Панда
- Пингвин
- Колибри
- Mobile friendly
- Перспективы поисковых алгоритмов Яндекса, Google и поиска в целом
Алгоритм поисковой системы.

Алгоритм поисковой системы (ПС) — набор формул, в соответствии с которыми осуществляется формирование выдачи и ранжирование веб-страниц. Основная задача алгоритма поисковой системы — продемонстрировать пользователю те ресурсы, которые максимально соответствуют его интересам и запросу. В процессе подбора учитывается контент, ключи, соответствие кода и других технических моментов запросу. Каждый день происходит эволюция поисковых систем.
Ниже рассмотрены поисковые алгоритмы ключевых поисковых систем Яндекса и Google.
Поисковые алгоритмы Яндекса.
Магадан.
Главные особенности поискового алгоритма Магадан Яндекса:
- Число учитываемых факторов увеличено в 2 раза.
- Улучшен географический классификатор.
- Модернизирована система обработки запросов, состоящих из многих слов.
- Добавлены новые классификаторы текстового содержимого и ссылок.
Доработаны пресс-портреты и погодные колдунщики. Алгоритм «Магадан» Яндекса обеспечил быстродействие при поиске информации, в ранжировании появился учет переводов наряду с прямыми вхождениями.
Алгоритм «Магадан» Яндекса обеспечил быстродействие при поиске информации, в ранжировании появился учет переводов наряду с прямыми вхождениями.
Находка.
Главные особенности поискового алгоритма Находка Яндекса:
- Добавлена инновационная методика машинного обучения.
- Повышено качество поиска по сложным запросам со стоп-фразами.
- Предложены новые санкции за перенаправления и умышленную подмену контента веб-страниц.
- Стал учитываться возраст веб-ресурса при раскрутке.
- Дополнительно увеличен словарный запас.
Арзамас.
Главные особенности поискового алгоритма Арзамас Яндекса:
- Добавлен учет региона.
- Присвоение региональности площадке происходит с учетом контактной информации и IP-адреса.
- Добавлены фильтры для веб-страниц с агрессивной рекламой.
- Улучшена система понимания языка.
- Модифицировано ранжирование по сложным запросам с многими словами.
Снежинск.

- Добавлены новые факторы, в том числе региональные.
- Добавлен фильтр АГС-2015.
- Упразднено негативное влияние контента большого объема с высокоплотным включением ключей.
- Запущена инновационная система Матрикснет.
Конаково.
Усовершенствованная версия алгоритма «Снежинск». Основная работа коснулась локального ранжирования и его модернизации.
Обнинск.
Главные особенности поискового алгоритма Обнинск Яндекса:
- Оптимизировано ранжирование по географически независимым запросам в рамках России.
- Ограничена весомость искусственных ссылок при ранжировании.
- Доработан алгоритм авторства.
- Модернизирован интерфейс просмотра дублей и копий веб-страниц.
- Увеличен транслитерационный словарь.
Краснодар.
Главные особенности поискового алгоритма Краснодар Яндекса:
- Добавлена классификация запросов пользователей по категориям.

- Расширен перечень факторов ранжирования: добавлены поведенческие.
- Полностью проиндексирована соцсеть ВКонтакте.
- Внедрены сниппеты с дополнительной информацией для отдельных компаний.
- Добавлен учет дополнительных словоформ в запросе при ранжировании.
Рейкьявик.
Главные особенности поискового алгоритма Рейкьявик Яндекса:
- Доработана система демонстрации подсказок.
- Модернизированы математические и игровые колдунщики.
- Внедрен учет пользовательских предпочтений для англоязычных запросов.
Алгоритм Рейкьявик — дебютный шаг Яндекса в формировании персонализированного поиска будущего.
Калининград.
Главные особенности поискового алгоритма Калининград Яндекса:
- Реализована система глобальной персонализации.
- Добавлены подсказки в сиреневых тонах.
- Предлагаемые подсказки изменяются с учетом предшествующего запроса.
Дублин.
Поисковая система Яндекса научилась отслеживать текущие предпочтения и интересы.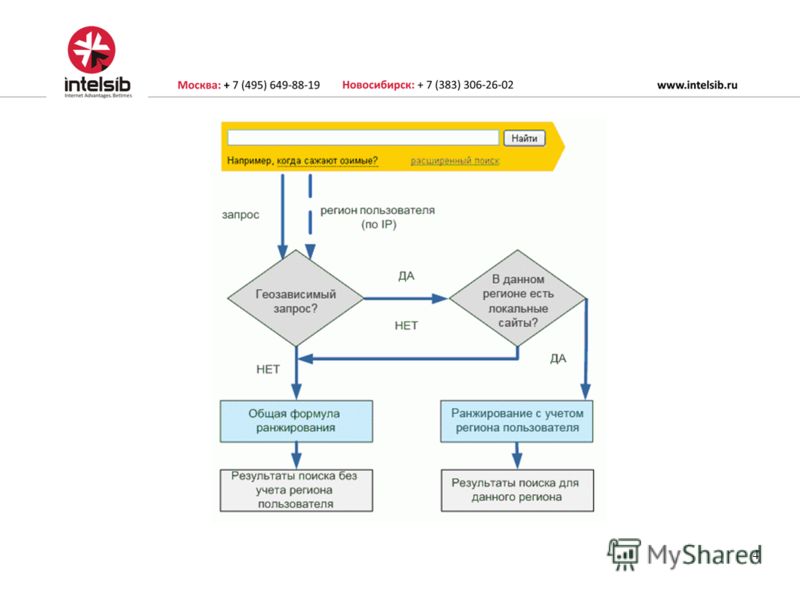
Поисковые алгоритмы Google.
PageRank.
Внедрение индекса цитирования позволило Google ранжировать страницы с учетом авторитетности и численности внешних ссылок.
Hilltop.
Алгоритм Hilltop помог эффективнее рассчитывать Google PageRank. Все страницы разделены на две категории — коммерческой и общей (некоммерческой) направленности.
Флорида.
Исключены из выдачи Google веб-страницы с переспамом ключей и повторяющимся анкором.
Орион.
Алгоритм Орион улучшил поисковую выдачу Google за счет быстрого вывода релевантных результатов. Главный фактор при ранжировании — качество ресурса.
Austin.
Алгоритм Google Austin добавил новые фильтры и санкции.
Caffeine.
Алгоритм Caffeine оптимизировал структуру поисковика. Поиск Google стал быстрее, численность проиндексированных страниц возросла.
Панда.
Алгоритм Панда стал инспектором качества веб-ресурсов Google. Он регулярно обновляется, что затрагивает как сигналы, по которым осуществляется выбор и наложения фильтров на некачественные сайты, так и общая база анализа.
Пингвин.
Алгоритм Google Пингвин нацелен на противодействие неестественным обратным ссылкам.
Колибри.
Алгоритм Колибри разработан Google с целью более качественного понимания пользовательских запросов и повышения релевантности выдачи.
Mobile friendly.
Алгоритм Google Mobile friendly затрагивает только мобильный поиск. Предполагает более высокое ранжирование сайтов с дружественным к мобильным устройствам дизайном, структурой и т.д.
Перспективы поисковых алгоритмов Яндекса, Google и поиска в целом
Основная цель алгоритмов поисковых систем — это повышение качества поиска, минимизация времени на анализ, упрощение процедуры.
В перспективе следует ожидать появления рубрик в поиске. Поисковики перейдут на анализ «живых данных», вводимых пользователем. Также возможна вторая волна развития различных надстроек в поиске.
Предположительно, поисковики в будущем станут:
- многорезультативными;
- ещё более актуальными;
- понимающими смысл фраз и словесных конструкций.

Пользователи смогут прибегать к экспертной помощи, чтобы найти нужную информацию.
Сейчас поисковики индексируют только 0,2% всей находящейся в Интернете информации. Остальные данные — различные базы, закрытые и конфиденциальные сведения не индексируются. Вероятно, дополнительным перспективным направлением работы окажется глубокий поиск, который будет затрагивать не только проиндексированную информацию, но и то, что пока невидимо для поисковых ботов.
Заберите ссылку на статью к себе, чтобы потом легко её найти!
Выберите, то, чем пользуетесь чаще всего:
Алгоритмы Яндекса – 24 алгоритма ранжирования поисковой системы
Поисковая система Яндекс помогает своим пользователям найти ответы на интересующие вопросы еще с 1997 года. Сегодня эта система занимает 56% всех поисковиков по России. Из-за популярности и активного роста компании Яндекс, также растёт количество и качество поисковых алгоритмов. Давайте разберём всё по порядку, как же работают алгоритмы Яндекса.
Содержание статьи
- Что такое поисковый алгоритм?
- Все алгоритмы Яндекса по годам
- Версия 7
- Версия 8 и Восьмерка SP1
- Магадан
- Находка
- Арзамас или Анадырь
- Снежинск
- Конаково и Конаково 1.1
- Обнинск
- Краснодар
- Рейкьявик
- Калининград
- Дублин
- Началово
- Одесса
- Амстердам
- Новый алгоритм «Минусинск» от Яндекс
- Киров
- Владивосток
- Палех
- Описание фильтра Баден-Баден от Яндекс
- Королев
- Андромеда
- Вега
- YATI
- Y1
- Выводы
Что такое поисковый алгоритм?
Поисковой алгоритм – это набор формул, с помощью которых решается задача выдачи (ранжирования) страниц по результатам поиска. Запрос пользователя осуществляется по определенным ключевым словам и фразам. Поисковая система сама выбирает наиболее подходящие web ресурсы, соответствующие конкретному запросу, в зависимости от множества правил которые формирую алгоритмы Яндекса.
Все алгоритмы Яндекса по годам
Начиная с момента создания, поисковая система Яндекс постоянно совершенствует и разрабатывает новые алгоритмы ранжирования сайтов. Это как уравнение, с помощью которого поисковик находит наиболее соответствующие ресурсы по запросу. Если поисковая формулировка будет составлена корректно и состоять из нескольких уточняющих слов, шанс на более четкий ответ от системы будет значительно выше.
| № | Дата создания | Название алгоритма |
| 1 | 20.12.2007 | «Версия 7» – Совершенно новый алгоритм ранжирования поисковой системы, после которого факт выдачи стал значительно лучше. |
| 2 | 17.01.2008 | «Версия 8». «Версия восемь SP1» – Добавился новый фильтр прогонов для ограничения накрутки ссылок |
| 3 | 16.05.2008 | «Магадан» – Стал возможен поиск по аббревиатуре и геолокации. Возможность распознать уникальность материала. |
| 4 | 11.09.2008 | «Находка» – Улучшения словаря поисковой системы Яндекс( добавление тезаурус), с помощью которого запрос стал дифференцировать слитное и раздельное написание слов. Во внимание при выдаче стал учитываться факт наличия стоп- слова. |
| 5 | 10.04.2009 24.06.2009 20.08, 31.08.2009 23.09, 28.09.2009 | «Арзамас» или же «Анадырь» – Ввод совершенно новой формулы ранжирования. Поиск стал возможен по региональности материала за счет геолокации пользователей. Формулы выдачи для 16 регионов России. |
| 6 | 17.11.2009 | «Снежинск» – Новый вид машинного обучения – Matrixnet, где учтены новые комбинации и возможности выдачи. |
| 7 | 22.12.2009 10.04.2010 | «Конаково» – Алгоритм с новыми формулами выдачи для 1250 городов России( в предыдущей версии 19 городов).«Конаково 1.1»Усовершенствование возможностей геозависимых вопросов. |
| 8 | 13.09.2010 | «Обнинск» – В Яндекс поиске стало доступным распознавание авторского текста, улучшение выдачи запросов на иностранных языках. |
| 9 | 15.21.2010 | «Краснодар» – Новая технология «Спектр» для расшифровки выдачи на двоякие запросы. Она формировалась по истории кликов или поведенческих факторах каждого пользователя. |
| 10 | 17.08.2011 | «Рейкьявик» – Поиск осуществлялся по индивидуальным предпочтениям пользователя. Работа с опечатками в тексте запроса. |
| 11 | 12.12.2012 | «Калининград» – Всплывающие поисковые подсказки. Индивидуализация выдачи для каждого конкретного пользователя на основании его запросов |
| 12 | 30.05.2013 | «Дублин» – Выдача на основании длительного анализа запросов пользователя. Адаптация поисковой системы под пользователя в момент формирования запроса. |
| 13 | 12.03.2014 | «Началово» – Алгоритм без взятия во внимание учета ссылок для коммерческих запросов поисковой системы. |
| 14 | 05.06.2014 | «Одесса» – В выдаче появились дополнительные острова запросов, при использовании которых не нужно было открывать новую ссылку. |
| 15 | 01.04.2015 | «Амстердам» – Результат выдачи дополняется разделом с дополнительными данными о запросе. |
| 16 | 15.05.2015 | «Минусинск» – Снижение расположения веб страниц с содержанием SEO рассылки. Только удаление некачественных ссылок могло вернуть позицию сайта в выдаче |
| 17 | 14.09.2015 | «Киров» – Обнаружение страниц с наилучшими результатами поведенческих реакций. В категорию топ попадали молодые ресурсы с наличием фактора низкого положения в поиске. |
| 18 | 02.02.2016 | «Владивосток» – Поиск адаптировался под возможности запросов с мобильных устройств. |
| 19 | 02.10.2016 | «Палех» – Работа над смысловой трактовкой запроса, а не только от ключевых слов. |
| 20 | 23.03.2017 | «Баден – Баден» – Фильтрация сайтов плохого качества ресурса, факта перегруженности ключевых вхождений. |
| 21 | 22.08.2017 | «Королев» – Алгоритм с обнаружением смыслового запроса пользователя с результатами на странице. |
| 22 | 19.11.2018 | «Андромеда» – Поиск предоставлял наличие быстрых ответов. Информация о популярности сайта и вовлеченности в него пользователей. |
| 23 | 17.12.2019 | «Вега» – Хранилище данных Яндекс выросло в два раза. Распределение запросов по смыслу. Совершенствование скоростной работы выдачи. |
| 24 | Сентябрь – ноябрь 2020 10.06.2010 | «YATI» – Улучшение фактора восприятия смысла на ресурсной странице. «Y1» – Улучшение языковой модели, поиск информации в видеоролике, результат оценки по отзывам, улучшение функций безопасности. |
Версия 7
Выпуск совершенно новой формулы ранжирования в системе Яндекс поиска, при которой значительно улучшилась выдача. Изменения произошли и в диагностике ранжирования однословных и многословных запросов.
Версия 8 и Восьмерка SP1
Усовершенствование ранжирования среди более авторитетных ресурсов. Появление фильтрации «прогонов» при накрутке ссылочных факторов. Отмечалось и снижение размера ссылок с главных страниц.
Отмечалось и снижение размера ссылок с главных страниц.
Магадан
Поиск запросов стал возможным по геолокации. Алгоритм позволил распознавать аббревиатуры и авторский текст. Индексация иностранных ресурсов. При этом покупка ссылок для увеличения позиции ресурсного сайта сведена на нет, а вывод сайта в топы затруднилась.
Находка
Совершенствование запросов поисковой системы yandex со слитным и раздельным правописанием, что стало возможным благодаря оптимизации словаря и внедрению тезаурус. При выдаче стали брать во внимание стоп – слова. А при запросе yandex в единственном и множественном числе наблюдалась разная выдача.
Арзамас или Анадырь
Новая усовершенствованная система алгоритмов пс yandex для региональных ресурсов. При выдаче учитывалась геопозиция пользователя, а ресурсным материалам присваивалась региональность ( во внимание брали 19 регионов Российской Федерации). Система yandex стала распознавать словосочетания, одинаковые по звучанию, но разные по смыслу. Сайты, использующие много рекламы, стали уступать свое место в поисковой строке.
Сайты, использующие много рекламы, стали уступать свое место в поисковой строке.
Снежинск
Внедрение в yandex совершенно нового машинного обучения Matrixnet, что отличало его значительной устойчивостью к переобучению. Это машинный способ считывания информации с учетом многих комбинаций и факторов. Учитывая многомиллионную информацию, которую должен найти и проверить поисковик, нужны быстрые ресурсы, которые за короткое время смогут дифференцировать всю информацию. Matrixnet справлялся с такой задачей. При этом появилась фильтрация мало полезного и некачественного контента. Распознавание и обработка информации с низким процентом уникальности.
Алгоритмы Яндекса – Конаково и Конаково 1.1
1250 городов Российской Федерации были задействованы в ранжировании и выдаче по региональной привязке ( до этого количество регионов составляло 19). Изменения алгоритма yandex в сторону улучшения запросов независимых по геолокации.
Обнинск
Поиск включил геонезависимые данные, которые занимали до 80% всех запросов, улучшив их выдачу.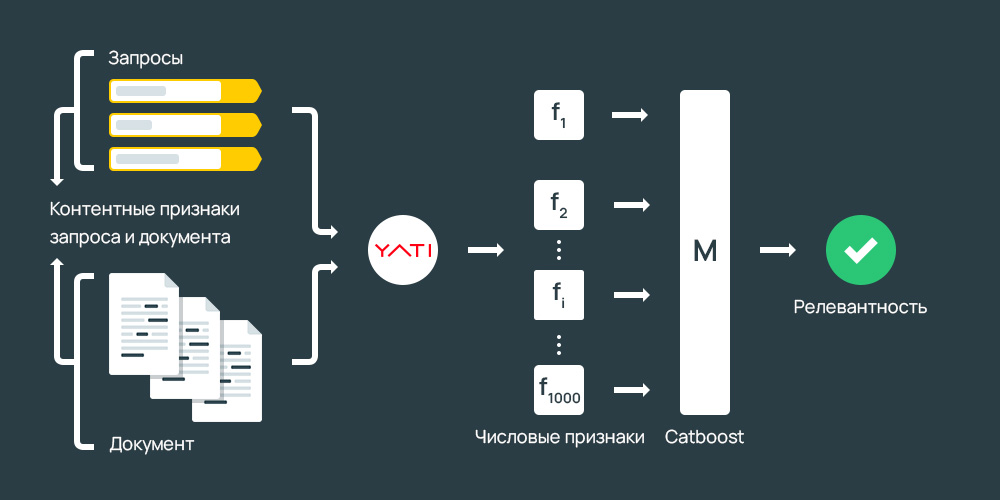 При ранжировании запросов yandex появилось понятие о «авторстве текста», при этом учитывался первородный источник создания информации и сайт дубляж. Улучшены возможности выдачи на иностранных запросах за счет расширенных возможностей словаря.
При ранжировании запросов yandex появилось понятие о «авторстве текста», при этом учитывался первородный источник создания информации и сайт дубляж. Улучшены возможности выдачи на иностранных запросах за счет расширенных возможностей словаря.
Краснодар
Алгоритм Яндекса – «Краснодар»Нововведение в поисковой системе Яндекс с появлением новой разработки «Спектр». Теперь система давала точную выдачу на двоякие запросы пользователей. Улучшение и оптимизация выдачи по геозависимым запросам. К примеру, слово «Наполеон» может подразумевать под собой имя известного полководца или же, не менее известный, десерт.
При этом результат выдачи будет опираться на истории переходов пользователя и информации, запрашиваемой ранее. С помощью этого алгоритма запросы стали делиться на категории. А описания под прямой ссылкой стали более развернуты.
Рейкьявик
Поиск стал учитывать языковые запросы пользователя. Выдача создавалась на основе предпочтений сайтов на англоязычном и русском языках. К нововведению Яндекс можно отнести и колдунщики- это краткий ответ на вопрос на запрашиваемой странице.
К нововведению Яндекс можно отнести и колдунщики- это краткий ответ на вопрос на запрашиваемой странице.
К примеру калькулятор валют, который отображается под поисковой строкой. Появилась возможность орфографической корректировки запроса в поисковике , а выдача формировалась как с опечаткой, так и без нее.
Калининград
Всплывающие поисковые подсказки позволяли быстрее вводить запрашиваемую информацию в адресную строку. Результаты выдачи Яндекс стали образовываться индивидуализировано предпочтениям и интересам пользователя. Например, если частые запросы были по выпечке, при введении слова «наполеон» в выдаче будут результаты десерта наполеон, а не имени и данных о полководце. С этого момента выдача стала индивидуальной для конкретного пользователя.
Дублин
В результате анализа истории пользователя за длительный отрезок времени – формировалась выдача. При этом анализ предпочтений проходил в режиме реального времени на только что сформировавшиеся запросы пользователя.
Началово
Произошла отмена учета ссылок Яндекс при ранжировании. Это коснулось только коммерческих вопросов города Москвы.
Полезно знать: Что такое семантическое ядро, как собрать для SEO сайта в 2022 году
Одесса
С этим алгоритмом произошли изменения дизайна результатов выдачи. При ответе на запрос появились всплывающие информационные окна, которые не требовали переход на новую страницу сайта. Это могла быть краткая информация о курсах валют, расписании самолета и даже прослушивания аудио прямо в момент работы с поисковой строкой. Позже Яндекс поиск ушел от этого нововведения.
Амстердам
Поисковик в результате выдачи выдавал дополнительное окно с кратким описанием запрашиваемого ресурса. Яндекс мог дать выдачу с помощью 10 млн. карточек.
Новый алгоритм «Минусинск» от Яндекс
Появились новые инструменты поисковой системы Яндекс для понижения страниц в рейтинге с преобладающим SEO содержанием. Теперь упор делается на качество ресурсов и органическую ссылочную долю. Веб-страницы, носящие в себе коммерческий контекст с покупными ссылками, опускались ниже на позиции в поисковой выдаче. Но вернуть высокое местоположение сайту можно было путем удаления таких ссылок.
Веб-страницы, носящие в себе коммерческий контекст с покупными ссылками, опускались ниже на позиции в поисковой выдаче. Но вернуть высокое местоположение сайту можно было путем удаления таких ссылок.
Киров
Оптимизация алгоритма Яндекса, главным фактором которого стал поиск ресурсов с лучшими показателями поведенческих реакций. В топе оказывались совсем новые сайты, имеющие незначительную позицию в выдаче.
Владивосток
Алгоритм поисковой системы Яндекс – «Владивосток»Обновление связано с оптимизацией Яндекс для мобильных устройств. Теперь при ранжировании учитывались различные виды гаджетов ( телефоны, планшеты, ноутбуки). Появился новый инструмент под названием mobile-friendly. Этот алгоритм от Яндекс позволил любителям мобильных устройств использовать поиск с различных смартфонов.
Палех
Внимание уделялось смысловой нагрузке запросов Яндекс. Если раньше выдача производилась за счет ключевых слов запроса, то сейчас стал возможным анализ заданной информации и наиболее четкая по смыслу выдача. Такая оптимизация была и по поиску новых заголовков ( Title). Упор в этой оптимизации на качество запроса и улучшение выдачи на редко задаваемые вопросы.
Такая оптимизация была и по поиску новых заголовков ( Title). Упор в этой оптимизации на качество запроса и улучшение выдачи на редко задаваемые вопросы.
Описание фильтра Баден-Баден от Яндекс
Алгоритм «Баден-Баден» определяет наличие и количество переоптимизированных текстов. То есть происходит фильтрация страниц Яндексом с большим количеством вхождений ключевых слов, со скрытыми слоями в тексте, сомнительным качеством ресурса и читабельностью.
Постраничный Баден-Баден накладывал запрет на часть оптимизированного ресурса, а хостовый на весь сайт со снижением позиции в выдаче.
Большой упор пришелся на SEO оптимизацию алгоритмов. Этот фактор важен для поискового продвижения и раскрутки веб страницы. Сайты, которые не берут во внимание SEO возможности, стали уходить на нижние позиции поискового рейтинга.
Королев
Оптимизация смысловой нагрузки запросов по тегу “title”. Теперь поисковая система Яндекс работала над смысловой частью ресурсов, противопоставлять его с содержанием запроса пользователя.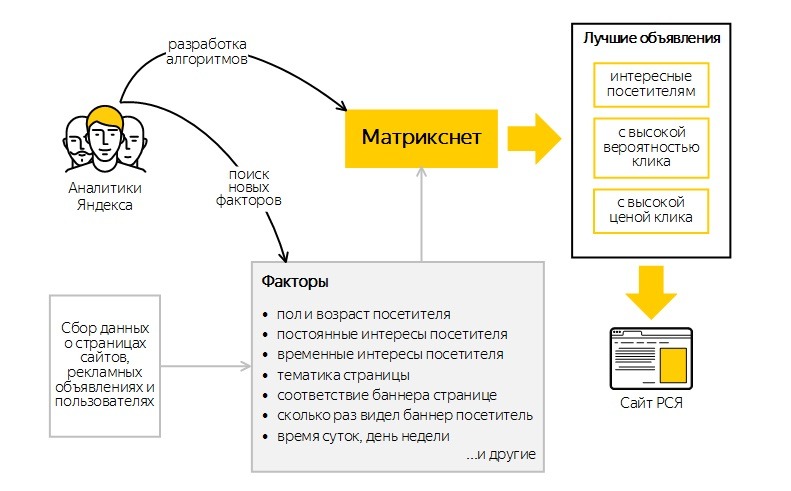 Здесь во внимание шли и статистические данные поведенческих факторов асессоров. Теперь можно было получить точный ответ на свой запрос даже при отсутствии совпадений и точных формулировок в запросе и результате выдачи.
Здесь во внимание шли и статистические данные поведенческих факторов асессоров. Теперь можно было получить точный ответ на свой запрос даже при отсутствии совпадений и точных формулировок в запросе и результате выдачи.
Андромеда
Андромеда – поисковый алгоритм ЯндексаПоявление коллекции в Яндекс. Теперь все ссылки, видеозаписи и изображения хранились в облаке. Появление колдунщиков – новая графа справа с развернутым ответом на заданный вопрос. Отображение информации о статусе сайта ( его позиции в выдаче, вовлеченность пользователей и верификацию).
Вега
Теперь возможности Яндекса стали шире, а информация для поисковой выдачи увеличилась в два раза. Для ускоренной выдачи на запросы улучшили смысловые кластеры базы данных. При выдаче на непопулярные запросы появились показатели экспертности, для дальнейшего улучшения работы асессоров. Совершенствование анализа геопозиции вплоть до районных данных.
YATI
Опять оптимизация Яндекс, связанная со смысловой составляющей выдачи и запросов. Она является своего рода последствием действующих правил. Алгоритмы Яндекса «Палех» и «Королев» это своего рода первые версии YATI. Это дало рекордные плоды по ранжированию за последние годы. Во внимание при выдаче берется фактор наличия заголовков, порядок расположения слов и анализ смысловой нагрузки выдачи и запроса.
Она является своего рода последствием действующих правил. Алгоритмы Яндекса «Палех» и «Королев» это своего рода первые версии YATI. Это дало рекордные плоды по ранжированию за последние годы. Во внимание при выдаче берется фактор наличия заголовков, порядок расположения слов и анализ смысловой нагрузки выдачи и запроса.
Y1
Алгоритм поисковой системы Яндекс – «Y1»Алгоритм, в котором применяется более 2000 новых улучшений. Появилась возможность выдачи по поиску в видеоролике, оценка страниц по отзывам пользователей, улучшение техник безопасности данных. Фактор улучшения Яндекс коснулся и языковой панели, которая теперь подстраивалась под стилистику любого текста.
Выводы
Система Яндекс поиска прошла большой путь становления и развития, в котором каждый год совершенствовался фактор развития и выдачи алгоритмов. Последние оптимизации сделали ответы на запрос пользователя быстрыми, четкими и логичными. Только понимая как работают алгоритмы Яндекса, можно создать сайт с высокой позицией в рейтинге и с такой же высокой популярностью по запросам пользователей.
Не потеряйте нас, подпишитесь на дайджест
и сразу получите: «10 лайфхаков по привлечению клиентов»
Алгоритмы искусственного интеллекта и машинного обучения Яндекса
Ранее в этом месяце Google представила свой последний алгоритм искусственного интеллекта, BERT, который, как говорят, является самым большим обновлением Google со времен RankBrain и влияет на 10% всех поисковых запросов.
BERT означает представление двунаправленного энкодера от трансформаторов. Преобразователи относятся к моделям, обрабатывающим слова по отношению ко всем другим словам в предложении, таким как сопоставление ключевых слов и синонимов.
BERT подробно освещался в Search Engine Journal Роджером Монтти и Мэттом Саузерн.
Однако алгоритмы искусственного интеллекта и машинного обучения Google — не единственные, которые используются поисковыми системами во всем мире.
Машинное обучение — это общий термин, охватывающий широкий спектр алгоритмов, которые обучаются на основе наборов данных для предоставления:
- рекомендаций.

- Решения.
- Предсказания.
Широко используется для ряда задач не только поисковыми системами, но и:
- Рекомендации по музыке и фильмам на стриминговых платформах.
- Прогнозы использования энергии в разных штатах.
Поисковые системы используют это для обработки данных из Интернета и некоторых автономных источников в случае Яндекса, чтобы предоставить пользователям лучшие результаты поиска и опыт.
Прошло десять лет с тех пор, как Яндекс впервые представил машинное обучение в поиске с запуском Matrixnet.
С тех пор поисковая система продолжала улучшать свои возможности искусственного интеллекта и машинного обучения с дальнейшими обновлениями, включая Палех и Королев.
Matrixnet, 2009
Matrixnet работает, беря тысячи переменных и «факторов ранжирования» и присваивая им различные веса на основе:
- Местоположение пользователя.
- Поисковый запрос.
- Установленные намерения пользователя
Это сделано для того, чтобы предоставить пользователю более релевантные и точные результаты.
Ощутимое влияние Matrixnet заключалось в том, что для более коротких запросов с несколькими распространенными интерпретациями некоммерческий контент стал более заметным на страницах результатов поиска по сравнению с более коммерческим контентом (и коммерческими веб-сайтами).
В тот же период, когда Яндекс запустил Матрикснет, поисковая система также приняла меры для предоставления пользователям более качественных результатов в зависимости от их местоположения. (Нет смысла кому-то во Владивостоке получать локальные результаты по Москве, так как это 113 часов на машине!)
Сделали это через алгоритм Арзамаса, который в том же году заменил Снежинск, а затем в 2010 году через Обинск.
Последнее позволило Яндексу лучше понять регион, в котором находится сайт, даже если веб-мастера не указали регион в Инструментах Яндекса для веб-мастеров.
Это заметно повлияло на веб-сайты с дорвеями местоположения и спамом с локальными ссылками.
Палех, 2016
В 2016 году (через год после RankBrain) Яндекс представил алгоритм Палеха. Палех использовал глубокие нейронные сети, чтобы лучше понять смысл поискового запроса.
Алгоритм использует нейронные сети, чтобы увидеть связи между запросом и документом, даже если они не содержат общих слов.
Эта технология наиболее полезна для сложных запросов, таких как поиск фильмов по неточным описаниям их сюжетов.
Королев, 2017
Основываясь на алгоритме Палеха, Яндекс выпустил обновление Королев в августе 2017 года. смысл страниц, в отличие от того, как Палех работал только с заголовками. Он также улучшает 150 страниц, которые анализировал Палех, благодаря своей способности работать с 200 000 страниц одновременно».
Подобно тому, как работает RankBrain, Korolyov становится более эффективным и точным с каждой дополнительной точкой данных, которую он получает, и все результаты затем возвращаются в основной алгоритм Matrixnet.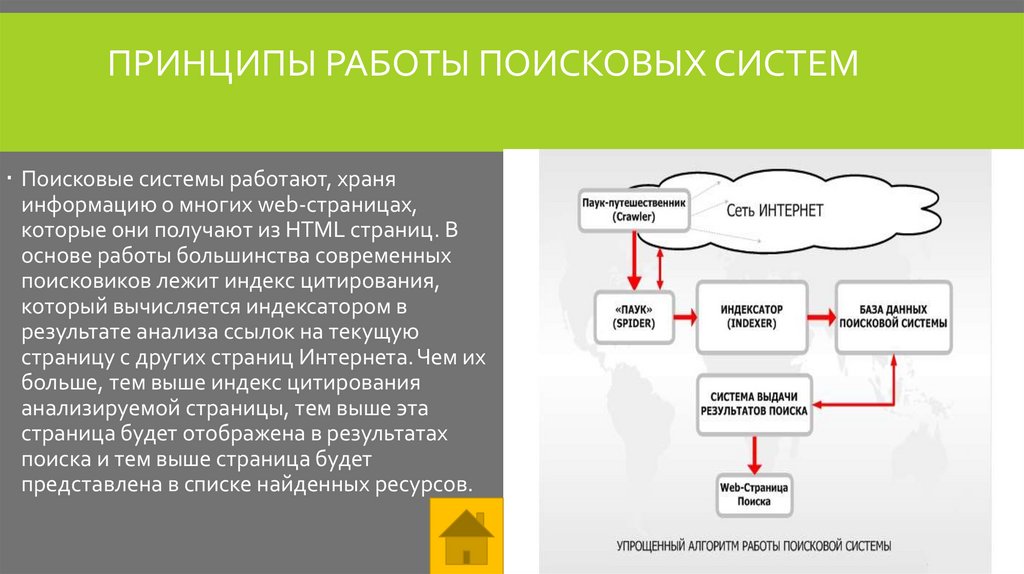
Одновременно с объявлением Королева Яндекс также сообщил, что Matrixnet начал:
- Учитывать данные с их краудсорсинговой платформы Толока (представьте себе вариант Amazon’s Mechanical Turks).
- Обрабатывать большие объемы анонимных пользовательских данных для дальнейшего улучшения и изменения наборов данных, с которыми работают алгоритмы машинного обучения.
Королев также ввел в поиск понятие семантических (контекстных) векторов, позволяющее выполнять «смысловой анализ» при отправке запроса пользователем. Это позволило поиску учитывать воспринимаемое значение всех запросов, которые привели пользователей на определенные страницы.
Это означало, что:
- На этапе индексации каждая страница была преобразована в семантические/контекстные векторы.
- Новые запросы могут быть поняты быстрее и эффективнее, с более точными результатами, чтобы не создавать отрицательных результатов поиска.
CatBoost, 2017
В 2018 году Яндекс представил преемника алгоритма машинного обучения Matrixnet — CatBoost.
По сравнению с Matrixnet CatBoost (с открытым исходным кодом) способен:
- Более точные прогнозы.
- Большая диверсификация результатов.
- Вспомогательные нечисловые переменные, такие как типы облаков, породы кошек и виды растений.
CatBoost использует технику машинного обучения, известную как повышение градиента, и обычно решает проблемы регрессии и классификации, которые визуально проявляются в виде деревьев решений.
На сегодняшний день CatBoost также используется вне поисковой системы Яндекса такими организациями, как Cloudflare и CERN.
Он используется там, где требуется повышение градиента на деревьях решений с уменьшенным риском переобучения, для таких задач, как борьба с заполнением учетных данных с помощью ботов.
Оптимизация для алгоритмов искусственного интеллекта Яндекса
Алгоритмы машинного обучения Яндекса — это лишь небольшая часть обновлений, которые поисковая система делала на протяжении многих лет для борьбы со ссылочным спамом и некачественным контентом, как и Google.
Как и в случае с процессами Google RankBrain (а теперь и BERT), нет реального способа напрямую оптимизировать алгоритмы машинного обучения, поскольку они учитывают Интернет в целом.
Как всегда, важно создавать контент, который приносит пользу пользователю, соответствует цели поиска и написан на естественном языке и для людей, а не для машин.
Дополнительные ресурсы:
- Яндекс SEO: интервью с поисковой командой Яндекса
- Полное руководство по Яндекс SEO
- 9 часто задаваемых вопросов о Яндекс SEO и контекстной рекламе, ответы
Категория Международный поиск
Как Яндекс сделал свое самое большое улучшение в поисковой системе с помощью Толоки / Хабра
Введение
Прежде всего, я должен отметить, что современные технологии машинного обучения по-прежнему полагаются на человеческую оценку. Люди транскрибируют звук в текст, чтобы настроить алгоритмы распознавания голоса; люди оценивают релевантность справочных документов поисковым запросам, чтобы на них ориентировались формулы ранжирования поиска; люди классифицируют изображения, чтобы, обучившись на этих примерах, нейросеть смогла делать это дальше без людей и лучше людей.
Толока умеет все перечисленное. Итак, пришло время рассказать вам больше о платформе.
Задачи, о которых я говорил выше, обычно решает Яндекс с помощью подготовленных специалистов — асессоров. Оценщики смотрят, насколько результаты поиска соответствуют запросу, находят спам среди найденных веб-страниц, классифицируют его и решают аналогичные проблемы для других сервисов.
Ирония заключается в том, что по мере развития новых технологий растет потребность в человеческой оценке. Недостаточно просто определить релевантность страницы поисковому запросу. Важно понимать, не засорена ли страница вредоносной рекламой? Содержит ли страница контент для взрослых? И если это так, означает ли запрос пользователя, что это именно тот контент, который он искал? Чтобы автоматически учитывать все эти факторы, вам нужно собрать достаточно примеров для обучения поисковой системы. А так как в интернете все постоянно меняется, тренировочные наборы нужно постоянно обновлять и поддерживать в актуальном состоянии. В целом, только для задач поисковых систем потребность в человеческих оценках измеряется миллионами в месяц, и это число только растет с каждым годом.
В целом, только для задач поисковых систем потребность в человеческих оценках измеряется миллионами в месяц, и это число только растет с каждым годом.
И не только это, поиск большего количества асессоров в разных странах — сложный процесс. Но для некоторых задач даже не требуется профессиональная подготовка — вот тогда мы полагаемся на краудсорсинг .
Толока
В фундаментальной логике любой краудсорсинговой платформы, а Толока в частности, нет ничего сложного. С одной стороны, Толока работает с пользователями, раздает задания, осуществляет платежи, а с другой стороны, Толока помогает клиентам получать результат с минимальными усилиями.
Некоторым компаниям нужны пользователи для классификации изображений, некоторым нужны пользователи для выбора определенного объекта на изображении. Потенциально задачи могут быть любыми с точки зрения входных данных, интерфейса и ожидаемых ответов. Например, вы можете проверить этот пост (на русском языке), где автор попросил толокеров (пользователей Толоки) сфотографировать свои счетчики воды, чтобы сделать набор данных для будущей нейронной сети, которая вводит измерения автоматически.
Как заработать с Толокой всем?
На самом деле очень просто! Если вам нужны люди для оценки данных даже с дополнительным обучением, то в Толоке есть множество руководств и готовых решений для постановки ваших задач. Вы можете выбрать любой аспект задачи: цену, качество оценки, рейтинги пользователей и т. д. Но если вы хотите зарабатывать с Толокой — вот вам краткое руководство. Лучше всего то, что вы получаете оплату практически мгновенно и можете легко вывести заработанные деньги.
Как вы обеспечиваете качество оценки?
Этот вопрос является серьезной проблемой для любой краудсорсинговой платформы. В Толоке есть старательные и внимательные люди, а есть ленивые, недобросовестные люди, умеющие писать сценарии. Основная задача — наградить честных людей и забанить пользователей скриптов. Для этого Толока обучена анализировать поведение пользователей. Клиенты теперь имеют возможность автоматически идентифицировать и ограничивать тех толокеров, которые, например, отвечают слишком быстро или чьи ответы не согласуются с ответами других. Также в Толоке есть возможность использовать контрольные задания и обязательное принятие до оплаты. И приемку тоже можно упростить. Выдавайте задания одним пользователям, а оценку их результатов другим.
Также в Толоке есть возможность использовать контрольные задания и обязательное принятие до оплаты. И приемку тоже можно упростить. Выдавайте задания одним пользователям, а оценку их результатов другим.
Улучшения
Итак, пришло время рассказать вам об улучшениях в Яндекс.Поиске и о том, как Толока уже помогла многим компаниям сделать их продукт лучше.
С помощью Толоки Яндекс создал новый поисковый алгоритм под названием ЯТИ (Еще один трансформер с улучшениями). В отличие от предыдущих алгоритмов, YATI основан на нейросетях, прошедших серьезную подготовку на реальных ключевых фразах пользователей и открываемых ими страницах. Помимо самообучения, результаты проверяются и дополняются асессорами – специалистами, которые проводят экспертную оценку качества ранжирования текста. Алгоритм учится делить текстовый документ на зоны, отличающиеся своей значимостью в контексте введенного пользователем запроса. Фрагменты текста из наиболее важных областей также выбираются для ранжирования, в то время как наименее важные области игнорируются и не влияют на позиционирование сайта в результатах поиска.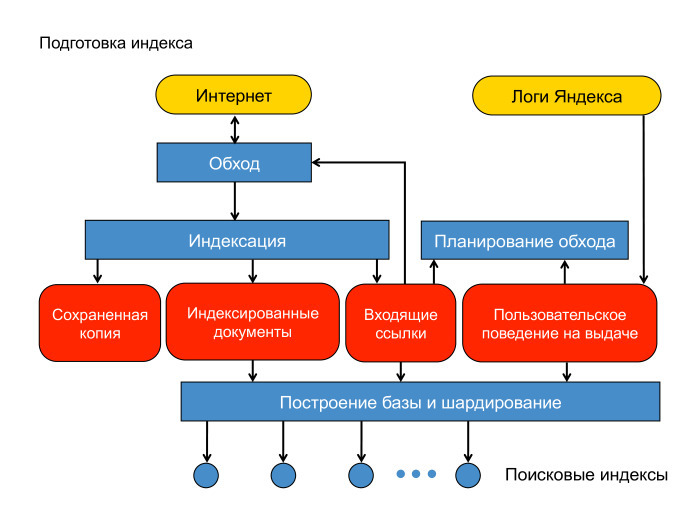 Если страница содержит небольшое количество текста, то все это повлияет на ранжирование документа. По заявлениям представителей Яндекса, YATI изначально «обращает внимание» на заголовки документов — они должны соответствовать определенным запросам пользователей. Только после того, как это будет подтверждено, весь документ начинает участвовать в ранжировании.
Если страница содержит небольшое количество текста, то все это повлияет на ранжирование документа. По заявлениям представителей Яндекса, YATI изначально «обращает внимание» на заголовки документов — они должны соответствовать определенным запросам пользователей. Только после того, как это будет подтверждено, весь документ начинает участвовать в ранжировании.
Что такое трансформатор YATI?
Трансформеры — это сложные и большие нейронные сети, работа которых направлена на решение задач обработки и генерации текста. Это новый виток развития нейронных сетей, открывающий огромные возможности для различных сфер, в частности для построения алгоритмов ранжирования в поисковых системах. Теперь алгоритм поиска может сегментировать текстовые элементы на части по различным признакам и обрабатывать их по отдельности. Элемент представляет собой слово, знаки препинания и другие последовательности символов. Как отмечалось выше, в YATI есть механизм внимания, благодаря которому фрагменты вводимого текста отделяются и обрабатываются отдельно. Например, это позволит понять, какая часть текста действительно важна для пользователей, и включить ее в факторы ранжирования, исключив при этом другие, неважные части. Это позволит значительно очистить результаты поиска от документов с некачественным содержанием.
Например, это позволит понять, какая часть текста действительно важна для пользователей, и включить ее в факторы ранжирования, исключив при этом другие, неважные части. Это позволит значительно очистить результаты поиска от документов с некачественным содержанием.
Последовательность алгоритма обучения
На основе задач и особенностей ранжирования сеть обучается правилам языка по принципу маскированного моделирования языка. Входными данными являются пользовательский запрос и заголовок документа. Цель подхода — научить алгоритм предсказывать вероятность появления документа из результатов поиска по заданному ключевому слову.
Следующий шаг — дообучение алгоритма с помощью асессоров. Сначала данные изучают пользователи сервиса Толока. Как вы понимаете, это некачественная оценка релевантности запроса документу. Для улучшения этих показателей после толокеров данные перепроверяются специалистами самого Яндекса. В результате этих действий данные получают определенные оценки релевантности.

После этого полученная аналитика и сами данные отправляются на обработку, чтобы объединить их в сегменты по определенным признакам. Благодаря сбору итоговых метрик алгоритм оценивает уровень релевантности документа и пользовательского запроса.
Результаты
По данным Яндекса, качество ранжирования значительно повысилось с момента внедрения алгоритма, и YATI стал самым значимым нововведением последнего десятилетия. Алгоритм научился корректно искать не только короткие ключевые фразы, но и целые текстовые фрагменты. Учитывается не только порядок и форма слов, но и контекст введенного запроса, который сопоставляется с изучаемым документом. Такие улучшения позволят алгоритму «понимать» естественность языка, находить смысловые связи между словами и т. д. Поэтому, если смотреть с точки зрения пользователей поисковой системы Яндекс, YATI значительно улучшит качество результатов. Теперь сайты будут ранжироваться с максимальным совпадением по смыслу.