Как это работает? Поисковые подсказки — Блог Яндекса
Когда вы начинаете вводить запрос в поисковой строке, Яндекс показывает варианты наиболее популярных запросов, начинающихся на те же самые буквы. Это поисковые подсказки — они помогают вам сэкономить время и не печатать запрос целиком. Яндекс понимает, какие подсказки показать, даже если вы забыли сменить раскладку клавиатуры или опечатались.
Подсказки появились в поиске Яндекса относительно недавно — в 2008 году. Сначала идея была в том, чтобы просто ускорить ввод поискового запроса. Чтобы вам не приходилось писать, скажем [метилпропенилендигидроксициннаменилакрилическая кислота что это] целиком. Со временем, однако, подсказки стали уметь гораздо больше. За этими возможностями стоит не одна сложная технология и постоянная работа. О них мы и хотим рассказать в этой записи.
Подготовка подсказок
Список поисковых подсказок формируется после фильтрации всего потока запросов к Яндексу. Также туда добавляются названия энциклопедических статей, музыкальных произведений и другого подходящего контента. Список проходит несколько фильтров, каждый из которых отсеивает некоторые типы запросов. Например, совсем редкие запросы или содержащие ненормативную лексику. Вместе с фильтрацией запросов в них исправляются опечатки. В итоге остаётся более сотни миллионов запросов — которые и становятся подсказками.
Как и ответы поиска на yandex.ru, поисковые подсказки зависят от того, где находится пользователь. Например, начиная запрос со слов [кинотеатр] или [ресторан], петербуржец и москвич наверняка имеют в виду заведения в своём городе. И подсказки им нужны для Санкт-Петербурга и Москвы соответственно. Поэтому для каждого региона составляется свой список поисковых подсказок, основанный на местных запросах.

Чтобы не тратить место на почти одинаковые запросы, мы их объединяем. Например, некоторые ищут [подарки на 8 марта], а некоторые — [подарки к 8 марта]. Такие запросы объединяют в одну подсказку, и, когда вы набираете «подарки», Яндекс показывает только один вариант — наиболее популярный. Конечно, если человек продолжит писать «подарки к», то набор подсказок изменится. К группировке запросов подходят очень аккуратно. Запросы, которые кажутся похожими машине, не всегда похожи для человека. Чтобы два запроса объединились в одну подсказку, они должны не только мало различаться по написанию, но и вести на одинаковые результаты поиска.
Актуальность и персонализация подсказок
Поскольку новые популярные запросы появляются постоянно, список поисковых подсказок регулярно обновляется — не реже, чем раз в день. А запросы, потерявшие актуальность, удаляются. Кроме того, у Яндекса есть специальный «быстрый» список подсказок — для запросов о событиях, которые произошли только что. Запросы для него отбираются по сложной формуле, которая учитывает, в том числе, насколько резко вырос поисковый интерес к теме, как много появилось новостных сообщений и постов в блогах. Быстрый список обновляется каждые полчаса.
Кроме того, Яндекс умеет определять, что будет больше интересовать людей в ближайшем будущем. Например, когда люди начинают писать в поиске «по», в обычной жизни им чаще всего нужна [погода], а перед 8 марта — [подарки] и [поздравления]. Поэтому Яндекс ежедневно обрабатывает все подсказки и для каждой строит прогноз — насколько она будет востребована на следующий день. Прогнозируемая востребованность учитывается при ранжировании списка подсказок.
В какой-то момент наши подсказки стали персональными. То есть научились учитывать не только ваш регион, но и историю запросов и меняться в соответствии с ней. Например, так выглядят подсказки и страница поисковой выдачи для двух людей с разн
yandex.ru
3 очевидных способа попасть в подсказки поисковых систем / ALTWeb Group corporate blog / Habr
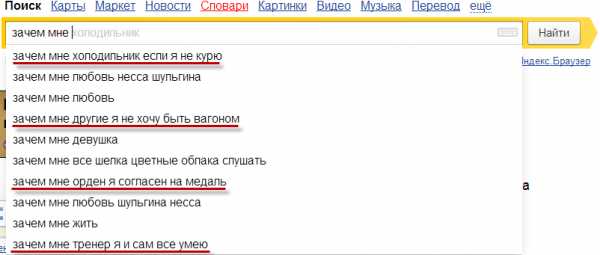
Поисковые подсказки появились у Google в 2004 году, у Яндекс эта технология была внедрена 4 года спустя. Подсказки позволяют пользователем быстрее ввести запрос, уточнить его, а также ввести его правильно. Для цифровой среды актуален вопрос «Может ли бренд попасть в подсказки поисковой системы?». На основе каких факторов пользователям предлагаются подсказки? Можно ли попасть в список подсказок через сервисы типа «В подсказке» и как это происходит на практике? Считается, что присутствие в подсказках повышает лояльность пользователей, которые, в большинстве своём, мыслят стереотипно: раз я часто вижу бренд в подсказках, значит, ему можно доверять.
Нахождение витального, брендированного, связанного с компанией запроса в подсказках — мечта любого бренда. Это может гарантировать увеличение траффика и особенно актуально для молодых сайтов, которым трудно «пробиться» в топ. Вместе с тем, попасть в подсказки может быть почти так же сложно, как попасть в топ: поисковые системы используют специальный алгоритм для формирования подсказок. Об алгоритме формирования подсказок и о том, как молодые сайты всё-таки могут там оказаться мы расскажем вам в этом посте.
Алгоритм формирования подсказок
- Сбор и отсев поисковых запросов пользователей для формирования подсказок проходит следующие этапы алгоритма:
- Сбор: входящие запросы пользователей в начале нужно собрать.
- Фильтрация: Исправить опечатки, отсеять нецензурную лексику и редкие запросы. На данном этапе, по разным источникам, остается от 15 до 25 миллионов запросов
- Группировка: отфильтрованные запросы разделяются на группы на основе одинаковых вхождений слов, как это видно на вводной картинке поста, где, например, собраны все подсказки, начинающиеся на «зачем мне …».
Здесь нужно отметить, что подсказки различаются по следующим параметрам:
- геотаргетинг
- язык
Поисковая система отмечает наиболее популярные запросы города, региона или страны, где вы сейчас находитесь — если вы даёте поисковику «видеть» ваше местоположение. В этом случае вы можете наблюдать подсказки типа:
гостиницы + в Москве, грузоперевозки + Ярославль и т.д.
Персональные подсказки на основе предыдущих поисков — ещё одна опция, которая строится на основе истории запросов пользователя в случае, если эта опция также включена.
Ранжирование подсказок
- популярность запроса
- ценность запроса для пользователя (определяется по персональным данным)
- специфика запроса (например, нецензурные или «адалт» подсказки не существуют
Здесь возможны комбинации, например, на ранжирование подсказки повлияет резко возроcшая популярность запроса за очень короткое время — даже если эта популярность не сохранялась длительное время. Как правило, это подсказки, посвященные значимым событиям, память о которых хранится в интернете. В данном случае, при ранжировании подсказки, поисковая система также учтёт резонанс о данном событии в социальных сетях и на форумах.
Когда подсказки удаляются?
- Потеря актуальности подсказки
- Подсказки, связанные с порнографическими сервисами (отсеиваются на начальном этапе)
- Подсказки, связанные с призывами к насилию или расовой ненависти (отсеиваются на начальном этапе)
- Подсказки, содержащие личную информацию
- Требование суда
- Очевидные накрутки
Как попасть в подсказки?
Механизмам работы алгоритма подсказок было посвящено очень интересное выступление руководителя и основателя ALTWeb Group Николая Хиврина на недавней онлайн-конференции, посвящённой вопросам цифрового маркетинга:
Источник
Поисковые системы борются с наличием брендов в подсказках, но иногда появление бренда в подсказках оправдано и даже поисковику приходится с этим согласится. Это происходит в следующих случаях:
Активная внешняя реклама
Можно попробовать составить рекламу так, чтобы стимулировать пользователей искать сайт. Большое количество запросов может — но не гарантирует — попадание бренда в подсказки.
Участие в мероприятиях
Мероприятие должно собирать большую аудиторию — это может обеспечить нужный объем запросов пользователей. Бренд может выступить на мероприятии в качестве спонсора, организатора или докладчика. Метод может повлиять на появление бренда в подсказках, но не гарантирует этого.
Сервис «В подсказке»
Добавив витальный (т. е. брендированный) запрос в сервис «В подсказке» вы даёте задание многочисленным пользователям, отобранным по географическому положению, начать искать ваш сайт по этому запросу. Таким образом, можно обеспечить как резкий всплеск запросов, связанных с брендом, так и стимулировать длительный интерес к конкретному запросу, что может обеспечить попадание в подсказки поисковых систем.
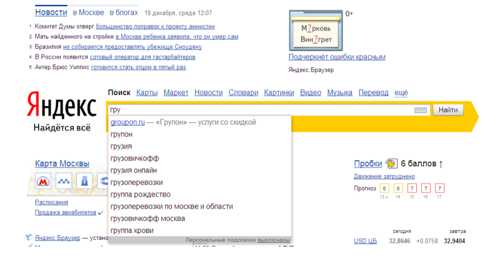
Пример попадания брендов в поисковые подсказки. Источник
Сервис «Вподсказке» позволяет добавить низкочастотный запрос в подсказки по высокочастотному. На скриншоте хорошо видно наличие нашумевшей компании «Грузовичкофф», которая оказалась в подсказках по одному из наиболее конкурентных и высокочастотных запросов «Грузоперевозки». Это почти что уникальный случай в цифровом маркетинге, который вы можете «пощупать» сами прямо сейчас, просто начните набирать запрос «грузоперевозки» в Яндексе.
Из всего вышесказанного можно сделать вывод, что поисковые подсказки также являются одним из инструментов цифрового маркетинга, связанным с узнаваемостью бренда и наличием трафика по витальным запросам. Таким образом, вам крупно повезло, если вы видите в подсказках название своей компании: это значит, что пользователи ищут вас, реагируют на ваши рекламные действия и доверие к компании растёт.
Сервис «В подсказке»
Доклад Николая Хиврина, посвящённый поисковым подсказкам
Подборка неожиданных сочетаний подсказок
habr.com
Поисковые подсказки Яндекс — как попасть в поисковые подсказки
Поисковые подсказки Яндекса экономят время пользователям каждый день. Не нужно вбивать запрос полностью, Яндекс подсветит продолжение слова или фразы. Останется только кликнуть по нужной подсказке.
Какие бывают подсказки
Полнотекстовые работают в десктопной версии, потому что на клавиатуре человек быстро печатает. Ему проще напечатать часть запроса, а затем выбрать нужный вариант из подсказок.
Пословные реализованы в веб-версии Яндекс.Браузера и мобильных приложениях. Пользователь вводит одно слово, а затем выбирает слова из предложенного списка, кликая по отдельному слову. При длинном запросе фраза набирается по словам отдельно. Каждую поисковую подсказку можно удалить, если нажать на крестик сбоку от фразы.
Подсказки-фактоиды. В мобильном поиске автоматически подсвечиваются сразу при вводе запроса погода, пробки, факты. Когда пользователь вводит погода в Москве, под строкой поиска подсвечивается текущая температура в виде подсказки. В Яндекс.Видео подсказки содержат номера сериалов и отдельных серий. Сначала пользователь выбирает сезон, затем серию этого сезона. При вводе названия фильма в подсказках показывается прямая ссылка на фильм.
Длинные. В 2017 г. в поисковых подсказках Яндекс произошли существенные изменения. Основное нововведение связано с обработкой длинных запросов. Еще с 2016 г. наметился тренд — пользователи стали вводить поисковые запросы длиной до семи слов в строку поиска. На конец 2017 г. доля длинных запросов составляет 10%. Поэтому теперь подсвечиваются длинные запросы, и такие подсказки работают в поиске, картинках и видео.
Исторические. Запросы, которые уже вводил пользователь, запоминаются системой и подсвечиваются приоритетно в поиске. Раньше исторические подсказки работали только в десктопной версии, теперь они доступны на мобильных телефонах и в поисковых сервисах Яндекс. Если пользователь что-то искал под своим логином, то, зайдя залогиненым на другом устройстве он увидит историю своих запросов.
Как рассчитываются подсказки в Яндекс
Офлайн метрики не базируются на действиях пользователей. Их вычисляют через математические формулы. В качестве основы при расчете лежит предположение, что пользователь сразу выберет нужную подсказку, как только ее увидит. После введения запроса подсчитывается общее количество действий пользователя. Такой показатель называется ExpectedActionsCount или EAC.
Второй показатель GuessProbability подсчитывает соотношение «правильных» подсказок к общему количеству подсказок. «Правильные» подсказки – пословные подсказки, которые видны пользователю до начала ввода следующего слова в запросе.
Первый и второй показатель коррелируются между собой. Если EAC уменьшается, то GuessProbability увеличивается. Анализируя обе метрики, поисковый алгоритм составляет из слов биграммы – устойчивые словосочетания из двух-трех слов, которые пользователи обычно вводят вместе: Триумфальная арка, Эйфелевая башня.
Средняя длина символов в запросах Яндекса равна 19, поэтому при отключенных поисковых подсказок в среднем 19 действий должен совершить пользователь при вводе каждого поискового запроса. После введения подсказок количество действий снизилось до 13,5. На конец 2017 г. показатель равняется 11,5.
Онлайн-метрика. В Яндексе используется показатель «время ввода в расчете на один символ запроса». Он не подвержен сезонности спроса. С помощью этой метрики проверяется удобство использования подсказок. Например, при тестировании интерфейса в виде графа обнаружилось, что скорость существенно снизилась. Пользователи стали слишком часто смотреть на предлагаемые подсказки, и как следствие, вводили запрос намного медленнее. Решение, которое первоначально выглядело революционным, на практике замедляло людям поиск.
Как попасть в подсказки
Считается, что пользователи больше доверяют бренду, если видят его среди поисковых подсказок Яндекса. Не можем с этим согласиться, потому что алгоритм отбора запросов основывается в том числе и на популярности слова. Яндекс не проводит репутационную экспертизу.
Он отбирает слова и фразы, которые чаще всего вводят в поисковую строку. Поэтому бренды и компании, засветившиеся в громких скандалах, тоже будут в подсказках. Причем, скорее всего, они будут на верхних строчках, потому что вокруг них сейчас шумиха, а Яндекс «горячие» запросы обновляет каждые полчаса. Например, в сетевых скандалах предпраздничной февральской недели 2018 засветились два бренда: производитель обуви Zenden и Магазин цифровой техники DNS. Оба находятся на верхних строчках в подсказках.
Компании не могут повлиять на включение их наименования в список подсказок. Агентства, предлагающие подобные услуги, обычно занимаются «накруткой» запроса в поиске. Делается это с помощью специальных программ или руками многочисленных фрилансеров. Хотя попадание бренда в список подсказок является результатом грамотной работы PR-отдела. Советуем развивать бренд традиционными способами. Чем более будут узнаваемы и востребованы компания и ее продукция, тем быстрее их наименования попадут в подсказки Яндекс. Особенно это актуально для региональных компаний, потому что конкуренция в региональном поиске Яндекс ниже.
Заключение
В Яндексе планируют развивать поисковые подсказки в сторону упрощения поиска. Поисковик хочет добиться результата, чтобы ответ на запрос пользователя уже появлялся во время ввода запроса. В мобильном поиске планируется добавить поиск по данным в телефоне: закладкам, контактам, файлам. Алгоритм отбора подсказок регулярно совершенствуется. Над ним работает постоянная команда поисковика, которая тестирует нововведения практически ежемесячно.
Гарантированный путь для компании попасть в список запросов – использовать классические PR-инструменты и развивать узнаваемость бренда. Чем больше потребителей будут интересоваться продукцией компании на длинном промежутке времени, тем чаще бренд будет присутствовать в списке подсказок. Накрутки подсказок не эффективны. При остановке накрутки бренд снова исключается из подсказок.
Материал подготовила Светлана Сирвида-Льорентэ.
www.ashmanov.com
Продвижение в поисковых подсказках Яндекс / Подсказкин
Максим Андреев Маркетолог, медицинский центр Яндекс подсказки для нас — это самый эффективный инструмент, который позволяет привлекать целевую аудиторию на сайт. Конверсия в заявки, обычно на 30% — 40% выше по сравнению с другой интернет рекламой. Мы рады, что являемся клиентом «Подсказкин» и надеемся на долгосрочное сотрудничество.
Кристина Ларкун Маркетолог, транспортная компания Поисковые подсказки действительно работают, за месяц, мы получили более 50 заявок по одному из направлений. Для сравнения, ранее с рекламы получали максимум 20 заявок. Спасибо за работу!
Сергей Кропоткин PR менеджер Выражаю благодарность компании «Подсказкин» за своевременное выполнение поставленных задач. Компания использует белые методы накрутки подсказок, что является безопасным для сайтов клиентов.
Галина Зорева Руководитель сети танцевальных студий В нашей сфере не просто найти эффективный инструмент для привлечения клиентов. К счастью, нашла информацию о Яндекс подсказках и вашу компанию. Работаем уже 4 месяца, результаты радуют. На данный момент, продвижение в подсказках стало основным способом получить горячих клиентов.
Сергей Рокотин Руководитель рекламного агентства Накрутка подсказок Яндекс — это новый инструмент, который мы включили в наш перечень услуг и рекомендуем своим клиентам благодаря компании «Подсказкин». Реклама в подсказках действительно эффективно работает, так как люди не воспринимают её как навязчивая реклама, которая уже всех достала.
Ксения Соловьева Менеджер РА в Москве Попасть в поисковые подсказки Яндекс, мы советуем нашим клиентам с 2017г., уже тогда мы понимали, что традиционные каналы такие как seo или директ, не справляются с поставленными задачами. То, чем пользуется большинство со временем перестает работать, поэтому необходимо использовать новые методы, которые даёт эта компания и сервис подсказок.
podskazkin.ru
Поисковые подсказки изнутри / Mail.ru Group corporate blog / Habr
Ночная зала. Тысячи таинственных ликов в темноте, подсвеченных голубоватым свечением мониторов. Оглушительный треск миллиона клавиш. Подобные выстрелам автомата удары по клавишам «Enter». Зловещее стрекотание сотен тысяч мышек… Так, наверняка, играло воображение каждого разработчика высоконагруженной системы. И если его вовремя не остановить, то может выйти целый триллер или фильм ужасов. Но в данной статье мы будем гораздо ближе к земле. Мы кратко рассмотрим известные подходы к решению задачи поисковых подсказок, как мы научились делать их полнотекстовыми, а также расскажем о парочке уловок, на которые мы пошли, чтобы придать им скорости, но при этом не научить жадности к ресурсам. В конце статьи вас ждёт бонус — небольшой рабочий пример.
- Поиск по подсказкам должен быть полнотекстовым, то есть должен уметь искать по текстам подсказок все слова из пользовательского запроса в любой их последовательности. Например, если пользователь ввёл запрос «смотреть», а в базе мы располагаем следующими подсказками:
то пользователь должен увидеть все три, несмотря на то, что слово «смотреть» находится в разных местах этих подсказок. - Запрос пользователя может быть неполным, пока набирает его на клавиатуре. Поэтому искать нужно не по словам, а по их префиксам. Для предыдущего примера мы должны увидеть все три подсказки не только по целому слову «смотреть», но и для любой его префиксной части. Например, «смотр».
- Поиск Mail.Ru — поисковик общего назначения, а значит разнообразие возможных запросов велико, и система должна уметь искать среди десятков миллионов подсказок.
- Скорость реакции крайне важна, поэтому мы хотим выдавать ответ за считанные миллисекунды.
- Наконец, сервис должен быть надёжной системой, работающей в режиме 24/7/365. Со всей России и стран СНГ наши подсказки ежесекундно обрабатывают тысячи запросов. Для отказоустойчивости, а, следовательно, ради простоты реализации и отладки, нам крайне желательно иметь в основе сервиса некую идею, которая была бы крайне проста и элегантна.
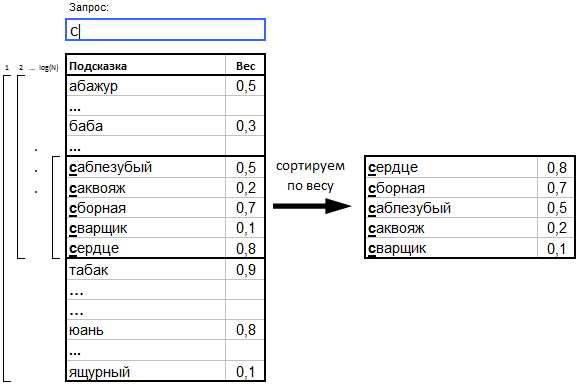
1. Префиксное автодополнение
a. Подсказки с весами (вес == популярность) сортируются в лексикографическом порядке по текстам подсказок.
b. Когда пользователь вводит запрос (префикс), бинарным поиском находится подмножество подсказок, начало которых удовлетворяет этому префиксу.
c. Найденное подмножество сортируется по убыванию веса, а ТОП самых «тяжёлых» подсказок отдаётся пользователю в качестве результата.
Очевидной оптимизацией такого подхода является Patricia Tree с весами в узлах дерева. При выборе самых «тяжёлых» запросов, как правило, используется очередь с приоритетами, либо segment tree, что даёт логарифмическое время поиска. При желании можно потратить память сервера, использовав алгоритм LCA via RMQ, и тогда мы получим очень быстрые префиксные подсказки. Плюсов у этого подхода целых три: скорость, компактность и простота реализации. Однако очевидным и самым неприятным недостатком является невозможность искать перестановки слов по текстам подсказок. Иными словами, такие подсказки будут лишь префиксными, а не полнотекстовыми.
2. Полнотекстовое автодополнение
a. Тексты подсказок и запрос пользователя рассматривается как последовательность слов.
b. Когда пользователь вводит запрос, в базе ищется подмножество подсказок, которые содержат все слова пользователя (а точнее, префиксы) вне зависимости от их позиции в подсказке.
c. Найденное подмножество сортируется по убыванию соответствия слов подсказки к словам запроса, затем по убыванию веса, и пользователю возвращается ТОП самых «тяжёлых».

Собственно, это и есть полнотекстовый подход, о котором будем говорить далее. По этой теме в интернете доступно обширное количество публикаций отечественных и зарубежных авторов. Например:
- Реализация нечёткого поиска — автор реализовал поисковые подсказки по названиям баров, ресторанов и прочих заведений, совмещённые с исправлением опечаток. Так как подсказок было всего ~2.5 тысячи, то достаточно оказалось искать перебором по всем подсказкам алгоритмом Вагнера-Фишера, модифицированного под поиск по префиксам слов. Метод качественный, но не подходит нам по причине низкой скорости.
- TASTIER approach — live-поиск по статьям, находит не только точное соответствие, но и связанные по теме публикации. Хранит контекст пользователя в оперативной памяти, чтобы адаптировать его по мере ввода пользовательского запроса, что довольно затратно по памяти и пагубно для скорости.
- Sphinx Simple autocomplete and correction suggestions — автодополнение на базе известного открытого поискового движка Sphinx. Основная идея автодополнения — использование wildcard’а в языке запросов MySQL: «the wor*». Исправление опечаток — на основе n-gram’ного подхода. Разумеется, такой поиск не совсем то, что нам нужно: ведь пользователь не обязательно набирает последнее слово; а как показывает практика, пользователь может вводить слова запроса как угодно, в любой последовательности. Кроме того, n-gram’ный подход потребует много ресурсов, чтобы применить его в real-time подсказках.
Приведённые выше и прочие не рассмотренные здесь подходы не удовлетворили нас по сочетанию: экономичность + скорость + простота. Поэтому мы разработали свой алгоритм, который соответствует нашим потребностям.
Перед описанием алгоритма сформулируем нашу задачу более формально. Итак, дано:
- Множество текстов подсказок S = {s1, s2, …, sN}, каждый из которых состоит из слов W(si) = {wi1, wi2, …, wiK}. Тексты подсказок мы получаем из логов запросов, которые пользователи задают нашей поисковой системе.
- Множество весов популярности подсказок F = {f1, f2, …, fN}. Под популярностью здесь мы будем понимать частоту употребления конкретного запроса, то есть как часто пользователи ищут что-то в нашей поисковой системе по данному запросу.
- Неполный пользовательский запрос, состоящий из упорядоченной последовательности префиксов Q = {p1, p2, …, pM}. Как мы уже сказали выше, запрос пользователя мы рассматриваем именно как последовательность префиксов, так как запрос может быть неполным.
Требуется:
- Найти множество R всех подсказок si из S, таких, что каждому префиксу pj из Q соответствует одно уникальное слово wk из W(si).
- Упорядочить найденное множество подсказок R по двум критериям:
- по убыванию соответствия порядка слов wk из W(si) порядку префиксов pi из пользовательского запроса Q;
- по убыванию веса популярности fl из F подсказок si из R.
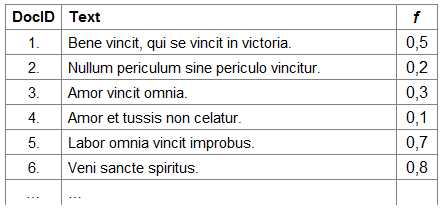
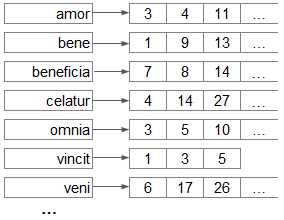
Так как нам нужен полнотекстовый поиск по подсказкам, то и в основу нашего индекса лёг классический подход к реализации полнотекстового поиска общего назначения, на котором базируется любой современный веб-поисковик. Полнотекстовый поиск в общем случае ведётся среди так называемых документов, то есть текстов, внутри которых мы хотим искать слова из запроса пользователя. Суть же алгоритма сводится к двум простым структурам данных, прямому и обратному индексам:
- прямой индекс — список документов, в котором можно найти этот документ по его id. Иными словами, прямой индекс — это массив строк (вектор документов), где id документа — это его индекс.
- обратный индекс — список слов, которые мы «выпотрошили» из всех документов. За каждым словом закреплён список отсортированных id документов (posting list), в которых это слово встретилось.
По этим двум структурам данных достаточно легко найти все документы, удовлетворяющие пользовательскому запросу. Для этого нужно:
- В обратном индексе: по словам из запроса найти списки id тех документов, где эти слова встречались. Получить пересечение этих списков — результирующий список id документов, где встречаются все слова из запроса.
- В прямом индексе: по полученным id найти исходные документы и «отдать» их пользователю.
Описанного вполне достаточно для данной статьи, поэтому за подробностями о поиске мы отправляем вас к книге Стэнфордского университета «An Introduction to Information Retrieval».
Классический алгоритм прост и хорош, но в чистом виде он неприменим к подсказкам, ведь слова в запросе в общем случае являются «незаконченными». Или, как мы сказали выше, запрос состоит не из слов, а скорее из префиксов. Для решения этой проблемы мы доработали обратный индекс, и вот что у нас получилось:
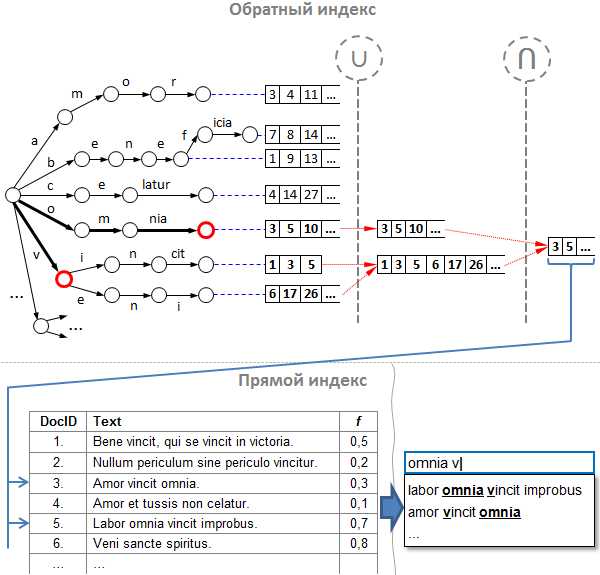
Прим: на рисунке здесь и далее для краткости некоторые узлы дерева «слиты» в один переход из нескольких символов.
Разберём поиск по индексу на примере:
- Предположим, что в нашем распоряжении есть указанный выше индекс, и пользователь уже ввёл часть запроса. Следующая введённая буква на клавиатуре, и вот мы получили неполный запрос «omnia v».
- Разбиваем запрос на слова-префиксы: получаем «omnia» и «v».
- По аналогии с поисковой системой, сначала по заданным словам-префиксам находим списки id подсказок в обратном индексе. Обратим внимание, что наш обратный индекс состоит из двух частей:
a. префиксное дерево (оно же «trie», оно же «бор»), содержащее слова, которые мы «выпотрошили» из текстов подсказок;
b. списки id подсказок — индексы текстов подсказок в прямом индексе, о котором речь пойдёт ниже. Списки отсортированы по возрастанию значения id и находятся в тех вершинах, где заканчиваются слова.
Надо сказать, что trie хорош для нас по двум причинам:- по нему можно найти любой префикс слова за время O(log(n)), где n — длина префикса;
- для заданного префикса легко определить все варианты его продолжений.
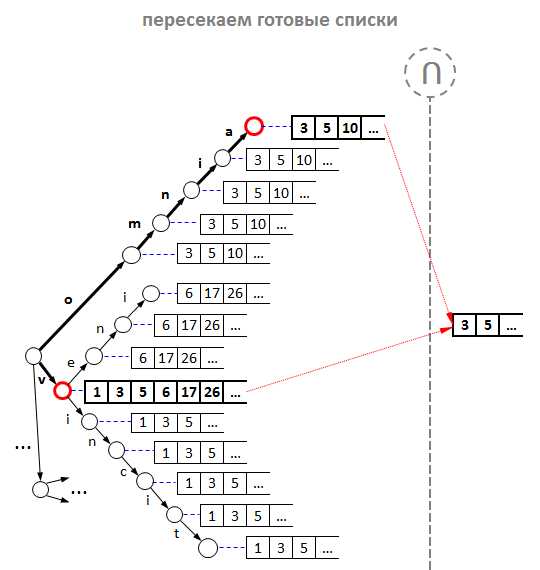
Итак, для каждого префикса углубляемся вниз по дереву и оказываемся в промежуточных узлах. Теперь нужно получить правильные списки id подсказок. - Объединяем списки всех дочерних узлов. Для чего? По аналогии с обычным поисковиком, мы должны бы пересечь списки id для каждого префикса, однако есть два «НО»:
a. во-первых, не всякий узел содержит список id подсказок, а только те узлы, в которых закачивается целое слово;
b. а во-вторых, каждый узел дерева имеет некое продолжение, за исключением листовых узлов. Это значит, что продолжений у одного префикса может быть целое множество, и эти продолжения нужно учесть.
Поэтому, прежде чем найти пресечение, нужно «просуммировать» списки id подсказок для каждого отдельно взятого префикса. Таким образом, для каждого префикса обходим дерево рекурсивно в глубину, начиная с того узла, где мы остановились в дереве по данному префиксу, и конструируем объединение всех списков его дочерних узлов алгоритмом слияния. На рисунке узлы, в которых мы остановились по префиксу, помечены красным кружком, а операция объединения помечена значком «U». - Теперь пересекаем синтетические списки-объединения каждого из префиксов. Надо сказать, что различных алгоритмов пересечения сортированных списков просто море, и каждый подходит больше для различных типов последовательностей. Один из самых эффективных — алгоритм Рикардо Баеза-Ятеса и Алехандро Салингера. В боевых подсказках мы используем свой алгоритм, который наиболее подходит для решения конкретной задачи, однако алгоритм Баеза-Ятеса-Салингера был для нас в своё время вдохновляющим.
- Теперь по найденным id ищем тексты подсказок. Прямой индекс в нашем случае ничем не отличается от прямого индекса любой поисковой системы, то есть представляет собой простой массив (вектор) строк. Кроме текстов подсказок здесь может быть любая дополнительная информация. В частности, здесь мы храним веса популярности.
Итак, к концу шестого этапа мы уже имеем все подсказки, в которых есть все префиксы из пользовательского запроса. Очевидно, что на деле количество подсказок, которые мы получаем к этому этапу, может быть очень много — тысячи или даже сотни тысяч, а «подсказать» пользователю нам нужно только лучшие. Такую задачу решает другой алгоритм — алгоритм ранжирования.
Далее мы рассмотрим один маленький приём, который позволит нам «наполовину» отранжировать подсказки, ровным счётом ничего не делая. И об этом мы поговорим ниже, по ходу рассмотрения двух проблем.
«Преждевременная оптимизация — корень всех зол» — твердит народная программистская мудрость, сформулированная Дональдом Кнутом. Но если мы реализуем приведённый выше алгоритм в чистом виде, то отхватим две проблемы с производительностью. Поэтому для нас отсутствие борьбы за скорость будет тем ещё злом.
Проблема первая — медленное объединение списков. Рассмотрим эту проблему подробнее:
- Предположим, в нашем дереве (трае) уже лежит 1000 слов, начинающихся на букву «а» (в реальной ситуации таких слов ещё больше).
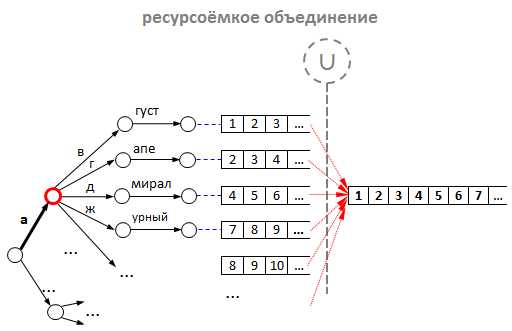
- Очевидно, что для 1000 слов минимальное среднее количество id подсказок будет также около 1000. То есть в среднем будет минимум 1000 подсказок, в которых есть слова, начинающиеся на букву «а».
- Теперь представим, что пользователь решил поискать что-нибудь на эту букву «а». По нашему алгоритму, для префикса «а» начинается операция объединения списков для всех дочерних узлов, которые лежат ниже узла «а». Очевидно, эта операция потребует приличных ресурсов: во-первых, на выделение памяти под новый список, а во-вторых, на копирование id в этот новый список.
Объединение можно оптимизировать использованием двух приёмов:
- зарезервировать память для итогового списка, дабы не выделять её при каждом новом запросе;
- производить объединение «ленивым» образом, то есть по мере необходимости.
Однако наши эксперименты показали, что любые ухищрения с объединением не идут ни в какое сравнение с оптимизацией за счёт кэширования. Да-да, мы просто стали складывать id подсказок в каждый узел дерева, а не только в листовые вершины. Итого: нет необходимости в объединении — готовые списки для каждого возможного префикса лежат прямо в узлах дерева. А наш обратный индекс приобрёл следующий вид:
Но стойте! В каждый узел дерева класть id подсказки?! Выглядит крайне расточительно, не правда ли? Но так ли это расточительно? Рассуждаем:
- Для каждой новой подсказки, нам придётся добавить её id столько раз, сколько символов содержится в её тексте. Это в худшем случае, так как для пробелов id добавлять не нужно, а для повторяющихся слов («винни пух и все
все все») повторно добавлять id тоже нет необходимости. - Например, при средней длине подсказки в 25 символов 1 миллион поисковых подсказок содержит 25 млн. символов. А если id подсказки — это 4-байтовое целое (стандартный int), то в худшем случае все списки id подсказок в обратном индексе займут в памяти: 4 байт * 25 000 000 = 100 Мбайт. А такой объём, очевидно, не так уж и расточителен, даже для обычной персоналки. Пропорционально, для 50 миллионов подсказок индекс займёт 5 Гбайт, что для полномасштабного сервиса поисковых подсказок вполне уместно.
Итак, проблему объединения списков мы решили путём кэширования всех списков для каждого возможного префикса.
Проблема вторая — медленное пересечение списков и ранжирование (сортировка) подсказок по весу. По нашему алгоритму после объединения следует два важных этапа, и каждый имеет проблемы с производительностью:
- Пересечение объединённых списков. В большой базе реальные списки слишком длинные, особенно для коротких префиксов. Поэтому пересечение списков для коротких запросов, как «а б», будет слишком долгим.
- Ранжирование подсказок, прежде всего, по убыванию веса. Итоговый список после пересечения может быть также довольно большим, поэтому сортировать тысячи id, как для запроса «а б», тоже оказывается накладно.
Помня, что для результата нам нужно всего-то 7-10 «самых хороших» подсказок, мы обнаружили очень простое решение, которое состоит из двух моментов:
- Правильный порядок id подсказок. Списки id составляем таким образом, чтобы подсказка с наибольшим весом имела наименьший id. Иными словами, подсказки нужно добавлять в индекс в порядке убывания их веса. Таким образом, результирующий список после пересечения уже будет отсортирован одновременно по убыванию веса и значению id. Такой подход мы называем «пре-ранжированием».
- Нам не нужно полное пересечение. Опытным путём было установлено: при пересечении можно брать не всё, а достаточно взять первых K подсказок (где K > N и пропорционально целевому количеству подсказок N), и среди них уже найдутся такие, из которых можно выбрать что-нибудь подходящее как по весу, так и по порядку слов. Например, если нам нужны ТОП N = 10 самых хороших подсказок, то нам достаточно выбрать из результирующего пересечения примерно первых K = 100. Для этого, при пересечении мы можем считать, сколько id в результирующем списке, и как только мы набрали первые 100, останавливаем пересечение.
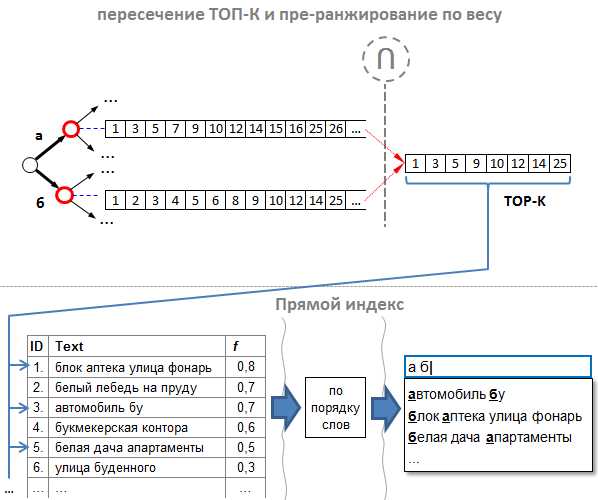
Таким образом, мы оптимизировали как ранжирование по весу, так и пересечение до «ленивых» K первых подсказок.
Как и было обещано в начале, мы выкладываем рабочий пример на C++, реализующий описанный в статье алгоритм. В качестве исходной базы можно использовать любой текстовый файл, где каждая строка — это подсказка. Наполнить его можно, например, пословицами и крылатыми выражениями на латыни (первоисточник), чтобы иметь возможность быстро получать их перевод на русский и наоборот.
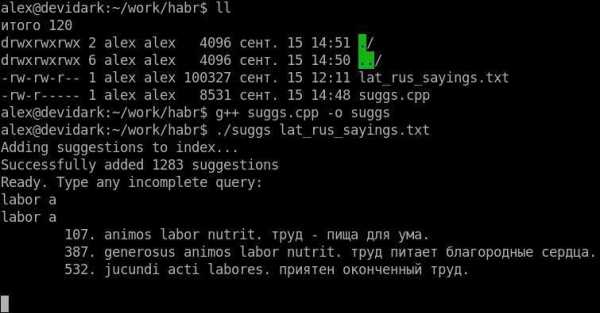
Не будем останавливаться на особенностях реализации, предоставив это читателю: благо пример довольно простой.
Конечно, представленный здесь алгоритм описан в самом общем виде, и многие вопросы остались за рамками рассмотрения статьи. Над чем ещё было бы полезно подумать разработчику подсказок:
- алгоритм ранжирования подсказок с учётом позиций слов;
- инвертирование языковой раскладки клавиатуры: «ghbdtn» -> «привет»;
- исправление опечаток в пользовательском запросе; здесь мы отправим вас к хорошей статье разработчиков из Microsoft: S. Chaudhuri, R. Kaushik, Extending Autocompletion To Tolerate Errors;
- конструирование концовки запроса пользователя для случая, когда нам нечего подсказать из базы заготовленных подсказок: «что пела в середине 80х алла пу» -> «что пела в середине 80х алла пугачева»;
- учёт географии пользователя: «кинотеатр» -> для пользователя из Саратова не стоит подсказывать московские и питерские кинотеатры, которые ищут часто из-за большой аудитории пользователей;
- масштабирование алгоритма на 2, 3 и более серверов, когда мы захотим добавить 100-200-500 миллионов подсказок и упрёмся в ресурсы памяти и процессора;
- и прочее, и прочее, что только можно ориентировать на нашего любимого пользователя и на наши потребности.
На этом всё. Спасибо за внимание.
Алексей Медвещек,
разработчик поисковых подсказок.
habr.com
что это, как их отключить, и можно ли использовать парсер для их сбора и формирования
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Поисковые подсказки – это всплывающее окно с популярными запросами, начинающимися с тех же букв, что и введенный пользователем запрос.
Представьте, что суфлер из своей будки незаметно подсказывает актеру текст, если он его забыл. При этом он ориентируется на роль персонажа, первую фразу актера и текст сценария.
Поисковая помощь посетителю предусмотрена в любой поисковой системе (ПС), а также при поиске через адресную строку веб-браузера. Главная задача – помочь пользователю более точно сформулировать поисковый вопрос, чтобы затем показать наиболее релевантную выдачу.
Как происходит формирование поисковых подсказок (ПП) в Яндексе и Гугле
Формирование подобных фраз происходит путем работы сложных алгоритмов при влиянии многих факторов. К ним относятся:
- Частота фраз в поиске. ПС предлагают пользователю наиболее популярные хвосты к введенному запросу.
- Регионы для коммерческого запроса. Если посетитель ищет окна в Воронеже, ПС, как правило, не дает ему хвост из других регионов.
- Ориентация на пользователя. ПС ориентируются на часто запрашиваемые этим пользователем слова, на историю его поиска и другую персональную информацию.
- Обновление. Относится к новостным вопросам, поэтому окно с подсказками обновляется постоянно.
- Фильтр. Удаляются нецензурные слова, запросы с ошибками и опечатками, низкопопулярные фразы.
Как отключить поисковые подсказки
Иногда всплывающее окно с уточняющими словами мешает работать с ПС. Часто выдаются ПП, которые пользователь искал ранее, и они стали ненужными, или на небольшом экране смартфона «съедается» видимое пространство, что создает определенные неудобства. Возможно, компьютером пользуется не один человек, и необходима настройка конфиденциальности поиска.
Рассмотрим, как отключить (удалить) всплывающие хвосты в поисковой строке на примере ПС Яндекс.
Вверху справа выберите «Настройки», перейдите к настройкам портала и выберите «Результаты поиска». Уберите флажки в полях персонального поиска и нажмите «Сохранить».
Чтобы убрать какую-то определенную ПП, начните вводить фразу в поисковой строке. Во всплывающем окне с мешающей ПП перейдите на нужную фразу и удалите ее. В Яндексе для этого предусмотрен «крестик» напротив нее, а в Гугле нужно перейти на ненужную фразу и нажать Shift+Del.
Негативные подсказки в поиске: можно ли их удалить
Может возникнуть такая ситуация, когда потенциальный клиент компании вбивает в строку поиска ее название, например «Мир Окон», и видит во всплывающем окне фразы типа «мир окон мошенники» или «мир окон развод». Человек обязательно из любопытства перейдет по фразе-подсказке, что усилит ее вес, и данная фраза-подсказка будет периодически выдаваться другим пользователям интернета. А по статистике, около 80% пользователей переходят по подсказкам или обращают на них внимание.
Фразы-подсказки могут быть удалены администрацией ПС по обращению, если в них отображается личная информация, они связаны с незаконными материалами, или удалить их постановил суд. Но может пройти более года с момента запуска механизма, который докажет честность компании.
Для быстрого устранения несправедливых негативных фраз-подсказок о компании, которые чаще всего распространяют по интернету конкуренты, нужно удалять негатив со сторонних площадок, писать положительные отзывы на сайтах, в соцсетях, блогах и т.д.
Как использовать поисковые подсказки
Всплывающие фразы интересны не только пользователям, но и интернет-маркетологам. Они уже давно научились использовать этот инструмент в своей работе. С помощью подсказок можно продвинуть веб-ресурс. Рассмотрим, что для этого нужно сделать.
Выдача названия компании в поисковых фразах-подсказках
Это не просто резкий прирост трафика, но и улучшение показателей лояльности потенциальных клиентов, повышение узнаваемости бренда. Но попасть во всплывающее окно даже сложнее, чем на первую страницу ПС. С накруткой фраз-подсказок постоянно борются ПС.
Черная накрутка подсказок
Нанятые пользователи или специально созданные скрипты с разных IP искусственно привлекают интерес к ресурсу, вводя в поисковую строку соответствующие запросы. Если они исходят с одного IP-адреса, то поисковик безжалостно удаляет ее из подсказок, так как подобные методы работы являются запрещенными. Заниматься накруткой бессмысленно, так как поисковые роботы в любом случае вычислят мошенничество.
Белая работа с подсказками
Попасть в окно ПП можно при помощи внешней рекламы, баннеров, тизеров, которые побуждают пользователей вводить запрос с упоминанием бренда. Вспомните рекламные баннеры от МТС с белым яйцом на красном фоне. Пользователи вводили разные вопросы, чтобы узнать, что это такое. А это был обычный, но грамотно преподнесенный ребрендинг.
Сбор семантического ядра сайта при помощи фраз-подсказок
ПП отображают популярные запросы реальных людей, поэтому SEO-специалисты ориентируются на них при составлении ключей для продвижения. Список родственных фраз можно получить, просматривая блок «вместе с этим часто ищут». Вводим запрос «стирка оренбург» в поисковую строку Яндекс, прокручиваем страницу выдачи и видим внизу:

ПП дают оптимизатору полную картину того, что именно ищут люди в поисковике.
Кроме того, их используют для подбора LSI-фраз (хвосты, синонимы и т.п.). LSI фразы семантически связаны с основными ключами. Например, при вводе запроса «двуспальная кровать» ПС выдаст хвосты типа «с подъемным механизмом», «с матрасом в комплекте дешево», «купить недорого». Данными LSI-фразами можно разбавить текст, при этом избавиться от переспама.
Вышеуказанный способ парсинга ПП самый простой, но все же трудно вручную изучать много вариантов. Поэтому оптимизаторы периодически пользуются парсерами.
Парсеры подсказок
Специальные сервисы помогают автоматически собирать ключи-подсказки, что экономит время SEO-специалиста, снижает вероятность пропуска важных фраз-ключей, повышает эффективность работы по продвижению. Рассмотрим некоторые из них.
- Key Collector – платная программа, обладающая расширенным функционалом. Работает с множеством регионов, разными ПС.
- Upcheck, Rush Analytics, A-parser – платные сервисы, ориентированные на ПС.
- Словодер – глубокий парсинг ПП в различных ПС в многопоточном режиме.
- Gscraper – бесплатный сервис, работающий с Гуглом.
- Магадан – бесплатная программа, которая использует Яндекс Wordstat.
- Также парсеры встраиваются в комплексные сервисы для продвижения веб-ресурсов, например, ПиксельТулс, Serpstat и т.д.
Поисковые подсказки – удобный инструмент для пользователя и незаменимый для SEO-специалиста. При этом потенциальный клиент получает наиболее релевантную выдачу, а продвигаемый сайт – прирост трафика и увеличение прибыли.
semantica.in
Как попасть в подсказки Яндекса?
Система подсказок была впервые введена в Google, а затем ее стал использовать и Яндекс.
С подсказками в поисковых системах сталкивался каждый. Стоит только дать Гуглу или Яндексу малейший повод, к примеру, ввести в строку «купить …», и в то же мгновение перед пользователем открывается масса возможных вариантов:
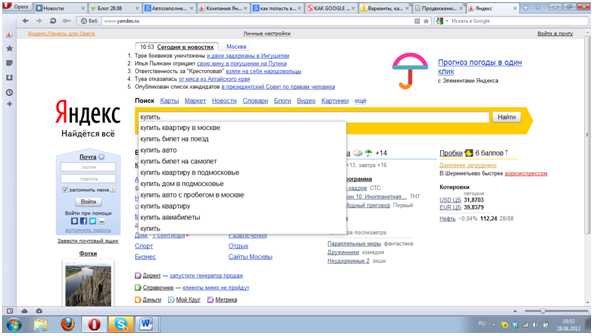
Сервис удобен пользователям тем, что экономит их время. Приходится куда меньше стучать пальцами по клавиатуре, к тому же поисковики щадят безграмотных и тех, кто забыл переключить раскладку: даже в случае неточного набора система исправит ошибку и постарается найти с пользователем общий язык. Удобно находить любимые сайты — часто набираемые названия вскоре оказываются в подсказках, а на вопрос, как удалить их из мгновенно всплывающих в поисковике фраз, ответ простой — отключить настройку.
Однако куда более интересны оказались подсказки для SEO-оптимизаторов, которые увидели в них еще одну возможность продвижения сайта. Попадание бренда в поисковые запросы означает не только увеличение траффика, но еще и делает потенциальных покупателей более лояльными к товару: многие пользователи уверены, что если фирма находится в подсказках, то она популярнее остальных и наверняка является одной из лучших. Однако попасть в поисковые подсказки Яндекса или Google ничуть не легче, чем в ТОП. Чтобы определиться с тем, как можно продвинуть нужный сайт в подсказки, начнем с описания работы этого сервиса.

Алгоритм формирования подсказок
Рассмотрим, как формируются поисковые подсказки в Яндексе.
Фильтры. Для начала все входящие запросы фильтруются системой. Так отсеивается нецензурная брань или очень редкие запросы и исправляются опечатки. После чего остается более 20 млн. запросов, которые группируются на основе одинаковых слов и выражений (например, «аренда квартиры» и «снять квартиру»).
Язык и регион. Подсказки отличаются друг от друга по языкам, это довольно очевидно. Поэтому в зависимости от того, какой язык был указан в настройках браузера, будут отличаться и подсказки поисковика. Кроме того, и Гугл, и Яндекс оценивают наиболее частые запросы в отдельности для каждого города, региона или страны. Поэтому введя запрос «шиномонтаж…», пользователь увидит прежде всего локальные подсказки:
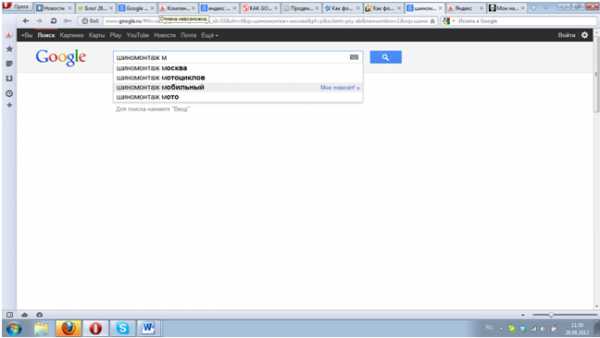
Персонализация. Если у пользователя включена функция Google «web history» («Мои находки» — у Яндекса), то поисковые системы персонализируют подсказки, основываясь на статистике пользовательских запросов. Они обычно выделяются цветом, так что отличить их несложно.
Ранжирование подсказок
Релевантность. При ранжировании подсказок играет роль не только популярность того или иного запроса, но еще и его ценность для пользователя, которая определяется как раз на основе персонализированных для каждого пользователя факторов.
Свежесть. У системы подсказок Google есть «слой свежести». К примеру, если вдруг какой-то запрос становится популярным за очень короткое время, то он может попасть в подсказки, хотя у него и нет длительной популярности. В будущем этот запрос может исчезнуть из-за того, что волна интереса к ресурсу упала.
Яндекс тоже обновляет подсказки – как минимум, один раз в день. Запросы, которые теряют свою актуальность, удаляются.
Как Google, система Яндекса следит за ростом запросов. Запросы о недавних событиях, которые заинтересовали большое количество пользователей, попадают в «быстрые» подсказки Яндекса, которые обновляются раз в полчаса. Отбор происходит на основе того, как резко вырос интерес к событию, как много новых публикаций и сообщений появилось в социальных сетях и пр.
Контент. На формирование подсказок в Google влияют не только прямые запросы, но еще и то, насколько требуемое сочетание встречается на разных сайтах. В качестве эксперимента блогер Риши Сакхани обратился к своим читателям в Твиттере сделать перепост (ретвит) двух фраз: Rishi Sakhani ROFL и Rishi Sakhani ha ha ha. Оба настолько распространились в Твиттере, что привлекли внимание Google (правда, фраза Rishi Sakhani ha ha ha попала почему-то в категорию связанных запросов, а не в подсказки).
Удаление.
Подсказки удаляются в том случае, если они:
• Содержат призывы к насилию или ненависти;
• Содержат чью-то личную информацию;
• Связаны с порноматериалами;
• Должны быть удалены на основе решения суда.
Накрутка подсказок. Регулярно использовать SEO-методы для накрутки подсказок в своих целях довольно сложно, так как и Google, и Яндекс борются с тем, чтобы в поисковых подсказках было по возможности как меньше брендов, и потому регулярно обновляют алгоритмы формирования и ранжирования.
Для того чтобы сформировать подсказку, обычно пользуются либо ручным способом, либо автоматизированным. В первом случае нужно обратиться в агентство социального маркетинга или на биржу типа Advego, с помощью которых нанятые пользователи будут искусственно создавать интерес к странице, вводя в поисковик нужные запросы. Метод дорогой. И пользы от него немного: на короткое время попасть в подсказки, конечно, можно, но как только набор подсказок обновится или система начнет замечать, что вопросы посылаются с одних и тех же IP, то подсказка незамедлительно будет удалена. Чтобы сохранить свои позиции, нужно постоянно поддерживать активность пользователей и по возможности обеспечивать приток «свежей крови».
Есть и другой способ — использовать набор IP-адресов, скрипты и прокси, т.е. создать систему, изображающую из себя уникальных пользователей со своими уникальными IP-адресами. Это дешевле и проще, чем использовать «SEO-рабов», но разрабатывать программное обеспечение для продвижения одного бренда слишком накладно. К тому же есть риск, что вскоре после использования этой методики ее разоблачат специалисты поисковой системы, примут контрмеры, и все труды по разработке и внедрению ПО пойдут впустую.
Однако все перечисленные выше способы относятся к чёрным методам оптимизации. При их обнаружении есть риск привлечь к своему сайту нездоровое внимание сотрудников службы борьбы со спамом поисковых систем. В результате сайт может потерять позиции не только в подсказках, но и в поисковой выдаче.
Для легального и безопасного продвижения больше подойдут белые методы. Попасть в подсказки можно и более традиционными способами – при помощи активной и продуманной внешней рекламы, которая сможет побудить пользователя обратиться в поисковую систему с запросом о компании. В этом случае можно было бы использовать тизерную рекламу (т.е. рекламу-загадку), для решения которой необходимо зайти на сайт. Так было, к примеру, во время ребрендинга компании МТС, которая разместила на улицах городов билборды с изображением белого яйца на красном фоне и вопросом «Что это?». Ажиотаж вокруг ребрендинга спровоцировал появление различных запросов в сети – как положительных, так, впрочем, и ироничных. Этот же принцип можно использовать и для продвижения бренда в поисковые подсказки.
Другой вариант — участвовать или же спонсировать профильные мероприятия, например, выставки или конференции. В конечном итоге это привлечет внимание новых людей, которые начнут искать компанию в Интернете и обязательно обратятся к поисковым системам.
www.optimism.ru