Виды ключевых запросов по частотности: НЧ, СЧ, ВЧ
Категории
Viktor Kotlyar
27 октября | 2021
Viktor Kotlyar
27 октября | 2021
Для продвижения сайта в поисковых системах по нужным ключевым словам, понадобится качественно оптимизированный текст. Чтобы его составить, начните со сбора ключевых слов.
Американское консалтинговое агентство iMPACT проводило интересное исследование. По их данным, только Google получает 360 млрд запросов за 2021 год. Ежедневно в поисковик приходит по 15% новых ключей. За всей этой массой нужно следить и вовремя обрабатывать.
Как понять, какие из найденных ключей лучше использовать и будет ли востребованным наш текст у читателя? С этой проблемой нам поможет понятие «частотность запросов».
Частотность запросов — это количественный показатель того, как часто пользователи вводят в поиск определенный ключ за заданный период времени. Чем популярнее запрос, тем больше трафика можно спрогнозировать на странице, где будет размещён текст.
Виды запросов по частотности
Запросы могут делиться на несколько видов:
- Низкочастотные (НЧ) — часто не превышают 100 показов в месяц. По таким ключам продвигаться легче и дешевле из-за слабого интереса пользователей. Пренебрегать низкочастотными запросами не стоит, т.к. по ним проще продвигаться. Выйдя в топ по нескольким НЧ ключам, можно рассчитывать на ощутимый прирост трафика.
- Среднечастотные (СЧ) — имеют 500-10000 показов в месяц в поисковых системах. По этим запросам продвигаться не на много сложнее, чем по НЧ. При этом, они поставляют хороший прирост трафика.
- Высокочастотные (ВЧ) — свыше 10000 показов в месяц.

Важно уточнить: частота ключей — достаточно вариативный показатель. Это значит, что в разных нишах классификация запросов по частоте может отличаться.
Например: заходим в планировщик ключевых слов Google и вводим ключ «бытовая техника». Получаем список новых ключевых слов. Отсортировав их по частоте, мы видим, что какие-то ключевики являются высокочастотными и имеют частотность свыше 10000:
Есть низкочастотные запросы с частотностью около 10 показов в месяц:
Если мы возьмем другую менее популярную нишу, то увидим, что высокочастотные ключи там имеют более низкую частотность показов в месяц:
Как определить частотностьВ каждой поисковой системе частота ключей может отличаться. Разберём, как можно определить частотность в двух самых популярных поисковых системах:
Разберём, как можно определить частотность в двух самых популярных поисковых системах:
- Google.
- Яндекс.
Как узнать частотность поисковых запросов в Google
Из примера выше видно, что я использую инструмент «Планировщик ключевых слов» сервиса «Google Ads». Это инструмент от Google, в котором можно искать новые ключевые слова и сразу же оценивать их частотность.
С помощью данного инструмента можно искать ключи по странам, языку и временным диапазонам.
Результаты нам показывают:
- Новые ключевые слова.
- Минимальную и максимальную частотность.
- Уровень конкуренции.
Как узнать частотность поисковых запросов в Яндекс
Для этого используем сервис Яндекса — Вордстат. Интерфейс достаточно простой. Всего лишь необходимо ввести поисковое слово в строку. Сервис покажет вам частоту введенного слова и подберет новые ключи, основываясь на интересах пользователей.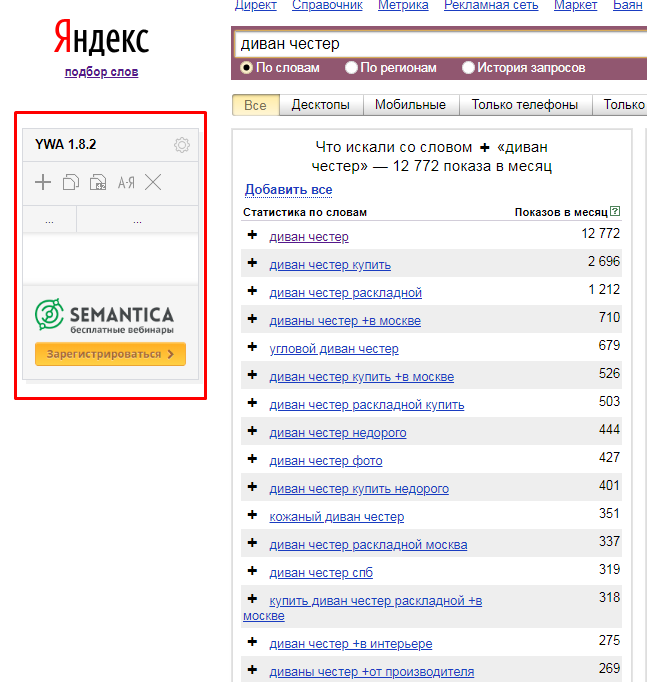
Небольшое напутствие читателю
Понимание правил работы с семантическим ядром и навыки дробления его по частотности — основная база для SEO-специалиста и продвижения любого сайта. Здесь есть свои особенности и их понимание упростит выход в топ вашему ресурсу.
В статье я постарался просто рассказать о частотности ключей и где их собирать. Этих знаний более чем достаточно для составления базовой эффективной семантики. Вы можете работать с ними сами, а можете обратиться к нам в UAATEAM. Мы проработаем глубокую семантику и предложим оптимальную стратегию продвижения.
- #Keyword
- #SEO
- #SEO-продвижение
Подписаться
Блог
Vacancy
Подписаться
Блог
Vacancy
Некорректно введен Email
Пожалуйста, заполните поля отмеченныеUP
Как посмотреть статистику запросов в Гугле
Чаще всего для подбора ключевых запросов используют Вордстат. Он помогает в работе с семантикой сайта, создании рекламных кампаний и анализе узнаваемости конкретных брендов. Но он работает только с поисковыми запросами Яндекса.
Он помогает в работе с семантикой сайта, создании рекламных кампаний и анализе узнаваемости конкретных брендов. Но он работает только с поисковыми запросами Яндекса.
Прямого аналога Вордстату у Google нет. Но есть другие инструменты.
Проанализируйте сезонный спрос и диапазон частотности в Google TrendsGoogle Trends — бесплатный сервис, выстраивающий графики популярности по конкретным ключевым словам. Он не показывает точное количество запросов, но для маркетингового анализа перед запуском контекстной рекламы или для анализа сезонных взлетов спроса он подходит. Тут же можно посмотреть, в каком регионе сконцентрирована ваша целевая аудитория.
Например, возьмем два запроса: один внезапный — «купить бобра Урюпинск», а другой просто й — «бижутерия».
По узкому запросу данных недостаточно, поэтому графика нет.
По низкочастотным запросам графики не выстраиваются
По запросу «бижутерия» график есть — видно, как меняется спрос в течение года.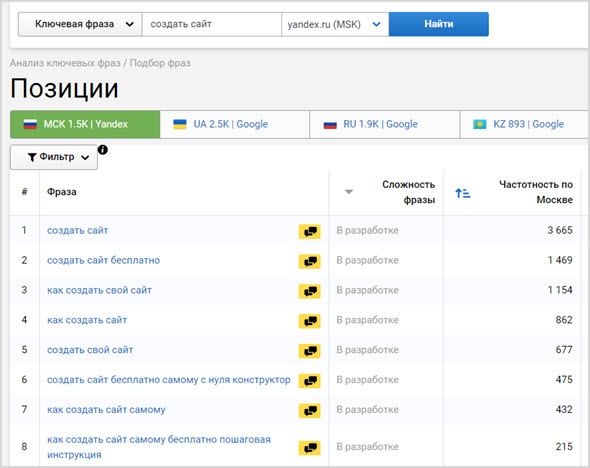
В верхней части сервиса можно настроить географию, категорию, период и тип поиска — по Ютубу, картинкам, новостям, товарам.
Точного количества запросов Google Trends не покажет. Цифра, которая появляется при наведении на точки в графике, обозначает проценты: на пике — 100 %, на нижней точке — 27 %.
Пик спроса приходится на 15–21 декабря, а вот в апреле бижутерию уже не очень хотят
Если надо решить, где открыть филиал или в какой локации запустить контекстную рекламу, пригодится другой график, показывающий уровень популярности по субрегионам.
Здесь тот же принцип: 100 — это максимальная концентрация по сравнению с остальными, а дальше список идет на убывание
Другая важная функция в Google Trends — сравнение графиков по разным поисковым запросам. Например, если написать в верхнем поле для ключевых слов мужскую и женскую бижутерию, сервис построит два графика разного цвета, максимально — пять.
При построении нескольких графиков 100% высчитывается по пиковой точке наиболее популярного
При работе с Google Trends желательно использовать операторы.
Кавычки. Если взять в кавычки фразу, сервис не будет менять порядок слов при сборе статистики и исключит схожие запросы. Например, если мы напишем в кавычках «бижутерия женская», Google Trends покажет график только по этому запросу. Запрос «женская бижутерия» он учитывать не будет.
Минус и плюс. Они нужны, чтобы уточнить запрос. К примеру, если мы хотим посмотреть, сколько раз запрашивали график гостиницы «Космос» в городе Свердловск, но знаем, что в Свердловске есть еще магазин с идентичным названием, запрос лучше строить так: «график космос свердловск +гостиница -магазин».
В самом низу страницы Google Trends собирает похожие тематические запросы и показывает уровень их популярности.
Полистайте страницы, отсюда тоже можно вытащить немного полезного
Узнайте количество запросов и посмотрите данные по ним в Google AdsОдин из подходящих для нас встроенных сервисов — это «Планировщик ключевых слов», или Google Keyword Planner.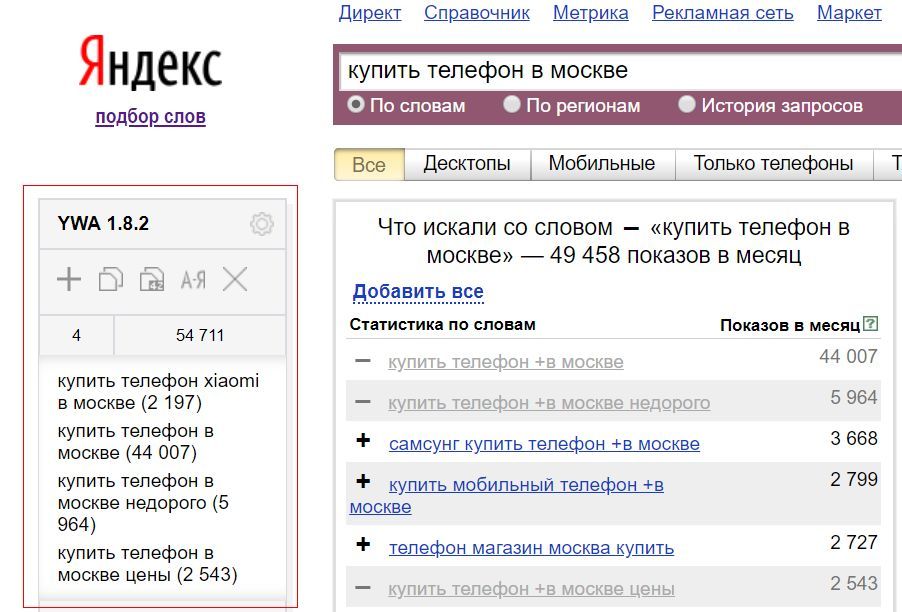
Если у вас есть гугл-аккаунт, авторизуйтесь в Google Ads, дождитесь настройки аккаунта и перейдите в «Планировщик». Он находится в меню в правом верхнем углу.
Google Keyword Planner вы найдете в разделе «Инструменты и настройки»
В «Планировщике» можно найти новые ключевые слова или посмотреть количество запросов. Для этого введите в поле ключевые слова или укажите адрес сайта. Можно заполнить оба поля, если нужно.
В «Планировщике» много полезных данных, и он бесплатный
Есть несколько нюансов:
если у вас нет работающих рекламных кампаний, «Планировщик» покажет не точную частотность ключевых слов, а примерный диапазон, например: от 10 до 100 000, от 1 до 10 000;
сервис предназначен для работы с контекстной рекламой, поэтому статистику показывает по рекламным объявлениям, а не по данным из поиска;
«Планировщик» подбирает дополнительные ключевые слова по принципу широкого соответствия: например к запросу «бижутерия» он может добавить «купить фурнитуру для бижутерии», поэтому при работе с семантикой нужно тщательно вычищать лишнее.

Все поля в «Планировщике» кликабельны: например можно добавить минус-слова, настроить фильтры, посмотреть уровень конкуренции по каждому запросу или выгрузить ключевые слова в CSV-файл или в Гугл Таблицы.
В результате бесплатно и быстро можно получить подробные статистические данные.
Читайте также:
Как пользоваться Яндекс.Вордстатом: инструкция для начинающих
Google Analytics — бесплатный сервис, который отслеживает статистику по сайту. У Яндекса эту функцию выполняет Яндекс.Метрика. Google Analytics работает с конкретным сайтом: собирает по нему данные, анализирует аудиторию, считает конверсию и прочее.
Чтобы узнать, по каким поисковым запросам люди приходят на ваш сайт, выберите в боковом левом меню «Источники трафика» > «Search Console» > «Запросы».
Здесь можно настроить периоды, сегменты аудитории и дополнительные параметры
Google Analytics помогает расширить семантическое ядро и оценить сайт с точки зрения SEO: бывает так, что специалист не включает в список важные поисковые запросы и сайт проседает в позициях. Анализ отчета поможет найти причину.
Анализ отчета поможет найти причину.
Кроме бесплатных сервисов есть и условно бесплатные.
Serpstat. Популярный ресурс, который помогает провести полный SEO-анализ сайта. Одна из функций — проверка частотности поисковых запросов по Гуглу и по Яндексу.
В суммарном отчете по запросам Serpstat строит диаграммы падения и взлета спроса и показывает конкурентов в поисковой выдаче. В бесплатном режиме количество запросов за сутки ограничено: всего 10. Минимальный тариф — $69 в месяц. Максимальный — $499.
Графиков в бесплатном режиме вполне хватает для базовой оптимизации
Keyword Tool. Инструмент, который подбирает синонимичные ключевые запросы с помощью функции автозаполнения в Google. В бесплатном режиме может показать сами поисковые запросы, но не выдает ни частотность, ни конкурентность, ни другие параметры.
В бесплатном режиме можно вводить 5 минус-слов, если надо больше — придется платить.
Базовый тариф — $69 в месяц, тариф для бизнеса — $159.
Гуглом сервис не ограничивается, но в бесплатном режиме дает мало информации
Key Collector. Платный многофункциональный сервис. Берет на себя массу рутинных задач по SEO. Подойдет при больших объемах, если вы постоянно работаете с оптимизацией. Цена — 1800 ? за лицензию. Есть накопительная скидка, которая привязывается к электронной почте: если вы захотите установить Key Collector на другой компьютер и используете тот же email, что и в первый раз, то следующая лицензия будет стоить 1600 ?.
Подстройте контент на сайте под голосовые поисковые запросыПро трафик с голосовых запросов пока нет абсолютно точных данных, но ключевые моменты из проведенных исследований выделить можно.
Подстройте карточку компании под поиск по географии. По данным BrightLocal, 46 % пользователей ежедневно используют голосовой помощник для поиска ближайших к себе заведений или предприятий. Если вы офлайн-бизнес, который могут искать по адресу, зарегистрируйтесь в Google My Business и пропишите свои контактные данные в карточке компании.
Если вы офлайн-бизнес, который могут искать по адресу, зарегистрируйтесь в Google My Business и пропишите свои контактные данные в карточке компании.
Оптимизируйте скорость страницы. Поиск голосом — скоростной поиск на ходу. Если ваша страница будет прогружаться год, люди не будут ждать.
Настройте адаптивность. Согласно исследованию PwC за 2018 год, 58 % пользователей используют голосовой поиск именно со смартфонов. Чтобы не упустить голосовой трафик, обязательно нужно настроить адаптивность под разные экраны.
Добейтесь первенства. При голосовом поиске люди не листают страницы, а ждут немедленного ответа вслух из смартфона или умной колонки. Поэтому в приоритете топ-1, а не топ-10. Конкуренция ужесточается.
Используйте естественный язык при создании контента. Сейчас активно развивается разговорный искусственный интеллект. Поисковые роботы все лучше распознают живые формулировки: не «купить козу Омск», а «где купить козу в Омске». Не бойтесь писать для людей и использовать естественную речь.
При комплексном продвижении сайта не стоит ограничиваться SEO, лучше также использовать соцсети, внешний контент-маркетинг и другие каналы.
Статистика по частотности запроса в Гугле поможет:
спрогнозировать поведение пользователей;
проанализировать сезонный спрос;
составить семантическое ядро;
отследить узнаваемость бренда;
оптимизировать контент под поисковик.
Однозначных ответов на вопрос, каким инструментом пользоваться при этом, нет: все зависит от целей, объемов работы и мелких различий в функционале. Пользуйтесь тем, что удобно, и помните: регулярная работа с аналитикой запросов в Google — мастхэв для маркетологов и SEO-специалистов. Если вам некогда заниматься аналитикой — наймите специалиста. Он поможет.
Workspace.LIVE — мы в Телеграме
Новости в мире диджитал, ответы экспертов на злободневные темы, опросы, статьи и многое другое. Подписывайтесь:
https://t.me/workspace
Подписывайтесь:
https://t.me/workspace
Восемь основных ошибок при составлении семантического ядра
Почему проект так медленно продвигается? Что с качеством органического трафика? Если эти вопросы появляются регулярно, возможно, SEO-специалист допустил одну из критических ошибок при сборе семантического ядра. Мы собрали топ обидных промахов в сборе семантики, влияющих на качество и эффективность продвижения проекта.
1. Составили маленькое семантическое ядро
Семантическое ядро должно охватывать как можно больше ключевых запросов. Количество запросов может очень различаться от проекта к проекту — для низкочастотной тематики это может быть несколько сотен запросов, а для высокочастотной — десятки тысяч. Конечно, все ключевые слова должны соответствовать тематике сайта. Чтобы не пропустить нужные, используйте знакомые многим сервисы:
- Яндекс.Вордстат показывает, какие запросы с определенным ключевым словом вводили за выбранный период.
 Для каждого ключевого слова показывается частотность;
Для каждого ключевого слова показывается частотность; - Упрощает работу плагин wordstat helper — он позволяет выбирать и копировать нужные ключи с частотностью или без неё;
- Keyword Planner от Google позволяет собирать ключевые слова из поиска;
- Serpstat — многофункциональная платформа: собирает ключевые запросы из поисковых систем, анализирует семантику конкурентов, а также предоставляет базу похожих слов для расширения семантики.
Подробно о том, как расширить семантическое ядро, читайте в статье.
2. Забыли про синонимы
Cемантическое ядро не будет на сто процентов полным без синонимов, альтернативных ключевых слов и фраз. Разные люди могут по-разному искать одно и то же, поэтому необходимо собрать максимум вариантов запросов. Например, спинной корректор могут искать как поясничный корсет или пояс для выпрямления осанки.
Для выявления синонимов стоит проверять поисковые подсказки в Google и Яндекс. Введя поисковой запрос «подставка для зонтов» в Google, можно сразу вооружиться еще несколькими фразами:
Также помогает правая колонка в сервисе Яндекс.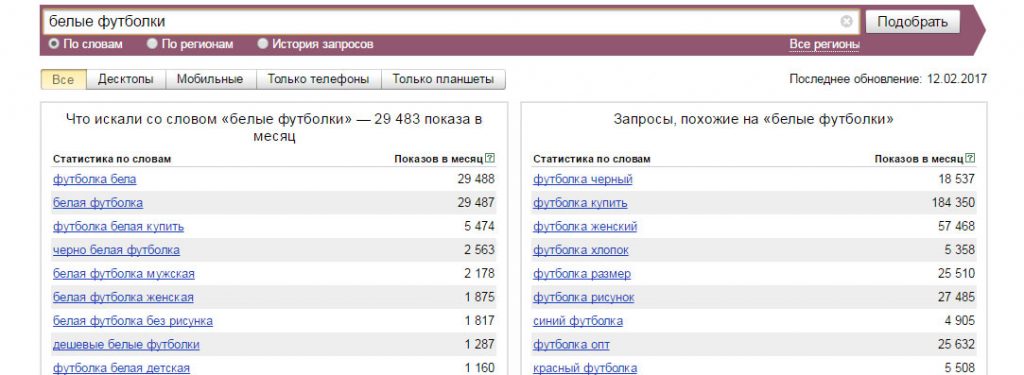 Вордстат:
Вордстат:
Пригодится и анализ сниппетов в выдаче по ключевой фразе. Для этого достаточно просто ввести основной запрос в поисковой системе и проанализировать заголовки. Велика вероятность, что мы сможем найти подходящие фразы, как в случае с «манекенами для единоборств»:
Отличный помощник в поиске синонимов — Serpstat. В сервисе встроена функция поиска альтернативных фраз. Для сбора семантики необходимо перейти в раздел «SEO анализ» — «Похожие фразы» и ввести основное ключевое слово, например, «анемометр»:
В результате получим дополнительные хорошие ключи для составления семантического ядра:
Но при всем разнообразии средств для сбора похожих фраз, мозговой штурм никто не отменял. Так что дерзайте 🙂
3. Включили в список только высокочастотные запросы
По низкочастотными запросами достаточно легко попасть на первые позиции. Также посетители, которые пришли по низкочастотному запросу, скорее сконвертируются в клиентов.
Плюсы низкочастотных запросов:
- ниже конкуренция и легче вывести в топ.
 Обычно по высокочастотным запросам все первые места прочно заняты гигантами отрасли и лидерами тематики, которых объективно потеснить будет практически невозможно. По узкоспециализированным запросам конкуренция меньше;
Обычно по высокочастотным запросам все первые места прочно заняты гигантами отрасли и лидерами тематики, которых объективно потеснить будет практически невозможно. По узкоспециализированным запросам конкуренция меньше; - для коммерческого проекта, велика вероятность, что посетитель, который пришел по низкочастотному запросу сконвертируется в клиента. Низкочастотные запросы — достаточно конкретные узконаправленные запросы, которые задает человек, которые знает, что хочет.
Следует ориентироваться и на тематику: частота, которую можно считать низкой в нише женской одежды, не будет таковой в тематике «охотничьи прицелы». Возьмем, например, проектирование домов. Для основного запроса «проект дома» высокочастотными будут считаться следующие запросы:
|
проекты домов |
16 229 |
|
проекты домов фото |
1 664 |
|
проекты одноэтажных домов |
1 610 |
|
проект дома цена |
1 368 |
Среднечастотные запросы:
|
проекты домов +до 100 м |
213 |
|
проекты домов +до 100 кв м |
212 |
|
проекты домов +до 150 |
209 |
|
проекты деревянных домов |
208 |
Низкочастотные запросы:
|
проекты цокольных домов +с мансардой |
47 |
|
проекты домов +из сип панелей +до 100 |
45 |
|
проекты домов +из профилированного бруса |
39 |
Под каждый отдельный вариант запроса должна быть создана отдельная страница. При ее грамотной оптимизации и наполнении качественным контентом можно легко получить хорошие результаты.
При ее грамотной оптимизации и наполнении качественным контентом можно легко получить хорошие результаты.
Подробно о том, как еще использовать низкочастотные запросы при продвижении, читайте в статье о креативном SEO.
4. Подобрали нецелевые запросы
Очень важно произвести чистку семантического ядра от нецелевых запросов. На этапе сбора ключевых слов попадается огромное количество запросов, которые не соответствуют тематике ресурса.
Например, при сборе семантики для магазина стандартных кроссовок, в котором реализация продукции производится только в розницу, не подойдут популярные запросы «светящиеся кроссовки» или «кроссовки оптом».
В Яндекс.Вордстат можно исключать определенные слова, используя стандартный синтаксис. Достаточно прописать слово, которое необходимо исключить, в формате «-светящиеся». Так можно исключать сразу несколько ключевых слов:
В Key Collector, одной из самых популярных программ для сбора и кластеризации семантического ядра, для этого реализован очень удобный и простой алгоритм. Мы можем удалить все ключевые слова с ненужными словами. Для этого на панели инструментов необходимо выбрать «Стоп-слова», прописать список для удаления в открывшемся окне и нажать на кнопку «Отметить все фразы в таблице».
Мы можем удалить все ключевые слова с ненужными словами. Для этого на панели инструментов необходимо выбрать «Стоп-слова», прописать список для удаления в открывшемся окне и нажать на кнопку «Отметить все фразы в таблице».
Расположение кнопки на панели инструментов Key Collector:
Алгоритм ввода и разметки стоп-слов:
Так мы отметим все ключи, которые нам не нужны, и сможем их удалить из списка:
Можно отсекать ненужные ключевые слова еще на этапе сбора. Для этого аналогичным образом прописываем стоп-слова и далее при запуске сбора подключаем список стоп слов:
5. Забыли про кластеризацию
Собранные ключевые запросы должны быть разбиты на группы. В первую очередь это необходимо для составления грамотной, полезной и удобной для пользователя структуры сайта. А также для следования принципу «одна страница — один ключ». Страницу гораздо легче продвигать под один ключ. Поэтому следует проанализировать возможность и целесообразность создания новых страниц, чтобы разделить ключевые слова при наличии «универсальных» страниц.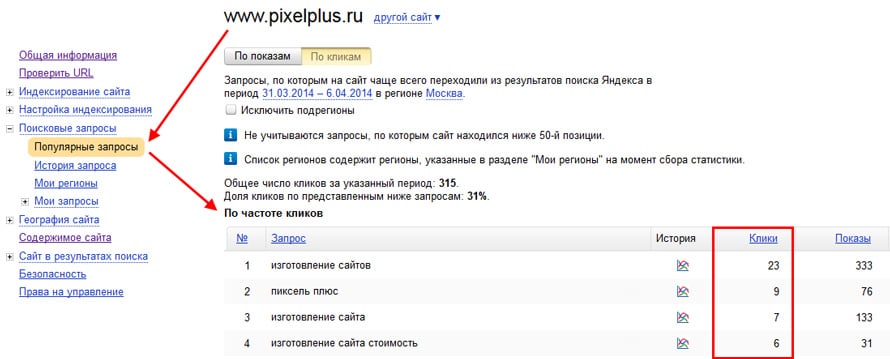
6. Неправильно разделили коммерческие и информационные запросы
Направленность веб-ресурса определяет типы запросов, которые необходимо использовать в семантическом ядре. Очевидно, что интернет-магазин необходимо продвигать на базе коммерческих запросов, а информационные запросы идеально подойдут для продвижения новостных или статейных порталов. Важно правильно определить, коммерческий запрос или информационный.
Самый простой способ определить — ввести запрос в поисковой системе. Если большая часть сайтов открывается по запросам с предложениями «купить», «заказать», с указанием цены, — это коммерческий запрос, в противном случае — информационный.
Есть сервисы, которые позволяют автоматически определять тип запроса. Например, такую функцию предлагает Semparser.
7. Подобрали «пустые» запросы
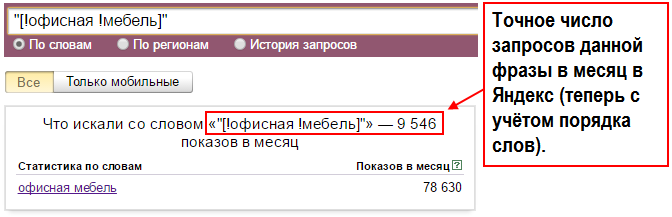
Важно избегать «пустых» запросов, которые входят в большое количество целевых словоформ, но сами по себе являются низкочастотными. Присутствие таких запросов легко проверить с помощью Яндекс. Вордстат. Если запрос поместить в кавычки, отобразится точная частота ввода именно этого запроса без его вхождения в запросы, состоящие из большего количества слов.
Вордстат. Если запрос поместить в кавычки, отобразится точная частота ввода именно этого запроса без его вхождения в запросы, состоящие из большего количества слов.
Например, может показаться, что запрос «крем на лето» достаточно популярный:
Но если проверить поиск по точному вхождению ключевого слова, окажется, что частотность не так уж велика:
Можем попробовать взять более узкий ключевой запрос и убедиться, что он интереснее для пользователей:
Вбивать каждый запрос отдельно не очень удобно и времязатратно. Поэтому некоторые программы и сервисы позволяют получить частоту для точного вхождения. Например, Key Collector:
8. Использовали ключевые слова с ошибками
Часто при сборе семантического ядра могут попадаться ключевые запросы с ошибками. Такие запросы необходимо отсеивать. При этом не стоит обращать внимание на то, что ошибочный запрос является высокочастотным.
Поисковые системы учитывают грамотность контента при ранжировании и предлагают правильный вариант пользователю, даже если при вводе запроса была допущена ошибка или опечатка.
Читайте также, как работать с оператором «квадратные скобки» в Яндекс.Вордстат.
Выводы
При составлении семантического ядра следующие ошибки могут негативно повлиять на дальнейшее продвижение сайта:
- Собрали маленькое семантическое ядро.
- Забыли о синонимах.
- Собрали только высокочастотные запросы.
- Подобрали нецелевые запросы.
- Забыли о кластеризации.
- Неправильно разделили коммерческие и информационные запросы.
- Подобрали и использовали пустые запросы.
- Использовали ключевые слова с ошибками.
А какие ошибки при сборе семантики встречались вам? Делитесь наблюдениями в комментариях, обсудим.
Long-tail SEO — как продвигаться по низкочастотным запросам и зачем это нужно
Семантическое ядро из ключевых слов — основа для продвижения сайта в поисковых системах. Сами ключи делятся на несколько типов по частотности — числу запросов по ключевой фразе. В среде интернет-маркетологов все еще считают, что запросы с низкой частотностью или состоящие из большого количества слов не подходят для продвижения сайтов. Потому что не могут обеспечить сопоставимый с высокочастотными ключевиками трафик. Но к низкочастотным относятся long-tail запросы. И с ними все обстоит немного иначе. При правильном подходе они могут стать эффективным инструментом для увеличения трафика.
В среде интернет-маркетологов все еще считают, что запросы с низкой частотностью или состоящие из большого количества слов не подходят для продвижения сайтов. Потому что не могут обеспечить сопоставимый с высокочастотными ключевиками трафик. Но к низкочастотным относятся long-tail запросы. И с ними все обстоит немного иначе. При правильном подходе они могут стать эффективным инструментом для увеличения трафика.
- Что такое long-tail запросы?
1.1 Тематические long-tail запросы
1.2 Дополняющие long-tail запросы
1.3 Смешанные long-tail запросы
- Почему LT-запросы релевантны для поиска?
2.1 Голосовой поиск
2.2 Форма вопроса
- Эффективность и преимущества long-tail SEO
3.1 Низкая конкуренция
3.2 Высокий показатель конверсии
3.3 Продвижение по общим ключевым словам конкретной тематики
- Как найти long-tail запросы?
5.1 Поиск LT с помощью Google Search Console
5. 2 Используйте поисковые подсказки
2 Используйте поисковые подсказки
5.3 Поиск через Яндекс.Вордстат
5.4 Поиск через Serpstat
5.5 Поиск через Ahrefs - Как продвигаться по длинному хвосту
6.1 Продвижение по тематическим long-tail запросам
6.2 Продвижение по дополняющим long-tail запросам
6.3 Продвижение по смешанным long-tail запросам
Long-tail запросы (LT) обладают невысокой частотностью и четко выражают намерения пользователя.
Их длина не имеет значения. В основном низкочастотные запросы состоят из трех и более слов, но точные запросы из одного или двух слов тоже включаются в категорию «длиннохвостых».
Соотношение частотности запроса и конверсии наглядно иллюстрирует кривая поискового спроса:
- в мире очень много пользователей интересуется смартфонами, вводя простой и высокочастотный запрос «smartphone»;
- можно выделить более узкую аудиторию, которую интересуют только смартфоны компании Samsung — базовый ключ данной категории с меньшей частотностью «samsung smartphones»;
- далее по кривой спроса запросы все с меньшей частотностью, например, «Samsung Galaxy smartphone»;
- в финальной части специалисты рассматривают длинный список запросов, частотность которых может составлять от одного до пяти показов в месяц или даже быть нулевой, например, «samsung galaxy series list and price».

Кривая поискового спроса показывает: огромное количество ключевых слов с низкой частотностью складывается в так называемый «длинный хвост». Потенциал которого начал возрастать по мере развития поисковых систем и сферы SEO в целом.
Можно выделить три основных категории запросов с длинным хвостом:
- тематические;
- дополняющие;
- смешанные.
Тематические long-tail запросы
Они указывают на конкретную тему. Наиболее точные, подойдут в качестве основных ключей для страниц, которые вы хотите продвигать по низкочастотным запросам.
Например, «как научиться плавать кролем». Частотность запроса низкая: до 540 показов в месяц без уточнения региона. Помимо спецэлементов (блоки с рекламой, видео, списком локальных компаний), выдача по нему полностью состоит из тематических материалов, точно дающих ответ на запрос пользователя.
У тематических длиннохвостых запросов такие характеристики:
- относительно сложная формулировка;
- высокая детализация;
- точный интент.

Выдача по ним низкоконкурентная и состоит из страниц конкретной узкой тематики. Используя грамотную стратегию продвижения, в топ по тематическим LT можно попасть без особых усилий.
Дополняющие long-tail запросы
Они указывают на конкретную тематику, но из-за низкой частотности дополняют одну или несколько более широких тем.
Скажем, запрос «техника шнуровки кроссовок». Его частотность — до 10 показов в месяц. Выдача будет состоять не только из страниц о способах шнуровки кроссовок, но и из страниц о технике шнуровки ботинок.
Частотность запроса «шнуровка ботинок», тоже относящегося к данной тематике, выше — от 1600 показов в месяц. В этом главная особенность дополняющих LT: повышенная конкуренция за счет выведения в выдаче результатов по общим запросам.
Использование такого типа long-tail в продвижении — более тонкий инструмент. Необходимо параллельно продвигаться по запросам высокой или средней частотности.
Смешанные long-tail запросы
Их нельзя точно отнести к какой-либо из двух ранее приведенных категорий. Смешанные LT могут относиться к конкретной узкой теме, но и охватывать несколько более широких.
Смешанные LT могут относиться к конкретной узкой теме, но и охватывать несколько более широких.
Примеры смешанных длиннохвостых запросов:
- Запросы с ярко выраженной сезонностью — «seo тренды 2022».
- Названия организаций, конкретных мест, культурные продукты (фильмы, книги, постановки) — «научный музей nemo».
- Низкочастотные запросы с указанием топонима — «где купить авто в Одессе».
Из-за специфики данных ключевых слов, поисковые системы не получают необходимого объема данных, чтобы предоставить специалистам аналитику по ним в таких инструментах, как Google Ads. Но есть некоторые способы анализа запросов из длинного хвоста и даже конкретные инструменты. О них расскажу дальше.
По данным Google 15% поисковых запросов новые, пользователи генерируют их каждый день. В основе этой статистики как раз низкочастотные запросы. Из-за уточнения или более сложного формулирования интента, пользователи создают новые поисковые запросы. И они влияют на алгоритмы ранжирования.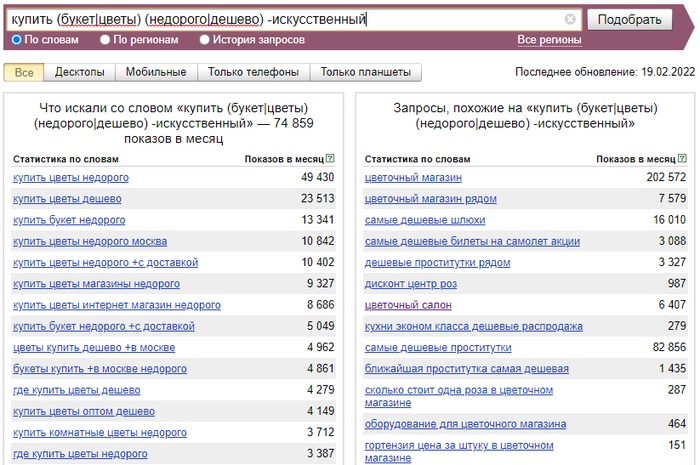
Голосовой поиск
Отчасти появление такого большого количества низкочастотных запросов связано с популярностью голосового поиска. Аксессуары, голосовые помощники, продукты вроде Google Home вызвали потребность в поиске на естественном для пользователя языке.
Поисковые системы начали лучше понимать контекст фраз, сленг и подстраиваться под «разговорный» стиль запросов. Разговорная речь развивается динамично, поэтому алгоритмы систем постоянно дорабатываются, чтобы корректно распознавать запросы при голосовом поиске.
Его популяризация работает и в обратную сторону: постоянное генерирование пользователями вариаций одного и того же запроса или фразы заставляет поисковые системы принять их за одинаковые. Это происходит для компенсации все большего числа запросов в поиске.
Форма вопроса
Помимо запросов голосом люди часто используют вопросы. Причем, один и тот же могут задать по-разному (использовать вводные слова, уточняющие детали). И алгоритмы поиска учатся разбираться в этих LT.
При этом системы могут принять вариации одного и того же запроса за одинаковые. Как понять, в каких случаях это происходит и почему?
Проведите N-граммный анализ. N-грамма — определенная последовательность из n элементов. В контексте ключевых слов:
- запрос «музыка» является 1-граммой;
- запрос «какую музыку можно использовать в тиктоке» — 6-граммой (последовательность из 6 слов).
Представление запроса с помощью N-граммы позволяет понять его естественность, а также вес каждого элемента n в рамках фразы.
Допустим, вы хотите оптимизировать контент под низкочастотные запросы в рамках тематики «велотренажеры». Запрос «какой недорогой велотренажер лучше купить» лучше разбить с помощью n-граммы. И провести неполный n-граммный анализ — вручную изменять каждое отдельное слово во фразе и смотреть, как и насколько сильно меняется поисковая выдача.
В отдельных случаях можно использовать платные и бесплатные инструменты для n-граммного анализа в SEO.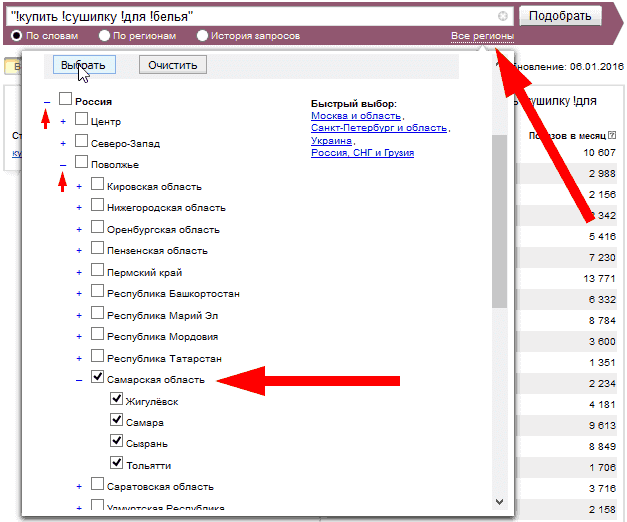 Например:
Например:
- !SEMTools;
- PEMAVOR;
- NGram Analyzer.
Конкретно в случае с велотренажерами замена слов «недорогой» на «бюджетный», «велотренажер» на «велосипедный тренажер» и даже «купить» на «выбрать» не будет играть существенной роли.
Выдача до изменений:
Выдача после изменений:
Но более заметное изменение поисковой выдачи произойдет при замене слова «недорогой» на «дешевый»:
В любом случае, при анализе выдачи следует учитывать, что основа тематики запроса зависит именно от слова «велотренажер», так как оно в полной степени характеризует интент.
Представление запросов с помощью N-грамм — это не панацея, как и подстраивание под голосовой поиск. Но они показывают, что long-tail релевантны для поиска. Статистика и поведение поисковых систем уже дают сигнал SEO-специалистам — использование низкочастотных запросов в продвижении стоит рассматривать в качестве метода, обладающего большим потенциалом.
Помимо адаптивности под голосовой поиск, продвижение по длиннохвостым ключевым словам предполагает наличие как минимум трех явных преимуществ.
Низкая конкуренция
Большинство сайтов продвигаются по высокочастотным запросам. В Украине по запросу «купить айфон 12» в Google выдается 21,5 тысяча результатов, а по запросу «айфон 12 128 гб купить» — до 100. Малое количество конкурентов по поисковой выдаче может позволить легче и быстрее выйти в топ, но это не означает что конкуренции не будет вообще.
Несмотря на низкую частотность, потребительский спрос может быть на среднем и высоком уровне. Поэтому при продвижении по низкочастотным ключевым словам проверяйте изменения выдачи и уровень конкуренции.
Высокий показатель конверсии
Данную особенность можно рассмотреть под углом воронки продаж.
Она включает в себя:
- Осведомленность. На данном этапе пользователь узнает о конкретном товаре и о возможности его приобретения.
- Интерес.
 У пользователя появляется интерес к товару и потребность в покупке.
У пользователя появляется интерес к товару и потребность в покупке. - Желание. Потребность сформирована, и пользователь хочет приобрести товар.
- Действие. Человек покупает товар, удовлетворяя потребность.
Например, при запросе «купить зубную щетку» пользователь ещё не находится на стадии полного осознания своей потребности, он не знает виды зубных щеток и не выбрал конкретную модель. А при запросе «купить электрическую зубную щетку орал би» первые два этапа воронки пройдены, человек конкретно знает, чего хочет, и находится в нескольких шагах от покупки.
Специфика низкочастотных запросов в том, что они являются более целевыми: пользователь может конкретнее сформулировать свою потребность, а значит, сильнее настроен на целевое действие.
Существуют и дополнительные преимущества продвижения именно по LT.
Продвижение по общим ключевым словам конкретной тематики
Для раскрытия данной особенности наиболее подходит продвижение по дополняющим длиннохвостым запросам, так как оно предполагает наличие главных тематических высокочастотных запросов. Поисковые системы понимают тематику запроса и могут определить схожие ключевые слова, которые относятся к одному и тому же интенту. Поэтому результат выдачи по LT может включать некоторые результаты и для основного ключа.
Поисковые системы понимают тематику запроса и могут определить схожие ключевые слова, которые относятся к одному и тому же интенту. Поэтому результат выдачи по LT может включать некоторые результаты и для основного ключа.
Но существует и обратный процесс, который стоит учитывать: при грамотной оптимизации низкочастотные запросы могут поднимать позиции сайта по основным высокочастотным запросам.
Все три преимущества продвижения по long-tail можно представить через принцип конкурентоспособности:
- Топовые позиции по высокочастотным запросам не всегда досягаемы, особенно в высококонкурентных нишах с большими бюджетами на продвижение.
- Эти трудности побуждают SEO-специалистов отказаться от простой, банальной и необдуманной стратегии прямой конкуренции с сайтами в топе и обратить внимание на не совсем привлекательные на первый взгляд long-tail запросы.
- Выбрав более «тонкую» стратегию продвижения в высококонкурентной нише с использованием низкочастотных ключей, можно добиться большего целевого трафика, и, как следствие, большего количества целевых действий.

Главный подготовительный этап перед продвижением по long-tail — найти их. Сделать это можно несколькими способами.
Поиск LT с помощью Google Search Console
Первым делом, для поиска низкочастотных запросов выгрузите список из вкладки «Эффективность» в Google Search Console. В ней содержатся ключевые слова, по которым уже ранжируется ваш сайт. И, как правило, большинство из них являются низкочастотными.
Так вы найдете готовые базовые long-tail запросы, под которые не придется создавать отдельные страницы и большое количество контента. Поисковые системы изначально распознают их как подходящие для страниц вашего сайта.
Используйте поисковые подсказки
Поисковые подсказки в Google и Яндекс — чуть ли не самый действенный способ найти длиннохвостые запросы. Просто начните вводить фразу в строку поиска. Система сама дополнит ее во всплывающем окне. Причем этот процесс происходит по принципу «чем более длинную фразу вводишь, тем менее частотный запрос получаешь».
Пример в Google:
Пример в Яндекс:
Также следует обратить внимание на дополнительные блоки со связанными запросами на странице поисковой выдачи, они тоже могут содержать полезные низкочастотные запросы.
Никогда не игнорируйте данный метод при подборе списка long-tail ключей, так как все запросы из поисковых подсказок являются реальными и естественными для пользователя.
Поиск через Яндекс.Вордстат
Яндекс.Вордстат — базовый бесплатный инструмент подбора ключевых слов: как высоко-, так и низкочастотных.
Через него можно собирать информационную семантику для любого русскоязычного региона, так как она является геонезависимой.
Поиск через Serpstat
Serpstat — платный инструмент с самым богатым набором функционала по подбору long-tail ключевиков.
Сервис позволяет искать ключевые фразы и фильтровать их по уровню необходимой частотности.
В поиске long-tail запросов вам помогут дополнительные разделы инструмента:
- «Похожие фразы».
 Позволит найти схожие и дополняющие тематику низкочастотные запросы и расширить список;
Позволит найти схожие и дополняющие тематику низкочастотные запросы и расширить список;
- «Поисковые подсказки». Не содержит статистические данные о запросах, но подойдет для быстрого подбора нативных long-tail ключей — наиболее естественных для повседневной человеческой речи;
- через «Поисковые вопросы» вы легко соберете информационную тематику по конкретной теме. Он наиболее подходит для формирования блока FAQ на коммерческих страницах и для создания основы для материалов блога сайта.
Поиск через Ahrefs
Второй платный инструмент в нашем списке. Функциональность схожа с Serpstat: есть возможность подобрать запросы и отфильтровать их по максимальной и минимальной частотности. А отчет Questions покажет поисковые вопросы по нужной тематике.
У сервиса несколько очень удобных особенностей:
- Выведение сразу нескольких категорий ключевых слов по вашему запросу. В специальном блоке Keyword ideas вы увидите информацию по ключевых словам, поисковым запросам, дополняющим long-tail и схожим фразам.
- Показ топа страниц по конкретному запросу с подробной информацией о ссылочном профиле и главным ключевым словом.
- Показ топа страниц схожей тематики.
Инструмент выделяется хорошей базой для англоязычного сегмента поиска. Если вы продвигаетесь под Америку, Европу или другие регионы, обязательно ознакомьтесь с ним.
Существует большое количество сторонних сайтов для подбора низкочастотных запросов с бесплатными или пробными версиями. Например, AnswerThePublic, который может показать целый кластер поисковых вопросов по основному запросу.
Используйте все возможные способы подбора long-tail запросов, исследуйте результаты поисковой выдачи по ним, кластеризируйте списки и отсеивайте ненужное, чтобы в конечном счете составить список наиболее подходящих ключей для продвижения.
После сбора подходящих запросов необходимо принять решение о правильной стратегии продвижения. Для этого важно знать, как поисковая система формирует выдачу и как понимает интент запроса.
Для этого важно знать, как поисковая система формирует выдачу и как понимает интент запроса.
Напомню, есть три типа LT-запросов. И каждый из них характеризует намерения поисковой системы.
|
Вид запросов |
Действия поисковой системы |
|
Тематические LT-запросы |
Система включает в результаты по конкретному запросу только целевые тематические страницы. |
|
Дополняющие LT-запросы |
Включает в поиск результаты по более частотным запросам. |
|
Смешанные LT-запросы |
Делает выдачу смешанной. |
Продвижение по тематическим long-tail запросам
Поисковая выдача по тематическим LT полностью состоит из тематических материалов, точно дающих ответ на запрос пользователя.
Вот выдача по запросу «как найти низкочастотные запросы».
Она состоит только из материалов, подходящих под конкретный запрос. Поэтому наиболее удачным будет создание отдельной страницы и продвижение ее под тематический LT или семантическую группу запросов.
Семантическая группа может состоять из вариантов ключевой фразы:
- «как найти низкочастотные запросы»;
- «как собрать низкочастотные запросы»;
- «как подобрать низкочастотные запросы».
Выдача по каждому запросу будет выглядеть практически одинаково, но изменения все-таки найдутся. Это дает вам выбор, как продвигаться, в зависимости от бюджета и времени. Можете создавать максимально узконаправленную страницу под каждый элемент из группы и продвигать ее отдельно. Или же создать общую страницу с более масштабным материалом и продвигать его сразу по нескольким вариантам ключевой фразы.
Можно пойти дальше и собрать еще менее частотные запросы, используя геотеги, сравнение одних терминов с другими, усложнение формы вопроса и так далее. Вы можете создать отдельный раздел на сайте под конкретную тематику и включать в него страницы с вопросами и точными ответами, каждая из которых будет продвигаться под конкретный запрос.
Вы можете создать отдельный раздел на сайте под конкретную тематику и включать в него страницы с вопросами и точными ответами, каждая из которых будет продвигаться под конкретный запрос.
Главное в данной схеме продвижения, чтобы выдача не содержала большого количества страниц конкурентов, в которых есть масштабные материалы, продвигаемые по высокочастотным запросам.
Используя такую стратегию, вы соберете больше трафика, выходя в топ по каждому низкочастотному запросу. А это сделать легче, чем продвинуть один или два высокочастотных запроса в топ в конкурентной нише. Каждая из страниц может собирать небольшое количество трафика, но в совокупности они обеспечат немалый объем. Причем, трафик по низкочастотным запросам будет более целевым.
Продвижение по дополняющим long-tail запросам
Выдача по дополняющим LT формируется с большим количеством страниц, продвигаемых по высокочастотным запросам. Выбрав этот тип продвижения, не стоит создавать отдельные страницы под каждый запрос. Потратите много усилий и бюджета, а поисковые системы будут считать их частью другой, более масштабной темы.
Потратите много усилий и бюджета, а поисковые системы будут считать их частью другой, более масштабной темы.
Поэтому дополняющие ключевые слова следует использовать в продвижении вспомогательно. Анализируя топ выдачи по ним, вы найдете основные запросы в тематике: они могут быть как тематическими long-tail, так и средне- или высокочастотными запросами.
В таком случае в своей стратегии продвижения опирайтесь на основные запросы, а для дополняющих long-tail фраз создайте дополнительные абзацы или блоки информации, например, блок FAQ.
Если сможете выйти в топ с такой страницей по основному запросу, в топ выйдут и большая часть LT, которые его дополняют. Так вы получите больше трафика по дополняющим long-tail запросам.
Продвижение по смешанным long-tail запросам
В выдачу по смешанному LT включены как страницы с точным удовлетворением интента пользователя, так и страницы, которые относятся к смежной широкой тематике.
Стратегия продвижения для ключевых слов с такой особенностью ранжирования гибкая. Можно продвигать запросы как дополняющие, а можно наоборот — как тематические.
Можно продвигать запросы как дополняющие, а можно наоборот — как тематические.
- В первом случае необходимо создавать большие материалы, которые будут включать много низкочастотных запросов и блоков с дополнительной информацией, а также значительно увеличивать степень авторитетности страницы для поисковых систем, прокачивая ссылочный профиль.
- Во втором случае нужен узконаправленный материал или несколько материалов под отдельные запросы с полным раскрытием темы, а также важно связать их между собой и с другими материалами на сайте с помощью внутренних ссылок.
Выбор стратегии зависит от наличия времени, бюджета и ваших умений. Но ясно одно — качественный и уникальный контент, полезный для пользователей, является одним из наиболее важных факторов при продвижении long-tail запросов.
Изучите топ выдачи по ключевым словам и составьте список контента, который необходимо упомянуть на странице, и особенностей, которые делают страницу качественной. Речь о технической оптимизации (скажем, скорость загрузки) или о требованиях поисковика к контенту. Данный список послужит вам основой для наращивания качественного контента вокруг long-tail запросов.
Речь о технической оптимизации (скажем, скорость загрузки) или о требованиях поисковика к контенту. Данный список послужит вам основой для наращивания качественного контента вокруг long-tail запросов.
LT — это тип низкочастотных запросов, которые четко выражают намерения пользователя. С развитием голосового поиска в частности и сферы SEO в целом они становятся все более интересны для продвижения. У них низкая конкуренция, высокий показатель конверсии, есть возможность попасть сразу в выдачу по схожим высокочастотным ключам.
Прежде, чем продвигаться по LT, вам нужно их найти. Для этого вам помогут ряд инструментов:
- Google Search Console;
- поисковые подсказки в Google и Яндекс;
- Яндекс.Вордстат;
- Serpstat;
- Ahrefs;
- сайты для подбора низкочастотных запросов, например, AnswerThePublic,
Есть три вида long-tail запросов:
- тематические — указывают на конкретную тематику, выдача по ним состоит из целевых страниц;
- дополняющие — дополняют одну или несколько более широких тем, в выдачу из-за низкой частотности попадут страницы смежной тематики;
- смешанные — относятся как к узкой теме, так и охватывают более широкую, выдача будет смешанная.

Под каждый из этих типов есть свои сценарии продвижения.
Long-tail seo — довольно гибкий инструмент, который в умелых руках может принести огромное количество целевого трафика на сайт. Но не следует зацикливаться на низкочастотных ключевиках и делать упор на создание 100 или 200 узконаправленных страниц, наполненных шаблонным контентом.
Грамотно внедряйте длиннохвостые ключевые слова в семантическое пространство вашего проекта, работайте над качеством контента, анализируйте нишу вашего сайта и следите за глобальной реакцией поисковых систем на LT-ключевики. Все это залог успеха в продвижении сайта по принципу long-tail.
Как собрать список ключевых фраз для поисковой рекламы
Поисковая реклама — это объявления, которые пользователь видит, когда ищет что-то в Яндексе, Гугле, Рамблере или любой другой поисковой системе. Обычно она выглядит как результаты запросов и размещается в верхней и нижней частях выдачи:
Первые результаты в поисковой выдаче Google помечены лейблом Ad или «Реклама»
Поисковая реклама работает так:
Рекламодатель собирает список запросов, по которым хочет показать свои рекламные объявления.
Под запросы он создаёт объявления, описывает товар или услугу.
Когда пользователь вводит запрос, он видит объявления, которые под него подходят.
Например, компания продаёт ульи и создала для ключевой фразы «купить улей деревянный» объявление со ссылкой на конкретную модель улья. Когда пользователь введёт такой запрос, он увидит рекламу компании в топе поисковой выдачи.
Получается, чтобы реклама работала эффективно, нужно собрать список слов или словосочетаний, которые потенциальный клиент будет искать. А затем создать для них варианты объявлений в рекламной системе поисковика. В этой статье поговорим о первой части: как собрать список ключевых фраз или ключей.
Содержание:
Зачем нужен список ключей
Какие бывают запросы
Из чего состоит запрос
Какие ключи использовать в рекламе
Как собирать поисковые запросы
Минус-слова
Инструменты для сбора ключевых слов
Читайте также:
Запуск рекламы в Google Ads для новичков
Полное руководство о том, как запустить рекламу в Гугле
| Читать |
Зачем нужен список ключей
Чем шире и точнее будет список ключевых слов, тем больше потенциальных клиентов вы сможете охватить и тем эффективнее будет работать реклама. Использовать только очевидные ключи вроде «купить [название товара]» — недостаточно.
Использовать только очевидные ключи вроде «купить [название товара]» — недостаточно.
Пользователь может формулировать потребность по-разному, для одного товара могут быть десятки и сотни ключей. Например, рекламу ульев можно показать для запросов:
- Купить улей для пчёл,
- Купить пчелиный улей,
- Недорогой деревянный улей,
- Ульи для пчёл где взять,
- Как выбрать улей,
- Изготовление ульев купить,
- Улей купить в Москве,
- Где купить улей на Академической.
И так далее.
Так что чем больше ключевых слов вы будете использовать, тем чаще пользователи будут видеть ваши объявления, тем выше будет трафик на сайт и тем больше продаж получит бизнес. А если указать всего несколько основных ключей, то можно потерять много потенциальных переходов по побочным запросам.
Какие бывают запросы
Запросы отличаются в зависимости от мотивации, её ещё называют интентом. По одним запросам пользователи ищут конкретный товар, чтобы сразу купить. По другим — справочную информацию, чтобы разобраться в моделях.
По одним запросам пользователи ищут конкретный товар, чтобы сразу купить. По другим — справочную информацию, чтобы разобраться в моделях.
В зависимости от того, что вы рекламируете и какие результаты хотите получить, в качестве ключевых фраз стоит использовать запросы разного характера. Вот какие они бывают:
Информационные. По таким запросам пользователь просто хочет получить информацию: подобрать рецепт, почитать обзоры товаров, узнать, что такое мурмурация. Например, «как выбрать окна» или «как покрасить детскую». При таком запросе у пользователя, скорее всего, нет потребности прямо сейчас выбрать фурнитуру или краску, он хочет разобраться в теме и уже потом, вероятно, что-то приобрести. Так что по таким запросам обычно продвигают не конкретные товары и услуги, а статьи, инструкции и обзоры.
В информационных запросах часто используют слова вроде «свойства», «характеристики» или «инструкция». Могут быть вопросительные слова «как», «зачем», «что такое» и «почему».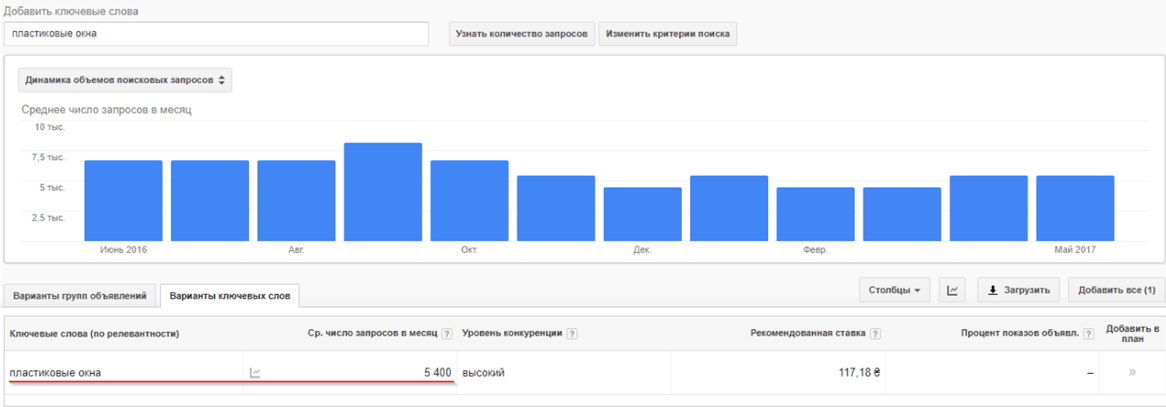
Мультимедийные. Есть подтип информационных запросов, по которым пользователь хочет получить в ответ на свой запрос в медиа: аудио, видео, фото, презентацию. Такой запрос говорит о том, что пользователь хочет что-то посмотреть или послушать прямо сейчас. Например:
- «видео причесок для длинных волос»,
- «установка смесителя видео»,
- «цветы обои на рабочий стол»
Владислав Наумов
Руководитель отдела SEO в Inweb
Продвигать подобного рода запросы сложно, так как первые места обычно заняты блоками с фотографиями или видеороликами с различных популярных мультимедиа-сайтов.
Коммерческие или транзакционные. Такие запросы говорят о явном намерении пользователя что-то купить, скачать или заказать. Например, если пользователь ищет «купить новый айфон X» или «заказать пиццу в Перово», он, вероятно, готов сделать покупку прямо сейчас или как минимум хочет сравнить условия.
Коммерческие запросы можно опознать по словам «купить», «заказать», «со скидкой», «с доставкой», «недорого». Они подсказывают, что аудитория более тёплая и, вероятно, склонна к покупке. Но и конкуренция в таких запросах обычно выше, об этом поговорим дальше.
Они подсказывают, что аудитория более тёплая и, вероятно, склонна к покупке. Но и конкуренция в таких запросах обычно выше, об этом поговорим дальше.
Пример информационного и коммерческого запроса для одинаковой категории товаров. Для первого в выдаче Яндекса рекламы нет, для второго — несколько объявлений
Геозависимые и геонезависимые. Если результаты поиска по запросу в одном городе или регионе будут отличаться от результатов в другом, то такой запрос называют геозависимым. Например, по запросу «заказать пиццу» в Москве покажут одни доставки, в Рязани — другие, значит, это геозависимый ключ.
Если запрос геонезависим, то локация пользователя не играет роли, результаты будут преимущественно одинаковые. Например, по запросу «как подготовить участок для строительства бани» вы увидите одинаковые результаты и в Коломне, и в Ярославле.
Геозависимые запросы обычно имеют коммерческий характер: «купить микроволновку в Ижевске», «бары в центре Калуги», «арендовать гараж в Серпухове».
А вот геонезависимые запросы могут быть как информационными, так и коммерческими.
Примеры коммерческих геонезависимых ключей
- «Онлайн-курс по большим данным». Если вы продвигаете цифровые продукты, то для них могут использовать одинаковые запросы в любой точке мира. Получается, что ключ геонезависимый и коммерческий.
- «Парикмахерская в Москве». В запросе конкретно указано, где мы ищем услугу, так что результаты в разных регионах будут одинаковые. Такой запрос тоже геонезависимый и коммерческий.
Навигационные. Иногда пользователь ищет определённую компанию или услугу на конкретном сайте. То есть, он точно знает, что ему нужно и куда он хочет попасть. Такие запросы называют навигационными или брендовыми. Например «сайт вконтакте» или «почта россии отследить посылку».
Владислав Наумов
Руководитель отдела SEO в Inweb
По вашим брендовым запросам могут рекламироваться конкуренты: так можно делать, если при этом не выдавать себя за другую компанию. Если в вашей нише есть сильные конкуренты, то собственные брендовые запросы тоже стоит использовать в рекламе.
Если в вашей нише есть сильные конкуренты, то собственные брендовые запросы тоже стоит использовать в рекламе.
Нечёткие или общие. По некоторым запросам сложно понять намерение пользователя, что именно он хочет получить. Например, если человек ищет «окна», его может интересовать что угодно: и старое телешоу на ТНТ, и установка пластиковых окон, и серия плакатов «Окна РОСТА». Такие запросы называют нечёткими.
Google теряется: мы ищем пластиковые окна, окна РОСТА или окно овертона?
Запросы отличаются также по тому, как часто их ищут и как много предложений по ним есть. Эти параметры называют частотностью и конкурентностью запросов:
Высоко-, средне- и низкочастотные. Одни товары и услуги ищут часто, другие — периодически, третьи — совсем редко. Популярность запроса отражает его частотность. Например, «купить окна» — высокочастотный запрос, его ищут больше 370 000 раз в месяц. «Купить профнастил рязань» ищут меньше 200 раз в месяц, это низкочастотный запрос.
Чёткого разделения нет, опорно может ориентироваться на такие диапазоны:
- Меньше 100–1000 запросов в месяц — низкочастотные.
- 1000–5000 — среднечастотные.
- Больше 5000 — высокочастотные.
Определение частотности зависит от ниши. Если товар массовый, например, айфон, то 2000 запросов в месяц будет средней или даже низкой частотой. Для менее востребованных предложений, например, аренды крупной строительной техники, при таком же количестве запрос можно считать высокочастотным.
В большинстве случаев на частотность влияет длина запроса. Чем больше в нём слов, тем реже именно такую комбинацию будут искать. В высокочастотных запросах обычно 1−2 слова, в среднечастотных — 2−4, в низкочастотных — до 10.
Например, запрос «холодильник Москва» состоит из двух слов, его ищут больше 120 тысяч раз в месяц, а «холодильник двухкамерный самсунг купить в москве» — состоит из 6 слов, его ищут меньше 200 раз. При этом за ними может скрываться один и тот же товар и одна и та же потребность.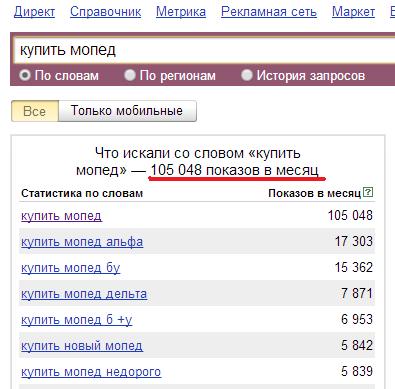
Илья Русаков
Основатель и руководитель агентства интернет-маркетинга impulse. guru, преподаватель в Нетологии, Skillbox и Деловой среде
Высокая частотность запроса часто говорит о том, что у пользователя ещё не сформировалась потребность. Например, «поставить окна» — очень популярный запрос, но если пользователь сформулировал его именно так, то у него, вероятно, ещё нет понимания продукта или он хочет поставить их самостоятельно. Если бы он действительно был готов прямо сейчас сделать выбор, то, скорее всего, искал что-то более конкретное, например «заказать пластиковые окна в детскую»
Частотность может зависеть от сезона. Например, зимой «новогодние ёлки» ищут часто, а летом — намного реже. Так что при сборе ключей не забывайте про сезонность и циклы покупательной активности: если планируете рекламу заранее, то расклад может измениться.
Узнать, как часто ищут запрос, поможет сервис подбора ключевых слов от Яндекса
Укажите ключевое слово, чтобы узнать, как часто его ищут. Можно посмотреть статистику по регионам и динамику спроса по месяцам за последние два года.
Можно посмотреть статистику по регионам и динамику спроса по месяцам за последние два года.
У запроса «новогодняя ёлка» есть характерный пик в декабре — в это время их ищут в 80 раз чаще, чем летом
Высоко-, средне- и низкоконкурентные. Некоторые товары и услуги предлагает сразу много продавцов, под них оптимизированы тысячи страниц. Другие позиции продвигают намного реже, конкуренция по ним ниже. Чем больше по запросу результатов с конкретными предложениями, тем выше конкурентность этого запроса.
Чтобы сравнить конкурентность запросов, можно посмотреть количество результатов по ним в поисковой выдаче. Например, Гугл по запросу «холодильник Москва» выдаёт 17 страниц подходящих результатов, а по запросу «холодильник двухкамерный самсунг купить в москве» — 5 страниц.
Но это не гарантированный способ: то, что в ответ на запрос найдётся много результатов, ещё не говорит однозначно, что по нему будет дорого запускать рекламу. Например, в выдаче может быть много информационных результатов, а коммерческих конкурентов — мало.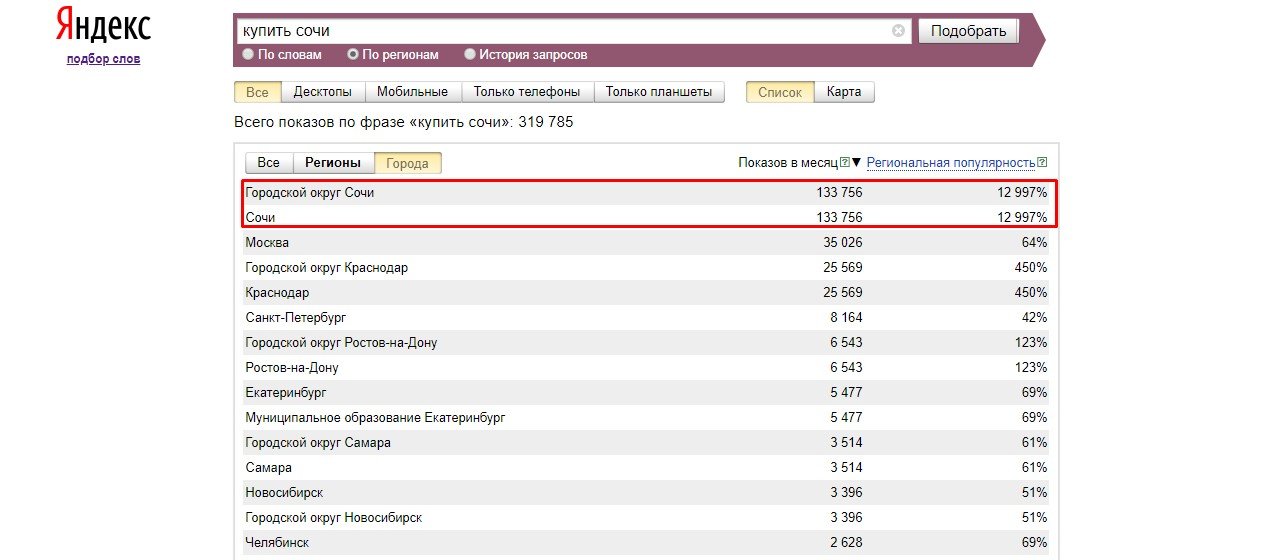
По запросу «сочинение как я провел лето» на 20% больше результатов, чем по запросу «мебель в москве», но это не коррелируют с рекламной конкурентностью
Владислав Наумов
Руководитель отдела SEO в Inweb
Оценить конкурентность запроса можно с помощью сервиса от Ahrefs. Укажите ключевое слово и страну, сервис попробует понять, насколько сложно будет по нему продвигаться.
Конкурентность влияет на стоимость клика. Чем выше конкуренция, тем, как правило, дороже реклама: за попадание в выдачу придётся соревноваться с большим количеством компаний, в том числе с большим бюджетом. Подробнее о ставках и работе с бюджетом расскажем в материалах по запуску контекстной рекламы.
Из чего состоит запрос
Вероятно, вы заметили, что запросы выглядят по-разному. Одни — короткие, из одного-двух слов. Другие — с большим количеством деталей. Это тоже важно для рекламы: структура запроса показывает намерение пользователя, а ещё влияет на частотность и конкурентность. Разберёмся со структурой поисковых запросов.
Разберёмся со структурой поисковых запросов.
Запрос состоит из трёх частей: тела, спецификатора и хвоста:
Тело — основной объект, который ищет пользователь. Например, телефон, окна или подшипники.
Спецификатор указывает на намерение пользователя — что он хочет сделать с объектом. Например, заказать, приготовить, починить или продать.
Хвост — часть запроса, которая детализирует потребность. Например, «быстро», «в Москве», «недорого».
Чем длиннее хвост запроса, тем обычно ниже его частотность. Например:
- «окна» — 7 982 965 запросов в месяц,
- «поставить окна» — 42 282 запросов в месяц,
- «поставить пластиковое окно» — 14 280 запросов в месяц,
- «поставить пластиковое окно в деревянном доме» — 1015 запросов в месяц.
Пример структуры запроса
Какие ключи использовать в рекламе
В зависимости от товаров и услуг, которыми вы занимаетесь, вы можете использовать разные запросы.
Если у вас товарный бизнес или вы оказываете услуги населению, то лучше всего работать с коммерческими запросами. Конкуренция здесь может быть выше, так что клик выйдет дороже, но и пользователи более заинтересованные, поэтому конверсия будет, скорее всего, выше.
Если у вас информационный проект, например, блог, или есть бренд-медиа, на которое вы хотите направить трафик, но SEO пока не приносит результатов, то вам подойдут информационные запросы. Пользователь ищет решение, вы ему его предлагаете. Если у вас есть полезные инструкции или обзоры товаров, на которые вы хотите направить рекламу, используйте информационные ключи.
Избегайте нечётких запросов. По ним обычно сложно понять мотив пользователя, скорее всего, большинству из них ваши товары не нужны, а они ищут какую-то общую информацию. Клики по таким ключам будут непредсказуемые.
Илья Русаков
Основатель и руководитель агентства интернет-маркетинга impulse. guru, преподаватель в Нетологии, Skillbox и Деловой среде
guru, преподаватель в Нетологии, Skillbox и Деловой среде
Разделять запросы на геозависимые и геонезависимые актуально скорее для SEO, чем для контекстной рекламы. Когда вы будете настраивать рекламную кампанию, вы сможете указать географию пользователей, которым хотите показать объявление. Так что наличие или отсутствие географических маркеров не так важно.
Больше используйте низко- и среднечастотные запросы. По высокочастотным запросам в большинстве ниш высокая конкуренция, из-за чего растёт цена на клик. Запросы с длинными хвостами говорят о конкретной потребности. В них можно найти узкую специализацию: трафика будет меньше, но цена за клик ниже, а конверсий больше.
По высококонкурентным ключам стоимость клика будет высокой — там уже соревнуется много компаний, которые готовы вкладывать значительный бюджет. Обратите внимание на средне- и низкоконкурентные запросы.
Как собирать поисковые запросы
Есть два основных подхода к сбору ключевых фраз: комбинация и парсинг по маркерным запросам. Рассмотрим оба.
Рассмотрим оба.
Комбинация
Собрать список ключей с помощью комбинации можно без дополнительных инструментов, хватит Экселя. Вот как это работает:
Шаг 1.
Возьмите основное тело запроса — товар или услугу, которую вы предлагаете. Запишите все возможные синонимы к нему. Например, для парикмахерской это может быть барбершоп или салон красоты.
Посмотрите не только с точки зрения того, как вы сами описываете свой бизнес, но и с точки зрения клиента — как он будет искать вас в интернете. Например, для парикмахерской это может быть запрос «подстричься».
Если использовать только очевидные запросы, то можно оказаться в очень конкурентной среде, так как такие же запросы уже используют все конкуренты. «[товар] купить», «[товар] заказать» и «[товар] выбрать» — обычно высокочастотные, но и высококонкурентные запросы.
Воспользуйтесь поисковыми подсказками, чтобы посмотреть, как люди формулируют запросы. Начните вбивать в поиск название товара или услуги и посмотрите, что вам предложат. Например, можно понять, что услуги ищут с указанием улицы:
Например, можно понять, что услуги ищут с указанием улицы:
Ещё один способ найти похожие — посмотреть в сервисе подбора слов от Яндекса. Он подскажет, какие ещё запросы используют пользователи. Например, «цветочный магазин» ищут как «цветочный салон» или «купить букет»:
Соберите таким образом все возможные тела запросов и занесите их в таблицу.
Шаг 2.
Добавьте спецификаторы, которые применимы к товару или услуге — действия, которые с ним можно завершить. Например, «запись» или «выбрать». Перемножьте тела и спецификаторы. Перемножить — значит скрестить между собой, чтобы получить все возможные формы. Например:
- Тела: парикмахерская, барбершоп
- Спецификаторы: запись, выбрать
Перемножаем: парикмахерская запись, парикмахерская выбрать, барбершоп запись, барбершоп выбрать.
Шаг 3.
Добавьте хвосты, которые могут использовать клиенты. Геопараметры, условия доставки или оказания услуг и так далее. И также перемножьте их с запросами, которые вы получили на предыдущем шаге.
Геопараметры, условия доставки или оказания услуг и так далее. И также перемножьте их с запросами, которые вы получили на предыдущем шаге.
- Тела: парикмахерская, барбершоп
- Спецификаторы: запись, выбрать
- Хвосты: в Москве, на выходных
Перемножаем: парикмахерская запись в Москве, парикмахерская запись на выходных, парикмахерская выбрать в Москве, парикмахерская выбрать на выходных, барбершоп запись в Москве, барбершоп запись на выходных, барбершоп выбрать в Москве, барбершоп выбрать на выходных.
На втором и третьем шаге тоже будут полезны поисковые подсказки и «Подбор слов» от Яндекса — воспользуйтесь ими, что собрать неожиданные спецификаторы и хвосты, о которых вы не подумали.
Шаг 4.
Просмотрите список, который получился. В результате перемножения могли получиться лишние запросы, по которым пользователь на вашем сайте не сможет найти подходящего решения. Например, у вас есть товары с доставкой, а есть — только с самовывозом.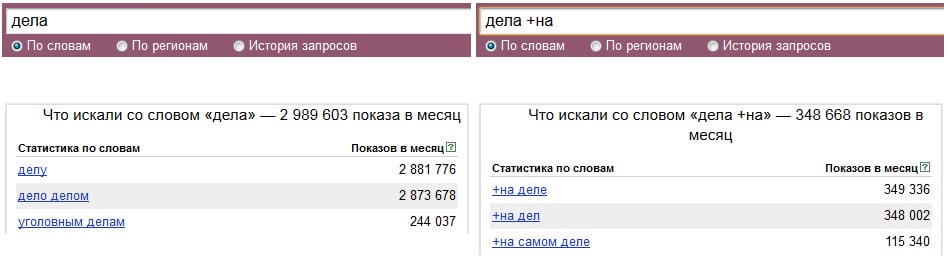 Не удаляйте такие ключи, а сохраните их отдельно и используйте в качестве минус-слов.
Не удаляйте такие ключи, а сохраните их отдельно и используйте в качестве минус-слов.
Илья Русаков
Основатель и руководитель агентства интернет-маркетинга impulse. guru, преподаватель в Нетологии, Skillbox и Деловой среде
У комбинации есть слабое место — есть вероятность, что вы упустите важные хвосты или спецификаторы, которые активно используют ваши покупатели. Чтобы этого не произошло, можно использовать второй подход к сбору ключей — парсинг.
Парсинг по маркерным запросам
Маркерный запрос обычно состоит из тела и коммерческого спецификатора, например, «заказать уборку». Для такого маркера нужно собрать как можно больше форм, вроде «заказать уборку на выходные», «заказать уборку со скидкой» или «заказать уборку эко-средствами». Процесс сбора этих запросов называют парсингом.
Парсить запросы можно вручную с помощью Wordstat или поисковых подсказок. Но это довольно трудоёмко, а если у вас много товаров или услуг — то становится практически бессмысленным: время, которые вы потратите на ручной сбор, может в итоге не окупиться.
Поэтому для парсинга обычно используют специальные инструменты, которые сами собирают данные из поисковых подсказок и сервисов по подбору ключевых слов. Они сами собирают массив запросов. Ваша задача — проверить его и убрать нецелевые. Например, информационные или с такими спецификаторами и хвостами, которые не соответствуют вашему бизнесу.
Парсинг помогает найти запросы, о которых вы изначально могли и не задуматься. Вполне возможно, ваши пользователи называют и ищут продукт не совсем так, как вы ожидаете — парсинг поможет это понять.
При этом парсинг даже с помощью специальных инструментов — всё равно трудозатратный процесс. Вам может понадобиться проверить несколько тысяч ключевых слов, чтобы удалить из них неподходящие. Если у вас широкий ассортимент, тогда сбор и очистка списка могут занять недели и даже месяцы. Возможно, в этом случае лучше использовать комбинацию.
Илья Русаков
Основатель и руководитель агентства интернет-маркетинга impulse. guru, преподаватель в Нетологии, Skillbox и Деловой среде
Если вы запускаете рекламу впервые, то я рекомендую использовать парсинг. Так вы сможете лучше погрузиться в структуру запросов, понять, как именно ваш товар ищут пользователи. А ещё — отфильтровать неподходящие запросы, чтобы не потратить деньги впустую.
Так вы сможете лучше погрузиться в структуру запросов, понять, как именно ваш товар ищут пользователи. А ещё — отфильтровать неподходящие запросы, чтобы не потратить деньги впустую.
Минус-слова
Во время сбора ключевых слов вы будете сталкиваться с запросами, которые не подходят для вашего бизнеса или рекламы. Например, какие-то запросы могут быть информационные, а вас интересуют только коммерческие. Или в каких-то запросах указаны условия, которые вы не предлагаете, например, доставка в тот же день. Такие ключи называют минус-словами.
Не нужно совсем удалять минус-слова — лучше сохранить их, чтобы использовать при настройке рекламной кампании. Во всех рекламных системах вы сможете указать не только запросы, по которым вы хотите показывать объявления, но и запросы, которые вы хотите проигнорировать. Тут вам и поможет список минус-слов.
Так что если во время парсинга или комбинации вы увидите ключ, который похож на ваш основной, но по каким-то причинам вам не подходит, не удаляйте его. Перенесите на отдельную вкладку и используйте при настройке рекламной кампании.
Перенесите на отдельную вкладку и используйте при настройке рекламной кампании.
Если видите неподходящие запросы под ваш продукт, сохраните их как минус-слова
Инструменты для сбора ключевых слов
Для поиска возможных ключей
Посмотреть популярность запросов можно в сервисе подборка слов от Яндекса — Вордстате. Он показывает, сколько раз указанный ключ искали за последний месяц, предлагает разные формы или альтернативные запросы. Вордстат может подсказать, какие ещё ключи стоит использовать для рекламы.
Сервис подбора слов от Яндекса
Использовать Вордстат удобно вместе с расширением от Semantica, там можно выбрать и скопировать все подходящие ключи, чтобы не переносить их по одному.
Yandex Wordstat Assistant от Semantica
Просто нажимайте на «+» рядом с подходящими ключами, а затем скопируйте их все вместе
У Гугла тоже есть сервис для подбора ключевых слов. Он не покажет точное количество запросов по ключам, зато покажет примерную вилку стоимости клика — так можно заранее спрогнозировать результат, который вы получите за свой бюджет.
Планировщик ключевых слов от Google
Сервис от Google показывает примерное количество запросов в месяц, уровень конкуренции и разброс ставок
Ещё один канал, где можно посмотреть, по каким запросам пользователи находят ваш сайт — системы аналитики Яндекс. Метрика и Google Analytics.
Как подключить к сайту Яндекс.Метрику
Как подключить к сайту Google Analytics
Пошаговое руководство по Яндекс. Метрике
Как узнать больше о поведении посетителей сайта и использовать это для роста бизнеса
| Читать |
Яндекс.Метрика покажет последние поисковые фразы, после которых пользователи переходили на ваш сайт
Если же у вас много товаров и услуг или широкая география присутствия, то в результате может получиться несколько сотен и даже тысяч запросов, по которым вы можете настроить рекламу на сайт. Работать с ними вручную невозможно, но это и не нужно — для большинства шагов есть инструменты, которые упростят задачу.
Илья Русаков
Основатель и руководитель агентства интернет-маркетинга impulse. guru, преподаватель в Нетологии, Skillbox и Деловой среде
Сервисы для автоматизированного сбора ключевых слов сами парсят Вордстат и поисковые подсказки. Вам достаточно указать глубину: сколько страниц ключевых слов вы хотите получить из Вордстата.
Вот некоторые из них:
Для автоматизированного сбора
Два популярных инструмента, которые используют, чтобы не собирать ключевые слова вручную — Key Collector и Rush Analytics. У них похожая функциональность: они собирают запросы из разных источников, могут их сгруппировать, чтобы вы могли их использовать в разных объявлениях. Они собирают не только ключевые слова, но их частотность, чтобы можно было отфильтровать высокочастотные или, наоборот, совсем редкие запросы.
Список возможностей, которые доступны в Rush Analytics. Для сбора поисковых запросов — Wordstat, Adwords, сбор подсказок
Основное отличие в том, что Key Collector — десктопная программа для Windows, за которую вы платите один раз. А Rush Analytics — облачный сервис, который не нагружает ресурсы вашего компьютера, но работает по подписке, то есть за него нужно платить регулярно.
А Rush Analytics — облачный сервис, который не нагружает ресурсы вашего компьютера, но работает по подписке, то есть за него нужно платить регулярно.
Илья Русаков
Основатель и руководитель агентства интернет-маркетинга impulse. guru, преподаватель в Нетологии, Skillbox и Деловой среде
Если вам нужно однократно собрать ключевые слова для рекламы, то проще использовать Rush Analytics. Его можно оплатить один раз на месяц и потом не использовать. А если планируете работать постоянно и используете Windows, то может быть выгоднее выбрать Key Collector.
У этих сервисов есть и другие возможности, которые могут быть полезны не только для контекстной рекламы, но и для SEO. Подробнее на сайтах Key Collector и Rush Analytics.
Есть сервисы, которые помогут проанализировать конкурентов — какие ключи они используют для рекламы. Например, анализ конкурентов есть в Serpstat и Spywords.
Serpstat Spywords
Подведём итог
Для запуска успешной контекстной рекламы вам потребуется список ключевых слов — запросов, по которым вы хотите показывать в поисковой выдаче свои объявления. Чем шире список, тем чаще вашу рекламу будут видеть пользователи.
Чем шире список, тем чаще вашу рекламу будут видеть пользователи.
Запускать рекламу только по очевидным запросам невыгодно: скорее всего, по ним будет более высокая конкуренция и более дорогой клик. Лучше использовать более детальные и менее конкурентные запросы.
В рекламе лучше всего использовать коммерческие запросы. Но если у вас контентный проект или есть блог, который может быть полезен покупателям, и вы готовы настраивать цепочку ретаргетинга, то можно использовать и информационные. Избегайте нечётких запросов.
Есть два способа собрать список ключевых слов: комбинация и парсинг. Первый подойдёт, если у вас большой ассортимент. Второй — если вы хотите собрать как можно более подробный список. Он может отнять больше времени, но в результате вы получите больше ключей.
Не удаляйте неподходящие запросы — они пригодятся вам как минус-слова при настройке рекламной кампании. Сохраните их на отдельной вкладке.
Чтобы собрать список ключей, воспользуйтесь поисковыми подсказками, сервисами подбора от Яндекса и Google. Чтобы автоматизировать эту задачу, подойдут Key Collector и Rush Analytics. Подсмотреть за конкурентами можно с помощью Serpstat и Spywords.
Чтобы автоматизировать эту задачу, подойдут Key Collector и Rush Analytics. Подсмотреть за конкурентами можно с помощью Serpstat и Spywords.
Текст: Слава Уфимцев
Иллюстрации, дизайн и верстка: Юлия Засс
Если материал вам понравился, поставьте лайк — это помогает другим узнать о нем и других статьях Tilda Education и поддерживает наш проект. Спасибо!
*Компания Meta Platforms Inc., владеющая социальными сетями Facebook и Instagram, по решению суда от 21.03.2022 признана экстремистской организацией, ее деятельность на территории России запрещена.
Читайте также:
Пошаговый гид по запуску рекламы в Инстаграме для новичков
Полный пошаговый гид по запуску рекламы в Фейсбуке для новичков
Полный пошаговый гид по запуску рекламы во ВКонтакте для новичков
Как найти и исправить ошибки SEO
Семантическое ядро – что это и как правильно составить семантику сайта, инструменты сбора и чистки СЯ
Как классифицировать запросы
При всем разнообразии запросов их можно объединить в несколько групп.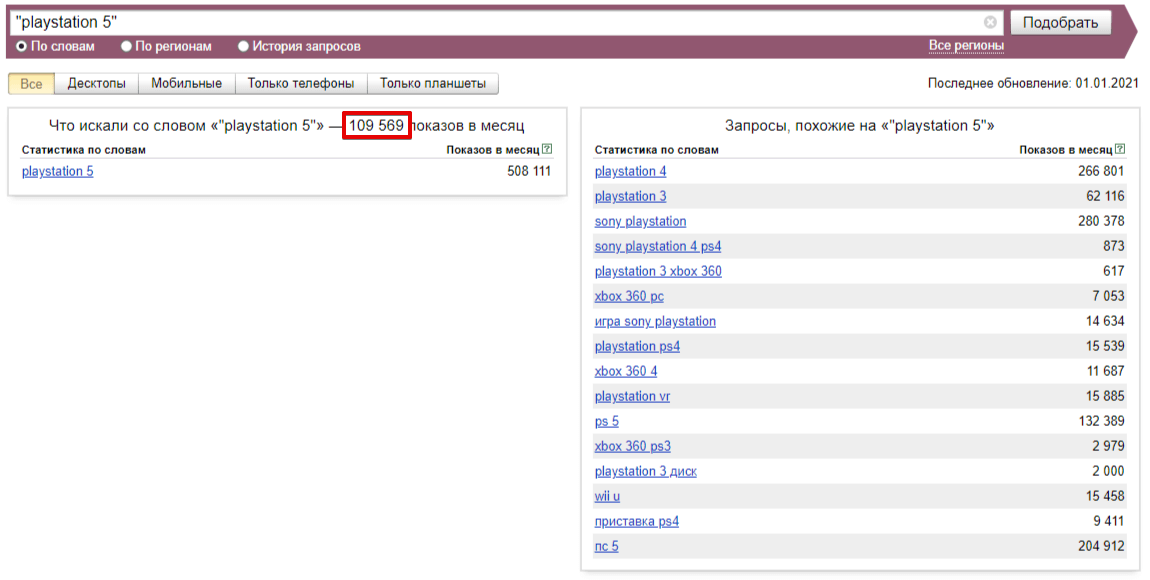 Когда понятно, к какой группе относится конкретный запрос, собирать ключевые слова и составлять семантическое ядро сайта становится значительно легче.
Когда понятно, к какой группе относится конкретный запрос, собирать ключевые слова и составлять семантическое ядро сайта становится значительно легче.
Частые и редкие запросы
Запросы отличаются частотностью.
- Высокочастотные запросы — слова, которые пользователи вбивают в строке поиска чаще всего. Например, «отдых в Турции». В этой фразе мало конкретики, а просто говорится о заграничном отдыхе на море. Частота повторов — более 10 тысяч.
- Среднечастотные запросы — их ещё называют уточняющими. К основной фразе высокочастотного запроса добавляются 1-2-3 слова, которые детально уточняют потребность. Например, «забронировать отдых в Турции» или «заказать отдых в Турции». Частота повторов — несколько тысяч.
- Низкочастотные запросы — состоят из 3-7 слов, имеют спецификатор или «хвост», конкретизирующий запрос. Например, «забронировать отдых в Турцию в Кемер из Москвы в мае».
 Чем конкретней запрос, тем меньше его частота. Например, такой подробный запрос обычно появляется в Интернете до 100 раз в месяц.
Чем конкретней запрос, тем меньше его частота. Например, такой подробный запрос обычно появляется в Интернете до 100 раз в месяц.
Нужно помнить, что частотность — это относительная величина. Для разных бизнесов, разных регионов и разных запросов цифры будут разные. Например, у запроса «купить iPhone 11» 70 911 показов в месяц, но его скорее можно отнести к среднечастотным.
А «воздушная гимнастика» набирает всего 17 720 запросов в месяц и это высокочастотный запрос.
Продвигать сайт со средним рекламным бюджетом можно по средне- и низкочастотным запросам. Высокочастотные при этом не удалять, а оставить в ядре и использовать их как идеи для контента. Если же рекламный бюджет большой, то можно активно продвигаться высокочастотным запросам.
Коммерческие и информационные запросы
Коммерческий запрос — тот, где ключевое слово подразумевает, что пользователь хочет купить товар или заказать услугу. Например, «купить абонемент», «запчасти тойота прайс», «нотариус тверская цена».
Например, «купить абонемент», «запчасти тойота прайс», «нотариус тверская цена».
Информационный запрос чаще направлен на поиск информации. Например «стиральная машина с сушкой отзывы», «барселона википедия», «никон d3500 характеристики».
В семантическом ядре сайта по продаже товаров и услуг коммерческие запросы должны быть обязательно. Однако это не значит, что некоммерческие можно полностью исключить. Если у вас есть блог или раздел с экспертными статьями, можно использовать информационные ключевые слова в публикуемых там материалах.
Геозависимые и геонезависимые запросы
При вводе запроса поисковая система учитывает местоположение пользователя. Если житель Москвы спросит Яндекс или Google «куда пойти в выходные», оба поисковика выдадут информацию, актуальную именно для Москвы, и не будут показывать события во Владивостоке, скажем. Это пример геозависимого запроса. «Купить кухню», «открытые катки», «как приручить дракона кинотеатр» — это всё тоже примеры геозависимых запросов.
При этом если пользователь находится в Москве и хочет поздравить родственницу в Новосибирске с днем рождения, то запрос «доставка цветов новосибирск» — это уже геонезависимый запрос. Геонезависимые запросы — это те, результаты которых не зависят от места. Например, «рецепт борща», «чернобыль нетфликс» «нотр дам париж».
Брендовые и витальные запросы
Если ключевая фраза содержит название бренда — это брендовый запрос. На сайте, соответственно, должен быть каталог товаров этой компании, название нужно прописывать в карточках товаров, в описании, характеристиках, а также не забыть указать в метатегах и заголовке Н1. Например, «лаки для ногтей OPI», «швейцарские часы tag heuer» и пр.
Если пользователь вводит поисковый запрос «natura siberica», поисковик не может определить его цель и понять, что лучше показать. Косметику бренда? Книгу о компании? Новости компании? Такие запросы называются витальными, по ним поисковая выдача покажет официальные страницы компаний и брендов.
Нечеткие запросы
По данным Яндекса, примерно 20% запросов пользователей — нечеткие. То есть алгоритм не может однозначно определить цель поиска. По запросу «ренессанс» можно искать гостиницу, эпоху Возрождения и страховую компанию одновременно. Для обработки таких запросов у Яндекса есть технология Спектр.
Спектр анализирует запросы всех пользователей и распределяет ключевые слова по категориям. При ранжировании результатов в выдачу попадают те сайты, которые, по мнению алгоритмов, с наибольшей вероятностью дадут ответ на вопрос пользователя. Нужно иметь в виду, что конкуренция по таким запросам может быть очень большой. Кроме того, из-за высокого количества нецелевых заходов конверсия сайта часто снижается.
Типы запросов, о которых мы говорили выше, можно также поделить на 4 большие группы для удобства работы с ними, то есть кластеризовать по следующему принципу:
- Транзакционные запросы — это все запросы пользователей, планирующих совершить действие.
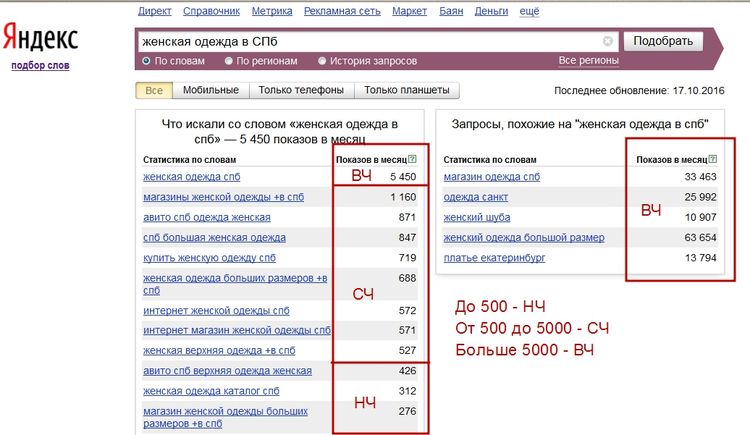 Сюда относятся коммерческие запросы, относящиеся к товарам и услугам — «купить», «заказать», но также и «скачать поваренную книгу», например.
Сюда относятся коммерческие запросы, относящиеся к товарам и услугам — «купить», «заказать», но также и «скачать поваренную книгу», например. - Информационные запросы — отвечают на вопросы пользователей «какой», «как», «где» и другие, то есть, связаны с поиском сведений и справочной информации. Например, «игорь ашманов биография».
- Навигационные запросы — те, по которым ищут конкретные модели товаров, компании, сайты, места и события. Например «конференция optimization 2020».
- Мультимедийные запросы — по ним ищут фотографии, аудио- и видеозаписи.
Сбор семантического ядра
Подбор ключевых слов и фраз для работы с семантическим ядром можно поделить на три этапа.
1 этап: определение базовых ключей
С помощью Яндекс.Метрики и Google Analytics можно посмотреть, по каким поисковым запросам находит сайт текущая аудитория — эти данные есть в кабинетах для вебмастеров.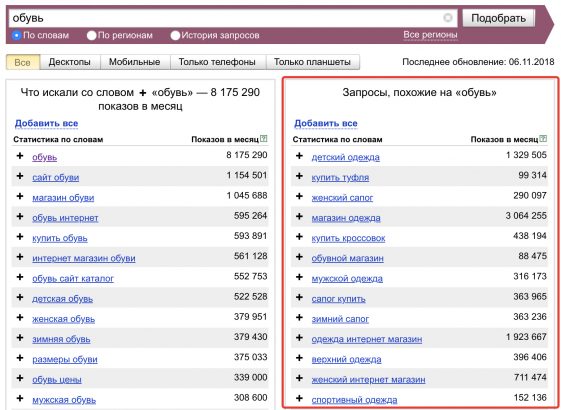 Если сайт новый и данных статистики еще нет, этот шаг можно пропустить и сразу перейти к брейншторму.
Если сайт новый и данных статистики еще нет, этот шаг можно пропустить и сразу перейти к брейншторму.
Соберите коллег и устройте мозговой штурм. Вам поможет таблица, в которую можно записывать все приходящие в голову или собранные из метрик поисковые фразы, слова и словоформы. Запишите синонимы, профессиональную терминологию и варианты написания, аббревиатуры, сокращения. Чем больше, тем лучше. На этом этапе записывайте всё, не вычеркивайте ни одну идею. При последующем анализе, скорее всего, окажется, что вы записали высокочастотные и низкоспецифичные фразы. Поэтому список нужно максимально расширить.
2 этап. Расширение семантического ядра
Эту задачу можно решать двумя способами.
- Анализ конкурентов. Их сайты могут стать источником новых идей. В мета-теге в исходном коде страницы посмотрите вручную, под какие ключевые слова она оптимизирована. Вы должны увидеть идущие через запятую ключевые запросы. Если у сайта конкурента открыты счетчики посещаемости, то проанализировать страницу можно через них.
 Но лучше воспользоваться специальными сервисами.
Но лучше воспользоваться специальными сервисами. - Инструменты для составления семантического ядра. Есть много платных и бесплатных сервисов, которые помогут не только расширить, но и почистить, и прокластеризовать базу запросов, а также выполнить другие рутинные задачи по работе с семантическим ядром. Подробнее о сервисах для работы с семантикой расскажем ниже.
3 этап. Исключение неподходящих запросов
Удалять неподходящие запросы лучше вручную. Это трудозатратный, но необходимый процесс. Если вы используете чисто сеошный подход — ориентируетесь на частотность и конкурентность ключей — рискуете пропустить очень перспективный низкочастотный ключ. Посмотрите на ключевой запрос глазами маркетолога. Возможно, у вас есть товар, подходящий под данный запрос. Тогда ключ пригодится в описании в карточке. А если товара нет, но вы понимаете, что есть пусть небольшая, но аудитория, которая интересуется вопросом, включите его в ядро и используйте как идею для контента в информационном разделе.
Сервисы от поисковых систем очень полезны, но не стоит слепо использовать все выданные слова. Некоторые из них могут совсем не подходить к тематике вашего сайта. Например, «купить авиабилет в Турцию» вам не подойдет, если вы занимаетесь продажей пакетов путевок по системе «все включено», и клиент не может купить только перелет.
Ключи, которые точно нужно исключить:
- упоминающие конкурентов, название их компаний, торговые марки,
- содержащие товары и услуги, которые вы не продаете и не оказываете,
- дубли — явные и неявные,
- упоминающие районы или адреса, где вы не работаете,
- слова с ошибками — поисковики (поисковая подсказка Яндекс и Google) давно научились понимать, что пользователи ищут, даже если те опечатались, ошиблись, ввели слово, не переключив раскладку языка и пр.
Инструменты для сбора семантического ядра
Сервисов для работы с семантическим ядром много, некоторые включают в себя широкий набор инструментов для любых задач, некоторые — только опции для работы с семантикой. Ниже расскажем о самых известных, а подробнее о лучших сервисах для SEO-продвижения, в том числе для работы с семантическим ядром, читайте в статье.
Ниже расскажем о самых известных, а подробнее о лучших сервисах для SEO-продвижения, в том числе для работы с семантическим ядром, читайте в статье.
- Яндекс.Wordstat. Простой, понятный и бесплатный инструмент, позволяющий проверить ключевые слова в семантическом ядре своего сайта на частотность, региональность и другие параметры. На предыдущем этапе вы собрали ключевые слова. Теперь проанализируйте их все с помощью сервиса подбора слов. Если ваш бизнес привязан к определенному региону, выберите его в настройках.
Скопируйте в ту же таблицу слова из правой и левой колонок. Можете удалить неподходящие ключи сразу, а можете оставить до следующего этапа. На нем они все равно должны отсеяться. Не забудьте проанализировать поисковые фразы не только для десктопов, но и для мобильных устройств. - Планировщик ключевых слов Google. Это сервис, аналогичный Вордстату, но ориентированный на запросы пользователей поисковой системы Google.
 Воспользуйтесь им тоже. Список ключевых слов у поисковиков будут отличаться. Кроме того, в отличие от Вордстата, в Планировщике можно делать поиск не только по ключам, но и по ссылкам. Сервис Google сделает анализ информации на странице и выдаст список запросов по теме.
Воспользуйтесь им тоже. Список ключевых слов у поисковиков будут отличаться. Кроме того, в отличие от Вордстата, в Планировщике можно делать поиск не только по ключам, но и по ссылкам. Сервис Google сделает анализ информации на странице и выдаст список запросов по теме. - SEMrush. Это комплексный инструмент, который подберет идеи ключевых фраз и поможет в составлении семантического ядра по базовому ключу, предложит смежные запросы, оценит частотность ключей, конкуренцию и выдачу Google по ним. Кроме того, сервис предложит оценку по 100-балльной шкале, насколько тяжело будет выйти в топ выдачи по выбранному ключевому слову.
- Serpstat. Платный инструмент для сбора семантики из поисковой выдачи, сайтов, объявлений и других открытых источников, анализа семантики своего сайта, кластеризации запросов. Из дополнительных полезных опций: возможность анализа семантики сайтов конкурентов, сравнение страниц сайта по ключевым словам и сбор вопросительных фраз.

- Key Collector. Многофункциональный инструмент, который будет полезен профессиональным интернет-маркетологам, тем, кто развивает несколько сайтов одновременно или собирает ядро для одного большого. Функционал сервиса:
- подбор ключевых слов с помощью Вордстат и парсинг поисковых подсказок,
- исключение неподходящих запросов и неявных дублей,
- фильтр по частотности,
- выявление сезонности запросов,
- сбор статистики из Метрики, Google Analytics и Ads, ВКонтакте, Liveinternet.ru и других.
Что делать с семантическим ядром?
После сбора ключевых слов их нужно кластеризовать — объединить по категориям похожие запросы. Кластеризация поможет грамотно распределить запросы по страницам сайта. Категории определяют тематика и структура сайта. Например, для сайта магазина косметики можно выделить кластер «Средства для лица», «Средства для волос» и так далее. Коммерческие запросы лучше отнести к продуктовым и посадочным страницам, а для блога, раздела о компании взять информационные.
Коммерческие запросы лучше отнести к продуктовым и посадочным страницам, а для блога, раздела о компании взять информационные.
Не используйте много ключевых слов на одной странице — поисковые роботы считают заспамленный текст некачественным и могут понизить сайт в выдаче. Оптимальное содержание запросов на странице — 4% от объема всего текста. Вписывайте ключи органично, используйте прямые вхождения только там, где это выглядит уместно.
Семантическое ядро также можно использовать, чтобы составить контент-план, а кластеры — для составления ТЗ на написания статей.
Выводы
- Составление семантического ядра — важный этап SEO-продвижения. Семантическое ядро нужно для улучшения структуры сайта, улучшения ранжирования в Поиске, роста органического трафика, составления контент-плана, запуска контекстной рекламы и понимания потребностей покупателей.
- Запросы можно классифицировать по частотности, направленности (коммерческие и информационные), геопривязке, привязке к бренду, а также кластеризовать на транзакционные, информационные, навигационные и мультимедийные — для удобства работы с семантическим ядром.

- Сбор семантики включает три этапа: сбор базовых ключей, расширение ядра дополнительными запросами и очистка базы от неподходящих запросов (мусорный, ошибочный, включающий названия конкурентов и неподходящий по тематике).
- Собранное семантическое ядро кластеризуйте на группы, вписывайте на страницы сайта и используйте для составления контент-плана и ТЗ для новых текстов.
Статью подготовила Бучнева Ольга. Закончила факультет журналистики, работала младшим редактором, копирайтером. Владеет навыками копирайта, рерайта, верстки в HTML. В свободное время ходит в кино, на выставки, читает, катается на роликах, любит пешие прогулки и путешествовать.
Стратегии и методы ограничения скорости | Центр облачной архитектуры
Введение
В этом документе объясняется, почему используется ограничение скорости, описываются стратегии и
методов ограничения скорости и объясняет, где ограничение скорости актуально для
Облачные продукты Google. Большая часть этой информации относится к нескольким слоям в
технологические стеки, но этот документ фокусируется на ограничении скорости в приложении
уровень.
Большая часть этой информации относится к нескольким слоям в
технологические стеки, но этот документ фокусируется на ограничении скорости в приложении
уровень.
Ограничение скорости относится к предотвращению увеличения частоты операций. превышение некоторого ограничения. В крупномасштабных системах ограничение скорости обычно используется для защиты базовых служб и ресурсов.
Зачем используется ограничение скорости
Ограничение скорости обычно применяется в качестве защитной меры для служб.
Общие службы должны защищать себя от чрезмерного использования — независимо от того,
или непреднамеренно — для поддержания доступности услуги. Даже хорошо масштабируемые системы
должны иметь ограничения на потребление на каком-то уровне. Чтобы система работала хорошо,
клиенты также должны быть разработаны с учетом ограничения скорости, чтобы уменьшить вероятность
каскадный сбой.
Ограничение скорости как на стороне клиента, так и на стороне сервера имеет решающее значение для
максимизация пропускной способности и минимизация сквозной задержки в больших распределенных
системы.
Предотвращение нехватки ресурсов
Наиболее распространенной причиной ограничения скорости является повышение доступности Услуги на основе API, избегая нехватки ресурсов. Многие основанные на нагрузке инциденты отказа в обслуживании в больших системах непреднамеренны — вызваны ошибками в программном обеспечении или конфигурациях в какой-либо другой части системы — не со злым умыслом атаки (такие как сетевые распределенные атаки типа «отказ в обслуживании»). Ресурс голодание, не вызванное злонамеренной атакой, иногда называют дружественный огонь отказ в обслуживании (DoS) .
Как правило, служба применяет ограничение скорости на этапе, предшествующем ограниченному
ресурс с некоторым запасом безопасности для предварительного предупреждения. Маржа требуется, потому что
может быть некоторое отставание в нагрузках, и защита ограничения скорости должна быть
до того, как произойдет критическая конкуренция за ресурс. Например,
RESTful API может применять ограничение скорости для защиты базовой базы данных; без
ограничение скорости, масштабируемая служба API может выполнять большое количество вызовов
базы данных одновременно, и база данных может быть не в состоянии отправить четкие
сигналы ограничения скорости.
Например,
RESTful API может применять ограничение скорости для защиты базовой базы данных; без
ограничение скорости, масштабируемая служба API может выполнять большое количество вызовов
базы данных одновременно, и база данных может быть не в состоянии отправить четкие
сигналы ограничения скорости.
Управление политиками и квотами
Когда емкость службы распределяется между многими пользователями или потребителями, она может
применять ограничение скорости для каждого пользователя, чтобы обеспечить справедливое и разумное использование, без
влияет на других пользователей. Эти ограничения могут применяться в течение более длительных периодов времени,
или они могут применяться к ресурсам, которые измеряются не скоростью, а
выделенное количество. Эти лимиты скорости и распределения вместе называются
до квот . Квоты также могут применяться к пакетам монетизации API или уровню бесплатного пользования.
пределы. Подробнее см.
Квоты и лимиты
раздел этого документа.
Важно понимать, как эти квоты распределяются между приложениями и проектов в вашей организации. Например, выпуск мошеннической канарейки в производственный проект может потреблять квоту на ресурс, используемый производственно-обслуживающим инфраструктура.
Управление потоком
В сложных связанных системах, которые обрабатывают большие объемы данных и сообщений, вы может использовать ограничение скорости для управления этими потоками — будь то объединение многих потоков в один сервис или распределение одного рабочего потока на множество воркеров.
Например, вы можете более равномерно распределить работу между работниками, ограничив
поток в каждого работника, предотвращая накопление очереди одним работником
необработанных элементов, в то время как другие работники простаивают. Балансы управления потоком, имеющие
предварительно выбранные данные, готовые к локальной обработке, с гарантией того, что каждый узел в
система имеет равные возможности для выполнения работы. Для получения дополнительной информации см.
Pub/Sub: управление потоком
раздел.
Для получения дополнительной информации см.
Pub/Sub: управление потоком
раздел.
Предотвращение чрезмерных затрат
Вы можете использовать ограничение ставок для контроля затрат — например, если базовый ресурс способен автоматически масштабироваться для удовлетворения спроса, но бюджет для этого использование ресурсов ограничено. Организация может использовать ограничение скорости, чтобы предотвратить эксперименты с выходом из-под контроля и накоплением крупных счетов. Этот Отчасти беспокойство вызывает то, почему многие квоты Google Cloud устанавливаются с начальным значения, которые могут быть увеличены по запросу. Организации, которые предлагая решения SaaS (программное обеспечение как услуга) с фиксированной стоимостью, которым необходимо моделировать их стоимость, цена и маржа на одного клиента.
Стратегии
В цепочке или сетке услуг многие узлы системы являются одновременно клиентами и
серверы. Каждая часть системы может вообще не применять стратегию ограничения скорости,
или может по-разному комбинировать одну или несколько стратегий, поэтому представление о
требуется вся система, чтобы убедиться, что все работает оптимально. Даже в
случаи, когда ограничение скорости реализовано полностью на стороне сервера,
клиент должен быть сконструирован так, чтобы реагировать соответствующим образом.
Каждая часть системы может вообще не применять стратегию ограничения скорости,
или может по-разному комбинировать одну или несколько стратегий, поэтому представление о
требуется вся система, чтобы убедиться, что все работает оптимально. Даже в
случаи, когда ограничение скорости реализовано полностью на стороне сервера,
клиент должен быть сконструирован так, чтобы реагировать соответствующим образом.
В большинстве случаев, если инструмент или инфраструктура, реализующая ваш
сама стратегия ограничения скорости не работает или недоступна, ваш сервис должен не удалось открыть и попытаться обслужить все запросы. Клиенты обычно не работают
за пределами квот, а сбой открытия менее разрушительно для
крупномасштабных систем, чем отказ закрытых. Неудачное закрытие приводит к
полное отключение по сравнению с отказом в открытии, что приводит к ухудшению состояния.
Решения о неудачном открытии или закрытии в основном относятся к серверу.
сторона, но знание того, какие методы повторной попытки клиенты используют при неудачном запросе
может повлиять на ваши решения о поведении сервера.
Без ограничения скорости
Важно рассмотреть вариант без ограничения скорости как пола в вашем проекте, то есть как наихудший случай, когда ваша система должна быть в состоянии разместить. Создайте свою систему с надежной обработкой ошибок в случае, если некоторые часть вашей стратегии ограничения скорости терпит неудачу, и понять, какие пользователи вашего служба получит в этих ситуациях. Убедитесь, что вы предоставляете полезную ошибку коды и что вы не допускаете утечки конфиденциальных данных в кодах ошибок. Использование тайм-аутов, сроки и шаблоны прерывания цепи помогают вашей службе быть более надежной в отсутствие ограничения скорости.
Проход через
Если ваша служба обращается к другим службам для выполнения запросов, вы можете выбрать, как вы передаете любые ограничивающие скорость сигналы от этих сервисов обратно в исходный абонент.
Примечание: В службах HTTP наиболее распространенный способ, которым службы сигнализируют о том, что они применение ограничения скорости путем возврата 429 код состояния в ответе HTTP. Ответ
Ответ 429 может предоставить дополнительную информацию.
о том, почему применяется ограничение (например, у пользователя freemium меньше квота,
или система находится на обслуживании).Самый простой вариант — пересылать только ответ об ограничении скорости от нисходящее обслуживание для вызывающего абонента. Альтернативой является принудительное ограничение скорости от имени нижестоящей службы и заблокировать вызывающего абонента.
Принудительное ограничение скорости
Наиболее распространенная стратегия ограничения скорости для службы заключается в применении одного или нескольких
Методы ограничения скорости.
Это ограничение скорости может быть введено для непосредственной защиты службы или
могут быть введены в действие для защиты нижестоящего ресурса, когда известно, что
нижестоящий сервис не имеет возможности защитить себя. Например, если вы
запуск службы API, которая подключается к устаревшей серверной системе, которая не
устойчив к большим нагрузкам, сервис API не должен использовать сквозной
стратегия, предполагающая, что устаревшая служба будет предоставлять свои собственные ограничения скорости
сигналы.
Чтобы применить ограничение скорости, сначала поймите, почему оно применяется в данном случае,
а затем определить, какие атрибуты запроса лучше всего подходят для использования в качестве
ограничивающий ключ (например, исходный IP-адрес, пользователь, API-ключ). После тебя
выберите ограничивающий ключ, ограничивающая реализация может использовать его для отслеживания использования.
При достижении лимитов сервис возвращает ограничивающий сигнал (обычно 429 ).
HTTP-ответ).
Отложить ответ
Если вычисление ответа требует больших затрат или времени, система может быть
не может дать оперативный ответ на запрос, что затрудняет
сервис для обработки большого количества запросов. Альтернатива ограничению скорости в
в этих случаях запросы помещаются в очередь и возвращаются в той или иной форме идентификатором задания.
Это позволяет службе поддерживать более высокую доступность и снижает
вычислительные усилия для клиентов, которые в противном случае могли бы выполнять длительные блокирующие вызовы
пока жду ответа.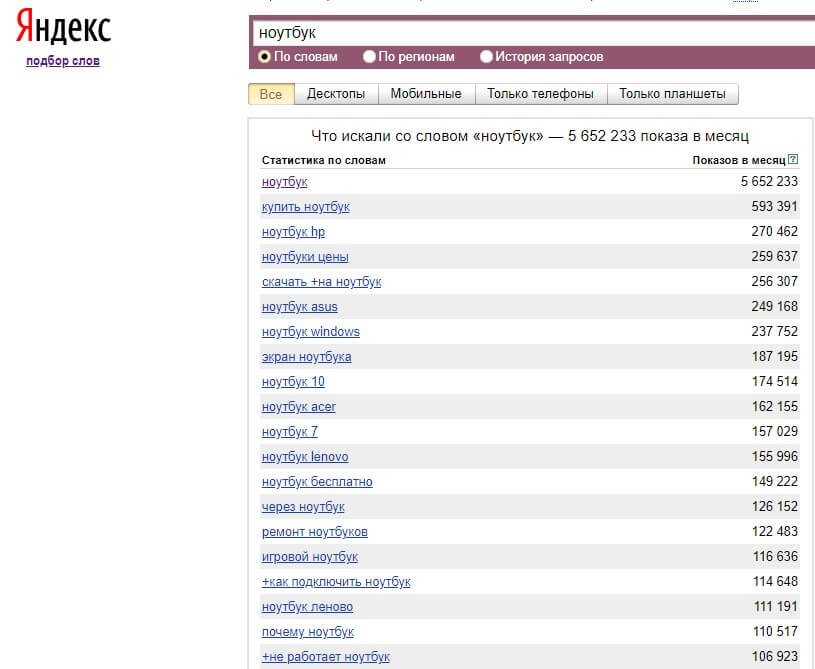 Каков результат отложенного ответа
возвращаемый вызывающему абоненту — это еще один набор вариантов, но обычно он включает в себя
опрос о состоянии идентификатора задания или через систему, полностью основанную на событиях, в которой
вызывающий абонент может зарегистрировать обратный вызов или подписаться на канал событий. Такой
системы выходит за рамки этого документа.
Каков результат отложенного ответа
возвращаемый вызывающему абоненту — это еще один набор вариантов, но обычно он включает в себя
опрос о состоянии идентификатора задания или через систему, полностью основанную на событиях, в которой
вызывающий абонент может зарегистрировать обратный вызов или подписаться на канал событий. Такой
системы выходит за рамки этого документа.
Шаблон отложенного ответа проще всего применить, когда требуется немедленный ответ. на запрос не содержит реальной информации. Если этот шаблон используется слишком часто, тогда это может увеличить сложность и режимы отказа вашей системы.
Стратегии на стороне клиента
Описанные стратегии применяются для ограничения скорости на стороне сервера. Тем не менее, эти стратегии могут повлиять на дизайн клиентов, особенно когда вы Учтите, что многие компоненты в распределенной системе являются одновременно и клиентскими, и сервер.
Поскольку основная цель службы при использовании ограничения скорости — защитить себя
и поддерживать доступность, основная цель клиента — выполнить запрос
это делает на службу.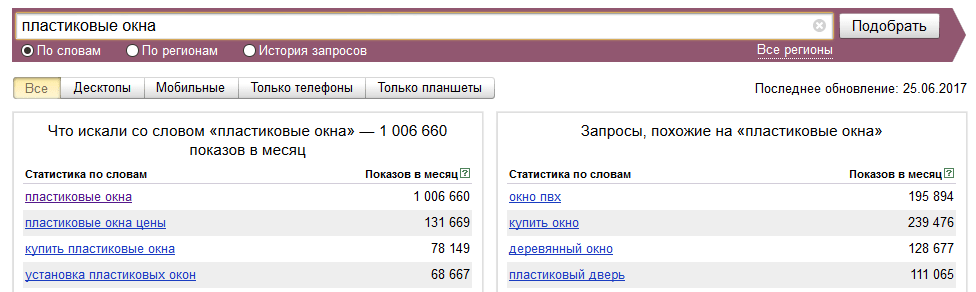 Служба может быть не в состоянии выполнить запрос от
клиент по разным причинам, включая следующие:
Служба может быть не в состоянии выполнить запрос от
клиент по разным причинам, включая следующие:
- Служба недоступна из-за сетевых условий.
- Служба вернула неспецифическую ошибку.
- Служба отклоняет запрос из-за проверки подлинности или авторизации. отказ.
- Запрос клиента недействителен или имеет неправильный формат.
- Служба ограничивает скорость вызывающего абонента и отправляет сигнал обратного давления
(обычно ответ
429).
Мы рекомендуем создавать клиенты, устойчивые к подобным проблемам. предоставлено Google клиентские библиотеки имеют множество встроенных функций, которые распознают описанные выше сценарии.
В ответ на ограничивающие скорость, периодические или неспецифические ошибки клиент
обычно следует повторить запрос после задержки. Это лучшая практика для этого
задержка экспоненциально увеличивается после каждого неудачного запроса, на который ссылаются
как экспоненциальная отсрочка . Когда многие клиенты могут делать по расписанию
запросы (например, получение результатов каждый час), дополнительное случайное время
( jitter ) следует применять к времени запроса, периоду отсрочки или к тому и другому.
чтобы гарантировать, что эти несколько экземпляров клиента не станут периодическими
громоподобное стадо,
и сами вызывают форму DDoS.
Когда многие клиенты могут делать по расписанию
запросы (например, получение результатов каждый час), дополнительное случайное время
( jitter ) следует применять к времени запроса, периоду отсрочки или к тому и другому.
чтобы гарантировать, что эти несколько экземпляров клиента не станут периодическими
громоподобное стадо,
и сами вызывают форму DDoS.
Представьте себе мобильное приложение со многими пользователями, которое регистрируется с помощью API ровно в полдень.
каждый день и применяет ту же детерминированную логику отсрочки. В полдень многие
клиенты звонят в службу, которая запускает ограничение скорости и возвращает ответы
с 429 код состояния. Затем клиенты послушно отступают и ждут
количество времени (детерминированная задержка) ровно 60 секунд, а затем в 12:01
служба получает еще один большой набор запросов. Добавляя случайное смещение
(джиттер) ко времени первоначального запроса или ко времени задержки, запросы
и повторные попытки могут быть распределены более равномерно, что дает сервису больше шансов
выполнения запросов.
В идеале неидемпотентные запросы могут выполняться в контексте сильно последовательная транзакция, но не все запросы на обслуживание могут предложить такие гарантии, и поэтому повторные попытки, которые мутируют данные, должны учитывать последствия дублирования действие.
Для ситуаций, когда разработчик клиента знает, что система, которую он зовет не устойчив к стрессовым нагрузкам и не поддерживает сигналы ограничения скорости (обратное давление), разработчик клиентской библиотеки или клиент разработчик приложения может самостоятельно применить регулирование, используя такой же методы ограничения скорости которые можно использовать на стороне сервера.
Для клиентов API, которые откладывают ответ с помощью асинхронного длительного выполнения идентификатор операции, клиент может войти в цикл блокировки, опрашивая статус отложенного ответа, снимая эту сложность с пользователя клиента библиотека.
Методы принудительного ограничения скорости
В общем, частота — это просто подсчет событий с течением времени. Однако там
несколько различных методов измерения и ограничения ставок, каждый из которых
их собственное использование и последствия.
Однако там
несколько различных методов измерения и ограничения ставок, каждый из которых
их собственное использование и последствия.
- Ведро токенов : A корзина с жетонами поддерживает скользящий и накапливающийся бюджет использования как баланс токенов . Этот метод признает, что не все входные данные для службы соответствуют 1:1 запросам. Ведро токенов добавляет токены с определенной скоростью. Когда делается запрос на обслуживание, сервис пытается отозвать токен (уменьшая количество токенов) для выполнения запроса. если нет токенов в корзине, служба достигла предела и отвечает обратное давление. Например, в службе GraphQL один запрос может результатом является несколько операций, которые составляются в результате. Эти каждая операция может занимать один токен. Таким образом, служба может отслеживать мощность, которую ему необходимо ограничить использованием, а не связывать метод ограничения скорости непосредственно на запросы.
- Негерметичное ведро : A
дырявое ведро
похож на ведро токенов, но скорость ограничена суммой, которую
может капать или вытекать из ведра.
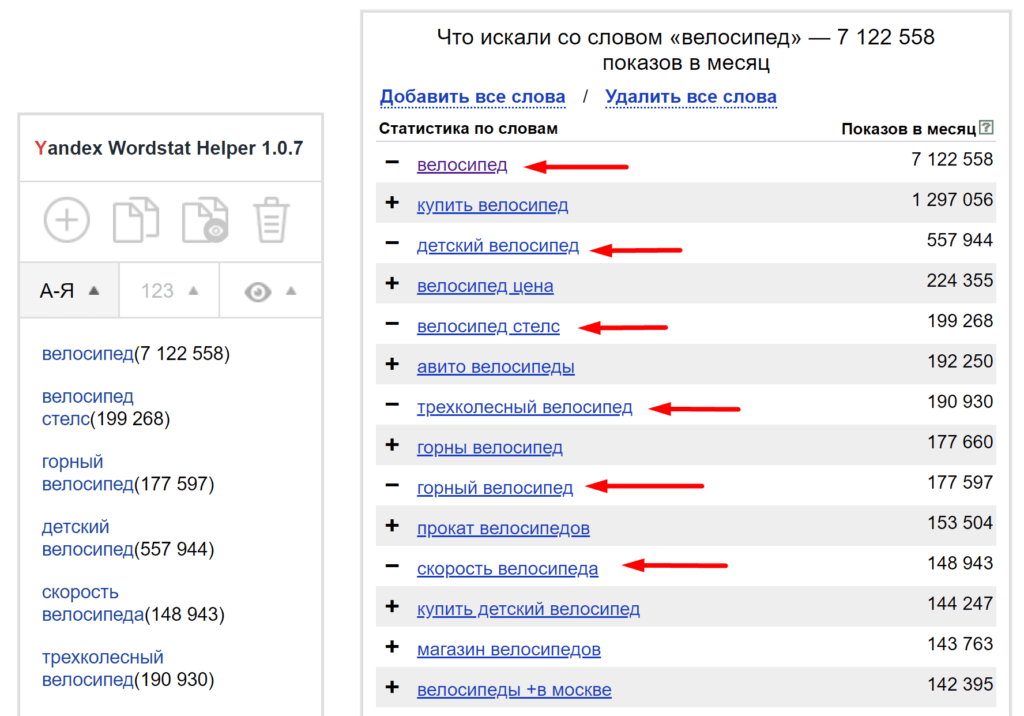 Эта техника признает, что
система имеет некоторую степень конечной способности удерживать запрос до тех пор, пока
служба может воздействовать на него; любое лишнее просто выливается через край и
отброшен. Это понятие буферной емкости (но не обязательно использование
дырявые ведра) также применяется к компонентам, смежным с вашим сервисом, таким как
балансировщики нагрузки и дисковые буферы ввода-вывода.
Эта техника признает, что
система имеет некоторую степень конечной способности удерживать запрос до тех пор, пока
служба может воздействовать на него; любое лишнее просто выливается через край и
отброшен. Это понятие буферной емкости (но не обязательно использование
дырявые ведра) также применяется к компонентам, смежным с вашим сервисом, таким как
балансировщики нагрузки и дисковые буферы ввода-вывода. - Фиксированное окно : Пределы фиксированного окна — например, 3000 запросов в час или 10 запросов в день — легко указать, но они могут резко увеличиваться в края окна, так как доступная квота сбрасывается. Рассмотрим, например, ограничение в 3000 запросов в час, что по-прежнему допускает всплеск всех 3000 запросов в первую минуту часа, что может перегрузить службу.
- Раздвижное окно : Раздвижные окна имеют преимущества фиксированного окна,
но катящееся окно времени сглаживает всплески. Такие системы, как Redis
облегчить эту технику с истекающими ключами.
При наличии множества независимо работающих экземпляров службы (например, Облачные функции) в распределенной системе, и сервис должен быть ограничен в целом нужно использовать быстрый, логически-глобальный (глобальный для всех запущенных функции, не обязательно географически глобальные) хранилище ключей и значений, такое как Redis, для синхронизировать различные предельные счетчики.
Функции ограничения скорости в Google Cloud
Каждый API Google (внутренний и внешний) обеспечивает определенную степень скорости ограничение или квота. Это фундаментальный принцип дизайна услуг в Google. В этом разделе рассматривается, как эти сервисы также предоставляют ограничение скорости как функцию. которые вы можете использовать при создании в Google Cloud.
Квоты и ограничения
Google Cloud применяет квоты, которые ограничивают объем определенного
Ресурс Google Cloud, который может использовать ваш проект. Тарифные квоты указать, сколько
ресурса можно использовать в заданное время, например запросов API в день. Вы можете
также установите свои собственные ограничения на то, сколько ресурсов можно использовать в данном
время; такие пользовательские ограничения называются caps .
Тарифные квоты указать, сколько
ресурса можно использовать в заданное время, например запросов API в день. Вы можете
также установите свои собственные ограничения на то, сколько ресурсов можно использовать в данном
время; такие пользовательские ограничения называются caps .
Для получения подробной информации о квотах и ограничениях, включая информацию о том, как установить ограничения и запросить увеличение квоты, см. Работа с квотами.
У каждого продукта Google Cloud есть страница со списком ограничений услуг. (например, максимальные размеры сообщений) и квоты на основе скорости (например, максимальный количество запросов в секунду для определенного API). На этих страницах также отмечается, вы можете запросить увеличение или нет. Чтобы найти эти страницы, начните с этот поиск.
Как правило, квоты Google Cloud указаны для каждого проекта, а количество окон — для каждого проекта.
секунду или минуту. Когда у вас есть несколько частей вашего решения, работающих в
проект, важно отметить, что они делят эти квоты.
Вы можете монитор как расходуется ваша квота, и даже устанавливайте оповещения об изменениях в том, как вы используют квоту или когда использование превышает определенное количество. Вы можете установить свою собственную кепку об использовании и использовании API оповещения о бюджете контролировать расходы, связанные с использованием API.
Cloud Tasks
Cloud Tasks — это полностью управляемая служба, которую вы можете использовать для управления выполнение, отправка и доставка большого количества распределенных задач. Используя Cloud Tasks, вы можете асинхронно выполнять работу вне запрос пользователя. Облачные задачи позволяют установить как скорость, так и ограничения параллелизма. Cloud Tasks использует метод ведра токенов, чтобы учесть степень из распирание в том, как сообщения доставляются в этих пределах.
Cloud Functions
Cloud Functions — это легкое вычислительное решение для разработчиков,
создавать одноцелевые автономные функции, которые реагируют на облачные события
без необходимости управлять сервером или средой выполнения. Облачные функции по умолчанию не имеют состояния и легко масштабируются:
управляемая инфраструктура автоматически создает экземпляры функций для обработки
загрузка входящего запроса. Из-за такого поведения масштабирования функции могут стать
мишени с высоким уровнем запросов, и если эти функции вызывают нижестоящие
службы, функции могут стать источником непреднамеренного отказа в обслуживании на тех
нижестоящие сервисы.
Облачные функции по умолчанию не имеют состояния и легко масштабируются:
управляемая инфраструктура автоматически создает экземпляры функций для обработки
загрузка входящего запроса. Из-за такого поведения масштабирования функции могут стать
мишени с высоким уровнем запросов, и если эти функции вызывают нижестоящие
службы, функции могут стать источником непреднамеренного отказа в обслуживании на тех
нижестоящие сервисы.
Одним из типов DoS-атак является исчерпание подключений к базам данных. Если каждая функция экземпляр устанавливает соединение базы данных с серверной частью, всплеск трафика может привести к автоматическому масштабированию многих экземпляров и, следовательно, к истощению доступная емкость соединений на серверах баз данных. Чтобы функции не масштабирование за пределами определенного количества экземпляров, сервис обеспечивает настройка максимального количества экземпляров для каждой функции.
Для фоновых функций Google Cloud вызывает вашу функцию с событием
полезная нагрузка и контекст. Вы можете указать, хотите ли вы, чтобы система
повторить доставку события
если ваша функция дает сбой или не может обработать событие — возможно, из-за того, что
будучи ограниченным по скорости чем-то нижестоящим.
Вы можете указать, хотите ли вы, чтобы система
повторить доставку события
если ваша функция дает сбой или не может обработать событие — возможно, из-за того, что
будучи ограниченным по скорости чем-то нижестоящим.
Хотя настройка максимального количества экземпляров может помочь вам ограничить параллелизм, это не дать прямой контроль над тем, сколько раз в секунду может быть вызвана ваша функция. См. Что дальше раздел для учебных пособий, демонстрирующих, как использовать Redis для глобальной координации скорости ограничение вызовов функций.
Pub/Sub: управление потоком
Pub/Sub — это полностью управляемая служба обмена сообщениями в реальном времени,
позволяет отправлять и получать сообщения между независимыми приложениями. Когда
перемещая большое количество сообщений через темы Pub/Sub, вы можете
необходимо настроить скорость обработки сообщений на клиентах-потребителях, чтобы
что потребители, работающие параллельно, эффективны и не держат слишком много
ожидающие сообщения, влияющие на общую задержку обработки. Чтобы настроить это
поведения, клиенты Pub/Sub выставляют несколько
настройки управления потоком.
Чтобы настроить это
поведения, клиенты Pub/Sub выставляют несколько
настройки управления потоком.
Cloud Run
Cloud Run — это управляемая вычислительная платформа, позволяющая запускать контейнеры без сохранения состояния, которые можно вызывать с помощью HTTP-запросов. в отличие Cloud Functions, один экземпляр контейнера может обрабатывать несколько Запросы одновременно если поддерживается обслуживающим стеком в контейнере.
Истио
Истио представляет собой независимую сервисную сетку с открытым исходным кодом, которая обеспечивает основы, которые вам нужно успешно запустить распределенную микросервисную архитектуру. А отказоустойчивая микросервисная архитектура требует, чтобы службы были защищены от мошеннические одноранговые сервисы, поэтому Istio обеспечивает ограничение скорости непосредственно в сервисной сетке.
Облачные конечные точки
Облачные конечные точки
— это система управления API, которая помогает вам защищать, контролировать,
анализировать и устанавливать квоты для ваших API, используя ту же инфраструктуру, что и Google
использует для своих собственных API.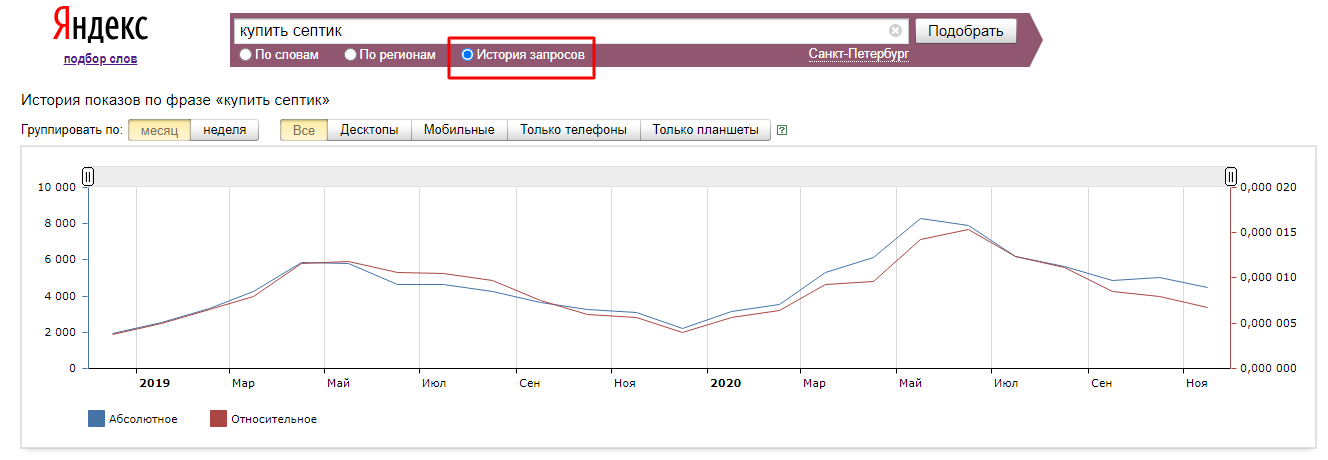 Как услуга, предназначенная для того, чтобы помочь вам предоставлять услуги
внешний мир, он дает возможность
настроить собственные квоты,
включая
тарифная политика.
Как услуга, предназначенная для того, чтобы помочь вам предоставлять услуги
внешний мир, он дает возможность
настроить собственные квоты,
включая
тарифная политика.
Apigee
Apigee — это платформа для разработки и управления API-прокси. API-прокси — это ваш интерфейс для разработчиков, которые хотят использовать ваши серверные службы. Скорее чем напрямую потреблять эти услуги, они получают доступ к прокси-серверу Apigee API. что вы создаете. Обычно Apigee помещают перед серверными службами, которые могут не иметь своих собственных возможностей ограничения скорости, поэтому ограничение скорости является встроенной функцией Апигей.
Google Cloud Armor
Google Cloud Armor использует глобальную инфраструктуру и системы безопасности Google
доставлять
защита от распределенных атак типа «отказ в обслуживании» (DDoS)
против инфраструктуры и приложений. Это включает в себя встроенную логику относительно
вредоносные всплески и высокая скорость загрузки ваших защищенных сервисов.
Project Shield
Хотя это и не сервис Google Cloud, Проект Щит использует инфраструктуру Google для защиты соответствующих сайтов от DDoS-атак.
Дополнительные методы повышения отказоустойчивости
Ограничение скорости на уровне приложения может предоставлять услуги с повышенным устойчивость, но устойчивость может быть дополнительно улучшена путем комбинирования ограничение скорости на уровне приложения с другими методами:
Кэширование : Хранение результатов, вычисление которых происходит медленно, позволяет сервису обрабатывать более высокую скорость запросов, что может привести к обратному давлению, ограничивающему скорость применять к клиентам реже.
Размыкание цепи :
Вы можете сделать сервисные сети более устойчивыми к проблемам, возникающим из-за
распространение повторяющихся ошибок путем временной блокировки частей системы
до спокойного состояния. Пример реализации см.
разрыв цепи
раздел документации Istio.
Пример реализации см.
разрыв цепи
раздел документации Istio.
Приоритизация : Не все пользователи системы имеют одинаковый приоритет. Рассмотреть возможность дополнительные факторы при разработке ключей ограничения скорости, чтобы гарантировать, что обслуживаются клиенты с более высоким приоритетом. Вы можете использовать сброс нагрузки чтобы снять с систем бремя низкоприоритетного трафика.
Ограничение скорости на нескольких уровнях : Если сетевой интерфейс вашей машины или ОС ядро перегружено, то ограничение скорости на уровне приложения никогда не может даже есть шанс начать. Вы можете применить ограничения скорости на уровне 3 в iptables, или локальные устройства могут ограничиваться на уровне 4. Вы также можете подвергаться настраиваемые ограничения скорости, применяемые к вводу-выводу вашей системы для таких вещей, как диск и сетевые буферы.
Мониторинг : Персоналу операционных систем необходимо знать
когда происходит дросселирование. Мониторинг ставок, превышающих квоты,
имеет решающее значение для управления инцидентами и выявления регрессий в программном обеспечении. Мы
рекомендуем реализовать такой мониторинг как для клиента, так и для сервера
перспективы услуг. Не все случаи ограничения скорости должны вызывать
оповещения, требующие немедленного внимания оперативного персонала. В неэкстремальных
случаях вы можете реагировать на ограничивающие сигналы позже, как часть рутинной
оценка и обслуживание вашей системы. Вы можете использовать журналы о том, когда
ограничение скорости возникает как сигнал о том, что вам нужно внести изменения, такие как
увеличение мощности компонента, запрос увеличения квоты или
изменение политики.
Мониторинг ставок, превышающих квоты,
имеет решающее значение для управления инцидентами и выявления регрессий в программном обеспечении. Мы
рекомендуем реализовать такой мониторинг как для клиента, так и для сервера
перспективы услуг. Не все случаи ограничения скорости должны вызывать
оповещения, требующие немедленного внимания оперативного персонала. В неэкстремальных
случаях вы можете реагировать на ограничивающие сигналы позже, как часть рутинной
оценка и обслуживание вашей системы. Вы можете использовать журналы о том, когда
ограничение скорости возникает как сигнал о том, что вам нужно внести изменения, такие как
увеличение мощности компонента, запрос увеличения квоты или
изменение политики.
Что дальше
Книги SRE имеют большие возможности для проектирования сложных систем.
Эти сообщения в блогах от других организаций дополнительно исследуют ограничение скорости:
- Масштабирование вашего API с помощью ограничителей скорости
- Объявление об ограничении скорости: служба Go/gRPC для общего ограничения скорости
- Как мы создали ограничение скорости, способное масштабироваться до миллионов доменов
- Альтернативный подход к ограничению скорости
- Высокопроизводительное ограничение скорости
- Как разработать масштабируемый алгоритм ограничения скорости
В этих учебниках представлены пошаговые инструкции по методам ограничения скорости:
- Бессерверные функции ограничения скорости с помощью Redis и VPC Connector
- Отсрочка запросов: асинхронные шаблоны для облачных функций
- Ознакомьтесь с эталонными архитектурами, диаграммами, учебными пособиями и рекомендациями по работе с Google Cloud.
 Взгляните на нашу
Центр облачной архитектуры.
Взгляните на нашу
Центр облачной архитектуры.
Заявление правила на основе скорости — AWS WAF, AWS Firewall Manager и AWS Shield Advanced
Правило на основе скорости отслеживает скорость запросов для каждого исходящего IP-адреса,
и запускает действие правила для IP-адресов со скоростью, превышающей лимит. Вы устанавливаете
limit как количество запросов за 5-минутный промежуток времени. Вы можете использовать этот тип
правило для временной блокировки запросов с IP-адреса, который отправляет
чрезмерные запросы. По умолчанию AWS WAF объединяет запросы на основе IP-адреса.
адрес из источника веб-запроса, но вы можете настроить правило для использования IP-адреса.
адрес из заголовка HTTP, например X-Forwarded-For вместо этого.
AWS WAF отслеживает и управляет веб-запросами отдельно для каждого экземпляра
правило на основе скорости, которое вы используете. Например, если вы предоставляете ту же ставку на основе
настройки правила в двух веб-списках ACL, каждый из двух операторов правила представляет собой
отдельный экземпляр правила на основе скорости и получает собственное отслеживание и
управление AWS WAF.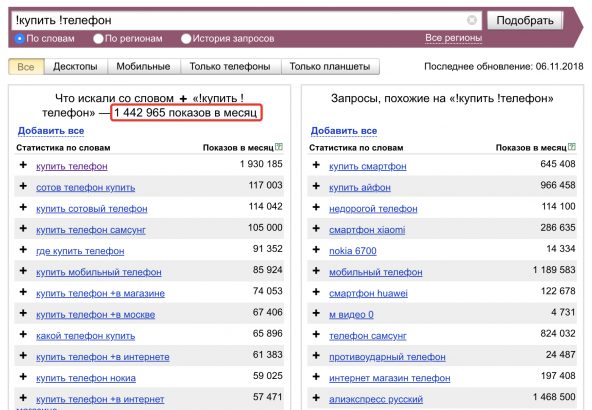 Если вы определяете правило на основе скорости внутри группы правил и
затем используйте эту группу правил в нескольких местах, каждое использование создает отдельный
экземпляр правила на основе скорости, которое получает собственное отслеживание и управление
АВС ВАФ.
Если вы определяете правило на основе скорости внутри группы правил и
затем используйте эту группу правил в нескольких местах, каждое использование создает отдельный
экземпляр правила на основе скорости, которое получает собственное отслеживание и управление
АВС ВАФ.
Когда срабатывает действие правила, AWS WAF применяет действие к дополнительным запросам с IP-адреса до тех пор, пока скорость запросов не упадет ниже предела. Это может занять минуту или две, чтобы изменение действия вступило в силу.
Вы можете получить список IP-адресов, которые в настоящее время заблокированы из-за ограничение скорости. Для получения информации см. Список IP-адресов, заблокированных на основе скорости. правила.
К правилам AWS WAF, основанным на скорости, относятся следующие предостережения:
Минимальная скорость, которую вы можете установить, равна 100.
AWS WAF проверяет скорость запросов каждые 30 секунд и подсчитывает запросы на предыдущие пять минут каждый раз.
 Из-за этого это
IP-адрес может отправлять запросы со слишком высокой скоростью для 30
секунд до того, как AWS WAF обнаружит и заблокирует его.
Из-за этого это
IP-адрес может отправлять запросы со слишком высокой скоростью для 30
секунд до того, как AWS WAF обнаружит и заблокирует его.AWS WAF может заблокировать до 10 000 IP-адресов. Если более 10 000 IP адреса отправляют запросы с высокой скоростью одновременно, AWS WAF будет только заблокировать 10 000 из них.
Вы можете сузить объем запросов, которые AWS WAF отслеживает и подсчитывает. Сделать таким образом, вы вкладываете еще один оператор с ограниченной областью действия в оператор, основанный на скорости. Затем AWS WAF подсчитывает только те запросы, которые соответствуют заявлению о снижении объема. За информацию об операторах с ограниченной областью см. в разделе Операторы с ограниченной областью действия.
Например, на основе недавних запросов, которые вы видели от злоумышленника в Соединенные Штаты, вы можете создать правило, основанное на частоте, со следующей областью действия: утверждение:
Допустим, вы также установили ограничение скорости в 1000.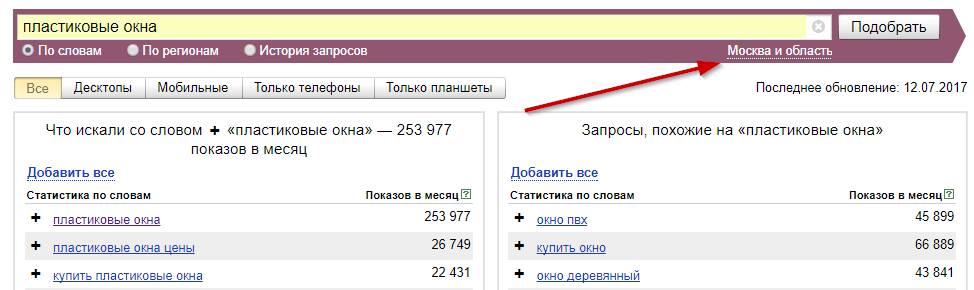 Для каждого IP-адреса AWS WAF
подсчитывает запросы, соответствующие критериям обоих вложенных операторов. Запросы, которые не соответствуют обоим
не учитываются. Если количество запросов для IP-адреса превышает 1000
в течение любого 5-минутного промежутка времени действие правила срабатывает для этого IP-адреса.
Для каждого IP-адреса AWS WAF
подсчитывает запросы, соответствующие критериям обоих вложенных операторов. Запросы, которые не соответствуют обоим
не учитываются. Если количество запросов для IP-адреса превышает 1000
в течение любого 5-минутного промежутка времени действие правила срабатывает для этого IP-адреса.
В качестве другого примера вы можете захотеть ограничить запросы на страницу входа в систему на вашем Веб-сайт. Для этого вы можете создать правило на основе скорости со следующим оператор соответствия вложенной строки:
Проверка Компонент запроса — это
путь URI.Тип совпадения равен
Начинается с строка.Строка для соответствия :
/login.
Добавив это правило, основанное на скорости, в веб-список управления доступом, вы можете ограничить запросы
страницу входа, не затрагивая остальную часть вашего сайта.
Не вкладывается — Вы не можете вложить это тип оператора внутри других операторов. Вы можете включить его непосредственно в веб-ACL и в группе правил.
(Необязательно) Заявление о сокращении области применения – Это тип правила принимает необязательный оператор области действия, чтобы сузить область действия запросы, которые отслеживает оператор на основе скорости. Дополнительные сведения см. в разделе операторы Scope-down.
WCU – 2 плюс любые дополнительные WCU для вложенный оператор.
В этом операторе используется следующий необязательный параметр:
(дополнительно) IP-конфигурация с переадресацией – По умолчанию AWS WAF агрегирует IP-адрес в Интернете. источник запроса, но вместо этого вы можете настроить правило для использования перенаправленный IP-адрес в заголовке HTTP, например
X-Forwarded-For. AWS WAF использует первый IP-адрес в заголовок. В этой конфигурации вы также указываете резервное поведение для применить к веб-запросу с неверным IP-адресом в указанном заголовок. Резервное поведение устанавливает соответствующий результат для запроса,
совпадать или не совпадать. Дополнительные сведения см. в разделе Переадресованный IP-адрес.
адрес.
Резервное поведение устанавливает соответствующий результат для запроса,
совпадать или не совпадать. Дополнительные сведения см. в разделе Переадресованный IP-адрес.
адрес.
Где найти
Построитель правил в вашем веб-ACL, на консоль – в соответствии с правилом , для Введите , выберите На основе скорости правило .
Заявление API –
RateBasedStatement
Javascript отключен или недоступен в вашем браузере.
Чтобы использовать документацию Amazon Web Services, должен быть включен Javascript. Инструкции см. на страницах справки вашего браузера.
Настройка частоты опроса и сбора данных для облачных интеграций
Наши облачные интеграции получают данные от API облачных провайдеров. В New Relic вы можете изменить некоторые настройки, связанные со сбором данных, для ваших облачных интеграций. Читайте дальше, чтобы узнать, какие изменения вы можете внести, и причины их внесения.
Обзор настроек
Облачные интеграции New Relic получают данные от API облачных провайдеров. Данные обычно собираются из API-интерфейсов мониторинга, таких как AWS CloudWatch, Azure Monitor и GCP Stackdriver, а метаданные инвентаризации собираются из API-интерфейсов конкретных сервисов.
Вы можете использовать панель мониторинга состояния учетной записи, чтобы увидеть, как ваши облачные интеграции обрабатывают данные от поставщика облачных услуг. Если вы хотите сообщать больше или меньше данных из ваших облачных интеграций или если вам нужно контролировать использование API-интерфейсов облачных провайдеров, чтобы предотвратить достижение лимитов скорости и регулирования в вашей облачной учетной записи, вы можете изменить параметры конфигурации, чтобы изменить количество данных, которые они сообщают. Два основных элемента управления:
- Изменить частоту опроса
- Изменить данные, которые сообщаются
Примеры бизнес-причин для изменения частоты опроса:
- Оплата: уменьшить частоту опроса.
 Прежде чем сделать это, убедитесь, что это сокращение не повлияет на любые условия предупреждений, заданные для ваших облачных интеграций.
Прежде чем сделать это, убедитесь, что это сокращение не повлияет на любые условия предупреждений, заданные для ваших облачных интеграций. - Новые службы: Если вы развертываете новую службу или конфигурацию и хотите чаще собирать данные, вы можете временно увеличить частоту опроса.
Осторожно
Изменение параметров конфигурации для ваших интеграций может повлиять на условия предупреждений и тенденции диаграммы.
Изменить частоту опроса
Конфигурация частоты опроса определяет, как часто New Relic сообщает данные от вашего облачного провайдера для каждой службы. По умолчанию частота опроса установлена на максимальную частоту, доступную для каждой службы.
Чтобы изменить частоту опроса для облачной интеграции:
- Перейдите на страницу one.newrelic.com > Инфраструктура .
- Выберите вкладку, соответствующую вашему поставщику облачных услуг.
- Выберите Настроить рядом с интеграцией.
- Используйте раскрывающиеся списки рядом с Интервал опроса данных каждые , чтобы выбрать, как часто вы хотите, чтобы New Relic собирала данные интеграции с облаком.
Укажите данные для извлечения
Вы можете указать, какую информацию вы хотите собирать для интеграции с облаком, включив сбор дополнительных данных и применив несколько фильтров к каждой интеграции.
Чтобы изменить эти настройки для интеграции с облаком:
- Перейдите по адресу one.newrelic.com > Инфраструктура .
- Выберите вкладку, соответствующую вашему поставщику облачных услуг.
- Выберите Настроить рядом с интеграцией.
- В разделе Сборы данных и фильтры установите нужные переключатели на .
- Для фильтров выберите или введите значения, которые вы хотите включить в отчетные данные.
Сбор данных
Для некоторых облачных интеграций требуется дополнительное количество вызовов API облачных провайдеров для сбора данных. Например, чтобы получить теги для кластеров AWS Elastic Map Reduce, требуется дополнительный вызов API сервиса.
Чтобы лучше контролировать количество вызовов API, отправляемых в вашу облачную учетную запись для этих интеграций, вы можете указать, когда вам нужно собирать эти типы данных. В зависимости от интеграции доступны различные переключатели сбора данных.
Toggle | Описание |
|---|---|
Соберите теги 9057 9000 Соберите теги 9057. Сбор тегов включен по умолчанию. Переключите этот параметр на Off , если вы не хотите, чтобы интеграция собирала теги ваших облачных ресурсов и, таким образом, уменьшала объем вызовов API. | |
Сбор расширенной инвентаризации | Некоторые интеграции могут собирать метаданные расширенной инвентаризации о ваших облачных ресурсах, выполняя дополнительные вызовы API к поставщику облачных услуг. Расширенный сбор инвентаря отключен по умолчанию . Переключите это на Вкл. , если вы хотите отслеживать расширенные запасы. Это увеличит количество вызовов API. |
Сбор данных сегментов | Доступно для интеграции с AWS Kinesis Streams. По умолчанию мы не сообщаем метрики сегментов. Переключите это на On , если вы хотите отслеживать показатели сегмента в дополнение к показателям потока данных. |
Сбор данных Lambda@Edge | Доступно для интеграции с AWS CloudFront. По умолчанию мы не сообщаем данные Lambda@Edge. Переключите это на На , если вы используете Lambda@Edge в AWS CloudFront и хотите получить метаданные местоположения выполнения Lambda. |
Сбор данных узла | Доступно для интеграции с AWS Elasticsearch. По умолчанию мы не сообщаем метрики узла Elasticsearch. Переключите это на On , если вы хотите отслеживать показатели узла в дополнение к показателям кластера. |
Сбор данных шлюза NAT и Сбор данных VPN | Доступно для интеграции с AWS VPC. По умолчанию мы не сообщаем ни о шлюзе NAT, ни о показателях VPN. Переключите их на On , если вы хотите отслеживать показатели и инвентарь шлюза NAT и VPN в дополнение к инвентаризации других объектов, связанных с VPC. |
Сбор IP-адресов | Доступно для интеграции с AWS EC2. По умолчанию мы собираем метаданные экземпляра EC2, которые включают общедоступные и частные IP-адреса, а также сведения о сетевом интерфейсе. |
Фильтры
Когда фильтр На вы указываете данные, которые вы хотите собрать; например, если ограничение для региона AWS равно On , выбранные вами регионы будут теми, для которых будут собираться данные. В зависимости от интеграции доступны различные фильтры:
Фильтр | Описание |
|---|---|
Регион | Выберите регионы, которые включают ресурсы, которые вы хотите отслеживать. |
Префиксы очереди | Доступно для интеграции с AWS SQS. Введите каждое имя или префикс для очередей, которые вы хотите отслеживать. Значения фильтра чувствительны к регистру. |
Префиксы балансировщика нагрузки | Доступно для интеграции с AWS ALB. Введите каждое имя или префикс для балансировщиков нагрузки приложений, которые вы хотите отслеживать. Значения фильтра чувствительны к регистру. |
Префиксы имен этапов | Доступно для интеграции с AWS API Gateway. Введите каждое имя или префикс для этапов, которые вы хотите отслеживать. Значения фильтра чувствительны к регистру. |
Ключ тега | Введите один ключ тега , связанный с ресурсами, которые вы хотите отслеживать. Значения фильтра чувствительны к регистру, и вы можете использовать этот фильтр в сочетании с фильтром значений тега . |
Значение тега | Введите одно значение тега , связанное с ресурсами, которые вы хотите отслеживать. Значения фильтра чувствительны к регистру, и вы можете использовать этот фильтр в сочетании с ключ тега . |
Группа ресурсов | Выберите группы ресурсов, связанные с ресурсами, которые вы хотите отслеживать. |
Возможное влияние на предупреждения и диаграммы
Изменение конфигурации интеграции может повлиять на условия предупреждений и диаграммы. Вот некоторые вещи, которые следует учитывать:
Если вы измените этот параметр… | Это может иметь следующие последствия… |
|---|---|
Любой параметр конфигурации | Лента событий также меняется. |
Любые фильтры | При создании условий оповещения после вы устанавливаете фильтры, убедитесь, что ваши оповещения не инициируются отфильтрованными ресурсами. |
Фильтр для регионов | Если вы фильтруете для определенных регионов, это может уменьшить объем данных, сообщаемых в New Relic, что может вызвать предупреждение. Если вы создадите условие оповещения для определенного региона, а затем отфильтруете этот регион, этот регион больше не будет сообщать данные и никогда не вызовет оповещение. |
Частота опроса | При создании предупреждения убедитесь, что вы определили пороговое значение для периода времени, превышающего частоту опроса. |
Теги и расширенный инвентарь | Если вы включите теги и/или расширенный инвентарь, New Relic сделает больше вызовов API к облачному провайдеру, что может увеличить счет за использование API вашего облачного провайдера. |
Регулировка запросов API для повышения пропускной способности
Вы можете настроить регулирование и квоты для своих API, чтобы защитить их от чрезмерной нагрузки
Запросы. И ограничения, и квоты применяются на основе максимальных усилий и должны рассматриваться скорее как целевые показатели.
чем гарантированные потолки запроса.
Шлюз API регулирует запросы к вашему API, используя алгоритм корзины токенов, где токен учитывается в запросе. В частности, API Gateway проверяет скорость и количество отправленных запросов для всех API в вашей учетной записи на каждую Область, край. В алгоритме корзины токенов всплеск может привести к заранее определенному превышению этих пределов, но другие факторы могут также в некоторых случаях приводят к превышению лимитов.
Когда отправленные запросы превышают стабильную скорость запросов и предельные значения пакетов, шлюз API начинает дросселировать
Запросы. Клиенты могут получить 429 Too Many Requests Ответы с ошибками на данный момент. При ловле такого
исключений, клиент может повторно отправить неудавшиеся запросы способом, ограничивающим скорость.
Как разработчик API, вы можете установить целевые ограничения для отдельных этапов или методов API, чтобы улучшить общее
производительность всех API в вашей учетной записи. Кроме того, вы можете включить планы использования, чтобы установить ограничения на клиенте.
отправка запросов на основе указанных ставок запросов и квот.
Темы
- Как применяются настройки ограничения регулирования в Шлюз API
- Регулирование на уровне учетной записи для каждого региона
- Настройка регулирования на уровне API и на уровне этапа цели в плане использования
- Настройка целей регулирования на уровне метода в плане использования plan
Как применяются настройки ограничения регулирования в Шлюз API
Прежде чем настраивать параметры ограничения и квоты для вашего API, полезно понять, как они применяются. через Amazon API Gateway.
Amazon API Gateway предоставляет четыре основных типа настроек, связанных с регулированием:
Ограничения регулирования AWS применяются ко всем учетным записям и клиентам в регионе.
Эти ограничения существуют для того, чтобы ваш API и ваша учетная запись не перегружались слишком большим количеством запросов.
Эти ограничения устанавливаются AWS и не могут быть изменены клиентом.Ограничения на учетную запись применяются ко всем API в учетной записи в указанном регионе. Ставка на уровне аккаунта лимит может быть увеличен по запросу — более высокие лимиты возможны с API, которые имеют более короткие тайм-ауты и меньшие полезные нагрузки. Чтобы запросить увеличение ограничений регулирования на уровне аккаунта для каждого региона, обратитесь в Центр поддержки AWS. Дополнительные сведения см. в разделе Квоты Amazon API Gateway и важные примечания. Обратите внимание, что эти ограничения не могут превышать ограничения регулирования AWS.
Ограничения регулирования для каждого API и этапа применяются на уровне метода API для этапа. Ты можно настроить одни и те же параметры для всех методов или настроить разные параметры дроссельной заслонки для каждого метода.
Обратите внимание, что эти ограничения не могут превышать ограничения регулирования AWS.Ограничения регулирования для каждого клиента применяются к клиентам, которые используют ключи API, связанные с ваш тарифный план в качестве идентификатора клиента. Обратите внимание, что эти ограничения не могут быть выше, чем ограничения для каждой учетной записи.
Настройки, относящиеся к регулированию шлюза API, применяются в следующем порядке:
Регулирование для каждого клиента или метода ограничения, которые вы устанавливаете для этапа использования API план
Ограничения регулирования для каждого метода, установленные для этапа API.
Регулирование на уровне учетной записи за Регион
Региональное регулирование AWS
Регулирование на уровне учетной записи по регионам
По умолчанию шлюз API ограничивает количество запросов в устойчивом состоянии в секунду (RPS) для всех API в AWS
учетная запись для каждого региона. Он также ограничивает всплеск (то есть максимальный размер корзины) для всех API в AWS.
учетная запись для каждого региона. В API Gateway предел пакета представляет собой целевое максимальное количество одновременных запросов.
отправки, которые API Gateway выполнит перед возвратом 429 Too Many Requests ответы об ошибках. Для большего
информацию о квотах регулирования см. в разделе Квоты Amazon API Gateway и важные примечания.
Настройка регулирования уровня API и этапа цели в плане использования
В плане использования можно установить цель регулирования для каждого метода для всех методов на уровне API или этапа в разделе Создать план использования .
Настройка целей регулирования на уровне метода в использовании plan
Вы можете установить дополнительные цели регулирования на уровне метода в Планы использования , как показано на
Создайте план использования. В шлюзе API
консоль, они устанавливаются путем указания Resource= , Метод = в методе настройки Параметр регулирования . <метод> Например, для зоомагазина
Например, вы можете указать Resource=/pets , Method=GET .
Javascript отключен или недоступен в вашем браузере.
Чтобы использовать документацию Amazon Web Services, должен быть включен Javascript. Инструкции см. на страницах справки вашего браузера.
Условные обозначения документов
AWS WAF
Частные API
Повышение стабильности экземпляра с ограничением скорости | Центр обработки данных и сервер Confluence 7.19
Когда автоматические интеграции или сценарии отправляют запросы в Confluence большими пакетами, это может повлиять на стабильность Confluence, что приведет к снижению производительности или даже простоям. С ограничением скорости вы можете контролировать, сколько внешних запросов REST API могут делать автоматизация и пользователи, и как часто они могут их делать, гарантируя, что ваш экземпляр Confluence останется стабильным.
На этой странице:
Как работает ограничение скорости
Вот некоторые подробности о том, как работает ограничение скорости в Confluence.
Ограниченные запросы…Ограничение скорости нацелено только на внешние запросы REST API, что означает, что запросы, сделанные в Confluence, никак не ограничиваются. Когда пользователи перемещаются по Confluence, создают страницы, комментируют и выполняют другие действия, на них не будет влиять ограничение скорости, поскольку мы рассматриваем это как обычный пользовательский опыт, который не должен ограничиваться.
Давайте лучше проиллюстрируем это на примере:
Механизмы аутентификации
Чтобы предоставить вам более подробную информацию о том, как мы распознаем, какие запросы должны быть ограничены, мы ориентируемся на внешние HTTP-запросы со следующими механизмами аутентификации:
- Basic аутентификация
- OAuth
- файл cookie JSESSIONID
..Из многих доступных методов обеспечения ограничения скорости мы выбрали использование ведра токенов, которое дает пользователям баланс токенов, которые можно обменять на запросы. Вот краткое описание того, как это работает:
Пользователям выдаются токены, которые обмениваются на запросы. Один токен равен одному запросу.
Пользователи получают новые токены с постоянной скоростью, поэтому они могут продолжать делать новые запросы. Это их разрешенные запросы, и их может быть, например, 10 каждую 1 минуту.
Токены добавляются в личное ведро пользователя до тех пор, пока оно не заполнится. Это их максимальные запросы, которые позволяют им регулировать использование токенов в соответствии с их собственной частотой, например, 20 каждые 2 минуты вместо 10 каждые 1 минуту, как указано в их обычной ставке.
Когда пользователь пытается отправить больше запросов, чем количество имеющихся у него токенов, успешными будут только те запросы, которые могут получить токены из корзины. Остальные завершатся сообщением об ошибке 429 (слишком много запросов). Пользователь может повторить эти запросы после получения новых токенов.
Confluence лучше всего сочетается с другими нашими продуктами, такими как Jira. Технически подобные продукты являются внешними по отношению к Confluence, поэтому их использование должно быть ограничено. Однако в данном случае мы рассматриваем их как относящиеся к одному и тому же пользовательскому опыту и не хотим применять какие-либо ограничения для запросов, поступающих из этих продуктов или к ним.
Как сейчас:
- Сервер: Никак не ограничен.
- Облако: существует известная проблема, связанная с ограничением скорости запросов, поступающих из/в облачные продукты. Мы прилагаем все усилия, чтобы отключить ограничения скорости для облачных продуктов, и это должно произойти в ближайшее время. На данный момент, если вы интегрируете Confluence с облаком Jira, вам следует установить более высокие ограничения скорости, чем обычно.
Общее предположение состоит в том, что приложения Marketplace устанавливаются в экземпляре Confluence, выполняют внутренние запросы из Confluence и не должны ограничиваться. Но как всегда это зависит от того, как работает приложение .
- Внутренний : Если приложение действительно работает внутри, улучшая взаимодействие с пользователем, оно не будет ограничено. Примером такого приложения может быть специальный баннер, отображаемый в пространстве Confluence. Допустим, этот баннер проверяет все созданные страницы и показывает победителя этой области — пользователя, который создал больше всего страниц за последний месяц. Трафик такой будет внутренний, не ограниченный.
- Внешний : Количество приложений, чьи запросы являются внешними по отношению к Confluence, ограничено. Допустим, у нас есть приложение, которое отображает настенный экран на телевизоре. Он запрашивает у Jira подробную информацию о досках, проблемах, назначенных лицах и т. д., а затем перетасовывает и отображает их по-своему, как ранее упомянутое настенное табло. Такое приложение отправляет внешние запросы и ведет себя так же, как пользователь, отправляющий запросы через терминал.
Это действительно зависит от приложения, но мы предполагаем, что большинство из них не должны быть ограничены.
Как работает ограничение скорости в кластере…Ограничение скорости доступно для центра обработки данных, поэтому, скорее всего, у вас есть кластер узлов за балансировщиком нагрузки. Вы должны знать, что каждый из ваших пользователей будет иметь отдельный лимит на каждом узле (ограничения скорости применяются к узлу, а не к кластеру).
Другими словами, если они использовали свои запросы, разрешенные на одном узле, и были ограничены по скорости, они теоретически могут отправлять запросы снова, если они начали новый сеанс на другом узле. Пользователи не могут переключаться между узлами, но имейте в виду, что это может произойти.
Какой бы лимит вы ни выбрали (например, 100 запросов каждый час), одинаковый лимит будет применяться к каждому узлу, вам не нужно устанавливать его отдельно. Это означает, что возможность каждого пользователя отправлять запросы по-прежнему будет ограничена, и Confluence останется стабильной независимо от того, на какой узел направляются их запросы.
Какой лимит выбрать?Установка правильного предела зависит от многих факторов, поэтому мы не можем дать вам простой ответ. Однако у нас есть некоторые предложения.
Поиск правильного ограничения
Первый шаг — понять объем трафика, который получает ваш экземпляр. Вы можете сделать это, проанализировав журнал доступа и найдя пользователя, который сделал больше всего запросов REST за день. Поскольку трафик пользовательского интерфейса не ограничен по скорости, это число будет выше, чем вам нужно в качестве ограничения скорости. Теперь это базовый номер — вам нужно изменить его, основываясь на следующих вопросах:
- Можете ли вы позволить себе прерывать работу ваших пользователей? Если интеграция ваших пользователей имеет решающее значение, подумайте об обновлении вашего оборудования. Чем важнее интеграции, тем выше должен быть предел — подумайте о том, чтобы умножить найденное число на два или три.
- В вашем экземпляре уже возникают проблемы из-за большого количества трафика REST? Если да, то выберите ограничение, близкое к базовому числу, которое вы нашли в день, когда у экземпляра не было проблем. И если вы не испытываете серьезных проблем, рассмотрите возможность добавления дополнительных 50% к базовому числу — это не должно мешать вашим пользователям, и вы все равно сохраните некоторую емкость.
В общем, выбранное вами ограничение должно обеспечивать безопасность вашего экземпляра, а не контролировать отдельных пользователей. Ограничение скорости больше связано с защитой Confluence от интеграций и скриптов, которые выходят из строя, а не с тем, чтобы пользователи не могли выполнять свою работу.
Как включить ограничение скорости
Для включения ограничения скорости необходимо глобальное разрешение системного администратора.
Чтобы включить ограничение скорости:
- В Confluence выберите > Общая конфигурация > Ограничение скорости .
- Изменить статус на Включено .
- Выберите один из вариантов: Разрешить неограниченные запросы , Блокировать все запросы или Ограничить запросы . Первое и второе касаются разрешенных и заблокированных списков. Для последнего варианта вам нужно ввести фактические ограничения. Подробнее о них вы можете прочитать ниже.
- Сохраните ваши изменения.
Обязательно добавьте исключения для пользователей, которым действительно нужны эти дополнительные запросы, особенно если вы выбрали белый или черный список. См. Добавление исключений.
Ограничение запросов — что это такое
Несмотря на то, что добавление в белый и черный списки не требует дополнительных объяснений, вы, вероятно, будете довольно часто использовать параметр Ограничение запросов либо в качестве глобальной настройки, либо в исключениях.
Давайте подробнее рассмотрим эту опцию и то, как она работает:
- Разрешенные запросы : Каждому пользователю разрешено определенное количество запросов в выбранный интервал времени. Это может быть 10 запросов в секунду, 100 запросов в час или любая другая конфигурация по вашему выбору.
- Максимальное количество запросов (дополнительно) : Разрешенные запросы, если они не отправляются часто, могут накапливаться до установленного максимума для каждого пользователя. Эта опция позволяет пользователям делать запросы с частотой, отличной от их обычной скорости (например, 20 запросов каждые 2 минуты вместо 10 запросов каждую минуту, как указано в их частоте), или накапливать больше запросов с течением времени и отправлять их одним пакетом. , если это то, что им нужно. Слишком продвинутый? Просто сделайте его равным разрешенным запросам и забудьте об этом поле — больше ничего не будет накапливаться.
Примеры
Пример 1. Разрешить количество запросов до 10 в час и максимальное количество запросов до 100…Разрешено запросов: 10/час | Максимальное количество запросов: 100
Один из разработчиков отправляет запросы на регулярной основе, 10 запросов в час в течение дня. Если они попытаются отправить 20 запросов за один раз, только 10 из них будут успешными. Они могут повторить оставшиеся 10 запросов в течение следующего часа, когда им разрешат новые запросы.
Другой разработчик не отправлял никаких запросов в течение последних 10 часов, поэтому их разрешенные запросы продолжали накапливаться, пока не достигли 100, что является максимальным количеством запросов, которые они могут иметь. Теперь они могут отправить пакет из 100 запросов, и все они будут успешными. Как только они израсходовали все доступные запросы, им нужно подождать еще час, и они получат только разрешенные 10 запросов.
Если этот же разработчик отправил только 50 из своих 100 запросов, он мог отправить еще 50 сразу или начать накапливать снова в течение следующего часа.
Разрешено запросов: 1/секунду | Максимальное количество запросов: 60
Разработчик может выбрать отправку 1 запроса в секунду или 60 запросов в минуту (с любой частотой).
Поскольку они могут использовать доступные 60 запросов с любой частотой, они также могут отправлять их все сразу или через очень короткие промежутки времени. В таком случае они превысят свою обычную скорость 1 запрос в секунду.
Нахождение правильного предела
Какой лимит выбрать?Установка правильного предела зависит от многих факторов, поэтому мы не можем дать вам простой ответ. Однако у нас есть некоторые предложения.
Поиск правильного ограничения
Первый шаг — понять размер трафика, который получает ваш экземпляр. Вы можете сделать это, проанализировав журнал доступа и найдя пользователя, который сделал больше всего запросов REST за день. Поскольку трафик пользовательского интерфейса не ограничен по скорости, это число будет выше, чем вам нужно в качестве ограничения скорости. Теперь это базовое число — вам нужно изменить его, основываясь на следующих вопросах:
- Можете ли вы позволить себе прерывать работу ваших пользователей? Если интеграция ваших пользователей имеет решающее значение, подумайте об обновлении вашего оборудования. Чем важнее интеграции, тем выше должен быть предел — подумайте о том, чтобы умножить найденное число на два или три.
- В вашем экземпляре уже возникают проблемы из-за большого количества трафика REST? Если да, то выберите ограничение, близкое к базовому числу, которое вы нашли в день, когда у экземпляра не было проблем. И если вы не испытываете серьезных проблем, рассмотрите возможность добавления дополнительных 50% к базовому числу — это не должно мешать вашим пользователям, и вы все равно сохраните некоторую емкость.
В общем, выбранное вами ограничение должно быть направлено на обеспечение безопасности вашего экземпляра, а не на контроль отдельных пользователей. Ограничение скорости больше связано с защитой Jira от интеграций и скриптов, которые выходят из строя, а не с тем, чтобы пользователи не могли выполнять свою работу.
Добавление исключений
Исключения — это специальные ограничения для пользователей, которым действительно нужно сделать больше запросов, чем другим. Любые исключения, которые вы выберете, будут иметь приоритет над глобальными настройками.
наконечник/отдыхСоздано с помощью Sketch.После добавления или изменения исключения вы сразу же увидите изменения, но применение новых настроек к пользователю может занять до 1 минуты.
Чтобы добавить исключение:
- Перейдите на вкладку Исключения .
- Нажмите Добавить исключение .
- Найдите пользователя и выберите его новые настройки.
Вы не можете выбирать группы, но можете выбрать нескольких пользователей. - Доступные здесь параметры такие же, как и в глобальных настройках: Разрешить неограниченные запросы , Блокировать все запросы или Назначить пользовательский лимит .
- Сохраните ваши изменения.
Если вы хотите отредактировать исключение позже, просто нажмите Изменить рядом с именем пользователя на вкладке Исключения .
Рекомендуется: добавить исключение для анонимного доступа
Confluence считает весь анонимный трафик одним пользователем: Анонимный . Если ваш сайт является общедоступным, и ваши ограничения скорости не слишком высоки, один человек может слить лимит, назначенный анониму. Рекомендуется добавить исключение для этой учетной записи с более высоким лимитом, а затем посмотреть, нужно ли вам увеличивать его дальше.
Идентификация пользователей с ограничением скорости
Когда пользователь ограничен скоростью, он сразу узнает об этом, так как получит сообщение об ошибке HTTP 429 (слишком много запросов). Вы можете определить пользователей, для которых было установлено ограничение скорости, открыв вкладку Список ограниченных учетных записей на странице настроек ограничения скорости. В списке показаны все пользователи из всего кластера.
Когда пользователь ограничен по скорости, отображение его в таблице занимает до 5 минут.
Необычные учетные записи
Вы узнаете пользователей, показанных в списке, по их именам. Однако может случиться так, что в списке будут показаны некоторые необычные учетные записи, поэтому вот что они означают:
- Неизвестно : это пользователь, который был удален в Confluence. Они не должны появляться в списке более 24 часов (поскольку их скорость больше не может быть ограничена), но вы можете увидеть их в списке исключений. Просто удалите для них любые настройки, им больше не нужно ограничение скорости.
- Анонимный : Эта запись собирает все запросы, которые не были сделаны из аутентифицированной учетной записи. Поскольку один пользователь может легко использовать ограничение для анонимного доступа, было бы неплохо добавить исключение для анонимного трафика и установить для него более высокий предел.
Просмотр ограниченных запросов в файле журнала Confluence
Вы также можете просмотреть информацию об ограниченных пользователях и запросах в файле журнала Confluence. Это полезно, если вы хотите получить более подробную информацию об URL-адресах, на которые направлены запросы или с которых они исходят.
Когда скорость запроса ограничена, вы увидите запись в журнале, похожую на эту:
2019-12-24 10:18:23,265 WARN [http-nio-8090-exec-7] [ratelimiting.internal. filter.RateLimitFilter] lambda$userHasBeenRateLimited$0 Пользователь [2c9d88986ee7cdaa016ee7d40bd20002] был ограничен в скорости -- URL: /rest/api/space/DS/content | идентификатор трассировки: 30c0edcb94620c83 | userName: exampleuser
Получение ограничения скорости — точка зрения пользователя
Когда пользователи отправляют аутентифицированные запросы, они увидят в ответе заголовки ограничения скорости. Эти заголовки добавляются к каждому ответу, а не только при ограничении скорости.
Заголовок | Описание |
|---|---|
xrtiTIM 9047. Новые токены не будут добавлены в вашу корзину после достижения этого лимита. Ваш администратор настраивает это как максимальные запросы. | |
X-RateLimit-Remaining | Оставшееся количество токенов. Это значение является точным, насколько это возможно во время запроса, но оно не всегда может быть правильным. |
X-RateLimit-Interval-Seconds | Интервал времени в секундах. Вы получаете партию новых токенов каждый временной интервал. |
X-RateLimit-FillRate | Количество токенов, которые вы получаете каждый временной интервал. Ваш администратор настраивает это как разрешенные запросы. |
повторная попытка после | Как долго вам нужно ждать, пока вы не получите новые жетоны. |
Когда скорость ограничена и ваш запрос не проходит, вы увидите сообщение об ошибке HTTP 429 (слишком много запросов). Вы можете использовать эти заголовки, чтобы настроить скрипты и средства автоматизации в соответствии с вашими ограничениями, заставив их отправлять запросы с разумной частотой.
Другие задачи
Добавление URL-адресов и ресурсов в белый список
Мы также добавили способ разрешить целые URL-адреса и ресурсы в вашем экземпляре Confluence с помощью системного свойства. Это следует использовать как быстрое исправление для чего-то, что имеет ограничение скорости, но не должно.
Когда его использовать? Например, приложение Marketplace добавило в Confluence новый API. Само приложение используется из пользовательского интерфейса, поэтому оно не должно быть ограничено, но может случиться так, что Confluence увидит этот трафик как внешний и применит ограничение скорости. В этом случае вы можете отключить приложение или увеличить лимит скорости, но это влечет за собой дополнительные сложности.
Чтобы обойти подобные проблемы, вы можете внести в белый список весь ресурс, добавленный приложением, чтобы он работал без каких-либо ограничений.
Чтобы исключить определенные URL-адреса из ограничения скорости:
- Остановить Confluence.
Добавьте системное свойство
com.atlassian.ratelimiting.whitelisted-url-patternsи задайте в качестве значения список URL-адресов, разделенных запятыми, например:-Dcom.atlassian.ratelimiting.whitelisted-url-patterns=/**/rest/applinks/**,/**/rest/capabilities,/**/rest/someapi
Способ добавления системных свойств зависит от того, как вы запускаете Confluence. Дополнительные сведения см. в разделе Настройка свойств системы.- Перезапустите Confluence.
Дополнительные сведения о создании шаблонов URL-адресов см. в разделе AntPathMatcher: шаблоны URL-адресов.
Внесение внешних приложений в белый список
Вы также можете внести в белый список потребительские ключи, что позволит снять ограничения скорости для внешних приложений, интегрированных через AppLinks.
Найдите потребительский ключ вашего приложения.
Перейдите > Общая конфигурация > Ссылки на приложения .
Найдите свое приложение и щелкните Изменить .
Скопируйте ключ потребителя из Входящая аутентификация .
Разрешить ключ потребителя.
Остановить слияние.
Добавьте системное свойство
com.atlassian.ratelimiting.whitelisted-oauth-consumersи задайте в качестве значения список ключей потребителей, разделенных запятыми, например:-Dcom.atlassian.ratelimiting.whitelisted-oauth-consumers=app-connector-for-confluence-server
Способ добавления системных свойств зависит от того, как вы запускаете Confluence.
Дополнительную информацию см. в разделе «Настройка свойств системы».Перезапустите Confluence.
После ввода потребительского ключа трафик, исходящий от соответствующего приложения, больше не будет ограничен.
Настройка вашего кода для ограничения скорости
Мы создали набор стратегий, которые вы можете применять в своем коде (скрипты, интеграции, приложения), чтобы он работал с ограничениями скорости, какими бы они ни были.
Дополнительные сведения см. в разделе Настройка кода для ограничения скорости.
- Статья
- 14 минут на чтение
Узнайте о регулировании в SharePoint Online и узнайте, как избежать регулирования или блокировки.
- Что такое дросселирование?
- Как справиться с дросселированием?
- Распространенные сценарии регулирования в SharePoint Online
- Специальные ограничения сценария
- Что делать, если вас заблокировали в SharePoint Online?
- Дополнительные ресурсы
Звучит знакомо? Вы запускаете приложение, например, для сканирования файлов в SharePoint Online, но оно регулируется. Или, что еще хуже, вас заблокируют. Что происходит и что вы можете сделать, чтобы остановить это?
Что такое дросселирование?
SharePoint Online использует регулирование для поддержания оптимальной производительности и надежности службы SharePoint Online. Регулирование ограничивает количество вызовов или операций API в течение временного окна, чтобы предотвратить чрезмерное использование ресурсов.
При превышении ограничений на использование SharePoint Online на короткое время блокирует любые дальнейшие запросы от этого клиента.
Для запросов, которые пользователь выполняет непосредственно в браузере, SharePoint Online перенаправляет вас на страницу сведений о регулировании, и запросы не выполняются.
Для запросов, отправляемых приложением, включая вызовы Microsoft Graph, CSOM или REST, SharePoint Online возвращает код состояния HTTP 429 («Слишком много запросов») или 503 («Сервер слишком занят»), и запросы не выполняются.
- HTTP 429 указывает, что вызывающее приложение отправило слишком много запросов во временном окне и превысило заданный предел.
- HTTP 503 указывает, что служба не готова обработать запрос. Распространенной причиной является то, что служба испытывает временные всплески нагрузки, чем ожидалось.
В обоих случаях в ответ включается заголовок Retry-After , указывающий, как долго вызывающее приложение должно ждать перед повторной попыткой или выполнением нового запроса. Регулируемые запросы засчитываются в лимиты использования, поэтому несоблюдение Retry-After может привести к усилению регулирования.
Если приложение-нарушитель продолжает превышать ограничения на использование, SharePoint Online может полностью заблокировать приложение или определенные шаблоны запросов от приложения; в этом случае приложение будет продолжать получать код состояния HTTP 503, и Microsoft уведомит арендатора о блокировке в Центре сообщений Office 365.
Регулирование пользователей
Регулирование ограничивает количество вызовов и операций, совместно выполняемых приложениями от имени пользователя, чтобы предотвратить чрезмерное использование ресурсов.
Тем не менее, пользователь редко подвергается регулированию в SharePoint Online. Сервис надежен и рассчитан на работу с большими объемами. Если вы и получаете ограничение, в 99% случаев это происходит из-за пользовательского кода, такого как настраиваемые веб-части, сложное представление списка и запросы или пользовательские приложения, которые запускают пользователи. Это не значит, что других способов задушить нет, просто они менее распространены. Например, один пользователь, синхронизирующий большой объем данных на 10 компьютерах одновременно, может привести к регулированию.
Регулирование приложений
В дополнение к регулированию по учетной записи пользователя ограничения также применяются к приложениям в арендаторе.
Каждое приложение имеет собственные ограничения в арендаторе, которые основаны на количестве лицензий, приобретенных для каждой организации (см. планы, указанные в разделе Ограничения SharePoint для включенных лицензий). Каждый запрос, который приложение делает во всех конечных точках API, включая Microsoft Graph, CSOM и REST, учитывается при использовании приложения.
SharePoint предоставляет различные API. Различные API имеют разную стоимость в зависимости от сложности API. Стоимость API нормируется SharePoint и выражается в единицах ресурсов. Ограничения приложения также определяются с помощью единиц ресурсов.
В таблице ниже указаны ограничения на количество единиц ресурсов для приложения в арендаторе:
| Количество лицензий | 0 – 1к | 1к – 5к | 5к - 15к | 15к - 50к | 50к+ |
|---|---|---|---|---|---|
| Приложение 1 минута | 1 200 | 2 400 | 3 600 | 4 800 | 6000 |
| Приложение ежедневно | 1 200 000 | 2 400 000 | 3 600 000 | 4 800 000 | 6 000 000 |
Примечание
Мы оставляем за собой право изменять ограничения ресурсов.
Что касается затрат на API, API Microsoft Graph имеют предопределенную стоимость единицы ресурса за запрос:
| Единицы ресурса за запрос | Операции |
|---|---|
| 1 | |
| 2 | |
| 5 |
Примечание
Мы оставляем за собой право изменять стоимость единицы ресурса API.
Дельта с токеном — это наиболее эффективный способ сканирования контента в SharePoint, и мы более подробно поговорим о передовых методах сканирования приложений. Чтобы помочь приложениям, которые следуют рекомендациям, мы снижаем стоимость единицы ресурса для дельта-запросов с токеном до 1 единицы ресурса, хотя это запрос с несколькими элементами. Дельта-запрос без токена считается запросом с несколькими элементами и стоит 2 единицы ресурса за запрос.
При пакетной обработке запросы в пакете оцениваются индивидуально по ресурсам.
CSOM и REST не имеют заранее определенной стоимости единицы ресурсов и обычно потребляют больше единиц ресурсов, чем API Microsoft Graph, для достижения той же функциональности. Помимо ограничений на единицы ресурсов, на CSOM и REST также распространяются другие внутренние ограничения ресурсов, поэтому, если приложения вызывают CSOM и REST, они могут испытывать большее регулирование, чем ограничения, описанные в этом документе. Мы настоятельно рекомендуем по возможности выбирать API Microsoft Graph вместо CSOM и REST API.
Поскольку лимиты приложений указаны в единицах ресурсов, фактическая скорость запросов, например количество запросов в минуту, зависит от выбора API приложения и соответствующей стоимости единицы ресурса API. Как правило, вы можете оценить частоту запросов, используя в среднем 2 единицы ресурсов на запрос, и разделить лимиты единиц ресурсов на 2, чтобы получить расчетную частоту запросов.
Несмотря на то, что каждое приложение имеет свои собственные ограничения в арендаторе, и мы разрешаем арендаторам запускать более одного приложения, несколько приложений, работающих с одним и тем же арендатором, используют одну и ту же корзину ресурсов, и в редких случаях это может привести к ограничению скорости, когда слишком много приложений отправляют запросы в это время.
Как бороться с дросселированием?
Ниже приведен краткий обзор передовых методов регулирования регулирования:
- Уменьшение количества одновременных запросов
- Избегайте скачков запросов
- По возможности выбирайте API Microsoft Graph вместо CSOM и REST API
- Использовать HTTP-заголовки
Retry-AfterиRateLimit - Украсьте свой трафик, чтобы мы знали, кто вы (подробнее см. раздел о лучших практиках оформления трафика ниже)
Как указывалось ранее, Microsoft Graph — это облачные API с последними улучшениями и оптимизациями. В целом Microsoft Graph потребляет меньше ресурсов, чем CSOM и REST, для достижения той же функциональности. Таким образом, внедрение Microsoft Graph может повысить производительность приложения и уменьшить троттлинг.
Если вы столкнулись с регулированием, мы требуем использовать HTTP-заголовок Retry-After , чтобы обеспечить минимальную задержку до снятия ограничения. RateLimit 9Заголовки HTTP 0059 посылают вам ранние сигналы, когда вы приближаетесь к ограничениям, и вы можете заблаговременно сокращать запросы, чтобы не нажимать дроссель.
Когда приложения подвергаются регулированию, SharePoint Online возвращает HTTP-заголовок Retry-After в запросе, указывающий, как долго в секундах вызывающее приложение должно ждать перед повторной попыткой или созданием нового запроса.
Соблюдение HTTP-заголовка Retry-After — это самый быстрый способ справиться с регулированием, поскольку SharePoint Online динамически определяет подходящее время для повторной попытки.
Регулируемые запросы засчитываются в лимиты использования, поэтому несоблюдение Retry-After может привести к усилению регулирования. Другими словами, агрессивные повторные попытки работают против вызывающих приложений, потому что, даже если вызовы завершаются неудачей, они все равно учитываются в ограничениях на использование. Соблюдение HTTP-заголовка Retry-After обеспечит кратчайшую задержку и уменьшит потери квот в регулируемых запросах.
В дополнение к заголовку Retry-After в ответе на регулируемые запросы SharePoint Online также возвращает заголовки IETF RateLimit для выбранных ограничений в определенных условиях, чтобы помочь приложениям управлять ограничением скорости. Мы рекомендуем приложениям использовать эти заголовки, чтобы не нажимать дроссель.
-
RateLimit-Limitсодержит лимит в текущем временном окне. -
RateLimit-Remainingуказывает оставшуюся квоту в текущем окне. -
RateLimit-Resetуказывает количество секунд до заполнения квоты.
Примечание
Эти заголовки в настоящее время находятся в бета-версии и могут быть изменены. В то время, когда были приняты заголовки, спецификация IETF находилась в черновике. Текущая реализация основана на черновике-03 спецификации IETF. Когда спецификация будет окончательной, возможны изменения, и мы будем адаптироваться к этим изменениям в будущем.
Заголовки RateLimit возвращаются на основе максимальных усилий , поэтому приложения могут не получать заголовки при всех условиях. Кроме того, существуют другие ограничения, которые не представлены в заголовках RateLimit , поэтому приложения могут регулироваться даже до достижения предела, описанного в заголовках RateLimit .
Ниже приведен список лимитов, для которых мы поддерживаем заголовки RateLimit . Политики и ценности могут быть изменены:
| предел | Состояние | предельное значение | Описание |
|---|---|---|---|
| Единица ресурсов приложения 1 минута | Использование >= 80% от лимита | Блок ресурсов | Когда приложение использует 80 % или более своего предела в 1 минуту, возвращаются предел, оставшееся время и сброс. |
Ниже приведены несколько примеров, которые помогут вам понять заголовки RateLimit :
- Приложение израсходовало 90 % своей квоты на единицу ресурсов (1080 из 1200), и его потребление находится в пределах всех применимых к нему ограничений. Запрос выполняется успешно, и возвращаются заголовки
RateLimit.
HTTP/1.1 200 Ок RateLimit-Limit: 1200 RateLimit-Осталось: 120 Сброс предела скорости: 5
- Приложение израсходовало 100% своей квоты на единицу ресурсов, поэтому оно регулируется этой политикой. Запрос регулируется, и
RateLimit 9Возвращаются заголовки 0059.Retry-AfterсоответствуетRateLimit-Reset.
HTTP/1.1 429 Слишком много запросов Повторить после: 31 RateLimit-Limit: 1200 RateLimit-осталось: 0 Сброс предела скорости: 31
- Приложение использовало 90 % своей квоты на единицу ресурсов, но его потребление уже достигло других пределов, которые не поддерживаются заголовками
RateLimit. В этом случае запрос регулируется, а заголовки RateLimitне возвращаются, чтобы избежать путаницы, хотя условие возврата заголовков выполнено.
HTTP/1.1 429 Слишком много запросов Повторить после: 9
Как украсить свой http трафик?
Хорошо оформленный трафик будет иметь приоритет над трафиком, который не оформлен должным образом.
Что такое неукрашенный трафик?
- Трафик не оформлен, если в вызовах API к SharePoint Online нет строки AppID/AppTitle и пользовательского агента. Строка агента пользователя должна быть в определенном формате, как описано ниже.
- Если вы разрабатываете веб-приложение, выполняемое в браузере, большинство современных браузеров не позволяют перезаписывать строку пользовательского агента, и вам не нужно это реализовывать.
Какие рекомендации?
Если вы создали приложение, рекомендуется зарегистрироваться и использовать AppID и AppTitle. Это обеспечит наилучшее общее впечатление и лучший путь для решения любых проблем в будущем.
Включите также информацию строки пользовательского агента, как определено на следующем шаге.Примечание
См. документацию по удостоверениям Майкрософт, например страницу «Быстрый старт: регистрация приложения на платформе удостоверений Майкрософт», для получения сведений о создании приложения Azure AD.
Не забудьте включить строку пользовательского агента в свой вызов API к SharePoint с соблюдением соглашения об именах
| Тип | Агент пользователя | Описание |
|---|---|---|
| Приложение ISV | ISV|CompanyName|AppName/Version | Идентифицировать как ISV и включить название компании, название приложения, разделенные вертикальной чертой, а затем добавить номер версии, разделенный косой чертой |
| Корпоративное приложение | NONIV|CompanyName|AppName/Version | Идентифицируйте как NONIV и включите название компании, имя приложения, разделенные вертикальной чертой, а затем добавьте номер версии, разделенный косой чертой |
- Если вы создаете собственные библиотеки JavaScript, которые используются для вызова API-интерфейсов SharePoint Online, убедитесь, что вы включили информацию об агенте пользователя в свой http-запрос и, возможно, зарегистрируете свое веб-приложение также как приложение, где это возможно. .
Примечание
Ожидается, что формат строки пользовательского агента будет соответствовать RFC2616, поэтому следуйте приведенным выше рекомендациям по правильным разделителям. Также можно дополнить существующую строку пользовательского агента запрошенной информацией.
Наиболее распространенными причинами регулирования для каждого пользователя в SharePoint Online являются объектная модель на стороне клиента (CSOM) или код передачи репрезентативного состояния (REST), который слишком часто выполняет слишком много действий.
Спорадический трафик
Постоянная загрузка или повторяющиеся сложные запросы к SharePoint Online должны быть оптимизированы для минимального воздействия. Несоблюдение рекомендаций по сканированию приложений, обрабатывающих файлы в большом количестве, скорее всего, приведет к регулированию. Эти приложения включают механизмы синхронизации, поставщики резервного копирования, поисковые индексаторы, механизмы классификации, инструменты предотвращения потери данных и любые другие инструменты, которые пытаются анализировать все данные и вносить в них изменения.
Перегруженный трафик
Один процесс резко превышает ограничения регулирования, постоянно, в течение длительного периода времени.
- Вы использовали веб-службы для создания инструмента для синхронизации свойств профилей пользователей. Инструмент обновляет свойства профиля пользователя на основе информации из вашей системы управления персоналом (HR). Инструмент делает вызовы на слишком высокой частоте.
- Вы запускаете сценарий нагрузочного тестирования в SharePoint Online, и вас ограничивают. Нагрузочное тестирование запрещено в SharePoint Online.
- Вы настроили свой сайт группы в SharePoint Online, например, добавив индикатор состояния на домашнюю страницу. Этот индикатор состояния часто обновляется, что приводит к слишком большому количеству обращений страницы к службе SharePoint Online, что приводит к регулированию.
- Запуск клиента OneDrive Sync при одновременном запуске приложений миграции или приложений, которые сканируют сайты и записывают данные обратно, может привести к большим объемам запросов, которые могут привести к регулированию.
Неподдерживаемые варианты использования
Неподдерживаемое использование SharePoint Online может привести к регулированию. Использование SharePoint и OneDrive в качестве промежуточной службы между Microsoft 365 и другим репозиторием является примером неподдерживаемого варианта использования.
Создание нескольких AppID для одного приложения
Не создавайте отдельные AppID, если приложения выполняют одни и те же операции, например резервное копирование или предотвращение потери данных. Приложения, работающие с одним и тем же арендатором, в конечном итоге используют один и тот же ресурс арендатора. Исторически сложилось так, что некоторые приложения пытались использовать этот подход, чтобы обойти регулирование приложения, но в конечном итоге это приводило к истощению ресурсов арендатора и вызывало регулирование нескольких приложений в арендаторе. Если этого нельзя избежать, каждый экземпляр пользовательского кода, который взаимодействует с SharePoint Online, должен быть спроектирован с учетом наличия регулирования.
Специфические ограничения сценария
При использовании проверки подлинности только для приложений с разрешением Sites.Read.All
При использовании API-интерфейсов поиска SharePoint Online с проверкой подлинности только для приложений и приложением с разрешением Sites.Read.All (или более сильным) , приложение будет зарегистрировано с полными разрешениями, и ему будет разрешено запрашивать весь ваш контент SharePoint Online (включая личный контент ODB пользователя).
Чтобы служба оставалась быстрой и надежной, запросы, использующие такое разрешение, регулируются до 25 запросов в секунду. Поисковый запрос вернет ошибку http 429.отклик. В ожидании восстановления регулирования вы должны обязательно приостановить все запросы поисковых запросов, которые вы можете отправлять в службу, используя аналогичное разрешение только для приложений. Выполнение большего количества вызовов во время получения ответов на дросселирование продлит время, необходимое для того, чтобы ваше приложение перестало регулироваться.
При поиске результатов поиска людей
При поиске с использованием источника результатов, который запрашивает результаты поиска людей, мы можем блокировать любые запросы, превышающие ограничение в 25 запросов в секунду. Это ограничение применяется ко всем запросам, использующим готовый источник результатов «Результаты местных пользователей», и ко всем запросам, использующим настраиваемые источники результатов поиска людей.
Если у вас есть приложения или компоненты, которые приводят к регулированию ваших запросов на поиск людей, мы рекомендуем вам:
- Подумайте, нужны ли запросы для вашего приложения. Например, если вы используете настраиваемый поисковый сайт, который делает много одновременных запросов, проверьте, можно ли удалить некоторые из этих запросов без существенного влияния на возможности поиска в вашей организации. Кроме того, вы можете попробовать наш современный поиск людей в Microsoft Search, выполнив поиск на стартовой странице SharePoint. Поиск людей в Microsoft Search оптимизирован для повышения производительности и получения более релевантных результатов.
- Избегайте одновременных запросов. Например, вместо того, чтобы выдавать 10 запросов одновременно, выдавайте их последовательно — выдавайте следующий запрос только после завершения предыдущего. Возможно, вам придется подумать о кэшировании этих результатов, если они вам нужны быстро, например, при загрузке страницы.
- Попробуйте объединить запросы в один запрос. Например, вместо 10 одновременных запросов для
WorkEmail:[email protected],WorkEmail:[email protected],...,WorkEmail:[email protected], попробуйте один запрос,WorkEmail:[email protected] WorkEmail:[email protected] ... WorkEmail:[email protected]. - Рассмотрите возможность использования API Microsoft Graph, если сценарий с большим объемом запросов (более 25 запросов в секунду) действительно необходим.
Блокировка — самая крайняя форма ограничения.