Как создать правильный файл robots.txt, настройка, директивы
Файл robots.txt — текстовый файл в формате .txt, ограничивающий поисковым роботам доступ к содержимому на http-сервере. Как определение, Robots.txt — это стандарт исключений для роботов, который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте. Рассмотрим описание robots.txt для случая, когда сайт не ограничивает доступ роботам к сайту.
Простой пример robots.txt:
User-agent: * Allow: /
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта, чтобы он был доступен по адресу:
ваш_сайт.ru/robots.txt
Для размещения файла robots.txt в корне сайта обычно необходим доступ через FTP
Если файл доступен, то вы увидите содержимое robots.txt в браузере.
Для чего нужен robots.txt
Roots.txt для сайта является важным аспектом поисковой оптимизации. Зачем нужен robots.txt? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое. Как, что, зачем и почему исключается уже было описано в статье про запрет индексации страниц сайта, здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование robots.txt подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы robots.txt, например директива Host или Sitemap, но об этом ниже.
Как создать robots.txt
Поскольку robots.txt — это текстовый файл, и чтобы создать файл robots.txt, можно воспользоваться любым текстовым редактором, например Блокнотом. Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt. Все просто, и создание файла robots.txt не должно вызвать проблем даже у новичков. О том, как составить robots.txt и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Вариант для ленивых — создать роботс онлайн и скачать файл robots.txt уже в готовом виде. Создание robots txt онлайн предлагает множество сервисов, выбор за вами. Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией, которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Редактирование robots.txt
После того, как вам удалось создать файл robots.txt онлайн или своими руками, вы можете редактировать robots.txt. Изменить его содержимое можно как угодно, главное — соблюдать некоторые правила и синтаксис robots.txt. В процессе работы над сайтом, файл роботс может меняться, и если вы производите редактирование robots.txt, то не забывайте выгружать на сайте обновленную, актуальную версию файла со всем изменениями. Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Правильная настройка robots.txt
Правильная настройка robots.txt позволяет избежать попадания частной информации в результаты поиска крупных поисковых систем. Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Чтобы понять, как сделать правильный robots txt, для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Правильный robots.txt начинается с директивы User-agent, которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно User-agent: * # Указывает директивы для всех роботов Яндекса User-agent: Yandex # Указывает директивы для только основного индексирующего робота Яндекса User-agent: YandexBot # Указывает директивы для всех роботов Google User-agent: Googlebot
Учитывайте, что подобная
Пример robots.txt с несколькими вхождениями User-agent:
# Будет использована всеми роботами Яндекса User-agent: Yandex Disallow: /*utm_ # Будет использована всеми роботами Google User-agent: Googlebot Disallow: /*utm_ # Будет использована всеми роботами кроме роботов Яндекса и Google User-agent: * Allow: /*utm_
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все страницы с UTM-метками. Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Пример правильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Как видно из примера, указания в robots.txt поступают блоками
Кроме того, важно соблюдать правильный порядок и сортировку команд в robots.txt при совместном использовании директив, например «Disallow» и «Allow». Директива «Allow» — разрешающая директива, является противоположностью команды robots.txt «Disallow» — запрещающей директивы.
Пример совместного использования директив в robots.txt:
User-agent: * Allow: /blog/page Disallow: /blog
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots.txt в правильной сортировке:
User-agent: * Disallow: /blog Allow: /blog/page
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
User-agent: * Allow: / Disallow: /blog Allow: /blog/page
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
User-agent: * Disallow: # равнозначно Allow: / Disallow: /blog Allow: /blog/page
Как составить правильный robots.txt и как пользоваться трактовкой директив — ваш выбор. Оба варианта будут правильными. Главное — не запутайтесь.
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Синтаксис robots.txt
Роботы поисковых систем добровольно следуют командам robots.txt — стандарту исключений для роботов, однако не все поисковые системы трактуют синтаксис robots.txt одинаково. Файл robots.txt имеет строго определённый синтаксис, но в то же время написать robots txt не сложно, так как его структура очень проста и легко понятна.
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt:
- Каждая директива начинается с новой строки;
- Не указывайте больше одной директивы в одной строке;
- Не ставьте пробел в начало строки;
- Параметр директивы должен быть в одну строку;
- Не нужно обрамлять параметры директив в кавычки;
- Параметры директив не требуют закрывающих точки с запятой;
- Команда в robots.txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
- Допускаются комментарии в robots.txt после знака решетки #;
- Пустой перевод строки может трактоваться как окончание директивы User-agent;
- Директива «Disallow: » (с пустым значением) равнозначна «Allow: /» — разрешить все;
- В директивах «Allow», «Disallow» указывается не более одного параметра;
- Название файла robots.txt не допускает наличие заглавных букв, ошибочное написание названия файла — Robots.txt или ROBOTS.TXT;
- Написание названия директив и параметров заглавными буквами считается плохим тоном и если по стандарту, robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий;
- Если параметр директивы является директорией, то перед название директории всегда ставится слеш «/», например: Disallow: /category
- Слишком большие robots.txt (более 32 Кб) считаются полностью разрешающими, равнозначными «Disallow: »;
- Недоступный по каким-либо причинам robots.txt может трактоваться как полностью разрешающий;
- Если robots.txt пустой, то он будет трактоваться как полностью разрешающий;
- В результате перечисления нескольких директив «User-agent» без пустого перевода строки, все последующие директивы «User-agent», кроме первой, могут быть проигнорированы;
- Использование любых символов национальных алфавитов в robots.txt не допускается.
Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
В роботсе должно быть указано строго только то, что нужно, и ничего лишнего. Не думайте, как прописать в robots txt все, что только можно и чем его заполнить. Идеальный robots txt — это тот, в котором меньше строк, но больше смысла. «Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка файла robots.txt в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
Для того, чтобы проверить robots.txt онлайн необходимо загрузить robots.txt на сайт в корневую директорию. Иначе, сервис может сообщить, что не удалось загрузить robots.txt. Рекомендуется предварительно проверить robots.txt на доступность по адресу где лежит файл, например: ваш_сайт.ru/robots.txt.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса, но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Disallow — запрещающая директива, которая чаще всего используется в файле robots.txt. Disallow запрещает индексацию сайта или его части, в зависимости от пути, указанного в параметре директивы Disallow.
Пример как в robots.txt запретить индексацию сайта:
User-agent: * Disallow: /
Данный пример закрывает от индексации весь сайт для всех роботов.
В параметре директивы Disallow допускается использование специальных символов * и $:
* — любое количество любых символов, например, параметру /page* удовлетворяет /page, /page1, /page-be-cool, /page/kak-skazat и т.д. Однако нет необходимости указывать * в конце каждого параметра, так как например, следующие директивы интерпретируются одинаково:
User-agent: Yandex Disallow: /page
User-agent: Yandex Disallow: /page*
$ — указывает на точное соответствие исключения значению параметра:
User-agent: Googlebot Disallow: /page$
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.
Если закрыть индексацию сайта robots.txt, в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы, можно воспользоваться не только robots txt, но и аналогичными html-тегами:
- <meta name=»robots» content=»noindex»/> — не индексировать содержимое страницы;
- <meta name=»robots» content=»nofollow»/> — не переходить по ссылкам на странице;
- <meta name=»robots» content=»none»/> — запрещено индексировать содержимое и переходить по ссылкам на странице;
- <meta name=»robots» content=»noindex, nofollow»/> — аналогично content=»none».
Разрешить индексацию: robots.txt Allow
Allow — разрешающая директива и противоположность директиве Disallow. Эта директива имеет синтаксис, сходный с Disallow.
Пример, как в robots.txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * Disallow: / Allow: /page
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
User-agent: * Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
User-agent: * Allow: /
Пустая директива Allow:
User-agent: * Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
User-agent: * Disallow: /
Главное зеркало сайта: robots.txt Host
Директива Host служит для указания роботу Яндекса главного зеркала Вашего сайта. Из всех популярных поисковых систем, директива Host распознаётся только роботами Яндекса. Директива Host полезна в том случае, если ваш сайт доступен по нескольким доменам, например:
mysite.ru mysite.com
Или для определения приоритета между:
mysite.ru www.mysite.ru
Роботу Яндекса можно указать, какое зеркало является главным. Директива Host указывается в блоке директивы «User-agent: Yandex» и в качестве параметра, указывается предпочтительный адрес сайта без «http://».
Пример robots.txt с указанием главного зеркала:
User-agent: Yandex Disallow: /page Host: mysite.ru
В качестве главного зеркала указывается доменное имя mysite.ru без www. Таки образом, в результатах поиска буде указан именно такой вид адреса.
User-agent: Yandex Disallow: /page Host: www.mysite.ru
В качестве основного зеркала указывается доменное имя www.mysite.ru.
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.txt sitemap
При помощи директивы Sitemap, в robots.txt можно указать расположение на сайте файла карты сайта sitemap.xml.
Пример robots.txt с указанием адреса карты сайта:
User-agent: * Disallow: /page Sitemap: http://www.mysite.ru/sitemap.xml
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param.
Синтаксис директивы Clean-param:
Clean-param: parm1[&parm2&parm3&parm4&..&parmn] [Путь]
Рассмотрим на примере страницы со следующим URL:
www.mysite.ru/page.html?&parm1=1&parm2=2&parm3=3
Пример robots.txt Clean-param:
Clean-param: parm1&parm2&parm3 /page.html # только для page.html
или
Clean-param: parm1&parm2&parm3 / # для всех
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
User-agent: Yandex Disallow: /page Crawl-delay: 3
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt.
Комментарии в robots.txt
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.
Примеры комментариев в robots.txt:
User-agent: * # Комментарий может идти от начала строки Disallow: /page # А может быть продолжением строки с директивой # Роботы # игнорируют # комментарии Host: www.mysite.ru
В заключении
Файл robots.txt — очень важный и нужный инструмент взаимодействия с поисковыми роботами и один из важнейших инструментов SEO, так как позволяет напрямую влиять на индексацию сайта. Используйте роботс правильно и с умом.
Если у вас есть вопросы — пишите в комментариях.
Рекомендуйте статью друзьям и не забывайте подписываться на блог.
Новые интересные статьи каждый день.
convertmonster.ru
Robots.txt — Как создать правильный robots.txt
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
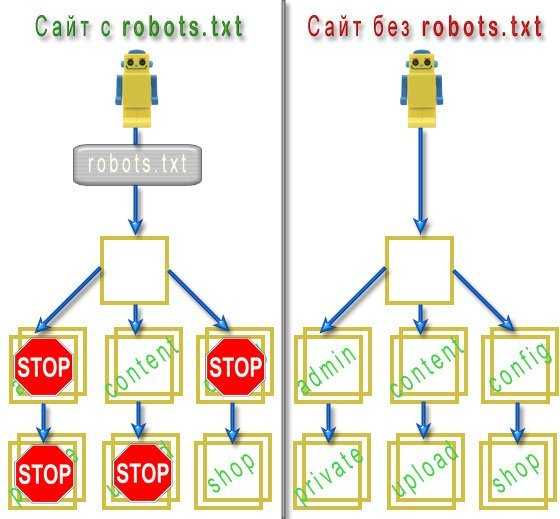
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:
Исключения Яндекса
Стандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:User-agent: *
Для конкретного бота:User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Следующие ссылки будут закрыты от индексации:
http://site.ru/?s=
http://site.ru/?s=keyword
http://site.ru/page/?s=keyword
http://site.ru/category/
Следующие ссылки будут открыты для индексации:
http://site.ru/category/cat1/
http://site.ru/category-folder/
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site.ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Host
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:Host: site.ru
Пример 2:Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:Crawl-delay: 3
Пример 2:Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Пример 1:
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Пример 2:
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: *
Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
- Закройте от индексирования админку сайта
- Закройте от индексирования личный кабинет, авторизацию, регистрацию
- Закройте от индексирования корзину, формы заказа, данные по доставке и заказам
- Закройте от индексирования ajax, json-скрипты
- Закройте от индексирования папку cgi
- Закройте от индексирования плагины, темы оформления, js, css для всех роботов, кроме Яндекса и Google
- Закройте от индексирования функционал поиска
- Закройте от индексирования служебные разделы, которые не несут никакой ценности для сайта в поиске (ошибка 404, список авторов)
- Закройте от индексирования технические дубли страниц, а также страницы, на которых весь контент в том или ином виде продублирован с других страниц (календари, архивы, RSS)
- Закройте от индексирования страницы с параметрами фильтров, сортировки, сравнения
- Закройте от индексирования страницы с параметрами UTM-меток и сессий
- Проверьте, что проиндексировано Яндексом и Google с помощью параметра «site:» (в поисковой строке наберите «site:site.ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
- Укажите Sitemap и Host
- По необходимости пропишите Crawl-Delay и Clean-Param
- Проверьте корректность robots.txt через инструменты Google и Яндекса (описано ниже)
- Через 2 недели перепроверьте, появились ли в поисковой выдаче новые страницы, которые не должны индексироваться. В случае необходимости повторить выше перечисленные шаги.
Пример robots.txt
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif User-agent: Yandex Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif Clean-Param: utm_source&utm_medium&utm_campaign Crawl-Delay: 0.5 Sitemap: https://site.ru/sitemap.xml Host: https://site.ru
Как добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
Типичные ошибки в robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
- robots.txt отсутствует
- в robots.txt сайт закрыт от индексирования (Disallow: /)
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий
- в файле указаны только директивы
Allow: *.css
Allow: *.js
Allow: *.png
Allow: *.jpg
Allow: *.gif
при этом файлы css, js, png, jpg, gif закрыты другими директивами в ряде директорий - директива Host прописана несколько раз
- в Host не указан протокол https
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта
P.S.
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
P.S.2
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
seogio.ru
составляем правильный роботс для WordPress и других систем
Содержание статьи
Вы знаете, насколько важна индексация — это основа основ в продвижении сайтов. Потому что если ваш сайт не индексируется, то хрен вы какой трафик из поиска получите. Если он индексируется некорректно — то у вас даже при прочих идеальных условиях будет обрубаться часть трафика. Тут все просто — если вы, например, запретили к индексации папку с изображениями, то у вас почти не будет по ним трафа (хотя многие сознательно идут на такой шаг).
Индексация сайта — это процесс, в ходе которого страницы вашего сайта попадают в Яндекс, Гугл или другой поисковик. И после этого пользователь может найти страницу вашего сайта по какому-нибудь запросу.
Управляете вы такой важной штукой, как индексация, именно посредством файла robots.txt. Начну с азов.
Что такое robots.txt
Robots.txt — файл, который говорит поисковой системе, какие разделы и страницы вашего сайта нужно включать в поиск, а какие — нельзя. Ну то есть он говорит не поисковой системе напрямую, а её роботу, который обходит все сайты интернета. Вот что такое роботс. Этот файл всегда создается в универсальном формате .txt, который сможет открыть даже компьютер вашего деда.
Вот видос от Яндекса:
Основное назначение – контроль за доступом к публикуемой информации. При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
Использование стандарта осуществляется на добровольной основе владельцами сайтов. Файл должен включать в себя специальные инструкции, на основе которых проводится проверка сайта поисковыми роботами.
Самый простой пример robots:
Данный код открывает весь сайт, структура которого должна быть безупречной.
Зачем закрывают какие-то страницы? Не проще ли открыть всё?
Смотрите — у каждого сайта есть свой лимит, который называется краулинговый бюджет. Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Где находится Robots
Robots традиционно загружают в корневой каталог сайта.
 Это корневой каталог, и в нем лежит роботс.
Это корневой каталог, и в нем лежит роботс.Для загрузки текстового файла обычно используется FTP доступ. Некоторые CMS, например WordPress или Joomla, позволяют создавать robots из админпанели.
Для чего нужен этот файл
А вот для чего:
- запрета на индексацию мусора — страниц и разделов, которые не содержат в себе полезный контент;
- разрешение индексации нужных страниц и разделов;
- чтобы давать разные задачи роботам разных поисковиков — то есть, например, Яндексу разрешить индексировать всё, а Рамблеру — ничего;
- можно также задавать роботам разные категории. Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;
- чтобы показать через директиву Host Яндексу, какое у сайта главное зеркало;
- еще некоторые вебмастера запрещают всяким нехорошим парсерам сканировать сайт с помощью этого файла;
То есть большую часть проблем по индексации он решает. Есть конечно помимо роботса еще и такие инструменты, как метатег роботс (не путайте!), заголовок Last-Modified и другие, но это уже для профессионалов и нужны они лишь в особых случаях. Для решения большинства базовых проблем с индексацией хватает манипуляций с роботсом.
Как работают поисковые роботы и как они обрабатывают данный файл
В большинстве случаев, очень упрощенно, они работают так:
- Обходят Интернет;
- Проверяют, какие документы разрешено индексировать, а какие запрещено;
- Включает разрешенные документы в базу;
- Затем уже другие механизмы решают, какие страницы достаточно полезны для включения в индекс.
Вот ссылка на справку Яндекса о работе поисковых роботов, но там все довольно отдаленно описано.
Справка Google свидетельствует: robots – рекомендация. Файл создается для того, чтобы страница не добавлялась в индекс поисковой системы, а не чтобы она не сканировалась поисковыми системами. Гугл позволяет запрещенной странице попасть в индекс, если на нее направляется ссылка внутри ресурса или с внешнего сайта.
По-разному ли Яндекс и Google воспринимают этот файл
Многие прописывают для роботов разных поисковиков разные директивы. Даже если список этих директив ничем не отличается.
Наверное, это для того, чтобы выразить уважение к Господину Поисковику. Как там раньше делали — «великий князь челом бьет… и просит выдать ярлык на княжение». Других соображений по поводу того, зачем разным юзер-агентам прописывают одни и те же директивы, у меня нет, да и вебмастера, так делающие, дать нормальных объяснений своим действиям не могут.
А те, кто может ответить, аргументируют это так: мол, Google не воспринимает директиву Host и поэтому её нужно указывать только для Яндекса, и вот почему, мол, для яндексовского юзер-агента нужны отдельные директивы. Но я скажу так: если какой-то робот не воспринимает какую-то директиву, то он её просто проигнорирует. Так что лично я не вижу смысла указывать одни и те же директивы для разных роботов отдельно. Хотя, отчасти понимаю перестраховщиков.
Чем может грозить неправильно составленный роботс
Некоторые при создании сайта на WordPress ставят галочку, чтобы система закрывала сайт от индексации (и забывают потом убрать её). Тогда Вордпресс автоматом ставит вам такой роботс, чтобы поисковики не включали ваш сайт в индекс, и это — самая страшная ошибка. Те страницы, на которые вы намерены получать трафик, обязательно должны быть открыты для индексации.
Потом, если вы не закрыли ненужные страницы от индексации, в индекс может попасть, как я уже говорил выше, очень много мусора (ненужных страниц), и они могут занять в индексе место нужных страниц.
Вообще, если вкратце, неправильный роботс грозит вам тем, что часть страниц не попадет в поиск и вы лишитесь части посетителей.
Как создать файл robots.txt
В Блокноте или другом редакторе создаем файл с расширением .txt, чтобы он в итоге назывался robots.txt. Заполняем его правильно (дальше расскажу, как) и загружаем в корень сайта. Готово!
Вот тут разработчик сайта Loftblog создает файл с нуля в режиме реального времени и делает настройку роботс:
Пример правильного robots.txt для WordPress
Составить правильный robots.txt для сайта WordPress проще всего. Я сам видел очень много таких роботсов (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Host: znet.ru User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Sitemap: http://znet.ru/sitemap.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Host: znet.ru
User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
Sitemap: http://znet.ru/sitemap.xml |
Этот роботс для WordPress довольно проверенный. Большую часть задач он выполняет — закрывает версию для печати, файлы админки, результаты поиска и так далее.
«Универсальный» роботс
Если вы ищете какое-то решение, которое подойдет для всех сайтов на всех CMS (или для лендинга), «волшебную таблетку» — такой нет. Для всех CMS одинаково хорошо подойдет лишь решение, при котором вы говорите разрешить все для индексации:
В остальном — нужно отталкиваться от системы, на которой написан ваш сайт. Потому что у каждой из них уникальная структура и разные разделы/служебные страницы.
Роботс для Joomla
Joomla — ужасный движок, вы ужасный человек, если до сих пор им пользуетесь. Дублей страниц там просто дофига. В основном нормально работает такой код (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: http://znet.ru/sitemap.xml User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Host: znet.ru Sitemap: http://znet.ru/sitemap.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: http://znet.ru/sitemap.xml
User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Host: znet.ru Sitemap: http://znet.ru/sitemap.xml |
Но я вам настоятельно советую отказаться от этого жестокого движка и перейти на WordPress (а если у вас интернет-магазин — на Opencart или Bitrix). Потому что Joomla — это жесть.
Robots для Битрикса
Как составить robots.txt для Битрикс (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /bitrix/ Disallow: /upload/ Disallow: /search/ Allow: /search/map.php Disallow: /club/search/ Disallow: /club/group/search/ Disallow: /club/forum/search/ Disallow: /communication/forum/search/ Disallow: /communication/blog/search.php Disallow: /club/gallery/tags/ Disallow: /examples/my-components/ Disallow: /examples/download/download_private/ Disallow: /auth/ Disallow: /auth.php Disallow: /personal/ Disallow: /communication/forum/user/ Disallow: /e-store/paid/detail.php Disallow: /e-store/affiliates/ Disallow: /club/$ Disallow: /club/messages/ Disallow: /club/log/ Disallow: /content/board/my/ Disallow: /content/links/my/ Disallow: /*/search/ Disallow: /*PAGE_NAME=search Disallow: /*PAGE_NAME=user_post Disallow: /*PAGE_NAME=detail_slide_show Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?print= Disallow: /*&print= Disallow: /*register=yes Disallow: /*forgot_password=yes Disallow: /*change_password=yes Disallow: /*login=yes Disallow: /*logout=yes Disallow: /*auth=yes Disallow: /*action=ADD_TO_COMPARE_LIST Disallow: /*action=DELETE_FROM_COMPARE_LIST Disallow: /*action=ADD2BASKET Disallow: /*action=BUY Disallow: /*print_course=Y Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*index.php$ Host: znet.ru Sitemap: http://znet.ru/sitemap.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
User-agent: * Disallow: /bitrix/ Disallow: /upload/ Disallow: /search/ Allow: /search/map.php Disallow: /club/search/ Disallow: /club/group/search/ Disallow: /club/forum/search/ Disallow: /communication/forum/search/ Disallow: /communication/blog/search.php Disallow: /club/gallery/tags/ Disallow: /examples/my-components/ Disallow: /examples/download/download_private/ Disallow: /auth/ Disallow: /auth.php Disallow: /personal/ Disallow: /communication/forum/user/ Disallow: /e-store/paid/detail.php Disallow: /e-store/affiliates/ Disallow: /club/$ Disallow: /club/messages/ Disallow: /club/log/ Disallow: /content/board/my/ Disallow: /content/links/my/ Disallow: /*/search/ Disallow: /*PAGE_NAME=search Disallow: /*PAGE_NAME=user_post Disallow: /*PAGE_NAME=detail_slide_show Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?print= Disallow: /*&print= Disallow: /*register=yes Disallow: /*forgot_password=yes Disallow: /*change_password=yes Disallow: /*login=yes Disallow: /*logout=yes Disallow: /*auth=yes Disallow: /*action=ADD_TO_COMPARE_LIST Disallow: /*action=DELETE_FROM_COMPARE_LIST Disallow: /*action=ADD2BASKET Disallow: /*action=BUY Disallow: /*print_course=Y Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*index.php$ Host: znet.ru Sitemap: http://znet.ru/sitemap.xml |
Как правильно составить роботс
У каждой поисковой системы есть свой User-Agent. Когда вы прописываете юзер-эйджент, то вы обращаетесь к какой-то определенной поисковой системе. Вот названия ботов поисковых систем:
Google: Googlebot
Яндекс: Yandex
Мэйл.ру: Mail.Ru
Yahoo!: Slurp
MSN: MSNBot
Рамблер: StackRambler
Это основные, которые включают ваш сайт в текстовые индексы поисковиков. А вот их вспомогательные роботы:
Googlebot-Mobile — это юзер-агент для мобильных
Googlebot-Image — это для картинок
Mediapartners-Google — этот робот сканирует содержание обьявлений AdSense
Adsbot-Google — это для качества целевых страниц AdWords
MSNBot-NewsBlogs – это для новостей MSN
Сначала в любом нормальном роботсе идет указание юзер-агента, а потом директивы ему. Юзер-агента мы указываем в первой строке, вот так:
Это будет обращение к роботу Яндекса. А вот обращение ко всем роботам всех систем сразу:
После юзер-агента идут указания, относящиеся именно к нему. Пример:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ |
Сначала мы прописываем директивы для всех интересующих нас юзер-агентов. Затем дополняем их тем, что нас интересует, и заканчиваем обычно ссылкой на XML-карту сайта:
Sitemap: http://znet.ru/sitemap.xml
Sitemap: http://znet.ru/sitemap.xml |
А вот что прописывать в директивах — это для каждой CMS, как я уже писал выше, по-разному. Но в принципе можно выделить основные типы страниц, которые нужно закрывать во всех роботсах.
Что нужно закрывать в нем
Всю эту хрень нужно закрыть от индексации:
- Страницы поиска. Обычно поиск генерирует очень много страниц, которые нам не будут нести трафика;
- Корзина и страница оформления заказа. Обычно они не должны попадать в индекс;
- Страницы пагинации. Некоторые мастера знают, как получать с них трафик, но если вы не профессионал, лучше закройте их;
- Фильтры и сравнение товаров могут генерировать мусорные страницы;
- Страницы регистрации и авторизации. На этих страницах вводится только конфиденциальная информация;
- Системные каталоги и файлы. Каждый ресурс включает в себя административную часть, таблицы CSS, скрипты. В индексе нам это все не нужно;
- Языковые версии, если вы не продвигаетесь в других странах и они нужны вам чисто для информации;
- Версии для печати.
Как закрыть страницы от индексации и использовать Disallow
Вот чтобы закрыть от индексации какой-то тип страниц, нам потребуется она. Disallow – директива для запрета индексации. Чтобы закрыть, допустим, страницу znet.ru/page.html на своем блоге, я должен добавить в роботс:
А если мне нужно закрыть все страницы, которые начинаются с http://znet.ru/instrumenty/? То есть страницы http://znet.ru/instrumenty/1.html, http://znet.ru/instrumenty/2.html и другие? Тогда я добавляю такую строку в роботс:
Короче, это самая нужная директива.
Нужно ли использовать директиву Allow?
Крайне редко ей пользуюсь. Вообще, она нужна для того, чтобы разрешать роботу индексировать определенные страницы. Но он индексирует все, что не запрещено. Так что Allow я почти не использую. За исключением редких случаев, например, таких:
Допустим, у меня в роботсе закрыта категория /instrumenty/. Но страницу http://znet.ru/instrumenty/44.html я должен открыть для индексации. Тогда у меня в роботс тхт будет написано так:
Disallow: /instrumenty/ Allow: /instrumenty/44.html
Disallow: /instrumenty/ Allow: /instrumenty/44.html |
В таком случае проблема будет решена. Как пишет Яндекс, «При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow». Короче, Allow я использую тогда, когда нужно перебить требования какой-то из директив Disallow.
Регулярные выражения
Когда прописываем директивы, мы можем использовать спецсимволы * и $ для создания регулярных выражений. Для чего они нужны? Давайте на практике рассмотрим:
User-agent: Yandex Disallow: /cgi-bin/*.aspx
User-agent: Yandex Disallow: /cgi-bin/*.aspx |
Такая директива запретит Яндексу индексировать страницы, которые начинаются на /cgi-bin/ и заканчиваются на .aspx, то есть вот эти страницы:
/cgi-bin/loh.aspx
/cgi-bin/pidr.aspx
И подобные им будут закрыты.
А вот спецсимвол $ «фиксирует» запрет какой-то конкретной страницы. То есть такой код:
User-agent: Yandex Disallow: /example$
User-agent: Yandex Disallow: /example$ |
Запретит индексировать страницу /example, но не запрещает индексировать страницы /example-user, /example.html и другие. Только конкретную страницу /example.
Для чего нужна директива Host
Если сайт доступен сразу по нескольким адресам, директива Host указывает главное зеркало одного ресурса. Эту директиву распознают только роботы Яндекса, остальные поисковики забивают на нее болт. Пример:
User-agent: Yandex Disallow: /page Host: znet.ru
User-agent: Yandex Disallow: /page Host: znet.ru |
Host используется в robots только один раз. Если же их будет указано несколько, учитываться будет только первая директива.
Что такое Crawl-delay
Директива Crawl-delay устанавливает минимальное время между завершением загрузки роботом страницы 1 и началом загрузки страницы 2. То есть если у вас в роботсе добавлено такое:
User-agent: Yandex Crawl-delay: 2
User-agent: Yandex Crawl-delay: 2 |
То таймаут между загрузками двух страниц составит две секунды.
Это нужно, если ваш сервер плохо выдерживает запросы на загрузку страниц. Но я скажу так: если это так и есть, то ваш сервер — говно, и тут не Crawl-delay нужно устанавливать, а менять сервер.
Нужно ли указывать Sitemap в роботсе
В конце роботса нужно указывать ссылку на сайтмап, да. Я вам скажу, что это очень круто помогает индексации.
Был у меня один сайт, который хреново индексировался месяца полтора, когда я еще только начинал в SEO. Я не мог никак понять, в чем причина. Оказалось, я просто не указал путь к сайтмапу. Когда я это сделал — все нужные страницы через 1 апдейт уже попали в индекс.
Указывается путь к сайтмапу так:
Sitemap: http://znet.ru/sitemap.xml
Sitemap: http://znet.ru/sitemap.xml |
Это если ваша карта сайта открывается по этому адресу. Если она открывается по другому адресу — прописывайте другой.
Прочие рекомендации к составлению
Рекомендую соблюдать:
- В одной строке — одна директива;
- Без пробелов в начале строк;
- Директива будет работать, только если написана целиком и без лишних знаков;
- Как пишет сам Яндекс, «Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке»;
- Правильный код роботс должен содержать как минимум одну директиву Dissallow.
А вот еще видео для продвинутых с вебмастерской Яндекса:
Как запретить индексацию всего сайта
Вот этот код поможет закрыть сайт от индексации:
User-agent: * Disallow: /
Пригодиться это может, если вы делаете новый сайт, но он еще не готов, и поэтому его лучше закрыть, чтобы он во время доработки не попал под какой-нибудь фильтр АГС.
Как проверить, правильно ли составлен файл
В Яндекс Вебмастере и Гугл Вебмастере есть инструмент, который поможет вам понять, правильно ли составлен роботс. Рекомендую обязательно проверять файл в этих сервисах перед размещением. В Яндекс Вебмастере вы также сможете добавить список страниц, чтобы проверить, разрешены ли они к индексации роботом.
znet.ru
Как составить robots.txt самостоятельно
Как правильно составить robots.txt и зачем он нужен, как закрыть индексацию через robots.txt и бесплатно проверить robots.txt с помощью онлайн-инструментов.
Как поисковики сканируют страницу
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots.txt.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта — Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI). - Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. - Быстро загружаются.
Проверьте скорость загрузки инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Посмотреть на сайт глазами поискового бота
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt. Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt«, название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами — http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Как составить robots.txt правильно
Файл можно составить в любом текстовом редакторе и сохранить в формате txt. В нем нужно прописать инструкцию для роботов: указание, каким роботам реагировать, и разрешение или запрет на сканирование файлов.
Инструкции отделяют друг от друга переносом строки.
Символы robots.txt
«*» — означает любую последовательность символов в файле.
«$» — ограничивает действия «*», представляет конец строки.
«/» — показывает, что закрывают для сканирования.
«/catalog/» — закрывают раздел каталога;
«/catalog» — закрывают все ссылки, которые начинаются с «/catalog».
«#» — используют для комментариев, боты игнорируют текст с этим символом.
User-agent: * Disallow: /catalog/ #запрещаем сканировать каталог
Директивы robots.txt
Директивы, которые распознают все краулеры:
User-agent
На первой строчке прописывают правило User-agent — указание того, какой робот должен реагировать на рекомендации. Если запрещающего правила нет, считается, что доступ к файлам открыт.
Для разного типа контента поисковики используют разных ботов:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.Маркета и другие.
Для отдельных ботов можно указать свою директиву, если есть необходимость в рекомендациях по типу контента.
User-agent: * — правило для всех поисковых роботов;
User-agent: Googlebot — только для основного поискового бота Google;
User-agent: YandexBot — только для основного бота Яндекса;
User-agent: Yandex — для всех ботов Яндекса. Если любой из ботов Яндекса обнаружит эту строку, то другие правила User-agent: * учитывать не будет.
Sitemap
Указывает ссылку на карту сайта — файл со структурой сайта, в котором перечислены страницы для индексации:
User-agent: * Sitemap: http://site.com/sitemap.xml
Некоторые веб-мастеры не делают карты сайтов, это не обязательное требование, но лучше составить Sitemap — этот файл краулеры воспринимают как структуру страниц, которые не можно, а нужно индексировать.
Disallow
Правило показывает, какую информацию ботам сканировать не нужно.
Если вы еще работаете над сайтом и не хотите, чтобы он появился в незавершенном виде, можно закрыть от сканирования весь сайт:
User-agent: * Disallow: /
После окончания работы над сайтом не забудьте снять блокировку.
Разрешить всем ботам сканировать весь сайт:
User-agent: * Disallow:
Для этой цели можно оставить robots.txt пустым.
Чтобы запретить одному боту сканировать, нужно только прописать запрет с упоминанием конкретного бота. Для остальных разрешение не нужно, оно идет по умолчанию:
Пользователь-агент: BadBot Disallow: /
Чтобы разрешить одному боту сканировать сайт, нужно прописать разрешение для одного и запрет для остальных:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Запретить ботам сканировать страницу:
User-agent: * Disallow: /page.html
Запретить сканировать конкретную папку с файлами:
User-agent: * Disallow: /name/
Запретить сканировать все файлы, которые заканчиваются на «.pdf»:
User-agent: * Disallow: /*.pdf$
Запретить сканировать раздел http://site.com/about/:
User-agent: * Disallow: /about/
Запись формата «Disallow: /about» без закрывающего «/» запретит доступ и к разделу
http://site.com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с «/about».
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Директива определяет те пути, которые доступны для указанных поисковых ботов. По сути, это Disallow-наоборот — директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл «photo.html» разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.html Disallow: /album1/
Заблокировать доступ к каталогам «site.com/catalog1/» и «site.com/catalog2/» но разрешить к «catalog2/subcatalog1/»:
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
«www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123″
«www.site. com/some_dir/get_book.pl?ref=site_2& book_id=123″
«www.site. com/some_dir/get_book.pl?ref=site_3& book_id=123″
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref/some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
«www.example. com/some_dir/get_book.pl? book_id=123″
Для адресов вида:
«www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df»
«www.example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid/index.php
Для адресов вида
«www.example1. com/forum/showthread.php? s=681498b9648949605&t=8243″
«www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s/forum/showthread.php
Если переходных параметров несколько:
«www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311″
«www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref/forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации. URL нужно писать без «http://» и без закрывающего слэша «/».
User-agent: Yandex Disallow: /about Host: www.site.com
Сейчас эту директиву уже не используют, если в ваших robots.txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
Crawl-delay
Раньше частая загрузка страниц нагружала сервер, поэтому для ботов устанавливали Crawl-delay — время ожидания робота в секундах между загрузками. Эту директиву можно не использовать, мощным серверам она не требуется.
Время ожидания — 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Напомним, что все кириллические ссылки нужно перевести в Punycode с помощью любого конвертера.
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3a
Пример robots.txt
Запись означает, что правило справедливо для всех роботов: запрещено сканировать ссылки из корзины, из встроенного поиска и админки, карта сайта находится по ссылке http://site.com/sitemap, ref не меняет содержание страницы get_book:
User-agent: * Disallow: /bin/ Disallow: /search/ Disallow: /admin/ Sitemap: http://site.com/sitemap Clean-param: ref/some_dir/get_book.pl
Составить robots.txt бесплатно поможет
инструмент для генерации robots.txt от PR-CY, он позволит закрыть или открыть весь сайт для ботов, указать путь к карте сайта, настроить ограничение на посещение страниц, закрыть доступ некоторым роботам и установить задержку:
 Графы инструмента для заполнения
Графы инструмента для заполненияДля проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Файл robots.txt не подходит для блокировки доступа к приватным файлам, но направляет краулеров к карте сайта и дает рекомендации для быстрого сканирования важных материалов ресурса.
pr-cy.ru
Создаем правильный файл robots.txt — настраиваем индексацию, директивы
- Зачем robots.txt в SEO?
- Создаем robots самостоятельно
- Синтаксис robots.txt
- Обращение к индексирующему роботу
- Запрет индексации Disallow
- Разрешение индексации Allow
- Директива host robots.txt
- Sitemap.xml в robots.txt
- Использование директивы Clean-param
- Использование директивы Crawl-delay
- Комментарии в robots.txt
- Маски в robots.txt
- Как правильно настроить robots.txt?
- Проверяем свой robots.txt
Robots — это обыкновенный текстовой файл (.txt), который располагается в корне сайта наряду c index.php и другими системными файлами. Его можно загрузить через FTP или создать в файловом менеджере у хост-провайдера. Создается данный файл как обыкновенный текстовой документ с самым простым форматом — TXT. Далее файлу присваивается имя ROBOTS. Выглядит это следующим образом:
(robots.txt в корневой папке WordPress)
После создание самого файла нужно убедиться, что он доступен по ссылке ваш домен/robots.txt. Именно по этому адресу поисковая система будет искать данный файл.
В большинстве систем управления сайтами роботс присутствует по умолчанию, однако зачастую он настроен не полностью или совсем пуст. В любом случае, нам придется его править, так как для 95% проектов шаблонный вариант не подойдет.
Зачем robots.txt в SEO?
Первое, на что обращает внимание оптимизатор при анализе/начале продвижения сайта — это роботс. Именно в нем располагаются все главные инструкции, которые касаются действий индексирующего робота. Именно в robots.txt мы исключаем из поиска страницы, прописываем пути к карте сайта, определяем главной зеркало сайта, а так же вносим другие важные инструкции.
Ошибки в директивах могут привести к полному исключению сайта из индекса. Отнестись к настройкам данного файла нужно осознано и очень серьезно, от этого будет зависеть будущий органический трафик.
Создаем robots самостоятельно
Сам процесс создания файла до безобразия прост. Необходимо просто создать текстовой документ, назвав его «robots». После этого, подключившись через FTP соединение, загрузить в корневую папку Вашего сайта. Обязательно проверьте, что бы роботс был доступен по адресу ваш домен/robots.txt. Не допускается наличие вложений, к примеру ваш домен/page/robots.txt.
Если Вы пользуетесь web ftp — файловым менеджером, который доступен в панели управления у любого хост-провайдера, то файл можно создать прямо там.
В итоге, у нас получается пустой роботс. Все инструкции мы будем вписывать вручную. Как это сделать, мы опишем ниже.
Используем online генераторы
Если создание своими руками это не для Вас, то существует множество online генераторов, которые помогут в этом. Но нужно помнить, что никакой генератор не сможет без Вас исключить из поиска весь «мусор» и не добавит главное зеркало, если Вы не знаете какое оно. Данный вариант подойдет лишь тем, кто не хочет писать рутинные повторяющиеся для большинства сайтов инструкции.
Сгенерированный онлайн роботс нужно будет в любом случае править «руками», поэтому без знаний синтаксиса и основ Вам не обойтись и в этом случае.
Используем готовые шаблоны
В Интернете есть множество шаблонов для распространенных CMS, таких как WordPress, Joomla!, MODx и т.д. От онлайн генераторов они отличаются только тем, что сам текстовой файл Вам нужно будет сделать самостоятельно. Шаблон позволяет не писать большинство стандартных директив, однако он не гарантирует правильную и полную настройку для Вашего ресурса. При использовании шаблонов так же нужны знания.
Синтаксис robots.txt
Использование правильного синтаксиса при настройке — это основа всего. Пропущенная запятая, слэш, звездочка или проблем могут «сбить» всю настройку. Безусловно, есть системы проверки файла, однако без знания синтаксиса они все равно не помогу. Мы по порядку рассмотрим все возможные инструкции, которые применяются при настройке robots.txt. Сначала самые популярные.
Обращение к индексирующему роботу
Любой файл robots начинается с директивы User-agent:, которая указывает для какой поисковой системы или для какого робота приведены инструкции ниже. Пример использования:
User-agent: Yandex User-agent: YandexBot User-agent: Googlebot
Строка 1 — Инструкции для всех роботов Яндекса
Строка 2 — Инструкции для основного индексирующего робота Яндекса
Строка 3 — Инструкции для основного индексирующего робота Google
Яндекс и Гугл имеют не один и даже не два робота. Действиями каждого можно управлять в нашем robots.txt. Давайте рассмотрим, какие бывают роботы и зачем они нужны.
Роботы Yandex
| Название | Описание | Предназначение |
| YandexBot | Основной индексирующий робот | Отвечает за основную органическую выдачу Яндекса. |
| YandexDirect | Работ контекстной рекламы | Оценивает сайты с точки зрения расположения на них контекстных объявлений. |
| YandexDirectDyn | Так же робот контекста | Отличается от предыдущего тем, что работает с динамическими баннерами. |
| YandexMedia | Индексация мультимедийных данных. | Отвечает, загружает и оценивает все, что связано с мультимедийными данными. |
| YandexImages | Индексация изображений | Отвечает за раздел Яндекса «Картинки» |
| YaDirectFetcher | Так же робот Яндекс Директ | Его особенность в том, что он интерпретирует файл robots особым образом. Подробнее о нем можно прочесть у Яндекса. |
| YandexBlogs | Индексация блогов | Данный робот отвечает за посты, комментарии, ответы и т.д. |
| YandexNews | Новостной робот | Отвечает за раздел «Новости». Индексирует все, что связано с периодикой. |
| YandexPagechecker | Робот микроразметки | Данный робот отвечает за индексацию и распознание микроразметки сайта. |
| YandexMetrika | Робот Яндекс Метрики | Тут все и так ясно. |
| YandexMarket | Робот Яндекс Маркета | Отвечает за индексацию товаров, описаний, цен и всего того, что относится к Маркету. |
| YandexCalendar | Робот Календаря | Отвечает за индексацию всего, что связано с Яндекс Календарем. |
Роботы Google
| Название | Описание | Предназначение |
| Googlebot | (Googlebot) Основной индексирующий роботом Google. | Индексирует основной текстовой контент страницы. Отвечает за основную органическую выдачу. Запрет приведет к полному отсутствия сайта в поиске. |
| Googlebot-News | (Googlebot News) Новостной робот. | Отвечает за индексирование сайта в новостях. Запрет приведет к отсутствию сайта в разделе «Новости» |
| Googlebot-Image | (Googlebot Images) Индексация изображений. | Отвечает за графический контент сайта. Запрет приведет к отсутствию сайта в выдаче в разделе «Изображения» |
| Googlebot-Video | (Googlebot Video) Индексация видео файлов. | Отвечает за видео контент. Запрет приведет к отсутствию сайта в выдаче в разделе «Видео» |
| Googlebot | (Google Smartphone) Робот для смартфонов. | Основной индексирующий робот для мобильных устройств. |
| Mediapartners-Google | (Google Mobile AdSense) Робот мобильной контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных мобильных объявлений. |
| Mediapartners-Google | (Google AdSense) Робот контекстной рекламы | Индексирует и оценивает сайт с целью размещения релевантных объявлений. |
| AdsBot-Google | (Google AdsBot) Проверка качества страницы. | Отвечает за качество целевой страницы — контент, скорость загрузки, навигация и т.д. |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений | Сканирование для мобильных приложений. Оценивает качество так же, как и предыдущий робот AdsBot |
Обычно robots.txt настраивается для всех роботов Яндекса и Гугла сразу. Очень редко приходится делать отдельные настройки для каждого конкретного краулера. Однако это возможно.
Другие поисковые системы, такие как Bing, Mail, Rambler, так же индексируют сайт и обращаются к robots.txt, однако мы не будем заострять на них внимание. Про менее популярные поисковики мы напишем отдельную статью.
Запрет индексации Disallow
Без сомнения самая популярная директива. Именно при помощи disallow страницы исключаются из индекса. Disallow — буквально означает запрет на индексацию страницы, раздела, файла или группы страниц (при помощи маски). Рассмотрим пример:
Disallow: /wp-admin Disallow: /wp-content/plugins Disallow: /img/images.jpg Disallow: /dogovor.pdf Disallow: */trackback Disallow: /*my
Строка 1 — запрет на индексацию всего раздела wp-admin
Строка 2 — запрет на индексацию подраздела plugins
Строка 3 — запрет на индексацию изображения в папке img
Строка 4 — запрет индексации документа
Строка 5 — запрет на индексацию trackback в любой папке на 1 уровень
Строка 6 — запрет на индексацию не только /my, но и /folder/my или /foldermy
Данная директива поддерживает маски, о которых мы подробнее напишем ниже.
После Disallow в обязательном порядке ставится пробел, а вот в конце строки пробела быть не должно. Так же, допускается написание комментария в одной строке с директивой через пробел после символа «#», однако это не рекомендуется.
Указание нескольких каталогов в одной инструкции не допускается!
Разрешение индексации Allow
Обратная Disallow директива Allow разрешает индексацию конкретного раздела. Заходить на Ваш сайт или нет решает поисковая система, но данная директива ей это позволяет. Обычно Allow не применяется, так как поисковая система старается индексировать весь материал сайта, который может быть полезен человеку.
Пример использования Allow
Allow: /img/ Allow: /dogovor.pdf Allow: /trackback.html Allow: /*my
Строка 1 — разрешает индексацию всего каталога /img/
Строка 2 — разрешает индексацию документа
Строка 3 — разрешает индексацию страницы
Строка 4 — разрешает индексацию по маске *my
Данная директива поддерживает и подчиняется всем тем же правилам, которые справедливы для Disallow.
Директива host robots.txt
Данная директива позволяет обозначить главное зеркало сайта. Обычно, зеркала отличаются наличием или отсутствием www. Данная директива применяется в каждом robots и учитывается большинством поисковых систем.
Пример использования:
Host: dh-agency.ru
Если вы не пропишите главное зеркало сайта через host, Яндекс сообщит Вам об этом в Вебмастере.
Не знаете главное зеркало сайта? Определить довольно просто. Вбейте в поиск Яндекса адрес своего сайта и посмотрите выдачу. Если перед доменом присутствует www, то значит главное зеркало у вас с www.
Если же сайт еще не участвует в поиске, то в Яндекс Вебмастере в разделе «Переезд сайта» Вы можете задать главное зеркало самостоятельно.
Sitemap.xml в robots.txt
Данную директиву желательно иметь в каждом robots.txt, так как ее используют yandex, google, а так же все основные поисковые системы. Директива представляет из себя ссылку на файл sitemap.xml в котором содержатся все страницы, которые предназначены для индексирования. Так же в sitemap указываются приоритеты и даты изменения.
Пример использования:
Sitemap: http://dh-agency.ru/sitemap.xml
О том, как правильно создавать sitemap.xml мы напишем чуть позже.
Использование директивы Clean-param
Очень полезная, но мало кем применяющаяся директива. Clean-param позволяет описать динамические части URL, которые не меняют содержимое страницы. Такими динамическими частями могут быть:
- Идентификаторы сессий;
- Идентификаторы пользователей;
- Различные индивидуальные префиксы не меняющие содержимое;
- Другие подобные элементы.
Clean-param позволяет поисковым системам не загружать один и тот же материал многократно, что делает обход сайта роботом намного эффективнее.
Объясним на примере. Предположим, что для определения с какого сайта перешел пользователь мы взяли параметр site. Данный параметр будет меняться в зависимости от ресурса, но контент страницы будет одним и тем же.
http://dh-agency.ru/folder/page.php?site=x&r_id=985 http://dh-agency.ru/folder/page.php?site=y&r_id=985 http://dh-agency.ru/folder/page.php?site=z&r_id=985
Все три ссылки разные, но они отдают одинаковое содержимое страницы, поэтому индексирующий робот загрузит 3 копии контента. Что бы этого избежать пропишем следующие директивы:
User-agent: Yandex Disallow: Clean-param: site /folder/page.php
В данном случае робот Яндекса либо сведет все страницы к одному варианту, либо проиндексирует ссылку без параметра. Если такая конечно есть.
Использование директивы Crawl-delay
Довольно редко используемая директива, которая позволяет задать роботу минимальный промежуток между загружаемыми страницами. Crawl-delay применяется, когда сервер нагружен и не успевает отвечать на запросы. Промежуток задается в секундах. К примеру:
User-agent: Yandex Crawl-delay: 3
В данном случае таймаут будет 3 секунды. Кстати, стоит отметить, что Яндекс поддерживает и не целые значения в данной директиве. К примеру, 0.4 секунды.
Комментарии в robots.txt
Хороший robots.txt всегда пишется с комментариями. Это упростит работу Вам и поможет будущим специалистам.
Что бы написать комментарий, который будет игнорировать робот поисковой системы, необходимо поставить символ «#». К примеру:
#мой роботс Disallow: /wp-admin Disallow: /wp-content/plugins
Так же возможно, но не желательно, использовать комментарий в одной строке с инструкцией.
Disallow: /wp-admin #исключаем wp admin Disallow: /wp-content/plugins
На данный момент никаких технических запретов по написанию комментария в одной строке с инструкцией нету, однако это считается плохим тоном.
Маски в robots.txt
Применение масок в robots.txt не только упрощает работу, но зачастую просто необходимо. Напомним, маска — это условная запись, которая содержит в себе имена нескольких файлов или папок. Маски применяются для групповых операций с файлами/папками. Предположим, что у нас есть список файлов в папке /documents/
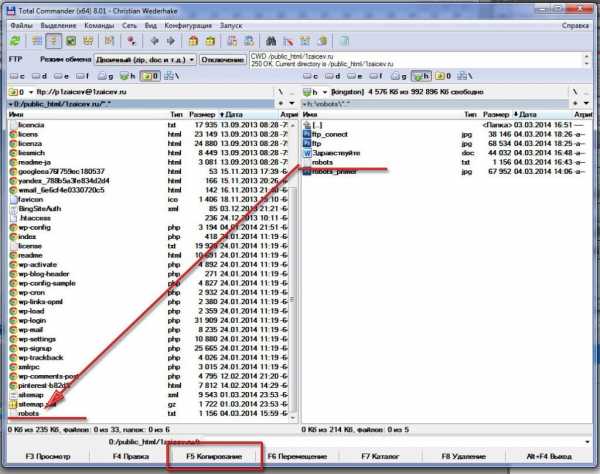
Среди этих файлов есть презентации в формате pdf. Мы не хотим, что бы их сканировал робот, поэтому исключаем из поиска.
Мы можем перечислять все файлы формата .pdf «в ручную»
Disallow: /documents/admin.pdf Disallow: /documents/r7.pdf Disallow: /documents/leto.pdf Disallow: /documents/sity.pdf Disallow: /documents/afrika.pdf Disallow: /documents/t-12.pdf
А можем сделать простую маску *.pdf и скрыть все файлы в одной инструкции.
Disallow: /documents/*.pdf
Удобно, не правда ли?
Маски создаются при помощи спецсимвола «*». Он обозначает любую последовательность символов, в том числе и пробел. Примеры использования:
Disallow: *.pdf Disallow: admin*.pdf Disallow: a*m.pdf Disallow: /img/*.* Disallow: img.* Disallow: &amp;=*
Стоит отметить, что по умолчанию спецсимвол «*» добавляется в конце каждой инструкции, которую Вы прописываете. То есть,
Disallow: /wp-admin # равносильно инструкции ниже Disallow: /wp-admin*
То есть, мы исключаем все, что находится в папке /wp-admin, а так же /wp-admin.html, /wp-admin.pdf и т.д. Для того, что бы этого не происходило необходимо в конце инструкции поставить другой спецсимвол — «$».
Disallow: /wp-admin$ #
В таком случае, мы уже не запрещаем файлы /wp-admin.html, /wp-admin.pdf и т.д
Как правильно настроить robots.txt?
С синтаксисом robots.txt мы разобрались выше, поэтому сейчас напишем как правильно настроить данный файл. Если для популярных CMS, таких как WordPress и Joomla!, уже есть готовые robots, то для самописного движка или редкой СУ Вам придется все настраивать вручную.
(Даже несмотря на наличие готовых robots.txt редактировать и удалять «уникальный мусор» Вам придется и в ВордПресс. Поэтому этот раздел будет полезен и для владельцев сайтов на ТОПовых CMS)
Что нужно исключать из индекса?
А.) В первую очередь из индекса исключаются дубликаты страниц в любом виде. Страница на сайте должна быть доступна только по одному адресу. То есть, при обращении к ресурсу робот должен получать по каждому URL уникальный контент.
Зачастую дубликаты появляются у систем управления сайтом при создании страниц. К примеру, одна и та же страница может быть доступна по техническому адресу /?p=391&preview=true и одновременно с этим иметь ЧПУ. Так же дубли могут возникать при работе с динамическими ссылками.
Всех их необходимо при помощи масок исключать из индекса.
Disallow: /*?* Disallow: /*% Disallow: /index.php Disallow: /*?page= Disallow: /*&amp;page=
Б.) Все страницы, которые имеют не уникальный контент, желательно убрать из индекса еще до того, как это сделает поисковая система.
В.) Из индекса должны быть исключены все страницы, которые используются при работе сценариев. К примеру, страница «Спасибо, сообщение отправлено!».
Г.) Желательно исключить все страницы, которые имеют индикаторы сессий
Disallow: *PHPSESSID= Disallow: *session_id=
Д.) В обязательном порядке из индекса должны быть исключены все файлы вашей cms. Это файлы панели администрации, различных баз, тем, шаблонов и т.д.
Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback
Е.) Пустые страницы и разделы, «не нужный» пользователям контент, результаты поиска и работы калькулятора так же должны быть недоступны роботу.
«Держа в чистоте» Ваш индекс Вы упрощаете жизнь и себе и индексирующему роботу.
Что нужно разрешать индексировать?
Да по сути все, что не запрещено. Есть только один нюанс. Поисковые системы по умолчанию индексируют любой полезный контент Вашего сайта, поэтому использовать директиву Allow в 90% случаев не нужно.
Корректный файл sitemap.xml и качественная перелинковка дадут гарантию, что все «нужные» страницы Вашего сайта будут проиндексированы.
Обязательны ли директивы host и sitemap?
Да, данные директивы обязательны. Прописать их не составит труда, но они гарантируют, что робот точно найдет sitemap.xml, и будет «знать» главное зеркало сайта.
Для каких поисковиков настраивать?
Инструкции файла robots.txt понимают все популярные поисковые системы. Если различий в инструкциях нету, то Вы можете прописать User-agent: * (Все директивы для всех поисковиков).
Однако, если Вы укажите инструкции для конкретного робота, к примеру Yandex, то все другие директивы Яндексом будут проигнорированы.
Нужны ли мне директивы Crawl-delay и Clean-param?
Если Вы используете динамические ссылки или же передаете параметры в URL, то Вам скорее всего понадобиться Clean-param, дабы не вводить робота в заблуждение. Использование данной директивы мы описали выше. Данная директива поможет Вам избежать ненужных дубликатов в поиске, что очень важно.
Использование Crawl-delay зависит исключительно от Вашего хостинга. Если Вы чувствуете, что сервер уже не справляется запросами, то желательно увеличить время межу ними.
Проверяем свой robots.txt
После настройки файла его необходимо проверить. Сделать это возможно через Ваш Вебмастер в разделе «Инструменты» -> «Анализ robots.txt»
Но нужно понимать, что данный онлайн инструмент сможет лишь найти синтаксическую ошибку. Он никак не убережет Вас от лишней исключенной страницы, а так же от мусора в выдаче.
dh-agency.ru
Как правильно создать robots.txt для сайта – полное руководство
От автора: поисковые роботы могут стать вашими друзьями, либо врагами. Все зависит от того, какие вы им дадите команды. Сегодня разберемся, как правильно создать robots.txt для сайта.
Создание самого файла
Robots.txt – это файл с инструкциями для поисковых роботов. Он создается в корне сайта. Вы можете прямо сейчас создать его на своем рабочем столе при помощи блокнота, как создается любой текстовый файл.
Для этого жмем правой кнопкой мыши по пустому пространству, выбираем Создать – Текстовый документ (не Word). Он откроется с помощью обычного блокнота. Назовите его robots, расширение у него и так уже правильное – txt. Это все, что касается создания самого файла.
Как составить robots.txt
Теперь остается заполнить файл нужными инструкциями. Собственно, у команд для роботов простейший синтаксис, намного проще, чем в любом языке программирования. Вообще заполнить файл можно двумя способами:
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееПосмотреть у другого сайта, скопировать и изменить под структуру своего проекта.
Написать самому
О первом способе я уже писал в предыдущей статье. Он подходит, если у сайтов одинаковые движки и нет существенной разницы в функционале. Например, все сайты на wordpress имеют одинаковую структуру, однако могут быть различные расширения, вроде форума, интернет-магазина и множества дополнительных каталогов. Если вы хотите знать, как изменить robots.txt читайте эту статью, можно также ознакомиться с предыдущей, но и в этой будет сказано достаточно много.
Например, у вас на сайте есть каталог /source, где хранятся исходники к тем статьям, что вы пишите на блог, а у другого веб-мастера нет такой директории. И вы, к примеру, хотите закрыть папку source от индексации. Если вы скопируете robots.txt у другого ресурса, то там такой команды не будет. Вам придется дописывать свои инструкции, удалять ненужное и т.д.
Так что в любом случае полезно знать основы синтаксиса инструкций для роботов, который вы сейчас и разберем.
Как писать свои инструкции роботам?
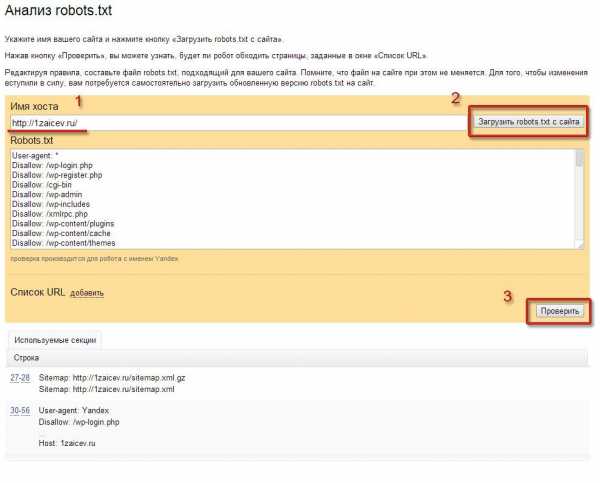
Первое, с чего начинается файл, это с указания того, к каким именно поисковым машинам обращены инструкции. Это делается так:
User-agent: Yandex Или User-agent: Googlebot
User-agent: Yandex Или User-agent: Googlebot |
Никаких точек с запятой в конце строчки ставить не нужно, это вам не программирование). В общем, тут понятно, что в первом случае инструкции будет читать только бот Яндекса, во втором – только Гугла. Если команды должны быть выполнены всеми роботами, пишут так: User-agent:
Команды
Отлично. С обращением к роботам мы разобрались. Это несложно. Вы можете представить это на простом примере. У вас есть трое младших братьев, Вася, Дима и Петя, а вы главный. Родители ушли и сказали вам, чтобы вы следили за ними.
Все трое чего-то просят у вас. Представь, что нужно дать им ответ так, как будто пишешь инструкции поисковым роботам. Это будет выглядеть примерно так:
User-agent: Vasya Allow: пойти на футбол User-agent: Dima Disallow: пойти на футбол (Дима в прошлый раз разбил стекло соседям, он наказан) User-agent: Petya Allow: сходить в кино (Пете уже 16 и он вообще в шоке, что должен у тебя еще и разрешения спрашивать, ну да ладно, пусть идет).
User-agent: Vasya Allow: пойти на футбол User-agent: Dima Disallow: пойти на футбол (Дима в прошлый раз разбил стекло соседям, он наказан) User-agent: Petya Allow: сходить в кино (Пете уже 16 и он вообще в шоке, что должен у тебя еще и разрешения спрашивать, ну да ладно, пусть идет). |
Таким образом, Вася радостно зашнуровывает кроссовки, Дима с опущенной головой смотрит в окно на брата, который уже думает, сколько голов забьет сегодня (Дима получил команду disallow, то есть запрет). Ну а Петя отправляется в свое кино.
Из этого примера несложно понять, что Allow – это разрешение, а Disallow – запрет. Но в robots.txt мы не людям раздаем команды, а роботам, поэтому вместо конкретных дел там прописываются адреса страниц и каталогов, которые нужно разрешить или запретить индексировать.
Например, у меня есть сайт site.ru. Он на движке wordpress. Начинаю писать инструкции:
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееUser-agent: * Disallow: /wp-admin/ Disallow: /wp-content/ Disallow: /wp-includes/ Allow: /wp-content/uploads/ Disallow: /source/ Ну и т.д.
User-agent: * Disallow: /wp-admin/ Disallow: /wp-content/ Disallow: /wp-includes/ Allow: /wp-content/uploads/ Disallow: /source/ Ну и т.д. |
Во-первых, я обратился ко всем роботам. Во-вторых, поставил запрет на индексацию папок самого движка, но при этом открыл роботу доступ к папке с загрузками. Там обычно хранятся все картинки, а их обычно не закрывают от индексации, если планируется получать трафик с поиска по картинкам.
Ну и помните, я ранее в статье говорил о том, что у вас могут быть дополнительные каталоги? Вы можете их создать самостоятельно для различных целей. Например, на одном из моих сайтов есть папка flash, куда я кидаю флэш-игры, чтобы потом их запустить на сайте. Либо source – в этой папке могут хранится файлы, доступные пользователям для загрузки.
В общем, абсолютно неважно, как называется папка. Если ее нужно закрыть, указываем путь к ней и команду Disallow.
Команда Allow нужна как раз для того, чтобы уже в закрытых разделах открыть какие-то части. Ведь по умолчанию, если у вас не будет файла robots.txt, весь сайт будет доступен к индексированию. Это и хорошо (уж точно что-то важное не закроете по ошибке), и в то же время плохо (будут открыты файлы и папки, которых не должно быть в выдаче).
Чтобы лучше понять этот момент, предлагаю еще раз просмотреть этот кусок:
Disallow: /wp-content/ Allow: /wp-content/uploads/
Disallow: /wp-content/ Allow: /wp-content/uploads/ |
Как видите, сначала мы ставим запрет на индексацию всего каталога wp-content. В нем хранятся все ваши шаблоны, плагины, но там же есть и картинки. Очевидно, что их то можно и открыть. Для этого нам и нужна команда Allow.
Дополнительные параметры
Перечисленные команды – не единственное, что можно указать в файле. Также есть такие: Host – указывает главное зеркало сайта. Кто не знал, у любого сайта по умолчанию есть два варианта написания его доменного имени: domain.com и www.domain.com.
Чтобы не возникло проблем, необходимо указать в качестве главного зеркала какой-то один вариант. Это можно сделать как в инструментах для веб-мастеров, как и в файле Robots.txt. Для этого пишем: Host: domain.com
Что это дает? Если кто-то попытается попасть на ваш сайт так: www.domain.com – его автоматически перекинет на вариант без www, потому что он будет признан главным зеркалом.
Вторая директива – sitemap. Я думаю вы уже поняли, что в ней задается путь к карте сайта в xml-формате. Пример: http://domain.com/sitemap.xml
Опять же, загрузить карту вы можете и в Яндекс.Вебмастере, также ее можно указать в robots.txt, чтобы робот прочитал эту строчку и четко понял, где ему искать карту сайта. Для робота карта сайта так же важна, как для Васи – мяч, с которым он пойдет на футбол. Это все равно, что он спрашивает у тебя (как у старшего брата) где мяч. А ты ему:
User-agent: Vasya Sitemap: посмотри в зале за диваном
User-agent: Vasya Sitemap: посмотри в зале за диваном |
Теперь вы знаете, как правильно настроить и изменить robots.txt для яндекса и вообще любого другого поисковика под свои нужды.
Что дает настройка файла?
Об этом я также уже говорил ранее, но скажу еще раз. Благодаря четко настроенному файлу с командами для роботов вы сможете спать спокойнее зная, что робот не залезет в ненужный раздел и не возьмет в индекс ненужные страницы.
Я также говорил, что настройка robots.txt не спасает от всего. В частности, она не спасает от дублей, которые возникает из-за того, что движки несовершенны. Прям как люди. Вы то разрешили Васе идти на футбол, но не факт, что он там не натворит того же, что и Дима. Вот так и с дублями: команду дать можно, но точно нельзя быть уверенным, что что-то лишнее не пролезет в индекс, испортив позиции.
Дублей тоже не нужно бояться, как огня. Например, тот же Яндекс более менее нормально относится к сайтам, у которых серьезные технические косяки. Другое дело, что если запустить дело, то и вправду можно лишиться серьезного процента трафика к себе. Впрочем, скоро в нашем разделе, посвященном SEO, будет статья о дублях, тогда и будем с ними воевать.
Как мне получить нормальный robots.txt, если я сам ничего не понимаю?
В конце концов, создание robots.txt — это не создание сайта. Как-то попроще, поэтому вы вполне можете банально скопировать содержимое файла у любого более менее успешного блоггера. Конечно, если у вас сайт на WordPress. Если он на другом движке, то вам и сайты нужно искать на этих же cms. Как посмотреть содержимое файла на чужом сайте я уже говорил: Domain.com/robots.txt
Итог
Я думаю, тут больше не о чем говорить, потому что не надо делать составление инструкций для роботов вашей целью на год. Это та задача, которую под силу выполнить даже новичку за 30-60 минут, а профессионалу вообще всего-то за пару минут. Все у вас получиться и можете в этом не сомневаться.
А чтобы узнать другие полезные и важные фишки для продвижения и раскрутки блога, можете посмотреть наш уникальный курс по раскрутке и монетизации сайта. Если вы примените оттуда 50-100% рекомендаций, то сможете в будущем успешно продвигать любые сайты.
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееХотите узнать, что необходимо для создания сайта?
Посмотрите видео и узнайте пошаговый план по созданию сайта с нуля!
Смотретьwebformyself.com
Правильный robots txt для сайта, инструкция новичкам
Здравствуйте друзья! В статье показано, что такое правильный robots txt для сайта, где он находится, способы создания файла robots, как адаптировать под себя файл robots с другого сайта, как его залить к себе на блог.
Что такое файл robots txt, зачем он нужен и за что он отвечает
Файл robots txt, это текстовый файл, который содержит инструкции для поисковых роботов. Перед обращением к страницам Вашего блога, робот ищет первым делом файл robots, поэтому он так важен. Файл robots txt это стандарт для исключения индексации роботом тех или иных страниц. От файла robots txt будет зависеть попадание в выдачу Ваших конфиденциальных данных. Правильный robots txt для сайта поможет в его продвижении, поскольку он является важным инструментов во взаимодействии Вашего сайта и поисковых роботов.
Не зря файл robots txt называют важнейшим инструментом SEO, этот маленький файл напрямую влияет на индексацию страниц сайта и сайта в целом. И наоборот, неправильный robots txt может исключить некоторые страницы, разделы или сайт в целом из поисковой выдачи. В этом случае можно иметь и 1000 статей на блоге, а посетителей на сайте просто не будет, будут чисто случайные прохожие.
На Яндекс вебмастере есть обучающее видео, в котором Яндекс сравнивает файл роботс тхт с коробкой Ваших личных вещей, которые Вы не хотите никому показывать. Чтобы посторонние не заглядывали в эту коробку, Вы её заклеиваете скотчем и пишете на ней – «Не открывать».
Роботы, как воспитанные личности, эту коробку не открывают и другим не смогут рассказать, что там находится. Если файла robots txt нет, то робот поисковой системы считает, что все файлы доступные, он откроет коробку, всё посмотрит и другим расскажет, что лежит в коробке. Чтобы робот не лазил в этот ящик, надо запретить ему туда лазить, делается это с помощью директивы Disallow, что переводится с английского – запретить, а Allow – разрешить.
Это обычный txt файл, который составляется в обычном блокноте или программе NotePad++, файл, который предлагает роботам не индексировать определённые страницы на сайте. Для чего это нужно:
- правильно составленный файл robots txt не позволяет роботам индексировать всякий мусор и не забивать поисковую выдачу ненужным материалом, а также не плодить дубли страниц, что является очень вредным явлением;
- не позволяет роботам индексировать информацию, которая нужна для служебного пользования;
- не позволяет роботам шпионам воровать конфиденциальные данные и использования их для отправки спама.
Это не означает, что мы что-то хотим спрятать от поисковиков, что-то тайное, просто эта информация не несёт ценности ни для поисковиков, ни для посетителей. Например, страница логина, RSS ленты и т.д. Кроме того, файл robots txt указывает зеркало сайта, а также карту сайта. По умолчанию на сайте, который делается на WordPress, файла robots txt нет. Поэтому нужно создать robots txt файл и залить его в корневую папку Вашего блога, в данной статье мы рассмотрим robots txt для WordPress, его создание, корректировку и заливку на сайт. Итак, сначала мы узнаем, где находится файл robots txt?
к оглавлению ↑Где находится robots txt, как увидеть его?
Думаю, многие новички задают себе вопрос – где находится robots txt? Находится файл в корневой папке сайта, в папке public_html, его можно увидеть достаточно просто. Вы можете зайти на хостинг, открыть папку своего сайта и посмотреть есть там этот файл или нет. В прилагаемом ниже видео, показано, как это сделать. Можно посмотреть файл и с помощью Яндекс вебмастера и Google webmaster, но об этом поговорим позже.
Есть вариант еще проще, который позволяет посмотреть не только свой robots txt, но и robots любого сайта, Вы можете robots скачать к себе на компьютер, а затем адаптировать его к себе и использовать на своём сайте (блоге). Делается это так – Вы открываете нужный Вам сайт (блог), и через слэш дописываете robots.txt (смотрите скрин)
и нажимаете Enter, открывается файл robots txt. В данном случае, Вы не можете видеть, где находится robots txt, но можете его посмотреть и скачать.
к оглавлению ↑Как создать правильный robots txt для сайта
Создать robots txt для сайта можно различными вариантами:
- использовать генераторы онлайн, которые быстро создадут файл robots txt, сайтов и сервисов, которые это умеют делать, достаточно много;
- использовать плагины для WordPress, которые помогут решить эту задачу;
- составить файл robots txt своими руками вручную в обычном блокноте или программе NotePad++;
- использовать готовый, правильный robots txt с чужого сайта (блога), заменив в нем адрес своего сайта.
Генераторы robots txt
Итак, ранее генераторами создания файлов robots txt я не пользовался, но перед написанием данной статьи решил протестировать 4 сервиса по генерации файлов robots txt, получил определённые результаты, о них позже скажу. Вот эти сервисы:
- SEOlib;
- сервис PR-CY;
- [urlspan]сервис Raskruty.ru[/urlspan];
- seo café зайти сюда можно по этой ссылке — info.seocafe.info/tools/robotsgenerator.
О том, как использовать генератор robots txt на практике, подробно показано в прилагаемом ниже видео. В процессе испытания пришел к выводу, что они для этого новичкам не подходят, и вот почему? Генератор позволяет только оформить правильную запись без ошибок самого файла, а для составления правильного robots txt все равно нужно обладать знаниями, надо знать, какие папки закрыть, какие нет. По этой причине использовать генератор robots txt чтобы создать файл, новичкам не рекомендую.
к оглавлению ↑Плагины robots txt для WordPress
Есть плагины, например, PC Robots.txt для создания файла. Этот плагин позволяет редактировать файл прямо в панели управления сайтом. Другой плагин iRobots.txt SEO – этот плагин с похожим функционалом. Вы можете найти кучу различных плагинов, которые позволяют работать с файлом robots txt. При желании Вы можете задать в поле «Поиск плагинов» словосочетание robots. txt и нажать кнопку «Поиск» и Вам будет предложено несколько плагинов. Конечно, о каждом из них надо прочитать, посмотреть отзывы.
Принцип работы плагинов robots txt для WordPress очень похож на работу генераторов. Чтобы получить правильный robots txt для сайта, нужны знания и опыт, а откуда он может быть у новичков? По моему мнению, от подобных сервисов можно получить больше вреда, чем пользы. А если устанавливать плагин, так он еще и хостинг нагрузит. По этой причине устанавливать плагин robots txt WordPress не рекомендую.
к оглавлению ↑Создать robots txt вручную
Можно создать robots txt вручную, используя обычный блокнот или программу NotePad++, но для этого должны быть знания и опыт. Новичкам этот вариант тоже подходит мало. Но со временем, когда появится опыт, можно будет это делать, причем составить файл robots txt для сайта, прописать директивы Disallow robots, закрыть от индексации нужные папки, выполнить проверку robots и его корректировку можно всего за 10 минут. На приведенном скрине показан роботс тхт в блокноте:
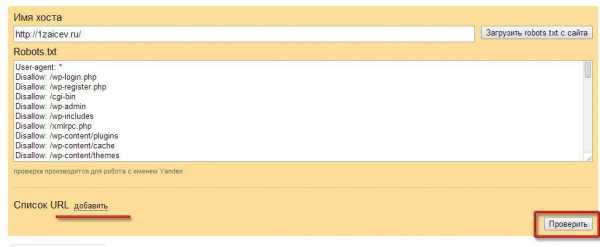
Сам порядок создания файла robots txt здесь рассматривать не будем, об этом подробно написано во многих источниках, например, в Яндекс вебмастер. Перед составлением файла роботс тхт, необходимо зайти в Яндекс Вебмастер, где подробно расписана каждая директива, что за что отвечает и на основании этой информации составить файл. (смотрите скрин).
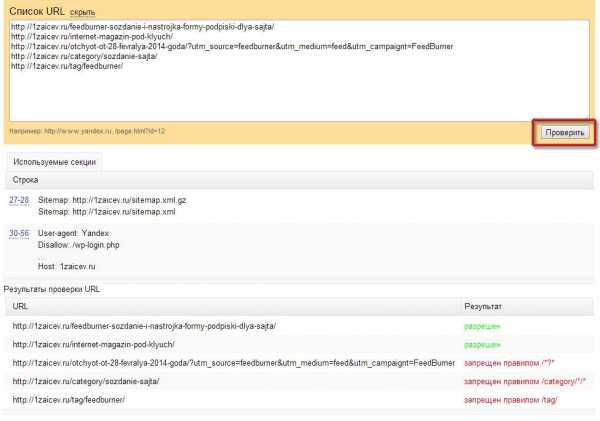
Кстати, новый Яндекс вебмастер предлагает подробную и развернутую информацию, статью о новом Яндекс вебмастере можно посмотреть на блоге. Точнее представлено две статьи, которые принесут большую пользу блоггерам и не только новичкам, советую прочитать.
Если Вы не новичок и хотите сделать robots txt самостоятельно, то нужно соблюдать ряд правил:
- Использование национальных символов в файле robots txt не допускается.
- Размер файла robots не должен превышать 32 Кбайт.
- В названии файла robots нельзя писать типа Robots или ROBOTS, файл нужно подписать именно так, как показано в статье.
- Каждую директиву нужно начинать с новой строки.
- В одной строке нельзя указывать больше одной директивы.
- Директива «Disallow» с пустой строкой равнозначна директиве «Allow» — разрешить, это надо помнить.
- Нельзя ставить пробел в начале строки.
- Если не сделать пробел между различными директивами «User-agent», то роботы воспримут только верхнюю директиву – остальные проигнорируют.
- Сам параметр директивы нужно прописать только одной строкой.
- Нельзя заключать параметры директивы в кавычки.
- Нельзя после директивы закрывать строку точкой с запятой.
- Если файл robots не будет обнаружен или будет пустой, то роботы будут это воспринимать, как «Всё разрешено».
- Можно делать комментарии в строке директивы (чтобы было понятно, что это за строка), но только после знака решетка #.
- Если сделать пробел между строками, то это будет означать конец директивы User-agent.
- В директивах «Disallow» и «Allow» должен быть указан только один параметр.
- Для директив, которые являются директорией ставится слэш, например – Disallow/ wp-admin.
- В разделе «Crawl-delay» нужно рекомендовать роботам временной интервал между скачиванием документов с сервера, обычно это 4-5 секунд.
- Важно — между директивами не должно быть пустых строк. Новая директива начинается через один пробел. Это означает конец правил для поискового робота, в прилагаемом видео это подробно показано. Звёздочки означают последовательность любых символов.
- Все правила я советую повторять отдельно для робота Яндекса, то есть все директивы, которые были прописаны для других роботов, повторить для Яндекса отдельно. В конце информации для робота Яндекса надо записать директиву хост (Host — она поддерживается только Яндексом) и указать свой блог. Хост указывает Яндексу, какое зеркало Вашего сайта главное с www или без.
- Кроме того в отдельной директории файла роботс тхт, то есть через пробел, рекомендуется указывать адрес карты вашего сайта. Создание файла можно сделать за несколько минут и начинается с фразы «User-agent:». Если Вы хотите закрыть от индексации, например, картинки, то надо прописать Disallow: /images/.
Использовать правильный robots txt с чужого сайта
Идеального файла не существует, периодически нужно пробовать экспериментировать и учитывать изменения в работе поисковых систем, учитывать те ошибки, которые со временем могут появиться на Вашем блоге. Поэтому для начала можно взять чужой проверенный файл robots txt и установить его к себе.
Обязательно надо изменить записи, которые отражают адрес Вашего блога в директории Host (смотрите скрин, смотрите также видео), а также заменить на свой адрес сайта в адресе карты сайта (две нижние строки). Со временем этот файл немного надо подкорректировать. Например, Вы обратили внимание, что у Вас начали появляться дубли страниц.
В разделе «Где находится robots txt, как увидеть», который находится выше, мы рассматривали, как посмотреть и скачать robots txt. Поэтому, нужно выбрать хороший трастовый сайт, у которого высокие показатели Тиц, высокая посещаемость, открыть и скачать правильный robots txt. Нужно сравнить несколько сайтов, выбрать для себя нужный файл роботс тхт и залить себе его на сайт.
к оглавлению ↑Как залить на сайт файл robots txt в корневую папку сайта
Как уже писалось, после создания сайта на WordPress, по умолчанию, файл robots txt отсутствует. Поэтому его надо создать и закачать в корневую папку нашего сайта (блога) на хостинг. Закачать файл достаточно просто. На хостинге TimeWeb можно закачать напрямую, на других хостингах закачать можно либо через FileZilla, либо через FTP соединение с помощью Total Commander. В видео, которое расположено ниже, показан процесс закачки файла robots txt на хостинг TimeWeb.
к оглавлению ↑Проверка файла robots txt
После закачки файла robots txt, нужно проверить его наличие и работу. Для этого можем посмотреть файл с браузера, как показано выше в разделе «Где находится robots txt, как увидеть». А проверить работу файла можно с помощью Яндекс вебмастера и Google webmaster. Помним, что для этого должны быть подтверждены права на управление сайтом, как в Яндексе, так и в Google.
Для проверки в Яндексе заходим в наш аккаунт Яндекс вебмастера, выбираем сайт, если у Вас их несколько. Выбираем «Настройка индексирования», «Анализ robots.txt», а дальше следуем инструкциям.

В Google вебмастер делаем аналогично, заходим в наш аккаунт, выбираем нужный сайт (если их несколько), нажимаем кнопку «Сканирование» и выбираем «Инструмент проверки файла robots.txt». Откроется файл robots txt, Вы можете его исправить или проверить.
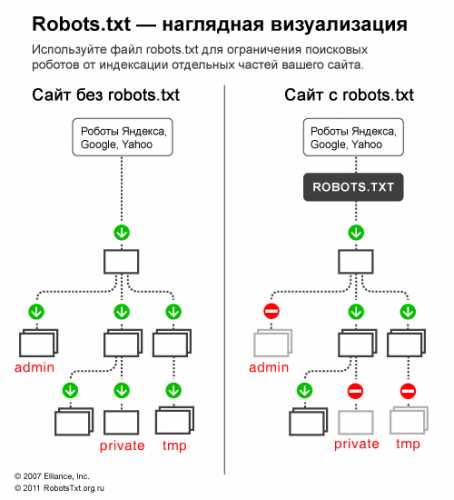
На этой же странице находятся отличные инструкции по работе с файлом robots txt, можете с ними ознакомиться. В заключении привожу видео, где показано что представляет собой файл robots txt, как его найти, как его посмотреть и скачать, как работать с генератором файла, как составить robots txt и адаптировать под себя, показана другая информация:
к оглавлению ↑Заключение
Итак, в данной статье мы рассмотрели вопрос, что собой представляет файл robots txt, выяснили, что этот файл является очень важным для сайта. Узнали, как сделать правильный robots txt, как адаптировать файл robots txt с чужого сайта к себе, как закачать его на свой блог, как его проверить.
Из статьи стало понятно, что новичкам, на первых порах, лучше использовать готовый и правильный robots txt, но надо не забыть заменить в нем в директории Host домен на свой, а также прописать адрес своего блога в картах сайта. Скачать мой файл robots txt можно здесь. Теперь, после исправления, можете использовать файл на своем блоге.
Отдельно по файлу robots txt есть сайт Вы можете зайти на него и узнать более подробную информацию. Надеюсь, у Вас всё получится и блог будет хорошо индексироваться. Удачи Вам!
С уважением, Иван Кунпан.
P.S. Для правильного продвижения блога надо правильно писать о оптимизировать статьи на блоге, тогда на нём будет высокая посещаемость и рейтинги. В этом Вам помогут мои инфопродукты, в которые вложен мой трёхлетний опыт. Можете получить следующие продукты:
Просмотров: 11727
Получайте новые статьи блога прямо себе на почту. Заполните форму, нажмите кнопку «Подписаться»
Вы можете почитать:
biz-iskun.ru